
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.71k
18.9k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 465
23.6k
| num_tokens_prompt
int64 556
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_22209
|
rasdani/github-patches
|
git_diff
|
cloudtools__troposphere-681
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ApiGateway Model Schema should be a Dict not a string
troposphere.apigateway.Model class contains a property called schema, it is defined as 'basestring', this property should be a dict.
Ideally, you should supply a class to represent 'Schema'
</issue>
<code>
[start of troposphere/apigateway.py]
1 from . import AWSObject, AWSProperty
2 from .validators import positive_integer
3
4
5 def validate_authorizer_ttl(ttl_value):
6 """ Validate authorizer ttl timeout
7 :param ttl_value: The TTL timeout in seconds
8 :return: The provided TTL value if valid
9 """
10 ttl_value = int(positive_integer(ttl_value))
11 if ttl_value > 3600:
12 raise ValueError("The AuthorizerResultTtlInSeconds should be <= 3600")
13 return ttl_value
14
15
16 class Account(AWSObject):
17 resource_type = "AWS::ApiGateway::Account"
18
19 props = {
20 "CloudWatchRoleArn": (basestring, False)
21 }
22
23
24 class StageKey(AWSProperty):
25
26 props = {
27 "RestApiId": (basestring, False),
28 "StageName": (basestring, False)
29 }
30
31
32 class ApiKey(AWSObject):
33 resource_type = "AWS::ApiGateway::ApiKey"
34
35 props = {
36 "Description": (basestring, False),
37 "Enabled": (bool, False),
38 "Name": (basestring, False),
39 "StageKeys": ([StageKey], False)
40 }
41
42
43 class Authorizer(AWSObject):
44 resource_type = "AWS::ApiGateway::Authorizer"
45
46 props = {
47 "AuthorizerCredentials": (basestring, False),
48 "AuthorizerResultTtlInSeconds": (validate_authorizer_ttl, False),
49 "AuthorizerUri": (basestring, True),
50 "IdentitySource": (basestring, True),
51 "IdentityValidationExpression": (basestring, False),
52 "Name": (basestring, True),
53 "ProviderARNs": ([basestring], False),
54 "RestApiId": (basestring, False),
55 "Type": (basestring, True)
56 }
57
58
59 class BasePathMapping(AWSObject):
60 resource_type = "AWS::ApiGateway::BasePathMapping"
61
62 props = {
63 "BasePath": (basestring, False),
64 "DomainName": (basestring, True),
65 "RestApiId": (basestring, True),
66 "Stage": (basestring, False)
67 }
68
69
70 class ClientCertificate(AWSObject):
71 resource_type = "AWS::ApiGateway::ClientCertificate"
72
73 props = {
74 "Description": (basestring, False)
75 }
76
77
78 class MethodSetting(AWSProperty):
79
80 props = {
81 "CacheDataEncrypted": (bool, False),
82 "CacheTtlInSeconds": (positive_integer, False),
83 "CachingEnabled": (bool, False),
84 "DataTraceEnabled": (bool, False),
85 "HttpMethod": (basestring, True),
86 "LoggingLevel": (basestring, False),
87 "MetricsEnabled": (bool, False),
88 "ResourcePath": (basestring, True),
89 "ThrottlingBurstLimit": (positive_integer, False),
90 "ThrottlingRateLimit": (positive_integer, False)
91 }
92
93
94 class StageDescription(AWSProperty):
95
96 props = {
97 "CacheClusterEnabled": (bool, False),
98 "CacheClusterSize": (basestring, False),
99 "CacheDataEncrypted": (bool, False),
100 "CacheTtlInSeconds": (positive_integer, False),
101 "CachingEnabled": (bool, False),
102 "ClientCertificateId": (basestring, False),
103 "DataTraceEnabled": (bool, False),
104 "Description": (basestring, False),
105 "LoggingLevel": (basestring, False),
106 "MethodSettings": ([MethodSetting], False),
107 "MetricsEnabled": (bool, False),
108 "StageName": (basestring, False),
109 "ThrottlingBurstLimit": (positive_integer, False),
110 "ThrottlingRateLimit": (positive_integer, False),
111 "Variables": (dict, False)
112 }
113
114
115 class Deployment(AWSObject):
116 resource_type = "AWS::ApiGateway::Deployment"
117
118 props = {
119 "Description": (basestring, False),
120 "RestApiId": (basestring, True),
121 "StageDescription": (StageDescription, False),
122 "StageName": (basestring, False)
123 }
124
125
126 class IntegrationResponse(AWSProperty):
127
128 props = {
129 "ResponseParameters": (dict, False),
130 "ResponseTemplates": (dict, False),
131 "SelectionPattern": (basestring, False),
132 "StatusCode": (basestring, False)
133 }
134
135
136 class Integration(AWSProperty):
137
138 props = {
139 "CacheKeyParameters": ([basestring], False),
140 "CacheNamespace": (basestring, False),
141 "Credentials": (basestring, False),
142 "IntegrationHttpMethod": (basestring, False),
143 "IntegrationResponses": ([IntegrationResponse], False),
144 "PassthroughBehavior": (basestring, False),
145 "RequestParameters": (dict, False),
146 "RequestTemplates": (dict, False),
147 "Type": (basestring, True),
148 "Uri": (basestring, False)
149 }
150
151
152 class MethodResponse(AWSProperty):
153
154 props = {
155 "ResponseModels": (dict, False),
156 "ResponseParameters": (dict, False),
157 "StatusCode": (basestring, True)
158 }
159
160
161 class Method(AWSObject):
162 resource_type = "AWS::ApiGateway::Method"
163
164 props = {
165 "ApiKeyRequired": (bool, False),
166 "AuthorizationType": (basestring, True),
167 "AuthorizerId": (basestring, False),
168 "HttpMethod": (basestring, True),
169 "Integration": (Integration, False),
170 "MethodResponses": ([MethodResponse], False),
171 "RequestModels": (dict, False),
172 "RequestParameters": (dict, False),
173 "ResourceId": (basestring, True),
174 "RestApiId": (basestring, True)
175 }
176
177
178 class Model(AWSObject):
179 resource_type = "AWS::ApiGateway::Model"
180
181 props = {
182 "ContentType": (basestring, False),
183 "Description": (basestring, False),
184 "Name": (basestring, False),
185 "RestApiId": (basestring, True),
186 "Schema": (basestring, False)
187 }
188
189
190 class Resource(AWSObject):
191 resource_type = "AWS::ApiGateway::Resource"
192
193 props = {
194 "ParentId": (basestring, True),
195 "PathPart": (basestring, True),
196 "RestApiId": (basestring, True)
197 }
198
199
200 class S3Location(AWSProperty):
201
202 props = {
203 "Bucket": (basestring, False),
204 "ETag": (basestring, False),
205 "Key": (basestring, False),
206 "Version": (basestring, False)
207 }
208
209
210 class RestApi(AWSObject):
211 resource_type = "AWS::ApiGateway::RestApi"
212
213 props = {
214 "Body": (dict, False),
215 "BodyS3Location": (S3Location, False),
216 "CloneFrom": (basestring, False),
217 "Description": (basestring, False),
218 "FailOnWarnings": (basestring, False),
219 "Name": (basestring, False),
220 "Parameters": ([basestring], False)
221 }
222
223
224 class Stage(AWSObject):
225 resource_type = "AWS::ApiGateway::Stage"
226
227 props = {
228 "CacheClusterEnabled": (bool, False),
229 "CacheClusterSize": (basestring, False),
230 "ClientCertificateId": (basestring, False),
231 "DeploymentId": (basestring, True),
232 "Description": (basestring, False),
233 "MethodSettings": ([MethodSetting], False),
234 "RestApiId": (basestring, True),
235 "StageName": (basestring, True),
236 "Variables": (dict, False)
237 }
238
239
240 class ApiStage(AWSProperty):
241 props = {
242 "ApiId": (basestring, False),
243 "Stage": (basestring, False),
244 }
245
246
247 class QuotaSettings(AWSProperty):
248 props = {
249 "Limit": (positive_integer, False),
250 "Offset": (positive_integer, False),
251 "Period": (basestring, False),
252 }
253
254
255 class ThrottleSettings(AWSProperty):
256 props = {
257 "BurstLimit": (positive_integer, False),
258 "RateLimit": (positive_integer, False),
259 }
260
261
262 class UsagePlan(AWSObject):
263 resource_type = "AWS::ApiGateway::UsagePlan"
264
265 props = {
266 "ApiStages": ([ApiStage], False),
267 "Description": (basestring, False),
268 "Quota": (QuotaSettings, False),
269 "Throttle": (ThrottleSettings, False),
270 "UsagePlanName": (basestring, False),
271 }
272
[end of troposphere/apigateway.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/troposphere/apigateway.py b/troposphere/apigateway.py
--- a/troposphere/apigateway.py
+++ b/troposphere/apigateway.py
@@ -1,5 +1,6 @@
-from . import AWSObject, AWSProperty
+from . import AWSHelperFn, AWSObject, AWSProperty
from .validators import positive_integer
+import json
def validate_authorizer_ttl(ttl_value):
@@ -183,9 +184,23 @@
"Description": (basestring, False),
"Name": (basestring, False),
"RestApiId": (basestring, True),
- "Schema": (basestring, False)
+ "Schema": ((basestring, dict), False)
}
+ def validate(self):
+ if 'Schema' in self.properties:
+ schema = self.properties.get('Schema')
+ if isinstance(schema, basestring):
+ # Verify it is a valid json string
+ json.loads(schema)
+ elif isinstance(schema, dict):
+ # Convert the dict to a basestring
+ self.properties['Schema'] = json.dumps(schema)
+ elif isinstance(schema, AWSHelperFn):
+ pass
+ else:
+ raise ValueError("Schema must be a str or dict")
+
class Resource(AWSObject):
resource_type = "AWS::ApiGateway::Resource"
|
{"golden_diff": "diff --git a/troposphere/apigateway.py b/troposphere/apigateway.py\n--- a/troposphere/apigateway.py\n+++ b/troposphere/apigateway.py\n@@ -1,5 +1,6 @@\n-from . import AWSObject, AWSProperty\n+from . import AWSHelperFn, AWSObject, AWSProperty\n from .validators import positive_integer\n+import json\n \n \n def validate_authorizer_ttl(ttl_value):\n@@ -183,9 +184,23 @@\n \"Description\": (basestring, False),\n \"Name\": (basestring, False),\n \"RestApiId\": (basestring, True),\n- \"Schema\": (basestring, False)\n+ \"Schema\": ((basestring, dict), False)\n }\n \n+ def validate(self):\n+ if 'Schema' in self.properties:\n+ schema = self.properties.get('Schema')\n+ if isinstance(schema, basestring):\n+ # Verify it is a valid json string\n+ json.loads(schema)\n+ elif isinstance(schema, dict):\n+ # Convert the dict to a basestring\n+ self.properties['Schema'] = json.dumps(schema)\n+ elif isinstance(schema, AWSHelperFn):\n+ pass\n+ else:\n+ raise ValueError(\"Schema must be a str or dict\")\n+\n \n class Resource(AWSObject):\n resource_type = \"AWS::ApiGateway::Resource\"\n", "issue": "ApiGateway Model Schema should be a Dict not a string\ntroposphere.apigateway.Model class contains a property called schema, it is defined as 'basestring', this property should be a dict.\r\n\r\nIdeally, you should supply a class to represent 'Schema'\n", "before_files": [{"content": "from . import AWSObject, AWSProperty\nfrom .validators import positive_integer\n\n\ndef validate_authorizer_ttl(ttl_value):\n \"\"\" Validate authorizer ttl timeout\n :param ttl_value: The TTL timeout in seconds\n :return: The provided TTL value if valid\n \"\"\"\n ttl_value = int(positive_integer(ttl_value))\n if ttl_value > 3600:\n raise ValueError(\"The AuthorizerResultTtlInSeconds should be <= 3600\")\n return ttl_value\n\n\nclass Account(AWSObject):\n resource_type = \"AWS::ApiGateway::Account\"\n\n props = {\n \"CloudWatchRoleArn\": (basestring, False)\n }\n\n\nclass StageKey(AWSProperty):\n\n props = {\n \"RestApiId\": (basestring, False),\n \"StageName\": (basestring, False)\n }\n\n\nclass ApiKey(AWSObject):\n resource_type = \"AWS::ApiGateway::ApiKey\"\n\n props = {\n \"Description\": (basestring, False),\n \"Enabled\": (bool, False),\n \"Name\": (basestring, False),\n \"StageKeys\": ([StageKey], False)\n }\n\n\nclass Authorizer(AWSObject):\n resource_type = \"AWS::ApiGateway::Authorizer\"\n\n props = {\n \"AuthorizerCredentials\": (basestring, False),\n \"AuthorizerResultTtlInSeconds\": (validate_authorizer_ttl, False),\n \"AuthorizerUri\": (basestring, True),\n \"IdentitySource\": (basestring, True),\n \"IdentityValidationExpression\": (basestring, False),\n \"Name\": (basestring, True),\n \"ProviderARNs\": ([basestring], False),\n \"RestApiId\": (basestring, False),\n \"Type\": (basestring, True)\n }\n\n\nclass BasePathMapping(AWSObject):\n resource_type = \"AWS::ApiGateway::BasePathMapping\"\n\n props = {\n \"BasePath\": (basestring, False),\n \"DomainName\": (basestring, True),\n \"RestApiId\": (basestring, True),\n \"Stage\": (basestring, False)\n }\n\n\nclass ClientCertificate(AWSObject):\n resource_type = \"AWS::ApiGateway::ClientCertificate\"\n\n props = {\n \"Description\": (basestring, False)\n }\n\n\nclass MethodSetting(AWSProperty):\n\n props = {\n \"CacheDataEncrypted\": (bool, False),\n \"CacheTtlInSeconds\": (positive_integer, False),\n \"CachingEnabled\": (bool, False),\n \"DataTraceEnabled\": (bool, False),\n \"HttpMethod\": (basestring, True),\n \"LoggingLevel\": (basestring, False),\n \"MetricsEnabled\": (bool, False),\n \"ResourcePath\": (basestring, True),\n \"ThrottlingBurstLimit\": (positive_integer, False),\n \"ThrottlingRateLimit\": (positive_integer, False)\n }\n\n\nclass StageDescription(AWSProperty):\n\n props = {\n \"CacheClusterEnabled\": (bool, False),\n \"CacheClusterSize\": (basestring, False),\n \"CacheDataEncrypted\": (bool, False),\n \"CacheTtlInSeconds\": (positive_integer, False),\n \"CachingEnabled\": (bool, False),\n \"ClientCertificateId\": (basestring, False),\n \"DataTraceEnabled\": (bool, False),\n \"Description\": (basestring, False),\n \"LoggingLevel\": (basestring, False),\n \"MethodSettings\": ([MethodSetting], False),\n \"MetricsEnabled\": (bool, False),\n \"StageName\": (basestring, False),\n \"ThrottlingBurstLimit\": (positive_integer, False),\n \"ThrottlingRateLimit\": (positive_integer, False),\n \"Variables\": (dict, False)\n }\n\n\nclass Deployment(AWSObject):\n resource_type = \"AWS::ApiGateway::Deployment\"\n\n props = {\n \"Description\": (basestring, False),\n \"RestApiId\": (basestring, True),\n \"StageDescription\": (StageDescription, False),\n \"StageName\": (basestring, False)\n }\n\n\nclass IntegrationResponse(AWSProperty):\n\n props = {\n \"ResponseParameters\": (dict, False),\n \"ResponseTemplates\": (dict, False),\n \"SelectionPattern\": (basestring, False),\n \"StatusCode\": (basestring, False)\n }\n\n\nclass Integration(AWSProperty):\n\n props = {\n \"CacheKeyParameters\": ([basestring], False),\n \"CacheNamespace\": (basestring, False),\n \"Credentials\": (basestring, False),\n \"IntegrationHttpMethod\": (basestring, False),\n \"IntegrationResponses\": ([IntegrationResponse], False),\n \"PassthroughBehavior\": (basestring, False),\n \"RequestParameters\": (dict, False),\n \"RequestTemplates\": (dict, False),\n \"Type\": (basestring, True),\n \"Uri\": (basestring, False)\n }\n\n\nclass MethodResponse(AWSProperty):\n\n props = {\n \"ResponseModels\": (dict, False),\n \"ResponseParameters\": (dict, False),\n \"StatusCode\": (basestring, True)\n }\n\n\nclass Method(AWSObject):\n resource_type = \"AWS::ApiGateway::Method\"\n\n props = {\n \"ApiKeyRequired\": (bool, False),\n \"AuthorizationType\": (basestring, True),\n \"AuthorizerId\": (basestring, False),\n \"HttpMethod\": (basestring, True),\n \"Integration\": (Integration, False),\n \"MethodResponses\": ([MethodResponse], False),\n \"RequestModels\": (dict, False),\n \"RequestParameters\": (dict, False),\n \"ResourceId\": (basestring, True),\n \"RestApiId\": (basestring, True)\n }\n\n\nclass Model(AWSObject):\n resource_type = \"AWS::ApiGateway::Model\"\n\n props = {\n \"ContentType\": (basestring, False),\n \"Description\": (basestring, False),\n \"Name\": (basestring, False),\n \"RestApiId\": (basestring, True),\n \"Schema\": (basestring, False)\n }\n\n\nclass Resource(AWSObject):\n resource_type = \"AWS::ApiGateway::Resource\"\n\n props = {\n \"ParentId\": (basestring, True),\n \"PathPart\": (basestring, True),\n \"RestApiId\": (basestring, True)\n }\n\n\nclass S3Location(AWSProperty):\n\n props = {\n \"Bucket\": (basestring, False),\n \"ETag\": (basestring, False),\n \"Key\": (basestring, False),\n \"Version\": (basestring, False)\n }\n\n\nclass RestApi(AWSObject):\n resource_type = \"AWS::ApiGateway::RestApi\"\n\n props = {\n \"Body\": (dict, False),\n \"BodyS3Location\": (S3Location, False),\n \"CloneFrom\": (basestring, False),\n \"Description\": (basestring, False),\n \"FailOnWarnings\": (basestring, False),\n \"Name\": (basestring, False),\n \"Parameters\": ([basestring], False)\n }\n\n\nclass Stage(AWSObject):\n resource_type = \"AWS::ApiGateway::Stage\"\n\n props = {\n \"CacheClusterEnabled\": (bool, False),\n \"CacheClusterSize\": (basestring, False),\n \"ClientCertificateId\": (basestring, False),\n \"DeploymentId\": (basestring, True),\n \"Description\": (basestring, False),\n \"MethodSettings\": ([MethodSetting], False),\n \"RestApiId\": (basestring, True),\n \"StageName\": (basestring, True),\n \"Variables\": (dict, False)\n }\n\n\nclass ApiStage(AWSProperty):\n props = {\n \"ApiId\": (basestring, False),\n \"Stage\": (basestring, False),\n }\n\n\nclass QuotaSettings(AWSProperty):\n props = {\n \"Limit\": (positive_integer, False),\n \"Offset\": (positive_integer, False),\n \"Period\": (basestring, False),\n }\n\n\nclass ThrottleSettings(AWSProperty):\n props = {\n \"BurstLimit\": (positive_integer, False),\n \"RateLimit\": (positive_integer, False),\n }\n\n\nclass UsagePlan(AWSObject):\n resource_type = \"AWS::ApiGateway::UsagePlan\"\n\n props = {\n \"ApiStages\": ([ApiStage], False),\n \"Description\": (basestring, False),\n \"Quota\": (QuotaSettings, False),\n \"Throttle\": (ThrottleSettings, False),\n \"UsagePlanName\": (basestring, False),\n }\n", "path": "troposphere/apigateway.py"}]}
| 3,196 | 302 |
gh_patches_debug_17815
|
rasdani/github-patches
|
git_diff
|
bentoml__BentoML-1211
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Cannot delete bento that was created with same name:version as an older (deleted) bento
**Describe the bug**
After deleting a bento, I cannot delete another bento that was created with that same name:version.
**To Reproduce**
1. Create a bento with `name:1` through `model_service.save(version='1')`.
2. In a shell, `bentoml delete name:1`
3. Create a new bento with the same name, again with `model_service.save(version='1')`.
4. Try to `bentoml delete name:1`
The error is the following:
```
Are you sure about delete name:1? This will delete the BentoService saved bundle files permanently [y/N]: y
[2020-10-27 15:22:33,477] ERROR - RPC ERROR DangerouslyDeleteBento: Multiple rows were found for one()
Error: bentoml-cli delete failed: INTERNAL:Multiple rows were found for one()
```
**Expected behavior**
I can endlessly delete and recreate bentos with the same name/version for testing.
**Environment:**
- OS: Ubuntu 20.04
- Python 3.8.5
- BentoML Version 0.9.2
</issue>
<code>
[start of bentoml/yatai/repository/metadata_store.py]
1 # Copyright 2019 Atalaya Tech, Inc.
2
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6
7 # http://www.apache.org/licenses/LICENSE-2.0
8
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import logging
16 import datetime
17
18 from sqlalchemy import (
19 Column,
20 Enum,
21 String,
22 Integer,
23 JSON,
24 Boolean,
25 DateTime,
26 UniqueConstraint,
27 desc,
28 )
29 from sqlalchemy.orm.exc import NoResultFound
30 from google.protobuf.json_format import ParseDict
31
32 from bentoml.utils import ProtoMessageToDict
33 from bentoml.exceptions import YataiRepositoryException
34 from bentoml.yatai.db import Base, create_session
35 from bentoml.yatai.label_store import (
36 filter_label_query,
37 get_labels,
38 list_labels,
39 add_or_update_labels,
40 RESOURCE_TYPE,
41 )
42 from bentoml.yatai.proto.repository_pb2 import (
43 UploadStatus,
44 BentoUri,
45 BentoServiceMetadata,
46 Bento as BentoPB,
47 ListBentoRequest,
48 )
49
50 logger = logging.getLogger(__name__)
51
52
53 DEFAULT_UPLOAD_STATUS = UploadStatus(status=UploadStatus.UNINITIALIZED)
54 DEFAULT_LIST_LIMIT = 40
55
56
57 class Bento(Base):
58 __tablename__ = 'bentos'
59 __table_args__ = tuple(UniqueConstraint('name', 'version', name='_name_version_uc'))
60
61 id = Column(Integer, primary_key=True)
62 name = Column(String, nullable=False)
63 version = Column(String, nullable=False)
64
65 # Storage URI for this Bento
66 uri = Column(String, nullable=False)
67
68 # Name is required for PostgreSQL and any future supported database which
69 # requires an explicitly named type, or an explicitly named constraint in order to
70 # generate the type and/or a table that uses it.
71 uri_type = Column(
72 Enum(*BentoUri.StorageType.keys(), name='uri_type'), default=BentoUri.UNSET
73 )
74
75 # JSON filed mapping directly to BentoServiceMetadata proto message
76 bento_service_metadata = Column(JSON, nullable=False, default={})
77
78 # Time of AddBento call, the time of Bento creation can be found in metadata field
79 created_at = Column(DateTime, default=datetime.datetime.utcnow)
80
81 # latest upload status, JSON message also includes last update timestamp
82 upload_status = Column(
83 JSON, nullable=False, default=ProtoMessageToDict(DEFAULT_UPLOAD_STATUS)
84 )
85
86 # mark as deleted
87 deleted = Column(Boolean, default=False)
88
89
90 def _bento_orm_obj_to_pb(bento_obj, labels=None):
91 # Backwards compatible support loading saved bundle created before 0.8.0
92 if (
93 'apis' in bento_obj.bento_service_metadata
94 and bento_obj.bento_service_metadata['apis']
95 ):
96 for api in bento_obj.bento_service_metadata['apis']:
97 if 'handler_type' in api:
98 api['input_type'] = api['handler_type']
99 del api['handler_type']
100 if 'handler_config' in api:
101 api['input_config'] = api['handler_config']
102 del api['handler_config']
103 if 'output_type' not in api:
104 api['output_type'] = 'DefaultOutput'
105
106 bento_service_metadata_pb = ParseDict(
107 bento_obj.bento_service_metadata, BentoServiceMetadata()
108 )
109 bento_uri = BentoUri(
110 uri=bento_obj.uri, type=BentoUri.StorageType.Value(bento_obj.uri_type)
111 )
112 if labels is not None:
113 bento_service_metadata_pb.labels.update(labels)
114 return BentoPB(
115 name=bento_obj.name,
116 version=bento_obj.version,
117 uri=bento_uri,
118 bento_service_metadata=bento_service_metadata_pb,
119 )
120
121
122 class BentoMetadataStore(object):
123 def __init__(self, sess_maker):
124 self.sess_maker = sess_maker
125
126 def add(self, bento_name, bento_version, uri, uri_type):
127 with create_session(self.sess_maker) as sess:
128 bento_obj = Bento()
129 bento_obj.name = bento_name
130 bento_obj.version = bento_version
131 bento_obj.uri = uri
132 bento_obj.uri_type = BentoUri.StorageType.Name(uri_type)
133 return sess.add(bento_obj)
134
135 def _get_latest(self, bento_name):
136 with create_session(self.sess_maker) as sess:
137 query = (
138 sess.query(Bento)
139 .filter_by(name=bento_name, deleted=False)
140 .order_by(desc(Bento.created_at))
141 .limit(1)
142 )
143
144 query_result = query.all()
145 if len(query_result) == 1:
146 labels = get_labels(sess, RESOURCE_TYPE.bento, query_result[0].id)
147 return _bento_orm_obj_to_pb(query_result[0], labels)
148 else:
149 return None
150
151 def get(self, bento_name, bento_version="latest"):
152 if bento_version.lower() == "latest":
153 return self._get_latest(bento_name)
154
155 with create_session(self.sess_maker) as sess:
156 try:
157 bento_obj = (
158 sess.query(Bento)
159 .filter_by(name=bento_name, version=bento_version)
160 .one()
161 )
162 if bento_obj.deleted:
163 # bento has been marked as deleted
164 return None
165 labels = get_labels(sess, RESOURCE_TYPE.bento, bento_obj.id)
166 return _bento_orm_obj_to_pb(bento_obj, labels)
167 except NoResultFound:
168 return None
169
170 def update_bento_service_metadata(
171 self, bento_name, bento_version, bento_service_metadata_pb
172 ):
173 with create_session(self.sess_maker) as sess:
174 try:
175 bento_obj = (
176 sess.query(Bento)
177 .filter_by(name=bento_name, version=bento_version, deleted=False)
178 .one()
179 )
180 service_metadata = ProtoMessageToDict(bento_service_metadata_pb)
181 bento_obj.bento_service_metadata = service_metadata
182 if service_metadata.get('labels', None) is not None:
183 bento = (
184 sess.query(Bento)
185 .filter_by(name=bento_name, version=bento_version)
186 .one()
187 )
188 add_or_update_labels(
189 sess, RESOURCE_TYPE.bento, bento.id, service_metadata['labels']
190 )
191 except NoResultFound:
192 raise YataiRepositoryException(
193 "Bento %s:%s is not found in repository" % bento_name, bento_version
194 )
195
196 def update_upload_status(self, bento_name, bento_version, upload_status_pb):
197 with create_session(self.sess_maker) as sess:
198 try:
199 bento_obj = (
200 sess.query(Bento)
201 .filter_by(name=bento_name, version=bento_version, deleted=False)
202 .one()
203 )
204 # TODO:
205 # if bento_obj.upload_status and bento_obj.upload_status.updated_at >
206 # upload_status_pb.updated_at, update should be ignored
207 bento_obj.upload_status = ProtoMessageToDict(upload_status_pb)
208 except NoResultFound:
209 raise YataiRepositoryException(
210 "Bento %s:%s is not found in repository" % bento_name, bento_version
211 )
212
213 def dangerously_delete(self, bento_name, bento_version):
214 with create_session(self.sess_maker) as sess:
215 try:
216 bento_obj = (
217 sess.query(Bento)
218 .filter_by(name=bento_name, version=bento_version)
219 .one()
220 )
221 if bento_obj.deleted:
222 raise YataiRepositoryException(
223 "Bento {}:{} has already been deleted".format(
224 bento_name, bento_version
225 )
226 )
227 bento_obj.deleted = True
228 except NoResultFound:
229 raise YataiRepositoryException(
230 "Bento %s:%s is not found in repository" % bento_name, bento_version
231 )
232
233 def list(
234 self,
235 bento_name=None,
236 offset=None,
237 limit=None,
238 label_selectors=None,
239 order_by=ListBentoRequest.created_at,
240 ascending_order=False,
241 ):
242 with create_session(self.sess_maker) as sess:
243 query = sess.query(Bento)
244 order_by = ListBentoRequest.SORTABLE_COLUMN.Name(order_by)
245 order_by_field = getattr(Bento, order_by)
246 order_by_action = (
247 order_by_field if ascending_order else desc(order_by_field)
248 )
249 query = query.order_by(order_by_action)
250 if bento_name:
251 # filter_by apply filtering criterion to a copy of the query
252 query = query.filter_by(name=bento_name)
253 query = query.filter_by(deleted=False)
254 if label_selectors.match_labels or label_selectors.match_expressions:
255 bento_ids = filter_label_query(
256 sess, RESOURCE_TYPE.bento, label_selectors
257 )
258 query = query.filter(Bento.id.in_(bento_ids))
259
260 # We are not defaulting limit to 200 in the signature,
261 # because protobuf will pass 0 as value
262 limit = limit or DEFAULT_LIST_LIMIT
263 # Limit and offset need to be called after order_by filter/filter_by is
264 # called
265 query = query.limit(limit)
266 if offset:
267 query = query.offset(offset)
268
269 query_result = query.all()
270 bento_ids = [bento_obj.id for bento_obj in query_result]
271 labels = list_labels(sess, RESOURCE_TYPE.bento, bento_ids)
272 result = [
273 _bento_orm_obj_to_pb(bento_obj, labels.get(str(bento_obj.id)))
274 for bento_obj in query_result
275 ]
276 return result
277
[end of bentoml/yatai/repository/metadata_store.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bentoml/yatai/repository/metadata_store.py b/bentoml/yatai/repository/metadata_store.py
--- a/bentoml/yatai/repository/metadata_store.py
+++ b/bentoml/yatai/repository/metadata_store.py
@@ -156,7 +156,7 @@
try:
bento_obj = (
sess.query(Bento)
- .filter_by(name=bento_name, version=bento_version)
+ .filter_by(name=bento_name, version=bento_version, deleted=False)
.one()
)
if bento_obj.deleted:
@@ -215,7 +215,7 @@
try:
bento_obj = (
sess.query(Bento)
- .filter_by(name=bento_name, version=bento_version)
+ .filter_by(name=bento_name, version=bento_version, deleted=False)
.one()
)
if bento_obj.deleted:
|
{"golden_diff": "diff --git a/bentoml/yatai/repository/metadata_store.py b/bentoml/yatai/repository/metadata_store.py\n--- a/bentoml/yatai/repository/metadata_store.py\n+++ b/bentoml/yatai/repository/metadata_store.py\n@@ -156,7 +156,7 @@\n try:\n bento_obj = (\n sess.query(Bento)\n- .filter_by(name=bento_name, version=bento_version)\n+ .filter_by(name=bento_name, version=bento_version, deleted=False)\n .one()\n )\n if bento_obj.deleted:\n@@ -215,7 +215,7 @@\n try:\n bento_obj = (\n sess.query(Bento)\n- .filter_by(name=bento_name, version=bento_version)\n+ .filter_by(name=bento_name, version=bento_version, deleted=False)\n .one()\n )\n if bento_obj.deleted:\n", "issue": "Cannot delete bento that was created with same name:version as an older (deleted) bento\n**Describe the bug**\r\nAfter deleting a bento, I cannot delete another bento that was created with that same name:version.\r\n\r\n**To Reproduce**\r\n1. Create a bento with `name:1` through `model_service.save(version='1')`.\r\n2. In a shell, `bentoml delete name:1`\r\n3. Create a new bento with the same name, again with `model_service.save(version='1')`.\r\n4. Try to `bentoml delete name:1`\r\n\r\nThe error is the following:\r\n```\r\nAre you sure about delete name:1? This will delete the BentoService saved bundle files permanently [y/N]: y \r\n[2020-10-27 15:22:33,477] ERROR - RPC ERROR DangerouslyDeleteBento: Multiple rows were found for one() \r\nError: bentoml-cli delete failed: INTERNAL:Multiple rows were found for one() \r\n```\r\n**Expected behavior**\r\nI can endlessly delete and recreate bentos with the same name/version for testing.\r\n\r\n**Environment:**\r\n - OS: Ubuntu 20.04\r\n - Python 3.8.5\r\n - BentoML Version 0.9.2\r\n\n", "before_files": [{"content": "# Copyright 2019 Atalaya Tech, Inc.\n\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n\n# http://www.apache.org/licenses/LICENSE-2.0\n\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport logging\nimport datetime\n\nfrom sqlalchemy import (\n Column,\n Enum,\n String,\n Integer,\n JSON,\n Boolean,\n DateTime,\n UniqueConstraint,\n desc,\n)\nfrom sqlalchemy.orm.exc import NoResultFound\nfrom google.protobuf.json_format import ParseDict\n\nfrom bentoml.utils import ProtoMessageToDict\nfrom bentoml.exceptions import YataiRepositoryException\nfrom bentoml.yatai.db import Base, create_session\nfrom bentoml.yatai.label_store import (\n filter_label_query,\n get_labels,\n list_labels,\n add_or_update_labels,\n RESOURCE_TYPE,\n)\nfrom bentoml.yatai.proto.repository_pb2 import (\n UploadStatus,\n BentoUri,\n BentoServiceMetadata,\n Bento as BentoPB,\n ListBentoRequest,\n)\n\nlogger = logging.getLogger(__name__)\n\n\nDEFAULT_UPLOAD_STATUS = UploadStatus(status=UploadStatus.UNINITIALIZED)\nDEFAULT_LIST_LIMIT = 40\n\n\nclass Bento(Base):\n __tablename__ = 'bentos'\n __table_args__ = tuple(UniqueConstraint('name', 'version', name='_name_version_uc'))\n\n id = Column(Integer, primary_key=True)\n name = Column(String, nullable=False)\n version = Column(String, nullable=False)\n\n # Storage URI for this Bento\n uri = Column(String, nullable=False)\n\n # Name is required for PostgreSQL and any future supported database which\n # requires an explicitly named type, or an explicitly named constraint in order to\n # generate the type and/or a table that uses it.\n uri_type = Column(\n Enum(*BentoUri.StorageType.keys(), name='uri_type'), default=BentoUri.UNSET\n )\n\n # JSON filed mapping directly to BentoServiceMetadata proto message\n bento_service_metadata = Column(JSON, nullable=False, default={})\n\n # Time of AddBento call, the time of Bento creation can be found in metadata field\n created_at = Column(DateTime, default=datetime.datetime.utcnow)\n\n # latest upload status, JSON message also includes last update timestamp\n upload_status = Column(\n JSON, nullable=False, default=ProtoMessageToDict(DEFAULT_UPLOAD_STATUS)\n )\n\n # mark as deleted\n deleted = Column(Boolean, default=False)\n\n\ndef _bento_orm_obj_to_pb(bento_obj, labels=None):\n # Backwards compatible support loading saved bundle created before 0.8.0\n if (\n 'apis' in bento_obj.bento_service_metadata\n and bento_obj.bento_service_metadata['apis']\n ):\n for api in bento_obj.bento_service_metadata['apis']:\n if 'handler_type' in api:\n api['input_type'] = api['handler_type']\n del api['handler_type']\n if 'handler_config' in api:\n api['input_config'] = api['handler_config']\n del api['handler_config']\n if 'output_type' not in api:\n api['output_type'] = 'DefaultOutput'\n\n bento_service_metadata_pb = ParseDict(\n bento_obj.bento_service_metadata, BentoServiceMetadata()\n )\n bento_uri = BentoUri(\n uri=bento_obj.uri, type=BentoUri.StorageType.Value(bento_obj.uri_type)\n )\n if labels is not None:\n bento_service_metadata_pb.labels.update(labels)\n return BentoPB(\n name=bento_obj.name,\n version=bento_obj.version,\n uri=bento_uri,\n bento_service_metadata=bento_service_metadata_pb,\n )\n\n\nclass BentoMetadataStore(object):\n def __init__(self, sess_maker):\n self.sess_maker = sess_maker\n\n def add(self, bento_name, bento_version, uri, uri_type):\n with create_session(self.sess_maker) as sess:\n bento_obj = Bento()\n bento_obj.name = bento_name\n bento_obj.version = bento_version\n bento_obj.uri = uri\n bento_obj.uri_type = BentoUri.StorageType.Name(uri_type)\n return sess.add(bento_obj)\n\n def _get_latest(self, bento_name):\n with create_session(self.sess_maker) as sess:\n query = (\n sess.query(Bento)\n .filter_by(name=bento_name, deleted=False)\n .order_by(desc(Bento.created_at))\n .limit(1)\n )\n\n query_result = query.all()\n if len(query_result) == 1:\n labels = get_labels(sess, RESOURCE_TYPE.bento, query_result[0].id)\n return _bento_orm_obj_to_pb(query_result[0], labels)\n else:\n return None\n\n def get(self, bento_name, bento_version=\"latest\"):\n if bento_version.lower() == \"latest\":\n return self._get_latest(bento_name)\n\n with create_session(self.sess_maker) as sess:\n try:\n bento_obj = (\n sess.query(Bento)\n .filter_by(name=bento_name, version=bento_version)\n .one()\n )\n if bento_obj.deleted:\n # bento has been marked as deleted\n return None\n labels = get_labels(sess, RESOURCE_TYPE.bento, bento_obj.id)\n return _bento_orm_obj_to_pb(bento_obj, labels)\n except NoResultFound:\n return None\n\n def update_bento_service_metadata(\n self, bento_name, bento_version, bento_service_metadata_pb\n ):\n with create_session(self.sess_maker) as sess:\n try:\n bento_obj = (\n sess.query(Bento)\n .filter_by(name=bento_name, version=bento_version, deleted=False)\n .one()\n )\n service_metadata = ProtoMessageToDict(bento_service_metadata_pb)\n bento_obj.bento_service_metadata = service_metadata\n if service_metadata.get('labels', None) is not None:\n bento = (\n sess.query(Bento)\n .filter_by(name=bento_name, version=bento_version)\n .one()\n )\n add_or_update_labels(\n sess, RESOURCE_TYPE.bento, bento.id, service_metadata['labels']\n )\n except NoResultFound:\n raise YataiRepositoryException(\n \"Bento %s:%s is not found in repository\" % bento_name, bento_version\n )\n\n def update_upload_status(self, bento_name, bento_version, upload_status_pb):\n with create_session(self.sess_maker) as sess:\n try:\n bento_obj = (\n sess.query(Bento)\n .filter_by(name=bento_name, version=bento_version, deleted=False)\n .one()\n )\n # TODO:\n # if bento_obj.upload_status and bento_obj.upload_status.updated_at >\n # upload_status_pb.updated_at, update should be ignored\n bento_obj.upload_status = ProtoMessageToDict(upload_status_pb)\n except NoResultFound:\n raise YataiRepositoryException(\n \"Bento %s:%s is not found in repository\" % bento_name, bento_version\n )\n\n def dangerously_delete(self, bento_name, bento_version):\n with create_session(self.sess_maker) as sess:\n try:\n bento_obj = (\n sess.query(Bento)\n .filter_by(name=bento_name, version=bento_version)\n .one()\n )\n if bento_obj.deleted:\n raise YataiRepositoryException(\n \"Bento {}:{} has already been deleted\".format(\n bento_name, bento_version\n )\n )\n bento_obj.deleted = True\n except NoResultFound:\n raise YataiRepositoryException(\n \"Bento %s:%s is not found in repository\" % bento_name, bento_version\n )\n\n def list(\n self,\n bento_name=None,\n offset=None,\n limit=None,\n label_selectors=None,\n order_by=ListBentoRequest.created_at,\n ascending_order=False,\n ):\n with create_session(self.sess_maker) as sess:\n query = sess.query(Bento)\n order_by = ListBentoRequest.SORTABLE_COLUMN.Name(order_by)\n order_by_field = getattr(Bento, order_by)\n order_by_action = (\n order_by_field if ascending_order else desc(order_by_field)\n )\n query = query.order_by(order_by_action)\n if bento_name:\n # filter_by apply filtering criterion to a copy of the query\n query = query.filter_by(name=bento_name)\n query = query.filter_by(deleted=False)\n if label_selectors.match_labels or label_selectors.match_expressions:\n bento_ids = filter_label_query(\n sess, RESOURCE_TYPE.bento, label_selectors\n )\n query = query.filter(Bento.id.in_(bento_ids))\n\n # We are not defaulting limit to 200 in the signature,\n # because protobuf will pass 0 as value\n limit = limit or DEFAULT_LIST_LIMIT\n # Limit and offset need to be called after order_by filter/filter_by is\n # called\n query = query.limit(limit)\n if offset:\n query = query.offset(offset)\n\n query_result = query.all()\n bento_ids = [bento_obj.id for bento_obj in query_result]\n labels = list_labels(sess, RESOURCE_TYPE.bento, bento_ids)\n result = [\n _bento_orm_obj_to_pb(bento_obj, labels.get(str(bento_obj.id)))\n for bento_obj in query_result\n ]\n return result\n", "path": "bentoml/yatai/repository/metadata_store.py"}]}
| 3,735 | 210 |
gh_patches_debug_541
|
rasdani/github-patches
|
git_diff
|
pyodide__pyodide-4806
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`pyodide build -h` should print help text
## 🐛 Bug
`pyodide build -h` treats `-h` as a package name rather than as a request for help text.
</issue>
<code>
[start of pyodide-build/pyodide_build/cli/build.py]
1 import re
2 import shutil
3 import sys
4 import tempfile
5 from pathlib import Path
6 from typing import Optional, cast, get_args
7 from urllib.parse import urlparse
8
9 import requests
10 import typer
11 from build import ConfigSettingsType
12
13 from ..build_env import check_emscripten_version, get_pyodide_root, init_environment
14 from ..io import _BuildSpecExports, _ExportTypes
15 from ..logger import logger
16 from ..out_of_tree import build
17 from ..out_of_tree.pypi import (
18 build_dependencies_for_wheel,
19 build_wheels_from_pypi_requirements,
20 fetch_pypi_package,
21 )
22 from ..pypabuild import parse_backend_flags
23
24
25 def convert_exports(exports: str) -> _BuildSpecExports:
26 if "," in exports:
27 return [x.strip() for x in exports.split(",") if x.strip()]
28 possible_exports = get_args(_ExportTypes)
29 if exports in possible_exports:
30 return cast(_ExportTypes, exports)
31 logger.stderr(
32 f"Expected exports to be one of "
33 '"pyinit", "requested", "whole_archive", '
34 "or a comma separated list of symbols to export. "
35 f'Got "{exports}".'
36 )
37 sys.exit(1)
38
39
40 def pypi(
41 package: str,
42 output_directory: Path,
43 exports: str,
44 config_settings: ConfigSettingsType,
45 ) -> Path:
46 """Fetch a wheel from pypi, or build from source if none available."""
47 with tempfile.TemporaryDirectory() as tmpdir:
48 srcdir = Path(tmpdir)
49
50 # get package from pypi
51 package_path = fetch_pypi_package(package, srcdir)
52 if not package_path.is_dir():
53 # a pure-python wheel has been downloaded - just copy to dist folder
54 dest_file = output_directory / package_path.name
55 shutil.copyfile(str(package_path), output_directory / package_path.name)
56 print(f"Successfully fetched: {package_path.name}")
57 return dest_file
58
59 built_wheel = build.run(
60 srcdir,
61 output_directory,
62 convert_exports(exports),
63 config_settings,
64 )
65 return built_wheel
66
67
68 def download_url(url: str, output_directory: Path) -> str:
69 with requests.get(url, stream=True) as response:
70 urlpath = Path(urlparse(response.url).path)
71 if urlpath.suffix == ".gz":
72 urlpath = urlpath.with_suffix("")
73 file_name = urlpath.name
74 with open(output_directory / file_name, "wb") as f:
75 for chunk in response.iter_content(chunk_size=1 << 20):
76 f.write(chunk)
77 return file_name
78
79
80 def url(
81 package_url: str,
82 output_directory: Path,
83 exports: str,
84 config_settings: ConfigSettingsType,
85 ) -> Path:
86 """Fetch a wheel or build sdist from url."""
87 with tempfile.TemporaryDirectory() as tmpdir:
88 tmppath = Path(tmpdir)
89 filename = download_url(package_url, tmppath)
90 if Path(filename).suffix == ".whl":
91 shutil.move(tmppath / filename, output_directory / filename)
92 return output_directory / filename
93
94 builddir = tmppath / "build"
95 shutil.unpack_archive(tmppath / filename, builddir)
96 files = list(builddir.iterdir())
97 if len(files) == 1 and files[0].is_dir():
98 # unzipped into subfolder
99 builddir = files[0]
100 wheel_path = build.run(
101 builddir, output_directory, convert_exports(exports), config_settings
102 )
103 return wheel_path
104
105
106 def source(
107 source_location: Path,
108 output_directory: Path,
109 exports: str,
110 config_settings: ConfigSettingsType,
111 ) -> Path:
112 """Use pypa/build to build a Python package from source"""
113 built_wheel = build.run(
114 source_location, output_directory, convert_exports(exports), config_settings
115 )
116 return built_wheel
117
118
119 # simple 'pyodide build' command
120 def main(
121 source_location: Optional[str] = typer.Argument( # noqa: UP007 typer does not accept list[str] | None yet.
122 "",
123 help="Build source, can be source folder, pypi version specification, "
124 "or url to a source dist archive or wheel file. If this is blank, it "
125 "will build the current directory.",
126 ),
127 output_directory: str = typer.Option(
128 "",
129 "--outdir",
130 "-o",
131 help="which directory should the output be placed into?",
132 ),
133 requirements_txt: str = typer.Option(
134 "",
135 "--requirements",
136 "-r",
137 help="Build a list of package requirements from a requirements.txt file",
138 ),
139 exports: str = typer.Option(
140 "requested",
141 envvar="PYODIDE_BUILD_EXPORTS",
142 help="Which symbols should be exported when linking .so files?",
143 ),
144 build_dependencies: bool = typer.Option(
145 False, help="Fetch dependencies from pypi and build them too."
146 ),
147 output_lockfile: str = typer.Option(
148 "",
149 help="Output list of resolved dependencies to a file in requirements.txt format",
150 ),
151 skip_dependency: list[str] = typer.Option(
152 [],
153 help="Skip building or resolving a single dependency, or a pyodide-lock.json file. "
154 "Use multiple times or provide a comma separated list to skip multiple dependencies.",
155 ),
156 skip_built_in_packages: bool = typer.Option(
157 True,
158 help="Don't build dependencies that are built into the pyodide distribution.",
159 ),
160 compression_level: int = typer.Option(
161 6, help="Compression level to use for the created zip file"
162 ),
163 config_setting: Optional[list[str]] = typer.Option( # noqa: UP007 typer does not accept list[str] | None yet.
164 None,
165 "--config-setting",
166 "-C",
167 help=(
168 "Settings to pass to the backend. "
169 "Works same as the --config-setting option of pypa/build."
170 ),
171 metavar="KEY[=VALUE]",
172 ),
173 ctx: typer.Context = typer.Context, # type: ignore[assignment]
174 ) -> None:
175 """Use pypa/build to build a Python package from source, pypi or url."""
176 init_environment()
177 try:
178 check_emscripten_version()
179 except RuntimeError as e:
180 print(e.args[0], file=sys.stderr)
181 sys.exit(1)
182
183 output_directory = output_directory or "./dist"
184
185 outpath = Path(output_directory).resolve()
186 outpath.mkdir(exist_ok=True)
187 extras: list[str] = []
188
189 # For backward compatibility, in addition to the `--config-setting` arguments, we also support
190 # passing config settings as positional arguments.
191 config_settings = parse_backend_flags((config_setting or []) + ctx.args)
192
193 if skip_built_in_packages:
194 package_lock_json = get_pyodide_root() / "dist" / "pyodide-lock.json"
195 skip_dependency.append(str(package_lock_json.absolute()))
196
197 if len(requirements_txt) > 0:
198 # a requirements.txt - build it (and optionally deps)
199 if not Path(requirements_txt).exists():
200 raise RuntimeError(
201 f"Couldn't find requirements text file {requirements_txt}"
202 )
203 reqs = []
204 with open(requirements_txt) as f:
205 raw_reqs = [x.strip() for x in f.readlines()]
206 for x in raw_reqs:
207 # remove comments
208 comment_pos = x.find("#")
209 if comment_pos != -1:
210 x = x[:comment_pos].strip()
211 if len(x) > 0:
212 if x[0] == "-":
213 raise RuntimeError(
214 f"pyodide build only supports name-based PEP508 requirements. [{x}] will not work."
215 )
216 if x.find("@") != -1:
217 raise RuntimeError(
218 f"pyodide build does not support URL based requirements. [{x}] will not work"
219 )
220 reqs.append(x)
221 try:
222 build_wheels_from_pypi_requirements(
223 reqs,
224 outpath,
225 build_dependencies,
226 skip_dependency,
227 # TODO: should we really use same "exports" value for all of our
228 # dependencies? Not sure this makes sense...
229 convert_exports(exports),
230 config_settings,
231 output_lockfile=output_lockfile,
232 )
233 except BaseException as e:
234 import traceback
235
236 print("Failed building multiple wheels:", traceback.format_exc())
237 raise e
238 return
239
240 if source_location is not None:
241 extras = re.findall(r"\[(\w+)\]", source_location)
242 if len(extras) != 0:
243 source_location = source_location[0 : source_location.find("[")]
244 if not source_location:
245 # build the current folder
246 wheel = source(Path.cwd(), outpath, exports, config_settings)
247 elif source_location.find("://") != -1:
248 wheel = url(source_location, outpath, exports, config_settings)
249 elif Path(source_location).is_dir():
250 # a folder, build it
251 wheel = source(
252 Path(source_location).resolve(), outpath, exports, config_settings
253 )
254 elif source_location.find("/") == -1:
255 # try fetch or build from pypi
256 wheel = pypi(source_location, outpath, exports, config_settings)
257 else:
258 raise RuntimeError(f"Couldn't determine source type for {source_location}")
259 # now build deps for wheel
260 if build_dependencies:
261 try:
262 build_dependencies_for_wheel(
263 wheel,
264 extras,
265 skip_dependency,
266 # TODO: should we really use same "exports" value for all of our
267 # dependencies? Not sure this makes sense...
268 convert_exports(exports),
269 config_settings,
270 output_lockfile=output_lockfile,
271 compression_level=compression_level,
272 )
273 except BaseException as e:
274 import traceback
275
276 print("Failed building dependencies for wheel:", traceback.format_exc())
277 wheel.unlink()
278 raise e
279
280
281 main.typer_kwargs = { # type: ignore[attr-defined]
282 "context_settings": {
283 "ignore_unknown_options": True,
284 "allow_extra_args": True,
285 },
286 }
287
[end of pyodide-build/pyodide_build/cli/build.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pyodide-build/pyodide_build/cli/build.py b/pyodide-build/pyodide_build/cli/build.py
--- a/pyodide-build/pyodide_build/cli/build.py
+++ b/pyodide-build/pyodide_build/cli/build.py
@@ -282,5 +282,6 @@
"context_settings": {
"ignore_unknown_options": True,
"allow_extra_args": True,
+ "help_option_names": ["-h", "--help"],
},
}
|
{"golden_diff": "diff --git a/pyodide-build/pyodide_build/cli/build.py b/pyodide-build/pyodide_build/cli/build.py\n--- a/pyodide-build/pyodide_build/cli/build.py\n+++ b/pyodide-build/pyodide_build/cli/build.py\n@@ -282,5 +282,6 @@\n \"context_settings\": {\n \"ignore_unknown_options\": True,\n \"allow_extra_args\": True,\n+ \"help_option_names\": [\"-h\", \"--help\"],\n },\n }\n", "issue": "`pyodide build -h` should print help text\n## \ud83d\udc1b Bug\r\n\r\n`pyodide build -h` treats `-h` as a package name rather than as a request for help text.\n", "before_files": [{"content": "import re\nimport shutil\nimport sys\nimport tempfile\nfrom pathlib import Path\nfrom typing import Optional, cast, get_args\nfrom urllib.parse import urlparse\n\nimport requests\nimport typer\nfrom build import ConfigSettingsType\n\nfrom ..build_env import check_emscripten_version, get_pyodide_root, init_environment\nfrom ..io import _BuildSpecExports, _ExportTypes\nfrom ..logger import logger\nfrom ..out_of_tree import build\nfrom ..out_of_tree.pypi import (\n build_dependencies_for_wheel,\n build_wheels_from_pypi_requirements,\n fetch_pypi_package,\n)\nfrom ..pypabuild import parse_backend_flags\n\n\ndef convert_exports(exports: str) -> _BuildSpecExports:\n if \",\" in exports:\n return [x.strip() for x in exports.split(\",\") if x.strip()]\n possible_exports = get_args(_ExportTypes)\n if exports in possible_exports:\n return cast(_ExportTypes, exports)\n logger.stderr(\n f\"Expected exports to be one of \"\n '\"pyinit\", \"requested\", \"whole_archive\", '\n \"or a comma separated list of symbols to export. \"\n f'Got \"{exports}\".'\n )\n sys.exit(1)\n\n\ndef pypi(\n package: str,\n output_directory: Path,\n exports: str,\n config_settings: ConfigSettingsType,\n) -> Path:\n \"\"\"Fetch a wheel from pypi, or build from source if none available.\"\"\"\n with tempfile.TemporaryDirectory() as tmpdir:\n srcdir = Path(tmpdir)\n\n # get package from pypi\n package_path = fetch_pypi_package(package, srcdir)\n if not package_path.is_dir():\n # a pure-python wheel has been downloaded - just copy to dist folder\n dest_file = output_directory / package_path.name\n shutil.copyfile(str(package_path), output_directory / package_path.name)\n print(f\"Successfully fetched: {package_path.name}\")\n return dest_file\n\n built_wheel = build.run(\n srcdir,\n output_directory,\n convert_exports(exports),\n config_settings,\n )\n return built_wheel\n\n\ndef download_url(url: str, output_directory: Path) -> str:\n with requests.get(url, stream=True) as response:\n urlpath = Path(urlparse(response.url).path)\n if urlpath.suffix == \".gz\":\n urlpath = urlpath.with_suffix(\"\")\n file_name = urlpath.name\n with open(output_directory / file_name, \"wb\") as f:\n for chunk in response.iter_content(chunk_size=1 << 20):\n f.write(chunk)\n return file_name\n\n\ndef url(\n package_url: str,\n output_directory: Path,\n exports: str,\n config_settings: ConfigSettingsType,\n) -> Path:\n \"\"\"Fetch a wheel or build sdist from url.\"\"\"\n with tempfile.TemporaryDirectory() as tmpdir:\n tmppath = Path(tmpdir)\n filename = download_url(package_url, tmppath)\n if Path(filename).suffix == \".whl\":\n shutil.move(tmppath / filename, output_directory / filename)\n return output_directory / filename\n\n builddir = tmppath / \"build\"\n shutil.unpack_archive(tmppath / filename, builddir)\n files = list(builddir.iterdir())\n if len(files) == 1 and files[0].is_dir():\n # unzipped into subfolder\n builddir = files[0]\n wheel_path = build.run(\n builddir, output_directory, convert_exports(exports), config_settings\n )\n return wheel_path\n\n\ndef source(\n source_location: Path,\n output_directory: Path,\n exports: str,\n config_settings: ConfigSettingsType,\n) -> Path:\n \"\"\"Use pypa/build to build a Python package from source\"\"\"\n built_wheel = build.run(\n source_location, output_directory, convert_exports(exports), config_settings\n )\n return built_wheel\n\n\n# simple 'pyodide build' command\ndef main(\n source_location: Optional[str] = typer.Argument( # noqa: UP007 typer does not accept list[str] | None yet.\n \"\",\n help=\"Build source, can be source folder, pypi version specification, \"\n \"or url to a source dist archive or wheel file. If this is blank, it \"\n \"will build the current directory.\",\n ),\n output_directory: str = typer.Option(\n \"\",\n \"--outdir\",\n \"-o\",\n help=\"which directory should the output be placed into?\",\n ),\n requirements_txt: str = typer.Option(\n \"\",\n \"--requirements\",\n \"-r\",\n help=\"Build a list of package requirements from a requirements.txt file\",\n ),\n exports: str = typer.Option(\n \"requested\",\n envvar=\"PYODIDE_BUILD_EXPORTS\",\n help=\"Which symbols should be exported when linking .so files?\",\n ),\n build_dependencies: bool = typer.Option(\n False, help=\"Fetch dependencies from pypi and build them too.\"\n ),\n output_lockfile: str = typer.Option(\n \"\",\n help=\"Output list of resolved dependencies to a file in requirements.txt format\",\n ),\n skip_dependency: list[str] = typer.Option(\n [],\n help=\"Skip building or resolving a single dependency, or a pyodide-lock.json file. \"\n \"Use multiple times or provide a comma separated list to skip multiple dependencies.\",\n ),\n skip_built_in_packages: bool = typer.Option(\n True,\n help=\"Don't build dependencies that are built into the pyodide distribution.\",\n ),\n compression_level: int = typer.Option(\n 6, help=\"Compression level to use for the created zip file\"\n ),\n config_setting: Optional[list[str]] = typer.Option( # noqa: UP007 typer does not accept list[str] | None yet.\n None,\n \"--config-setting\",\n \"-C\",\n help=(\n \"Settings to pass to the backend. \"\n \"Works same as the --config-setting option of pypa/build.\"\n ),\n metavar=\"KEY[=VALUE]\",\n ),\n ctx: typer.Context = typer.Context, # type: ignore[assignment]\n) -> None:\n \"\"\"Use pypa/build to build a Python package from source, pypi or url.\"\"\"\n init_environment()\n try:\n check_emscripten_version()\n except RuntimeError as e:\n print(e.args[0], file=sys.stderr)\n sys.exit(1)\n\n output_directory = output_directory or \"./dist\"\n\n outpath = Path(output_directory).resolve()\n outpath.mkdir(exist_ok=True)\n extras: list[str] = []\n\n # For backward compatibility, in addition to the `--config-setting` arguments, we also support\n # passing config settings as positional arguments.\n config_settings = parse_backend_flags((config_setting or []) + ctx.args)\n\n if skip_built_in_packages:\n package_lock_json = get_pyodide_root() / \"dist\" / \"pyodide-lock.json\"\n skip_dependency.append(str(package_lock_json.absolute()))\n\n if len(requirements_txt) > 0:\n # a requirements.txt - build it (and optionally deps)\n if not Path(requirements_txt).exists():\n raise RuntimeError(\n f\"Couldn't find requirements text file {requirements_txt}\"\n )\n reqs = []\n with open(requirements_txt) as f:\n raw_reqs = [x.strip() for x in f.readlines()]\n for x in raw_reqs:\n # remove comments\n comment_pos = x.find(\"#\")\n if comment_pos != -1:\n x = x[:comment_pos].strip()\n if len(x) > 0:\n if x[0] == \"-\":\n raise RuntimeError(\n f\"pyodide build only supports name-based PEP508 requirements. [{x}] will not work.\"\n )\n if x.find(\"@\") != -1:\n raise RuntimeError(\n f\"pyodide build does not support URL based requirements. [{x}] will not work\"\n )\n reqs.append(x)\n try:\n build_wheels_from_pypi_requirements(\n reqs,\n outpath,\n build_dependencies,\n skip_dependency,\n # TODO: should we really use same \"exports\" value for all of our\n # dependencies? Not sure this makes sense...\n convert_exports(exports),\n config_settings,\n output_lockfile=output_lockfile,\n )\n except BaseException as e:\n import traceback\n\n print(\"Failed building multiple wheels:\", traceback.format_exc())\n raise e\n return\n\n if source_location is not None:\n extras = re.findall(r\"\\[(\\w+)\\]\", source_location)\n if len(extras) != 0:\n source_location = source_location[0 : source_location.find(\"[\")]\n if not source_location:\n # build the current folder\n wheel = source(Path.cwd(), outpath, exports, config_settings)\n elif source_location.find(\"://\") != -1:\n wheel = url(source_location, outpath, exports, config_settings)\n elif Path(source_location).is_dir():\n # a folder, build it\n wheel = source(\n Path(source_location).resolve(), outpath, exports, config_settings\n )\n elif source_location.find(\"/\") == -1:\n # try fetch or build from pypi\n wheel = pypi(source_location, outpath, exports, config_settings)\n else:\n raise RuntimeError(f\"Couldn't determine source type for {source_location}\")\n # now build deps for wheel\n if build_dependencies:\n try:\n build_dependencies_for_wheel(\n wheel,\n extras,\n skip_dependency,\n # TODO: should we really use same \"exports\" value for all of our\n # dependencies? Not sure this makes sense...\n convert_exports(exports),\n config_settings,\n output_lockfile=output_lockfile,\n compression_level=compression_level,\n )\n except BaseException as e:\n import traceback\n\n print(\"Failed building dependencies for wheel:\", traceback.format_exc())\n wheel.unlink()\n raise e\n\n\nmain.typer_kwargs = { # type: ignore[attr-defined]\n \"context_settings\": {\n \"ignore_unknown_options\": True,\n \"allow_extra_args\": True,\n },\n}\n", "path": "pyodide-build/pyodide_build/cli/build.py"}]}
| 3,546 | 109 |
gh_patches_debug_15144
|
rasdani/github-patches
|
git_diff
|
mindspore-lab__mindnlp-643
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
multi30k dataset url not avaliable
</issue>
<code>
[start of mindnlp/dataset/machine_translation/multi30k.py]
1 # Copyright 2022 Huawei Technologies Co., Ltd
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 # ============================================================================
15 """
16 Multi30k load function
17 """
18 # pylint: disable=C0103
19
20 import os
21 import re
22 from operator import itemgetter
23 from typing import Union, Tuple
24 from mindspore.dataset import TextFileDataset, transforms
25 from mindspore.dataset import text
26 from mindnlp.utils.download import cache_file
27 from mindnlp.dataset.register import load_dataset, process
28 from mindnlp.configs import DEFAULT_ROOT
29 from mindnlp.utils import untar
30
31 URL = {
32 "train": "http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/training.tar.gz",
33 "valid": "http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/validation.tar.gz",
34 "test": "http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/mmt16_task1_test.tar.gz",
35 }
36
37 MD5 = {
38 "train": "8ebce33f4ebeb71dcb617f62cba077b7",
39 "valid": "2a46f18dbae0df0becc56e33d4e28e5d",
40 "test": "f63b12fc6f95beb3bfca2c393e861063",
41 }
42
43
44 @load_dataset.register
45 def Multi30k(root: str = DEFAULT_ROOT, split: Union[Tuple[str], str] = ('train', 'valid', 'test'),
46 language_pair: Tuple[str] = ('de', 'en'), proxies=None):
47 r"""
48 Load the Multi30k dataset
49
50 Args:
51 root (str): Directory where the datasets are saved.
52 Default:~/.mindnlp
53 split (str|Tuple[str]): Split or splits to be returned.
54 Default:('train', 'valid', 'test').
55 language_pair (Tuple[str]): Tuple containing src and tgt language.
56 Default: ('de', 'en').
57 proxies (dict): a dict to identify proxies,for example: {"https": "https://127.0.0.1:7890"}.
58
59 Returns:
60 - **datasets_list** (list) -A list of loaded datasets.
61 If only one type of dataset is specified,such as 'trian',
62 this dataset is returned instead of a list of datasets.
63
64 Raises:
65 TypeError: If `root` is not a string.
66 TypeError: If `split` is not a string or Tuple[str].
67 TypeError: If `language_pair` is not a Tuple[str].
68 RuntimeError: If the length of `language_pair` is not 2.
69 RuntimeError: If `language_pair` is neither ('de', 'en') nor ('en', 'de').
70
71 Examples:
72 >>> root = os.path.join(os.path.expanduser('~'), ".mindnlp")
73 >>> split = ('train', 'valid', 'test')
74 >>> language_pair = ('de', 'en')
75 >>> dataset_train, dataset_valid, dataset_test = Multi30k(root, split, language_pair)
76 >>> train_iter = dataset_train.create_tuple_iterator()
77 >>> print(next(train_iter))
78 [Tensor(shape=[], dtype=String, value=\
79 'Ein Mann mit einem orangefarbenen Hut, der etwas anstarrt.'),
80 Tensor(shape=[], dtype=String, value= 'A man in an orange hat starring at something.')]
81
82 """
83
84 assert len(
85 language_pair) == 2, "language_pair must contain only 2 elements:\
86 src and tgt language respectively"
87 assert tuple(sorted(language_pair)) == (
88 "de",
89 "en",
90 ), "language_pair must be either ('de','en') or ('en', 'de')"
91
92 if root == DEFAULT_ROOT:
93 cache_dir = os.path.join(root, "datasets", "Multi30k")
94 else:
95 cache_dir = root
96
97 file_list = []
98
99 untar_files = []
100 source_files = []
101 target_files = []
102
103 datasets_list = []
104
105 if isinstance(split, str):
106 file_path, _ = cache_file(
107 None, cache_dir=cache_dir, url=URL[split], md5sum=MD5[split], proxies=proxies)
108 file_list.append(file_path)
109
110 else:
111 urls = itemgetter(*split)(URL)
112 md5s = itemgetter(*split)(MD5)
113 for i, url in enumerate(urls):
114 file_path, _ = cache_file(
115 None, cache_dir=cache_dir, url=url, md5sum=md5s[i], proxies=proxies)
116 file_list.append(file_path)
117
118 for file in file_list:
119 untar_files.append(untar(file, os.path.dirname(file)))
120
121 regexp = r".de"
122 if language_pair == ("en", "de"):
123 regexp = r".en"
124
125 for file_pair in untar_files:
126 for file in file_pair:
127 match = re.search(regexp, file)
128 if match:
129 source_files.append(file)
130 else:
131 target_files.append(file)
132
133 for i in range(len(untar_files)):
134 source_dataset = TextFileDataset(
135 os.path.join(cache_dir, source_files[i]), shuffle=False)
136 source_dataset = source_dataset.rename(["text"], [language_pair[0]])
137 target_dataset = TextFileDataset(
138 os.path.join(cache_dir, target_files[i]), shuffle=False)
139 target_dataset = target_dataset.rename(["text"], [language_pair[1]])
140 datasets = source_dataset.zip(target_dataset)
141 datasets_list.append(datasets)
142
143 if len(datasets_list) == 1:
144 return datasets_list[0]
145 return datasets_list
146
147 @process.register
148 def Multi30k_Process(dataset, vocab, batch_size=64, max_len=500, \
149 drop_remainder=False):
150 """
151 the process of the Multi30k dataset
152
153 Args:
154 dataset (GeneratorDataset): Multi30k dataset.
155 vocab (Vocab): vocabulary object, used to store the mapping of token and index.
156 batch_size (int): The number of rows each batch is created with. Default: 64.
157 max_len (int): The max length of the sentence. Default: 500.
158 drop_remainder (bool): When the last batch of data contains a data entry smaller than batch_size, whether
159 to discard the batch and not pass it to the next operation. Default: False.
160
161 Returns:
162 - **dataset** (MapDataset) - dataset after transforms.
163
164 Raises:
165 TypeError: If `input_column` is not a string.
166
167 Examples:
168 >>> train_dataset = Multi30k(
169 >>> root=self.root,
170 >>> split="train",
171 >>> language_pair=("de", "en")
172 >>> )
173 >>> tokenizer = BasicTokenizer(True)
174 >>> train_dataset = train_dataset.map([tokenizer], 'en')
175 >>> train_dataset = train_dataset.map([tokenizer], 'de')
176 >>> en_vocab = text.Vocab.from_dataset(train_dataset, 'en', special_tokens=
177 >>> ['<pad>', '<unk>'], special_first= True)
178 >>> de_vocab = text.Vocab.from_dataset(train_dataset, 'de', special_tokens=
179 >>> ['<pad>', '<unk>'], special_first= True)
180 >>> vocab = {'en':en_vocab, 'de':de_vocab}
181 >>> train_dataset = process('Multi30k', train_dataset, vocab = vocab)
182 """
183
184 en_pad_value = vocab['en'].tokens_to_ids('<pad>')
185 de_pad_value = vocab['de'].tokens_to_ids('<pad>')
186
187 en_lookup_op = text.Lookup(vocab['en'], unknown_token='<unk>')
188 de_lookup_op = text.Lookup(vocab['de'], unknown_token='<unk>')
189
190 dataset = dataset.map([en_lookup_op], 'en')
191 dataset = dataset.map([de_lookup_op], 'de')
192
193 en_pad_op = transforms.PadEnd([max_len], en_pad_value)
194 de_pad_op = transforms.PadEnd([max_len], de_pad_value)
195
196 dataset = dataset.map([en_pad_op], 'en')
197 dataset = dataset.map([de_pad_op], 'de')
198
199 dataset = dataset.batch(batch_size, drop_remainder=drop_remainder)
200 return dataset
201
[end of mindnlp/dataset/machine_translation/multi30k.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mindnlp/dataset/machine_translation/multi30k.py b/mindnlp/dataset/machine_translation/multi30k.py
--- a/mindnlp/dataset/machine_translation/multi30k.py
+++ b/mindnlp/dataset/machine_translation/multi30k.py
@@ -29,15 +29,15 @@
from mindnlp.utils import untar
URL = {
- "train": "http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/training.tar.gz",
- "valid": "http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/validation.tar.gz",
- "test": "http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/mmt16_task1_test.tar.gz",
+ "train": "https://openi.pcl.ac.cn/lvyufeng/multi30k/raw/branch/master/training.tar.gz",
+ "valid": "https://openi.pcl.ac.cn/lvyufeng/multi30k/raw/branch/master/validation.tar.gz",
+ "test": "https://openi.pcl.ac.cn/lvyufeng/multi30k/raw/branch/master/mmt16_task1_test.tar.gz",
}
MD5 = {
"train": "8ebce33f4ebeb71dcb617f62cba077b7",
"valid": "2a46f18dbae0df0becc56e33d4e28e5d",
- "test": "f63b12fc6f95beb3bfca2c393e861063",
+ "test": "1586ce11f70cba049e9ed3d64db08843",
}
|
{"golden_diff": "diff --git a/mindnlp/dataset/machine_translation/multi30k.py b/mindnlp/dataset/machine_translation/multi30k.py\n--- a/mindnlp/dataset/machine_translation/multi30k.py\n+++ b/mindnlp/dataset/machine_translation/multi30k.py\n@@ -29,15 +29,15 @@\n from mindnlp.utils import untar\n \n URL = {\n- \"train\": \"http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/training.tar.gz\",\n- \"valid\": \"http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/validation.tar.gz\",\n- \"test\": \"http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/mmt16_task1_test.tar.gz\",\n+ \"train\": \"https://openi.pcl.ac.cn/lvyufeng/multi30k/raw/branch/master/training.tar.gz\",\n+ \"valid\": \"https://openi.pcl.ac.cn/lvyufeng/multi30k/raw/branch/master/validation.tar.gz\",\n+ \"test\": \"https://openi.pcl.ac.cn/lvyufeng/multi30k/raw/branch/master/mmt16_task1_test.tar.gz\",\n }\n \n MD5 = {\n \"train\": \"8ebce33f4ebeb71dcb617f62cba077b7\",\n \"valid\": \"2a46f18dbae0df0becc56e33d4e28e5d\",\n- \"test\": \"f63b12fc6f95beb3bfca2c393e861063\",\n+ \"test\": \"1586ce11f70cba049e9ed3d64db08843\",\n }\n", "issue": "multi30k dataset url not avaliable\n\n", "before_files": [{"content": "# Copyright 2022 Huawei Technologies Co., Ltd\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ============================================================================\n\"\"\"\nMulti30k load function\n\"\"\"\n# pylint: disable=C0103\n\nimport os\nimport re\nfrom operator import itemgetter\nfrom typing import Union, Tuple\nfrom mindspore.dataset import TextFileDataset, transforms\nfrom mindspore.dataset import text\nfrom mindnlp.utils.download import cache_file\nfrom mindnlp.dataset.register import load_dataset, process\nfrom mindnlp.configs import DEFAULT_ROOT\nfrom mindnlp.utils import untar\n\nURL = {\n \"train\": \"http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/training.tar.gz\",\n \"valid\": \"http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/validation.tar.gz\",\n \"test\": \"http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/mmt16_task1_test.tar.gz\",\n}\n\nMD5 = {\n \"train\": \"8ebce33f4ebeb71dcb617f62cba077b7\",\n \"valid\": \"2a46f18dbae0df0becc56e33d4e28e5d\",\n \"test\": \"f63b12fc6f95beb3bfca2c393e861063\",\n}\n\n\n@load_dataset.register\ndef Multi30k(root: str = DEFAULT_ROOT, split: Union[Tuple[str], str] = ('train', 'valid', 'test'),\n language_pair: Tuple[str] = ('de', 'en'), proxies=None):\n r\"\"\"\n Load the Multi30k dataset\n\n Args:\n root (str): Directory where the datasets are saved.\n Default:~/.mindnlp\n split (str|Tuple[str]): Split or splits to be returned.\n Default:('train', 'valid', 'test').\n language_pair (Tuple[str]): Tuple containing src and tgt language.\n Default: ('de', 'en').\n proxies (dict): a dict to identify proxies,for example: {\"https\": \"https://127.0.0.1:7890\"}.\n\n Returns:\n - **datasets_list** (list) -A list of loaded datasets.\n If only one type of dataset is specified,such as 'trian',\n this dataset is returned instead of a list of datasets.\n\n Raises:\n TypeError: If `root` is not a string.\n TypeError: If `split` is not a string or Tuple[str].\n TypeError: If `language_pair` is not a Tuple[str].\n RuntimeError: If the length of `language_pair` is not 2.\n RuntimeError: If `language_pair` is neither ('de', 'en') nor ('en', 'de').\n\n Examples:\n >>> root = os.path.join(os.path.expanduser('~'), \".mindnlp\")\n >>> split = ('train', 'valid', 'test')\n >>> language_pair = ('de', 'en')\n >>> dataset_train, dataset_valid, dataset_test = Multi30k(root, split, language_pair)\n >>> train_iter = dataset_train.create_tuple_iterator()\n >>> print(next(train_iter))\n [Tensor(shape=[], dtype=String, value=\\\n 'Ein Mann mit einem orangefarbenen Hut, der etwas anstarrt.'),\n Tensor(shape=[], dtype=String, value= 'A man in an orange hat starring at something.')]\n\n \"\"\"\n\n assert len(\n language_pair) == 2, \"language_pair must contain only 2 elements:\\\n src and tgt language respectively\"\n assert tuple(sorted(language_pair)) == (\n \"de\",\n \"en\",\n ), \"language_pair must be either ('de','en') or ('en', 'de')\"\n\n if root == DEFAULT_ROOT:\n cache_dir = os.path.join(root, \"datasets\", \"Multi30k\")\n else:\n cache_dir = root\n\n file_list = []\n\n untar_files = []\n source_files = []\n target_files = []\n\n datasets_list = []\n\n if isinstance(split, str):\n file_path, _ = cache_file(\n None, cache_dir=cache_dir, url=URL[split], md5sum=MD5[split], proxies=proxies)\n file_list.append(file_path)\n\n else:\n urls = itemgetter(*split)(URL)\n md5s = itemgetter(*split)(MD5)\n for i, url in enumerate(urls):\n file_path, _ = cache_file(\n None, cache_dir=cache_dir, url=url, md5sum=md5s[i], proxies=proxies)\n file_list.append(file_path)\n\n for file in file_list:\n untar_files.append(untar(file, os.path.dirname(file)))\n\n regexp = r\".de\"\n if language_pair == (\"en\", \"de\"):\n regexp = r\".en\"\n\n for file_pair in untar_files:\n for file in file_pair:\n match = re.search(regexp, file)\n if match:\n source_files.append(file)\n else:\n target_files.append(file)\n\n for i in range(len(untar_files)):\n source_dataset = TextFileDataset(\n os.path.join(cache_dir, source_files[i]), shuffle=False)\n source_dataset = source_dataset.rename([\"text\"], [language_pair[0]])\n target_dataset = TextFileDataset(\n os.path.join(cache_dir, target_files[i]), shuffle=False)\n target_dataset = target_dataset.rename([\"text\"], [language_pair[1]])\n datasets = source_dataset.zip(target_dataset)\n datasets_list.append(datasets)\n\n if len(datasets_list) == 1:\n return datasets_list[0]\n return datasets_list\n\[email protected]\ndef Multi30k_Process(dataset, vocab, batch_size=64, max_len=500, \\\n drop_remainder=False):\n \"\"\"\n the process of the Multi30k dataset\n\n Args:\n dataset (GeneratorDataset): Multi30k dataset.\n vocab (Vocab): vocabulary object, used to store the mapping of token and index.\n batch_size (int): The number of rows each batch is created with. Default: 64.\n max_len (int): The max length of the sentence. Default: 500.\n drop_remainder (bool): When the last batch of data contains a data entry smaller than batch_size, whether\n to discard the batch and not pass it to the next operation. Default: False.\n\n Returns:\n - **dataset** (MapDataset) - dataset after transforms.\n\n Raises:\n TypeError: If `input_column` is not a string.\n\n Examples:\n >>> train_dataset = Multi30k(\n >>> root=self.root,\n >>> split=\"train\",\n >>> language_pair=(\"de\", \"en\")\n >>> )\n >>> tokenizer = BasicTokenizer(True)\n >>> train_dataset = train_dataset.map([tokenizer], 'en')\n >>> train_dataset = train_dataset.map([tokenizer], 'de')\n >>> en_vocab = text.Vocab.from_dataset(train_dataset, 'en', special_tokens=\n >>> ['<pad>', '<unk>'], special_first= True)\n >>> de_vocab = text.Vocab.from_dataset(train_dataset, 'de', special_tokens=\n >>> ['<pad>', '<unk>'], special_first= True)\n >>> vocab = {'en':en_vocab, 'de':de_vocab}\n >>> train_dataset = process('Multi30k', train_dataset, vocab = vocab)\n \"\"\"\n\n en_pad_value = vocab['en'].tokens_to_ids('<pad>')\n de_pad_value = vocab['de'].tokens_to_ids('<pad>')\n\n en_lookup_op = text.Lookup(vocab['en'], unknown_token='<unk>')\n de_lookup_op = text.Lookup(vocab['de'], unknown_token='<unk>')\n\n dataset = dataset.map([en_lookup_op], 'en')\n dataset = dataset.map([de_lookup_op], 'de')\n\n en_pad_op = transforms.PadEnd([max_len], en_pad_value)\n de_pad_op = transforms.PadEnd([max_len], de_pad_value)\n\n dataset = dataset.map([en_pad_op], 'en')\n dataset = dataset.map([de_pad_op], 'de')\n\n dataset = dataset.batch(batch_size, drop_remainder=drop_remainder)\n return dataset\n", "path": "mindnlp/dataset/machine_translation/multi30k.py"}]}
| 2,990 | 428 |
gh_patches_debug_26582
|
rasdani/github-patches
|
git_diff
|
akvo__akvo-rsr-1741
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Prevent automatic publishing of projects
## Test plan
GIVEN a project that is going to be published
WHEN the project is published
THEN a notification mail will be sent to Kasper
## Issue description
Somehow there are projects (mainly from Commonsites and Akvo) that get published automatically, even though they shouldn't be. This should be prevented and fixed.
Note; I can't find the reason why this happens. I suspect the API, but then again, this only happens for Akvo and Commonsites projects. Therefore I'll monitor it for now.
</issue>
<code>
[start of akvo/rsr/models/publishing_status.py]
1 # -*- coding: utf-8 -*-
2
3 # Akvo RSR is covered by the GNU Affero General Public License.
4 # See more details in the license.txt file located at the root folder of the Akvo RSR module.
5 # For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.
6
7 from django.core.exceptions import ValidationError
8 from django.db import models
9 from django.utils.translation import ugettext_lazy as _
10
11 from ..fields import ValidXMLCharField
12
13
14 class PublishingStatus(models.Model):
15 """Keep track of publishing status."""
16 STATUS_PUBLISHED = 'published'
17 STATUS_UNPUBLISHED = 'unpublished'
18 PUBLISHING_STATUS = (
19 (STATUS_UNPUBLISHED, _(u'Unpublished')),
20 (STATUS_PUBLISHED, _(u'Published')),
21 )
22
23 project = models.OneToOneField('Project',)
24 status = ValidXMLCharField(max_length=30,
25 choices=PUBLISHING_STATUS,
26 db_index=True, default=STATUS_UNPUBLISHED)
27
28 def clean(self):
29 """Projects can only be published, when several checks have been performed."""
30 if self.status == 'published':
31 validation_errors = []
32
33 if not self.project.title:
34 validation_errors.append(
35 ValidationError(_('Project needs to have a title.'),
36 code='title')
37 )
38
39 if not self.project.subtitle:
40 validation_errors.append(
41 ValidationError(_('Project needs to have a subtitle.'),
42 code='subtitle')
43 )
44
45 if not self.project.project_plan_summary:
46 validation_errors.append(
47 ValidationError(_('Project needs to have the project plan summary filled in.'),
48 code='summary')
49 )
50
51 if not self.project.goals_overview:
52 validation_errors.append(
53 ValidationError(_('Project needs to have the goals overview field filled in.'),
54 code='goals_overview')
55 )
56
57 if not self.project.date_start_planned:
58 validation_errors.append(
59 ValidationError(
60 _('Project needs to have the planned start date field filled in.'),
61 code='goals_overview')
62 )
63
64 if not self.project.partners:
65 validation_errors.append(
66 ValidationError(_('Project needs to have at least one valid partner.'),
67 code='partners')
68 )
69 elif not self.project.partnerships.filter(
70 partner_type__in=['field', 'funding', 'support']
71 ).exists():
72 validation_errors.append(
73 ValidationError(
74 _('Project needs to have at least one field, funding or support partner.'),
75 code='partners'
76 )
77 )
78 else:
79 for funding_partner in self.project.partnerships.filter(partner_type='funding'):
80 if not funding_partner.funding_amount:
81 validation_errors.append(
82 ValidationError(_('All funding partners should have a funding amount.'),
83 code='partners'
84 )
85 )
86 break
87
88 if not self.project.sync_owner:
89 validation_errors.append(
90 ValidationError(_('Project needs to have a reporting organisation.'),
91 code='reporting_org')
92 )
93
94 if not self.project.current_image:
95 validation_errors.append(
96 ValidationError(_('Project needs to have a photo.'),
97 code='current_image')
98 )
99
100 if not self.project.locations.all():
101 validation_errors.append(
102 ValidationError(_('Project needs to have at least one location.'),
103 code='location')
104 )
105 else:
106 for location in self.project.locations.all():
107 if not location.latitude or not location.longitude or not location.country:
108 validation_errors.append(
109 ValidationError(
110 _('All locations need to have a latitude, longitude and country '
111 'specified.'),
112 code='location')
113 )
114 break
115
116 if not self.project.budget_items.all():
117 validation_errors.append(
118 ValidationError(_('Project needs to have at least one budget item.'),
119 code='budget_item')
120 )
121 elif not self.project.budget_items.filter(amount__gt=0).exists():
122 validation_errors.append(
123 ValidationError(
124 _('Project needs to have at least one budget item with an amount.'),
125 code='budget_item'
126 )
127 )
128
129 if not self.project.sectors.all():
130 validation_errors.append(
131 ValidationError(_('Project needs to have at least one sector.'),
132 code='sector')
133 )
134 else:
135 for sector in self.project.sectors.all():
136 if not sector.sector_code:
137 validation_errors.append(
138 ValidationError(_('All sectors need to have a sector code.'),
139 code='sector')
140 )
141 break
142
143 if validation_errors:
144 raise ValidationError(validation_errors)
145
146 class Meta:
147 app_label = 'rsr'
148 verbose_name = _(u'publishing status')
149 verbose_name_plural = _(u'publishing statuses')
150 ordering = ('-status', 'project')
151
[end of akvo/rsr/models/publishing_status.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/akvo/rsr/models/publishing_status.py b/akvo/rsr/models/publishing_status.py
--- a/akvo/rsr/models/publishing_status.py
+++ b/akvo/rsr/models/publishing_status.py
@@ -4,8 +4,12 @@
# See more details in the license.txt file located at the root folder of the Akvo RSR module.
# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.
+from django.conf import settings
from django.core.exceptions import ValidationError
+from django.core.mail import send_mail
from django.db import models
+from django.db.models.signals import post_save
+from django.dispatch import receiver
from django.utils.translation import ugettext_lazy as _
from ..fields import ValidXMLCharField
@@ -148,3 +152,15 @@
verbose_name = _(u'publishing status')
verbose_name_plural = _(u'publishing statuses')
ordering = ('-status', 'project')
+
+
+@receiver(post_save, sender=PublishingStatus)
+def update_denormalized_project(sender, **kwargs):
+ "Send notification that a project is published."
+ publishing_status = kwargs['instance']
+ if publishing_status.status == PublishingStatus.STATUS_PUBLISHED:
+ send_mail(
+ 'Project %s has been published' % str(publishing_status.project.pk),
+ '', getattr(settings, "DEFAULT_FROM_EMAIL", "[email protected]"),
+ getattr(settings, "NOTIFY_PUBLISH", ["[email protected]"])
+ )
|
{"golden_diff": "diff --git a/akvo/rsr/models/publishing_status.py b/akvo/rsr/models/publishing_status.py\n--- a/akvo/rsr/models/publishing_status.py\n+++ b/akvo/rsr/models/publishing_status.py\n@@ -4,8 +4,12 @@\n # See more details in the license.txt file located at the root folder of the Akvo RSR module.\n # For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n \n+from django.conf import settings\n from django.core.exceptions import ValidationError\n+from django.core.mail import send_mail\n from django.db import models\n+from django.db.models.signals import post_save\n+from django.dispatch import receiver\n from django.utils.translation import ugettext_lazy as _\n \n from ..fields import ValidXMLCharField\n@@ -148,3 +152,15 @@\n verbose_name = _(u'publishing status')\n verbose_name_plural = _(u'publishing statuses')\n ordering = ('-status', 'project')\n+\n+\n+@receiver(post_save, sender=PublishingStatus)\n+def update_denormalized_project(sender, **kwargs):\n+ \"Send notification that a project is published.\"\n+ publishing_status = kwargs['instance']\n+ if publishing_status.status == PublishingStatus.STATUS_PUBLISHED:\n+ send_mail(\n+ 'Project %s has been published' % str(publishing_status.project.pk),\n+ '', getattr(settings, \"DEFAULT_FROM_EMAIL\", \"[email protected]\"),\n+ getattr(settings, \"NOTIFY_PUBLISH\", [\"[email protected]\"])\n+ )\n", "issue": "Prevent automatic publishing of projects\n## Test plan\n\nGIVEN a project that is going to be published\nWHEN the project is published\nTHEN a notification mail will be sent to Kasper\n## Issue description\n\nSomehow there are projects (mainly from Commonsites and Akvo) that get published automatically, even though they shouldn't be. This should be prevented and fixed.\n\nNote; I can't find the reason why this happens. I suspect the API, but then again, this only happens for Akvo and Commonsites projects. Therefore I'll monitor it for now.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Akvo RSR is covered by the GNU Affero General Public License.\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\nfrom django.core.exceptions import ValidationError\nfrom django.db import models\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom ..fields import ValidXMLCharField\n\n\nclass PublishingStatus(models.Model):\n \"\"\"Keep track of publishing status.\"\"\"\n STATUS_PUBLISHED = 'published'\n STATUS_UNPUBLISHED = 'unpublished'\n PUBLISHING_STATUS = (\n (STATUS_UNPUBLISHED, _(u'Unpublished')),\n (STATUS_PUBLISHED, _(u'Published')),\n )\n\n project = models.OneToOneField('Project',)\n status = ValidXMLCharField(max_length=30,\n choices=PUBLISHING_STATUS,\n db_index=True, default=STATUS_UNPUBLISHED)\n\n def clean(self):\n \"\"\"Projects can only be published, when several checks have been performed.\"\"\"\n if self.status == 'published':\n validation_errors = []\n\n if not self.project.title:\n validation_errors.append(\n ValidationError(_('Project needs to have a title.'),\n code='title')\n )\n\n if not self.project.subtitle:\n validation_errors.append(\n ValidationError(_('Project needs to have a subtitle.'),\n code='subtitle')\n )\n\n if not self.project.project_plan_summary:\n validation_errors.append(\n ValidationError(_('Project needs to have the project plan summary filled in.'),\n code='summary')\n )\n\n if not self.project.goals_overview:\n validation_errors.append(\n ValidationError(_('Project needs to have the goals overview field filled in.'),\n code='goals_overview')\n )\n\n if not self.project.date_start_planned:\n validation_errors.append(\n ValidationError(\n _('Project needs to have the planned start date field filled in.'),\n code='goals_overview')\n )\n\n if not self.project.partners:\n validation_errors.append(\n ValidationError(_('Project needs to have at least one valid partner.'),\n code='partners')\n )\n elif not self.project.partnerships.filter(\n partner_type__in=['field', 'funding', 'support']\n ).exists():\n validation_errors.append(\n ValidationError(\n _('Project needs to have at least one field, funding or support partner.'),\n code='partners'\n )\n )\n else:\n for funding_partner in self.project.partnerships.filter(partner_type='funding'):\n if not funding_partner.funding_amount:\n validation_errors.append(\n ValidationError(_('All funding partners should have a funding amount.'),\n code='partners'\n )\n )\n break\n\n if not self.project.sync_owner:\n validation_errors.append(\n ValidationError(_('Project needs to have a reporting organisation.'),\n code='reporting_org')\n )\n\n if not self.project.current_image:\n validation_errors.append(\n ValidationError(_('Project needs to have a photo.'),\n code='current_image')\n )\n\n if not self.project.locations.all():\n validation_errors.append(\n ValidationError(_('Project needs to have at least one location.'),\n code='location')\n )\n else:\n for location in self.project.locations.all():\n if not location.latitude or not location.longitude or not location.country:\n validation_errors.append(\n ValidationError(\n _('All locations need to have a latitude, longitude and country '\n 'specified.'),\n code='location')\n )\n break\n\n if not self.project.budget_items.all():\n validation_errors.append(\n ValidationError(_('Project needs to have at least one budget item.'),\n code='budget_item')\n )\n elif not self.project.budget_items.filter(amount__gt=0).exists():\n validation_errors.append(\n ValidationError(\n _('Project needs to have at least one budget item with an amount.'),\n code='budget_item'\n )\n )\n\n if not self.project.sectors.all():\n validation_errors.append(\n ValidationError(_('Project needs to have at least one sector.'),\n code='sector')\n )\n else:\n for sector in self.project.sectors.all():\n if not sector.sector_code:\n validation_errors.append(\n ValidationError(_('All sectors need to have a sector code.'),\n code='sector')\n )\n break\n\n if validation_errors:\n raise ValidationError(validation_errors)\n\n class Meta:\n app_label = 'rsr'\n verbose_name = _(u'publishing status')\n verbose_name_plural = _(u'publishing statuses')\n ordering = ('-status', 'project')\n", "path": "akvo/rsr/models/publishing_status.py"}]}
| 1,978 | 351 |
gh_patches_debug_6376
|
rasdani/github-patches
|
git_diff
|
dotkom__onlineweb4-1693
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Filtering on attendance event on attendees admin doesn't work
This is only relevant for the admin panel and not the dashboard.
```
DisallowedModelAdminLookup at /admin/events/attendee/
Filtering by event__event__title not allowed
```
Can be reproduced by simply going to `/admin/events/attendee/` and filtering by some event.
</issue>
<code>
[start of apps/events/admin.py]
1 # -*- coding: utf-8 -*-
2
3 from django.contrib import admin, messages
4 from django.utils.translation import ugettext as _
5 from reversion.admin import VersionAdmin
6
7 from apps.events.models import (AttendanceEvent, Attendee, CompanyEvent, Event, Extras,
8 FieldOfStudyRule, GradeRule, GroupRestriction, Reservation,
9 Reservee, RuleBundle, UserGroupRule)
10 from apps.feedback.admin import FeedbackRelationInline
11
12
13 class AttendeeInline(admin.TabularInline):
14 model = Attendee
15 extra = 1
16 classes = ('grp-collapse grp-open',) # style
17 inline_classes = ('grp-collapse grp-open',) # style
18
19
20 class CompanyInline(admin.TabularInline):
21 model = CompanyEvent
22 max_num = 20
23 extra = 0
24 classes = ('grp-collapse grp-open',) # style
25 inline_classes = ('grp-collapse grp-open',) # style
26
27
28 class RuleBundleInline(admin.TabularInline):
29 model = RuleBundle
30 extra = 1
31 max_num = 20
32 classes = ('grp-collapse grp-open',) # style
33 inline_classes = ('grp-collapse grp-open',) # style
34
35
36 class ExtrasInline(admin.TabularInline):
37 model = Extras
38 extra = 1
39 max_num = 20
40 classes = ('grp-collapse grp-open',) # style
41 inline_classes = ('grp-collapse grp-open',) # style
42
43
44 class GroupRestrictionInline(admin.TabularInline):
45 model = GroupRestriction
46 extra = 0
47 max_num = 1
48 classes = ('grp-collapse grp-open',) # style
49 inline_classes = ('grp-collapse grp-open',) # style
50 filter_horizontal = ('groups',)
51
52
53 def mark_paid(modeladmin, request, queryset):
54 queryset.update(paid=True)
55 mark_paid.short_description = "Merk som betalt"
56
57
58 def mark_not_paid(modeladmin, request, queryset):
59 queryset.update(paid=False)
60 mark_not_paid.short_description = "Merk som ikke betalt"
61
62
63 def mark_attended(modeladmin, request, queryset):
64 queryset.update(attended=True)
65 mark_attended.short_description = "Merk som møtt"
66
67
68 def mark_not_attended(modeladmin, request, queryset):
69 queryset.update(attended=False)
70 mark_not_attended.short_description = "Merk som ikke møtt"
71
72
73 class AttendeeAdmin(VersionAdmin):
74 model = Attendee
75 list_display = ('user', 'event', 'paid', 'attended', 'note', 'extras')
76 list_filter = ('event__event__title',)
77 actions = [mark_paid, mark_attended, mark_not_paid, mark_not_attended]
78
79 # Disable delete_selected http://bit.ly/1o4nleN
80 def get_actions(self, request):
81 actions = super(AttendeeAdmin, self).get_actions(request)
82 if 'delete_selected' in actions:
83 del actions['delete_selected']
84 return actions
85
86 def delete_model(self, request, obj):
87 event = obj.event.event
88 event.attendance_event.notify_waiting_list(host=request.META['HTTP_HOST'], unattended_user=obj.user)
89 obj.delete()
90
91
92 class CompanyEventAdmin(VersionAdmin):
93 model = CompanyEvent
94 inlines = (CompanyInline,)
95
96
97 class ExtrasAdmin(VersionAdmin):
98 model = Extras
99 fk_name = 'choice'
100 # inlines = (ExtrasInline,)
101
102
103 class RuleBundleAdmin(VersionAdmin):
104 model = RuleBundle
105
106
107 class FieldOfStudyRuleAdmin(VersionAdmin):
108 model = FieldOfStudyRule
109
110
111 class GradeRuleAdmin(VersionAdmin):
112 model = GradeRule
113
114
115 class UserGroupRuleAdmin(VersionAdmin):
116 model = UserGroupRule
117
118
119 class AttendanceEventInline(admin.StackedInline):
120 model = AttendanceEvent
121 max_num = 1
122 extra = 0
123 filter_horizontal = ('rule_bundles',)
124 classes = ('grp-collapse grp-open',) # style
125 inline_classes = ('grp-collapse grp-open',) # style
126 exclude = ("marks_has_been_set",)
127
128
129 class EventAdmin(VersionAdmin):
130 inlines = (AttendanceEventInline, FeedbackRelationInline, CompanyInline, GroupRestrictionInline)
131 exclude = ("author", )
132 search_fields = ('title',)
133
134 def save_model(self, request, obj, form, change):
135 if not change: # created
136 obj.author = request.user
137 else:
138 # If attendance max capacity changed we will notify users that they are now on the attend list
139 old_event = Event.objects.get(id=obj.id)
140 if old_event.is_attendance_event():
141 old_waitlist_size = old_event.attendance_event.waitlist_qs.count()
142 if old_waitlist_size > 0:
143 diff_capacity = obj.attendance_event.max_capacity - old_event.attendance_event.max_capacity
144 if diff_capacity > 0:
145 if diff_capacity > old_waitlist_size:
146 diff_capacity = old_waitlist_size
147 # Using old_event because max_capacity has already been changed in obj
148 old_event.attendance_event.notify_waiting_list(host=request.META['HTTP_HOST'],
149 extra_capacity=diff_capacity)
150 obj.save()
151
152 def save_formset(self, request, form, formset, change):
153 instances = formset.save(commit=False)
154 for instance in instances:
155 instance.save()
156 formset.save_m2m()
157
158
159 class ReserveeInline(admin.TabularInline):
160 model = Reservee
161 extra = 1
162 classes = ('grp-collapse grp-open',) # style
163 inline_classes = ('grp-collapse grp-open',) # style
164
165
166 class ReservationAdmin(VersionAdmin):
167 model = Reservation
168 inlines = (ReserveeInline,)
169 max_num = 1
170 extra = 0
171 list_display = ('attendance_event', '_number_of_seats_taken', 'seats', '_attendees', '_max_capacity')
172 classes = ('grp-collapse grp-open',) # style
173 inline_classes = ('grp-collapse grp-open',) # style
174
175 def _number_of_seats_taken(self, obj):
176 return obj.number_of_seats_taken
177 _number_of_seats_taken.short_description = _("Fylte reservasjoner")
178
179 def _attendees(self, obj):
180 return obj.attendance_event.number_of_attendees
181 _attendees.short_description = _("Antall deltakere")
182
183 def _max_capacity(self, obj):
184 return obj.attendance_event.max_capacity
185 _max_capacity.short_description = _("Arrangementets maks-kapasitet")
186
187 def save_model(self, request, obj, form, change):
188 attendance_event = AttendanceEvent.objects.get(pk=obj.attendance_event.event)
189 number_of_free_seats = attendance_event.max_capacity - attendance_event.number_of_attendees
190 if number_of_free_seats < obj.seats:
191 obj.seats = number_of_free_seats
192 self.message_user(request, _(
193 "Du har valgt et antall reserverte plasser som overskrider antallet ledige plasser for dette "
194 "arrangementet. Antallet ble automatisk justert til %d (alle ledige plasser)."
195 ) % number_of_free_seats, messages.WARNING)
196 obj.save()
197
198
199 admin.site.register(Event, EventAdmin)
200 admin.site.register(Attendee, AttendeeAdmin)
201 admin.site.register(RuleBundle, RuleBundleAdmin)
202 admin.site.register(Extras, ExtrasAdmin)
203 admin.site.register(GradeRule, GradeRuleAdmin)
204 admin.site.register(UserGroupRule, UserGroupRuleAdmin)
205 admin.site.register(FieldOfStudyRule, FieldOfStudyRuleAdmin)
206 admin.site.register(Reservation, ReservationAdmin)
207
[end of apps/events/admin.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/apps/events/admin.py b/apps/events/admin.py
--- a/apps/events/admin.py
+++ b/apps/events/admin.py
@@ -73,7 +73,7 @@
class AttendeeAdmin(VersionAdmin):
model = Attendee
list_display = ('user', 'event', 'paid', 'attended', 'note', 'extras')
- list_filter = ('event__event__title',)
+ list_filter = ('event__event',)
actions = [mark_paid, mark_attended, mark_not_paid, mark_not_attended]
# Disable delete_selected http://bit.ly/1o4nleN
|
{"golden_diff": "diff --git a/apps/events/admin.py b/apps/events/admin.py\n--- a/apps/events/admin.py\n+++ b/apps/events/admin.py\n@@ -73,7 +73,7 @@\n class AttendeeAdmin(VersionAdmin):\n model = Attendee\n list_display = ('user', 'event', 'paid', 'attended', 'note', 'extras')\n- list_filter = ('event__event__title',)\n+ list_filter = ('event__event',)\n actions = [mark_paid, mark_attended, mark_not_paid, mark_not_attended]\n \n # Disable delete_selected http://bit.ly/1o4nleN\n", "issue": "Filtering on attendance event on attendees admin doesn't work\nThis is only relevant for the admin panel and not the dashboard.\n\n```\nDisallowedModelAdminLookup at /admin/events/attendee/\nFiltering by event__event__title not allowed\n```\n\nCan be reproduced by simply going to `/admin/events/attendee/` and filtering by some event.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\nfrom django.contrib import admin, messages\nfrom django.utils.translation import ugettext as _\nfrom reversion.admin import VersionAdmin\n\nfrom apps.events.models import (AttendanceEvent, Attendee, CompanyEvent, Event, Extras,\n FieldOfStudyRule, GradeRule, GroupRestriction, Reservation,\n Reservee, RuleBundle, UserGroupRule)\nfrom apps.feedback.admin import FeedbackRelationInline\n\n\nclass AttendeeInline(admin.TabularInline):\n model = Attendee\n extra = 1\n classes = ('grp-collapse grp-open',) # style\n inline_classes = ('grp-collapse grp-open',) # style\n\n\nclass CompanyInline(admin.TabularInline):\n model = CompanyEvent\n max_num = 20\n extra = 0\n classes = ('grp-collapse grp-open',) # style\n inline_classes = ('grp-collapse grp-open',) # style\n\n\nclass RuleBundleInline(admin.TabularInline):\n model = RuleBundle\n extra = 1\n max_num = 20\n classes = ('grp-collapse grp-open',) # style\n inline_classes = ('grp-collapse grp-open',) # style\n\n\nclass ExtrasInline(admin.TabularInline):\n model = Extras\n extra = 1\n max_num = 20\n classes = ('grp-collapse grp-open',) # style\n inline_classes = ('grp-collapse grp-open',) # style\n\n\nclass GroupRestrictionInline(admin.TabularInline):\n model = GroupRestriction\n extra = 0\n max_num = 1\n classes = ('grp-collapse grp-open',) # style\n inline_classes = ('grp-collapse grp-open',) # style\n filter_horizontal = ('groups',)\n\n\ndef mark_paid(modeladmin, request, queryset):\n queryset.update(paid=True)\nmark_paid.short_description = \"Merk som betalt\"\n\n\ndef mark_not_paid(modeladmin, request, queryset):\n queryset.update(paid=False)\nmark_not_paid.short_description = \"Merk som ikke betalt\"\n\n\ndef mark_attended(modeladmin, request, queryset):\n queryset.update(attended=True)\nmark_attended.short_description = \"Merk som m\u00f8tt\"\n\n\ndef mark_not_attended(modeladmin, request, queryset):\n queryset.update(attended=False)\nmark_not_attended.short_description = \"Merk som ikke m\u00f8tt\"\n\n\nclass AttendeeAdmin(VersionAdmin):\n model = Attendee\n list_display = ('user', 'event', 'paid', 'attended', 'note', 'extras')\n list_filter = ('event__event__title',)\n actions = [mark_paid, mark_attended, mark_not_paid, mark_not_attended]\n\n # Disable delete_selected http://bit.ly/1o4nleN\n def get_actions(self, request):\n actions = super(AttendeeAdmin, self).get_actions(request)\n if 'delete_selected' in actions:\n del actions['delete_selected']\n return actions\n\n def delete_model(self, request, obj):\n event = obj.event.event\n event.attendance_event.notify_waiting_list(host=request.META['HTTP_HOST'], unattended_user=obj.user)\n obj.delete()\n\n\nclass CompanyEventAdmin(VersionAdmin):\n model = CompanyEvent\n inlines = (CompanyInline,)\n\n\nclass ExtrasAdmin(VersionAdmin):\n model = Extras\n fk_name = 'choice'\n # inlines = (ExtrasInline,)\n\n\nclass RuleBundleAdmin(VersionAdmin):\n model = RuleBundle\n\n\nclass FieldOfStudyRuleAdmin(VersionAdmin):\n model = FieldOfStudyRule\n\n\nclass GradeRuleAdmin(VersionAdmin):\n model = GradeRule\n\n\nclass UserGroupRuleAdmin(VersionAdmin):\n model = UserGroupRule\n\n\nclass AttendanceEventInline(admin.StackedInline):\n model = AttendanceEvent\n max_num = 1\n extra = 0\n filter_horizontal = ('rule_bundles',)\n classes = ('grp-collapse grp-open',) # style\n inline_classes = ('grp-collapse grp-open',) # style\n exclude = (\"marks_has_been_set\",)\n\n\nclass EventAdmin(VersionAdmin):\n inlines = (AttendanceEventInline, FeedbackRelationInline, CompanyInline, GroupRestrictionInline)\n exclude = (\"author\", )\n search_fields = ('title',)\n\n def save_model(self, request, obj, form, change):\n if not change: # created\n obj.author = request.user\n else:\n # If attendance max capacity changed we will notify users that they are now on the attend list\n old_event = Event.objects.get(id=obj.id)\n if old_event.is_attendance_event():\n old_waitlist_size = old_event.attendance_event.waitlist_qs.count()\n if old_waitlist_size > 0:\n diff_capacity = obj.attendance_event.max_capacity - old_event.attendance_event.max_capacity\n if diff_capacity > 0:\n if diff_capacity > old_waitlist_size:\n diff_capacity = old_waitlist_size\n # Using old_event because max_capacity has already been changed in obj\n old_event.attendance_event.notify_waiting_list(host=request.META['HTTP_HOST'],\n extra_capacity=diff_capacity)\n obj.save()\n\n def save_formset(self, request, form, formset, change):\n instances = formset.save(commit=False)\n for instance in instances:\n instance.save()\n formset.save_m2m()\n\n\nclass ReserveeInline(admin.TabularInline):\n model = Reservee\n extra = 1\n classes = ('grp-collapse grp-open',) # style\n inline_classes = ('grp-collapse grp-open',) # style\n\n\nclass ReservationAdmin(VersionAdmin):\n model = Reservation\n inlines = (ReserveeInline,)\n max_num = 1\n extra = 0\n list_display = ('attendance_event', '_number_of_seats_taken', 'seats', '_attendees', '_max_capacity')\n classes = ('grp-collapse grp-open',) # style\n inline_classes = ('grp-collapse grp-open',) # style\n\n def _number_of_seats_taken(self, obj):\n return obj.number_of_seats_taken\n _number_of_seats_taken.short_description = _(\"Fylte reservasjoner\")\n\n def _attendees(self, obj):\n return obj.attendance_event.number_of_attendees\n _attendees.short_description = _(\"Antall deltakere\")\n\n def _max_capacity(self, obj):\n return obj.attendance_event.max_capacity\n _max_capacity.short_description = _(\"Arrangementets maks-kapasitet\")\n\n def save_model(self, request, obj, form, change):\n attendance_event = AttendanceEvent.objects.get(pk=obj.attendance_event.event)\n number_of_free_seats = attendance_event.max_capacity - attendance_event.number_of_attendees\n if number_of_free_seats < obj.seats:\n obj.seats = number_of_free_seats\n self.message_user(request, _(\n \"Du har valgt et antall reserverte plasser som overskrider antallet ledige plasser for dette \"\n \"arrangementet. Antallet ble automatisk justert til %d (alle ledige plasser).\"\n ) % number_of_free_seats, messages.WARNING)\n obj.save()\n\n\nadmin.site.register(Event, EventAdmin)\nadmin.site.register(Attendee, AttendeeAdmin)\nadmin.site.register(RuleBundle, RuleBundleAdmin)\nadmin.site.register(Extras, ExtrasAdmin)\nadmin.site.register(GradeRule, GradeRuleAdmin)\nadmin.site.register(UserGroupRule, UserGroupRuleAdmin)\nadmin.site.register(FieldOfStudyRule, FieldOfStudyRuleAdmin)\nadmin.site.register(Reservation, ReservationAdmin)\n", "path": "apps/events/admin.py"}]}
| 2,789 | 136 |
gh_patches_debug_25722
|
rasdani/github-patches
|
git_diff
|
CiviWiki__OpenCiviWiki-1015
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
User object not retrieved.
### Description
When I try running the project locally and I try registering a user, It shows an error.
### What should have happened?
I expect the registration to work successfully.
### What browser(s) are you seeing the problem on?
_No response_
### Further details
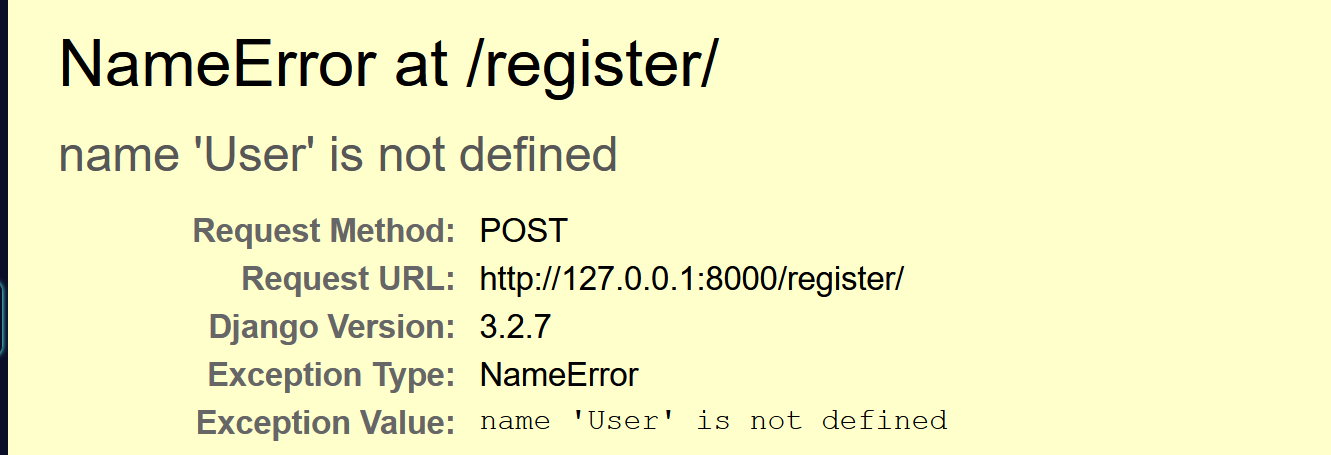

</issue>
<code>
[start of project/accounts/forms.py]
1 import re
2 from django.core.files.images import get_image_dimensions
3 from django import forms
4 from django.contrib.auth.forms import (
5 SetPasswordForm,
6 PasswordResetForm as AuthRecoverUserForm,
7 )
8 from django.forms.models import ModelForm
9 from django.contrib.auth import get_user_model
10 from django.contrib.auth.tokens import default_token_generator
11 from django.contrib.sites.shortcuts import get_current_site
12 from django.utils.encoding import force_bytes
13 from django.utils.http import urlsafe_base64_encode
14 from django.template.loader import render_to_string
15 from django.utils.translation import ugettext_lazy as _
16 from django.conf import settings
17
18 from accounts.utils import send_email
19 from .reserved_usernames import RESERVED_USERNAMES
20 from accounts.models import Profile
21
22
23 class UserRegistrationForm(ModelForm):
24 """
25 This class is used to register a new user in Civiwiki
26
27 Components:
28 - Email - from registration form
29 - Username - from registration form
30 - Password - from registration form
31 - Error_Message
32 - Invalid_Username - Usernames may only use lowercase characters or numbers
33 - Email_Exists - An account exists for this email address
34 - Invalid_Password - Password can not be entirely numeric
35 - Invalid_Password_Length - Password must be at least 4 characters
36 """
37
38 email = forms.EmailField(required=True)
39 username = forms.CharField(required=True)
40 password = forms.CharField(required=True, widget=forms.PasswordInput())
41
42 error_message = {
43 "invalid_username": _(
44 "Usernames may only use lowercase characters or numbers."
45 ),
46 "email_exists": _("An account exists for this email address."),
47 "username_exists": _("Sorry, this username already exists."),
48 "invalid_password": _("Password can not be entirely numeric."),
49 "invalid_password_length": _("Password must be at least 4 characters."),
50 }
51
52 class Meta:
53 model = get_user_model()
54 fields = ("username", "email", "password")
55
56 def clean_email(self):
57 """
58 Used to make sure user entered email address is a valid email address
59
60 Returns email
61 """
62
63 email = self.cleaned_data.get("email")
64
65 if User.objects.filter(email=email).exists():
66 raise forms.ValidationError(self.error_message["email_exists"])
67
68 return email
69
70 def clean_username(self):
71 """
72 Used to make sure that usernames meet the Civiwiki standards
73
74 Requirements:
75 - Username can only be made of lower case alphanumeric values
76 - Username cannot match entries from RESERVED_USERNAMES
77
78 Returns username
79 """
80
81 username = self.cleaned_data.get("username")
82
83 if not re.match(r"^[0-9a-z]*$", username):
84 raise forms.ValidationError(self.error_message["invalid_username"])
85
86 if (
87 User.objects.filter(username=username).exists()
88 or username in RESERVED_USERNAMES
89 ):
90 raise forms.ValidationError(self.error_message["username_exists"])
91
92 return username
93
94 def clean_password(self):
95 """
96 Used to make sure that passwords meet the Civiwiki standards
97
98 Requirements:
99 - At least 4 characters in length
100 - Cannot be all numbers
101
102 Returns password
103 """
104
105 password = self.cleaned_data.get("password")
106
107 if len(password) < 4:
108 raise forms.ValidationError(self.error_message["invalid_password_length"])
109
110 if password.isdigit():
111 raise forms.ValidationError(self.error_message["invalid_password"])
112
113 return password
114
115
116 class PasswordResetForm(SetPasswordForm):
117 """
118 A form that lets a user reset their password
119 """
120
121 error_messages = dict(
122 SetPasswordForm.error_messages,
123 **{
124 "invalid_password": _("Password can not be entirely numeric."),
125 "invalid_password_length": _("Password must be at least 4 characters."),
126 }
127 )
128
129 def clean_new_password1(self):
130 """
131 Used to make sure that new passwords meet the Civiwiki standards
132
133 Must be:
134 - At least 4 characters in length
135 - Cannot be all numbers
136
137 Returns new password
138 """
139
140 password = self.cleaned_data.get("new_password1")
141
142 if len(password) < 4:
143 raise forms.ValidationError(self.error_messages["invalid_password_length"])
144
145 if password.isdigit():
146 raise forms.ValidationError(self.error_messages["invalid_password"])
147
148 return password
149
150
151 class RecoverUserForm(AuthRecoverUserForm):
152 """
153 Send custom recovery mail with a task runner mostly taken from PasswordResetForm in auth
154 """
155
156 def save(
157 self,
158 domain_override=None,
159 subject_template_name=None,
160 email_template_name=None,
161 use_https=False,
162 token_generator=default_token_generator,
163 from_email=None,
164 request=None,
165 html_email_template_name=None,
166 extra_email_context=None,
167 ):
168 """
169 Generates a one-use only link for resetting password and sends to the
170 user.
171 """
172 email = self.cleaned_data["email"]
173
174 for user in self.get_users(email):
175 uid = urlsafe_base64_encode(force_bytes(user.pk))
176 token = token_generator.make_token(user)
177 domain = get_current_site(request).domain
178 base_url = "http://{domain}/auth/password_reset/{uid}/{token}/"
179 url_with_code = base_url.format(domain=domain, uid=uid, token=token)
180 body_txt = """You're receiving this email because you requested an account recovery
181 email for your user account at {domain}. Your username for this email
182 is: {username}. If you also need to reset your password, please go to
183 the following page and choose a new password."""
184
185 email_body = body_txt.format(domain=domain, username=user.username)
186
187 context = {
188 "title": "Profile Recovery for CiviWiki",
189 "greeting": "Recover your account on CiviWiki",
190 "body": email_body,
191 "link": url_with_code,
192 }
193
194 text_message_template = "email/base_text_template.txt"
195 html_message_template = "email/base_email_template.html"
196
197 message = render_to_string(text_message_template, context)
198 html_message = render_to_string(html_message_template, context)
199 sender = settings.EMAIL_HOST_USER
200 send_email(
201 subject="Profile Recovery for CiviWiki",
202 message=message,
203 sender=settings.EMAIL_HOST_USER,
204 recipient_list=[email],
205 html_message=html_message,
206 )
207
208
209 class UpdateProfile(forms.ModelForm):
210 """
211 Form for updating Profile data
212 """
213
214 def __init__(self, *args, **kwargs):
215 readonly = kwargs.pop("readonly", False)
216 super(UpdateProfile, self).__init__(*args, **kwargs)
217 if readonly:
218 self.disable_fields()
219
220 def disable_fields(self):
221 for _, field in self.fields.items():
222 field.disabled = True
223
224 class Meta:
225 model = Profile
226 fields = [
227 "first_name",
228 "last_name",
229 "about_me",
230 "profile_image",
231 "username",
232 "email",
233 ]
234
235 first_name = forms.CharField(label="First Name", max_length=63, required=False)
236 last_name = forms.CharField(label="Last Name", max_length=63, required=False)
237 about_me = forms.CharField(label="About Me", max_length=511, required=False)
238 email = forms.EmailField(label="Email", disabled=True)
239 username = forms.CharField(label="Username", disabled=True)
240 profile_image = forms.ImageField(required=False)
241
242
243 class UpdatePassword(forms.ModelForm):
244 """
245 Form for updating User Password
246 """
247
248 class Meta:
249 model = get_user_model()
250 fields = ["password", "verify"]
251
252 password = forms.CharField(
253 label="Password",
254 widget=forms.PasswordInput(
255 attrs={
256 "class": "form-control",
257 "placeholder": "Password",
258 "required": "True",
259 }
260 ),
261 )
262 verify = forms.CharField(
263 label="Password Verify",
264 widget=forms.PasswordInput(
265 attrs={
266 "class": "form-control",
267 "placeholder": "Password Verify",
268 "required": "True",
269 }
270 ),
271 help_text="Please retype your password.",
272 )
273
274 def clean(self):
275 """
276 Verifies that the passwords match
277 """
278 clean_data = super(UpdatePassword, self).clean()
279 if "password" in clean_data and "verify" in clean_data:
280 if clean_data["password"] != clean_data["verify"]:
281 raise forms.ValidationError("Passwords don't match.")
282 else:
283 raise forms.ValidationError("Both password fields need to be filled out.")
284 return clean_data
285
286
287 class UpdateProfileImage(forms.ModelForm):
288 """
289 Form for updating profile image
290 """
291
292 class Meta:
293 model = Profile
294 fields = ["profile_image"]
295
296 profile_image = forms.ImageField()
297
298 def clean_profile_image(self):
299 """
300 This function is used to make sure that profile images follow Civiwiki standards.
301
302 Requirements:
303 - Height cannot exceed 960px
304 - Width cannot exceed 1280px
305 - Image must be (jpg, jpeg, pjeg, png)
306 - File size cannot exceed 2MB
307 """
308 profile_image = self.cleaned_data["profile_image"]
309
310 try:
311 w, h = get_image_dimensions(profile_image)
312
313 # validate dimensions
314 max_height = 960
315 max_width = 1280
316 if w > max_width or h > max_height:
317 raise forms.ValidationError(
318 u"Please use an image that is {w} x {h} pixels or smaller.".format(
319 w=max_width, h=max_height
320 )
321 )
322
323 # validate content type
324 main, sub = profile_image.content_type.split("/")
325 if not (main == "image" and sub in ["jpg", "jpeg", "pjpeg", "png"]):
326 raise forms.ValidationError(u"Please use a JPEG or PNG image.")
327
328 # validate file size
329 if len(profile_image) > (2000 * 1024):
330 raise forms.ValidationError(
331 "Profile image file size may not exceed 2MB."
332 )
333
334 except AttributeError:
335 pass
336
337 return profile_image
338
[end of project/accounts/forms.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/project/accounts/forms.py b/project/accounts/forms.py
--- a/project/accounts/forms.py
+++ b/project/accounts/forms.py
@@ -62,7 +62,7 @@
email = self.cleaned_data.get("email")
- if User.objects.filter(email=email).exists():
+ if get_user_model().objects.filter(email=email).exists():
raise forms.ValidationError(self.error_message["email_exists"])
return email
@@ -84,7 +84,7 @@
raise forms.ValidationError(self.error_message["invalid_username"])
if (
- User.objects.filter(username=username).exists()
+ get_user_model().objects.filter(username=username).exists()
or username in RESERVED_USERNAMES
):
raise forms.ValidationError(self.error_message["username_exists"])
@@ -200,7 +200,7 @@
send_email(
subject="Profile Recovery for CiviWiki",
message=message,
- sender=settings.EMAIL_HOST_USER,
+ sender=sender,
recipient_list=[email],
html_message=html_message,
)
|
{"golden_diff": "diff --git a/project/accounts/forms.py b/project/accounts/forms.py\n--- a/project/accounts/forms.py\n+++ b/project/accounts/forms.py\n@@ -62,7 +62,7 @@\n \n email = self.cleaned_data.get(\"email\")\n \n- if User.objects.filter(email=email).exists():\n+ if get_user_model().objects.filter(email=email).exists():\n raise forms.ValidationError(self.error_message[\"email_exists\"])\n \n return email\n@@ -84,7 +84,7 @@\n raise forms.ValidationError(self.error_message[\"invalid_username\"])\n \n if (\n- User.objects.filter(username=username).exists()\n+ get_user_model().objects.filter(username=username).exists()\n or username in RESERVED_USERNAMES\n ):\n raise forms.ValidationError(self.error_message[\"username_exists\"])\n@@ -200,7 +200,7 @@\n send_email(\n subject=\"Profile Recovery for CiviWiki\",\n message=message,\n- sender=settings.EMAIL_HOST_USER,\n+ sender=sender,\n recipient_list=[email],\n html_message=html_message,\n )\n", "issue": "User object not retrieved.\n### Description\r\n\r\nWhen I try running the project locally and I try registering a user, It shows an error.\r\n\r\n\r\n\r\n\r\n### What should have happened?\r\n\r\nI expect the registration to work successfully.\r\n\r\n### What browser(s) are you seeing the problem on?\r\n\r\n_No response_\r\n\r\n### Further details\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "import re\nfrom django.core.files.images import get_image_dimensions\nfrom django import forms\nfrom django.contrib.auth.forms import (\n SetPasswordForm,\n PasswordResetForm as AuthRecoverUserForm,\n)\nfrom django.forms.models import ModelForm\nfrom django.contrib.auth import get_user_model\nfrom django.contrib.auth.tokens import default_token_generator\nfrom django.contrib.sites.shortcuts import get_current_site\nfrom django.utils.encoding import force_bytes\nfrom django.utils.http import urlsafe_base64_encode\nfrom django.template.loader import render_to_string\nfrom django.utils.translation import ugettext_lazy as _\nfrom django.conf import settings\n\nfrom accounts.utils import send_email\nfrom .reserved_usernames import RESERVED_USERNAMES\nfrom accounts.models import Profile\n\n\nclass UserRegistrationForm(ModelForm):\n \"\"\"\n This class is used to register a new user in Civiwiki\n\n Components:\n - Email - from registration form\n - Username - from registration form\n - Password - from registration form\n - Error_Message\n - Invalid_Username - Usernames may only use lowercase characters or numbers\n - Email_Exists - An account exists for this email address\n - Invalid_Password - Password can not be entirely numeric\n - Invalid_Password_Length - Password must be at least 4 characters\n \"\"\"\n\n email = forms.EmailField(required=True)\n username = forms.CharField(required=True)\n password = forms.CharField(required=True, widget=forms.PasswordInput())\n\n error_message = {\n \"invalid_username\": _(\n \"Usernames may only use lowercase characters or numbers.\"\n ),\n \"email_exists\": _(\"An account exists for this email address.\"),\n \"username_exists\": _(\"Sorry, this username already exists.\"),\n \"invalid_password\": _(\"Password can not be entirely numeric.\"),\n \"invalid_password_length\": _(\"Password must be at least 4 characters.\"),\n }\n\n class Meta:\n model = get_user_model()\n fields = (\"username\", \"email\", \"password\")\n\n def clean_email(self):\n \"\"\"\n Used to make sure user entered email address is a valid email address\n\n Returns email\n \"\"\"\n\n email = self.cleaned_data.get(\"email\")\n\n if User.objects.filter(email=email).exists():\n raise forms.ValidationError(self.error_message[\"email_exists\"])\n\n return email\n\n def clean_username(self):\n \"\"\"\n Used to make sure that usernames meet the Civiwiki standards\n\n Requirements:\n - Username can only be made of lower case alphanumeric values\n - Username cannot match entries from RESERVED_USERNAMES\n\n Returns username\n \"\"\"\n\n username = self.cleaned_data.get(\"username\")\n\n if not re.match(r\"^[0-9a-z]*$\", username):\n raise forms.ValidationError(self.error_message[\"invalid_username\"])\n\n if (\n User.objects.filter(username=username).exists()\n or username in RESERVED_USERNAMES\n ):\n raise forms.ValidationError(self.error_message[\"username_exists\"])\n\n return username\n\n def clean_password(self):\n \"\"\"\n Used to make sure that passwords meet the Civiwiki standards\n\n Requirements:\n - At least 4 characters in length\n - Cannot be all numbers\n\n Returns password\n \"\"\"\n\n password = self.cleaned_data.get(\"password\")\n\n if len(password) < 4:\n raise forms.ValidationError(self.error_message[\"invalid_password_length\"])\n\n if password.isdigit():\n raise forms.ValidationError(self.error_message[\"invalid_password\"])\n\n return password\n\n\nclass PasswordResetForm(SetPasswordForm):\n \"\"\"\n A form that lets a user reset their password\n \"\"\"\n\n error_messages = dict(\n SetPasswordForm.error_messages,\n **{\n \"invalid_password\": _(\"Password can not be entirely numeric.\"),\n \"invalid_password_length\": _(\"Password must be at least 4 characters.\"),\n }\n )\n\n def clean_new_password1(self):\n \"\"\"\n Used to make sure that new passwords meet the Civiwiki standards\n\n Must be:\n - At least 4 characters in length\n - Cannot be all numbers\n\n Returns new password\n \"\"\"\n\n password = self.cleaned_data.get(\"new_password1\")\n\n if len(password) < 4:\n raise forms.ValidationError(self.error_messages[\"invalid_password_length\"])\n\n if password.isdigit():\n raise forms.ValidationError(self.error_messages[\"invalid_password\"])\n\n return password\n\n\nclass RecoverUserForm(AuthRecoverUserForm):\n \"\"\"\n Send custom recovery mail with a task runner mostly taken from PasswordResetForm in auth\n \"\"\"\n\n def save(\n self,\n domain_override=None,\n subject_template_name=None,\n email_template_name=None,\n use_https=False,\n token_generator=default_token_generator,\n from_email=None,\n request=None,\n html_email_template_name=None,\n extra_email_context=None,\n ):\n \"\"\"\n Generates a one-use only link for resetting password and sends to the\n user.\n \"\"\"\n email = self.cleaned_data[\"email\"]\n\n for user in self.get_users(email):\n uid = urlsafe_base64_encode(force_bytes(user.pk))\n token = token_generator.make_token(user)\n domain = get_current_site(request).domain\n base_url = \"http://{domain}/auth/password_reset/{uid}/{token}/\"\n url_with_code = base_url.format(domain=domain, uid=uid, token=token)\n body_txt = \"\"\"You're receiving this email because you requested an account recovery\n email for your user account at {domain}. Your username for this email\n is: {username}. If you also need to reset your password, please go to\n the following page and choose a new password.\"\"\"\n\n email_body = body_txt.format(domain=domain, username=user.username)\n\n context = {\n \"title\": \"Profile Recovery for CiviWiki\",\n \"greeting\": \"Recover your account on CiviWiki\",\n \"body\": email_body,\n \"link\": url_with_code,\n }\n\n text_message_template = \"email/base_text_template.txt\"\n html_message_template = \"email/base_email_template.html\"\n\n message = render_to_string(text_message_template, context)\n html_message = render_to_string(html_message_template, context)\n sender = settings.EMAIL_HOST_USER\n send_email(\n subject=\"Profile Recovery for CiviWiki\",\n message=message,\n sender=settings.EMAIL_HOST_USER,\n recipient_list=[email],\n html_message=html_message,\n )\n\n\nclass UpdateProfile(forms.ModelForm):\n \"\"\"\n Form for updating Profile data\n \"\"\"\n\n def __init__(self, *args, **kwargs):\n readonly = kwargs.pop(\"readonly\", False)\n super(UpdateProfile, self).__init__(*args, **kwargs)\n if readonly:\n self.disable_fields()\n\n def disable_fields(self):\n for _, field in self.fields.items():\n field.disabled = True\n\n class Meta:\n model = Profile\n fields = [\n \"first_name\",\n \"last_name\",\n \"about_me\",\n \"profile_image\",\n \"username\",\n \"email\",\n ]\n\n first_name = forms.CharField(label=\"First Name\", max_length=63, required=False)\n last_name = forms.CharField(label=\"Last Name\", max_length=63, required=False)\n about_me = forms.CharField(label=\"About Me\", max_length=511, required=False)\n email = forms.EmailField(label=\"Email\", disabled=True)\n username = forms.CharField(label=\"Username\", disabled=True)\n profile_image = forms.ImageField(required=False)\n\n\nclass UpdatePassword(forms.ModelForm):\n \"\"\"\n Form for updating User Password\n \"\"\"\n\n class Meta:\n model = get_user_model()\n fields = [\"password\", \"verify\"]\n\n password = forms.CharField(\n label=\"Password\",\n widget=forms.PasswordInput(\n attrs={\n \"class\": \"form-control\",\n \"placeholder\": \"Password\",\n \"required\": \"True\",\n }\n ),\n )\n verify = forms.CharField(\n label=\"Password Verify\",\n widget=forms.PasswordInput(\n attrs={\n \"class\": \"form-control\",\n \"placeholder\": \"Password Verify\",\n \"required\": \"True\",\n }\n ),\n help_text=\"Please retype your password.\",\n )\n\n def clean(self):\n \"\"\"\n Verifies that the passwords match\n \"\"\"\n clean_data = super(UpdatePassword, self).clean()\n if \"password\" in clean_data and \"verify\" in clean_data:\n if clean_data[\"password\"] != clean_data[\"verify\"]:\n raise forms.ValidationError(\"Passwords don't match.\")\n else:\n raise forms.ValidationError(\"Both password fields need to be filled out.\")\n return clean_data\n\n\nclass UpdateProfileImage(forms.ModelForm):\n \"\"\"\n Form for updating profile image\n \"\"\"\n\n class Meta:\n model = Profile\n fields = [\"profile_image\"]\n\n profile_image = forms.ImageField()\n\n def clean_profile_image(self):\n \"\"\"\n This function is used to make sure that profile images follow Civiwiki standards.\n\n Requirements:\n - Height cannot exceed 960px\n - Width cannot exceed 1280px\n - Image must be (jpg, jpeg, pjeg, png)\n - File size cannot exceed 2MB\n \"\"\"\n profile_image = self.cleaned_data[\"profile_image\"]\n\n try:\n w, h = get_image_dimensions(profile_image)\n\n # validate dimensions\n max_height = 960\n max_width = 1280\n if w > max_width or h > max_height:\n raise forms.ValidationError(\n u\"Please use an image that is {w} x {h} pixels or smaller.\".format(\n w=max_width, h=max_height\n )\n )\n\n # validate content type\n main, sub = profile_image.content_type.split(\"/\")\n if not (main == \"image\" and sub in [\"jpg\", \"jpeg\", \"pjpeg\", \"png\"]):\n raise forms.ValidationError(u\"Please use a JPEG or PNG image.\")\n\n # validate file size\n if len(profile_image) > (2000 * 1024):\n raise forms.ValidationError(\n \"Profile image file size may not exceed 2MB.\"\n )\n\n except AttributeError:\n pass\n\n return profile_image\n", "path": "project/accounts/forms.py"}]}
| 3,789 | 226 |
gh_patches_debug_27859
|
rasdani/github-patches
|
git_diff
|
pulp__pulpcore-2338
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Reduce memory usage of the pipeline
Author: @bmbouter (bmbouter)
Redmine Issue: 9635, https://pulp.plan.io/issues/9635
---
## Motivation
It would be nice if users could specify a desired maximum amount of RAM to be used during sync. For example, a user can say I only want 1500 MB of RAM to be used max.
## What is already in place
The stages pipeline restricts memory usage by only allowing 1000 declarative content objects between each stage (so for 8-9 stages that's 8000-9000 declarative content objects. This happens [here](https://github.com/pulp/pulpcore/blob/main/pulpcore/plugin/stages/api.py#L217).
Interestingly the docstring says this defaults to 100, but it seems to actually be 1000!
Also the stages perform batching, so they will only taking in a limited number of items (the batch size). That happens [with minsize](https://github.com/pulp/pulpcore/blob/main/pulpcore/plugin/stages/api.py#L84).
## Why this isn't enough
These are count-based mechnisms and don't correspond to actual MB or GB of memory used. Some content units vary a lot in how much memory each DeclarativeContent objects take up.
Another lesser problem is that it doesn't help plugin writers restrict their usage of memory in FirstStage.
## Idea
Add a new param called `max_mb` to base Remote, which defaults to None. If specified, the user will be specifying the desired maximum MB used by process syncing.
Have the queues between the stages, and the bather implementation, both check the total memory the current process is using and asyncio.sleep() polling until it goes down. This should keep the maximum amount used by all objects roughly to that number.
## Details
Introduce a new `MBSizeQueue` which is a wrapper around `asyncio.Queue` used today. It will have the same `put()` call, only wait if the amount of memory in use is greater than the remote is configured for.
Then introduce the same memory checking feature in the batcher. I'm not completely sure this second part is needed though.
We have to be very careful not to deadlock with this feature. For example, we have to account for the base case where even a single item is larger than the memory desired. Repos in pulp_rpm have had a single unit use more than 1.2G if I remember right, so if someone was syncing with 800 MB and we weren't careful to allow that unit to still flow through the pipeline we'd deadlock.....
</issue>
<code>
[start of pulpcore/plugin/stages/api.py]
1 import asyncio
2 import logging
3
4 from gettext import gettext as _
5
6 from django.conf import settings
7
8 from .profiler import ProfilingQueue
9
10
11 log = logging.getLogger(__name__)
12
13
14 class Stage:
15 """
16 The base class for all Stages API stages.
17
18 To make a stage, inherit from this class and implement :meth:`run` on the subclass.
19 """
20
21 def __init__(self):
22 self._in_q = None
23 self._out_q = None
24
25 def _connect(self, in_q, out_q):
26 """
27 Connect to queues within a pipeline.
28
29 Args:
30 in_q (asyncio.Queue): The stage input queue.
31 out_q (asyncio.Queue): The stage output queue.
32 """
33 self._in_q = in_q
34 self._out_q = out_q
35
36 async def __call__(self):
37 """
38 This coroutine makes the stage callable.
39
40 It calls :meth:`run` and signals the next stage that its work is finished.
41 """
42 log.debug(_("%(name)s - begin."), {"name": self})
43 await self.run()
44 await self._out_q.put(None)
45 log.debug(_("%(name)s - put end-marker."), {"name": self})
46
47 async def run(self):
48 """
49 The coroutine that is run as part of this stage.
50
51 Returns:
52 The coroutine that runs this stage.
53
54 """
55 raise NotImplementedError(_("A plugin writer must implement this method"))
56
57 async def items(self):
58 """
59 Asynchronous iterator yielding items of :class:`DeclarativeContent` from `self._in_q`.
60
61 The iterator will get instances of :class:`DeclarativeContent` one by one as they get
62 available.
63
64 Yields:
65 An instance of :class:`DeclarativeContent`
66
67 Examples:
68 Used in stages to get d_content instances one by one from `self._in_q`::
69
70 class MyStage(Stage):
71 async def run(self):
72 async for d_content in self.items():
73 # process declarative content
74 await self.put(d_content)
75
76 """
77 while True:
78 content = await self._in_q.get()
79 if content is None:
80 break
81 log.debug("%(name)s - next: %(content)s.", {"name": self, "content": content})
82 yield content
83
84 async def batches(self, minsize=500):
85 """
86 Asynchronous iterator yielding batches of :class:`DeclarativeContent` from `self._in_q`.
87
88 The iterator will try to get as many instances of
89 :class:`DeclarativeContent` as possible without blocking, but
90 at least `minsize` instances.
91
92 Args:
93 minsize (int): The minimum batch size to yield (unless it is the final batch)
94
95 Yields:
96 A list of :class:`DeclarativeContent` instances
97
98 Examples:
99 Used in stages to get large chunks of d_content instances from `self._in_q`::
100
101 class MyStage(Stage):
102 async def run(self):
103 async for batch in self.batches():
104 for d_content in batch:
105 # process declarative content
106 await self.put(d_content)
107
108 """
109 batch = []
110 shutdown = False
111 no_block = False
112 thaw_queue_event = asyncio.Event()
113
114 def add_to_batch(content):
115 nonlocal batch
116 nonlocal shutdown
117 nonlocal no_block
118 nonlocal thaw_queue_event
119
120 if content is None:
121 shutdown = True
122 log.debug(_("%(name)s - shutdown."), {"name": self})
123 else:
124 if not content.does_batch:
125 no_block = True
126 content._thaw_queue_event = thaw_queue_event
127 batch.append(content)
128
129 get_listener = asyncio.ensure_future(self._in_q.get())
130 thaw_event_listener = asyncio.ensure_future(thaw_queue_event.wait())
131 while not shutdown:
132 done, pending = await asyncio.wait(
133 [thaw_event_listener, get_listener], return_when=asyncio.FIRST_COMPLETED
134 )
135 if thaw_event_listener in done:
136 thaw_event_listener = asyncio.ensure_future(thaw_queue_event.wait())
137 no_block = True
138 if get_listener in done:
139 content = await get_listener
140 add_to_batch(content)
141 get_listener = asyncio.ensure_future(self._in_q.get())
142 while not shutdown:
143 try:
144 content = self._in_q.get_nowait()
145 except asyncio.QueueEmpty:
146 break
147 else:
148 add_to_batch(content)
149
150 if batch and (len(batch) >= minsize or shutdown or no_block):
151 log.debug(
152 _("%(name)s - next batch[%(length)d]."), {"name": self, "length": len(batch)}
153 )
154 for content in batch:
155 content._thaw_queue_event = None
156 thaw_queue_event.clear()
157 yield batch
158 batch = []
159 no_block = False
160 thaw_event_listener.cancel()
161 get_listener.cancel()
162
163 async def put(self, item):
164 """
165 Coroutine to pass items to the next stage.
166
167 Args:
168 item: A handled instance of :class:`pulpcore.plugin.stages.DeclarativeContent`
169
170 Raises:
171 ValueError: When `item` is None.
172 """
173 if item is None:
174 raise ValueError(_("(None) not permitted."))
175 await self._out_q.put(item)
176 log.debug("{name} - put: {content}".format(name=self, content=item))
177
178 def __str__(self):
179 return "[{id}] {name}".format(id=id(self), name=self.__class__.__name__)
180
181
182 async def create_pipeline(stages, maxsize=1000):
183 """
184 A coroutine that builds a Stages API linear pipeline from the list `stages` and runs it.
185
186 Each stage is an instance of a class derived from :class:`pulpcore.plugin.stages.Stage` that
187 implements the :meth:`run` coroutine. This coroutine reads asyncromously either from the
188 `items()` iterator or the `batches()` iterator and outputs the items with `put()`. Here is an
189 example of the simplest stage that only passes data::
190
191 class MyStage(Stage):
192 async def run(self):
193 async for d_content in self.items(): # Fetch items from the previous stage
194 await self.put(d_content) # Hand them over to the next stage
195
196 Args:
197 stages (list of coroutines): A list of Stages API compatible coroutines.
198 maxsize (int): The maximum amount of items a queue between two stages should hold. Optional
199 and defaults to 100.
200
201 Returns:
202 A single coroutine that can be used to run, wait, or cancel the entire pipeline with.
203 Raises:
204 ValueError: When a stage instance is specified more than once.
205 """
206 futures = []
207 history = set()
208 in_q = None
209 for i, stage in enumerate(stages):
210 if stage in history:
211 raise ValueError(_("Each stage instance must be unique."))
212 history.add(stage)
213 if i < len(stages) - 1:
214 if settings.PROFILE_STAGES_API:
215 out_q = ProfilingQueue.make_and_record_queue(stages[i + 1], i + 1, maxsize)
216 else:
217 out_q = asyncio.Queue(maxsize=maxsize)
218 else:
219 out_q = None
220 stage._connect(in_q, out_q)
221 futures.append(asyncio.ensure_future(stage()))
222 in_q = out_q
223
224 try:
225 await asyncio.gather(*futures)
226 except Exception:
227 # One of the stages raised an exception, cancel all stages...
228 pending = []
229 for task in futures:
230 if not task.done():
231 task.cancel()
232 pending.append(task)
233 # ...and run until all Exceptions show up
234 if pending:
235 await asyncio.wait(pending, timeout=60)
236 raise
237
238
239 class EndStage(Stage):
240 """
241 A Stages API stage that drains incoming items and does nothing with the items. This is
242 required at the end of all pipelines.
243
244 Without this stage, the `maxsize` of the last stage's `_out_q` could fill up and block the
245 entire pipeline.
246 """
247
248 async def __call__(self):
249 """
250 This method drains items from the last queue and drops them.
251
252 Importantly it does not try to put items into the nonexistent next queue.
253 """
254 # We overwrite __call__ here to avoid trying to put None in `self._out_q`.
255 async for _ in self.items(): # noqa
256 pass
257
[end of pulpcore/plugin/stages/api.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pulpcore/plugin/stages/api.py b/pulpcore/plugin/stages/api.py
--- a/pulpcore/plugin/stages/api.py
+++ b/pulpcore/plugin/stages/api.py
@@ -179,12 +179,12 @@
return "[{id}] {name}".format(id=id(self), name=self.__class__.__name__)
-async def create_pipeline(stages, maxsize=1000):
+async def create_pipeline(stages, maxsize=1):
"""
A coroutine that builds a Stages API linear pipeline from the list `stages` and runs it.
Each stage is an instance of a class derived from :class:`pulpcore.plugin.stages.Stage` that
- implements the :meth:`run` coroutine. This coroutine reads asyncromously either from the
+ implements the :meth:`run` coroutine. This coroutine reads asynchronously either from the
`items()` iterator or the `batches()` iterator and outputs the items with `put()`. Here is an
example of the simplest stage that only passes data::
@@ -196,7 +196,7 @@
Args:
stages (list of coroutines): A list of Stages API compatible coroutines.
maxsize (int): The maximum amount of items a queue between two stages should hold. Optional
- and defaults to 100.
+ and defaults to 1.
Returns:
A single coroutine that can be used to run, wait, or cancel the entire pipeline with.
|
{"golden_diff": "diff --git a/pulpcore/plugin/stages/api.py b/pulpcore/plugin/stages/api.py\n--- a/pulpcore/plugin/stages/api.py\n+++ b/pulpcore/plugin/stages/api.py\n@@ -179,12 +179,12 @@\n return \"[{id}] {name}\".format(id=id(self), name=self.__class__.__name__)\n \n \n-async def create_pipeline(stages, maxsize=1000):\n+async def create_pipeline(stages, maxsize=1):\n \"\"\"\n A coroutine that builds a Stages API linear pipeline from the list `stages` and runs it.\n \n Each stage is an instance of a class derived from :class:`pulpcore.plugin.stages.Stage` that\n- implements the :meth:`run` coroutine. This coroutine reads asyncromously either from the\n+ implements the :meth:`run` coroutine. This coroutine reads asynchronously either from the\n `items()` iterator or the `batches()` iterator and outputs the items with `put()`. Here is an\n example of the simplest stage that only passes data::\n \n@@ -196,7 +196,7 @@\n Args:\n stages (list of coroutines): A list of Stages API compatible coroutines.\n maxsize (int): The maximum amount of items a queue between two stages should hold. Optional\n- and defaults to 100.\n+ and defaults to 1.\n \n Returns:\n A single coroutine that can be used to run, wait, or cancel the entire pipeline with.\n", "issue": "Reduce memory usage of the pipeline\nAuthor: @bmbouter (bmbouter)\n\n\nRedmine Issue: 9635, https://pulp.plan.io/issues/9635\n\n---\n\n## Motivation\r\n\r\nIt would be nice if users could specify a desired maximum amount of RAM to be used during sync. For example, a user can say I only want 1500 MB of RAM to be used max.\r\n\r\n## What is already in place\r\n\r\nThe stages pipeline restricts memory usage by only allowing 1000 declarative content objects between each stage (so for 8-9 stages that's 8000-9000 declarative content objects. This happens [here](https://github.com/pulp/pulpcore/blob/main/pulpcore/plugin/stages/api.py#L217).\r\n\r\nInterestingly the docstring says this defaults to 100, but it seems to actually be 1000!\r\n\r\nAlso the stages perform batching, so they will only taking in a limited number of items (the batch size). That happens [with minsize](https://github.com/pulp/pulpcore/blob/main/pulpcore/plugin/stages/api.py#L84).\r\n\r\n## Why this isn't enough\r\n\r\nThese are count-based mechnisms and don't correspond to actual MB or GB of memory used. Some content units vary a lot in how much memory each DeclarativeContent objects take up.\r\n\r\nAnother lesser problem is that it doesn't help plugin writers restrict their usage of memory in FirstStage.\r\n\r\n## Idea\r\n\r\nAdd a new param called `max_mb` to base Remote, which defaults to None. If specified, the user will be specifying the desired maximum MB used by process syncing.\r\n\r\nHave the queues between the stages, and the bather implementation, both check the total memory the current process is using and asyncio.sleep() polling until it goes down. This should keep the maximum amount used by all objects roughly to that number.\r\n\r\n## Details\r\n\r\nIntroduce a new `MBSizeQueue` which is a wrapper around `asyncio.Queue` used today. It will have the same `put()` call, only wait if the amount of memory in use is greater than the remote is configured for.\r\n\r\nThen introduce the same memory checking feature in the batcher. I'm not completely sure this second part is needed though.\r\n\r\nWe have to be very careful not to deadlock with this feature. For example, we have to account for the base case where even a single item is larger than the memory desired. Repos in pulp_rpm have had a single unit use more than 1.2G if I remember right, so if someone was syncing with 800 MB and we weren't careful to allow that unit to still flow through the pipeline we'd deadlock.....\n\n\n\n", "before_files": [{"content": "import asyncio\nimport logging\n\nfrom gettext import gettext as _\n\nfrom django.conf import settings\n\nfrom .profiler import ProfilingQueue\n\n\nlog = logging.getLogger(__name__)\n\n\nclass Stage:\n \"\"\"\n The base class for all Stages API stages.\n\n To make a stage, inherit from this class and implement :meth:`run` on the subclass.\n \"\"\"\n\n def __init__(self):\n self._in_q = None\n self._out_q = None\n\n def _connect(self, in_q, out_q):\n \"\"\"\n Connect to queues within a pipeline.\n\n Args:\n in_q (asyncio.Queue): The stage input queue.\n out_q (asyncio.Queue): The stage output queue.\n \"\"\"\n self._in_q = in_q\n self._out_q = out_q\n\n async def __call__(self):\n \"\"\"\n This coroutine makes the stage callable.\n\n It calls :meth:`run` and signals the next stage that its work is finished.\n \"\"\"\n log.debug(_(\"%(name)s - begin.\"), {\"name\": self})\n await self.run()\n await self._out_q.put(None)\n log.debug(_(\"%(name)s - put end-marker.\"), {\"name\": self})\n\n async def run(self):\n \"\"\"\n The coroutine that is run as part of this stage.\n\n Returns:\n The coroutine that runs this stage.\n\n \"\"\"\n raise NotImplementedError(_(\"A plugin writer must implement this method\"))\n\n async def items(self):\n \"\"\"\n Asynchronous iterator yielding items of :class:`DeclarativeContent` from `self._in_q`.\n\n The iterator will get instances of :class:`DeclarativeContent` one by one as they get\n available.\n\n Yields:\n An instance of :class:`DeclarativeContent`\n\n Examples:\n Used in stages to get d_content instances one by one from `self._in_q`::\n\n class MyStage(Stage):\n async def run(self):\n async for d_content in self.items():\n # process declarative content\n await self.put(d_content)\n\n \"\"\"\n while True:\n content = await self._in_q.get()\n if content is None:\n break\n log.debug(\"%(name)s - next: %(content)s.\", {\"name\": self, \"content\": content})\n yield content\n\n async def batches(self, minsize=500):\n \"\"\"\n Asynchronous iterator yielding batches of :class:`DeclarativeContent` from `self._in_q`.\n\n The iterator will try to get as many instances of\n :class:`DeclarativeContent` as possible without blocking, but\n at least `minsize` instances.\n\n Args:\n minsize (int): The minimum batch size to yield (unless it is the final batch)\n\n Yields:\n A list of :class:`DeclarativeContent` instances\n\n Examples:\n Used in stages to get large chunks of d_content instances from `self._in_q`::\n\n class MyStage(Stage):\n async def run(self):\n async for batch in self.batches():\n for d_content in batch:\n # process declarative content\n await self.put(d_content)\n\n \"\"\"\n batch = []\n shutdown = False\n no_block = False\n thaw_queue_event = asyncio.Event()\n\n def add_to_batch(content):\n nonlocal batch\n nonlocal shutdown\n nonlocal no_block\n nonlocal thaw_queue_event\n\n if content is None:\n shutdown = True\n log.debug(_(\"%(name)s - shutdown.\"), {\"name\": self})\n else:\n if not content.does_batch:\n no_block = True\n content._thaw_queue_event = thaw_queue_event\n batch.append(content)\n\n get_listener = asyncio.ensure_future(self._in_q.get())\n thaw_event_listener = asyncio.ensure_future(thaw_queue_event.wait())\n while not shutdown:\n done, pending = await asyncio.wait(\n [thaw_event_listener, get_listener], return_when=asyncio.FIRST_COMPLETED\n )\n if thaw_event_listener in done:\n thaw_event_listener = asyncio.ensure_future(thaw_queue_event.wait())\n no_block = True\n if get_listener in done:\n content = await get_listener\n add_to_batch(content)\n get_listener = asyncio.ensure_future(self._in_q.get())\n while not shutdown:\n try:\n content = self._in_q.get_nowait()\n except asyncio.QueueEmpty:\n break\n else:\n add_to_batch(content)\n\n if batch and (len(batch) >= minsize or shutdown or no_block):\n log.debug(\n _(\"%(name)s - next batch[%(length)d].\"), {\"name\": self, \"length\": len(batch)}\n )\n for content in batch:\n content._thaw_queue_event = None\n thaw_queue_event.clear()\n yield batch\n batch = []\n no_block = False\n thaw_event_listener.cancel()\n get_listener.cancel()\n\n async def put(self, item):\n \"\"\"\n Coroutine to pass items to the next stage.\n\n Args:\n item: A handled instance of :class:`pulpcore.plugin.stages.DeclarativeContent`\n\n Raises:\n ValueError: When `item` is None.\n \"\"\"\n if item is None:\n raise ValueError(_(\"(None) not permitted.\"))\n await self._out_q.put(item)\n log.debug(\"{name} - put: {content}\".format(name=self, content=item))\n\n def __str__(self):\n return \"[{id}] {name}\".format(id=id(self), name=self.__class__.__name__)\n\n\nasync def create_pipeline(stages, maxsize=1000):\n \"\"\"\n A coroutine that builds a Stages API linear pipeline from the list `stages` and runs it.\n\n Each stage is an instance of a class derived from :class:`pulpcore.plugin.stages.Stage` that\n implements the :meth:`run` coroutine. This coroutine reads asyncromously either from the\n `items()` iterator or the `batches()` iterator and outputs the items with `put()`. Here is an\n example of the simplest stage that only passes data::\n\n class MyStage(Stage):\n async def run(self):\n async for d_content in self.items(): # Fetch items from the previous stage\n await self.put(d_content) # Hand them over to the next stage\n\n Args:\n stages (list of coroutines): A list of Stages API compatible coroutines.\n maxsize (int): The maximum amount of items a queue between two stages should hold. Optional\n and defaults to 100.\n\n Returns:\n A single coroutine that can be used to run, wait, or cancel the entire pipeline with.\n Raises:\n ValueError: When a stage instance is specified more than once.\n \"\"\"\n futures = []\n history = set()\n in_q = None\n for i, stage in enumerate(stages):\n if stage in history:\n raise ValueError(_(\"Each stage instance must be unique.\"))\n history.add(stage)\n if i < len(stages) - 1:\n if settings.PROFILE_STAGES_API:\n out_q = ProfilingQueue.make_and_record_queue(stages[i + 1], i + 1, maxsize)\n else:\n out_q = asyncio.Queue(maxsize=maxsize)\n else:\n out_q = None\n stage._connect(in_q, out_q)\n futures.append(asyncio.ensure_future(stage()))\n in_q = out_q\n\n try:\n await asyncio.gather(*futures)\n except Exception:\n # One of the stages raised an exception, cancel all stages...\n pending = []\n for task in futures:\n if not task.done():\n task.cancel()\n pending.append(task)\n # ...and run until all Exceptions show up\n if pending:\n await asyncio.wait(pending, timeout=60)\n raise\n\n\nclass EndStage(Stage):\n \"\"\"\n A Stages API stage that drains incoming items and does nothing with the items. This is\n required at the end of all pipelines.\n\n Without this stage, the `maxsize` of the last stage's `_out_q` could fill up and block the\n entire pipeline.\n \"\"\"\n\n async def __call__(self):\n \"\"\"\n This method drains items from the last queue and drops them.\n\n Importantly it does not try to put items into the nonexistent next queue.\n \"\"\"\n # We overwrite __call__ here to avoid trying to put None in `self._out_q`.\n async for _ in self.items(): # noqa\n pass\n", "path": "pulpcore/plugin/stages/api.py"}]}
| 3,625 | 335 |
gh_patches_debug_6130
|
rasdani/github-patches
|
git_diff
|
python-poetry__poetry-1754
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fix simple typo: specificed -> specified
- [x] I am on the [latest](https://github.com/python-poetry/poetry/releases/latest) Poetry version.
- [x] I have searched the [issues](https://github.com/python-poetry/poetry/issues) of this repo and believe that this is not a duplicate.
- [x] If an exception occurs when executing a command, I executed it again in debug mode (`-vvv` option).
## Issue
# Issue Type
[x] Bug (Typo)
# Steps to Replicate
1. Examine poetry/masonry/builders/builder.py.
2. Search for `specificed`.
# Expected Behaviour
1. Should read `specified`.
</issue>
<code>
[start of poetry/masonry/builders/builder.py]
1 # -*- coding: utf-8 -*-
2 import re
3 import shutil
4 import tempfile
5
6 from collections import defaultdict
7 from contextlib import contextmanager
8 from typing import Set
9 from typing import Union
10
11 from clikit.api.io.flags import VERY_VERBOSE
12
13 from poetry.utils._compat import Path
14 from poetry.utils._compat import glob
15 from poetry.utils._compat import lru_cache
16 from poetry.utils._compat import to_str
17 from poetry.vcs import get_vcs
18
19 from ..metadata import Metadata
20 from ..utils.module import Module
21 from ..utils.package_include import PackageInclude
22
23
24 AUTHOR_REGEX = re.compile(r"(?u)^(?P<name>[- .,\w\d'’\"()]+) <(?P<email>.+?)>$")
25
26 METADATA_BASE = """\
27 Metadata-Version: 2.1
28 Name: {name}
29 Version: {version}
30 Summary: {summary}
31 """
32
33
34 class Builder(object):
35 AVAILABLE_PYTHONS = {"2", "2.7", "3", "3.4", "3.5", "3.6", "3.7"}
36
37 format = None
38
39 def __init__(
40 self, poetry, env, io, ignore_packages_formats=False
41 ): # type: ("Poetry", "Env", "IO", bool) -> None
42 self._poetry = poetry
43 self._env = env
44 self._io = io
45 self._package = poetry.package
46 self._path = poetry.file.parent
47
48 packages = []
49 for p in self._package.packages:
50 formats = p.get("format", [])
51 if not isinstance(formats, list):
52 formats = [formats]
53
54 if (
55 formats
56 and self.format
57 and self.format not in formats
58 and not ignore_packages_formats
59 ):
60 continue
61
62 packages.append(p)
63
64 self._module = Module(
65 self._package.name,
66 self._path.as_posix(),
67 packages=packages,
68 includes=self._package.include,
69 )
70 self._meta = Metadata.from_package(self._package)
71
72 def build(self):
73 raise NotImplementedError()
74
75 @lru_cache(maxsize=None)
76 def find_excluded_files(self): # type: () -> Set[str]
77 # Checking VCS
78 vcs = get_vcs(self._path)
79 if not vcs:
80 vcs_ignored_files = set()
81 else:
82 vcs_ignored_files = set(vcs.get_ignored_files())
83
84 explicitely_excluded = set()
85 for excluded_glob in self._package.exclude:
86
87 for excluded in glob(
88 Path(self._path, excluded_glob).as_posix(), recursive=True
89 ):
90 explicitely_excluded.add(
91 Path(excluded).relative_to(self._path).as_posix()
92 )
93
94 ignored = vcs_ignored_files | explicitely_excluded
95 result = set()
96 for file in ignored:
97 result.add(file)
98
99 # The list of excluded files might be big and we will do a lot
100 # containment check (x in excluded).
101 # Returning a set make those tests much much faster.
102 return result
103
104 def is_excluded(self, filepath): # type: (Union[str, Path]) -> bool
105 exclude_path = Path(filepath)
106
107 while True:
108 if exclude_path.as_posix() in self.find_excluded_files():
109 return True
110
111 if len(exclude_path.parts) > 1:
112 exclude_path = exclude_path.parent
113 else:
114 break
115
116 return False
117
118 def find_files_to_add(self, exclude_build=True): # type: (bool) -> list
119 """
120 Finds all files to add to the tarball
121 """
122 to_add = []
123
124 for include in self._module.includes:
125 for file in include.elements:
126 if "__pycache__" in str(file):
127 continue
128
129 if file.is_dir():
130 continue
131
132 file = file.relative_to(self._path)
133
134 if self.is_excluded(file) and isinstance(include, PackageInclude):
135 continue
136
137 if file.suffix == ".pyc":
138 continue
139
140 if file in to_add:
141 # Skip duplicates
142 continue
143
144 self._io.write_line(
145 " - Adding: <comment>{}</comment>".format(str(file)), VERY_VERBOSE
146 )
147 to_add.append(file)
148
149 # Include project files
150 self._io.write_line(
151 " - Adding: <comment>pyproject.toml</comment>", VERY_VERBOSE
152 )
153 to_add.append(Path("pyproject.toml"))
154
155 # If a license file exists, add it
156 for license_file in self._path.glob("LICENSE*"):
157 self._io.write_line(
158 " - Adding: <comment>{}</comment>".format(
159 license_file.relative_to(self._path)
160 ),
161 VERY_VERBOSE,
162 )
163 to_add.append(license_file.relative_to(self._path))
164
165 # If a README is specificed we need to include it
166 # to avoid errors
167 if "readme" in self._poetry.local_config:
168 readme = self._path / self._poetry.local_config["readme"]
169 if readme.exists():
170 self._io.write_line(
171 " - Adding: <comment>{}</comment>".format(
172 readme.relative_to(self._path)
173 ),
174 VERY_VERBOSE,
175 )
176 to_add.append(readme.relative_to(self._path))
177
178 # If a build script is specified and explicitely required
179 # we add it to the list of files
180 if self._package.build and not exclude_build:
181 to_add.append(Path(self._package.build))
182
183 return sorted(to_add)
184
185 def get_metadata_content(self): # type: () -> bytes
186 content = METADATA_BASE.format(
187 name=self._meta.name,
188 version=self._meta.version,
189 summary=to_str(self._meta.summary),
190 )
191
192 # Optional fields
193 if self._meta.home_page:
194 content += "Home-page: {}\n".format(self._meta.home_page)
195
196 if self._meta.license:
197 content += "License: {}\n".format(self._meta.license)
198
199 if self._meta.keywords:
200 content += "Keywords: {}\n".format(self._meta.keywords)
201
202 if self._meta.author:
203 content += "Author: {}\n".format(to_str(self._meta.author))
204
205 if self._meta.author_email:
206 content += "Author-email: {}\n".format(to_str(self._meta.author_email))
207
208 if self._meta.maintainer:
209 content += "Maintainer: {}\n".format(to_str(self._meta.maintainer))
210
211 if self._meta.maintainer_email:
212 content += "Maintainer-email: {}\n".format(
213 to_str(self._meta.maintainer_email)
214 )
215
216 if self._meta.requires_python:
217 content += "Requires-Python: {}\n".format(self._meta.requires_python)
218
219 for classifier in self._meta.classifiers:
220 content += "Classifier: {}\n".format(classifier)
221
222 for extra in sorted(self._meta.provides_extra):
223 content += "Provides-Extra: {}\n".format(extra)
224
225 for dep in sorted(self._meta.requires_dist):
226 content += "Requires-Dist: {}\n".format(dep)
227
228 for url in sorted(self._meta.project_urls, key=lambda u: u[0]):
229 content += "Project-URL: {}\n".format(to_str(url))
230
231 if self._meta.description_content_type:
232 content += "Description-Content-Type: {}\n".format(
233 self._meta.description_content_type
234 )
235
236 if self._meta.description is not None:
237 content += "\n" + to_str(self._meta.description) + "\n"
238
239 return content
240
241 def convert_entry_points(self): # type: () -> dict
242 result = defaultdict(list)
243
244 # Scripts -> Entry points
245 for name, ep in self._poetry.local_config.get("scripts", {}).items():
246 extras = ""
247 if isinstance(ep, dict):
248 extras = "[{}]".format(", ".join(ep["extras"]))
249 ep = ep["callable"]
250
251 result["console_scripts"].append("{} = {}{}".format(name, ep, extras))
252
253 # Plugins -> entry points
254 plugins = self._poetry.local_config.get("plugins", {})
255 for groupname, group in plugins.items():
256 for name, ep in sorted(group.items()):
257 result[groupname].append("{} = {}".format(name, ep))
258
259 for groupname in result:
260 result[groupname] = sorted(result[groupname])
261
262 return dict(result)
263
264 @classmethod
265 def convert_author(cls, author): # type: (...) -> dict
266 m = AUTHOR_REGEX.match(author)
267
268 name = m.group("name")
269 email = m.group("email")
270
271 return {"name": name, "email": email}
272
273 @classmethod
274 @contextmanager
275 def temporary_directory(cls, *args, **kwargs):
276 try:
277 from tempfile import TemporaryDirectory
278
279 with TemporaryDirectory(*args, **kwargs) as name:
280 yield name
281 except ImportError:
282 name = tempfile.mkdtemp(*args, **kwargs)
283
284 yield name
285
286 shutil.rmtree(name)
287
[end of poetry/masonry/builders/builder.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/poetry/masonry/builders/builder.py b/poetry/masonry/builders/builder.py
--- a/poetry/masonry/builders/builder.py
+++ b/poetry/masonry/builders/builder.py
@@ -162,7 +162,7 @@
)
to_add.append(license_file.relative_to(self._path))
- # If a README is specificed we need to include it
+ # If a README is specified we need to include it
# to avoid errors
if "readme" in self._poetry.local_config:
readme = self._path / self._poetry.local_config["readme"]
|
{"golden_diff": "diff --git a/poetry/masonry/builders/builder.py b/poetry/masonry/builders/builder.py\n--- a/poetry/masonry/builders/builder.py\n+++ b/poetry/masonry/builders/builder.py\n@@ -162,7 +162,7 @@\n )\n to_add.append(license_file.relative_to(self._path))\n \n- # If a README is specificed we need to include it\n+ # If a README is specified we need to include it\n # to avoid errors\n if \"readme\" in self._poetry.local_config:\n readme = self._path / self._poetry.local_config[\"readme\"]\n", "issue": "Fix simple typo: specificed -> specified\n- [x] I am on the [latest](https://github.com/python-poetry/poetry/releases/latest) Poetry version.\n- [x] I have searched the [issues](https://github.com/python-poetry/poetry/issues) of this repo and believe that this is not a duplicate.\n- [x] If an exception occurs when executing a command, I executed it again in debug mode (`-vvv` option).\n\n## Issue\n\n# Issue Type\n\n[x] Bug (Typo)\n\n# Steps to Replicate\n\n1. Examine poetry/masonry/builders/builder.py.\n2. Search for `specificed`.\n\n# Expected Behaviour\n\n1. Should read `specified`.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nimport re\nimport shutil\nimport tempfile\n\nfrom collections import defaultdict\nfrom contextlib import contextmanager\nfrom typing import Set\nfrom typing import Union\n\nfrom clikit.api.io.flags import VERY_VERBOSE\n\nfrom poetry.utils._compat import Path\nfrom poetry.utils._compat import glob\nfrom poetry.utils._compat import lru_cache\nfrom poetry.utils._compat import to_str\nfrom poetry.vcs import get_vcs\n\nfrom ..metadata import Metadata\nfrom ..utils.module import Module\nfrom ..utils.package_include import PackageInclude\n\n\nAUTHOR_REGEX = re.compile(r\"(?u)^(?P<name>[- .,\\w\\d'\u2019\\\"()]+) <(?P<email>.+?)>$\")\n\nMETADATA_BASE = \"\"\"\\\nMetadata-Version: 2.1\nName: {name}\nVersion: {version}\nSummary: {summary}\n\"\"\"\n\n\nclass Builder(object):\n AVAILABLE_PYTHONS = {\"2\", \"2.7\", \"3\", \"3.4\", \"3.5\", \"3.6\", \"3.7\"}\n\n format = None\n\n def __init__(\n self, poetry, env, io, ignore_packages_formats=False\n ): # type: (\"Poetry\", \"Env\", \"IO\", bool) -> None\n self._poetry = poetry\n self._env = env\n self._io = io\n self._package = poetry.package\n self._path = poetry.file.parent\n\n packages = []\n for p in self._package.packages:\n formats = p.get(\"format\", [])\n if not isinstance(formats, list):\n formats = [formats]\n\n if (\n formats\n and self.format\n and self.format not in formats\n and not ignore_packages_formats\n ):\n continue\n\n packages.append(p)\n\n self._module = Module(\n self._package.name,\n self._path.as_posix(),\n packages=packages,\n includes=self._package.include,\n )\n self._meta = Metadata.from_package(self._package)\n\n def build(self):\n raise NotImplementedError()\n\n @lru_cache(maxsize=None)\n def find_excluded_files(self): # type: () -> Set[str]\n # Checking VCS\n vcs = get_vcs(self._path)\n if not vcs:\n vcs_ignored_files = set()\n else:\n vcs_ignored_files = set(vcs.get_ignored_files())\n\n explicitely_excluded = set()\n for excluded_glob in self._package.exclude:\n\n for excluded in glob(\n Path(self._path, excluded_glob).as_posix(), recursive=True\n ):\n explicitely_excluded.add(\n Path(excluded).relative_to(self._path).as_posix()\n )\n\n ignored = vcs_ignored_files | explicitely_excluded\n result = set()\n for file in ignored:\n result.add(file)\n\n # The list of excluded files might be big and we will do a lot\n # containment check (x in excluded).\n # Returning a set make those tests much much faster.\n return result\n\n def is_excluded(self, filepath): # type: (Union[str, Path]) -> bool\n exclude_path = Path(filepath)\n\n while True:\n if exclude_path.as_posix() in self.find_excluded_files():\n return True\n\n if len(exclude_path.parts) > 1:\n exclude_path = exclude_path.parent\n else:\n break\n\n return False\n\n def find_files_to_add(self, exclude_build=True): # type: (bool) -> list\n \"\"\"\n Finds all files to add to the tarball\n \"\"\"\n to_add = []\n\n for include in self._module.includes:\n for file in include.elements:\n if \"__pycache__\" in str(file):\n continue\n\n if file.is_dir():\n continue\n\n file = file.relative_to(self._path)\n\n if self.is_excluded(file) and isinstance(include, PackageInclude):\n continue\n\n if file.suffix == \".pyc\":\n continue\n\n if file in to_add:\n # Skip duplicates\n continue\n\n self._io.write_line(\n \" - Adding: <comment>{}</comment>\".format(str(file)), VERY_VERBOSE\n )\n to_add.append(file)\n\n # Include project files\n self._io.write_line(\n \" - Adding: <comment>pyproject.toml</comment>\", VERY_VERBOSE\n )\n to_add.append(Path(\"pyproject.toml\"))\n\n # If a license file exists, add it\n for license_file in self._path.glob(\"LICENSE*\"):\n self._io.write_line(\n \" - Adding: <comment>{}</comment>\".format(\n license_file.relative_to(self._path)\n ),\n VERY_VERBOSE,\n )\n to_add.append(license_file.relative_to(self._path))\n\n # If a README is specificed we need to include it\n # to avoid errors\n if \"readme\" in self._poetry.local_config:\n readme = self._path / self._poetry.local_config[\"readme\"]\n if readme.exists():\n self._io.write_line(\n \" - Adding: <comment>{}</comment>\".format(\n readme.relative_to(self._path)\n ),\n VERY_VERBOSE,\n )\n to_add.append(readme.relative_to(self._path))\n\n # If a build script is specified and explicitely required\n # we add it to the list of files\n if self._package.build and not exclude_build:\n to_add.append(Path(self._package.build))\n\n return sorted(to_add)\n\n def get_metadata_content(self): # type: () -> bytes\n content = METADATA_BASE.format(\n name=self._meta.name,\n version=self._meta.version,\n summary=to_str(self._meta.summary),\n )\n\n # Optional fields\n if self._meta.home_page:\n content += \"Home-page: {}\\n\".format(self._meta.home_page)\n\n if self._meta.license:\n content += \"License: {}\\n\".format(self._meta.license)\n\n if self._meta.keywords:\n content += \"Keywords: {}\\n\".format(self._meta.keywords)\n\n if self._meta.author:\n content += \"Author: {}\\n\".format(to_str(self._meta.author))\n\n if self._meta.author_email:\n content += \"Author-email: {}\\n\".format(to_str(self._meta.author_email))\n\n if self._meta.maintainer:\n content += \"Maintainer: {}\\n\".format(to_str(self._meta.maintainer))\n\n if self._meta.maintainer_email:\n content += \"Maintainer-email: {}\\n\".format(\n to_str(self._meta.maintainer_email)\n )\n\n if self._meta.requires_python:\n content += \"Requires-Python: {}\\n\".format(self._meta.requires_python)\n\n for classifier in self._meta.classifiers:\n content += \"Classifier: {}\\n\".format(classifier)\n\n for extra in sorted(self._meta.provides_extra):\n content += \"Provides-Extra: {}\\n\".format(extra)\n\n for dep in sorted(self._meta.requires_dist):\n content += \"Requires-Dist: {}\\n\".format(dep)\n\n for url in sorted(self._meta.project_urls, key=lambda u: u[0]):\n content += \"Project-URL: {}\\n\".format(to_str(url))\n\n if self._meta.description_content_type:\n content += \"Description-Content-Type: {}\\n\".format(\n self._meta.description_content_type\n )\n\n if self._meta.description is not None:\n content += \"\\n\" + to_str(self._meta.description) + \"\\n\"\n\n return content\n\n def convert_entry_points(self): # type: () -> dict\n result = defaultdict(list)\n\n # Scripts -> Entry points\n for name, ep in self._poetry.local_config.get(\"scripts\", {}).items():\n extras = \"\"\n if isinstance(ep, dict):\n extras = \"[{}]\".format(\", \".join(ep[\"extras\"]))\n ep = ep[\"callable\"]\n\n result[\"console_scripts\"].append(\"{} = {}{}\".format(name, ep, extras))\n\n # Plugins -> entry points\n plugins = self._poetry.local_config.get(\"plugins\", {})\n for groupname, group in plugins.items():\n for name, ep in sorted(group.items()):\n result[groupname].append(\"{} = {}\".format(name, ep))\n\n for groupname in result:\n result[groupname] = sorted(result[groupname])\n\n return dict(result)\n\n @classmethod\n def convert_author(cls, author): # type: (...) -> dict\n m = AUTHOR_REGEX.match(author)\n\n name = m.group(\"name\")\n email = m.group(\"email\")\n\n return {\"name\": name, \"email\": email}\n\n @classmethod\n @contextmanager\n def temporary_directory(cls, *args, **kwargs):\n try:\n from tempfile import TemporaryDirectory\n\n with TemporaryDirectory(*args, **kwargs) as name:\n yield name\n except ImportError:\n name = tempfile.mkdtemp(*args, **kwargs)\n\n yield name\n\n shutil.rmtree(name)\n", "path": "poetry/masonry/builders/builder.py"}]}
| 3,435 | 148 |
gh_patches_debug_4692
|
rasdani/github-patches
|
git_diff
|
watchdogpolska__feder-322
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
brak zapytań w zakładce SQL w Django debug toolbar

</issue>
<code>
[start of config/settings/local.py]
1 # -*- coding: utf-8 -*-
2 '''
3 Local settings
4
5 - Run in Debug mode
6 - Use console backend for emails
7 - Add Django Debug Toolbar
8 - Add django-extensions as app
9 '''
10
11 from .common import * # noqa
12
13 # DEBUG
14 # ------------------------------------------------------------------------------
15 DEBUG = env.bool('DJANGO_DEBUG', default=True)
16 TEMPLATES[0]['OPTIONS']['debug'] = DEBUG
17
18 # SECRET CONFIGURATION
19 # ------------------------------------------------------------------------------
20 # See: https://docs.djangoproject.com/en/dev/ref/settings/#secret-key
21 # Note: This key only used for development and testing.
22 SECRET_KEY = env("DJANGO_SECRET_KEY", default='CHANGEME!!!')
23
24 # Mail settings
25 # ------------------------------------------------------------------------------
26 EMAIL_HOST = 'localhost'
27 EMAIL_PORT = 1025
28 EMAIL_BACKEND = env('DJANGO_EMAIL_BACKEND',
29 default='django.core.mail.backends.console.EmailBackend')
30 EMAIL_NOTIFICATION = '[email protected]'
31
32 # CACHING
33 # ------------------------------------------------------------------------------
34 CACHES = {
35 'default': {
36 'BACKEND': 'django.core.cache.backends.locmem.LocMemCache',
37 'LOCATION': ''
38 }
39 }
40
41 # django-debug-toolbar
42 # ------------------------------------------------------------------------------
43 MIDDLEWARE_CLASSES += ('debug_toolbar.middleware.DebugToolbarMiddleware',)
44 INSTALLED_APPS += ('debug_toolbar', )
45
46 INTERNAL_IPS = ('127.0.0.1', '10.0.2.2',)
47
48 DEBUG_TOOLBAR_CONFIG = {
49 'DISABLE_PANELS': [
50 'debug_toolbar.panels.redirects.RedirectsPanel',
51 'debug_toolbar.panels.redirects.RedirectsPanel',
52 ],
53 'SHOW_TEMPLATE_CONTEXT': True,
54 }
55
56 # django-extensions
57 # ------------------------------------------------------------------------------
58 INSTALLED_APPS += ('django_extensions', )
59
60 # TESTING
61 # ------------------------------------------------------------------------------
62 TEST_RUNNER = 'django.test.runner.DiscoverRunner'
63
64 # Your local stuff: Below this line define 3rd party library settings
65 # To get all sql queries sent by Django from py shell
66 EMAILLABS_APP_KEY = env('EMAILLABS_APP_KEY', default="Dummy")
67
68 EMAILLABS_SECRET_KEY = env('EMAILLABS_SECRET_KEY', default="Dummy")
69
[end of config/settings/local.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/config/settings/local.py b/config/settings/local.py
--- a/config/settings/local.py
+++ b/config/settings/local.py
@@ -40,7 +40,7 @@
# django-debug-toolbar
# ------------------------------------------------------------------------------
-MIDDLEWARE_CLASSES += ('debug_toolbar.middleware.DebugToolbarMiddleware',)
+# MIDDLEWARE_CLASSES += ('debug_toolbar.middleware.DebugToolbarMiddleware',)
INSTALLED_APPS += ('debug_toolbar', )
INTERNAL_IPS = ('127.0.0.1', '10.0.2.2',)
|
{"golden_diff": "diff --git a/config/settings/local.py b/config/settings/local.py\n--- a/config/settings/local.py\n+++ b/config/settings/local.py\n@@ -40,7 +40,7 @@\n \n # django-debug-toolbar\n # ------------------------------------------------------------------------------\n-MIDDLEWARE_CLASSES += ('debug_toolbar.middleware.DebugToolbarMiddleware',)\n+# MIDDLEWARE_CLASSES += ('debug_toolbar.middleware.DebugToolbarMiddleware',)\n INSTALLED_APPS += ('debug_toolbar', )\n \n INTERNAL_IPS = ('127.0.0.1', '10.0.2.2',)\n", "issue": "brak zapyta\u0144 w zak\u0142adce SQL w Django debug toolbar \n\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n'''\nLocal settings\n\n- Run in Debug mode\n- Use console backend for emails\n- Add Django Debug Toolbar\n- Add django-extensions as app\n'''\n\nfrom .common import * # noqa\n\n# DEBUG\n# ------------------------------------------------------------------------------\nDEBUG = env.bool('DJANGO_DEBUG', default=True)\nTEMPLATES[0]['OPTIONS']['debug'] = DEBUG\n\n# SECRET CONFIGURATION\n# ------------------------------------------------------------------------------\n# See: https://docs.djangoproject.com/en/dev/ref/settings/#secret-key\n# Note: This key only used for development and testing.\nSECRET_KEY = env(\"DJANGO_SECRET_KEY\", default='CHANGEME!!!')\n\n# Mail settings\n# ------------------------------------------------------------------------------\nEMAIL_HOST = 'localhost'\nEMAIL_PORT = 1025\nEMAIL_BACKEND = env('DJANGO_EMAIL_BACKEND',\n default='django.core.mail.backends.console.EmailBackend')\nEMAIL_NOTIFICATION = '[email protected]'\n\n# CACHING\n# ------------------------------------------------------------------------------\nCACHES = {\n 'default': {\n 'BACKEND': 'django.core.cache.backends.locmem.LocMemCache',\n 'LOCATION': ''\n }\n}\n\n# django-debug-toolbar\n# ------------------------------------------------------------------------------\nMIDDLEWARE_CLASSES += ('debug_toolbar.middleware.DebugToolbarMiddleware',)\nINSTALLED_APPS += ('debug_toolbar', )\n\nINTERNAL_IPS = ('127.0.0.1', '10.0.2.2',)\n\nDEBUG_TOOLBAR_CONFIG = {\n 'DISABLE_PANELS': [\n 'debug_toolbar.panels.redirects.RedirectsPanel',\n 'debug_toolbar.panels.redirects.RedirectsPanel',\n ],\n 'SHOW_TEMPLATE_CONTEXT': True,\n}\n\n# django-extensions\n# ------------------------------------------------------------------------------\nINSTALLED_APPS += ('django_extensions', )\n\n# TESTING\n# ------------------------------------------------------------------------------\nTEST_RUNNER = 'django.test.runner.DiscoverRunner'\n\n# Your local stuff: Below this line define 3rd party library settings\n# To get all sql queries sent by Django from py shell\nEMAILLABS_APP_KEY = env('EMAILLABS_APP_KEY', default=\"Dummy\")\n\nEMAILLABS_SECRET_KEY = env('EMAILLABS_SECRET_KEY', default=\"Dummy\")\n", "path": "config/settings/local.py"}]}
| 1,194 | 111 |
gh_patches_debug_48771
|
rasdani/github-patches
|
git_diff
|
OpenNMT__OpenNMT-py-1086
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
bug in tally_parameters
Hi - there's a bug in _tally_parameters because `elif 'decoder' or 'generator' in name:` will always evaluate to True, since a string is True. I'd submit the fix, but I've already got a fork with some unrelated changes on the file I don't want to submit :)
</issue>
<code>
[start of onmt/train_single.py]
1 #!/usr/bin/env python
2 """
3 Training on a single process
4 """
5
6 import configargparse
7
8 import os
9 import random
10 import torch
11
12 import onmt.opts as opts
13
14 from onmt.inputters.inputter import build_dataset_iter, lazily_load_dataset, \
15 _load_fields, _collect_report_features
16 from onmt.model_builder import build_model
17 from onmt.utils.optimizers import build_optim
18 from onmt.trainer import build_trainer
19 from onmt.models import build_model_saver
20 from onmt.utils.logging import init_logger, logger
21
22
23 def _check_save_model_path(opt):
24 save_model_path = os.path.abspath(opt.save_model)
25 model_dirname = os.path.dirname(save_model_path)
26 if not os.path.exists(model_dirname):
27 os.makedirs(model_dirname)
28
29
30 def _tally_parameters(model):
31 n_params = sum([p.nelement() for p in model.parameters()])
32 enc = 0
33 dec = 0
34 for name, param in model.named_parameters():
35 if 'encoder' in name:
36 enc += param.nelement()
37 elif 'decoder' or 'generator' in name:
38 dec += param.nelement()
39 return n_params, enc, dec
40
41
42 def training_opt_postprocessing(opt, device_id):
43 if opt.word_vec_size != -1:
44 opt.src_word_vec_size = opt.word_vec_size
45 opt.tgt_word_vec_size = opt.word_vec_size
46
47 if opt.layers != -1:
48 opt.enc_layers = opt.layers
49 opt.dec_layers = opt.layers
50
51 if opt.rnn_size != -1:
52 opt.enc_rnn_size = opt.rnn_size
53 opt.dec_rnn_size = opt.rnn_size
54 if opt.model_type == 'text' and opt.enc_rnn_size != opt.dec_rnn_size:
55 raise AssertionError("""We do not support different encoder and
56 decoder rnn sizes for translation now.""")
57
58 opt.brnn = (opt.encoder_type == "brnn")
59
60 if opt.rnn_type == "SRU" and not opt.gpu_ranks:
61 raise AssertionError("Using SRU requires -gpu_ranks set.")
62
63 if torch.cuda.is_available() and not opt.gpu_ranks:
64 logger.info("WARNING: You have a CUDA device, \
65 should run with -gpu_ranks")
66
67 if opt.seed > 0:
68 torch.manual_seed(opt.seed)
69 # this one is needed for torchtext random call (shuffled iterator)
70 # in multi gpu it ensures datasets are read in the same order
71 random.seed(opt.seed)
72 # some cudnn methods can be random even after fixing the seed
73 # unless you tell it to be deterministic
74 torch.backends.cudnn.deterministic = True
75
76 if device_id >= 0:
77 torch.cuda.set_device(device_id)
78 if opt.seed > 0:
79 # These ensure same initialization in multi gpu mode
80 torch.cuda.manual_seed(opt.seed)
81
82 return opt
83
84
85 def main(opt, device_id):
86 opt = training_opt_postprocessing(opt, device_id)
87 init_logger(opt.log_file)
88 # Load checkpoint if we resume from a previous training.
89 if opt.train_from:
90 logger.info('Loading checkpoint from %s' % opt.train_from)
91 checkpoint = torch.load(opt.train_from,
92 map_location=lambda storage, loc: storage)
93
94 # Load default opts values then overwrite it with opts from
95 # the checkpoint. It's usefull in order to re-train a model
96 # after adding a new option (not set in checkpoint)
97 dummy_parser = configargparse.ArgumentParser()
98 opts.model_opts(dummy_parser)
99 default_opt = dummy_parser.parse_known_args([])[0]
100
101 model_opt = default_opt
102 model_opt.__dict__.update(checkpoint['opt'].__dict__)
103 else:
104 checkpoint = None
105 model_opt = opt
106
107 # Peek the first dataset to determine the data_type.
108 # (All datasets have the same data_type).
109 first_dataset = next(lazily_load_dataset("train", opt))
110 data_type = first_dataset.data_type
111
112 # Load fields generated from preprocess phase.
113 fields = _load_fields(first_dataset, data_type, opt, checkpoint)
114
115 # Report src/tgt features.
116
117 src_features, tgt_features = _collect_report_features(fields)
118 for j, feat in enumerate(src_features):
119 logger.info(' * src feature %d size = %d'
120 % (j, len(fields[feat].vocab)))
121 for j, feat in enumerate(tgt_features):
122 logger.info(' * tgt feature %d size = %d'
123 % (j, len(fields[feat].vocab)))
124
125 # Build model.
