
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.71k
18.9k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 465
23.6k
| num_tokens_prompt
int64 556
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_38163
|
rasdani/github-patches
|
git_diff
|
google__jax-736
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
namedtuple support in arguments to transformed functions
It would be great if `xla.abstractify` would also accept namedtuples. Loop state's can consist of quite a lot of values and organizing them in a namedtuple rather than a tuple would make things nicer.
</issue>
<code>
[start of jax/tree_util.py]
1 # Copyright 2018 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Utilities for working with tree-like container data structures.
16
17 The code here is independent of JAX. The only dependence is on jax.util, which
18 itself has no JAX-specific code.
19
20 This module provides a small set of utility functions for working with tree-like
21 data structures, such as nested tuples, lists, and dicts. We call these
22 structures pytrees. They are trees in that they are defined recursively (any
23 non-pytree is a pytree, i.e. a leaf, and any pytree of pytrees is a pytree) and
24 can be operated on recursively (object identity equivalence is not preserved by
25 mapping operations, and the structures cannot contain reference cycles).
26
27 The set of Python types that are considered pytree nodes (e.g. that can be
28 mapped over, rather than treated as leaves) is extensible. There is a single
29 module-level registry of types, and class hierarchy is ignored. By registering a
30 new pytree node type, that type in effect becomes transparent to the utility
31 functions in this file.
32 """
33
34 from __future__ import absolute_import
35 from __future__ import division
36 from __future__ import print_function
37
38 from collections import namedtuple
39 import itertools as it
40 from six.moves import reduce
41
42 from .util import unzip2, concatenate, partial, safe_map
43
44 map = safe_map
45
46
47 def tree_map(f, tree):
48 """Map a function over a pytree to produce a new pytree.
49
50 Args:
51 f: function to be applied at each leaf.
52 tree: a pytree to be mapped over.
53
54 Returns:
55 A new pytree with the same structure as `tree` but with the value at each
56 leaf given by `f(x)` where `x` is the value at the corresponding leaf in
57 `tree`.
58 """
59 node_type = node_types.get(type(tree))
60 if node_type:
61 children, node_spec = node_type.to_iterable(tree)
62 new_children = [tree_map(f, child) for child in children]
63 return node_type.from_iterable(node_spec, new_children)
64 else:
65 return f(tree)
66
67 def tree_multimap(f, tree, *rest):
68 """Map a multi-input function over pytree args to produce a new pytree.
69
70 Args:
71 f: function that takes `1 + len(rest)` arguments, to be applied at the
72 corresponding leaves of the pytrees.
73 tree: a pytree to be mapped over, with each leaf providing the first
74 positional argument to `f`.
75 *rest: a tuple of pytrees, each with the same structure as `tree`.
76
77 Returns:
78 A new pytree with the same structure as `tree` but with the value at each
79 leaf given by `f(x, *xs)` where `x` is the value at the corresponding leaf
80 in `tree` and `xs` is the tuple of values at corresponding leaves in `rest`.
81 """
82 node_type = node_types.get(type(tree))
83 if node_type:
84 children, aux_data = node_type.to_iterable(tree)
85 all_children = [children]
86 for other_tree in rest:
87 other_node_type = node_types.get(type(other_tree))
88 if node_type != other_node_type:
89 raise TypeError('Mismatch: {} != {}'.format(other_node_type, node_type))
90 other_children, other_aux_data = node_type.to_iterable(other_tree)
91 if other_aux_data != aux_data:
92 raise TypeError('Mismatch: {} != {}'.format(other_aux_data, aux_data))
93 all_children.append(other_children)
94
95 new_children = [tree_multimap(f, *xs) for xs in zip(*all_children)]
96 return node_type.from_iterable(aux_data, new_children)
97 else:
98 return f(tree, *rest)
99
100
101 def tree_reduce(f, tree):
102 flat, _ = tree_flatten(tree)
103 return reduce(f, flat)
104
105
106 def tree_all(tree):
107 flat, _ = tree_flatten(tree)
108 return all(flat)
109
110
111 def process_pytree(process_node, tree):
112 return walk_pytree(process_node, lambda x: x, tree)
113
114
115 def walk_pytree(f_node, f_leaf, tree):
116 node_type = node_types.get(type(tree))
117 if node_type:
118 children, node_spec = node_type.to_iterable(tree)
119 proc_children, child_specs = unzip2([walk_pytree(f_node, f_leaf, child)
120 for child in children])
121 tree_def = PyTreeDef(node_type, node_spec, child_specs)
122 return f_node(proc_children), tree_def
123 else:
124 return f_leaf(tree), leaf
125
126
127 def build_tree(treedef, xs):
128 if treedef is leaf:
129 return xs
130 else:
131 # We use 'iter' for clearer error messages
132 children = map(build_tree, iter(treedef.children), iter(xs))
133 return treedef.node_type.from_iterable(treedef.node_data, children)
134
135
136 tree_flatten = partial(walk_pytree, concatenate, lambda x: [x])
137
138 def tree_unflatten(treedef, xs):
139 return _tree_unflatten(iter(xs), treedef)
140
141 def _tree_unflatten(xs, treedef):
142 if treedef is leaf:
143 return next(xs)
144 else:
145 children = map(partial(_tree_unflatten, xs), treedef.children)
146 return treedef.node_type.from_iterable(treedef.node_data, children)
147
148
149 def tree_transpose(outer_treedef, inner_treedef, pytree_to_transpose):
150 flat, treedef = tree_flatten(pytree_to_transpose)
151 expected_treedef = _nested_treedef(inner_treedef, outer_treedef)
152 if treedef != expected_treedef:
153 raise TypeError("Mismatch\n{}\n != \n{}".format(treedef, expected_treedef))
154
155 inner_size = _num_leaves(inner_treedef)
156 outer_size = _num_leaves(outer_treedef)
157 flat = iter(flat)
158 lol = [[next(flat) for _ in range(inner_size)] for __ in range(outer_size)]
159 transposed_lol = zip(*lol)
160 subtrees = map(partial(tree_unflatten, outer_treedef), transposed_lol)
161 return tree_unflatten(inner_treedef, subtrees)
162
163 def _num_leaves(treedef):
164 return 1 if treedef is leaf else sum(map(_num_leaves, treedef.children))
165
166 def _nested_treedef(inner, outer):
167 # just used in tree_transpose error checking
168 if outer is leaf:
169 return inner
170 else:
171 children = map(partial(_nested_treedef, inner), outer.children)
172 return PyTreeDef(outer.node_type, outer.node_data, tuple(children))
173
174
175 def tree_structure(tree):
176 _, spec = process_pytree(lambda _: None, tree)
177 return spec
178
179
180 class PyTreeDef(object):
181 def __init__(self, node_type, node_data, children):
182 self.node_type = node_type
183 self.node_data = node_data
184 self.children = children
185
186 def __repr__(self):
187 if self.node_data is None:
188 data_repr = ""
189 else:
190 data_repr = "[{}]".format(self.node_data)
191
192 return "PyTree({}{}, [{}])".format(self.node_type.name, data_repr,
193 ','.join(map(repr, self.children)))
194
195 def __hash__(self):
196 return hash((self.node_type, self.node_data, tuple(self.children)))
197
198 def __eq__(self, other):
199 if other is leaf:
200 return False
201 else:
202 return (self.node_type == other.node_type and
203 self.node_data == other.node_data and
204 self.children == other.children)
205
206 def __ne__(self, other):
207 return not self == other
208
209
210 class PyLeaf(object):
211 def __repr__(self):
212 return '*'
213
214 leaf = PyLeaf()
215
216 def dict_to_iterable(xs):
217 keys = tuple(sorted(xs.keys()))
218 return tuple(map(xs.get, keys)), keys
219
220 class NodeType(object):
221 def __init__(self, name, to_iterable, from_iterable):
222 self.name = name
223 self.to_iterable = to_iterable
224 self.from_iterable = from_iterable
225
226 def __repr__(self):
227 return self.name
228
229 node_types = {}
230
231 def register_pytree_node(py_type, to_iterable, from_iterable):
232 assert py_type not in node_types
233 node_types[py_type] = NodeType(str(py_type), to_iterable, from_iterable)
234
235 register_pytree_node(tuple, lambda xs: (xs, None), lambda _, xs: tuple(xs))
236 register_pytree_node(list, lambda xs: (tuple(xs), None), lambda _, xs: list(xs))
237 register_pytree_node(dict, dict_to_iterable, lambda keys, xs: dict(zip(keys, xs)))
238 register_pytree_node(type(None), lambda z: ((), None), lambda _, xs: None)
239
[end of jax/tree_util.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/jax/tree_util.py b/jax/tree_util.py
--- a/jax/tree_util.py
+++ b/jax/tree_util.py
@@ -56,7 +56,7 @@
leaf given by `f(x)` where `x` is the value at the corresponding leaf in
`tree`.
"""
- node_type = node_types.get(type(tree))
+ node_type = _get_node_type(tree)
if node_type:
children, node_spec = node_type.to_iterable(tree)
new_children = [tree_map(f, child) for child in children]
@@ -79,12 +79,12 @@
leaf given by `f(x, *xs)` where `x` is the value at the corresponding leaf
in `tree` and `xs` is the tuple of values at corresponding leaves in `rest`.
"""
- node_type = node_types.get(type(tree))
+ node_type = _get_node_type(tree)
if node_type:
children, aux_data = node_type.to_iterable(tree)
all_children = [children]
for other_tree in rest:
- other_node_type = node_types.get(type(other_tree))
+ other_node_type = _get_node_type(other_tree)
if node_type != other_node_type:
raise TypeError('Mismatch: {} != {}'.format(other_node_type, node_type))
other_children, other_aux_data = node_type.to_iterable(other_tree)
@@ -113,7 +113,7 @@
def walk_pytree(f_node, f_leaf, tree):
- node_type = node_types.get(type(tree))
+ node_type = _get_node_type(tree)
if node_type:
children, node_spec = node_type.to_iterable(tree)
proc_children, child_specs = unzip2([walk_pytree(f_node, f_leaf, child)
@@ -236,3 +236,20 @@
register_pytree_node(list, lambda xs: (tuple(xs), None), lambda _, xs: list(xs))
register_pytree_node(dict, dict_to_iterable, lambda keys, xs: dict(zip(keys, xs)))
register_pytree_node(type(None), lambda z: ((), None), lambda _, xs: None)
+
+
+# To handle namedtuples, we can't just use the standard table of node_types
+# because every namedtuple creates its own type and thus would require its own
+# entry in the table. Instead we use a heuristic check on the type itself to
+# decide whether it's a namedtuple type, and if so treat it as a pytree node.
+def _get_node_type(maybe_tree):
+ t = type(maybe_tree)
+ return node_types.get(t) or _namedtuple_node(t)
+
+def _namedtuple_node(t):
+ if t.__bases__ == (tuple,) and hasattr(t, '_fields'):
+ return NamedtupleNode
+
+NamedtupleNode = NodeType('namedtuple',
+ lambda xs: (tuple(xs), type(xs)),
+ lambda t, xs: t(*xs))
|
{"golden_diff": "diff --git a/jax/tree_util.py b/jax/tree_util.py\n--- a/jax/tree_util.py\n+++ b/jax/tree_util.py\n@@ -56,7 +56,7 @@\n leaf given by `f(x)` where `x` is the value at the corresponding leaf in\n `tree`.\n \"\"\"\n- node_type = node_types.get(type(tree))\n+ node_type = _get_node_type(tree)\n if node_type:\n children, node_spec = node_type.to_iterable(tree)\n new_children = [tree_map(f, child) for child in children]\n@@ -79,12 +79,12 @@\n leaf given by `f(x, *xs)` where `x` is the value at the corresponding leaf\n in `tree` and `xs` is the tuple of values at corresponding leaves in `rest`.\n \"\"\"\n- node_type = node_types.get(type(tree))\n+ node_type = _get_node_type(tree)\n if node_type:\n children, aux_data = node_type.to_iterable(tree)\n all_children = [children]\n for other_tree in rest:\n- other_node_type = node_types.get(type(other_tree))\n+ other_node_type = _get_node_type(other_tree)\n if node_type != other_node_type:\n raise TypeError('Mismatch: {} != {}'.format(other_node_type, node_type))\n other_children, other_aux_data = node_type.to_iterable(other_tree)\n@@ -113,7 +113,7 @@\n \n \n def walk_pytree(f_node, f_leaf, tree):\n- node_type = node_types.get(type(tree))\n+ node_type = _get_node_type(tree)\n if node_type:\n children, node_spec = node_type.to_iterable(tree)\n proc_children, child_specs = unzip2([walk_pytree(f_node, f_leaf, child)\n@@ -236,3 +236,20 @@\n register_pytree_node(list, lambda xs: (tuple(xs), None), lambda _, xs: list(xs))\n register_pytree_node(dict, dict_to_iterable, lambda keys, xs: dict(zip(keys, xs)))\n register_pytree_node(type(None), lambda z: ((), None), lambda _, xs: None)\n+\n+\n+# To handle namedtuples, we can't just use the standard table of node_types\n+# because every namedtuple creates its own type and thus would require its own\n+# entry in the table. Instead we use a heuristic check on the type itself to\n+# decide whether it's a namedtuple type, and if so treat it as a pytree node.\n+def _get_node_type(maybe_tree):\n+ t = type(maybe_tree)\n+ return node_types.get(t) or _namedtuple_node(t)\n+\n+def _namedtuple_node(t):\n+ if t.__bases__ == (tuple,) and hasattr(t, '_fields'):\n+ return NamedtupleNode\n+\n+NamedtupleNode = NodeType('namedtuple',\n+ lambda xs: (tuple(xs), type(xs)),\n+ lambda t, xs: t(*xs))\n", "issue": "namedtuple support in arguments to transformed functions\nIt would be great if `xla.abstractify` would also accept namedtuples. Loop state's can consist of quite a lot of values and organizing them in a namedtuple rather than a tuple would make things nicer.\n", "before_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Utilities for working with tree-like container data structures.\n\nThe code here is independent of JAX. The only dependence is on jax.util, which\nitself has no JAX-specific code.\n\nThis module provides a small set of utility functions for working with tree-like\ndata structures, such as nested tuples, lists, and dicts. We call these\nstructures pytrees. They are trees in that they are defined recursively (any\nnon-pytree is a pytree, i.e. a leaf, and any pytree of pytrees is a pytree) and\ncan be operated on recursively (object identity equivalence is not preserved by\nmapping operations, and the structures cannot contain reference cycles).\n\nThe set of Python types that are considered pytree nodes (e.g. that can be\nmapped over, rather than treated as leaves) is extensible. There is a single\nmodule-level registry of types, and class hierarchy is ignored. By registering a\nnew pytree node type, that type in effect becomes transparent to the utility\nfunctions in this file.\n\"\"\"\n\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nfrom collections import namedtuple\nimport itertools as it\nfrom six.moves import reduce\n\nfrom .util import unzip2, concatenate, partial, safe_map\n\nmap = safe_map\n\n\ndef tree_map(f, tree):\n \"\"\"Map a function over a pytree to produce a new pytree.\n\n Args:\n f: function to be applied at each leaf.\n tree: a pytree to be mapped over.\n\n Returns:\n A new pytree with the same structure as `tree` but with the value at each\n leaf given by `f(x)` where `x` is the value at the corresponding leaf in\n `tree`.\n \"\"\"\n node_type = node_types.get(type(tree))\n if node_type:\n children, node_spec = node_type.to_iterable(tree)\n new_children = [tree_map(f, child) for child in children]\n return node_type.from_iterable(node_spec, new_children)\n else:\n return f(tree)\n\ndef tree_multimap(f, tree, *rest):\n \"\"\"Map a multi-input function over pytree args to produce a new pytree.\n\n Args:\n f: function that takes `1 + len(rest)` arguments, to be applied at the\n corresponding leaves of the pytrees.\n tree: a pytree to be mapped over, with each leaf providing the first\n positional argument to `f`.\n *rest: a tuple of pytrees, each with the same structure as `tree`.\n\n Returns:\n A new pytree with the same structure as `tree` but with the value at each\n leaf given by `f(x, *xs)` where `x` is the value at the corresponding leaf\n in `tree` and `xs` is the tuple of values at corresponding leaves in `rest`.\n \"\"\"\n node_type = node_types.get(type(tree))\n if node_type:\n children, aux_data = node_type.to_iterable(tree)\n all_children = [children]\n for other_tree in rest:\n other_node_type = node_types.get(type(other_tree))\n if node_type != other_node_type:\n raise TypeError('Mismatch: {} != {}'.format(other_node_type, node_type))\n other_children, other_aux_data = node_type.to_iterable(other_tree)\n if other_aux_data != aux_data:\n raise TypeError('Mismatch: {} != {}'.format(other_aux_data, aux_data))\n all_children.append(other_children)\n\n new_children = [tree_multimap(f, *xs) for xs in zip(*all_children)]\n return node_type.from_iterable(aux_data, new_children)\n else:\n return f(tree, *rest)\n\n\ndef tree_reduce(f, tree):\n flat, _ = tree_flatten(tree)\n return reduce(f, flat)\n\n\ndef tree_all(tree):\n flat, _ = tree_flatten(tree)\n return all(flat)\n\n\ndef process_pytree(process_node, tree):\n return walk_pytree(process_node, lambda x: x, tree)\n\n\ndef walk_pytree(f_node, f_leaf, tree):\n node_type = node_types.get(type(tree))\n if node_type:\n children, node_spec = node_type.to_iterable(tree)\n proc_children, child_specs = unzip2([walk_pytree(f_node, f_leaf, child)\n for child in children])\n tree_def = PyTreeDef(node_type, node_spec, child_specs)\n return f_node(proc_children), tree_def\n else:\n return f_leaf(tree), leaf\n\n\ndef build_tree(treedef, xs):\n if treedef is leaf:\n return xs\n else:\n # We use 'iter' for clearer error messages\n children = map(build_tree, iter(treedef.children), iter(xs))\n return treedef.node_type.from_iterable(treedef.node_data, children)\n\n\ntree_flatten = partial(walk_pytree, concatenate, lambda x: [x])\n\ndef tree_unflatten(treedef, xs):\n return _tree_unflatten(iter(xs), treedef)\n\ndef _tree_unflatten(xs, treedef):\n if treedef is leaf:\n return next(xs)\n else:\n children = map(partial(_tree_unflatten, xs), treedef.children)\n return treedef.node_type.from_iterable(treedef.node_data, children)\n\n\ndef tree_transpose(outer_treedef, inner_treedef, pytree_to_transpose):\n flat, treedef = tree_flatten(pytree_to_transpose)\n expected_treedef = _nested_treedef(inner_treedef, outer_treedef)\n if treedef != expected_treedef:\n raise TypeError(\"Mismatch\\n{}\\n != \\n{}\".format(treedef, expected_treedef))\n\n inner_size = _num_leaves(inner_treedef)\n outer_size = _num_leaves(outer_treedef)\n flat = iter(flat)\n lol = [[next(flat) for _ in range(inner_size)] for __ in range(outer_size)]\n transposed_lol = zip(*lol)\n subtrees = map(partial(tree_unflatten, outer_treedef), transposed_lol)\n return tree_unflatten(inner_treedef, subtrees)\n\ndef _num_leaves(treedef):\n return 1 if treedef is leaf else sum(map(_num_leaves, treedef.children))\n\ndef _nested_treedef(inner, outer):\n # just used in tree_transpose error checking\n if outer is leaf:\n return inner\n else:\n children = map(partial(_nested_treedef, inner), outer.children)\n return PyTreeDef(outer.node_type, outer.node_data, tuple(children))\n\n\ndef tree_structure(tree):\n _, spec = process_pytree(lambda _: None, tree)\n return spec\n\n\nclass PyTreeDef(object):\n def __init__(self, node_type, node_data, children):\n self.node_type = node_type\n self.node_data = node_data\n self.children = children\n\n def __repr__(self):\n if self.node_data is None:\n data_repr = \"\"\n else:\n data_repr = \"[{}]\".format(self.node_data)\n\n return \"PyTree({}{}, [{}])\".format(self.node_type.name, data_repr,\n ','.join(map(repr, self.children)))\n\n def __hash__(self):\n return hash((self.node_type, self.node_data, tuple(self.children)))\n\n def __eq__(self, other):\n if other is leaf:\n return False\n else:\n return (self.node_type == other.node_type and\n self.node_data == other.node_data and\n self.children == other.children)\n\n def __ne__(self, other):\n return not self == other\n\n\nclass PyLeaf(object):\n def __repr__(self):\n return '*'\n\nleaf = PyLeaf()\n\ndef dict_to_iterable(xs):\n keys = tuple(sorted(xs.keys()))\n return tuple(map(xs.get, keys)), keys\n\nclass NodeType(object):\n def __init__(self, name, to_iterable, from_iterable):\n self.name = name\n self.to_iterable = to_iterable\n self.from_iterable = from_iterable\n\n def __repr__(self):\n return self.name\n\nnode_types = {}\n\ndef register_pytree_node(py_type, to_iterable, from_iterable):\n assert py_type not in node_types\n node_types[py_type] = NodeType(str(py_type), to_iterable, from_iterable)\n\nregister_pytree_node(tuple, lambda xs: (xs, None), lambda _, xs: tuple(xs))\nregister_pytree_node(list, lambda xs: (tuple(xs), None), lambda _, xs: list(xs))\nregister_pytree_node(dict, dict_to_iterable, lambda keys, xs: dict(zip(keys, xs)))\nregister_pytree_node(type(None), lambda z: ((), None), lambda _, xs: None)\n", "path": "jax/tree_util.py"}]}
| 3,254 | 652 |
gh_patches_debug_4122
|
rasdani/github-patches
|
git_diff
|
mozilla__bugbug-3897
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Restrict the training set of the StepsToReproduce model only to defects
Given that STRs don't apply to enhancement or task.
</issue>
<code>
[start of bugbug/models/stepstoreproduce.py]
1 # -*- coding: utf-8 -*-
2 # This Source Code Form is subject to the terms of the Mozilla Public
3 # License, v. 2.0. If a copy of the MPL was not distributed with this file,
4 # You can obtain one at http://mozilla.org/MPL/2.0/.
5
6 import logging
7
8 import xgboost
9 from imblearn.pipeline import Pipeline as ImblearnPipeline
10 from imblearn.under_sampling import RandomUnderSampler
11 from sklearn.compose import ColumnTransformer
12 from sklearn.feature_extraction import DictVectorizer
13 from sklearn.pipeline import Pipeline
14
15 from bugbug import bug_features, bugzilla, feature_cleanup, utils
16 from bugbug.model import BugModel
17
18 logging.basicConfig(level=logging.INFO)
19 logger = logging.getLogger(__name__)
20
21
22 class StepsToReproduceModel(BugModel):
23 def __init__(self, lemmatization=False):
24 BugModel.__init__(self, lemmatization)
25
26 feature_extractors = [
27 bug_features.HasRegressionRange(),
28 bug_features.Severity(),
29 bug_features.Keywords({"stepswanted"}),
30 bug_features.IsCoverityIssue(),
31 bug_features.HasCrashSignature(),
32 bug_features.HasURL(),
33 bug_features.HasW3CURL(),
34 bug_features.HasGithubURL(),
35 bug_features.Whiteboard(),
36 bug_features.Patches(),
37 bug_features.Landings(),
38 ]
39
40 cleanup_functions = [
41 feature_cleanup.fileref(),
42 feature_cleanup.url(),
43 feature_cleanup.synonyms(),
44 ]
45
46 self.extraction_pipeline = Pipeline(
47 [
48 (
49 "bug_extractor",
50 bug_features.BugExtractor(feature_extractors, cleanup_functions),
51 ),
52 ]
53 )
54
55 self.clf = ImblearnPipeline(
56 [
57 (
58 "union",
59 ColumnTransformer(
60 [
61 ("data", DictVectorizer(), "data"),
62 ("title", self.text_vectorizer(), "title"),
63 ("comments", self.text_vectorizer(), "comments"),
64 ]
65 ),
66 ),
67 ("sampler", RandomUnderSampler(random_state=0)),
68 (
69 "estimator",
70 xgboost.XGBClassifier(n_jobs=utils.get_physical_cpu_count()),
71 ),
72 ]
73 )
74
75 def get_labels(self):
76 classes = {}
77
78 for bug_data in bugzilla.get_bugs():
79 if "cf_has_str" in bug_data:
80 if bug_data["cf_has_str"] == "no":
81 classes[int(bug_data["id"])] = 0
82 elif bug_data["cf_has_str"] == "yes":
83 classes[int(bug_data["id"])] = 1
84 elif "stepswanted" in bug_data["keywords"]:
85 classes[int(bug_data["id"])] = 0
86 else:
87 for entry in bug_data["history"]:
88 for change in entry["changes"]:
89 if change["removed"].startswith("stepswanted"):
90 classes[int(bug_data["id"])] = 1
91
92 logger.info(
93 "%d bugs have no steps to reproduce",
94 sum(label == 0 for label in classes.values()),
95 )
96 logger.info(
97 "%d bugs have steps to reproduce",
98 sum(label == 1 for label in classes.values()),
99 )
100
101 return classes, [0, 1]
102
103 def overwrite_classes(self, bugs, classes, probabilities):
104 for i, bug in enumerate(bugs):
105 if "cf_has_str" in bug and bug["cf_has_str"] == "no":
106 classes[i] = 0 if not probabilities else [1.0, 0.0]
107 elif "cf_has_str" in bug and bug["cf_has_str"] == "yes":
108 classes[i] = 1 if not probabilities else [0.0, 1.0]
109 elif "stepswanted" in bug["keywords"]:
110 classes[i] = 0 if not probabilities else [1.0, 0.0]
111
112 return classes
113
114 def get_feature_names(self):
115 return self.clf.named_steps["union"].get_feature_names_out()
116
[end of bugbug/models/stepstoreproduce.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bugbug/models/stepstoreproduce.py b/bugbug/models/stepstoreproduce.py
--- a/bugbug/models/stepstoreproduce.py
+++ b/bugbug/models/stepstoreproduce.py
@@ -76,6 +76,8 @@
classes = {}
for bug_data in bugzilla.get_bugs():
+ if bug_data["type"] != "defect":
+ continue
if "cf_has_str" in bug_data:
if bug_data["cf_has_str"] == "no":
classes[int(bug_data["id"])] = 0
|
{"golden_diff": "diff --git a/bugbug/models/stepstoreproduce.py b/bugbug/models/stepstoreproduce.py\n--- a/bugbug/models/stepstoreproduce.py\n+++ b/bugbug/models/stepstoreproduce.py\n@@ -76,6 +76,8 @@\n classes = {}\n \n for bug_data in bugzilla.get_bugs():\n+ if bug_data[\"type\"] != \"defect\":\n+ continue\n if \"cf_has_str\" in bug_data:\n if bug_data[\"cf_has_str\"] == \"no\":\n classes[int(bug_data[\"id\"])] = 0\n", "issue": "Restrict the training set of the StepsToReproduce model only to defects\nGiven that STRs don't apply to enhancement or task.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# This Source Code Form is subject to the terms of the Mozilla Public\n# License, v. 2.0. If a copy of the MPL was not distributed with this file,\n# You can obtain one at http://mozilla.org/MPL/2.0/.\n\nimport logging\n\nimport xgboost\nfrom imblearn.pipeline import Pipeline as ImblearnPipeline\nfrom imblearn.under_sampling import RandomUnderSampler\nfrom sklearn.compose import ColumnTransformer\nfrom sklearn.feature_extraction import DictVectorizer\nfrom sklearn.pipeline import Pipeline\n\nfrom bugbug import bug_features, bugzilla, feature_cleanup, utils\nfrom bugbug.model import BugModel\n\nlogging.basicConfig(level=logging.INFO)\nlogger = logging.getLogger(__name__)\n\n\nclass StepsToReproduceModel(BugModel):\n def __init__(self, lemmatization=False):\n BugModel.__init__(self, lemmatization)\n\n feature_extractors = [\n bug_features.HasRegressionRange(),\n bug_features.Severity(),\n bug_features.Keywords({\"stepswanted\"}),\n bug_features.IsCoverityIssue(),\n bug_features.HasCrashSignature(),\n bug_features.HasURL(),\n bug_features.HasW3CURL(),\n bug_features.HasGithubURL(),\n bug_features.Whiteboard(),\n bug_features.Patches(),\n bug_features.Landings(),\n ]\n\n cleanup_functions = [\n feature_cleanup.fileref(),\n feature_cleanup.url(),\n feature_cleanup.synonyms(),\n ]\n\n self.extraction_pipeline = Pipeline(\n [\n (\n \"bug_extractor\",\n bug_features.BugExtractor(feature_extractors, cleanup_functions),\n ),\n ]\n )\n\n self.clf = ImblearnPipeline(\n [\n (\n \"union\",\n ColumnTransformer(\n [\n (\"data\", DictVectorizer(), \"data\"),\n (\"title\", self.text_vectorizer(), \"title\"),\n (\"comments\", self.text_vectorizer(), \"comments\"),\n ]\n ),\n ),\n (\"sampler\", RandomUnderSampler(random_state=0)),\n (\n \"estimator\",\n xgboost.XGBClassifier(n_jobs=utils.get_physical_cpu_count()),\n ),\n ]\n )\n\n def get_labels(self):\n classes = {}\n\n for bug_data in bugzilla.get_bugs():\n if \"cf_has_str\" in bug_data:\n if bug_data[\"cf_has_str\"] == \"no\":\n classes[int(bug_data[\"id\"])] = 0\n elif bug_data[\"cf_has_str\"] == \"yes\":\n classes[int(bug_data[\"id\"])] = 1\n elif \"stepswanted\" in bug_data[\"keywords\"]:\n classes[int(bug_data[\"id\"])] = 0\n else:\n for entry in bug_data[\"history\"]:\n for change in entry[\"changes\"]:\n if change[\"removed\"].startswith(\"stepswanted\"):\n classes[int(bug_data[\"id\"])] = 1\n\n logger.info(\n \"%d bugs have no steps to reproduce\",\n sum(label == 0 for label in classes.values()),\n )\n logger.info(\n \"%d bugs have steps to reproduce\",\n sum(label == 1 for label in classes.values()),\n )\n\n return classes, [0, 1]\n\n def overwrite_classes(self, bugs, classes, probabilities):\n for i, bug in enumerate(bugs):\n if \"cf_has_str\" in bug and bug[\"cf_has_str\"] == \"no\":\n classes[i] = 0 if not probabilities else [1.0, 0.0]\n elif \"cf_has_str\" in bug and bug[\"cf_has_str\"] == \"yes\":\n classes[i] = 1 if not probabilities else [0.0, 1.0]\n elif \"stepswanted\" in bug[\"keywords\"]:\n classes[i] = 0 if not probabilities else [1.0, 0.0]\n\n return classes\n\n def get_feature_names(self):\n return self.clf.named_steps[\"union\"].get_feature_names_out()\n", "path": "bugbug/models/stepstoreproduce.py"}]}
| 1,654 | 131 |
gh_patches_debug_10433
|
rasdani/github-patches
|
git_diff
|
scikit-image__scikit-image-1086
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
filter.threshold_isodata fails on 16-bit int images
The problem is the following line in threshholding.py:threshold_isodata():
```
binnums = np.arange(pmf.size, dtype=np.uint8)
```
Obviously the histogram bin numbers for images with more than 255 intensity levels don't get generated properly, leading to hilarity. Changing that to dtype=np.uint16 should do the trick for 8- and 16-bit images, and float images as long as the nbins parameter is < 2**16. (This wouldn't work for 32-bit integer images -- are these even supported though?)
</issue>
<code>
[start of skimage/filter/thresholding.py]
1 __all__ = ['threshold_adaptive',
2 'threshold_otsu',
3 'threshold_yen',
4 'threshold_isodata']
5
6 import numpy as np
7 import scipy.ndimage
8 from skimage.exposure import histogram
9
10
11 def threshold_adaptive(image, block_size, method='gaussian', offset=0,
12 mode='reflect', param=None):
13 """Applies an adaptive threshold to an array.
14
15 Also known as local or dynamic thresholding where the threshold value is
16 the weighted mean for the local neighborhood of a pixel subtracted by a
17 constant. Alternatively the threshold can be determined dynamically by a a
18 given function using the 'generic' method.
19
20 Parameters
21 ----------
22 image : (N, M) ndarray
23 Input image.
24 block_size : int
25 Uneven size of pixel neighborhood which is used to calculate the
26 threshold value (e.g. 3, 5, 7, ..., 21, ...).
27 method : {'generic', 'gaussian', 'mean', 'median'}, optional
28 Method used to determine adaptive threshold for local neighbourhood in
29 weighted mean image.
30
31 * 'generic': use custom function (see `param` parameter)
32 * 'gaussian': apply gaussian filter (see `param` parameter for custom\
33 sigma value)
34 * 'mean': apply arithmetic mean filter
35 * 'median': apply median rank filter
36
37 By default the 'gaussian' method is used.
38 offset : float, optional
39 Constant subtracted from weighted mean of neighborhood to calculate
40 the local threshold value. Default offset is 0.
41 mode : {'reflect', 'constant', 'nearest', 'mirror', 'wrap'}, optional
42 The mode parameter determines how the array borders are handled, where
43 cval is the value when mode is equal to 'constant'.
44 Default is 'reflect'.
45 param : {int, function}, optional
46 Either specify sigma for 'gaussian' method or function object for
47 'generic' method. This functions takes the flat array of local
48 neighbourhood as a single argument and returns the calculated
49 threshold for the centre pixel.
50
51 Returns
52 -------
53 threshold : (N, M) ndarray
54 Thresholded binary image
55
56 References
57 ----------
58 .. [1] http://docs.opencv.org/modules/imgproc/doc/miscellaneous_transformations.html?highlight=threshold#adaptivethreshold
59
60 Examples
61 --------
62 >>> from skimage.data import camera
63 >>> image = camera()[:50, :50]
64 >>> binary_image1 = threshold_adaptive(image, 15, 'mean')
65 >>> func = lambda arr: arr.mean()
66 >>> binary_image2 = threshold_adaptive(image, 15, 'generic', param=func)
67 """
68 thresh_image = np.zeros(image.shape, 'double')
69 if method == 'generic':
70 scipy.ndimage.generic_filter(image, param, block_size,
71 output=thresh_image, mode=mode)
72 elif method == 'gaussian':
73 if param is None:
74 # automatically determine sigma which covers > 99% of distribution
75 sigma = (block_size - 1) / 6.0
76 else:
77 sigma = param
78 scipy.ndimage.gaussian_filter(image, sigma, output=thresh_image,
79 mode=mode)
80 elif method == 'mean':
81 mask = 1. / block_size * np.ones((block_size,))
82 # separation of filters to speedup convolution
83 scipy.ndimage.convolve1d(image, mask, axis=0, output=thresh_image,
84 mode=mode)
85 scipy.ndimage.convolve1d(thresh_image, mask, axis=1,
86 output=thresh_image, mode=mode)
87 elif method == 'median':
88 scipy.ndimage.median_filter(image, block_size, output=thresh_image,
89 mode=mode)
90
91 return image > (thresh_image - offset)
92
93
94 def threshold_otsu(image, nbins=256):
95 """Return threshold value based on Otsu's method.
96
97 Parameters
98 ----------
99 image : array
100 Input image.
101 nbins : int, optional
102 Number of bins used to calculate histogram. This value is ignored for
103 integer arrays.
104
105 Returns
106 -------
107 threshold : float
108 Upper threshold value. All pixels intensities that less or equal of
109 this value assumed as foreground.
110
111 References
112 ----------
113 .. [1] Wikipedia, http://en.wikipedia.org/wiki/Otsu's_Method
114
115 Examples
116 --------
117 >>> from skimage.data import camera
118 >>> image = camera()
119 >>> thresh = threshold_otsu(image)
120 >>> binary = image <= thresh
121 """
122 hist, bin_centers = histogram(image, nbins)
123 hist = hist.astype(float)
124
125 # class probabilities for all possible thresholds
126 weight1 = np.cumsum(hist)
127 weight2 = np.cumsum(hist[::-1])[::-1]
128 # class means for all possible thresholds
129 mean1 = np.cumsum(hist * bin_centers) / weight1
130 mean2 = (np.cumsum((hist * bin_centers)[::-1]) / weight2[::-1])[::-1]
131
132 # Clip ends to align class 1 and class 2 variables:
133 # The last value of `weight1`/`mean1` should pair with zero values in
134 # `weight2`/`mean2`, which do not exist.
135 variance12 = weight1[:-1] * weight2[1:] * (mean1[:-1] - mean2[1:]) ** 2
136
137 idx = np.argmax(variance12)
138 threshold = bin_centers[:-1][idx]
139 return threshold
140
141
142 def threshold_yen(image, nbins=256):
143 """Return threshold value based on Yen's method.
144
145 Parameters
146 ----------
147 image : array
148 Input image.
149 nbins : int, optional
150 Number of bins used to calculate histogram. This value is ignored for
151 integer arrays.
152
153 Returns
154 -------
155 threshold : float
156 Upper threshold value. All pixels intensities that less or equal of
157 this value assumed as foreground.
158
159 References
160 ----------
161 .. [1] Yen J.C., Chang F.J., and Chang S. (1995) "A New Criterion
162 for Automatic Multilevel Thresholding" IEEE Trans. on Image
163 Processing, 4(3): 370-378
164 .. [2] Sezgin M. and Sankur B. (2004) "Survey over Image Thresholding
165 Techniques and Quantitative Performance Evaluation" Journal of
166 Electronic Imaging, 13(1): 146-165,
167 http://www.busim.ee.boun.edu.tr/~sankur/SankurFolder/Threshold_survey.pdf
168 .. [3] ImageJ AutoThresholder code, http://fiji.sc/wiki/index.php/Auto_Threshold
169
170 Examples
171 --------
172 >>> from skimage.data import camera
173 >>> image = camera()
174 >>> thresh = threshold_yen(image)
175 >>> binary = image <= thresh
176 """
177 hist, bin_centers = histogram(image, nbins)
178 # On blank images (e.g. filled with 0) with int dtype, `histogram()`
179 # returns `bin_centers` containing only one value. Speed up with it.
180 if bin_centers.size == 1:
181 return bin_centers[0]
182
183 # Calculate probability mass function
184 pmf = hist.astype(np.float32) / hist.sum()
185 P1 = np.cumsum(pmf) # Cumulative normalized histogram
186 P1_sq = np.cumsum(pmf ** 2)
187 # Get cumsum calculated from end of squared array:
188 P2_sq = np.cumsum(pmf[::-1] ** 2)[::-1]
189 # P2_sq indexes is shifted +1. I assume, with P1[:-1] it's help avoid '-inf'
190 # in crit. ImageJ Yen implementation replaces those values by zero.
191 crit = np.log(((P1_sq[:-1] * P2_sq[1:]) ** -1) *
192 (P1[:-1] * (1.0 - P1[:-1])) ** 2)
193 return bin_centers[crit.argmax()]
194
195
196 def threshold_isodata(image, nbins=256):
197 """Return threshold value based on ISODATA method.
198
199 Histogram-based threshold, known as Ridler-Calvard method or intermeans.
200
201 Parameters
202 ----------
203 image : array
204 Input image.
205 nbins : int, optional
206 Number of bins used to calculate histogram. This value is ignored for
207 integer arrays.
208
209 Returns
210 -------
211 threshold : float or int, corresponding input array dtype.
212 Upper threshold value. All pixels intensities that less or equal of
213 this value assumed as background.
214
215 References
216 ----------
217 .. [1] Ridler, TW & Calvard, S (1978), "Picture thresholding using an
218 iterative selection method"
219 .. [2] IEEE Transactions on Systems, Man and Cybernetics 8: 630-632,
220 http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=4310039
221 .. [3] Sezgin M. and Sankur B. (2004) "Survey over Image Thresholding
222 Techniques and Quantitative Performance Evaluation" Journal of
223 Electronic Imaging, 13(1): 146-165,
224 http://www.busim.ee.boun.edu.tr/~sankur/SankurFolder/Threshold_survey.pdf
225 .. [4] ImageJ AutoThresholder code,
226 http://fiji.sc/wiki/index.php/Auto_Threshold
227
228 Examples
229 --------
230 >>> from skimage.data import coins
231 >>> image = coins()
232 >>> thresh = threshold_isodata(image)
233 >>> binary = image > thresh
234 """
235 hist, bin_centers = histogram(image, nbins)
236 # On blank images (e.g. filled with 0) with int dtype, `histogram()`
237 # returns `bin_centers` containing only one value. Speed up with it.
238 if bin_centers.size == 1:
239 return bin_centers[0]
240 # It is not necessary to calculate the probability mass function here,
241 # because the l and h fractions already include the normalization.
242 pmf = hist.astype(np.float32) # / hist.sum()
243 cpmfl = np.cumsum(pmf, dtype=np.float32)
244 cpmfh = np.cumsum(pmf[::-1], dtype=np.float32)[::-1]
245
246 binnums = np.arange(pmf.size, dtype=np.uint8)
247 # l and h contain average value of pixels in sum of bins, calculated
248 # from lower to higher and from higher to lower respectively.
249 l = np.ma.divide(np.cumsum(pmf * binnums, dtype=np.float32), cpmfl)
250 h = np.ma.divide(
251 np.cumsum((pmf[::-1] * binnums[::-1]), dtype=np.float32)[::-1],
252 cpmfh)
253
254 allmean = (l + h) / 2.0
255 threshold = bin_centers[np.nonzero(allmean.round() == binnums)[0][0]]
256 # This implementation returns threshold where
257 # `background <= threshold < foreground`.
258 return threshold
259
[end of skimage/filter/thresholding.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/skimage/filter/thresholding.py b/skimage/filter/thresholding.py
--- a/skimage/filter/thresholding.py
+++ b/skimage/filter/thresholding.py
@@ -243,7 +243,7 @@
cpmfl = np.cumsum(pmf, dtype=np.float32)
cpmfh = np.cumsum(pmf[::-1], dtype=np.float32)[::-1]
- binnums = np.arange(pmf.size, dtype=np.uint8)
+ binnums = np.arange(pmf.size, dtype=np.min_scalar_type(nbins))
# l and h contain average value of pixels in sum of bins, calculated
# from lower to higher and from higher to lower respectively.
l = np.ma.divide(np.cumsum(pmf * binnums, dtype=np.float32), cpmfl)
|
{"golden_diff": "diff --git a/skimage/filter/thresholding.py b/skimage/filter/thresholding.py\n--- a/skimage/filter/thresholding.py\n+++ b/skimage/filter/thresholding.py\n@@ -243,7 +243,7 @@\n cpmfl = np.cumsum(pmf, dtype=np.float32)\n cpmfh = np.cumsum(pmf[::-1], dtype=np.float32)[::-1]\n \n- binnums = np.arange(pmf.size, dtype=np.uint8)\n+ binnums = np.arange(pmf.size, dtype=np.min_scalar_type(nbins))\n # l and h contain average value of pixels in sum of bins, calculated\n # from lower to higher and from higher to lower respectively.\n l = np.ma.divide(np.cumsum(pmf * binnums, dtype=np.float32), cpmfl)\n", "issue": "filter.threshold_isodata fails on 16-bit int images\nThe problem is the following line in threshholding.py:threshold_isodata():\n\n```\n binnums = np.arange(pmf.size, dtype=np.uint8)\n```\n\nObviously the histogram bin numbers for images with more than 255 intensity levels don't get generated properly, leading to hilarity. Changing that to dtype=np.uint16 should do the trick for 8- and 16-bit images, and float images as long as the nbins parameter is < 2**16. (This wouldn't work for 32-bit integer images -- are these even supported though?)\n\n", "before_files": [{"content": "__all__ = ['threshold_adaptive',\n 'threshold_otsu',\n 'threshold_yen',\n 'threshold_isodata']\n\nimport numpy as np\nimport scipy.ndimage\nfrom skimage.exposure import histogram\n\n\ndef threshold_adaptive(image, block_size, method='gaussian', offset=0,\n mode='reflect', param=None):\n \"\"\"Applies an adaptive threshold to an array.\n\n Also known as local or dynamic thresholding where the threshold value is\n the weighted mean for the local neighborhood of a pixel subtracted by a\n constant. Alternatively the threshold can be determined dynamically by a a\n given function using the 'generic' method.\n\n Parameters\n ----------\n image : (N, M) ndarray\n Input image.\n block_size : int\n Uneven size of pixel neighborhood which is used to calculate the\n threshold value (e.g. 3, 5, 7, ..., 21, ...).\n method : {'generic', 'gaussian', 'mean', 'median'}, optional\n Method used to determine adaptive threshold for local neighbourhood in\n weighted mean image.\n\n * 'generic': use custom function (see `param` parameter)\n * 'gaussian': apply gaussian filter (see `param` parameter for custom\\\n sigma value)\n * 'mean': apply arithmetic mean filter\n * 'median': apply median rank filter\n\n By default the 'gaussian' method is used.\n offset : float, optional\n Constant subtracted from weighted mean of neighborhood to calculate\n the local threshold value. Default offset is 0.\n mode : {'reflect', 'constant', 'nearest', 'mirror', 'wrap'}, optional\n The mode parameter determines how the array borders are handled, where\n cval is the value when mode is equal to 'constant'.\n Default is 'reflect'.\n param : {int, function}, optional\n Either specify sigma for 'gaussian' method or function object for\n 'generic' method. This functions takes the flat array of local\n neighbourhood as a single argument and returns the calculated\n threshold for the centre pixel.\n\n Returns\n -------\n threshold : (N, M) ndarray\n Thresholded binary image\n\n References\n ----------\n .. [1] http://docs.opencv.org/modules/imgproc/doc/miscellaneous_transformations.html?highlight=threshold#adaptivethreshold\n\n Examples\n --------\n >>> from skimage.data import camera\n >>> image = camera()[:50, :50]\n >>> binary_image1 = threshold_adaptive(image, 15, 'mean')\n >>> func = lambda arr: arr.mean()\n >>> binary_image2 = threshold_adaptive(image, 15, 'generic', param=func)\n \"\"\"\n thresh_image = np.zeros(image.shape, 'double')\n if method == 'generic':\n scipy.ndimage.generic_filter(image, param, block_size,\n output=thresh_image, mode=mode)\n elif method == 'gaussian':\n if param is None:\n # automatically determine sigma which covers > 99% of distribution\n sigma = (block_size - 1) / 6.0\n else:\n sigma = param\n scipy.ndimage.gaussian_filter(image, sigma, output=thresh_image,\n mode=mode)\n elif method == 'mean':\n mask = 1. / block_size * np.ones((block_size,))\n # separation of filters to speedup convolution\n scipy.ndimage.convolve1d(image, mask, axis=0, output=thresh_image,\n mode=mode)\n scipy.ndimage.convolve1d(thresh_image, mask, axis=1,\n output=thresh_image, mode=mode)\n elif method == 'median':\n scipy.ndimage.median_filter(image, block_size, output=thresh_image,\n mode=mode)\n\n return image > (thresh_image - offset)\n\n\ndef threshold_otsu(image, nbins=256):\n \"\"\"Return threshold value based on Otsu's method.\n\n Parameters\n ----------\n image : array\n Input image.\n nbins : int, optional\n Number of bins used to calculate histogram. This value is ignored for\n integer arrays.\n\n Returns\n -------\n threshold : float\n Upper threshold value. All pixels intensities that less or equal of\n this value assumed as foreground.\n\n References\n ----------\n .. [1] Wikipedia, http://en.wikipedia.org/wiki/Otsu's_Method\n\n Examples\n --------\n >>> from skimage.data import camera\n >>> image = camera()\n >>> thresh = threshold_otsu(image)\n >>> binary = image <= thresh\n \"\"\"\n hist, bin_centers = histogram(image, nbins)\n hist = hist.astype(float)\n\n # class probabilities for all possible thresholds\n weight1 = np.cumsum(hist)\n weight2 = np.cumsum(hist[::-1])[::-1]\n # class means for all possible thresholds\n mean1 = np.cumsum(hist * bin_centers) / weight1\n mean2 = (np.cumsum((hist * bin_centers)[::-1]) / weight2[::-1])[::-1]\n\n # Clip ends to align class 1 and class 2 variables:\n # The last value of `weight1`/`mean1` should pair with zero values in\n # `weight2`/`mean2`, which do not exist.\n variance12 = weight1[:-1] * weight2[1:] * (mean1[:-1] - mean2[1:]) ** 2\n\n idx = np.argmax(variance12)\n threshold = bin_centers[:-1][idx]\n return threshold\n\n\ndef threshold_yen(image, nbins=256):\n \"\"\"Return threshold value based on Yen's method.\n\n Parameters\n ----------\n image : array\n Input image.\n nbins : int, optional\n Number of bins used to calculate histogram. This value is ignored for\n integer arrays.\n\n Returns\n -------\n threshold : float\n Upper threshold value. All pixels intensities that less or equal of\n this value assumed as foreground.\n\n References\n ----------\n .. [1] Yen J.C., Chang F.J., and Chang S. (1995) \"A New Criterion\n for Automatic Multilevel Thresholding\" IEEE Trans. on Image\n Processing, 4(3): 370-378\n .. [2] Sezgin M. and Sankur B. (2004) \"Survey over Image Thresholding\n Techniques and Quantitative Performance Evaluation\" Journal of\n Electronic Imaging, 13(1): 146-165,\n http://www.busim.ee.boun.edu.tr/~sankur/SankurFolder/Threshold_survey.pdf\n .. [3] ImageJ AutoThresholder code, http://fiji.sc/wiki/index.php/Auto_Threshold\n\n Examples\n --------\n >>> from skimage.data import camera\n >>> image = camera()\n >>> thresh = threshold_yen(image)\n >>> binary = image <= thresh\n \"\"\"\n hist, bin_centers = histogram(image, nbins)\n # On blank images (e.g. filled with 0) with int dtype, `histogram()`\n # returns `bin_centers` containing only one value. Speed up with it.\n if bin_centers.size == 1:\n return bin_centers[0]\n\n # Calculate probability mass function\n pmf = hist.astype(np.float32) / hist.sum()\n P1 = np.cumsum(pmf) # Cumulative normalized histogram\n P1_sq = np.cumsum(pmf ** 2)\n # Get cumsum calculated from end of squared array:\n P2_sq = np.cumsum(pmf[::-1] ** 2)[::-1]\n # P2_sq indexes is shifted +1. I assume, with P1[:-1] it's help avoid '-inf'\n # in crit. ImageJ Yen implementation replaces those values by zero.\n crit = np.log(((P1_sq[:-1] * P2_sq[1:]) ** -1) *\n (P1[:-1] * (1.0 - P1[:-1])) ** 2)\n return bin_centers[crit.argmax()]\n\n\ndef threshold_isodata(image, nbins=256):\n \"\"\"Return threshold value based on ISODATA method.\n\n Histogram-based threshold, known as Ridler-Calvard method or intermeans.\n\n Parameters\n ----------\n image : array\n Input image.\n nbins : int, optional\n Number of bins used to calculate histogram. This value is ignored for\n integer arrays.\n\n Returns\n -------\n threshold : float or int, corresponding input array dtype.\n Upper threshold value. All pixels intensities that less or equal of\n this value assumed as background.\n\n References\n ----------\n .. [1] Ridler, TW & Calvard, S (1978), \"Picture thresholding using an\n iterative selection method\"\n .. [2] IEEE Transactions on Systems, Man and Cybernetics 8: 630-632,\n http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=4310039\n .. [3] Sezgin M. and Sankur B. (2004) \"Survey over Image Thresholding\n Techniques and Quantitative Performance Evaluation\" Journal of\n Electronic Imaging, 13(1): 146-165,\n http://www.busim.ee.boun.edu.tr/~sankur/SankurFolder/Threshold_survey.pdf\n .. [4] ImageJ AutoThresholder code,\n http://fiji.sc/wiki/index.php/Auto_Threshold\n\n Examples\n --------\n >>> from skimage.data import coins\n >>> image = coins()\n >>> thresh = threshold_isodata(image)\n >>> binary = image > thresh\n \"\"\"\n hist, bin_centers = histogram(image, nbins)\n # On blank images (e.g. filled with 0) with int dtype, `histogram()`\n # returns `bin_centers` containing only one value. Speed up with it.\n if bin_centers.size == 1:\n return bin_centers[0]\n # It is not necessary to calculate the probability mass function here,\n # because the l and h fractions already include the normalization.\n pmf = hist.astype(np.float32) # / hist.sum()\n cpmfl = np.cumsum(pmf, dtype=np.float32)\n cpmfh = np.cumsum(pmf[::-1], dtype=np.float32)[::-1]\n\n binnums = np.arange(pmf.size, dtype=np.uint8)\n # l and h contain average value of pixels in sum of bins, calculated\n # from lower to higher and from higher to lower respectively.\n l = np.ma.divide(np.cumsum(pmf * binnums, dtype=np.float32), cpmfl)\n h = np.ma.divide(\n np.cumsum((pmf[::-1] * binnums[::-1]), dtype=np.float32)[::-1],\n cpmfh)\n\n allmean = (l + h) / 2.0\n threshold = bin_centers[np.nonzero(allmean.round() == binnums)[0][0]]\n # This implementation returns threshold where\n # `background <= threshold < foreground`.\n return threshold\n", "path": "skimage/filter/thresholding.py"}]}
| 3,812 | 188 |
gh_patches_debug_36958
|
rasdani/github-patches
|
git_diff
|
mitmproxy__mitmproxy-1655
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Handle `bytes` in request parameters
When POST data is encoded as UTF8, `har_dump.py` would bail with
```
TypeError: b'xxxxx' is not JSON serializable
```
(please excuse my poor python, feel free to reject and solve in some other canonical way)
</issue>
<code>
[start of examples/har_dump.py]
1 """
2 This inline script can be used to dump flows as HAR files.
3 """
4
5
6 import pprint
7 import json
8 import sys
9 import base64
10 import zlib
11
12 from datetime import datetime
13 import pytz
14
15 import mitmproxy
16
17 from mitmproxy import version
18 from mitmproxy.utils import strutils
19 from mitmproxy.net.http import cookies
20
21 HAR = {}
22
23 # A list of server seen till now is maintained so we can avoid
24 # using 'connect' time for entries that use an existing connection.
25 SERVERS_SEEN = set()
26
27
28 def start():
29 """
30 Called once on script startup before any other events.
31 """
32 if len(sys.argv) != 2:
33 raise ValueError(
34 'Usage: -s "har_dump.py filename" '
35 '(- will output to stdout, filenames ending with .zhar '
36 'will result in compressed har)'
37 )
38
39 HAR.update({
40 "log": {
41 "version": "1.2",
42 "creator": {
43 "name": "mitmproxy har_dump",
44 "version": "0.1",
45 "comment": "mitmproxy version %s" % version.MITMPROXY
46 },
47 "entries": []
48 }
49 })
50
51
52 def response(flow):
53 """
54 Called when a server response has been received.
55 """
56
57 # -1 indicates that these values do not apply to current request
58 ssl_time = -1
59 connect_time = -1
60
61 if flow.server_conn and flow.server_conn not in SERVERS_SEEN:
62 connect_time = (flow.server_conn.timestamp_tcp_setup -
63 flow.server_conn.timestamp_start)
64
65 if flow.server_conn.timestamp_ssl_setup is not None:
66 ssl_time = (flow.server_conn.timestamp_ssl_setup -
67 flow.server_conn.timestamp_tcp_setup)
68
69 SERVERS_SEEN.add(flow.server_conn)
70
71 # Calculate raw timings from timestamps. DNS timings can not be calculated
72 # for lack of a way to measure it. The same goes for HAR blocked.
73 # mitmproxy will open a server connection as soon as it receives the host
74 # and port from the client connection. So, the time spent waiting is actually
75 # spent waiting between request.timestamp_end and response.timestamp_start
76 # thus it correlates to HAR wait instead.
77 timings_raw = {
78 'send': flow.request.timestamp_end - flow.request.timestamp_start,
79 'receive': flow.response.timestamp_end - flow.response.timestamp_start,
80 'wait': flow.response.timestamp_start - flow.request.timestamp_end,
81 'connect': connect_time,
82 'ssl': ssl_time,
83 }
84
85 # HAR timings are integers in ms, so we re-encode the raw timings to that format.
86 timings = dict([(k, int(1000 * v)) for k, v in timings_raw.items()])
87
88 # full_time is the sum of all timings.
89 # Timings set to -1 will be ignored as per spec.
90 full_time = sum(v for v in timings.values() if v > -1)
91
92 started_date_time = format_datetime(datetime.utcfromtimestamp(flow.request.timestamp_start))
93
94 # Response body size and encoding
95 response_body_size = len(flow.response.raw_content)
96 response_body_decoded_size = len(flow.response.content)
97 response_body_compression = response_body_decoded_size - response_body_size
98
99 entry = {
100 "startedDateTime": started_date_time,
101 "time": full_time,
102 "request": {
103 "method": flow.request.method,
104 "url": flow.request.url,
105 "httpVersion": flow.request.http_version,
106 "cookies": format_request_cookies(flow.request.cookies.fields),
107 "headers": name_value(flow.request.headers),
108 "queryString": name_value(flow.request.query or {}),
109 "headersSize": len(str(flow.request.headers)),
110 "bodySize": len(flow.request.content),
111 },
112 "response": {
113 "status": flow.response.status_code,
114 "statusText": flow.response.reason,
115 "httpVersion": flow.response.http_version,
116 "cookies": format_response_cookies(flow.response.cookies.fields),
117 "headers": name_value(flow.response.headers),
118 "content": {
119 "size": response_body_size,
120 "compression": response_body_compression,
121 "mimeType": flow.response.headers.get('Content-Type', '')
122 },
123 "redirectURL": flow.response.headers.get('Location', ''),
124 "headersSize": len(str(flow.response.headers)),
125 "bodySize": response_body_size,
126 },
127 "cache": {},
128 "timings": timings,
129 }
130
131 # Store binay data as base64
132 if strutils.is_mostly_bin(flow.response.content):
133 b64 = base64.b64encode(flow.response.content)
134 entry["response"]["content"]["text"] = b64.decode('ascii')
135 entry["response"]["content"]["encoding"] = "base64"
136 else:
137 entry["response"]["content"]["text"] = flow.response.text
138
139 if flow.request.method in ["POST", "PUT", "PATCH"]:
140 entry["request"]["postData"] = {
141 "mimeType": flow.request.headers.get("Content-Type", "").split(";")[0],
142 "text": flow.request.content,
143 "params": name_value(flow.request.urlencoded_form)
144 }
145
146 if flow.server_conn:
147 entry["serverIPAddress"] = str(flow.server_conn.ip_address.address[0])
148
149 HAR["log"]["entries"].append(entry)
150
151
152 def done():
153 """
154 Called once on script shutdown, after any other events.
155 """
156 dump_file = sys.argv[1]
157
158 if dump_file == '-':
159 mitmproxy.ctx.log(pprint.pformat(HAR))
160 else:
161 json_dump = json.dumps(HAR, indent=2)
162
163 if dump_file.endswith('.zhar'):
164 json_dump = zlib.compress(json_dump, 9)
165
166 with open(dump_file, "w") as f:
167 f.write(json_dump)
168
169 mitmproxy.ctx.log("HAR dump finished (wrote %s bytes to file)" % len(json_dump))
170
171
172 def format_datetime(dt):
173 return dt.replace(tzinfo=pytz.timezone("UTC")).isoformat()
174
175
176 def format_cookies(cookie_list):
177 rv = []
178
179 for name, value, attrs in cookie_list:
180 cookie_har = {
181 "name": name,
182 "value": value,
183 }
184
185 # HAR only needs some attributes
186 for key in ["path", "domain", "comment"]:
187 if key in attrs:
188 cookie_har[key] = attrs[key]
189
190 # These keys need to be boolean!
191 for key in ["httpOnly", "secure"]:
192 cookie_har[key] = bool(key in attrs)
193
194 # Expiration time needs to be formatted
195 expire_ts = cookies.get_expiration_ts(attrs)
196 if expire_ts is not None:
197 cookie_har["expires"] = format_datetime(datetime.fromtimestamp(expire_ts))
198
199 rv.append(cookie_har)
200
201 return rv
202
203
204 def format_request_cookies(fields):
205 return format_cookies(cookies.group_cookies(fields))
206
207
208 def format_response_cookies(fields):
209 return format_cookies((c[0], c[1].value, c[1].attrs) for c in fields)
210
211
212 def name_value(obj):
213 """
214 Convert (key, value) pairs to HAR format.
215 """
216 return [{"name": k, "value": v} for k, v in obj.items()]
217
[end of examples/har_dump.py]
[start of pathod/language/generators.py]
1 import string
2 import random
3 import mmap
4
5 import sys
6
7 DATATYPES = dict(
8 ascii_letters=string.ascii_letters.encode(),
9 ascii_lowercase=string.ascii_lowercase.encode(),
10 ascii_uppercase=string.ascii_uppercase.encode(),
11 digits=string.digits.encode(),
12 hexdigits=string.hexdigits.encode(),
13 octdigits=string.octdigits.encode(),
14 punctuation=string.punctuation.encode(),
15 whitespace=string.whitespace.encode(),
16 ascii=string.printable.encode(),
17 bytes=bytes(bytearray(range(256)))
18 )
19
20
21 class TransformGenerator:
22
23 """
24 Perform a byte-by-byte transform another generator - that is, for each
25 input byte, the transformation must produce one output byte.
26
27 gen: A generator to wrap
28 transform: A function (offset, data) -> transformed
29 """
30
31 def __init__(self, gen, transform):
32 self.gen = gen
33 self.transform = transform
34
35 def __len__(self):
36 return len(self.gen)
37
38 def __getitem__(self, x):
39 d = self.gen.__getitem__(x)
40 if isinstance(x, slice):
41 return self.transform(x.start, d)
42 return self.transform(x, d)
43
44 def __repr__(self):
45 return "'transform(%s)'" % self.gen
46
47
48 def rand_byte(chars):
49 """
50 Return a random character as byte from a charset.
51 """
52 # bytearray has consistent behaviour on both Python 2 and 3
53 # while bytes does not
54 return bytes([random.choice(chars)])
55
56
57 class RandomGenerator:
58
59 def __init__(self, dtype, length):
60 self.dtype = dtype
61 self.length = length
62
63 def __len__(self):
64 return self.length
65
66 def __getitem__(self, x):
67 chars = DATATYPES[self.dtype]
68 if isinstance(x, slice):
69 return b"".join(rand_byte(chars) for _ in range(*x.indices(min(self.length, sys.maxsize))))
70 return rand_byte(chars)
71
72 def __repr__(self):
73 return "%s random from %s" % (self.length, self.dtype)
74
75
76 class FileGenerator:
77
78 def __init__(self, path):
79 self.path = path
80 self.fp = open(path, "rb")
81 self.map = mmap.mmap(self.fp.fileno(), 0, access=mmap.ACCESS_READ)
82
83 def __len__(self):
84 return len(self.map)
85
86 def __getitem__(self, x):
87 if isinstance(x, slice):
88 return self.map.__getitem__(x)
89 # A slice of length 1 returns a byte object (not an integer)
90 return self.map.__getitem__(slice(x, x + 1 or self.map.size()))
91
92 def __repr__(self):
93 return "<%s" % self.path
94
[end of pathod/language/generators.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/har_dump.py b/examples/har_dump.py
--- a/examples/har_dump.py
+++ b/examples/har_dump.py
@@ -3,7 +3,6 @@
"""
-import pprint
import json
import sys
import base64
@@ -128,19 +127,22 @@
"timings": timings,
}
- # Store binay data as base64
+ # Store binary data as base64
if strutils.is_mostly_bin(flow.response.content):
- b64 = base64.b64encode(flow.response.content)
- entry["response"]["content"]["text"] = b64.decode('ascii')
+ entry["response"]["content"]["text"] = base64.b64encode(flow.response.content).decode()
entry["response"]["content"]["encoding"] = "base64"
else:
- entry["response"]["content"]["text"] = flow.response.text
+ entry["response"]["content"]["text"] = flow.response.get_text(strict=False)
if flow.request.method in ["POST", "PUT", "PATCH"]:
+ params = [
+ {"name": a.decode("utf8", "surrogateescape"), "value": b.decode("utf8", "surrogateescape")}
+ for a, b in flow.request.urlencoded_form.items(multi=True)
+ ]
entry["request"]["postData"] = {
"mimeType": flow.request.headers.get("Content-Type", "").split(";")[0],
- "text": flow.request.content,
- "params": name_value(flow.request.urlencoded_form)
+ "text": flow.request.get_text(strict=False),
+ "params": params
}
if flow.server_conn:
@@ -155,16 +157,17 @@
"""
dump_file = sys.argv[1]
+ json_dump = json.dumps(HAR, indent=2) # type: str
+
if dump_file == '-':
- mitmproxy.ctx.log(pprint.pformat(HAR))
+ mitmproxy.ctx.log(json_dump)
else:
- json_dump = json.dumps(HAR, indent=2)
-
+ raw = json_dump.encode() # type: bytes
if dump_file.endswith('.zhar'):
- json_dump = zlib.compress(json_dump, 9)
+ raw = zlib.compress(raw, 9)
- with open(dump_file, "w") as f:
- f.write(json_dump)
+ with open(dump_file, "wb") as f:
+ f.write(raw)
mitmproxy.ctx.log("HAR dump finished (wrote %s bytes to file)" % len(json_dump))
diff --git a/pathod/language/generators.py b/pathod/language/generators.py
--- a/pathod/language/generators.py
+++ b/pathod/language/generators.py
@@ -14,7 +14,7 @@
punctuation=string.punctuation.encode(),
whitespace=string.whitespace.encode(),
ascii=string.printable.encode(),
- bytes=bytes(bytearray(range(256)))
+ bytes=bytes(range(256))
)
|
{"golden_diff": "diff --git a/examples/har_dump.py b/examples/har_dump.py\n--- a/examples/har_dump.py\n+++ b/examples/har_dump.py\n@@ -3,7 +3,6 @@\n \"\"\"\n \n \n-import pprint\n import json\n import sys\n import base64\n@@ -128,19 +127,22 @@\n \"timings\": timings,\n }\n \n- # Store binay data as base64\n+ # Store binary data as base64\n if strutils.is_mostly_bin(flow.response.content):\n- b64 = base64.b64encode(flow.response.content)\n- entry[\"response\"][\"content\"][\"text\"] = b64.decode('ascii')\n+ entry[\"response\"][\"content\"][\"text\"] = base64.b64encode(flow.response.content).decode()\n entry[\"response\"][\"content\"][\"encoding\"] = \"base64\"\n else:\n- entry[\"response\"][\"content\"][\"text\"] = flow.response.text\n+ entry[\"response\"][\"content\"][\"text\"] = flow.response.get_text(strict=False)\n \n if flow.request.method in [\"POST\", \"PUT\", \"PATCH\"]:\n+ params = [\n+ {\"name\": a.decode(\"utf8\", \"surrogateescape\"), \"value\": b.decode(\"utf8\", \"surrogateescape\")}\n+ for a, b in flow.request.urlencoded_form.items(multi=True)\n+ ]\n entry[\"request\"][\"postData\"] = {\n \"mimeType\": flow.request.headers.get(\"Content-Type\", \"\").split(\";\")[0],\n- \"text\": flow.request.content,\n- \"params\": name_value(flow.request.urlencoded_form)\n+ \"text\": flow.request.get_text(strict=False),\n+ \"params\": params\n }\n \n if flow.server_conn:\n@@ -155,16 +157,17 @@\n \"\"\"\n dump_file = sys.argv[1]\n \n+ json_dump = json.dumps(HAR, indent=2) # type: str\n+\n if dump_file == '-':\n- mitmproxy.ctx.log(pprint.pformat(HAR))\n+ mitmproxy.ctx.log(json_dump)\n else:\n- json_dump = json.dumps(HAR, indent=2)\n-\n+ raw = json_dump.encode() # type: bytes\n if dump_file.endswith('.zhar'):\n- json_dump = zlib.compress(json_dump, 9)\n+ raw = zlib.compress(raw, 9)\n \n- with open(dump_file, \"w\") as f:\n- f.write(json_dump)\n+ with open(dump_file, \"wb\") as f:\n+ f.write(raw)\n \n mitmproxy.ctx.log(\"HAR dump finished (wrote %s bytes to file)\" % len(json_dump))\n \ndiff --git a/pathod/language/generators.py b/pathod/language/generators.py\n--- a/pathod/language/generators.py\n+++ b/pathod/language/generators.py\n@@ -14,7 +14,7 @@\n punctuation=string.punctuation.encode(),\n whitespace=string.whitespace.encode(),\n ascii=string.printable.encode(),\n- bytes=bytes(bytearray(range(256)))\n+ bytes=bytes(range(256))\n )\n", "issue": "Handle `bytes` in request parameters\nWhen POST data is encoded as UTF8, `har_dump.py` would bail with\n\n```\nTypeError: b'xxxxx' is not JSON serializable\n```\n\n(please excuse my poor python, feel free to reject and solve in some other canonical way)\n\n", "before_files": [{"content": "\"\"\"\nThis inline script can be used to dump flows as HAR files.\n\"\"\"\n\n\nimport pprint\nimport json\nimport sys\nimport base64\nimport zlib\n\nfrom datetime import datetime\nimport pytz\n\nimport mitmproxy\n\nfrom mitmproxy import version\nfrom mitmproxy.utils import strutils\nfrom mitmproxy.net.http import cookies\n\nHAR = {}\n\n# A list of server seen till now is maintained so we can avoid\n# using 'connect' time for entries that use an existing connection.\nSERVERS_SEEN = set()\n\n\ndef start():\n \"\"\"\n Called once on script startup before any other events.\n \"\"\"\n if len(sys.argv) != 2:\n raise ValueError(\n 'Usage: -s \"har_dump.py filename\" '\n '(- will output to stdout, filenames ending with .zhar '\n 'will result in compressed har)'\n )\n\n HAR.update({\n \"log\": {\n \"version\": \"1.2\",\n \"creator\": {\n \"name\": \"mitmproxy har_dump\",\n \"version\": \"0.1\",\n \"comment\": \"mitmproxy version %s\" % version.MITMPROXY\n },\n \"entries\": []\n }\n })\n\n\ndef response(flow):\n \"\"\"\n Called when a server response has been received.\n \"\"\"\n\n # -1 indicates that these values do not apply to current request\n ssl_time = -1\n connect_time = -1\n\n if flow.server_conn and flow.server_conn not in SERVERS_SEEN:\n connect_time = (flow.server_conn.timestamp_tcp_setup -\n flow.server_conn.timestamp_start)\n\n if flow.server_conn.timestamp_ssl_setup is not None:\n ssl_time = (flow.server_conn.timestamp_ssl_setup -\n flow.server_conn.timestamp_tcp_setup)\n\n SERVERS_SEEN.add(flow.server_conn)\n\n # Calculate raw timings from timestamps. DNS timings can not be calculated\n # for lack of a way to measure it. The same goes for HAR blocked.\n # mitmproxy will open a server connection as soon as it receives the host\n # and port from the client connection. So, the time spent waiting is actually\n # spent waiting between request.timestamp_end and response.timestamp_start\n # thus it correlates to HAR wait instead.\n timings_raw = {\n 'send': flow.request.timestamp_end - flow.request.timestamp_start,\n 'receive': flow.response.timestamp_end - flow.response.timestamp_start,\n 'wait': flow.response.timestamp_start - flow.request.timestamp_end,\n 'connect': connect_time,\n 'ssl': ssl_time,\n }\n\n # HAR timings are integers in ms, so we re-encode the raw timings to that format.\n timings = dict([(k, int(1000 * v)) for k, v in timings_raw.items()])\n\n # full_time is the sum of all timings.\n # Timings set to -1 will be ignored as per spec.\n full_time = sum(v for v in timings.values() if v > -1)\n\n started_date_time = format_datetime(datetime.utcfromtimestamp(flow.request.timestamp_start))\n\n # Response body size and encoding\n response_body_size = len(flow.response.raw_content)\n response_body_decoded_size = len(flow.response.content)\n response_body_compression = response_body_decoded_size - response_body_size\n\n entry = {\n \"startedDateTime\": started_date_time,\n \"time\": full_time,\n \"request\": {\n \"method\": flow.request.method,\n \"url\": flow.request.url,\n \"httpVersion\": flow.request.http_version,\n \"cookies\": format_request_cookies(flow.request.cookies.fields),\n \"headers\": name_value(flow.request.headers),\n \"queryString\": name_value(flow.request.query or {}),\n \"headersSize\": len(str(flow.request.headers)),\n \"bodySize\": len(flow.request.content),\n },\n \"response\": {\n \"status\": flow.response.status_code,\n \"statusText\": flow.response.reason,\n \"httpVersion\": flow.response.http_version,\n \"cookies\": format_response_cookies(flow.response.cookies.fields),\n \"headers\": name_value(flow.response.headers),\n \"content\": {\n \"size\": response_body_size,\n \"compression\": response_body_compression,\n \"mimeType\": flow.response.headers.get('Content-Type', '')\n },\n \"redirectURL\": flow.response.headers.get('Location', ''),\n \"headersSize\": len(str(flow.response.headers)),\n \"bodySize\": response_body_size,\n },\n \"cache\": {},\n \"timings\": timings,\n }\n\n # Store binay data as base64\n if strutils.is_mostly_bin(flow.response.content):\n b64 = base64.b64encode(flow.response.content)\n entry[\"response\"][\"content\"][\"text\"] = b64.decode('ascii')\n entry[\"response\"][\"content\"][\"encoding\"] = \"base64\"\n else:\n entry[\"response\"][\"content\"][\"text\"] = flow.response.text\n\n if flow.request.method in [\"POST\", \"PUT\", \"PATCH\"]:\n entry[\"request\"][\"postData\"] = {\n \"mimeType\": flow.request.headers.get(\"Content-Type\", \"\").split(\";\")[0],\n \"text\": flow.request.content,\n \"params\": name_value(flow.request.urlencoded_form)\n }\n\n if flow.server_conn:\n entry[\"serverIPAddress\"] = str(flow.server_conn.ip_address.address[0])\n\n HAR[\"log\"][\"entries\"].append(entry)\n\n\ndef done():\n \"\"\"\n Called once on script shutdown, after any other events.\n \"\"\"\n dump_file = sys.argv[1]\n\n if dump_file == '-':\n mitmproxy.ctx.log(pprint.pformat(HAR))\n else:\n json_dump = json.dumps(HAR, indent=2)\n\n if dump_file.endswith('.zhar'):\n json_dump = zlib.compress(json_dump, 9)\n\n with open(dump_file, \"w\") as f:\n f.write(json_dump)\n\n mitmproxy.ctx.log(\"HAR dump finished (wrote %s bytes to file)\" % len(json_dump))\n\n\ndef format_datetime(dt):\n return dt.replace(tzinfo=pytz.timezone(\"UTC\")).isoformat()\n\n\ndef format_cookies(cookie_list):\n rv = []\n\n for name, value, attrs in cookie_list:\n cookie_har = {\n \"name\": name,\n \"value\": value,\n }\n\n # HAR only needs some attributes\n for key in [\"path\", \"domain\", \"comment\"]:\n if key in attrs:\n cookie_har[key] = attrs[key]\n\n # These keys need to be boolean!\n for key in [\"httpOnly\", \"secure\"]:\n cookie_har[key] = bool(key in attrs)\n\n # Expiration time needs to be formatted\n expire_ts = cookies.get_expiration_ts(attrs)\n if expire_ts is not None:\n cookie_har[\"expires\"] = format_datetime(datetime.fromtimestamp(expire_ts))\n\n rv.append(cookie_har)\n\n return rv\n\n\ndef format_request_cookies(fields):\n return format_cookies(cookies.group_cookies(fields))\n\n\ndef format_response_cookies(fields):\n return format_cookies((c[0], c[1].value, c[1].attrs) for c in fields)\n\n\ndef name_value(obj):\n \"\"\"\n Convert (key, value) pairs to HAR format.\n \"\"\"\n return [{\"name\": k, \"value\": v} for k, v in obj.items()]\n", "path": "examples/har_dump.py"}, {"content": "import string\nimport random\nimport mmap\n\nimport sys\n\nDATATYPES = dict(\n ascii_letters=string.ascii_letters.encode(),\n ascii_lowercase=string.ascii_lowercase.encode(),\n ascii_uppercase=string.ascii_uppercase.encode(),\n digits=string.digits.encode(),\n hexdigits=string.hexdigits.encode(),\n octdigits=string.octdigits.encode(),\n punctuation=string.punctuation.encode(),\n whitespace=string.whitespace.encode(),\n ascii=string.printable.encode(),\n bytes=bytes(bytearray(range(256)))\n)\n\n\nclass TransformGenerator:\n\n \"\"\"\n Perform a byte-by-byte transform another generator - that is, for each\n input byte, the transformation must produce one output byte.\n\n gen: A generator to wrap\n transform: A function (offset, data) -> transformed\n \"\"\"\n\n def __init__(self, gen, transform):\n self.gen = gen\n self.transform = transform\n\n def __len__(self):\n return len(self.gen)\n\n def __getitem__(self, x):\n d = self.gen.__getitem__(x)\n if isinstance(x, slice):\n return self.transform(x.start, d)\n return self.transform(x, d)\n\n def __repr__(self):\n return \"'transform(%s)'\" % self.gen\n\n\ndef rand_byte(chars):\n \"\"\"\n Return a random character as byte from a charset.\n \"\"\"\n # bytearray has consistent behaviour on both Python 2 and 3\n # while bytes does not\n return bytes([random.choice(chars)])\n\n\nclass RandomGenerator:\n\n def __init__(self, dtype, length):\n self.dtype = dtype\n self.length = length\n\n def __len__(self):\n return self.length\n\n def __getitem__(self, x):\n chars = DATATYPES[self.dtype]\n if isinstance(x, slice):\n return b\"\".join(rand_byte(chars) for _ in range(*x.indices(min(self.length, sys.maxsize))))\n return rand_byte(chars)\n\n def __repr__(self):\n return \"%s random from %s\" % (self.length, self.dtype)\n\n\nclass FileGenerator:\n\n def __init__(self, path):\n self.path = path\n self.fp = open(path, \"rb\")\n self.map = mmap.mmap(self.fp.fileno(), 0, access=mmap.ACCESS_READ)\n\n def __len__(self):\n return len(self.map)\n\n def __getitem__(self, x):\n if isinstance(x, slice):\n return self.map.__getitem__(x)\n # A slice of length 1 returns a byte object (not an integer)\n return self.map.__getitem__(slice(x, x + 1 or self.map.size()))\n\n def __repr__(self):\n return \"<%s\" % self.path\n", "path": "pathod/language/generators.py"}]}
| 3,514 | 691 |
gh_patches_debug_20629
|
rasdani/github-patches
|
git_diff
|
pfnet__pytorch-pfn-extras-107
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[ONNX] Single input is not exported correctly
When exporting ONNX with single input, input tensor is split and input shape will be wrong.
https://github.com/pfnet/pytorch-pfn-extras/blob/2c5e1440f3137f48d651e705fddb7ea0251583d3/pytorch_pfn_extras/onnx/export_testcase.py#L177
</issue>
<code>
[start of pytorch_pfn_extras/onnx/export_testcase.py]
1 import datetime
2 import io
3 import json
4 import os
5 import subprocess
6 import warnings
7
8 import onnx
9 import onnx.numpy_helper
10 import torch
11 import torch.autograd
12 from torch.onnx import OperatorExportTypes
13 from torch.onnx.symbolic_helper import _default_onnx_opset_version
14 from torch.onnx.utils import _export as torch_export
15
16 from pytorch_pfn_extras.onnx.annotate import init_annotate
17 from pytorch_pfn_extras.onnx.strip_large_tensor import \
18 LARGE_TENSOR_DATA_THRESHOLD
19 from pytorch_pfn_extras.onnx.strip_large_tensor import is_large_tensor
20 from pytorch_pfn_extras.onnx.strip_large_tensor import _strip_raw_data
21 from pytorch_pfn_extras.onnx.strip_large_tensor import \
22 _strip_large_initializer_raw_data
23
24
25 def _export_meta(model, out_dir, strip_large_tensor_data):
26 ret = {
27 'generated_at': datetime.datetime.now().isoformat(),
28 'output_directory': out_dir,
29 'exporter': 'torch-onnx-utils',
30 'strip_large_tensor_data': strip_large_tensor_data,
31 }
32 try:
33 git_status = subprocess.Popen(['git', 'status'],
34 stdout=subprocess.PIPE,
35 stderr=subprocess.PIPE)
36 git_status.communicate()
37
38 def strip_cmd(cmd):
39 return os.popen(cmd).read().strip()
40 if git_status.returncode == 0:
41 ret['git'] = {
42 'branch': strip_cmd('git rev-parse --abbrev-ref HEAD'),
43 'commit': strip_cmd('git rev-parse HEAD'),
44 'remote': strip_cmd('git ls-remote --get-url origin'),
45 'commit_date': strip_cmd('git show -s --format=%ci HEAD'),
46 }
47 except FileNotFoundError:
48 pass
49
50 return ret
51
52
53 def _export_util(model, args, f, **kwargs):
54 """Wrap operator type to export
55
56 Copied from torch.onnx.utils.export, to get output values.
57 """
58 aten = kwargs.get('aten', False)
59 export_raw_ir = kwargs.get('export_raw_ir', False)
60 operator_export_type = kwargs.get('operator_export_type', None)
61
62 if aten or export_raw_ir:
63 assert operator_export_type is None
64 assert aten ^ export_raw_ir
65 operator_export_type = OperatorExportTypes.ATEN if\
66 aten else OperatorExportTypes.RAW
67 elif operator_export_type is None:
68 if torch.onnx.PYTORCH_ONNX_CAFFE2_BUNDLE:
69 operator_export_type = OperatorExportTypes.ONNX_ATEN_FALLBACK
70 else:
71 operator_export_type = OperatorExportTypes.ONNX
72
73 return torch_export(model, args, f, _retain_param_name=True, **kwargs)
74
75
76 def _export(
77 model, args, strip_large_tensor_data=False,
78 large_tensor_threshold=LARGE_TENSOR_DATA_THRESHOLD, **kwargs):
79 model.zero_grad()
80 bytesio = io.BytesIO()
81 opset_ver = kwargs.get('opset_version', None)
82 if opset_ver is None:
83 opset_ver = _default_onnx_opset_version
84 strip_doc_string = kwargs.pop('strip_doc_string', True)
85 with init_annotate(model, opset_ver) as ann:
86 outs = _export_util(
87 model, args, bytesio, strip_doc_string=False, **kwargs)
88 onnx_graph = onnx.load(io.BytesIO(bytesio.getvalue()))
89 onnx_graph = ann.set_annotate(onnx_graph)
90 onnx_graph = ann.reorg_anchor(onnx_graph)
91 if strip_doc_string:
92 for node in onnx_graph.graph.node:
93 node.doc_string = b''
94 if strip_large_tensor_data:
95 _strip_large_initializer_raw_data(onnx_graph, large_tensor_threshold)
96
97 return onnx_graph, outs
98
99
100 def export(
101 model, args, f, return_output=False, strip_large_tensor_data=False,
102 large_tensor_threshold=LARGE_TENSOR_DATA_THRESHOLD, **kwargs):
103 """Export model into ONNX Graph.
104
105 Args:
106 f: A file-like object or a string file path to be written to this
107 file.
108 return_output (bool): If True, return output values come from the
109 model.
110 strip_large_tensor_data (bool): If True, this function will strip
111 data of large tensors to reduce ONNX file size for benchmarking
112 large_tensor_threshold (int): If number of elements of tensor is
113 larger than this value, the tensor is stripped when
114 *strip_large_tensor_data* is True
115 """
116 onnx_graph, outs = _export(
117 model, args, strip_large_tensor_data, large_tensor_threshold,
118 **kwargs)
119
120 if hasattr(f, 'write'):
121 f.write(onnx_graph.SerializeToString())
122 else:
123 assert isinstance(f, str)
124 warnings.warn(
125 'When export ONNX graph as file, "export_testcase" is '
126 'strongly recommended, please consider use it instead',
127 UserWarning)
128 with open(f, 'wb') as fp:
129 fp.write(onnx_graph.SerializeToString())
130
131 if return_output:
132 return outs
133
134
135 def export_testcase(
136 model, args, out_dir, *, output_grad=False, metadata=True,
137 model_overwrite=True, strip_large_tensor_data=False,
138 large_tensor_threshold=LARGE_TENSOR_DATA_THRESHOLD,
139 return_output=False, **kwargs):
140 """Export model and I/O tensors of the model in protobuf format.
141
142 Args:
143 output_grad (bool or Tensor): If True, this function will output
144 model's gradient with names 'gradient_%d.pb'. If set Tensor,
145 use it as gradient *input*. The gradient inputs are output as
146 'gradient_input_%d.pb' along with gradient.
147 metadata (bool): If True, output meta information taken from git log.
148 model_overwrite (bool): If False and model.onnx has already existed,
149 only export input/output data as another test dataset.
150 strip_large_tensor_data (bool): If True, this function will strip
151 data of large tensors to reduce ONNX file size for benchmarking
152 large_tensor_threshold (int): If number of elements of tensor is
153 larger than this value, the tensor is stripped when
154 *strip_large_tensor_data* is True
155 """
156
157 os.makedirs(out_dir, exist_ok=True)
158 input_names = kwargs.pop(
159 'input_names',
160 ['input_{}'.format(i) for i in range(len(args))])
161 assert len(input_names) == len(args)
162
163 onnx_graph, outs = _export(
164 model, args, strip_large_tensor_data, large_tensor_threshold,
165 input_names=input_names, **kwargs)
166
167 # Remove unused inputs
168 # - When keep_initializers_as_inputs=True, inputs contains initializers.
169 # So we have to filt initializers.
170 # - model.onnx is already issued, so we can modify args here.
171 initializer_names = [init.name for init in onnx_graph.graph.initializer]
172 used_input_index_list = []
173 for used_input in onnx_graph.graph.input:
174 if used_input.name not in initializer_names:
175 used_input_index_list.append(input_names.index(used_input.name))
176 input_names = [input_names[i] for i in used_input_index_list]
177 args = [args[i] for i in used_input_index_list]
178
179 output_path = os.path.join(out_dir, 'model.onnx')
180 is_on_memory = True
181 if model_overwrite or (not os.path.isfile(output_path)):
182 is_on_memory = False
183 with open(output_path, 'wb') as fp:
184 fp.write(onnx_graph.SerializeToString())
185
186 def write_to_pb(f, tensor, name=None):
187 array = tensor.detach().cpu().numpy()
188 with open(f, 'wb') as fp:
189 t = onnx.numpy_helper.from_array(array, name)
190 if (strip_large_tensor_data and
191 is_large_tensor(t, large_tensor_threshold)):
192 _strip_raw_data(t)
193 fp.write(t.SerializeToString())
194
195 if isinstance(args, torch.Tensor):
196 args = args,
197 if isinstance(outs, torch.Tensor):
198 outs = outs,
199 data_set_path = os.path.join(out_dir, 'test_data_set_0')
200 seq_id = 0
201 while is_on_memory and os.path.exists(data_set_path):
202 seq_id += 1
203 data_set_path = os.path.join(
204 out_dir, 'test_data_set_{:d}'.format(seq_id))
205 os.makedirs(data_set_path, exist_ok=True)
206 for i, (arg, name) in enumerate(zip(args, input_names)):
207 f = os.path.join(data_set_path, 'input_{}.pb'.format(i))
208 write_to_pb(f, arg, name)
209
210 output_names = kwargs.get('output_names')
211 if output_names is None:
212 if isinstance(outs, dict):
213 output_names = outs.keys()
214 else:
215 output_names = [None] * len(outs)
216 for i, name in enumerate(output_names):
217 if isinstance(outs, dict):
218 out = outs[name]
219 else:
220 out = outs[i]
221 if isinstance(out, (list, tuple)):
222 assert len(out) == 1, \
223 'Models returning nested lists/tuples are not supported yet'
224 out = out[0]
225 f = os.path.join(data_set_path, 'output_{}.pb'.format(i))
226 write_to_pb(f, out, name)
227
228 if output_grad is not False:
229 if isinstance(output_grad, bool):
230 output_grad = [torch.ones_like(outs[idx])
231 for idx in range(len(output_names))]
232 if isinstance(output_grad, torch.Tensor):
233 output_grad = [output_grad]
234 for idx in range(len(output_names)):
235 write_to_pb(
236 os.path.join(data_set_path, 'gradient_input_{}.pb'.format(
237 idx)), output_grad[idx],
238 output_names[idx])
239 if len(output_names) == len(outs):
240 torch.autograd.backward(outs, grad_tensors=output_grad)
241 else:
242 assert len(
243 output_names) == 1, 'Single output names is only supported'
244 outs[0].backward(output_grad[0])
245
246 for i, (name, param) in enumerate(model.named_parameters()):
247 f = os.path.join(data_set_path, 'gradient_{}.pb'.format(i))
248 # NOTE: name does not follow C identifier syntax rules,
249 # like "fc1.bias", not cleanse for now
250 if param.grad is None:
251 warnings.warn(
252 'Parameter `{}` does not have gradient value'.format(name))
253 else:
254 write_to_pb(f, param.grad, name)
255
256 if metadata:
257 with open(os.path.join(out_dir, 'meta.json'), 'w') as f:
258 json.dump(_export_meta(model, out_dir,
259 strip_large_tensor_data), f, indent=2)
260
261 if return_output:
262 return outs
263
[end of pytorch_pfn_extras/onnx/export_testcase.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pytorch_pfn_extras/onnx/export_testcase.py b/pytorch_pfn_extras/onnx/export_testcase.py
--- a/pytorch_pfn_extras/onnx/export_testcase.py
+++ b/pytorch_pfn_extras/onnx/export_testcase.py
@@ -163,6 +163,10 @@
onnx_graph, outs = _export(
model, args, strip_large_tensor_data, large_tensor_threshold,
input_names=input_names, **kwargs)
+ if isinstance(args, torch.Tensor):
+ args = args,
+ if isinstance(outs, torch.Tensor):
+ outs = outs,
# Remove unused inputs
# - When keep_initializers_as_inputs=True, inputs contains initializers.
@@ -192,10 +196,6 @@
_strip_raw_data(t)
fp.write(t.SerializeToString())
- if isinstance(args, torch.Tensor):
- args = args,
- if isinstance(outs, torch.Tensor):
- outs = outs,
data_set_path = os.path.join(out_dir, 'test_data_set_0')
seq_id = 0
while is_on_memory and os.path.exists(data_set_path):
|
{"golden_diff": "diff --git a/pytorch_pfn_extras/onnx/export_testcase.py b/pytorch_pfn_extras/onnx/export_testcase.py\n--- a/pytorch_pfn_extras/onnx/export_testcase.py\n+++ b/pytorch_pfn_extras/onnx/export_testcase.py\n@@ -163,6 +163,10 @@\n onnx_graph, outs = _export(\n model, args, strip_large_tensor_data, large_tensor_threshold,\n input_names=input_names, **kwargs)\n+ if isinstance(args, torch.Tensor):\n+ args = args,\n+ if isinstance(outs, torch.Tensor):\n+ outs = outs,\n \n # Remove unused inputs\n # - When keep_initializers_as_inputs=True, inputs contains initializers.\n@@ -192,10 +196,6 @@\n _strip_raw_data(t)\n fp.write(t.SerializeToString())\n \n- if isinstance(args, torch.Tensor):\n- args = args,\n- if isinstance(outs, torch.Tensor):\n- outs = outs,\n data_set_path = os.path.join(out_dir, 'test_data_set_0')\n seq_id = 0\n while is_on_memory and os.path.exists(data_set_path):\n", "issue": "[ONNX] Single input is not exported correctly\nWhen exporting ONNX with single input, input tensor is split and input shape will be wrong.\r\n\r\nhttps://github.com/pfnet/pytorch-pfn-extras/blob/2c5e1440f3137f48d651e705fddb7ea0251583d3/pytorch_pfn_extras/onnx/export_testcase.py#L177\n", "before_files": [{"content": "import datetime\nimport io\nimport json\nimport os\nimport subprocess\nimport warnings\n\nimport onnx\nimport onnx.numpy_helper\nimport torch\nimport torch.autograd\nfrom torch.onnx import OperatorExportTypes\nfrom torch.onnx.symbolic_helper import _default_onnx_opset_version\nfrom torch.onnx.utils import _export as torch_export\n\nfrom pytorch_pfn_extras.onnx.annotate import init_annotate\nfrom pytorch_pfn_extras.onnx.strip_large_tensor import \\\n LARGE_TENSOR_DATA_THRESHOLD\nfrom pytorch_pfn_extras.onnx.strip_large_tensor import is_large_tensor\nfrom pytorch_pfn_extras.onnx.strip_large_tensor import _strip_raw_data\nfrom pytorch_pfn_extras.onnx.strip_large_tensor import \\\n _strip_large_initializer_raw_data\n\n\ndef _export_meta(model, out_dir, strip_large_tensor_data):\n ret = {\n 'generated_at': datetime.datetime.now().isoformat(),\n 'output_directory': out_dir,\n 'exporter': 'torch-onnx-utils',\n 'strip_large_tensor_data': strip_large_tensor_data,\n }\n try:\n git_status = subprocess.Popen(['git', 'status'],\n stdout=subprocess.PIPE,\n stderr=subprocess.PIPE)\n git_status.communicate()\n\n def strip_cmd(cmd):\n return os.popen(cmd).read().strip()\n if git_status.returncode == 0:\n ret['git'] = {\n 'branch': strip_cmd('git rev-parse --abbrev-ref HEAD'),\n 'commit': strip_cmd('git rev-parse HEAD'),\n 'remote': strip_cmd('git ls-remote --get-url origin'),\n 'commit_date': strip_cmd('git show -s --format=%ci HEAD'),\n }\n except FileNotFoundError:\n pass\n\n return ret\n\n\ndef _export_util(model, args, f, **kwargs):\n \"\"\"Wrap operator type to export\n\n Copied from torch.onnx.utils.export, to get output values.\n \"\"\"\n aten = kwargs.get('aten', False)\n export_raw_ir = kwargs.get('export_raw_ir', False)\n operator_export_type = kwargs.get('operator_export_type', None)\n\n if aten or export_raw_ir:\n assert operator_export_type is None\n assert aten ^ export_raw_ir\n operator_export_type = OperatorExportTypes.ATEN if\\\n aten else OperatorExportTypes.RAW\n elif operator_export_type is None:\n if torch.onnx.PYTORCH_ONNX_CAFFE2_BUNDLE:\n operator_export_type = OperatorExportTypes.ONNX_ATEN_FALLBACK\n else:\n operator_export_type = OperatorExportTypes.ONNX\n\n return torch_export(model, args, f, _retain_param_name=True, **kwargs)\n\n\ndef _export(\n model, args, strip_large_tensor_data=False,\n large_tensor_threshold=LARGE_TENSOR_DATA_THRESHOLD, **kwargs):\n model.zero_grad()\n bytesio = io.BytesIO()\n opset_ver = kwargs.get('opset_version', None)\n if opset_ver is None:\n opset_ver = _default_onnx_opset_version\n strip_doc_string = kwargs.pop('strip_doc_string', True)\n with init_annotate(model, opset_ver) as ann:\n outs = _export_util(\n model, args, bytesio, strip_doc_string=False, **kwargs)\n onnx_graph = onnx.load(io.BytesIO(bytesio.getvalue()))\n onnx_graph = ann.set_annotate(onnx_graph)\n onnx_graph = ann.reorg_anchor(onnx_graph)\n if strip_doc_string:\n for node in onnx_graph.graph.node:\n node.doc_string = b''\n if strip_large_tensor_data:\n _strip_large_initializer_raw_data(onnx_graph, large_tensor_threshold)\n\n return onnx_graph, outs\n\n\ndef export(\n model, args, f, return_output=False, strip_large_tensor_data=False,\n large_tensor_threshold=LARGE_TENSOR_DATA_THRESHOLD, **kwargs):\n \"\"\"Export model into ONNX Graph.\n\n Args:\n f: A file-like object or a string file path to be written to this\n file.\n return_output (bool): If True, return output values come from the\n model.\n strip_large_tensor_data (bool): If True, this function will strip\n data of large tensors to reduce ONNX file size for benchmarking\n large_tensor_threshold (int): If number of elements of tensor is\n larger than this value, the tensor is stripped when\n *strip_large_tensor_data* is True\n \"\"\"\n onnx_graph, outs = _export(\n model, args, strip_large_tensor_data, large_tensor_threshold,\n **kwargs)\n\n if hasattr(f, 'write'):\n f.write(onnx_graph.SerializeToString())\n else:\n assert isinstance(f, str)\n warnings.warn(\n 'When export ONNX graph as file, \"export_testcase\" is '\n 'strongly recommended, please consider use it instead',\n UserWarning)\n with open(f, 'wb') as fp:\n fp.write(onnx_graph.SerializeToString())\n\n if return_output:\n return outs\n\n\ndef export_testcase(\n model, args, out_dir, *, output_grad=False, metadata=True,\n model_overwrite=True, strip_large_tensor_data=False,\n large_tensor_threshold=LARGE_TENSOR_DATA_THRESHOLD,\n return_output=False, **kwargs):\n \"\"\"Export model and I/O tensors of the model in protobuf format.\n\n Args:\n output_grad (bool or Tensor): If True, this function will output\n model's gradient with names 'gradient_%d.pb'. If set Tensor,\n use it as gradient *input*. The gradient inputs are output as\n 'gradient_input_%d.pb' along with gradient.\n metadata (bool): If True, output meta information taken from git log.\n model_overwrite (bool): If False and model.onnx has already existed,\n only export input/output data as another test dataset.\n strip_large_tensor_data (bool): If True, this function will strip\n data of large tensors to reduce ONNX file size for benchmarking\n large_tensor_threshold (int): If number of elements of tensor is\n larger than this value, the tensor is stripped when\n *strip_large_tensor_data* is True\n \"\"\"\n\n os.makedirs(out_dir, exist_ok=True)\n input_names = kwargs.pop(\n 'input_names',\n ['input_{}'.format(i) for i in range(len(args))])\n assert len(input_names) == len(args)\n\n onnx_graph, outs = _export(\n model, args, strip_large_tensor_data, large_tensor_threshold,\n input_names=input_names, **kwargs)\n\n # Remove unused inputs\n # - When keep_initializers_as_inputs=True, inputs contains initializers.\n # So we have to filt initializers.\n # - model.onnx is already issued, so we can modify args here.\n initializer_names = [init.name for init in onnx_graph.graph.initializer]\n used_input_index_list = []\n for used_input in onnx_graph.graph.input:\n if used_input.name not in initializer_names:\n used_input_index_list.append(input_names.index(used_input.name))\n input_names = [input_names[i] for i in used_input_index_list]\n args = [args[i] for i in used_input_index_list]\n\n output_path = os.path.join(out_dir, 'model.onnx')\n is_on_memory = True\n if model_overwrite or (not os.path.isfile(output_path)):\n is_on_memory = False\n with open(output_path, 'wb') as fp:\n fp.write(onnx_graph.SerializeToString())\n\n def write_to_pb(f, tensor, name=None):\n array = tensor.detach().cpu().numpy()\n with open(f, 'wb') as fp:\n t = onnx.numpy_helper.from_array(array, name)\n if (strip_large_tensor_data and\n is_large_tensor(t, large_tensor_threshold)):\n _strip_raw_data(t)\n fp.write(t.SerializeToString())\n\n if isinstance(args, torch.Tensor):\n args = args,\n if isinstance(outs, torch.Tensor):\n outs = outs,\n data_set_path = os.path.join(out_dir, 'test_data_set_0')\n seq_id = 0\n while is_on_memory and os.path.exists(data_set_path):\n seq_id += 1\n data_set_path = os.path.join(\n out_dir, 'test_data_set_{:d}'.format(seq_id))\n os.makedirs(data_set_path, exist_ok=True)\n for i, (arg, name) in enumerate(zip(args, input_names)):\n f = os.path.join(data_set_path, 'input_{}.pb'.format(i))\n write_to_pb(f, arg, name)\n\n output_names = kwargs.get('output_names')\n if output_names is None:\n if isinstance(outs, dict):\n output_names = outs.keys()\n else:\n output_names = [None] * len(outs)\n for i, name in enumerate(output_names):\n if isinstance(outs, dict):\n out = outs[name]\n else:\n out = outs[i]\n if isinstance(out, (list, tuple)):\n assert len(out) == 1, \\\n 'Models returning nested lists/tuples are not supported yet'\n out = out[0]\n f = os.path.join(data_set_path, 'output_{}.pb'.format(i))\n write_to_pb(f, out, name)\n\n if output_grad is not False:\n if isinstance(output_grad, bool):\n output_grad = [torch.ones_like(outs[idx])\n for idx in range(len(output_names))]\n if isinstance(output_grad, torch.Tensor):\n output_grad = [output_grad]\n for idx in range(len(output_names)):\n write_to_pb(\n os.path.join(data_set_path, 'gradient_input_{}.pb'.format(\n idx)), output_grad[idx],\n output_names[idx])\n if len(output_names) == len(outs):\n torch.autograd.backward(outs, grad_tensors=output_grad)\n else:\n assert len(\n output_names) == 1, 'Single output names is only supported'\n outs[0].backward(output_grad[0])\n\n for i, (name, param) in enumerate(model.named_parameters()):\n f = os.path.join(data_set_path, 'gradient_{}.pb'.format(i))\n # NOTE: name does not follow C identifier syntax rules,\n # like \"fc1.bias\", not cleanse for now\n if param.grad is None:\n warnings.warn(\n 'Parameter `{}` does not have gradient value'.format(name))\n else:\n write_to_pb(f, param.grad, name)\n\n if metadata:\n with open(os.path.join(out_dir, 'meta.json'), 'w') as f:\n json.dump(_export_meta(model, out_dir,\n strip_large_tensor_data), f, indent=2)\n\n if return_output:\n return outs\n", "path": "pytorch_pfn_extras/onnx/export_testcase.py"}]}
| 3,650 | 261 |
gh_patches_debug_28779
|
rasdani/github-patches
|
git_diff
|
PaddlePaddle__PaddleDetection-1960
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
当返回的roidbs为空时,卡在if isinstance(item, collections.Sequence) and len(item) == 0
def _load_batch(self):
batch = []
bs = 0
while bs != self._batch_size:
if self._pos >= self.size():
break
pos = self.indexes[self._pos]
sample = copy.deepcopy(self._roidbs[pos])
sample["curr_iter"] = self._curr_iter
self._pos += 1
if self._drop_empty and self._fields and 'gt_bbox' in sample:
if _has_empty(sample['gt_bbox']):
经自己测试 如果record有数据 但是roidbs里面bbox数据为[],会一直循环 跳不出去 望加个判断修复下
</issue>
<code>
[start of ppdet/data/source/coco.py]
1 # Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import os
16 import numpy as np
17
18 from .dataset import DataSet
19 from ppdet.core.workspace import register, serializable
20
21 import logging
22 logger = logging.getLogger(__name__)
23
24
25 @register
26 @serializable
27 class COCODataSet(DataSet):
28 """
29 Load COCO records with annotations in json file 'anno_path'
30
31 Args:
32 dataset_dir (str): root directory for dataset.
33 image_dir (str): directory for images.
34 anno_path (str): json file path.
35 sample_num (int): number of samples to load, -1 means all.
36 with_background (bool): whether load background as a class.
37 if True, total class number will be 81. default True.
38 """
39
40 def __init__(self,
41 image_dir=None,
42 anno_path=None,
43 dataset_dir=None,
44 sample_num=-1,
45 with_background=True,
46 load_semantic=False):
47 super(COCODataSet, self).__init__(
48 image_dir=image_dir,
49 anno_path=anno_path,
50 dataset_dir=dataset_dir,
51 sample_num=sample_num,
52 with_background=with_background)
53 self.anno_path = anno_path
54 self.sample_num = sample_num
55 self.with_background = with_background
56 # `roidbs` is list of dict whose structure is:
57 # {
58 # 'im_file': im_fname, # image file name
59 # 'im_id': img_id, # image id
60 # 'h': im_h, # height of image
61 # 'w': im_w, # width
62 # 'is_crowd': is_crowd,
63 # 'gt_score': gt_score,
64 # 'gt_class': gt_class,
65 # 'gt_bbox': gt_bbox,
66 # 'gt_poly': gt_poly,
67 # }
68 self.roidbs = None
69 # a dict used to map category name to class id
70 self.cname2cid = None
71 self.load_image_only = False
72 self.load_semantic = load_semantic
73
74 def load_roidb_and_cname2cid(self):
75 anno_path = os.path.join(self.dataset_dir, self.anno_path)
76 image_dir = os.path.join(self.dataset_dir, self.image_dir)
77
78 assert anno_path.endswith('.json'), \
79 'invalid coco annotation file: ' + anno_path
80 from pycocotools.coco import COCO
81 coco = COCO(anno_path)
82 img_ids = coco.getImgIds()
83 cat_ids = coco.getCatIds()
84 records = []
85 ct = 0
86
87 # when with_background = True, mapping category to classid, like:
88 # background:0, first_class:1, second_class:2, ...
89 catid2clsid = dict({
90 catid: i + int(self.with_background)
91 for i, catid in enumerate(cat_ids)
92 })
93 cname2cid = dict({
94 coco.loadCats(catid)[0]['name']: clsid
95 for catid, clsid in catid2clsid.items()
96 })
97
98 if 'annotations' not in coco.dataset:
99 self.load_image_only = True
100 logger.warn('Annotation file: {} does not contains ground truth '
101 'and load image information only.'.format(anno_path))
102
103 for img_id in img_ids:
104 img_anno = coco.loadImgs(img_id)[0]
105 im_fname = img_anno['file_name']
106 im_w = float(img_anno['width'])
107 im_h = float(img_anno['height'])
108
109 im_path = os.path.join(image_dir,
110 im_fname) if image_dir else im_fname
111 if not os.path.exists(im_path):
112 logger.warn('Illegal image file: {}, and it will be '
113 'ignored'.format(im_path))
114 continue
115
116 if im_w < 0 or im_h < 0:
117 logger.warn('Illegal width: {} or height: {} in annotation, '
118 'and im_id: {} will be ignored'.format(im_w, im_h,
119 img_id))
120 continue
121
122 coco_rec = {
123 'im_file': im_path,
124 'im_id': np.array([img_id]),
125 'h': im_h,
126 'w': im_w,
127 }
128
129 if not self.load_image_only:
130 ins_anno_ids = coco.getAnnIds(imgIds=img_id, iscrowd=False)
131 instances = coco.loadAnns(ins_anno_ids)
132
133 bboxes = []
134 for inst in instances:
135 x, y, box_w, box_h = inst['bbox']
136 x1 = max(0, x)
137 y1 = max(0, y)
138 x2 = min(im_w - 1, x1 + max(0, box_w - 1))
139 y2 = min(im_h - 1, y1 + max(0, box_h - 1))
140 if x2 >= x1 and y2 >= y1:
141 inst['clean_bbox'] = [x1, y1, x2, y2]
142 bboxes.append(inst)
143 else:
144 logger.warn(
145 'Found an invalid bbox in annotations: im_id: {}, '
146 'x1: {}, y1: {}, x2: {}, y2: {}.'.format(
147 img_id, x1, y1, x2, y2))
148 num_bbox = len(bboxes)
149
150 gt_bbox = np.zeros((num_bbox, 4), dtype=np.float32)
151 gt_class = np.zeros((num_bbox, 1), dtype=np.int32)
152 gt_score = np.ones((num_bbox, 1), dtype=np.float32)
153 is_crowd = np.zeros((num_bbox, 1), dtype=np.int32)
154 difficult = np.zeros((num_bbox, 1), dtype=np.int32)
155 gt_poly = [None] * num_bbox
156
157 for i, box in enumerate(bboxes):
158 catid = box['category_id']
159 gt_class[i][0] = catid2clsid[catid]
160 gt_bbox[i, :] = box['clean_bbox']
161 is_crowd[i][0] = box['iscrowd']
162 if 'segmentation' in box:
163 gt_poly[i] = box['segmentation']
164
165 coco_rec.update({
166 'is_crowd': is_crowd,
167 'gt_class': gt_class,
168 'gt_bbox': gt_bbox,
169 'gt_score': gt_score,
170 'gt_poly': gt_poly,
171 })
172
173 if self.load_semantic:
174 seg_path = os.path.join(self.dataset_dir, 'stuffthingmaps',
175 'train2017', im_fname[:-3] + 'png')
176 coco_rec.update({'semantic': seg_path})
177
178 logger.debug('Load file: {}, im_id: {}, h: {}, w: {}.'.format(
179 im_path, img_id, im_h, im_w))
180 records.append(coco_rec)
181 ct += 1
182 if self.sample_num > 0 and ct >= self.sample_num:
183 break
184 assert len(records) > 0, 'not found any coco record in %s' % (anno_path)
185 logger.debug('{} samples in file {}'.format(ct, anno_path))
186 self.roidbs, self.cname2cid = records, cname2cid
187
[end of ppdet/data/source/coco.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ppdet/data/source/coco.py b/ppdet/data/source/coco.py
--- a/ppdet/data/source/coco.py
+++ b/ppdet/data/source/coco.py
@@ -146,6 +146,8 @@
'x1: {}, y1: {}, x2: {}, y2: {}.'.format(
img_id, x1, y1, x2, y2))
num_bbox = len(bboxes)
+ if num_bbox <= 0:
+ continue
gt_bbox = np.zeros((num_bbox, 4), dtype=np.float32)
gt_class = np.zeros((num_bbox, 1), dtype=np.int32)
@@ -154,6 +156,7 @@
difficult = np.zeros((num_bbox, 1), dtype=np.int32)
gt_poly = [None] * num_bbox
+ has_segmentation = False
for i, box in enumerate(bboxes):
catid = box['category_id']
gt_class[i][0] = catid2clsid[catid]
@@ -161,6 +164,10 @@
is_crowd[i][0] = box['iscrowd']
if 'segmentation' in box:
gt_poly[i] = box['segmentation']
+ has_segmentation = True
+
+ if has_segmentation and not any(gt_poly):
+ continue
coco_rec.update({
'is_crowd': is_crowd,
|
{"golden_diff": "diff --git a/ppdet/data/source/coco.py b/ppdet/data/source/coco.py\n--- a/ppdet/data/source/coco.py\n+++ b/ppdet/data/source/coco.py\n@@ -146,6 +146,8 @@\n 'x1: {}, y1: {}, x2: {}, y2: {}.'.format(\n img_id, x1, y1, x2, y2))\n num_bbox = len(bboxes)\n+ if num_bbox <= 0:\n+ continue\n \n gt_bbox = np.zeros((num_bbox, 4), dtype=np.float32)\n gt_class = np.zeros((num_bbox, 1), dtype=np.int32)\n@@ -154,6 +156,7 @@\n difficult = np.zeros((num_bbox, 1), dtype=np.int32)\n gt_poly = [None] * num_bbox\n \n+ has_segmentation = False\n for i, box in enumerate(bboxes):\n catid = box['category_id']\n gt_class[i][0] = catid2clsid[catid]\n@@ -161,6 +164,10 @@\n is_crowd[i][0] = box['iscrowd']\n if 'segmentation' in box:\n gt_poly[i] = box['segmentation']\n+ has_segmentation = True\n+\n+ if has_segmentation and not any(gt_poly):\n+ continue\n \n coco_rec.update({\n 'is_crowd': is_crowd,\n", "issue": "\u5f53\u8fd4\u56de\u7684roidbs\u4e3a\u7a7a\u65f6\uff0c\u5361\u5728if isinstance(item, collections.Sequence) and len(item) == 0\n def _load_batch(self):\r\n batch = []\r\n bs = 0\r\n while bs != self._batch_size:\r\n if self._pos >= self.size():\r\n break\r\n pos = self.indexes[self._pos]\r\n sample = copy.deepcopy(self._roidbs[pos])\r\n sample[\"curr_iter\"] = self._curr_iter\r\n self._pos += 1\r\n\r\n if self._drop_empty and self._fields and 'gt_bbox' in sample:\r\n if _has_empty(sample['gt_bbox']):\r\n\r\n\u7ecf\u81ea\u5df1\u6d4b\u8bd5 \u5982\u679crecord\u6709\u6570\u636e \u4f46\u662froidbs\u91cc\u9762bbox\u6570\u636e\u4e3a[]\uff0c\u4f1a\u4e00\u76f4\u5faa\u73af \u8df3\u4e0d\u51fa\u53bb \u671b\u52a0\u4e2a\u5224\u65ad\u4fee\u590d\u4e0b\n", "before_files": [{"content": "# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\nimport numpy as np\n\nfrom .dataset import DataSet\nfrom ppdet.core.workspace import register, serializable\n\nimport logging\nlogger = logging.getLogger(__name__)\n\n\n@register\n@serializable\nclass COCODataSet(DataSet):\n \"\"\"\n Load COCO records with annotations in json file 'anno_path'\n\n Args:\n dataset_dir (str): root directory for dataset.\n image_dir (str): directory for images.\n anno_path (str): json file path.\n sample_num (int): number of samples to load, -1 means all.\n with_background (bool): whether load background as a class.\n if True, total class number will be 81. default True.\n \"\"\"\n\n def __init__(self,\n image_dir=None,\n anno_path=None,\n dataset_dir=None,\n sample_num=-1,\n with_background=True,\n load_semantic=False):\n super(COCODataSet, self).__init__(\n image_dir=image_dir,\n anno_path=anno_path,\n dataset_dir=dataset_dir,\n sample_num=sample_num,\n with_background=with_background)\n self.anno_path = anno_path\n self.sample_num = sample_num\n self.with_background = with_background\n # `roidbs` is list of dict whose structure is:\n # {\n # 'im_file': im_fname, # image file name\n # 'im_id': img_id, # image id\n # 'h': im_h, # height of image\n # 'w': im_w, # width\n # 'is_crowd': is_crowd,\n # 'gt_score': gt_score,\n # 'gt_class': gt_class,\n # 'gt_bbox': gt_bbox,\n # 'gt_poly': gt_poly,\n # }\n self.roidbs = None\n # a dict used to map category name to class id\n self.cname2cid = None\n self.load_image_only = False\n self.load_semantic = load_semantic\n\n def load_roidb_and_cname2cid(self):\n anno_path = os.path.join(self.dataset_dir, self.anno_path)\n image_dir = os.path.join(self.dataset_dir, self.image_dir)\n\n assert anno_path.endswith('.json'), \\\n 'invalid coco annotation file: ' + anno_path\n from pycocotools.coco import COCO\n coco = COCO(anno_path)\n img_ids = coco.getImgIds()\n cat_ids = coco.getCatIds()\n records = []\n ct = 0\n\n # when with_background = True, mapping category to classid, like:\n # background:0, first_class:1, second_class:2, ...\n catid2clsid = dict({\n catid: i + int(self.with_background)\n for i, catid in enumerate(cat_ids)\n })\n cname2cid = dict({\n coco.loadCats(catid)[0]['name']: clsid\n for catid, clsid in catid2clsid.items()\n })\n\n if 'annotations' not in coco.dataset:\n self.load_image_only = True\n logger.warn('Annotation file: {} does not contains ground truth '\n 'and load image information only.'.format(anno_path))\n\n for img_id in img_ids:\n img_anno = coco.loadImgs(img_id)[0]\n im_fname = img_anno['file_name']\n im_w = float(img_anno['width'])\n im_h = float(img_anno['height'])\n\n im_path = os.path.join(image_dir,\n im_fname) if image_dir else im_fname\n if not os.path.exists(im_path):\n logger.warn('Illegal image file: {}, and it will be '\n 'ignored'.format(im_path))\n continue\n\n if im_w < 0 or im_h < 0:\n logger.warn('Illegal width: {} or height: {} in annotation, '\n 'and im_id: {} will be ignored'.format(im_w, im_h,\n img_id))\n continue\n\n coco_rec = {\n 'im_file': im_path,\n 'im_id': np.array([img_id]),\n 'h': im_h,\n 'w': im_w,\n }\n\n if not self.load_image_only:\n ins_anno_ids = coco.getAnnIds(imgIds=img_id, iscrowd=False)\n instances = coco.loadAnns(ins_anno_ids)\n\n bboxes = []\n for inst in instances:\n x, y, box_w, box_h = inst['bbox']\n x1 = max(0, x)\n y1 = max(0, y)\n x2 = min(im_w - 1, x1 + max(0, box_w - 1))\n y2 = min(im_h - 1, y1 + max(0, box_h - 1))\n if x2 >= x1 and y2 >= y1:\n inst['clean_bbox'] = [x1, y1, x2, y2]\n bboxes.append(inst)\n else:\n logger.warn(\n 'Found an invalid bbox in annotations: im_id: {}, '\n 'x1: {}, y1: {}, x2: {}, y2: {}.'.format(\n img_id, x1, y1, x2, y2))\n num_bbox = len(bboxes)\n\n gt_bbox = np.zeros((num_bbox, 4), dtype=np.float32)\n gt_class = np.zeros((num_bbox, 1), dtype=np.int32)\n gt_score = np.ones((num_bbox, 1), dtype=np.float32)\n is_crowd = np.zeros((num_bbox, 1), dtype=np.int32)\n difficult = np.zeros((num_bbox, 1), dtype=np.int32)\n gt_poly = [None] * num_bbox\n\n for i, box in enumerate(bboxes):\n catid = box['category_id']\n gt_class[i][0] = catid2clsid[catid]\n gt_bbox[i, :] = box['clean_bbox']\n is_crowd[i][0] = box['iscrowd']\n if 'segmentation' in box:\n gt_poly[i] = box['segmentation']\n\n coco_rec.update({\n 'is_crowd': is_crowd,\n 'gt_class': gt_class,\n 'gt_bbox': gt_bbox,\n 'gt_score': gt_score,\n 'gt_poly': gt_poly,\n })\n\n if self.load_semantic:\n seg_path = os.path.join(self.dataset_dir, 'stuffthingmaps',\n 'train2017', im_fname[:-3] + 'png')\n coco_rec.update({'semantic': seg_path})\n\n logger.debug('Load file: {}, im_id: {}, h: {}, w: {}.'.format(\n im_path, img_id, im_h, im_w))\n records.append(coco_rec)\n ct += 1\n if self.sample_num > 0 and ct >= self.sample_num:\n break\n assert len(records) > 0, 'not found any coco record in %s' % (anno_path)\n logger.debug('{} samples in file {}'.format(ct, anno_path))\n self.roidbs, self.cname2cid = records, cname2cid\n", "path": "ppdet/data/source/coco.py"}]}
| 2,876 | 329 |
gh_patches_debug_58
|
rasdani/github-patches
|
git_diff
|
Anselmoo__spectrafit-701
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Bug]: ASCII Char in creating branch
### Is there an existing issue for this?
- [X] I have searched the existing issues
### Current Behavior
Is crashing
### Expected Behavior
Is realising a change in changeling
### Steps To Reproduce
_No response_
### ⚙️ Environment
```markdown
- OS:
- Python:
- spectrafit:
```
### Anything else?
_No response_
### Code of Conduct
- [X] I agree to follow this project's Code of Conduct
</issue>
<code>
[start of spectrafit/__init__.py]
1 """SpectraFit, fast command line tool for fitting data."""
2 __version__ = "1.0.0b1"
3
[end of spectrafit/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/spectrafit/__init__.py b/spectrafit/__init__.py
--- a/spectrafit/__init__.py
+++ b/spectrafit/__init__.py
@@ -1,2 +1,2 @@
"""SpectraFit, fast command line tool for fitting data."""
-__version__ = "1.0.0b1"
+__version__ = "1.0.0b2"
|
{"golden_diff": "diff --git a/spectrafit/__init__.py b/spectrafit/__init__.py\n--- a/spectrafit/__init__.py\n+++ b/spectrafit/__init__.py\n@@ -1,2 +1,2 @@\n \"\"\"SpectraFit, fast command line tool for fitting data.\"\"\"\n-__version__ = \"1.0.0b1\"\n+__version__ = \"1.0.0b2\"\n", "issue": "[Bug]: ASCII Char in creating branch\n### Is there an existing issue for this?\n\n- [X] I have searched the existing issues\n\n### Current Behavior\n\nIs crashing\n\n### Expected Behavior\n\nIs realising a change in changeling\n\n### Steps To Reproduce\n\n_No response_\n\n### \u2699\ufe0f Environment\n\n```markdown\n- OS:\r\n- Python:\r\n- spectrafit:\n```\n\n\n### Anything else?\n\n_No response_\n\n### Code of Conduct\n\n- [X] I agree to follow this project's Code of Conduct\n", "before_files": [{"content": "\"\"\"SpectraFit, fast command line tool for fitting data.\"\"\"\n__version__ = \"1.0.0b1\"\n", "path": "spectrafit/__init__.py"}]}
| 674 | 96 |
gh_patches_debug_35958
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-2644
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Spider advanceautoparts is broken
During the global build at 2021-05-21-20-28-08, spider **advanceautoparts** failed with **0 features** and **405 errors**.
Here's [the log](https://data.alltheplaces.xyz/runs/2021-05-21-20-28-08/logs/advanceautoparts.log) and [the output](https://data.alltheplaces.xyz/runs/2021-05-21-20-28-08/output/advanceautoparts.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-05-21-20-28-08/output/advanceautoparts.geojson))
</issue>
<code>
[start of locations/spiders/advanceautoparts.py]
1 import json
2 import re
3
4 import scrapy
5
6 from locations.hours import OpeningHours
7 from locations.items import GeojsonPointItem
8
9
10 class AdvanceautopartsSpider(scrapy.Spider):
11
12 name = "advanceautoparts"
13 item_attributes = {"brand": "Advance Auto Parts", "brand_wikidata": "Q4686051"}
14 allowed_domains = ["stores.advanceautoparts.com"]
15 start_urls = ("https://stores.advanceautoparts.com/sitemap.xml",)
16
17 def parse(self, response):
18 response.selector.remove_namespaces()
19 urls = response.xpath("//loc/text()").getall()
20 storeRe = re.compile(r"^https://stores.advanceautoparts.com/[^/]+/[^/]+/[^/]+$")
21 for url in urls:
22 if storeRe.fullmatch(url):
23 yield scrapy.Request(url, callback=self.parse_store)
24
25 def parse_hours(self, store_hours):
26 opening_hours = OpeningHours()
27
28 for weekday in store_hours:
29 day = weekday.get("day").title()
30 for interval in weekday.get("intervals", []):
31 open_time = str(interval.get("start"))
32 close_time = str(interval.get("end"))
33 opening_hours.add_range(
34 day=day[:2],
35 open_time=open_time,
36 close_time=close_time,
37 time_format="%H%M",
38 )
39
40 return opening_hours.as_opening_hours()
41
42 def parse_store(self, response):
43 name = response.xpath('//h1[@itemprop="name"]/text()').extract_first()
44
45 js = json.loads(response.xpath('//script[@class="js-map-config"]/text()').get())
46 ref = js["entities"][0]["profile"]["meta"]["id"]
47
48 hours = response.xpath(
49 '//div[@class="c-hours-details-wrapper js-hours-table"]/@data-days'
50 ).extract_first()
51 try:
52 opening_hours = self.parse_hours(json.loads(hours))
53 except ValueError:
54 opening_hours = None
55
56 properties = {
57 "addr_full": response.xpath(
58 'normalize-space(//meta[@itemprop="streetAddress"]/@content)'
59 ).extract_first(),
60 "phone": response.xpath(
61 'normalize-space(//div[@itemprop="telephone"]/text())'
62 ).extract_first(),
63 "city": response.xpath(
64 'normalize-space(//meta[@itemprop="addressLocality"]/@content)'
65 ).extract_first(),
66 "state": response.xpath(
67 'normalize-space(//abbr[@itemprop="addressRegion"]/text())'
68 ).extract_first(),
69 "postcode": response.xpath(
70 'normalize-space(//span[@itemprop="postalCode"]/text())'
71 ).extract_first(),
72 "ref": ref,
73 "website": response.url,
74 "lat": response.xpath(
75 'normalize-space(//meta[@itemprop="latitude"]/@content)'
76 ).extract_first(),
77 "lon": response.xpath(
78 'normalize-space(//meta[@itemprop="longitude"]/@content)'
79 ).extract_first(),
80 "name": name,
81 "opening_hours": opening_hours,
82 "extras": {"shop": "car_parts"},
83 }
84 yield GeojsonPointItem(**properties)
85
[end of locations/spiders/advanceautoparts.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/locations/spiders/advanceautoparts.py b/locations/spiders/advanceautoparts.py
--- a/locations/spiders/advanceautoparts.py
+++ b/locations/spiders/advanceautoparts.py
@@ -45,38 +45,22 @@
js = json.loads(response.xpath('//script[@class="js-map-config"]/text()').get())
ref = js["entities"][0]["profile"]["meta"]["id"]
- hours = response.xpath(
- '//div[@class="c-hours-details-wrapper js-hours-table"]/@data-days'
- ).extract_first()
+ hours = response.xpath('//div[@class="c-hours-details-wrapper js-hours-table"]/@data-days').extract_first()
try:
opening_hours = self.parse_hours(json.loads(hours))
except ValueError:
opening_hours = None
properties = {
- "addr_full": response.xpath(
- 'normalize-space(//meta[@itemprop="streetAddress"]/@content)'
- ).extract_first(),
- "phone": response.xpath(
- 'normalize-space(//div[@itemprop="telephone"]/text())'
- ).extract_first(),
- "city": response.xpath(
- 'normalize-space(//meta[@itemprop="addressLocality"]/@content)'
- ).extract_first(),
- "state": response.xpath(
- 'normalize-space(//abbr[@itemprop="addressRegion"]/text())'
- ).extract_first(),
- "postcode": response.xpath(
- 'normalize-space(//span[@itemprop="postalCode"]/text())'
- ).extract_first(),
+ "addr_full": response.xpath('normalize-space(//meta[@itemprop="streetAddress"]/@content)').extract_first(),
+ "phone": response.xpath('normalize-space(//div[@itemprop="telephone"]/text())').extract_first(),
+ "city": response.xpath('normalize-space(//meta[@itemprop="addressLocality"]/@content)').extract_first(),
+ "state": response.xpath('normalize-space(//abbr[@itemprop="addressRegion"]/text())').extract_first(),
+ "postcode": response.xpath('normalize-space(//span[@itemprop="postalCode"]/text())').extract_first(),
"ref": ref,
"website": response.url,
- "lat": response.xpath(
- 'normalize-space(//meta[@itemprop="latitude"]/@content)'
- ).extract_first(),
- "lon": response.xpath(
- 'normalize-space(//meta[@itemprop="longitude"]/@content)'
- ).extract_first(),
+ "lat": response.xpath('normalize-space(//meta[@itemprop="latitude"]/@content)').extract_first(),
+ "lon": response.xpath('normalize-space(//meta[@itemprop="longitude"]/@content)').extract_first(),
"name": name,
"opening_hours": opening_hours,
"extras": {"shop": "car_parts"},
|
{"golden_diff": "diff --git a/locations/spiders/advanceautoparts.py b/locations/spiders/advanceautoparts.py\n--- a/locations/spiders/advanceautoparts.py\n+++ b/locations/spiders/advanceautoparts.py\n@@ -45,38 +45,22 @@\n js = json.loads(response.xpath('//script[@class=\"js-map-config\"]/text()').get())\n ref = js[\"entities\"][0][\"profile\"][\"meta\"][\"id\"]\n \n- hours = response.xpath(\n- '//div[@class=\"c-hours-details-wrapper js-hours-table\"]/@data-days'\n- ).extract_first()\n+ hours = response.xpath('//div[@class=\"c-hours-details-wrapper js-hours-table\"]/@data-days').extract_first()\n try:\n opening_hours = self.parse_hours(json.loads(hours))\n except ValueError:\n opening_hours = None\n \n properties = {\n- \"addr_full\": response.xpath(\n- 'normalize-space(//meta[@itemprop=\"streetAddress\"]/@content)'\n- ).extract_first(),\n- \"phone\": response.xpath(\n- 'normalize-space(//div[@itemprop=\"telephone\"]/text())'\n- ).extract_first(),\n- \"city\": response.xpath(\n- 'normalize-space(//meta[@itemprop=\"addressLocality\"]/@content)'\n- ).extract_first(),\n- \"state\": response.xpath(\n- 'normalize-space(//abbr[@itemprop=\"addressRegion\"]/text())'\n- ).extract_first(),\n- \"postcode\": response.xpath(\n- 'normalize-space(//span[@itemprop=\"postalCode\"]/text())'\n- ).extract_first(),\n+ \"addr_full\": response.xpath('normalize-space(//meta[@itemprop=\"streetAddress\"]/@content)').extract_first(),\n+ \"phone\": response.xpath('normalize-space(//div[@itemprop=\"telephone\"]/text())').extract_first(),\n+ \"city\": response.xpath('normalize-space(//meta[@itemprop=\"addressLocality\"]/@content)').extract_first(),\n+ \"state\": response.xpath('normalize-space(//abbr[@itemprop=\"addressRegion\"]/text())').extract_first(),\n+ \"postcode\": response.xpath('normalize-space(//span[@itemprop=\"postalCode\"]/text())').extract_first(),\n \"ref\": ref,\n \"website\": response.url,\n- \"lat\": response.xpath(\n- 'normalize-space(//meta[@itemprop=\"latitude\"]/@content)'\n- ).extract_first(),\n- \"lon\": response.xpath(\n- 'normalize-space(//meta[@itemprop=\"longitude\"]/@content)'\n- ).extract_first(),\n+ \"lat\": response.xpath('normalize-space(//meta[@itemprop=\"latitude\"]/@content)').extract_first(),\n+ \"lon\": response.xpath('normalize-space(//meta[@itemprop=\"longitude\"]/@content)').extract_first(),\n \"name\": name,\n \"opening_hours\": opening_hours,\n \"extras\": {\"shop\": \"car_parts\"},\n", "issue": "Spider advanceautoparts is broken\nDuring the global build at 2021-05-21-20-28-08, spider **advanceautoparts** failed with **0 features** and **405 errors**.\n\nHere's [the log](https://data.alltheplaces.xyz/runs/2021-05-21-20-28-08/logs/advanceautoparts.log) and [the output](https://data.alltheplaces.xyz/runs/2021-05-21-20-28-08/output/advanceautoparts.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-05-21-20-28-08/output/advanceautoparts.geojson))\n", "before_files": [{"content": "import json\nimport re\n\nimport scrapy\n\nfrom locations.hours import OpeningHours\nfrom locations.items import GeojsonPointItem\n\n\nclass AdvanceautopartsSpider(scrapy.Spider):\n\n name = \"advanceautoparts\"\n item_attributes = {\"brand\": \"Advance Auto Parts\", \"brand_wikidata\": \"Q4686051\"}\n allowed_domains = [\"stores.advanceautoparts.com\"]\n start_urls = (\"https://stores.advanceautoparts.com/sitemap.xml\",)\n\n def parse(self, response):\n response.selector.remove_namespaces()\n urls = response.xpath(\"//loc/text()\").getall()\n storeRe = re.compile(r\"^https://stores.advanceautoparts.com/[^/]+/[^/]+/[^/]+$\")\n for url in urls:\n if storeRe.fullmatch(url):\n yield scrapy.Request(url, callback=self.parse_store)\n\n def parse_hours(self, store_hours):\n opening_hours = OpeningHours()\n\n for weekday in store_hours:\n day = weekday.get(\"day\").title()\n for interval in weekday.get(\"intervals\", []):\n open_time = str(interval.get(\"start\"))\n close_time = str(interval.get(\"end\"))\n opening_hours.add_range(\n day=day[:2],\n open_time=open_time,\n close_time=close_time,\n time_format=\"%H%M\",\n )\n\n return opening_hours.as_opening_hours()\n\n def parse_store(self, response):\n name = response.xpath('//h1[@itemprop=\"name\"]/text()').extract_first()\n\n js = json.loads(response.xpath('//script[@class=\"js-map-config\"]/text()').get())\n ref = js[\"entities\"][0][\"profile\"][\"meta\"][\"id\"]\n\n hours = response.xpath(\n '//div[@class=\"c-hours-details-wrapper js-hours-table\"]/@data-days'\n ).extract_first()\n try:\n opening_hours = self.parse_hours(json.loads(hours))\n except ValueError:\n opening_hours = None\n\n properties = {\n \"addr_full\": response.xpath(\n 'normalize-space(//meta[@itemprop=\"streetAddress\"]/@content)'\n ).extract_first(),\n \"phone\": response.xpath(\n 'normalize-space(//div[@itemprop=\"telephone\"]/text())'\n ).extract_first(),\n \"city\": response.xpath(\n 'normalize-space(//meta[@itemprop=\"addressLocality\"]/@content)'\n ).extract_first(),\n \"state\": response.xpath(\n 'normalize-space(//abbr[@itemprop=\"addressRegion\"]/text())'\n ).extract_first(),\n \"postcode\": response.xpath(\n 'normalize-space(//span[@itemprop=\"postalCode\"]/text())'\n ).extract_first(),\n \"ref\": ref,\n \"website\": response.url,\n \"lat\": response.xpath(\n 'normalize-space(//meta[@itemprop=\"latitude\"]/@content)'\n ).extract_first(),\n \"lon\": response.xpath(\n 'normalize-space(//meta[@itemprop=\"longitude\"]/@content)'\n ).extract_first(),\n \"name\": name,\n \"opening_hours\": opening_hours,\n \"extras\": {\"shop\": \"car_parts\"},\n }\n yield GeojsonPointItem(**properties)\n", "path": "locations/spiders/advanceautoparts.py"}]}
| 1,565 | 627 |
gh_patches_debug_24842
|
rasdani/github-patches
|
git_diff
|
Kinto__kinto-667
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Relax record id validation
Do we really need to ensure that posted record ids match a uuid regex?
We can generate a uuid when a record without id is posted, and leave the usage of uuid in our official clients.
But is there any reason to use a different regex that collection and bucket names?
edit: The usecase is the Web sync extension chrome.storage.sync: since any key is accepted, it takes the md5 of the key to "generate" UUIDs. Instead we could let the client push any key as record id.
- Related #140
</issue>
<code>
[start of kinto/views/records.py]
1 import copy
2
3 import jsonschema
4 from kinto.core import resource
5 from kinto.core.errors import raise_invalid
6 from jsonschema import exceptions as jsonschema_exceptions
7 from pyramid.security import Authenticated
8 from pyramid.settings import asbool
9
10 from kinto.views import object_exists_or_404
11
12
13 class RecordSchema(resource.ResourceSchema):
14 class Options:
15 preserve_unknown = True
16
17
18 _parent_path = '/buckets/{{bucket_id}}/collections/{{collection_id}}'
19
20
21 @resource.register(name='record',
22 collection_path=_parent_path + '/records',
23 record_path=_parent_path + '/records/{{id}}')
24 class Record(resource.ShareableResource):
25
26 mapping = RecordSchema()
27 schema_field = 'schema'
28
29 def __init__(self, *args, **kwargs):
30 super(Record, self).__init__(*args, **kwargs)
31
32 # Check if already fetched before (in batch).
33 collections = self.request.bound_data.setdefault('collections', {})
34 collection_uri = self.get_parent_id(self.request)
35 if collection_uri not in collections:
36 # Unknown yet, fetch from storage.
37 collection_parent_id = '/buckets/%s' % self.bucket_id
38 collection = object_exists_or_404(self.request,
39 collection_id='collection',
40 parent_id=collection_parent_id,
41 object_id=self.collection_id)
42 collections[collection_uri] = collection
43
44 self._collection = collections[collection_uri]
45
46 def get_parent_id(self, request):
47 self.bucket_id = request.matchdict['bucket_id']
48 self.collection_id = request.matchdict['collection_id']
49 return '/buckets/%s/collections/%s' % (self.bucket_id,
50 self.collection_id)
51
52 def is_known_field(self, field_name):
53 """Without schema, any field is considered as known."""
54 return True
55
56 def process_record(self, new, old=None):
57 """Validate records against collection schema, if any."""
58 new = super(Record, self).process_record(new, old)
59
60 schema = self._collection.get('schema')
61 settings = self.request.registry.settings
62 schema_validation = 'experimental_collection_schema_validation'
63 if not schema or not asbool(settings.get(schema_validation)):
64 return new
65
66 collection_timestamp = self._collection[self.model.modified_field]
67
68 try:
69 stripped = copy.deepcopy(new)
70 stripped.pop(self.model.id_field, None)
71 stripped.pop(self.model.modified_field, None)
72 stripped.pop(self.model.permissions_field, None)
73 stripped.pop(self.schema_field, None)
74 jsonschema.validate(stripped, schema)
75 except jsonschema_exceptions.ValidationError as e:
76 try:
77 field = e.path.pop() if e.path else e.validator_value.pop()
78 except AttributeError:
79 field = None
80 raise_invalid(self.request, name=field, description=e.message)
81
82 new[self.schema_field] = collection_timestamp
83 return new
84
85 def collection_get(self):
86 result = super(Record, self).collection_get()
87 self._handle_cache_expires(self.request.response)
88 return result
89
90 def get(self):
91 result = super(Record, self).get()
92 self._handle_cache_expires(self.request.response)
93 return result
94
95 def _handle_cache_expires(self, response):
96 """If the parent collection defines a ``cache_expires`` attribute,
97 then cache-control response headers are sent.
98
99 .. note::
100
101 Those headers are also sent if the
102 ``kinto.record_cache_expires_seconds`` setting is defined.
103 """
104 is_anonymous = Authenticated not in self.request.effective_principals
105 if not is_anonymous:
106 return
107
108 cache_expires = self._collection.get('cache_expires')
109 if cache_expires is None:
110 by_bucket = '%s_record_cache_expires_seconds' % (self.bucket_id)
111 by_collection = '%s_%s_record_cache_expires_seconds' % (
112 self.bucket_id, self.collection_id)
113 settings = self.request.registry.settings
114 cache_expires = settings.get(by_collection,
115 settings.get(by_bucket))
116
117 if cache_expires is not None:
118 response.cache_expires(seconds=int(cache_expires))
119
[end of kinto/views/records.py]
[start of kinto/views/__init__.py]
1 import random
2 import string
3
4 from kinto.core.storage import generators, exceptions
5 from pyramid import httpexceptions
6
7
8 class NameGenerator(generators.Generator):
9 def __call__(self):
10 ascii_letters = ('abcdefghijklmopqrstuvwxyz'
11 'ABCDEFGHIJKLMOPQRSTUVWXYZ')
12 alphabet = ascii_letters + string.digits + '-_'
13 letters = [random.choice(ascii_letters + string.digits)]
14 letters += [random.choice(alphabet) for x in range(7)]
15 return ''.join(letters)
16
17
18 def object_exists_or_404(request, collection_id, object_id, parent_id=''):
19 storage = request.registry.storage
20 try:
21 return storage.get(collection_id=collection_id,
22 parent_id=parent_id,
23 object_id=object_id)
24 except exceptions.RecordNotFoundError:
25 # XXX: We gave up putting details about parent id here (See #53).
26 raise httpexceptions.HTTPNotFound()
27
[end of kinto/views/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kinto/views/__init__.py b/kinto/views/__init__.py
--- a/kinto/views/__init__.py
+++ b/kinto/views/__init__.py
@@ -15,6 +15,12 @@
return ''.join(letters)
+class RelaxedUUID(generators.UUID4):
+ """A generator that generates UUIDs but accepts any string.
+ """
+ regexp = generators.Generator.regexp
+
+
def object_exists_or_404(request, collection_id, object_id, parent_id=''):
storage = request.registry.storage
try:
diff --git a/kinto/views/records.py b/kinto/views/records.py
--- a/kinto/views/records.py
+++ b/kinto/views/records.py
@@ -7,7 +7,7 @@
from pyramid.security import Authenticated
from pyramid.settings import asbool
-from kinto.views import object_exists_or_404
+from kinto.views import RelaxedUUID, object_exists_or_404
class RecordSchema(resource.ResourceSchema):
@@ -29,6 +29,8 @@
def __init__(self, *args, **kwargs):
super(Record, self).__init__(*args, **kwargs)
+ self.model.id_generator = RelaxedUUID()
+
# Check if already fetched before (in batch).
collections = self.request.bound_data.setdefault('collections', {})
collection_uri = self.get_parent_id(self.request)
|
{"golden_diff": "diff --git a/kinto/views/__init__.py b/kinto/views/__init__.py\n--- a/kinto/views/__init__.py\n+++ b/kinto/views/__init__.py\n@@ -15,6 +15,12 @@\n return ''.join(letters)\n \n \n+class RelaxedUUID(generators.UUID4):\n+ \"\"\"A generator that generates UUIDs but accepts any string.\n+ \"\"\"\n+ regexp = generators.Generator.regexp\n+\n+\n def object_exists_or_404(request, collection_id, object_id, parent_id=''):\n storage = request.registry.storage\n try:\ndiff --git a/kinto/views/records.py b/kinto/views/records.py\n--- a/kinto/views/records.py\n+++ b/kinto/views/records.py\n@@ -7,7 +7,7 @@\n from pyramid.security import Authenticated\n from pyramid.settings import asbool\n \n-from kinto.views import object_exists_or_404\n+from kinto.views import RelaxedUUID, object_exists_or_404\n \n \n class RecordSchema(resource.ResourceSchema):\n@@ -29,6 +29,8 @@\n def __init__(self, *args, **kwargs):\n super(Record, self).__init__(*args, **kwargs)\n \n+ self.model.id_generator = RelaxedUUID()\n+\n # Check if already fetched before (in batch).\n collections = self.request.bound_data.setdefault('collections', {})\n collection_uri = self.get_parent_id(self.request)\n", "issue": "Relax record id validation\nDo we really need to ensure that posted record ids match a uuid regex?\n\nWe can generate a uuid when a record without id is posted, and leave the usage of uuid in our official clients.\nBut is there any reason to use a different regex that collection and bucket names?\n\nedit: The usecase is the Web sync extension chrome.storage.sync: since any key is accepted, it takes the md5 of the key to \"generate\" UUIDs. Instead we could let the client push any key as record id.\n- Related #140 \n\n", "before_files": [{"content": "import copy\n\nimport jsonschema\nfrom kinto.core import resource\nfrom kinto.core.errors import raise_invalid\nfrom jsonschema import exceptions as jsonschema_exceptions\nfrom pyramid.security import Authenticated\nfrom pyramid.settings import asbool\n\nfrom kinto.views import object_exists_or_404\n\n\nclass RecordSchema(resource.ResourceSchema):\n class Options:\n preserve_unknown = True\n\n\n_parent_path = '/buckets/{{bucket_id}}/collections/{{collection_id}}'\n\n\[email protected](name='record',\n collection_path=_parent_path + '/records',\n record_path=_parent_path + '/records/{{id}}')\nclass Record(resource.ShareableResource):\n\n mapping = RecordSchema()\n schema_field = 'schema'\n\n def __init__(self, *args, **kwargs):\n super(Record, self).__init__(*args, **kwargs)\n\n # Check if already fetched before (in batch).\n collections = self.request.bound_data.setdefault('collections', {})\n collection_uri = self.get_parent_id(self.request)\n if collection_uri not in collections:\n # Unknown yet, fetch from storage.\n collection_parent_id = '/buckets/%s' % self.bucket_id\n collection = object_exists_or_404(self.request,\n collection_id='collection',\n parent_id=collection_parent_id,\n object_id=self.collection_id)\n collections[collection_uri] = collection\n\n self._collection = collections[collection_uri]\n\n def get_parent_id(self, request):\n self.bucket_id = request.matchdict['bucket_id']\n self.collection_id = request.matchdict['collection_id']\n return '/buckets/%s/collections/%s' % (self.bucket_id,\n self.collection_id)\n\n def is_known_field(self, field_name):\n \"\"\"Without schema, any field is considered as known.\"\"\"\n return True\n\n def process_record(self, new, old=None):\n \"\"\"Validate records against collection schema, if any.\"\"\"\n new = super(Record, self).process_record(new, old)\n\n schema = self._collection.get('schema')\n settings = self.request.registry.settings\n schema_validation = 'experimental_collection_schema_validation'\n if not schema or not asbool(settings.get(schema_validation)):\n return new\n\n collection_timestamp = self._collection[self.model.modified_field]\n\n try:\n stripped = copy.deepcopy(new)\n stripped.pop(self.model.id_field, None)\n stripped.pop(self.model.modified_field, None)\n stripped.pop(self.model.permissions_field, None)\n stripped.pop(self.schema_field, None)\n jsonschema.validate(stripped, schema)\n except jsonschema_exceptions.ValidationError as e:\n try:\n field = e.path.pop() if e.path else e.validator_value.pop()\n except AttributeError:\n field = None\n raise_invalid(self.request, name=field, description=e.message)\n\n new[self.schema_field] = collection_timestamp\n return new\n\n def collection_get(self):\n result = super(Record, self).collection_get()\n self._handle_cache_expires(self.request.response)\n return result\n\n def get(self):\n result = super(Record, self).get()\n self._handle_cache_expires(self.request.response)\n return result\n\n def _handle_cache_expires(self, response):\n \"\"\"If the parent collection defines a ``cache_expires`` attribute,\n then cache-control response headers are sent.\n\n .. note::\n\n Those headers are also sent if the\n ``kinto.record_cache_expires_seconds`` setting is defined.\n \"\"\"\n is_anonymous = Authenticated not in self.request.effective_principals\n if not is_anonymous:\n return\n\n cache_expires = self._collection.get('cache_expires')\n if cache_expires is None:\n by_bucket = '%s_record_cache_expires_seconds' % (self.bucket_id)\n by_collection = '%s_%s_record_cache_expires_seconds' % (\n self.bucket_id, self.collection_id)\n settings = self.request.registry.settings\n cache_expires = settings.get(by_collection,\n settings.get(by_bucket))\n\n if cache_expires is not None:\n response.cache_expires(seconds=int(cache_expires))\n", "path": "kinto/views/records.py"}, {"content": "import random\nimport string\n\nfrom kinto.core.storage import generators, exceptions\nfrom pyramid import httpexceptions\n\n\nclass NameGenerator(generators.Generator):\n def __call__(self):\n ascii_letters = ('abcdefghijklmopqrstuvwxyz'\n 'ABCDEFGHIJKLMOPQRSTUVWXYZ')\n alphabet = ascii_letters + string.digits + '-_'\n letters = [random.choice(ascii_letters + string.digits)]\n letters += [random.choice(alphabet) for x in range(7)]\n return ''.join(letters)\n\n\ndef object_exists_or_404(request, collection_id, object_id, parent_id=''):\n storage = request.registry.storage\n try:\n return storage.get(collection_id=collection_id,\n parent_id=parent_id,\n object_id=object_id)\n except exceptions.RecordNotFoundError:\n # XXX: We gave up putting details about parent id here (See #53).\n raise httpexceptions.HTTPNotFound()\n", "path": "kinto/views/__init__.py"}]}
| 2,044 | 316 |
gh_patches_debug_27223
|
rasdani/github-patches
|
git_diff
|
mitmproxy__mitmproxy-5322
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
mailcap deprecated for Python 3.11 removed for Python 3.13
I've been following this Python dev mailing thread which proposed to deprecate `mailcap` from the standard library: https://mail.python.org/archives/list/[email protected]/thread/EB2BS4DBWSTBIOPQL5QTBSIOBORWSCMJ/
After a code search I noticed that you were the only library I recognized which used this module:
https://grep.app/search?q=import%20mailcap
https://github.com/mitmproxy/mitmproxy/blob/4f7f64c516341c586c9f8cb6593217ff3e359351/mitmproxy/tools/console/master.py#L2
Please be aware the Steering Council just accepted this deprecation proposal meaning the module will be deprecated for Python 3.11 removed for Python 3.13.
(I don't have any affiliation with this decision, I am just trying to proactively raise awareness)
</issue>
<code>
[start of mitmproxy/tools/console/master.py]
1 import asyncio
2 import mailcap
3 import mimetypes
4 import os
5 import os.path
6 import shlex
7 import shutil
8 import stat
9 import subprocess
10 import sys
11 import tempfile
12 import contextlib
13 import threading
14
15 from tornado.platform.asyncio import AddThreadSelectorEventLoop
16
17 import urwid
18
19 from mitmproxy import addons
20 from mitmproxy import master
21 from mitmproxy import log
22 from mitmproxy.addons import errorcheck, intercept
23 from mitmproxy.addons import eventstore
24 from mitmproxy.addons import readfile
25 from mitmproxy.addons import view
26 from mitmproxy.contrib.tornado import patch_tornado
27 from mitmproxy.tools.console import consoleaddons
28 from mitmproxy.tools.console import defaultkeys
29 from mitmproxy.tools.console import keymap
30 from mitmproxy.tools.console import palettes
31 from mitmproxy.tools.console import signals
32 from mitmproxy.tools.console import window
33
34
35 class ConsoleMaster(master.Master):
36 def __init__(self, opts):
37 super().__init__(opts)
38
39 self.view: view.View = view.View()
40 self.events = eventstore.EventStore()
41 self.events.sig_add.connect(self.sig_add_log)
42
43 self.stream_path = None
44 self.keymap = keymap.Keymap(self)
45 defaultkeys.map(self.keymap)
46 self.options.errored.connect(self.options_error)
47
48 self.view_stack = []
49
50 self.addons.add(*addons.default_addons())
51 self.addons.add(
52 intercept.Intercept(),
53 self.view,
54 self.events,
55 readfile.ReadFile(),
56 consoleaddons.ConsoleAddon(self),
57 keymap.KeymapConfig(),
58 errorcheck.ErrorCheck(log_to_stderr=True),
59 )
60
61 self.window = None
62
63 def __setattr__(self, name, value):
64 super().__setattr__(name, value)
65 signals.update_settings.send(self)
66
67 def options_error(self, opts, exc):
68 signals.status_message.send(message=str(exc), expire=1)
69
70 def prompt_for_exit(self):
71 signals.status_prompt_onekey.send(
72 self,
73 prompt="Quit",
74 keys=(
75 ("yes", "y"),
76 ("no", "n"),
77 ),
78 callback=self.quit,
79 )
80
81 def sig_add_log(self, event_store, entry: log.LogEntry):
82 if log.log_tier(self.options.console_eventlog_verbosity) < log.log_tier(
83 entry.level
84 ):
85 return
86 if entry.level in ("error", "warn", "alert"):
87 signals.status_message.send(
88 message=(
89 entry.level,
90 f"{entry.level.title()}: {str(entry.msg).lstrip()}",
91 ),
92 expire=5,
93 )
94
95 def sig_call_in(self, sender, seconds, callback, args=()):
96 def cb(*_):
97 return callback(*args)
98
99 self.loop.set_alarm_in(seconds, cb)
100
101 @contextlib.contextmanager
102 def uistopped(self):
103 self.loop.stop()
104 try:
105 yield
106 finally:
107 self.loop.start()
108 self.loop.screen_size = None
109 self.loop.draw_screen()
110
111 def get_editor(self) -> str:
112 # based upon https://github.com/pallets/click/blob/main/src/click/_termui_impl.py
113 if m := os.environ.get("MITMPROXY_EDITOR"):
114 return m
115 if m := os.environ.get("EDITOR"):
116 return m
117 for editor in "sensible-editor", "nano", "vim":
118 if shutil.which(editor):
119 return editor
120 if os.name == "nt":
121 return "notepad"
122 else:
123 return "vi"
124
125 def spawn_editor(self, data):
126 text = not isinstance(data, bytes)
127 fd, name = tempfile.mkstemp("", "mitmproxy", text=text)
128 with open(fd, "w" if text else "wb") as f:
129 f.write(data)
130 c = self.get_editor()
131 cmd = shlex.split(c)
132 cmd.append(name)
133 with self.uistopped():
134 try:
135 subprocess.call(cmd)
136 except:
137 signals.status_message.send(message="Can't start editor: %s" % c)
138 else:
139 with open(name, "r" if text else "rb") as f:
140 data = f.read()
141 os.unlink(name)
142 return data
143
144 def spawn_external_viewer(self, data, contenttype):
145 if contenttype:
146 contenttype = contenttype.split(";")[0]
147 ext = mimetypes.guess_extension(contenttype) or ""
148 else:
149 ext = ""
150 fd, name = tempfile.mkstemp(ext, "mproxy")
151 os.write(fd, data)
152 os.close(fd)
153
154 # read-only to remind the user that this is a view function
155 os.chmod(name, stat.S_IREAD)
156
157 cmd = None
158 shell = False
159
160 if contenttype:
161 c = mailcap.getcaps()
162 cmd, _ = mailcap.findmatch(c, contenttype, filename=name)
163 if cmd:
164 shell = True
165 if not cmd:
166 # hm which one should get priority?
167 c = (
168 os.environ.get("MITMPROXY_EDITOR")
169 or os.environ.get("PAGER")
170 or os.environ.get("EDITOR")
171 )
172 if not c:
173 c = "less"
174 cmd = shlex.split(c)
175 cmd.append(name)
176 with self.uistopped():
177 try:
178 subprocess.call(cmd, shell=shell)
179 except:
180 signals.status_message.send(
181 message="Can't start external viewer: %s" % " ".join(c)
182 )
183 # add a small delay before deletion so that the file is not removed before being loaded by the viewer
184 t = threading.Timer(1.0, os.unlink, args=[name])
185 t.start()
186
187 def set_palette(self, opts, updated):
188 self.ui.register_palette(
189 palettes.palettes[opts.console_palette].palette(
190 opts.console_palette_transparent
191 )
192 )
193 self.ui.clear()
194
195 def inject_key(self, key):
196 self.loop.process_input([key])
197
198 async def running(self) -> None:
199 if not sys.stdout.isatty():
200 print(
201 "Error: mitmproxy's console interface requires a tty. "
202 "Please run mitmproxy in an interactive shell environment.",
203 file=sys.stderr,
204 )
205 sys.exit(1)
206
207 if os.name != "nt" and "utf" not in urwid.detected_encoding.lower():
208 print(
209 f"mitmproxy expects a UTF-8 console environment, not {urwid.detected_encoding!r}. "
210 f"Set your LANG environment variable to something like en_US.UTF-8.",
211 file=sys.stderr,
212 )
213 # Experimental (04/2022): We just don't exit here and see if/how that affects users.
214 # sys.exit(1)
215 urwid.set_encoding("utf8")
216
217 signals.call_in.connect(self.sig_call_in)
218 self.ui = window.Screen()
219 self.ui.set_terminal_properties(256)
220 self.set_palette(self.options, None)
221 self.options.subscribe(
222 self.set_palette, ["console_palette", "console_palette_transparent"]
223 )
224
225 loop = asyncio.get_running_loop()
226 if isinstance(loop, getattr(asyncio, "ProactorEventLoop", tuple())):
227 patch_tornado()
228 # fix for https://bugs.python.org/issue37373
229 loop = AddThreadSelectorEventLoop(loop) # type: ignore
230 self.loop = urwid.MainLoop(
231 urwid.SolidFill("x"),
232 event_loop=urwid.AsyncioEventLoop(loop=loop),
233 screen=self.ui,
234 handle_mouse=self.options.console_mouse,
235 )
236 self.window = window.Window(self)
237 self.loop.widget = self.window
238 self.window.refresh()
239
240 self.loop.start()
241
242 await super().running()
243
244 async def done(self):
245 self.loop.stop()
246 await super().done()
247
248 def overlay(self, widget, **kwargs):
249 self.window.set_overlay(widget, **kwargs)
250
251 def switch_view(self, name):
252 self.window.push(name)
253
254 def quit(self, a):
255 if a != "n":
256 self.shutdown()
257
[end of mitmproxy/tools/console/master.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mitmproxy/tools/console/master.py b/mitmproxy/tools/console/master.py
--- a/mitmproxy/tools/console/master.py
+++ b/mitmproxy/tools/console/master.py
@@ -1,5 +1,4 @@
import asyncio
-import mailcap
import mimetypes
import os
import os.path
@@ -154,28 +153,20 @@
# read-only to remind the user that this is a view function
os.chmod(name, stat.S_IREAD)
- cmd = None
- shell = False
+ # hm which one should get priority?
+ c = (
+ os.environ.get("MITMPROXY_EDITOR")
+ or os.environ.get("PAGER")
+ or os.environ.get("EDITOR")
+ )
+ if not c:
+ c = "less"
+ cmd = shlex.split(c)
+ cmd.append(name)
- if contenttype:
- c = mailcap.getcaps()
- cmd, _ = mailcap.findmatch(c, contenttype, filename=name)
- if cmd:
- shell = True
- if not cmd:
- # hm which one should get priority?
- c = (
- os.environ.get("MITMPROXY_EDITOR")
- or os.environ.get("PAGER")
- or os.environ.get("EDITOR")
- )
- if not c:
- c = "less"
- cmd = shlex.split(c)
- cmd.append(name)
with self.uistopped():
try:
- subprocess.call(cmd, shell=shell)
+ subprocess.call(cmd, shell=False)
except:
signals.status_message.send(
message="Can't start external viewer: %s" % " ".join(c)
|
{"golden_diff": "diff --git a/mitmproxy/tools/console/master.py b/mitmproxy/tools/console/master.py\n--- a/mitmproxy/tools/console/master.py\n+++ b/mitmproxy/tools/console/master.py\n@@ -1,5 +1,4 @@\n import asyncio\n-import mailcap\n import mimetypes\n import os\n import os.path\n@@ -154,28 +153,20 @@\n # read-only to remind the user that this is a view function\n os.chmod(name, stat.S_IREAD)\n \n- cmd = None\n- shell = False\n+ # hm which one should get priority?\n+ c = (\n+ os.environ.get(\"MITMPROXY_EDITOR\")\n+ or os.environ.get(\"PAGER\")\n+ or os.environ.get(\"EDITOR\")\n+ )\n+ if not c:\n+ c = \"less\"\n+ cmd = shlex.split(c)\n+ cmd.append(name)\n \n- if contenttype:\n- c = mailcap.getcaps()\n- cmd, _ = mailcap.findmatch(c, contenttype, filename=name)\n- if cmd:\n- shell = True\n- if not cmd:\n- # hm which one should get priority?\n- c = (\n- os.environ.get(\"MITMPROXY_EDITOR\")\n- or os.environ.get(\"PAGER\")\n- or os.environ.get(\"EDITOR\")\n- )\n- if not c:\n- c = \"less\"\n- cmd = shlex.split(c)\n- cmd.append(name)\n with self.uistopped():\n try:\n- subprocess.call(cmd, shell=shell)\n+ subprocess.call(cmd, shell=False)\n except:\n signals.status_message.send(\n message=\"Can't start external viewer: %s\" % \" \".join(c)\n", "issue": "mailcap deprecated for Python 3.11 removed for Python 3.13\nI've been following this Python dev mailing thread which proposed to deprecate `mailcap` from the standard library: https://mail.python.org/archives/list/[email protected]/thread/EB2BS4DBWSTBIOPQL5QTBSIOBORWSCMJ/\r\n\r\nAfter a code search I noticed that you were the only library I recognized which used this module: \r\nhttps://grep.app/search?q=import%20mailcap\r\nhttps://github.com/mitmproxy/mitmproxy/blob/4f7f64c516341c586c9f8cb6593217ff3e359351/mitmproxy/tools/console/master.py#L2\r\n\r\nPlease be aware the Steering Council just accepted this deprecation proposal meaning the module will be deprecated for Python 3.11 removed for Python 3.13.\r\n\r\n(I don't have any affiliation with this decision, I am just trying to proactively raise awareness)\n", "before_files": [{"content": "import asyncio\nimport mailcap\nimport mimetypes\nimport os\nimport os.path\nimport shlex\nimport shutil\nimport stat\nimport subprocess\nimport sys\nimport tempfile\nimport contextlib\nimport threading\n\nfrom tornado.platform.asyncio import AddThreadSelectorEventLoop\n\nimport urwid\n\nfrom mitmproxy import addons\nfrom mitmproxy import master\nfrom mitmproxy import log\nfrom mitmproxy.addons import errorcheck, intercept\nfrom mitmproxy.addons import eventstore\nfrom mitmproxy.addons import readfile\nfrom mitmproxy.addons import view\nfrom mitmproxy.contrib.tornado import patch_tornado\nfrom mitmproxy.tools.console import consoleaddons\nfrom mitmproxy.tools.console import defaultkeys\nfrom mitmproxy.tools.console import keymap\nfrom mitmproxy.tools.console import palettes\nfrom mitmproxy.tools.console import signals\nfrom mitmproxy.tools.console import window\n\n\nclass ConsoleMaster(master.Master):\n def __init__(self, opts):\n super().__init__(opts)\n\n self.view: view.View = view.View()\n self.events = eventstore.EventStore()\n self.events.sig_add.connect(self.sig_add_log)\n\n self.stream_path = None\n self.keymap = keymap.Keymap(self)\n defaultkeys.map(self.keymap)\n self.options.errored.connect(self.options_error)\n\n self.view_stack = []\n\n self.addons.add(*addons.default_addons())\n self.addons.add(\n intercept.Intercept(),\n self.view,\n self.events,\n readfile.ReadFile(),\n consoleaddons.ConsoleAddon(self),\n keymap.KeymapConfig(),\n errorcheck.ErrorCheck(log_to_stderr=True),\n )\n\n self.window = None\n\n def __setattr__(self, name, value):\n super().__setattr__(name, value)\n signals.update_settings.send(self)\n\n def options_error(self, opts, exc):\n signals.status_message.send(message=str(exc), expire=1)\n\n def prompt_for_exit(self):\n signals.status_prompt_onekey.send(\n self,\n prompt=\"Quit\",\n keys=(\n (\"yes\", \"y\"),\n (\"no\", \"n\"),\n ),\n callback=self.quit,\n )\n\n def sig_add_log(self, event_store, entry: log.LogEntry):\n if log.log_tier(self.options.console_eventlog_verbosity) < log.log_tier(\n entry.level\n ):\n return\n if entry.level in (\"error\", \"warn\", \"alert\"):\n signals.status_message.send(\n message=(\n entry.level,\n f\"{entry.level.title()}: {str(entry.msg).lstrip()}\",\n ),\n expire=5,\n )\n\n def sig_call_in(self, sender, seconds, callback, args=()):\n def cb(*_):\n return callback(*args)\n\n self.loop.set_alarm_in(seconds, cb)\n\n @contextlib.contextmanager\n def uistopped(self):\n self.loop.stop()\n try:\n yield\n finally:\n self.loop.start()\n self.loop.screen_size = None\n self.loop.draw_screen()\n\n def get_editor(self) -> str:\n # based upon https://github.com/pallets/click/blob/main/src/click/_termui_impl.py\n if m := os.environ.get(\"MITMPROXY_EDITOR\"):\n return m\n if m := os.environ.get(\"EDITOR\"):\n return m\n for editor in \"sensible-editor\", \"nano\", \"vim\":\n if shutil.which(editor):\n return editor\n if os.name == \"nt\":\n return \"notepad\"\n else:\n return \"vi\"\n\n def spawn_editor(self, data):\n text = not isinstance(data, bytes)\n fd, name = tempfile.mkstemp(\"\", \"mitmproxy\", text=text)\n with open(fd, \"w\" if text else \"wb\") as f:\n f.write(data)\n c = self.get_editor()\n cmd = shlex.split(c)\n cmd.append(name)\n with self.uistopped():\n try:\n subprocess.call(cmd)\n except:\n signals.status_message.send(message=\"Can't start editor: %s\" % c)\n else:\n with open(name, \"r\" if text else \"rb\") as f:\n data = f.read()\n os.unlink(name)\n return data\n\n def spawn_external_viewer(self, data, contenttype):\n if contenttype:\n contenttype = contenttype.split(\";\")[0]\n ext = mimetypes.guess_extension(contenttype) or \"\"\n else:\n ext = \"\"\n fd, name = tempfile.mkstemp(ext, \"mproxy\")\n os.write(fd, data)\n os.close(fd)\n\n # read-only to remind the user that this is a view function\n os.chmod(name, stat.S_IREAD)\n\n cmd = None\n shell = False\n\n if contenttype:\n c = mailcap.getcaps()\n cmd, _ = mailcap.findmatch(c, contenttype, filename=name)\n if cmd:\n shell = True\n if not cmd:\n # hm which one should get priority?\n c = (\n os.environ.get(\"MITMPROXY_EDITOR\")\n or os.environ.get(\"PAGER\")\n or os.environ.get(\"EDITOR\")\n )\n if not c:\n c = \"less\"\n cmd = shlex.split(c)\n cmd.append(name)\n with self.uistopped():\n try:\n subprocess.call(cmd, shell=shell)\n except:\n signals.status_message.send(\n message=\"Can't start external viewer: %s\" % \" \".join(c)\n )\n # add a small delay before deletion so that the file is not removed before being loaded by the viewer\n t = threading.Timer(1.0, os.unlink, args=[name])\n t.start()\n\n def set_palette(self, opts, updated):\n self.ui.register_palette(\n palettes.palettes[opts.console_palette].palette(\n opts.console_palette_transparent\n )\n )\n self.ui.clear()\n\n def inject_key(self, key):\n self.loop.process_input([key])\n\n async def running(self) -> None:\n if not sys.stdout.isatty():\n print(\n \"Error: mitmproxy's console interface requires a tty. \"\n \"Please run mitmproxy in an interactive shell environment.\",\n file=sys.stderr,\n )\n sys.exit(1)\n\n if os.name != \"nt\" and \"utf\" not in urwid.detected_encoding.lower():\n print(\n f\"mitmproxy expects a UTF-8 console environment, not {urwid.detected_encoding!r}. \"\n f\"Set your LANG environment variable to something like en_US.UTF-8.\",\n file=sys.stderr,\n )\n # Experimental (04/2022): We just don't exit here and see if/how that affects users.\n # sys.exit(1)\n urwid.set_encoding(\"utf8\")\n\n signals.call_in.connect(self.sig_call_in)\n self.ui = window.Screen()\n self.ui.set_terminal_properties(256)\n self.set_palette(self.options, None)\n self.options.subscribe(\n self.set_palette, [\"console_palette\", \"console_palette_transparent\"]\n )\n\n loop = asyncio.get_running_loop()\n if isinstance(loop, getattr(asyncio, \"ProactorEventLoop\", tuple())):\n patch_tornado()\n # fix for https://bugs.python.org/issue37373\n loop = AddThreadSelectorEventLoop(loop) # type: ignore\n self.loop = urwid.MainLoop(\n urwid.SolidFill(\"x\"),\n event_loop=urwid.AsyncioEventLoop(loop=loop),\n screen=self.ui,\n handle_mouse=self.options.console_mouse,\n )\n self.window = window.Window(self)\n self.loop.widget = self.window\n self.window.refresh()\n\n self.loop.start()\n\n await super().running()\n\n async def done(self):\n self.loop.stop()\n await super().done()\n\n def overlay(self, widget, **kwargs):\n self.window.set_overlay(widget, **kwargs)\n\n def switch_view(self, name):\n self.window.push(name)\n\n def quit(self, a):\n if a != \"n\":\n self.shutdown()\n", "path": "mitmproxy/tools/console/master.py"}]}
| 3,178 | 385 |
gh_patches_debug_43674
|
rasdani/github-patches
|
git_diff
|
dotkom__onlineweb4-293
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Menu is missing link to admin page when user is logged in
Should only be visible when it's a privileged user with access to the panel
</issue>
<code>
[start of apps/authentication/forms.py]
1 # -*- coding: utf-8 -*-
2
3 import datetime
4 import re
5
6 from django import forms
7 from django.contrib import auth
8 from django.utils.translation import ugettext as _
9
10 from apps.authentication.models import OnlineUser as User
11
12 class LoginForm(forms.Form):
13 username = forms.CharField(widget=forms.TextInput(), label=_("Brukernavn"), max_length=50)
14 password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_("Passord"))
15 user = None
16
17 def clean(self):
18 if self._errors:
19 return
20
21 user = auth.authenticate(username=self.cleaned_data['username'], password=self.cleaned_data['password'])
22
23 if user:
24 if user.is_active:
25 self.user = user
26 else:
27 self._errors['username'] = self.error_class([_("Din konto er ikke aktiv. Forsøk gjenoppretning av passord.")])
28 else:
29 self._errors['username'] = self.error_class([_("Kontoen eksisterer ikke, eller kombinasjonen av brukernavn og passord er feil.")])
30 return self.cleaned_data
31
32 def login(self, request):
33 try:
34 User.objects.get(username=request.POST['username'])
35 except:
36 return False
37 if self.is_valid():
38 auth.login(request, self.user)
39 request.session.set_expiry(0)
40 return True
41 return False
42
43 class RegisterForm(forms.Form):
44 username = forms.CharField(label=_("brukernavn"), max_length=20)
45 first_name = forms.CharField(label=_("fornavn"), max_length=50)
46 last_name = forms.CharField(label=_("etternavn"), max_length=50)
47 email = forms.EmailField(label=_("epost"), max_length=50)
48 password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_("passord"))
49 repeat_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_("gjenta passord"))
50 address = forms.CharField(label=_("adresse"), max_length=50)
51 zip_code = forms.CharField(label=_("postnummer"), max_length=4)
52 phone = forms.CharField(label=_("telefon"), max_length=20)
53
54 def clean(self):
55 super(RegisterForm, self).clean()
56 if self.is_valid():
57 cleaned_data = self.cleaned_data
58
59 # Check passwords
60 if cleaned_data['password'] != cleaned_data['repeat_password']:
61 self._errors['repeat_password'] = self.error_class([_("Passordene er ikke like.")])
62
63 # Check username
64 username = cleaned_data['username']
65 if User.objects.filter(username=username).count() > 0:
66 self._errors['username'] = self.error_class([_("Brukernavnet er allerede registrert.")])
67 if not re.match("^[a-zA-Z0-9_-]+$", username):
68 self._errors['username'] = self.error_class([_("Ditt brukernavn inneholdt ulovlige tegn. Lovlige tegn: a-Z 0-9 - _")])
69
70 # Check email
71 email = cleaned_data['email']
72 if User.objects.filter(email=email).count() > 0:
73 self._errors['email'] = self.error_class([_("Det fins allerede en bruker med denne epostadressen.")])
74
75 # ZIP code digits only
76 zip_code = cleaned_data['zip_code']
77 if len(zip_code) != 4 or not zip_code.isdigit():
78 self._errors['zip_code'] = self.error_class([_("Postnummer må bestå av fire siffer.")])
79
80 return cleaned_data
81
82 class RecoveryForm(forms.Form):
83 email = forms.EmailField(label="Email", max_length=50)
84
85 class ChangePasswordForm(forms.Form):
86 new_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_("nytt passord"))
87 repeat_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_("gjenta passord"))
88
89 def clean(self):
90 super(ChangePasswordForm, self).clean()
91 if self.is_valid():
92 cleaned_data = self.cleaned_data
93
94 # Check passwords
95 if cleaned_data['new_password'] != cleaned_data['repeat_password']:
96 self._errors['repeat_password'] = self.error_class([_("Passordene er ikke like.")])
97
98 return cleaned_data
99
100
101 class NewEmailForm(forms.Form):
102 new_email = forms.EmailField(_(u"ny epostadresse"))
103
[end of apps/authentication/forms.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/apps/authentication/forms.py b/apps/authentication/forms.py
--- a/apps/authentication/forms.py
+++ b/apps/authentication/forms.py
@@ -11,7 +11,7 @@
class LoginForm(forms.Form):
username = forms.CharField(widget=forms.TextInput(), label=_("Brukernavn"), max_length=50)
- password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_("Passord"))
+ password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_(u"Passord"))
user = None
def clean(self):
@@ -24,9 +24,9 @@
if user.is_active:
self.user = user
else:
- self._errors['username'] = self.error_class([_("Din konto er ikke aktiv. Forsøk gjenoppretning av passord.")])
+ self._errors['username'] = self.error_class([_(u"Din konto er ikke aktiv. Forsøk gjenoppretning av passord.")])
else:
- self._errors['username'] = self.error_class([_("Kontoen eksisterer ikke, eller kombinasjonen av brukernavn og passord er feil.")])
+ self._errors['username'] = self.error_class([_(u"Kontoen eksisterer ikke, eller kombinasjonen av brukernavn og passord er feil.")])
return self.cleaned_data
def login(self, request):
@@ -58,24 +58,24 @@
# Check passwords
if cleaned_data['password'] != cleaned_data['repeat_password']:
- self._errors['repeat_password'] = self.error_class([_("Passordene er ikke like.")])
+ self._errors['repeat_password'] = self.error_class([_(u"Passordene er ikke like.")])
# Check username
username = cleaned_data['username']
if User.objects.filter(username=username).count() > 0:
- self._errors['username'] = self.error_class([_("Brukernavnet er allerede registrert.")])
+ self._errors['username'] = self.error_class([_(u"Brukernavnet er allerede registrert.")])
if not re.match("^[a-zA-Z0-9_-]+$", username):
- self._errors['username'] = self.error_class([_("Ditt brukernavn inneholdt ulovlige tegn. Lovlige tegn: a-Z 0-9 - _")])
+ self._errors['username'] = self.error_class([_(u"Ditt brukernavn inneholdt ulovlige tegn. Lovlige tegn: a-Z 0-9 - _")])
# Check email
email = cleaned_data['email']
if User.objects.filter(email=email).count() > 0:
- self._errors['email'] = self.error_class([_("Det fins allerede en bruker med denne epostadressen.")])
+ self._errors['email'] = self.error_class([_(u"Det fins allerede en bruker med denne epostadressen.")])
# ZIP code digits only
zip_code = cleaned_data['zip_code']
if len(zip_code) != 4 or not zip_code.isdigit():
- self._errors['zip_code'] = self.error_class([_("Postnummer må bestå av fire siffer.")])
+ self._errors['zip_code'] = self.error_class([_(u"Postnummer må bestå av fire siffer.")])
return cleaned_data
@@ -83,8 +83,8 @@
email = forms.EmailField(label="Email", max_length=50)
class ChangePasswordForm(forms.Form):
- new_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_("nytt passord"))
- repeat_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_("gjenta passord"))
+ new_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_(u"nytt passord"))
+ repeat_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_(u"gjenta passord"))
def clean(self):
super(ChangePasswordForm, self).clean()
@@ -93,7 +93,7 @@
# Check passwords
if cleaned_data['new_password'] != cleaned_data['repeat_password']:
- self._errors['repeat_password'] = self.error_class([_("Passordene er ikke like.")])
+ self._errors['repeat_password'] = self.error_class([_(u"Passordene er ikke like.")])
return cleaned_data
|
{"golden_diff": "diff --git a/apps/authentication/forms.py b/apps/authentication/forms.py\n--- a/apps/authentication/forms.py\n+++ b/apps/authentication/forms.py\n@@ -11,7 +11,7 @@\n \n class LoginForm(forms.Form):\n username = forms.CharField(widget=forms.TextInput(), label=_(\"Brukernavn\"), max_length=50)\n- password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_(\"Passord\"))\n+ password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_(u\"Passord\"))\n user = None\n \n def clean(self):\n@@ -24,9 +24,9 @@\n if user.is_active:\n self.user = user\n else:\n- self._errors['username'] = self.error_class([_(\"Din konto er ikke aktiv. Fors\u00f8k gjenoppretning av passord.\")])\n+ self._errors['username'] = self.error_class([_(u\"Din konto er ikke aktiv. Fors\u00f8k gjenoppretning av passord.\")])\n else:\n- self._errors['username'] = self.error_class([_(\"Kontoen eksisterer ikke, eller kombinasjonen av brukernavn og passord er feil.\")])\n+ self._errors['username'] = self.error_class([_(u\"Kontoen eksisterer ikke, eller kombinasjonen av brukernavn og passord er feil.\")])\n return self.cleaned_data\n \n def login(self, request):\n@@ -58,24 +58,24 @@\n \n # Check passwords\n if cleaned_data['password'] != cleaned_data['repeat_password']:\n- self._errors['repeat_password'] = self.error_class([_(\"Passordene er ikke like.\")])\n+ self._errors['repeat_password'] = self.error_class([_(u\"Passordene er ikke like.\")])\n \n # Check username\n username = cleaned_data['username']\n if User.objects.filter(username=username).count() > 0:\n- self._errors['username'] = self.error_class([_(\"Brukernavnet er allerede registrert.\")])\n+ self._errors['username'] = self.error_class([_(u\"Brukernavnet er allerede registrert.\")])\n if not re.match(\"^[a-zA-Z0-9_-]+$\", username):\n- self._errors['username'] = self.error_class([_(\"Ditt brukernavn inneholdt ulovlige tegn. Lovlige tegn: a-Z 0-9 - _\")])\n+ self._errors['username'] = self.error_class([_(u\"Ditt brukernavn inneholdt ulovlige tegn. Lovlige tegn: a-Z 0-9 - _\")])\n \n # Check email\n email = cleaned_data['email']\n if User.objects.filter(email=email).count() > 0:\n- self._errors['email'] = self.error_class([_(\"Det fins allerede en bruker med denne epostadressen.\")])\n+ self._errors['email'] = self.error_class([_(u\"Det fins allerede en bruker med denne epostadressen.\")])\n \n # ZIP code digits only\n zip_code = cleaned_data['zip_code']\n if len(zip_code) != 4 or not zip_code.isdigit():\n- self._errors['zip_code'] = self.error_class([_(\"Postnummer m\u00e5 best\u00e5 av fire siffer.\")])\n+ self._errors['zip_code'] = self.error_class([_(u\"Postnummer m\u00e5 best\u00e5 av fire siffer.\")])\n \n return cleaned_data \n \n@@ -83,8 +83,8 @@\n email = forms.EmailField(label=\"Email\", max_length=50)\n \n class ChangePasswordForm(forms.Form):\n- new_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_(\"nytt passord\"))\n- repeat_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_(\"gjenta passord\"))\n+ new_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_(u\"nytt passord\"))\n+ repeat_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_(u\"gjenta passord\"))\n \n def clean(self):\n super(ChangePasswordForm, self).clean()\n@@ -93,7 +93,7 @@\n \n # Check passwords\n if cleaned_data['new_password'] != cleaned_data['repeat_password']:\n- self._errors['repeat_password'] = self.error_class([_(\"Passordene er ikke like.\")])\n+ self._errors['repeat_password'] = self.error_class([_(u\"Passordene er ikke like.\")])\n \n return cleaned_data\n", "issue": "Menu is missing link to admin page when user is logged in\nShould only be visible when it's a privileged user with access to the panel \n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\nimport datetime\nimport re\n\nfrom django import forms\nfrom django.contrib import auth\nfrom django.utils.translation import ugettext as _\n\nfrom apps.authentication.models import OnlineUser as User\n\nclass LoginForm(forms.Form):\n username = forms.CharField(widget=forms.TextInput(), label=_(\"Brukernavn\"), max_length=50)\n password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_(\"Passord\"))\n user = None\n\n def clean(self):\n if self._errors:\n return\n \n user = auth.authenticate(username=self.cleaned_data['username'], password=self.cleaned_data['password'])\n\n if user:\n if user.is_active:\n self.user = user\n else:\n self._errors['username'] = self.error_class([_(\"Din konto er ikke aktiv. Fors\u00f8k gjenoppretning av passord.\")])\n else:\n self._errors['username'] = self.error_class([_(\"Kontoen eksisterer ikke, eller kombinasjonen av brukernavn og passord er feil.\")])\n return self.cleaned_data\n\n def login(self, request):\n try:\n User.objects.get(username=request.POST['username'])\n except:\n return False\n if self.is_valid():\n auth.login(request, self.user)\n request.session.set_expiry(0)\n return True\n return False\n\nclass RegisterForm(forms.Form):\n username = forms.CharField(label=_(\"brukernavn\"), max_length=20)\n first_name = forms.CharField(label=_(\"fornavn\"), max_length=50)\n last_name = forms.CharField(label=_(\"etternavn\"), max_length=50)\n email = forms.EmailField(label=_(\"epost\"), max_length=50)\n password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_(\"passord\"))\n repeat_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_(\"gjenta passord\"))\n address = forms.CharField(label=_(\"adresse\"), max_length=50)\n zip_code = forms.CharField(label=_(\"postnummer\"), max_length=4)\n phone = forms.CharField(label=_(\"telefon\"), max_length=20)\n \n def clean(self):\n super(RegisterForm, self).clean()\n if self.is_valid():\n cleaned_data = self.cleaned_data\n\n # Check passwords\n if cleaned_data['password'] != cleaned_data['repeat_password']:\n self._errors['repeat_password'] = self.error_class([_(\"Passordene er ikke like.\")])\n\n # Check username\n username = cleaned_data['username']\n if User.objects.filter(username=username).count() > 0:\n self._errors['username'] = self.error_class([_(\"Brukernavnet er allerede registrert.\")])\n if not re.match(\"^[a-zA-Z0-9_-]+$\", username):\n self._errors['username'] = self.error_class([_(\"Ditt brukernavn inneholdt ulovlige tegn. Lovlige tegn: a-Z 0-9 - _\")])\n\n # Check email\n email = cleaned_data['email']\n if User.objects.filter(email=email).count() > 0:\n self._errors['email'] = self.error_class([_(\"Det fins allerede en bruker med denne epostadressen.\")])\n\n # ZIP code digits only\n zip_code = cleaned_data['zip_code']\n if len(zip_code) != 4 or not zip_code.isdigit():\n self._errors['zip_code'] = self.error_class([_(\"Postnummer m\u00e5 best\u00e5 av fire siffer.\")])\n\n return cleaned_data \n\nclass RecoveryForm(forms.Form):\n email = forms.EmailField(label=\"Email\", max_length=50)\n\nclass ChangePasswordForm(forms.Form):\n new_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_(\"nytt passord\"))\n repeat_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=_(\"gjenta passord\"))\n\n def clean(self):\n super(ChangePasswordForm, self).clean()\n if self.is_valid():\n cleaned_data = self.cleaned_data\n\n # Check passwords\n if cleaned_data['new_password'] != cleaned_data['repeat_password']:\n self._errors['repeat_password'] = self.error_class([_(\"Passordene er ikke like.\")])\n\n return cleaned_data\n\n\nclass NewEmailForm(forms.Form):\n new_email = forms.EmailField(_(u\"ny epostadresse\"))\n", "path": "apps/authentication/forms.py"}]}
| 1,705 | 1,001 |
gh_patches_debug_17187
|
rasdani/github-patches
|
git_diff
|
DataDog__integrations-extras-320
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Filebeat instance cache is broken (which breaks increment metrics)
**Output of the [info page](https://docs.datadoghq.com/agent/faq/agent-commands/#agent-status-and-information)**
```text
====================
Collector (v 5.30.1)
====================
Status date: 2019-01-08 06:09:58 (10s ago)
Pid: 4468
Platform: Linux-3.13.0-163-generic-x86_64-with-Ubuntu-14.04-trusty
Python Version: 2.7.15, 64bit
Logs: <stderr>, /var/log/datadog/collector.log
<snip>
filebeat (custom)
-----------------
- instance #0 [OK]
- Collected 1 metric, 0 events & 0 service checks
<snip>
```
**Additional environment details (Operating System, Cloud provider, etc):**
Filebeat version 6.5.1
**Steps to reproduce the issue:**
1. Install and configure filebeat check with:
```yaml
init_config:
instances:
- registry_file_path: /var/lib/filebeat/registry
stats_endpoint: http://localhost:5066/stats
```
**Describe the results you received:**
Metrics in `GAUGE_METRIC_NAMES` are reported to Datadog, but none of the metrics in `INCREMENT_METRIC_NAMES` are.
**Describe the results you expected:**
All listed metrics in the above variables and present in `http://localhost:5066/stats` are reported.
**Additional information you deem important (e.g. issue happens only occasionally):**
The issue is here: https://github.com/DataDog/integrations-extras/blob/2eff6e2dd2b123214cd562b93a9b45753e27a959/filebeat/check.py#L211-L218
Line 213 checks for `instance_key` in `self.instance_cache`, but that key is never actually put in that dictionary. The only keys in that dictionary are `'config'` and `'profiler'`, added on lines 217 and 218.
The result of this is that the `FilebeatCheckInstanceConfig` and `FilebeatCheckHttpProfiler` are re-created every check, which means that the `_previous_increment_values` property on FilebeatCheckHttpProfiler is always empty, which means no increment metrics are ever reported.
This appears to have been introduced in #250.
</issue>
<code>
[start of filebeat/check.py]
1 # (C) Datadog, Inc. 2010-2016
2 # All rights reserved
3 # Licensed under Simplified BSD License (see LICENSE)
4
5 # stdlib
6 import collections
7 import errno
8 import numbers
9 import os
10 import re
11 import sre_constants
12
13 # 3rd party
14 import requests
15 import simplejson
16
17 # project
18 from datadog_checks.checks import AgentCheck
19 from datadog_checks.utils.containers import hash_mutable
20
21
22 EVENT_TYPE = SOURCE_TYPE_NAME = 'filebeat'
23
24
25 class FilebeatCheckHttpProfiler(object):
26 '''
27 Filebeat's HTTP profiler gives a bunch of counter variables; their value holds little interest,
28 what we really want is the delta in between runs. This class is responsible for caching the
29 values from the previous run
30 '''
31
32 INCREMENT_METRIC_NAMES = [
33 'filebeat.harvester.closed',
34 'filebeat.harvester.files.truncated',
35 'filebeat.harvester.open_files',
36 'filebeat.harvester.skipped',
37 'filebeat.harvester.started',
38 'filebeat.prospector.log.files.renamed',
39 'filebeat.prospector.log.files.truncated',
40 'libbeat.config.module.running',
41 'libbeat.config.module.starts',
42 'libbeat.config.module.stops',
43 'libbeat.config.reloads',
44 'libbeat.es.call_count.PublishEvents',
45 'libbeat.es.publish.read_bytes',
46 'libbeat.es.publish.read_errors',
47 'libbeat.es.publish.write_bytes',
48 'libbeat.es.publish.write_errors',
49 'libbeat.es.published_and_acked_events',
50 'libbeat.es.published_but_not_acked_events',
51 'libbeat.kafka.call_count.PublishEvents',
52 'libbeat.kafka.published_and_acked_events',
53 'libbeat.kafka.published_but_not_acked_events',
54 'libbeat.logstash.call_count.PublishEvents',
55 'libbeat.logstash.publish.read_bytes',
56 'libbeat.logstash.publish.read_errors',
57 'libbeat.logstash.publish.write_bytes',
58 'libbeat.logstash.publish.write_errors',
59 'libbeat.logstash.published_and_acked_events',
60 'libbeat.logstash.published_but_not_acked_events',
61 'libbeat.output.events.dropped',
62 'libbeat.output.events.failed',
63 'libbeat.pipeline.events.dropped',
64 'libbeat.pipeline.events.failed',
65 'libbeat.publisher.messages_in_worker_queues',
66 'libbeat.publisher.published_events',
67 'libbeat.redis.publish.read_bytes',
68 'libbeat.redis.publish.read_errors',
69 'libbeat.redis.publish.write_bytes',
70 'libbeat.redis.publish.write_errors',
71 'publish.events',
72 'registrar.states.cleanup',
73 'registrar.states.current',
74 'registrar.states.update',
75 'registrar.writes'
76 ]
77
78 GAUGE_METRIC_NAMES = [
79 'filebeat.harvester.running'
80 ]
81
82 VARS_ROUTE = 'debug/vars'
83
84 def __init__(self, config):
85 self._config = config
86 self._previous_increment_values = {}
87 # regex matching ain't free, let's cache this
88 self._should_keep_metrics = {}
89
90 def gather_metrics(self):
91 response = self._make_request()
92
93 return {
94 'increment': self._gather_increment_metrics(response),
95 'gauge': self._gather_gauge_metrics(response)
96 }
97
98 def _make_request(self):
99
100 response = requests.get(self._config.stats_endpoint, timeout=self._config.timeout)
101 response.raise_for_status()
102
103 return self.flatten(response.json())
104
105 def _gather_increment_metrics(self, response):
106 new_values = {name: response[name] for name in self.INCREMENT_METRIC_NAMES
107 if self._should_keep_metric(name) and name in response}
108
109 deltas = self._compute_increment_deltas(new_values)
110
111 self._previous_increment_values = new_values
112
113 return deltas
114
115 def _compute_increment_deltas(self, new_values):
116 deltas = {}
117
118 for name, new_value in new_values.iteritems():
119 if name not in self._previous_increment_values \
120 or self._previous_increment_values[name] > new_value:
121 # either the agent or filebeat got restarted, we're not
122 # reporting anything this time around
123 return {}
124 deltas[name] = new_value - self._previous_increment_values[name]
125
126 return deltas
127
128 def _gather_gauge_metrics(self, response):
129 return {name: response[name] for name in self.GAUGE_METRIC_NAMES
130 if self._should_keep_metric(name) and name in response}
131
132 def _should_keep_metric(self, name):
133 if name not in self._should_keep_metrics:
134 self._should_keep_metrics[name] = self._config.should_keep_metric(name)
135 return self._should_keep_metrics[name]
136
137 def flatten(self, d, parent_key='', sep='.'):
138 items = []
139 for k, v in d.items():
140 new_key = parent_key + sep + k if parent_key else k
141 if isinstance(v, collections.MutableMapping):
142 items.extend(self.flatten(v, new_key, sep=sep).items())
143 else:
144 items.append((new_key, v))
145 return dict(items)
146
147
148 class FilebeatCheckInstanceConfig(object):
149
150 def __init__(self, instance):
151 self._registry_file_path = instance.get('registry_file_path')
152 if self._registry_file_path is None:
153 raise Exception('An absolute path to a filebeat registry path must be specified')
154
155 self._stats_endpoint = instance.get('stats_endpoint')
156
157 self._only_metrics = instance.get('only_metrics', [])
158 if not isinstance(self._only_metrics, list):
159 raise Exception("If given, filebeat's only_metrics must be a list of regexes, got %s" % (
160 self._only_metrics, ))
161
162 self._timeout = instance.get('timeout', 2)
163 if not isinstance(self._timeout, numbers.Real) or self._timeout <= 0:
164 raise Exception("If given, filebeats timeout must be a positive number, got %s" % (self._timeout, ))
165
166 @property
167 def registry_file_path(self):
168 return self._registry_file_path
169
170 @property
171 def stats_endpoint(self):
172 return self._stats_endpoint
173
174 @property
175 def timeout(self):
176 return self._timeout
177
178 def should_keep_metric(self, metric_name):
179
180 if not self._only_metrics:
181 return True
182
183 return any(re.search(regex, metric_name) for regex in self._compiled_regexes())
184
185 def _compiled_regexes(self):
186 try:
187 return self._only_metrics_regexes
188 except AttributeError:
189 self._only_metrics_regexes = self._compile_regexes()
190 return self._compiled_regexes()
191
192 def _compile_regexes(self):
193 compiled_regexes = []
194
195 for regex in self._only_metrics:
196 try:
197 compiled_regexes.append(re.compile(regex))
198 except sre_constants.error as ex:
199 raise Exception(
200 'Invalid only_metric regex for filebeat: "%s", error: %s' % (regex, ex))
201
202 return compiled_regexes
203
204
205 class FilebeatCheck(AgentCheck):
206
207 def __init__(self, *args, **kwargs):
208 AgentCheck.__init__(self, *args, **kwargs)
209 self.instance_cache = {}
210
211 def check(self, instance):
212 instance_key = hash_mutable(instance)
213 if instance_key in self.instance_cache:
214 config = self.instance_cache['config']
215 profiler = self.instance_cache['profiler']
216 else:
217 self.instance_cache['config'] = config = FilebeatCheckInstanceConfig(instance)
218 self.instance_cache['profiler'] = profiler = FilebeatCheckHttpProfiler(config)
219
220 self._process_registry(config)
221 self._gather_http_profiler_metrics(config, profiler)
222
223 def _process_registry(self, config):
224 registry_contents = self._parse_registry_file(config.registry_file_path)
225
226 if isinstance(registry_contents, dict):
227 # filebeat version < 5
228 registry_contents = registry_contents.values()
229
230 for item in registry_contents:
231 self._process_registry_item(item)
232
233 def _parse_registry_file(self, registry_file_path):
234 try:
235 with open(registry_file_path) as registry_file:
236 return simplejson.load(registry_file)
237 except IOError as ex:
238 self.log.error('Cannot read the registry log file at %s: %s' % (registry_file_path, ex))
239
240 if ex.errno == errno.EACCES:
241 self.log.error('You might be interesting in having a look at https://github.com/elastic/beats/pull/6455')
242
243 return []
244
245 def _process_registry_item(self, item):
246 source = item['source']
247 offset = item['offset']
248
249 try:
250 stats = os.stat(source)
251
252 if self._is_same_file(stats, item['FileStateOS']):
253 unprocessed_bytes = stats.st_size - offset
254
255 self.gauge('filebeat.registry.unprocessed_bytes', unprocessed_bytes,
256 tags=['source:{0}'.format(source)])
257 else:
258 self.log.debug("Filebeat source %s appears to have changed" % (source, ))
259 except OSError:
260 self.log.debug("Unable to get stats on filebeat source %s" % (source, ))
261
262 def _is_same_file(self, stats, file_state_os):
263 return stats.st_dev == file_state_os['device'] and stats.st_ino == file_state_os['inode']
264
265 def _gather_http_profiler_metrics(self, config, profiler):
266 try:
267 all_metrics = profiler.gather_metrics()
268 except StandardError as ex:
269 self.log.error('Error when fetching metrics from %s: %s' % (config.stats_endpoint, ex))
270 return
271
272 tags = ['stats_endpoint:{0}'.format(config.stats_endpoint)]
273
274 for action, metrics in all_metrics.iteritems():
275 method = getattr(self, action)
276
277 for name, value in metrics.iteritems():
278 method(name, value, tags)
279
[end of filebeat/check.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/filebeat/check.py b/filebeat/check.py
--- a/filebeat/check.py
+++ b/filebeat/check.py
@@ -211,11 +211,12 @@
def check(self, instance):
instance_key = hash_mutable(instance)
if instance_key in self.instance_cache:
- config = self.instance_cache['config']
- profiler = self.instance_cache['profiler']
+ config = self.instance_cache[instance_key]['config']
+ profiler = self.instance_cache[instance_key]['profiler']
else:
- self.instance_cache['config'] = config = FilebeatCheckInstanceConfig(instance)
- self.instance_cache['profiler'] = profiler = FilebeatCheckHttpProfiler(config)
+ config = FilebeatCheckInstanceConfig(instance)
+ profiler = FilebeatCheckHttpProfiler(config)
+ self.instance_cache[instance_key] = {'config': config, 'profiler': profiler}
self._process_registry(config)
self._gather_http_profiler_metrics(config, profiler)
|
{"golden_diff": "diff --git a/filebeat/check.py b/filebeat/check.py\n--- a/filebeat/check.py\n+++ b/filebeat/check.py\n@@ -211,11 +211,12 @@\n def check(self, instance):\n instance_key = hash_mutable(instance)\n if instance_key in self.instance_cache:\n- config = self.instance_cache['config']\n- profiler = self.instance_cache['profiler']\n+ config = self.instance_cache[instance_key]['config']\n+ profiler = self.instance_cache[instance_key]['profiler']\n else:\n- self.instance_cache['config'] = config = FilebeatCheckInstanceConfig(instance)\n- self.instance_cache['profiler'] = profiler = FilebeatCheckHttpProfiler(config)\n+ config = FilebeatCheckInstanceConfig(instance)\n+ profiler = FilebeatCheckHttpProfiler(config)\n+ self.instance_cache[instance_key] = {'config': config, 'profiler': profiler}\n \n self._process_registry(config)\n self._gather_http_profiler_metrics(config, profiler)\n", "issue": "Filebeat instance cache is broken (which breaks increment metrics)\n**Output of the [info page](https://docs.datadoghq.com/agent/faq/agent-commands/#agent-status-and-information)**\r\n\r\n```text\r\n====================\r\nCollector (v 5.30.1)\r\n====================\r\n\r\n Status date: 2019-01-08 06:09:58 (10s ago)\r\n Pid: 4468\r\n Platform: Linux-3.13.0-163-generic-x86_64-with-Ubuntu-14.04-trusty\r\n Python Version: 2.7.15, 64bit\r\n Logs: <stderr>, /var/log/datadog/collector.log\r\n<snip>\r\n filebeat (custom)\r\n -----------------\r\n - instance #0 [OK]\r\n - Collected 1 metric, 0 events & 0 service checks\r\n<snip>\r\n```\r\n\r\n**Additional environment details (Operating System, Cloud provider, etc):**\r\nFilebeat version 6.5.1\r\n\r\n**Steps to reproduce the issue:**\r\n1. Install and configure filebeat check with:\r\n```yaml\r\ninit_config:\r\n\r\ninstances:\r\n - registry_file_path: /var/lib/filebeat/registry\r\n stats_endpoint: http://localhost:5066/stats\r\n```\r\n\r\n**Describe the results you received:**\r\nMetrics in `GAUGE_METRIC_NAMES` are reported to Datadog, but none of the metrics in `INCREMENT_METRIC_NAMES` are.\r\n\r\n**Describe the results you expected:**\r\nAll listed metrics in the above variables and present in `http://localhost:5066/stats` are reported.\r\n\r\n**Additional information you deem important (e.g. issue happens only occasionally):**\r\nThe issue is here: https://github.com/DataDog/integrations-extras/blob/2eff6e2dd2b123214cd562b93a9b45753e27a959/filebeat/check.py#L211-L218\r\n\r\nLine 213 checks for `instance_key` in `self.instance_cache`, but that key is never actually put in that dictionary. The only keys in that dictionary are `'config'` and `'profiler'`, added on lines 217 and 218.\r\n\r\nThe result of this is that the `FilebeatCheckInstanceConfig` and `FilebeatCheckHttpProfiler` are re-created every check, which means that the `_previous_increment_values` property on FilebeatCheckHttpProfiler is always empty, which means no increment metrics are ever reported.\r\n\r\nThis appears to have been introduced in #250.\n", "before_files": [{"content": "# (C) Datadog, Inc. 2010-2016\n# All rights reserved\n# Licensed under Simplified BSD License (see LICENSE)\n\n# stdlib\nimport collections\nimport errno\nimport numbers\nimport os\nimport re\nimport sre_constants\n\n# 3rd party\nimport requests\nimport simplejson\n\n# project\nfrom datadog_checks.checks import AgentCheck\nfrom datadog_checks.utils.containers import hash_mutable\n\n\nEVENT_TYPE = SOURCE_TYPE_NAME = 'filebeat'\n\n\nclass FilebeatCheckHttpProfiler(object):\n '''\n Filebeat's HTTP profiler gives a bunch of counter variables; their value holds little interest,\n what we really want is the delta in between runs. This class is responsible for caching the\n values from the previous run\n '''\n\n INCREMENT_METRIC_NAMES = [\n 'filebeat.harvester.closed',\n 'filebeat.harvester.files.truncated',\n 'filebeat.harvester.open_files',\n 'filebeat.harvester.skipped',\n 'filebeat.harvester.started',\n 'filebeat.prospector.log.files.renamed',\n 'filebeat.prospector.log.files.truncated',\n 'libbeat.config.module.running',\n 'libbeat.config.module.starts',\n 'libbeat.config.module.stops',\n 'libbeat.config.reloads',\n 'libbeat.es.call_count.PublishEvents',\n 'libbeat.es.publish.read_bytes',\n 'libbeat.es.publish.read_errors',\n 'libbeat.es.publish.write_bytes',\n 'libbeat.es.publish.write_errors',\n 'libbeat.es.published_and_acked_events',\n 'libbeat.es.published_but_not_acked_events',\n 'libbeat.kafka.call_count.PublishEvents',\n 'libbeat.kafka.published_and_acked_events',\n 'libbeat.kafka.published_but_not_acked_events',\n 'libbeat.logstash.call_count.PublishEvents',\n 'libbeat.logstash.publish.read_bytes',\n 'libbeat.logstash.publish.read_errors',\n 'libbeat.logstash.publish.write_bytes',\n 'libbeat.logstash.publish.write_errors',\n 'libbeat.logstash.published_and_acked_events',\n 'libbeat.logstash.published_but_not_acked_events',\n 'libbeat.output.events.dropped',\n 'libbeat.output.events.failed',\n 'libbeat.pipeline.events.dropped',\n 'libbeat.pipeline.events.failed',\n 'libbeat.publisher.messages_in_worker_queues',\n 'libbeat.publisher.published_events',\n 'libbeat.redis.publish.read_bytes',\n 'libbeat.redis.publish.read_errors',\n 'libbeat.redis.publish.write_bytes',\n 'libbeat.redis.publish.write_errors',\n 'publish.events',\n 'registrar.states.cleanup',\n 'registrar.states.current',\n 'registrar.states.update',\n 'registrar.writes'\n ]\n\n GAUGE_METRIC_NAMES = [\n 'filebeat.harvester.running'\n ]\n\n VARS_ROUTE = 'debug/vars'\n\n def __init__(self, config):\n self._config = config\n self._previous_increment_values = {}\n # regex matching ain't free, let's cache this\n self._should_keep_metrics = {}\n\n def gather_metrics(self):\n response = self._make_request()\n\n return {\n 'increment': self._gather_increment_metrics(response),\n 'gauge': self._gather_gauge_metrics(response)\n }\n\n def _make_request(self):\n\n response = requests.get(self._config.stats_endpoint, timeout=self._config.timeout)\n response.raise_for_status()\n\n return self.flatten(response.json())\n\n def _gather_increment_metrics(self, response):\n new_values = {name: response[name] for name in self.INCREMENT_METRIC_NAMES\n if self._should_keep_metric(name) and name in response}\n\n deltas = self._compute_increment_deltas(new_values)\n\n self._previous_increment_values = new_values\n\n return deltas\n\n def _compute_increment_deltas(self, new_values):\n deltas = {}\n\n for name, new_value in new_values.iteritems():\n if name not in self._previous_increment_values \\\n or self._previous_increment_values[name] > new_value:\n # either the agent or filebeat got restarted, we're not\n # reporting anything this time around\n return {}\n deltas[name] = new_value - self._previous_increment_values[name]\n\n return deltas\n\n def _gather_gauge_metrics(self, response):\n return {name: response[name] for name in self.GAUGE_METRIC_NAMES\n if self._should_keep_metric(name) and name in response}\n\n def _should_keep_metric(self, name):\n if name not in self._should_keep_metrics:\n self._should_keep_metrics[name] = self._config.should_keep_metric(name)\n return self._should_keep_metrics[name]\n\n def flatten(self, d, parent_key='', sep='.'):\n items = []\n for k, v in d.items():\n new_key = parent_key + sep + k if parent_key else k\n if isinstance(v, collections.MutableMapping):\n items.extend(self.flatten(v, new_key, sep=sep).items())\n else:\n items.append((new_key, v))\n return dict(items)\n\n\nclass FilebeatCheckInstanceConfig(object):\n\n def __init__(self, instance):\n self._registry_file_path = instance.get('registry_file_path')\n if self._registry_file_path is None:\n raise Exception('An absolute path to a filebeat registry path must be specified')\n\n self._stats_endpoint = instance.get('stats_endpoint')\n\n self._only_metrics = instance.get('only_metrics', [])\n if not isinstance(self._only_metrics, list):\n raise Exception(\"If given, filebeat's only_metrics must be a list of regexes, got %s\" % (\n self._only_metrics, ))\n\n self._timeout = instance.get('timeout', 2)\n if not isinstance(self._timeout, numbers.Real) or self._timeout <= 0:\n raise Exception(\"If given, filebeats timeout must be a positive number, got %s\" % (self._timeout, ))\n\n @property\n def registry_file_path(self):\n return self._registry_file_path\n\n @property\n def stats_endpoint(self):\n return self._stats_endpoint\n\n @property\n def timeout(self):\n return self._timeout\n\n def should_keep_metric(self, metric_name):\n\n if not self._only_metrics:\n return True\n\n return any(re.search(regex, metric_name) for regex in self._compiled_regexes())\n\n def _compiled_regexes(self):\n try:\n return self._only_metrics_regexes\n except AttributeError:\n self._only_metrics_regexes = self._compile_regexes()\n return self._compiled_regexes()\n\n def _compile_regexes(self):\n compiled_regexes = []\n\n for regex in self._only_metrics:\n try:\n compiled_regexes.append(re.compile(regex))\n except sre_constants.error as ex:\n raise Exception(\n 'Invalid only_metric regex for filebeat: \"%s\", error: %s' % (regex, ex))\n\n return compiled_regexes\n\n\nclass FilebeatCheck(AgentCheck):\n\n def __init__(self, *args, **kwargs):\n AgentCheck.__init__(self, *args, **kwargs)\n self.instance_cache = {}\n\n def check(self, instance):\n instance_key = hash_mutable(instance)\n if instance_key in self.instance_cache:\n config = self.instance_cache['config']\n profiler = self.instance_cache['profiler']\n else:\n self.instance_cache['config'] = config = FilebeatCheckInstanceConfig(instance)\n self.instance_cache['profiler'] = profiler = FilebeatCheckHttpProfiler(config)\n\n self._process_registry(config)\n self._gather_http_profiler_metrics(config, profiler)\n\n def _process_registry(self, config):\n registry_contents = self._parse_registry_file(config.registry_file_path)\n\n if isinstance(registry_contents, dict):\n # filebeat version < 5\n registry_contents = registry_contents.values()\n\n for item in registry_contents:\n self._process_registry_item(item)\n\n def _parse_registry_file(self, registry_file_path):\n try:\n with open(registry_file_path) as registry_file:\n return simplejson.load(registry_file)\n except IOError as ex:\n self.log.error('Cannot read the registry log file at %s: %s' % (registry_file_path, ex))\n\n if ex.errno == errno.EACCES:\n self.log.error('You might be interesting in having a look at https://github.com/elastic/beats/pull/6455')\n\n return []\n\n def _process_registry_item(self, item):\n source = item['source']\n offset = item['offset']\n\n try:\n stats = os.stat(source)\n\n if self._is_same_file(stats, item['FileStateOS']):\n unprocessed_bytes = stats.st_size - offset\n\n self.gauge('filebeat.registry.unprocessed_bytes', unprocessed_bytes,\n tags=['source:{0}'.format(source)])\n else:\n self.log.debug(\"Filebeat source %s appears to have changed\" % (source, ))\n except OSError:\n self.log.debug(\"Unable to get stats on filebeat source %s\" % (source, ))\n\n def _is_same_file(self, stats, file_state_os):\n return stats.st_dev == file_state_os['device'] and stats.st_ino == file_state_os['inode']\n\n def _gather_http_profiler_metrics(self, config, profiler):\n try:\n all_metrics = profiler.gather_metrics()\n except StandardError as ex:\n self.log.error('Error when fetching metrics from %s: %s' % (config.stats_endpoint, ex))\n return\n\n tags = ['stats_endpoint:{0}'.format(config.stats_endpoint)]\n\n for action, metrics in all_metrics.iteritems():\n method = getattr(self, action)\n\n for name, value in metrics.iteritems():\n method(name, value, tags)\n", "path": "filebeat/check.py"}]}
| 3,977 | 220 |
gh_patches_debug_23037
|
rasdani/github-patches
|
git_diff
|
e-valuation__EvaP-1221
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Contact modal broken in Firefox
The contact modal does not work in Firefox, because `event` is undefined. Chrome provides this in global scope, that's why it's working there (see https://stackoverflow.com/questions/18274383/ajax-post-working-in-chrome-but-not-in-firefox).
</issue>
<code>
[start of evap/evaluation/views.py]
1 import logging
2
3 from django.conf import settings
4 from django.contrib import messages, auth
5 from django.contrib.auth.decorators import login_required
6 from django.core.mail import EmailMessage
7 from django.http import HttpResponse
8 from django.shortcuts import redirect, render
9 from django.utils.translation import ugettext as _
10 from django.views.decorators.http import require_POST
11 from django.views.decorators.debug import sensitive_post_parameters
12 from django.views.i18n import set_language
13
14 from evap.evaluation.forms import NewKeyForm, LoginUsernameForm
15 from evap.evaluation.models import UserProfile, FaqSection, EmailTemplate, Semester
16
17 logger = logging.getLogger(__name__)
18
19
20 @sensitive_post_parameters("password")
21 def index(request):
22 """Main entry page into EvaP providing all the login options available. The username/password
23 login is thought to be used for internal users, e.g. by connecting to a LDAP directory.
24 The login key mechanism is meant to be used to include external participants, e.g. visiting
25 students or visiting contributors.
26 """
27
28 # parse the form data into the respective form
29 submit_type = request.POST.get("submit_type", "no_submit")
30 new_key_form = NewKeyForm(request.POST if submit_type == "new_key" else None)
31 login_username_form = LoginUsernameForm(request, request.POST if submit_type == "login_username" else None)
32
33 # process form data
34 if request.method == 'POST':
35 if new_key_form.is_valid():
36 # user wants a new login key
37 profile = new_key_form.get_user()
38 profile.ensure_valid_login_key()
39 profile.save()
40
41 EmailTemplate.send_login_url_to_user(new_key_form.get_user())
42
43 messages.success(request, _("We sent you an email with a one-time login URL. Please check your inbox."))
44 return redirect('evaluation:index')
45 elif login_username_form.is_valid():
46 # user would like to login with username and password and passed password test
47 auth.login(request, login_username_form.get_user())
48
49 # clean up our test cookie
50 if request.session.test_cookie_worked():
51 request.session.delete_test_cookie()
52
53 # if not logged in by now, render form
54 if not request.user.is_authenticated:
55 # set test cookie to verify whether they work in the next step
56 request.session.set_test_cookie()
57
58 template_data = dict(new_key_form=new_key_form, login_username_form=login_username_form)
59 return render(request, "index.html", template_data)
60 else:
61 user, __ = UserProfile.objects.get_or_create(username=request.user.username)
62
63 # check for redirect variable
64 redirect_to = request.GET.get("next", None)
65 if redirect_to is not None:
66 return redirect(redirect_to)
67
68 # redirect user to appropriate start page
69 if request.user.is_reviewer:
70 return redirect('staff:semester_view', Semester.active_semester().id)
71 if request.user.is_staff:
72 return redirect('staff:index')
73 elif request.user.is_grade_publisher:
74 return redirect('grades:semester_view', Semester.active_semester().id)
75 elif user.is_student:
76 return redirect('student:index')
77 elif user.is_contributor_or_delegate:
78 return redirect('contributor:index')
79 else:
80 return redirect('results:index')
81
82
83 def faq(request):
84 return render(request, "faq.html", dict(sections=FaqSection.objects.all()))
85
86
87 def legal_notice(request):
88 return render(request, "legal_notice.html", dict())
89
90
91 @require_POST
92 @login_required
93 def contact(request):
94 message = request.POST.get("message")
95 title = request.POST.get("title")
96 subject = "[EvaP] Message from {}".format(request.user.username)
97
98 if message:
99 mail = EmailMessage(
100 subject=subject,
101 body="{}\n{} ({})\n\n{}".format(title, request.user.username, request.user.email, message),
102 to=[settings.CONTACT_EMAIL])
103 try:
104 mail.send()
105 logger.info('Sent contact email: \n{}\n'.format(mail.message()))
106 except Exception:
107 logger.exception('An exception occurred when sending the following contact email:\n{}\n'.format(mail.message()))
108 raise
109
110 return HttpResponse()
111
112
113 @require_POST
114 def set_lang(request):
115 if request.user.is_authenticated:
116 user = request.user
117 user.language = request.POST['language']
118 user.save()
119
120 return set_language(request)
121
[end of evap/evaluation/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/evap/evaluation/views.py b/evap/evaluation/views.py
--- a/evap/evaluation/views.py
+++ b/evap/evaluation/views.py
@@ -4,7 +4,7 @@
from django.contrib import messages, auth
from django.contrib.auth.decorators import login_required
from django.core.mail import EmailMessage
-from django.http import HttpResponse
+from django.http import HttpResponse, HttpResponseBadRequest
from django.shortcuts import redirect, render
from django.utils.translation import ugettext as _
from django.views.decorators.http import require_POST
@@ -103,11 +103,12 @@
try:
mail.send()
logger.info('Sent contact email: \n{}\n'.format(mail.message()))
+ return HttpResponse()
except Exception:
logger.exception('An exception occurred when sending the following contact email:\n{}\n'.format(mail.message()))
raise
- return HttpResponse()
+ return HttpResponseBadRequest()
@require_POST
|
{"golden_diff": "diff --git a/evap/evaluation/views.py b/evap/evaluation/views.py\n--- a/evap/evaluation/views.py\n+++ b/evap/evaluation/views.py\n@@ -4,7 +4,7 @@\n from django.contrib import messages, auth\n from django.contrib.auth.decorators import login_required\n from django.core.mail import EmailMessage\n-from django.http import HttpResponse\n+from django.http import HttpResponse, HttpResponseBadRequest\n from django.shortcuts import redirect, render\n from django.utils.translation import ugettext as _\n from django.views.decorators.http import require_POST\n@@ -103,11 +103,12 @@\n try:\n mail.send()\n logger.info('Sent contact email: \\n{}\\n'.format(mail.message()))\n+ return HttpResponse()\n except Exception:\n logger.exception('An exception occurred when sending the following contact email:\\n{}\\n'.format(mail.message()))\n raise\n \n- return HttpResponse()\n+ return HttpResponseBadRequest()\n \n \n @require_POST\n", "issue": "Contact modal broken in Firefox\nThe contact modal does not work in Firefox, because `event` is undefined. Chrome provides this in global scope, that's why it's working there (see https://stackoverflow.com/questions/18274383/ajax-post-working-in-chrome-but-not-in-firefox).\n", "before_files": [{"content": "import logging\n\nfrom django.conf import settings\nfrom django.contrib import messages, auth\nfrom django.contrib.auth.decorators import login_required\nfrom django.core.mail import EmailMessage\nfrom django.http import HttpResponse\nfrom django.shortcuts import redirect, render\nfrom django.utils.translation import ugettext as _\nfrom django.views.decorators.http import require_POST\nfrom django.views.decorators.debug import sensitive_post_parameters\nfrom django.views.i18n import set_language\n\nfrom evap.evaluation.forms import NewKeyForm, LoginUsernameForm\nfrom evap.evaluation.models import UserProfile, FaqSection, EmailTemplate, Semester\n\nlogger = logging.getLogger(__name__)\n\n\n@sensitive_post_parameters(\"password\")\ndef index(request):\n \"\"\"Main entry page into EvaP providing all the login options available. The username/password\n login is thought to be used for internal users, e.g. by connecting to a LDAP directory.\n The login key mechanism is meant to be used to include external participants, e.g. visiting\n students or visiting contributors.\n \"\"\"\n\n # parse the form data into the respective form\n submit_type = request.POST.get(\"submit_type\", \"no_submit\")\n new_key_form = NewKeyForm(request.POST if submit_type == \"new_key\" else None)\n login_username_form = LoginUsernameForm(request, request.POST if submit_type == \"login_username\" else None)\n\n # process form data\n if request.method == 'POST':\n if new_key_form.is_valid():\n # user wants a new login key\n profile = new_key_form.get_user()\n profile.ensure_valid_login_key()\n profile.save()\n\n EmailTemplate.send_login_url_to_user(new_key_form.get_user())\n\n messages.success(request, _(\"We sent you an email with a one-time login URL. Please check your inbox.\"))\n return redirect('evaluation:index')\n elif login_username_form.is_valid():\n # user would like to login with username and password and passed password test\n auth.login(request, login_username_form.get_user())\n\n # clean up our test cookie\n if request.session.test_cookie_worked():\n request.session.delete_test_cookie()\n\n # if not logged in by now, render form\n if not request.user.is_authenticated:\n # set test cookie to verify whether they work in the next step\n request.session.set_test_cookie()\n\n template_data = dict(new_key_form=new_key_form, login_username_form=login_username_form)\n return render(request, \"index.html\", template_data)\n else:\n user, __ = UserProfile.objects.get_or_create(username=request.user.username)\n\n # check for redirect variable\n redirect_to = request.GET.get(\"next\", None)\n if redirect_to is not None:\n return redirect(redirect_to)\n\n # redirect user to appropriate start page\n if request.user.is_reviewer:\n return redirect('staff:semester_view', Semester.active_semester().id)\n if request.user.is_staff:\n return redirect('staff:index')\n elif request.user.is_grade_publisher:\n return redirect('grades:semester_view', Semester.active_semester().id)\n elif user.is_student:\n return redirect('student:index')\n elif user.is_contributor_or_delegate:\n return redirect('contributor:index')\n else:\n return redirect('results:index')\n\n\ndef faq(request):\n return render(request, \"faq.html\", dict(sections=FaqSection.objects.all()))\n\n\ndef legal_notice(request):\n return render(request, \"legal_notice.html\", dict())\n\n\n@require_POST\n@login_required\ndef contact(request):\n message = request.POST.get(\"message\")\n title = request.POST.get(\"title\")\n subject = \"[EvaP] Message from {}\".format(request.user.username)\n\n if message:\n mail = EmailMessage(\n subject=subject,\n body=\"{}\\n{} ({})\\n\\n{}\".format(title, request.user.username, request.user.email, message),\n to=[settings.CONTACT_EMAIL])\n try:\n mail.send()\n logger.info('Sent contact email: \\n{}\\n'.format(mail.message()))\n except Exception:\n logger.exception('An exception occurred when sending the following contact email:\\n{}\\n'.format(mail.message()))\n raise\n\n return HttpResponse()\n\n\n@require_POST\ndef set_lang(request):\n if request.user.is_authenticated:\n user = request.user\n user.language = request.POST['language']\n user.save()\n\n return set_language(request)\n", "path": "evap/evaluation/views.py"}]}
| 1,782 | 207 |
gh_patches_debug_33662
|
rasdani/github-patches
|
git_diff
|
aws-cloudformation__cfn-lint-2011
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Duplicate properties on a resource can cause unhandled exceptions
*cfn-lint version: (`cfn-lint --version`)*
0.48.3
*Description of issue.*
Duplicate properties can cause unhandled exceptions
Please provide as much information as possible:
* Template linting issues:
* Please provide a CloudFormation sample that generated the issue.
* If present, please add links to the (official) documentation for clarification.
* Validate if the issue still exists with the latest version of `cfn-lint` and/or the latest Spec files
e.g.
```yaml
PublicHttpsListener:
Type: 'AWS::ElasticLoadBalancingV2::Listener'
Properties:
LoadBalancerArn: !Ref PublicLoadBalancer
Port: 443
Protocol: HTTPS
Certificates: !Ref LoadBalancerCertificateArn
DefaultActions:
- Type: fixed-response
FixedResponseConfig:
StatusCode: 404
Port: 443
Protocol: HTTPS
```
results in:
```bash
Traceback (most recent call last):
File "/Users/nick.chadwick/Projects/msd/miniconda3/bin/cfn-lint", line 10, in <module>
sys.exit(main())
File "/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/__main__.py", line 28, in main
(template, rules, errors) = cfnlint.core.get_template_rules(filename, args)
File "/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/core.py", line 187, in get_template_rules
(template, errors) = cfnlint.decode.decode(filename)
File "/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/decode/__init__.py", line 28, in decode
template = cfn_yaml.load(filename)
File "/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/decode/cfn_yaml.py", line 237, in load
return loads(content, filename)
File "/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/decode/cfn_yaml.py", line 215, in loads
template = loader.get_single_data()
File "/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/yaml/constructor.py", line 51, in get_single_data
return self.construct_document(node)
File "/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/yaml/constructor.py", line 55, in construct_document
data = self.construct_object(node)
File "/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/yaml/constructor.py", line 100, in construct_object
data = constructor(self, node)
File "/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/decode/cfn_yaml.py", line 81, in construct_yaml_map
value = self.construct_object(value_node, False)
File "/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/yaml/constructor.py", line 100, in construct_object
data = constructor(self, node)
File "/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/decode/cfn_yaml.py", line 81, in construct_yaml_map
value = self.construct_object(value_node, False)
File "/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/yaml/constructor.py", line 100, in construct_object
data = constructor(self, node)
File "/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/decode/cfn_yaml.py", line 81, in construct_yaml_map
value = self.construct_object(value_node, False)
File "/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/yaml/constructor.py", line 100, in construct_object
data = constructor(self, node)
File "/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/decode/cfn_yaml.py", line 98, in construct_yaml_map
key, mapping[key].start_mark.line + 1),
AttributeError: 'int' object has no attribute 'start_mark'
```
* Feature request:
* Please provide argumentation about the missing feature. Context is key!
Cfn-lint uses the [CloudFormation Resource Specifications](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/cfn-resource-specification.html) as the base to do validation. These files are included as part of the application version. Please update to the latest version of `cfn-lint` or update the spec files manually (`cfn-lint -u`)
</issue>
<code>
[start of src/cfnlint/decode/cfn_yaml.py]
1 """
2 Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
3 SPDX-License-Identifier: MIT-0
4 """
5 import fileinput
6 import logging
7 import sys
8 import six
9 from yaml.composer import Composer
10 from yaml.reader import Reader
11 from yaml.scanner import Scanner
12 from yaml.resolver import Resolver
13 from yaml import ScalarNode
14 from yaml import SequenceNode
15 from yaml import MappingNode
16 from yaml.constructor import SafeConstructor
17 from yaml.constructor import ConstructorError
18 import cfnlint
19 from cfnlint.decode.node import str_node, dict_node, list_node
20
21 try:
22 from yaml.cyaml import CParser as Parser # pylint: disable=ungrouped-imports
23 cyaml = True
24 except ImportError:
25 from yaml.parser import Parser # pylint: disable=ungrouped-imports
26 cyaml = False
27
28 UNCONVERTED_SUFFIXES = ['Ref', 'Condition']
29 FN_PREFIX = 'Fn::'
30
31 LOGGER = logging.getLogger(__name__)
32
33
34 class CfnParseError(ConstructorError):
35 """
36 Error thrown when the template contains Cfn Error
37 """
38
39 def __init__(self, filename, errors):
40
41 if isinstance(errors, cfnlint.rules.Match):
42 errors = [errors]
43
44 # Call the base class constructor with the parameters it needs
45 super(CfnParseError, self).__init__(errors[0].message)
46
47 # Now for your custom code...