126 model = build_model(model_opt, opt, fields, checkpoint)
127 n_params, enc, dec = _tally_parameters(model)
128 logger.info('encoder: %d' % enc)
129 logger.info('decoder: %d' % dec)
130 logger.info('* number of parameters: %d' % n_params)
131 _check_save_model_path(opt)
132
133 # Build optimizer.
134 optim = build_optim(model, opt, checkpoint)
135
136 # Build model saver
137 model_saver = build_model_saver(model_opt, opt, model, fields, optim)
138
139 trainer = build_trainer(opt, device_id, model, fields,
140 optim, data_type, model_saver=model_saver)
141
142 def train_iter_fct(): return build_dataset_iter(
143 lazily_load_dataset("train", opt), fields, opt)
144
145 def valid_iter_fct(): return build_dataset_iter(
146 lazily_load_dataset("valid", opt), fields, opt, is_train=False)
147
148 # Do training.
149 if len(opt.gpu_ranks):
150 logger.info('Starting training on GPU: %s' % opt.gpu_ranks)
151 else:
152 logger.info('Starting training on CPU, could be very slow')
153 trainer.train(train_iter_fct, valid_iter_fct, opt.train_steps,
154 opt.valid_steps)
155
156 if opt.tensorboard:
157 trainer.report_manager.tensorboard_writer.close()
158
159
160 if __name__ == "__main__":
161 parser = configargparse.ArgumentParser(
162 description='train.py',
163 formatter_class=configargparse.ArgumentDefaultsHelpFormatter)
164
165 opts.add_md_help_argument(parser)
166 opts.model_opts(parser)
167 opts.train_opts(parser)
168
169 opt = parser.parse_args()
170 main(opt)
171
[end of onmt/train_single.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/onmt/train_single.py b/onmt/train_single.py
--- a/onmt/train_single.py
+++ b/onmt/train_single.py
@@ -34,7 +34,7 @@
for name, param in model.named_parameters():
if 'encoder' in name:
enc += param.nelement()
- elif 'decoder' or 'generator' in name:
+ elif ('decoder' or 'generator') in name:
dec += param.nelement()
return n_params, enc, dec
|
{"golden_diff": "diff --git a/onmt/train_single.py b/onmt/train_single.py\n--- a/onmt/train_single.py\n+++ b/onmt/train_single.py\n@@ -34,7 +34,7 @@\n for name, param in model.named_parameters():\n if 'encoder' in name:\n enc += param.nelement()\n- elif 'decoder' or 'generator' in name:\n+ elif ('decoder' or 'generator') in name:\n dec += param.nelement()\n return n_params, enc, dec\n", "issue": "bug in tally_parameters\nHi - there's a bug in _tally_parameters because `elif 'decoder' or 'generator' in name:` will always evaluate to True, since a string is True. I'd submit the fix, but I've already got a fork with some unrelated changes on the file I don't want to submit :)\n", "before_files": [{"content": "#!/usr/bin/env python\n\"\"\"\n Training on a single process\n\"\"\"\n\nimport configargparse\n\nimport os\nimport random\nimport torch\n\nimport onmt.opts as opts\n\nfrom onmt.inputters.inputter import build_dataset_iter, lazily_load_dataset, \\\n _load_fields, _collect_report_features\nfrom onmt.model_builder import build_model\nfrom onmt.utils.optimizers import build_optim\nfrom onmt.trainer import build_trainer\nfrom onmt.models import build_model_saver\nfrom onmt.utils.logging import init_logger, logger\n\n\ndef _check_save_model_path(opt):\n save_model_path = os.path.abspath(opt.save_model)\n model_dirname = os.path.dirname(save_model_path)\n if not os.path.exists(model_dirname):\n os.makedirs(model_dirname)\n\n\ndef _tally_parameters(model):\n n_params = sum([p.nelement() for p in model.parameters()])\n enc = 0\n dec = 0\n for name, param in model.named_parameters():\n if 'encoder' in name:\n enc += param.nelement()\n elif 'decoder' or 'generator' in name:\n dec += param.nelement()\n return n_params, enc, dec\n\n\ndef training_opt_postprocessing(opt, device_id):\n if opt.word_vec_size != -1:\n opt.src_word_vec_size = opt.word_vec_size\n opt.tgt_word_vec_size = opt.word_vec_size\n\n if opt.layers != -1:\n opt.enc_layers = opt.layers\n opt.dec_layers = opt.layers\n\n if opt.rnn_size != -1:\n opt.enc_rnn_size = opt.rnn_size\n opt.dec_rnn_size = opt.rnn_size\n if opt.model_type == 'text' and opt.enc_rnn_size != opt.dec_rnn_size:\n raise AssertionError(\"\"\"We do not support different encoder and\n decoder rnn sizes for translation now.\"\"\")\n\n opt.brnn = (opt.encoder_type == \"brnn\")\n\n if opt.rnn_type == \"SRU\" and not opt.gpu_ranks:\n raise AssertionError(\"Using SRU requires -gpu_ranks set.\")\n\n if torch.cuda.is_available() and not opt.gpu_ranks:\n logger.info(\"WARNING: You have a CUDA device, \\\n should run with -gpu_ranks\")\n\n if opt.seed > 0:\n torch.manual_seed(opt.seed)\n # this one is needed for torchtext random call (shuffled iterator)\n # in multi gpu it ensures datasets are read in the same order\n random.seed(opt.seed)\n # some cudnn methods can be random even after fixing the seed\n # unless you tell it to be deterministic\n torch.backends.cudnn.deterministic = True\n\n if device_id >= 0:\n torch.cuda.set_device(device_id)\n if opt.seed > 0:\n # These ensure same initialization in multi gpu mode\n torch.cuda.manual_seed(opt.seed)\n\n return opt\n\n\ndef main(opt, device_id):\n opt = training_opt_postprocessing(opt, device_id)\n init_logger(opt.log_file)\n # Load checkpoint if we resume from a previous training.\n if opt.train_from:\n logger.info('Loading checkpoint from %s' % opt.train_from)\n checkpoint = torch.load(opt.train_from,\n map_location=lambda storage, loc: storage)\n\n # Load default opts values then overwrite it with opts from\n # the checkpoint. It's usefull in order to re-train a model\n # after adding a new option (not set in checkpoint)\n dummy_parser = configargparse.ArgumentParser()\n opts.model_opts(dummy_parser)\n default_opt = dummy_parser.parse_known_args([])[0]\n\n model_opt = default_opt\n model_opt.__dict__.update(checkpoint['opt'].__dict__)\n else:\n checkpoint = None\n model_opt = opt\n\n # Peek the first dataset to determine the data_type.\n # (All datasets have the same data_type).\n first_dataset = next(lazily_load_dataset(\"train\", opt))\n data_type = first_dataset.data_type\n\n # Load fields generated from preprocess phase.\n fields = _load_fields(first_dataset, data_type, opt, checkpoint)\n\n # Report src/tgt features.\n\n src_features, tgt_features = _collect_report_features(fields)\n for j, feat in enumerate(src_features):\n logger.info(' * src feature %d size = %d'\n % (j, len(fields[feat].vocab)))\n for j, feat in enumerate(tgt_features):\n logger.info(' * tgt feature %d size = %d'\n % (j, len(fields[feat].vocab)))\n\n # Build model.\n model = build_model(model_opt, opt, fields, checkpoint)\n n_params, enc, dec = _tally_parameters(model)\n logger.info('encoder: %d' % enc)\n logger.info('decoder: %d' % dec)\n logger.info('* number of parameters: %d' % n_params)\n _check_save_model_path(opt)\n\n # Build optimizer.\n optim = build_optim(model, opt, checkpoint)\n\n # Build model saver\n model_saver = build_model_saver(model_opt, opt, model, fields, optim)\n\n trainer = build_trainer(opt, device_id, model, fields,\n optim, data_type, model_saver=model_saver)\n\n def train_iter_fct(): return build_dataset_iter(\n lazily_load_dataset(\"train\", opt), fields, opt)\n\n def valid_iter_fct(): return build_dataset_iter(\n lazily_load_dataset(\"valid\", opt), fields, opt, is_train=False)\n\n # Do training.\n if len(opt.gpu_ranks):\n logger.info('Starting training on GPU: %s' % opt.gpu_ranks)\n else:\n logger.info('Starting training on CPU, could be very slow')\n trainer.train(train_iter_fct, valid_iter_fct, opt.train_steps,\n opt.valid_steps)\n\n if opt.tensorboard:\n trainer.report_manager.tensorboard_writer.close()\n\n\nif __name__ == \"__main__\":\n parser = configargparse.ArgumentParser(\n description='train.py',\n formatter_class=configargparse.ArgumentDefaultsHelpFormatter)\n\n opts.add_md_help_argument(parser)\n opts.model_opts(parser)\n opts.train_opts(parser)\n\n opt = parser.parse_args()\n main(opt)\n", "path": "onmt/train_single.py"}]}
| 2,365 | 111 |
gh_patches_debug_1380
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-4633
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Dunelm spider output is missing 41 branches (dunelm_gb)
The Dunelm spider dunelm_gb is consistently returning 138 branches for the last few weeks. However, Dunelm's own online store-finder at https://www.dunelm.com/stores/a-z lists 179 branches. All of the 138 are included in the 179, meaning the spider is missing 41.
For example, the following branches appear on Dunelm's website, but aren't returned by the spider:
- https://www.dunelm.com/stores/altrincham
- https://www.dunelm.com/stores/basildon
- https://www.dunelm.com/stores/beckton
- https://www.dunelm.com/stores/beverley
I'm afraid I can't figure out how to manually replicate the spider's request, to check whether the missing branches are missing from the API return, or are just not being picked up by the spider for some reason.
I don't know if there's any connection between the missing stores. The Basildon one only opened recently in April 2022 ([source](https://www.echo-news.co.uk/news/20100489.dunelm-opens-mayflower-retail-park-basildon/)) but the Altrincham store has been around since 2017 ([source](https://www.messengernewspapers.co.uk/news/whereyoulive/15122706.customers-attend-opening-of-dunelms-new-altrincham-store/)). I've checked a few of the missing branches and found facebook supprt groupswith recent posts, suggesting that the stores are indeed still open.
If the API isn't returning all the stores, then perhaps the online list at https://www.dunelm.com/stores/a-z could be used by the spider instead, or maybe https://www.dunelm.com/sitemap/static-sitemap.xml (which also seems to include all 179).
</issue>
<code>
[start of locations/spiders/dunelm_gb.py]
1 from scrapy.http import JsonRequest
2 from scrapy.spiders import Spider
3
4 from locations.dict_parser import DictParser
5 from locations.hours import OpeningHours
6
7
8 class DunelmGB(Spider):
9 name = "dunelm_gb"
10 item_attributes = {"brand": "Dunelm", "brand_wikidata": "Q5315020"}
11
12 def start_requests(self):
13 yield JsonRequest(
14 url="https://fy8plebn34-dsn.algolia.net/1/indexes/*/queries?x-algolia-application-id=FY8PLEBN34&x-algolia-api-key=ae9bc9ca475f6c3d7579016da0305a33",
15 data={
16 "requests": [
17 {
18 "indexName": "stores_prod",
19 "params": "hitsPerPage=300",
20 }
21 ]
22 },
23 )
24
25 def parse(self, response, **kwargs):
26 for store in response.json()["results"][0]["hits"]:
27 store["location"] = store["_geoloc"]
28
29 item = DictParser.parse(store)
30
31 item["ref"] = store["sapStoreId"]
32 item["website"] = "https://www.dunelm.com/stores/" + store["uri"]
33
34 oh = OpeningHours()
35 for rule in store["openingHours"]:
36 oh.add_range(rule["day"], rule["open"], rule["close"])
37
38 item["opening_hours"] = oh.as_opening_hours()
39
40 item["email"] = store["email"]
41 item["extras"] = {"storeType": store.get("storeType")}
42
43 yield item
44
[end of locations/spiders/dunelm_gb.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/locations/spiders/dunelm_gb.py b/locations/spiders/dunelm_gb.py
--- a/locations/spiders/dunelm_gb.py
+++ b/locations/spiders/dunelm_gb.py
@@ -37,7 +37,6 @@
item["opening_hours"] = oh.as_opening_hours()
- item["email"] = store["email"]
item["extras"] = {"storeType": store.get("storeType")}
yield item
|
{"golden_diff": "diff --git a/locations/spiders/dunelm_gb.py b/locations/spiders/dunelm_gb.py\n--- a/locations/spiders/dunelm_gb.py\n+++ b/locations/spiders/dunelm_gb.py\n@@ -37,7 +37,6 @@\n \n item[\"opening_hours\"] = oh.as_opening_hours()\n \n- item[\"email\"] = store[\"email\"]\n item[\"extras\"] = {\"storeType\": store.get(\"storeType\")}\n \n yield item\n", "issue": "Dunelm spider output is missing 41 branches (dunelm_gb)\nThe Dunelm spider dunelm_gb is consistently returning 138 branches for the last few weeks. However, Dunelm's own online store-finder at https://www.dunelm.com/stores/a-z lists 179 branches. All of the 138 are included in the 179, meaning the spider is missing 41.\r\n\r\nFor example, the following branches appear on Dunelm's website, but aren't returned by the spider:\r\n- https://www.dunelm.com/stores/altrincham\r\n- https://www.dunelm.com/stores/basildon\r\n- https://www.dunelm.com/stores/beckton\r\n- https://www.dunelm.com/stores/beverley\r\n\r\nI'm afraid I can't figure out how to manually replicate the spider's request, to check whether the missing branches are missing from the API return, or are just not being picked up by the spider for some reason.\r\n\r\nI don't know if there's any connection between the missing stores. The Basildon one only opened recently in April 2022 ([source](https://www.echo-news.co.uk/news/20100489.dunelm-opens-mayflower-retail-park-basildon/)) but the Altrincham store has been around since 2017 ([source](https://www.messengernewspapers.co.uk/news/whereyoulive/15122706.customers-attend-opening-of-dunelms-new-altrincham-store/)). I've checked a few of the missing branches and found facebook supprt groupswith recent posts, suggesting that the stores are indeed still open.\r\n\r\nIf the API isn't returning all the stores, then perhaps the online list at https://www.dunelm.com/stores/a-z could be used by the spider instead, or maybe https://www.dunelm.com/sitemap/static-sitemap.xml (which also seems to include all 179).\n", "before_files": [{"content": "from scrapy.http import JsonRequest\nfrom scrapy.spiders import Spider\n\nfrom locations.dict_parser import DictParser\nfrom locations.hours import OpeningHours\n\n\nclass DunelmGB(Spider):\n name = \"dunelm_gb\"\n item_attributes = {\"brand\": \"Dunelm\", \"brand_wikidata\": \"Q5315020\"}\n\n def start_requests(self):\n yield JsonRequest(\n url=\"https://fy8plebn34-dsn.algolia.net/1/indexes/*/queries?x-algolia-application-id=FY8PLEBN34&x-algolia-api-key=ae9bc9ca475f6c3d7579016da0305a33\",\n data={\n \"requests\": [\n {\n \"indexName\": \"stores_prod\",\n \"params\": \"hitsPerPage=300\",\n }\n ]\n },\n )\n\n def parse(self, response, **kwargs):\n for store in response.json()[\"results\"][0][\"hits\"]:\n store[\"location\"] = store[\"_geoloc\"]\n\n item = DictParser.parse(store)\n\n item[\"ref\"] = store[\"sapStoreId\"]\n item[\"website\"] = \"https://www.dunelm.com/stores/\" + store[\"uri\"]\n\n oh = OpeningHours()\n for rule in store[\"openingHours\"]:\n oh.add_range(rule[\"day\"], rule[\"open\"], rule[\"close\"])\n\n item[\"opening_hours\"] = oh.as_opening_hours()\n\n item[\"email\"] = store[\"email\"]\n item[\"extras\"] = {\"storeType\": store.get(\"storeType\")}\n\n yield item\n", "path": "locations/spiders/dunelm_gb.py"}]}
| 1,411 | 107 |
gh_patches_debug_25407
|
rasdani/github-patches
|
git_diff
|
googleapis__google-auth-library-python-1394
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
google.oauth2.service_account.Credential objects are not pickleable if cryptography is installed
#### Environment details
- OS: MacOS 13.5.2
- Python version: 3.9
- pip version: 23.1.2
- `google-auth` version: 2.22.0
#### Steps to reproduce
Install `cryptography`
Run:
```
import pickle
from google.oauth2 import service_account
credentials = service_account.Credentials.from_service_account_file("credentials.json")
pickle.dumps(credentials)
```
The object in question seems to be `credentials._signer` which is either a pickleable pure Python object if `cryptography` is not installed, or else an unpickleable `google.auth.crypt._cryptography_rsa.RSASigner` if it is. Specifically, the signer._key object is of type `cryptography.hazmat.backends.openssl.rsa._RSAPrivateKey`.
This conversation on SO seems related: https://stackoverflow.com/questions/39321606/cant-pickle-an-rsa-key-to-send-over-a-socket
This is impacting the Storage SDK's multiprocessing capability: https://github.com/googleapis/python-storage/issues/1116 despite efforts to work around it.
</issue>
<code>
[start of google/auth/crypt/es256.py]
1 # Copyright 2017 Google Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """ECDSA (ES256) verifier and signer that use the ``cryptography`` library.
16 """
17
18 from cryptography import utils # type: ignore
19 import cryptography.exceptions
20 from cryptography.hazmat import backends
21 from cryptography.hazmat.primitives import hashes
22 from cryptography.hazmat.primitives import serialization
23 from cryptography.hazmat.primitives.asymmetric import ec
24 from cryptography.hazmat.primitives.asymmetric import padding
25 from cryptography.hazmat.primitives.asymmetric.utils import decode_dss_signature
26 from cryptography.hazmat.primitives.asymmetric.utils import encode_dss_signature
27 import cryptography.x509
28
29 from google.auth import _helpers
30 from google.auth.crypt import base
31
32
33 _CERTIFICATE_MARKER = b"-----BEGIN CERTIFICATE-----"
34 _BACKEND = backends.default_backend()
35 _PADDING = padding.PKCS1v15()
36
37
38 class ES256Verifier(base.Verifier):
39 """Verifies ECDSA cryptographic signatures using public keys.
40
41 Args:
42 public_key (
43 cryptography.hazmat.primitives.asymmetric.ec.ECDSAPublicKey):
44 The public key used to verify signatures.
45 """
46
47 def __init__(self, public_key):
48 self._pubkey = public_key
49
50 @_helpers.copy_docstring(base.Verifier)
51 def verify(self, message, signature):
52 # First convert (r||s) raw signature to ASN1 encoded signature.
53 sig_bytes = _helpers.to_bytes(signature)
54 if len(sig_bytes) != 64:
55 return False
56 r = (
57 int.from_bytes(sig_bytes[:32], byteorder="big")
58 if _helpers.is_python_3()
59 else utils.int_from_bytes(sig_bytes[:32], byteorder="big")
60 )
61 s = (
62 int.from_bytes(sig_bytes[32:], byteorder="big")
63 if _helpers.is_python_3()
64 else utils.int_from_bytes(sig_bytes[32:], byteorder="big")
65 )
66 asn1_sig = encode_dss_signature(r, s)
67
68 message = _helpers.to_bytes(message)
69 try:
70 self._pubkey.verify(asn1_sig, message, ec.ECDSA(hashes.SHA256()))
71 return True
72 except (ValueError, cryptography.exceptions.InvalidSignature):
73 return False
74
75 @classmethod
76 def from_string(cls, public_key):
77 """Construct an Verifier instance from a public key or public
78 certificate string.
79
80 Args:
81 public_key (Union[str, bytes]): The public key in PEM format or the
82 x509 public key certificate.
83
84 Returns:
85 Verifier: The constructed verifier.
86
87 Raises:
88 ValueError: If the public key can't be parsed.
89 """
90 public_key_data = _helpers.to_bytes(public_key)
91
92 if _CERTIFICATE_MARKER in public_key_data:
93 cert = cryptography.x509.load_pem_x509_certificate(
94 public_key_data, _BACKEND
95 )
96 pubkey = cert.public_key()
97
98 else:
99 pubkey = serialization.load_pem_public_key(public_key_data, _BACKEND)
100
101 return cls(pubkey)
102
103
104 class ES256Signer(base.Signer, base.FromServiceAccountMixin):
105 """Signs messages with an ECDSA private key.
106
107 Args:
108 private_key (
109 cryptography.hazmat.primitives.asymmetric.ec.ECDSAPrivateKey):
110 The private key to sign with.
111 key_id (str): Optional key ID used to identify this private key. This
112 can be useful to associate the private key with its associated
113 public key or certificate.
114 """
115
116 def __init__(self, private_key, key_id=None):
117 self._key = private_key
118 self._key_id = key_id
119
120 @property # type: ignore
121 @_helpers.copy_docstring(base.Signer)
122 def key_id(self):
123 return self._key_id
124
125 @_helpers.copy_docstring(base.Signer)
126 def sign(self, message):
127 message = _helpers.to_bytes(message)
128 asn1_signature = self._key.sign(message, ec.ECDSA(hashes.SHA256()))
129
130 # Convert ASN1 encoded signature to (r||s) raw signature.
131 (r, s) = decode_dss_signature(asn1_signature)
132 return (
133 (r.to_bytes(32, byteorder="big") + s.to_bytes(32, byteorder="big"))
134 if _helpers.is_python_3()
135 else (utils.int_to_bytes(r, 32) + utils.int_to_bytes(s, 32))
136 )
137
138 @classmethod
139 def from_string(cls, key, key_id=None):
140 """Construct a RSASigner from a private key in PEM format.
141
142 Args:
143 key (Union[bytes, str]): Private key in PEM format.
144 key_id (str): An optional key id used to identify the private key.
145
146 Returns:
147 google.auth.crypt._cryptography_rsa.RSASigner: The
148 constructed signer.
149
150 Raises:
151 ValueError: If ``key`` is not ``bytes`` or ``str`` (unicode).
152 UnicodeDecodeError: If ``key`` is ``bytes`` but cannot be decoded
153 into a UTF-8 ``str``.
154 ValueError: If ``cryptography`` "Could not deserialize key data."
155 """
156 key = _helpers.to_bytes(key)
157 private_key = serialization.load_pem_private_key(
158 key, password=None, backend=_BACKEND
159 )
160 return cls(private_key, key_id=key_id)
161
[end of google/auth/crypt/es256.py]
[start of google/auth/crypt/_cryptography_rsa.py]
1 # Copyright 2017 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """RSA verifier and signer that use the ``cryptography`` library.
16
17 This is a much faster implementation than the default (in
18 ``google.auth.crypt._python_rsa``), which depends on the pure-Python
19 ``rsa`` library.
20 """
21
22 import cryptography.exceptions
23 from cryptography.hazmat import backends
24 from cryptography.hazmat.primitives import hashes
25 from cryptography.hazmat.primitives import serialization
26 from cryptography.hazmat.primitives.asymmetric import padding
27 import cryptography.x509
28
29 from google.auth import _helpers
30 from google.auth.crypt import base
31
32 _CERTIFICATE_MARKER = b"-----BEGIN CERTIFICATE-----"
33 _BACKEND = backends.default_backend()
34 _PADDING = padding.PKCS1v15()
35 _SHA256 = hashes.SHA256()
36
37
38 class RSAVerifier(base.Verifier):
39 """Verifies RSA cryptographic signatures using public keys.
40
41 Args:
42 public_key (
43 cryptography.hazmat.primitives.asymmetric.rsa.RSAPublicKey):
44 The public key used to verify signatures.
45 """
46
47 def __init__(self, public_key):
48 self._pubkey = public_key
49
50 @_helpers.copy_docstring(base.Verifier)
51 def verify(self, message, signature):
52 message = _helpers.to_bytes(message)
53 try:
54 self._pubkey.verify(signature, message, _PADDING, _SHA256)
55 return True
56 except (ValueError, cryptography.exceptions.InvalidSignature):
57 return False
58
59 @classmethod
60 def from_string(cls, public_key):
61 """Construct an Verifier instance from a public key or public
62 certificate string.
63
64 Args:
65 public_key (Union[str, bytes]): The public key in PEM format or the
66 x509 public key certificate.
67
68 Returns:
69 Verifier: The constructed verifier.
70
71 Raises:
72 ValueError: If the public key can't be parsed.
73 """
74 public_key_data = _helpers.to_bytes(public_key)
75
76 if _CERTIFICATE_MARKER in public_key_data:
77 cert = cryptography.x509.load_pem_x509_certificate(
78 public_key_data, _BACKEND
79 )
80 pubkey = cert.public_key()
81
82 else:
83 pubkey = serialization.load_pem_public_key(public_key_data, _BACKEND)
84
85 return cls(pubkey)
86
87
88 class RSASigner(base.Signer, base.FromServiceAccountMixin):
89 """Signs messages with an RSA private key.
90
91 Args:
92 private_key (
93 cryptography.hazmat.primitives.asymmetric.rsa.RSAPrivateKey):
94 The private key to sign with.
95 key_id (str): Optional key ID used to identify this private key. This
96 can be useful to associate the private key with its associated
97 public key or certificate.
98 """
99
100 def __init__(self, private_key, key_id=None):
101 self._key = private_key
102 self._key_id = key_id
103
104 @property # type: ignore
105 @_helpers.copy_docstring(base.Signer)
106 def key_id(self):
107 return self._key_id
108
109 @_helpers.copy_docstring(base.Signer)
110 def sign(self, message):
111 message = _helpers.to_bytes(message)
112 return self._key.sign(message, _PADDING, _SHA256)
113
114 @classmethod
115 def from_string(cls, key, key_id=None):
116 """Construct a RSASigner from a private key in PEM format.
117
118 Args:
119 key (Union[bytes, str]): Private key in PEM format.
120 key_id (str): An optional key id used to identify the private key.
121
122 Returns:
123 google.auth.crypt._cryptography_rsa.RSASigner: The
124 constructed signer.
125
126 Raises:
127 ValueError: If ``key`` is not ``bytes`` or ``str`` (unicode).
128 UnicodeDecodeError: If ``key`` is ``bytes`` but cannot be decoded
129 into a UTF-8 ``str``.
130 ValueError: If ``cryptography`` "Could not deserialize key data."
131 """
132 key = _helpers.to_bytes(key)
133 private_key = serialization.load_pem_private_key(
134 key, password=None, backend=_BACKEND
135 )
136 return cls(private_key, key_id=key_id)
137
[end of google/auth/crypt/_cryptography_rsa.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/google/auth/crypt/_cryptography_rsa.py b/google/auth/crypt/_cryptography_rsa.py
--- a/google/auth/crypt/_cryptography_rsa.py
+++ b/google/auth/crypt/_cryptography_rsa.py
@@ -134,3 +134,18 @@
key, password=None, backend=_BACKEND
)
return cls(private_key, key_id=key_id)
+
+ def __getstate__(self):
+ """Pickle helper that serializes the _key attribute."""
+ state = self.__dict__.copy()
+ state["_key"] = self._key.private_bytes(
+ encoding=serialization.Encoding.PEM,
+ format=serialization.PrivateFormat.PKCS8,
+ encryption_algorithm=serialization.NoEncryption(),
+ )
+ return state
+
+ def __setstate__(self, state):
+ """Pickle helper that deserializes the _key attribute."""
+ state["_key"] = serialization.load_pem_private_key(state["_key"], None)
+ self.__dict__.update(state)
diff --git a/google/auth/crypt/es256.py b/google/auth/crypt/es256.py
--- a/google/auth/crypt/es256.py
+++ b/google/auth/crypt/es256.py
@@ -158,3 +158,18 @@
key, password=None, backend=_BACKEND
)
return cls(private_key, key_id=key_id)
+
+ def __getstate__(self):
+ """Pickle helper that serializes the _key attribute."""
+ state = self.__dict__.copy()
+ state["_key"] = self._key.private_bytes(
+ encoding=serialization.Encoding.PEM,
+ format=serialization.PrivateFormat.PKCS8,
+ encryption_algorithm=serialization.NoEncryption(),
+ )
+ return state
+
+ def __setstate__(self, state):
+ """Pickle helper that deserializes the _key attribute."""
+ state["_key"] = serialization.load_pem_private_key(state["_key"], None)
+ self.__dict__.update(state)
|
{"golden_diff": "diff --git a/google/auth/crypt/_cryptography_rsa.py b/google/auth/crypt/_cryptography_rsa.py\n--- a/google/auth/crypt/_cryptography_rsa.py\n+++ b/google/auth/crypt/_cryptography_rsa.py\n@@ -134,3 +134,18 @@\n key, password=None, backend=_BACKEND\n )\n return cls(private_key, key_id=key_id)\n+\n+ def __getstate__(self):\n+ \"\"\"Pickle helper that serializes the _key attribute.\"\"\"\n+ state = self.__dict__.copy()\n+ state[\"_key\"] = self._key.private_bytes(\n+ encoding=serialization.Encoding.PEM,\n+ format=serialization.PrivateFormat.PKCS8,\n+ encryption_algorithm=serialization.NoEncryption(),\n+ )\n+ return state\n+\n+ def __setstate__(self, state):\n+ \"\"\"Pickle helper that deserializes the _key attribute.\"\"\"\n+ state[\"_key\"] = serialization.load_pem_private_key(state[\"_key\"], None)\n+ self.__dict__.update(state)\ndiff --git a/google/auth/crypt/es256.py b/google/auth/crypt/es256.py\n--- a/google/auth/crypt/es256.py\n+++ b/google/auth/crypt/es256.py\n@@ -158,3 +158,18 @@\n key, password=None, backend=_BACKEND\n )\n return cls(private_key, key_id=key_id)\n+\n+ def __getstate__(self):\n+ \"\"\"Pickle helper that serializes the _key attribute.\"\"\"\n+ state = self.__dict__.copy()\n+ state[\"_key\"] = self._key.private_bytes(\n+ encoding=serialization.Encoding.PEM,\n+ format=serialization.PrivateFormat.PKCS8,\n+ encryption_algorithm=serialization.NoEncryption(),\n+ )\n+ return state\n+\n+ def __setstate__(self, state):\n+ \"\"\"Pickle helper that deserializes the _key attribute.\"\"\"\n+ state[\"_key\"] = serialization.load_pem_private_key(state[\"_key\"], None)\n+ self.__dict__.update(state)\n", "issue": "google.oauth2.service_account.Credential objects are not pickleable if cryptography is installed\n#### Environment details\r\n\r\n - OS: MacOS 13.5.2\r\n - Python version: 3.9\r\n - pip version: 23.1.2\r\n - `google-auth` version: 2.22.0\r\n\r\n#### Steps to reproduce\r\n\r\nInstall `cryptography`\r\n\r\nRun:\r\n```\r\nimport pickle\r\nfrom google.oauth2 import service_account\r\n\r\ncredentials = service_account.Credentials.from_service_account_file(\"credentials.json\")\r\n\r\npickle.dumps(credentials)\r\n```\r\n\r\nThe object in question seems to be `credentials._signer` which is either a pickleable pure Python object if `cryptography` is not installed, or else an unpickleable `google.auth.crypt._cryptography_rsa.RSASigner` if it is. Specifically, the signer._key object is of type `cryptography.hazmat.backends.openssl.rsa._RSAPrivateKey`.\r\n\r\nThis conversation on SO seems related: https://stackoverflow.com/questions/39321606/cant-pickle-an-rsa-key-to-send-over-a-socket\r\n\r\nThis is impacting the Storage SDK's multiprocessing capability: https://github.com/googleapis/python-storage/issues/1116 despite efforts to work around it.\n", "before_files": [{"content": "# Copyright 2017 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"ECDSA (ES256) verifier and signer that use the ``cryptography`` library.\n\"\"\"\n\nfrom cryptography import utils # type: ignore\nimport cryptography.exceptions\nfrom cryptography.hazmat import backends\nfrom cryptography.hazmat.primitives import hashes\nfrom cryptography.hazmat.primitives import serialization\nfrom cryptography.hazmat.primitives.asymmetric import ec\nfrom cryptography.hazmat.primitives.asymmetric import padding\nfrom cryptography.hazmat.primitives.asymmetric.utils import decode_dss_signature\nfrom cryptography.hazmat.primitives.asymmetric.utils import encode_dss_signature\nimport cryptography.x509\n\nfrom google.auth import _helpers\nfrom google.auth.crypt import base\n\n\n_CERTIFICATE_MARKER = b\"-----BEGIN CERTIFICATE-----\"\n_BACKEND = backends.default_backend()\n_PADDING = padding.PKCS1v15()\n\n\nclass ES256Verifier(base.Verifier):\n \"\"\"Verifies ECDSA cryptographic signatures using public keys.\n\n Args:\n public_key (\n cryptography.hazmat.primitives.asymmetric.ec.ECDSAPublicKey):\n The public key used to verify signatures.\n \"\"\"\n\n def __init__(self, public_key):\n self._pubkey = public_key\n\n @_helpers.copy_docstring(base.Verifier)\n def verify(self, message, signature):\n # First convert (r||s) raw signature to ASN1 encoded signature.\n sig_bytes = _helpers.to_bytes(signature)\n if len(sig_bytes) != 64:\n return False\n r = (\n int.from_bytes(sig_bytes[:32], byteorder=\"big\")\n if _helpers.is_python_3()\n else utils.int_from_bytes(sig_bytes[:32], byteorder=\"big\")\n )\n s = (\n int.from_bytes(sig_bytes[32:], byteorder=\"big\")\n if _helpers.is_python_3()\n else utils.int_from_bytes(sig_bytes[32:], byteorder=\"big\")\n )\n asn1_sig = encode_dss_signature(r, s)\n\n message = _helpers.to_bytes(message)\n try:\n self._pubkey.verify(asn1_sig, message, ec.ECDSA(hashes.SHA256()))\n return True\n except (ValueError, cryptography.exceptions.InvalidSignature):\n return False\n\n @classmethod\n def from_string(cls, public_key):\n \"\"\"Construct an Verifier instance from a public key or public\n certificate string.\n\n Args:\n public_key (Union[str, bytes]): The public key in PEM format or the\n x509 public key certificate.\n\n Returns:\n Verifier: The constructed verifier.\n\n Raises:\n ValueError: If the public key can't be parsed.\n \"\"\"\n public_key_data = _helpers.to_bytes(public_key)\n\n if _CERTIFICATE_MARKER in public_key_data:\n cert = cryptography.x509.load_pem_x509_certificate(\n public_key_data, _BACKEND\n )\n pubkey = cert.public_key()\n\n else:\n pubkey = serialization.load_pem_public_key(public_key_data, _BACKEND)\n\n return cls(pubkey)\n\n\nclass ES256Signer(base.Signer, base.FromServiceAccountMixin):\n \"\"\"Signs messages with an ECDSA private key.\n\n Args:\n private_key (\n cryptography.hazmat.primitives.asymmetric.ec.ECDSAPrivateKey):\n The private key to sign with.\n key_id (str): Optional key ID used to identify this private key. This\n can be useful to associate the private key with its associated\n public key or certificate.\n \"\"\"\n\n def __init__(self, private_key, key_id=None):\n self._key = private_key\n self._key_id = key_id\n\n @property # type: ignore\n @_helpers.copy_docstring(base.Signer)\n def key_id(self):\n return self._key_id\n\n @_helpers.copy_docstring(base.Signer)\n def sign(self, message):\n message = _helpers.to_bytes(message)\n asn1_signature = self._key.sign(message, ec.ECDSA(hashes.SHA256()))\n\n # Convert ASN1 encoded signature to (r||s) raw signature.\n (r, s) = decode_dss_signature(asn1_signature)\n return (\n (r.to_bytes(32, byteorder=\"big\") + s.to_bytes(32, byteorder=\"big\"))\n if _helpers.is_python_3()\n else (utils.int_to_bytes(r, 32) + utils.int_to_bytes(s, 32))\n )\n\n @classmethod\n def from_string(cls, key, key_id=None):\n \"\"\"Construct a RSASigner from a private key in PEM format.\n\n Args:\n key (Union[bytes, str]): Private key in PEM format.\n key_id (str): An optional key id used to identify the private key.\n\n Returns:\n google.auth.crypt._cryptography_rsa.RSASigner: The\n constructed signer.\n\n Raises:\n ValueError: If ``key`` is not ``bytes`` or ``str`` (unicode).\n UnicodeDecodeError: If ``key`` is ``bytes`` but cannot be decoded\n into a UTF-8 ``str``.\n ValueError: If ``cryptography`` \"Could not deserialize key data.\"\n \"\"\"\n key = _helpers.to_bytes(key)\n private_key = serialization.load_pem_private_key(\n key, password=None, backend=_BACKEND\n )\n return cls(private_key, key_id=key_id)\n", "path": "google/auth/crypt/es256.py"}, {"content": "# Copyright 2017 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"RSA verifier and signer that use the ``cryptography`` library.\n\nThis is a much faster implementation than the default (in\n``google.auth.crypt._python_rsa``), which depends on the pure-Python\n``rsa`` library.\n\"\"\"\n\nimport cryptography.exceptions\nfrom cryptography.hazmat import backends\nfrom cryptography.hazmat.primitives import hashes\nfrom cryptography.hazmat.primitives import serialization\nfrom cryptography.hazmat.primitives.asymmetric import padding\nimport cryptography.x509\n\nfrom google.auth import _helpers\nfrom google.auth.crypt import base\n\n_CERTIFICATE_MARKER = b\"-----BEGIN CERTIFICATE-----\"\n_BACKEND = backends.default_backend()\n_PADDING = padding.PKCS1v15()\n_SHA256 = hashes.SHA256()\n\n\nclass RSAVerifier(base.Verifier):\n \"\"\"Verifies RSA cryptographic signatures using public keys.\n\n Args:\n public_key (\n cryptography.hazmat.primitives.asymmetric.rsa.RSAPublicKey):\n The public key used to verify signatures.\n \"\"\"\n\n def __init__(self, public_key):\n self._pubkey = public_key\n\n @_helpers.copy_docstring(base.Verifier)\n def verify(self, message, signature):\n message = _helpers.to_bytes(message)\n try:\n self._pubkey.verify(signature, message, _PADDING, _SHA256)\n return True\n except (ValueError, cryptography.exceptions.InvalidSignature):\n return False\n\n @classmethod\n def from_string(cls, public_key):\n \"\"\"Construct an Verifier instance from a public key or public\n certificate string.\n\n Args:\n public_key (Union[str, bytes]): The public key in PEM format or the\n x509 public key certificate.\n\n Returns:\n Verifier: The constructed verifier.\n\n Raises:\n ValueError: If the public key can't be parsed.\n \"\"\"\n public_key_data = _helpers.to_bytes(public_key)\n\n if _CERTIFICATE_MARKER in public_key_data:\n cert = cryptography.x509.load_pem_x509_certificate(\n public_key_data, _BACKEND\n )\n pubkey = cert.public_key()\n\n else:\n pubkey = serialization.load_pem_public_key(public_key_data, _BACKEND)\n\n return cls(pubkey)\n\n\nclass RSASigner(base.Signer, base.FromServiceAccountMixin):\n \"\"\"Signs messages with an RSA private key.\n\n Args:\n private_key (\n cryptography.hazmat.primitives.asymmetric.rsa.RSAPrivateKey):\n The private key to sign with.\n key_id (str): Optional key ID used to identify this private key. This\n can be useful to associate the private key with its associated\n public key or certificate.\n \"\"\"\n\n def __init__(self, private_key, key_id=None):\n self._key = private_key\n self._key_id = key_id\n\n @property # type: ignore\n @_helpers.copy_docstring(base.Signer)\n def key_id(self):\n return self._key_id\n\n @_helpers.copy_docstring(base.Signer)\n def sign(self, message):\n message = _helpers.to_bytes(message)\n return self._key.sign(message, _PADDING, _SHA256)\n\n @classmethod\n def from_string(cls, key, key_id=None):\n \"\"\"Construct a RSASigner from a private key in PEM format.\n\n Args:\n key (Union[bytes, str]): Private key in PEM format.\n key_id (str): An optional key id used to identify the private key.\n\n Returns:\n google.auth.crypt._cryptography_rsa.RSASigner: The\n constructed signer.\n\n Raises:\n ValueError: If ``key`` is not ``bytes`` or ``str`` (unicode).\n UnicodeDecodeError: If ``key`` is ``bytes`` but cannot be decoded\n into a UTF-8 ``str``.\n ValueError: If ``cryptography`` \"Could not deserialize key data.\"\n \"\"\"\n key = _helpers.to_bytes(key)\n private_key = serialization.load_pem_private_key(\n key, password=None, backend=_BACKEND\n )\n return cls(private_key, key_id=key_id)\n", "path": "google/auth/crypt/_cryptography_rsa.py"}]}
| 3,877 | 454 |
gh_patches_debug_1793
|
rasdani/github-patches
|
git_diff
|
pytorch__text-2144
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Implementing __contains__ for vocab.Vectors class
## 🚀 Feature
Isn't it better to implement \_\_contains\_\_ for Vectors class? In this way, one can easily find out whether a vocab is in the self.itos or not.
</issue>
<code>
[start of torchtext/vocab/vectors.py]
1 import gzip
2 import logging
3 import os
4 import tarfile
5 import zipfile
6 from functools import partial
7 from urllib.request import urlretrieve
8
9 import torch
10 from tqdm import tqdm
11
12 from ..utils import reporthook
13
14 logger = logging.getLogger(__name__)
15
16
17 def _infer_shape(f):
18 num_lines, vector_dim = 0, None
19 for line in f:
20 if vector_dim is None:
21 row = line.rstrip().split(b" ")
22 vector = row[1:]
23 # Assuming word, [vector] format
24 if len(vector) > 2:
25 # The header present in some (w2v) formats contains two elements.
26 vector_dim = len(vector)
27 num_lines += 1 # First element read
28 else:
29 num_lines += 1
30 f.seek(0)
31 return num_lines, vector_dim
32
33
34 class Vectors(object):
35 def __init__(self, name, cache=None, url=None, unk_init=None, max_vectors=None) -> None:
36 """
37 Args:
38
39 name: name of the file that contains the vectors
40 cache: directory for cached vectors
41 url: url for download if vectors not found in cache
42 unk_init (callback): by default, initialize out-of-vocabulary word vectors
43 to zero vectors; can be any function that takes in a Tensor and returns a Tensor of the same size
44 max_vectors (int): this can be used to limit the number of
45 pre-trained vectors loaded.
46 Most pre-trained vector sets are sorted
47 in the descending order of word frequency.
48 Thus, in situations where the entire set doesn't fit in memory,
49 or is not needed for another reason, passing `max_vectors`
50 can limit the size of the loaded set.
51 """
52
53 cache = ".vector_cache" if cache is None else cache
54 self.itos = None
55 self.stoi = None
56 self.vectors = None
57 self.dim = None
58 self.unk_init = torch.Tensor.zero_ if unk_init is None else unk_init
59 self.cache(name, cache, url=url, max_vectors=max_vectors)
60
61 def __getitem__(self, token):
62 if token in self.stoi:
63 return self.vectors[self.stoi[token]]
64 else:
65 return self.unk_init(torch.Tensor(self.dim))
66
67 def cache(self, name, cache, url=None, max_vectors=None):
68 import ssl
69
70 ssl._create_default_https_context = ssl._create_unverified_context
71 if os.path.isfile(name):
72 path = name
73 if max_vectors:
74 file_suffix = "_{}.pt".format(max_vectors)
75 else:
76 file_suffix = ".pt"
77 path_pt = os.path.join(cache, os.path.basename(name)) + file_suffix
78 else:
79 path = os.path.join(cache, name)
80 if max_vectors:
81 file_suffix = "_{}.pt".format(max_vectors)
82 else:
83 file_suffix = ".pt"
84 path_pt = path + file_suffix
85
86 if not os.path.isfile(path_pt):
87 if not os.path.isfile(path) and url:
88 logger.info("Downloading vectors from {}".format(url))
89 if not os.path.exists(cache):
90 os.makedirs(cache)
91 dest = os.path.join(cache, os.path.basename(url))
92 if not os.path.isfile(dest):
93 with tqdm(unit="B", unit_scale=True, miniters=1, desc=dest) as t:
94 try:
95 urlretrieve(url, dest, reporthook=reporthook(t))
96 except KeyboardInterrupt as e: # remove the partial zip file
97 os.remove(dest)
98 raise e
99 logger.info("Extracting vectors into {}".format(cache))
100 ext = os.path.splitext(dest)[1][1:]
101 if ext == "zip":
102 with zipfile.ZipFile(dest, "r") as zf:
103 zf.extractall(cache)
104 elif ext == "gz":
105 if dest.endswith(".tar.gz"):
106 with tarfile.open(dest, "r:gz") as tar:
107 tar.extractall(path=cache)
108 if not os.path.isfile(path):
109 raise RuntimeError("no vectors found at {}".format(path))
110
111 logger.info("Loading vectors from {}".format(path))
112 ext = os.path.splitext(path)[1][1:]
113 if ext == "gz":
114 open_file = gzip.open
115 else:
116 open_file = open
117
118 vectors_loaded = 0
119 with open_file(path, "rb") as f:
120 num_lines, dim = _infer_shape(f)
121 if not max_vectors or max_vectors > num_lines:
122 max_vectors = num_lines
123
124 itos, vectors, dim = [], torch.zeros((max_vectors, dim)), None
125
126 for line in tqdm(f, total=max_vectors):
127 # Explicitly splitting on " " is important, so we don't
128 # get rid of Unicode non-breaking spaces in the vectors.
129 entries = line.rstrip().split(b" ")
130
131 word, entries = entries[0], entries[1:]
132 if dim is None and len(entries) > 1:
133 dim = len(entries)
134 elif len(entries) == 1:
135 logger.warning(
136 "Skipping token {} with 1-dimensional " "vector {}; likely a header".format(word, entries)
137 )
138 continue
139 elif dim != len(entries):
140 raise RuntimeError(
141 "Vector for token {} has {} dimensions, but previously "
142 "read vectors have {} dimensions. All vectors must have "
143 "the same number of dimensions.".format(word, len(entries), dim)
144 )
145
146 try:
147 if isinstance(word, bytes):
148 word = word.decode("utf-8")
149 except UnicodeDecodeError:
150 logger.info("Skipping non-UTF8 token {}".format(repr(word)))
151 continue
152
153 vectors[vectors_loaded] = torch.tensor([float(x) for x in entries])
154 vectors_loaded += 1
155 itos.append(word)
156
157 if vectors_loaded == max_vectors:
158 break
159
160 self.itos = itos
161 self.stoi = {word: i for i, word in enumerate(itos)}
162 self.vectors = torch.Tensor(vectors).view(-1, dim)
163 self.dim = dim
164 logger.info("Saving vectors to {}".format(path_pt))
165 if not os.path.exists(cache):
166 os.makedirs(cache)
167 torch.save((self.itos, self.stoi, self.vectors, self.dim), path_pt)
168 else:
169 logger.info("Loading vectors from {}".format(path_pt))
170 self.itos, self.stoi, self.vectors, self.dim = torch.load(path_pt)
171
172 def __len__(self):
173 return len(self.vectors)
174
175 def get_vecs_by_tokens(self, tokens, lower_case_backup=False):
176 """Look up embedding vectors of tokens.
177
178 Args:
179 tokens: a token or a list of tokens. if `tokens` is a string,
180 returns a 1-D tensor of shape `self.dim`; if `tokens` is a
181 list of strings, returns a 2-D tensor of shape=(len(tokens),
182 self.dim).
183 lower_case_backup : Whether to look up the token in the lower case.
184 If False, each token in the original case will be looked up;
185 if True, each token in the original case will be looked up first,
186 if not found in the keys of the property `stoi`, the token in the
187 lower case will be looked up. Default: False.
188
189 Examples:
190 >>> examples = ['chip', 'baby', 'Beautiful']
191 >>> vec = text.vocab.GloVe(name='6B', dim=50)
192 >>> ret = vec.get_vecs_by_tokens(examples, lower_case_backup=True)
193 """
194 to_reduce = False
195
196 if not isinstance(tokens, list):
197 tokens = [tokens]
198 to_reduce = True
199
200 if not lower_case_backup:
201 indices = [self[token] for token in tokens]
202 else:
203 indices = [self[token] if token in self.stoi else self[token.lower()] for token in tokens]
204
205 vecs = torch.stack(indices)
206 return vecs[0] if to_reduce else vecs
207
208
209 class GloVe(Vectors):
210 url = {
211 "42B": "http://nlp.stanford.edu/data/glove.42B.300d.zip",
212 "840B": "http://nlp.stanford.edu/data/glove.840B.300d.zip",
213 "twitter.27B": "http://nlp.stanford.edu/data/glove.twitter.27B.zip",
214 "6B": "http://nlp.stanford.edu/data/glove.6B.zip",
215 }
216
217 def __init__(self, name="840B", dim=300, **kwargs) -> None:
218 url = self.url[name]
219 name = "glove.{}.{}d.txt".format(name, str(dim))
220 super(GloVe, self).__init__(name, url=url, **kwargs)
221
222
223 class FastText(Vectors):
224
225 url_base = "https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.{}.vec"
226
227 def __init__(self, language="en", **kwargs) -> None:
228 url = self.url_base.format(language)
229 name = os.path.basename(url)
230 super(FastText, self).__init__(name, url=url, **kwargs)
231
232
233 class CharNGram(Vectors):
234
235 name = "charNgram.txt"
236 url = "http://www.logos.t.u-tokyo.ac.jp/~hassy/publications/arxiv2016jmt/" "jmt_pre-trained_embeddings.tar.gz"
237
238 def __init__(self, **kwargs) -> None:
239 super(CharNGram, self).__init__(self.name, url=self.url, **kwargs)
240
241 def __getitem__(self, token):
242 vector = torch.Tensor(1, self.dim).zero_()
243 if token == "<unk>":
244 return self.unk_init(vector)
245 chars = ["#BEGIN#"] + list(token) + ["#END#"]
246 num_vectors = 0
247 for n in [2, 3, 4]:
248 end = len(chars) - n + 1
249 grams = [chars[i : (i + n)] for i in range(end)]
250 for gram in grams:
251 gram_key = "{}gram-{}".format(n, "".join(gram))
252 if gram_key in self.stoi:
253 vector += self.vectors[self.stoi[gram_key]]
254 num_vectors += 1
255 if num_vectors > 0:
256 vector /= num_vectors
257 else:
258 vector = self.unk_init(vector)
259 return vector
260
261
262 pretrained_aliases = {
263 "charngram.100d": partial(CharNGram),
264 "fasttext.en.300d": partial(FastText, language="en"),
265 "fasttext.simple.300d": partial(FastText, language="simple"),
266 "glove.42B.300d": partial(GloVe, name="42B", dim="300"),
267 "glove.840B.300d": partial(GloVe, name="840B", dim="300"),
268 "glove.twitter.27B.25d": partial(GloVe, name="twitter.27B", dim="25"),
269 "glove.twitter.27B.50d": partial(GloVe, name="twitter.27B", dim="50"),
270 "glove.twitter.27B.100d": partial(GloVe, name="twitter.27B", dim="100"),
271 "glove.twitter.27B.200d": partial(GloVe, name="twitter.27B", dim="200"),
272 "glove.6B.50d": partial(GloVe, name="6B", dim="50"),
273 "glove.6B.100d": partial(GloVe, name="6B", dim="100"),
274 "glove.6B.200d": partial(GloVe, name="6B", dim="200"),
275 "glove.6B.300d": partial(GloVe, name="6B", dim="300"),
276 }
277 """Mapping from string name to factory function"""
278
[end of torchtext/vocab/vectors.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/torchtext/vocab/vectors.py b/torchtext/vocab/vectors.py
--- a/torchtext/vocab/vectors.py
+++ b/torchtext/vocab/vectors.py
@@ -64,6 +64,9 @@
else:
return self.unk_init(torch.Tensor(self.dim))
+ def __contains__(self, token):
+ return token in self.stoi
+
def cache(self, name, cache, url=None, max_vectors=None):
import ssl
|
{"golden_diff": "diff --git a/torchtext/vocab/vectors.py b/torchtext/vocab/vectors.py\n--- a/torchtext/vocab/vectors.py\n+++ b/torchtext/vocab/vectors.py\n@@ -64,6 +64,9 @@\n else:\n return self.unk_init(torch.Tensor(self.dim))\n \n+ def __contains__(self, token):\n+ return token in self.stoi\n+\n def cache(self, name, cache, url=None, max_vectors=None):\n import ssl\n", "issue": "Implementing __contains__ for vocab.Vectors class\n## \ud83d\ude80 Feature\r\n\r\nIsn't it better to implement \\_\\_contains\\_\\_ for Vectors class? In this way, one can easily find out whether a vocab is in the self.itos or not. \n", "before_files": [{"content": "import gzip\nimport logging\nimport os\nimport tarfile\nimport zipfile\nfrom functools import partial\nfrom urllib.request import urlretrieve\n\nimport torch\nfrom tqdm import tqdm\n\nfrom ..utils import reporthook\n\nlogger = logging.getLogger(__name__)\n\n\ndef _infer_shape(f):\n num_lines, vector_dim = 0, None\n for line in f:\n if vector_dim is None:\n row = line.rstrip().split(b\" \")\n vector = row[1:]\n # Assuming word, [vector] format\n if len(vector) > 2:\n # The header present in some (w2v) formats contains two elements.\n vector_dim = len(vector)\n num_lines += 1 # First element read\n else:\n num_lines += 1\n f.seek(0)\n return num_lines, vector_dim\n\n\nclass Vectors(object):\n def __init__(self, name, cache=None, url=None, unk_init=None, max_vectors=None) -> None:\n \"\"\"\n Args:\n\n name: name of the file that contains the vectors\n cache: directory for cached vectors\n url: url for download if vectors not found in cache\n unk_init (callback): by default, initialize out-of-vocabulary word vectors\n to zero vectors; can be any function that takes in a Tensor and returns a Tensor of the same size\n max_vectors (int): this can be used to limit the number of\n pre-trained vectors loaded.\n Most pre-trained vector sets are sorted\n in the descending order of word frequency.\n Thus, in situations where the entire set doesn't fit in memory,\n or is not needed for another reason, passing `max_vectors`\n can limit the size of the loaded set.\n \"\"\"\n\n cache = \".vector_cache\" if cache is None else cache\n self.itos = None\n self.stoi = None\n self.vectors = None\n self.dim = None\n self.unk_init = torch.Tensor.zero_ if unk_init is None else unk_init\n self.cache(name, cache, url=url, max_vectors=max_vectors)\n\n def __getitem__(self, token):\n if token in self.stoi:\n return self.vectors[self.stoi[token]]\n else:\n return self.unk_init(torch.Tensor(self.dim))\n\n def cache(self, name, cache, url=None, max_vectors=None):\n import ssl\n\n ssl._create_default_https_context = ssl._create_unverified_context\n if os.path.isfile(name):\n path = name\n if max_vectors:\n file_suffix = \"_{}.pt\".format(max_vectors)\n else:\n file_suffix = \".pt\"\n path_pt = os.path.join(cache, os.path.basename(name)) + file_suffix\n else:\n path = os.path.join(cache, name)\n if max_vectors:\n file_suffix = \"_{}.pt\".format(max_vectors)\n else:\n file_suffix = \".pt\"\n path_pt = path + file_suffix\n\n if not os.path.isfile(path_pt):\n if not os.path.isfile(path) and url:\n logger.info(\"Downloading vectors from {}\".format(url))\n if not os.path.exists(cache):\n os.makedirs(cache)\n dest = os.path.join(cache, os.path.basename(url))\n if not os.path.isfile(dest):\n with tqdm(unit=\"B\", unit_scale=True, miniters=1, desc=dest) as t:\n try:\n urlretrieve(url, dest, reporthook=reporthook(t))\n except KeyboardInterrupt as e: # remove the partial zip file\n os.remove(dest)\n raise e\n logger.info(\"Extracting vectors into {}\".format(cache))\n ext = os.path.splitext(dest)[1][1:]\n if ext == \"zip\":\n with zipfile.ZipFile(dest, \"r\") as zf:\n zf.extractall(cache)\n elif ext == \"gz\":\n if dest.endswith(\".tar.gz\"):\n with tarfile.open(dest, \"r:gz\") as tar:\n tar.extractall(path=cache)\n if not os.path.isfile(path):\n raise RuntimeError(\"no vectors found at {}\".format(path))\n\n logger.info(\"Loading vectors from {}\".format(path))\n ext = os.path.splitext(path)[1][1:]\n if ext == \"gz\":\n open_file = gzip.open\n else:\n open_file = open\n\n vectors_loaded = 0\n with open_file(path, \"rb\") as f:\n num_lines, dim = _infer_shape(f)\n if not max_vectors or max_vectors > num_lines:\n max_vectors = num_lines\n\n itos, vectors, dim = [], torch.zeros((max_vectors, dim)), None\n\n for line in tqdm(f, total=max_vectors):\n # Explicitly splitting on \" \" is important, so we don't\n # get rid of Unicode non-breaking spaces in the vectors.\n entries = line.rstrip().split(b\" \")\n\n word, entries = entries[0], entries[1:]\n if dim is None and len(entries) > 1:\n dim = len(entries)\n elif len(entries) == 1:\n logger.warning(\n \"Skipping token {} with 1-dimensional \" \"vector {}; likely a header\".format(word, entries)\n )\n continue\n elif dim != len(entries):\n raise RuntimeError(\n \"Vector for token {} has {} dimensions, but previously \"\n \"read vectors have {} dimensions. All vectors must have \"\n \"the same number of dimensions.\".format(word, len(entries), dim)\n )\n\n try:\n if isinstance(word, bytes):\n word = word.decode(\"utf-8\")\n except UnicodeDecodeError:\n logger.info(\"Skipping non-UTF8 token {}\".format(repr(word)))\n continue\n\n vectors[vectors_loaded] = torch.tensor([float(x) for x in entries])\n vectors_loaded += 1\n itos.append(word)\n\n if vectors_loaded == max_vectors:\n break\n\n self.itos = itos\n self.stoi = {word: i for i, word in enumerate(itos)}\n self.vectors = torch.Tensor(vectors).view(-1, dim)\n self.dim = dim\n logger.info(\"Saving vectors to {}\".format(path_pt))\n if not os.path.exists(cache):\n os.makedirs(cache)\n torch.save((self.itos, self.stoi, self.vectors, self.dim), path_pt)\n else:\n logger.info(\"Loading vectors from {}\".format(path_pt))\n self.itos, self.stoi, self.vectors, self.dim = torch.load(path_pt)\n\n def __len__(self):\n return len(self.vectors)\n\n def get_vecs_by_tokens(self, tokens, lower_case_backup=False):\n \"\"\"Look up embedding vectors of tokens.\n\n Args:\n tokens: a token or a list of tokens. if `tokens` is a string,\n returns a 1-D tensor of shape `self.dim`; if `tokens` is a\n list of strings, returns a 2-D tensor of shape=(len(tokens),\n self.dim).\n lower_case_backup : Whether to look up the token in the lower case.\n If False, each token in the original case will be looked up;\n if True, each token in the original case will be looked up first,\n if not found in the keys of the property `stoi`, the token in the\n lower case will be looked up. Default: False.\n\n Examples:\n >>> examples = ['chip', 'baby', 'Beautiful']\n >>> vec = text.vocab.GloVe(name='6B', dim=50)\n >>> ret = vec.get_vecs_by_tokens(examples, lower_case_backup=True)\n \"\"\"\n to_reduce = False\n\n if not isinstance(tokens, list):\n tokens = [tokens]\n to_reduce = True\n\n if not lower_case_backup:\n indices = [self[token] for token in tokens]\n else:\n indices = [self[token] if token in self.stoi else self[token.lower()] for token in tokens]\n\n vecs = torch.stack(indices)\n return vecs[0] if to_reduce else vecs\n\n\nclass GloVe(Vectors):\n url = {\n \"42B\": \"http://nlp.stanford.edu/data/glove.42B.300d.zip\",\n \"840B\": \"http://nlp.stanford.edu/data/glove.840B.300d.zip\",\n \"twitter.27B\": \"http://nlp.stanford.edu/data/glove.twitter.27B.zip\",\n \"6B\": \"http://nlp.stanford.edu/data/glove.6B.zip\",\n }\n\n def __init__(self, name=\"840B\", dim=300, **kwargs) -> None:\n url = self.url[name]\n name = \"glove.{}.{}d.txt\".format(name, str(dim))\n super(GloVe, self).__init__(name, url=url, **kwargs)\n\n\nclass FastText(Vectors):\n\n url_base = \"https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.{}.vec\"\n\n def __init__(self, language=\"en\", **kwargs) -> None:\n url = self.url_base.format(language)\n name = os.path.basename(url)\n super(FastText, self).__init__(name, url=url, **kwargs)\n\n\nclass CharNGram(Vectors):\n\n name = \"charNgram.txt\"\n url = \"http://www.logos.t.u-tokyo.ac.jp/~hassy/publications/arxiv2016jmt/\" \"jmt_pre-trained_embeddings.tar.gz\"\n\n def __init__(self, **kwargs) -> None:\n super(CharNGram, self).__init__(self.name, url=self.url, **kwargs)\n\n def __getitem__(self, token):\n vector = torch.Tensor(1, self.dim).zero_()\n if token == \"<unk>\":\n return self.unk_init(vector)\n chars = [\"#BEGIN#\"] + list(token) + [\"#END#\"]\n num_vectors = 0\n for n in [2, 3, 4]:\n end = len(chars) - n + 1\n grams = [chars[i : (i + n)] for i in range(end)]\n for gram in grams:\n gram_key = \"{}gram-{}\".format(n, \"\".join(gram))\n if gram_key in self.stoi:\n vector += self.vectors[self.stoi[gram_key]]\n num_vectors += 1\n if num_vectors > 0:\n vector /= num_vectors\n else:\n vector = self.unk_init(vector)\n return vector\n\n\npretrained_aliases = {\n \"charngram.100d\": partial(CharNGram),\n \"fasttext.en.300d\": partial(FastText, language=\"en\"),\n \"fasttext.simple.300d\": partial(FastText, language=\"simple\"),\n \"glove.42B.300d\": partial(GloVe, name=\"42B\", dim=\"300\"),\n \"glove.840B.300d\": partial(GloVe, name=\"840B\", dim=\"300\"),\n \"glove.twitter.27B.25d\": partial(GloVe, name=\"twitter.27B\", dim=\"25\"),\n \"glove.twitter.27B.50d\": partial(GloVe, name=\"twitter.27B\", dim=\"50\"),\n \"glove.twitter.27B.100d\": partial(GloVe, name=\"twitter.27B\", dim=\"100\"),\n \"glove.twitter.27B.200d\": partial(GloVe, name=\"twitter.27B\", dim=\"200\"),\n \"glove.6B.50d\": partial(GloVe, name=\"6B\", dim=\"50\"),\n \"glove.6B.100d\": partial(GloVe, name=\"6B\", dim=\"100\"),\n \"glove.6B.200d\": partial(GloVe, name=\"6B\", dim=\"200\"),\n \"glove.6B.300d\": partial(GloVe, name=\"6B\", dim=\"300\"),\n}\n\"\"\"Mapping from string name to factory function\"\"\"\n", "path": "torchtext/vocab/vectors.py"}]}
| 3,989 | 111 |
gh_patches_debug_23682
|
rasdani/github-patches
|
git_diff
|
sunpy__sunpy-3960
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Remove sunpy.instr.aia.aiaprep
The `aiaprep` function should be removed from the `sunpy.instr` subpackage. Any AIA specific functionality should transition to the new [`aiapy` package](https://gitlab.com/LMSAL_HUB/aia_hub/aiapy).
This is part of the broader goal of moving instrument-specific functionality out of the core sunpy package and into affiliated packages.
</issue>
<code>
[start of sunpy/instr/aia.py]
1 """
2 This module provides processing routines for data captured with the AIA
3 instrument on SDO.
4 """
5 import numpy as np
6
7 import astropy.units as u
8
9 from sunpy.map.sources.sdo import AIAMap, HMIMap
10
11 __all__ = ['aiaprep']
12
13
14 def aiaprep(aiamap):
15 """
16 Processes a level 1 `~sunpy.map.sources.sdo.AIAMap` into a level 1.5
17 `~sunpy.map.sources.sdo.AIAMap`.
18
19 Rotates, scales and translates the image so that solar North is aligned
20 with the y axis, each pixel is 0.6 arcsec across, and the center of the
21 Sun is at the center of the image. The actual transformation is done by Map's `~sunpy.map.mapbase.GenericMap.rotate` method.
22
23 This function is similar in functionality to ``aia_prep`` in SSWIDL, but
24 it does not use the same transformation to rotate the image and it handles
25 the meta data differently. It should therefore not be expected to produce
26 the same results.
27
28 Parameters
29 ----------
30 aiamap : `~sunpy.map.sources.sdo.AIAMap`
31 A `sunpy.map.Map` from AIA.
32
33 Returns
34 -------
35 `~sunpy.map.sources.sdo.AIAMap`:
36 A level 1.5 copy of `~sunpy.map.sources.sdo.AIAMap`.
37
38 Notes
39 -----
40 This routine modifies the header information to the standard PCi_j WCS
41 formalism. The FITS header resulting in saving a file after this
42 procedure will therefore differ from the original file.
43 """
44
45 if not isinstance(aiamap, (AIAMap, HMIMap)):
46 raise ValueError("Input must be an AIAMap or HMIMap.")
47
48 # Target scale is 0.6 arcsec/pixel, but this needs to be adjusted if the map
49 # has already been rescaled.
50 if ((aiamap.scale[0] / 0.6).round() != 1.0 * u.arcsec / u.pix
51 and aiamap.data.shape != (4096, 4096)):
52 scale = (aiamap.scale[0] / 0.6).round() * 0.6 * u.arcsec
53 else:
54 scale = 0.6 * u.arcsec # pragma: no cover # can't test this because it needs a full res image
55 scale_factor = aiamap.scale[0] / scale
56
57 tempmap = aiamap.rotate(recenter=True, scale=scale_factor.value, missing=aiamap.min())
58
59 # extract center from padded aiamap.rotate output
60 # crpix1 and crpix2 will be equal (recenter=True), as aiaprep does not work with submaps
61 center = np.floor(tempmap.meta['crpix1'])
62 range_side = (center + np.array([-1, 1]) * aiamap.data.shape[0] / 2) * u.pix
63 newmap = tempmap.submap(u.Quantity([range_side[0], range_side[0]]),
64 u.Quantity([range_side[1], range_side[1]]))
65
66 newmap.meta['r_sun'] = newmap.meta['rsun_obs'] / newmap.meta['cdelt1']
67 newmap.meta['lvl_num'] = 1.5
68 newmap.meta['bitpix'] = -64
69
70 return newmap
71
[end of sunpy/instr/aia.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sunpy/instr/aia.py b/sunpy/instr/aia.py
--- a/sunpy/instr/aia.py
+++ b/sunpy/instr/aia.py
@@ -7,10 +7,13 @@
import astropy.units as u
from sunpy.map.sources.sdo import AIAMap, HMIMap
+from sunpy.util.decorators import deprecated
__all__ = ['aiaprep']
+@deprecated("2.0", alternative="`register` in aiapy (https://aiapy.readthedocs.io) for converting \
+AIA images to level 1.5")
def aiaprep(aiamap):
"""
Processes a level 1 `~sunpy.map.sources.sdo.AIAMap` into a level 1.5
@@ -18,7 +21,8 @@
Rotates, scales and translates the image so that solar North is aligned
with the y axis, each pixel is 0.6 arcsec across, and the center of the
- Sun is at the center of the image. The actual transformation is done by Map's `~sunpy.map.mapbase.GenericMap.rotate` method.
+ Sun is at the center of the image. The actual transformation is done by Map's
+ `~sunpy.map.mapbase.GenericMap.rotate` method.
This function is similar in functionality to ``aia_prep`` in SSWIDL, but
it does not use the same transformation to rotate the image and it handles
|
{"golden_diff": "diff --git a/sunpy/instr/aia.py b/sunpy/instr/aia.py\n--- a/sunpy/instr/aia.py\n+++ b/sunpy/instr/aia.py\n@@ -7,10 +7,13 @@\n import astropy.units as u\n \n from sunpy.map.sources.sdo import AIAMap, HMIMap\n+from sunpy.util.decorators import deprecated\n \n __all__ = ['aiaprep']\n \n \n+@deprecated(\"2.0\", alternative=\"`register` in aiapy (https://aiapy.readthedocs.io) for converting \\\n+AIA images to level 1.5\")\n def aiaprep(aiamap):\n \"\"\"\n Processes a level 1 `~sunpy.map.sources.sdo.AIAMap` into a level 1.5\n@@ -18,7 +21,8 @@\n \n Rotates, scales and translates the image so that solar North is aligned\n with the y axis, each pixel is 0.6 arcsec across, and the center of the\n- Sun is at the center of the image. The actual transformation is done by Map's `~sunpy.map.mapbase.GenericMap.rotate` method.\n+ Sun is at the center of the image. The actual transformation is done by Map's\n+ `~sunpy.map.mapbase.GenericMap.rotate` method.\n \n This function is similar in functionality to ``aia_prep`` in SSWIDL, but\n it does not use the same transformation to rotate the image and it handles\n", "issue": "Remove sunpy.instr.aia.aiaprep\nThe `aiaprep` function should be removed from the `sunpy.instr` subpackage. Any AIA specific functionality should transition to the new [`aiapy` package](https://gitlab.com/LMSAL_HUB/aia_hub/aiapy).\r\n\r\nThis is part of the broader goal of moving instrument-specific functionality out of the core sunpy package and into affiliated packages.\n", "before_files": [{"content": "\"\"\"\nThis module provides processing routines for data captured with the AIA\ninstrument on SDO.\n\"\"\"\nimport numpy as np\n\nimport astropy.units as u\n\nfrom sunpy.map.sources.sdo import AIAMap, HMIMap\n\n__all__ = ['aiaprep']\n\n\ndef aiaprep(aiamap):\n \"\"\"\n Processes a level 1 `~sunpy.map.sources.sdo.AIAMap` into a level 1.5\n `~sunpy.map.sources.sdo.AIAMap`.\n\n Rotates, scales and translates the image so that solar North is aligned\n with the y axis, each pixel is 0.6 arcsec across, and the center of the\n Sun is at the center of the image. The actual transformation is done by Map's `~sunpy.map.mapbase.GenericMap.rotate` method.\n\n This function is similar in functionality to ``aia_prep`` in SSWIDL, but\n it does not use the same transformation to rotate the image and it handles\n the meta data differently. It should therefore not be expected to produce\n the same results.\n\n Parameters\n ----------\n aiamap : `~sunpy.map.sources.sdo.AIAMap`\n A `sunpy.map.Map` from AIA.\n\n Returns\n -------\n `~sunpy.map.sources.sdo.AIAMap`:\n A level 1.5 copy of `~sunpy.map.sources.sdo.AIAMap`.\n\n Notes\n -----\n This routine modifies the header information to the standard PCi_j WCS\n formalism. The FITS header resulting in saving a file after this\n procedure will therefore differ from the original file.\n \"\"\"\n\n if not isinstance(aiamap, (AIAMap, HMIMap)):\n raise ValueError(\"Input must be an AIAMap or HMIMap.\")\n\n # Target scale is 0.6 arcsec/pixel, but this needs to be adjusted if the map\n # has already been rescaled.\n if ((aiamap.scale[0] / 0.6).round() != 1.0 * u.arcsec / u.pix\n and aiamap.data.shape != (4096, 4096)):\n scale = (aiamap.scale[0] / 0.6).round() * 0.6 * u.arcsec\n else:\n scale = 0.6 * u.arcsec # pragma: no cover # can't test this because it needs a full res image\n scale_factor = aiamap.scale[0] / scale\n\n tempmap = aiamap.rotate(recenter=True, scale=scale_factor.value, missing=aiamap.min())\n\n # extract center from padded aiamap.rotate output\n # crpix1 and crpix2 will be equal (recenter=True), as aiaprep does not work with submaps\n center = np.floor(tempmap.meta['crpix1'])\n range_side = (center + np.array([-1, 1]) * aiamap.data.shape[0] / 2) * u.pix\n newmap = tempmap.submap(u.Quantity([range_side[0], range_side[0]]),\n u.Quantity([range_side[1], range_side[1]]))\n\n newmap.meta['r_sun'] = newmap.meta['rsun_obs'] / newmap.meta['cdelt1']\n newmap.meta['lvl_num'] = 1.5\n newmap.meta['bitpix'] = -64\n\n return newmap\n", "path": "sunpy/instr/aia.py"}]}
| 1,529 | 329 |
gh_patches_debug_1436
|
rasdani/github-patches
|
git_diff
|
microsoft__botbuilder-python-1303
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bump azure-cosmos to v3.2.0
**Is your feature request related to a problem? Please describe.**
We're currently on `azure-cosmos` v3.1.2. Not a ton of changes in 3.2.0, but it looks like it will be their last stable version, now that they're working on v4:

**Additional context**
Need to ensure all Cosmos tests are run live before merging (they're skipped by default).
[enhancement]
</issue>
<code>
[start of libraries/botbuilder-azure/setup.py]
1 # Copyright (c) Microsoft Corporation. All rights reserved.
2 # Licensed under the MIT License.
3
4 import os
5 from setuptools import setup
6
7 REQUIRES = [
8 "azure-cosmos==3.1.2",
9 "azure-storage-blob==2.1.0",
10 "botbuilder-schema==4.10.0",
11 "botframework-connector==4.10.0",
12 "jsonpickle==1.2",
13 ]
14 TEST_REQUIRES = ["aiounittest==1.3.0"]
15
16 root = os.path.abspath(os.path.dirname(__file__))
17
18 with open(os.path.join(root, "botbuilder", "azure", "about.py")) as f:
19 package_info = {}
20 info = f.read()
21 exec(info, package_info)
22
23 with open(os.path.join(root, "README.rst"), encoding="utf-8") as f:
24 long_description = f.read()
25
26 setup(
27 name=package_info["__title__"],
28 version=package_info["__version__"],
29 url=package_info["__uri__"],
30 author=package_info["__author__"],
31 description=package_info["__description__"],
32 keywords=["BotBuilderAzure", "bots", "ai", "botframework", "botbuilder", "azure"],
33 long_description=long_description,
34 long_description_content_type="text/x-rst",
35 license=package_info["__license__"],
36 packages=["botbuilder.azure"],
37 install_requires=REQUIRES + TEST_REQUIRES,
38 tests_require=TEST_REQUIRES,
39 classifiers=[
40 "Programming Language :: Python :: 3.7",
41 "Intended Audience :: Developers",
42 "License :: OSI Approved :: MIT License",
43 "Operating System :: OS Independent",
44 "Development Status :: 5 - Production/Stable",
45 "Topic :: Scientific/Engineering :: Artificial Intelligence",
46 ],
47 )
48
[end of libraries/botbuilder-azure/setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/libraries/botbuilder-azure/setup.py b/libraries/botbuilder-azure/setup.py
--- a/libraries/botbuilder-azure/setup.py
+++ b/libraries/botbuilder-azure/setup.py
@@ -5,7 +5,7 @@
from setuptools import setup
REQUIRES = [
- "azure-cosmos==3.1.2",
+ "azure-cosmos==3.2.0",
"azure-storage-blob==2.1.0",
"botbuilder-schema==4.10.0",
"botframework-connector==4.10.0",
|
{"golden_diff": "diff --git a/libraries/botbuilder-azure/setup.py b/libraries/botbuilder-azure/setup.py\n--- a/libraries/botbuilder-azure/setup.py\n+++ b/libraries/botbuilder-azure/setup.py\n@@ -5,7 +5,7 @@\n from setuptools import setup\n \n REQUIRES = [\n- \"azure-cosmos==3.1.2\",\n+ \"azure-cosmos==3.2.0\",\n \"azure-storage-blob==2.1.0\",\n \"botbuilder-schema==4.10.0\",\n \"botframework-connector==4.10.0\",\n", "issue": "Bump azure-cosmos to v3.2.0\n**Is your feature request related to a problem? Please describe.**\r\n\r\nWe're currently on `azure-cosmos` v3.1.2. Not a ton of changes in 3.2.0, but it looks like it will be their last stable version, now that they're working on v4:\r\n\r\n\r\n\r\n**Additional context**\r\n\r\nNeed to ensure all Cosmos tests are run live before merging (they're skipped by default).\r\n\r\n[enhancement]\r\n\n", "before_files": [{"content": "# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License.\n\nimport os\nfrom setuptools import setup\n\nREQUIRES = [\n \"azure-cosmos==3.1.2\",\n \"azure-storage-blob==2.1.0\",\n \"botbuilder-schema==4.10.0\",\n \"botframework-connector==4.10.0\",\n \"jsonpickle==1.2\",\n]\nTEST_REQUIRES = [\"aiounittest==1.3.0\"]\n\nroot = os.path.abspath(os.path.dirname(__file__))\n\nwith open(os.path.join(root, \"botbuilder\", \"azure\", \"about.py\")) as f:\n package_info = {}\n info = f.read()\n exec(info, package_info)\n\nwith open(os.path.join(root, \"README.rst\"), encoding=\"utf-8\") as f:\n long_description = f.read()\n\nsetup(\n name=package_info[\"__title__\"],\n version=package_info[\"__version__\"],\n url=package_info[\"__uri__\"],\n author=package_info[\"__author__\"],\n description=package_info[\"__description__\"],\n keywords=[\"BotBuilderAzure\", \"bots\", \"ai\", \"botframework\", \"botbuilder\", \"azure\"],\n long_description=long_description,\n long_description_content_type=\"text/x-rst\",\n license=package_info[\"__license__\"],\n packages=[\"botbuilder.azure\"],\n install_requires=REQUIRES + TEST_REQUIRES,\n tests_require=TEST_REQUIRES,\n classifiers=[\n \"Programming Language :: Python :: 3.7\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: MIT License\",\n \"Operating System :: OS Independent\",\n \"Development Status :: 5 - Production/Stable\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n)\n", "path": "libraries/botbuilder-azure/setup.py"}]}
| 1,187 | 135 |
gh_patches_debug_5415
|
rasdani/github-patches
|
git_diff
|
rasterio__rasterio-748
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
rio warp --like does not consider dtype
The rio warp help text says
```
--like PATH Raster dataset to use as a template for
obtaining affine transform (bounds and
resolution), crs, data type, and driver used
to create the output.
```
But the data type does not appear to be affected.
```
$ rio info data1.l3a.vnir1.tif | jq .dtype
"uint8"
$ rio info data1.l3a.tir10.tif | jq .dtype
"uint16"
$ rio warp data1.l3a.tir10.tif /tmp/out.tif --like data1.l3a.vnir1.tif
$ rio info /tmp/out.tif | jq .dtype # dtype is not "like" vnir1, should be uint8
"uint16"
```
This might just be a simple matter of changing the help text to reflect the actual behavior. Or it could be considered a bug. Not sure.
</issue>
<code>
[start of rasterio/rio/warp.py]
1 import logging
2 from math import ceil
3 import warnings
4
5 import click
6 from cligj import files_inout_arg, format_opt
7
8 from .helpers import resolve_inout
9 from . import options
10 import rasterio
11 from rasterio import crs
12 from rasterio.env import Env
13 from rasterio.errors import CRSError
14 from rasterio.transform import Affine
15 from rasterio.warp import (
16 reproject, Resampling, calculate_default_transform, transform_bounds)
17
18
19 # Improper usage of rio-warp can lead to accidental creation of
20 # extremely large datasets. We'll put a hard limit on the size of
21 # datasets and raise a usage error if the limits are exceeded.
22 MAX_OUTPUT_WIDTH = 100000
23 MAX_OUTPUT_HEIGHT = 100000
24
25
26 def bounds_handler(ctx, param, value):
27 """Warn about future usage changes."""
28 if value:
29 click.echo(
30 "Future Warning: "
31 "the semantics of the `--bounds` option will change in Rasterio "
32 "version 1.0 from bounds of the source dataset to bounds of the "
33 "destination dataset.", err=True)
34 return value
35
36
37 def x_dst_bounds_handler(ctx, param, value):
38 """Warn about future usage changes."""
39 if value:
40 click.echo(
41 "Future Warning: "
42 "the `--x-dst-bounds` option will be removed in Rasterio version "
43 "1.0 in favor of `--bounds`.", err=True)
44 return value
45
46
47 @click.command(short_help='Warp a raster dataset.')
48 @files_inout_arg
49 @options.output_opt
50 @format_opt
51 @options.like_file_opt
52 @click.option('--dst-crs', default=None,
53 help='Target coordinate reference system.')
54 @options.dimensions_opt
55 @click.option(
56 '--src-bounds',
57 nargs=4, type=float, default=None,
58 help="Determine output extent from source bounds: left bottom right top "
59 "(note: for future backwards compatibility in 1.0).")
60 @click.option(
61 '--x-dst-bounds',
62 nargs=4, type=float, default=None, callback=x_dst_bounds_handler,
63 help="Set output extent from bounding values: left bottom right top "
64 "(note: this option will be removed in 1.0).")
65 @click.option(
66 '--bounds',
67 nargs=4, type=float, default=None, callback=bounds_handler,
68 help="Determine output extent from source bounds: left bottom right top "
69 "(note: the semantics of this option will change to those of "
70 "`--x-dst-bounds` in version 1.0).")
71 @options.resolution_opt
72 @click.option('--resampling', type=click.Choice([r.name for r in Resampling]),
73 default='nearest', help="Resampling method.",
74 show_default=True)
75 @click.option('--threads', type=int, default=1,
76 help='Number of processing threads.')
77 @click.option('--check-invert-proj', type=bool, default=True,
78 help='Constrain output to valid coordinate region in dst-crs')
79 @options.force_overwrite_opt
80 @options.creation_options
81 @click.pass_context
82 def warp(ctx, files, output, driver, like, dst_crs, dimensions, src_bounds,
83 x_dst_bounds, bounds, res, resampling, threads, check_invert_proj,
84 force_overwrite, creation_options):
85 """
86 Warp a raster dataset.
87
88 If a template raster is provided using the --like option, the
89 coordinate reference system, affine transform, and dimensions of
90 that raster will be used for the output. In this case --dst-crs,
91 --bounds, --res, and --dimensions options are ignored.
92
93 \b
94 $ rio warp input.tif output.tif --like template.tif
95
96 The output coordinate reference system may be either a PROJ.4 or
97 EPSG:nnnn string,
98
99 \b
100 --dst-crs EPSG:4326
101 --dst-crs '+proj=longlat +ellps=WGS84 +datum=WGS84'
102
103 or a JSON text-encoded PROJ.4 object.
104
105 \b
106 --dst-crs '{"proj": "utm", "zone": 18, ...}'
107
108 If --dimensions are provided, --res and --bounds are ignored.
109 Resolution is calculated based on the relationship between the
110 raster bounds in the target coordinate system and the dimensions,
111 and may produce rectangular rather than square pixels.
112
113 \b
114 $ rio warp input.tif output.tif --dimensions 100 200 \\
115 > --dst-crs EPSG:4326
116
117 If --bounds are provided, --res is required if --dst-crs is provided
118 (defaults to source raster resolution otherwise).
119
120 \b
121 $ rio warp input.tif output.tif \\
122 > --bounds -78 22 -76 24 --res 0.1 --dst-crs EPSG:4326
123
124 """
125
126 verbosity = (ctx.obj and ctx.obj.get('verbosity')) or 1
127
128 output, files = resolve_inout(
129 files=files, output=output, force_overwrite=force_overwrite)
130
131 resampling = Resampling[resampling] # get integer code for method
132
133 if not len(res):
134 # Click sets this as an empty tuple if not provided
135 res = None
136 else:
137 # Expand one value to two if needed
138 res = (res[0], res[0]) if len(res) == 1 else res
139
140 with Env(CPL_DEBUG=verbosity > 2,
141 CHECK_WITH_INVERT_PROJ=check_invert_proj) as env:
142 with rasterio.open(files[0]) as src:
143 l, b, r, t = src.bounds
144 out_kwargs = src.meta.copy()
145 out_kwargs['driver'] = driver
146
147 # Sort out the bounds options.
148 src_bounds = bounds or src_bounds
149 dst_bounds = x_dst_bounds
150 if src_bounds and dst_bounds:
151 raise click.BadParameter(
152 "Source and destination bounds may not be specified "
153 "simultaneously.")
154
155 if like:
156 with rasterio.open(like) as template_ds:
157 dst_crs = template_ds.crs
158 dst_transform = template_ds.affine
159 dst_height = template_ds.height
160 dst_width = template_ds.width
161
162 elif dst_crs is not None:
163 try:
164 dst_crs = crs.from_string(dst_crs)
165 except ValueError as err:
166 raise click.BadParameter(
167 str(err), param='dst_crs', param_hint='dst_crs')
168
169 if dimensions:
170 # Calculate resolution appropriate for dimensions
171 # in target.
172 dst_width, dst_height = dimensions
173 try:
174 xmin, ymin, xmax, ymax = transform_bounds(
175 src.crs, dst_crs, *src.bounds)
176 except CRSError as err:
177 raise click.BadParameter(
178 str(err), param='dst_crs', param_hint='dst_crs')
179 dst_transform = Affine(
180 (xmax - xmin) / float(dst_width),
181 0, xmin, 0,
182 (ymin - ymax) / float(dst_height),
183 ymax
184 )
185
186 elif src_bounds or dst_bounds:
187 if not res:
188 raise click.BadParameter(
189 "Required when using --bounds.",
190 param='res', param_hint='res')
191
192 if src_bounds:
193 try:
194 xmin, ymin, xmax, ymax = transform_bounds(
195 src.crs, dst_crs, *src_bounds)
196 except CRSError as err:
197 raise click.BadParameter(
198 str(err), param='dst_crs',
199 param_hint='dst_crs')
200 else:
201 xmin, ymin, xmax, ymax = dst_bounds
202
203 dst_transform = Affine(res[0], 0, xmin, 0, -res[1], ymax)
204 dst_width = max(int(ceil((xmax - xmin) / res[0])), 1)
205 dst_height = max(int(ceil((ymax - ymin) / res[1])), 1)
206
207 else:
208 try:
209 dst_transform, dst_width, dst_height = calculate_default_transform(
210 src.crs, dst_crs, src.width, src.height,
211 *src.bounds, resolution=res)
212 except CRSError as err:
213 raise click.BadParameter(
214 str(err), param='dst_crs', param_hint='dst_crs')
215 elif dimensions:
216 # Same projection, different dimensions, calculate resolution.
217 dst_crs = src.crs
218 dst_width, dst_height = dimensions
219 dst_transform = Affine(
220 (r - l) / float(dst_width),
221 0, l, 0,
222 (b - t) / float(dst_height),
223 t
224 )
225
226 elif src_bounds or dst_bounds:
227 # Same projection, different dimensions and possibly
228 # different resolution.
229 if not res:
230 res = (src.affine.a, -src.affine.e)
231
232 dst_crs = src.crs
233 xmin, ymin, xmax, ymax = (src_bounds or dst_bounds)
234 dst_transform = Affine(res[0], 0, xmin, 0, -res[1], ymax)
235 dst_width = max(int(ceil((xmax - xmin) / res[0])), 1)
236 dst_height = max(int(ceil((ymax - ymin) / res[1])), 1)
237
238 elif res:
239 # Same projection, different resolution.
240 dst_crs = src.crs
241 dst_transform = Affine(res[0], 0, l, 0, -res[1], t)
242 dst_width = max(int(ceil((r - l) / res[0])), 1)
243 dst_height = max(int(ceil((t - b) / res[1])), 1)
244
245 else:
246 dst_crs = src.crs
247 dst_transform = src.affine
248 dst_width = src.width
249 dst_height = src.height
250
251 # When the bounds option is misused, extreme values of
252 # destination width and height may result.
253 if (dst_width < 0 or dst_height < 0 or
254 dst_width > MAX_OUTPUT_WIDTH or
255 dst_height > MAX_OUTPUT_HEIGHT):
256 raise click.BadParameter(
257 "Invalid output dimensions: {0}.".format(
258 (dst_width, dst_height)))
259
260 out_kwargs.update({
261 'crs': dst_crs,
262 'transform': dst_transform,
263 'affine': dst_transform,
264 'width': dst_width,
265 'height': dst_height
266 })
267
268 out_kwargs.update(**creation_options)
269
270 with rasterio.open(output, 'w', **out_kwargs) as dst:
271 for i in range(1, src.count + 1):
272
273 reproject(
274 source=rasterio.band(src, i),
275 destination=rasterio.band(dst, i),
276 src_transform=src.affine,
277 src_crs=src.crs,
278 # src_nodata=#TODO
279 dst_transform=out_kwargs['transform'],
280 dst_crs=out_kwargs['crs'],
281 # dst_nodata=#TODO
282 resampling=resampling,
283 num_threads=threads)
284
[end of rasterio/rio/warp.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/rasterio/rio/warp.py b/rasterio/rio/warp.py
--- a/rasterio/rio/warp.py
+++ b/rasterio/rio/warp.py
@@ -48,7 +48,11 @@
@files_inout_arg
@options.output_opt
@format_opt
[email protected]_file_opt
[email protected](
+ '--like',
+ type=click.Path(exists=True),
+ help='Raster dataset to use as a template for obtaining affine '
+ 'transform (bounds and resolution), and crs.')
@click.option('--dst-crs', default=None,
help='Target coordinate reference system.')
@options.dimensions_opt
|
{"golden_diff": "diff --git a/rasterio/rio/warp.py b/rasterio/rio/warp.py\n--- a/rasterio/rio/warp.py\n+++ b/rasterio/rio/warp.py\n@@ -48,7 +48,11 @@\n @files_inout_arg\n @options.output_opt\n @format_opt\[email protected]_file_opt\[email protected](\n+ '--like',\n+ type=click.Path(exists=True),\n+ help='Raster dataset to use as a template for obtaining affine '\n+ 'transform (bounds and resolution), and crs.')\n @click.option('--dst-crs', default=None,\n help='Target coordinate reference system.')\n @options.dimensions_opt\n", "issue": "rio warp --like does not consider dtype\nThe rio warp help text says\n\n```\n --like PATH Raster dataset to use as a template for\n obtaining affine transform (bounds and\n resolution), crs, data type, and driver used\n to create the output.\n```\n\nBut the data type does not appear to be affected. \n\n```\n$ rio info data1.l3a.vnir1.tif | jq .dtype\n\"uint8\"\n$ rio info data1.l3a.tir10.tif | jq .dtype\n\"uint16\"\n$ rio warp data1.l3a.tir10.tif /tmp/out.tif --like data1.l3a.vnir1.tif\n$ rio info /tmp/out.tif | jq .dtype # dtype is not \"like\" vnir1, should be uint8\n\"uint16\"\n```\n\nThis might just be a simple matter of changing the help text to reflect the actual behavior. Or it could be considered a bug. Not sure.\n\n", "before_files": [{"content": "import logging\nfrom math import ceil\nimport warnings\n\nimport click\nfrom cligj import files_inout_arg, format_opt\n\nfrom .helpers import resolve_inout\nfrom . import options\nimport rasterio\nfrom rasterio import crs\nfrom rasterio.env import Env\nfrom rasterio.errors import CRSError\nfrom rasterio.transform import Affine\nfrom rasterio.warp import (\n reproject, Resampling, calculate_default_transform, transform_bounds)\n\n\n# Improper usage of rio-warp can lead to accidental creation of\n# extremely large datasets. We'll put a hard limit on the size of\n# datasets and raise a usage error if the limits are exceeded.\nMAX_OUTPUT_WIDTH = 100000\nMAX_OUTPUT_HEIGHT = 100000\n\n\ndef bounds_handler(ctx, param, value):\n \"\"\"Warn about future usage changes.\"\"\"\n if value:\n click.echo(\n \"Future Warning: \"\n \"the semantics of the `--bounds` option will change in Rasterio \"\n \"version 1.0 from bounds of the source dataset to bounds of the \"\n \"destination dataset.\", err=True)\n return value\n\n\ndef x_dst_bounds_handler(ctx, param, value):\n \"\"\"Warn about future usage changes.\"\"\"\n if value:\n click.echo(\n \"Future Warning: \"\n \"the `--x-dst-bounds` option will be removed in Rasterio version \"\n \"1.0 in favor of `--bounds`.\", err=True)\n return value\n\n\[email protected](short_help='Warp a raster dataset.')\n@files_inout_arg\[email protected]_opt\n@format_opt\[email protected]_file_opt\[email protected]('--dst-crs', default=None,\n help='Target coordinate reference system.')\[email protected]_opt\[email protected](\n '--src-bounds',\n nargs=4, type=float, default=None,\n help=\"Determine output extent from source bounds: left bottom right top \"\n \"(note: for future backwards compatibility in 1.0).\")\[email protected](\n '--x-dst-bounds',\n nargs=4, type=float, default=None, callback=x_dst_bounds_handler,\n help=\"Set output extent from bounding values: left bottom right top \"\n \"(note: this option will be removed in 1.0).\")\[email protected](\n '--bounds',\n nargs=4, type=float, default=None, callback=bounds_handler,\n help=\"Determine output extent from source bounds: left bottom right top \"\n \"(note: the semantics of this option will change to those of \"\n \"`--x-dst-bounds` in version 1.0).\")\[email protected]_opt\[email protected]('--resampling', type=click.Choice([r.name for r in Resampling]),\n default='nearest', help=\"Resampling method.\",\n show_default=True)\[email protected]('--threads', type=int, default=1,\n help='Number of processing threads.')\[email protected]('--check-invert-proj', type=bool, default=True,\n help='Constrain output to valid coordinate region in dst-crs')\[email protected]_overwrite_opt\[email protected]_options\[email protected]_context\ndef warp(ctx, files, output, driver, like, dst_crs, dimensions, src_bounds,\n x_dst_bounds, bounds, res, resampling, threads, check_invert_proj,\n force_overwrite, creation_options):\n \"\"\"\n Warp a raster dataset.\n\n If a template raster is provided using the --like option, the\n coordinate reference system, affine transform, and dimensions of\n that raster will be used for the output. In this case --dst-crs,\n --bounds, --res, and --dimensions options are ignored.\n\n \\b\n $ rio warp input.tif output.tif --like template.tif\n\n The output coordinate reference system may be either a PROJ.4 or\n EPSG:nnnn string,\n\n \\b\n --dst-crs EPSG:4326\n --dst-crs '+proj=longlat +ellps=WGS84 +datum=WGS84'\n\n or a JSON text-encoded PROJ.4 object.\n\n \\b\n --dst-crs '{\"proj\": \"utm\", \"zone\": 18, ...}'\n\n If --dimensions are provided, --res and --bounds are ignored.\n Resolution is calculated based on the relationship between the\n raster bounds in the target coordinate system and the dimensions,\n and may produce rectangular rather than square pixels.\n\n \\b\n $ rio warp input.tif output.tif --dimensions 100 200 \\\\\n > --dst-crs EPSG:4326\n\n If --bounds are provided, --res is required if --dst-crs is provided\n (defaults to source raster resolution otherwise).\n\n \\b\n $ rio warp input.tif output.tif \\\\\n > --bounds -78 22 -76 24 --res 0.1 --dst-crs EPSG:4326\n\n \"\"\"\n\n verbosity = (ctx.obj and ctx.obj.get('verbosity')) or 1\n\n output, files = resolve_inout(\n files=files, output=output, force_overwrite=force_overwrite)\n\n resampling = Resampling[resampling] # get integer code for method\n\n if not len(res):\n # Click sets this as an empty tuple if not provided\n res = None\n else:\n # Expand one value to two if needed\n res = (res[0], res[0]) if len(res) == 1 else res\n\n with Env(CPL_DEBUG=verbosity > 2,\n CHECK_WITH_INVERT_PROJ=check_invert_proj) as env:\n with rasterio.open(files[0]) as src:\n l, b, r, t = src.bounds\n out_kwargs = src.meta.copy()\n out_kwargs['driver'] = driver\n\n # Sort out the bounds options.\n src_bounds = bounds or src_bounds\n dst_bounds = x_dst_bounds\n if src_bounds and dst_bounds:\n raise click.BadParameter(\n \"Source and destination bounds may not be specified \"\n \"simultaneously.\")\n\n if like:\n with rasterio.open(like) as template_ds:\n dst_crs = template_ds.crs\n dst_transform = template_ds.affine\n dst_height = template_ds.height\n dst_width = template_ds.width\n\n elif dst_crs is not None:\n try:\n dst_crs = crs.from_string(dst_crs)\n except ValueError as err:\n raise click.BadParameter(\n str(err), param='dst_crs', param_hint='dst_crs')\n\n if dimensions:\n # Calculate resolution appropriate for dimensions\n # in target.\n dst_width, dst_height = dimensions\n try:\n xmin, ymin, xmax, ymax = transform_bounds(\n src.crs, dst_crs, *src.bounds)\n except CRSError as err:\n raise click.BadParameter(\n str(err), param='dst_crs', param_hint='dst_crs')\n dst_transform = Affine(\n (xmax - xmin) / float(dst_width),\n 0, xmin, 0,\n (ymin - ymax) / float(dst_height),\n ymax\n )\n\n elif src_bounds or dst_bounds:\n if not res:\n raise click.BadParameter(\n \"Required when using --bounds.\",\n param='res', param_hint='res')\n\n if src_bounds:\n try:\n xmin, ymin, xmax, ymax = transform_bounds(\n src.crs, dst_crs, *src_bounds)\n except CRSError as err:\n raise click.BadParameter(\n str(err), param='dst_crs',\n param_hint='dst_crs')\n else:\n xmin, ymin, xmax, ymax = dst_bounds\n\n dst_transform = Affine(res[0], 0, xmin, 0, -res[1], ymax)\n dst_width = max(int(ceil((xmax - xmin) / res[0])), 1)\n dst_height = max(int(ceil((ymax - ymin) / res[1])), 1)\n\n else:\n try:\n dst_transform, dst_width, dst_height = calculate_default_transform(\n src.crs, dst_crs, src.width, src.height,\n *src.bounds, resolution=res)\n except CRSError as err:\n raise click.BadParameter(\n str(err), param='dst_crs', param_hint='dst_crs')\n elif dimensions:\n # Same projection, different dimensions, calculate resolution.\n dst_crs = src.crs\n dst_width, dst_height = dimensions\n dst_transform = Affine(\n (r - l) / float(dst_width),\n 0, l, 0,\n (b - t) / float(dst_height),\n t\n )\n\n elif src_bounds or dst_bounds:\n # Same projection, different dimensions and possibly\n # different resolution.\n if not res:\n res = (src.affine.a, -src.affine.e)\n\n dst_crs = src.crs\n xmin, ymin, xmax, ymax = (src_bounds or dst_bounds)\n dst_transform = Affine(res[0], 0, xmin, 0, -res[1], ymax)\n dst_width = max(int(ceil((xmax - xmin) / res[0])), 1)\n dst_height = max(int(ceil((ymax - ymin) / res[1])), 1)\n\n elif res:\n # Same projection, different resolution.\n dst_crs = src.crs\n dst_transform = Affine(res[0], 0, l, 0, -res[1], t)\n dst_width = max(int(ceil((r - l) / res[0])), 1)\n dst_height = max(int(ceil((t - b) / res[1])), 1)\n\n else:\n dst_crs = src.crs\n dst_transform = src.affine\n dst_width = src.width\n dst_height = src.height\n\n # When the bounds option is misused, extreme values of\n # destination width and height may result.\n if (dst_width < 0 or dst_height < 0 or\n dst_width > MAX_OUTPUT_WIDTH or\n dst_height > MAX_OUTPUT_HEIGHT):\n raise click.BadParameter(\n \"Invalid output dimensions: {0}.\".format(\n (dst_width, dst_height)))\n\n out_kwargs.update({\n 'crs': dst_crs,\n 'transform': dst_transform,\n 'affine': dst_transform,\n 'width': dst_width,\n 'height': dst_height\n })\n\n out_kwargs.update(**creation_options)\n\n with rasterio.open(output, 'w', **out_kwargs) as dst:\n for i in range(1, src.count + 1):\n\n reproject(\n source=rasterio.band(src, i),\n destination=rasterio.band(dst, i),\n src_transform=src.affine,\n src_crs=src.crs,\n # src_nodata=#TODO\n dst_transform=out_kwargs['transform'],\n dst_crs=out_kwargs['crs'],\n # dst_nodata=#TODO\n resampling=resampling,\n num_threads=threads)\n", "path": "rasterio/rio/warp.py"}]}
| 3,926 | 151 |
gh_patches_debug_18572
|
rasdani/github-patches
|
git_diff
|
bookwyrm-social__bookwyrm-2130
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
should be able to see logged-in user's following/followers
**Describe the bug**
if i click on the following users (https://ziurkes.group.lt/user/athinkingmeat/following) - i get 403 page, which is not expected. i would expect to see my own following/follower users.
**To Reproduce**
Steps to reproduce the behavior:
just click on following/followers on logged-in user's profile page
**Expected behavior**
should see a list of following users
**Screenshots**
<img width="552" alt="image" src="https://user-images.githubusercontent.com/81133/169102523-1891c406-aab5-485f-9c9b-d9caa9ca3c6f.png">
**Instance**
https://ziurkes.group.lt
</issue>
<code>
[start of bookwyrm/views/user.py]
1 """ non-interactive pages """
2 from django.contrib.auth.decorators import login_required
3 from django.core.exceptions import PermissionDenied
4 from django.core.paginator import Paginator
5 from django.db.models import Q, Count
6 from django.http import Http404
7 from django.shortcuts import redirect
8 from django.template.response import TemplateResponse
9 from django.utils import timezone
10 from django.views import View
11 from django.views.decorators.http import require_POST
12
13 from bookwyrm import models
14 from bookwyrm.activitypub import ActivitypubResponse
15 from bookwyrm.settings import PAGE_LENGTH
16 from .helpers import get_user_from_username, is_api_request
17
18
19 # pylint: disable=no-self-use
20 class User(View):
21 """user profile page"""
22
23 def get(self, request, username):
24 """profile page for a user"""
25 user = get_user_from_username(request.user, username)
26
27 if is_api_request(request):
28 # we have a json request
29 return ActivitypubResponse(user.to_activity())
30 # otherwise we're at a UI view
31
32 shelf_preview = []
33
34 # only show shelves that should be visible
35 is_self = request.user.id == user.id
36 if not is_self:
37 shelves = (
38 models.Shelf.privacy_filter(
39 request.user, privacy_levels=["public", "followers"]
40 )
41 .filter(user=user, books__isnull=False)
42 .distinct()
43 )
44 else:
45 shelves = user.shelf_set.filter(books__isnull=False).distinct()
46
47 for user_shelf in shelves.all()[:3]:
48 shelf_preview.append(
49 {
50 "name": user_shelf.name,
51 "local_path": user_shelf.local_path,
52 "books": user_shelf.books.all()[:3],
53 "size": user_shelf.books.count(),
54 }
55 )
56
57 # user's posts
58 activities = (
59 models.Status.privacy_filter(
60 request.user,
61 )
62 .filter(user=user)
63 .select_related(
64 "user",
65 "reply_parent",
66 "review__book",
67 "comment__book",
68 "quotation__book",
69 )
70 .prefetch_related(
71 "mention_books",
72 "mention_users",
73 "attachments",
74 )
75 )
76
77 paginated = Paginator(activities, PAGE_LENGTH)
78 goal = models.AnnualGoal.objects.filter(
79 user=user, year=timezone.now().year
80 ).first()
81 if goal:
82 try:
83 goal.raise_visible_to_user(request.user)
84 except Http404:
85 goal = None
86
87 data = {
88 "user": user,
89 "is_self": is_self,
90 "shelves": shelf_preview,
91 "shelf_count": shelves.count(),
92 "activities": paginated.get_page(request.GET.get("page", 1)),
93 "goal": goal,
94 }
95
96 return TemplateResponse(request, "user/user.html", data)
97
98
99 class Followers(View):
100 """list of followers view"""
101
102 def get(self, request, username):
103 """list of followers"""
104 user = get_user_from_username(request.user, username)
105
106 if is_api_request(request):
107 return ActivitypubResponse(user.to_followers_activity(**request.GET))
108
109 if user.hide_follows:
110 raise PermissionDenied()
111
112 followers = annotate_if_follows(request.user, user.followers)
113 paginated = Paginator(followers.all(), PAGE_LENGTH)
114 data = {
115 "user": user,
116 "is_self": request.user.id == user.id,
117 "follow_list": paginated.get_page(request.GET.get("page")),
118 }
119 return TemplateResponse(request, "user/relationships/followers.html", data)
120
121
122 class Following(View):
123 """list of following view"""
124
125 def get(self, request, username):
126 """list of followers"""
127 user = get_user_from_username(request.user, username)
128
129 if is_api_request(request):
130 return ActivitypubResponse(user.to_following_activity(**request.GET))
131
132 if user.hide_follows:
133 raise PermissionDenied()
134
135 following = annotate_if_follows(request.user, user.following)
136 paginated = Paginator(following.all(), PAGE_LENGTH)
137 data = {
138 "user": user,
139 "is_self": request.user.id == user.id,
140 "follow_list": paginated.get_page(request.GET.get("page")),
141 }
142 return TemplateResponse(request, "user/relationships/following.html", data)
143
144
145 def annotate_if_follows(user, queryset):
146 """Sort a list of users by if you follow them"""
147 if not user.is_authenticated:
148 return queryset.order_by("-created_date")
149
150 return queryset.annotate(
151 request_user_follows=Count("followers", filter=Q(followers=user))
152 ).order_by("-request_user_follows", "-created_date")
153
154
155 @require_POST
156 @login_required
157 def hide_suggestions(request):
158 """not everyone wants user suggestions"""
159 request.user.show_suggested_users = False
160 request.user.save(broadcast=False, update_fields=["show_suggested_users"])
161 return redirect(request.headers.get("Referer", "/"))
162
163
164 # pylint: disable=unused-argument
165 def user_redirect(request, username):
166 """redirect to a user's feed"""
167 return redirect("user-feed", username=username)
168
[end of bookwyrm/views/user.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bookwyrm/views/user.py b/bookwyrm/views/user.py
--- a/bookwyrm/views/user.py
+++ b/bookwyrm/views/user.py
@@ -106,7 +106,7 @@
if is_api_request(request):
return ActivitypubResponse(user.to_followers_activity(**request.GET))
- if user.hide_follows:
+ if user.hide_follows and user != request.user:
raise PermissionDenied()
followers = annotate_if_follows(request.user, user.followers)
@@ -129,7 +129,7 @@
if is_api_request(request):
return ActivitypubResponse(user.to_following_activity(**request.GET))
- if user.hide_follows:
+ if user.hide_follows and user != request.user:
raise PermissionDenied()
following = annotate_if_follows(request.user, user.following)
|
{"golden_diff": "diff --git a/bookwyrm/views/user.py b/bookwyrm/views/user.py\n--- a/bookwyrm/views/user.py\n+++ b/bookwyrm/views/user.py\n@@ -106,7 +106,7 @@\n if is_api_request(request):\n return ActivitypubResponse(user.to_followers_activity(**request.GET))\n \n- if user.hide_follows:\n+ if user.hide_follows and user != request.user:\n raise PermissionDenied()\n \n followers = annotate_if_follows(request.user, user.followers)\n@@ -129,7 +129,7 @@\n if is_api_request(request):\n return ActivitypubResponse(user.to_following_activity(**request.GET))\n \n- if user.hide_follows:\n+ if user.hide_follows and user != request.user:\n raise PermissionDenied()\n \n following = annotate_if_follows(request.user, user.following)\n", "issue": "should be able to see logged-in user's following/followers\n**Describe the bug**\r\nif i click on the following users (https://ziurkes.group.lt/user/athinkingmeat/following) - i get 403 page, which is not expected. i would expect to see my own following/follower users.\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\njust click on following/followers on logged-in user's profile page\r\n\r\n**Expected behavior**\r\nshould see a list of following users\r\n\r\n**Screenshots**\r\n<img width=\"552\" alt=\"image\" src=\"https://user-images.githubusercontent.com/81133/169102523-1891c406-aab5-485f-9c9b-d9caa9ca3c6f.png\">\r\n\r\n**Instance**\r\nhttps://ziurkes.group.lt\r\n\r\n\n", "before_files": [{"content": "\"\"\" non-interactive pages \"\"\"\nfrom django.contrib.auth.decorators import login_required\nfrom django.core.exceptions import PermissionDenied\nfrom django.core.paginator import Paginator\nfrom django.db.models import Q, Count\nfrom django.http import Http404\nfrom django.shortcuts import redirect\nfrom django.template.response import TemplateResponse\nfrom django.utils import timezone\nfrom django.views import View\nfrom django.views.decorators.http import require_POST\n\nfrom bookwyrm import models\nfrom bookwyrm.activitypub import ActivitypubResponse\nfrom bookwyrm.settings import PAGE_LENGTH\nfrom .helpers import get_user_from_username, is_api_request\n\n\n# pylint: disable=no-self-use\nclass User(View):\n \"\"\"user profile page\"\"\"\n\n def get(self, request, username):\n \"\"\"profile page for a user\"\"\"\n user = get_user_from_username(request.user, username)\n\n if is_api_request(request):\n # we have a json request\n return ActivitypubResponse(user.to_activity())\n # otherwise we're at a UI view\n\n shelf_preview = []\n\n # only show shelves that should be visible\n is_self = request.user.id == user.id\n if not is_self:\n shelves = (\n models.Shelf.privacy_filter(\n request.user, privacy_levels=[\"public\", \"followers\"]\n )\n .filter(user=user, books__isnull=False)\n .distinct()\n )\n else:\n shelves = user.shelf_set.filter(books__isnull=False).distinct()\n\n for user_shelf in shelves.all()[:3]:\n shelf_preview.append(\n {\n \"name\": user_shelf.name,\n \"local_path\": user_shelf.local_path,\n \"books\": user_shelf.books.all()[:3],\n \"size\": user_shelf.books.count(),\n }\n )\n\n # user's posts\n activities = (\n models.Status.privacy_filter(\n request.user,\n )\n .filter(user=user)\n .select_related(\n \"user\",\n \"reply_parent\",\n \"review__book\",\n \"comment__book\",\n \"quotation__book\",\n )\n .prefetch_related(\n \"mention_books\",\n \"mention_users\",\n \"attachments\",\n )\n )\n\n paginated = Paginator(activities, PAGE_LENGTH)\n goal = models.AnnualGoal.objects.filter(\n user=user, year=timezone.now().year\n ).first()\n if goal:\n try:\n goal.raise_visible_to_user(request.user)\n except Http404:\n goal = None\n\n data = {\n \"user\": user,\n \"is_self\": is_self,\n \"shelves\": shelf_preview,\n \"shelf_count\": shelves.count(),\n \"activities\": paginated.get_page(request.GET.get(\"page\", 1)),\n \"goal\": goal,\n }\n\n return TemplateResponse(request, \"user/user.html\", data)\n\n\nclass Followers(View):\n \"\"\"list of followers view\"\"\"\n\n def get(self, request, username):\n \"\"\"list of followers\"\"\"\n user = get_user_from_username(request.user, username)\n\n if is_api_request(request):\n return ActivitypubResponse(user.to_followers_activity(**request.GET))\n\n if user.hide_follows:\n raise PermissionDenied()\n\n followers = annotate_if_follows(request.user, user.followers)\n paginated = Paginator(followers.all(), PAGE_LENGTH)\n data = {\n \"user\": user,\n \"is_self\": request.user.id == user.id,\n \"follow_list\": paginated.get_page(request.GET.get(\"page\")),\n }\n return TemplateResponse(request, \"user/relationships/followers.html\", data)\n\n\nclass Following(View):\n \"\"\"list of following view\"\"\"\n\n def get(self, request, username):\n \"\"\"list of followers\"\"\"\n user = get_user_from_username(request.user, username)\n\n if is_api_request(request):\n return ActivitypubResponse(user.to_following_activity(**request.GET))\n\n if user.hide_follows:\n raise PermissionDenied()\n\n following = annotate_if_follows(request.user, user.following)\n paginated = Paginator(following.all(), PAGE_LENGTH)\n data = {\n \"user\": user,\n \"is_self\": request.user.id == user.id,\n \"follow_list\": paginated.get_page(request.GET.get(\"page\")),\n }\n return TemplateResponse(request, \"user/relationships/following.html\", data)\n\n\ndef annotate_if_follows(user, queryset):\n \"\"\"Sort a list of users by if you follow them\"\"\"\n if not user.is_authenticated:\n return queryset.order_by(\"-created_date\")\n\n return queryset.annotate(\n request_user_follows=Count(\"followers\", filter=Q(followers=user))\n ).order_by(\"-request_user_follows\", \"-created_date\")\n\n\n@require_POST\n@login_required\ndef hide_suggestions(request):\n \"\"\"not everyone wants user suggestions\"\"\"\n request.user.show_suggested_users = False\n request.user.save(broadcast=False, update_fields=[\"show_suggested_users\"])\n return redirect(request.headers.get(\"Referer\", \"/\"))\n\n\n# pylint: disable=unused-argument\ndef user_redirect(request, username):\n \"\"\"redirect to a user's feed\"\"\"\n return redirect(\"user-feed\", username=username)\n", "path": "bookwyrm/views/user.py"}]}
| 2,226 | 190 |
gh_patches_debug_5319
|
rasdani/github-patches
|
git_diff
|
cloud-custodian__cloud-custodian-5879
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
AWS common filters page has a link pointing to 404 link
On this page: https://cloudcustodian.io/docs/aws/resources/aws-common-filters.html#aws-common-filters-config-compliance
There is a bit.ly link: https://bit.ly/2mblVpq
The bit.ly link points to a non-existent capitalone.github.io link (throws 404): http://capitalone.github.io/cloud-custodian/docs/policy/lambda.html#config-rules
I believe the bit.ly link should be updated to point to this page in the cloud custodian docs: https://cloudcustodian.io/docs/policy/lambda.html#config-rules
AWS common filters page has a link pointing to 404 link
On this page: https://cloudcustodian.io/docs/aws/resources/aws-common-filters.html#aws-common-filters-config-compliance
There is a bit.ly link: https://bit.ly/2mblVpq
The bit.ly link points to a non-existent capitalone.github.io link (throws 404): http://capitalone.github.io/cloud-custodian/docs/policy/lambda.html#config-rules
I believe the bit.ly link should be updated to point to this page in the cloud custodian docs: https://cloudcustodian.io/docs/policy/lambda.html#config-rules
</issue>
<code>
[start of c7n/filters/config.py]
1 # Copyright 2018 Capital One Services, LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 from c7n.filters import ValueFilter
15 from c7n.manager import resources
16 from c7n.utils import local_session, type_schema
17
18 from .core import Filter
19
20
21 class ConfigCompliance(Filter):
22 """Filter resources by their compliance with one or more AWS config rules.
23
24 An example of using the filter to find all ec2 instances that have
25 been registered as non compliant in the last 30 days against two
26 custom AWS Config rules.
27
28 :example:
29
30 .. code-block:: yaml
31
32 policies:
33 - name: non-compliant-ec2
34 resource: ec2
35 filters:
36 - type: config-compliance
37 eval_filters:
38 - type: value
39 key: ResultRecordedTime
40 value_type: age
41 value: 30
42 op: less-than
43 rules:
44 - custodian-ec2-encryption-required
45 - custodian-ec2-tags-required
46
47 Also note, custodian has direct support for deploying policies as config
48 rules see https://bit.ly/2mblVpq
49 """
50 permissions = ('config:DescribeComplianceByConfigRule',)
51 schema = type_schema(
52 'config-compliance',
53 required=('rules',),
54 op={'enum': ['or', 'and']},
55 eval_filters={'type': 'array', 'items': {
56 'oneOf': [
57 {'$ref': '#/definitions/filters/valuekv'},
58 {'$ref': '#/definitions/filters/value'}]}},
59 states={'type': 'array', 'items': {'enum': [
60 'COMPLIANT', 'NON_COMPLIANT',
61 'NOT_APPLICABLE', 'INSUFFICIENT_DATA']}},
62 rules={'type': 'array', 'items': {'type': 'string'}})
63 schema_alias = True
64 annotation_key = 'c7n:config-compliance'
65
66 def get_resource_map(self, filters, resource_model, resources):
67 rule_ids = self.data.get('rules')
68 states = self.data.get('states', ['NON_COMPLIANT'])
69 op = self.data.get('op', 'or') == 'or' and any or all
70
71 client = local_session(self.manager.session_factory).client('config')
72 resource_map = {}
73
74 for rid in rule_ids:
75 pager = client.get_paginator('get_compliance_details_by_config_rule')
76 for page in pager.paginate(
77 ConfigRuleName=rid, ComplianceTypes=states):
78 evaluations = page.get('EvaluationResults', ())
79
80 for e in evaluations:
81 rident = e['EvaluationResultIdentifier'][
82 'EvaluationResultQualifier']
83 # for multi resource type rules, only look at
84 # results for the resource type currently being
85 # processed.
86 if rident['ResourceType'] not in (
87 resource_model.config_type,
88 resource_model.cfn_type):
89 continue
90
91 if not filters:
92 resource_map.setdefault(
93 rident['ResourceId'], []).append(e)
94 continue
95
96 if op([f.match(e) for f in filters]):
97 resource_map.setdefault(
98 rident['ResourceId'], []).append(e)
99
100 return resource_map
101
102 def process(self, resources, event=None):
103 filters = []
104 for f in self.data.get('eval_filters', ()):
105 vf = ValueFilter(f)
106 vf.annotate = False
107 filters.append(vf)
108
109 resource_model = self.manager.get_model()
110 resource_map = self.get_resource_map(filters, resource_model, resources)
111
112 # Avoid static/import time dep on boto in filters package
113 from c7n.resources.aws import Arn
114 results = []
115 for arn, r in zip(self.manager.get_arns(resources), resources):
116 # many aws provided rules are inconsistent in their
117 # treatment of resource ids, some use arns, some use names
118 # as identifiers for the same resource type. security
119 # hub in particular is bad at consistency.
120 rid = None
121 if arn in resource_map:
122 rid = arn
123 elif r[resource_model.id] in resource_map:
124 rid = r[resource_model.id]
125 if arn == r[resource_model.id] and not rid:
126 rid = Arn.parse(arn).resource
127 if rid not in resource_map:
128 rid = None
129 if rid is None:
130 continue
131 r[self.annotation_key] = resource_map[rid]
132 results.append(r)
133 return results
134
135 @classmethod
136 def register_resources(klass, registry, resource_class):
137 """model resource subscriber on resource registration.
138
139 Watch for new resource types being registered if they are
140 supported by aws config, automatically, register the
141 config-compliance filter.
142 """
143 if (resource_class.resource_type.cfn_type is None and
144 resource_class.resource_type.config_type is None):
145 return
146 resource_class.filter_registry.register('config-compliance', klass)
147
148
149 resources.subscribe(ConfigCompliance.register_resources)
150
[end of c7n/filters/config.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/c7n/filters/config.py b/c7n/filters/config.py
--- a/c7n/filters/config.py
+++ b/c7n/filters/config.py
@@ -45,7 +45,7 @@
- custodian-ec2-tags-required
Also note, custodian has direct support for deploying policies as config
- rules see https://bit.ly/2mblVpq
+ rules see https://cloudcustodian.io/docs/policy/lambda.html#config-rules
"""
permissions = ('config:DescribeComplianceByConfigRule',)
schema = type_schema(
|
{"golden_diff": "diff --git a/c7n/filters/config.py b/c7n/filters/config.py\n--- a/c7n/filters/config.py\n+++ b/c7n/filters/config.py\n@@ -45,7 +45,7 @@\n - custodian-ec2-tags-required\n \n Also note, custodian has direct support for deploying policies as config\n- rules see https://bit.ly/2mblVpq\n+ rules see https://cloudcustodian.io/docs/policy/lambda.html#config-rules\n \"\"\"\n permissions = ('config:DescribeComplianceByConfigRule',)\n schema = type_schema(\n", "issue": "AWS common filters page has a link pointing to 404 link\nOn this page: https://cloudcustodian.io/docs/aws/resources/aws-common-filters.html#aws-common-filters-config-compliance\r\n\r\nThere is a bit.ly link: https://bit.ly/2mblVpq\r\n\r\nThe bit.ly link points to a non-existent capitalone.github.io link (throws 404): http://capitalone.github.io/cloud-custodian/docs/policy/lambda.html#config-rules\r\n\r\nI believe the bit.ly link should be updated to point to this page in the cloud custodian docs: https://cloudcustodian.io/docs/policy/lambda.html#config-rules\nAWS common filters page has a link pointing to 404 link\nOn this page: https://cloudcustodian.io/docs/aws/resources/aws-common-filters.html#aws-common-filters-config-compliance\r\n\r\nThere is a bit.ly link: https://bit.ly/2mblVpq\r\n\r\nThe bit.ly link points to a non-existent capitalone.github.io link (throws 404): http://capitalone.github.io/cloud-custodian/docs/policy/lambda.html#config-rules\r\n\r\nI believe the bit.ly link should be updated to point to this page in the cloud custodian docs: https://cloudcustodian.io/docs/policy/lambda.html#config-rules\n", "before_files": [{"content": "# Copyright 2018 Capital One Services, LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom c7n.filters import ValueFilter\nfrom c7n.manager import resources\nfrom c7n.utils import local_session, type_schema\n\nfrom .core import Filter\n\n\nclass ConfigCompliance(Filter):\n \"\"\"Filter resources by their compliance with one or more AWS config rules.\n\n An example of using the filter to find all ec2 instances that have\n been registered as non compliant in the last 30 days against two\n custom AWS Config rules.\n\n :example:\n\n .. code-block:: yaml\n\n policies:\n - name: non-compliant-ec2\n resource: ec2\n filters:\n - type: config-compliance\n eval_filters:\n - type: value\n key: ResultRecordedTime\n value_type: age\n value: 30\n op: less-than\n rules:\n - custodian-ec2-encryption-required\n - custodian-ec2-tags-required\n\n Also note, custodian has direct support for deploying policies as config\n rules see https://bit.ly/2mblVpq\n \"\"\"\n permissions = ('config:DescribeComplianceByConfigRule',)\n schema = type_schema(\n 'config-compliance',\n required=('rules',),\n op={'enum': ['or', 'and']},\n eval_filters={'type': 'array', 'items': {\n 'oneOf': [\n {'$ref': '#/definitions/filters/valuekv'},\n {'$ref': '#/definitions/filters/value'}]}},\n states={'type': 'array', 'items': {'enum': [\n 'COMPLIANT', 'NON_COMPLIANT',\n 'NOT_APPLICABLE', 'INSUFFICIENT_DATA']}},\n rules={'type': 'array', 'items': {'type': 'string'}})\n schema_alias = True\n annotation_key = 'c7n:config-compliance'\n\n def get_resource_map(self, filters, resource_model, resources):\n rule_ids = self.data.get('rules')\n states = self.data.get('states', ['NON_COMPLIANT'])\n op = self.data.get('op', 'or') == 'or' and any or all\n\n client = local_session(self.manager.session_factory).client('config')\n resource_map = {}\n\n for rid in rule_ids:\n pager = client.get_paginator('get_compliance_details_by_config_rule')\n for page in pager.paginate(\n ConfigRuleName=rid, ComplianceTypes=states):\n evaluations = page.get('EvaluationResults', ())\n\n for e in evaluations:\n rident = e['EvaluationResultIdentifier'][\n 'EvaluationResultQualifier']\n # for multi resource type rules, only look at\n # results for the resource type currently being\n # processed.\n if rident['ResourceType'] not in (\n resource_model.config_type,\n resource_model.cfn_type):\n continue\n\n if not filters:\n resource_map.setdefault(\n rident['ResourceId'], []).append(e)\n continue\n\n if op([f.match(e) for f in filters]):\n resource_map.setdefault(\n rident['ResourceId'], []).append(e)\n\n return resource_map\n\n def process(self, resources, event=None):\n filters = []\n for f in self.data.get('eval_filters', ()):\n vf = ValueFilter(f)\n vf.annotate = False\n filters.append(vf)\n\n resource_model = self.manager.get_model()\n resource_map = self.get_resource_map(filters, resource_model, resources)\n\n # Avoid static/import time dep on boto in filters package\n from c7n.resources.aws import Arn\n results = []\n for arn, r in zip(self.manager.get_arns(resources), resources):\n # many aws provided rules are inconsistent in their\n # treatment of resource ids, some use arns, some use names\n # as identifiers for the same resource type. security\n # hub in particular is bad at consistency.\n rid = None\n if arn in resource_map:\n rid = arn\n elif r[resource_model.id] in resource_map:\n rid = r[resource_model.id]\n if arn == r[resource_model.id] and not rid:\n rid = Arn.parse(arn).resource\n if rid not in resource_map:\n rid = None\n if rid is None:\n continue\n r[self.annotation_key] = resource_map[rid]\n results.append(r)\n return results\n\n @classmethod\n def register_resources(klass, registry, resource_class):\n \"\"\"model resource subscriber on resource registration.\n\n Watch for new resource types being registered if they are\n supported by aws config, automatically, register the\n config-compliance filter.\n \"\"\"\n if (resource_class.resource_type.cfn_type is None and\n resource_class.resource_type.config_type is None):\n return\n resource_class.filter_registry.register('config-compliance', klass)\n\n\nresources.subscribe(ConfigCompliance.register_resources)\n", "path": "c7n/filters/config.py"}]}
| 2,351 | 134 |
gh_patches_debug_365
|
rasdani/github-patches
|
git_diff
|
pypa__pipenv-5495
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Include missing package data for Safety
### The issue
#5491
### The fix
Include the missing package data for Safety.
### The checklist
* [ ] Build wheels and test if it is working fine.
<!--
### If this is a patch to the `vendor` directory...
Please try to refrain from submitting patches directly to `vendor` or `patched`, but raise your issue to the upstream project instead, and inform Pipenv to upgrade when the upstream project accepts the fix.
A pull request to upgrade vendor packages is strongly discouraged, unless there is a very good reason (e.g. you need to test Pipenv’s integration to a new vendor feature). Pipenv audits and performs vendor upgrades regularly, generally before a new release is about to drop.
If your patch is not or cannot be accepted by upstream, but is essential to Pipenv (make sure to discuss this with maintainers!), please remember to attach a patch file in `tasks/vendoring/patched`, so this divergence from upstream can be recorded and replayed afterwards.
-->
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2 import codecs
3 import os
4 import sys
5
6 from setuptools import find_packages, setup
7
8 here = os.path.abspath(os.path.dirname(__file__))
9
10 with codecs.open(os.path.join(here, "README.md"), encoding="utf-8") as f:
11 long_description = "\n" + f.read()
12
13 about = {}
14
15 with open(os.path.join(here, "pipenv", "__version__.py")) as f:
16 exec(f.read(), about)
17
18 if sys.argv[-1] == "publish":
19 os.system("python setup.py sdist bdist_wheel upload")
20 sys.exit()
21
22 required = [
23 "certifi",
24 "setuptools>=36.2.1",
25 "virtualenv-clone>=0.2.5",
26 "virtualenv",
27 ]
28 extras = {
29 "dev": [
30 "towncrier",
31 "bs4",
32 "sphinx",
33 "flake8>=3.3.0,<4.0",
34 "black;python_version>='3.7'",
35 "parver",
36 "invoke",
37 ],
38 "tests": ["pytest>=5.0", "pytest-timeout", "pytest-xdist", "flaky", "mock"],
39 }
40
41
42 setup(
43 name="pipenv",
44 version=about["__version__"],
45 description="Python Development Workflow for Humans.",
46 long_description=long_description,
47 long_description_content_type="text/markdown",
48 author="Pipenv maintainer team",
49 author_email="[email protected]",
50 url="https://github.com/pypa/pipenv",
51 packages=find_packages(exclude=["tests", "tests.*", "tasks", "tasks.*"]),
52 entry_points={
53 "console_scripts": [
54 "pipenv=pipenv:cli",
55 "pipenv-resolver=pipenv.resolver:main",
56 ]
57 },
58 package_data={
59 "": ["LICENSE", "NOTICES"],
60 "pipenv.patched.safety": ["VERSION", "safety-policy-template.yml"],
61 "pipenv.patched.pip._vendor.certifi": ["*.pem"],
62 "pipenv.patched.pip._vendor.requests": ["*.pem"],
63 "pipenv.patched.pip._vendor.distlib._backport": ["sysconfig.cfg"],
64 "pipenv.patched.pip._vendor.distlib": [
65 "t32.exe",
66 "t64.exe",
67 "w32.exe",
68 "w64.exe",
69 ],
70 },
71 python_requires=">=3.7",
72 zip_safe=True,
73 setup_requires=[],
74 install_requires=required,
75 extras_require=extras,
76 include_package_data=True,
77 license="MIT",
78 classifiers=[
79 "License :: OSI Approved :: MIT License",
80 "Programming Language :: Python",
81 "Programming Language :: Python :: 3",
82 "Programming Language :: Python :: 3.7",
83 "Programming Language :: Python :: 3.8",
84 "Programming Language :: Python :: 3.9",
85 "Programming Language :: Python :: 3.10",
86 "Programming Language :: Python :: 3.11",
87 "Programming Language :: Python :: Implementation :: CPython",
88 "Programming Language :: Python :: Implementation :: PyPy",
89 ],
90 )
91
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -67,6 +67,7 @@
"w32.exe",
"w64.exe",
],
+ "pipenv.vendor.ruamel": ["yaml"],
},
python_requires=">=3.7",
zip_safe=True,
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -67,6 +67,7 @@\n \"w32.exe\",\n \"w64.exe\",\n ],\n+ \"pipenv.vendor.ruamel\": [\"yaml\"],\n },\n python_requires=\">=3.7\",\n zip_safe=True,\n", "issue": "Include missing package data for Safety\n### The issue\r\n\r\n#5491 \r\n\r\n### The fix\r\n\r\nInclude the missing package data for Safety.\r\n\r\n### The checklist\r\n\r\n* [ ] Build wheels and test if it is working fine.\r\n\r\n<!--\r\n### If this is a patch to the `vendor` directory...\r\n\r\nPlease try to refrain from submitting patches directly to `vendor` or `patched`, but raise your issue to the upstream project instead, and inform Pipenv to upgrade when the upstream project accepts the fix.\r\n\r\nA pull request to upgrade vendor packages is strongly discouraged, unless there is a very good reason (e.g. you need to test Pipenv\u2019s integration to a new vendor feature). Pipenv audits and performs vendor upgrades regularly, generally before a new release is about to drop.\r\n\r\nIf your patch is not or cannot be accepted by upstream, but is essential to Pipenv (make sure to discuss this with maintainers!), please remember to attach a patch file in `tasks/vendoring/patched`, so this divergence from upstream can be recorded and replayed afterwards.\r\n-->\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\nimport codecs\nimport os\nimport sys\n\nfrom setuptools import find_packages, setup\n\nhere = os.path.abspath(os.path.dirname(__file__))\n\nwith codecs.open(os.path.join(here, \"README.md\"), encoding=\"utf-8\") as f:\n long_description = \"\\n\" + f.read()\n\nabout = {}\n\nwith open(os.path.join(here, \"pipenv\", \"__version__.py\")) as f:\n exec(f.read(), about)\n\nif sys.argv[-1] == \"publish\":\n os.system(\"python setup.py sdist bdist_wheel upload\")\n sys.exit()\n\nrequired = [\n \"certifi\",\n \"setuptools>=36.2.1\",\n \"virtualenv-clone>=0.2.5\",\n \"virtualenv\",\n]\nextras = {\n \"dev\": [\n \"towncrier\",\n \"bs4\",\n \"sphinx\",\n \"flake8>=3.3.0,<4.0\",\n \"black;python_version>='3.7'\",\n \"parver\",\n \"invoke\",\n ],\n \"tests\": [\"pytest>=5.0\", \"pytest-timeout\", \"pytest-xdist\", \"flaky\", \"mock\"],\n}\n\n\nsetup(\n name=\"pipenv\",\n version=about[\"__version__\"],\n description=\"Python Development Workflow for Humans.\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n author=\"Pipenv maintainer team\",\n author_email=\"[email protected]\",\n url=\"https://github.com/pypa/pipenv\",\n packages=find_packages(exclude=[\"tests\", \"tests.*\", \"tasks\", \"tasks.*\"]),\n entry_points={\n \"console_scripts\": [\n \"pipenv=pipenv:cli\",\n \"pipenv-resolver=pipenv.resolver:main\",\n ]\n },\n package_data={\n \"\": [\"LICENSE\", \"NOTICES\"],\n \"pipenv.patched.safety\": [\"VERSION\", \"safety-policy-template.yml\"],\n \"pipenv.patched.pip._vendor.certifi\": [\"*.pem\"],\n \"pipenv.patched.pip._vendor.requests\": [\"*.pem\"],\n \"pipenv.patched.pip._vendor.distlib._backport\": [\"sysconfig.cfg\"],\n \"pipenv.patched.pip._vendor.distlib\": [\n \"t32.exe\",\n \"t64.exe\",\n \"w32.exe\",\n \"w64.exe\",\n ],\n },\n python_requires=\">=3.7\",\n zip_safe=True,\n setup_requires=[],\n install_requires=required,\n extras_require=extras,\n include_package_data=True,\n license=\"MIT\",\n classifiers=[\n \"License :: OSI Approved :: MIT License\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Programming Language :: Python :: 3.11\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n ],\n)\n", "path": "setup.py"}]}
| 1,619 | 76 |
gh_patches_debug_260
|
rasdani/github-patches
|
git_diff
|
keras-team__keras-637
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Misiing import in list_pictures
`list_pictures` abborts with error `NameError: global name 're' is not defined`
</issue>
<code>
[start of keras/preprocessing/image.py]
1 from __future__ import absolute_import
2
3 import numpy as np
4 from scipy import ndimage
5 from scipy import linalg
6
7 from os import listdir
8 from os.path import isfile, join
9 import random, math
10 from six.moves import range
11
12 '''
13 Fairly basic set of tools for realtime data augmentation on image data.
14 Can easily be extended to include new transforms, new preprocessing methods, etc...
15 '''
16
17 def random_rotation(x, rg, fill_mode="nearest", cval=0.):
18 angle = random.uniform(-rg, rg)
19 x = ndimage.interpolation.rotate(x, angle, axes=(1,2), reshape=False, mode=fill_mode, cval=cval)
20 return x
21
22 def random_shift(x, wrg, hrg, fill_mode="nearest", cval=0.):
23 crop_left_pixels = 0
24 crop_right_pixels = 0
25 crop_top_pixels = 0
26 crop_bottom_pixels = 0
27
28 original_w = x.shape[1]
29 original_h = x.shape[2]
30
31 if wrg:
32 crop = random.uniform(0., wrg)
33 split = random.uniform(0, 1)
34 crop_left_pixels = int(split*crop*x.shape[1])
35 crop_right_pixels = int((1-split)*crop*x.shape[1])
36
37 if hrg:
38 crop = random.uniform(0., hrg)
39 split = random.uniform(0, 1)
40 crop_top_pixels = int(split*crop*x.shape[2])
41 crop_bottom_pixels = int((1-split)*crop*x.shape[2])
42
43 x = ndimage.interpolation.shift(x, (0, crop_left_pixels, crop_top_pixels), mode=fill_mode, cval=cval)
44 return x
45
46 def horizontal_flip(x):
47 for i in range(x.shape[0]):
48 x[i] = np.fliplr(x[i])
49 return x
50
51 def vertical_flip(x):
52 for i in range(x.shape[0]):
53 x[i] = np.flipud(x[i])
54 return x
55
56
57 def random_barrel_transform(x, intensity):
58 # TODO
59 pass
60
61 def random_shear(x, intensity):
62 # TODO
63 pass
64
65 def random_channel_shift(x, rg):
66 # TODO
67 pass
68
69 def random_zoom(x, rg, fill_mode="nearest", cval=0.):
70 zoom_w = random.uniform(1.-rg, 1.)
71 zoom_h = random.uniform(1.-rg, 1.)
72 x = ndimage.interpolation.zoom(x, zoom=(1., zoom_w, zoom_h), mode=fill_mode, cval=cval)
73 return x # shape of result will be different from shape of input!
74
75
76
77
78 def array_to_img(x, scale=True):
79 from PIL import Image
80 x = x.transpose(1, 2, 0)
81 if scale:
82 x += max(-np.min(x), 0)
83 x /= np.max(x)
84 x *= 255
85 if x.shape[2] == 3:
86 # RGB
87 return Image.fromarray(x.astype("uint8"), "RGB")
88 else:
89 # grayscale
90 return Image.fromarray(x[:,:,0].astype("uint8"), "L")
91
92
93 def img_to_array(img):
94 x = np.asarray(img, dtype='float32')
95 if len(x.shape)==3:
96 # RGB: height, width, channel -> channel, height, width
97 x = x.transpose(2, 0, 1)
98 else:
99 # grayscale: height, width -> channel, height, width
100 x = x.reshape((1, x.shape[0], x.shape[1]))
101 return x
102
103
104 def load_img(path, grayscale=False):
105 from PIL import Image
106 img = Image.open(open(path))
107 if grayscale:
108 img = img.convert('L')
109 else: # Assure 3 channel even when loaded image is grayscale
110 img = img.convert('RGB')
111 return img
112
113
114 def list_pictures(directory, ext='jpg|jpeg|bmp|png'):
115 return [join(directory,f) for f in listdir(directory) \
116 if isfile(join(directory,f)) and re.match('([\w]+\.(?:' + ext + '))', f)]
117
118
119
120 class ImageDataGenerator(object):
121 '''
122 Generate minibatches with
123 realtime data augmentation.
124 '''
125 def __init__(self,
126 featurewise_center=True, # set input mean to 0 over the dataset
127 samplewise_center=False, # set each sample mean to 0
128 featurewise_std_normalization=True, # divide inputs by std of the dataset
129 samplewise_std_normalization=False, # divide each input by its std
130
131 zca_whitening=False, # apply ZCA whitening
132 rotation_range=0., # degrees (0 to 180)
133 width_shift_range=0., # fraction of total width
134 height_shift_range=0., # fraction of total height
135 horizontal_flip=False,
136 vertical_flip=False,
137 ):
138 self.__dict__.update(locals())
139 self.mean = None
140 self.std = None
141 self.principal_components = None
142
143
144 def flow(self, X, y, batch_size=32, shuffle=False, seed=None, save_to_dir=None, save_prefix="", save_format="jpeg"):
145 if seed:
146 random.seed(seed)
147
148 if shuffle:
149 seed = random.randint(1, 10e6)
150 np.random.seed(seed)
151 np.random.shuffle(X)
152 np.random.seed(seed)
153 np.random.shuffle(y)
154
155 nb_batch = int(math.ceil(float(X.shape[0])/batch_size))
156 for b in range(nb_batch):
157 batch_end = (b+1)*batch_size
158 if batch_end > X.shape[0]:
159 nb_samples = X.shape[0] - b*batch_size
160 else:
161 nb_samples = batch_size
162
163 bX = np.zeros(tuple([nb_samples]+list(X.shape)[1:]))
164 for i in range(nb_samples):
165 x = X[b*batch_size+i]
166 x = self.random_transform(x.astype("float32"))
167 x = self.standardize(x)
168 bX[i] = x
169
170 if save_to_dir:
171 for i in range(nb_samples):
172 img = array_to_img(bX[i], scale=True)
173 img.save(save_to_dir + "/" + save_prefix + "_" + str(i) + "." + save_format)
174
175 yield bX, y[b*batch_size:b*batch_size+nb_samples]
176
177
178 def standardize(self, x):
179 if self.featurewise_center:
180 x -= self.mean
181 if self.featurewise_std_normalization:
182 x /= self.std
183
184 if self.zca_whitening:
185 flatx = np.reshape(x, (x.shape[0]*x.shape[1]*x.shape[2]))
186 whitex = np.dot(flatx, self.principal_components)
187 x = np.reshape(whitex, (x.shape[0], x.shape[1], x.shape[2]))
188
189 if self.samplewise_center:
190 x -= np.mean(x)
191 if self.samplewise_std_normalization:
192 x /= np.std(x)
193
194 return x
195
196
197 def random_transform(self, x):
198 if self.rotation_range:
199 x = random_rotation(x, self.rotation_range)
200 if self.width_shift_range or self.height_shift_range:
201 x = random_shift(x, self.width_shift_range, self.height_shift_range)
202 if self.horizontal_flip:
203 if random.random() < 0.5:
204 x = horizontal_flip(x)
205 if self.vertical_flip:
206 if random.random() < 0.5:
207 x = vertical_flip(x)
208
209 # TODO:
210 # zoom
211 # barrel/fisheye
212 # shearing
213 # channel shifting
214 return x
215
216
217 def fit(self, X,
218 augment=False, # fit on randomly augmented samples
219 rounds=1, # if augment, how many augmentation passes over the data do we use
220 seed=None
221 ):
222 '''
223 Required for featurewise_center, featurewise_std_normalization and zca_whitening.
224 '''
225 X = np.copy(X)
226
227 if augment:
228 aX = np.zeros(tuple([rounds*X.shape[0]]+list(X.shape)[1:]))
229 for r in range(rounds):
230 for i in range(X.shape[0]):
231 img = array_to_img(X[i])
232 img = self.random_transform(img)
233 aX[i+r*X.shape[0]] = img_to_array(img)
234 X = aX
235
236 if self.featurewise_center:
237 self.mean = np.mean(X, axis=0)
238 X -= self.mean
239 if self.featurewise_std_normalization:
240 self.std = np.std(X, axis=0)
241 X /= self.std
242
243 if self.zca_whitening:
244 flatX = np.reshape(X, (X.shape[0], X.shape[1]*X.shape[2]*X.shape[3]))
245 fudge = 10e-6
246 sigma = np.dot(flatX.T, flatX) / flatX.shape[1]
247 U, S, V = linalg.svd(sigma)
248 self.principal_components = np.dot(np.dot(U, np.diag(1. / np.sqrt(S + fudge))), U.T)
249
250
251
[end of keras/preprocessing/image.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/keras/preprocessing/image.py b/keras/preprocessing/image.py
--- a/keras/preprocessing/image.py
+++ b/keras/preprocessing/image.py
@@ -1,6 +1,7 @@
from __future__ import absolute_import
import numpy as np
+import re
from scipy import ndimage
from scipy import linalg
|
{"golden_diff": "diff --git a/keras/preprocessing/image.py b/keras/preprocessing/image.py\n--- a/keras/preprocessing/image.py\n+++ b/keras/preprocessing/image.py\n@@ -1,6 +1,7 @@\n from __future__ import absolute_import\n \n import numpy as np\n+import re\n from scipy import ndimage\n from scipy import linalg\n", "issue": "Misiing import in list_pictures\n`list_pictures` abborts with error `NameError: global name 're' is not defined`\n\n", "before_files": [{"content": "from __future__ import absolute_import\n\nimport numpy as np\nfrom scipy import ndimage\nfrom scipy import linalg\n\nfrom os import listdir\nfrom os.path import isfile, join\nimport random, math\nfrom six.moves import range\n\n'''\n Fairly basic set of tools for realtime data augmentation on image data.\n Can easily be extended to include new transforms, new preprocessing methods, etc...\n'''\n\ndef random_rotation(x, rg, fill_mode=\"nearest\", cval=0.):\n angle = random.uniform(-rg, rg)\n x = ndimage.interpolation.rotate(x, angle, axes=(1,2), reshape=False, mode=fill_mode, cval=cval)\n return x\n\ndef random_shift(x, wrg, hrg, fill_mode=\"nearest\", cval=0.):\n crop_left_pixels = 0\n crop_right_pixels = 0\n crop_top_pixels = 0\n crop_bottom_pixels = 0\n\n original_w = x.shape[1]\n original_h = x.shape[2]\n\n if wrg:\n crop = random.uniform(0., wrg)\n split = random.uniform(0, 1)\n crop_left_pixels = int(split*crop*x.shape[1])\n crop_right_pixels = int((1-split)*crop*x.shape[1])\n\n if hrg:\n crop = random.uniform(0., hrg)\n split = random.uniform(0, 1)\n crop_top_pixels = int(split*crop*x.shape[2])\n crop_bottom_pixels = int((1-split)*crop*x.shape[2])\n\n x = ndimage.interpolation.shift(x, (0, crop_left_pixels, crop_top_pixels), mode=fill_mode, cval=cval)\n return x\n\ndef horizontal_flip(x):\n for i in range(x.shape[0]):\n x[i] = np.fliplr(x[i])\n return x\n\ndef vertical_flip(x):\n for i in range(x.shape[0]):\n x[i] = np.flipud(x[i])\n return x\n\n\ndef random_barrel_transform(x, intensity):\n # TODO\n pass\n\ndef random_shear(x, intensity):\n # TODO\n pass\n\ndef random_channel_shift(x, rg):\n # TODO\n pass\n\ndef random_zoom(x, rg, fill_mode=\"nearest\", cval=0.):\n zoom_w = random.uniform(1.-rg, 1.)\n zoom_h = random.uniform(1.-rg, 1.)\n x = ndimage.interpolation.zoom(x, zoom=(1., zoom_w, zoom_h), mode=fill_mode, cval=cval)\n return x # shape of result will be different from shape of input!\n\n\n\n\ndef array_to_img(x, scale=True):\n from PIL import Image\n x = x.transpose(1, 2, 0) \n if scale:\n x += max(-np.min(x), 0)\n x /= np.max(x)\n x *= 255\n if x.shape[2] == 3:\n # RGB\n return Image.fromarray(x.astype(\"uint8\"), \"RGB\")\n else:\n # grayscale\n return Image.fromarray(x[:,:,0].astype(\"uint8\"), \"L\")\n\n\ndef img_to_array(img):\n x = np.asarray(img, dtype='float32')\n if len(x.shape)==3:\n # RGB: height, width, channel -> channel, height, width\n x = x.transpose(2, 0, 1)\n else:\n # grayscale: height, width -> channel, height, width\n x = x.reshape((1, x.shape[0], x.shape[1]))\n return x\n\n\ndef load_img(path, grayscale=False):\n from PIL import Image\n img = Image.open(open(path))\n if grayscale:\n img = img.convert('L')\n else: # Assure 3 channel even when loaded image is grayscale\n img = img.convert('RGB')\n return img\n\n\ndef list_pictures(directory, ext='jpg|jpeg|bmp|png'):\n return [join(directory,f) for f in listdir(directory) \\\n if isfile(join(directory,f)) and re.match('([\\w]+\\.(?:' + ext + '))', f)]\n\n\n\nclass ImageDataGenerator(object):\n '''\n Generate minibatches with \n realtime data augmentation.\n '''\n def __init__(self, \n featurewise_center=True, # set input mean to 0 over the dataset\n samplewise_center=False, # set each sample mean to 0\n featurewise_std_normalization=True, # divide inputs by std of the dataset\n samplewise_std_normalization=False, # divide each input by its std\n\n zca_whitening=False, # apply ZCA whitening\n rotation_range=0., # degrees (0 to 180)\n width_shift_range=0., # fraction of total width\n height_shift_range=0., # fraction of total height\n horizontal_flip=False,\n vertical_flip=False,\n ):\n self.__dict__.update(locals())\n self.mean = None\n self.std = None\n self.principal_components = None\n\n\n def flow(self, X, y, batch_size=32, shuffle=False, seed=None, save_to_dir=None, save_prefix=\"\", save_format=\"jpeg\"):\n if seed:\n random.seed(seed)\n\n if shuffle:\n seed = random.randint(1, 10e6)\n np.random.seed(seed)\n np.random.shuffle(X)\n np.random.seed(seed)\n np.random.shuffle(y)\n\n nb_batch = int(math.ceil(float(X.shape[0])/batch_size))\n for b in range(nb_batch):\n batch_end = (b+1)*batch_size\n if batch_end > X.shape[0]:\n nb_samples = X.shape[0] - b*batch_size\n else:\n nb_samples = batch_size\n\n bX = np.zeros(tuple([nb_samples]+list(X.shape)[1:]))\n for i in range(nb_samples):\n x = X[b*batch_size+i]\n x = self.random_transform(x.astype(\"float32\"))\n x = self.standardize(x)\n bX[i] = x\n\n if save_to_dir:\n for i in range(nb_samples):\n img = array_to_img(bX[i], scale=True)\n img.save(save_to_dir + \"/\" + save_prefix + \"_\" + str(i) + \".\" + save_format)\n\n yield bX, y[b*batch_size:b*batch_size+nb_samples]\n\n\n def standardize(self, x):\n if self.featurewise_center:\n x -= self.mean\n if self.featurewise_std_normalization:\n x /= self.std\n\n if self.zca_whitening:\n flatx = np.reshape(x, (x.shape[0]*x.shape[1]*x.shape[2]))\n whitex = np.dot(flatx, self.principal_components)\n x = np.reshape(whitex, (x.shape[0], x.shape[1], x.shape[2]))\n\n if self.samplewise_center:\n x -= np.mean(x)\n if self.samplewise_std_normalization:\n x /= np.std(x)\n\n return x\n\n\n def random_transform(self, x):\n if self.rotation_range:\n x = random_rotation(x, self.rotation_range)\n if self.width_shift_range or self.height_shift_range:\n x = random_shift(x, self.width_shift_range, self.height_shift_range)\n if self.horizontal_flip:\n if random.random() < 0.5:\n x = horizontal_flip(x)\n if self.vertical_flip:\n if random.random() < 0.5:\n x = vertical_flip(x)\n\n # TODO:\n # zoom\n # barrel/fisheye\n # shearing\n # channel shifting\n return x\n\n\n def fit(self, X, \n augment=False, # fit on randomly augmented samples\n rounds=1, # if augment, how many augmentation passes over the data do we use\n seed=None\n ):\n '''\n Required for featurewise_center, featurewise_std_normalization and zca_whitening.\n '''\n X = np.copy(X)\n \n if augment:\n aX = np.zeros(tuple([rounds*X.shape[0]]+list(X.shape)[1:]))\n for r in range(rounds):\n for i in range(X.shape[0]):\n img = array_to_img(X[i])\n img = self.random_transform(img)\n aX[i+r*X.shape[0]] = img_to_array(img)\n X = aX\n\n if self.featurewise_center:\n self.mean = np.mean(X, axis=0)\n X -= self.mean\n if self.featurewise_std_normalization:\n self.std = np.std(X, axis=0)\n X /= self.std\n\n if self.zca_whitening:\n flatX = np.reshape(X, (X.shape[0], X.shape[1]*X.shape[2]*X.shape[3]))\n fudge = 10e-6\n sigma = np.dot(flatX.T, flatX) / flatX.shape[1]\n U, S, V = linalg.svd(sigma)\n self.principal_components = np.dot(np.dot(U, np.diag(1. / np.sqrt(S + fudge))), U.T)\n\n\n", "path": "keras/preprocessing/image.py"}]}
| 3,237 | 79 |
gh_patches_debug_16409
|
rasdani/github-patches
|
git_diff
|
pydantic__pydantic-2220
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Inherited dataclasses don't resolve forward refs
# Bug
```
pydantic version: 1.5.1
python version: 3.8.2
```
a.py:
```py
from __future__ import annotations
from uuid import UUID
from pydantic.dataclasses import dataclass
@dataclass
class A:
uuid: UUID
# workaround
# def __post_init__(self):
# self.__pydantic_model__.update_forward_refs(**globals())
```
b.py:
```py
from __future__ import annotations
from uuid import uuid4
from pydantic.dataclasses import dataclass
from a import A
@dataclass
class B(A):
pass
B(uuid=uuid4())
```
`B(uuid=uuid4())` throws `field "uuid" not yet prepared so type is still a ForwardRef, you might need to call B.update_forward_refs()`.
</issue>
<code>
[start of pydantic/dataclasses.py]
1 from typing import TYPE_CHECKING, Any, Callable, Dict, Optional, Type, TypeVar, Union, overload
2
3 from .class_validators import gather_all_validators
4 from .error_wrappers import ValidationError
5 from .errors import DataclassTypeError
6 from .fields import Required
7 from .main import create_model, validate_model
8 from .utils import ClassAttribute
9
10 if TYPE_CHECKING:
11 from .main import BaseConfig, BaseModel # noqa: F401
12 from .typing import CallableGenerator
13
14 DataclassT = TypeVar('DataclassT', bound='Dataclass')
15
16 class Dataclass:
17 __pydantic_model__: Type[BaseModel]
18 __initialised__: bool
19 __post_init_original__: Optional[Callable[..., None]]
20 __processed__: Optional[ClassAttribute]
21
22 def __init__(self, *args: Any, **kwargs: Any) -> None:
23 pass
24
25 @classmethod
26 def __get_validators__(cls: Type['Dataclass']) -> 'CallableGenerator':
27 pass
28
29 @classmethod
30 def __validate__(cls: Type['DataclassT'], v: Any) -> 'DataclassT':
31 pass
32
33 def __call__(self: 'DataclassT', *args: Any, **kwargs: Any) -> 'DataclassT':
34 pass
35
36
37 def _validate_dataclass(cls: Type['DataclassT'], v: Any) -> 'DataclassT':
38 if isinstance(v, cls):
39 return v
40 elif isinstance(v, (list, tuple)):
41 return cls(*v)
42 elif isinstance(v, dict):
43 return cls(**v)
44 # In nested dataclasses, v can be of type `dataclasses.dataclass`.
45 # But to validate fields `cls` will be in fact a `pydantic.dataclasses.dataclass`,
46 # which inherits directly from the class of `v`.
47 elif is_builtin_dataclass(v) and cls.__bases__[0] is type(v):
48 import dataclasses
49
50 return cls(**dataclasses.asdict(v))
51 else:
52 raise DataclassTypeError(class_name=cls.__name__)
53
54
55 def _get_validators(cls: Type['Dataclass']) -> 'CallableGenerator':
56 yield cls.__validate__
57
58
59 def setattr_validate_assignment(self: 'Dataclass', name: str, value: Any) -> None:
60 if self.__initialised__:
61 d = dict(self.__dict__)
62 d.pop(name, None)
63 known_field = self.__pydantic_model__.__fields__.get(name, None)
64 if known_field:
65 value, error_ = known_field.validate(value, d, loc=name, cls=self.__class__)
66 if error_:
67 raise ValidationError([error_], self.__class__)
68
69 object.__setattr__(self, name, value)
70
71
72 def is_builtin_dataclass(_cls: Type[Any]) -> bool:
73 """
74 `dataclasses.is_dataclass` is True if one of the class parents is a `dataclass`.
75 This is why we also add a class attribute `__processed__` to only consider 'direct' built-in dataclasses
76 """
77 import dataclasses
78
79 return not hasattr(_cls, '__processed__') and dataclasses.is_dataclass(_cls)
80
81
82 def _process_class(
83 _cls: Type[Any],
84 init: bool,
85 repr: bool,
86 eq: bool,
87 order: bool,
88 unsafe_hash: bool,
89 frozen: bool,
90 config: Optional[Type[Any]],
91 ) -> Type['Dataclass']:
92 import dataclasses
93
94 post_init_original = getattr(_cls, '__post_init__', None)
95 if post_init_original and post_init_original.__name__ == '_pydantic_post_init':
96 post_init_original = None
97 if not post_init_original:
98 post_init_original = getattr(_cls, '__post_init_original__', None)
99
100 post_init_post_parse = getattr(_cls, '__post_init_post_parse__', None)
101
102 def _pydantic_post_init(self: 'Dataclass', *initvars: Any) -> None:
103 if post_init_original is not None:
104 post_init_original(self, *initvars)
105 d, _, validation_error = validate_model(self.__pydantic_model__, self.__dict__, cls=self.__class__)
106 if validation_error:
107 raise validation_error
108 object.__setattr__(self, '__dict__', d)
109 object.__setattr__(self, '__initialised__', True)
110 if post_init_post_parse is not None:
111 post_init_post_parse(self, *initvars)
112
113 # If the class is already a dataclass, __post_init__ will not be called automatically
114 # so no validation will be added.
115 # We hence create dynamically a new dataclass:
116 # ```
117 # @dataclasses.dataclass
118 # class NewClass(_cls):
119 # __post_init__ = _pydantic_post_init
120 # ```
121 # with the exact same fields as the base dataclass
122 # and register it on module level to address pickle problem:
123 # https://github.com/samuelcolvin/pydantic/issues/2111
124 if is_builtin_dataclass(_cls):
125 uniq_class_name = f'_Pydantic_{_cls.__name__}_{id(_cls)}'
126 _cls = type(
127 # for pretty output new class will have the name as original
128 _cls.__name__,
129 (_cls,),
130 {
131 '__annotations__': _cls.__annotations__,
132 '__post_init__': _pydantic_post_init,
133 # attrs for pickle to find this class
134 '__module__': __name__,
135 '__qualname__': uniq_class_name,
136 },
137 )
138 globals()[uniq_class_name] = _cls
139 else:
140 _cls.__post_init__ = _pydantic_post_init
141 cls: Type['Dataclass'] = dataclasses.dataclass( # type: ignore
142 _cls, init=init, repr=repr, eq=eq, order=order, unsafe_hash=unsafe_hash, frozen=frozen
143 )
144 cls.__processed__ = ClassAttribute('__processed__', True)
145
146 fields: Dict[str, Any] = {}
147 for field in dataclasses.fields(cls):
148
149 if field.default != dataclasses.MISSING:
150 field_value = field.default
151 # mypy issue 7020 and 708
152 elif field.default_factory != dataclasses.MISSING: # type: ignore
153 field_value = field.default_factory() # type: ignore
154 else:
155 field_value = Required
156
157 fields[field.name] = (field.type, field_value)
158
159 validators = gather_all_validators(cls)
160 cls.__pydantic_model__ = create_model(
161 cls.__name__, __config__=config, __module__=_cls.__module__, __validators__=validators, **fields
162 )
163
164 cls.__initialised__ = False
165 cls.__validate__ = classmethod(_validate_dataclass) # type: ignore[assignment]
166 cls.__get_validators__ = classmethod(_get_validators) # type: ignore[assignment]
167 if post_init_original:
168 cls.__post_init_original__ = post_init_original
169
170 if cls.__pydantic_model__.__config__.validate_assignment and not frozen:
171 cls.__setattr__ = setattr_validate_assignment # type: ignore[assignment]
172
173 return cls
174
175
176 @overload
177 def dataclass(
178 *,
179 init: bool = True,
180 repr: bool = True,
181 eq: bool = True,
182 order: bool = False,
183 unsafe_hash: bool = False,
184 frozen: bool = False,
185 config: Type[Any] = None,
186 ) -> Callable[[Type[Any]], Type['Dataclass']]:
187 ...
188
189
190 @overload
191 def dataclass(
192 _cls: Type[Any],
193 *,
194 init: bool = True,
195 repr: bool = True,
196 eq: bool = True,
197 order: bool = False,
198 unsafe_hash: bool = False,
199 frozen: bool = False,
200 config: Type[Any] = None,
201 ) -> Type['Dataclass']:
202 ...
203
204
205 def dataclass(
206 _cls: Optional[Type[Any]] = None,
207 *,
208 init: bool = True,
209 repr: bool = True,
210 eq: bool = True,
211 order: bool = False,
212 unsafe_hash: bool = False,
213 frozen: bool = False,
214 config: Type[Any] = None,
215 ) -> Union[Callable[[Type[Any]], Type['Dataclass']], Type['Dataclass']]:
216 """
217 Like the python standard lib dataclasses but with type validation.
218
219 Arguments are the same as for standard dataclasses, except for validate_assignment which has the same meaning
220 as Config.validate_assignment.
221 """
222
223 def wrap(cls: Type[Any]) -> Type['Dataclass']:
224 return _process_class(cls, init, repr, eq, order, unsafe_hash, frozen, config)
225
226 if _cls is None:
227 return wrap
228
229 return wrap(_cls)
230
231
232 def make_dataclass_validator(_cls: Type[Any], config: Type['BaseConfig']) -> 'CallableGenerator':
233 """
234 Create a pydantic.dataclass from a builtin dataclass to add type validation
235 and yield the validators
236 It retrieves the parameters of the dataclass and forwards them to the newly created dataclass
237 """
238 dataclass_params = _cls.__dataclass_params__
239 stdlib_dataclass_parameters = {param: getattr(dataclass_params, param) for param in dataclass_params.__slots__}
240 cls = dataclass(_cls, config=config, **stdlib_dataclass_parameters)
241 yield from _get_validators(cls)
242
[end of pydantic/dataclasses.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pydantic/dataclasses.py b/pydantic/dataclasses.py
--- a/pydantic/dataclasses.py
+++ b/pydantic/dataclasses.py
@@ -5,6 +5,7 @@
from .errors import DataclassTypeError
from .fields import Required
from .main import create_model, validate_model
+from .typing import resolve_annotations
from .utils import ClassAttribute
if TYPE_CHECKING:
@@ -128,7 +129,7 @@
_cls.__name__,
(_cls,),
{
- '__annotations__': _cls.__annotations__,
+ '__annotations__': resolve_annotations(_cls.__annotations__, _cls.__module__),
'__post_init__': _pydantic_post_init,
# attrs for pickle to find this class
'__module__': __name__,
|
{"golden_diff": "diff --git a/pydantic/dataclasses.py b/pydantic/dataclasses.py\n--- a/pydantic/dataclasses.py\n+++ b/pydantic/dataclasses.py\n@@ -5,6 +5,7 @@\n from .errors import DataclassTypeError\n from .fields import Required\n from .main import create_model, validate_model\n+from .typing import resolve_annotations\n from .utils import ClassAttribute\n \n if TYPE_CHECKING:\n@@ -128,7 +129,7 @@\n _cls.__name__,\n (_cls,),\n {\n- '__annotations__': _cls.__annotations__,\n+ '__annotations__': resolve_annotations(_cls.__annotations__, _cls.__module__),\n '__post_init__': _pydantic_post_init,\n # attrs for pickle to find this class\n '__module__': __name__,\n", "issue": "Inherited dataclasses don't resolve forward refs\n# Bug\r\n\r\n```\r\npydantic version: 1.5.1\r\npython version: 3.8.2\r\n```\r\n\r\na.py:\r\n```py\r\nfrom __future__ import annotations\r\nfrom uuid import UUID\r\nfrom pydantic.dataclasses import dataclass\r\n\r\n@dataclass\r\nclass A:\r\n uuid: UUID\r\n\r\n # workaround\r\n # def __post_init__(self):\r\n # self.__pydantic_model__.update_forward_refs(**globals())\r\n```\r\n\r\nb.py:\r\n```py\r\nfrom __future__ import annotations\r\nfrom uuid import uuid4\r\nfrom pydantic.dataclasses import dataclass\r\nfrom a import A\r\n\r\n@dataclass\r\nclass B(A):\r\n pass\r\n\r\nB(uuid=uuid4())\r\n```\r\n\r\n`B(uuid=uuid4())` throws `field \"uuid\" not yet prepared so type is still a ForwardRef, you might need to call B.update_forward_refs()`.\n", "before_files": [{"content": "from typing import TYPE_CHECKING, Any, Callable, Dict, Optional, Type, TypeVar, Union, overload\n\nfrom .class_validators import gather_all_validators\nfrom .error_wrappers import ValidationError\nfrom .errors import DataclassTypeError\nfrom .fields import Required\nfrom .main import create_model, validate_model\nfrom .utils import ClassAttribute\n\nif TYPE_CHECKING:\n from .main import BaseConfig, BaseModel # noqa: F401\n from .typing import CallableGenerator\n\n DataclassT = TypeVar('DataclassT', bound='Dataclass')\n\n class Dataclass:\n __pydantic_model__: Type[BaseModel]\n __initialised__: bool\n __post_init_original__: Optional[Callable[..., None]]\n __processed__: Optional[ClassAttribute]\n\n def __init__(self, *args: Any, **kwargs: Any) -> None:\n pass\n\n @classmethod\n def __get_validators__(cls: Type['Dataclass']) -> 'CallableGenerator':\n pass\n\n @classmethod\n def __validate__(cls: Type['DataclassT'], v: Any) -> 'DataclassT':\n pass\n\n def __call__(self: 'DataclassT', *args: Any, **kwargs: Any) -> 'DataclassT':\n pass\n\n\ndef _validate_dataclass(cls: Type['DataclassT'], v: Any) -> 'DataclassT':\n if isinstance(v, cls):\n return v\n elif isinstance(v, (list, tuple)):\n return cls(*v)\n elif isinstance(v, dict):\n return cls(**v)\n # In nested dataclasses, v can be of type `dataclasses.dataclass`.\n # But to validate fields `cls` will be in fact a `pydantic.dataclasses.dataclass`,\n # which inherits directly from the class of `v`.\n elif is_builtin_dataclass(v) and cls.__bases__[0] is type(v):\n import dataclasses\n\n return cls(**dataclasses.asdict(v))\n else:\n raise DataclassTypeError(class_name=cls.__name__)\n\n\ndef _get_validators(cls: Type['Dataclass']) -> 'CallableGenerator':\n yield cls.__validate__\n\n\ndef setattr_validate_assignment(self: 'Dataclass', name: str, value: Any) -> None:\n if self.__initialised__:\n d = dict(self.__dict__)\n d.pop(name, None)\n known_field = self.__pydantic_model__.__fields__.get(name, None)\n if known_field:\n value, error_ = known_field.validate(value, d, loc=name, cls=self.__class__)\n if error_:\n raise ValidationError([error_], self.__class__)\n\n object.__setattr__(self, name, value)\n\n\ndef is_builtin_dataclass(_cls: Type[Any]) -> bool:\n \"\"\"\n `dataclasses.is_dataclass` is True if one of the class parents is a `dataclass`.\n This is why we also add a class attribute `__processed__` to only consider 'direct' built-in dataclasses\n \"\"\"\n import dataclasses\n\n return not hasattr(_cls, '__processed__') and dataclasses.is_dataclass(_cls)\n\n\ndef _process_class(\n _cls: Type[Any],\n init: bool,\n repr: bool,\n eq: bool,\n order: bool,\n unsafe_hash: bool,\n frozen: bool,\n config: Optional[Type[Any]],\n) -> Type['Dataclass']:\n import dataclasses\n\n post_init_original = getattr(_cls, '__post_init__', None)\n if post_init_original and post_init_original.__name__ == '_pydantic_post_init':\n post_init_original = None\n if not post_init_original:\n post_init_original = getattr(_cls, '__post_init_original__', None)\n\n post_init_post_parse = getattr(_cls, '__post_init_post_parse__', None)\n\n def _pydantic_post_init(self: 'Dataclass', *initvars: Any) -> None:\n if post_init_original is not None:\n post_init_original(self, *initvars)\n d, _, validation_error = validate_model(self.__pydantic_model__, self.__dict__, cls=self.__class__)\n if validation_error:\n raise validation_error\n object.__setattr__(self, '__dict__', d)\n object.__setattr__(self, '__initialised__', True)\n if post_init_post_parse is not None:\n post_init_post_parse(self, *initvars)\n\n # If the class is already a dataclass, __post_init__ will not be called automatically\n # so no validation will be added.\n # We hence create dynamically a new dataclass:\n # ```\n # @dataclasses.dataclass\n # class NewClass(_cls):\n # __post_init__ = _pydantic_post_init\n # ```\n # with the exact same fields as the base dataclass\n # and register it on module level to address pickle problem:\n # https://github.com/samuelcolvin/pydantic/issues/2111\n if is_builtin_dataclass(_cls):\n uniq_class_name = f'_Pydantic_{_cls.__name__}_{id(_cls)}'\n _cls = type(\n # for pretty output new class will have the name as original\n _cls.__name__,\n (_cls,),\n {\n '__annotations__': _cls.__annotations__,\n '__post_init__': _pydantic_post_init,\n # attrs for pickle to find this class\n '__module__': __name__,\n '__qualname__': uniq_class_name,\n },\n )\n globals()[uniq_class_name] = _cls\n else:\n _cls.__post_init__ = _pydantic_post_init\n cls: Type['Dataclass'] = dataclasses.dataclass( # type: ignore\n _cls, init=init, repr=repr, eq=eq, order=order, unsafe_hash=unsafe_hash, frozen=frozen\n )\n cls.__processed__ = ClassAttribute('__processed__', True)\n\n fields: Dict[str, Any] = {}\n for field in dataclasses.fields(cls):\n\n if field.default != dataclasses.MISSING:\n field_value = field.default\n # mypy issue 7020 and 708\n elif field.default_factory != dataclasses.MISSING: # type: ignore\n field_value = field.default_factory() # type: ignore\n else:\n field_value = Required\n\n fields[field.name] = (field.type, field_value)\n\n validators = gather_all_validators(cls)\n cls.__pydantic_model__ = create_model(\n cls.__name__, __config__=config, __module__=_cls.__module__, __validators__=validators, **fields\n )\n\n cls.__initialised__ = False\n cls.__validate__ = classmethod(_validate_dataclass) # type: ignore[assignment]\n cls.__get_validators__ = classmethod(_get_validators) # type: ignore[assignment]\n if post_init_original:\n cls.__post_init_original__ = post_init_original\n\n if cls.__pydantic_model__.__config__.validate_assignment and not frozen:\n cls.__setattr__ = setattr_validate_assignment # type: ignore[assignment]\n\n return cls\n\n\n@overload\ndef dataclass(\n *,\n init: bool = True,\n repr: bool = True,\n eq: bool = True,\n order: bool = False,\n unsafe_hash: bool = False,\n frozen: bool = False,\n config: Type[Any] = None,\n) -> Callable[[Type[Any]], Type['Dataclass']]:\n ...\n\n\n@overload\ndef dataclass(\n _cls: Type[Any],\n *,\n init: bool = True,\n repr: bool = True,\n eq: bool = True,\n order: bool = False,\n unsafe_hash: bool = False,\n frozen: bool = False,\n config: Type[Any] = None,\n) -> Type['Dataclass']:\n ...\n\n\ndef dataclass(\n _cls: Optional[Type[Any]] = None,\n *,\n init: bool = True,\n repr: bool = True,\n eq: bool = True,\n order: bool = False,\n unsafe_hash: bool = False,\n frozen: bool = False,\n config: Type[Any] = None,\n) -> Union[Callable[[Type[Any]], Type['Dataclass']], Type['Dataclass']]:\n \"\"\"\n Like the python standard lib dataclasses but with type validation.\n\n Arguments are the same as for standard dataclasses, except for validate_assignment which has the same meaning\n as Config.validate_assignment.\n \"\"\"\n\n def wrap(cls: Type[Any]) -> Type['Dataclass']:\n return _process_class(cls, init, repr, eq, order, unsafe_hash, frozen, config)\n\n if _cls is None:\n return wrap\n\n return wrap(_cls)\n\n\ndef make_dataclass_validator(_cls: Type[Any], config: Type['BaseConfig']) -> 'CallableGenerator':\n \"\"\"\n Create a pydantic.dataclass from a builtin dataclass to add type validation\n and yield the validators\n It retrieves the parameters of the dataclass and forwards them to the newly created dataclass\n \"\"\"\n dataclass_params = _cls.__dataclass_params__\n stdlib_dataclass_parameters = {param: getattr(dataclass_params, param) for param in dataclass_params.__slots__}\n cls = dataclass(_cls, config=config, **stdlib_dataclass_parameters)\n yield from _get_validators(cls)\n", "path": "pydantic/dataclasses.py"}]}
| 3,419 | 177 |
gh_patches_debug_2459
|
rasdani/github-patches
|
git_diff
|
microsoft__botbuilder-python-1190
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
No module named 'botbuilder.ai.qna.dialogs' - Python QnA Sample 49
## Version
botbuilder-ai - 4.9.1
## Describe the bug
I was trying out the QnA Maker Sample - 49.qnamaker-all-features . I've configured my QnA KB and also the config.py with the necessary info. However the module botbuilder.ai.qna.dialogs does not seem to exist. I've manually verified for the class QnAMakermDialog and it does not exist
> from botbuilder.ai.qna.dialogs import QnAMakermDialog
## To Reproduce
Steps to reproduce the behavior:
1. Download the sample 49.qnamaker-all-features
2. Install the necessary requirements and configure QnAMaker.
3. Run python app.py in the folder
## Expected behavior
The sample should've run successfully.
[bug]
</issue>
<code>
[start of libraries/botbuilder-ai/setup.py]
1 # Copyright (c) Microsoft Corporation. All rights reserved.
2 # Licensed under the MIT License.