48 self.filename = filename
49 self.matches = errors
50
51 def build_match(filename, message, line_number, column_number, key):
52 return cfnlint.rules.Match(
53 line_number + 1, column_number + 1, line_number + 1,
54 column_number + 1 + len(key), filename, cfnlint.rules.ParseError(), message=message)
55
56 class NodeConstructor(SafeConstructor):
57 """
58 Node Constructors for loading different types in Yaml
59 """
60
61 def __init__(self, filename):
62 # Call the base class constructor
63 super(NodeConstructor, self).__init__()
64
65 self.filename = filename
66
67 # To support lazy loading, the original constructors first yield
68 # an empty object, then fill them in when iterated. Due to
69 # laziness we omit this behaviour (and will only do "deep
70 # construction") by first exhausting iterators, then yielding
71 # copies.
72 def construct_yaml_map(self, node):
73
74 # Check for duplicate keys on the current level, this is not desirable
75 # because a dict does not support this. It overwrites it with the last
76 # occurance, which can give unexpected results
77 mapping = {}
78 self.flatten_mapping(node)
79 for key_node, value_node in node.value:
80 key = self.construct_object(key_node, False)
81 value = self.construct_object(value_node, False)
82
83 if key in mapping:
84 raise CfnParseError(
85 self.filename,
86 [
87 build_match(
88 filename=self.filename,
89 message='Duplicate resource found "{}" (line {})'.format(
90 key, key_node.start_mark.line + 1),
91 line_number=key_node.start_mark.line,
92 column_number=key_node.start_mark.column,
93 key=key
94 ),
95 build_match(
96 filename=self.filename,
97 message='Duplicate resource found "{}" (line {})'.format(
98 key, mapping[key].start_mark.line + 1),
99 line_number=mapping[key].start_mark.line,
100 column_number=mapping[key].start_mark.column,
101 key=key
102 )
103 ]
104 )
105 mapping[key] = value
106
107 obj, = SafeConstructor.construct_yaml_map(self, node)
108 return dict_node(obj, node.start_mark, node.end_mark)
109
110 def construct_yaml_str(self, node):
111 obj = SafeConstructor.construct_yaml_str(self, node)
112 assert isinstance(obj, (six.string_types))
113 return str_node(obj, node.start_mark, node.end_mark)
114
115 def construct_yaml_seq(self, node):
116 obj, = SafeConstructor.construct_yaml_seq(self, node)
117 assert isinstance(obj, list)
118 return list_node(obj, node.start_mark, node.end_mark)
119
120 def construct_yaml_null_error(self, node):
121 """Throw a null error"""
122 raise CfnParseError(
123 self.filename,
124 [
125 build_match(
126 filename=self.filename,
127 message='Null value at line {0} column {1}'.format(
128 node.start_mark.line + 1, node.start_mark.column + 1),
129 line_number=node.start_mark.line,
130 column_number=node.start_mark.column,
131 key=' ',
132 )
133 ]
134 )
135
136
137 NodeConstructor.add_constructor(
138 u'tag:yaml.org,2002:map',
139 NodeConstructor.construct_yaml_map)
140
141 NodeConstructor.add_constructor(
142 u'tag:yaml.org,2002:str',
143 NodeConstructor.construct_yaml_str)
144
145 NodeConstructor.add_constructor(
146 u'tag:yaml.org,2002:seq',
147 NodeConstructor.construct_yaml_seq)
148
149 NodeConstructor.add_constructor(
150 u'tag:yaml.org,2002:null',
151 NodeConstructor.construct_yaml_null_error)
152
153
154 class MarkedLoader(Reader, Scanner, Parser, Composer, NodeConstructor, Resolver):
155 """
156 Class for marked loading YAML
157 """
158 # pylint: disable=non-parent-init-called,super-init-not-called
159
160 def __init__(self, stream, filename):
161 Reader.__init__(self, stream)
162 Scanner.__init__(self)
163 if cyaml:
164 Parser.__init__(self, stream)
165 else:
166 Parser.__init__(self)
167 Composer.__init__(self)
168 SafeConstructor.__init__(self)
169 Resolver.__init__(self)
170 NodeConstructor.__init__(self, filename)
171
172
173 def multi_constructor(loader, tag_suffix, node):
174 """
175 Deal with !Ref style function format
176 """
177
178 if tag_suffix not in UNCONVERTED_SUFFIXES:
179 tag_suffix = '{}{}'.format(FN_PREFIX, tag_suffix)
180
181 constructor = None
182 if tag_suffix == 'Fn::GetAtt':
183 constructor = construct_getatt
184 elif isinstance(node, ScalarNode):
185 constructor = loader.construct_scalar
186 elif isinstance(node, SequenceNode):
187 constructor = loader.construct_sequence
188 elif isinstance(node, MappingNode):
189 constructor = loader.construct_mapping
190 else:
191 raise 'Bad tag: !{}'.format(tag_suffix)
192
193 return dict_node({tag_suffix: constructor(node)}, node.start_mark, node.end_mark)
194
195
196 def construct_getatt(node):
197 """
198 Reconstruct !GetAtt into a list
199 """
200
201 if isinstance(node.value, (six.string_types)):
202 return list_node(node.value.split('.', 1), node.start_mark, node.end_mark)
203 if isinstance(node.value, list):
204 return list_node([s.value for s in node.value], node.start_mark, node.end_mark)
205
206 raise ValueError('Unexpected node type: {}'.format(type(node.value)))
207
208
209 def loads(yaml_string, fname=None):
210 """
211 Load the given YAML string
212 """
213 loader = MarkedLoader(yaml_string, fname)
214 loader.add_multi_constructor('!', multi_constructor)
215 template = loader.get_single_data()
216 # Convert an empty file to an empty dict
217 if template is None:
218 template = {}
219
220 return template
221
222
223 def load(filename):
224 """
225 Load the given YAML file
226 """
227
228 content = ''
229
230 if not sys.stdin.isatty():
231 for line in fileinput.input(files=filename):
232 content = content + line
233 else:
234 with open(filename) as fp:
235 content = fp.read()
236
237 return loads(content, filename)
238
[end of src/cfnlint/decode/cfn_yaml.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/cfnlint/decode/cfn_yaml.py b/src/cfnlint/decode/cfn_yaml.py
--- a/src/cfnlint/decode/cfn_yaml.py
+++ b/src/cfnlint/decode/cfn_yaml.py
@@ -80,28 +80,29 @@
key = self.construct_object(key_node, False)
value = self.construct_object(value_node, False)
- if key in mapping:
- raise CfnParseError(
- self.filename,
- [
- build_match(
- filename=self.filename,
- message='Duplicate resource found "{}" (line {})'.format(
- key, key_node.start_mark.line + 1),
- line_number=key_node.start_mark.line,
- column_number=key_node.start_mark.column,
- key=key
- ),
- build_match(
- filename=self.filename,
- message='Duplicate resource found "{}" (line {})'.format(
- key, mapping[key].start_mark.line + 1),
- line_number=mapping[key].start_mark.line,
- column_number=mapping[key].start_mark.column,
- key=key
- )
- ]
- )
+ for key_dup in mapping:
+ if key_dup == key:
+ raise CfnParseError(
+ self.filename,
+ [
+ build_match(
+ filename=self.filename,
+ message='Duplicate resource found "{}" (line {})'.format(
+ key, key_dup.start_mark.line + 1),
+ line_number=key_dup.start_mark.line,
+ column_number=key_dup.start_mark.column,
+ key=key
+ ),
+ build_match(
+ filename=self.filename,
+ message='Duplicate resource found "{}" (line {})'.format(
+ key, key_node.start_mark.line + 1),
+ line_number=key_node.start_mark.line,
+ column_number=key_node.start_mark.column,
+ key=key
+ ),
+ ]
+ )
mapping[key] = value
obj, = SafeConstructor.construct_yaml_map(self, node)
|
{"golden_diff": "diff --git a/src/cfnlint/decode/cfn_yaml.py b/src/cfnlint/decode/cfn_yaml.py\n--- a/src/cfnlint/decode/cfn_yaml.py\n+++ b/src/cfnlint/decode/cfn_yaml.py\n@@ -80,28 +80,29 @@\n key = self.construct_object(key_node, False)\n value = self.construct_object(value_node, False)\n \n- if key in mapping:\n- raise CfnParseError(\n- self.filename,\n- [\n- build_match(\n- filename=self.filename,\n- message='Duplicate resource found \"{}\" (line {})'.format(\n- key, key_node.start_mark.line + 1),\n- line_number=key_node.start_mark.line,\n- column_number=key_node.start_mark.column,\n- key=key\n- ),\n- build_match(\n- filename=self.filename,\n- message='Duplicate resource found \"{}\" (line {})'.format(\n- key, mapping[key].start_mark.line + 1),\n- line_number=mapping[key].start_mark.line,\n- column_number=mapping[key].start_mark.column,\n- key=key\n- )\n- ]\n- )\n+ for key_dup in mapping:\n+ if key_dup == key:\n+ raise CfnParseError(\n+ self.filename,\n+ [\n+ build_match(\n+ filename=self.filename,\n+ message='Duplicate resource found \"{}\" (line {})'.format(\n+ key, key_dup.start_mark.line + 1),\n+ line_number=key_dup.start_mark.line,\n+ column_number=key_dup.start_mark.column,\n+ key=key\n+ ),\n+ build_match(\n+ filename=self.filename,\n+ message='Duplicate resource found \"{}\" (line {})'.format(\n+ key, key_node.start_mark.line + 1),\n+ line_number=key_node.start_mark.line,\n+ column_number=key_node.start_mark.column,\n+ key=key\n+ ),\n+ ]\n+ )\n mapping[key] = value\n \n obj, = SafeConstructor.construct_yaml_map(self, node)\n", "issue": "Duplicate properties on a resource can cause unhandled exceptions\n*cfn-lint version: (`cfn-lint --version`)*\r\n0.48.3\r\n\r\n*Description of issue.*\r\nDuplicate properties can cause unhandled exceptions\r\n\r\nPlease provide as much information as possible:\r\n* Template linting issues:\r\n * Please provide a CloudFormation sample that generated the issue.\r\n * If present, please add links to the (official) documentation for clarification.\r\n * Validate if the issue still exists with the latest version of `cfn-lint` and/or the latest Spec files\r\n\r\ne.g.\r\n```yaml\r\n PublicHttpsListener:\r\n Type: 'AWS::ElasticLoadBalancingV2::Listener'\r\n Properties:\r\n LoadBalancerArn: !Ref PublicLoadBalancer\r\n Port: 443\r\n Protocol: HTTPS\r\n Certificates: !Ref LoadBalancerCertificateArn\r\n DefaultActions:\r\n - Type: fixed-response\r\n FixedResponseConfig:\r\n StatusCode: 404\r\n Port: 443\r\n Protocol: HTTPS\r\n```\r\nresults in:\r\n```bash\r\nTraceback (most recent call last):\r\n File \"/Users/nick.chadwick/Projects/msd/miniconda3/bin/cfn-lint\", line 10, in <module>\r\n sys.exit(main())\r\n File \"/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/__main__.py\", line 28, in main\r\n (template, rules, errors) = cfnlint.core.get_template_rules(filename, args)\r\n File \"/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/core.py\", line 187, in get_template_rules\r\n (template, errors) = cfnlint.decode.decode(filename)\r\n File \"/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/decode/__init__.py\", line 28, in decode\r\n template = cfn_yaml.load(filename)\r\n File \"/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/decode/cfn_yaml.py\", line 237, in load\r\n return loads(content, filename)\r\n File \"/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/decode/cfn_yaml.py\", line 215, in loads\r\n template = loader.get_single_data()\r\n File \"/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/yaml/constructor.py\", line 51, in get_single_data\r\n return self.construct_document(node)\r\n File \"/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/yaml/constructor.py\", line 55, in construct_document\r\n data = self.construct_object(node)\r\n File \"/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/yaml/constructor.py\", line 100, in construct_object\r\n data = constructor(self, node)\r\n File \"/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/decode/cfn_yaml.py\", line 81, in construct_yaml_map\r\n value = self.construct_object(value_node, False)\r\n File \"/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/yaml/constructor.py\", line 100, in construct_object\r\n data = constructor(self, node)\r\n File \"/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/decode/cfn_yaml.py\", line 81, in construct_yaml_map\r\n value = self.construct_object(value_node, False)\r\n File \"/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/yaml/constructor.py\", line 100, in construct_object\r\n data = constructor(self, node)\r\n File \"/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/decode/cfn_yaml.py\", line 81, in construct_yaml_map\r\n value = self.construct_object(value_node, False)\r\n File \"/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/yaml/constructor.py\", line 100, in construct_object\r\n data = constructor(self, node)\r\n File \"/Users/nick.chadwick/Projects/msd/miniconda3/lib/python3.7/site-packages/cfnlint/decode/cfn_yaml.py\", line 98, in construct_yaml_map\r\n key, mapping[key].start_mark.line + 1),\r\nAttributeError: 'int' object has no attribute 'start_mark'\r\n```\r\n* Feature request:\r\n * Please provide argumentation about the missing feature. Context is key!\r\n\r\n\r\nCfn-lint uses the [CloudFormation Resource Specifications](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/cfn-resource-specification.html) as the base to do validation. These files are included as part of the application version. Please update to the latest version of `cfn-lint` or update the spec files manually (`cfn-lint -u`)\r\n\n", "before_files": [{"content": "\"\"\"\nCopyright Amazon.com, Inc. or its affiliates. All Rights Reserved.\nSPDX-License-Identifier: MIT-0\n\"\"\"\nimport fileinput\nimport logging\nimport sys\nimport six\nfrom yaml.composer import Composer\nfrom yaml.reader import Reader\nfrom yaml.scanner import Scanner\nfrom yaml.resolver import Resolver\nfrom yaml import ScalarNode\nfrom yaml import SequenceNode\nfrom yaml import MappingNode\nfrom yaml.constructor import SafeConstructor\nfrom yaml.constructor import ConstructorError\nimport cfnlint\nfrom cfnlint.decode.node import str_node, dict_node, list_node\n\ntry:\n from yaml.cyaml import CParser as Parser # pylint: disable=ungrouped-imports\n cyaml = True\nexcept ImportError:\n from yaml.parser import Parser # pylint: disable=ungrouped-imports\n cyaml = False\n\nUNCONVERTED_SUFFIXES = ['Ref', 'Condition']\nFN_PREFIX = 'Fn::'\n\nLOGGER = logging.getLogger(__name__)\n\n\nclass CfnParseError(ConstructorError):\n \"\"\"\n Error thrown when the template contains Cfn Error\n \"\"\"\n\n def __init__(self, filename, errors):\n\n if isinstance(errors, cfnlint.rules.Match):\n errors = [errors]\n\n # Call the base class constructor with the parameters it needs\n super(CfnParseError, self).__init__(errors[0].message)\n\n # Now for your custom code...\n self.filename = filename\n self.matches = errors\n\ndef build_match(filename, message, line_number, column_number, key):\n return cfnlint.rules.Match(\n line_number + 1, column_number + 1, line_number + 1,\n column_number + 1 + len(key), filename, cfnlint.rules.ParseError(), message=message)\n\nclass NodeConstructor(SafeConstructor):\n \"\"\"\n Node Constructors for loading different types in Yaml\n \"\"\"\n\n def __init__(self, filename):\n # Call the base class constructor\n super(NodeConstructor, self).__init__()\n\n self.filename = filename\n\n # To support lazy loading, the original constructors first yield\n # an empty object, then fill them in when iterated. Due to\n # laziness we omit this behaviour (and will only do \"deep\n # construction\") by first exhausting iterators, then yielding\n # copies.\n def construct_yaml_map(self, node):\n\n # Check for duplicate keys on the current level, this is not desirable\n # because a dict does not support this. It overwrites it with the last\n # occurance, which can give unexpected results\n mapping = {}\n self.flatten_mapping(node)\n for key_node, value_node in node.value:\n key = self.construct_object(key_node, False)\n value = self.construct_object(value_node, False)\n\n if key in mapping:\n raise CfnParseError(\n self.filename,\n [\n build_match(\n filename=self.filename,\n message='Duplicate resource found \"{}\" (line {})'.format(\n key, key_node.start_mark.line + 1),\n line_number=key_node.start_mark.line,\n column_number=key_node.start_mark.column,\n key=key\n ),\n build_match(\n filename=self.filename,\n message='Duplicate resource found \"{}\" (line {})'.format(\n key, mapping[key].start_mark.line + 1),\n line_number=mapping[key].start_mark.line,\n column_number=mapping[key].start_mark.column,\n key=key\n )\n ]\n )\n mapping[key] = value\n\n obj, = SafeConstructor.construct_yaml_map(self, node)\n return dict_node(obj, node.start_mark, node.end_mark)\n\n def construct_yaml_str(self, node):\n obj = SafeConstructor.construct_yaml_str(self, node)\n assert isinstance(obj, (six.string_types))\n return str_node(obj, node.start_mark, node.end_mark)\n\n def construct_yaml_seq(self, node):\n obj, = SafeConstructor.construct_yaml_seq(self, node)\n assert isinstance(obj, list)\n return list_node(obj, node.start_mark, node.end_mark)\n\n def construct_yaml_null_error(self, node):\n \"\"\"Throw a null error\"\"\"\n raise CfnParseError(\n self.filename,\n [\n build_match(\n filename=self.filename,\n message='Null value at line {0} column {1}'.format(\n node.start_mark.line + 1, node.start_mark.column + 1),\n line_number=node.start_mark.line,\n column_number=node.start_mark.column,\n key=' ',\n )\n ]\n )\n\n\nNodeConstructor.add_constructor(\n u'tag:yaml.org,2002:map',\n NodeConstructor.construct_yaml_map)\n\nNodeConstructor.add_constructor(\n u'tag:yaml.org,2002:str',\n NodeConstructor.construct_yaml_str)\n\nNodeConstructor.add_constructor(\n u'tag:yaml.org,2002:seq',\n NodeConstructor.construct_yaml_seq)\n\nNodeConstructor.add_constructor(\n u'tag:yaml.org,2002:null',\n NodeConstructor.construct_yaml_null_error)\n\n\nclass MarkedLoader(Reader, Scanner, Parser, Composer, NodeConstructor, Resolver):\n \"\"\"\n Class for marked loading YAML\n \"\"\"\n # pylint: disable=non-parent-init-called,super-init-not-called\n\n def __init__(self, stream, filename):\n Reader.__init__(self, stream)\n Scanner.__init__(self)\n if cyaml:\n Parser.__init__(self, stream)\n else:\n Parser.__init__(self)\n Composer.__init__(self)\n SafeConstructor.__init__(self)\n Resolver.__init__(self)\n NodeConstructor.__init__(self, filename)\n\n\ndef multi_constructor(loader, tag_suffix, node):\n \"\"\"\n Deal with !Ref style function format\n \"\"\"\n\n if tag_suffix not in UNCONVERTED_SUFFIXES:\n tag_suffix = '{}{}'.format(FN_PREFIX, tag_suffix)\n\n constructor = None\n if tag_suffix == 'Fn::GetAtt':\n constructor = construct_getatt\n elif isinstance(node, ScalarNode):\n constructor = loader.construct_scalar\n elif isinstance(node, SequenceNode):\n constructor = loader.construct_sequence\n elif isinstance(node, MappingNode):\n constructor = loader.construct_mapping\n else:\n raise 'Bad tag: !{}'.format(tag_suffix)\n\n return dict_node({tag_suffix: constructor(node)}, node.start_mark, node.end_mark)\n\n\ndef construct_getatt(node):\n \"\"\"\n Reconstruct !GetAtt into a list\n \"\"\"\n\n if isinstance(node.value, (six.string_types)):\n return list_node(node.value.split('.', 1), node.start_mark, node.end_mark)\n if isinstance(node.value, list):\n return list_node([s.value for s in node.value], node.start_mark, node.end_mark)\n\n raise ValueError('Unexpected node type: {}'.format(type(node.value)))\n\n\ndef loads(yaml_string, fname=None):\n \"\"\"\n Load the given YAML string\n \"\"\"\n loader = MarkedLoader(yaml_string, fname)\n loader.add_multi_constructor('!', multi_constructor)\n template = loader.get_single_data()\n # Convert an empty file to an empty dict\n if template is None:\n template = {}\n\n return template\n\n\ndef load(filename):\n \"\"\"\n Load the given YAML file\n \"\"\"\n\n content = ''\n\n if not sys.stdin.isatty():\n for line in fileinput.input(files=filename):\n content = content + line\n else:\n with open(filename) as fp:\n content = fp.read()\n\n return loads(content, filename)\n", "path": "src/cfnlint/decode/cfn_yaml.py"}]}
| 3,928 | 449 |
gh_patches_debug_12075
|
rasdani/github-patches
|
git_diff
|
urllib3__urllib3-3333
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Emscripten support emits an InsecureRequestWarning even when using HTTPS
This is a side-effect of us using JavaScript APIs instead of Python TLS and setting `is_verified` on the `EmscriptenHTTPConnection` so urllib3 is emitting an `InsecureRequestWarning` for every request, even ones that are using HTTPS.
* Set the proper value of `is_verified` depending on whether the request is HTTP or HTTPS.
* Add a test case that asserts that an `InsecureRequestWarning` is emitted for HTTP and isn't emitted for HTTPS.
</issue>
<code>
[start of src/urllib3/contrib/emscripten/connection.py]
1 from __future__ import annotations
2
3 import os
4 import typing
5
6 # use http.client.HTTPException for consistency with non-emscripten
7 from http.client import HTTPException as HTTPException # noqa: F401
8 from http.client import ResponseNotReady
9
10 from ..._base_connection import _TYPE_BODY
11 from ...connection import HTTPConnection, ProxyConfig, port_by_scheme
12 from ...exceptions import TimeoutError
13 from ...response import BaseHTTPResponse
14 from ...util.connection import _TYPE_SOCKET_OPTIONS
15 from ...util.timeout import _DEFAULT_TIMEOUT, _TYPE_TIMEOUT
16 from ...util.url import Url
17 from .fetch import _RequestError, _TimeoutError, send_request, send_streaming_request
18 from .request import EmscriptenRequest
19 from .response import EmscriptenHttpResponseWrapper, EmscriptenResponse
20
21 if typing.TYPE_CHECKING:
22 from ..._base_connection import BaseHTTPConnection, BaseHTTPSConnection
23
24
25 class EmscriptenHTTPConnection:
26 default_port: typing.ClassVar[int] = port_by_scheme["http"]
27 default_socket_options: typing.ClassVar[_TYPE_SOCKET_OPTIONS]
28
29 timeout: None | (float)
30
31 host: str
32 port: int
33 blocksize: int
34 source_address: tuple[str, int] | None
35 socket_options: _TYPE_SOCKET_OPTIONS | None
36
37 proxy: Url | None
38 proxy_config: ProxyConfig | None
39
40 is_verified: bool = False
41 proxy_is_verified: bool | None = None
42
43 _response: EmscriptenResponse | None
44
45 def __init__(
46 self,
47 host: str,
48 port: int = 0,
49 *,
50 timeout: _TYPE_TIMEOUT = _DEFAULT_TIMEOUT,
51 source_address: tuple[str, int] | None = None,
52 blocksize: int = 8192,
53 socket_options: _TYPE_SOCKET_OPTIONS | None = None,
54 proxy: Url | None = None,
55 proxy_config: ProxyConfig | None = None,
56 ) -> None:
57 self.host = host
58 self.port = port
59 self.timeout = timeout if isinstance(timeout, float) else 0.0
60 self.scheme = "http"
61 self._closed = True
62 self._response = None
63 # ignore these things because we don't
64 # have control over that stuff
65 self.proxy = None
66 self.proxy_config = None
67 self.blocksize = blocksize
68 self.source_address = None
69 self.socket_options = None
70
71 def set_tunnel(
72 self,
73 host: str,
74 port: int | None = 0,
75 headers: typing.Mapping[str, str] | None = None,
76 scheme: str = "http",
77 ) -> None:
78 pass
79
80 def connect(self) -> None:
81 pass
82
83 def request(
84 self,
85 method: str,
86 url: str,
87 body: _TYPE_BODY | None = None,
88 headers: typing.Mapping[str, str] | None = None,
89 # We know *at least* botocore is depending on the order of the
90 # first 3 parameters so to be safe we only mark the later ones
91 # as keyword-only to ensure we have space to extend.
92 *,
93 chunked: bool = False,
94 preload_content: bool = True,
95 decode_content: bool = True,
96 enforce_content_length: bool = True,
97 ) -> None:
98 self._closed = False
99 if url.startswith("/"):
100 # no scheme / host / port included, make a full url
101 url = f"{self.scheme}://{self.host}:{self.port}" + url
102 request = EmscriptenRequest(
103 url=url,
104 method=method,
105 timeout=self.timeout if self.timeout else 0,
106 decode_content=decode_content,
107 )
108 request.set_body(body)
109 if headers:
110 for k, v in headers.items():
111 request.set_header(k, v)
112 self._response = None
113 try:
114 if not preload_content:
115 self._response = send_streaming_request(request)
116 if self._response is None:
117 self._response = send_request(request)
118 except _TimeoutError as e:
119 raise TimeoutError(e.message) from e
120 except _RequestError as e:
121 raise HTTPException(e.message) from e
122
123 def getresponse(self) -> BaseHTTPResponse:
124 if self._response is not None:
125 return EmscriptenHttpResponseWrapper(
126 internal_response=self._response,
127 url=self._response.request.url,
128 connection=self,
129 )
130 else:
131 raise ResponseNotReady()
132
133 def close(self) -> None:
134 self._closed = True
135 self._response = None
136
137 @property
138 def is_closed(self) -> bool:
139 """Whether the connection either is brand new or has been previously closed.
140 If this property is True then both ``is_connected`` and ``has_connected_to_proxy``
141 properties must be False.
142 """
143 return self._closed
144
145 @property
146 def is_connected(self) -> bool:
147 """Whether the connection is actively connected to any origin (proxy or target)"""
148 return True
149
150 @property
151 def has_connected_to_proxy(self) -> bool:
152 """Whether the connection has successfully connected to its proxy.
153 This returns False if no proxy is in use. Used to determine whether
154 errors are coming from the proxy layer or from tunnelling to the target origin.
155 """
156 return False
157
158
159 class EmscriptenHTTPSConnection(EmscriptenHTTPConnection):
160 default_port = port_by_scheme["https"]
161 # all this is basically ignored, as browser handles https
162 cert_reqs: int | str | None = None
163 ca_certs: str | None = None
164 ca_cert_dir: str | None = None
165 ca_cert_data: None | str | bytes = None
166 cert_file: str | None
167 key_file: str | None
168 key_password: str | None
169 ssl_context: typing.Any | None
170 ssl_version: int | str | None = None
171 ssl_minimum_version: int | None = None
172 ssl_maximum_version: int | None = None
173 assert_hostname: None | str | typing.Literal[False]
174 assert_fingerprint: str | None = None
175
176 def __init__(
177 self,
178 host: str,
179 port: int = 0,
180 *,
181 timeout: _TYPE_TIMEOUT = _DEFAULT_TIMEOUT,
182 source_address: tuple[str, int] | None = None,
183 blocksize: int = 16384,
184 socket_options: None
185 | _TYPE_SOCKET_OPTIONS = HTTPConnection.default_socket_options,
186 proxy: Url | None = None,
187 proxy_config: ProxyConfig | None = None,
188 cert_reqs: int | str | None = None,
189 assert_hostname: None | str | typing.Literal[False] = None,
190 assert_fingerprint: str | None = None,
191 server_hostname: str | None = None,
192 ssl_context: typing.Any | None = None,
193 ca_certs: str | None = None,
194 ca_cert_dir: str | None = None,
195 ca_cert_data: None | str | bytes = None,
196 ssl_minimum_version: int | None = None,
197 ssl_maximum_version: int | None = None,
198 ssl_version: int | str | None = None, # Deprecated
199 cert_file: str | None = None,
200 key_file: str | None = None,
201 key_password: str | None = None,
202 ) -> None:
203 super().__init__(
204 host,
205 port=port,
206 timeout=timeout,
207 source_address=source_address,
208 blocksize=blocksize,
209 socket_options=socket_options,
210 proxy=proxy,
211 proxy_config=proxy_config,
212 )
213 self.scheme = "https"
214
215 self.key_file = key_file
216 self.cert_file = cert_file
217 self.key_password = key_password
218 self.ssl_context = ssl_context
219 self.server_hostname = server_hostname
220 self.assert_hostname = assert_hostname
221 self.assert_fingerprint = assert_fingerprint
222 self.ssl_version = ssl_version
223 self.ssl_minimum_version = ssl_minimum_version
224 self.ssl_maximum_version = ssl_maximum_version
225 self.ca_certs = ca_certs and os.path.expanduser(ca_certs)
226 self.ca_cert_dir = ca_cert_dir and os.path.expanduser(ca_cert_dir)
227 self.ca_cert_data = ca_cert_data
228
229 self.cert_reqs = None
230
231 def set_cert(
232 self,
233 key_file: str | None = None,
234 cert_file: str | None = None,
235 cert_reqs: int | str | None = None,
236 key_password: str | None = None,
237 ca_certs: str | None = None,
238 assert_hostname: None | str | typing.Literal[False] = None,
239 assert_fingerprint: str | None = None,
240 ca_cert_dir: str | None = None,
241 ca_cert_data: None | str | bytes = None,
242 ) -> None:
243 pass
244
245
246 # verify that this class implements BaseHTTP(s) connection correctly
247 if typing.TYPE_CHECKING:
248 _supports_http_protocol: BaseHTTPConnection = EmscriptenHTTPConnection("", 0)
249 _supports_https_protocol: BaseHTTPSConnection = EmscriptenHTTPSConnection("", 0)
250
[end of src/urllib3/contrib/emscripten/connection.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/urllib3/contrib/emscripten/connection.py b/src/urllib3/contrib/emscripten/connection.py
--- a/src/urllib3/contrib/emscripten/connection.py
+++ b/src/urllib3/contrib/emscripten/connection.py
@@ -67,6 +67,7 @@
self.blocksize = blocksize
self.source_address = None
self.socket_options = None
+ self.is_verified = False
def set_tunnel(
self,
@@ -228,6 +229,10 @@
self.cert_reqs = None
+ # The browser will automatically verify all requests.
+ # We have no control over that setting.
+ self.is_verified = True
+
def set_cert(
self,
key_file: str | None = None,
|
{"golden_diff": "diff --git a/src/urllib3/contrib/emscripten/connection.py b/src/urllib3/contrib/emscripten/connection.py\n--- a/src/urllib3/contrib/emscripten/connection.py\n+++ b/src/urllib3/contrib/emscripten/connection.py\n@@ -67,6 +67,7 @@\n self.blocksize = blocksize\n self.source_address = None\n self.socket_options = None\n+ self.is_verified = False\n \n def set_tunnel(\n self,\n@@ -228,6 +229,10 @@\n \n self.cert_reqs = None\n \n+ # The browser will automatically verify all requests.\n+ # We have no control over that setting.\n+ self.is_verified = True\n+\n def set_cert(\n self,\n key_file: str | None = None,\n", "issue": "Emscripten support emits an InsecureRequestWarning even when using HTTPS\nThis is a side-effect of us using JavaScript APIs instead of Python TLS and setting `is_verified` on the `EmscriptenHTTPConnection` so urllib3 is emitting an `InsecureRequestWarning` for every request, even ones that are using HTTPS.\r\n\r\n* Set the proper value of `is_verified` depending on whether the request is HTTP or HTTPS.\r\n* Add a test case that asserts that an `InsecureRequestWarning` is emitted for HTTP and isn't emitted for HTTPS.\r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nimport os\nimport typing\n\n# use http.client.HTTPException for consistency with non-emscripten\nfrom http.client import HTTPException as HTTPException # noqa: F401\nfrom http.client import ResponseNotReady\n\nfrom ..._base_connection import _TYPE_BODY\nfrom ...connection import HTTPConnection, ProxyConfig, port_by_scheme\nfrom ...exceptions import TimeoutError\nfrom ...response import BaseHTTPResponse\nfrom ...util.connection import _TYPE_SOCKET_OPTIONS\nfrom ...util.timeout import _DEFAULT_TIMEOUT, _TYPE_TIMEOUT\nfrom ...util.url import Url\nfrom .fetch import _RequestError, _TimeoutError, send_request, send_streaming_request\nfrom .request import EmscriptenRequest\nfrom .response import EmscriptenHttpResponseWrapper, EmscriptenResponse\n\nif typing.TYPE_CHECKING:\n from ..._base_connection import BaseHTTPConnection, BaseHTTPSConnection\n\n\nclass EmscriptenHTTPConnection:\n default_port: typing.ClassVar[int] = port_by_scheme[\"http\"]\n default_socket_options: typing.ClassVar[_TYPE_SOCKET_OPTIONS]\n\n timeout: None | (float)\n\n host: str\n port: int\n blocksize: int\n source_address: tuple[str, int] | None\n socket_options: _TYPE_SOCKET_OPTIONS | None\n\n proxy: Url | None\n proxy_config: ProxyConfig | None\n\n is_verified: bool = False\n proxy_is_verified: bool | None = None\n\n _response: EmscriptenResponse | None\n\n def __init__(\n self,\n host: str,\n port: int = 0,\n *,\n timeout: _TYPE_TIMEOUT = _DEFAULT_TIMEOUT,\n source_address: tuple[str, int] | None = None,\n blocksize: int = 8192,\n socket_options: _TYPE_SOCKET_OPTIONS | None = None,\n proxy: Url | None = None,\n proxy_config: ProxyConfig | None = None,\n ) -> None:\n self.host = host\n self.port = port\n self.timeout = timeout if isinstance(timeout, float) else 0.0\n self.scheme = \"http\"\n self._closed = True\n self._response = None\n # ignore these things because we don't\n # have control over that stuff\n self.proxy = None\n self.proxy_config = None\n self.blocksize = blocksize\n self.source_address = None\n self.socket_options = None\n\n def set_tunnel(\n self,\n host: str,\n port: int | None = 0,\n headers: typing.Mapping[str, str] | None = None,\n scheme: str = \"http\",\n ) -> None:\n pass\n\n def connect(self) -> None:\n pass\n\n def request(\n self,\n method: str,\n url: str,\n body: _TYPE_BODY | None = None,\n headers: typing.Mapping[str, str] | None = None,\n # We know *at least* botocore is depending on the order of the\n # first 3 parameters so to be safe we only mark the later ones\n # as keyword-only to ensure we have space to extend.\n *,\n chunked: bool = False,\n preload_content: bool = True,\n decode_content: bool = True,\n enforce_content_length: bool = True,\n ) -> None:\n self._closed = False\n if url.startswith(\"/\"):\n # no scheme / host / port included, make a full url\n url = f\"{self.scheme}://{self.host}:{self.port}\" + url\n request = EmscriptenRequest(\n url=url,\n method=method,\n timeout=self.timeout if self.timeout else 0,\n decode_content=decode_content,\n )\n request.set_body(body)\n if headers:\n for k, v in headers.items():\n request.set_header(k, v)\n self._response = None\n try:\n if not preload_content:\n self._response = send_streaming_request(request)\n if self._response is None:\n self._response = send_request(request)\n except _TimeoutError as e:\n raise TimeoutError(e.message) from e\n except _RequestError as e:\n raise HTTPException(e.message) from e\n\n def getresponse(self) -> BaseHTTPResponse:\n if self._response is not None:\n return EmscriptenHttpResponseWrapper(\n internal_response=self._response,\n url=self._response.request.url,\n connection=self,\n )\n else:\n raise ResponseNotReady()\n\n def close(self) -> None:\n self._closed = True\n self._response = None\n\n @property\n def is_closed(self) -> bool:\n \"\"\"Whether the connection either is brand new or has been previously closed.\n If this property is True then both ``is_connected`` and ``has_connected_to_proxy``\n properties must be False.\n \"\"\"\n return self._closed\n\n @property\n def is_connected(self) -> bool:\n \"\"\"Whether the connection is actively connected to any origin (proxy or target)\"\"\"\n return True\n\n @property\n def has_connected_to_proxy(self) -> bool:\n \"\"\"Whether the connection has successfully connected to its proxy.\n This returns False if no proxy is in use. Used to determine whether\n errors are coming from the proxy layer or from tunnelling to the target origin.\n \"\"\"\n return False\n\n\nclass EmscriptenHTTPSConnection(EmscriptenHTTPConnection):\n default_port = port_by_scheme[\"https\"]\n # all this is basically ignored, as browser handles https\n cert_reqs: int | str | None = None\n ca_certs: str | None = None\n ca_cert_dir: str | None = None\n ca_cert_data: None | str | bytes = None\n cert_file: str | None\n key_file: str | None\n key_password: str | None\n ssl_context: typing.Any | None\n ssl_version: int | str | None = None\n ssl_minimum_version: int | None = None\n ssl_maximum_version: int | None = None\n assert_hostname: None | str | typing.Literal[False]\n assert_fingerprint: str | None = None\n\n def __init__(\n self,\n host: str,\n port: int = 0,\n *,\n timeout: _TYPE_TIMEOUT = _DEFAULT_TIMEOUT,\n source_address: tuple[str, int] | None = None,\n blocksize: int = 16384,\n socket_options: None\n | _TYPE_SOCKET_OPTIONS = HTTPConnection.default_socket_options,\n proxy: Url | None = None,\n proxy_config: ProxyConfig | None = None,\n cert_reqs: int | str | None = None,\n assert_hostname: None | str | typing.Literal[False] = None,\n assert_fingerprint: str | None = None,\n server_hostname: str | None = None,\n ssl_context: typing.Any | None = None,\n ca_certs: str | None = None,\n ca_cert_dir: str | None = None,\n ca_cert_data: None | str | bytes = None,\n ssl_minimum_version: int | None = None,\n ssl_maximum_version: int | None = None,\n ssl_version: int | str | None = None, # Deprecated\n cert_file: str | None = None,\n key_file: str | None = None,\n key_password: str | None = None,\n ) -> None:\n super().__init__(\n host,\n port=port,\n timeout=timeout,\n source_address=source_address,\n blocksize=blocksize,\n socket_options=socket_options,\n proxy=proxy,\n proxy_config=proxy_config,\n )\n self.scheme = \"https\"\n\n self.key_file = key_file\n self.cert_file = cert_file\n self.key_password = key_password\n self.ssl_context = ssl_context\n self.server_hostname = server_hostname\n self.assert_hostname = assert_hostname\n self.assert_fingerprint = assert_fingerprint\n self.ssl_version = ssl_version\n self.ssl_minimum_version = ssl_minimum_version\n self.ssl_maximum_version = ssl_maximum_version\n self.ca_certs = ca_certs and os.path.expanduser(ca_certs)\n self.ca_cert_dir = ca_cert_dir and os.path.expanduser(ca_cert_dir)\n self.ca_cert_data = ca_cert_data\n\n self.cert_reqs = None\n\n def set_cert(\n self,\n key_file: str | None = None,\n cert_file: str | None = None,\n cert_reqs: int | str | None = None,\n key_password: str | None = None,\n ca_certs: str | None = None,\n assert_hostname: None | str | typing.Literal[False] = None,\n assert_fingerprint: str | None = None,\n ca_cert_dir: str | None = None,\n ca_cert_data: None | str | bytes = None,\n ) -> None:\n pass\n\n\n# verify that this class implements BaseHTTP(s) connection correctly\nif typing.TYPE_CHECKING:\n _supports_http_protocol: BaseHTTPConnection = EmscriptenHTTPConnection(\"\", 0)\n _supports_https_protocol: BaseHTTPSConnection = EmscriptenHTTPSConnection(\"\", 0)\n", "path": "src/urllib3/contrib/emscripten/connection.py"}]}
| 3,315 | 183 |
gh_patches_debug_1565
|
rasdani/github-patches
|
git_diff
|
kserve__kserve-3020
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
response id in response should return request id if present
/kind bug
**What steps did you take and what happened:**
[A clear and concise description of what the bug is.]
When a request is sent with request id, the response should contain the request id so that the response and request can be easily co-related. Most frameworks and applications return the request id as the response id.
**What did you expect to happen:**
Return a generated uuid as response id if no request id is sent but return the request id if available.
**Environment:**
- KServe Version: 0.10.1
</issue>
<code>
[start of python/kserve/kserve/utils/utils.py]
1 # Copyright 2021 The KServe Authors.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import os
16 import sys
17 import uuid
18 from kserve.protocol.grpc.grpc_predict_v2_pb2 import InferParameter
19 from typing import Dict, Union
20
21 from kserve.utils.numpy_codec import from_np_dtype
22 import pandas as pd
23 import numpy as np
24 import psutil
25 from cloudevents.conversion import to_binary, to_structured
26 from cloudevents.http import CloudEvent
27 from grpc import ServicerContext
28 from kserve.protocol.infer_type import InferOutput, InferRequest, InferResponse
29
30
31 def is_running_in_k8s():
32 return os.path.isdir('/var/run/secrets/kubernetes.io/')
33
34
35 def get_current_k8s_namespace():
36 with open('/var/run/secrets/kubernetes.io/serviceaccount/namespace', 'r') as f:
37 return f.readline()
38
39
40 def get_default_target_namespace():
41 if not is_running_in_k8s():
42 return 'default'
43 return get_current_k8s_namespace()
44
45
46 def get_isvc_namespace(inferenceservice):
47 return inferenceservice.metadata.namespace or get_default_target_namespace()
48
49
50 def get_ig_namespace(inferencegraph):
51 return inferencegraph.metadata.namespace or get_default_target_namespace()
52
53
54 def cpu_count():
55 """Get the available CPU count for this system.
56 Takes the minimum value from the following locations:
57 - Total system cpus available on the host.
58 - CPU Affinity (if set)
59 - Cgroups limit (if set)
60 """
61 count = os.cpu_count()
62
63 # Check CPU affinity if available
64 try:
65 affinity_count = len(psutil.Process().cpu_affinity())
66 if affinity_count > 0:
67 count = min(count, affinity_count)
68 except Exception:
69 pass
70
71 # Check cgroups if available
72 if sys.platform == "linux":
73 try:
74 with open("/sys/fs/cgroup/cpu,cpuacct/cpu.cfs_quota_us") as f:
75 quota = int(f.read())
76 with open("/sys/fs/cgroup/cpu,cpuacct/cpu.cfs_period_us") as f:
77 period = int(f.read())
78 cgroups_count = int(quota / period)
79 if cgroups_count > 0:
80 count = min(count, cgroups_count)
81 except Exception:
82 pass
83
84 return count
85
86
87 def is_structured_cloudevent(body: Dict) -> bool:
88 """Returns True if the JSON request body resembles a structured CloudEvent"""
89 return "time" in body \
90 and "type" in body \
91 and "source" in body \
92 and "id" in body \
93 and "specversion" in body \
94 and "data" in body
95
96
97 def create_response_cloudevent(model_name: str, response: Dict, req_attributes: Dict,
98 binary_event=False) -> tuple:
99 ce_attributes = {}
100
101 if os.getenv("CE_MERGE", "false").lower() == "true":
102 if binary_event:
103 ce_attributes = req_attributes
104 if "datacontenttype" in ce_attributes: # Optional field so must check
105 del ce_attributes["datacontenttype"]
106 else:
107 ce_attributes = req_attributes
108
109 # Remove these fields so we generate new ones
110 del ce_attributes["id"]
111 del ce_attributes["time"]
112
113 ce_attributes["type"] = os.getenv("CE_TYPE", "io.kserve.inference.response")
114 ce_attributes["source"] = os.getenv("CE_SOURCE", f"io.kserve.inference.{model_name}")
115
116 event = CloudEvent(ce_attributes, response)
117
118 if binary_event:
119 event_headers, event_body = to_binary(event)
120 else:
121 event_headers, event_body = to_structured(event)
122
123 return event_headers, event_body
124
125
126 def generate_uuid() -> str:
127 return str(uuid.uuid4())
128
129
130 def to_headers(context: ServicerContext) -> Dict[str, str]:
131 metadata = context.invocation_metadata()
132 if hasattr(context, "trailing_metadata"):
133 metadata += context.trailing_metadata()
134 headers = {}
135 for metadatum in metadata:
136 headers[metadatum.key] = metadatum.value
137
138 return headers
139
140
141 def get_predict_input(payload: Union[Dict, InferRequest]) -> Union[np.ndarray, pd.DataFrame]:
142 if isinstance(payload, Dict):
143 instances = payload["inputs"] if "inputs" in payload else payload["instances"]
144 if len(instances) == 0:
145 return np.array(instances)
146 if isinstance(instances[0], Dict):
147 dfs = []
148 for input in instances:
149 dfs.append(pd.DataFrame(input))
150 inputs = pd.concat(dfs, axis=0)
151 return inputs
152 else:
153 return np.array(instances)
154
155 elif isinstance(payload, InferRequest):
156 content_type = ''
157 parameters = payload.parameters
158 if parameters:
159 if isinstance(parameters.get("content_type"), InferParameter):
160 # for v2 grpc, we get InferParameter obj eg: {"content_type": string_param: "pd"}
161 content_type = str(parameters.get("content_type").string_param)
162 else:
163 # for v2 http, we get string eg: {"content_type": "pd"}
164 content_type = parameters.get("content_type")
165
166 if content_type == "pd":
167 return payload.as_dataframe()
168 else:
169 input = payload.inputs[0]
170 return input.as_numpy()
171
172
173 def get_predict_response(payload: Union[Dict, InferRequest], result: Union[np.ndarray, pd.DataFrame],
174 model_name: str) -> Union[Dict, InferResponse]:
175 if isinstance(payload, Dict):
176 infer_outputs = result
177 if isinstance(result, pd.DataFrame):
178 infer_outputs = []
179 for label, row in result.iterrows():
180 infer_outputs.append(row.to_dict())
181 elif isinstance(result, np.ndarray):
182 infer_outputs = result.tolist()
183 return {"predictions": infer_outputs}
184 elif isinstance(payload, InferRequest):
185 infer_outputs = []
186 if isinstance(result, pd.DataFrame):
187 for col in result.columns:
188 infer_output = InferOutput(
189 name=col,
190 shape=list(result[col].shape),
191 datatype=from_np_dtype(result[col].dtype),
192 data=result[col].tolist()
193 )
194 infer_outputs.append(infer_output)
195 else:
196 infer_output = InferOutput(
197 name="output-0",
198 shape=list(result.shape),
199 datatype=from_np_dtype(result.dtype),
200 data=result.flatten().tolist()
201 )
202 infer_outputs.append(infer_output)
203 return InferResponse(
204 model_name=model_name,
205 infer_outputs=infer_outputs,
206 response_id=generate_uuid()
207 )
208
209
210 def strtobool(val: str) -> bool:
211 """Convert a string representation of truth to True or False.
212
213 True values are 'y', 'yes', 't', 'true', 'on', and '1'; false values
214 are 'n', 'no', 'f', 'false', 'off', and '0'. Raises ValueError if
215 'val' is anything else.
216
217 Adapted from deprecated `distutils`
218 https://github.com/python/cpython/blob/3.11/Lib/distutils/util.py
219 """
220 val = val.lower()
221 if val in ('y', 'yes', 't', 'true', 'on', '1'):
222 return True
223 elif val in ('n', 'no', 'f', 'false', 'off', '0'):
224 return False
225 else:
226 raise ValueError("invalid truth value %r" % (val,))
227
[end of python/kserve/kserve/utils/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/python/kserve/kserve/utils/utils.py b/python/kserve/kserve/utils/utils.py
--- a/python/kserve/kserve/utils/utils.py
+++ b/python/kserve/kserve/utils/utils.py
@@ -203,7 +203,7 @@
return InferResponse(
model_name=model_name,
infer_outputs=infer_outputs,
- response_id=generate_uuid()
+ response_id=payload.id if payload.id else generate_uuid()
)
|
{"golden_diff": "diff --git a/python/kserve/kserve/utils/utils.py b/python/kserve/kserve/utils/utils.py\n--- a/python/kserve/kserve/utils/utils.py\n+++ b/python/kserve/kserve/utils/utils.py\n@@ -203,7 +203,7 @@\n return InferResponse(\n model_name=model_name,\n infer_outputs=infer_outputs,\n- response_id=generate_uuid()\n+ response_id=payload.id if payload.id else generate_uuid()\n )\n", "issue": "response id in response should return request id if present\n/kind bug\r\n\r\n**What steps did you take and what happened:**\r\n[A clear and concise description of what the bug is.]\r\n\r\nWhen a request is sent with request id, the response should contain the request id so that the response and request can be easily co-related. Most frameworks and applications return the request id as the response id.\r\n\r\n**What did you expect to happen:**\r\nReturn a generated uuid as response id if no request id is sent but return the request id if available.\r\n\r\n**Environment:**\r\n\r\n- KServe Version: 0.10.1\r\n\r\n\n", "before_files": [{"content": "# Copyright 2021 The KServe Authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\nimport sys\nimport uuid\nfrom kserve.protocol.grpc.grpc_predict_v2_pb2 import InferParameter\nfrom typing import Dict, Union\n\nfrom kserve.utils.numpy_codec import from_np_dtype\nimport pandas as pd\nimport numpy as np\nimport psutil\nfrom cloudevents.conversion import to_binary, to_structured\nfrom cloudevents.http import CloudEvent\nfrom grpc import ServicerContext\nfrom kserve.protocol.infer_type import InferOutput, InferRequest, InferResponse\n\n\ndef is_running_in_k8s():\n return os.path.isdir('/var/run/secrets/kubernetes.io/')\n\n\ndef get_current_k8s_namespace():\n with open('/var/run/secrets/kubernetes.io/serviceaccount/namespace', 'r') as f:\n return f.readline()\n\n\ndef get_default_target_namespace():\n if not is_running_in_k8s():\n return 'default'\n return get_current_k8s_namespace()\n\n\ndef get_isvc_namespace(inferenceservice):\n return inferenceservice.metadata.namespace or get_default_target_namespace()\n\n\ndef get_ig_namespace(inferencegraph):\n return inferencegraph.metadata.namespace or get_default_target_namespace()\n\n\ndef cpu_count():\n \"\"\"Get the available CPU count for this system.\n Takes the minimum value from the following locations:\n - Total system cpus available on the host.\n - CPU Affinity (if set)\n - Cgroups limit (if set)\n \"\"\"\n count = os.cpu_count()\n\n # Check CPU affinity if available\n try:\n affinity_count = len(psutil.Process().cpu_affinity())\n if affinity_count > 0:\n count = min(count, affinity_count)\n except Exception:\n pass\n\n # Check cgroups if available\n if sys.platform == \"linux\":\n try:\n with open(\"/sys/fs/cgroup/cpu,cpuacct/cpu.cfs_quota_us\") as f:\n quota = int(f.read())\n with open(\"/sys/fs/cgroup/cpu,cpuacct/cpu.cfs_period_us\") as f:\n period = int(f.read())\n cgroups_count = int(quota / period)\n if cgroups_count > 0:\n count = min(count, cgroups_count)\n except Exception:\n pass\n\n return count\n\n\ndef is_structured_cloudevent(body: Dict) -> bool:\n \"\"\"Returns True if the JSON request body resembles a structured CloudEvent\"\"\"\n return \"time\" in body \\\n and \"type\" in body \\\n and \"source\" in body \\\n and \"id\" in body \\\n and \"specversion\" in body \\\n and \"data\" in body\n\n\ndef create_response_cloudevent(model_name: str, response: Dict, req_attributes: Dict,\n binary_event=False) -> tuple:\n ce_attributes = {}\n\n if os.getenv(\"CE_MERGE\", \"false\").lower() == \"true\":\n if binary_event:\n ce_attributes = req_attributes\n if \"datacontenttype\" in ce_attributes: # Optional field so must check\n del ce_attributes[\"datacontenttype\"]\n else:\n ce_attributes = req_attributes\n\n # Remove these fields so we generate new ones\n del ce_attributes[\"id\"]\n del ce_attributes[\"time\"]\n\n ce_attributes[\"type\"] = os.getenv(\"CE_TYPE\", \"io.kserve.inference.response\")\n ce_attributes[\"source\"] = os.getenv(\"CE_SOURCE\", f\"io.kserve.inference.{model_name}\")\n\n event = CloudEvent(ce_attributes, response)\n\n if binary_event:\n event_headers, event_body = to_binary(event)\n else:\n event_headers, event_body = to_structured(event)\n\n return event_headers, event_body\n\n\ndef generate_uuid() -> str:\n return str(uuid.uuid4())\n\n\ndef to_headers(context: ServicerContext) -> Dict[str, str]:\n metadata = context.invocation_metadata()\n if hasattr(context, \"trailing_metadata\"):\n metadata += context.trailing_metadata()\n headers = {}\n for metadatum in metadata:\n headers[metadatum.key] = metadatum.value\n\n return headers\n\n\ndef get_predict_input(payload: Union[Dict, InferRequest]) -> Union[np.ndarray, pd.DataFrame]:\n if isinstance(payload, Dict):\n instances = payload[\"inputs\"] if \"inputs\" in payload else payload[\"instances\"]\n if len(instances) == 0:\n return np.array(instances)\n if isinstance(instances[0], Dict):\n dfs = []\n for input in instances:\n dfs.append(pd.DataFrame(input))\n inputs = pd.concat(dfs, axis=0)\n return inputs\n else:\n return np.array(instances)\n\n elif isinstance(payload, InferRequest):\n content_type = ''\n parameters = payload.parameters\n if parameters:\n if isinstance(parameters.get(\"content_type\"), InferParameter):\n # for v2 grpc, we get InferParameter obj eg: {\"content_type\": string_param: \"pd\"}\n content_type = str(parameters.get(\"content_type\").string_param)\n else:\n # for v2 http, we get string eg: {\"content_type\": \"pd\"}\n content_type = parameters.get(\"content_type\")\n\n if content_type == \"pd\":\n return payload.as_dataframe()\n else:\n input = payload.inputs[0]\n return input.as_numpy()\n\n\ndef get_predict_response(payload: Union[Dict, InferRequest], result: Union[np.ndarray, pd.DataFrame],\n model_name: str) -> Union[Dict, InferResponse]:\n if isinstance(payload, Dict):\n infer_outputs = result\n if isinstance(result, pd.DataFrame):\n infer_outputs = []\n for label, row in result.iterrows():\n infer_outputs.append(row.to_dict())\n elif isinstance(result, np.ndarray):\n infer_outputs = result.tolist()\n return {\"predictions\": infer_outputs}\n elif isinstance(payload, InferRequest):\n infer_outputs = []\n if isinstance(result, pd.DataFrame):\n for col in result.columns:\n infer_output = InferOutput(\n name=col,\n shape=list(result[col].shape),\n datatype=from_np_dtype(result[col].dtype),\n data=result[col].tolist()\n )\n infer_outputs.append(infer_output)\n else:\n infer_output = InferOutput(\n name=\"output-0\",\n shape=list(result.shape),\n datatype=from_np_dtype(result.dtype),\n data=result.flatten().tolist()\n )\n infer_outputs.append(infer_output)\n return InferResponse(\n model_name=model_name,\n infer_outputs=infer_outputs,\n response_id=generate_uuid()\n )\n\n\ndef strtobool(val: str) -> bool:\n \"\"\"Convert a string representation of truth to True or False.\n\n True values are 'y', 'yes', 't', 'true', 'on', and '1'; false values\n are 'n', 'no', 'f', 'false', 'off', and '0'. Raises ValueError if\n 'val' is anything else.\n\n Adapted from deprecated `distutils`\n https://github.com/python/cpython/blob/3.11/Lib/distutils/util.py\n \"\"\"\n val = val.lower()\n if val in ('y', 'yes', 't', 'true', 'on', '1'):\n return True\n elif val in ('n', 'no', 'f', 'false', 'off', '0'):\n return False\n else:\n raise ValueError(\"invalid truth value %r\" % (val,))\n", "path": "python/kserve/kserve/utils/utils.py"}]}
| 2,958 | 100 |
gh_patches_debug_2976
|
rasdani/github-patches
|
git_diff
|
qtile__qtile-1644
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Can't use asyncio event loop in widgets
I am creating a widget that uses asyncio to run some external command (with `asyncio.create_subprocess_exec`). It doesn't work, and raises the `RuntimeError("Cannot add child handler, the child watcher does not have a loop attached")` exception instead.
If my understanding of the code is correct, calling `set_event_loop` after `new_event_loop` should fix this issue, but I'm not sure whether it will cause other problems.
</issue>
<code>
[start of libqtile/core/session_manager.py]
1 import asyncio
2 import os
3
4 from libqtile import ipc
5 from libqtile.backend import base
6 from libqtile.core.manager import Qtile
7
8
9 class SessionManager:
10 def __init__(
11 self, kore: base.Core, config, *, fname: str = None, no_spawn=False, state=None
12 ) -> None:
13 """Manages a qtile session
14
15 :param kore:
16 The core backend to use for the session.
17 :param config:
18 The configuration to use for the qtile instance.
19 :param fname:
20 The file name to use as the qtile socket file.
21 :param no_spawn:
22 If the instance has already been started, then don't re-run the
23 startup once hook.
24 :param state:
25 The state to restart the qtile instance with.
26 """
27 eventloop = asyncio.new_event_loop()
28
29 self.qtile = Qtile(kore, config, eventloop, no_spawn=no_spawn, state=state)
30
31 if fname is None:
32 # Dots might appear in the host part of the display name
33 # during remote X sessions. Let's strip the host part first
34 display_name = kore.display_name
35 display_number = display_name.partition(":")[2]
36 if "." not in display_number:
37 display_name += ".0"
38 fname = ipc.find_sockfile(display_name)
39
40 if os.path.exists(fname):
41 os.unlink(fname)
42 self.server = ipc.Server(fname, self.qtile.server.call, eventloop)
43
44 def loop(self) -> None:
45 """Run the event loop"""
46 with self.server:
47 self.qtile.loop()
48
[end of libqtile/core/session_manager.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/libqtile/core/session_manager.py b/libqtile/core/session_manager.py
--- a/libqtile/core/session_manager.py
+++ b/libqtile/core/session_manager.py
@@ -25,6 +25,7 @@
The state to restart the qtile instance with.
"""
eventloop = asyncio.new_event_loop()
+ asyncio.set_event_loop(eventloop)
self.qtile = Qtile(kore, config, eventloop, no_spawn=no_spawn, state=state)
|
{"golden_diff": "diff --git a/libqtile/core/session_manager.py b/libqtile/core/session_manager.py\n--- a/libqtile/core/session_manager.py\n+++ b/libqtile/core/session_manager.py\n@@ -25,6 +25,7 @@\n The state to restart the qtile instance with.\n \"\"\"\n eventloop = asyncio.new_event_loop()\n+ asyncio.set_event_loop(eventloop)\n \n self.qtile = Qtile(kore, config, eventloop, no_spawn=no_spawn, state=state)\n", "issue": "Can't use asyncio event loop in widgets\nI am creating a widget that uses asyncio to run some external command (with `asyncio.create_subprocess_exec`). It doesn't work, and raises the `RuntimeError(\"Cannot add child handler, the child watcher does not have a loop attached\")` exception instead.\r\n\r\nIf my understanding of the code is correct, calling `set_event_loop` after `new_event_loop` should fix this issue, but I'm not sure whether it will cause other problems.\n", "before_files": [{"content": "import asyncio\nimport os\n\nfrom libqtile import ipc\nfrom libqtile.backend import base\nfrom libqtile.core.manager import Qtile\n\n\nclass SessionManager:\n def __init__(\n self, kore: base.Core, config, *, fname: str = None, no_spawn=False, state=None\n ) -> None:\n \"\"\"Manages a qtile session\n\n :param kore:\n The core backend to use for the session.\n :param config:\n The configuration to use for the qtile instance.\n :param fname:\n The file name to use as the qtile socket file.\n :param no_spawn:\n If the instance has already been started, then don't re-run the\n startup once hook.\n :param state:\n The state to restart the qtile instance with.\n \"\"\"\n eventloop = asyncio.new_event_loop()\n\n self.qtile = Qtile(kore, config, eventloop, no_spawn=no_spawn, state=state)\n\n if fname is None:\n # Dots might appear in the host part of the display name\n # during remote X sessions. Let's strip the host part first\n display_name = kore.display_name\n display_number = display_name.partition(\":\")[2]\n if \".\" not in display_number:\n display_name += \".0\"\n fname = ipc.find_sockfile(display_name)\n\n if os.path.exists(fname):\n os.unlink(fname)\n self.server = ipc.Server(fname, self.qtile.server.call, eventloop)\n\n def loop(self) -> None:\n \"\"\"Run the event loop\"\"\"\n with self.server:\n self.qtile.loop()\n", "path": "libqtile/core/session_manager.py"}]}
| 1,078 | 108 |
gh_patches_debug_17499
|
rasdani/github-patches
|
git_diff
|
pyinstaller__pyinstaller-7183
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Hooks: Runtime hook for subprocess block launching standalone cmd
<!--
Welcome to the PyInstaller issue tracker! Before creating an issue, please heed the following:
1. This tracker should only be used to report bugs and request features / enhancements to PyInstaller
- For questions and general support, use the discussions forum.
2. Use the search function before creating a new issue. Duplicates will be closed and directed to
the original discussion.
3. When making a bug report, make sure you provide all required information. The easier it is for
maintainers to reproduce, the faster it'll be fixed.
-->
<!-- +++ ONLY TEXT +++ DO NOT POST IMAGES +++ -->
## Description of the issue
In windowed build using `PySide2`, `subprocess.Popen(["cmd"])` no longer work (cmd open then close immediately). I figured out that the issue come from the subprocess hook (since v4.8, pr #6364). If I comment out this file, `cmd` start showing again and stay alive.
### Context information (for bug reports)
* Output of `pyinstaller --version`: ```5.4.1```
* Version of Python: 3.7 / 3.8 / 3.9 / 3.10
* Platform: Windows
* How you installed Python: python.org/downloads
* Did you also try this on another platform? Does it work there? → not relevant on other platform.
### A minimal example program which shows the error
A cmd shows up at start, if you comment the hook it stays alive, if you don't the cmd disappear instantly.
```
import subprocess
import sys
from PySide2 import QtWidgets
class CmdExemple(QtWidgets.QMainWindow):
def __init__(self):
super().__init__()
p = subprocess.Popen(["cmd"])
if __name__ == "__main__":
app = QtWidgets.QApplication(sys.argv)
window = CmdExemple()
window.show()
exitCode = app.exec_()
sys.exit(exitCode)
```
</issue>
<code>
[start of PyInstaller/hooks/rthooks/pyi_rth_subprocess.py]
1 #-----------------------------------------------------------------------------
2 # Copyright (c) 2021-2022, PyInstaller Development Team.
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 #
7 # The full license is in the file COPYING.txt, distributed with this software.
8 #
9 # SPDX-License-Identifier: Apache-2.0
10 #-----------------------------------------------------------------------------
11
12 import subprocess
13 import sys
14 import io
15
16
17 class Popen(subprocess.Popen):
18
19 # In windowed mode, force any unused pipes (stdin, stdout and stderr) to be DEVNULL instead of inheriting the
20 # invalid corresponding handles from this parent process.
21 if sys.platform == "win32" and not isinstance(sys.stdout, io.IOBase):
22
23 def _get_handles(self, stdin, stdout, stderr):
24 stdin, stdout, stderr = (subprocess.DEVNULL if pipe is None else pipe for pipe in (stdin, stdout, stderr))
25 return super()._get_handles(stdin, stdout, stderr)
26
27
28 subprocess.Popen = Popen
29
[end of PyInstaller/hooks/rthooks/pyi_rth_subprocess.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/PyInstaller/hooks/rthooks/pyi_rth_subprocess.py b/PyInstaller/hooks/rthooks/pyi_rth_subprocess.py
deleted file mode 100644
--- a/PyInstaller/hooks/rthooks/pyi_rth_subprocess.py
+++ /dev/null
@@ -1,28 +0,0 @@
-#-----------------------------------------------------------------------------
-# Copyright (c) 2021-2022, PyInstaller Development Team.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-#
-# The full license is in the file COPYING.txt, distributed with this software.
-#
-# SPDX-License-Identifier: Apache-2.0
-#-----------------------------------------------------------------------------
-
-import subprocess
-import sys
-import io
-
-
-class Popen(subprocess.Popen):
-
- # In windowed mode, force any unused pipes (stdin, stdout and stderr) to be DEVNULL instead of inheriting the
- # invalid corresponding handles from this parent process.
- if sys.platform == "win32" and not isinstance(sys.stdout, io.IOBase):
-
- def _get_handles(self, stdin, stdout, stderr):
- stdin, stdout, stderr = (subprocess.DEVNULL if pipe is None else pipe for pipe in (stdin, stdout, stderr))
- return super()._get_handles(stdin, stdout, stderr)
-
-
-subprocess.Popen = Popen
|
{"golden_diff": "diff --git a/PyInstaller/hooks/rthooks/pyi_rth_subprocess.py b/PyInstaller/hooks/rthooks/pyi_rth_subprocess.py\ndeleted file mode 100644\n--- a/PyInstaller/hooks/rthooks/pyi_rth_subprocess.py\n+++ /dev/null\n@@ -1,28 +0,0 @@\n-#-----------------------------------------------------------------------------\n-# Copyright (c) 2021-2022, PyInstaller Development Team.\n-#\n-# Licensed under the Apache License, Version 2.0 (the \"License\");\n-# you may not use this file except in compliance with the License.\n-#\n-# The full license is in the file COPYING.txt, distributed with this software.\n-#\n-# SPDX-License-Identifier: Apache-2.0\n-#-----------------------------------------------------------------------------\n-\n-import subprocess\n-import sys\n-import io\n-\n-\n-class Popen(subprocess.Popen):\n-\n- # In windowed mode, force any unused pipes (stdin, stdout and stderr) to be DEVNULL instead of inheriting the\n- # invalid corresponding handles from this parent process.\n- if sys.platform == \"win32\" and not isinstance(sys.stdout, io.IOBase):\n-\n- def _get_handles(self, stdin, stdout, stderr):\n- stdin, stdout, stderr = (subprocess.DEVNULL if pipe is None else pipe for pipe in (stdin, stdout, stderr))\n- return super()._get_handles(stdin, stdout, stderr)\n-\n-\n-subprocess.Popen = Popen\n", "issue": "Hooks: Runtime hook for subprocess block launching standalone cmd\n<!--\r\nWelcome to the PyInstaller issue tracker! Before creating an issue, please heed the following:\r\n\r\n1. This tracker should only be used to report bugs and request features / enhancements to PyInstaller\r\n - For questions and general support, use the discussions forum.\r\n2. Use the search function before creating a new issue. Duplicates will be closed and directed to\r\n the original discussion.\r\n3. When making a bug report, make sure you provide all required information. The easier it is for\r\n maintainers to reproduce, the faster it'll be fixed.\r\n-->\r\n\r\n<!-- +++ ONLY TEXT +++ DO NOT POST IMAGES +++ -->\r\n\r\n## Description of the issue\r\nIn windowed build using `PySide2`, `subprocess.Popen([\"cmd\"])` no longer work (cmd open then close immediately). I figured out that the issue come from the subprocess hook (since v4.8, pr #6364). If I comment out this file, `cmd` start showing again and stay alive.\r\n\r\n### Context information (for bug reports)\r\n\r\n* Output of `pyinstaller --version`: ```5.4.1```\r\n* Version of Python: 3.7 / 3.8 / 3.9 / 3.10\r\n* Platform: Windows\r\n* How you installed Python: python.org/downloads\r\n* Did you also try this on another platform? Does it work there? \u2192 not relevant on other platform.\r\n\r\n### A minimal example program which shows the error\r\nA cmd shows up at start, if you comment the hook it stays alive, if you don't the cmd disappear instantly.\r\n\r\n```\r\nimport subprocess\r\nimport sys\r\n\r\nfrom PySide2 import QtWidgets\r\n\r\nclass CmdExemple(QtWidgets.QMainWindow):\r\n def __init__(self):\r\n super().__init__()\r\n p = subprocess.Popen([\"cmd\"])\r\n\r\nif __name__ == \"__main__\":\r\n app = QtWidgets.QApplication(sys.argv)\r\n window = CmdExemple()\r\n window.show()\r\n exitCode = app.exec_()\r\n sys.exit(exitCode)\r\n```\r\n\n", "before_files": [{"content": "#-----------------------------------------------------------------------------\n# Copyright (c) 2021-2022, PyInstaller Development Team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n#\n# The full license is in the file COPYING.txt, distributed with this software.\n#\n# SPDX-License-Identifier: Apache-2.0\n#-----------------------------------------------------------------------------\n\nimport subprocess\nimport sys\nimport io\n\n\nclass Popen(subprocess.Popen):\n\n # In windowed mode, force any unused pipes (stdin, stdout and stderr) to be DEVNULL instead of inheriting the\n # invalid corresponding handles from this parent process.\n if sys.platform == \"win32\" and not isinstance(sys.stdout, io.IOBase):\n\n def _get_handles(self, stdin, stdout, stderr):\n stdin, stdout, stderr = (subprocess.DEVNULL if pipe is None else pipe for pipe in (stdin, stdout, stderr))\n return super()._get_handles(stdin, stdout, stderr)\n\n\nsubprocess.Popen = Popen\n", "path": "PyInstaller/hooks/rthooks/pyi_rth_subprocess.py"}]}
| 1,259 | 322 |
gh_patches_debug_14873
|
rasdani/github-patches
|
git_diff
|
TencentBlueKing__bk-user-410
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[优化] HTTP API 数据源同步报错
对应API 没有按照要求, 返回`count/results`, 此时取空
实际上这里的逻辑会`results`的第一条, 处理; 但是没有很好地校验
会报错
```
Task bkuser_core.categories.tasks.adapter_sync[78744136-5e83-4605-8503-d4d8ed90f9e3] raised unexpected: IndexError('list index out of range',)
Traceback (most recent call last):
File "/usr/local/lib/python3.6/site-packages/celery/app/trace.py", line 412, in trace_task
R = retval = fun(*args, **kwargs)
File "/usr/local/lib/python3.6/site-packages/celery/app/trace.py", line 704, in __protected_call__
return self.run(*args, **kwargs)
File "/usr/local/lib/python3.6/site-packages/celery/app/autoretry.py", line 50, in run
raise task.retry(exc=exc, **retry_kwargs)
File "/usr/local/lib/python3.6/site-packages/celery/app/task.py", line 706, in retry
raise_with_context(exc)
File "/usr/local/lib/python3.6/site-packages/celery/app/autoretry.py", line 35, in run
return task._orig_run(*args, **kwargs)
File "/app/bkuser_core/categories/tasks.py", line 111, in adapter_sync
plugin.sync(instance_id=instance_id, task_id=task_id, *args, **kwargs)
File "/app/bkuser_core/categories/plugins/plugin.py", line 124, in sync
syncer.sync(*args, **kwargs)
File "/app/bkuser_core/categories/plugins/custom/sycner.py", line 45, in sync
self._sync_department()
File "/app/bkuser_core/categories/plugins/custom/sycner.py", line 50, in _sync_department
self._load2sync_manager(self.client.fetch_departments())
File "/app/bkuser_core/categories/plugins/custom/sycner.py", line 74, in _load2sync_manager
category=self.category, db_sync_manager=self.db_sync_manager, items=items, context=self.context
File "/app/bkuser_core/categories/plugins/custom/helpers.py", line 277, in init_helper
return _map[items.custom_type](
File "/app/bkuser_core/categories/plugins/custom/models.py", line 81, in custom_type
return type(list(self.items_map.values())[0])
IndexError: list index out of range
```
</issue>
<code>
[start of src/api/bkuser_core/categories/plugins/custom/client.py]
1 # -*- coding: utf-8 -*-
2 """
3 TencentBlueKing is pleased to support the open source community by making 蓝鲸智云-用户管理(Bk-User) available.
4 Copyright (C) 2017-2021 THL A29 Limited, a Tencent company. All rights reserved.
5 Licensed under the MIT License (the "License"); you may not use this file except in compliance with the License.
6 You may obtain a copy of the License at http://opensource.org/licenses/MIT
7 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
8 an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
9 specific language governing permissions and limitations under the License.
10 """
11 import logging
12 from dataclasses import dataclass
13 from typing import Optional
14
15 import curlify
16 import requests
17
18 from bkuser_core.categories.plugins.custom.exceptions import CustomAPIRequestFailed
19 from bkuser_core.categories.plugins.custom.models import CustomDepartment, CustomProfile, CustomTypeList
20 from bkuser_core.user_settings.loader import ConfigProvider
21
22 logger = logging.getLogger(__name__)
23
24
25 @dataclass
26 class PageInfo:
27 page: int
28 page_size: int
29
30
31 @dataclass
32 class CustomDataClient:
33 category_id: int
34 api_host: str
35 paths: dict
36
37 @classmethod
38 def from_config(cls):
39 """从配置中创建客户端"""
40
41 def __post_init__(self):
42 self.config_loader = ConfigProvider(self.category_id)
43
44 def _fetch_items(self, path: str):
45 url = "/".join(s.strip("/") for s in [self.api_host, path])
46 resp = requests.get(url, timeout=30)
47
48 curl_format = curlify.to_curl(resp.request)
49 logger.debug("going to call: %s", url)
50 if resp.status_code >= 400:
51 logger.error(
52 "failed to request api, status code: %s cUrl format: %s",
53 resp.status_code,
54 curl_format,
55 )
56 raise CustomAPIRequestFailed()
57
58 try:
59 resp_body = resp.json()
60 except Exception as e:
61 logger.exception("failed to parse resp as json, cUrl format: %s", curl_format)
62 raise CustomAPIRequestFailed() from e
63
64 # results not present in response body
65 if "results" not in resp_body:
66 logger.error("no `results` in response, cUrl format: %s", curl_format)
67 raise CustomAPIRequestFailed("there got no `results` in response body")
68
69 results = resp_body.get("results", [])
70 # results not a list
71 if not isinstance(results, list):
72 logger.error("`results` in response is not a list, cUrl format: %s", curl_format)
73 raise CustomAPIRequestFailed("the `results` in response is not a list")
74
75 return results
76
77 def fetch_profiles(self, page_info: Optional[PageInfo] = None) -> CustomTypeList:
78 """获取 profile 对象列表"""
79 results = self._fetch_items(path=self.paths["profile"])
80 return CustomTypeList.from_list([CustomProfile.from_dict(x) for x in results])
81
82 def fetch_departments(self, page_info: Optional[PageInfo] = None) -> CustomTypeList:
83 """获取 department 对象列表"""
84 results = self._fetch_items(path=self.paths["department"])
85 return CustomTypeList.from_list([CustomDepartment.from_dict(x) for x in results])
86
[end of src/api/bkuser_core/categories/plugins/custom/client.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/api/bkuser_core/categories/plugins/custom/client.py b/src/api/bkuser_core/categories/plugins/custom/client.py
--- a/src/api/bkuser_core/categories/plugins/custom/client.py
+++ b/src/api/bkuser_core/categories/plugins/custom/client.py
@@ -72,6 +72,12 @@
logger.error("`results` in response is not a list, cUrl format: %s", curl_format)
raise CustomAPIRequestFailed("the `results` in response is not a list")
+ # currently, if the results is empty, CustomTypeList.custom_type will raise IndexError(task fail)
+ # so, here, we should check here: results size should not be empty
+ if not results:
+ logger.error("`results` in response is empty, cUrl format: %s", curl_format)
+ raise CustomAPIRequestFailed("the `results` in response is empty")
+
return results
def fetch_profiles(self, page_info: Optional[PageInfo] = None) -> CustomTypeList:
|
{"golden_diff": "diff --git a/src/api/bkuser_core/categories/plugins/custom/client.py b/src/api/bkuser_core/categories/plugins/custom/client.py\n--- a/src/api/bkuser_core/categories/plugins/custom/client.py\n+++ b/src/api/bkuser_core/categories/plugins/custom/client.py\n@@ -72,6 +72,12 @@\n logger.error(\"`results` in response is not a list, cUrl format: %s\", curl_format)\n raise CustomAPIRequestFailed(\"the `results` in response is not a list\")\n \n+ # currently, if the results is empty, CustomTypeList.custom_type will raise IndexError(task fail)\n+ # so, here, we should check here: results size should not be empty\n+ if not results:\n+ logger.error(\"`results` in response is empty, cUrl format: %s\", curl_format)\n+ raise CustomAPIRequestFailed(\"the `results` in response is empty\")\n+\n return results\n \n def fetch_profiles(self, page_info: Optional[PageInfo] = None) -> CustomTypeList:\n", "issue": "[\u4f18\u5316] HTTP API \u6570\u636e\u6e90\u540c\u6b65\u62a5\u9519\n\u5bf9\u5e94API \u6ca1\u6709\u6309\u7167\u8981\u6c42, \u8fd4\u56de`count/results`, \u6b64\u65f6\u53d6\u7a7a\r\n\r\n\u5b9e\u9645\u4e0a\u8fd9\u91cc\u7684\u903b\u8f91\u4f1a`results`\u7684\u7b2c\u4e00\u6761, \u5904\u7406; \u4f46\u662f\u6ca1\u6709\u5f88\u597d\u5730\u6821\u9a8c\r\n\r\n\u4f1a\u62a5\u9519\r\n\r\n```\r\nTask bkuser_core.categories.tasks.adapter_sync[78744136-5e83-4605-8503-d4d8ed90f9e3] raised unexpected: IndexError('list index out of range',)\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.6/site-packages/celery/app/trace.py\", line 412, in trace_task\r\n R = retval = fun(*args, **kwargs)\r\n File \"/usr/local/lib/python3.6/site-packages/celery/app/trace.py\", line 704, in __protected_call__\r\n return self.run(*args, **kwargs)\r\n File \"/usr/local/lib/python3.6/site-packages/celery/app/autoretry.py\", line 50, in run\r\n raise task.retry(exc=exc, **retry_kwargs)\r\n File \"/usr/local/lib/python3.6/site-packages/celery/app/task.py\", line 706, in retry\r\n raise_with_context(exc)\r\n File \"/usr/local/lib/python3.6/site-packages/celery/app/autoretry.py\", line 35, in run\r\n return task._orig_run(*args, **kwargs)\r\n File \"/app/bkuser_core/categories/tasks.py\", line 111, in adapter_sync\r\n plugin.sync(instance_id=instance_id, task_id=task_id, *args, **kwargs)\r\n File \"/app/bkuser_core/categories/plugins/plugin.py\", line 124, in sync\r\n syncer.sync(*args, **kwargs)\r\n File \"/app/bkuser_core/categories/plugins/custom/sycner.py\", line 45, in sync\r\n self._sync_department()\r\n File \"/app/bkuser_core/categories/plugins/custom/sycner.py\", line 50, in _sync_department\r\n self._load2sync_manager(self.client.fetch_departments())\r\n File \"/app/bkuser_core/categories/plugins/custom/sycner.py\", line 74, in _load2sync_manager\r\n category=self.category, db_sync_manager=self.db_sync_manager, items=items, context=self.context\r\n File \"/app/bkuser_core/categories/plugins/custom/helpers.py\", line 277, in init_helper\r\n return _map[items.custom_type](\r\n File \"/app/bkuser_core/categories/plugins/custom/models.py\", line 81, in custom_type\r\n return type(list(self.items_map.values())[0])\r\nIndexError: list index out of range\r\n```\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\nTencentBlueKing is pleased to support the open source community by making \u84dd\u9cb8\u667a\u4e91-\u7528\u6237\u7ba1\u7406(Bk-User) available.\nCopyright (C) 2017-2021 THL A29 Limited, a Tencent company. All rights reserved.\nLicensed under the MIT License (the \"License\"); you may not use this file except in compliance with the License.\nYou may obtain a copy of the License at http://opensource.org/licenses/MIT\nUnless required by applicable law or agreed to in writing, software distributed under the License is distributed on\nan \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the\nspecific language governing permissions and limitations under the License.\n\"\"\"\nimport logging\nfrom dataclasses import dataclass\nfrom typing import Optional\n\nimport curlify\nimport requests\n\nfrom bkuser_core.categories.plugins.custom.exceptions import CustomAPIRequestFailed\nfrom bkuser_core.categories.plugins.custom.models import CustomDepartment, CustomProfile, CustomTypeList\nfrom bkuser_core.user_settings.loader import ConfigProvider\n\nlogger = logging.getLogger(__name__)\n\n\n@dataclass\nclass PageInfo:\n page: int\n page_size: int\n\n\n@dataclass\nclass CustomDataClient:\n category_id: int\n api_host: str\n paths: dict\n\n @classmethod\n def from_config(cls):\n \"\"\"\u4ece\u914d\u7f6e\u4e2d\u521b\u5efa\u5ba2\u6237\u7aef\"\"\"\n\n def __post_init__(self):\n self.config_loader = ConfigProvider(self.category_id)\n\n def _fetch_items(self, path: str):\n url = \"/\".join(s.strip(\"/\") for s in [self.api_host, path])\n resp = requests.get(url, timeout=30)\n\n curl_format = curlify.to_curl(resp.request)\n logger.debug(\"going to call: %s\", url)\n if resp.status_code >= 400:\n logger.error(\n \"failed to request api, status code: %s cUrl format: %s\",\n resp.status_code,\n curl_format,\n )\n raise CustomAPIRequestFailed()\n\n try:\n resp_body = resp.json()\n except Exception as e:\n logger.exception(\"failed to parse resp as json, cUrl format: %s\", curl_format)\n raise CustomAPIRequestFailed() from e\n\n # results not present in response body\n if \"results\" not in resp_body:\n logger.error(\"no `results` in response, cUrl format: %s\", curl_format)\n raise CustomAPIRequestFailed(\"there got no `results` in response body\")\n\n results = resp_body.get(\"results\", [])\n # results not a list\n if not isinstance(results, list):\n logger.error(\"`results` in response is not a list, cUrl format: %s\", curl_format)\n raise CustomAPIRequestFailed(\"the `results` in response is not a list\")\n\n return results\n\n def fetch_profiles(self, page_info: Optional[PageInfo] = None) -> CustomTypeList:\n \"\"\"\u83b7\u53d6 profile \u5bf9\u8c61\u5217\u8868\"\"\"\n results = self._fetch_items(path=self.paths[\"profile\"])\n return CustomTypeList.from_list([CustomProfile.from_dict(x) for x in results])\n\n def fetch_departments(self, page_info: Optional[PageInfo] = None) -> CustomTypeList:\n \"\"\"\u83b7\u53d6 department \u5bf9\u8c61\u5217\u8868\"\"\"\n results = self._fetch_items(path=self.paths[\"department\"])\n return CustomTypeList.from_list([CustomDepartment.from_dict(x) for x in results])\n", "path": "src/api/bkuser_core/categories/plugins/custom/client.py"}]}
| 2,057 | 224 |
gh_patches_debug_15510
|
rasdani/github-patches
|
git_diff
|
searxng__searxng-2035
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bug: duckduckgo engine
**Version of SearXNG, commit number if you are using on master branch and stipulate if you forked SearXNG**
Repository: https://github.com/searxng/searxng
Branch: master
Version: 2022.09.09-eb3d185e
<!-- Check if these values are correct -->
**How did you install SearXNG?**
<!-- Did you install SearXNG using the official wiki or using searxng-docker
or manually by executing the searx/webapp.py file? -->
**What happened?**
<!-- A clear and concise description of what the bug is. -->
installed via docker / when running a search, duck duck go is sending an access denied error. this did not happen before
**How To Reproduce**
<!-- How can we reproduce this issue? (as minimally and as precisely as possible) -->
**Expected behavior**
<!-- A clear and concise description of what you expected to happen. -->
**Screenshots & Logs**
<!-- If applicable, add screenshots, logs to help explain your problem. -->
**Additional context**
<!-- Add any other context about the problem here. -->
**Technical report**
Error
* Error: httpx.ReadTimeout
* Percentage: 0
* Parameters: `(None, None, 'lite.duckduckgo.com')`
* File name: `searx/search/processors/online.py:107`
* Function: `_send_http_request`
* Code: `response = req(params['url'], **request_args)`
Error
* Error: searx.exceptions.SearxEngineAccessDeniedException
* Percentage: 0
* Parameters: `('HTTP error 403',)`
* File name: `searx/search/processors/online.py:107`
* Function: `_send_http_request`
* Code: `response = req(params['url'], **request_args)`
Bug: duckduckgo engine
**Version of SearXNG, commit number if you are using on master branch and stipulate if you forked SearXNG**
Repository: https://github.com/searxng/searxng
Branch: master
Version: 2022.09.09-eb3d185e
<!-- Check if these values are correct -->
**How did you install SearXNG?**
<!-- Did you install SearXNG using the official wiki or using searxng-docker
or manually by executing the searx/webapp.py file? -->
**What happened?**
<!-- A clear and concise description of what the bug is. -->
installed via docker / when running a search, duck duck go is sending an access denied error. this did not happen before
**How To Reproduce**
<!-- How can we reproduce this issue? (as minimally and as precisely as possible) -->
**Expected behavior**
<!-- A clear and concise description of what you expected to happen. -->
**Screenshots & Logs**
<!-- If applicable, add screenshots, logs to help explain your problem. -->
**Additional context**
<!-- Add any other context about the problem here. -->
**Technical report**
Error
* Error: httpx.ReadTimeout
* Percentage: 0
* Parameters: `(None, None, 'lite.duckduckgo.com')`
* File name: `searx/search/processors/online.py:107`
* Function: `_send_http_request`
* Code: `response = req(params['url'], **request_args)`
Error
* Error: searx.exceptions.SearxEngineAccessDeniedException
* Percentage: 0
* Parameters: `('HTTP error 403',)`
* File name: `searx/search/processors/online.py:107`
* Function: `_send_http_request`
* Code: `response = req(params['url'], **request_args)`
</issue>
<code>
[start of searx/engines/duckduckgo.py]
1 # SPDX-License-Identifier: AGPL-3.0-or-later
2 # lint: pylint
3 """DuckDuckGo Lite
4 """
5
6 from json import loads
7
8 from lxml.html import fromstring
9
10 from searx.utils import (
11 dict_subset,
12 eval_xpath,
13 eval_xpath_getindex,
14 extract_text,
15 match_language,
16 )
17 from searx.network import get
18
19 # about
20 about = {
21 "website": 'https://lite.duckduckgo.com/lite',
22 "wikidata_id": 'Q12805',
23 "official_api_documentation": 'https://duckduckgo.com/api',
24 "use_official_api": False,
25 "require_api_key": False,
26 "results": 'HTML',
27 }
28
29 # engine dependent config
30 categories = ['general', 'web']
31 paging = True
32 supported_languages_url = 'https://duckduckgo.com/util/u588.js'
33 time_range_support = True
34 send_accept_language_header = True
35
36 language_aliases = {
37 'ar-SA': 'ar-XA',
38 'es-419': 'es-XL',
39 'ja': 'jp-JP',
40 'ko': 'kr-KR',
41 'sl-SI': 'sl-SL',
42 'zh-TW': 'tzh-TW',
43 'zh-HK': 'tzh-HK',
44 }
45
46 time_range_dict = {'day': 'd', 'week': 'w', 'month': 'm', 'year': 'y'}
47
48 # search-url
49 url = 'https://lite.duckduckgo.com/lite'
50 url_ping = 'https://duckduckgo.com/t/sl_l'
51
52 # match query's language to a region code that duckduckgo will accept
53 def get_region_code(lang, lang_list=None):
54 if lang == 'all':
55 return None
56
57 lang_code = match_language(lang, lang_list or [], language_aliases, 'wt-WT')
58 lang_parts = lang_code.split('-')
59
60 # country code goes first
61 return lang_parts[1].lower() + '-' + lang_parts[0].lower()
62
63
64 def request(query, params):
65
66 params['url'] = url
67 params['method'] = 'POST'
68
69 params['data']['q'] = query
70
71 # The API is not documented, so we do some reverse engineering and emulate
72 # what https://lite.duckduckgo.com/lite/ does when you press "next Page"
73 # link again and again ..
74
75 params['headers']['Content-Type'] = 'application/x-www-form-urlencoded'
76
77 # initial page does not have an offset
78 if params['pageno'] == 2:
79 # second page does have an offset of 30
80 offset = (params['pageno'] - 1) * 30
81 params['data']['s'] = offset
82 params['data']['dc'] = offset + 1
83
84 elif params['pageno'] > 2:
85 # third and following pages do have an offset of 30 + n*50
86 offset = 30 + (params['pageno'] - 2) * 50
87 params['data']['s'] = offset
88 params['data']['dc'] = offset + 1
89
90 # initial page does not have additional data in the input form
91 if params['pageno'] > 1:
92 # request the second page (and more pages) needs 'o' and 'api' arguments
93 params['data']['o'] = 'json'
94 params['data']['api'] = 'd.js'
95
96 # initial page does not have additional data in the input form
97 if params['pageno'] > 2:
98 # request the third page (and more pages) some more arguments
99 params['data']['nextParams'] = ''
100 params['data']['v'] = ''
101 params['data']['vqd'] = ''
102
103 region_code = get_region_code(params['language'], supported_languages)
104 if region_code:
105 params['data']['kl'] = region_code
106 params['cookies']['kl'] = region_code
107
108 params['data']['df'] = ''
109 if params['time_range'] in time_range_dict:
110 params['data']['df'] = time_range_dict[params['time_range']]
111 params['cookies']['df'] = time_range_dict[params['time_range']]
112
113 logger.debug("param data: %s", params['data'])
114 logger.debug("param cookies: %s", params['cookies'])
115 return params
116
117
118 # get response from search-request
119 def response(resp):
120
121 headers_ping = dict_subset(resp.request.headers, ['User-Agent', 'Accept-Encoding', 'Accept', 'Cookie'])
122 get(url_ping, headers=headers_ping)
123
124 if resp.status_code == 303:
125 return []
126
127 results = []
128 doc = fromstring(resp.text)
129
130 result_table = eval_xpath(doc, '//html/body/form/div[@class="filters"]/table')
131 if not len(result_table) >= 3:
132 # no more results
133 return []
134 result_table = result_table[2]
135
136 tr_rows = eval_xpath(result_table, './/tr')
137
138 # In the last <tr> is the form of the 'previous/next page' links
139 tr_rows = tr_rows[:-1]
140
141 len_tr_rows = len(tr_rows)
142 offset = 0
143
144 while len_tr_rows >= offset + 4:
145
146 # assemble table rows we need to scrap
147 tr_title = tr_rows[offset]
148 tr_content = tr_rows[offset + 1]
149 offset += 4
150
151 # ignore sponsored Adds <tr class="result-sponsored">
152 if tr_content.get('class') == 'result-sponsored':
153 continue
154
155 a_tag = eval_xpath_getindex(tr_title, './/td//a[@class="result-link"]', 0, None)
156 if a_tag is None:
157 continue
158
159 td_content = eval_xpath_getindex(tr_content, './/td[@class="result-snippet"]', 0, None)
160 if td_content is None:
161 continue
162
163 results.append(
164 {
165 'title': a_tag.text_content(),
166 'content': extract_text(td_content),
167 'url': a_tag.get('href'),
168 }
169 )
170
171 return results
172
173
174 # get supported languages from their site
175 def _fetch_supported_languages(resp):
176
177 # response is a js file with regions as an embedded object
178 response_page = resp.text
179 response_page = response_page[response_page.find('regions:{') + 8 :]
180 response_page = response_page[: response_page.find('}') + 1]
181
182 regions_json = loads(response_page)
183 supported_languages = map((lambda x: x[3:] + '-' + x[:2].upper()), regions_json.keys())
184
185 return list(supported_languages)
186
[end of searx/engines/duckduckgo.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/searx/engines/duckduckgo.py b/searx/engines/duckduckgo.py
--- a/searx/engines/duckduckgo.py
+++ b/searx/engines/duckduckgo.py
@@ -18,7 +18,7 @@
# about
about = {
- "website": 'https://lite.duckduckgo.com/lite',
+ "website": 'https://lite.duckduckgo.com/lite/',
"wikidata_id": 'Q12805',
"official_api_documentation": 'https://duckduckgo.com/api',
"use_official_api": False,
@@ -46,7 +46,7 @@
time_range_dict = {'day': 'd', 'week': 'w', 'month': 'm', 'year': 'y'}
# search-url
-url = 'https://lite.duckduckgo.com/lite'
+url = 'https://lite.duckduckgo.com/lite/'
url_ping = 'https://duckduckgo.com/t/sl_l'
# match query's language to a region code that duckduckgo will accept
|
{"golden_diff": "diff --git a/searx/engines/duckduckgo.py b/searx/engines/duckduckgo.py\n--- a/searx/engines/duckduckgo.py\n+++ b/searx/engines/duckduckgo.py\n@@ -18,7 +18,7 @@\n \n # about\n about = {\n- \"website\": 'https://lite.duckduckgo.com/lite',\n+ \"website\": 'https://lite.duckduckgo.com/lite/',\n \"wikidata_id\": 'Q12805',\n \"official_api_documentation\": 'https://duckduckgo.com/api',\n \"use_official_api\": False,\n@@ -46,7 +46,7 @@\n time_range_dict = {'day': 'd', 'week': 'w', 'month': 'm', 'year': 'y'}\n \n # search-url\n-url = 'https://lite.duckduckgo.com/lite'\n+url = 'https://lite.duckduckgo.com/lite/'\n url_ping = 'https://duckduckgo.com/t/sl_l'\n \n # match query's language to a region code that duckduckgo will accept\n", "issue": "Bug: duckduckgo engine\n**Version of SearXNG, commit number if you are using on master branch and stipulate if you forked SearXNG**\r\nRepository: https://github.com/searxng/searxng\r\nBranch: master\r\nVersion: 2022.09.09-eb3d185e\r\n<!-- Check if these values are correct -->\r\n\r\n**How did you install SearXNG?**\r\n<!-- Did you install SearXNG using the official wiki or using searxng-docker\r\nor manually by executing the searx/webapp.py file? -->\r\n**What happened?**\r\n<!-- A clear and concise description of what the bug is. -->\r\ninstalled via docker / when running a search, duck duck go is sending an access denied error. this did not happen before\r\n**How To Reproduce**\r\n<!-- How can we reproduce this issue? (as minimally and as precisely as possible) -->\r\n\r\n**Expected behavior**\r\n<!-- A clear and concise description of what you expected to happen. -->\r\n\r\n**Screenshots & Logs**\r\n<!-- If applicable, add screenshots, logs to help explain your problem. -->\r\n\r\n**Additional context**\r\n<!-- Add any other context about the problem here. -->\r\n\r\n**Technical report**\r\n\r\nError\r\n * Error: httpx.ReadTimeout\r\n * Percentage: 0\r\n * Parameters: `(None, None, 'lite.duckduckgo.com')`\r\n * File name: `searx/search/processors/online.py:107`\r\n * Function: `_send_http_request`\r\n * Code: `response = req(params['url'], **request_args)`\r\n\r\nError\r\n * Error: searx.exceptions.SearxEngineAccessDeniedException\r\n * Percentage: 0\r\n * Parameters: `('HTTP error 403',)`\r\n * File name: `searx/search/processors/online.py:107`\r\n * Function: `_send_http_request`\r\n * Code: `response = req(params['url'], **request_args)`\r\n\r\n\nBug: duckduckgo engine\n**Version of SearXNG, commit number if you are using on master branch and stipulate if you forked SearXNG**\r\nRepository: https://github.com/searxng/searxng\r\nBranch: master\r\nVersion: 2022.09.09-eb3d185e\r\n<!-- Check if these values are correct -->\r\n\r\n**How did you install SearXNG?**\r\n<!-- Did you install SearXNG using the official wiki or using searxng-docker\r\nor manually by executing the searx/webapp.py file? -->\r\n**What happened?**\r\n<!-- A clear and concise description of what the bug is. -->\r\ninstalled via docker / when running a search, duck duck go is sending an access denied error. this did not happen before\r\n**How To Reproduce**\r\n<!-- How can we reproduce this issue? (as minimally and as precisely as possible) -->\r\n\r\n**Expected behavior**\r\n<!-- A clear and concise description of what you expected to happen. -->\r\n\r\n**Screenshots & Logs**\r\n<!-- If applicable, add screenshots, logs to help explain your problem. -->\r\n\r\n**Additional context**\r\n<!-- Add any other context about the problem here. -->\r\n\r\n**Technical report**\r\n\r\nError\r\n * Error: httpx.ReadTimeout\r\n * Percentage: 0\r\n * Parameters: `(None, None, 'lite.duckduckgo.com')`\r\n * File name: `searx/search/processors/online.py:107`\r\n * Function: `_send_http_request`\r\n * Code: `response = req(params['url'], **request_args)`\r\n\r\nError\r\n * Error: searx.exceptions.SearxEngineAccessDeniedException\r\n * Percentage: 0\r\n * Parameters: `('HTTP error 403',)`\r\n * File name: `searx/search/processors/online.py:107`\r\n * Function: `_send_http_request`\r\n * Code: `response = req(params['url'], **request_args)`\r\n\r\n\n", "before_files": [{"content": "# SPDX-License-Identifier: AGPL-3.0-or-later\n# lint: pylint\n\"\"\"DuckDuckGo Lite\n\"\"\"\n\nfrom json import loads\n\nfrom lxml.html import fromstring\n\nfrom searx.utils import (\n dict_subset,\n eval_xpath,\n eval_xpath_getindex,\n extract_text,\n match_language,\n)\nfrom searx.network import get\n\n# about\nabout = {\n \"website\": 'https://lite.duckduckgo.com/lite',\n \"wikidata_id\": 'Q12805',\n \"official_api_documentation\": 'https://duckduckgo.com/api',\n \"use_official_api\": False,\n \"require_api_key\": False,\n \"results\": 'HTML',\n}\n\n# engine dependent config\ncategories = ['general', 'web']\npaging = True\nsupported_languages_url = 'https://duckduckgo.com/util/u588.js'\ntime_range_support = True\nsend_accept_language_header = True\n\nlanguage_aliases = {\n 'ar-SA': 'ar-XA',\n 'es-419': 'es-XL',\n 'ja': 'jp-JP',\n 'ko': 'kr-KR',\n 'sl-SI': 'sl-SL',\n 'zh-TW': 'tzh-TW',\n 'zh-HK': 'tzh-HK',\n}\n\ntime_range_dict = {'day': 'd', 'week': 'w', 'month': 'm', 'year': 'y'}\n\n# search-url\nurl = 'https://lite.duckduckgo.com/lite'\nurl_ping = 'https://duckduckgo.com/t/sl_l'\n\n# match query's language to a region code that duckduckgo will accept\ndef get_region_code(lang, lang_list=None):\n if lang == 'all':\n return None\n\n lang_code = match_language(lang, lang_list or [], language_aliases, 'wt-WT')\n lang_parts = lang_code.split('-')\n\n # country code goes first\n return lang_parts[1].lower() + '-' + lang_parts[0].lower()\n\n\ndef request(query, params):\n\n params['url'] = url\n params['method'] = 'POST'\n\n params['data']['q'] = query\n\n # The API is not documented, so we do some reverse engineering and emulate\n # what https://lite.duckduckgo.com/lite/ does when you press \"next Page\"\n # link again and again ..\n\n params['headers']['Content-Type'] = 'application/x-www-form-urlencoded'\n\n # initial page does not have an offset\n if params['pageno'] == 2:\n # second page does have an offset of 30\n offset = (params['pageno'] - 1) * 30\n params['data']['s'] = offset\n params['data']['dc'] = offset + 1\n\n elif params['pageno'] > 2:\n # third and following pages do have an offset of 30 + n*50\n offset = 30 + (params['pageno'] - 2) * 50\n params['data']['s'] = offset\n params['data']['dc'] = offset + 1\n\n # initial page does not have additional data in the input form\n if params['pageno'] > 1:\n # request the second page (and more pages) needs 'o' and 'api' arguments\n params['data']['o'] = 'json'\n params['data']['api'] = 'd.js'\n\n # initial page does not have additional data in the input form\n if params['pageno'] > 2:\n # request the third page (and more pages) some more arguments\n params['data']['nextParams'] = ''\n params['data']['v'] = ''\n params['data']['vqd'] = ''\n\n region_code = get_region_code(params['language'], supported_languages)\n if region_code:\n params['data']['kl'] = region_code\n params['cookies']['kl'] = region_code\n\n params['data']['df'] = ''\n if params['time_range'] in time_range_dict:\n params['data']['df'] = time_range_dict[params['time_range']]\n params['cookies']['df'] = time_range_dict[params['time_range']]\n\n logger.debug(\"param data: %s\", params['data'])\n logger.debug(\"param cookies: %s\", params['cookies'])\n return params\n\n\n# get response from search-request\ndef response(resp):\n\n headers_ping = dict_subset(resp.request.headers, ['User-Agent', 'Accept-Encoding', 'Accept', 'Cookie'])\n get(url_ping, headers=headers_ping)\n\n if resp.status_code == 303:\n return []\n\n results = []\n doc = fromstring(resp.text)\n\n result_table = eval_xpath(doc, '//html/body/form/div[@class=\"filters\"]/table')\n if not len(result_table) >= 3:\n # no more results\n return []\n result_table = result_table[2]\n\n tr_rows = eval_xpath(result_table, './/tr')\n\n # In the last <tr> is the form of the 'previous/next page' links\n tr_rows = tr_rows[:-1]\n\n len_tr_rows = len(tr_rows)\n offset = 0\n\n while len_tr_rows >= offset + 4:\n\n # assemble table rows we need to scrap\n tr_title = tr_rows[offset]\n tr_content = tr_rows[offset + 1]\n offset += 4\n\n # ignore sponsored Adds <tr class=\"result-sponsored\">\n if tr_content.get('class') == 'result-sponsored':\n continue\n\n a_tag = eval_xpath_getindex(tr_title, './/td//a[@class=\"result-link\"]', 0, None)\n if a_tag is None:\n continue\n\n td_content = eval_xpath_getindex(tr_content, './/td[@class=\"result-snippet\"]', 0, None)\n if td_content is None:\n continue\n\n results.append(\n {\n 'title': a_tag.text_content(),\n 'content': extract_text(td_content),\n 'url': a_tag.get('href'),\n }\n )\n\n return results\n\n\n# get supported languages from their site\ndef _fetch_supported_languages(resp):\n\n # response is a js file with regions as an embedded object\n response_page = resp.text\n response_page = response_page[response_page.find('regions:{') + 8 :]\n response_page = response_page[: response_page.find('}') + 1]\n\n regions_json = loads(response_page)\n supported_languages = map((lambda x: x[3:] + '-' + x[:2].upper()), regions_json.keys())\n\n return list(supported_languages)\n", "path": "searx/engines/duckduckgo.py"}]}
| 3,325 | 253 |
gh_patches_debug_28587
|
rasdani/github-patches
|
git_diff
|
PlasmaPy__PlasmaPy-138
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Check consistency of argument ordering in physics
Here are a few example signatures straight from `physics.transport`:
```
def Coulomb_logarithm(n_e, T, particles, V=None):
def Debye_length(T_e, n_e):
def Debye_number(T_e, n_e):
def upper_hybrid_frequency(B, n_e):
```
It would be nice to ensure that non-keyword arguments, where applicable, have the same ordering - like in other scientific packages, like Numpy, a consistent API is helpful for being able to call multiple functions without having to check the signature each time you call them.
Any consistent ordering would be welcome - but common sense takes precedence.
</issue>
<code>
[start of plasmapy/physics/transport.py]
1 """Functions to calculate transport coefficients."""
2
3 from astropy import units
4 import numpy as np
5 from ..utils import check_quantity, _check_relativistic
6 from ..constants import (m_p, m_e, c, mu0, k_B, e, eps0, pi, h, hbar)
7 from ..atomic import (ion_mass, charge_state)
8 from .parameters import Debye_length
9
10
11 @check_quantity({"n_e": {"units": units.m**-3},
12 "T": {"units": units.K, "can_be_negative": False}
13 })
14 def Coulomb_logarithm(n_e, T, particles, V=None):
15 r"""Estimates the Coulomb logarithm.
16
17 Parameters
18 ----------
19 n_e : Quantity
20 The electron density in units convertible to per cubic meter.
21
22 T : Quantity
23 Temperature in units of temperature or energy per particle,
24 which is assumed to be equal for both the test particle and
25 the target particle
26
27 particles : tuple
28 A tuple containing string representations of the test particle
29 (listed first) and the target particle (listed second)
30
31 V : Quantity, optional
32 The relative velocity between particles. If not provided,
33 thermal velocity is assumed: :math:`\mu V^2 \sim 3 k_B T`
34 where `mu` is the reduced mass.
35
36 Returns
37 -------
38 lnLambda : float or numpy.ndarray
39 An estimate of the Coulomb logarithm that is accurate to
40 roughly its reciprocal.
41
42 Raises
43 ------
44 ValueError
45 If the mass or charge of either particle cannot be found, or
46 any of the inputs contain incorrect values.
47
48 UnitConversionError
49 If the units on any of the inputs are incorrect
50
51 UserWarning
52 If the inputted velocity is greater than 80% of the speed of
53 light.
54
55 TypeError
56 If the n_e, T, or V are not Quantities.
57
58 Notes
59 -----
60 The Coulomb logarithm is given by
61
62 .. math::
63 \ln{\Lambda} \equiv \ln\left( \frac{b_{max}}{b_{min}} \right)
64
65 where :math:`b_{min}` and :math:`b_{max}` are the inner and outer
66 impact parameters for Coulomb collisions _[1].
67
68 The outer impact parameter is given by the Debye length:
69 :math:`b_{min} = \lambda_D` which is a function of electron
70 temperature and electron density. At distances greater than the
71 Debye length, electric fields from other particles will be
72 screened out due to electrons rearranging themselves.
73
74 The choice of inner impact parameter is more controversial. There
75 are two main possibilities. The first possibility is that the
76 inner impact parameter corresponds to a deflection angle of 90
77 degrees. The second possibility is that the inner impact
78 parameter is a de Broglie wavelength, :math:`\lambda_B`
79 corresponding to the reduced mass of the two particles and the
80 relative velocity between collisions. This function uses the
81 standard practice of choosing the inner impact parameter to be the
82 maximum of these two possibilities. Some inconsistencies exist in
83 the literature on how to define the inner impact parameter _[2].
84
85 Errors associated with the Coulomb logarithm are of order its
86 inverse If the Coulomb logarithm is of order unity, then the
87 assumptions made in the standard analysis of Coulomb collisions
88 are invalid.
89
90 Examples
91 --------
92 >>> from astropy import units as u
93 >>> Coulomb_logarithm(T=1e6*units.K, n_e=1e19*units.m**-3, ('e', 'p'))
94 14.748259780491056
95 >>> Coulomb_logarithm(1e6*units.K, 1e19*units.m**-3, ('e', 'p'),
96 V=1e6*u.m/u.s)
97
98 References
99 ----------
100 .. [1] Physics of Fully Ionized Gases, L. Spitzer (1962)
101
102 .. [2] Comparison of Coulomb Collision Rates in the Plasma Physics
103 and Magnetically Confined Fusion Literature, W. Fundamenski and
104 O.E. Garcia, EFDA–JET–R(07)01
105 (http://www.euro-fusionscipub.org/wp-content/uploads/2014/11/EFDR07001.pdf)
106
107 """
108
109 if not isinstance(particles, (list, tuple)) or len(particles) != 2:
110 raise ValueError("The third input of Coulomb_logarithm must be a list "
111 "or tuple containing representations of two charged "
112 "particles.")
113
114 masses = np.zeros(2)*units.kg
115 charges = np.zeros(2)*units.C
116
117 for particle, i in zip(particles, range(2)):
118
119 try:
120 masses[i] = ion_mass(particles[i])
121 except Exception:
122 raise ValueError("Unable to find mass of particle: " +
123 str(particles[i]) + " in Coulomb_logarithm.")
124
125 try:
126 charges[i] = np.abs(e*charge_state(particles[i]))
127 if charges[i] is None:
128 raise
129 except Exception:
130 raise ValueError("Unable to find charge of particle: " +
131 str(particles[i]) + " in Coulomb_logarithm.")
132
133 reduced_mass = masses[0] * masses[1] / (masses[0] + masses[1])
134
135 # The outer impact parameter is the Debye length. At distances
136 # greater than the Debye length, the electrostatic potential of a
137 # single particle is screened out by the electrostatic potentials
138 # of other particles. Past this distance, the electric fields of
139 # individual particles do not affect each other much. This
140 # expression neglects screening by heavier ions.
141
142 T = T.to(units.K, equivalencies=units.temperature_energy())
143
144 b_max = Debye_length(T, n_e)
145
146 # The choice of inner impact parameter is more controversial.
147 # There are two broad possibilities, and the expressions in the
148 # literature often differ by factors of order unity or by
149 # interchanging the reduced mass with the test particle mass.
150
151 # The relative velocity is a source of uncertainty. It is
152 # reasonable to make an assumption relating the thermal energy to
153 # the kinetic energy: reduced_mass*velocity**2 is approximately
154 # equal to 3*k_B*T.
155
156 # If no relative velocity is inputted, then we make an assumption
157 # that relates the thermal energy to the kinetic energy:
158 # reduced_mass*velocity**2 is approximately equal to 3*k_B*T.
159
160 if V is None:
161 V = np.sqrt(3 * k_B * T / reduced_mass)
162 else:
163 _check_relativistic(V, 'Coulomb_logarithm', betafrac=0.8)
164
165 # The first possibility is that the inner impact parameter
166 # corresponds to a deflection of 90 degrees, which is valid when
167 # classical effects dominate.
168
169 b_perp = charges[0] * charges[1] / (4 * pi * eps0 * reduced_mass * V**2)
170
171 # The second possibility is that the inner impact parameter is a
172 # de Broglie wavelength. There remains some ambiguity as to which
173 # mass to choose to go into the de Broglie wavelength calculation.
174 # Here we use the reduced mass, which will be of the same order as
175 # mass of the smaller particle and thus the longer de Broglie
176 # wavelength.
177
178 b_deBroglie = hbar / (2 * reduced_mass * V)
179
180 # Coulomb-style collisions will not happen for impact parameters
181 # shorter than either of these two impact parameters, so we choose
182 # the larger of these two possibilities.
183
184 b_min = np.zeros_like(b_perp)
185
186 for i in range(b_min.size):
187
188 if b_perp.flat[i] > b_deBroglie.flat[i]:
189 b_min.flat[i] = b_perp.flat[i]
190 else:
191 b_min.flat[i] = b_deBroglie.flat[i]
192
193 # Now that we know how many approximations have to go into plasma
194 # transport theory, we shall celebrate by returning the Coulomb
195 # logarithm.