3
4 import os
5 from setuptools import setup
6
7 REQUIRES = [
8 "azure-cognitiveservices-language-luis==0.2.0",
9 "botbuilder-schema>=4.7.1",
10 "botbuilder-core>=4.7.1",
11 "aiohttp==3.6.2",
12 ]
13
14 TESTS_REQUIRES = ["aiounittest>=1.1.0"]
15
16 root = os.path.abspath(os.path.dirname(__file__))
17
18 with open(os.path.join(root, "botbuilder", "ai", "about.py")) as f:
19 package_info = {}
20 info = f.read()
21 exec(info, package_info)
22
23 with open(os.path.join(root, "README.rst"), encoding="utf-8") as f:
24 long_description = f.read()
25
26 setup(
27 name=package_info["__title__"],
28 version=package_info["__version__"],
29 url=package_info["__uri__"],
30 author=package_info["__author__"],
31 description=package_info["__description__"],
32 keywords="botbuilder-ai LUIS QnAMaker bots ai botframework botbuilder",
33 long_description=long_description,
34 long_description_content_type="text/x-rst",
35 license=package_info["__license__"],
36 packages=[
37 "botbuilder.ai",
38 "botbuilder.ai.qna",
39 "botbuilder.ai.luis",
40 "botbuilder.ai.qna.models",
41 "botbuilder.ai.qna.utils",
42 ],
43 install_requires=REQUIRES + TESTS_REQUIRES,
44 tests_require=TESTS_REQUIRES,
45 include_package_data=True,
46 classifiers=[
47 "Programming Language :: Python :: 3.7",
48 "Intended Audience :: Developers",
49 "License :: OSI Approved :: MIT License",
50 "Operating System :: OS Independent",
51 "Development Status :: 5 - Production/Stable",
52 "Topic :: Scientific/Engineering :: Artificial Intelligence",
53 ],
54 )
55
[end of libraries/botbuilder-ai/setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/libraries/botbuilder-ai/setup.py b/libraries/botbuilder-ai/setup.py
--- a/libraries/botbuilder-ai/setup.py
+++ b/libraries/botbuilder-ai/setup.py
@@ -39,6 +39,7 @@
"botbuilder.ai.luis",
"botbuilder.ai.qna.models",
"botbuilder.ai.qna.utils",
+ "botbuilder.ai.qna.dialogs",
],
install_requires=REQUIRES + TESTS_REQUIRES,
tests_require=TESTS_REQUIRES,
|
{"golden_diff": "diff --git a/libraries/botbuilder-ai/setup.py b/libraries/botbuilder-ai/setup.py\n--- a/libraries/botbuilder-ai/setup.py\n+++ b/libraries/botbuilder-ai/setup.py\n@@ -39,6 +39,7 @@\n \"botbuilder.ai.luis\",\n \"botbuilder.ai.qna.models\",\n \"botbuilder.ai.qna.utils\",\n+ \"botbuilder.ai.qna.dialogs\",\n ],\n install_requires=REQUIRES + TESTS_REQUIRES,\n tests_require=TESTS_REQUIRES,\n", "issue": "No module named 'botbuilder.ai.qna.dialogs' - Python QnA Sample 49\n## Version\r\nbotbuilder-ai - 4.9.1\r\n\r\n## Describe the bug\r\nI was trying out the QnA Maker Sample - 49.qnamaker-all-features . I've configured my QnA KB and also the config.py with the necessary info. However the module botbuilder.ai.qna.dialogs does not seem to exist. I've manually verified for the class QnAMakermDialog and it does not exist\r\n\r\n> from botbuilder.ai.qna.dialogs import QnAMakermDialog\r\n\r\n## To Reproduce\r\nSteps to reproduce the behavior:\r\n1. Download the sample 49.qnamaker-all-features\r\n2. Install the necessary requirements and configure QnAMaker.\r\n3. Run python app.py in the folder\r\n\r\n## Expected behavior\r\nThe sample should've run successfully.\r\n\r\n\r\n[bug]\r\n\n", "before_files": [{"content": "# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License.\n\nimport os\nfrom setuptools import setup\n\nREQUIRES = [\n \"azure-cognitiveservices-language-luis==0.2.0\",\n \"botbuilder-schema>=4.7.1\",\n \"botbuilder-core>=4.7.1\",\n \"aiohttp==3.6.2\",\n]\n\nTESTS_REQUIRES = [\"aiounittest>=1.1.0\"]\n\nroot = os.path.abspath(os.path.dirname(__file__))\n\nwith open(os.path.join(root, \"botbuilder\", \"ai\", \"about.py\")) as f:\n package_info = {}\n info = f.read()\n exec(info, package_info)\n\nwith open(os.path.join(root, \"README.rst\"), encoding=\"utf-8\") as f:\n long_description = f.read()\n\nsetup(\n name=package_info[\"__title__\"],\n version=package_info[\"__version__\"],\n url=package_info[\"__uri__\"],\n author=package_info[\"__author__\"],\n description=package_info[\"__description__\"],\n keywords=\"botbuilder-ai LUIS QnAMaker bots ai botframework botbuilder\",\n long_description=long_description,\n long_description_content_type=\"text/x-rst\",\n license=package_info[\"__license__\"],\n packages=[\n \"botbuilder.ai\",\n \"botbuilder.ai.qna\",\n \"botbuilder.ai.luis\",\n \"botbuilder.ai.qna.models\",\n \"botbuilder.ai.qna.utils\",\n ],\n install_requires=REQUIRES + TESTS_REQUIRES,\n tests_require=TESTS_REQUIRES,\n include_package_data=True,\n classifiers=[\n \"Programming Language :: Python :: 3.7\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: MIT License\",\n \"Operating System :: OS Independent\",\n \"Development Status :: 5 - Production/Stable\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n)\n", "path": "libraries/botbuilder-ai/setup.py"}]}
| 1,266 | 120 |
gh_patches_debug_16702
|
rasdani/github-patches
|
git_diff
|
common-workflow-language__cwltool-586
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
--pack should preserve @namespace
---
## Expected Behavior
cwltool should resolve file formats specified as links (e.g., after `--pack`-ing a workflow)
## Steps to reproduce
```
cd /path/to/common-workflow-language/v1.0/v1.0
cwltool --pack formattest2.cwl > formattest2-packed.cwl
cwltool formattest2-packed.cwl formattest2-job.json
```
Expected output:
```
{
"output": {
"format": "http://edamontology.org/format_2330",
"checksum": "sha1$97fe1b50b4582cebc7d853796ebd62e3e163aa3f",
"basename": "output.txt",
"location": "file:///Users/anton/Programming/CWL/cwltool/cwltool/schemas/v1.0/output.txt",
"path": "/Users/anton/Programming/CWL/cwltool/cwltool/schemas/v1.0/output.txt",
"class": "File",
"size": 1111
}
}
```
Produced output:
```
{
"output": {
"format": "edam:format_2330",
"checksum": "sha1$97fe1b50b4582cebc7d853796ebd62e3e163aa3f",
"basename": "output.txt",
"location": "file:///Users/anton/Programming/CWL/cwltool/cwltool/schemas/v1.0/output.txt",
"path": "/Users/anton/Programming/CWL/cwltool/cwltool/schemas/v1.0/output.txt",
"class": "File",
"size": 1111
}
}
```
## Your Environment
* cwltool version:
1.0.20171107133715
</issue>
<code>
[start of cwltool/pack.py]
1 from __future__ import absolute_import
2 import copy
3 import re
4 from typing import Any, Callable, Dict, List, Set, Text, Union, cast
5
6 from schema_salad.ref_resolver import Loader, SubLoader
7 from six.moves import urllib
8 from ruamel.yaml.comments import CommentedSeq, CommentedMap
9
10 from .process import shortname, uniquename
11 import six
12
13
14 def flatten_deps(d, files): # type: (Any, Set[Text]) -> None
15 if isinstance(d, list):
16 for s in d:
17 flatten_deps(s, files)
18 elif isinstance(d, dict):
19 if d["class"] == "File":
20 files.add(d["location"])
21 if "secondaryFiles" in d:
22 flatten_deps(d["secondaryFiles"], files)
23 if "listing" in d:
24 flatten_deps(d["listing"], files)
25
26
27 def find_run(d, loadref, runs): # type: (Any, Callable[[Text, Text], Union[Dict, List, Text]], Set[Text]) -> None
28 if isinstance(d, list):
29 for s in d:
30 find_run(s, loadref, runs)
31 elif isinstance(d, dict):
32 if "run" in d and isinstance(d["run"], six.string_types):
33 if d["run"] not in runs:
34 runs.add(d["run"])
35 find_run(loadref(None, d["run"]), loadref, runs)
36 for s in d.values():
37 find_run(s, loadref, runs)
38
39
40 def find_ids(d, ids): # type: (Any, Set[Text]) -> None
41 if isinstance(d, list):
42 for s in d:
43 find_ids(s, ids)
44 elif isinstance(d, dict):
45 for i in ("id", "name"):
46 if i in d and isinstance(d[i], six.string_types):
47 ids.add(d[i])
48 for s in d.values():
49 find_ids(s, ids)
50
51
52 def replace_refs(d, rewrite, stem, newstem):
53 # type: (Any, Dict[Text, Text], Text, Text) -> None
54 if isinstance(d, list):
55 for s, v in enumerate(d):
56 if isinstance(v, six.string_types):
57 if v in rewrite:
58 d[s] = rewrite[v]
59 elif v.startswith(stem):
60 d[s] = newstem + v[len(stem):]
61 else:
62 replace_refs(v, rewrite, stem, newstem)
63 elif isinstance(d, dict):
64 for s, v in d.items():
65 if isinstance(v, six.string_types):
66 if v in rewrite:
67 d[s] = rewrite[v]
68 elif v.startswith(stem):
69 id_ = v[len(stem):]
70 # prevent appending newstems if tool is already packed
71 if id_.startswith(newstem.strip("#")):
72 d[s] = "#" + id_
73 else:
74 d[s] = newstem + id_
75 replace_refs(v, rewrite, stem, newstem)
76
77 def import_embed(d, seen):
78 # type: (Any, Set[Text]) -> None
79 if isinstance(d, list):
80 for v in d:
81 import_embed(v, seen)
82 elif isinstance(d, dict):
83 for n in ("id", "name"):
84 if n in d:
85 if d[n] in seen:
86 this = d[n]
87 d.clear()
88 d["$import"] = this
89 else:
90 this = d[n]
91 seen.add(this)
92 break
93
94 for k in sorted(d.keys()):
95 import_embed(d[k], seen)
96
97
98 def pack(document_loader, processobj, uri, metadata):
99 # type: (Loader, Union[Dict[Text, Any], List[Dict[Text, Any]]], Text, Dict[Text, Text]) -> Dict[Text, Any]
100
101 document_loader = SubLoader(document_loader)
102 document_loader.idx = {}
103 if isinstance(processobj, dict):
104 document_loader.idx[processobj["id"]] = CommentedMap(six.iteritems(processobj))
105 elif isinstance(processobj, list):
106 path, frag = urllib.parse.urldefrag(uri)
107 for po in processobj:
108 if not frag:
109 if po["id"].endswith("#main"):
110 uri = po["id"]
111 document_loader.idx[po["id"]] = CommentedMap(six.iteritems(po))
112
113 def loadref(b, u):
114 # type: (Text, Text) -> Union[Dict, List, Text]
115 return document_loader.resolve_ref(u, base_url=b)[0]
116
117 runs = {uri}
118 find_run(processobj, loadref, runs)
119
120 ids = set() # type: Set[Text]
121 for f in runs:
122 find_ids(document_loader.resolve_ref(f)[0], ids)
123
124 names = set() # type: Set[Text]
125 rewrite = {} # type: Dict[Text, Text]
126
127 mainpath, _ = urllib.parse.urldefrag(uri)
128
129 def rewrite_id(r, mainuri):
130 # type: (Text, Text) -> None
131 if r == mainuri:
132 rewrite[r] = "#main"
133 elif r.startswith(mainuri) and r[len(mainuri)] in ("#", "/"):
134 path, frag = urllib.parse.urldefrag(r)
135 rewrite[r] = "#"+frag
136 else:
137 path, frag = urllib.parse.urldefrag(r)
138 if path == mainpath:
139 rewrite[r] = "#" + uniquename(frag, names)
140 else:
141 if path not in rewrite:
142 rewrite[path] = "#" + uniquename(shortname(path), names)
143
144 sortedids = sorted(ids)
145
146 for r in sortedids:
147 if r in document_loader.idx:
148 rewrite_id(r, uri)
149
150 packed = {"$graph": [], "cwlVersion": metadata["cwlVersion"]
151 } # type: Dict[Text, Any]
152
153 schemas = set() # type: Set[Text]
154 for r in sorted(runs):
155 dcr, metadata = document_loader.resolve_ref(r)
156 if isinstance(dcr, CommentedSeq):
157 dcr = dcr[0]
158 dcr = cast(CommentedMap, dcr)
159 if not isinstance(dcr, dict):
160 continue
161 for doc in (dcr, metadata):
162 if "$schemas" in doc:
163 for s in doc["$schemas"]:
164 schemas.add(s)
165 if dcr.get("class") not in ("Workflow", "CommandLineTool", "ExpressionTool"):
166 continue
167 dc = cast(Dict[Text, Any], copy.deepcopy(dcr))
168 v = rewrite[r]
169 dc["id"] = v
170 for n in ("name", "cwlVersion", "$namespaces", "$schemas"):
171 if n in dc:
172 del dc[n]
173 packed["$graph"].append(dc)
174
175 if schemas:
176 packed["$schemas"] = list(schemas)
177
178 for r in rewrite:
179 v = rewrite[r]
180 replace_refs(packed, rewrite, r + "/" if "#" in r else r + "#", v + "/")
181
182 import_embed(packed, set())
183
184 if len(packed["$graph"]) == 1:
185 # duplicate 'cwlVersion' inside $graph when there is a single item
186 # because we're printing contents inside '$graph' rather than whole dict
187 packed["$graph"][0]["cwlVersion"] = packed["cwlVersion"]
188
189 return packed
190
[end of cwltool/pack.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/cwltool/pack.py b/cwltool/pack.py
--- a/cwltool/pack.py
+++ b/cwltool/pack.py
@@ -149,6 +149,7 @@
packed = {"$graph": [], "cwlVersion": metadata["cwlVersion"]
} # type: Dict[Text, Any]
+ namespaces = metadata.get('$namespaces', None)
schemas = set() # type: Set[Text]
for r in sorted(runs):
@@ -185,5 +186,7 @@
# duplicate 'cwlVersion' inside $graph when there is a single item
# because we're printing contents inside '$graph' rather than whole dict
packed["$graph"][0]["cwlVersion"] = packed["cwlVersion"]
+ if namespaces:
+ packed["$graph"][0]["$namespaces"] = dict(cast(Dict, namespaces))
return packed
|
{"golden_diff": "diff --git a/cwltool/pack.py b/cwltool/pack.py\n--- a/cwltool/pack.py\n+++ b/cwltool/pack.py\n@@ -149,6 +149,7 @@\n \n packed = {\"$graph\": [], \"cwlVersion\": metadata[\"cwlVersion\"]\n } # type: Dict[Text, Any]\n+ namespaces = metadata.get('$namespaces', None)\n \n schemas = set() # type: Set[Text]\n for r in sorted(runs):\n@@ -185,5 +186,7 @@\n # duplicate 'cwlVersion' inside $graph when there is a single item\n # because we're printing contents inside '$graph' rather than whole dict\n packed[\"$graph\"][0][\"cwlVersion\"] = packed[\"cwlVersion\"]\n+ if namespaces:\n+ packed[\"$graph\"][0][\"$namespaces\"] = dict(cast(Dict, namespaces))\n \n return packed\n", "issue": "--pack should preserve @namespace\n---\r\n\r\n## Expected Behavior\r\ncwltool should resolve file formats specified as links (e.g., after `--pack`-ing a workflow)\r\n\r\n## Steps to reproduce\r\n```\r\ncd /path/to/common-workflow-language/v1.0/v1.0\r\ncwltool --pack formattest2.cwl > formattest2-packed.cwl\r\ncwltool formattest2-packed.cwl formattest2-job.json\r\n```\r\n\r\nExpected output:\r\n```\r\n{\r\n \"output\": {\r\n \"format\": \"http://edamontology.org/format_2330\", \r\n \"checksum\": \"sha1$97fe1b50b4582cebc7d853796ebd62e3e163aa3f\", \r\n \"basename\": \"output.txt\", \r\n \"location\": \"file:///Users/anton/Programming/CWL/cwltool/cwltool/schemas/v1.0/output.txt\", \r\n \"path\": \"/Users/anton/Programming/CWL/cwltool/cwltool/schemas/v1.0/output.txt\", \r\n \"class\": \"File\", \r\n \"size\": 1111\r\n }\r\n}\r\n```\r\n\r\nProduced output:\r\n```\r\n{\r\n \"output\": {\r\n \"format\": \"edam:format_2330\", \r\n \"checksum\": \"sha1$97fe1b50b4582cebc7d853796ebd62e3e163aa3f\", \r\n \"basename\": \"output.txt\", \r\n \"location\": \"file:///Users/anton/Programming/CWL/cwltool/cwltool/schemas/v1.0/output.txt\", \r\n \"path\": \"/Users/anton/Programming/CWL/cwltool/cwltool/schemas/v1.0/output.txt\", \r\n \"class\": \"File\", \r\n \"size\": 1111\r\n }\r\n}\r\n```\r\n\r\n## Your Environment\r\n* cwltool version: \r\n1.0.20171107133715\r\n\n", "before_files": [{"content": "from __future__ import absolute_import\nimport copy\nimport re\nfrom typing import Any, Callable, Dict, List, Set, Text, Union, cast\n\nfrom schema_salad.ref_resolver import Loader, SubLoader\nfrom six.moves import urllib\nfrom ruamel.yaml.comments import CommentedSeq, CommentedMap\n\nfrom .process import shortname, uniquename\nimport six\n\n\ndef flatten_deps(d, files): # type: (Any, Set[Text]) -> None\n if isinstance(d, list):\n for s in d:\n flatten_deps(s, files)\n elif isinstance(d, dict):\n if d[\"class\"] == \"File\":\n files.add(d[\"location\"])\n if \"secondaryFiles\" in d:\n flatten_deps(d[\"secondaryFiles\"], files)\n if \"listing\" in d:\n flatten_deps(d[\"listing\"], files)\n\n\ndef find_run(d, loadref, runs): # type: (Any, Callable[[Text, Text], Union[Dict, List, Text]], Set[Text]) -> None\n if isinstance(d, list):\n for s in d:\n find_run(s, loadref, runs)\n elif isinstance(d, dict):\n if \"run\" in d and isinstance(d[\"run\"], six.string_types):\n if d[\"run\"] not in runs:\n runs.add(d[\"run\"])\n find_run(loadref(None, d[\"run\"]), loadref, runs)\n for s in d.values():\n find_run(s, loadref, runs)\n\n\ndef find_ids(d, ids): # type: (Any, Set[Text]) -> None\n if isinstance(d, list):\n for s in d:\n find_ids(s, ids)\n elif isinstance(d, dict):\n for i in (\"id\", \"name\"):\n if i in d and isinstance(d[i], six.string_types):\n ids.add(d[i])\n for s in d.values():\n find_ids(s, ids)\n\n\ndef replace_refs(d, rewrite, stem, newstem):\n # type: (Any, Dict[Text, Text], Text, Text) -> None\n if isinstance(d, list):\n for s, v in enumerate(d):\n if isinstance(v, six.string_types):\n if v in rewrite:\n d[s] = rewrite[v]\n elif v.startswith(stem):\n d[s] = newstem + v[len(stem):]\n else:\n replace_refs(v, rewrite, stem, newstem)\n elif isinstance(d, dict):\n for s, v in d.items():\n if isinstance(v, six.string_types):\n if v in rewrite:\n d[s] = rewrite[v]\n elif v.startswith(stem):\n id_ = v[len(stem):]\n # prevent appending newstems if tool is already packed\n if id_.startswith(newstem.strip(\"#\")):\n d[s] = \"#\" + id_\n else:\n d[s] = newstem + id_\n replace_refs(v, rewrite, stem, newstem)\n\ndef import_embed(d, seen):\n # type: (Any, Set[Text]) -> None\n if isinstance(d, list):\n for v in d:\n import_embed(v, seen)\n elif isinstance(d, dict):\n for n in (\"id\", \"name\"):\n if n in d:\n if d[n] in seen:\n this = d[n]\n d.clear()\n d[\"$import\"] = this\n else:\n this = d[n]\n seen.add(this)\n break\n\n for k in sorted(d.keys()):\n import_embed(d[k], seen)\n\n\ndef pack(document_loader, processobj, uri, metadata):\n # type: (Loader, Union[Dict[Text, Any], List[Dict[Text, Any]]], Text, Dict[Text, Text]) -> Dict[Text, Any]\n\n document_loader = SubLoader(document_loader)\n document_loader.idx = {}\n if isinstance(processobj, dict):\n document_loader.idx[processobj[\"id\"]] = CommentedMap(six.iteritems(processobj))\n elif isinstance(processobj, list):\n path, frag = urllib.parse.urldefrag(uri)\n for po in processobj:\n if not frag:\n if po[\"id\"].endswith(\"#main\"):\n uri = po[\"id\"]\n document_loader.idx[po[\"id\"]] = CommentedMap(six.iteritems(po))\n\n def loadref(b, u):\n # type: (Text, Text) -> Union[Dict, List, Text]\n return document_loader.resolve_ref(u, base_url=b)[0]\n\n runs = {uri}\n find_run(processobj, loadref, runs)\n\n ids = set() # type: Set[Text]\n for f in runs:\n find_ids(document_loader.resolve_ref(f)[0], ids)\n\n names = set() # type: Set[Text]\n rewrite = {} # type: Dict[Text, Text]\n\n mainpath, _ = urllib.parse.urldefrag(uri)\n\n def rewrite_id(r, mainuri):\n # type: (Text, Text) -> None\n if r == mainuri:\n rewrite[r] = \"#main\"\n elif r.startswith(mainuri) and r[len(mainuri)] in (\"#\", \"/\"):\n path, frag = urllib.parse.urldefrag(r)\n rewrite[r] = \"#\"+frag\n else:\n path, frag = urllib.parse.urldefrag(r)\n if path == mainpath:\n rewrite[r] = \"#\" + uniquename(frag, names)\n else:\n if path not in rewrite:\n rewrite[path] = \"#\" + uniquename(shortname(path), names)\n\n sortedids = sorted(ids)\n\n for r in sortedids:\n if r in document_loader.idx:\n rewrite_id(r, uri)\n\n packed = {\"$graph\": [], \"cwlVersion\": metadata[\"cwlVersion\"]\n } # type: Dict[Text, Any]\n\n schemas = set() # type: Set[Text]\n for r in sorted(runs):\n dcr, metadata = document_loader.resolve_ref(r)\n if isinstance(dcr, CommentedSeq):\n dcr = dcr[0]\n dcr = cast(CommentedMap, dcr)\n if not isinstance(dcr, dict):\n continue\n for doc in (dcr, metadata):\n if \"$schemas\" in doc:\n for s in doc[\"$schemas\"]:\n schemas.add(s)\n if dcr.get(\"class\") not in (\"Workflow\", \"CommandLineTool\", \"ExpressionTool\"):\n continue\n dc = cast(Dict[Text, Any], copy.deepcopy(dcr))\n v = rewrite[r]\n dc[\"id\"] = v\n for n in (\"name\", \"cwlVersion\", \"$namespaces\", \"$schemas\"):\n if n in dc:\n del dc[n]\n packed[\"$graph\"].append(dc)\n\n if schemas:\n packed[\"$schemas\"] = list(schemas)\n\n for r in rewrite:\n v = rewrite[r]\n replace_refs(packed, rewrite, r + \"/\" if \"#\" in r else r + \"#\", v + \"/\")\n\n import_embed(packed, set())\n\n if len(packed[\"$graph\"]) == 1:\n # duplicate 'cwlVersion' inside $graph when there is a single item\n # because we're printing contents inside '$graph' rather than whole dict\n packed[\"$graph\"][0][\"cwlVersion\"] = packed[\"cwlVersion\"]\n\n return packed\n", "path": "cwltool/pack.py"}]}
| 3,051 | 213 |
gh_patches_debug_12648
|
rasdani/github-patches
|
git_diff
|
elastic__apm-agent-python-885
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
dictionary changed size during iteration
Same problem to https://github.com/elastic/apm-agent-python/issues/717
```
File "/elasticapm/base.py", line 180, in <lambda>
local_var,
File "/elasticapm/utils/__init__.py", line 64, in varmap
ret = func(name, dict((k, varmap(func, v, context, k, **kwargs)) for k, v in compat.iteritems(var)), **kwargs)
File "/elasticapm/utils/__init__.py", line 64, in <genexpr>
ret = func(name, dict((k, varmap(func, v, context, k, **kwargs)) for k, v in compat.iteritems(var)), **kwargs)
RuntimeError: dictionary changed size during iteration
```
Environment (please complete the following information)
OS: Ubuntu 20.04 stable
Python version: 2.7.18
Framework and version Django 1.3
APM Server version: 7.6.0
Agent version: 5.8
dictionary changed size during iteration
Same problem to https://github.com/elastic/apm-agent-python/issues/717
```
File "/elasticapm/base.py", line 180, in <lambda>
local_var,
File "/elasticapm/utils/__init__.py", line 64, in varmap
ret = func(name, dict((k, varmap(func, v, context, k, **kwargs)) for k, v in compat.iteritems(var)), **kwargs)
File "/elasticapm/utils/__init__.py", line 64, in <genexpr>
ret = func(name, dict((k, varmap(func, v, context, k, **kwargs)) for k, v in compat.iteritems(var)), **kwargs)
RuntimeError: dictionary changed size during iteration
```
Environment (please complete the following information)
OS: Ubuntu 20.04 stable
Python version: 2.7.18
Framework and version Django 1.3
APM Server version: 7.6.0
Agent version: 5.8
</issue>
<code>
[start of elasticapm/utils/__init__.py]
1 # BSD 3-Clause License
2 #
3 # Copyright (c) 2012, the Sentry Team, see AUTHORS for more details
4 # Copyright (c) 2019, Elasticsearch BV
5 # All rights reserved.
6 #
7 # Redistribution and use in source and binary forms, with or without
8 # modification, are permitted provided that the following conditions are met:
9 #
10 # * Redistributions of source code must retain the above copyright notice, this
11 # list of conditions and the following disclaimer.
12 #
13 # * Redistributions in binary form must reproduce the above copyright notice,
14 # this list of conditions and the following disclaimer in the documentation
15 # and/or other materials provided with the distribution.
16 #
17 # * Neither the name of the copyright holder nor the names of its
18 # contributors may be used to endorse or promote products derived from
19 # this software without specific prior written permission.
20 #
21 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
22 # AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
23 # IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
24 # DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
25 # FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
26 # DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
27 # SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
28 # CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
29 # OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
30
31 import base64
32 import os
33 import re
34 from functools import partial
35
36 from elasticapm.conf import constants
37 from elasticapm.utils import compat, encoding
38
39 try:
40 from functools import partialmethod
41
42 partial_types = (partial, partialmethod)
43 except ImportError:
44 # Python 2
45 partial_types = (partial,)
46
47
48 default_ports = {"https": 443, "http": 80, "postgresql": 5432, "mysql": 3306, "mssql": 1433}
49
50
51 def varmap(func, var, context=None, name=None, **kwargs):
52 """
53 Executes ``func(key_name, value)`` on all values,
54 recursively discovering dict and list scoped
55 values.
56 """
57 if context is None:
58 context = set()
59 objid = id(var)
60 if objid in context:
61 return func(name, "<...>", **kwargs)
62 context.add(objid)
63 if isinstance(var, dict):
64 ret = func(name, dict((k, varmap(func, v, context, k, **kwargs)) for k, v in compat.iteritems(var)), **kwargs)
65 elif isinstance(var, (list, tuple)):
66 ret = func(name, [varmap(func, f, context, name, **kwargs) for f in var], **kwargs)
67 else:
68 ret = func(name, var, **kwargs)
69 context.remove(objid)
70 return ret
71
72
73 def get_name_from_func(func):
74 # partials don't have `__module__` or `__name__`, so we use the values from the "inner" function
75 if isinstance(func, partial_types):
76 return "partial({})".format(get_name_from_func(func.func))
77 elif hasattr(func, "_partialmethod") and hasattr(func._partialmethod, "func"):
78 return "partial({})".format(get_name_from_func(func._partialmethod.func))
79
80 module = func.__module__
81
82 if hasattr(func, "__name__"):
83 view_name = func.__name__
84 else: # Fall back if there's no __name__
85 view_name = func.__class__.__name__
86
87 return "{0}.{1}".format(module, view_name)
88
89
90 def build_name_with_http_method_prefix(name, request):
91 return " ".join((request.method, name)) if name else name
92
93
94 def is_master_process():
95 # currently only recognizes uwsgi master process
96 try:
97 import uwsgi
98
99 return os.getpid() == uwsgi.masterpid()
100 except ImportError:
101 return False
102
103
104 def get_url_dict(url):
105 parse_result = compat.urlparse.urlparse(url)
106
107 url_dict = {
108 "full": encoding.keyword_field(url),
109 "protocol": parse_result.scheme + ":",
110 "hostname": encoding.keyword_field(parse_result.hostname),
111 "pathname": encoding.keyword_field(parse_result.path),
112 }
113
114 port = None if parse_result.port is None else str(parse_result.port)
115
116 if port:
117 url_dict["port"] = port
118 if parse_result.query:
119 url_dict["search"] = encoding.keyword_field("?" + parse_result.query)
120 return url_dict
121
122
123 def sanitize_url(url):
124 if "@" not in url:
125 return url
126 parts = compat.urlparse.urlparse(url)
127 return url.replace("%s:%s" % (parts.username, parts.password), "%s:%s" % (parts.username, constants.MASK))
128
129
130 def get_host_from_url(url):
131 parsed_url = compat.urlparse.urlparse(url)
132 host = parsed_url.hostname or " "
133
134 if parsed_url.port and default_ports.get(parsed_url.scheme) != parsed_url.port:
135 host += ":" + str(parsed_url.port)
136
137 return host
138
139
140 def url_to_destination(url, service_type="external"):
141 parts = compat.urlparse.urlsplit(url)
142 hostname = parts.hostname
143 # preserve brackets for IPv6 URLs
144 if "://[" in url:
145 hostname = "[%s]" % hostname
146 try:
147 port = parts.port
148 except ValueError:
149 # Malformed port, just use None rather than raising an exception
150 port = None
151 default_port = default_ports.get(parts.scheme, None)
152 name = "%s://%s" % (parts.scheme, hostname)
153 resource = hostname
154 if not port and parts.scheme in default_ports:
155 port = default_ports[parts.scheme]
156 if port:
157 if port != default_port:
158 name += ":%d" % port
159 resource += ":%d" % port
160 return {"service": {"name": name, "resource": resource, "type": service_type}}
161
162
163 def read_pem_file(file_obj):
164 cert = b""
165 for line in file_obj:
166 if line.startswith(b"-----BEGIN CERTIFICATE-----"):
167 break
168 # scan until we find the first END CERTIFICATE marker
169 for line in file_obj:
170 if line.startswith(b"-----END CERTIFICATE-----"):
171 break
172 cert += line.strip()
173 return base64.b64decode(cert)
174
175
176 def starmatch_to_regex(pattern):
177 i, n = 0, len(pattern)
178 res = []
179 while i < n:
180 c = pattern[i]
181 i = i + 1
182 if c == "*":
183 res.append(".*")
184 else:
185 res.append(re.escape(c))
186 return re.compile(r"(?:%s)\Z" % "".join(res), re.IGNORECASE | re.DOTALL)
187
[end of elasticapm/utils/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/elasticapm/utils/__init__.py b/elasticapm/utils/__init__.py
--- a/elasticapm/utils/__init__.py
+++ b/elasticapm/utils/__init__.py
@@ -61,7 +61,10 @@
return func(name, "<...>", **kwargs)
context.add(objid)
if isinstance(var, dict):
- ret = func(name, dict((k, varmap(func, v, context, k, **kwargs)) for k, v in compat.iteritems(var)), **kwargs)
+ # iterate over a copy of the dictionary to avoid "dictionary changed size during iteration" issues
+ ret = func(
+ name, dict((k, varmap(func, v, context, k, **kwargs)) for k, v in compat.iteritems(var.copy())), **kwargs
+ )
elif isinstance(var, (list, tuple)):
ret = func(name, [varmap(func, f, context, name, **kwargs) for f in var], **kwargs)
else:
|
{"golden_diff": "diff --git a/elasticapm/utils/__init__.py b/elasticapm/utils/__init__.py\n--- a/elasticapm/utils/__init__.py\n+++ b/elasticapm/utils/__init__.py\n@@ -61,7 +61,10 @@\n return func(name, \"<...>\", **kwargs)\n context.add(objid)\n if isinstance(var, dict):\n- ret = func(name, dict((k, varmap(func, v, context, k, **kwargs)) for k, v in compat.iteritems(var)), **kwargs)\n+ # iterate over a copy of the dictionary to avoid \"dictionary changed size during iteration\" issues\n+ ret = func(\n+ name, dict((k, varmap(func, v, context, k, **kwargs)) for k, v in compat.iteritems(var.copy())), **kwargs\n+ )\n elif isinstance(var, (list, tuple)):\n ret = func(name, [varmap(func, f, context, name, **kwargs) for f in var], **kwargs)\n else:\n", "issue": "dictionary changed size during iteration\nSame problem to https://github.com/elastic/apm-agent-python/issues/717\r\n\r\n```\r\n File \"/elasticapm/base.py\", line 180, in <lambda>\r\n local_var,\r\n File \"/elasticapm/utils/__init__.py\", line 64, in varmap\r\n ret = func(name, dict((k, varmap(func, v, context, k, **kwargs)) for k, v in compat.iteritems(var)), **kwargs)\r\n File \"/elasticapm/utils/__init__.py\", line 64, in <genexpr>\r\n ret = func(name, dict((k, varmap(func, v, context, k, **kwargs)) for k, v in compat.iteritems(var)), **kwargs)\r\n\r\nRuntimeError: dictionary changed size during iteration\r\n```\r\n\r\nEnvironment (please complete the following information)\r\n\r\nOS: Ubuntu 20.04 stable\r\nPython version: 2.7.18\r\nFramework and version Django 1.3\r\nAPM Server version: 7.6.0\r\nAgent version: 5.8\ndictionary changed size during iteration\nSame problem to https://github.com/elastic/apm-agent-python/issues/717\r\n\r\n```\r\n File \"/elasticapm/base.py\", line 180, in <lambda>\r\n local_var,\r\n File \"/elasticapm/utils/__init__.py\", line 64, in varmap\r\n ret = func(name, dict((k, varmap(func, v, context, k, **kwargs)) for k, v in compat.iteritems(var)), **kwargs)\r\n File \"/elasticapm/utils/__init__.py\", line 64, in <genexpr>\r\n ret = func(name, dict((k, varmap(func, v, context, k, **kwargs)) for k, v in compat.iteritems(var)), **kwargs)\r\n\r\nRuntimeError: dictionary changed size during iteration\r\n```\r\n\r\nEnvironment (please complete the following information)\r\n\r\nOS: Ubuntu 20.04 stable\r\nPython version: 2.7.18\r\nFramework and version Django 1.3\r\nAPM Server version: 7.6.0\r\nAgent version: 5.8\n", "before_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2012, the Sentry Team, see AUTHORS for more details\n# Copyright (c) 2019, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n\nimport base64\nimport os\nimport re\nfrom functools import partial\n\nfrom elasticapm.conf import constants\nfrom elasticapm.utils import compat, encoding\n\ntry:\n from functools import partialmethod\n\n partial_types = (partial, partialmethod)\nexcept ImportError:\n # Python 2\n partial_types = (partial,)\n\n\ndefault_ports = {\"https\": 443, \"http\": 80, \"postgresql\": 5432, \"mysql\": 3306, \"mssql\": 1433}\n\n\ndef varmap(func, var, context=None, name=None, **kwargs):\n \"\"\"\n Executes ``func(key_name, value)`` on all values,\n recursively discovering dict and list scoped\n values.\n \"\"\"\n if context is None:\n context = set()\n objid = id(var)\n if objid in context:\n return func(name, \"<...>\", **kwargs)\n context.add(objid)\n if isinstance(var, dict):\n ret = func(name, dict((k, varmap(func, v, context, k, **kwargs)) for k, v in compat.iteritems(var)), **kwargs)\n elif isinstance(var, (list, tuple)):\n ret = func(name, [varmap(func, f, context, name, **kwargs) for f in var], **kwargs)\n else:\n ret = func(name, var, **kwargs)\n context.remove(objid)\n return ret\n\n\ndef get_name_from_func(func):\n # partials don't have `__module__` or `__name__`, so we use the values from the \"inner\" function\n if isinstance(func, partial_types):\n return \"partial({})\".format(get_name_from_func(func.func))\n elif hasattr(func, \"_partialmethod\") and hasattr(func._partialmethod, \"func\"):\n return \"partial({})\".format(get_name_from_func(func._partialmethod.func))\n\n module = func.__module__\n\n if hasattr(func, \"__name__\"):\n view_name = func.__name__\n else: # Fall back if there's no __name__\n view_name = func.__class__.__name__\n\n return \"{0}.{1}\".format(module, view_name)\n\n\ndef build_name_with_http_method_prefix(name, request):\n return \" \".join((request.method, name)) if name else name\n\n\ndef is_master_process():\n # currently only recognizes uwsgi master process\n try:\n import uwsgi\n\n return os.getpid() == uwsgi.masterpid()\n except ImportError:\n return False\n\n\ndef get_url_dict(url):\n parse_result = compat.urlparse.urlparse(url)\n\n url_dict = {\n \"full\": encoding.keyword_field(url),\n \"protocol\": parse_result.scheme + \":\",\n \"hostname\": encoding.keyword_field(parse_result.hostname),\n \"pathname\": encoding.keyword_field(parse_result.path),\n }\n\n port = None if parse_result.port is None else str(parse_result.port)\n\n if port:\n url_dict[\"port\"] = port\n if parse_result.query:\n url_dict[\"search\"] = encoding.keyword_field(\"?\" + parse_result.query)\n return url_dict\n\n\ndef sanitize_url(url):\n if \"@\" not in url:\n return url\n parts = compat.urlparse.urlparse(url)\n return url.replace(\"%s:%s\" % (parts.username, parts.password), \"%s:%s\" % (parts.username, constants.MASK))\n\n\ndef get_host_from_url(url):\n parsed_url = compat.urlparse.urlparse(url)\n host = parsed_url.hostname or \" \"\n\n if parsed_url.port and default_ports.get(parsed_url.scheme) != parsed_url.port:\n host += \":\" + str(parsed_url.port)\n\n return host\n\n\ndef url_to_destination(url, service_type=\"external\"):\n parts = compat.urlparse.urlsplit(url)\n hostname = parts.hostname\n # preserve brackets for IPv6 URLs\n if \"://[\" in url:\n hostname = \"[%s]\" % hostname\n try:\n port = parts.port\n except ValueError:\n # Malformed port, just use None rather than raising an exception\n port = None\n default_port = default_ports.get(parts.scheme, None)\n name = \"%s://%s\" % (parts.scheme, hostname)\n resource = hostname\n if not port and parts.scheme in default_ports:\n port = default_ports[parts.scheme]\n if port:\n if port != default_port:\n name += \":%d\" % port\n resource += \":%d\" % port\n return {\"service\": {\"name\": name, \"resource\": resource, \"type\": service_type}}\n\n\ndef read_pem_file(file_obj):\n cert = b\"\"\n for line in file_obj:\n if line.startswith(b\"-----BEGIN CERTIFICATE-----\"):\n break\n # scan until we find the first END CERTIFICATE marker\n for line in file_obj:\n if line.startswith(b\"-----END CERTIFICATE-----\"):\n break\n cert += line.strip()\n return base64.b64decode(cert)\n\n\ndef starmatch_to_regex(pattern):\n i, n = 0, len(pattern)\n res = []\n while i < n:\n c = pattern[i]\n i = i + 1\n if c == \"*\":\n res.append(\".*\")\n else:\n res.append(re.escape(c))\n return re.compile(r\"(?:%s)\\Z\" % \"\".join(res), re.IGNORECASE | re.DOTALL)\n", "path": "elasticapm/utils/__init__.py"}]}
| 2,979 | 226 |
gh_patches_debug_13874
|
rasdani/github-patches
|
git_diff
|
GPflow__GPflow-1164
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
GPflow2 set_default_float and set_default_int accept tf dtypes but that breaks code
Some functions such as the Gauss-Hermite quadrature code call `numpy_array.astype(default_float())`, which fails if `default_float()` returns a *tensorflow* dtype such as `tf.float64` instead of `np.float64`. However, `gpflow.config.set_default_float()` explicitly allows both numpy and tensorflow dtypes as arguments.
</issue>
<code>
[start of gpflow/config/__config__.py]
1 import contextlib
2 import enum
3 import os
4 from dataclasses import dataclass, field, replace
5 from typing import Dict, Optional, Union
6
7 import numpy as np
8 import tabulate
9 import tensorflow as tf
10 import tensorflow_probability as tfp
11
12
13 __all__ = [
14 "Config", "as_context", "config", "set_config",
15 "default_float", "set_default_float",
16 "default_int", "set_default_int",
17 "default_jitter", "set_default_jitter",
18 "default_positive_bijector", "set_default_positive_bijector",
19 "default_positive_minimum", "set_default_positive_minimum",
20 "default_summary_fmt", "set_default_summary_fmt",
21 "positive_bijector_type_map"
22 ]
23
24
25 __config = None
26
27
28 class _Values(enum.Enum):
29 """Setting's names collection with default values. The `name` method returns name
30 of the environment variable. E.g. for `SUMMARY_FMT` field the environment variable
31 will be `GPFLOW_SUMMARY_FMT`."""
32 INT = np.int32
33 FLOAT = np.float64
34 POSITIVE_BIJECTOR = "softplus"
35 POSITIVE_MINIMUM = None
36 SUMMARY_FMT = None
37 JITTER = 1e-6
38
39 @property
40 def name(self):
41 return f"GPFLOW_{super().name}"
42
43
44 def default(value: _Values):
45 """Checks if value is set in the environment."""
46 return os.getenv(value.name, default=value.value)
47
48
49 @dataclass(frozen=True)
50 class Config:
51 """
52 Immutable object for storing global GPflow settings
53
54 Args:
55 int: Integer data type, int32 or int64.
56 float: Float data type, float32 or float64
57 jitter: Jitter value. Mainly used for for making badly conditioned matrices more stable.
58 Default value is `1e-6`.
59 positive_bijector: Method for positive bijector, either "softplus" or "exp".
60 Default is "softplus".
61 positive_minimum: Lower level for the positive transformation.
62 summary_fmt: Summary format for module printing.
63 """
64
65 int: type = field(default_factory=lambda: default(_Values.INT))
66 float: type = field(default_factory=lambda: default(_Values.FLOAT))
67 jitter: float = field(default_factory=lambda: default(_Values.JITTER))
68 positive_bijector: str = field(default_factory=lambda: default(_Values.POSITIVE_BIJECTOR))
69 positive_minimum: float = field(default_factory=lambda: default(_Values.POSITIVE_MINIMUM))
70 summary_fmt: str = field(default_factory=lambda: default(_Values.SUMMARY_FMT))
71
72
73 def config() -> Config:
74 """Returns current active config."""
75 return __config
76
77
78 def default_int():
79 return config().int
80
81
82 def default_float():
83 return config().float
84
85
86 def default_jitter():
87 return config().jitter
88
89
90 def default_positive_bijector():
91 return config().positive_bijector
92
93
94 def default_positive_minimum():
95 return config().positive_minimum
96
97
98 def default_summary_fmt():
99 return config().summary_fmt
100
101
102 def set_config(new_config: Config):
103 """Update GPflow config"""
104 global __config
105 __config = new_config
106
107
108 def set_default_int(value_type):
109 try:
110 tf_dtype = tf.as_dtype(value_type) # Test that it's a tensorflow-valid dtype
111 except TypeError:
112 raise TypeError(f"{value_type} is not a valid tf or np dtype")
113
114 if not tf_dtype.is_integer:
115 raise TypeError(f"{value_type} is not an integer dtype")
116
117 set_config(replace(config(), int=value_type))
118
119
120 def set_default_float(value_type):
121 try:
122 tf_dtype = tf.as_dtype(value_type) # Test that it's a tensorflow-valid dtype
123 except TypeError:
124 raise TypeError(f"{value_type} is not a valid tf or np dtype")
125
126 if not tf_dtype.is_floating:
127 raise TypeError(f"{value_type} is not a float dtype")
128
129 set_config(replace(config(), float=value_type))
130
131
132 def set_default_jitter(value: float):
133 if not (isinstance(value, (tf.Tensor, np.ndarray)) and len(value.shape) == 0) and \
134 not isinstance(value, float):
135 raise TypeError("Expected float32 or float64 scalar value")
136
137 if value < 0:
138 raise ValueError("Jitter must be non-negative")
139
140 set_config(replace(config(), jitter=value))
141
142
143 def set_default_positive_bijector(value: str):
144 type_map = positive_bijector_type_map()
145 if isinstance(value, str):
146 value = value.lower()
147 if value not in type_map:
148 raise ValueError(f"`{value}` not in set of valid bijectors: {sorted(type_map)}")
149
150 set_config(replace(config(), positive_bijector=value))
151
152
153 def set_default_positive_minimum(value: float):
154 if not (isinstance(value, (tf.Tensor, np.ndarray)) and len(value.shape) == 0) and \
155 not isinstance(value, float):
156 raise TypeError("Expected float32 or float64 scalar value")
157
158 if value < 0:
159 raise ValueError("Value must be non-negative")
160
161 set_config(replace(config(), positive_minimum=value))
162
163
164 def set_default_summary_fmt(value: str):
165 formats = tabulate.tabulate_formats + ['notebook', None]
166 if value not in formats:
167 raise ValueError(f"Summary does not support '{value}' format")
168
169 set_config(replace(config(), summary_fmt=value))
170
171
172 def positive_bijector_type_map() -> Dict[str, type]:
173 return {
174 "exp": tfp.bijectors.Exp,
175 "softplus": tfp.bijectors.Softplus,
176 }
177
178
179 @contextlib.contextmanager
180 def as_context(temporary_config: Optional[Config] = None):
181 """Ensure that global configs defaults, with a context manager. Useful for testing."""
182 current_config = config()
183 temporary_config = replace(current_config) if temporary_config is None else temporary_config
184 try:
185 set_config(temporary_config)
186 yield
187 finally:
188 set_config(current_config)
189
190
191 # Set global config.
192 set_config(Config())
193
[end of gpflow/config/__config__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/gpflow/config/__config__.py b/gpflow/config/__config__.py
--- a/gpflow/config/__config__.py
+++ b/gpflow/config/__config__.py
@@ -114,7 +114,7 @@
if not tf_dtype.is_integer:
raise TypeError(f"{value_type} is not an integer dtype")
- set_config(replace(config(), int=value_type))
+ set_config(replace(config(), int=tf_dtype.as_numpy_dtype))
def set_default_float(value_type):
@@ -126,7 +126,7 @@
if not tf_dtype.is_floating:
raise TypeError(f"{value_type} is not a float dtype")
- set_config(replace(config(), float=value_type))
+ set_config(replace(config(), float=tf_dtype.as_numpy_dtype))
def set_default_jitter(value: float):
|
{"golden_diff": "diff --git a/gpflow/config/__config__.py b/gpflow/config/__config__.py\n--- a/gpflow/config/__config__.py\n+++ b/gpflow/config/__config__.py\n@@ -114,7 +114,7 @@\n if not tf_dtype.is_integer:\n raise TypeError(f\"{value_type} is not an integer dtype\")\n \n- set_config(replace(config(), int=value_type))\n+ set_config(replace(config(), int=tf_dtype.as_numpy_dtype))\n \n \n def set_default_float(value_type):\n@@ -126,7 +126,7 @@\n if not tf_dtype.is_floating:\n raise TypeError(f\"{value_type} is not a float dtype\")\n \n- set_config(replace(config(), float=value_type))\n+ set_config(replace(config(), float=tf_dtype.as_numpy_dtype))\n \n \n def set_default_jitter(value: float):\n", "issue": "GPflow2 set_default_float and set_default_int accept tf dtypes but that breaks code\nSome functions such as the Gauss-Hermite quadrature code call `numpy_array.astype(default_float())`, which fails if `default_float()` returns a *tensorflow* dtype such as `tf.float64` instead of `np.float64`. However, `gpflow.config.set_default_float()` explicitly allows both numpy and tensorflow dtypes as arguments.\n", "before_files": [{"content": "import contextlib\nimport enum\nimport os\nfrom dataclasses import dataclass, field, replace\nfrom typing import Dict, Optional, Union\n\nimport numpy as np\nimport tabulate\nimport tensorflow as tf\nimport tensorflow_probability as tfp\n\n\n__all__ = [\n \"Config\", \"as_context\", \"config\", \"set_config\",\n \"default_float\", \"set_default_float\",\n \"default_int\", \"set_default_int\",\n \"default_jitter\", \"set_default_jitter\",\n \"default_positive_bijector\", \"set_default_positive_bijector\",\n \"default_positive_minimum\", \"set_default_positive_minimum\",\n \"default_summary_fmt\", \"set_default_summary_fmt\",\n \"positive_bijector_type_map\"\n]\n\n\n__config = None\n\n\nclass _Values(enum.Enum):\n \"\"\"Setting's names collection with default values. The `name` method returns name\n of the environment variable. E.g. for `SUMMARY_FMT` field the environment variable\n will be `GPFLOW_SUMMARY_FMT`.\"\"\"\n INT = np.int32\n FLOAT = np.float64\n POSITIVE_BIJECTOR = \"softplus\"\n POSITIVE_MINIMUM = None\n SUMMARY_FMT = None\n JITTER = 1e-6\n\n @property\n def name(self):\n return f\"GPFLOW_{super().name}\"\n\n\ndef default(value: _Values):\n \"\"\"Checks if value is set in the environment.\"\"\"\n return os.getenv(value.name, default=value.value)\n\n\n@dataclass(frozen=True)\nclass Config:\n \"\"\"\n Immutable object for storing global GPflow settings\n\n Args:\n int: Integer data type, int32 or int64.\n float: Float data type, float32 or float64\n jitter: Jitter value. Mainly used for for making badly conditioned matrices more stable.\n Default value is `1e-6`.\n positive_bijector: Method for positive bijector, either \"softplus\" or \"exp\".\n Default is \"softplus\".\n positive_minimum: Lower level for the positive transformation.\n summary_fmt: Summary format for module printing.\n \"\"\"\n\n int: type = field(default_factory=lambda: default(_Values.INT))\n float: type = field(default_factory=lambda: default(_Values.FLOAT))\n jitter: float = field(default_factory=lambda: default(_Values.JITTER))\n positive_bijector: str = field(default_factory=lambda: default(_Values.POSITIVE_BIJECTOR))\n positive_minimum: float = field(default_factory=lambda: default(_Values.POSITIVE_MINIMUM))\n summary_fmt: str = field(default_factory=lambda: default(_Values.SUMMARY_FMT))\n\n\ndef config() -> Config:\n \"\"\"Returns current active config.\"\"\"\n return __config\n\n\ndef default_int():\n return config().int\n\n\ndef default_float():\n return config().float\n\n\ndef default_jitter():\n return config().jitter\n\n\ndef default_positive_bijector():\n return config().positive_bijector\n\n\ndef default_positive_minimum():\n return config().positive_minimum\n\n\ndef default_summary_fmt():\n return config().summary_fmt\n\n\ndef set_config(new_config: Config):\n \"\"\"Update GPflow config\"\"\"\n global __config\n __config = new_config\n\n\ndef set_default_int(value_type):\n try:\n tf_dtype = tf.as_dtype(value_type) # Test that it's a tensorflow-valid dtype\n except TypeError:\n raise TypeError(f\"{value_type} is not a valid tf or np dtype\")\n\n if not tf_dtype.is_integer:\n raise TypeError(f\"{value_type} is not an integer dtype\")\n\n set_config(replace(config(), int=value_type))\n\n\ndef set_default_float(value_type):\n try:\n tf_dtype = tf.as_dtype(value_type) # Test that it's a tensorflow-valid dtype\n except TypeError:\n raise TypeError(f\"{value_type} is not a valid tf or np dtype\")\n\n if not tf_dtype.is_floating:\n raise TypeError(f\"{value_type} is not a float dtype\")\n\n set_config(replace(config(), float=value_type))\n\n\ndef set_default_jitter(value: float):\n if not (isinstance(value, (tf.Tensor, np.ndarray)) and len(value.shape) == 0) and \\\n not isinstance(value, float):\n raise TypeError(\"Expected float32 or float64 scalar value\")\n\n if value < 0:\n raise ValueError(\"Jitter must be non-negative\")\n\n set_config(replace(config(), jitter=value))\n\n\ndef set_default_positive_bijector(value: str):\n type_map = positive_bijector_type_map()\n if isinstance(value, str):\n value = value.lower()\n if value not in type_map:\n raise ValueError(f\"`{value}` not in set of valid bijectors: {sorted(type_map)}\")\n\n set_config(replace(config(), positive_bijector=value))\n\n\ndef set_default_positive_minimum(value: float):\n if not (isinstance(value, (tf.Tensor, np.ndarray)) and len(value.shape) == 0) and \\\n not isinstance(value, float):\n raise TypeError(\"Expected float32 or float64 scalar value\")\n\n if value < 0:\n raise ValueError(\"Value must be non-negative\")\n\n set_config(replace(config(), positive_minimum=value))\n\n\ndef set_default_summary_fmt(value: str):\n formats = tabulate.tabulate_formats + ['notebook', None]\n if value not in formats:\n raise ValueError(f\"Summary does not support '{value}' format\")\n\n set_config(replace(config(), summary_fmt=value))\n\n\ndef positive_bijector_type_map() -> Dict[str, type]:\n return {\n \"exp\": tfp.bijectors.Exp,\n \"softplus\": tfp.bijectors.Softplus,\n }\n\n\[email protected]\ndef as_context(temporary_config: Optional[Config] = None):\n \"\"\"Ensure that global configs defaults, with a context manager. Useful for testing.\"\"\"\n current_config = config()\n temporary_config = replace(current_config) if temporary_config is None else temporary_config\n try:\n set_config(temporary_config)\n yield\n finally:\n set_config(current_config)\n\n\n# Set global config.\nset_config(Config())\n", "path": "gpflow/config/__config__.py"}]}
| 2,444 | 191 |
gh_patches_debug_11389
|
rasdani/github-patches
|
git_diff
|
microsoft__Qcodes-1316
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Unable to install qcodes after uninstalling it
Uninstalling and installing qcodes again (with `pip install -e .`) results in the following exception:
```
(qcodes3) C:\Users\Administrator>pip list -e
Package Version Location
------------------- ------- ------------------------------------------------------------
plottr 0.0.1 c:\users\administrator\onedrive\bf4\code\plottr
pytopo 0.0.1 c:\users\administrator\onedrive\bf4\code\pytopo
qcodes 0.1.11 c:\users\administrator\onedrive\bf4\code\qcodes
qdev-wrappers 0.1 c:\users\administrator\onedrive\bf4\code\qdev-wrappers
StationQ 0.1 c:\users\administrator\onedrive\bf4\code\stationq
v0-characterization 0.0.1 c:\users\administrator\onedrive\bf4\code\v0_characterization
You are using pip version 10.0.1, however version 18.1 is available.
You should consider upgrading via the 'python -m pip install --upgrade pip' command.
(qcodes3) C:\Users\Administrator>pip uninstall qcodes
Uninstalling qcodes-0.1.11:
Would remove:
c:\programdata\anaconda3\envs\qcodes3\lib\site-packages\qcodes.egg-link
Proceed (y/n)? y
Successfully uninstalled qcodes-0.1.11
You are using pip version 10.0.1, however version 18.1 is available.
You should consider upgrading via the 'python -m pip install --upgrade pip' command.
(qcodes3) C:\Users\Administrator>cd OneDrive\BF4\Code\Qcodes
(qcodes3) C:\Users\Administrator\OneDrive\BF4\Code\Qcodes>pip install -e .
Obtaining file:///C:/Users/Administrator/OneDrive/BF4/Code/Qcodes
Complete output from command python setup.py egg_info:
get_version: 0.1.11
running egg_info
writing qcodes.egg-info\PKG-INFO
writing dependency_links to qcodes.egg-info\dependency_links.txt
writing requirements to qcodes.egg-info\requires.txt
writing top-level names to qcodes.egg-info\top_level.txt
reading manifest file 'qcodes.egg-info\SOURCES.txt'
writing manifest file 'qcodes.egg-info\SOURCES.txt'
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "C:\Users\Administrator\OneDrive\BF4\Code\Qcodes\setup.py", line 109, in <module>
module = import_module(module_name)
File "C:\ProgramData\Anaconda3\envs\qcodes3\lib\importlib\__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 994, in _gcd_import
File "<frozen importlib._bootstrap>", line 971, in _find_and_load
File "<frozen importlib._bootstrap>", line 955, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 665, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 678, in exec_module
File "<frozen importlib._bootstrap>", line 219, in _call_with_frames_removed
File "C:\ProgramData\Anaconda3\envs\qcodes3\lib\site-packages\pyqtgraph\__init__.py", line 13, in <module>
from .Qt import QtGui
File "C:\ProgramData\Anaconda3\envs\qcodes3\lib\site-packages\pyqtgraph\Qt.py", line 44, in <module>
raise Exception("PyQtGraph requires one of PyQt4, PyQt5 or PySide; none of these packages could be imported.")
Exception: PyQtGraph requires one of PyQt4, PyQt5 or PySide; none of these packages could be imported.
*****
***** package matplotlib must be at least version 2.2.3.
***** Please upgrade it (pip install -U matplotlib or conda install matplotlib)
***** in order to use MatPlot
*****
----------------------------------------
Command "python setup.py egg_info" failed with error code 1 in C:\Users\Administrator\OneDrive\BF4\Code\Qcodes\
You are using pip version 10.0.1, however version 18.1 is available.
You should consider upgrading via the 'python -m pip install --upgrade pip' command.
```
</issue>
<code>
[start of setup.py]
1 from setuptools import setup, find_packages
2 from distutils.version import StrictVersion
3 from importlib import import_module
4 import re
5
6
7 def get_version(verbose=1):
8 """ Extract version information from source code """
9
10 try:
11 with open('qcodes/version.py', 'r') as f:
12 ln = f.readline()
13 # print(ln)
14 m = re.search('.* ''(.*)''', ln)
15 version = (m.group(1)).strip('\'')
16 except Exception as E:
17 print(E)
18 version = 'none'
19 if verbose:
20 print('get_version: %s' % version)
21 return version
22
23
24 def readme():
25 with open('README.rst') as f:
26 return f.read()
27
28
29 extras = {
30 'MatPlot': ('matplotlib', '2.2.3'),
31 'QtPlot': ('pyqtgraph', '0.10.0'),
32 'coverage tests': ('coverage', '4.0'),
33 'Slack': ('slacker', '0.9.42')
34 }
35 extras_require = {k: '>='.join(v) for k, v in extras.items()}
36
37 setup(name='qcodes',
38 version=get_version(),
39 use_2to3=False,
40
41 maintainer='Jens H Nielsen',
42 maintainer_email='[email protected]',
43 description='Python-based data acquisition framework developed by the '
44 'Copenhagen / Delft / Sydney / Microsoft quantum computing '
45 'consortium',
46 long_description=readme(),
47 url='https://github.com/QCoDeS/Qcodes',
48 classifiers=[
49 'Development Status :: 3 - Alpha',
50 'Intended Audience :: Science/Research',
51 'Programming Language :: Python :: 3 :: Only',
52 'Programming Language :: Python :: 3.6',
53 'Topic :: Scientific/Engineering'
54 ],
55 license='MIT',
56 # if we want to install without tests:
57 # packages=find_packages(exclude=["*.tests", "tests"]),
58 packages=find_packages(),
59 package_data={'qcodes': ['monitor/dist/*', 'monitor/dist/js/*',
60 'monitor/dist/css/*', 'config/*.json',
61 'instrument/sims/*.yaml',
62 'tests/dataset/fixtures/2018-01-17/*/*']},
63 install_requires=[
64 'numpy>=1.10',
65 'pyvisa>=1.9.1',
66 'h5py>=2.6',
67 'websockets>=3.2',
68 'jsonschema',
69 'pyzmq',
70 'wrapt'
71 ],
72
73 test_suite='qcodes.tests',
74 extras_require=extras_require,
75
76 # I think the only part of qcodes that would care about zip_safe
77 # is utils.helpers.reload_code; users of a zip-installed package
78 # shouldn't be needing to do this anyway, but we should test first.
79 zip_safe=False)
80
81 version_template = '''
82 *****
83 ***** package {0} must be at least version {1}.
84 ***** Please upgrade it (pip install -U {0} or conda install {0})
85 ***** in order to use {2}
86 *****
87 '''
88
89 missing_template = '''
90 *****
91 ***** package {0} not found
92 ***** Please install it (pip install {0} or conda install {0})
93 ***** in order to use {1}
94 *****
95 '''
96
97 valueerror_template = '''
98 *****
99 ***** package {0} version not understood
100 ***** Please make sure the installed version ({1})
101 ***** is compatible with the minimum required version ({2})
102 ***** in order to use {3}
103 *****
104 '''
105
106 # now test the versions of extras
107 for extra, (module_name, min_version) in extras.items():
108 try:
109 module = import_module(module_name)
110 if StrictVersion(module.__version__) < StrictVersion(min_version):
111 print(version_template.format(module_name, min_version, extra))
112 except ImportError:
113 print(missing_template.format(module_name, extra))
114 except ValueError:
115 print(valueerror_template.format(
116 module_name, module.__version__, min_version, extra))
117
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -103,6 +103,13 @@
*****
'''
+othererror_template = '''
+*****
+***** could not import package {0}. Please try importing it from
+***** the commandline to diagnose the issue.
+*****
+'''
+
# now test the versions of extras
for extra, (module_name, min_version) in extras.items():
try:
@@ -114,3 +121,5 @@
except ValueError:
print(valueerror_template.format(
module_name, module.__version__, min_version, extra))
+ except:
+ print(othererror_template.format(module_name))
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -103,6 +103,13 @@\n *****\n '''\n \n+othererror_template = '''\n+*****\n+***** could not import package {0}. Please try importing it from \n+***** the commandline to diagnose the issue.\n+*****\n+'''\n+\n # now test the versions of extras\n for extra, (module_name, min_version) in extras.items():\n try:\n@@ -114,3 +121,5 @@\n except ValueError:\n print(valueerror_template.format(\n module_name, module.__version__, min_version, extra))\n+ except:\n+ print(othererror_template.format(module_name))\n", "issue": "Unable to install qcodes after uninstalling it\nUninstalling and installing qcodes again (with `pip install -e .`) results in the following exception:\r\n\r\n```\r\n(qcodes3) C:\\Users\\Administrator>pip list -e\r\nPackage Version Location\r\n------------------- ------- ------------------------------------------------------------\r\nplottr 0.0.1 c:\\users\\administrator\\onedrive\\bf4\\code\\plottr\r\npytopo 0.0.1 c:\\users\\administrator\\onedrive\\bf4\\code\\pytopo\r\nqcodes 0.1.11 c:\\users\\administrator\\onedrive\\bf4\\code\\qcodes\r\nqdev-wrappers 0.1 c:\\users\\administrator\\onedrive\\bf4\\code\\qdev-wrappers\r\nStationQ 0.1 c:\\users\\administrator\\onedrive\\bf4\\code\\stationq\r\nv0-characterization 0.0.1 c:\\users\\administrator\\onedrive\\bf4\\code\\v0_characterization\r\nYou are using pip version 10.0.1, however version 18.1 is available.\r\nYou should consider upgrading via the 'python -m pip install --upgrade pip' command.\r\n\r\n(qcodes3) C:\\Users\\Administrator>pip uninstall qcodes\r\nUninstalling qcodes-0.1.11:\r\n Would remove:\r\n c:\\programdata\\anaconda3\\envs\\qcodes3\\lib\\site-packages\\qcodes.egg-link\r\nProceed (y/n)? y\r\n Successfully uninstalled qcodes-0.1.11\r\nYou are using pip version 10.0.1, however version 18.1 is available.\r\nYou should consider upgrading via the 'python -m pip install --upgrade pip' command.\r\n\r\n(qcodes3) C:\\Users\\Administrator>cd OneDrive\\BF4\\Code\\Qcodes\r\n\r\n(qcodes3) C:\\Users\\Administrator\\OneDrive\\BF4\\Code\\Qcodes>pip install -e .\r\nObtaining file:///C:/Users/Administrator/OneDrive/BF4/Code/Qcodes\r\n Complete output from command python setup.py egg_info:\r\n get_version: 0.1.11\r\n running egg_info\r\n writing qcodes.egg-info\\PKG-INFO\r\n writing dependency_links to qcodes.egg-info\\dependency_links.txt\r\n writing requirements to qcodes.egg-info\\requires.txt\r\n writing top-level names to qcodes.egg-info\\top_level.txt\r\n reading manifest file 'qcodes.egg-info\\SOURCES.txt'\r\n writing manifest file 'qcodes.egg-info\\SOURCES.txt'\r\n Traceback (most recent call last):\r\n File \"<string>\", line 1, in <module>\r\n File \"C:\\Users\\Administrator\\OneDrive\\BF4\\Code\\Qcodes\\setup.py\", line 109, in <module>\r\n module = import_module(module_name)\r\n File \"C:\\ProgramData\\Anaconda3\\envs\\qcodes3\\lib\\importlib\\__init__.py\", line 126, in import_module\r\n return _bootstrap._gcd_import(name[level:], package, level)\r\n File \"<frozen importlib._bootstrap>\", line 994, in _gcd_import\r\n File \"<frozen importlib._bootstrap>\", line 971, in _find_and_load\r\n File \"<frozen importlib._bootstrap>\", line 955, in _find_and_load_unlocked\r\n File \"<frozen importlib._bootstrap>\", line 665, in _load_unlocked\r\n File \"<frozen importlib._bootstrap_external>\", line 678, in exec_module\r\n File \"<frozen importlib._bootstrap>\", line 219, in _call_with_frames_removed\r\n File \"C:\\ProgramData\\Anaconda3\\envs\\qcodes3\\lib\\site-packages\\pyqtgraph\\__init__.py\", line 13, in <module>\r\n from .Qt import QtGui\r\n File \"C:\\ProgramData\\Anaconda3\\envs\\qcodes3\\lib\\site-packages\\pyqtgraph\\Qt.py\", line 44, in <module>\r\n raise Exception(\"PyQtGraph requires one of PyQt4, PyQt5 or PySide; none of these packages could be imported.\")\r\n Exception: PyQtGraph requires one of PyQt4, PyQt5 or PySide; none of these packages could be imported.\r\n\r\n *****\r\n ***** package matplotlib must be at least version 2.2.3.\r\n ***** Please upgrade it (pip install -U matplotlib or conda install matplotlib)\r\n ***** in order to use MatPlot\r\n *****\r\n\r\n\r\n ----------------------------------------\r\nCommand \"python setup.py egg_info\" failed with error code 1 in C:\\Users\\Administrator\\OneDrive\\BF4\\Code\\Qcodes\\\r\nYou are using pip version 10.0.1, however version 18.1 is available.\r\nYou should consider upgrading via the 'python -m pip install --upgrade pip' command.\r\n\r\n```\r\n\n", "before_files": [{"content": "from setuptools import setup, find_packages\nfrom distutils.version import StrictVersion\nfrom importlib import import_module\nimport re\n\n\ndef get_version(verbose=1):\n \"\"\" Extract version information from source code \"\"\"\n\n try:\n with open('qcodes/version.py', 'r') as f:\n ln = f.readline()\n # print(ln)\n m = re.search('.* ''(.*)''', ln)\n version = (m.group(1)).strip('\\'')\n except Exception as E:\n print(E)\n version = 'none'\n if verbose:\n print('get_version: %s' % version)\n return version\n\n\ndef readme():\n with open('README.rst') as f:\n return f.read()\n\n\nextras = {\n 'MatPlot': ('matplotlib', '2.2.3'),\n 'QtPlot': ('pyqtgraph', '0.10.0'),\n 'coverage tests': ('coverage', '4.0'),\n 'Slack': ('slacker', '0.9.42')\n}\nextras_require = {k: '>='.join(v) for k, v in extras.items()}\n\nsetup(name='qcodes',\n version=get_version(),\n use_2to3=False,\n\n maintainer='Jens H Nielsen',\n maintainer_email='[email protected]',\n description='Python-based data acquisition framework developed by the '\n 'Copenhagen / Delft / Sydney / Microsoft quantum computing '\n 'consortium',\n long_description=readme(),\n url='https://github.com/QCoDeS/Qcodes',\n classifiers=[\n 'Development Status :: 3 - Alpha',\n 'Intended Audience :: Science/Research',\n 'Programming Language :: Python :: 3 :: Only',\n 'Programming Language :: Python :: 3.6',\n 'Topic :: Scientific/Engineering'\n ],\n license='MIT',\n # if we want to install without tests:\n # packages=find_packages(exclude=[\"*.tests\", \"tests\"]),\n packages=find_packages(),\n package_data={'qcodes': ['monitor/dist/*', 'monitor/dist/js/*',\n 'monitor/dist/css/*', 'config/*.json',\n 'instrument/sims/*.yaml',\n 'tests/dataset/fixtures/2018-01-17/*/*']},\n install_requires=[\n 'numpy>=1.10',\n 'pyvisa>=1.9.1',\n 'h5py>=2.6',\n 'websockets>=3.2',\n 'jsonschema',\n 'pyzmq',\n 'wrapt'\n ],\n\n test_suite='qcodes.tests',\n extras_require=extras_require,\n\n # I think the only part of qcodes that would care about zip_safe\n # is utils.helpers.reload_code; users of a zip-installed package\n # shouldn't be needing to do this anyway, but we should test first.\n zip_safe=False)\n\nversion_template = '''\n*****\n***** package {0} must be at least version {1}.\n***** Please upgrade it (pip install -U {0} or conda install {0})\n***** in order to use {2}\n*****\n'''\n\nmissing_template = '''\n*****\n***** package {0} not found\n***** Please install it (pip install {0} or conda install {0})\n***** in order to use {1}\n*****\n'''\n\nvalueerror_template = '''\n*****\n***** package {0} version not understood\n***** Please make sure the installed version ({1})\n***** is compatible with the minimum required version ({2})\n***** in order to use {3}\n*****\n'''\n\n# now test the versions of extras\nfor extra, (module_name, min_version) in extras.items():\n try:\n module = import_module(module_name)\n if StrictVersion(module.__version__) < StrictVersion(min_version):\n print(version_template.format(module_name, min_version, extra))\n except ImportError:\n print(missing_template.format(module_name, extra))\n except ValueError:\n print(valueerror_template.format(\n module_name, module.__version__, min_version, extra))\n", "path": "setup.py"}]}
| 2,730 | 154 |
gh_patches_debug_17374
|
rasdani/github-patches
|
git_diff
|
psf__black-2793
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Should we switch our Sphinx HTML theme away from Alabaster?
As far as I know, Black has stuck with the same old theme from day one. I'll admit it's nice and fits in nicely with the more rustic / old vibe the all of the branding has (eg. Ford-like logo, name based off quote that's quite old). Unfortunately there's a few hard-to-workaround issues:
- Phones or really any devices with small screens are not supported at all
- Due to limitations (ie. no scrolling support in the sidebar), there's custom CSS, see [`/docs/_static/custom.css`](https://github.com/psf/black/blob/main/docs/_static/custom.css) - now I'm no web dev and I'm not sure if anyone else on the maintainer team is ... so if anything goes wrong we could easily become screwed
Also in general the theme is less friendly towards certain structural layouts (the TOCs are quite limiting - makes content hard to navigate if you aren't careful). It's not a big deal now and hopefully ever (redesigns are tiring and cause a lot of churn) but at least having the option is nice. Oh and not to mention that Alabaster [seems to be lacking attention](https://github.com/bitprophet/alabaster/commits/master).
The main alternatives I know of are [Furo](https://pradyunsg.me/furo/) and [ReadTheDocs](https://sphinx-rtd-theme.readthedocs.io/en/stable/).
But this is a big noticeable change and does touch the concept of project branding which I've tried to avoid as much as possible since I've joined (never felt like I held enough authority to bring it up). Hopefully the discussion is worthwhile even if the answer is _"no, we aren't changing it"_ :)
edit: I'll provide previews for the two alternatives I mentioned, sadly I just thought of this idea after posting this so gimme a moment
</issue>
<code>
[start of docs/conf.py]
1 # -*- coding: utf-8 -*-
2 #
3 # Configuration file for the Sphinx documentation builder.
4 #
5 # This file does only contain a selection of the most common options. For a
6 # full list see the documentation:
7 # http://www.sphinx-doc.org/en/stable/config
8
9 # -- Path setup --------------------------------------------------------------
10
11 # If extensions (or modules to document with autodoc) are in another directory,
12 # add these directories to sys.path here. If the directory is relative to the
13 # documentation root, use os.path.abspath to make it absolute, like shown here.
14 #
15
16 import os
17 import string
18 from pathlib import Path
19
20 from pkg_resources import get_distribution
21
22 CURRENT_DIR = Path(__file__).parent
23
24
25 def make_pypi_svg(version: str) -> None:
26 template: Path = CURRENT_DIR / "_static" / "pypi_template.svg"
27 target: Path = CURRENT_DIR / "_static" / "pypi.svg"
28 with open(str(template), "r", encoding="utf8") as f:
29 svg: str = string.Template(f.read()).substitute(version=version)
30 with open(str(target), "w", encoding="utf8") as f:
31 f.write(svg)
32
33
34 # Necessary so Click doesn't hit an encode error when called by
35 # sphinxcontrib-programoutput on Windows.
36 os.putenv("pythonioencoding", "utf-8")
37
38 # -- Project information -----------------------------------------------------
39
40 project = "Black"
41 copyright = "2018-Present, Łukasz Langa and contributors to Black"
42 author = "Łukasz Langa and contributors to Black"
43
44 # Autopopulate version
45 # The version, including alpha/beta/rc tags, but not commit hash and datestamps
46 release = get_distribution("black").version.split("+")[0]
47 # The short X.Y version.
48 version = release
49 for sp in "abcfr":
50 version = version.split(sp)[0]
51
52 make_pypi_svg(release)
53
54
55 # -- General configuration ---------------------------------------------------
56
57 # If your documentation needs a minimal Sphinx version, state it here.
58 needs_sphinx = "3.0"
59
60 # Add any Sphinx extension module names here, as strings. They can be
61 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
62 # ones.
63 extensions = [
64 "sphinx.ext.autodoc",
65 "sphinx.ext.intersphinx",
66 "sphinx.ext.napoleon",
67 "myst_parser",
68 "sphinxcontrib.programoutput",
69 "sphinx_copybutton",
70 ]
71
72 # If you need extensions of a certain version or higher, list them here.
73 needs_extensions = {"myst_parser": "0.13.7"}
74
75 # Add any paths that contain templates here, relative to this directory.
76 templates_path = ["_templates"]
77
78 # The suffix(es) of source filenames.
79 # You can specify multiple suffix as a list of string:
80 source_suffix = [".rst", ".md"]
81
82 # The master toctree document.
83 master_doc = "index"
84
85 # The language for content autogenerated by Sphinx. Refer to documentation
86 # for a list of supported languages.
87 #
88 # This is also used if you do content translation via gettext catalogs.
89 # Usually you set "language" from the command line for these cases.
90 language = None
91
92 # List of patterns, relative to source directory, that match files and
93 # directories to ignore when looking for source files.
94 # This pattern also affects html_static_path and html_extra_path .
95
96 exclude_patterns = ["_build", "Thumbs.db", ".DS_Store"]
97
98 # The name of the Pygments (syntax highlighting) style to use.
99 pygments_style = "sphinx"
100
101 # We need headers to be linkable to so ask MyST-Parser to autogenerate anchor IDs for
102 # headers up to and including level 3.
103 myst_heading_anchors = 3
104
105 # Prettier support formatting some MyST syntax but not all, so let's disable the
106 # unsupported yet still enabled by default ones.
107 myst_disable_syntax = [
108 "myst_block_break",
109 "myst_line_comment",
110 "math_block",
111 ]
112
113 # -- Options for HTML output -------------------------------------------------
114
115 # The theme to use for HTML and HTML Help pages. See the documentation for
116 # a list of builtin themes.
117 #
118 html_theme = "alabaster"
119
120 html_sidebars = {
121 "**": [
122 "about.html",
123 "navigation.html",
124 "relations.html",
125 "searchbox.html",
126 ]
127 }
128
129 html_theme_options = {
130 "show_related": False,
131 "description": "“Any color you like.”",
132 "github_button": True,
133 "github_user": "psf",
134 "github_repo": "black",
135 "github_type": "star",
136 "show_powered_by": True,
137 "fixed_sidebar": True,
138 "logo": "logo2.png",
139 }
140
141
142 # Add any paths that contain custom static files (such as style sheets) here,
143 # relative to this directory. They are copied after the builtin static files,
144 # so a file named "default.css" will overwrite the builtin "default.css".
145 html_static_path = ["_static"]
146
147 # Custom sidebar templates, must be a dictionary that maps document names
148 # to template names.
149 #
150 # The default sidebars (for documents that don't match any pattern) are
151 # defined by theme itself. Builtin themes are using these templates by
152 # default: ``['localtoc.html', 'relations.html', 'sourcelink.html',
153 # 'searchbox.html']``.
154 #
155 # html_sidebars = {}
156
157
158 # -- Options for HTMLHelp output ---------------------------------------------
159
160 # Output file base name for HTML help builder.
161 htmlhelp_basename = "blackdoc"
162
163
164 # -- Options for LaTeX output ------------------------------------------------
165
166 # Grouping the document tree into LaTeX files. List of tuples
167 # (source start file, target name, title,
168 # author, documentclass [howto, manual, or own class]).
169 latex_documents = [
170 (
171 master_doc,
172 "black.tex",
173 "Documentation for Black",
174 "Łukasz Langa and contributors to Black",
175 "manual",
176 )
177 ]
178
179
180 # -- Options for manual page output ------------------------------------------
181
182 # One entry per manual page. List of tuples
183 # (source start file, name, description, authors, manual section).
184 man_pages = [(master_doc, "black", "Documentation for Black", [author], 1)]
185
186
187 # -- Options for Texinfo output ----------------------------------------------
188
189 # Grouping the document tree into Texinfo files. List of tuples
190 # (source start file, target name, title, author,
191 # dir menu entry, description, category)
192 texinfo_documents = [
193 (
194 master_doc,
195 "Black",
196 "Documentation for Black",
197 author,
198 "Black",
199 "The uncompromising Python code formatter",
200 "Miscellaneous",
201 )
202 ]
203
204
205 # -- Options for Epub output -------------------------------------------------
206
207 # Bibliographic Dublin Core info.
208 epub_title = project
209 epub_author = author
210 epub_publisher = author
211 epub_copyright = copyright
212
213 # The unique identifier of the text. This can be a ISBN number
214 # or the project homepage.
215 #
216 # epub_identifier = ''
217
218 # A unique identification for the text.
219 #
220 # epub_uid = ''
221
222 # A list of files that should not be packed into the epub file.
223 epub_exclude_files = ["search.html"]
224
225
226 # -- Extension configuration -------------------------------------------------
227
228 autodoc_member_order = "bysource"
229
230 # -- Options for intersphinx extension ---------------------------------------
231
232 # Example configuration for intersphinx: refer to the Python standard library.
233 intersphinx_mapping = {"https://docs.python.org/3/": None}
234
[end of docs/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -115,29 +115,8 @@
# The theme to use for HTML and HTML Help pages. See the documentation for
# a list of builtin themes.
#
-html_theme = "alabaster"
-
-html_sidebars = {
- "**": [
- "about.html",
- "navigation.html",
- "relations.html",
- "searchbox.html",
- ]
-}
-
-html_theme_options = {
- "show_related": False,
- "description": "“Any color you like.”",
- "github_button": True,
- "github_user": "psf",
- "github_repo": "black",
- "github_type": "star",
- "show_powered_by": True,
- "fixed_sidebar": True,
- "logo": "logo2.png",
-}
-
+html_theme = "furo"
+html_logo = "_static/logo2-readme.png"
# Add any paths that contain custom static files (such as style sheets) here,
# relative to this directory. They are copied after the builtin static files,
|
{"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -115,29 +115,8 @@\n # The theme to use for HTML and HTML Help pages. See the documentation for\n # a list of builtin themes.\n #\n-html_theme = \"alabaster\"\n-\n-html_sidebars = {\n- \"**\": [\n- \"about.html\",\n- \"navigation.html\",\n- \"relations.html\",\n- \"searchbox.html\",\n- ]\n-}\n-\n-html_theme_options = {\n- \"show_related\": False,\n- \"description\": \"\u201cAny color you like.\u201d\",\n- \"github_button\": True,\n- \"github_user\": \"psf\",\n- \"github_repo\": \"black\",\n- \"github_type\": \"star\",\n- \"show_powered_by\": True,\n- \"fixed_sidebar\": True,\n- \"logo\": \"logo2.png\",\n-}\n-\n+html_theme = \"furo\"\n+html_logo = \"_static/logo2-readme.png\"\n \n # Add any paths that contain custom static files (such as style sheets) here,\n # relative to this directory. They are copied after the builtin static files,\n", "issue": "Should we switch our Sphinx HTML theme away from Alabaster?\nAs far as I know, Black has stuck with the same old theme from day one. I'll admit it's nice and fits in nicely with the more rustic / old vibe the all of the branding has (eg. Ford-like logo, name based off quote that's quite old). Unfortunately there's a few hard-to-workaround issues:\r\n\r\n- Phones or really any devices with small screens are not supported at all\r\n- Due to limitations (ie. no scrolling support in the sidebar), there's custom CSS, see [`/docs/_static/custom.css`](https://github.com/psf/black/blob/main/docs/_static/custom.css) - now I'm no web dev and I'm not sure if anyone else on the maintainer team is ... so if anything goes wrong we could easily become screwed\r\n\r\nAlso in general the theme is less friendly towards certain structural layouts (the TOCs are quite limiting - makes content hard to navigate if you aren't careful). It's not a big deal now and hopefully ever (redesigns are tiring and cause a lot of churn) but at least having the option is nice. Oh and not to mention that Alabaster [seems to be lacking attention](https://github.com/bitprophet/alabaster/commits/master).\r\n\r\nThe main alternatives I know of are [Furo](https://pradyunsg.me/furo/) and [ReadTheDocs](https://sphinx-rtd-theme.readthedocs.io/en/stable/).\r\n\r\nBut this is a big noticeable change and does touch the concept of project branding which I've tried to avoid as much as possible since I've joined (never felt like I held enough authority to bring it up). Hopefully the discussion is worthwhile even if the answer is _\"no, we aren't changing it\"_ :)\r\n\r\nedit: I'll provide previews for the two alternatives I mentioned, sadly I just thought of this idea after posting this so gimme a moment\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Configuration file for the Sphinx documentation builder.\n#\n# This file does only contain a selection of the most common options. For a\n# full list see the documentation:\n# http://www.sphinx-doc.org/en/stable/config\n\n# -- Path setup --------------------------------------------------------------\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\n\nimport os\nimport string\nfrom pathlib import Path\n\nfrom pkg_resources import get_distribution\n\nCURRENT_DIR = Path(__file__).parent\n\n\ndef make_pypi_svg(version: str) -> None:\n template: Path = CURRENT_DIR / \"_static\" / \"pypi_template.svg\"\n target: Path = CURRENT_DIR / \"_static\" / \"pypi.svg\"\n with open(str(template), \"r\", encoding=\"utf8\") as f:\n svg: str = string.Template(f.read()).substitute(version=version)\n with open(str(target), \"w\", encoding=\"utf8\") as f:\n f.write(svg)\n\n\n# Necessary so Click doesn't hit an encode error when called by\n# sphinxcontrib-programoutput on Windows.\nos.putenv(\"pythonioencoding\", \"utf-8\")\n\n# -- Project information -----------------------------------------------------\n\nproject = \"Black\"\ncopyright = \"2018-Present, \u0141ukasz Langa and contributors to Black\"\nauthor = \"\u0141ukasz Langa and contributors to Black\"\n\n# Autopopulate version\n# The version, including alpha/beta/rc tags, but not commit hash and datestamps\nrelease = get_distribution(\"black\").version.split(\"+\")[0]\n# The short X.Y version.\nversion = release\nfor sp in \"abcfr\":\n version = version.split(sp)[0]\n\nmake_pypi_svg(release)\n\n\n# -- General configuration ---------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\nneeds_sphinx = \"3.0\"\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n \"sphinx.ext.autodoc\",\n \"sphinx.ext.intersphinx\",\n \"sphinx.ext.napoleon\",\n \"myst_parser\",\n \"sphinxcontrib.programoutput\",\n \"sphinx_copybutton\",\n]\n\n# If you need extensions of a certain version or higher, list them here.\nneeds_extensions = {\"myst_parser\": \"0.13.7\"}\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = [\"_templates\"]\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\nsource_suffix = [\".rst\", \".md\"]\n\n# The master toctree document.\nmaster_doc = \"index\"\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = None\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path .\n\nexclude_patterns = [\"_build\", \"Thumbs.db\", \".DS_Store\"]\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = \"sphinx\"\n\n# We need headers to be linkable to so ask MyST-Parser to autogenerate anchor IDs for\n# headers up to and including level 3.\nmyst_heading_anchors = 3\n\n# Prettier support formatting some MyST syntax but not all, so let's disable the\n# unsupported yet still enabled by default ones.\nmyst_disable_syntax = [\n \"myst_block_break\",\n \"myst_line_comment\",\n \"math_block\",\n]\n\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\nhtml_theme = \"alabaster\"\n\nhtml_sidebars = {\n \"**\": [\n \"about.html\",\n \"navigation.html\",\n \"relations.html\",\n \"searchbox.html\",\n ]\n}\n\nhtml_theme_options = {\n \"show_related\": False,\n \"description\": \"\u201cAny color you like.\u201d\",\n \"github_button\": True,\n \"github_user\": \"psf\",\n \"github_repo\": \"black\",\n \"github_type\": \"star\",\n \"show_powered_by\": True,\n \"fixed_sidebar\": True,\n \"logo\": \"logo2.png\",\n}\n\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = [\"_static\"]\n\n# Custom sidebar templates, must be a dictionary that maps document names\n# to template names.\n#\n# The default sidebars (for documents that don't match any pattern) are\n# defined by theme itself. Builtin themes are using these templates by\n# default: ``['localtoc.html', 'relations.html', 'sourcelink.html',\n# 'searchbox.html']``.\n#\n# html_sidebars = {}\n\n\n# -- Options for HTMLHelp output ---------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = \"blackdoc\"\n\n\n# -- Options for LaTeX output ------------------------------------------------\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (\n master_doc,\n \"black.tex\",\n \"Documentation for Black\",\n \"\u0141ukasz Langa and contributors to Black\",\n \"manual\",\n )\n]\n\n\n# -- Options for manual page output ------------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [(master_doc, \"black\", \"Documentation for Black\", [author], 1)]\n\n\n# -- Options for Texinfo output ----------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (\n master_doc,\n \"Black\",\n \"Documentation for Black\",\n author,\n \"Black\",\n \"The uncompromising Python code formatter\",\n \"Miscellaneous\",\n )\n]\n\n\n# -- Options for Epub output -------------------------------------------------\n\n# Bibliographic Dublin Core info.\nepub_title = project\nepub_author = author\nepub_publisher = author\nepub_copyright = copyright\n\n# The unique identifier of the text. This can be a ISBN number\n# or the project homepage.\n#\n# epub_identifier = ''\n\n# A unique identification for the text.\n#\n# epub_uid = ''\n\n# A list of files that should not be packed into the epub file.\nepub_exclude_files = [\"search.html\"]\n\n\n# -- Extension configuration -------------------------------------------------\n\nautodoc_member_order = \"bysource\"\n\n# -- Options for intersphinx extension ---------------------------------------\n\n# Example configuration for intersphinx: refer to the Python standard library.\nintersphinx_mapping = {\"https://docs.python.org/3/\": None}\n", "path": "docs/conf.py"}]}
| 3,153 | 261 |
gh_patches_debug_60755
|
rasdani/github-patches
|
git_diff
|
MTES-MCT__aides-territoires-174
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Mauvais article et mauvaise casse pour message d'erreur sur adresse mail
Sur la page `/comptes/connexion/`, on voit :
```
Saisissez un Adresse e-mail…
```
Alors que l'on devrait avoir :
```
Saisissez une adresse e-mail…
```

La base du message d'erreur vient des [fichiers de traduction de Django](https://github.com/django/django/blob/6376278a904e2f8b34893a7166508dfd205fdceb/django/contrib/auth/locale/fr/LC_MESSAGES/django.po) :
```py
msgid ""
"Please enter a correct %(username)s and password. Note that both fields may "
"be case-sensitive."
msgstr ""
"Saisissez un %(username)s et un mot de passe valides. Remarquez que chacun "
"de ces champs est sensible à la casse (différenciation des majuscules/"
"minuscules)."
```
Et à la place du placeholder `%(username)s`, on a `Adresse e-mail` dans ce projet.
Dans le fichier de traduction (`django.po`) du projet actuel, on voit :
```py
msgid "Email address"
msgstr "Adresse e-mail"
```
</issue>
<code>
[start of src/accounts/forms.py]
1 from django import forms
2 from django.utils.translation import ugettext_lazy as _
3 from django.contrib.auth.forms import AuthenticationForm
4 from django.contrib.auth import password_validation
5
6 from accounts.models import User
7
8
9 class RegisterForm(forms.ModelForm):
10 """Form used to create new user accounts."""
11
12 email = forms.EmailField(
13 label=_('Your email address'),
14 required=True,
15 help_text=_('We will send a confirmation link to '
16 'this address before creating the account.'))
17 full_name = forms.CharField(
18 label=_('Your full name'),
19 required=True,
20 help_text=_('This is how we will address you in our communications.'))
21 ml_consent = forms.BooleanField(
22 label=_('I want to receive news and communications from the service.'),
23 required=False,
24 help_text=_('You will be able to unsubscribe at any time.'))
25
26 class Meta:
27 model = User
28 fields = ['full_name', 'email', 'ml_consent']
29
30 def __init__(self, *args, **kwargs):
31 super().__init__(*args, **kwargs)
32 self.fields['full_name'].widget.attrs.update({'autofocus': True})
33 self.fields['email'].widget.attrs.update({
34 'placeholder': _('Please double-check this value.')})
35
36 def clean_email(self):
37 email = self.cleaned_data['email']
38 return email.lower()
39
40
41 class LoginForm(AuthenticationForm):
42 username = forms.EmailField(
43 label=_('Your email address'),
44 required=True)
45 password = forms.CharField(
46 label=_('Your password'),
47 required=True,
48 strip=False,
49 widget=forms.PasswordInput)
50
51 def clean_username(self):
52 """Don't prevent users to login when they user uppercase emails."""
53
54 username = self.cleaned_data['username']
55 return username.lower()
56
57
58 class PasswordResetForm(forms.Form):
59 """Password reset request form."""
60
61 username = forms.EmailField(
62 label=_('Your email address'),
63 required=True)
64
65
66 class ProfileForm(forms.ModelForm):
67 """Edit profile related user data."""
68
69 new_password = forms.CharField(
70 label=_('Choose a new password'),
71 required=False,
72 strip=False,
73 help_text=password_validation.password_validators_help_text_html(),
74 widget=forms.PasswordInput(attrs={
75 'placeholder': _('Leave empty to keep your existing password')
76 }))
77
78 class Meta:
79 model = User
80 fields = ['full_name', 'new_password', 'ml_consent']
81 labels = {
82 'full_name': _('Your full name'),
83 'ml_consent':
84 _('Yes, I want to receive news about the service.'),
85 }
86 help_texts = {
87 'full_name':
88 _('This is how we will address you in our ' 'communications.'),
89 'ml_consent':
90 _('We will send regular updates (no more than once a month) '
91 'about the new features and updates about our service.'),
92 }
93
94 def _post_clean(self):
95 super()._post_clean()
96 # Validate the password after self.instance is updated with form data
97 # by super().
98 password = self.cleaned_data.get('new_password')
99 if password:
100 try:
101 password_validation.validate_password(password, self.instance)
102 except forms.ValidationError as error:
103 self.add_error('new_password', error)
104
105 def save(self, commit=True):
106 user = super().save(commit=False)
107
108 new_password = self.cleaned_data['new_password']
109 if new_password:
110 user.set_password(new_password)
111
112 if commit:
113 user.save()
114 return user
115
116
117 class ContributorProfileForm(forms.ModelForm):
118 """Edit contributor profile related user data."""
119
120 class Meta:
121 model = User
122 fields = ['organization', 'role', 'contact_phone']
123 labels = {
124 'organization': _('Your organization'),
125 'role': _('Your position'),
126 }
127
[end of src/accounts/forms.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/accounts/forms.py b/src/accounts/forms.py
--- a/src/accounts/forms.py
+++ b/src/accounts/forms.py
@@ -39,6 +39,13 @@
class LoginForm(AuthenticationForm):
+ error_messages = {
+ 'invalid_login': _(
+ 'Please enter a correct email address and password.'
+ ),
+ 'inactive': _('This account is inactive.'),
+ }
+
username = forms.EmailField(
label=_('Your email address'),
required=True)
|
{"golden_diff": "diff --git a/src/accounts/forms.py b/src/accounts/forms.py\n--- a/src/accounts/forms.py\n+++ b/src/accounts/forms.py\n@@ -39,6 +39,13 @@\n \n \n class LoginForm(AuthenticationForm):\n+ error_messages = {\n+ 'invalid_login': _(\n+ 'Please enter a correct email address and password.'\n+ ),\n+ 'inactive': _('This account is inactive.'),\n+ }\n+\n username = forms.EmailField(\n label=_('Your email address'),\n required=True)\n", "issue": "Mauvais article et mauvaise casse pour message d'erreur sur adresse mail\nSur la page `/comptes/connexion/`, on voit : \r\n\r\n```\r\nSaisissez un Adresse e-mail\u2026\r\n```\r\n\r\nAlors que l'on devrait avoir : \r\n\r\n```\r\nSaisissez une adresse e-mail\u2026\r\n```\r\n\r\n\r\n\r\nLa base du message d'erreur vient des [fichiers de traduction de Django](https://github.com/django/django/blob/6376278a904e2f8b34893a7166508dfd205fdceb/django/contrib/auth/locale/fr/LC_MESSAGES/django.po) : \r\n\r\n```py\r\nmsgid \"\"\r\n\"Please enter a correct %(username)s and password. Note that both fields may \"\r\n\"be case-sensitive.\"\r\nmsgstr \"\"\r\n\"Saisissez un %(username)s et un mot de passe valides. Remarquez que chacun \"\r\n\"de ces champs est sensible \u00e0 la casse (diff\u00e9renciation des majuscules/\"\r\n\"minuscules).\"\r\n```\r\n\r\nEt \u00e0 la place du placeholder `%(username)s`, on a `Adresse e-mail` dans ce projet.\r\n\r\nDans le fichier de traduction (`django.po`) du projet actuel, on voit : \r\n\r\n```py\r\nmsgid \"Email address\"\r\nmsgstr \"Adresse e-mail\"\r\n```\n", "before_files": [{"content": "from django import forms\nfrom django.utils.translation import ugettext_lazy as _\nfrom django.contrib.auth.forms import AuthenticationForm\nfrom django.contrib.auth import password_validation\n\nfrom accounts.models import User\n\n\nclass RegisterForm(forms.ModelForm):\n \"\"\"Form used to create new user accounts.\"\"\"\n\n email = forms.EmailField(\n label=_('Your email address'),\n required=True,\n help_text=_('We will send a confirmation link to '\n 'this address before creating the account.'))\n full_name = forms.CharField(\n label=_('Your full name'),\n required=True,\n help_text=_('This is how we will address you in our communications.'))\n ml_consent = forms.BooleanField(\n label=_('I want to receive news and communications from the service.'),\n required=False,\n help_text=_('You will be able to unsubscribe at any time.'))\n\n class Meta:\n model = User\n fields = ['full_name', 'email', 'ml_consent']\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.fields['full_name'].widget.attrs.update({'autofocus': True})\n self.fields['email'].widget.attrs.update({\n 'placeholder': _('Please double-check this value.')})\n\n def clean_email(self):\n email = self.cleaned_data['email']\n return email.lower()\n\n\nclass LoginForm(AuthenticationForm):\n username = forms.EmailField(\n label=_('Your email address'),\n required=True)\n password = forms.CharField(\n label=_('Your password'),\n required=True,\n strip=False,\n widget=forms.PasswordInput)\n\n def clean_username(self):\n \"\"\"Don't prevent users to login when they user uppercase emails.\"\"\"\n\n username = self.cleaned_data['username']\n return username.lower()\n\n\nclass PasswordResetForm(forms.Form):\n \"\"\"Password reset request form.\"\"\"\n\n username = forms.EmailField(\n label=_('Your email address'),\n required=True)\n\n\nclass ProfileForm(forms.ModelForm):\n \"\"\"Edit profile related user data.\"\"\"\n\n new_password = forms.CharField(\n label=_('Choose a new password'),\n required=False,\n strip=False,\n help_text=password_validation.password_validators_help_text_html(),\n widget=forms.PasswordInput(attrs={\n 'placeholder': _('Leave empty to keep your existing password')\n }))\n\n class Meta:\n model = User\n fields = ['full_name', 'new_password', 'ml_consent']\n labels = {\n 'full_name': _('Your full name'),\n 'ml_consent':\n _('Yes, I want to receive news about the service.'),\n }\n help_texts = {\n 'full_name':\n _('This is how we will address you in our ' 'communications.'),\n 'ml_consent':\n _('We will send regular updates (no more than once a month) '\n 'about the new features and updates about our service.'),\n }\n\n def _post_clean(self):\n super()._post_clean()\n # Validate the password after self.instance is updated with form data\n # by super().\n password = self.cleaned_data.get('new_password')\n if password:\n try:\n password_validation.validate_password(password, self.instance)\n except forms.ValidationError as error:\n self.add_error('new_password', error)\n\n def save(self, commit=True):\n user = super().save(commit=False)\n\n new_password = self.cleaned_data['new_password']\n if new_password:\n user.set_password(new_password)\n\n if commit:\n user.save()\n return user\n\n\nclass ContributorProfileForm(forms.ModelForm):\n \"\"\"Edit contributor profile related user data.\"\"\"\n\n class Meta:\n model = User\n fields = ['organization', 'role', 'contact_phone']\n labels = {\n 'organization': _('Your organization'),\n 'role': _('Your position'),\n }\n", "path": "src/accounts/forms.py"}]}
| 1,957 | 110 |
gh_patches_debug_35502
|
rasdani/github-patches
|
git_diff
|
rasterio__rasterio-457
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add a function to easily display a matotlib histogram in rio-insp
See #455 for background
Might be useful to surface this both in `rio insp` and as `rasterio.show_histogram()`.
</issue>
<code>
[start of rasterio/tool.py]
1
2 import code
3 import collections
4 import logging
5
6 try:
7 import matplotlib.pyplot as plt
8 except ImportError:
9 plt = None
10
11 import numpy
12
13 import rasterio
14
15
16 logger = logging.getLogger('rasterio')
17
18 Stats = collections.namedtuple('Stats', ['min', 'max', 'mean'])
19
20 # Collect dictionary of functions for use in the interpreter in main()
21 funcs = locals()
22
23
24 def show(source, cmap='gray'):
25 """Show a raster using matplotlib.
26
27 The raster may be either an ndarray or a (dataset, bidx)
28 tuple.
29 """
30 if isinstance(source, tuple):
31 arr = source[0].read(source[1])
32 else:
33 arr = source
34 if plt is not None:
35 plt.imshow(arr, cmap=cmap)
36 plt.show()
37 else:
38 raise ImportError("matplotlib could not be imported")
39
40
41 def stats(source):
42 """Return a tuple with raster min, max, and mean.
43 """
44 if isinstance(source, tuple):
45 arr = source[0].read(source[1])
46 else:
47 arr = source
48 return Stats(numpy.min(arr), numpy.max(arr), numpy.mean(arr))
49
50
51 def main(banner, dataset, alt_interpreter=None):
52 """ Main entry point for use with python interpreter """
53 local = dict(funcs, src=dataset, np=numpy, rio=rasterio, plt=plt)
54 if not alt_interpreter:
55 code.interact(banner, local=local)
56 elif alt_interpreter == 'ipython':
57 import IPython
58 IPython.InteractiveShell.banner1 = banner
59 IPython.start_ipython(argv=[], user_ns=local)
60 else:
61 raise ValueError("Unsupported interpreter '%s'" % alt_interpreter)
62
63 return 0
64
[end of rasterio/tool.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/rasterio/tool.py b/rasterio/tool.py
--- a/rasterio/tool.py
+++ b/rasterio/tool.py
@@ -11,6 +11,7 @@
import numpy
import rasterio
+from rasterio.five import zip_longest
logger = logging.getLogger('rasterio')
@@ -48,6 +49,76 @@
return Stats(numpy.min(arr), numpy.max(arr), numpy.mean(arr))
+def show_hist(source, bins=10, masked=True, title='Histogram'):
+
+ """
+ Easily display a histogram with matplotlib.
+
+ Parameters
+ ----------
+ bins : int, optional
+ Compute histogram across N bins.
+ data : np.array or rasterio.Band or tuple(dataset, bidx)
+ Input data to display. The first three arrays in multi-dimensional
+ arrays are plotted as red, green, and blue.
+ masked : bool, optional
+ When working with a `rasterio.Band()` object, specifies if the data
+ should be masked on read.
+ title : str, optional
+ Title for the figure.
+ """
+
+ if plt is None:
+ raise ImportError("Could not import matplotlib")
+
+ if isinstance(source, (tuple, rasterio.Band)):
+ arr = source[0].read(source[1], masked=masked)
+ else:
+ arr = source
+
+ # The histogram is computed individually for each 'band' in the array
+ # so we need the overall min/max to constrain the plot
+ rng = arr.min(), arr.max()
+
+ if len(arr.shape) is 2:
+ arr = [arr]
+ colors = ['gold']
+ else:
+ colors = ('red', 'green', 'blue', 'violet', 'gold', 'saddlebrown')
+
+ # If a rasterio.Band() is given make sure the proper index is displayed
+ # in the legend.
+ if isinstance(source, (tuple, rasterio.Band)):
+ labels = [str(source[1])]
+ else:
+ labels = (str(i + 1) for i in range(len(arr)))
+
+ # This loop should add a single plot each band in the input array,
+ # regardless of if the number of bands exceeds the number of colors.
+ # The colors slicing ensures that the number of iterations always
+ # matches the number of bands.
+ # The goal is to provide a curated set of colors for working with
+ # smaller datasets and let matplotlib define additional colors when
+ # working with larger datasets.
+ for bnd, color, label in zip_longest(arr, colors[:len(arr)], labels):
+
+ plt.hist(
+ bnd.flatten(),
+ bins=bins,
+ alpha=0.5,
+ color=color,
+ label=label,
+ range=rng
+ )
+
+ plt.legend(loc="upper right")
+ plt.title(title, fontweight='bold')
+ plt.grid(True)
+ plt.xlabel('DN')
+ plt.ylabel('Frequency')
+ plt.show()
+
+
def main(banner, dataset, alt_interpreter=None):
""" Main entry point for use with python interpreter """
local = dict(funcs, src=dataset, np=numpy, rio=rasterio, plt=plt)
|
{"golden_diff": "diff --git a/rasterio/tool.py b/rasterio/tool.py\n--- a/rasterio/tool.py\n+++ b/rasterio/tool.py\n@@ -11,6 +11,7 @@\n import numpy\n \n import rasterio\n+from rasterio.five import zip_longest\n \n \n logger = logging.getLogger('rasterio')\n@@ -48,6 +49,76 @@\n return Stats(numpy.min(arr), numpy.max(arr), numpy.mean(arr))\n \n \n+def show_hist(source, bins=10, masked=True, title='Histogram'):\n+\n+ \"\"\"\n+ Easily display a histogram with matplotlib.\n+\n+ Parameters\n+ ----------\n+ bins : int, optional\n+ Compute histogram across N bins.\n+ data : np.array or rasterio.Band or tuple(dataset, bidx)\n+ Input data to display. The first three arrays in multi-dimensional\n+ arrays are plotted as red, green, and blue.\n+ masked : bool, optional\n+ When working with a `rasterio.Band()` object, specifies if the data\n+ should be masked on read.\n+ title : str, optional\n+ Title for the figure.\n+ \"\"\"\n+\n+ if plt is None:\n+ raise ImportError(\"Could not import matplotlib\")\n+\n+ if isinstance(source, (tuple, rasterio.Band)):\n+ arr = source[0].read(source[1], masked=masked)\n+ else:\n+ arr = source\n+\n+ # The histogram is computed individually for each 'band' in the array\n+ # so we need the overall min/max to constrain the plot\n+ rng = arr.min(), arr.max()\n+\n+ if len(arr.shape) is 2:\n+ arr = [arr]\n+ colors = ['gold']\n+ else:\n+ colors = ('red', 'green', 'blue', 'violet', 'gold', 'saddlebrown')\n+\n+ # If a rasterio.Band() is given make sure the proper index is displayed\n+ # in the legend.\n+ if isinstance(source, (tuple, rasterio.Band)):\n+ labels = [str(source[1])]\n+ else:\n+ labels = (str(i + 1) for i in range(len(arr)))\n+\n+ # This loop should add a single plot each band in the input array,\n+ # regardless of if the number of bands exceeds the number of colors.\n+ # The colors slicing ensures that the number of iterations always\n+ # matches the number of bands.\n+ # The goal is to provide a curated set of colors for working with\n+ # smaller datasets and let matplotlib define additional colors when\n+ # working with larger datasets.\n+ for bnd, color, label in zip_longest(arr, colors[:len(arr)], labels):\n+\n+ plt.hist(\n+ bnd.flatten(),\n+ bins=bins,\n+ alpha=0.5,\n+ color=color,\n+ label=label,\n+ range=rng\n+ )\n+\n+ plt.legend(loc=\"upper right\")\n+ plt.title(title, fontweight='bold')\n+ plt.grid(True)\n+ plt.xlabel('DN')\n+ plt.ylabel('Frequency')\n+ plt.show()\n+\n+\n def main(banner, dataset, alt_interpreter=None):\n \"\"\" Main entry point for use with python interpreter \"\"\"\n local = dict(funcs, src=dataset, np=numpy, rio=rasterio, plt=plt)\n", "issue": "Add a function to easily display a matotlib histogram in rio-insp\nSee #455 for background \n\nMight be useful to surface this both in `rio insp` and as `rasterio.show_histogram()`.\n\n", "before_files": [{"content": "\nimport code\nimport collections\nimport logging\n\ntry:\n import matplotlib.pyplot as plt\nexcept ImportError:\n plt = None\n\nimport numpy\n\nimport rasterio\n\n\nlogger = logging.getLogger('rasterio')\n\nStats = collections.namedtuple('Stats', ['min', 'max', 'mean'])\n\n# Collect dictionary of functions for use in the interpreter in main()\nfuncs = locals()\n\n\ndef show(source, cmap='gray'):\n \"\"\"Show a raster using matplotlib.\n\n The raster may be either an ndarray or a (dataset, bidx)\n tuple.\n \"\"\"\n if isinstance(source, tuple):\n arr = source[0].read(source[1])\n else:\n arr = source\n if plt is not None:\n plt.imshow(arr, cmap=cmap)\n plt.show()\n else:\n raise ImportError(\"matplotlib could not be imported\")\n\n\ndef stats(source):\n \"\"\"Return a tuple with raster min, max, and mean.\n \"\"\"\n if isinstance(source, tuple):\n arr = source[0].read(source[1])\n else:\n arr = source\n return Stats(numpy.min(arr), numpy.max(arr), numpy.mean(arr))\n\n\ndef main(banner, dataset, alt_interpreter=None):\n \"\"\" Main entry point for use with python interpreter \"\"\"\n local = dict(funcs, src=dataset, np=numpy, rio=rasterio, plt=plt)\n if not alt_interpreter:\n code.interact(banner, local=local)\n elif alt_interpreter == 'ipython':\n import IPython\n IPython.InteractiveShell.banner1 = banner\n IPython.start_ipython(argv=[], user_ns=local)\n else:\n raise ValueError(\"Unsupported interpreter '%s'\" % alt_interpreter)\n\n return 0\n", "path": "rasterio/tool.py"}]}
| 1,076 | 745 |
gh_patches_debug_33357
|
rasdani/github-patches
|
git_diff
|
paperless-ngx__paperless-ngx-5142
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[BUG] duplicate key value violates unique constraint "documents_customfieldinstance_unique_document_field"
### Description
I have 3 custom fields of type "Document Link" in a Consumption template. Since the current version, the following error message appears and the document is not imported.
### Steps to reproduce
1. Creating a custom attribute with the type "Document Link"
2. Creating a template with the custom attribute
3. Importing a new file via the consum directory
4. Template match the new file
5. Import fails
### Webserver logs
```bash
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/usr/local/lib/python3.11/site-packages/celery/app/trace.py", line 477, in trace_task
R = retval = fun(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/celery/app/trace.py", line 760, in __protected_call__
return self.run(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/src/paperless/src/documents/tasks.py", line 167, in consume_file
document = Consumer().try_consume_file(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/src/paperless/src/documents/consumer.py", line 577, in try_consume_file
self._fail(
File "/usr/src/paperless/src/documents/consumer.py", line 115, in _fail
raise ConsumerError(f"{self.filename}: {log_message or message}") from exception
documents.consumer.ConsumerError: ASN231228001_[ar].pdf: The following error occurred while storing document ASN231228001_[ar].pdf after parsing: duplicate key value violates unique constraint "documents_customfieldinstance_unique_document_field"
DETAIL: Key (document_id, field_id)=(1, 1) already exists.
```
### Browser logs
```bash
[2023-12-28 15:37:48,629] [INFO] [paperless.management.consumer] Using inotify to watch directory for changes: /usr/src/paperless/consume
[2023-12-28 16:05:00,040] [DEBUG] [paperless.classifier] Document classification model does not exist (yet), not performing automatic matching.
[2023-12-28 16:05:00,043] [WARNING] [paperless.tasks] Classifier error: No training data available.
[2023-12-28 16:16:58,574] [INFO] [paperless.management.consumer] Adding /usr/src/paperless/consume/ASN231228001_[ar].pdf to the task queue.
[2023-12-28 16:16:58,681] [DEBUG] [paperless.barcodes] Scanning for barcodes using ZXING
[2023-12-28 16:17:02,426] [DEBUG] [paperless.barcodes] Upscaling image by 2.0 for better barcode detection
[2023-12-28 16:17:07,894] [DEBUG] [paperless.barcodes] Barcode of type BarcodeFormat.QRCode found: ASN231228001
[2023-12-28 16:17:07,923] [DEBUG] [paperless.barcodes] Upscaling image by 2.0 for better barcode detection
[2023-12-28 16:17:19,043] [DEBUG] [paperless.barcodes] Found ASN Barcode: ASN231228001
[2023-12-28 16:17:19,043] [DEBUG] [paperless.barcodes] Found ASN Barcode: ASN231228001
[2023-12-28 16:17:19,043] [INFO] [paperless.tasks] Found ASN in barcode: 231228001
[2023-12-28 16:17:19,087] [INFO] [paperless.matching] Document matched template Arztrechnung
[2023-12-28 16:17:19,100] [INFO] [paperless.matching] Document matched template Rechnung
[2023-12-28 16:17:19,107] [INFO] [paperless.matching] Document did not match template Zahlungserinnerung
[2023-12-28 16:17:19,107] [DEBUG] [paperless.matching] Document filename ASN231228001_[ar].pdf does not match *[ze]*
[2023-12-28 16:17:19,107] [INFO] [paperless.matching] Document matched template Mahnung
[2023-12-28 16:17:19,150] [INFO] [paperless.consumer] Consuming ASN231228001_[ar].pdf
[2023-12-28 16:17:19,164] [DEBUG] [paperless.consumer] Detected mime type: application/pdf
[2023-12-28 16:17:19,167] [DEBUG] [paperless.consumer] Parser: RasterisedDocumentParser
[2023-12-28 16:17:19,169] [DEBUG] [paperless.consumer] Parsing ASN231228001_[ar].pdf...
[2023-12-28 16:17:19,307] [DEBUG] [paperless.parsing.tesseract] Calling OCRmyPDF with args: {'input_file': PosixPath('/tmp/paperless/paperless-ngx4ifi0ip2/ASN231228001_[ar].pdf'), 'output_file': PosixPath('/tmp/paperless/paperless-6q98pv8s/archive.pdf'), 'use_threads': True, 'jobs': 4, 'language': 'deu', 'output_type': 'pdfa', 'progress_bar': False, 'color_conversion_strategy': 'RGB', 'skip_text': True, 'clean': True, 'deskew': True, 'rotate_pages': True, 'rotate_pages_threshold': 12.0, 'sidecar': PosixPath('/tmp/paperless/paperless-6q98pv8s/sidecar.txt')}
[2023-12-28 16:17:55,539] [DEBUG] [paperless.parsing.tesseract] Using text from sidecar file
[2023-12-28 16:17:55,540] [DEBUG] [paperless.consumer] Generating thumbnail for ASN231228001_[ar].pdf...
[2023-12-28 16:17:55,543] [DEBUG] [paperless.parsing] Execute: convert -density 300 -scale 500x5000> -alpha remove -strip -auto-orient /tmp/paperless/paperless-6q98pv8s/archive.pdf[0] /tmp/paperless/paperless-6q98pv8s/convert.webp
[2023-12-28 16:17:59,548] [DEBUG] [paperless.classifier] Document classification model does not exist (yet), not performing automatic matching.
[2023-12-28 16:17:59,551] [DEBUG] [paperless.consumer] Saving record to database
[2023-12-28 16:17:59,551] [DEBUG] [paperless.consumer] Creation date from parse_date: 2014-10-14 00:00:00+00:00
[2023-12-28 16:17:59,685] [ERROR] [paperless.consumer] The following error occurred while storing document ASN231228001_[ar].pdf after parsing: duplicate key value violates unique constraint "documents_customfieldinstance_unique_document_field"
```
### Paperless-ngx version
2.2.0
### Host OS
Ubuntu 22.04
### Installation method
Docker - official image
### Browser
_No response_
### Configuration changes
_No response_
### Other
I have performed a new installation of Paperless-NGX.
### Please confirm the following
- [X] I believe this issue is a bug that affects all users of Paperless-ngx, not something specific to my installation.
- [X] I have already searched for relevant existing issues and discussions before opening this report.
- [X] I have updated the title field above with a concise description.
</issue>
<code>
[start of src/documents/data_models.py]
1 import dataclasses
2 import datetime
3 from enum import IntEnum
4 from pathlib import Path
5 from typing import Optional
6
7 import magic
8
9
10 @dataclasses.dataclass
11 class DocumentMetadataOverrides:
12 """
13 Manages overrides for document fields which normally would
14 be set from content or matching. All fields default to None,
15 meaning no override is happening
16 """
17
18 filename: Optional[str] = None
19 title: Optional[str] = None
20 correspondent_id: Optional[int] = None
21 document_type_id: Optional[int] = None
22 tag_ids: Optional[list[int]] = None
23 storage_path_id: Optional[int] = None
24 created: Optional[datetime.datetime] = None
25 asn: Optional[int] = None
26 owner_id: Optional[int] = None
27 view_users: Optional[list[int]] = None
28 view_groups: Optional[list[int]] = None
29 change_users: Optional[list[int]] = None
30 change_groups: Optional[list[int]] = None
31 custom_field_ids: Optional[list[int]] = None
32
33 def update(self, other: "DocumentMetadataOverrides") -> "DocumentMetadataOverrides":
34 """
35 Merges two DocumentMetadataOverrides objects such that object B's overrides
36 are only applied if the property is empty in object A or merged if multiple
37 are accepted.
38
39 The update is an in-place modification of self
40 """
41 # only if empty
42 if self.title is None:
43 self.title = other.title
44 if self.correspondent_id is None:
45 self.correspondent_id = other.correspondent_id
46 if self.document_type_id is None:
47 self.document_type_id = other.document_type_id
48 if self.storage_path_id is None:
49 self.storage_path_id = other.storage_path_id
50 if self.owner_id is None:
51 self.owner_id = other.owner_id
52
53 # merge
54 if self.tag_ids is None:
55 self.tag_ids = other.tag_ids
56 elif other.tag_ids is not None:
57 self.tag_ids.extend(other.tag_ids)
58
59 if self.view_users is None:
60 self.view_users = other.view_users
61 elif other.view_users is not None:
62 self.view_users.extend(other.view_users)
63
64 if self.view_groups is None:
65 self.view_groups = other.view_groups
66 elif other.view_groups is not None:
67 self.view_groups.extend(other.view_groups)
68
69 if self.change_users is None:
70 self.change_users = other.change_users
71 elif other.change_users is not None:
72 self.change_users.extend(other.change_users)
73
74 if self.change_groups is None:
75 self.change_groups = other.change_groups
76 elif other.change_groups is not None:
77 self.change_groups.extend(other.change_groups)
78
79 if self.custom_field_ids is None:
80 self.custom_field_ids = other.custom_field_ids
81 elif other.custom_field_ids is not None:
82 self.custom_field_ids.extend(other.custom_field_ids)
83
84 return self
85
86
87 class DocumentSource(IntEnum):
88 """
89 The source of an incoming document. May have other uses in the future
90 """
91
92 ConsumeFolder = 1
93 ApiUpload = 2
94 MailFetch = 3
95
96
97 @dataclasses.dataclass
98 class ConsumableDocument:
99 """
100 Encapsulates an incoming document, either from consume folder, API upload
101 or mail fetching and certain useful operations on it.
102 """
103
104 source: DocumentSource
105 original_file: Path
106 mailrule_id: Optional[int] = None
107 mime_type: str = dataclasses.field(init=False, default=None)
108
109 def __post_init__(self):
110 """
111 After a dataclass is initialized, this is called to finalize some data
112 1. Make sure the original path is an absolute, fully qualified path
113 2. Get the mime type of the file
114 """
115 # Always fully qualify the path first thing
116 # Just in case, convert to a path if it's a str
117 self.original_file = Path(self.original_file).resolve()
118
119 # Get the file type once at init
120 # Note this function isn't called when the object is unpickled
121 self.mime_type = magic.from_file(self.original_file, mime=True)
122
[end of src/documents/data_models.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/documents/data_models.py b/src/documents/data_models.py
--- a/src/documents/data_models.py
+++ b/src/documents/data_models.py
@@ -55,31 +55,37 @@
self.tag_ids = other.tag_ids
elif other.tag_ids is not None:
self.tag_ids.extend(other.tag_ids)
+ self.tag_ids = list(set(self.tag_ids))
if self.view_users is None:
self.view_users = other.view_users
elif other.view_users is not None:
self.view_users.extend(other.view_users)
+ self.view_users = list(set(self.view_users))
if self.view_groups is None:
self.view_groups = other.view_groups
elif other.view_groups is not None:
self.view_groups.extend(other.view_groups)
+ self.view_groups = list(set(self.view_groups))
if self.change_users is None:
self.change_users = other.change_users
elif other.change_users is not None:
self.change_users.extend(other.change_users)
+ self.change_users = list(set(self.change_users))
if self.change_groups is None:
self.change_groups = other.change_groups
elif other.change_groups is not None:
self.change_groups.extend(other.change_groups)
+ self.change_groups = list(set(self.change_groups))
if self.custom_field_ids is None:
self.custom_field_ids = other.custom_field_ids
elif other.custom_field_ids is not None:
self.custom_field_ids.extend(other.custom_field_ids)
+ self.custom_field_ids = list(set(self.custom_field_ids))
return self
|
{"golden_diff": "diff --git a/src/documents/data_models.py b/src/documents/data_models.py\n--- a/src/documents/data_models.py\n+++ b/src/documents/data_models.py\n@@ -55,31 +55,37 @@\n self.tag_ids = other.tag_ids\n elif other.tag_ids is not None:\n self.tag_ids.extend(other.tag_ids)\n+ self.tag_ids = list(set(self.tag_ids))\n \n if self.view_users is None:\n self.view_users = other.view_users\n elif other.view_users is not None:\n self.view_users.extend(other.view_users)\n+ self.view_users = list(set(self.view_users))\n \n if self.view_groups is None:\n self.view_groups = other.view_groups\n elif other.view_groups is not None:\n self.view_groups.extend(other.view_groups)\n+ self.view_groups = list(set(self.view_groups))\n \n if self.change_users is None:\n self.change_users = other.change_users\n elif other.change_users is not None:\n self.change_users.extend(other.change_users)\n+ self.change_users = list(set(self.change_users))\n \n if self.change_groups is None:\n self.change_groups = other.change_groups\n elif other.change_groups is not None:\n self.change_groups.extend(other.change_groups)\n+ self.change_groups = list(set(self.change_groups))\n \n if self.custom_field_ids is None:\n self.custom_field_ids = other.custom_field_ids\n elif other.custom_field_ids is not None:\n self.custom_field_ids.extend(other.custom_field_ids)\n+ self.custom_field_ids = list(set(self.custom_field_ids))\n \n return self\n", "issue": "[BUG] duplicate key value violates unique constraint \"documents_customfieldinstance_unique_document_field\"\n### Description\n\nI have 3 custom fields of type \"Document Link\" in a Consumption template. Since the current version, the following error message appears and the document is not imported.\n\n### Steps to reproduce\n\n1. Creating a custom attribute with the type \"Document Link\"\r\n2. Creating a template with the custom attribute\r\n3. Importing a new file via the consum directory \r\n4. Template match the new file\r\n5. Import fails\n\n### Webserver logs\n\n```bash\nThe above exception was the direct cause of the following exception:\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.11/site-packages/celery/app/trace.py\", line 477, in trace_task\r\n R = retval = fun(*args, **kwargs)\r\n ^^^^^^^^^^^^^^^^^^^^\r\n File \"/usr/local/lib/python3.11/site-packages/celery/app/trace.py\", line 760, in __protected_call__\r\n return self.run(*args, **kwargs)\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"/usr/src/paperless/src/documents/tasks.py\", line 167, in consume_file\r\n document = Consumer().try_consume_file(\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"/usr/src/paperless/src/documents/consumer.py\", line 577, in try_consume_file\r\n self._fail(\r\n File \"/usr/src/paperless/src/documents/consumer.py\", line 115, in _fail\r\n raise ConsumerError(f\"{self.filename}: {log_message or message}\") from exception\r\n\r\ndocuments.consumer.ConsumerError: ASN231228001_[ar].pdf: The following error occurred while storing document ASN231228001_[ar].pdf after parsing: duplicate key value violates unique constraint \"documents_customfieldinstance_unique_document_field\"\r\n\r\nDETAIL: Key (document_id, field_id)=(1, 1) already exists.\n```\n\n\n### Browser logs\n\n```bash\n[2023-12-28 15:37:48,629] [INFO] [paperless.management.consumer] Using inotify to watch directory for changes: /usr/src/paperless/consume\r\n[2023-12-28 16:05:00,040] [DEBUG] [paperless.classifier] Document classification model does not exist (yet), not performing automatic matching.\r\n[2023-12-28 16:05:00,043] [WARNING] [paperless.tasks] Classifier error: No training data available.\r\n[2023-12-28 16:16:58,574] [INFO] [paperless.management.consumer] Adding /usr/src/paperless/consume/ASN231228001_[ar].pdf to the task queue.\r\n[2023-12-28 16:16:58,681] [DEBUG] [paperless.barcodes] Scanning for barcodes using ZXING\r\n[2023-12-28 16:17:02,426] [DEBUG] [paperless.barcodes] Upscaling image by 2.0 for better barcode detection\r\n[2023-12-28 16:17:07,894] [DEBUG] [paperless.barcodes] Barcode of type BarcodeFormat.QRCode found: ASN231228001\r\n[2023-12-28 16:17:07,923] [DEBUG] [paperless.barcodes] Upscaling image by 2.0 for better barcode detection\r\n[2023-12-28 16:17:19,043] [DEBUG] [paperless.barcodes] Found ASN Barcode: ASN231228001\r\n[2023-12-28 16:17:19,043] [DEBUG] [paperless.barcodes] Found ASN Barcode: ASN231228001\r\n[2023-12-28 16:17:19,043] [INFO] [paperless.tasks] Found ASN in barcode: 231228001\r\n[2023-12-28 16:17:19,087] [INFO] [paperless.matching] Document matched template Arztrechnung\r\n[2023-12-28 16:17:19,100] [INFO] [paperless.matching] Document matched template Rechnung\r\n[2023-12-28 16:17:19,107] [INFO] [paperless.matching] Document did not match template Zahlungserinnerung\r\n[2023-12-28 16:17:19,107] [DEBUG] [paperless.matching] Document filename ASN231228001_[ar].pdf does not match *[ze]*\r\n[2023-12-28 16:17:19,107] [INFO] [paperless.matching] Document matched template Mahnung\r\n[2023-12-28 16:17:19,150] [INFO] [paperless.consumer] Consuming ASN231228001_[ar].pdf\r\n[2023-12-28 16:17:19,164] [DEBUG] [paperless.consumer] Detected mime type: application/pdf\r\n[2023-12-28 16:17:19,167] [DEBUG] [paperless.consumer] Parser: RasterisedDocumentParser\r\n[2023-12-28 16:17:19,169] [DEBUG] [paperless.consumer] Parsing ASN231228001_[ar].pdf...\r\n[2023-12-28 16:17:19,307] [DEBUG] [paperless.parsing.tesseract] Calling OCRmyPDF with args: {'input_file': PosixPath('/tmp/paperless/paperless-ngx4ifi0ip2/ASN231228001_[ar].pdf'), 'output_file': PosixPath('/tmp/paperless/paperless-6q98pv8s/archive.pdf'), 'use_threads': True, 'jobs': 4, 'language': 'deu', 'output_type': 'pdfa', 'progress_bar': False, 'color_conversion_strategy': 'RGB', 'skip_text': True, 'clean': True, 'deskew': True, 'rotate_pages': True, 'rotate_pages_threshold': 12.0, 'sidecar': PosixPath('/tmp/paperless/paperless-6q98pv8s/sidecar.txt')}\r\n[2023-12-28 16:17:55,539] [DEBUG] [paperless.parsing.tesseract] Using text from sidecar file\r\n[2023-12-28 16:17:55,540] [DEBUG] [paperless.consumer] Generating thumbnail for ASN231228001_[ar].pdf...\r\n[2023-12-28 16:17:55,543] [DEBUG] [paperless.parsing] Execute: convert -density 300 -scale 500x5000> -alpha remove -strip -auto-orient /tmp/paperless/paperless-6q98pv8s/archive.pdf[0] /tmp/paperless/paperless-6q98pv8s/convert.webp\r\n[2023-12-28 16:17:59,548] [DEBUG] [paperless.classifier] Document classification model does not exist (yet), not performing automatic matching.\r\n[2023-12-28 16:17:59,551] [DEBUG] [paperless.consumer] Saving record to database\r\n[2023-12-28 16:17:59,551] [DEBUG] [paperless.consumer] Creation date from parse_date: 2014-10-14 00:00:00+00:00\r\n[2023-12-28 16:17:59,685] [ERROR] [paperless.consumer] The following error occurred while storing document ASN231228001_[ar].pdf after parsing: duplicate key value violates unique constraint \"documents_customfieldinstance_unique_document_field\"\n```\n\n\n### Paperless-ngx version\n\n2.2.0\n\n### Host OS\n\nUbuntu 22.04\n\n### Installation method\n\nDocker - official image\n\n### Browser\n\n_No response_\n\n### Configuration changes\n\n_No response_\n\n### Other\n\nI have performed a new installation of Paperless-NGX.\n\n### Please confirm the following\n\n- [X] I believe this issue is a bug that affects all users of Paperless-ngx, not something specific to my installation.\n- [X] I have already searched for relevant existing issues and discussions before opening this report.\n- [X] I have updated the title field above with a concise description.\n", "before_files": [{"content": "import dataclasses\nimport datetime\nfrom enum import IntEnum\nfrom pathlib import Path\nfrom typing import Optional\n\nimport magic\n\n\[email protected]\nclass DocumentMetadataOverrides:\n \"\"\"\n Manages overrides for document fields which normally would\n be set from content or matching. All fields default to None,\n meaning no override is happening\n \"\"\"\n\n filename: Optional[str] = None\n title: Optional[str] = None\n correspondent_id: Optional[int] = None\n document_type_id: Optional[int] = None\n tag_ids: Optional[list[int]] = None\n storage_path_id: Optional[int] = None\n created: Optional[datetime.datetime] = None\n asn: Optional[int] = None\n owner_id: Optional[int] = None\n view_users: Optional[list[int]] = None\n view_groups: Optional[list[int]] = None\n change_users: Optional[list[int]] = None\n change_groups: Optional[list[int]] = None\n custom_field_ids: Optional[list[int]] = None\n\n def update(self, other: \"DocumentMetadataOverrides\") -> \"DocumentMetadataOverrides\":\n \"\"\"\n Merges two DocumentMetadataOverrides objects such that object B's overrides\n are only applied if the property is empty in object A or merged if multiple\n are accepted.\n\n The update is an in-place modification of self\n \"\"\"\n # only if empty\n if self.title is None:\n self.title = other.title\n if self.correspondent_id is None:\n self.correspondent_id = other.correspondent_id\n if self.document_type_id is None:\n self.document_type_id = other.document_type_id\n if self.storage_path_id is None:\n self.storage_path_id = other.storage_path_id\n if self.owner_id is None:\n self.owner_id = other.owner_id\n\n # merge\n if self.tag_ids is None:\n self.tag_ids = other.tag_ids\n elif other.tag_ids is not None:\n self.tag_ids.extend(other.tag_ids)\n\n if self.view_users is None:\n self.view_users = other.view_users\n elif other.view_users is not None:\n self.view_users.extend(other.view_users)\n\n if self.view_groups is None:\n self.view_groups = other.view_groups\n elif other.view_groups is not None:\n self.view_groups.extend(other.view_groups)\n\n if self.change_users is None:\n self.change_users = other.change_users\n elif other.change_users is not None:\n self.change_users.extend(other.change_users)\n\n if self.change_groups is None:\n self.change_groups = other.change_groups\n elif other.change_groups is not None:\n self.change_groups.extend(other.change_groups)\n\n if self.custom_field_ids is None:\n self.custom_field_ids = other.custom_field_ids\n elif other.custom_field_ids is not None:\n self.custom_field_ids.extend(other.custom_field_ids)\n\n return self\n\n\nclass DocumentSource(IntEnum):\n \"\"\"\n The source of an incoming document. May have other uses in the future\n \"\"\"\n\n ConsumeFolder = 1\n ApiUpload = 2\n MailFetch = 3\n\n\[email protected]\nclass ConsumableDocument:\n \"\"\"\n Encapsulates an incoming document, either from consume folder, API upload\n or mail fetching and certain useful operations on it.\n \"\"\"\n\n source: DocumentSource\n original_file: Path\n mailrule_id: Optional[int] = None\n mime_type: str = dataclasses.field(init=False, default=None)\n\n def __post_init__(self):\n \"\"\"\n After a dataclass is initialized, this is called to finalize some data\n 1. Make sure the original path is an absolute, fully qualified path\n 2. Get the mime type of the file\n \"\"\"\n # Always fully qualify the path first thing\n # Just in case, convert to a path if it's a str\n self.original_file = Path(self.original_file).resolve()\n\n # Get the file type once at init\n # Note this function isn't called when the object is unpickled\n self.mime_type = magic.from_file(self.original_file, mime=True)\n", "path": "src/documents/data_models.py"}]}
| 3,862 | 338 |
gh_patches_debug_31361
|
rasdani/github-patches
|
git_diff
|
crytic__slither-2114
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Bug]: Slither detects already triaged results
### Describe the issue:
Slither seems to be detecting issues that have already been triaged into the `slither.db.json` from time to time.
This makes it difficult to get consistent results between runs after triaging findings, and also generates false positives when running Slither in CI.
This could be related to the ID of the findings that is stored in the DB file, which seems to vary between runs.
### Code example to reproduce the issue:
Public sample to reproduce the issue with instructions here: https://github.com/balancer/balancer-v2-monorepo/pull/2514.
### Version:
`0.9.3`
### Relevant log output:
```shell
# Following the instructions in the PR mentioned above, this is the output after triaging all the results.
# Running slither two times in a row outputs different results:
juan@M16:~/prj/bal/pkg/solidity-utils$ yarn slither
Nothing to compile
INFO:Detectors:
LogExpMath.exp(int256) (contracts/math/LogExpMath.sol#146-281) performs a multiplication on the result of a division:
- product = (product * a3) / ONE_20 (contracts/math/LogExpMath.sol#198)
- product = (product * a4) / ONE_20 (contracts/math/LogExpMath.sol#202)
LogExpMath.exp(int256) (contracts/math/LogExpMath.sol#146-281) performs a multiplication on the result of a division:
- product = (product * a3) / ONE_20 (contracts/math/LogExpMath.sol#198)
- product = (product * a5) / ONE_20 (contracts/math/LogExpMath.sol#206)
LogExpMath.exp(int256) (contracts/math/LogExpMath.sol#146-281) performs a multiplication on the result of a division:
- product = (product * a7) / ONE_20 (contracts/math/LogExpMath.sol#214)
- product = (product * a8) / ONE_20 (contracts/math/LogExpMath.sol#218)
LogExpMath._ln(int256) (contracts/math/LogExpMath.sol#326-458) performs a multiplication on the result of a division:
- a = (a * ONE_20) / a3 (contracts/math/LogExpMath.sol#372)
- a = (a * ONE_20) / a4 (contracts/math/LogExpMath.sol#377)
LogExpMath._ln(int256) (contracts/math/LogExpMath.sol#326-458) performs a multiplication on the result of a division:
- a = (a * ONE_20) / a5 (contracts/math/LogExpMath.sol#382)
- a = (a * ONE_20) / a6 (contracts/math/LogExpMath.sol#387)
Reference: https://github.com/crytic/slither/wiki/Detector-Documentation#divide-before-multiply
INFO:Slither:. analyzed (72 contracts with 85 detectors), 5 result(s) found
juan@M16:~/prj/bal/pkg/solidity-utils$ yarn slither
Nothing to compile
INFO:Detectors:
LogExpMath.exp(int256) (contracts/math/LogExpMath.sol#146-281) performs a multiplication on the result of a division:
- product = (product * a3) / ONE_20 (contracts/math/LogExpMath.sol#198)
- product = (product * a5) / ONE_20 (contracts/math/LogExpMath.sol#206)
LogExpMath.exp(int256) (contracts/math/LogExpMath.sol#146-281) performs a multiplication on the result of a division:
- product = (product * a4) / ONE_20 (contracts/math/LogExpMath.sol#202)
- product = (product * a6) / ONE_20 (contracts/math/LogExpMath.sol#210)
LogExpMath.exp(int256) (contracts/math/LogExpMath.sol#146-281) performs a multiplication on the result of a division:
- product = (product * a7) / ONE_20 (contracts/math/LogExpMath.sol#214)
- product = (product * a8) / ONE_20 (contracts/math/LogExpMath.sol#218)
Reference: https://github.com/crytic/slither/wiki/Detector-Documentation#divide-before-multiply
INFO:Slither:. analyzed (72 contracts with 85 detectors), 3 result(s) found
juan@M16:~/prj/bal/pkg/solidity-utils$
```
</issue>
<code>
[start of slither/detectors/statements/divide_before_multiply.py]
1 """
2 Module detecting possible loss of precision due to divide before multiple
3 """
4 from collections import defaultdict
5 from typing import DefaultDict, List, Set, Tuple
6
7 from slither.core.cfg.node import Node
8 from slither.core.declarations.contract import Contract
9 from slither.core.declarations.function_contract import FunctionContract
10 from slither.detectors.abstract_detector import (
11 AbstractDetector,
12 DetectorClassification,
13 DETECTOR_INFO,
14 )
15 from slither.slithir.operations import Binary, Assignment, BinaryType, LibraryCall, Operation
16 from slither.slithir.utils.utils import LVALUE
17 from slither.slithir.variables import Constant
18 from slither.utils.output import Output
19
20
21 def is_division(ir: Operation) -> bool:
22 if isinstance(ir, Binary):
23 if ir.type == BinaryType.DIVISION:
24 return True
25
26 if isinstance(ir, LibraryCall):
27 if ir.function.name and ir.function.name.lower() in [
28 "div",
29 "safediv",
30 ]:
31 if len(ir.arguments) == 2:
32 if ir.lvalue:
33 return True
34 return False
35
36
37 def is_multiplication(ir: Operation) -> bool:
38 if isinstance(ir, Binary):
39 if ir.type == BinaryType.MULTIPLICATION:
40 return True
41
42 if isinstance(ir, LibraryCall):
43 if ir.function.name and ir.function.name.lower() in [
44 "mul",
45 "safemul",
46 ]:
47 if len(ir.arguments) == 2:
48 if ir.lvalue:
49 return True
50 return False
51
52
53 def is_assert(node: Node) -> bool:
54 if node.contains_require_or_assert():
55 return True
56 # Old Solidity code where using an internal 'assert(bool)' function
57 # While we dont check that this function is correct, we assume it is
58 # To avoid too many FP
59 if "assert(bool)" in [c.full_name for c in node.internal_calls]:
60 return True
61 return False
62
63
64 # pylint: disable=too-many-branches
65 def _explore(
66 to_explore: Set[Node], f_results: List[List[Node]], divisions: DefaultDict[LVALUE, List[Node]]
67 ) -> None:
68 explored = set()
69 while to_explore: # pylint: disable=too-many-nested-blocks
70 node = to_explore.pop()
71
72 if node in explored:
73 continue
74 explored.add(node)
75
76 equality_found = False
77 # List of nodes related to one bug instance
78 node_results: List[Node] = []
79
80 for ir in node.irs:
81 if isinstance(ir, Assignment):
82 if ir.rvalue in divisions:
83 # Avoid dupplicate. We dont use set so we keep the order of the nodes
84 if node not in divisions[ir.rvalue]: # type: ignore
85 divisions[ir.lvalue] = divisions[ir.rvalue] + [node] # type: ignore
86 else:
87 divisions[ir.lvalue] = divisions[ir.rvalue] # type: ignore
88
89 if is_division(ir):
90 divisions[ir.lvalue] = [node] # type: ignore
91
92 if is_multiplication(ir):
93 mul_arguments = ir.read if isinstance(ir, Binary) else ir.arguments # type: ignore
94 nodes = []
95 for r in mul_arguments:
96 if not isinstance(r, Constant) and (r in divisions):
97 # Dont add node already present to avoid dupplicate
98 # We dont use set to keep the order of the nodes
99 if node in divisions[r]:
100 nodes += [n for n in divisions[r] if n not in nodes]
101 else:
102 nodes += [n for n in divisions[r] + [node] if n not in nodes]
103 if nodes:
104 node_results = nodes
105
106 if isinstance(ir, Binary) and ir.type == BinaryType.EQUAL:
107 equality_found = True
108
109 if node_results:
110 # We do not track the case where the multiplication is done in a require() or assert()
111 # Which also contains a ==, to prevent FP due to the form
112 # assert(a == b * c + a % b)
113 if not (is_assert(node) and equality_found):
114 f_results.append(node_results)
115
116 for son in node.sons:
117 to_explore.add(son)
118
119
120 def detect_divide_before_multiply(
121 contract: Contract,
122 ) -> List[Tuple[FunctionContract, List[Node]]]:
123 """
124 Detects and returns all nodes with multiplications of division results.
125 :param contract: Contract to detect assignment within.
126 :return: A list of nodes with multiplications of divisions.
127 """
128
129 # Create our result set.
130 # List of tuple (function -> list(list(nodes)))
131 # Each list(nodes) of the list is one bug instances
132 # Each node in the list(nodes) is involved in the bug
133 results: List[Tuple[FunctionContract, List[Node]]] = []
134
135 # Loop for each function and modifier.
136 for function in contract.functions_declared:
137 if not function.entry_point:
138 continue
139
140 # List of list(nodes)
141 # Each list(nodes) is one bug instances
142 f_results: List[List[Node]] = []
143
144 # lvalue -> node
145 # track all the division results (and the assignment of the division results)
146 divisions: DefaultDict[LVALUE, List[Node]] = defaultdict(list)
147
148 _explore({function.entry_point}, f_results, divisions)
149
150 for f_result in f_results:
151 results.append((function, f_result))
152
153 # Return the resulting set of nodes with divisions before multiplications
154 return results
155
156
157 class DivideBeforeMultiply(AbstractDetector):
158 """
159 Divide before multiply
160 """
161
162 ARGUMENT = "divide-before-multiply"
163 HELP = "Imprecise arithmetic operations order"
164 IMPACT = DetectorClassification.MEDIUM
165 CONFIDENCE = DetectorClassification.MEDIUM
166
167 WIKI = "https://github.com/crytic/slither/wiki/Detector-Documentation#divide-before-multiply"
168
169 WIKI_TITLE = "Divide before multiply"
170 WIKI_DESCRIPTION = """Solidity's integer division truncates. Thus, performing division before multiplication can lead to precision loss."""
171
172 # region wiki_exploit_scenario
173 WIKI_EXPLOIT_SCENARIO = """
174 ```solidity
175 contract A {
176 function f(uint n) public {
177 coins = (oldSupply / n) * interest;
178 }
179 }
180 ```
181 If `n` is greater than `oldSupply`, `coins` will be zero. For example, with `oldSupply = 5; n = 10, interest = 2`, coins will be zero.
182 If `(oldSupply * interest / n)` was used, `coins` would have been `1`.
183 In general, it's usually a good idea to re-arrange arithmetic to perform multiplication before division, unless the limit of a smaller type makes this dangerous."""
184 # endregion wiki_exploit_scenario
185
186 WIKI_RECOMMENDATION = """Consider ordering multiplication before division."""
187
188 def _detect(self) -> List[Output]:
189 """
190 Detect divisions before multiplications
191 """
192 results = []
193 for contract in self.contracts:
194 divisions_before_multiplications = detect_divide_before_multiply(contract)
195 if divisions_before_multiplications:
196 for (func, nodes) in divisions_before_multiplications:
197
198 info: DETECTOR_INFO = [
199 func,
200 " performs a multiplication on the result of a division:\n",
201 ]
202
203 # sort the nodes to get deterministic results
204 nodes.sort(key=lambda x: x.node_id)
205
206 for node in nodes:
207 info += ["\t- ", node, "\n"]
208
209 res = self.generate_result(info)
210 results.append(res)
211
212 return results
213
[end of slither/detectors/statements/divide_before_multiply.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/slither/detectors/statements/divide_before_multiply.py b/slither/detectors/statements/divide_before_multiply.py
--- a/slither/detectors/statements/divide_before_multiply.py
+++ b/slither/detectors/statements/divide_before_multiply.py
@@ -2,7 +2,7 @@
Module detecting possible loss of precision due to divide before multiple
"""
from collections import defaultdict
-from typing import DefaultDict, List, Set, Tuple
+from typing import DefaultDict, List, Tuple
from slither.core.cfg.node import Node
from slither.core.declarations.contract import Contract
@@ -63,7 +63,7 @@
# pylint: disable=too-many-branches
def _explore(
- to_explore: Set[Node], f_results: List[List[Node]], divisions: DefaultDict[LVALUE, List[Node]]
+ to_explore: List[Node], f_results: List[List[Node]], divisions: DefaultDict[LVALUE, List[Node]]
) -> None:
explored = set()
while to_explore: # pylint: disable=too-many-nested-blocks
@@ -114,7 +114,7 @@
f_results.append(node_results)
for son in node.sons:
- to_explore.add(son)
+ to_explore.append(son)
def detect_divide_before_multiply(
@@ -145,7 +145,7 @@
# track all the division results (and the assignment of the division results)
divisions: DefaultDict[LVALUE, List[Node]] = defaultdict(list)
- _explore({function.entry_point}, f_results, divisions)
+ _explore([function.entry_point], f_results, divisions)
for f_result in f_results:
results.append((function, f_result))
|
{"golden_diff": "diff --git a/slither/detectors/statements/divide_before_multiply.py b/slither/detectors/statements/divide_before_multiply.py\n--- a/slither/detectors/statements/divide_before_multiply.py\n+++ b/slither/detectors/statements/divide_before_multiply.py\n@@ -2,7 +2,7 @@\n Module detecting possible loss of precision due to divide before multiple\n \"\"\"\n from collections import defaultdict\n-from typing import DefaultDict, List, Set, Tuple\n+from typing import DefaultDict, List, Tuple\n \n from slither.core.cfg.node import Node\n from slither.core.declarations.contract import Contract\n@@ -63,7 +63,7 @@\n \n # pylint: disable=too-many-branches\n def _explore(\n- to_explore: Set[Node], f_results: List[List[Node]], divisions: DefaultDict[LVALUE, List[Node]]\n+ to_explore: List[Node], f_results: List[List[Node]], divisions: DefaultDict[LVALUE, List[Node]]\n ) -> None:\n explored = set()\n while to_explore: # pylint: disable=too-many-nested-blocks\n@@ -114,7 +114,7 @@\n f_results.append(node_results)\n \n for son in node.sons:\n- to_explore.add(son)\n+ to_explore.append(son)\n \n \n def detect_divide_before_multiply(\n@@ -145,7 +145,7 @@\n # track all the division results (and the assignment of the division results)\n divisions: DefaultDict[LVALUE, List[Node]] = defaultdict(list)\n \n- _explore({function.entry_point}, f_results, divisions)\n+ _explore([function.entry_point], f_results, divisions)\n \n for f_result in f_results:\n results.append((function, f_result))\n", "issue": "[Bug]: Slither detects already triaged results\n### Describe the issue:\r\n\r\nSlither seems to be detecting issues that have already been triaged into the `slither.db.json` from time to time.\r\nThis makes it difficult to get consistent results between runs after triaging findings, and also generates false positives when running Slither in CI.\r\n\r\nThis could be related to the ID of the findings that is stored in the DB file, which seems to vary between runs.\r\n\r\n### Code example to reproduce the issue:\r\n\r\nPublic sample to reproduce the issue with instructions here: https://github.com/balancer/balancer-v2-monorepo/pull/2514.\r\n\r\n### Version:\r\n\r\n`0.9.3`\r\n\r\n### Relevant log output:\r\n\r\n```shell\r\n# Following the instructions in the PR mentioned above, this is the output after triaging all the results.\r\n# Running slither two times in a row outputs different results:\r\n\r\njuan@M16:~/prj/bal/pkg/solidity-utils$ yarn slither\r\nNothing to compile\r\nINFO:Detectors:\r\nLogExpMath.exp(int256) (contracts/math/LogExpMath.sol#146-281) performs a multiplication on the result of a division:\r\n\t- product = (product * a3) / ONE_20 (contracts/math/LogExpMath.sol#198)\r\n\t- product = (product * a4) / ONE_20 (contracts/math/LogExpMath.sol#202)\r\nLogExpMath.exp(int256) (contracts/math/LogExpMath.sol#146-281) performs a multiplication on the result of a division:\r\n\t- product = (product * a3) / ONE_20 (contracts/math/LogExpMath.sol#198)\r\n\t- product = (product * a5) / ONE_20 (contracts/math/LogExpMath.sol#206)\r\nLogExpMath.exp(int256) (contracts/math/LogExpMath.sol#146-281) performs a multiplication on the result of a division:\r\n\t- product = (product * a7) / ONE_20 (contracts/math/LogExpMath.sol#214)\r\n\t- product = (product * a8) / ONE_20 (contracts/math/LogExpMath.sol#218)\r\nLogExpMath._ln(int256) (contracts/math/LogExpMath.sol#326-458) performs a multiplication on the result of a division:\r\n\t- a = (a * ONE_20) / a3 (contracts/math/LogExpMath.sol#372)\r\n\t- a = (a * ONE_20) / a4 (contracts/math/LogExpMath.sol#377)\r\nLogExpMath._ln(int256) (contracts/math/LogExpMath.sol#326-458) performs a multiplication on the result of a division:\r\n\t- a = (a * ONE_20) / a5 (contracts/math/LogExpMath.sol#382)\r\n\t- a = (a * ONE_20) / a6 (contracts/math/LogExpMath.sol#387)\r\nReference: https://github.com/crytic/slither/wiki/Detector-Documentation#divide-before-multiply\r\nINFO:Slither:. analyzed (72 contracts with 85 detectors), 5 result(s) found\r\n\r\n\r\njuan@M16:~/prj/bal/pkg/solidity-utils$ yarn slither\r\nNothing to compile\r\nINFO:Detectors:\r\nLogExpMath.exp(int256) (contracts/math/LogExpMath.sol#146-281) performs a multiplication on the result of a division:\r\n\t- product = (product * a3) / ONE_20 (contracts/math/LogExpMath.sol#198)\r\n\t- product = (product * a5) / ONE_20 (contracts/math/LogExpMath.sol#206)\r\nLogExpMath.exp(int256) (contracts/math/LogExpMath.sol#146-281) performs a multiplication on the result of a division:\r\n\t- product = (product * a4) / ONE_20 (contracts/math/LogExpMath.sol#202)\r\n\t- product = (product * a6) / ONE_20 (contracts/math/LogExpMath.sol#210)\r\nLogExpMath.exp(int256) (contracts/math/LogExpMath.sol#146-281) performs a multiplication on the result of a division:\r\n\t- product = (product * a7) / ONE_20 (contracts/math/LogExpMath.sol#214)\r\n\t- product = (product * a8) / ONE_20 (contracts/math/LogExpMath.sol#218)\r\nReference: https://github.com/crytic/slither/wiki/Detector-Documentation#divide-before-multiply\r\nINFO:Slither:. analyzed (72 contracts with 85 detectors), 3 result(s) found\r\njuan@M16:~/prj/bal/pkg/solidity-utils$\r\n```\r\n\n", "before_files": [{"content": "\"\"\"\nModule detecting possible loss of precision due to divide before multiple\n\"\"\"\nfrom collections import defaultdict\nfrom typing import DefaultDict, List, Set, Tuple\n\nfrom slither.core.cfg.node import Node\nfrom slither.core.declarations.contract import Contract\nfrom slither.core.declarations.function_contract import FunctionContract\nfrom slither.detectors.abstract_detector import (\n AbstractDetector,\n DetectorClassification,\n DETECTOR_INFO,\n)\nfrom slither.slithir.operations import Binary, Assignment, BinaryType, LibraryCall, Operation\nfrom slither.slithir.utils.utils import LVALUE\nfrom slither.slithir.variables import Constant\nfrom slither.utils.output import Output\n\n\ndef is_division(ir: Operation) -> bool:\n if isinstance(ir, Binary):\n if ir.type == BinaryType.DIVISION:\n return True\n\n if isinstance(ir, LibraryCall):\n if ir.function.name and ir.function.name.lower() in [\n \"div\",\n \"safediv\",\n ]:\n if len(ir.arguments) == 2:\n if ir.lvalue:\n return True\n return False\n\n\ndef is_multiplication(ir: Operation) -> bool:\n if isinstance(ir, Binary):\n if ir.type == BinaryType.MULTIPLICATION:\n return True\n\n if isinstance(ir, LibraryCall):\n if ir.function.name and ir.function.name.lower() in [\n \"mul\",\n \"safemul\",\n ]:\n if len(ir.arguments) == 2:\n if ir.lvalue:\n return True\n return False\n\n\ndef is_assert(node: Node) -> bool:\n if node.contains_require_or_assert():\n return True\n # Old Solidity code where using an internal 'assert(bool)' function\n # While we dont check that this function is correct, we assume it is\n # To avoid too many FP\n if \"assert(bool)\" in [c.full_name for c in node.internal_calls]:\n return True\n return False\n\n\n# pylint: disable=too-many-branches\ndef _explore(\n to_explore: Set[Node], f_results: List[List[Node]], divisions: DefaultDict[LVALUE, List[Node]]\n) -> None:\n explored = set()\n while to_explore: # pylint: disable=too-many-nested-blocks\n node = to_explore.pop()\n\n if node in explored:\n continue\n explored.add(node)\n\n equality_found = False\n # List of nodes related to one bug instance\n node_results: List[Node] = []\n\n for ir in node.irs:\n if isinstance(ir, Assignment):\n if ir.rvalue in divisions:\n # Avoid dupplicate. We dont use set so we keep the order of the nodes\n if node not in divisions[ir.rvalue]: # type: ignore\n divisions[ir.lvalue] = divisions[ir.rvalue] + [node] # type: ignore\n else:\n divisions[ir.lvalue] = divisions[ir.rvalue] # type: ignore\n\n if is_division(ir):\n divisions[ir.lvalue] = [node] # type: ignore\n\n if is_multiplication(ir):\n mul_arguments = ir.read if isinstance(ir, Binary) else ir.arguments # type: ignore\n nodes = []\n for r in mul_arguments:\n if not isinstance(r, Constant) and (r in divisions):\n # Dont add node already present to avoid dupplicate\n # We dont use set to keep the order of the nodes\n if node in divisions[r]:\n nodes += [n for n in divisions[r] if n not in nodes]\n else:\n nodes += [n for n in divisions[r] + [node] if n not in nodes]\n if nodes:\n node_results = nodes\n\n if isinstance(ir, Binary) and ir.type == BinaryType.EQUAL:\n equality_found = True\n\n if node_results:\n # We do not track the case where the multiplication is done in a require() or assert()\n # Which also contains a ==, to prevent FP due to the form\n # assert(a == b * c + a % b)\n if not (is_assert(node) and equality_found):\n f_results.append(node_results)\n\n for son in node.sons:\n to_explore.add(son)\n\n\ndef detect_divide_before_multiply(\n contract: Contract,\n) -> List[Tuple[FunctionContract, List[Node]]]:\n \"\"\"\n Detects and returns all nodes with multiplications of division results.\n :param contract: Contract to detect assignment within.\n :return: A list of nodes with multiplications of divisions.\n \"\"\"\n\n # Create our result set.\n # List of tuple (function -> list(list(nodes)))\n # Each list(nodes) of the list is one bug instances\n # Each node in the list(nodes) is involved in the bug\n results: List[Tuple[FunctionContract, List[Node]]] = []\n\n # Loop for each function and modifier.\n for function in contract.functions_declared:\n if not function.entry_point:\n continue\n\n # List of list(nodes)\n # Each list(nodes) is one bug instances\n f_results: List[List[Node]] = []\n\n # lvalue -> node\n # track all the division results (and the assignment of the division results)\n divisions: DefaultDict[LVALUE, List[Node]] = defaultdict(list)\n\n _explore({function.entry_point}, f_results, divisions)\n\n for f_result in f_results:\n results.append((function, f_result))\n\n # Return the resulting set of nodes with divisions before multiplications\n return results\n\n\nclass DivideBeforeMultiply(AbstractDetector):\n \"\"\"\n Divide before multiply\n \"\"\"\n\n ARGUMENT = \"divide-before-multiply\"\n HELP = \"Imprecise arithmetic operations order\"\n IMPACT = DetectorClassification.MEDIUM\n CONFIDENCE = DetectorClassification.MEDIUM\n\n WIKI = \"https://github.com/crytic/slither/wiki/Detector-Documentation#divide-before-multiply\"\n\n WIKI_TITLE = \"Divide before multiply\"\n WIKI_DESCRIPTION = \"\"\"Solidity's integer division truncates. Thus, performing division before multiplication can lead to precision loss.\"\"\"\n\n # region wiki_exploit_scenario\n WIKI_EXPLOIT_SCENARIO = \"\"\"\n```solidity\ncontract A {\n\tfunction f(uint n) public {\n coins = (oldSupply / n) * interest;\n }\n}\n```\nIf `n` is greater than `oldSupply`, `coins` will be zero. For example, with `oldSupply = 5; n = 10, interest = 2`, coins will be zero. \nIf `(oldSupply * interest / n)` was used, `coins` would have been `1`. \nIn general, it's usually a good idea to re-arrange arithmetic to perform multiplication before division, unless the limit of a smaller type makes this dangerous.\"\"\"\n # endregion wiki_exploit_scenario\n\n WIKI_RECOMMENDATION = \"\"\"Consider ordering multiplication before division.\"\"\"\n\n def _detect(self) -> List[Output]:\n \"\"\"\n Detect divisions before multiplications\n \"\"\"\n results = []\n for contract in self.contracts:\n divisions_before_multiplications = detect_divide_before_multiply(contract)\n if divisions_before_multiplications:\n for (func, nodes) in divisions_before_multiplications:\n\n info: DETECTOR_INFO = [\n func,\n \" performs a multiplication on the result of a division:\\n\",\n ]\n\n # sort the nodes to get deterministic results\n nodes.sort(key=lambda x: x.node_id)\n\n for node in nodes:\n info += [\"\\t- \", node, \"\\n\"]\n\n res = self.generate_result(info)\n results.append(res)\n\n return results\n", "path": "slither/detectors/statements/divide_before_multiply.py"}]}
| 3,853 | 395 |
gh_patches_debug_36267
|
rasdani/github-patches
|
git_diff
|
liberapay__liberapay.com-129
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fix sign-in
We seem to have a problem with old cookies from a different account preventing log in.
Goal page is not accessible once connected
"405 Method Not Allowed"
on this page
https://liberapay.com/unisson/goal.html when i want to change my goal
I'm connected on my account.
Fix sign-in
We seem to have a problem with old cookies from a different account preventing log in.
</issue>
<code>
[start of liberapay/security/authentication.py]
1 """Defines website authentication helpers.
2 """
3 import binascii
4
5 from aspen import Response
6 from liberapay.constants import SESSION
7 from liberapay.models.participant import Participant
8
9
10 class _ANON(object):
11 ANON = True
12 is_admin = False
13 id = None
14 __bool__ = __nonzero__ = lambda *a: False
15 get_tip_to = lambda self, tippee: Participant._zero_tip_dict(tippee)
16 __repr__ = lambda self: '<ANON>'
17
18
19 ANON = _ANON()
20
21
22 def sign_in(request, state):
23 try:
24 body = request.body
25 except Response:
26 return
27
28 p = None
29
30 if body.get('log-in.username'):
31 p = Participant.authenticate(
32 'username', 'password',
33 body.pop('log-in.username'), body.pop('log-in.password')
34 )
35 if p and p.status == 'closed':
36 p.update_status('active')
37
38 elif body.get('sign-in.username'):
39 if body.pop('sign-in.terms') != 'agree':
40 raise Response(400, 'you have to agree to the terms')
41 kind = body.pop('sign-in.kind')
42 if kind not in ('individual', 'organization'):
43 raise Response(400, 'bad kind')
44 with state['website'].db.get_cursor() as c:
45 p = Participant.make_active(
46 body.pop('sign-in.username'), kind, body.pop('sign-in.password'),
47 cursor=c
48 )
49 p.add_email(body.pop('sign-in.email'), cursor=c)
50 p.authenticated = True
51
52 if p:
53 response = state.setdefault('response', Response())
54 p.sign_in(response.headers.cookie)
55 if body.pop('form.repost', None) != 'true':
56 response.redirect(request.line.uri)
57 state['user'] = p
58
59
60 def start_user_as_anon():
61 """Make sure we always have a user object, regardless of exceptions during authentication.
62 """
63 return {'user': ANON}
64
65
66 def authenticate_user_if_possible(request, state, user):
67 """This signs the user in.
68 """
69 if request.line.uri.startswith('/assets/'):
70 return
71 if 'Authorization' in request.headers:
72 header = request.headers['authorization']
73 if not header.startswith('Basic '):
74 raise Response(401, 'Unsupported authentication method')
75 try:
76 creds = binascii.a2b_base64(header[len('Basic '):]).split(':', 1)
77 except binascii.Error:
78 raise Response(400, 'Malformed "Authorization" header')
79 participant = Participant.authenticate('id', 'password', *creds)
80 if not participant:
81 raise Response(401)
82 return {'user': participant}
83 elif SESSION in request.headers.cookie:
84 creds = request.headers.cookie[SESSION].value.split(':', 1)
85 p = Participant.authenticate('id', 'session', *creds)
86 if p:
87 return {'user': p}
88 elif request.method == 'POST':
89 sign_in(request, state)
90
91
92 def add_auth_to_response(response, request=None, user=ANON):
93 if request is None:
94 return # early parsing must've failed
95 if request.line.uri.startswith('/assets/'):
96 return # assets never get auth headers
97
98 if SESSION in request.headers.cookie:
99 if not user.ANON:
100 user.keep_signed_in(response.headers.cookie)
101
[end of liberapay/security/authentication.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/liberapay/security/authentication.py b/liberapay/security/authentication.py
--- a/liberapay/security/authentication.py
+++ b/liberapay/security/authentication.py
@@ -19,12 +19,15 @@
ANON = _ANON()
-def sign_in(request, state):
+def sign_in_with_form_data(request, state):
try:
body = request.body
except Response:
return
+ if not isinstance(body, dict):
+ return
+
p = None
if body.get('log-in.username'):
@@ -49,12 +52,7 @@
p.add_email(body.pop('sign-in.email'), cursor=c)
p.authenticated = True
- if p:
- response = state.setdefault('response', Response())
- p.sign_in(response.headers.cookie)
- if body.pop('form.repost', None) != 'true':
- response.redirect(request.line.uri)
- state['user'] = p
+ return p
def start_user_as_anon():
@@ -68,6 +66,8 @@
"""
if request.line.uri.startswith('/assets/'):
return
+
+ # HTTP auth
if 'Authorization' in request.headers:
header = request.headers['authorization']
if not header.startswith('Basic '):
@@ -80,13 +80,26 @@
if not participant:
raise Response(401)
return {'user': participant}
- elif SESSION in request.headers.cookie:
+
+ # Cookie and form auth
+ # We want to try cookie auth first, but we want form auth to supersede it
+ p = None
+ response = state.setdefault('response', Response())
+ if SESSION in request.headers.cookie:
creds = request.headers.cookie[SESSION].value.split(':', 1)
p = Participant.authenticate('id', 'session', *creds)
if p:
- return {'user': p}
- elif request.method == 'POST':
- sign_in(request, state)
+ state['user'] = p
+ if request.method == 'POST':
+ old_p = p
+ p = sign_in_with_form_data(request, state)
+ if p:
+ if old_p:
+ old_p.sign_out(response.headers.cookie)
+ p.sign_in(response.headers.cookie)
+ state['user'] = p
+ if request.body.pop('form.repost', None) != 'true':
+ response.redirect(request.line.uri)
def add_auth_to_response(response, request=None, user=ANON):
|
{"golden_diff": "diff --git a/liberapay/security/authentication.py b/liberapay/security/authentication.py\n--- a/liberapay/security/authentication.py\n+++ b/liberapay/security/authentication.py\n@@ -19,12 +19,15 @@\n ANON = _ANON()\n \n \n-def sign_in(request, state):\n+def sign_in_with_form_data(request, state):\n try:\n body = request.body\n except Response:\n return\n \n+ if not isinstance(body, dict):\n+ return\n+\n p = None\n \n if body.get('log-in.username'):\n@@ -49,12 +52,7 @@\n p.add_email(body.pop('sign-in.email'), cursor=c)\n p.authenticated = True\n \n- if p:\n- response = state.setdefault('response', Response())\n- p.sign_in(response.headers.cookie)\n- if body.pop('form.repost', None) != 'true':\n- response.redirect(request.line.uri)\n- state['user'] = p\n+ return p\n \n \n def start_user_as_anon():\n@@ -68,6 +66,8 @@\n \"\"\"\n if request.line.uri.startswith('/assets/'):\n return\n+\n+ # HTTP auth\n if 'Authorization' in request.headers:\n header = request.headers['authorization']\n if not header.startswith('Basic '):\n@@ -80,13 +80,26 @@\n if not participant:\n raise Response(401)\n return {'user': participant}\n- elif SESSION in request.headers.cookie:\n+\n+ # Cookie and form auth\n+ # We want to try cookie auth first, but we want form auth to supersede it\n+ p = None\n+ response = state.setdefault('response', Response())\n+ if SESSION in request.headers.cookie:\n creds = request.headers.cookie[SESSION].value.split(':', 1)\n p = Participant.authenticate('id', 'session', *creds)\n if p:\n- return {'user': p}\n- elif request.method == 'POST':\n- sign_in(request, state)\n+ state['user'] = p\n+ if request.method == 'POST':\n+ old_p = p\n+ p = sign_in_with_form_data(request, state)\n+ if p:\n+ if old_p:\n+ old_p.sign_out(response.headers.cookie)\n+ p.sign_in(response.headers.cookie)\n+ state['user'] = p\n+ if request.body.pop('form.repost', None) != 'true':\n+ response.redirect(request.line.uri)\n \n \n def add_auth_to_response(response, request=None, user=ANON):\n", "issue": "Fix sign-in\nWe seem to have a problem with old cookies from a different account preventing log in.\n\nGoal page is not accessible once connected\n\"405 Method Not Allowed\"\non this page \nhttps://liberapay.com/unisson/goal.html when i want to change my goal\nI'm connected on my account.\n\nFix sign-in\nWe seem to have a problem with old cookies from a different account preventing log in.\n\n", "before_files": [{"content": "\"\"\"Defines website authentication helpers.\n\"\"\"\nimport binascii\n\nfrom aspen import Response\nfrom liberapay.constants import SESSION\nfrom liberapay.models.participant import Participant\n\n\nclass _ANON(object):\n ANON = True\n is_admin = False\n id = None\n __bool__ = __nonzero__ = lambda *a: False\n get_tip_to = lambda self, tippee: Participant._zero_tip_dict(tippee)\n __repr__ = lambda self: '<ANON>'\n\n\nANON = _ANON()\n\n\ndef sign_in(request, state):\n try:\n body = request.body\n except Response:\n return\n\n p = None\n\n if body.get('log-in.username'):\n p = Participant.authenticate(\n 'username', 'password',\n body.pop('log-in.username'), body.pop('log-in.password')\n )\n if p and p.status == 'closed':\n p.update_status('active')\n\n elif body.get('sign-in.username'):\n if body.pop('sign-in.terms') != 'agree':\n raise Response(400, 'you have to agree to the terms')\n kind = body.pop('sign-in.kind')\n if kind not in ('individual', 'organization'):\n raise Response(400, 'bad kind')\n with state['website'].db.get_cursor() as c:\n p = Participant.make_active(\n body.pop('sign-in.username'), kind, body.pop('sign-in.password'),\n cursor=c\n )\n p.add_email(body.pop('sign-in.email'), cursor=c)\n p.authenticated = True\n\n if p:\n response = state.setdefault('response', Response())\n p.sign_in(response.headers.cookie)\n if body.pop('form.repost', None) != 'true':\n response.redirect(request.line.uri)\n state['user'] = p\n\n\ndef start_user_as_anon():\n \"\"\"Make sure we always have a user object, regardless of exceptions during authentication.\n \"\"\"\n return {'user': ANON}\n\n\ndef authenticate_user_if_possible(request, state, user):\n \"\"\"This signs the user in.\n \"\"\"\n if request.line.uri.startswith('/assets/'):\n return\n if 'Authorization' in request.headers:\n header = request.headers['authorization']\n if not header.startswith('Basic '):\n raise Response(401, 'Unsupported authentication method')\n try:\n creds = binascii.a2b_base64(header[len('Basic '):]).split(':', 1)\n except binascii.Error:\n raise Response(400, 'Malformed \"Authorization\" header')\n participant = Participant.authenticate('id', 'password', *creds)\n if not participant:\n raise Response(401)\n return {'user': participant}\n elif SESSION in request.headers.cookie:\n creds = request.headers.cookie[SESSION].value.split(':', 1)\n p = Participant.authenticate('id', 'session', *creds)\n if p:\n return {'user': p}\n elif request.method == 'POST':\n sign_in(request, state)\n\n\ndef add_auth_to_response(response, request=None, user=ANON):\n if request is None:\n return # early parsing must've failed\n if request.line.uri.startswith('/assets/'):\n return # assets never get auth headers\n\n if SESSION in request.headers.cookie:\n if not user.ANON:\n user.keep_signed_in(response.headers.cookie)\n", "path": "liberapay/security/authentication.py"}]}
| 1,552 | 564 |
gh_patches_debug_18062
|
rasdani/github-patches
|
git_diff
|
ansible__ansible-modules-extras-1313
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
pam_limits - improve documentation
- Adds `comment` parameter
- Adds new examples with:
- `comment` parameter
- `value=unlimited`
- `limit_type=-`
pam_limits - improve documentation
- Adds `comment` parameter
- Adds new examples with:
- `comment` parameter
- `value=unlimited`
- `limit_type=-`
</issue>
<code>
[start of system/pam_limits.py]
1 #!/usr/bin/python
2 # -*- coding: utf-8 -*-
3
4 # (c) 2014, Sebastien Rohaut <[email protected]>
5 #
6 # This file is part of Ansible
7 #
8 # Ansible is free software: you can redistribute it and/or modify
9 # it under the terms of the GNU General Public License as published by
10 # the Free Software Foundation, either version 3 of the License, or
11 # (at your option) any later version.
12 #
13 # Ansible is distributed in the hope that it will be useful,
14 # but WITHOUT ANY WARRANTY; without even the implied warranty of
15 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
16 # GNU General Public License for more details.
17 #
18 # You should have received a copy of the GNU General Public License
19 # along with Ansible. If not, see <http://www.gnu.org/licenses/>.
20
21 import os
22 import os.path
23 import shutil
24 import re
25
26 DOCUMENTATION = '''
27 ---
28 module: pam_limits
29 version_added: "2.0"
30 short_description: Modify Linux PAM limits
31 description:
32 - The M(pam_limits) module modify PAM limits, default in /etc/security/limits.conf.
33 For the full documentation, see man limits.conf(5).
34 options:
35 domain:
36 description:
37 - A username, @groupname, wildcard, uid/gid range.
38 required: true
39 limit_type:
40 description:
41 - Limit type, see C(man limits) for an explanation
42 required: true
43 choices: [ "hard", "soft", "-" ]
44 limit_item:
45 description:
46 - The limit to be set
47 required: true
48 choices: [ "core", "data", "fsize", "memlock", "nofile", "rss", "stack", "cpu", "nproc", "as", "maxlogins", "maxsyslogins", "priority", "locks", "sigpending", "msgqueue", "nice", "rtprio", "chroot" ]
49 value:
50 description:
51 - The value of the limit.
52 required: true
53 backup:
54 description:
55 - Create a backup file including the timestamp information so you can get
56 the original file back if you somehow clobbered it incorrectly.
57 required: false
58 choices: [ "yes", "no" ]
59 default: "no"
60 use_min:
61 description:
62 - If set to C(yes), the minimal value will be used or conserved.
63 If the specified value is inferior to the value in the file, file content is replaced with the new value,
64 else content is not modified.
65 required: false
66 choices: [ "yes", "no" ]
67 default: "no"
68 use_max:
69 description:
70 - If set to C(yes), the maximal value will be used or conserved.
71 If the specified value is superior to the value in the file, file content is replaced with the new value,
72 else content is not modified.
73 required: false
74 choices: [ "yes", "no" ]
75 default: "no"
76 dest:
77 description:
78 - Modify the limits.conf path.
79 required: false
80 default: "/etc/security/limits.conf"
81 '''
82
83 EXAMPLES = '''
84 # Add or modify limits for the user joe
85 - pam_limits: domain=joe limit_type=soft limit_item=nofile value=64000
86
87 # Add or modify limits for the user joe. Keep or set the maximal value
88 - pam_limits: domain=joe limit_type=soft limit_item=nofile value=1000000
89 '''
90
91 def main():
92
93 pam_items = [ 'core', 'data', 'fsize', 'memlock', 'nofile', 'rss', 'stack', 'cpu', 'nproc', 'as', 'maxlogins', 'maxsyslogins', 'priority', 'locks', 'sigpending', 'msgqueue', 'nice', 'rtprio', 'chroot' ]
94
95 pam_types = [ 'soft', 'hard', '-' ]
96
97 limits_conf = '/etc/security/limits.conf'
98
99 module = AnsibleModule(
100 # not checking because of daisy chain to file module
101 argument_spec = dict(
102 domain = dict(required=True, type='str'),
103 limit_type = dict(required=True, type='str', choices=pam_types),
104 limit_item = dict(required=True, type='str', choices=pam_items),
105 value = dict(required=True, type='str'),
106 use_max = dict(default=False, type='bool'),
107 use_min = dict(default=False, type='bool'),
108 backup = dict(default=False, type='bool'),
109 dest = dict(default=limits_conf, type='str'),
110 comment = dict(required=False, default='', type='str')
111 )
112 )
113
114 domain = module.params['domain']
115 limit_type = module.params['limit_type']
116 limit_item = module.params['limit_item']
117 value = module.params['value']
118 use_max = module.params['use_max']
119 use_min = module.params['use_min']
120 backup = module.params['backup']
121 limits_conf = module.params['dest']
122 new_comment = module.params['comment']
123
124 changed = False
125
126 if os.path.isfile(limits_conf):
127 if not os.access(limits_conf, os.W_OK):
128 module.fail_json(msg="%s is not writable. Use sudo" % (limits_conf) )
129 else:
130 module.fail_json(msg="%s is not visible (check presence, access rights, use sudo)" % (limits_conf) )
131
132 if use_max and use_min:
133 module.fail_json(msg="Cannot use use_min and use_max at the same time." )
134
135 if not (value in ['unlimited', 'infinity', '-1'] or value.isdigit()):
136 module.fail_json(msg="Argument 'value' can be one of 'unlimited', 'infinity', '-1' or positive number. Refer to manual pages for more details.")
137
138 # Backup
139 if backup:
140 backup_file = module.backup_local(limits_conf)
141
142 space_pattern = re.compile(r'\s+')
143
144 message = ''
145 f = open (limits_conf, 'r')
146 # Tempfile
147 nf = tempfile.NamedTemporaryFile(delete = False)
148
149 found = False
150 new_value = value
151
152 for line in f:
153
154 if line.startswith('#'):
155 nf.write(line)
156 continue
157
158 newline = re.sub(space_pattern, ' ', line).strip()
159 if not newline:
160 nf.write(line)
161 continue
162
163 # Remove comment in line
164 newline = newline.split('#',1)[0]
165 try:
166 old_comment = line.split('#',1)[1]
167 except:
168 old_comment = ''
169
170 newline = newline.rstrip()
171
172 if not new_comment:
173 new_comment = old_comment
174
175 if new_comment:
176 new_comment = "\t#"+new_comment
177
178 line_fields = newline.split(' ')
179
180 if len(line_fields) != 4:
181 nf.write(line)
182 continue
183
184 line_domain = line_fields[0]
185 line_type = line_fields[1]
186 line_item = line_fields[2]
187 actual_value = line_fields[3]
188
189 if not (actual_value in ['unlimited', 'infinity', '-1'] or actual_value.isdigit()):
190 module.fail_json(msg="Invalid configuration of '%s'. Current value of %s is unsupported." % (limits_conf, line_item))
191
192 # Found the line
193 if line_domain == domain and line_type == limit_type and line_item == limit_item:
194 found = True
195 if value == actual_value:
196 message = line
197 nf.write(line)
198 continue
199
200 actual_value_unlimited = actual_value in ['unlimited', 'infinity', '-1']
201 value_unlimited = value in ['unlimited', 'infinity', '-1']
202
203 if use_max:
204 if value.isdigit() and actual_value.isdigit():
205 new_value = max(int(value), int(actual_value))
206 elif actual_value_unlimited:
207 new_value = actual_value
208 else:
209 new_value = value
210
211 if use_min:
212 if value.isdigit() and actual_value.isdigit():
213 new_value = min(int(value), int(actual_value))
214 elif value_unlimited:
215 new_value = actual_value
216 else:
217 new_value = value
218
219 # Change line only if value has changed
220 if new_value != actual_value:
221 changed = True
222 new_limit = domain + "\t" + limit_type + "\t" + limit_item + "\t" + str(new_value) + new_comment + "\n"
223 message = new_limit
224 nf.write(new_limit)
225 else:
226 message = line
227 nf.write(line)
228 else:
229 nf.write(line)
230
231 if not found:
232 changed = True
233 new_limit = domain + "\t" + limit_type + "\t" + limit_item + "\t" + str(new_value) + new_comment + "\n"
234 message = new_limit
235 nf.write(new_limit)
236
237 f.close()
238 nf.close()
239
240 # Copy tempfile to newfile
241 module.atomic_move(nf.name, f.name)
242
243 res_args = dict(
244 changed = changed, msg = message
245 )
246
247 if backup:
248 res_args['backup_file'] = backup_file
249
250 module.exit_json(**res_args)
251
252
253 # import module snippets
254 from ansible.module_utils.basic import *
255 main()
256
[end of system/pam_limits.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/system/pam_limits.py b/system/pam_limits.py
--- a/system/pam_limits.py
+++ b/system/pam_limits.py
@@ -78,14 +78,22 @@
- Modify the limits.conf path.
required: false
default: "/etc/security/limits.conf"
+ comment:
+ description:
+ - Comment associated with the limit.
+ required: false
+ default: ''
'''
EXAMPLES = '''
-# Add or modify limits for the user joe
+# Add or modify nofile soft limit for the user joe
- pam_limits: domain=joe limit_type=soft limit_item=nofile value=64000
-# Add or modify limits for the user joe. Keep or set the maximal value
-- pam_limits: domain=joe limit_type=soft limit_item=nofile value=1000000
+# Add or modify fsize hard limit for the user smith. Keep or set the maximal value.
+- pam_limits: domain=smith limit_type=hard limit_item=fsize value=1000000 use_max=yes
+
+# Add or modify memlock, both soft and hard, limit for the user james with a comment.
+- pam_limits: domain=james limit_type=- limit_item=memlock value=unlimited comment="unlimited memory lock for james"
'''
def main():
|
{"golden_diff": "diff --git a/system/pam_limits.py b/system/pam_limits.py\n--- a/system/pam_limits.py\n+++ b/system/pam_limits.py\n@@ -78,14 +78,22 @@\n - Modify the limits.conf path.\n required: false\n default: \"/etc/security/limits.conf\"\n+ comment:\n+ description:\n+ - Comment associated with the limit.\n+ required: false\n+ default: ''\n '''\n \n EXAMPLES = '''\n-# Add or modify limits for the user joe\n+# Add or modify nofile soft limit for the user joe\n - pam_limits: domain=joe limit_type=soft limit_item=nofile value=64000\n \n-# Add or modify limits for the user joe. Keep or set the maximal value\n-- pam_limits: domain=joe limit_type=soft limit_item=nofile value=1000000\n+# Add or modify fsize hard limit for the user smith. Keep or set the maximal value.\n+- pam_limits: domain=smith limit_type=hard limit_item=fsize value=1000000 use_max=yes\n+\n+# Add or modify memlock, both soft and hard, limit for the user james with a comment.\n+- pam_limits: domain=james limit_type=- limit_item=memlock value=unlimited comment=\"unlimited memory lock for james\"\n '''\n \n def main():\n", "issue": "pam_limits - improve documentation\n- Adds `comment` parameter\n- Adds new examples with:\n - `comment` parameter\n - `value=unlimited`\n - `limit_type=-`\n\npam_limits - improve documentation\n- Adds `comment` parameter\n- Adds new examples with:\n - `comment` parameter\n - `value=unlimited`\n - `limit_type=-`\n\n", "before_files": [{"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n# (c) 2014, Sebastien Rohaut <[email protected]>\n#\n# This file is part of Ansible\n#\n# Ansible is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Ansible is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Ansible. If not, see <http://www.gnu.org/licenses/>.\n\nimport os\nimport os.path\nimport shutil\nimport re\n\nDOCUMENTATION = '''\n---\nmodule: pam_limits\nversion_added: \"2.0\"\nshort_description: Modify Linux PAM limits\ndescription:\n - The M(pam_limits) module modify PAM limits, default in /etc/security/limits.conf.\n For the full documentation, see man limits.conf(5).\noptions:\n domain:\n description:\n - A username, @groupname, wildcard, uid/gid range.\n required: true\n limit_type:\n description:\n - Limit type, see C(man limits) for an explanation\n required: true\n choices: [ \"hard\", \"soft\", \"-\" ]\n limit_item:\n description:\n - The limit to be set\n required: true\n choices: [ \"core\", \"data\", \"fsize\", \"memlock\", \"nofile\", \"rss\", \"stack\", \"cpu\", \"nproc\", \"as\", \"maxlogins\", \"maxsyslogins\", \"priority\", \"locks\", \"sigpending\", \"msgqueue\", \"nice\", \"rtprio\", \"chroot\" ]\n value:\n description:\n - The value of the limit.\n required: true\n backup:\n description:\n - Create a backup file including the timestamp information so you can get\n the original file back if you somehow clobbered it incorrectly.\n required: false\n choices: [ \"yes\", \"no\" ]\n default: \"no\"\n use_min:\n description:\n - If set to C(yes), the minimal value will be used or conserved.\n If the specified value is inferior to the value in the file, file content is replaced with the new value,\n else content is not modified.\n required: false\n choices: [ \"yes\", \"no\" ]\n default: \"no\"\n use_max:\n description:\n - If set to C(yes), the maximal value will be used or conserved.\n If the specified value is superior to the value in the file, file content is replaced with the new value,\n else content is not modified.\n required: false\n choices: [ \"yes\", \"no\" ]\n default: \"no\"\n dest:\n description:\n - Modify the limits.conf path.\n required: false\n default: \"/etc/security/limits.conf\"\n'''\n\nEXAMPLES = '''\n# Add or modify limits for the user joe\n- pam_limits: domain=joe limit_type=soft limit_item=nofile value=64000\n\n# Add or modify limits for the user joe. Keep or set the maximal value\n- pam_limits: domain=joe limit_type=soft limit_item=nofile value=1000000\n'''\n\ndef main():\n\n pam_items = [ 'core', 'data', 'fsize', 'memlock', 'nofile', 'rss', 'stack', 'cpu', 'nproc', 'as', 'maxlogins', 'maxsyslogins', 'priority', 'locks', 'sigpending', 'msgqueue', 'nice', 'rtprio', 'chroot' ]\n\n pam_types = [ 'soft', 'hard', '-' ]\n\n limits_conf = '/etc/security/limits.conf'\n\n module = AnsibleModule(\n # not checking because of daisy chain to file module\n argument_spec = dict(\n domain = dict(required=True, type='str'),\n limit_type = dict(required=True, type='str', choices=pam_types),\n limit_item = dict(required=True, type='str', choices=pam_items),\n value = dict(required=True, type='str'),\n use_max = dict(default=False, type='bool'),\n use_min = dict(default=False, type='bool'),\n backup = dict(default=False, type='bool'),\n dest = dict(default=limits_conf, type='str'),\n comment = dict(required=False, default='', type='str')\n )\n )\n\n domain = module.params['domain']\n limit_type = module.params['limit_type']\n limit_item = module.params['limit_item']\n value = module.params['value']\n use_max = module.params['use_max']\n use_min = module.params['use_min']\n backup = module.params['backup']\n limits_conf = module.params['dest']\n new_comment = module.params['comment']\n\n changed = False\n\n if os.path.isfile(limits_conf):\n if not os.access(limits_conf, os.W_OK):\n module.fail_json(msg=\"%s is not writable. Use sudo\" % (limits_conf) )\n else:\n module.fail_json(msg=\"%s is not visible (check presence, access rights, use sudo)\" % (limits_conf) )\n\n if use_max and use_min:\n module.fail_json(msg=\"Cannot use use_min and use_max at the same time.\" )\n\n if not (value in ['unlimited', 'infinity', '-1'] or value.isdigit()):\n module.fail_json(msg=\"Argument 'value' can be one of 'unlimited', 'infinity', '-1' or positive number. Refer to manual pages for more details.\")\n\n # Backup\n if backup:\n backup_file = module.backup_local(limits_conf)\n\n space_pattern = re.compile(r'\\s+')\n\n message = ''\n f = open (limits_conf, 'r')\n # Tempfile\n nf = tempfile.NamedTemporaryFile(delete = False)\n\n found = False\n new_value = value\n\n for line in f:\n\n if line.startswith('#'):\n nf.write(line)\n continue\n\n newline = re.sub(space_pattern, ' ', line).strip()\n if not newline:\n nf.write(line)\n continue\n\n # Remove comment in line\n newline = newline.split('#',1)[0]\n try:\n old_comment = line.split('#',1)[1]\n except:\n old_comment = ''\n\n newline = newline.rstrip()\n\n if not new_comment:\n new_comment = old_comment\n\n if new_comment:\n new_comment = \"\\t#\"+new_comment\n\n line_fields = newline.split(' ')\n\n if len(line_fields) != 4:\n nf.write(line)\n continue\n\n line_domain = line_fields[0]\n line_type = line_fields[1]\n line_item = line_fields[2]\n actual_value = line_fields[3]\n\n if not (actual_value in ['unlimited', 'infinity', '-1'] or actual_value.isdigit()):\n module.fail_json(msg=\"Invalid configuration of '%s'. Current value of %s is unsupported.\" % (limits_conf, line_item))\n\n # Found the line\n if line_domain == domain and line_type == limit_type and line_item == limit_item:\n found = True\n if value == actual_value:\n message = line\n nf.write(line)\n continue\n\n actual_value_unlimited = actual_value in ['unlimited', 'infinity', '-1']\n value_unlimited = value in ['unlimited', 'infinity', '-1']\n\n if use_max:\n if value.isdigit() and actual_value.isdigit():\n new_value = max(int(value), int(actual_value))\n elif actual_value_unlimited:\n new_value = actual_value\n else:\n new_value = value\n\n if use_min:\n if value.isdigit() and actual_value.isdigit():\n new_value = min(int(value), int(actual_value))\n elif value_unlimited:\n new_value = actual_value\n else:\n new_value = value\n\n # Change line only if value has changed\n if new_value != actual_value:\n changed = True\n new_limit = domain + \"\\t\" + limit_type + \"\\t\" + limit_item + \"\\t\" + str(new_value) + new_comment + \"\\n\"\n message = new_limit\n nf.write(new_limit)\n else:\n message = line\n nf.write(line)\n else:\n nf.write(line)\n\n if not found:\n changed = True\n new_limit = domain + \"\\t\" + limit_type + \"\\t\" + limit_item + \"\\t\" + str(new_value) + new_comment + \"\\n\"\n message = new_limit\n nf.write(new_limit)\n\n f.close()\n nf.close()\n\n # Copy tempfile to newfile\n module.atomic_move(nf.name, f.name)\n\n res_args = dict(\n changed = changed, msg = message\n )\n\n if backup:\n res_args['backup_file'] = backup_file\n\n module.exit_json(**res_args)\n\n\n# import module snippets\nfrom ansible.module_utils.basic import *\nmain()\n", "path": "system/pam_limits.py"}]}
| 3,337 | 296 |
gh_patches_debug_18954
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-center-index-9784
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[request] imgui/any. "Docking" feature
### Package Details
* Package Name/Version: **imgui/any**
* Homepage: **https://github.com/ocornut/imgui**
There is a feature "Docking" in this library that lives in a separate branch a long time (from 2018) and is still regularly updated over time (last merge from master about 14 days ago). I'd wanted to have a package with this feature, maybe something like `imgui/1.84.2-docking`
</issue>
<code>
[start of recipes/imgui/all/conanfile.py]
1 from conans import ConanFile, CMake, tools
2 import os
3
4 required_conan_version = ">=1.33.0"
5
6
7 class IMGUIConan(ConanFile):
8 name = "imgui"
9 url = "https://github.com/conan-io/conan-center-index"
10 homepage = "https://github.com/ocornut/imgui"
11 description = "Bloat-free Immediate Mode Graphical User interface for C++ with minimal dependencies"
12 topics = ("dear", "imgui", "gui", "graphical", "bloat-free", )
13 license = "MIT"
14
15 settings = "os", "arch", "compiler", "build_type"
16 options = {
17 "shared": [True, False],
18 "fPIC": [True, False],
19 }
20 default_options = {
21 "shared": False,
22 "fPIC": True,
23 }
24
25 exports_sources = "CMakeLists.txt"
26 generators = "cmake"
27 _cmake = None
28
29 @property
30 def _source_subfolder(self):
31 return "source_subfolder"
32
33 def config_options(self):
34 if self.settings.os == "Windows":
35 del self.options.fPIC
36
37 def configure(self):
38 if self.options.shared:
39 del self.options.fPIC
40
41 def source(self):
42 tools.get(**self.conan_data["sources"][self.version],
43 destination=self._source_subfolder, strip_root=True)
44
45 def _configure_cmake(self):
46 if self._cmake:
47 return self._cmake
48 self._cmake = CMake(self)
49 self._cmake.configure()
50 return self._cmake
51
52 def build(self):
53 cmake = self._configure_cmake()
54 cmake.build()
55
56 def package(self):
57 self.copy(pattern="LICENSE.txt", dst="licenses", src=self._source_subfolder)
58 backends_folder = os.path.join(
59 self._source_subfolder,
60 "backends" if tools.Version(self.version) >= "1.80" else "examples"
61 )
62 self.copy(pattern="imgui_impl_*",
63 dst=os.path.join("res", "bindings"),
64 src=backends_folder)
65 cmake = self._configure_cmake()
66 cmake.install()
67
68 def package_info(self):
69 self.cpp_info.libs = ["imgui"]
70 self.cpp_info.defines.append("IMGUI_USER_CONFIG=\"imgui_user_config.h\"")
71 if self.settings.os == "Linux":
72 self.cpp_info.system_libs.append("m")
73 self.cpp_info.srcdirs = [os.path.join("res", "bindings")]
74
75 bin_path = os.path.join(self.package_folder, "bin")
76 self.output.info("Appending PATH env var with : {}".format(bin_path))
77 self.env_info.PATH.append(bin_path)
78
[end of recipes/imgui/all/conanfile.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/recipes/imgui/all/conanfile.py b/recipes/imgui/all/conanfile.py
--- a/recipes/imgui/all/conanfile.py
+++ b/recipes/imgui/all/conanfile.py
@@ -1,5 +1,6 @@
from conans import ConanFile, CMake, tools
import os
+import re
required_conan_version = ">=1.33.0"
@@ -55,9 +56,11 @@
def package(self):
self.copy(pattern="LICENSE.txt", dst="licenses", src=self._source_subfolder)
+ m = re.match(r'cci\.\d{8}\+(?P<version>\d+\.\d+)\.docking', str(self.version))
+ version = tools.Version(m.group('version')) if m else tools.Version(self.version)
backends_folder = os.path.join(
self._source_subfolder,
- "backends" if tools.Version(self.version) >= "1.80" else "examples"
+ "backends" if version >= "1.80" else "examples"
)
self.copy(pattern="imgui_impl_*",
dst=os.path.join("res", "bindings"),
|
{"golden_diff": "diff --git a/recipes/imgui/all/conanfile.py b/recipes/imgui/all/conanfile.py\n--- a/recipes/imgui/all/conanfile.py\n+++ b/recipes/imgui/all/conanfile.py\n@@ -1,5 +1,6 @@\n from conans import ConanFile, CMake, tools\n import os\n+import re\n \n required_conan_version = \">=1.33.0\"\n \n@@ -55,9 +56,11 @@\n \n def package(self):\n self.copy(pattern=\"LICENSE.txt\", dst=\"licenses\", src=self._source_subfolder)\n+ m = re.match(r'cci\\.\\d{8}\\+(?P<version>\\d+\\.\\d+)\\.docking', str(self.version))\n+ version = tools.Version(m.group('version')) if m else tools.Version(self.version)\n backends_folder = os.path.join(\n self._source_subfolder,\n- \"backends\" if tools.Version(self.version) >= \"1.80\" else \"examples\"\n+ \"backends\" if version >= \"1.80\" else \"examples\"\n )\n self.copy(pattern=\"imgui_impl_*\",\n dst=os.path.join(\"res\", \"bindings\"),\n", "issue": "[request] imgui/any. \"Docking\" feature\n### Package Details\r\n * Package Name/Version: **imgui/any**\r\n * Homepage: **https://github.com/ocornut/imgui**\r\n\r\nThere is a feature \"Docking\" in this library that lives in a separate branch a long time (from 2018) and is still regularly updated over time (last merge from master about 14 days ago). I'd wanted to have a package with this feature, maybe something like `imgui/1.84.2-docking`\n", "before_files": [{"content": "from conans import ConanFile, CMake, tools\nimport os\n\nrequired_conan_version = \">=1.33.0\"\n\n\nclass IMGUIConan(ConanFile):\n name = \"imgui\"\n url = \"https://github.com/conan-io/conan-center-index\"\n homepage = \"https://github.com/ocornut/imgui\"\n description = \"Bloat-free Immediate Mode Graphical User interface for C++ with minimal dependencies\"\n topics = (\"dear\", \"imgui\", \"gui\", \"graphical\", \"bloat-free\", )\n license = \"MIT\"\n\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n options = {\n \"shared\": [True, False],\n \"fPIC\": [True, False],\n }\n default_options = {\n \"shared\": False,\n \"fPIC\": True,\n }\n\n exports_sources = \"CMakeLists.txt\"\n generators = \"cmake\"\n _cmake = None\n\n @property\n def _source_subfolder(self):\n return \"source_subfolder\"\n\n def config_options(self):\n if self.settings.os == \"Windows\":\n del self.options.fPIC\n\n def configure(self):\n if self.options.shared:\n del self.options.fPIC\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version],\n destination=self._source_subfolder, strip_root=True)\n\n def _configure_cmake(self):\n if self._cmake:\n return self._cmake\n self._cmake = CMake(self)\n self._cmake.configure()\n return self._cmake\n\n def build(self):\n cmake = self._configure_cmake()\n cmake.build()\n\n def package(self):\n self.copy(pattern=\"LICENSE.txt\", dst=\"licenses\", src=self._source_subfolder)\n backends_folder = os.path.join(\n self._source_subfolder,\n \"backends\" if tools.Version(self.version) >= \"1.80\" else \"examples\"\n )\n self.copy(pattern=\"imgui_impl_*\",\n dst=os.path.join(\"res\", \"bindings\"),\n src=backends_folder)\n cmake = self._configure_cmake()\n cmake.install()\n\n def package_info(self):\n self.cpp_info.libs = [\"imgui\"]\n self.cpp_info.defines.append(\"IMGUI_USER_CONFIG=\\\"imgui_user_config.h\\\"\")\n if self.settings.os == \"Linux\":\n self.cpp_info.system_libs.append(\"m\")\n self.cpp_info.srcdirs = [os.path.join(\"res\", \"bindings\")]\n\n bin_path = os.path.join(self.package_folder, \"bin\")\n self.output.info(\"Appending PATH env var with : {}\".format(bin_path))\n self.env_info.PATH.append(bin_path)\n", "path": "recipes/imgui/all/conanfile.py"}]}
| 1,407 | 264 |
gh_patches_debug_34249
|
rasdani/github-patches
|
git_diff
|
OpenMined__PySyft-5385
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add ability to load multiple libs in one call
## Description
`sy.load()` should accept any valid sequence of strings, variadic args, a list, tuple or set of strings like:
```
sy.load("pydp", "opacus")
sy.load(["pydp", "opacus"])
sy.load(("pydp", "opacus"))
sy.load({"pydp", "opacus"})
```
## Definition of Done
Loading multiple libs in one go is possible with tests to show it works.
</issue>
<code>
[start of src/syft/lib/__init__.py]
1 # stdlib
2 import importlib
3 import sys
4 from types import ModuleType
5 from typing import Any
6 from typing import Any as TypeAny
7 from typing import Dict as TypeDict
8 from typing import Optional
9 from typing import Union as TypeUnion
10 import warnings
11
12 # third party
13 from packaging import version
14
15 # syft relative
16 from ..ast.globals import Globals
17 from ..core.node.abstract.node import AbstractNodeClient
18 from ..lib.plan import create_plan_ast
19 from ..lib.python import create_python_ast
20 from ..lib.remote_dataloader import create_remote_dataloader_ast
21 from ..lib.torch import create_torch_ast
22 from ..lib.torchvision import create_torchvision_ast
23 from ..logger import critical
24 from ..logger import traceback_and_raise
25 from ..logger import warning
26 from .misc import create_union_ast
27
28
29 class VendorLibraryImportException(Exception):
30 pass
31
32
33 def vendor_requirements_available(vendor_requirements: TypeDict[str, TypeAny]) -> bool:
34 """
35 Check whether torch or python version is supported
36
37 Args:
38 vendor_requirements: dictionary containing version of python or torch to be supported
39
40 Returns:
41 True if system supports all vendor requirements
42
43 """
44 # see if python version is supported
45 if "python" in vendor_requirements:
46 python_reqs = vendor_requirements["python"]
47
48 PYTHON_VERSION = sys.version_info
49 min_version = python_reqs.get("min_version", None)
50 if min_version is not None:
51 if PYTHON_VERSION < min_version:
52 traceback_and_raise(
53 VendorLibraryImportException(
54 f"Unable to load {vendor_requirements['lib']}."
55 + f"Python: {PYTHON_VERSION} < {min_version}"
56 )
57 )
58 max_version = python_reqs.get("max_version", None)
59 if max_version is not None:
60 if PYTHON_VERSION > max_version:
61 traceback_and_raise(
62 VendorLibraryImportException(
63 f"Unable to load {vendor_requirements['lib']}."
64 + f"Python: {PYTHON_VERSION} > {max_version}"
65 )
66 )
67
68 # see if torch version is supported
69 if "torch" in vendor_requirements:
70 torch_reqs = vendor_requirements["torch"]
71 # third party
72 import torch
73
74 TORCH_VERSION = version.parse(torch.__version__.split("+")[0])
75 min_version = torch_reqs.get("min_version", None)
76 if min_version is not None:
77 if TORCH_VERSION < version.parse(min_version):
78 traceback_and_raise(
79 VendorLibraryImportException(
80 f"Unable to load {vendor_requirements['lib']}."
81 + f"Torch: {TORCH_VERSION} < {min_version}"
82 )
83 )
84
85 max_version = torch_reqs.get("max_version", None)
86 if max_version is not None:
87 if TORCH_VERSION > version.parse(max_version):
88 traceback_and_raise(
89 VendorLibraryImportException(
90 f"Unable to load {vendor_requirements['lib']}."
91 + f"Torch: {TORCH_VERSION} > {max_version}"
92 )
93 )
94
95 return True
96
97
98 def _add_lib(
99 *, vendor_ast: ModuleType, ast_or_client: TypeUnion[Globals, AbstractNodeClient]
100 ) -> None:
101 update_ast = getattr(vendor_ast, "update_ast", None)
102 post_update_ast = getattr(vendor_ast, "post_update_ast", None)
103 if update_ast is not None:
104 update_ast(ast_or_client=ast_or_client)
105 if post_update_ast is not None:
106 post_update_ast(ast_or_client=ast_or_client)
107
108
109 def _regenerate_unions(*, lib_ast: Globals, client: TypeAny = None) -> None:
110 union_misc_ast = getattr(
111 getattr(create_union_ast(lib_ast=lib_ast, client=client), "syft"), "lib"
112 )
113 if client is not None:
114 client.syft.lib.add_attr(attr_name="misc", attr=union_misc_ast.attrs["misc"])
115 else:
116 lib_ast.syft.lib.add_attr(attr_name="misc", attr=union_misc_ast.attrs["misc"])
117
118
119 def _load_lib(*, lib: str, options: TypeDict[str, TypeAny] = {}) -> None:
120 """
121 Load and Update Node with given library module
122
123 Args:
124 lib: name of library to load and update Node with
125 options: external requirements for loading library successfully
126 """
127 _ = importlib.import_module(lib)
128 vendor_ast = importlib.import_module(f"syft.lib.{lib}")
129 PACKAGE_SUPPORT = getattr(vendor_ast, "PACKAGE_SUPPORT", None)
130 PACKAGE_SUPPORT.update(options)
131 if PACKAGE_SUPPORT is not None and vendor_requirements_available(
132 vendor_requirements=PACKAGE_SUPPORT
133 ):
134 global lib_ast
135 _add_lib(vendor_ast=vendor_ast, ast_or_client=lib_ast)
136 # cache the constructor for future created clients
137 lib_ast.loaded_lib_constructors[lib] = getattr(vendor_ast, "update_ast", None)
138 _regenerate_unions(lib_ast=lib_ast)
139
140 for _, client in lib_ast.registered_clients.items():
141 _add_lib(vendor_ast=vendor_ast, ast_or_client=client)
142 _regenerate_unions(lib_ast=lib_ast, client=client)
143
144
145 def load(lib: str, options: TypeDict[str, TypeAny] = {}) -> None:
146 """
147 Load and Update Node with given library module
148
149 Args:
150 lib: name of library to load and update Node with
151 options: external requirements for loading library successfully
152 """
153 try:
154 _load_lib(lib=lib, options=options)
155 except VendorLibraryImportException as e:
156 critical(e)
157 except Exception as e:
158 critical(f"Unable to load package support for: {lib}. {e}")
159
160
161 def load_lib(lib: str, options: TypeDict[str, TypeAny] = {}) -> None:
162 """
163 Load and Update Node with given library module
164 load_lib() is deprecated please use load() in the future
165
166 Args:
167 lib: name of library to load and update Node with
168 options: external requirements for loading library successfully
169
170 """
171 msg = "load_lib() is deprecated please use load() in the future"
172 warning(msg, print=True)
173 warnings.warn(msg, DeprecationWarning)
174 load(lib=lib, options=options)
175
176
177 # now we need to load the relevant frameworks onto the node
178 def create_lib_ast(client: Optional[Any] = None) -> Globals:
179 """
180 Create AST and load the relevant frameworks onto the node
181
182 Args:
183 client: VM client onto whom the frameworks need to be loaded
184
185 Returns:
186 AST for client of type Globals
187
188 """
189 python_ast = create_python_ast(client=client)
190 torch_ast = create_torch_ast(client=client)
191 torchvision_ast = create_torchvision_ast(client=client)
192 # numpy_ast = create_numpy_ast()
193 plan_ast = create_plan_ast(client=client)
194 remote_dataloader_ast = create_remote_dataloader_ast(client=client)
195
196 lib_ast = Globals(client=client)
197 lib_ast.add_attr(attr_name="syft", attr=python_ast.attrs["syft"])
198 lib_ast.add_attr(attr_name="torch", attr=torch_ast.attrs["torch"])
199 lib_ast.add_attr(attr_name="torchvision", attr=torchvision_ast.attrs["torchvision"])
200 lib_ast.syft.add_attr("core", attr=plan_ast.syft.core)
201 lib_ast.syft.core.add_attr(
202 "remote_dataloader", remote_dataloader_ast.syft.core.remote_dataloader
203 )
204
205 # let the misc creation be always the last, as it needs the full ast solved
206 # to properly generated unions
207 union_misc_ast = getattr(getattr(create_union_ast(lib_ast, client), "syft"), "lib")
208 lib_ast.syft.lib.add_attr(attr_name="misc", attr=union_misc_ast.attrs["misc"])
209
210 return lib_ast
211
212
213 lib_ast = create_lib_ast(None)
214
[end of src/syft/lib/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/syft/lib/__init__.py b/src/syft/lib/__init__.py
--- a/src/syft/lib/__init__.py
+++ b/src/syft/lib/__init__.py
@@ -5,7 +5,11 @@
from typing import Any
from typing import Any as TypeAny
from typing import Dict as TypeDict
+from typing import Iterable
+from typing import List as TypeList
from typing import Optional
+from typing import Set as TypeSet
+from typing import Tuple as TypeTuple
from typing import Union as TypeUnion
import warnings
@@ -142,20 +146,42 @@
_regenerate_unions(lib_ast=lib_ast, client=client)
-def load(lib: str, options: TypeDict[str, TypeAny] = {}) -> None:
+def load(
+ *libs: TypeUnion[TypeList[str], TypeTuple[str], TypeSet[str], str],
+ options: TypeDict[str, TypeAny] = {},
+ **kwargs: str,
+) -> None:
"""
Load and Update Node with given library module
Args:
- lib: name of library to load and update Node with
+ *libs: names of libraries to load and update Node with (can be variadic, tuple, list, set)
options: external requirements for loading library successfully
+ **kwargs: for backward compatibility with calls like `syft.load(lib = "opacus")`
"""
- try:
- _load_lib(lib=lib, options=options)
- except VendorLibraryImportException as e:
- critical(e)
- except Exception as e:
- critical(f"Unable to load package support for: {lib}. {e}")
+ # For backward compatibility with calls like `syft.load(lib = "opacus")`
+ if "lib" in kwargs.keys():
+ libs += tuple(kwargs["lib"])
+
+ if isinstance(libs[0], Iterable):
+ if not isinstance(libs[0], str):
+ libs = tuple(libs[0])
+ for lib in libs:
+ if isinstance(lib, str):
+ try:
+ _load_lib(lib=str(lib), options=options)
+ except VendorLibraryImportException as e:
+ critical(e)
+ except Exception as e:
+ critical(f"Unable to load package support for: {lib}. {e}")
+ else:
+ critical(
+ f"Unable to load package support for: {lib}. Pass lib name as string object."
+ )
+ else:
+ critical(
+ "Unable to load package support for any library. Iterable object not found."
+ )
def load_lib(lib: str, options: TypeDict[str, TypeAny] = {}) -> None:
|
{"golden_diff": "diff --git a/src/syft/lib/__init__.py b/src/syft/lib/__init__.py\n--- a/src/syft/lib/__init__.py\n+++ b/src/syft/lib/__init__.py\n@@ -5,7 +5,11 @@\n from typing import Any\n from typing import Any as TypeAny\n from typing import Dict as TypeDict\n+from typing import Iterable\n+from typing import List as TypeList\n from typing import Optional\n+from typing import Set as TypeSet\n+from typing import Tuple as TypeTuple\n from typing import Union as TypeUnion\n import warnings\n \n@@ -142,20 +146,42 @@\n _regenerate_unions(lib_ast=lib_ast, client=client)\n \n \n-def load(lib: str, options: TypeDict[str, TypeAny] = {}) -> None:\n+def load(\n+ *libs: TypeUnion[TypeList[str], TypeTuple[str], TypeSet[str], str],\n+ options: TypeDict[str, TypeAny] = {},\n+ **kwargs: str,\n+) -> None:\n \"\"\"\n Load and Update Node with given library module\n \n Args:\n- lib: name of library to load and update Node with\n+ *libs: names of libraries to load and update Node with (can be variadic, tuple, list, set)\n options: external requirements for loading library successfully\n+ **kwargs: for backward compatibility with calls like `syft.load(lib = \"opacus\")`\n \"\"\"\n- try:\n- _load_lib(lib=lib, options=options)\n- except VendorLibraryImportException as e:\n- critical(e)\n- except Exception as e:\n- critical(f\"Unable to load package support for: {lib}. {e}\")\n+ # For backward compatibility with calls like `syft.load(lib = \"opacus\")`\n+ if \"lib\" in kwargs.keys():\n+ libs += tuple(kwargs[\"lib\"])\n+\n+ if isinstance(libs[0], Iterable):\n+ if not isinstance(libs[0], str):\n+ libs = tuple(libs[0])\n+ for lib in libs:\n+ if isinstance(lib, str):\n+ try:\n+ _load_lib(lib=str(lib), options=options)\n+ except VendorLibraryImportException as e:\n+ critical(e)\n+ except Exception as e:\n+ critical(f\"Unable to load package support for: {lib}. {e}\")\n+ else:\n+ critical(\n+ f\"Unable to load package support for: {lib}. Pass lib name as string object.\"\n+ )\n+ else:\n+ critical(\n+ \"Unable to load package support for any library. Iterable object not found.\"\n+ )\n \n \n def load_lib(lib: str, options: TypeDict[str, TypeAny] = {}) -> None:\n", "issue": "Add ability to load multiple libs in one call\n## Description\r\n`sy.load()` should accept any valid sequence of strings, variadic args, a list, tuple or set of strings like:\r\n```\r\nsy.load(\"pydp\", \"opacus\")\r\nsy.load([\"pydp\", \"opacus\"])\r\nsy.load((\"pydp\", \"opacus\"))\r\nsy.load({\"pydp\", \"opacus\"})\r\n```\r\n\r\n## Definition of Done\r\nLoading multiple libs in one go is possible with tests to show it works.\n", "before_files": [{"content": "# stdlib\nimport importlib\nimport sys\nfrom types import ModuleType\nfrom typing import Any\nfrom typing import Any as TypeAny\nfrom typing import Dict as TypeDict\nfrom typing import Optional\nfrom typing import Union as TypeUnion\nimport warnings\n\n# third party\nfrom packaging import version\n\n# syft relative\nfrom ..ast.globals import Globals\nfrom ..core.node.abstract.node import AbstractNodeClient\nfrom ..lib.plan import create_plan_ast\nfrom ..lib.python import create_python_ast\nfrom ..lib.remote_dataloader import create_remote_dataloader_ast\nfrom ..lib.torch import create_torch_ast\nfrom ..lib.torchvision import create_torchvision_ast\nfrom ..logger import critical\nfrom ..logger import traceback_and_raise\nfrom ..logger import warning\nfrom .misc import create_union_ast\n\n\nclass VendorLibraryImportException(Exception):\n pass\n\n\ndef vendor_requirements_available(vendor_requirements: TypeDict[str, TypeAny]) -> bool:\n \"\"\"\n Check whether torch or python version is supported\n\n Args:\n vendor_requirements: dictionary containing version of python or torch to be supported\n\n Returns:\n True if system supports all vendor requirements\n\n \"\"\"\n # see if python version is supported\n if \"python\" in vendor_requirements:\n python_reqs = vendor_requirements[\"python\"]\n\n PYTHON_VERSION = sys.version_info\n min_version = python_reqs.get(\"min_version\", None)\n if min_version is not None:\n if PYTHON_VERSION < min_version:\n traceback_and_raise(\n VendorLibraryImportException(\n f\"Unable to load {vendor_requirements['lib']}.\"\n + f\"Python: {PYTHON_VERSION} < {min_version}\"\n )\n )\n max_version = python_reqs.get(\"max_version\", None)\n if max_version is not None:\n if PYTHON_VERSION > max_version:\n traceback_and_raise(\n VendorLibraryImportException(\n f\"Unable to load {vendor_requirements['lib']}.\"\n + f\"Python: {PYTHON_VERSION} > {max_version}\"\n )\n )\n\n # see if torch version is supported\n if \"torch\" in vendor_requirements:\n torch_reqs = vendor_requirements[\"torch\"]\n # third party\n import torch\n\n TORCH_VERSION = version.parse(torch.__version__.split(\"+\")[0])\n min_version = torch_reqs.get(\"min_version\", None)\n if min_version is not None:\n if TORCH_VERSION < version.parse(min_version):\n traceback_and_raise(\n VendorLibraryImportException(\n f\"Unable to load {vendor_requirements['lib']}.\"\n + f\"Torch: {TORCH_VERSION} < {min_version}\"\n )\n )\n\n max_version = torch_reqs.get(\"max_version\", None)\n if max_version is not None:\n if TORCH_VERSION > version.parse(max_version):\n traceback_and_raise(\n VendorLibraryImportException(\n f\"Unable to load {vendor_requirements['lib']}.\"\n + f\"Torch: {TORCH_VERSION} > {max_version}\"\n )\n )\n\n return True\n\n\ndef _add_lib(\n *, vendor_ast: ModuleType, ast_or_client: TypeUnion[Globals, AbstractNodeClient]\n) -> None:\n update_ast = getattr(vendor_ast, \"update_ast\", None)\n post_update_ast = getattr(vendor_ast, \"post_update_ast\", None)\n if update_ast is not None:\n update_ast(ast_or_client=ast_or_client)\n if post_update_ast is not None:\n post_update_ast(ast_or_client=ast_or_client)\n\n\ndef _regenerate_unions(*, lib_ast: Globals, client: TypeAny = None) -> None:\n union_misc_ast = getattr(\n getattr(create_union_ast(lib_ast=lib_ast, client=client), \"syft\"), \"lib\"\n )\n if client is not None:\n client.syft.lib.add_attr(attr_name=\"misc\", attr=union_misc_ast.attrs[\"misc\"])\n else:\n lib_ast.syft.lib.add_attr(attr_name=\"misc\", attr=union_misc_ast.attrs[\"misc\"])\n\n\ndef _load_lib(*, lib: str, options: TypeDict[str, TypeAny] = {}) -> None:\n \"\"\"\n Load and Update Node with given library module\n\n Args:\n lib: name of library to load and update Node with\n options: external requirements for loading library successfully\n \"\"\"\n _ = importlib.import_module(lib)\n vendor_ast = importlib.import_module(f\"syft.lib.{lib}\")\n PACKAGE_SUPPORT = getattr(vendor_ast, \"PACKAGE_SUPPORT\", None)\n PACKAGE_SUPPORT.update(options)\n if PACKAGE_SUPPORT is not None and vendor_requirements_available(\n vendor_requirements=PACKAGE_SUPPORT\n ):\n global lib_ast\n _add_lib(vendor_ast=vendor_ast, ast_or_client=lib_ast)\n # cache the constructor for future created clients\n lib_ast.loaded_lib_constructors[lib] = getattr(vendor_ast, \"update_ast\", None)\n _regenerate_unions(lib_ast=lib_ast)\n\n for _, client in lib_ast.registered_clients.items():\n _add_lib(vendor_ast=vendor_ast, ast_or_client=client)\n _regenerate_unions(lib_ast=lib_ast, client=client)\n\n\ndef load(lib: str, options: TypeDict[str, TypeAny] = {}) -> None:\n \"\"\"\n Load and Update Node with given library module\n\n Args:\n lib: name of library to load and update Node with\n options: external requirements for loading library successfully\n \"\"\"\n try:\n _load_lib(lib=lib, options=options)\n except VendorLibraryImportException as e:\n critical(e)\n except Exception as e:\n critical(f\"Unable to load package support for: {lib}. {e}\")\n\n\ndef load_lib(lib: str, options: TypeDict[str, TypeAny] = {}) -> None:\n \"\"\"\n Load and Update Node with given library module\n load_lib() is deprecated please use load() in the future\n\n Args:\n lib: name of library to load and update Node with\n options: external requirements for loading library successfully\n\n \"\"\"\n msg = \"load_lib() is deprecated please use load() in the future\"\n warning(msg, print=True)\n warnings.warn(msg, DeprecationWarning)\n load(lib=lib, options=options)\n\n\n# now we need to load the relevant frameworks onto the node\ndef create_lib_ast(client: Optional[Any] = None) -> Globals:\n \"\"\"\n Create AST and load the relevant frameworks onto the node\n\n Args:\n client: VM client onto whom the frameworks need to be loaded\n\n Returns:\n AST for client of type Globals\n\n \"\"\"\n python_ast = create_python_ast(client=client)\n torch_ast = create_torch_ast(client=client)\n torchvision_ast = create_torchvision_ast(client=client)\n # numpy_ast = create_numpy_ast()\n plan_ast = create_plan_ast(client=client)\n remote_dataloader_ast = create_remote_dataloader_ast(client=client)\n\n lib_ast = Globals(client=client)\n lib_ast.add_attr(attr_name=\"syft\", attr=python_ast.attrs[\"syft\"])\n lib_ast.add_attr(attr_name=\"torch\", attr=torch_ast.attrs[\"torch\"])\n lib_ast.add_attr(attr_name=\"torchvision\", attr=torchvision_ast.attrs[\"torchvision\"])\n lib_ast.syft.add_attr(\"core\", attr=plan_ast.syft.core)\n lib_ast.syft.core.add_attr(\n \"remote_dataloader\", remote_dataloader_ast.syft.core.remote_dataloader\n )\n\n # let the misc creation be always the last, as it needs the full ast solved\n # to properly generated unions\n union_misc_ast = getattr(getattr(create_union_ast(lib_ast, client), \"syft\"), \"lib\")\n lib_ast.syft.lib.add_attr(attr_name=\"misc\", attr=union_misc_ast.attrs[\"misc\"])\n\n return lib_ast\n\n\nlib_ast = create_lib_ast(None)\n", "path": "src/syft/lib/__init__.py"}]}
| 2,878 | 603 |
gh_patches_debug_26771
|
rasdani/github-patches
|
git_diff
|
searx__searx-3472
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
remove distutils usage
In Python 3.10 and 3.11, distutils has been formally marked as deprecated. Code that imports distutils will no longer work from Python 3.12.
`searx_extra/update/update_firefox_version.py` still uses distutils. Maybe its use of `distutils.version` can be replaced by the `packaging` module?
See https://peps.python.org/pep-0632/
</issue>
<code>
[start of searx_extra/update/update_firefox_version.py]
1 #!/usr/bin/env python
2
3 import json
4 import requests
5 import re
6 from os.path import dirname, join
7 from urllib.parse import urlparse, urljoin
8 from distutils.version import LooseVersion, StrictVersion
9 from lxml import html
10 from searx import searx_dir
11
12 URL = 'https://ftp.mozilla.org/pub/firefox/releases/'
13 RELEASE_PATH = '/pub/firefox/releases/'
14
15 NORMAL_REGEX = re.compile('^[0-9]+\.[0-9](\.[0-9])?$')
16 # BETA_REGEX = re.compile('.*[0-9]b([0-9\-a-z]+)$')
17 # ESR_REGEX = re.compile('^[0-9]+\.[0-9](\.[0-9])?esr$')
18
19 #
20 useragents = {
21 "versions": (),
22 "os": ('Windows NT 10.0; WOW64',
23 'X11; Linux x86_64'),
24 "ua": "Mozilla/5.0 ({os}; rv:{version}) Gecko/20100101 Firefox/{version}"
25 }
26
27
28 def fetch_firefox_versions():
29 resp = requests.get(URL, timeout=2.0)
30 if resp.status_code != 200:
31 raise Exception("Error fetching firefox versions, HTTP code " + resp.status_code)
32 else:
33 dom = html.fromstring(resp.text)
34 versions = []
35
36 for link in dom.xpath('//a/@href'):
37 url = urlparse(urljoin(URL, link))
38 path = url.path
39 if path.startswith(RELEASE_PATH):
40 version = path[len(RELEASE_PATH):-1]
41 if NORMAL_REGEX.match(version):
42 versions.append(LooseVersion(version))
43
44 list.sort(versions, reverse=True)
45 return versions
46
47
48 def fetch_firefox_last_versions():
49 versions = fetch_firefox_versions()
50
51 result = []
52 major_last = versions[0].version[0]
53 major_list = (major_last, major_last - 1)
54 for version in versions:
55 major_current = version.version[0]
56 if major_current in major_list:
57 result.append(version.vstring)
58
59 return result
60
61
62 def get_useragents_filename():
63 return join(join(searx_dir, "data"), "useragents.json")
64
65
66 useragents["versions"] = fetch_firefox_last_versions()
67 with open(get_useragents_filename(), "w") as f:
68 json.dump(useragents, f, indent=4, ensure_ascii=False)
69
[end of searx_extra/update/update_firefox_version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/searx_extra/update/update_firefox_version.py b/searx_extra/update/update_firefox_version.py
--- a/searx_extra/update/update_firefox_version.py
+++ b/searx_extra/update/update_firefox_version.py
@@ -5,7 +5,7 @@
import re
from os.path import dirname, join
from urllib.parse import urlparse, urljoin
-from distutils.version import LooseVersion, StrictVersion
+from packaging.version import Version, parse
from lxml import html
from searx import searx_dir
@@ -39,7 +39,7 @@
if path.startswith(RELEASE_PATH):
version = path[len(RELEASE_PATH):-1]
if NORMAL_REGEX.match(version):
- versions.append(LooseVersion(version))
+ versions.append(Version(version))
list.sort(versions, reverse=True)
return versions
@@ -49,12 +49,12 @@
versions = fetch_firefox_versions()
result = []
- major_last = versions[0].version[0]
+ major_last = versions[0].major
major_list = (major_last, major_last - 1)
for version in versions:
- major_current = version.version[0]
+ major_current = version.major
if major_current in major_list:
- result.append(version.vstring)
+ result.append(str(version))
return result
|
{"golden_diff": "diff --git a/searx_extra/update/update_firefox_version.py b/searx_extra/update/update_firefox_version.py\n--- a/searx_extra/update/update_firefox_version.py\n+++ b/searx_extra/update/update_firefox_version.py\n@@ -5,7 +5,7 @@\n import re\n from os.path import dirname, join\n from urllib.parse import urlparse, urljoin\n-from distutils.version import LooseVersion, StrictVersion\n+from packaging.version import Version, parse\n from lxml import html\n from searx import searx_dir\n \n@@ -39,7 +39,7 @@\n if path.startswith(RELEASE_PATH):\n version = path[len(RELEASE_PATH):-1]\n if NORMAL_REGEX.match(version):\n- versions.append(LooseVersion(version))\n+ versions.append(Version(version))\n \n list.sort(versions, reverse=True)\n return versions\n@@ -49,12 +49,12 @@\n versions = fetch_firefox_versions()\n \n result = []\n- major_last = versions[0].version[0]\n+ major_last = versions[0].major\n major_list = (major_last, major_last - 1)\n for version in versions:\n- major_current = version.version[0]\n+ major_current = version.major\n if major_current in major_list:\n- result.append(version.vstring)\n+ result.append(str(version))\n \n return result\n", "issue": "remove distutils usage\nIn Python 3.10 and 3.11, distutils has been formally marked as deprecated. Code that imports distutils will no longer work from Python 3.12.\r\n\r\n`searx_extra/update/update_firefox_version.py` still uses distutils. Maybe its use of `distutils.version` can be replaced by the `packaging` module?\r\n\r\nSee https://peps.python.org/pep-0632/\n", "before_files": [{"content": "#!/usr/bin/env python\n\nimport json\nimport requests\nimport re\nfrom os.path import dirname, join\nfrom urllib.parse import urlparse, urljoin\nfrom distutils.version import LooseVersion, StrictVersion\nfrom lxml import html\nfrom searx import searx_dir\n\nURL = 'https://ftp.mozilla.org/pub/firefox/releases/'\nRELEASE_PATH = '/pub/firefox/releases/'\n\nNORMAL_REGEX = re.compile('^[0-9]+\\.[0-9](\\.[0-9])?$')\n# BETA_REGEX = re.compile('.*[0-9]b([0-9\\-a-z]+)$')\n# ESR_REGEX = re.compile('^[0-9]+\\.[0-9](\\.[0-9])?esr$')\n\n# \nuseragents = {\n \"versions\": (),\n \"os\": ('Windows NT 10.0; WOW64',\n 'X11; Linux x86_64'),\n \"ua\": \"Mozilla/5.0 ({os}; rv:{version}) Gecko/20100101 Firefox/{version}\"\n}\n\n\ndef fetch_firefox_versions():\n resp = requests.get(URL, timeout=2.0)\n if resp.status_code != 200:\n raise Exception(\"Error fetching firefox versions, HTTP code \" + resp.status_code)\n else:\n dom = html.fromstring(resp.text)\n versions = []\n\n for link in dom.xpath('//a/@href'):\n url = urlparse(urljoin(URL, link))\n path = url.path\n if path.startswith(RELEASE_PATH):\n version = path[len(RELEASE_PATH):-1]\n if NORMAL_REGEX.match(version):\n versions.append(LooseVersion(version))\n\n list.sort(versions, reverse=True)\n return versions\n\n\ndef fetch_firefox_last_versions():\n versions = fetch_firefox_versions()\n\n result = []\n major_last = versions[0].version[0]\n major_list = (major_last, major_last - 1)\n for version in versions:\n major_current = version.version[0]\n if major_current in major_list:\n result.append(version.vstring)\n\n return result\n\n\ndef get_useragents_filename():\n return join(join(searx_dir, \"data\"), \"useragents.json\")\n\n\nuseragents[\"versions\"] = fetch_firefox_last_versions()\nwith open(get_useragents_filename(), \"w\") as f:\n json.dump(useragents, f, indent=4, ensure_ascii=False)\n", "path": "searx_extra/update/update_firefox_version.py"}]}
| 1,302 | 304 |
gh_patches_debug_60668
|
rasdani/github-patches
|
git_diff
|
hydroshare__hydroshare-2260
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Rename userInfo/ API endpoint to user/
Placeholder ticket
</issue>
<code>
[start of hs_rest_api/urls.py]
1 from django.conf.urls import patterns, url
2 from hs_core import views
3 from hs_file_types import views as file_type_views
4
5 from rest_framework_swagger.views import get_swagger_view
6
7 schema_view = get_swagger_view(title='Hydroshare API')
8
9 urlpatterns = patterns(
10 '',
11
12 # Swagger Docs View
13 url(r'^$', schema_view),
14
15 # resource API
16 url(r'^resource/types/$', views.resource_rest_api.ResourceTypes.as_view(),
17 name='list_resource_types'),
18
19 # DEPRECATED: use from above instead
20 url(r'^resourceTypes/$', views.resource_rest_api.ResourceTypes.as_view(),
21 name='DEPRECATED_list_resource_types'),
22
23 # DEPRECATED: use GET /resource/ instead
24 url(r'^resourceList/$', views.resource_rest_api.ResourceList.as_view(),
25 name='DEPRECATED_list_resources'),
26
27 url(r'^resource/$', views.resource_rest_api.ResourceListCreate.as_view(),
28 name='list_create_resource'),
29
30 # Public endpoint for resource flags
31 url(r'^resource/(?P<pk>[0-9a-f-]+)/flag/$', views.set_resource_flag_public,
32 name='public_set_resource_flag'),
33
34 url(r'^resource/(?P<pk>[0-9a-f-]+)/$',
35 views.resource_rest_api.ResourceReadUpdateDelete.as_view(),
36 name='get_update_delete_resource'),
37
38 # Create new version of a resource
39 url(r'^resource/(?P<pk>[0-9a-f-]+)/version/$', views.create_new_version_resource_public,
40 name='new_version_resource_public'),
41
42 # public copy resource endpoint
43 url(r'^resource/(?P<pk>[0-9a-f-]+)/copy/$',
44 views.copy_resource_public, name='copy_resource_public'),
45
46 # DEPRECATED: use form above instead
47 url(r'^resource/accessRules/(?P<pk>[0-9a-f-]+)/$',
48 views.resource_rest_api.AccessRulesUpdate.as_view(),
49 name='DEPRECATED_update_access_rules'),
50
51 url(r'^resource/(?P<pk>[0-9a-f-]+)/sysmeta/$',
52 views.resource_rest_api.SystemMetadataRetrieve.as_view(),
53 name='get_system_metadata'),
54
55 # DEPRECATED: use from above instead
56 url(r'^sysmeta/(?P<pk>[0-9a-f-]+)/$',
57 views.resource_rest_api.SystemMetadataRetrieve.as_view(),
58 name='DEPRECATED_get_system_metadata'),
59
60 url(r'^resource/(?P<pk>[0-9a-f-]+)/scimeta/$',
61 views.resource_rest_api.ScienceMetadataRetrieveUpdate.as_view(),
62 name='get_update_science_metadata'),
63
64 # Resource metadata editing
65 url(r'^resource/(?P<pk>[0-9a-f-]+)/scimeta/elements/$',
66 views.resource_metadata_rest_api.MetadataElementsRetrieveUpdate.as_view(),
67 name='get_update_science_metadata_elements'),
68
69 # Update key-value metadata
70 url(r'^resource/(?P<pk>[0-9a-f-]+)/scimeta/custom/$',
71 views.update_key_value_metadata_public,
72 name='update_custom_metadata'),
73
74 # DEPRECATED: use from above instead
75 url(r'^scimeta/(?P<pk>[0-9a-f-]+)/$',
76 views.resource_rest_api.ScienceMetadataRetrieveUpdate.as_view(),
77 name='DEPRECATED_get_update_science_metadata'),
78
79 url(r'^resource/(?P<pk>[A-z0-9]+)/map/$',
80 views.resource_rest_api.ResourceMapRetrieve.as_view(),
81 name='get_resource_map'),
82
83 # Patterns are now checked in the view class.
84 url(r'^resource/(?P<pk>[0-9a-f-]+)/files/(?P<pathname>.+)/$',
85 views.resource_rest_api.ResourceFileCRUD.as_view(),
86 name='get_update_delete_resource_file'),
87
88 url(r'^resource/(?P<pk>[0-9a-f-]+)/files/$',
89 views.resource_rest_api.ResourceFileListCreate.as_view(),
90 name='list_create_resource_file'),
91
92 url(r'^resource/(?P<pk>[0-9a-f-]+)/folders/(?P<pathname>.*)/$',
93 views.resource_folder_rest_api.ResourceFolders.as_view(),
94 name='list_manipulate_folders'),
95
96 # public unzip endpoint
97 url(r'^resource/(?P<pk>[0-9a-f-]+)/functions/unzip/(?P<pathname>.*)/$',
98 views.resource_folder_hierarchy.data_store_folder_unzip_public),
99
100 # public zip folder endpoint
101 url(r'^resource/(?P<pk>[0-9a-f-]+)/functions/zip/$',
102 views.resource_folder_hierarchy.data_store_folder_zip_public),
103
104 # public move or rename
105 url(r'^resource/(?P<pk>[0-9a-f-]+)/functions/move-or-rename/$',
106 views.resource_folder_hierarchy.data_store_file_or_folder_move_or_rename_public),
107
108 url(r'^resource/(?P<pk>[0-9a-f-]+)/functions/set-file-type/(?P<file_path>.*)/'
109 r'(?P<hs_file_type>[A-z]+)/$',
110 file_type_views.set_file_type_public,
111 name="set_file_type_public"),
112
113 # DEPRECATED: use form above instead. Added unused POST for simplicity
114 url(r'^resource/(?P<pk>[0-9a-f-]+)/file_list/$',
115 views.resource_rest_api.ResourceFileListCreate.as_view(),
116 name='DEPRECATED_get_resource_file_list'),
117
118 url(r'^taskstatus/(?P<task_id>[A-z0-9\-]+)/$',
119 views.resource_rest_api.CheckTaskStatus.as_view(),
120 name='get_task_status'),
121
122 url(r'^userInfo/$',
123 views.user_rest_api.UserInfo.as_view(), name='get_logged_in_user_info'),
124
125 # Resource Access
126 url(r'^resource/(?P<pk>[0-9a-f-]+)/access/$',
127 views.resource_access_api.ResourceAccessUpdateDelete.as_view(),
128 name='get_update_delete_resource_access'),
129 )
130
[end of hs_rest_api/urls.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/hs_rest_api/urls.py b/hs_rest_api/urls.py
--- a/hs_rest_api/urls.py
+++ b/hs_rest_api/urls.py
@@ -119,6 +119,9 @@
views.resource_rest_api.CheckTaskStatus.as_view(),
name='get_task_status'),
+ url(r'^user/$',
+ views.user_rest_api.UserInfo.as_view(), name='get_logged_in_user_info'),
+
url(r'^userInfo/$',
views.user_rest_api.UserInfo.as_view(), name='get_logged_in_user_info'),
|
{"golden_diff": "diff --git a/hs_rest_api/urls.py b/hs_rest_api/urls.py\n--- a/hs_rest_api/urls.py\n+++ b/hs_rest_api/urls.py\n@@ -119,6 +119,9 @@\n views.resource_rest_api.CheckTaskStatus.as_view(),\n name='get_task_status'),\n \n+ url(r'^user/$',\n+ views.user_rest_api.UserInfo.as_view(), name='get_logged_in_user_info'),\n+\n url(r'^userInfo/$',\n views.user_rest_api.UserInfo.as_view(), name='get_logged_in_user_info'),\n", "issue": "Rename userInfo/ API endpoint to user/\nPlaceholder ticket\n", "before_files": [{"content": "from django.conf.urls import patterns, url\nfrom hs_core import views\nfrom hs_file_types import views as file_type_views\n\nfrom rest_framework_swagger.views import get_swagger_view\n\nschema_view = get_swagger_view(title='Hydroshare API')\n\nurlpatterns = patterns(\n '',\n\n # Swagger Docs View\n url(r'^$', schema_view),\n\n # resource API\n url(r'^resource/types/$', views.resource_rest_api.ResourceTypes.as_view(),\n name='list_resource_types'),\n\n # DEPRECATED: use from above instead\n url(r'^resourceTypes/$', views.resource_rest_api.ResourceTypes.as_view(),\n name='DEPRECATED_list_resource_types'),\n\n # DEPRECATED: use GET /resource/ instead\n url(r'^resourceList/$', views.resource_rest_api.ResourceList.as_view(),\n name='DEPRECATED_list_resources'),\n\n url(r'^resource/$', views.resource_rest_api.ResourceListCreate.as_view(),\n name='list_create_resource'),\n\n # Public endpoint for resource flags\n url(r'^resource/(?P<pk>[0-9a-f-]+)/flag/$', views.set_resource_flag_public,\n name='public_set_resource_flag'),\n\n url(r'^resource/(?P<pk>[0-9a-f-]+)/$',\n views.resource_rest_api.ResourceReadUpdateDelete.as_view(),\n name='get_update_delete_resource'),\n\n # Create new version of a resource\n url(r'^resource/(?P<pk>[0-9a-f-]+)/version/$', views.create_new_version_resource_public,\n name='new_version_resource_public'),\n\n # public copy resource endpoint\n url(r'^resource/(?P<pk>[0-9a-f-]+)/copy/$',\n views.copy_resource_public, name='copy_resource_public'),\n\n # DEPRECATED: use form above instead\n url(r'^resource/accessRules/(?P<pk>[0-9a-f-]+)/$',\n views.resource_rest_api.AccessRulesUpdate.as_view(),\n name='DEPRECATED_update_access_rules'),\n\n url(r'^resource/(?P<pk>[0-9a-f-]+)/sysmeta/$',\n views.resource_rest_api.SystemMetadataRetrieve.as_view(),\n name='get_system_metadata'),\n\n # DEPRECATED: use from above instead\n url(r'^sysmeta/(?P<pk>[0-9a-f-]+)/$',\n views.resource_rest_api.SystemMetadataRetrieve.as_view(),\n name='DEPRECATED_get_system_metadata'),\n\n url(r'^resource/(?P<pk>[0-9a-f-]+)/scimeta/$',\n views.resource_rest_api.ScienceMetadataRetrieveUpdate.as_view(),\n name='get_update_science_metadata'),\n\n # Resource metadata editing\n url(r'^resource/(?P<pk>[0-9a-f-]+)/scimeta/elements/$',\n views.resource_metadata_rest_api.MetadataElementsRetrieveUpdate.as_view(),\n name='get_update_science_metadata_elements'),\n\n # Update key-value metadata\n url(r'^resource/(?P<pk>[0-9a-f-]+)/scimeta/custom/$',\n views.update_key_value_metadata_public,\n name='update_custom_metadata'),\n\n # DEPRECATED: use from above instead\n url(r'^scimeta/(?P<pk>[0-9a-f-]+)/$',\n views.resource_rest_api.ScienceMetadataRetrieveUpdate.as_view(),\n name='DEPRECATED_get_update_science_metadata'),\n\n url(r'^resource/(?P<pk>[A-z0-9]+)/map/$',\n views.resource_rest_api.ResourceMapRetrieve.as_view(),\n name='get_resource_map'),\n\n # Patterns are now checked in the view class.\n url(r'^resource/(?P<pk>[0-9a-f-]+)/files/(?P<pathname>.+)/$',\n views.resource_rest_api.ResourceFileCRUD.as_view(),\n name='get_update_delete_resource_file'),\n\n url(r'^resource/(?P<pk>[0-9a-f-]+)/files/$',\n views.resource_rest_api.ResourceFileListCreate.as_view(),\n name='list_create_resource_file'),\n\n url(r'^resource/(?P<pk>[0-9a-f-]+)/folders/(?P<pathname>.*)/$',\n views.resource_folder_rest_api.ResourceFolders.as_view(),\n name='list_manipulate_folders'),\n\n # public unzip endpoint\n url(r'^resource/(?P<pk>[0-9a-f-]+)/functions/unzip/(?P<pathname>.*)/$',\n views.resource_folder_hierarchy.data_store_folder_unzip_public),\n\n # public zip folder endpoint\n url(r'^resource/(?P<pk>[0-9a-f-]+)/functions/zip/$',\n views.resource_folder_hierarchy.data_store_folder_zip_public),\n\n # public move or rename\n url(r'^resource/(?P<pk>[0-9a-f-]+)/functions/move-or-rename/$',\n views.resource_folder_hierarchy.data_store_file_or_folder_move_or_rename_public),\n\n url(r'^resource/(?P<pk>[0-9a-f-]+)/functions/set-file-type/(?P<file_path>.*)/'\n r'(?P<hs_file_type>[A-z]+)/$',\n file_type_views.set_file_type_public,\n name=\"set_file_type_public\"),\n\n # DEPRECATED: use form above instead. Added unused POST for simplicity\n url(r'^resource/(?P<pk>[0-9a-f-]+)/file_list/$',\n views.resource_rest_api.ResourceFileListCreate.as_view(),\n name='DEPRECATED_get_resource_file_list'),\n\n url(r'^taskstatus/(?P<task_id>[A-z0-9\\-]+)/$',\n views.resource_rest_api.CheckTaskStatus.as_view(),\n name='get_task_status'),\n\n url(r'^userInfo/$',\n views.user_rest_api.UserInfo.as_view(), name='get_logged_in_user_info'),\n\n # Resource Access\n url(r'^resource/(?P<pk>[0-9a-f-]+)/access/$',\n views.resource_access_api.ResourceAccessUpdateDelete.as_view(),\n name='get_update_delete_resource_access'),\n)\n", "path": "hs_rest_api/urls.py"}]}
| 2,097 | 124 |
gh_patches_debug_23600
|
rasdani/github-patches
|
git_diff
|
cal-itp__benefits-222
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
use `rel="noopener noreferrer"` for external links
1. GitHub link
2. Privacy Policy link
3. Transit agency link
<img width="974" alt="image" src="https://user-images.githubusercontent.com/3673236/142677414-95011bb6-2aaf-4136-a7e3-03cfc27f40f0.png">
</issue>
<code>
[start of benefits/core/viewmodels.py]
1 """
2 The core application: view model definitions for the root of the webapp.
3 """
4 from django.utils.translation import pgettext, ugettext as _
5
6 from benefits.core import models
7
8 from . import session
9
10
11 class Button:
12 """
13 Represents a clickable button as styled <a> element (with optional label):
14 * label: str
15 * id: str
16 * classes: str, str[]
17 * text: str
18 * url: str
19 """
20
21 def __init__(self, **kwargs):
22 classes = kwargs.get("classes", [])
23 if isinstance(classes, str):
24 classes = classes.split()
25
26 self.classes = ["btn", "btn-lg"]
27 self.classes.extend(classes)
28 self.id = kwargs.get("id")
29 self.label = kwargs.get("label")
30 self.text = kwargs.get("text", "Button")
31 self.url = kwargs.get("url")
32 self.target = kwargs.get("target")
33
34 @staticmethod
35 def agency_contact_links(agency):
36 """Create link buttons for agency contact information."""
37 return [
38 # fmt: off
39 Button.link(classes="agency-url", label=agency.long_name, text=agency.info_url, url=agency.info_url, target="_blank"), # noqa: E501
40 Button.link(classes="agency-phone", text=agency.phone, url=f"tel:{agency.phone}"),
41 # fmt: on
42 ]
43
44 @staticmethod
45 def home(request, text=_("core.buttons.home")):
46 """Create a button back to this session's origin."""
47 return Button.primary(text=text, url=session.origin(request))
48
49 @staticmethod
50 def link(**kwargs):
51 classes = kwargs.pop("classes", [])
52 if isinstance(classes, str):
53 classes = classes.split(" ")
54 classes.insert(0, "btn-link")
55 return Button(classes=classes, **kwargs)
56
57 @staticmethod
58 def primary(**kwargs):
59 classes = kwargs.pop("classes", [])
60 if isinstance(classes, str):
61 classes = classes.split(" ")
62 classes.insert(0, "btn-primary")
63 return Button(classes=classes, **kwargs)
64
65 @staticmethod
66 def outline_primary(**kwargs):
67 classes = kwargs.pop("classes", [])
68 if isinstance(classes, str):
69 classes = classes.split(" ")
70 classes.insert(0, "btn-outline-primary")
71 return Button(classes=classes, **kwargs)
72
73
74 class Image:
75 """Represents a generic image."""
76
77 def __init__(self, src, alt):
78 self.src = src
79 if not self.src.startswith("http"):
80 self.src = f"img/{self.src}"
81
82 self.alt = alt
83
84
85 class Icon(Image):
86 """Represents an icon."""
87
88 def __init__(self, icon, alt):
89 super().__init__(src=f"icon/{icon}.svg", alt=alt)
90
91
92 class MediaItem:
93 """
94 Represents a list item:
95 * icon: core.viewmodels.Icon
96 * heading: str
97 * details: str
98 """
99
100 def __init__(self, icon, heading, details):
101 self.icon = icon
102 self.heading = heading
103 self.details = details
104
105
106 class Page:
107 """
108 Represents a page of content:
109 * title: str
110 * image: core.viewmodels.Image
111 * icon: core.viewmodels.Icon
112 * content_title: str
113 * media: core.viewmodels.MediaItem[]
114 * paragraphs: str[]
115 * form: django.forms.Form
116 * forms: django.forms.Form[]
117 * button: core.viewmodels.Button
118 * buttons: core.viewmodels.Button[]
119 * classes: str[]
120 """
121
122 def __init__(self, **kwargs):
123 self.title = kwargs.get("title")
124 if self.title is None:
125 self.title = _("core.page.title")
126 else:
127 self.title = f"{_('core.page.title')}: {self.title}"
128
129 self.image = kwargs.get("image")
130 self.icon = kwargs.get("icon")
131 self.content_title = kwargs.get("content_title")
132 self.media = kwargs.get("media", [])
133 self.paragraphs = kwargs.get("paragraphs", [])
134 self.steps = kwargs.get("steps")
135
136 self.forms = kwargs.get("forms", [])
137 if not isinstance(self.forms, list):
138 self.forms = [self.forms]
139 if "form" in kwargs:
140 self.forms.append(kwargs.get("form"))
141
142 self.buttons = kwargs.get("buttons", [])
143 if not isinstance(self.buttons, list):
144 self.buttons = [self.buttons]
145 if "button" in kwargs:
146 self.buttons.append(kwargs.get("button"))
147
148 self.classes = kwargs.get("classes", [])
149 if not isinstance(self.classes, list):
150 self.classes = self.classes.split(" ")
151 if isinstance(self.image, Image):
152 self.classes.append("with-image")
153
154 def context_dict(self):
155 """Return a context dict for a Page."""
156 return {"page": self}
157
158
159 class ErrorPage(Page):
160 """
161 Represents an error page:
162 * title: str
163 * icon: core.viewmodels.Icon
164 * content_title: str
165 * paragraphs: str[]
166 * button: core.viewmodels.Button
167 """
168
169 def __init__(self, **kwargs):
170 super().__init__(
171 title=kwargs.get("title", _("core.error")),
172 icon=kwargs.get("icon", Icon("sadbus", pgettext("image alt text", "core.icons.sadbus"))),
173 content_title=kwargs.get("content_title", _("core.error")),
174 paragraphs=kwargs.get("paragraphs", [_("core.error.server.content_title")]),
175 button=kwargs.get("button"),
176 )
177
178 @staticmethod
179 def error(
180 title=_("core.error.server.title"),
181 content_title=_("core.error.server.title"),
182 paragraphs=[_("core.error.server.p1"), _("core.error.server.p2")],
183 **kwargs,
184 ):
185 """Create a new core.viewmodels.ErrorPage instance with defaults for a generic error."""
186 return ErrorPage(title=title, content_title=content_title, paragraphs=paragraphs, **kwargs)
187
188 @staticmethod
189 def not_found(
190 title=_("core.error.notfound.title"),
191 content_title=_("core.error.notfound.content_title"),
192 paragraphs=[_("core.error.notfound.p1")],
193 **kwargs,
194 ):
195 """Create a new core.viewmodels.ErrorPage with defaults for a 404."""
196 path = kwargs.pop("path", None)
197 if path and title:
198 title = f"{title}: {path}"
199 elif path and not title:
200 title = path
201 return ErrorPage(title=title, content_title=content_title, paragraphs=paragraphs, **kwargs)
202
203
204 class PaymentProcessor:
205 """
206 Represents a core.models.PaymentProcessor:
207 * model: core.models.PaymentProcessor
208 * access_token: str
209 * element_id: str
210 * color: str
211 * [name: str]
212 * [loading_text: str]
213 """
214
215 def __init__(self, model, access_token, element_id, color, name=None, loading_text=_("core.buttons.wait")):
216 if isinstance(model, models.PaymentProcessor):
217 self.access_token = access_token
218 self.element_id = element_id
219 self.color = color
220 self.name = name or model.name
221 self.loading_text = loading_text
222 self.card_tokenize_url = model.card_tokenize_url
223 self.card_tokenize_func = model.card_tokenize_func
224 self.card_tokenize_env = model.card_tokenize_env
225
226 def context_dict(self):
227 """Return a context dict for a PaymentProcessor."""
228 return {"payment_processor": self}
229
230
231 class TransitAgency:
232 """
233 Represents a core.models.TransitAgency:
234 * model: core.models.TransitAgency
235 """
236
237 def __init__(self, model):
238 if isinstance(model, models.TransitAgency):
239 self.slug = model.slug
240 self.short_name = model.short_name
241 self.long_name = model.long_name
242 self.agency_id = model.agency_id
243 self.merchant_id = model.merchant_id
244 self.info_url = model.info_url
245 self.phone = model.phone
246
247 def context_dict(self):
248 """Return a context dict for a TransitAgency."""
249 return {"agency": self}
250
[end of benefits/core/viewmodels.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/benefits/core/viewmodels.py b/benefits/core/viewmodels.py
--- a/benefits/core/viewmodels.py
+++ b/benefits/core/viewmodels.py
@@ -16,6 +16,8 @@
* classes: str, str[]
* text: str
* url: str
+ * target: str
+ * rel: str
"""
def __init__(self, **kwargs):
@@ -30,13 +32,14 @@
self.text = kwargs.get("text", "Button")
self.url = kwargs.get("url")
self.target = kwargs.get("target")
+ self.rel = kwargs.get("rel")
@staticmethod
def agency_contact_links(agency):
"""Create link buttons for agency contact information."""
return [
# fmt: off
- Button.link(classes="agency-url", label=agency.long_name, text=agency.info_url, url=agency.info_url, target="_blank"), # noqa: E501
+ Button.link(classes="agency-url", label=agency.long_name, text=agency.info_url, url=agency.info_url, target="_blank", rel="noopener noreferrer"), # noqa: E501
Button.link(classes="agency-phone", text=agency.phone, url=f"tel:{agency.phone}"),
# fmt: on
]
|
{"golden_diff": "diff --git a/benefits/core/viewmodels.py b/benefits/core/viewmodels.py\n--- a/benefits/core/viewmodels.py\n+++ b/benefits/core/viewmodels.py\n@@ -16,6 +16,8 @@\n * classes: str, str[]\n * text: str\n * url: str\n+ * target: str\n+ * rel: str\n \"\"\"\n \n def __init__(self, **kwargs):\n@@ -30,13 +32,14 @@\n self.text = kwargs.get(\"text\", \"Button\")\n self.url = kwargs.get(\"url\")\n self.target = kwargs.get(\"target\")\n+ self.rel = kwargs.get(\"rel\")\n \n @staticmethod\n def agency_contact_links(agency):\n \"\"\"Create link buttons for agency contact information.\"\"\"\n return [\n # fmt: off\n- Button.link(classes=\"agency-url\", label=agency.long_name, text=agency.info_url, url=agency.info_url, target=\"_blank\"), # noqa: E501\n+ Button.link(classes=\"agency-url\", label=agency.long_name, text=agency.info_url, url=agency.info_url, target=\"_blank\", rel=\"noopener noreferrer\"), # noqa: E501\n Button.link(classes=\"agency-phone\", text=agency.phone, url=f\"tel:{agency.phone}\"),\n # fmt: on\n ]\n", "issue": "use `rel=\"noopener noreferrer\"` for external links\n1. GitHub link\r\n2. Privacy Policy link\r\n3. Transit agency link\r\n\r\n<img width=\"974\" alt=\"image\" src=\"https://user-images.githubusercontent.com/3673236/142677414-95011bb6-2aaf-4136-a7e3-03cfc27f40f0.png\">\r\n\n", "before_files": [{"content": "\"\"\"\nThe core application: view model definitions for the root of the webapp.\n\"\"\"\nfrom django.utils.translation import pgettext, ugettext as _\n\nfrom benefits.core import models\n\nfrom . import session\n\n\nclass Button:\n \"\"\"\n Represents a clickable button as styled <a> element (with optional label):\n * label: str\n * id: str\n * classes: str, str[]\n * text: str\n * url: str\n \"\"\"\n\n def __init__(self, **kwargs):\n classes = kwargs.get(\"classes\", [])\n if isinstance(classes, str):\n classes = classes.split()\n\n self.classes = [\"btn\", \"btn-lg\"]\n self.classes.extend(classes)\n self.id = kwargs.get(\"id\")\n self.label = kwargs.get(\"label\")\n self.text = kwargs.get(\"text\", \"Button\")\n self.url = kwargs.get(\"url\")\n self.target = kwargs.get(\"target\")\n\n @staticmethod\n def agency_contact_links(agency):\n \"\"\"Create link buttons for agency contact information.\"\"\"\n return [\n # fmt: off\n Button.link(classes=\"agency-url\", label=agency.long_name, text=agency.info_url, url=agency.info_url, target=\"_blank\"), # noqa: E501\n Button.link(classes=\"agency-phone\", text=agency.phone, url=f\"tel:{agency.phone}\"),\n # fmt: on\n ]\n\n @staticmethod\n def home(request, text=_(\"core.buttons.home\")):\n \"\"\"Create a button back to this session's origin.\"\"\"\n return Button.primary(text=text, url=session.origin(request))\n\n @staticmethod\n def link(**kwargs):\n classes = kwargs.pop(\"classes\", [])\n if isinstance(classes, str):\n classes = classes.split(\" \")\n classes.insert(0, \"btn-link\")\n return Button(classes=classes, **kwargs)\n\n @staticmethod\n def primary(**kwargs):\n classes = kwargs.pop(\"classes\", [])\n if isinstance(classes, str):\n classes = classes.split(\" \")\n classes.insert(0, \"btn-primary\")\n return Button(classes=classes, **kwargs)\n\n @staticmethod\n def outline_primary(**kwargs):\n classes = kwargs.pop(\"classes\", [])\n if isinstance(classes, str):\n classes = classes.split(\" \")\n classes.insert(0, \"btn-outline-primary\")\n return Button(classes=classes, **kwargs)\n\n\nclass Image:\n \"\"\"Represents a generic image.\"\"\"\n\n def __init__(self, src, alt):\n self.src = src\n if not self.src.startswith(\"http\"):\n self.src = f\"img/{self.src}\"\n\n self.alt = alt\n\n\nclass Icon(Image):\n \"\"\"Represents an icon.\"\"\"\n\n def __init__(self, icon, alt):\n super().__init__(src=f\"icon/{icon}.svg\", alt=alt)\n\n\nclass MediaItem:\n \"\"\"\n Represents a list item:\n * icon: core.viewmodels.Icon\n * heading: str\n * details: str\n \"\"\"\n\n def __init__(self, icon, heading, details):\n self.icon = icon\n self.heading = heading\n self.details = details\n\n\nclass Page:\n \"\"\"\n Represents a page of content:\n * title: str\n * image: core.viewmodels.Image\n * icon: core.viewmodels.Icon\n * content_title: str\n * media: core.viewmodels.MediaItem[]\n * paragraphs: str[]\n * form: django.forms.Form\n * forms: django.forms.Form[]\n * button: core.viewmodels.Button\n * buttons: core.viewmodels.Button[]\n * classes: str[]\n \"\"\"\n\n def __init__(self, **kwargs):\n self.title = kwargs.get(\"title\")\n if self.title is None:\n self.title = _(\"core.page.title\")\n else:\n self.title = f\"{_('core.page.title')}: {self.title}\"\n\n self.image = kwargs.get(\"image\")\n self.icon = kwargs.get(\"icon\")\n self.content_title = kwargs.get(\"content_title\")\n self.media = kwargs.get(\"media\", [])\n self.paragraphs = kwargs.get(\"paragraphs\", [])\n self.steps = kwargs.get(\"steps\")\n\n self.forms = kwargs.get(\"forms\", [])\n if not isinstance(self.forms, list):\n self.forms = [self.forms]\n if \"form\" in kwargs:\n self.forms.append(kwargs.get(\"form\"))\n\n self.buttons = kwargs.get(\"buttons\", [])\n if not isinstance(self.buttons, list):\n self.buttons = [self.buttons]\n if \"button\" in kwargs:\n self.buttons.append(kwargs.get(\"button\"))\n\n self.classes = kwargs.get(\"classes\", [])\n if not isinstance(self.classes, list):\n self.classes = self.classes.split(\" \")\n if isinstance(self.image, Image):\n self.classes.append(\"with-image\")\n\n def context_dict(self):\n \"\"\"Return a context dict for a Page.\"\"\"\n return {\"page\": self}\n\n\nclass ErrorPage(Page):\n \"\"\"\n Represents an error page:\n * title: str\n * icon: core.viewmodels.Icon\n * content_title: str\n * paragraphs: str[]\n * button: core.viewmodels.Button\n \"\"\"\n\n def __init__(self, **kwargs):\n super().__init__(\n title=kwargs.get(\"title\", _(\"core.error\")),\n icon=kwargs.get(\"icon\", Icon(\"sadbus\", pgettext(\"image alt text\", \"core.icons.sadbus\"))),\n content_title=kwargs.get(\"content_title\", _(\"core.error\")),\n paragraphs=kwargs.get(\"paragraphs\", [_(\"core.error.server.content_title\")]),\n button=kwargs.get(\"button\"),\n )\n\n @staticmethod\n def error(\n title=_(\"core.error.server.title\"),\n content_title=_(\"core.error.server.title\"),\n paragraphs=[_(\"core.error.server.p1\"), _(\"core.error.server.p2\")],\n **kwargs,\n ):\n \"\"\"Create a new core.viewmodels.ErrorPage instance with defaults for a generic error.\"\"\"\n return ErrorPage(title=title, content_title=content_title, paragraphs=paragraphs, **kwargs)\n\n @staticmethod\n def not_found(\n title=_(\"core.error.notfound.title\"),\n content_title=_(\"core.error.notfound.content_title\"),\n paragraphs=[_(\"core.error.notfound.p1\")],\n **kwargs,\n ):\n \"\"\"Create a new core.viewmodels.ErrorPage with defaults for a 404.\"\"\"\n path = kwargs.pop(\"path\", None)\n if path and title:\n title = f\"{title}: {path}\"\n elif path and not title:\n title = path\n return ErrorPage(title=title, content_title=content_title, paragraphs=paragraphs, **kwargs)\n\n\nclass PaymentProcessor:\n \"\"\"\n Represents a core.models.PaymentProcessor:\n * model: core.models.PaymentProcessor\n * access_token: str\n * element_id: str\n * color: str\n * [name: str]\n * [loading_text: str]\n \"\"\"\n\n def __init__(self, model, access_token, element_id, color, name=None, loading_text=_(\"core.buttons.wait\")):\n if isinstance(model, models.PaymentProcessor):\n self.access_token = access_token\n self.element_id = element_id\n self.color = color\n self.name = name or model.name\n self.loading_text = loading_text\n self.card_tokenize_url = model.card_tokenize_url\n self.card_tokenize_func = model.card_tokenize_func\n self.card_tokenize_env = model.card_tokenize_env\n\n def context_dict(self):\n \"\"\"Return a context dict for a PaymentProcessor.\"\"\"\n return {\"payment_processor\": self}\n\n\nclass TransitAgency:\n \"\"\"\n Represents a core.models.TransitAgency:\n * model: core.models.TransitAgency\n \"\"\"\n\n def __init__(self, model):\n if isinstance(model, models.TransitAgency):\n self.slug = model.slug\n self.short_name = model.short_name\n self.long_name = model.long_name\n self.agency_id = model.agency_id\n self.merchant_id = model.merchant_id\n self.info_url = model.info_url\n self.phone = model.phone\n\n def context_dict(self):\n \"\"\"Return a context dict for a TransitAgency.\"\"\"\n return {\"agency\": self}\n", "path": "benefits/core/viewmodels.py"}]}
| 3,034 | 300 |
gh_patches_debug_22803
|
rasdani/github-patches
|
git_diff
|
python-poetry__poetry-6191
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Include strtobool in utils.extras to speed up the shell command
# Pull Request Check List
<!-- This is just a reminder about the most common mistakes. Please make sure that you tick all *appropriate* boxes. But please read our [contribution guide](https://python-poetry.org/docs/contributing/) at least once, it will save you unnecessary review cycles! -->
- [x] Added **tests** for changed code.
- [ ] Updated **documentation** for changed code. (The change doesn't reflect in the current doc)
<!-- If you have *any* questions to *any* of the points above, just **submit and ask**! This checklist is here to *help* you, not to deter you from contributing! -->
# What does this PR do?
This line `from distutils.util import strtobool` in `console.commands.shell` is slow and makes poetry shell command slow, since importing `distutils.util` also does a bunch of other things.
`strtobool` is a very simple function (~10 lines), if poetry includes this function itself, for example, putting it in utils.extras.py and use from poetry.utils.extras import strtobool, poetry shell would run faster.
[Discord discussion link](https://discord.com/channels/487711540787675139/974839878669987840/988024065933594704)
</issue>
<code>
[start of src/poetry/console/commands/shell.py]
1 from __future__ import annotations
2
3 import sys
4
5 from distutils.util import strtobool
6 from os import environ
7 from typing import TYPE_CHECKING
8 from typing import cast
9
10 from poetry.console.commands.env_command import EnvCommand
11
12
13 if TYPE_CHECKING:
14 from poetry.utils.env import VirtualEnv
15
16
17 class ShellCommand(EnvCommand):
18 name = "shell"
19 description = "Spawns a shell within the virtual environment."
20
21 help = """The <info>shell</> command spawns a shell, according to the
22 <comment>$SHELL</> environment variable, within the virtual environment.
23 If one doesn't exist yet, it will be created.
24 """
25
26 def handle(self) -> int:
27 from poetry.utils.shell import Shell
28
29 # Check if it's already activated or doesn't exist and won't be created
30 venv_activated = strtobool(environ.get("POETRY_ACTIVE", "0")) or getattr(
31 sys, "real_prefix", sys.prefix
32 ) == str(self.env.path)
33 if venv_activated:
34 self.line(
35 f"Virtual environment already activated: <info>{self.env.path}</>"
36 )
37
38 return 0
39
40 self.line(f"Spawning shell within <info>{self.env.path}</>")
41
42 # Be sure that we have the right type of environment.
43 env = self.env
44 assert env.is_venv()
45 env = cast("VirtualEnv", env)
46
47 # Setting this to avoid spawning unnecessary nested shells
48 environ["POETRY_ACTIVE"] = "1"
49 shell = Shell.get()
50 shell.activate(env)
51 environ.pop("POETRY_ACTIVE")
52
53 return 0
54
[end of src/poetry/console/commands/shell.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/poetry/console/commands/shell.py b/src/poetry/console/commands/shell.py
--- a/src/poetry/console/commands/shell.py
+++ b/src/poetry/console/commands/shell.py
@@ -2,7 +2,6 @@
import sys
-from distutils.util import strtobool
from os import environ
from typing import TYPE_CHECKING
from typing import cast
@@ -27,10 +26,7 @@
from poetry.utils.shell import Shell
# Check if it's already activated or doesn't exist and won't be created
- venv_activated = strtobool(environ.get("POETRY_ACTIVE", "0")) or getattr(
- sys, "real_prefix", sys.prefix
- ) == str(self.env.path)
- if venv_activated:
+ if self._is_venv_activated():
self.line(
f"Virtual environment already activated: <info>{self.env.path}</>"
)
@@ -51,3 +47,8 @@
environ.pop("POETRY_ACTIVE")
return 0
+
+ def _is_venv_activated(self) -> bool:
+ return bool(environ.get("POETRY_ACTIVE")) or getattr(
+ sys, "real_prefix", sys.prefix
+ ) == str(self.env.path)
|
{"golden_diff": "diff --git a/src/poetry/console/commands/shell.py b/src/poetry/console/commands/shell.py\n--- a/src/poetry/console/commands/shell.py\n+++ b/src/poetry/console/commands/shell.py\n@@ -2,7 +2,6 @@\n \n import sys\n \n-from distutils.util import strtobool\n from os import environ\n from typing import TYPE_CHECKING\n from typing import cast\n@@ -27,10 +26,7 @@\n from poetry.utils.shell import Shell\n \n # Check if it's already activated or doesn't exist and won't be created\n- venv_activated = strtobool(environ.get(\"POETRY_ACTIVE\", \"0\")) or getattr(\n- sys, \"real_prefix\", sys.prefix\n- ) == str(self.env.path)\n- if venv_activated:\n+ if self._is_venv_activated():\n self.line(\n f\"Virtual environment already activated: <info>{self.env.path}</>\"\n )\n@@ -51,3 +47,8 @@\n environ.pop(\"POETRY_ACTIVE\")\n \n return 0\n+\n+ def _is_venv_activated(self) -> bool:\n+ return bool(environ.get(\"POETRY_ACTIVE\")) or getattr(\n+ sys, \"real_prefix\", sys.prefix\n+ ) == str(self.env.path)\n", "issue": "Include strtobool in utils.extras to speed up the shell command\n# Pull Request Check List\r\n\r\n<!-- This is just a reminder about the most common mistakes. Please make sure that you tick all *appropriate* boxes. But please read our [contribution guide](https://python-poetry.org/docs/contributing/) at least once, it will save you unnecessary review cycles! -->\r\n\r\n- [x] Added **tests** for changed code.\r\n- [ ] Updated **documentation** for changed code. (The change doesn't reflect in the current doc)\r\n\r\n<!-- If you have *any* questions to *any* of the points above, just **submit and ask**! This checklist is here to *help* you, not to deter you from contributing! -->\r\n\r\n# What does this PR do?\r\n\r\nThis line `from distutils.util import strtobool` in `console.commands.shell` is slow and makes poetry shell command slow, since importing `distutils.util` also does a bunch of other things. \r\n\r\n`strtobool` is a very simple function (~10 lines), if poetry includes this function itself, for example, putting it in utils.extras.py and use from poetry.utils.extras import strtobool, poetry shell would run faster.\r\n\r\n[Discord discussion link](https://discord.com/channels/487711540787675139/974839878669987840/988024065933594704)\n", "before_files": [{"content": "from __future__ import annotations\n\nimport sys\n\nfrom distutils.util import strtobool\nfrom os import environ\nfrom typing import TYPE_CHECKING\nfrom typing import cast\n\nfrom poetry.console.commands.env_command import EnvCommand\n\n\nif TYPE_CHECKING:\n from poetry.utils.env import VirtualEnv\n\n\nclass ShellCommand(EnvCommand):\n name = \"shell\"\n description = \"Spawns a shell within the virtual environment.\"\n\n help = \"\"\"The <info>shell</> command spawns a shell, according to the\n<comment>$SHELL</> environment variable, within the virtual environment.\nIf one doesn't exist yet, it will be created.\n\"\"\"\n\n def handle(self) -> int:\n from poetry.utils.shell import Shell\n\n # Check if it's already activated or doesn't exist and won't be created\n venv_activated = strtobool(environ.get(\"POETRY_ACTIVE\", \"0\")) or getattr(\n sys, \"real_prefix\", sys.prefix\n ) == str(self.env.path)\n if venv_activated:\n self.line(\n f\"Virtual environment already activated: <info>{self.env.path}</>\"\n )\n\n return 0\n\n self.line(f\"Spawning shell within <info>{self.env.path}</>\")\n\n # Be sure that we have the right type of environment.\n env = self.env\n assert env.is_venv()\n env = cast(\"VirtualEnv\", env)\n\n # Setting this to avoid spawning unnecessary nested shells\n environ[\"POETRY_ACTIVE\"] = \"1\"\n shell = Shell.get()\n shell.activate(env)\n environ.pop(\"POETRY_ACTIVE\")\n\n return 0\n", "path": "src/poetry/console/commands/shell.py"}]}
| 1,333 | 297 |
gh_patches_debug_31360
|
rasdani/github-patches
|
git_diff
|
saulpw__visidata-2275
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[tsv] add CLI option to use NUL as delimiter
It's useful to parse output from GNU grep's `-Z` option. That produces lines that in Python are `f'{filename}\0{line}\n'`, instead of the usual `f'{filename}:{line}\n'`.
Right now the command line can't be used to specify a NUL delimiter, as in `vd --delimiter="\0"`, because `sys.argv` strings are NUL-terminated and can't ever contain NUL.
My workarounds for now are to use .visidatarc, either add a temporary line:
`vd.option('delimiter', '\x00', 'field delimiter to use for tsv/usv filetype', replay=True)`.
or add a new filetype to allow `vd -f nsv`:
```
@VisiData.api
def open_nsv(vd, p):
tsv = TsvSheet(p.base_stem, source=p)
tsv.delimiter = '\x00'
tsv.reload()
return tsv
```
Can `open_nsv()` be written without `reload()` right now? I couldn't think of another way to set `delimiter` for TsvSheet.
</issue>
<code>
[start of visidata/loaders/tsv.py]
1 import os
2 import contextlib
3 import itertools
4 import collections
5 import math
6 import time
7
8 from visidata import vd, asyncthread, options, Progress, ColumnItem, SequenceSheet, Sheet, VisiData
9 from visidata import namedlist, filesize
10
11 vd.option('delimiter', '\t', 'field delimiter to use for tsv/usv filetype', replay=True)
12 vd.option('row_delimiter', '\n', 'row delimiter to use for tsv/usv filetype', replay=True)
13 vd.option('tsv_safe_newline', '\u001e', 'replacement for newline character when saving to tsv', replay=True)
14 vd.option('tsv_safe_tab', '\u001f', 'replacement for tab character when saving to tsv', replay=True)
15
16
17 @VisiData.api
18 def open_tsv(vd, p):
19 return TsvSheet(p.base_stem, source=p)
20
21
22 def adaptive_bufferer(fp, max_buffer_size=65536):
23 """Loading e.g. tsv files goes faster with a large buffer. But when the input stream
24 is slow (e.g. 1 byte/second) and the buffer size is large, it can take a long time until
25 the buffer is filled. Only when the buffer is filled (or the input stream is finished)
26 you can see the data visiualized in visidata. That's why we use an adaptive buffer.
27 For fast input streams, the buffer becomes large, for slow input streams, the buffer stays
28 small"""
29 buffer_size = 8
30 processed_buffer_size = 0
31 previous_start_time = time.time()
32 while True:
33 next_chunk = fp.read(max(buffer_size, 1))
34 if not next_chunk:
35 break
36
37 yield next_chunk
38
39 processed_buffer_size += len(next_chunk)
40
41 current_time = time.time()
42 current_delta = current_time - previous_start_time
43
44 if current_delta < 1:
45 # if it takes longer than one second to fill the buffer, double the size of the buffer
46 buffer_size = min(buffer_size * 2, max_buffer_size)
47 else:
48 # if it takes less than one second, increase the buffer size so it takes about
49 # 1 second to fill it
50 previous_start_time = current_time
51 buffer_size = math.ceil(min(processed_buffer_size / current_delta, max_buffer_size))
52 processed_buffer_size = 0
53
54 def splitter(stream, delim='\n'):
55 'Generates one line/row/record at a time from stream, separated by delim'
56
57 buf = type(delim)()
58
59 for chunk in stream:
60 buf += chunk
61
62 *rows, buf = buf.split(delim)
63 yield from rows
64
65 buf = buf.rstrip(delim) # trim empty trailing lines
66 if buf:
67 yield from buf.rstrip(delim).split(delim)
68
69
70 # rowdef: list
71 class TsvSheet(SequenceSheet):
72 delimiter = ''
73 row_delimiter = ''
74
75 def iterload(self):
76 delim = self.delimiter or self.options.delimiter
77 rowdelim = self.row_delimiter or self.options.row_delimiter
78
79 with self.open_text_source() as fp:
80 for line in splitter(adaptive_bufferer(fp), rowdelim):
81 if not line or fp._regex_skip.match(line):
82 continue
83
84 row = list(line.split(delim))
85
86 if len(row) < self.nVisibleCols:
87 # extend rows that are missing entries
88 row.extend([None]*(self.nVisibleCols-len(row)))
89
90 yield row
91
92
93 @VisiData.api
94 def save_tsv(vd, p, vs, delimiter='', row_delimiter=''):
95 'Write sheet to file `fn` as TSV.'
96 unitsep = delimiter or vs.options.delimiter
97 rowsep = row_delimiter or vs.options.row_delimiter
98 trdict = vs.safe_trdict()
99
100 with p.open(mode='w', encoding=vs.options.save_encoding) as fp:
101 colhdr = unitsep.join(col.name.translate(trdict) for col in vs.visibleCols) + rowsep
102 fp.write(colhdr)
103
104 for dispvals in vs.iterdispvals(format=True):
105 fp.write(unitsep.join(dispvals.values()))
106 fp.write(rowsep)
107
108
109 @Sheet.api
110 def append_tsv_row(vs, row):
111 'Append `row` to vs.source, creating file with correct headers if necessary. For internal use only.'
112 if not vs.source.exists():
113 with contextlib.suppress(FileExistsError):
114 parentdir = vs.source.parent
115 if parentdir:
116 os.makedirs(parentdir)
117
118 # Write tsv header for Sheet `vs` to Path `p`
119 trdict = vs.safe_trdict()
120 unitsep = options.delimiter
121
122 with vs.source.open(mode='w') as fp:
123 colhdr = unitsep.join(col.name.translate(trdict) for col in vs.visibleCols) + vs.options.row_delimiter
124 if colhdr.strip(): # is anything but whitespace
125 fp.write(colhdr)
126
127 newrow = ''
128
129 contents = vs.source.open(mode='r').read()
130 if not contents.endswith('\n'): #1569
131 newrow += '\n'
132
133 newrow += '\t'.join(col.getDisplayValue(row) for col in vs.visibleCols) + '\n'
134
135 with vs.source.open(mode='a') as fp:
136 fp.write(newrow)
137
138
139 TsvSheet.options.regex_skip = '^#.*'
140
141 vd.addGlobals({
142 'TsvSheet': TsvSheet,
143 })
144
[end of visidata/loaders/tsv.py]
[start of visidata/features/xsv_guide.py]
1 from visidata import GuideSheet, vd
2
3
4 class XsvGuide(GuideSheet):
5 guide_text = '''# CSV/TSV options
6
7 ## `tsv` (Tab Separated Values), as simple as it gets
8
9 - {help.options.delimiter}
10 - {help.options.row_delimiter}
11 - {help.options.tsv_safe_newline}
12 - {help.options.tsv_safe_tab}
13
14 Use `-f usv` for Unicode separators U+241F and U+241E.
15 Use `-f lsv` for awk-like records.
16
17 ## `csv` (Comma Separated Values) for maximum computibility
18
19 .csv files are a scourge upon the earth, and still regrettably common.
20 All csv_* options are passed unchanged into csv.reader() and csv.writer().
21
22 - {help.options.csv_dialect}
23 - Accepted dialects are `excel-tab`, `unix`, and `excel`.
24 - {help.options.csv_delimiter}
25 - {help.options.csv_quotechar}
26 - {help.options.csv_skipinitialspace}
27 - {help.options.csv_escapechar}
28 - {help.options.csv_lineterminator}
29
30 ## Saving TSV/CSV files
31
32 - {help.options.save_filetype}
33 - {help.options.safety_first}
34
35 ## Useful options for text formats in general
36
37 - {help.options.regex_skip}
38 - {help.options.save_encoding}
39 '''
40
41
42 vd.addGuide('XsvGuide', XsvGuide)
43
[end of visidata/features/xsv_guide.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/visidata/features/xsv_guide.py b/visidata/features/xsv_guide.py
--- a/visidata/features/xsv_guide.py
+++ b/visidata/features/xsv_guide.py
@@ -13,6 +13,8 @@
Use `-f usv` for Unicode separators U+241F and U+241E.
Use `-f lsv` for awk-like records.
+ Use `--delimiter=` (an empty string) to make '\0' the value separator.
+ Use `--row-delimiter=` to make '\0' the row separator.
## `csv` (Comma Separated Values) for maximum computibility
diff --git a/visidata/loaders/tsv.py b/visidata/loaders/tsv.py
--- a/visidata/loaders/tsv.py
+++ b/visidata/loaders/tsv.py
@@ -75,6 +75,14 @@
def iterload(self):
delim = self.delimiter or self.options.delimiter
rowdelim = self.row_delimiter or self.options.row_delimiter
+ if delim == '':
+ vd.warning("using '\\x00' as field delimiter")
+ delim = '\x00' #2272
+ if rowdelim == '':
+ vd.warning("using '\\x00' as row delimiter")
+ rowdelim = '\x00'
+ if delim == rowdelim:
+ vd.fail('field delimiter and row delimiter cannot be the same')
with self.open_text_source() as fp:
for line in splitter(adaptive_bufferer(fp), rowdelim):
@@ -95,6 +103,14 @@
'Write sheet to file `fn` as TSV.'
unitsep = delimiter or vs.options.delimiter
rowsep = row_delimiter or vs.options.row_delimiter
+ if unitsep == '':
+ vd.warning("saving with '\\x00' as field delimiter")
+ unitsep = '\x00'
+ if rowsep == '':
+ vd.warning("saving with '\\x00' as row delimiter")
+ rowsep = '\x00'
+ if unitsep == rowsep:
+ vd.fail('field delimiter and row delimiter cannot be the same')
trdict = vs.safe_trdict()
with p.open(mode='w', encoding=vs.options.save_encoding) as fp:
|
{"golden_diff": "diff --git a/visidata/features/xsv_guide.py b/visidata/features/xsv_guide.py\n--- a/visidata/features/xsv_guide.py\n+++ b/visidata/features/xsv_guide.py\n@@ -13,6 +13,8 @@\n \n Use `-f usv` for Unicode separators U+241F and U+241E.\n Use `-f lsv` for awk-like records.\n+ Use `--delimiter=` (an empty string) to make '\\0' the value separator.\n+ Use `--row-delimiter=` to make '\\0' the row separator.\n \n ## `csv` (Comma Separated Values) for maximum computibility\n \ndiff --git a/visidata/loaders/tsv.py b/visidata/loaders/tsv.py\n--- a/visidata/loaders/tsv.py\n+++ b/visidata/loaders/tsv.py\n@@ -75,6 +75,14 @@\n def iterload(self):\n delim = self.delimiter or self.options.delimiter\n rowdelim = self.row_delimiter or self.options.row_delimiter\n+ if delim == '':\n+ vd.warning(\"using '\\\\x00' as field delimiter\")\n+ delim = '\\x00' #2272\n+ if rowdelim == '':\n+ vd.warning(\"using '\\\\x00' as row delimiter\")\n+ rowdelim = '\\x00'\n+ if delim == rowdelim:\n+ vd.fail('field delimiter and row delimiter cannot be the same')\n \n with self.open_text_source() as fp:\n for line in splitter(adaptive_bufferer(fp), rowdelim):\n@@ -95,6 +103,14 @@\n 'Write sheet to file `fn` as TSV.'\n unitsep = delimiter or vs.options.delimiter\n rowsep = row_delimiter or vs.options.row_delimiter\n+ if unitsep == '':\n+ vd.warning(\"saving with '\\\\x00' as field delimiter\")\n+ unitsep = '\\x00'\n+ if rowsep == '':\n+ vd.warning(\"saving with '\\\\x00' as row delimiter\")\n+ rowsep = '\\x00'\n+ if unitsep == rowsep:\n+ vd.fail('field delimiter and row delimiter cannot be the same')\n trdict = vs.safe_trdict()\n \n with p.open(mode='w', encoding=vs.options.save_encoding) as fp:\n", "issue": "[tsv] add CLI option to use NUL as delimiter\nIt's useful to parse output from GNU grep's `-Z` option. That produces lines that in Python are `f'{filename}\\0{line}\\n'`, instead of the usual `f'{filename}:{line}\\n'`.\r\n\r\nRight now the command line can't be used to specify a NUL delimiter, as in `vd --delimiter=\"\\0\"`, because `sys.argv` strings are NUL-terminated and can't ever contain NUL.\r\n\r\nMy workarounds for now are to use .visidatarc, either add a temporary line:\r\n`vd.option('delimiter', '\\x00', 'field delimiter to use for tsv/usv filetype', replay=True)`.\r\nor add a new filetype to allow `vd -f nsv`:\r\n```\r\[email protected]\r\ndef open_nsv(vd, p):\r\n tsv = TsvSheet(p.base_stem, source=p)\r\n tsv.delimiter = '\\x00'\r\n tsv.reload()\r\n return tsv\r\n```\r\nCan `open_nsv()` be written without `reload()` right now? I couldn't think of another way to set `delimiter` for TsvSheet.\n", "before_files": [{"content": "import os\nimport contextlib\nimport itertools\nimport collections\nimport math\nimport time\n\nfrom visidata import vd, asyncthread, options, Progress, ColumnItem, SequenceSheet, Sheet, VisiData\nfrom visidata import namedlist, filesize\n\nvd.option('delimiter', '\\t', 'field delimiter to use for tsv/usv filetype', replay=True)\nvd.option('row_delimiter', '\\n', 'row delimiter to use for tsv/usv filetype', replay=True)\nvd.option('tsv_safe_newline', '\\u001e', 'replacement for newline character when saving to tsv', replay=True)\nvd.option('tsv_safe_tab', '\\u001f', 'replacement for tab character when saving to tsv', replay=True)\n\n\[email protected]\ndef open_tsv(vd, p):\n return TsvSheet(p.base_stem, source=p)\n\n\ndef adaptive_bufferer(fp, max_buffer_size=65536):\n \"\"\"Loading e.g. tsv files goes faster with a large buffer. But when the input stream\n is slow (e.g. 1 byte/second) and the buffer size is large, it can take a long time until\n the buffer is filled. Only when the buffer is filled (or the input stream is finished)\n you can see the data visiualized in visidata. That's why we use an adaptive buffer.\n For fast input streams, the buffer becomes large, for slow input streams, the buffer stays\n small\"\"\"\n buffer_size = 8\n processed_buffer_size = 0\n previous_start_time = time.time()\n while True:\n next_chunk = fp.read(max(buffer_size, 1))\n if not next_chunk:\n break\n\n yield next_chunk\n\n processed_buffer_size += len(next_chunk)\n\n current_time = time.time()\n current_delta = current_time - previous_start_time\n\n if current_delta < 1:\n # if it takes longer than one second to fill the buffer, double the size of the buffer\n buffer_size = min(buffer_size * 2, max_buffer_size)\n else:\n # if it takes less than one second, increase the buffer size so it takes about\n # 1 second to fill it\n previous_start_time = current_time\n buffer_size = math.ceil(min(processed_buffer_size / current_delta, max_buffer_size))\n processed_buffer_size = 0\n\ndef splitter(stream, delim='\\n'):\n 'Generates one line/row/record at a time from stream, separated by delim'\n\n buf = type(delim)()\n\n for chunk in stream:\n buf += chunk\n\n *rows, buf = buf.split(delim)\n yield from rows\n\n buf = buf.rstrip(delim) # trim empty trailing lines\n if buf:\n yield from buf.rstrip(delim).split(delim)\n\n\n# rowdef: list\nclass TsvSheet(SequenceSheet):\n delimiter = ''\n row_delimiter = ''\n\n def iterload(self):\n delim = self.delimiter or self.options.delimiter\n rowdelim = self.row_delimiter or self.options.row_delimiter\n\n with self.open_text_source() as fp:\n for line in splitter(adaptive_bufferer(fp), rowdelim):\n if not line or fp._regex_skip.match(line):\n continue\n\n row = list(line.split(delim))\n\n if len(row) < self.nVisibleCols:\n # extend rows that are missing entries\n row.extend([None]*(self.nVisibleCols-len(row)))\n\n yield row\n\n\[email protected]\ndef save_tsv(vd, p, vs, delimiter='', row_delimiter=''):\n 'Write sheet to file `fn` as TSV.'\n unitsep = delimiter or vs.options.delimiter\n rowsep = row_delimiter or vs.options.row_delimiter\n trdict = vs.safe_trdict()\n\n with p.open(mode='w', encoding=vs.options.save_encoding) as fp:\n colhdr = unitsep.join(col.name.translate(trdict) for col in vs.visibleCols) + rowsep\n fp.write(colhdr)\n\n for dispvals in vs.iterdispvals(format=True):\n fp.write(unitsep.join(dispvals.values()))\n fp.write(rowsep)\n\n\[email protected]\ndef append_tsv_row(vs, row):\n 'Append `row` to vs.source, creating file with correct headers if necessary. For internal use only.'\n if not vs.source.exists():\n with contextlib.suppress(FileExistsError):\n parentdir = vs.source.parent\n if parentdir:\n os.makedirs(parentdir)\n\n # Write tsv header for Sheet `vs` to Path `p`\n trdict = vs.safe_trdict()\n unitsep = options.delimiter\n\n with vs.source.open(mode='w') as fp:\n colhdr = unitsep.join(col.name.translate(trdict) for col in vs.visibleCols) + vs.options.row_delimiter\n if colhdr.strip(): # is anything but whitespace\n fp.write(colhdr)\n\n newrow = ''\n\n contents = vs.source.open(mode='r').read()\n if not contents.endswith('\\n'): #1569\n newrow += '\\n'\n\n newrow += '\\t'.join(col.getDisplayValue(row) for col in vs.visibleCols) + '\\n'\n\n with vs.source.open(mode='a') as fp:\n fp.write(newrow)\n\n\nTsvSheet.options.regex_skip = '^#.*'\n\nvd.addGlobals({\n 'TsvSheet': TsvSheet,\n})\n", "path": "visidata/loaders/tsv.py"}, {"content": "from visidata import GuideSheet, vd\n\n\nclass XsvGuide(GuideSheet):\n guide_text = '''# CSV/TSV options\n\n ## `tsv` (Tab Separated Values), as simple as it gets\n\n - {help.options.delimiter}\n - {help.options.row_delimiter}\n - {help.options.tsv_safe_newline}\n - {help.options.tsv_safe_tab}\n\n Use `-f usv` for Unicode separators U+241F and U+241E.\n Use `-f lsv` for awk-like records.\n\n ## `csv` (Comma Separated Values) for maximum computibility\n\n .csv files are a scourge upon the earth, and still regrettably common.\n All csv_* options are passed unchanged into csv.reader() and csv.writer().\n\n - {help.options.csv_dialect}\n - Accepted dialects are `excel-tab`, `unix`, and `excel`.\n - {help.options.csv_delimiter}\n - {help.options.csv_quotechar}\n - {help.options.csv_skipinitialspace}\n - {help.options.csv_escapechar}\n - {help.options.csv_lineterminator}\n\n ## Saving TSV/CSV files\n\n - {help.options.save_filetype}\n - {help.options.safety_first}\n\n ## Useful options for text formats in general\n\n - {help.options.regex_skip}\n - {help.options.save_encoding}\n '''\n\n\nvd.addGuide('XsvGuide', XsvGuide)\n", "path": "visidata/features/xsv_guide.py"}]}
| 2,750 | 532 |
gh_patches_debug_37972
|
rasdani/github-patches
|
git_diff
|
mitmproxy__mitmproxy-3063
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
add_signal_handler is strictly UNIX only.
https://github.com/mitmproxy/mitmproxy/blob/4e126c0fbaafffd23e1a80926de6a99c897f9af0/mitmproxy/tools/main.py#L124
According to the `asyncio` documentation for [Python 3.6](https://docs.python.org/3/library/asyncio-eventloop.html#asyncio.AbstractEventLoop.add_signal_handler) , `add_signal_handler` is supported for UNIX system only. I haven't experienced or tested this issue but it maybe a potential risk since mitmproxy supports multiple platforms.
If someone has a Windows OS and/or some knowledge about asyncio maybe you could verify this.
</issue>
<code>
[start of mitmproxy/tools/main.py]
1 from __future__ import print_function # this is here for the version check to work on Python 2.
2
3 import asyncio
4 import sys
5
6 if sys.version_info < (3, 6):
7 # This must be before any mitmproxy imports, as they already break!
8 # Keep all other imports below with the 'noqa' magic comment.
9 print("#" * 49, file=sys.stderr)
10 print("# mitmproxy requires Python 3.6 or higher! #", file=sys.stderr)
11 print("#" * 49, file=sys.stderr)
12
13 import argparse # noqa
14 import os # noqa
15 import signal # noqa
16 import typing # noqa
17
18 from mitmproxy.tools import cmdline # noqa
19 from mitmproxy import exceptions, master # noqa
20 from mitmproxy import options # noqa
21 from mitmproxy import optmanager # noqa
22 from mitmproxy import proxy # noqa
23 from mitmproxy import log # noqa
24 from mitmproxy.utils import debug, arg_check # noqa
25
26
27 def assert_utf8_env():
28 spec = ""
29 for i in ["LANG", "LC_CTYPE", "LC_ALL"]:
30 spec += os.environ.get(i, "").lower()
31 if "utf" not in spec:
32 print(
33 "Error: mitmproxy requires a UTF console environment.",
34 file=sys.stderr
35 )
36 print(
37 "Set your LANG environment variable to something like en_US.UTF-8",
38 file=sys.stderr
39 )
40 sys.exit(1)
41
42
43 def process_options(parser, opts, args):
44 if args.version:
45 print(debug.dump_system_info())
46 sys.exit(0)
47 if args.quiet or args.options or args.commands:
48 # also reduce log verbosity if --options or --commands is passed,
49 # we don't want log messages from regular startup then.
50 args.termlog_verbosity = 'error'
51 args.flow_detail = 0
52 if args.verbose:
53 args.termlog_verbosity = 'debug'
54 args.flow_detail = 2
55
56 adict = {}
57 for n in dir(args):
58 if n in opts:
59 adict[n] = getattr(args, n)
60 opts.merge(adict)
61
62 return proxy.config.ProxyConfig(opts)
63
64
65 def run(
66 master_cls: typing.Type[master.Master],
67 make_parser: typing.Callable[[options.Options], argparse.ArgumentParser],
68 arguments: typing.Sequence[str],
69 extra: typing.Callable[[typing.Any], dict] = None
70 ): # pragma: no cover
71 """
72 extra: Extra argument processing callable which returns a dict of
73 options.
74 """
75 debug.register_info_dumpers()
76
77 opts = options.Options()
78 master = master_cls(opts)
79
80 parser = make_parser(opts)
81
82 # To make migration from 2.x to 3.0 bearable.
83 if "-R" in sys.argv and sys.argv[sys.argv.index("-R") + 1].startswith("http"):
84 print("-R is used for specifying replacements.\n"
85 "To use mitmproxy in reverse mode please use --mode reverse:SPEC instead")
86
87 try:
88 args = parser.parse_args(arguments)
89 except SystemExit:
90 arg_check.check()
91 sys.exit(1)
92 try:
93 unknown = optmanager.load_paths(opts, args.conf)
94 pconf = process_options(parser, opts, args)
95 server: typing.Any = None
96 if pconf.options.server:
97 try:
98 server = proxy.server.ProxyServer(pconf)
99 except exceptions.ServerException as v:
100 print(str(v), file=sys.stderr)
101 sys.exit(1)
102 else:
103 server = proxy.server.DummyServer(pconf)
104
105 master.server = server
106 master.addons.trigger("configure", opts.keys())
107 master.addons.trigger("tick")
108 opts.update_known(**unknown)
109 if args.options:
110 print(optmanager.dump_defaults(opts))
111 sys.exit(0)
112 if args.commands:
113 master.commands.dump()
114 sys.exit(0)
115 opts.set(*args.setoptions)
116 if extra:
117 opts.update(**extra(args))
118
119 def cleankill(*args, **kwargs):
120 master.shutdown()
121 signal.signal(signal.SIGTERM, cleankill)
122 loop = asyncio.get_event_loop()
123 for signame in ('SIGINT', 'SIGTERM'):
124 loop.add_signal_handler(getattr(signal, signame), master.shutdown)
125 master.run()
126 except exceptions.OptionsError as e:
127 print("%s: %s" % (sys.argv[0], e), file=sys.stderr)
128 sys.exit(1)
129 except (KeyboardInterrupt, RuntimeError) as e:
130 pass
131 return master
132
133
134 def mitmproxy(args=None): # pragma: no cover
135 if os.name == "nt":
136 print("Error: mitmproxy's console interface is not supported on Windows. "
137 "You can run mitmdump or mitmweb instead.", file=sys.stderr)
138 sys.exit(1)
139
140 assert_utf8_env()
141
142 from mitmproxy.tools import console
143 return run(console.master.ConsoleMaster, cmdline.mitmproxy, args)
144
145
146 def mitmdump(args=None): # pragma: no cover
147 from mitmproxy.tools import dump
148
149 def extra(args):
150 if args.filter_args:
151 v = " ".join(args.filter_args)
152 return dict(
153 save_stream_filter=v,
154 readfile_filter=v,
155 dumper_filter=v,
156 )
157 return {}
158
159 m = run(dump.DumpMaster, cmdline.mitmdump, args, extra)
160 if m and m.errorcheck.has_errored:
161 sys.exit(1)
162 return m
163
164
165 def mitmweb(args=None): # pragma: no cover
166 from mitmproxy.tools import web
167 return run(web.master.WebMaster, cmdline.mitmweb, args)
168
[end of mitmproxy/tools/main.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mitmproxy/tools/main.py b/mitmproxy/tools/main.py
--- a/mitmproxy/tools/main.py
+++ b/mitmproxy/tools/main.py
@@ -67,7 +67,7 @@
make_parser: typing.Callable[[options.Options], argparse.ArgumentParser],
arguments: typing.Sequence[str],
extra: typing.Callable[[typing.Any], dict] = None
-): # pragma: no cover
+) -> master.Master: # pragma: no cover
"""
extra: Extra argument processing callable which returns a dict of
options.
@@ -121,7 +121,11 @@
signal.signal(signal.SIGTERM, cleankill)
loop = asyncio.get_event_loop()
for signame in ('SIGINT', 'SIGTERM'):
- loop.add_signal_handler(getattr(signal, signame), master.shutdown)
+ try:
+ loop.add_signal_handler(getattr(signal, signame), master.shutdown)
+ except NotImplementedError:
+ # Not supported on Windows
+ pass
master.run()
except exceptions.OptionsError as e:
print("%s: %s" % (sys.argv[0], e), file=sys.stderr)
@@ -131,19 +135,18 @@
return master
-def mitmproxy(args=None): # pragma: no cover
+def mitmproxy(args=None) -> typing.Optional[int]: # pragma: no cover
if os.name == "nt":
print("Error: mitmproxy's console interface is not supported on Windows. "
"You can run mitmdump or mitmweb instead.", file=sys.stderr)
- sys.exit(1)
-
+ return 1
assert_utf8_env()
-
from mitmproxy.tools import console
- return run(console.master.ConsoleMaster, cmdline.mitmproxy, args)
+ run(console.master.ConsoleMaster, cmdline.mitmproxy, args)
+ return None
-def mitmdump(args=None): # pragma: no cover
+def mitmdump(args=None) -> typing.Optional[int]: # pragma: no cover
from mitmproxy.tools import dump
def extra(args):
@@ -157,11 +160,12 @@
return {}
m = run(dump.DumpMaster, cmdline.mitmdump, args, extra)
- if m and m.errorcheck.has_errored:
- sys.exit(1)
- return m
+ if m and m.errorcheck.has_errored: # type: ignore
+ return 1
+ return None
-def mitmweb(args=None): # pragma: no cover
+def mitmweb(args=None) -> typing.Optional[int]: # pragma: no cover
from mitmproxy.tools import web
- return run(web.master.WebMaster, cmdline.mitmweb, args)
+ run(web.master.WebMaster, cmdline.mitmweb, args)
+ return None
|
{"golden_diff": "diff --git a/mitmproxy/tools/main.py b/mitmproxy/tools/main.py\n--- a/mitmproxy/tools/main.py\n+++ b/mitmproxy/tools/main.py\n@@ -67,7 +67,7 @@\n make_parser: typing.Callable[[options.Options], argparse.ArgumentParser],\n arguments: typing.Sequence[str],\n extra: typing.Callable[[typing.Any], dict] = None\n-): # pragma: no cover\n+) -> master.Master: # pragma: no cover\n \"\"\"\n extra: Extra argument processing callable which returns a dict of\n options.\n@@ -121,7 +121,11 @@\n signal.signal(signal.SIGTERM, cleankill)\n loop = asyncio.get_event_loop()\n for signame in ('SIGINT', 'SIGTERM'):\n- loop.add_signal_handler(getattr(signal, signame), master.shutdown)\n+ try:\n+ loop.add_signal_handler(getattr(signal, signame), master.shutdown)\n+ except NotImplementedError:\n+ # Not supported on Windows\n+ pass\n master.run()\n except exceptions.OptionsError as e:\n print(\"%s: %s\" % (sys.argv[0], e), file=sys.stderr)\n@@ -131,19 +135,18 @@\n return master\n \n \n-def mitmproxy(args=None): # pragma: no cover\n+def mitmproxy(args=None) -> typing.Optional[int]: # pragma: no cover\n if os.name == \"nt\":\n print(\"Error: mitmproxy's console interface is not supported on Windows. \"\n \"You can run mitmdump or mitmweb instead.\", file=sys.stderr)\n- sys.exit(1)\n-\n+ return 1\n assert_utf8_env()\n-\n from mitmproxy.tools import console\n- return run(console.master.ConsoleMaster, cmdline.mitmproxy, args)\n+ run(console.master.ConsoleMaster, cmdline.mitmproxy, args)\n+ return None\n \n \n-def mitmdump(args=None): # pragma: no cover\n+def mitmdump(args=None) -> typing.Optional[int]: # pragma: no cover\n from mitmproxy.tools import dump\n \n def extra(args):\n@@ -157,11 +160,12 @@\n return {}\n \n m = run(dump.DumpMaster, cmdline.mitmdump, args, extra)\n- if m and m.errorcheck.has_errored:\n- sys.exit(1)\n- return m\n+ if m and m.errorcheck.has_errored: # type: ignore\n+ return 1\n+ return None\n \n \n-def mitmweb(args=None): # pragma: no cover\n+def mitmweb(args=None) -> typing.Optional[int]: # pragma: no cover\n from mitmproxy.tools import web\n- return run(web.master.WebMaster, cmdline.mitmweb, args)\n+ run(web.master.WebMaster, cmdline.mitmweb, args)\n+ return None\n", "issue": "add_signal_handler is strictly UNIX only. \nhttps://github.com/mitmproxy/mitmproxy/blob/4e126c0fbaafffd23e1a80926de6a99c897f9af0/mitmproxy/tools/main.py#L124\r\nAccording to the `asyncio` documentation for [Python 3.6](https://docs.python.org/3/library/asyncio-eventloop.html#asyncio.AbstractEventLoop.add_signal_handler) , `add_signal_handler` is supported for UNIX system only. I haven't experienced or tested this issue but it maybe a potential risk since mitmproxy supports multiple platforms. \r\n\r\nIf someone has a Windows OS and/or some knowledge about asyncio maybe you could verify this.\n", "before_files": [{"content": "from __future__ import print_function # this is here for the version check to work on Python 2.\n\nimport asyncio\nimport sys\n\nif sys.version_info < (3, 6):\n # This must be before any mitmproxy imports, as they already break!\n # Keep all other imports below with the 'noqa' magic comment.\n print(\"#\" * 49, file=sys.stderr)\n print(\"# mitmproxy requires Python 3.6 or higher! #\", file=sys.stderr)\n print(\"#\" * 49, file=sys.stderr)\n\nimport argparse # noqa\nimport os # noqa\nimport signal # noqa\nimport typing # noqa\n\nfrom mitmproxy.tools import cmdline # noqa\nfrom mitmproxy import exceptions, master # noqa\nfrom mitmproxy import options # noqa\nfrom mitmproxy import optmanager # noqa\nfrom mitmproxy import proxy # noqa\nfrom mitmproxy import log # noqa\nfrom mitmproxy.utils import debug, arg_check # noqa\n\n\ndef assert_utf8_env():\n spec = \"\"\n for i in [\"LANG\", \"LC_CTYPE\", \"LC_ALL\"]:\n spec += os.environ.get(i, \"\").lower()\n if \"utf\" not in spec:\n print(\n \"Error: mitmproxy requires a UTF console environment.\",\n file=sys.stderr\n )\n print(\n \"Set your LANG environment variable to something like en_US.UTF-8\",\n file=sys.stderr\n )\n sys.exit(1)\n\n\ndef process_options(parser, opts, args):\n if args.version:\n print(debug.dump_system_info())\n sys.exit(0)\n if args.quiet or args.options or args.commands:\n # also reduce log verbosity if --options or --commands is passed,\n # we don't want log messages from regular startup then.\n args.termlog_verbosity = 'error'\n args.flow_detail = 0\n if args.verbose:\n args.termlog_verbosity = 'debug'\n args.flow_detail = 2\n\n adict = {}\n for n in dir(args):\n if n in opts:\n adict[n] = getattr(args, n)\n opts.merge(adict)\n\n return proxy.config.ProxyConfig(opts)\n\n\ndef run(\n master_cls: typing.Type[master.Master],\n make_parser: typing.Callable[[options.Options], argparse.ArgumentParser],\n arguments: typing.Sequence[str],\n extra: typing.Callable[[typing.Any], dict] = None\n): # pragma: no cover\n \"\"\"\n extra: Extra argument processing callable which returns a dict of\n options.\n \"\"\"\n debug.register_info_dumpers()\n\n opts = options.Options()\n master = master_cls(opts)\n\n parser = make_parser(opts)\n\n # To make migration from 2.x to 3.0 bearable.\n if \"-R\" in sys.argv and sys.argv[sys.argv.index(\"-R\") + 1].startswith(\"http\"):\n print(\"-R is used for specifying replacements.\\n\"\n \"To use mitmproxy in reverse mode please use --mode reverse:SPEC instead\")\n\n try:\n args = parser.parse_args(arguments)\n except SystemExit:\n arg_check.check()\n sys.exit(1)\n try:\n unknown = optmanager.load_paths(opts, args.conf)\n pconf = process_options(parser, opts, args)\n server: typing.Any = None\n if pconf.options.server:\n try:\n server = proxy.server.ProxyServer(pconf)\n except exceptions.ServerException as v:\n print(str(v), file=sys.stderr)\n sys.exit(1)\n else:\n server = proxy.server.DummyServer(pconf)\n\n master.server = server\n master.addons.trigger(\"configure\", opts.keys())\n master.addons.trigger(\"tick\")\n opts.update_known(**unknown)\n if args.options:\n print(optmanager.dump_defaults(opts))\n sys.exit(0)\n if args.commands:\n master.commands.dump()\n sys.exit(0)\n opts.set(*args.setoptions)\n if extra:\n opts.update(**extra(args))\n\n def cleankill(*args, **kwargs):\n master.shutdown()\n signal.signal(signal.SIGTERM, cleankill)\n loop = asyncio.get_event_loop()\n for signame in ('SIGINT', 'SIGTERM'):\n loop.add_signal_handler(getattr(signal, signame), master.shutdown)\n master.run()\n except exceptions.OptionsError as e:\n print(\"%s: %s\" % (sys.argv[0], e), file=sys.stderr)\n sys.exit(1)\n except (KeyboardInterrupt, RuntimeError) as e:\n pass\n return master\n\n\ndef mitmproxy(args=None): # pragma: no cover\n if os.name == \"nt\":\n print(\"Error: mitmproxy's console interface is not supported on Windows. \"\n \"You can run mitmdump or mitmweb instead.\", file=sys.stderr)\n sys.exit(1)\n\n assert_utf8_env()\n\n from mitmproxy.tools import console\n return run(console.master.ConsoleMaster, cmdline.mitmproxy, args)\n\n\ndef mitmdump(args=None): # pragma: no cover\n from mitmproxy.tools import dump\n\n def extra(args):\n if args.filter_args:\n v = \" \".join(args.filter_args)\n return dict(\n save_stream_filter=v,\n readfile_filter=v,\n dumper_filter=v,\n )\n return {}\n\n m = run(dump.DumpMaster, cmdline.mitmdump, args, extra)\n if m and m.errorcheck.has_errored:\n sys.exit(1)\n return m\n\n\ndef mitmweb(args=None): # pragma: no cover\n from mitmproxy.tools import web\n return run(web.master.WebMaster, cmdline.mitmweb, args)\n", "path": "mitmproxy/tools/main.py"}]}
| 2,343 | 644 |
gh_patches_debug_59502
|
rasdani/github-patches
|
git_diff
|
Lightning-AI__pytorch-lightning-579
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Using print_nan_grads in the Trainer results in an error
**Describe the bug**
When using
```
print_nan_grads=True
```
in the Trainer, I am getting the error below.
trainer.fit(lstm_model)
File "/Users/anaconda3/envs/snorkel/lib/python3.6/site-packages/pytorch_lightning/trainer/trainer.py", line 364, in fit
self.run_pretrain_routine(model)
File "/Users/anaconda3/envs/snorkel/lib/python3.6/site-packages/pytorch_lightning/trainer/trainer.py", line 471, in run_pretrain_routine
self.train()
File "/Users/anaconda3/envs/snorkel/lib/python3.6/site-packages/pytorch_lightning/trainer/train_loop_mixin.py", line 60, in train
self.run_training_epoch()
File "/Users/anaconda3/envs/snorkel/lib/python3.6/site-packages/pytorch_lightning/trainer/train_loop_mixin.py", line 99, in run_training_epoch
output = self.run_training_batch(batch, batch_nb)
File "/Users/anaconda3/envs/snorkel/lib/python3.6/site-packages/pytorch_lightning/trainer/train_loop_mixin.py", line 219, in run_training_batch
self.print_nan_gradients()
File "/Users/anaconda3/envs/snorkel/lib/python3.6/site-packages/pytorch_lightning/trainer/training_tricks_mixin.py", line 16, in print_nan_gradients
if torch.isnan(param.grad.float()).any():
AttributeError: 'NoneType' object has no attribute 'float'
**To Reproduce**
Steps to reproduce the behavior:
If some param object, does not have **.grad**, then that object should not be checked for nans
</issue>
<code>
[start of pytorch_lightning/trainer/training_tricks_mixin.py]
1 import torch
2 import logging
3 from pytorch_lightning.callbacks import GradientAccumulationScheduler
4
5
6 class TrainerTrainingTricksMixin(object):
7
8 def clip_gradients(self):
9 if self.gradient_clip_val > 0:
10 model = self.get_model()
11 torch.nn.utils.clip_grad_norm_(model.parameters(), self.gradient_clip_val)
12
13 def print_nan_gradients(self):
14 model = self.get_model()
15 for param in model.parameters():
16 if torch.isnan(param.grad.float()).any():
17 logging.info(param, param.grad)
18
19 def configure_accumulated_gradients(self, accumulate_grad_batches):
20 self.accumulate_grad_batches = None
21
22 if isinstance(accumulate_grad_batches, dict):
23 self.accumulation_scheduler = GradientAccumulationScheduler(accumulate_grad_batches)
24 elif isinstance(accumulate_grad_batches, int):
25 schedule = {1: accumulate_grad_batches}
26 self.accumulation_scheduler = GradientAccumulationScheduler(schedule)
27 else:
28 raise TypeError("Gradient accumulation supports only int and dict types")
29
[end of pytorch_lightning/trainer/training_tricks_mixin.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pytorch_lightning/trainer/training_tricks_mixin.py b/pytorch_lightning/trainer/training_tricks_mixin.py
--- a/pytorch_lightning/trainer/training_tricks_mixin.py
+++ b/pytorch_lightning/trainer/training_tricks_mixin.py
@@ -13,7 +13,7 @@
def print_nan_gradients(self):
model = self.get_model()
for param in model.parameters():
- if torch.isnan(param.grad.float()).any():
+ if (param.grad is not None) and torch.isnan(param.grad.float()).any():
logging.info(param, param.grad)
def configure_accumulated_gradients(self, accumulate_grad_batches):
|
{"golden_diff": "diff --git a/pytorch_lightning/trainer/training_tricks_mixin.py b/pytorch_lightning/trainer/training_tricks_mixin.py\n--- a/pytorch_lightning/trainer/training_tricks_mixin.py\n+++ b/pytorch_lightning/trainer/training_tricks_mixin.py\n@@ -13,7 +13,7 @@\n def print_nan_gradients(self):\n model = self.get_model()\n for param in model.parameters():\n- if torch.isnan(param.grad.float()).any():\n+ if (param.grad is not None) and torch.isnan(param.grad.float()).any():\n logging.info(param, param.grad)\n \n def configure_accumulated_gradients(self, accumulate_grad_batches):\n", "issue": "Using print_nan_grads in the Trainer results in an error\n**Describe the bug**\r\nWhen using \r\n```\r\nprint_nan_grads=True\r\n```\r\nin the Trainer, I am getting the error below.\r\n\r\ntrainer.fit(lstm_model)\r\n File \"/Users/anaconda3/envs/snorkel/lib/python3.6/site-packages/pytorch_lightning/trainer/trainer.py\", line 364, in fit\r\n self.run_pretrain_routine(model)\r\n File \"/Users/anaconda3/envs/snorkel/lib/python3.6/site-packages/pytorch_lightning/trainer/trainer.py\", line 471, in run_pretrain_routine\r\n self.train()\r\n File \"/Users/anaconda3/envs/snorkel/lib/python3.6/site-packages/pytorch_lightning/trainer/train_loop_mixin.py\", line 60, in train\r\n self.run_training_epoch()\r\n File \"/Users/anaconda3/envs/snorkel/lib/python3.6/site-packages/pytorch_lightning/trainer/train_loop_mixin.py\", line 99, in run_training_epoch\r\n output = self.run_training_batch(batch, batch_nb)\r\n File \"/Users/anaconda3/envs/snorkel/lib/python3.6/site-packages/pytorch_lightning/trainer/train_loop_mixin.py\", line 219, in run_training_batch\r\n self.print_nan_gradients()\r\n File \"/Users/anaconda3/envs/snorkel/lib/python3.6/site-packages/pytorch_lightning/trainer/training_tricks_mixin.py\", line 16, in print_nan_gradients\r\n if torch.isnan(param.grad.float()).any():\r\nAttributeError: 'NoneType' object has no attribute 'float'\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\nIf some param object, does not have **.grad**, then that object should not be checked for nans\r\n\n", "before_files": [{"content": "import torch\nimport logging\nfrom pytorch_lightning.callbacks import GradientAccumulationScheduler\n\n\nclass TrainerTrainingTricksMixin(object):\n\n def clip_gradients(self):\n if self.gradient_clip_val > 0:\n model = self.get_model()\n torch.nn.utils.clip_grad_norm_(model.parameters(), self.gradient_clip_val)\n\n def print_nan_gradients(self):\n model = self.get_model()\n for param in model.parameters():\n if torch.isnan(param.grad.float()).any():\n logging.info(param, param.grad)\n\n def configure_accumulated_gradients(self, accumulate_grad_batches):\n self.accumulate_grad_batches = None\n\n if isinstance(accumulate_grad_batches, dict):\n self.accumulation_scheduler = GradientAccumulationScheduler(accumulate_grad_batches)\n elif isinstance(accumulate_grad_batches, int):\n schedule = {1: accumulate_grad_batches}\n self.accumulation_scheduler = GradientAccumulationScheduler(schedule)\n else:\n raise TypeError(\"Gradient accumulation supports only int and dict types\")\n", "path": "pytorch_lightning/trainer/training_tricks_mixin.py"}]}
| 1,204 | 148 |
gh_patches_debug_16660
|
rasdani/github-patches
|
git_diff
|
PrefectHQ__prefect-4767
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
document loading external files with `Git` storage
## Current behavior
<!-- Please describe how the feature works today -->
No docs
## Proposed behavior
<!-- Please describe your proposed change to the current behavior -->
Create an example doc illustration how to use `Git` storage to load external files (non-python files) from a repo with `Git` storage
## Example
<!-- Please give an example of how the enhancement would be useful -->
</issue>
<code>
[start of src/prefect/utilities/storage.py]
1 import binascii
2 import importlib
3 import json
4 import sys
5 import warnings
6 from operator import attrgetter
7 from typing import TYPE_CHECKING
8 from distutils.version import LooseVersion
9
10 import cloudpickle
11
12 import prefect
13 from prefect.exceptions import FlowStorageError
14
15 if TYPE_CHECKING:
16 from prefect.core.flow import Flow # pylint: disable=W0611
17
18
19 def get_flow_image(flow: "Flow") -> str:
20 """
21 Retrieve the image to use for this flow deployment. Will start by looking for
22 an `image` value in the flow's `environment.metadata`. If not found then it will fall
23 back to using the `flow.storage`.
24
25 Args:
26 - flow (Flow): A flow object
27
28 Returns:
29 - str: a full image name to use for this flow run
30
31 Raises:
32 - ValueError: if deployment attempted on unsupported Storage type and `image` not
33 present in environment metadata
34 """
35 environment = flow.environment
36 if (
37 environment is not None
38 and hasattr(environment, "metadata")
39 and environment.metadata.get("image")
40 ):
41 return environment.metadata.get("image", "")
42 else:
43 storage = flow.storage
44 if not isinstance(storage, prefect.storage.Docker):
45 raise ValueError(
46 f"Storage for flow run {flow.name} is not of type Docker and "
47 f"environment has no `image` attribute in the metadata field."
48 )
49
50 return storage.name
51
52
53 def extract_flow_from_file(
54 file_path: str = None, file_contents: str = None, flow_name: str = None
55 ) -> "Flow":
56 """
57 Extract a flow object from a file.
58
59 Args:
60 - file_path (str, optional): A file path pointing to a .py file containing a flow
61 - file_contents (str, optional): The string contents of a .py file containing a flow
62 - flow_name (str, optional): A specific name of a flow to extract from a file.
63 If not set then the first flow object retrieved from file will be returned.
64
65 Returns:
66 - Flow: A flow object extracted from a file
67
68 Raises:
69 - ValueError: if both `file_path` and `file_contents` are provided or neither are.
70 """
71 if file_path is not None:
72 if file_contents is not None:
73 raise ValueError(
74 "Provide either `file_path` or `file_contents` but not both."
75 )
76
77 with open(file_path, "r") as f:
78 contents = f.read()
79 elif file_contents is not None:
80 contents = file_contents
81 else:
82 raise ValueError("Provide either `file_path` or `file_contents`.")
83
84 # Load objects from file into dict
85 exec_vals = {} # type: ignore
86 exec(contents, exec_vals)
87
88 # Grab flow name from values loaded via exec
89 flows = {o.name: o for o in exec_vals.values() if isinstance(o, prefect.Flow)}
90 if flows:
91 if flow_name:
92 if flow_name in flows:
93 return flows[flow_name]
94 else:
95 flows_list = "\n".join("- %r" % n for n in sorted(flows))
96 raise ValueError(
97 f"Flow {flow_name!r} not found in file. Found flows:\n{flows_list}"
98 )
99 else:
100 return list(flows.values())[0]
101 else:
102 raise ValueError("No flows found in file.")
103
104
105 def extract_flow_from_module(module_str: str, flow_name: str = None) -> "Flow":
106 """
107 Extract a flow object from a python module.
108
109 Args:
110 - module_str (str): A module path pointing to a .py file containing a flow.
111 For example, 'myrepo.mymodule.myflow' where myflow.py contains the flow.
112 Additionally, `:` can be used to access module's attribute, for example,
113 'myrepo.mymodule.myflow:flow' or 'myrepo.mymodule.myflow:MyObj.newflow'.
114 - flow_name (str, optional): A specific name of a flow to extract from a file.
115 If not provided, the `module_str` must have an attribute specifier
116 or only one `Flow` object must be present in the module, otherwise
117 an error will be raised.
118
119 Returns:
120 - Flow: A flow object extracted from a file
121 """
122 mod_name, obj_name_present, obj_name = module_str.partition(":")
123
124 module = importlib.import_module(mod_name)
125
126 if obj_name_present:
127 try:
128 flow = attrgetter(obj_name)(module)
129 except AttributeError:
130 raise ValueError(f"Failed to find flow at {module_str!r}") from None
131 if callable(flow):
132 flow = flow()
133 if not isinstance(flow, prefect.Flow):
134 raise TypeError(
135 f"Object at {module_str!r} is a {type(flow)} not a `prefect.Flow`"
136 )
137 if flow_name is not None and flow.name != flow_name:
138 raise ValueError(
139 f"Flow at {module_str!r} is named {flow.name!r}, expected {flow_name!r}"
140 )
141 return flow
142 else:
143 flows = {}
144 for attr in dir(module):
145 obj = getattr(module, attr, None)
146 if isinstance(obj, prefect.Flow):
147 flows[obj.name] = obj
148 if flow_name is not None:
149 if flow_name in flows:
150 return flows[flow_name]
151 raise ValueError(f"Failed to find flow {flow_name!r} in {module_str!r}")
152 elif len(flows) == 1:
153 return flows.popitem()[1]
154 elif len(flows) > 1:
155 raise ValueError(
156 "Multiple flows found in {module_str!r}, please provide `flow_name` to select one."
157 )
158 else:
159 raise ValueError("No flows found in {module_str!r}")
160
161
162 def flow_to_bytes_pickle(flow: "Flow") -> bytes:
163 """Serialize a flow to bytes.
164
165 The flow is serialized using `cloudpickle`, with some extra metadata on
166 included via JSON. The flow can be reloaded using `flow_from_bytes_pickle`.
167
168 Args:
169 - flow (Flow): the flow to be serialized.
170
171 Returns:
172 - bytes: a serialized representation of the flow.
173 """
174 flow_data = binascii.b2a_base64(
175 cloudpickle.dumps(flow, protocol=4), newline=False
176 ).decode("utf-8")
177 out = json.dumps({"flow": flow_data, "versions": _get_versions()})
178 return out.encode("utf-8")
179
180
181 def _get_versions() -> dict:
182 """Get version info on libraries where a version-mismatch between
183 registration and execution environment may cause a flow to fail to load
184 properly"""
185 return {
186 "cloudpickle": cloudpickle.__version__,
187 "prefect": prefect.__version__,
188 "python": "%d.%d.%d" % sys.version_info[:3],
189 }
190
191
192 def flow_from_bytes_pickle(data: bytes) -> "Flow":
193 """Load a flow from bytes."""
194 try:
195 info = json.loads(data.decode("utf-8"))
196 except Exception:
197 # Serialized using older version of prefect, use cloudpickle directly
198 flow_bytes = data
199 reg_versions = {}
200 else:
201 flow_bytes = binascii.a2b_base64(info["flow"])
202 reg_versions = info["versions"]
203
204 run_versions = _get_versions()
205
206 try:
207 flow = cloudpickle.loads(flow_bytes)
208 except Exception as exc:
209 parts = ["An error occurred while unpickling the flow:", f" {exc!r}"]
210 # Check for mismatched versions to provide a better error if possible
211 mismatches = []
212 for name, v1 in sorted(reg_versions.items()):
213 if name in run_versions:
214 v2 = run_versions[name]
215 if LooseVersion(v1) != v2:
216 mismatches.append(
217 f" - {name}: (flow built with {v1!r}, currently running with {v2!r})"
218 )
219 if mismatches:
220 parts.append(
221 "This may be due to one of the following version mismatches between "
222 "the flow build and execution environments:"
223 )
224 parts.extend(mismatches)
225 if isinstance(exc, ImportError):
226 # If it's an import error, also note that the user may need to package
227 # their dependencies
228 prefix = "This also may" if mismatches else "This may"
229 parts.append(
230 f"{prefix} be due to a missing Python module in your current "
231 "environment. Please ensure you have all required flow "
232 "dependencies installed."
233 )
234 raise FlowStorageError("\n".join(parts)) from exc
235
236 run_prefect = run_versions["prefect"]
237 reg_prefect = reg_versions.get("prefect")
238 if reg_prefect and LooseVersion(reg_prefect) != run_prefect:
239 # If we didn't error above, still check that the prefect versions match
240 # and warn if they don't. Prefect version mismatches *may* work, but
241 # they may also error later leading to confusing behavior.
242 warnings.warn(
243 f"This flow was built using Prefect {reg_prefect!r}, but you currently "
244 f"have Prefect {run_prefect!r} installed. We recommend loading flows "
245 "with the same Prefect version they were built with, failure to do so "
246 "may result in errors."
247 )
248 return flow
249
[end of src/prefect/utilities/storage.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/prefect/utilities/storage.py b/src/prefect/utilities/storage.py
--- a/src/prefect/utilities/storage.py
+++ b/src/prefect/utilities/storage.py
@@ -4,7 +4,7 @@
import sys
import warnings
from operator import attrgetter
-from typing import TYPE_CHECKING
+from typing import TYPE_CHECKING, Dict, Any
from distutils.version import LooseVersion
import cloudpickle
@@ -82,7 +82,9 @@
raise ValueError("Provide either `file_path` or `file_contents`.")
# Load objects from file into dict
- exec_vals = {} # type: ignore
+ # if a file_path has been provided, provide __file__ as a global variable
+ # so it resolves correctly during extraction
+ exec_vals: Dict[str, Any] = {"__file__": file_path} if file_path else {}
exec(contents, exec_vals)
# Grab flow name from values loaded via exec
|
{"golden_diff": "diff --git a/src/prefect/utilities/storage.py b/src/prefect/utilities/storage.py\n--- a/src/prefect/utilities/storage.py\n+++ b/src/prefect/utilities/storage.py\n@@ -4,7 +4,7 @@\n import sys\n import warnings\n from operator import attrgetter\n-from typing import TYPE_CHECKING\n+from typing import TYPE_CHECKING, Dict, Any\n from distutils.version import LooseVersion\n \n import cloudpickle\n@@ -82,7 +82,9 @@\n raise ValueError(\"Provide either `file_path` or `file_contents`.\")\n \n # Load objects from file into dict\n- exec_vals = {} # type: ignore\n+ # if a file_path has been provided, provide __file__ as a global variable\n+ # so it resolves correctly during extraction\n+ exec_vals: Dict[str, Any] = {\"__file__\": file_path} if file_path else {}\n exec(contents, exec_vals)\n \n # Grab flow name from values loaded via exec\n", "issue": "document loading external files with `Git` storage\n## Current behavior\r\n<!-- Please describe how the feature works today -->\r\nNo docs\r\n\r\n\r\n## Proposed behavior\r\n<!-- Please describe your proposed change to the current behavior -->\r\nCreate an example doc illustration how to use `Git` storage to load external files (non-python files) from a repo with `Git` storage\r\n\r\n\r\n\r\n## Example\r\n<!-- Please give an example of how the enhancement would be useful -->\r\n\n", "before_files": [{"content": "import binascii\nimport importlib\nimport json\nimport sys\nimport warnings\nfrom operator import attrgetter\nfrom typing import TYPE_CHECKING\nfrom distutils.version import LooseVersion\n\nimport cloudpickle\n\nimport prefect\nfrom prefect.exceptions import FlowStorageError\n\nif TYPE_CHECKING:\n from prefect.core.flow import Flow # pylint: disable=W0611\n\n\ndef get_flow_image(flow: \"Flow\") -> str:\n \"\"\"\n Retrieve the image to use for this flow deployment. Will start by looking for\n an `image` value in the flow's `environment.metadata`. If not found then it will fall\n back to using the `flow.storage`.\n\n Args:\n - flow (Flow): A flow object\n\n Returns:\n - str: a full image name to use for this flow run\n\n Raises:\n - ValueError: if deployment attempted on unsupported Storage type and `image` not\n present in environment metadata\n \"\"\"\n environment = flow.environment\n if (\n environment is not None\n and hasattr(environment, \"metadata\")\n and environment.metadata.get(\"image\")\n ):\n return environment.metadata.get(\"image\", \"\")\n else:\n storage = flow.storage\n if not isinstance(storage, prefect.storage.Docker):\n raise ValueError(\n f\"Storage for flow run {flow.name} is not of type Docker and \"\n f\"environment has no `image` attribute in the metadata field.\"\n )\n\n return storage.name\n\n\ndef extract_flow_from_file(\n file_path: str = None, file_contents: str = None, flow_name: str = None\n) -> \"Flow\":\n \"\"\"\n Extract a flow object from a file.\n\n Args:\n - file_path (str, optional): A file path pointing to a .py file containing a flow\n - file_contents (str, optional): The string contents of a .py file containing a flow\n - flow_name (str, optional): A specific name of a flow to extract from a file.\n If not set then the first flow object retrieved from file will be returned.\n\n Returns:\n - Flow: A flow object extracted from a file\n\n Raises:\n - ValueError: if both `file_path` and `file_contents` are provided or neither are.\n \"\"\"\n if file_path is not None:\n if file_contents is not None:\n raise ValueError(\n \"Provide either `file_path` or `file_contents` but not both.\"\n )\n\n with open(file_path, \"r\") as f:\n contents = f.read()\n elif file_contents is not None:\n contents = file_contents\n else:\n raise ValueError(\"Provide either `file_path` or `file_contents`.\")\n\n # Load objects from file into dict\n exec_vals = {} # type: ignore\n exec(contents, exec_vals)\n\n # Grab flow name from values loaded via exec\n flows = {o.name: o for o in exec_vals.values() if isinstance(o, prefect.Flow)}\n if flows:\n if flow_name:\n if flow_name in flows:\n return flows[flow_name]\n else:\n flows_list = \"\\n\".join(\"- %r\" % n for n in sorted(flows))\n raise ValueError(\n f\"Flow {flow_name!r} not found in file. Found flows:\\n{flows_list}\"\n )\n else:\n return list(flows.values())[0]\n else:\n raise ValueError(\"No flows found in file.\")\n\n\ndef extract_flow_from_module(module_str: str, flow_name: str = None) -> \"Flow\":\n \"\"\"\n Extract a flow object from a python module.\n\n Args:\n - module_str (str): A module path pointing to a .py file containing a flow.\n For example, 'myrepo.mymodule.myflow' where myflow.py contains the flow.\n Additionally, `:` can be used to access module's attribute, for example,\n 'myrepo.mymodule.myflow:flow' or 'myrepo.mymodule.myflow:MyObj.newflow'.\n - flow_name (str, optional): A specific name of a flow to extract from a file.\n If not provided, the `module_str` must have an attribute specifier\n or only one `Flow` object must be present in the module, otherwise\n an error will be raised.\n\n Returns:\n - Flow: A flow object extracted from a file\n \"\"\"\n mod_name, obj_name_present, obj_name = module_str.partition(\":\")\n\n module = importlib.import_module(mod_name)\n\n if obj_name_present:\n try:\n flow = attrgetter(obj_name)(module)\n except AttributeError:\n raise ValueError(f\"Failed to find flow at {module_str!r}\") from None\n if callable(flow):\n flow = flow()\n if not isinstance(flow, prefect.Flow):\n raise TypeError(\n f\"Object at {module_str!r} is a {type(flow)} not a `prefect.Flow`\"\n )\n if flow_name is not None and flow.name != flow_name:\n raise ValueError(\n f\"Flow at {module_str!r} is named {flow.name!r}, expected {flow_name!r}\"\n )\n return flow\n else:\n flows = {}\n for attr in dir(module):\n obj = getattr(module, attr, None)\n if isinstance(obj, prefect.Flow):\n flows[obj.name] = obj\n if flow_name is not None:\n if flow_name in flows:\n return flows[flow_name]\n raise ValueError(f\"Failed to find flow {flow_name!r} in {module_str!r}\")\n elif len(flows) == 1:\n return flows.popitem()[1]\n elif len(flows) > 1:\n raise ValueError(\n \"Multiple flows found in {module_str!r}, please provide `flow_name` to select one.\"\n )\n else:\n raise ValueError(\"No flows found in {module_str!r}\")\n\n\ndef flow_to_bytes_pickle(flow: \"Flow\") -> bytes:\n \"\"\"Serialize a flow to bytes.\n\n The flow is serialized using `cloudpickle`, with some extra metadata on\n included via JSON. The flow can be reloaded using `flow_from_bytes_pickle`.\n\n Args:\n - flow (Flow): the flow to be serialized.\n\n Returns:\n - bytes: a serialized representation of the flow.\n \"\"\"\n flow_data = binascii.b2a_base64(\n cloudpickle.dumps(flow, protocol=4), newline=False\n ).decode(\"utf-8\")\n out = json.dumps({\"flow\": flow_data, \"versions\": _get_versions()})\n return out.encode(\"utf-8\")\n\n\ndef _get_versions() -> dict:\n \"\"\"Get version info on libraries where a version-mismatch between\n registration and execution environment may cause a flow to fail to load\n properly\"\"\"\n return {\n \"cloudpickle\": cloudpickle.__version__,\n \"prefect\": prefect.__version__,\n \"python\": \"%d.%d.%d\" % sys.version_info[:3],\n }\n\n\ndef flow_from_bytes_pickle(data: bytes) -> \"Flow\":\n \"\"\"Load a flow from bytes.\"\"\"\n try:\n info = json.loads(data.decode(\"utf-8\"))\n except Exception:\n # Serialized using older version of prefect, use cloudpickle directly\n flow_bytes = data\n reg_versions = {}\n else:\n flow_bytes = binascii.a2b_base64(info[\"flow\"])\n reg_versions = info[\"versions\"]\n\n run_versions = _get_versions()\n\n try:\n flow = cloudpickle.loads(flow_bytes)\n except Exception as exc:\n parts = [\"An error occurred while unpickling the flow:\", f\" {exc!r}\"]\n # Check for mismatched versions to provide a better error if possible\n mismatches = []\n for name, v1 in sorted(reg_versions.items()):\n if name in run_versions:\n v2 = run_versions[name]\n if LooseVersion(v1) != v2:\n mismatches.append(\n f\" - {name}: (flow built with {v1!r}, currently running with {v2!r})\"\n )\n if mismatches:\n parts.append(\n \"This may be due to one of the following version mismatches between \"\n \"the flow build and execution environments:\"\n )\n parts.extend(mismatches)\n if isinstance(exc, ImportError):\n # If it's an import error, also note that the user may need to package\n # their dependencies\n prefix = \"This also may\" if mismatches else \"This may\"\n parts.append(\n f\"{prefix} be due to a missing Python module in your current \"\n \"environment. Please ensure you have all required flow \"\n \"dependencies installed.\"\n )\n raise FlowStorageError(\"\\n\".join(parts)) from exc\n\n run_prefect = run_versions[\"prefect\"]\n reg_prefect = reg_versions.get(\"prefect\")\n if reg_prefect and LooseVersion(reg_prefect) != run_prefect:\n # If we didn't error above, still check that the prefect versions match\n # and warn if they don't. Prefect version mismatches *may* work, but\n # they may also error later leading to confusing behavior.\n warnings.warn(\n f\"This flow was built using Prefect {reg_prefect!r}, but you currently \"\n f\"have Prefect {run_prefect!r} installed. We recommend loading flows \"\n \"with the same Prefect version they were built with, failure to do so \"\n \"may result in errors.\"\n )\n return flow\n", "path": "src/prefect/utilities/storage.py"}]}
| 3,319 | 220 |
gh_patches_debug_33388
|
rasdani/github-patches
|
git_diff
|
goauthentik__authentik-5153
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Celery CPU usage 100% on new install
**Describe the bug**
I'm using the attached docker-compose and env file (don't worry about the secrets in the env file).
[env.txt](https://github.com/goauthentik/authentik/files/10758594/env.txt)
[docker-compose.yml.txt](https://github.com/goauthentik/authentik/files/10758616/docker-compose.yml.txt)
**To Reproduce**
Run `docker-compose up` with the default configuration. Watch as celery uses 100% of a single CPU core. I've followed the setup guide from scratch twice to make sure I was getting as close as possible to a default install.
**Logs**
<details>
<summary>Stacktrace from authentik</summary>
```
Traceback (most recent call last):
django.db.utils.InterfaceError: connection already closed
```
</details>
**Version and Deployment (please complete the following information):**
- authentik version: 2023.2.2
- Deployment: docker compose
</issue>
<code>
[start of authentik/root/celery.py]
1 """authentik core celery"""
2 import os
3 from contextvars import ContextVar
4 from logging.config import dictConfig
5 from typing import Callable
6
7 from celery import Celery
8 from celery.signals import (
9 after_task_publish,
10 setup_logging,
11 task_failure,
12 task_internal_error,
13 task_postrun,
14 task_prerun,
15 worker_ready,
16 )
17 from django.conf import settings
18 from django.db import ProgrammingError
19 from structlog.contextvars import STRUCTLOG_KEY_PREFIX
20 from structlog.stdlib import get_logger
21
22 from authentik.lib.sentry import before_send
23 from authentik.lib.utils.errors import exception_to_string
24
25 # set the default Django settings module for the 'celery' program.
26 os.environ.setdefault("DJANGO_SETTINGS_MODULE", "authentik.root.settings")
27
28 LOGGER = get_logger()
29 CELERY_APP = Celery("authentik")
30 CTX_TASK_ID = ContextVar(STRUCTLOG_KEY_PREFIX + "task_id", default=Ellipsis)
31
32
33 @setup_logging.connect
34 def config_loggers(*args, **kwargs):
35 """Apply logging settings from settings.py to celery"""
36 dictConfig(settings.LOGGING)
37
38
39 @after_task_publish.connect
40 def after_task_publish_hook(sender=None, headers=None, body=None, **kwargs):
41 """Log task_id after it was published"""
42 info = headers if "task" in headers else body
43 LOGGER.info("Task published", task_id=info.get("id", ""), task_name=info.get("task", ""))
44
45
46 @task_prerun.connect
47 def task_prerun_hook(task_id: str, task, *args, **kwargs):
48 """Log task_id on worker"""
49 request_id = "task-" + task_id.replace("-", "")
50 CTX_TASK_ID.set(request_id)
51 LOGGER.info("Task started", task_id=task_id, task_name=task.__name__)
52
53
54 @task_postrun.connect
55 def task_postrun_hook(task_id, task, *args, retval=None, state=None, **kwargs):
56 """Log task_id on worker"""
57 CTX_TASK_ID.set(...)
58 LOGGER.info("Task finished", task_id=task_id, task_name=task.__name__, state=state)
59
60
61 @task_failure.connect
62 @task_internal_error.connect
63 def task_error_hook(task_id, exception: Exception, traceback, *args, **kwargs):
64 """Create system event for failed task"""
65 from authentik.events.models import Event, EventAction
66
67 LOGGER.warning("Task failure", exc=exception)
68 CTX_TASK_ID.set(...)
69 if before_send({}, {"exc_info": (None, exception, None)}) is not None:
70 Event.new(EventAction.SYSTEM_EXCEPTION, message=exception_to_string(exception)).save()
71
72
73 def _get_startup_tasks() -> list[Callable]:
74 """Get all tasks to be run on startup"""
75 from authentik.admin.tasks import clear_update_notifications
76 from authentik.outposts.tasks import outpost_connection_discovery, outpost_controller_all
77 from authentik.providers.proxy.tasks import proxy_set_defaults
78
79 return [
80 clear_update_notifications,
81 outpost_connection_discovery,
82 outpost_controller_all,
83 proxy_set_defaults,
84 ]
85
86
87 @worker_ready.connect
88 def worker_ready_hook(*args, **kwargs):
89 """Run certain tasks on worker start"""
90
91 LOGGER.info("Dispatching startup tasks...")
92 for task in _get_startup_tasks():
93 try:
94 task.delay()
95 except ProgrammingError as exc:
96 LOGGER.warning("Startup task failed", task=task, exc=exc)
97 from authentik.blueprints.v1.tasks import start_blueprint_watcher
98
99 start_blueprint_watcher()
100
101
102 # Using a string here means the worker doesn't have to serialize
103 # the configuration object to child processes.
104 # - namespace='CELERY' means all celery-related configuration keys
105 # should have a `CELERY_` prefix.
106 CELERY_APP.config_from_object(settings, namespace="CELERY")
107
108 # Load task modules from all registered Django app configs.
109 CELERY_APP.autodiscover_tasks()
110
[end of authentik/root/celery.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/authentik/root/celery.py b/authentik/root/celery.py
--- a/authentik/root/celery.py
+++ b/authentik/root/celery.py
@@ -2,9 +2,12 @@
import os
from contextvars import ContextVar
from logging.config import dictConfig
+from pathlib import Path
+from tempfile import gettempdir
from typing import Callable
-from celery import Celery
+from celery import Celery, bootsteps
+from celery.apps.worker import Worker
from celery.signals import (
after_task_publish,
setup_logging,
@@ -28,6 +31,7 @@
LOGGER = get_logger()
CELERY_APP = Celery("authentik")
CTX_TASK_ID = ContextVar(STRUCTLOG_KEY_PREFIX + "task_id", default=Ellipsis)
+HEARTBEAT_FILE = Path(gettempdir() + "/authentik-worker")
@setup_logging.connect
@@ -99,6 +103,33 @@
start_blueprint_watcher()
+class LivenessProbe(bootsteps.StartStopStep):
+ """Add a timed task to touch a temporary file for healthchecking reasons"""
+
+ requires = {"celery.worker.components:Timer"}
+
+ def __init__(self, parent, **kwargs):
+ super().__init__(parent, **kwargs)
+ self.requests = []
+ self.tref = None
+
+ def start(self, parent: Worker):
+ self.tref = parent.timer.call_repeatedly(
+ 10.0,
+ self.update_heartbeat_file,
+ (parent,),
+ priority=10,
+ )
+ self.update_heartbeat_file(parent)
+
+ def stop(self, parent: Worker):
+ HEARTBEAT_FILE.unlink(missing_ok=True)
+
+ def update_heartbeat_file(self, worker: Worker):
+ """Touch heartbeat file"""
+ HEARTBEAT_FILE.touch()
+
+
# Using a string here means the worker doesn't have to serialize
# the configuration object to child processes.
# - namespace='CELERY' means all celery-related configuration keys
@@ -107,3 +138,4 @@
# Load task modules from all registered Django app configs.
CELERY_APP.autodiscover_tasks()
+CELERY_APP.steps["worker"].add(LivenessProbe)
|
{"golden_diff": "diff --git a/authentik/root/celery.py b/authentik/root/celery.py\n--- a/authentik/root/celery.py\n+++ b/authentik/root/celery.py\n@@ -2,9 +2,12 @@\n import os\n from contextvars import ContextVar\n from logging.config import dictConfig\n+from pathlib import Path\n+from tempfile import gettempdir\n from typing import Callable\n \n-from celery import Celery\n+from celery import Celery, bootsteps\n+from celery.apps.worker import Worker\n from celery.signals import (\n after_task_publish,\n setup_logging,\n@@ -28,6 +31,7 @@\n LOGGER = get_logger()\n CELERY_APP = Celery(\"authentik\")\n CTX_TASK_ID = ContextVar(STRUCTLOG_KEY_PREFIX + \"task_id\", default=Ellipsis)\n+HEARTBEAT_FILE = Path(gettempdir() + \"/authentik-worker\")\n \n \n @setup_logging.connect\n@@ -99,6 +103,33 @@\n start_blueprint_watcher()\n \n \n+class LivenessProbe(bootsteps.StartStopStep):\n+ \"\"\"Add a timed task to touch a temporary file for healthchecking reasons\"\"\"\n+\n+ requires = {\"celery.worker.components:Timer\"}\n+\n+ def __init__(self, parent, **kwargs):\n+ super().__init__(parent, **kwargs)\n+ self.requests = []\n+ self.tref = None\n+\n+ def start(self, parent: Worker):\n+ self.tref = parent.timer.call_repeatedly(\n+ 10.0,\n+ self.update_heartbeat_file,\n+ (parent,),\n+ priority=10,\n+ )\n+ self.update_heartbeat_file(parent)\n+\n+ def stop(self, parent: Worker):\n+ HEARTBEAT_FILE.unlink(missing_ok=True)\n+\n+ def update_heartbeat_file(self, worker: Worker):\n+ \"\"\"Touch heartbeat file\"\"\"\n+ HEARTBEAT_FILE.touch()\n+\n+\n # Using a string here means the worker doesn't have to serialize\n # the configuration object to child processes.\n # - namespace='CELERY' means all celery-related configuration keys\n@@ -107,3 +138,4 @@\n \n # Load task modules from all registered Django app configs.\n CELERY_APP.autodiscover_tasks()\n+CELERY_APP.steps[\"worker\"].add(LivenessProbe)\n", "issue": "Celery CPU usage 100% on new install\n**Describe the bug**\r\n\r\nI'm using the attached docker-compose and env file (don't worry about the secrets in the env file).\r\n\r\n[env.txt](https://github.com/goauthentik/authentik/files/10758594/env.txt)\r\n[docker-compose.yml.txt](https://github.com/goauthentik/authentik/files/10758616/docker-compose.yml.txt)\r\n\r\n\r\n**To Reproduce**\r\n\r\nRun `docker-compose up` with the default configuration. Watch as celery uses 100% of a single CPU core. I've followed the setup guide from scratch twice to make sure I was getting as close as possible to a default install.\r\n\r\n**Logs**\r\n<details>\r\n <summary>Stacktrace from authentik</summary>\r\n\r\n```\r\nTraceback (most recent call last):\r\ndjango.db.utils.InterfaceError: connection already closed\r\n```\r\n</details>\r\n\r\n\r\n**Version and Deployment (please complete the following information):**\r\n- authentik version: 2023.2.2\r\n- Deployment: docker compose\r\n\r\n\r\n \n", "before_files": [{"content": "\"\"\"authentik core celery\"\"\"\nimport os\nfrom contextvars import ContextVar\nfrom logging.config import dictConfig\nfrom typing import Callable\n\nfrom celery import Celery\nfrom celery.signals import (\n after_task_publish,\n setup_logging,\n task_failure,\n task_internal_error,\n task_postrun,\n task_prerun,\n worker_ready,\n)\nfrom django.conf import settings\nfrom django.db import ProgrammingError\nfrom structlog.contextvars import STRUCTLOG_KEY_PREFIX\nfrom structlog.stdlib import get_logger\n\nfrom authentik.lib.sentry import before_send\nfrom authentik.lib.utils.errors import exception_to_string\n\n# set the default Django settings module for the 'celery' program.\nos.environ.setdefault(\"DJANGO_SETTINGS_MODULE\", \"authentik.root.settings\")\n\nLOGGER = get_logger()\nCELERY_APP = Celery(\"authentik\")\nCTX_TASK_ID = ContextVar(STRUCTLOG_KEY_PREFIX + \"task_id\", default=Ellipsis)\n\n\n@setup_logging.connect\ndef config_loggers(*args, **kwargs):\n \"\"\"Apply logging settings from settings.py to celery\"\"\"\n dictConfig(settings.LOGGING)\n\n\n@after_task_publish.connect\ndef after_task_publish_hook(sender=None, headers=None, body=None, **kwargs):\n \"\"\"Log task_id after it was published\"\"\"\n info = headers if \"task\" in headers else body\n LOGGER.info(\"Task published\", task_id=info.get(\"id\", \"\"), task_name=info.get(\"task\", \"\"))\n\n\n@task_prerun.connect\ndef task_prerun_hook(task_id: str, task, *args, **kwargs):\n \"\"\"Log task_id on worker\"\"\"\n request_id = \"task-\" + task_id.replace(\"-\", \"\")\n CTX_TASK_ID.set(request_id)\n LOGGER.info(\"Task started\", task_id=task_id, task_name=task.__name__)\n\n\n@task_postrun.connect\ndef task_postrun_hook(task_id, task, *args, retval=None, state=None, **kwargs):\n \"\"\"Log task_id on worker\"\"\"\n CTX_TASK_ID.set(...)\n LOGGER.info(\"Task finished\", task_id=task_id, task_name=task.__name__, state=state)\n\n\n@task_failure.connect\n@task_internal_error.connect\ndef task_error_hook(task_id, exception: Exception, traceback, *args, **kwargs):\n \"\"\"Create system event for failed task\"\"\"\n from authentik.events.models import Event, EventAction\n\n LOGGER.warning(\"Task failure\", exc=exception)\n CTX_TASK_ID.set(...)\n if before_send({}, {\"exc_info\": (None, exception, None)}) is not None:\n Event.new(EventAction.SYSTEM_EXCEPTION, message=exception_to_string(exception)).save()\n\n\ndef _get_startup_tasks() -> list[Callable]:\n \"\"\"Get all tasks to be run on startup\"\"\"\n from authentik.admin.tasks import clear_update_notifications\n from authentik.outposts.tasks import outpost_connection_discovery, outpost_controller_all\n from authentik.providers.proxy.tasks import proxy_set_defaults\n\n return [\n clear_update_notifications,\n outpost_connection_discovery,\n outpost_controller_all,\n proxy_set_defaults,\n ]\n\n\n@worker_ready.connect\ndef worker_ready_hook(*args, **kwargs):\n \"\"\"Run certain tasks on worker start\"\"\"\n\n LOGGER.info(\"Dispatching startup tasks...\")\n for task in _get_startup_tasks():\n try:\n task.delay()\n except ProgrammingError as exc:\n LOGGER.warning(\"Startup task failed\", task=task, exc=exc)\n from authentik.blueprints.v1.tasks import start_blueprint_watcher\n\n start_blueprint_watcher()\n\n\n# Using a string here means the worker doesn't have to serialize\n# the configuration object to child processes.\n# - namespace='CELERY' means all celery-related configuration keys\n# should have a `CELERY_` prefix.\nCELERY_APP.config_from_object(settings, namespace=\"CELERY\")\n\n# Load task modules from all registered Django app configs.\nCELERY_APP.autodiscover_tasks()\n", "path": "authentik/root/celery.py"}]}
| 1,847 | 510 |
gh_patches_debug_24550
|
rasdani/github-patches
|
git_diff
|
litestar-org__litestar-1293
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Enhancement: Add a way to override default OpenAPI response descriptions
**What's the feature you'd like to ask for.**
Currently there is no way to replace the default OpenAPI description for HTTP 400 errors. For example, you currently can't do this:
```python
@starlite.post(
"/path",
responses={
400: starlite.ResponseSpec(
model=MyErrorModel, description="A more detailed error description"
)
},
)
async def login() -> starlite.Response:
...
```
If you do, you will get this error on startup:
```console
starlite.exceptions.http_exceptions.ImproperlyConfiguredException: 500: Additional response for status code 400 already exists in success or error responses
```
This makes it impossible to add more detailed error descriptions or properly document response shapes if you want your endpoint to return a different error shape.
**Additional context**
Removing this bit of code would allow the default HTTP 400 description to be replaced:
https://github.com/seladb/starlite/blob/51ae7eebda3e6834a6520471bfdb9cad2ab790c5/starlite/openapi/responses.py#L217-L220
</issue>
<code>
[start of starlite/_openapi/responses.py]
1 from copy import copy
2 from http import HTTPStatus
3 from operator import attrgetter
4 from typing import TYPE_CHECKING, Any, Dict, Iterator, List, Optional, Tuple, Type
5
6 from pydantic_openapi_schema.v3_1_0 import Response
7 from pydantic_openapi_schema.v3_1_0.header import Header
8 from pydantic_openapi_schema.v3_1_0.media_type import MediaType as OpenAPISchemaMediaType
9 from pydantic_openapi_schema.v3_1_0.schema import Schema
10 from typing_extensions import get_args, get_origin
11
12 from starlite._openapi.enums import OpenAPIFormat, OpenAPIType
13 from starlite._openapi.schema import create_schema
14 from starlite._openapi.utils import pascal_case_to_text
15 from starlite._signature.models import SignatureField
16 from starlite.enums import MediaType
17 from starlite.exceptions import HTTPException, ImproperlyConfiguredException, ValidationException
18 from starlite.response import Response as StarliteResponse
19 from starlite.response_containers import File, Redirect, Stream, Template
20 from starlite.utils import get_enum_string_value, get_name, is_class_and_subclass
21
22 __all__ = (
23 "create_additional_responses",
24 "create_cookie_schema",
25 "create_error_responses",
26 "create_responses",
27 "create_success_response",
28 )
29
30
31 if TYPE_CHECKING:
32 from pydantic_openapi_schema.v3_1_0.responses import Responses
33
34 from starlite.datastructures.cookie import Cookie
35 from starlite.handlers.http_handlers import HTTPRouteHandler
36 from starlite.plugins.base import OpenAPISchemaPluginProtocol
37
38
39 def create_cookie_schema(cookie: "Cookie") -> Schema:
40 """Given a Cookie instance, return its corresponding OpenAPI schema.
41
42 Args:
43 cookie: Cookie
44
45 Returns:
46 Schema
47 """
48 cookie_copy = copy(cookie)
49 cookie_copy.value = "<string>"
50 value = cookie_copy.to_header(header="")
51 return Schema(description=cookie.description or "", example=value)
52
53
54 def create_success_response(
55 route_handler: "HTTPRouteHandler", generate_examples: bool, plugins: List["OpenAPISchemaPluginProtocol"]
56 ) -> Response:
57 """Create the schema for a success response."""
58 signature = route_handler.signature
59 default_descriptions: Dict[Any, str] = {
60 Stream: "Stream Response",
61 Redirect: "Redirect Response",
62 File: "File Download",
63 }
64 description = (
65 route_handler.response_description
66 or default_descriptions.get(signature.return_annotation)
67 or HTTPStatus(route_handler.status_code).description
68 )
69
70 if signature.return_annotation not in {signature.empty, None, Redirect, File, Stream}:
71 return_annotation = signature.return_annotation
72 if signature.return_annotation is Template:
73 return_annotation = str # since templates return str
74 route_handler.media_type = get_enum_string_value(MediaType.HTML)
75 elif is_class_and_subclass(get_origin(signature.return_annotation), StarliteResponse):
76 return_annotation = get_args(signature.return_annotation)[0] or Any
77
78 schema = create_schema(
79 field=SignatureField.create(field_type=return_annotation),
80 generate_examples=generate_examples,
81 plugins=plugins,
82 )
83 schema.contentEncoding = route_handler.content_encoding
84 schema.contentMediaType = route_handler.content_media_type
85 response = Response(
86 content={
87 route_handler.media_type: OpenAPISchemaMediaType(
88 media_type_schema=schema,
89 )
90 },
91 description=description,
92 )
93
94 elif signature.return_annotation is Redirect:
95 response = Response(
96 content=None,
97 description=description,
98 headers={
99 "location": Header(
100 param_schema=Schema(type=OpenAPIType.STRING), description="target path for the redirect"
101 )
102 },
103 )
104
105 elif signature.return_annotation in (File, Stream):
106 response = Response(
107 content={
108 route_handler.media_type: OpenAPISchemaMediaType(
109 media_type_schema=Schema(
110 type=OpenAPIType.STRING,
111 contentEncoding=route_handler.content_encoding or "application/octet-stream",
112 contentMediaType=route_handler.content_media_type,
113 ),
114 )
115 },
116 description=description,
117 headers={
118 "content-length": Header(
119 param_schema=Schema(type=OpenAPIType.STRING), description="File size in bytes"
120 ),
121 "last-modified": Header(
122 param_schema=Schema(type=OpenAPIType.STRING, schema_format=OpenAPIFormat.DATE_TIME),
123 description="Last modified data-time in RFC 2822 format",
124 ),
125 "etag": Header(param_schema=Schema(type=OpenAPIType.STRING), description="Entity tag"),
126 },
127 )
128
129 else:
130 response = Response(
131 content=None,
132 description=description,
133 )
134
135 if response.headers is None:
136 response.headers = {}
137
138 for response_header in route_handler.resolve_response_headers():
139 header = Header()
140 for attribute_name, attribute_value in response_header.dict(exclude_none=True).items():
141 if attribute_name == "value":
142 header.param_schema = create_schema(
143 field=SignatureField.create(field_type=type(attribute_value)),
144 generate_examples=False,
145 plugins=plugins,
146 )
147
148 elif attribute_name != "documentation_only":
149 setattr(header, attribute_name, attribute_value)
150 response.headers[response_header.name] = header
151
152 if cookies := route_handler.resolve_response_cookies():
153 response.headers["Set-Cookie"] = Header(
154 param_schema=Schema(
155 allOf=[create_cookie_schema(cookie=cookie) for cookie in sorted(cookies, key=attrgetter("key"))]
156 )
157 )
158
159 return response
160
161
162 def create_error_responses(exceptions: List[Type[HTTPException]]) -> Iterator[Tuple[str, Response]]:
163 """Create the schema for error responses, if any."""
164 grouped_exceptions: Dict[int, List[Type[HTTPException]]] = {}
165 for exc in exceptions:
166 if not grouped_exceptions.get(exc.status_code):
167 grouped_exceptions[exc.status_code] = []
168 grouped_exceptions[exc.status_code].append(exc)
169 for status_code, exception_group in grouped_exceptions.items():
170 exceptions_schemas = [
171 Schema(
172 type=OpenAPIType.OBJECT,
173 required=["detail", "status_code"],
174 properties={
175 "status_code": Schema(type=OpenAPIType.INTEGER),
176 "detail": Schema(type=OpenAPIType.STRING),
177 "extra": Schema(
178 type=[OpenAPIType.NULL, OpenAPIType.OBJECT, OpenAPIType.ARRAY], additionalProperties=Schema()
179 ),
180 },
181 description=pascal_case_to_text(get_name(exc)),
182 examples=[{"status_code": status_code, "detail": HTTPStatus(status_code).phrase, "extra": {}}],
183 )
184 for exc in exception_group
185 ]
186 if len(exceptions_schemas) > 1: # noqa: SIM108
187 schema = Schema(oneOf=exceptions_schemas) # type:ignore[arg-type]
188 else:
189 schema = exceptions_schemas[0]
190 yield str(status_code), Response(
191 description=HTTPStatus(status_code).description,
192 content={MediaType.JSON: OpenAPISchemaMediaType(media_type_schema=schema)},
193 )
194
195
196 def create_additional_responses(
197 route_handler: "HTTPRouteHandler", plugins: List["OpenAPISchemaPluginProtocol"]
198 ) -> Iterator[Tuple[str, Response]]:
199 """Create the schema for additional responses, if any."""
200 if not route_handler.responses:
201 return
202
203 for status_code, additional_response in route_handler.responses.items():
204 schema = create_schema(
205 field=SignatureField.create(field_type=additional_response.model),
206 generate_examples=additional_response.generate_examples,
207 plugins=plugins,
208 )
209 yield str(status_code), Response(
210 description=additional_response.description,
211 content={additional_response.media_type: OpenAPISchemaMediaType(media_type_schema=schema)},
212 )
213
214
215 def create_responses(
216 route_handler: "HTTPRouteHandler",
217 raises_validation_error: bool,
218 generate_examples: bool,
219 plugins: List["OpenAPISchemaPluginProtocol"],
220 ) -> Optional["Responses"]:
221 """Create a Response model embedded in a `Responses` dictionary for the given RouteHandler or return None."""
222
223 responses: "Responses" = {
224 str(route_handler.status_code): create_success_response(
225 route_handler=route_handler,
226 generate_examples=generate_examples,
227 plugins=plugins,
228 ),
229 }
230
231 exceptions = list(route_handler.raises or [])
232 if raises_validation_error and ValidationException not in exceptions:
233 exceptions.append(ValidationException)
234 for status_code, response in create_error_responses(exceptions=exceptions):
235 responses[status_code] = response
236
237 for status_code, response in create_additional_responses(route_handler, plugins):
238 if status_code in responses:
239 raise ImproperlyConfiguredException(
240 f"Additional response for status code {status_code} already exists in success or error responses"
241 )
242
243 responses[status_code] = response
244
245 return responses or None
246
[end of starlite/_openapi/responses.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/starlite/_openapi/responses.py b/starlite/_openapi/responses.py
--- a/starlite/_openapi/responses.py
+++ b/starlite/_openapi/responses.py
@@ -14,7 +14,7 @@
from starlite._openapi.utils import pascal_case_to_text
from starlite._signature.models import SignatureField
from starlite.enums import MediaType
-from starlite.exceptions import HTTPException, ImproperlyConfiguredException, ValidationException
+from starlite.exceptions import HTTPException, ValidationException
from starlite.response import Response as StarliteResponse
from starlite.response_containers import File, Redirect, Stream, Template
from starlite.utils import get_enum_string_value, get_name, is_class_and_subclass
@@ -235,11 +235,6 @@
responses[status_code] = response
for status_code, response in create_additional_responses(route_handler, plugins):
- if status_code in responses:
- raise ImproperlyConfiguredException(
- f"Additional response for status code {status_code} already exists in success or error responses"
- )
-
responses[status_code] = response
return responses or None
|
{"golden_diff": "diff --git a/starlite/_openapi/responses.py b/starlite/_openapi/responses.py\n--- a/starlite/_openapi/responses.py\n+++ b/starlite/_openapi/responses.py\n@@ -14,7 +14,7 @@\n from starlite._openapi.utils import pascal_case_to_text\n from starlite._signature.models import SignatureField\n from starlite.enums import MediaType\n-from starlite.exceptions import HTTPException, ImproperlyConfiguredException, ValidationException\n+from starlite.exceptions import HTTPException, ValidationException\n from starlite.response import Response as StarliteResponse\n from starlite.response_containers import File, Redirect, Stream, Template\n from starlite.utils import get_enum_string_value, get_name, is_class_and_subclass\n@@ -235,11 +235,6 @@\n responses[status_code] = response\n \n for status_code, response in create_additional_responses(route_handler, plugins):\n- if status_code in responses:\n- raise ImproperlyConfiguredException(\n- f\"Additional response for status code {status_code} already exists in success or error responses\"\n- )\n-\n responses[status_code] = response\n \n return responses or None\n", "issue": "Enhancement: Add a way to override default OpenAPI response descriptions\n**What's the feature you'd like to ask for.**\r\nCurrently there is no way to replace the default OpenAPI description for HTTP 400 errors. For example, you currently can't do this:\r\n\r\n```python\r\[email protected](\r\n \"/path\",\r\n responses={\r\n 400: starlite.ResponseSpec(\r\n model=MyErrorModel, description=\"A more detailed error description\"\r\n )\r\n },\r\n)\r\nasync def login() -> starlite.Response:\r\n ...\r\n```\r\n\r\nIf you do, you will get this error on startup:\r\n\r\n```console\r\nstarlite.exceptions.http_exceptions.ImproperlyConfiguredException: 500: Additional response for status code 400 already exists in success or error responses\r\n```\r\n\r\nThis makes it impossible to add more detailed error descriptions or properly document response shapes if you want your endpoint to return a different error shape.\r\n\r\n**Additional context**\r\nRemoving this bit of code would allow the default HTTP 400 description to be replaced:\r\nhttps://github.com/seladb/starlite/blob/51ae7eebda3e6834a6520471bfdb9cad2ab790c5/starlite/openapi/responses.py#L217-L220\r\n\n", "before_files": [{"content": "from copy import copy\nfrom http import HTTPStatus\nfrom operator import attrgetter\nfrom typing import TYPE_CHECKING, Any, Dict, Iterator, List, Optional, Tuple, Type\n\nfrom pydantic_openapi_schema.v3_1_0 import Response\nfrom pydantic_openapi_schema.v3_1_0.header import Header\nfrom pydantic_openapi_schema.v3_1_0.media_type import MediaType as OpenAPISchemaMediaType\nfrom pydantic_openapi_schema.v3_1_0.schema import Schema\nfrom typing_extensions import get_args, get_origin\n\nfrom starlite._openapi.enums import OpenAPIFormat, OpenAPIType\nfrom starlite._openapi.schema import create_schema\nfrom starlite._openapi.utils import pascal_case_to_text\nfrom starlite._signature.models import SignatureField\nfrom starlite.enums import MediaType\nfrom starlite.exceptions import HTTPException, ImproperlyConfiguredException, ValidationException\nfrom starlite.response import Response as StarliteResponse\nfrom starlite.response_containers import File, Redirect, Stream, Template\nfrom starlite.utils import get_enum_string_value, get_name, is_class_and_subclass\n\n__all__ = (\n \"create_additional_responses\",\n \"create_cookie_schema\",\n \"create_error_responses\",\n \"create_responses\",\n \"create_success_response\",\n)\n\n\nif TYPE_CHECKING:\n from pydantic_openapi_schema.v3_1_0.responses import Responses\n\n from starlite.datastructures.cookie import Cookie\n from starlite.handlers.http_handlers import HTTPRouteHandler\n from starlite.plugins.base import OpenAPISchemaPluginProtocol\n\n\ndef create_cookie_schema(cookie: \"Cookie\") -> Schema:\n \"\"\"Given a Cookie instance, return its corresponding OpenAPI schema.\n\n Args:\n cookie: Cookie\n\n Returns:\n Schema\n \"\"\"\n cookie_copy = copy(cookie)\n cookie_copy.value = \"<string>\"\n value = cookie_copy.to_header(header=\"\")\n return Schema(description=cookie.description or \"\", example=value)\n\n\ndef create_success_response(\n route_handler: \"HTTPRouteHandler\", generate_examples: bool, plugins: List[\"OpenAPISchemaPluginProtocol\"]\n) -> Response:\n \"\"\"Create the schema for a success response.\"\"\"\n signature = route_handler.signature\n default_descriptions: Dict[Any, str] = {\n Stream: \"Stream Response\",\n Redirect: \"Redirect Response\",\n File: \"File Download\",\n }\n description = (\n route_handler.response_description\n or default_descriptions.get(signature.return_annotation)\n or HTTPStatus(route_handler.status_code).description\n )\n\n if signature.return_annotation not in {signature.empty, None, Redirect, File, Stream}:\n return_annotation = signature.return_annotation\n if signature.return_annotation is Template:\n return_annotation = str # since templates return str\n route_handler.media_type = get_enum_string_value(MediaType.HTML)\n elif is_class_and_subclass(get_origin(signature.return_annotation), StarliteResponse):\n return_annotation = get_args(signature.return_annotation)[0] or Any\n\n schema = create_schema(\n field=SignatureField.create(field_type=return_annotation),\n generate_examples=generate_examples,\n plugins=plugins,\n )\n schema.contentEncoding = route_handler.content_encoding\n schema.contentMediaType = route_handler.content_media_type\n response = Response(\n content={\n route_handler.media_type: OpenAPISchemaMediaType(\n media_type_schema=schema,\n )\n },\n description=description,\n )\n\n elif signature.return_annotation is Redirect:\n response = Response(\n content=None,\n description=description,\n headers={\n \"location\": Header(\n param_schema=Schema(type=OpenAPIType.STRING), description=\"target path for the redirect\"\n )\n },\n )\n\n elif signature.return_annotation in (File, Stream):\n response = Response(\n content={\n route_handler.media_type: OpenAPISchemaMediaType(\n media_type_schema=Schema(\n type=OpenAPIType.STRING,\n contentEncoding=route_handler.content_encoding or \"application/octet-stream\",\n contentMediaType=route_handler.content_media_type,\n ),\n )\n },\n description=description,\n headers={\n \"content-length\": Header(\n param_schema=Schema(type=OpenAPIType.STRING), description=\"File size in bytes\"\n ),\n \"last-modified\": Header(\n param_schema=Schema(type=OpenAPIType.STRING, schema_format=OpenAPIFormat.DATE_TIME),\n description=\"Last modified data-time in RFC 2822 format\",\n ),\n \"etag\": Header(param_schema=Schema(type=OpenAPIType.STRING), description=\"Entity tag\"),\n },\n )\n\n else:\n response = Response(\n content=None,\n description=description,\n )\n\n if response.headers is None:\n response.headers = {}\n\n for response_header in route_handler.resolve_response_headers():\n header = Header()\n for attribute_name, attribute_value in response_header.dict(exclude_none=True).items():\n if attribute_name == \"value\":\n header.param_schema = create_schema(\n field=SignatureField.create(field_type=type(attribute_value)),\n generate_examples=False,\n plugins=plugins,\n )\n\n elif attribute_name != \"documentation_only\":\n setattr(header, attribute_name, attribute_value)\n response.headers[response_header.name] = header\n\n if cookies := route_handler.resolve_response_cookies():\n response.headers[\"Set-Cookie\"] = Header(\n param_schema=Schema(\n allOf=[create_cookie_schema(cookie=cookie) for cookie in sorted(cookies, key=attrgetter(\"key\"))]\n )\n )\n\n return response\n\n\ndef create_error_responses(exceptions: List[Type[HTTPException]]) -> Iterator[Tuple[str, Response]]:\n \"\"\"Create the schema for error responses, if any.\"\"\"\n grouped_exceptions: Dict[int, List[Type[HTTPException]]] = {}\n for exc in exceptions:\n if not grouped_exceptions.get(exc.status_code):\n grouped_exceptions[exc.status_code] = []\n grouped_exceptions[exc.status_code].append(exc)\n for status_code, exception_group in grouped_exceptions.items():\n exceptions_schemas = [\n Schema(\n type=OpenAPIType.OBJECT,\n required=[\"detail\", \"status_code\"],\n properties={\n \"status_code\": Schema(type=OpenAPIType.INTEGER),\n \"detail\": Schema(type=OpenAPIType.STRING),\n \"extra\": Schema(\n type=[OpenAPIType.NULL, OpenAPIType.OBJECT, OpenAPIType.ARRAY], additionalProperties=Schema()\n ),\n },\n description=pascal_case_to_text(get_name(exc)),\n examples=[{\"status_code\": status_code, \"detail\": HTTPStatus(status_code).phrase, \"extra\": {}}],\n )\n for exc in exception_group\n ]\n if len(exceptions_schemas) > 1: # noqa: SIM108\n schema = Schema(oneOf=exceptions_schemas) # type:ignore[arg-type]\n else:\n schema = exceptions_schemas[0]\n yield str(status_code), Response(\n description=HTTPStatus(status_code).description,\n content={MediaType.JSON: OpenAPISchemaMediaType(media_type_schema=schema)},\n )\n\n\ndef create_additional_responses(\n route_handler: \"HTTPRouteHandler\", plugins: List[\"OpenAPISchemaPluginProtocol\"]\n) -> Iterator[Tuple[str, Response]]:\n \"\"\"Create the schema for additional responses, if any.\"\"\"\n if not route_handler.responses:\n return\n\n for status_code, additional_response in route_handler.responses.items():\n schema = create_schema(\n field=SignatureField.create(field_type=additional_response.model),\n generate_examples=additional_response.generate_examples,\n plugins=plugins,\n )\n yield str(status_code), Response(\n description=additional_response.description,\n content={additional_response.media_type: OpenAPISchemaMediaType(media_type_schema=schema)},\n )\n\n\ndef create_responses(\n route_handler: \"HTTPRouteHandler\",\n raises_validation_error: bool,\n generate_examples: bool,\n plugins: List[\"OpenAPISchemaPluginProtocol\"],\n) -> Optional[\"Responses\"]:\n \"\"\"Create a Response model embedded in a `Responses` dictionary for the given RouteHandler or return None.\"\"\"\n\n responses: \"Responses\" = {\n str(route_handler.status_code): create_success_response(\n route_handler=route_handler,\n generate_examples=generate_examples,\n plugins=plugins,\n ),\n }\n\n exceptions = list(route_handler.raises or [])\n if raises_validation_error and ValidationException not in exceptions:\n exceptions.append(ValidationException)\n for status_code, response in create_error_responses(exceptions=exceptions):\n responses[status_code] = response\n\n for status_code, response in create_additional_responses(route_handler, plugins):\n if status_code in responses:\n raise ImproperlyConfiguredException(\n f\"Additional response for status code {status_code} already exists in success or error responses\"\n )\n\n responses[status_code] = response\n\n return responses or None\n", "path": "starlite/_openapi/responses.py"}]}
| 3,334 | 259 |
gh_patches_debug_17928
|
rasdani/github-patches
|
git_diff
|
openvinotoolkit__datumaro-1109
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Error installing via pip
Greetings.
recently I tried to install datumaro via pip on Windows 10.
I tried to do it on two devices and in both cases an error occured during installation due to encoding issues.
` ...File "C:\Users\User\AppData\Local\Programs\Python\Python311\Lib\encodings\cp1251.py", line 23, in decode
return codecs.charmap_decode(input,self.errors,decoding_table)[0]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
UnicodeDecodeError: 'charmap' codec can't decode byte 0x98 in position 3870: character maps to <undefined>
[end of output]`
I tried to change encoding settings in PyCharm but it brought no results. I also tried to install different versions of datumaro (default, headless, versions), updated pip and used pip3. Python version is 3.11 hovewer I doubt it is involved.
Obviously it is Windows encoding issue, but I failed to find any related issues concerning the problem. Had someone seen the same error?
</issue>
<code>
[start of setup.py]
1 # Copyright (C) 2019-2022 Intel Corporation
2 #
3 # SPDX-License-Identifier: MIT
4
5 # ruff: noqa: E501
6
7 import os
8 import os.path as osp
9 import re
10 from distutils.util import strtobool
11
12 import setuptools
13 from pybind11.setup_helpers import Pybind11Extension, build_ext
14
15
16 def find_version(project_dir=None):
17 if not project_dir:
18 project_dir = osp.dirname(osp.abspath(__file__))
19
20 file_path = osp.join(project_dir, "datumaro", "version.py")
21
22 with open(file_path, "r") as version_file:
23 version_text = version_file.read()
24
25 # PEP440:
26 # https://www.python.org/dev/peps/pep-0440/#appendix-b-parsing-version-strings-with-regular-expressions
27 pep_regex = r"([1-9]\d*!)?(0|[1-9]\d*)(\.(0|[1-9]\d*))*((a|b|rc)(0|[1-9]\d*))?(\.post(0|[1-9]\d*))?(\.dev(0|[1-9]\d*))?"
28 version_regex = r"__version__\s*=\s*.(" + pep_regex + ")."
29 match = re.match(version_regex, version_text)
30 if not match:
31 raise RuntimeError("Failed to find version string in '%s'" % file_path)
32
33 version = version_text[match.start(1) : match.end(1)]
34 return version
35
36
37 CORE_REQUIREMENTS_FILE = "requirements-core.txt"
38 DEFAULT_REQUIREMENTS_FILE = "requirements-default.txt"
39
40
41 def parse_requirements(filename=CORE_REQUIREMENTS_FILE):
42 with open(filename) as fh:
43 return fh.readlines()
44
45
46 CORE_REQUIREMENTS = parse_requirements(CORE_REQUIREMENTS_FILE)
47 if strtobool(os.getenv("DATUMARO_HEADLESS", "0").lower()):
48 CORE_REQUIREMENTS.append("opencv-python-headless")
49 else:
50 CORE_REQUIREMENTS.append("opencv-python")
51
52 DEFAULT_REQUIREMENTS = parse_requirements(DEFAULT_REQUIREMENTS_FILE)
53
54 with open("README.md", "r") as fh:
55 long_description = fh.read()
56
57 ext_modules = [
58 Pybind11Extension(
59 "datumaro._capi",
60 ["src/datumaro/capi/pybind.cpp"],
61 define_macros=[("VERSION_INFO", find_version("./src"))],
62 extra_compile_args=["-O3"],
63 ),
64 ]
65
66 setuptools.setup(
67 name="datumaro",
68 version=find_version("./src"),
69 author="Intel",
70 author_email="[email protected]",
71 description="Dataset Management Framework (Datumaro)",
72 long_description=long_description,
73 long_description_content_type="text/markdown",
74 url="https://github.com/openvinotoolkit/datumaro",
75 package_dir={"": "src"},
76 packages=setuptools.find_packages(where="src", include=["datumaro*"]),
77 classifiers=[
78 "Programming Language :: Python :: 3",
79 "License :: OSI Approved :: MIT License",
80 "Operating System :: OS Independent",
81 ],
82 python_requires=">=3.8",
83 install_requires=CORE_REQUIREMENTS,
84 extras_require={
85 "tf": ["tensorflow"],
86 "tfds": ["tensorflow-datasets"],
87 "tf-gpu": ["tensorflow-gpu"],
88 "default": DEFAULT_REQUIREMENTS,
89 },
90 ext_modules=ext_modules,
91 entry_points={
92 "console_scripts": [
93 "datum=datumaro.cli.__main__:main",
94 ],
95 },
96 cmdclass={"build_ext": build_ext},
97 package_data={
98 "datumaro.plugins.synthetic_data": ["background_colors.txt"],
99 "datumaro.plugins.openvino_plugin.samples": ["coco.class", "imagenet.class"],
100 },
101 include_package_data=True,
102 )
103
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -19,7 +19,7 @@
file_path = osp.join(project_dir, "datumaro", "version.py")
- with open(file_path, "r") as version_file:
+ with open(file_path, "r", encoding="utf-8") as version_file:
version_text = version_file.read()
# PEP440:
@@ -39,7 +39,7 @@
def parse_requirements(filename=CORE_REQUIREMENTS_FILE):
- with open(filename) as fh:
+ with open(filename, "r", encoding="utf-8") as fh:
return fh.readlines()
@@ -51,7 +51,7 @@
DEFAULT_REQUIREMENTS = parse_requirements(DEFAULT_REQUIREMENTS_FILE)
-with open("README.md", "r") as fh:
+with open("README.md", "r", encoding="utf-8") as fh:
long_description = fh.read()
ext_modules = [
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -19,7 +19,7 @@\n \n file_path = osp.join(project_dir, \"datumaro\", \"version.py\")\n \n- with open(file_path, \"r\") as version_file:\n+ with open(file_path, \"r\", encoding=\"utf-8\") as version_file:\n version_text = version_file.read()\n \n # PEP440:\n@@ -39,7 +39,7 @@\n \n \n def parse_requirements(filename=CORE_REQUIREMENTS_FILE):\n- with open(filename) as fh:\n+ with open(filename, \"r\", encoding=\"utf-8\") as fh:\n return fh.readlines()\n \n \n@@ -51,7 +51,7 @@\n \n DEFAULT_REQUIREMENTS = parse_requirements(DEFAULT_REQUIREMENTS_FILE)\n \n-with open(\"README.md\", \"r\") as fh:\n+with open(\"README.md\", \"r\", encoding=\"utf-8\") as fh:\n long_description = fh.read()\n \n ext_modules = [\n", "issue": "Error installing via pip\nGreetings.\r\nrecently I tried to install datumaro via pip on Windows 10. \r\nI tried to do it on two devices and in both cases an error occured during installation due to encoding issues.\r\n\r\n` ...File \"C:\\Users\\User\\AppData\\Local\\Programs\\Python\\Python311\\Lib\\encodings\\cp1251.py\", line 23, in decode\r\n return codecs.charmap_decode(input,self.errors,decoding_table)[0]\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n UnicodeDecodeError: 'charmap' codec can't decode byte 0x98 in position 3870: character maps to <undefined>\r\n [end of output]`\r\n\r\nI tried to change encoding settings in PyCharm but it brought no results. I also tried to install different versions of datumaro (default, headless, versions), updated pip and used pip3. Python version is 3.11 hovewer I doubt it is involved.\r\nObviously it is Windows encoding issue, but I failed to find any related issues concerning the problem. Had someone seen the same error? \r\n\r\n\r\n\n", "before_files": [{"content": "# Copyright (C) 2019-2022 Intel Corporation\n#\n# SPDX-License-Identifier: MIT\n\n# ruff: noqa: E501\n\nimport os\nimport os.path as osp\nimport re\nfrom distutils.util import strtobool\n\nimport setuptools\nfrom pybind11.setup_helpers import Pybind11Extension, build_ext\n\n\ndef find_version(project_dir=None):\n if not project_dir:\n project_dir = osp.dirname(osp.abspath(__file__))\n\n file_path = osp.join(project_dir, \"datumaro\", \"version.py\")\n\n with open(file_path, \"r\") as version_file:\n version_text = version_file.read()\n\n # PEP440:\n # https://www.python.org/dev/peps/pep-0440/#appendix-b-parsing-version-strings-with-regular-expressions\n pep_regex = r\"([1-9]\\d*!)?(0|[1-9]\\d*)(\\.(0|[1-9]\\d*))*((a|b|rc)(0|[1-9]\\d*))?(\\.post(0|[1-9]\\d*))?(\\.dev(0|[1-9]\\d*))?\"\n version_regex = r\"__version__\\s*=\\s*.(\" + pep_regex + \").\"\n match = re.match(version_regex, version_text)\n if not match:\n raise RuntimeError(\"Failed to find version string in '%s'\" % file_path)\n\n version = version_text[match.start(1) : match.end(1)]\n return version\n\n\nCORE_REQUIREMENTS_FILE = \"requirements-core.txt\"\nDEFAULT_REQUIREMENTS_FILE = \"requirements-default.txt\"\n\n\ndef parse_requirements(filename=CORE_REQUIREMENTS_FILE):\n with open(filename) as fh:\n return fh.readlines()\n\n\nCORE_REQUIREMENTS = parse_requirements(CORE_REQUIREMENTS_FILE)\nif strtobool(os.getenv(\"DATUMARO_HEADLESS\", \"0\").lower()):\n CORE_REQUIREMENTS.append(\"opencv-python-headless\")\nelse:\n CORE_REQUIREMENTS.append(\"opencv-python\")\n\nDEFAULT_REQUIREMENTS = parse_requirements(DEFAULT_REQUIREMENTS_FILE)\n\nwith open(\"README.md\", \"r\") as fh:\n long_description = fh.read()\n\next_modules = [\n Pybind11Extension(\n \"datumaro._capi\",\n [\"src/datumaro/capi/pybind.cpp\"],\n define_macros=[(\"VERSION_INFO\", find_version(\"./src\"))],\n extra_compile_args=[\"-O3\"],\n ),\n]\n\nsetuptools.setup(\n name=\"datumaro\",\n version=find_version(\"./src\"),\n author=\"Intel\",\n author_email=\"[email protected]\",\n description=\"Dataset Management Framework (Datumaro)\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n url=\"https://github.com/openvinotoolkit/datumaro\",\n package_dir={\"\": \"src\"},\n packages=setuptools.find_packages(where=\"src\", include=[\"datumaro*\"]),\n classifiers=[\n \"Programming Language :: Python :: 3\",\n \"License :: OSI Approved :: MIT License\",\n \"Operating System :: OS Independent\",\n ],\n python_requires=\">=3.8\",\n install_requires=CORE_REQUIREMENTS,\n extras_require={\n \"tf\": [\"tensorflow\"],\n \"tfds\": [\"tensorflow-datasets\"],\n \"tf-gpu\": [\"tensorflow-gpu\"],\n \"default\": DEFAULT_REQUIREMENTS,\n },\n ext_modules=ext_modules,\n entry_points={\n \"console_scripts\": [\n \"datum=datumaro.cli.__main__:main\",\n ],\n },\n cmdclass={\"build_ext\": build_ext},\n package_data={\n \"datumaro.plugins.synthetic_data\": [\"background_colors.txt\"],\n \"datumaro.plugins.openvino_plugin.samples\": [\"coco.class\", \"imagenet.class\"],\n },\n include_package_data=True,\n)\n", "path": "setup.py"}]}
| 1,800 | 226 |
gh_patches_debug_27401
|
rasdani/github-patches
|
git_diff
|
scrapy__scrapy-2395
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Sitemap spider not robust against wrong sitemap URLs in robots.txt
[The "specs"](http://www.sitemaps.org/protocol.html#submit_robots) do say that the URL should be a "full URL":
> You can specify the location of the Sitemap using a robots.txt file. To do this, simply add the following line including the full URL to the sitemap:
> `Sitemap: http://www.example.com/sitemap.xml`
But some robots.txt use relative ones.
Example: http://www.asos.com/robots.txt
```
User-agent: *
Sitemap: /sitemap.ashx
Sitemap: http://www.asos.com/sitemap.xml
Disallow: /basket/
(...)
```
Spider:
```
from scrapy.spiders import SitemapSpider
class TestSpider(SitemapSpider):
name = "test"
sitemap_urls = [
'http://www.asos.com/robots.txt',
]
def parse(self, response):
self.logger.info('parsing %r' % response.url)
```
Logs:
```
$ scrapy runspider spider.py
Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.90 Safari/537.36'
2016-11-09 17:46:19 [scrapy] INFO: Scrapy 1.2.1 started (bot: scrapybot)
(...)
2016-11-09 17:46:19 [scrapy] DEBUG: Crawled (200) <GET http://www.asos.com/robots.txt> (referer: None)
2016-11-09 17:46:19 [scrapy] ERROR: Spider error processing <GET http://www.asos.com/robots.txt> (referer: None)
Traceback (most recent call last):
File "/home/paul/.virtualenvs/scrapy12/local/lib/python2.7/site-packages/scrapy/utils/defer.py", line 102, in iter_errback
yield next(it)
File "/home/paul/.virtualenvs/scrapy12/local/lib/python2.7/site-packages/scrapy/spidermiddlewares/offsite.py", line 29, in process_spider_output
for x in result:
File "/home/paul/.virtualenvs/scrapy12/local/lib/python2.7/site-packages/scrapy/spidermiddlewares/referer.py", line 22, in <genexpr>
return (_set_referer(r) for r in result or ())
File "/home/paul/.virtualenvs/scrapy12/local/lib/python2.7/site-packages/scrapy/spidermiddlewares/urllength.py", line 37, in <genexpr>
return (r for r in result or () if _filter(r))
File "/home/paul/.virtualenvs/scrapy12/local/lib/python2.7/site-packages/scrapy/spidermiddlewares/depth.py", line 58, in <genexpr>
return (r for r in result or () if _filter(r))
File "/home/paul/.virtualenvs/scrapy12/local/lib/python2.7/site-packages/scrapy/spiders/sitemap.py", line 36, in _parse_sitemap
yield Request(url, callback=self._parse_sitemap)
File "/home/paul/.virtualenvs/scrapy12/local/lib/python2.7/site-packages/scrapy/http/request/__init__.py", line 25, in __init__
self._set_url(url)
File "/home/paul/.virtualenvs/scrapy12/local/lib/python2.7/site-packages/scrapy/http/request/__init__.py", line 57, in _set_url
raise ValueError('Missing scheme in request url: %s' % self._url)
ValueError: Missing scheme in request url: /sitemap.ashx
2016-11-09 17:46:19 [scrapy] INFO: Closing spider (finished)
2016-11-09 17:46:19 [scrapy] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 291,
'downloader/request_count': 1,
'downloader/request_method_count/GET': 1,
'downloader/response_bytes': 1857,
'downloader/response_count': 1,
'downloader/response_status_count/200': 1,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2016, 11, 9, 16, 46, 19, 332383),
'log_count/DEBUG': 2,
'log_count/ERROR': 1,
'log_count/INFO': 7,
'response_received_count': 1,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'spider_exceptions/ValueError': 1,
'start_time': datetime.datetime(2016, 11, 9, 16, 46, 19, 71714)}
2016-11-09 17:46:19 [scrapy] INFO: Spider closed (finished)
```
</issue>
<code>
[start of scrapy/spiders/sitemap.py]
1 import re
2 import logging
3 import six
4
5 from scrapy.spiders import Spider
6 from scrapy.http import Request, XmlResponse
7 from scrapy.utils.sitemap import Sitemap, sitemap_urls_from_robots
8 from scrapy.utils.gz import gunzip, is_gzipped
9
10 logger = logging.getLogger(__name__)
11
12
13 class SitemapSpider(Spider):
14
15 sitemap_urls = ()
16 sitemap_rules = [('', 'parse')]
17 sitemap_follow = ['']
18 sitemap_alternate_links = False
19
20 def __init__(self, *a, **kw):
21 super(SitemapSpider, self).__init__(*a, **kw)
22 self._cbs = []
23 for r, c in self.sitemap_rules:
24 if isinstance(c, six.string_types):
25 c = getattr(self, c)
26 self._cbs.append((regex(r), c))
27 self._follow = [regex(x) for x in self.sitemap_follow]
28
29 def start_requests(self):
30 for url in self.sitemap_urls:
31 yield Request(url, self._parse_sitemap)
32
33 def _parse_sitemap(self, response):
34 if response.url.endswith('/robots.txt'):
35 for url in sitemap_urls_from_robots(response.text):
36 yield Request(url, callback=self._parse_sitemap)
37 else:
38 body = self._get_sitemap_body(response)
39 if body is None:
40 logger.warning("Ignoring invalid sitemap: %(response)s",
41 {'response': response}, extra={'spider': self})
42 return
43
44 s = Sitemap(body)
45 if s.type == 'sitemapindex':
46 for loc in iterloc(s, self.sitemap_alternate_links):
47 if any(x.search(loc) for x in self._follow):
48 yield Request(loc, callback=self._parse_sitemap)
49 elif s.type == 'urlset':
50 for loc in iterloc(s):
51 for r, c in self._cbs:
52 if r.search(loc):
53 yield Request(loc, callback=c)
54 break
55
56 def _get_sitemap_body(self, response):
57 """Return the sitemap body contained in the given response,
58 or None if the response is not a sitemap.