196
197 ln_Lambda = np.log(b_max/b_min)
198 ln_Lambda = ln_Lambda.to(units.dimensionless_unscaled).value
199
200 return ln_Lambda
201
[end of plasmapy/physics/transport.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/plasmapy/physics/transport.py b/plasmapy/physics/transport.py
--- a/plasmapy/physics/transport.py
+++ b/plasmapy/physics/transport.py
@@ -8,21 +8,22 @@
from .parameters import Debye_length
-@check_quantity({"n_e": {"units": units.m**-3},
- "T": {"units": units.K, "can_be_negative": False}
+@check_quantity({"T": {"units": units.K, "can_be_negative": False},
+ "n_e": {"units": units.m**-3}
})
-def Coulomb_logarithm(n_e, T, particles, V=None):
+def Coulomb_logarithm(T, n_e, particles, V=None):
r"""Estimates the Coulomb logarithm.
Parameters
----------
- n_e : Quantity
- The electron density in units convertible to per cubic meter.
T : Quantity
- Temperature in units of temperature or energy per particle,
- which is assumed to be equal for both the test particle and
- the target particle
+ Temperature in units of temperature or energy per particle,
+ which is assumed to be equal for both the test particle and
+ the target particle
+
+ n_e : Quantity
+ The electron density in units convertible to per cubic meter.
particles : tuple
A tuple containing string representations of the test particle
@@ -90,9 +91,9 @@
Examples
--------
>>> from astropy import units as u
- >>> Coulomb_logarithm(T=1e6*units.K, n_e=1e19*units.m**-3, ('e', 'p'))
+ >>> Coulomb_logarithm(T=1e6*u.K, n_e=1e19*u.m**-3, ('e', 'p'))
14.748259780491056
- >>> Coulomb_logarithm(1e6*units.K, 1e19*units.m**-3, ('e', 'p'),
+ >>> Coulomb_logarithm(1e6*u.K, 1e19*u.m**-3, ('e', 'p'),
V=1e6*u.m/u.s)
References
|
{"golden_diff": "diff --git a/plasmapy/physics/transport.py b/plasmapy/physics/transport.py\n--- a/plasmapy/physics/transport.py\n+++ b/plasmapy/physics/transport.py\n@@ -8,21 +8,22 @@\n from .parameters import Debye_length\n \n \n-@check_quantity({\"n_e\": {\"units\": units.m**-3},\n- \"T\": {\"units\": units.K, \"can_be_negative\": False}\n+@check_quantity({\"T\": {\"units\": units.K, \"can_be_negative\": False},\n+ \"n_e\": {\"units\": units.m**-3}\n })\n-def Coulomb_logarithm(n_e, T, particles, V=None):\n+def Coulomb_logarithm(T, n_e, particles, V=None):\n r\"\"\"Estimates the Coulomb logarithm.\n \n Parameters\n ----------\n- n_e : Quantity\n- The electron density in units convertible to per cubic meter.\n \n T : Quantity\n- Temperature in units of temperature or energy per particle,\n- which is assumed to be equal for both the test particle and\n- the target particle\n+ Temperature in units of temperature or energy per particle,\n+ which is assumed to be equal for both the test particle and\n+ the target particle\n+\n+ n_e : Quantity\n+ The electron density in units convertible to per cubic meter.\n \n particles : tuple\n A tuple containing string representations of the test particle\n@@ -90,9 +91,9 @@\n Examples\n --------\n >>> from astropy import units as u\n- >>> Coulomb_logarithm(T=1e6*units.K, n_e=1e19*units.m**-3, ('e', 'p'))\n+ >>> Coulomb_logarithm(T=1e6*u.K, n_e=1e19*u.m**-3, ('e', 'p'))\n 14.748259780491056\n- >>> Coulomb_logarithm(1e6*units.K, 1e19*units.m**-3, ('e', 'p'),\n+ >>> Coulomb_logarithm(1e6*u.K, 1e19*u.m**-3, ('e', 'p'),\n V=1e6*u.m/u.s)\n \n References\n", "issue": "Check consistency of argument ordering in physics\nHere are a few example signatures straight from `physics.transport`:\r\n\r\n```\r\ndef Coulomb_logarithm(n_e, T, particles, V=None):\r\ndef Debye_length(T_e, n_e):\r\ndef Debye_number(T_e, n_e):\r\ndef upper_hybrid_frequency(B, n_e):\r\n```\r\nIt would be nice to ensure that non-keyword arguments, where applicable, have the same ordering - like in other scientific packages, like Numpy, a consistent API is helpful for being able to call multiple functions without having to check the signature each time you call them.\r\n\r\nAny consistent ordering would be welcome - but common sense takes precedence.\n", "before_files": [{"content": "\"\"\"Functions to calculate transport coefficients.\"\"\"\n\nfrom astropy import units\nimport numpy as np\nfrom ..utils import check_quantity, _check_relativistic\nfrom ..constants import (m_p, m_e, c, mu0, k_B, e, eps0, pi, h, hbar)\nfrom ..atomic import (ion_mass, charge_state)\nfrom .parameters import Debye_length\n\n\n@check_quantity({\"n_e\": {\"units\": units.m**-3},\n \"T\": {\"units\": units.K, \"can_be_negative\": False}\n })\ndef Coulomb_logarithm(n_e, T, particles, V=None):\n r\"\"\"Estimates the Coulomb logarithm.\n\n Parameters\n ----------\n n_e : Quantity\n The electron density in units convertible to per cubic meter.\n\n T : Quantity\n Temperature in units of temperature or energy per particle,\n which is assumed to be equal for both the test particle and\n the target particle\n\n particles : tuple\n A tuple containing string representations of the test particle\n (listed first) and the target particle (listed second)\n\n V : Quantity, optional\n The relative velocity between particles. If not provided,\n thermal velocity is assumed: :math:`\\mu V^2 \\sim 3 k_B T`\n where `mu` is the reduced mass.\n\n Returns\n -------\n lnLambda : float or numpy.ndarray\n An estimate of the Coulomb logarithm that is accurate to\n roughly its reciprocal.\n\n Raises\n ------\n ValueError\n If the mass or charge of either particle cannot be found, or\n any of the inputs contain incorrect values.\n\n UnitConversionError\n If the units on any of the inputs are incorrect\n\n UserWarning\n If the inputted velocity is greater than 80% of the speed of\n light.\n\n TypeError\n If the n_e, T, or V are not Quantities.\n\n Notes\n -----\n The Coulomb logarithm is given by\n\n .. math::\n \\ln{\\Lambda} \\equiv \\ln\\left( \\frac{b_{max}}{b_{min}} \\right)\n\n where :math:`b_{min}` and :math:`b_{max}` are the inner and outer\n impact parameters for Coulomb collisions _[1].\n\n The outer impact parameter is given by the Debye length:\n :math:`b_{min} = \\lambda_D` which is a function of electron\n temperature and electron density. At distances greater than the\n Debye length, electric fields from other particles will be\n screened out due to electrons rearranging themselves.\n\n The choice of inner impact parameter is more controversial. There\n are two main possibilities. The first possibility is that the\n inner impact parameter corresponds to a deflection angle of 90\n degrees. The second possibility is that the inner impact\n parameter is a de Broglie wavelength, :math:`\\lambda_B`\n corresponding to the reduced mass of the two particles and the\n relative velocity between collisions. This function uses the\n standard practice of choosing the inner impact parameter to be the\n maximum of these two possibilities. Some inconsistencies exist in\n the literature on how to define the inner impact parameter _[2].\n\n Errors associated with the Coulomb logarithm are of order its\n inverse If the Coulomb logarithm is of order unity, then the\n assumptions made in the standard analysis of Coulomb collisions\n are invalid.\n\n Examples\n --------\n >>> from astropy import units as u\n >>> Coulomb_logarithm(T=1e6*units.K, n_e=1e19*units.m**-3, ('e', 'p'))\n 14.748259780491056\n >>> Coulomb_logarithm(1e6*units.K, 1e19*units.m**-3, ('e', 'p'),\n V=1e6*u.m/u.s)\n\n References\n ----------\n .. [1] Physics of Fully Ionized Gases, L. Spitzer (1962)\n\n .. [2] Comparison of Coulomb Collision Rates in the Plasma Physics\n and Magnetically Confined Fusion Literature, W. Fundamenski and\n O.E. Garcia, EFDA\u2013JET\u2013R(07)01\n (http://www.euro-fusionscipub.org/wp-content/uploads/2014/11/EFDR07001.pdf)\n\n \"\"\"\n\n if not isinstance(particles, (list, tuple)) or len(particles) != 2:\n raise ValueError(\"The third input of Coulomb_logarithm must be a list \"\n \"or tuple containing representations of two charged \"\n \"particles.\")\n\n masses = np.zeros(2)*units.kg\n charges = np.zeros(2)*units.C\n\n for particle, i in zip(particles, range(2)):\n\n try:\n masses[i] = ion_mass(particles[i])\n except Exception:\n raise ValueError(\"Unable to find mass of particle: \" +\n str(particles[i]) + \" in Coulomb_logarithm.\")\n\n try:\n charges[i] = np.abs(e*charge_state(particles[i]))\n if charges[i] is None:\n raise\n except Exception:\n raise ValueError(\"Unable to find charge of particle: \" +\n str(particles[i]) + \" in Coulomb_logarithm.\")\n\n reduced_mass = masses[0] * masses[1] / (masses[0] + masses[1])\n\n # The outer impact parameter is the Debye length. At distances\n # greater than the Debye length, the electrostatic potential of a\n # single particle is screened out by the electrostatic potentials\n # of other particles. Past this distance, the electric fields of\n # individual particles do not affect each other much. This\n # expression neglects screening by heavier ions.\n\n T = T.to(units.K, equivalencies=units.temperature_energy())\n\n b_max = Debye_length(T, n_e)\n\n # The choice of inner impact parameter is more controversial.\n # There are two broad possibilities, and the expressions in the\n # literature often differ by factors of order unity or by\n # interchanging the reduced mass with the test particle mass.\n\n # The relative velocity is a source of uncertainty. It is\n # reasonable to make an assumption relating the thermal energy to\n # the kinetic energy: reduced_mass*velocity**2 is approximately\n # equal to 3*k_B*T.\n\n # If no relative velocity is inputted, then we make an assumption\n # that relates the thermal energy to the kinetic energy:\n # reduced_mass*velocity**2 is approximately equal to 3*k_B*T.\n\n if V is None:\n V = np.sqrt(3 * k_B * T / reduced_mass)\n else:\n _check_relativistic(V, 'Coulomb_logarithm', betafrac=0.8)\n\n # The first possibility is that the inner impact parameter\n # corresponds to a deflection of 90 degrees, which is valid when\n # classical effects dominate.\n\n b_perp = charges[0] * charges[1] / (4 * pi * eps0 * reduced_mass * V**2)\n\n # The second possibility is that the inner impact parameter is a\n # de Broglie wavelength. There remains some ambiguity as to which\n # mass to choose to go into the de Broglie wavelength calculation.\n # Here we use the reduced mass, which will be of the same order as\n # mass of the smaller particle and thus the longer de Broglie\n # wavelength.\n\n b_deBroglie = hbar / (2 * reduced_mass * V)\n\n # Coulomb-style collisions will not happen for impact parameters\n # shorter than either of these two impact parameters, so we choose\n # the larger of these two possibilities.\n\n b_min = np.zeros_like(b_perp)\n\n for i in range(b_min.size):\n\n if b_perp.flat[i] > b_deBroglie.flat[i]:\n b_min.flat[i] = b_perp.flat[i]\n else:\n b_min.flat[i] = b_deBroglie.flat[i]\n\n # Now that we know how many approximations have to go into plasma\n # transport theory, we shall celebrate by returning the Coulomb\n # logarithm.\n\n ln_Lambda = np.log(b_max/b_min)\n ln_Lambda = ln_Lambda.to(units.dimensionless_unscaled).value\n\n return ln_Lambda\n", "path": "plasmapy/physics/transport.py"}]}
| 3,074 | 522 |
gh_patches_debug_26936
|
rasdani/github-patches
|
git_diff
|
kartoza__prj.app-435
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
500 on bad certificate number
# Problem
When I try and add a bad certificate number, then I get a 500, I should get a 404.
See:
http://staging.changelog.qgis.org/en/qgis/certificate/0246242/
# Proposed Solution
Return a 404
</issue>
<code>
[start of django_project/certification/views/certificate.py]
1 # coding=utf-8
2 from django.http import Http404
3 from django.views.generic import CreateView, DetailView
4 from django.core.urlresolvers import reverse
5 from braces.views import LoginRequiredMixin
6 from ..models import Certificate, Course, Attendee
7 from ..forms import CertificateForm
8
9
10 class CertificateMixin(object):
11 """Mixin class to provide standard settings for Certificate."""
12
13 model = Certificate
14 form_class = CertificateForm
15
16
17 class CertificateCreateView(
18 LoginRequiredMixin, CertificateMixin, CreateView):
19 """Create view for Certificate."""
20
21 context_object_name = 'certificate'
22 template_name = 'certificate/create.html'
23
24 def get_success_url(self):
25 """Define the redirect URL.
26
27 After successful creation of the object, the User will be redirected
28 to the Course detail page.
29
30 :returns: URL
31 :rtype: HttpResponse
32 """
33
34 return reverse('course-detail', kwargs={
35 'project_slug': self.project_slug,
36 'organisation_slug': self.organisation_slug,
37 'slug': self.course_slug
38 })
39
40 def get_context_data(self, **kwargs):
41 """Get the context data which is passed to a template.
42
43 :param kwargs: Any arguments to pass to the superclass.
44 :type kwargs: dict
45
46 :returns: Context data which will be passed to the template.
47 :rtype: dict
48 """
49
50 context = super(
51 CertificateCreateView, self).get_context_data(**kwargs)
52 context['course'] = Course.objects.get(slug=self.course_slug)
53 context['attendee'] = Attendee.objects.get(pk=self.pk)
54 return context
55
56 def get_form_kwargs(self):
57 """Get keyword arguments from form.
58
59 :returns keyword argument from the form
60 :rtype: dict
61 """
62
63 kwargs = super(CertificateCreateView, self).get_form_kwargs()
64 self.project_slug = self.kwargs.get('project_slug', None)
65 self.organisation_slug = self.kwargs.get('organisation_slug', None)
66 self.course_slug = self.kwargs.get('course_slug', None)
67 self.pk = self.kwargs.get('pk', None)
68 self.course = Course.objects.get(slug=self.course_slug)
69 self.attendee = Attendee.objects.get(pk=self.pk)
70 kwargs.update({
71 'user': self.request.user,
72 'course': self.course,
73 'attendee': self.attendee,
74 })
75 return kwargs
76
77
78 class CertificateDetailView(DetailView):
79 """Detail view for Certificate."""
80
81 model = Certificate
82 context_object_name = 'certificate'
83 template_name = 'certificate/detail.html'
84
85 def get_context_data(self, **kwargs):
86 """Get the context data which is passed to a template.
87
88 :param kwargs: Any arguments to pass to the superclass.
89 :type kwargs: dict
90
91 :returns: Context data which will be passed to the template.
92 :rtype: dict
93 """
94
95 self.certificateID = self.kwargs.get('id', None)
96 context = super(
97 CertificateDetailView, self).get_context_data(**kwargs)
98 context['certificate'] = \
99 Certificate.objects.get(certificateID=self.certificateID)
100 return context
101
102 def get_queryset(self):
103 """Get the queryset for this view.
104
105 :returns: Queryset which is all certificate in the
106 corresponding organisation.
107 :rtype: QuerySet
108 """
109
110 qs = Certificate.objects.all()
111 return qs
112
113 def get_object(self, queryset=None):
114 """Get the object for this view.
115
116 :param queryset: A query set
117 :type queryset: QuerySet
118
119 :returns: Queryset which is filtered to only show a certificate
120 depends on the input certificate ID.
121 :rtype: QuerySet
122 :raises: Http404
123 """
124
125 if queryset is None:
126 queryset = self.get_queryset()
127 certificateID = self.kwargs.get('id', None)
128 if certificateID:
129 obj = queryset.get(
130 certificateID=certificateID)
131 return obj
132 else:
133 raise Http404('Sorry! Certificate by this ID is not exist.')
134
[end of django_project/certification/views/certificate.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/django_project/certification/views/certificate.py b/django_project/certification/views/certificate.py
--- a/django_project/certification/views/certificate.py
+++ b/django_project/certification/views/certificate.py
@@ -93,10 +93,15 @@
"""
self.certificateID = self.kwargs.get('id', None)
+ self.project_slug = self.kwargs.get('project_slug', None)
context = super(
CertificateDetailView, self).get_context_data(**kwargs)
- context['certificate'] = \
- Certificate.objects.get(certificateID=self.certificateID)
+ issued_id = \
+ Certificate.objects.all().values_list('certificateID', flat=True)
+ if self.certificateID in issued_id:
+ context['certificate'] = \
+ Certificate.objects.get(certificateID=self.certificateID)
+ context['project_slug'] = self.project_slug
return context
def get_queryset(self):
@@ -126,8 +131,10 @@
queryset = self.get_queryset()
certificateID = self.kwargs.get('id', None)
if certificateID:
- obj = queryset.get(
- certificateID=certificateID)
- return obj
+ try:
+ obj = queryset.get(certificateID=certificateID)
+ return obj
+ except Certificate.DoesNotExist:
+ return None
else:
raise Http404('Sorry! Certificate by this ID is not exist.')
|
{"golden_diff": "diff --git a/django_project/certification/views/certificate.py b/django_project/certification/views/certificate.py\n--- a/django_project/certification/views/certificate.py\n+++ b/django_project/certification/views/certificate.py\n@@ -93,10 +93,15 @@\n \"\"\"\n \n self.certificateID = self.kwargs.get('id', None)\n+ self.project_slug = self.kwargs.get('project_slug', None)\n context = super(\n CertificateDetailView, self).get_context_data(**kwargs)\n- context['certificate'] = \\\n- Certificate.objects.get(certificateID=self.certificateID)\n+ issued_id = \\\n+ Certificate.objects.all().values_list('certificateID', flat=True)\n+ if self.certificateID in issued_id:\n+ context['certificate'] = \\\n+ Certificate.objects.get(certificateID=self.certificateID)\n+ context['project_slug'] = self.project_slug\n return context\n \n def get_queryset(self):\n@@ -126,8 +131,10 @@\n queryset = self.get_queryset()\n certificateID = self.kwargs.get('id', None)\n if certificateID:\n- obj = queryset.get(\n- certificateID=certificateID)\n- return obj\n+ try:\n+ obj = queryset.get(certificateID=certificateID)\n+ return obj\n+ except Certificate.DoesNotExist:\n+ return None\n else:\n raise Http404('Sorry! Certificate by this ID is not exist.')\n", "issue": "500 on bad certificate number\n# Problem\r\n\r\nWhen I try and add a bad certificate number, then I get a 500, I should get a 404.\r\nSee:\r\nhttp://staging.changelog.qgis.org/en/qgis/certificate/0246242/\r\n\r\n# Proposed Solution\r\n\r\nReturn a 404\n", "before_files": [{"content": "# coding=utf-8\nfrom django.http import Http404\nfrom django.views.generic import CreateView, DetailView\nfrom django.core.urlresolvers import reverse\nfrom braces.views import LoginRequiredMixin\nfrom ..models import Certificate, Course, Attendee\nfrom ..forms import CertificateForm\n\n\nclass CertificateMixin(object):\n \"\"\"Mixin class to provide standard settings for Certificate.\"\"\"\n\n model = Certificate\n form_class = CertificateForm\n\n\nclass CertificateCreateView(\n LoginRequiredMixin, CertificateMixin, CreateView):\n \"\"\"Create view for Certificate.\"\"\"\n\n context_object_name = 'certificate'\n template_name = 'certificate/create.html'\n\n def get_success_url(self):\n \"\"\"Define the redirect URL.\n\n After successful creation of the object, the User will be redirected\n to the Course detail page.\n\n :returns: URL\n :rtype: HttpResponse\n \"\"\"\n\n return reverse('course-detail', kwargs={\n 'project_slug': self.project_slug,\n 'organisation_slug': self.organisation_slug,\n 'slug': self.course_slug\n })\n\n def get_context_data(self, **kwargs):\n \"\"\"Get the context data which is passed to a template.\n\n :param kwargs: Any arguments to pass to the superclass.\n :type kwargs: dict\n\n :returns: Context data which will be passed to the template.\n :rtype: dict\n \"\"\"\n\n context = super(\n CertificateCreateView, self).get_context_data(**kwargs)\n context['course'] = Course.objects.get(slug=self.course_slug)\n context['attendee'] = Attendee.objects.get(pk=self.pk)\n return context\n\n def get_form_kwargs(self):\n \"\"\"Get keyword arguments from form.\n\n :returns keyword argument from the form\n :rtype: dict\n \"\"\"\n\n kwargs = super(CertificateCreateView, self).get_form_kwargs()\n self.project_slug = self.kwargs.get('project_slug', None)\n self.organisation_slug = self.kwargs.get('organisation_slug', None)\n self.course_slug = self.kwargs.get('course_slug', None)\n self.pk = self.kwargs.get('pk', None)\n self.course = Course.objects.get(slug=self.course_slug)\n self.attendee = Attendee.objects.get(pk=self.pk)\n kwargs.update({\n 'user': self.request.user,\n 'course': self.course,\n 'attendee': self.attendee,\n })\n return kwargs\n\n\nclass CertificateDetailView(DetailView):\n \"\"\"Detail view for Certificate.\"\"\"\n\n model = Certificate\n context_object_name = 'certificate'\n template_name = 'certificate/detail.html'\n\n def get_context_data(self, **kwargs):\n \"\"\"Get the context data which is passed to a template.\n\n :param kwargs: Any arguments to pass to the superclass.\n :type kwargs: dict\n\n :returns: Context data which will be passed to the template.\n :rtype: dict\n \"\"\"\n\n self.certificateID = self.kwargs.get('id', None)\n context = super(\n CertificateDetailView, self).get_context_data(**kwargs)\n context['certificate'] = \\\n Certificate.objects.get(certificateID=self.certificateID)\n return context\n\n def get_queryset(self):\n \"\"\"Get the queryset for this view.\n\n :returns: Queryset which is all certificate in the\n corresponding organisation.\n :rtype: QuerySet\n \"\"\"\n\n qs = Certificate.objects.all()\n return qs\n\n def get_object(self, queryset=None):\n \"\"\"Get the object for this view.\n\n :param queryset: A query set\n :type queryset: QuerySet\n\n :returns: Queryset which is filtered to only show a certificate\n depends on the input certificate ID.\n :rtype: QuerySet\n :raises: Http404\n \"\"\"\n\n if queryset is None:\n queryset = self.get_queryset()\n certificateID = self.kwargs.get('id', None)\n if certificateID:\n obj = queryset.get(\n certificateID=certificateID)\n return obj\n else:\n raise Http404('Sorry! Certificate by this ID is not exist.')\n", "path": "django_project/certification/views/certificate.py"}]}
| 1,786 | 323 |
gh_patches_debug_6999
|
rasdani/github-patches
|
git_diff
|
qutebrowser__qutebrowser-7793
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
prompt_queue is None at shutdown
Seeing this in various crash reports:
```pytb
Traceback (most recent call last):
File "/usr/lib/python3.9/site-packages/qutebrowser/misc/quitter.py", line 225, in shutdown
if prompt.prompt_queue.shutdown():
AttributeError: 'NoneType' object has no attribute 'shutdown'
```
https://crashes.qutebrowser.org/lists?search=prompt_queue.shutdown
</issue>
<code>
[start of qutebrowser/misc/quitter.py]
1 # Copyright 2014-2021 Florian Bruhin (The Compiler) <[email protected]>
2 #
3 # This file is part of qutebrowser.
4 #
5 # qutebrowser is free software: you can redistribute it and/or modify
6 # it under the terms of the GNU General Public License as published by
7 # the Free Software Foundation, either version 3 of the License, or
8 # (at your option) any later version.
9 #
10 # qutebrowser is distributed in the hope that it will be useful,
11 # but WITHOUT ANY WARRANTY; without even the implied warranty of
12 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
13 # GNU General Public License for more details.
14 #
15 # You should have received a copy of the GNU General Public License
16 # along with qutebrowser. If not, see <https://www.gnu.org/licenses/>.
17
18 """Helpers related to quitting qutebrowser cleanly."""
19
20 import os
21 import os.path
22 import sys
23 import json
24 import atexit
25 import shutil
26 import argparse
27 import tokenize
28 import functools
29 import subprocess
30 from typing import Iterable, Mapping, MutableSequence, Sequence, cast
31
32 from qutebrowser.qt.core import QObject, pyqtSignal, QTimer
33 try:
34 import hunter
35 except ImportError:
36 hunter = None
37
38 import qutebrowser
39 from qutebrowser.api import cmdutils
40 from qutebrowser.utils import log, qtlog
41 from qutebrowser.misc import sessions, ipc, objects
42 from qutebrowser.mainwindow import prompt
43 from qutebrowser.completion.models import miscmodels
44
45
46 instance = cast('Quitter', None)
47
48
49 class Quitter(QObject):
50
51 """Utility class to quit/restart the QApplication.
52
53 Attributes:
54 quit_status: The current quitting status.
55 is_shutting_down: Whether we're currently shutting down.
56 _args: The argparse namespace.
57 """
58
59 shutting_down = pyqtSignal() # Emitted immediately before shut down
60
61 def __init__(self, *,
62 args: argparse.Namespace,
63 parent: QObject = None) -> None:
64 super().__init__(parent)
65 self.quit_status = {
66 'crash': True,
67 'tabs': False,
68 'main': False,
69 }
70 self.is_shutting_down = False
71 self._args = args
72
73 def on_last_window_closed(self) -> None:
74 """Slot which gets invoked when the last window was closed."""
75 self.shutdown(last_window=True)
76
77 def _compile_modules(self) -> None:
78 """Compile all modules to catch SyntaxErrors."""
79 if os.path.basename(sys.argv[0]) == 'qutebrowser':
80 # Launched via launcher script
81 return
82 elif hasattr(sys, 'frozen'):
83 return
84 else:
85 path = os.path.abspath(os.path.dirname(qutebrowser.__file__))
86 if not os.path.isdir(path):
87 # Probably running from a python egg.
88 return
89
90 for dirpath, _dirnames, filenames in os.walk(path):
91 for fn in filenames:
92 if os.path.splitext(fn)[1] == '.py' and os.path.isfile(fn):
93 with tokenize.open(os.path.join(dirpath, fn)) as f:
94 compile(f.read(), fn, 'exec')
95
96 def _get_restart_args(
97 self, pages: Iterable[str] = (),
98 session: str = None,
99 override_args: Mapping[str, str] = None
100 ) -> Sequence[str]:
101 """Get args to relaunch qutebrowser.
102
103 Args:
104 pages: The pages to re-open.
105 session: The session to load, or None.
106 override_args: Argument overrides as a dict.
107
108 Return:
109 The commandline as a list of strings.
110 """
111 if os.path.basename(sys.argv[0]) == 'qutebrowser':
112 # Launched via launcher script
113 args = [sys.argv[0]]
114 elif hasattr(sys, 'frozen'):
115 args = [sys.executable]
116 else:
117 args = [sys.executable, '-m', 'qutebrowser']
118
119 # Add all open pages so they get reopened.
120 page_args: MutableSequence[str] = []
121 for win in pages:
122 page_args.extend(win)
123 page_args.append('')
124
125 # Serialize the argparse namespace into json and pass that to the new
126 # process via --json-args.
127 # We do this as there's no way to "unparse" the namespace while
128 # ignoring some arguments.
129 argdict = vars(self._args)
130 argdict['session'] = None
131 argdict['url'] = []
132 argdict['command'] = page_args[:-1]
133 argdict['json_args'] = None
134 # Ensure the given session (or none at all) gets opened.
135 if session is None:
136 argdict['session'] = None
137 argdict['override_restore'] = True
138 else:
139 argdict['session'] = session
140 argdict['override_restore'] = False
141 # Ensure :restart works with --temp-basedir
142 if self._args.temp_basedir:
143 argdict['temp_basedir'] = False
144 argdict['temp_basedir_restarted'] = True
145
146 if override_args is not None:
147 argdict.update(override_args)
148
149 # Dump the data
150 data = json.dumps(argdict)
151 args += ['--json-args', data]
152
153 log.destroy.debug("args: {}".format(args))
154
155 return args
156
157 def restart(self, pages: Sequence[str] = (),
158 session: str = None,
159 override_args: Mapping[str, str] = None) -> bool:
160 """Inner logic to restart qutebrowser.
161
162 The "better" way to restart is to pass a session (_restart usually) as
163 that'll save the complete state.
164
165 However we don't do that (and pass a list of pages instead) when we
166 restart because of an exception, as that's a lot simpler and we don't
167 want to risk anything going wrong.
168
169 Args:
170 pages: A list of URLs to open.
171 session: The session to load, or None.
172 override_args: Argument overrides as a dict.
173
174 Return:
175 True if the restart succeeded, False otherwise.
176 """
177 self._compile_modules()
178 log.destroy.debug("sys.executable: {}".format(sys.executable))
179 log.destroy.debug("sys.path: {}".format(sys.path))
180 log.destroy.debug("sys.argv: {}".format(sys.argv))
181 log.destroy.debug("frozen: {}".format(hasattr(sys, 'frozen')))
182
183 # Save the session if one is given.
184 if session is not None:
185 sessions.session_manager.save(session, with_private=True)
186
187 # Make sure we're not accepting a connection from the new process
188 # before we fully exited.
189 assert ipc.server is not None
190 ipc.server.shutdown()
191
192 # Open a new process and immediately shutdown the existing one
193 try:
194 args = self._get_restart_args(pages, session, override_args)
195 subprocess.Popen(args) # pylint: disable=consider-using-with
196 except OSError:
197 log.destroy.exception("Failed to restart")
198 return False
199 else:
200 return True
201
202 def shutdown(self, status: int = 0,
203 session: sessions.ArgType = None,
204 last_window: bool = False,
205 is_restart: bool = False) -> None:
206 """Quit qutebrowser.
207
208 Args:
209 status: The status code to exit with.
210 session: A session name if saving should be forced.
211 last_window: If the shutdown was triggered due to the last window
212 closing.
213 is_restart: If we're planning to restart.
214 """
215 if self.is_shutting_down:
216 return
217 self.is_shutting_down = True
218 log.destroy.debug("Shutting down with status {}, session {}...".format(
219 status, session))
220
221 sessions.shutdown(session, last_window=last_window)
222 prompt.prompt_queue.shutdown()
223
224 # If shutdown was called while we were asking a question, we're in
225 # a still sub-eventloop (which gets quit now) and not in the main
226 # one.
227 # But there's also other situations where it's problematic to shut down
228 # immediately (e.g. when we're just starting up).
229 # This means we need to defer the real shutdown to when we're back
230 # in the real main event loop, or we'll get a segfault.
231 log.destroy.debug("Deferring shutdown stage 2")
232 QTimer.singleShot(
233 0, functools.partial(self._shutdown_2, status, is_restart=is_restart))
234
235 def _shutdown_2(self, status: int, is_restart: bool) -> None:
236 """Second stage of shutdown."""
237 log.destroy.debug("Stage 2 of shutting down...")
238
239 # Tell everything to shut itself down
240 self.shutting_down.emit()
241
242 # Delete temp basedir
243 if ((self._args.temp_basedir or self._args.temp_basedir_restarted) and
244 not is_restart):
245 atexit.register(shutil.rmtree, self._args.basedir,
246 ignore_errors=True)
247
248 # Now we can hopefully quit without segfaults
249 log.destroy.debug("Deferring QApplication::exit...")
250 # We use a singleshot timer to exit here to minimize the likelihood of
251 # segfaults.
252 QTimer.singleShot(0, functools.partial(self._shutdown_3, status))
253
254 def _shutdown_3(self, status: int) -> None:
255 """Finally shut down the QApplication."""
256 log.destroy.debug("Now calling QApplication::exit.")
257 if 'debug-exit' in objects.debug_flags:
258 if hunter is None:
259 print("Not logging late shutdown because hunter could not be "
260 "imported!", file=sys.stderr)
261 else:
262 print("Now logging late shutdown.", file=sys.stderr)
263 hunter.trace()
264 objects.qapp.exit(status)
265
266
267 @cmdutils.register(name='quit')
268 @cmdutils.argument('session', completion=miscmodels.session)
269 def quit_(save: bool = False,
270 session: sessions.ArgType = None) -> None:
271 """Quit qutebrowser.
272
273 Args:
274 save: When given, save the open windows even if auto_save.session
275 is turned off.
276 session: The name of the session to save.
277 """
278 if session is not None and not save:
279 raise cmdutils.CommandError("Session name given without --save!")
280 if save and session is None:
281 session = sessions.default
282
283 instance.shutdown(session=session)
284
285
286 @cmdutils.register()
287 def restart() -> None:
288 """Restart qutebrowser while keeping existing tabs open."""
289 try:
290 ok = instance.restart(session='_restart')
291 except sessions.SessionError as e:
292 log.destroy.exception("Failed to save session!")
293 raise cmdutils.CommandError("Failed to save session: {}!"
294 .format(e))
295 except SyntaxError as e:
296 log.destroy.exception("Got SyntaxError")
297 raise cmdutils.CommandError("SyntaxError in {}:{}: {}".format(
298 e.filename, e.lineno, e))
299 if ok:
300 instance.shutdown(is_restart=True)
301
302
303 def init(args: argparse.Namespace) -> None:
304 """Initialize the global Quitter instance."""
305 global instance
306 instance = Quitter(args=args, parent=objects.qapp)
307 instance.shutting_down.connect(qtlog.shutdown_log)
308 objects.qapp.lastWindowClosed.connect(instance.on_last_window_closed)
309
[end of qutebrowser/misc/quitter.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/qutebrowser/misc/quitter.py b/qutebrowser/misc/quitter.py
--- a/qutebrowser/misc/quitter.py
+++ b/qutebrowser/misc/quitter.py
@@ -219,7 +219,8 @@
status, session))
sessions.shutdown(session, last_window=last_window)
- prompt.prompt_queue.shutdown()
+ if prompt.prompt_queue is not None:
+ prompt.prompt_queue.shutdown()
# If shutdown was called while we were asking a question, we're in
# a still sub-eventloop (which gets quit now) and not in the main
|
{"golden_diff": "diff --git a/qutebrowser/misc/quitter.py b/qutebrowser/misc/quitter.py\n--- a/qutebrowser/misc/quitter.py\n+++ b/qutebrowser/misc/quitter.py\n@@ -219,7 +219,8 @@\n status, session))\n \n sessions.shutdown(session, last_window=last_window)\n- prompt.prompt_queue.shutdown()\n+ if prompt.prompt_queue is not None:\n+ prompt.prompt_queue.shutdown()\n \n # If shutdown was called while we were asking a question, we're in\n # a still sub-eventloop (which gets quit now) and not in the main\n", "issue": "prompt_queue is None at shutdown\nSeeing this in various crash reports:\r\n\r\n```pytb\r\nTraceback (most recent call last):\r\n File \"/usr/lib/python3.9/site-packages/qutebrowser/misc/quitter.py\", line 225, in shutdown\r\n if prompt.prompt_queue.shutdown():\r\nAttributeError: 'NoneType' object has no attribute 'shutdown'\r\n```\r\n\r\nhttps://crashes.qutebrowser.org/lists?search=prompt_queue.shutdown\n", "before_files": [{"content": "# Copyright 2014-2021 Florian Bruhin (The Compiler) <[email protected]>\n#\n# This file is part of qutebrowser.\n#\n# qutebrowser is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# qutebrowser is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with qutebrowser. If not, see <https://www.gnu.org/licenses/>.\n\n\"\"\"Helpers related to quitting qutebrowser cleanly.\"\"\"\n\nimport os\nimport os.path\nimport sys\nimport json\nimport atexit\nimport shutil\nimport argparse\nimport tokenize\nimport functools\nimport subprocess\nfrom typing import Iterable, Mapping, MutableSequence, Sequence, cast\n\nfrom qutebrowser.qt.core import QObject, pyqtSignal, QTimer\ntry:\n import hunter\nexcept ImportError:\n hunter = None\n\nimport qutebrowser\nfrom qutebrowser.api import cmdutils\nfrom qutebrowser.utils import log, qtlog\nfrom qutebrowser.misc import sessions, ipc, objects\nfrom qutebrowser.mainwindow import prompt\nfrom qutebrowser.completion.models import miscmodels\n\n\ninstance = cast('Quitter', None)\n\n\nclass Quitter(QObject):\n\n \"\"\"Utility class to quit/restart the QApplication.\n\n Attributes:\n quit_status: The current quitting status.\n is_shutting_down: Whether we're currently shutting down.\n _args: The argparse namespace.\n \"\"\"\n\n shutting_down = pyqtSignal() # Emitted immediately before shut down\n\n def __init__(self, *,\n args: argparse.Namespace,\n parent: QObject = None) -> None:\n super().__init__(parent)\n self.quit_status = {\n 'crash': True,\n 'tabs': False,\n 'main': False,\n }\n self.is_shutting_down = False\n self._args = args\n\n def on_last_window_closed(self) -> None:\n \"\"\"Slot which gets invoked when the last window was closed.\"\"\"\n self.shutdown(last_window=True)\n\n def _compile_modules(self) -> None:\n \"\"\"Compile all modules to catch SyntaxErrors.\"\"\"\n if os.path.basename(sys.argv[0]) == 'qutebrowser':\n # Launched via launcher script\n return\n elif hasattr(sys, 'frozen'):\n return\n else:\n path = os.path.abspath(os.path.dirname(qutebrowser.__file__))\n if not os.path.isdir(path):\n # Probably running from a python egg.\n return\n\n for dirpath, _dirnames, filenames in os.walk(path):\n for fn in filenames:\n if os.path.splitext(fn)[1] == '.py' and os.path.isfile(fn):\n with tokenize.open(os.path.join(dirpath, fn)) as f:\n compile(f.read(), fn, 'exec')\n\n def _get_restart_args(\n self, pages: Iterable[str] = (),\n session: str = None,\n override_args: Mapping[str, str] = None\n ) -> Sequence[str]:\n \"\"\"Get args to relaunch qutebrowser.\n\n Args:\n pages: The pages to re-open.\n session: The session to load, or None.\n override_args: Argument overrides as a dict.\n\n Return:\n The commandline as a list of strings.\n \"\"\"\n if os.path.basename(sys.argv[0]) == 'qutebrowser':\n # Launched via launcher script\n args = [sys.argv[0]]\n elif hasattr(sys, 'frozen'):\n args = [sys.executable]\n else:\n args = [sys.executable, '-m', 'qutebrowser']\n\n # Add all open pages so they get reopened.\n page_args: MutableSequence[str] = []\n for win in pages:\n page_args.extend(win)\n page_args.append('')\n\n # Serialize the argparse namespace into json and pass that to the new\n # process via --json-args.\n # We do this as there's no way to \"unparse\" the namespace while\n # ignoring some arguments.\n argdict = vars(self._args)\n argdict['session'] = None\n argdict['url'] = []\n argdict['command'] = page_args[:-1]\n argdict['json_args'] = None\n # Ensure the given session (or none at all) gets opened.\n if session is None:\n argdict['session'] = None\n argdict['override_restore'] = True\n else:\n argdict['session'] = session\n argdict['override_restore'] = False\n # Ensure :restart works with --temp-basedir\n if self._args.temp_basedir:\n argdict['temp_basedir'] = False\n argdict['temp_basedir_restarted'] = True\n\n if override_args is not None:\n argdict.update(override_args)\n\n # Dump the data\n data = json.dumps(argdict)\n args += ['--json-args', data]\n\n log.destroy.debug(\"args: {}\".format(args))\n\n return args\n\n def restart(self, pages: Sequence[str] = (),\n session: str = None,\n override_args: Mapping[str, str] = None) -> bool:\n \"\"\"Inner logic to restart qutebrowser.\n\n The \"better\" way to restart is to pass a session (_restart usually) as\n that'll save the complete state.\n\n However we don't do that (and pass a list of pages instead) when we\n restart because of an exception, as that's a lot simpler and we don't\n want to risk anything going wrong.\n\n Args:\n pages: A list of URLs to open.\n session: The session to load, or None.\n override_args: Argument overrides as a dict.\n\n Return:\n True if the restart succeeded, False otherwise.\n \"\"\"\n self._compile_modules()\n log.destroy.debug(\"sys.executable: {}\".format(sys.executable))\n log.destroy.debug(\"sys.path: {}\".format(sys.path))\n log.destroy.debug(\"sys.argv: {}\".format(sys.argv))\n log.destroy.debug(\"frozen: {}\".format(hasattr(sys, 'frozen')))\n\n # Save the session if one is given.\n if session is not None:\n sessions.session_manager.save(session, with_private=True)\n\n # Make sure we're not accepting a connection from the new process\n # before we fully exited.\n assert ipc.server is not None\n ipc.server.shutdown()\n\n # Open a new process and immediately shutdown the existing one\n try:\n args = self._get_restart_args(pages, session, override_args)\n subprocess.Popen(args) # pylint: disable=consider-using-with\n except OSError:\n log.destroy.exception(\"Failed to restart\")\n return False\n else:\n return True\n\n def shutdown(self, status: int = 0,\n session: sessions.ArgType = None,\n last_window: bool = False,\n is_restart: bool = False) -> None:\n \"\"\"Quit qutebrowser.\n\n Args:\n status: The status code to exit with.\n session: A session name if saving should be forced.\n last_window: If the shutdown was triggered due to the last window\n closing.\n is_restart: If we're planning to restart.\n \"\"\"\n if self.is_shutting_down:\n return\n self.is_shutting_down = True\n log.destroy.debug(\"Shutting down with status {}, session {}...\".format(\n status, session))\n\n sessions.shutdown(session, last_window=last_window)\n prompt.prompt_queue.shutdown()\n\n # If shutdown was called while we were asking a question, we're in\n # a still sub-eventloop (which gets quit now) and not in the main\n # one.\n # But there's also other situations where it's problematic to shut down\n # immediately (e.g. when we're just starting up).\n # This means we need to defer the real shutdown to when we're back\n # in the real main event loop, or we'll get a segfault.\n log.destroy.debug(\"Deferring shutdown stage 2\")\n QTimer.singleShot(\n 0, functools.partial(self._shutdown_2, status, is_restart=is_restart))\n\n def _shutdown_2(self, status: int, is_restart: bool) -> None:\n \"\"\"Second stage of shutdown.\"\"\"\n log.destroy.debug(\"Stage 2 of shutting down...\")\n\n # Tell everything to shut itself down\n self.shutting_down.emit()\n\n # Delete temp basedir\n if ((self._args.temp_basedir or self._args.temp_basedir_restarted) and\n not is_restart):\n atexit.register(shutil.rmtree, self._args.basedir,\n ignore_errors=True)\n\n # Now we can hopefully quit without segfaults\n log.destroy.debug(\"Deferring QApplication::exit...\")\n # We use a singleshot timer to exit here to minimize the likelihood of\n # segfaults.\n QTimer.singleShot(0, functools.partial(self._shutdown_3, status))\n\n def _shutdown_3(self, status: int) -> None:\n \"\"\"Finally shut down the QApplication.\"\"\"\n log.destroy.debug(\"Now calling QApplication::exit.\")\n if 'debug-exit' in objects.debug_flags:\n if hunter is None:\n print(\"Not logging late shutdown because hunter could not be \"\n \"imported!\", file=sys.stderr)\n else:\n print(\"Now logging late shutdown.\", file=sys.stderr)\n hunter.trace()\n objects.qapp.exit(status)\n\n\[email protected](name='quit')\[email protected]('session', completion=miscmodels.session)\ndef quit_(save: bool = False,\n session: sessions.ArgType = None) -> None:\n \"\"\"Quit qutebrowser.\n\n Args:\n save: When given, save the open windows even if auto_save.session\n is turned off.\n session: The name of the session to save.\n \"\"\"\n if session is not None and not save:\n raise cmdutils.CommandError(\"Session name given without --save!\")\n if save and session is None:\n session = sessions.default\n\n instance.shutdown(session=session)\n\n\[email protected]()\ndef restart() -> None:\n \"\"\"Restart qutebrowser while keeping existing tabs open.\"\"\"\n try:\n ok = instance.restart(session='_restart')\n except sessions.SessionError as e:\n log.destroy.exception(\"Failed to save session!\")\n raise cmdutils.CommandError(\"Failed to save session: {}!\"\n .format(e))\n except SyntaxError as e:\n log.destroy.exception(\"Got SyntaxError\")\n raise cmdutils.CommandError(\"SyntaxError in {}:{}: {}\".format(\n e.filename, e.lineno, e))\n if ok:\n instance.shutdown(is_restart=True)\n\n\ndef init(args: argparse.Namespace) -> None:\n \"\"\"Initialize the global Quitter instance.\"\"\"\n global instance\n instance = Quitter(args=args, parent=objects.qapp)\n instance.shutting_down.connect(qtlog.shutdown_log)\n objects.qapp.lastWindowClosed.connect(instance.on_last_window_closed)\n", "path": "qutebrowser/misc/quitter.py"}]}
| 3,890 | 132 |
gh_patches_debug_15443
|
rasdani/github-patches
|
git_diff
|
yt-dlp__yt-dlp-4043
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
www.breitbart.com
### Checklist
- [X] I'm reporting a new site support request
- [X] I've verified that I'm running yt-dlp version **2022.05.18** ([update instructions](https://github.com/yt-dlp/yt-dlp#update)) or later (specify commit)
- [X] I've checked that all provided URLs are playable in a browser with the same IP and same login details
- [X] I've checked that none of provided URLs [violate any copyrights](https://github.com/ytdl-org/youtube-dl#can-you-add-support-for-this-anime-video-site-or-site-which-shows-current-movies-for-free) or contain any [DRM](https://en.wikipedia.org/wiki/Digital_rights_management) to the best of my knowledge
- [X] I've searched the [bugtracker](https://github.com/yt-dlp/yt-dlp/issues?q=) for similar issues including closed ones. DO NOT post duplicates
- [X] I've read the [guidelines for opening an issue](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#opening-an-issue)
- [X] I've read about [sharing account credentials](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#are-you-willing-to-share-account-details-if-needed) and am willing to share it if required
### Region
_No response_
### Example URLs
https://www.breitbart.com/clips/2022/06/08/kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere/
### Description
Embedded Fox News video not detected. Can be played in Firefox and even be downloaded using an extension named HLS Dowloader.
### Verbose log
```shell
"C:\Users\a\Desktop\MPC-BE\yt-dlp.exe" -vU https://www.breitbart.com/clips/2022/06/08/kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere/
[debug] Command-line config: ['-vU', 'https://www.breitbart.com/clips/2022/06/08/kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere/']
[debug] Encodings: locale cp1252, fs utf-8, pref cp1252, out utf-8, error utf-8, screen utf-8
[debug] yt-dlp version 2022.05.18 [b14d523] (win_exe)
[debug] Python version 3.7.9 (CPython 32bit) - Windows-10-10.0.19041-SP0
[debug] Checking exe version: ffprobe -bsfs
[debug] Checking exe version: avprobe -bsfs
[debug] Checking exe version: ffmpeg -bsfs
[debug] Checking exe version: avconv -bsfs
[debug] exe versions: none
[debug] Optional libraries: Cryptodome-3.14.1, brotli-1.0.9, certifi-2021.10.08, mutagen-1.45.1, sqlite3-2.6.0, websockets-10.3
[debug] Proxy map: {}
Latest version: 2022.05.18, Current version: 2022.05.18
yt-dlp is up to date (2022.05.18)
[debug] [generic] Extracting URL: https://www.breitbart.com/clips/2022/06/08/kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere/
[generic] kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere: Requesting header
WARNING: [generic] Falling back on generic information extractor.
[generic] kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere: Downloading webpage
[generic] kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere: Extracting information
[debug] Looking for video embeds
[debug] Identified a Open Graph video info
[debug] Default format spec: best/bestvideo+bestaudio
[info] kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere-21285488: Downloading 1 format(s): 0
[debug] Invoking http downloader on "https://media.breitbart.com/media/2022/06/kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere-21285488.mp3"
[debug] File locking is not supported on this platform. Proceeding without locking
[download] Destination: Kennedy - 'Price of Gas Is So High that It Would Be Cheaper to Buy Cocaine and Just Run Everywhere' [kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere-21285488].mp3
[download] 100% of 997.70KiB in 00:00
```
</issue>
<code>
[start of yt_dlp/extractor/foxnews.py]
1 import re
2
3 from .amp import AMPIE
4 from .common import InfoExtractor
5
6
7 class FoxNewsIE(AMPIE):
8 IE_NAME = 'foxnews'
9 IE_DESC = 'Fox News and Fox Business Video'
10 _VALID_URL = r'https?://(?P<host>video\.(?:insider\.)?fox(?:news|business)\.com)/v/(?:video-embed\.html\?video_id=)?(?P<id>\d+)'
11 _TESTS = [
12 {
13 'url': 'http://video.foxnews.com/v/3937480/frozen-in-time/#sp=show-clips',
14 'md5': '32aaded6ba3ef0d1c04e238d01031e5e',
15 'info_dict': {
16 'id': '3937480',
17 'ext': 'flv',
18 'title': 'Frozen in Time',
19 'description': '16-year-old girl is size of toddler',
20 'duration': 265,
21 'timestamp': 1304411491,
22 'upload_date': '20110503',
23 'thumbnail': r're:^https?://.*\.jpg$',
24 },
25 },
26 {
27 'url': 'http://video.foxnews.com/v/3922535568001/rep-luis-gutierrez-on-if-obamas-immigration-plan-is-legal/#sp=show-clips',
28 'md5': '5846c64a1ea05ec78175421b8323e2df',
29 'info_dict': {
30 'id': '3922535568001',
31 'ext': 'mp4',
32 'title': "Rep. Luis Gutierrez on if Obama's immigration plan is legal",
33 'description': "Congressman discusses president's plan",
34 'duration': 292,
35 'timestamp': 1417662047,
36 'upload_date': '20141204',
37 'thumbnail': r're:^https?://.*\.jpg$',
38 },
39 'params': {
40 # m3u8 download
41 'skip_download': True,
42 },
43 },
44 {
45 'url': 'http://video.foxnews.com/v/video-embed.html?video_id=3937480&d=video.foxnews.com',
46 'only_matching': True,
47 },
48 {
49 'url': 'http://video.foxbusiness.com/v/4442309889001',
50 'only_matching': True,
51 },
52 {
53 # From http://insider.foxnews.com/2016/08/25/univ-wisconsin-student-group-pushing-silence-certain-words
54 'url': 'http://video.insider.foxnews.com/v/video-embed.html?video_id=5099377331001&autoplay=true&share_url=http://insider.foxnews.com/2016/08/25/univ-wisconsin-student-group-pushing-silence-certain-words&share_title=Student%20Group:%20Saying%20%27Politically%20Correct,%27%20%27Trash%27%20and%20%27Lame%27%20Is%20Offensive&share=true',
55 'only_matching': True,
56 },
57 ]
58
59 @staticmethod
60 def _extract_urls(webpage):
61 return [
62 mobj.group('url')
63 for mobj in re.finditer(
64 r'<(?:amp-)?iframe[^>]+\bsrc=(["\'])(?P<url>(?:https?:)?//video\.foxnews\.com/v/video-embed\.html?.*?\bvideo_id=\d+.*?)\1',
65 webpage)]
66
67 def _real_extract(self, url):
68 host, video_id = self._match_valid_url(url).groups()
69
70 info = self._extract_feed_info(
71 'http://%s/v/feed/video/%s.js?template=fox' % (host, video_id))
72 info['id'] = video_id
73 return info
74
75
76 class FoxNewsArticleIE(InfoExtractor):
77 _VALID_URL = r'https?://(?:www\.)?(?:insider\.)?foxnews\.com/(?!v)([^/]+/)+(?P<id>[a-z-]+)'
78 IE_NAME = 'foxnews:article'
79
80 _TESTS = [{
81 # data-video-id
82 'url': 'http://www.foxnews.com/politics/2016/09/08/buzz-about-bud-clinton-camp-denies-claims-wore-earpiece-at-forum.html',
83 'md5': '83d44e1aff1433e7a29a7b537d1700b5',
84 'info_dict': {
85 'id': '5116295019001',
86 'ext': 'mp4',
87 'title': 'Trump and Clinton asked to defend positions on Iraq War',
88 'description': 'Veterans react on \'The Kelly File\'',
89 'timestamp': 1473301045,
90 'upload_date': '20160908',
91 },
92 }, {
93 # iframe embed
94 'url': 'http://www.foxnews.com/us/2018/03/09/parkland-survivor-kyle-kashuv-on-meeting-trump-his-app-to-prevent-another-school-shooting.amp.html?__twitter_impression=true',
95 'info_dict': {
96 'id': '5748266721001',
97 'ext': 'flv',
98 'title': 'Kyle Kashuv has a positive message for the Trump White House',
99 'description': 'Marjory Stoneman Douglas student disagrees with classmates.',
100 'thumbnail': r're:^https?://.*\.jpg$',
101 'duration': 229,
102 'timestamp': 1520594670,
103 'upload_date': '20180309',
104 },
105 'params': {
106 'skip_download': True,
107 },
108 }, {
109 'url': 'http://insider.foxnews.com/2016/08/25/univ-wisconsin-student-group-pushing-silence-certain-words',
110 'only_matching': True,
111 }]
112
113 def _real_extract(self, url):
114 display_id = self._match_id(url)
115 webpage = self._download_webpage(url, display_id)
116
117 video_id = self._html_search_regex(
118 r'data-video-id=([\'"])(?P<id>[^\'"]+)\1',
119 webpage, 'video ID', group='id', default=None)
120 if video_id:
121 return self.url_result(
122 'http://video.foxnews.com/v/' + video_id, FoxNewsIE.ie_key())
123
124 return self.url_result(
125 FoxNewsIE._extract_urls(webpage)[0], FoxNewsIE.ie_key())
126
[end of yt_dlp/extractor/foxnews.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/yt_dlp/extractor/foxnews.py b/yt_dlp/extractor/foxnews.py
--- a/yt_dlp/extractor/foxnews.py
+++ b/yt_dlp/extractor/foxnews.py
@@ -59,10 +59,13 @@
@staticmethod
def _extract_urls(webpage):
return [
- mobj.group('url')
+ f'https://video.foxnews.com/v/video-embed.html?video_id={mobj.group("video_id")}'
for mobj in re.finditer(
- r'<(?:amp-)?iframe[^>]+\bsrc=(["\'])(?P<url>(?:https?:)?//video\.foxnews\.com/v/video-embed\.html?.*?\bvideo_id=\d+.*?)\1',
- webpage)]
+ r'''(?x)
+ <(?:script|(?:amp-)?iframe)[^>]+\bsrc=["\']
+ (?:https?:)?//video\.foxnews\.com/v/(?:video-embed\.html|embed\.js)\?
+ (?:[^>"\']+&)?(?:video_)?id=(?P<video_id>\d+)
+ ''', webpage)]
def _real_extract(self, url):
host, video_id = self._match_valid_url(url).groups()
|
{"golden_diff": "diff --git a/yt_dlp/extractor/foxnews.py b/yt_dlp/extractor/foxnews.py\n--- a/yt_dlp/extractor/foxnews.py\n+++ b/yt_dlp/extractor/foxnews.py\n@@ -59,10 +59,13 @@\n @staticmethod\n def _extract_urls(webpage):\n return [\n- mobj.group('url')\n+ f'https://video.foxnews.com/v/video-embed.html?video_id={mobj.group(\"video_id\")}'\n for mobj in re.finditer(\n- r'<(?:amp-)?iframe[^>]+\\bsrc=([\"\\'])(?P<url>(?:https?:)?//video\\.foxnews\\.com/v/video-embed\\.html?.*?\\bvideo_id=\\d+.*?)\\1',\n- webpage)]\n+ r'''(?x)\n+ <(?:script|(?:amp-)?iframe)[^>]+\\bsrc=[\"\\']\n+ (?:https?:)?//video\\.foxnews\\.com/v/(?:video-embed\\.html|embed\\.js)\\?\n+ (?:[^>\"\\']+&)?(?:video_)?id=(?P<video_id>\\d+)\n+ ''', webpage)]\n \n def _real_extract(self, url):\n host, video_id = self._match_valid_url(url).groups()\n", "issue": "www.breitbart.com\n### Checklist\n\n- [X] I'm reporting a new site support request\n- [X] I've verified that I'm running yt-dlp version **2022.05.18** ([update instructions](https://github.com/yt-dlp/yt-dlp#update)) or later (specify commit)\n- [X] I've checked that all provided URLs are playable in a browser with the same IP and same login details\n- [X] I've checked that none of provided URLs [violate any copyrights](https://github.com/ytdl-org/youtube-dl#can-you-add-support-for-this-anime-video-site-or-site-which-shows-current-movies-for-free) or contain any [DRM](https://en.wikipedia.org/wiki/Digital_rights_management) to the best of my knowledge\n- [X] I've searched the [bugtracker](https://github.com/yt-dlp/yt-dlp/issues?q=) for similar issues including closed ones. DO NOT post duplicates\n- [X] I've read the [guidelines for opening an issue](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#opening-an-issue)\n- [X] I've read about [sharing account credentials](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#are-you-willing-to-share-account-details-if-needed) and am willing to share it if required\n\n### Region\n\n_No response_\n\n### Example URLs\n\nhttps://www.breitbart.com/clips/2022/06/08/kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere/\n\n### Description\n\nEmbedded Fox News video not detected. Can be played in Firefox and even be downloaded using an extension named HLS Dowloader.\n\n### Verbose log\n\n```shell\n\"C:\\Users\\a\\Desktop\\MPC-BE\\yt-dlp.exe\" -vU https://www.breitbart.com/clips/2022/06/08/kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere/\r\n[debug] Command-line config: ['-vU', 'https://www.breitbart.com/clips/2022/06/08/kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere/']\r\n[debug] Encodings: locale cp1252, fs utf-8, pref cp1252, out utf-8, error utf-8, screen utf-8\r\n[debug] yt-dlp version 2022.05.18 [b14d523] (win_exe)\r\n[debug] Python version 3.7.9 (CPython 32bit) - Windows-10-10.0.19041-SP0\r\n[debug] Checking exe version: ffprobe -bsfs\r\n[debug] Checking exe version: avprobe -bsfs\r\n[debug] Checking exe version: ffmpeg -bsfs\r\n[debug] Checking exe version: avconv -bsfs\r\n[debug] exe versions: none\r\n[debug] Optional libraries: Cryptodome-3.14.1, brotli-1.0.9, certifi-2021.10.08, mutagen-1.45.1, sqlite3-2.6.0, websockets-10.3\r\n[debug] Proxy map: {}\r\nLatest version: 2022.05.18, Current version: 2022.05.18\r\nyt-dlp is up to date (2022.05.18)\r\n[debug] [generic] Extracting URL: https://www.breitbart.com/clips/2022/06/08/kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere/\r\n[generic] kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere: Requesting header\r\nWARNING: [generic] Falling back on generic information extractor.\r\n[generic] kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere: Downloading webpage\r\n[generic] kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere: Extracting information\r\n[debug] Looking for video embeds\r\n[debug] Identified a Open Graph video info\r\n[debug] Default format spec: best/bestvideo+bestaudio\r\n[info] kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere-21285488: Downloading 1 format(s): 0\r\n[debug] Invoking http downloader on \"https://media.breitbart.com/media/2022/06/kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere-21285488.mp3\"\r\n[debug] File locking is not supported on this platform. Proceeding without locking\r\n[download] Destination: Kennedy - 'Price of Gas Is So High that It Would Be Cheaper to Buy Cocaine and Just Run Everywhere' [kennedy-price-of-gas-is-so-high-that-it-would-be-cheaper-to-buy-cocaine-and-just-run-everywhere-21285488].mp3\r\n[download] 100% of 997.70KiB in 00:00\n```\n\n", "before_files": [{"content": "import re\n\nfrom .amp import AMPIE\nfrom .common import InfoExtractor\n\n\nclass FoxNewsIE(AMPIE):\n IE_NAME = 'foxnews'\n IE_DESC = 'Fox News and Fox Business Video'\n _VALID_URL = r'https?://(?P<host>video\\.(?:insider\\.)?fox(?:news|business)\\.com)/v/(?:video-embed\\.html\\?video_id=)?(?P<id>\\d+)'\n _TESTS = [\n {\n 'url': 'http://video.foxnews.com/v/3937480/frozen-in-time/#sp=show-clips',\n 'md5': '32aaded6ba3ef0d1c04e238d01031e5e',\n 'info_dict': {\n 'id': '3937480',\n 'ext': 'flv',\n 'title': 'Frozen in Time',\n 'description': '16-year-old girl is size of toddler',\n 'duration': 265,\n 'timestamp': 1304411491,\n 'upload_date': '20110503',\n 'thumbnail': r're:^https?://.*\\.jpg$',\n },\n },\n {\n 'url': 'http://video.foxnews.com/v/3922535568001/rep-luis-gutierrez-on-if-obamas-immigration-plan-is-legal/#sp=show-clips',\n 'md5': '5846c64a1ea05ec78175421b8323e2df',\n 'info_dict': {\n 'id': '3922535568001',\n 'ext': 'mp4',\n 'title': \"Rep. Luis Gutierrez on if Obama's immigration plan is legal\",\n 'description': \"Congressman discusses president's plan\",\n 'duration': 292,\n 'timestamp': 1417662047,\n 'upload_date': '20141204',\n 'thumbnail': r're:^https?://.*\\.jpg$',\n },\n 'params': {\n # m3u8 download\n 'skip_download': True,\n },\n },\n {\n 'url': 'http://video.foxnews.com/v/video-embed.html?video_id=3937480&d=video.foxnews.com',\n 'only_matching': True,\n },\n {\n 'url': 'http://video.foxbusiness.com/v/4442309889001',\n 'only_matching': True,\n },\n {\n # From http://insider.foxnews.com/2016/08/25/univ-wisconsin-student-group-pushing-silence-certain-words\n 'url': 'http://video.insider.foxnews.com/v/video-embed.html?video_id=5099377331001&autoplay=true&share_url=http://insider.foxnews.com/2016/08/25/univ-wisconsin-student-group-pushing-silence-certain-words&share_title=Student%20Group:%20Saying%20%27Politically%20Correct,%27%20%27Trash%27%20and%20%27Lame%27%20Is%20Offensive&share=true',\n 'only_matching': True,\n },\n ]\n\n @staticmethod\n def _extract_urls(webpage):\n return [\n mobj.group('url')\n for mobj in re.finditer(\n r'<(?:amp-)?iframe[^>]+\\bsrc=([\"\\'])(?P<url>(?:https?:)?//video\\.foxnews\\.com/v/video-embed\\.html?.*?\\bvideo_id=\\d+.*?)\\1',\n webpage)]\n\n def _real_extract(self, url):\n host, video_id = self._match_valid_url(url).groups()\n\n info = self._extract_feed_info(\n 'http://%s/v/feed/video/%s.js?template=fox' % (host, video_id))\n info['id'] = video_id\n return info\n\n\nclass FoxNewsArticleIE(InfoExtractor):\n _VALID_URL = r'https?://(?:www\\.)?(?:insider\\.)?foxnews\\.com/(?!v)([^/]+/)+(?P<id>[a-z-]+)'\n IE_NAME = 'foxnews:article'\n\n _TESTS = [{\n # data-video-id\n 'url': 'http://www.foxnews.com/politics/2016/09/08/buzz-about-bud-clinton-camp-denies-claims-wore-earpiece-at-forum.html',\n 'md5': '83d44e1aff1433e7a29a7b537d1700b5',\n 'info_dict': {\n 'id': '5116295019001',\n 'ext': 'mp4',\n 'title': 'Trump and Clinton asked to defend positions on Iraq War',\n 'description': 'Veterans react on \\'The Kelly File\\'',\n 'timestamp': 1473301045,\n 'upload_date': '20160908',\n },\n }, {\n # iframe embed\n 'url': 'http://www.foxnews.com/us/2018/03/09/parkland-survivor-kyle-kashuv-on-meeting-trump-his-app-to-prevent-another-school-shooting.amp.html?__twitter_impression=true',\n 'info_dict': {\n 'id': '5748266721001',\n 'ext': 'flv',\n 'title': 'Kyle Kashuv has a positive message for the Trump White House',\n 'description': 'Marjory Stoneman Douglas student disagrees with classmates.',\n 'thumbnail': r're:^https?://.*\\.jpg$',\n 'duration': 229,\n 'timestamp': 1520594670,\n 'upload_date': '20180309',\n },\n 'params': {\n 'skip_download': True,\n },\n }, {\n 'url': 'http://insider.foxnews.com/2016/08/25/univ-wisconsin-student-group-pushing-silence-certain-words',\n 'only_matching': True,\n }]\n\n def _real_extract(self, url):\n display_id = self._match_id(url)\n webpage = self._download_webpage(url, display_id)\n\n video_id = self._html_search_regex(\n r'data-video-id=([\\'\"])(?P<id>[^\\'\"]+)\\1',\n webpage, 'video ID', group='id', default=None)\n if video_id:\n return self.url_result(\n 'http://video.foxnews.com/v/' + video_id, FoxNewsIE.ie_key())\n\n return self.url_result(\n FoxNewsIE._extract_urls(webpage)[0], FoxNewsIE.ie_key())\n", "path": "yt_dlp/extractor/foxnews.py"}]}
| 3,719 | 298 |
gh_patches_debug_34950
|
rasdani/github-patches
|
git_diff
|
jupyterhub__jupyterhub-2971
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
singleuser server version check spams the logs
**Describe the bug**
We have ~277 active single user servers in our deployment right now and on restart of the hub service we see this for each one:
> Mar 4 09:20:45 hub-7bccd48cd5-mp4fk hub [W 2020-03-04 15:20:45.996 JupyterHub _version:56] jupyterhub version 1.2.0dev != jupyterhub-singleuser version 1.1.0. This could cause failure to authenticate and result in redirect loops!
My only complaint is that logging that per server is redundant and spams the logs. Can we just log that once per restart of the hub?
**To Reproduce**
Have the jupyterhub and jupyterhub-singleuser services at different minor versions.
**Expected behavior**
Just log the warning once since there is no user/server specific context in the message.
**Compute Information**
- 1.2.0dev - we're running with a custom build based on b4391d0f796864a5b01167701d95eafce3ad987e so that we can pick up the performance fix for issue #2928.
</issue>
<code>
[start of jupyterhub/_version.py]
1 """JupyterHub version info"""
2 # Copyright (c) Jupyter Development Team.
3 # Distributed under the terms of the Modified BSD License.
4
5 version_info = (
6 1,
7 2,
8 0,
9 # "", # release (b1, rc1, or "" for final or dev)
10 "dev", # dev or nothing for beta/rc/stable releases
11 )
12
13 # pep 440 version: no dot before beta/rc, but before .dev
14 # 0.1.0rc1
15 # 0.1.0a1
16 # 0.1.0b1.dev
17 # 0.1.0.dev
18
19 __version__ = ".".join(map(str, version_info[:3])) + ".".join(version_info[3:])
20
21
22 def _check_version(hub_version, singleuser_version, log):
23 """Compare Hub and single-user server versions"""
24 if not hub_version:
25 log.warning(
26 "Hub has no version header, which means it is likely < 0.8. Expected %s",
27 __version__,
28 )
29 return
30
31 if not singleuser_version:
32 log.warning(
33 "Single-user server has no version header, which means it is likely < 0.8. Expected %s",
34 __version__,
35 )
36 return
37
38 # compare minor X.Y versions
39 if hub_version != singleuser_version:
40 from distutils.version import LooseVersion as V
41
42 hub_major_minor = V(hub_version).version[:2]
43 singleuser_major_minor = V(singleuser_version).version[:2]
44 extra = ""
45 if singleuser_major_minor == hub_major_minor:
46 # patch-level mismatch or lower, log difference at debug-level
47 # because this should be fine
48 log_method = log.debug
49 else:
50 # log warning-level for more significant mismatch, such as 0.8 vs 0.9, etc.
51 log_method = log.warning
52 extra = " This could cause failure to authenticate and result in redirect loops!"
53 log_method(
54 "jupyterhub version %s != jupyterhub-singleuser version %s." + extra,
55 hub_version,
56 singleuser_version,
57 )
58 else:
59 log.debug(
60 "jupyterhub and jupyterhub-singleuser both on version %s" % hub_version
61 )
62
[end of jupyterhub/_version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/jupyterhub/_version.py b/jupyterhub/_version.py
--- a/jupyterhub/_version.py
+++ b/jupyterhub/_version.py
@@ -18,6 +18,15 @@
__version__ = ".".join(map(str, version_info[:3])) + ".".join(version_info[3:])
+# Singleton flag to only log the major/minor mismatch warning once per mismatch combo.
+_version_mismatch_warning_logged = {}
+
+
+def reset_globals():
+ """Used to reset globals between test cases."""
+ global _version_mismatch_warning_logged
+ _version_mismatch_warning_logged = {}
+
def _check_version(hub_version, singleuser_version, log):
"""Compare Hub and single-user server versions"""
@@ -42,19 +51,27 @@
hub_major_minor = V(hub_version).version[:2]
singleuser_major_minor = V(singleuser_version).version[:2]
extra = ""
+ do_log = True
if singleuser_major_minor == hub_major_minor:
# patch-level mismatch or lower, log difference at debug-level
# because this should be fine
log_method = log.debug
else:
# log warning-level for more significant mismatch, such as 0.8 vs 0.9, etc.
- log_method = log.warning
- extra = " This could cause failure to authenticate and result in redirect loops!"
- log_method(
- "jupyterhub version %s != jupyterhub-singleuser version %s." + extra,
- hub_version,
- singleuser_version,
- )
+ key = '%s-%s' % (hub_version, singleuser_version)
+ global _version_mismatch_warning_logged
+ if _version_mismatch_warning_logged.get(key):
+ do_log = False # We already logged this warning so don't log it again.
+ else:
+ log_method = log.warning
+ extra = " This could cause failure to authenticate and result in redirect loops!"
+ _version_mismatch_warning_logged[key] = True
+ if do_log:
+ log_method(
+ "jupyterhub version %s != jupyterhub-singleuser version %s." + extra,
+ hub_version,
+ singleuser_version,
+ )
else:
log.debug(
"jupyterhub and jupyterhub-singleuser both on version %s" % hub_version
|
{"golden_diff": "diff --git a/jupyterhub/_version.py b/jupyterhub/_version.py\n--- a/jupyterhub/_version.py\n+++ b/jupyterhub/_version.py\n@@ -18,6 +18,15 @@\n \n __version__ = \".\".join(map(str, version_info[:3])) + \".\".join(version_info[3:])\n \n+# Singleton flag to only log the major/minor mismatch warning once per mismatch combo.\n+_version_mismatch_warning_logged = {}\n+\n+\n+def reset_globals():\n+ \"\"\"Used to reset globals between test cases.\"\"\"\n+ global _version_mismatch_warning_logged\n+ _version_mismatch_warning_logged = {}\n+\n \n def _check_version(hub_version, singleuser_version, log):\n \"\"\"Compare Hub and single-user server versions\"\"\"\n@@ -42,19 +51,27 @@\n hub_major_minor = V(hub_version).version[:2]\n singleuser_major_minor = V(singleuser_version).version[:2]\n extra = \"\"\n+ do_log = True\n if singleuser_major_minor == hub_major_minor:\n # patch-level mismatch or lower, log difference at debug-level\n # because this should be fine\n log_method = log.debug\n else:\n # log warning-level for more significant mismatch, such as 0.8 vs 0.9, etc.\n- log_method = log.warning\n- extra = \" This could cause failure to authenticate and result in redirect loops!\"\n- log_method(\n- \"jupyterhub version %s != jupyterhub-singleuser version %s.\" + extra,\n- hub_version,\n- singleuser_version,\n- )\n+ key = '%s-%s' % (hub_version, singleuser_version)\n+ global _version_mismatch_warning_logged\n+ if _version_mismatch_warning_logged.get(key):\n+ do_log = False # We already logged this warning so don't log it again.\n+ else:\n+ log_method = log.warning\n+ extra = \" This could cause failure to authenticate and result in redirect loops!\"\n+ _version_mismatch_warning_logged[key] = True\n+ if do_log:\n+ log_method(\n+ \"jupyterhub version %s != jupyterhub-singleuser version %s.\" + extra,\n+ hub_version,\n+ singleuser_version,\n+ )\n else:\n log.debug(\n \"jupyterhub and jupyterhub-singleuser both on version %s\" % hub_version\n", "issue": "singleuser server version check spams the logs\n**Describe the bug**\r\n\r\nWe have ~277 active single user servers in our deployment right now and on restart of the hub service we see this for each one:\r\n\r\n> Mar 4 09:20:45 hub-7bccd48cd5-mp4fk hub [W 2020-03-04 15:20:45.996 JupyterHub _version:56] jupyterhub version 1.2.0dev != jupyterhub-singleuser version 1.1.0. This could cause failure to authenticate and result in redirect loops! \r\n\r\nMy only complaint is that logging that per server is redundant and spams the logs. Can we just log that once per restart of the hub?\r\n\r\n**To Reproduce**\r\n\r\nHave the jupyterhub and jupyterhub-singleuser services at different minor versions.\r\n\r\n**Expected behavior**\r\n\r\nJust log the warning once since there is no user/server specific context in the message.\r\n\r\n**Compute Information**\r\n - 1.2.0dev - we're running with a custom build based on b4391d0f796864a5b01167701d95eafce3ad987e so that we can pick up the performance fix for issue #2928.\n", "before_files": [{"content": "\"\"\"JupyterHub version info\"\"\"\n# Copyright (c) Jupyter Development Team.\n# Distributed under the terms of the Modified BSD License.\n\nversion_info = (\n 1,\n 2,\n 0,\n # \"\", # release (b1, rc1, or \"\" for final or dev)\n \"dev\", # dev or nothing for beta/rc/stable releases\n)\n\n# pep 440 version: no dot before beta/rc, but before .dev\n# 0.1.0rc1\n# 0.1.0a1\n# 0.1.0b1.dev\n# 0.1.0.dev\n\n__version__ = \".\".join(map(str, version_info[:3])) + \".\".join(version_info[3:])\n\n\ndef _check_version(hub_version, singleuser_version, log):\n \"\"\"Compare Hub and single-user server versions\"\"\"\n if not hub_version:\n log.warning(\n \"Hub has no version header, which means it is likely < 0.8. Expected %s\",\n __version__,\n )\n return\n\n if not singleuser_version:\n log.warning(\n \"Single-user server has no version header, which means it is likely < 0.8. Expected %s\",\n __version__,\n )\n return\n\n # compare minor X.Y versions\n if hub_version != singleuser_version:\n from distutils.version import LooseVersion as V\n\n hub_major_minor = V(hub_version).version[:2]\n singleuser_major_minor = V(singleuser_version).version[:2]\n extra = \"\"\n if singleuser_major_minor == hub_major_minor:\n # patch-level mismatch or lower, log difference at debug-level\n # because this should be fine\n log_method = log.debug\n else:\n # log warning-level for more significant mismatch, such as 0.8 vs 0.9, etc.\n log_method = log.warning\n extra = \" This could cause failure to authenticate and result in redirect loops!\"\n log_method(\n \"jupyterhub version %s != jupyterhub-singleuser version %s.\" + extra,\n hub_version,\n singleuser_version,\n )\n else:\n log.debug(\n \"jupyterhub and jupyterhub-singleuser both on version %s\" % hub_version\n )\n", "path": "jupyterhub/_version.py"}]}
| 1,448 | 528 |
gh_patches_debug_35171
|
rasdani/github-patches
|
git_diff
|
awslabs__gluonts-709
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Tracking: mxnet 1.6
### To update
- [x] documentation
- [x] README.md
- [x] test-dependencies
### Fix
- [x] https://github.com/awslabs/gluon-ts/issues/583
### Other
- [x] Update `numpy~1.18`
</issue>
<code>
[start of src/gluonts/model/seq2seq/_forking_network.py]
1 # Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License").
4 # You may not use this file except in compliance with the License.
5 # A copy of the License is located at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # or in the "license" file accompanying this file. This file is distributed
10 # on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either
11 # express or implied. See the License for the specific language governing
12 # permissions and limitations under the License.
13
14 # Third-party imports
15 from mxnet import gluon, nd
16
17 # First-party imports
18 from gluonts.block.decoder import Seq2SeqDecoder
19 from gluonts.block.enc2dec import Seq2SeqEnc2Dec
20 from gluonts.block.encoder import Seq2SeqEncoder
21 from gluonts.block.quantile_output import QuantileOutput
22 from gluonts.core.component import validated
23 from gluonts.model.common import Tensor
24
25 nd_None = nd.array([])
26
27
28 class ForkingSeq2SeqNetworkBase(gluon.HybridBlock):
29 """
30 Base network for the :class:`ForkingSeq2SeqEstimator`.
31
32 Parameters
33 ----------
34 encoder: Seq2SeqEncoder
35 encoder block
36 enc2dec: Seq2SeqEnc2Dec
37 encoder to decoder mapping block
38 decoder: Seq2SeqDecoder
39 decoder block
40 quantile_output: QuantileOutput
41 quantile output block
42 kwargs: dict
43 dictionary of Gluon HybridBlock parameters
44 """
45
46 @validated()
47 def __init__(
48 self,
49 encoder: Seq2SeqEncoder,
50 enc2dec: Seq2SeqEnc2Dec,
51 decoder: Seq2SeqDecoder,
52 quantile_output: QuantileOutput,
53 **kwargs,
54 ) -> None:
55 super().__init__(**kwargs)
56
57 self.encoder = encoder
58 self.enc2dec = enc2dec
59 self.decoder = decoder
60 self.quantile_output = quantile_output
61
62 with self.name_scope():
63 self.quantile_proj = quantile_output.get_quantile_proj()
64 self.loss = quantile_output.get_loss()
65
66
67 class ForkingSeq2SeqTrainingNetwork(ForkingSeq2SeqNetworkBase):
68 # noinspection PyMethodOverriding
69 def hybrid_forward(
70 self, F, past_target: Tensor, future_target: Tensor
71 ) -> Tensor:
72 """
73 Parameters
74 ----------
75 F: mx.symbol or mx.ndarray
76 Gluon function space
77 past_target: Tensor
78 FIXME
79 future_target: Tensor
80 shape (num_ts, encoder_length, 1) FIXME
81
82 Returns
83 -------
84 loss with shape (FIXME, FIXME)
85 """
86
87 # FIXME: can we factor out a common prefix in the base network?
88 feat_static_real = nd_None
89 past_feat_dynamic_real = nd_None
90 future_feat_dynamic_real = nd_None
91
92 enc_output_static, enc_output_dynamic = self.encoder(
93 past_target, feat_static_real, past_feat_dynamic_real
94 )
95
96 dec_input_static, dec_input_dynamic, _ = self.enc2dec(
97 enc_output_static, enc_output_dynamic, future_feat_dynamic_real
98 )
99
100 dec_output = self.decoder(dec_input_dynamic, dec_input_static)
101 dec_dist_output = self.quantile_proj(dec_output)
102
103 loss = self.loss(future_target, dec_dist_output)
104 return loss.mean(axis=1)
105
106
107 class ForkingSeq2SeqPredictionNetwork(ForkingSeq2SeqNetworkBase):
108 # noinspection PyMethodOverriding
109 def hybrid_forward(self, F, past_target: Tensor) -> Tensor:
110 """
111 Parameters
112 ----------
113 F: mx.symbol or mx.ndarray
114 Gluon function space
115 past_target: Tensor
116 FIXME
117
118 Returns
119 -------
120 prediction tensor with shape (FIXME, FIXME)
121 """
122
123 # FIXME: can we factor out a common prefix in the base network?
124 feat_static_real = nd_None
125 past_feat_dynamic_real = nd_None
126 future_feat_dynamic_real = nd_None
127
128 enc_output_static, enc_output_dynamic = self.encoder(
129 past_target, feat_static_real, past_feat_dynamic_real
130 )
131
132 enc_output_static = (
133 nd_None if enc_output_static is None else enc_output_static
134 )
135
136 dec_inp_static, dec_inp_dynamic, _ = self.enc2dec(
137 enc_output_static, enc_output_dynamic, future_feat_dynamic_real
138 )
139
140 dec_output = self.decoder(dec_inp_dynamic, dec_inp_static)
141 fcst_output = F.slice_axis(dec_output, axis=1, begin=-1, end=None)
142 fcst_output = F.squeeze(fcst_output, axis=1)
143
144 predictions = self.quantile_proj(fcst_output).swapaxes(2, 1)
145 return predictions
146
[end of src/gluonts/model/seq2seq/_forking_network.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/gluonts/model/seq2seq/_forking_network.py b/src/gluonts/model/seq2seq/_forking_network.py
--- a/src/gluonts/model/seq2seq/_forking_network.py
+++ b/src/gluonts/model/seq2seq/_forking_network.py
@@ -12,7 +12,8 @@
# permissions and limitations under the License.
# Third-party imports
-from mxnet import gluon, nd
+import mxnet as mx
+from mxnet import gluon
# First-party imports
from gluonts.block.decoder import Seq2SeqDecoder
@@ -22,8 +23,6 @@
from gluonts.core.component import validated
from gluonts.model.common import Tensor
-nd_None = nd.array([])
-
class ForkingSeq2SeqNetworkBase(gluon.HybridBlock):
"""
@@ -85,9 +84,9 @@
"""
# FIXME: can we factor out a common prefix in the base network?
- feat_static_real = nd_None
- past_feat_dynamic_real = nd_None
- future_feat_dynamic_real = nd_None
+ feat_static_real = F.zeros(shape=(1,))
+ past_feat_dynamic_real = F.zeros(shape=(1,))
+ future_feat_dynamic_real = F.zeros(shape=(1,))
enc_output_static, enc_output_dynamic = self.encoder(
past_target, feat_static_real, past_feat_dynamic_real
@@ -121,16 +120,18 @@
"""
# FIXME: can we factor out a common prefix in the base network?
- feat_static_real = nd_None
- past_feat_dynamic_real = nd_None
- future_feat_dynamic_real = nd_None
+ feat_static_real = F.zeros(shape=(1,))
+ past_feat_dynamic_real = F.zeros(shape=(1,))
+ future_feat_dynamic_real = F.zeros(shape=(1,))
enc_output_static, enc_output_dynamic = self.encoder(
past_target, feat_static_real, past_feat_dynamic_real
)
enc_output_static = (
- nd_None if enc_output_static is None else enc_output_static
+ F.zeros(shape=(1,))
+ if enc_output_static is None
+ else enc_output_static
)
dec_inp_static, dec_inp_dynamic, _ = self.enc2dec(
|
{"golden_diff": "diff --git a/src/gluonts/model/seq2seq/_forking_network.py b/src/gluonts/model/seq2seq/_forking_network.py\n--- a/src/gluonts/model/seq2seq/_forking_network.py\n+++ b/src/gluonts/model/seq2seq/_forking_network.py\n@@ -12,7 +12,8 @@\n # permissions and limitations under the License.\n \n # Third-party imports\n-from mxnet import gluon, nd\n+import mxnet as mx\n+from mxnet import gluon\n \n # First-party imports\n from gluonts.block.decoder import Seq2SeqDecoder\n@@ -22,8 +23,6 @@\n from gluonts.core.component import validated\n from gluonts.model.common import Tensor\n \n-nd_None = nd.array([])\n-\n \n class ForkingSeq2SeqNetworkBase(gluon.HybridBlock):\n \"\"\"\n@@ -85,9 +84,9 @@\n \"\"\"\n \n # FIXME: can we factor out a common prefix in the base network?\n- feat_static_real = nd_None\n- past_feat_dynamic_real = nd_None\n- future_feat_dynamic_real = nd_None\n+ feat_static_real = F.zeros(shape=(1,))\n+ past_feat_dynamic_real = F.zeros(shape=(1,))\n+ future_feat_dynamic_real = F.zeros(shape=(1,))\n \n enc_output_static, enc_output_dynamic = self.encoder(\n past_target, feat_static_real, past_feat_dynamic_real\n@@ -121,16 +120,18 @@\n \"\"\"\n \n # FIXME: can we factor out a common prefix in the base network?\n- feat_static_real = nd_None\n- past_feat_dynamic_real = nd_None\n- future_feat_dynamic_real = nd_None\n+ feat_static_real = F.zeros(shape=(1,))\n+ past_feat_dynamic_real = F.zeros(shape=(1,))\n+ future_feat_dynamic_real = F.zeros(shape=(1,))\n \n enc_output_static, enc_output_dynamic = self.encoder(\n past_target, feat_static_real, past_feat_dynamic_real\n )\n \n enc_output_static = (\n- nd_None if enc_output_static is None else enc_output_static\n+ F.zeros(shape=(1,))\n+ if enc_output_static is None\n+ else enc_output_static\n )\n \n dec_inp_static, dec_inp_dynamic, _ = self.enc2dec(\n", "issue": "Tracking: mxnet 1.6\n### To update\r\n\r\n- [x] documentation\r\n- [x] README.md\r\n- [x] test-dependencies\r\n\r\n### Fix\r\n\r\n- [x] https://github.com/awslabs/gluon-ts/issues/583\r\n\r\n### Other\r\n\r\n- [x] Update `numpy~1.18`\n", "before_files": [{"content": "# Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\").\n# You may not use this file except in compliance with the License.\n# A copy of the License is located at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# or in the \"license\" file accompanying this file. This file is distributed\n# on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either\n# express or implied. See the License for the specific language governing\n# permissions and limitations under the License.\n\n# Third-party imports\nfrom mxnet import gluon, nd\n\n# First-party imports\nfrom gluonts.block.decoder import Seq2SeqDecoder\nfrom gluonts.block.enc2dec import Seq2SeqEnc2Dec\nfrom gluonts.block.encoder import Seq2SeqEncoder\nfrom gluonts.block.quantile_output import QuantileOutput\nfrom gluonts.core.component import validated\nfrom gluonts.model.common import Tensor\n\nnd_None = nd.array([])\n\n\nclass ForkingSeq2SeqNetworkBase(gluon.HybridBlock):\n \"\"\"\n Base network for the :class:`ForkingSeq2SeqEstimator`.\n\n Parameters\n ----------\n encoder: Seq2SeqEncoder\n encoder block\n enc2dec: Seq2SeqEnc2Dec\n encoder to decoder mapping block\n decoder: Seq2SeqDecoder\n decoder block\n quantile_output: QuantileOutput\n quantile output block\n kwargs: dict\n dictionary of Gluon HybridBlock parameters\n \"\"\"\n\n @validated()\n def __init__(\n self,\n encoder: Seq2SeqEncoder,\n enc2dec: Seq2SeqEnc2Dec,\n decoder: Seq2SeqDecoder,\n quantile_output: QuantileOutput,\n **kwargs,\n ) -> None:\n super().__init__(**kwargs)\n\n self.encoder = encoder\n self.enc2dec = enc2dec\n self.decoder = decoder\n self.quantile_output = quantile_output\n\n with self.name_scope():\n self.quantile_proj = quantile_output.get_quantile_proj()\n self.loss = quantile_output.get_loss()\n\n\nclass ForkingSeq2SeqTrainingNetwork(ForkingSeq2SeqNetworkBase):\n # noinspection PyMethodOverriding\n def hybrid_forward(\n self, F, past_target: Tensor, future_target: Tensor\n ) -> Tensor:\n \"\"\"\n Parameters\n ----------\n F: mx.symbol or mx.ndarray\n Gluon function space\n past_target: Tensor\n FIXME\n future_target: Tensor\n shape (num_ts, encoder_length, 1) FIXME\n\n Returns\n -------\n loss with shape (FIXME, FIXME)\n \"\"\"\n\n # FIXME: can we factor out a common prefix in the base network?\n feat_static_real = nd_None\n past_feat_dynamic_real = nd_None\n future_feat_dynamic_real = nd_None\n\n enc_output_static, enc_output_dynamic = self.encoder(\n past_target, feat_static_real, past_feat_dynamic_real\n )\n\n dec_input_static, dec_input_dynamic, _ = self.enc2dec(\n enc_output_static, enc_output_dynamic, future_feat_dynamic_real\n )\n\n dec_output = self.decoder(dec_input_dynamic, dec_input_static)\n dec_dist_output = self.quantile_proj(dec_output)\n\n loss = self.loss(future_target, dec_dist_output)\n return loss.mean(axis=1)\n\n\nclass ForkingSeq2SeqPredictionNetwork(ForkingSeq2SeqNetworkBase):\n # noinspection PyMethodOverriding\n def hybrid_forward(self, F, past_target: Tensor) -> Tensor:\n \"\"\"\n Parameters\n ----------\n F: mx.symbol or mx.ndarray\n Gluon function space\n past_target: Tensor\n FIXME\n\n Returns\n -------\n prediction tensor with shape (FIXME, FIXME)\n \"\"\"\n\n # FIXME: can we factor out a common prefix in the base network?\n feat_static_real = nd_None\n past_feat_dynamic_real = nd_None\n future_feat_dynamic_real = nd_None\n\n enc_output_static, enc_output_dynamic = self.encoder(\n past_target, feat_static_real, past_feat_dynamic_real\n )\n\n enc_output_static = (\n nd_None if enc_output_static is None else enc_output_static\n )\n\n dec_inp_static, dec_inp_dynamic, _ = self.enc2dec(\n enc_output_static, enc_output_dynamic, future_feat_dynamic_real\n )\n\n dec_output = self.decoder(dec_inp_dynamic, dec_inp_static)\n fcst_output = F.slice_axis(dec_output, axis=1, begin=-1, end=None)\n fcst_output = F.squeeze(fcst_output, axis=1)\n\n predictions = self.quantile_proj(fcst_output).swapaxes(2, 1)\n return predictions\n", "path": "src/gluonts/model/seq2seq/_forking_network.py"}]}
| 2,015 | 514 |
gh_patches_debug_35010
|
rasdani/github-patches
|
git_diff
|
ephios-dev__ephios-884
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Improve calendar design
As a user, I expect the event calendar view to display the shifts in small boxes with times inside of each calendar day (similiar to Google Calendar etc.)
</issue>
<code>
[start of ephios/core/calendar.py]
1 from calendar import HTMLCalendar, day_abbr
2 from datetime import date, datetime
3 from itertools import groupby
4
5 from django.utils.formats import date_format
6 from django.utils.translation import gettext as _
7
8
9 class ShiftCalendar(HTMLCalendar):
10 cssclass_month = "table table-fixed"
11
12 def __init__(self, shifts, *args, **kwargs):
13 super().__init__(*args, **kwargs)
14 self.shifts = {
15 k: list(v) for (k, v) in groupby(shifts, lambda shift: shift.start_time.date().day)
16 }
17
18 def formatmonth(self, theyear, themonth, withyear=True):
19 self.year, self.month = theyear, themonth
20 return super().formatmonth(theyear, themonth)
21
22 def formatmonthname(self, theyear, themonth, withyear=True):
23 dt = datetime(theyear, themonth, 1)
24 return f'<tr><th colspan="7" class="month">{date_format(dt, format="b Y")}</th></tr>'
25
26 def formatweekday(self, day):
27 return f'<th class="{self.cssclasses[day]}">{_(day_abbr[day])}</th>'
28
29 def formatday(self, day, weekday):
30 if day != 0:
31 cssclass = self.cssclasses[weekday]
32 if date.today() == date(self.year, self.month, day):
33 cssclass += " calendar-today"
34 if day in self.shifts:
35 cssclass += " filled"
36 body = ["<br />"]
37 for shift in self.shifts[day]:
38 body.append(f'<a href="{shift.event.get_absolute_url()}">')
39 body.append(shift.event.title)
40 body.append("</a><br />")
41 return self.day_cell(cssclass, f"{day} {''.join(body)}")
42 return self.day_cell(cssclass, day)
43 return self.day_cell("noday", " ")
44
45 def day_cell(self, cssclass, body):
46 return f'<td class="calendar-row-height p-1 break-word {cssclass}">{body}</td>'
47
[end of ephios/core/calendar.py]
[start of ephios/extra/colors.py]
1 # inspired by https://jfelix.info/blog/how-to-make-a-text-color-fit-any-background-color
2 from math import sqrt
3
4 from ephios.core.models import EventType
5
6
7 def calculate_luminance(rgb: tuple):
8 r, g, b = map(
9 lambda channel: channel / 255 / 12.92
10 if channel / 255 <= 0.03928
11 else ((channel / 255 + 0.055) / 1.055) ** 2.4,
12 rgb,
13 )
14 return 0.2126 * r + 0.7152 * g + 0.0722 * b
15
16
17 def get_text_color_for_background(background_luminance: int):
18 return "#000000" if background_luminance > sqrt(1.05 * 0.05) - 0.05 else "#ffffff"
19
20
21 def get_eventtype_color_style(eventtype: EventType):
22 luminance = calculate_luminance(
23 (
24 int(eventtype.color[1:3], 16),
25 int(eventtype.color[3:5], 16),
26 int(eventtype.color[5:7], 16),
27 )
28 )
29 text_color = get_text_color_for_background(luminance)
30 return f".badge-{eventtype.pk}-color{{background-color:{eventtype.color};color:{text_color}}}"
31
[end of ephios/extra/colors.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ephios/core/calendar.py b/ephios/core/calendar.py
--- a/ephios/core/calendar.py
+++ b/ephios/core/calendar.py
@@ -2,6 +2,7 @@
from datetime import date, datetime
from itertools import groupby
+from django.template.loader import render_to_string
from django.utils.formats import date_format
from django.utils.translation import gettext as _
@@ -24,23 +25,20 @@
return f'<tr><th colspan="7" class="month">{date_format(dt, format="b Y")}</th></tr>'
def formatweekday(self, day):
- return f'<th class="{self.cssclasses[day]}">{_(day_abbr[day])}</th>'
+ return f'<th class="text-center {self.cssclasses[day]}">{_(day_abbr[day])}</th>'
def formatday(self, day, weekday):
if day != 0:
cssclass = self.cssclasses[weekday]
- if date.today() == date(self.year, self.month, day):
- cssclass += " calendar-today"
+ today = date.today() == date(self.year, self.month, day)
if day in self.shifts:
cssclass += " filled"
- body = ["<br />"]
- for shift in self.shifts[day]:
- body.append(f'<a href="{shift.event.get_absolute_url()}">')
- body.append(shift.event.title)
- body.append("</a><br />")
- return self.day_cell(cssclass, f"{day} {''.join(body)}")
- return self.day_cell(cssclass, day)
+ content = render_to_string(
+ "core/fragments/calendar_day.html",
+ {"day": day, "shifts": self.shifts.get(day, None), "today": today},
+ )
+ return self.day_cell(cssclass, content)
return self.day_cell("noday", " ")
def day_cell(self, cssclass, body):
- return f'<td class="calendar-row-height p-1 break-word {cssclass}">{body}</td>'
+ return f'<td class="calendar-row-height p-0 pe-1 p-lg-1 {cssclass}">{body}</td>'
diff --git a/ephios/extra/colors.py b/ephios/extra/colors.py
--- a/ephios/extra/colors.py
+++ b/ephios/extra/colors.py
@@ -27,4 +27,6 @@
)
)
text_color = get_text_color_for_background(luminance)
- return f".badge-{eventtype.pk}-color{{background-color:{eventtype.color};color:{text_color}}}"
+ return (
+ f".eventtype-{eventtype.pk}-color{{background-color:{eventtype.color};color:{text_color}}}"
+ )
|
{"golden_diff": "diff --git a/ephios/core/calendar.py b/ephios/core/calendar.py\n--- a/ephios/core/calendar.py\n+++ b/ephios/core/calendar.py\n@@ -2,6 +2,7 @@\n from datetime import date, datetime\n from itertools import groupby\n \n+from django.template.loader import render_to_string\n from django.utils.formats import date_format\n from django.utils.translation import gettext as _\n \n@@ -24,23 +25,20 @@\n return f'<tr><th colspan=\"7\" class=\"month\">{date_format(dt, format=\"b Y\")}</th></tr>'\n \n def formatweekday(self, day):\n- return f'<th class=\"{self.cssclasses[day]}\">{_(day_abbr[day])}</th>'\n+ return f'<th class=\"text-center {self.cssclasses[day]}\">{_(day_abbr[day])}</th>'\n \n def formatday(self, day, weekday):\n if day != 0:\n cssclass = self.cssclasses[weekday]\n- if date.today() == date(self.year, self.month, day):\n- cssclass += \" calendar-today\"\n+ today = date.today() == date(self.year, self.month, day)\n if day in self.shifts:\n cssclass += \" filled\"\n- body = [\"<br />\"]\n- for shift in self.shifts[day]:\n- body.append(f'<a href=\"{shift.event.get_absolute_url()}\">')\n- body.append(shift.event.title)\n- body.append(\"</a><br />\")\n- return self.day_cell(cssclass, f\"{day} {''.join(body)}\")\n- return self.day_cell(cssclass, day)\n+ content = render_to_string(\n+ \"core/fragments/calendar_day.html\",\n+ {\"day\": day, \"shifts\": self.shifts.get(day, None), \"today\": today},\n+ )\n+ return self.day_cell(cssclass, content)\n return self.day_cell(\"noday\", \" \")\n \n def day_cell(self, cssclass, body):\n- return f'<td class=\"calendar-row-height p-1 break-word {cssclass}\">{body}</td>'\n+ return f'<td class=\"calendar-row-height p-0 pe-1 p-lg-1 {cssclass}\">{body}</td>'\ndiff --git a/ephios/extra/colors.py b/ephios/extra/colors.py\n--- a/ephios/extra/colors.py\n+++ b/ephios/extra/colors.py\n@@ -27,4 +27,6 @@\n )\n )\n text_color = get_text_color_for_background(luminance)\n- return f\".badge-{eventtype.pk}-color{{background-color:{eventtype.color};color:{text_color}}}\"\n+ return (\n+ f\".eventtype-{eventtype.pk}-color{{background-color:{eventtype.color};color:{text_color}}}\"\n+ )\n", "issue": "Improve calendar design\nAs a user, I expect the event calendar view to display the shifts in small boxes with times inside of each calendar day (similiar to Google Calendar etc.)\n", "before_files": [{"content": "from calendar import HTMLCalendar, day_abbr\nfrom datetime import date, datetime\nfrom itertools import groupby\n\nfrom django.utils.formats import date_format\nfrom django.utils.translation import gettext as _\n\n\nclass ShiftCalendar(HTMLCalendar):\n cssclass_month = \"table table-fixed\"\n\n def __init__(self, shifts, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.shifts = {\n k: list(v) for (k, v) in groupby(shifts, lambda shift: shift.start_time.date().day)\n }\n\n def formatmonth(self, theyear, themonth, withyear=True):\n self.year, self.month = theyear, themonth\n return super().formatmonth(theyear, themonth)\n\n def formatmonthname(self, theyear, themonth, withyear=True):\n dt = datetime(theyear, themonth, 1)\n return f'<tr><th colspan=\"7\" class=\"month\">{date_format(dt, format=\"b Y\")}</th></tr>'\n\n def formatweekday(self, day):\n return f'<th class=\"{self.cssclasses[day]}\">{_(day_abbr[day])}</th>'\n\n def formatday(self, day, weekday):\n if day != 0:\n cssclass = self.cssclasses[weekday]\n if date.today() == date(self.year, self.month, day):\n cssclass += \" calendar-today\"\n if day in self.shifts:\n cssclass += \" filled\"\n body = [\"<br />\"]\n for shift in self.shifts[day]:\n body.append(f'<a href=\"{shift.event.get_absolute_url()}\">')\n body.append(shift.event.title)\n body.append(\"</a><br />\")\n return self.day_cell(cssclass, f\"{day} {''.join(body)}\")\n return self.day_cell(cssclass, day)\n return self.day_cell(\"noday\", \" \")\n\n def day_cell(self, cssclass, body):\n return f'<td class=\"calendar-row-height p-1 break-word {cssclass}\">{body}</td>'\n", "path": "ephios/core/calendar.py"}, {"content": "# inspired by https://jfelix.info/blog/how-to-make-a-text-color-fit-any-background-color\nfrom math import sqrt\n\nfrom ephios.core.models import EventType\n\n\ndef calculate_luminance(rgb: tuple):\n r, g, b = map(\n lambda channel: channel / 255 / 12.92\n if channel / 255 <= 0.03928\n else ((channel / 255 + 0.055) / 1.055) ** 2.4,\n rgb,\n )\n return 0.2126 * r + 0.7152 * g + 0.0722 * b\n\n\ndef get_text_color_for_background(background_luminance: int):\n return \"#000000\" if background_luminance > sqrt(1.05 * 0.05) - 0.05 else \"#ffffff\"\n\n\ndef get_eventtype_color_style(eventtype: EventType):\n luminance = calculate_luminance(\n (\n int(eventtype.color[1:3], 16),\n int(eventtype.color[3:5], 16),\n int(eventtype.color[5:7], 16),\n )\n )\n text_color = get_text_color_for_background(luminance)\n return f\".badge-{eventtype.pk}-color{{background-color:{eventtype.color};color:{text_color}}}\"\n", "path": "ephios/extra/colors.py"}]}
| 1,507 | 627 |
gh_patches_debug_34121
|
rasdani/github-patches
|
git_diff
|
pyca__cryptography-3785
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Implement One Shot AESGCM
Much like our ChaCha20Poly1305 and AESCCM classes we should do AESGCM. Then we can update our streaming GCM docs to point at the one shot as a better option if you aren't dealing with large volumes of data.
</issue>
<code>
[start of src/cryptography/hazmat/backends/openssl/aead.py]
1 # This file is dual licensed under the terms of the Apache License, Version
2 # 2.0, and the BSD License. See the LICENSE file in the root of this repository
3 # for complete details.
4
5 from __future__ import absolute_import, division, print_function
6
7 from cryptography.exceptions import InvalidTag
8
9
10 _ENCRYPT = 1
11 _DECRYPT = 0
12
13
14 def _aead_cipher_name(cipher):
15 from cryptography.hazmat.primitives.ciphers.aead import (
16 AESCCM, ChaCha20Poly1305
17 )
18 if isinstance(cipher, ChaCha20Poly1305):
19 return b"chacha20-poly1305"
20 else:
21 assert isinstance(cipher, AESCCM)
22 return "aes-{0}-ccm".format(len(cipher._key) * 8).encode("ascii")
23
24
25 def _aead_setup(backend, cipher_name, key, nonce, tag, tag_len, operation):
26 evp_cipher = backend._lib.EVP_get_cipherbyname(cipher_name)
27 backend.openssl_assert(evp_cipher != backend._ffi.NULL)
28 ctx = backend._lib.EVP_CIPHER_CTX_new()
29 ctx = backend._ffi.gc(ctx, backend._lib.EVP_CIPHER_CTX_free)
30 res = backend._lib.EVP_CipherInit_ex(
31 ctx, evp_cipher,
32 backend._ffi.NULL,
33 backend._ffi.NULL,
34 backend._ffi.NULL,
35 int(operation == _ENCRYPT)
36 )
37 backend.openssl_assert(res != 0)
38 res = backend._lib.EVP_CIPHER_CTX_set_key_length(ctx, len(key))
39 backend.openssl_assert(res != 0)
40 res = backend._lib.EVP_CIPHER_CTX_ctrl(
41 ctx, backend._lib.EVP_CTRL_AEAD_SET_IVLEN, len(nonce),
42 backend._ffi.NULL
43 )
44 backend.openssl_assert(res != 0)
45 if operation == _DECRYPT:
46 res = backend._lib.EVP_CIPHER_CTX_ctrl(
47 ctx, backend._lib.EVP_CTRL_AEAD_SET_TAG, len(tag), tag
48 )
49 backend.openssl_assert(res != 0)
50 else:
51 res = backend._lib.EVP_CIPHER_CTX_ctrl(
52 ctx, backend._lib.EVP_CTRL_AEAD_SET_TAG, tag_len, backend._ffi.NULL
53 )
54
55 res = backend._lib.EVP_CipherInit_ex(
56 ctx,
57 backend._ffi.NULL,
58 backend._ffi.NULL,
59 key,
60 nonce,
61 int(operation == _ENCRYPT)
62 )
63 backend.openssl_assert(res != 0)
64 return ctx
65
66
67 def _set_length(backend, ctx, data_len):
68 intptr = backend._ffi.new("int *")
69 res = backend._lib.EVP_CipherUpdate(
70 ctx,
71 backend._ffi.NULL,
72 intptr,
73 backend._ffi.NULL,
74 data_len
75 )
76 backend.openssl_assert(res != 0)
77
78
79 def _process_aad(backend, ctx, associated_data):
80 outlen = backend._ffi.new("int *")
81 res = backend._lib.EVP_CipherUpdate(
82 ctx, backend._ffi.NULL, outlen, associated_data, len(associated_data)
83 )
84 backend.openssl_assert(res != 0)
85
86
87 def _process_data(backend, ctx, data):
88 outlen = backend._ffi.new("int *")
89 buf = backend._ffi.new("unsigned char[]", len(data))
90 res = backend._lib.EVP_CipherUpdate(ctx, buf, outlen, data, len(data))
91 backend.openssl_assert(res != 0)
92 return backend._ffi.buffer(buf, outlen[0])[:]
93
94
95 def _encrypt(backend, cipher, nonce, data, associated_data, tag_length):
96 from cryptography.hazmat.primitives.ciphers.aead import AESCCM
97 cipher_name = _aead_cipher_name(cipher)
98 ctx = _aead_setup(
99 backend, cipher_name, cipher._key, nonce, None, tag_length, _ENCRYPT
100 )
101 # CCM requires us to pass the length of the data before processing anything
102 # However calling this with any other AEAD results in an error
103 if isinstance(cipher, AESCCM):
104 _set_length(backend, ctx, len(data))
105
106 _process_aad(backend, ctx, associated_data)
107 processed_data = _process_data(backend, ctx, data)
108 outlen = backend._ffi.new("int *")
109 res = backend._lib.EVP_CipherFinal_ex(ctx, backend._ffi.NULL, outlen)
110 backend.openssl_assert(res != 0)
111 backend.openssl_assert(outlen[0] == 0)
112 tag_buf = backend._ffi.new("unsigned char[]", tag_length)
113 res = backend._lib.EVP_CIPHER_CTX_ctrl(
114 ctx, backend._lib.EVP_CTRL_AEAD_GET_TAG, tag_length, tag_buf
115 )
116 backend.openssl_assert(res != 0)
117 tag = backend._ffi.buffer(tag_buf)[:]
118
119 return processed_data + tag
120
121
122 def _decrypt(backend, cipher, nonce, data, associated_data, tag_length):
123 from cryptography.hazmat.primitives.ciphers.aead import AESCCM
124 if len(data) < tag_length:
125 raise InvalidTag
126 tag = data[-tag_length:]
127 data = data[:-tag_length]
128 cipher_name = _aead_cipher_name(cipher)
129 ctx = _aead_setup(
130 backend, cipher_name, cipher._key, nonce, tag, tag_length, _DECRYPT
131 )
132 # CCM requires us to pass the length of the data before processing anything
133 # However calling this with any other AEAD results in an error
134 if isinstance(cipher, AESCCM):
135 _set_length(backend, ctx, len(data))
136
137 _process_aad(backend, ctx, associated_data)
138 # CCM has a different error path if the tag doesn't match. Errors are
139 # raised in Update and Final is irrelevant.
140 if isinstance(cipher, AESCCM):
141 outlen = backend._ffi.new("int *")
142 buf = backend._ffi.new("unsigned char[]", len(data))
143 res = backend._lib.EVP_CipherUpdate(ctx, buf, outlen, data, len(data))
144 if res != 1:
145 backend._consume_errors()
146 raise InvalidTag
147
148 processed_data = backend._ffi.buffer(buf, outlen[0])[:]
149 else:
150 processed_data = _process_data(backend, ctx, data)
151 outlen = backend._ffi.new("int *")
152 res = backend._lib.EVP_CipherFinal_ex(ctx, backend._ffi.NULL, outlen)
153 if res == 0:
154 backend._consume_errors()
155 raise InvalidTag
156
157 return processed_data
158
[end of src/cryptography/hazmat/backends/openssl/aead.py]
[start of src/cryptography/hazmat/primitives/ciphers/aead.py]
1 # This file is dual licensed under the terms of the Apache License, Version
2 # 2.0, and the BSD License. See the LICENSE file in the root of this repository
3 # for complete details.
4
5 from __future__ import absolute_import, division, print_function
6
7 import os
8
9 from cryptography import exceptions, utils
10 from cryptography.hazmat.backends.openssl import aead
11 from cryptography.hazmat.backends.openssl.backend import backend
12
13
14 class ChaCha20Poly1305(object):
15 def __init__(self, key):
16 if not backend.aead_cipher_supported(self):
17 raise exceptions.UnsupportedAlgorithm(
18 "ChaCha20Poly1305 is not supported by this version of OpenSSL",
19 exceptions._Reasons.UNSUPPORTED_CIPHER
20 )
21 utils._check_bytes("key", key)
22
23 if len(key) != 32:
24 raise ValueError("ChaCha20Poly1305 key must be 32 bytes.")
25
26 self._key = key
27
28 @classmethod
29 def generate_key(cls):
30 return os.urandom(32)
31
32 def encrypt(self, nonce, data, associated_data):
33 if associated_data is None:
34 associated_data = b""
35
36 self._check_params(nonce, data, associated_data)
37 return aead._encrypt(
38 backend, self, nonce, data, associated_data, 16
39 )
40
41 def decrypt(self, nonce, data, associated_data):
42 if associated_data is None:
43 associated_data = b""
44
45 self._check_params(nonce, data, associated_data)
46 return aead._decrypt(
47 backend, self, nonce, data, associated_data, 16
48 )
49
50 def _check_params(self, nonce, data, associated_data):
51 utils._check_bytes("nonce", nonce)
52 utils._check_bytes("data", data)
53 utils._check_bytes("associated_data", associated_data)
54 if len(nonce) != 12:
55 raise ValueError("Nonce must be 12 bytes")
56
57
58 class AESCCM(object):
59 def __init__(self, key, tag_length=16):
60 utils._check_bytes("key", key)
61 if len(key) not in (16, 24, 32):
62 raise ValueError("AESCCM key must be 128, 192, or 256 bits.")