59 """
60 if isinstance(response, XmlResponse):
61 return response.body
62 elif is_gzipped(response):
63 return gunzip(response.body)
64 elif response.url.endswith('.xml'):
65 return response.body
66 elif response.url.endswith('.xml.gz'):
67 return gunzip(response.body)
68
69
70 def regex(x):
71 if isinstance(x, six.string_types):
72 return re.compile(x)
73 return x
74
75
76 def iterloc(it, alt=False):
77 for d in it:
78 yield d['loc']
79
80 # Also consider alternate URLs (xhtml:link rel="alternate")
81 if alt and 'alternate' in d:
82 for l in d['alternate']:
83 yield l
84
[end of scrapy/spiders/sitemap.py]
[start of scrapy/utils/sitemap.py]
1 """
2 Module for processing Sitemaps.
3
4 Note: The main purpose of this module is to provide support for the
5 SitemapSpider, its API is subject to change without notice.
6 """
7 import lxml.etree
8
9
10 class Sitemap(object):
11 """Class to parse Sitemap (type=urlset) and Sitemap Index
12 (type=sitemapindex) files"""
13
14 def __init__(self, xmltext):
15 xmlp = lxml.etree.XMLParser(recover=True, remove_comments=True, resolve_entities=False)
16 self._root = lxml.etree.fromstring(xmltext, parser=xmlp)
17 rt = self._root.tag
18 self.type = self._root.tag.split('}', 1)[1] if '}' in rt else rt
19
20 def __iter__(self):
21 for elem in self._root.getchildren():
22 d = {}
23 for el in elem.getchildren():
24 tag = el.tag
25 name = tag.split('}', 1)[1] if '}' in tag else tag
26
27 if name == 'link':
28 if 'href' in el.attrib:
29 d.setdefault('alternate', []).append(el.get('href'))
30 else:
31 d[name] = el.text.strip() if el.text else ''
32
33 if 'loc' in d:
34 yield d
35
36
37 def sitemap_urls_from_robots(robots_text):
38 """Return an iterator over all sitemap urls contained in the given
39 robots.txt file
40 """
41 for line in robots_text.splitlines():
42 if line.lstrip().lower().startswith('sitemap:'):
43 yield line.split(':', 1)[1].strip()
44
[end of scrapy/utils/sitemap.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scrapy/spiders/sitemap.py b/scrapy/spiders/sitemap.py
--- a/scrapy/spiders/sitemap.py
+++ b/scrapy/spiders/sitemap.py
@@ -32,7 +32,7 @@
def _parse_sitemap(self, response):
if response.url.endswith('/robots.txt'):
- for url in sitemap_urls_from_robots(response.text):
+ for url in sitemap_urls_from_robots(response.text, base_url=response.url):
yield Request(url, callback=self._parse_sitemap)
else:
body = self._get_sitemap_body(response)
diff --git a/scrapy/utils/sitemap.py b/scrapy/utils/sitemap.py
--- a/scrapy/utils/sitemap.py
+++ b/scrapy/utils/sitemap.py
@@ -4,7 +4,9 @@
Note: The main purpose of this module is to provide support for the
SitemapSpider, its API is subject to change without notice.
"""
+
import lxml.etree
+from six.moves.urllib.parse import urljoin
class Sitemap(object):
@@ -34,10 +36,11 @@
yield d
-def sitemap_urls_from_robots(robots_text):
+def sitemap_urls_from_robots(robots_text, base_url=None):
"""Return an iterator over all sitemap urls contained in the given
robots.txt file
"""
for line in robots_text.splitlines():
if line.lstrip().lower().startswith('sitemap:'):
- yield line.split(':', 1)[1].strip()
+ url = line.split(':', 1)[1].strip()
+ yield urljoin(base_url, url)
|
{"golden_diff": "diff --git a/scrapy/spiders/sitemap.py b/scrapy/spiders/sitemap.py\n--- a/scrapy/spiders/sitemap.py\n+++ b/scrapy/spiders/sitemap.py\n@@ -32,7 +32,7 @@\n \n def _parse_sitemap(self, response):\n if response.url.endswith('/robots.txt'):\n- for url in sitemap_urls_from_robots(response.text):\n+ for url in sitemap_urls_from_robots(response.text, base_url=response.url):\n yield Request(url, callback=self._parse_sitemap)\n else:\n body = self._get_sitemap_body(response)\ndiff --git a/scrapy/utils/sitemap.py b/scrapy/utils/sitemap.py\n--- a/scrapy/utils/sitemap.py\n+++ b/scrapy/utils/sitemap.py\n@@ -4,7 +4,9 @@\n Note: The main purpose of this module is to provide support for the\n SitemapSpider, its API is subject to change without notice.\n \"\"\"\n+\n import lxml.etree\n+from six.moves.urllib.parse import urljoin\n \n \n class Sitemap(object):\n@@ -34,10 +36,11 @@\n yield d\n \n \n-def sitemap_urls_from_robots(robots_text):\n+def sitemap_urls_from_robots(robots_text, base_url=None):\n \"\"\"Return an iterator over all sitemap urls contained in the given\n robots.txt file\n \"\"\"\n for line in robots_text.splitlines():\n if line.lstrip().lower().startswith('sitemap:'):\n- yield line.split(':', 1)[1].strip()\n+ url = line.split(':', 1)[1].strip()\n+ yield urljoin(base_url, url)\n", "issue": "Sitemap spider not robust against wrong sitemap URLs in robots.txt\n[The \"specs\"](http://www.sitemaps.org/protocol.html#submit_robots) do say that the URL should be a \"full URL\":\r\n\r\n> You can specify the location of the Sitemap using a robots.txt file. To do this, simply add the following line including the full URL to the sitemap:\r\n> `Sitemap: http://www.example.com/sitemap.xml`\r\n\r\nBut some robots.txt use relative ones.\r\n\r\nExample: http://www.asos.com/robots.txt\r\n\r\n```\r\nUser-agent: *\r\nSitemap: /sitemap.ashx\r\nSitemap: http://www.asos.com/sitemap.xml\r\nDisallow: /basket/\r\n(...)\r\n```\r\n\r\nSpider:\r\n```\r\nfrom scrapy.spiders import SitemapSpider\r\n\r\n\r\nclass TestSpider(SitemapSpider):\r\n name = \"test\"\r\n sitemap_urls = [\r\n 'http://www.asos.com/robots.txt',\r\n ]\r\n\r\n def parse(self, response):\r\n self.logger.info('parsing %r' % response.url)\r\n```\r\nLogs:\r\n\r\n```\r\n$ scrapy runspider spider.py\r\nLinux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.90 Safari/537.36'\r\n2016-11-09 17:46:19 [scrapy] INFO: Scrapy 1.2.1 started (bot: scrapybot)\r\n(...)\r\n2016-11-09 17:46:19 [scrapy] DEBUG: Crawled (200) <GET http://www.asos.com/robots.txt> (referer: None)\r\n2016-11-09 17:46:19 [scrapy] ERROR: Spider error processing <GET http://www.asos.com/robots.txt> (referer: None)\r\nTraceback (most recent call last):\r\n File \"/home/paul/.virtualenvs/scrapy12/local/lib/python2.7/site-packages/scrapy/utils/defer.py\", line 102, in iter_errback\r\n yield next(it)\r\n File \"/home/paul/.virtualenvs/scrapy12/local/lib/python2.7/site-packages/scrapy/spidermiddlewares/offsite.py\", line 29, in process_spider_output\r\n for x in result:\r\n File \"/home/paul/.virtualenvs/scrapy12/local/lib/python2.7/site-packages/scrapy/spidermiddlewares/referer.py\", line 22, in <genexpr>\r\n return (_set_referer(r) for r in result or ())\r\n File \"/home/paul/.virtualenvs/scrapy12/local/lib/python2.7/site-packages/scrapy/spidermiddlewares/urllength.py\", line 37, in <genexpr>\r\n return (r for r in result or () if _filter(r))\r\n File \"/home/paul/.virtualenvs/scrapy12/local/lib/python2.7/site-packages/scrapy/spidermiddlewares/depth.py\", line 58, in <genexpr>\r\n return (r for r in result or () if _filter(r))\r\n File \"/home/paul/.virtualenvs/scrapy12/local/lib/python2.7/site-packages/scrapy/spiders/sitemap.py\", line 36, in _parse_sitemap\r\n yield Request(url, callback=self._parse_sitemap)\r\n File \"/home/paul/.virtualenvs/scrapy12/local/lib/python2.7/site-packages/scrapy/http/request/__init__.py\", line 25, in __init__\r\n self._set_url(url)\r\n File \"/home/paul/.virtualenvs/scrapy12/local/lib/python2.7/site-packages/scrapy/http/request/__init__.py\", line 57, in _set_url\r\n raise ValueError('Missing scheme in request url: %s' % self._url)\r\nValueError: Missing scheme in request url: /sitemap.ashx\r\n2016-11-09 17:46:19 [scrapy] INFO: Closing spider (finished)\r\n2016-11-09 17:46:19 [scrapy] INFO: Dumping Scrapy stats:\r\n{'downloader/request_bytes': 291,\r\n 'downloader/request_count': 1,\r\n 'downloader/request_method_count/GET': 1,\r\n 'downloader/response_bytes': 1857,\r\n 'downloader/response_count': 1,\r\n 'downloader/response_status_count/200': 1,\r\n 'finish_reason': 'finished',\r\n 'finish_time': datetime.datetime(2016, 11, 9, 16, 46, 19, 332383),\r\n 'log_count/DEBUG': 2,\r\n 'log_count/ERROR': 1,\r\n 'log_count/INFO': 7,\r\n 'response_received_count': 1,\r\n 'scheduler/dequeued': 1,\r\n 'scheduler/dequeued/memory': 1,\r\n 'scheduler/enqueued': 1,\r\n 'scheduler/enqueued/memory': 1,\r\n 'spider_exceptions/ValueError': 1,\r\n 'start_time': datetime.datetime(2016, 11, 9, 16, 46, 19, 71714)}\r\n2016-11-09 17:46:19 [scrapy] INFO: Spider closed (finished)\r\n```\n", "before_files": [{"content": "import re\nimport logging\nimport six\n\nfrom scrapy.spiders import Spider\nfrom scrapy.http import Request, XmlResponse\nfrom scrapy.utils.sitemap import Sitemap, sitemap_urls_from_robots\nfrom scrapy.utils.gz import gunzip, is_gzipped\n\nlogger = logging.getLogger(__name__)\n\n\nclass SitemapSpider(Spider):\n\n sitemap_urls = ()\n sitemap_rules = [('', 'parse')]\n sitemap_follow = ['']\n sitemap_alternate_links = False\n\n def __init__(self, *a, **kw):\n super(SitemapSpider, self).__init__(*a, **kw)\n self._cbs = []\n for r, c in self.sitemap_rules:\n if isinstance(c, six.string_types):\n c = getattr(self, c)\n self._cbs.append((regex(r), c))\n self._follow = [regex(x) for x in self.sitemap_follow]\n\n def start_requests(self):\n for url in self.sitemap_urls:\n yield Request(url, self._parse_sitemap)\n\n def _parse_sitemap(self, response):\n if response.url.endswith('/robots.txt'):\n for url in sitemap_urls_from_robots(response.text):\n yield Request(url, callback=self._parse_sitemap)\n else:\n body = self._get_sitemap_body(response)\n if body is None:\n logger.warning(\"Ignoring invalid sitemap: %(response)s\",\n {'response': response}, extra={'spider': self})\n return\n\n s = Sitemap(body)\n if s.type == 'sitemapindex':\n for loc in iterloc(s, self.sitemap_alternate_links):\n if any(x.search(loc) for x in self._follow):\n yield Request(loc, callback=self._parse_sitemap)\n elif s.type == 'urlset':\n for loc in iterloc(s):\n for r, c in self._cbs:\n if r.search(loc):\n yield Request(loc, callback=c)\n break\n\n def _get_sitemap_body(self, response):\n \"\"\"Return the sitemap body contained in the given response,\n or None if the response is not a sitemap.\n \"\"\"\n if isinstance(response, XmlResponse):\n return response.body\n elif is_gzipped(response):\n return gunzip(response.body)\n elif response.url.endswith('.xml'):\n return response.body\n elif response.url.endswith('.xml.gz'):\n return gunzip(response.body)\n\n\ndef regex(x):\n if isinstance(x, six.string_types):\n return re.compile(x)\n return x\n\n\ndef iterloc(it, alt=False):\n for d in it:\n yield d['loc']\n\n # Also consider alternate URLs (xhtml:link rel=\"alternate\")\n if alt and 'alternate' in d:\n for l in d['alternate']:\n yield l\n", "path": "scrapy/spiders/sitemap.py"}, {"content": "\"\"\"\nModule for processing Sitemaps.\n\nNote: The main purpose of this module is to provide support for the\nSitemapSpider, its API is subject to change without notice.\n\"\"\"\nimport lxml.etree\n\n\nclass Sitemap(object):\n \"\"\"Class to parse Sitemap (type=urlset) and Sitemap Index\n (type=sitemapindex) files\"\"\"\n\n def __init__(self, xmltext):\n xmlp = lxml.etree.XMLParser(recover=True, remove_comments=True, resolve_entities=False)\n self._root = lxml.etree.fromstring(xmltext, parser=xmlp)\n rt = self._root.tag\n self.type = self._root.tag.split('}', 1)[1] if '}' in rt else rt\n\n def __iter__(self):\n for elem in self._root.getchildren():\n d = {}\n for el in elem.getchildren():\n tag = el.tag\n name = tag.split('}', 1)[1] if '}' in tag else tag\n\n if name == 'link':\n if 'href' in el.attrib:\n d.setdefault('alternate', []).append(el.get('href'))\n else:\n d[name] = el.text.strip() if el.text else ''\n\n if 'loc' in d:\n yield d\n\n\ndef sitemap_urls_from_robots(robots_text):\n \"\"\"Return an iterator over all sitemap urls contained in the given\n robots.txt file\n \"\"\"\n for line in robots_text.splitlines():\n if line.lstrip().lower().startswith('sitemap:'):\n yield line.split(':', 1)[1].strip()\n", "path": "scrapy/utils/sitemap.py"}]}
| 2,924 | 356 |
gh_patches_debug_2474
|
rasdani/github-patches
|
git_diff
|
mlflow__mlflow-6881
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[FR] Add the ability to search runs based on 'user_id'
### Willingness to contribute
No. I cannot contribute this feature at this time.
### Proposal Summary
Enable run search to perform searches based on the `user_id` that submitted the run.
### Motivation
> #### What is the use case for this feature?
To return runs that have been initiated by a particular user while using run search functionality.
> #### Why is this use case valuable to support for MLflow users in general?
Quality of life improvement for navigating within the UI
> #### Why is this use case valuable to support for your project(s) or organization?
> #### Why is it currently difficult to achieve this use case?
It is not supported right now.
### Details
_No response_
### What component(s) does this bug affect?
- [ ] `area/artifacts`: Artifact stores and artifact logging
- [ ] `area/build`: Build and test infrastructure for MLflow
- [ ] `area/docs`: MLflow documentation pages
- [ ] `area/examples`: Example code
- [ ] `area/model-registry`: Model Registry service, APIs, and the fluent client calls for Model Registry
- [ ] `area/models`: MLmodel format, model serialization/deserialization, flavors
- [ ] `area/pipelines`: Pipelines, Pipeline APIs, Pipeline configs, Pipeline Templates
- [ ] `area/projects`: MLproject format, project running backends
- [ ] `area/scoring`: MLflow Model server, model deployment tools, Spark UDFs
- [ ] `area/server-infra`: MLflow Tracking server backend
- [X] `area/tracking`: Tracking Service, tracking client APIs, autologging
### What interface(s) does this bug affect?
- [ ] `area/uiux`: Front-end, user experience, plotting, JavaScript, JavaScript dev server
- [ ] `area/docker`: Docker use across MLflow's components, such as MLflow Projects and MLflow Models
- [ ] `area/sqlalchemy`: Use of SQLAlchemy in the Tracking Service or Model Registry
- [ ] `area/windows`: Windows support
### What language(s) does this bug affect?
- [ ] `language/r`: R APIs and clients
- [ ] `language/java`: Java APIs and clients
- [ ] `language/new`: Proposals for new client languages
### What integration(s) does this bug affect?
- [ ] `integrations/azure`: Azure and Azure ML integrations
- [ ] `integrations/sagemaker`: SageMaker integrations
- [ ] `integrations/databricks`: Databricks integrations
</issue>
<code>
[start of mlflow/entities/run_info.py]
1 from mlflow.entities.run_status import RunStatus
2 from mlflow.entities._mlflow_object import _MLflowObject
3 from mlflow.entities.lifecycle_stage import LifecycleStage
4 from mlflow.exceptions import MlflowException
5
6 from mlflow.protos.service_pb2 import RunInfo as ProtoRunInfo
7 from mlflow.protos.databricks_pb2 import INVALID_PARAMETER_VALUE
8
9
10 def check_run_is_active(run_info):
11 if run_info.lifecycle_stage != LifecycleStage.ACTIVE:
12 raise MlflowException(
13 "The run {} must be in 'active' lifecycle_stage.".format(run_info.run_id),
14 error_code=INVALID_PARAMETER_VALUE,
15 )
16
17
18 class searchable_attribute(property):
19 # Wrapper class over property to designate some of the properties as searchable
20 # run attributes
21 pass
22
23
24 class orderable_attribute(property):
25 # Wrapper class over property to designate some of the properties as orderable
26 # run attributes
27 pass
28
29
30 class RunInfo(_MLflowObject):
31 """
32 Metadata about a run.
33 """
34
35 def __init__(
36 self,
37 run_uuid,
38 experiment_id,
39 user_id,
40 status,
41 start_time,
42 end_time,
43 lifecycle_stage,
44 artifact_uri=None,
45 run_id=None,
46 run_name=None,
47 ):
48 if experiment_id is None:
49 raise Exception("experiment_id cannot be None")
50 if user_id is None:
51 raise Exception("user_id cannot be None")
52 if status is None:
53 raise Exception("status cannot be None")
54 if start_time is None:
55 raise Exception("start_time cannot be None")
56 actual_run_id = run_id or run_uuid
57 if actual_run_id is None:
58 raise Exception("run_id and run_uuid cannot both be None")
59 self._run_uuid = actual_run_id
60 self._run_id = actual_run_id
61 self._experiment_id = experiment_id
62 self._user_id = user_id
63 self._status = status
64 self._start_time = start_time
65 self._end_time = end_time
66 self._lifecycle_stage = lifecycle_stage
67 self._artifact_uri = artifact_uri
68 self._run_name = run_name
69
70 def __eq__(self, other):
71 if type(other) is type(self):
72 # TODO deep equality here?
73 return self.__dict__ == other.__dict__
74 return False
75
76 def _copy_with_overrides(self, status=None, end_time=None, lifecycle_stage=None, run_name=None):
77 """A copy of the RunInfo with certain attributes modified."""
78 proto = self.to_proto()
79 if status:
80 proto.status = status
81 if end_time:
82 proto.end_time = end_time
83 if lifecycle_stage:
84 proto.lifecycle_stage = lifecycle_stage
85 if run_name:
86 proto.run_name = run_name
87 return RunInfo.from_proto(proto)
88
89 @property
90 def run_uuid(self):
91 """[Deprecated, use run_id instead] String containing run UUID."""
92 return self._run_uuid
93
94 @property
95 def run_id(self):
96 """String containing run id."""
97 return self._run_id
98
99 @property
100 def experiment_id(self):
101 """String ID of the experiment for the current run."""
102 return self._experiment_id
103
104 @property
105 def run_name(self):
106 """String containing run name."""
107 return self._run_name
108
109 def _set_run_name(self, new_name):
110 self._run_name = new_name
111
112 @property
113 def user_id(self):
114 """String ID of the user who initiated this run."""
115 return self._user_id
116
117 @searchable_attribute
118 def status(self):
119 """
120 One of the values in :py:class:`mlflow.entities.RunStatus`
121 describing the status of the run.
122 """
123 return self._status
124
125 @searchable_attribute
126 def start_time(self):
127 """Start time of the run, in number of milliseconds since the UNIX epoch."""
128 return self._start_time
129
130 @searchable_attribute
131 def end_time(self):
132 """End time of the run, in number of milliseconds since the UNIX epoch."""
133 return self._end_time
134
135 @searchable_attribute
136 def artifact_uri(self):
137 """String root artifact URI of the run."""
138 return self._artifact_uri
139
140 @property
141 def lifecycle_stage(self):
142 return self._lifecycle_stage
143
144 def to_proto(self):
145 proto = ProtoRunInfo()
146 proto.run_uuid = self.run_uuid
147 proto.run_id = self.run_id
148 if self.run_name is not None:
149 proto.run_name = self.run_name
150 proto.experiment_id = self.experiment_id
151 proto.user_id = self.user_id
152 proto.status = RunStatus.from_string(self.status)
153 proto.start_time = self.start_time
154 if self.end_time:
155 proto.end_time = self.end_time
156 if self.artifact_uri:
157 proto.artifact_uri = self.artifact_uri
158 proto.lifecycle_stage = self.lifecycle_stage
159 return proto
160
161 @classmethod
162 def from_proto(cls, proto):
163 end_time = proto.end_time
164 # The proto2 default scalar value of zero indicates that the run's end time is absent.
165 # An absent end time is represented with a NoneType in the `RunInfo` class
166 if end_time == 0:
167 end_time = None
168 return cls(
169 run_uuid=proto.run_uuid,
170 run_id=proto.run_id,
171 run_name=proto.run_name,
172 experiment_id=proto.experiment_id,
173 user_id=proto.user_id,
174 status=RunStatus.to_string(proto.status),
175 start_time=proto.start_time,
176 end_time=end_time,
177 lifecycle_stage=proto.lifecycle_stage,
178 artifact_uri=proto.artifact_uri,
179 )
180
181 @classmethod
182 def get_searchable_attributes(cls):
183 return sorted(
184 [p for p in cls.__dict__ if isinstance(getattr(cls, p), searchable_attribute)]
185 )
186
187 @classmethod
188 def get_orderable_attributes(cls):
189 # Note that all searchable attributes are also orderable.
190 return sorted(
191 [
192 p
193 for p in cls.__dict__
194 if isinstance(getattr(cls, p), (searchable_attribute, orderable_attribute))
195 ]
196 )
197
[end of mlflow/entities/run_info.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mlflow/entities/run_info.py b/mlflow/entities/run_info.py
--- a/mlflow/entities/run_info.py
+++ b/mlflow/entities/run_info.py
@@ -109,7 +109,7 @@
def _set_run_name(self, new_name):
self._run_name = new_name
- @property
+ @searchable_attribute
def user_id(self):
"""String ID of the user who initiated this run."""
return self._user_id
|
{"golden_diff": "diff --git a/mlflow/entities/run_info.py b/mlflow/entities/run_info.py\n--- a/mlflow/entities/run_info.py\n+++ b/mlflow/entities/run_info.py\n@@ -109,7 +109,7 @@\n def _set_run_name(self, new_name):\n self._run_name = new_name\n \n- @property\n+ @searchable_attribute\n def user_id(self):\n \"\"\"String ID of the user who initiated this run.\"\"\"\n return self._user_id\n", "issue": "[FR] Add the ability to search runs based on 'user_id'\n### Willingness to contribute\n\nNo. I cannot contribute this feature at this time.\n\n### Proposal Summary\n\nEnable run search to perform searches based on the `user_id` that submitted the run. \n\n### Motivation\n\n> #### What is the use case for this feature?\r\nTo return runs that have been initiated by a particular user while using run search functionality.\r\n\r\n> #### Why is this use case valuable to support for MLflow users in general?\r\nQuality of life improvement for navigating within the UI\r\n\r\n> #### Why is this use case valuable to support for your project(s) or organization?\r\n\r\n> #### Why is it currently difficult to achieve this use case?\r\nIt is not supported right now.\r\n\n\n### Details\n\n_No response_\n\n### What component(s) does this bug affect?\n\n- [ ] `area/artifacts`: Artifact stores and artifact logging\n- [ ] `area/build`: Build and test infrastructure for MLflow\n- [ ] `area/docs`: MLflow documentation pages\n- [ ] `area/examples`: Example code\n- [ ] `area/model-registry`: Model Registry service, APIs, and the fluent client calls for Model Registry\n- [ ] `area/models`: MLmodel format, model serialization/deserialization, flavors\n- [ ] `area/pipelines`: Pipelines, Pipeline APIs, Pipeline configs, Pipeline Templates\n- [ ] `area/projects`: MLproject format, project running backends\n- [ ] `area/scoring`: MLflow Model server, model deployment tools, Spark UDFs\n- [ ] `area/server-infra`: MLflow Tracking server backend\n- [X] `area/tracking`: Tracking Service, tracking client APIs, autologging\n\n### What interface(s) does this bug affect?\n\n- [ ] `area/uiux`: Front-end, user experience, plotting, JavaScript, JavaScript dev server\n- [ ] `area/docker`: Docker use across MLflow's components, such as MLflow Projects and MLflow Models\n- [ ] `area/sqlalchemy`: Use of SQLAlchemy in the Tracking Service or Model Registry\n- [ ] `area/windows`: Windows support\n\n### What language(s) does this bug affect?\n\n- [ ] `language/r`: R APIs and clients\n- [ ] `language/java`: Java APIs and clients\n- [ ] `language/new`: Proposals for new client languages\n\n### What integration(s) does this bug affect?\n\n- [ ] `integrations/azure`: Azure and Azure ML integrations\n- [ ] `integrations/sagemaker`: SageMaker integrations\n- [ ] `integrations/databricks`: Databricks integrations\n", "before_files": [{"content": "from mlflow.entities.run_status import RunStatus\nfrom mlflow.entities._mlflow_object import _MLflowObject\nfrom mlflow.entities.lifecycle_stage import LifecycleStage\nfrom mlflow.exceptions import MlflowException\n\nfrom mlflow.protos.service_pb2 import RunInfo as ProtoRunInfo\nfrom mlflow.protos.databricks_pb2 import INVALID_PARAMETER_VALUE\n\n\ndef check_run_is_active(run_info):\n if run_info.lifecycle_stage != LifecycleStage.ACTIVE:\n raise MlflowException(\n \"The run {} must be in 'active' lifecycle_stage.\".format(run_info.run_id),\n error_code=INVALID_PARAMETER_VALUE,\n )\n\n\nclass searchable_attribute(property):\n # Wrapper class over property to designate some of the properties as searchable\n # run attributes\n pass\n\n\nclass orderable_attribute(property):\n # Wrapper class over property to designate some of the properties as orderable\n # run attributes\n pass\n\n\nclass RunInfo(_MLflowObject):\n \"\"\"\n Metadata about a run.\n \"\"\"\n\n def __init__(\n self,\n run_uuid,\n experiment_id,\n user_id,\n status,\n start_time,\n end_time,\n lifecycle_stage,\n artifact_uri=None,\n run_id=None,\n run_name=None,\n ):\n if experiment_id is None:\n raise Exception(\"experiment_id cannot be None\")\n if user_id is None:\n raise Exception(\"user_id cannot be None\")\n if status is None:\n raise Exception(\"status cannot be None\")\n if start_time is None:\n raise Exception(\"start_time cannot be None\")\n actual_run_id = run_id or run_uuid\n if actual_run_id is None:\n raise Exception(\"run_id and run_uuid cannot both be None\")\n self._run_uuid = actual_run_id\n self._run_id = actual_run_id\n self._experiment_id = experiment_id\n self._user_id = user_id\n self._status = status\n self._start_time = start_time\n self._end_time = end_time\n self._lifecycle_stage = lifecycle_stage\n self._artifact_uri = artifact_uri\n self._run_name = run_name\n\n def __eq__(self, other):\n if type(other) is type(self):\n # TODO deep equality here?\n return self.__dict__ == other.__dict__\n return False\n\n def _copy_with_overrides(self, status=None, end_time=None, lifecycle_stage=None, run_name=None):\n \"\"\"A copy of the RunInfo with certain attributes modified.\"\"\"\n proto = self.to_proto()\n if status:\n proto.status = status\n if end_time:\n proto.end_time = end_time\n if lifecycle_stage:\n proto.lifecycle_stage = lifecycle_stage\n if run_name:\n proto.run_name = run_name\n return RunInfo.from_proto(proto)\n\n @property\n def run_uuid(self):\n \"\"\"[Deprecated, use run_id instead] String containing run UUID.\"\"\"\n return self._run_uuid\n\n @property\n def run_id(self):\n \"\"\"String containing run id.\"\"\"\n return self._run_id\n\n @property\n def experiment_id(self):\n \"\"\"String ID of the experiment for the current run.\"\"\"\n return self._experiment_id\n\n @property\n def run_name(self):\n \"\"\"String containing run name.\"\"\"\n return self._run_name\n\n def _set_run_name(self, new_name):\n self._run_name = new_name\n\n @property\n def user_id(self):\n \"\"\"String ID of the user who initiated this run.\"\"\"\n return self._user_id\n\n @searchable_attribute\n def status(self):\n \"\"\"\n One of the values in :py:class:`mlflow.entities.RunStatus`\n describing the status of the run.\n \"\"\"\n return self._status\n\n @searchable_attribute\n def start_time(self):\n \"\"\"Start time of the run, in number of milliseconds since the UNIX epoch.\"\"\"\n return self._start_time\n\n @searchable_attribute\n def end_time(self):\n \"\"\"End time of the run, in number of milliseconds since the UNIX epoch.\"\"\"\n return self._end_time\n\n @searchable_attribute\n def artifact_uri(self):\n \"\"\"String root artifact URI of the run.\"\"\"\n return self._artifact_uri\n\n @property\n def lifecycle_stage(self):\n return self._lifecycle_stage\n\n def to_proto(self):\n proto = ProtoRunInfo()\n proto.run_uuid = self.run_uuid\n proto.run_id = self.run_id\n if self.run_name is not None:\n proto.run_name = self.run_name\n proto.experiment_id = self.experiment_id\n proto.user_id = self.user_id\n proto.status = RunStatus.from_string(self.status)\n proto.start_time = self.start_time\n if self.end_time:\n proto.end_time = self.end_time\n if self.artifact_uri:\n proto.artifact_uri = self.artifact_uri\n proto.lifecycle_stage = self.lifecycle_stage\n return proto\n\n @classmethod\n def from_proto(cls, proto):\n end_time = proto.end_time\n # The proto2 default scalar value of zero indicates that the run's end time is absent.\n # An absent end time is represented with a NoneType in the `RunInfo` class\n if end_time == 0:\n end_time = None\n return cls(\n run_uuid=proto.run_uuid,\n run_id=proto.run_id,\n run_name=proto.run_name,\n experiment_id=proto.experiment_id,\n user_id=proto.user_id,\n status=RunStatus.to_string(proto.status),\n start_time=proto.start_time,\n end_time=end_time,\n lifecycle_stage=proto.lifecycle_stage,\n artifact_uri=proto.artifact_uri,\n )\n\n @classmethod\n def get_searchable_attributes(cls):\n return sorted(\n [p for p in cls.__dict__ if isinstance(getattr(cls, p), searchable_attribute)]\n )\n\n @classmethod\n def get_orderable_attributes(cls):\n # Note that all searchable attributes are also orderable.\n return sorted(\n [\n p\n for p in cls.__dict__\n if isinstance(getattr(cls, p), (searchable_attribute, orderable_attribute))\n ]\n )\n", "path": "mlflow/entities/run_info.py"}]}
| 2,908 | 107 |
gh_patches_debug_25967
|
rasdani/github-patches
|
git_diff
|
google__turbinia-524
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Turbinia's setup.py seems to be broken with the latest version of pip
Turbinia can't be isntalled with the latest version of `pip`. (20.1)
```
Collecting pip
Downloading pip-20.1-py2.py3-none-any.whl (1.5 MB)
Installing collected packages: pip
Attempting uninstall: pip
Found existing installation: pip 20.0.2
Uninstalling pip-20.0.2:
Successfully uninstalled pip-20.0.2
Successfully installed pip-20.1
[snip]
Collecting turbinia==20190819.6
Downloading turbinia-20190819.6.tar.gz (88 kB)
ERROR: Command errored out with exit status 1:
command: /opt/hostedtoolcache/Python/3.6.10/x64/bin/python -c 'import sys, setuptools, tokenize; sys.argv[0] = '"'"'/tmp/pip-install-jz1lyg2d/turbinia/setup.py'"'"'; __file__='"'"'/tmp/pip-install-jz1lyg2d/turbinia/setup.py'"'"';f=getattr(tokenize, '"'"'open'"'"', open)(__file__);code=f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' egg_info --egg-base /tmp/pip-pip-egg-info-rm1k5ext
cwd: /tmp/pip-install-jz1lyg2d/turbinia/
Complete output (7 lines):
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/tmp/pip-install-jz1lyg2d/turbinia/setup.py", line 65, in <module>
'requirements.txt', session=False)
File "/tmp/pip-install-jz1lyg2d/turbinia/setup.py", line 64, in <listcomp>
install_requires=[str(req.req) for req in parse_requirements(
AttributeError: 'ParsedRequirement' object has no attribute 'req'
```
Works fine on pip 19.1.1.
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 #
4 # Copyright 2017 Google Inc.
5 #
6 # Licensed under the Apache License, Version 2.0 (the "License");
7 # you may not use this file except in compliance with the License.
8 # You may obtain a copy of the License at
9 #
10 # http://www.apache.org/licenses/LICENSE-2.0
11 #
12 # Unless required by applicable law or agreed to in writing, software
13 # distributed under the License is distributed on an "AS IS" BASIS,
14 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
15 # See the License for the specific language governing permissions and
16 # limitations under the License.
17 """This is the setup file for the project."""
18
19 # yapf: disable
20
21 from __future__ import unicode_literals
22
23 import sys
24
25 from setuptools import find_packages
26 from setuptools import setup
27
28 try: # for pip >= 10
29 from pip._internal.req import parse_requirements
30 except ImportError: # for pip <= 9.0.3
31 from pip.req import parse_requirements
32
33
34 # make sure turbinia is in path
35 sys.path.insert(0, '.')
36
37 import turbinia # pylint: disable=wrong-import-position
38
39 turbinia_description = (
40 'Turbinia is an open-source framework for deploying, managing, and running'
41 'forensic workloads on cloud platforms. It is intended to automate running '
42 'of common forensic processing tools (i.e. Plaso, TSK, strings, etc) to '
43 'help with processing evidence in the Cloud, scaling the processing of '
44 'large amounts of evidence, and decreasing response time by parallelizing'
45 'processing where possible.')
46
47 setup(
48 name='turbinia',
49 version=turbinia.__version__,
50 description='Automation and Scaling of Digital Forensics Tools',
51 long_description=turbinia_description,
52 license='Apache License, Version 2.0',
53 url='http://turbinia.plumbing/',
54 maintainer='Turbinia development team',
55 maintainer_email='[email protected]',
56 classifiers=[
57 'Development Status :: 4 - Beta',
58 'Environment :: Console',
59 'Operating System :: OS Independent',
60 'Programming Language :: Python',
61 ],
62 packages=find_packages(),
63 include_package_data=True,
64 zip_safe=False,
65 entry_points={'console_scripts': ['turbiniactl=turbinia.turbiniactl:main']},
66 install_requires=[str(req.req) for req in parse_requirements(
67 'requirements.txt', session=False)
68 ],
69 extras_require={
70 'dev': ['mock', 'nose', 'yapf', 'celery~=4.1', 'coverage'],
71 'local': ['celery~=4.1', 'kombu~=4.1', 'redis~=3.0'],
72 'worker': ['plaso>=20171118', 'pyhindsight>=2.2.0']
73 }
74 )
75
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -25,11 +25,6 @@
from setuptools import find_packages
from setuptools import setup
-try: # for pip >= 10
- from pip._internal.req import parse_requirements
-except ImportError: # for pip <= 9.0.3
- from pip.req import parse_requirements
-
# make sure turbinia is in path
sys.path.insert(0, '.')
@@ -44,6 +39,9 @@
'large amounts of evidence, and decreasing response time by parallelizing'
'processing where possible.')
+requirements = []
+with open('requirements.txt','r') as f:
+ requirements = f.read().splitlines()
setup(
name='turbinia',
version=turbinia.__version__,
@@ -63,9 +61,7 @@
include_package_data=True,
zip_safe=False,
entry_points={'console_scripts': ['turbiniactl=turbinia.turbiniactl:main']},
- install_requires=[str(req.req) for req in parse_requirements(
- 'requirements.txt', session=False)
- ],
+ install_requires=requirements,
extras_require={
'dev': ['mock', 'nose', 'yapf', 'celery~=4.1', 'coverage'],
'local': ['celery~=4.1', 'kombu~=4.1', 'redis~=3.0'],
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -25,11 +25,6 @@\n from setuptools import find_packages\n from setuptools import setup\n \n-try: # for pip >= 10\n- from pip._internal.req import parse_requirements\n-except ImportError: # for pip <= 9.0.3\n- from pip.req import parse_requirements\n-\n \n # make sure turbinia is in path\n sys.path.insert(0, '.')\n@@ -44,6 +39,9 @@\n 'large amounts of evidence, and decreasing response time by parallelizing'\n 'processing where possible.')\n \n+requirements = []\n+with open('requirements.txt','r') as f:\n+ requirements = f.read().splitlines()\n setup(\n name='turbinia',\n version=turbinia.__version__,\n@@ -63,9 +61,7 @@\n include_package_data=True,\n zip_safe=False,\n entry_points={'console_scripts': ['turbiniactl=turbinia.turbiniactl:main']},\n- install_requires=[str(req.req) for req in parse_requirements(\n- 'requirements.txt', session=False)\n- ],\n+ install_requires=requirements,\n extras_require={\n 'dev': ['mock', 'nose', 'yapf', 'celery~=4.1', 'coverage'],\n 'local': ['celery~=4.1', 'kombu~=4.1', 'redis~=3.0'],\n", "issue": "Turbinia's setup.py seems to be broken with the latest version of pip\nTurbinia can't be isntalled with the latest version of `pip`. (20.1)\r\n\r\n```\r\nCollecting pip\r\n Downloading pip-20.1-py2.py3-none-any.whl (1.5 MB)\r\nInstalling collected packages: pip\r\n Attempting uninstall: pip\r\n Found existing installation: pip 20.0.2\r\n Uninstalling pip-20.0.2:\r\n Successfully uninstalled pip-20.0.2\r\nSuccessfully installed pip-20.1\r\n[snip]\r\nCollecting turbinia==20190819.6\r\n Downloading turbinia-20190819.6.tar.gz (88 kB)\r\n ERROR: Command errored out with exit status 1:\r\n command: /opt/hostedtoolcache/Python/3.6.10/x64/bin/python -c 'import sys, setuptools, tokenize; sys.argv[0] = '\"'\"'/tmp/pip-install-jz1lyg2d/turbinia/setup.py'\"'\"'; __file__='\"'\"'/tmp/pip-install-jz1lyg2d/turbinia/setup.py'\"'\"';f=getattr(tokenize, '\"'\"'open'\"'\"', open)(__file__);code=f.read().replace('\"'\"'\\r\\n'\"'\"', '\"'\"'\\n'\"'\"');f.close();exec(compile(code, __file__, '\"'\"'exec'\"'\"'))' egg_info --egg-base /tmp/pip-pip-egg-info-rm1k5ext\r\n cwd: /tmp/pip-install-jz1lyg2d/turbinia/\r\n Complete output (7 lines):\r\n Traceback (most recent call last):\r\n File \"<string>\", line 1, in <module>\r\n File \"/tmp/pip-install-jz1lyg2d/turbinia/setup.py\", line 65, in <module>\r\n 'requirements.txt', session=False)\r\n File \"/tmp/pip-install-jz1lyg2d/turbinia/setup.py\", line 64, in <listcomp>\r\n install_requires=[str(req.req) for req in parse_requirements(\r\n AttributeError: 'ParsedRequirement' object has no attribute 'req'\r\n```\r\n\r\nWorks fine on pip 19.1.1.\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n#\n# Copyright 2017 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"This is the setup file for the project.\"\"\"\n\n# yapf: disable\n\nfrom __future__ import unicode_literals\n\nimport sys\n\nfrom setuptools import find_packages\nfrom setuptools import setup\n\ntry: # for pip >= 10\n from pip._internal.req import parse_requirements\nexcept ImportError: # for pip <= 9.0.3\n from pip.req import parse_requirements\n\n\n# make sure turbinia is in path\nsys.path.insert(0, '.')\n\nimport turbinia # pylint: disable=wrong-import-position\n\nturbinia_description = (\n 'Turbinia is an open-source framework for deploying, managing, and running'\n 'forensic workloads on cloud platforms. It is intended to automate running '\n 'of common forensic processing tools (i.e. Plaso, TSK, strings, etc) to '\n 'help with processing evidence in the Cloud, scaling the processing of '\n 'large amounts of evidence, and decreasing response time by parallelizing'\n 'processing where possible.')\n\nsetup(\n name='turbinia',\n version=turbinia.__version__,\n description='Automation and Scaling of Digital Forensics Tools',\n long_description=turbinia_description,\n license='Apache License, Version 2.0',\n url='http://turbinia.plumbing/',\n maintainer='Turbinia development team',\n maintainer_email='[email protected]',\n classifiers=[\n 'Development Status :: 4 - Beta',\n 'Environment :: Console',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python',\n ],\n packages=find_packages(),\n include_package_data=True,\n zip_safe=False,\n entry_points={'console_scripts': ['turbiniactl=turbinia.turbiniactl:main']},\n install_requires=[str(req.req) for req in parse_requirements(\n 'requirements.txt', session=False)\n ],\n extras_require={\n 'dev': ['mock', 'nose', 'yapf', 'celery~=4.1', 'coverage'],\n 'local': ['celery~=4.1', 'kombu~=4.1', 'redis~=3.0'],\n 'worker': ['plaso>=20171118', 'pyhindsight>=2.2.0']\n }\n)\n", "path": "setup.py"}]}
| 1,833 | 331 |
gh_patches_debug_64426
|
rasdani/github-patches
|
git_diff
|
pwndbg__pwndbg-1619
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Disable search-memory-packet back only on broken GDB version
Tl;dr: Use the workaround from https://github.com/pwndbg/pwndbg/pull/322/files only for broken gdb versions
Disable search-memory-packet back only on broken GDB version
Tl;dr: Use the workaround from https://github.com/pwndbg/pwndbg/pull/322/files only for broken gdb versions
</issue>
<code>
[start of pwndbg/__init__.py]
1 import signal
2
3 import gdb
4
5 import pwndbg.color
6 import pwndbg.commands
7 import pwndbg.gdblib
8 from pwndbg.commands import load_commands
9 from pwndbg.gdblib import load_gdblib
10
11 load_commands()
12 load_gdblib()
13
14 # TODO: Convert these to gdblib modules and remove this
15 try:
16 import pwndbg.disasm
17 import pwndbg.disasm.arm
18 import pwndbg.disasm.jump
19 import pwndbg.disasm.mips
20 import pwndbg.disasm.ppc
21 import pwndbg.disasm.sparc
22 import pwndbg.disasm.x86
23 import pwndbg.heap
24 except ModuleNotFoundError:
25 pass
26
27 import pwndbg.exception
28 import pwndbg.lib.version
29 import pwndbg.ui
30
31 __version__ = pwndbg.lib.version.__version__
32 version = __version__
33
34 from pwndbg.gdblib import prompt
35
36 prompt.set_prompt()
37
38 pre_commands = """
39 set confirm off
40 set verbose off
41 set pagination off
42 set height 0
43 set history save on
44 set follow-fork-mode child
45 set backtrace past-main on
46 set step-mode on
47 set print pretty on
48 set width %i
49 handle SIGALRM nostop print nopass
50 handle SIGBUS stop print nopass
51 handle SIGPIPE nostop print nopass
52 handle SIGSEGV stop print nopass
53 """.strip() % (
54 pwndbg.ui.get_window_size()[1]
55 )
56
57 for line in pre_commands.strip().splitlines():
58 gdb.execute(line)
59
60 # This may throw an exception, see pwndbg/pwndbg#27
61 try:
62 gdb.execute("set disassembly-flavor intel")
63 except gdb.error:
64 pass
65
66 # handle resize event to align width and completion
67 signal.signal(
68 signal.SIGWINCH,
69 lambda signum, frame: gdb.execute("set width %i" % pwndbg.ui.get_window_size()[1]),
70 )
71
72 # Reading Comment file
73 from pwndbg.commands import comments
74
75 comments.init()
76
77 from pwndbg.gdblib import config_mod
78
79 config_mod.init_params()
80
[end of pwndbg/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pwndbg/__init__.py b/pwndbg/__init__.py
--- a/pwndbg/__init__.py
+++ b/pwndbg/__init__.py
@@ -54,6 +54,10 @@
pwndbg.ui.get_window_size()[1]
)
+# See https://github.com/pwndbg/pwndbg/issues/808
+if int(getattr(gdb, "VERSION", "0.0").split(".")[0]) <= 9:
+ pre_commands += "\nset remote search-memory-packet off"
+
for line in pre_commands.strip().splitlines():
gdb.execute(line)
|
{"golden_diff": "diff --git a/pwndbg/__init__.py b/pwndbg/__init__.py\n--- a/pwndbg/__init__.py\n+++ b/pwndbg/__init__.py\n@@ -54,6 +54,10 @@\n pwndbg.ui.get_window_size()[1]\n )\n \n+# See https://github.com/pwndbg/pwndbg/issues/808\n+if int(getattr(gdb, \"VERSION\", \"0.0\").split(\".\")[0]) <= 9:\n+ pre_commands += \"\\nset remote search-memory-packet off\"\n+\n for line in pre_commands.strip().splitlines():\n gdb.execute(line)\n", "issue": "Disable search-memory-packet back only on broken GDB version\nTl;dr: Use the workaround from https://github.com/pwndbg/pwndbg/pull/322/files only for broken gdb versions\nDisable search-memory-packet back only on broken GDB version\nTl;dr: Use the workaround from https://github.com/pwndbg/pwndbg/pull/322/files only for broken gdb versions\n", "before_files": [{"content": "import signal\n\nimport gdb\n\nimport pwndbg.color\nimport pwndbg.commands\nimport pwndbg.gdblib\nfrom pwndbg.commands import load_commands\nfrom pwndbg.gdblib import load_gdblib\n\nload_commands()\nload_gdblib()\n\n# TODO: Convert these to gdblib modules and remove this\ntry:\n import pwndbg.disasm\n import pwndbg.disasm.arm\n import pwndbg.disasm.jump\n import pwndbg.disasm.mips\n import pwndbg.disasm.ppc\n import pwndbg.disasm.sparc\n import pwndbg.disasm.x86\n import pwndbg.heap\nexcept ModuleNotFoundError:\n pass\n\nimport pwndbg.exception\nimport pwndbg.lib.version\nimport pwndbg.ui\n\n__version__ = pwndbg.lib.version.__version__\nversion = __version__\n\nfrom pwndbg.gdblib import prompt\n\nprompt.set_prompt()\n\npre_commands = \"\"\"\nset confirm off\nset verbose off\nset pagination off\nset height 0\nset history save on\nset follow-fork-mode child\nset backtrace past-main on\nset step-mode on\nset print pretty on\nset width %i\nhandle SIGALRM nostop print nopass\nhandle SIGBUS stop print nopass\nhandle SIGPIPE nostop print nopass\nhandle SIGSEGV stop print nopass\n\"\"\".strip() % (\n pwndbg.ui.get_window_size()[1]\n)\n\nfor line in pre_commands.strip().splitlines():\n gdb.execute(line)\n\n# This may throw an exception, see pwndbg/pwndbg#27\ntry:\n gdb.execute(\"set disassembly-flavor intel\")\nexcept gdb.error:\n pass\n\n# handle resize event to align width and completion\nsignal.signal(\n signal.SIGWINCH,\n lambda signum, frame: gdb.execute(\"set width %i\" % pwndbg.ui.get_window_size()[1]),\n)\n\n# Reading Comment file\nfrom pwndbg.commands import comments\n\ncomments.init()\n\nfrom pwndbg.gdblib import config_mod\n\nconfig_mod.init_params()\n", "path": "pwndbg/__init__.py"}]}
| 1,241 | 140 |
gh_patches_debug_8240
|
rasdani/github-patches
|
git_diff
|
scoutapp__scout_apm_python-329
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Metadata should have language / language_version fields
Standardizing metadata between the various agents - put a fixed `python` string in `language`, and the version (`3.4.1` or whatever) in `language_version`
Keep the existing fields for now. Need to ensure that the CoreAgent handles them nicely when missing.
</issue>
<code>
[start of src/scout_apm/core/metadata.py]
1 # coding=utf-8
2 from __future__ import absolute_import, division, print_function, unicode_literals
3
4 import datetime as dt
5 import logging
6 import sys
7 from os import getpid
8
9 from scout_apm.core.commands import ApplicationEvent
10 from scout_apm.core.config import scout_config
11 from scout_apm.core.socket import CoreAgentSocket
12
13 logger = logging.getLogger(__name__)
14
15
16 class AppMetadata(object):
17 @classmethod
18 def report(cls):
19 event = ApplicationEvent(
20 event_type="scout.metadata",
21 event_value=cls.data(),
22 source="Pid: " + str(getpid()),
23 timestamp=dt.datetime.utcnow(),
24 )
25 CoreAgentSocket.instance().send(event)
26
27 @classmethod
28 def data(cls):
29 try:
30 data = {
31 "language": "python",
32 "version": "{}.{}.{}".format(*sys.version_info[:3]),
33 "server_time": dt.datetime.utcnow().isoformat() + "Z",
34 "framework": scout_config.value("framework"),
35 "framework_version": scout_config.value("framework_version"),
36 "environment": "",
37 "app_server": scout_config.value("app_server"),
38 "hostname": scout_config.value("hostname"),
39 "database_engine": "", # Detected
40 "database_adapter": "", # Raw
41 "application_name": "", # Environment.application_name,
42 "libraries": cls.get_python_packages_versions(),
43 "paas": "",
44 "application_root": scout_config.value("application_root"),
45 "scm_subdirectory": scout_config.value("scm_subdirectory"),
46 "git_sha": scout_config.value("revision_sha"),
47 }
48 except Exception as e:
49 logger.debug("Exception in AppMetadata: %r", e)
50 data = {}
51
52 return data
53
54 @classmethod
55 def get_python_packages_versions(cls):
56 try:
57 import pkg_resources
58 except ImportError:
59 return []
60
61 return list(
62 sorted(
63 (distribution.project_name, distribution.version)
64 for distribution in pkg_resources.working_set
65 )
66 )
67
[end of src/scout_apm/core/metadata.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/scout_apm/core/metadata.py b/src/scout_apm/core/metadata.py
--- a/src/scout_apm/core/metadata.py
+++ b/src/scout_apm/core/metadata.py
@@ -29,6 +29,8 @@
try:
data = {
"language": "python",
+ "language_version": "{}.{}.{}".format(*sys.version_info[:3]),
+ # Deprecated: (see #327)
"version": "{}.{}.{}".format(*sys.version_info[:3]),
"server_time": dt.datetime.utcnow().isoformat() + "Z",
"framework": scout_config.value("framework"),
|
{"golden_diff": "diff --git a/src/scout_apm/core/metadata.py b/src/scout_apm/core/metadata.py\n--- a/src/scout_apm/core/metadata.py\n+++ b/src/scout_apm/core/metadata.py\n@@ -29,6 +29,8 @@\n try:\n data = {\n \"language\": \"python\",\n+ \"language_version\": \"{}.{}.{}\".format(*sys.version_info[:3]),\n+ # Deprecated: (see #327)\n \"version\": \"{}.{}.{}\".format(*sys.version_info[:3]),\n \"server_time\": dt.datetime.utcnow().isoformat() + \"Z\",\n \"framework\": scout_config.value(\"framework\"),\n", "issue": "Metadata should have language / language_version fields\nStandardizing metadata between the various agents - put a fixed `python` string in `language`, and the version (`3.4.1` or whatever) in `language_version`\r\n\r\nKeep the existing fields for now. Need to ensure that the CoreAgent handles them nicely when missing.\n", "before_files": [{"content": "# coding=utf-8\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport datetime as dt\nimport logging\nimport sys\nfrom os import getpid\n\nfrom scout_apm.core.commands import ApplicationEvent\nfrom scout_apm.core.config import scout_config\nfrom scout_apm.core.socket import CoreAgentSocket\n\nlogger = logging.getLogger(__name__)\n\n\nclass AppMetadata(object):\n @classmethod\n def report(cls):\n event = ApplicationEvent(\n event_type=\"scout.metadata\",\n event_value=cls.data(),\n source=\"Pid: \" + str(getpid()),\n timestamp=dt.datetime.utcnow(),\n )\n CoreAgentSocket.instance().send(event)\n\n @classmethod\n def data(cls):\n try:\n data = {\n \"language\": \"python\",\n \"version\": \"{}.{}.{}\".format(*sys.version_info[:3]),\n \"server_time\": dt.datetime.utcnow().isoformat() + \"Z\",\n \"framework\": scout_config.value(\"framework\"),\n \"framework_version\": scout_config.value(\"framework_version\"),\n \"environment\": \"\",\n \"app_server\": scout_config.value(\"app_server\"),\n \"hostname\": scout_config.value(\"hostname\"),\n \"database_engine\": \"\", # Detected\n \"database_adapter\": \"\", # Raw\n \"application_name\": \"\", # Environment.application_name,\n \"libraries\": cls.get_python_packages_versions(),\n \"paas\": \"\",\n \"application_root\": scout_config.value(\"application_root\"),\n \"scm_subdirectory\": scout_config.value(\"scm_subdirectory\"),\n \"git_sha\": scout_config.value(\"revision_sha\"),\n }\n except Exception as e:\n logger.debug(\"Exception in AppMetadata: %r\", e)\n data = {}\n\n return data\n\n @classmethod\n def get_python_packages_versions(cls):\n try:\n import pkg_resources\n except ImportError:\n return []\n\n return list(\n sorted(\n (distribution.project_name, distribution.version)\n for distribution in pkg_resources.working_set\n )\n )\n", "path": "src/scout_apm/core/metadata.py"}]}
| 1,164 | 146 |
gh_patches_debug_325
|
rasdani/github-patches
|
git_diff
|
Kinto__kinto-1302
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Cannot import name `Utc`
While trying to debug #1299 I encountered the following error:
```
$ make serve
...
~/.virtualenvs/test/bin/kinto migrate --ini config/kinto.ini
Traceback (most recent call last):
File "~/.virtualenvs/test/bin/kinto", line 11, in <module>
load_entry_point('kinto', 'console_scripts', 'kinto')()
File "~/.virtualenvs/test/lib/python3.5/site-packages/pkg_resources/__init__.py", line 560, in load_entry_point
return get_distribution(dist).load_entry_point(group, name)
File "~/.virtualenvs/test/lib/python3.5/site-packages/pkg_resources/__init__.py", line 2648, in load_entry_point
return ep.load()
File "~/.virtualenvs/test/lib/python3.5/site-packages/pkg_resources/__init__.py", line 2302, in load
return self.resolve()
File "~/.virtualenvs/test/lib/python3.5/site-packages/pkg_resources/__init__.py", line 2308, in resolve
module = __import__(self.module_name, fromlist=['__name__'], level=0)
File "~/mozilla/kinto/kinto/__init__.py", line 4, in <module>
import kinto.core
File "~/mozilla/kinto/kinto/core/__init__.py", line 10, in <module>
from kinto.core import errors
File "~/mozilla/kinto/kinto/core/errors.py", line 1, in <module>
import colander
File "~/.virtualenvs/test/lib/python3.5/site-packages/colander/__init__.py", line 22, in <module>
from . import iso8601
File "~/.virtualenvs/test/lib/python3.5/site-packages/colander/iso8601.py", line 3, in <module>
from iso8601.iso8601 import (parse_date, ParseError, Utc, FixedOffset, UTC, ZERO, ISO8601_REGEX)
ImportError: cannot import name 'Utc'
Makefile:87 : la recette pour la cible « migrate » a échouée
make: *** [migrate] Erreur 1
```
Cannot import name `Utc`
While trying to debug #1299 I encountered the following error:
```
$ make serve
...
~/.virtualenvs/test/bin/kinto migrate --ini config/kinto.ini
Traceback (most recent call last):
File "~/.virtualenvs/test/bin/kinto", line 11, in <module>
load_entry_point('kinto', 'console_scripts', 'kinto')()
File "~/.virtualenvs/test/lib/python3.5/site-packages/pkg_resources/__init__.py", line 560, in load_entry_point
return get_distribution(dist).load_entry_point(group, name)
File "~/.virtualenvs/test/lib/python3.5/site-packages/pkg_resources/__init__.py", line 2648, in load_entry_point
return ep.load()
File "~/.virtualenvs/test/lib/python3.5/site-packages/pkg_resources/__init__.py", line 2302, in load
return self.resolve()
File "~/.virtualenvs/test/lib/python3.5/site-packages/pkg_resources/__init__.py", line 2308, in resolve
module = __import__(self.module_name, fromlist=['__name__'], level=0)
File "~/mozilla/kinto/kinto/__init__.py", line 4, in <module>
import kinto.core
File "~/mozilla/kinto/kinto/core/__init__.py", line 10, in <module>
from kinto.core import errors
File "~/mozilla/kinto/kinto/core/errors.py", line 1, in <module>
import colander
File "~/.virtualenvs/test/lib/python3.5/site-packages/colander/__init__.py", line 22, in <module>
from . import iso8601
File "~/.virtualenvs/test/lib/python3.5/site-packages/colander/iso8601.py", line 3, in <module>
from iso8601.iso8601 import (parse_date, ParseError, Utc, FixedOffset, UTC, ZERO, ISO8601_REGEX)
ImportError: cannot import name 'Utc'
Makefile:87 : la recette pour la cible « migrate » a échouée
make: *** [migrate] Erreur 1
```
</issue>
<code>
[start of setup.py]
1 import codecs
2 import os
3 from setuptools import setup, find_packages
4
5 here = os.path.abspath(os.path.dirname(__file__))
6
7
8 def read_file(filename):
9 """Open a related file and return its content."""
10 with codecs.open(os.path.join(here, filename), encoding='utf-8') as f:
11 content = f.read()
12 return content
13
14
15 README = read_file('README.rst')
16 CHANGELOG = read_file('CHANGELOG.rst')
17 CONTRIBUTORS = read_file('CONTRIBUTORS.rst')
18
19 REQUIREMENTS = [
20 'bcrypt',
21 'colander >= 1.3.2',
22 'cornice >= 2.4',
23 'cornice_swagger >= 0.5.1',
24 'jsonschema',
25 'jsonpatch',
26 'logging-color-formatter >= 1.0.1', # Message interpolations.
27 'python-dateutil',
28 'pyramid > 1.8, < 1.9b1',
29 'pyramid_multiauth >= 0.8', # User on policy selected event.
30 'transaction',
31 # pyramid_tm changed the location of their tween in 2.x and one of
32 # our tests fails on 2.0.
33 'pyramid_tm >= 2.1',
34 'requests',
35 'waitress',
36 'ujson >= 1.35'
37 ]
38
39 POSTGRESQL_REQUIRES = [
40 'SQLAlchemy',
41 'psycopg2 > 2.5',
42 'zope.sqlalchemy',
43 ]
44
45 REDIS_REQUIRES = [
46 'kinto_redis'
47 ]
48
49 SETUP_REQUIRES = [
50 'pytest-runner'
51 ]
52
53 TEST_REQUIREMENTS = [
54 'bravado_core',
55 'pytest',
56 'WebTest'
57 ]
58
59 DEPENDENCY_LINKS = [
60 ]
61
62 MONITORING_REQUIRES = [
63 'raven',
64 'statsd',
65 'newrelic',
66 'werkzeug',
67 ]
68
69 ENTRY_POINTS = {
70 'paste.app_factory': [
71 'main = kinto:main',
72 ],
73 'console_scripts': [
74 'kinto = kinto.__main__:main'
75 ],
76 }
77
78
79 setup(name='kinto',
80 version='7.3.2.dev0',
81 description='Kinto Web Service - Store, Sync, Share, and Self-Host.',
82 long_description="{}\n\n{}\n\n{}".format(README, CHANGELOG, CONTRIBUTORS),
83 license='Apache License (2.0)',
84 classifiers=[
85 "Programming Language :: Python",
86 "Programming Language :: Python :: 3",
87 "Programming Language :: Python :: 3.5",
88 "Programming Language :: Python :: 3.6",
89 "Programming Language :: Python :: Implementation :: CPython",
90 "Topic :: Internet :: WWW/HTTP",
91 "Topic :: Internet :: WWW/HTTP :: WSGI :: Application",
92 "License :: OSI Approved :: Apache Software License"
93 ],
94 keywords="web sync json storage services",
95 author='Mozilla Services',
96 author_email='[email protected]',
97 url='https://github.com/Kinto/kinto',
98 packages=find_packages(),
99 package_data={'': ['*.rst', '*.py', '*.yaml']},
100 include_package_data=True,
101 zip_safe=False,
102 setup_requires=SETUP_REQUIRES,
103 tests_require=TEST_REQUIREMENTS,
104 install_requires=REQUIREMENTS,
105 extras_require={
106 'redis': REDIS_REQUIRES,
107 'postgresql': POSTGRESQL_REQUIRES,
108 'monitoring': MONITORING_REQUIRES,
109 },
110 test_suite="tests",
111 dependency_links=DEPENDENCY_LINKS,
112 entry_points=ENTRY_POINTS)
113
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -18,6 +18,7 @@
REQUIREMENTS = [
'bcrypt',
+ 'iso8601==0.1.11', # Refs #1301
'colander >= 1.3.2',
'cornice >= 2.4',
'cornice_swagger >= 0.5.1',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -18,6 +18,7 @@\n \n REQUIREMENTS = [\n 'bcrypt',\n+ 'iso8601==0.1.11', # Refs #1301\n 'colander >= 1.3.2',\n 'cornice >= 2.4',\n 'cornice_swagger >= 0.5.1',\n", "issue": "Cannot import name `Utc`\nWhile trying to debug #1299 I encountered the following error:\r\n```\r\n$ make serve\r\n...\r\n~/.virtualenvs/test/bin/kinto migrate --ini config/kinto.ini\r\nTraceback (most recent call last):\r\n File \"~/.virtualenvs/test/bin/kinto\", line 11, in <module>\r\n load_entry_point('kinto', 'console_scripts', 'kinto')()\r\n File \"~/.virtualenvs/test/lib/python3.5/site-packages/pkg_resources/__init__.py\", line 560, in load_entry_point\r\n return get_distribution(dist).load_entry_point(group, name)\r\n File \"~/.virtualenvs/test/lib/python3.5/site-packages/pkg_resources/__init__.py\", line 2648, in load_entry_point\r\n return ep.load()\r\n File \"~/.virtualenvs/test/lib/python3.5/site-packages/pkg_resources/__init__.py\", line 2302, in load\r\n return self.resolve()\r\n File \"~/.virtualenvs/test/lib/python3.5/site-packages/pkg_resources/__init__.py\", line 2308, in resolve\r\n module = __import__(self.module_name, fromlist=['__name__'], level=0)\r\n File \"~/mozilla/kinto/kinto/__init__.py\", line 4, in <module>\r\n import kinto.core\r\n File \"~/mozilla/kinto/kinto/core/__init__.py\", line 10, in <module>\r\n from kinto.core import errors\r\n File \"~/mozilla/kinto/kinto/core/errors.py\", line 1, in <module>\r\n import colander\r\n File \"~/.virtualenvs/test/lib/python3.5/site-packages/colander/__init__.py\", line 22, in <module>\r\n from . import iso8601\r\n File \"~/.virtualenvs/test/lib/python3.5/site-packages/colander/iso8601.py\", line 3, in <module>\r\n from iso8601.iso8601 import (parse_date, ParseError, Utc, FixedOffset, UTC, ZERO, ISO8601_REGEX)\r\nImportError: cannot import name 'Utc'\r\nMakefile:87\u00a0: la recette pour la cible \u00ab\u00a0migrate\u00a0\u00bb a \u00e9chou\u00e9e\r\nmake: *** [migrate] Erreur 1\r\n```\nCannot import name `Utc`\nWhile trying to debug #1299 I encountered the following error:\r\n```\r\n$ make serve\r\n...\r\n~/.virtualenvs/test/bin/kinto migrate --ini config/kinto.ini\r\nTraceback (most recent call last):\r\n File \"~/.virtualenvs/test/bin/kinto\", line 11, in <module>\r\n load_entry_point('kinto', 'console_scripts', 'kinto')()\r\n File \"~/.virtualenvs/test/lib/python3.5/site-packages/pkg_resources/__init__.py\", line 560, in load_entry_point\r\n return get_distribution(dist).load_entry_point(group, name)\r\n File \"~/.virtualenvs/test/lib/python3.5/site-packages/pkg_resources/__init__.py\", line 2648, in load_entry_point\r\n return ep.load()\r\n File \"~/.virtualenvs/test/lib/python3.5/site-packages/pkg_resources/__init__.py\", line 2302, in load\r\n return self.resolve()\r\n File \"~/.virtualenvs/test/lib/python3.5/site-packages/pkg_resources/__init__.py\", line 2308, in resolve\r\n module = __import__(self.module_name, fromlist=['__name__'], level=0)\r\n File \"~/mozilla/kinto/kinto/__init__.py\", line 4, in <module>\r\n import kinto.core\r\n File \"~/mozilla/kinto/kinto/core/__init__.py\", line 10, in <module>\r\n from kinto.core import errors\r\n File \"~/mozilla/kinto/kinto/core/errors.py\", line 1, in <module>\r\n import colander\r\n File \"~/.virtualenvs/test/lib/python3.5/site-packages/colander/__init__.py\", line 22, in <module>\r\n from . import iso8601\r\n File \"~/.virtualenvs/test/lib/python3.5/site-packages/colander/iso8601.py\", line 3, in <module>\r\n from iso8601.iso8601 import (parse_date, ParseError, Utc, FixedOffset, UTC, ZERO, ISO8601_REGEX)\r\nImportError: cannot import name 'Utc'\r\nMakefile:87\u00a0: la recette pour la cible \u00ab\u00a0migrate\u00a0\u00bb a \u00e9chou\u00e9e\r\nmake: *** [migrate] Erreur 1\r\n```\n", "before_files": [{"content": "import codecs\nimport os\nfrom setuptools import setup, find_packages\n\nhere = os.path.abspath(os.path.dirname(__file__))\n\n\ndef read_file(filename):\n \"\"\"Open a related file and return its content.\"\"\"\n with codecs.open(os.path.join(here, filename), encoding='utf-8') as f:\n content = f.read()\n return content\n\n\nREADME = read_file('README.rst')\nCHANGELOG = read_file('CHANGELOG.rst')\nCONTRIBUTORS = read_file('CONTRIBUTORS.rst')\n\nREQUIREMENTS = [\n 'bcrypt',\n 'colander >= 1.3.2',\n 'cornice >= 2.4',\n 'cornice_swagger >= 0.5.1',\n 'jsonschema',\n 'jsonpatch',\n 'logging-color-formatter >= 1.0.1', # Message interpolations.\n 'python-dateutil',\n 'pyramid > 1.8, < 1.9b1',\n 'pyramid_multiauth >= 0.8', # User on policy selected event.\n 'transaction',\n # pyramid_tm changed the location of their tween in 2.x and one of\n # our tests fails on 2.0.\n 'pyramid_tm >= 2.1',\n 'requests',\n 'waitress',\n 'ujson >= 1.35'\n]\n\nPOSTGRESQL_REQUIRES = [\n 'SQLAlchemy',\n 'psycopg2 > 2.5',\n 'zope.sqlalchemy',\n]\n\nREDIS_REQUIRES = [\n 'kinto_redis'\n]\n\nSETUP_REQUIRES = [\n 'pytest-runner'\n]\n\nTEST_REQUIREMENTS = [\n 'bravado_core',\n 'pytest',\n 'WebTest'\n]\n\nDEPENDENCY_LINKS = [\n]\n\nMONITORING_REQUIRES = [\n 'raven',\n 'statsd',\n 'newrelic',\n 'werkzeug',\n]\n\nENTRY_POINTS = {\n 'paste.app_factory': [\n 'main = kinto:main',\n ],\n 'console_scripts': [\n 'kinto = kinto.__main__:main'\n ],\n}\n\n\nsetup(name='kinto',\n version='7.3.2.dev0',\n description='Kinto Web Service - Store, Sync, Share, and Self-Host.',\n long_description=\"{}\\n\\n{}\\n\\n{}\".format(README, CHANGELOG, CONTRIBUTORS),\n license='Apache License (2.0)',\n classifiers=[\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Topic :: Internet :: WWW/HTTP\",\n \"Topic :: Internet :: WWW/HTTP :: WSGI :: Application\",\n \"License :: OSI Approved :: Apache Software License\"\n ],\n keywords=\"web sync json storage services\",\n author='Mozilla Services',\n author_email='[email protected]',\n url='https://github.com/Kinto/kinto',\n packages=find_packages(),\n package_data={'': ['*.rst', '*.py', '*.yaml']},\n include_package_data=True,\n zip_safe=False,\n setup_requires=SETUP_REQUIRES,\n tests_require=TEST_REQUIREMENTS,\n install_requires=REQUIREMENTS,\n extras_require={\n 'redis': REDIS_REQUIRES,\n 'postgresql': POSTGRESQL_REQUIRES,\n 'monitoring': MONITORING_REQUIRES,\n },\n test_suite=\"tests\",\n dependency_links=DEPENDENCY_LINKS,\n entry_points=ENTRY_POINTS)\n", "path": "setup.py"}]}
| 2,554 | 103 |
gh_patches_debug_13083
|
rasdani/github-patches
|
git_diff
|
NVIDIA__NeMo-5260
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fix links to speaker identification notebook
# What does this PR do ?
Fixes #5258
**Collection**: [Note which collection this PR will affect]
# Changelog
- Add specific line by line info of high level changes in this PR.
# Usage
* You can potentially add a usage example below
```python
# Add a code snippet demonstrating how to use this
```
# Before your PR is "Ready for review"
**Pre checks**:
- [ ] Make sure you read and followed [Contributor guidelines](https://github.com/NVIDIA/NeMo/blob/main/CONTRIBUTING.md)
- [ ] Did you write any new necessary tests?
- [ ] Did you add or update any necessary documentation?
- [ ] Does the PR affect components that are optional to install? (Ex: Numba, Pynini, Apex etc)
- [ ] Reviewer: Does the PR have correct import guards for all optional libraries?
**PR Type**:
- [ ] New Feature
- [ ] Bugfix
- [ ] Documentation
If you haven't finished some of the above items you can still open "Draft" PR.
## Who can review?
Anyone in the community is free to review the PR once the checks have passed.
[Contributor guidelines](https://github.com/NVIDIA/NeMo/blob/main/CONTRIBUTING.md) contains specific people who can review PRs to various areas.
# Additional Information
* Related to # (issue)
</issue>
<code>
[start of examples/speaker_tasks/recognition/speaker_reco.py]
1 # Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import os
16
17 import pytorch_lightning as pl
18 import torch
19 from omegaconf import OmegaConf
20 from pytorch_lightning import seed_everything
21
22 from nemo.collections.asr.models import EncDecSpeakerLabelModel
23 from nemo.core.config import hydra_runner
24 from nemo.utils import logging
25 from nemo.utils.exp_manager import exp_manager
26
27 """
28 Basic run (on GPU for 10 epochs for 2 class training):
29 EXP_NAME=sample_run
30 python ./speaker_reco.py --config-path='conf' --config-name='SpeakerNet_recognition_3x2x512.yaml' \
31 trainer.max_epochs=10 \
32 model.train_ds.batch_size=64 model.validation_ds.batch_size=64 \
33 model.train_ds.manifest_filepath="<train_manifest>" model.validation_ds.manifest_filepath="<dev_manifest>" \
34 model.test_ds.manifest_filepath="<test_manifest>" \
35 trainer.devices=1 \
36 model.decoder.params.num_classes=2 \
37 exp_manager.name=$EXP_NAME +exp_manager.use_datetime_version=False \
38 exp_manager.exp_dir='./speaker_exps'
39
40 See https://github.com/NVIDIA/NeMo/blob/main/tutorials/speaker_tasks/Speaker_Recognition_Verification.ipynb for notebook tutorial
41
42 Optional: Use tarred dataset to speech up data loading.
43 Prepare ONE manifest that contains all training data you would like to include. Validation should use non-tarred dataset.
44 Note that it's possible that tarred datasets impacts validation scores because it drop values in order to have same amount of files per tarfile;
45 Scores might be off since some data is missing.
46
47 Use the `convert_to_tarred_audio_dataset.py` script under <NEMO_ROOT>/speech_recognition/scripts in order to prepare tarred audio dataset.
48 For details, please see TarredAudioToClassificationLabelDataset in <NEMO_ROOT>/nemo/collections/asr/data/audio_to_label.py
49 """
50
51 seed_everything(42)
52
53
54 @hydra_runner(config_path="conf", config_name="SpeakerNet_verification_3x2x256.yaml")
55 def main(cfg):
56
57 logging.info(f'Hydra config: {OmegaConf.to_yaml(cfg)}')
58 trainer = pl.Trainer(**cfg.trainer)
59 log_dir = exp_manager(trainer, cfg.get("exp_manager", None))
60 speaker_model = EncDecSpeakerLabelModel(cfg=cfg.model, trainer=trainer)
61 trainer.fit(speaker_model)
62 if not trainer.fast_dev_run:
63 model_path = os.path.join(log_dir, '..', 'spkr.nemo')
64 speaker_model.save_to(model_path)
65
66 torch.distributed.destroy_process_group()
67 if hasattr(cfg.model, 'test_ds') and cfg.model.test_ds.manifest_filepath is not None:
68 if trainer.is_global_zero:
69 trainer = pl.Trainer(devices=1, accelerator=cfg.trainer.accelerator, strategy=cfg.trainer.strategy)
70 if speaker_model.prepare_test(trainer):
71 trainer.test(speaker_model)
72
73
74 if __name__ == '__main__':
75 main()
76
[end of examples/speaker_tasks/recognition/speaker_reco.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/speaker_tasks/recognition/speaker_reco.py b/examples/speaker_tasks/recognition/speaker_reco.py
--- a/examples/speaker_tasks/recognition/speaker_reco.py
+++ b/examples/speaker_tasks/recognition/speaker_reco.py
@@ -37,7 +37,7 @@
exp_manager.name=$EXP_NAME +exp_manager.use_datetime_version=False \
exp_manager.exp_dir='./speaker_exps'
-See https://github.com/NVIDIA/NeMo/blob/main/tutorials/speaker_tasks/Speaker_Recognition_Verification.ipynb for notebook tutorial
+See https://github.com/NVIDIA/NeMo/blob/main/tutorials/speaker_tasks/Speaker_Identification_Verification.ipynb for notebook tutorial
Optional: Use tarred dataset to speech up data loading.
Prepare ONE manifest that contains all training data you would like to include. Validation should use non-tarred dataset.
|
{"golden_diff": "diff --git a/examples/speaker_tasks/recognition/speaker_reco.py b/examples/speaker_tasks/recognition/speaker_reco.py\n--- a/examples/speaker_tasks/recognition/speaker_reco.py\n+++ b/examples/speaker_tasks/recognition/speaker_reco.py\n@@ -37,7 +37,7 @@\n exp_manager.name=$EXP_NAME +exp_manager.use_datetime_version=False \\\n exp_manager.exp_dir='./speaker_exps'\n \n-See https://github.com/NVIDIA/NeMo/blob/main/tutorials/speaker_tasks/Speaker_Recognition_Verification.ipynb for notebook tutorial\n+See https://github.com/NVIDIA/NeMo/blob/main/tutorials/speaker_tasks/Speaker_Identification_Verification.ipynb for notebook tutorial\n \n Optional: Use tarred dataset to speech up data loading.\n Prepare ONE manifest that contains all training data you would like to include. Validation should use non-tarred dataset.\n", "issue": "Fix links to speaker identification notebook\n# What does this PR do ?\r\n\r\nFixes #5258\r\n\r\n**Collection**: [Note which collection this PR will affect]\r\n\r\n# Changelog \r\n- Add specific line by line info of high level changes in this PR.\r\n\r\n# Usage\r\n* You can potentially add a usage example below\r\n\r\n```python\r\n# Add a code snippet demonstrating how to use this \r\n```\r\n\r\n# Before your PR is \"Ready for review\"\r\n**Pre checks**:\r\n- [ ] Make sure you read and followed [Contributor guidelines](https://github.com/NVIDIA/NeMo/blob/main/CONTRIBUTING.md)\r\n- [ ] Did you write any new necessary tests?\r\n- [ ] Did you add or update any necessary documentation?\r\n- [ ] Does the PR affect components that are optional to install? (Ex: Numba, Pynini, Apex etc)\r\n - [ ] Reviewer: Does the PR have correct import guards for all optional libraries?\r\n \r\n**PR Type**:\r\n- [ ] New Feature\r\n- [ ] Bugfix\r\n- [ ] Documentation\r\n\r\nIf you haven't finished some of the above items you can still open \"Draft\" PR.\r\n\r\n\r\n## Who can review?\r\n\r\nAnyone in the community is free to review the PR once the checks have passed. \r\n[Contributor guidelines](https://github.com/NVIDIA/NeMo/blob/main/CONTRIBUTING.md) contains specific people who can review PRs to various areas.\r\n\r\n# Additional Information\r\n* Related to # (issue)\r\n\n", "before_files": [{"content": "# Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\n\nimport pytorch_lightning as pl\nimport torch\nfrom omegaconf import OmegaConf\nfrom pytorch_lightning import seed_everything\n\nfrom nemo.collections.asr.models import EncDecSpeakerLabelModel\nfrom nemo.core.config import hydra_runner\nfrom nemo.utils import logging\nfrom nemo.utils.exp_manager import exp_manager\n\n\"\"\"\nBasic run (on GPU for 10 epochs for 2 class training):\nEXP_NAME=sample_run\npython ./speaker_reco.py --config-path='conf' --config-name='SpeakerNet_recognition_3x2x512.yaml' \\\n trainer.max_epochs=10 \\\n model.train_ds.batch_size=64 model.validation_ds.batch_size=64 \\\n model.train_ds.manifest_filepath=\"<train_manifest>\" model.validation_ds.manifest_filepath=\"<dev_manifest>\" \\\n model.test_ds.manifest_filepath=\"<test_manifest>\" \\\n trainer.devices=1 \\\n model.decoder.params.num_classes=2 \\\n exp_manager.name=$EXP_NAME +exp_manager.use_datetime_version=False \\\n exp_manager.exp_dir='./speaker_exps'\n\nSee https://github.com/NVIDIA/NeMo/blob/main/tutorials/speaker_tasks/Speaker_Recognition_Verification.ipynb for notebook tutorial\n\nOptional: Use tarred dataset to speech up data loading.\n Prepare ONE manifest that contains all training data you would like to include. Validation should use non-tarred dataset.\n Note that it's possible that tarred datasets impacts validation scores because it drop values in order to have same amount of files per tarfile; \n Scores might be off since some data is missing. \n \n Use the `convert_to_tarred_audio_dataset.py` script under <NEMO_ROOT>/speech_recognition/scripts in order to prepare tarred audio dataset.\n For details, please see TarredAudioToClassificationLabelDataset in <NEMO_ROOT>/nemo/collections/asr/data/audio_to_label.py\n\"\"\"\n\nseed_everything(42)\n\n\n@hydra_runner(config_path=\"conf\", config_name=\"SpeakerNet_verification_3x2x256.yaml\")\ndef main(cfg):\n\n logging.info(f'Hydra config: {OmegaConf.to_yaml(cfg)}')\n trainer = pl.Trainer(**cfg.trainer)\n log_dir = exp_manager(trainer, cfg.get(\"exp_manager\", None))\n speaker_model = EncDecSpeakerLabelModel(cfg=cfg.model, trainer=trainer)\n trainer.fit(speaker_model)\n if not trainer.fast_dev_run:\n model_path = os.path.join(log_dir, '..', 'spkr.nemo')\n speaker_model.save_to(model_path)\n\n torch.distributed.destroy_process_group()\n if hasattr(cfg.model, 'test_ds') and cfg.model.test_ds.manifest_filepath is not None:\n if trainer.is_global_zero:\n trainer = pl.Trainer(devices=1, accelerator=cfg.trainer.accelerator, strategy=cfg.trainer.strategy)\n if speaker_model.prepare_test(trainer):\n trainer.test(speaker_model)\n\n\nif __name__ == '__main__':\n main()\n", "path": "examples/speaker_tasks/recognition/speaker_reco.py"}]}
| 1,787 | 195 |
gh_patches_debug_39518
|
rasdani/github-patches
|
git_diff
|
pallets__werkzeug-2441
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Performance issue for some data handling in MultipartDecoder
When using werkzeug handling file upload, werkzeug use FormDataParser and MultipartDecoder, in here: https://github.com/pallets/werkzeug/blob/edef71c243e1e1396092f7b5f82ddad6c6f766cf/src/werkzeug/sansio/multipart.py#L187 , if for some part of data, the var data_length is always 0, that will always generate a 'werkzeug.sansio.multipart.NeedData', so the source code will run self.buffer.find(b"--",...) ( https://github.com/pallets/werkzeug/blob/edef71c243e1e1396092f7b5f82ddad6c6f766cf/src/werkzeug/sansio/multipart.py#L182 ) again and again, which will take longer and longer time(I think it is O(n²)), in the end the upload of file will take much longer time than other most of the files.
<!--
Describe how to replicate the bug.
Include a minimal reproducible example that demonstrates the bug.
Include the full traceback if there was an exception.
-->
Generate a file, which will having a b'\r' in a bound of MultipartDecoder.buffer, and all the data after there is no "\r".
Example of this kind of file:
```
def test52():
with open("uploadfile.dat","wb") as f:
def _gen():
yield b"\r"
for i in range(30000000):
yield b"1234567890"
for i in _gen():
f.write(i)
if __name__ == '__main__':
test52()
```
Then upload this file with werkzeug: werkzeug.formparser.parse_form_data() , it will reproduce the issue
<!--
Describe the expected behavior that should have happened but didn't.
-->
Need to handle file quickly, but actually very slow
Environment:
- Python version:3.6.5
- Werkzeug version: latest: edef71c243e1e1396092f7b5f82ddad6c6f766cf
There is a workaround, here( https://github.com/pallets/werkzeug/blob/edef71c243e1e1396092f7b5f82ddad6c6f766cf/src/werkzeug/formparser.py#L348 ) , buffer_size: int = 64 * 1024, that's too small, to handle several hundrers of MBytes of data, that will run too many times, if this buffer_size can be given by user, for example user give: 16 * 1024 * 1024, that will reduce the time a lot.
</issue>
<code>
[start of src/werkzeug/sansio/multipart.py]
1 import re
2 from dataclasses import dataclass
3 from enum import auto
4 from enum import Enum
5 from typing import cast
6 from typing import List
7 from typing import Optional
8 from typing import Tuple
9
10 from .._internal import _to_bytes
11 from .._internal import _to_str
12 from ..datastructures import Headers
13 from ..exceptions import RequestEntityTooLarge
14 from ..http import parse_options_header
15
16
17 class Event:
18 pass
19
20
21 @dataclass(frozen=True)
22 class Preamble(Event):
23 data: bytes
24
25
26 @dataclass(frozen=True)
27 class Field(Event):
28 name: str
29 headers: Headers
30
31
32 @dataclass(frozen=True)
33 class File(Event):
34 name: str
35 filename: str
36 headers: Headers
37
38
39 @dataclass(frozen=True)
40 class Data(Event):
41 data: bytes
42 more_data: bool
43
44
45 @dataclass(frozen=True)
46 class Epilogue(Event):
47 data: bytes
48
49
50 class NeedData(Event):
51 pass
52
53
54 NEED_DATA = NeedData()
55
56
57 class State(Enum):
58 PREAMBLE = auto()
59 PART = auto()
60 DATA = auto()
61 EPILOGUE = auto()
62 COMPLETE = auto()
63
64
65 # Multipart line breaks MUST be CRLF (\r\n) by RFC-7578, except that
66 # many implementations break this and either use CR or LF alone.
67 LINE_BREAK = b"(?:\r\n|\n|\r)"
68 BLANK_LINE_RE = re.compile(b"(?:\r\n\r\n|\r\r|\n\n)", re.MULTILINE)
69 LINE_BREAK_RE = re.compile(LINE_BREAK, re.MULTILINE)
70 # Header values can be continued via a space or tab after the linebreak, as
71 # per RFC2231
72 HEADER_CONTINUATION_RE = re.compile(b"%s[ \t]" % LINE_BREAK, re.MULTILINE)
73
74
75 class MultipartDecoder:
76 """Decodes a multipart message as bytes into Python events.
77
78 The part data is returned as available to allow the caller to save
79 the data from memory to disk, if desired.
80 """
81
82 def __init__(
83 self,
84 boundary: bytes,
85 max_form_memory_size: Optional[int] = None,
86 ) -> None:
87 self.buffer = bytearray()
88 self.complete = False
89 self.max_form_memory_size = max_form_memory_size
90 self.state = State.PREAMBLE
91 self.boundary = boundary
92
93 # Note in the below \h i.e. horizontal whitespace is used
94 # as [^\S\n\r] as \h isn't supported in python.
95
96 # The preamble must end with a boundary where the boundary is
97 # prefixed by a line break, RFC2046. Except that many
98 # implementations including Werkzeug's tests omit the line
99 # break prefix. In addition the first boundary could be the
100 # epilogue boundary (for empty form-data) hence the matching
101 # group to understand if it is an epilogue boundary.
102 self.preamble_re = re.compile(
103 rb"%s?--%s(--[^\S\n\r]*%s?|[^\S\n\r]*%s)"
104 % (LINE_BREAK, re.escape(boundary), LINE_BREAK, LINE_BREAK),
105 re.MULTILINE,
106 )
107 # A boundary must include a line break prefix and suffix, and
108 # may include trailing whitespace. In addition the boundary
109 # could be the epilogue boundary hence the matching group to
110 # understand if it is an epilogue boundary.
111 self.boundary_re = re.compile(
112 rb"%s--%s(--[^\S\n\r]*%s?|[^\S\n\r]*%s)"
113 % (LINE_BREAK, re.escape(boundary), LINE_BREAK, LINE_BREAK),
114 re.MULTILINE,
115 )
116
117 def last_newline(self) -> int:
118 try:
119 last_nl = self.buffer.rindex(b"\n")
120 except ValueError:
121 last_nl = len(self.buffer)
122 try:
123 last_cr = self.buffer.rindex(b"\r")
124 except ValueError:
125 last_cr = len(self.buffer)
126
127 return min(last_nl, last_cr)
128
129 def receive_data(self, data: Optional[bytes]) -> None:
130 if data is None:
131 self.complete = True
132 elif (
133 self.max_form_memory_size is not None
134 and len(self.buffer) + len(data) > self.max_form_memory_size
135 ):
136 raise RequestEntityTooLarge()
137 else:
138 self.buffer.extend(data)
139
140 def next_event(self) -> Event:
141 event: Event = NEED_DATA
142
143 if self.state == State.PREAMBLE:
144 match = self.preamble_re.search(self.buffer)
145 if match is not None:
146 if match.group(1).startswith(b"--"):
147 self.state = State.EPILOGUE
148 else:
149 self.state = State.PART
150 data = bytes(self.buffer[: match.start()])
151 del self.buffer[: match.end()]
152 event = Preamble(data=data)
153
154 elif self.state == State.PART:
155 match = BLANK_LINE_RE.search(self.buffer)
156 if match is not None:
157 headers = self._parse_headers(self.buffer[: match.start()])
158 del self.buffer[: match.end()]
159
160 if "content-disposition" not in headers:
161 raise ValueError("Missing Content-Disposition header")
162
163 disposition, extra = parse_options_header(
164 headers["content-disposition"]
165 )
166 name = cast(str, extra.get("name"))
167 filename = extra.get("filename")
168 if filename is not None:
169 event = File(
170 filename=filename,
171 headers=headers,
172 name=name,
173 )
174 else:
175 event = Field(
176 headers=headers,
177 name=name,
178 )
179 self.state = State.DATA
180
181 elif self.state == State.DATA:
182 if self.buffer.find(b"--" + self.boundary) == -1:
183 # No complete boundary in the buffer, but there may be
184 # a partial boundary at the end. As the boundary
185 # starts with either a nl or cr find the earliest and
186 # return up to that as data.
187 data_length = del_index = self.last_newline()
188 more_data = True
189 else:
190 match = self.boundary_re.search(self.buffer)
191 if match is not None:
192 if match.group(1).startswith(b"--"):
193 self.state = State.EPILOGUE
194 else:
195 self.state = State.PART
196 data_length = match.start()
197 del_index = match.end()
198 else:
199 data_length = del_index = self.last_newline()
200 more_data = match is None
201
202 data = bytes(self.buffer[:data_length])
203 del self.buffer[:del_index]
204 if data or not more_data:
205 event = Data(data=data, more_data=more_data)
206
207 elif self.state == State.EPILOGUE and self.complete:
208 event = Epilogue(data=bytes(self.buffer))
209 del self.buffer[:]
210 self.state = State.COMPLETE
211
212 if self.complete and isinstance(event, NeedData):
213 raise ValueError(f"Invalid form-data cannot parse beyond {self.state}")
214
215 return event
216
217 def _parse_headers(self, data: bytes) -> Headers:
218 headers: List[Tuple[str, str]] = []
219 # Merge the continued headers into one line
220 data = HEADER_CONTINUATION_RE.sub(b" ", data)
221 # Now there is one header per line
222 for line in data.splitlines():
223 if line.strip() != b"":
224 name, value = _to_str(line).strip().split(":", 1)
225 headers.append((name.strip(), value.strip()))
226 return Headers(headers)
227
228
229 class MultipartEncoder:
230 def __init__(self, boundary: bytes) -> None:
231 self.boundary = boundary
232 self.state = State.PREAMBLE
233
234 def send_event(self, event: Event) -> bytes:
235 if isinstance(event, Preamble) and self.state == State.PREAMBLE:
236 self.state = State.PART
237 return event.data
238 elif isinstance(event, (Field, File)) and self.state in {
239 State.PREAMBLE,
240 State.PART,
241 State.DATA,
242 }:
243 self.state = State.DATA
244 data = b"\r\n--" + self.boundary + b"\r\n"
245 data += b'Content-Disposition: form-data; name="%s"' % _to_bytes(event.name)
246 if isinstance(event, File):
247 data += b'; filename="%s"' % _to_bytes(event.filename)
248 data += b"\r\n"
249 for name, value in cast(Field, event).headers:
250 if name.lower() != "content-disposition":
251 data += _to_bytes(f"{name}: {value}\r\n")
252 data += b"\r\n"
253 return data
254 elif isinstance(event, Data) and self.state == State.DATA:
255 return event.data
256 elif isinstance(event, Epilogue):
257 self.state = State.COMPLETE
258 return b"\r\n--" + self.boundary + b"--\r\n" + event.data
259 else:
260 raise ValueError(f"Cannot generate {event} in state: {self.state}")
261
[end of src/werkzeug/sansio/multipart.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/werkzeug/sansio/multipart.py b/src/werkzeug/sansio/multipart.py
--- a/src/werkzeug/sansio/multipart.py
+++ b/src/werkzeug/sansio/multipart.py
@@ -70,6 +70,10 @@
# Header values can be continued via a space or tab after the linebreak, as
# per RFC2231
HEADER_CONTINUATION_RE = re.compile(b"%s[ \t]" % LINE_BREAK, re.MULTILINE)
+# This must be long enough to contain any line breaks plus any
+# additional boundary markers (--) such that they will be found in a
+# subsequent search
+SEARCH_EXTRA_LENGTH = 8
class MultipartDecoder:
@@ -113,6 +117,7 @@
% (LINE_BREAK, re.escape(boundary), LINE_BREAK, LINE_BREAK),
re.MULTILINE,
)
+ self._search_position = 0
def last_newline(self) -> int:
try:
@@ -141,7 +146,7 @@
event: Event = NEED_DATA
if self.state == State.PREAMBLE:
- match = self.preamble_re.search(self.buffer)
+ match = self.preamble_re.search(self.buffer, self._search_position)
if match is not None:
if match.group(1).startswith(b"--"):
self.state = State.EPILOGUE
@@ -150,9 +155,17 @@
data = bytes(self.buffer[: match.start()])
del self.buffer[: match.end()]
event = Preamble(data=data)
+ self._search_position = 0
+ else:
+ # Update the search start position to be equal to the
+ # current buffer length (already searched) minus a
+ # safe buffer for part of the search target.
+ self._search_position = max(
+ 0, len(self.buffer) - len(self.boundary) - SEARCH_EXTRA_LENGTH
+ )
elif self.state == State.PART:
- match = BLANK_LINE_RE.search(self.buffer)
+ match = BLANK_LINE_RE.search(self.buffer, self._search_position)
if match is not None:
headers = self._parse_headers(self.buffer[: match.start()])
del self.buffer[: match.end()]
@@ -177,6 +190,12 @@
name=name,
)
self.state = State.DATA
+ self._search_position = 0
+ else:
+ # Update the search start position to be equal to the
+ # current buffer length (already searched) minus a
+ # safe buffer for part of the search target.
+ self._search_position = max(0, len(self.buffer) - SEARCH_EXTRA_LENGTH)
elif self.state == State.DATA:
if self.buffer.find(b"--" + self.boundary) == -1:
|
{"golden_diff": "diff --git a/src/werkzeug/sansio/multipart.py b/src/werkzeug/sansio/multipart.py\n--- a/src/werkzeug/sansio/multipart.py\n+++ b/src/werkzeug/sansio/multipart.py\n@@ -70,6 +70,10 @@\n # Header values can be continued via a space or tab after the linebreak, as\n # per RFC2231\n HEADER_CONTINUATION_RE = re.compile(b\"%s[ \\t]\" % LINE_BREAK, re.MULTILINE)\n+# This must be long enough to contain any line breaks plus any\n+# additional boundary markers (--) such that they will be found in a\n+# subsequent search\n+SEARCH_EXTRA_LENGTH = 8\n \n \n class MultipartDecoder:\n@@ -113,6 +117,7 @@\n % (LINE_BREAK, re.escape(boundary), LINE_BREAK, LINE_BREAK),\n re.MULTILINE,\n )\n+ self._search_position = 0\n \n def last_newline(self) -> int:\n try:\n@@ -141,7 +146,7 @@\n event: Event = NEED_DATA\n \n if self.state == State.PREAMBLE:\n- match = self.preamble_re.search(self.buffer)\n+ match = self.preamble_re.search(self.buffer, self._search_position)\n if match is not None:\n if match.group(1).startswith(b\"--\"):\n self.state = State.EPILOGUE\n@@ -150,9 +155,17 @@\n data = bytes(self.buffer[: match.start()])\n del self.buffer[: match.end()]\n event = Preamble(data=data)\n+ self._search_position = 0\n+ else:\n+ # Update the search start position to be equal to the\n+ # current buffer length (already searched) minus a\n+ # safe buffer for part of the search target.\n+ self._search_position = max(\n+ 0, len(self.buffer) - len(self.boundary) - SEARCH_EXTRA_LENGTH\n+ )\n \n elif self.state == State.PART:\n- match = BLANK_LINE_RE.search(self.buffer)\n+ match = BLANK_LINE_RE.search(self.buffer, self._search_position)\n if match is not None:\n headers = self._parse_headers(self.buffer[: match.start()])\n del self.buffer[: match.end()]\n@@ -177,6 +190,12 @@\n name=name,\n )\n self.state = State.DATA\n+ self._search_position = 0\n+ else:\n+ # Update the search start position to be equal to the\n+ # current buffer length (already searched) minus a\n+ # safe buffer for part of the search target.\n+ self._search_position = max(0, len(self.buffer) - SEARCH_EXTRA_LENGTH)\n \n elif self.state == State.DATA:\n if self.buffer.find(b\"--\" + self.boundary) == -1:\n", "issue": "Performance issue for some data handling in MultipartDecoder\nWhen using werkzeug handling file upload, werkzeug use FormDataParser and MultipartDecoder, in here: https://github.com/pallets/werkzeug/blob/edef71c243e1e1396092f7b5f82ddad6c6f766cf/src/werkzeug/sansio/multipart.py#L187 , if for some part of data, the var data_length is always 0, that will always generate a 'werkzeug.sansio.multipart.NeedData', so the source code will run self.buffer.find(b\"--\",...) ( https://github.com/pallets/werkzeug/blob/edef71c243e1e1396092f7b5f82ddad6c6f766cf/src/werkzeug/sansio/multipart.py#L182 ) again and again, which will take longer and longer time(I think it is O(n\u00b2)), in the end the upload of file will take much longer time than other most of the files.\r\n\r\n<!--\r\nDescribe how to replicate the bug.\r\n\r\nInclude a minimal reproducible example that demonstrates the bug.\r\nInclude the full traceback if there was an exception.\r\n-->\r\nGenerate a file, which will having a b'\\r' in a bound of MultipartDecoder.buffer, and all the data after there is no \"\\r\".\r\nExample of this kind of file:\r\n```\r\ndef test52():\r\n with open(\"uploadfile.dat\",\"wb\") as f:\r\n def _gen():\r\n yield b\"\\r\"\r\n for i in range(30000000):\r\n yield b\"1234567890\"\r\n for i in _gen():\r\n f.write(i)\r\n\r\nif __name__ == '__main__':\r\n test52()\r\n```\r\nThen upload this file with werkzeug: werkzeug.formparser.parse_form_data() , it will reproduce the issue\r\n<!--\r\nDescribe the expected behavior that should have happened but didn't.\r\n-->\r\nNeed to handle file quickly, but actually very slow\r\n\r\nEnvironment:\r\n\r\n- Python version:3.6.5\r\n- Werkzeug version: latest: edef71c243e1e1396092f7b5f82ddad6c6f766cf\r\n\r\nThere is a workaround, here( https://github.com/pallets/werkzeug/blob/edef71c243e1e1396092f7b5f82ddad6c6f766cf/src/werkzeug/formparser.py#L348 ) , buffer_size: int = 64 * 1024, that's too small, to handle several hundrers of MBytes of data, that will run too many times, if this buffer_size can be given by user, for example user give: 16 * 1024 * 1024, that will reduce the time a lot.\r\n\n", "before_files": [{"content": "import re\nfrom dataclasses import dataclass\nfrom enum import auto\nfrom enum import Enum\nfrom typing import cast\nfrom typing import List\nfrom typing import Optional\nfrom typing import Tuple\n\nfrom .._internal import _to_bytes\nfrom .._internal import _to_str\nfrom ..datastructures import Headers\nfrom ..exceptions import RequestEntityTooLarge\nfrom ..http import parse_options_header\n\n\nclass Event:\n pass\n\n\n@dataclass(frozen=True)\nclass Preamble(Event):\n data: bytes\n\n\n@dataclass(frozen=True)\nclass Field(Event):\n name: str\n headers: Headers\n\n\n@dataclass(frozen=True)\nclass File(Event):\n name: str\n filename: str\n headers: Headers\n\n\n@dataclass(frozen=True)\nclass Data(Event):\n data: bytes\n more_data: bool\n\n\n@dataclass(frozen=True)\nclass Epilogue(Event):\n data: bytes\n\n\nclass NeedData(Event):\n pass\n\n\nNEED_DATA = NeedData()\n\n\nclass State(Enum):\n PREAMBLE = auto()\n PART = auto()\n DATA = auto()\n EPILOGUE = auto()\n COMPLETE = auto()\n\n\n# Multipart line breaks MUST be CRLF (\\r\\n) by RFC-7578, except that\n# many implementations break this and either use CR or LF alone.\nLINE_BREAK = b\"(?:\\r\\n|\\n|\\r)\"\nBLANK_LINE_RE = re.compile(b\"(?:\\r\\n\\r\\n|\\r\\r|\\n\\n)\", re.MULTILINE)\nLINE_BREAK_RE = re.compile(LINE_BREAK, re.MULTILINE)\n# Header values can be continued via a space or tab after the linebreak, as\n# per RFC2231\nHEADER_CONTINUATION_RE = re.compile(b\"%s[ \\t]\" % LINE_BREAK, re.MULTILINE)\n\n\nclass MultipartDecoder:\n \"\"\"Decodes a multipart message as bytes into Python events.\n\n The part data is returned as available to allow the caller to save\n the data from memory to disk, if desired.\n \"\"\"\n\n def __init__(\n self,\n boundary: bytes,\n max_form_memory_size: Optional[int] = None,\n ) -> None:\n self.buffer = bytearray()\n self.complete = False\n self.max_form_memory_size = max_form_memory_size\n self.state = State.PREAMBLE\n self.boundary = boundary\n\n # Note in the below \\h i.e. horizontal whitespace is used\n # as [^\\S\\n\\r] as \\h isn't supported in python.\n\n # The preamble must end with a boundary where the boundary is\n # prefixed by a line break, RFC2046. Except that many\n # implementations including Werkzeug's tests omit the line\n # break prefix. In addition the first boundary could be the\n # epilogue boundary (for empty form-data) hence the matching\n # group to understand if it is an epilogue boundary.\n self.preamble_re = re.compile(\n rb\"%s?--%s(--[^\\S\\n\\r]*%s?|[^\\S\\n\\r]*%s)\"\n % (LINE_BREAK, re.escape(boundary), LINE_BREAK, LINE_BREAK),\n re.MULTILINE,\n )\n # A boundary must include a line break prefix and suffix, and\n # may include trailing whitespace. In addition the boundary\n # could be the epilogue boundary hence the matching group to\n # understand if it is an epilogue boundary.\n self.boundary_re = re.compile(\n rb\"%s--%s(--[^\\S\\n\\r]*%s?|[^\\S\\n\\r]*%s)\"\n % (LINE_BREAK, re.escape(boundary), LINE_BREAK, LINE_BREAK),\n re.MULTILINE,\n )\n\n def last_newline(self) -> int:\n try:\n last_nl = self.buffer.rindex(b\"\\n\")\n except ValueError:\n last_nl = len(self.buffer)\n try:\n last_cr = self.buffer.rindex(b\"\\r\")\n except ValueError:\n last_cr = len(self.buffer)\n\n return min(last_nl, last_cr)\n\n def receive_data(self, data: Optional[bytes]) -> None:\n if data is None:\n self.complete = True\n elif (\n self.max_form_memory_size is not None\n and len(self.buffer) + len(data) > self.max_form_memory_size\n ):\n raise RequestEntityTooLarge()\n else:\n self.buffer.extend(data)\n\n def next_event(self) -> Event:\n event: Event = NEED_DATA\n\n if self.state == State.PREAMBLE:\n match = self.preamble_re.search(self.buffer)\n if match is not None:\n if match.group(1).startswith(b\"--\"):\n self.state = State.EPILOGUE\n else:\n self.state = State.PART\n data = bytes(self.buffer[: match.start()])\n del self.buffer[: match.end()]\n event = Preamble(data=data)\n\n elif self.state == State.PART:\n match = BLANK_LINE_RE.search(self.buffer)\n if match is not None:\n headers = self._parse_headers(self.buffer[: match.start()])\n del self.buffer[: match.end()]\n\n if \"content-disposition\" not in headers:\n raise ValueError(\"Missing Content-Disposition header\")\n\n disposition, extra = parse_options_header(\n headers[\"content-disposition\"]\n )\n name = cast(str, extra.get(\"name\"))\n filename = extra.get(\"filename\")\n if filename is not None:\n event = File(\n filename=filename,\n headers=headers,\n name=name,\n )\n else:\n event = Field(\n headers=headers,\n name=name,\n )\n self.state = State.DATA\n\n elif self.state == State.DATA:\n if self.buffer.find(b\"--\" + self.boundary) == -1:\n # No complete boundary in the buffer, but there may be\n # a partial boundary at the end. As the boundary\n # starts with either a nl or cr find the earliest and\n # return up to that as data.\n data_length = del_index = self.last_newline()\n more_data = True\n else:\n match = self.boundary_re.search(self.buffer)\n if match is not None:\n if match.group(1).startswith(b\"--\"):\n self.state = State.EPILOGUE\n else:\n self.state = State.PART\n data_length = match.start()\n del_index = match.end()\n else:\n data_length = del_index = self.last_newline()\n more_data = match is None\n\n data = bytes(self.buffer[:data_length])\n del self.buffer[:del_index]\n if data or not more_data:\n event = Data(data=data, more_data=more_data)\n\n elif self.state == State.EPILOGUE and self.complete:\n event = Epilogue(data=bytes(self.buffer))\n del self.buffer[:]\n self.state = State.COMPLETE\n\n if self.complete and isinstance(event, NeedData):\n raise ValueError(f\"Invalid form-data cannot parse beyond {self.state}\")\n\n return event\n\n def _parse_headers(self, data: bytes) -> Headers:\n headers: List[Tuple[str, str]] = []\n # Merge the continued headers into one line\n data = HEADER_CONTINUATION_RE.sub(b\" \", data)\n # Now there is one header per line\n for line in data.splitlines():\n if line.strip() != b\"\":\n name, value = _to_str(line).strip().split(\":\", 1)\n headers.append((name.strip(), value.strip()))\n return Headers(headers)\n\n\nclass MultipartEncoder:\n def __init__(self, boundary: bytes) -> None:\n self.boundary = boundary\n self.state = State.PREAMBLE\n\n def send_event(self, event: Event) -> bytes:\n if isinstance(event, Preamble) and self.state == State.PREAMBLE:\n self.state = State.PART\n return event.data\n elif isinstance(event, (Field, File)) and self.state in {\n State.PREAMBLE,\n State.PART,\n State.DATA,\n }:\n self.state = State.DATA\n data = b\"\\r\\n--\" + self.boundary + b\"\\r\\n\"\n data += b'Content-Disposition: form-data; name=\"%s\"' % _to_bytes(event.name)\n if isinstance(event, File):\n data += b'; filename=\"%s\"' % _to_bytes(event.filename)\n data += b\"\\r\\n\"\n for name, value in cast(Field, event).headers:\n if name.lower() != \"content-disposition\":\n data += _to_bytes(f\"{name}: {value}\\r\\n\")\n data += b\"\\r\\n\"\n return data\n elif isinstance(event, Data) and self.state == State.DATA:\n return event.data\n elif isinstance(event, Epilogue):\n self.state = State.COMPLETE\n return b\"\\r\\n--\" + self.boundary + b\"--\\r\\n\" + event.data\n else:\n raise ValueError(f\"Cannot generate {event} in state: {self.state}\")\n", "path": "src/werkzeug/sansio/multipart.py"}]}
| 3,831 | 631 |
gh_patches_debug_31535
|
rasdani/github-patches
|
git_diff
|
liqd__adhocracy4-1155
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
No Validation or Error when Phases in Dashboard are set in Illogical Order
URL: https://meinberlin-dev.liqd.net/projekte/module/burgerinnenhaushalt-2-phasen/?mode=list
user: Project initiator
expected behaviour: If I have more than one phase in a module, I would expect them to only be able to be set to occur in 1st proposal, 2nd rating, and 3rd voting time slots. If I make a mistake, I hope I am alerted and cannot publish this.
behaviour: Both 3-phase and 2-phase modules can be published with phases that make no sense in their time line. Users can set up and publish modules with voting phases that occur before rating and proposal phases. There is no validation or error.
important screensize: any
device & browser: any
Comment/Question: moved from mB: https://github.com/liqd/a4-meinberlin/issues/4029
Screenshot?
2-Phase module published with reverse phases:
<img width="600" alt="Bildschirmfoto 2021-12-08 um 12 41 47" src="https://user-images.githubusercontent.com/35491681/145202707-b0d39c50-e5a1-476b-9afa-542cc9a85687.png">
</issue>
<code>
[start of adhocracy4/phases/forms.py]
1 from django.forms.models import BaseInlineFormSet
2 from django.utils.translation import gettext_lazy as _
3
4
5 class PhaseInlineFormSet(BaseInlineFormSet):
6 def clean(self):
7 """
8 Make sure phases of the same module don't overlap.
9 """
10 super().clean()
11 phase_dates = []
12 for form in self.forms:
13 if 'start_date' in form.cleaned_data \
14 and 'end_date' in form.cleaned_data \
15 and form.cleaned_data['start_date'] is not None \
16 and form.cleaned_data['end_date'] is not None:
17 start_date = form.cleaned_data['start_date']
18 end_date = form.cleaned_data['end_date']
19 if phase_dates:
20 for phase_date in phase_dates:
21 if (start_date < phase_date[1]
22 and phase_date[0] < end_date):
23 msg = _('Phases cannot run at the same time '
24 'and must follow after each other.')
25 form.add_error('end_date', msg)
26 if start_date and end_date:
27 phase_dates.append((start_date, end_date))
28
[end of adhocracy4/phases/forms.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/adhocracy4/phases/forms.py b/adhocracy4/phases/forms.py
--- a/adhocracy4/phases/forms.py
+++ b/adhocracy4/phases/forms.py
@@ -4,9 +4,7 @@
class PhaseInlineFormSet(BaseInlineFormSet):
def clean(self):
- """
- Make sure phases of the same module don't overlap.
- """
+ """Make sure phases of the same module don't overlap."""
super().clean()
phase_dates = []
for form in self.forms:
@@ -16,6 +14,7 @@
and form.cleaned_data['end_date'] is not None:
start_date = form.cleaned_data['start_date']
end_date = form.cleaned_data['end_date']
+ weight = form.instance.weight
if phase_dates:
for phase_date in phase_dates:
if (start_date < phase_date[1]
@@ -23,5 +22,12 @@
msg = _('Phases cannot run at the same time '
'and must follow after each other.')
form.add_error('end_date', msg)
+ if ((start_date < phase_date[0]
+ and weight > phase_date[2])
+ or (start_date > phase_date[0]
+ and weight < phase_date[2])):
+ msg = _('Phases need to be in same order '
+ 'as in form.')
+ form.add_error('start_date', msg)
if start_date and end_date:
- phase_dates.append((start_date, end_date))
+ phase_dates.append((start_date, end_date, weight))
|
{"golden_diff": "diff --git a/adhocracy4/phases/forms.py b/adhocracy4/phases/forms.py\n--- a/adhocracy4/phases/forms.py\n+++ b/adhocracy4/phases/forms.py\n@@ -4,9 +4,7 @@\n \n class PhaseInlineFormSet(BaseInlineFormSet):\n def clean(self):\n- \"\"\"\n- Make sure phases of the same module don't overlap.\n- \"\"\"\n+ \"\"\"Make sure phases of the same module don't overlap.\"\"\"\n super().clean()\n phase_dates = []\n for form in self.forms:\n@@ -16,6 +14,7 @@\n and form.cleaned_data['end_date'] is not None:\n start_date = form.cleaned_data['start_date']\n end_date = form.cleaned_data['end_date']\n+ weight = form.instance.weight\n if phase_dates:\n for phase_date in phase_dates:\n if (start_date < phase_date[1]\n@@ -23,5 +22,12 @@\n msg = _('Phases cannot run at the same time '\n 'and must follow after each other.')\n form.add_error('end_date', msg)\n+ if ((start_date < phase_date[0]\n+ and weight > phase_date[2])\n+ or (start_date > phase_date[0]\n+ and weight < phase_date[2])):\n+ msg = _('Phases need to be in same order '\n+ 'as in form.')\n+ form.add_error('start_date', msg)\n if start_date and end_date:\n- phase_dates.append((start_date, end_date))\n+ phase_dates.append((start_date, end_date, weight))\n", "issue": "No Validation or Error when Phases in Dashboard are set in Illogical Order\nURL: https://meinberlin-dev.liqd.net/projekte/module/burgerinnenhaushalt-2-phasen/?mode=list\r\nuser: Project initiator\r\nexpected behaviour: If I have more than one phase in a module, I would expect them to only be able to be set to occur in 1st proposal, 2nd rating, and 3rd voting time slots. If I make a mistake, I hope I am alerted and cannot publish this.\r\nbehaviour: Both 3-phase and 2-phase modules can be published with phases that make no sense in their time line. Users can set up and publish modules with voting phases that occur before rating and proposal phases. There is no validation or error.\r\nimportant screensize: any\r\ndevice & browser: any\r\nComment/Question: moved from mB: https://github.com/liqd/a4-meinberlin/issues/4029\r\n\r\nScreenshot?\r\n2-Phase module published with reverse phases:\r\n<img width=\"600\" alt=\"Bildschirmfoto 2021-12-08 um 12 41 47\" src=\"https://user-images.githubusercontent.com/35491681/145202707-b0d39c50-e5a1-476b-9afa-542cc9a85687.png\">\r\n\r\n\n", "before_files": [{"content": "from django.forms.models import BaseInlineFormSet\nfrom django.utils.translation import gettext_lazy as _\n\n\nclass PhaseInlineFormSet(BaseInlineFormSet):\n def clean(self):\n \"\"\"\n Make sure phases of the same module don't overlap.\n \"\"\"\n super().clean()\n phase_dates = []\n for form in self.forms:\n if 'start_date' in form.cleaned_data \\\n and 'end_date' in form.cleaned_data \\\n and form.cleaned_data['start_date'] is not None \\\n and form.cleaned_data['end_date'] is not None:\n start_date = form.cleaned_data['start_date']\n end_date = form.cleaned_data['end_date']\n if phase_dates:\n for phase_date in phase_dates:\n if (start_date < phase_date[1]\n and phase_date[0] < end_date):\n msg = _('Phases cannot run at the same time '\n 'and must follow after each other.')\n form.add_error('end_date', msg)\n if start_date and end_date:\n phase_dates.append((start_date, end_date))\n", "path": "adhocracy4/phases/forms.py"}]}
| 1,128 | 354 |
gh_patches_debug_2292
|
rasdani/github-patches
|
git_diff
|
ipython__ipython-10213
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
remove usage of backports.shutil_get_terminal_size
This is for pre-3.3 Python.
Pretty easy it should only require deleting lines.
Maybe a few need to be dedented.
</issue>
<code>
[start of IPython/utils/terminal.py]
1 # encoding: utf-8
2 """
3 Utilities for working with terminals.
4
5 Authors:
6
7 * Brian E. Granger
8 * Fernando Perez
9 * Alexander Belchenko (e-mail: bialix AT ukr.net)
10 """
11
12 # Copyright (c) IPython Development Team.
13 # Distributed under the terms of the Modified BSD License.
14
15 import os
16 import sys
17 import warnings
18 try:
19 from shutil import get_terminal_size as _get_terminal_size
20 except ImportError:
21 # use backport on Python 2
22 from backports.shutil_get_terminal_size import get_terminal_size as _get_terminal_size
23
24 from . import py3compat
25
26 #-----------------------------------------------------------------------------
27 # Code
28 #-----------------------------------------------------------------------------
29
30 # This variable is part of the expected API of the module:
31 ignore_termtitle = True
32
33
34
35 if os.name == 'posix':
36 def _term_clear():
37 os.system('clear')
38 elif sys.platform == 'win32':
39 def _term_clear():
40 os.system('cls')
41 else:
42 def _term_clear():
43 pass
44
45
46
47 def toggle_set_term_title(val):
48 """Control whether set_term_title is active or not.
49
50 set_term_title() allows writing to the console titlebar. In embedded
51 widgets this can cause problems, so this call can be used to toggle it on
52 or off as needed.
53
54 The default state of the module is for the function to be disabled.
55
56 Parameters
57 ----------
58 val : bool
59 If True, set_term_title() actually writes to the terminal (using the
60 appropriate platform-specific module). If False, it is a no-op.
61 """
62 global ignore_termtitle
63 ignore_termtitle = not(val)
64
65
66 def _set_term_title(*args,**kw):
67 """Dummy no-op."""
68 pass
69
70
71 def _set_term_title_xterm(title):
72 """ Change virtual terminal title in xterm-workalikes """
73 sys.stdout.write('\033]0;%s\007' % title)
74
75 if os.name == 'posix':
76 TERM = os.environ.get('TERM','')
77 if TERM.startswith('xterm'):
78 _set_term_title = _set_term_title_xterm
79 elif sys.platform == 'win32':
80 try:
81 import ctypes
82
83 SetConsoleTitleW = ctypes.windll.kernel32.SetConsoleTitleW
84 SetConsoleTitleW.argtypes = [ctypes.c_wchar_p]
85
86 def _set_term_title(title):
87 """Set terminal title using ctypes to access the Win32 APIs."""
88 SetConsoleTitleW(title)
89 except ImportError:
90 def _set_term_title(title):
91 """Set terminal title using the 'title' command."""
92 global ignore_termtitle
93
94 try:
95 # Cannot be on network share when issuing system commands
96 curr = os.getcwd()
97 os.chdir("C:")
98 ret = os.system("title " + title)
99 finally:
100 os.chdir(curr)
101 if ret:
102 # non-zero return code signals error, don't try again
103 ignore_termtitle = True
104
105
106 def set_term_title(title):
107 """Set terminal title using the necessary platform-dependent calls."""
108 if ignore_termtitle:
109 return
110 _set_term_title(title)
111
112
113 def freeze_term_title():
114 warnings.warn("This function is deprecated, use toggle_set_term_title()")
115 global ignore_termtitle
116 ignore_termtitle = True
117
118
119 def get_terminal_size(defaultx=80, defaulty=25):
120 return _get_terminal_size((defaultx, defaulty))
121
[end of IPython/utils/terminal.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/IPython/utils/terminal.py b/IPython/utils/terminal.py
--- a/IPython/utils/terminal.py
+++ b/IPython/utils/terminal.py
@@ -15,11 +15,7 @@
import os
import sys
import warnings
-try:
- from shutil import get_terminal_size as _get_terminal_size
-except ImportError:
- # use backport on Python 2
- from backports.shutil_get_terminal_size import get_terminal_size as _get_terminal_size
+from shutil import get_terminal_size as _get_terminal_size
from . import py3compat
|
{"golden_diff": "diff --git a/IPython/utils/terminal.py b/IPython/utils/terminal.py\n--- a/IPython/utils/terminal.py\n+++ b/IPython/utils/terminal.py\n@@ -15,11 +15,7 @@\n import os\n import sys\n import warnings\n-try:\n- from shutil import get_terminal_size as _get_terminal_size\n-except ImportError:\n- # use backport on Python 2\n- from backports.shutil_get_terminal_size import get_terminal_size as _get_terminal_size\n+from shutil import get_terminal_size as _get_terminal_size\n \n from . import py3compat\n", "issue": "remove usage of backports.shutil_get_terminal_size\nThis is for pre-3.3 Python.\r\n\r\nPretty easy it should only require deleting lines. \r\nMaybe a few need to be dedented.\n", "before_files": [{"content": "# encoding: utf-8\n\"\"\"\nUtilities for working with terminals.\n\nAuthors:\n\n* Brian E. Granger\n* Fernando Perez\n* Alexander Belchenko (e-mail: bialix AT ukr.net)\n\"\"\"\n\n# Copyright (c) IPython Development Team.\n# Distributed under the terms of the Modified BSD License.\n\nimport os\nimport sys\nimport warnings\ntry:\n from shutil import get_terminal_size as _get_terminal_size\nexcept ImportError:\n # use backport on Python 2\n from backports.shutil_get_terminal_size import get_terminal_size as _get_terminal_size\n\nfrom . import py3compat\n\n#-----------------------------------------------------------------------------\n# Code\n#-----------------------------------------------------------------------------\n\n# This variable is part of the expected API of the module:\nignore_termtitle = True\n\n\n\nif os.name == 'posix':\n def _term_clear():\n os.system('clear')\nelif sys.platform == 'win32':\n def _term_clear():\n os.system('cls')\nelse:\n def _term_clear():\n pass\n\n\n\ndef toggle_set_term_title(val):\n \"\"\"Control whether set_term_title is active or not.\n\n set_term_title() allows writing to the console titlebar. In embedded\n widgets this can cause problems, so this call can be used to toggle it on\n or off as needed.\n\n The default state of the module is for the function to be disabled.\n\n Parameters\n ----------\n val : bool\n If True, set_term_title() actually writes to the terminal (using the\n appropriate platform-specific module). If False, it is a no-op.\n \"\"\"\n global ignore_termtitle\n ignore_termtitle = not(val)\n\n\ndef _set_term_title(*args,**kw):\n \"\"\"Dummy no-op.\"\"\"\n pass\n\n\ndef _set_term_title_xterm(title):\n \"\"\" Change virtual terminal title in xterm-workalikes \"\"\"\n sys.stdout.write('\\033]0;%s\\007' % title)\n\nif os.name == 'posix':\n TERM = os.environ.get('TERM','')\n if TERM.startswith('xterm'):\n _set_term_title = _set_term_title_xterm\nelif sys.platform == 'win32':\n try:\n import ctypes\n\n SetConsoleTitleW = ctypes.windll.kernel32.SetConsoleTitleW\n SetConsoleTitleW.argtypes = [ctypes.c_wchar_p]\n \n def _set_term_title(title):\n \"\"\"Set terminal title using ctypes to access the Win32 APIs.\"\"\"\n SetConsoleTitleW(title)\n except ImportError:\n def _set_term_title(title):\n \"\"\"Set terminal title using the 'title' command.\"\"\"\n global ignore_termtitle\n\n try:\n # Cannot be on network share when issuing system commands\n curr = os.getcwd()\n os.chdir(\"C:\")\n ret = os.system(\"title \" + title)\n finally:\n os.chdir(curr)\n if ret:\n # non-zero return code signals error, don't try again\n ignore_termtitle = True\n\n\ndef set_term_title(title):\n \"\"\"Set terminal title using the necessary platform-dependent calls.\"\"\"\n if ignore_termtitle:\n return\n _set_term_title(title)\n\n\ndef freeze_term_title():\n warnings.warn(\"This function is deprecated, use toggle_set_term_title()\")\n global ignore_termtitle\n ignore_termtitle = True\n\n\ndef get_terminal_size(defaultx=80, defaulty=25):\n return _get_terminal_size((defaultx, defaulty))\n", "path": "IPython/utils/terminal.py"}]}
| 1,579 | 130 |
gh_patches_debug_879
|
rasdani/github-patches
|
git_diff
|
getpelican__pelican-1507
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
abbr support doesn't work for multiline
Eg:
``` rst
this is an :abbr:`TLA (Three Letter
Abbreviation)`
```
will output
`<abbr>TLA (Three Letter Abbreviation)</abbr>`
instead of
`<abbr title="Three Letter Abbreviation">TLA</abbr>`
I believe this could be fixed by adding the `re.M` flag to the `re.compile` call on this line: https://github.com/getpelican/pelican/blob/636fd6cc380f2537924532a587c70e96a386e25c/pelican/rstdirectives.py#L101
This refs ticket #395
</issue>
<code>
[start of pelican/rstdirectives.py]
1 # -*- coding: utf-8 -*-
2 from __future__ import unicode_literals, print_function
3
4 from docutils import nodes, utils
5 from docutils.parsers.rst import directives, roles, Directive
6 from pygments.formatters import HtmlFormatter
7 from pygments import highlight
8 from pygments.lexers import get_lexer_by_name, TextLexer
9 import re
10 import six
11 import pelican.settings as pys
12
13
14 class Pygments(Directive):
15 """ Source code syntax highlighting.
16 """
17 required_arguments = 1
18 optional_arguments = 0
19 final_argument_whitespace = True
20 option_spec = {
21 'anchorlinenos': directives.flag,
22 'classprefix': directives.unchanged,
23 'hl_lines': directives.unchanged,
24 'lineanchors': directives.unchanged,
25 'linenos': directives.unchanged,
26 'linenospecial': directives.nonnegative_int,
27 'linenostart': directives.nonnegative_int,
28 'linenostep': directives.nonnegative_int,
29 'lineseparator': directives.unchanged,
30 'linespans': directives.unchanged,
31 'nobackground': directives.flag,
32 'nowrap': directives.flag,
33 'tagsfile': directives.unchanged,
34 'tagurlformat': directives.unchanged,
35 }
36 has_content = True
37
38 def run(self):
39 self.assert_has_content()
40 try:
41 lexer = get_lexer_by_name(self.arguments[0])
42 except ValueError:
43 # no lexer found - use the text one instead of an exception
44 lexer = TextLexer()
45
46 # Fetch the defaults
47 if pys.PYGMENTS_RST_OPTIONS is not None:
48 for k, v in six.iteritems(pys.PYGMENTS_RST_OPTIONS):
49 # Locally set options overrides the defaults
50 if k not in self.options:
51 self.options[k] = v
52
53 if ('linenos' in self.options and
54 self.options['linenos'] not in ('table', 'inline')):
55 if self.options['linenos'] == 'none':
56 self.options.pop('linenos')
57 else:
58 self.options['linenos'] = 'table'
59
60 for flag in ('nowrap', 'nobackground', 'anchorlinenos'):
61 if flag in self.options:
62 self.options[flag] = True
63
64 # noclasses should already default to False, but just in case...
65 formatter = HtmlFormatter(noclasses=False, **self.options)
66 parsed = highlight('\n'.join(self.content), lexer, formatter)
67 return [nodes.raw('', parsed, format='html')]
68
69 directives.register_directive('code-block', Pygments)
70 directives.register_directive('sourcecode', Pygments)
71
72
73 _abbr_re = re.compile('\((.*)\)$')
74
75
76 class abbreviation(nodes.Inline, nodes.TextElement):
77 pass
78
79
80 def abbr_role(typ, rawtext, text, lineno, inliner, options={}, content=[]):
81 text = utils.unescape(text)
82 m = _abbr_re.search(text)
83 if m is None:
84 return [abbreviation(text, text)], []
85 abbr = text[:m.start()].strip()
86 expl = m.group(1)
87 return [abbreviation(abbr, abbr, explanation=expl)], []
88
89 roles.register_local_role('abbr', abbr_role)
90
[end of pelican/rstdirectives.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pelican/rstdirectives.py b/pelican/rstdirectives.py
--- a/pelican/rstdirectives.py
+++ b/pelican/rstdirectives.py
@@ -70,7 +70,7 @@
directives.register_directive('sourcecode', Pygments)
-_abbr_re = re.compile('\((.*)\)$')
+_abbr_re = re.compile('\((.*)\)$', re.DOTALL)
class abbreviation(nodes.Inline, nodes.TextElement):
|
{"golden_diff": "diff --git a/pelican/rstdirectives.py b/pelican/rstdirectives.py\n--- a/pelican/rstdirectives.py\n+++ b/pelican/rstdirectives.py\n@@ -70,7 +70,7 @@\n directives.register_directive('sourcecode', Pygments)\n \n \n-_abbr_re = re.compile('\\((.*)\\)$')\n+_abbr_re = re.compile('\\((.*)\\)$', re.DOTALL)\n \n \n class abbreviation(nodes.Inline, nodes.TextElement):\n", "issue": "abbr support doesn't work for multiline\nEg:\n\n``` rst\nthis is an :abbr:`TLA (Three Letter\nAbbreviation)`\n```\n\nwill output\n`<abbr>TLA (Three Letter Abbreviation)</abbr>`\n\ninstead of\n`<abbr title=\"Three Letter Abbreviation\">TLA</abbr>`\n\nI believe this could be fixed by adding the `re.M` flag to the `re.compile` call on this line: https://github.com/getpelican/pelican/blob/636fd6cc380f2537924532a587c70e96a386e25c/pelican/rstdirectives.py#L101\n\nThis refs ticket #395 \n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import unicode_literals, print_function\n\nfrom docutils import nodes, utils\nfrom docutils.parsers.rst import directives, roles, Directive\nfrom pygments.formatters import HtmlFormatter\nfrom pygments import highlight\nfrom pygments.lexers import get_lexer_by_name, TextLexer\nimport re\nimport six\nimport pelican.settings as pys\n\n\nclass Pygments(Directive):\n \"\"\" Source code syntax highlighting.\n \"\"\"\n required_arguments = 1\n optional_arguments = 0\n final_argument_whitespace = True\n option_spec = {\n 'anchorlinenos': directives.flag,\n 'classprefix': directives.unchanged,\n 'hl_lines': directives.unchanged,\n 'lineanchors': directives.unchanged,\n 'linenos': directives.unchanged,\n 'linenospecial': directives.nonnegative_int,\n 'linenostart': directives.nonnegative_int,\n 'linenostep': directives.nonnegative_int,\n 'lineseparator': directives.unchanged,\n 'linespans': directives.unchanged,\n 'nobackground': directives.flag,\n 'nowrap': directives.flag,\n 'tagsfile': directives.unchanged,\n 'tagurlformat': directives.unchanged,\n }\n has_content = True\n\n def run(self):\n self.assert_has_content()\n try:\n lexer = get_lexer_by_name(self.arguments[0])\n except ValueError:\n # no lexer found - use the text one instead of an exception\n lexer = TextLexer()\n\n # Fetch the defaults\n if pys.PYGMENTS_RST_OPTIONS is not None:\n for k, v in six.iteritems(pys.PYGMENTS_RST_OPTIONS):\n # Locally set options overrides the defaults\n if k not in self.options:\n self.options[k] = v\n\n if ('linenos' in self.options and\n self.options['linenos'] not in ('table', 'inline')):\n if self.options['linenos'] == 'none':\n self.options.pop('linenos')\n else:\n self.options['linenos'] = 'table'\n\n for flag in ('nowrap', 'nobackground', 'anchorlinenos'):\n if flag in self.options:\n self.options[flag] = True\n\n # noclasses should already default to False, but just in case...\n formatter = HtmlFormatter(noclasses=False, **self.options)\n parsed = highlight('\\n'.join(self.content), lexer, formatter)\n return [nodes.raw('', parsed, format='html')]\n\ndirectives.register_directive('code-block', Pygments)\ndirectives.register_directive('sourcecode', Pygments)\n\n\n_abbr_re = re.compile('\\((.*)\\)$')\n\n\nclass abbreviation(nodes.Inline, nodes.TextElement):\n pass\n\n\ndef abbr_role(typ, rawtext, text, lineno, inliner, options={}, content=[]):\n text = utils.unescape(text)\n m = _abbr_re.search(text)\n if m is None:\n return [abbreviation(text, text)], []\n abbr = text[:m.start()].strip()\n expl = m.group(1)\n return [abbreviation(abbr, abbr, explanation=expl)], []\n\nroles.register_local_role('abbr', abbr_role)\n", "path": "pelican/rstdirectives.py"}]}
| 1,578 | 108 |
gh_patches_debug_602
|
rasdani/github-patches
|
git_diff
|
pex-tool__pex-1844
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Release 2.1.97
On the docket:
+ [x] Avoid ENOEXEC for Pex internal --venvs. #1843
</issue>
<code>
[start of pex/version.py]
1 # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 __version__ = "2.1.96"
5
[end of pex/version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pex/version.py b/pex/version.py
--- a/pex/version.py
+++ b/pex/version.py
@@ -1,4 +1,4 @@
# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
# Licensed under the Apache License, Version 2.0 (see LICENSE).
-__version__ = "2.1.96"
+__version__ = "2.1.97"
|
{"golden_diff": "diff --git a/pex/version.py b/pex/version.py\n--- a/pex/version.py\n+++ b/pex/version.py\n@@ -1,4 +1,4 @@\n # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n # Licensed under the Apache License, Version 2.0 (see LICENSE).\n \n-__version__ = \"2.1.96\"\n+__version__ = \"2.1.97\"\n", "issue": "Release 2.1.97\nOn the docket:\r\n+ [x] Avoid ENOEXEC for Pex internal --venvs. #1843\r\n\n", "before_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = \"2.1.96\"\n", "path": "pex/version.py"}]}
| 619 | 96 |
gh_patches_debug_1026
|
rasdani/github-patches
|
git_diff
|
pytorch__ignite-1365
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
MyPy: improve ignite.base module
## 🚀 Feature
Currently, mypy ignores all errors for all modules. We have to rework our typing such that mypy checks the code.
In this issue, let's improve https://github.com/pytorch/ignite/tree/master/ignite/base module such that mypy passes on it.
For Hacktoberfest contributors, feel free to ask questions for details if any and say that you would like to tackle the issue.
Please, take a look at CONTRIBUTING guide.
Improve typing for ignite.handlers module (1343)
Fixes #1343
Description:
Improves typing (when possible) for `ignite.handlers` module.
Check list:
* [x] New tests are added (if a new feature is added)
* [ ] New doc strings: description and/or example code are in RST format
* [ ] Documentation is updated (if required)
</issue>
<code>
[start of ignite/base/mixins.py]
1 from collections import OrderedDict
2 from collections.abc import Mapping
3
4
5 class Serializable:
6
7 _state_dict_all_req_keys = ()
8 _state_dict_one_of_opt_keys = ()
9
10 def state_dict(self) -> OrderedDict:
11 pass
12
13 def load_state_dict(self, state_dict: Mapping) -> None:
14 if not isinstance(state_dict, Mapping):
15 raise TypeError("Argument state_dict should be a dictionary, but given {}".format(type(state_dict)))
16
17 for k in self._state_dict_all_req_keys:
18 if k not in state_dict:
19 raise ValueError(
20 "Required state attribute '{}' is absent in provided state_dict '{}'".format(k, state_dict.keys())
21 )
22 opts = [k in state_dict for k in self._state_dict_one_of_opt_keys]
23 if len(opts) > 0 and ((not any(opts)) or (all(opts))):
24 raise ValueError("state_dict should contain only one of '{}' keys".format(self._state_dict_one_of_opt_keys))
25
[end of ignite/base/mixins.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ignite/base/mixins.py b/ignite/base/mixins.py
--- a/ignite/base/mixins.py
+++ b/ignite/base/mixins.py
@@ -4,8 +4,8 @@
class Serializable:
- _state_dict_all_req_keys = ()
- _state_dict_one_of_opt_keys = ()
+ _state_dict_all_req_keys = () # type: tuple
+ _state_dict_one_of_opt_keys = () # type: tuple
def state_dict(self) -> OrderedDict:
pass
|
{"golden_diff": "diff --git a/ignite/base/mixins.py b/ignite/base/mixins.py\n--- a/ignite/base/mixins.py\n+++ b/ignite/base/mixins.py\n@@ -4,8 +4,8 @@\n \n class Serializable:\n \n- _state_dict_all_req_keys = ()\n- _state_dict_one_of_opt_keys = ()\n+ _state_dict_all_req_keys = () # type: tuple\n+ _state_dict_one_of_opt_keys = () # type: tuple\n \n def state_dict(self) -> OrderedDict:\n pass\n", "issue": "MyPy: improve ignite.base module\n## \ud83d\ude80 Feature\r\n\r\nCurrently, mypy ignores all errors for all modules. We have to rework our typing such that mypy checks the code.\r\nIn this issue, let's improve https://github.com/pytorch/ignite/tree/master/ignite/base module such that mypy passes on it.\r\n\r\nFor Hacktoberfest contributors, feel free to ask questions for details if any and say that you would like to tackle the issue.\r\nPlease, take a look at CONTRIBUTING guide.\nImprove typing for ignite.handlers module (1343)\nFixes #1343 \r\n\r\nDescription:\r\n\r\nImproves typing (when possible) for `ignite.handlers` module.\r\n\r\nCheck list:\r\n* [x] New tests are added (if a new feature is added)\r\n* [ ] New doc strings: description and/or example code are in RST format\r\n* [ ] Documentation is updated (if required)\r\n\n", "before_files": [{"content": "from collections import OrderedDict\nfrom collections.abc import Mapping\n\n\nclass Serializable:\n\n _state_dict_all_req_keys = ()\n _state_dict_one_of_opt_keys = ()\n\n def state_dict(self) -> OrderedDict:\n pass\n\n def load_state_dict(self, state_dict: Mapping) -> None:\n if not isinstance(state_dict, Mapping):\n raise TypeError(\"Argument state_dict should be a dictionary, but given {}\".format(type(state_dict)))\n\n for k in self._state_dict_all_req_keys:\n if k not in state_dict:\n raise ValueError(\n \"Required state attribute '{}' is absent in provided state_dict '{}'\".format(k, state_dict.keys())\n )\n opts = [k in state_dict for k in self._state_dict_one_of_opt_keys]\n if len(opts) > 0 and ((not any(opts)) or (all(opts))):\n raise ValueError(\"state_dict should contain only one of '{}' keys\".format(self._state_dict_one_of_opt_keys))\n", "path": "ignite/base/mixins.py"}]}
| 975 | 121 |
gh_patches_debug_20281
|
rasdani/github-patches
|
git_diff
|
pallets__werkzeug-2126
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[BUG] Multipart data parse regression
Seems that there is a regression in the new MultiPartPaser implementation
The following does not work in `Werkzeug==2.0.0`; but, works in `Werkzeug<2.0.0`.
```
from werkzeug.formparser import MultiPartParser
from io import BytesIO
parser = MultiPartParser()
boundary = b'----------a_BoUnDaRy9009049739267083$'
f = BytesIO(b'------------a_BoUnDaRy9009049739267083$\r\nContent-Disposition: form-data; name="file"; filename="/home/marc/workspace/data-governance/tests/functional_tests/test_data_governance_api/controllers/work_unit_data/NaValues.csv"\r\nContent-Type: text/csv\r\n\r\n"I was told that I was not able to receive a pay increase because I was at the top of the pay range for my level. This indicates to me that I need to either be promoted to the next level, or look elsewhere for employment."\r\nProject Management seems inconsistent some are well run some are not transparent and all over the place. Hiring contractors also are not managed well and may have resulted to project overruns.\r\nNA\r\n"1. How can diversity and inclusion efforts just be tailored to minority group?2. Is it appropriate to use the term ""blacks"" when sending out a company email around diversity and inclusion?3. Again, an actual HR department would resolve this"\r\nNaN\r\n------------a_BoUnDaRy9009049739267083$--\r\n')
form, files = parser.parse(f, boundary, 965)
```
It results in the following error:
```
Traceback (most recent call last):
File "/home/*/flaskapp_fail.py", line 57, in <module>
form, files = parser.parse(f, boundary, 965)
File "/home/*/lib/python3.8/site-packages/werkzeug/formparser.py", line 459, in parse
event = parser.next_event()
File "/home/*/lib/python3.8/site-packages/werkzeug/sansio/multipart.py", line 213, in next_event
raise ValueError(f"Invalid form-data cannot parse beyond {self.state}")
ValueError: Invalid form-data cannot parse beyond State.PREAMBLE
```
Environment:
- Python version: 3.8.5
- Werkzeug version: 2.0.0
</issue>
<code>
[start of src/werkzeug/sansio/multipart.py]
1 import re
2 from dataclasses import dataclass
3 from enum import auto
4 from enum import Enum
5 from typing import cast
6 from typing import List
7 from typing import Optional
8 from typing import Tuple
9
10 from .._internal import _to_bytes
11 from .._internal import _to_str
12 from ..datastructures import Headers
13 from ..exceptions import RequestEntityTooLarge
14 from ..http import parse_options_header
15
16
17 class Event:
18 pass
19
20
21 @dataclass(frozen=True)
22 class Preamble(Event):
23 data: bytes
24
25
26 @dataclass(frozen=True)
27 class Field(Event):
28 name: str
29 headers: Headers
30
31
32 @dataclass(frozen=True)
33 class File(Event):
34 name: str
35 filename: str
36 headers: Headers
37
38
39 @dataclass(frozen=True)
40 class Data(Event):
41 data: bytes
42 more_data: bool
43
44
45 @dataclass(frozen=True)
46 class Epilogue(Event):
47 data: bytes
48
49
50 class NeedData(Event):
51 pass
52
53
54 NEED_DATA = NeedData()
55
56
57 class State(Enum):
58 PREAMBLE = auto()
59 PART = auto()
60 DATA = auto()
61 EPILOGUE = auto()
62 COMPLETE = auto()
63
64
65 # Multipart line breaks MUST be CRLF (\r\n) by RFC-7578, except that
66 # many implementations break this and either use CR or LF alone.
67 LINE_BREAK = b"(?:\r\n|\n|\r)"
68 BLANK_LINE_RE = re.compile(b"(?:\r\n\r\n|\r\r|\n\n)", re.MULTILINE)
69 LINE_BREAK_RE = re.compile(LINE_BREAK, re.MULTILINE)
70 # Header values can be continued via a space or tab after the linebreak, as
71 # per RFC2231
72 HEADER_CONTINUATION_RE = re.compile(b"%s[ \t]" % LINE_BREAK, re.MULTILINE)
73
74
75 class MultipartDecoder:
76 """Decodes a multipart message as bytes into Python events.
77
78 The part data is returned as available to allow the caller to save
79 the data from memory to disk, if desired.
80 """
81
82 def __init__(
83 self,
84 boundary: bytes,
85 max_form_memory_size: Optional[int] = None,
86 ) -> None:
87 self.buffer = bytearray()
88 self.complete = False
89 self.max_form_memory_size = max_form_memory_size
90 self.state = State.PREAMBLE
91 self.boundary = boundary
92
93 # Note in the below \h i.e. horizontal whitespace is used
94 # as [^\S\n\r] as \h isn't supported in python.
95
96 # The preamble must end with a boundary where the boundary is
97 # prefixed by a line break, RFC2046. Except that many
98 # implementations including Werkzeug's tests omit the line
99 # break prefix. In addition the first boundary could be the
100 # epilogue boundary (for empty form-data) hence the matching
101 # group to understand if it is an epilogue boundary.
102 self.preamble_re = re.compile(
103 br"%s?--%s(--[^\S\n\r]*%s?|[^\S\n\r]*%s)"
104 % (LINE_BREAK, boundary, LINE_BREAK, LINE_BREAK),
105 re.MULTILINE,
106 )
107 # A boundary must include a line break prefix and suffix, and
108 # may include trailing whitespace. In addition the boundary
109 # could be the epilogue boundary hence the matching group to
110 # understand if it is an epilogue boundary.
111 self.boundary_re = re.compile(
112 br"%s--%s(--[^\S\n\r]*%s?|[^\S\n\r]*%s)"
113 % (LINE_BREAK, boundary, LINE_BREAK, LINE_BREAK),
114 re.MULTILINE,
115 )
116
117 def last_newline(self) -> int:
118 try:
119 last_nl = self.buffer.rindex(b"\n")
120 except ValueError:
121 last_nl = len(self.buffer)
122 try:
123 last_cr = self.buffer.rindex(b"\r")
124 except ValueError:
125 last_cr = len(self.buffer)
126
127 return min(last_nl, last_cr)
128
129 def receive_data(self, data: Optional[bytes]) -> None:
130 if data is None:
131 self.complete = True
132 elif (
133 self.max_form_memory_size is not None
134 and len(self.buffer) + len(data) > self.max_form_memory_size
135 ):
136 raise RequestEntityTooLarge()
137 else:
138 self.buffer.extend(data)
139
140 def next_event(self) -> Event:
141 event: Event = NEED_DATA
142
143 if self.state == State.PREAMBLE:
144 match = self.preamble_re.search(self.buffer)
145 if match is not None:
146 if match.group(1).startswith(b"--"):
147 self.state = State.EPILOGUE
148 else:
149 self.state = State.PART
150 data = bytes(self.buffer[: match.start()])
151 del self.buffer[: match.end()]
152 event = Preamble(data=data)
153
154 elif self.state == State.PART:
155 match = BLANK_LINE_RE.search(self.buffer)
156 if match is not None:
157 headers = self._parse_headers(self.buffer[: match.start()])
158 del self.buffer[: match.end()]
159
160 if "content-disposition" not in headers:
161 raise ValueError("Missing Content-Disposition header")
162
163 disposition, extra = parse_options_header(
164 headers["content-disposition"]
165 )
166 name = cast(str, extra.get("name"))
167 filename = extra.get("filename")
168 if filename is not None:
169 event = File(
170 filename=filename,
171 headers=headers,
172 name=name,
173 )
174 else:
175 event = Field(
176 headers=headers,
177 name=name,
178 )
179 self.state = State.DATA
180
181 elif self.state == State.DATA:
182 if self.buffer.find(b"--" + self.boundary) == -1:
183 # No complete boundary in the buffer, but there may be
184 # a partial boundary at the end. As the boundary
185 # starts with either a nl or cr find the earliest and
186 # return up to that as data.
187 data_length = del_index = self.last_newline()
188 more_data = True
189 else:
190 match = self.boundary_re.search(self.buffer)
191 if match is not None:
192 if match.group(1).startswith(b"--"):
193 self.state = State.EPILOGUE
194 else:
195 self.state = State.PART
196 data_length = match.start()
197 del_index = match.end()
198 else:
199 data_length = del_index = self.last_newline()
200 more_data = match is None
201
202 data = bytes(self.buffer[:data_length])
203 del self.buffer[:del_index]
204 if data or not more_data:
205 event = Data(data=data, more_data=more_data)
206
207 elif self.state == State.EPILOGUE and self.complete:
208 event = Epilogue(data=bytes(self.buffer))
209 del self.buffer[:]
210 self.state = State.COMPLETE
211
212 if self.complete and isinstance(event, NeedData):
213 raise ValueError(f"Invalid form-data cannot parse beyond {self.state}")
214
215 return event
216
217 def _parse_headers(self, data: bytes) -> Headers:
218 headers: List[Tuple[str, str]] = []
219 # Merge the continued headers into one line
220 data = HEADER_CONTINUATION_RE.sub(b" ", data)
221 # Now there is one header per line
222 for line in data.splitlines():
223 if line.strip() != b"":
224 name, value = _to_str(line).strip().split(":", 1)
225 headers.append((name.strip(), value.strip()))
226 return Headers(headers)
227
228
229 class MultipartEncoder:
230 def __init__(self, boundary: bytes) -> None:
231 self.boundary = boundary
232 self.state = State.PREAMBLE
233
234 def send_event(self, event: Event) -> bytes:
235 if isinstance(event, Preamble) and self.state == State.PREAMBLE:
236 self.state = State.PART
237 return event.data
238 elif isinstance(event, (Field, File)) and self.state in {
239 State.PREAMBLE,
240 State.PART,
241 State.DATA,
242 }:
243 self.state = State.DATA
244 data = b"\r\n--" + self.boundary + b"\r\n"
245 data += b'Content-Disposition: form-data; name="%s"' % _to_bytes(event.name)
246 if isinstance(event, File):
247 data += b'; filename="%s"' % _to_bytes(event.filename)
248 data += b"\r\n"
249 for name, value in cast(Field, event).headers:
250 if name.lower() != "content-disposition":
251 data += _to_bytes(f"{name}: {value}\r\n")
252 data += b"\r\n"
253 return data
254 elif isinstance(event, Data) and self.state == State.DATA:
255 return event.data
256 elif isinstance(event, Epilogue):
257 self.state = State.COMPLETE
258 return b"\r\n--" + self.boundary + b"--\r\n" + event.data
259 else:
260 raise ValueError(f"Cannot generate {event} in state: {self.state}")
261
[end of src/werkzeug/sansio/multipart.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/werkzeug/sansio/multipart.py b/src/werkzeug/sansio/multipart.py
--- a/src/werkzeug/sansio/multipart.py
+++ b/src/werkzeug/sansio/multipart.py
@@ -101,7 +101,7 @@
# group to understand if it is an epilogue boundary.
self.preamble_re = re.compile(
br"%s?--%s(--[^\S\n\r]*%s?|[^\S\n\r]*%s)"
- % (LINE_BREAK, boundary, LINE_BREAK, LINE_BREAK),
+ % (LINE_BREAK, re.escape(boundary), LINE_BREAK, LINE_BREAK),
re.MULTILINE,
)
# A boundary must include a line break prefix and suffix, and
@@ -110,7 +110,7 @@
# understand if it is an epilogue boundary.
self.boundary_re = re.compile(
br"%s--%s(--[^\S\n\r]*%s?|[^\S\n\r]*%s)"
- % (LINE_BREAK, boundary, LINE_BREAK, LINE_BREAK),
+ % (LINE_BREAK, re.escape(boundary), LINE_BREAK, LINE_BREAK),
re.MULTILINE,
)
|
{"golden_diff": "diff --git a/src/werkzeug/sansio/multipart.py b/src/werkzeug/sansio/multipart.py\n--- a/src/werkzeug/sansio/multipart.py\n+++ b/src/werkzeug/sansio/multipart.py\n@@ -101,7 +101,7 @@\n # group to understand if it is an epilogue boundary.\n self.preamble_re = re.compile(\n br\"%s?--%s(--[^\\S\\n\\r]*%s?|[^\\S\\n\\r]*%s)\"\n- % (LINE_BREAK, boundary, LINE_BREAK, LINE_BREAK),\n+ % (LINE_BREAK, re.escape(boundary), LINE_BREAK, LINE_BREAK),\n re.MULTILINE,\n )\n # A boundary must include a line break prefix and suffix, and\n@@ -110,7 +110,7 @@\n # understand if it is an epilogue boundary.\n self.boundary_re = re.compile(\n br\"%s--%s(--[^\\S\\n\\r]*%s?|[^\\S\\n\\r]*%s)\"\n- % (LINE_BREAK, boundary, LINE_BREAK, LINE_BREAK),\n+ % (LINE_BREAK, re.escape(boundary), LINE_BREAK, LINE_BREAK),\n re.MULTILINE,\n )\n", "issue": "[BUG] Multipart data parse regression\nSeems that there is a regression in the new MultiPartPaser implementation\r\n\r\nThe following does not work in `Werkzeug==2.0.0`; but, works in `Werkzeug<2.0.0`.\r\n\r\n```\r\nfrom werkzeug.formparser import MultiPartParser\r\nfrom io import BytesIO\r\n\r\nparser = MultiPartParser()\r\n\r\nboundary = b'----------a_BoUnDaRy9009049739267083$'\r\n\r\nf = BytesIO(b'------------a_BoUnDaRy9009049739267083$\\r\\nContent-Disposition: form-data; name=\"file\"; filename=\"/home/marc/workspace/data-governance/tests/functional_tests/test_data_governance_api/controllers/work_unit_data/NaValues.csv\"\\r\\nContent-Type: text/csv\\r\\n\\r\\n\"I was told that I was not able to receive a pay increase because I was at the top of the pay range for my level. This indicates to me that I need to either be promoted to the next level, or look elsewhere for employment.\"\\r\\nProject Management seems inconsistent some are well run some are not transparent and all over the place. Hiring contractors also are not managed well and may have resulted to project overruns.\\r\\nNA\\r\\n\"1. How can diversity and inclusion efforts just be tailored to minority group?2. Is it appropriate to use the term \"\"blacks\"\" when sending out a company email around diversity and inclusion?3. Again, an actual HR department would resolve this\"\\r\\nNaN\\r\\n------------a_BoUnDaRy9009049739267083$--\\r\\n')\r\n\r\nform, files = parser.parse(f, boundary, 965)\r\n```\r\n\r\nIt results in the following error:\r\n\r\n```\r\n\r\nTraceback (most recent call last):\r\n File \"/home/*/flaskapp_fail.py\", line 57, in <module>\r\n form, files = parser.parse(f, boundary, 965)\r\n File \"/home/*/lib/python3.8/site-packages/werkzeug/formparser.py\", line 459, in parse\r\n event = parser.next_event()\r\n File \"/home/*/lib/python3.8/site-packages/werkzeug/sansio/multipart.py\", line 213, in next_event\r\n raise ValueError(f\"Invalid form-data cannot parse beyond {self.state}\")\r\nValueError: Invalid form-data cannot parse beyond State.PREAMBLE\r\n```\r\n\r\n\r\nEnvironment:\r\n\r\n- Python version: 3.8.5\r\n- Werkzeug version: 2.0.0\r\n\n", "before_files": [{"content": "import re\nfrom dataclasses import dataclass\nfrom enum import auto\nfrom enum import Enum\nfrom typing import cast\nfrom typing import List\nfrom typing import Optional\nfrom typing import Tuple\n\nfrom .._internal import _to_bytes\nfrom .._internal import _to_str\nfrom ..datastructures import Headers\nfrom ..exceptions import RequestEntityTooLarge\nfrom ..http import parse_options_header\n\n\nclass Event:\n pass\n\n\n@dataclass(frozen=True)\nclass Preamble(Event):\n data: bytes\n\n\n@dataclass(frozen=True)\nclass Field(Event):\n name: str\n headers: Headers\n\n\n@dataclass(frozen=True)\nclass File(Event):\n name: str\n filename: str\n headers: Headers\n\n\n@dataclass(frozen=True)\nclass Data(Event):\n data: bytes\n more_data: bool\n\n\n@dataclass(frozen=True)\nclass Epilogue(Event):\n data: bytes\n\n\nclass NeedData(Event):\n pass\n\n\nNEED_DATA = NeedData()\n\n\nclass State(Enum):\n PREAMBLE = auto()\n PART = auto()\n DATA = auto()\n EPILOGUE = auto()\n COMPLETE = auto()\n\n\n# Multipart line breaks MUST be CRLF (\\r\\n) by RFC-7578, except that\n# many implementations break this and either use CR or LF alone.\nLINE_BREAK = b\"(?:\\r\\n|\\n|\\r)\"\nBLANK_LINE_RE = re.compile(b\"(?:\\r\\n\\r\\n|\\r\\r|\\n\\n)\", re.MULTILINE)\nLINE_BREAK_RE = re.compile(LINE_BREAK, re.MULTILINE)\n# Header values can be continued via a space or tab after the linebreak, as\n# per RFC2231\nHEADER_CONTINUATION_RE = re.compile(b\"%s[ \\t]\" % LINE_BREAK, re.MULTILINE)\n\n\nclass MultipartDecoder:\n \"\"\"Decodes a multipart message as bytes into Python events.\n\n The part data is returned as available to allow the caller to save\n the data from memory to disk, if desired.\n \"\"\"\n\n def __init__(\n self,\n boundary: bytes,\n max_form_memory_size: Optional[int] = None,\n ) -> None:\n self.buffer = bytearray()\n self.complete = False\n self.max_form_memory_size = max_form_memory_size\n self.state = State.PREAMBLE\n self.boundary = boundary\n\n # Note in the below \\h i.e. horizontal whitespace is used\n # as [^\\S\\n\\r] as \\h isn't supported in python.\n\n # The preamble must end with a boundary where the boundary is\n # prefixed by a line break, RFC2046. Except that many\n # implementations including Werkzeug's tests omit the line\n # break prefix. In addition the first boundary could be the\n # epilogue boundary (for empty form-data) hence the matching\n # group to understand if it is an epilogue boundary.\n self.preamble_re = re.compile(\n br\"%s?--%s(--[^\\S\\n\\r]*%s?|[^\\S\\n\\r]*%s)\"\n % (LINE_BREAK, boundary, LINE_BREAK, LINE_BREAK),\n re.MULTILINE,\n )\n # A boundary must include a line break prefix and suffix, and\n # may include trailing whitespace. In addition the boundary\n # could be the epilogue boundary hence the matching group to\n # understand if it is an epilogue boundary.\n self.boundary_re = re.compile(\n br\"%s--%s(--[^\\S\\n\\r]*%s?|[^\\S\\n\\r]*%s)\"\n % (LINE_BREAK, boundary, LINE_BREAK, LINE_BREAK),\n re.MULTILINE,\n )\n\n def last_newline(self) -> int:\n try:\n last_nl = self.buffer.rindex(b\"\\n\")\n except ValueError:\n last_nl = len(self.buffer)\n try:\n last_cr = self.buffer.rindex(b\"\\r\")\n except ValueError:\n last_cr = len(self.buffer)\n\n return min(last_nl, last_cr)\n\n def receive_data(self, data: Optional[bytes]) -> None:\n if data is None:\n self.complete = True\n elif (\n self.max_form_memory_size is not None\n and len(self.buffer) + len(data) > self.max_form_memory_size\n ):\n raise RequestEntityTooLarge()\n else:\n self.buffer.extend(data)\n\n def next_event(self) -> Event:\n event: Event = NEED_DATA\n\n if self.state == State.PREAMBLE:\n match = self.preamble_re.search(self.buffer)\n if match is not None:\n if match.group(1).startswith(b\"--\"):\n self.state = State.EPILOGUE\n else:\n self.state = State.PART\n data = bytes(self.buffer[: match.start()])\n del self.buffer[: match.end()]\n event = Preamble(data=data)\n\n elif self.state == State.PART:\n match = BLANK_LINE_RE.search(self.buffer)\n if match is not None:\n headers = self._parse_headers(self.buffer[: match.start()])\n del self.buffer[: match.end()]\n\n if \"content-disposition\" not in headers:\n raise ValueError(\"Missing Content-Disposition header\")\n\n disposition, extra = parse_options_header(\n headers[\"content-disposition\"]\n )\n name = cast(str, extra.get(\"name\"))\n filename = extra.get(\"filename\")\n if filename is not None:\n event = File(\n filename=filename,\n headers=headers,\n name=name,\n )\n else:\n event = Field(\n headers=headers,\n name=name,\n )\n self.state = State.DATA\n\n elif self.state == State.DATA:\n if self.buffer.find(b\"--\" + self.boundary) == -1:\n # No complete boundary in the buffer, but there may be\n # a partial boundary at the end. As the boundary\n # starts with either a nl or cr find the earliest and\n # return up to that as data.\n data_length = del_index = self.last_newline()\n more_data = True\n else:\n match = self.boundary_re.search(self.buffer)\n if match is not None:\n if match.group(1).startswith(b\"--\"):\n self.state = State.EPILOGUE\n else:\n self.state = State.PART\n data_length = match.start()\n del_index = match.end()\n else:\n data_length = del_index = self.last_newline()\n more_data = match is None\n\n data = bytes(self.buffer[:data_length])\n del self.buffer[:del_index]\n if data or not more_data:\n event = Data(data=data, more_data=more_data)\n\n elif self.state == State.EPILOGUE and self.complete:\n event = Epilogue(data=bytes(self.buffer))\n del self.buffer[:]\n self.state = State.COMPLETE\n\n if self.complete and isinstance(event, NeedData):\n raise ValueError(f\"Invalid form-data cannot parse beyond {self.state}\")\n\n return event\n\n def _parse_headers(self, data: bytes) -> Headers:\n headers: List[Tuple[str, str]] = []\n # Merge the continued headers into one line\n data = HEADER_CONTINUATION_RE.sub(b\" \", data)\n # Now there is one header per line\n for line in data.splitlines():\n if line.strip() != b\"\":\n name, value = _to_str(line).strip().split(\":\", 1)\n headers.append((name.strip(), value.strip()))\n return Headers(headers)\n\n\nclass MultipartEncoder:\n def __init__(self, boundary: bytes) -> None:\n self.boundary = boundary\n self.state = State.PREAMBLE\n\n def send_event(self, event: Event) -> bytes:\n if isinstance(event, Preamble) and self.state == State.PREAMBLE:\n self.state = State.PART\n return event.data\n elif isinstance(event, (Field, File)) and self.state in {\n State.PREAMBLE,\n State.PART,\n State.DATA,\n }:\n self.state = State.DATA\n data = b\"\\r\\n--\" + self.boundary + b\"\\r\\n\"\n data += b'Content-Disposition: form-data; name=\"%s\"' % _to_bytes(event.name)\n if isinstance(event, File):\n data += b'; filename=\"%s\"' % _to_bytes(event.filename)\n data += b\"\\r\\n\"\n for name, value in cast(Field, event).headers:\n if name.lower() != \"content-disposition\":\n data += _to_bytes(f\"{name}: {value}\\r\\n\")\n data += b\"\\r\\n\"\n return data\n elif isinstance(event, Data) and self.state == State.DATA:\n return event.data\n elif isinstance(event, Epilogue):\n self.state = State.COMPLETE\n return b\"\\r\\n--\" + self.boundary + b\"--\\r\\n\" + event.data\n else:\n raise ValueError(f\"Cannot generate {event} in state: {self.state}\")\n", "path": "src/werkzeug/sansio/multipart.py"}]}
| 3,739 | 270 |
gh_patches_debug_19753
|
rasdani/github-patches
|
git_diff
|
lk-geimfari__mimesis-323
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Change how works generating data by schema
The current design is bad for following reasons:
`Field` is an object which can represent any method of any provider and it's mean that is data provider which should return data and it's the only thing that we want by this object, but here how it works right now:
```
>>> from mimesis.schema import Field
>>> from mimesis.enums import Gender
_ = Field('en')
>>> _ = Field('en')
>>> app_schema = (
... lambda: {
... "id": _('uuid'),
... "name": _('word'),
... "version": _('version'),
... "owner": {
... "email": _('email'),
... "token": _('token'),
... "creator": _('full_name', gender=Gender.FEMALE),
... },
... }
... )
>>> _.fill(schema=app_schema, iterations=10)
```
It looks really annoying.
It should be done using another way because here every instance of `Field` contains method `fill`, but why? Good question... because this is disgusting API designed by me. And now I see my mistake and suggest that it be corrected.
I suggest this:
```
from mimesis.schema import Field, Schema
_ = Field('en')
app_data = Schema(lambda: {
"id": _('uuid'),
"name": _('word'),
"version": _('version'),
"owner": {
"email": _('email'),
"token": _('token'),
"creator": _('full_name', gender=Gender.FEMALE),
},
}).create(iterations=20)
```
I think that is much better because the code is much more readable and looks more logical.
</issue>
<code>
[start of mimesis/providers/development.py]
1 from mimesis.data import (BACKEND, CONTAINER, FRONTEND, LICENSES, NOSQL, OS,
2 PROGRAMMING_LANGS, SQL)
3 from mimesis.providers.base import BaseProvider
4
5
6 class Development(BaseProvider):
7 """Class for getting fake data for Developers."""
8
9 def software_license(self) -> str:
10 """Get a random software license from list.
11
12 :return: License name.
13
14 :Example:
15 The BSD 3-Clause License.
16 """
17 return self.random.choice(LICENSES)
18
19 def version(self, pre_release: bool = False) -> str:
20 """Generate a random version information.
21
22 :param pre_release: Pre-release.
23 :return: The version of software.
24
25 :Example:
26 0.11.3-alpha.1
27 """
28 major, minor, patch = self.random.randints(3, 0, 10)
29 version = '{}.{}.{}'.format(major, minor, patch)
30
31 if pre_release:
32 suffixes = ('alpha', 'beta', 'rc')
33 suffix = self.random.choice(suffixes)
34 number = self.random.randint(1, 11)
35 return '{}-{}.{}'.format(version, suffix, number)
36
37 return version
38
39 def database(self, nosql: bool = False) -> str:
40 """Get a random database name.
41
42 :param bool nosql: only NoSQL databases.
43 :return: Database name.
44
45 :Example:
46 PostgreSQL.
47 """
48 if nosql:
49 return self.random.choice(NOSQL)
50 return self.random.choice(SQL)
51
52 def container(self) -> str:
53 """Get a random containerization system.
54
55 :return: Containerization system.
56
57 :Example:
58 Docker.
59 """
60 return self.random.choice(CONTAINER)
61
62 def version_control_system(self) -> str:
63 """Get a random version control system.
64
65 :return: Version control system
66
67 :Example:
68 Git
69 """
70 vcs = ('Git', 'Subversion')
71 return self.random.choice(vcs)
72
73 def programming_language(self) -> str:
74 """Get a random programming language from the list.
75
76 :return: Programming language.
77
78 :Example:
79 Erlang.
80 """
81 return self.random.choice(PROGRAMMING_LANGS)
82
83 def backend(self) -> str:
84 """Get a random backend stack.
85
86 :return: Stack.
87
88 :Example:
89 Elixir/Phoenix
90 """
91 return self.random.choice(BACKEND)
92
93 def frontend(self) -> str:
94 """Get a random front-end stack.
95
96 :return: Stack.
97
98 :Example:
99 JS/React.
100 """
101 return self.random.choice(FRONTEND)
102
103 def os(self) -> str:
104 """Get a random operating system or distributive name.
105
106 :return: The name of OS.
107
108 :Example:
109 Gentoo
110 """
111 return self.random.choice(OS)
112
113 def boolean(self) -> bool:
114 """Get a random boolean value.
115
116 :return: True of False.
117 """
118 values = (0, 1)
119 value = self.random.choice(values)
120 return bool(value)
121
[end of mimesis/providers/development.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mimesis/providers/development.py b/mimesis/providers/development.py
--- a/mimesis/providers/development.py
+++ b/mimesis/providers/development.py
@@ -16,16 +16,28 @@
"""
return self.random.choice(LICENSES)
- def version(self, pre_release: bool = False) -> str:
+ def version(self, calver: bool = False, pre_release: bool = False) -> str:
"""Generate a random version information.
+ :param calver: Use calendar versioning.
:param pre_release: Pre-release.
:return: The version of software.
-
+.
:Example:
0.11.3-alpha.1
"""
+ version = '{}.{}.{}'
major, minor, patch = self.random.randints(3, 0, 10)
+
+ if calver:
+ if minor == 0:
+ minor += 1
+
+ if patch == 0:
+ patch += 1
+ major = self.random.randint(2016, 2018)
+ return version.format(major, minor, patch)
+
version = '{}.{}.{}'.format(major, minor, patch)
if pre_release:
|
{"golden_diff": "diff --git a/mimesis/providers/development.py b/mimesis/providers/development.py\n--- a/mimesis/providers/development.py\n+++ b/mimesis/providers/development.py\n@@ -16,16 +16,28 @@\n \"\"\"\n return self.random.choice(LICENSES)\n \n- def version(self, pre_release: bool = False) -> str:\n+ def version(self, calver: bool = False, pre_release: bool = False) -> str:\n \"\"\"Generate a random version information.\n \n+ :param calver: Use calendar versioning.\n :param pre_release: Pre-release.\n :return: The version of software.\n-\n+.\n :Example:\n 0.11.3-alpha.1\n \"\"\"\n+ version = '{}.{}.{}'\n major, minor, patch = self.random.randints(3, 0, 10)\n+\n+ if calver:\n+ if minor == 0:\n+ minor += 1\n+\n+ if patch == 0:\n+ patch += 1\n+ major = self.random.randint(2016, 2018)\n+ return version.format(major, minor, patch)\n+\n version = '{}.{}.{}'.format(major, minor, patch)\n \n if pre_release:\n", "issue": "Change how works generating data by schema\nThe current design is bad for following reasons:\r\n\r\n`Field` is an object which can represent any method of any provider and it's mean that is data provider which should return data and it's the only thing that we want by this object, but here how it works right now:\r\n\r\n```\r\n>>> from mimesis.schema import Field\r\n>>> from mimesis.enums import Gender\r\n_ = Field('en')\r\n>>> _ = Field('en')\r\n>>> app_schema = (\r\n... lambda: {\r\n... \"id\": _('uuid'),\r\n... \"name\": _('word'),\r\n... \"version\": _('version'),\r\n... \"owner\": {\r\n... \"email\": _('email'),\r\n... \"token\": _('token'),\r\n... \"creator\": _('full_name', gender=Gender.FEMALE),\r\n... },\r\n... }\r\n... )\r\n>>> _.fill(schema=app_schema, iterations=10)\r\n```\r\n\r\nIt looks really annoying.\r\n\r\nIt should be done using another way because here every instance of `Field` contains method `fill`, but why? Good question... because this is disgusting API designed by me. And now I see my mistake and suggest that it be corrected.\r\n\r\nI suggest this:\r\n\r\n```\r\nfrom mimesis.schema import Field, Schema\r\n_ = Field('en')\r\napp_data = Schema(lambda: {\r\n \"id\": _('uuid'),\r\n \"name\": _('word'),\r\n \"version\": _('version'),\r\n \"owner\": {\r\n \"email\": _('email'),\r\n \"token\": _('token'),\r\n \"creator\": _('full_name', gender=Gender.FEMALE),\r\n },\r\n}).create(iterations=20)\r\n```\r\n\r\nI think that is much better because the code is much more readable and looks more logical.\n", "before_files": [{"content": "from mimesis.data import (BACKEND, CONTAINER, FRONTEND, LICENSES, NOSQL, OS,\n PROGRAMMING_LANGS, SQL)\nfrom mimesis.providers.base import BaseProvider\n\n\nclass Development(BaseProvider):\n \"\"\"Class for getting fake data for Developers.\"\"\"\n\n def software_license(self) -> str:\n \"\"\"Get a random software license from list.\n\n :return: License name.\n\n :Example:\n The BSD 3-Clause License.\n \"\"\"\n return self.random.choice(LICENSES)\n\n def version(self, pre_release: bool = False) -> str:\n \"\"\"Generate a random version information.\n\n :param pre_release: Pre-release.\n :return: The version of software.\n\n :Example:\n 0.11.3-alpha.1\n \"\"\"\n major, minor, patch = self.random.randints(3, 0, 10)\n version = '{}.{}.{}'.format(major, minor, patch)\n\n if pre_release:\n suffixes = ('alpha', 'beta', 'rc')\n suffix = self.random.choice(suffixes)\n number = self.random.randint(1, 11)\n return '{}-{}.{}'.format(version, suffix, number)\n\n return version\n\n def database(self, nosql: bool = False) -> str:\n \"\"\"Get a random database name.\n\n :param bool nosql: only NoSQL databases.\n :return: Database name.\n\n :Example:\n PostgreSQL.\n \"\"\"\n if nosql:\n return self.random.choice(NOSQL)\n return self.random.choice(SQL)\n\n def container(self) -> str:\n \"\"\"Get a random containerization system.\n\n :return: Containerization system.\n\n :Example:\n Docker.\n \"\"\"\n return self.random.choice(CONTAINER)\n\n def version_control_system(self) -> str:\n \"\"\"Get a random version control system.\n\n :return: Version control system\n\n :Example:\n Git\n \"\"\"\n vcs = ('Git', 'Subversion')\n return self.random.choice(vcs)\n\n def programming_language(self) -> str:\n \"\"\"Get a random programming language from the list.\n\n :return: Programming language.\n\n :Example:\n Erlang.\n \"\"\"\n return self.random.choice(PROGRAMMING_LANGS)\n\n def backend(self) -> str:\n \"\"\"Get a random backend stack.\n\n :return: Stack.\n\n :Example:\n Elixir/Phoenix\n \"\"\"\n return self.random.choice(BACKEND)\n\n def frontend(self) -> str:\n \"\"\"Get a random front-end stack.\n\n :return: Stack.\n\n :Example:\n JS/React.\n \"\"\"\n return self.random.choice(FRONTEND)\n\n def os(self) -> str:\n \"\"\"Get a random operating system or distributive name.\n\n :return: The name of OS.\n\n :Example:\n Gentoo\n \"\"\"\n return self.random.choice(OS)\n\n def boolean(self) -> bool:\n \"\"\"Get a random boolean value.\n\n :return: True of False.\n \"\"\"\n values = (0, 1)\n value = self.random.choice(values)\n return bool(value)\n", "path": "mimesis/providers/development.py"}]}
| 1,841 | 286 |
gh_patches_debug_60161
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-center-index-1706
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[odbc] CMake module name
odbc/2.3.7
According to CMake module, it should use capital letters: https://cmake.org/cmake/help/v3.12/module/FindODBC.html
</issue>
<code>
[start of recipes/odbc/all/conanfile.py]
1 import os
2 from conans import ConanFile, AutoToolsBuildEnvironment, tools
3 from conans.errors import ConanInvalidConfiguration
4
5
6 class OdbcConan(ConanFile):
7 name = 'odbc'
8 description = 'Package providing unixODBC'
9 url = 'https://github.com/conan-io/conan-center-index'
10 homepage = "http://www.unixodbc.org"
11 license = ('LGPL-2.1', 'GPL-2.1')
12
13 settings = 'os', 'compiler', 'build_type', 'arch'
14 options = {'shared': [True, False], 'fPIC': [True, False], 'with_libiconv': [True, False]}
15 default_options = {'shared': False, 'fPIC': True, 'with_libiconv': True}
16 topics = ('odbc', 'database', 'dbms', 'data-access')
17
18 _source_subfolder = 'source_subfolder'
19
20 def configure(self):
21 del self.settings.compiler.libcxx # Pure C
22 del self.settings.compiler.cppstd
23 if self.settings.os == "Windows":
24 raise ConanInvalidConfiguration("Windows not supported yet. Please, open an issue if you need such support")
25
26 def requirements(self):
27 if self.options.with_libiconv:
28 self.requires("libiconv/1.16")
29
30 def source(self):
31 tools.get(**self.conan_data["sources"][self.version])
32 extracted_dir = 'unixODBC-%s' % self.version
33 os.rename(extracted_dir, self._source_subfolder)
34
35 def build(self):
36 env_build = AutoToolsBuildEnvironment(self)
37 static_flag = 'no' if self.options.shared else 'yes'
38 shared_flag = 'yes' if self.options.shared else 'no'
39 libiconv_flag = 'yes' if self.options.with_libiconv else 'no'
40 args = ['--enable-static=%s' % static_flag,
41 '--enable-shared=%s' % shared_flag,
42 '--enable-ltdl-install',
43 '--enable-iconv=%s' % libiconv_flag]
44 if self.options.with_libiconv:
45 libiconv_prefix = self.deps_cpp_info["libiconv"].rootpath
46 args.append('--with-libiconv-prefix=%s' % libiconv_prefix)
47
48 env_build.configure(configure_dir=self._source_subfolder, args=args)
49 env_build.make()
50 env_build.install()
51 tools.rmdir(os.path.join(self.package_folder, "share"))
52 tools.rmdir(os.path.join(self.package_folder, "etc"))
53 tools.rmdir(os.path.join(self.package_folder, "lib", "pkgconfig"))
54 os.remove(os.path.join(self.package_folder, "lib", "libodbc.la"))
55 os.remove(os.path.join(self.package_folder, "lib", "libodbccr.la"))
56 os.remove(os.path.join(self.package_folder, "lib", "libodbcinst.la"))
57 os.remove(os.path.join(self.package_folder, "lib", "libltdl.la"))
58
59 def package(self):
60 self.copy('COPYING', src=self._source_subfolder, dst="licenses")
61
62 def package_info(self):
63 self.env_info.path.append(os.path.join(self.package_folder, 'bin'))
64
65 self.cpp_info.libs = ['odbc', 'odbccr', 'odbcinst', 'ltdl']
66 if self.settings.os == 'Linux':
67 self.cpp_info.libs.append('dl')
68
[end of recipes/odbc/all/conanfile.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/recipes/odbc/all/conanfile.py b/recipes/odbc/all/conanfile.py
--- a/recipes/odbc/all/conanfile.py
+++ b/recipes/odbc/all/conanfile.py
@@ -60,6 +60,9 @@
self.copy('COPYING', src=self._source_subfolder, dst="licenses")
def package_info(self):
+ self.cpp_info.names["cmake_find_package"] = "ODBC"
+ self.cpp_info.names["cmake_find_package_multi"] = "ODBC"
+
self.env_info.path.append(os.path.join(self.package_folder, 'bin'))
self.cpp_info.libs = ['odbc', 'odbccr', 'odbcinst', 'ltdl']
|
{"golden_diff": "diff --git a/recipes/odbc/all/conanfile.py b/recipes/odbc/all/conanfile.py\n--- a/recipes/odbc/all/conanfile.py\n+++ b/recipes/odbc/all/conanfile.py\n@@ -60,6 +60,9 @@\n self.copy('COPYING', src=self._source_subfolder, dst=\"licenses\")\n \n def package_info(self):\n+ self.cpp_info.names[\"cmake_find_package\"] = \"ODBC\"\n+ self.cpp_info.names[\"cmake_find_package_multi\"] = \"ODBC\"\n+\n self.env_info.path.append(os.path.join(self.package_folder, 'bin'))\n \n self.cpp_info.libs = ['odbc', 'odbccr', 'odbcinst', 'ltdl']\n", "issue": "[odbc] CMake module name\nodbc/2.3.7\r\n\r\nAccording to CMake module, it should use capital letters: https://cmake.org/cmake/help/v3.12/module/FindODBC.html\n", "before_files": [{"content": "import os\nfrom conans import ConanFile, AutoToolsBuildEnvironment, tools\nfrom conans.errors import ConanInvalidConfiguration\n\n\nclass OdbcConan(ConanFile):\n name = 'odbc'\n description = 'Package providing unixODBC'\n url = 'https://github.com/conan-io/conan-center-index'\n homepage = \"http://www.unixodbc.org\"\n license = ('LGPL-2.1', 'GPL-2.1')\n\n settings = 'os', 'compiler', 'build_type', 'arch'\n options = {'shared': [True, False], 'fPIC': [True, False], 'with_libiconv': [True, False]}\n default_options = {'shared': False, 'fPIC': True, 'with_libiconv': True}\n topics = ('odbc', 'database', 'dbms', 'data-access')\n\n _source_subfolder = 'source_subfolder'\n\n def configure(self):\n del self.settings.compiler.libcxx # Pure C\n del self.settings.compiler.cppstd\n if self.settings.os == \"Windows\":\n raise ConanInvalidConfiguration(\"Windows not supported yet. Please, open an issue if you need such support\")\n\n def requirements(self):\n if self.options.with_libiconv:\n self.requires(\"libiconv/1.16\")\n \n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version])\n extracted_dir = 'unixODBC-%s' % self.version\n os.rename(extracted_dir, self._source_subfolder)\n\n def build(self):\n env_build = AutoToolsBuildEnvironment(self)\n static_flag = 'no' if self.options.shared else 'yes'\n shared_flag = 'yes' if self.options.shared else 'no'\n libiconv_flag = 'yes' if self.options.with_libiconv else 'no'\n args = ['--enable-static=%s' % static_flag,\n '--enable-shared=%s' % shared_flag,\n '--enable-ltdl-install',\n '--enable-iconv=%s' % libiconv_flag]\n if self.options.with_libiconv:\n libiconv_prefix = self.deps_cpp_info[\"libiconv\"].rootpath\n args.append('--with-libiconv-prefix=%s' % libiconv_prefix)\n\n env_build.configure(configure_dir=self._source_subfolder, args=args)\n env_build.make()\n env_build.install()\n tools.rmdir(os.path.join(self.package_folder, \"share\"))\n tools.rmdir(os.path.join(self.package_folder, \"etc\"))\n tools.rmdir(os.path.join(self.package_folder, \"lib\", \"pkgconfig\"))\n os.remove(os.path.join(self.package_folder, \"lib\", \"libodbc.la\"))\n os.remove(os.path.join(self.package_folder, \"lib\", \"libodbccr.la\"))\n os.remove(os.path.join(self.package_folder, \"lib\", \"libodbcinst.la\"))\n os.remove(os.path.join(self.package_folder, \"lib\", \"libltdl.la\"))\n\n def package(self):\n self.copy('COPYING', src=self._source_subfolder, dst=\"licenses\")\n\n def package_info(self):\n self.env_info.path.append(os.path.join(self.package_folder, 'bin'))\n\n self.cpp_info.libs = ['odbc', 'odbccr', 'odbcinst', 'ltdl']\n if self.settings.os == 'Linux':\n self.cpp_info.libs.append('dl')\n", "path": "recipes/odbc/all/conanfile.py"}]}
| 1,462 | 167 |
gh_patches_debug_32339
|
rasdani/github-patches
|
git_diff
|
pypa__pip-6678
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
pip._internal.utils.glibc_version_string() can use os.confstr('CS_GNU_LIBC_VERSION') to avoid ctypes
Currently, the pip._internal.utils.glibc_version_string() function is implemented with ctypes to access gnu_get_libc_version() function. But os.confstr('CS_GNU_LIBC_VERSION') could be used instead to avoid ctypes.
I recently modified platform.libc_ver() on Python stdlib to use os.confstr('CS_GNU_LIBC_VERSION') is available:
* https://bugs.python.org/issue35389
* https://github.com/python/cpython/blob/d4efd917ac24940063a1ce80073fe3570c5f07f8/Lib/platform.py#L174-L183
```py
if executable is None:
try:
ver = os.confstr('CS_GNU_LIBC_VERSION')
# parse 'glibc 2.28' as ('glibc', '2.28')
parts = ver.split(maxsplit=1)
if len(parts) == 2:
return tuple(parts)
except (AttributeError, ValueError, OSError):
# os.confstr() or CS_GNU_LIBC_VERSION value not available
pass
```
Note: I noticed this issue when an user reported a traceback in pip when the ctypes is not available: https://mail.python.org/archives/list/[email protected]/thread/MTIRNYFAZTQQPHKAQXXREP33NYV2TW2J/
Handle ImportError and OSError when importing ctypes (#6543)
Non-dynamic executables can raise OSError when importing ctypes
because dlopen(NULL) is called on module import and dlopen()
won't work on non-dynamic executables.
This commit teaches the glibc version sniffing module to
handle a missing or not working ctypes module.
With this change applied, `pip install` works on non-dynamic / fully statically linked Python executables on Linux.
</issue>
<code>
[start of src/pip/_internal/utils/glibc.py]
1 from __future__ import absolute_import
2
3 import ctypes
4 import re
5 import warnings
6
7 from pip._internal.utils.typing import MYPY_CHECK_RUNNING
8
9 if MYPY_CHECK_RUNNING:
10 from typing import Optional, Tuple
11
12
13 def glibc_version_string():
14 # type: () -> Optional[str]
15 "Returns glibc version string, or None if not using glibc."
16
17 # ctypes.CDLL(None) internally calls dlopen(NULL), and as the dlopen
18 # manpage says, "If filename is NULL, then the returned handle is for the
19 # main program". This way we can let the linker do the work to figure out
20 # which libc our process is actually using.
21 process_namespace = ctypes.CDLL(None)
22 try:
23 gnu_get_libc_version = process_namespace.gnu_get_libc_version
24 except AttributeError:
25 # Symbol doesn't exist -> therefore, we are not linked to
26 # glibc.
27 return None
28
29 # Call gnu_get_libc_version, which returns a string like "2.5"
30 gnu_get_libc_version.restype = ctypes.c_char_p
31 version_str = gnu_get_libc_version()
32 # py2 / py3 compatibility:
33 if not isinstance(version_str, str):
34 version_str = version_str.decode("ascii")
35
36 return version_str
37
38
39 # Separated out from have_compatible_glibc for easier unit testing
40 def check_glibc_version(version_str, required_major, minimum_minor):
41 # type: (str, int, int) -> bool
42 # Parse string and check against requested version.
43 #
44 # We use a regexp instead of str.split because we want to discard any
45 # random junk that might come after the minor version -- this might happen
46 # in patched/forked versions of glibc (e.g. Linaro's version of glibc
47 # uses version strings like "2.20-2014.11"). See gh-3588.
48 m = re.match(r"(?P<major>[0-9]+)\.(?P<minor>[0-9]+)", version_str)
49 if not m:
50 warnings.warn("Expected glibc version with 2 components major.minor,"
51 " got: %s" % version_str, RuntimeWarning)
52 return False
53 return (int(m.group("major")) == required_major and
54 int(m.group("minor")) >= minimum_minor)
55
56
57 def have_compatible_glibc(required_major, minimum_minor):
58 # type: (int, int) -> bool
59 version_str = glibc_version_string() # type: Optional[str]
60 if version_str is None:
61 return False
62 return check_glibc_version(version_str, required_major, minimum_minor)
63
64
65 # platform.libc_ver regularly returns completely nonsensical glibc
66 # versions. E.g. on my computer, platform says:
67 #
68 # ~$ python2.7 -c 'import platform; print(platform.libc_ver())'
69 # ('glibc', '2.7')
70 # ~$ python3.5 -c 'import platform; print(platform.libc_ver())'
71 # ('glibc', '2.9')
72 #
73 # But the truth is:
74 #
75 # ~$ ldd --version
76 # ldd (Debian GLIBC 2.22-11) 2.22
77 #
78 # This is unfortunate, because it means that the linehaul data on libc
79 # versions that was generated by pip 8.1.2 and earlier is useless and
80 # misleading. Solution: instead of using platform, use our code that actually
81 # works.
82 def libc_ver():
83 # type: () -> Tuple[str, str]
84 """Try to determine the glibc version
85
86 Returns a tuple of strings (lib, version) which default to empty strings
87 in case the lookup fails.
88 """
89 glibc_version = glibc_version_string()
90 if glibc_version is None:
91 return ("", "")
92 else:
93 return ("glibc", glibc_version)
94
[end of src/pip/_internal/utils/glibc.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/pip/_internal/utils/glibc.py b/src/pip/_internal/utils/glibc.py
--- a/src/pip/_internal/utils/glibc.py
+++ b/src/pip/_internal/utils/glibc.py
@@ -1,6 +1,6 @@
from __future__ import absolute_import
-import ctypes
+import os
import re
import warnings
@@ -13,6 +13,33 @@
def glibc_version_string():
# type: () -> Optional[str]
"Returns glibc version string, or None if not using glibc."
+ return glibc_version_string_confstr() or glibc_version_string_ctypes()
+
+
+def glibc_version_string_confstr():
+ # type: () -> Optional[str]
+ "Primary implementation of glibc_version_string using os.confstr."
+ # os.confstr is quite a bit faster than ctypes.DLL. It's also less likely
+ # to be broken or missing. This strategy is used in the standard library
+ # platform module:
+ # https://github.com/python/cpython/blob/fcf1d003bf4f0100c9d0921ff3d70e1127ca1b71/Lib/platform.py#L175-L183
+ try:
+ # os.confstr("CS_GNU_LIBC_VERSION") returns a string like "glibc 2.17":
+ _, version = os.confstr("CS_GNU_LIBC_VERSION").split()
+ except (AttributeError, OSError, ValueError):
+ # os.confstr() or CS_GNU_LIBC_VERSION not available (or a bad value)...
+ return None
+ return version
+
+
+def glibc_version_string_ctypes():
+ # type: () -> Optional[str]
+ "Fallback implementation of glibc_version_string using ctypes."
+
+ try:
+ import ctypes
+ except ImportError:
+ return None
# ctypes.CDLL(None) internally calls dlopen(NULL), and as the dlopen
# manpage says, "If filename is NULL, then the returned handle is for the
@@ -56,7 +83,7 @@
def have_compatible_glibc(required_major, minimum_minor):
# type: (int, int) -> bool
- version_str = glibc_version_string() # type: Optional[str]
+ version_str = glibc_version_string()
if version_str is None:
return False
return check_glibc_version(version_str, required_major, minimum_minor)
|
{"golden_diff": "diff --git a/src/pip/_internal/utils/glibc.py b/src/pip/_internal/utils/glibc.py\n--- a/src/pip/_internal/utils/glibc.py\n+++ b/src/pip/_internal/utils/glibc.py\n@@ -1,6 +1,6 @@\n from __future__ import absolute_import\n \n-import ctypes\n+import os\n import re\n import warnings\n \n@@ -13,6 +13,33 @@\n def glibc_version_string():\n # type: () -> Optional[str]\n \"Returns glibc version string, or None if not using glibc.\"\n+ return glibc_version_string_confstr() or glibc_version_string_ctypes()\n+\n+\n+def glibc_version_string_confstr():\n+ # type: () -> Optional[str]\n+ \"Primary implementation of glibc_version_string using os.confstr.\"\n+ # os.confstr is quite a bit faster than ctypes.DLL. It's also less likely\n+ # to be broken or missing. This strategy is used in the standard library\n+ # platform module:\n+ # https://github.com/python/cpython/blob/fcf1d003bf4f0100c9d0921ff3d70e1127ca1b71/Lib/platform.py#L175-L183\n+ try:\n+ # os.confstr(\"CS_GNU_LIBC_VERSION\") returns a string like \"glibc 2.17\":\n+ _, version = os.confstr(\"CS_GNU_LIBC_VERSION\").split()\n+ except (AttributeError, OSError, ValueError):\n+ # os.confstr() or CS_GNU_LIBC_VERSION not available (or a bad value)...\n+ return None\n+ return version\n+\n+\n+def glibc_version_string_ctypes():\n+ # type: () -> Optional[str]\n+ \"Fallback implementation of glibc_version_string using ctypes.\"\n+\n+ try:\n+ import ctypes\n+ except ImportError:\n+ return None\n \n # ctypes.CDLL(None) internally calls dlopen(NULL), and as the dlopen\n # manpage says, \"If filename is NULL, then the returned handle is for the\n@@ -56,7 +83,7 @@\n \n def have_compatible_glibc(required_major, minimum_minor):\n # type: (int, int) -> bool\n- version_str = glibc_version_string() # type: Optional[str]\n+ version_str = glibc_version_string()\n if version_str is None:\n return False\n return check_glibc_version(version_str, required_major, minimum_minor)\n", "issue": "pip._internal.utils.glibc_version_string() can use os.confstr('CS_GNU_LIBC_VERSION') to avoid ctypes\nCurrently, the pip._internal.utils.glibc_version_string() function is implemented with ctypes to access gnu_get_libc_version() function. But os.confstr('CS_GNU_LIBC_VERSION') could be used instead to avoid ctypes.\r\n\r\nI recently modified platform.libc_ver() on Python stdlib to use os.confstr('CS_GNU_LIBC_VERSION') is available:\r\n* https://bugs.python.org/issue35389\r\n* https://github.com/python/cpython/blob/d4efd917ac24940063a1ce80073fe3570c5f07f8/Lib/platform.py#L174-L183\r\n\r\n```py\r\n if executable is None:\r\n try:\r\n ver = os.confstr('CS_GNU_LIBC_VERSION')\r\n # parse 'glibc 2.28' as ('glibc', '2.28')\r\n parts = ver.split(maxsplit=1)\r\n if len(parts) == 2:\r\n return tuple(parts)\r\n except (AttributeError, ValueError, OSError):\r\n # os.confstr() or CS_GNU_LIBC_VERSION value not available\r\n pass\r\n```\r\n\r\nNote: I noticed this issue when an user reported a traceback in pip when the ctypes is not available: https://mail.python.org/archives/list/[email protected]/thread/MTIRNYFAZTQQPHKAQXXREP33NYV2TW2J/\nHandle ImportError and OSError when importing ctypes (#6543)\nNon-dynamic executables can raise OSError when importing ctypes\r\nbecause dlopen(NULL) is called on module import and dlopen()\r\nwon't work on non-dynamic executables.\r\n\r\nThis commit teaches the glibc version sniffing module to\r\nhandle a missing or not working ctypes module.\r\n\r\nWith this change applied, `pip install` works on non-dynamic / fully statically linked Python executables on Linux.\r\n\n", "before_files": [{"content": "from __future__ import absolute_import\n\nimport ctypes\nimport re\nimport warnings\n\nfrom pip._internal.utils.typing import MYPY_CHECK_RUNNING\n\nif MYPY_CHECK_RUNNING:\n from typing import Optional, Tuple\n\n\ndef glibc_version_string():\n # type: () -> Optional[str]\n \"Returns glibc version string, or None if not using glibc.\"\n\n # ctypes.CDLL(None) internally calls dlopen(NULL), and as the dlopen\n # manpage says, \"If filename is NULL, then the returned handle is for the\n # main program\". This way we can let the linker do the work to figure out\n # which libc our process is actually using.\n process_namespace = ctypes.CDLL(None)\n try:\n gnu_get_libc_version = process_namespace.gnu_get_libc_version\n except AttributeError:\n # Symbol doesn't exist -> therefore, we are not linked to\n # glibc.\n return None\n\n # Call gnu_get_libc_version, which returns a string like \"2.5\"\n gnu_get_libc_version.restype = ctypes.c_char_p\n version_str = gnu_get_libc_version()\n # py2 / py3 compatibility:\n if not isinstance(version_str, str):\n version_str = version_str.decode(\"ascii\")\n\n return version_str\n\n\n# Separated out from have_compatible_glibc for easier unit testing\ndef check_glibc_version(version_str, required_major, minimum_minor):\n # type: (str, int, int) -> bool\n # Parse string and check against requested version.\n #\n # We use a regexp instead of str.split because we want to discard any\n # random junk that might come after the minor version -- this might happen\n # in patched/forked versions of glibc (e.g. Linaro's version of glibc\n # uses version strings like \"2.20-2014.11\"). See gh-3588.\n m = re.match(r\"(?P<major>[0-9]+)\\.(?P<minor>[0-9]+)\", version_str)\n if not m:\n warnings.warn(\"Expected glibc version with 2 components major.minor,\"\n \" got: %s\" % version_str, RuntimeWarning)\n return False\n return (int(m.group(\"major\")) == required_major and\n int(m.group(\"minor\")) >= minimum_minor)\n\n\ndef have_compatible_glibc(required_major, minimum_minor):\n # type: (int, int) -> bool\n version_str = glibc_version_string() # type: Optional[str]\n if version_str is None:\n return False\n return check_glibc_version(version_str, required_major, minimum_minor)\n\n\n# platform.libc_ver regularly returns completely nonsensical glibc\n# versions. E.g. on my computer, platform says:\n#\n# ~$ python2.7 -c 'import platform; print(platform.libc_ver())'\n# ('glibc', '2.7')\n# ~$ python3.5 -c 'import platform; print(platform.libc_ver())'\n# ('glibc', '2.9')\n#\n# But the truth is:\n#\n# ~$ ldd --version\n# ldd (Debian GLIBC 2.22-11) 2.22\n#\n# This is unfortunate, because it means that the linehaul data on libc\n# versions that was generated by pip 8.1.2 and earlier is useless and\n# misleading. Solution: instead of using platform, use our code that actually\n# works.\ndef libc_ver():\n # type: () -> Tuple[str, str]\n \"\"\"Try to determine the glibc version\n\n Returns a tuple of strings (lib, version) which default to empty strings\n in case the lookup fails.\n \"\"\"\n glibc_version = glibc_version_string()\n if glibc_version is None:\n return (\"\", \"\")\n else:\n return (\"glibc\", glibc_version)\n", "path": "src/pip/_internal/utils/glibc.py"}]}
| 2,024 | 560 |
gh_patches_debug_2312
|
rasdani/github-patches
|
git_diff
|
ivy-llc__ivy-13468
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
hanning
</issue>
<code>
[start of ivy/functional/frontends/jax/numpy/manipulations.py]
1 # local
2 import ivy
3 from ivy.functional.frontends.jax.func_wrapper import (
4 to_ivy_arrays_and_back,
5 handle_jax_dtype,
6 )
7 from ivy.functional.frontends.jax.numpy import promote_types_of_jax_inputs
8
9
10 @to_ivy_arrays_and_back
11 def clip(a, a_min=None, a_max=None, out=None):
12 ivy.utils.assertions.check_all_or_any_fn(
13 a_min,
14 a_max,
15 fn=ivy.exists,
16 type="any",
17 limit=[1, 2],
18 message="at most one of a_min or a_max can be None",
19 )
20 a = ivy.array(a)
21 if a_min is None:
22 a, a_max = promote_types_of_jax_inputs(a, a_max)
23 return ivy.minimum(a, a_max, out=out)
24 if a_max is None:
25 a, a_min = promote_types_of_jax_inputs(a, a_min)
26 return ivy.maximum(a, a_min, out=out)
27 return ivy.clip(a, a_min, a_max, out=out)
28
29
30 @handle_jax_dtype
31 @to_ivy_arrays_and_back
32 def concatenate(arrays, axis=0, dtype=None):
33 ret = ivy.concat(arrays, axis=axis)
34 if dtype:
35 ret = ivy.array(ret, dtype=dtype)
36 return ret
37
38
39 @to_ivy_arrays_and_back
40 def repeat(a, repeats, axis=None, *, total_repeat_length=None):
41 return ivy.repeat(a, repeats, axis=axis)
42
43
44 @to_ivy_arrays_and_back
45 def reshape(a, newshape, order="C"):
46 return ivy.reshape(a, shape=newshape, order=order)
47
48
49 @to_ivy_arrays_and_back
50 def ravel(a, order="C"):
51 return ivy.reshape(a, shape=(-1,), order=order)
52
53
54 @to_ivy_arrays_and_back
55 def resize(a, new_shape):
56 a = ivy.array(a)
57 resized_a = ivy.reshape(a, new_shape)
58 return resized_a
59
60
61 @to_ivy_arrays_and_back
62 def moveaxis(a, source, destination):
63 return ivy.moveaxis(a, source, destination)
64
65
66 @to_ivy_arrays_and_back
67 def flipud(m):
68 return ivy.flipud(m, out=None)
69
70
71 @to_ivy_arrays_and_back
72 def transpose(a, axes=None):
73 if not axes:
74 axes = list(range(len(a.shape)))[::-1]
75 if type(axes) is int:
76 axes = [axes]
77 if (len(a.shape) == 0 and not axes) or (len(a.shape) == 1 and axes[0] == 0):
78 return a
79 return ivy.permute_dims(a, axes, out=None)
80
81
82 @to_ivy_arrays_and_back
83 def flip(m, axis=None):
84 return ivy.flip(m, axis=axis)
85
86
87 @to_ivy_arrays_and_back
88 def fliplr(m):
89 return ivy.fliplr(m)
90
91
92 @to_ivy_arrays_and_back
93 def expand_dims(a, axis):
94 return ivy.expand_dims(a, axis=axis)
95
96
97 @to_ivy_arrays_and_back
98 def stack(arrays, axis=0, out=None, dtype=None):
99 if dtype:
100 return ivy.astype(
101 ivy.stack(arrays, axis=axis, out=out), ivy.as_ivy_dtype(dtype)
102 )
103 return ivy.stack(arrays, axis=axis, out=out)
104
105
106 @to_ivy_arrays_and_back
107 def take(
108 a,
109 indices,
110 axis=None,
111 out=None,
112 mode=None,
113 unique_indices=False,
114 indices_are_sorted=False,
115 fill_value=None,
116 ):
117 return ivy.take_along_axis(a, indices, axis, out=out)
118
119
120 @to_ivy_arrays_and_back
121 def broadcast_arrays(*args):
122 return ivy.broadcast_arrays(*args)
123
124
125 @to_ivy_arrays_and_back
126 def broadcast_shapes(*shapes):
127 return ivy.broadcast_shapes(*shapes)
128
129
130 @to_ivy_arrays_and_back
131 def broadcast_to(arr, shape):
132 return ivy.broadcast_to(arr, shape)
133
134
135 @to_ivy_arrays_and_back
136 def append(arr, values, axis=None):
137 if axis is None:
138 return ivy.concat((ivy.flatten(arr), ivy.flatten(values)), axis=0)
139 else:
140 return ivy.concat((arr, values), axis=axis)
141
142
143 @to_ivy_arrays_and_back
144 def swapaxes(a, axis1, axis2):
145 return ivy.swapaxes(a, axis1, axis2)
146
147
148 @to_ivy_arrays_and_back
149 def atleast_3d(*arys):
150 return ivy.atleast_3d(*arys)
151
152
153 @to_ivy_arrays_and_back
154 def atleast_1d(*arys):
155 return ivy.atleast_1d(*arys)
156
157
158 @to_ivy_arrays_and_back
159 def atleast_2d(*arys):
160 return ivy.atleast_2d(*arys)
161
162
163 @to_ivy_arrays_and_back
164 def tril(m, k=0):
165 return ivy.tril(m, k=k)
166
167
168 @to_ivy_arrays_and_back
169 def block(arr, block_size):
170 if isinstance(arr, ivy.Array):
171 arr_blocks = ivy.reshape(
172 arr, ivy.concat([ivy.shape(arr)[:-1], [-1, block_size]], 0)
173 )
174 return arr_blocks
175
176
177 @to_ivy_arrays_and_back
178 def squeeze(a, axis=None):
179 return ivy.squeeze(a, axis)
180
181
182 @to_ivy_arrays_and_back
183 def rot90(m, k=1, axes=(0, 1)):
184 return ivy.rot90(m, k=k, axes=axes)
185
186
187 @to_ivy_arrays_and_back
188 def split(ary, indices_or_sections, axis=0):
189 if isinstance(indices_or_sections, (list, tuple)):
190 indices_or_sections = (
191 ivy.diff(indices_or_sections, prepend=[0], append=[ary.shape[axis]])
192 .astype(ivy.int8)
193 .to_list()
194 )
195 return ivy.split(
196 ary, num_or_size_splits=indices_or_sections, axis=axis, with_remainder=False
197 )
198
199
200 @to_ivy_arrays_and_back
201 def array_split(ary, indices_or_sections, axis=0):
202 if isinstance(indices_or_sections, (list, tuple)):
203 indices_or_sections = (
204 ivy.diff(indices_or_sections, prepend=[0], append=[ary.shape[axis]])
205 .astype(ivy.int8)
206 .to_list()
207 )
208 return ivy.split(
209 ary, num_or_size_splits=indices_or_sections, axis=axis, with_remainder=True
210 )
211
212
213 @to_ivy_arrays_and_back
214 def tile(A, reps):
215 return ivy.tile(A, reps)
216
217
218 @to_ivy_arrays_and_back
219 def dsplit(ary, indices_or_sections):
220 return ivy.dsplit(ary, indices_or_sections)
221
222
223 @to_ivy_arrays_and_back
224 def dstack(tup, dtype=None):
225 return ivy.dstack(tup)
226
227
228 @to_ivy_arrays_and_back
229 def vsplit(ary, indices_or_sections):
230 return ivy.vsplit(ary, indices_or_sections)
231
232
233 @to_ivy_arrays_and_back
234 def hsplit(ary, indices_or_sections):
235 return ivy.hsplit(ary, indices_or_sections)
236
237
238 @to_ivy_arrays_and_back
239 def roll(a, shift, axis=None):
240 return ivy.roll(a, shift, axis=axis)
241
242
243 @to_ivy_arrays_and_back
244 def row_stack(tup):
245 if len(ivy.shape(tup[0])) == 1:
246 xs = []
247 for t in tup:
248 xs += [ivy.reshape(t, (1, ivy.shape(t)[0]))]
249 return ivy.concat(xs, axis=0)
250 return ivy.concat(tup, axis=0)
251
252
253 @to_ivy_arrays_and_back
254 def hamming(M):
255 if M <= 1:
256 return ivy.ones([M], dtype=ivy.float64)
257 n = ivy.arange(M)
258 ret = 0.54 - 0.46 * ivy.cos(2.0 * ivy.pi * n / (M - 1))
259 return ret
260
[end of ivy/functional/frontends/jax/numpy/manipulations.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ivy/functional/frontends/jax/numpy/manipulations.py b/ivy/functional/frontends/jax/numpy/manipulations.py
--- a/ivy/functional/frontends/jax/numpy/manipulations.py
+++ b/ivy/functional/frontends/jax/numpy/manipulations.py
@@ -257,3 +257,12 @@
n = ivy.arange(M)
ret = 0.54 - 0.46 * ivy.cos(2.0 * ivy.pi * n / (M - 1))
return ret
+
+
+@to_ivy_arrays_and_back
+def hanning(M):
+ if M <= 1:
+ return ivy.ones([M], dtype=ivy.float64)
+ n = ivy.arange(M)
+ ret = 0.5 * (1 - ivy.cos(2.0 * ivy.pi * n / (M - 1)))
+ return ret
|
{"golden_diff": "diff --git a/ivy/functional/frontends/jax/numpy/manipulations.py b/ivy/functional/frontends/jax/numpy/manipulations.py\n--- a/ivy/functional/frontends/jax/numpy/manipulations.py\n+++ b/ivy/functional/frontends/jax/numpy/manipulations.py\n@@ -257,3 +257,12 @@\n n = ivy.arange(M)\n ret = 0.54 - 0.46 * ivy.cos(2.0 * ivy.pi * n / (M - 1))\n return ret\n+\n+\n+@to_ivy_arrays_and_back\n+def hanning(M):\n+ if M <= 1:\n+ return ivy.ones([M], dtype=ivy.float64)\n+ n = ivy.arange(M)\n+ ret = 0.5 * (1 - ivy.cos(2.0 * ivy.pi * n / (M - 1)))\n+ return ret\n", "issue": "hanning\n\n", "before_files": [{"content": "# local\nimport ivy\nfrom ivy.functional.frontends.jax.func_wrapper import (\n to_ivy_arrays_and_back,\n handle_jax_dtype,\n)\nfrom ivy.functional.frontends.jax.numpy import promote_types_of_jax_inputs\n\n\n@to_ivy_arrays_and_back\ndef clip(a, a_min=None, a_max=None, out=None):\n ivy.utils.assertions.check_all_or_any_fn(\n a_min,\n a_max,\n fn=ivy.exists,\n type=\"any\",\n limit=[1, 2],\n message=\"at most one of a_min or a_max can be None\",\n )\n a = ivy.array(a)\n if a_min is None:\n a, a_max = promote_types_of_jax_inputs(a, a_max)\n return ivy.minimum(a, a_max, out=out)\n if a_max is None:\n a, a_min = promote_types_of_jax_inputs(a, a_min)\n return ivy.maximum(a, a_min, out=out)\n return ivy.clip(a, a_min, a_max, out=out)\n\n\n@handle_jax_dtype\n@to_ivy_arrays_and_back\ndef concatenate(arrays, axis=0, dtype=None):\n ret = ivy.concat(arrays, axis=axis)\n if dtype:\n ret = ivy.array(ret, dtype=dtype)\n return ret\n\n\n@to_ivy_arrays_and_back\ndef repeat(a, repeats, axis=None, *, total_repeat_length=None):\n return ivy.repeat(a, repeats, axis=axis)\n\n\n@to_ivy_arrays_and_back\ndef reshape(a, newshape, order=\"C\"):\n return ivy.reshape(a, shape=newshape, order=order)\n\n\n@to_ivy_arrays_and_back\ndef ravel(a, order=\"C\"):\n return ivy.reshape(a, shape=(-1,), order=order)\n\n\n@to_ivy_arrays_and_back\ndef resize(a, new_shape):\n a = ivy.array(a)\n resized_a = ivy.reshape(a, new_shape)\n return resized_a\n\n\n@to_ivy_arrays_and_back\ndef moveaxis(a, source, destination):\n return ivy.moveaxis(a, source, destination)\n\n\n@to_ivy_arrays_and_back\ndef flipud(m):\n return ivy.flipud(m, out=None)\n\n\n@to_ivy_arrays_and_back\ndef transpose(a, axes=None):\n if not axes:\n axes = list(range(len(a.shape)))[::-1]\n if type(axes) is int:\n axes = [axes]\n if (len(a.shape) == 0 and not axes) or (len(a.shape) == 1 and axes[0] == 0):\n return a\n return ivy.permute_dims(a, axes, out=None)\n\n\n@to_ivy_arrays_and_back\ndef flip(m, axis=None):\n return ivy.flip(m, axis=axis)\n\n\n@to_ivy_arrays_and_back\ndef fliplr(m):\n return ivy.fliplr(m)\n\n\n@to_ivy_arrays_and_back\ndef expand_dims(a, axis):\n return ivy.expand_dims(a, axis=axis)\n\n\n@to_ivy_arrays_and_back\ndef stack(arrays, axis=0, out=None, dtype=None):\n if dtype:\n return ivy.astype(\n ivy.stack(arrays, axis=axis, out=out), ivy.as_ivy_dtype(dtype)\n )\n return ivy.stack(arrays, axis=axis, out=out)\n\n\n@to_ivy_arrays_and_back\ndef take(\n a,\n indices,\n axis=None,\n out=None,\n mode=None,\n unique_indices=False,\n indices_are_sorted=False,\n fill_value=None,\n):\n return ivy.take_along_axis(a, indices, axis, out=out)\n\n\n@to_ivy_arrays_and_back\ndef broadcast_arrays(*args):\n return ivy.broadcast_arrays(*args)\n\n\n@to_ivy_arrays_and_back\ndef broadcast_shapes(*shapes):\n return ivy.broadcast_shapes(*shapes)\n\n\n@to_ivy_arrays_and_back\ndef broadcast_to(arr, shape):\n return ivy.broadcast_to(arr, shape)\n\n\n@to_ivy_arrays_and_back\ndef append(arr, values, axis=None):\n if axis is None:\n return ivy.concat((ivy.flatten(arr), ivy.flatten(values)), axis=0)\n else:\n return ivy.concat((arr, values), axis=axis)\n\n\n@to_ivy_arrays_and_back\ndef swapaxes(a, axis1, axis2):\n return ivy.swapaxes(a, axis1, axis2)\n\n\n@to_ivy_arrays_and_back\ndef atleast_3d(*arys):\n return ivy.atleast_3d(*arys)\n\n\n@to_ivy_arrays_and_back\ndef atleast_1d(*arys):\n return ivy.atleast_1d(*arys)\n\n\n@to_ivy_arrays_and_back\ndef atleast_2d(*arys):\n return ivy.atleast_2d(*arys)\n\n\n@to_ivy_arrays_and_back\ndef tril(m, k=0):\n return ivy.tril(m, k=k)\n\n\n@to_ivy_arrays_and_back\ndef block(arr, block_size):\n if isinstance(arr, ivy.Array):\n arr_blocks = ivy.reshape(\n arr, ivy.concat([ivy.shape(arr)[:-1], [-1, block_size]], 0)\n )\n return arr_blocks\n\n\n@to_ivy_arrays_and_back\ndef squeeze(a, axis=None):\n return ivy.squeeze(a, axis)\n\n\n@to_ivy_arrays_and_back\ndef rot90(m, k=1, axes=(0, 1)):\n return ivy.rot90(m, k=k, axes=axes)\n\n\n@to_ivy_arrays_and_back\ndef split(ary, indices_or_sections, axis=0):\n if isinstance(indices_or_sections, (list, tuple)):\n indices_or_sections = (\n ivy.diff(indices_or_sections, prepend=[0], append=[ary.shape[axis]])\n .astype(ivy.int8)\n .to_list()\n )\n return ivy.split(\n ary, num_or_size_splits=indices_or_sections, axis=axis, with_remainder=False\n )\n\n\n@to_ivy_arrays_and_back\ndef array_split(ary, indices_or_sections, axis=0):\n if isinstance(indices_or_sections, (list, tuple)):\n indices_or_sections = (\n ivy.diff(indices_or_sections, prepend=[0], append=[ary.shape[axis]])\n .astype(ivy.int8)\n .to_list()\n )\n return ivy.split(\n ary, num_or_size_splits=indices_or_sections, axis=axis, with_remainder=True\n )\n\n\n@to_ivy_arrays_and_back\ndef tile(A, reps):\n return ivy.tile(A, reps)\n\n\n@to_ivy_arrays_and_back\ndef dsplit(ary, indices_or_sections):\n return ivy.dsplit(ary, indices_or_sections)\n\n\n@to_ivy_arrays_and_back\ndef dstack(tup, dtype=None):\n return ivy.dstack(tup)\n\n\n@to_ivy_arrays_and_back\ndef vsplit(ary, indices_or_sections):\n return ivy.vsplit(ary, indices_or_sections)\n\n\n@to_ivy_arrays_and_back\ndef hsplit(ary, indices_or_sections):\n return ivy.hsplit(ary, indices_or_sections)\n\n\n@to_ivy_arrays_and_back\ndef roll(a, shift, axis=None):\n return ivy.roll(a, shift, axis=axis)\n\n\n@to_ivy_arrays_and_back\ndef row_stack(tup):\n if len(ivy.shape(tup[0])) == 1:\n xs = []\n for t in tup:\n xs += [ivy.reshape(t, (1, ivy.shape(t)[0]))]\n return ivy.concat(xs, axis=0)\n return ivy.concat(tup, axis=0)\n\n\n@to_ivy_arrays_and_back\ndef hamming(M):\n if M <= 1:\n return ivy.ones([M], dtype=ivy.float64)\n n = ivy.arange(M)\n ret = 0.54 - 0.46 * ivy.cos(2.0 * ivy.pi * n / (M - 1))\n return ret\n", "path": "ivy/functional/frontends/jax/numpy/manipulations.py"}]}
| 3,038 | 217 |
gh_patches_debug_5336
|
rasdani/github-patches
|
git_diff
|
openstates__openstates-scrapers-1441
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
MA: Where are the Republicans?
All state legislators in MA are in either the Democratic party or Other. It's a nice fantasy but it's not reality!
</issue>
<code>
[start of openstates/ma/legislators.py]
1 import re
2
3 import lxml.html
4 from billy.scrape.legislators import LegislatorScraper, Legislator
5
6
7 def clean_district(district):
8 mappings = {
9 1: 'First',
10 2: 'Second',
11 3: 'Third',
12 4: 'Fourth',
13 5: 'Fifth',
14 6: 'Sixth',
15 7: 'Seventh',
16 8: 'Eighth',
17 9: 'Ninth',
18 10: 'Tenth',
19 11: 'Eleventh',
20 12: 'Twelfth',
21 13: 'Thirteenth',
22 14: 'Fourteenth',
23 15: 'Fifteenth',
24 16: 'Sixteenth',
25 17: 'Seventeenth',
26 18: 'Eighteenth',
27 19: 'Nineteenth',
28 20: 'Twentieth',
29 }
30 pieces = re.match('(\d+)\w\w\s(.+)', district)
31 if pieces:
32 ordinal, rest = pieces.groups()
33 ordinal = int(ordinal)
34 if ordinal <= 20:
35 ordinal = mappings[ordinal]
36 elif ordinal < 30:
37 ordinal = 'Twenty-' + mappings[ordinal-20]
38 elif ordinal == 30:
39 ordinal = 'Thirtieth'
40 elif ordinal < 40:
41 ordinal = 'Thirty-' + mappings[ordinal-30]
42 district = '{} {}'.format(ordinal, rest)
43
44 return district
45
46
47 class MALegislatorScraper(LegislatorScraper):
48 jurisdiction = 'ma'
49
50 def scrape(self, chamber, term):
51 self.validate_term(term, latest_only=True)
52
53 if chamber == 'upper':
54 chamber_type = 'Senate'
55 else:
56 chamber_type = 'House'
57
58 url = "https://malegislature.gov/People/%s" % chamber_type
59 page = self.get(url).text
60 doc = lxml.html.fromstring(page)
61 doc.make_links_absolute("https://malegislature.gov")
62
63 for member_url in doc.xpath('//td[@class="pictureCol"]/a/@href'):
64 self.scrape_member(chamber, term, member_url)
65
66 def scrape_member(self, chamber, term, member_url):
67 page = self.get(member_url).text
68 root = lxml.html.fromstring(page)
69 root.make_links_absolute(member_url)
70
71 photo_url = root.xpath('//div[@class="thumbPhoto"]/img/@src')[0]
72 full_name = root.xpath('//h1/span')[0].tail.strip()
73
74 email = root.xpath('//a[contains(@href, "mailto")]/@href')[0]
75 email = email.replace('mailto:', '')
76
77 party, district = root.xpath('//h1/span')[1].text.split('-')
78 party = party.strip()
79 district = clean_district(district.strip())
80
81 if party == 'Democrat':
82 party = 'Democratic'
83 elif party == 'R':
84 party = 'Republican'
85 else:
86 party = 'Other'
87
88 leg = Legislator(term, chamber, district, full_name, party=party,
89 photo_url=photo_url, url=member_url)
90 leg.add_source(member_url)
91
92 # offices
93
94 # this bool is so we only attach the email to one office
95 # and we make sure to create at least one office
96 email_stored = True
97 if email:
98 email_stored = False
99
100 for addr in root.xpath('//address/div[@class="contactGroup"]'):
101 office_name = addr.xpath('../preceding-sibling::h4/text()'
102 )[0].strip()
103 address = addr.xpath('a')[0].text_content()
104 address = re.sub('\s{2,}', '\n', address)
105
106 phone = fax = next = None
107 for phonerow in addr.xpath('./div/div'):
108 phonerow = phonerow.text_content().strip()
109 if phonerow == 'Phone:':
110 next = 'phone'
111 elif phonerow == 'Fax:':
112 next = 'fax'
113 elif next == 'phone':
114 phone = phonerow
115 next = None
116 elif next == 'fax':
117 fax = phonerow
118 next = None
119 else:
120 self.warning('unknown phonerow %s', phonerow)
121
122 # all pieces collected
123 if 'District' in office_name:
124 otype = 'district'
125 elif 'State' in office_name:
126 otype = 'capitol'
127
128 if not email_stored:
129 email_stored = True
130 leg.add_office(otype, office_name, phone=phone, fax=fax,
131 address=address, email=email)
132 else:
133 leg.add_office(otype, office_name, phone=phone, fax=fax,
134 address=address)
135
136 if not email_stored:
137 leg.add_office('capitol', 'Capitol Office', email=email)
138
139 self.save_legislator(leg)
140
[end of openstates/ma/legislators.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/openstates/ma/legislators.py b/openstates/ma/legislators.py
--- a/openstates/ma/legislators.py
+++ b/openstates/ma/legislators.py
@@ -78,9 +78,9 @@
party = party.strip()
district = clean_district(district.strip())
- if party == 'Democrat':
+ if party in ('D', 'Democrat', 'Democratic'):
party = 'Democratic'
- elif party == 'R':
+ elif party in ('R', 'Republican'):
party = 'Republican'
else:
party = 'Other'
|
{"golden_diff": "diff --git a/openstates/ma/legislators.py b/openstates/ma/legislators.py\n--- a/openstates/ma/legislators.py\n+++ b/openstates/ma/legislators.py\n@@ -78,9 +78,9 @@\n party = party.strip()\n district = clean_district(district.strip())\n \n- if party == 'Democrat':\n+ if party in ('D', 'Democrat', 'Democratic'):\n party = 'Democratic'\n- elif party == 'R':\n+ elif party in ('R', 'Republican'):\n party = 'Republican'\n else:\n party = 'Other'\n", "issue": "MA: Where are the Republicans?\nAll state legislators in MA are in either the Democratic party or Other. It's a nice fantasy but it's not reality!\r\n\n", "before_files": [{"content": "import re\n\nimport lxml.html\nfrom billy.scrape.legislators import LegislatorScraper, Legislator\n\n\ndef clean_district(district):\n mappings = {\n 1: 'First',\n 2: 'Second',\n 3: 'Third',\n 4: 'Fourth',\n 5: 'Fifth',\n 6: 'Sixth',\n 7: 'Seventh',\n 8: 'Eighth',\n 9: 'Ninth',\n 10: 'Tenth',\n 11: 'Eleventh',\n 12: 'Twelfth',\n 13: 'Thirteenth',\n 14: 'Fourteenth',\n 15: 'Fifteenth',\n 16: 'Sixteenth',\n 17: 'Seventeenth',\n 18: 'Eighteenth',\n 19: 'Nineteenth',\n 20: 'Twentieth',\n }\n pieces = re.match('(\\d+)\\w\\w\\s(.+)', district)\n if pieces:\n ordinal, rest = pieces.groups()\n ordinal = int(ordinal)\n if ordinal <= 20:\n ordinal = mappings[ordinal]\n elif ordinal < 30:\n ordinal = 'Twenty-' + mappings[ordinal-20]\n elif ordinal == 30:\n ordinal = 'Thirtieth'\n elif ordinal < 40:\n ordinal = 'Thirty-' + mappings[ordinal-30]\n district = '{} {}'.format(ordinal, rest)\n\n return district\n\n\nclass MALegislatorScraper(LegislatorScraper):\n jurisdiction = 'ma'\n\n def scrape(self, chamber, term):\n self.validate_term(term, latest_only=True)\n\n if chamber == 'upper':\n chamber_type = 'Senate'\n else:\n chamber_type = 'House'\n\n url = \"https://malegislature.gov/People/%s\" % chamber_type\n page = self.get(url).text\n doc = lxml.html.fromstring(page)\n doc.make_links_absolute(\"https://malegislature.gov\")\n\n for member_url in doc.xpath('//td[@class=\"pictureCol\"]/a/@href'):\n self.scrape_member(chamber, term, member_url)\n\n def scrape_member(self, chamber, term, member_url):\n page = self.get(member_url).text\n root = lxml.html.fromstring(page)\n root.make_links_absolute(member_url)\n\n photo_url = root.xpath('//div[@class=\"thumbPhoto\"]/img/@src')[0]\n full_name = root.xpath('//h1/span')[0].tail.strip()\n\n email = root.xpath('//a[contains(@href, \"mailto\")]/@href')[0]\n email = email.replace('mailto:', '')\n\n party, district = root.xpath('//h1/span')[1].text.split('-')\n party = party.strip()\n district = clean_district(district.strip())\n\n if party == 'Democrat':\n party = 'Democratic'\n elif party == 'R':\n party = 'Republican'\n else:\n party = 'Other'\n\n leg = Legislator(term, chamber, district, full_name, party=party,\n photo_url=photo_url, url=member_url)\n leg.add_source(member_url)\n\n # offices\n\n # this bool is so we only attach the email to one office\n # and we make sure to create at least one office\n email_stored = True\n if email:\n email_stored = False\n\n for addr in root.xpath('//address/div[@class=\"contactGroup\"]'):\n office_name = addr.xpath('../preceding-sibling::h4/text()'\n )[0].strip()\n address = addr.xpath('a')[0].text_content()\n address = re.sub('\\s{2,}', '\\n', address)\n\n phone = fax = next = None\n for phonerow in addr.xpath('./div/div'):\n phonerow = phonerow.text_content().strip()\n if phonerow == 'Phone:':\n next = 'phone'\n elif phonerow == 'Fax:':\n next = 'fax'\n elif next == 'phone':\n phone = phonerow\n next = None\n elif next == 'fax':\n fax = phonerow\n next = None\n else:\n self.warning('unknown phonerow %s', phonerow)\n\n # all pieces collected\n if 'District' in office_name:\n otype = 'district'\n elif 'State' in office_name:\n otype = 'capitol'\n\n if not email_stored:\n email_stored = True\n leg.add_office(otype, office_name, phone=phone, fax=fax,\n address=address, email=email)\n else:\n leg.add_office(otype, office_name, phone=phone, fax=fax,\n address=address)\n\n if not email_stored:\n leg.add_office('capitol', 'Capitol Office', email=email)\n\n self.save_legislator(leg)\n", "path": "openstates/ma/legislators.py"}]}
| 1,987 | 140 |
gh_patches_debug_34695
|
rasdani/github-patches
|
git_diff
|
numpy__numpy-7952
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Building Numpy package fails with TypeError: __init__() takes from 3 to 4 positional arguments but 13 were given
I'm trying in build Numpy on Ubuntu Server Xenial (Armbian 5.14). I have installed `libexpat1-dev`, `libpython3-dev`, `libpython3.5-dev`, `python3-dev`, `python3.5-dev`, `build-essential`, `gcc`, `gfortran`, `gfortran-5`, `libgfortran-5-dev`, `libgfortran3`, `libblas-common`, `libblas-dev`, `libblas3`, `libopenblas-base`, `libopenblas-dev`, `cython`, `libpng-dev`. Cloned git repo to a dir and ran `python3 setup.py build`. Here's the log:
`$ python3 setup.py build`
`Running from numpy source directory.`
`Cythonizing sources`
`numpy/random/mtrand/mtrand.pyx has not changed`
`Traceback (most recent call last):`
`File "setup.py", line 390, in <module>`
`setup_package()`
`File "setup.py", line 382, in setup_package`
`setup(**metadata)`
`File "/home/odroid/downloads/numpy/numpy/distutils/core.py", line 135, in setup
config = configuration()`
`File "setup.py", line 165, in configuration`
`config.add_subpackage('numpy')`
`File "/home/odroid/downloads/numpy/numpy/distutils/misc_util.py", line 1001, in add_subpackage`
`caller_level = 2)`
`File "/home/odroid/downloads/numpy/numpy/distutils/misc_util.py", line 970, in get_subpackage`
`caller_level = caller_level + 1)`
`File "/home/odroid/downloads/numpy/numpy/distutils/misc_util.py", line 907, in _get_configuration_from_setup_py`
`config = setup_module.configuration(*args)`
`File "numpy/setup.py", line 10, in configuration`
`config.add_subpackage('core')`
`File "/home/odroid/downloads/numpy/numpy/distutils/misc_util.py", line 1001, in add_subpackage`
`caller_level = 2)`
`File "/home/odroid/downloads/numpy/numpy/distutils/misc_util.py", line 970, in get_subpackage`
`caller_level = caller_level + 1)`
`File "/home/odroid/downloads/numpy/numpy/distutils/misc_util.py", line 907, in _get_configuration_from_setup_py`
`config = setup_module.configuration(*args)`
`File "numpy/core/setup.py", line 638, in configuration
generate_numpy_api]`
`File "/home/odroid/downloads/numpy/numpy/distutils/misc_util.py", line 1483, in add_extension`
`ext = Extension(**ext_args)`
`File "/home/odroid/downloads/numpy/numpy/distutils/extension.py", line 52, in __init__
export_symbols)`
`TypeError: __init__() takes from 3 to 4 positional arguments but 13 were given`
How can it be fixed?
</issue>
<code>
[start of numpy/distutils/extension.py]
1 """distutils.extension
2
3 Provides the Extension class, used to describe C/C++ extension
4 modules in setup scripts.
5
6 Overridden to support f2py.
7
8 """
9 from __future__ import division, absolute_import, print_function
10
11 import sys
12 import re
13 from distutils.extension import Extension as old_Extension
14
15 if sys.version_info[0] >= 3:
16 basestring = str
17
18
19 cxx_ext_re = re.compile(r'.*[.](cpp|cxx|cc)\Z', re.I).match
20 fortran_pyf_ext_re = re.compile(r'.*[.](f90|f95|f77|for|ftn|f|pyf)\Z', re.I).match
21
22 class Extension(old_Extension):
23 def __init__ (self, name, sources,
24 include_dirs=None,
25 define_macros=None,
26 undef_macros=None,
27 library_dirs=None,
28 libraries=None,
29 runtime_library_dirs=None,
30 extra_objects=None,
31 extra_compile_args=None,
32 extra_link_args=None,
33 export_symbols=None,
34 swig_opts=None,
35 depends=None,
36 language=None,
37 f2py_options=None,
38 module_dirs=None,
39 extra_f77_compile_args=None,
40 extra_f90_compile_args=None,
41 ):
42 old_Extension.__init__(self, name, [],
43 include_dirs,
44 define_macros,
45 undef_macros,
46 library_dirs,
47 libraries,
48 runtime_library_dirs,
49 extra_objects,
50 extra_compile_args,
51 extra_link_args,
52 export_symbols)
53 # Avoid assert statements checking that sources contains strings:
54 self.sources = sources
55
56 # Python 2.4 distutils new features
57 self.swig_opts = swig_opts or []
58 # swig_opts is assumed to be a list. Here we handle the case where it
59 # is specified as a string instead.
60 if isinstance(self.swig_opts, basestring):
61 import warnings
62 msg = "swig_opts is specified as a string instead of a list"
63 warnings.warn(msg, SyntaxWarning)
64 self.swig_opts = self.swig_opts.split()
65
66 # Python 2.3 distutils new features
67 self.depends = depends or []
68 self.language = language
69
70 # numpy_distutils features
71 self.f2py_options = f2py_options or []
72 self.module_dirs = module_dirs or []
73 self.extra_f77_compile_args = extra_f77_compile_args or []
74 self.extra_f90_compile_args = extra_f90_compile_args or []
75
76 return
77
78 def has_cxx_sources(self):
79 for source in self.sources:
80 if cxx_ext_re(str(source)):
81 return True
82 return False
83
84 def has_f2py_sources(self):
85 for source in self.sources:
86 if fortran_pyf_ext_re(source):
87 return True
88 return False
89
90 # class Extension
91
[end of numpy/distutils/extension.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/numpy/distutils/extension.py b/numpy/distutils/extension.py
--- a/numpy/distutils/extension.py
+++ b/numpy/distutils/extension.py
@@ -20,36 +20,39 @@
fortran_pyf_ext_re = re.compile(r'.*[.](f90|f95|f77|for|ftn|f|pyf)\Z', re.I).match
class Extension(old_Extension):
- def __init__ (self, name, sources,
- include_dirs=None,
- define_macros=None,
- undef_macros=None,
- library_dirs=None,
- libraries=None,
- runtime_library_dirs=None,
- extra_objects=None,
- extra_compile_args=None,
- extra_link_args=None,
- export_symbols=None,
- swig_opts=None,
- depends=None,
- language=None,
- f2py_options=None,
- module_dirs=None,
- extra_f77_compile_args=None,
- extra_f90_compile_args=None,
- ):
- old_Extension.__init__(self, name, [],
- include_dirs,
- define_macros,
- undef_macros,
- library_dirs,
- libraries,
- runtime_library_dirs,
- extra_objects,
- extra_compile_args,
- extra_link_args,
- export_symbols)
+ def __init__ (
+ self, name, sources,
+ include_dirs=None,
+ define_macros=None,
+ undef_macros=None,
+ library_dirs=None,
+ libraries=None,
+ runtime_library_dirs=None,
+ extra_objects=None,
+ extra_compile_args=None,
+ extra_link_args=None,
+ export_symbols=None,
+ swig_opts=None,
+ depends=None,
+ language=None,
+ f2py_options=None,
+ module_dirs=None,
+ extra_f77_compile_args=None,
+ extra_f90_compile_args=None,):
+
+ old_Extension.__init__(
+ self, name, [],
+ include_dirs=include_dirs,
+ define_macros=define_macros,
+ undef_macros=undef_macros,
+ library_dirs=library_dirs,
+ libraries=libraries,
+ runtime_library_dirs=runtime_library_dirs,
+ extra_objects=extra_objects,
+ extra_compile_args=extra_compile_args,
+ extra_link_args=extra_link_args,
+ export_symbols=export_symbols)
+
# Avoid assert statements checking that sources contains strings:
self.sources = sources
|
{"golden_diff": "diff --git a/numpy/distutils/extension.py b/numpy/distutils/extension.py\n--- a/numpy/distutils/extension.py\n+++ b/numpy/distutils/extension.py\n@@ -20,36 +20,39 @@\n fortran_pyf_ext_re = re.compile(r'.*[.](f90|f95|f77|for|ftn|f|pyf)\\Z', re.I).match\n \n class Extension(old_Extension):\n- def __init__ (self, name, sources,\n- include_dirs=None,\n- define_macros=None,\n- undef_macros=None,\n- library_dirs=None,\n- libraries=None,\n- runtime_library_dirs=None,\n- extra_objects=None,\n- extra_compile_args=None,\n- extra_link_args=None,\n- export_symbols=None,\n- swig_opts=None,\n- depends=None,\n- language=None,\n- f2py_options=None,\n- module_dirs=None,\n- extra_f77_compile_args=None,\n- extra_f90_compile_args=None,\n- ):\n- old_Extension.__init__(self, name, [],\n- include_dirs,\n- define_macros,\n- undef_macros,\n- library_dirs,\n- libraries,\n- runtime_library_dirs,\n- extra_objects,\n- extra_compile_args,\n- extra_link_args,\n- export_symbols)\n+ def __init__ (\n+ self, name, sources,\n+ include_dirs=None,\n+ define_macros=None,\n+ undef_macros=None,\n+ library_dirs=None,\n+ libraries=None,\n+ runtime_library_dirs=None,\n+ extra_objects=None,\n+ extra_compile_args=None,\n+ extra_link_args=None,\n+ export_symbols=None,\n+ swig_opts=None,\n+ depends=None,\n+ language=None,\n+ f2py_options=None,\n+ module_dirs=None,\n+ extra_f77_compile_args=None,\n+ extra_f90_compile_args=None,):\n+\n+ old_Extension.__init__(\n+ self, name, [],\n+ include_dirs=include_dirs,\n+ define_macros=define_macros,\n+ undef_macros=undef_macros,\n+ library_dirs=library_dirs,\n+ libraries=libraries,\n+ runtime_library_dirs=runtime_library_dirs,\n+ extra_objects=extra_objects,\n+ extra_compile_args=extra_compile_args,\n+ extra_link_args=extra_link_args,\n+ export_symbols=export_symbols)\n+\n # Avoid assert statements checking that sources contains strings:\n self.sources = sources\n", "issue": "Building Numpy package fails with TypeError: __init__() takes from 3 to 4 positional arguments but 13 were given\nI'm trying in build Numpy on Ubuntu Server Xenial (Armbian 5.14). I have installed `libexpat1-dev`, `libpython3-dev`, `libpython3.5-dev`, `python3-dev`, `python3.5-dev`, `build-essential`, `gcc`, `gfortran`, `gfortran-5`, `libgfortran-5-dev`, `libgfortran3`, `libblas-common`, `libblas-dev`, `libblas3`, `libopenblas-base`, `libopenblas-dev`, `cython`, `libpng-dev`. Cloned git repo to a dir and ran `python3 setup.py build`. Here's the log:\n\n`$ python3 setup.py build`\n\n`Running from numpy source directory.`\n`Cythonizing sources`\n`numpy/random/mtrand/mtrand.pyx has not changed`\n`Traceback (most recent call last):`\n`File \"setup.py\", line 390, in <module>`\n`setup_package()`\n`File \"setup.py\", line 382, in setup_package`\n`setup(**metadata)`\n`File \"/home/odroid/downloads/numpy/numpy/distutils/core.py\", line 135, in setup\n config = configuration()`\n`File \"setup.py\", line 165, in configuration`\n`config.add_subpackage('numpy')`\n`File \"/home/odroid/downloads/numpy/numpy/distutils/misc_util.py\", line 1001, in add_subpackage`\n`caller_level = 2)`\n`File \"/home/odroid/downloads/numpy/numpy/distutils/misc_util.py\", line 970, in get_subpackage`\n`caller_level = caller_level + 1)`\n`File \"/home/odroid/downloads/numpy/numpy/distutils/misc_util.py\", line 907, in _get_configuration_from_setup_py`\n`config = setup_module.configuration(*args)`\n`File \"numpy/setup.py\", line 10, in configuration`\n`config.add_subpackage('core')`\n`File \"/home/odroid/downloads/numpy/numpy/distutils/misc_util.py\", line 1001, in add_subpackage`\n`caller_level = 2)`\n`File \"/home/odroid/downloads/numpy/numpy/distutils/misc_util.py\", line 970, in get_subpackage`\n`caller_level = caller_level + 1)`\n`File \"/home/odroid/downloads/numpy/numpy/distutils/misc_util.py\", line 907, in _get_configuration_from_setup_py`\n`config = setup_module.configuration(*args)`\n`File \"numpy/core/setup.py\", line 638, in configuration\n generate_numpy_api]`\n`File \"/home/odroid/downloads/numpy/numpy/distutils/misc_util.py\", line 1483, in add_extension`\n`ext = Extension(**ext_args)`\n`File \"/home/odroid/downloads/numpy/numpy/distutils/extension.py\", line 52, in __init__\n export_symbols)`\n`TypeError: __init__() takes from 3 to 4 positional arguments but 13 were given`\n\nHow can it be fixed?\n\n", "before_files": [{"content": "\"\"\"distutils.extension\n\nProvides the Extension class, used to describe C/C++ extension\nmodules in setup scripts.\n\nOverridden to support f2py.\n\n\"\"\"\nfrom __future__ import division, absolute_import, print_function\n\nimport sys\nimport re\nfrom distutils.extension import Extension as old_Extension\n\nif sys.version_info[0] >= 3:\n basestring = str\n\n\ncxx_ext_re = re.compile(r'.*[.](cpp|cxx|cc)\\Z', re.I).match\nfortran_pyf_ext_re = re.compile(r'.*[.](f90|f95|f77|for|ftn|f|pyf)\\Z', re.I).match\n\nclass Extension(old_Extension):\n def __init__ (self, name, sources,\n include_dirs=None,\n define_macros=None,\n undef_macros=None,\n library_dirs=None,\n libraries=None,\n runtime_library_dirs=None,\n extra_objects=None,\n extra_compile_args=None,\n extra_link_args=None,\n export_symbols=None,\n swig_opts=None,\n depends=None,\n language=None,\n f2py_options=None,\n module_dirs=None,\n extra_f77_compile_args=None,\n extra_f90_compile_args=None,\n ):\n old_Extension.__init__(self, name, [],\n include_dirs,\n define_macros,\n undef_macros,\n library_dirs,\n libraries,\n runtime_library_dirs,\n extra_objects,\n extra_compile_args,\n extra_link_args,\n export_symbols)\n # Avoid assert statements checking that sources contains strings:\n self.sources = sources\n\n # Python 2.4 distutils new features\n self.swig_opts = swig_opts or []\n # swig_opts is assumed to be a list. Here we handle the case where it\n # is specified as a string instead.\n if isinstance(self.swig_opts, basestring):\n import warnings\n msg = \"swig_opts is specified as a string instead of a list\"\n warnings.warn(msg, SyntaxWarning)\n self.swig_opts = self.swig_opts.split()\n\n # Python 2.3 distutils new features\n self.depends = depends or []\n self.language = language\n\n # numpy_distutils features\n self.f2py_options = f2py_options or []\n self.module_dirs = module_dirs or []\n self.extra_f77_compile_args = extra_f77_compile_args or []\n self.extra_f90_compile_args = extra_f90_compile_args or []\n\n return\n\n def has_cxx_sources(self):\n for source in self.sources:\n if cxx_ext_re(str(source)):\n return True\n return False\n\n def has_f2py_sources(self):\n for source in self.sources:\n if fortran_pyf_ext_re(source):\n return True\n return False\n\n# class Extension\n", "path": "numpy/distutils/extension.py"}]}
| 2,023 | 544 |
gh_patches_debug_31333
|
rasdani/github-patches
|
git_diff
|
biopython__biopython-1271
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`Bio.PDB.PDBIO.set_structure()` alters parent of chains, residues and atoms
Calling the `set_structure` method of the `Bio.PDB.PDBIO` class alters the parent of (non-`Structure`) entities in a non-obvious way. For example, this script:
```python
import Bio.PDB
pdbio = Bio.PDB.PDBIO()
parser = Bio.PDB.MMCIFParser()
structure = parser.get_structure("12as", "12as.cif")
for chain in structure[0]:
old_id = chain.id
chain.id = " "
pdbio.set_structure(chain)
chain.id = old_id
```
Gives this error from line 91 of `Bio/PDB/Entity.py`:
```
ValueError: Cannot change id from `B` to ` `. The id ` ` is already used for a sibling of this entity.
```
Removing the call to `set_structure` acts as I would expect: temporarily renaming the chain name, and then reverting it without problems.
When `set_structure` is called with an `Entity` other than a `Structure` object, it constructs a `Structure` and populates it with the entity using the `add` method, which calls `set_parent` on the entity. To me, this isn't very intuitive: I don't expect writing an object to have side effects that act on that object.
I think a good solution to this would be to call `copy()` in `set_structure` before `add`ing the entity to the new `Structure` object. That is, change `sb.structure.add(pdb_object)` to `sb.structure.add(pdb_object.copy())` in `Bio.PDB.PDBIO.set_structure`. I'm happy to make a pull request if people agree that this is an issue.
</issue>
<code>
[start of Bio/PDB/PDBIO.py]
1 # Copyright (C) 2002, Thomas Hamelryck ([email protected])
2 # This code is part of the Biopython distribution and governed by its
3 # license. Please see the LICENSE file that should have been included
4 # as part of this package.
5
6 """Output of PDB files."""
7
8 from Bio._py3k import basestring
9
10 from Bio.PDB.StructureBuilder import StructureBuilder # To allow saving of chains, residues, etc..
11 from Bio.Data.IUPACData import atom_weights # Allowed Elements
12
13
14 _ATOM_FORMAT_STRING = "%s%5i %-4s%c%3s %c%4i%c %8.3f%8.3f%8.3f%s%6.2f %4s%2s%2s\n"
15
16
17 class Select(object):
18 """Select everything for PDB output (for use as a base class).
19
20 Default selection (everything) during writing - can be used as base class
21 to implement selective output. This selects which entities will be written out.
22 """
23
24 def __repr__(self):
25 """Represent the output as a string for debugging."""
26 return "<Select all>"
27
28 def accept_model(self, model):
29 """Overload this to reject models for output."""
30 return 1
31
32 def accept_chain(self, chain):
33 """Overload this to reject chains for output."""
34 return 1
35
36 def accept_residue(self, residue):
37 """Overload this to reject residues for output."""
38 return 1
39
40 def accept_atom(self, atom):
41 """Overload this to reject atoms for output."""
42 return 1
43
44
45 class PDBIO(object):
46 """Write a Structure object (or a subset of a Structure object) as a PDB file.
47
48 Examples
49 --------
50 >>> p=PDBParser()
51 >>> s=p.get_structure("1fat", "1fat.pdb")
52 >>> io=PDBIO()
53 >>> io.set_structure(s)
54 >>> io.save("out.pdb")
55
56 """
57
58 def __init__(self, use_model_flag=0):
59 """Create the PDBIO object.
60
61 :param use_model_flag: if 1, force use of the MODEL record in output.
62 :type use_model_flag: int
63 """
64 self.use_model_flag = use_model_flag
65
66 # private mathods
67
68 def _get_atom_line(self, atom, hetfield, segid, atom_number, resname,
69 resseq, icode, chain_id, charge=" "):
70 """Return an ATOM PDB string (PRIVATE)."""
71 if hetfield != " ":
72 record_type = "HETATM"
73 else:
74 record_type = "ATOM "
75
76 if atom.element:
77 element = atom.element.strip().upper()
78 if element.capitalize() not in atom_weights:
79 raise ValueError("Unrecognised element %r" % atom.element)
80 element = element.rjust(2)
81 else:
82 element = " "
83
84 name = atom.get_fullname().strip()
85 # Pad atom name if:
86 # - smaller than 4 characters
87 # AND - is not C, N, O, S, H, F, P, ..., one letter elements
88 # AND - first character is NOT numeric (funky hydrogen naming rules)
89 if len(name) < 4 and name[:1].isalpha() and len(element.strip()) < 2:
90 name = " " + name
91
92 altloc = atom.get_altloc()
93 x, y, z = atom.get_coord()
94 bfactor = atom.get_bfactor()
95 occupancy = atom.get_occupancy()
96 try:
97 occupancy_str = "%6.2f" % occupancy
98 except TypeError:
99 if occupancy is None:
100 occupancy_str = " " * 6
101 import warnings
102 from Bio import BiopythonWarning
103 warnings.warn("Missing occupancy in atom %s written as blank" %
104 repr(atom.get_full_id()), BiopythonWarning)
105 else:
106 raise TypeError("Invalid occupancy %r in atom %r"
107 % (occupancy, atom.get_full_id()))
108
109 args = (record_type, atom_number, name, altloc, resname, chain_id,
110 resseq, icode, x, y, z, occupancy_str, bfactor, segid,
111 element, charge)
112 return _ATOM_FORMAT_STRING % args
113
114 # Public methods
115
116 def set_structure(self, pdb_object):
117 """Check what the user is providing and build a structure."""
118 if pdb_object.level == "S":
119 structure = pdb_object
120 else:
121 sb = StructureBuilder()
122 sb.init_structure('pdb')
123 sb.init_seg(' ')
124 # Build parts as necessary
125 if pdb_object.level == "M":
126 sb.structure.add(pdb_object)
127 self.structure = sb.structure
128 else:
129 sb.init_model(0)
130 if pdb_object.level == "C":
131 sb.structure[0].add(pdb_object)
132 else:
133 sb.init_chain('A')
134 if pdb_object.level == "R":
135 try:
136 parent_id = pdb_object.parent.id
137 sb.structure[0]['A'].id = parent_id
138 except Exception:
139 pass
140 sb.structure[0]['A'].add(pdb_object)
141 else:
142 # Atom
143 sb.init_residue('DUM', ' ', 1, ' ')
144 try:
145 parent_id = pdb_object.parent.parent.id
146 sb.structure[0]['A'].id = parent_id
147 except Exception:
148 pass
149 sb.structure[0]['A'].child_list[0].add(pdb_object)
150
151 # Return structure
152 structure = sb.structure
153 self.structure = structure
154
155 def save(self, file, select=Select(), write_end=True, preserve_atom_numbering=False):
156 """Save structure to a file.
157
158 :param file: output file
159 :type file: string or filehandle
160
161 :param select: selects which entities will be written.
162 :type select: object
163
164 Typically select is a subclass of L{Select}, it should
165 have the following methods:
166
167 - accept_model(model)
168 - accept_chain(chain)
169 - accept_residue(residue)
170 - accept_atom(atom)
171
172 These methods should return 1 if the entity is to be
173 written out, 0 otherwise.
174
175 Typically select is a subclass of L{Select}.
176 """
177 get_atom_line = self._get_atom_line
178 if isinstance(file, basestring):
179 fp = open(file, "w")
180 close_file = 1
181 else:
182 # filehandle, I hope :-)
183 fp = file
184 close_file = 0
185 # multiple models?
186 if len(self.structure) > 1 or self.use_model_flag:
187 model_flag = 1
188 else:
189 model_flag = 0
190 for model in self.structure.get_list():
191 if not select.accept_model(model):
192 continue
193 # necessary for ENDMDL
194 # do not write ENDMDL if no residues were written
195 # for this model
196 model_residues_written = 0
197 if not preserve_atom_numbering:
198 atom_number = 1
199 if model_flag:
200 fp.write("MODEL %s\n" % model.serial_num)
201 for chain in model.get_list():
202 if not select.accept_chain(chain):
203 continue
204 chain_id = chain.get_id()
205 # necessary for TER
206 # do not write TER if no residues were written
207 # for this chain
208 chain_residues_written = 0
209 for residue in chain.get_unpacked_list():
210 if not select.accept_residue(residue):
211 continue
212 hetfield, resseq, icode = residue.get_id()
213 resname = residue.get_resname()
214 segid = residue.get_segid()
215 for atom in residue.get_unpacked_list():
216 if select.accept_atom(atom):
217 chain_residues_written = 1
218 model_residues_written = 1
219 if preserve_atom_numbering:
220 atom_number = atom.get_serial_number()
221 s = get_atom_line(atom, hetfield, segid, atom_number, resname,
222 resseq, icode, chain_id)
223 fp.write(s)
224 if not preserve_atom_numbering:
225 atom_number += 1
226 if chain_residues_written:
227 fp.write("TER %5i %3s %c%4i%c \n"
228 % (atom_number, resname, chain_id, resseq, icode))
229
230 if model_flag and model_residues_written:
231 fp.write("ENDMDL\n")
232 if write_end:
233 fp.write('END\n')
234 if close_file:
235 fp.close()
236
[end of Bio/PDB/PDBIO.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/Bio/PDB/PDBIO.py b/Bio/PDB/PDBIO.py
--- a/Bio/PDB/PDBIO.py
+++ b/Bio/PDB/PDBIO.py
@@ -123,12 +123,12 @@
sb.init_seg(' ')
# Build parts as necessary
if pdb_object.level == "M":
- sb.structure.add(pdb_object)
+ sb.structure.add(pdb_object.copy())
self.structure = sb.structure
else:
sb.init_model(0)
if pdb_object.level == "C":
- sb.structure[0].add(pdb_object)
+ sb.structure[0].add(pdb_object.copy())
else:
sb.init_chain('A')
if pdb_object.level == "R":
@@ -137,7 +137,7 @@
sb.structure[0]['A'].id = parent_id
except Exception:
pass
- sb.structure[0]['A'].add(pdb_object)
+ sb.structure[0]['A'].add(pdb_object.copy())
else:
# Atom
sb.init_residue('DUM', ' ', 1, ' ')
@@ -146,7 +146,7 @@
sb.structure[0]['A'].id = parent_id
except Exception:
pass
- sb.structure[0]['A'].child_list[0].add(pdb_object)
+ sb.structure[0]['A'].child_list[0].add(pdb_object.copy())
# Return structure
structure = sb.structure
|
{"golden_diff": "diff --git a/Bio/PDB/PDBIO.py b/Bio/PDB/PDBIO.py\n--- a/Bio/PDB/PDBIO.py\n+++ b/Bio/PDB/PDBIO.py\n@@ -123,12 +123,12 @@\n sb.init_seg(' ')\n # Build parts as necessary\n if pdb_object.level == \"M\":\n- sb.structure.add(pdb_object)\n+ sb.structure.add(pdb_object.copy())\n self.structure = sb.structure\n else:\n sb.init_model(0)\n if pdb_object.level == \"C\":\n- sb.structure[0].add(pdb_object)\n+ sb.structure[0].add(pdb_object.copy())\n else:\n sb.init_chain('A')\n if pdb_object.level == \"R\":\n@@ -137,7 +137,7 @@\n sb.structure[0]['A'].id = parent_id\n except Exception:\n pass\n- sb.structure[0]['A'].add(pdb_object)\n+ sb.structure[0]['A'].add(pdb_object.copy())\n else:\n # Atom\n sb.init_residue('DUM', ' ', 1, ' ')\n@@ -146,7 +146,7 @@\n sb.structure[0]['A'].id = parent_id\n except Exception:\n pass\n- sb.structure[0]['A'].child_list[0].add(pdb_object)\n+ sb.structure[0]['A'].child_list[0].add(pdb_object.copy())\n \n # Return structure\n structure = sb.structure\n", "issue": "`Bio.PDB.PDBIO.set_structure()` alters parent of chains, residues and atoms\nCalling the `set_structure` method of the `Bio.PDB.PDBIO` class alters the parent of (non-`Structure`) entities in a non-obvious way. For example, this script:\r\n```python\r\nimport Bio.PDB\r\npdbio = Bio.PDB.PDBIO()\r\nparser = Bio.PDB.MMCIFParser()\r\nstructure = parser.get_structure(\"12as\", \"12as.cif\")\r\nfor chain in structure[0]:\r\n old_id = chain.id\r\n chain.id = \" \"\r\n pdbio.set_structure(chain)\r\n chain.id = old_id\r\n```\r\nGives this error from line 91 of `Bio/PDB/Entity.py`:\r\n```\r\nValueError: Cannot change id from `B` to ` `. The id ` ` is already used for a sibling of this entity.\r\n```\r\nRemoving the call to `set_structure` acts as I would expect: temporarily renaming the chain name, and then reverting it without problems.\r\n\r\nWhen `set_structure` is called with an `Entity` other than a `Structure` object, it constructs a `Structure` and populates it with the entity using the `add` method, which calls `set_parent` on the entity. To me, this isn't very intuitive: I don't expect writing an object to have side effects that act on that object.\r\n\r\nI think a good solution to this would be to call `copy()` in `set_structure` before `add`ing the entity to the new `Structure` object. That is, change `sb.structure.add(pdb_object)` to `sb.structure.add(pdb_object.copy())` in `Bio.PDB.PDBIO.set_structure`. I'm happy to make a pull request if people agree that this is an issue.\n", "before_files": [{"content": "# Copyright (C) 2002, Thomas Hamelryck ([email protected])\n# This code is part of the Biopython distribution and governed by its\n# license. Please see the LICENSE file that should have been included\n# as part of this package.\n\n\"\"\"Output of PDB files.\"\"\"\n\nfrom Bio._py3k import basestring\n\nfrom Bio.PDB.StructureBuilder import StructureBuilder # To allow saving of chains, residues, etc..\nfrom Bio.Data.IUPACData import atom_weights # Allowed Elements\n\n\n_ATOM_FORMAT_STRING = \"%s%5i %-4s%c%3s %c%4i%c %8.3f%8.3f%8.3f%s%6.2f %4s%2s%2s\\n\"\n\n\nclass Select(object):\n \"\"\"Select everything for PDB output (for use as a base class).\n\n Default selection (everything) during writing - can be used as base class\n to implement selective output. This selects which entities will be written out.\n \"\"\"\n\n def __repr__(self):\n \"\"\"Represent the output as a string for debugging.\"\"\"\n return \"<Select all>\"\n\n def accept_model(self, model):\n \"\"\"Overload this to reject models for output.\"\"\"\n return 1\n\n def accept_chain(self, chain):\n \"\"\"Overload this to reject chains for output.\"\"\"\n return 1\n\n def accept_residue(self, residue):\n \"\"\"Overload this to reject residues for output.\"\"\"\n return 1\n\n def accept_atom(self, atom):\n \"\"\"Overload this to reject atoms for output.\"\"\"\n return 1\n\n\nclass PDBIO(object):\n \"\"\"Write a Structure object (or a subset of a Structure object) as a PDB file.\n\n Examples\n --------\n >>> p=PDBParser()\n >>> s=p.get_structure(\"1fat\", \"1fat.pdb\")\n >>> io=PDBIO()\n >>> io.set_structure(s)\n >>> io.save(\"out.pdb\")\n\n \"\"\"\n\n def __init__(self, use_model_flag=0):\n \"\"\"Create the PDBIO object.\n\n :param use_model_flag: if 1, force use of the MODEL record in output.\n :type use_model_flag: int\n \"\"\"\n self.use_model_flag = use_model_flag\n\n # private mathods\n\n def _get_atom_line(self, atom, hetfield, segid, atom_number, resname,\n resseq, icode, chain_id, charge=\" \"):\n \"\"\"Return an ATOM PDB string (PRIVATE).\"\"\"\n if hetfield != \" \":\n record_type = \"HETATM\"\n else:\n record_type = \"ATOM \"\n\n if atom.element:\n element = atom.element.strip().upper()\n if element.capitalize() not in atom_weights:\n raise ValueError(\"Unrecognised element %r\" % atom.element)\n element = element.rjust(2)\n else:\n element = \" \"\n\n name = atom.get_fullname().strip()\n # Pad atom name if:\n # - smaller than 4 characters\n # AND - is not C, N, O, S, H, F, P, ..., one letter elements\n # AND - first character is NOT numeric (funky hydrogen naming rules)\n if len(name) < 4 and name[:1].isalpha() and len(element.strip()) < 2:\n name = \" \" + name\n\n altloc = atom.get_altloc()\n x, y, z = atom.get_coord()\n bfactor = atom.get_bfactor()\n occupancy = atom.get_occupancy()\n try:\n occupancy_str = \"%6.2f\" % occupancy\n except TypeError:\n if occupancy is None:\n occupancy_str = \" \" * 6\n import warnings\n from Bio import BiopythonWarning\n warnings.warn(\"Missing occupancy in atom %s written as blank\" %\n repr(atom.get_full_id()), BiopythonWarning)\n else:\n raise TypeError(\"Invalid occupancy %r in atom %r\"\n % (occupancy, atom.get_full_id()))\n\n args = (record_type, atom_number, name, altloc, resname, chain_id,\n resseq, icode, x, y, z, occupancy_str, bfactor, segid,\n element, charge)\n return _ATOM_FORMAT_STRING % args\n\n # Public methods\n\n def set_structure(self, pdb_object):\n \"\"\"Check what the user is providing and build a structure.\"\"\"\n if pdb_object.level == \"S\":\n structure = pdb_object\n else:\n sb = StructureBuilder()\n sb.init_structure('pdb')\n sb.init_seg(' ')\n # Build parts as necessary\n if pdb_object.level == \"M\":\n sb.structure.add(pdb_object)\n self.structure = sb.structure\n else:\n sb.init_model(0)\n if pdb_object.level == \"C\":\n sb.structure[0].add(pdb_object)\n else:\n sb.init_chain('A')\n if pdb_object.level == \"R\":\n try:\n parent_id = pdb_object.parent.id\n sb.structure[0]['A'].id = parent_id\n except Exception:\n pass\n sb.structure[0]['A'].add(pdb_object)\n else:\n # Atom\n sb.init_residue('DUM', ' ', 1, ' ')\n try:\n parent_id = pdb_object.parent.parent.id\n sb.structure[0]['A'].id = parent_id\n except Exception:\n pass\n sb.structure[0]['A'].child_list[0].add(pdb_object)\n\n # Return structure\n structure = sb.structure\n self.structure = structure\n\n def save(self, file, select=Select(), write_end=True, preserve_atom_numbering=False):\n \"\"\"Save structure to a file.\n\n :param file: output file\n :type file: string or filehandle\n\n :param select: selects which entities will be written.\n :type select: object\n\n Typically select is a subclass of L{Select}, it should\n have the following methods:\n\n - accept_model(model)\n - accept_chain(chain)\n - accept_residue(residue)\n - accept_atom(atom)\n\n These methods should return 1 if the entity is to be\n written out, 0 otherwise.\n\n Typically select is a subclass of L{Select}.\n \"\"\"\n get_atom_line = self._get_atom_line\n if isinstance(file, basestring):\n fp = open(file, \"w\")\n close_file = 1\n else:\n # filehandle, I hope :-)\n fp = file\n close_file = 0\n # multiple models?\n if len(self.structure) > 1 or self.use_model_flag:\n model_flag = 1\n else:\n model_flag = 0\n for model in self.structure.get_list():\n if not select.accept_model(model):\n continue\n # necessary for ENDMDL\n # do not write ENDMDL if no residues were written\n # for this model\n model_residues_written = 0\n if not preserve_atom_numbering:\n atom_number = 1\n if model_flag:\n fp.write(\"MODEL %s\\n\" % model.serial_num)\n for chain in model.get_list():\n if not select.accept_chain(chain):\n continue\n chain_id = chain.get_id()\n # necessary for TER\n # do not write TER if no residues were written\n # for this chain\n chain_residues_written = 0\n for residue in chain.get_unpacked_list():\n if not select.accept_residue(residue):\n continue\n hetfield, resseq, icode = residue.get_id()\n resname = residue.get_resname()\n segid = residue.get_segid()\n for atom in residue.get_unpacked_list():\n if select.accept_atom(atom):\n chain_residues_written = 1\n model_residues_written = 1\n if preserve_atom_numbering:\n atom_number = atom.get_serial_number()\n s = get_atom_line(atom, hetfield, segid, atom_number, resname,\n resseq, icode, chain_id)\n fp.write(s)\n if not preserve_atom_numbering:\n atom_number += 1\n if chain_residues_written:\n fp.write(\"TER %5i %3s %c%4i%c \\n\"\n % (atom_number, resname, chain_id, resseq, icode))\n\n if model_flag and model_residues_written:\n fp.write(\"ENDMDL\\n\")\n if write_end:\n fp.write('END\\n')\n if close_file:\n fp.close()\n", "path": "Bio/PDB/PDBIO.py"}]}
| 3,414 | 342 |
gh_patches_debug_3273
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-366
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Flask Extension Gunicorn GLogging Error With Access Logs
**Describe your environment**
Using Python 3.6, with a basic flask application with gunicorn.
**Python Libs**:
```
Flask==1.1.1
gunicorn==20.0.4
opentelemetry-sdk==0.3a0
opentelemetry-ext-flask==0.3a0
```
**Reproducible Structure**
```
app/
- __init__.py
- api.py
- wsgi.py
config/
- gunicorn_config.py
-log_config.py
```
**app/\_\_init\_\_.py**
```
from app import api
from flask import Flask
from opentelemetry.ext.flask import instrument_app
def create_app():
app = Flask(__name__)
instrument_app(app)
app.register_blueprint(api.blueprint)
return app
```
**app/api.py**
```
from flask import Blueprint
blueprint = Blueprint('api', __name__)
@blueprint.route('/')
def index():
return {'status': 'success'}
```
**app/wsgi.py**
```
from app import create_app
app = create_app()
```
**config/gunicorn_config.py**
```
import logging.config
import os
from config.log_config import LOGGING, LOG_LEVEL
workers = os.environ.get('GUNICORN_WORKERS', 4)
bind = "{}:{}".format(os.environ.get('GUNICORN_HOST', '0.0.0.0'), os.environ.get('GUNICORN_PORT', 8000))
loglevel = LOG_LEVEL
logconfig_dict = LOGGING
timeout = os.environ.get('GUNICORN_WORKER_TIMEOUT', 60)
```
**config/log_config.py**
```
import os
LOG_LEVEL = os.environ.get('LOG_LEVEL', 'DEBUG')
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
}
```
**Steps to reproduce**
At the root of the above, run `gunicorn -c config/gunicorn_config.py app.wsgi:app`
Hit the base endpoint `curl http://localhost:8000`
Get the following error thrown by gunicorn:
```
Traceback (most recent call last):
File "/Users/disflux/miniconda3/envs/flasktest/lib/python3.6/site-packages/gunicorn/workers/sync.py", line 184, in handle_request
self.log.access(resp, req, environ, request_time)
File "/Users/disflux/miniconda3/envs/flasktest/lib/python3.6/site-packages/gunicorn/glogging.py", line 341, in access
request_time))
File "/Users/disflux/miniconda3/envs/flasktest/lib/python3.6/site-packages/gunicorn/glogging.py", line 323, in atoms
atoms.update({"{%s}e" % k.lower(): v for k, v in environ_variables})
File "/Users/disflux/miniconda3/envs/flasktest/lib/python3.6/site-packages/gunicorn/glogging.py", line 323, in <dictcomp>
atoms.update({"{%s}e" % k.lower(): v for k, v in environ_variables})
AttributeError: 'object' object has no attribute 'lower'
```
It appears that the error is caused by adding Objects as keys to the environment, which is done by OpenTelemetry here:
https://github.com/open-telemetry/opentelemetry-python/blob/master/ext/opentelemetry-ext-flask/src/opentelemetry/ext/flask/__init__.py#L15-L17
This ends up triggering the error in Gunicorn Glogging:
https://github.com/benoitc/gunicorn/blob/master/gunicorn/glogging.py#L326
Note: Gunicorn only executes this if certain logging configuration is enabled (access logs), as indicated by the if statement here:
https://github.com/benoitc/gunicorn/blob/master/gunicorn/glogging.py#L335-L338
**What is the expected behavior?**
No errors :)
I'd expect that we wouldn't be storing objects as a key in the environment.
</issue>
<code>
[start of ext/opentelemetry-ext-flask/src/opentelemetry/ext/flask/__init__.py]
1 # Note: This package is not named "flask" because of
2 # https://github.com/PyCQA/pylint/issues/2648
3
4 import logging
5
6 from flask import request as flask_request
7
8 import opentelemetry.ext.wsgi as otel_wsgi
9 from opentelemetry import propagators, trace
10 from opentelemetry.ext.flask.version import __version__
11 from opentelemetry.util import time_ns
12
13 logger = logging.getLogger(__name__)
14
15 _ENVIRON_STARTTIME_KEY = object()
16 _ENVIRON_SPAN_KEY = object()
17 _ENVIRON_ACTIVATION_KEY = object()
18
19
20 def instrument_app(flask):
21 """Makes the passed-in Flask object traced by OpenTelemetry.
22
23 You must not call this function multiple times on the same Flask object.
24 """
25
26 wsgi = flask.wsgi_app
27
28 def wrapped_app(environ, start_response):
29 # We want to measure the time for route matching, etc.
30 # In theory, we could start the span here and use update_name later
31 # but that API is "highly discouraged" so we better avoid it.
32 environ[_ENVIRON_STARTTIME_KEY] = time_ns()
33
34 def _start_response(status, response_headers, *args, **kwargs):
35 span = flask_request.environ.get(_ENVIRON_SPAN_KEY)
36 if span:
37 otel_wsgi.add_response_attributes(
38 span, status, response_headers
39 )
40 else:
41 logger.warning(
42 "Flask environ's OpenTelemetry span missing at _start_response(%s)",
43 status,
44 )
45 return start_response(status, response_headers, *args, **kwargs)
46
47 return wsgi(environ, _start_response)
48
49 flask.wsgi_app = wrapped_app
50
51 flask.before_request(_before_flask_request)
52 flask.teardown_request(_teardown_flask_request)
53
54
55 def _before_flask_request():
56 environ = flask_request.environ
57 span_name = flask_request.endpoint or otel_wsgi.get_default_span_name(
58 environ
59 )
60 parent_span = propagators.extract(
61 otel_wsgi.get_header_from_environ, environ
62 )
63
64 tracer = trace.tracer_source().get_tracer(__name__, __version__)
65
66 attributes = otel_wsgi.collect_request_attributes(environ)
67 if flask_request.url_rule:
68 # For 404 that result from no route found, etc, we don't have a url_rule.
69 attributes["http.route"] = flask_request.url_rule.rule
70 span = tracer.start_span(
71 span_name,
72 parent_span,
73 kind=trace.SpanKind.SERVER,
74 attributes=attributes,
75 start_time=environ.get(_ENVIRON_STARTTIME_KEY),
76 )
77 activation = tracer.use_span(span, end_on_exit=True)
78 activation.__enter__()
79 environ[_ENVIRON_ACTIVATION_KEY] = activation
80 environ[_ENVIRON_SPAN_KEY] = span
81
82
83 def _teardown_flask_request(exc):
84 activation = flask_request.environ.get(_ENVIRON_ACTIVATION_KEY)
85 if not activation:
86 logger.warning(
87 "Flask environ's OpenTelemetry activation missing at _teardown_flask_request(%s)",
88 exc,
89 )
90 return
91
92 if exc is None:
93 activation.__exit__(None, None, None)
94 else:
95 activation.__exit__(
96 type(exc), exc, getattr(exc, "__traceback__", None)
97 )
98
[end of ext/opentelemetry-ext-flask/src/opentelemetry/ext/flask/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ext/opentelemetry-ext-flask/src/opentelemetry/ext/flask/__init__.py b/ext/opentelemetry-ext-flask/src/opentelemetry/ext/flask/__init__.py
--- a/ext/opentelemetry-ext-flask/src/opentelemetry/ext/flask/__init__.py
+++ b/ext/opentelemetry-ext-flask/src/opentelemetry/ext/flask/__init__.py
@@ -12,9 +12,9 @@
logger = logging.getLogger(__name__)
-_ENVIRON_STARTTIME_KEY = object()
-_ENVIRON_SPAN_KEY = object()
-_ENVIRON_ACTIVATION_KEY = object()
+_ENVIRON_STARTTIME_KEY = "opentelemetry-flask.starttime_key"
+_ENVIRON_SPAN_KEY = "opentelemetry-flask.span_key"
+_ENVIRON_ACTIVATION_KEY = "opentelemetry-flask.activation_key"
def instrument_app(flask):
|
{"golden_diff": "diff --git a/ext/opentelemetry-ext-flask/src/opentelemetry/ext/flask/__init__.py b/ext/opentelemetry-ext-flask/src/opentelemetry/ext/flask/__init__.py\n--- a/ext/opentelemetry-ext-flask/src/opentelemetry/ext/flask/__init__.py\n+++ b/ext/opentelemetry-ext-flask/src/opentelemetry/ext/flask/__init__.py\n@@ -12,9 +12,9 @@\n \n logger = logging.getLogger(__name__)\n \n-_ENVIRON_STARTTIME_KEY = object()\n-_ENVIRON_SPAN_KEY = object()\n-_ENVIRON_ACTIVATION_KEY = object()\n+_ENVIRON_STARTTIME_KEY = \"opentelemetry-flask.starttime_key\"\n+_ENVIRON_SPAN_KEY = \"opentelemetry-flask.span_key\"\n+_ENVIRON_ACTIVATION_KEY = \"opentelemetry-flask.activation_key\"\n \n \n def instrument_app(flask):\n", "issue": "Flask Extension Gunicorn GLogging Error With Access Logs\n**Describe your environment**\r\nUsing Python 3.6, with a basic flask application with gunicorn.\r\n\r\n**Python Libs**:\r\n```\r\nFlask==1.1.1\r\ngunicorn==20.0.4\r\nopentelemetry-sdk==0.3a0\r\nopentelemetry-ext-flask==0.3a0\r\n```\r\n**Reproducible Structure**\r\n```\r\napp/\r\n- __init__.py\r\n- api.py\r\n- wsgi.py\r\nconfig/\r\n- gunicorn_config.py\r\n-log_config.py\r\n```\r\n\r\n**app/\\_\\_init\\_\\_.py**\r\n```\r\nfrom app import api\r\nfrom flask import Flask\r\nfrom opentelemetry.ext.flask import instrument_app\r\n\r\ndef create_app():\r\n\tapp = Flask(__name__)\r\n\r\n\tinstrument_app(app)\r\n\tapp.register_blueprint(api.blueprint)\r\n\r\n\treturn app\r\n```\r\n\r\n**app/api.py**\r\n```\r\nfrom flask import Blueprint\r\n\r\nblueprint = Blueprint('api', __name__)\r\n\r\[email protected]('/')\r\ndef index():\r\n\treturn {'status': 'success'}\r\n```\r\n\r\n**app/wsgi.py**\r\n```\r\nfrom app import create_app\r\n\r\n\r\napp = create_app()\r\n```\r\n\r\n**config/gunicorn_config.py**\r\n```\r\nimport logging.config\r\nimport os\r\n\r\nfrom config.log_config import LOGGING, LOG_LEVEL\r\n\r\nworkers = os.environ.get('GUNICORN_WORKERS', 4)\r\nbind = \"{}:{}\".format(os.environ.get('GUNICORN_HOST', '0.0.0.0'), os.environ.get('GUNICORN_PORT', 8000))\r\n\r\nloglevel = LOG_LEVEL\r\nlogconfig_dict = LOGGING\r\n\r\ntimeout = os.environ.get('GUNICORN_WORKER_TIMEOUT', 60)\r\n```\r\n\r\n**config/log_config.py**\r\n```\r\nimport os\r\n\r\nLOG_LEVEL = os.environ.get('LOG_LEVEL', 'DEBUG')\r\n\r\nLOGGING = {\r\n 'version': 1,\r\n 'disable_existing_loggers': False,\r\n}\r\n```\r\n\r\n**Steps to reproduce**\r\nAt the root of the above, run `gunicorn -c config/gunicorn_config.py app.wsgi:app`\r\n\r\nHit the base endpoint `curl http://localhost:8000`\r\n\r\nGet the following error thrown by gunicorn:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/Users/disflux/miniconda3/envs/flasktest/lib/python3.6/site-packages/gunicorn/workers/sync.py\", line 184, in handle_request\r\n self.log.access(resp, req, environ, request_time)\r\n File \"/Users/disflux/miniconda3/envs/flasktest/lib/python3.6/site-packages/gunicorn/glogging.py\", line 341, in access\r\n request_time))\r\n File \"/Users/disflux/miniconda3/envs/flasktest/lib/python3.6/site-packages/gunicorn/glogging.py\", line 323, in atoms\r\n atoms.update({\"{%s}e\" % k.lower(): v for k, v in environ_variables})\r\n File \"/Users/disflux/miniconda3/envs/flasktest/lib/python3.6/site-packages/gunicorn/glogging.py\", line 323, in <dictcomp>\r\n atoms.update({\"{%s}e\" % k.lower(): v for k, v in environ_variables})\r\nAttributeError: 'object' object has no attribute 'lower'\r\n```\r\n\r\nIt appears that the error is caused by adding Objects as keys to the environment, which is done by OpenTelemetry here:\r\nhttps://github.com/open-telemetry/opentelemetry-python/blob/master/ext/opentelemetry-ext-flask/src/opentelemetry/ext/flask/__init__.py#L15-L17\r\n\r\nThis ends up triggering the error in Gunicorn Glogging:\r\nhttps://github.com/benoitc/gunicorn/blob/master/gunicorn/glogging.py#L326\r\n\r\nNote: Gunicorn only executes this if certain logging configuration is enabled (access logs), as indicated by the if statement here:\r\nhttps://github.com/benoitc/gunicorn/blob/master/gunicorn/glogging.py#L335-L338\r\n\r\n**What is the expected behavior?**\r\nNo errors :)\r\n\r\nI'd expect that we wouldn't be storing objects as a key in the environment.\r\n\n", "before_files": [{"content": "# Note: This package is not named \"flask\" because of\n# https://github.com/PyCQA/pylint/issues/2648\n\nimport logging\n\nfrom flask import request as flask_request\n\nimport opentelemetry.ext.wsgi as otel_wsgi\nfrom opentelemetry import propagators, trace\nfrom opentelemetry.ext.flask.version import __version__\nfrom opentelemetry.util import time_ns\n\nlogger = logging.getLogger(__name__)\n\n_ENVIRON_STARTTIME_KEY = object()\n_ENVIRON_SPAN_KEY = object()\n_ENVIRON_ACTIVATION_KEY = object()\n\n\ndef instrument_app(flask):\n \"\"\"Makes the passed-in Flask object traced by OpenTelemetry.\n\n You must not call this function multiple times on the same Flask object.\n \"\"\"\n\n wsgi = flask.wsgi_app\n\n def wrapped_app(environ, start_response):\n # We want to measure the time for route matching, etc.\n # In theory, we could start the span here and use update_name later\n # but that API is \"highly discouraged\" so we better avoid it.\n environ[_ENVIRON_STARTTIME_KEY] = time_ns()\n\n def _start_response(status, response_headers, *args, **kwargs):\n span = flask_request.environ.get(_ENVIRON_SPAN_KEY)\n if span:\n otel_wsgi.add_response_attributes(\n span, status, response_headers\n )\n else:\n logger.warning(\n \"Flask environ's OpenTelemetry span missing at _start_response(%s)\",\n status,\n )\n return start_response(status, response_headers, *args, **kwargs)\n\n return wsgi(environ, _start_response)\n\n flask.wsgi_app = wrapped_app\n\n flask.before_request(_before_flask_request)\n flask.teardown_request(_teardown_flask_request)\n\n\ndef _before_flask_request():\n environ = flask_request.environ\n span_name = flask_request.endpoint or otel_wsgi.get_default_span_name(\n environ\n )\n parent_span = propagators.extract(\n otel_wsgi.get_header_from_environ, environ\n )\n\n tracer = trace.tracer_source().get_tracer(__name__, __version__)\n\n attributes = otel_wsgi.collect_request_attributes(environ)\n if flask_request.url_rule:\n # For 404 that result from no route found, etc, we don't have a url_rule.\n attributes[\"http.route\"] = flask_request.url_rule.rule\n span = tracer.start_span(\n span_name,\n parent_span,\n kind=trace.SpanKind.SERVER,\n attributes=attributes,\n start_time=environ.get(_ENVIRON_STARTTIME_KEY),\n )\n activation = tracer.use_span(span, end_on_exit=True)\n activation.__enter__()\n environ[_ENVIRON_ACTIVATION_KEY] = activation\n environ[_ENVIRON_SPAN_KEY] = span\n\n\ndef _teardown_flask_request(exc):\n activation = flask_request.environ.get(_ENVIRON_ACTIVATION_KEY)\n if not activation:\n logger.warning(\n \"Flask environ's OpenTelemetry activation missing at _teardown_flask_request(%s)\",\n exc,\n )\n return\n\n if exc is None:\n activation.__exit__(None, None, None)\n else:\n activation.__exit__(\n type(exc), exc, getattr(exc, \"__traceback__\", None)\n )\n", "path": "ext/opentelemetry-ext-flask/src/opentelemetry/ext/flask/__init__.py"}]}
| 2,362 | 188 |
gh_patches_debug_24249
|
rasdani/github-patches
|
git_diff
|
lutris__lutris-1232
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
latest version 0.4.21 thinks i don't have a vulkan loader
Got the new message pop up to say I don't have a Vulkan loader installed. This is on an Ubuntu 18.10 fresh upgrade.
I do:
> liam@liam-main:~$ sudo apt install libvulkan1 libvulkan1:i386
[sudo] password for liam:
Reading package lists... Done
Building dependency tree
Reading state information... Done
libvulkan1 is already the newest version (1.1.82.0-0ubuntu1).
libvulkan1:i386 is already the newest version (1.1.82.0-0ubuntu1).
0 to upgrade, 0 to newly install, 0 to remove and 5 not to upgrade.
Need more details? Let me know.
</issue>
<code>
[start of lutris/util/vulkan.py]
1 """Vulkan helper module"""
2 import os
3 import re
4 from enum import Enum
5
6 class vulkan_available(Enum):
7 NONE = 0
8 THIRTY_TWO = 1
9 SIXTY_FOUR = 2
10 ALL = 3
11
12 def search_for_file(directory):
13 if os.path.isdir(directory):
14 pattern = re.compile(r'^libvulkan\.so')
15 files = [f for f in os.listdir(directory) if os.path.isfile(os.path.join(directory, f))]
16 files = [os.path.join(directory, f) for f in files if pattern.search(f)]
17 if files:
18 return True
19 return False
20
21 def vulkan_check():
22 vulkan_lib = search_for_file("/usr/lib")
23 vulkan_lib32 = search_for_file("/usr/lib32")
24 vulkan_lib_multi = search_for_file("/usr/lib/x86_64-linux-gnu")
25 vulkan_lib32_multi = search_for_file("/usr/lib32/i386-linux-gnu")
26 has_32_bit = vulkan_lib32 or vulkan_lib32_multi
27 has_64_bit = vulkan_lib or vulkan_lib_multi
28
29 if not (has_64_bit or has_32_bit):
30 return vulkan_available.NONE
31 if has_64_bit and not has_32_bit:
32 return vulkan_available.SIXTY_FOUR
33 if not has_64_bit and has_32_bit:
34 return vulkan_available.THIRTY_TWO
35 return vulkan_available.ALL
36
[end of lutris/util/vulkan.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lutris/util/vulkan.py b/lutris/util/vulkan.py
--- a/lutris/util/vulkan.py
+++ b/lutris/util/vulkan.py
@@ -1,6 +1,7 @@
"""Vulkan helper module"""
import os
import re
+import subprocess
from enum import Enum
class vulkan_available(Enum):
@@ -9,22 +10,16 @@
SIXTY_FOUR = 2
ALL = 3
-def search_for_file(directory):
- if os.path.isdir(directory):
- pattern = re.compile(r'^libvulkan\.so')
- files = [f for f in os.listdir(directory) if os.path.isfile(os.path.join(directory, f))]
- files = [os.path.join(directory, f) for f in files if pattern.search(f)]
- if files:
- return True
- return False
-
def vulkan_check():
- vulkan_lib = search_for_file("/usr/lib")
- vulkan_lib32 = search_for_file("/usr/lib32")
- vulkan_lib_multi = search_for_file("/usr/lib/x86_64-linux-gnu")
- vulkan_lib32_multi = search_for_file("/usr/lib32/i386-linux-gnu")
- has_32_bit = vulkan_lib32 or vulkan_lib32_multi
- has_64_bit = vulkan_lib or vulkan_lib_multi
+ has_64_bit = False
+ has_32_bit = False
+ for line in subprocess.check_output(["ldconfig", "-p"]).splitlines():
+ line = str(line)
+ if 'libvulkan' in line:
+ if 'x86-64' in line:
+ has_64_bit = True
+ else:
+ has_32_bit = True
if not (has_64_bit or has_32_bit):
return vulkan_available.NONE
|
{"golden_diff": "diff --git a/lutris/util/vulkan.py b/lutris/util/vulkan.py\n--- a/lutris/util/vulkan.py\n+++ b/lutris/util/vulkan.py\n@@ -1,6 +1,7 @@\n \"\"\"Vulkan helper module\"\"\"\n import os\n import re\n+import subprocess\n from enum import Enum\n \n class vulkan_available(Enum):\n@@ -9,22 +10,16 @@\n SIXTY_FOUR = 2\n ALL = 3\n \n-def search_for_file(directory):\n- if os.path.isdir(directory):\n- pattern = re.compile(r'^libvulkan\\.so')\n- files = [f for f in os.listdir(directory) if os.path.isfile(os.path.join(directory, f))]\n- files = [os.path.join(directory, f) for f in files if pattern.search(f)]\n- if files:\n- return True\n- return False\n-\n def vulkan_check():\n- vulkan_lib = search_for_file(\"/usr/lib\")\n- vulkan_lib32 = search_for_file(\"/usr/lib32\")\n- vulkan_lib_multi = search_for_file(\"/usr/lib/x86_64-linux-gnu\")\n- vulkan_lib32_multi = search_for_file(\"/usr/lib32/i386-linux-gnu\")\n- has_32_bit = vulkan_lib32 or vulkan_lib32_multi\n- has_64_bit = vulkan_lib or vulkan_lib_multi\n+ has_64_bit = False\n+ has_32_bit = False\n+ for line in subprocess.check_output([\"ldconfig\", \"-p\"]).splitlines():\n+ line = str(line)\n+ if 'libvulkan' in line:\n+ if 'x86-64' in line:\n+ has_64_bit = True\n+ else:\n+ has_32_bit = True\n \n if not (has_64_bit or has_32_bit):\n return vulkan_available.NONE\n", "issue": "latest version 0.4.21 thinks i don't have a vulkan loader\nGot the new message pop up to say I don't have a Vulkan loader installed. This is on an Ubuntu 18.10 fresh upgrade.\r\n\r\nI do:\r\n\r\n> liam@liam-main:~$ sudo apt install libvulkan1 libvulkan1:i386 \r\n[sudo] password for liam: \r\nReading package lists... Done\r\nBuilding dependency tree \r\nReading state information... Done\r\nlibvulkan1 is already the newest version (1.1.82.0-0ubuntu1).\r\nlibvulkan1:i386 is already the newest version (1.1.82.0-0ubuntu1).\r\n0 to upgrade, 0 to newly install, 0 to remove and 5 not to upgrade.\r\n\r\nNeed more details? Let me know.\n", "before_files": [{"content": "\"\"\"Vulkan helper module\"\"\"\nimport os\nimport re\nfrom enum import Enum\n\nclass vulkan_available(Enum):\n NONE = 0\n THIRTY_TWO = 1\n SIXTY_FOUR = 2\n ALL = 3\n\ndef search_for_file(directory):\n if os.path.isdir(directory):\n pattern = re.compile(r'^libvulkan\\.so')\n files = [f for f in os.listdir(directory) if os.path.isfile(os.path.join(directory, f))]\n files = [os.path.join(directory, f) for f in files if pattern.search(f)]\n if files:\n return True\n return False\n\ndef vulkan_check():\n vulkan_lib = search_for_file(\"/usr/lib\")\n vulkan_lib32 = search_for_file(\"/usr/lib32\")\n vulkan_lib_multi = search_for_file(\"/usr/lib/x86_64-linux-gnu\")\n vulkan_lib32_multi = search_for_file(\"/usr/lib32/i386-linux-gnu\")\n has_32_bit = vulkan_lib32 or vulkan_lib32_multi\n has_64_bit = vulkan_lib or vulkan_lib_multi\n\n if not (has_64_bit or has_32_bit):\n return vulkan_available.NONE\n if has_64_bit and not has_32_bit:\n return vulkan_available.SIXTY_FOUR\n if not has_64_bit and has_32_bit:\n return vulkan_available.THIRTY_TWO\n return vulkan_available.ALL\n", "path": "lutris/util/vulkan.py"}]}
| 1,116 | 431 |
gh_patches_debug_2132
|
rasdani/github-patches
|
git_diff
|
marshmallow-code__webargs-414
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Schema factory only variable fail - can't pass list type
Looking at the [schema factory docs](https://webargs.readthedocs.io/en/latest/advanced.html#schema-factories), I'm interested in trying the
```
# Filter based on 'fields' query parameter
only = request.args.get("fields", None)
```
part.
However, when I try appending something like `?fields=some_field` to my HTTP request, I get the following error:
```
File "edited/marshmallow/schema.py", line 349, in __init__
raise StringNotCollectionError('"only" should be a list of strings')
```
As far as I can see, webargs always passes the query string parameters as strings. I tried wrapping it in square brackets, but I think I'm barking up the wrong tree. Have I misunderstood something, or is this a bug?
</issue>
<code>
[start of examples/schema_example.py]
1 """Example implementation of using a marshmallow Schema for both request input
2 and output with a `use_schema` decorator.
3 Run the app:
4
5 $ python examples/schema_example.py
6
7 Try the following with httpie (a cURL-like utility, http://httpie.org):
8
9 $ pip install httpie
10 $ http GET :5001/users/
11 $ http GET :5001/users/42
12 $ http POST :5001/users/ usename=brian first_name=Brian last_name=May
13 $ http PATCH :5001/users/42 username=freddie
14 $ http GET :5001/users/ limit==1
15 """
16 import functools
17 from flask import Flask, request, jsonify
18 import random
19
20 from marshmallow import Schema, fields, post_dump
21 from webargs.flaskparser import parser, use_kwargs
22
23 app = Flask(__name__)
24
25 ##### Fake database and models #####
26
27
28 class Model:
29 def __init__(self, **kwargs):
30 self.__dict__.update(kwargs)
31
32 def update(self, **kwargs):
33 self.__dict__.update(kwargs)
34
35 @classmethod
36 def insert(cls, db, **kwargs):
37 collection = db[cls.collection]
38 new_id = None
39 if "id" in kwargs: # for setting up fixtures
40 new_id = kwargs.pop("id")
41 else: # find a new id
42 found_id = False
43 while not found_id:
44 new_id = random.randint(1, 9999)
45 if new_id not in collection:
46 found_id = True
47 new_record = cls(id=new_id, **kwargs)
48 collection[new_id] = new_record
49 return new_record
50
51
52 class User(Model):
53 collection = "users"
54
55
56 db = {"users": {}}
57
58
59 ##### use_schema #####
60
61
62 def use_schema(schema, list_view=False, locations=None):
63 """View decorator for using a marshmallow schema to
64 (1) parse a request's input and
65 (2) serializing the view's output to a JSON response.
66 """
67
68 def decorator(func):
69 @functools.wraps(func)
70 def wrapped(*args, **kwargs):
71 use_args_wrapper = parser.use_args(schema, locations=locations)
72 # Function wrapped with use_args
73 func_with_args = use_args_wrapper(func)
74 ret = func_with_args(*args, **kwargs)
75 # Serialize and jsonify the return value
76 return jsonify(schema.dump(ret, many=list_view).data)
77
78 return wrapped
79
80 return decorator
81
82
83 ##### Schemas #####
84
85
86 class UserSchema(Schema):
87 id = fields.Int(dump_only=True)
88 username = fields.Str()
89 first_name = fields.Str()
90 last_name = fields.Str()
91
92 class Meta:
93 strict = True
94
95 @post_dump(pass_many=True)
96 def wrap_with_envelope(self, data, many, **kwargs):
97 return {"data": data}
98
99
100 ##### Routes #####
101
102
103 @app.route("/users/<int:user_id>", methods=["GET", "PATCH"])
104 @use_schema(UserSchema())
105 def user_detail(reqargs, user_id):
106 user = db["users"].get(user_id)
107 if not user:
108 return jsonify({"message": "User not found"}), 404
109 if request.method == "PATCH" and reqargs:
110 user.update(**reqargs)
111 return user
112
113
114 # You can add additional arguments with use_kwargs
115 @app.route("/users/", methods=["GET", "POST"])
116 @use_kwargs({"limit": fields.Int(missing=10, location="query")})
117 @use_schema(UserSchema(), list_view=True)
118 def user_list(reqargs, limit):
119 users = db["users"].values()
120 if request.method == "POST":
121 User.insert(db=db, **reqargs)
122 return list(users)[:limit]
123
124
125 # Return validation errors as JSON
126 @app.errorhandler(422)
127 @app.errorhandler(400)
128 def handle_validation_error(err):
129 exc = getattr(err, "exc", None)
130 if exc:
131 headers = err.data["headers"]
132 messages = exc.messages
133 else:
134 headers = None
135 messages = ["Invalid request."]
136 if headers:
137 return jsonify({"errors": messages}), err.code, headers
138 else:
139 return jsonify({"errors": messages}), err.code
140
141
142 if __name__ == "__main__":
143 User.insert(
144 db=db, id=42, username="fred", first_name="Freddie", last_name="Mercury"
145 )
146 app.run(port=5001, debug=True)
147
[end of examples/schema_example.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/schema_example.py b/examples/schema_example.py
--- a/examples/schema_example.py
+++ b/examples/schema_example.py
@@ -89,9 +89,6 @@
first_name = fields.Str()
last_name = fields.Str()
- class Meta:
- strict = True
-
@post_dump(pass_many=True)
def wrap_with_envelope(self, data, many, **kwargs):
return {"data": data}
|
{"golden_diff": "diff --git a/examples/schema_example.py b/examples/schema_example.py\n--- a/examples/schema_example.py\n+++ b/examples/schema_example.py\n@@ -89,9 +89,6 @@\n first_name = fields.Str()\n last_name = fields.Str()\n \n- class Meta:\n- strict = True\n-\n @post_dump(pass_many=True)\n def wrap_with_envelope(self, data, many, **kwargs):\n return {\"data\": data}\n", "issue": "Schema factory only variable fail - can't pass list type\nLooking at the [schema factory docs](https://webargs.readthedocs.io/en/latest/advanced.html#schema-factories), I'm interested in trying the\r\n```\r\n# Filter based on 'fields' query parameter\r\nonly = request.args.get(\"fields\", None)\r\n```\r\npart.\r\n\r\nHowever, when I try appending something like `?fields=some_field` to my HTTP request, I get the following error:\r\n```\r\nFile \"edited/marshmallow/schema.py\", line 349, in __init__\r\n raise StringNotCollectionError('\"only\" should be a list of strings')\r\n```\r\n\r\nAs far as I can see, webargs always passes the query string parameters as strings. I tried wrapping it in square brackets, but I think I'm barking up the wrong tree. Have I misunderstood something, or is this a bug?\n", "before_files": [{"content": "\"\"\"Example implementation of using a marshmallow Schema for both request input\nand output with a `use_schema` decorator.\nRun the app:\n\n $ python examples/schema_example.py\n\nTry the following with httpie (a cURL-like utility, http://httpie.org):\n\n $ pip install httpie\n $ http GET :5001/users/\n $ http GET :5001/users/42\n $ http POST :5001/users/ usename=brian first_name=Brian last_name=May\n $ http PATCH :5001/users/42 username=freddie\n $ http GET :5001/users/ limit==1\n\"\"\"\nimport functools\nfrom flask import Flask, request, jsonify\nimport random\n\nfrom marshmallow import Schema, fields, post_dump\nfrom webargs.flaskparser import parser, use_kwargs\n\napp = Flask(__name__)\n\n##### Fake database and models #####\n\n\nclass Model:\n def __init__(self, **kwargs):\n self.__dict__.update(kwargs)\n\n def update(self, **kwargs):\n self.__dict__.update(kwargs)\n\n @classmethod\n def insert(cls, db, **kwargs):\n collection = db[cls.collection]\n new_id = None\n if \"id\" in kwargs: # for setting up fixtures\n new_id = kwargs.pop(\"id\")\n else: # find a new id\n found_id = False\n while not found_id:\n new_id = random.randint(1, 9999)\n if new_id not in collection:\n found_id = True\n new_record = cls(id=new_id, **kwargs)\n collection[new_id] = new_record\n return new_record\n\n\nclass User(Model):\n collection = \"users\"\n\n\ndb = {\"users\": {}}\n\n\n##### use_schema #####\n\n\ndef use_schema(schema, list_view=False, locations=None):\n \"\"\"View decorator for using a marshmallow schema to\n (1) parse a request's input and\n (2) serializing the view's output to a JSON response.\n \"\"\"\n\n def decorator(func):\n @functools.wraps(func)\n def wrapped(*args, **kwargs):\n use_args_wrapper = parser.use_args(schema, locations=locations)\n # Function wrapped with use_args\n func_with_args = use_args_wrapper(func)\n ret = func_with_args(*args, **kwargs)\n # Serialize and jsonify the return value\n return jsonify(schema.dump(ret, many=list_view).data)\n\n return wrapped\n\n return decorator\n\n\n##### Schemas #####\n\n\nclass UserSchema(Schema):\n id = fields.Int(dump_only=True)\n username = fields.Str()\n first_name = fields.Str()\n last_name = fields.Str()\n\n class Meta:\n strict = True\n\n @post_dump(pass_many=True)\n def wrap_with_envelope(self, data, many, **kwargs):\n return {\"data\": data}\n\n\n##### Routes #####\n\n\[email protected](\"/users/<int:user_id>\", methods=[\"GET\", \"PATCH\"])\n@use_schema(UserSchema())\ndef user_detail(reqargs, user_id):\n user = db[\"users\"].get(user_id)\n if not user:\n return jsonify({\"message\": \"User not found\"}), 404\n if request.method == \"PATCH\" and reqargs:\n user.update(**reqargs)\n return user\n\n\n# You can add additional arguments with use_kwargs\[email protected](\"/users/\", methods=[\"GET\", \"POST\"])\n@use_kwargs({\"limit\": fields.Int(missing=10, location=\"query\")})\n@use_schema(UserSchema(), list_view=True)\ndef user_list(reqargs, limit):\n users = db[\"users\"].values()\n if request.method == \"POST\":\n User.insert(db=db, **reqargs)\n return list(users)[:limit]\n\n\n# Return validation errors as JSON\[email protected](422)\[email protected](400)\ndef handle_validation_error(err):\n exc = getattr(err, \"exc\", None)\n if exc:\n headers = err.data[\"headers\"]\n messages = exc.messages\n else:\n headers = None\n messages = [\"Invalid request.\"]\n if headers:\n return jsonify({\"errors\": messages}), err.code, headers\n else:\n return jsonify({\"errors\": messages}), err.code\n\n\nif __name__ == \"__main__\":\n User.insert(\n db=db, id=42, username=\"fred\", first_name=\"Freddie\", last_name=\"Mercury\"\n )\n app.run(port=5001, debug=True)\n", "path": "examples/schema_example.py"}]}
| 2,046 | 97 |
gh_patches_debug_793
|
rasdani/github-patches
|
git_diff
|
scrapy__scrapy-742
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Sort spider names on 'scrapy list' command
Hey there,
i think the spider names on the `scrapy list` command should be order by name in the console output.
</issue>
<code>
[start of scrapy/commands/list.py]
1 from __future__ import print_function
2 from scrapy.command import ScrapyCommand
3
4 class Command(ScrapyCommand):
5
6 requires_project = True
7 default_settings = {'LOG_ENABLED': False}
8
9 def short_desc(self):
10 return "List available spiders"
11
12 def run(self, args, opts):
13 crawler = self.crawler_process.create_crawler()
14 for s in crawler.spiders.list():
15 print(s)
16
[end of scrapy/commands/list.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scrapy/commands/list.py b/scrapy/commands/list.py
--- a/scrapy/commands/list.py
+++ b/scrapy/commands/list.py
@@ -11,5 +11,5 @@
def run(self, args, opts):
crawler = self.crawler_process.create_crawler()
- for s in crawler.spiders.list():
+ for s in sorted(crawler.spiders.list()):
print(s)
|
{"golden_diff": "diff --git a/scrapy/commands/list.py b/scrapy/commands/list.py\n--- a/scrapy/commands/list.py\n+++ b/scrapy/commands/list.py\n@@ -11,5 +11,5 @@\n \n def run(self, args, opts):\n crawler = self.crawler_process.create_crawler()\n- for s in crawler.spiders.list():\n+ for s in sorted(crawler.spiders.list()):\n print(s)\n", "issue": "Sort spider names on 'scrapy list' command\nHey there, \n\ni think the spider names on the `scrapy list` command should be order by name in the console output. \n\n", "before_files": [{"content": "from __future__ import print_function\nfrom scrapy.command import ScrapyCommand\n\nclass Command(ScrapyCommand):\n\n requires_project = True\n default_settings = {'LOG_ENABLED': False}\n\n def short_desc(self):\n return \"List available spiders\"\n\n def run(self, args, opts):\n crawler = self.crawler_process.create_crawler()\n for s in crawler.spiders.list():\n print(s)\n", "path": "scrapy/commands/list.py"}]}
| 686 | 95 |
gh_patches_debug_16812
|
rasdani/github-patches
|
git_diff
|
scikit-hep__pyhf-2455
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
In Python 3.12 tarfile raises DeprecationWarning: Python 3.14 will, by default, filter extracted tar archives and reject files or modify their metadata.
While testing Python 3.12 in CI
https://github.com/scikit-hep/pyhf/blob/adddb0797c564a0158a8e2e69a58ee1f98604bf7/tests/test_scripts.py#L591-L604
raised
```pytb
> assert ret.success
E assert False
E + where False = <pytest_console_scripts.RunResult object at 0x29fd18b90>.success
...
DeprecationWarning: Python 3.14 will, by default, filter extracted tar archives and reject files or modify their metadata. Use the filter argument to control this behavior.
```
This should get fixed before Python 3.12 support is added.
</issue>
<code>
[start of src/pyhf/contrib/utils.py]
1 """Helper utilities for common tasks."""
2
3 import logging
4 import tarfile
5 import zipfile
6 from io import BytesIO
7 from pathlib import Path
8 from shutil import rmtree
9 from urllib.parse import urlsplit
10
11 from pyhf import exceptions
12
13 log = logging.getLogger(__name__)
14
15 __all__ = ["download"]
16
17
18 def __dir__():
19 return __all__
20
21
22 try:
23 import requests
24
25 def download(archive_url, output_directory, force=False, compress=False):
26 """
27 Download the patchset archive from the remote URL and extract it in a
28 directory at the path given.
29
30 Example:
31
32 >>> from pyhf.contrib.utils import download
33 >>> download("https://doi.org/10.17182/hepdata.90607.v3/r3", "1Lbb-likelihoods") # doctest: +SKIP
34 >>> import os
35 >>> sorted(os.listdir("1Lbb-likelihoods")) # doctest: +SKIP
36 ['BkgOnly.json', 'README.md', 'patchset.json']
37 >>> download("https://doi.org/10.17182/hepdata.90607.v3/r3", "1Lbb-likelihoods.tar.gz", compress=True) # doctest: +SKIP
38 >>> import glob
39 >>> glob.glob("1Lbb-likelihoods.tar.gz") # doctest: +SKIP
40 ['1Lbb-likelihoods.tar.gz']
41
42 Args:
43 archive_url (:obj:`str`): The URL of the :class:`~pyhf.patchset.PatchSet` archive to download.
44 output_directory (:obj:`str`): Name of the directory to unpack the archive into.
45 force (:obj:`bool`): Force download from non-approved host. Default is ``False``.
46 compress (:obj:`bool`): Keep the archive in a compressed ``tar.gz`` form. Default is ``False``.
47
48 Raises:
49 :class:`~pyhf.exceptions.InvalidArchiveHost`: if the provided archive host name is not known to be valid
50 """
51 if not force:
52 valid_hosts = ["www.hepdata.net", "doi.org"]
53 netloc = urlsplit(archive_url).netloc
54 if netloc not in valid_hosts:
55 raise exceptions.InvalidArchiveHost(
56 f"{netloc} is not an approved archive host: {', '.join(str(host) for host in valid_hosts)}\n"
57 + "To download an archive from this host use the --force option."
58 )
59
60 # c.f. https://github.com/scikit-hep/pyhf/issues/1491
61 # > Use content negotiation at the landing page for the resource that
62 # > the DOI resolves to. DataCite content negotiation is forwarding all
63 # > requests with unknown content types to the URL registered in the
64 # > handle system.
65 # c.f. https://blog.datacite.org/changes-to-doi-content-negotiation/
66 # The HEPData landing page for the resource file can check if the Accept
67 # request HTTP header matches the content type of the resource file and
68 # return the content directly if so.
69 with requests.get(
70 archive_url, headers={"Accept": "application/x-tar, application/zip"}
71 ) as response:
72 if response.status_code != 200:
73 raise exceptions.InvalidArchive(
74 f"{archive_url} gives a response code of {response.status_code}.\n"
75 + "There is either something temporarily wrong with the archive host"
76 + f" or {archive_url} is an invalid URL."
77 )
78
79 if compress:
80 with open(output_directory, "wb") as archive:
81 archive.write(response.content)
82 else:
83 # Support for file-like objects for tarfile.is_tarfile was added
84 # in Python 3.9, so as pyhf is currently Python 3.8+ then can't
85 # do tarfile.is_tarfile(BytesIO(response.content)).
86 # Instead, just use a 'try except' block to determine if the
87 # archive is a valid tarfile.
88 # TODO: Simplify after pyhf is Python 3.9+ only
89 try:
90 # Use transparent compression to allow for .tar or .tar.gz
91 with tarfile.open(
92 mode="r:*", fileobj=BytesIO(response.content)
93 ) as archive:
94 archive.extractall(output_directory)
95 except tarfile.ReadError:
96 if not zipfile.is_zipfile(BytesIO(response.content)):
97 raise exceptions.InvalidArchive(
98 f"The archive downloaded from {archive_url} is not a tarfile"
99 + " or a zipfile and so can not be opened as one."
100 )
101
102 output_directory = Path(output_directory)
103 if output_directory.exists():
104 rmtree(output_directory)
105 with zipfile.ZipFile(BytesIO(response.content)) as archive:
106 archive.extractall(output_directory)
107
108 # zipfile.ZipFile.extractall extracts to a directory
109 # below a target directory, so to match the extraction
110 # path of tarfile.TarFile.extractall move the extracted
111 # directory to a temporary path and then replace the
112 # output directory target with the contents at the
113 # temporary path.
114 # The directory is moved instead of being extracted one
115 # directory up and then renamed as the name of the
116 # zipfile directory is set at zipfile creation time and
117 # isn't knowable in advance.
118 child_path = next(iter(output_directory.iterdir()))
119 _tmp_path = output_directory.parent.joinpath(
120 Path(output_directory.name + "__tmp__")
121 )
122 child_path.replace(_tmp_path)
123 # the zipfile could contain remnant __MACOSX directories
124 # from creation time
125 rmtree(output_directory)
126 _tmp_path.replace(output_directory)
127
128 except ModuleNotFoundError:
129 log.error(
130 "\nInstallation of the contrib extra is required to use pyhf.contrib.utils.download"
131 + "\nPlease install with: python -m pip install 'pyhf[contrib]'\n",
132 exc_info=True,
133 )
134
[end of src/pyhf/contrib/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/pyhf/contrib/utils.py b/src/pyhf/contrib/utils.py
--- a/src/pyhf/contrib/utils.py
+++ b/src/pyhf/contrib/utils.py
@@ -91,7 +91,12 @@
with tarfile.open(
mode="r:*", fileobj=BytesIO(response.content)
) as archive:
- archive.extractall(output_directory)
+ # TODO: Simplify after pyhf is Python 3.12+ only
+ # c.f. https://docs.python.org/3.12/library/tarfile.html#extraction-filters
+ if hasattr(tarfile, "data_filter"):
+ archive.extractall(output_directory, filter="data")
+ else:
+ archive.extractall(output_directory)
except tarfile.ReadError:
if not zipfile.is_zipfile(BytesIO(response.content)):
raise exceptions.InvalidArchive(
|
{"golden_diff": "diff --git a/src/pyhf/contrib/utils.py b/src/pyhf/contrib/utils.py\n--- a/src/pyhf/contrib/utils.py\n+++ b/src/pyhf/contrib/utils.py\n@@ -91,7 +91,12 @@\n with tarfile.open(\n mode=\"r:*\", fileobj=BytesIO(response.content)\n ) as archive:\n- archive.extractall(output_directory)\n+ # TODO: Simplify after pyhf is Python 3.12+ only\n+ # c.f. https://docs.python.org/3.12/library/tarfile.html#extraction-filters\n+ if hasattr(tarfile, \"data_filter\"):\n+ archive.extractall(output_directory, filter=\"data\")\n+ else:\n+ archive.extractall(output_directory)\n except tarfile.ReadError:\n if not zipfile.is_zipfile(BytesIO(response.content)):\n raise exceptions.InvalidArchive(\n", "issue": "In Python 3.12 tarfile raises DeprecationWarning: Python 3.14 will, by default, filter extracted tar archives and reject files or modify their metadata.\nWhile testing Python 3.12 in CI\r\n\r\nhttps://github.com/scikit-hep/pyhf/blob/adddb0797c564a0158a8e2e69a58ee1f98604bf7/tests/test_scripts.py#L591-L604\r\n\r\nraised\r\n\r\n```pytb\r\n> assert ret.success\r\nE assert False\r\nE + where False = <pytest_console_scripts.RunResult object at 0x29fd18b90>.success\r\n...\r\nDeprecationWarning: Python 3.14 will, by default, filter extracted tar archives and reject files or modify their metadata. Use the filter argument to control this behavior.\r\n```\r\n\r\nThis should get fixed before Python 3.12 support is added.\n", "before_files": [{"content": "\"\"\"Helper utilities for common tasks.\"\"\"\n\nimport logging\nimport tarfile\nimport zipfile\nfrom io import BytesIO\nfrom pathlib import Path\nfrom shutil import rmtree\nfrom urllib.parse import urlsplit\n\nfrom pyhf import exceptions\n\nlog = logging.getLogger(__name__)\n\n__all__ = [\"download\"]\n\n\ndef __dir__():\n return __all__\n\n\ntry:\n import requests\n\n def download(archive_url, output_directory, force=False, compress=False):\n \"\"\"\n Download the patchset archive from the remote URL and extract it in a\n directory at the path given.\n\n Example:\n\n >>> from pyhf.contrib.utils import download\n >>> download(\"https://doi.org/10.17182/hepdata.90607.v3/r3\", \"1Lbb-likelihoods\") # doctest: +SKIP\n >>> import os\n >>> sorted(os.listdir(\"1Lbb-likelihoods\")) # doctest: +SKIP\n ['BkgOnly.json', 'README.md', 'patchset.json']\n >>> download(\"https://doi.org/10.17182/hepdata.90607.v3/r3\", \"1Lbb-likelihoods.tar.gz\", compress=True) # doctest: +SKIP\n >>> import glob\n >>> glob.glob(\"1Lbb-likelihoods.tar.gz\") # doctest: +SKIP\n ['1Lbb-likelihoods.tar.gz']\n\n Args:\n archive_url (:obj:`str`): The URL of the :class:`~pyhf.patchset.PatchSet` archive to download.\n output_directory (:obj:`str`): Name of the directory to unpack the archive into.\n force (:obj:`bool`): Force download from non-approved host. Default is ``False``.\n compress (:obj:`bool`): Keep the archive in a compressed ``tar.gz`` form. Default is ``False``.\n\n Raises:\n :class:`~pyhf.exceptions.InvalidArchiveHost`: if the provided archive host name is not known to be valid\n \"\"\"\n if not force:\n valid_hosts = [\"www.hepdata.net\", \"doi.org\"]\n netloc = urlsplit(archive_url).netloc\n if netloc not in valid_hosts:\n raise exceptions.InvalidArchiveHost(\n f\"{netloc} is not an approved archive host: {', '.join(str(host) for host in valid_hosts)}\\n\"\n + \"To download an archive from this host use the --force option.\"\n )\n\n # c.f. https://github.com/scikit-hep/pyhf/issues/1491\n # > Use content negotiation at the landing page for the resource that\n # > the DOI resolves to. DataCite content negotiation is forwarding all\n # > requests with unknown content types to the URL registered in the\n # > handle system.\n # c.f. https://blog.datacite.org/changes-to-doi-content-negotiation/\n # The HEPData landing page for the resource file can check if the Accept\n # request HTTP header matches the content type of the resource file and\n # return the content directly if so.\n with requests.get(\n archive_url, headers={\"Accept\": \"application/x-tar, application/zip\"}\n ) as response:\n if response.status_code != 200:\n raise exceptions.InvalidArchive(\n f\"{archive_url} gives a response code of {response.status_code}.\\n\"\n + \"There is either something temporarily wrong with the archive host\"\n + f\" or {archive_url} is an invalid URL.\"\n )\n\n if compress:\n with open(output_directory, \"wb\") as archive:\n archive.write(response.content)\n else:\n # Support for file-like objects for tarfile.is_tarfile was added\n # in Python 3.9, so as pyhf is currently Python 3.8+ then can't\n # do tarfile.is_tarfile(BytesIO(response.content)).\n # Instead, just use a 'try except' block to determine if the\n # archive is a valid tarfile.\n # TODO: Simplify after pyhf is Python 3.9+ only\n try:\n # Use transparent compression to allow for .tar or .tar.gz\n with tarfile.open(\n mode=\"r:*\", fileobj=BytesIO(response.content)\n ) as archive:\n archive.extractall(output_directory)\n except tarfile.ReadError:\n if not zipfile.is_zipfile(BytesIO(response.content)):\n raise exceptions.InvalidArchive(\n f\"The archive downloaded from {archive_url} is not a tarfile\"\n + \" or a zipfile and so can not be opened as one.\"\n )\n\n output_directory = Path(output_directory)\n if output_directory.exists():\n rmtree(output_directory)\n with zipfile.ZipFile(BytesIO(response.content)) as archive:\n archive.extractall(output_directory)\n\n # zipfile.ZipFile.extractall extracts to a directory\n # below a target directory, so to match the extraction\n # path of tarfile.TarFile.extractall move the extracted\n # directory to a temporary path and then replace the\n # output directory target with the contents at the\n # temporary path.\n # The directory is moved instead of being extracted one\n # directory up and then renamed as the name of the\n # zipfile directory is set at zipfile creation time and\n # isn't knowable in advance.\n child_path = next(iter(output_directory.iterdir()))\n _tmp_path = output_directory.parent.joinpath(\n Path(output_directory.name + \"__tmp__\")\n )\n child_path.replace(_tmp_path)\n # the zipfile could contain remnant __MACOSX directories\n # from creation time\n rmtree(output_directory)\n _tmp_path.replace(output_directory)\n\nexcept ModuleNotFoundError:\n log.error(\n \"\\nInstallation of the contrib extra is required to use pyhf.contrib.utils.download\"\n + \"\\nPlease install with: python -m pip install 'pyhf[contrib]'\\n\",\n exc_info=True,\n )\n", "path": "src/pyhf/contrib/utils.py"}]}
| 2,338 | 194 |
gh_patches_debug_12216
|
rasdani/github-patches
|
git_diff
|
liqd__a4-meinberlin-563
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Making messages for translation has system dependent output
When calling `make makemessages` the output of the generated "djangojs.po" is dependent on the system configuration.
For example in my case it inserts messages from:
"adhocracy4/node_modules/ajv/dist/regenerator.min.js" and
"adhocracy4/node_modules/js-yaml/dist/js-yaml.min.js"
</issue>
<code>
[start of apps/contrib/management/commands/makemessages.py]
1 from os import path
2
3 from django.conf import settings
4 from django.core.management.commands import makemessages
5
6
7 def get_module_dir(name):
8 module = __import__(name)
9 return path.dirname(module.__file__)
10
11
12 class Command(makemessages.Command):
13 msgmerge_options = (
14 makemessages.Command.msgmerge_options + ['--no-fuzzy-matching']
15 )
16
17 def handle(self, *args, **options):
18 if options['domain'] == 'djangojs':
19 if options['extensions'] is None:
20 options['extensions'] = ['js', 'jsx']
21 return super().handle(*args, **options)
22
23 def find_files(self, root):
24 a4js_paths = super().find_files(
25 path.join(settings.BASE_DIR, 'node_modules', 'adhocracy4')
26 )
27 a4_paths = super().find_files(get_module_dir('adhocracy4'))
28 apps_paths = super().find_files(path.relpath(get_module_dir('apps')))
29 meinberlin_paths = super().find_files(
30 path.relpath(get_module_dir('meinberlin'))
31 )
32
33 return a4js_paths + a4_paths + apps_paths + meinberlin_paths
34
[end of apps/contrib/management/commands/makemessages.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/apps/contrib/management/commands/makemessages.py b/apps/contrib/management/commands/makemessages.py
--- a/apps/contrib/management/commands/makemessages.py
+++ b/apps/contrib/management/commands/makemessages.py
@@ -21,9 +21,9 @@
return super().handle(*args, **options)
def find_files(self, root):
- a4js_paths = super().find_files(
- path.join(settings.BASE_DIR, 'node_modules', 'adhocracy4')
- )
+ a4js_paths = super().find_files(path.join(
+ settings.BASE_DIR, 'node_modules', 'adhocracy4', 'adhocracy4'
+ ))
a4_paths = super().find_files(get_module_dir('adhocracy4'))
apps_paths = super().find_files(path.relpath(get_module_dir('apps')))
meinberlin_paths = super().find_files(
|
{"golden_diff": "diff --git a/apps/contrib/management/commands/makemessages.py b/apps/contrib/management/commands/makemessages.py\n--- a/apps/contrib/management/commands/makemessages.py\n+++ b/apps/contrib/management/commands/makemessages.py\n@@ -21,9 +21,9 @@\n return super().handle(*args, **options)\n \n def find_files(self, root):\n- a4js_paths = super().find_files(\n- path.join(settings.BASE_DIR, 'node_modules', 'adhocracy4')\n- )\n+ a4js_paths = super().find_files(path.join(\n+ settings.BASE_DIR, 'node_modules', 'adhocracy4', 'adhocracy4'\n+ ))\n a4_paths = super().find_files(get_module_dir('adhocracy4'))\n apps_paths = super().find_files(path.relpath(get_module_dir('apps')))\n meinberlin_paths = super().find_files(\n", "issue": "Making messages for translation has system dependent output\nWhen calling `make makemessages` the output of the generated \"djangojs.po\" is dependent on the system configuration. \r\nFor example in my case it inserts messages from:\r\n\"adhocracy4/node_modules/ajv/dist/regenerator.min.js\" and\r\n\"adhocracy4/node_modules/js-yaml/dist/js-yaml.min.js\"\n", "before_files": [{"content": "from os import path\n\nfrom django.conf import settings\nfrom django.core.management.commands import makemessages\n\n\ndef get_module_dir(name):\n module = __import__(name)\n return path.dirname(module.__file__)\n\n\nclass Command(makemessages.Command):\n msgmerge_options = (\n makemessages.Command.msgmerge_options + ['--no-fuzzy-matching']\n )\n\n def handle(self, *args, **options):\n if options['domain'] == 'djangojs':\n if options['extensions'] is None:\n options['extensions'] = ['js', 'jsx']\n return super().handle(*args, **options)\n\n def find_files(self, root):\n a4js_paths = super().find_files(\n path.join(settings.BASE_DIR, 'node_modules', 'adhocracy4')\n )\n a4_paths = super().find_files(get_module_dir('adhocracy4'))\n apps_paths = super().find_files(path.relpath(get_module_dir('apps')))\n meinberlin_paths = super().find_files(\n path.relpath(get_module_dir('meinberlin'))\n )\n\n return a4js_paths + a4_paths + apps_paths + meinberlin_paths\n", "path": "apps/contrib/management/commands/makemessages.py"}]}
| 941 | 206 |
gh_patches_debug_40262
|
rasdani/github-patches
|
git_diff
|
weecology__retriever-1145
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Gentry site_code incorrectly includes directory name
At some point a behavior changed that caused site names extracted from the file names in gentry-forest-transects to including the directory in which they were located. This leads to site_code values like `africa/NDAKANNI`, which isn't what we want.
</issue>
<code>
[start of scripts/gentry_forest_transects.py]
1 #retriever
2 """Retriever script for Alwyn H. Gentry Forest Transect Dataset
3
4 """
5 from __future__ import print_function
6 # from __future__ import unicode_literals
7 from builtins import str
8 from builtins import range
9
10 import os
11 import sys
12 import zipfile
13 import xlrd
14 from retriever.lib.templates import Script
15 from retriever.lib.models import Table
16 from retriever.lib.excel import Excel
17 from pkg_resources import parse_version
18 try:
19 from retriever.lib.defaults import VERSION
20 except ImportError:
21 from retriever import VERSION
22
23 TAX_GROUPS = 9756 # 9819
24
25
26 class main(Script):
27 def __init__(self, **kwargs):
28 Script.__init__(self, **kwargs)
29 self.title = "Alwyn H. Gentry Forest Transect Dataset"
30 self.name = "gentry-forest-transects"
31 self.retriever_minimum_version = '2.0.dev'
32 self.version = '1.4.2'
33 self.urls = {"stems": "http://www.mobot.org/mobot/gentry/123/all_Excel.zip",
34 "sites": "https://ndownloader.figshare.com/files/5515373",
35 "species": "",
36 "counts": ""}
37 self.keywords = ["plants", "global-scale", "observational"]
38 self.ref = "http://www.mobot.org/mobot/research/gentry/welcome.shtml"
39 self.citation = "Phillips, O. and Miller, J.S., 2002. Global patterns of plant diversity: Alwyn H. Gentry's forest transect data set. Missouri Botanical Press."
40 self.addendum = """Researchers who make use of the data in publications are requested to acknowledge Alwyn H. Gentry, the Missouri Botanical Garden, and collectors who assisted Gentry or contributed data for specific sites. It is also requested that a reprint of any publication making use of the Gentry Forest Transect Data be sent to:
41
42 Bruce E. Ponman
43 Missouri Botanical Garden
44 P.O. Box 299
45 St. Louis, MO 63166-0299
46 U.S.A. """
47
48 if parse_version(VERSION) <= parse_version("2.0.0"):
49 self.shortname = self.name
50 self.name = self.title
51 self.tags = self.keywords
52
53 def download(self, engine=None, debug=False):
54 Script.download(self, engine, debug)
55
56 self.engine.auto_create_table(Table("sites"), url=self.urls["sites"], filename='gentry_sites.csv')
57 self.engine.insert_data_from_url(self.urls["sites"])
58
59 self.engine.download_file(self.urls["stems"], "all_Excel.zip")
60 local_zip = zipfile.ZipFile(self.engine.format_filename("all_Excel.zip"))
61 filelist = local_zip.namelist()
62 local_zip.close()
63 self.engine.download_files_from_archive(self.urls["stems"], filelist)
64
65 if parse_version(VERSION).__str__() < parse_version("2.1.dev").__str__():
66 filelist = [os.path.basename(filename) for filename in filelist]
67
68 # Currently all_Excel.zip is missing CURUYUQU.xls
69 # Download it separately and add it to the file list
70 if not self.engine.find_file('CURUYUQU.xls'):
71 self.engine.download_file("http://www.mobot.org/mobot/gentry/123/samerica/CURUYUQU.xls", "CURUYUQU.xls")
72 filelist.append('CURUYUQU.xls')
73
74 lines = []
75 tax = []
76 for filename in filelist:
77 print("Extracting data from " + filename + "...")
78 book = xlrd.open_workbook(self.engine.format_filename(filename))
79 sh = book.sheet_by_index(0)
80 rows = sh.nrows
81 cn = {'stems': []}
82 n = 0
83 for colnum, c in enumerate(sh.row(0)):
84 if not Excel.empty_cell(c):
85 cid = c.value.lower().strip()
86 # line number column is sometimes named differently
87 if cid in ["sub", "number"]:
88 cid = "line"
89 # the "number of individuals" column is named in various
90 # different ways; they always at least contain "nd"
91 if "nd" in cid:
92 cid = "count"
93 # in QUIAPACA.xls the "number of individuals" column is
94 # misnamed "STEMDBH" just like the stems columns, so weep
95 # for the state of scientific data and then fix manually
96 if filename == "QUIAPACA.xls" and colnum == 13:
97 cid = "count"
98
99 # if column is a stem, add it to the list of stems;
100 # otherwise, make note of the column name/number
101 if "stem" in cid or "dbh" in cid:
102 cn["stems"].append(n)
103 else:
104 cn[cid] = n
105 n += 1
106 # sometimes, a data file does not contain a liana or count column
107 if not "liana" in list(cn.keys()):
108 cn["liana"] = -1
109 if not "count" in list(cn.keys()):
110 cn["count"] = -1
111 for i in range(1, rows):
112 row = sh.row(i)
113 cellcount = len(row)
114 # make sure the row is real, not just empty cells
115 if not all(Excel.empty_cell(cell) for cell in row):
116 try:
117 this_line = {}
118
119 # get the following information from the appropriate columns
120 for i in ["line", "family", "genus", "species",
121 "liana", "count"]:
122 if cn[i] > -1:
123 if row[cn[i]].ctype != 2:
124 # if the cell type(ctype) is not a number
125 this_line[i] = row[cn[i]].value.lower().strip().replace("\\", "/").replace('"', '')
126 else:
127 this_line[i] = row[cn[i]].value
128 if this_line[i] == '`':
129 this_line[i] = 1
130 this_line["stems"] = [row[c]
131 for c in cn["stems"]
132 if not Excel.empty_cell(row[c])]
133 this_line["site"] = filename[0:-4]
134
135 # Manually correct CEDRAL data, which has a single line
136 # that is shifted by one to the left starting at Liana
137 if this_line["site"] == "CEDRAL" and type(this_line["liana"]) == float:
138 this_line["liana"] = ""
139 this_line["count"] = 3
140 this_line["stems"] = [2.5, 2.5, 30, 18, 25]
141
142 lines.append(this_line)
143
144 # Check how far the species is identified
145 full_id = 0
146 if len(this_line["species"]) < 3:
147 if len(this_line["genus"]) < 3:
148 id_level = "family"
149 else:
150 id_level = "genus"
151 else:
152 id_level = "species"
153 full_id = 1
154 tax.append((this_line["family"],
155 this_line["genus"],
156 this_line["species"],
157 id_level,
158 str(full_id)))
159 except:
160 raise
161 pass
162
163 tax = sorted(tax, key=lambda group: group[0] + " " + group[1] + " " + group[2])
164 unique_tax = []
165 tax_dict = {}
166 tax_count = 0
167
168 # Get all unique families/genera/species
169 print("\n")
170 for group in tax:
171 if not (group in unique_tax):
172 unique_tax.append(group)
173 tax_count += 1
174 tax_dict[group[0:3]] = tax_count
175 if tax_count % 10 == 0:
176 msg = "Generating taxonomic groups: " + str(tax_count) + " / " + str(TAX_GROUPS)
177 sys.stdout.flush()
178 sys.stdout.write(msg + "\b" * len(msg))
179 print("\n")
180 # Create species table
181 table = Table("species", delimiter=",")
182 table.columns=[("species_id" , ("pk-int",) ),
183 ("family" , ("char", ) ),
184 ("genus" , ("char", ) ),
185 ("species" , ("char", ) ),
186 ("id_level" , ("char", 10) ),
187 ("full_id" , ("int",) )]
188
189 data = [[str(tax_dict[group[:3]])] + ['"%s"' % g for g in group]
190 for group in unique_tax]
191 table.pk = 'species_id'
192 table.contains_pk = True
193
194 self.engine.table = table
195 self.engine.create_table()
196 self.engine.add_to_table(data)
197
198 # Create stems table
199 table = Table("stems", delimiter=",")
200 table.columns=[("stem_id" , ("pk-auto",) ),
201 ("line" , ("int",) ),
202 ("species_id" , ("int",) ),
203 ("site_code" , ("char", 12) ),
204 ("liana" , ("char", 10) ),
205 ("stem" , ("double",) )]
206 stems = []
207 counts = []
208 for line in lines:
209 try:
210 liana = line["liana"]
211 except KeyError:
212 liana = ""
213 species_info = [line["line"],
214 tax_dict[(line["family"],
215 line["genus"],
216 line["species"])],
217 line["site"],
218 liana
219 ]
220 try:
221 counts.append([value for value in species_info + [line["count"]]])
222 except KeyError:
223 pass
224
225 for i in line["stems"]:
226 stem = species_info + [str(i)]
227 stems.append(stem)
228
229 self.engine.table = table
230 self.engine.create_table()
231 self.engine.add_to_table(stems)
232
233 # Create counts table
234 table = Table("counts", delimiter=",", contains_pk=False)
235 table.columns=[("count_id" , ("pk-auto",) ),
236 ("line" , ("int",) ),
237 ("species_id" , ("int",) ),
238 ("site_code" , ("char", 12) ),
239 ("liana" , ("char", 10) ),
240 ("count" , ("double",) )]
241 self.engine.table = table
242 self.engine.create_table()
243 self.engine.add_to_table(counts)
244
245 return self.engine
246 SCRIPT = main()
247
[end of scripts/gentry_forest_transects.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scripts/gentry_forest_transects.py b/scripts/gentry_forest_transects.py
--- a/scripts/gentry_forest_transects.py
+++ b/scripts/gentry_forest_transects.py
@@ -1,9 +1,6 @@
#retriever
-"""Retriever script for Alwyn H. Gentry Forest Transect Dataset
+"""Retriever script for Alwyn H. Gentry Forest Transect Dataset"""
-"""
-from __future__ import print_function
-# from __future__ import unicode_literals
from builtins import str
from builtins import range
@@ -29,7 +26,7 @@
self.title = "Alwyn H. Gentry Forest Transect Dataset"
self.name = "gentry-forest-transects"
self.retriever_minimum_version = '2.0.dev'
- self.version = '1.4.2'
+ self.version = '1.4.3'
self.urls = {"stems": "http://www.mobot.org/mobot/gentry/123/all_Excel.zip",
"sites": "https://ndownloader.figshare.com/files/5515373",
"species": "",
@@ -74,7 +71,6 @@
lines = []
tax = []
for filename in filelist:
- print("Extracting data from " + filename + "...")
book = xlrd.open_workbook(self.engine.format_filename(filename))
sh = book.sheet_by_index(0)
rows = sh.nrows
@@ -130,7 +126,8 @@
this_line["stems"] = [row[c]
for c in cn["stems"]
if not Excel.empty_cell(row[c])]
- this_line["site"] = filename[0:-4]
+ site_code, _ = os.path.splitext(os.path.basename(filename))
+ this_line["site"] = site_code
# Manually correct CEDRAL data, which has a single line
# that is shifted by one to the left starting at Liana
@@ -166,17 +163,11 @@
tax_count = 0
# Get all unique families/genera/species
- print("\n")
for group in tax:
if not (group in unique_tax):
unique_tax.append(group)
tax_count += 1
tax_dict[group[0:3]] = tax_count
- if tax_count % 10 == 0:
- msg = "Generating taxonomic groups: " + str(tax_count) + " / " + str(TAX_GROUPS)
- sys.stdout.flush()
- sys.stdout.write(msg + "\b" * len(msg))
- print("\n")
# Create species table
table = Table("species", delimiter=",")
table.columns=[("species_id" , ("pk-int",) ),
|
{"golden_diff": "diff --git a/scripts/gentry_forest_transects.py b/scripts/gentry_forest_transects.py\n--- a/scripts/gentry_forest_transects.py\n+++ b/scripts/gentry_forest_transects.py\n@@ -1,9 +1,6 @@\n #retriever\n-\"\"\"Retriever script for Alwyn H. Gentry Forest Transect Dataset\n+\"\"\"Retriever script for Alwyn H. Gentry Forest Transect Dataset\"\"\"\n \n-\"\"\"\n-from __future__ import print_function\n-# from __future__ import unicode_literals\n from builtins import str\n from builtins import range\n \n@@ -29,7 +26,7 @@\n self.title = \"Alwyn H. Gentry Forest Transect Dataset\"\n self.name = \"gentry-forest-transects\"\n self.retriever_minimum_version = '2.0.dev'\n- self.version = '1.4.2'\n+ self.version = '1.4.3'\n self.urls = {\"stems\": \"http://www.mobot.org/mobot/gentry/123/all_Excel.zip\",\n \"sites\": \"https://ndownloader.figshare.com/files/5515373\",\n \"species\": \"\",\n@@ -74,7 +71,6 @@\n lines = []\n tax = []\n for filename in filelist:\n- print(\"Extracting data from \" + filename + \"...\")\n book = xlrd.open_workbook(self.engine.format_filename(filename))\n sh = book.sheet_by_index(0)\n rows = sh.nrows\n@@ -130,7 +126,8 @@\n this_line[\"stems\"] = [row[c]\n for c in cn[\"stems\"]\n if not Excel.empty_cell(row[c])]\n- this_line[\"site\"] = filename[0:-4]\n+ site_code, _ = os.path.splitext(os.path.basename(filename))\n+ this_line[\"site\"] = site_code\n \n # Manually correct CEDRAL data, which has a single line\n # that is shifted by one to the left starting at Liana\n@@ -166,17 +163,11 @@\n tax_count = 0\n \n # Get all unique families/genera/species\n- print(\"\\n\")\n for group in tax:\n if not (group in unique_tax):\n unique_tax.append(group)\n tax_count += 1\n tax_dict[group[0:3]] = tax_count\n- if tax_count % 10 == 0:\n- msg = \"Generating taxonomic groups: \" + str(tax_count) + \" / \" + str(TAX_GROUPS)\n- sys.stdout.flush()\n- sys.stdout.write(msg + \"\\b\" * len(msg))\n- print(\"\\n\")\n # Create species table\n table = Table(\"species\", delimiter=\",\")\n table.columns=[(\"species_id\" , (\"pk-int\",) ),\n", "issue": "Gentry site_code incorrectly includes directory name\nAt some point a behavior changed that caused site names extracted from the file names in gentry-forest-transects to including the directory in which they were located. This leads to site_code values like `africa/NDAKANNI`, which isn't what we want.\n", "before_files": [{"content": "#retriever\n\"\"\"Retriever script for Alwyn H. Gentry Forest Transect Dataset\n\n\"\"\"\nfrom __future__ import print_function\n# from __future__ import unicode_literals\nfrom builtins import str\nfrom builtins import range\n\nimport os\nimport sys\nimport zipfile\nimport xlrd\nfrom retriever.lib.templates import Script\nfrom retriever.lib.models import Table\nfrom retriever.lib.excel import Excel\nfrom pkg_resources import parse_version\ntry:\n from retriever.lib.defaults import VERSION\nexcept ImportError:\n from retriever import VERSION\n\nTAX_GROUPS = 9756 # 9819\n\n\nclass main(Script):\n def __init__(self, **kwargs):\n Script.__init__(self, **kwargs)\n self.title = \"Alwyn H. Gentry Forest Transect Dataset\"\n self.name = \"gentry-forest-transects\"\n self.retriever_minimum_version = '2.0.dev'\n self.version = '1.4.2'\n self.urls = {\"stems\": \"http://www.mobot.org/mobot/gentry/123/all_Excel.zip\",\n \"sites\": \"https://ndownloader.figshare.com/files/5515373\",\n \"species\": \"\",\n \"counts\": \"\"}\n self.keywords = [\"plants\", \"global-scale\", \"observational\"]\n self.ref = \"http://www.mobot.org/mobot/research/gentry/welcome.shtml\"\n self.citation = \"Phillips, O. and Miller, J.S., 2002. Global patterns of plant diversity: Alwyn H. Gentry's forest transect data set. Missouri Botanical Press.\"\n self.addendum = \"\"\"Researchers who make use of the data in publications are requested to acknowledge Alwyn H. Gentry, the Missouri Botanical Garden, and collectors who assisted Gentry or contributed data for specific sites. It is also requested that a reprint of any publication making use of the Gentry Forest Transect Data be sent to:\n\nBruce E. Ponman\nMissouri Botanical Garden\nP.O. Box 299\nSt. Louis, MO 63166-0299\nU.S.A. \"\"\"\n\n if parse_version(VERSION) <= parse_version(\"2.0.0\"):\n self.shortname = self.name\n self.name = self.title\n self.tags = self.keywords\n\n def download(self, engine=None, debug=False):\n Script.download(self, engine, debug)\n\n self.engine.auto_create_table(Table(\"sites\"), url=self.urls[\"sites\"], filename='gentry_sites.csv')\n self.engine.insert_data_from_url(self.urls[\"sites\"])\n\n self.engine.download_file(self.urls[\"stems\"], \"all_Excel.zip\")\n local_zip = zipfile.ZipFile(self.engine.format_filename(\"all_Excel.zip\"))\n filelist = local_zip.namelist()\n local_zip.close()\n self.engine.download_files_from_archive(self.urls[\"stems\"], filelist)\n\n if parse_version(VERSION).__str__() < parse_version(\"2.1.dev\").__str__():\n filelist = [os.path.basename(filename) for filename in filelist]\n\n # Currently all_Excel.zip is missing CURUYUQU.xls\n # Download it separately and add it to the file list\n if not self.engine.find_file('CURUYUQU.xls'):\n self.engine.download_file(\"http://www.mobot.org/mobot/gentry/123/samerica/CURUYUQU.xls\", \"CURUYUQU.xls\")\n filelist.append('CURUYUQU.xls')\n\n lines = []\n tax = []\n for filename in filelist:\n print(\"Extracting data from \" + filename + \"...\")\n book = xlrd.open_workbook(self.engine.format_filename(filename))\n sh = book.sheet_by_index(0)\n rows = sh.nrows\n cn = {'stems': []}\n n = 0\n for colnum, c in enumerate(sh.row(0)):\n if not Excel.empty_cell(c):\n cid = c.value.lower().strip()\n # line number column is sometimes named differently\n if cid in [\"sub\", \"number\"]:\n cid = \"line\"\n # the \"number of individuals\" column is named in various\n # different ways; they always at least contain \"nd\"\n if \"nd\" in cid:\n cid = \"count\"\n # in QUIAPACA.xls the \"number of individuals\" column is\n # misnamed \"STEMDBH\" just like the stems columns, so weep\n # for the state of scientific data and then fix manually\n if filename == \"QUIAPACA.xls\" and colnum == 13:\n cid = \"count\"\n\n # if column is a stem, add it to the list of stems;\n # otherwise, make note of the column name/number\n if \"stem\" in cid or \"dbh\" in cid:\n cn[\"stems\"].append(n)\n else:\n cn[cid] = n\n n += 1\n # sometimes, a data file does not contain a liana or count column\n if not \"liana\" in list(cn.keys()):\n cn[\"liana\"] = -1\n if not \"count\" in list(cn.keys()):\n cn[\"count\"] = -1\n for i in range(1, rows):\n row = sh.row(i)\n cellcount = len(row)\n # make sure the row is real, not just empty cells\n if not all(Excel.empty_cell(cell) for cell in row):\n try:\n this_line = {}\n\n # get the following information from the appropriate columns\n for i in [\"line\", \"family\", \"genus\", \"species\",\n \"liana\", \"count\"]:\n if cn[i] > -1:\n if row[cn[i]].ctype != 2:\n # if the cell type(ctype) is not a number\n this_line[i] = row[cn[i]].value.lower().strip().replace(\"\\\\\", \"/\").replace('\"', '')\n else:\n this_line[i] = row[cn[i]].value\n if this_line[i] == '`':\n this_line[i] = 1\n this_line[\"stems\"] = [row[c]\n for c in cn[\"stems\"]\n if not Excel.empty_cell(row[c])]\n this_line[\"site\"] = filename[0:-4]\n\n # Manually correct CEDRAL data, which has a single line\n # that is shifted by one to the left starting at Liana\n if this_line[\"site\"] == \"CEDRAL\" and type(this_line[\"liana\"]) == float:\n this_line[\"liana\"] = \"\"\n this_line[\"count\"] = 3\n this_line[\"stems\"] = [2.5, 2.5, 30, 18, 25]\n\n lines.append(this_line)\n\n # Check how far the species is identified\n full_id = 0\n if len(this_line[\"species\"]) < 3:\n if len(this_line[\"genus\"]) < 3:\n id_level = \"family\"\n else:\n id_level = \"genus\"\n else:\n id_level = \"species\"\n full_id = 1\n tax.append((this_line[\"family\"],\n this_line[\"genus\"],\n this_line[\"species\"],\n id_level,\n str(full_id)))\n except:\n raise\n pass\n\n tax = sorted(tax, key=lambda group: group[0] + \" \" + group[1] + \" \" + group[2])\n unique_tax = []\n tax_dict = {}\n tax_count = 0\n\n # Get all unique families/genera/species\n print(\"\\n\")\n for group in tax:\n if not (group in unique_tax):\n unique_tax.append(group)\n tax_count += 1\n tax_dict[group[0:3]] = tax_count\n if tax_count % 10 == 0:\n msg = \"Generating taxonomic groups: \" + str(tax_count) + \" / \" + str(TAX_GROUPS)\n sys.stdout.flush()\n sys.stdout.write(msg + \"\\b\" * len(msg))\n print(\"\\n\")\n # Create species table\n table = Table(\"species\", delimiter=\",\")\n table.columns=[(\"species_id\" , (\"pk-int\",) ),\n (\"family\" , (\"char\", ) ),\n (\"genus\" , (\"char\", ) ),\n (\"species\" , (\"char\", ) ),\n (\"id_level\" , (\"char\", 10) ),\n (\"full_id\" , (\"int\",) )]\n\n data = [[str(tax_dict[group[:3]])] + ['\"%s\"' % g for g in group]\n for group in unique_tax]\n table.pk = 'species_id'\n table.contains_pk = True\n\n self.engine.table = table\n self.engine.create_table()\n self.engine.add_to_table(data)\n\n # Create stems table\n table = Table(\"stems\", delimiter=\",\")\n table.columns=[(\"stem_id\" , (\"pk-auto\",) ),\n (\"line\" , (\"int\",) ),\n (\"species_id\" , (\"int\",) ),\n (\"site_code\" , (\"char\", 12) ),\n (\"liana\" , (\"char\", 10) ),\n (\"stem\" , (\"double\",) )]\n stems = []\n counts = []\n for line in lines:\n try:\n liana = line[\"liana\"]\n except KeyError:\n liana = \"\"\n species_info = [line[\"line\"],\n tax_dict[(line[\"family\"],\n line[\"genus\"],\n line[\"species\"])],\n line[\"site\"],\n liana\n ]\n try:\n counts.append([value for value in species_info + [line[\"count\"]]])\n except KeyError:\n pass\n\n for i in line[\"stems\"]:\n stem = species_info + [str(i)]\n stems.append(stem)\n\n self.engine.table = table\n self.engine.create_table()\n self.engine.add_to_table(stems)\n\n # Create counts table\n table = Table(\"counts\", delimiter=\",\", contains_pk=False)\n table.columns=[(\"count_id\" , (\"pk-auto\",) ),\n (\"line\" , (\"int\",) ),\n (\"species_id\" , (\"int\",) ),\n (\"site_code\" , (\"char\", 12) ),\n (\"liana\" , (\"char\", 10) ),\n (\"count\" , (\"double\",) )]\n self.engine.table = table\n self.engine.create_table()\n self.engine.add_to_table(counts)\n\n return self.engine\nSCRIPT = main()\n", "path": "scripts/gentry_forest_transects.py"}]}
| 3,592 | 632 |
gh_patches_debug_13242
|
rasdani/github-patches
|
git_diff
|
nf-core__tools-1964
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
nf-core modules install is asking for two files
### Description of the bug
nf-core modules install is asking for two files: main.nf and nextflow.config. I think this is not necessary, since one can use a different naming convention for both files.
https://github.com/nf-core/modules/issues/2272
I think this can be just a warning since you can decide to install the modules outside a nf-core pipeline
### Command used and terminal output
_No response_
### System information
_No response_
</issue>
<code>
[start of nf_core/modules/modules_command.py]
1 import logging
2 import os
3 import shutil
4 from pathlib import Path
5
6 import yaml
7
8 import nf_core.modules.module_utils
9 import nf_core.utils
10
11 from .modules_json import ModulesJson
12 from .modules_repo import ModulesRepo
13
14 log = logging.getLogger(__name__)
15
16
17 class ModuleCommand:
18 """
19 Base class for the 'nf-core modules' commands
20 """
21
22 def __init__(self, dir, remote_url=None, branch=None, no_pull=False, hide_progress=False):
23 """
24 Initialise the ModulesCommand object
25 """
26 self.modules_repo = ModulesRepo(remote_url, branch, no_pull, hide_progress)
27 self.hide_progress = hide_progress
28 self.dir = dir
29 self.default_modules_path = Path("modules", "nf-core")
30 self.default_tests_path = Path("tests", "modules", "nf-core")
31 try:
32 if self.dir:
33 self.dir, self.repo_type = nf_core.modules.module_utils.get_repo_type(self.dir)
34 else:
35 self.repo_type = None
36 except LookupError as e:
37 raise UserWarning(e)
38
39 def get_modules_clone_modules(self):
40 """
41 Get the modules available in a clone of nf-core/modules
42 """
43 module_base_path = Path(self.dir, self.default_modules_path)
44 return [
45 str(Path(dir).relative_to(module_base_path))
46 for dir, _, files in os.walk(module_base_path)
47 if "main.nf" in files
48 ]
49
50 def get_local_modules(self):
51 """
52 Get the local modules in a pipeline
53 """
54 local_module_dir = Path(self.dir, "modules", "local")
55 return [str(path.relative_to(local_module_dir)) for path in local_module_dir.iterdir() if path.suffix == ".nf"]
56
57 def has_valid_directory(self):
58 """Check that we were given a pipeline or clone of nf-core/modules"""
59 if self.repo_type == "modules":
60 return True
61 if self.dir is None or not os.path.exists(self.dir):
62 log.error(f"Could not find pipeline: {self.dir}")
63 return False
64 main_nf = os.path.join(self.dir, "main.nf")
65 nf_config = os.path.join(self.dir, "nextflow.config")
66 if not os.path.exists(main_nf) and not os.path.exists(nf_config):
67 raise UserWarning(f"Could not find a 'main.nf' or 'nextflow.config' file in '{self.dir}'")
68 return True
69
70 def has_modules_file(self):
71 """Checks whether a module.json file has been created and creates one if it is missing"""
72 modules_json_path = os.path.join(self.dir, "modules.json")
73 if not os.path.exists(modules_json_path):
74 log.info("Creating missing 'module.json' file.")
75 ModulesJson(self.dir).create()
76
77 def clear_module_dir(self, module_name, module_dir):
78 """Removes all files in the module directory"""
79 try:
80 shutil.rmtree(module_dir)
81 # Try cleaning up empty parent if tool/subtool and tool/ is empty
82 if module_name.count("/") > 0:
83 parent_dir = os.path.dirname(module_dir)
84 try:
85 os.rmdir(parent_dir)
86 except OSError:
87 log.debug(f"Parent directory not empty: '{parent_dir}'")
88 else:
89 log.debug(f"Deleted orphan tool directory: '{parent_dir}'")
90 log.debug(f"Successfully removed {module_name} module")
91 return True
92 except OSError as e:
93 log.error(f"Could not remove module: {e}")
94 return False
95
96 def modules_from_repo(self, install_dir):
97 """
98 Gets the modules installed from a certain repository
99
100 Args:
101 install_dir (str): The name of the directory where modules are installed
102
103 Returns:
104 [str]: The names of the modules
105 """
106 repo_dir = Path(self.dir, "modules", install_dir)
107 if not repo_dir.exists():
108 raise LookupError(f"Nothing installed from {install_dir} in pipeline")
109
110 return [
111 str(Path(dir_path).relative_to(repo_dir)) for dir_path, _, files in os.walk(repo_dir) if "main.nf" in files
112 ]
113
114 def install_module_files(self, module_name, module_version, modules_repo, install_dir):
115 """
116 Installs a module into the given directory
117
118 Args:
119 module_name (str): The name of the module
120 module_version (str): Git SHA for the version of the module to be installed
121 modules_repo (ModulesRepo): A correctly configured ModulesRepo object
122 install_dir (str): The path to where the module should be installed (should be the 'modules/' dir of the pipeline)
123
124 Returns:
125 (bool): Whether the operation was successful of not
126 """
127 return modules_repo.install_module(module_name, install_dir, module_version)
128
129 def load_lint_config(self):
130 """Parse a pipeline lint config file.
131
132 Look for a file called either `.nf-core-lint.yml` or
133 `.nf-core-lint.yaml` in the pipeline root directory and parse it.
134 (`.yml` takes precedence).
135
136 Add parsed config to the `self.lint_config` class attribute.
137 """
138 config_fn = os.path.join(self.dir, ".nf-core-lint.yml")
139
140 # Pick up the file if it's .yaml instead of .yml
141 if not os.path.isfile(config_fn):
142 config_fn = os.path.join(self.dir, ".nf-core-lint.yaml")
143
144 # Load the YAML
145 try:
146 with open(config_fn, "r") as fh:
147 self.lint_config = yaml.safe_load(fh)
148 except FileNotFoundError:
149 log.debug(f"No lint config file found: {config_fn}")
150
151 def check_modules_structure(self):
152 """
153 Check that the structure of the modules directory in a pipeline is the correct one:
154 modules/nf-core/TOOL/SUBTOOL
155
156 Prior to nf-core/tools release 2.6 the directory structure had an additional level of nesting:
157 modules/nf-core/modules/TOOL/SUBTOOL
158 """
159 if self.repo_type == "pipeline":
160 wrong_location_modules = []
161 for directory, _, files in os.walk(Path(self.dir, "modules")):
162 if "main.nf" in files:
163 module_path = Path(directory).relative_to(Path(self.dir, "modules"))
164 parts = module_path.parts
165 # Check that there are modules installed directly under the 'modules' directory
166 if parts[1] == "modules":
167 wrong_location_modules.append(module_path)
168 # If there are modules installed in the wrong location
169 if len(wrong_location_modules) > 0:
170 log.info("The modules folder structure is outdated. Reinstalling modules.")
171 # Remove the local copy of the modules repository
172 log.info(f"Updating '{self.modules_repo.local_repo_dir}'")
173 self.modules_repo.setup_local_repo(
174 self.modules_repo.remote_url, self.modules_repo.branch, self.hide_progress
175 )
176 # Move wrong modules to the right directory
177 for module in wrong_location_modules:
178 modules_dir = Path("modules").resolve()
179 module_name = str(Path(*module.parts[2:]))
180 correct_dir = Path(modules_dir, self.modules_repo.repo_path, Path(module_name))
181 wrong_dir = Path(modules_dir, module)
182 shutil.move(wrong_dir, correct_dir)
183 log.info(f"Moved {wrong_dir} to {correct_dir}.")
184 # Check if a path file exists
185 patch_path = correct_dir / Path(module_name + ".diff")
186 self.check_patch_paths(patch_path, module_name)
187 shutil.rmtree(Path(self.dir, "modules", self.modules_repo.repo_path, "modules"))
188 # Regenerate modules.json file
189 modules_json = ModulesJson(self.dir)
190 modules_json.check_up_to_date()
191
192 def check_patch_paths(self, patch_path, module_name):
193 """
194 Check that paths in patch files are updated to the new modules path
195 """
196 if patch_path.exists():
197 log.info(f"Modules {module_name} contains a patch file.")
198 rewrite = False
199 with open(patch_path, "r") as fh:
200 lines = fh.readlines()
201 for index, line in enumerate(lines):
202 # Check if there are old paths in the patch file and replace
203 if f"modules/{self.modules_repo.repo_path}/modules/{module_name}/" in line:
204 rewrite = True
205 lines[index] = line.replace(
206 f"modules/{self.modules_repo.repo_path}/modules/{module_name}/",
207 f"modules/{self.modules_repo.repo_path}/{module_name}/",
208 )
209 if rewrite:
210 log.info(f"Updating paths in {patch_path}")
211 with open(patch_path, "w") as fh:
212 for line in lines:
213 fh.write(line)
214 # Update path in modules.json if the file is in the correct format
215 modules_json = ModulesJson(self.dir)
216 modules_json.load()
217 if modules_json.has_git_url_and_modules():
218 modules_json.modules_json["repos"][self.modules_repo.remote_url]["modules"][
219 self.modules_repo.repo_path
220 ][module_name]["patch"] = str(patch_path.relative_to(Path(self.dir).resolve()))
221 modules_json.dump()
222
[end of nf_core/modules/modules_command.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/nf_core/modules/modules_command.py b/nf_core/modules/modules_command.py
--- a/nf_core/modules/modules_command.py
+++ b/nf_core/modules/modules_command.py
@@ -64,7 +64,9 @@
main_nf = os.path.join(self.dir, "main.nf")
nf_config = os.path.join(self.dir, "nextflow.config")
if not os.path.exists(main_nf) and not os.path.exists(nf_config):
- raise UserWarning(f"Could not find a 'main.nf' or 'nextflow.config' file in '{self.dir}'")
+ if Path(self.dir).resolve().parts[-1].startswith("nf-core"):
+ raise UserWarning(f"Could not find a 'main.nf' or 'nextflow.config' file in '{self.dir}'")
+ log.warning(f"Could not find a 'main.nf' or 'nextflow.config' file in '{self.dir}'")
return True
def has_modules_file(self):
|
{"golden_diff": "diff --git a/nf_core/modules/modules_command.py b/nf_core/modules/modules_command.py\n--- a/nf_core/modules/modules_command.py\n+++ b/nf_core/modules/modules_command.py\n@@ -64,7 +64,9 @@\n main_nf = os.path.join(self.dir, \"main.nf\")\n nf_config = os.path.join(self.dir, \"nextflow.config\")\n if not os.path.exists(main_nf) and not os.path.exists(nf_config):\n- raise UserWarning(f\"Could not find a 'main.nf' or 'nextflow.config' file in '{self.dir}'\")\n+ if Path(self.dir).resolve().parts[-1].startswith(\"nf-core\"):\n+ raise UserWarning(f\"Could not find a 'main.nf' or 'nextflow.config' file in '{self.dir}'\")\n+ log.warning(f\"Could not find a 'main.nf' or 'nextflow.config' file in '{self.dir}'\")\n return True\n \n def has_modules_file(self):\n", "issue": "nf-core modules install is asking for two files\n### Description of the bug\n\nnf-core modules install is asking for two files: main.nf and nextflow.config. I think this is not necessary, since one can use a different naming convention for both files.\r\n\r\nhttps://github.com/nf-core/modules/issues/2272\r\n\r\nI think this can be just a warning since you can decide to install the modules outside a nf-core pipeline\r\n\n\n### Command used and terminal output\n\n_No response_\n\n### System information\n\n_No response_\n", "before_files": [{"content": "import logging\nimport os\nimport shutil\nfrom pathlib import Path\n\nimport yaml\n\nimport nf_core.modules.module_utils\nimport nf_core.utils\n\nfrom .modules_json import ModulesJson\nfrom .modules_repo import ModulesRepo\n\nlog = logging.getLogger(__name__)\n\n\nclass ModuleCommand:\n \"\"\"\n Base class for the 'nf-core modules' commands\n \"\"\"\n\n def __init__(self, dir, remote_url=None, branch=None, no_pull=False, hide_progress=False):\n \"\"\"\n Initialise the ModulesCommand object\n \"\"\"\n self.modules_repo = ModulesRepo(remote_url, branch, no_pull, hide_progress)\n self.hide_progress = hide_progress\n self.dir = dir\n self.default_modules_path = Path(\"modules\", \"nf-core\")\n self.default_tests_path = Path(\"tests\", \"modules\", \"nf-core\")\n try:\n if self.dir:\n self.dir, self.repo_type = nf_core.modules.module_utils.get_repo_type(self.dir)\n else:\n self.repo_type = None\n except LookupError as e:\n raise UserWarning(e)\n\n def get_modules_clone_modules(self):\n \"\"\"\n Get the modules available in a clone of nf-core/modules\n \"\"\"\n module_base_path = Path(self.dir, self.default_modules_path)\n return [\n str(Path(dir).relative_to(module_base_path))\n for dir, _, files in os.walk(module_base_path)\n if \"main.nf\" in files\n ]\n\n def get_local_modules(self):\n \"\"\"\n Get the local modules in a pipeline\n \"\"\"\n local_module_dir = Path(self.dir, \"modules\", \"local\")\n return [str(path.relative_to(local_module_dir)) for path in local_module_dir.iterdir() if path.suffix == \".nf\"]\n\n def has_valid_directory(self):\n \"\"\"Check that we were given a pipeline or clone of nf-core/modules\"\"\"\n if self.repo_type == \"modules\":\n return True\n if self.dir is None or not os.path.exists(self.dir):\n log.error(f\"Could not find pipeline: {self.dir}\")\n return False\n main_nf = os.path.join(self.dir, \"main.nf\")\n nf_config = os.path.join(self.dir, \"nextflow.config\")\n if not os.path.exists(main_nf) and not os.path.exists(nf_config):\n raise UserWarning(f\"Could not find a 'main.nf' or 'nextflow.config' file in '{self.dir}'\")\n return True\n\n def has_modules_file(self):\n \"\"\"Checks whether a module.json file has been created and creates one if it is missing\"\"\"\n modules_json_path = os.path.join(self.dir, \"modules.json\")\n if not os.path.exists(modules_json_path):\n log.info(\"Creating missing 'module.json' file.\")\n ModulesJson(self.dir).create()\n\n def clear_module_dir(self, module_name, module_dir):\n \"\"\"Removes all files in the module directory\"\"\"\n try:\n shutil.rmtree(module_dir)\n # Try cleaning up empty parent if tool/subtool and tool/ is empty\n if module_name.count(\"/\") > 0:\n parent_dir = os.path.dirname(module_dir)\n try:\n os.rmdir(parent_dir)\n except OSError:\n log.debug(f\"Parent directory not empty: '{parent_dir}'\")\n else:\n log.debug(f\"Deleted orphan tool directory: '{parent_dir}'\")\n log.debug(f\"Successfully removed {module_name} module\")\n return True\n except OSError as e:\n log.error(f\"Could not remove module: {e}\")\n return False\n\n def modules_from_repo(self, install_dir):\n \"\"\"\n Gets the modules installed from a certain repository\n\n Args:\n install_dir (str): The name of the directory where modules are installed\n\n Returns:\n [str]: The names of the modules\n \"\"\"\n repo_dir = Path(self.dir, \"modules\", install_dir)\n if not repo_dir.exists():\n raise LookupError(f\"Nothing installed from {install_dir} in pipeline\")\n\n return [\n str(Path(dir_path).relative_to(repo_dir)) for dir_path, _, files in os.walk(repo_dir) if \"main.nf\" in files\n ]\n\n def install_module_files(self, module_name, module_version, modules_repo, install_dir):\n \"\"\"\n Installs a module into the given directory\n\n Args:\n module_name (str): The name of the module\n module_version (str): Git SHA for the version of the module to be installed\n modules_repo (ModulesRepo): A correctly configured ModulesRepo object\n install_dir (str): The path to where the module should be installed (should be the 'modules/' dir of the pipeline)\n\n Returns:\n (bool): Whether the operation was successful of not\n \"\"\"\n return modules_repo.install_module(module_name, install_dir, module_version)\n\n def load_lint_config(self):\n \"\"\"Parse a pipeline lint config file.\n\n Look for a file called either `.nf-core-lint.yml` or\n `.nf-core-lint.yaml` in the pipeline root directory and parse it.\n (`.yml` takes precedence).\n\n Add parsed config to the `self.lint_config` class attribute.\n \"\"\"\n config_fn = os.path.join(self.dir, \".nf-core-lint.yml\")\n\n # Pick up the file if it's .yaml instead of .yml\n if not os.path.isfile(config_fn):\n config_fn = os.path.join(self.dir, \".nf-core-lint.yaml\")\n\n # Load the YAML\n try:\n with open(config_fn, \"r\") as fh:\n self.lint_config = yaml.safe_load(fh)\n except FileNotFoundError:\n log.debug(f\"No lint config file found: {config_fn}\")\n\n def check_modules_structure(self):\n \"\"\"\n Check that the structure of the modules directory in a pipeline is the correct one:\n modules/nf-core/TOOL/SUBTOOL\n\n Prior to nf-core/tools release 2.6 the directory structure had an additional level of nesting:\n modules/nf-core/modules/TOOL/SUBTOOL\n \"\"\"\n if self.repo_type == \"pipeline\":\n wrong_location_modules = []\n for directory, _, files in os.walk(Path(self.dir, \"modules\")):\n if \"main.nf\" in files:\n module_path = Path(directory).relative_to(Path(self.dir, \"modules\"))\n parts = module_path.parts\n # Check that there are modules installed directly under the 'modules' directory\n if parts[1] == \"modules\":\n wrong_location_modules.append(module_path)\n # If there are modules installed in the wrong location\n if len(wrong_location_modules) > 0:\n log.info(\"The modules folder structure is outdated. Reinstalling modules.\")\n # Remove the local copy of the modules repository\n log.info(f\"Updating '{self.modules_repo.local_repo_dir}'\")\n self.modules_repo.setup_local_repo(\n self.modules_repo.remote_url, self.modules_repo.branch, self.hide_progress\n )\n # Move wrong modules to the right directory\n for module in wrong_location_modules:\n modules_dir = Path(\"modules\").resolve()\n module_name = str(Path(*module.parts[2:]))\n correct_dir = Path(modules_dir, self.modules_repo.repo_path, Path(module_name))\n wrong_dir = Path(modules_dir, module)\n shutil.move(wrong_dir, correct_dir)\n log.info(f\"Moved {wrong_dir} to {correct_dir}.\")\n # Check if a path file exists\n patch_path = correct_dir / Path(module_name + \".diff\")\n self.check_patch_paths(patch_path, module_name)\n shutil.rmtree(Path(self.dir, \"modules\", self.modules_repo.repo_path, \"modules\"))\n # Regenerate modules.json file\n modules_json = ModulesJson(self.dir)\n modules_json.check_up_to_date()\n\n def check_patch_paths(self, patch_path, module_name):\n \"\"\"\n Check that paths in patch files are updated to the new modules path\n \"\"\"\n if patch_path.exists():\n log.info(f\"Modules {module_name} contains a patch file.\")\n rewrite = False\n with open(patch_path, \"r\") as fh:\n lines = fh.readlines()\n for index, line in enumerate(lines):\n # Check if there are old paths in the patch file and replace\n if f\"modules/{self.modules_repo.repo_path}/modules/{module_name}/\" in line:\n rewrite = True\n lines[index] = line.replace(\n f\"modules/{self.modules_repo.repo_path}/modules/{module_name}/\",\n f\"modules/{self.modules_repo.repo_path}/{module_name}/\",\n )\n if rewrite:\n log.info(f\"Updating paths in {patch_path}\")\n with open(patch_path, \"w\") as fh:\n for line in lines:\n fh.write(line)\n # Update path in modules.json if the file is in the correct format\n modules_json = ModulesJson(self.dir)\n modules_json.load()\n if modules_json.has_git_url_and_modules():\n modules_json.modules_json[\"repos\"][self.modules_repo.remote_url][\"modules\"][\n self.modules_repo.repo_path\n ][module_name][\"patch\"] = str(patch_path.relative_to(Path(self.dir).resolve()))\n modules_json.dump()\n", "path": "nf_core/modules/modules_command.py"}]}
| 3,158 | 215 |
gh_patches_debug_11453
|
rasdani/github-patches
|
git_diff
|
saleor__saleor-3535
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Attribute filters are not available in subcategories
### What I'm trying to achieve
I'm trying to filter products in subcategories by attributes of this products
### Steps to reproduce the problem
1. Create category and then create 2 or more subcategory
2. Add product to last subcategory
3. Select category, than subcategory and try to filter products by attributes
### What I expected to happen
Attribute filters are not available in subcategories! Filters by attributes available only in last subcategory. For example, i have category "Phones" with subcategories by companies names -> phone model. If i select last subcategory "Iphone 8", i got all filters, but if i select subcategory "Apple", i got filter only by price range.
So, how to enable these filters? Can i modify some template or python code by myself, or you guys will do it some later?
### Screenshots


</issue>
<code>
[start of saleor/product/filters.py]
1 from collections import OrderedDict
2
3 from django.db.models import Q
4 from django.forms import CheckboxSelectMultiple
5 from django.utils.translation import pgettext_lazy
6 from django_filters import MultipleChoiceFilter, OrderingFilter, RangeFilter
7
8 from ..core.filters import SortedFilterSet
9 from .models import Attribute, Product
10
11 SORT_BY_FIELDS = OrderedDict([
12 ('name', pgettext_lazy('Product list sorting option', 'name')),
13 ('price', pgettext_lazy('Product list sorting option', 'price')),
14 ('updated_at', pgettext_lazy(
15 'Product list sorting option', 'last updated'))])
16
17
18 class ProductFilter(SortedFilterSet):
19 sort_by = OrderingFilter(
20 label=pgettext_lazy('Product list sorting form', 'Sort by'),
21 fields=SORT_BY_FIELDS.keys(),
22 field_labels=SORT_BY_FIELDS)
23 price = RangeFilter(
24 label=pgettext_lazy('Currency amount', 'Price'))
25
26 class Meta:
27 model = Product
28 fields = []
29
30 def __init__(self, *args, **kwargs):
31 super().__init__(*args, **kwargs)
32 self.product_attributes, self.variant_attributes = (
33 self._get_attributes())
34 self.filters.update(self._get_product_attributes_filters())
35 self.filters.update(self._get_product_variants_attributes_filters())
36 self.filters = OrderedDict(sorted(self.filters.items()))
37
38 def _get_attributes(self):
39 q_product_attributes = self._get_product_attributes_lookup()
40 q_variant_attributes = self._get_variant_attributes_lookup()
41 product_attributes = (
42 Attribute.objects.all()
43 .prefetch_related('translations', 'values__translations')
44 .filter(q_product_attributes)
45 .distinct())
46 variant_attributes = (
47 Attribute.objects.all()
48 .prefetch_related('translations', 'values__translations')
49 .filter(q_variant_attributes)
50 .distinct())
51 return product_attributes, variant_attributes
52
53 def _get_product_attributes_lookup(self):
54 raise NotImplementedError()
55
56 def _get_variant_attributes_lookup(self):
57 raise NotImplementedError()
58
59 def _get_product_attributes_filters(self):
60 filters = {}
61 for attribute in self.product_attributes:
62 filters[attribute.slug] = MultipleChoiceFilter(
63 field_name='attributes__%s' % attribute.pk,
64 label=attribute.translated.name,
65 widget=CheckboxSelectMultiple,
66 choices=self._get_attribute_choices(attribute))
67 return filters
68
69 def _get_product_variants_attributes_filters(self):
70 filters = {}
71 for attribute in self.variant_attributes:
72 filters[attribute.slug] = MultipleChoiceFilter(
73 field_name='variants__attributes__%s' % attribute.pk,
74 label=attribute.translated.name,
75 widget=CheckboxSelectMultiple,
76 choices=self._get_attribute_choices(attribute))
77 return filters
78
79 def _get_attribute_choices(self, attribute):
80 return [
81 (choice.pk, choice.translated.name)
82 for choice in attribute.values.all()]
83
84
85 class ProductCategoryFilter(ProductFilter):
86 def __init__(self, *args, **kwargs):
87 self.category = kwargs.pop('category')
88 super().__init__(*args, **kwargs)
89
90 def _get_product_attributes_lookup(self):
91 return Q(product_type__products__category=self.category)
92
93 def _get_variant_attributes_lookup(self):
94 return Q(product_variant_type__products__category=self.category)
95
96
97 class ProductCollectionFilter(ProductFilter):
98 def __init__(self, *args, **kwargs):
99 self.collection = kwargs.pop('collection')
100 super().__init__(*args, **kwargs)
101
102 def _get_product_attributes_lookup(self):
103 return Q(product_type__products__collections=self.collection)
104
105 def _get_variant_attributes_lookup(self):
106 return Q(product_variant_type__products__collections=self.collection)
107
[end of saleor/product/filters.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/saleor/product/filters.py b/saleor/product/filters.py
--- a/saleor/product/filters.py
+++ b/saleor/product/filters.py
@@ -88,10 +88,12 @@
super().__init__(*args, **kwargs)
def _get_product_attributes_lookup(self):
- return Q(product_type__products__category=self.category)
+ categories = self.category.get_descendants(include_self=True)
+ return Q(product_type__products__category__in=categories)
def _get_variant_attributes_lookup(self):
- return Q(product_variant_type__products__category=self.category)
+ categories = self.category.get_descendants(include_self=True)
+ return Q(product_variant_type__products__category__in=categories)
class ProductCollectionFilter(ProductFilter):
|
{"golden_diff": "diff --git a/saleor/product/filters.py b/saleor/product/filters.py\n--- a/saleor/product/filters.py\n+++ b/saleor/product/filters.py\n@@ -88,10 +88,12 @@\n super().__init__(*args, **kwargs)\n \n def _get_product_attributes_lookup(self):\n- return Q(product_type__products__category=self.category)\n+ categories = self.category.get_descendants(include_self=True)\n+ return Q(product_type__products__category__in=categories)\n \n def _get_variant_attributes_lookup(self):\n- return Q(product_variant_type__products__category=self.category)\n+ categories = self.category.get_descendants(include_self=True)\n+ return Q(product_variant_type__products__category__in=categories)\n \n \n class ProductCollectionFilter(ProductFilter):\n", "issue": "Attribute filters are not available in subcategories\n### What I'm trying to achieve\r\n\r\nI'm trying to filter products in subcategories by attributes of this products\r\n\r\n### Steps to reproduce the problem\r\n1. Create category and then create 2 or more subcategory\r\n2. Add product to last subcategory\r\n3. Select category, than subcategory and try to filter products by attributes\r\n\r\n### What I expected to happen\r\n\r\nAttribute filters are not available in subcategories! Filters by attributes available only in last subcategory. For example, i have category \"Phones\" with subcategories by companies names -> phone model. If i select last subcategory \"Iphone 8\", i got all filters, but if i select subcategory \"Apple\", i got filter only by price range.\r\n\r\nSo, how to enable these filters? Can i modify some template or python code by myself, or you guys will do it some later?\r\n\r\n### Screenshots\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "from collections import OrderedDict\n\nfrom django.db.models import Q\nfrom django.forms import CheckboxSelectMultiple\nfrom django.utils.translation import pgettext_lazy\nfrom django_filters import MultipleChoiceFilter, OrderingFilter, RangeFilter\n\nfrom ..core.filters import SortedFilterSet\nfrom .models import Attribute, Product\n\nSORT_BY_FIELDS = OrderedDict([\n ('name', pgettext_lazy('Product list sorting option', 'name')),\n ('price', pgettext_lazy('Product list sorting option', 'price')),\n ('updated_at', pgettext_lazy(\n 'Product list sorting option', 'last updated'))])\n\n\nclass ProductFilter(SortedFilterSet):\n sort_by = OrderingFilter(\n label=pgettext_lazy('Product list sorting form', 'Sort by'),\n fields=SORT_BY_FIELDS.keys(),\n field_labels=SORT_BY_FIELDS)\n price = RangeFilter(\n label=pgettext_lazy('Currency amount', 'Price'))\n\n class Meta:\n model = Product\n fields = []\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.product_attributes, self.variant_attributes = (\n self._get_attributes())\n self.filters.update(self._get_product_attributes_filters())\n self.filters.update(self._get_product_variants_attributes_filters())\n self.filters = OrderedDict(sorted(self.filters.items()))\n\n def _get_attributes(self):\n q_product_attributes = self._get_product_attributes_lookup()\n q_variant_attributes = self._get_variant_attributes_lookup()\n product_attributes = (\n Attribute.objects.all()\n .prefetch_related('translations', 'values__translations')\n .filter(q_product_attributes)\n .distinct())\n variant_attributes = (\n Attribute.objects.all()\n .prefetch_related('translations', 'values__translations')\n .filter(q_variant_attributes)\n .distinct())\n return product_attributes, variant_attributes\n\n def _get_product_attributes_lookup(self):\n raise NotImplementedError()\n\n def _get_variant_attributes_lookup(self):\n raise NotImplementedError()\n\n def _get_product_attributes_filters(self):\n filters = {}\n for attribute in self.product_attributes:\n filters[attribute.slug] = MultipleChoiceFilter(\n field_name='attributes__%s' % attribute.pk,\n label=attribute.translated.name,\n widget=CheckboxSelectMultiple,\n choices=self._get_attribute_choices(attribute))\n return filters\n\n def _get_product_variants_attributes_filters(self):\n filters = {}\n for attribute in self.variant_attributes:\n filters[attribute.slug] = MultipleChoiceFilter(\n field_name='variants__attributes__%s' % attribute.pk,\n label=attribute.translated.name,\n widget=CheckboxSelectMultiple,\n choices=self._get_attribute_choices(attribute))\n return filters\n\n def _get_attribute_choices(self, attribute):\n return [\n (choice.pk, choice.translated.name)\n for choice in attribute.values.all()]\n\n\nclass ProductCategoryFilter(ProductFilter):\n def __init__(self, *args, **kwargs):\n self.category = kwargs.pop('category')\n super().__init__(*args, **kwargs)\n\n def _get_product_attributes_lookup(self):\n return Q(product_type__products__category=self.category)\n\n def _get_variant_attributes_lookup(self):\n return Q(product_variant_type__products__category=self.category)\n\n\nclass ProductCollectionFilter(ProductFilter):\n def __init__(self, *args, **kwargs):\n self.collection = kwargs.pop('collection')\n super().__init__(*args, **kwargs)\n\n def _get_product_attributes_lookup(self):\n return Q(product_type__products__collections=self.collection)\n\n def _get_variant_attributes_lookup(self):\n return Q(product_variant_type__products__collections=self.collection)\n", "path": "saleor/product/filters.py"}]}
| 1,844 | 176 |
gh_patches_debug_35909
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-center-index-2521
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[request] pcre/8.44
### Package Details
* Package Name/Version: **pcre/8.44**
* Changelog: **http://www.pcre.org/original/changelog.txt**
The above mentioned version is newly released by the upstream project and not yet available as a recipe. Please add this version.