63
64 self._key = key
65 if not isinstance(tag_length, int):
66 raise TypeError("tag_length must be an integer")
67
68 if tag_length not in (4, 6, 8, 12, 14, 16):
69 raise ValueError("Invalid tag_length")
70
71 self._tag_length = tag_length
72
73 if not backend.aead_cipher_supported(self):
74 raise exceptions.UnsupportedAlgorithm(
75 "AESCCM is not supported by this version of OpenSSL",
76 exceptions._Reasons.UNSUPPORTED_CIPHER
77 )
78
79 @classmethod
80 def generate_key(cls, bit_length):
81 if not isinstance(bit_length, int):
82 raise TypeError("bit_length must be an integer")
83
84 if bit_length not in (128, 192, 256):
85 raise ValueError("bit_length must be 128, 192, or 256")
86
87 return os.urandom(bit_length // 8)
88
89 def encrypt(self, nonce, data, associated_data):
90 if associated_data is None:
91 associated_data = b""
92
93 self._check_params(nonce, data, associated_data)
94 self._validate_lengths(nonce, len(data))
95 return aead._encrypt(
96 backend, self, nonce, data, associated_data, self._tag_length
97 )
98
99 def decrypt(self, nonce, data, associated_data):
100 if associated_data is None:
101 associated_data = b""
102
103 self._check_params(nonce, data, associated_data)
104 return aead._decrypt(
105 backend, self, nonce, data, associated_data, self._tag_length
106 )
107
108 def _validate_lengths(self, nonce, data_len):
109 # For information about computing this, see
110 # https://tools.ietf.org/html/rfc3610#section-2.1
111 l = 15 - len(nonce)
112 if 2 ** (8 * l) < data_len:
113 raise ValueError("Nonce too long for data")
114
115 def _check_params(self, nonce, data, associated_data):
116 utils._check_bytes("nonce", nonce)
117 utils._check_bytes("data", data)
118 utils._check_bytes("associated_data", associated_data)
119 if not 7 <= len(nonce) <= 13:
120 raise ValueError("Nonce must be between 7 and 13 bytes")
121
[end of src/cryptography/hazmat/primitives/ciphers/aead.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/cryptography/hazmat/backends/openssl/aead.py b/src/cryptography/hazmat/backends/openssl/aead.py
--- a/src/cryptography/hazmat/backends/openssl/aead.py
+++ b/src/cryptography/hazmat/backends/openssl/aead.py
@@ -13,13 +13,15 @@
def _aead_cipher_name(cipher):
from cryptography.hazmat.primitives.ciphers.aead import (
- AESCCM, ChaCha20Poly1305
+ AESCCM, AESGCM, ChaCha20Poly1305
)
if isinstance(cipher, ChaCha20Poly1305):
return b"chacha20-poly1305"
- else:
- assert isinstance(cipher, AESCCM)
+ elif isinstance(cipher, AESCCM):
return "aes-{0}-ccm".format(len(cipher._key) * 8).encode("ascii")
+ else:
+ assert isinstance(cipher, AESGCM)
+ return "aes-{0}-gcm".format(len(cipher._key) * 8).encode("ascii")
def _aead_setup(backend, cipher_name, key, nonce, tag, tag_len, operation):
diff --git a/src/cryptography/hazmat/primitives/ciphers/aead.py b/src/cryptography/hazmat/primitives/ciphers/aead.py
--- a/src/cryptography/hazmat/primitives/ciphers/aead.py
+++ b/src/cryptography/hazmat/primitives/ciphers/aead.py
@@ -118,3 +118,45 @@
utils._check_bytes("associated_data", associated_data)
if not 7 <= len(nonce) <= 13:
raise ValueError("Nonce must be between 7 and 13 bytes")
+
+
+class AESGCM(object):
+ def __init__(self, key):
+ utils._check_bytes("key", key)
+ if len(key) not in (16, 24, 32):
+ raise ValueError("AESGCM key must be 128, 192, or 256 bits.")
+
+ self._key = key
+
+ @classmethod
+ def generate_key(cls, bit_length):
+ if not isinstance(bit_length, int):
+ raise TypeError("bit_length must be an integer")
+
+ if bit_length not in (128, 192, 256):
+ raise ValueError("bit_length must be 128, 192, or 256")
+
+ return os.urandom(bit_length // 8)
+
+ def encrypt(self, nonce, data, associated_data):
+ if associated_data is None:
+ associated_data = b""
+
+ self._check_params(nonce, data, associated_data)
+ return aead._encrypt(
+ backend, self, nonce, data, associated_data, 16
+ )
+
+ def decrypt(self, nonce, data, associated_data):
+ if associated_data is None:
+ associated_data = b""
+
+ self._check_params(nonce, data, associated_data)
+ return aead._decrypt(
+ backend, self, nonce, data, associated_data, 16
+ )
+
+ def _check_params(self, nonce, data, associated_data):
+ utils._check_bytes("nonce", nonce)
+ utils._check_bytes("data", data)
+ utils._check_bytes("associated_data", associated_data)
|
{"golden_diff": "diff --git a/src/cryptography/hazmat/backends/openssl/aead.py b/src/cryptography/hazmat/backends/openssl/aead.py\n--- a/src/cryptography/hazmat/backends/openssl/aead.py\n+++ b/src/cryptography/hazmat/backends/openssl/aead.py\n@@ -13,13 +13,15 @@\n \n def _aead_cipher_name(cipher):\n from cryptography.hazmat.primitives.ciphers.aead import (\n- AESCCM, ChaCha20Poly1305\n+ AESCCM, AESGCM, ChaCha20Poly1305\n )\n if isinstance(cipher, ChaCha20Poly1305):\n return b\"chacha20-poly1305\"\n- else:\n- assert isinstance(cipher, AESCCM)\n+ elif isinstance(cipher, AESCCM):\n return \"aes-{0}-ccm\".format(len(cipher._key) * 8).encode(\"ascii\")\n+ else:\n+ assert isinstance(cipher, AESGCM)\n+ return \"aes-{0}-gcm\".format(len(cipher._key) * 8).encode(\"ascii\")\n \n \n def _aead_setup(backend, cipher_name, key, nonce, tag, tag_len, operation):\ndiff --git a/src/cryptography/hazmat/primitives/ciphers/aead.py b/src/cryptography/hazmat/primitives/ciphers/aead.py\n--- a/src/cryptography/hazmat/primitives/ciphers/aead.py\n+++ b/src/cryptography/hazmat/primitives/ciphers/aead.py\n@@ -118,3 +118,45 @@\n utils._check_bytes(\"associated_data\", associated_data)\n if not 7 <= len(nonce) <= 13:\n raise ValueError(\"Nonce must be between 7 and 13 bytes\")\n+\n+\n+class AESGCM(object):\n+ def __init__(self, key):\n+ utils._check_bytes(\"key\", key)\n+ if len(key) not in (16, 24, 32):\n+ raise ValueError(\"AESGCM key must be 128, 192, or 256 bits.\")\n+\n+ self._key = key\n+\n+ @classmethod\n+ def generate_key(cls, bit_length):\n+ if not isinstance(bit_length, int):\n+ raise TypeError(\"bit_length must be an integer\")\n+\n+ if bit_length not in (128, 192, 256):\n+ raise ValueError(\"bit_length must be 128, 192, or 256\")\n+\n+ return os.urandom(bit_length // 8)\n+\n+ def encrypt(self, nonce, data, associated_data):\n+ if associated_data is None:\n+ associated_data = b\"\"\n+\n+ self._check_params(nonce, data, associated_data)\n+ return aead._encrypt(\n+ backend, self, nonce, data, associated_data, 16\n+ )\n+\n+ def decrypt(self, nonce, data, associated_data):\n+ if associated_data is None:\n+ associated_data = b\"\"\n+\n+ self._check_params(nonce, data, associated_data)\n+ return aead._decrypt(\n+ backend, self, nonce, data, associated_data, 16\n+ )\n+\n+ def _check_params(self, nonce, data, associated_data):\n+ utils._check_bytes(\"nonce\", nonce)\n+ utils._check_bytes(\"data\", data)\n+ utils._check_bytes(\"associated_data\", associated_data)\n", "issue": "Implement One Shot AESGCM\nMuch like our ChaCha20Poly1305 and AESCCM classes we should do AESGCM. Then we can update our streaming GCM docs to point at the one shot as a better option if you aren't dealing with large volumes of data.\n", "before_files": [{"content": "# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\nfrom __future__ import absolute_import, division, print_function\n\nfrom cryptography.exceptions import InvalidTag\n\n\n_ENCRYPT = 1\n_DECRYPT = 0\n\n\ndef _aead_cipher_name(cipher):\n from cryptography.hazmat.primitives.ciphers.aead import (\n AESCCM, ChaCha20Poly1305\n )\n if isinstance(cipher, ChaCha20Poly1305):\n return b\"chacha20-poly1305\"\n else:\n assert isinstance(cipher, AESCCM)\n return \"aes-{0}-ccm\".format(len(cipher._key) * 8).encode(\"ascii\")\n\n\ndef _aead_setup(backend, cipher_name, key, nonce, tag, tag_len, operation):\n evp_cipher = backend._lib.EVP_get_cipherbyname(cipher_name)\n backend.openssl_assert(evp_cipher != backend._ffi.NULL)\n ctx = backend._lib.EVP_CIPHER_CTX_new()\n ctx = backend._ffi.gc(ctx, backend._lib.EVP_CIPHER_CTX_free)\n res = backend._lib.EVP_CipherInit_ex(\n ctx, evp_cipher,\n backend._ffi.NULL,\n backend._ffi.NULL,\n backend._ffi.NULL,\n int(operation == _ENCRYPT)\n )\n backend.openssl_assert(res != 0)\n res = backend._lib.EVP_CIPHER_CTX_set_key_length(ctx, len(key))\n backend.openssl_assert(res != 0)\n res = backend._lib.EVP_CIPHER_CTX_ctrl(\n ctx, backend._lib.EVP_CTRL_AEAD_SET_IVLEN, len(nonce),\n backend._ffi.NULL\n )\n backend.openssl_assert(res != 0)\n if operation == _DECRYPT:\n res = backend._lib.EVP_CIPHER_CTX_ctrl(\n ctx, backend._lib.EVP_CTRL_AEAD_SET_TAG, len(tag), tag\n )\n backend.openssl_assert(res != 0)\n else:\n res = backend._lib.EVP_CIPHER_CTX_ctrl(\n ctx, backend._lib.EVP_CTRL_AEAD_SET_TAG, tag_len, backend._ffi.NULL\n )\n\n res = backend._lib.EVP_CipherInit_ex(\n ctx,\n backend._ffi.NULL,\n backend._ffi.NULL,\n key,\n nonce,\n int(operation == _ENCRYPT)\n )\n backend.openssl_assert(res != 0)\n return ctx\n\n\ndef _set_length(backend, ctx, data_len):\n intptr = backend._ffi.new(\"int *\")\n res = backend._lib.EVP_CipherUpdate(\n ctx,\n backend._ffi.NULL,\n intptr,\n backend._ffi.NULL,\n data_len\n )\n backend.openssl_assert(res != 0)\n\n\ndef _process_aad(backend, ctx, associated_data):\n outlen = backend._ffi.new(\"int *\")\n res = backend._lib.EVP_CipherUpdate(\n ctx, backend._ffi.NULL, outlen, associated_data, len(associated_data)\n )\n backend.openssl_assert(res != 0)\n\n\ndef _process_data(backend, ctx, data):\n outlen = backend._ffi.new(\"int *\")\n buf = backend._ffi.new(\"unsigned char[]\", len(data))\n res = backend._lib.EVP_CipherUpdate(ctx, buf, outlen, data, len(data))\n backend.openssl_assert(res != 0)\n return backend._ffi.buffer(buf, outlen[0])[:]\n\n\ndef _encrypt(backend, cipher, nonce, data, associated_data, tag_length):\n from cryptography.hazmat.primitives.ciphers.aead import AESCCM\n cipher_name = _aead_cipher_name(cipher)\n ctx = _aead_setup(\n backend, cipher_name, cipher._key, nonce, None, tag_length, _ENCRYPT\n )\n # CCM requires us to pass the length of the data before processing anything\n # However calling this with any other AEAD results in an error\n if isinstance(cipher, AESCCM):\n _set_length(backend, ctx, len(data))\n\n _process_aad(backend, ctx, associated_data)\n processed_data = _process_data(backend, ctx, data)\n outlen = backend._ffi.new(\"int *\")\n res = backend._lib.EVP_CipherFinal_ex(ctx, backend._ffi.NULL, outlen)\n backend.openssl_assert(res != 0)\n backend.openssl_assert(outlen[0] == 0)\n tag_buf = backend._ffi.new(\"unsigned char[]\", tag_length)\n res = backend._lib.EVP_CIPHER_CTX_ctrl(\n ctx, backend._lib.EVP_CTRL_AEAD_GET_TAG, tag_length, tag_buf\n )\n backend.openssl_assert(res != 0)\n tag = backend._ffi.buffer(tag_buf)[:]\n\n return processed_data + tag\n\n\ndef _decrypt(backend, cipher, nonce, data, associated_data, tag_length):\n from cryptography.hazmat.primitives.ciphers.aead import AESCCM\n if len(data) < tag_length:\n raise InvalidTag\n tag = data[-tag_length:]\n data = data[:-tag_length]\n cipher_name = _aead_cipher_name(cipher)\n ctx = _aead_setup(\n backend, cipher_name, cipher._key, nonce, tag, tag_length, _DECRYPT\n )\n # CCM requires us to pass the length of the data before processing anything\n # However calling this with any other AEAD results in an error\n if isinstance(cipher, AESCCM):\n _set_length(backend, ctx, len(data))\n\n _process_aad(backend, ctx, associated_data)\n # CCM has a different error path if the tag doesn't match. Errors are\n # raised in Update and Final is irrelevant.\n if isinstance(cipher, AESCCM):\n outlen = backend._ffi.new(\"int *\")\n buf = backend._ffi.new(\"unsigned char[]\", len(data))\n res = backend._lib.EVP_CipherUpdate(ctx, buf, outlen, data, len(data))\n if res != 1:\n backend._consume_errors()\n raise InvalidTag\n\n processed_data = backend._ffi.buffer(buf, outlen[0])[:]\n else:\n processed_data = _process_data(backend, ctx, data)\n outlen = backend._ffi.new(\"int *\")\n res = backend._lib.EVP_CipherFinal_ex(ctx, backend._ffi.NULL, outlen)\n if res == 0:\n backend._consume_errors()\n raise InvalidTag\n\n return processed_data\n", "path": "src/cryptography/hazmat/backends/openssl/aead.py"}, {"content": "# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\nfrom __future__ import absolute_import, division, print_function\n\nimport os\n\nfrom cryptography import exceptions, utils\nfrom cryptography.hazmat.backends.openssl import aead\nfrom cryptography.hazmat.backends.openssl.backend import backend\n\n\nclass ChaCha20Poly1305(object):\n def __init__(self, key):\n if not backend.aead_cipher_supported(self):\n raise exceptions.UnsupportedAlgorithm(\n \"ChaCha20Poly1305 is not supported by this version of OpenSSL\",\n exceptions._Reasons.UNSUPPORTED_CIPHER\n )\n utils._check_bytes(\"key\", key)\n\n if len(key) != 32:\n raise ValueError(\"ChaCha20Poly1305 key must be 32 bytes.\")\n\n self._key = key\n\n @classmethod\n def generate_key(cls):\n return os.urandom(32)\n\n def encrypt(self, nonce, data, associated_data):\n if associated_data is None:\n associated_data = b\"\"\n\n self._check_params(nonce, data, associated_data)\n return aead._encrypt(\n backend, self, nonce, data, associated_data, 16\n )\n\n def decrypt(self, nonce, data, associated_data):\n if associated_data is None:\n associated_data = b\"\"\n\n self._check_params(nonce, data, associated_data)\n return aead._decrypt(\n backend, self, nonce, data, associated_data, 16\n )\n\n def _check_params(self, nonce, data, associated_data):\n utils._check_bytes(\"nonce\", nonce)\n utils._check_bytes(\"data\", data)\n utils._check_bytes(\"associated_data\", associated_data)\n if len(nonce) != 12:\n raise ValueError(\"Nonce must be 12 bytes\")\n\n\nclass AESCCM(object):\n def __init__(self, key, tag_length=16):\n utils._check_bytes(\"key\", key)\n if len(key) not in (16, 24, 32):\n raise ValueError(\"AESCCM key must be 128, 192, or 256 bits.\")\n\n self._key = key\n if not isinstance(tag_length, int):\n raise TypeError(\"tag_length must be an integer\")\n\n if tag_length not in (4, 6, 8, 12, 14, 16):\n raise ValueError(\"Invalid tag_length\")\n\n self._tag_length = tag_length\n\n if not backend.aead_cipher_supported(self):\n raise exceptions.UnsupportedAlgorithm(\n \"AESCCM is not supported by this version of OpenSSL\",\n exceptions._Reasons.UNSUPPORTED_CIPHER\n )\n\n @classmethod\n def generate_key(cls, bit_length):\n if not isinstance(bit_length, int):\n raise TypeError(\"bit_length must be an integer\")\n\n if bit_length not in (128, 192, 256):\n raise ValueError(\"bit_length must be 128, 192, or 256\")\n\n return os.urandom(bit_length // 8)\n\n def encrypt(self, nonce, data, associated_data):\n if associated_data is None:\n associated_data = b\"\"\n\n self._check_params(nonce, data, associated_data)\n self._validate_lengths(nonce, len(data))\n return aead._encrypt(\n backend, self, nonce, data, associated_data, self._tag_length\n )\n\n def decrypt(self, nonce, data, associated_data):\n if associated_data is None:\n associated_data = b\"\"\n\n self._check_params(nonce, data, associated_data)\n return aead._decrypt(\n backend, self, nonce, data, associated_data, self._tag_length\n )\n\n def _validate_lengths(self, nonce, data_len):\n # For information about computing this, see\n # https://tools.ietf.org/html/rfc3610#section-2.1\n l = 15 - len(nonce)\n if 2 ** (8 * l) < data_len:\n raise ValueError(\"Nonce too long for data\")\n\n def _check_params(self, nonce, data, associated_data):\n utils._check_bytes(\"nonce\", nonce)\n utils._check_bytes(\"data\", data)\n utils._check_bytes(\"associated_data\", associated_data)\n if not 7 <= len(nonce) <= 13:\n raise ValueError(\"Nonce must be between 7 and 13 bytes\")\n", "path": "src/cryptography/hazmat/primitives/ciphers/aead.py"}]}
| 3,757 | 789 |
gh_patches_debug_25935
|
rasdani/github-patches
|
git_diff
|
MycroftAI__mycroft-core-837
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Lock kills service on autoreload
the service is running a tornado instance that autoreloads the service if a file in the mycroft-core tree is modified. The service also contains a Lock that ensures only one service instance is loaded. When the service is reloaded the same PID is used and the lock kills it.
</issue>
<code>
[start of mycroft/lock/__init__.py]
1
2 # Time-stamp: <2017-04-06 15:55:05 dmendyke> -*- mode: python; -*-
3
4 # Copyright 2016 Mycroft AI, Inc.
5 #
6 # This file is part of Mycroft Core.
7 #
8 # Mycroft Core is free software: you can redistribute it and/or modify
9 # it under the terms of the GNU General Public License as published by
10 # the Free Software Foundation, either version 3 of the License, or
11 # (at your option) any later version.
12 #
13 # Mycroft Core is distributed in the hope that it will be useful,
14 # but WITHOUT ANY WARRANTY; without even the implied warranty of
15 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
16 # GNU General Public License for more details.
17 #
18 # You should have received a copy of the GNU General Public License
19 # along with Mycroft Core. If not, see <http://www.gnu.org/licenses/>.
20
21 #
22 # Required Modules
23 from signal import getsignal, signal, SIGKILL, SIGINT, SIGTERM # signals
24 import os # Operating System functions
25
26
27 #
28 # Written by Daniel Mendyke [[email protected]]
29 __author__ = 'dmendyke'
30
31
32 #
33 # Wrapper around chain of handler functions for a specific system level signal.
34 # Often used to trap Ctrl-C for specific application purposes.
35 class Signal(object): # python 3+ class Signal
36
37 '''
38 Capture and replace a signal handler with a user supplied function.
39 The user supplied function is always called first then the previous
40 handler, if it exists, will be called. It is possible to chain several
41 signal handlers together by creating multiply instances of objects of
42 this class, providing a different user functions for each instance. All
43 provided user functions will be called in LIFO order.
44 '''
45
46 #
47 # Constructor
48 # Get the previous handler function then set the passed function
49 # as the new handler function for this signal
50
51 def __init__(self, sig_value, func):
52 '''
53 Create an instance of the signal handler class.
54
55 sig_value: The ID value of the signal to be captured.
56 func: User supplied function that will act as the new signal handler.
57 '''
58 super(Signal, self).__init__() # python 3+ 'super().__init__()
59 self.__sig_value = sig_value
60 self.__user_func = func # store user passed function
61 self.__previous_func = getsignal(sig_value) # get current handler
62 signal(sig_value, self)
63
64 #
65 # Called to handle the passed signal
66 def __call__(self, signame, sf):
67 '''
68 Allows the instance of this class to be called as a function.
69 When called it runs the user supplied signal handler than
70 checks to see if there is a previously defined handler. If
71 there is a previously defined handler call it.
72 '''
73 self.__user_func() # call user function
74 if self.__previous_func:
75 self.__previous_func(signame, sf)
76
77 #
78 # reset the signal handler
79 def __del__(self):
80 '''
81 Class destructor. Called during garbage collection.
82 Resets the signal handler to the previous function.
83 '''
84 signal(self.__sig_value, self.__previous_func)
85
86 # End class Signal
87
88
89 # ----------------------------------------------------------------------------
90 # ----------------------------------------------------------------------------
91
92
93 #
94 # Create, delete and manipulate a PID file for this service
95 # ------------------------------------------------------------------------------
96 class Lock(object): # python 3+ 'class Lock'
97
98 '''
99 Create and maintains the PID lock file for this application process.
100 The PID lock file is located in /tmp/mycroft/*.pid. If another process
101 of the same type is started, this class will 'attempt' to stop the
102 previously running process and then change the process ID in the lock file.
103 '''
104
105 #
106 # Class constants
107 DIRECTORY = '/tmp/mycroft'
108 FILE = '/{}.pid'
109
110 #
111 # Constructor
112 def __init__(self, service):
113 '''
114 Builds the instance of this object. Holds the lock until the
115 object is garbage collected.
116
117 service: Text string. The name of the service application
118 to be locked (ie: skills, voice)
119 '''
120 super(Lock, self).__init__() # python 3+ 'super().__init__()'
121 self.__pid = os.getpid() # PID of this application
122 self.path = Lock.DIRECTORY + Lock.FILE.format(service)
123 self.set_handlers() # set signal handlers
124 self.create()
125
126 #
127 # Reset the signal handlers to the 'delete' function
128 def set_handlers(self):
129 '''
130 Trap both SIGINT and SIGTERM to gracefully clean up PID files
131 '''
132 self.__handlers = {SIGINT: Signal(SIGINT, self.delete)}
133 self.__handlers = {SIGTERM: Signal(SIGTERM, self.delete)}
134
135 #
136 # Check to see if the PID already exists
137 # If it does exits perform several things:
138 # Stop the current process
139 # Delete the exiting file
140 def exists(self):
141 '''
142 Check to see if the PID lock file currently exists. If it does
143 than send a SIGTERM signal to the process defined by the value
144 in the lock file. Catch the keyboard interrupt exception to
145 prevent propagation if stopped by use of Ctrl-C.
146 '''
147 if not os.path.isfile(self.path):
148 return
149 with open(self.path, 'r') as L:
150 try:
151 os.kill(int(L.read()), SIGKILL)
152 except Exception as E:
153 pass
154
155 #
156 # Create a lock file for this server process
157 def touch(self):
158 '''
159 If needed, create the '/tmp/mycroft' directory than open the
160 lock file for writting and store the current process ID (PID)
161 as text.
162 '''
163 if not os.path.exists(Lock.DIRECTORY):
164 os.makedirs(Lock.DIRECTORY)
165 with open(self.path, 'w') as L:
166 L.write('{}'.format(self.__pid))
167
168 #
169 # Create the PID file
170 def create(self):
171 '''
172 Checks to see if a lock file for this service already exists,
173 if so have it killed. In either case write the process ID of
174 the current service process to to the existing or newly created
175 lock file in /tmp/mycroft/
176 '''
177 self.exists() # check for current running process
178 self.touch()
179
180 #
181 # Delete the PID file - but only if it has not been overwritten
182 # by a duplicate service application
183 def delete(self, *args):
184 '''
185 If the PID lock file contains the PID of this process delete it.
186
187 *args: Ignored. Required as this fuction is called as a signel
188 handler.
189 '''
190 with open(self.path, 'r') as L:
191 if self.__pid == L.read():
192 os.unlink(self.path)
193
194 # End class Lock
195
[end of mycroft/lock/__init__.py]
[start of mycroft/messagebus/service/main.py]
1 # Copyright 2016 Mycroft AI, Inc.
2 #
3 # This file is part of Mycroft Core.
4 #
5 # Mycroft Core is free software: you can redistribute it and/or modify
6 # it under the terms of the GNU General Public License as published by
7 # the Free Software Foundation, either version 3 of the License, or
8 # (at your option) any later version.
9 #
10 # Mycroft Core is distributed in the hope that it will be useful,
11 # but WITHOUT ANY WARRANTY; without even the implied warranty of
12 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
13 # GNU General Public License for more details.
14 #
15 # You should have received a copy of the GNU General Public License
16 # along with Mycroft Core. If not, see <http://www.gnu.org/licenses/>.
17
18 import tornado.ioloop as ioloop
19 import tornado.web as web
20
21 from mycroft.configuration import ConfigurationManager
22 from mycroft.messagebus.service.ws import WebsocketEventHandler
23 from mycroft.util import validate_param
24 from mycroft.lock import Lock # creates/supports PID locking file
25
26
27 __author__ = 'seanfitz', 'jdorleans'
28
29 settings = {
30 'debug': True
31 }
32
33
34 def main():
35 import tornado.options
36 lock = Lock("service")
37 tornado.options.parse_command_line()
38 config = ConfigurationManager.get().get("websocket")
39
40 host = config.get("host")
41 port = config.get("port")
42 route = config.get("route")
43 validate_param(host, "websocket.host")
44 validate_param(port, "websocket.port")
45 validate_param(route, "websocket.route")
46
47 routes = [
48 (route, WebsocketEventHandler)
49 ]
50 application = web.Application(routes, **settings)
51 application.listen(port, host)
52 ioloop.IOLoop.instance().start()
53
54
55 if __name__ == "__main__":
56 main()
57
[end of mycroft/messagebus/service/main.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mycroft/lock/__init__.py b/mycroft/lock/__init__.py
--- a/mycroft/lock/__init__.py
+++ b/mycroft/lock/__init__.py
@@ -187,8 +187,11 @@
*args: Ignored. Required as this fuction is called as a signel
handler.
'''
- with open(self.path, 'r') as L:
- if self.__pid == L.read():
- os.unlink(self.path)
-
+ try:
+ with open(self.path, 'r') as L:
+ pid = int(L.read())
+ if self.__pid == pid:
+ os.unlink(self.path)
+ except IOError:
+ pass
# End class Lock
diff --git a/mycroft/messagebus/service/main.py b/mycroft/messagebus/service/main.py
--- a/mycroft/messagebus/service/main.py
+++ b/mycroft/messagebus/service/main.py
@@ -17,6 +17,7 @@
import tornado.ioloop as ioloop
import tornado.web as web
+import tornado.autoreload as autoreload
from mycroft.configuration import ConfigurationManager
from mycroft.messagebus.service.ws import WebsocketEventHandler
@@ -35,6 +36,13 @@
import tornado.options
lock = Lock("service")
tornado.options.parse_command_line()
+
+ def reload_hook():
+ """ Hook to release lock when autoreload is triggered. """
+ lock.delete()
+
+ tornado.autoreload.add_reload_hook(reload_hook)
+
config = ConfigurationManager.get().get("websocket")
host = config.get("host")
|
{"golden_diff": "diff --git a/mycroft/lock/__init__.py b/mycroft/lock/__init__.py\n--- a/mycroft/lock/__init__.py\n+++ b/mycroft/lock/__init__.py\n@@ -187,8 +187,11 @@\n *args: Ignored. Required as this fuction is called as a signel\n handler.\n '''\n- with open(self.path, 'r') as L:\n- if self.__pid == L.read():\n- os.unlink(self.path)\n-\n+ try:\n+ with open(self.path, 'r') as L:\n+ pid = int(L.read())\n+ if self.__pid == pid:\n+ os.unlink(self.path)\n+ except IOError:\n+ pass\n # End class Lock\ndiff --git a/mycroft/messagebus/service/main.py b/mycroft/messagebus/service/main.py\n--- a/mycroft/messagebus/service/main.py\n+++ b/mycroft/messagebus/service/main.py\n@@ -17,6 +17,7 @@\n \n import tornado.ioloop as ioloop\n import tornado.web as web\n+import tornado.autoreload as autoreload\n \n from mycroft.configuration import ConfigurationManager\n from mycroft.messagebus.service.ws import WebsocketEventHandler\n@@ -35,6 +36,13 @@\n import tornado.options\n lock = Lock(\"service\")\n tornado.options.parse_command_line()\n+\n+ def reload_hook():\n+ \"\"\" Hook to release lock when autoreload is triggered. \"\"\"\n+ lock.delete()\n+\n+ tornado.autoreload.add_reload_hook(reload_hook)\n+\n config = ConfigurationManager.get().get(\"websocket\")\n \n host = config.get(\"host\")\n", "issue": "Lock kills service on autoreload\nthe service is running a tornado instance that autoreloads the service if a file in the mycroft-core tree is modified. The service also contains a Lock that ensures only one service instance is loaded. When the service is reloaded the same PID is used and the lock kills it.\n", "before_files": [{"content": "\n# Time-stamp: <2017-04-06 15:55:05 dmendyke> -*- mode: python; -*-\n\n# Copyright 2016 Mycroft AI, Inc.\n#\n# This file is part of Mycroft Core.\n#\n# Mycroft Core is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Mycroft Core is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Mycroft Core. If not, see <http://www.gnu.org/licenses/>.\n\n#\n# Required Modules\nfrom signal import getsignal, signal, SIGKILL, SIGINT, SIGTERM # signals\nimport os # Operating System functions\n\n\n#\n# Written by Daniel Mendyke [[email protected]]\n__author__ = 'dmendyke'\n\n\n#\n# Wrapper around chain of handler functions for a specific system level signal.\n# Often used to trap Ctrl-C for specific application purposes.\nclass Signal(object): # python 3+ class Signal\n\n '''\n Capture and replace a signal handler with a user supplied function.\n The user supplied function is always called first then the previous\n handler, if it exists, will be called. It is possible to chain several\n signal handlers together by creating multiply instances of objects of\n this class, providing a different user functions for each instance. All\n provided user functions will be called in LIFO order.\n '''\n\n #\n # Constructor\n # Get the previous handler function then set the passed function\n # as the new handler function for this signal\n\n def __init__(self, sig_value, func):\n '''\n Create an instance of the signal handler class.\n\n sig_value: The ID value of the signal to be captured.\n func: User supplied function that will act as the new signal handler.\n '''\n super(Signal, self).__init__() # python 3+ 'super().__init__()\n self.__sig_value = sig_value\n self.__user_func = func # store user passed function\n self.__previous_func = getsignal(sig_value) # get current handler\n signal(sig_value, self)\n\n #\n # Called to handle the passed signal\n def __call__(self, signame, sf):\n '''\n Allows the instance of this class to be called as a function.\n When called it runs the user supplied signal handler than\n checks to see if there is a previously defined handler. If\n there is a previously defined handler call it.\n '''\n self.__user_func() # call user function\n if self.__previous_func:\n self.__previous_func(signame, sf)\n\n #\n # reset the signal handler\n def __del__(self):\n '''\n Class destructor. Called during garbage collection.\n Resets the signal handler to the previous function.\n '''\n signal(self.__sig_value, self.__previous_func)\n\n # End class Signal\n\n\n# ----------------------------------------------------------------------------\n# ----------------------------------------------------------------------------\n\n\n#\n# Create, delete and manipulate a PID file for this service\n# ------------------------------------------------------------------------------\nclass Lock(object): # python 3+ 'class Lock'\n\n '''\n Create and maintains the PID lock file for this application process.\n The PID lock file is located in /tmp/mycroft/*.pid. If another process\n of the same type is started, this class will 'attempt' to stop the\n previously running process and then change the process ID in the lock file.\n '''\n\n #\n # Class constants\n DIRECTORY = '/tmp/mycroft'\n FILE = '/{}.pid'\n\n #\n # Constructor\n def __init__(self, service):\n '''\n Builds the instance of this object. Holds the lock until the\n object is garbage collected.\n\n service: Text string. The name of the service application\n to be locked (ie: skills, voice)\n '''\n super(Lock, self).__init__() # python 3+ 'super().__init__()'\n self.__pid = os.getpid() # PID of this application\n self.path = Lock.DIRECTORY + Lock.FILE.format(service)\n self.set_handlers() # set signal handlers\n self.create()\n\n #\n # Reset the signal handlers to the 'delete' function\n def set_handlers(self):\n '''\n Trap both SIGINT and SIGTERM to gracefully clean up PID files\n '''\n self.__handlers = {SIGINT: Signal(SIGINT, self.delete)}\n self.__handlers = {SIGTERM: Signal(SIGTERM, self.delete)}\n\n #\n # Check to see if the PID already exists\n # If it does exits perform several things:\n # Stop the current process\n # Delete the exiting file\n def exists(self):\n '''\n Check to see if the PID lock file currently exists. If it does\n than send a SIGTERM signal to the process defined by the value\n in the lock file. Catch the keyboard interrupt exception to\n prevent propagation if stopped by use of Ctrl-C.\n '''\n if not os.path.isfile(self.path):\n return\n with open(self.path, 'r') as L:\n try:\n os.kill(int(L.read()), SIGKILL)\n except Exception as E:\n pass\n\n #\n # Create a lock file for this server process\n def touch(self):\n '''\n If needed, create the '/tmp/mycroft' directory than open the\n lock file for writting and store the current process ID (PID)\n as text.\n '''\n if not os.path.exists(Lock.DIRECTORY):\n os.makedirs(Lock.DIRECTORY)\n with open(self.path, 'w') as L:\n L.write('{}'.format(self.__pid))\n\n #\n # Create the PID file\n def create(self):\n '''\n Checks to see if a lock file for this service already exists,\n if so have it killed. In either case write the process ID of\n the current service process to to the existing or newly created\n lock file in /tmp/mycroft/\n '''\n self.exists() # check for current running process\n self.touch()\n\n #\n # Delete the PID file - but only if it has not been overwritten\n # by a duplicate service application\n def delete(self, *args):\n '''\n If the PID lock file contains the PID of this process delete it.\n\n *args: Ignored. Required as this fuction is called as a signel\n handler.\n '''\n with open(self.path, 'r') as L:\n if self.__pid == L.read():\n os.unlink(self.path)\n\n # End class Lock\n", "path": "mycroft/lock/__init__.py"}, {"content": "# Copyright 2016 Mycroft AI, Inc.\n#\n# This file is part of Mycroft Core.\n#\n# Mycroft Core is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Mycroft Core is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Mycroft Core. If not, see <http://www.gnu.org/licenses/>.\n\nimport tornado.ioloop as ioloop\nimport tornado.web as web\n\nfrom mycroft.configuration import ConfigurationManager\nfrom mycroft.messagebus.service.ws import WebsocketEventHandler\nfrom mycroft.util import validate_param\nfrom mycroft.lock import Lock # creates/supports PID locking file\n\n\n__author__ = 'seanfitz', 'jdorleans'\n\nsettings = {\n 'debug': True\n}\n\n\ndef main():\n import tornado.options\n lock = Lock(\"service\")\n tornado.options.parse_command_line()\n config = ConfigurationManager.get().get(\"websocket\")\n\n host = config.get(\"host\")\n port = config.get(\"port\")\n route = config.get(\"route\")\n validate_param(host, \"websocket.host\")\n validate_param(port, \"websocket.port\")\n validate_param(route, \"websocket.route\")\n\n routes = [\n (route, WebsocketEventHandler)\n ]\n application = web.Application(routes, **settings)\n application.listen(port, host)\n ioloop.IOLoop.instance().start()\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "mycroft/messagebus/service/main.py"}]}
| 3,135 | 363 |
gh_patches_debug_15713
|
rasdani/github-patches
|
git_diff
|
netket__netket-122
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Save and load objects from python
The last main design issue to be solved for v2.0 concerns saving and loading objects from python.
Pybind11 has some [pickling support](https://pybind11.readthedocs.io/en/stable/advanced/classes.html#pickling-support).
However, the design issue to be addressed is how to serialize objects stored internally as pointers.
Basically, each pickable object needs to define a GetState function, returning a python tuple of the arguments needed to construct the object.
```c++
py::tuple GetState(const Pickleable &p) {
return py::make_tuple(p.Field1(),p.Field2(),...);
}
```
However, if the `Pickeable` stores a pointer to some abstract object (say Hilbert), then one obviously cannot do:
```c++
py::tuple GetState(const Pickleable &p) {
auto hilbert= p.GetHilbert(); //NO!
return py::make_tuple(p.Field1(),p.Field2(),hilbert);
}
```
Suggestions are welcome.
</issue>
<code>
[start of Tutorials/PyNetKet/machine.py]
1 # Copyright 2018 The Simons Foundation, Inc. - All Rights Reserved.
2
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6
7 # http://www.apache.org/licenses/LICENSE-2.0
8
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from __future__ import print_function
16 import netket as nk
17 import networkx as nx
18 import numpy as np
19 from mpi4py import MPI
20 import scipy.sparse as sparse
21
22 #Constructing a 1d lattice
23 g = nk.graph.Hypercube(L=4, ndim=1)
24
25 # Hilbert space of spins from given graph
26 hi = nk.hilbert.Spin(s=0.5, graph=g)
27
28 #Hamiltonian
29 ha = nk.operator.Ising(h=1.0, hilbert=hi)
30
31 #Machine
32 ma = nk.machine.RbmSpin(hilbert=hi, alpha=1)
33 ma.InitRandomPars(seed=1234, sigma=0.1)
34 print(ma.GetParameters())
35
36 #Layer
37 a = np.ones(3, dtype=complex)
38 b = np.zeros(3, dtype=complex)
39 act = nk.activation.Tanh()
40
41 act(a, b)
42 print(b)
43
[end of Tutorials/PyNetKet/machine.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/Tutorials/PyNetKet/machine.py b/Tutorials/PyNetKet/machine.py
--- a/Tutorials/PyNetKet/machine.py
+++ b/Tutorials/PyNetKet/machine.py
@@ -19,24 +19,20 @@
from mpi4py import MPI
import scipy.sparse as sparse
-#Constructing a 1d lattice
-g = nk.graph.Hypercube(L=4, ndim=1)
+# Constructing a 1d lattice
+g = nk.graph.Hypercube(length=4, n_dim=1)
# Hilbert space of spins from given graph
hi = nk.hilbert.Spin(s=0.5, graph=g)
-#Hamiltonian
+# Hamiltonian
ha = nk.operator.Ising(h=1.0, hilbert=hi)
-#Machine
+# Machine
ma = nk.machine.RbmSpin(hilbert=hi, alpha=1)
-ma.InitRandomPars(seed=1234, sigma=0.1)
-print(ma.GetParameters())
+ma.init_random_parameters(seed=1234, sigma=0.1)
-#Layer
-a = np.ones(3, dtype=complex)
-b = np.zeros(3, dtype=complex)
-act = nk.activation.Tanh()
-
-act(a, b)
-print(b)
+ma.save("test.wf")
+ma.parameters = np.zeros(ma.n_par)
+ma.load("test.wf")
+print(ma.parameters)
|
{"golden_diff": "diff --git a/Tutorials/PyNetKet/machine.py b/Tutorials/PyNetKet/machine.py\n--- a/Tutorials/PyNetKet/machine.py\n+++ b/Tutorials/PyNetKet/machine.py\n@@ -19,24 +19,20 @@\n from mpi4py import MPI\n import scipy.sparse as sparse\n \n-#Constructing a 1d lattice\n-g = nk.graph.Hypercube(L=4, ndim=1)\n+# Constructing a 1d lattice\n+g = nk.graph.Hypercube(length=4, n_dim=1)\n \n # Hilbert space of spins from given graph\n hi = nk.hilbert.Spin(s=0.5, graph=g)\n \n-#Hamiltonian\n+# Hamiltonian\n ha = nk.operator.Ising(h=1.0, hilbert=hi)\n \n-#Machine\n+# Machine\n ma = nk.machine.RbmSpin(hilbert=hi, alpha=1)\n-ma.InitRandomPars(seed=1234, sigma=0.1)\n-print(ma.GetParameters())\n+ma.init_random_parameters(seed=1234, sigma=0.1)\n \n-#Layer\n-a = np.ones(3, dtype=complex)\n-b = np.zeros(3, dtype=complex)\n-act = nk.activation.Tanh()\n-\n-act(a, b)\n-print(b)\n+ma.save(\"test.wf\")\n+ma.parameters = np.zeros(ma.n_par)\n+ma.load(\"test.wf\")\n+print(ma.parameters)\n", "issue": "Save and load objects from python\nThe last main design issue to be solved for v2.0 concerns saving and loading objects from python.\r\n\r\nPybind11 has some [pickling support](https://pybind11.readthedocs.io/en/stable/advanced/classes.html#pickling-support).\r\n\r\nHowever, the design issue to be addressed is how to serialize objects stored internally as pointers.\r\nBasically, each pickable object needs to define a GetState function, returning a python tuple of the arguments needed to construct the object. \r\n\r\n```c++\r\npy::tuple GetState(const Pickleable &p) { \r\n return py::make_tuple(p.Field1(),p.Field2(),...);\r\n}\r\n```\r\nHowever, if the `Pickeable` stores a pointer to some abstract object (say Hilbert), then one obviously cannot do: \r\n```c++\r\npy::tuple GetState(const Pickleable &p) { \r\n auto hilbert= p.GetHilbert(); //NO! \r\n return py::make_tuple(p.Field1(),p.Field2(),hilbert);\r\n}\r\n```\r\n\r\nSuggestions are welcome. \n", "before_files": [{"content": "# Copyright 2018 The Simons Foundation, Inc. - All Rights Reserved.\n\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n\n# http://www.apache.org/licenses/LICENSE-2.0\n\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom __future__ import print_function\nimport netket as nk\nimport networkx as nx\nimport numpy as np\nfrom mpi4py import MPI\nimport scipy.sparse as sparse\n\n#Constructing a 1d lattice\ng = nk.graph.Hypercube(L=4, ndim=1)\n\n# Hilbert space of spins from given graph\nhi = nk.hilbert.Spin(s=0.5, graph=g)\n\n#Hamiltonian\nha = nk.operator.Ising(h=1.0, hilbert=hi)\n\n#Machine\nma = nk.machine.RbmSpin(hilbert=hi, alpha=1)\nma.InitRandomPars(seed=1234, sigma=0.1)\nprint(ma.GetParameters())\n\n#Layer\na = np.ones(3, dtype=complex)\nb = np.zeros(3, dtype=complex)\nact = nk.activation.Tanh()\n\nact(a, b)\nprint(b)\n", "path": "Tutorials/PyNetKet/machine.py"}]}
| 1,194 | 332 |
gh_patches_debug_37866
|
rasdani/github-patches
|
git_diff
|
napari__napari-2298
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Plugin discovery appears to be broken
## 🐛 Bug
If I go to "Plugins > Install/Uninstall packages", I now see an empty list, and no progress widget:
<img width="1192" alt="Screen Shot 2021-02-04 at 3 15 02 pm" src="https://user-images.githubusercontent.com/492549/106844231-1977b780-66fc-11eb-812b-b3d581d255f9.png">
## Environment
This is using the latest nightly bundle build, but I also experienced it on master.
napari: 0.4.5.dev9+g79ab358
Platform: macOS-10.15.7-x86_64-i386-64bit
System: MacOS 10.15.7
Python: 3.8.7 (default, Jan 2 2021, 04:16:43) [Clang 11.0.0 (clang-1100.0.33.17)]
Qt: 5.15.2
PySide2: 5.15.2
NumPy: 1.19.3
SciPy: 1.6.0
Dask: 2021.01.1
VisPy: 0.6.6
OpenGL:
- GL version: 2.1 ATI-3.10.19
- MAX_TEXTURE_SIZE: 16384
Screens:
- screen #1: resolution 2048x1152, scale 2.0
- screen #2: resolution 1536x960, scale 2.0
Plugins:
- svg: 0.1.4
</issue>
<code>
[start of napari/plugins/pypi.py]
1 """
2 These convenience functions will be useful for searching pypi for packages
3 that match the plugin naming convention, and retrieving related metadata.
4 """
5 import json
6 import re
7 from concurrent.futures import ThreadPoolExecutor, as_completed
8 from functools import lru_cache
9 from typing import Dict, Generator, List, NamedTuple, Optional
10 from urllib import error, parse, request
11
12 PYPI_SIMPLE_API_URL = 'https://pypi.org/simple/'
13
14 setup_py_entrypoint = re.compile(
15 r"entry_points\s?=\s?([^}]*napari.plugin[^}]*)}"
16 )
17 setup_py_pypi_name = re.compile(
18 r"setup\s?\(.*name\s?=\s?['\"]([^'\"]+)['\"]", re.DOTALL
19 )
20
21
22 class ProjectInfo(NamedTuple):
23 """Info associated with a PyPI Project."""
24
25 name: str
26 version: str
27 url: str
28 summary: str
29 author: str
30 license: str
31
32
33 @lru_cache(maxsize=128)
34 def get_packages_by_prefix(prefix: str) -> Dict[str, str]:
35 """Search for packages starting with ``prefix`` on pypi.
36
37 Packages using naming convention: http://bit.ly/pynaming-convention
38 can be autodiscovered on pypi using the SIMPLE API:
39 https://www.python.org/dev/peps/pep-0503/
40
41 Returns
42 -------
43 dict
44 {name: url} for all packages at pypi that start with ``prefix``
45 """
46
47 with request.urlopen(PYPI_SIMPLE_API_URL) as response:
48 html = response.read().decode()
49
50 return {
51 name: PYPI_SIMPLE_API_URL + url
52 for url, name in re.findall(
53 f'<a href="/simple/(.+)">({prefix}.*)</a>', html
54 )
55 }
56
57
58 @lru_cache(maxsize=128)
59 def get_packages_by_classifier(classifier: str) -> List[str]:
60 """Search for packages declaring ``classifier`` on PyPI
61
62 Yields
63 ------
64 name : str
65 name of all packages at pypi that declare ``classifier``
66 """
67
68 url = f"https://pypi.org/search/?c={parse.quote_plus(classifier)}"
69 with request.urlopen(url) as response:
70 html = response.read().decode()
71
72 return re.findall('class="package-snippet__name">(.+)</span>', html)
73
74
75 @lru_cache(maxsize=128)
76 def get_package_versions(name: str) -> List[str]:
77 """Get available versions of a package on pypi
78
79 Parameters
80 ----------
81 name : str
82 name of the package
83
84 Returns
85 -------
86 tuple
87 versions available on pypi
88 """
89 with request.urlopen(PYPI_SIMPLE_API_URL + name) as response:
90 html = response.read()
91
92 return re.findall(f'>{name}-(.+).tar', html.decode())
93
94
95 @lru_cache(maxsize=128)
96 def ensure_published_at_pypi(
97 name: str, min_dev_status=3
98 ) -> Optional[ProjectInfo]:
99 """Return name if ``name`` is a package in PyPI with dev_status > min."""
100 try:
101 with request.urlopen(f'https://pypi.org/pypi/{name}/json') as resp:
102 info = json.loads(resp.read().decode()).get("info")
103 except error.HTTPError:
104 return None
105 classifiers = info.get("classifiers")
106 for i in range(1, min_dev_status):
107 if any(f'Development Status :: {1}' in x for x in classifiers):
108 return None
109
110 return ProjectInfo(
111 name=normalized_name(info["name"]),
112 version=info["version"],
113 url=info["home_page"],
114 summary=info["summary"],
115 author=info["author"],
116 license=info["license"] or "UNKNOWN",
117 )
118
119
120 def iter_napari_plugin_info(
121 skip={'napari-plugin-engine'},
122 ) -> Generator[ProjectInfo, None, None]:
123 """Return a generator that yields ProjectInfo of available napari plugins.
124
125 By default, requires that packages are at least "Alpha" stage of
126 development. to allow lower, change the ``min_dev_status`` argument to
127 ``ensure_published_at_pypi``.
128 """
129 already_yielded = set()
130 with ThreadPoolExecutor(max_workers=8) as executor:
131 futures = [
132 executor.submit(ensure_published_at_pypi, name)
133 for name in get_packages_by_classifier("Framework :: napari")
134 if name not in skip
135 ]
136
137 for future in as_completed(futures):
138 info = future.result()
139 if info and info not in already_yielded:
140 already_yielded.add(info)
141 yield info
142
143
144 def normalized_name(name) -> str:
145 return re.sub(r"[-_.]+", "-", name).lower()
146
[end of napari/plugins/pypi.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/napari/plugins/pypi.py b/napari/plugins/pypi.py
--- a/napari/plugins/pypi.py
+++ b/napari/plugins/pypi.py
@@ -4,11 +4,14 @@
"""
import json
import re
+import ssl
from concurrent.futures import ThreadPoolExecutor, as_completed
-from functools import lru_cache
+from functools import lru_cache, partial
from typing import Dict, Generator, List, NamedTuple, Optional
from urllib import error, parse, request
+import certifi
+
PYPI_SIMPLE_API_URL = 'https://pypi.org/simple/'
setup_py_entrypoint = re.compile(
@@ -18,6 +21,9 @@
r"setup\s?\(.*name\s?=\s?['\"]([^'\"]+)['\"]", re.DOTALL
)
+context = ssl.create_default_context(cafile=certifi.where())
+urlopen = partial(request.urlopen, context=context)
+
class ProjectInfo(NamedTuple):
"""Info associated with a PyPI Project."""
@@ -44,7 +50,7 @@
{name: url} for all packages at pypi that start with ``prefix``
"""
- with request.urlopen(PYPI_SIMPLE_API_URL) as response:
+ with urlopen(PYPI_SIMPLE_API_URL) as response:
html = response.read().decode()
return {
@@ -66,7 +72,7 @@
"""
url = f"https://pypi.org/search/?c={parse.quote_plus(classifier)}"
- with request.urlopen(url) as response:
+ with urlopen(url) as response:
html = response.read().decode()
return re.findall('class="package-snippet__name">(.+)</span>', html)
@@ -86,7 +92,7 @@
tuple
versions available on pypi
"""
- with request.urlopen(PYPI_SIMPLE_API_URL + name) as response:
+ with urlopen(PYPI_SIMPLE_API_URL + name) as response:
html = response.read()
return re.findall(f'>{name}-(.+).tar', html.decode())
@@ -98,7 +104,7 @@
) -> Optional[ProjectInfo]:
"""Return name if ``name`` is a package in PyPI with dev_status > min."""
try:
- with request.urlopen(f'https://pypi.org/pypi/{name}/json') as resp:
+ with urlopen(f'https://pypi.org/pypi/{name}/json') as resp:
info = json.loads(resp.read().decode()).get("info")
except error.HTTPError:
return None
|
{"golden_diff": "diff --git a/napari/plugins/pypi.py b/napari/plugins/pypi.py\n--- a/napari/plugins/pypi.py\n+++ b/napari/plugins/pypi.py\n@@ -4,11 +4,14 @@\n \"\"\"\n import json\n import re\n+import ssl\n from concurrent.futures import ThreadPoolExecutor, as_completed\n-from functools import lru_cache\n+from functools import lru_cache, partial\n from typing import Dict, Generator, List, NamedTuple, Optional\n from urllib import error, parse, request\n \n+import certifi\n+\n PYPI_SIMPLE_API_URL = 'https://pypi.org/simple/'\n \n setup_py_entrypoint = re.compile(\n@@ -18,6 +21,9 @@\n r\"setup\\s?\\(.*name\\s?=\\s?['\\\"]([^'\\\"]+)['\\\"]\", re.DOTALL\n )\n \n+context = ssl.create_default_context(cafile=certifi.where())\n+urlopen = partial(request.urlopen, context=context)\n+\n \n class ProjectInfo(NamedTuple):\n \"\"\"Info associated with a PyPI Project.\"\"\"\n@@ -44,7 +50,7 @@\n {name: url} for all packages at pypi that start with ``prefix``\n \"\"\"\n \n- with request.urlopen(PYPI_SIMPLE_API_URL) as response:\n+ with urlopen(PYPI_SIMPLE_API_URL) as response:\n html = response.read().decode()\n \n return {\n@@ -66,7 +72,7 @@\n \"\"\"\n \n url = f\"https://pypi.org/search/?c={parse.quote_plus(classifier)}\"\n- with request.urlopen(url) as response:\n+ with urlopen(url) as response:\n html = response.read().decode()\n \n return re.findall('class=\"package-snippet__name\">(.+)</span>', html)\n@@ -86,7 +92,7 @@\n tuple\n versions available on pypi\n \"\"\"\n- with request.urlopen(PYPI_SIMPLE_API_URL + name) as response:\n+ with urlopen(PYPI_SIMPLE_API_URL + name) as response:\n html = response.read()\n \n return re.findall(f'>{name}-(.+).tar', html.decode())\n@@ -98,7 +104,7 @@\n ) -> Optional[ProjectInfo]:\n \"\"\"Return name if ``name`` is a package in PyPI with dev_status > min.\"\"\"\n try:\n- with request.urlopen(f'https://pypi.org/pypi/{name}/json') as resp:\n+ with urlopen(f'https://pypi.org/pypi/{name}/json') as resp:\n info = json.loads(resp.read().decode()).get(\"info\")\n except error.HTTPError:\n return None\n", "issue": "Plugin discovery appears to be broken\n## \ud83d\udc1b Bug\r\n\r\nIf I go to \"Plugins > Install/Uninstall packages\", I now see an empty list, and no progress widget:\r\n\r\n<img width=\"1192\" alt=\"Screen Shot 2021-02-04 at 3 15 02 pm\" src=\"https://user-images.githubusercontent.com/492549/106844231-1977b780-66fc-11eb-812b-b3d581d255f9.png\">\r\n\r\n## Environment\r\n\r\nThis is using the latest nightly bundle build, but I also experienced it on master.\r\n\r\nnapari: 0.4.5.dev9+g79ab358\r\nPlatform: macOS-10.15.7-x86_64-i386-64bit\r\nSystem: MacOS 10.15.7\r\nPython: 3.8.7 (default, Jan 2 2021, 04:16:43) [Clang 11.0.0 (clang-1100.0.33.17)]\r\nQt: 5.15.2\r\nPySide2: 5.15.2\r\nNumPy: 1.19.3\r\nSciPy: 1.6.0\r\nDask: 2021.01.1\r\nVisPy: 0.6.6\r\n\r\nOpenGL:\r\n- GL version: 2.1 ATI-3.10.19\r\n- MAX_TEXTURE_SIZE: 16384\r\n\r\nScreens:\r\n- screen #1: resolution 2048x1152, scale 2.0\r\n- screen #2: resolution 1536x960, scale 2.0\r\n\r\nPlugins:\r\n- svg: 0.1.4\n", "before_files": [{"content": "\"\"\"\nThese convenience functions will be useful for searching pypi for packages\nthat match the plugin naming convention, and retrieving related metadata.\n\"\"\"\nimport json\nimport re\nfrom concurrent.futures import ThreadPoolExecutor, as_completed\nfrom functools import lru_cache\nfrom typing import Dict, Generator, List, NamedTuple, Optional\nfrom urllib import error, parse, request\n\nPYPI_SIMPLE_API_URL = 'https://pypi.org/simple/'\n\nsetup_py_entrypoint = re.compile(\n r\"entry_points\\s?=\\s?([^}]*napari.plugin[^}]*)}\"\n)\nsetup_py_pypi_name = re.compile(\n r\"setup\\s?\\(.*name\\s?=\\s?['\\\"]([^'\\\"]+)['\\\"]\", re.DOTALL\n)\n\n\nclass ProjectInfo(NamedTuple):\n \"\"\"Info associated with a PyPI Project.\"\"\"\n\n name: str\n version: str\n url: str\n summary: str\n author: str\n license: str\n\n\n@lru_cache(maxsize=128)\ndef get_packages_by_prefix(prefix: str) -> Dict[str, str]:\n \"\"\"Search for packages starting with ``prefix`` on pypi.\n\n Packages using naming convention: http://bit.ly/pynaming-convention\n can be autodiscovered on pypi using the SIMPLE API:\n https://www.python.org/dev/peps/pep-0503/\n\n Returns\n -------\n dict\n {name: url} for all packages at pypi that start with ``prefix``\n \"\"\"\n\n with request.urlopen(PYPI_SIMPLE_API_URL) as response:\n html = response.read().decode()\n\n return {\n name: PYPI_SIMPLE_API_URL + url\n for url, name in re.findall(\n f'<a href=\"/simple/(.+)\">({prefix}.*)</a>', html\n )\n }\n\n\n@lru_cache(maxsize=128)\ndef get_packages_by_classifier(classifier: str) -> List[str]:\n \"\"\"Search for packages declaring ``classifier`` on PyPI\n\n Yields\n ------\n name : str\n name of all packages at pypi that declare ``classifier``\n \"\"\"\n\n url = f\"https://pypi.org/search/?c={parse.quote_plus(classifier)}\"\n with request.urlopen(url) as response:\n html = response.read().decode()\n\n return re.findall('class=\"package-snippet__name\">(.+)</span>', html)\n\n\n@lru_cache(maxsize=128)\ndef get_package_versions(name: str) -> List[str]:\n \"\"\"Get available versions of a package on pypi\n\n Parameters\n ----------\n name : str\n name of the package\n\n Returns\n -------\n tuple\n versions available on pypi\n \"\"\"\n with request.urlopen(PYPI_SIMPLE_API_URL + name) as response:\n html = response.read()\n\n return re.findall(f'>{name}-(.+).tar', html.decode())\n\n\n@lru_cache(maxsize=128)\ndef ensure_published_at_pypi(\n name: str, min_dev_status=3\n) -> Optional[ProjectInfo]:\n \"\"\"Return name if ``name`` is a package in PyPI with dev_status > min.\"\"\"\n try:\n with request.urlopen(f'https://pypi.org/pypi/{name}/json') as resp:\n info = json.loads(resp.read().decode()).get(\"info\")\n except error.HTTPError:\n return None\n classifiers = info.get(\"classifiers\")\n for i in range(1, min_dev_status):\n if any(f'Development Status :: {1}' in x for x in classifiers):\n return None\n\n return ProjectInfo(\n name=normalized_name(info[\"name\"]),\n version=info[\"version\"],\n url=info[\"home_page\"],\n summary=info[\"summary\"],\n author=info[\"author\"],\n license=info[\"license\"] or \"UNKNOWN\",\n )\n\n\ndef iter_napari_plugin_info(\n skip={'napari-plugin-engine'},\n) -> Generator[ProjectInfo, None, None]:\n \"\"\"Return a generator that yields ProjectInfo of available napari plugins.\n\n By default, requires that packages are at least \"Alpha\" stage of\n development. to allow lower, change the ``min_dev_status`` argument to\n ``ensure_published_at_pypi``.\n \"\"\"\n already_yielded = set()\n with ThreadPoolExecutor(max_workers=8) as executor:\n futures = [\n executor.submit(ensure_published_at_pypi, name)\n for name in get_packages_by_classifier(\"Framework :: napari\")\n if name not in skip\n ]\n\n for future in as_completed(futures):\n info = future.result()\n if info and info not in already_yielded:\n already_yielded.add(info)\n yield info\n\n\ndef normalized_name(name) -> str:\n return re.sub(r\"[-_.]+\", \"-\", name).lower()\n", "path": "napari/plugins/pypi.py"}]}
| 2,346 | 577 |
gh_patches_debug_16817
|
rasdani/github-patches
|
git_diff
|
microsoft__ptvsd-1992
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Using Ctrl+C causes launcher to print traceback
## Environment data
- PTVSD version: master
- OS and version: linux
- Python version (& distribution if applicable, e.g. Anaconda): 3.7
- Using VS Code or Visual Studio: VSC
## Actual behavior
```console
Traceback (most recent call last):
File "/usr/lib/python3.7/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/usr/lib/python3.7/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/home/kanadig/GIT/ptvsd/src/ptvsd/launcher/__main__.py", line 74, in <module>
main()
File "/home/kanadig/GIT/ptvsd/src/ptvsd/launcher/__main__.py", line 37, in main
adapter.channel.wait()
File "/home/kanadig/GIT/ptvsd/src/ptvsd/launcher/../../ptvsd/common/messaging.py", line 1231, in wait
parser_thread.join()
File "/usr/lib/python3.7/threading.py", line 1032, in join
self._wait_for_tstate_lock()
File "/usr/lib/python3.7/threading.py", line 1048, in _wait_for_tstate_lock
elif lock.acquire(block, timeout):
KeyboardInterrupt
```
## Expected behavior
This is normal way to shutdown the servers. Show not print exception in launcher.
</issue>
<code>
[start of src/ptvsd/launcher/__main__.py]
1 # Copyright (c) Microsoft Corporation. All rights reserved.
2 # Licensed under the MIT License. See LICENSE in the project root
3 # for license information.
4
5 from __future__ import absolute_import, division, print_function, unicode_literals
6
7 __all__ = ["main"]
8
9 import locale
10 import os
11 import sys
12
13 # WARNING: ptvsd and submodules must not be imported on top level in this module,
14 # and should be imported locally inside main() instead.
15
16 # Force absolute path on Python 2.
17 __file__ = os.path.abspath(__file__)
18
19
20 def main():
21 from ptvsd.common import log
22 from ptvsd import launcher
23 from ptvsd.launcher import debuggee
24
25 log.to_file(prefix="ptvsd.launcher")
26 log.describe_environment("ptvsd.launcher startup environment:")
27
28 def option(name, type, *args):
29 try:
30 return type(os.environ.pop(name, *args))
31 except Exception:
32 raise log.exception("Error parsing {0!r}:", name)
33
34 launcher_port = option("PTVSD_LAUNCHER_PORT", int)
35
36 launcher.connect(launcher_port)
37 launcher.channel.wait()
38
39 if debuggee.process is not None:
40 sys.exit(debuggee.process.returncode)
41
42
43 if __name__ == "__main__":
44 # ptvsd can also be invoked directly rather than via -m. In this case, the first
45 # entry on sys.path is the one added automatically by Python for the directory
46 # containing this file. This means that import ptvsd will not work, since we need
47 # the parent directory of ptvsd/ to be in sys.path, rather than ptvsd/launcher/.
48 #
49 # The other issue is that many other absolute imports will break, because they
50 # will be resolved relative to ptvsd/launcher/ - e.g. `import state` will then try
51 # to import ptvsd/launcher/state.py.
52 #
53 # To fix both, we need to replace the automatically added entry such that it points
54 # at parent directory of ptvsd/ instead of ptvsd/launcher, import ptvsd with that
55 # in sys.path, and then remove the first entry entry altogether, so that it doesn't
56 # affect any further imports we might do. For example, suppose the user did:
57 #
58 # python /foo/bar/ptvsd/launcher ...
59 #
60 # At the beginning of this script, sys.path will contain "/foo/bar/ptvsd/launcher"
61 # as the first entry. What we want is to replace it with "/foo/bar', then import
62 # ptvsd with that in effect, and then remove the replaced entry before any more
63 # code runs. The imported ptvsd module will remain in sys.modules, and thus all
64 # future imports of it or its submodules will resolve accordingly.
65 if "ptvsd" not in sys.modules:
66 # Do not use dirname() to walk up - this can be a relative path, e.g. ".".
67 sys.path[0] = sys.path[0] + "/../../"
68 __import__("ptvsd")
69 del sys.path[0]
70
71 # Load locale settings.
72 locale.setlocale(locale.LC_ALL, "")
73
74 main()
75
[end of src/ptvsd/launcher/__main__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/ptvsd/launcher/__main__.py b/src/ptvsd/launcher/__main__.py
--- a/src/ptvsd/launcher/__main__.py
+++ b/src/ptvsd/launcher/__main__.py
@@ -8,6 +8,7 @@
import locale
import os
+import signal
import sys
# WARNING: ptvsd and submodules must not be imported on top level in this module,
@@ -25,6 +26,11 @@
log.to_file(prefix="ptvsd.launcher")
log.describe_environment("ptvsd.launcher startup environment:")
+ # Disable exceptions on Ctrl+C - we want to allow the debuggee process to handle
+ # these, or not, as it sees fit. If the debuggee exits on Ctrl+C, the launcher
+ # will also exit, so it doesn't need to observe the signal directly.
+ signal.signal(signal.SIGINT, signal.SIG_IGN)
+
def option(name, type, *args):
try:
return type(os.environ.pop(name, *args))
|
{"golden_diff": "diff --git a/src/ptvsd/launcher/__main__.py b/src/ptvsd/launcher/__main__.py\n--- a/src/ptvsd/launcher/__main__.py\n+++ b/src/ptvsd/launcher/__main__.py\n@@ -8,6 +8,7 @@\n \n import locale\n import os\n+import signal\n import sys\n \n # WARNING: ptvsd and submodules must not be imported on top level in this module,\n@@ -25,6 +26,11 @@\n log.to_file(prefix=\"ptvsd.launcher\")\n log.describe_environment(\"ptvsd.launcher startup environment:\")\n \n+ # Disable exceptions on Ctrl+C - we want to allow the debuggee process to handle\n+ # these, or not, as it sees fit. If the debuggee exits on Ctrl+C, the launcher\n+ # will also exit, so it doesn't need to observe the signal directly.\n+ signal.signal(signal.SIGINT, signal.SIG_IGN)\n+\n def option(name, type, *args):\n try:\n return type(os.environ.pop(name, *args))\n", "issue": "Using Ctrl+C causes launcher to print traceback\n## Environment data\r\n\r\n- PTVSD version: master\r\n- OS and version: linux\r\n- Python version (& distribution if applicable, e.g. Anaconda): 3.7\r\n- Using VS Code or Visual Studio: VSC\r\n\r\n## Actual behavior\r\n\r\n```console\r\nTraceback (most recent call last):\r\n File \"/usr/lib/python3.7/runpy.py\", line 193, in _run_module_as_main\r\n \"__main__\", mod_spec)\r\n File \"/usr/lib/python3.7/runpy.py\", line 85, in _run_code\r\n exec(code, run_globals)\r\n File \"/home/kanadig/GIT/ptvsd/src/ptvsd/launcher/__main__.py\", line 74, in <module>\r\n main()\r\n File \"/home/kanadig/GIT/ptvsd/src/ptvsd/launcher/__main__.py\", line 37, in main\r\n adapter.channel.wait()\r\n File \"/home/kanadig/GIT/ptvsd/src/ptvsd/launcher/../../ptvsd/common/messaging.py\", line 1231, in wait\r\n parser_thread.join()\r\n File \"/usr/lib/python3.7/threading.py\", line 1032, in join\r\n self._wait_for_tstate_lock()\r\n File \"/usr/lib/python3.7/threading.py\", line 1048, in _wait_for_tstate_lock\r\n elif lock.acquire(block, timeout):\r\nKeyboardInterrupt\r\n```\r\n\r\n## Expected behavior\r\n\r\nThis is normal way to shutdown the servers. Show not print exception in launcher.\r\n\r\n\n", "before_files": [{"content": "# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License. See LICENSE in the project root\n# for license information.\n\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\n__all__ = [\"main\"]\n\nimport locale\nimport os\nimport sys\n\n# WARNING: ptvsd and submodules must not be imported on top level in this module,\n# and should be imported locally inside main() instead.\n\n# Force absolute path on Python 2.\n__file__ = os.path.abspath(__file__)\n\n\ndef main():\n from ptvsd.common import log\n from ptvsd import launcher\n from ptvsd.launcher import debuggee\n\n log.to_file(prefix=\"ptvsd.launcher\")\n log.describe_environment(\"ptvsd.launcher startup environment:\")\n\n def option(name, type, *args):\n try:\n return type(os.environ.pop(name, *args))\n except Exception:\n raise log.exception(\"Error parsing {0!r}:\", name)\n\n launcher_port = option(\"PTVSD_LAUNCHER_PORT\", int)\n\n launcher.connect(launcher_port)\n launcher.channel.wait()\n\n if debuggee.process is not None:\n sys.exit(debuggee.process.returncode)\n\n\nif __name__ == \"__main__\":\n # ptvsd can also be invoked directly rather than via -m. In this case, the first\n # entry on sys.path is the one added automatically by Python for the directory\n # containing this file. This means that import ptvsd will not work, since we need\n # the parent directory of ptvsd/ to be in sys.path, rather than ptvsd/launcher/.\n #\n # The other issue is that many other absolute imports will break, because they\n # will be resolved relative to ptvsd/launcher/ - e.g. `import state` will then try\n # to import ptvsd/launcher/state.py.\n #\n # To fix both, we need to replace the automatically added entry such that it points\n # at parent directory of ptvsd/ instead of ptvsd/launcher, import ptvsd with that\n # in sys.path, and then remove the first entry entry altogether, so that it doesn't\n # affect any further imports we might do. For example, suppose the user did:\n #\n # python /foo/bar/ptvsd/launcher ...\n #\n # At the beginning of this script, sys.path will contain \"/foo/bar/ptvsd/launcher\"\n # as the first entry. What we want is to replace it with \"/foo/bar', then import\n # ptvsd with that in effect, and then remove the replaced entry before any more\n # code runs. The imported ptvsd module will remain in sys.modules, and thus all\n # future imports of it or its submodules will resolve accordingly.\n if \"ptvsd\" not in sys.modules:\n # Do not use dirname() to walk up - this can be a relative path, e.g. \".\".\n sys.path[0] = sys.path[0] + \"/../../\"\n __import__(\"ptvsd\")\n del sys.path[0]\n\n # Load locale settings.\n locale.setlocale(locale.LC_ALL, \"\")\n\n main()\n", "path": "src/ptvsd/launcher/__main__.py"}]}
| 1,756 | 240 |
gh_patches_debug_58138
|
rasdani/github-patches
|
git_diff
|
gammapy__gammapy-3911
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
string representation of various Maker classes may cause a TypeError
This was tested against Gammapy 0.19 and the development version.
In some cases, printing (or using the string representation in another way) of an instance of a `gammapy.makers.Maker` subclass may cause a TypeError.
An example directly from the tutorials (introduction, low-level analysis):
```
from astropy import units
from regions import CircleSkyRegion
from gammapy.makers import FoVBackgroundMaker
from astropy.coordinates import SkyCoord
from gammapy.maps import WcsGeom, MapAxis
energy_axis = MapAxis.from_energy_bounds(1.0, 10.0, 4, unit="TeV")
geom = WcsGeom.create(
skydir=(83.633, 22.014),
binsz=0.02,
width=(2, 2),
frame="icrs",
proj="CAR",
axes=[],
)
circle = CircleSkyRegion(
center=SkyCoord("83.63 deg", "22.14 deg"), radius=0.2 * units.deg
)
exclusion_mask = ~geom.region_mask(regions=[circle])
maker_fov = FoVBackgroundMaker(method="fit", exclusion_mask=exclusion_mask)
str(maker_fov)
```
will cause a
```
TypeError: Cannot parse "not available" as a Quantity. It does not start with a number.
```
(full traceback at the bottom).
The reason is in the `__str__` implementation of the `gammapy.makers.Maker` abstract class:
```
def __str__(self):
# <snip>
for name in names:
value = getattr(self, name, "not available")
if value == "not available":
continue
else:
s += f"\t{name:{max_len}s}: {value}\n"
return s.expandtabs(tabsize=2)
```
When an attribute is not found, it is set to the string "not available". Otherwise, the attribute's value is retrieved.
The resulting value is then compared to the string "not available" to determine whether it is an existing attribute. But some classes can't compare to string. In this particular case, comparing an instance of `WcsNDMap` fails this comparison, resulting (indirectly) in the `TypeError`.
Perhaps the most Pythonic solution is to have `WcsNDMap` handle comparisons with any arbirtrary type, and return `False`. This is what Python does: `1 == "abc"` is valid and returns `False`; similar for e.g. `1 = ["abc", 5.5]`.
Perhaps easier, and in my opinion semantically better, is to use
```
value = getattr(self, name, None)
if value is None:
continue
s += f"\t{name:{max_len}s}: {value}\n"
```
since `None` signifies the optional type in Python.
Though even better, in my opinion, is to simply use
```
for name in names:
try:
value = getattr(self, name)
except AttributeError:
continue
s += f"\t{name:{max_len}s}: {value}\n"
```
After all, this is what exceptions are for. (People sometimes mention speed reasons if the lookup fails a lot of times, but I don't think that's relevant here for a `__str__` implementation.)
I would even simply use `self.name`, but that'll fail because `Maker` is an abstract class, so more dynamic retrieval of attributes is required. I assume this is why it's implemented in its current way.
-----
Full traceback:
```
Traceback (most recent call last):
File "/home/user/.miniconda3/envs/gammapy-dev/lib/python3.7/site-packages/astropy/units/quantity.py", line 333, in __new__
value = float(v.group())
AttributeError: 'NoneType' object has no attribute 'group'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "gammapy_maker_str.py", line 22, in <module>
str(maker_fov)
File "/home/user/.miniconda3/envs/gammapy-dev/lib/python3.7/site-packages/gammapy/makers/core.py", line 31, in __str__
if value == "not available":
File "/home/user/.miniconda3/envs/gammapy-dev/lib/python3.7/site-packages/gammapy/maps/core.py", line 1612, in __eq__
return self._arithmetics(np.equal, other, copy=True)
File "/home/user/.miniconda3/envs/gammapy-dev/lib/python3.7/site-packages/gammapy/maps/core.py", line 1552, in _arithmetics
q = u.Quantity(other, copy=False)
File "/home/user/.miniconda3/envs/gammapy-dev/lib/python3.7/site-packages/astropy/units/quantity.py", line 338, in __new__
.format(value, cls.__name__))
TypeError: Cannot parse "not available" as a Quantity. It does not start with a number.
```
</issue>
<code>
[start of gammapy/makers/core.py]
1 # Licensed under a 3-clause BSD style license - see LICENSE.rst
2 import abc
3 import numpy as np
4
5 __all__ = ["Maker"]
6
7
8 class Maker(abc.ABC):
9 """Abstract maker base class."""
10
11 @property
12 @abc.abstractmethod
13 def tag(self):
14 pass
15
16 @abc.abstractmethod
17 def run(self):
18 pass
19
20 def __str__(self):
21 s = f"{self.__class__.__name__}\n"
22 s += "-" * (len(s) - 1) + "\n\n"
23
24 names = self.__init__.__code__.co_varnames
25
26 max_len = np.max([len(_) for _ in names]) + 1
27
28 for name in names:
29 value = getattr(self, name, "not available")
30
31 if value == "not available":
32 continue
33 else:
34 s += f"\t{name:{max_len}s}: {value}\n"
35
36 return s.expandtabs(tabsize=2)
37
[end of gammapy/makers/core.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/gammapy/makers/core.py b/gammapy/makers/core.py
--- a/gammapy/makers/core.py
+++ b/gammapy/makers/core.py
@@ -26,9 +26,9 @@
max_len = np.max([len(_) for _ in names]) + 1
for name in names:
- value = getattr(self, name, "not available")
+ value = getattr(self, name, None)
- if value == "not available":
+ if value is None:
continue
else:
s += f"\t{name:{max_len}s}: {value}\n"
|
{"golden_diff": "diff --git a/gammapy/makers/core.py b/gammapy/makers/core.py\n--- a/gammapy/makers/core.py\n+++ b/gammapy/makers/core.py\n@@ -26,9 +26,9 @@\n max_len = np.max([len(_) for _ in names]) + 1\n \n for name in names:\n- value = getattr(self, name, \"not available\")\n+ value = getattr(self, name, None)\n \n- if value == \"not available\":\n+ if value is None:\n continue\n else:\n s += f\"\\t{name:{max_len}s}: {value}\\n\"\n", "issue": "string representation of various Maker classes may cause a TypeError\nThis was tested against Gammapy 0.19 and the development version.\r\n\r\nIn some cases, printing (or using the string representation in another way) of an instance of a `gammapy.makers.Maker` subclass may cause a TypeError.\r\n\r\nAn example directly from the tutorials (introduction, low-level analysis):\r\n```\r\nfrom astropy import units\r\nfrom regions import CircleSkyRegion\r\nfrom gammapy.makers import FoVBackgroundMaker\r\nfrom astropy.coordinates import SkyCoord\r\nfrom gammapy.maps import WcsGeom, MapAxis\r\n\r\nenergy_axis = MapAxis.from_energy_bounds(1.0, 10.0, 4, unit=\"TeV\")\r\ngeom = WcsGeom.create(\r\n skydir=(83.633, 22.014),\r\n binsz=0.02,\r\n width=(2, 2),\r\n frame=\"icrs\",\r\n proj=\"CAR\",\r\n axes=[],\r\n)\r\ncircle = CircleSkyRegion(\r\n center=SkyCoord(\"83.63 deg\", \"22.14 deg\"), radius=0.2 * units.deg\r\n)\r\nexclusion_mask = ~geom.region_mask(regions=[circle])\r\nmaker_fov = FoVBackgroundMaker(method=\"fit\", exclusion_mask=exclusion_mask)\r\nstr(maker_fov)\r\n```\r\n\r\nwill cause a \r\n```\r\nTypeError: Cannot parse \"not available\" as a Quantity. It does not start with a number.\r\n```\r\n(full traceback at the bottom).\r\n\r\nThe reason is in the `__str__` implementation of the `gammapy.makers.Maker` abstract class:\r\n```\r\n def __str__(self):\r\n # <snip>\r\n for name in names:\r\n value = getattr(self, name, \"not available\")\r\n\r\n if value == \"not available\":\r\n continue\r\n else:\r\n s += f\"\\t{name:{max_len}s}: {value}\\n\"\r\n\r\n return s.expandtabs(tabsize=2)\r\n```\r\n\r\nWhen an attribute is not found, it is set to the string \"not available\". Otherwise, the attribute's value is retrieved.\r\nThe resulting value is then compared to the string \"not available\" to determine whether it is an existing attribute. But some classes can't compare to string. In this particular case, comparing an instance of `WcsNDMap` fails this comparison, resulting (indirectly) in the `TypeError`.\r\n\r\nPerhaps the most Pythonic solution is to have `WcsNDMap` handle comparisons with any arbirtrary type, and return `False`. This is what Python does: `1 == \"abc\"` is valid and returns `False`; similar for e.g. `1 = [\"abc\", 5.5]`.\r\n\r\nPerhaps easier, and in my opinion semantically better, is to use\r\n```\r\nvalue = getattr(self, name, None)\r\nif value is None:\r\n continue\r\ns += f\"\\t{name:{max_len}s}: {value}\\n\"\r\n```\r\nsince `None` signifies the optional type in Python.\r\n\r\nThough even better, in my opinion, is to simply use\r\n```\r\nfor name in names:\r\n try:\r\n value = getattr(self, name)\r\n except AttributeError:\r\n continue\r\n s += f\"\\t{name:{max_len}s}: {value}\\n\" \r\n```\r\nAfter all, this is what exceptions are for. (People sometimes mention speed reasons if the lookup fails a lot of times, but I don't think that's relevant here for a `__str__` implementation.)\r\n\r\nI would even simply use `self.name`, but that'll fail because `Maker` is an abstract class, so more dynamic retrieval of attributes is required. I assume this is why it's implemented in its current way.\r\n\r\n\r\n-----\r\n\r\nFull traceback:\r\n```\r\nTraceback (most recent call last):\r\n File \"/home/user/.miniconda3/envs/gammapy-dev/lib/python3.7/site-packages/astropy/units/quantity.py\", line 333, in __new__\r\n value = float(v.group())\r\nAttributeError: 'NoneType' object has no attribute 'group'\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"gammapy_maker_str.py\", line 22, in <module>\r\n str(maker_fov)\r\n File \"/home/user/.miniconda3/envs/gammapy-dev/lib/python3.7/site-packages/gammapy/makers/core.py\", line 31, in __str__\r\n if value == \"not available\":\r\n File \"/home/user/.miniconda3/envs/gammapy-dev/lib/python3.7/site-packages/gammapy/maps/core.py\", line 1612, in __eq__\r\n return self._arithmetics(np.equal, other, copy=True)\r\n File \"/home/user/.miniconda3/envs/gammapy-dev/lib/python3.7/site-packages/gammapy/maps/core.py\", line 1552, in _arithmetics\r\n q = u.Quantity(other, copy=False)\r\n File \"/home/user/.miniconda3/envs/gammapy-dev/lib/python3.7/site-packages/astropy/units/quantity.py\", line 338, in __new__\r\n .format(value, cls.__name__))\r\nTypeError: Cannot parse \"not available\" as a Quantity. It does not start with a number.\r\n```\r\n\n", "before_files": [{"content": "# Licensed under a 3-clause BSD style license - see LICENSE.rst\nimport abc\nimport numpy as np\n\n__all__ = [\"Maker\"]\n\n\nclass Maker(abc.ABC):\n \"\"\"Abstract maker base class.\"\"\"\n\n @property\n @abc.abstractmethod\n def tag(self):\n pass\n\n @abc.abstractmethod\n def run(self):\n pass\n\n def __str__(self):\n s = f\"{self.__class__.__name__}\\n\"\n s += \"-\" * (len(s) - 1) + \"\\n\\n\"\n\n names = self.__init__.__code__.co_varnames\n\n max_len = np.max([len(_) for _ in names]) + 1\n\n for name in names:\n value = getattr(self, name, \"not available\")\n\n if value == \"not available\":\n continue\n else:\n s += f\"\\t{name:{max_len}s}: {value}\\n\"\n\n return s.expandtabs(tabsize=2)\n", "path": "gammapy/makers/core.py"}]}
| 1,971 | 144 |
gh_patches_debug_30680
|
rasdani/github-patches
|
git_diff
|
Kinto__kinto-1941
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Optimize use of jsonschema.validate()
It could be interesting to investigate if the fastjsonschema lib would give us better perfs :)
I marked this as easy-pick since everything happens in `schema_validation.py`
https://github.com/horejsek/python-fastjsonschema/
</issue>
<code>
[start of kinto/schema_validation.py]
1 import colander
2 from jsonschema import ValidationError, SchemaError, RefResolutionError, validate
3
4 try: # pragma: no cover
5 from jsonschema import Draft7Validator as DraftValidator
6 except ImportError:
7 from jsonschema import Draft4Validator as DraftValidator
8
9 from pyramid.settings import asbool
10
11 from kinto.core import utils
12 from kinto.core.errors import raise_invalid
13 from kinto.views import object_exists_or_404
14
15
16 class JSONSchemaMapping(colander.SchemaNode):
17 def schema_type(self, **kw):
18 return colander.Mapping(unknown="preserve")
19
20 def deserialize(self, cstruct=colander.null):
21 # Start by deserializing a simple mapping.
22 validated = super().deserialize(cstruct)
23
24 # In case it is optional in parent schema.
25 if not validated or validated in (colander.null, colander.drop):
26 return validated
27 try:
28 check_schema(validated)
29 except ValidationError as e:
30 self.raise_invalid(e.message)
31 return validated
32
33
34 def check_schema(data):
35 try:
36 DraftValidator.check_schema(data)
37 except SchemaError as e:
38 message = e.path.pop() + e.message
39 raise ValidationError(message)
40
41
42 def validate_schema(data, schema, ignore_fields=[]):
43 required_fields = [f for f in schema.get("required", []) if f not in ignore_fields]
44 # jsonschema doesn't accept 'required': [] yet.
45 # See https://github.com/Julian/jsonschema/issues/337.
46 # In the meantime, strip out 'required' if no other fields are required.
47 if required_fields:
48 schema = {**schema, "required": required_fields}
49 else:
50 schema = {f: v for f, v in schema.items() if f != "required"}
51
52 data = {f: v for f, v in data.items() if f not in ignore_fields}
53
54 try:
55 validate(data, schema)
56 except ValidationError as e:
57 if e.path:
58 field = e.path[-1]
59 elif e.validator_value:
60 field = e.validator_value[-1]
61 else:
62 field = e.schema_path[-1]
63 e.field = field
64 raise e
65 # Raise an error here if a reference in the schema doesn't resolve.
66 # jsonschema doesn't provide schema validation checking upon creation yet,
67 # it must be validated against data.
68 # See https://github.com/Julian/jsonschema/issues/399
69 # For future support https://github.com/Julian/jsonschema/issues/346.
70 except RefResolutionError as e:
71 raise e
72
73
74 def validate_from_bucket_schema_or_400(data, resource_name, request, ignore_fields=[]):
75 """Lookup in the parent objects if a schema was defined for this resource.
76
77 If the schema validation feature is enabled, if a schema is/are defined, and if the
78 data does not validate it/them, then it raises a 400 exception.
79 """
80 settings = request.registry.settings
81 schema_validation = "experimental_collection_schema_validation"
82 # If disabled from settings, do nothing.
83 if not asbool(settings.get(schema_validation)):
84 return
85
86 bucket_id = request.matchdict["bucket_id"]
87 bucket_uri = utils.instance_uri(request, "bucket", id=bucket_id)
88 buckets = request.bound_data.setdefault("buckets", {})
89 if bucket_uri not in buckets:
90 # Unknown yet, fetch from storage.
91 bucket = object_exists_or_404(
92 request, resource_name="bucket", parent_id="", object_id=bucket_id
93 )
94 buckets[bucket_uri] = bucket
95
96 # Let's see if the bucket defines a schema for this resource.
97 metadata_field = f"{resource_name}:schema"
98 bucket = buckets[bucket_uri]
99 if metadata_field not in bucket:
100 return
101
102 # Validate or fail with 400.
103 schema = bucket[metadata_field]
104 try:
105 validate_schema(data, schema, ignore_fields=ignore_fields)
106 except ValidationError as e:
107 raise_invalid(request, name=e.field, description=e.message)
108 except RefResolutionError as e:
109 raise_invalid(request, name="schema", description=str(e))
110
[end of kinto/schema_validation.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kinto/schema_validation.py b/kinto/schema_validation.py
--- a/kinto/schema_validation.py
+++ b/kinto/schema_validation.py
@@ -1,5 +1,6 @@
import colander
-from jsonschema import ValidationError, SchemaError, RefResolutionError, validate
+from jsonschema import ValidationError, SchemaError, RefResolutionError
+from jsonschema.validators import validator_for
try: # pragma: no cover
from jsonschema import Draft7Validator as DraftValidator
@@ -39,6 +40,34 @@
raise ValidationError(message)
+# Module level global that stores a version of every possible schema (as a <class 'dict'>)
+# turned into a jsonschema instance (as <class 'jsonschema.validators.Validator'>).
+_schema_cache = {}
+
+
+def validate(data, schema):
+ """Raise a ValidationError or a RefResolutionError if the data doesn't validate
+ with the given schema.
+
+ Note that this function is just a "wrapper" on `jsonschema.validate()` but with
+ some memoization based on the schema for better repeat performance.
+ """
+ # Because the schema is a dict, it can't be used as a hash key so it needs to be
+ # "transformed" to something that is hashable. The quickest solution is to convert
+ # it to a string.
+ # Note that the order of the dict will determine the string it becomes. The solution
+ # to that would a canonical serializer like `json.dumps(..., sort_keys=True)` but it's
+ # overkill since the assumption is that the schema is very unlikely to be exactly
+ # the same but different order.
+ cache_key = str(schema)
+ if cache_key not in _schema_cache:
+ # This is essentially what the `jsonschema.validate()` shortcut function does.
+ cls = validator_for(schema)
+ cls.check_schema(schema)
+ _schema_cache[cache_key] = cls(schema)
+ return _schema_cache[cache_key].validate(data)
+
+
def validate_schema(data, schema, ignore_fields=[]):
required_fields = [f for f in schema.get("required", []) if f not in ignore_fields]
# jsonschema doesn't accept 'required': [] yet.
|
{"golden_diff": "diff --git a/kinto/schema_validation.py b/kinto/schema_validation.py\n--- a/kinto/schema_validation.py\n+++ b/kinto/schema_validation.py\n@@ -1,5 +1,6 @@\n import colander\n-from jsonschema import ValidationError, SchemaError, RefResolutionError, validate\n+from jsonschema import ValidationError, SchemaError, RefResolutionError\n+from jsonschema.validators import validator_for\n \n try: # pragma: no cover\n from jsonschema import Draft7Validator as DraftValidator\n@@ -39,6 +40,34 @@\n raise ValidationError(message)\n \n \n+# Module level global that stores a version of every possible schema (as a <class 'dict'>)\n+# turned into a jsonschema instance (as <class 'jsonschema.validators.Validator'>).\n+_schema_cache = {}\n+\n+\n+def validate(data, schema):\n+ \"\"\"Raise a ValidationError or a RefResolutionError if the data doesn't validate\n+ with the given schema.\n+\n+ Note that this function is just a \"wrapper\" on `jsonschema.validate()` but with\n+ some memoization based on the schema for better repeat performance.\n+ \"\"\"\n+ # Because the schema is a dict, it can't be used as a hash key so it needs to be\n+ # \"transformed\" to something that is hashable. The quickest solution is to convert\n+ # it to a string.\n+ # Note that the order of the dict will determine the string it becomes. The solution\n+ # to that would a canonical serializer like `json.dumps(..., sort_keys=True)` but it's\n+ # overkill since the assumption is that the schema is very unlikely to be exactly\n+ # the same but different order.\n+ cache_key = str(schema)\n+ if cache_key not in _schema_cache:\n+ # This is essentially what the `jsonschema.validate()` shortcut function does.\n+ cls = validator_for(schema)\n+ cls.check_schema(schema)\n+ _schema_cache[cache_key] = cls(schema)\n+ return _schema_cache[cache_key].validate(data)\n+\n+\n def validate_schema(data, schema, ignore_fields=[]):\n required_fields = [f for f in schema.get(\"required\", []) if f not in ignore_fields]\n # jsonschema doesn't accept 'required': [] yet.\n", "issue": "Optimize use of jsonschema.validate()\nIt could be interesting to investigate if the fastjsonschema lib would give us better perfs :)\r\n\r\nI marked this as easy-pick since everything happens in `schema_validation.py`\r\n\r\nhttps://github.com/horejsek/python-fastjsonschema/\n", "before_files": [{"content": "import colander\nfrom jsonschema import ValidationError, SchemaError, RefResolutionError, validate\n\ntry: # pragma: no cover\n from jsonschema import Draft7Validator as DraftValidator\nexcept ImportError:\n from jsonschema import Draft4Validator as DraftValidator\n\nfrom pyramid.settings import asbool\n\nfrom kinto.core import utils\nfrom kinto.core.errors import raise_invalid\nfrom kinto.views import object_exists_or_404\n\n\nclass JSONSchemaMapping(colander.SchemaNode):\n def schema_type(self, **kw):\n return colander.Mapping(unknown=\"preserve\")\n\n def deserialize(self, cstruct=colander.null):\n # Start by deserializing a simple mapping.\n validated = super().deserialize(cstruct)\n\n # In case it is optional in parent schema.\n if not validated or validated in (colander.null, colander.drop):\n return validated\n try:\n check_schema(validated)\n except ValidationError as e:\n self.raise_invalid(e.message)\n return validated\n\n\ndef check_schema(data):\n try:\n DraftValidator.check_schema(data)\n except SchemaError as e:\n message = e.path.pop() + e.message\n raise ValidationError(message)\n\n\ndef validate_schema(data, schema, ignore_fields=[]):\n required_fields = [f for f in schema.get(\"required\", []) if f not in ignore_fields]\n # jsonschema doesn't accept 'required': [] yet.\n # See https://github.com/Julian/jsonschema/issues/337.\n # In the meantime, strip out 'required' if no other fields are required.\n if required_fields:\n schema = {**schema, \"required\": required_fields}\n else:\n schema = {f: v for f, v in schema.items() if f != \"required\"}\n\n data = {f: v for f, v in data.items() if f not in ignore_fields}\n\n try:\n validate(data, schema)\n except ValidationError as e:\n if e.path:\n field = e.path[-1]\n elif e.validator_value:\n field = e.validator_value[-1]\n else:\n field = e.schema_path[-1]\n e.field = field\n raise e\n # Raise an error here if a reference in the schema doesn't resolve.\n # jsonschema doesn't provide schema validation checking upon creation yet,\n # it must be validated against data.\n # See https://github.com/Julian/jsonschema/issues/399\n # For future support https://github.com/Julian/jsonschema/issues/346.\n except RefResolutionError as e:\n raise e\n\n\ndef validate_from_bucket_schema_or_400(data, resource_name, request, ignore_fields=[]):\n \"\"\"Lookup in the parent objects if a schema was defined for this resource.\n\n If the schema validation feature is enabled, if a schema is/are defined, and if the\n data does not validate it/them, then it raises a 400 exception.\n \"\"\"\n settings = request.registry.settings\n schema_validation = \"experimental_collection_schema_validation\"\n # If disabled from settings, do nothing.\n if not asbool(settings.get(schema_validation)):\n return\n\n bucket_id = request.matchdict[\"bucket_id\"]\n bucket_uri = utils.instance_uri(request, \"bucket\", id=bucket_id)\n buckets = request.bound_data.setdefault(\"buckets\", {})\n if bucket_uri not in buckets:\n # Unknown yet, fetch from storage.\n bucket = object_exists_or_404(\n request, resource_name=\"bucket\", parent_id=\"\", object_id=bucket_id\n )\n buckets[bucket_uri] = bucket\n\n # Let's see if the bucket defines a schema for this resource.\n metadata_field = f\"{resource_name}:schema\"\n bucket = buckets[bucket_uri]\n if metadata_field not in bucket:\n return\n\n # Validate or fail with 400.\n schema = bucket[metadata_field]\n try:\n validate_schema(data, schema, ignore_fields=ignore_fields)\n except ValidationError as e:\n raise_invalid(request, name=e.field, description=e.message)\n except RefResolutionError as e:\n raise_invalid(request, name=\"schema\", description=str(e))\n", "path": "kinto/schema_validation.py"}]}
| 1,715 | 492 |
gh_patches_debug_6142
|
rasdani/github-patches
|
git_diff
|
Textualize__textual-4424
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Docs change - use `pane` instead of `tab` for an event listener on tab change
We tried adding an event listener for a tab change using the docs here, but couldn't get it to work: https://textual.textualize.io/guide/events/#applying-css-selectors-to-arbitrary-attributes. Should the docs be updated to use `pane` instead of `tab`, or are we doing something wrong? Specifically this snippet:
```python
@on(TabbedContent.TabActivated, tab="#home")
def home_tab(self) -> None:
self.log("Switched back to home tab.")
```
I got it working, I think it's related to the breaking change described in https://github.com/Textualize/textual/blob/main/CHANGELOG.md#0460---2023-12-17
> Breaking change: tab is no longer a @on decorator selector for TabbedContent.TabActivated -- use pane instead https://github.com/Textualize/textual/pull/3815
</issue>
<code>
[start of src/textual/_on.py]
1 from __future__ import annotations
2
3 from typing import Callable, TypeVar
4
5 from .css.model import SelectorSet
6 from .css.parse import parse_selectors
7 from .css.tokenizer import TokenError
8 from .message import Message
9
10 DecoratedType = TypeVar("DecoratedType")
11
12
13 class OnDecoratorError(Exception):
14 """Errors related to the `on` decorator.
15
16 Typically raised at import time as an early warning system.
17 """
18
19
20 class OnNoWidget(Exception):
21 """A selector was applied to an attribute that isn't a widget."""
22
23
24 def on(
25 message_type: type[Message], selector: str | None = None, **kwargs: str
26 ) -> Callable[[DecoratedType], DecoratedType]:
27 """Decorator to declare that the method is a message handler.
28
29 The decorator accepts an optional CSS selector that will be matched against a widget exposed by
30 a `control` property on the message.
31
32 Example:
33 ```python
34 # Handle the press of buttons with ID "#quit".
35 @on(Button.Pressed, "#quit")
36 def quit_button(self) -> None:
37 self.app.quit()
38 ```
39
40 Keyword arguments can be used to match additional selectors for attributes
41 listed in [`ALLOW_SELECTOR_MATCH`][textual.message.Message.ALLOW_SELECTOR_MATCH].
42
43 Example:
44 ```python
45 # Handle the activation of the tab "#home" within the `TabbedContent` "#tabs".
46 @on(TabbedContent.TabActivated, "#tabs", tab="#home")
47 def switch_to_home(self) -> None:
48 self.log("Switching back to the home tab.")
49 ...
50 ```
51
52 Args:
53 message_type: The message type (i.e. the class).
54 selector: An optional [selector](/guide/CSS#selectors). If supplied, the handler will only be called if `selector`
55 matches the widget from the `control` attribute of the message.
56 **kwargs: Additional selectors for other attributes of the message.
57 """
58
59 selectors: dict[str, str] = {}
60 if selector is not None:
61 selectors["control"] = selector
62 if kwargs:
63 selectors.update(kwargs)
64
65 parsed_selectors: dict[str, tuple[SelectorSet, ...]] = {}
66 for attribute, css_selector in selectors.items():
67 if attribute == "control":
68 if message_type.control == Message.control:
69 raise OnDecoratorError(
70 "The message class must have a 'control' to match with the on decorator"
71 )
72 elif attribute not in message_type.ALLOW_SELECTOR_MATCH:
73 raise OnDecoratorError(
74 f"The attribute {attribute!r} can't be matched; have you added it to "
75 + f"{message_type.__name__}.ALLOW_SELECTOR_MATCH?"
76 )
77 try:
78 parsed_selectors[attribute] = parse_selectors(css_selector)
79 except TokenError:
80 raise OnDecoratorError(
81 f"Unable to parse selector {css_selector!r} for {attribute}; check for syntax errors"
82 ) from None
83
84 def decorator(method: DecoratedType) -> DecoratedType:
85 """Store message and selector in function attribute, return callable unaltered."""
86
87 if not hasattr(method, "_textual_on"):
88 setattr(method, "_textual_on", [])
89 getattr(method, "_textual_on").append((message_type, parsed_selectors))
90
91 return method
92
93 return decorator
94
[end of src/textual/_on.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/textual/_on.py b/src/textual/_on.py
--- a/src/textual/_on.py
+++ b/src/textual/_on.py
@@ -43,7 +43,7 @@
Example:
```python
# Handle the activation of the tab "#home" within the `TabbedContent` "#tabs".
- @on(TabbedContent.TabActivated, "#tabs", tab="#home")
+ @on(TabbedContent.TabActivated, "#tabs", pane="#home")
def switch_to_home(self) -> None:
self.log("Switching back to the home tab.")
...
|
{"golden_diff": "diff --git a/src/textual/_on.py b/src/textual/_on.py\n--- a/src/textual/_on.py\n+++ b/src/textual/_on.py\n@@ -43,7 +43,7 @@\n Example:\n ```python\n # Handle the activation of the tab \"#home\" within the `TabbedContent` \"#tabs\".\n- @on(TabbedContent.TabActivated, \"#tabs\", tab=\"#home\")\n+ @on(TabbedContent.TabActivated, \"#tabs\", pane=\"#home\")\n def switch_to_home(self) -> None:\n self.log(\"Switching back to the home tab.\")\n ...\n", "issue": "Docs change - use `pane` instead of `tab` for an event listener on tab change\nWe tried adding an event listener for a tab change using the docs here, but couldn't get it to work: https://textual.textualize.io/guide/events/#applying-css-selectors-to-arbitrary-attributes. Should the docs be updated to use `pane` instead of `tab`, or are we doing something wrong? Specifically this snippet:\r\n\r\n```python\r\n@on(TabbedContent.TabActivated, tab=\"#home\")\r\ndef home_tab(self) -> None:\r\n self.log(\"Switched back to home tab.\")\r\n```\r\n\r\nI got it working, I think it's related to the breaking change described in https://github.com/Textualize/textual/blob/main/CHANGELOG.md#0460---2023-12-17\r\n\r\n> Breaking change: tab is no longer a @on decorator selector for TabbedContent.TabActivated -- use pane instead https://github.com/Textualize/textual/pull/3815\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom typing import Callable, TypeVar\n\nfrom .css.model import SelectorSet\nfrom .css.parse import parse_selectors\nfrom .css.tokenizer import TokenError\nfrom .message import Message\n\nDecoratedType = TypeVar(\"DecoratedType\")\n\n\nclass OnDecoratorError(Exception):\n \"\"\"Errors related to the `on` decorator.\n\n Typically raised at import time as an early warning system.\n \"\"\"\n\n\nclass OnNoWidget(Exception):\n \"\"\"A selector was applied to an attribute that isn't a widget.\"\"\"\n\n\ndef on(\n message_type: type[Message], selector: str | None = None, **kwargs: str\n) -> Callable[[DecoratedType], DecoratedType]:\n \"\"\"Decorator to declare that the method is a message handler.\n\n The decorator accepts an optional CSS selector that will be matched against a widget exposed by\n a `control` property on the message.\n\n Example:\n ```python\n # Handle the press of buttons with ID \"#quit\".\n @on(Button.Pressed, \"#quit\")\n def quit_button(self) -> None:\n self.app.quit()\n ```\n\n Keyword arguments can be used to match additional selectors for attributes\n listed in [`ALLOW_SELECTOR_MATCH`][textual.message.Message.ALLOW_SELECTOR_MATCH].\n\n Example:\n ```python\n # Handle the activation of the tab \"#home\" within the `TabbedContent` \"#tabs\".\n @on(TabbedContent.TabActivated, \"#tabs\", tab=\"#home\")\n def switch_to_home(self) -> None:\n self.log(\"Switching back to the home tab.\")\n ...\n ```\n\n Args:\n message_type: The message type (i.e. the class).\n selector: An optional [selector](/guide/CSS#selectors). If supplied, the handler will only be called if `selector`\n matches the widget from the `control` attribute of the message.\n **kwargs: Additional selectors for other attributes of the message.\n \"\"\"\n\n selectors: dict[str, str] = {}\n if selector is not None:\n selectors[\"control\"] = selector\n if kwargs:\n selectors.update(kwargs)\n\n parsed_selectors: dict[str, tuple[SelectorSet, ...]] = {}\n for attribute, css_selector in selectors.items():\n if attribute == \"control\":\n if message_type.control == Message.control:\n raise OnDecoratorError(\n \"The message class must have a 'control' to match with the on decorator\"\n )\n elif attribute not in message_type.ALLOW_SELECTOR_MATCH:\n raise OnDecoratorError(\n f\"The attribute {attribute!r} can't be matched; have you added it to \"\n + f\"{message_type.__name__}.ALLOW_SELECTOR_MATCH?\"\n )\n try:\n parsed_selectors[attribute] = parse_selectors(css_selector)\n except TokenError:\n raise OnDecoratorError(\n f\"Unable to parse selector {css_selector!r} for {attribute}; check for syntax errors\"\n ) from None\n\n def decorator(method: DecoratedType) -> DecoratedType:\n \"\"\"Store message and selector in function attribute, return callable unaltered.\"\"\"\n\n if not hasattr(method, \"_textual_on\"):\n setattr(method, \"_textual_on\", [])\n getattr(method, \"_textual_on\").append((message_type, parsed_selectors))\n\n return method\n\n return decorator\n", "path": "src/textual/_on.py"}]}
| 1,654 | 136 |
gh_patches_debug_9111
|
rasdani/github-patches
|
git_diff
|
e2nIEE__pandapower-291
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
fixed rundcpp with single bus network
csr_matrix dimesions has to be specified explicitly.
Issue #288
</issue>
<code>
[start of setup.py]
1 # -*- coding: utf-8 -*-
2
3 # Copyright (c) 2016-2018 by University of Kassel and Fraunhofer Institute for Energy Economics
4 # and Energy System Technology (IEE), Kassel. All rights reserved.
5
6
7
8 from setuptools import setup, find_packages
9
10 with open('README.rst', 'rb') as f:
11 install = f.read().decode('utf-8')
12 with open('CHANGELOG.rst', 'rb') as f:
13 changelog = f.read().decode('utf-8')
14
15 long_description = '\n\n'.join((install, changelog))
16
17 setup(
18 name='pandapower',
19 version='1.6.1',
20 author='Leon Thurner, Alexander Scheidler',
21 author_email='[email protected], [email protected]',
22 description='Convenient Power System Modelling and Analysis based on PYPOWER and pandas',
23 long_description=long_description,
24 url='www.pandapower.org',
25 license='BSD',
26 install_requires=["pypower>=5.0.1",
27 "pandas>=0.17.0",
28 "networkx",
29 "numpy",
30 "scipy"],
31 extras_require = {":python_version<'3.0'": ["future"]},
32 packages=find_packages(),
33 include_package_data=True,
34 classifiers=[
35 'Development Status :: 5 - Production/Stable',
36 'Environment :: Console',
37 'Intended Audience :: Developers',
38 'Intended Audience :: Education',
39 'Intended Audience :: Science/Research',
40 'License :: OSI Approved :: BSD License',
41 'Natural Language :: English',
42 'Operating System :: OS Independent',
43 'Programming Language :: Python',
44 'Programming Language :: Python :: 2',
45 'Programming Language :: Python :: 2.7',
46 'Programming Language :: Python :: 3',
47 'Programming Language :: Python :: 3.4',
48 'Programming Language :: Python :: 3.5',
49 'Programming Language :: Python :: 3.6',
50 'Topic :: Scientific/Engineering',
51 ],
52 )
53
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -21,7 +21,7 @@
author_email='[email protected], [email protected]',
description='Convenient Power System Modelling and Analysis based on PYPOWER and pandas',
long_description=long_description,
- url='www.pandapower.org',
+ url='http://www.pandapower.org',
license='BSD',
install_requires=["pypower>=5.0.1",
"pandas>=0.17.0",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -21,7 +21,7 @@\n author_email='[email protected], [email protected]',\n description='Convenient Power System Modelling and Analysis based on PYPOWER and pandas',\n long_description=long_description,\n- url='www.pandapower.org',\n+ url='http://www.pandapower.org',\n license='BSD',\n install_requires=[\"pypower>=5.0.1\",\n \"pandas>=0.17.0\",\n", "issue": "fixed rundcpp with single bus network\ncsr_matrix dimesions has to be specified explicitly.\r\n\r\nIssue #288 \n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright (c) 2016-2018 by University of Kassel and Fraunhofer Institute for Energy Economics\n# and Energy System Technology (IEE), Kassel. All rights reserved.\n\n\n\nfrom setuptools import setup, find_packages\n\nwith open('README.rst', 'rb') as f:\n install = f.read().decode('utf-8')\nwith open('CHANGELOG.rst', 'rb') as f:\n changelog = f.read().decode('utf-8')\n\nlong_description = '\\n\\n'.join((install, changelog))\n\nsetup(\n name='pandapower',\n version='1.6.1',\n author='Leon Thurner, Alexander Scheidler',\n author_email='[email protected], [email protected]',\n description='Convenient Power System Modelling and Analysis based on PYPOWER and pandas',\n long_description=long_description,\n url='www.pandapower.org',\n license='BSD',\n install_requires=[\"pypower>=5.0.1\",\n \"pandas>=0.17.0\",\n \"networkx\",\n \"numpy\",\n \"scipy\"],\n extras_require = {\":python_version<'3.0'\": [\"future\"]},\n packages=find_packages(),\n include_package_data=True,\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Console',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Education',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: BSD License',\n 'Natural Language :: English',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Topic :: Scientific/Engineering',\n ],\n)\n", "path": "setup.py"}]}
| 1,114 | 141 |
gh_patches_debug_20552
|
rasdani/github-patches
|
git_diff
|
pycontribs__jira-86
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
JIRAError does not correctly display full error information
There seems to be a bug in `JIRAError.__str__`
```
if self.response and hasattr(self.response, 'text'):
t += "\n\tresponse text = " % self.response.headers
```
https://github.com/pycontribs/jira/blob/master/jira/utils.py#L161
1. This checks for the `text` attribute but then uses the `headers` attribute (cut-and-paste error from the lines above?)
2. The response object is "Truthy" based upon the HTTP response, so in the case of a HTTP error it is actually "False" so the conditional check fails.
3. Which is just as well, because once you fix this you'll see that the format string is invalid and causes an exception because it is missing a %s at the end
:-)
I'll submit a pull request to fix this up shortly.
</issue>
<code>
[start of jira/utils.py]
1 # -*- coding: utf-8 -*-
2 from __future__ import unicode_literals
3 import threading
4 import json
5 import logging
6
7
8 class CaseInsensitiveDict(dict):
9
10 """
11 A case-insensitive ``dict``-like object.
12
13 Implements all methods and operations of
14 ``collections.MutableMapping`` as well as dict's ``copy``. Also
15 provides ``lower_items``.
16
17 All keys are expected to be strings. The structure remembers the
18 case of the last key to be set, and ``iter(instance)``,
19 ``keys()``, ``items()``, ``iterkeys()``, and ``iteritems()``
20 will contain case-sensitive keys. However, querying and contains
21 testing is case insensitive::
22
23 cid = CaseInsensitiveDict()
24 cid['Accept'] = 'application/json'
25 cid['aCCEPT'] == 'application/json' # True
26 list(cid) == ['Accept'] # True
27
28 For example, ``headers['content-encoding']`` will return the
29 value of a ``'Content-Encoding'`` response header, regardless
30 of how the header name was originally stored.
31 C
32 If the constructor, ``.update``, or equality comparison
33 operations are given keys that have equal ``.lower()``s, the
34 behavior is undefined.
35
36 """
37
38 def __init__(self, *args, **kw):
39 super(CaseInsensitiveDict, self).__init__(*args, **kw)
40
41 self.itemlist = {}
42 for key, value in super(CaseInsensitiveDict, self).items():
43 if key != key.lower():
44 self[key.lower()] = value
45 self.pop(key, None)
46
47 #self.itemlist[key.lower()] = value
48
49 def __setitem__(self, key, value):
50 super(CaseInsensitiveDict, self).__setitem__(key.lower(), value)
51
52 # def __iter__(self):
53 # return iter(self.itemlist)
54
55 # def keys(self):
56 # return self.itemlist
57
58 # def values(self):
59 # return [self[key] for key in self]
60
61 # def itervalues(self):
62 # return (self[key] for key in self)
63
64
65 def threaded_requests(requests):
66 for fn, url, request_args in requests:
67 th = threading.Thread(
68 target=fn, args=(url,), kwargs=request_args, name=url,
69 )
70 th.start()
71
72 for th in threading.enumerate():
73 if th.name.startswith('http'):
74 th.join()
75
76
77 def json_loads(r):
78 raise_on_error(r)
79 if len(r.text): # r.status_code != 204:
80 return json.loads(r.text)
81 else:
82 # json.loads() fails with empy bodies
83 return {}
84
85
86 def raise_on_error(r, verb='???', **kwargs):
87 request = kwargs.get('request', None)
88 headers = kwargs.get('headers', None)
89
90 if r is None:
91 raise JIRAError(None, **kwargs)
92
93 if r.status_code >= 400:
94 error = ''
95 if r.status_code == 403 and "x-authentication-denied-reason" in r.headers:
96 error = r.headers["x-authentication-denied-reason"]
97 elif r.text:
98 try:
99 response = json.loads(r.text)
100 if 'message' in response:
101 # JIRA 5.1 errors
102 error = response['message']
103 elif 'errorMessages' in response and len(response['errorMessages']) > 0:
104 # JIRA 5.0.x error messages sometimes come wrapped in this array
105 # Sometimes this is present but empty
106 errorMessages = response['errorMessages']
107 if isinstance(errorMessages, (list, tuple)):
108 error = errorMessages[0]
109 else:
110 error = errorMessages
111 elif 'errors' in response and len(response['errors']) > 0:
112 # JIRA 6.x error messages are found in this array.
113 error_list = response['errors'].values()
114 error = ", ".join(error_list)
115 else:
116 error = r.text
117 except ValueError:
118 error = r.text
119 raise JIRAError(
120 r.status_code, error, r.url, request=request, response=r, **kwargs)
121 # for debugging weird errors on CI
122 if r.status_code not in [200, 201, 202, 204]:
123 raise JIRAError(r.status_code, request=request, response=r, **kwargs)
124 # testing for the WTH bug exposed on
125 # https://answers.atlassian.com/questions/11457054/answers/11975162
126 if r.status_code == 200 and len(r.text) == 0 \
127 and 'X-Seraph-LoginReason' in r.headers \
128 and 'AUTHENTICATED_FAILED' in r.headers['X-Seraph-LoginReason']:
129 pass
130
131
132 class JIRAError(Exception):
133
134 """General error raised for all problems in operation of the client."""
135
136 def __init__(self, status_code=None, text=None, url=None, request=None, response=None, **kwargs):
137 self.status_code = status_code
138 self.text = text
139 self.url = url
140 self.request = request
141 self.response = response
142 self.headers = kwargs.get('headers', None)
143
144 def __str__(self):
145 t = "JiraError HTTP %s" % self.status_code
146 if self.text:
147 t += "\n\ttext: %s" % self.text
148 if self.url:
149 t += "\n\turl: %s" % self.url
150
151 if self.request and hasattr(self.request, 'headers'):
152 t += "\n\trequest headers = " % self.request.headers
153
154 if self.request and hasattr(self.request, 'text'):
155 t += "\n\trequest text = " % self.request.text
156
157 if self.response and hasattr(self.response, 'headers'):
158 t += "\n\tresponse headers = " % self.response.headers
159
160 if self.response and hasattr(self.response, 'text'):
161 t += "\n\tresponse text = " % self.response.headers
162
163 t += '\n'
164 return t
165
166
167 def get_error_list(r):
168 error_list = []
169 if r.status_code >= 400:
170 if r.status_code == 403 and "x-authentication-denied-reason" in r.headers:
171 error_list = [r.headers["x-authentication-denied-reason"]]
172 elif r.text:
173 try:
174 response = json_loads(r)
175 if 'message' in response:
176 # JIRA 5.1 errors
177 error_list = [response['message']]
178 elif 'errorMessages' in response and len(response['errorMessages']) > 0:
179 # JIRA 5.0.x error messages sometimes come wrapped in this array
180 # Sometimes this is present but empty
181 errorMessages = response['errorMessages']
182 if isinstance(errorMessages, (list, tuple)):
183 error_list = errorMessages
184 else:
185 error_list = [errorMessages]
186 elif 'errors' in response and len(response['errors']) > 0:
187 # JIRA 6.x error messages are found in this array.
188 error_list = response['errors'].values()
189 else:
190 error_list = [r.text]
191 except ValueError:
192 error_list = [r.text]
193 return error_list
194
[end of jira/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/jira/utils.py b/jira/utils.py
--- a/jira/utils.py
+++ b/jira/utils.py
@@ -148,17 +148,17 @@
if self.url:
t += "\n\turl: %s" % self.url
- if self.request and hasattr(self.request, 'headers'):
- t += "\n\trequest headers = " % self.request.headers
+ if self.request is not None and hasattr(self.request, 'headers'):
+ t += "\n\trequest headers = %s" % self.request.headers
- if self.request and hasattr(self.request, 'text'):
- t += "\n\trequest text = " % self.request.text
+ if self.request is not None and hasattr(self.request, 'text'):
+ t += "\n\trequest text = %s" % self.request.text
- if self.response and hasattr(self.response, 'headers'):
- t += "\n\tresponse headers = " % self.response.headers
+ if self.response is not None and hasattr(self.response, 'headers'):
+ t += "\n\tresponse headers = %s" % self.response.headers
- if self.response and hasattr(self.response, 'text'):
- t += "\n\tresponse text = " % self.response.headers
+ if self.response is not None and hasattr(self.response, 'text'):
+ t += "\n\tresponse text = %s" % self.response.text
t += '\n'
return t
|
{"golden_diff": "diff --git a/jira/utils.py b/jira/utils.py\n--- a/jira/utils.py\n+++ b/jira/utils.py\n@@ -148,17 +148,17 @@\n if self.url:\n t += \"\\n\\turl: %s\" % self.url\n \n- if self.request and hasattr(self.request, 'headers'):\n- t += \"\\n\\trequest headers = \" % self.request.headers\n+ if self.request is not None and hasattr(self.request, 'headers'):\n+ t += \"\\n\\trequest headers = %s\" % self.request.headers\n \n- if self.request and hasattr(self.request, 'text'):\n- t += \"\\n\\trequest text = \" % self.request.text\n+ if self.request is not None and hasattr(self.request, 'text'):\n+ t += \"\\n\\trequest text = %s\" % self.request.text\n \n- if self.response and hasattr(self.response, 'headers'):\n- t += \"\\n\\tresponse headers = \" % self.response.headers\n+ if self.response is not None and hasattr(self.response, 'headers'):\n+ t += \"\\n\\tresponse headers = %s\" % self.response.headers\n \n- if self.response and hasattr(self.response, 'text'):\n- t += \"\\n\\tresponse text = \" % self.response.headers\n+ if self.response is not None and hasattr(self.response, 'text'):\n+ t += \"\\n\\tresponse text = %s\" % self.response.text\n \n t += '\\n'\n return t\n", "issue": "JIRAError does not correctly display full error information\nThere seems to be a bug in `JIRAError.__str__`\n\n```\n if self.response and hasattr(self.response, 'text'):\n t += \"\\n\\tresponse text = \" % self.response.headers\n```\n\nhttps://github.com/pycontribs/jira/blob/master/jira/utils.py#L161\n1. This checks for the `text` attribute but then uses the `headers` attribute (cut-and-paste error from the lines above?)\n2. The response object is \"Truthy\" based upon the HTTP response, so in the case of a HTTP error it is actually \"False\" so the conditional check fails.\n3. Which is just as well, because once you fix this you'll see that the format string is invalid and causes an exception because it is missing a %s at the end\n\n:-)\n\nI'll submit a pull request to fix this up shortly.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import unicode_literals\nimport threading\nimport json\nimport logging\n\n\nclass CaseInsensitiveDict(dict):\n\n \"\"\"\n A case-insensitive ``dict``-like object.\n\n Implements all methods and operations of\n ``collections.MutableMapping`` as well as dict's ``copy``. Also\n provides ``lower_items``.\n\n All keys are expected to be strings. The structure remembers the\n case of the last key to be set, and ``iter(instance)``,\n ``keys()``, ``items()``, ``iterkeys()``, and ``iteritems()``\n will contain case-sensitive keys. However, querying and contains\n testing is case insensitive::\n\n cid = CaseInsensitiveDict()\n cid['Accept'] = 'application/json'\n cid['aCCEPT'] == 'application/json' # True\n list(cid) == ['Accept'] # True\n\n For example, ``headers['content-encoding']`` will return the\n value of a ``'Content-Encoding'`` response header, regardless\n of how the header name was originally stored.\nC\n If the constructor, ``.update``, or equality comparison\n operations are given keys that have equal ``.lower()``s, the\n behavior is undefined.\n\n \"\"\"\n\n def __init__(self, *args, **kw):\n super(CaseInsensitiveDict, self).__init__(*args, **kw)\n\n self.itemlist = {}\n for key, value in super(CaseInsensitiveDict, self).items():\n if key != key.lower():\n self[key.lower()] = value\n self.pop(key, None)\n\n #self.itemlist[key.lower()] = value\n\n def __setitem__(self, key, value):\n super(CaseInsensitiveDict, self).__setitem__(key.lower(), value)\n\n # def __iter__(self):\n # return iter(self.itemlist)\n\n # def keys(self):\n # return self.itemlist\n\n # def values(self):\n # return [self[key] for key in self]\n\n # def itervalues(self):\n # return (self[key] for key in self)\n\n\ndef threaded_requests(requests):\n for fn, url, request_args in requests:\n th = threading.Thread(\n target=fn, args=(url,), kwargs=request_args, name=url,\n )\n th.start()\n\n for th in threading.enumerate():\n if th.name.startswith('http'):\n th.join()\n\n\ndef json_loads(r):\n raise_on_error(r)\n if len(r.text): # r.status_code != 204:\n return json.loads(r.text)\n else:\n # json.loads() fails with empy bodies\n return {}\n\n\ndef raise_on_error(r, verb='???', **kwargs):\n request = kwargs.get('request', None)\n headers = kwargs.get('headers', None)\n\n if r is None:\n raise JIRAError(None, **kwargs)\n\n if r.status_code >= 400:\n error = ''\n if r.status_code == 403 and \"x-authentication-denied-reason\" in r.headers:\n error = r.headers[\"x-authentication-denied-reason\"]\n elif r.text:\n try:\n response = json.loads(r.text)\n if 'message' in response:\n # JIRA 5.1 errors\n error = response['message']\n elif 'errorMessages' in response and len(response['errorMessages']) > 0:\n # JIRA 5.0.x error messages sometimes come wrapped in this array\n # Sometimes this is present but empty\n errorMessages = response['errorMessages']\n if isinstance(errorMessages, (list, tuple)):\n error = errorMessages[0]\n else:\n error = errorMessages\n elif 'errors' in response and len(response['errors']) > 0:\n # JIRA 6.x error messages are found in this array.\n error_list = response['errors'].values()\n error = \", \".join(error_list)\n else:\n error = r.text\n except ValueError:\n error = r.text\n raise JIRAError(\n r.status_code, error, r.url, request=request, response=r, **kwargs)\n # for debugging weird errors on CI\n if r.status_code not in [200, 201, 202, 204]:\n raise JIRAError(r.status_code, request=request, response=r, **kwargs)\n # testing for the WTH bug exposed on\n # https://answers.atlassian.com/questions/11457054/answers/11975162\n if r.status_code == 200 and len(r.text) == 0 \\\n and 'X-Seraph-LoginReason' in r.headers \\\n and 'AUTHENTICATED_FAILED' in r.headers['X-Seraph-LoginReason']:\n pass\n\n\nclass JIRAError(Exception):\n\n \"\"\"General error raised for all problems in operation of the client.\"\"\"\n\n def __init__(self, status_code=None, text=None, url=None, request=None, response=None, **kwargs):\n self.status_code = status_code\n self.text = text\n self.url = url\n self.request = request\n self.response = response\n self.headers = kwargs.get('headers', None)\n\n def __str__(self):\n t = \"JiraError HTTP %s\" % self.status_code\n if self.text:\n t += \"\\n\\ttext: %s\" % self.text\n if self.url:\n t += \"\\n\\turl: %s\" % self.url\n\n if self.request and hasattr(self.request, 'headers'):\n t += \"\\n\\trequest headers = \" % self.request.headers\n\n if self.request and hasattr(self.request, 'text'):\n t += \"\\n\\trequest text = \" % self.request.text\n\n if self.response and hasattr(self.response, 'headers'):\n t += \"\\n\\tresponse headers = \" % self.response.headers\n\n if self.response and hasattr(self.response, 'text'):\n t += \"\\n\\tresponse text = \" % self.response.headers\n\n t += '\\n'\n return t\n\n\ndef get_error_list(r):\n error_list = []\n if r.status_code >= 400:\n if r.status_code == 403 and \"x-authentication-denied-reason\" in r.headers:\n error_list = [r.headers[\"x-authentication-denied-reason\"]]\n elif r.text:\n try:\n response = json_loads(r)\n if 'message' in response:\n # JIRA 5.1 errors\n error_list = [response['message']]\n elif 'errorMessages' in response and len(response['errorMessages']) > 0:\n # JIRA 5.0.x error messages sometimes come wrapped in this array\n # Sometimes this is present but empty\n errorMessages = response['errorMessages']\n if isinstance(errorMessages, (list, tuple)):\n error_list = errorMessages\n else:\n error_list = [errorMessages]\n elif 'errors' in response and len(response['errors']) > 0:\n # JIRA 6.x error messages are found in this array.\n error_list = response['errors'].values()\n else:\n error_list = [r.text]\n except ValueError:\n error_list = [r.text]\n return error_list\n", "path": "jira/utils.py"}]}
| 2,812 | 326 |
gh_patches_debug_38084
|
rasdani/github-patches
|
git_diff
|
vyperlang__vyper-1470
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fails: Using empty `bytes[256]` default function parameter on internal constant and private functions
### Version Information
* vyper Version: 0.1.0b10
* OS: osx
* Python Version: 3.7.3
### What's your issue about?
Calling `mint()` on the following contract throws when making use of the default parameters:
```python
@private
@constant
def _checkForERC777TokensInterface_Recipient(
_to: address,
_amount: uint256,
_data: bytes[256]="",
):
assert True
@public
def mint(
_to: address,
_amount: uint256,
_data: bytes[256]="",
):
# NOTE: fails (stack underflow) because of default _data parameter
self._checkForERC777TokensInterface_Recipient(
_to,
_amount,
_data,
)
```
#### Using `web3js`:
This throws: `Error: Returned error: VM Exception while processing transaction: stack underflow`
```javascript
await erc777Token.mint(
wallet.address,
100,
);
```
This works:
```javascript
await erc777Token.mint(
wallet.address,
100,
'0x0000000000000000000000000000000000000001',
);
```
### How can this be solved?
I posted a solution further down (use `data: bytes[256]="0x0"` in `mint()`).
Maybe everything is fine and one should just not use default parameters in internal functions...
In that case this issue can be closed.
</issue>
<code>
[start of vyper/parser/self_call.py]
1 import itertools
2
3 from vyper.exceptions import (
4 ConstancyViolationException,
5 )
6 from vyper.parser.lll_node import (
7 LLLnode,
8 )
9 from vyper.parser.parser_utils import (
10 getpos,
11 pack_arguments,
12 )
13 from vyper.signatures.function_signature import (
14 FunctionSignature,
15 )
16 from vyper.types import (
17 BaseType,
18 ByteArrayLike,
19 ListType,
20 TupleLike,
21 ceil32,
22 get_size_of_type,
23 get_static_size_of_type,
24 )
25
26
27 def call_lookup_specs(stmt_expr, context):
28 from vyper.parser.expr import Expr
29 method_name = stmt_expr.func.attr
30 expr_args = [Expr(arg, context).lll_node for arg in stmt_expr.args]
31 sig = FunctionSignature.lookup_sig(context.sigs, method_name, expr_args, stmt_expr, context)
32 return method_name, expr_args, sig
33
34
35 def make_call(stmt_expr, context):
36 method_name, _, sig = call_lookup_specs(stmt_expr, context)
37
38 if context.is_constant() and not sig.const:
39 raise ConstancyViolationException(
40 "May not call non-constant function '%s' within %s." % (
41 method_name,
42 context.pp_constancy(),
43 ),
44 getpos(stmt_expr)
45 )
46
47 if sig.private:
48 return call_self_private(stmt_expr, context, sig)
49 else:
50 return call_self_public(stmt_expr, context, sig)
51
52
53 def call_make_placeholder(stmt_expr, context, sig):
54 if sig.output_type is None:
55 return 0, 0, 0
56
57 output_placeholder = context.new_placeholder(typ=sig.output_type)
58 out_size = get_size_of_type(sig.output_type) * 32
59 returner = output_placeholder
60
61 if not sig.private and isinstance(sig.output_type, ByteArrayLike):
62 returner = output_placeholder + 32
63
64 return output_placeholder, returner, out_size
65
66
67 def call_self_private(stmt_expr, context, sig):
68 # ** Private Call **
69 # Steps:
70 # (x) push current local variables
71 # (x) push arguments
72 # (x) push jumpdest (callback ptr)
73 # (x) jump to label
74 # (x) pop return values
75 # (x) pop local variables
76
77 method_name, expr_args, sig = call_lookup_specs(stmt_expr, context)
78 pre_init = []
79 pop_local_vars = []
80 push_local_vars = []
81 pop_return_values = []
82 push_args = []
83
84 # Push local variables.
85 if context.vars:
86 var_slots = [(v.pos, v.size) for name, v in context.vars.items()]
87 var_slots.sort(key=lambda x: x[0])
88 mem_from, mem_to = var_slots[0][0], var_slots[-1][0] + var_slots[-1][1] * 32
89 push_local_vars = [
90 ['mload', pos] for pos in range(mem_from, mem_to, 32)
91 ]
92 pop_local_vars = [
93 ['mstore', pos, 'pass'] for pos in reversed(range(mem_from, mem_to, 32))
94 ]
95
96 # Push Arguments
97 if expr_args:
98 inargs, inargsize, arg_pos = pack_arguments(
99 sig,
100 expr_args,
101 context,
102 return_placeholder=False,
103 pos=getpos(stmt_expr),
104 )
105 push_args += [inargs] # copy arguments first, to not mess up the push/pop sequencing.
106
107 static_arg_size = 32 * sum(
108 [get_static_size_of_type(arg.typ)
109 for arg in expr_args])
110 static_pos = arg_pos + static_arg_size
111 total_arg_size = ceil32(inargsize - 4)
112
113 if static_arg_size != total_arg_size: # requires dynamic section.
114 ident = 'push_args_%d_%d_%d' % (sig.method_id, stmt_expr.lineno, stmt_expr.col_offset)
115 start_label = ident + '_start'
116 end_label = ident + '_end'
117 i_placeholder = context.new_placeholder(BaseType('uint256'))
118 push_args += [
119 ['mstore', i_placeholder, arg_pos + total_arg_size],
120 ['label', start_label],
121 ['if', ['lt', ['mload', i_placeholder], static_pos], ['goto', end_label]],
122 [
123 'if_unchecked',
124 ['ne', ['mload', ['mload', i_placeholder]], 0],
125 ['mload', ['mload', i_placeholder]],
126 ],
127 ['mstore', i_placeholder, ['sub', ['mload', i_placeholder], 32]], # decrease i
128 ['goto', start_label],
129 ['label', end_label]
130 ]
131
132 # push static section
133 push_args += [
134 ['mload', pos] for pos in reversed(range(arg_pos, static_pos, 32))
135 ]
136
137 # Jump to function label.
138 jump_to_func = [
139 ['add', ['pc'], 6], # set callback pointer.
140 ['goto', 'priv_{}'.format(sig.method_id)],
141 ['jumpdest'],
142 ]
143
144 # Pop return values.
145 returner = [0]
146 if sig.output_type:
147 output_placeholder, returner, output_size = call_make_placeholder(stmt_expr, context, sig)
148 if output_size > 0:
149 dynamic_offsets = []
150 if isinstance(sig.output_type, (BaseType, ListType)):
151 pop_return_values = [
152 ['mstore', ['add', output_placeholder, pos], 'pass']
153 for pos in range(0, output_size, 32)
154 ]
155 elif isinstance(sig.output_type, ByteArrayLike):
156 dynamic_offsets = [(0, sig.output_type)]
157 pop_return_values = [
158 ['pop', 'pass'],
159 ]
160 elif isinstance(sig.output_type, TupleLike):
161 static_offset = 0
162 pop_return_values = []
163 for out_type in sig.output_type.members:
164 if isinstance(out_type, ByteArrayLike):
165 pop_return_values.append(
166 ['mstore', ['add', output_placeholder, static_offset], 'pass']
167 )
168 dynamic_offsets.append(
169 (['mload', ['add', output_placeholder, static_offset]], out_type)
170 )
171 else:
172 pop_return_values.append(
173 ['mstore', ['add', output_placeholder, static_offset], 'pass']
174 )
175 static_offset += 32
176
177 # append dynamic unpacker.
178 dyn_idx = 0
179 for in_memory_offset, _out_type in dynamic_offsets:
180 ident = "%d_%d_arg_%d" % (stmt_expr.lineno, stmt_expr.col_offset, dyn_idx)
181 dyn_idx += 1
182 start_label = 'dyn_unpack_start_' + ident
183 end_label = 'dyn_unpack_end_' + ident
184 i_placeholder = context.new_placeholder(typ=BaseType('uint256'))
185 begin_pos = ['add', output_placeholder, in_memory_offset]
186 # loop until length.
187 o = LLLnode.from_list(
188 ['seq_unchecked',
189 ['mstore', begin_pos, 'pass'], # get len
190 ['mstore', i_placeholder, 0],
191 ['label', start_label],
192 [ # break
193 'if',
194 ['ge', ['mload', i_placeholder], ['ceil32', ['mload', begin_pos]]],
195 ['goto', end_label]
196 ],
197 [ # pop into correct memory slot.
198 'mstore',
199 ['add', ['add', begin_pos, 32], ['mload', i_placeholder]],
200 'pass',
201 ],
202 # increment i
203 ['mstore', i_placeholder, ['add', 32, ['mload', i_placeholder]]],
204 ['goto', start_label],
205 ['label', end_label]],
206 typ=None, annotation='dynamic unpacker', pos=getpos(stmt_expr))
207 pop_return_values.append(o)
208
209 call_body = list(itertools.chain(
210 ['seq_unchecked'],
211 pre_init,
212 push_local_vars,
213 push_args,
214 jump_to_func,
215 pop_return_values,
216 pop_local_vars,
217 [returner],
218 ))
219 # If we have no return, we need to pop off
220 pop_returner_call_body = ['pop', call_body] if sig.output_type is None else call_body
221
222 o = LLLnode.from_list(
223 pop_returner_call_body,
224 typ=sig.output_type,
225 location='memory',
226 pos=getpos(stmt_expr),
227 annotation='Internal Call: %s' % method_name,
228 add_gas_estimate=sig.gas
229 )
230 o.gas += sig.gas
231 return o
232
233
234 def call_self_public(stmt_expr, context, sig):
235 # self.* style call to a public function.
236 method_name, expr_args, sig = call_lookup_specs(stmt_expr, context)
237 add_gas = sig.gas # gas of call
238 inargs, inargsize, _ = pack_arguments(sig, expr_args, context, pos=getpos(stmt_expr))
239 output_placeholder, returner, output_size = call_make_placeholder(stmt_expr, context, sig)
240 assert_call = [
241 'assert',
242 ['call', ['gas'], ['address'], 0, inargs, inargsize, output_placeholder, output_size],
243 ]
244 if output_size > 0:
245 assert_call = ['seq', assert_call, returner]
246 o = LLLnode.from_list(
247 assert_call,
248 typ=sig.output_type,
249 location='memory',
250 pos=getpos(stmt_expr),
251 add_gas_estimate=add_gas,
252 annotation='Internal Call: %s' % method_name,
253 )
254 o.gas += sig.gas
255 return o
256
[end of vyper/parser/self_call.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/vyper/parser/self_call.py b/vyper/parser/self_call.py
--- a/vyper/parser/self_call.py
+++ b/vyper/parser/self_call.py
@@ -18,9 +18,9 @@
ByteArrayLike,
ListType,
TupleLike,
- ceil32,
get_size_of_type,
get_static_size_of_type,
+ has_dynamic_data,
)
@@ -108,22 +108,42 @@
[get_static_size_of_type(arg.typ)
for arg in expr_args])
static_pos = arg_pos + static_arg_size
- total_arg_size = ceil32(inargsize - 4)
+ needs_dyn_section = any(
+ [has_dynamic_data(arg.typ)
+ for arg in expr_args])
- if static_arg_size != total_arg_size: # requires dynamic section.
+ if needs_dyn_section:
ident = 'push_args_%d_%d_%d' % (sig.method_id, stmt_expr.lineno, stmt_expr.col_offset)
start_label = ident + '_start'
end_label = ident + '_end'
i_placeholder = context.new_placeholder(BaseType('uint256'))
+
+ # Calculate copy start position.
+ # Given | static | dynamic | section in memory,
+ # copy backwards so the values are in order on the stack.
+ # We calculate i, the end of the whole encoded part
+ # (i.e. the starting index for copy)
+ # by taking ceil32(len<arg>) + offset<arg> + arg_pos
+ # for the last dynamic argument and arg_pos is the start
+ # the whole argument section.
+ for idx, arg in enumerate(expr_args):
+ if isinstance(arg.typ, ByteArrayLike):
+ last_idx = idx
push_args += [
- ['mstore', i_placeholder, arg_pos + total_arg_size],
+ ['with', 'offset', ['mload', arg_pos + last_idx * 32],
+ ['with', 'len_pos', ['add', arg_pos, 'offset'],
+ ['with', 'len_value', ['mload', 'len_pos'],
+ ['mstore', i_placeholder,
+ ['add', 'len_pos', ['ceil32', 'len_value']]]]]]
+ ]
+ # loop from end of dynamic section to start of dynamic section,
+ # pushing each element onto the stack.
+ push_args += [
+
['label', start_label],
- ['if', ['lt', ['mload', i_placeholder], static_pos], ['goto', end_label]],
- [
- 'if_unchecked',
- ['ne', ['mload', ['mload', i_placeholder]], 0],
- ['mload', ['mload', i_placeholder]],
- ],
+ ['if', ['lt', ['mload', i_placeholder], static_pos],
+ ['goto', end_label]],
+ ['mload', ['mload', i_placeholder]],
['mstore', i_placeholder, ['sub', ['mload', i_placeholder], 32]], # decrease i
['goto', start_label],
['label', end_label]
|
{"golden_diff": "diff --git a/vyper/parser/self_call.py b/vyper/parser/self_call.py\n--- a/vyper/parser/self_call.py\n+++ b/vyper/parser/self_call.py\n@@ -18,9 +18,9 @@\n ByteArrayLike,\n ListType,\n TupleLike,\n- ceil32,\n get_size_of_type,\n get_static_size_of_type,\n+ has_dynamic_data,\n )\n \n \n@@ -108,22 +108,42 @@\n [get_static_size_of_type(arg.typ)\n for arg in expr_args])\n static_pos = arg_pos + static_arg_size\n- total_arg_size = ceil32(inargsize - 4)\n+ needs_dyn_section = any(\n+ [has_dynamic_data(arg.typ)\n+ for arg in expr_args])\n \n- if static_arg_size != total_arg_size: # requires dynamic section.\n+ if needs_dyn_section:\n ident = 'push_args_%d_%d_%d' % (sig.method_id, stmt_expr.lineno, stmt_expr.col_offset)\n start_label = ident + '_start'\n end_label = ident + '_end'\n i_placeholder = context.new_placeholder(BaseType('uint256'))\n+\n+ # Calculate copy start position.\n+ # Given | static | dynamic | section in memory,\n+ # copy backwards so the values are in order on the stack.\n+ # We calculate i, the end of the whole encoded part\n+ # (i.e. the starting index for copy)\n+ # by taking ceil32(len<arg>) + offset<arg> + arg_pos\n+ # for the last dynamic argument and arg_pos is the start\n+ # the whole argument section.\n+ for idx, arg in enumerate(expr_args):\n+ if isinstance(arg.typ, ByteArrayLike):\n+ last_idx = idx\n push_args += [\n- ['mstore', i_placeholder, arg_pos + total_arg_size],\n+ ['with', 'offset', ['mload', arg_pos + last_idx * 32],\n+ ['with', 'len_pos', ['add', arg_pos, 'offset'],\n+ ['with', 'len_value', ['mload', 'len_pos'],\n+ ['mstore', i_placeholder,\n+ ['add', 'len_pos', ['ceil32', 'len_value']]]]]]\n+ ]\n+ # loop from end of dynamic section to start of dynamic section,\n+ # pushing each element onto the stack.\n+ push_args += [\n+\n ['label', start_label],\n- ['if', ['lt', ['mload', i_placeholder], static_pos], ['goto', end_label]],\n- [\n- 'if_unchecked',\n- ['ne', ['mload', ['mload', i_placeholder]], 0],\n- ['mload', ['mload', i_placeholder]],\n- ],\n+ ['if', ['lt', ['mload', i_placeholder], static_pos],\n+ ['goto', end_label]],\n+ ['mload', ['mload', i_placeholder]],\n ['mstore', i_placeholder, ['sub', ['mload', i_placeholder], 32]], # decrease i\n ['goto', start_label],\n ['label', end_label]\n", "issue": "Fails: Using empty `bytes[256]` default function parameter on internal constant and private functions\n### Version Information\r\n\r\n* vyper Version: 0.1.0b10\r\n* OS: osx\r\n* Python Version: 3.7.3\r\n\r\n### What's your issue about?\r\n\r\nCalling `mint()` on the following contract throws when making use of the default parameters:\r\n\r\n```python\r\n@private\r\n@constant\r\ndef _checkForERC777TokensInterface_Recipient(\r\n _to: address,\r\n _amount: uint256,\r\n _data: bytes[256]=\"\",\r\n ):\r\n assert True\r\n\r\n\r\n@public\r\ndef mint(\r\n _to: address,\r\n _amount: uint256,\r\n _data: bytes[256]=\"\",\r\n ):\r\n # NOTE: fails (stack underflow) because of default _data parameter\r\n self._checkForERC777TokensInterface_Recipient(\r\n _to,\r\n _amount,\r\n _data,\r\n )\r\n```\r\n\r\n#### Using `web3js`:\r\n\r\nThis throws: `Error: Returned error: VM Exception while processing transaction: stack underflow`\r\n```javascript\r\nawait erc777Token.mint(\r\n wallet.address,\r\n 100,\r\n );\r\n```\r\n\r\nThis works:\r\n```javascript\r\n await erc777Token.mint(\r\n wallet.address,\r\n 100,\r\n '0x0000000000000000000000000000000000000001',\r\n );\r\n```\r\n\r\n### How can this be solved?\r\n\r\nI posted a solution further down (use `data: bytes[256]=\"0x0\"` in `mint()`). \r\nMaybe everything is fine and one should just not use default parameters in internal functions...\r\nIn that case this issue can be closed.\r\n\n", "before_files": [{"content": "import itertools\n\nfrom vyper.exceptions import (\n ConstancyViolationException,\n)\nfrom vyper.parser.lll_node import (\n LLLnode,\n)\nfrom vyper.parser.parser_utils import (\n getpos,\n pack_arguments,\n)\nfrom vyper.signatures.function_signature import (\n FunctionSignature,\n)\nfrom vyper.types import (\n BaseType,\n ByteArrayLike,\n ListType,\n TupleLike,\n ceil32,\n get_size_of_type,\n get_static_size_of_type,\n)\n\n\ndef call_lookup_specs(stmt_expr, context):\n from vyper.parser.expr import Expr\n method_name = stmt_expr.func.attr\n expr_args = [Expr(arg, context).lll_node for arg in stmt_expr.args]\n sig = FunctionSignature.lookup_sig(context.sigs, method_name, expr_args, stmt_expr, context)\n return method_name, expr_args, sig\n\n\ndef make_call(stmt_expr, context):\n method_name, _, sig = call_lookup_specs(stmt_expr, context)\n\n if context.is_constant() and not sig.const:\n raise ConstancyViolationException(\n \"May not call non-constant function '%s' within %s.\" % (\n method_name,\n context.pp_constancy(),\n ),\n getpos(stmt_expr)\n )\n\n if sig.private:\n return call_self_private(stmt_expr, context, sig)\n else:\n return call_self_public(stmt_expr, context, sig)\n\n\ndef call_make_placeholder(stmt_expr, context, sig):\n if sig.output_type is None:\n return 0, 0, 0\n\n output_placeholder = context.new_placeholder(typ=sig.output_type)\n out_size = get_size_of_type(sig.output_type) * 32\n returner = output_placeholder\n\n if not sig.private and isinstance(sig.output_type, ByteArrayLike):\n returner = output_placeholder + 32\n\n return output_placeholder, returner, out_size\n\n\ndef call_self_private(stmt_expr, context, sig):\n # ** Private Call **\n # Steps:\n # (x) push current local variables\n # (x) push arguments\n # (x) push jumpdest (callback ptr)\n # (x) jump to label\n # (x) pop return values\n # (x) pop local variables\n\n method_name, expr_args, sig = call_lookup_specs(stmt_expr, context)\n pre_init = []\n pop_local_vars = []\n push_local_vars = []\n pop_return_values = []\n push_args = []\n\n # Push local variables.\n if context.vars:\n var_slots = [(v.pos, v.size) for name, v in context.vars.items()]\n var_slots.sort(key=lambda x: x[0])\n mem_from, mem_to = var_slots[0][0], var_slots[-1][0] + var_slots[-1][1] * 32\n push_local_vars = [\n ['mload', pos] for pos in range(mem_from, mem_to, 32)\n ]\n pop_local_vars = [\n ['mstore', pos, 'pass'] for pos in reversed(range(mem_from, mem_to, 32))\n ]\n\n # Push Arguments\n if expr_args:\n inargs, inargsize, arg_pos = pack_arguments(\n sig,\n expr_args,\n context,\n return_placeholder=False,\n pos=getpos(stmt_expr),\n )\n push_args += [inargs] # copy arguments first, to not mess up the push/pop sequencing.\n\n static_arg_size = 32 * sum(\n [get_static_size_of_type(arg.typ)\n for arg in expr_args])\n static_pos = arg_pos + static_arg_size\n total_arg_size = ceil32(inargsize - 4)\n\n if static_arg_size != total_arg_size: # requires dynamic section.\n ident = 'push_args_%d_%d_%d' % (sig.method_id, stmt_expr.lineno, stmt_expr.col_offset)\n start_label = ident + '_start'\n end_label = ident + '_end'\n i_placeholder = context.new_placeholder(BaseType('uint256'))\n push_args += [\n ['mstore', i_placeholder, arg_pos + total_arg_size],\n ['label', start_label],\n ['if', ['lt', ['mload', i_placeholder], static_pos], ['goto', end_label]],\n [\n 'if_unchecked',\n ['ne', ['mload', ['mload', i_placeholder]], 0],\n ['mload', ['mload', i_placeholder]],\n ],\n ['mstore', i_placeholder, ['sub', ['mload', i_placeholder], 32]], # decrease i\n ['goto', start_label],\n ['label', end_label]\n ]\n\n # push static section\n push_args += [\n ['mload', pos] for pos in reversed(range(arg_pos, static_pos, 32))\n ]\n\n # Jump to function label.\n jump_to_func = [\n ['add', ['pc'], 6], # set callback pointer.\n ['goto', 'priv_{}'.format(sig.method_id)],\n ['jumpdest'],\n ]\n\n # Pop return values.\n returner = [0]\n if sig.output_type:\n output_placeholder, returner, output_size = call_make_placeholder(stmt_expr, context, sig)\n if output_size > 0:\n dynamic_offsets = []\n if isinstance(sig.output_type, (BaseType, ListType)):\n pop_return_values = [\n ['mstore', ['add', output_placeholder, pos], 'pass']\n for pos in range(0, output_size, 32)\n ]\n elif isinstance(sig.output_type, ByteArrayLike):\n dynamic_offsets = [(0, sig.output_type)]\n pop_return_values = [\n ['pop', 'pass'],\n ]\n elif isinstance(sig.output_type, TupleLike):\n static_offset = 0\n pop_return_values = []\n for out_type in sig.output_type.members:\n if isinstance(out_type, ByteArrayLike):\n pop_return_values.append(\n ['mstore', ['add', output_placeholder, static_offset], 'pass']\n )\n dynamic_offsets.append(\n (['mload', ['add', output_placeholder, static_offset]], out_type)\n )\n else:\n pop_return_values.append(\n ['mstore', ['add', output_placeholder, static_offset], 'pass']\n )\n static_offset += 32\n\n # append dynamic unpacker.\n dyn_idx = 0\n for in_memory_offset, _out_type in dynamic_offsets:\n ident = \"%d_%d_arg_%d\" % (stmt_expr.lineno, stmt_expr.col_offset, dyn_idx)\n dyn_idx += 1\n start_label = 'dyn_unpack_start_' + ident\n end_label = 'dyn_unpack_end_' + ident\n i_placeholder = context.new_placeholder(typ=BaseType('uint256'))\n begin_pos = ['add', output_placeholder, in_memory_offset]\n # loop until length.\n o = LLLnode.from_list(\n ['seq_unchecked',\n ['mstore', begin_pos, 'pass'], # get len\n ['mstore', i_placeholder, 0],\n ['label', start_label],\n [ # break\n 'if',\n ['ge', ['mload', i_placeholder], ['ceil32', ['mload', begin_pos]]],\n ['goto', end_label]\n ],\n [ # pop into correct memory slot.\n 'mstore',\n ['add', ['add', begin_pos, 32], ['mload', i_placeholder]],\n 'pass',\n ],\n # increment i\n ['mstore', i_placeholder, ['add', 32, ['mload', i_placeholder]]],\n ['goto', start_label],\n ['label', end_label]],\n typ=None, annotation='dynamic unpacker', pos=getpos(stmt_expr))\n pop_return_values.append(o)\n\n call_body = list(itertools.chain(\n ['seq_unchecked'],\n pre_init,\n push_local_vars,\n push_args,\n jump_to_func,\n pop_return_values,\n pop_local_vars,\n [returner],\n ))\n # If we have no return, we need to pop off\n pop_returner_call_body = ['pop', call_body] if sig.output_type is None else call_body\n\n o = LLLnode.from_list(\n pop_returner_call_body,\n typ=sig.output_type,\n location='memory',\n pos=getpos(stmt_expr),\n annotation='Internal Call: %s' % method_name,\n add_gas_estimate=sig.gas\n )\n o.gas += sig.gas\n return o\n\n\ndef call_self_public(stmt_expr, context, sig):\n # self.* style call to a public function.\n method_name, expr_args, sig = call_lookup_specs(stmt_expr, context)\n add_gas = sig.gas # gas of call\n inargs, inargsize, _ = pack_arguments(sig, expr_args, context, pos=getpos(stmt_expr))\n output_placeholder, returner, output_size = call_make_placeholder(stmt_expr, context, sig)\n assert_call = [\n 'assert',\n ['call', ['gas'], ['address'], 0, inargs, inargsize, output_placeholder, output_size],\n ]\n if output_size > 0:\n assert_call = ['seq', assert_call, returner]\n o = LLLnode.from_list(\n assert_call,\n typ=sig.output_type,\n location='memory',\n pos=getpos(stmt_expr),\n add_gas_estimate=add_gas,\n annotation='Internal Call: %s' % method_name,\n )\n o.gas += sig.gas\n return o\n", "path": "vyper/parser/self_call.py"}]}
| 3,684 | 695 |
gh_patches_debug_7187
|
rasdani/github-patches
|
git_diff
|
DataDog__dd-trace-py-4213
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Disabling intrument_middleware via code not working in Django
### Which version of dd-trace-py are you using?
1.1.2
### Which version of pip are you using?
22.0.4
### Which version of the libraries are you using?
/
### How can we reproduce your problem?
Disable `instrument_middleware` via config code in Django integration does not work:
Example: (neither of these work):
```python
ddtrace.config.django.instrument_middleware = False
ddtrace.config.django["instrument_middleware"] = False
```
Configuring this via env variable (`DD_DJANGO_INSTRUMENT_MIDDLEWARE`) works.
</issue>
<code>
[start of ddtrace/contrib/django/__init__.py]
1 """
2 The Django__ integration traces requests, views, template renderers, database
3 and cache calls in a Django application.
4
5
6 Enable Django tracing automatically via ``ddtrace-run``::
7
8 ddtrace-run python manage.py runserver
9
10
11 Django tracing can also be enabled manually::
12
13 from ddtrace import patch_all
14 patch_all()
15
16
17 To have Django capture the tracer logs, ensure the ``LOGGING`` variable in
18 ``settings.py`` looks similar to::
19
20 LOGGING = {
21 'loggers': {
22 'ddtrace': {
23 'handlers': ['console'],
24 'level': 'WARNING',
25 },
26 },
27 }
28
29
30 Configuration
31 ~~~~~~~~~~~~~
32 .. py:data:: ddtrace.config.django['distributed_tracing_enabled']
33
34 Whether or not to parse distributed tracing headers from requests received by your Django app.
35
36 Default: ``True``
37
38 .. py:data:: ddtrace.config.django['service_name']
39
40 The service name reported for your Django app.
41
42 Can also be configured via the ``DD_SERVICE`` environment variable.
43
44 Default: ``'django'``
45
46 .. py:data:: ddtrace.config.django['cache_service_name']
47
48 The service name reported for your Django app cache layer.
49
50 Can also be configured via the ``DD_DJANGO_CACHE_SERVICE_NAME`` environment variable.
51
52 Default: ``'django'``
53
54 .. py:data:: ddtrace.config.django['database_service_name']
55
56 A string reported as the service name of the Django app database layer.
57
58 Can also be configured via the ``DD_DJANGO_DATABASE_SERVICE_NAME`` environment variable.
59
60 Takes precedence over database_service_name_prefix.
61
62 Default: ``''``
63
64 .. py:data:: ddtrace.config.django['database_service_name_prefix']
65
66 A string to be prepended to the service name reported for your Django app database layer.
67
68 Can also be configured via the ``DD_DJANGO_DATABASE_SERVICE_NAME_PREFIX`` environment variable.
69
70 The database service name is the name of the database appended with 'db'. Has a lower precedence than database_service_name.
71
72 Default: ``''``
73
74 .. py:data:: ddtrace.config.django["trace_fetch_methods"]
75
76 Whether or not to trace fetch methods.
77
78 Can also configured via the ``DD_DJANGO_TRACE_FETCH_METHODS`` environment variable.
79
80 Default: ``False``
81
82 .. py:data:: ddtrace.config.django['instrument_middleware']
83
84 Whether or not to instrument middleware.
85
86 Can also be enabled with the ``DD_DJANGO_INSTRUMENT_MIDDLEWARE`` environment variable.
87
88 Default: ``True``
89
90 .. py:data:: ddtrace.config.django['instrument_templates']
91
92 Whether or not to instrument template rendering.
93
94 Can also be enabled with the ``DD_DJANGO_INSTRUMENT_TEMPLATES`` environment variable.
95
96 Default: ``True``
97
98 .. py:data:: ddtrace.config.django['instrument_databases']
99
100 Whether or not to instrument databases.
101
102 Can also be enabled with the ``DD_DJANGO_INSTRUMENT_DATABASES`` environment variable.
103
104 Default: ``True``
105
106 .. py:data:: ddtrace.config.django['instrument_caches']
107
108 Whether or not to instrument caches.
109
110 Can also be enabled with the ``DD_DJANGO_INSTRUMENT_CACHES`` environment variable.
111
112 Default: ``True``
113
114 .. py:data:: ddtrace.config.django['trace_query_string']
115
116 Whether or not to include the query string as a tag.
117
118 Default: ``False``
119
120 .. py:data:: ddtrace.config.django['include_user_name']
121
122 Whether or not to include the authenticated user's username as a tag on the root request span.
123
124 Default: ``True``
125
126 .. py:data:: ddtrace.config.django['use_handler_resource_format']
127
128 Whether or not to use the resource format `"{method} {handler}"`. Can also be
129 enabled with the ``DD_DJANGO_USE_HANDLER_RESOURCE_FORMAT`` environment
130 variable.
131
132 The default resource format for Django >= 2.2.0 is otherwise `"{method} {urlpattern}"`.
133
134 Default: ``False``
135
136 .. py:data:: ddtrace.config.django['use_legacy_resource_format']
137
138 Whether or not to use the legacy resource format `"{handler}"`. Can also be
139 enabled with the ``DD_DJANGO_USE_LEGACY_RESOURCE_FORMAT`` environment
140 variable.
141
142 The default resource format for Django >= 2.2.0 is otherwise `"{method} {urlpattern}"`.
143
144 Default: ``False``
145
146 Example::
147
148 from ddtrace import config
149
150 # Enable distributed tracing
151 config.django['distributed_tracing_enabled'] = True
152
153 # Override service name
154 config.django['service_name'] = 'custom-service-name'
155
156
157 :ref:`Headers tracing <http-headers-tracing>` is supported for this integration.
158
159 .. __: https://www.djangoproject.com/
160 """ # noqa: E501
161 from ...internal.utils.importlib import require_modules
162
163
164 required_modules = ["django"]
165
166 with require_modules(required_modules) as missing_modules:
167 if not missing_modules:
168 from . import patch as _patch
169 from .patch import patch
170 from .patch import unpatch
171
172 __all__ = ["patch", "unpatch", "_patch"]
173
[end of ddtrace/contrib/django/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ddtrace/contrib/django/__init__.py b/ddtrace/contrib/django/__init__.py
--- a/ddtrace/contrib/django/__init__.py
+++ b/ddtrace/contrib/django/__init__.py
@@ -29,6 +29,13 @@
Configuration
~~~~~~~~~~~~~
+
+.. important::
+
+ Note that the in-code configuration must be run before Django is instrumented. This means that in-code configuration
+ will not work with ``ddtrace-run`` and before a call to ``patch`` or ``patch_all``.
+
+
.. py:data:: ddtrace.config.django['distributed_tracing_enabled']
Whether or not to parse distributed tracing headers from requests received by your Django app.
|
{"golden_diff": "diff --git a/ddtrace/contrib/django/__init__.py b/ddtrace/contrib/django/__init__.py\n--- a/ddtrace/contrib/django/__init__.py\n+++ b/ddtrace/contrib/django/__init__.py\n@@ -29,6 +29,13 @@\n \n Configuration\n ~~~~~~~~~~~~~\n+\n+.. important::\n+\n+ Note that the in-code configuration must be run before Django is instrumented. This means that in-code configuration\n+ will not work with ``ddtrace-run`` and before a call to ``patch`` or ``patch_all``.\n+\n+\n .. py:data:: ddtrace.config.django['distributed_tracing_enabled']\n \n Whether or not to parse distributed tracing headers from requests received by your Django app.\n", "issue": "Disabling intrument_middleware via code not working in Django\n### Which version of dd-trace-py are you using?\r\n\r\n1.1.2\r\n\r\n### Which version of pip are you using?\r\n\r\n22.0.4\r\n\r\n### Which version of the libraries are you using?\r\n\r\n/\r\n\r\n### How can we reproduce your problem?\r\n\r\nDisable `instrument_middleware` via config code in Django integration does not work:\r\n\r\nExample: (neither of these work):\r\n\r\n```python\r\nddtrace.config.django.instrument_middleware = False\r\nddtrace.config.django[\"instrument_middleware\"] = False\r\n```\r\n\r\n\r\nConfiguring this via env variable (`DD_DJANGO_INSTRUMENT_MIDDLEWARE`) works.\n", "before_files": [{"content": "\"\"\"\nThe Django__ integration traces requests, views, template renderers, database\nand cache calls in a Django application.\n\n\nEnable Django tracing automatically via ``ddtrace-run``::\n\n ddtrace-run python manage.py runserver\n\n\nDjango tracing can also be enabled manually::\n\n from ddtrace import patch_all\n patch_all()\n\n\nTo have Django capture the tracer logs, ensure the ``LOGGING`` variable in\n``settings.py`` looks similar to::\n\n LOGGING = {\n 'loggers': {\n 'ddtrace': {\n 'handlers': ['console'],\n 'level': 'WARNING',\n },\n },\n }\n\n\nConfiguration\n~~~~~~~~~~~~~\n.. py:data:: ddtrace.config.django['distributed_tracing_enabled']\n\n Whether or not to parse distributed tracing headers from requests received by your Django app.\n\n Default: ``True``\n\n.. py:data:: ddtrace.config.django['service_name']\n\n The service name reported for your Django app.\n\n Can also be configured via the ``DD_SERVICE`` environment variable.\n\n Default: ``'django'``\n\n.. py:data:: ddtrace.config.django['cache_service_name']\n\n The service name reported for your Django app cache layer.\n\n Can also be configured via the ``DD_DJANGO_CACHE_SERVICE_NAME`` environment variable.\n\n Default: ``'django'``\n\n.. py:data:: ddtrace.config.django['database_service_name']\n\n A string reported as the service name of the Django app database layer.\n\n Can also be configured via the ``DD_DJANGO_DATABASE_SERVICE_NAME`` environment variable.\n\n Takes precedence over database_service_name_prefix.\n\n Default: ``''``\n\n.. py:data:: ddtrace.config.django['database_service_name_prefix']\n\n A string to be prepended to the service name reported for your Django app database layer.\n\n Can also be configured via the ``DD_DJANGO_DATABASE_SERVICE_NAME_PREFIX`` environment variable.\n\n The database service name is the name of the database appended with 'db'. Has a lower precedence than database_service_name.\n\n Default: ``''``\n\n.. py:data:: ddtrace.config.django[\"trace_fetch_methods\"]\n\n Whether or not to trace fetch methods.\n\n Can also configured via the ``DD_DJANGO_TRACE_FETCH_METHODS`` environment variable.\n\n Default: ``False``\n\n.. py:data:: ddtrace.config.django['instrument_middleware']\n\n Whether or not to instrument middleware.\n\n Can also be enabled with the ``DD_DJANGO_INSTRUMENT_MIDDLEWARE`` environment variable.\n\n Default: ``True``\n\n.. py:data:: ddtrace.config.django['instrument_templates']\n\n Whether or not to instrument template rendering.\n\n Can also be enabled with the ``DD_DJANGO_INSTRUMENT_TEMPLATES`` environment variable.\n\n Default: ``True``\n\n.. py:data:: ddtrace.config.django['instrument_databases']\n\n Whether or not to instrument databases.\n\n Can also be enabled with the ``DD_DJANGO_INSTRUMENT_DATABASES`` environment variable.\n\n Default: ``True``\n\n.. py:data:: ddtrace.config.django['instrument_caches']\n\n Whether or not to instrument caches.\n\n Can also be enabled with the ``DD_DJANGO_INSTRUMENT_CACHES`` environment variable.\n\n Default: ``True``\n\n.. py:data:: ddtrace.config.django['trace_query_string']\n\n Whether or not to include the query string as a tag.\n\n Default: ``False``\n\n.. py:data:: ddtrace.config.django['include_user_name']\n\n Whether or not to include the authenticated user's username as a tag on the root request span.\n\n Default: ``True``\n\n.. py:data:: ddtrace.config.django['use_handler_resource_format']\n\n Whether or not to use the resource format `\"{method} {handler}\"`. Can also be\n enabled with the ``DD_DJANGO_USE_HANDLER_RESOURCE_FORMAT`` environment\n variable.\n\n The default resource format for Django >= 2.2.0 is otherwise `\"{method} {urlpattern}\"`.\n\n Default: ``False``\n\n.. py:data:: ddtrace.config.django['use_legacy_resource_format']\n\n Whether or not to use the legacy resource format `\"{handler}\"`. Can also be\n enabled with the ``DD_DJANGO_USE_LEGACY_RESOURCE_FORMAT`` environment\n variable.\n\n The default resource format for Django >= 2.2.0 is otherwise `\"{method} {urlpattern}\"`.\n\n Default: ``False``\n\nExample::\n\n from ddtrace import config\n\n # Enable distributed tracing\n config.django['distributed_tracing_enabled'] = True\n\n # Override service name\n config.django['service_name'] = 'custom-service-name'\n\n\n:ref:`Headers tracing <http-headers-tracing>` is supported for this integration.\n\n.. __: https://www.djangoproject.com/\n\"\"\" # noqa: E501\nfrom ...internal.utils.importlib import require_modules\n\n\nrequired_modules = [\"django\"]\n\nwith require_modules(required_modules) as missing_modules:\n if not missing_modules:\n from . import patch as _patch\n from .patch import patch\n from .patch import unpatch\n\n __all__ = [\"patch\", \"unpatch\", \"_patch\"]\n", "path": "ddtrace/contrib/django/__init__.py"}]}
| 2,239 | 162 |
gh_patches_debug_11101
|
rasdani/github-patches
|
git_diff
|
mkdocs__mkdocs-379
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Missing pages build the previous page rather than being skipped
The output shows a warning and that the page is missing, but we incorrectly re-render the previous page in it's place.
</issue>
<code>
[start of mkdocs/build.py]
1 # coding: utf-8
2 from __future__ import print_function
3
4 from jinja2.exceptions import TemplateNotFound
5 from mkdocs import nav, toc, utils
6 from mkdocs.compat import urljoin, PY2
7 from mkdocs.relative_path_ext import RelativePathExtension
8 import jinja2
9 import json
10 import markdown
11 import os
12 import logging
13
14 log = logging.getLogger('mkdocs')
15
16
17 def convert_markdown(markdown_source, site_navigation=None, extensions=(), strict=False):
18 """
19 Convert the Markdown source file to HTML content, and additionally
20 return the parsed table of contents, and a dictionary of any metadata
21 that was specified in the Markdown file.
22
23 `extensions` is an optional sequence of Python Markdown extensions to add
24 to the default set.
25 """
26
27 # Generate the HTML from the markdown source
28 builtin_extensions = ['meta', 'toc', 'tables', 'fenced_code']
29 mkdocs_extensions = [RelativePathExtension(site_navigation, strict), ]
30 extensions = builtin_extensions + mkdocs_extensions + list(extensions)
31 md = markdown.Markdown(
32 extensions=extensions
33 )
34 html_content = md.convert(markdown_source)
35 meta = md.Meta
36 toc_html = md.toc
37
38 # Post process the generated table of contents into a data structure
39 table_of_contents = toc.TableOfContents(toc_html)
40
41 return (html_content, table_of_contents, meta)
42
43
44 def get_global_context(nav, config):
45 """
46 Given the SiteNavigation and config, generate the context which is relevant
47 to app pages.
48 """
49
50 site_name = config['site_name']
51
52 if config['site_favicon']:
53 site_favicon = nav.url_context.make_relative('/' + config['site_favicon'])
54 else:
55 site_favicon = None
56
57 page_description = config['site_description']
58
59 extra_javascript = utils.create_media_urls(nav=nav, url_list=config['extra_javascript'])
60
61 extra_css = utils.create_media_urls(nav=nav, url_list=config['extra_css'])
62
63 return {
64 'site_name': site_name,
65 'site_author': config['site_author'],
66 'favicon': site_favicon,
67 'page_description': page_description,
68
69 # Note that there's intentionally repetition here. Rather than simply
70 # provide the config dictionary we instead pass everything explicitly.
71 #
72 # This helps ensure that we can throughly document the context that
73 # gets passed to themes.
74 'repo_url': config['repo_url'],
75 'repo_name': config['repo_name'],
76 'nav': nav,
77 'base_url': nav.url_context.make_relative('/'),
78 'homepage_url': nav.homepage.url,
79
80 'extra_css': extra_css,
81 'extra_javascript': extra_javascript,
82
83 'include_nav': config['include_nav'],
84 'include_next_prev': config['include_next_prev'],
85 'include_search': config['include_search'],
86
87 'copyright': config['copyright'],
88 'google_analytics': config['google_analytics']
89 }
90
91
92 def get_page_context(page, content, nav, toc, meta, config):
93 """
94 Generate the page context by extending the global context and adding page
95 specific variables.
96 """
97
98 if page.is_homepage or page.title is None:
99 page_title = None
100 else:
101 page_title = page.title
102
103 if page.is_homepage:
104 page_description = config['site_description']
105 else:
106 page_description = None
107
108 if config['site_url']:
109 base = config['site_url']
110 if not base.endswith('/'):
111 base += '/'
112 canonical_url = urljoin(base, page.abs_url.lstrip('/'))
113 else:
114 canonical_url = None
115
116 return {
117 'page_title': page_title,
118 'page_description': page_description,
119
120 'content': content,
121 'toc': toc,
122 'meta': meta,
123
124
125 'canonical_url': canonical_url,
126
127 'current_page': page,
128 'previous_page': page.previous_page,
129 'next_page': page.next_page,
130 }
131
132
133 def build_404(config, env, site_navigation):
134
135 try:
136 template = env.get_template('404.html')
137 except TemplateNotFound:
138 return
139
140 global_context = get_global_context(site_navigation, config)
141
142 output_content = template.render(global_context)
143 output_path = os.path.join(config['site_dir'], '404.html')
144 utils.write_file(output_content.encode('utf-8'), output_path)
145
146
147 def build_pages(config, dump_json=False):
148 """
149 Builds all the pages and writes them into the build directory.
150 """
151 site_navigation = nav.SiteNavigation(config['pages'], config['use_directory_urls'])
152 loader = jinja2.FileSystemLoader(config['theme_dir'])
153 env = jinja2.Environment(loader=loader)
154
155 build_404(config, env, site_navigation)
156
157 for page in site_navigation.walk_pages():
158 # Read the input file
159 input_path = os.path.join(config['docs_dir'], page.input_path)
160 try:
161 input_content = open(input_path, 'r').read()
162 except IOError:
163 log.error('file not found: %s' % input_path)
164 if PY2:
165 input_content = input_content.decode('utf-8')
166
167 # Process the markdown text
168 html_content, table_of_contents, meta = convert_markdown(
169 input_content, site_navigation,
170 extensions=config['markdown_extensions'], strict=config['strict']
171 )
172
173 context = get_global_context(site_navigation, config)
174 context.update(get_page_context(
175 page, html_content, site_navigation,
176 table_of_contents, meta, config
177 ))
178
179 # Allow 'template:' override in md source files.
180 if 'template' in meta:
181 template = env.get_template(meta['template'][0])
182 else:
183 template = env.get_template('base.html')
184
185 # Render the template.
186 output_content = template.render(context)
187
188 # Write the output file.
189 output_path = os.path.join(config['site_dir'], page.output_path)
190 if dump_json:
191 json_context = {
192 'content': context['content'],
193 'title': context['current_page'].title,
194 'url': context['current_page'].abs_url,
195 'language': 'en',
196 }
197 utils.write_file(json.dumps(json_context, indent=4).encode('utf-8'), output_path.replace('.html', '.json'))
198 else:
199 utils.write_file(output_content.encode('utf-8'), output_path)
200
201
202 def build(config, live_server=False, dump_json=False, clean_site_dir=False):
203 """
204 Perform a full site build.
205 """
206 if clean_site_dir:
207 print("Cleaning site directory")
208 utils.clean_directory(config['site_dir'])
209 if not live_server:
210 print("Building documentation to directory: %s" % config['site_dir'])
211 if not clean_site_dir and site_directory_contains_stale_files(config['site_dir']):
212 print("Directory %s contains stale files. Use --clean to remove them." % config['site_dir'])
213
214 if dump_json:
215 build_pages(config, dump_json=True)
216 else:
217 # Reversed as we want to take the media files from the builtin theme
218 # and then from the custom theme_dir so the custom versions take take
219 # precedence.
220 for theme_dir in reversed(config['theme_dir']):
221 utils.copy_media_files(theme_dir, config['site_dir'])
222 utils.copy_media_files(config['docs_dir'], config['site_dir'])
223 build_pages(config)
224
225
226 def site_directory_contains_stale_files(site_directory):
227 """
228 Check if the site directory contains stale files from a previous build.
229 Right now the check returns true if the directory is not empty.
230 A more sophisticated approach should be found to trigger only if there are
231 files that won't be overwritten anyway.
232 """
233 if os.path.exists(site_directory):
234 if os.listdir(site_directory):
235 return True
236 return False
237
[end of mkdocs/build.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mkdocs/build.py b/mkdocs/build.py
--- a/mkdocs/build.py
+++ b/mkdocs/build.py
@@ -157,10 +157,13 @@
for page in site_navigation.walk_pages():
# Read the input file
input_path = os.path.join(config['docs_dir'], page.input_path)
+
try:
input_content = open(input_path, 'r').read()
except IOError:
log.error('file not found: %s' % input_path)
+ continue
+
if PY2:
input_content = input_content.decode('utf-8')
|
{"golden_diff": "diff --git a/mkdocs/build.py b/mkdocs/build.py\n--- a/mkdocs/build.py\n+++ b/mkdocs/build.py\n@@ -157,10 +157,13 @@\n for page in site_navigation.walk_pages():\n # Read the input file\n input_path = os.path.join(config['docs_dir'], page.input_path)\n+\n try:\n input_content = open(input_path, 'r').read()\n except IOError:\n log.error('file not found: %s' % input_path)\n+ continue\n+\n if PY2:\n input_content = input_content.decode('utf-8')\n", "issue": "Missing pages build the previous page rather than being skipped\nThe output shows a warning and that the page is missing, but we incorrectly re-render the previous page in it's place.\n\n", "before_files": [{"content": "# coding: utf-8\nfrom __future__ import print_function\n\nfrom jinja2.exceptions import TemplateNotFound\nfrom mkdocs import nav, toc, utils\nfrom mkdocs.compat import urljoin, PY2\nfrom mkdocs.relative_path_ext import RelativePathExtension\nimport jinja2\nimport json\nimport markdown\nimport os\nimport logging\n\nlog = logging.getLogger('mkdocs')\n\n\ndef convert_markdown(markdown_source, site_navigation=None, extensions=(), strict=False):\n \"\"\"\n Convert the Markdown source file to HTML content, and additionally\n return the parsed table of contents, and a dictionary of any metadata\n that was specified in the Markdown file.\n\n `extensions` is an optional sequence of Python Markdown extensions to add\n to the default set.\n \"\"\"\n\n # Generate the HTML from the markdown source\n builtin_extensions = ['meta', 'toc', 'tables', 'fenced_code']\n mkdocs_extensions = [RelativePathExtension(site_navigation, strict), ]\n extensions = builtin_extensions + mkdocs_extensions + list(extensions)\n md = markdown.Markdown(\n extensions=extensions\n )\n html_content = md.convert(markdown_source)\n meta = md.Meta\n toc_html = md.toc\n\n # Post process the generated table of contents into a data structure\n table_of_contents = toc.TableOfContents(toc_html)\n\n return (html_content, table_of_contents, meta)\n\n\ndef get_global_context(nav, config):\n \"\"\"\n Given the SiteNavigation and config, generate the context which is relevant\n to app pages.\n \"\"\"\n\n site_name = config['site_name']\n\n if config['site_favicon']:\n site_favicon = nav.url_context.make_relative('/' + config['site_favicon'])\n else:\n site_favicon = None\n\n page_description = config['site_description']\n\n extra_javascript = utils.create_media_urls(nav=nav, url_list=config['extra_javascript'])\n\n extra_css = utils.create_media_urls(nav=nav, url_list=config['extra_css'])\n\n return {\n 'site_name': site_name,\n 'site_author': config['site_author'],\n 'favicon': site_favicon,\n 'page_description': page_description,\n\n # Note that there's intentionally repetition here. Rather than simply\n # provide the config dictionary we instead pass everything explicitly.\n #\n # This helps ensure that we can throughly document the context that\n # gets passed to themes.\n 'repo_url': config['repo_url'],\n 'repo_name': config['repo_name'],\n 'nav': nav,\n 'base_url': nav.url_context.make_relative('/'),\n 'homepage_url': nav.homepage.url,\n\n 'extra_css': extra_css,\n 'extra_javascript': extra_javascript,\n\n 'include_nav': config['include_nav'],\n 'include_next_prev': config['include_next_prev'],\n 'include_search': config['include_search'],\n\n 'copyright': config['copyright'],\n 'google_analytics': config['google_analytics']\n }\n\n\ndef get_page_context(page, content, nav, toc, meta, config):\n \"\"\"\n Generate the page context by extending the global context and adding page\n specific variables.\n \"\"\"\n\n if page.is_homepage or page.title is None:\n page_title = None\n else:\n page_title = page.title\n\n if page.is_homepage:\n page_description = config['site_description']\n else:\n page_description = None\n\n if config['site_url']:\n base = config['site_url']\n if not base.endswith('/'):\n base += '/'\n canonical_url = urljoin(base, page.abs_url.lstrip('/'))\n else:\n canonical_url = None\n\n return {\n 'page_title': page_title,\n 'page_description': page_description,\n\n 'content': content,\n 'toc': toc,\n 'meta': meta,\n\n\n 'canonical_url': canonical_url,\n\n 'current_page': page,\n 'previous_page': page.previous_page,\n 'next_page': page.next_page,\n }\n\n\ndef build_404(config, env, site_navigation):\n\n try:\n template = env.get_template('404.html')\n except TemplateNotFound:\n return\n\n global_context = get_global_context(site_navigation, config)\n\n output_content = template.render(global_context)\n output_path = os.path.join(config['site_dir'], '404.html')\n utils.write_file(output_content.encode('utf-8'), output_path)\n\n\ndef build_pages(config, dump_json=False):\n \"\"\"\n Builds all the pages and writes them into the build directory.\n \"\"\"\n site_navigation = nav.SiteNavigation(config['pages'], config['use_directory_urls'])\n loader = jinja2.FileSystemLoader(config['theme_dir'])\n env = jinja2.Environment(loader=loader)\n\n build_404(config, env, site_navigation)\n\n for page in site_navigation.walk_pages():\n # Read the input file\n input_path = os.path.join(config['docs_dir'], page.input_path)\n try:\n input_content = open(input_path, 'r').read()\n except IOError:\n log.error('file not found: %s' % input_path)\n if PY2:\n input_content = input_content.decode('utf-8')\n\n # Process the markdown text\n html_content, table_of_contents, meta = convert_markdown(\n input_content, site_navigation,\n extensions=config['markdown_extensions'], strict=config['strict']\n )\n\n context = get_global_context(site_navigation, config)\n context.update(get_page_context(\n page, html_content, site_navigation,\n table_of_contents, meta, config\n ))\n\n # Allow 'template:' override in md source files.\n if 'template' in meta:\n template = env.get_template(meta['template'][0])\n else:\n template = env.get_template('base.html')\n\n # Render the template.\n output_content = template.render(context)\n\n # Write the output file.\n output_path = os.path.join(config['site_dir'], page.output_path)\n if dump_json:\n json_context = {\n 'content': context['content'],\n 'title': context['current_page'].title,\n 'url': context['current_page'].abs_url,\n 'language': 'en',\n }\n utils.write_file(json.dumps(json_context, indent=4).encode('utf-8'), output_path.replace('.html', '.json'))\n else:\n utils.write_file(output_content.encode('utf-8'), output_path)\n\n\ndef build(config, live_server=False, dump_json=False, clean_site_dir=False):\n \"\"\"\n Perform a full site build.\n \"\"\"\n if clean_site_dir:\n print(\"Cleaning site directory\")\n utils.clean_directory(config['site_dir'])\n if not live_server:\n print(\"Building documentation to directory: %s\" % config['site_dir'])\n if not clean_site_dir and site_directory_contains_stale_files(config['site_dir']):\n print(\"Directory %s contains stale files. Use --clean to remove them.\" % config['site_dir'])\n\n if dump_json:\n build_pages(config, dump_json=True)\n else:\n # Reversed as we want to take the media files from the builtin theme\n # and then from the custom theme_dir so the custom versions take take\n # precedence.\n for theme_dir in reversed(config['theme_dir']):\n utils.copy_media_files(theme_dir, config['site_dir'])\n utils.copy_media_files(config['docs_dir'], config['site_dir'])\n build_pages(config)\n\n\ndef site_directory_contains_stale_files(site_directory):\n \"\"\"\n Check if the site directory contains stale files from a previous build.\n Right now the check returns true if the directory is not empty.\n A more sophisticated approach should be found to trigger only if there are\n files that won't be overwritten anyway.\n \"\"\"\n if os.path.exists(site_directory):\n if os.listdir(site_directory):\n return True\n return False\n", "path": "mkdocs/build.py"}]}
| 2,876 | 138 |
gh_patches_debug_1964
|
rasdani/github-patches
|
git_diff
|
kserve__kserve-1137
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Installed KFServing SDK 0.4 but getting import error while running the custom built image
/kind bug
**What steps did you take and what happened:**
Run a custom built image with KFServing SDK 0.4.
```
Traceback (most recent call last):
File "/python3/lib/python3.7/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/python3/lib/python3.7/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/job/blambda-function/image_transformer_v2/__main__.py", line 15, in <module>
import kfserving
File "/python3/lib/python3.7/site-packages/kfserving/__init__.py", line 18, in <module>
from .storage import Storage
File "/python3/lib/python3.7/site-packages/kfserving/storage.py", line 23, in <module>
from google.cloud import storage
File "/python3/lib/python3.7/site-packages/google/cloud/storage/__init__.py", line 39, in <module>
from google.cloud.storage.batch import Batch
File "/python3/lib/python3.7/site-packages/google/cloud/storage/batch.py", line 31, in <module>
from google.cloud.storage._http import Connection
File "/python3/lib/python3.7/site-packages/google/cloud/storage/_http.py", line 17, in <module>
from google.cloud import _http
File "/python3/lib/python3.7/site-packages/google/cloud/_http.py", line 22, in <module>
from six.moves import collections_abc
ImportError: cannot import name 'collections_abc' from 'six.moves' (unknown location)
```
**What did you expect to happen:**
**Anything else you would like to add:**
We have fixed this in master branch but looks like we need to patch the setup.py in 0.4 branch and release a new minor version
**Environment:**
- Istio Version:
- Knative Version:
- KFServing Version:
- Kubeflow version:
- Kfdef:[k8s_istio/istio_dex/gcp_basic_auth/gcp_iap/aws/aws_cognito/ibm]
- Minikube version:
- Kubernetes version: (use `kubectl version`):
- OS (e.g. from `/etc/os-release`):
</issue>
<code>
[start of python/alibiexplainer/setup.py]
1 # Copyright 2019 kubeflow.org.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from setuptools import setup, find_packages
16
17 tests_require = [
18 'pytest',
19 'pytest-tornasync',
20 'mypy'
21 ]
22
23 setup(
24 name='alibiexplainer',
25 version='0.4.0',
26 author_email='[email protected]',
27 license='../../LICENSE.txt',
28 url='https://github.com/kubeflow/kfserving/python/kfserving/alibiexplainer',
29 description='Model Explaination Server. \
30 Not intended for use outside KFServing Frameworks Images',
31 long_description=open('README.md').read(),
32 python_requires='>=3.6',
33 packages=find_packages("alibiexplainer"),
34 install_requires=[
35 "kfserving>=0.4.0",
36 "alibi==0.4.0",
37 "scikit-learn>=0.20.3",
38 "argparse>=1.4.0",
39 "requests>=2.22.0",
40 "joblib>=0.13.2",
41 "pandas>=0.24.2",
42 "numpy>=1.16.3",
43 "dill>=0.3.0",
44 "spacy>=2.1.4"
45 ],
46 tests_require=tests_require,
47 extras_require={'test': tests_require}
48 )
49
[end of python/alibiexplainer/setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/python/alibiexplainer/setup.py b/python/alibiexplainer/setup.py
--- a/python/alibiexplainer/setup.py
+++ b/python/alibiexplainer/setup.py
@@ -32,6 +32,7 @@
python_requires='>=3.6',
packages=find_packages("alibiexplainer"),
install_requires=[
+ "shap==0.35",
"kfserving>=0.4.0",
"alibi==0.4.0",
"scikit-learn>=0.20.3",
|
{"golden_diff": "diff --git a/python/alibiexplainer/setup.py b/python/alibiexplainer/setup.py\n--- a/python/alibiexplainer/setup.py\n+++ b/python/alibiexplainer/setup.py\n@@ -32,6 +32,7 @@\n python_requires='>=3.6',\n packages=find_packages(\"alibiexplainer\"),\n install_requires=[\n+ \"shap==0.35\",\n \"kfserving>=0.4.0\",\n \"alibi==0.4.0\",\n \"scikit-learn>=0.20.3\",\n", "issue": "Installed KFServing SDK 0.4 but getting import error while running the custom built image\n/kind bug\r\n\r\n**What steps did you take and what happened:**\r\nRun a custom built image with KFServing SDK 0.4.\r\n```\r\nTraceback (most recent call last):\r\n File \"/python3/lib/python3.7/runpy.py\", line 193, in _run_module_as_main\r\n \"__main__\", mod_spec)\r\n File \"/python3/lib/python3.7/runpy.py\", line 85, in _run_code\r\n exec(code, run_globals)\r\n File \"/job/blambda-function/image_transformer_v2/__main__.py\", line 15, in <module>\r\n import kfserving\r\n File \"/python3/lib/python3.7/site-packages/kfserving/__init__.py\", line 18, in <module>\r\n from .storage import Storage\r\n File \"/python3/lib/python3.7/site-packages/kfserving/storage.py\", line 23, in <module>\r\n from google.cloud import storage\r\n File \"/python3/lib/python3.7/site-packages/google/cloud/storage/__init__.py\", line 39, in <module>\r\n from google.cloud.storage.batch import Batch\r\n File \"/python3/lib/python3.7/site-packages/google/cloud/storage/batch.py\", line 31, in <module>\r\n from google.cloud.storage._http import Connection\r\n File \"/python3/lib/python3.7/site-packages/google/cloud/storage/_http.py\", line 17, in <module>\r\n from google.cloud import _http\r\n File \"/python3/lib/python3.7/site-packages/google/cloud/_http.py\", line 22, in <module>\r\n from six.moves import collections_abc\r\nImportError: cannot import name 'collections_abc' from 'six.moves' (unknown location)\r\n```\r\n\r\n\r\n**What did you expect to happen:**\r\n\r\n\r\n**Anything else you would like to add:**\r\nWe have fixed this in master branch but looks like we need to patch the setup.py in 0.4 branch and release a new minor version\r\n\r\n**Environment:**\r\n\r\n- Istio Version:\r\n- Knative Version:\r\n- KFServing Version:\r\n- Kubeflow version:\r\n- Kfdef:[k8s_istio/istio_dex/gcp_basic_auth/gcp_iap/aws/aws_cognito/ibm]\r\n- Minikube version:\r\n- Kubernetes version: (use `kubectl version`):\r\n- OS (e.g. from `/etc/os-release`):\r\n\n", "before_files": [{"content": "# Copyright 2019 kubeflow.org.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom setuptools import setup, find_packages\n\ntests_require = [\n 'pytest',\n 'pytest-tornasync',\n 'mypy'\n]\n\nsetup(\n name='alibiexplainer',\n version='0.4.0',\n author_email='[email protected]',\n license='../../LICENSE.txt',\n url='https://github.com/kubeflow/kfserving/python/kfserving/alibiexplainer',\n description='Model Explaination Server. \\\n Not intended for use outside KFServing Frameworks Images',\n long_description=open('README.md').read(),\n python_requires='>=3.6',\n packages=find_packages(\"alibiexplainer\"),\n install_requires=[\n \"kfserving>=0.4.0\",\n \"alibi==0.4.0\",\n \"scikit-learn>=0.20.3\",\n \"argparse>=1.4.0\",\n \"requests>=2.22.0\",\n \"joblib>=0.13.2\",\n \"pandas>=0.24.2\",\n \"numpy>=1.16.3\",\n \"dill>=0.3.0\",\n \"spacy>=2.1.4\"\n ],\n tests_require=tests_require,\n extras_require={'test': tests_require}\n)\n", "path": "python/alibiexplainer/setup.py"}]}
| 1,578 | 123 |
gh_patches_debug_53356
|
rasdani/github-patches
|
git_diff
|
facebookresearch__hydra-1887
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Ray-Plugin] Add support for Python 3.9
Python 3.9 support depends on https://github.com/ray-project/ray/issues/12788
Related to #1062
</issue>
<code>
[start of plugins/hydra_ray_launcher/setup.py]
1 # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
2 # type: ignore
3 from pathlib import Path
4
5 from read_version import read_version
6 from setuptools import find_namespace_packages, setup
7
8 setup(
9 name="hydra-ray-launcher",
10 version=read_version("hydra_plugins/hydra_ray_launcher", "__init__.py"),
11 author="Jieru Hu",
12 author_email="[email protected]",
13 description="Hydra Ray launcher plugin",
14 long_description=(Path(__file__).parent / "README.md").read_text(),
15 long_description_content_type="text/markdown",
16 url="https://github.com/facebookresearch/hydra/",
17 packages=find_namespace_packages(include=["hydra_plugins.*"]),
18 classifiers=[
19 "License :: OSI Approved :: MIT License",
20 "Programming Language :: Python :: 3.7",
21 "Programming Language :: Python :: 3.8",
22 # "Programming Language :: Python :: 3.9",
23 "Operating System :: MacOS",
24 "Operating System :: POSIX :: Linux",
25 ],
26 install_requires=[
27 "boto3==1.17.17",
28 "hydra-core>=1.1.0.dev7",
29 "ray[default]==1.6.0",
30 # https://github.com/aio-libs/aiohttp/issues/6203
31 "aiohttp!=3.8.0",
32 "cloudpickle==1.6.0",
33 "pickle5==0.0.11",
34 ],
35 include_package_data=True,
36 )
37
[end of plugins/hydra_ray_launcher/setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/plugins/hydra_ray_launcher/setup.py b/plugins/hydra_ray_launcher/setup.py
--- a/plugins/hydra_ray_launcher/setup.py
+++ b/plugins/hydra_ray_launcher/setup.py
@@ -19,7 +19,7 @@
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
- # "Programming Language :: Python :: 3.9",
+ "Programming Language :: Python :: 3.9",
"Operating System :: MacOS",
"Operating System :: POSIX :: Linux",
],
|
{"golden_diff": "diff --git a/plugins/hydra_ray_launcher/setup.py b/plugins/hydra_ray_launcher/setup.py\n--- a/plugins/hydra_ray_launcher/setup.py\n+++ b/plugins/hydra_ray_launcher/setup.py\n@@ -19,7 +19,7 @@\n \"License :: OSI Approved :: MIT License\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n- # \"Programming Language :: Python :: 3.9\",\n+ \"Programming Language :: Python :: 3.9\",\n \"Operating System :: MacOS\",\n \"Operating System :: POSIX :: Linux\",\n ],\n", "issue": "[Ray-Plugin] Add support for Python 3.9\nPython 3.9 support depends on https://github.com/ray-project/ray/issues/12788\r\n\r\nRelated to #1062 \n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\n# type: ignore\nfrom pathlib import Path\n\nfrom read_version import read_version\nfrom setuptools import find_namespace_packages, setup\n\nsetup(\n name=\"hydra-ray-launcher\",\n version=read_version(\"hydra_plugins/hydra_ray_launcher\", \"__init__.py\"),\n author=\"Jieru Hu\",\n author_email=\"[email protected]\",\n description=\"Hydra Ray launcher plugin\",\n long_description=(Path(__file__).parent / \"README.md\").read_text(),\n long_description_content_type=\"text/markdown\",\n url=\"https://github.com/facebookresearch/hydra/\",\n packages=find_namespace_packages(include=[\"hydra_plugins.*\"]),\n classifiers=[\n \"License :: OSI Approved :: MIT License\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n # \"Programming Language :: Python :: 3.9\",\n \"Operating System :: MacOS\",\n \"Operating System :: POSIX :: Linux\",\n ],\n install_requires=[\n \"boto3==1.17.17\",\n \"hydra-core>=1.1.0.dev7\",\n \"ray[default]==1.6.0\",\n # https://github.com/aio-libs/aiohttp/issues/6203\n \"aiohttp!=3.8.0\",\n \"cloudpickle==1.6.0\",\n \"pickle5==0.0.11\",\n ],\n include_package_data=True,\n)\n", "path": "plugins/hydra_ray_launcher/setup.py"}]}
| 984 | 135 |
gh_patches_debug_37246
|
rasdani/github-patches
|
git_diff
|
GeotrekCE__Geotrek-admin-1335
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Infrastructures are duplicated in list if they received multiple intervention the same year
- Filter infrastructures by year
- If the infrastructure has received several interventions this same year, it will appear multiple times in the list
Related #293
</issue>
<code>
[start of geotrek/common/filters.py]
1 import sys
2 from decimal import Decimal
3
4 from django.utils.translation import ugettext_lazy as _
5
6 from django_filters import RangeFilter, Filter
7 from mapentity.filters import MapEntityFilterSet
8
9
10 class OptionalRangeFilter(RangeFilter):
11 def __init__(self, *args, **kwargs):
12 super(OptionalRangeFilter, self).__init__(*args, **kwargs)
13 self.field.fields[0].label = _('min %s') % self.field.label
14 self.field.fields[1].label = _('max %s') % self.field.label
15
16 def filter(self, qs, value):
17 if value:
18 if value.start and not value.stop:
19 value = slice(value.start, Decimal(sys.maxint), value.step)
20 if not value.start and value.stop:
21 value = slice(Decimal(-(sys.maxint + 1)), value.stop, value.step)
22 return super(OptionalRangeFilter, self).filter(qs, value)
23
24
25 class YearFilter(Filter):
26 def do_filter(self, qs, year):
27 return qs.filter(**{
28 '%s__year' % self.name: year,
29 })
30
31 def filter(self, qs, value):
32 try:
33 year = int(value)
34 except (ValueError, TypeError):
35 year = -1
36 return qs if year < 0 else self.do_filter(qs, year)
37
38
39 class YearBetweenFilter(YearFilter):
40 def __init__(self, *args, **kwargs):
41 assert len(kwargs['name']) == 2
42 super(YearBetweenFilter, self).__init__(*args, **kwargs)
43
44 def do_filter(self, qs, year):
45 begin, end = self.name
46 qs = qs.filter(**{
47 '%s__lte' % begin: year,
48 '%s__gte' % end: year,
49 })
50 return qs
51
52
53 class StructureRelatedFilterSet(MapEntityFilterSet):
54 class Meta(MapEntityFilterSet.Meta):
55 fields = MapEntityFilterSet.Meta.fields + ['structure']
56
[end of geotrek/common/filters.py]
[start of geotrek/land/views.py]
1 from mapentity.views import (MapEntityLayer, MapEntityList, MapEntityJsonList, MapEntityFormat,
2 MapEntityDetail, MapEntityDocument, MapEntityCreate, MapEntityUpdate, MapEntityDelete)
3
4 from geotrek.core.views import CreateFromTopologyMixin
5 from .models import (PhysicalEdge, LandEdge, CompetenceEdge,
6 WorkManagementEdge, SignageManagementEdge)
7 from .filters import PhysicalEdgeFilterSet, LandEdgeFilterSet, CompetenceEdgeFilterSet, WorkManagementEdgeFilterSet, SignageManagementEdgeFilterSet
8 from .forms import PhysicalEdgeForm, LandEdgeForm, CompetenceEdgeForm, WorkManagementEdgeForm, SignageManagementEdgeForm
9
10
11 class PhysicalEdgeLayer(MapEntityLayer):
12 queryset = PhysicalEdge.objects.existing()
13 properties = ['color_index', 'name']
14
15
16 class PhysicalEdgeList(MapEntityList):
17 queryset = PhysicalEdge.objects.existing()
18 filterform = PhysicalEdgeFilterSet
19 columns = ['id', 'physical_type']
20
21
22 class PhysicalEdgeJsonList(MapEntityJsonList, PhysicalEdgeList):
23 pass
24
25
26 class PhysicalEdgeFormatList(MapEntityFormat, PhysicalEdgeList):
27 pass
28
29
30 class PhysicalEdgeDetail(MapEntityDetail):
31 queryset = PhysicalEdge.objects.existing()
32
33
34 class PhysicalEdgeDocument(MapEntityDocument):
35 model = PhysicalEdge
36
37
38 class PhysicalEdgeCreate(CreateFromTopologyMixin, MapEntityCreate):
39 model = PhysicalEdge
40 form_class = PhysicalEdgeForm
41
42
43 class PhysicalEdgeUpdate(MapEntityUpdate):
44 queryset = PhysicalEdge.objects.existing()
45 form_class = PhysicalEdgeForm
46
47
48 class PhysicalEdgeDelete(MapEntityDelete):
49 model = PhysicalEdge
50
51
52 class LandEdgeLayer(MapEntityLayer):
53 queryset = LandEdge.objects.existing()
54 properties = ['color_index', 'name']
55
56
57 class LandEdgeList(MapEntityList):
58 queryset = LandEdge.objects.existing()
59 filterform = LandEdgeFilterSet
60 columns = ['id', 'land_type']
61
62
63 class LandEdgeJsonList(MapEntityJsonList, LandEdgeList):
64 pass
65
66
67 class LandEdgeFormatList(MapEntityFormat, LandEdgeList):
68 pass
69
70
71 class LandEdgeDetail(MapEntityDetail):
72 queryset = LandEdge.objects.existing()
73
74
75 class LandEdgeDocument(MapEntityDocument):
76 model = LandEdge
77
78
79 class LandEdgeCreate(CreateFromTopologyMixin, MapEntityCreate):
80 model = LandEdge
81 form_class = LandEdgeForm
82
83
84 class LandEdgeUpdate(MapEntityUpdate):
85 queryset = LandEdge.objects.existing()
86 form_class = LandEdgeForm
87
88
89 class LandEdgeDelete(MapEntityDelete):
90 model = LandEdge
91
92
93 class CompetenceEdgeLayer(MapEntityLayer):
94 queryset = CompetenceEdge.objects.existing()
95 properties = ['color_index', 'name']
96
97
98 class CompetenceEdgeList(MapEntityList):
99 queryset = CompetenceEdge.objects.existing()
100 filterform = CompetenceEdgeFilterSet
101 columns = ['id', 'organization']
102
103
104 class CompetenceEdgeJsonList(MapEntityJsonList, CompetenceEdgeList):
105 pass
106
107
108 class CompetenceEdgeFormatList(MapEntityFormat, CompetenceEdgeList):
109 pass
110
111
112 class CompetenceEdgeDetail(MapEntityDetail):
113 queryset = CompetenceEdge.objects.existing()
114
115
116 class CompetenceEdgeDocument(MapEntityDocument):
117 model = CompetenceEdge
118
119
120 class CompetenceEdgeCreate(CreateFromTopologyMixin, MapEntityCreate):
121 model = CompetenceEdge
122 form_class = CompetenceEdgeForm
123
124
125 class CompetenceEdgeUpdate(MapEntityUpdate):
126 queryset = CompetenceEdge.objects.existing()
127 form_class = CompetenceEdgeForm
128
129
130 class CompetenceEdgeDelete(MapEntityDelete):
131 model = CompetenceEdge
132
133
134 class WorkManagementEdgeLayer(MapEntityLayer):
135 queryset = WorkManagementEdge.objects.existing()
136 properties = ['color_index', 'name']
137
138
139 class WorkManagementEdgeList(MapEntityList):
140 queryset = WorkManagementEdge.objects.existing()
141 filterform = WorkManagementEdgeFilterSet
142 columns = ['id', 'organization']
143
144
145 class WorkManagementEdgeJsonList(MapEntityJsonList, WorkManagementEdgeList):
146 pass
147
148
149 class WorkManagementEdgeFormatList(MapEntityFormat, WorkManagementEdgeList):
150 pass
151
152
153 class WorkManagementEdgeDetail(MapEntityDetail):
154 queryset = WorkManagementEdge.objects.existing()
155
156
157 class WorkManagementEdgeDocument(MapEntityDocument):
158 model = WorkManagementEdge
159
160
161 class WorkManagementEdgeCreate(CreateFromTopologyMixin, MapEntityCreate):
162 model = WorkManagementEdge
163 form_class = WorkManagementEdgeForm
164
165
166 class WorkManagementEdgeUpdate(MapEntityUpdate):
167 queryset = WorkManagementEdge.objects.existing()
168 form_class = WorkManagementEdgeForm
169
170
171 class WorkManagementEdgeDelete(MapEntityDelete):
172 model = WorkManagementEdge
173
174
175 class SignageManagementEdgeLayer(MapEntityLayer):
176 queryset = SignageManagementEdge.objects.existing()
177 properties = ['color_index', 'name']
178
179
180 class SignageManagementEdgeList(MapEntityList):
181 queryset = SignageManagementEdge.objects.existing()
182 filterform = SignageManagementEdgeFilterSet
183 columns = ['id', 'organization']
184
185
186 class SignageManagementEdgeJsonList(MapEntityJsonList, SignageManagementEdgeList):
187 pass
188
189
190 class SignageManagementEdgeFormatList(MapEntityFormat, SignageManagementEdgeList):
191 pass
192
193
194 class SignageManagementEdgeDetail(MapEntityDetail):
195 queryset = SignageManagementEdge.objects.existing()
196
197
198 class SignageManagementEdgeDocument(MapEntityDocument):
199 model = SignageManagementEdge
200
201
202 class SignageManagementEdgeCreate(CreateFromTopologyMixin, MapEntityCreate):
203 model = SignageManagementEdge
204 form_class = SignageManagementEdgeForm
205
206
207 class SignageManagementEdgeUpdate(MapEntityUpdate):
208 queryset = SignageManagementEdge.objects.existing()
209 form_class = SignageManagementEdgeForm
210
211
212 class SignageManagementEdgeDelete(MapEntityDelete):
213 model = SignageManagementEdge
214
[end of geotrek/land/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/geotrek/common/filters.py b/geotrek/common/filters.py
--- a/geotrek/common/filters.py
+++ b/geotrek/common/filters.py
@@ -26,7 +26,7 @@
def do_filter(self, qs, year):
return qs.filter(**{
'%s__year' % self.name: year,
- })
+ }).distinct()
def filter(self, qs, value):
try:
diff --git a/geotrek/land/views.py b/geotrek/land/views.py
--- a/geotrek/land/views.py
+++ b/geotrek/land/views.py
@@ -16,7 +16,7 @@
class PhysicalEdgeList(MapEntityList):
queryset = PhysicalEdge.objects.existing()
filterform = PhysicalEdgeFilterSet
- columns = ['id', 'physical_type']
+ columns = ['id', 'physical_type', 'length']
class PhysicalEdgeJsonList(MapEntityJsonList, PhysicalEdgeList):
@@ -57,7 +57,7 @@
class LandEdgeList(MapEntityList):
queryset = LandEdge.objects.existing()
filterform = LandEdgeFilterSet
- columns = ['id', 'land_type']
+ columns = ['id', 'land_type', 'length']
class LandEdgeJsonList(MapEntityJsonList, LandEdgeList):
@@ -98,7 +98,7 @@
class CompetenceEdgeList(MapEntityList):
queryset = CompetenceEdge.objects.existing()
filterform = CompetenceEdgeFilterSet
- columns = ['id', 'organization']
+ columns = ['id', 'organization', 'length']
class CompetenceEdgeJsonList(MapEntityJsonList, CompetenceEdgeList):
@@ -139,7 +139,7 @@
class WorkManagementEdgeList(MapEntityList):
queryset = WorkManagementEdge.objects.existing()
filterform = WorkManagementEdgeFilterSet
- columns = ['id', 'organization']
+ columns = ['id', 'organization', 'length']
class WorkManagementEdgeJsonList(MapEntityJsonList, WorkManagementEdgeList):
@@ -180,7 +180,7 @@
class SignageManagementEdgeList(MapEntityList):
queryset = SignageManagementEdge.objects.existing()
filterform = SignageManagementEdgeFilterSet
- columns = ['id', 'organization']
+ columns = ['id', 'organization', 'length']
class SignageManagementEdgeJsonList(MapEntityJsonList, SignageManagementEdgeList):
|
{"golden_diff": "diff --git a/geotrek/common/filters.py b/geotrek/common/filters.py\n--- a/geotrek/common/filters.py\n+++ b/geotrek/common/filters.py\n@@ -26,7 +26,7 @@\n def do_filter(self, qs, year):\n return qs.filter(**{\n '%s__year' % self.name: year,\n- })\n+ }).distinct()\n \n def filter(self, qs, value):\n try:\ndiff --git a/geotrek/land/views.py b/geotrek/land/views.py\n--- a/geotrek/land/views.py\n+++ b/geotrek/land/views.py\n@@ -16,7 +16,7 @@\n class PhysicalEdgeList(MapEntityList):\n queryset = PhysicalEdge.objects.existing()\n filterform = PhysicalEdgeFilterSet\n- columns = ['id', 'physical_type']\n+ columns = ['id', 'physical_type', 'length']\n \n \n class PhysicalEdgeJsonList(MapEntityJsonList, PhysicalEdgeList):\n@@ -57,7 +57,7 @@\n class LandEdgeList(MapEntityList):\n queryset = LandEdge.objects.existing()\n filterform = LandEdgeFilterSet\n- columns = ['id', 'land_type']\n+ columns = ['id', 'land_type', 'length']\n \n \n class LandEdgeJsonList(MapEntityJsonList, LandEdgeList):\n@@ -98,7 +98,7 @@\n class CompetenceEdgeList(MapEntityList):\n queryset = CompetenceEdge.objects.existing()\n filterform = CompetenceEdgeFilterSet\n- columns = ['id', 'organization']\n+ columns = ['id', 'organization', 'length']\n \n \n class CompetenceEdgeJsonList(MapEntityJsonList, CompetenceEdgeList):\n@@ -139,7 +139,7 @@\n class WorkManagementEdgeList(MapEntityList):\n queryset = WorkManagementEdge.objects.existing()\n filterform = WorkManagementEdgeFilterSet\n- columns = ['id', 'organization']\n+ columns = ['id', 'organization', 'length']\n \n \n class WorkManagementEdgeJsonList(MapEntityJsonList, WorkManagementEdgeList):\n@@ -180,7 +180,7 @@\n class SignageManagementEdgeList(MapEntityList):\n queryset = SignageManagementEdge.objects.existing()\n filterform = SignageManagementEdgeFilterSet\n- columns = ['id', 'organization']\n+ columns = ['id', 'organization', 'length']\n \n \n class SignageManagementEdgeJsonList(MapEntityJsonList, SignageManagementEdgeList):\n", "issue": "Infrastructures are duplicated in list if they received multiple intervention the same year\n- Filter infrastructures by year\n- If the infrastructure has received several interventions this same year, it will appear multiple times in the list\n\nRelated #293 \n\n", "before_files": [{"content": "import sys\nfrom decimal import Decimal\n\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom django_filters import RangeFilter, Filter\nfrom mapentity.filters import MapEntityFilterSet\n\n\nclass OptionalRangeFilter(RangeFilter):\n def __init__(self, *args, **kwargs):\n super(OptionalRangeFilter, self).__init__(*args, **kwargs)\n self.field.fields[0].label = _('min %s') % self.field.label\n self.field.fields[1].label = _('max %s') % self.field.label\n\n def filter(self, qs, value):\n if value:\n if value.start and not value.stop:\n value = slice(value.start, Decimal(sys.maxint), value.step)\n if not value.start and value.stop:\n value = slice(Decimal(-(sys.maxint + 1)), value.stop, value.step)\n return super(OptionalRangeFilter, self).filter(qs, value)\n\n\nclass YearFilter(Filter):\n def do_filter(self, qs, year):\n return qs.filter(**{\n '%s__year' % self.name: year,\n })\n\n def filter(self, qs, value):\n try:\n year = int(value)\n except (ValueError, TypeError):\n year = -1\n return qs if year < 0 else self.do_filter(qs, year)\n\n\nclass YearBetweenFilter(YearFilter):\n def __init__(self, *args, **kwargs):\n assert len(kwargs['name']) == 2\n super(YearBetweenFilter, self).__init__(*args, **kwargs)\n\n def do_filter(self, qs, year):\n begin, end = self.name\n qs = qs.filter(**{\n '%s__lte' % begin: year,\n '%s__gte' % end: year,\n })\n return qs\n\n\nclass StructureRelatedFilterSet(MapEntityFilterSet):\n class Meta(MapEntityFilterSet.Meta):\n fields = MapEntityFilterSet.Meta.fields + ['structure']\n", "path": "geotrek/common/filters.py"}, {"content": "from mapentity.views import (MapEntityLayer, MapEntityList, MapEntityJsonList, MapEntityFormat,\n MapEntityDetail, MapEntityDocument, MapEntityCreate, MapEntityUpdate, MapEntityDelete)\n\nfrom geotrek.core.views import CreateFromTopologyMixin\nfrom .models import (PhysicalEdge, LandEdge, CompetenceEdge,\n WorkManagementEdge, SignageManagementEdge)\nfrom .filters import PhysicalEdgeFilterSet, LandEdgeFilterSet, CompetenceEdgeFilterSet, WorkManagementEdgeFilterSet, SignageManagementEdgeFilterSet\nfrom .forms import PhysicalEdgeForm, LandEdgeForm, CompetenceEdgeForm, WorkManagementEdgeForm, SignageManagementEdgeForm\n\n\nclass PhysicalEdgeLayer(MapEntityLayer):\n queryset = PhysicalEdge.objects.existing()\n properties = ['color_index', 'name']\n\n\nclass PhysicalEdgeList(MapEntityList):\n queryset = PhysicalEdge.objects.existing()\n filterform = PhysicalEdgeFilterSet\n columns = ['id', 'physical_type']\n\n\nclass PhysicalEdgeJsonList(MapEntityJsonList, PhysicalEdgeList):\n pass\n\n\nclass PhysicalEdgeFormatList(MapEntityFormat, PhysicalEdgeList):\n pass\n\n\nclass PhysicalEdgeDetail(MapEntityDetail):\n queryset = PhysicalEdge.objects.existing()\n\n\nclass PhysicalEdgeDocument(MapEntityDocument):\n model = PhysicalEdge\n\n\nclass PhysicalEdgeCreate(CreateFromTopologyMixin, MapEntityCreate):\n model = PhysicalEdge\n form_class = PhysicalEdgeForm\n\n\nclass PhysicalEdgeUpdate(MapEntityUpdate):\n queryset = PhysicalEdge.objects.existing()\n form_class = PhysicalEdgeForm\n\n\nclass PhysicalEdgeDelete(MapEntityDelete):\n model = PhysicalEdge\n\n\nclass LandEdgeLayer(MapEntityLayer):\n queryset = LandEdge.objects.existing()\n properties = ['color_index', 'name']\n\n\nclass LandEdgeList(MapEntityList):\n queryset = LandEdge.objects.existing()\n filterform = LandEdgeFilterSet\n columns = ['id', 'land_type']\n\n\nclass LandEdgeJsonList(MapEntityJsonList, LandEdgeList):\n pass\n\n\nclass LandEdgeFormatList(MapEntityFormat, LandEdgeList):\n pass\n\n\nclass LandEdgeDetail(MapEntityDetail):\n queryset = LandEdge.objects.existing()\n\n\nclass LandEdgeDocument(MapEntityDocument):\n model = LandEdge\n\n\nclass LandEdgeCreate(CreateFromTopologyMixin, MapEntityCreate):\n model = LandEdge\n form_class = LandEdgeForm\n\n\nclass LandEdgeUpdate(MapEntityUpdate):\n queryset = LandEdge.objects.existing()\n form_class = LandEdgeForm\n\n\nclass LandEdgeDelete(MapEntityDelete):\n model = LandEdge\n\n\nclass CompetenceEdgeLayer(MapEntityLayer):\n queryset = CompetenceEdge.objects.existing()\n properties = ['color_index', 'name']\n\n\nclass CompetenceEdgeList(MapEntityList):\n queryset = CompetenceEdge.objects.existing()\n filterform = CompetenceEdgeFilterSet\n columns = ['id', 'organization']\n\n\nclass CompetenceEdgeJsonList(MapEntityJsonList, CompetenceEdgeList):\n pass\n\n\nclass CompetenceEdgeFormatList(MapEntityFormat, CompetenceEdgeList):\n pass\n\n\nclass CompetenceEdgeDetail(MapEntityDetail):\n queryset = CompetenceEdge.objects.existing()\n\n\nclass CompetenceEdgeDocument(MapEntityDocument):\n model = CompetenceEdge\n\n\nclass CompetenceEdgeCreate(CreateFromTopologyMixin, MapEntityCreate):\n model = CompetenceEdge\n form_class = CompetenceEdgeForm\n\n\nclass CompetenceEdgeUpdate(MapEntityUpdate):\n queryset = CompetenceEdge.objects.existing()\n form_class = CompetenceEdgeForm\n\n\nclass CompetenceEdgeDelete(MapEntityDelete):\n model = CompetenceEdge\n\n\nclass WorkManagementEdgeLayer(MapEntityLayer):\n queryset = WorkManagementEdge.objects.existing()\n properties = ['color_index', 'name']\n\n\nclass WorkManagementEdgeList(MapEntityList):\n queryset = WorkManagementEdge.objects.existing()\n filterform = WorkManagementEdgeFilterSet\n columns = ['id', 'organization']\n\n\nclass WorkManagementEdgeJsonList(MapEntityJsonList, WorkManagementEdgeList):\n pass\n\n\nclass WorkManagementEdgeFormatList(MapEntityFormat, WorkManagementEdgeList):\n pass\n\n\nclass WorkManagementEdgeDetail(MapEntityDetail):\n queryset = WorkManagementEdge.objects.existing()\n\n\nclass WorkManagementEdgeDocument(MapEntityDocument):\n model = WorkManagementEdge\n\n\nclass WorkManagementEdgeCreate(CreateFromTopologyMixin, MapEntityCreate):\n model = WorkManagementEdge\n form_class = WorkManagementEdgeForm\n\n\nclass WorkManagementEdgeUpdate(MapEntityUpdate):\n queryset = WorkManagementEdge.objects.existing()\n form_class = WorkManagementEdgeForm\n\n\nclass WorkManagementEdgeDelete(MapEntityDelete):\n model = WorkManagementEdge\n\n\nclass SignageManagementEdgeLayer(MapEntityLayer):\n queryset = SignageManagementEdge.objects.existing()\n properties = ['color_index', 'name']\n\n\nclass SignageManagementEdgeList(MapEntityList):\n queryset = SignageManagementEdge.objects.existing()\n filterform = SignageManagementEdgeFilterSet\n columns = ['id', 'organization']\n\n\nclass SignageManagementEdgeJsonList(MapEntityJsonList, SignageManagementEdgeList):\n pass\n\n\nclass SignageManagementEdgeFormatList(MapEntityFormat, SignageManagementEdgeList):\n pass\n\n\nclass SignageManagementEdgeDetail(MapEntityDetail):\n queryset = SignageManagementEdge.objects.existing()\n\n\nclass SignageManagementEdgeDocument(MapEntityDocument):\n model = SignageManagementEdge\n\n\nclass SignageManagementEdgeCreate(CreateFromTopologyMixin, MapEntityCreate):\n model = SignageManagementEdge\n form_class = SignageManagementEdgeForm\n\n\nclass SignageManagementEdgeUpdate(MapEntityUpdate):\n queryset = SignageManagementEdge.objects.existing()\n form_class = SignageManagementEdgeForm\n\n\nclass SignageManagementEdgeDelete(MapEntityDelete):\n model = SignageManagementEdge\n", "path": "geotrek/land/views.py"}]}
| 2,948 | 549 |
gh_patches_debug_6885
|
rasdani/github-patches
|
git_diff
|
mlflow__mlflow-2699
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[BUG] `pip: not found` on `mlflow models build-docker`
Thank you for submitting an issue. Please refer to our [issue policy](https://www.github.com/mlflow/mlflow/blob/master/ISSUE_POLICY.md)
for information on what types of issues we address. For help with debugging your code, please refer to [Stack Overflow](https://stackoverflow.com/questions/tagged/mlflow).
Please fill in this template and do not delete it unless you are sure your issue is outside its scope.
### System information
- **Have I written custom code (as opposed to using a stock example script provided in MLflow)**: no
- **OS Platform and Distribution (e.g., Linux Ubuntu 16.04)**: Macos/Alpine
- **MLflow installed from (source or binary)**: source
- **MLflow version (run ``mlflow --version``)**: 1.7.2
- **Python version**: 3.7.0
- **npm version, if running the dev UI**: no
- **Exact command to reproduce**: mlflow models build-docker -m runs:/{run_id}/model -n test:test
### Describe the problem
Describe the problem clearly here. Include descriptions of the expected behavior and the actual behavior.
From today building docker image stoped to work with this command `/bin/sh: 1: pip: not found`
### Code to reproduce issue
Provide a reproducible test case that is the bare minimum necessary to generate the problem.
Delete docker image cache and run specified above command.
### Other info / logs
Include any logs or source code that would be helpful to diagnose the problem. If including tracebacks,
please include the full traceback. Large logs and files should be attached.
Building docker image for run: 11b73737169841fb867916b8788ce111
2020/04/12 21:18:07 INFO mlflow.models.cli: Selected backend for flavor 'python_function'
2020/04/12 21:18:24 INFO mlflow.models.docker_utils: Building docker image with name mlflow-image-vectors:latest
/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl/
/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir
/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model
/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/MLmodel
/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code
/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code/mlflow_utils
/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code/mlflow_utils/Dockerfile
/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code/mlflow_utils/mlflow_model.py
/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code/mlflow_utils/__init__.py
/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code/mlflow_utils/__pycache__
/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code/mlflow_utils/__pycache__/mlflow_model.cpython-37.pyc
/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code/mlflow_utils/__pycache__/__init__.cpython-37.pyc
/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code/mlflow_image_vectors
/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code/mlflow_image_vectors/__init__.py
/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code/mlflow_image_vectors/models
/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code/mlflow_image_vectors/models/__init__.py
/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code/mlflow_image_vectors/models/__pycache__
/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code/mlflow_image_vectors/models/__pycache__/keras_inception_v3_u128.cpython-37.pyc
/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code/mlflow_image_vectors/models/__pycache__/__init__.cpython-37.pyc
/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code/mlflow_image_vectors/models/keras_inception_v3_u128.py
/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code/mlflow_image_vectors/__pycache__
/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code/mlflow_image_vectors/__pycache__/__init__.cpython-37.pyc
/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/python_model.pkl
/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/conda.yaml
/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//Dockerfile
Sending build context to Docker daemon 35.33kB
Step 1/17 : FROM ubuntu:18.04
---> 4e5021d210f6
Step 2/17 : RUN apt-get -y update && apt-get install -y --no-install-recommends wget curl nginx ca-certificates bzip2 build-essential cmake openjdk-8-jdk git-core maven && rm -rf /var/lib/apt/lists/*
---> Using cache
---> 3e1b0ec18fb3
Step 3/17 : RUN curl https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh >> miniconda.sh
---> Using cache
---> b4b068e2d493
Step 4/17 : RUN bash ./miniconda.sh -b -p /miniconda; rm ./miniconda.sh;
---> Using cache
---> 52f146aa012c
Step 5/17 : ENV PATH="/miniconda/bin:$PATH"
---> Using cache
---> 6e7758289f76
Step 6/17 : ENV JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
---> Using cache
---> 20e01d0c1b79
Step 7/17 : ENV GUNICORN_CMD_ARGS="--timeout 60 -k gevent"
---> Using cache
---> 8d9d20195e8e
Step 8/17 : WORKDIR /opt/mlflow
---> Using cache
---> 51d39c46e3bc
Step 9/17 : RUN pip install mlflow==1.7.2
---> Running in b69369bccce1
/bin/sh: 1: pip: not found
The command '/bin/sh -c pip install mlflow==1.7.2' returned a non-zero code: 127
</issue>
<code>
[start of mlflow/models/docker_utils.py]
1 import os
2 from subprocess import Popen, PIPE, STDOUT
3 import logging
4
5 import mlflow
6 import mlflow.version
7 from mlflow.utils.file_utils import TempDir, _copy_project
8 from mlflow.utils.logging_utils import eprint
9
10 _logger = logging.getLogger(__name__)
11
12 DISABLE_ENV_CREATION = "MLFLOW_DISABLE_ENV_CREATION"
13
14 _DOCKERFILE_TEMPLATE = """
15 # Build an image that can serve mlflow models.
16 FROM ubuntu:18.04
17
18 RUN apt-get -y update && apt-get install -y --no-install-recommends \
19 wget \
20 curl \
21 nginx \
22 ca-certificates \
23 bzip2 \
24 build-essential \
25 cmake \
26 openjdk-8-jdk \
27 git-core \
28 maven \
29 && rm -rf /var/lib/apt/lists/*
30
31 # Download and setup miniconda
32 RUN curl https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh >> miniconda.sh
33 RUN bash ./miniconda.sh -b -p /miniconda; rm ./miniconda.sh;
34 ENV PATH="/miniconda/bin:$PATH"
35 ENV JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
36 ENV GUNICORN_CMD_ARGS="--timeout 60 -k gevent"
37 # Set up the program in the image
38 WORKDIR /opt/mlflow
39
40 {install_mlflow}
41
42 {custom_setup_steps}
43 {entrypoint}
44 """
45
46
47 def _get_mlflow_install_step(dockerfile_context_dir, mlflow_home):
48 """
49 Get docker build commands for installing MLflow given a Docker context dir and optional source
50 directory
51 """
52 if mlflow_home:
53 mlflow_dir = _copy_project(
54 src_path=mlflow_home, dst_path=dockerfile_context_dir)
55 return (
56 "COPY {mlflow_dir} /opt/mlflow\n"
57 "RUN pip install /opt/mlflow\n"
58 "RUN cd /opt/mlflow/mlflow/java/scoring && "
59 "mvn --batch-mode package -DskipTests && "
60 "mkdir -p /opt/java/jars && "
61 "mv /opt/mlflow/mlflow/java/scoring/target/"
62 "mlflow-scoring-*-with-dependencies.jar /opt/java/jars\n"
63 ).format(mlflow_dir=mlflow_dir)
64 else:
65 return (
66 "RUN pip install mlflow=={version}\n"
67 "RUN mvn "
68 " --batch-mode dependency:copy"
69 " -Dartifact=org.mlflow:mlflow-scoring:{version}:pom"
70 " -DoutputDirectory=/opt/java\n"
71 "RUN mvn "
72 " --batch-mode dependency:copy"
73 " -Dartifact=org.mlflow:mlflow-scoring:{version}:jar"
74 " -DoutputDirectory=/opt/java/jars\n"
75 "RUN cp /opt/java/mlflow-scoring-{version}.pom /opt/java/pom.xml\n"
76 "RUN cd /opt/java && mvn "
77 "--batch-mode dependency:copy-dependencies -DoutputDirectory=/opt/java/jars\n"
78 ).format(version=mlflow.version.VERSION)
79
80
81 def _build_image(image_name, entrypoint, mlflow_home=None, custom_setup_steps_hook=None):
82 """
83 Build an MLflow Docker image that can be used to serve a
84 The image is built locally and it requires Docker to run.
85
86 :param image_name: Docker image name.
87 :param entry_point: String containing ENTRYPOINT directive for docker image
88 :param mlflow_home: (Optional) Path to a local copy of the MLflow GitHub repository.
89 If specified, the image will install MLflow from this directory.
90 If None, it will install MLflow from pip.
91 :param custom_setup_steps_hook: (Optional) Single-argument function that takes the string path
92 of a dockerfile context directory and returns a string containing Dockerfile commands to
93 run during the image build step.