</issue>
<code>
[start of recipes/pcre/all/conanfile.py]
1 from conans import ConanFile, CMake, tools
2 import os
3
4
5 class PCREConan(ConanFile):
6 name = "pcre"
7 url = "https://github.com/conan-io/conan-center-index"
8 homepage = "https://www.pcre.org"
9 description = "Perl Compatible Regular Expressions"
10 topics = ("regex", "regexp", "PCRE")
11 license = "BSD-3-Clause"
12 exports_sources = ["CMakeLists.txt"]
13 generators = "cmake"
14 settings = "os", "arch", "compiler", "build_type"
15 options = {
16 "shared": [True, False],
17 "fPIC": [True, False],
18 "with_bzip2": [True, False],
19 "with_zlib": [True, False],
20 "with_jit": [True, False],
21 "build_pcrecpp": [True, False],
22 "build_pcregrep": [True, False],
23 "with_utf": [True, False],
24 "with_unicode_properties": [True, False]
25 }
26 default_options = {'shared': False, 'fPIC': True, 'with_bzip2': True, 'with_zlib': True, 'with_jit': False, 'build_pcrecpp': False, 'build_pcregrep': False, 'with_utf': False, 'with_unicode_properties': False}
27 _source_subfolder = "source_subfolder"
28 _build_subfolder = "build_subfolder"
29
30 def config_options(self):
31 if self.settings.os == "Windows":
32 del self.options.fPIC
33
34 def configure(self):
35 if not self.options.build_pcrecpp:
36 del self.settings.compiler.libcxx
37 del self.settings.compiler.cppstd
38 if self.options.with_unicode_properties:
39 self.options.with_utf = True
40
41 def patch_cmake(self):
42 """Patch CMake file to avoid man and share during install stage
43 """
44 cmake_file = os.path.join(self._source_subfolder, "CMakeLists.txt")
45 tools.replace_in_file(cmake_file, "INSTALL(FILES ${man1} DESTINATION man/man1)", "")
46 tools.replace_in_file(cmake_file, "INSTALL(FILES ${man3} DESTINATION man/man3)", "")
47 tools.replace_in_file(cmake_file, "INSTALL(FILES ${html} DESTINATION share/doc/pcre/html)", "")
48
49 def source(self):
50 tools.get(**self.conan_data["sources"][self.version])
51 extracted_dir = self.name + "-" + self.version
52 os.rename(extracted_dir, self._source_subfolder)
53 self.patch_cmake()
54
55 def requirements(self):
56 if self.options.with_bzip2:
57 self.requires("bzip2/1.0.8")
58 if self.options.with_zlib:
59 self.requires("zlib/1.2.11")
60
61 def _configure_cmake(self):
62 cmake = CMake(self)
63 cmake.definitions["PCRE_BUILD_TESTS"] = False
64 cmake.definitions["PCRE_BUILD_PCREGREP"] = self.options.build_pcregrep
65 cmake.definitions["PCRE_BUILD_PCRECPP"] = self.options.build_pcrecpp
66 cmake.definitions["PCRE_SUPPORT_LIBZ"] = self.options.with_zlib
67 cmake.definitions["PCRE_SUPPORT_LIBBZ2"] = self.options.with_bzip2
68 cmake.definitions["PCRE_SUPPORT_JIT"] = self.options.with_jit
69 cmake.definitions["PCRE_SUPPORT_UTF"] = self.options.with_utf
70 cmake.definitions["PCRE_SUPPORT_UNICODE_PROPERTIES"] = self.options.with_unicode_properties
71 cmake.definitions["PCRE_SUPPORT_LIBREADLINE"] = False
72 cmake.definitions["PCRE_SUPPORT_LIBEDIT"] = False
73 if self.settings.os == "Windows" and self.settings.compiler == "Visual Studio":
74 cmake.definitions["PCRE_STATIC_RUNTIME"] = not self.options.shared and "MT" in self.settings.compiler.runtime
75 cmake.configure(build_folder=self._build_subfolder)
76 return cmake
77
78 def build(self):
79 cmake = self._configure_cmake()
80 cmake.build()
81
82 def package(self):
83 self.copy(pattern="LICENCE", dst="licenses", src=self._source_subfolder)
84 cmake = self._configure_cmake()
85 cmake.install()
86
87 def package_info(self):
88 if self.settings.os == "Windows" and self.settings.build_type == 'Debug':
89 self.cpp_info.libs = ['pcreposixd', 'pcred']
90 else:
91 self.cpp_info.libs = ['pcreposix', 'pcre']
92 if not self.options.shared:
93 self.cpp_info.defines.append("PCRE_STATIC=1")
94 self.cpp_info.names['pkg_config'] = 'libpcre'
95
96 self.cpp_info.names["cmake_find_package"] = "PCRE"
97 self.cpp_info.names["cmake_find_package_multi"] = "PCRE"
98
[end of recipes/pcre/all/conanfile.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/recipes/pcre/all/conanfile.py b/recipes/pcre/all/conanfile.py
--- a/recipes/pcre/all/conanfile.py
+++ b/recipes/pcre/all/conanfile.py
@@ -23,9 +23,25 @@
"with_utf": [True, False],
"with_unicode_properties": [True, False]
}
- default_options = {'shared': False, 'fPIC': True, 'with_bzip2': True, 'with_zlib': True, 'with_jit': False, 'build_pcrecpp': False, 'build_pcregrep': False, 'with_utf': False, 'with_unicode_properties': False}
- _source_subfolder = "source_subfolder"
- _build_subfolder = "build_subfolder"
+ default_options = {
+ 'shared': False,
+ 'fPIC': True,
+ 'with_bzip2': True,
+ 'with_zlib': True,
+ 'with_jit': False,
+ 'build_pcrecpp': False,
+ 'build_pcregrep': False,
+ 'with_utf': False,
+ 'with_unicode_properties': False
+ }
+
+ @property
+ def _source_subfolder(self):
+ return "source_subfolder"
+
+ @property
+ def _build_subfolder(self):
+ return "build_subfolder"
def config_options(self):
if self.settings.os == "Windows":
@@ -42,15 +58,17 @@
"""Patch CMake file to avoid man and share during install stage
"""
cmake_file = os.path.join(self._source_subfolder, "CMakeLists.txt")
- tools.replace_in_file(cmake_file, "INSTALL(FILES ${man1} DESTINATION man/man1)", "")
- tools.replace_in_file(cmake_file, "INSTALL(FILES ${man3} DESTINATION man/man3)", "")
- tools.replace_in_file(cmake_file, "INSTALL(FILES ${html} DESTINATION share/doc/pcre/html)", "")
+ tools.replace_in_file(
+ cmake_file, "INSTALL(FILES ${man1} DESTINATION man/man1)", "")
+ tools.replace_in_file(
+ cmake_file, "INSTALL(FILES ${man3} DESTINATION man/man3)", "")
+ tools.replace_in_file(
+ cmake_file, "INSTALL(FILES ${html} DESTINATION share/doc/pcre/html)", "")
def source(self):
tools.get(**self.conan_data["sources"][self.version])
extracted_dir = self.name + "-" + self.version
os.rename(extracted_dir, self._source_subfolder)
- self.patch_cmake()
def requirements(self):
if self.options.with_bzip2:
@@ -76,6 +94,7 @@
return cmake
def build(self):
+ self.patch_cmake()
cmake = self._configure_cmake()
cmake.build()
|
{"golden_diff": "diff --git a/recipes/pcre/all/conanfile.py b/recipes/pcre/all/conanfile.py\n--- a/recipes/pcre/all/conanfile.py\n+++ b/recipes/pcre/all/conanfile.py\n@@ -23,9 +23,25 @@\n \"with_utf\": [True, False],\n \"with_unicode_properties\": [True, False]\n }\n- default_options = {'shared': False, 'fPIC': True, 'with_bzip2': True, 'with_zlib': True, 'with_jit': False, 'build_pcrecpp': False, 'build_pcregrep': False, 'with_utf': False, 'with_unicode_properties': False}\n- _source_subfolder = \"source_subfolder\"\n- _build_subfolder = \"build_subfolder\"\n+ default_options = {\n+ 'shared': False,\n+ 'fPIC': True,\n+ 'with_bzip2': True,\n+ 'with_zlib': True,\n+ 'with_jit': False,\n+ 'build_pcrecpp': False,\n+ 'build_pcregrep': False,\n+ 'with_utf': False,\n+ 'with_unicode_properties': False\n+ }\n+\n+ @property\n+ def _source_subfolder(self):\n+ return \"source_subfolder\"\n+\n+ @property\n+ def _build_subfolder(self):\n+ return \"build_subfolder\"\n \n def config_options(self):\n if self.settings.os == \"Windows\":\n@@ -42,15 +58,17 @@\n \"\"\"Patch CMake file to avoid man and share during install stage\n \"\"\"\n cmake_file = os.path.join(self._source_subfolder, \"CMakeLists.txt\")\n- tools.replace_in_file(cmake_file, \"INSTALL(FILES ${man1} DESTINATION man/man1)\", \"\")\n- tools.replace_in_file(cmake_file, \"INSTALL(FILES ${man3} DESTINATION man/man3)\", \"\")\n- tools.replace_in_file(cmake_file, \"INSTALL(FILES ${html} DESTINATION share/doc/pcre/html)\", \"\")\n+ tools.replace_in_file(\n+ cmake_file, \"INSTALL(FILES ${man1} DESTINATION man/man1)\", \"\")\n+ tools.replace_in_file(\n+ cmake_file, \"INSTALL(FILES ${man3} DESTINATION man/man3)\", \"\")\n+ tools.replace_in_file(\n+ cmake_file, \"INSTALL(FILES ${html} DESTINATION share/doc/pcre/html)\", \"\")\n \n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version])\n extracted_dir = self.name + \"-\" + self.version\n os.rename(extracted_dir, self._source_subfolder)\n- self.patch_cmake()\n \n def requirements(self):\n if self.options.with_bzip2:\n@@ -76,6 +94,7 @@\n return cmake\n \n def build(self):\n+ self.patch_cmake()\n cmake = self._configure_cmake()\n cmake.build()\n", "issue": "[request] pcre/8.44\n### Package Details\r\n * Package Name/Version: **pcre/8.44**\r\n * Changelog: **http://www.pcre.org/original/changelog.txt**\r\n\r\n\r\nThe above mentioned version is newly released by the upstream project and not yet available as a recipe. Please add this version.\r\n\n", "before_files": [{"content": "from conans import ConanFile, CMake, tools\nimport os\n\n\nclass PCREConan(ConanFile):\n name = \"pcre\"\n url = \"https://github.com/conan-io/conan-center-index\"\n homepage = \"https://www.pcre.org\"\n description = \"Perl Compatible Regular Expressions\"\n topics = (\"regex\", \"regexp\", \"PCRE\")\n license = \"BSD-3-Clause\"\n exports_sources = [\"CMakeLists.txt\"]\n generators = \"cmake\"\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n options = {\n \"shared\": [True, False],\n \"fPIC\": [True, False],\n \"with_bzip2\": [True, False],\n \"with_zlib\": [True, False],\n \"with_jit\": [True, False],\n \"build_pcrecpp\": [True, False],\n \"build_pcregrep\": [True, False],\n \"with_utf\": [True, False],\n \"with_unicode_properties\": [True, False]\n }\n default_options = {'shared': False, 'fPIC': True, 'with_bzip2': True, 'with_zlib': True, 'with_jit': False, 'build_pcrecpp': False, 'build_pcregrep': False, 'with_utf': False, 'with_unicode_properties': False}\n _source_subfolder = \"source_subfolder\"\n _build_subfolder = \"build_subfolder\"\n\n def config_options(self):\n if self.settings.os == \"Windows\":\n del self.options.fPIC\n\n def configure(self):\n if not self.options.build_pcrecpp:\n del self.settings.compiler.libcxx\n del self.settings.compiler.cppstd\n if self.options.with_unicode_properties:\n self.options.with_utf = True\n\n def patch_cmake(self):\n \"\"\"Patch CMake file to avoid man and share during install stage\n \"\"\"\n cmake_file = os.path.join(self._source_subfolder, \"CMakeLists.txt\")\n tools.replace_in_file(cmake_file, \"INSTALL(FILES ${man1} DESTINATION man/man1)\", \"\")\n tools.replace_in_file(cmake_file, \"INSTALL(FILES ${man3} DESTINATION man/man3)\", \"\")\n tools.replace_in_file(cmake_file, \"INSTALL(FILES ${html} DESTINATION share/doc/pcre/html)\", \"\")\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version])\n extracted_dir = self.name + \"-\" + self.version\n os.rename(extracted_dir, self._source_subfolder)\n self.patch_cmake()\n\n def requirements(self):\n if self.options.with_bzip2:\n self.requires(\"bzip2/1.0.8\")\n if self.options.with_zlib:\n self.requires(\"zlib/1.2.11\")\n\n def _configure_cmake(self):\n cmake = CMake(self)\n cmake.definitions[\"PCRE_BUILD_TESTS\"] = False\n cmake.definitions[\"PCRE_BUILD_PCREGREP\"] = self.options.build_pcregrep\n cmake.definitions[\"PCRE_BUILD_PCRECPP\"] = self.options.build_pcrecpp\n cmake.definitions[\"PCRE_SUPPORT_LIBZ\"] = self.options.with_zlib\n cmake.definitions[\"PCRE_SUPPORT_LIBBZ2\"] = self.options.with_bzip2\n cmake.definitions[\"PCRE_SUPPORT_JIT\"] = self.options.with_jit\n cmake.definitions[\"PCRE_SUPPORT_UTF\"] = self.options.with_utf\n cmake.definitions[\"PCRE_SUPPORT_UNICODE_PROPERTIES\"] = self.options.with_unicode_properties\n cmake.definitions[\"PCRE_SUPPORT_LIBREADLINE\"] = False\n cmake.definitions[\"PCRE_SUPPORT_LIBEDIT\"] = False\n if self.settings.os == \"Windows\" and self.settings.compiler == \"Visual Studio\":\n cmake.definitions[\"PCRE_STATIC_RUNTIME\"] = not self.options.shared and \"MT\" in self.settings.compiler.runtime\n cmake.configure(build_folder=self._build_subfolder)\n return cmake\n\n def build(self):\n cmake = self._configure_cmake()\n cmake.build()\n\n def package(self):\n self.copy(pattern=\"LICENCE\", dst=\"licenses\", src=self._source_subfolder)\n cmake = self._configure_cmake()\n cmake.install()\n\n def package_info(self):\n if self.settings.os == \"Windows\" and self.settings.build_type == 'Debug':\n self.cpp_info.libs = ['pcreposixd', 'pcred']\n else:\n self.cpp_info.libs = ['pcreposix', 'pcre']\n if not self.options.shared:\n self.cpp_info.defines.append(\"PCRE_STATIC=1\")\n self.cpp_info.names['pkg_config'] = 'libpcre'\n\n self.cpp_info.names[\"cmake_find_package\"] = \"PCRE\"\n self.cpp_info.names[\"cmake_find_package_multi\"] = \"PCRE\"\n", "path": "recipes/pcre/all/conanfile.py"}]}
| 1,846 | 642 |
gh_patches_debug_4701
|
rasdani/github-patches
|
git_diff
|
pypi__warehouse-7327
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
WebAuthN user verification flag should be set to discouraged
The current setting on the Pypi site is to ignore the UserVerificationOption setting in the `navigator.credentials.create()` call. Based on [this chromium documentation](https://chromium.googlesource.com/chromium/src/+/master/content/browser/webauth/uv_preferred.md), it appears to be set to "preferred" by default.
TL:DR; it interrupts the login flow by popping up a pin entry dialog upon tapping my yubikey, then requires me to tap again after successful pin entry. This is not the recommended setting for second-factor credentials, only for passwordless [[1](https://developers.yubico.com/WebAuthn/WebAuthn_Developer_Guide/User_Presence_vs_User_Verification.html)].
Please explicitly set this to [discouraged](https://w3c.github.io/webauthn/#enum-userVerificationRequirement) instead, so that I will no longer have PIN prompts on second-factor login.
</issue>
<code>
[start of warehouse/utils/webauthn.py]
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12
13 import base64
14 import os
15
16 import webauthn as pywebauthn
17
18 from webauthn.webauthn import (
19 AuthenticationRejectedException as _AuthenticationRejectedException,
20 RegistrationRejectedException as _RegistrationRejectedException,
21 )
22
23
24 class AuthenticationRejectedException(Exception):
25 pass
26
27
28 class RegistrationRejectedException(Exception):
29 pass
30
31
32 WebAuthnCredential = pywebauthn.WebAuthnCredential
33
34
35 def _get_webauthn_users(user, *, rp_id):
36 """
37 Returns a webauthn.WebAuthnUser instance corresponding
38 to the given user model, with properties suitable for
39 usage within the webauthn API.
40 """
41 return [
42 pywebauthn.WebAuthnUser(
43 str(user.id),
44 user.username,
45 user.name,
46 None,
47 credential.credential_id,
48 credential.public_key,
49 credential.sign_count,
50 rp_id,
51 )
52 for credential in user.webauthn
53 ]
54
55
56 def _webauthn_b64decode(encoded):
57 padding = "=" * (len(encoded) % 4)
58 return base64.urlsafe_b64decode(encoded + padding)
59
60
61 def _webauthn_b64encode(source):
62 return base64.urlsafe_b64encode(source).rstrip(b"=")
63
64
65 def generate_webauthn_challenge():
66 """
67 Returns a random challenge suitable for use within
68 Webauthn's credential and configuration option objects.
69
70 See: https://w3c.github.io/webauthn/#cryptographic-challenges
71 """
72 # NOTE: Webauthn recommends at least 16 bytes of entropy,
73 # we go with 32 because it doesn't cost us anything.
74 return _webauthn_b64encode(os.urandom(32)).decode()
75
76
77 def get_credential_options(user, *, challenge, rp_name, rp_id):
78 """
79 Returns a dictionary of options for credential creation
80 on the client side.
81 """
82 options = pywebauthn.WebAuthnMakeCredentialOptions(
83 challenge, rp_name, rp_id, str(user.id), user.username, user.name, None
84 )
85
86 return options.registration_dict
87
88
89 def get_assertion_options(user, *, challenge, rp_id):
90 """
91 Returns a dictionary of options for assertion retrieval
92 on the client side.
93 """
94 options = pywebauthn.WebAuthnAssertionOptions(
95 _get_webauthn_users(user, rp_id=rp_id), challenge
96 )
97
98 return options.assertion_dict
99
100
101 def verify_registration_response(response, challenge, *, rp_id, origin):
102 """
103 Validates the challenge and attestation information
104 sent from the client during device registration.
105
106 Returns a WebAuthnCredential on success.
107 Raises RegistrationRejectedException on failire.
108 """
109 # NOTE: We re-encode the challenge below, because our
110 # response's clientData.challenge is encoded twice:
111 # first for the entire clientData payload, and then again
112 # for the individual challenge.
113 encoded_challenge = _webauthn_b64encode(challenge.encode()).decode()
114 response = pywebauthn.WebAuthnRegistrationResponse(
115 rp_id, origin, response, encoded_challenge, self_attestation_permitted=True
116 )
117 try:
118 return response.verify()
119 except _RegistrationRejectedException as e:
120 raise RegistrationRejectedException(str(e))
121
122
123 def verify_assertion_response(assertion, *, challenge, user, origin, rp_id):
124 """
125 Validates the challenge and assertion information
126 sent from the client during authentication.
127
128 Returns an updated signage count on success.
129 Raises AuthenticationRejectedException on failure.
130 """
131 webauthn_users = _get_webauthn_users(user, rp_id=rp_id)
132 cred_ids = [cred.credential_id for cred in webauthn_users]
133 encoded_challenge = _webauthn_b64encode(challenge.encode()).decode()
134
135 for webauthn_user in webauthn_users:
136 response = pywebauthn.WebAuthnAssertionResponse(
137 webauthn_user,
138 assertion,
139 encoded_challenge,
140 origin,
141 allow_credentials=cred_ids,
142 )
143 try:
144 return (webauthn_user.credential_id, response.verify())
145 except _AuthenticationRejectedException:
146 pass
147
148 # If we exit the loop, then we've failed to verify the assertion against
149 # any of the user's WebAuthn credentials. Fail.
150 raise AuthenticationRejectedException("Invalid WebAuthn credential")
151
[end of warehouse/utils/webauthn.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/warehouse/utils/webauthn.py b/warehouse/utils/webauthn.py
--- a/warehouse/utils/webauthn.py
+++ b/warehouse/utils/webauthn.py
@@ -80,7 +80,14 @@
on the client side.
"""
options = pywebauthn.WebAuthnMakeCredentialOptions(
- challenge, rp_name, rp_id, str(user.id), user.username, user.name, None
+ challenge,
+ rp_name,
+ rp_id,
+ str(user.id),
+ user.username,
+ user.name,
+ None,
+ user_verification="discouraged",
)
return options.registration_dict
|
{"golden_diff": "diff --git a/warehouse/utils/webauthn.py b/warehouse/utils/webauthn.py\n--- a/warehouse/utils/webauthn.py\n+++ b/warehouse/utils/webauthn.py\n@@ -80,7 +80,14 @@\n on the client side.\n \"\"\"\n options = pywebauthn.WebAuthnMakeCredentialOptions(\n- challenge, rp_name, rp_id, str(user.id), user.username, user.name, None\n+ challenge,\n+ rp_name,\n+ rp_id,\n+ str(user.id),\n+ user.username,\n+ user.name,\n+ None,\n+ user_verification=\"discouraged\",\n )\n \n return options.registration_dict\n", "issue": "WebAuthN user verification flag should be set to discouraged\nThe current setting on the Pypi site is to ignore the UserVerificationOption setting in the `navigator.credentials.create()` call. Based on [this chromium documentation](https://chromium.googlesource.com/chromium/src/+/master/content/browser/webauth/uv_preferred.md), it appears to be set to \"preferred\" by default.\r\n\r\nTL:DR; it interrupts the login flow by popping up a pin entry dialog upon tapping my yubikey, then requires me to tap again after successful pin entry. This is not the recommended setting for second-factor credentials, only for passwordless [[1](https://developers.yubico.com/WebAuthn/WebAuthn_Developer_Guide/User_Presence_vs_User_Verification.html)].\r\n\r\nPlease explicitly set this to [discouraged](https://w3c.github.io/webauthn/#enum-userVerificationRequirement) instead, so that I will no longer have PIN prompts on second-factor login.\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport base64\nimport os\n\nimport webauthn as pywebauthn\n\nfrom webauthn.webauthn import (\n AuthenticationRejectedException as _AuthenticationRejectedException,\n RegistrationRejectedException as _RegistrationRejectedException,\n)\n\n\nclass AuthenticationRejectedException(Exception):\n pass\n\n\nclass RegistrationRejectedException(Exception):\n pass\n\n\nWebAuthnCredential = pywebauthn.WebAuthnCredential\n\n\ndef _get_webauthn_users(user, *, rp_id):\n \"\"\"\n Returns a webauthn.WebAuthnUser instance corresponding\n to the given user model, with properties suitable for\n usage within the webauthn API.\n \"\"\"\n return [\n pywebauthn.WebAuthnUser(\n str(user.id),\n user.username,\n user.name,\n None,\n credential.credential_id,\n credential.public_key,\n credential.sign_count,\n rp_id,\n )\n for credential in user.webauthn\n ]\n\n\ndef _webauthn_b64decode(encoded):\n padding = \"=\" * (len(encoded) % 4)\n return base64.urlsafe_b64decode(encoded + padding)\n\n\ndef _webauthn_b64encode(source):\n return base64.urlsafe_b64encode(source).rstrip(b\"=\")\n\n\ndef generate_webauthn_challenge():\n \"\"\"\n Returns a random challenge suitable for use within\n Webauthn's credential and configuration option objects.\n\n See: https://w3c.github.io/webauthn/#cryptographic-challenges\n \"\"\"\n # NOTE: Webauthn recommends at least 16 bytes of entropy,\n # we go with 32 because it doesn't cost us anything.\n return _webauthn_b64encode(os.urandom(32)).decode()\n\n\ndef get_credential_options(user, *, challenge, rp_name, rp_id):\n \"\"\"\n Returns a dictionary of options for credential creation\n on the client side.\n \"\"\"\n options = pywebauthn.WebAuthnMakeCredentialOptions(\n challenge, rp_name, rp_id, str(user.id), user.username, user.name, None\n )\n\n return options.registration_dict\n\n\ndef get_assertion_options(user, *, challenge, rp_id):\n \"\"\"\n Returns a dictionary of options for assertion retrieval\n on the client side.\n \"\"\"\n options = pywebauthn.WebAuthnAssertionOptions(\n _get_webauthn_users(user, rp_id=rp_id), challenge\n )\n\n return options.assertion_dict\n\n\ndef verify_registration_response(response, challenge, *, rp_id, origin):\n \"\"\"\n Validates the challenge and attestation information\n sent from the client during device registration.\n\n Returns a WebAuthnCredential on success.\n Raises RegistrationRejectedException on failire.\n \"\"\"\n # NOTE: We re-encode the challenge below, because our\n # response's clientData.challenge is encoded twice:\n # first for the entire clientData payload, and then again\n # for the individual challenge.\n encoded_challenge = _webauthn_b64encode(challenge.encode()).decode()\n response = pywebauthn.WebAuthnRegistrationResponse(\n rp_id, origin, response, encoded_challenge, self_attestation_permitted=True\n )\n try:\n return response.verify()\n except _RegistrationRejectedException as e:\n raise RegistrationRejectedException(str(e))\n\n\ndef verify_assertion_response(assertion, *, challenge, user, origin, rp_id):\n \"\"\"\n Validates the challenge and assertion information\n sent from the client during authentication.\n\n Returns an updated signage count on success.\n Raises AuthenticationRejectedException on failure.\n \"\"\"\n webauthn_users = _get_webauthn_users(user, rp_id=rp_id)\n cred_ids = [cred.credential_id for cred in webauthn_users]\n encoded_challenge = _webauthn_b64encode(challenge.encode()).decode()\n\n for webauthn_user in webauthn_users:\n response = pywebauthn.WebAuthnAssertionResponse(\n webauthn_user,\n assertion,\n encoded_challenge,\n origin,\n allow_credentials=cred_ids,\n )\n try:\n return (webauthn_user.credential_id, response.verify())\n except _AuthenticationRejectedException:\n pass\n\n # If we exit the loop, then we've failed to verify the assertion against\n # any of the user's WebAuthn credentials. Fail.\n raise AuthenticationRejectedException(\"Invalid WebAuthn credential\")\n", "path": "warehouse/utils/webauthn.py"}]}
| 2,161 | 149 |
gh_patches_debug_22378
|
rasdani/github-patches
|
git_diff
|
Mailu__Mailu-3011
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Vulnerability in ClamAV
## Environment & Version
### Environment
- [ ] docker compose
- [x] kubernetes
- [ ] docker swarm
### Version
- Version: `master`
## Description
ClamAV version 0.105.2 is vulnerable to [CVE-2023-20197](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2023-20197)
Unfortunately, ClamAV will not provide any update in the 0.105 branch, as it is EOL see https://blog.clamav.net/2023/07/2023-08-16-releases.html
## Replication Steps
```
$ docker run --pull=always --rm -it ghcr.io/mailu/clamav:master clamd --version
master: Pulling from mailu/clamav
Digest: sha256:dd088fc80ab063b0588160a69fce034d5d1f33db6d85d57296154fc51cdeaffa
Status: Image is up to date for ghcr.io/mailu/clamav:master
ClamAV 0.105.2
```
## Observed behaviour
ClamAV is in a vulnerable state
## Expected behaviour
I expect ClamAV to be updated to a fixed version (1.1.1 or 1.0.2)
</issue>
<code>
[start of core/admin/start.py]
1 #!/usr/bin/env python3
2
3 import os
4 import os.path
5 import time
6 import logging as log
7 import sys
8 from socrate import system
9
10 os.system("chown mailu:mailu -R /dkim")
11 os.system("find /data | grep -v /fetchmail | xargs -n1 chown mailu:mailu")
12 system.drop_privs_to('mailu')
13
14 system.set_env(['SECRET'])
15
16 os.system("flask mailu advertise")
17 os.system("flask db upgrade")
18
19 account = os.environ.get("INITIAL_ADMIN_ACCOUNT")
20 domain = os.environ.get("INITIAL_ADMIN_DOMAIN")
21 password = os.environ.get("INITIAL_ADMIN_PW")
22
23 if account is not None and domain is not None and password is not None:
24 mode = os.environ.get("INITIAL_ADMIN_MODE", default="ifmissing")
25 log.info("Creating initial admin account %s@%s with mode %s", account, domain, mode)
26 os.system("flask mailu admin %s %s '%s' --mode %s" % (account, domain, password, mode))
27
28 def test_unsupported():
29 import codecs
30 if os.path.isfile(codecs.decode('/.qbpxrerai', 'rot13')) or os.environ.get(codecs.decode('V_XABJ_ZL_FRGHC_QBRFAG_SVG_ERDHVERZRAGF_NAQ_JBAG_SVYR_VFFHRF_JVGUBHG_CNGPURF', 'rot13'), None):
31 return
32 print('Your system is not supported. Please start by reading the documentation and then http://www.catb.org/~esr/faqs/smart-questions.html')
33 while True:
34 time.sleep(5)
35
36 def test_DNS():
37 import dns.resolver
38 import dns.exception
39 import dns.flags
40 import dns.rdtypes
41 import dns.rdatatype
42 import dns.rdataclass
43 import time
44 # DNS stub configured to do DNSSEC enabled queries
45 resolver = dns.resolver.Resolver()
46 resolver.use_edns(0, dns.flags.DO, 1232)
47 resolver.flags = dns.flags.AD | dns.flags.RD
48 nameservers = resolver.nameservers
49 for ns in nameservers:
50 resolver.nameservers=[ns]
51 while True:
52 try:
53 result = resolver.resolve('example.org', dns.rdatatype.A, dns.rdataclass.IN, lifetime=10)
54 except Exception as e:
55 log.critical("Your DNS resolver at %s is not working (%s). Please see https://mailu.io/master/faq.html#the-admin-container-won-t-start-and-its-log-says-critical-your-dns-resolver-isn-t-doing-dnssec-validation", ns, e)
56 else:
57 if result.response.flags & dns.flags.AD:
58 break
59 log.critical("Your DNS resolver at %s isn't doing DNSSEC validation; Please see https://mailu.io/master/faq.html#the-admin-container-won-t-start-and-its-log-says-critical-your-dns-resolver-isn-t-doing-dnssec-validation.", ns)
60 time.sleep(5)
61
62 test_DNS()
63 test_unsupported()
64
65 cmdline = [
66 "gunicorn",
67 "--threads", f"{os.cpu_count()}",
68 # If SUBNET6 is defined, gunicorn must listen on IPv6 as well as IPv4
69 "-b", f"{'[::]' if os.environ.get('SUBNET6') else '0.0.0.0'}:8080",
70 "--logger-class mailu.Logger",
71 "--worker-tmp-dir /dev/shm",
72 "--error-logfile", "-",
73 "--preload"
74 ]
75
76 # logging
77 if log.root.level <= log.INFO:
78 cmdline.extend(["--access-logfile", "-"])
79
80 cmdline.append("'mailu:create_app()'")
81
82 os.system(" ".join(cmdline))
83
[end of core/admin/start.py]
[start of core/rspamd/start.py]
1 #!/usr/bin/env python3
2
3 import os
4 import glob
5 import logging as log
6 import requests
7 import shutil
8 import sys
9 import time
10 from socrate import system,conf
11
12 env = system.set_env()
13
14 # Actual startup script
15
16 config_files = []
17 for rspamd_file in glob.glob("/conf/*"):
18 conf.jinja(rspamd_file, env, os.path.join("/etc/rspamd/local.d", os.path.basename(rspamd_file)))
19 if rspamd_file != '/conf/forbidden_file_extension.map':
20 config_files.append(os.path.basename(rspamd_file))
21
22 for override_file in glob.glob("/overrides/*"):
23 if os.path.basename(override_file) not in config_files:
24 shutil.copyfile(override_file, os.path.join("/etc/rspamd/local.d", os.path.basename(override_file)))
25
26 # Admin may not be up just yet
27 healthcheck = f'http://{env["ADMIN_ADDRESS"]}:8080/internal/rspamd/local_domains'
28 while True:
29 time.sleep(1)
30 try:
31 if requests.get(healthcheck,timeout=2).ok:
32 break
33 except:
34 pass
35 log.warning("Admin is not up just yet, retrying in 1 second")
36
37 # Run rspamd
38 os.system("mkdir -m 755 -p /run/rspamd")
39 os.system("chown rspamd:rspamd /run/rspamd")
40 os.system("find /var/lib/rspamd | grep -v /filter | xargs -n1 chown rspamd:rspamd")
41 os.execv("/usr/sbin/rspamd", ["rspamd", "-f", "-u", "rspamd", "-g", "rspamd"])
42
[end of core/rspamd/start.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/core/admin/start.py b/core/admin/start.py
--- a/core/admin/start.py
+++ b/core/admin/start.py
@@ -27,7 +27,7 @@
def test_unsupported():
import codecs
- if os.path.isfile(codecs.decode('/.qbpxrerai', 'rot13')) or os.environ.get(codecs.decode('V_XABJ_ZL_FRGHC_QBRFAG_SVG_ERDHVERZRAGF_NAQ_JBAG_SVYR_VFFHRF_JVGUBHG_CNGPURF', 'rot13'), None):
+ if os.path.isfile(codecs.decode('/.qbpxrerai', 'rot13')) or os.environ.get(codecs.decode('V_XABJ_ZL_FRGHC_QBRFAG_SVG_ERDHVERZRAGF_NAQ_JBAG_SVYR_VFFHRF_JVGUBHG_CNGPURF', 'rot13'), None) or os.environ.get(codecs.decode('ZNVYH_URYZ_PUNEG', 'rot13'), None):
return
print('Your system is not supported. Please start by reading the documentation and then http://www.catb.org/~esr/faqs/smart-questions.html')
while True:
diff --git a/core/rspamd/start.py b/core/rspamd/start.py
--- a/core/rspamd/start.py
+++ b/core/rspamd/start.py
@@ -38,4 +38,4 @@
os.system("mkdir -m 755 -p /run/rspamd")
os.system("chown rspamd:rspamd /run/rspamd")
os.system("find /var/lib/rspamd | grep -v /filter | xargs -n1 chown rspamd:rspamd")
-os.execv("/usr/sbin/rspamd", ["rspamd", "-f", "-u", "rspamd", "-g", "rspamd"])
+os.execv("/usr/bin/rspamd", ["rspamd", "-f", "-u", "rspamd", "-g", "rspamd"])
|
{"golden_diff": "diff --git a/core/admin/start.py b/core/admin/start.py\n--- a/core/admin/start.py\n+++ b/core/admin/start.py\n@@ -27,7 +27,7 @@\n \n def test_unsupported():\n import codecs\n- if os.path.isfile(codecs.decode('/.qbpxrerai', 'rot13')) or os.environ.get(codecs.decode('V_XABJ_ZL_FRGHC_QBRFAG_SVG_ERDHVERZRAGF_NAQ_JBAG_SVYR_VFFHRF_JVGUBHG_CNGPURF', 'rot13'), None):\n+ if os.path.isfile(codecs.decode('/.qbpxrerai', 'rot13')) or os.environ.get(codecs.decode('V_XABJ_ZL_FRGHC_QBRFAG_SVG_ERDHVERZRAGF_NAQ_JBAG_SVYR_VFFHRF_JVGUBHG_CNGPURF', 'rot13'), None) or os.environ.get(codecs.decode('ZNVYH_URYZ_PUNEG', 'rot13'), None):\n return\n print('Your system is not supported. Please start by reading the documentation and then http://www.catb.org/~esr/faqs/smart-questions.html')\n while True:\ndiff --git a/core/rspamd/start.py b/core/rspamd/start.py\n--- a/core/rspamd/start.py\n+++ b/core/rspamd/start.py\n@@ -38,4 +38,4 @@\n os.system(\"mkdir -m 755 -p /run/rspamd\")\n os.system(\"chown rspamd:rspamd /run/rspamd\")\n os.system(\"find /var/lib/rspamd | grep -v /filter | xargs -n1 chown rspamd:rspamd\")\n-os.execv(\"/usr/sbin/rspamd\", [\"rspamd\", \"-f\", \"-u\", \"rspamd\", \"-g\", \"rspamd\"])\n+os.execv(\"/usr/bin/rspamd\", [\"rspamd\", \"-f\", \"-u\", \"rspamd\", \"-g\", \"rspamd\"])\n", "issue": "Vulnerability in ClamAV\n\r\n## Environment & Version\r\n\r\n### Environment\r\n\r\n- [ ] docker compose\r\n- [x] kubernetes\r\n- [ ] docker swarm\r\n\r\n### Version\r\n\r\n- Version: `master`\r\n\r\n## Description\r\nClamAV version 0.105.2 is vulnerable to [CVE-2023-20197](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2023-20197)\r\nUnfortunately, ClamAV will not provide any update in the 0.105 branch, as it is EOL see https://blog.clamav.net/2023/07/2023-08-16-releases.html\r\n\r\n## Replication Steps\r\n```\r\n$ docker run --pull=always --rm -it ghcr.io/mailu/clamav:master clamd --version\r\nmaster: Pulling from mailu/clamav\r\nDigest: sha256:dd088fc80ab063b0588160a69fce034d5d1f33db6d85d57296154fc51cdeaffa\r\nStatus: Image is up to date for ghcr.io/mailu/clamav:master\r\nClamAV 0.105.2\r\n```\r\n\r\n## Observed behaviour\r\nClamAV is in a vulnerable state\r\n\r\n## Expected behaviour\r\nI expect ClamAV to be updated to a fixed version (1.1.1 or 1.0.2)\r\n\r\n\n", "before_files": [{"content": "#!/usr/bin/env python3\n\nimport os\nimport os.path\nimport time\nimport logging as log\nimport sys\nfrom socrate import system\n\nos.system(\"chown mailu:mailu -R /dkim\")\nos.system(\"find /data | grep -v /fetchmail | xargs -n1 chown mailu:mailu\")\nsystem.drop_privs_to('mailu')\n\nsystem.set_env(['SECRET'])\n\nos.system(\"flask mailu advertise\")\nos.system(\"flask db upgrade\")\n\naccount = os.environ.get(\"INITIAL_ADMIN_ACCOUNT\")\ndomain = os.environ.get(\"INITIAL_ADMIN_DOMAIN\")\npassword = os.environ.get(\"INITIAL_ADMIN_PW\")\n\nif account is not None and domain is not None and password is not None:\n mode = os.environ.get(\"INITIAL_ADMIN_MODE\", default=\"ifmissing\")\n log.info(\"Creating initial admin account %s@%s with mode %s\", account, domain, mode)\n os.system(\"flask mailu admin %s %s '%s' --mode %s\" % (account, domain, password, mode))\n\ndef test_unsupported():\n import codecs\n if os.path.isfile(codecs.decode('/.qbpxrerai', 'rot13')) or os.environ.get(codecs.decode('V_XABJ_ZL_FRGHC_QBRFAG_SVG_ERDHVERZRAGF_NAQ_JBAG_SVYR_VFFHRF_JVGUBHG_CNGPURF', 'rot13'), None):\n return\n print('Your system is not supported. Please start by reading the documentation and then http://www.catb.org/~esr/faqs/smart-questions.html')\n while True:\n time.sleep(5)\n\ndef test_DNS():\n import dns.resolver\n import dns.exception\n import dns.flags\n import dns.rdtypes\n import dns.rdatatype\n import dns.rdataclass\n import time\n # DNS stub configured to do DNSSEC enabled queries\n resolver = dns.resolver.Resolver()\n resolver.use_edns(0, dns.flags.DO, 1232)\n resolver.flags = dns.flags.AD | dns.flags.RD\n nameservers = resolver.nameservers\n for ns in nameservers:\n resolver.nameservers=[ns]\n while True:\n try:\n result = resolver.resolve('example.org', dns.rdatatype.A, dns.rdataclass.IN, lifetime=10)\n except Exception as e:\n log.critical(\"Your DNS resolver at %s is not working (%s). Please see https://mailu.io/master/faq.html#the-admin-container-won-t-start-and-its-log-says-critical-your-dns-resolver-isn-t-doing-dnssec-validation\", ns, e)\n else:\n if result.response.flags & dns.flags.AD:\n break\n log.critical(\"Your DNS resolver at %s isn't doing DNSSEC validation; Please see https://mailu.io/master/faq.html#the-admin-container-won-t-start-and-its-log-says-critical-your-dns-resolver-isn-t-doing-dnssec-validation.\", ns)\n time.sleep(5)\n\ntest_DNS()\ntest_unsupported()\n\ncmdline = [\n \"gunicorn\",\n \"--threads\", f\"{os.cpu_count()}\",\n # If SUBNET6 is defined, gunicorn must listen on IPv6 as well as IPv4\n \"-b\", f\"{'[::]' if os.environ.get('SUBNET6') else '0.0.0.0'}:8080\",\n \"--logger-class mailu.Logger\",\n \"--worker-tmp-dir /dev/shm\",\n\t\"--error-logfile\", \"-\",\n\t\"--preload\"\n]\n\n# logging\nif log.root.level <= log.INFO:\n\tcmdline.extend([\"--access-logfile\", \"-\"])\n\ncmdline.append(\"'mailu:create_app()'\")\n\nos.system(\" \".join(cmdline))\n", "path": "core/admin/start.py"}, {"content": "#!/usr/bin/env python3\n\nimport os\nimport glob\nimport logging as log\nimport requests\nimport shutil\nimport sys\nimport time\nfrom socrate import system,conf\n\nenv = system.set_env()\n\n# Actual startup script\n\nconfig_files = []\nfor rspamd_file in glob.glob(\"/conf/*\"):\n conf.jinja(rspamd_file, env, os.path.join(\"/etc/rspamd/local.d\", os.path.basename(rspamd_file)))\n if rspamd_file != '/conf/forbidden_file_extension.map':\n config_files.append(os.path.basename(rspamd_file))\n\nfor override_file in glob.glob(\"/overrides/*\"):\n if os.path.basename(override_file) not in config_files:\n shutil.copyfile(override_file, os.path.join(\"/etc/rspamd/local.d\", os.path.basename(override_file)))\n\n# Admin may not be up just yet\nhealthcheck = f'http://{env[\"ADMIN_ADDRESS\"]}:8080/internal/rspamd/local_domains'\nwhile True:\n time.sleep(1)\n try:\n if requests.get(healthcheck,timeout=2).ok:\n break\n except:\n pass\n log.warning(\"Admin is not up just yet, retrying in 1 second\")\n\n# Run rspamd\nos.system(\"mkdir -m 755 -p /run/rspamd\")\nos.system(\"chown rspamd:rspamd /run/rspamd\")\nos.system(\"find /var/lib/rspamd | grep -v /filter | xargs -n1 chown rspamd:rspamd\")\nos.execv(\"/usr/sbin/rspamd\", [\"rspamd\", \"-f\", \"-u\", \"rspamd\", \"-g\", \"rspamd\"])\n", "path": "core/rspamd/start.py"}]}
| 2,335 | 450 |
gh_patches_debug_19593
|
rasdani/github-patches
|
git_diff
|
urllib3__urllib3-432
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add documentation for HTTPResponse `io` support
Reminder for @eteq re #187:
> Would you be up for adding a bit to the documentation/comments which talks about the use cases or benefits of this? That would be greatly appreciated. :)
</issue>
<code>
[start of urllib3/response.py]
1 import zlib
2 import io
3 from socket import timeout as SocketTimeout
4
5 from ._collections import HTTPHeaderDict
6 from .exceptions import ProtocolError, DecodeError, ReadTimeoutError
7 from .packages.six import string_types as basestring, binary_type
8 from .connection import HTTPException, BaseSSLError
9 from .util.response import is_fp_closed
10
11
12
13 class DeflateDecoder(object):
14
15 def __init__(self):
16 self._first_try = True
17 self._data = binary_type()
18 self._obj = zlib.decompressobj()
19
20 def __getattr__(self, name):
21 return getattr(self._obj, name)
22
23 def decompress(self, data):
24 if not self._first_try:
25 return self._obj.decompress(data)
26
27 self._data += data
28 try:
29 return self._obj.decompress(data)
30 except zlib.error:
31 self._first_try = False
32 self._obj = zlib.decompressobj(-zlib.MAX_WBITS)
33 try:
34 return self.decompress(self._data)
35 finally:
36 self._data = None
37
38
39 def _get_decoder(mode):
40 if mode == 'gzip':
41 return zlib.decompressobj(16 + zlib.MAX_WBITS)
42
43 return DeflateDecoder()
44
45
46 class HTTPResponse(io.IOBase):
47 """
48 HTTP Response container.
49
50 Backwards-compatible to httplib's HTTPResponse but the response ``body`` is
51 loaded and decoded on-demand when the ``data`` property is accessed.
52
53 Extra parameters for behaviour not present in httplib.HTTPResponse:
54
55 :param preload_content:
56 If True, the response's body will be preloaded during construction.
57
58 :param decode_content:
59 If True, attempts to decode specific content-encoding's based on headers
60 (like 'gzip' and 'deflate') will be skipped and raw data will be used
61 instead.
62
63 :param original_response:
64 When this HTTPResponse wrapper is generated from an httplib.HTTPResponse
65 object, it's convenient to include the original for debug purposes. It's
66 otherwise unused.
67 """
68
69 CONTENT_DECODERS = ['gzip', 'deflate']
70 REDIRECT_STATUSES = [301, 302, 303, 307, 308]
71
72 def __init__(self, body='', headers=None, status=0, version=0, reason=None,
73 strict=0, preload_content=True, decode_content=True,
74 original_response=None, pool=None, connection=None):
75
76 self.headers = HTTPHeaderDict()
77 if headers:
78 self.headers.update(headers)
79 self.status = status
80 self.version = version
81 self.reason = reason
82 self.strict = strict
83 self.decode_content = decode_content
84
85 self._decoder = None
86 self._body = None
87 self._fp = None
88 self._original_response = original_response
89 self._fp_bytes_read = 0
90
91 if body and isinstance(body, (basestring, binary_type)):
92 self._body = body
93
94 self._pool = pool
95 self._connection = connection
96
97 if hasattr(body, 'read'):
98 self._fp = body
99
100 if preload_content and not self._body:
101 self._body = self.read(decode_content=decode_content)
102
103 def get_redirect_location(self):
104 """
105 Should we redirect and where to?
106
107 :returns: Truthy redirect location string if we got a redirect status
108 code and valid location. ``None`` if redirect status and no
109 location. ``False`` if not a redirect status code.
110 """
111 if self.status in self.REDIRECT_STATUSES:
112 return self.headers.get('location')
113
114 return False
115
116 def release_conn(self):
117 if not self._pool or not self._connection:
118 return
119
120 self._pool._put_conn(self._connection)
121 self._connection = None
122
123 @property
124 def data(self):
125 # For backwords-compat with earlier urllib3 0.4 and earlier.
126 if self._body:
127 return self._body
128
129 if self._fp:
130 return self.read(cache_content=True)
131
132 def tell(self):
133 """
134 Obtain the number of bytes pulled over the wire so far. May differ from
135 the amount of content returned by :meth:``HTTPResponse.read`` if bytes
136 are encoded on the wire (e.g, compressed).
137 """
138 return self._fp_bytes_read
139
140 def read(self, amt=None, decode_content=None, cache_content=False):
141 """
142 Similar to :meth:`httplib.HTTPResponse.read`, but with two additional
143 parameters: ``decode_content`` and ``cache_content``.
144
145 :param amt:
146 How much of the content to read. If specified, caching is skipped
147 because it doesn't make sense to cache partial content as the full
148 response.
149
150 :param decode_content:
151 If True, will attempt to decode the body based on the
152 'content-encoding' header.
153
154 :param cache_content:
155 If True, will save the returned data such that the same result is
156 returned despite of the state of the underlying file object. This
157 is useful if you want the ``.data`` property to continue working
158 after having ``.read()`` the file object. (Overridden if ``amt`` is
159 set.)
160 """
161 # Note: content-encoding value should be case-insensitive, per RFC 7230
162 # Section 3.2
163 content_encoding = self.headers.get('content-encoding', '').lower()
164 if self._decoder is None:
165 if content_encoding in self.CONTENT_DECODERS:
166 self._decoder = _get_decoder(content_encoding)
167 if decode_content is None:
168 decode_content = self.decode_content
169
170 if self._fp is None:
171 return
172
173 flush_decoder = False
174
175 try:
176 try:
177 if amt is None:
178 # cStringIO doesn't like amt=None
179 data = self._fp.read()
180 flush_decoder = True
181 else:
182 cache_content = False
183 data = self._fp.read(amt)
184 if amt != 0 and not data: # Platform-specific: Buggy versions of Python.
185 # Close the connection when no data is returned
186 #
187 # This is redundant to what httplib/http.client _should_
188 # already do. However, versions of python released before
189 # December 15, 2012 (http://bugs.python.org/issue16298) do
190 # not properly close the connection in all cases. There is
191 # no harm in redundantly calling close.
192 self._fp.close()
193 flush_decoder = True
194
195 except SocketTimeout:
196 # FIXME: Ideally we'd like to include the url in the ReadTimeoutError but
197 # there is yet no clean way to get at it from this context.
198 raise ReadTimeoutError(self._pool, None, 'Read timed out.')
199
200 except BaseSSLError as e:
201 # FIXME: Is there a better way to differentiate between SSLErrors?
202 if not 'read operation timed out' in str(e): # Defensive:
203 # This shouldn't happen but just in case we're missing an edge
204 # case, let's avoid swallowing SSL errors.
205 raise
206
207 raise ReadTimeoutError(self._pool, None, 'Read timed out.')
208
209 except HTTPException as e:
210 # This includes IncompleteRead.
211 raise ProtocolError('Connection broken: %r' % e, e)
212
213 self._fp_bytes_read += len(data)
214
215 try:
216 if decode_content and self._decoder:
217 data = self._decoder.decompress(data)
218 except (IOError, zlib.error) as e:
219 raise DecodeError(
220 "Received response with content-encoding: %s, but "
221 "failed to decode it." % content_encoding, e)
222
223 if flush_decoder and decode_content and self._decoder:
224 buf = self._decoder.decompress(binary_type())
225 data += buf + self._decoder.flush()
226
227 if cache_content:
228 self._body = data
229
230 return data
231
232 finally:
233 if self._original_response and self._original_response.isclosed():
234 self.release_conn()
235
236 def stream(self, amt=2**16, decode_content=None):
237 """
238 A generator wrapper for the read() method. A call will block until
239 ``amt`` bytes have been read from the connection or until the
240 connection is closed.
241
242 :param amt:
243 How much of the content to read. The generator will return up to
244 much data per iteration, but may return less. This is particularly
245 likely when using compressed data. However, the empty string will
246 never be returned.
247
248 :param decode_content:
249 If True, will attempt to decode the body based on the
250 'content-encoding' header.
251 """
252 while not is_fp_closed(self._fp):
253 data = self.read(amt=amt, decode_content=decode_content)
254
255 if data:
256 yield data
257
258 @classmethod
259 def from_httplib(ResponseCls, r, **response_kw):
260 """
261 Given an :class:`httplib.HTTPResponse` instance ``r``, return a
262 corresponding :class:`urllib3.response.HTTPResponse` object.
263
264 Remaining parameters are passed to the HTTPResponse constructor, along
265 with ``original_response=r``.
266 """
267
268 headers = HTTPHeaderDict()
269 for k, v in r.getheaders():
270 headers.add(k, v)
271
272 # HTTPResponse objects in Python 3 don't have a .strict attribute
273 strict = getattr(r, 'strict', 0)
274 return ResponseCls(body=r,
275 headers=headers,
276 status=r.status,
277 version=r.version,
278 reason=r.reason,
279 strict=strict,
280 original_response=r,
281 **response_kw)
282
283 # Backwards-compatibility methods for httplib.HTTPResponse
284 def getheaders(self):
285 return self.headers
286
287 def getheader(self, name, default=None):
288 return self.headers.get(name, default)
289
290 # Overrides from io.IOBase
291 def close(self):
292 if not self.closed:
293 self._fp.close()
294
295 @property
296 def closed(self):
297 if self._fp is None:
298 return True
299 elif hasattr(self._fp, 'closed'):
300 return self._fp.closed
301 elif hasattr(self._fp, 'isclosed'): # Python 2
302 return self._fp.isclosed()
303 else:
304 return True
305
306 def fileno(self):
307 if self._fp is None:
308 raise IOError("HTTPResponse has no file to get a fileno from")
309 elif hasattr(self._fp, "fileno"):
310 return self._fp.fileno()
311 else:
312 raise IOError("The file-like object this HTTPResponse is wrapped "
313 "around has no file descriptor")
314
315 def flush(self):
316 if self._fp is not None and hasattr(self._fp, 'flush'):
317 return self._fp.flush()
318
319 def readable(self):
320 return True
321
[end of urllib3/response.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/urllib3/response.py b/urllib3/response.py
--- a/urllib3/response.py
+++ b/urllib3/response.py
@@ -48,7 +48,10 @@
HTTP Response container.
Backwards-compatible to httplib's HTTPResponse but the response ``body`` is
- loaded and decoded on-demand when the ``data`` property is accessed.
+ loaded and decoded on-demand when the ``data`` property is accessed. This
+ class is also compatible with the Python standard library's :mod:`io`
+ module, and can hence be treated as a readable object in the context of that
+ framework.
Extra parameters for behaviour not present in httplib.HTTPResponse:
@@ -317,4 +320,14 @@
return self._fp.flush()
def readable(self):
+ # This method is required for `io` module compatibility.
return True
+
+ def readinto(self, b):
+ # This method is required for `io` module compatibility.
+ temp = self.read(len(b))
+ if len(temp) == 0:
+ return 0
+ else:
+ b[:len(temp)] = temp
+ return len(temp)
|
{"golden_diff": "diff --git a/urllib3/response.py b/urllib3/response.py\n--- a/urllib3/response.py\n+++ b/urllib3/response.py\n@@ -48,7 +48,10 @@\n HTTP Response container.\n \n Backwards-compatible to httplib's HTTPResponse but the response ``body`` is\n- loaded and decoded on-demand when the ``data`` property is accessed.\n+ loaded and decoded on-demand when the ``data`` property is accessed. This\n+ class is also compatible with the Python standard library's :mod:`io`\n+ module, and can hence be treated as a readable object in the context of that\n+ framework.\n \n Extra parameters for behaviour not present in httplib.HTTPResponse:\n \n@@ -317,4 +320,14 @@\n return self._fp.flush()\n \n def readable(self):\n+ # This method is required for `io` module compatibility.\n return True\n+\n+ def readinto(self, b):\n+ # This method is required for `io` module compatibility.\n+ temp = self.read(len(b))\n+ if len(temp) == 0:\n+ return 0\n+ else:\n+ b[:len(temp)] = temp\n+ return len(temp)\n", "issue": "Add documentation for HTTPResponse `io` support\nReminder for @eteq re #187:\n\n> Would you be up for adding a bit to the documentation/comments which talks about the use cases or benefits of this? That would be greatly appreciated. :)\n\n", "before_files": [{"content": "import zlib\nimport io\nfrom socket import timeout as SocketTimeout\n\nfrom ._collections import HTTPHeaderDict\nfrom .exceptions import ProtocolError, DecodeError, ReadTimeoutError\nfrom .packages.six import string_types as basestring, binary_type\nfrom .connection import HTTPException, BaseSSLError\nfrom .util.response import is_fp_closed\n\n\n\nclass DeflateDecoder(object):\n\n def __init__(self):\n self._first_try = True\n self._data = binary_type()\n self._obj = zlib.decompressobj()\n\n def __getattr__(self, name):\n return getattr(self._obj, name)\n\n def decompress(self, data):\n if not self._first_try:\n return self._obj.decompress(data)\n\n self._data += data\n try:\n return self._obj.decompress(data)\n except zlib.error:\n self._first_try = False\n self._obj = zlib.decompressobj(-zlib.MAX_WBITS)\n try:\n return self.decompress(self._data)\n finally:\n self._data = None\n\n\ndef _get_decoder(mode):\n if mode == 'gzip':\n return zlib.decompressobj(16 + zlib.MAX_WBITS)\n\n return DeflateDecoder()\n\n\nclass HTTPResponse(io.IOBase):\n \"\"\"\n HTTP Response container.\n\n Backwards-compatible to httplib's HTTPResponse but the response ``body`` is\n loaded and decoded on-demand when the ``data`` property is accessed.\n\n Extra parameters for behaviour not present in httplib.HTTPResponse:\n\n :param preload_content:\n If True, the response's body will be preloaded during construction.\n\n :param decode_content:\n If True, attempts to decode specific content-encoding's based on headers\n (like 'gzip' and 'deflate') will be skipped and raw data will be used\n instead.\n\n :param original_response:\n When this HTTPResponse wrapper is generated from an httplib.HTTPResponse\n object, it's convenient to include the original for debug purposes. It's\n otherwise unused.\n \"\"\"\n\n CONTENT_DECODERS = ['gzip', 'deflate']\n REDIRECT_STATUSES = [301, 302, 303, 307, 308]\n\n def __init__(self, body='', headers=None, status=0, version=0, reason=None,\n strict=0, preload_content=True, decode_content=True,\n original_response=None, pool=None, connection=None):\n\n self.headers = HTTPHeaderDict()\n if headers:\n self.headers.update(headers)\n self.status = status\n self.version = version\n self.reason = reason\n self.strict = strict\n self.decode_content = decode_content\n\n self._decoder = None\n self._body = None\n self._fp = None\n self._original_response = original_response\n self._fp_bytes_read = 0\n\n if body and isinstance(body, (basestring, binary_type)):\n self._body = body\n\n self._pool = pool\n self._connection = connection\n\n if hasattr(body, 'read'):\n self._fp = body\n\n if preload_content and not self._body:\n self._body = self.read(decode_content=decode_content)\n\n def get_redirect_location(self):\n \"\"\"\n Should we redirect and where to?\n\n :returns: Truthy redirect location string if we got a redirect status\n code and valid location. ``None`` if redirect status and no\n location. ``False`` if not a redirect status code.\n \"\"\"\n if self.status in self.REDIRECT_STATUSES:\n return self.headers.get('location')\n\n return False\n\n def release_conn(self):\n if not self._pool or not self._connection:\n return\n\n self._pool._put_conn(self._connection)\n self._connection = None\n\n @property\n def data(self):\n # For backwords-compat with earlier urllib3 0.4 and earlier.\n if self._body:\n return self._body\n\n if self._fp:\n return self.read(cache_content=True)\n\n def tell(self):\n \"\"\"\n Obtain the number of bytes pulled over the wire so far. May differ from\n the amount of content returned by :meth:``HTTPResponse.read`` if bytes\n are encoded on the wire (e.g, compressed).\n \"\"\"\n return self._fp_bytes_read\n\n def read(self, amt=None, decode_content=None, cache_content=False):\n \"\"\"\n Similar to :meth:`httplib.HTTPResponse.read`, but with two additional\n parameters: ``decode_content`` and ``cache_content``.\n\n :param amt:\n How much of the content to read. If specified, caching is skipped\n because it doesn't make sense to cache partial content as the full\n response.\n\n :param decode_content:\n If True, will attempt to decode the body based on the\n 'content-encoding' header.\n\n :param cache_content:\n If True, will save the returned data such that the same result is\n returned despite of the state of the underlying file object. This\n is useful if you want the ``.data`` property to continue working\n after having ``.read()`` the file object. (Overridden if ``amt`` is\n set.)\n \"\"\"\n # Note: content-encoding value should be case-insensitive, per RFC 7230\n # Section 3.2\n content_encoding = self.headers.get('content-encoding', '').lower()\n if self._decoder is None:\n if content_encoding in self.CONTENT_DECODERS:\n self._decoder = _get_decoder(content_encoding)\n if decode_content is None:\n decode_content = self.decode_content\n\n if self._fp is None:\n return\n\n flush_decoder = False\n\n try:\n try:\n if amt is None:\n # cStringIO doesn't like amt=None\n data = self._fp.read()\n flush_decoder = True\n else:\n cache_content = False\n data = self._fp.read(amt)\n if amt != 0 and not data: # Platform-specific: Buggy versions of Python.\n # Close the connection when no data is returned\n #\n # This is redundant to what httplib/http.client _should_\n # already do. However, versions of python released before\n # December 15, 2012 (http://bugs.python.org/issue16298) do\n # not properly close the connection in all cases. There is\n # no harm in redundantly calling close.\n self._fp.close()\n flush_decoder = True\n\n except SocketTimeout:\n # FIXME: Ideally we'd like to include the url in the ReadTimeoutError but\n # there is yet no clean way to get at it from this context.\n raise ReadTimeoutError(self._pool, None, 'Read timed out.')\n\n except BaseSSLError as e:\n # FIXME: Is there a better way to differentiate between SSLErrors?\n if not 'read operation timed out' in str(e): # Defensive:\n # This shouldn't happen but just in case we're missing an edge\n # case, let's avoid swallowing SSL errors.\n raise\n\n raise ReadTimeoutError(self._pool, None, 'Read timed out.')\n\n except HTTPException as e:\n # This includes IncompleteRead.\n raise ProtocolError('Connection broken: %r' % e, e)\n\n self._fp_bytes_read += len(data)\n\n try:\n if decode_content and self._decoder:\n data = self._decoder.decompress(data)\n except (IOError, zlib.error) as e:\n raise DecodeError(\n \"Received response with content-encoding: %s, but \"\n \"failed to decode it.\" % content_encoding, e)\n\n if flush_decoder and decode_content and self._decoder:\n buf = self._decoder.decompress(binary_type())\n data += buf + self._decoder.flush()\n\n if cache_content:\n self._body = data\n\n return data\n\n finally:\n if self._original_response and self._original_response.isclosed():\n self.release_conn()\n\n def stream(self, amt=2**16, decode_content=None):\n \"\"\"\n A generator wrapper for the read() method. A call will block until\n ``amt`` bytes have been read from the connection or until the\n connection is closed.\n\n :param amt:\n How much of the content to read. The generator will return up to\n much data per iteration, but may return less. This is particularly\n likely when using compressed data. However, the empty string will\n never be returned.\n\n :param decode_content:\n If True, will attempt to decode the body based on the\n 'content-encoding' header.\n \"\"\"\n while not is_fp_closed(self._fp):\n data = self.read(amt=amt, decode_content=decode_content)\n\n if data:\n yield data\n\n @classmethod\n def from_httplib(ResponseCls, r, **response_kw):\n \"\"\"\n Given an :class:`httplib.HTTPResponse` instance ``r``, return a\n corresponding :class:`urllib3.response.HTTPResponse` object.\n\n Remaining parameters are passed to the HTTPResponse constructor, along\n with ``original_response=r``.\n \"\"\"\n\n headers = HTTPHeaderDict()\n for k, v in r.getheaders():\n headers.add(k, v)\n\n # HTTPResponse objects in Python 3 don't have a .strict attribute\n strict = getattr(r, 'strict', 0)\n return ResponseCls(body=r,\n headers=headers,\n status=r.status,\n version=r.version,\n reason=r.reason,\n strict=strict,\n original_response=r,\n **response_kw)\n\n # Backwards-compatibility methods for httplib.HTTPResponse\n def getheaders(self):\n return self.headers\n\n def getheader(self, name, default=None):\n return self.headers.get(name, default)\n\n # Overrides from io.IOBase\n def close(self):\n if not self.closed:\n self._fp.close()\n\n @property\n def closed(self):\n if self._fp is None:\n return True\n elif hasattr(self._fp, 'closed'):\n return self._fp.closed\n elif hasattr(self._fp, 'isclosed'): # Python 2\n return self._fp.isclosed()\n else:\n return True\n\n def fileno(self):\n if self._fp is None:\n raise IOError(\"HTTPResponse has no file to get a fileno from\")\n elif hasattr(self._fp, \"fileno\"):\n return self._fp.fileno()\n else:\n raise IOError(\"The file-like object this HTTPResponse is wrapped \"\n \"around has no file descriptor\")\n\n def flush(self):\n if self._fp is not None and hasattr(self._fp, 'flush'):\n return self._fp.flush()\n\n def readable(self):\n return True\n", "path": "urllib3/response.py"}]}
| 3,828 | 278 |
gh_patches_debug_44463
|
rasdani/github-patches
|
git_diff
|
PaddlePaddle__PaddleSeg-224
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
在应用labelme2seg.py转化labelme生成的json过程,报错如下
在line 81,有判断语句:
if lbl.min >= 0 and lbl.max() <= 255:
总是报错:‘tuple’ object has no attribute 'min'
看源码,不应该这样啊,请问是什么原因?
</issue>
<code>
[start of pdseg/tools/labelme2seg.py]
1 #!/usr/bin/env python
2
3 from __future__ import print_function
4
5 import argparse
6 import glob
7 import json
8 import os
9 import os.path as osp
10
11 import numpy as np
12 import PIL.Image
13 import labelme
14
15 from gray2pseudo_color import get_color_map_list
16
17
18 def parse_args():
19 parser = argparse.ArgumentParser(
20 formatter_class=argparse.ArgumentDefaultsHelpFormatter
21 )
22 parser.add_argument('input_dir',
23 help='input annotated directory')
24 return parser.parse_args()
25
26
27 def main(args):
28 output_dir = osp.join(args.input_dir, 'annotations')
29 if not osp.exists(output_dir):
30 os.makedirs(output_dir)
31 print('Creating annotations directory:', output_dir)
32
33 # get the all class names for the given dataset
34 class_names = ['_background_']
35 for label_file in glob.glob(osp.join(args.input_dir, '*.json')):
36 with open(label_file) as f:
37 data = json.load(f)
38 for shape in data['shapes']:
39 label = shape['label']
40 cls_name = label
41 if not cls_name in class_names:
42 class_names.append(cls_name)
43
44 class_name_to_id = {}
45 for i, class_name in enumerate(class_names):
46 class_id = i # starts with 0
47 class_name_to_id[class_name] = class_id
48 if class_id == 0:
49 assert class_name == '_background_'
50 class_names = tuple(class_names)
51 print('class_names:', class_names)
52
53 out_class_names_file = osp.join(args.input_dir, 'class_names.txt')
54 with open(out_class_names_file, 'w') as f:
55 f.writelines('\n'.join(class_names))
56 print('Saved class_names:', out_class_names_file)
57
58 color_map = get_color_map_list(256)
59
60 for label_file in glob.glob(osp.join(args.input_dir, '*.json')):
61 print('Generating dataset from:', label_file)
62 with open(label_file) as f:
63 base = osp.splitext(osp.basename(label_file))[0]
64 out_png_file = osp.join(
65 output_dir, base + '.png')
66
67 data = json.load(f)
68
69 img_file = osp.join(osp.dirname(label_file), data['imagePath'])
70 img = np.asarray(PIL.Image.open(img_file))
71
72 lbl = labelme.utils.shapes_to_label(
73 img_shape=img.shape,
74 shapes=data['shapes'],
75 label_name_to_value=class_name_to_id,
76 )
77
78 if osp.splitext(out_png_file)[1] != '.png':
79 out_png_file += '.png'
80 # Assume label ranges [0, 255] for uint8,
81 if lbl.min() >= 0 and lbl.max() <= 255:
82 lbl_pil = PIL.Image.fromarray(lbl.astype(np.uint8), mode='P')
83 lbl_pil.putpalette(color_map)
84 lbl_pil.save(out_png_file)
85 else:
86 raise ValueError(
87 '[%s] Cannot save the pixel-wise class label as PNG. '
88 'Please consider using the .npy format.' % out_png_file
89 )
90
91
92 if __name__ == '__main__':
93 args = parse_args()
94 main(args)
95
[end of pdseg/tools/labelme2seg.py]
[start of pdseg/tools/jingling2seg.py]
1 #!/usr/bin/env python
2
3 from __future__ import print_function
4
5 import argparse
6 import glob
7 import json
8 import os
9 import os.path as osp
10
11 import numpy as np
12 import PIL.Image
13 import labelme
14
15 from gray2pseudo_color import get_color_map_list
16
17
18 def parse_args():
19 parser = argparse.ArgumentParser(
20 formatter_class=argparse.ArgumentDefaultsHelpFormatter
21 )
22 parser.add_argument('input_dir',
23 help='input annotated directory')
24 return parser.parse_args()
25
26
27 def main(args):
28 output_dir = osp.join(args.input_dir, 'annotations')
29 if not osp.exists(output_dir):
30 os.makedirs(output_dir)
31 print('Creating annotations directory:', output_dir)
32
33 # get the all class names for the given dataset
34 class_names = ['_background_']
35 for label_file in glob.glob(osp.join(args.input_dir, '*.json')):
36 with open(label_file) as f:
37 data = json.load(f)
38 if data['outputs']:
39 for output in data['outputs']['object']:
40 name = output['name']
41 cls_name = name
42 if not cls_name in class_names:
43 class_names.append(cls_name)
44
45 class_name_to_id = {}
46 for i, class_name in enumerate(class_names):
47 class_id = i # starts with 0
48 class_name_to_id[class_name] = class_id
49 if class_id == 0:
50 assert class_name == '_background_'
51 class_names = tuple(class_names)
52 print('class_names:', class_names)
53
54 out_class_names_file = osp.join(args.input_dir, 'class_names.txt')
55 with open(out_class_names_file, 'w') as f:
56 f.writelines('\n'.join(class_names))
57 print('Saved class_names:', out_class_names_file)
58
59 color_map = get_color_map_list(256)
60
61 for label_file in glob.glob(osp.join(args.input_dir, '*.json')):
62 print('Generating dataset from:', label_file)
63 with open(label_file) as f:
64 base = osp.splitext(osp.basename(label_file))[0]
65 out_png_file = osp.join(
66 output_dir, base + '.png')
67
68 data = json.load(f)
69
70 data_shapes = []
71 if data['outputs']:
72 for output in data['outputs']['object']:
73 if 'polygon' in output.keys():
74 polygon = output['polygon']
75 name = output['name']
76
77 # convert jingling format to labelme format
78 points = []
79 for i in range(1, int(len(polygon) / 2) + 1):
80 points.append([polygon['x' + str(i)], polygon['y' + str(i)]])
81 shape = {'label': name, 'points': points, 'shape_type': 'polygon'}
82 data_shapes.append(shape)
83
84 if 'size' not in data:
85 continue
86 data_size = data['size']
87 img_shape = (data_size['height'], data_size['width'], data_size['depth'])
88
89 lbl = labelme.utils.shapes_to_label(
90 img_shape=img_shape,
91 shapes=data_shapes,
92 label_name_to_value=class_name_to_id,
93 )
94
95 if osp.splitext(out_png_file)[1] != '.png':
96 out_png_file += '.png'
97 # Assume label ranges [0, 255] for uint8,
98 if lbl.min() >= 0 and lbl.max() <= 255:
99 lbl_pil = PIL.Image.fromarray(lbl.astype(np.uint8), mode='P')
100 lbl_pil.putpalette(color_map)
101 lbl_pil.save(out_png_file)
102 else:
103 raise ValueError(
104 '[%s] Cannot save the pixel-wise class label as PNG. '
105 'Please consider using the .npy format.' % out_png_file
106 )
107
108
109 if __name__ == '__main__':
110 args = parse_args()
111 main(args)
112
[end of pdseg/tools/jingling2seg.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pdseg/tools/jingling2seg.py b/pdseg/tools/jingling2seg.py
--- a/pdseg/tools/jingling2seg.py
+++ b/pdseg/tools/jingling2seg.py
@@ -17,10 +17,8 @@
def parse_args():
parser = argparse.ArgumentParser(
- formatter_class=argparse.ArgumentDefaultsHelpFormatter
- )
- parser.add_argument('input_dir',
- help='input annotated directory')
+ formatter_class=argparse.ArgumentDefaultsHelpFormatter)
+ parser.add_argument('input_dir', help='input annotated directory')
return parser.parse_args()
@@ -62,8 +60,7 @@
print('Generating dataset from:', label_file)
with open(label_file) as f:
base = osp.splitext(osp.basename(label_file))[0]
- out_png_file = osp.join(
- output_dir, base + '.png')
+ out_png_file = osp.join(output_dir, base + '.png')
data = json.load(f)
@@ -77,16 +74,22 @@
# convert jingling format to labelme format
points = []
for i in range(1, int(len(polygon) / 2) + 1):
- points.append([polygon['x' + str(i)], polygon['y' + str(i)]])
- shape = {'label': name, 'points': points, 'shape_type': 'polygon'}
+ points.append(
+ [polygon['x' + str(i)], polygon['y' + str(i)]])
+ shape = {
+ 'label': name,
+ 'points': points,
+ 'shape_type': 'polygon'
+ }
data_shapes.append(shape)
if 'size' not in data:
continue
data_size = data['size']
- img_shape = (data_size['height'], data_size['width'], data_size['depth'])
+ img_shape = (data_size['height'], data_size['width'],
+ data_size['depth'])
- lbl = labelme.utils.shapes_to_label(
+ lbl, _ = labelme.utils.shapes_to_label(
img_shape=img_shape,
shapes=data_shapes,
label_name_to_value=class_name_to_id,
@@ -102,8 +105,7 @@
else:
raise ValueError(
'[%s] Cannot save the pixel-wise class label as PNG. '
- 'Please consider using the .npy format.' % out_png_file
- )
+ 'Please consider using the .npy format.' % out_png_file)
if __name__ == '__main__':
diff --git a/pdseg/tools/labelme2seg.py b/pdseg/tools/labelme2seg.py
--- a/pdseg/tools/labelme2seg.py
+++ b/pdseg/tools/labelme2seg.py
@@ -17,10 +17,8 @@
def parse_args():
parser = argparse.ArgumentParser(
- formatter_class=argparse.ArgumentDefaultsHelpFormatter
- )
- parser.add_argument('input_dir',
- help='input annotated directory')
+ formatter_class=argparse.ArgumentDefaultsHelpFormatter)
+ parser.add_argument('input_dir', help='input annotated directory')
return parser.parse_args()
@@ -61,15 +59,14 @@
print('Generating dataset from:', label_file)
with open(label_file) as f:
base = osp.splitext(osp.basename(label_file))[0]
- out_png_file = osp.join(
- output_dir, base + '.png')
+ out_png_file = osp.join(output_dir, base + '.png')
data = json.load(f)
img_file = osp.join(osp.dirname(label_file), data['imagePath'])
img = np.asarray(PIL.Image.open(img_file))
- lbl = labelme.utils.shapes_to_label(
+ lbl, _ = labelme.utils.shapes_to_label(
img_shape=img.shape,
shapes=data['shapes'],
label_name_to_value=class_name_to_id,
@@ -85,8 +82,7 @@
else:
raise ValueError(
'[%s] Cannot save the pixel-wise class label as PNG. '
- 'Please consider using the .npy format.' % out_png_file
- )
+ 'Please consider using the .npy format.' % out_png_file)
if __name__ == '__main__':
|
{"golden_diff": "diff --git a/pdseg/tools/jingling2seg.py b/pdseg/tools/jingling2seg.py\n--- a/pdseg/tools/jingling2seg.py\n+++ b/pdseg/tools/jingling2seg.py\n@@ -17,10 +17,8 @@\n \n def parse_args():\n parser = argparse.ArgumentParser(\n- formatter_class=argparse.ArgumentDefaultsHelpFormatter\n- )\n- parser.add_argument('input_dir',\n- help='input annotated directory')\n+ formatter_class=argparse.ArgumentDefaultsHelpFormatter)\n+ parser.add_argument('input_dir', help='input annotated directory')\n return parser.parse_args()\n \n \n@@ -62,8 +60,7 @@\n print('Generating dataset from:', label_file)\n with open(label_file) as f:\n base = osp.splitext(osp.basename(label_file))[0]\n- out_png_file = osp.join(\n- output_dir, base + '.png')\n+ out_png_file = osp.join(output_dir, base + '.png')\n \n data = json.load(f)\n \n@@ -77,16 +74,22 @@\n # convert jingling format to labelme format\n points = []\n for i in range(1, int(len(polygon) / 2) + 1):\n- points.append([polygon['x' + str(i)], polygon['y' + str(i)]])\n- shape = {'label': name, 'points': points, 'shape_type': 'polygon'}\n+ points.append(\n+ [polygon['x' + str(i)], polygon['y' + str(i)]])\n+ shape = {\n+ 'label': name,\n+ 'points': points,\n+ 'shape_type': 'polygon'\n+ }\n data_shapes.append(shape)\n \n if 'size' not in data:\n continue\n data_size = data['size']\n- img_shape = (data_size['height'], data_size['width'], data_size['depth'])\n+ img_shape = (data_size['height'], data_size['width'],\n+ data_size['depth'])\n \n- lbl = labelme.utils.shapes_to_label(\n+ lbl, _ = labelme.utils.shapes_to_label(\n img_shape=img_shape,\n shapes=data_shapes,\n label_name_to_value=class_name_to_id,\n@@ -102,8 +105,7 @@\n else:\n raise ValueError(\n '[%s] Cannot save the pixel-wise class label as PNG. '\n- 'Please consider using the .npy format.' % out_png_file\n- )\n+ 'Please consider using the .npy format.' % out_png_file)\n \n \n if __name__ == '__main__':\ndiff --git a/pdseg/tools/labelme2seg.py b/pdseg/tools/labelme2seg.py\n--- a/pdseg/tools/labelme2seg.py\n+++ b/pdseg/tools/labelme2seg.py\n@@ -17,10 +17,8 @@\n \n def parse_args():\n parser = argparse.ArgumentParser(\n- formatter_class=argparse.ArgumentDefaultsHelpFormatter\n- )\n- parser.add_argument('input_dir',\n- help='input annotated directory')\n+ formatter_class=argparse.ArgumentDefaultsHelpFormatter)\n+ parser.add_argument('input_dir', help='input annotated directory')\n return parser.parse_args()\n \n \n@@ -61,15 +59,14 @@\n print('Generating dataset from:', label_file)\n with open(label_file) as f:\n base = osp.splitext(osp.basename(label_file))[0]\n- out_png_file = osp.join(\n- output_dir, base + '.png')\n+ out_png_file = osp.join(output_dir, base + '.png')\n \n data = json.load(f)\n \n img_file = osp.join(osp.dirname(label_file), data['imagePath'])\n img = np.asarray(PIL.Image.open(img_file))\n \n- lbl = labelme.utils.shapes_to_label(\n+ lbl, _ = labelme.utils.shapes_to_label(\n img_shape=img.shape,\n shapes=data['shapes'],\n label_name_to_value=class_name_to_id,\n@@ -85,8 +82,7 @@\n else:\n raise ValueError(\n '[%s] Cannot save the pixel-wise class label as PNG. '\n- 'Please consider using the .npy format.' % out_png_file\n- )\n+ 'Please consider using the .npy format.' % out_png_file)\n \n \n if __name__ == '__main__':\n", "issue": "\u5728\u5e94\u7528labelme2seg.py\u8f6c\u5316labelme\u751f\u6210\u7684json\u8fc7\u7a0b\uff0c\u62a5\u9519\u5982\u4e0b\n\u5728line 81,\u6709\u5224\u65ad\u8bed\u53e5\uff1a\r\n if lbl.min >= 0 and lbl.max() <= 255:\r\n\u603b\u662f\u62a5\u9519\uff1a\u2018tuple\u2019 object has no attribute 'min'\r\n\u770b\u6e90\u7801\uff0c\u4e0d\u5e94\u8be5\u8fd9\u6837\u554a\uff0c\u8bf7\u95ee\u662f\u4ec0\u4e48\u539f\u56e0\uff1f\r\n\r\n\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\n\nfrom __future__ import print_function\n\nimport argparse\nimport glob\nimport json\nimport os\nimport os.path as osp\n\nimport numpy as np\nimport PIL.Image\nimport labelme\n\nfrom gray2pseudo_color import get_color_map_list\n\n\ndef parse_args():\n parser = argparse.ArgumentParser(\n formatter_class=argparse.ArgumentDefaultsHelpFormatter\n )\n parser.add_argument('input_dir',\n help='input annotated directory')\n return parser.parse_args()\n\n\ndef main(args):\n output_dir = osp.join(args.input_dir, 'annotations')\n if not osp.exists(output_dir):\n os.makedirs(output_dir)\n print('Creating annotations directory:', output_dir)\n\n # get the all class names for the given dataset\n class_names = ['_background_']\n for label_file in glob.glob(osp.join(args.input_dir, '*.json')):\n with open(label_file) as f:\n data = json.load(f)\n for shape in data['shapes']:\n label = shape['label']\n cls_name = label\n if not cls_name in class_names:\n class_names.append(cls_name)\n\n class_name_to_id = {}\n for i, class_name in enumerate(class_names):\n class_id = i # starts with 0\n class_name_to_id[class_name] = class_id\n if class_id == 0:\n assert class_name == '_background_'\n class_names = tuple(class_names)\n print('class_names:', class_names)\n\n out_class_names_file = osp.join(args.input_dir, 'class_names.txt')\n with open(out_class_names_file, 'w') as f:\n f.writelines('\\n'.join(class_names))\n print('Saved class_names:', out_class_names_file)\n\n color_map = get_color_map_list(256)\n\n for label_file in glob.glob(osp.join(args.input_dir, '*.json')):\n print('Generating dataset from:', label_file)\n with open(label_file) as f:\n base = osp.splitext(osp.basename(label_file))[0]\n out_png_file = osp.join(\n output_dir, base + '.png')\n\n data = json.load(f)\n\n img_file = osp.join(osp.dirname(label_file), data['imagePath'])\n img = np.asarray(PIL.Image.open(img_file))\n\n lbl = labelme.utils.shapes_to_label(\n img_shape=img.shape,\n shapes=data['shapes'],\n label_name_to_value=class_name_to_id,\n )\n\n if osp.splitext(out_png_file)[1] != '.png':\n out_png_file += '.png'\n # Assume label ranges [0, 255] for uint8,\n if lbl.min() >= 0 and lbl.max() <= 255:\n lbl_pil = PIL.Image.fromarray(lbl.astype(np.uint8), mode='P')\n lbl_pil.putpalette(color_map)\n lbl_pil.save(out_png_file)\n else:\n raise ValueError(\n '[%s] Cannot save the pixel-wise class label as PNG. '\n 'Please consider using the .npy format.' % out_png_file\n )\n\n\nif __name__ == '__main__':\n args = parse_args()\n main(args)\n", "path": "pdseg/tools/labelme2seg.py"}, {"content": "#!/usr/bin/env python\n\nfrom __future__ import print_function\n\nimport argparse\nimport glob\nimport json\nimport os\nimport os.path as osp\n\nimport numpy as np\nimport PIL.Image\nimport labelme\n\nfrom gray2pseudo_color import get_color_map_list\n\n\ndef parse_args():\n parser = argparse.ArgumentParser(\n formatter_class=argparse.ArgumentDefaultsHelpFormatter\n )\n parser.add_argument('input_dir',\n help='input annotated directory')\n return parser.parse_args()\n\n\ndef main(args):\n output_dir = osp.join(args.input_dir, 'annotations')\n if not osp.exists(output_dir):\n os.makedirs(output_dir)\n print('Creating annotations directory:', output_dir)\n\n # get the all class names for the given dataset\n class_names = ['_background_']\n for label_file in glob.glob(osp.join(args.input_dir, '*.json')):\n with open(label_file) as f:\n data = json.load(f)\n if data['outputs']:\n for output in data['outputs']['object']:\n name = output['name']\n cls_name = name\n if not cls_name in class_names:\n class_names.append(cls_name)\n\n class_name_to_id = {}\n for i, class_name in enumerate(class_names):\n class_id = i # starts with 0\n class_name_to_id[class_name] = class_id\n if class_id == 0:\n assert class_name == '_background_'\n class_names = tuple(class_names)\n print('class_names:', class_names)\n\n out_class_names_file = osp.join(args.input_dir, 'class_names.txt')\n with open(out_class_names_file, 'w') as f:\n f.writelines('\\n'.join(class_names))\n print('Saved class_names:', out_class_names_file)\n\n color_map = get_color_map_list(256)\n\n for label_file in glob.glob(osp.join(args.input_dir, '*.json')):\n print('Generating dataset from:', label_file)\n with open(label_file) as f:\n base = osp.splitext(osp.basename(label_file))[0]\n out_png_file = osp.join(\n output_dir, base + '.png')\n\n data = json.load(f)\n\n data_shapes = []\n if data['outputs']:\n for output in data['outputs']['object']:\n if 'polygon' in output.keys():\n polygon = output['polygon']\n name = output['name']\n\n # convert jingling format to labelme format\n points = []\n for i in range(1, int(len(polygon) / 2) + 1):\n points.append([polygon['x' + str(i)], polygon['y' + str(i)]])\n shape = {'label': name, 'points': points, 'shape_type': 'polygon'}\n data_shapes.append(shape)\n\n if 'size' not in data:\n continue\n data_size = data['size']\n img_shape = (data_size['height'], data_size['width'], data_size['depth'])\n\n lbl = labelme.utils.shapes_to_label(\n img_shape=img_shape,\n shapes=data_shapes,\n label_name_to_value=class_name_to_id,\n )\n\n if osp.splitext(out_png_file)[1] != '.png':\n out_png_file += '.png'\n # Assume label ranges [0, 255] for uint8,\n if lbl.min() >= 0 and lbl.max() <= 255:\n lbl_pil = PIL.Image.fromarray(lbl.astype(np.uint8), mode='P')\n lbl_pil.putpalette(color_map)\n lbl_pil.save(out_png_file)\n else:\n raise ValueError(\n '[%s] Cannot save the pixel-wise class label as PNG. '\n 'Please consider using the .npy format.' % out_png_file\n )\n\n\nif __name__ == '__main__':\n args = parse_args()\n main(args)\n", "path": "pdseg/tools/jingling2seg.py"}]}
| 2,572 | 971 |
gh_patches_debug_5013
|
rasdani/github-patches
|
git_diff
|
internetarchive__openlibrary-8831
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`providers/isbndb.py` crashes when the `'subjects'` value is a literal `None`
<!-- IMPORTANT: Before posting, be sure to redact or remove sensitive data, such as passwords, secret keys, session cookies, etc. -->
<!-- What problem are we solving? What does the experience look like today? What are the symptoms? -->
### Evidence / Screenshot (if possible)
Sometimes the `'subjects'` key in the ISBNdb dump have literal `None` values, which would cause an error even if doing something like `data.get('subjects', [])`, because it would return `None` instead of `[]`.
E.g., consider the following record:
```python
{
'isbn': '0134878868',
'msrp': '0.00',
'title': 'Learn Adobe Premiere Pro Cc For Video Communication',
'isbn13': '9780134878867',
'authors': ['Dockery, Joe (author.)'],
'binding': 'Electronic Resource',
'language': 'en',
'subjects': None,
}
```
This would crash with:
```python
^^^^^^^^^^^^^^^^^^^
File "/openlibrary/scripts/providers/isbndb.py", line 73, in __init__
self.subjects = [
^
TypeError: 'NoneType' object is not iterable
```
### Stakeholders
<!-- @ tag stakeholders of this bug -->
@mekarpeles
</issue>
<code>
[start of scripts/providers/isbndb.py]
1 import re
2 import json
3 import logging
4 import os
5 from typing import Any, Final
6 import requests
7
8 from json import JSONDecodeError
9
10 from openlibrary.config import load_config
11 from openlibrary.core.imports import Batch
12 from openlibrary.plugins.upstream.utils import get_marc21_language
13 from scripts.partner_batch_imports import is_published_in_future_year
14 from scripts.solr_builder.solr_builder.fn_to_cli import FnToCLI
15
16 logger = logging.getLogger("openlibrary.importer.isbndb")
17
18 SCHEMA_URL = (
19 "https://raw.githubusercontent.com/internetarchive"
20 "/openlibrary-client/master/olclient/schemata/import.schema.json"
21 )
22
23 NONBOOK: Final = ['dvd', 'dvd-rom', 'cd', 'cd-rom', 'cassette', 'sheet music', 'audio']
24 RE_YEAR = re.compile(r'(\d{4})')
25
26
27 def is_nonbook(binding: str, nonbooks: list[str]) -> bool:
28 """
29 Determine whether binding, or a substring of binding, split on " ", is
30 contained within nonbooks.
31 """
32 words = binding.split(" ")
33 return any(word.casefold() in nonbooks for word in words)
34
35
36 class ISBNdb:
37 ACTIVE_FIELDS = [
38 'authors',
39 'isbn_13',
40 'languages',
41 'number_of_pages',
42 'publish_date',
43 'publishers',
44 'source_records',
45 'subjects',
46 'title',
47 ]
48 INACTIVE_FIELDS = [
49 "copyright",
50 "dewey",
51 "doi",
52 "height",
53 "issn",
54 "lccn",
55 "length",
56 "width",
57 'lc_classifications',
58 'pagination',
59 'weight',
60 ]
61 REQUIRED_FIELDS = requests.get(SCHEMA_URL).json()['required']
62
63 def __init__(self, data: dict[str, Any]):
64 self.isbn_13 = [data.get('isbn13')]
65 self.source_id = f'idb:{self.isbn_13[0]}'
66 self.title = data.get('title')
67 self.publish_date = self._get_year(data) # 'YYYY'
68 self.publishers = self._get_list_if_present(data.get('publisher'))
69 self.authors = self.contributors(data)
70 self.number_of_pages = data.get('pages')
71 self.languages = self._get_languages(data)
72 self.source_records = [self.source_id]
73 self.subjects = [
74 subject.capitalize() for subject in data.get('subjects', '') if subject
75 ]
76 self.binding = data.get('binding', '')
77
78 # Assert importable
79 for field in self.REQUIRED_FIELDS + ['isbn_13']:
80 assert getattr(self, field), field
81 assert is_nonbook(self.binding, NONBOOK) is False, "is_nonbook() returned True"
82 assert self.isbn_13 != [
83 "9780000000002"
84 ], f"known bad ISBN: {self.isbn_13}" # TODO: this should do more than ignore one known-bad ISBN.
85
86 def _get_languages(self, data: dict[str, Any]) -> list[str] | None:
87 """Extract a list of MARC 21 format languages from an ISBNDb JSONL line."""
88 language_line = data.get('language')
89 if not language_line:
90 return None
91
92 possible_languages = re.split(',| |;', language_line)
93 unique_languages = []
94
95 for language in possible_languages:
96 if (
97 marc21_language := get_marc21_language(language)
98 ) and marc21_language not in unique_languages:
99 unique_languages.append(marc21_language)
100
101 return unique_languages or None
102
103 def _get_list_if_present(self, item: str | None) -> list[str] | None:
104 """Return items as a list, or None."""
105 return [item] if item else None
106
107 def _get_year(self, data: dict[str, Any]) -> str | None:
108 """Return a year str/int as a four digit string, or None."""
109 result = ""
110 if publish_date := data.get('date_published'):
111 if isinstance(publish_date, str):
112 m = RE_YEAR.search(publish_date)
113 result = m.group(1) if m else None # type: ignore[assignment]
114 else:
115 result = str(publish_date)[:4]
116
117 return result or None
118
119 def _get_subjects(self, data: dict[str, Any]) -> list[str] | None:
120 """Return a list of subjects None."""
121 subjects = [
122 subject.capitalize() for subject in data.get('subjects', '') if subject
123 ]
124 return subjects or None
125
126 @staticmethod
127 def contributors(data: dict[str, Any]) -> list[dict[str, Any]] | None:
128 """Return a list of author-dicts or None."""
129
130 def make_author(name):
131 author = {'name': name}
132 return author
133
134 if contributors := data.get('authors'):
135 # form list of author dicts
136 authors = [make_author(c) for c in contributors if c[0]]
137 return authors
138
139 return None
140
141 def json(self):
142 """Return a JSON representation of the object."""
143 return {
144 field: getattr(self, field)
145 for field in self.ACTIVE_FIELDS
146 if getattr(self, field)
147 }
148
149
150 def load_state(path: str, logfile: str) -> tuple[list[str], int]:
151 """Retrieves starting point from logfile, if log exists
152
153 Takes as input a path which expands to an ordered candidate list
154 of isbndb* filenames to process, the location of the
155 logfile, and determines which of those files are remaining, as
156 well as what our offset is in that file.
157
158 e.g. if we request path containing f1, f2, f3 and our log
159 says f2,100 then we start our processing at f2 at the 100th line.
160
161 This assumes the script is being called w/ e.g.:
162 /1/var/tmp/imports/2021-08/Bibliographic/*/
163 """
164 filenames = sorted(
165 os.path.join(path, f) for f in os.listdir(path) if f.startswith("isbndb")
166 )
167 try:
168 with open(logfile) as fin:
169 active_fname, offset = next(fin).strip().split(',')
170 unfinished_filenames = filenames[filenames.index(active_fname) :]
171 return unfinished_filenames, int(offset)
172 except (ValueError, OSError):
173 return filenames, 0
174
175
176 def get_line(line: bytes) -> dict | None:
177 """converts a line to a book item"""
178 json_object = None
179 try:
180 json_object = json.loads(line)
181 except JSONDecodeError as e:
182 logger.info(f"json decoding failed for: {line!r}: {e!r}")
183
184 return json_object
185
186
187 def get_line_as_biblio(line: bytes, status: str) -> dict | None:
188 if json_object := get_line(line):
189 b = ISBNdb(json_object)
190 return {'ia_id': b.source_id, 'status': status, 'data': b.json()}
191
192 return None
193
194
195 def update_state(logfile: str, fname: str, line_num: int = 0) -> None:
196 """Records the last file we began processing and the current line"""
197 with open(logfile, 'w') as fout:
198 fout.write(f'{fname},{line_num}\n')
199
200
201 # TODO: It's possible `batch_import()` could be modified to take a parsing function
202 # and a filter function instead of hardcoding in `csv_to_ol_json_item()` and some filters.
203 def batch_import(path: str, batch: Batch, import_status: str, batch_size: int = 5000):
204 logfile = os.path.join(path, 'import.log')
205 filenames, offset = load_state(path, logfile)
206
207 for fname in filenames:
208 book_items = []
209 with open(fname, 'rb') as f:
210 logger.info(f"Processing: {fname} from line {offset}")
211 for line_num, line in enumerate(f):
212 # skip over already processed records
213 if offset:
214 if offset > line_num:
215 continue
216 offset = 0
217
218 try:
219 book_item = get_line_as_biblio(line=line, status=import_status)
220 assert book_item is not None
221 if not any(
222 [
223 "independently published"
224 in book_item['data'].get('publishers', ''),
225 is_published_in_future_year(book_item["data"]),
226 ]
227 ):
228 book_items.append(book_item)
229 except (AssertionError, IndexError) as e:
230 logger.info(f"Error: {e!r} from {line!r}")
231
232 # If we have enough items, submit a batch
233 if not ((line_num + 1) % batch_size):
234 batch.add_items(book_items)
235 update_state(logfile, fname, line_num)
236 book_items = [] # clear added items
237
238 # Add any remaining book_items to batch
239 if book_items:
240 batch.add_items(book_items)
241 update_state(logfile, fname, line_num)
242
243
244 def main(ol_config: str, batch_path: str, import_status: str = 'staged') -> None:
245 load_config(ol_config)
246
247 # Partner data is offset ~15 days from start of month
248 batch_name = "isbndb_bulk_import"
249 batch = Batch.find(batch_name) or Batch.new(batch_name)
250 batch_import(path=batch_path, batch=batch, import_status=import_status)
251
252
253 if __name__ == '__main__':
254 FnToCLI(main).run()
255
[end of scripts/providers/isbndb.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scripts/providers/isbndb.py b/scripts/providers/isbndb.py
--- a/scripts/providers/isbndb.py
+++ b/scripts/providers/isbndb.py
@@ -71,7 +71,7 @@
self.languages = self._get_languages(data)
self.source_records = [self.source_id]
self.subjects = [
- subject.capitalize() for subject in data.get('subjects', '') if subject
+ subject.capitalize() for subject in (data.get('subjects') or []) if subject
]
self.binding = data.get('binding', '')
|
{"golden_diff": "diff --git a/scripts/providers/isbndb.py b/scripts/providers/isbndb.py\n--- a/scripts/providers/isbndb.py\n+++ b/scripts/providers/isbndb.py\n@@ -71,7 +71,7 @@\n self.languages = self._get_languages(data)\n self.source_records = [self.source_id]\n self.subjects = [\n- subject.capitalize() for subject in data.get('subjects', '') if subject\n+ subject.capitalize() for subject in (data.get('subjects') or []) if subject\n ]\n self.binding = data.get('binding', '')\n", "issue": "`providers/isbndb.py` crashes when the `'subjects'` value is a literal `None`\n<!-- IMPORTANT: Before posting, be sure to redact or remove sensitive data, such as passwords, secret keys, session cookies, etc. -->\r\n<!-- What problem are we solving? What does the experience look like today? What are the symptoms? -->\r\n\r\n### Evidence / Screenshot (if possible)\r\n\r\n \r\nSometimes the `'subjects'` key in the ISBNdb dump have literal `None` values, which would cause an error even if doing something like `data.get('subjects', [])`, because it would return `None` instead of `[]`.\r\n \r\nE.g., consider the following record:\r\n```python\r\n{\r\n 'isbn': '0134878868',\r\n 'msrp': '0.00',\r\n 'title': 'Learn Adobe Premiere Pro Cc For Video Communication',\r\n 'isbn13': '9780134878867',\r\n 'authors': ['Dockery, Joe (author.)'],\r\n 'binding': 'Electronic Resource',\r\n 'language': 'en',\r\n 'subjects': None,\r\n}\r\n```\r\nThis would crash with:\r\n```python\r\n ^^^^^^^^^^^^^^^^^^^\r\n File \"/openlibrary/scripts/providers/isbndb.py\", line 73, in __init__\r\n self.subjects = [\r\n ^\r\nTypeError: 'NoneType' object is not iterable\r\n```\r\n\r\n### Stakeholders\r\n<!-- @ tag stakeholders of this bug -->\r\n@mekarpeles \n", "before_files": [{"content": "import re\nimport json\nimport logging\nimport os\nfrom typing import Any, Final\nimport requests\n\nfrom json import JSONDecodeError\n\nfrom openlibrary.config import load_config\nfrom openlibrary.core.imports import Batch\nfrom openlibrary.plugins.upstream.utils import get_marc21_language\nfrom scripts.partner_batch_imports import is_published_in_future_year\nfrom scripts.solr_builder.solr_builder.fn_to_cli import FnToCLI\n\nlogger = logging.getLogger(\"openlibrary.importer.isbndb\")\n\nSCHEMA_URL = (\n \"https://raw.githubusercontent.com/internetarchive\"\n \"/openlibrary-client/master/olclient/schemata/import.schema.json\"\n)\n\nNONBOOK: Final = ['dvd', 'dvd-rom', 'cd', 'cd-rom', 'cassette', 'sheet music', 'audio']\nRE_YEAR = re.compile(r'(\\d{4})')\n\n\ndef is_nonbook(binding: str, nonbooks: list[str]) -> bool:\n \"\"\"\n Determine whether binding, or a substring of binding, split on \" \", is\n contained within nonbooks.\n \"\"\"\n words = binding.split(\" \")\n return any(word.casefold() in nonbooks for word in words)\n\n\nclass ISBNdb:\n ACTIVE_FIELDS = [\n 'authors',\n 'isbn_13',\n 'languages',\n 'number_of_pages',\n 'publish_date',\n 'publishers',\n 'source_records',\n 'subjects',\n 'title',\n ]\n INACTIVE_FIELDS = [\n \"copyright\",\n \"dewey\",\n \"doi\",\n \"height\",\n \"issn\",\n \"lccn\",\n \"length\",\n \"width\",\n 'lc_classifications',\n 'pagination',\n 'weight',\n ]\n REQUIRED_FIELDS = requests.get(SCHEMA_URL).json()['required']\n\n def __init__(self, data: dict[str, Any]):\n self.isbn_13 = [data.get('isbn13')]\n self.source_id = f'idb:{self.isbn_13[0]}'\n self.title = data.get('title')\n self.publish_date = self._get_year(data) # 'YYYY'\n self.publishers = self._get_list_if_present(data.get('publisher'))\n self.authors = self.contributors(data)\n self.number_of_pages = data.get('pages')\n self.languages = self._get_languages(data)\n self.source_records = [self.source_id]\n self.subjects = [\n subject.capitalize() for subject in data.get('subjects', '') if subject\n ]\n self.binding = data.get('binding', '')\n\n # Assert importable\n for field in self.REQUIRED_FIELDS + ['isbn_13']:\n assert getattr(self, field), field\n assert is_nonbook(self.binding, NONBOOK) is False, \"is_nonbook() returned True\"\n assert self.isbn_13 != [\n \"9780000000002\"\n ], f\"known bad ISBN: {self.isbn_13}\" # TODO: this should do more than ignore one known-bad ISBN.\n\n def _get_languages(self, data: dict[str, Any]) -> list[str] | None:\n \"\"\"Extract a list of MARC 21 format languages from an ISBNDb JSONL line.\"\"\"\n language_line = data.get('language')\n if not language_line:\n return None\n\n possible_languages = re.split(',| |;', language_line)\n unique_languages = []\n\n for language in possible_languages:\n if (\n marc21_language := get_marc21_language(language)\n ) and marc21_language not in unique_languages:\n unique_languages.append(marc21_language)\n\n return unique_languages or None\n\n def _get_list_if_present(self, item: str | None) -> list[str] | None:\n \"\"\"Return items as a list, or None.\"\"\"\n return [item] if item else None\n\n def _get_year(self, data: dict[str, Any]) -> str | None:\n \"\"\"Return a year str/int as a four digit string, or None.\"\"\"\n result = \"\"\n if publish_date := data.get('date_published'):\n if isinstance(publish_date, str):\n m = RE_YEAR.search(publish_date)\n result = m.group(1) if m else None # type: ignore[assignment]\n else:\n result = str(publish_date)[:4]\n\n return result or None\n\n def _get_subjects(self, data: dict[str, Any]) -> list[str] | None:\n \"\"\"Return a list of subjects None.\"\"\"\n subjects = [\n subject.capitalize() for subject in data.get('subjects', '') if subject\n ]\n return subjects or None\n\n @staticmethod\n def contributors(data: dict[str, Any]) -> list[dict[str, Any]] | None:\n \"\"\"Return a list of author-dicts or None.\"\"\"\n\n def make_author(name):\n author = {'name': name}\n return author\n\n if contributors := data.get('authors'):\n # form list of author dicts\n authors = [make_author(c) for c in contributors if c[0]]\n return authors\n\n return None\n\n def json(self):\n \"\"\"Return a JSON representation of the object.\"\"\"\n return {\n field: getattr(self, field)\n for field in self.ACTIVE_FIELDS\n if getattr(self, field)\n }\n\n\ndef load_state(path: str, logfile: str) -> tuple[list[str], int]:\n \"\"\"Retrieves starting point from logfile, if log exists\n\n Takes as input a path which expands to an ordered candidate list\n of isbndb* filenames to process, the location of the\n logfile, and determines which of those files are remaining, as\n well as what our offset is in that file.\n\n e.g. if we request path containing f1, f2, f3 and our log\n says f2,100 then we start our processing at f2 at the 100th line.\n\n This assumes the script is being called w/ e.g.:\n /1/var/tmp/imports/2021-08/Bibliographic/*/\n \"\"\"\n filenames = sorted(\n os.path.join(path, f) for f in os.listdir(path) if f.startswith(\"isbndb\")\n )\n try:\n with open(logfile) as fin:\n active_fname, offset = next(fin).strip().split(',')\n unfinished_filenames = filenames[filenames.index(active_fname) :]\n return unfinished_filenames, int(offset)\n except (ValueError, OSError):\n return filenames, 0\n\n\ndef get_line(line: bytes) -> dict | None:\n \"\"\"converts a line to a book item\"\"\"\n json_object = None\n try:\n json_object = json.loads(line)\n except JSONDecodeError as e:\n logger.info(f\"json decoding failed for: {line!r}: {e!r}\")\n\n return json_object\n\n\ndef get_line_as_biblio(line: bytes, status: str) -> dict | None:\n if json_object := get_line(line):\n b = ISBNdb(json_object)\n return {'ia_id': b.source_id, 'status': status, 'data': b.json()}\n\n return None\n\n\ndef update_state(logfile: str, fname: str, line_num: int = 0) -> None:\n \"\"\"Records the last file we began processing and the current line\"\"\"\n with open(logfile, 'w') as fout:\n fout.write(f'{fname},{line_num}\\n')\n\n\n# TODO: It's possible `batch_import()` could be modified to take a parsing function\n# and a filter function instead of hardcoding in `csv_to_ol_json_item()` and some filters.\ndef batch_import(path: str, batch: Batch, import_status: str, batch_size: int = 5000):\n logfile = os.path.join(path, 'import.log')\n filenames, offset = load_state(path, logfile)\n\n for fname in filenames:\n book_items = []\n with open(fname, 'rb') as f:\n logger.info(f\"Processing: {fname} from line {offset}\")\n for line_num, line in enumerate(f):\n # skip over already processed records\n if offset:\n if offset > line_num:\n continue\n offset = 0\n\n try:\n book_item = get_line_as_biblio(line=line, status=import_status)\n assert book_item is not None\n if not any(\n [\n \"independently published\"\n in book_item['data'].get('publishers', ''),\n is_published_in_future_year(book_item[\"data\"]),\n ]\n ):\n book_items.append(book_item)\n except (AssertionError, IndexError) as e:\n logger.info(f\"Error: {e!r} from {line!r}\")\n\n # If we have enough items, submit a batch\n if not ((line_num + 1) % batch_size):\n batch.add_items(book_items)\n update_state(logfile, fname, line_num)\n book_items = [] # clear added items\n\n # Add any remaining book_items to batch\n if book_items:\n batch.add_items(book_items)\n update_state(logfile, fname, line_num)\n\n\ndef main(ol_config: str, batch_path: str, import_status: str = 'staged') -> None:\n load_config(ol_config)\n\n # Partner data is offset ~15 days from start of month\n batch_name = \"isbndb_bulk_import\"\n batch = Batch.find(batch_name) or Batch.new(batch_name)\n batch_import(path=batch_path, batch=batch, import_status=import_status)\n\n\nif __name__ == '__main__':\n FnToCLI(main).run()\n", "path": "scripts/providers/isbndb.py"}]}
| 3,627 | 126 |
gh_patches_debug_1382
|
rasdani/github-patches
|
git_diff
|
aws-cloudformation__cfn-lint-2168
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Unknown warning about unpublished metrics
*cfn-lint version: 0.55.0*
*Description of issue.*
`cfn-lint template.yaml` is outputting `There are unpublished metrics. Please make sure you call publish after you record all metrics.` where previous versions of `cfn-lint` did not. This is causing the Atom plugin to display a really intrusive error message on every save event.
Frustratingly, I can't find any information on what this message means
</issue>
<code>
[start of src/cfnlint/transform.py]
1 """
2 Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
3 SPDX-License-Identifier: MIT-0
4 """
5 import os
6 import logging
7 import six
8 import samtranslator
9 from samtranslator.parser import parser
10 from samtranslator.translator.translator import Translator
11 from samtranslator.public.exceptions import InvalidDocumentException
12
13 from cfnlint.helpers import load_resource, convert_dict, format_json_string
14 from cfnlint.data import Serverless
15 from cfnlint.rules import Match, TransformError
16 LOGGER = logging.getLogger('cfnlint')
17
18
19 class Transform(object):
20 """
21 Application Serverless Module tranform Wrapper.
22 Based on code from AWS SAM CLI:
23 https://github.com/awslabs/aws-sam-cli/blob/develop/samcli/commands/validate/lib/sam_template_validator.py
24 """
25
26 def __init__(self, filename, template, region):
27 """
28 Initialize Transform class
29 """
30 self._filename = filename
31 self._template = template
32 self._region = region
33 self._parameters = {}
34
35 self._managed_policy_map = self.load_managed_policies()
36 self._sam_parser = parser.Parser()
37
38 def template(self):
39 """Get the template"""
40 return self._template
41
42 def load_managed_policies(self):
43 """
44 Load the ManagedPolicies locally, based on the AWS-CLI:
45 https://github.com/awslabs/aws-sam-cli/blob/develop/samcli/lib/samlib/default_managed_policies.json
46 """
47 return load_resource(Serverless, 'ManagedPolicies.json')
48
49 def _replace_local_codeuri(self):
50 """
51 Replaces the CodeUri in AWS::Serverless::Function and DefinitionUri in
52 AWS::Serverless::Api to a fake S3 Uri. This is to support running the
53 SAM Translator with valid values for these fields. If this is not done,
54 the template is invalid in the eyes of SAM Translator (the translator
55 does not support local paths)
56 """
57
58 all_resources = self._template.get('Resources', {})
59
60 template_globals = self._template.get('Globals', {})
61 auto_publish_alias = template_globals.get('Function', {}).get('AutoPublishAlias')
62 if isinstance(auto_publish_alias, dict):
63 if len(auto_publish_alias) == 1:
64 for k, v in auto_publish_alias.items():
65 if k == 'Ref':
66 if v in self._template.get('Parameters'):
67 self._parameters[v] = 'Alias'
68
69
70 for _, resource in all_resources.items():
71
72 resource_type = resource.get('Type')
73 resource_dict = resource.get('Properties')
74
75 if resource_type == 'AWS::Serverless::Function':
76
77 Transform._update_to_s3_uri('CodeUri', resource_dict)
78 auto_publish_alias = resource_dict.get('AutoPublishAlias')
79 if isinstance(auto_publish_alias, dict):
80 if len(auto_publish_alias) == 1:
81 for k, v in auto_publish_alias.items():
82 if k == 'Ref':
83 if v in self._template.get('Parameters'):
84 self._parameters[v] = 'Alias'
85 if resource_type in ['AWS::Serverless::LayerVersion']:
86 if resource_dict.get('ContentUri'):
87 Transform._update_to_s3_uri('ContentUri', resource_dict)
88 if resource_type == 'AWS::Serverless::Application':
89 if resource_dict.get('Location'):
90 resource_dict['Location'] = ''
91 Transform._update_to_s3_uri('Location', resource_dict)
92 if resource_type == 'AWS::Serverless::Api':
93 if ('DefinitionBody' not in resource_dict and
94 'Auth' not in resource_dict and 'Cors' not in resource_dict):
95 Transform._update_to_s3_uri('DefinitionUri', resource_dict)
96 else:
97 resource_dict['DefinitionBody'] = ''
98 if resource_type == 'AWS::Serverless::StateMachine' and resource_dict.get('DefinitionUri'):
99 Transform._update_to_s3_uri('DefinitionUri', resource_dict)
100
101 def transform_template(self):
102 """
103 Transform the Template using the Serverless Application Model.
104 """
105 matches = []
106
107 try:
108 # Output the SAM Translator version in debug mode
109 LOGGER.info('SAM Translator: %s', samtranslator.__version__)
110
111 sam_translator = Translator(
112 managed_policy_map=self._managed_policy_map,
113 sam_parser=self._sam_parser)
114
115 self._replace_local_codeuri()
116
117 # Tell SAM to use the region we're linting in, this has to be
118 # controlled using the default AWS mechanisms, see also:
119 # https://github.com/awslabs/serverless-application-model/blob/master/samtranslator/translator/arn_generator.py
120 LOGGER.info('Setting AWS_DEFAULT_REGION to %s', self._region)
121 os.environ['AWS_DEFAULT_REGION'] = self._region
122
123 self._template = convert_dict(
124 sam_translator.translate(sam_template=self._template,
125 parameter_values=self._parameters))
126
127 LOGGER.info('Transformed template: \n%s',
128 format_json_string(self._template))
129 except InvalidDocumentException as e:
130 message = 'Error transforming template: {0}'
131 for cause in e.causes:
132 matches.append(Match(
133 1, 1,
134 1, 1,
135 self._filename,
136 TransformError(), message.format(cause.message)))
137 except Exception as e: # pylint: disable=W0703
138 LOGGER.debug('Error transforming template: %s', str(e))
139 LOGGER.debug('Stack trace: %s', e, exc_info=True)
140 message = 'Error transforming template: {0}'
141 matches.append(Match(
142 1, 1,
143 1, 1,
144 self._filename,
145 TransformError(), message.format(str(e))))
146
147 return matches
148
149 @staticmethod
150 def is_s3_uri(uri):
151 """
152 Checks the uri and determines if it is a valid S3 Uri
153 Parameters
154 ----------
155 uri str, required
156 Uri to check
157 Returns
158 -------
159 bool
160 Returns True if the uri given is an S3 uri, otherwise False
161 """
162 return isinstance(uri, six.string_types) and uri.startswith('s3://')
163
164 @staticmethod
165 def _update_to_s3_uri(
166 property_key, resource_property_dict,
167 s3_uri_value='s3://bucket/value'):
168 """
169 Updates the 'property_key' in the 'resource_property_dict' to the
170 value of 's3_uri_value'
171 Note: The function will mutate the resource_property_dict that is pass
172 in Parameters
173 ----------
174 property_key str, required
175 Key in the resource_property_dict
176 resource_property_dict dict, required
177 Property dictionary of a Resource in the template to replace
178 s3_uri_value str, optional
179 Value to update the value of the property_key to
180 """
181 uri_property = resource_property_dict.get(property_key, '.')
182
183 # ignore if dict or already an S3 Uri
184 if isinstance(uri_property, dict):
185 if len(uri_property) == 1:
186 for k in uri_property.keys():
187 if k == 'Ref':
188 resource_property_dict[property_key] = s3_uri_value
189 return
190 if Transform.is_s3_uri(uri_property):
191 return
192
193 resource_property_dict[property_key] = s3_uri_value
194
[end of src/cfnlint/transform.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/cfnlint/transform.py b/src/cfnlint/transform.py
--- a/src/cfnlint/transform.py
+++ b/src/cfnlint/transform.py
@@ -15,6 +15,8 @@
from cfnlint.rules import Match, TransformError
LOGGER = logging.getLogger('cfnlint')
+samtranslator_logger = logging.getLogger('samtranslator')
+samtranslator_logger.setLevel(logging.CRITICAL)
class Transform(object):
"""
|
{"golden_diff": "diff --git a/src/cfnlint/transform.py b/src/cfnlint/transform.py\n--- a/src/cfnlint/transform.py\n+++ b/src/cfnlint/transform.py\n@@ -15,6 +15,8 @@\n from cfnlint.rules import Match, TransformError\n LOGGER = logging.getLogger('cfnlint')\n \n+samtranslator_logger = logging.getLogger('samtranslator')\n+samtranslator_logger.setLevel(logging.CRITICAL)\n \n class Transform(object):\n \"\"\"\n", "issue": "Unknown warning about unpublished metrics\n*cfn-lint version: 0.55.0*\r\n\r\n*Description of issue.*\r\n\r\n`cfn-lint template.yaml` is outputting `There are unpublished metrics. Please make sure you call publish after you record all metrics.` where previous versions of `cfn-lint` did not. This is causing the Atom plugin to display a really intrusive error message on every save event.\r\n\r\nFrustratingly, I can't find any information on what this message means\n", "before_files": [{"content": "\"\"\"\nCopyright Amazon.com, Inc. or its affiliates. All Rights Reserved.\nSPDX-License-Identifier: MIT-0\n\"\"\"\nimport os\nimport logging\nimport six\nimport samtranslator\nfrom samtranslator.parser import parser\nfrom samtranslator.translator.translator import Translator\nfrom samtranslator.public.exceptions import InvalidDocumentException\n\nfrom cfnlint.helpers import load_resource, convert_dict, format_json_string\nfrom cfnlint.data import Serverless\nfrom cfnlint.rules import Match, TransformError\nLOGGER = logging.getLogger('cfnlint')\n\n\nclass Transform(object):\n \"\"\"\n Application Serverless Module tranform Wrapper.\n Based on code from AWS SAM CLI:\n https://github.com/awslabs/aws-sam-cli/blob/develop/samcli/commands/validate/lib/sam_template_validator.py\n \"\"\"\n\n def __init__(self, filename, template, region):\n \"\"\"\n Initialize Transform class\n \"\"\"\n self._filename = filename\n self._template = template\n self._region = region\n self._parameters = {}\n\n self._managed_policy_map = self.load_managed_policies()\n self._sam_parser = parser.Parser()\n\n def template(self):\n \"\"\"Get the template\"\"\"\n return self._template\n\n def load_managed_policies(self):\n \"\"\"\n Load the ManagedPolicies locally, based on the AWS-CLI:\n https://github.com/awslabs/aws-sam-cli/blob/develop/samcli/lib/samlib/default_managed_policies.json\n \"\"\"\n return load_resource(Serverless, 'ManagedPolicies.json')\n\n def _replace_local_codeuri(self):\n \"\"\"\n Replaces the CodeUri in AWS::Serverless::Function and DefinitionUri in\n AWS::Serverless::Api to a fake S3 Uri. This is to support running the\n SAM Translator with valid values for these fields. If this is not done,\n the template is invalid in the eyes of SAM Translator (the translator\n does not support local paths)\n \"\"\"\n\n all_resources = self._template.get('Resources', {})\n\n template_globals = self._template.get('Globals', {})\n auto_publish_alias = template_globals.get('Function', {}).get('AutoPublishAlias')\n if isinstance(auto_publish_alias, dict):\n if len(auto_publish_alias) == 1:\n for k, v in auto_publish_alias.items():\n if k == 'Ref':\n if v in self._template.get('Parameters'):\n self._parameters[v] = 'Alias'\n\n\n for _, resource in all_resources.items():\n\n resource_type = resource.get('Type')\n resource_dict = resource.get('Properties')\n\n if resource_type == 'AWS::Serverless::Function':\n\n Transform._update_to_s3_uri('CodeUri', resource_dict)\n auto_publish_alias = resource_dict.get('AutoPublishAlias')\n if isinstance(auto_publish_alias, dict):\n if len(auto_publish_alias) == 1:\n for k, v in auto_publish_alias.items():\n if k == 'Ref':\n if v in self._template.get('Parameters'):\n self._parameters[v] = 'Alias'\n if resource_type in ['AWS::Serverless::LayerVersion']:\n if resource_dict.get('ContentUri'):\n Transform._update_to_s3_uri('ContentUri', resource_dict)\n if resource_type == 'AWS::Serverless::Application':\n if resource_dict.get('Location'):\n resource_dict['Location'] = ''\n Transform._update_to_s3_uri('Location', resource_dict)\n if resource_type == 'AWS::Serverless::Api':\n if ('DefinitionBody' not in resource_dict and\n 'Auth' not in resource_dict and 'Cors' not in resource_dict):\n Transform._update_to_s3_uri('DefinitionUri', resource_dict)\n else:\n resource_dict['DefinitionBody'] = ''\n if resource_type == 'AWS::Serverless::StateMachine' and resource_dict.get('DefinitionUri'):\n Transform._update_to_s3_uri('DefinitionUri', resource_dict)\n\n def transform_template(self):\n \"\"\"\n Transform the Template using the Serverless Application Model.\n \"\"\"\n matches = []\n\n try:\n # Output the SAM Translator version in debug mode\n LOGGER.info('SAM Translator: %s', samtranslator.__version__)\n\n sam_translator = Translator(\n managed_policy_map=self._managed_policy_map,\n sam_parser=self._sam_parser)\n\n self._replace_local_codeuri()\n\n # Tell SAM to use the region we're linting in, this has to be\n # controlled using the default AWS mechanisms, see also:\n # https://github.com/awslabs/serverless-application-model/blob/master/samtranslator/translator/arn_generator.py\n LOGGER.info('Setting AWS_DEFAULT_REGION to %s', self._region)\n os.environ['AWS_DEFAULT_REGION'] = self._region\n\n self._template = convert_dict(\n sam_translator.translate(sam_template=self._template,\n parameter_values=self._parameters))\n\n LOGGER.info('Transformed template: \\n%s',\n format_json_string(self._template))\n except InvalidDocumentException as e:\n message = 'Error transforming template: {0}'\n for cause in e.causes:\n matches.append(Match(\n 1, 1,\n 1, 1,\n self._filename,\n TransformError(), message.format(cause.message)))\n except Exception as e: # pylint: disable=W0703\n LOGGER.debug('Error transforming template: %s', str(e))\n LOGGER.debug('Stack trace: %s', e, exc_info=True)\n message = 'Error transforming template: {0}'\n matches.append(Match(\n 1, 1,\n 1, 1,\n self._filename,\n TransformError(), message.format(str(e))))\n\n return matches\n\n @staticmethod\n def is_s3_uri(uri):\n \"\"\"\n Checks the uri and determines if it is a valid S3 Uri\n Parameters\n ----------\n uri str, required\n Uri to check\n Returns\n -------\n bool\n Returns True if the uri given is an S3 uri, otherwise False\n \"\"\"\n return isinstance(uri, six.string_types) and uri.startswith('s3://')\n\n @staticmethod\n def _update_to_s3_uri(\n property_key, resource_property_dict,\n s3_uri_value='s3://bucket/value'):\n \"\"\"\n Updates the 'property_key' in the 'resource_property_dict' to the\n value of 's3_uri_value'\n Note: The function will mutate the resource_property_dict that is pass\n in Parameters\n ----------\n property_key str, required\n Key in the resource_property_dict\n resource_property_dict dict, required\n Property dictionary of a Resource in the template to replace\n s3_uri_value str, optional\n Value to update the value of the property_key to\n \"\"\"\n uri_property = resource_property_dict.get(property_key, '.')\n\n # ignore if dict or already an S3 Uri\n if isinstance(uri_property, dict):\n if len(uri_property) == 1:\n for k in uri_property.keys():\n if k == 'Ref':\n resource_property_dict[property_key] = s3_uri_value\n return\n if Transform.is_s3_uri(uri_property):\n return\n\n resource_property_dict[property_key] = s3_uri_value\n", "path": "src/cfnlint/transform.py"}]}
| 2,677 | 100 |
gh_patches_debug_1706
|
rasdani/github-patches
|
git_diff
|
googleapis__google-cloud-python-196
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
gcloud.storage.iterator.KeyDataIterator chunking is off-by-one
'get_headers' computes the "Range:" header as '_bytes_written' - '_bytes_written + CHUNK_SIZE':
https://github.com/GoogleCloudPlatform/gcloud-python/blob/1f2aaf3606802f4f02eeb30e22e1082ef7f4594e/gcloud/storage/iterator.py#L215
and the '_bytes_written' gets updated to bump by the size of the chunk the server returns. Consider the initial read, assuming a CHUNK_SIZE of 100:
Range: bytes=0-100
Note that, per RFC2616. this will return up to 101 bytes (both bytes-position values are inclusive):
http://www.w3.org/Protocols/rfc2616/rfc2616-sec14.html#sec14.35.1
</issue>
<code>
[start of gcloud/storage/iterator.py]
1 """Iterators for paging through API responses.
2
3 These iterators
4 simplify the process
5 of paging through API responses
6 where the response
7 is a list of results
8 with a ``nextPageToken``.
9
10 To make an iterator work,
11 just override the ``get_items_from_response`` method
12 so that given a response
13 (containing a page of results)
14 it parses those results
15 into an iterable
16 of the actual objects you want::
17
18 class MyIterator(Iterator):
19 def get_items_from_response(self, response):
20 items = response.get('items', [])
21 for item in items:
22 yield MyItemClass.from_dict(item, other_arg=True)
23
24 You then can use this
25 to get **all** the results
26 from a resource::
27
28 >>> iterator = MyIterator(...)
29 >>> list(iterator) # Convert to a list (consumes all values).
30
31 Or you can walk your way through items
32 and call off the search early
33 if you find what you're looking for
34 (resulting in possibly fewer requests)::
35
36 >>> for item in MyIterator(...):
37 >>> print item.name
38 >>> if not item.is_valid:
39 >>> break
40 """
41
42
43 class Iterator(object):
44 """A generic class for iterating through Cloud Storage list responses.
45
46 :type connection: :class:`gcloud.storage.connection.Connection`
47 :param connection: The connection to use to make requests.
48
49 :type path: string
50 :param path: The path to query for the list of items.
51 """
52
53 def __init__(self, connection, path):
54 self.connection = connection
55 self.path = path
56 self.page_number = 0
57 self.next_page_token = None
58
59 def __iter__(self):
60 """Iterate through the list of items."""
61
62 while self.has_next_page():
63 response = self.get_next_page_response()
64 for item in self.get_items_from_response(response):
65 yield item
66
67 def has_next_page(self):
68 """Determines whether or not this iterator has more pages.
69
70 :rtype: bool
71 :returns: Whether the iterator has more pages or not.
72 """
73
74 if self.page_number == 0:
75 return True
76
77 return self.next_page_token is not None
78
79 def get_query_params(self):
80 """Getter for query parameters for the next request.
81
82 :rtype: dict or None
83 :returns: A dictionary of query parameters or None if there are none.
84 """
85
86 if self.next_page_token:
87 return {'pageToken': self.next_page_token}
88
89 def get_next_page_response(self):
90 """Requests the next page from the path provided.
91
92 :rtype: dict
93 :returns: The parsed JSON response of the next page's contents.
94 """
95
96 if not self.has_next_page():
97 raise RuntimeError('No more pages. Try resetting the iterator.')
98
99 response = self.connection.api_request(
100 method='GET', path=self.path, query_params=self.get_query_params())
101
102 self.page_number += 1
103 self.next_page_token = response.get('nextPageToken')
104
105 return response
106
107 def reset(self):
108 """Resets the iterator to the beginning."""
109 self.page_number = 0
110 self.next_page_token = None
111
112 def get_items_from_response(self, response): #pragma NO COVER
113 """Factory method called while iterating. This should be overriden.
114
115 This method should be overridden by a subclass.
116 It should accept the API response
117 of a request for the next page of items,
118 and return a list (or other iterable)
119 of items.
120
121 Typically this method will construct
122 a Bucket or a Key
123 from the page of results in the response.
124
125 :type response: dict
126 :param response: The response of asking for the next page of items.
127
128 :rtype: iterable
129 :returns: Items that the iterator should yield.
130 """
131 raise NotImplementedError
132
133
134 class BucketIterator(Iterator):
135 """An iterator listing all buckets.
136
137 You shouldn't have to use this directly,
138 but instead should use the helper methods
139 on :class:`gcloud.storage.connection.Connection` objects.
140
141 :type connection: :class:`gcloud.storage.connection.Connection`
142 :param connection: The connection to use for querying the list of buckets.
143 """
144
145 def __init__(self, connection):
146 super(BucketIterator, self).__init__(connection=connection, path='/b')
147
148 def get_items_from_response(self, response):
149 """Factory method which yields :class:`gcloud.storage.bucket.Bucket` items from a response.
150
151 :type response: dict
152 :param response: The JSON API response for a page of buckets.
153 """
154
155 from gcloud.storage.bucket import Bucket
156 for item in response.get('items', []):
157 yield Bucket.from_dict(item, connection=self.connection)
158
159
160 class KeyIterator(Iterator):
161 """An iterator listing keys.
162
163 You shouldn't have to use this directly,
164 but instead should use the helper methods
165 on :class:`gcloud.storage.key.Key` objects.
166
167 :type bucket: :class:`gcloud.storage.bucket.Bucket`
168 :param bucket: The bucket from which to list keys.
169 """
170
171 def __init__(self, bucket):
172 self.bucket = bucket
173 super(KeyIterator, self).__init__(
174 connection=bucket.connection, path=bucket.path + '/o')
175
176 def get_items_from_response(self, response):
177 """Factory method which yields :class:`gcloud.storage.key.Key` items from a response.
178
179 :type response: dict
180 :param response: The JSON API response for a page of keys.
181 """
182
183 from gcloud.storage.key import Key
184 for item in response.get('items', []):
185 yield Key.from_dict(item, bucket=self.bucket)
186
187
188 class KeyDataIterator(object):
189
190 def __init__(self, key):
191 self.key = key
192 self.reset()
193
194 def __iter__(self):
195 while self.has_more_data():
196 yield self.get_next_chunk()
197
198 def reset(self):
199 self._bytes_written = 0
200 self._total_bytes = None
201
202 def has_more_data(self):
203 if self._bytes_written == 0:
204 return True
205 elif not self._total_bytes:
206 # self._total_bytes **should** be set by this point.
207 # If it isn't, something is wrong.
208 raise ValueError('Size of object is unknown... This is bad.')
209 else:
210 return (self._bytes_written < self._total_bytes)
211
212 def get_headers(self):
213 start = self._bytes_written
214 end = self._bytes_written + self.key.CHUNK_SIZE
215
216 if self._total_bytes and end > self._total_bytes:
217 end = ''
218
219 return {'Range': 'bytes=%s-%s' % (start, end)}
220
221 def get_url(self):
222 return self.key.connection.build_api_url(
223 path=self.key.path, query_params={'alt': 'media'})
224
225 def get_next_chunk(self):
226 if not self.has_more_data():
227 raise RuntimeError('No more data in this iterator. Try resetting.')
228
229 response, content = self.key.connection.make_request(
230 method='GET', url=self.get_url(), headers=self.get_headers())
231
232 if response.status in (200, 206):
233 self._bytes_written += len(content)
234
235 if 'content-range' in response:
236 content_range = response['content-range']
237 self._total_bytes = int(content_range.rsplit('/', 1)[1])
238
239 return content
240
241 # Expected a 200 or a 206... Got something else, which is bad.
242 raise Exception(response)
243
[end of gcloud/storage/iterator.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/gcloud/storage/iterator.py b/gcloud/storage/iterator.py
--- a/gcloud/storage/iterator.py
+++ b/gcloud/storage/iterator.py
@@ -211,7 +211,7 @@
def get_headers(self):
start = self._bytes_written
- end = self._bytes_written + self.key.CHUNK_SIZE
+ end = self._bytes_written + self.key.CHUNK_SIZE - 1
if self._total_bytes and end > self._total_bytes:
end = ''
|
{"golden_diff": "diff --git a/gcloud/storage/iterator.py b/gcloud/storage/iterator.py\n--- a/gcloud/storage/iterator.py\n+++ b/gcloud/storage/iterator.py\n@@ -211,7 +211,7 @@\n \n def get_headers(self):\n start = self._bytes_written\n- end = self._bytes_written + self.key.CHUNK_SIZE\n+ end = self._bytes_written + self.key.CHUNK_SIZE - 1\n \n if self._total_bytes and end > self._total_bytes:\n end = ''\n", "issue": "gcloud.storage.iterator.KeyDataIterator chunking is off-by-one\n'get_headers' computes the \"Range:\" header as '_bytes_written' - '_bytes_written + CHUNK_SIZE':\n\nhttps://github.com/GoogleCloudPlatform/gcloud-python/blob/1f2aaf3606802f4f02eeb30e22e1082ef7f4594e/gcloud/storage/iterator.py#L215\n\nand the '_bytes_written' gets updated to bump by the size of the chunk the server returns. Consider the initial read, assuming a CHUNK_SIZE of 100:\n\n Range: bytes=0-100\n\nNote that, per RFC2616. this will return up to 101 bytes (both bytes-position values are inclusive):\n\nhttp://www.w3.org/Protocols/rfc2616/rfc2616-sec14.html#sec14.35.1\n\n", "before_files": [{"content": "\"\"\"Iterators for paging through API responses.\n\nThese iterators\nsimplify the process\nof paging through API responses\nwhere the response\nis a list of results\nwith a ``nextPageToken``.\n\nTo make an iterator work,\njust override the ``get_items_from_response`` method\nso that given a response\n(containing a page of results)\nit parses those results\ninto an iterable\nof the actual objects you want::\n\n class MyIterator(Iterator):\n def get_items_from_response(self, response):\n items = response.get('items', [])\n for item in items:\n yield MyItemClass.from_dict(item, other_arg=True)\n\nYou then can use this\nto get **all** the results\nfrom a resource::\n\n >>> iterator = MyIterator(...)\n >>> list(iterator) # Convert to a list (consumes all values).\n\nOr you can walk your way through items\nand call off the search early\nif you find what you're looking for\n(resulting in possibly fewer requests)::\n\n >>> for item in MyIterator(...):\n >>> print item.name\n >>> if not item.is_valid:\n >>> break\n\"\"\"\n\n\nclass Iterator(object):\n \"\"\"A generic class for iterating through Cloud Storage list responses.\n\n :type connection: :class:`gcloud.storage.connection.Connection`\n :param connection: The connection to use to make requests.\n\n :type path: string\n :param path: The path to query for the list of items.\n \"\"\"\n\n def __init__(self, connection, path):\n self.connection = connection\n self.path = path\n self.page_number = 0\n self.next_page_token = None\n\n def __iter__(self):\n \"\"\"Iterate through the list of items.\"\"\"\n\n while self.has_next_page():\n response = self.get_next_page_response()\n for item in self.get_items_from_response(response):\n yield item\n\n def has_next_page(self):\n \"\"\"Determines whether or not this iterator has more pages.\n\n :rtype: bool\n :returns: Whether the iterator has more pages or not.\n \"\"\"\n\n if self.page_number == 0:\n return True\n\n return self.next_page_token is not None\n\n def get_query_params(self):\n \"\"\"Getter for query parameters for the next request.\n\n :rtype: dict or None\n :returns: A dictionary of query parameters or None if there are none.\n \"\"\"\n\n if self.next_page_token:\n return {'pageToken': self.next_page_token}\n\n def get_next_page_response(self):\n \"\"\"Requests the next page from the path provided.\n\n :rtype: dict\n :returns: The parsed JSON response of the next page's contents.\n \"\"\"\n\n if not self.has_next_page():\n raise RuntimeError('No more pages. Try resetting the iterator.')\n\n response = self.connection.api_request(\n method='GET', path=self.path, query_params=self.get_query_params())\n\n self.page_number += 1\n self.next_page_token = response.get('nextPageToken')\n\n return response\n\n def reset(self):\n \"\"\"Resets the iterator to the beginning.\"\"\"\n self.page_number = 0\n self.next_page_token = None\n\n def get_items_from_response(self, response): #pragma NO COVER\n \"\"\"Factory method called while iterating. This should be overriden.\n\n This method should be overridden by a subclass.\n It should accept the API response\n of a request for the next page of items,\n and return a list (or other iterable)\n of items.\n\n Typically this method will construct\n a Bucket or a Key\n from the page of results in the response.\n\n :type response: dict\n :param response: The response of asking for the next page of items.\n\n :rtype: iterable\n :returns: Items that the iterator should yield.\n \"\"\"\n raise NotImplementedError\n\n\nclass BucketIterator(Iterator):\n \"\"\"An iterator listing all buckets.\n\n You shouldn't have to use this directly,\n but instead should use the helper methods\n on :class:`gcloud.storage.connection.Connection` objects.\n\n :type connection: :class:`gcloud.storage.connection.Connection`\n :param connection: The connection to use for querying the list of buckets.\n \"\"\"\n\n def __init__(self, connection):\n super(BucketIterator, self).__init__(connection=connection, path='/b')\n\n def get_items_from_response(self, response):\n \"\"\"Factory method which yields :class:`gcloud.storage.bucket.Bucket` items from a response.\n\n :type response: dict\n :param response: The JSON API response for a page of buckets.\n \"\"\"\n\n from gcloud.storage.bucket import Bucket\n for item in response.get('items', []):\n yield Bucket.from_dict(item, connection=self.connection)\n\n\nclass KeyIterator(Iterator):\n \"\"\"An iterator listing keys.\n\n You shouldn't have to use this directly,\n but instead should use the helper methods\n on :class:`gcloud.storage.key.Key` objects.\n\n :type bucket: :class:`gcloud.storage.bucket.Bucket`\n :param bucket: The bucket from which to list keys.\n \"\"\"\n\n def __init__(self, bucket):\n self.bucket = bucket\n super(KeyIterator, self).__init__(\n connection=bucket.connection, path=bucket.path + '/o')\n\n def get_items_from_response(self, response):\n \"\"\"Factory method which yields :class:`gcloud.storage.key.Key` items from a response.\n\n :type response: dict\n :param response: The JSON API response for a page of keys.\n \"\"\"\n\n from gcloud.storage.key import Key\n for item in response.get('items', []):\n yield Key.from_dict(item, bucket=self.bucket)\n\n\nclass KeyDataIterator(object):\n\n def __init__(self, key):\n self.key = key\n self.reset()\n\n def __iter__(self):\n while self.has_more_data():\n yield self.get_next_chunk()\n\n def reset(self):\n self._bytes_written = 0\n self._total_bytes = None\n\n def has_more_data(self):\n if self._bytes_written == 0:\n return True\n elif not self._total_bytes:\n # self._total_bytes **should** be set by this point.\n # If it isn't, something is wrong.\n raise ValueError('Size of object is unknown... This is bad.')\n else:\n return (self._bytes_written < self._total_bytes)\n\n def get_headers(self):\n start = self._bytes_written\n end = self._bytes_written + self.key.CHUNK_SIZE\n\n if self._total_bytes and end > self._total_bytes:\n end = ''\n\n return {'Range': 'bytes=%s-%s' % (start, end)}\n\n def get_url(self):\n return self.key.connection.build_api_url(\n path=self.key.path, query_params={'alt': 'media'})\n\n def get_next_chunk(self):\n if not self.has_more_data():\n raise RuntimeError('No more data in this iterator. Try resetting.')\n\n response, content = self.key.connection.make_request(\n method='GET', url=self.get_url(), headers=self.get_headers())\n\n if response.status in (200, 206):\n self._bytes_written += len(content)\n\n if 'content-range' in response:\n content_range = response['content-range']\n self._total_bytes = int(content_range.rsplit('/', 1)[1])\n\n return content\n\n # Expected a 200 or a 206... Got something else, which is bad.\n raise Exception(response)\n", "path": "gcloud/storage/iterator.py"}]}
| 3,018 | 116 |
gh_patches_debug_28313
|
rasdani/github-patches
|
git_diff
|
wemake-services__wemake-python-styleguide-182
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Feature: count async function as a module member
Currently we count only regular functions and classes as module members: https://github.com/wemake-services/wemake-python-styleguide/blob/master/wemake_python_styleguide/visitors/ast/complexity/counts.py#L40-L60
What needs to be done?
1. We need to count `AsyncFunctionDef` as well
2. We need to improve `ModuleMembers` type to include `AsyncFunctionDef`
3. We need to refactor how handler for each node works: there's no need to duplicate the logic, so it can just be: `visit_AsyncFunctionDef = visit_FunctionDef = visit_ClassDef`
4. We need to improve unit tests to include `async` functions as well: https://github.com/wemake-services/wemake-python-styleguide/blob/master/tests/test_visitors/test_ast/test_complexity/test_counts/test_module_counts.py
</issue>
<code>
[start of wemake_python_styleguide/types.py]
1 # -*- coding: utf-8 -*-
2
3 """
4 This module contains custom ``mypy`` types that we commonly use.
5
6 Policy
7 ------
8
9 If any of the following statements is true, move the type to this file:
10
11 - if type is used in multiple files
12 - if type is complex enough it has to be documented
13 - if type is very important for the public API
14
15 """
16
17 import ast
18 from typing import TYPE_CHECKING, Tuple, Type, Union
19
20 if TYPE_CHECKING: # pragma: no cover
21 from typing_extensions import Protocol # noqa: Z435
22
23 # This solves cycle imports problem:
24 from .visitors import base # noqa: F401,Z300,Z435
25 else:
26 # We do not need to do anything if type checker is not working:
27 Protocol = object
28
29 #: Visitor type definition:
30 VisitorClass = Type['base.BaseVisitor']
31
32 #: In cases we need to work with both import types:
33 AnyImport = Union[ast.Import, ast.ImportFrom]
34
35 #: Flake8 API format to return error messages:
36 CheckResult = Tuple[int, int, str, type]
37
38 #: Code members that we count in a module:
39 ModuleMembers = Union[ast.FunctionDef, ast.ClassDef]
40
41
42 class ConfigurationOptions(Protocol):
43 """
44 Provides structure for the options we use in our checker.
45
46 Then this protocol is passed to each individual visitor and used there.
47 It uses structural sub-typing, and does not represent any kind of a real
48 class or structure.
49
50 This class actually works only when running type check.
51 At other cases it is just an ``object``.
52
53 See also:
54 https://mypy.readthedocs.io/en/latest/protocols.html
55
56 """
57
58 # General:
59 min_variable_length: int
60 i_control_code: bool
61
62 # Complexity:
63 max_arguments: int
64 max_local_variables: int
65 max_returns: int
66 max_expressions: int
67 max_offset_blocks: int
68 max_elifs: int
69 max_module_members: int
70 max_methods: int
71 max_line_complexity: int
72 max_jones_score: int
73 max_imports: int
74 max_conditions: int
75
76 # File names:
77 min_module_name_length: int
78
[end of wemake_python_styleguide/types.py]
[start of wemake_python_styleguide/visitors/ast/complexity/counts.py]
1 # -*- coding: utf-8 -*-
2
3 import ast
4 from collections import defaultdict
5 from typing import DefaultDict, Union
6
7 from wemake_python_styleguide.logics.functions import is_method
8 from wemake_python_styleguide.types import AnyImport, ModuleMembers
9 from wemake_python_styleguide.violations.complexity import (
10 TooManyConditionsViolation,
11 TooManyImportsViolation,
12 TooManyMethodsViolation,
13 TooManyModuleMembersViolation,
14 )
15 from wemake_python_styleguide.visitors.base import BaseNodeVisitor
16
17 ConditionNodes = Union[ast.If, ast.While, ast.IfExp]
18
19
20 class ModuleMembersVisitor(BaseNodeVisitor):
21 """Counts classes and functions in a module."""
22
23 def __init__(self, *args, **kwargs) -> None:
24 """Creates a counter for tracked metrics."""
25 super().__init__(*args, **kwargs)
26 self._public_items_count = 0
27
28 def _check_members_count(self, node: ModuleMembers) -> None:
29 """This method increases the number of module members."""
30 parent = getattr(node, 'parent', None)
31 is_real_method = is_method(getattr(node, 'function_type', None))
32
33 if isinstance(parent, ast.Module) and not is_real_method:
34 self._public_items_count += 1
35
36 def _post_visit(self) -> None:
37 if self._public_items_count > self.options.max_module_members:
38 self.add_violation(TooManyModuleMembersViolation())
39
40 def visit_ClassDef(self, node: ast.ClassDef) -> None:
41 """
42 Counts the number of `class`es in a single module.
43
44 Raises:
45 TooManyModuleMembersViolation
46
47 """
48 self._check_members_count(node)
49 self.generic_visit(node)
50
51 def visit_FunctionDef(self, node: ast.FunctionDef) -> None:
52 """
53 Counts the number of functions in a single module.
54
55 Raises:
56 TooManyModuleMembersViolation
57
58 """
59 self._check_members_count(node)
60 self.generic_visit(node)
61
62
63 class ImportMembersVisitor(BaseNodeVisitor):
64 """Counts imports in a module."""
65
66 def __init__(self, *args, **kwargs) -> None:
67 """Creates a counter for tracked metrics."""
68 super().__init__(*args, **kwargs)
69 self._imports_count = 0
70
71 def _post_visit(self) -> None:
72 if self._imports_count > self.options.max_imports:
73 self.add_violation(
74 TooManyImportsViolation(text=str(self._imports_count)),
75 )
76
77 def visit_Import(self, node: AnyImport) -> None:
78 """
79 Counts the number of ``import`` and ``from ... import ...``.
80
81 Raises:
82 TooManyImportsViolation
83
84 """
85 self._imports_count += 1
86 self.generic_visit(node)
87
88 visit_ImportFrom = visit_Import
89
90
91 class MethodMembersVisitor(BaseNodeVisitor):
92 """Counts methods in a single class."""
93
94 def __init__(self, *args, **kwargs) -> None:
95 """Creates a counter for tracked methods in different classes."""
96 super().__init__(*args, **kwargs)
97 self._methods: DefaultDict[ast.ClassDef, int] = defaultdict(int)
98
99 def _check_method(self, node: ast.FunctionDef) -> None:
100 parent = getattr(node, 'parent', None)
101 if isinstance(parent, ast.ClassDef):
102 self._methods[parent] += 1
103
104 def _post_visit(self) -> None:
105 for node, count in self._methods.items():
106 if count > self.options.max_methods:
107 self.add_violation(TooManyMethodsViolation(text=node.name))
108
109 def visit_FunctionDef(self, node: ast.FunctionDef) -> None:
110 """
111 Counts the number of methods in a single class.
112
113 Raises:
114 TooManyMethodsViolation
115
116 """
117 self._check_method(node)
118 self.generic_visit(node)
119
120
121 class ConditionsVisitor(BaseNodeVisitor):
122 """Checks ``if`` and ``while`` statements for condition counts."""
123
124 def __init__(self, *args, **kwargs) -> None:
125 """Creates a counter for tracked conditions."""
126 super().__init__(*args, **kwargs)
127 self._conditions: DefaultDict[ast.AST, int] = defaultdict(int)
128
129 def _check_conditions(self, node: ast.AST) -> None:
130 for condition in ast.walk(node):
131 if isinstance(condition, (ast.And, ast.Or)):
132 self._conditions[node] += 1
133
134 def _post_visit(self) -> None:
135 for node, count in self._conditions.items():
136 if count > self.options.max_conditions - 1:
137 self.add_violation(
138 TooManyConditionsViolation(node, text=str(count)),
139 )
140
141 def visit_comprehension(self, node: ast.comprehension) -> None:
142 """
143 Counts the number of conditions in list comprehensions.
144
145 Raises:
146 TooManyConditionsViolation
147
148 """
149 if node.ifs:
150 # We only check the first `if`, since it is forbidden
151 # to have more than one at a time
152 # by `MultipleIfsInComprehensionViolation`
153 self._check_conditions(node.ifs[0])
154 self.generic_visit(node)
155
156 def visit_If(self, node: ConditionNodes) -> None:
157 """
158 Counts the number of conditions.
159
160 Raises:
161 TooManyConditionsViolation
162
163 """
164 self._check_conditions(node.test)
165 self.generic_visit(node)
166
167 visit_While = visit_IfExp = visit_If
168
[end of wemake_python_styleguide/visitors/ast/complexity/counts.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/wemake_python_styleguide/types.py b/wemake_python_styleguide/types.py
--- a/wemake_python_styleguide/types.py
+++ b/wemake_python_styleguide/types.py
@@ -36,7 +36,7 @@
CheckResult = Tuple[int, int, str, type]
#: Code members that we count in a module:
-ModuleMembers = Union[ast.FunctionDef, ast.ClassDef]
+ModuleMembers = Union[ast.FunctionDef, ast.ClassDef, ast.AsyncFunctionDef]
class ConfigurationOptions(Protocol):
diff --git a/wemake_python_styleguide/visitors/ast/complexity/counts.py b/wemake_python_styleguide/visitors/ast/complexity/counts.py
--- a/wemake_python_styleguide/visitors/ast/complexity/counts.py
+++ b/wemake_python_styleguide/visitors/ast/complexity/counts.py
@@ -37,9 +37,9 @@
if self._public_items_count > self.options.max_module_members:
self.add_violation(TooManyModuleMembersViolation())
- def visit_ClassDef(self, node: ast.ClassDef) -> None:
+ def visit_module_members(self, node: ModuleMembers) -> None:
"""
- Counts the number of `class`es in a single module.
+ Counts the number of ModuleMembers in a single module.
Raises:
TooManyModuleMembersViolation
@@ -48,16 +48,8 @@
self._check_members_count(node)
self.generic_visit(node)
- def visit_FunctionDef(self, node: ast.FunctionDef) -> None:
- """
- Counts the number of functions in a single module.
-
- Raises:
- TooManyModuleMembersViolation
-
- """
- self._check_members_count(node)
- self.generic_visit(node)
+ visit_ClassDef = visit_module_members
+ visit_AsyncFunctionDef = visit_FunctionDef = visit_module_members
class ImportMembersVisitor(BaseNodeVisitor):
|
{"golden_diff": "diff --git a/wemake_python_styleguide/types.py b/wemake_python_styleguide/types.py\n--- a/wemake_python_styleguide/types.py\n+++ b/wemake_python_styleguide/types.py\n@@ -36,7 +36,7 @@\n CheckResult = Tuple[int, int, str, type]\n \n #: Code members that we count in a module:\n-ModuleMembers = Union[ast.FunctionDef, ast.ClassDef]\n+ModuleMembers = Union[ast.FunctionDef, ast.ClassDef, ast.AsyncFunctionDef]\n \n \n class ConfigurationOptions(Protocol):\ndiff --git a/wemake_python_styleguide/visitors/ast/complexity/counts.py b/wemake_python_styleguide/visitors/ast/complexity/counts.py\n--- a/wemake_python_styleguide/visitors/ast/complexity/counts.py\n+++ b/wemake_python_styleguide/visitors/ast/complexity/counts.py\n@@ -37,9 +37,9 @@\n if self._public_items_count > self.options.max_module_members:\n self.add_violation(TooManyModuleMembersViolation())\n \n- def visit_ClassDef(self, node: ast.ClassDef) -> None:\n+ def visit_module_members(self, node: ModuleMembers) -> None:\n \"\"\"\n- Counts the number of `class`es in a single module.\n+ Counts the number of ModuleMembers in a single module.\n \n Raises:\n TooManyModuleMembersViolation\n@@ -48,16 +48,8 @@\n self._check_members_count(node)\n self.generic_visit(node)\n \n- def visit_FunctionDef(self, node: ast.FunctionDef) -> None:\n- \"\"\"\n- Counts the number of functions in a single module.\n-\n- Raises:\n- TooManyModuleMembersViolation\n-\n- \"\"\"\n- self._check_members_count(node)\n- self.generic_visit(node)\n+ visit_ClassDef = visit_module_members\n+ visit_AsyncFunctionDef = visit_FunctionDef = visit_module_members\n \n \n class ImportMembersVisitor(BaseNodeVisitor):\n", "issue": "Feature: count async function as a module member\nCurrently we count only regular functions and classes as module members: https://github.com/wemake-services/wemake-python-styleguide/blob/master/wemake_python_styleguide/visitors/ast/complexity/counts.py#L40-L60\r\n\r\nWhat needs to be done?\r\n1. We need to count `AsyncFunctionDef` as well\r\n2. We need to improve `ModuleMembers` type to include `AsyncFunctionDef`\r\n3. We need to refactor how handler for each node works: there's no need to duplicate the logic, so it can just be: `visit_AsyncFunctionDef = visit_FunctionDef = visit_ClassDef`\r\n4. We need to improve unit tests to include `async` functions as well: https://github.com/wemake-services/wemake-python-styleguide/blob/master/tests/test_visitors/test_ast/test_complexity/test_counts/test_module_counts.py\r\n\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n\"\"\"\nThis module contains custom ``mypy`` types that we commonly use.\n\nPolicy\n------\n\nIf any of the following statements is true, move the type to this file:\n\n- if type is used in multiple files\n- if type is complex enough it has to be documented\n- if type is very important for the public API\n\n\"\"\"\n\nimport ast\nfrom typing import TYPE_CHECKING, Tuple, Type, Union\n\nif TYPE_CHECKING: # pragma: no cover\n from typing_extensions import Protocol # noqa: Z435\n\n # This solves cycle imports problem:\n from .visitors import base # noqa: F401,Z300,Z435\nelse:\n # We do not need to do anything if type checker is not working:\n Protocol = object\n\n#: Visitor type definition:\nVisitorClass = Type['base.BaseVisitor']\n\n#: In cases we need to work with both import types:\nAnyImport = Union[ast.Import, ast.ImportFrom]\n\n#: Flake8 API format to return error messages:\nCheckResult = Tuple[int, int, str, type]\n\n#: Code members that we count in a module:\nModuleMembers = Union[ast.FunctionDef, ast.ClassDef]\n\n\nclass ConfigurationOptions(Protocol):\n \"\"\"\n Provides structure for the options we use in our checker.\n\n Then this protocol is passed to each individual visitor and used there.\n It uses structural sub-typing, and does not represent any kind of a real\n class or structure.\n\n This class actually works only when running type check.\n At other cases it is just an ``object``.\n\n See also:\n https://mypy.readthedocs.io/en/latest/protocols.html\n\n \"\"\"\n\n # General:\n min_variable_length: int\n i_control_code: bool\n\n # Complexity:\n max_arguments: int\n max_local_variables: int\n max_returns: int\n max_expressions: int\n max_offset_blocks: int\n max_elifs: int\n max_module_members: int\n max_methods: int\n max_line_complexity: int\n max_jones_score: int\n max_imports: int\n max_conditions: int\n\n # File names:\n min_module_name_length: int\n", "path": "wemake_python_styleguide/types.py"}, {"content": "# -*- coding: utf-8 -*-\n\nimport ast\nfrom collections import defaultdict\nfrom typing import DefaultDict, Union\n\nfrom wemake_python_styleguide.logics.functions import is_method\nfrom wemake_python_styleguide.types import AnyImport, ModuleMembers\nfrom wemake_python_styleguide.violations.complexity import (\n TooManyConditionsViolation,\n TooManyImportsViolation,\n TooManyMethodsViolation,\n TooManyModuleMembersViolation,\n)\nfrom wemake_python_styleguide.visitors.base import BaseNodeVisitor\n\nConditionNodes = Union[ast.If, ast.While, ast.IfExp]\n\n\nclass ModuleMembersVisitor(BaseNodeVisitor):\n \"\"\"Counts classes and functions in a module.\"\"\"\n\n def __init__(self, *args, **kwargs) -> None:\n \"\"\"Creates a counter for tracked metrics.\"\"\"\n super().__init__(*args, **kwargs)\n self._public_items_count = 0\n\n def _check_members_count(self, node: ModuleMembers) -> None:\n \"\"\"This method increases the number of module members.\"\"\"\n parent = getattr(node, 'parent', None)\n is_real_method = is_method(getattr(node, 'function_type', None))\n\n if isinstance(parent, ast.Module) and not is_real_method:\n self._public_items_count += 1\n\n def _post_visit(self) -> None:\n if self._public_items_count > self.options.max_module_members:\n self.add_violation(TooManyModuleMembersViolation())\n\n def visit_ClassDef(self, node: ast.ClassDef) -> None:\n \"\"\"\n Counts the number of `class`es in a single module.\n\n Raises:\n TooManyModuleMembersViolation\n\n \"\"\"\n self._check_members_count(node)\n self.generic_visit(node)\n\n def visit_FunctionDef(self, node: ast.FunctionDef) -> None:\n \"\"\"\n Counts the number of functions in a single module.\n\n Raises:\n TooManyModuleMembersViolation\n\n \"\"\"\n self._check_members_count(node)\n self.generic_visit(node)\n\n\nclass ImportMembersVisitor(BaseNodeVisitor):\n \"\"\"Counts imports in a module.\"\"\"\n\n def __init__(self, *args, **kwargs) -> None:\n \"\"\"Creates a counter for tracked metrics.\"\"\"\n super().__init__(*args, **kwargs)\n self._imports_count = 0\n\n def _post_visit(self) -> None:\n if self._imports_count > self.options.max_imports:\n self.add_violation(\n TooManyImportsViolation(text=str(self._imports_count)),\n )\n\n def visit_Import(self, node: AnyImport) -> None:\n \"\"\"\n Counts the number of ``import`` and ``from ... import ...``.\n\n Raises:\n TooManyImportsViolation\n\n \"\"\"\n self._imports_count += 1\n self.generic_visit(node)\n\n visit_ImportFrom = visit_Import\n\n\nclass MethodMembersVisitor(BaseNodeVisitor):\n \"\"\"Counts methods in a single class.\"\"\"\n\n def __init__(self, *args, **kwargs) -> None:\n \"\"\"Creates a counter for tracked methods in different classes.\"\"\"\n super().__init__(*args, **kwargs)\n self._methods: DefaultDict[ast.ClassDef, int] = defaultdict(int)\n\n def _check_method(self, node: ast.FunctionDef) -> None:\n parent = getattr(node, 'parent', None)\n if isinstance(parent, ast.ClassDef):\n self._methods[parent] += 1\n\n def _post_visit(self) -> None:\n for node, count in self._methods.items():\n if count > self.options.max_methods:\n self.add_violation(TooManyMethodsViolation(text=node.name))\n\n def visit_FunctionDef(self, node: ast.FunctionDef) -> None:\n \"\"\"\n Counts the number of methods in a single class.\n\n Raises:\n TooManyMethodsViolation\n\n \"\"\"\n self._check_method(node)\n self.generic_visit(node)\n\n\nclass ConditionsVisitor(BaseNodeVisitor):\n \"\"\"Checks ``if`` and ``while`` statements for condition counts.\"\"\"\n\n def __init__(self, *args, **kwargs) -> None:\n \"\"\"Creates a counter for tracked conditions.\"\"\"\n super().__init__(*args, **kwargs)\n self._conditions: DefaultDict[ast.AST, int] = defaultdict(int)\n\n def _check_conditions(self, node: ast.AST) -> None:\n for condition in ast.walk(node):\n if isinstance(condition, (ast.And, ast.Or)):\n self._conditions[node] += 1\n\n def _post_visit(self) -> None:\n for node, count in self._conditions.items():\n if count > self.options.max_conditions - 1:\n self.add_violation(\n TooManyConditionsViolation(node, text=str(count)),\n )\n\n def visit_comprehension(self, node: ast.comprehension) -> None:\n \"\"\"\n Counts the number of conditions in list comprehensions.\n\n Raises:\n TooManyConditionsViolation\n\n \"\"\"\n if node.ifs:\n # We only check the first `if`, since it is forbidden\n # to have more than one at a time\n # by `MultipleIfsInComprehensionViolation`\n self._check_conditions(node.ifs[0])\n self.generic_visit(node)\n\n def visit_If(self, node: ConditionNodes) -> None:\n \"\"\"\n Counts the number of conditions.\n\n Raises:\n TooManyConditionsViolation\n\n \"\"\"\n self._check_conditions(node.test)\n self.generic_visit(node)\n\n visit_While = visit_IfExp = visit_If\n", "path": "wemake_python_styleguide/visitors/ast/complexity/counts.py"}]}
| 3,008 | 441 |
gh_patches_debug_13868
|
rasdani/github-patches
|
git_diff
|
scrapy__scrapy-5691
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Warning: Unable to determine whether or not callable is a generator with a return value [unable to parse decorated class methods]
### Description
If you have a decorated spider method, `scrapy.utils.misc` [throws a warning](https://github.com/scrapy/scrapy/blob/master/scrapy/utils/misc.py#L240-L264) saying that it cannot determine if the callable is a generator with a return value.
`ast.parse()` fails [here](https://github.com/scrapy/scrapy/blob/master/scrapy/utils/misc.py#L228-L230) when called with a decorated method.
### Steps to Reproduce
I just copied the logic from `misc.py` and used it to analyze a class with the same overall code structure:
```python
import re
import ast
import inspect
class Foo:
@classmethod
def func(self):
"""
Description of func
"""
return
code = re.sub(r"^[\t ]+", "", inspect.getsource(Foo.func))
tree = ast.parse(code)
```
```
python3 test.py
> IndentationError: unexpected indent
```
The regex replacement isn't accounting for a possible decorator, so the code ends up looking like:
```
@classmethod
def func(self):
"""
Description of func
"""
return
```
**Expected behavior:** I'd like to be able to use decorated methods without dealing with noisy logs.
**Actual behavior:** My container logs are filled with tons of warning messages. The only workaround is to avoid the usage of decorators.
**Reproduces how often:** 100% of the time to my knowledge
### Versions
```
$ scrapy version --verbose
Scrapy : 2.5.1
lxml : 4.6.4.0
libxml2 : 2.9.10
cssselect : 1.1.0
parsel : 1.6.0
w3lib : 1.22.0
Twisted : 21.7.0
Python : 3.8.2 (default, Dec 21 2020, 15:06:04) - [Clang 12.0.0 (clang-1200.0.32.29)]
pyOpenSSL : 21.0.0 (OpenSSL 1.1.1l 24 Aug 2021)
cryptography : 35.0.0
Platform : macOS-10.15.7-x86_64-i386-64bit
```
### Additional context
This is my first time filing a Scrapy issue. I'm happy to add more context if necessary, and apologies in advance if this has already been discussed elsewhere (fwiw I couldn't find anything).
</issue>
<code>
[start of scrapy/utils/misc.py]
1 """Helper functions which don't fit anywhere else"""
2 import ast
3 import inspect
4 import os
5 import re
6 import hashlib
7 import warnings
8 from collections import deque
9 from contextlib import contextmanager
10 from importlib import import_module
11 from pkgutil import iter_modules
12
13 from w3lib.html import replace_entities
14
15 from scrapy.utils.datatypes import LocalWeakReferencedCache
16 from scrapy.utils.python import flatten, to_unicode
17 from scrapy.item import Item
18 from scrapy.utils.deprecate import ScrapyDeprecationWarning
19
20
21 _ITERABLE_SINGLE_VALUES = dict, Item, str, bytes
22
23
24 def arg_to_iter(arg):
25 """Convert an argument to an iterable. The argument can be a None, single
26 value, or an iterable.
27
28 Exception: if arg is a dict, [arg] will be returned
29 """
30 if arg is None:
31 return []
32 elif not isinstance(arg, _ITERABLE_SINGLE_VALUES) and hasattr(arg, '__iter__'):
33 return arg
34 else:
35 return [arg]
36
37
38 def load_object(path):
39 """Load an object given its absolute object path, and return it.
40
41 The object can be the import path of a class, function, variable or an
42 instance, e.g. 'scrapy.downloadermiddlewares.redirect.RedirectMiddleware'.
43
44 If ``path`` is not a string, but is a callable object, such as a class or
45 a function, then return it as is.
46 """
47
48 if not isinstance(path, str):
49 if callable(path):
50 return path
51 else:
52 raise TypeError("Unexpected argument type, expected string "
53 f"or object, got: {type(path)}")
54
55 try:
56 dot = path.rindex('.')
57 except ValueError:
58 raise ValueError(f"Error loading object '{path}': not a full path")
59
60 module, name = path[:dot], path[dot + 1:]
61 mod = import_module(module)
62
63 try:
64 obj = getattr(mod, name)
65 except AttributeError:
66 raise NameError(f"Module '{module}' doesn't define any object named '{name}'")
67
68 return obj
69
70
71 def walk_modules(path):
72 """Loads a module and all its submodules from the given module path and
73 returns them. If *any* module throws an exception while importing, that
74 exception is thrown back.
75
76 For example: walk_modules('scrapy.utils')
77 """
78
79 mods = []
80 mod = import_module(path)
81 mods.append(mod)
82 if hasattr(mod, '__path__'):
83 for _, subpath, ispkg in iter_modules(mod.__path__):
84 fullpath = path + '.' + subpath
85 if ispkg:
86 mods += walk_modules(fullpath)
87 else:
88 submod = import_module(fullpath)
89 mods.append(submod)
90 return mods
91
92
93 def extract_regex(regex, text, encoding='utf-8'):
94 """Extract a list of unicode strings from the given text/encoding using the following policies:
95
96 * if the regex contains a named group called "extract" that will be returned
97 * if the regex contains multiple numbered groups, all those will be returned (flattened)
98 * if the regex doesn't contain any group the entire regex matching is returned
99 """
100 warnings.warn(
101 "scrapy.utils.misc.extract_regex has moved to parsel.utils.extract_regex.",
102 ScrapyDeprecationWarning,
103 stacklevel=2
104 )
105
106 if isinstance(regex, str):
107 regex = re.compile(regex, re.UNICODE)
108
109 try:
110 strings = [regex.search(text).group('extract')] # named group
111 except Exception:
112 strings = regex.findall(text) # full regex or numbered groups
113 strings = flatten(strings)
114
115 if isinstance(text, str):
116 return [replace_entities(s, keep=['lt', 'amp']) for s in strings]
117 else:
118 return [replace_entities(to_unicode(s, encoding), keep=['lt', 'amp'])
119 for s in strings]
120
121
122 def md5sum(file):
123 """Calculate the md5 checksum of a file-like object without reading its
124 whole content in memory.
125
126 >>> from io import BytesIO
127 >>> md5sum(BytesIO(b'file content to hash'))
128 '784406af91dd5a54fbb9c84c2236595a'
129 """
130 m = hashlib.md5()
131 while True:
132 d = file.read(8096)
133 if not d:
134 break
135 m.update(d)
136 return m.hexdigest()
137
138
139 def rel_has_nofollow(rel):
140 """Return True if link rel attribute has nofollow type"""
141 return rel is not None and 'nofollow' in rel.replace(',', ' ').split()
142
143
144 def create_instance(objcls, settings, crawler, *args, **kwargs):
145 """Construct a class instance using its ``from_crawler`` or
146 ``from_settings`` constructors, if available.
147
148 At least one of ``settings`` and ``crawler`` needs to be different from
149 ``None``. If ``settings `` is ``None``, ``crawler.settings`` will be used.
150 If ``crawler`` is ``None``, only the ``from_settings`` constructor will be
151 tried.
152
153 ``*args`` and ``**kwargs`` are forwarded to the constructors.
154
155 Raises ``ValueError`` if both ``settings`` and ``crawler`` are ``None``.
156
157 .. versionchanged:: 2.2
158 Raises ``TypeError`` if the resulting instance is ``None`` (e.g. if an
159 extension has not been implemented correctly).
160 """
161 if settings is None:
162 if crawler is None:
163 raise ValueError("Specify at least one of settings and crawler.")
164 settings = crawler.settings
165 if crawler and hasattr(objcls, 'from_crawler'):
166 instance = objcls.from_crawler(crawler, *args, **kwargs)
167 method_name = 'from_crawler'
168 elif hasattr(objcls, 'from_settings'):
169 instance = objcls.from_settings(settings, *args, **kwargs)
170 method_name = 'from_settings'
171 else:
172 instance = objcls(*args, **kwargs)
173 method_name = '__new__'
174 if instance is None:
175 raise TypeError(f"{objcls.__qualname__}.{method_name} returned None")
176 return instance
177
178
179 @contextmanager
180 def set_environ(**kwargs):
181 """Temporarily set environment variables inside the context manager and
182 fully restore previous environment afterwards
183 """
184
185 original_env = {k: os.environ.get(k) for k in kwargs}
186 os.environ.update(kwargs)
187 try:
188 yield
189 finally:
190 for k, v in original_env.items():
191 if v is None:
192 del os.environ[k]
193 else:
194 os.environ[k] = v
195
196
197 def walk_callable(node):
198 """Similar to ``ast.walk``, but walks only function body and skips nested
199 functions defined within the node.
200 """
201 todo = deque([node])
202 walked_func_def = False
203 while todo:
204 node = todo.popleft()
205 if isinstance(node, ast.FunctionDef):
206 if walked_func_def:
207 continue
208 walked_func_def = True
209 todo.extend(ast.iter_child_nodes(node))
210 yield node
211
212
213 _generator_callbacks_cache = LocalWeakReferencedCache(limit=128)
214
215
216 def is_generator_with_return_value(callable):
217 """
218 Returns True if a callable is a generator function which includes a
219 'return' statement with a value different than None, False otherwise
220 """
221 if callable in _generator_callbacks_cache:
222 return _generator_callbacks_cache[callable]
223
224 def returns_none(return_node):
225 value = return_node.value
226 return value is None or isinstance(value, ast.NameConstant) and value.value is None
227
228 if inspect.isgeneratorfunction(callable):
229 code = re.sub(r"^[\t ]+", "", inspect.getsource(callable))
230 tree = ast.parse(code)
231 for node in walk_callable(tree):
232 if isinstance(node, ast.Return) and not returns_none(node):
233 _generator_callbacks_cache[callable] = True
234 return _generator_callbacks_cache[callable]
235
236 _generator_callbacks_cache[callable] = False
237 return _generator_callbacks_cache[callable]
238
239
240 def warn_on_generator_with_return_value(spider, callable):
241 """
242 Logs a warning if a callable is a generator function and includes
243 a 'return' statement with a value different than None
244 """
245 try:
246 if is_generator_with_return_value(callable):
247 warnings.warn(
248 f'The "{spider.__class__.__name__}.{callable.__name__}" method is '
249 'a generator and includes a "return" statement with a value '
250 'different than None. This could lead to unexpected behaviour. Please see '
251 'https://docs.python.org/3/reference/simple_stmts.html#the-return-statement '
252 'for details about the semantics of the "return" statement within generators',
253 stacklevel=2,
254 )
255 except IndentationError:
256 callable_name = spider.__class__.__name__ + "." + callable.__name__
257 warnings.warn(
258 f'Unable to determine whether or not "{callable_name}" is a generator with a return value. '
259 'This will not prevent your code from working, but it prevents Scrapy from detecting '
260 f'potential issues in your implementation of "{callable_name}". Please, report this in the '
261 'Scrapy issue tracker (https://github.com/scrapy/scrapy/issues), '
262 f'including the code of "{callable_name}"',
263 stacklevel=2,
264 )
265
[end of scrapy/utils/misc.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scrapy/utils/misc.py b/scrapy/utils/misc.py
--- a/scrapy/utils/misc.py
+++ b/scrapy/utils/misc.py
@@ -226,7 +226,14 @@
return value is None or isinstance(value, ast.NameConstant) and value.value is None
if inspect.isgeneratorfunction(callable):
- code = re.sub(r"^[\t ]+", "", inspect.getsource(callable))
+ src = inspect.getsource(callable)
+ pattern = re.compile(r"(^[\t ]+)")
+ code = pattern.sub("", src)
+
+ match = pattern.match(src) # finds indentation
+ if match:
+ code = re.sub(f"\n{match.group(0)}", "\n", code) # remove indentation
+
tree = ast.parse(code)
for node in walk_callable(tree):
if isinstance(node, ast.Return) and not returns_none(node):
|
{"golden_diff": "diff --git a/scrapy/utils/misc.py b/scrapy/utils/misc.py\n--- a/scrapy/utils/misc.py\n+++ b/scrapy/utils/misc.py\n@@ -226,7 +226,14 @@\n return value is None or isinstance(value, ast.NameConstant) and value.value is None\n \n if inspect.isgeneratorfunction(callable):\n- code = re.sub(r\"^[\\t ]+\", \"\", inspect.getsource(callable))\n+ src = inspect.getsource(callable)\n+ pattern = re.compile(r\"(^[\\t ]+)\")\n+ code = pattern.sub(\"\", src)\n+\n+ match = pattern.match(src) # finds indentation\n+ if match:\n+ code = re.sub(f\"\\n{match.group(0)}\", \"\\n\", code) # remove indentation\n+\n tree = ast.parse(code)\n for node in walk_callable(tree):\n if isinstance(node, ast.Return) and not returns_none(node):\n", "issue": "Warning: Unable to determine whether or not callable is a generator with a return value [unable to parse decorated class methods]\n### Description\r\n\r\nIf you have a decorated spider method, `scrapy.utils.misc` [throws a warning](https://github.com/scrapy/scrapy/blob/master/scrapy/utils/misc.py#L240-L264) saying that it cannot determine if the callable is a generator with a return value.\r\n\r\n`ast.parse()` fails [here](https://github.com/scrapy/scrapy/blob/master/scrapy/utils/misc.py#L228-L230) when called with a decorated method.\r\n\r\n### Steps to Reproduce\r\n\r\nI just copied the logic from `misc.py` and used it to analyze a class with the same overall code structure:\r\n\r\n```python\r\nimport re\r\nimport ast\r\nimport inspect\r\n\r\nclass Foo:\r\n @classmethod\r\n def func(self):\r\n \"\"\"\r\n Description of func\r\n \"\"\" \r\n return\r\n\r\ncode = re.sub(r\"^[\\t ]+\", \"\", inspect.getsource(Foo.func))\r\ntree = ast.parse(code)\r\n```\r\n\r\n```\r\npython3 test.py\r\n> IndentationError: unexpected indent\r\n```\r\n\r\nThe regex replacement isn't accounting for a possible decorator, so the code ends up looking like:\r\n\r\n```\r\n@classmethod\r\n def func(self):\r\n \"\"\"\r\n Description of func\r\n \"\"\" \r\n return\r\n```\r\n\r\n**Expected behavior:** I'd like to be able to use decorated methods without dealing with noisy logs.\r\n\r\n**Actual behavior:** My container logs are filled with tons of warning messages. The only workaround is to avoid the usage of decorators.\r\n\r\n**Reproduces how often:** 100% of the time to my knowledge\r\n\r\n### Versions\r\n\r\n```\r\n$ scrapy version --verbose\r\n\r\nScrapy : 2.5.1\r\nlxml : 4.6.4.0\r\nlibxml2 : 2.9.10\r\ncssselect : 1.1.0\r\nparsel : 1.6.0\r\nw3lib : 1.22.0\r\nTwisted : 21.7.0\r\nPython : 3.8.2 (default, Dec 21 2020, 15:06:04) - [Clang 12.0.0 (clang-1200.0.32.29)]\r\npyOpenSSL : 21.0.0 (OpenSSL 1.1.1l 24 Aug 2021)\r\ncryptography : 35.0.0\r\nPlatform : macOS-10.15.7-x86_64-i386-64bit\r\n```\r\n\r\n### Additional context\r\n\r\nThis is my first time filing a Scrapy issue. I'm happy to add more context if necessary, and apologies in advance if this has already been discussed elsewhere (fwiw I couldn't find anything).\n", "before_files": [{"content": "\"\"\"Helper functions which don't fit anywhere else\"\"\"\nimport ast\nimport inspect\nimport os\nimport re\nimport hashlib\nimport warnings\nfrom collections import deque\nfrom contextlib import contextmanager\nfrom importlib import import_module\nfrom pkgutil import iter_modules\n\nfrom w3lib.html import replace_entities\n\nfrom scrapy.utils.datatypes import LocalWeakReferencedCache\nfrom scrapy.utils.python import flatten, to_unicode\nfrom scrapy.item import Item\nfrom scrapy.utils.deprecate import ScrapyDeprecationWarning\n\n\n_ITERABLE_SINGLE_VALUES = dict, Item, str, bytes\n\n\ndef arg_to_iter(arg):\n \"\"\"Convert an argument to an iterable. The argument can be a None, single\n value, or an iterable.\n\n Exception: if arg is a dict, [arg] will be returned\n \"\"\"\n if arg is None:\n return []\n elif not isinstance(arg, _ITERABLE_SINGLE_VALUES) and hasattr(arg, '__iter__'):\n return arg\n else:\n return [arg]\n\n\ndef load_object(path):\n \"\"\"Load an object given its absolute object path, and return it.\n\n The object can be the import path of a class, function, variable or an\n instance, e.g. 'scrapy.downloadermiddlewares.redirect.RedirectMiddleware'.\n\n If ``path`` is not a string, but is a callable object, such as a class or\n a function, then return it as is.\n \"\"\"\n\n if not isinstance(path, str):\n if callable(path):\n return path\n else:\n raise TypeError(\"Unexpected argument type, expected string \"\n f\"or object, got: {type(path)}\")\n\n try:\n dot = path.rindex('.')\n except ValueError:\n raise ValueError(f\"Error loading object '{path}': not a full path\")\n\n module, name = path[:dot], path[dot + 1:]\n mod = import_module(module)\n\n try:\n obj = getattr(mod, name)\n except AttributeError:\n raise NameError(f\"Module '{module}' doesn't define any object named '{name}'\")\n\n return obj\n\n\ndef walk_modules(path):\n \"\"\"Loads a module and all its submodules from the given module path and\n returns them. If *any* module throws an exception while importing, that\n exception is thrown back.\n\n For example: walk_modules('scrapy.utils')\n \"\"\"\n\n mods = []\n mod = import_module(path)\n mods.append(mod)\n if hasattr(mod, '__path__'):\n for _, subpath, ispkg in iter_modules(mod.__path__):\n fullpath = path + '.' + subpath\n if ispkg:\n mods += walk_modules(fullpath)\n else:\n submod = import_module(fullpath)\n mods.append(submod)\n return mods\n\n\ndef extract_regex(regex, text, encoding='utf-8'):\n \"\"\"Extract a list of unicode strings from the given text/encoding using the following policies:\n\n * if the regex contains a named group called \"extract\" that will be returned\n * if the regex contains multiple numbered groups, all those will be returned (flattened)\n * if the regex doesn't contain any group the entire regex matching is returned\n \"\"\"\n warnings.warn(\n \"scrapy.utils.misc.extract_regex has moved to parsel.utils.extract_regex.\",\n ScrapyDeprecationWarning,\n stacklevel=2\n )\n\n if isinstance(regex, str):\n regex = re.compile(regex, re.UNICODE)\n\n try:\n strings = [regex.search(text).group('extract')] # named group\n except Exception:\n strings = regex.findall(text) # full regex or numbered groups\n strings = flatten(strings)\n\n if isinstance(text, str):\n return [replace_entities(s, keep=['lt', 'amp']) for s in strings]\n else:\n return [replace_entities(to_unicode(s, encoding), keep=['lt', 'amp'])\n for s in strings]\n\n\ndef md5sum(file):\n \"\"\"Calculate the md5 checksum of a file-like object without reading its\n whole content in memory.\n\n >>> from io import BytesIO\n >>> md5sum(BytesIO(b'file content to hash'))\n '784406af91dd5a54fbb9c84c2236595a'\n \"\"\"\n m = hashlib.md5()\n while True:\n d = file.read(8096)\n if not d:\n break\n m.update(d)\n return m.hexdigest()\n\n\ndef rel_has_nofollow(rel):\n \"\"\"Return True if link rel attribute has nofollow type\"\"\"\n return rel is not None and 'nofollow' in rel.replace(',', ' ').split()\n\n\ndef create_instance(objcls, settings, crawler, *args, **kwargs):\n \"\"\"Construct a class instance using its ``from_crawler`` or\n ``from_settings`` constructors, if available.\n\n At least one of ``settings`` and ``crawler`` needs to be different from\n ``None``. If ``settings `` is ``None``, ``crawler.settings`` will be used.\n If ``crawler`` is ``None``, only the ``from_settings`` constructor will be\n tried.\n\n ``*args`` and ``**kwargs`` are forwarded to the constructors.\n\n Raises ``ValueError`` if both ``settings`` and ``crawler`` are ``None``.\n\n .. versionchanged:: 2.2\n Raises ``TypeError`` if the resulting instance is ``None`` (e.g. if an\n extension has not been implemented correctly).\n \"\"\"\n if settings is None:\n if crawler is None:\n raise ValueError(\"Specify at least one of settings and crawler.\")\n settings = crawler.settings\n if crawler and hasattr(objcls, 'from_crawler'):\n instance = objcls.from_crawler(crawler, *args, **kwargs)\n method_name = 'from_crawler'\n elif hasattr(objcls, 'from_settings'):\n instance = objcls.from_settings(settings, *args, **kwargs)\n method_name = 'from_settings'\n else:\n instance = objcls(*args, **kwargs)\n method_name = '__new__'\n if instance is None:\n raise TypeError(f\"{objcls.__qualname__}.{method_name} returned None\")\n return instance\n\n\n@contextmanager\ndef set_environ(**kwargs):\n \"\"\"Temporarily set environment variables inside the context manager and\n fully restore previous environment afterwards\n \"\"\"\n\n original_env = {k: os.environ.get(k) for k in kwargs}\n os.environ.update(kwargs)\n try:\n yield\n finally:\n for k, v in original_env.items():\n if v is None:\n del os.environ[k]\n else:\n os.environ[k] = v\n\n\ndef walk_callable(node):\n \"\"\"Similar to ``ast.walk``, but walks only function body and skips nested\n functions defined within the node.\n \"\"\"\n todo = deque([node])\n walked_func_def = False\n while todo:\n node = todo.popleft()\n if isinstance(node, ast.FunctionDef):\n if walked_func_def:\n continue\n walked_func_def = True\n todo.extend(ast.iter_child_nodes(node))\n yield node\n\n\n_generator_callbacks_cache = LocalWeakReferencedCache(limit=128)\n\n\ndef is_generator_with_return_value(callable):\n \"\"\"\n Returns True if a callable is a generator function which includes a\n 'return' statement with a value different than None, False otherwise\n \"\"\"\n if callable in _generator_callbacks_cache:\n return _generator_callbacks_cache[callable]\n\n def returns_none(return_node):\n value = return_node.value\n return value is None or isinstance(value, ast.NameConstant) and value.value is None\n\n if inspect.isgeneratorfunction(callable):\n code = re.sub(r\"^[\\t ]+\", \"\", inspect.getsource(callable))\n tree = ast.parse(code)\n for node in walk_callable(tree):\n if isinstance(node, ast.Return) and not returns_none(node):\n _generator_callbacks_cache[callable] = True\n return _generator_callbacks_cache[callable]\n\n _generator_callbacks_cache[callable] = False\n return _generator_callbacks_cache[callable]\n\n\ndef warn_on_generator_with_return_value(spider, callable):\n \"\"\"\n Logs a warning if a callable is a generator function and includes\n a 'return' statement with a value different than None\n \"\"\"\n try:\n if is_generator_with_return_value(callable):\n warnings.warn(\n f'The \"{spider.__class__.__name__}.{callable.__name__}\" method is '\n 'a generator and includes a \"return\" statement with a value '\n 'different than None. This could lead to unexpected behaviour. Please see '\n 'https://docs.python.org/3/reference/simple_stmts.html#the-return-statement '\n 'for details about the semantics of the \"return\" statement within generators',\n stacklevel=2,\n )\n except IndentationError:\n callable_name = spider.__class__.__name__ + \".\" + callable.__name__\n warnings.warn(\n f'Unable to determine whether or not \"{callable_name}\" is a generator with a return value. '\n 'This will not prevent your code from working, but it prevents Scrapy from detecting '\n f'potential issues in your implementation of \"{callable_name}\". Please, report this in the '\n 'Scrapy issue tracker (https://github.com/scrapy/scrapy/issues), '\n f'including the code of \"{callable_name}\"',\n stacklevel=2,\n )\n", "path": "scrapy/utils/misc.py"}]}
| 3,887 | 202 |
gh_patches_debug_31674
|
rasdani/github-patches
|
git_diff
|
getredash__redash-5734
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Error to load MongoDB collections
### Issue Summary
When you create a Mongodb data source using a mongodb user which has access to a databse but doesn't have privileges to find records in a specific collection under the database, redash can't refresh the schema as it tried to get a data sample even though the user doesn't have access to the collection, that probably happens because the command list_collections returns a list of all collections regardless if the user has access to its data or not.
### Steps to Reproduce
1. Create a role in mongodb and give access only to certain collections.
2. Create a user in mongodb and assign the previous role to it.
3. Create a data source in redash.
4. Try selecting the newly created data source in the query page.
### Technical details:
* Redash Version: 10.1.0
* Browser/OS: Any
* How did you install Redash: Tried with Helm chart and aws market place
</issue>
<code>
[start of redash/query_runner/mongodb.py]
1 import datetime
2 import logging
3 import re
4
5 from dateutil.parser import parse
6
7 from redash.query_runner import *
8 from redash.utils import JSONEncoder, json_dumps, json_loads, parse_human_time
9
10 logger = logging.getLogger(__name__)
11
12 try:
13 import pymongo
14 from bson.objectid import ObjectId
15 from bson.timestamp import Timestamp
16 from bson.decimal128 import Decimal128
17 from bson.son import SON
18 from bson.json_util import object_hook as bson_object_hook
19
20 enabled = True
21
22 except ImportError:
23 enabled = False
24
25
26 TYPES_MAP = {
27 str: TYPE_STRING,
28 bytes: TYPE_STRING,
29 int: TYPE_INTEGER,
30 float: TYPE_FLOAT,
31 bool: TYPE_BOOLEAN,
32 datetime.datetime: TYPE_DATETIME,
33 }
34
35
36 class MongoDBJSONEncoder(JSONEncoder):
37 def default(self, o):
38 if isinstance(o, ObjectId):
39 return str(o)
40 elif isinstance(o, Timestamp):
41 return super(MongoDBJSONEncoder, self).default(o.as_datetime())
42 elif isinstance(o, Decimal128):
43 return o.to_decimal()
44 return super(MongoDBJSONEncoder, self).default(o)
45
46
47 date_regex = re.compile('ISODate\("(.*)"\)', re.IGNORECASE)
48
49
50 def parse_oids(oids):
51 if not isinstance(oids, list):
52 raise Exception("$oids takes an array as input.")