94 """
95 mlflow_home = os.path.abspath(mlflow_home) if mlflow_home else None
96 with TempDir() as tmp:
97 cwd = tmp.path()
98 install_mlflow = _get_mlflow_install_step(cwd, mlflow_home)
99 custom_setup_steps = custom_setup_steps_hook(cwd) if custom_setup_steps_hook else ""
100 with open(os.path.join(cwd, "Dockerfile"), "w") as f:
101 f.write(_DOCKERFILE_TEMPLATE.format(
102 install_mlflow=install_mlflow, custom_setup_steps=custom_setup_steps,
103 entrypoint=entrypoint))
104 _logger.info("Building docker image with name %s", image_name)
105 os.system('find {cwd}/'.format(cwd=cwd))
106 proc = Popen(["docker", "build", "-t", image_name, "-f", "Dockerfile", "."],
107 cwd=cwd,
108 stdout=PIPE,
109 stderr=STDOUT,
110 universal_newlines=True)
111 for x in iter(proc.stdout.readline, ""):
112 eprint(x, end='')
113
[end of mlflow/models/docker_utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mlflow/models/docker_utils.py b/mlflow/models/docker_utils.py
--- a/mlflow/models/docker_utils.py
+++ b/mlflow/models/docker_utils.py
@@ -29,7 +29,7 @@
&& rm -rf /var/lib/apt/lists/*
# Download and setup miniconda
-RUN curl https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh >> miniconda.sh
+RUN curl -L https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh >> miniconda.sh
RUN bash ./miniconda.sh -b -p /miniconda; rm ./miniconda.sh;
ENV PATH="/miniconda/bin:$PATH"
ENV JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
|
{"golden_diff": "diff --git a/mlflow/models/docker_utils.py b/mlflow/models/docker_utils.py\n--- a/mlflow/models/docker_utils.py\n+++ b/mlflow/models/docker_utils.py\n@@ -29,7 +29,7 @@\n && rm -rf /var/lib/apt/lists/*\n \n # Download and setup miniconda\n-RUN curl https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh >> miniconda.sh\n+RUN curl -L https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh >> miniconda.sh\n RUN bash ./miniconda.sh -b -p /miniconda; rm ./miniconda.sh;\n ENV PATH=\"/miniconda/bin:$PATH\"\n ENV JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64\n", "issue": "[BUG] `pip: not found` on `mlflow models build-docker`\nThank you for submitting an issue. Please refer to our [issue policy](https://www.github.com/mlflow/mlflow/blob/master/ISSUE_POLICY.md)\r\nfor information on what types of issues we address. For help with debugging your code, please refer to [Stack Overflow](https://stackoverflow.com/questions/tagged/mlflow).\r\n\r\nPlease fill in this template and do not delete it unless you are sure your issue is outside its scope.\r\n\r\n### System information\r\n- **Have I written custom code (as opposed to using a stock example script provided in MLflow)**: no\r\n- **OS Platform and Distribution (e.g., Linux Ubuntu 16.04)**: Macos/Alpine\r\n- **MLflow installed from (source or binary)**: source\r\n- **MLflow version (run ``mlflow --version``)**: 1.7.2\r\n- **Python version**: 3.7.0\r\n- **npm version, if running the dev UI**: no\r\n- **Exact command to reproduce**: mlflow models build-docker -m runs:/{run_id}/model -n test:test\r\n\r\n### Describe the problem\r\nDescribe the problem clearly here. Include descriptions of the expected behavior and the actual behavior.\r\n\r\nFrom today building docker image stoped to work with this command `/bin/sh: 1: pip: not found`\r\n\r\n### Code to reproduce issue\r\nProvide a reproducible test case that is the bare minimum necessary to generate the problem.\r\n\r\nDelete docker image cache and run specified above command. \r\n\r\n### Other info / logs\r\nInclude any logs or source code that would be helpful to diagnose the problem. If including tracebacks,\r\nplease include the full traceback. Large logs and files should be attached.\r\n\r\nBuilding docker image for run: 11b73737169841fb867916b8788ce111\r\n2020/04/12 21:18:07 INFO mlflow.models.cli: Selected backend for flavor 'python_function'\r\n2020/04/12 21:18:24 INFO mlflow.models.docker_utils: Building docker image with name mlflow-image-vectors:latest\r\n/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl/\r\n/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir\r\n/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model\r\n/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/MLmodel\r\n/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code\r\n/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code/mlflow_utils\r\n/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code/mlflow_utils/Dockerfile\r\n/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code/mlflow_utils/mlflow_model.py\r\n/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code/mlflow_utils/__init__.py\r\n/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code/mlflow_utils/__pycache__\r\n/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code/mlflow_utils/__pycache__/mlflow_model.cpython-37.pyc\r\n/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code/mlflow_utils/__pycache__/__init__.cpython-37.pyc\r\n/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code/mlflow_image_vectors\r\n/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code/mlflow_image_vectors/__init__.py\r\n/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code/mlflow_image_vectors/models\r\n/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code/mlflow_image_vectors/models/__init__.py\r\n/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code/mlflow_image_vectors/models/__pycache__\r\n/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code/mlflow_image_vectors/models/__pycache__/keras_inception_v3_u128.cpython-37.pyc\r\n/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code/mlflow_image_vectors/models/__pycache__/__init__.cpython-37.pyc\r\n/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code/mlflow_image_vectors/models/keras_inception_v3_u128.py\r\n/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code/mlflow_image_vectors/__pycache__\r\n/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/code/mlflow_image_vectors/__pycache__/__init__.cpython-37.pyc\r\n/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/python_model.pkl\r\n/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//model_dir/model/conda.yaml\r\n/var/folders/m1/xp7nclf15g5cw_ty2b7n4fb80000gn/T/tmplxi4s8jl//Dockerfile\r\nSending build context to Docker daemon 35.33kB\r\n\r\nStep 1/17 : FROM ubuntu:18.04\r\n ---> 4e5021d210f6\r\nStep 2/17 : RUN apt-get -y update && apt-get install -y --no-install-recommends wget curl nginx ca-certificates bzip2 build-essential cmake openjdk-8-jdk git-core maven && rm -rf /var/lib/apt/lists/*\r\n ---> Using cache\r\n ---> 3e1b0ec18fb3\r\nStep 3/17 : RUN curl https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh >> miniconda.sh\r\n ---> Using cache\r\n ---> b4b068e2d493\r\nStep 4/17 : RUN bash ./miniconda.sh -b -p /miniconda; rm ./miniconda.sh;\r\n ---> Using cache\r\n ---> 52f146aa012c\r\nStep 5/17 : ENV PATH=\"/miniconda/bin:$PATH\"\r\n ---> Using cache\r\n ---> 6e7758289f76\r\nStep 6/17 : ENV JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64\r\n ---> Using cache\r\n ---> 20e01d0c1b79\r\nStep 7/17 : ENV GUNICORN_CMD_ARGS=\"--timeout 60 -k gevent\"\r\n ---> Using cache\r\n ---> 8d9d20195e8e\r\nStep 8/17 : WORKDIR /opt/mlflow\r\n ---> Using cache\r\n ---> 51d39c46e3bc\r\nStep 9/17 : RUN pip install mlflow==1.7.2\r\n ---> Running in b69369bccce1\r\n/bin/sh: 1: pip: not found\r\nThe command '/bin/sh -c pip install mlflow==1.7.2' returned a non-zero code: 127\n", "before_files": [{"content": "import os\nfrom subprocess import Popen, PIPE, STDOUT\nimport logging\n\nimport mlflow\nimport mlflow.version\nfrom mlflow.utils.file_utils import TempDir, _copy_project\nfrom mlflow.utils.logging_utils import eprint\n\n_logger = logging.getLogger(__name__)\n\nDISABLE_ENV_CREATION = \"MLFLOW_DISABLE_ENV_CREATION\"\n\n_DOCKERFILE_TEMPLATE = \"\"\"\n# Build an image that can serve mlflow models.\nFROM ubuntu:18.04\n\nRUN apt-get -y update && apt-get install -y --no-install-recommends \\\n wget \\\n curl \\\n nginx \\\n ca-certificates \\\n bzip2 \\\n build-essential \\\n cmake \\\n openjdk-8-jdk \\\n git-core \\\n maven \\\n && rm -rf /var/lib/apt/lists/*\n\n# Download and setup miniconda\nRUN curl https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh >> miniconda.sh\nRUN bash ./miniconda.sh -b -p /miniconda; rm ./miniconda.sh;\nENV PATH=\"/miniconda/bin:$PATH\"\nENV JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64\nENV GUNICORN_CMD_ARGS=\"--timeout 60 -k gevent\"\n# Set up the program in the image\nWORKDIR /opt/mlflow\n\n{install_mlflow}\n\n{custom_setup_steps}\n{entrypoint}\n\"\"\"\n\n\ndef _get_mlflow_install_step(dockerfile_context_dir, mlflow_home):\n \"\"\"\n Get docker build commands for installing MLflow given a Docker context dir and optional source\n directory\n \"\"\"\n if mlflow_home:\n mlflow_dir = _copy_project(\n src_path=mlflow_home, dst_path=dockerfile_context_dir)\n return (\n \"COPY {mlflow_dir} /opt/mlflow\\n\"\n \"RUN pip install /opt/mlflow\\n\"\n \"RUN cd /opt/mlflow/mlflow/java/scoring && \"\n \"mvn --batch-mode package -DskipTests && \"\n \"mkdir -p /opt/java/jars && \"\n \"mv /opt/mlflow/mlflow/java/scoring/target/\"\n \"mlflow-scoring-*-with-dependencies.jar /opt/java/jars\\n\"\n ).format(mlflow_dir=mlflow_dir)\n else:\n return (\n \"RUN pip install mlflow=={version}\\n\"\n \"RUN mvn \"\n \" --batch-mode dependency:copy\"\n \" -Dartifact=org.mlflow:mlflow-scoring:{version}:pom\"\n \" -DoutputDirectory=/opt/java\\n\"\n \"RUN mvn \"\n \" --batch-mode dependency:copy\"\n \" -Dartifact=org.mlflow:mlflow-scoring:{version}:jar\"\n \" -DoutputDirectory=/opt/java/jars\\n\"\n \"RUN cp /opt/java/mlflow-scoring-{version}.pom /opt/java/pom.xml\\n\"\n \"RUN cd /opt/java && mvn \"\n \"--batch-mode dependency:copy-dependencies -DoutputDirectory=/opt/java/jars\\n\"\n ).format(version=mlflow.version.VERSION)\n\n\ndef _build_image(image_name, entrypoint, mlflow_home=None, custom_setup_steps_hook=None):\n \"\"\"\n Build an MLflow Docker image that can be used to serve a\n The image is built locally and it requires Docker to run.\n\n :param image_name: Docker image name.\n :param entry_point: String containing ENTRYPOINT directive for docker image\n :param mlflow_home: (Optional) Path to a local copy of the MLflow GitHub repository.\n If specified, the image will install MLflow from this directory.\n If None, it will install MLflow from pip.\n :param custom_setup_steps_hook: (Optional) Single-argument function that takes the string path\n of a dockerfile context directory and returns a string containing Dockerfile commands to\n run during the image build step.\n \"\"\"\n mlflow_home = os.path.abspath(mlflow_home) if mlflow_home else None\n with TempDir() as tmp:\n cwd = tmp.path()\n install_mlflow = _get_mlflow_install_step(cwd, mlflow_home)\n custom_setup_steps = custom_setup_steps_hook(cwd) if custom_setup_steps_hook else \"\"\n with open(os.path.join(cwd, \"Dockerfile\"), \"w\") as f:\n f.write(_DOCKERFILE_TEMPLATE.format(\n install_mlflow=install_mlflow, custom_setup_steps=custom_setup_steps,\n entrypoint=entrypoint))\n _logger.info(\"Building docker image with name %s\", image_name)\n os.system('find {cwd}/'.format(cwd=cwd))\n proc = Popen([\"docker\", \"build\", \"-t\", image_name, \"-f\", \"Dockerfile\", \".\"],\n cwd=cwd,\n stdout=PIPE,\n stderr=STDOUT,\n universal_newlines=True)\n for x in iter(proc.stdout.readline, \"\"):\n eprint(x, end='')\n", "path": "mlflow/models/docker_utils.py"}]}
| 4,021 | 191 |
gh_patches_debug_609
|
rasdani/github-patches
|
git_diff
|
pypi__warehouse-3165
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add a "shortlink" for projects
**From user testing:**
When viewing projects on PyPI, some users type the URL directly if they know the project name.
We should create a shortlink like`pypi.org/p/myproject` which would redirect to `pypi.org/projects/myproject`
cc @di for feedback / guidance.
---
**Good First Issue**: This issue is good for first time contributors. If you've already contributed to Warehouse, please work on [another issue without this label](https://github.com/pypa/warehouse/issues?utf8=%E2%9C%93&q=is%3Aissue+is%3Aopen+-label%3A%22good+first+issue%22) instead. If there is not a corresponding pull request for this issue, it is up for grabs. For directions for getting set up, see our [Getting Started Guide](https://warehouse.pypa.io/development/getting-started/). If you are working on this issue and have questions, please feel free to ask them here, [`#pypa-dev` on Freenode](https://webchat.freenode.net/?channels=%23pypa-dev), or the [pypa-dev mailing list](https://groups.google.com/forum/#!forum/pypa-dev).
</issue>
<code>
[start of warehouse/routes.py]
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12
13
14 def includeme(config):
15 # We need to get the value of the Warehouse and Forklift domains, we'll use
16 # these to segregate the Warehouse routes from the Forklift routes until
17 # Forklift is properly split out into it's own project.
18 warehouse = config.get_settings().get("warehouse.domain")
19 files_url = config.get_settings()["files.url"]
20
21 # Simple Route for health checks.
22 config.add_route("health", "/_health/")
23
24 # Internal route to make it easier to force a particular status for
25 # debugging HTTPException templates.
26 config.add_route("force-status", "/_force-status/{status:[45]\d\d}/")
27
28 # Basic global routes
29 config.add_route("index", "/", domain=warehouse)
30 config.add_route("robots.txt", "/robots.txt", domain=warehouse)
31 config.add_route("opensearch.xml", "/opensearch.xml", domain=warehouse)
32 config.add_route("index.sitemap.xml", "/sitemap.xml", domain=warehouse)
33 config.add_route(
34 "bucket.sitemap.xml",
35 "/{bucket}.sitemap.xml",
36 domain=warehouse,
37 )
38
39 # Some static, template driven pages
40 config.add_template_view("help", "/help/", "pages/help.html")
41 config.add_template_view("security", "/security/", "pages/security.html")
42 config.add_template_view(
43 "sponsors",
44 "/sponsors/",
45 # Use the full resource path here to make it able to be overridden by
46 # pypi-theme.
47 "warehouse:templates/pages/sponsors.html",
48 )
49
50 # Our legal policies
51 config.add_policy("terms-of-use", "terms.md")
52
53 # HTML Snippets for including into other pages.
54 config.add_route(
55 "includes.current-user-indicator",
56 "/_includes/current-user-indicator/",
57 domain=warehouse,
58 )
59 config.add_route(
60 "includes.flash-messages",
61 "/_includes/flash-messages/",
62 domain=warehouse,
63 )
64 config.add_route(
65 "includes.current-user-profile-callout",
66 "/_includes/current-user-profile-callout/{username}",
67 factory="warehouse.accounts.models:UserFactory",
68 traverse="/{username}",
69 domain=warehouse,
70 )
71 config.add_route(
72 "includes.edit-project-button",
73 "/_includes/edit-project-button/{project_name}",
74 factory="warehouse.packaging.models:ProjectFactory",
75 traverse="/{project_name}",
76 domain=warehouse,
77 )
78 config.add_route(
79 "includes.edit-profile-button",
80 "/_includes/edit-profile-button/{username}",
81 factory="warehouse.accounts.models:UserFactory",
82 traverse="/{username}",
83 domain=warehouse,
84 )
85
86 # Search Routes
87 config.add_route("search", "/search/", domain=warehouse)
88
89 # Accounts
90 config.add_route(
91 "accounts.profile",
92 "/user/{username}/",
93 factory="warehouse.accounts.models:UserFactory",
94 traverse="/{username}",
95 domain=warehouse,
96 )
97 config.add_route("accounts.login", "/account/login/", domain=warehouse)
98 config.add_route("accounts.logout", "/account/logout/", domain=warehouse)
99 config.add_route(
100 "accounts.register",
101 "/account/register/",
102 domain=warehouse,
103 )
104 config.add_route(
105 "accounts.request-password-reset",
106 "/account/request-password-reset/",
107 domain=warehouse,
108 )
109 config.add_route(
110 "accounts.reset-password",
111 "/account/reset-password/",
112 domain=warehouse,
113 )
114 config.add_route(
115 "accounts.verify-email",
116 "/account/verify-email/",
117 domain=warehouse,
118 )
119
120 # Management (views for logged-in users)
121 config.add_route("manage.account", "/manage/account/", domain=warehouse)
122 config.add_route("manage.projects", "/manage/projects/", domain=warehouse)
123 config.add_route(
124 "manage.project.settings",
125 "/manage/project/{project_name}/settings/",
126 factory="warehouse.packaging.models:ProjectFactory",
127 traverse="/{project_name}",
128 domain=warehouse,
129 )
130 config.add_route(
131 "manage.project.delete_project",
132 "/manage/project/{project_name}/delete_project/",
133 factory="warehouse.packaging.models:ProjectFactory",
134 traverse="/{project_name}",
135 domain=warehouse,
136 )
137 config.add_route(
138 "manage.project.releases",
139 "/manage/project/{project_name}/releases/",
140 factory="warehouse.packaging.models:ProjectFactory",
141 traverse="/{project_name}",
142 domain=warehouse,
143 )
144 config.add_route(
145 "manage.project.release",
146 "/manage/project/{project_name}/release/{version}/",
147 factory="warehouse.packaging.models:ProjectFactory",
148 traverse="/{project_name}/{version}",
149 domain=warehouse,
150 )
151 config.add_route(
152 "manage.project.roles",
153 "/manage/project/{project_name}/collaboration/",
154 factory="warehouse.packaging.models:ProjectFactory",
155 traverse="/{project_name}",
156 domain=warehouse,
157 )
158 config.add_route(
159 "manage.project.change_role",
160 "/manage/project/{project_name}/collaboration/change/",
161 factory="warehouse.packaging.models:ProjectFactory",
162 traverse="/{project_name}",
163 domain=warehouse,
164 )
165 config.add_route(
166 "manage.project.delete_role",
167 "/manage/project/{project_name}/collaboration/delete/",
168 factory="warehouse.packaging.models:ProjectFactory",
169 traverse="/{project_name}",
170 domain=warehouse,
171 )
172 config.add_route(
173 "manage.project.history",
174 "/manage/project/{project_name}/history/",
175 factory="warehouse.packaging.models:ProjectFactory",
176 traverse="/{project_name}",
177 domain=warehouse,
178 )
179
180 # Packaging
181 config.add_route(
182 "packaging.project",
183 "/project/{name}/",
184 factory="warehouse.packaging.models:ProjectFactory",
185 traverse="/{name}",
186 domain=warehouse,
187 )
188 config.add_route(
189 "packaging.release",
190 "/project/{name}/{version}/",
191 factory="warehouse.packaging.models:ProjectFactory",
192 traverse="/{name}/{version}",
193 domain=warehouse,
194 )
195 config.add_route("packaging.file", files_url)
196
197 # RSS
198 config.add_route("rss.updates", "/rss/updates.xml", domain=warehouse)
199 config.add_route("rss.packages", "/rss/packages.xml", domain=warehouse)
200
201 # Legacy URLs
202 config.add_route("legacy.api.simple.index", "/simple/", domain=warehouse)
203 config.add_route(
204 "legacy.api.simple.detail",
205 "/simple/{name}/",
206 factory="warehouse.packaging.models:ProjectFactory",
207 traverse="/{name}/",
208 read_only=True,
209 domain=warehouse,
210 )
211 config.add_route(
212 "legacy.api.json.project",
213 "/pypi/{name}/json",
214 factory="warehouse.packaging.models:ProjectFactory",
215 traverse="/{name}",
216 read_only=True,
217 domain=warehouse,
218 )
219 config.add_route(
220 "legacy.api.json.release",
221 "/pypi/{name}/{version}/json",
222 factory="warehouse.packaging.models:ProjectFactory",
223 traverse="/{name}/{version}",
224 read_only=True,
225 domain=warehouse,
226 )
227
228 # Legacy Action URLs
229 # TODO: We should probably add Warehouse routes for these that just error
230 # and direct people to use upload.pypi.io
231 config.add_pypi_action_route(
232 "legacy.api.pypi.file_upload",
233 "file_upload",
234 domain=warehouse,
235 )
236 config.add_pypi_action_route(
237 "legacy.api.pypi.submit",
238 "submit",
239 domain=warehouse,
240 )
241 config.add_pypi_action_route(
242 "legacy.api.pypi.submit_pkg_info",
243 "submit_pkg_info",
244 domain=warehouse,
245 )
246 config.add_pypi_action_route(
247 "legacy.api.pypi.doc_upload",
248 "doc_upload",
249 domain=warehouse,
250 )
251 config.add_pypi_action_route(
252 "legacy.api.pypi.doap",
253 "doap",
254 domain=warehouse,
255 )
256 config.add_pypi_action_route(
257 "legacy.api.pypi.list_classifiers",
258 "list_classifiers",
259 domain=warehouse,
260 )
261
262 # Legacy XMLRPC
263 config.add_xmlrpc_endpoint(
264 "pypi",
265 pattern="/pypi",
266 header="Content-Type:text/xml",
267 domain=warehouse,
268 )
269
270 # Legacy Documentation
271 config.add_route("legacy.docs", config.registry.settings["docs.url"])
272
273 # Legacy Redirects
274 config.add_redirect("/pypi/{name}/", "/project/{name}/", domain=warehouse)
275 config.add_redirect(
276 "/pypi/{name}/{version}/",
277 "/project/{name}/{version}/",
278 domain=warehouse,
279 )
280 config.add_redirect("/packages/{path:.*}", files_url, domain=warehouse)
281
282 # Legacy Action Redirects
283 config.add_pypi_action_redirect(
284 "rss",
285 "/rss/updates.xml",
286 domain=warehouse,
287 )
288 config.add_pypi_action_redirect(
289 "packages_rss",
290 "/rss/packages.xml",
291 domain=warehouse,
292 )
293
[end of warehouse/routes.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/warehouse/routes.py b/warehouse/routes.py
--- a/warehouse/routes.py
+++ b/warehouse/routes.py
@@ -178,6 +178,7 @@
)
# Packaging
+ config.add_redirect('/p/{name}/', '/project/{name}/', domain=warehouse)
config.add_route(
"packaging.project",
"/project/{name}/",
|
{"golden_diff": "diff --git a/warehouse/routes.py b/warehouse/routes.py\n--- a/warehouse/routes.py\n+++ b/warehouse/routes.py\n@@ -178,6 +178,7 @@\n )\n \n # Packaging\n+ config.add_redirect('/p/{name}/', '/project/{name}/', domain=warehouse)\n config.add_route(\n \"packaging.project\",\n \"/project/{name}/\",\n", "issue": "Add a \"shortlink\" for projects\n**From user testing:**\r\n\r\nWhen viewing projects on PyPI, some users type the URL directly if they know the project name.\r\n\r\nWe should create a shortlink like`pypi.org/p/myproject` which would redirect to `pypi.org/projects/myproject`\r\n\r\ncc @di for feedback / guidance.\r\n\r\n---\r\n\r\n**Good First Issue**: This issue is good for first time contributors. If you've already contributed to Warehouse, please work on [another issue without this label](https://github.com/pypa/warehouse/issues?utf8=%E2%9C%93&q=is%3Aissue+is%3Aopen+-label%3A%22good+first+issue%22) instead. If there is not a corresponding pull request for this issue, it is up for grabs. For directions for getting set up, see our [Getting Started Guide](https://warehouse.pypa.io/development/getting-started/). If you are working on this issue and have questions, please feel free to ask them here, [`#pypa-dev` on Freenode](https://webchat.freenode.net/?channels=%23pypa-dev), or the [pypa-dev mailing list](https://groups.google.com/forum/#!forum/pypa-dev).\r\n\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\ndef includeme(config):\n # We need to get the value of the Warehouse and Forklift domains, we'll use\n # these to segregate the Warehouse routes from the Forklift routes until\n # Forklift is properly split out into it's own project.\n warehouse = config.get_settings().get(\"warehouse.domain\")\n files_url = config.get_settings()[\"files.url\"]\n\n # Simple Route for health checks.\n config.add_route(\"health\", \"/_health/\")\n\n # Internal route to make it easier to force a particular status for\n # debugging HTTPException templates.\n config.add_route(\"force-status\", \"/_force-status/{status:[45]\\d\\d}/\")\n\n # Basic global routes\n config.add_route(\"index\", \"/\", domain=warehouse)\n config.add_route(\"robots.txt\", \"/robots.txt\", domain=warehouse)\n config.add_route(\"opensearch.xml\", \"/opensearch.xml\", domain=warehouse)\n config.add_route(\"index.sitemap.xml\", \"/sitemap.xml\", domain=warehouse)\n config.add_route(\n \"bucket.sitemap.xml\",\n \"/{bucket}.sitemap.xml\",\n domain=warehouse,\n )\n\n # Some static, template driven pages\n config.add_template_view(\"help\", \"/help/\", \"pages/help.html\")\n config.add_template_view(\"security\", \"/security/\", \"pages/security.html\")\n config.add_template_view(\n \"sponsors\",\n \"/sponsors/\",\n # Use the full resource path here to make it able to be overridden by\n # pypi-theme.\n \"warehouse:templates/pages/sponsors.html\",\n )\n\n # Our legal policies\n config.add_policy(\"terms-of-use\", \"terms.md\")\n\n # HTML Snippets for including into other pages.\n config.add_route(\n \"includes.current-user-indicator\",\n \"/_includes/current-user-indicator/\",\n domain=warehouse,\n )\n config.add_route(\n \"includes.flash-messages\",\n \"/_includes/flash-messages/\",\n domain=warehouse,\n )\n config.add_route(\n \"includes.current-user-profile-callout\",\n \"/_includes/current-user-profile-callout/{username}\",\n factory=\"warehouse.accounts.models:UserFactory\",\n traverse=\"/{username}\",\n domain=warehouse,\n )\n config.add_route(\n \"includes.edit-project-button\",\n \"/_includes/edit-project-button/{project_name}\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{project_name}\",\n domain=warehouse,\n )\n config.add_route(\n \"includes.edit-profile-button\",\n \"/_includes/edit-profile-button/{username}\",\n factory=\"warehouse.accounts.models:UserFactory\",\n traverse=\"/{username}\",\n domain=warehouse,\n )\n\n # Search Routes\n config.add_route(\"search\", \"/search/\", domain=warehouse)\n\n # Accounts\n config.add_route(\n \"accounts.profile\",\n \"/user/{username}/\",\n factory=\"warehouse.accounts.models:UserFactory\",\n traverse=\"/{username}\",\n domain=warehouse,\n )\n config.add_route(\"accounts.login\", \"/account/login/\", domain=warehouse)\n config.add_route(\"accounts.logout\", \"/account/logout/\", domain=warehouse)\n config.add_route(\n \"accounts.register\",\n \"/account/register/\",\n domain=warehouse,\n )\n config.add_route(\n \"accounts.request-password-reset\",\n \"/account/request-password-reset/\",\n domain=warehouse,\n )\n config.add_route(\n \"accounts.reset-password\",\n \"/account/reset-password/\",\n domain=warehouse,\n )\n config.add_route(\n \"accounts.verify-email\",\n \"/account/verify-email/\",\n domain=warehouse,\n )\n\n # Management (views for logged-in users)\n config.add_route(\"manage.account\", \"/manage/account/\", domain=warehouse)\n config.add_route(\"manage.projects\", \"/manage/projects/\", domain=warehouse)\n config.add_route(\n \"manage.project.settings\",\n \"/manage/project/{project_name}/settings/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{project_name}\",\n domain=warehouse,\n )\n config.add_route(\n \"manage.project.delete_project\",\n \"/manage/project/{project_name}/delete_project/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{project_name}\",\n domain=warehouse,\n )\n config.add_route(\n \"manage.project.releases\",\n \"/manage/project/{project_name}/releases/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{project_name}\",\n domain=warehouse,\n )\n config.add_route(\n \"manage.project.release\",\n \"/manage/project/{project_name}/release/{version}/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{project_name}/{version}\",\n domain=warehouse,\n )\n config.add_route(\n \"manage.project.roles\",\n \"/manage/project/{project_name}/collaboration/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{project_name}\",\n domain=warehouse,\n )\n config.add_route(\n \"manage.project.change_role\",\n \"/manage/project/{project_name}/collaboration/change/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{project_name}\",\n domain=warehouse,\n )\n config.add_route(\n \"manage.project.delete_role\",\n \"/manage/project/{project_name}/collaboration/delete/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{project_name}\",\n domain=warehouse,\n )\n config.add_route(\n \"manage.project.history\",\n \"/manage/project/{project_name}/history/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{project_name}\",\n domain=warehouse,\n )\n\n # Packaging\n config.add_route(\n \"packaging.project\",\n \"/project/{name}/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{name}\",\n domain=warehouse,\n )\n config.add_route(\n \"packaging.release\",\n \"/project/{name}/{version}/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{name}/{version}\",\n domain=warehouse,\n )\n config.add_route(\"packaging.file\", files_url)\n\n # RSS\n config.add_route(\"rss.updates\", \"/rss/updates.xml\", domain=warehouse)\n config.add_route(\"rss.packages\", \"/rss/packages.xml\", domain=warehouse)\n\n # Legacy URLs\n config.add_route(\"legacy.api.simple.index\", \"/simple/\", domain=warehouse)\n config.add_route(\n \"legacy.api.simple.detail\",\n \"/simple/{name}/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{name}/\",\n read_only=True,\n domain=warehouse,\n )\n config.add_route(\n \"legacy.api.json.project\",\n \"/pypi/{name}/json\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{name}\",\n read_only=True,\n domain=warehouse,\n )\n config.add_route(\n \"legacy.api.json.release\",\n \"/pypi/{name}/{version}/json\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{name}/{version}\",\n read_only=True,\n domain=warehouse,\n )\n\n # Legacy Action URLs\n # TODO: We should probably add Warehouse routes for these that just error\n # and direct people to use upload.pypi.io\n config.add_pypi_action_route(\n \"legacy.api.pypi.file_upload\",\n \"file_upload\",\n domain=warehouse,\n )\n config.add_pypi_action_route(\n \"legacy.api.pypi.submit\",\n \"submit\",\n domain=warehouse,\n )\n config.add_pypi_action_route(\n \"legacy.api.pypi.submit_pkg_info\",\n \"submit_pkg_info\",\n domain=warehouse,\n )\n config.add_pypi_action_route(\n \"legacy.api.pypi.doc_upload\",\n \"doc_upload\",\n domain=warehouse,\n )\n config.add_pypi_action_route(\n \"legacy.api.pypi.doap\",\n \"doap\",\n domain=warehouse,\n )\n config.add_pypi_action_route(\n \"legacy.api.pypi.list_classifiers\",\n \"list_classifiers\",\n domain=warehouse,\n )\n\n # Legacy XMLRPC\n config.add_xmlrpc_endpoint(\n \"pypi\",\n pattern=\"/pypi\",\n header=\"Content-Type:text/xml\",\n domain=warehouse,\n )\n\n # Legacy Documentation\n config.add_route(\"legacy.docs\", config.registry.settings[\"docs.url\"])\n\n # Legacy Redirects\n config.add_redirect(\"/pypi/{name}/\", \"/project/{name}/\", domain=warehouse)\n config.add_redirect(\n \"/pypi/{name}/{version}/\",\n \"/project/{name}/{version}/\",\n domain=warehouse,\n )\n config.add_redirect(\"/packages/{path:.*}\", files_url, domain=warehouse)\n\n # Legacy Action Redirects\n config.add_pypi_action_redirect(\n \"rss\",\n \"/rss/updates.xml\",\n domain=warehouse,\n )\n config.add_pypi_action_redirect(\n \"packages_rss\",\n \"/rss/packages.xml\",\n domain=warehouse,\n )\n", "path": "warehouse/routes.py"}]}
| 3,625 | 88 |
gh_patches_debug_15342
|
rasdani/github-patches
|
git_diff
|
spotify__luigi-2477
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
race condition on lock :(
I think there is a race condition on
**luigi/lock.py", line 93, in acquire_for**
```python
# Check if there is a pid file corresponding to this name
if not os.path.exists(pid_dir):
os.mkdir(pid_dir)
```
between `if not [...]` and `mkdir` another process could have created the pid_dir resulting in an unhandled OSError exception.
I think that ignore the exception if the folder exists will be enough, or perhaps just create the folder and say sorry if it was just there...
</issue>
<code>
[start of luigi/lock.py]
1 # -*- coding: utf-8 -*-
2 #
3 # Copyright 2012-2015 Spotify AB
4 #
5 # Licensed under the Apache License, Version 2.0 (the "License");
6 # you may not use this file except in compliance with the License.
7 # You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing, software
12 # distributed under the License is distributed on an "AS IS" BASIS,
13 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 # See the License for the specific language governing permissions and
15 # limitations under the License.
16 #
17 """
18 Locking functionality when launching things from the command line.
19 Uses a pidfile.
20 This prevents multiple identical workflows to be launched simultaneously.
21 """
22 from __future__ import print_function
23
24 import hashlib
25 import os
26 import sys
27 from subprocess import Popen, PIPE
28
29 from luigi import six
30
31
32 def getpcmd(pid):
33 """
34 Returns command of process.
35
36 :param pid:
37 """
38 if os.name == "nt":
39 # Use wmic command instead of ps on Windows.
40 cmd = 'wmic path win32_process where ProcessID=%s get Commandline 2> nul' % (pid, )
41 with os.popen(cmd, 'r') as p:
42 lines = [line for line in p.readlines() if line.strip("\r\n ") != ""]
43 if lines:
44 _, val = lines
45 return val
46 elif sys.platform == "darwin":
47 # Use pgrep instead of /proc on macOS.
48 pidfile = ".%d.pid" % (pid, )
49 with open(pidfile, 'w') as f:
50 f.write(str(pid))
51 try:
52 p = Popen(['pgrep', '-lf', '-F', pidfile], stdout=PIPE)
53 stdout, _ = p.communicate()
54 line = stdout.decode('utf8').strip()
55 if line:
56 _, scmd = line.split(' ', 1)
57 return scmd
58 finally:
59 os.unlink(pidfile)
60 else:
61 # Use the /proc filesystem
62 # At least on android there have been some issues with not all
63 # process infos being readable. In these cases using the `ps` command
64 # worked. See the pull request at
65 # https://github.com/spotify/luigi/pull/1876
66 try:
67 with open('/proc/{0}/cmdline'.format(pid), 'r') as fh:
68 if six.PY3:
69 return fh.read().replace('\0', ' ').rstrip()
70 else:
71 return fh.read().replace('\0', ' ').decode('utf8').rstrip()
72 except IOError:
73 # the system may not allow reading the command line
74 # of a process owned by another user
75 pass
76
77 # Fallback instead of None, for e.g. Cygwin where -o is an "unknown option" for the ps command:
78 return '[PROCESS_WITH_PID={}]'.format(pid)
79
80
81 def get_info(pid_dir, my_pid=None):
82 # Check the name and pid of this process
83 if my_pid is None:
84 my_pid = os.getpid()
85
86 my_cmd = getpcmd(my_pid)
87 cmd_hash = my_cmd.encode('utf8')
88 pid_file = os.path.join(pid_dir, hashlib.md5(cmd_hash).hexdigest()) + '.pid'
89
90 return my_pid, my_cmd, pid_file
91
92
93 def acquire_for(pid_dir, num_available=1, kill_signal=None):
94 """
95 Makes sure the process is only run once at the same time with the same name.
96
97 Notice that we since we check the process name, different parameters to the same
98 command can spawn multiple processes at the same time, i.e. running
99 "/usr/bin/my_process" does not prevent anyone from launching
100 "/usr/bin/my_process --foo bar".
101 """
102
103 my_pid, my_cmd, pid_file = get_info(pid_dir)
104
105 # Check if there is a pid file corresponding to this name
106 if not os.path.exists(pid_dir):
107 os.mkdir(pid_dir)
108 os.chmod(pid_dir, 0o777)
109
110 # Let variable "pids" be all pids who exist in the .pid-file who are still
111 # about running the same command.
112 pids = {pid for pid in _read_pids_file(pid_file) if getpcmd(pid) == my_cmd}
113
114 if kill_signal is not None:
115 for pid in pids:
116 os.kill(pid, kill_signal)
117 print('Sent kill signal to Pids: {}'.format(pids))
118 # We allow for the killer to progress, yet we don't want these to stack
119 # up! So we only allow it once.
120 num_available += 1
121
122 if len(pids) >= num_available:
123 # We are already running under a different pid
124 print('Pid(s) {} already running'.format(pids))
125 if kill_signal is not None:
126 print('Note: There have (probably) been 1 other "--take-lock"'
127 ' process which continued to run! Probably no need to run'
128 ' this one as well.')
129 return False
130
131 _write_pids_file(pid_file, pids | {my_pid})
132
133 return True
134
135
136 def _read_pids_file(pid_file):
137 # First setup a python 2 vs 3 compatibility
138 # http://stackoverflow.com/a/21368622/621449
139 try:
140 FileNotFoundError
141 except NameError:
142 # Should only happen on python 2
143 FileNotFoundError = IOError
144 # If the file happen to not exist, simply return
145 # an empty set()
146 try:
147 with open(pid_file, 'r') as f:
148 return {int(pid_str.strip()) for pid_str in f if pid_str.strip()}
149 except FileNotFoundError:
150 return set()
151
152
153 def _write_pids_file(pid_file, pids_set):
154 with open(pid_file, 'w') as f:
155 f.writelines('{}\n'.format(pid) for pid in pids_set)
156
157 # Make the .pid-file writable by all (when the os allows for it)
158 if os.name != 'nt':
159 s = os.stat(pid_file)
160 if os.getuid() == s.st_uid:
161 os.chmod(pid_file, s.st_mode | 0o777)
162
[end of luigi/lock.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/luigi/lock.py b/luigi/lock.py
--- a/luigi/lock.py
+++ b/luigi/lock.py
@@ -21,6 +21,7 @@
"""
from __future__ import print_function
+import errno
import hashlib
import os
import sys
@@ -102,10 +103,14 @@
my_pid, my_cmd, pid_file = get_info(pid_dir)
- # Check if there is a pid file corresponding to this name
- if not os.path.exists(pid_dir):
+ # Create a pid file if it does not exist
+ try:
os.mkdir(pid_dir)
os.chmod(pid_dir, 0o777)
+ except OSError as exc:
+ if exc.errno != errno.EEXIST:
+ raise
+ pass
# Let variable "pids" be all pids who exist in the .pid-file who are still
# about running the same command.
|
{"golden_diff": "diff --git a/luigi/lock.py b/luigi/lock.py\n--- a/luigi/lock.py\n+++ b/luigi/lock.py\n@@ -21,6 +21,7 @@\n \"\"\"\n from __future__ import print_function\n \n+import errno\n import hashlib\n import os\n import sys\n@@ -102,10 +103,14 @@\n \n my_pid, my_cmd, pid_file = get_info(pid_dir)\n \n- # Check if there is a pid file corresponding to this name\n- if not os.path.exists(pid_dir):\n+ # Create a pid file if it does not exist\n+ try:\n os.mkdir(pid_dir)\n os.chmod(pid_dir, 0o777)\n+ except OSError as exc:\n+ if exc.errno != errno.EEXIST:\n+ raise\n+ pass\n \n # Let variable \"pids\" be all pids who exist in the .pid-file who are still\n # about running the same command.\n", "issue": "race condition on lock :(\nI think there is a race condition on \r\n**luigi/lock.py\", line 93, in acquire_for**\r\n\r\n```python\r\n# Check if there is a pid file corresponding to this name\r\nif not os.path.exists(pid_dir):\r\n os.mkdir(pid_dir)\r\n```\r\nbetween `if not [...]` and `mkdir` another process could have created the pid_dir resulting in an unhandled OSError exception.\r\n\r\nI think that ignore the exception if the folder exists will be enough, or perhaps just create the folder and say sorry if it was just there...\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Copyright 2012-2015 Spotify AB\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n\"\"\"\nLocking functionality when launching things from the command line.\nUses a pidfile.\nThis prevents multiple identical workflows to be launched simultaneously.\n\"\"\"\nfrom __future__ import print_function\n\nimport hashlib\nimport os\nimport sys\nfrom subprocess import Popen, PIPE\n\nfrom luigi import six\n\n\ndef getpcmd(pid):\n \"\"\"\n Returns command of process.\n\n :param pid:\n \"\"\"\n if os.name == \"nt\":\n # Use wmic command instead of ps on Windows.\n cmd = 'wmic path win32_process where ProcessID=%s get Commandline 2> nul' % (pid, )\n with os.popen(cmd, 'r') as p:\n lines = [line for line in p.readlines() if line.strip(\"\\r\\n \") != \"\"]\n if lines:\n _, val = lines\n return val\n elif sys.platform == \"darwin\":\n # Use pgrep instead of /proc on macOS.\n pidfile = \".%d.pid\" % (pid, )\n with open(pidfile, 'w') as f:\n f.write(str(pid))\n try:\n p = Popen(['pgrep', '-lf', '-F', pidfile], stdout=PIPE)\n stdout, _ = p.communicate()\n line = stdout.decode('utf8').strip()\n if line:\n _, scmd = line.split(' ', 1)\n return scmd\n finally:\n os.unlink(pidfile)\n else:\n # Use the /proc filesystem\n # At least on android there have been some issues with not all\n # process infos being readable. In these cases using the `ps` command\n # worked. See the pull request at\n # https://github.com/spotify/luigi/pull/1876\n try:\n with open('/proc/{0}/cmdline'.format(pid), 'r') as fh:\n if six.PY3:\n return fh.read().replace('\\0', ' ').rstrip()\n else:\n return fh.read().replace('\\0', ' ').decode('utf8').rstrip()\n except IOError:\n # the system may not allow reading the command line\n # of a process owned by another user\n pass\n\n # Fallback instead of None, for e.g. Cygwin where -o is an \"unknown option\" for the ps command:\n return '[PROCESS_WITH_PID={}]'.format(pid)\n\n\ndef get_info(pid_dir, my_pid=None):\n # Check the name and pid of this process\n if my_pid is None:\n my_pid = os.getpid()\n\n my_cmd = getpcmd(my_pid)\n cmd_hash = my_cmd.encode('utf8')\n pid_file = os.path.join(pid_dir, hashlib.md5(cmd_hash).hexdigest()) + '.pid'\n\n return my_pid, my_cmd, pid_file\n\n\ndef acquire_for(pid_dir, num_available=1, kill_signal=None):\n \"\"\"\n Makes sure the process is only run once at the same time with the same name.\n\n Notice that we since we check the process name, different parameters to the same\n command can spawn multiple processes at the same time, i.e. running\n \"/usr/bin/my_process\" does not prevent anyone from launching\n \"/usr/bin/my_process --foo bar\".\n \"\"\"\n\n my_pid, my_cmd, pid_file = get_info(pid_dir)\n\n # Check if there is a pid file corresponding to this name\n if not os.path.exists(pid_dir):\n os.mkdir(pid_dir)\n os.chmod(pid_dir, 0o777)\n\n # Let variable \"pids\" be all pids who exist in the .pid-file who are still\n # about running the same command.\n pids = {pid for pid in _read_pids_file(pid_file) if getpcmd(pid) == my_cmd}\n\n if kill_signal is not None:\n for pid in pids:\n os.kill(pid, kill_signal)\n print('Sent kill signal to Pids: {}'.format(pids))\n # We allow for the killer to progress, yet we don't want these to stack\n # up! So we only allow it once.\n num_available += 1\n\n if len(pids) >= num_available:\n # We are already running under a different pid\n print('Pid(s) {} already running'.format(pids))\n if kill_signal is not None:\n print('Note: There have (probably) been 1 other \"--take-lock\"'\n ' process which continued to run! Probably no need to run'\n ' this one as well.')\n return False\n\n _write_pids_file(pid_file, pids | {my_pid})\n\n return True\n\n\ndef _read_pids_file(pid_file):\n # First setup a python 2 vs 3 compatibility\n # http://stackoverflow.com/a/21368622/621449\n try:\n FileNotFoundError\n except NameError:\n # Should only happen on python 2\n FileNotFoundError = IOError\n # If the file happen to not exist, simply return\n # an empty set()\n try:\n with open(pid_file, 'r') as f:\n return {int(pid_str.strip()) for pid_str in f if pid_str.strip()}\n except FileNotFoundError:\n return set()\n\n\ndef _write_pids_file(pid_file, pids_set):\n with open(pid_file, 'w') as f:\n f.writelines('{}\\n'.format(pid) for pid in pids_set)\n\n # Make the .pid-file writable by all (when the os allows for it)\n if os.name != 'nt':\n s = os.stat(pid_file)\n if os.getuid() == s.st_uid:\n os.chmod(pid_file, s.st_mode | 0o777)\n", "path": "luigi/lock.py"}]}
| 2,434 | 222 |
gh_patches_debug_64143
|
rasdani/github-patches
|
git_diff
|
scoutapp__scout_apm_python-433
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Don't crash the socket for unrecognized responses
Before #400 when testing against the core agent I discovered the python agent crashes when the core agent doesn't return the expected response, like:
```
2019-11-25T18:08:49+0000 DEBUG scout_apm.core.socket CoreAgentSocket thread exception: error('unpack requires a buffer of 4 bytes')
Traceback (most recent call last):
File "/Users/chainz/Documents/Projects/scout_apm_python/src/scout_apm/core/socket.py", line 102, in run
result = self._send(body)
File "/Users/chainz/Documents/Projects/scout_apm_python/src/scout_apm/core/socket.py", line 171, in _send
self._read_response()
File "/Users/chainz/Documents/Projects/scout_apm_python/src/scout_apm/core/socket.py", line 183, in _read_response
size = struct.unpack(">I", raw_size)[0]
struct.error: unpack requires a buffer of 4 bytes
```
I think we should make this more robust - we can avoid trying to unpack a response that isn't the right length. The Core agent was sending back nothing on parse error.
</issue>
<code>
[start of src/scout_apm/core/socket.py]
1 # coding=utf-8
2 from __future__ import absolute_import, division, print_function, unicode_literals
3
4 import json
5 import logging
6 import os
7 import socket
8 import struct
9 import threading
10 import time
11
12 from scout_apm.compat import queue
13 from scout_apm.core.commands import Register
14 from scout_apm.core.config import scout_config
15
16 SECOND = 1 # time unit - monkey-patched in tests to make them run faster
17
18 logger = logging.getLogger(__name__)
19
20
21 class CoreAgentSocket(threading.Thread):
22 _instance = None
23 _instance_lock = threading.Lock()
24
25 @classmethod
26 def instance(cls):
27 with cls._instance_lock:
28 # No instance exists yet.
29 if cls._instance is None:
30 cls._instance = cls()
31 return cls._instance
32
33 # An instance exists but is no longer running.
34 if not cls._instance.running():
35 cls._instance = cls()
36 return cls._instance
37
38 # An instance exists and is running (or in the process of
39 # starting or in the process of stopping). In any case,
40 # return this instance.
41 return cls._instance
42
43 def __init__(self, *args, **kwargs):
44 super(CoreAgentSocket, self).__init__()
45 # Socket related
46 self.socket_path = scout_config.value("socket_path")
47 self.socket = socket.socket(socket.AF_UNIX, socket.SOCK_STREAM)
48
49 # Threading control related
50 self._started_event = threading.Event()
51 self._stop_event = threading.Event()
52 self._stopped_event = threading.Event()
53
54 # Command queues
55 self.command_queue = queue.Queue(maxsize=500)
56
57 # Set Thread options
58 self.daemon = True
59
60 # Set the started event here to avoid races in the class instance()
61 # method. If there is an exception in the socket thread then it will
62 # clear this event on exit.
63 self._started_event.set()
64
65 # Now call start() which eventually launches run() in another thread.
66 self.start()
67
68 def __del__(self):
69 self.stop()
70
71 def running(self):
72 return self._started_event.is_set()
73
74 def stop(self):
75 if self._started_event.is_set():
76 self._stop_event.set()
77 self.command_queue.put(None, False) # unblock self.command_queue.get
78 stopped = self._stopped_event.wait(2 * SECOND)
79 if stopped:
80 return True
81 else:
82 logger.debug("CoreAgentSocket Failed to stop thread within timeout!")
83 return False
84 else:
85 return True
86
87 def run(self):
88 """
89 Called by the threading system
90 """
91
92 try:
93 self._connect()
94 self._register()
95 while True:
96 try:
97 body = self.command_queue.get(block=True, timeout=1 * SECOND)
98 except queue.Empty:
99 body = None
100
101 if body is not None:
102 result = self._send(body)
103 if result:
104 self.command_queue.task_done()
105 else:
106 # Something was wrong with the socket.
107 self._disconnect()
108 self._connect()
109 self._register()
110
111 # Check for stop event after a read from the queue. This is to
112 # allow you to open a socket, immediately send to it, and then
113 # stop it. We do this in the Metadata send at application start
114 # time
115 if self._stop_event.is_set():
116 logger.debug("CoreAgentSocket thread stopping.")
117 break
118 except Exception as exc:
119 logger.debug("CoreAgentSocket thread exception: %r", exc, exc_info=exc)
120 finally:
121 self._started_event.clear()
122 self._stop_event.clear()
123 self._stopped_event.set()
124 logger.debug("CoreAgentSocket thread stopped.")
125
126 def send(self, command):
127 try:
128 self.command_queue.put(command, False)
129 except queue.Full as exc:
130 # TODO mark the command as not queued?
131 logger.debug("CoreAgentSocket error on send: %r", exc, exc_info=exc)
132
133 def _send(self, command):
134 msg = command.message()
135
136 try:
137 data = json.dumps(msg)
138 except (ValueError, TypeError) as exc:
139 logger.debug(
140 "Exception when serializing command message: %r", exc, exc_info=exc
141 )
142 return False
143
144 try:
145 self.socket.sendall(self._message_length(data))
146 except OSError as exc:
147 logger.debug(
148 "CoreAgentSocket exception on length _send: "
149 "%r on PID: %s on thread: %s",
150 exc,
151 os.getpid(),
152 threading.current_thread(),
153 exc_info=exc,
154 )
155 return None
156
157 try:
158 self.socket.sendall(data.encode())
159 except OSError as exc:
160 logger.debug(
161 "CoreAgentSocket exception on data _send: "
162 "%r on PID: %s on thread: %s",
163 exc,
164 os.getpid(),
165 threading.current_thread(),
166 exc_info=exc,
167 )
168 return None
169
170 # TODO do something with the response sent back in reply to command
171 self._read_response()
172
173 return True
174
175 def _message_length(self, body):
176 length = len(body)
177 return struct.pack(">I", length)
178
179 def _read_response(self):
180 try:
181 raw_size = self.socket.recv(4)
182 size = struct.unpack(">I", raw_size)[0]
183 message = bytearray(0)
184
185 while len(message) < size:
186 recv = self.socket.recv(size)
187 message += recv
188
189 return message
190 except OSError as exc:
191 logger.debug(
192 "CoreAgentSocket error on read response: %r", exc, exc_info=exc
193 )
194 return None
195
196 def _register(self):
197 self._send(
198 Register(
199 app=scout_config.value("name"),
200 key=scout_config.value("key"),
201 hostname=scout_config.value("hostname"),
202 )
203 )
204
205 def _connect(self, connect_attempts=5, retry_wait_secs=1):
206 for attempt in range(1, connect_attempts + 1):
207 logger.debug(
208 "CoreAgentSocket attempt %d, connecting to %s, PID: %s, Thread: %s",
209 attempt,
210 self.socket_path,
211 os.getpid(),
212 threading.current_thread(),
213 )
214 try:
215 self.socket.connect(self.socket_path)
216 self.socket.settimeout(3 * SECOND)
217 logger.debug("CoreAgentSocket is connected")
218 return True
219 except socket.error as exc:
220 logger.debug("CoreAgentSocket connection error: %r", exc, exc_info=exc)
221 # Return without waiting when reaching the maximum number of attempts.
222 if attempt >= connect_attempts:
223 return False
224 time.sleep(retry_wait_secs * SECOND)
225
226 def _disconnect(self):
227 logger.debug("CoreAgentSocket disconnecting from %s", self.socket_path)
228 try:
229 self.socket.close()
230 except socket.error as exc:
231 logger.debug(
232 "CoreAgentSocket exception on disconnect: %r", exc, exc_info=exc
233 )
234 finally:
235 self.socket = socket.socket(socket.AF_UNIX, socket.SOCK_STREAM)
236
[end of src/scout_apm/core/socket.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/scout_apm/core/socket.py b/src/scout_apm/core/socket.py
--- a/src/scout_apm/core/socket.py
+++ b/src/scout_apm/core/socket.py
@@ -179,6 +179,9 @@
def _read_response(self):
try:
raw_size = self.socket.recv(4)
+ if len(raw_size) != 4:
+ # Ignore invalid responses
+ return None
size = struct.unpack(">I", raw_size)[0]
message = bytearray(0)
|
{"golden_diff": "diff --git a/src/scout_apm/core/socket.py b/src/scout_apm/core/socket.py\n--- a/src/scout_apm/core/socket.py\n+++ b/src/scout_apm/core/socket.py\n@@ -179,6 +179,9 @@\n def _read_response(self):\n try:\n raw_size = self.socket.recv(4)\n+ if len(raw_size) != 4:\n+ # Ignore invalid responses\n+ return None\n size = struct.unpack(\">I\", raw_size)[0]\n message = bytearray(0)\n", "issue": "Don't crash the socket for unrecognized responses\nBefore #400 when testing against the core agent I discovered the python agent crashes when the core agent doesn't return the expected response, like:\r\n\r\n```\r\n2019-11-25T18:08:49+0000 DEBUG scout_apm.core.socket CoreAgentSocket thread exception: error('unpack requires a buffer of 4 bytes')\r\nTraceback (most recent call last):\r\n File \"/Users/chainz/Documents/Projects/scout_apm_python/src/scout_apm/core/socket.py\", line 102, in run\r\n result = self._send(body)\r\n File \"/Users/chainz/Documents/Projects/scout_apm_python/src/scout_apm/core/socket.py\", line 171, in _send\r\n self._read_response()\r\n File \"/Users/chainz/Documents/Projects/scout_apm_python/src/scout_apm/core/socket.py\", line 183, in _read_response\r\n size = struct.unpack(\">I\", raw_size)[0]\r\nstruct.error: unpack requires a buffer of 4 bytes\r\n```\r\n\r\nI think we should make this more robust - we can avoid trying to unpack a response that isn't the right length. The Core agent was sending back nothing on parse error.\n", "before_files": [{"content": "# coding=utf-8\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport json\nimport logging\nimport os\nimport socket\nimport struct\nimport threading\nimport time\n\nfrom scout_apm.compat import queue\nfrom scout_apm.core.commands import Register\nfrom scout_apm.core.config import scout_config\n\nSECOND = 1 # time unit - monkey-patched in tests to make them run faster\n\nlogger = logging.getLogger(__name__)\n\n\nclass CoreAgentSocket(threading.Thread):\n _instance = None\n _instance_lock = threading.Lock()\n\n @classmethod\n def instance(cls):\n with cls._instance_lock:\n # No instance exists yet.\n if cls._instance is None:\n cls._instance = cls()\n return cls._instance\n\n # An instance exists but is no longer running.\n if not cls._instance.running():\n cls._instance = cls()\n return cls._instance\n\n # An instance exists and is running (or in the process of\n # starting or in the process of stopping). In any case,\n # return this instance.\n return cls._instance\n\n def __init__(self, *args, **kwargs):\n super(CoreAgentSocket, self).__init__()\n # Socket related\n self.socket_path = scout_config.value(\"socket_path\")\n self.socket = socket.socket(socket.AF_UNIX, socket.SOCK_STREAM)\n\n # Threading control related\n self._started_event = threading.Event()\n self._stop_event = threading.Event()\n self._stopped_event = threading.Event()\n\n # Command queues\n self.command_queue = queue.Queue(maxsize=500)\n\n # Set Thread options\n self.daemon = True\n\n # Set the started event here to avoid races in the class instance()\n # method. If there is an exception in the socket thread then it will\n # clear this event on exit.\n self._started_event.set()\n\n # Now call start() which eventually launches run() in another thread.\n self.start()\n\n def __del__(self):\n self.stop()\n\n def running(self):\n return self._started_event.is_set()\n\n def stop(self):\n if self._started_event.is_set():\n self._stop_event.set()\n self.command_queue.put(None, False) # unblock self.command_queue.get\n stopped = self._stopped_event.wait(2 * SECOND)\n if stopped:\n return True\n else:\n logger.debug(\"CoreAgentSocket Failed to stop thread within timeout!\")\n return False\n else:\n return True\n\n def run(self):\n \"\"\"\n Called by the threading system\n \"\"\"\n\n try:\n self._connect()\n self._register()\n while True:\n try:\n body = self.command_queue.get(block=True, timeout=1 * SECOND)\n except queue.Empty:\n body = None\n\n if body is not None:\n result = self._send(body)\n if result:\n self.command_queue.task_done()\n else:\n # Something was wrong with the socket.\n self._disconnect()\n self._connect()\n self._register()\n\n # Check for stop event after a read from the queue. This is to\n # allow you to open a socket, immediately send to it, and then\n # stop it. We do this in the Metadata send at application start\n # time\n if self._stop_event.is_set():\n logger.debug(\"CoreAgentSocket thread stopping.\")\n break\n except Exception as exc:\n logger.debug(\"CoreAgentSocket thread exception: %r\", exc, exc_info=exc)\n finally:\n self._started_event.clear()\n self._stop_event.clear()\n self._stopped_event.set()\n logger.debug(\"CoreAgentSocket thread stopped.\")\n\n def send(self, command):\n try:\n self.command_queue.put(command, False)\n except queue.Full as exc:\n # TODO mark the command as not queued?\n logger.debug(\"CoreAgentSocket error on send: %r\", exc, exc_info=exc)\n\n def _send(self, command):\n msg = command.message()\n\n try:\n data = json.dumps(msg)\n except (ValueError, TypeError) as exc:\n logger.debug(\n \"Exception when serializing command message: %r\", exc, exc_info=exc\n )\n return False\n\n try:\n self.socket.sendall(self._message_length(data))\n except OSError as exc:\n logger.debug(\n \"CoreAgentSocket exception on length _send: \"\n \"%r on PID: %s on thread: %s\",\n exc,\n os.getpid(),\n threading.current_thread(),\n exc_info=exc,\n )\n return None\n\n try:\n self.socket.sendall(data.encode())\n except OSError as exc:\n logger.debug(\n \"CoreAgentSocket exception on data _send: \"\n \"%r on PID: %s on thread: %s\",\n exc,\n os.getpid(),\n threading.current_thread(),\n exc_info=exc,\n )\n return None\n\n # TODO do something with the response sent back in reply to command\n self._read_response()\n\n return True\n\n def _message_length(self, body):\n length = len(body)\n return struct.pack(\">I\", length)\n\n def _read_response(self):\n try:\n raw_size = self.socket.recv(4)\n size = struct.unpack(\">I\", raw_size)[0]\n message = bytearray(0)\n\n while len(message) < size:\n recv = self.socket.recv(size)\n message += recv\n\n return message\n except OSError as exc:\n logger.debug(\n \"CoreAgentSocket error on read response: %r\", exc, exc_info=exc\n )\n return None\n\n def _register(self):\n self._send(\n Register(\n app=scout_config.value(\"name\"),\n key=scout_config.value(\"key\"),\n hostname=scout_config.value(\"hostname\"),\n )\n )\n\n def _connect(self, connect_attempts=5, retry_wait_secs=1):\n for attempt in range(1, connect_attempts + 1):\n logger.debug(\n \"CoreAgentSocket attempt %d, connecting to %s, PID: %s, Thread: %s\",\n attempt,\n self.socket_path,\n os.getpid(),\n threading.current_thread(),\n )\n try:\n self.socket.connect(self.socket_path)\n self.socket.settimeout(3 * SECOND)\n logger.debug(\"CoreAgentSocket is connected\")\n return True\n except socket.error as exc:\n logger.debug(\"CoreAgentSocket connection error: %r\", exc, exc_info=exc)\n # Return without waiting when reaching the maximum number of attempts.\n if attempt >= connect_attempts:\n return False\n time.sleep(retry_wait_secs * SECOND)\n\n def _disconnect(self):\n logger.debug(\"CoreAgentSocket disconnecting from %s\", self.socket_path)\n try:\n self.socket.close()\n except socket.error as exc:\n logger.debug(\n \"CoreAgentSocket exception on disconnect: %r\", exc, exc_info=exc\n )\n finally:\n self.socket = socket.socket(socket.AF_UNIX, socket.SOCK_STREAM)\n", "path": "src/scout_apm/core/socket.py"}]}
| 2,956 | 121 |
gh_patches_debug_32967
|
rasdani/github-patches
|
git_diff
|
deepset-ai__haystack-5199
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Import utils fetch_archive_from_http url parsing URL format assumption
**Describe the bug**
The function `fetch_archive_from_http` from import utils makes the assumption that a URL ends with the file extension. This assumption prevents fetching an archive from a URL that contains a query after the file extension. See also [RFC 3986](http://tools.ietf.org/html/rfc3986#section-3).
Fetching an archive from an [Amazon S3 presigned URL](https://docs.aws.amazon.com/AmazonS3/latest/userguide/using-presigned-url.html) is one use case that results in this bug.
**Error message**
`Skipped url https:/<S3_BUCKET_NAME>.s3.<REGION>.amazonaws.com/filename.tar.xz?response-content-disposition=inline&X-Amz-Security-Token=<TOKEN>&X-Amz-Algorithm=<X-AMZ-ALGORITHM>&X-Amz-Date=<X-AMZ-DATE>&X-Amz-SignedHeaders=host&X-Amz-Expires=<X-AMZ-EXPIRES>&X-Amz-Credential=<CREDENTIAL>&X-Amz-Signature=<SIGNATURE> as file type is not supported here. See haystack documentation for support of more file types`
**Expected behavior**
I expect the function to fetch the archive without an error.
**Additional context**
Add any other context about the problem here, like document types / preprocessing steps / settings of reader etc.
**To Reproduce**
1. Create an Amazon S3 bucket.
2. Upload a tar.xz archive into your Amazon S3 bucket.
3. Create an [Amazon S3 presigned URL](https://docs.aws.amazon.com/AmazonS3/latest/userguide/ShareObjectPreSignedURL.html) for your archive.
4. Fetch your archive from the Amazon S# presigned URL
```python
from haystack.utils import fetch_archive_from_http
url = "<YOUR_PRESIGNED_URL_FROM_STEP_3>"
fetch_archive_from_http(url, output_dir="my_archive_dir")
```
**FAQ Check**
- [x] Have you had a look at [our new FAQ page](https://docs.haystack.deepset.ai/docs/faq)?
**System:**
- OS: n/a
- GPU/CPU: n/a
- Haystack version (commit or version number): v1.17.x
- DocumentStore: n/a
- Reader: n/a
- Retriever: n/a
</issue>
<code>
[start of haystack/utils/import_utils.py]
1 import io
2 import gzip
3 import tarfile
4 import zipfile
5 import logging
6 import importlib
7 import importlib.util
8 from pathlib import Path
9 from typing import Optional, Dict, Union, Tuple, List
10
11 import requests
12
13 from haystack.errors import DatasetsError
14 from haystack.schema import Document
15
16
17 logger = logging.getLogger(__name__)
18
19
20 def load_documents_from_hf_datasets(dataset_name: str, split: Optional[str] = "train") -> List[Document]:
21 """
22 Load a list of Haystack Documents from a remote Hugging Face dataset.
23
24 :param dataset_name: A Hugging Face dataset containing Haystack Documents
25 :param split: The split of the Hugging Face dataset to load from. By default, this is set to "train".
26 :return: a List of Haystack Documents
27 """
28 try:
29 from datasets import load_dataset, load_dataset_builder
30 except ImportError:
31 raise ImportError(
32 "Failed to import `datasets`, Run 'pip install datasets>=2.6.0' "
33 "to install the datasets library to use this function."
34 )
35
36 dataset = load_dataset_builder(dataset_name)
37 if "content" not in dataset.info.features.keys():
38 raise DatasetsError(
39 f"{dataset_name} does not contain a `content` field which is required by Haystack to "
40 f"create `Document` objects."
41 )
42
43 remote_dataset = load_dataset(dataset_name, split=split)
44 documents = [Document.from_dict(document) for document in remote_dataset]
45
46 return documents
47
48
49 def fetch_archive_from_http(
50 url: str,
51 output_dir: str,
52 proxies: Optional[Dict[str, str]] = None,
53 timeout: Union[float, Tuple[float, float]] = 10.0,
54 ) -> bool:
55 """
56 Fetch an archive (zip, gz or tar.gz) from a url via http and extract content to an output directory.
57
58 :param url: http address
59 :param output_dir: local path
60 :param proxies: proxies details as required by requests library
61 :param timeout: How many seconds to wait for the server to send data before giving up,
62 as a float, or a :ref:`(connect timeout, read timeout) <timeouts>` tuple.
63 Defaults to 10 seconds.
64 :return: if anything got fetched
65 """
66 # verify & prepare local directory
67 path = Path(output_dir)
68 if not path.exists():
69 path.mkdir(parents=True)
70
71 is_not_empty = len(list(Path(path).rglob("*"))) > 0
72 if is_not_empty:
73 logger.info("Found data stored in '%s'. Delete this first if you really want to fetch new data.", output_dir)
74 return False
75 else:
76 logger.info("Fetching from %s to '%s'", url, output_dir)
77
78 _, _, archive_extension = url.rpartition(".")
79 request_data = requests.get(url, proxies=proxies, timeout=timeout)
80
81 if archive_extension == "zip":
82 zip_archive = zipfile.ZipFile(io.BytesIO(request_data.content))
83 zip_archive.extractall(output_dir)
84 elif archive_extension == "gz" and not "tar.gz" in url:
85 gzip_archive = gzip.GzipFile(fileobj=io.BytesIO(request_data.content))
86 file_content = gzip_archive.read()
87 file_name = url.split("/")[-1][: -(len(archive_extension) + 1)]
88 with open(f"{output_dir}/{file_name}", "wb") as file:
89 file.write(file_content)
90 elif archive_extension in ["gz", "bz2", "xz"]:
91 tar_archive = tarfile.open(fileobj=io.BytesIO(request_data.content), mode="r|*")
92 tar_archive.extractall(output_dir)
93 else:
94 logger.warning(
95 "Skipped url %s as file type is not supported here. "
96 "See haystack documentation for support of more file types",
97 url,
98 )
99
100 return True
101
102
103 def is_whisper_available():
104 return importlib.util.find_spec("whisper") is not None
105
[end of haystack/utils/import_utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/haystack/utils/import_utils.py b/haystack/utils/import_utils.py
--- a/haystack/utils/import_utils.py
+++ b/haystack/utils/import_utils.py
@@ -7,6 +7,8 @@
import importlib.util
from pathlib import Path
from typing import Optional, Dict, Union, Tuple, List
+from urllib.parse import urlparse, unquote
+from os.path import splitext, basename
import requests
@@ -93,6 +95,20 @@
return documents
+def get_filename_extension_from_url(url: str) -> Tuple[str, str]:
+ """
+ Extracts the filename and file extension from an url.
+
+ :param url: http address
+ :return: Tuple (filename, file extension) of the file at the url.
+ """
+ parsed = urlparse(url)
+ root, extension = splitext(parsed.path)
+ archive_extension = extension[1:]
+ file_name = unquote(basename(root[1:]))
+ return file_name, archive_extension
+
+
def fetch_archive_from_http(
url: str,
output_dir: str,
@@ -122,7 +138,7 @@
else:
logger.info("Fetching from %s to '%s'", url, output_dir)
- _, _, archive_extension = url.rpartition(".")
+ file_name, archive_extension = get_filename_extension_from_url(url)
request_data = requests.get(url, proxies=proxies, timeout=timeout)
if archive_extension == "zip":
@@ -131,7 +147,6 @@
elif archive_extension == "gz" and not "tar.gz" in url:
gzip_archive = gzip.GzipFile(fileobj=io.BytesIO(request_data.content))
file_content = gzip_archive.read()
- file_name = url.split("/")[-1][: -(len(archive_extension) + 1)]
with open(f"{output_dir}/{file_name}", "wb") as file:
file.write(file_content)
elif archive_extension in ["gz", "bz2", "xz"]:
|
{"golden_diff": "diff --git a/haystack/utils/import_utils.py b/haystack/utils/import_utils.py\n--- a/haystack/utils/import_utils.py\n+++ b/haystack/utils/import_utils.py\n@@ -7,6 +7,8 @@\n import importlib.util\n from pathlib import Path\n from typing import Optional, Dict, Union, Tuple, List\n+from urllib.parse import urlparse, unquote\n+from os.path import splitext, basename\n \n import requests\n \n@@ -93,6 +95,20 @@\n return documents\n \n \n+def get_filename_extension_from_url(url: str) -> Tuple[str, str]:\n+ \"\"\"\n+ Extracts the filename and file extension from an url.\n+\n+ :param url: http address\n+ :return: Tuple (filename, file extension) of the file at the url.\n+ \"\"\"\n+ parsed = urlparse(url)\n+ root, extension = splitext(parsed.path)\n+ archive_extension = extension[1:]\n+ file_name = unquote(basename(root[1:]))\n+ return file_name, archive_extension\n+\n+\n def fetch_archive_from_http(\n url: str,\n output_dir: str,\n@@ -122,7 +138,7 @@\n else:\n logger.info(\"Fetching from %s to '%s'\", url, output_dir)\n \n- _, _, archive_extension = url.rpartition(\".\")\n+ file_name, archive_extension = get_filename_extension_from_url(url)\n request_data = requests.get(url, proxies=proxies, timeout=timeout)\n \n if archive_extension == \"zip\":\n@@ -131,7 +147,6 @@\n elif archive_extension == \"gz\" and not \"tar.gz\" in url:\n gzip_archive = gzip.GzipFile(fileobj=io.BytesIO(request_data.content))\n file_content = gzip_archive.read()\n- file_name = url.split(\"/\")[-1][: -(len(archive_extension) + 1)]\n with open(f\"{output_dir}/{file_name}\", \"wb\") as file:\n file.write(file_content)\n elif archive_extension in [\"gz\", \"bz2\", \"xz\"]:\n", "issue": "Import utils fetch_archive_from_http url parsing URL format assumption\n**Describe the bug**\r\nThe function `fetch_archive_from_http` from import utils makes the assumption that a URL ends with the file extension. This assumption prevents fetching an archive from a URL that contains a query after the file extension. See also [RFC 3986](http://tools.ietf.org/html/rfc3986#section-3).\r\n\r\nFetching an archive from an [Amazon S3 presigned URL](https://docs.aws.amazon.com/AmazonS3/latest/userguide/using-presigned-url.html) is one use case that results in this bug.\r\n\r\n**Error message**\r\n`Skipped url https:/<S3_BUCKET_NAME>.s3.<REGION>.amazonaws.com/filename.tar.xz?response-content-disposition=inline&X-Amz-Security-Token=<TOKEN>&X-Amz-Algorithm=<X-AMZ-ALGORITHM>&X-Amz-Date=<X-AMZ-DATE>&X-Amz-SignedHeaders=host&X-Amz-Expires=<X-AMZ-EXPIRES>&X-Amz-Credential=<CREDENTIAL>&X-Amz-Signature=<SIGNATURE> as file type is not supported here. See haystack documentation for support of more file types`\r\n\r\n**Expected behavior**\r\nI expect the function to fetch the archive without an error.\r\n\r\n**Additional context**\r\nAdd any other context about the problem here, like document types / preprocessing steps / settings of reader etc.\r\n\r\n**To Reproduce**\r\n1. Create an Amazon S3 bucket.\r\n2. Upload a tar.xz archive into your Amazon S3 bucket.\r\n3. Create an [Amazon S3 presigned URL](https://docs.aws.amazon.com/AmazonS3/latest/userguide/ShareObjectPreSignedURL.html) for your archive.\r\n4. Fetch your archive from the Amazon S# presigned URL\r\n```python\r\nfrom haystack.utils import fetch_archive_from_http\r\n\r\nurl = \"<YOUR_PRESIGNED_URL_FROM_STEP_3>\"\r\nfetch_archive_from_http(url, output_dir=\"my_archive_dir\")\r\n```\r\n\r\n**FAQ Check**\r\n- [x] Have you had a look at [our new FAQ page](https://docs.haystack.deepset.ai/docs/faq)?\r\n\r\n**System:**\r\n - OS: n/a\r\n - GPU/CPU: n/a\r\n - Haystack version (commit or version number): v1.17.x\r\n - DocumentStore: n/a\r\n - Reader: n/a\r\n - Retriever: n/a\r\n\n", "before_files": [{"content": "import io\nimport gzip\nimport tarfile\nimport zipfile\nimport logging\nimport importlib\nimport importlib.util\nfrom pathlib import Path\nfrom typing import Optional, Dict, Union, Tuple, List\n\nimport requests\n\nfrom haystack.errors import DatasetsError\nfrom haystack.schema import Document\n\n\nlogger = logging.getLogger(__name__)\n\n\ndef load_documents_from_hf_datasets(dataset_name: str, split: Optional[str] = \"train\") -> List[Document]:\n \"\"\"\n Load a list of Haystack Documents from a remote Hugging Face dataset.\n\n :param dataset_name: A Hugging Face dataset containing Haystack Documents\n :param split: The split of the Hugging Face dataset to load from. By default, this is set to \"train\".\n :return: a List of Haystack Documents\n \"\"\"\n try:\n from datasets import load_dataset, load_dataset_builder\n except ImportError:\n raise ImportError(\n \"Failed to import `datasets`, Run 'pip install datasets>=2.6.0' \"\n \"to install the datasets library to use this function.\"\n )\n\n dataset = load_dataset_builder(dataset_name)\n if \"content\" not in dataset.info.features.keys():\n raise DatasetsError(\n f\"{dataset_name} does not contain a `content` field which is required by Haystack to \"\n f\"create `Document` objects.\"\n )\n\n remote_dataset = load_dataset(dataset_name, split=split)\n documents = [Document.from_dict(document) for document in remote_dataset]\n\n return documents\n\n\ndef fetch_archive_from_http(\n url: str,\n output_dir: str,\n proxies: Optional[Dict[str, str]] = None,\n timeout: Union[float, Tuple[float, float]] = 10.0,\n) -> bool:\n \"\"\"\n Fetch an archive (zip, gz or tar.gz) from a url via http and extract content to an output directory.\n\n :param url: http address\n :param output_dir: local path\n :param proxies: proxies details as required by requests library\n :param timeout: How many seconds to wait for the server to send data before giving up,\n as a float, or a :ref:`(connect timeout, read timeout) <timeouts>` tuple.\n Defaults to 10 seconds.\n :return: if anything got fetched\n \"\"\"\n # verify & prepare local directory\n path = Path(output_dir)\n if not path.exists():\n path.mkdir(parents=True)\n\n is_not_empty = len(list(Path(path).rglob(\"*\"))) > 0\n if is_not_empty:\n logger.info(\"Found data stored in '%s'. Delete this first if you really want to fetch new data.\", output_dir)\n return False\n else:\n logger.info(\"Fetching from %s to '%s'\", url, output_dir)\n\n _, _, archive_extension = url.rpartition(\".\")\n request_data = requests.get(url, proxies=proxies, timeout=timeout)\n\n if archive_extension == \"zip\":\n zip_archive = zipfile.ZipFile(io.BytesIO(request_data.content))\n zip_archive.extractall(output_dir)\n elif archive_extension == \"gz\" and not \"tar.gz\" in url:\n gzip_archive = gzip.GzipFile(fileobj=io.BytesIO(request_data.content))\n file_content = gzip_archive.read()\n file_name = url.split(\"/\")[-1][: -(len(archive_extension) + 1)]\n with open(f\"{output_dir}/{file_name}\", \"wb\") as file:\n file.write(file_content)\n elif archive_extension in [\"gz\", \"bz2\", \"xz\"]:\n tar_archive = tarfile.open(fileobj=io.BytesIO(request_data.content), mode=\"r|*\")\n tar_archive.extractall(output_dir)\n else:\n logger.warning(\n \"Skipped url %s as file type is not supported here. \"\n \"See haystack documentation for support of more file types\",\n url,\n )\n\n return True\n\n\ndef is_whisper_available():\n return importlib.util.find_spec(\"whisper\") is not None\n", "path": "haystack/utils/import_utils.py"}]}
| 2,121 | 452 |
gh_patches_debug_457
|
rasdani/github-patches
|
git_diff
|
cowrie__cowrie-1063
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Can't enter using "oracle" or "tomcat" users
Hello.
I'm using stock userdb.txt file, where "oracle" and "tomcat" users are defined with any password. When using these users, the ssh client gives me an error of "Permission denied (publickey,password)" after entering three times any password.
The ugly thing is that in cowrie.json file appear entries of "cowrie.login.success" type with the message "login attempt [oracle/password] suceeded", which is, obviously, incorrect.
Thanks a lot
</issue>
<code>
[start of src/cowrie/shell/pwd.py]
1 # Copyright (c) 2015 Michel Oosterhof <[email protected]>
2 # All rights reserved.
3 #
4 # Redistribution and use in source and binary forms, with or without
5 # modification, are permitted provided that the following conditions
6 # are met:
7 #
8 # 1. Redistributions of source code must retain the above copyright
9 # notice, this list of conditions and the following disclaimer.
10 # 2. Redistributions in binary form must reproduce the above copyright
11 # notice, this list of conditions and the following disclaimer in the
12 # documentation and/or other materials provided with the distribution.
13 # 3. The names of the author(s) may not be used to endorse or promote
14 # products derived from this software without specific prior written
15 # permission.
16 #
17 # THIS SOFTWARE IS PROVIDED BY THE AUTHORS ``AS IS'' AND ANY EXPRESS OR
18 # IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES
19 # OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED.
20 # IN NO EVENT SHALL THE AUTHORS BE LIABLE FOR ANY DIRECT, INDIRECT,
21 # INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING,
22 # BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
23 # LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED
24 # AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
25 # OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY
26 # OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF
27 # SUCH DAMAGE.
28
29 from __future__ import absolute_import, division
30
31 from binascii import crc32
32 from random import randint, seed
33
34 from cowrie.core.config import CONFIG
35
36
37 class Passwd(object):
38 """
39 This class contains code to handle the users and their properties in
40 /etc/passwd. Note that contrary to the name, it does not handle any
41 passwords.
42 """
43
44 def __init__(self):
45 self.passwd_file = '%s/etc/passwd' % (CONFIG.get('honeypot', 'contents_path'),)
46 self.load()
47
48 def load(self):
49 """
50 Load /etc/passwd
51 """
52 self.passwd = []
53 with open(self.passwd_file, 'r') as f:
54 while True:
55 rawline = f.readline()
56 if not rawline:
57 break
58
59 line = rawline.strip()
60 if not line:
61 continue
62
63 if line.startswith('#'):
64 continue
65
66 (pw_name, pw_passwd, pw_uid, pw_gid, pw_gecos, pw_dir,
67 pw_shell) = line.split(':')
68
69 e = {}
70 e["pw_name"] = pw_name
71 e["pw_passwd"] = pw_passwd
72 e["pw_gecos"] = pw_gecos
73 e["pw_dir"] = pw_dir
74 e["pw_shell"] = pw_shell
75 try:
76 e["pw_uid"] = int(pw_uid)
77 except ValueError:
78 e["pw_uid"] = 1001
79 try:
80 e["pw_gid"] = int(pw_gid)
81 except ValueError:
82 e["pw_gid"] = 1001
83
84 self.passwd.append(e)
85
86 def save(self):
87 """
88 Save the user db
89 Note: this is subject to races between cowrie instances, but hey ...
90 """
91 # with open(self.passwd_file, 'w') as f:
92 # for (login, uid, passwd) in self.userdb:
93 # f.write('%s:%d:%s\n' % (login, uid, passwd))
94 raise NotImplementedError
95
96 def getpwnam(self, name):
97 """
98 Get passwd entry for username
99 """
100 for _ in self.passwd:
101 if name == _["pw_name"]:
102 return _
103 raise KeyError("getpwnam(): name not found in passwd file: " + name)
104
105 def getpwuid(self, uid):
106 """
107 Get passwd entry for uid
108 """
109 for _ in self.passwd:
110 if uid == _["pw_uid"]:
111 return _
112 raise KeyError("getpwuid(): uid not found in passwd file: " + str(uid))
113
114 def setpwentry(self, name):
115 """
116 If the user is not in /etc/passwd, creates a new user entry for the session
117 """
118
119 # ensure consistent uid and gid
120 seed_id = crc32(name)
121 seed(seed_id)
122
123 e = {}
124 e["pw_name"] = name
125 e["pw_passwd"] = "x"
126 e["pw_gecos"] = 0
127 e["pw_dir"] = "/home/" + name
128 e["pw_shell"] = "/bin/bash"
129 e["pw_uid"] = randint(1500, 10000)
130 e["pw_gid"] = e["pw_uid"]
131 self.passwd.append(e)
132 return e
133
134
135 class Group(object):
136 """
137 This class contains code to handle the groups and their properties in
138 /etc/group.
139 """
140
141 def __init__(self):
142 self.group_file = '%s/etc/group' % (CONFIG.get('honeypot', 'contents_path'),)
143 self.load()
144
145 def load(self):
146 """
147 Load /etc/group
148 """
149 self.group = []
150 with open(self.group_file, 'r') as f:
151 while True:
152 rawline = f.readline()
153 if not rawline:
154 break
155
156 line = rawline.strip()
157 if not line:
158 continue
159
160 if line.startswith('#'):
161 continue
162
163 (gr_name, gr_passwd, gr_gid, gr_mem) = line.split(':')
164
165 e = {}
166 e["gr_name"] = gr_name
167 try:
168 e["gr_gid"] = int(gr_gid)
169 except ValueError:
170 e["gr_gid"] = 1001
171 e["gr_mem"] = gr_mem
172
173 self.group.append(e)
174
175 def save(self):
176 """
177 Save the group db
178 Note: this is subject to races between cowrie instances, but hey ...
179 """
180 # with open(self.group_file, 'w') as f:
181 # for (login, uid, passwd) in self.userdb:
182 # f.write('%s:%d:%s\n' % (login, uid, passwd))
183 raise NotImplementedError
184
185 def getgrnam(self, name):
186 """
187 Get group entry for groupname
188 """
189 for _ in self.group:
190 if name == _["gr_name"]:
191 return _
192 raise KeyError("getgrnam(): name not found in group file: " + name)
193
194 def getgrgid(self, uid):
195 """
196 Get group entry for gid
197 """
198 for _ in self.group:
199 if uid == _["gr_gid"]:
200 return _
201 raise KeyError("getgruid(): uid not found in group file: " + str(uid))
202
[end of src/cowrie/shell/pwd.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/cowrie/shell/pwd.py b/src/cowrie/shell/pwd.py
--- a/src/cowrie/shell/pwd.py
+++ b/src/cowrie/shell/pwd.py
@@ -117,7 +117,7 @@
"""
# ensure consistent uid and gid
- seed_id = crc32(name)
+ seed_id = crc32(name.encode("utf-8"))
seed(seed_id)
e = {}
|
{"golden_diff": "diff --git a/src/cowrie/shell/pwd.py b/src/cowrie/shell/pwd.py\n--- a/src/cowrie/shell/pwd.py\n+++ b/src/cowrie/shell/pwd.py\n@@ -117,7 +117,7 @@\n \"\"\"\n \n # ensure consistent uid and gid\n- seed_id = crc32(name)\n+ seed_id = crc32(name.encode(\"utf-8\"))\n seed(seed_id)\n \n e = {}\n", "issue": "Can't enter using \"oracle\" or \"tomcat\" users\nHello.\r\nI'm using stock userdb.txt file, where \"oracle\" and \"tomcat\" users are defined with any password. When using these users, the ssh client gives me an error of \"Permission denied (publickey,password)\" after entering three times any password.\r\n\r\nThe ugly thing is that in cowrie.json file appear entries of \"cowrie.login.success\" type with the message \"login attempt [oracle/password] suceeded\", which is, obviously, incorrect.\r\n\r\nThanks a lot\n", "before_files": [{"content": "# Copyright (c) 2015 Michel Oosterhof <[email protected]>\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions\n# are met:\n#\n# 1. Redistributions of source code must retain the above copyright\n# notice, this list of conditions and the following disclaimer.\n# 2. Redistributions in binary form must reproduce the above copyright\n# notice, this list of conditions and the following disclaimer in the\n# documentation and/or other materials provided with the distribution.\n# 3. The names of the author(s) may not be used to endorse or promote\n# products derived from this software without specific prior written\n# permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE AUTHORS ``AS IS'' AND ANY EXPRESS OR\n# IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES\n# OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED.\n# IN NO EVENT SHALL THE AUTHORS BE LIABLE FOR ANY DIRECT, INDIRECT,\n# INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING,\n# BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;\n# LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED\n# AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY\n# OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF\n# SUCH DAMAGE.\n\nfrom __future__ import absolute_import, division\n\nfrom binascii import crc32\nfrom random import randint, seed\n\nfrom cowrie.core.config import CONFIG\n\n\nclass Passwd(object):\n \"\"\"\n This class contains code to handle the users and their properties in\n /etc/passwd. Note that contrary to the name, it does not handle any\n passwords.\n \"\"\"\n\n def __init__(self):\n self.passwd_file = '%s/etc/passwd' % (CONFIG.get('honeypot', 'contents_path'),)\n self.load()\n\n def load(self):\n \"\"\"\n Load /etc/passwd\n \"\"\"\n self.passwd = []\n with open(self.passwd_file, 'r') as f:\n while True:\n rawline = f.readline()\n if not rawline:\n break\n\n line = rawline.strip()\n if not line:\n continue\n\n if line.startswith('#'):\n continue\n\n (pw_name, pw_passwd, pw_uid, pw_gid, pw_gecos, pw_dir,\n pw_shell) = line.split(':')\n\n e = {}\n e[\"pw_name\"] = pw_name\n e[\"pw_passwd\"] = pw_passwd\n e[\"pw_gecos\"] = pw_gecos\n e[\"pw_dir\"] = pw_dir\n e[\"pw_shell\"] = pw_shell\n try:\n e[\"pw_uid\"] = int(pw_uid)\n except ValueError:\n e[\"pw_uid\"] = 1001\n try:\n e[\"pw_gid\"] = int(pw_gid)\n except ValueError:\n e[\"pw_gid\"] = 1001\n\n self.passwd.append(e)\n\n def save(self):\n \"\"\"\n Save the user db\n Note: this is subject to races between cowrie instances, but hey ...\n \"\"\"\n # with open(self.passwd_file, 'w') as f:\n # for (login, uid, passwd) in self.userdb:\n # f.write('%s:%d:%s\\n' % (login, uid, passwd))\n raise NotImplementedError\n\n def getpwnam(self, name):\n \"\"\"\n Get passwd entry for username\n \"\"\"\n for _ in self.passwd:\n if name == _[\"pw_name\"]:\n return _\n raise KeyError(\"getpwnam(): name not found in passwd file: \" + name)\n\n def getpwuid(self, uid):\n \"\"\"\n Get passwd entry for uid\n \"\"\"\n for _ in self.passwd:\n if uid == _[\"pw_uid\"]:\n return _\n raise KeyError(\"getpwuid(): uid not found in passwd file: \" + str(uid))\n\n def setpwentry(self, name):\n \"\"\"\n If the user is not in /etc/passwd, creates a new user entry for the session\n \"\"\"\n\n # ensure consistent uid and gid\n seed_id = crc32(name)\n seed(seed_id)\n\n e = {}\n e[\"pw_name\"] = name\n e[\"pw_passwd\"] = \"x\"\n e[\"pw_gecos\"] = 0\n e[\"pw_dir\"] = \"/home/\" + name\n e[\"pw_shell\"] = \"/bin/bash\"\n e[\"pw_uid\"] = randint(1500, 10000)\n e[\"pw_gid\"] = e[\"pw_uid\"]\n self.passwd.append(e)\n return e\n\n\nclass Group(object):\n \"\"\"\n This class contains code to handle the groups and their properties in\n /etc/group.\n \"\"\"\n\n def __init__(self):\n self.group_file = '%s/etc/group' % (CONFIG.get('honeypot', 'contents_path'),)\n self.load()\n\n def load(self):\n \"\"\"\n Load /etc/group\n \"\"\"\n self.group = []\n with open(self.group_file, 'r') as f:\n while True:\n rawline = f.readline()\n if not rawline:\n break\n\n line = rawline.strip()\n if not line:\n continue\n\n if line.startswith('#'):\n continue\n\n (gr_name, gr_passwd, gr_gid, gr_mem) = line.split(':')\n\n e = {}\n e[\"gr_name\"] = gr_name\n try:\n e[\"gr_gid\"] = int(gr_gid)\n except ValueError:\n e[\"gr_gid\"] = 1001\n e[\"gr_mem\"] = gr_mem\n\n self.group.append(e)\n\n def save(self):\n \"\"\"\n Save the group db\n Note: this is subject to races between cowrie instances, but hey ...\n \"\"\"\n # with open(self.group_file, 'w') as f:\n # for (login, uid, passwd) in self.userdb:\n # f.write('%s:%d:%s\\n' % (login, uid, passwd))\n raise NotImplementedError\n\n def getgrnam(self, name):\n \"\"\"\n Get group entry for groupname\n \"\"\"\n for _ in self.group:\n if name == _[\"gr_name\"]:\n return _\n raise KeyError(\"getgrnam(): name not found in group file: \" + name)\n\n def getgrgid(self, uid):\n \"\"\"\n Get group entry for gid\n \"\"\"\n for _ in self.group:\n if uid == _[\"gr_gid\"]:\n return _\n raise KeyError(\"getgruid(): uid not found in group file: \" + str(uid))\n", "path": "src/cowrie/shell/pwd.py"}]}
| 2,643 | 108 |
gh_patches_debug_26200
|
rasdani/github-patches
|
git_diff
|
ethereum__web3.py-2939
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
web3.datastructures.AttributeDict.__hash__ fails if event logs contain list objects
* Version: 5.31.1
* Python: 3.8
* OS: linux
* pip freeze output omitted since not a package specific issue
### What was wrong?
Note: Not exactly an issue but something I had to circumvent myself when using the library and thinking it may be helpful if `web3.py` handled it instead directly.
I was trying to use functions requiring `__hash__` on event logs and the code failed saying lists are not hashable [here](https://github.com/ethereum/web3.py/blob/402d001b4f0a19720d859efe3c9e0ece39168224/web3/datastructures.py#L117). This happens if the event logs contain `list` objects nested inside them (which some smart contracts seem to return), as lists by default are mutable and thus not hashable in Python.
### How can it be fixed?
Would it make sense to (possibly recursively) cast any present lists to tuples inside the hash function to avoid crashes? Would some detection mechanism inside these pseudo-immutable classes be helpful to make sure they are indeed hashable (e.g., raising an error if a list is added)?
Any thoughts?
</issue>
<code>
[start of web3/datastructures.py]
1 from collections import (
2 OrderedDict,
3 )
4 from collections.abc import (
5 Hashable,
6 )
7 from typing import (
8 Any,
9 Callable,
10 Dict,
11 Iterator,
12 List,
13 Mapping,
14 MutableMapping,
15 Optional,
16 Sequence,
17 Type,
18 TypeVar,
19 Union,
20 cast,
21 )
22
23 from eth_utils import (
24 is_integer,
25 )
26
27 from web3._utils.formatters import (
28 recursive_map,
29 )
30
31 # Hashable must be immutable:
32 # "the implementation of hashable collections requires that a
33 # key's hash value is immutable"
34 # https://docs.python.org/3/reference/datamodel.html#object.__hash__
35
36 T = TypeVar("T")
37 TKey = TypeVar("TKey", bound=Hashable)
38 TValue = TypeVar("TValue")
39
40
41 class ReadableAttributeDict(Mapping[TKey, TValue]):
42 """
43 The read attributes for the AttributeDict types
44 """
45
46 def __init__(
47 self, dictionary: Dict[TKey, TValue], *args: Any, **kwargs: Any
48 ) -> None:
49 # type ignored on 46/50 b/c dict() expects str index type not TKey
50 self.__dict__ = dict(dictionary) # type: ignore
51 self.__dict__.update(dict(*args, **kwargs))
52
53 def __getitem__(self, key: TKey) -> TValue:
54 return self.__dict__[key] # type: ignore
55
56 def __iter__(self) -> Iterator[Any]:
57 return iter(self.__dict__)
58
59 def __len__(self) -> int:
60 return len(self.__dict__)
61
62 def __repr__(self) -> str:
63 return self.__class__.__name__ + f"({self.__dict__!r})"
64
65 def _repr_pretty_(self, builder: Any, cycle: bool) -> None:
66 """
67 Custom pretty output for the IPython console
68 https://ipython.readthedocs.io/en/stable/api/generated/IPython.lib.pretty.html#extending # noqa: E501
69 """
70 builder.text(self.__class__.__name__ + "(")
71 if cycle:
72 builder.text("<cycle>")
73 else:
74 builder.pretty(self.__dict__)
75 builder.text(")")
76
77 @classmethod
78 def _apply_if_mapping(cls: Type[T], value: TValue) -> Union[T, TValue]:
79 if isinstance(value, Mapping):
80 # error: Too many arguments for "object"
81 return cls(value) # type: ignore
82 else:
83 return value
84
85 @classmethod
86 def recursive(cls, value: TValue) -> "ReadableAttributeDict[TKey, TValue]":
87 return recursive_map(cls._apply_if_mapping, value)
88
89
90 class MutableAttributeDict(
91 MutableMapping[TKey, TValue], ReadableAttributeDict[TKey, TValue]
92 ):
93 def __setitem__(self, key: Any, val: Any) -> None:
94 self.__dict__[key] = val
95
96 def __delitem__(self, key: Any) -> None:
97 del self.__dict__[key]
98
99
100 class AttributeDict(ReadableAttributeDict[TKey, TValue], Hashable):
101 """
102 This provides superficial immutability, someone could hack around it
103 """
104
105 def __setattr__(self, attr: str, val: TValue) -> None:
106 if attr == "__dict__":
107 super().__setattr__(attr, val)
108 else:
109 raise TypeError(
110 "This data is immutable -- create a copy instead of modifying"
111 )
112
113 def __delattr__(self, key: str) -> None:
114 raise TypeError("This data is immutable -- create a copy instead of modifying")
115
116 def __hash__(self) -> int:
117 return hash(tuple(sorted(self.items())))
118
119 def __eq__(self, other: Any) -> bool:
120 if isinstance(other, Mapping):
121 return self.__dict__ == dict(other)
122 else:
123 return False
124
125
126 class NamedElementOnion(Mapping[TKey, TValue]):
127 """
128 Add layers to an onion-shaped structure. Optionally, inject to a specific layer.
129 This structure is iterable, where the outermost layer is first, and innermost
130 is last.
131 """
132
133 def __init__(
134 self,
135 init_elements: Sequence[Any],
136 valid_element: Callable[..., bool] = callable,
137 ) -> None:
138 self._queue: "OrderedDict[Any, Any]" = OrderedDict()
139 for element in reversed(init_elements):
140 if valid_element(element):
141 self.add(element)
142 else:
143 self.add(*element)
144
145 def add(self, element: TValue, name: Optional[TKey] = None) -> None:
146 if name is None:
147 name = cast(TKey, element)
148
149 if name in self._queue:
150 if name is element:
151 raise ValueError("You can't add the same un-named instance twice")
152 else:
153 raise ValueError(
154 "You can't add the same name again, use replace instead"
155 )
156
157 self._queue[name] = element
158
159 def inject(
160 self, element: TValue, name: Optional[TKey] = None, layer: Optional[int] = None
161 ) -> None:
162 """
163 Inject a named element to an arbitrary layer in the onion.
164
165 The current implementation only supports insertion at the innermost layer,
166 or at the outermost layer. Note that inserting to the outermost is equivalent
167 to calling :meth:`add` .
168 """
169 if not is_integer(layer):
170 raise TypeError("The layer for insertion must be an int.")
171 elif layer != 0 and layer != len(self._queue):
172 raise NotImplementedError(
173 f"You can only insert to the beginning or end of a {type(self)}, "
174 f"currently. You tried to insert to {layer}, but only 0 and "
175 f"{len(self._queue)} are permitted. "
176 )
177
178 self.add(element, name=name)
179
180 if layer == 0:
181 if name is None:
182 name = cast(TKey, element)
183 self._queue.move_to_end(name, last=False)
184 elif layer == len(self._queue):
185 return
186 else:
187 raise AssertionError(
188 "Impossible to reach: earlier validation raises an error"
189 )
190
191 def clear(self) -> None:
192 self._queue.clear()
193
194 def replace(self, old: TKey, new: TKey) -> TValue:
195 if old not in self._queue:
196 raise ValueError(
197 "You can't replace unless one already exists, use add instead"
198 )
199 to_be_replaced = self._queue[old]
200 if to_be_replaced is old:
201 # re-insert with new name in old slot
202 self._replace_with_new_name(old, new)
203 else:
204 self._queue[old] = new
205 return to_be_replaced
206
207 def remove(self, old: TKey) -> None:
208 if old not in self._queue:
209 raise ValueError("You can only remove something that has been added")
210 del self._queue[old]
211
212 @property
213 def middlewares(self) -> Sequence[Any]:
214 """
215 Returns middlewares in the appropriate order to be imported into a new Web3
216 instance (reversed _queue order) as a list of (middleware, name) tuples.
217 """
218 return [(val, key) for key, val in reversed(self._queue.items())]
219
220 def _replace_with_new_name(self, old: TKey, new: TKey) -> None:
221 self._queue[new] = new
222 found_old = False
223 for key in list(self._queue.keys()):
224 if not found_old:
225 if key == old:
226 found_old = True
227 continue
228 elif key != new:
229 self._queue.move_to_end(key)
230 del self._queue[old]
231
232 def __iter__(self) -> Iterator[TKey]:
233 elements = self._queue.values()
234 if not isinstance(elements, Sequence):
235 # type ignored b/c elements is set as _OrderedDictValuesView[Any] on 210
236 elements = list(elements) # type: ignore
237 return iter(reversed(elements))
238
239 def __add__(self, other: Any) -> "NamedElementOnion[TKey, TValue]":
240 if not isinstance(other, NamedElementOnion):
241 raise NotImplementedError(
242 "You can only combine with another NamedElementOnion"
243 )
244 combined = self._queue.copy()
245 combined.update(other._queue)
246 return NamedElementOnion(cast(List[Any], combined.items()))
247
248 def __contains__(self, element: Any) -> bool:
249 return element in self._queue
250
251 def __getitem__(self, element: TKey) -> TValue:
252 return self._queue[element]
253
254 def __len__(self) -> int:
255 return len(self._queue)
256
257 def __reversed__(self) -> Iterator[TValue]:
258 elements = cast(List[Any], self._queue.values())
259 if not isinstance(elements, Sequence):
260 elements = list(elements)
261 return iter(elements)
262
[end of web3/datastructures.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/web3/datastructures.py b/web3/datastructures.py
--- a/web3/datastructures.py
+++ b/web3/datastructures.py
@@ -114,7 +114,7 @@
raise TypeError("This data is immutable -- create a copy instead of modifying")
def __hash__(self) -> int:
- return hash(tuple(sorted(self.items())))
+ return hash(tuple(sorted(tupleize_lists_nested(self).items())))
def __eq__(self, other: Any) -> bool:
if isinstance(other, Mapping):
@@ -123,6 +123,29 @@
return False
+def tupleize_lists_nested(d: Mapping[TKey, TValue]) -> AttributeDict[TKey, TValue]:
+ """
+ Unhashable types inside dicts will throw an error if attempted to be hashed.
+ This method converts lists to tuples, rendering them hashable.
+ Other unhashable types found will raise a TypeError
+ """
+
+ def _to_tuple(lst: List[Any]) -> Any:
+ return tuple(_to_tuple(i) if isinstance(i, list) else i for i in lst)
+
+ ret = dict()
+ for k, v in d.items():
+ if isinstance(v, List):
+ ret[k] = _to_tuple(v)
+ elif isinstance(v, Mapping):
+ ret[k] = tupleize_lists_nested(v)
+ elif not isinstance(v, Hashable):
+ raise TypeError(f"Found unhashable type '{type(v).__name__}': {v}")
+ else:
+ ret[k] = v
+ return AttributeDict(ret)
+
+
class NamedElementOnion(Mapping[TKey, TValue]):
"""
Add layers to an onion-shaped structure. Optionally, inject to a specific layer.
|
{"golden_diff": "diff --git a/web3/datastructures.py b/web3/datastructures.py\n--- a/web3/datastructures.py\n+++ b/web3/datastructures.py\n@@ -114,7 +114,7 @@\n raise TypeError(\"This data is immutable -- create a copy instead of modifying\")\n \n def __hash__(self) -> int:\n- return hash(tuple(sorted(self.items())))\n+ return hash(tuple(sorted(tupleize_lists_nested(self).items())))\n \n def __eq__(self, other: Any) -> bool:\n if isinstance(other, Mapping):\n@@ -123,6 +123,29 @@\n return False\n \n \n+def tupleize_lists_nested(d: Mapping[TKey, TValue]) -> AttributeDict[TKey, TValue]:\n+ \"\"\"\n+ Unhashable types inside dicts will throw an error if attempted to be hashed.\n+ This method converts lists to tuples, rendering them hashable.\n+ Other unhashable types found will raise a TypeError\n+ \"\"\"\n+\n+ def _to_tuple(lst: List[Any]) -> Any:\n+ return tuple(_to_tuple(i) if isinstance(i, list) else i for i in lst)\n+\n+ ret = dict()\n+ for k, v in d.items():\n+ if isinstance(v, List):\n+ ret[k] = _to_tuple(v)\n+ elif isinstance(v, Mapping):\n+ ret[k] = tupleize_lists_nested(v)\n+ elif not isinstance(v, Hashable):\n+ raise TypeError(f\"Found unhashable type '{type(v).__name__}': {v}\")\n+ else:\n+ ret[k] = v\n+ return AttributeDict(ret)\n+\n+\n class NamedElementOnion(Mapping[TKey, TValue]):\n \"\"\"\n Add layers to an onion-shaped structure. Optionally, inject to a specific layer.\n", "issue": "web3.datastructures.AttributeDict.__hash__ fails if event logs contain list objects\n* Version: 5.31.1\r\n* Python: 3.8\r\n* OS: linux\r\n* pip freeze output omitted since not a package specific issue\r\n\r\n### What was wrong?\r\n\r\nNote: Not exactly an issue but something I had to circumvent myself when using the library and thinking it may be helpful if `web3.py` handled it instead directly.\r\n\r\nI was trying to use functions requiring `__hash__` on event logs and the code failed saying lists are not hashable [here](https://github.com/ethereum/web3.py/blob/402d001b4f0a19720d859efe3c9e0ece39168224/web3/datastructures.py#L117). This happens if the event logs contain `list` objects nested inside them (which some smart contracts seem to return), as lists by default are mutable and thus not hashable in Python.\r\n\r\n### How can it be fixed?\r\n\r\nWould it make sense to (possibly recursively) cast any present lists to tuples inside the hash function to avoid crashes? Would some detection mechanism inside these pseudo-immutable classes be helpful to make sure they are indeed hashable (e.g., raising an error if a list is added)?\r\n\r\nAny thoughts?\n", "before_files": [{"content": "from collections import (\n OrderedDict,\n)\nfrom collections.abc import (\n Hashable,\n)\nfrom typing import (\n Any,\n Callable,\n Dict,\n Iterator,\n List,\n Mapping,\n MutableMapping,\n Optional,\n Sequence,\n Type,\n TypeVar,\n Union,\n cast,\n)\n\nfrom eth_utils import (\n is_integer,\n)\n\nfrom web3._utils.formatters import (\n recursive_map,\n)\n\n# Hashable must be immutable:\n# \"the implementation of hashable collections requires that a\n# key's hash value is immutable\"\n# https://docs.python.org/3/reference/datamodel.html#object.__hash__\n\nT = TypeVar(\"T\")\nTKey = TypeVar(\"TKey\", bound=Hashable)\nTValue = TypeVar(\"TValue\")\n\n\nclass ReadableAttributeDict(Mapping[TKey, TValue]):\n \"\"\"\n The read attributes for the AttributeDict types\n \"\"\"\n\n def __init__(\n self, dictionary: Dict[TKey, TValue], *args: Any, **kwargs: Any\n ) -> None:\n # type ignored on 46/50 b/c dict() expects str index type not TKey\n self.__dict__ = dict(dictionary) # type: ignore\n self.__dict__.update(dict(*args, **kwargs))\n\n def __getitem__(self, key: TKey) -> TValue:\n return self.__dict__[key] # type: ignore\n\n def __iter__(self) -> Iterator[Any]:\n return iter(self.__dict__)\n\n def __len__(self) -> int:\n return len(self.__dict__)\n\n def __repr__(self) -> str:\n return self.__class__.__name__ + f\"({self.__dict__!r})\"\n\n def _repr_pretty_(self, builder: Any, cycle: bool) -> None:\n \"\"\"\n Custom pretty output for the IPython console\n https://ipython.readthedocs.io/en/stable/api/generated/IPython.lib.pretty.html#extending # noqa: E501\n \"\"\"\n builder.text(self.__class__.__name__ + \"(\")\n if cycle:\n builder.text(\"<cycle>\")\n else:\n builder.pretty(self.__dict__)\n builder.text(\")\")\n\n @classmethod\n def _apply_if_mapping(cls: Type[T], value: TValue) -> Union[T, TValue]:\n if isinstance(value, Mapping):\n # error: Too many arguments for \"object\"\n return cls(value) # type: ignore\n else:\n return value\n\n @classmethod\n def recursive(cls, value: TValue) -> \"ReadableAttributeDict[TKey, TValue]\":\n return recursive_map(cls._apply_if_mapping, value)\n\n\nclass MutableAttributeDict(\n MutableMapping[TKey, TValue], ReadableAttributeDict[TKey, TValue]\n):\n def __setitem__(self, key: Any, val: Any) -> None:\n self.__dict__[key] = val\n\n def __delitem__(self, key: Any) -> None:\n del self.__dict__[key]\n\n\nclass AttributeDict(ReadableAttributeDict[TKey, TValue], Hashable):\n \"\"\"\n This provides superficial immutability, someone could hack around it\n \"\"\"\n\n def __setattr__(self, attr: str, val: TValue) -> None:\n if attr == \"__dict__\":\n super().__setattr__(attr, val)\n else:\n raise TypeError(\n \"This data is immutable -- create a copy instead of modifying\"\n )\n\n def __delattr__(self, key: str) -> None:\n raise TypeError(\"This data is immutable -- create a copy instead of modifying\")\n\n def __hash__(self) -> int:\n return hash(tuple(sorted(self.items())))\n\n def __eq__(self, other: Any) -> bool:\n if isinstance(other, Mapping):\n return self.__dict__ == dict(other)\n else:\n return False\n\n\nclass NamedElementOnion(Mapping[TKey, TValue]):\n \"\"\"\n Add layers to an onion-shaped structure. Optionally, inject to a specific layer.\n This structure is iterable, where the outermost layer is first, and innermost\n is last.\n \"\"\"\n\n def __init__(\n self,\n init_elements: Sequence[Any],\n valid_element: Callable[..., bool] = callable,\n ) -> None:\n self._queue: \"OrderedDict[Any, Any]\" = OrderedDict()\n for element in reversed(init_elements):\n if valid_element(element):\n self.add(element)\n else:\n self.add(*element)\n\n def add(self, element: TValue, name: Optional[TKey] = None) -> None:\n if name is None:\n name = cast(TKey, element)\n\n if name in self._queue:\n if name is element:\n raise ValueError(\"You can't add the same un-named instance twice\")\n else:\n raise ValueError(\n \"You can't add the same name again, use replace instead\"\n )\n\n self._queue[name] = element\n\n def inject(\n self, element: TValue, name: Optional[TKey] = None, layer: Optional[int] = None\n ) -> None:\n \"\"\"\n Inject a named element to an arbitrary layer in the onion.\n\n The current implementation only supports insertion at the innermost layer,\n or at the outermost layer. Note that inserting to the outermost is equivalent\n to calling :meth:`add` .\n \"\"\"\n if not is_integer(layer):\n raise TypeError(\"The layer for insertion must be an int.\")\n elif layer != 0 and layer != len(self._queue):\n raise NotImplementedError(\n f\"You can only insert to the beginning or end of a {type(self)}, \"\n f\"currently. You tried to insert to {layer}, but only 0 and \"\n f\"{len(self._queue)} are permitted. \"\n )\n\n self.add(element, name=name)\n\n if layer == 0:\n if name is None:\n name = cast(TKey, element)\n self._queue.move_to_end(name, last=False)\n elif layer == len(self._queue):\n return\n else:\n raise AssertionError(\n \"Impossible to reach: earlier validation raises an error\"\n )\n\n def clear(self) -> None:\n self._queue.clear()\n\n def replace(self, old: TKey, new: TKey) -> TValue:\n if old not in self._queue:\n raise ValueError(\n \"You can't replace unless one already exists, use add instead\"\n )\n to_be_replaced = self._queue[old]\n if to_be_replaced is old:\n # re-insert with new name in old slot\n self._replace_with_new_name(old, new)\n else:\n self._queue[old] = new\n return to_be_replaced\n\n def remove(self, old: TKey) -> None:\n if old not in self._queue:\n raise ValueError(\"You can only remove something that has been added\")\n del self._queue[old]\n\n @property\n def middlewares(self) -> Sequence[Any]:\n \"\"\"\n Returns middlewares in the appropriate order to be imported into a new Web3\n instance (reversed _queue order) as a list of (middleware, name) tuples.\n \"\"\"\n return [(val, key) for key, val in reversed(self._queue.items())]\n\n def _replace_with_new_name(self, old: TKey, new: TKey) -> None:\n self._queue[new] = new\n found_old = False\n for key in list(self._queue.keys()):\n if not found_old:\n if key == old:\n found_old = True\n continue\n elif key != new:\n self._queue.move_to_end(key)\n del self._queue[old]\n\n def __iter__(self) -> Iterator[TKey]:\n elements = self._queue.values()\n if not isinstance(elements, Sequence):\n # type ignored b/c elements is set as _OrderedDictValuesView[Any] on 210\n elements = list(elements) # type: ignore\n return iter(reversed(elements))\n\n def __add__(self, other: Any) -> \"NamedElementOnion[TKey, TValue]\":\n if not isinstance(other, NamedElementOnion):\n raise NotImplementedError(\n \"You can only combine with another NamedElementOnion\"\n )\n combined = self._queue.copy()\n combined.update(other._queue)\n return NamedElementOnion(cast(List[Any], combined.items()))\n\n def __contains__(self, element: Any) -> bool:\n return element in self._queue\n\n def __getitem__(self, element: TKey) -> TValue:\n return self._queue[element]\n\n def __len__(self) -> int:\n return len(self._queue)\n\n def __reversed__(self) -> Iterator[TValue]:\n elements = cast(List[Any], self._queue.values())\n if not isinstance(elements, Sequence):\n elements = list(elements)\n return iter(elements)\n", "path": "web3/datastructures.py"}]}
| 3,420 | 388 |
gh_patches_debug_24241
|
rasdani/github-patches
|
git_diff
|
Mailu__Mailu-2144
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Cannot send email after upgrade to 1.9 `non DNSSEC destination`
## Before you open your issue
- [x] Check if no issue or pull-request for this already exists.