53
54 return [bson_object_hook({"$oid": oid}) for oid in oids]
55
56
57 def datetime_parser(dct):
58 for k, v in dct.items():
59 if isinstance(v, str):
60 m = date_regex.findall(v)
61 if len(m) > 0:
62 dct[k] = parse(m[0], yearfirst=True)
63
64 if "$humanTime" in dct:
65 return parse_human_time(dct["$humanTime"])
66
67 if "$oids" in dct:
68 return parse_oids(dct["$oids"])
69
70 return bson_object_hook(dct)
71
72
73 def parse_query_json(query):
74 query_data = json_loads(query, object_hook=datetime_parser)
75 return query_data
76
77
78 def _get_column_by_name(columns, column_name):
79 for c in columns:
80 if "name" in c and c["name"] == column_name:
81 return c
82
83 return None
84
85
86 def parse_results(results):
87 rows = []
88 columns = []
89
90 for row in results:
91 parsed_row = {}
92
93 for key in row:
94 if isinstance(row[key], dict):
95 for inner_key in row[key]:
96 column_name = "{}.{}".format(key, inner_key)
97 if _get_column_by_name(columns, column_name) is None:
98 columns.append(
99 {
100 "name": column_name,
101 "friendly_name": column_name,
102 "type": TYPES_MAP.get(
103 type(row[key][inner_key]), TYPE_STRING
104 ),
105 }
106 )
107
108 parsed_row[column_name] = row[key][inner_key]
109
110 else:
111 if _get_column_by_name(columns, key) is None:
112 columns.append(
113 {
114 "name": key,
115 "friendly_name": key,
116 "type": TYPES_MAP.get(type(row[key]), TYPE_STRING),
117 }
118 )
119
120 parsed_row[key] = row[key]
121
122 rows.append(parsed_row)
123
124 return rows, columns
125
126
127 class MongoDB(BaseQueryRunner):
128 should_annotate_query = False
129
130 @classmethod
131 def configuration_schema(cls):
132 return {
133 "type": "object",
134 "properties": {
135 "connectionString": {"type": "string", "title": "Connection String"},
136 "username": {"type": "string"},
137 "password": {"type": "string"},
138 "dbName": {"type": "string", "title": "Database Name"},
139 "replicaSetName": {"type": "string", "title": "Replica Set Name"},
140 "readPreference": {
141 "type": "string",
142 "extendedEnum": [
143 {"value": "primaryPreferred", "name": "Primary Preferred"},
144 {"value": "primary", "name": "Primary"},
145 {"value": "secondary", "name": "Secondary"},
146 {"value": "secondaryPreferred", "name": "Secondary Preferred"},
147 {"value": "nearest", "name": "Nearest"},
148 ],
149 "title": "Replica Set Read Preference",
150 },
151 },
152 "secret": ["password"],
153 "required": ["connectionString", "dbName"],
154 }
155
156 @classmethod
157 def enabled(cls):
158 return enabled
159
160 def __init__(self, configuration):
161 super(MongoDB, self).__init__(configuration)
162
163 self.syntax = "json"
164
165 self.db_name = self.configuration["dbName"]
166
167 self.is_replica_set = (
168 True
169 if "replicaSetName" in self.configuration
170 and self.configuration["replicaSetName"]
171 else False
172 )
173
174 def _get_db(self):
175 kwargs = {}
176 if self.is_replica_set:
177 kwargs["replicaSet"] = self.configuration["replicaSetName"]
178 readPreference = self.configuration.get("readPreference")
179 if readPreference:
180 kwargs["readPreference"] = readPreference
181
182 if "username" in self.configuration:
183 kwargs["username"] = self.configuration["username"]
184
185 if "password" in self.configuration:
186 kwargs["password"] = self.configuration["password"]
187
188 db_connection = pymongo.MongoClient(
189 self.configuration["connectionString"], **kwargs
190 )
191
192 return db_connection[self.db_name]
193
194 def test_connection(self):
195 db = self._get_db()
196 if not db.command("connectionStatus")["ok"]:
197 raise Exception("MongoDB connection error")
198
199 return db
200
201 def _merge_property_names(self, columns, document):
202 for property in document:
203 if property not in columns:
204 columns.append(property)
205
206 def _is_collection_a_view(self, db, collection_name):
207 if "viewOn" in db[collection_name].options():
208 return True
209 else:
210 return False
211
212 def _get_collection_fields(self, db, collection_name):
213 # Since MongoDB is a document based database and each document doesn't have
214 # to have the same fields as another documet in the collection its a bit hard to
215 # show these attributes as fields in the schema.
216 #
217 # For now, the logic is to take the first and last documents (last is determined
218 # by the Natural Order (http://www.mongodb.org/display/DOCS/Sorting+and+Natural+Order)
219 # as we don't know the correct order. In most single server installations it would be
220 # fine. In replicaset when reading from non master it might not return the really last
221 # document written.
222 collection_is_a_view = self._is_collection_a_view(db, collection_name)
223 documents_sample = []
224 if collection_is_a_view:
225 for d in db[collection_name].find().limit(2):
226 documents_sample.append(d)
227 else:
228 for d in db[collection_name].find().sort([("$natural", 1)]).limit(1):
229 documents_sample.append(d)
230
231 for d in db[collection_name].find().sort([("$natural", -1)]).limit(1):
232 documents_sample.append(d)
233 columns = []
234 for d in documents_sample:
235 self._merge_property_names(columns, d)
236 return columns
237
238 def get_schema(self, get_stats=False):
239 schema = {}
240 db = self._get_db()
241 for collection_name in db.collection_names():
242 if collection_name.startswith("system."):
243 continue
244 columns = self._get_collection_fields(db, collection_name)
245 schema[collection_name] = {
246 "name": collection_name,
247 "columns": sorted(columns),
248 }
249
250 return list(schema.values())
251
252 def run_query(self, query, user):
253 db = self._get_db()
254
255 logger.debug(
256 "mongodb connection string: %s", self.configuration["connectionString"]
257 )
258 logger.debug("mongodb got query: %s", query)
259
260 try:
261 query_data = parse_query_json(query)
262 except ValueError:
263 return None, "Invalid query format. The query is not a valid JSON."
264
265 if "collection" not in query_data:
266 return None, "'collection' must have a value to run a query"
267 else:
268 collection = query_data["collection"]
269
270 q = query_data.get("query", None)
271 f = None
272
273 aggregate = query_data.get("aggregate", None)
274 if aggregate:
275 for step in aggregate:
276 if "$sort" in step:
277 sort_list = []
278 for sort_item in step["$sort"]:
279 sort_list.append((sort_item["name"], sort_item["direction"]))
280
281 step["$sort"] = SON(sort_list)
282
283 if "fields" in query_data:
284 f = query_data["fields"]
285
286 s = None
287 if "sort" in query_data and query_data["sort"]:
288 s = []
289 for field_data in query_data["sort"]:
290 s.append((field_data["name"], field_data["direction"]))
291
292 columns = []
293 rows = []
294
295 cursor = None
296 if q or (not q and not aggregate):
297 if s:
298 cursor = db[collection].find(q, f).sort(s)
299 else:
300 cursor = db[collection].find(q, f)
301
302 if "skip" in query_data:
303 cursor = cursor.skip(query_data["skip"])
304
305 if "limit" in query_data:
306 cursor = cursor.limit(query_data["limit"])
307
308 if "count" in query_data:
309 cursor = cursor.count()
310
311 elif aggregate:
312 allow_disk_use = query_data.get("allowDiskUse", False)
313 r = db[collection].aggregate(aggregate, allowDiskUse=allow_disk_use)
314
315 # Backwards compatibility with older pymongo versions.
316 #
317 # Older pymongo version would return a dictionary from an aggregate command.
318 # The dict would contain a "result" key which would hold the cursor.
319 # Newer ones return pymongo.command_cursor.CommandCursor.
320 if isinstance(r, dict):
321 cursor = r["result"]
322 else:
323 cursor = r
324
325 if "count" in query_data:
326 columns.append(
327 {"name": "count", "friendly_name": "count", "type": TYPE_INTEGER}
328 )
329
330 rows.append({"count": cursor})
331 else:
332 rows, columns = parse_results(cursor)
333
334 if f:
335 ordered_columns = []
336 for k in sorted(f, key=f.get):
337 column = _get_column_by_name(columns, k)
338 if column:
339 ordered_columns.append(column)
340
341 columns = ordered_columns
342
343 if query_data.get("sortColumns"):
344 reverse = query_data["sortColumns"] == "desc"
345 columns = sorted(columns, key=lambda col: col["name"], reverse=reverse)
346
347 data = {"columns": columns, "rows": rows}
348 error = None
349 json_data = json_dumps(data, cls=MongoDBJSONEncoder)
350
351 return json_data, error
352
353
354 register(MongoDB)
355
[end of redash/query_runner/mongodb.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/redash/query_runner/mongodb.py b/redash/query_runner/mongodb.py
--- a/redash/query_runner/mongodb.py
+++ b/redash/query_runner/mongodb.py
@@ -221,15 +221,21 @@
# document written.
collection_is_a_view = self._is_collection_a_view(db, collection_name)
documents_sample = []
- if collection_is_a_view:
- for d in db[collection_name].find().limit(2):
- documents_sample.append(d)
- else:
- for d in db[collection_name].find().sort([("$natural", 1)]).limit(1):
- documents_sample.append(d)
-
- for d in db[collection_name].find().sort([("$natural", -1)]).limit(1):
- documents_sample.append(d)
+ try:
+ if collection_is_a_view:
+ for d in db[collection_name].find().limit(2):
+ documents_sample.append(d)
+ else:
+ for d in db[collection_name].find().sort([("$natural", 1)]).limit(1):
+ documents_sample.append(d)
+
+ for d in db[collection_name].find().sort([("$natural", -1)]).limit(1):
+ documents_sample.append(d)
+ except Exception as ex:
+ template = "An exception of type {0} occurred. Arguments:\n{1!r}"
+ message = template.format(type(ex).__name__, ex.args)
+ logger.error(message)
+ return []
columns = []
for d in documents_sample:
self._merge_property_names(columns, d)
@@ -242,10 +248,11 @@
if collection_name.startswith("system."):
continue
columns = self._get_collection_fields(db, collection_name)
- schema[collection_name] = {
- "name": collection_name,
- "columns": sorted(columns),
- }
+ if columns:
+ schema[collection_name] = {
+ "name": collection_name,
+ "columns": sorted(columns),
+ }
return list(schema.values())
|
{"golden_diff": "diff --git a/redash/query_runner/mongodb.py b/redash/query_runner/mongodb.py\n--- a/redash/query_runner/mongodb.py\n+++ b/redash/query_runner/mongodb.py\n@@ -221,15 +221,21 @@\n # document written.\n collection_is_a_view = self._is_collection_a_view(db, collection_name)\n documents_sample = []\n- if collection_is_a_view:\n- for d in db[collection_name].find().limit(2):\n- documents_sample.append(d)\n- else:\n- for d in db[collection_name].find().sort([(\"$natural\", 1)]).limit(1):\n- documents_sample.append(d)\n-\n- for d in db[collection_name].find().sort([(\"$natural\", -1)]).limit(1):\n- documents_sample.append(d)\n+ try:\n+ if collection_is_a_view:\n+ for d in db[collection_name].find().limit(2):\n+ documents_sample.append(d)\n+ else:\n+ for d in db[collection_name].find().sort([(\"$natural\", 1)]).limit(1):\n+ documents_sample.append(d)\n+\n+ for d in db[collection_name].find().sort([(\"$natural\", -1)]).limit(1):\n+ documents_sample.append(d)\n+ except Exception as ex:\n+ template = \"An exception of type {0} occurred. Arguments:\\n{1!r}\"\n+ message = template.format(type(ex).__name__, ex.args)\n+ logger.error(message)\n+ return []\n columns = []\n for d in documents_sample:\n self._merge_property_names(columns, d)\n@@ -242,10 +248,11 @@\n if collection_name.startswith(\"system.\"):\n continue\n columns = self._get_collection_fields(db, collection_name)\n- schema[collection_name] = {\n- \"name\": collection_name,\n- \"columns\": sorted(columns),\n- }\n+ if columns:\n+ schema[collection_name] = {\n+ \"name\": collection_name,\n+ \"columns\": sorted(columns),\n+ }\n \n return list(schema.values())\n", "issue": "Error to load MongoDB collections\n### Issue Summary\r\n\r\nWhen you create a Mongodb data source using a mongodb user which has access to a databse but doesn't have privileges to find records in a specific collection under the database, redash can't refresh the schema as it tried to get a data sample even though the user doesn't have access to the collection, that probably happens because the command list_collections returns a list of all collections regardless if the user has access to its data or not.\r\n\r\n### Steps to Reproduce\r\n\r\n1. Create a role in mongodb and give access only to certain collections.\r\n2. Create a user in mongodb and assign the previous role to it.\r\n3. Create a data source in redash.\r\n4. Try selecting the newly created data source in the query page.\r\n\r\n### Technical details:\r\n\r\n* Redash Version: 10.1.0\r\n* Browser/OS: Any\r\n* How did you install Redash: Tried with Helm chart and aws market place\r\n\n", "before_files": [{"content": "import datetime\nimport logging\nimport re\n\nfrom dateutil.parser import parse\n\nfrom redash.query_runner import *\nfrom redash.utils import JSONEncoder, json_dumps, json_loads, parse_human_time\n\nlogger = logging.getLogger(__name__)\n\ntry:\n import pymongo\n from bson.objectid import ObjectId\n from bson.timestamp import Timestamp\n from bson.decimal128 import Decimal128\n from bson.son import SON\n from bson.json_util import object_hook as bson_object_hook\n\n enabled = True\n\nexcept ImportError:\n enabled = False\n\n\nTYPES_MAP = {\n str: TYPE_STRING,\n bytes: TYPE_STRING,\n int: TYPE_INTEGER,\n float: TYPE_FLOAT,\n bool: TYPE_BOOLEAN,\n datetime.datetime: TYPE_DATETIME,\n}\n\n\nclass MongoDBJSONEncoder(JSONEncoder):\n def default(self, o):\n if isinstance(o, ObjectId):\n return str(o)\n elif isinstance(o, Timestamp):\n return super(MongoDBJSONEncoder, self).default(o.as_datetime())\n elif isinstance(o, Decimal128):\n return o.to_decimal()\n return super(MongoDBJSONEncoder, self).default(o)\n\n\ndate_regex = re.compile('ISODate\\(\"(.*)\"\\)', re.IGNORECASE)\n\n\ndef parse_oids(oids):\n if not isinstance(oids, list):\n raise Exception(\"$oids takes an array as input.\")\n\n return [bson_object_hook({\"$oid\": oid}) for oid in oids]\n\n\ndef datetime_parser(dct):\n for k, v in dct.items():\n if isinstance(v, str):\n m = date_regex.findall(v)\n if len(m) > 0:\n dct[k] = parse(m[0], yearfirst=True)\n\n if \"$humanTime\" in dct:\n return parse_human_time(dct[\"$humanTime\"])\n\n if \"$oids\" in dct:\n return parse_oids(dct[\"$oids\"])\n\n return bson_object_hook(dct)\n\n\ndef parse_query_json(query):\n query_data = json_loads(query, object_hook=datetime_parser)\n return query_data\n\n\ndef _get_column_by_name(columns, column_name):\n for c in columns:\n if \"name\" in c and c[\"name\"] == column_name:\n return c\n\n return None\n\n\ndef parse_results(results):\n rows = []\n columns = []\n\n for row in results:\n parsed_row = {}\n\n for key in row:\n if isinstance(row[key], dict):\n for inner_key in row[key]:\n column_name = \"{}.{}\".format(key, inner_key)\n if _get_column_by_name(columns, column_name) is None:\n columns.append(\n {\n \"name\": column_name,\n \"friendly_name\": column_name,\n \"type\": TYPES_MAP.get(\n type(row[key][inner_key]), TYPE_STRING\n ),\n }\n )\n\n parsed_row[column_name] = row[key][inner_key]\n\n else:\n if _get_column_by_name(columns, key) is None:\n columns.append(\n {\n \"name\": key,\n \"friendly_name\": key,\n \"type\": TYPES_MAP.get(type(row[key]), TYPE_STRING),\n }\n )\n\n parsed_row[key] = row[key]\n\n rows.append(parsed_row)\n\n return rows, columns\n\n\nclass MongoDB(BaseQueryRunner):\n should_annotate_query = False\n\n @classmethod\n def configuration_schema(cls):\n return {\n \"type\": \"object\",\n \"properties\": {\n \"connectionString\": {\"type\": \"string\", \"title\": \"Connection String\"},\n \"username\": {\"type\": \"string\"},\n \"password\": {\"type\": \"string\"},\n \"dbName\": {\"type\": \"string\", \"title\": \"Database Name\"},\n \"replicaSetName\": {\"type\": \"string\", \"title\": \"Replica Set Name\"},\n \"readPreference\": {\n \"type\": \"string\",\n \"extendedEnum\": [\n {\"value\": \"primaryPreferred\", \"name\": \"Primary Preferred\"},\n {\"value\": \"primary\", \"name\": \"Primary\"},\n {\"value\": \"secondary\", \"name\": \"Secondary\"},\n {\"value\": \"secondaryPreferred\", \"name\": \"Secondary Preferred\"},\n {\"value\": \"nearest\", \"name\": \"Nearest\"},\n ],\n \"title\": \"Replica Set Read Preference\",\n },\n },\n \"secret\": [\"password\"],\n \"required\": [\"connectionString\", \"dbName\"],\n }\n\n @classmethod\n def enabled(cls):\n return enabled\n\n def __init__(self, configuration):\n super(MongoDB, self).__init__(configuration)\n\n self.syntax = \"json\"\n\n self.db_name = self.configuration[\"dbName\"]\n\n self.is_replica_set = (\n True\n if \"replicaSetName\" in self.configuration\n and self.configuration[\"replicaSetName\"]\n else False\n )\n\n def _get_db(self):\n kwargs = {}\n if self.is_replica_set:\n kwargs[\"replicaSet\"] = self.configuration[\"replicaSetName\"]\n readPreference = self.configuration.get(\"readPreference\")\n if readPreference:\n kwargs[\"readPreference\"] = readPreference\n\n if \"username\" in self.configuration:\n kwargs[\"username\"] = self.configuration[\"username\"]\n\n if \"password\" in self.configuration:\n kwargs[\"password\"] = self.configuration[\"password\"]\n\n db_connection = pymongo.MongoClient(\n self.configuration[\"connectionString\"], **kwargs\n )\n\n return db_connection[self.db_name]\n\n def test_connection(self):\n db = self._get_db()\n if not db.command(\"connectionStatus\")[\"ok\"]:\n raise Exception(\"MongoDB connection error\")\n\n return db\n\n def _merge_property_names(self, columns, document):\n for property in document:\n if property not in columns:\n columns.append(property)\n\n def _is_collection_a_view(self, db, collection_name):\n if \"viewOn\" in db[collection_name].options():\n return True\n else:\n return False\n\n def _get_collection_fields(self, db, collection_name):\n # Since MongoDB is a document based database and each document doesn't have\n # to have the same fields as another documet in the collection its a bit hard to\n # show these attributes as fields in the schema.\n #\n # For now, the logic is to take the first and last documents (last is determined\n # by the Natural Order (http://www.mongodb.org/display/DOCS/Sorting+and+Natural+Order)\n # as we don't know the correct order. In most single server installations it would be\n # fine. In replicaset when reading from non master it might not return the really last\n # document written.\n collection_is_a_view = self._is_collection_a_view(db, collection_name)\n documents_sample = []\n if collection_is_a_view:\n for d in db[collection_name].find().limit(2):\n documents_sample.append(d)\n else:\n for d in db[collection_name].find().sort([(\"$natural\", 1)]).limit(1):\n documents_sample.append(d)\n\n for d in db[collection_name].find().sort([(\"$natural\", -1)]).limit(1):\n documents_sample.append(d)\n columns = []\n for d in documents_sample:\n self._merge_property_names(columns, d)\n return columns\n\n def get_schema(self, get_stats=False):\n schema = {}\n db = self._get_db()\n for collection_name in db.collection_names():\n if collection_name.startswith(\"system.\"):\n continue\n columns = self._get_collection_fields(db, collection_name)\n schema[collection_name] = {\n \"name\": collection_name,\n \"columns\": sorted(columns),\n }\n\n return list(schema.values())\n\n def run_query(self, query, user):\n db = self._get_db()\n\n logger.debug(\n \"mongodb connection string: %s\", self.configuration[\"connectionString\"]\n )\n logger.debug(\"mongodb got query: %s\", query)\n\n try:\n query_data = parse_query_json(query)\n except ValueError:\n return None, \"Invalid query format. The query is not a valid JSON.\"\n\n if \"collection\" not in query_data:\n return None, \"'collection' must have a value to run a query\"\n else:\n collection = query_data[\"collection\"]\n\n q = query_data.get(\"query\", None)\n f = None\n\n aggregate = query_data.get(\"aggregate\", None)\n if aggregate:\n for step in aggregate:\n if \"$sort\" in step:\n sort_list = []\n for sort_item in step[\"$sort\"]:\n sort_list.append((sort_item[\"name\"], sort_item[\"direction\"]))\n\n step[\"$sort\"] = SON(sort_list)\n\n if \"fields\" in query_data:\n f = query_data[\"fields\"]\n\n s = None\n if \"sort\" in query_data and query_data[\"sort\"]:\n s = []\n for field_data in query_data[\"sort\"]:\n s.append((field_data[\"name\"], field_data[\"direction\"]))\n\n columns = []\n rows = []\n\n cursor = None\n if q or (not q and not aggregate):\n if s:\n cursor = db[collection].find(q, f).sort(s)\n else:\n cursor = db[collection].find(q, f)\n\n if \"skip\" in query_data:\n cursor = cursor.skip(query_data[\"skip\"])\n\n if \"limit\" in query_data:\n cursor = cursor.limit(query_data[\"limit\"])\n\n if \"count\" in query_data:\n cursor = cursor.count()\n\n elif aggregate:\n allow_disk_use = query_data.get(\"allowDiskUse\", False)\n r = db[collection].aggregate(aggregate, allowDiskUse=allow_disk_use)\n\n # Backwards compatibility with older pymongo versions.\n #\n # Older pymongo version would return a dictionary from an aggregate command.\n # The dict would contain a \"result\" key which would hold the cursor.\n # Newer ones return pymongo.command_cursor.CommandCursor.\n if isinstance(r, dict):\n cursor = r[\"result\"]\n else:\n cursor = r\n\n if \"count\" in query_data:\n columns.append(\n {\"name\": \"count\", \"friendly_name\": \"count\", \"type\": TYPE_INTEGER}\n )\n\n rows.append({\"count\": cursor})\n else:\n rows, columns = parse_results(cursor)\n\n if f:\n ordered_columns = []\n for k in sorted(f, key=f.get):\n column = _get_column_by_name(columns, k)\n if column:\n ordered_columns.append(column)\n\n columns = ordered_columns\n\n if query_data.get(\"sortColumns\"):\n reverse = query_data[\"sortColumns\"] == \"desc\"\n columns = sorted(columns, key=lambda col: col[\"name\"], reverse=reverse)\n\n data = {\"columns\": columns, \"rows\": rows}\n error = None\n json_data = json_dumps(data, cls=MongoDBJSONEncoder)\n\n return json_data, error\n\n\nregister(MongoDB)\n", "path": "redash/query_runner/mongodb.py"}]}
| 4,079 | 470 |
gh_patches_debug_4414
|
rasdani/github-patches
|
git_diff
|
Lightning-AI__pytorch-lightning-3459
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Error in transfer_batch_to_device when None type is in the batch
<!--
### Common bugs:
1. Tensorboard not showing in Jupyter-notebook see [issue 79](https://github.com/PyTorchLightning/pytorch-lightning/issues/79).
2. PyTorch 1.1.0 vs 1.2.0 support [see FAQ](https://github.com/PyTorchLightning/pytorch-lightning#faq)
-->
## 🐛 Bug
<!-- A clear and concise description of what the bug is. -->
### To Reproduce
Steps to reproduce the behavior:
1. There should be no `torchtext` pre-installed
2. Run the sample code
<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->
#### Code sample
```import torch
from torch.utils.data import DataLoader
import pytorch_lightning as pl
def collate_fn(batch):
return batch
class MyDataModule(pl.LightningDataModule):
def __init__(self):
super().__init__()
def prepare_data(self):
pass
def setup(self, stage):
self.train = [{"input": torch.randn(1,2), "output": None}]
def train_dataloader(self):
return DataLoader(self.train, batch_size=1, collate_fn=collate_fn)
class MyModel(pl.LightningModule):
def __init__(self):
super().__init__()
self.linear = torch.nn.Linear(2, 1)
def forward(self, x):
return self.linear(x)
def configure_optimizers(self):
return torch.optim.Adam(self.parameters())
def training_step(self, batch, batch_idx):
x = batch[0]["input"]
y = batch[0]["output"]
loss = self(x)
result = pl.TrainResult(loss)
result.log('train_loss', loss, on_epoch=True)
return result
def main():
# Dataset
data_module = MyDataModule()
# Model
model = MyModel()
# Train
trainer = pl.Trainer(max_steps=1)
trainer.fit(model, datamodule=data_module)
if __name__ == "__main__":
main()
```
<!-- Ideally attach a minimal code sample to reproduce the decried issue.
Minimal means having the shortest code but still preserving the bug. -->
### Expected behavior
The above code runs fine if the package `torchtext` is installed. However, the code raises following error if `torchtext` is not available and I believe this inconsistency is a bug.
```
File "python3.6/site-packages/pytorch_lightning/utilities/apply_func.py", line 122, in batch_to
return data.to(device, **kwargs)
AttributeError: 'NoneType' object has no attribute 'to'
python-BaseException
```
I think this line of the [code](https://github.com/PyTorchLightning/pytorch-lightning/blob/f46318ebfeb785a659c49091a6871584ccde3ee1/pytorch_lightning/utilities/apply_func.py#L24) is the cause of the problem
<!-- A clear and concise description of what you expected to happen. -->
### Environment
* CUDA:
- GPU:
- TITAN Xp
- TITAN Xp
- TITAN Xp
- TITAN Xp
- TITAN Xp
- TITAN Xp
- TITAN Xp
- TITAN Xp
- available: True
- version: 10.2
* Packages:
- numpy: 1.18.4
- pyTorch_debug: False
- pyTorch_version: 1.6.0
- pytorch-lightning: 0.9.0
- tensorboard: 2.2.1
- tqdm: 4.46.0
* System:
- OS: Linux
- architecture:
- 64bit
- ELF
- processor: x86_64
- python: 3.6.8
- version: #81~16.04.1-Ubuntu SMP Tue Nov 26 16:34:21 UTC 2019
</issue>
<code>
[start of pytorch_lightning/utilities/apply_func.py]
1 # Copyright The PyTorch Lightning team.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import importlib
16 from abc import ABC
17 from collections.abc import Mapping, Sequence
18 from copy import copy
19 from typing import Any, Callable, Union
20
21 import torch
22
23 TORCHTEXT_AVAILABLE = importlib.util.find_spec("torchtext") is not None
24 if TORCHTEXT_AVAILABLE:
25 from torchtext.data import Batch
26 else:
27 Batch = type(None)
28
29
30 def apply_to_collection(data: Any, dtype: Union[type, tuple], function: Callable, *args, **kwargs) -> Any:
31 """
32 Recursively applies a function to all elements of a certain dtype.
33
34 Args:
35 data: the collection to apply the function to
36 dtype: the given function will be applied to all elements of this dtype
37 function: the function to apply
38 *args: positional arguments (will be forwarded to calls of ``function``)
39 **kwargs: keyword arguments (will be forwarded to calls of ``function``)
40
41 Returns:
42 the resulting collection
43
44 """
45 elem_type = type(data)
46
47 # Breaking condition
48 if isinstance(data, dtype):
49 return function(data, *args, **kwargs)
50
51 # Recursively apply to collection items
52 elif isinstance(data, Mapping):
53 return elem_type({k: apply_to_collection(v, dtype, function, *args, **kwargs)
54 for k, v in data.items()})
55 elif isinstance(data, tuple) and hasattr(data, '_fields'): # named tuple
56 return elem_type(*(apply_to_collection(d, dtype, function, *args, **kwargs) for d in data))
57 elif isinstance(data, Sequence) and not isinstance(data, str):
58 return elem_type([apply_to_collection(d, dtype, function, *args, **kwargs) for d in data])
59
60 # data is neither of dtype, nor a collection
61 return data
62
63
64 class TransferableDataType(ABC):
65 """
66 A custom type for data that can be moved to a torch device via `.to(...)`.
67
68 Example:
69
70 >>> isinstance(dict, TransferableDataType)
71 False
72 >>> isinstance(torch.rand(2, 3), TransferableDataType)
73 True
74 >>> class CustomObject:
75 ... def __init__(self):
76 ... self.x = torch.rand(2, 2)
77 ... def to(self, device):
78 ... self.x = self.x.to(device)
79 ... return self
80 >>> isinstance(CustomObject(), TransferableDataType)
81 True
82 """
83
84 @classmethod
85 def __subclasshook__(cls, subclass):
86 if cls is TransferableDataType:
87 to = getattr(subclass, "to", None)
88 return callable(to)
89 return NotImplemented
90
91
92 def move_data_to_device(batch: Any, device: torch.device):
93 """
94 Transfers a collection of data to the given device. Any object that defines a method
95 ``to(device)`` will be moved and all other objects in the collection will be left untouched.
96
97 Args:
98 batch: A tensor or collection of tensors or anything that has a method `.to(...)`.
99 See :func:`apply_to_collection` for a list of supported collection types.
100 device: The device to which the data should be moved
101
102 Return:
103 the same collection but with all contained tensors residing on the new device.
104
105 See Also:
106 - :meth:`torch.Tensor.to`
107 - :class:`torch.device`
108 """
109
110 def batch_to(data):
111 # try to move torchtext data first
112 if TORCHTEXT_AVAILABLE and isinstance(data, Batch):
113
114 # Shallow copy because each Batch has a reference to Dataset which contains all examples
115 device_data = copy(data)
116 for field in data.fields:
117 device_field = move_data_to_device(getattr(data, field), device)
118 setattr(device_data, field, device_field)
119 return device_data
120
121 kwargs = dict(non_blocking=True) if isinstance(data, torch.Tensor) else {}
122 return data.to(device, **kwargs)
123
124 return apply_to_collection(batch, dtype=(TransferableDataType, Batch), function=batch_to)
125
[end of pytorch_lightning/utilities/apply_func.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pytorch_lightning/utilities/apply_func.py b/pytorch_lightning/utilities/apply_func.py
--- a/pytorch_lightning/utilities/apply_func.py
+++ b/pytorch_lightning/utilities/apply_func.py
@@ -121,4 +121,5 @@
kwargs = dict(non_blocking=True) if isinstance(data, torch.Tensor) else {}
return data.to(device, **kwargs)
- return apply_to_collection(batch, dtype=(TransferableDataType, Batch), function=batch_to)
+ dtype = (TransferableDataType, Batch) if TORCHTEXT_AVAILABLE else TransferableDataType
+ return apply_to_collection(batch, dtype=dtype, function=batch_to)
|
{"golden_diff": "diff --git a/pytorch_lightning/utilities/apply_func.py b/pytorch_lightning/utilities/apply_func.py\n--- a/pytorch_lightning/utilities/apply_func.py\n+++ b/pytorch_lightning/utilities/apply_func.py\n@@ -121,4 +121,5 @@\n kwargs = dict(non_blocking=True) if isinstance(data, torch.Tensor) else {}\n return data.to(device, **kwargs)\n \n- return apply_to_collection(batch, dtype=(TransferableDataType, Batch), function=batch_to)\n+ dtype = (TransferableDataType, Batch) if TORCHTEXT_AVAILABLE else TransferableDataType\n+ return apply_to_collection(batch, dtype=dtype, function=batch_to)\n", "issue": "Error in transfer_batch_to_device when None type is in the batch\n<!-- \r\n### Common bugs:\r\n1. Tensorboard not showing in Jupyter-notebook see [issue 79](https://github.com/PyTorchLightning/pytorch-lightning/issues/79). \r\n2. PyTorch 1.1.0 vs 1.2.0 support [see FAQ](https://github.com/PyTorchLightning/pytorch-lightning#faq) \r\n-->\r\n\r\n## \ud83d\udc1b Bug\r\n\r\n<!-- A clear and concise description of what the bug is. -->\r\n\r\n### To Reproduce\r\n\r\nSteps to reproduce the behavior:\r\n\r\n1. There should be no `torchtext` pre-installed\r\n2. Run the sample code\r\n\r\n<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->\r\n\r\n\r\n#### Code sample\r\n```import torch\r\nfrom torch.utils.data import DataLoader\r\nimport pytorch_lightning as pl\r\n\r\n\r\ndef collate_fn(batch):\r\n return batch\r\n\r\n\r\nclass MyDataModule(pl.LightningDataModule):\r\n def __init__(self):\r\n super().__init__()\r\n\r\n def prepare_data(self):\r\n pass\r\n\r\n def setup(self, stage):\r\n self.train = [{\"input\": torch.randn(1,2), \"output\": None}]\r\n\r\n def train_dataloader(self):\r\n return DataLoader(self.train, batch_size=1, collate_fn=collate_fn)\r\n\r\n\r\nclass MyModel(pl.LightningModule):\r\n def __init__(self):\r\n super().__init__()\r\n self.linear = torch.nn.Linear(2, 1)\r\n\r\n def forward(self, x):\r\n return self.linear(x)\r\n\r\n def configure_optimizers(self):\r\n return torch.optim.Adam(self.parameters())\r\n\r\n def training_step(self, batch, batch_idx):\r\n x = batch[0][\"input\"]\r\n y = batch[0][\"output\"]\r\n loss = self(x)\r\n result = pl.TrainResult(loss)\r\n result.log('train_loss', loss, on_epoch=True)\r\n return result\r\n\r\n\r\ndef main():\r\n # Dataset\r\n data_module = MyDataModule()\r\n\r\n # Model\r\n model = MyModel()\r\n\r\n # Train\r\n trainer = pl.Trainer(max_steps=1)\r\n trainer.fit(model, datamodule=data_module)\r\n\r\n\r\nif __name__ == \"__main__\":\r\n main()\r\n```\r\n<!-- Ideally attach a minimal code sample to reproduce the decried issue. \r\nMinimal means having the shortest code but still preserving the bug. -->\r\n\r\n### Expected behavior\r\nThe above code runs fine if the package `torchtext` is installed. However, the code raises following error if `torchtext` is not available and I believe this inconsistency is a bug.\r\n\r\n```\r\n File \"python3.6/site-packages/pytorch_lightning/utilities/apply_func.py\", line 122, in batch_to\r\n return data.to(device, **kwargs)\r\nAttributeError: 'NoneType' object has no attribute 'to'\r\npython-BaseException\r\n```\r\n\r\nI think this line of the [code](https://github.com/PyTorchLightning/pytorch-lightning/blob/f46318ebfeb785a659c49091a6871584ccde3ee1/pytorch_lightning/utilities/apply_func.py#L24) is the cause of the problem \r\n\r\n<!-- A clear and concise description of what you expected to happen. -->\r\n\r\n### Environment\r\n* CUDA:\r\n\t- GPU:\r\n\t\t- TITAN Xp\r\n\t\t- TITAN Xp\r\n\t\t- TITAN Xp\r\n\t\t- TITAN Xp\r\n\t\t- TITAN Xp\r\n\t\t- TITAN Xp\r\n\t\t- TITAN Xp\r\n\t\t- TITAN Xp\r\n\t- available: True\r\n\t- version: 10.2\r\n* Packages:\r\n\t- numpy: 1.18.4\r\n\t- pyTorch_debug: False\r\n\t- pyTorch_version: 1.6.0\r\n\t- pytorch-lightning: 0.9.0\r\n\t- tensorboard: 2.2.1\r\n\t- tqdm: 4.46.0\r\n* System:\r\n\t- OS: Linux\r\n\t- architecture:\r\n\t\t- 64bit\r\n\t\t- ELF\r\n\t- processor: x86_64\r\n\t- python: 3.6.8\r\n\t- version: #81~16.04.1-Ubuntu SMP Tue Nov 26 16:34:21 UTC 2019\r\n\n", "before_files": [{"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport importlib\nfrom abc import ABC\nfrom collections.abc import Mapping, Sequence\nfrom copy import copy\nfrom typing import Any, Callable, Union\n\nimport torch\n\nTORCHTEXT_AVAILABLE = importlib.util.find_spec(\"torchtext\") is not None\nif TORCHTEXT_AVAILABLE:\n from torchtext.data import Batch\nelse:\n Batch = type(None)\n\n\ndef apply_to_collection(data: Any, dtype: Union[type, tuple], function: Callable, *args, **kwargs) -> Any:\n \"\"\"\n Recursively applies a function to all elements of a certain dtype.\n\n Args:\n data: the collection to apply the function to\n dtype: the given function will be applied to all elements of this dtype\n function: the function to apply\n *args: positional arguments (will be forwarded to calls of ``function``)\n **kwargs: keyword arguments (will be forwarded to calls of ``function``)\n\n Returns:\n the resulting collection\n\n \"\"\"\n elem_type = type(data)\n\n # Breaking condition\n if isinstance(data, dtype):\n return function(data, *args, **kwargs)\n\n # Recursively apply to collection items\n elif isinstance(data, Mapping):\n return elem_type({k: apply_to_collection(v, dtype, function, *args, **kwargs)\n for k, v in data.items()})\n elif isinstance(data, tuple) and hasattr(data, '_fields'): # named tuple\n return elem_type(*(apply_to_collection(d, dtype, function, *args, **kwargs) for d in data))\n elif isinstance(data, Sequence) and not isinstance(data, str):\n return elem_type([apply_to_collection(d, dtype, function, *args, **kwargs) for d in data])\n\n # data is neither of dtype, nor a collection\n return data\n\n\nclass TransferableDataType(ABC):\n \"\"\"\n A custom type for data that can be moved to a torch device via `.to(...)`.\n\n Example:\n\n >>> isinstance(dict, TransferableDataType)\n False\n >>> isinstance(torch.rand(2, 3), TransferableDataType)\n True\n >>> class CustomObject:\n ... def __init__(self):\n ... self.x = torch.rand(2, 2)\n ... def to(self, device):\n ... self.x = self.x.to(device)\n ... return self\n >>> isinstance(CustomObject(), TransferableDataType)\n True\n \"\"\"\n\n @classmethod\n def __subclasshook__(cls, subclass):\n if cls is TransferableDataType:\n to = getattr(subclass, \"to\", None)\n return callable(to)\n return NotImplemented\n\n\ndef move_data_to_device(batch: Any, device: torch.device):\n \"\"\"\n Transfers a collection of data to the given device. Any object that defines a method\n ``to(device)`` will be moved and all other objects in the collection will be left untouched.\n\n Args:\n batch: A tensor or collection of tensors or anything that has a method `.to(...)`.\n See :func:`apply_to_collection` for a list of supported collection types.\n device: The device to which the data should be moved\n\n Return:\n the same collection but with all contained tensors residing on the new device.\n\n See Also:\n - :meth:`torch.Tensor.to`\n - :class:`torch.device`\n \"\"\"\n\n def batch_to(data):\n # try to move torchtext data first\n if TORCHTEXT_AVAILABLE and isinstance(data, Batch):\n\n # Shallow copy because each Batch has a reference to Dataset which contains all examples\n device_data = copy(data)\n for field in data.fields:\n device_field = move_data_to_device(getattr(data, field), device)\n setattr(device_data, field, device_field)\n return device_data\n\n kwargs = dict(non_blocking=True) if isinstance(data, torch.Tensor) else {}\n return data.to(device, **kwargs)\n\n return apply_to_collection(batch, dtype=(TransferableDataType, Batch), function=batch_to)\n", "path": "pytorch_lightning/utilities/apply_func.py"}]}
| 2,785 | 150 |
gh_patches_debug_37341
|
rasdani/github-patches
|
git_diff
|
python__mypy-440
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Refactor overloads away in 'random' stubs
It seems that all the `@overload` decorators in `stubs/3.2/random.py` could be represented without overloading, such as by using union types.
</issue>
<code>
[start of stubs/3.2/random.py]
1 # Stubs for random
2 # Ron Murawski <[email protected]>
3 # Updated by Jukka Lehtosalo
4
5 # based on http://docs.python.org/3.2/library/random.html
6
7 # ----- random classes -----
8
9 import _random
10 from typing import (
11 Any, overload, typevar, Sequence, List, Function, AbstractSet
12 )
13
14 t = typevar('t')
15
16 class Random(_random.Random):
17 def __init__(self, x: Any = None) -> None: pass
18 def seed(self, a: Any = None, version: int = 2) -> None: pass
19 def getstate(self) -> tuple: pass
20 def setstate(self, state: tuple) -> None: pass
21 def getrandbits(self, k: int) -> int: pass
22
23 @overload
24 def randrange(self, stop: int) -> int: pass
25 @overload
26 def randrange(self, start: int, stop: int, step: int = 1) -> int: pass
27
28 def randint(self, a: int, b: int) -> int: pass
29 def choice(self, seq: Sequence[t]) -> t: pass
30
31 @overload
32 def shuffle(self, x: List[Any]) -> None: pass
33 @overload
34 def shuffle(self, x: List[Any], random: Function[[], float]) -> None: pass
35
36 @overload
37 def sample(self, population: Sequence[t], k: int) -> List[t]: pass
38 @overload
39 def sample(self, population: AbstractSet[t], k: int) -> List[t]: pass
40
41 def random(self) -> float: pass
42 def uniform(self, a: float, b: float) -> float: pass
43 def triangular(self, low: float = 0.0, high: float = 1.0,
44 mode: float = None) -> float: pass
45 def betavariate(self, alpha: float, beta: float) -> float: pass
46 def expovariate(self, lambd: float) -> float: pass
47 def gammavariate(self, alpha: float, beta: float) -> float: pass
48 def gauss(self, mu: float, sigma: float) -> float: pass
49 def lognormvariate(self, mu: float, sigma: float) -> float: pass
50 def normalvariate(self, mu: float, sigma: float) -> float: pass
51 def vonmisesvariate(self, mu: float, kappa: float) -> float: pass
52 def paretovariate(self, alpha: float) -> float: pass
53 def weibullvariate(self, alpha: float, beta: float) -> float: pass
54
55 # SystemRandom is not implemented for all OS's; good on Windows & Linux
56 class SystemRandom:
57 def __init__(self, randseed: object = None) -> None: pass
58 def random(self) -> float: pass
59 def getrandbits(self, k: int) -> int: pass
60 def seed(self, arg: object) -> None: pass
61
62 # ----- random function stubs -----
63 def seed(a: Any = None, version: int = 2) -> None: pass
64 def getstate() -> object: pass
65 def setstate(state: object) -> None: pass
66 def getrandbits(k: int) -> int: pass
67
68 @overload
69 def randrange(stop: int) -> int: pass
70 @overload
71 def randrange(start: int, stop: int, step: int = 1) -> int: pass
72
73 def randint(a: int, b: int) -> int: pass
74 def choice(seq: Sequence[t]) -> t: pass
75
76 @overload
77 def shuffle(x: List[Any]) -> None: pass
78 @overload
79 def shuffle(x: List[Any], random: Function[[], float]) -> None: pass
80
81 @overload
82 def sample(population: Sequence[t], k: int) -> List[t]: pass
83 @overload
84 def sample(population: AbstractSet[t], k: int) -> List[t]: pass
85
86 def random() -> float: pass
87 def uniform(a: float, b: float) -> float: pass
88 def triangular(low: float = 0.0, high: float = 1.0,
89 mode: float = None) -> float: pass
90 def betavariate(alpha: float, beta: float) -> float: pass
91 def expovariate(lambd: float) -> float: pass
92 def gammavariate(alpha: float, beta: float) -> float: pass
93 def gauss(mu: float, sigma: float) -> float: pass
94 def lognormvariate(mu: float, sigma: float) -> float: pass
95 def normalvariate(mu: float, sigma: float) -> float: pass
96 def vonmisesvariate(mu: float, kappa: float) -> float: pass
97 def paretovariate(alpha: float) -> float: pass
98 def weibullvariate(alpha: float, beta: float) -> float: pass
99
[end of stubs/3.2/random.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/stubs/3.2/random.py b/stubs/3.2/random.py
--- a/stubs/3.2/random.py
+++ b/stubs/3.2/random.py
@@ -8,7 +8,7 @@
import _random
from typing import (
- Any, overload, typevar, Sequence, List, Function, AbstractSet
+ Any, typevar, Sequence, List, Function, AbstractSet, Union
)
t = typevar('t')
@@ -19,25 +19,11 @@
def getstate(self) -> tuple: pass
def setstate(self, state: tuple) -> None: pass
def getrandbits(self, k: int) -> int: pass
-
- @overload
- def randrange(self, stop: int) -> int: pass
- @overload
- def randrange(self, start: int, stop: int, step: int = 1) -> int: pass
-
+ def randrange(self, start: int, stop: Union[int, None] = None, step: int = 1) -> int: pass
def randint(self, a: int, b: int) -> int: pass
def choice(self, seq: Sequence[t]) -> t: pass
-
- @overload
- def shuffle(self, x: List[Any]) -> None: pass
- @overload
- def shuffle(self, x: List[Any], random: Function[[], float]) -> None: pass
-
- @overload
- def sample(self, population: Sequence[t], k: int) -> List[t]: pass
- @overload
- def sample(self, population: AbstractSet[t], k: int) -> List[t]: pass
-
+ def shuffle(self, x: List[Any], random: Union[Function[[], float], None] = None) -> None: pass
+ def sample(self, population: Union[Sequence[t], AbstractSet[t]], k: int) -> List[t]: pass
def random(self) -> float: pass
def uniform(self, a: float, b: float) -> float: pass
def triangular(self, low: float = 0.0, high: float = 1.0,
@@ -64,25 +50,11 @@
def getstate() -> object: pass
def setstate(state: object) -> None: pass
def getrandbits(k: int) -> int: pass
-
-@overload
-def randrange(stop: int) -> int: pass
-@overload
-def randrange(start: int, stop: int, step: int = 1) -> int: pass
-
+def randrange(start: int, stop: Union[None, int] = None, step: int = 1) -> int: pass
def randint(a: int, b: int) -> int: pass
def choice(seq: Sequence[t]) -> t: pass
-
-@overload
-def shuffle(x: List[Any]) -> None: pass
-@overload
-def shuffle(x: List[Any], random: Function[[], float]) -> None: pass
-
-@overload
-def sample(population: Sequence[t], k: int) -> List[t]: pass
-@overload
-def sample(population: AbstractSet[t], k: int) -> List[t]: pass
-
+def shuffle(x: List[Any], random: Union[Function[[], float], None] = None) -> None: pass
+def sample(population: Union[Sequence[t], AbstractSet[t]], k: int) -> List[t]: pass
def random() -> float: pass
def uniform(a: float, b: float) -> float: pass
def triangular(low: float = 0.0, high: float = 1.0,
|
{"golden_diff": "diff --git a/stubs/3.2/random.py b/stubs/3.2/random.py\n--- a/stubs/3.2/random.py\n+++ b/stubs/3.2/random.py\n@@ -8,7 +8,7 @@\n \n import _random\n from typing import (\n- Any, overload, typevar, Sequence, List, Function, AbstractSet\n+ Any, typevar, Sequence, List, Function, AbstractSet, Union\n )\n \n t = typevar('t')\n@@ -19,25 +19,11 @@\n def getstate(self) -> tuple: pass\n def setstate(self, state: tuple) -> None: pass\n def getrandbits(self, k: int) -> int: pass\n-\n- @overload\n- def randrange(self, stop: int) -> int: pass\n- @overload\n- def randrange(self, start: int, stop: int, step: int = 1) -> int: pass\n-\n+ def randrange(self, start: int, stop: Union[int, None] = None, step: int = 1) -> int: pass\n def randint(self, a: int, b: int) -> int: pass\n def choice(self, seq: Sequence[t]) -> t: pass\n-\n- @overload\n- def shuffle(self, x: List[Any]) -> None: pass\n- @overload\n- def shuffle(self, x: List[Any], random: Function[[], float]) -> None: pass\n-\n- @overload\n- def sample(self, population: Sequence[t], k: int) -> List[t]: pass\n- @overload\n- def sample(self, population: AbstractSet[t], k: int) -> List[t]: pass\n-\n+ def shuffle(self, x: List[Any], random: Union[Function[[], float], None] = None) -> None: pass\n+ def sample(self, population: Union[Sequence[t], AbstractSet[t]], k: int) -> List[t]: pass\n def random(self) -> float: pass\n def uniform(self, a: float, b: float) -> float: pass\n def triangular(self, low: float = 0.0, high: float = 1.0,\n@@ -64,25 +50,11 @@\n def getstate() -> object: pass\n def setstate(state: object) -> None: pass\n def getrandbits(k: int) -> int: pass\n-\n-@overload\n-def randrange(stop: int) -> int: pass\n-@overload\n-def randrange(start: int, stop: int, step: int = 1) -> int: pass\n-\n+def randrange(start: int, stop: Union[None, int] = None, step: int = 1) -> int: pass\n def randint(a: int, b: int) -> int: pass\n def choice(seq: Sequence[t]) -> t: pass\n-\n-@overload\n-def shuffle(x: List[Any]) -> None: pass\n-@overload\n-def shuffle(x: List[Any], random: Function[[], float]) -> None: pass\n-\n-@overload\n-def sample(population: Sequence[t], k: int) -> List[t]: pass\n-@overload\n-def sample(population: AbstractSet[t], k: int) -> List[t]: pass\n-\n+def shuffle(x: List[Any], random: Union[Function[[], float], None] = None) -> None: pass\n+def sample(population: Union[Sequence[t], AbstractSet[t]], k: int) -> List[t]: pass\n def random() -> float: pass\n def uniform(a: float, b: float) -> float: pass\n def triangular(low: float = 0.0, high: float = 1.0,\n", "issue": "Refactor overloads away in 'random' stubs\nIt seems that all the `@overload` decorators in `stubs/3.2/random.py` could be represented without overloading, such as by using union types.\n\n", "before_files": [{"content": "# Stubs for random\n# Ron Murawski <[email protected]>\n# Updated by Jukka Lehtosalo\n\n# based on http://docs.python.org/3.2/library/random.html\n\n# ----- random classes -----\n\nimport _random\nfrom typing import (\n Any, overload, typevar, Sequence, List, Function, AbstractSet\n)\n\nt = typevar('t')\n\nclass Random(_random.Random):\n def __init__(self, x: Any = None) -> None: pass\n def seed(self, a: Any = None, version: int = 2) -> None: pass\n def getstate(self) -> tuple: pass\n def setstate(self, state: tuple) -> None: pass\n def getrandbits(self, k: int) -> int: pass\n\n @overload\n def randrange(self, stop: int) -> int: pass\n @overload\n def randrange(self, start: int, stop: int, step: int = 1) -> int: pass\n\n def randint(self, a: int, b: int) -> int: pass\n def choice(self, seq: Sequence[t]) -> t: pass\n\n @overload\n def shuffle(self, x: List[Any]) -> None: pass\n @overload\n def shuffle(self, x: List[Any], random: Function[[], float]) -> None: pass\n\n @overload\n def sample(self, population: Sequence[t], k: int) -> List[t]: pass\n @overload\n def sample(self, population: AbstractSet[t], k: int) -> List[t]: pass\n\n def random(self) -> float: pass\n def uniform(self, a: float, b: float) -> float: pass\n def triangular(self, low: float = 0.0, high: float = 1.0,\n mode: float = None) -> float: pass\n def betavariate(self, alpha: float, beta: float) -> float: pass\n def expovariate(self, lambd: float) -> float: pass\n def gammavariate(self, alpha: float, beta: float) -> float: pass\n def gauss(self, mu: float, sigma: float) -> float: pass\n def lognormvariate(self, mu: float, sigma: float) -> float: pass\n def normalvariate(self, mu: float, sigma: float) -> float: pass\n def vonmisesvariate(self, mu: float, kappa: float) -> float: pass\n def paretovariate(self, alpha: float) -> float: pass\n def weibullvariate(self, alpha: float, beta: float) -> float: pass\n\n# SystemRandom is not implemented for all OS's; good on Windows & Linux\nclass SystemRandom:\n def __init__(self, randseed: object = None) -> None: pass\n def random(self) -> float: pass\n def getrandbits(self, k: int) -> int: pass\n def seed(self, arg: object) -> None: pass\n\n# ----- random function stubs -----\ndef seed(a: Any = None, version: int = 2) -> None: pass\ndef getstate() -> object: pass\ndef setstate(state: object) -> None: pass\ndef getrandbits(k: int) -> int: pass\n\n@overload\ndef randrange(stop: int) -> int: pass\n@overload\ndef randrange(start: int, stop: int, step: int = 1) -> int: pass\n\ndef randint(a: int, b: int) -> int: pass\ndef choice(seq: Sequence[t]) -> t: pass\n\n@overload\ndef shuffle(x: List[Any]) -> None: pass\n@overload\ndef shuffle(x: List[Any], random: Function[[], float]) -> None: pass\n\n@overload\ndef sample(population: Sequence[t], k: int) -> List[t]: pass\n@overload\ndef sample(population: AbstractSet[t], k: int) -> List[t]: pass\n\ndef random() -> float: pass\ndef uniform(a: float, b: float) -> float: pass\ndef triangular(low: float = 0.0, high: float = 1.0,\n mode: float = None) -> float: pass\ndef betavariate(alpha: float, beta: float) -> float: pass\ndef expovariate(lambd: float) -> float: pass\ndef gammavariate(alpha: float, beta: float) -> float: pass\ndef gauss(mu: float, sigma: float) -> float: pass\ndef lognormvariate(mu: float, sigma: float) -> float: pass\ndef normalvariate(mu: float, sigma: float) -> float: pass\ndef vonmisesvariate(mu: float, kappa: float) -> float: pass\ndef paretovariate(alpha: float) -> float: pass\ndef weibullvariate(alpha: float, beta: float) -> float: pass\n", "path": "stubs/3.2/random.py"}]}
| 1,892 | 843 |
gh_patches_debug_60352
|
rasdani/github-patches
|
git_diff
|
blaze__blaze-1129
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
add column names to compute.json response in blaze server
xref: https://github.com/bokeh/bokeh/issues/2330
</issue>
<code>
[start of blaze/server/server.py]
1 from __future__ import absolute_import, division, print_function
2
3 import socket
4
5 import flask
6 from flask import Blueprint, Flask, request
7
8 from toolz import assoc
9
10 from datashape.predicates import iscollection, isscalar
11 from odo import odo
12
13 import blaze
14 from blaze import compute
15 from blaze.expr import utils as expr_utils
16 from blaze.compute import compute_up
17
18 from .serialization import json
19 from ..interactive import InteractiveSymbol, coerce_scalar
20 from ..expr import Expr, symbol
21
22 from datashape import Mono, discover
23
24
25 __all__ = 'Server', 'to_tree', 'from_tree'
26
27 # http://www.speedguide.net/port.php?port=6363
28 # http://en.wikipedia.org/wiki/List_of_TCP_and_UDP_port_numbers
29 DEFAULT_PORT = 6363
30
31
32 api = Blueprint('api', __name__)
33 pickle_extension_api = Blueprint('pickle_extension_api', __name__)
34
35
36 def _get_option(option, options):
37 try:
38 return options[option]
39 except KeyError:
40 # Provides a more informative error message.
41 raise TypeError(
42 'The blaze api must be registered with {option}'.format(
43 option=option,
44 ),
45 )
46
47
48 def _register_api(app, options, first_registration=False):
49 """
50 Register the data with the blueprint.
51 """
52 _get_data.cache[app] = _get_option('data', options)
53 _get_format.cache[app] = dict(
54 (f.name, f) for f in _get_option('formats', options)
55 )
56 # Call the original register function.
57 Blueprint.register(api, app, options, first_registration)
58
59 api.register = _register_api
60
61
62 def _get_data():
63 """
64 Retrieve the current application's data for use in the blaze server
65 endpoints.
66 """
67 return _get_data.cache[flask.current_app]
68 _get_data.cache = {}
69
70
71 def _get_format(name):
72 return _get_format.cache[flask.current_app][name]
73 _get_format.cache = {}
74
75
76 class Server(object):
77
78 """ Blaze Data Server
79
80 Host local data through a web API
81
82 Parameters
83 ----------
84 data : ``dict`` or ``None``, optional
85 A dictionary mapping dataset name to any data format that blaze
86 understands.
87
88 formats : ``iterable[SerializationFormat]``, optional
89 An iterable of supported serialization formats. By default, the
90 server will support JSON.
91 A serialization format is an object that supports:
92 name, loads, and dumps.
93
94 Examples
95 --------
96 >>> from pandas import DataFrame
97 >>> df = DataFrame([[1, 'Alice', 100],
98 ... [2, 'Bob', -200],
99 ... [3, 'Alice', 300],
100 ... [4, 'Dennis', 400],
101 ... [5, 'Bob', -500]],
102 ... columns=['id', 'name', 'amount'])
103
104 >>> server = Server({'accounts': df})
105 >>> server.run() # doctest: +SKIP
106 """
107 __slots__ = 'app', 'data', 'port'
108
109 def __init__(self, data=None, formats=None):
110 app = self.app = Flask('blaze.server.server')
111 if data is None:
112 data = dict()
113 app.register_blueprint(
114 api,
115 data=data,
116 formats=formats if formats is not None else (json,),
117 )
118 self.data = data
119
120 def run(self, *args, **kwargs):
121 """Run the server"""
122 port = kwargs.pop('port', DEFAULT_PORT)
123 self.port = port
124 try:
125 self.app.run(*args, port=port, **kwargs)
126 except socket.error:
127 print("\tOops, couldn't connect on port %d. Is it busy?" % port)
128 if kwargs.get('retry', True):
129 # Attempt to start the server on a new port.
130 self.run(*args, **assoc(kwargs, 'port', port + 1))
131
132
133 @api.route('/datashape')
134 def dataset():
135 return str(discover(_get_data()))
136
137
138 def to_tree(expr, names=None):
139 """ Represent Blaze expression with core data structures
140
141 Transform a Blaze expression into a form using only strings, dicts, lists
142 and base types (int, float, datetime, ....) This form can be useful for
143 serialization.
144
145 Parameters
146 ----------
147
148 expr: Blaze Expression
149
150 Examples
151 --------
152
153 >>> t = symbol('t', 'var * {x: int32, y: int32}')
154 >>> to_tree(t) # doctest: +SKIP
155 {'op': 'Symbol',
156 'args': ['t', 'var * { x : int32, y : int32 }', False]}
157
158
159 >>> to_tree(t.x.sum()) # doctest: +SKIP
160 {'op': 'sum',
161 'args': [
162 {'op': 'Column',
163 'args': [
164 {
165 'op': 'Symbol'
166 'args': ['t', 'var * { x : int32, y : int32 }', False]
167 }
168 'x']
169 }]
170 }
171
172 Simplify expresion using explicit ``names`` dictionary. In the example
173 below we replace the ``Symbol`` node with the string ``'t'``.
174
175 >>> tree = to_tree(t.x, names={t: 't'})
176 >>> tree # doctest: +SKIP
177 {'op': 'Column', 'args': ['t', 'x']}
178
179 >>> from_tree(tree, namespace={'t': t})
180 t.x
181
182 See Also
183 --------
184
185 blaze.server.server.from_tree
186 """
187 if names and expr in names:
188 return names[expr]
189 if isinstance(expr, tuple):
190 return [to_tree(arg, names=names) for arg in expr]
191 if isinstance(expr, expr_utils._slice):
192 return to_tree(expr.as_slice(), names=names)
193 if isinstance(expr, slice):
194 return {'op': 'slice',
195 'args': [to_tree(arg, names=names) for arg in
196 [expr.start, expr.stop, expr.step]]}
197 elif isinstance(expr, Mono):
198 return str(expr)
199 elif isinstance(expr, InteractiveSymbol):
200 return to_tree(symbol(expr._name, expr.dshape), names)
201 elif isinstance(expr, Expr):
202 return {'op': type(expr).__name__,
203 'args': [to_tree(arg, names) for arg in expr._args]}
204 else:
205 return expr
206
207
208 def expression_from_name(name):
209 """
210
211 >>> expression_from_name('By')
212 <class 'blaze.expr.split_apply_combine.By'>
213
214 >>> expression_from_name('And')
215 <class 'blaze.expr.arithmetic.And'>
216 """
217 import blaze
218 if hasattr(blaze, name):
219 return getattr(blaze, name)
220 if hasattr(blaze.expr, name):
221 return getattr(blaze.expr, name)
222 for signature, func in compute_up.funcs.items():
223 try:
224 if signature[0].__name__ == name:
225 return signature[0]
226 except TypeError:
227 pass
228 raise ValueError('%s not found in compute_up' % name)
229
230
231 def from_tree(expr, namespace=None):
232 """ Convert core data structures to Blaze expression
233
234 Core data structure representations created by ``to_tree`` are converted
235 back into Blaze expressions.
236
237 Parameters
238 ----------
239 expr : dict
240
241 Examples
242 --------
243
244 >>> t = symbol('t', 'var * {x: int32, y: int32}')
245 >>> tree = to_tree(t)
246 >>> tree # doctest: +SKIP
247 {'op': 'Symbol',
248 'args': ['t', 'var * { x : int32, y : int32 }', False]}
249
250 >>> from_tree(tree)
251 t
252
253 >>> tree = to_tree(t.x.sum())
254 >>> tree # doctest: +SKIP
255 {'op': 'sum',
256 'args': [
257 {'op': 'Field',
258 'args': [
259 {
260 'op': 'Symbol'
261 'args': ['t', 'var * { x : int32, y : int32 }', False]
262 }
263 'x']
264 }]
265 }
266
267 >>> from_tree(tree)
268 sum(t.x)
269
270 Simplify expresion using explicit ``names`` dictionary. In the example
271 below we replace the ``Symbol`` node with the string ``'t'``.
272
273 >>> tree = to_tree(t.x, names={t: 't'})
274 >>> tree # doctest: +SKIP
275 {'op': 'Field', 'args': ['t', 'x']}
276
277 >>> from_tree(tree, namespace={'t': t})
278 t.x
279
280 See Also
281 --------
282
283 blaze.server.server.to_tree
284 """
285 if isinstance(expr, dict):
286 op, args = expr['op'], expr['args']
287 if 'slice' == op:
288 return expr_utils._slice(*[from_tree(arg, namespace)
289 for arg in args])
290 if hasattr(blaze.expr, op):
291 cls = getattr(blaze.expr, op)
292 else:
293 cls = expression_from_name(op)
294 if 'Symbol' in op:
295 children = [from_tree(arg) for arg in args]
296 else:
297 children = [from_tree(arg, namespace) for arg in args]
298 return cls(*children)
299 elif isinstance(expr, list):
300 return tuple(from_tree(arg, namespace) for arg in expr)
301 if namespace and expr in namespace:
302 return namespace[expr]
303 else:
304 return expr
305
306
307 @api.route('/compute.<serial_format>', methods=['POST', 'PUT', 'GET'])
308 def compserver(serial_format):
309 try:
310 serial = _get_format(serial_format)
311 except KeyError:
312 return 'Unsupported serialization format', 404
313
314 try:
315 payload = serial.loads(request.data)
316 except ValueError:
317 return ("Bad data. Got %s " % request.data, 400) # 400: Bad Request
318
319 ns = payload.get('namespace', dict())
320 dataset = _get_data()
321 ns[':leaf'] = symbol('leaf', discover(dataset))
322
323 expr = from_tree(payload['expr'], namespace=ns)
324 assert len(expr._leaves()) == 1
325 leaf = expr._leaves()[0]
326
327 try:
328 result = compute(expr, {leaf: dataset})
329
330 if iscollection(expr.dshape):
331 result = odo(result, list)
332 elif isscalar(expr.dshape):
333 result = coerce_scalar(result, str(expr.dshape))
334 except NotImplementedError as e:
335 # 501: Not Implemented
336 return ("Computation not supported:\n%s" % e, 501)
337 except Exception as e:
338 # 500: Internal Server Error
339 return ("Computation failed with message:\n%s" % e, 500)
340
341 return serial.dumps({'datashape': str(expr.dshape), 'data': result})
342
[end of blaze/server/server.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/blaze/server/server.py b/blaze/server/server.py
--- a/blaze/server/server.py
+++ b/blaze/server/server.py
@@ -338,4 +338,8 @@
# 500: Internal Server Error
return ("Computation failed with message:\n%s" % e, 500)
- return serial.dumps({'datashape': str(expr.dshape), 'data': result})
+ return serial.dumps({
+ 'datashape': str(expr.dshape),
+ 'data': result,
+ 'names': expr.fields
+ })
|
{"golden_diff": "diff --git a/blaze/server/server.py b/blaze/server/server.py\n--- a/blaze/server/server.py\n+++ b/blaze/server/server.py\n@@ -338,4 +338,8 @@\n # 500: Internal Server Error\n return (\"Computation failed with message:\\n%s\" % e, 500)\n \n- return serial.dumps({'datashape': str(expr.dshape), 'data': result})\n+ return serial.dumps({\n+ 'datashape': str(expr.dshape),\n+ 'data': result,\n+ 'names': expr.fields\n+ })\n", "issue": "add column names to compute.json response in blaze server\nxref: https://github.com/bokeh/bokeh/issues/2330\n\n", "before_files": [{"content": "from __future__ import absolute_import, division, print_function\n\nimport socket\n\nimport flask\nfrom flask import Blueprint, Flask, request\n\nfrom toolz import assoc\n\nfrom datashape.predicates import iscollection, isscalar\nfrom odo import odo\n\nimport blaze\nfrom blaze import compute\nfrom blaze.expr import utils as expr_utils\nfrom blaze.compute import compute_up\n\nfrom .serialization import json\nfrom ..interactive import InteractiveSymbol, coerce_scalar\nfrom ..expr import Expr, symbol\n\nfrom datashape import Mono, discover\n\n\n__all__ = 'Server', 'to_tree', 'from_tree'\n\n# http://www.speedguide.net/port.php?port=6363\n# http://en.wikipedia.org/wiki/List_of_TCP_and_UDP_port_numbers\nDEFAULT_PORT = 6363\n\n\napi = Blueprint('api', __name__)\npickle_extension_api = Blueprint('pickle_extension_api', __name__)\n\n\ndef _get_option(option, options):\n try:\n return options[option]\n except KeyError:\n # Provides a more informative error message.\n raise TypeError(\n 'The blaze api must be registered with {option}'.format(\n option=option,\n ),\n )\n\n\ndef _register_api(app, options, first_registration=False):\n \"\"\"\n Register the data with the blueprint.\n \"\"\"\n _get_data.cache[app] = _get_option('data', options)\n _get_format.cache[app] = dict(\n (f.name, f) for f in _get_option('formats', options)\n )\n # Call the original register function.\n Blueprint.register(api, app, options, first_registration)\n\napi.register = _register_api\n\n\ndef _get_data():\n \"\"\"\n Retrieve the current application's data for use in the blaze server\n endpoints.\n \"\"\"\n return _get_data.cache[flask.current_app]\n_get_data.cache = {}\n\n\ndef _get_format(name):\n return _get_format.cache[flask.current_app][name]\n_get_format.cache = {}\n\n\nclass Server(object):\n\n \"\"\" Blaze Data Server\n\n Host local data through a web API\n\n Parameters\n ----------\n data : ``dict`` or ``None``, optional\n A dictionary mapping dataset name to any data format that blaze\n understands.\n\n formats : ``iterable[SerializationFormat]``, optional\n An iterable of supported serialization formats. By default, the\n server will support JSON.\n A serialization format is an object that supports:\n name, loads, and dumps.\n\n Examples\n --------\n >>> from pandas import DataFrame\n >>> df = DataFrame([[1, 'Alice', 100],\n ... [2, 'Bob', -200],\n ... [3, 'Alice', 300],\n ... [4, 'Dennis', 400],\n ... [5, 'Bob', -500]],\n ... columns=['id', 'name', 'amount'])\n\n >>> server = Server({'accounts': df})\n >>> server.run() # doctest: +SKIP\n \"\"\"\n __slots__ = 'app', 'data', 'port'\n\n def __init__(self, data=None, formats=None):\n app = self.app = Flask('blaze.server.server')\n if data is None:\n data = dict()\n app.register_blueprint(\n api,\n data=data,\n formats=formats if formats is not None else (json,),\n )\n self.data = data\n\n def run(self, *args, **kwargs):\n \"\"\"Run the server\"\"\"\n port = kwargs.pop('port', DEFAULT_PORT)\n self.port = port\n try:\n self.app.run(*args, port=port, **kwargs)\n except socket.error:\n print(\"\\tOops, couldn't connect on port %d. Is it busy?\" % port)\n if kwargs.get('retry', True):\n # Attempt to start the server on a new port.\n self.run(*args, **assoc(kwargs, 'port', port + 1))\n\n\[email protected]('/datashape')\ndef dataset():\n return str(discover(_get_data()))\n\n\ndef to_tree(expr, names=None):\n \"\"\" Represent Blaze expression with core data structures\n\n Transform a Blaze expression into a form using only strings, dicts, lists\n and base types (int, float, datetime, ....) This form can be useful for\n serialization.\n\n Parameters\n ----------\n\n expr: Blaze Expression\n\n Examples\n --------\n\n >>> t = symbol('t', 'var * {x: int32, y: int32}')\n >>> to_tree(t) # doctest: +SKIP\n {'op': 'Symbol',\n 'args': ['t', 'var * { x : int32, y : int32 }', False]}\n\n\n >>> to_tree(t.x.sum()) # doctest: +SKIP\n {'op': 'sum',\n 'args': [\n {'op': 'Column',\n 'args': [\n {\n 'op': 'Symbol'\n 'args': ['t', 'var * { x : int32, y : int32 }', False]\n }\n 'x']\n }]\n }\n\n Simplify expresion using explicit ``names`` dictionary. In the example\n below we replace the ``Symbol`` node with the string ``'t'``.\n\n >>> tree = to_tree(t.x, names={t: 't'})\n >>> tree # doctest: +SKIP\n {'op': 'Column', 'args': ['t', 'x']}\n\n >>> from_tree(tree, namespace={'t': t})\n t.x\n\n See Also\n --------\n\n blaze.server.server.from_tree\n \"\"\"\n if names and expr in names:\n return names[expr]\n if isinstance(expr, tuple):\n return [to_tree(arg, names=names) for arg in expr]\n if isinstance(expr, expr_utils._slice):\n return to_tree(expr.as_slice(), names=names)\n if isinstance(expr, slice):\n return {'op': 'slice',\n 'args': [to_tree(arg, names=names) for arg in\n [expr.start, expr.stop, expr.step]]}\n elif isinstance(expr, Mono):\n return str(expr)\n elif isinstance(expr, InteractiveSymbol):\n return to_tree(symbol(expr._name, expr.dshape), names)\n elif isinstance(expr, Expr):\n return {'op': type(expr).__name__,\n 'args': [to_tree(arg, names) for arg in expr._args]}\n else:\n return expr\n\n\ndef expression_from_name(name):\n \"\"\"\n\n >>> expression_from_name('By')\n <class 'blaze.expr.split_apply_combine.By'>\n\n >>> expression_from_name('And')\n <class 'blaze.expr.arithmetic.And'>\n \"\"\"\n import blaze\n if hasattr(blaze, name):\n return getattr(blaze, name)\n if hasattr(blaze.expr, name):\n return getattr(blaze.expr, name)\n for signature, func in compute_up.funcs.items():\n try:\n if signature[0].__name__ == name:\n return signature[0]\n except TypeError:\n pass\n raise ValueError('%s not found in compute_up' % name)\n\n\ndef from_tree(expr, namespace=None):\n \"\"\" Convert core data structures to Blaze expression\n\n Core data structure representations created by ``to_tree`` are converted\n back into Blaze expressions.\n\n Parameters\n ----------\n expr : dict\n\n Examples\n --------\n\n >>> t = symbol('t', 'var * {x: int32, y: int32}')\n >>> tree = to_tree(t)\n >>> tree # doctest: +SKIP\n {'op': 'Symbol',\n 'args': ['t', 'var * { x : int32, y : int32 }', False]}\n\n >>> from_tree(tree)\n t\n\n >>> tree = to_tree(t.x.sum())\n >>> tree # doctest: +SKIP\n {'op': 'sum',\n 'args': [\n {'op': 'Field',\n 'args': [\n {\n 'op': 'Symbol'\n 'args': ['t', 'var * { x : int32, y : int32 }', False]\n }\n 'x']\n }]\n }\n\n >>> from_tree(tree)\n sum(t.x)\n\n Simplify expresion using explicit ``names`` dictionary. In the example\n below we replace the ``Symbol`` node with the string ``'t'``.\n\n >>> tree = to_tree(t.x, names={t: 't'})\n >>> tree # doctest: +SKIP\n {'op': 'Field', 'args': ['t', 'x']}\n\n >>> from_tree(tree, namespace={'t': t})\n t.x\n\n See Also\n --------\n\n blaze.server.server.to_tree\n \"\"\"\n if isinstance(expr, dict):\n op, args = expr['op'], expr['args']\n if 'slice' == op:\n return expr_utils._slice(*[from_tree(arg, namespace)\n for arg in args])\n if hasattr(blaze.expr, op):\n cls = getattr(blaze.expr, op)\n else:\n cls = expression_from_name(op)\n if 'Symbol' in op:\n children = [from_tree(arg) for arg in args]\n else:\n children = [from_tree(arg, namespace) for arg in args]\n return cls(*children)\n elif isinstance(expr, list):\n return tuple(from_tree(arg, namespace) for arg in expr)\n if namespace and expr in namespace:\n return namespace[expr]\n else:\n return expr\n\n\[email protected]('/compute.<serial_format>', methods=['POST', 'PUT', 'GET'])\ndef compserver(serial_format):\n try:\n serial = _get_format(serial_format)\n except KeyError:\n return 'Unsupported serialization format', 404\n\n try:\n payload = serial.loads(request.data)\n except ValueError:\n return (\"Bad data. Got %s \" % request.data, 400) # 400: Bad Request\n\n ns = payload.get('namespace', dict())\n dataset = _get_data()\n ns[':leaf'] = symbol('leaf', discover(dataset))\n\n expr = from_tree(payload['expr'], namespace=ns)\n assert len(expr._leaves()) == 1\n leaf = expr._leaves()[0]\n\n try:\n result = compute(expr, {leaf: dataset})\n\n if iscollection(expr.dshape):\n result = odo(result, list)\n elif isscalar(expr.dshape):\n result = coerce_scalar(result, str(expr.dshape))\n except NotImplementedError as e:\n # 501: Not Implemented\n return (\"Computation not supported:\\n%s\" % e, 501)\n except Exception as e:\n # 500: Internal Server Error\n return (\"Computation failed with message:\\n%s\" % e, 500)\n\n return serial.dumps({'datashape': str(expr.dshape), 'data': result})\n", "path": "blaze/server/server.py"}]}
| 3,894 | 134 |
gh_patches_debug_11834
|
rasdani/github-patches
|
git_diff
|
cleanlab__cleanlab-412
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
CI: Suppress complex mypy typing in docs.cleanlab.ai
If docs.cleanlab.ai shows the mypy type annotations, the current signatures look a bit intimidating, eg. for: `cleanlab.internal.validation`
https://docs.cleanlab.ai/master/cleanlab/internal/validation.html
Plan is to use https://github.com/tox-dev/sphinx-autodoc-typehints to auto-tag parameters in docstrings based on the function signatures.
Consider the docstring for `cleanlab.internal.validation.labels_to_array`:
https://docs.cleanlab.ai/master/cleanlab/internal/validation.html#cleanlab.internal.validation.labels_to_array
The docstring would not change as the tags have been hard-coded. But the signature at the top would read:
```
cleanlab.internal.validation.labels_to_array(y)
```
instead of
```
cleanlab.internal.validation.labels_to_array(y: Union[list, ndarray, Series, DataFrame, generic]) → ndarray
```
This plan requires ironing out details with unrolling/expanding custom types like `LabelLike`.
It will take some effort to review all hard-coded types/tags in docstrings, because they won't be replaced with the auto-tag.
</issue>
<code>
[start of docs/source/conf.py]
1 # Configuration file for the Sphinx documentation builder.
2 #
3 # This file only contains a selection of the most common options. For a full
4 # list see the documentation:
5 # https://www.sphinx-doc.org/en/master/usage/configuration.html
6
7 # -- Path setup --------------------------------------------------------------
8
9 # If extensions (or modules to document with autodoc) are in another directory,
10 # add these directories to sys.path here. If the directory is relative to the
11 # documentation root, use os.path.abspath to make it absolute, like shown here.
12
13 import os
14 import sys
15 import datetime
16 import shutil
17
18 sys.path.insert(0, os.path.abspath("../../cleanlab"))
19
20 # -- Project information -----------------------------------------------------
21
22 project = "cleanlab"
23 copyright = f"{datetime.datetime.now().year}, Cleanlab Inc."
24 author = "Cleanlab Inc."
25
26 # -- General configuration ---------------------------------------------------
27
28 # Add any Sphinx extension module names here, as strings. They can be
29 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
30 # ones.
31 extensions = [
32 "sphinx.ext.napoleon",
33 "nbsphinx",
34 "sphinx.ext.autodoc",
35 "autodocsumm",
36 "sphinx.ext.viewcode",
37 "sphinx.ext.todo",
38 "sphinx_tabs.tabs",
39 "sphinx_multiversion",
40 "sphinx_copybutton",
41 "sphinxcontrib.katex",
42 ]
43
44 numpy_show_class_members = True
45
46 # Don't add .txt suffix to source files:
47 html_sourcelink_suffix = ""
48
49 # Add any paths that contain templates here, relative to this directory.
50 templates_path = ["_templates"]
51
52 # List of patterns, relative to source directory, that match files and
53 # directories to ignore when looking for source files.
54 # This pattern also affects html_static_path and html_extra_path.
55 exclude_patterns = ["_build"]
56
57 autosummary_generate = True
58
59 # -- Options for apidoc extension ----------------------------------------------
60
61 # apidoc_module_dir = "cleanlab/cleanlab"
62
63 # -- Options for todo extension ----------------------------------------------
64
65 # If true, `todo` and `todoList` produce output, else they produce nothing.
66 todo_include_todos = True
67
68
69 # -- Options for Napoleon extension -------------------------------------------
70
71 napoleon_google_docstring = False
72 napoleon_numpy_docstring = True
73 napoleon_include_init_with_doc = False
74 napoleon_include_private_with_doc = False
75 napoleon_include_special_with_doc = True
76 napoleon_use_admonition_for_examples = False
77 napoleon_use_admonition_for_notes = False
78 napoleon_use_admonition_for_references = False
79 napoleon_use_ivar = False
80 napoleon_use_param = True
81 napoleon_use_rtype = True
82 napoleon_preprocess_types = True
83 napoleon_type_aliases = None
84 napoleon_attr_annotations = True
85
86 # -- Options for autodoc extension -------------------------------------------
87
88 # This value selects what content will be inserted into the main body of an autoclass
89 # directive
90 #
91 # http://www.sphinx-doc.org/en/master/usage/extensions/autodoc.html#directive-autoclass
92 autoclass_content = "class"
93
94
95 # Default options to an ..autoXXX directive.
96 autodoc_default_options = {
97 "autosummary": True,
98 "members": None,
99 "inherited-members": None,
100 "show-inheritance": None,
101 "special-members": "__call__",
102 }
103
104 # Subclasses should show parent classes docstrings if they don't override them.
105 autodoc_inherit_docstrings = True
106
107 # -- Options for katex extension -------------------------------------------
108
109 if os.getenv("CI") or shutil.which("katex") is not None:
110 # requires that the machine have `katex` installed: `npm install -g katex`
111 katex_prerender = True
112
113 # -- Variables Setting ---------------------------------------------------
114
115 # Determine doc site URL (DOCS_SITE_URL)
116 # Check if it's running in production repo
117 if os.getenv("GITHUB_REPOSITORY") == "cleanlab/cleanlab":
118 DOCS_SITE_URL = "/"
119 else:
120 DOCS_SITE_URL = "/cleanlab-docs/"
121
122 gh_env_file = os.getenv("GITHUB_ENV")
123 if gh_env_file is not None:
124 with open(gh_env_file, "a") as f:
125 f.write(f"\nDOCS_SITE_URL={DOCS_SITE_URL}") # Set to Environment Var
126
127 GITHUB_REPOSITORY_OWNER = os.getenv("GITHUB_REPOSITORY_OWNER") or "cleanlab"
128 GITHUB_REF_NAME = os.getenv("GITHUB_REF_NAME") or "master"
129
130 # Pass additional variables to Jinja templates
131 html_context = {
132 "DOCS_SITE_URL": DOCS_SITE_URL,
133 }
134
135 # -- nbsphinx Configuration ---------------------------------------------------
136
137 # This is processed by Jinja2 and inserted before each notebook
138 nbsphinx_prolog = (
139 """
140 {% set docname = env.doc2path(env.docname, base=None) %}
141
142 .. raw:: html
143
144 <style>
145 .nbinput .prompt,
146 .nboutput .prompt {
147 display: none;
148 }
149
150 .output_area {
151 max-height: 300px;
152 overflow: auto;
153 }
154
155 .dataframe {
156 background: #D7D7D7;
157 }
158
159 th {
160 color:black;
161 }
162 </style>
163
164 <script type="text/javascript">
165 window.addEventListener('load', () => {
166 const h1_element = document.getElementsByTagName("h1");
167 h1_element[0].insertAdjacentHTML("afterend", `
168 <p>
169 <a style="background-color:white;color:black;padding:4px 12px;text-decoration:none;display:inline-block;border-radius:8px;box-shadow:0 2px 4px 0 rgba(0, 0, 0, 0.2), 0 3px 10px 0 rgba(0, 0, 0, 0.19)" href="https://colab.research.google.com/github/"""
170 + GITHUB_REPOSITORY_OWNER
171 + """/cleanlab-docs/blob/master/"""
172 + GITHUB_REF_NAME
173 + """/{{ docname|e }}" target="_blank">
174 <img src="https://colab.research.google.com/img/colab_favicon_256px.png" alt="" style="width:40px;height:40px;vertical-align:middle">
175 <span style="vertical-align:middle">Run in Google Colab</span>
176 </a>
177 </p>
178 `);
179 })
180
181 </script>
182 """
183 )
184
185 # Change this to "always" before running in the doc's CI/CD server
186 if os.getenv("CI"):
187 nbsphinx_execute = "always"
188 if os.getenv("SKIP_NOTEBOOKS", "0") != "0":
189 nbsphinx_execute = "never"
190
191 # -- Options for HTML output -------------------------------------------------
192
193 # The theme to use for HTML and HTML Help pages. See the documentation for
194 # a list of builtin themes.
195 #
196 html_theme = "furo"
197 html_favicon = "https://raw.githubusercontent.com/cleanlab/assets/a4483476d449f2f05a4c7cde329e72358099cc07/cleanlab/cleanlab_favicon.svg"
198 html_title = "cleanlab"
199 html_logo = (
200 "https://raw.githubusercontent.com/cleanlab/assets/master/cleanlab/cleanlab_logo_only.png"
201 )
202 html_theme_options = {
203 "footer_icons": [
204 {
205 "name": "GitHub",
206 "url": "https://github.com/cleanlab/cleanlab",
207 "html": """
208 <svg stroke="currentColor" fill="currentColor" stroke-width="0" viewBox="0 0 16 16">
209 <path fill-rule="evenodd" d="M8 0C3.58 0 0 3.58 0 8c0 3.54 2.29 6.53 5.47 7.59.4.07.55-.17.55-.38 0-.19-.01-.82-.01-1.49-2.01.37-2.53-.49-2.69-.94-.09-.23-.48-.94-.82-1.13-.28-.15-.68-.52-.01-.53.63-.01 1.08.58 1.23.82.72 1.21 1.87.87 2.33.66.07-.52.28-.87.51-1.07-1.78-.2-3.64-.89-3.64-3.95 0-.87.31-1.59.82-2.15-.08-.2-.36-1.02.08-2.12 0 0 .67-.21 2.2.82.64-.18 1.32-.27 2-.27.68 0 1.36.09 2 .27 1.53-1.04 2.2-.82 2.2-.82.44 1.1.16 1.92.08 2.12.51.56.82 1.27.82 2.15 0 3.07-1.87 3.75-3.65 3.95.29.25.54.73.54 1.48 0 1.07-.01 1.93-.01 2.2 0 .21.15.46.55.38A8.013 8.013 0 0 0 16 8c0-4.42-3.58-8-8-8z"></path>
210 </svg>
211 """,
212 "class": "",
213 },
214 ],
215 }
216
217 # Add any paths that contain custom static files (such as style sheets) here,
218 # relative to this directory. They are copied after the builtin static files,
219 # so a file named "default.css" will overwrite the builtin "default.css".
220 html_static_path = ["_static"]
221
222 html_sidebars = {
223 "**": [
224 "brand.html",
225 "sidebar/search.html",
226 "sidebar/scroll-start.html",
227 "sidebar/navigation.html",
228 "sidebar/ethical-ads.html",
229 "versioning.html",
230 "sidebar/scroll-end.html",
231 ],
232 }
233
[end of docs/source/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/source/conf.py b/docs/source/conf.py
--- a/docs/source/conf.py
+++ b/docs/source/conf.py
@@ -39,6 +39,7 @@
"sphinx_multiversion",
"sphinx_copybutton",
"sphinxcontrib.katex",
+ "sphinx_autodoc_typehints",
]
numpy_show_class_members = True
@@ -78,7 +79,7 @@
napoleon_use_admonition_for_references = False
napoleon_use_ivar = False
napoleon_use_param = True
-napoleon_use_rtype = True
+napoleon_use_rtype = False
napoleon_preprocess_types = True
napoleon_type_aliases = None
napoleon_attr_annotations = True
|
{"golden_diff": "diff --git a/docs/source/conf.py b/docs/source/conf.py\n--- a/docs/source/conf.py\n+++ b/docs/source/conf.py\n@@ -39,6 +39,7 @@\n \"sphinx_multiversion\",\n \"sphinx_copybutton\",\n \"sphinxcontrib.katex\",\n+ \"sphinx_autodoc_typehints\",\n ]\n \n numpy_show_class_members = True\n@@ -78,7 +79,7 @@\n napoleon_use_admonition_for_references = False\n napoleon_use_ivar = False\n napoleon_use_param = True\n-napoleon_use_rtype = True\n+napoleon_use_rtype = False\n napoleon_preprocess_types = True\n napoleon_type_aliases = None\n napoleon_attr_annotations = True\n", "issue": "CI: Suppress complex mypy typing in docs.cleanlab.ai\n If docs.cleanlab.ai shows the mypy type annotations, the current signatures look a bit intimidating, eg. for: `cleanlab.internal.validation`\nhttps://docs.cleanlab.ai/master/cleanlab/internal/validation.html \n\n\nPlan is to use https://github.com/tox-dev/sphinx-autodoc-typehints to auto-tag parameters in docstrings based on the function signatures.\n\nConsider the docstring for `cleanlab.internal.validation.labels_to_array`:\nhttps://docs.cleanlab.ai/master/cleanlab/internal/validation.html#cleanlab.internal.validation.labels_to_array\n\nThe docstring would not change as the tags have been hard-coded. But the signature at the top would read:\n```\ncleanlab.internal.validation.labels_to_array(y)\n```\ninstead of\n```\ncleanlab.internal.validation.labels_to_array(y: Union[list, ndarray, Series, DataFrame, generic]) \u2192 ndarray\n```\n\nThis plan requires ironing out details with unrolling/expanding custom types like `LabelLike`. \nIt will take some effort to review all hard-coded types/tags in docstrings, because they won't be replaced with the auto-tag.\n", "before_files": [{"content": "# Configuration file for the Sphinx documentation builder.\n#\n# This file only contains a selection of the most common options. For a full\n# list see the documentation:\n# https://www.sphinx-doc.org/en/master/usage/configuration.html\n\n# -- Path setup --------------------------------------------------------------\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n\nimport os\nimport sys\nimport datetime\nimport shutil\n\nsys.path.insert(0, os.path.abspath(\"../../cleanlab\"))\n\n# -- Project information -----------------------------------------------------\n\nproject = \"cleanlab\"\ncopyright = f\"{datetime.datetime.now().year}, Cleanlab Inc.\"\nauthor = \"Cleanlab Inc.\"\n\n# -- General configuration ---------------------------------------------------\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n \"sphinx.ext.napoleon\",\n \"nbsphinx\",\n \"sphinx.ext.autodoc\",\n \"autodocsumm\",\n \"sphinx.ext.viewcode\",\n \"sphinx.ext.todo\",\n \"sphinx_tabs.tabs\",\n \"sphinx_multiversion\",\n \"sphinx_copybutton\",\n \"sphinxcontrib.katex\",\n]\n\nnumpy_show_class_members = True\n\n# Don't add .txt suffix to source files:\nhtml_sourcelink_suffix = \"\"\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = [\"_templates\"]\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path.\nexclude_patterns = [\"_build\"]\n\nautosummary_generate = True\n\n# -- Options for apidoc extension ----------------------------------------------\n\n# apidoc_module_dir = \"cleanlab/cleanlab\"\n\n# -- Options for todo extension ----------------------------------------------\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = True\n\n\n# -- Options for Napoleon extension -------------------------------------------\n\nnapoleon_google_docstring = False\nnapoleon_numpy_docstring = True\nnapoleon_include_init_with_doc = False\nnapoleon_include_private_with_doc = False\nnapoleon_include_special_with_doc = True\nnapoleon_use_admonition_for_examples = False\nnapoleon_use_admonition_for_notes = False\nnapoleon_use_admonition_for_references = False\nnapoleon_use_ivar = False\nnapoleon_use_param = True\nnapoleon_use_rtype = True\nnapoleon_preprocess_types = True\nnapoleon_type_aliases = None\nnapoleon_attr_annotations = True\n\n# -- Options for autodoc extension -------------------------------------------\n\n# This value selects what content will be inserted into the main body of an autoclass\n# directive\n#\n# http://www.sphinx-doc.org/en/master/usage/extensions/autodoc.html#directive-autoclass\nautoclass_content = \"class\"\n\n\n# Default options to an ..autoXXX directive.\nautodoc_default_options = {\n \"autosummary\": True,\n \"members\": None,\n \"inherited-members\": None,\n \"show-inheritance\": None,\n \"special-members\": \"__call__\",\n}\n\n# Subclasses should show parent classes docstrings if they don't override them.\nautodoc_inherit_docstrings = True\n\n# -- Options for katex extension -------------------------------------------\n\nif os.getenv(\"CI\") or shutil.which(\"katex\") is not None:\n # requires that the machine have `katex` installed: `npm install -g katex`\n katex_prerender = True\n\n# -- Variables Setting ---------------------------------------------------\n\n# Determine doc site URL (DOCS_SITE_URL)\n# Check if it's running in production repo\nif os.getenv(\"GITHUB_REPOSITORY\") == \"cleanlab/cleanlab\":\n DOCS_SITE_URL = \"/\"\nelse:\n DOCS_SITE_URL = \"/cleanlab-docs/\"\n\ngh_env_file = os.getenv(\"GITHUB_ENV\")\nif gh_env_file is not None:\n with open(gh_env_file, \"a\") as f:\n f.write(f\"\\nDOCS_SITE_URL={DOCS_SITE_URL}\") # Set to Environment Var\n\nGITHUB_REPOSITORY_OWNER = os.getenv(\"GITHUB_REPOSITORY_OWNER\") or \"cleanlab\"\nGITHUB_REF_NAME = os.getenv(\"GITHUB_REF_NAME\") or \"master\"\n\n# Pass additional variables to Jinja templates\nhtml_context = {\n \"DOCS_SITE_URL\": DOCS_SITE_URL,\n}\n\n# -- nbsphinx Configuration ---------------------------------------------------\n\n# This is processed by Jinja2 and inserted before each notebook\nnbsphinx_prolog = (\n \"\"\"\n{% set docname = env.doc2path(env.docname, base=None) %}\n\n.. raw:: html\n\n <style>\n .nbinput .prompt,\n .nboutput .prompt {\n display: none;\n }\n\n .output_area {\n max-height: 300px;\n overflow: auto;\n }\n\n .dataframe {\n background: #D7D7D7;\n }\n \n th {\n color:black;\n }\n </style>\n\n <script type=\"text/javascript\">\n window.addEventListener('load', () => {\n const h1_element = document.getElementsByTagName(\"h1\");\n h1_element[0].insertAdjacentHTML(\"afterend\", `\n <p>\n <a style=\"background-color:white;color:black;padding:4px 12px;text-decoration:none;display:inline-block;border-radius:8px;box-shadow:0 2px 4px 0 rgba(0, 0, 0, 0.2), 0 3px 10px 0 rgba(0, 0, 0, 0.19)\" href=\"https://colab.research.google.com/github/\"\"\"\n + GITHUB_REPOSITORY_OWNER\n + \"\"\"/cleanlab-docs/blob/master/\"\"\"\n + GITHUB_REF_NAME\n + \"\"\"/{{ docname|e }}\" target=\"_blank\">\n <img src=\"https://colab.research.google.com/img/colab_favicon_256px.png\" alt=\"\" style=\"width:40px;height:40px;vertical-align:middle\">\n <span style=\"vertical-align:middle\">Run in Google Colab</span>\n </a>\n </p>\n `);\n })\n\n </script>\n\"\"\"\n)\n\n# Change this to \"always\" before running in the doc's CI/CD server\nif os.getenv(\"CI\"):\n nbsphinx_execute = \"always\"\nif os.getenv(\"SKIP_NOTEBOOKS\", \"0\") != \"0\":\n nbsphinx_execute = \"never\"\n\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\nhtml_theme = \"furo\"\nhtml_favicon = \"https://raw.githubusercontent.com/cleanlab/assets/a4483476d449f2f05a4c7cde329e72358099cc07/cleanlab/cleanlab_favicon.svg\"\nhtml_title = \"cleanlab\"\nhtml_logo = (\n \"https://raw.githubusercontent.com/cleanlab/assets/master/cleanlab/cleanlab_logo_only.png\"\n)\nhtml_theme_options = {\n \"footer_icons\": [\n {\n \"name\": \"GitHub\",\n \"url\": \"https://github.com/cleanlab/cleanlab\",\n \"html\": \"\"\"\n <svg stroke=\"currentColor\" fill=\"currentColor\" stroke-width=\"0\" viewBox=\"0 0 16 16\">\n <path fill-rule=\"evenodd\" d=\"M8 0C3.58 0 0 3.58 0 8c0 3.54 2.29 6.53 5.47 7.59.4.07.55-.17.55-.38 0-.19-.01-.82-.01-1.49-2.01.37-2.53-.49-2.69-.94-.09-.23-.48-.94-.82-1.13-.28-.15-.68-.52-.01-.53.63-.01 1.08.58 1.23.82.72 1.21 1.87.87 2.33.66.07-.52.28-.87.51-1.07-1.78-.2-3.64-.89-3.64-3.95 0-.87.31-1.59.82-2.15-.08-.2-.36-1.02.08-2.12 0 0 .67-.21 2.2.82.64-.18 1.32-.27 2-.27.68 0 1.36.09 2 .27 1.53-1.04 2.2-.82 2.2-.82.44 1.1.16 1.92.08 2.12.51.56.82 1.27.82 2.15 0 3.07-1.87 3.75-3.65 3.95.29.25.54.73.54 1.48 0 1.07-.01 1.93-.01 2.2 0 .21.15.46.55.38A8.013 8.013 0 0 0 16 8c0-4.42-3.58-8-8-8z\"></path>\n </svg>\n \"\"\",\n \"class\": \"\",\n },\n ],\n}\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = [\"_static\"]\n\nhtml_sidebars = {\n \"**\": [\n \"brand.html\",\n \"sidebar/search.html\",\n \"sidebar/scroll-start.html\",\n \"sidebar/navigation.html\",\n \"sidebar/ethical-ads.html\",\n \"versioning.html\",\n \"sidebar/scroll-end.html\",\n ],\n}\n", "path": "docs/source/conf.py"}]}
| 3,710 | 162 |
gh_patches_debug_5826
|
rasdani/github-patches
|
git_diff
|
voxel51__fiftyone-2588
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[BUG] Sorting by similarity does not work on develop
On `develop`, nothing happens when clicking `Apply` below to sort by similarity in the App:
```py
import fiftyone as fo
import fiftyone.brain as fob
import fiftyone.zoo as foz
dataset = foz.load_zoo_dataset("quickstart")
model = foz.load_zoo_model("clip-vit-base32-torch")
fob.compute_similarity(dataset, model=model, brain_key="clip")
session = fo.launch_app(dataset)
```
<img width="628" alt="Screen Shot 2023-01-30 at 11 32 57 AM" src="https://user-images.githubusercontent.com/25985824/215537611-86a2385a-9279-410d-ac36-4ec5c7537551.png">
</issue>
<code>
[start of fiftyone/server/routes/sort.py]
1 """
2 FiftyOne Server /sort route
3
4 | Copyright 2017-2023, Voxel51, Inc.
5 | `voxel51.com <https://voxel51.com/>`_
6 |
7 """
8 from starlette.endpoints import HTTPEndpoint
9 from starlette.requests import Request
10
11 import fiftyone.core.dataset as fod
12 import fiftyone.core.fields as fof
13 import fiftyone.core.view as fov
14
15 from fiftyone.server.decorators import route
16 import fiftyone.server.events as fose
17 from fiftyone.server.query import serialize_dataset
18 import fiftyone.server.view as fosv
19
20
21 class Sort(HTTPEndpoint):
22 @route
23 async def post(self, request: Request, data: dict):
24 dataset_name = data.get("dataset", None)
25 filters = data.get("filters", {})
26 stages = data.get("view", None)
27 extended = data.get("extended", None)
28 dist_field = data.get("dist_field", None)
29
30 dataset = fod.load_dataset(dataset_name)
31
32 changed = False
33 if dist_field and not dataset.get_field(dist_field):
34 dataset.add_sample_field(dist_field, fof.FloatField)
35 changed = True
36
37 fosv.get_view(dataset_name, stages=stages, filters=filters)
38
39 state = fose.get_state().copy()
40 view = fosv.get_view(dataset_name, stages=stages, filters=filters)
41 state.dataset = view._dataset
42
43 if isinstance(view, fov.DatasetView):
44 state.view = view
45 else:
46 view = None
47
48 return {
49 "dataset": await serialize_dataset(
50 dataset_name=dataset_name,
51 serialized_view=stages,
52 view_name=view.name,
53 )
54 if changed
55 else None,
56 "state": state.serialize(),
57 }
58
[end of fiftyone/server/routes/sort.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/fiftyone/server/routes/sort.py b/fiftyone/server/routes/sort.py
--- a/fiftyone/server/routes/sort.py
+++ b/fiftyone/server/routes/sort.py
@@ -24,9 +24,7 @@
dataset_name = data.get("dataset", None)
filters = data.get("filters", {})
stages = data.get("view", None)
- extended = data.get("extended", None)
dist_field = data.get("dist_field", None)
-
dataset = fod.load_dataset(dataset_name)
changed = False
|
{"golden_diff": "diff --git a/fiftyone/server/routes/sort.py b/fiftyone/server/routes/sort.py\n--- a/fiftyone/server/routes/sort.py\n+++ b/fiftyone/server/routes/sort.py\n@@ -24,9 +24,7 @@\n dataset_name = data.get(\"dataset\", None)\n filters = data.get(\"filters\", {})\n stages = data.get(\"view\", None)\n- extended = data.get(\"extended\", None)\n dist_field = data.get(\"dist_field\", None)\n-\n dataset = fod.load_dataset(dataset_name)\n \n changed = False\n", "issue": "[BUG] Sorting by similarity does not work on develop\nOn `develop`, nothing happens when clicking `Apply` below to sort by similarity in the App:\r\n\r\n```py\r\nimport fiftyone as fo\r\nimport fiftyone.brain as fob\r\nimport fiftyone.zoo as foz\r\n\r\ndataset = foz.load_zoo_dataset(\"quickstart\")\r\n\r\nmodel = foz.load_zoo_model(\"clip-vit-base32-torch\")\r\nfob.compute_similarity(dataset, model=model, brain_key=\"clip\")\r\n\r\nsession = fo.launch_app(dataset)\r\n```\r\n\r\n<img width=\"628\" alt=\"Screen Shot 2023-01-30 at 11 32 57 AM\" src=\"https://user-images.githubusercontent.com/25985824/215537611-86a2385a-9279-410d-ac36-4ec5c7537551.png\">\r\n\n", "before_files": [{"content": "\"\"\"\nFiftyOne Server /sort route\n\n| Copyright 2017-2023, Voxel51, Inc.\n| `voxel51.com <https://voxel51.com/>`_\n|\n\"\"\"\nfrom starlette.endpoints import HTTPEndpoint\nfrom starlette.requests import Request\n\nimport fiftyone.core.dataset as fod\nimport fiftyone.core.fields as fof\nimport fiftyone.core.view as fov\n\nfrom fiftyone.server.decorators import route\nimport fiftyone.server.events as fose\nfrom fiftyone.server.query import serialize_dataset\nimport fiftyone.server.view as fosv\n\n\nclass Sort(HTTPEndpoint):\n @route\n async def post(self, request: Request, data: dict):\n dataset_name = data.get(\"dataset\", None)\n filters = data.get(\"filters\", {})\n stages = data.get(\"view\", None)\n extended = data.get(\"extended\", None)\n dist_field = data.get(\"dist_field\", None)\n\n dataset = fod.load_dataset(dataset_name)\n\n changed = False\n if dist_field and not dataset.get_field(dist_field):\n dataset.add_sample_field(dist_field, fof.FloatField)\n changed = True\n\n fosv.get_view(dataset_name, stages=stages, filters=filters)\n\n state = fose.get_state().copy()\n view = fosv.get_view(dataset_name, stages=stages, filters=filters)\n state.dataset = view._dataset\n\n if isinstance(view, fov.DatasetView):\n state.view = view\n else:\n view = None\n\n return {\n \"dataset\": await serialize_dataset(\n dataset_name=dataset_name,\n serialized_view=stages,\n view_name=view.name,\n )\n if changed\n else None,\n \"state\": state.serialize(),\n }\n", "path": "fiftyone/server/routes/sort.py"}]}
| 1,242 | 125 |
gh_patches_debug_26138
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-4504
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Some ansible playbooks cause checkov crash
Continuation of #4471
The following playbook (probably because of missing tasks) still causes checkov to crash:
```yaml
- name: Sample play
hosts:
- test
roles:
- role: somerole
```
cc @gruebel
</issue>
<code>
[start of checkov/ansible/graph_builder/local_graph.py]
1 from __future__ import annotations
2
3 import logging
4 from copy import deepcopy
5 from pathlib import Path
6 from typing import Any
7
8 from checkov.common.graph.graph_builder import CustomAttributes
9 from checkov.common.graph.graph_builder.consts import GraphSource, SELF_REFERENCE
10 from checkov.common.graph.graph_builder.graph_components.block_types import BlockType
11 from checkov.common.graph.graph_builder.graph_components.blocks import Block
12 from checkov.common.runners.graph_builder.local_graph import ObjectLocalGraph
13 from checkov.common.util.consts import START_LINE, END_LINE
14 from checkov.ansible.graph_builder.graph_components.resource_types import ResourceType
15 from checkov.ansible.utils import get_scannable_file_paths, TASK_RESERVED_KEYWORDS, parse_file
16
17
18 class AnsibleLocalGraph(ObjectLocalGraph):
19 def __init__(self, definitions: dict[str | Path, dict[str, Any] | list[dict[str, Any]]]) -> None:
20 super().__init__(definitions=definitions)
21
22 self.source = GraphSource.ANSIBLE
23
24 def _create_vertices(self) -> None:
25 for file_path, definition in self.definitions.items():
26 if not isinstance(definition, list):
27 logging.debug(f"definition of file {file_path} has the wrong type {type(definition)}")
28 continue
29
30 file_path = str(file_path)
31
32 for code_block in definition:
33 if ResourceType.TASKS in code_block:
34 for task in code_block[ResourceType.TASKS]:
35 self._process_blocks(file_path=file_path, task=task)
36 else:
37 self._process_blocks(file_path=file_path, task=code_block)
38
39 def _process_blocks(self, file_path: str, task: Any, prefix: str = "") -> None:
40 """Checks for possible block usage"""
41
42 if not task or not isinstance(task, dict):
43 return
44
45 if "block" in task and isinstance(task["block"], list):
46 prefix += f"{ResourceType.BLOCK}." # with each nested level an extra block prefix is added
47 self._create_block_vertices(file_path=file_path, block=task, prefix=prefix)
48
49 for block_task in task["block"]:
50 self._process_blocks(file_path=file_path, task=block_task, prefix=prefix)
51 else:
52 self._create_tasks_vertices(file_path=file_path, task=task, prefix=prefix)
53
54 def _create_tasks_vertices(self, file_path: str, task: Any, prefix: str = "") -> None:
55 """Creates tasks vertices"""
56
57 if not task or not isinstance(task, dict):
58 return
59
60 # grab the task name at the beginning before trying to find the actual module name
61 task_name = task.get("name") or "unknown"
62
63 for name, config in task.items():
64 if name in TASK_RESERVED_KEYWORDS:
65 continue
66 if name in (START_LINE, END_LINE):
67 continue
68
69 resource_type = f"{ResourceType.TASKS}.{name}"
70
71 if isinstance(config, str):
72 # this happens when modules have no parameters and are directly used with the user input
73 # ex. ansible.builtin.command: cat /etc/passwd
74 config = {SELF_REFERENCE: config}
75 elif config is None:
76 # this happens when modules have no parameters and are passed no value
77 # ex. amazon.aws.ec2_instance_info:
78 config = {
79 START_LINE: task[START_LINE],
80 END_LINE: task[END_LINE],
81 }
82
83 attributes = deepcopy(config)
84 attributes[CustomAttributes.RESOURCE_TYPE] = resource_type
85
86 # only the module code is relevant for validation,
87 # but in the check result the whole task should be visible
88 attributes[START_LINE] = task[START_LINE]
89 attributes[END_LINE] = task[END_LINE]
90
91 self.vertices.append(
92 Block(
93 name=f"{resource_type}.{task_name}",
94 config=config,
95 path=file_path,
96 block_type=BlockType.RESOURCE,
97 attributes=attributes,
98 id=f"{resource_type}.{prefix}{task_name}",
99 source=self.source,
100 )
101 )
102
103 # no need to further check
104 break
105
106 def _create_block_vertices(self, file_path: str, block: dict[str, Any], prefix: str = "") -> None:
107 """Creates block vertices"""
108
109 # grab the block name, if it exists
110 block_name = block.get("name") or "unknown"
111
112 config = block
113 attributes = deepcopy(config)
114 attributes[CustomAttributes.RESOURCE_TYPE] = ResourceType.BLOCK
115 del attributes[ResourceType.BLOCK] # the real block content are tasks, which have their own vertices
116
117 self.vertices.append(
118 Block(
119 name=f"{ResourceType.BLOCK}.{block_name}",
120 config=config,
121 path=file_path,
122 block_type=BlockType.RESOURCE,
123 attributes=attributes,
124 id=f"{prefix}{block_name}",
125 source=self.source,
126 )
127 )
128
129 def _create_edges(self) -> None:
130 return None
131
132 @staticmethod
133 def get_files_definitions(root_folder: str | Path) -> dict[str | Path, dict[str, Any] | list[dict[str, Any]]]:
134 definitions: "dict[str | Path, dict[str, Any] | list[dict[str, Any]]]" = {}
135 file_paths = get_scannable_file_paths(root_folder=root_folder)
136
137 for file_path in file_paths:
138 result = parse_file(f=file_path)
139 if result is not None:
140 definitions[file_path] = result[0]
141
142 return definitions
143
[end of checkov/ansible/graph_builder/local_graph.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/checkov/ansible/graph_builder/local_graph.py b/checkov/ansible/graph_builder/local_graph.py
--- a/checkov/ansible/graph_builder/local_graph.py
+++ b/checkov/ansible/graph_builder/local_graph.py
@@ -42,11 +42,11 @@
if not task or not isinstance(task, dict):
return
- if "block" in task and isinstance(task["block"], list):
+ if ResourceType.BLOCK in task and isinstance(task[ResourceType.BLOCK], list):
prefix += f"{ResourceType.BLOCK}." # with each nested level an extra block prefix is added
self._create_block_vertices(file_path=file_path, block=task, prefix=prefix)
- for block_task in task["block"]:
+ for block_task in task[ResourceType.BLOCK]:
self._process_blocks(file_path=file_path, task=block_task, prefix=prefix)
else:
self._create_tasks_vertices(file_path=file_path, task=task, prefix=prefix)
@@ -65,6 +65,9 @@
continue
if name in (START_LINE, END_LINE):
continue
+ if isinstance(config, list):
+ # either it is actually not an Ansible file or a playbook without tasks refs
+ continue
resource_type = f"{ResourceType.TASKS}.{name}"
|
{"golden_diff": "diff --git a/checkov/ansible/graph_builder/local_graph.py b/checkov/ansible/graph_builder/local_graph.py\n--- a/checkov/ansible/graph_builder/local_graph.py\n+++ b/checkov/ansible/graph_builder/local_graph.py\n@@ -42,11 +42,11 @@\n if not task or not isinstance(task, dict):\n return\n \n- if \"block\" in task and isinstance(task[\"block\"], list):\n+ if ResourceType.BLOCK in task and isinstance(task[ResourceType.BLOCK], list):\n prefix += f\"{ResourceType.BLOCK}.\" # with each nested level an extra block prefix is added\n self._create_block_vertices(file_path=file_path, block=task, prefix=prefix)\n \n- for block_task in task[\"block\"]:\n+ for block_task in task[ResourceType.BLOCK]:\n self._process_blocks(file_path=file_path, task=block_task, prefix=prefix)\n else:\n self._create_tasks_vertices(file_path=file_path, task=task, prefix=prefix)\n@@ -65,6 +65,9 @@\n continue\n if name in (START_LINE, END_LINE):\n continue\n+ if isinstance(config, list):\n+ # either it is actually not an Ansible file or a playbook without tasks refs\n+ continue\n \n resource_type = f\"{ResourceType.TASKS}.{name}\"\n", "issue": "Some ansible playbooks cause checkov crash\nContinuation of #4471 \r\n\r\nThe following playbook (probably because of missing tasks) still causes checkov to crash:\r\n\r\n```yaml\r\n- name: Sample play\r\n hosts:\r\n - test\r\n roles:\r\n - role: somerole\r\n```\r\n\r\ncc @gruebel \n", "before_files": [{"content": "from __future__ import annotations\n\nimport logging\nfrom copy import deepcopy\nfrom pathlib import Path\nfrom typing import Any\n\nfrom checkov.common.graph.graph_builder import CustomAttributes\nfrom checkov.common.graph.graph_builder.consts import GraphSource, SELF_REFERENCE\nfrom checkov.common.graph.graph_builder.graph_components.block_types import BlockType\nfrom checkov.common.graph.graph_builder.graph_components.blocks import Block\nfrom checkov.common.runners.graph_builder.local_graph import ObjectLocalGraph\nfrom checkov.common.util.consts import START_LINE, END_LINE\nfrom checkov.ansible.graph_builder.graph_components.resource_types import ResourceType\nfrom checkov.ansible.utils import get_scannable_file_paths, TASK_RESERVED_KEYWORDS, parse_file\n\n\nclass AnsibleLocalGraph(ObjectLocalGraph):\n def __init__(self, definitions: dict[str | Path, dict[str, Any] | list[dict[str, Any]]]) -> None:\n super().__init__(definitions=definitions)\n\n self.source = GraphSource.ANSIBLE\n\n def _create_vertices(self) -> None:\n for file_path, definition in self.definitions.items():\n if not isinstance(definition, list):\n logging.debug(f\"definition of file {file_path} has the wrong type {type(definition)}\")\n continue\n\n file_path = str(file_path)\n\n for code_block in definition:\n if ResourceType.TASKS in code_block:\n for task in code_block[ResourceType.TASKS]:\n self._process_blocks(file_path=file_path, task=task)\n else:\n self._process_blocks(file_path=file_path, task=code_block)\n\n def _process_blocks(self, file_path: str, task: Any, prefix: str = \"\") -> None:\n \"\"\"Checks for possible block usage\"\"\"\n\n if not task or not isinstance(task, dict):\n return\n\n if \"block\" in task and isinstance(task[\"block\"], list):\n prefix += f\"{ResourceType.BLOCK}.\" # with each nested level an extra block prefix is added\n self._create_block_vertices(file_path=file_path, block=task, prefix=prefix)\n\n for block_task in task[\"block\"]:\n self._process_blocks(file_path=file_path, task=block_task, prefix=prefix)\n else:\n self._create_tasks_vertices(file_path=file_path, task=task, prefix=prefix)\n\n def _create_tasks_vertices(self, file_path: str, task: Any, prefix: str = \"\") -> None:\n \"\"\"Creates tasks vertices\"\"\"\n\n if not task or not isinstance(task, dict):\n return\n\n # grab the task name at the beginning before trying to find the actual module name\n task_name = task.get(\"name\") or \"unknown\"\n\n for name, config in task.items():\n if name in TASK_RESERVED_KEYWORDS:\n continue\n if name in (START_LINE, END_LINE):\n continue\n\n resource_type = f\"{ResourceType.TASKS}.{name}\"\n\n if isinstance(config, str):\n # this happens when modules have no parameters and are directly used with the user input\n # ex. ansible.builtin.command: cat /etc/passwd\n config = {SELF_REFERENCE: config}\n elif config is None:\n # this happens when modules have no parameters and are passed no value\n # ex. amazon.aws.ec2_instance_info:\n config = {\n START_LINE: task[START_LINE],\n END_LINE: task[END_LINE],\n }\n\n attributes = deepcopy(config)\n attributes[CustomAttributes.RESOURCE_TYPE] = resource_type\n\n # only the module code is relevant for validation,\n # but in the check result the whole task should be visible\n attributes[START_LINE] = task[START_LINE]\n attributes[END_LINE] = task[END_LINE]\n\n self.vertices.append(\n Block(\n name=f\"{resource_type}.{task_name}\",\n config=config,\n path=file_path,\n block_type=BlockType.RESOURCE,\n attributes=attributes,\n id=f\"{resource_type}.{prefix}{task_name}\",\n source=self.source,\n )\n )\n\n # no need to further check\n break\n\n def _create_block_vertices(self, file_path: str, block: dict[str, Any], prefix: str = \"\") -> None:\n \"\"\"Creates block vertices\"\"\"\n\n # grab the block name, if it exists\n block_name = block.get(\"name\") or \"unknown\"\n\n config = block\n attributes = deepcopy(config)\n attributes[CustomAttributes.RESOURCE_TYPE] = ResourceType.BLOCK\n del attributes[ResourceType.BLOCK] # the real block content are tasks, which have their own vertices\n\n self.vertices.append(\n Block(\n name=f\"{ResourceType.BLOCK}.{block_name}\",\n config=config,\n path=file_path,\n block_type=BlockType.RESOURCE,\n attributes=attributes,\n id=f\"{prefix}{block_name}\",\n source=self.source,\n )\n )\n\n def _create_edges(self) -> None:\n return None\n\n @staticmethod\n def get_files_definitions(root_folder: str | Path) -> dict[str | Path, dict[str, Any] | list[dict[str, Any]]]:\n definitions: \"dict[str | Path, dict[str, Any] | list[dict[str, Any]]]\" = {}\n file_paths = get_scannable_file_paths(root_folder=root_folder)\n\n for file_path in file_paths:\n result = parse_file(f=file_path)\n if result is not None:\n definitions[file_path] = result[0]\n\n return definitions\n", "path": "checkov/ansible/graph_builder/local_graph.py"}]}
| 2,112 | 293 |
gh_patches_debug_61235
|
rasdani/github-patches
|
git_diff
|
facebookresearch__CompilerGym-548
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Improve examples documentation to make it clear that they are standalone
## 🚀 Feature
Tangentially to #532, I think it would be good to add a "Usage" section to examples/README.md that makes it clear that these example scripts can be used through pip-installed CompilerGym, and possibly split the examples rules out of the top level makefile into an examples/Makefile file for standalone usage.
## Motivation
It is not clear whether the included examples require building from source (they don't) or can be used on their own (they can).
</issue>
<code>
[start of examples/setup.py]
1 #!/usr/bin/env python3
2 #
3 # Copyright (c) Facebook, Inc. and its affiliates.
4 #
5 # This source code is licensed under the MIT license found in the
6 # LICENSE file in the root directory of this source tree.
7
8 import distutils.util
9
10 import setuptools
11
12 with open("../VERSION") as f:
13 version = f.read().strip()
14 with open("requirements.txt") as f:
15 requirements = [ln.split("#")[0].rstrip() for ln in f.readlines()]
16
17 setuptools.setup(
18 name="compiler_gym_examples",
19 version=version,
20 description="Example code for CompilerGym",
21 author="Facebook AI Research",
22 url="https://github.com/facebookresearch/CompilerGym",
23 license="MIT",
24 install_requires=requirements,
25 packages=[
26 "llvm_autotuning",
27 "llvm_autotuning.autotuners",
28 "llvm_rl",
29 "llvm_rl.model",
30 ],
31 python_requires=">=3.8",
32 platforms=[distutils.util.get_platform()],
33 zip_safe=False,
34 )
35
[end of examples/setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/setup.py b/examples/setup.py
--- a/examples/setup.py
+++ b/examples/setup.py
@@ -13,6 +13,8 @@
version = f.read().strip()
with open("requirements.txt") as f:
requirements = [ln.split("#")[0].rstrip() for ln in f.readlines()]
+with open("../tests/requirements.txt") as f:
+ requirements += [ln.split("#")[0].rstrip() for ln in f.readlines()]
setuptools.setup(
name="compiler_gym_examples",
|
{"golden_diff": "diff --git a/examples/setup.py b/examples/setup.py\n--- a/examples/setup.py\n+++ b/examples/setup.py\n@@ -13,6 +13,8 @@\n version = f.read().strip()\n with open(\"requirements.txt\") as f:\n requirements = [ln.split(\"#\")[0].rstrip() for ln in f.readlines()]\n+with open(\"../tests/requirements.txt\") as f:\n+ requirements += [ln.split(\"#\")[0].rstrip() for ln in f.readlines()]\n \n setuptools.setup(\n name=\"compiler_gym_examples\",\n", "issue": "Improve examples documentation to make it clear that they are standalone\n## \ud83d\ude80 Feature\r\n\r\nTangentially to #532, I think it would be good to add a \"Usage\" section to examples/README.md that makes it clear that these example scripts can be used through pip-installed CompilerGym, and possibly split the examples rules out of the top level makefile into an examples/Makefile file for standalone usage.\r\n\r\n## Motivation\r\n\r\nIt is not clear whether the included examples require building from source (they don't) or can be used on their own (they can).\n", "before_files": [{"content": "#!/usr/bin/env python3\n#\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\nimport distutils.util\n\nimport setuptools\n\nwith open(\"../VERSION\") as f:\n version = f.read().strip()\nwith open(\"requirements.txt\") as f:\n requirements = [ln.split(\"#\")[0].rstrip() for ln in f.readlines()]\n\nsetuptools.setup(\n name=\"compiler_gym_examples\",\n version=version,\n description=\"Example code for CompilerGym\",\n author=\"Facebook AI Research\",\n url=\"https://github.com/facebookresearch/CompilerGym\",\n license=\"MIT\",\n install_requires=requirements,\n packages=[\n \"llvm_autotuning\",\n \"llvm_autotuning.autotuners\",\n \"llvm_rl\",\n \"llvm_rl.model\",\n ],\n python_requires=\">=3.8\",\n platforms=[distutils.util.get_platform()],\n zip_safe=False,\n)\n", "path": "examples/setup.py"}]}
| 933 | 114 |
gh_patches_debug_23256
|
rasdani/github-patches
|
git_diff
|
deepset-ai__haystack-3901
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Better model security with new PyTorch version
When loading PyTorch models from the modelhub, arbitrary code can be executed. See [here.](https://huggingface.co/docs/hub/security-pickle#pickle-scanning)
Seems like PyTorch already solved this:
- Issue on the PyTorch Repo: https://github.com/pytorch/pytorch/issues/52596
- By default, this is not available in torch==1.13. TORCH_FORCE_WEIGHTS_ONLY_LOAD needs to be set to True which allows global override to safe only model loading via.
Test
Test haystack tests with new flags
**Solution:**
- Bump up PyTorch version to 1.13
**Behaviour**
- Secure by default TORCH_FORCE_WEIGHTS_ONLY_LOAD always set to true when Haystack loads any models
</issue>
<code>
[start of haystack/__init__.py]
1 # pylint: disable=wrong-import-position,wrong-import-order
2
3 from typing import Union
4 from types import ModuleType
5
6 try:
7 from importlib import metadata
8 except (ModuleNotFoundError, ImportError):
9 # Python <= 3.7
10 import importlib_metadata as metadata # type: ignore
11
12 __version__: str = str(metadata.version("farm-haystack"))
13
14
15 # Logging is not configured here on purpose, see https://github.com/deepset-ai/haystack/issues/2485
16 import logging
17
18 import pandas as pd
19
20 from haystack.schema import Document, Answer, Label, MultiLabel, Span, EvaluationResult
21 from haystack.nodes.base import BaseComponent
22 from haystack.pipelines.base import Pipeline
23
24
25 pd.options.display.max_colwidth = 80
26
[end of haystack/__init__.py]
[start of haystack/environment.py]
1 import os
2 import platform
3 import sys
4 from typing import Any, Dict
5 import torch
6 import transformers
7
8 from haystack import __version__
9
10
11 HAYSTACK_EXECUTION_CONTEXT = "HAYSTACK_EXECUTION_CONTEXT"
12 HAYSTACK_DOCKER_CONTAINER = "HAYSTACK_DOCKER_CONTAINER"
13
14 # Any remote API (OpenAI, Cohere etc.)
15 HAYSTACK_REMOTE_API_BACKOFF_SEC = "HAYSTACK_REMOTE_API_BACKOFF_SEC"
16 HAYSTACK_REMOTE_API_MAX_RETRIES = "HAYSTACK_REMOTE_API_MAX_RETRIES"
17
18 env_meta_data: Dict[str, Any] = {}
19
20
21 def get_or_create_env_meta_data() -> Dict[str, Any]:
22 """
23 Collects meta data about the setup that is used with Haystack, such as: operating system, python version, Haystack version, transformers version, pytorch version, number of GPUs, execution environment, and the value stored in the env variable HAYSTACK_EXECUTION_CONTEXT.
24 """
25 global env_meta_data # pylint: disable=global-statement
26 if not env_meta_data:
27 env_meta_data = {
28 "os_version": platform.release(),
29 "os_family": platform.system(),
30 "os_machine": platform.machine(),
31 "python_version": platform.python_version(),
32 "haystack_version": __version__,
33 "transformers_version": transformers.__version__,
34 "torch_version": torch.__version__,
35 "torch_cuda_version": torch.version.cuda if torch.cuda.is_available() else 0,
36 "n_gpu": torch.cuda.device_count() if torch.cuda.is_available() else 0,
37 "n_cpu": os.cpu_count(),
38 "context": os.environ.get(HAYSTACK_EXECUTION_CONTEXT),
39 "execution_env": _get_execution_environment(),
40 }
41 return env_meta_data
42
43
44 def _get_execution_environment():
45 """
46 Identifies the execution environment that Haystack is running in.
47 Options are: colab notebook, kubernetes, CPU/GPU docker container, test environment, jupyter notebook, python script
48 """
49 if os.environ.get("CI", "False").lower() == "true":
50 execution_env = "ci"
51 elif "google.colab" in sys.modules:
52 execution_env = "colab"
53 elif "KUBERNETES_SERVICE_HOST" in os.environ:
54 execution_env = "kubernetes"
55 elif HAYSTACK_DOCKER_CONTAINER in os.environ:
56 execution_env = os.environ.get(HAYSTACK_DOCKER_CONTAINER)
57 # check if pytest is imported
58 elif "pytest" in sys.modules:
59 execution_env = "test"
60 else:
61 try:
62 execution_env = get_ipython().__class__.__name__ # pylint: disable=undefined-variable
63 except NameError:
64 execution_env = "script"
65 return execution_env
66
[end of haystack/environment.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/haystack/__init__.py b/haystack/__init__.py
--- a/haystack/__init__.py
+++ b/haystack/__init__.py
@@ -20,6 +20,8 @@
from haystack.schema import Document, Answer, Label, MultiLabel, Span, EvaluationResult
from haystack.nodes.base import BaseComponent
from haystack.pipelines.base import Pipeline
+from haystack.environment import set_pytorch_secure_model_loading
pd.options.display.max_colwidth = 80
+set_pytorch_secure_model_loading()
diff --git a/haystack/environment.py b/haystack/environment.py
--- a/haystack/environment.py
+++ b/haystack/environment.py
@@ -1,3 +1,4 @@
+import logging
import os
import platform
import sys
@@ -17,6 +18,18 @@
env_meta_data: Dict[str, Any] = {}
+logger = logging.getLogger(__name__)
+
+
+def set_pytorch_secure_model_loading(flag_val="1"):
+ # To load secure only model pytorch requires value of
+ # TORCH_FORCE_WEIGHTS_ONLY_LOAD to be ["1", "y", "yes", "true"]
+ os_flag_val = os.getenv("TORCH_FORCE_WEIGHTS_ONLY_LOAD")
+ if os_flag_val is None:
+ os.environ["TORCH_FORCE_WEIGHTS_ONLY_LOAD"] = flag_val
+ else:
+ logger.info("TORCH_FORCE_WEIGHTS_ONLY_LOAD is already set to %s, Haystack will use the same.", os_flag_val)
+
def get_or_create_env_meta_data() -> Dict[str, Any]:
"""
|
{"golden_diff": "diff --git a/haystack/__init__.py b/haystack/__init__.py\n--- a/haystack/__init__.py\n+++ b/haystack/__init__.py\n@@ -20,6 +20,8 @@\n from haystack.schema import Document, Answer, Label, MultiLabel, Span, EvaluationResult\n from haystack.nodes.base import BaseComponent\n from haystack.pipelines.base import Pipeline\n+from haystack.environment import set_pytorch_secure_model_loading\n \n \n pd.options.display.max_colwidth = 80\n+set_pytorch_secure_model_loading()\ndiff --git a/haystack/environment.py b/haystack/environment.py\n--- a/haystack/environment.py\n+++ b/haystack/environment.py\n@@ -1,3 +1,4 @@\n+import logging\n import os\n import platform\n import sys\n@@ -17,6 +18,18 @@\n \n env_meta_data: Dict[str, Any] = {}\n \n+logger = logging.getLogger(__name__)\n+\n+\n+def set_pytorch_secure_model_loading(flag_val=\"1\"):\n+ # To load secure only model pytorch requires value of\n+ # TORCH_FORCE_WEIGHTS_ONLY_LOAD to be [\"1\", \"y\", \"yes\", \"true\"]\n+ os_flag_val = os.getenv(\"TORCH_FORCE_WEIGHTS_ONLY_LOAD\")\n+ if os_flag_val is None:\n+ os.environ[\"TORCH_FORCE_WEIGHTS_ONLY_LOAD\"] = flag_val\n+ else:\n+ logger.info(\"TORCH_FORCE_WEIGHTS_ONLY_LOAD is already set to %s, Haystack will use the same.\", os_flag_val)\n+\n \n def get_or_create_env_meta_data() -> Dict[str, Any]:\n \"\"\"\n", "issue": "Better model security with new PyTorch version\nWhen loading PyTorch models from the modelhub, arbitrary code can be executed. See [here.](https://huggingface.co/docs/hub/security-pickle#pickle-scanning)\r\n\r\nSeems like PyTorch already solved this:\r\n- Issue on the PyTorch Repo: https://github.com/pytorch/pytorch/issues/52596\r\n- By default, this is not available in torch==1.13. TORCH_FORCE_WEIGHTS_ONLY_LOAD needs to be set to True which allows global override to safe only model loading via.\r\n\r\nTest\r\nTest haystack tests with new flags\r\n\r\n**Solution:**\r\n- Bump up PyTorch version to 1.13\r\n\r\n**Behaviour**\r\n- Secure by default TORCH_FORCE_WEIGHTS_ONLY_LOAD always set to true when Haystack loads any models\r\n\r\n\n", "before_files": [{"content": "# pylint: disable=wrong-import-position,wrong-import-order\n\nfrom typing import Union\nfrom types import ModuleType\n\ntry:\n from importlib import metadata\nexcept (ModuleNotFoundError, ImportError):\n # Python <= 3.7\n import importlib_metadata as metadata # type: ignore\n\n__version__: str = str(metadata.version(\"farm-haystack\"))\n\n\n# Logging is not configured here on purpose, see https://github.com/deepset-ai/haystack/issues/2485\nimport logging\n\nimport pandas as pd\n\nfrom haystack.schema import Document, Answer, Label, MultiLabel, Span, EvaluationResult\nfrom haystack.nodes.base import BaseComponent\nfrom haystack.pipelines.base import Pipeline\n\n\npd.options.display.max_colwidth = 80\n", "path": "haystack/__init__.py"}, {"content": "import os\nimport platform\nimport sys\nfrom typing import Any, Dict\nimport torch\nimport transformers\n\nfrom haystack import __version__\n\n\nHAYSTACK_EXECUTION_CONTEXT = \"HAYSTACK_EXECUTION_CONTEXT\"\nHAYSTACK_DOCKER_CONTAINER = \"HAYSTACK_DOCKER_CONTAINER\"\n\n# Any remote API (OpenAI, Cohere etc.)\nHAYSTACK_REMOTE_API_BACKOFF_SEC = \"HAYSTACK_REMOTE_API_BACKOFF_SEC\"\nHAYSTACK_REMOTE_API_MAX_RETRIES = \"HAYSTACK_REMOTE_API_MAX_RETRIES\"\n\nenv_meta_data: Dict[str, Any] = {}\n\n\ndef get_or_create_env_meta_data() -> Dict[str, Any]:\n \"\"\"\n Collects meta data about the setup that is used with Haystack, such as: operating system, python version, Haystack version, transformers version, pytorch version, number of GPUs, execution environment, and the value stored in the env variable HAYSTACK_EXECUTION_CONTEXT.\n \"\"\"\n global env_meta_data # pylint: disable=global-statement\n if not env_meta_data:\n env_meta_data = {\n \"os_version\": platform.release(),\n \"os_family\": platform.system(),\n \"os_machine\": platform.machine(),\n \"python_version\": platform.python_version(),\n \"haystack_version\": __version__,\n \"transformers_version\": transformers.__version__,\n \"torch_version\": torch.__version__,\n \"torch_cuda_version\": torch.version.cuda if torch.cuda.is_available() else 0,\n \"n_gpu\": torch.cuda.device_count() if torch.cuda.is_available() else 0,\n \"n_cpu\": os.cpu_count(),\n \"context\": os.environ.get(HAYSTACK_EXECUTION_CONTEXT),\n \"execution_env\": _get_execution_environment(),\n }\n return env_meta_data\n\n\ndef _get_execution_environment():\n \"\"\"\n Identifies the execution environment that Haystack is running in.\n Options are: colab notebook, kubernetes, CPU/GPU docker container, test environment, jupyter notebook, python script\n \"\"\"\n if os.environ.get(\"CI\", \"False\").lower() == \"true\":\n execution_env = \"ci\"\n elif \"google.colab\" in sys.modules:\n execution_env = \"colab\"\n elif \"KUBERNETES_SERVICE_HOST\" in os.environ:\n execution_env = \"kubernetes\"\n elif HAYSTACK_DOCKER_CONTAINER in os.environ:\n execution_env = os.environ.get(HAYSTACK_DOCKER_CONTAINER)\n # check if pytest is imported\n elif \"pytest\" in sys.modules:\n execution_env = \"test\"\n else:\n try:\n execution_env = get_ipython().__class__.__name__ # pylint: disable=undefined-variable\n except NameError:\n execution_env = \"script\"\n return execution_env\n", "path": "haystack/environment.py"}]}
| 1,646 | 355 |
gh_patches_debug_27290
|
rasdani/github-patches
|
git_diff
|
GPflow__GPflow-957
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
SwitchedLikelihood fails in conjunction with likelihoods relying on the quadrature fallback
Are there any tips and trick to using the Student T likelihood? Below is an example of some data that I have... similar to the gpflow example of a coregionalized model with a student T. When I run the code below, I get this error.
``` File "/opt/conda/lib/python3.6/site-packages/gpflow-1.3.0-py3.6.egg/gpflow/quadrature.py", line 187, in eval_func
feval = f(*Xs, **Ys) # f should be elementwise: return shape N x H**Din
File "/opt/conda/lib/python3.6/site-packages/gpflow-1.3.0-py3.6.egg/gpflow/decors.py", line 67, in tensor_mode_wrapper
result = method(obj, *args, **kwargs)
File "/opt/conda/lib/python3.6/site-packages/gpflow-1.3.0-py3.6.egg/gpflow/likelihoods.py", line 217, in logp
return logdensities.student_t(Y, F, self.scale, self.df)
File "/opt/conda/lib/python3.6/site-packages/gpflow-1.3.0-py3.6.egg/gpflow/logdensities.py", line 59, in student_t
tf.log(1. + (1. / df) * (tf.square((x - mean) / scale)))
```
maybe a convergence error...? I have tried playing around with the jitter parameter and the degrees of freedom, but to no avail. Any ideas?
Thanks!
Below is a minimal bug-reproducing example
```
import gpflow as gpflow
import numpy as np
idx = np.array([0]*12 + [1]*15 + [2]*36)
X_aug = np.c_[np.random.randn(12+15+36, 1), idx]
Y_aug = np.c_[np.random.randn(12+15+36, 1), idx]
k1 = gpflow.kernels.Matern32(1, variance=.1, active_dims=[0]) +gpflow.kernels.White(1)
coreg = gpflow.kernels.Coregion(1, output_dim=3, rank=3, active_dims=[1])
kern = k1 * coreg
# build a variational model. This likelihood switches between Student-T noise with different variances:
lik = gpflow.likelihoods.SwitchedLikelihood([gpflow.likelihoods.StudentT(), gpflow.likelihoods.StudentT(), gpflow.likelihoods.StudentT()])
m = gpflow.models.VGP(X_aug, Y_aug, kern=kern, likelihood=lik)
## optimization errors out
gpflow.train.ScipyOptimizer().minimize(m)
</issue>
<code>
[start of gpflow/models/model.py]
1 # Copyright 2016 James Hensman, Mark van der Wilk, Valentine Svensson, alexggmatthews, fujiisoup
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import abc
16
17 import numpy as np
18 import tensorflow as tf
19
20 from .. import settings
21 from ..core.compilable import Build
22 from ..params import Parameterized, DataHolder
23 from ..decors import autoflow
24 from ..mean_functions import Zero
25
26
27 class Model(Parameterized):
28 def __init__(self, name=None):
29 """
30 Name is a string describing this model.
31 """
32 super(Model, self).__init__(name=name)
33 self._objective = None
34 self._likelihood_tensor = None
35
36 @property
37 def objective(self):
38 return self._objective
39
40 @property
41 def likelihood_tensor(self):
42 return self._likelihood_tensor
43
44 @autoflow()
45 def compute_log_prior(self):
46 """Compute the log prior of the model."""
47 return self.prior_tensor
48
49 @autoflow()
50 def compute_log_likelihood(self):
51 """Compute the log likelihood of the model."""
52 return self.likelihood_tensor
53
54 def is_built(self, graph):
55 is_built = super().is_built(graph)
56 if is_built is not Build.YES:
57 return is_built
58 if self._likelihood_tensor is None:
59 return Build.NO
60 return Build.YES
61
62 def build_objective(self):
63 likelihood = self._build_likelihood()
64 priors = []
65 for param in self.parameters:
66 unconstrained = param.unconstrained_tensor
67 constrained = param._build_constrained(unconstrained)
68 priors.append(param._build_prior(unconstrained, constrained))
69 prior = self._build_prior(priors)
70 return self._build_objective(likelihood, prior)
71
72 def _clear(self):
73 super(Model, self)._clear()
74 self._likelihood_tensor = None
75 self._objective = None
76
77 def _build(self):
78 super(Model, self)._build()
79 likelihood = self._build_likelihood()
80 prior = self.prior_tensor
81 objective = self._build_objective(likelihood, prior)
82 self._likelihood_tensor = likelihood
83 self._objective = objective
84
85 def sample_feed_dict(self, sample):
86 tensor_feed_dict = {}
87 for param in self.parameters:
88 if not param.trainable: continue
89 constrained_value = sample[param.pathname]
90 unconstrained_value = param.transform.backward(constrained_value)
91 tensor = param.unconstrained_tensor
92 tensor_feed_dict[tensor] = unconstrained_value
93 return tensor_feed_dict
94
95 def _build_objective(self, likelihood_tensor, prior_tensor):
96 func = tf.add(likelihood_tensor, prior_tensor, name='nonneg_objective')
97 return tf.negative(func, name='objective')
98
99 @abc.abstractmethod
100 def _build_likelihood(self):
101 pass
102
103
104 class GPModel(Model):
105 r"""
106 A base class for Gaussian process models, that is, those of the form
107
108 .. math::
109 :nowrap:
110
111 \begin{align}
112 \theta & \sim p(\theta) \\
113 f & \sim \mathcal{GP}(m(x), k(x, x'; \theta)) \\
114 f_i & = f(x_i) \\
115 y_i\,|\,f_i & \sim p(y_i|f_i)
116 \end{align}
117
118 This class mostly adds functionality to compile predictions. To use it,
119 inheriting classes must define a build_predict function, which computes
120 the means and variances of the latent function. This gets compiled
121 similarly to build_likelihood in the Model class.
122
123 These predictions are then pushed through the likelihood to obtain means
124 and variances of held out data, self.predict_y.
125
126 The predictions can also be used to compute the (log) density of held-out
127 data via self.predict_density.
128
129 For handling another data (Xnew, Ynew), set the new value to self.X and self.Y
130
131 >>> m.X = Xnew
132 >>> m.Y = Ynew
133 """
134
135 def __init__(self, X, Y, kern, likelihood, mean_function,
136 num_latent=None, name=None):
137 super(GPModel, self).__init__(name=name)
138 self.num_latent = num_latent or Y.shape[1]
139 self.mean_function = mean_function or Zero(output_dim=self.num_latent)
140 self.kern = kern
141 self.likelihood = likelihood
142
143 if isinstance(X, np.ndarray):
144 # X is a data matrix; each row represents one instance
145 X = DataHolder(X)
146 if isinstance(Y, np.ndarray):
147 # Y is a data matrix, rows correspond to the rows in X,
148 # columns are treated independently
149 Y = DataHolder(Y)
150 self.X, self.Y = X, Y
151
152 @autoflow((settings.float_type, [None, None]))
153 def predict_f(self, Xnew):
154 """
155 Compute the mean and variance of the latent function(s) at the points
156 Xnew.
157 """
158 return self._build_predict(Xnew)
159
160 @autoflow((settings.float_type, [None, None]))
161 def predict_f_full_cov(self, Xnew):
162 """
163 Compute the mean and covariance matrix of the latent function(s) at the
164 points Xnew.
165 """
166 return self._build_predict(Xnew, full_cov=True)
167
168 @autoflow((settings.float_type, [None, None]), (tf.int32, []))
169 def predict_f_samples(self, Xnew, num_samples):
170 """
171 Produce samples from the posterior latent function(s) at the points
172 Xnew.
173 """
174 mu, var = self._build_predict(Xnew, full_cov=True) # N x P, # P x N x N
175 jitter = tf.eye(tf.shape(mu)[0], dtype=settings.float_type) * settings.jitter
176 samples = []
177 for i in range(self.num_latent):
178 L = tf.cholesky(var[i, :, :] + jitter)
179 shape = tf.stack([tf.shape(L)[0], num_samples])
180 V = tf.random_normal(shape, dtype=settings.float_type)
181 samples.append(mu[:, i:i + 1] + tf.matmul(L, V))
182 return tf.transpose(tf.stack(samples))
183
184 @autoflow((settings.float_type, [None, None]))
185 def predict_y(self, Xnew):
186 """
187 Compute the mean and variance of held-out data at the points Xnew
188 """
189 pred_f_mean, pred_f_var = self._build_predict(Xnew)
190 return self.likelihood.predict_mean_and_var(pred_f_mean, pred_f_var)
191
192 @autoflow((settings.float_type, [None, None]), (settings.float_type, [None, None]))
193 def predict_density(self, Xnew, Ynew):
194 """
195 Compute the (log) density of the data Ynew at the points Xnew
196
197 Note that this computes the log density of the data individually,
198 ignoring correlations between them. The result is a matrix the same
199 shape as Ynew containing the log densities.
200 """
201 pred_f_mean, pred_f_var = self._build_predict(Xnew)
202 return self.likelihood.predict_density(pred_f_mean, pred_f_var, Ynew)
203
204 @abc.abstractmethod
205 def _build_predict(self, *args, **kwargs):
206 pass
207
[end of gpflow/models/model.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/gpflow/models/model.py b/gpflow/models/model.py
--- a/gpflow/models/model.py
+++ b/gpflow/models/model.py
@@ -22,6 +22,7 @@
from ..params import Parameterized, DataHolder
from ..decors import autoflow
from ..mean_functions import Zero
+from ..likelihoods import SwitchedLikelihood
class Model(Parameterized):
@@ -135,7 +136,22 @@
def __init__(self, X, Y, kern, likelihood, mean_function,
num_latent=None, name=None):
super(GPModel, self).__init__(name=name)
- self.num_latent = num_latent or Y.shape[1]
+ if num_latent is None:
+ # Note: It's not nice for `Model` to need to be aware of specific
+ # likelihoods as here. However, `num_latent` is a bit more broken
+ # in general, specifically regarding multioutput kernels. We
+ # should fix this in the future.
+ # It also has slightly problematic assumptions re the output
+ # dimensions of mean_function.
+ num_latent = Y.shape[1]
+ if isinstance(likelihood, SwitchedLikelihood):
+ # the SwitchedLikelihood partitions/stitches based on the last
+ # column in Y, but we should not add a separate latent GP for
+ # this! hence decrement by 1
+ assert num_latent >= 2
+ num_latent -= 1
+
+ self.num_latent = num_latent
self.mean_function = mean_function or Zero(output_dim=self.num_latent)
self.kern = kern
self.likelihood = likelihood
|
{"golden_diff": "diff --git a/gpflow/models/model.py b/gpflow/models/model.py\n--- a/gpflow/models/model.py\n+++ b/gpflow/models/model.py\n@@ -22,6 +22,7 @@\n from ..params import Parameterized, DataHolder\n from ..decors import autoflow\n from ..mean_functions import Zero\n+from ..likelihoods import SwitchedLikelihood\n \n \n class Model(Parameterized):\n@@ -135,7 +136,22 @@\n def __init__(self, X, Y, kern, likelihood, mean_function,\n num_latent=None, name=None):\n super(GPModel, self).__init__(name=name)\n- self.num_latent = num_latent or Y.shape[1]\n+ if num_latent is None:\n+ # Note: It's not nice for `Model` to need to be aware of specific\n+ # likelihoods as here. However, `num_latent` is a bit more broken\n+ # in general, specifically regarding multioutput kernels. We\n+ # should fix this in the future.\n+ # It also has slightly problematic assumptions re the output\n+ # dimensions of mean_function.\n+ num_latent = Y.shape[1]\n+ if isinstance(likelihood, SwitchedLikelihood):\n+ # the SwitchedLikelihood partitions/stitches based on the last\n+ # column in Y, but we should not add a separate latent GP for\n+ # this! hence decrement by 1\n+ assert num_latent >= 2\n+ num_latent -= 1\n+\n+ self.num_latent = num_latent\n self.mean_function = mean_function or Zero(output_dim=self.num_latent)\n self.kern = kern\n self.likelihood = likelihood\n", "issue": "SwitchedLikelihood fails in conjunction with likelihoods relying on the quadrature fallback\nAre there any tips and trick to using the Student T likelihood? Below is an example of some data that I have... similar to the gpflow example of a coregionalized model with a student T. When I run the code below, I get this error.\r\n\r\n``` File \"/opt/conda/lib/python3.6/site-packages/gpflow-1.3.0-py3.6.egg/gpflow/quadrature.py\", line 187, in eval_func\r\n feval = f(*Xs, **Ys) # f should be elementwise: return shape N x H**Din\r\n File \"/opt/conda/lib/python3.6/site-packages/gpflow-1.3.0-py3.6.egg/gpflow/decors.py\", line 67, in tensor_mode_wrapper\r\n result = method(obj, *args, **kwargs)\r\n File \"/opt/conda/lib/python3.6/site-packages/gpflow-1.3.0-py3.6.egg/gpflow/likelihoods.py\", line 217, in logp\r\n return logdensities.student_t(Y, F, self.scale, self.df)\r\n File \"/opt/conda/lib/python3.6/site-packages/gpflow-1.3.0-py3.6.egg/gpflow/logdensities.py\", line 59, in student_t\r\n tf.log(1. + (1. / df) * (tf.square((x - mean) / scale)))\r\n```\r\n\r\nmaybe a convergence error...? I have tried playing around with the jitter parameter and the degrees of freedom, but to no avail. Any ideas?\r\n\r\nThanks!\r\n\r\n Below is a minimal bug-reproducing example\r\n```\r\nimport gpflow as gpflow\r\nimport numpy as np\r\n\r\nidx = np.array([0]*12 + [1]*15 + [2]*36)\r\nX_aug = np.c_[np.random.randn(12+15+36, 1), idx]\r\nY_aug = np.c_[np.random.randn(12+15+36, 1), idx]\r\n\r\nk1 = gpflow.kernels.Matern32(1, variance=.1, active_dims=[0]) +gpflow.kernels.White(1)\r\ncoreg = gpflow.kernels.Coregion(1, output_dim=3, rank=3, active_dims=[1])\r\nkern = k1 * coreg\r\n\r\n# build a variational model. This likelihood switches between Student-T noise with different variances:\r\nlik = gpflow.likelihoods.SwitchedLikelihood([gpflow.likelihoods.StudentT(), gpflow.likelihoods.StudentT(), gpflow.likelihoods.StudentT()])\r\nm = gpflow.models.VGP(X_aug, Y_aug, kern=kern, likelihood=lik)\r\n## optimization errors out\r\ngpflow.train.ScipyOptimizer().minimize(m)\r\n \n", "before_files": [{"content": "# Copyright 2016 James Hensman, Mark van der Wilk, Valentine Svensson, alexggmatthews, fujiisoup\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport abc\n\nimport numpy as np\nimport tensorflow as tf\n\nfrom .. import settings\nfrom ..core.compilable import Build\nfrom ..params import Parameterized, DataHolder\nfrom ..decors import autoflow\nfrom ..mean_functions import Zero\n\n\nclass Model(Parameterized):\n def __init__(self, name=None):\n \"\"\"\n Name is a string describing this model.\n \"\"\"\n super(Model, self).__init__(name=name)\n self._objective = None\n self._likelihood_tensor = None\n\n @property\n def objective(self):\n return self._objective\n\n @property\n def likelihood_tensor(self):\n return self._likelihood_tensor\n\n @autoflow()\n def compute_log_prior(self):\n \"\"\"Compute the log prior of the model.\"\"\"\n return self.prior_tensor\n\n @autoflow()\n def compute_log_likelihood(self):\n \"\"\"Compute the log likelihood of the model.\"\"\"\n return self.likelihood_tensor\n\n def is_built(self, graph):\n is_built = super().is_built(graph)\n if is_built is not Build.YES:\n return is_built\n if self._likelihood_tensor is None:\n return Build.NO\n return Build.YES\n\n def build_objective(self):\n likelihood = self._build_likelihood()\n priors = []\n for param in self.parameters:\n unconstrained = param.unconstrained_tensor\n constrained = param._build_constrained(unconstrained)\n priors.append(param._build_prior(unconstrained, constrained))\n prior = self._build_prior(priors)\n return self._build_objective(likelihood, prior)\n\n def _clear(self):\n super(Model, self)._clear()\n self._likelihood_tensor = None\n self._objective = None\n\n def _build(self):\n super(Model, self)._build()\n likelihood = self._build_likelihood()\n prior = self.prior_tensor\n objective = self._build_objective(likelihood, prior)\n self._likelihood_tensor = likelihood\n self._objective = objective\n\n def sample_feed_dict(self, sample):\n tensor_feed_dict = {}\n for param in self.parameters:\n if not param.trainable: continue\n constrained_value = sample[param.pathname]\n unconstrained_value = param.transform.backward(constrained_value)\n tensor = param.unconstrained_tensor\n tensor_feed_dict[tensor] = unconstrained_value\n return tensor_feed_dict\n\n def _build_objective(self, likelihood_tensor, prior_tensor):\n func = tf.add(likelihood_tensor, prior_tensor, name='nonneg_objective')\n return tf.negative(func, name='objective')\n\n @abc.abstractmethod\n def _build_likelihood(self):\n pass\n\n\nclass GPModel(Model):\n r\"\"\"\n A base class for Gaussian process models, that is, those of the form\n\n .. math::\n :nowrap:\n\n \\begin{align}\n \\theta & \\sim p(\\theta) \\\\\n f & \\sim \\mathcal{GP}(m(x), k(x, x'; \\theta)) \\\\\n f_i & = f(x_i) \\\\\n y_i\\,|\\,f_i & \\sim p(y_i|f_i)\n \\end{align}\n\n This class mostly adds functionality to compile predictions. To use it,\n inheriting classes must define a build_predict function, which computes\n the means and variances of the latent function. This gets compiled\n similarly to build_likelihood in the Model class.\n\n These predictions are then pushed through the likelihood to obtain means\n and variances of held out data, self.predict_y.\n\n The predictions can also be used to compute the (log) density of held-out\n data via self.predict_density.\n\n For handling another data (Xnew, Ynew), set the new value to self.X and self.Y\n\n >>> m.X = Xnew\n >>> m.Y = Ynew\n \"\"\"\n\n def __init__(self, X, Y, kern, likelihood, mean_function,\n num_latent=None, name=None):\n super(GPModel, self).__init__(name=name)\n self.num_latent = num_latent or Y.shape[1]\n self.mean_function = mean_function or Zero(output_dim=self.num_latent)\n self.kern = kern\n self.likelihood = likelihood\n\n if isinstance(X, np.ndarray):\n # X is a data matrix; each row represents one instance\n X = DataHolder(X)\n if isinstance(Y, np.ndarray):\n # Y is a data matrix, rows correspond to the rows in X,\n # columns are treated independently\n Y = DataHolder(Y)\n self.X, self.Y = X, Y\n\n @autoflow((settings.float_type, [None, None]))\n def predict_f(self, Xnew):\n \"\"\"\n Compute the mean and variance of the latent function(s) at the points\n Xnew.\n \"\"\"\n return self._build_predict(Xnew)\n\n @autoflow((settings.float_type, [None, None]))\n def predict_f_full_cov(self, Xnew):\n \"\"\"\n Compute the mean and covariance matrix of the latent function(s) at the\n points Xnew.\n \"\"\"\n return self._build_predict(Xnew, full_cov=True)\n\n @autoflow((settings.float_type, [None, None]), (tf.int32, []))\n def predict_f_samples(self, Xnew, num_samples):\n \"\"\"\n Produce samples from the posterior latent function(s) at the points\n Xnew.\n \"\"\"\n mu, var = self._build_predict(Xnew, full_cov=True) # N x P, # P x N x N\n jitter = tf.eye(tf.shape(mu)[0], dtype=settings.float_type) * settings.jitter\n samples = []\n for i in range(self.num_latent):\n L = tf.cholesky(var[i, :, :] + jitter)\n shape = tf.stack([tf.shape(L)[0], num_samples])\n V = tf.random_normal(shape, dtype=settings.float_type)\n samples.append(mu[:, i:i + 1] + tf.matmul(L, V))\n return tf.transpose(tf.stack(samples))\n\n @autoflow((settings.float_type, [None, None]))\n def predict_y(self, Xnew):\n \"\"\"\n Compute the mean and variance of held-out data at the points Xnew\n \"\"\"\n pred_f_mean, pred_f_var = self._build_predict(Xnew)\n return self.likelihood.predict_mean_and_var(pred_f_mean, pred_f_var)\n\n @autoflow((settings.float_type, [None, None]), (settings.float_type, [None, None]))\n def predict_density(self, Xnew, Ynew):\n \"\"\"\n Compute the (log) density of the data Ynew at the points Xnew\n\n Note that this computes the log density of the data individually,\n ignoring correlations between them. The result is a matrix the same\n shape as Ynew containing the log densities.\n \"\"\"\n pred_f_mean, pred_f_var = self._build_predict(Xnew)\n return self.likelihood.predict_density(pred_f_mean, pred_f_var, Ynew)\n\n @abc.abstractmethod\n def _build_predict(self, *args, **kwargs):\n pass\n", "path": "gpflow/models/model.py"}]}
| 3,395 | 386 |
gh_patches_debug_1621
|
rasdani/github-patches
|
git_diff
|
mathesar-foundation__mathesar-1707
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Explorations should not auto-save
New Explorations are currently persistent, any change made immediately saves the exploration. This behaviour is not preferred since we'd like the user to be able to run and discard queries.
[Mail thread containing related discussion](https://groups.google.com/a/mathesar.org/g/mathesar-developers/c/RQJSiDQu1Tg/m/uLHj30yFAgAJ).
New behaviour proposed:
* New Exploration: Auto-save is not preferred
- User opens Data Explorer
- User joins tables, does any number of operations
- This should not get saved automatically
- It should get saved when user manually clicks Save button
* Editing existing Exploration: ~~Auto-save is preferred~~ Auto save is not preferred (Refer https://github.com/centerofci/mathesar/issues/1590#issuecomment-1238204655)
- Users edits an existing exploration in the Data Explorer
- User makes changes to it
- ~~The changes are auto-saved~~ User has to click the Save button or Ctrl+s to save the changes
- We have undo-redo to improve the user's editing experience
Implement Exploration Page functionality
This is a placeholder issue to implement a page to view a single exploration.
</issue>
<code>
[start of mathesar/views.py]
1 from django.shortcuts import render, redirect, get_object_or_404
2
3 from mathesar.models.base import Database, Schema, Table
4 from mathesar.api.serializers.databases import DatabaseSerializer, TypeSerializer
5 from mathesar.api.serializers.schemas import SchemaSerializer
6 from mathesar.api.serializers.tables import TableSerializer
7 from mathesar.api.serializers.queries import QuerySerializer
8 from mathesar.database.types import UIType
9 from mathesar.models.query import UIQuery
10
11
12 def get_schema_list(request, database):
13 schema_serializer = SchemaSerializer(
14 Schema.objects.filter(database=database),
15 many=True,
16 context={'request': request}
17 )
18 return schema_serializer.data
19
20
21 def get_database_list(request):
22 database_serializer = DatabaseSerializer(
23 Database.objects.all(),
24 many=True,
25 context={'request': request}
26 )
27 return database_serializer.data
28
29
30 def get_table_list(request, schema):
31 if schema is None:
32 return []
33 table_serializer = TableSerializer(
34 Table.objects.filter(schema=schema),
35 many=True,
36 context={'request': request}
37 )
38 return table_serializer.data
39
40
41 def get_queries_list(request, schema):
42 if schema is None:
43 return []
44 query_serializer = QuerySerializer(
45 UIQuery.objects.all(),
46 many=True,
47 context={'request': request}
48 )
49 return query_serializer.data
50
51
52 def get_ui_type_list(request, database):
53 if database is None:
54 return []
55 type_serializer = TypeSerializer(
56 UIType,
57 many=True,
58 context={'request': request}
59 )
60 return type_serializer.data
61
62
63 def get_common_data(request, database, schema=None):
64 return {
65 'current_db': database.name if database else None,
66 'current_schema': schema.id if schema else None,
67 'schemas': get_schema_list(request, database),
68 'databases': get_database_list(request),
69 'tables': get_table_list(request, schema),
70 'queries': get_queries_list(request, schema),
71 'abstract_types': get_ui_type_list(request, database)
72 }
73
74
75 def get_current_database(request, db_name):
76 # if there's a DB name passed in, try to retrieve the database, or return a 404 error.
77 if db_name is not None:
78 return get_object_or_404(Database, name=db_name)
79 else:
80 try:
81 # Try to get the first database available
82 return Database.objects.order_by('id').first()
83 except Database.DoesNotExist:
84 return None
85
86
87 def get_current_schema(request, schema_id, database):
88 # if there's a schema ID passed in, try to retrieve the schema, or return a 404 error.
89 if schema_id is not None:
90 return get_object_or_404(Schema, id=schema_id)
91 else:
92 try:
93 # Try to get the first schema in the DB
94 return Schema.objects.filter(database=database).order_by('id').first()
95 except Schema.DoesNotExist:
96 return None
97
98
99 def render_schema(request, database, schema):
100 # if there's no schema available, redirect to the schemas page.
101 if not schema:
102 return redirect('schemas', db_name=database.name)
103 else:
104 # We are redirecting so that the correct URL is passed to the frontend.
105 return redirect('schema_home', db_name=database.name, schema_id=schema.id)
106
107
108 def home(request):
109 database = get_current_database(request, None)
110 return redirect('schemas', db_name=database.name)
111
112
113 def schema_home(request, db_name, schema_id, **kwargs):
114 database = get_current_database(request, db_name)
115 schema = get_current_schema(request, schema_id, database)
116 return render(request, 'mathesar/index.html', {
117 'common_data': get_common_data(request, database, schema)
118 })
119
120
121 def schemas(request, db_name):
122 database = get_current_database(request, db_name)
123 return render(request, 'mathesar/index.html', {
124 'common_data': get_common_data(request, database, None)
125 })
126
[end of mathesar/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mathesar/views.py b/mathesar/views.py
--- a/mathesar/views.py
+++ b/mathesar/views.py
@@ -42,7 +42,7 @@
if schema is None:
return []
query_serializer = QuerySerializer(
- UIQuery.objects.all(),
+ UIQuery.objects.filter(base_table__schema=schema),
many=True,
context={'request': request}
)
|
{"golden_diff": "diff --git a/mathesar/views.py b/mathesar/views.py\n--- a/mathesar/views.py\n+++ b/mathesar/views.py\n@@ -42,7 +42,7 @@\n if schema is None:\n return []\n query_serializer = QuerySerializer(\n- UIQuery.objects.all(),\n+ UIQuery.objects.filter(base_table__schema=schema),\n many=True,\n context={'request': request}\n )\n", "issue": "Explorations should not auto-save\nNew Explorations are currently persistent, any change made immediately saves the exploration. This behaviour is not preferred since we'd like the user to be able to run and discard queries.\r\n\r\n[Mail thread containing related discussion](https://groups.google.com/a/mathesar.org/g/mathesar-developers/c/RQJSiDQu1Tg/m/uLHj30yFAgAJ).\r\n\r\nNew behaviour proposed:\r\n\r\n* New Exploration: Auto-save is not preferred\r\n - User opens Data Explorer\r\n - User joins tables, does any number of operations\r\n - This should not get saved automatically\r\n - It should get saved when user manually clicks Save button\r\n\r\n* Editing existing Exploration: ~~Auto-save is preferred~~ Auto save is not preferred (Refer https://github.com/centerofci/mathesar/issues/1590#issuecomment-1238204655)\r\n - Users edits an existing exploration in the Data Explorer\r\n - User makes changes to it\r\n - ~~The changes are auto-saved~~ User has to click the Save button or Ctrl+s to save the changes\r\n - We have undo-redo to improve the user's editing experience\nImplement Exploration Page functionality\nThis is a placeholder issue to implement a page to view a single exploration.\n", "before_files": [{"content": "from django.shortcuts import render, redirect, get_object_or_404\n\nfrom mathesar.models.base import Database, Schema, Table\nfrom mathesar.api.serializers.databases import DatabaseSerializer, TypeSerializer\nfrom mathesar.api.serializers.schemas import SchemaSerializer\nfrom mathesar.api.serializers.tables import TableSerializer\nfrom mathesar.api.serializers.queries import QuerySerializer\nfrom mathesar.database.types import UIType\nfrom mathesar.models.query import UIQuery\n\n\ndef get_schema_list(request, database):\n schema_serializer = SchemaSerializer(\n Schema.objects.filter(database=database),\n many=True,\n context={'request': request}\n )\n return schema_serializer.data\n\n\ndef get_database_list(request):\n database_serializer = DatabaseSerializer(\n Database.objects.all(),\n many=True,\n context={'request': request}\n )\n return database_serializer.data\n\n\ndef get_table_list(request, schema):\n if schema is None:\n return []\n table_serializer = TableSerializer(\n Table.objects.filter(schema=schema),\n many=True,\n context={'request': request}\n )\n return table_serializer.data\n\n\ndef get_queries_list(request, schema):\n if schema is None:\n return []\n query_serializer = QuerySerializer(\n UIQuery.objects.all(),\n many=True,\n context={'request': request}\n )\n return query_serializer.data\n\n\ndef get_ui_type_list(request, database):\n if database is None:\n return []\n type_serializer = TypeSerializer(\n UIType,\n many=True,\n context={'request': request}\n )\n return type_serializer.data\n\n\ndef get_common_data(request, database, schema=None):\n return {\n 'current_db': database.name if database else None,\n 'current_schema': schema.id if schema else None,\n 'schemas': get_schema_list(request, database),\n 'databases': get_database_list(request),\n 'tables': get_table_list(request, schema),\n 'queries': get_queries_list(request, schema),\n 'abstract_types': get_ui_type_list(request, database)\n }\n\n\ndef get_current_database(request, db_name):\n # if there's a DB name passed in, try to retrieve the database, or return a 404 error.\n if db_name is not None:\n return get_object_or_404(Database, name=db_name)\n else:\n try:\n # Try to get the first database available\n return Database.objects.order_by('id').first()\n except Database.DoesNotExist:\n return None\n\n\ndef get_current_schema(request, schema_id, database):\n # if there's a schema ID passed in, try to retrieve the schema, or return a 404 error.\n if schema_id is not None:\n return get_object_or_404(Schema, id=schema_id)\n else:\n try:\n # Try to get the first schema in the DB\n return Schema.objects.filter(database=database).order_by('id').first()\n except Schema.DoesNotExist:\n return None\n\n\ndef render_schema(request, database, schema):\n # if there's no schema available, redirect to the schemas page.\n if not schema:\n return redirect('schemas', db_name=database.name)\n else:\n # We are redirecting so that the correct URL is passed to the frontend.\n return redirect('schema_home', db_name=database.name, schema_id=schema.id)\n\n\ndef home(request):\n database = get_current_database(request, None)\n return redirect('schemas', db_name=database.name)\n\n\ndef schema_home(request, db_name, schema_id, **kwargs):\n database = get_current_database(request, db_name)\n schema = get_current_schema(request, schema_id, database)\n return render(request, 'mathesar/index.html', {\n 'common_data': get_common_data(request, database, schema)\n })\n\n\ndef schemas(request, db_name):\n database = get_current_database(request, db_name)\n return render(request, 'mathesar/index.html', {\n 'common_data': get_common_data(request, database, None)\n })\n", "path": "mathesar/views.py"}]}
| 1,936 | 89 |
gh_patches_debug_11719
|
rasdani/github-patches
|
git_diff
|
streamlit__streamlit-7306
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
CachedStFunctionWarning with st.code
### Checklist
- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [X] I added a very descriptive title to this issue.
- [X] I have provided sufficient information below to help reproduce this issue.
### Summary
I am getting 'CachedStFunctionWarning' for st.code. Using `@st.cache_data(experimental_allow_widgets=True) ` as suggested in the warning does not help.

### Reproducible Code Example
[](https://issues.streamlit.app/?issue=gh-7055)
```Python
@st.cache_data(experimental_allow_widgets=True, show_spinner=False)
def foo(i):
options = ["foo", "bar", "baz", "qux"]
st.code(options)
r = st.radio("radio", options, index=i)
return r
foo(1)
```
### Steps To Reproduce
1. Use code provided above
2. See warning message
### Expected Behavior
Warning is not shown for st.code or using `@st.cache_data(experimental_allow_widgets=True) ` suppresses the warning.
### Current Behavior

### Is this a regression?
- [X] Yes, this used to work in a previous version.
### Debug info
Streamlit version: 1.23.1
Python version: 3.11.1
### Additional Information
Further infos/community question [here](https://discuss.streamlit.io/t/st-cache-data-experimental-allow-widgets-true-is-not-working-with-st-code/47638)
CachedStFunctionWarning with st.code
### Checklist
- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [X] I added a very descriptive title to this issue.
- [X] I have provided sufficient information below to help reproduce this issue.
### Summary
I am getting 'CachedStFunctionWarning' for st.code. Using `@st.cache_data(experimental_allow_widgets=True) ` as suggested in the warning does not help.

### Reproducible Code Example
[](https://issues.streamlit.app/?issue=gh-7055)
```Python
@st.cache_data(experimental_allow_widgets=True, show_spinner=False)
def foo(i):
options = ["foo", "bar", "baz", "qux"]
st.code(options)
r = st.radio("radio", options, index=i)
return r
foo(1)
```
### Steps To Reproduce
1. Use code provided above
2. See warning message
### Expected Behavior
Warning is not shown for st.code or using `@st.cache_data(experimental_allow_widgets=True) ` suppresses the warning.
### Current Behavior

### Is this a regression?
- [X] Yes, this used to work in a previous version.
### Debug info
Streamlit version: 1.23.1
Python version: 3.11.1
### Additional Information
Further infos/community question [here](https://discuss.streamlit.io/t/st-cache-data-experimental-allow-widgets-true-is-not-working-with-st-code/47638)
</issue>
<code>
[start of lib/streamlit/elements/__init__.py]
1 # Copyright (c) Streamlit Inc. (2018-2022) Snowflake Inc. (2022)
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 WIDGETS = [
16 "button",
17 "camera_input",
18 "chat_input",
19 "checkbox",
20 "color_picker",
21 "component_instance",
22 "download_button",
23 "file_uploader",
24 "form",
25 "multiselect",
26 "number_input",
27 "radio",
28 "selectbox",
29 "select_slider",
30 "slider",
31 "text_input",
32 "text_area",
33 "time_input",
34 "date_input",
35 ]
36 NONWIDGET_ELEMENTS = [
37 "alert",
38 "area_chart",
39 "arrow_area_chart",
40 "arrow_bar_chart",
41 "arrow_data_frame",
42 "arrow_line_chart",
43 "arrow_table",
44 "arrow_vega_lite_chart",
45 "audio",
46 "balloons",
47 "bar_chart",
48 "bokeh_chart",
49 "data_frame",
50 "dataframe_selector",
51 "deck_gl_json_chart",
52 "doc_string",
53 "empty",
54 "exception",
55 "graphviz_chart",
56 "heading",
57 "iframe",
58 "imgs",
59 "json",
60 "legacy_altair",
61 "legacy_data_frame",
62 "legacy_vega_lite",
63 "line_chart",
64 "markdown",
65 "metric",
66 "plotly_chart",
67 "progress",
68 "pyplot",
69 "snow",
70 "table",
71 "text",
72 "vega_lite_chart",
73 "video",
74 "write",
75 ]
76
[end of lib/streamlit/elements/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lib/streamlit/elements/__init__.py b/lib/streamlit/elements/__init__.py
--- a/lib/streamlit/elements/__init__.py
+++ b/lib/streamlit/elements/__init__.py
@@ -46,6 +46,7 @@
"balloons",
"bar_chart",
"bokeh_chart",
+ "code",
"data_frame",
"dataframe_selector",
"deck_gl_json_chart",
@@ -61,6 +62,9 @@
"legacy_data_frame",
"legacy_vega_lite",
"line_chart",
+ # link_button unlike button and download_button is not a widget. It only sends a
+ # forward messages to the frontend, and not sends trigger value back.
+ "link_button",
"markdown",
"metric",
"plotly_chart",
|
{"golden_diff": "diff --git a/lib/streamlit/elements/__init__.py b/lib/streamlit/elements/__init__.py\n--- a/lib/streamlit/elements/__init__.py\n+++ b/lib/streamlit/elements/__init__.py\n@@ -46,6 +46,7 @@\n \"balloons\",\n \"bar_chart\",\n \"bokeh_chart\",\n+ \"code\",\n \"data_frame\",\n \"dataframe_selector\",\n \"deck_gl_json_chart\",\n@@ -61,6 +62,9 @@\n \"legacy_data_frame\",\n \"legacy_vega_lite\",\n \"line_chart\",\n+ # link_button unlike button and download_button is not a widget. It only sends a\n+ # forward messages to the frontend, and not sends trigger value back.\n+ \"link_button\",\n \"markdown\",\n \"metric\",\n \"plotly_chart\",\n", "issue": "CachedStFunctionWarning with st.code\n### Checklist\r\n\r\n- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.\r\n- [X] I added a very descriptive title to this issue.\r\n- [X] I have provided sufficient information below to help reproduce this issue.\r\n\r\n### Summary\r\n\r\nI am getting 'CachedStFunctionWarning' for st.code. Using `@st.cache_data(experimental_allow_widgets=True) ` as suggested in the warning does not help. \r\n\r\n\r\n\r\n### Reproducible Code Example\r\n\r\n[](https://issues.streamlit.app/?issue=gh-7055)\r\n\r\n```Python\r\[email protected]_data(experimental_allow_widgets=True, show_spinner=False)\r\ndef foo(i):\r\n options = [\"foo\", \"bar\", \"baz\", \"qux\"]\r\n st.code(options)\r\n r = st.radio(\"radio\", options, index=i)\r\n return r\r\n\r\nfoo(1)\r\n```\r\n\r\n\r\n### Steps To Reproduce\r\n\r\n1. Use code provided above\r\n2. See warning message\r\n\r\n### Expected Behavior\r\n\r\nWarning is not shown for st.code or using `@st.cache_data(experimental_allow_widgets=True) ` suppresses the warning.\r\n\r\n### Current Behavior\r\n\r\n\r\n\r\n\r\n### Is this a regression?\r\n\r\n- [X] Yes, this used to work in a previous version.\r\n\r\n### Debug info\r\n\r\nStreamlit version: 1.23.1\r\nPython version: 3.11.1\r\n\r\n\r\n### Additional Information\r\n\r\nFurther infos/community question [here](https://discuss.streamlit.io/t/st-cache-data-experimental-allow-widgets-true-is-not-working-with-st-code/47638)\nCachedStFunctionWarning with st.code\n### Checklist\r\n\r\n- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.\r\n- [X] I added a very descriptive title to this issue.\r\n- [X] I have provided sufficient information below to help reproduce this issue.\r\n\r\n### Summary\r\n\r\nI am getting 'CachedStFunctionWarning' for st.code. Using `@st.cache_data(experimental_allow_widgets=True) ` as suggested in the warning does not help. \r\n\r\n\r\n\r\n### Reproducible Code Example\r\n\r\n[](https://issues.streamlit.app/?issue=gh-7055)\r\n\r\n```Python\r\[email protected]_data(experimental_allow_widgets=True, show_spinner=False)\r\ndef foo(i):\r\n options = [\"foo\", \"bar\", \"baz\", \"qux\"]\r\n st.code(options)\r\n r = st.radio(\"radio\", options, index=i)\r\n return r\r\n\r\nfoo(1)\r\n```\r\n\r\n\r\n### Steps To Reproduce\r\n\r\n1. Use code provided above\r\n2. See warning message\r\n\r\n### Expected Behavior\r\n\r\nWarning is not shown for st.code or using `@st.cache_data(experimental_allow_widgets=True) ` suppresses the warning.\r\n\r\n### Current Behavior\r\n\r\n\r\n\r\n\r\n### Is this a regression?\r\n\r\n- [X] Yes, this used to work in a previous version.\r\n\r\n### Debug info\r\n\r\nStreamlit version: 1.23.1\r\nPython version: 3.11.1\r\n\r\n\r\n### Additional Information\r\n\r\nFurther infos/community question [here](https://discuss.streamlit.io/t/st-cache-data-experimental-allow-widgets-true-is-not-working-with-st-code/47638)\n", "before_files": [{"content": "# Copyright (c) Streamlit Inc. (2018-2022) Snowflake Inc. (2022)\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nWIDGETS = [\n \"button\",\n \"camera_input\",\n \"chat_input\",\n \"checkbox\",\n \"color_picker\",\n \"component_instance\",\n \"download_button\",\n \"file_uploader\",\n \"form\",\n \"multiselect\",\n \"number_input\",\n \"radio\",\n \"selectbox\",\n \"select_slider\",\n \"slider\",\n \"text_input\",\n \"text_area\",\n \"time_input\",\n \"date_input\",\n]\nNONWIDGET_ELEMENTS = [\n \"alert\",\n \"area_chart\",\n \"arrow_area_chart\",\n \"arrow_bar_chart\",\n \"arrow_data_frame\",\n \"arrow_line_chart\",\n \"arrow_table\",\n \"arrow_vega_lite_chart\",\n \"audio\",\n \"balloons\",\n \"bar_chart\",\n \"bokeh_chart\",\n \"data_frame\",\n \"dataframe_selector\",\n \"deck_gl_json_chart\",\n \"doc_string\",\n \"empty\",\n \"exception\",\n \"graphviz_chart\",\n \"heading\",\n \"iframe\",\n \"imgs\",\n \"json\",\n \"legacy_altair\",\n \"legacy_data_frame\",\n \"legacy_vega_lite\",\n \"line_chart\",\n \"markdown\",\n \"metric\",\n \"plotly_chart\",\n \"progress\",\n \"pyplot\",\n \"snow\",\n \"table\",\n \"text\",\n \"vega_lite_chart\",\n \"video\",\n \"write\",\n]\n", "path": "lib/streamlit/elements/__init__.py"}]}
| 2,089 | 186 |
gh_patches_debug_18470
|
rasdani/github-patches
|
git_diff
|
getnikola__nikola-1664
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
nikola bootswatch_theme paper installs slate
I seem to be getting an issue when I try to install the [paper](https://bootswatch.com/paper/) theme from bootswatch by running `nikola bootswatch_theme paper`, it seems to install slate instead.
The output is as follows:
```
$ nikola bootswatch_theme paper
[2015-04-16T00:24:34Z] WARNING: Nikola: Your BASE_URL doesn't end in / -- adding it, but please fix it in your config file!
[2015-04-16T00:24:34Z] WARNING: Nikola: In order to USE_BUNDLES, you must install the "webassets" Python package.
[2015-04-16T00:24:34Z] WARNING: bundles: Setting USE_BUNDLES to False.
[2015-04-16T00:24:34Z] INFO: bootswatch_theme: Creating 'custom' theme from 'slate' and 'bootstrap3'
[2015-04-16T00:24:34Z] INFO: bootswatch_theme: Downloading: http://bootswatch.com/slate/bootstrap.min.css
INFO:requests.packages.urllib3.connectionpool:Starting new HTTP connection (1): bootswatch.com
[2015-04-16T00:24:34Z] INFO: bootswatch_theme: Downloading: http://bootswatch.com/slate/bootstrap.css
INFO:requests.packages.urllib3.connectionpool:Starting new HTTP connection (1): bootswatch.com
[2015-04-16T00:24:34Z] NOTICE: bootswatch_theme: Theme created. Change the THEME setting to "custom" to use it.
```
If you notice it says `Creating 'custom' theme from 'slate' and 'bootstrap3'` and installs slate instead.
This is on osx but I was able replicate it on my friends box as well which is running fedora.
</issue>
<code>
[start of nikola/plugins/command/bootswatch_theme.py]
1 # -*- coding: utf-8 -*-
2
3 # Copyright © 2012-2015 Roberto Alsina and others.
4
5 # Permission is hereby granted, free of charge, to any
6 # person obtaining a copy of this software and associated
7 # documentation files (the "Software"), to deal in the
8 # Software without restriction, including without limitation
9 # the rights to use, copy, modify, merge, publish,
10 # distribute, sublicense, and/or sell copies of the
11 # Software, and to permit persons to whom the Software is
12 # furnished to do so, subject to the following conditions:
13 #
14 # The above copyright notice and this permission notice
15 # shall be included in all copies or substantial portions of
16 # the Software.
17 #
18 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY
19 # KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE
20 # WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR
21 # PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS
22 # OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR
23 # OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
24 # OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
25 # SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
26
27 from __future__ import print_function
28 import os
29
30 try:
31 import requests
32 except ImportError:
33 requests = None # NOQA
34
35 from nikola.plugin_categories import Command
36 from nikola import utils
37
38 LOGGER = utils.get_logger('bootswatch_theme', utils.STDERR_HANDLER)
39
40
41 class CommandBootswatchTheme(Command):
42 """Given a swatch name from bootswatch.com and a parent theme, creates a custom theme."""
43
44 name = "bootswatch_theme"
45 doc_usage = "[options]"
46 doc_purpose = "given a swatch name from bootswatch.com and a parent theme, creates a custom"\
47 " theme"
48 cmd_options = [
49 {
50 'name': 'name',
51 'short': 'n',
52 'long': 'name',
53 'default': 'custom',
54 'type': str,
55 'help': 'New theme name (default: custom)',
56 },
57 {
58 'name': 'swatch',
59 'short': 's',
60 'default': 'slate',
61 'type': str,
62 'help': 'Name of the swatch from bootswatch.com.'
63 },
64 {
65 'name': 'parent',
66 'short': 'p',
67 'long': 'parent',
68 'default': 'bootstrap3',
69 'help': 'Parent theme name (default: bootstrap3)',
70 },
71 ]
72
73 def _execute(self, options, args):
74 """Given a swatch name and a parent theme, creates a custom theme."""
75 if requests is None:
76 utils.req_missing(['requests'], 'install Bootswatch themes')
77
78 name = options['name']
79 swatch = options['swatch']
80 parent = options['parent']
81 version = ''
82
83 # See if we need bootswatch for bootstrap v2 or v3
84 themes = utils.get_theme_chain(parent)
85 if 'bootstrap3' not in themes and 'bootstrap3-jinja' not in themes:
86 version = '2'
87 elif 'bootstrap' not in themes and 'bootstrap-jinja' not in themes:
88 LOGGER.warn('"bootswatch_theme" only makes sense for themes that use bootstrap')
89 elif 'bootstrap3-gradients' in themes or 'bootstrap3-gradients-jinja' in themes:
90 LOGGER.warn('"bootswatch_theme" doesn\'t work well with the bootstrap3-gradients family')
91
92 LOGGER.info("Creating '{0}' theme from '{1}' and '{2}'".format(name, swatch, parent))
93 utils.makedirs(os.path.join('themes', name, 'assets', 'css'))
94 for fname in ('bootstrap.min.css', 'bootstrap.css'):
95 url = 'http://bootswatch.com'
96 if version:
97 url += '/' + version
98 url = '/'.join((url, swatch, fname))
99 LOGGER.info("Downloading: " + url)
100 data = requests.get(url).text
101 with open(os.path.join('themes', name, 'assets', 'css', fname),
102 'wb+') as output:
103 output.write(data.encode('utf-8'))
104
105 with open(os.path.join('themes', name, 'parent'), 'wb+') as output:
106 output.write(parent.encode('utf-8'))
107 LOGGER.notice('Theme created. Change the THEME setting to "{0}" to use it.'.format(name))
108
[end of nikola/plugins/command/bootswatch_theme.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/nikola/plugins/command/bootswatch_theme.py b/nikola/plugins/command/bootswatch_theme.py
--- a/nikola/plugins/command/bootswatch_theme.py
+++ b/nikola/plugins/command/bootswatch_theme.py
@@ -26,6 +26,7 @@
from __future__ import print_function
import os
+import sys
try:
import requests
@@ -57,7 +58,7 @@
{
'name': 'swatch',
'short': 's',
- 'default': 'slate',
+ 'default': '',
'type': str,
'help': 'Name of the swatch from bootswatch.com.'
},
@@ -77,6 +78,9 @@
name = options['name']
swatch = options['swatch']
+ if not swatch:
+ LOGGER.error('The -s option is mandatory')
+ sys.exit(1)
parent = options['parent']
version = ''
|
{"golden_diff": "diff --git a/nikola/plugins/command/bootswatch_theme.py b/nikola/plugins/command/bootswatch_theme.py\n--- a/nikola/plugins/command/bootswatch_theme.py\n+++ b/nikola/plugins/command/bootswatch_theme.py\n@@ -26,6 +26,7 @@\n \n from __future__ import print_function\n import os\n+import sys\n \n try:\n import requests\n@@ -57,7 +58,7 @@\n {\n 'name': 'swatch',\n 'short': 's',\n- 'default': 'slate',\n+ 'default': '',\n 'type': str,\n 'help': 'Name of the swatch from bootswatch.com.'\n },\n@@ -77,6 +78,9 @@\n \n name = options['name']\n swatch = options['swatch']\n+ if not swatch:\n+ LOGGER.error('The -s option is mandatory')\n+ sys.exit(1)\n parent = options['parent']\n version = ''\n", "issue": "nikola bootswatch_theme paper installs slate\nI seem to be getting an issue when I try to install the [paper](https://bootswatch.com/paper/) theme from bootswatch by running `nikola bootswatch_theme paper`, it seems to install slate instead. \n\nThe output is as follows:\n\n```\n$ nikola bootswatch_theme paper\n[2015-04-16T00:24:34Z] WARNING: Nikola: Your BASE_URL doesn't end in / -- adding it, but please fix it in your config file!\n[2015-04-16T00:24:34Z] WARNING: Nikola: In order to USE_BUNDLES, you must install the \"webassets\" Python package.\n[2015-04-16T00:24:34Z] WARNING: bundles: Setting USE_BUNDLES to False.\n[2015-04-16T00:24:34Z] INFO: bootswatch_theme: Creating 'custom' theme from 'slate' and 'bootstrap3'\n[2015-04-16T00:24:34Z] INFO: bootswatch_theme: Downloading: http://bootswatch.com/slate/bootstrap.min.css\nINFO:requests.packages.urllib3.connectionpool:Starting new HTTP connection (1): bootswatch.com\n[2015-04-16T00:24:34Z] INFO: bootswatch_theme: Downloading: http://bootswatch.com/slate/bootstrap.css\nINFO:requests.packages.urllib3.connectionpool:Starting new HTTP connection (1): bootswatch.com\n[2015-04-16T00:24:34Z] NOTICE: bootswatch_theme: Theme created. Change the THEME setting to \"custom\" to use it.\n```\n\nIf you notice it says `Creating 'custom' theme from 'slate' and 'bootstrap3'` and installs slate instead. \n\nThis is on osx but I was able replicate it on my friends box as well which is running fedora.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright \u00a9 2012-2015 Roberto Alsina and others.\n\n# Permission is hereby granted, free of charge, to any\n# person obtaining a copy of this software and associated\n# documentation files (the \"Software\"), to deal in the\n# Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the\n# Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice\n# shall be included in all copies or substantial portions of\n# the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY\n# KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE\n# WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR\n# PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS\n# OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR\n# OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR\n# OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\nfrom __future__ import print_function\nimport os\n\ntry:\n import requests\nexcept ImportError:\n requests = None # NOQA\n\nfrom nikola.plugin_categories import Command\nfrom nikola import utils\n\nLOGGER = utils.get_logger('bootswatch_theme', utils.STDERR_HANDLER)\n\n\nclass CommandBootswatchTheme(Command):\n \"\"\"Given a swatch name from bootswatch.com and a parent theme, creates a custom theme.\"\"\"\n\n name = \"bootswatch_theme\"\n doc_usage = \"[options]\"\n doc_purpose = \"given a swatch name from bootswatch.com and a parent theme, creates a custom\"\\\n \" theme\"\n cmd_options = [\n {\n 'name': 'name',\n 'short': 'n',\n 'long': 'name',\n 'default': 'custom',\n 'type': str,\n 'help': 'New theme name (default: custom)',\n },\n {\n 'name': 'swatch',\n 'short': 's',\n 'default': 'slate',\n 'type': str,\n 'help': 'Name of the swatch from bootswatch.com.'\n },\n {\n 'name': 'parent',\n 'short': 'p',\n 'long': 'parent',\n 'default': 'bootstrap3',\n 'help': 'Parent theme name (default: bootstrap3)',\n },\n ]\n\n def _execute(self, options, args):\n \"\"\"Given a swatch name and a parent theme, creates a custom theme.\"\"\"\n if requests is None:\n utils.req_missing(['requests'], 'install Bootswatch themes')\n\n name = options['name']\n swatch = options['swatch']\n parent = options['parent']\n version = ''\n\n # See if we need bootswatch for bootstrap v2 or v3\n themes = utils.get_theme_chain(parent)\n if 'bootstrap3' not in themes and 'bootstrap3-jinja' not in themes:\n version = '2'\n elif 'bootstrap' not in themes and 'bootstrap-jinja' not in themes:\n LOGGER.warn('\"bootswatch_theme\" only makes sense for themes that use bootstrap')\n elif 'bootstrap3-gradients' in themes or 'bootstrap3-gradients-jinja' in themes:\n LOGGER.warn('\"bootswatch_theme\" doesn\\'t work well with the bootstrap3-gradients family')\n\n LOGGER.info(\"Creating '{0}' theme from '{1}' and '{2}'\".format(name, swatch, parent))\n utils.makedirs(os.path.join('themes', name, 'assets', 'css'))\n for fname in ('bootstrap.min.css', 'bootstrap.css'):\n url = 'http://bootswatch.com'\n if version:\n url += '/' + version\n url = '/'.join((url, swatch, fname))\n LOGGER.info(\"Downloading: \" + url)\n data = requests.get(url).text\n with open(os.path.join('themes', name, 'assets', 'css', fname),\n 'wb+') as output:\n output.write(data.encode('utf-8'))\n\n with open(os.path.join('themes', name, 'parent'), 'wb+') as output:\n output.write(parent.encode('utf-8'))\n LOGGER.notice('Theme created. Change the THEME setting to \"{0}\" to use it.'.format(name))\n", "path": "nikola/plugins/command/bootswatch_theme.py"}]}
| 2,200 | 220 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.