- [x] Check [documentation](https://mailu.io/master/) and [FAQ](https://mailu.io/master/faq.html). (Tip, use the search function on the documentation page)
- [x] You understand `Mailu` is made by volunteers in their **free time** — be conscise, civil and accept that delays can occur.
- [x] The title of the issue should be short and simple. It should contain specific terms related to the actual issue. Be specific while writing the title.
## Environment & Versions
### Environment
- [x] docker-compose
- [ ] kubernetes
- [ ] docker swarm
### Versions
1.9
## Description
Thanks for all the work! 1.9 seems like an amazing release overall ❤️
I upgraded to 1.9, generated the new docker-compose file with the tool.
Copied the relevant env variables over and started everything.
I can still receive mails, and send internal one (from and to my own domain)
I cannot send mails to external providers.
after restoring from backup everything works in 1.8
```
Final-Recipient: rfc822; ******
Original-Recipient: rfc822;******
Action: delayed
Status: 4.7.5
Diagnostic-Code: X-Postfix; non DNSSEC destination
Will-Retry-Until: Fri, 7 Jan 2022 18:38:34 +0000 (UTC)
Return-Path: <*****>
From: Cloud <*******>
DKIM-Signature: v=1; a=rsa-sha256; c=relaxed/relaxed; d=nicco.io; s=dkim;
t=1641148715;
h=from:from:reply-to:subject:subject:date:date:message-id:message-id:
to:to:cc:mime-version:mime-version:content-type:content-type:
in-reply-to:in-reply-to:references:references;
bh=Q0j3Ph9l8nLeBMIzdq6aOtNcsZOyiD8WuiQSGgc2oeY=;
b=nF+9OZeRSSEDZ995inbj/6nDYgbTDMhPGc63Gab3FN1A984PxY7rDoHIhkO5nvh2wzNZG6
5jIAmfCyYfHriJawNrtcKeUA4wBO5YgYPWag6CbGmWQ8sGSIty2fjIO0W4dWfWy+OjsksX
sJ2TK8uft8Ax9F9QmQKMuZHBP3Myh/I=
Content-Type: multipart/mixed;
boundary="Apple-Mail=_DD0DBE9A-59E8-455E-B4DD-1317DF1D24F9"
Mime-Version: 1.0
Subject: =*****
Date: Sun, 2 Jan 2022 19:38:33 +0100
References: <****>
<****>
<****>
<****>
To: ***
In-Reply-To: ****
Message-Id: ****
X-Spam-Level: *
X-Spamd-Bar: +
Authentication-Results: *****;
auth=pass smtp.mailfrom=*****
```
</issue>
<code>
[start of core/admin/start.py]
1 #!/usr/bin/python3
2
3 import os
4 import logging as log
5 import sys
6
7 log.basicConfig(stream=sys.stderr, level=os.environ.get("LOG_LEVEL", "INFO"))
8
9 os.system("flask mailu advertise")
10 os.system("flask db upgrade")
11
12 account = os.environ.get("INITIAL_ADMIN_ACCOUNT")
13 domain = os.environ.get("INITIAL_ADMIN_DOMAIN")
14 password = os.environ.get("INITIAL_ADMIN_PW")
15
16 if account is not None and domain is not None and password is not None:
17 mode = os.environ.get("INITIAL_ADMIN_MODE", default="ifmissing")
18 log.info("Creating initial admin accout %s@%s with mode %s",account,domain,mode)
19 os.system("flask mailu admin %s %s '%s' --mode %s" % (account, domain, password, mode))
20
21 start_command="".join([
22 "gunicorn --threads ", str(os.cpu_count()),
23 " -b :80 ",
24 "--access-logfile - " if (log.root.level<=log.INFO) else "",
25 "--error-logfile - ",
26 "--preload ",
27 "'mailu:create_app()'"])
28
29 os.system(start_command)
30
[end of core/admin/start.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/core/admin/start.py b/core/admin/start.py
--- a/core/admin/start.py
+++ b/core/admin/start.py
@@ -18,6 +18,34 @@
log.info("Creating initial admin accout %s@%s with mode %s",account,domain,mode)
os.system("flask mailu admin %s %s '%s' --mode %s" % (account, domain, password, mode))
+def test_DNS():
+ import dns.resolver
+ import dns.exception
+ import dns.flags
+ import dns.rdtypes
+ import dns.rdatatype
+ import dns.rdataclass
+ import time
+ # DNS stub configured to do DNSSEC enabled queries
+ resolver = dns.resolver.Resolver()
+ resolver.use_edns(0, 0, 1232)
+ resolver.flags = dns.flags.AD | dns.flags.RD
+ nameservers = resolver.nameservers
+ for ns in nameservers:
+ resolver.nameservers=[ns]
+ while True:
+ try:
+ result = resolver.query('example.org', dns.rdatatype.A, dns.rdataclass.IN, lifetime=10)
+ except Exception as e:
+ log.critical("Your DNS resolver at %s is not working (%s). Please use another resolver or enable unbound via https://setup.mailu.io.", ns, e);
+ else:
+ if result.response.flags & dns.flags.AD:
+ break
+ log.critical("Your DNS resolver at %s isn't doing DNSSEC validation; Please use another resolver or enable unbound via https://setup.mailu.io.", ns)
+ time.sleep(5)
+
+test_DNS()
+
start_command="".join([
"gunicorn --threads ", str(os.cpu_count()),
" -b :80 ",
|
{"golden_diff": "diff --git a/core/admin/start.py b/core/admin/start.py\n--- a/core/admin/start.py\n+++ b/core/admin/start.py\n@@ -18,6 +18,34 @@\n log.info(\"Creating initial admin accout %s@%s with mode %s\",account,domain,mode)\n os.system(\"flask mailu admin %s %s '%s' --mode %s\" % (account, domain, password, mode))\n \n+def test_DNS():\n+ import dns.resolver\n+ import dns.exception\n+ import dns.flags\n+ import dns.rdtypes\n+ import dns.rdatatype\n+ import dns.rdataclass\n+ import time\n+ # DNS stub configured to do DNSSEC enabled queries\n+ resolver = dns.resolver.Resolver()\n+ resolver.use_edns(0, 0, 1232)\n+ resolver.flags = dns.flags.AD | dns.flags.RD\n+ nameservers = resolver.nameservers\n+ for ns in nameservers:\n+ resolver.nameservers=[ns]\n+ while True:\n+ try:\n+ result = resolver.query('example.org', dns.rdatatype.A, dns.rdataclass.IN, lifetime=10)\n+ except Exception as e:\n+ log.critical(\"Your DNS resolver at %s is not working (%s). Please use another resolver or enable unbound via https://setup.mailu.io.\", ns, e);\n+ else:\n+ if result.response.flags & dns.flags.AD:\n+ break\n+ log.critical(\"Your DNS resolver at %s isn't doing DNSSEC validation; Please use another resolver or enable unbound via https://setup.mailu.io.\", ns)\n+ time.sleep(5)\n+\n+test_DNS()\n+\n start_command=\"\".join([\n \"gunicorn --threads \", str(os.cpu_count()),\n \" -b :80 \",\n", "issue": "Cannot send email after upgrade to 1.9 `non DNSSEC destination`\n## Before you open your issue\r\n- [x] Check if no issue or pull-request for this already exists.\r\n- [x] Check [documentation](https://mailu.io/master/) and [FAQ](https://mailu.io/master/faq.html). (Tip, use the search function on the documentation page)\r\n- [x] You understand `Mailu` is made by volunteers in their **free time** \u2014 be conscise, civil and accept that delays can occur.\r\n- [x] The title of the issue should be short and simple. It should contain specific terms related to the actual issue. Be specific while writing the title.\r\n\r\n## Environment & Versions\r\n### Environment\r\n - [x] docker-compose\r\n - [ ] kubernetes\r\n - [ ] docker swarm\r\n\r\n### Versions\r\n1.9\r\n\r\n## Description\r\nThanks for all the work! 1.9 seems like an amazing release overall \u2764\ufe0f \r\n\r\nI upgraded to 1.9, generated the new docker-compose file with the tool.\r\nCopied the relevant env variables over and started everything.\r\nI can still receive mails, and send internal one (from and to my own domain)\r\nI cannot send mails to external providers.\r\n\r\nafter restoring from backup everything works in 1.8\r\n\r\n```\r\nFinal-Recipient: rfc822; ******\r\nOriginal-Recipient: rfc822;******\r\nAction: delayed\r\nStatus: 4.7.5\r\nDiagnostic-Code: X-Postfix; non DNSSEC destination\r\nWill-Retry-Until: Fri, 7 Jan 2022 18:38:34 +0000 (UTC)\r\nReturn-Path: <*****>\r\nFrom: Cloud <*******>\r\nDKIM-Signature: v=1; a=rsa-sha256; c=relaxed/relaxed; d=nicco.io; s=dkim;\r\n\tt=1641148715;\r\n\th=from:from:reply-to:subject:subject:date:date:message-id:message-id:\r\n\t to:to:cc:mime-version:mime-version:content-type:content-type:\r\n\t in-reply-to:in-reply-to:references:references;\r\n\tbh=Q0j3Ph9l8nLeBMIzdq6aOtNcsZOyiD8WuiQSGgc2oeY=;\r\n\tb=nF+9OZeRSSEDZ995inbj/6nDYgbTDMhPGc63Gab3FN1A984PxY7rDoHIhkO5nvh2wzNZG6\r\n\t5jIAmfCyYfHriJawNrtcKeUA4wBO5YgYPWag6CbGmWQ8sGSIty2fjIO0W4dWfWy+OjsksX\r\n\tsJ2TK8uft8Ax9F9QmQKMuZHBP3Myh/I=\r\nContent-Type: multipart/mixed;\r\n\tboundary=\"Apple-Mail=_DD0DBE9A-59E8-455E-B4DD-1317DF1D24F9\"\r\nMime-Version: 1.0\r\nSubject: =*****\r\nDate: Sun, 2 Jan 2022 19:38:33 +0100\r\nReferences: <****>\r\n<****>\r\n<****>\r\n<****>\r\nTo: ***\r\nIn-Reply-To: ****\r\nMessage-Id: ****\r\nX-Spam-Level: *\r\nX-Spamd-Bar: +\r\nAuthentication-Results: *****;\r\n\tauth=pass smtp.mailfrom=*****\r\n```\n", "before_files": [{"content": "#!/usr/bin/python3\n\nimport os\nimport logging as log\nimport sys\n\nlog.basicConfig(stream=sys.stderr, level=os.environ.get(\"LOG_LEVEL\", \"INFO\"))\n\nos.system(\"flask mailu advertise\")\nos.system(\"flask db upgrade\")\n\naccount = os.environ.get(\"INITIAL_ADMIN_ACCOUNT\")\ndomain = os.environ.get(\"INITIAL_ADMIN_DOMAIN\")\npassword = os.environ.get(\"INITIAL_ADMIN_PW\")\n\nif account is not None and domain is not None and password is not None:\n mode = os.environ.get(\"INITIAL_ADMIN_MODE\", default=\"ifmissing\")\n log.info(\"Creating initial admin accout %s@%s with mode %s\",account,domain,mode)\n os.system(\"flask mailu admin %s %s '%s' --mode %s\" % (account, domain, password, mode))\n\nstart_command=\"\".join([\n \"gunicorn --threads \", str(os.cpu_count()),\n \" -b :80 \",\n \"--access-logfile - \" if (log.root.level<=log.INFO) else \"\",\n \"--error-logfile - \",\n \"--preload \",\n \"'mailu:create_app()'\"])\n\nos.system(start_command)\n", "path": "core/admin/start.py"}]}
| 1,614 | 407 |
gh_patches_debug_32551
|
rasdani/github-patches
|
git_diff
|
conda__conda-9166
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
conda env list behavior is inconsistent between Linux/macOS and Windows
## Current Behavior
On UNIX-family operating systems (Linux and macOS), `conda env list` generates a list of all environments belonging to the current user. This behavior changes if `conda` is executed with UID 0, in which case `conda` attempts to find all user home directories on the system and list all environments belonging to all users.
This is not consistent with the behavior on Windows. On Windows, `conda env list` always attempts to find all user home directories on the system, and displays all environments belonging to all users. This occurs whether or not the current user is an administrator.
This behavior is not documented in the Conda user guide, which just says that `conda env list` is used "to see a list of all your environments." https://conda.io/projects/conda/en/latest/user-guide/tasks/manage-environments.html#viewing-a-list-of-your-environments
### Steps to Reproduce
On macOS/Linux, this will list the current user's environments only:
```
conda env list
```
Running this command with `sudo` will list all environments on the system:
```
sudo conda env list
```
On Windows, running this command from either a standard prompt or from an administrative prompts with elevated permissions will list all environments on the system (as long as the executing user can read the environment configuration file for the user that actually owns the environment):
```
conda env list
```
## Expected Behavior
I would expect one of the two following behaviors:
1. `conda env list` only lists the current user's environment on any operating system.
2. `conda env list` only lists the current user's environment, unless it is executed as an administrator. This behavior should be consistent between Windows and macOS.
The current behavior on Windows (all users) and macOS/Linux (admins) should only be executed for administrators, if at all. In particular, the current Windows code finds all sibling directories of the current user's home folder and tries to check each one of them for an environment configuration file. In environments where Windows home directories are redirected onto a common network share, this may result in `conda env list` firing off a large number of I/O operations as it tries to access all home directories on the network share.
</issue>
<code>
[start of conda/core/envs_manager.py]
1 # -*- coding: utf-8 -*-
2 # Copyright (C) 2012 Anaconda, Inc
3 # SPDX-License-Identifier: BSD-3-Clause
4 from __future__ import absolute_import, division, print_function, unicode_literals
5
6 from errno import EACCES, EROFS, ENOENT
7 from logging import getLogger
8 from os import devnull, listdir
9 from os.path import dirname, isdir, isfile, join, normpath
10
11 from .prefix_data import PrefixData
12 from ..base.context import context
13 from ..common.compat import ensure_text_type, on_win, open
14 from ..common.path import expand
15 from ..gateways.disk.read import yield_lines
16 from ..gateways.disk.test import is_conda_environment
17
18 log = getLogger(__name__)
19
20 # The idea is to mock this to return '/dev/null' (or some temp file) instead.
21 def get_user_environments_txt_file(userhome='~'):
22 return expand(join(userhome, '.conda', 'environments.txt'))
23
24
25 def register_env(location):
26 user_environments_txt_file = get_user_environments_txt_file()
27 location = normpath(location)
28
29 if ("placehold_pl" in location or "skeleton_" in location
30 or user_environments_txt_file == devnull):
31 # Don't record envs created by conda-build.
32 return
33
34 if location in yield_lines(user_environments_txt_file):
35 # Nothing to do. Location is already recorded in a known environments.txt file.
36 return
37
38 try:
39 with open(user_environments_txt_file, 'a') as fh:
40 fh.write(ensure_text_type(location))
41 fh.write('\n')
42 except EnvironmentError as e:
43 if e.errno in (EACCES, EROFS, ENOENT):
44 log.warn("Unable to register environment. Path not writable or missing.\n"
45 " environment location: %s\n"
46 " registry file: %s", location, user_environments_txt_file)
47 else:
48 raise
49
50
51 def unregister_env(location):
52 if isdir(location):
53 meta_dir = join(location, 'conda-meta')
54 if isdir(meta_dir):
55 meta_dir_contents = listdir(meta_dir)
56 if len(meta_dir_contents) > 1:
57 # if there are any files left other than 'conda-meta/history'
58 # then don't unregister
59 return
60
61 _clean_environments_txt(get_user_environments_txt_file(), location)
62
63
64 def list_all_known_prefixes():
65 all_env_paths = set()
66 if on_win:
67 home_dir_dir = dirname(expand('~'))
68 for home_dir in listdir(home_dir_dir):
69 environments_txt_file = get_user_environments_txt_file(join(home_dir_dir, home_dir))
70 if isfile(environments_txt_file):
71 all_env_paths.update(_clean_environments_txt(environments_txt_file))
72 else:
73 from os import geteuid
74 from pwd import getpwall
75 if geteuid() == 0:
76 search_dirs = tuple(pwentry.pw_dir for pwentry in getpwall()) or (expand('~'),)
77 else:
78 search_dirs = (expand('~'),)
79 for home_dir in search_dirs:
80 environments_txt_file = get_user_environments_txt_file(home_dir)
81 if isfile(environments_txt_file):
82 all_env_paths.update(_clean_environments_txt(environments_txt_file))
83
84 # in case environments.txt files aren't complete, also add all known conda environments in
85 # all envs_dirs
86 envs_dirs = (envs_dir for envs_dir in context.envs_dirs if isdir(envs_dir))
87 all_env_paths.update(path for path in (
88 join(envs_dir, name) for envs_dir in envs_dirs for name in listdir(envs_dir)
89 ) if path not in all_env_paths and is_conda_environment(path))
90
91 all_env_paths.add(context.root_prefix)
92 return sorted(all_env_paths)
93
94
95 def query_all_prefixes(spec):
96 for prefix in list_all_known_prefixes():
97 prefix_recs = tuple(PrefixData(prefix).query(spec))
98 if prefix_recs:
99 yield prefix, prefix_recs
100
101
102 def _clean_environments_txt(environments_txt_file, remove_location=None):
103 if not isfile(environments_txt_file):
104 return ()
105
106 if remove_location:
107 remove_location = normpath(remove_location)
108 environments_txt_lines = tuple(yield_lines(environments_txt_file))
109 environments_txt_lines_cleaned = tuple(
110 prefix for prefix in environments_txt_lines
111 if prefix != remove_location and is_conda_environment(prefix)
112 )
113 if environments_txt_lines_cleaned != environments_txt_lines:
114 _rewrite_environments_txt(environments_txt_file, environments_txt_lines_cleaned)
115 return environments_txt_lines_cleaned
116
117
118 def _rewrite_environments_txt(environments_txt_file, prefixes):
119 try:
120 with open(environments_txt_file, 'w') as fh:
121 fh.write('\n'.join(prefixes))
122 fh.write('\n')
123 except EnvironmentError as e:
124 log.info("File not cleaned: %s", environments_txt_file)
125 log.debug('%r', e, exc_info=True)
126
[end of conda/core/envs_manager.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/conda/core/envs_manager.py b/conda/core/envs_manager.py
--- a/conda/core/envs_manager.py
+++ b/conda/core/envs_manager.py
@@ -11,6 +11,7 @@
from .prefix_data import PrefixData
from ..base.context import context
from ..common.compat import ensure_text_type, on_win, open
+from ..common._os import is_admin
from ..common.path import expand
from ..gateways.disk.read import yield_lines
from ..gateways.disk.test import is_conda_environment
@@ -63,23 +64,21 @@
def list_all_known_prefixes():
all_env_paths = set()
- if on_win:
- home_dir_dir = dirname(expand('~'))
- for home_dir in listdir(home_dir_dir):
- environments_txt_file = get_user_environments_txt_file(join(home_dir_dir, home_dir))
- if isfile(environments_txt_file):
- all_env_paths.update(_clean_environments_txt(environments_txt_file))
- else:
- from os import geteuid
- from pwd import getpwall
- if geteuid() == 0:
- search_dirs = tuple(pwentry.pw_dir for pwentry in getpwall()) or (expand('~'),)
+ # If the user is an admin, load environments from all user home directories
+ if is_admin():
+ if on_win:
+ home_dir_dir = dirname(expand('~'))
+ search_dirs = tuple(join(home_dir_dir, d) for d in listdir(home_dir_dir))
else:
- search_dirs = (expand('~'),)
- for home_dir in search_dirs:
- environments_txt_file = get_user_environments_txt_file(home_dir)
- if isfile(environments_txt_file):
- all_env_paths.update(_clean_environments_txt(environments_txt_file))
+ from pwd import getpwall
+ search_dirs = tuple(pwentry.pw_dir for pwentry in getpwall()) or (expand('~'),)
+ else:
+ search_dirs = (expand('~'),)
+ for home_dir in search_dirs:
+ environments_txt_file = get_user_environments_txt_file(home_dir)
+ if isfile(environments_txt_file):
+ all_env_paths.update(_clean_environments_txt(environments_txt_file))
+
# in case environments.txt files aren't complete, also add all known conda environments in
# all envs_dirs
|
{"golden_diff": "diff --git a/conda/core/envs_manager.py b/conda/core/envs_manager.py\n--- a/conda/core/envs_manager.py\n+++ b/conda/core/envs_manager.py\n@@ -11,6 +11,7 @@\n from .prefix_data import PrefixData\n from ..base.context import context\n from ..common.compat import ensure_text_type, on_win, open\n+from ..common._os import is_admin\n from ..common.path import expand\n from ..gateways.disk.read import yield_lines\n from ..gateways.disk.test import is_conda_environment\n@@ -63,23 +64,21 @@\n \n def list_all_known_prefixes():\n all_env_paths = set()\n- if on_win:\n- home_dir_dir = dirname(expand('~'))\n- for home_dir in listdir(home_dir_dir):\n- environments_txt_file = get_user_environments_txt_file(join(home_dir_dir, home_dir))\n- if isfile(environments_txt_file):\n- all_env_paths.update(_clean_environments_txt(environments_txt_file))\n- else:\n- from os import geteuid\n- from pwd import getpwall\n- if geteuid() == 0:\n- search_dirs = tuple(pwentry.pw_dir for pwentry in getpwall()) or (expand('~'),)\n+ # If the user is an admin, load environments from all user home directories\n+ if is_admin():\n+ if on_win:\n+ home_dir_dir = dirname(expand('~'))\n+ search_dirs = tuple(join(home_dir_dir, d) for d in listdir(home_dir_dir))\n else:\n- search_dirs = (expand('~'),)\n- for home_dir in search_dirs:\n- environments_txt_file = get_user_environments_txt_file(home_dir)\n- if isfile(environments_txt_file):\n- all_env_paths.update(_clean_environments_txt(environments_txt_file))\n+ from pwd import getpwall\n+ search_dirs = tuple(pwentry.pw_dir for pwentry in getpwall()) or (expand('~'),)\n+ else:\n+ search_dirs = (expand('~'),)\n+ for home_dir in search_dirs:\n+ environments_txt_file = get_user_environments_txt_file(home_dir)\n+ if isfile(environments_txt_file):\n+ all_env_paths.update(_clean_environments_txt(environments_txt_file))\n+\n \n # in case environments.txt files aren't complete, also add all known conda environments in\n # all envs_dirs\n", "issue": "conda env list behavior is inconsistent between Linux/macOS and Windows\n## Current Behavior\r\n\r\nOn UNIX-family operating systems (Linux and macOS), `conda env list` generates a list of all environments belonging to the current user. This behavior changes if `conda` is executed with UID 0, in which case `conda` attempts to find all user home directories on the system and list all environments belonging to all users.\r\n\r\nThis is not consistent with the behavior on Windows. On Windows, `conda env list` always attempts to find all user home directories on the system, and displays all environments belonging to all users. This occurs whether or not the current user is an administrator.\r\n\r\nThis behavior is not documented in the Conda user guide, which just says that `conda env list` is used \"to see a list of all your environments.\" https://conda.io/projects/conda/en/latest/user-guide/tasks/manage-environments.html#viewing-a-list-of-your-environments\r\n\r\n### Steps to Reproduce\r\n\r\nOn macOS/Linux, this will list the current user's environments only:\r\n\r\n```\r\nconda env list\r\n```\r\n\r\nRunning this command with `sudo` will list all environments on the system:\r\n\r\n```\r\nsudo conda env list\r\n```\r\n\r\nOn Windows, running this command from either a standard prompt or from an administrative prompts with elevated permissions will list all environments on the system (as long as the executing user can read the environment configuration file for the user that actually owns the environment):\r\n\r\n```\r\nconda env list\r\n```\r\n\r\n## Expected Behavior\r\n\r\nI would expect one of the two following behaviors:\r\n\r\n1. `conda env list` only lists the current user's environment on any operating system.\r\n2. `conda env list` only lists the current user's environment, unless it is executed as an administrator. This behavior should be consistent between Windows and macOS. \r\n\r\nThe current behavior on Windows (all users) and macOS/Linux (admins) should only be executed for administrators, if at all. In particular, the current Windows code finds all sibling directories of the current user's home folder and tries to check each one of them for an environment configuration file. In environments where Windows home directories are redirected onto a common network share, this may result in `conda env list` firing off a large number of I/O operations as it tries to access all home directories on the network share.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright (C) 2012 Anaconda, Inc\n# SPDX-License-Identifier: BSD-3-Clause\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nfrom errno import EACCES, EROFS, ENOENT\nfrom logging import getLogger\nfrom os import devnull, listdir\nfrom os.path import dirname, isdir, isfile, join, normpath\n\nfrom .prefix_data import PrefixData\nfrom ..base.context import context\nfrom ..common.compat import ensure_text_type, on_win, open\nfrom ..common.path import expand\nfrom ..gateways.disk.read import yield_lines\nfrom ..gateways.disk.test import is_conda_environment\n\nlog = getLogger(__name__)\n\n# The idea is to mock this to return '/dev/null' (or some temp file) instead.\ndef get_user_environments_txt_file(userhome='~'):\n return expand(join(userhome, '.conda', 'environments.txt'))\n\n\ndef register_env(location):\n user_environments_txt_file = get_user_environments_txt_file()\n location = normpath(location)\n\n if (\"placehold_pl\" in location or \"skeleton_\" in location\n or user_environments_txt_file == devnull):\n # Don't record envs created by conda-build.\n return\n\n if location in yield_lines(user_environments_txt_file):\n # Nothing to do. Location is already recorded in a known environments.txt file.\n return\n\n try:\n with open(user_environments_txt_file, 'a') as fh:\n fh.write(ensure_text_type(location))\n fh.write('\\n')\n except EnvironmentError as e:\n if e.errno in (EACCES, EROFS, ENOENT):\n log.warn(\"Unable to register environment. Path not writable or missing.\\n\"\n \" environment location: %s\\n\"\n \" registry file: %s\", location, user_environments_txt_file)\n else:\n raise\n\n\ndef unregister_env(location):\n if isdir(location):\n meta_dir = join(location, 'conda-meta')\n if isdir(meta_dir):\n meta_dir_contents = listdir(meta_dir)\n if len(meta_dir_contents) > 1:\n # if there are any files left other than 'conda-meta/history'\n # then don't unregister\n return\n\n _clean_environments_txt(get_user_environments_txt_file(), location)\n\n\ndef list_all_known_prefixes():\n all_env_paths = set()\n if on_win:\n home_dir_dir = dirname(expand('~'))\n for home_dir in listdir(home_dir_dir):\n environments_txt_file = get_user_environments_txt_file(join(home_dir_dir, home_dir))\n if isfile(environments_txt_file):\n all_env_paths.update(_clean_environments_txt(environments_txt_file))\n else:\n from os import geteuid\n from pwd import getpwall\n if geteuid() == 0:\n search_dirs = tuple(pwentry.pw_dir for pwentry in getpwall()) or (expand('~'),)\n else:\n search_dirs = (expand('~'),)\n for home_dir in search_dirs:\n environments_txt_file = get_user_environments_txt_file(home_dir)\n if isfile(environments_txt_file):\n all_env_paths.update(_clean_environments_txt(environments_txt_file))\n\n # in case environments.txt files aren't complete, also add all known conda environments in\n # all envs_dirs\n envs_dirs = (envs_dir for envs_dir in context.envs_dirs if isdir(envs_dir))\n all_env_paths.update(path for path in (\n join(envs_dir, name) for envs_dir in envs_dirs for name in listdir(envs_dir)\n ) if path not in all_env_paths and is_conda_environment(path))\n\n all_env_paths.add(context.root_prefix)\n return sorted(all_env_paths)\n\n\ndef query_all_prefixes(spec):\n for prefix in list_all_known_prefixes():\n prefix_recs = tuple(PrefixData(prefix).query(spec))\n if prefix_recs:\n yield prefix, prefix_recs\n\n\ndef _clean_environments_txt(environments_txt_file, remove_location=None):\n if not isfile(environments_txt_file):\n return ()\n\n if remove_location:\n remove_location = normpath(remove_location)\n environments_txt_lines = tuple(yield_lines(environments_txt_file))\n environments_txt_lines_cleaned = tuple(\n prefix for prefix in environments_txt_lines\n if prefix != remove_location and is_conda_environment(prefix)\n )\n if environments_txt_lines_cleaned != environments_txt_lines:\n _rewrite_environments_txt(environments_txt_file, environments_txt_lines_cleaned)\n return environments_txt_lines_cleaned\n\n\ndef _rewrite_environments_txt(environments_txt_file, prefixes):\n try:\n with open(environments_txt_file, 'w') as fh:\n fh.write('\\n'.join(prefixes))\n fh.write('\\n')\n except EnvironmentError as e:\n log.info(\"File not cleaned: %s\", environments_txt_file)\n log.debug('%r', e, exc_info=True)\n", "path": "conda/core/envs_manager.py"}]}
| 2,377 | 537 |
gh_patches_debug_18837
|
rasdani/github-patches
|
git_diff
|
numba__numba-1919
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Numba UnicodeEncodeError after importing unicode_literals
Taking example below from numba documentation with the only addition of `unicode_literals` import and the doc string that contains unicode characters:
```
from __future__ import unicode_literals
from numba import jit
from numpy import arange
# jit decorator tells Numba to compile this function.
# The argument types will be inferred by Numba when function is called.
@jit
def sum2d(arr):
""" – """
M, N = arr.shape
result = 0.0
for i in range(M):
for j in range(N):
result += arr[i,j]
return result
a = arange(9).reshape(3,3)
print(sum2d(a))
```
Gives an error below. The error appears only after `unicode_literals` is imported:
```
raise patched_exception
UnicodeEncodeError: 'ascii' codec can't encode character u'\u2013' in position 1: ordinal not in range(128)
D:\Anaconda\envs\py2k\lib\site-packages\numba\compiler.py:257: UnicodeEncodeError
```
`python = 2.7.11`
`numba = 0.25.0`
</issue>
<code>
[start of numba/targets/cpu.py]
1 from __future__ import print_function, absolute_import
2
3 import sys
4
5 import llvmlite.llvmpy.core as lc
6 import llvmlite.binding as ll
7
8 from numba import _dynfunc, config
9 from numba.callwrapper import PyCallWrapper
10 from .base import BaseContext, PYOBJECT
11 from numba import utils, cgutils, types
12 from numba.utils import cached_property
13 from numba.targets import callconv, codegen, externals, intrinsics, listobj, setobj
14 from .options import TargetOptions
15 from numba.runtime import rtsys
16
17 # Keep those structures in sync with _dynfunc.c.
18
19 class ClosureBody(cgutils.Structure):
20 _fields = [('env', types.pyobject)]
21
22
23 class EnvBody(cgutils.Structure):
24 _fields = [
25 ('globals', types.pyobject),
26 ('consts', types.pyobject),
27 ]
28
29
30 class CPUContext(BaseContext):
31 """
32 Changes BaseContext calling convention
33 """
34 # Overrides
35 def create_module(self, name):
36 return self._internal_codegen._create_empty_module(name)
37
38 def init(self):
39 self.is32bit = (utils.MACHINE_BITS == 32)
40 self._internal_codegen = codegen.JITCPUCodegen("numba.exec")
41
42 # Map external C functions.
43 externals.c_math_functions.install(self)
44 externals.c_numpy_functions.install(self)
45
46 # Initialize NRT runtime
47 rtsys.initialize(self)
48
49 def load_additional_registries(self):
50 # Add target specific implementations
51 from . import (cffiimpl, cmathimpl, mathimpl, npyimpl, operatorimpl,
52 printimpl, randomimpl)
53 self.install_registry(cmathimpl.registry)
54 self.install_registry(cffiimpl.registry)
55 self.install_registry(mathimpl.registry)
56 self.install_registry(npyimpl.registry)
57 self.install_registry(operatorimpl.registry)
58 self.install_registry(printimpl.registry)
59 self.install_registry(randomimpl.registry)
60 # Initialize PRNG state
61 randomimpl.random_init()
62
63 @property
64 def target_data(self):
65 return self._internal_codegen.target_data
66
67 def with_aot_codegen(self, name, **aot_options):
68 aot_codegen = codegen.AOTCPUCodegen(name, **aot_options)
69 return self.subtarget(_internal_codegen=aot_codegen,
70 aot_mode=True)
71
72 def codegen(self):
73 return self._internal_codegen
74
75 @cached_property
76 def call_conv(self):
77 return callconv.CPUCallConv(self)
78
79 def get_env_from_closure(self, builder, clo):
80 """
81 From the pointer *clo* to a _dynfunc.Closure, get a pointer
82 to the enclosed _dynfunc.Environment.
83 """
84 with cgutils.if_unlikely(builder, cgutils.is_null(builder, clo)):
85 self.debug_print(builder, "Fatal error: missing _dynfunc.Closure")
86 builder.unreachable()
87
88 clo_body_ptr = cgutils.pointer_add(
89 builder, clo, _dynfunc._impl_info['offsetof_closure_body'])
90 clo_body = ClosureBody(self, builder, ref=clo_body_ptr, cast_ref=True)
91 return clo_body.env
92
93 def get_env_body(self, builder, envptr):
94 """
95 From the given *envptr* (a pointer to a _dynfunc.Environment object),
96 get a EnvBody allowing structured access to environment fields.
97 """
98 body_ptr = cgutils.pointer_add(
99 builder, envptr, _dynfunc._impl_info['offsetof_env_body'])
100 return EnvBody(self, builder, ref=body_ptr, cast_ref=True)
101
102 def get_generator_state(self, builder, genptr, return_type):
103 """
104 From the given *genptr* (a pointer to a _dynfunc.Generator object),
105 get a pointer to its state area.
106 """
107 return cgutils.pointer_add(
108 builder, genptr, _dynfunc._impl_info['offsetof_generator_state'],
109 return_type=return_type)
110
111 def build_list(self, builder, list_type, items):
112 """
113 Build a list from the Numba *list_type* and its initial *items*.
114 """
115 return listobj.build_list(self, builder, list_type, items)
116
117 def build_set(self, builder, set_type, items):
118 """
119 Build a set from the Numba *set_type* and its initial *items*.
120 """
121 return setobj.build_set(self, builder, set_type, items)
122
123 def post_lowering(self, mod, library):
124 if self.is32bit:
125 # 32-bit machine needs to replace all 64-bit div/rem to avoid
126 # calls to compiler-rt
127 intrinsics.fix_divmod(mod)
128
129 library.add_linking_library(rtsys.library)
130
131 def create_cpython_wrapper(self, library, fndesc, env, call_helper,
132 release_gil=False):
133 wrapper_module = self.create_module("wrapper")
134 fnty = self.call_conv.get_function_type(fndesc.restype, fndesc.argtypes)
135 wrapper_callee = wrapper_module.add_function(fnty, fndesc.llvm_func_name)
136 builder = PyCallWrapper(self, wrapper_module, wrapper_callee,
137 fndesc, env, call_helper=call_helper,
138 release_gil=release_gil)
139 builder.build()
140 library.add_ir_module(wrapper_module)
141
142 def get_executable(self, library, fndesc, env):
143 """
144 Returns
145 -------
146 (cfunc, fnptr)
147
148 - cfunc
149 callable function (Can be None)
150 - fnptr
151 callable function address
152 - env
153 an execution environment (from _dynfunc)
154 """
155 # Code generation
156 baseptr = library.get_pointer_to_function(fndesc.llvm_func_name)
157 fnptr = library.get_pointer_to_function(fndesc.llvm_cpython_wrapper_name)
158
159 cfunc = _dynfunc.make_function(fndesc.lookup_module(),
160 fndesc.qualname.split('.')[-1],
161 fndesc.doc, fnptr, env,
162 # objects to keepalive with the function
163 (library,)
164 )
165
166 return cfunc
167
168 def calc_array_sizeof(self, ndim):
169 '''
170 Calculate the size of an array struct on the CPU target
171 '''
172 aryty = types.Array(types.int32, ndim, 'A')
173 return self.get_abi_sizeof(self.get_value_type(aryty))
174
175
176 # ----------------------------------------------------------------------------
177 # TargetOptions
178
179 class CPUTargetOptions(TargetOptions):
180 OPTIONS = {
181 "nopython": bool,
182 "nogil": bool,
183 "forceobj": bool,
184 "looplift": bool,
185 "boundcheck": bool,
186 "_nrt": bool,
187 "no_rewrites": bool,
188 }
189
190
191 # ----------------------------------------------------------------------------
192 # Internal
193
194 def remove_refct_calls(func):
195 """
196 Remove redundant incref/decref within on a per block basis
197 """
198 for bb in func.basic_blocks:
199 remove_null_refct_call(bb)
200 remove_refct_pairs(bb)
201
202
203 def remove_null_refct_call(bb):
204 """
205 Remove refct api calls to NULL pointer
206 """
207 pass
208 ## Skipped for now
209 # for inst in bb.instructions:
210 # if isinstance(inst, lc.CallOrInvokeInstruction):
211 # fname = inst.called_function.name
212 # if fname == "Py_IncRef" or fname == "Py_DecRef":
213 # arg = inst.args[0]
214 # print(type(arg))
215 # if isinstance(arg, lc.ConstantPointerNull):
216 # inst.erase_from_parent()
217
218
219 def remove_refct_pairs(bb):
220 """
221 Remove incref decref pairs on the same variable
222 """
223
224 didsomething = True
225
226 while didsomething:
227 didsomething = False
228
229 increfs = {}
230 decrefs = {}
231
232 # Mark
233 for inst in bb.instructions:
234 if isinstance(inst, lc.CallOrInvokeInstruction):
235 fname = inst.called_function.name
236 if fname == "Py_IncRef":
237 arg = inst.operands[0]
238 increfs[arg] = inst
239 elif fname == "Py_DecRef":
240 arg = inst.operands[0]
241 decrefs[arg] = inst
242
243 # Sweep
244 for val in increfs.keys():
245 if val in decrefs:
246 increfs[val].erase_from_parent()
247 decrefs[val].erase_from_parent()
248 didsomething = True
249
[end of numba/targets/cpu.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/numba/targets/cpu.py b/numba/targets/cpu.py
--- a/numba/targets/cpu.py
+++ b/numba/targets/cpu.py
@@ -156,9 +156,12 @@
baseptr = library.get_pointer_to_function(fndesc.llvm_func_name)
fnptr = library.get_pointer_to_function(fndesc.llvm_cpython_wrapper_name)
+ # Note: we avoid reusing the original docstring to avoid encoding
+ # issues on Python 2, see issue #1908
+ doc = "compiled wrapper for %r" % (fndesc.qualname,)
cfunc = _dynfunc.make_function(fndesc.lookup_module(),
fndesc.qualname.split('.')[-1],
- fndesc.doc, fnptr, env,
+ doc, fnptr, env,
# objects to keepalive with the function
(library,)
)
|
{"golden_diff": "diff --git a/numba/targets/cpu.py b/numba/targets/cpu.py\n--- a/numba/targets/cpu.py\n+++ b/numba/targets/cpu.py\n@@ -156,9 +156,12 @@\n baseptr = library.get_pointer_to_function(fndesc.llvm_func_name)\n fnptr = library.get_pointer_to_function(fndesc.llvm_cpython_wrapper_name)\n \n+ # Note: we avoid reusing the original docstring to avoid encoding\n+ # issues on Python 2, see issue #1908\n+ doc = \"compiled wrapper for %r\" % (fndesc.qualname,)\n cfunc = _dynfunc.make_function(fndesc.lookup_module(),\n fndesc.qualname.split('.')[-1],\n- fndesc.doc, fnptr, env,\n+ doc, fnptr, env,\n # objects to keepalive with the function\n (library,)\n )\n", "issue": "Numba UnicodeEncodeError after importing unicode_literals \nTaking example below from numba documentation with the only addition of `unicode_literals` import and the doc string that contains unicode characters:\n\n```\nfrom __future__ import unicode_literals\nfrom numba import jit\nfrom numpy import arange\n\n# jit decorator tells Numba to compile this function.\n# The argument types will be inferred by Numba when function is called.\n@jit\ndef sum2d(arr):\n \"\"\" \u2013 \"\"\"\n M, N = arr.shape\n result = 0.0\n for i in range(M):\n for j in range(N):\n result += arr[i,j]\n return result\n\na = arange(9).reshape(3,3)\nprint(sum2d(a))\n```\n\nGives an error below. The error appears only after `unicode_literals` is imported:\n\n```\nraise patched_exception\nUnicodeEncodeError: 'ascii' codec can't encode character u'\\u2013' in position 1: ordinal not in range(128)\n\nD:\\Anaconda\\envs\\py2k\\lib\\site-packages\\numba\\compiler.py:257: UnicodeEncodeError\n```\n\n`python = 2.7.11`\n`numba = 0.25.0`\n\n", "before_files": [{"content": "from __future__ import print_function, absolute_import\n\nimport sys\n\nimport llvmlite.llvmpy.core as lc\nimport llvmlite.binding as ll\n\nfrom numba import _dynfunc, config\nfrom numba.callwrapper import PyCallWrapper\nfrom .base import BaseContext, PYOBJECT\nfrom numba import utils, cgutils, types\nfrom numba.utils import cached_property\nfrom numba.targets import callconv, codegen, externals, intrinsics, listobj, setobj\nfrom .options import TargetOptions\nfrom numba.runtime import rtsys\n\n# Keep those structures in sync with _dynfunc.c.\n\nclass ClosureBody(cgutils.Structure):\n _fields = [('env', types.pyobject)]\n\n\nclass EnvBody(cgutils.Structure):\n _fields = [\n ('globals', types.pyobject),\n ('consts', types.pyobject),\n ]\n\n\nclass CPUContext(BaseContext):\n \"\"\"\n Changes BaseContext calling convention\n \"\"\"\n # Overrides\n def create_module(self, name):\n return self._internal_codegen._create_empty_module(name)\n\n def init(self):\n self.is32bit = (utils.MACHINE_BITS == 32)\n self._internal_codegen = codegen.JITCPUCodegen(\"numba.exec\")\n\n # Map external C functions.\n externals.c_math_functions.install(self)\n externals.c_numpy_functions.install(self)\n\n # Initialize NRT runtime\n rtsys.initialize(self)\n\n def load_additional_registries(self):\n # Add target specific implementations\n from . import (cffiimpl, cmathimpl, mathimpl, npyimpl, operatorimpl,\n printimpl, randomimpl)\n self.install_registry(cmathimpl.registry)\n self.install_registry(cffiimpl.registry)\n self.install_registry(mathimpl.registry)\n self.install_registry(npyimpl.registry)\n self.install_registry(operatorimpl.registry)\n self.install_registry(printimpl.registry)\n self.install_registry(randomimpl.registry)\n # Initialize PRNG state\n randomimpl.random_init()\n\n @property\n def target_data(self):\n return self._internal_codegen.target_data\n\n def with_aot_codegen(self, name, **aot_options):\n aot_codegen = codegen.AOTCPUCodegen(name, **aot_options)\n return self.subtarget(_internal_codegen=aot_codegen,\n aot_mode=True)\n\n def codegen(self):\n return self._internal_codegen\n\n @cached_property\n def call_conv(self):\n return callconv.CPUCallConv(self)\n\n def get_env_from_closure(self, builder, clo):\n \"\"\"\n From the pointer *clo* to a _dynfunc.Closure, get a pointer\n to the enclosed _dynfunc.Environment.\n \"\"\"\n with cgutils.if_unlikely(builder, cgutils.is_null(builder, clo)):\n self.debug_print(builder, \"Fatal error: missing _dynfunc.Closure\")\n builder.unreachable()\n\n clo_body_ptr = cgutils.pointer_add(\n builder, clo, _dynfunc._impl_info['offsetof_closure_body'])\n clo_body = ClosureBody(self, builder, ref=clo_body_ptr, cast_ref=True)\n return clo_body.env\n\n def get_env_body(self, builder, envptr):\n \"\"\"\n From the given *envptr* (a pointer to a _dynfunc.Environment object),\n get a EnvBody allowing structured access to environment fields.\n \"\"\"\n body_ptr = cgutils.pointer_add(\n builder, envptr, _dynfunc._impl_info['offsetof_env_body'])\n return EnvBody(self, builder, ref=body_ptr, cast_ref=True)\n\n def get_generator_state(self, builder, genptr, return_type):\n \"\"\"\n From the given *genptr* (a pointer to a _dynfunc.Generator object),\n get a pointer to its state area.\n \"\"\"\n return cgutils.pointer_add(\n builder, genptr, _dynfunc._impl_info['offsetof_generator_state'],\n return_type=return_type)\n\n def build_list(self, builder, list_type, items):\n \"\"\"\n Build a list from the Numba *list_type* and its initial *items*.\n \"\"\"\n return listobj.build_list(self, builder, list_type, items)\n\n def build_set(self, builder, set_type, items):\n \"\"\"\n Build a set from the Numba *set_type* and its initial *items*.\n \"\"\"\n return setobj.build_set(self, builder, set_type, items)\n\n def post_lowering(self, mod, library):\n if self.is32bit:\n # 32-bit machine needs to replace all 64-bit div/rem to avoid\n # calls to compiler-rt\n intrinsics.fix_divmod(mod)\n\n library.add_linking_library(rtsys.library)\n\n def create_cpython_wrapper(self, library, fndesc, env, call_helper,\n release_gil=False):\n wrapper_module = self.create_module(\"wrapper\")\n fnty = self.call_conv.get_function_type(fndesc.restype, fndesc.argtypes)\n wrapper_callee = wrapper_module.add_function(fnty, fndesc.llvm_func_name)\n builder = PyCallWrapper(self, wrapper_module, wrapper_callee,\n fndesc, env, call_helper=call_helper,\n release_gil=release_gil)\n builder.build()\n library.add_ir_module(wrapper_module)\n\n def get_executable(self, library, fndesc, env):\n \"\"\"\n Returns\n -------\n (cfunc, fnptr)\n\n - cfunc\n callable function (Can be None)\n - fnptr\n callable function address\n - env\n an execution environment (from _dynfunc)\n \"\"\"\n # Code generation\n baseptr = library.get_pointer_to_function(fndesc.llvm_func_name)\n fnptr = library.get_pointer_to_function(fndesc.llvm_cpython_wrapper_name)\n\n cfunc = _dynfunc.make_function(fndesc.lookup_module(),\n fndesc.qualname.split('.')[-1],\n fndesc.doc, fnptr, env,\n # objects to keepalive with the function\n (library,)\n )\n\n return cfunc\n\n def calc_array_sizeof(self, ndim):\n '''\n Calculate the size of an array struct on the CPU target\n '''\n aryty = types.Array(types.int32, ndim, 'A')\n return self.get_abi_sizeof(self.get_value_type(aryty))\n\n\n# ----------------------------------------------------------------------------\n# TargetOptions\n\nclass CPUTargetOptions(TargetOptions):\n OPTIONS = {\n \"nopython\": bool,\n \"nogil\": bool,\n \"forceobj\": bool,\n \"looplift\": bool,\n \"boundcheck\": bool,\n \"_nrt\": bool,\n \"no_rewrites\": bool,\n }\n\n\n# ----------------------------------------------------------------------------\n# Internal\n\ndef remove_refct_calls(func):\n \"\"\"\n Remove redundant incref/decref within on a per block basis\n \"\"\"\n for bb in func.basic_blocks:\n remove_null_refct_call(bb)\n remove_refct_pairs(bb)\n\n\ndef remove_null_refct_call(bb):\n \"\"\"\n Remove refct api calls to NULL pointer\n \"\"\"\n pass\n ## Skipped for now\n # for inst in bb.instructions:\n # if isinstance(inst, lc.CallOrInvokeInstruction):\n # fname = inst.called_function.name\n # if fname == \"Py_IncRef\" or fname == \"Py_DecRef\":\n # arg = inst.args[0]\n # print(type(arg))\n # if isinstance(arg, lc.ConstantPointerNull):\n # inst.erase_from_parent()\n\n\ndef remove_refct_pairs(bb):\n \"\"\"\n Remove incref decref pairs on the same variable\n \"\"\"\n\n didsomething = True\n\n while didsomething:\n didsomething = False\n\n increfs = {}\n decrefs = {}\n\n # Mark\n for inst in bb.instructions:\n if isinstance(inst, lc.CallOrInvokeInstruction):\n fname = inst.called_function.name\n if fname == \"Py_IncRef\":\n arg = inst.operands[0]\n increfs[arg] = inst\n elif fname == \"Py_DecRef\":\n arg = inst.operands[0]\n decrefs[arg] = inst\n\n # Sweep\n for val in increfs.keys():\n if val in decrefs:\n increfs[val].erase_from_parent()\n decrefs[val].erase_from_parent()\n didsomething = True\n", "path": "numba/targets/cpu.py"}]}
| 3,276 | 208 |
gh_patches_debug_23287
|
rasdani/github-patches
|
git_diff
|
PrefectHQ__prefect-5541
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Default option for DateTimeParameter
## Current behavior
You can set a default value for a `Parameter`, ie:
```
my_param = Parameter('my_param', default=None)
my_other_param = Parameter('my_other_param', default='hi')
```
but not for a `DateTimeParameter`. If nothing is supplied by the user, it will default to `None` if it's optional (`required = False`), and will raise an error if `required = True`.
When a DateTimeParameter is in a flow, it's likely that there's code later in the flow which operates on this date (eg. adding days) and which expect `DateTime` objects. Some of these operations raise errors when they're provided with a `NoneType` object. This means that if a `DateTimeParameter` is optional, it is likely to result in errors downstream. This means that we need to supply a value for all DateTimeParameters each time we run the flow (this gets cumbersome if we are testing and triggering repeated runs through the UI with the same DateTimeParameters each time).
## Proposed behavior
It would be awesome if we can set default values for `DateTimeParameter`s too which mirrors the behaviour of the defaults on `Parameter`. That is, if a `DateTimeParameter` is optional but we have provided a default, the flow can still run using this default value rather than raising an error or needing to supply values each time we run a flow. Currently, we would have to handle the `None` case when it's required (eg. `if date is None then date=...`), but this is effectively the same as setting a default. It would be better and more readable if the default was attached to the `DateTimeParameter` argument upfront.
To stay consistent with the behaviour of `Parameter`, if a `DateTimeParameter` is required and a default is provided, it will still raise a 'no parameter received' error if nothing is supplied by the user.
Ideally we could pass through a `Date` or `DateTime` object, but a string would suffice too, if JSON-serializable requirements get in the way.
## Example
```
# Ideal
from pendulum import DateTime
my_date = DateTimeParameter('my_date', default=DateTime(2020, 9, 1))
# Admitting a string would be ok too
my_other_date = DateTimeParameter('my_other_date', default='2021-01-01T00:00:00+00:00')
```
</issue>
<code>
[start of src/prefect/core/parameter.py]
1 from typing import TYPE_CHECKING, Any, Dict, Iterable, Union, Optional
2
3 import pendulum
4
5 import prefect
6 from prefect.engine.serializers import DateTimeSerializer
7 import prefect.engine.signals
8 import prefect.triggers
9 from prefect.core.task import Task, NoDefault
10 from prefect.engine.results import PrefectResult
11
12 if TYPE_CHECKING:
13 from prefect.core.flow import Flow # pylint: disable=W0611
14
15
16 no_default = NoDefault.value
17
18 JSONSerializableParameterValue = Optional[
19 Union[NoDefault, str, int, float, bool, list, dict]
20 ]
21
22
23 class Parameter(Task):
24 """
25 A Parameter is a special task that defines a required flow input.
26
27 A parameter's "slug" is automatically -- and immutably -- set to the parameter name.
28 Flows enforce slug uniqueness across all tasks, so this ensures that the flow has
29 no other parameters by the same name.
30
31 Args:
32 - name (str): the Parameter name.
33 - default (any, optional): A default value for the parameter. Must be a JSON-Serializable type.
34 - required (bool, optional): If True, the Parameter is required and the
35 default value is ignored. Defaults to `False` if a `default` is
36 provided, otherwise `True`.
37 - tags ([str], optional): A list of tags for this parameter
38
39 """
40
41 def __init__(
42 self,
43 name: str,
44 default: JSONSerializableParameterValue = no_default,
45 required: bool = None,
46 tags: Iterable[str] = None,
47 ):
48 if required is None:
49 required = default is no_default
50 if default is no_default:
51 default = None
52 self.required = required
53 self.default = default
54
55 super().__init__(
56 name=name, slug=name, tags=tags, result=PrefectResult(), checkpoint=True
57 )
58
59 def __repr__(self) -> str:
60 return "<Parameter: {self.name}>".format(self=self)
61
62 def __call__(self, flow: "Flow" = None) -> "Parameter": # type: ignore
63 """
64 Calling a Parameter adds it to a flow.
65
66 Args:
67 - flow (Flow, optional): The flow to set dependencies on, defaults to the current
68 flow in context if no flow is specified
69
70 Returns:
71 - Task: a new Task instance
72
73 """
74 result = super().bind(flow=flow)
75 assert isinstance(result, Parameter) # mypy assert
76 return result
77
78 def copy(self, name: str, **task_args: Any) -> "Task": # type: ignore
79 """
80 Creates a copy of the Parameter with a new name.
81
82 Args:
83 - name (str): the new Parameter name
84 - **task_args (dict, optional): a dictionary of task attribute keyword arguments,
85 these attributes will be set on the new copy
86
87 Raises:
88 - AttributeError: if any passed `task_args` are not attributes of the original
89
90 Returns:
91 - Parameter: a copy of the current Parameter, with a new name and any attributes
92 updated from `task_args`
93 """
94 return super().copy(name=name, slug=name, **task_args)
95
96 def run(self) -> Any:
97 params = prefect.context.get("parameters") or {}
98 if self.required and self.name not in params:
99 self.logger.debug(
100 'Parameter "{}" was required but not provided.'.format(self.name)
101 )
102 raise prefect.engine.signals.FAIL(
103 'Parameter "{}" was required but not provided.'.format(self.name)
104 )
105 return params.get(self.name, self.default)
106
107 # Serialization ------------------------------------------------------------
108
109 def serialize(self) -> Dict[str, Any]:
110 """
111 Creates a serialized representation of this parameter
112
113 Returns:
114 - dict representing this parameter
115 """
116 return prefect.serialization.task.ParameterSchema().dump(self)
117
118
119 class DateTimeParameter(Parameter):
120 """
121 A DateTimeParameter that casts its input as a DateTime
122
123 Args:
124 - name (str): the Parameter name.
125 - required (bool, optional): If True, the Parameter is required. Otherwise, it
126 is optional and will return `None` if no value is provided.
127 - tags ([str], optional): A list of tags for this parameter
128 """
129
130 def __init__(
131 self,
132 name: str,
133 required: bool = True,
134 tags: Iterable[str] = None,
135 ) -> None:
136 default = no_default if required else None
137 super().__init__(name=name, default=default, required=required, tags=tags)
138 self.result = PrefectResult(serializer=DateTimeSerializer())
139
140 def run(self) -> Any:
141 value = super().run()
142 if value is None:
143 return value
144 elif isinstance(value, str):
145 return pendulum.parse(value)
146 else:
147 return pendulum.instance(value)
148
[end of src/prefect/core/parameter.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/prefect/core/parameter.py b/src/prefect/core/parameter.py
--- a/src/prefect/core/parameter.py
+++ b/src/prefect/core/parameter.py
@@ -122,6 +122,8 @@
Args:
- name (str): the Parameter name.
+ - default (any, optional): A default value for the parameter. Must be a JSON-Serializable type,
+ and must be parseable by pendulum.
- required (bool, optional): If True, the Parameter is required. Otherwise, it
is optional and will return `None` if no value is provided.
- tags ([str], optional): A list of tags for this parameter
@@ -130,10 +132,10 @@
def __init__(
self,
name: str,
+ default: JSONSerializableParameterValue = no_default,
required: bool = True,
tags: Iterable[str] = None,
) -> None:
- default = no_default if required else None
super().__init__(name=name, default=default, required=required, tags=tags)
self.result = PrefectResult(serializer=DateTimeSerializer())
|
{"golden_diff": "diff --git a/src/prefect/core/parameter.py b/src/prefect/core/parameter.py\n--- a/src/prefect/core/parameter.py\n+++ b/src/prefect/core/parameter.py\n@@ -122,6 +122,8 @@\n \n Args:\n - name (str): the Parameter name.\n+ - default (any, optional): A default value for the parameter. Must be a JSON-Serializable type,\n+ and must be parseable by pendulum.\n - required (bool, optional): If True, the Parameter is required. Otherwise, it\n is optional and will return `None` if no value is provided.\n - tags ([str], optional): A list of tags for this parameter\n@@ -130,10 +132,10 @@\n def __init__(\n self,\n name: str,\n+ default: JSONSerializableParameterValue = no_default,\n required: bool = True,\n tags: Iterable[str] = None,\n ) -> None:\n- default = no_default if required else None\n super().__init__(name=name, default=default, required=required, tags=tags)\n self.result = PrefectResult(serializer=DateTimeSerializer())\n", "issue": "Default option for DateTimeParameter\n## Current behavior\r\nYou can set a default value for a `Parameter`, ie:\r\n```\r\nmy_param = Parameter('my_param', default=None)\r\nmy_other_param = Parameter('my_other_param', default='hi')\r\n```\r\nbut not for a `DateTimeParameter`. If nothing is supplied by the user, it will default to `None` if it's optional (`required = False`), and will raise an error if `required = True`.\r\n\r\nWhen a DateTimeParameter is in a flow, it's likely that there's code later in the flow which operates on this date (eg. adding days) and which expect `DateTime` objects. Some of these operations raise errors when they're provided with a `NoneType` object. This means that if a `DateTimeParameter` is optional, it is likely to result in errors downstream. This means that we need to supply a value for all DateTimeParameters each time we run the flow (this gets cumbersome if we are testing and triggering repeated runs through the UI with the same DateTimeParameters each time).\r\n\r\n## Proposed behavior\r\nIt would be awesome if we can set default values for `DateTimeParameter`s too which mirrors the behaviour of the defaults on `Parameter`. That is, if a `DateTimeParameter` is optional but we have provided a default, the flow can still run using this default value rather than raising an error or needing to supply values each time we run a flow. Currently, we would have to handle the `None` case when it's required (eg. `if date is None then date=...`), but this is effectively the same as setting a default. It would be better and more readable if the default was attached to the `DateTimeParameter` argument upfront.\r\n\r\nTo stay consistent with the behaviour of `Parameter`, if a `DateTimeParameter` is required and a default is provided, it will still raise a 'no parameter received' error if nothing is supplied by the user.\r\n\r\nIdeally we could pass through a `Date` or `DateTime` object, but a string would suffice too, if JSON-serializable requirements get in the way.\r\n\r\n## Example\r\n```\r\n# Ideal\r\nfrom pendulum import DateTime\r\nmy_date = DateTimeParameter('my_date', default=DateTime(2020, 9, 1))\r\n# Admitting a string would be ok too\r\nmy_other_date = DateTimeParameter('my_other_date', default='2021-01-01T00:00:00+00:00')\r\n```\r\n\n", "before_files": [{"content": "from typing import TYPE_CHECKING, Any, Dict, Iterable, Union, Optional\n\nimport pendulum\n\nimport prefect\nfrom prefect.engine.serializers import DateTimeSerializer\nimport prefect.engine.signals\nimport prefect.triggers\nfrom prefect.core.task import Task, NoDefault\nfrom prefect.engine.results import PrefectResult\n\nif TYPE_CHECKING:\n from prefect.core.flow import Flow # pylint: disable=W0611\n\n\nno_default = NoDefault.value\n\nJSONSerializableParameterValue = Optional[\n Union[NoDefault, str, int, float, bool, list, dict]\n]\n\n\nclass Parameter(Task):\n \"\"\"\n A Parameter is a special task that defines a required flow input.\n\n A parameter's \"slug\" is automatically -- and immutably -- set to the parameter name.\n Flows enforce slug uniqueness across all tasks, so this ensures that the flow has\n no other parameters by the same name.\n\n Args:\n - name (str): the Parameter name.\n - default (any, optional): A default value for the parameter. Must be a JSON-Serializable type.\n - required (bool, optional): If True, the Parameter is required and the\n default value is ignored. Defaults to `False` if a `default` is\n provided, otherwise `True`.\n - tags ([str], optional): A list of tags for this parameter\n\n \"\"\"\n\n def __init__(\n self,\n name: str,\n default: JSONSerializableParameterValue = no_default,\n required: bool = None,\n tags: Iterable[str] = None,\n ):\n if required is None:\n required = default is no_default\n if default is no_default:\n default = None\n self.required = required\n self.default = default\n\n super().__init__(\n name=name, slug=name, tags=tags, result=PrefectResult(), checkpoint=True\n )\n\n def __repr__(self) -> str:\n return \"<Parameter: {self.name}>\".format(self=self)\n\n def __call__(self, flow: \"Flow\" = None) -> \"Parameter\": # type: ignore\n \"\"\"\n Calling a Parameter adds it to a flow.\n\n Args:\n - flow (Flow, optional): The flow to set dependencies on, defaults to the current\n flow in context if no flow is specified\n\n Returns:\n - Task: a new Task instance\n\n \"\"\"\n result = super().bind(flow=flow)\n assert isinstance(result, Parameter) # mypy assert\n return result\n\n def copy(self, name: str, **task_args: Any) -> \"Task\": # type: ignore\n \"\"\"\n Creates a copy of the Parameter with a new name.\n\n Args:\n - name (str): the new Parameter name\n - **task_args (dict, optional): a dictionary of task attribute keyword arguments,\n these attributes will be set on the new copy\n\n Raises:\n - AttributeError: if any passed `task_args` are not attributes of the original\n\n Returns:\n - Parameter: a copy of the current Parameter, with a new name and any attributes\n updated from `task_args`\n \"\"\"\n return super().copy(name=name, slug=name, **task_args)\n\n def run(self) -> Any:\n params = prefect.context.get(\"parameters\") or {}\n if self.required and self.name not in params:\n self.logger.debug(\n 'Parameter \"{}\" was required but not provided.'.format(self.name)\n )\n raise prefect.engine.signals.FAIL(\n 'Parameter \"{}\" was required but not provided.'.format(self.name)\n )\n return params.get(self.name, self.default)\n\n # Serialization ------------------------------------------------------------\n\n def serialize(self) -> Dict[str, Any]:\n \"\"\"\n Creates a serialized representation of this parameter\n\n Returns:\n - dict representing this parameter\n \"\"\"\n return prefect.serialization.task.ParameterSchema().dump(self)\n\n\nclass DateTimeParameter(Parameter):\n \"\"\"\n A DateTimeParameter that casts its input as a DateTime\n\n Args:\n - name (str): the Parameter name.\n - required (bool, optional): If True, the Parameter is required. Otherwise, it\n is optional and will return `None` if no value is provided.\n - tags ([str], optional): A list of tags for this parameter\n \"\"\"\n\n def __init__(\n self,\n name: str,\n required: bool = True,\n tags: Iterable[str] = None,\n ) -> None:\n default = no_default if required else None\n super().__init__(name=name, default=default, required=required, tags=tags)\n self.result = PrefectResult(serializer=DateTimeSerializer())\n\n def run(self) -> Any:\n value = super().run()\n if value is None:\n return value\n elif isinstance(value, str):\n return pendulum.parse(value)\n else:\n return pendulum.instance(value)\n", "path": "src/prefect/core/parameter.py"}]}
| 2,448 | 261 |
gh_patches_debug_18079
|
rasdani/github-patches
|
git_diff
|
modin-project__modin-3016
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Document modin.experimental.sklearn
This should include docstrings and purposes of everything inside modin.experimental.sklearn.
</issue>
<code>
[start of modin/experimental/sklearn/model_selection/__init__.py]
1 # Licensed to Modin Development Team under one or more contributor license agreements.
2 # See the NOTICE file distributed with this work for additional information regarding
3 # copyright ownership. The Modin Development Team licenses this file to you under the
4 # Apache License, Version 2.0 (the "License"); you may not use this file except in
5 # compliance with the License. You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software distributed under
10 # the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF
11 # ANY KIND, either express or implied. See the License for the specific language
12 # governing permissions and limitations under the License.
13
14 from .train_test_split import train_test_split
15
16 __all__ = ["train_test_split"]
17
[end of modin/experimental/sklearn/model_selection/__init__.py]
[start of modin/experimental/sklearn/__init__.py]
1 # Licensed to Modin Development Team under one or more contributor license agreements.
2 # See the NOTICE file distributed with this work for additional information regarding
3 # copyright ownership. The Modin Development Team licenses this file to you under the
4 # Apache License, Version 2.0 (the "License"); you may not use this file except in
5 # compliance with the License. You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software distributed under
10 # the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF
11 # ANY KIND, either express or implied. See the License for the specific language
12 # governing permissions and limitations under the License.
13
[end of modin/experimental/sklearn/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/modin/experimental/sklearn/__init__.py b/modin/experimental/sklearn/__init__.py
--- a/modin/experimental/sklearn/__init__.py
+++ b/modin/experimental/sklearn/__init__.py
@@ -10,3 +10,5 @@
# the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF
# ANY KIND, either express or implied. See the License for the specific language
# governing permissions and limitations under the License.
+
+"""Module holds experimental scikit-learn specific functionality for Modin."""
diff --git a/modin/experimental/sklearn/model_selection/__init__.py b/modin/experimental/sklearn/model_selection/__init__.py
--- a/modin/experimental/sklearn/model_selection/__init__.py
+++ b/modin/experimental/sklearn/model_selection/__init__.py
@@ -11,6 +11,8 @@
# ANY KIND, either express or implied. See the License for the specific language
# governing permissions and limitations under the License.
+"""Module holds model selection specific functionality."""
+
from .train_test_split import train_test_split
__all__ = ["train_test_split"]
|
{"golden_diff": "diff --git a/modin/experimental/sklearn/__init__.py b/modin/experimental/sklearn/__init__.py\n--- a/modin/experimental/sklearn/__init__.py\n+++ b/modin/experimental/sklearn/__init__.py\n@@ -10,3 +10,5 @@\n # the License is distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF\n # ANY KIND, either express or implied. See the License for the specific language\n # governing permissions and limitations under the License.\n+\n+\"\"\"Module holds experimental scikit-learn specific functionality for Modin.\"\"\"\ndiff --git a/modin/experimental/sklearn/model_selection/__init__.py b/modin/experimental/sklearn/model_selection/__init__.py\n--- a/modin/experimental/sklearn/model_selection/__init__.py\n+++ b/modin/experimental/sklearn/model_selection/__init__.py\n@@ -11,6 +11,8 @@\n # ANY KIND, either express or implied. See the License for the specific language\n # governing permissions and limitations under the License.\n \n+\"\"\"Module holds model selection specific functionality.\"\"\"\n+\n from .train_test_split import train_test_split\n \n __all__ = [\"train_test_split\"]\n", "issue": "Document modin.experimental.sklearn\nThis should include docstrings and purposes of everything inside modin.experimental.sklearn.\n", "before_files": [{"content": "# Licensed to Modin Development Team under one or more contributor license agreements.\n# See the NOTICE file distributed with this work for additional information regarding\n# copyright ownership. The Modin Development Team licenses this file to you under the\n# Apache License, Version 2.0 (the \"License\"); you may not use this file except in\n# compliance with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software distributed under\n# the License is distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF\n# ANY KIND, either express or implied. See the License for the specific language\n# governing permissions and limitations under the License.\n\nfrom .train_test_split import train_test_split\n\n__all__ = [\"train_test_split\"]\n", "path": "modin/experimental/sklearn/model_selection/__init__.py"}, {"content": "# Licensed to Modin Development Team under one or more contributor license agreements.\n# See the NOTICE file distributed with this work for additional information regarding\n# copyright ownership. The Modin Development Team licenses this file to you under the\n# Apache License, Version 2.0 (the \"License\"); you may not use this file except in\n# compliance with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software distributed under\n# the License is distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF\n# ANY KIND, either express or implied. See the License for the specific language\n# governing permissions and limitations under the License.\n", "path": "modin/experimental/sklearn/__init__.py"}]}
| 994 | 261 |
gh_patches_debug_5648
|
rasdani/github-patches
|
git_diff
|
pydantic__pydantic-8341
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Upgrade ruff target version to Python 3.8
### Initial Checks
- [X] I confirm that I'm using Pydantic V2
### Description
I deemed this as an action left out from [Dropping Python 3.7 Support](https://github.com/pydantic/pydantic/issues/7187)
1. Update ruff's `target-version` to `py38`
2. Run `make format` and adopt minimal changes to conform
### Example Code
```Python
(pydantic-3.12) PS D:\dev\Elkiwa\pydantic> make format
PDM, version 2.10.4
pdm run ruff --fix pydantic tests docs/plugins
pdm run ruff format pydantic tests docs/plugins
164 files left unchanged
```
### Python, Pydantic & OS Version
```Text
pydantic version: 2.6.0a1
pydantic-core version: 2.14.5
pydantic-core build: profile=release pgo=true
install path: D:\dev\Elkiwa\pydantic\pydantic
python version: 3.12.1 (tags/v3.12.1:2305ca5, Dec 7 2023, 22:03:25) [MSC v.1937 64 bit (AMD64)]
platform: Windows-11-10.0.22631-SP0
related packages: email-validator-2.1.0.post1 mypy-1.1.1 pydantic-extra-types-2.1.0 pydantic-settings-2.1.0 typing_extensions-4.8.0
commit: a3c3037f
```
</issue>
<code>
[start of pydantic/plugin/_loader.py]
1 from __future__ import annotations
2
3 import sys
4 import warnings
5 from typing import TYPE_CHECKING, Iterable
6
7 from typing_extensions import Final
8
9 if sys.version_info >= (3, 8):
10 import importlib.metadata as importlib_metadata
11 else:
12 import importlib_metadata
13
14
15 if TYPE_CHECKING:
16 from . import PydanticPluginProtocol
17
18
19 PYDANTIC_ENTRY_POINT_GROUP: Final[str] = 'pydantic'
20
21 # cache of plugins
22 _plugins: dict[str, PydanticPluginProtocol] | None = None
23 # return no plugins while loading plugins to avoid recursion and errors while import plugins
24 # this means that if plugins use pydantic
25 _loading_plugins: bool = False
26
27
28 def get_plugins() -> Iterable[PydanticPluginProtocol]:
29 """Load plugins for Pydantic.
30
31 Inspired by: https://github.com/pytest-dev/pluggy/blob/1.3.0/src/pluggy/_manager.py#L376-L402
32 """
33 global _plugins, _loading_plugins
34 if _loading_plugins:
35 # this happens when plugins themselves use pydantic, we return no plugins
36 return ()
37 elif _plugins is None:
38 _plugins = {}
39 # set _loading_plugins so any plugins that use pydantic don't themselves use plugins
40 _loading_plugins = True
41 try:
42 for dist in importlib_metadata.distributions():
43 for entry_point in dist.entry_points:
44 if entry_point.group != PYDANTIC_ENTRY_POINT_GROUP:
45 continue
46 if entry_point.value in _plugins:
47 continue
48 try:
49 _plugins[entry_point.value] = entry_point.load()
50 except (ImportError, AttributeError) as e:
51 warnings.warn(
52 f'{e.__class__.__name__} while loading the `{entry_point.name}` Pydantic plugin, '
53 f'this plugin will not be installed.\n\n{e!r}'
54 )
55 finally:
56 _loading_plugins = False
57
58 return _plugins.values()
59
[end of pydantic/plugin/_loader.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pydantic/plugin/_loader.py b/pydantic/plugin/_loader.py
--- a/pydantic/plugin/_loader.py
+++ b/pydantic/plugin/_loader.py
@@ -1,16 +1,8 @@
from __future__ import annotations
-import sys
+import importlib.metadata as importlib_metadata
import warnings
-from typing import TYPE_CHECKING, Iterable
-
-from typing_extensions import Final
-
-if sys.version_info >= (3, 8):
- import importlib.metadata as importlib_metadata
-else:
- import importlib_metadata
-
+from typing import TYPE_CHECKING, Final, Iterable
if TYPE_CHECKING:
from . import PydanticPluginProtocol
|
{"golden_diff": "diff --git a/pydantic/plugin/_loader.py b/pydantic/plugin/_loader.py\n--- a/pydantic/plugin/_loader.py\n+++ b/pydantic/plugin/_loader.py\n@@ -1,16 +1,8 @@\n from __future__ import annotations\n \n-import sys\n+import importlib.metadata as importlib_metadata\n import warnings\n-from typing import TYPE_CHECKING, Iterable\n-\n-from typing_extensions import Final\n-\n-if sys.version_info >= (3, 8):\n- import importlib.metadata as importlib_metadata\n-else:\n- import importlib_metadata\n-\n+from typing import TYPE_CHECKING, Final, Iterable\n \n if TYPE_CHECKING:\n from . import PydanticPluginProtocol\n", "issue": "Upgrade ruff target version to Python 3.8\n### Initial Checks\r\n\r\n- [X] I confirm that I'm using Pydantic V2\r\n\r\n### Description\r\n\r\nI deemed this as an action left out from [Dropping Python 3.7 Support](https://github.com/pydantic/pydantic/issues/7187)\r\n\r\n1. Update ruff's `target-version` to `py38`\r\n2. Run `make format` and adopt minimal changes to conform\r\n\r\n### Example Code\r\n\r\n```Python\r\n(pydantic-3.12) PS D:\\dev\\Elkiwa\\pydantic> make format\r\nPDM, version 2.10.4\r\npdm run ruff --fix pydantic tests docs/plugins\r\npdm run ruff format pydantic tests docs/plugins\r\n164 files left unchanged\r\n```\r\n\r\n\r\n### Python, Pydantic & OS Version\r\n\r\n```Text\r\n pydantic version: 2.6.0a1\r\n pydantic-core version: 2.14.5\r\n pydantic-core build: profile=release pgo=true\r\n install path: D:\\dev\\Elkiwa\\pydantic\\pydantic\r\n python version: 3.12.1 (tags/v3.12.1:2305ca5, Dec 7 2023, 22:03:25) [MSC v.1937 64 bit (AMD64)]\r\n platform: Windows-11-10.0.22631-SP0\r\n related packages: email-validator-2.1.0.post1 mypy-1.1.1 pydantic-extra-types-2.1.0 pydantic-settings-2.1.0 typing_extensions-4.8.0\r\n commit: a3c3037f\r\n```\r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nimport sys\nimport warnings\nfrom typing import TYPE_CHECKING, Iterable\n\nfrom typing_extensions import Final\n\nif sys.version_info >= (3, 8):\n import importlib.metadata as importlib_metadata\nelse:\n import importlib_metadata\n\n\nif TYPE_CHECKING:\n from . import PydanticPluginProtocol\n\n\nPYDANTIC_ENTRY_POINT_GROUP: Final[str] = 'pydantic'\n\n# cache of plugins\n_plugins: dict[str, PydanticPluginProtocol] | None = None\n# return no plugins while loading plugins to avoid recursion and errors while import plugins\n# this means that if plugins use pydantic\n_loading_plugins: bool = False\n\n\ndef get_plugins() -> Iterable[PydanticPluginProtocol]:\n \"\"\"Load plugins for Pydantic.\n\n Inspired by: https://github.com/pytest-dev/pluggy/blob/1.3.0/src/pluggy/_manager.py#L376-L402\n \"\"\"\n global _plugins, _loading_plugins\n if _loading_plugins:\n # this happens when plugins themselves use pydantic, we return no plugins\n return ()\n elif _plugins is None:\n _plugins = {}\n # set _loading_plugins so any plugins that use pydantic don't themselves use plugins\n _loading_plugins = True\n try:\n for dist in importlib_metadata.distributions():\n for entry_point in dist.entry_points:\n if entry_point.group != PYDANTIC_ENTRY_POINT_GROUP:\n continue\n if entry_point.value in _plugins:\n continue\n try:\n _plugins[entry_point.value] = entry_point.load()\n except (ImportError, AttributeError) as e:\n warnings.warn(\n f'{e.__class__.__name__} while loading the `{entry_point.name}` Pydantic plugin, '\n f'this plugin will not be installed.\\n\\n{e!r}'\n )\n finally:\n _loading_plugins = False\n\n return _plugins.values()\n", "path": "pydantic/plugin/_loader.py"}]}
| 1,493 | 151 |
gh_patches_debug_16761
|
rasdani/github-patches
|
git_diff
|
vllm-project__vllm-5194
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Bug]: assert parts[0] == "base_model" AssertionError
### Your current environment
```text
PyTorch version: 2.3.0+cu121
Is debug build: False
CUDA used to build PyTorch: 12.1
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.3 LTS (x86_64)
GCC version: (conda-forge gcc 13.2.0-7) 13.2.0
Clang version: Could not collect
CMake version: version 3.29.3
Libc version: glibc-2.35
Python version: 3.10.14 (main, May 6 2024, 19:42:50) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-105-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 12.1.105
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
GPU 3: NVIDIA GeForce RTX 3090
Nvidia driver version: 535.171.04
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.9.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.9.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.9.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.9.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.9.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.9.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.9.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 46 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 88
On-line CPU(s) list: 0-87
Vendor ID: GenuineIntel
Model name: Intel(R) Xeon(R) CPU E5-2696 v4 @ 2.20GHz
CPU family: 6
Model: 79
Thread(s) per core: 2
Core(s) per socket: 22
Socket(s): 2
Stepping: 1
CPU max MHz: 3700.0000
CPU min MHz: 1200.0000
BogoMIPS: 4399.72
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single pti intel_ppin ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm cqm rdt_a rdseed adx smap intel_pt xsaveopt cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts md_clear flush_l1d
Virtualization: VT-x
L1d cache: 1.4 MiB (44 instances)
L1i cache: 1.4 MiB (44 instances)
L2 cache: 11 MiB (44 instances)
L3 cache: 110 MiB (2 instances)
NUMA node(s): 2
NUMA node0 CPU(s): 0-21,44-65
NUMA node1 CPU(s): 22-43,66-87
Vulnerability Gather data sampling: Not affected
Vulnerability Itlb multihit: KVM: Mitigation: VMX disabled
Vulnerability L1tf: Mitigation; PTE Inversion; VMX conditional cache flushes, SMT vulnerable
Vulnerability Mds: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Meltdown: Mitigation; PTI
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Retbleed: Not affected
Vulnerability Spec rstack overflow: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, IBRS_FW, STIBP conditional, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Mitigation; Clear CPU buffers; SMT vulnerable
Versions of relevant libraries:
[pip3] numpy==1.26.4
[pip3] nvidia-nccl-cu12==2.20.5
[pip3] torch==2.3.0
[pip3] triton==2.3.0
[pip3] vllm_nccl_cu12==2.18.1.0.4.0
[conda] numpy 1.26.4 pypi_0 pypi
[conda] nvidia-nccl-cu12 2.20.5 pypi_0 pypi
[conda] torch 2.3.0 pypi_0 pypi
[conda] triton 2.3.0 pypi_0 pypi
[conda] vllm-nccl-cu12 2.18.1.0.4.0 pypi_0 pypiROCM Version: Could not collect
Neuron SDK Version: N/A
vLLM Version: 0.4.2
vLLM Build Flags:
CUDA Archs: Not Set; ROCm: Disabled; Neuron: Disabled
GPU Topology:
GPU0 GPU1 GPU2 GPU3 CPU Affinity NUMA Affinity GPU NUMA ID
GPU0 X PHB SYS SYS 0-21,44-65 0 N/A
GPU1 PHB X SYS SYS 0-21,44-65 0 N/A
GPU2 SYS SYS X PHB 22-43,66-87 1 N/A
GPU3 SYS SYS PHB X 22-43,66-87 1 N/A
Legend:
X = Self
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
PIX = Connection traversing at most a single PCIe bridge
NV# = Connection traversing a bonded set of # NVLinks
```
### 🐛 Describe the bug
CUDA_VISIBLE_DEVICES=0,1 python -m vllm.entrypoints.openai.api_server \
--model /home/greatwall/app/edison/models/Qwen1.5-14B-Chat \
--trust-remote-code \
--served-model-name qwen14B \
--max-model-len 4096 \
--gpu-memory-utilization 0.9 \
--enable-lora \
--lora-modules lora1=/home/greatwall/app/edison/output/qwen1half-14b-chat/v65-20240515-143141/checkpoint-1110 \
--host 0.0.0.0 \
--port 8088 \
--tensor-parallel-size 2 \
--enforce-eager
</issue>
<code>
[start of vllm/lora/utils.py]
1 from typing import List, Optional, Set, Tuple, Type
2
3 from torch import nn
4 from transformers import PretrainedConfig
5
6 from vllm.config import LoRAConfig
7 from vllm.logger import init_logger
8 from vllm.lora.fully_sharded_layers import (
9 ColumnParallelLinearWithShardedLoRA,
10 MergedColumnParallelLinearWithShardedLoRA,
11 MergedQKVParallelLinearWithShardedLora, RowParallelLinearWithShardedLoRA)
12 # being imported for _all_lora_classes below
13 # yapf conflicts with isort for this block
14 # yapf: disable
15 from vllm.lora.layers import (BaseLayerWithLoRA, ColumnParallelLinearWithLoRA,
16 LinearScalingRotaryEmbeddingWithLora,
17 LogitsProcessorWithLoRA,
18 MergedColumnParallelLinearWithLoRA,
19 MergedQKVParallelLinearWithLora,
20 QKVParallelLinearWithLora,
21 RowParallelLinearWithLoRA,
22 VocabParallelEmbeddingWithLoRA)
23 # yapf: enable
24 from vllm.model_executor.layers.logits_processor import LogitsProcessor
25 from vllm.model_executor.layers.vocab_parallel_embedding import ParallelLMHead
26
27 logger = init_logger(__name__)
28
29 _all_lora_classes: Set[Type[BaseLayerWithLoRA]] = {
30 VocabParallelEmbeddingWithLoRA,
31 ColumnParallelLinearWithLoRA,
32 MergedColumnParallelLinearWithLoRA,
33 QKVParallelLinearWithLora,
34 MergedQKVParallelLinearWithLora,
35 RowParallelLinearWithLoRA,
36 LogitsProcessorWithLoRA,
37 ColumnParallelLinearWithShardedLoRA,
38 MergedColumnParallelLinearWithShardedLoRA,
39 MergedQKVParallelLinearWithShardedLora,
40 RowParallelLinearWithShardedLoRA,
41 LinearScalingRotaryEmbeddingWithLora,
42 }
43
44
45 def from_layer(layer: nn.Module,
46 max_loras: int,
47 lora_config: LoRAConfig,
48 packed_modules_list: List,
49 model_config: Optional[PretrainedConfig] = None) -> nn.Module:
50 for lora_cls in _all_lora_classes:
51 # specifying kwargs so they can be easily accessed in decorator
52 if lora_cls.can_replace_layer(source_layer=layer,
53 lora_config=lora_config,
54 packed_modules_list=packed_modules_list,
55 model_config=model_config):
56 ret = lora_cls(layer)
57 ret.create_lora_weights(max_loras, lora_config, model_config)
58 return ret
59 return layer
60
61
62 def from_layer_logits_processor(
63 layer: LogitsProcessor,
64 lm_head: ParallelLMHead,
65 max_loras: int,
66 lora_config: LoRAConfig,
67 model_config: Optional[PretrainedConfig] = None,
68 ) -> LogitsProcessorWithLoRA:
69 ret = LogitsProcessorWithLoRA(layer, lm_head.embedding_dim,
70 lm_head.weight.dtype, lm_head.weight.device,
71 lm_head.get_sharded_to_full_mapping())
72 ret.create_lora_weights(max_loras, lora_config, model_config)
73 return ret
74
75
76 def replace_submodule(model: nn.Module, module_name: str,
77 new_module: nn.Module) -> nn.Module:
78 """Replace a submodule in a model with a new module."""
79 parent = model.get_submodule(".".join(module_name.split(".")[:-1]))
80 target_name = module_name.split(".")[-1]
81 setattr(parent, target_name, new_module)
82 return new_module
83
84
85 def parse_fine_tuned_lora_name(name: str) -> Tuple[str, bool]:
86 """Parse the name of lora weights.
87
88 args:
89 name: the name of the fine-tuned LoRA, e.g.
90 base_model.model.dense1.weight
91 return:
92 Tuple(module_name, is_lora_a):
93 module_name: the name of the module, e.g. model.dense1,
94 is_lora_a whether the tensor is lora_a or lora_b.
95 """
96 parts = name.split(".")
97 assert parts[0] == "base_model"
98 assert parts[1] == "model"
99 if parts[-1] == "weight":
100 assert parts[-2] == "lora_A" or parts[-2] == "lora_B"
101 return ".".join(parts[2:-2]), parts[-2] == "lora_A"
102
103 if parts[-1] == "lora_embedding_A" or parts[-1] == "lora_embedding_B":
104 return ".".join(parts[2:-1]), parts[-1] == "lora_embedding_A"
105
106 raise ValueError(f"{name} is unsupported format")
107
[end of vllm/lora/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/vllm/lora/utils.py b/vllm/lora/utils.py
--- a/vllm/lora/utils.py
+++ b/vllm/lora/utils.py
@@ -94,13 +94,12 @@
is_lora_a whether the tensor is lora_a or lora_b.
"""
parts = name.split(".")
- assert parts[0] == "base_model"
- assert parts[1] == "model"
- if parts[-1] == "weight":
- assert parts[-2] == "lora_A" or parts[-2] == "lora_B"
- return ".".join(parts[2:-2]), parts[-2] == "lora_A"
- if parts[-1] == "lora_embedding_A" or parts[-1] == "lora_embedding_B":
- return ".".join(parts[2:-1]), parts[-1] == "lora_embedding_A"
+ if len(parts) >= 2 and parts[0] == "base_model" and parts[1] == "model":
+ if parts[-1] == "weight":
+ if parts[-2] == "lora_A" or parts[-2] == "lora_B":
+ return ".".join(parts[2:-2]), parts[-2] == "lora_A"
+ elif parts[-1] == "lora_embedding_A" or parts[-1] == "lora_embedding_B":
+ return ".".join(parts[2:-1]), parts[-1] == "lora_embedding_A"
- raise ValueError(f"{name} is unsupported format")
+ raise ValueError(f"{name} is unsupported LoRA weight")
|
{"golden_diff": "diff --git a/vllm/lora/utils.py b/vllm/lora/utils.py\n--- a/vllm/lora/utils.py\n+++ b/vllm/lora/utils.py\n@@ -94,13 +94,12 @@\n is_lora_a whether the tensor is lora_a or lora_b.\n \"\"\"\n parts = name.split(\".\")\n- assert parts[0] == \"base_model\"\n- assert parts[1] == \"model\"\n- if parts[-1] == \"weight\":\n- assert parts[-2] == \"lora_A\" or parts[-2] == \"lora_B\"\n- return \".\".join(parts[2:-2]), parts[-2] == \"lora_A\"\n \n- if parts[-1] == \"lora_embedding_A\" or parts[-1] == \"lora_embedding_B\":\n- return \".\".join(parts[2:-1]), parts[-1] == \"lora_embedding_A\"\n+ if len(parts) >= 2 and parts[0] == \"base_model\" and parts[1] == \"model\":\n+ if parts[-1] == \"weight\":\n+ if parts[-2] == \"lora_A\" or parts[-2] == \"lora_B\":\n+ return \".\".join(parts[2:-2]), parts[-2] == \"lora_A\"\n+ elif parts[-1] == \"lora_embedding_A\" or parts[-1] == \"lora_embedding_B\":\n+ return \".\".join(parts[2:-1]), parts[-1] == \"lora_embedding_A\"\n \n- raise ValueError(f\"{name} is unsupported format\")\n+ raise ValueError(f\"{name} is unsupported LoRA weight\")\n", "issue": "[Bug]: assert parts[0] == \"base_model\" AssertionError\n### Your current environment\n\n```text\r\nPyTorch version: 2.3.0+cu121\r\nIs debug build: False\r\nCUDA used to build PyTorch: 12.1\r\nROCM used to build PyTorch: N/A\r\n\r\nOS: Ubuntu 22.04.3 LTS (x86_64)\r\nGCC version: (conda-forge gcc 13.2.0-7) 13.2.0\r\nClang version: Could not collect\r\nCMake version: version 3.29.3\r\nLibc version: glibc-2.35\r\n\r\nPython version: 3.10.14 (main, May 6 2024, 19:42:50) [GCC 11.2.0] (64-bit runtime)\r\nPython platform: Linux-5.15.0-105-generic-x86_64-with-glibc2.35\r\nIs CUDA available: True\r\nCUDA runtime version: 12.1.105\r\nCUDA_MODULE_LOADING set to: LAZY\r\nGPU models and configuration: \r\nGPU 0: NVIDIA GeForce RTX 3090\r\nGPU 1: NVIDIA GeForce RTX 3090\r\nGPU 2: NVIDIA GeForce RTX 3090\r\nGPU 3: NVIDIA GeForce RTX 3090\r\n\r\nNvidia driver version: 535.171.04\r\ncuDNN version: Probably one of the following:\r\n/usr/lib/x86_64-linux-gnu/libcudnn.so.8.9.0\r\n/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.9.0\r\n/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.9.0\r\n/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.9.0\r\n/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.9.0\r\n/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.9.0\r\n/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.9.0\r\nHIP runtime version: N/A\r\nMIOpen runtime version: N/A\r\nIs XNNPACK available: True\r\n\r\nCPU:\r\nArchitecture: x86_64\r\nCPU op-mode(s): 32-bit, 64-bit\r\nAddress sizes: 46 bits physical, 48 bits virtual\r\nByte Order: Little Endian\r\nCPU(s): 88\r\nOn-line CPU(s) list: 0-87\r\nVendor ID: GenuineIntel\r\nModel name: Intel(R) Xeon(R) CPU E5-2696 v4 @ 2.20GHz\r\nCPU family: 6\r\nModel: 79\r\nThread(s) per core: 2\r\nCore(s) per socket: 22\r\nSocket(s): 2\r\nStepping: 1\r\nCPU max MHz: 3700.0000\r\nCPU min MHz: 1200.0000\r\nBogoMIPS: 4399.72\r\nFlags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single pti intel_ppin ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm cqm rdt_a rdseed adx smap intel_pt xsaveopt cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts md_clear flush_l1d\r\nVirtualization: VT-x\r\nL1d cache: 1.4 MiB (44 instances)\r\nL1i cache: 1.4 MiB (44 instances)\r\nL2 cache: 11 MiB (44 instances)\r\nL3 cache: 110 MiB (2 instances)\r\nNUMA node(s): 2\r\nNUMA node0 CPU(s): 0-21,44-65\r\nNUMA node1 CPU(s): 22-43,66-87\r\nVulnerability Gather data sampling: Not affected\r\nVulnerability Itlb multihit: KVM: Mitigation: VMX disabled\r\nVulnerability L1tf: Mitigation; PTE Inversion; VMX conditional cache flushes, SMT vulnerable\r\nVulnerability Mds: Mitigation; Clear CPU buffers; SMT vulnerable\r\nVulnerability Meltdown: Mitigation; PTI\r\nVulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable\r\nVulnerability Retbleed: Not affected\r\nVulnerability Spec rstack overflow: Not affected\r\nVulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp\r\nVulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization\r\nVulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, IBRS_FW, STIBP conditional, RSB filling, PBRSB-eIBRS Not affected\r\nVulnerability Srbds: Not affected\r\nVulnerability Tsx async abort: Mitigation; Clear CPU buffers; SMT vulnerable\r\n\r\nVersions of relevant libraries:\r\n[pip3] numpy==1.26.4\r\n[pip3] nvidia-nccl-cu12==2.20.5\r\n[pip3] torch==2.3.0\r\n[pip3] triton==2.3.0\r\n[pip3] vllm_nccl_cu12==2.18.1.0.4.0\r\n[conda] numpy 1.26.4 pypi_0 pypi\r\n[conda] nvidia-nccl-cu12 2.20.5 pypi_0 pypi\r\n[conda] torch 2.3.0 pypi_0 pypi\r\n[conda] triton 2.3.0 pypi_0 pypi\r\n[conda] vllm-nccl-cu12 2.18.1.0.4.0 pypi_0 pypiROCM Version: Could not collect\r\nNeuron SDK Version: N/A\r\nvLLM Version: 0.4.2\r\nvLLM Build Flags:\r\nCUDA Archs: Not Set; ROCm: Disabled; Neuron: Disabled\r\nGPU Topology:\r\nGPU0 GPU1 GPU2 GPU3 CPU Affinity NUMA Affinity GPU NUMA ID\r\nGPU0 X PHB SYS SYS 0-21,44-65 0 N/A\r\nGPU1 PHB X SYS SYS 0-21,44-65 0 N/A\r\nGPU2 SYS SYS X PHB 22-43,66-87 1 N/A\r\nGPU3 SYS SYS PHB X 22-43,66-87 1 N/A\r\n\r\nLegend:\r\n\r\n X = Self\r\n SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)\r\n NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node\r\n PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)\r\n PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)\r\n PIX = Connection traversing at most a single PCIe bridge\r\n NV# = Connection traversing a bonded set of # NVLinks\r\n```\r\n\n\n### \ud83d\udc1b Describe the bug\n\nCUDA_VISIBLE_DEVICES=0,1 python -m vllm.entrypoints.openai.api_server \\\r\n --model /home/greatwall/app/edison/models/Qwen1.5-14B-Chat \\\r\n --trust-remote-code \\\r\n --served-model-name qwen14B \\\r\n --max-model-len 4096 \\\r\n --gpu-memory-utilization 0.9 \\\r\n --enable-lora \\\r\n --lora-modules lora1=/home/greatwall/app/edison/output/qwen1half-14b-chat/v65-20240515-143141/checkpoint-1110 \\\r\n --host 0.0.0.0 \\\r\n --port 8088 \\\r\n --tensor-parallel-size 2 \\\r\n --enforce-eager\n", "before_files": [{"content": "from typing import List, Optional, Set, Tuple, Type\n\nfrom torch import nn\nfrom transformers import PretrainedConfig\n\nfrom vllm.config import LoRAConfig\nfrom vllm.logger import init_logger\nfrom vllm.lora.fully_sharded_layers import (\n ColumnParallelLinearWithShardedLoRA,\n MergedColumnParallelLinearWithShardedLoRA,\n MergedQKVParallelLinearWithShardedLora, RowParallelLinearWithShardedLoRA)\n# being imported for _all_lora_classes below\n# yapf conflicts with isort for this block\n# yapf: disable\nfrom vllm.lora.layers import (BaseLayerWithLoRA, ColumnParallelLinearWithLoRA,\n LinearScalingRotaryEmbeddingWithLora,\n LogitsProcessorWithLoRA,\n MergedColumnParallelLinearWithLoRA,\n MergedQKVParallelLinearWithLora,\n QKVParallelLinearWithLora,\n RowParallelLinearWithLoRA,\n VocabParallelEmbeddingWithLoRA)\n# yapf: enable\nfrom vllm.model_executor.layers.logits_processor import LogitsProcessor\nfrom vllm.model_executor.layers.vocab_parallel_embedding import ParallelLMHead\n\nlogger = init_logger(__name__)\n\n_all_lora_classes: Set[Type[BaseLayerWithLoRA]] = {\n VocabParallelEmbeddingWithLoRA,\n ColumnParallelLinearWithLoRA,\n MergedColumnParallelLinearWithLoRA,\n QKVParallelLinearWithLora,\n MergedQKVParallelLinearWithLora,\n RowParallelLinearWithLoRA,\n LogitsProcessorWithLoRA,\n ColumnParallelLinearWithShardedLoRA,\n MergedColumnParallelLinearWithShardedLoRA,\n MergedQKVParallelLinearWithShardedLora,\n RowParallelLinearWithShardedLoRA,\n LinearScalingRotaryEmbeddingWithLora,\n}\n\n\ndef from_layer(layer: nn.Module,\n max_loras: int,\n lora_config: LoRAConfig,\n packed_modules_list: List,\n model_config: Optional[PretrainedConfig] = None) -> nn.Module:\n for lora_cls in _all_lora_classes:\n # specifying kwargs so they can be easily accessed in decorator\n if lora_cls.can_replace_layer(source_layer=layer,\n lora_config=lora_config,\n packed_modules_list=packed_modules_list,\n model_config=model_config):\n ret = lora_cls(layer)\n ret.create_lora_weights(max_loras, lora_config, model_config)\n return ret\n return layer\n\n\ndef from_layer_logits_processor(\n layer: LogitsProcessor,\n lm_head: ParallelLMHead,\n max_loras: int,\n lora_config: LoRAConfig,\n model_config: Optional[PretrainedConfig] = None,\n) -> LogitsProcessorWithLoRA:\n ret = LogitsProcessorWithLoRA(layer, lm_head.embedding_dim,\n lm_head.weight.dtype, lm_head.weight.device,\n lm_head.get_sharded_to_full_mapping())\n ret.create_lora_weights(max_loras, lora_config, model_config)\n return ret\n\n\ndef replace_submodule(model: nn.Module, module_name: str,\n new_module: nn.Module) -> nn.Module:\n \"\"\"Replace a submodule in a model with a new module.\"\"\"\n parent = model.get_submodule(\".\".join(module_name.split(\".\")[:-1]))\n target_name = module_name.split(\".\")[-1]\n setattr(parent, target_name, new_module)\n return new_module\n\n\ndef parse_fine_tuned_lora_name(name: str) -> Tuple[str, bool]:\n \"\"\"Parse the name of lora weights.\n\n args:\n name: the name of the fine-tuned LoRA, e.g.\n base_model.model.dense1.weight\n return:\n Tuple(module_name, is_lora_a):\n module_name: the name of the module, e.g. model.dense1,\n is_lora_a whether the tensor is lora_a or lora_b.\n \"\"\"\n parts = name.split(\".\")\n assert parts[0] == \"base_model\"\n assert parts[1] == \"model\"\n if parts[-1] == \"weight\":\n assert parts[-2] == \"lora_A\" or parts[-2] == \"lora_B\"\n return \".\".join(parts[2:-2]), parts[-2] == \"lora_A\"\n\n if parts[-1] == \"lora_embedding_A\" or parts[-1] == \"lora_embedding_B\":\n return \".\".join(parts[2:-1]), parts[-1] == \"lora_embedding_A\"\n\n raise ValueError(f\"{name} is unsupported format\")\n", "path": "vllm/lora/utils.py"}]}
| 3,921 | 371 |
gh_patches_debug_52252
|
rasdani/github-patches
|
git_diff
|
mitmproxy__mitmproxy-1463
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Can't view options
##### Steps to reproduce the problem:
1. `mitmproxy`
2. Press `o`
##### What is the expected behavior?
No Crash!
##### What went wrong?
mitmproxy crashed!
```
~/dev/mitmproxy (master) > env/bin/mitmproxy 03:29:44
Traceback (most recent call last):
File "/home/dufferzafar/dev/mitmproxy/mitmproxy/console/master.py", line 537, in run
self.loop.run()
File "/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/main_loop.py", line 278, in run
self._run()
File "/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/main_loop.py", line 376, in _run
self.event_loop.run()
File "/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/main_loop.py", line 682, in run
self._loop()
File "/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/main_loop.py", line 719, in _loop
self._watch_files[fd]()
File "/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/raw_display.py", line 393, in <lambda>
event_loop, callback, self.get_available_raw_input())
File "/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/raw_display.py", line 493, in parse_input
callback(processed, processed_codes)
File "/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/main_loop.py", line 403, in _update
self.process_input(keys)
File "/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/main_loop.py", line 503, in process_input
k = self._topmost_widget.keypress(self.screen_size, k)
File "/home/dufferzafar/dev/mitmproxy/mitmproxy/console/window.py", line 89, in keypress
self.master.view_options()
File "/home/dufferzafar/dev/mitmproxy/mitmproxy/console/master.py", line 572, in view_options
options.help_context,
File "/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/blinker/base.py", line 267, in send
for receiver in self.receivers_for(sender)]
File "/home/dufferzafar/dev/mitmproxy/mitmproxy/console/master.py", line 333, in sig_push_view_state
self.loop.draw_screen()
File "/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/main_loop.py", line 578, in draw_screen
canvas = self._topmost_widget.render(self.screen_size, focus=True)
File "/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/widget.py", line 141, in cached_render
canv = fn(self, size, focus=focus)
File "/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/container.py", line 1083, in render
focus and self.focus_part == 'body')
File "/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/widget.py", line 141, in cached_render
canv = fn(self, size, focus=focus)
File "/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/decoration.py", line 225, in render
canv = self._original_widget.render(size, focus=focus)
File "/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/widget.py", line 141, in cached_render
canv = fn(self, size, focus=focus)
File "/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/widget.py", line 1751, in render
canv = get_delegate(self).render(size, focus=focus)
File "/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/widget.py", line 141, in cached_render
canv = fn(self, size, focus=focus)
File "/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/container.py", line 1083, in render
focus and self.focus_part == 'body')
File "/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/widget.py", line 141, in cached_render
canv = fn(self, size, focus=focus)
File "/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/listbox.py", line 457, in render
(maxcol, maxrow), focus=focus)
File "/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/listbox.py", line 339, in calculate_visible
self._set_focus_complete( (maxcol, maxrow), focus )
File "/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/listbox.py", line 704, in _set_focus_complete
(maxcol,maxrow), focus)
File "/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/listbox.py", line 674, in _set_focus_first_selectable
(maxcol, maxrow), focus=focus)
File "/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/listbox.py", line 402, in calculate_visible
next, pos = self.body.get_next( pos )
File "/home/dufferzafar/dev/mitmproxy/mitmproxy/console/select.py", line 57, in get_next
return self.options[pos + 1].render(False), pos + 1
File "/home/dufferzafar/dev/mitmproxy/mitmproxy/console/select.py", line 94, in render
self.getstate(),
File "/home/dufferzafar/dev/mitmproxy/mitmproxy/console/options.py", line 97, in <lambda>
lambda: master.server.config.ssl_insecure,
AttributeError: ProxyConfig instance has no attribute 'ssl_insecure'
mitmproxy has crashed!
Please lodge a bug report at:
https://github.com/mitmproxy/mitmproxy
Shutting down...
```
</issue>
<code>
[start of mitmproxy/proxy/config.py]
1 from __future__ import absolute_import, print_function, division
2
3 import base64
4 import collections
5 import os
6 import re
7 from netlib import strutils
8
9 import six
10 from OpenSSL import SSL, crypto
11
12 from mitmproxy import exceptions
13 from netlib import certutils
14 from netlib import tcp
15 from netlib.http import authentication
16 from netlib.http import url
17
18 CONF_BASENAME = "mitmproxy"
19
20
21 class HostMatcher(object):
22
23 def __init__(self, patterns=tuple()):
24 self.patterns = list(patterns)
25 self.regexes = [re.compile(p, re.IGNORECASE) for p in self.patterns]
26
27 def __call__(self, address):
28 if not address:
29 return False
30 address = tcp.Address.wrap(address)
31 host = "%s:%s" % (address.host, address.port)
32 if any(rex.search(host) for rex in self.regexes):
33 return True
34 else:
35 return False
36
37 def __bool__(self):
38 return bool(self.patterns)
39
40 if six.PY2:
41 __nonzero__ = __bool__
42
43
44 ServerSpec = collections.namedtuple("ServerSpec", "scheme address")
45
46
47 def parse_server_spec(spec):
48 try:
49 p = url.parse(spec)
50 if p[0] not in (b"http", b"https"):
51 raise ValueError()
52 except ValueError:
53 raise exceptions.OptionsError(
54 "Invalid server specification: %s" % spec
55 )
56 host, port = p[1:3]
57 address = tcp.Address((host.decode("ascii"), port))
58 scheme = p[0].decode("ascii").lower()
59 return ServerSpec(scheme, address)
60
61
62 def parse_upstream_auth(auth):
63 pattern = re.compile(".+:")
64 if pattern.search(auth) is None:
65 raise exceptions.OptionsError(
66 "Invalid upstream auth specification: %s" % auth
67 )
68 return b"Basic" + b" " + base64.b64encode(strutils.always_bytes(auth))
69
70
71 class ProxyConfig:
72
73 def __init__(self, options):
74 self.options = options
75
76 self.authenticator = None
77 self.check_ignore = None
78 self.check_tcp = None
79 self.certstore = None
80 self.clientcerts = None
81 self.openssl_verification_mode_server = None
82 self.configure(options, set(options.keys()))
83 options.changed.connect(self.configure)
84
85 def configure(self, options, updated):
86 # type: (mitmproxy.options.Options, Any) -> None
87 if options.add_upstream_certs_to_client_chain and not options.ssl_insecure:
88 raise exceptions.OptionsError(
89 "The verify-upstream-cert requires certificate verification to be disabled. "
90 "If upstream certificates are verified then extra upstream certificates are "
91 "not available for inclusion to the client chain."
92 )
93
94 if options.ssl_insecure:
95 self.openssl_verification_mode_server = SSL.VERIFY_NONE
96 else:
97 self.openssl_verification_mode_server = SSL.VERIFY_PEER
98
99 self.check_ignore = HostMatcher(options.ignore_hosts)
100 self.check_tcp = HostMatcher(options.tcp_hosts)
101
102 self.openssl_method_client, self.openssl_options_client = \
103 tcp.sslversion_choices[options.ssl_version_client]
104 self.openssl_method_server, self.openssl_options_server = \
105 tcp.sslversion_choices[options.ssl_version_server]
106
107 certstore_path = os.path.expanduser(options.cadir)
108 if not os.path.exists(os.path.dirname(certstore_path)):
109 raise exceptions.OptionsError(
110 "Certificate Authority parent directory does not exist: %s" %
111 os.path.dirname(options.cadir)
112 )
113 self.certstore = certutils.CertStore.from_store(
114 certstore_path,
115 CONF_BASENAME
116 )
117
118 if options.clientcerts:
119 clientcerts = os.path.expanduser(options.clientcerts)
120 if not os.path.exists(clientcerts):
121 raise exceptions.OptionsError(
122 "Client certificate path does not exist: %s" %
123 options.clientcerts
124 )
125 self.clientcerts = clientcerts
126
127 for spec, cert in options.certs:
128 cert = os.path.expanduser(cert)
129 if not os.path.exists(cert):
130 raise exceptions.OptionsError(
131 "Certificate file does not exist: %s" % cert
132 )
133 try:
134 self.certstore.add_cert_file(spec, cert)
135 except crypto.Error:
136 raise exceptions.OptionsError(
137 "Invalid certificate format: %s" % cert
138 )
139
140 self.upstream_server = None
141 self.upstream_auth = None
142 if options.upstream_server:
143 self.upstream_server = parse_server_spec(options.upstream_server)
144 if options.upstream_auth:
145 self.upstream_auth = parse_upstream_auth(options.upstream_auth)
146
147 self.authenticator = authentication.NullProxyAuth(None)
148 needsauth = any(
149 [
150 options.auth_nonanonymous,
151 options.auth_singleuser,
152 options.auth_htpasswd
153 ]
154 )
155 if needsauth:
156 if options.mode == "transparent":
157 raise exceptions.OptionsError(
158 "Proxy Authentication not supported in transparent mode."
159 )
160 elif options.mode == "socks5":
161 raise exceptions.OptionsError(
162 "Proxy Authentication not supported in SOCKS mode. "
163 "https://github.com/mitmproxy/mitmproxy/issues/738"
164 )
165 elif options.auth_singleuser:
166 parts = options.auth_singleuser.split(':')
167 if len(parts) != 2:
168 raise exceptions.OptionsError(
169 "Invalid single-user specification. "
170 "Please use the format username:password"
171 )
172 password_manager = authentication.PassManSingleUser(*parts)
173 elif options.auth_nonanonymous:
174 password_manager = authentication.PassManNonAnon()
175 elif options.auth_htpasswd:
176 try:
177 password_manager = authentication.PassManHtpasswd(
178 options.auth_htpasswd
179 )
180 except ValueError as v:
181 raise exceptions.OptionsError(str(v))
182 self.authenticator = authentication.BasicProxyAuth(
183 password_manager,
184 "mitmproxy"
185 )
186
[end of mitmproxy/proxy/config.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mitmproxy/proxy/config.py b/mitmproxy/proxy/config.py
--- a/mitmproxy/proxy/config.py
+++ b/mitmproxy/proxy/config.py
@@ -78,6 +78,7 @@
self.check_tcp = None
self.certstore = None
self.clientcerts = None
+ self.ssl_insecure = False
self.openssl_verification_mode_server = None
self.configure(options, set(options.keys()))
options.changed.connect(self.configure)
|
{"golden_diff": "diff --git a/mitmproxy/proxy/config.py b/mitmproxy/proxy/config.py\n--- a/mitmproxy/proxy/config.py\n+++ b/mitmproxy/proxy/config.py\n@@ -78,6 +78,7 @@\n self.check_tcp = None\n self.certstore = None\n self.clientcerts = None\n+ self.ssl_insecure = False\n self.openssl_verification_mode_server = None\n self.configure(options, set(options.keys()))\n options.changed.connect(self.configure)\n", "issue": "Can't view options\n##### Steps to reproduce the problem:\n1. `mitmproxy`\n2. Press `o`\n##### What is the expected behavior?\n\nNo Crash!\n##### What went wrong?\n\nmitmproxy crashed!\n\n```\n~/dev/mitmproxy (master) > env/bin/mitmproxy 03:29:44\nTraceback (most recent call last):\n File \"/home/dufferzafar/dev/mitmproxy/mitmproxy/console/master.py\", line 537, in run\n self.loop.run()\n File \"/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/main_loop.py\", line 278, in run\n self._run()\n File \"/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/main_loop.py\", line 376, in _run\n self.event_loop.run()\n File \"/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/main_loop.py\", line 682, in run\n self._loop()\n File \"/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/main_loop.py\", line 719, in _loop\n self._watch_files[fd]()\n File \"/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/raw_display.py\", line 393, in <lambda>\n event_loop, callback, self.get_available_raw_input())\n File \"/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/raw_display.py\", line 493, in parse_input\n callback(processed, processed_codes)\n File \"/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/main_loop.py\", line 403, in _update\n self.process_input(keys)\n File \"/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/main_loop.py\", line 503, in process_input\n k = self._topmost_widget.keypress(self.screen_size, k)\n File \"/home/dufferzafar/dev/mitmproxy/mitmproxy/console/window.py\", line 89, in keypress\n self.master.view_options()\n File \"/home/dufferzafar/dev/mitmproxy/mitmproxy/console/master.py\", line 572, in view_options\n options.help_context,\n File \"/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/blinker/base.py\", line 267, in send\n for receiver in self.receivers_for(sender)]\n File \"/home/dufferzafar/dev/mitmproxy/mitmproxy/console/master.py\", line 333, in sig_push_view_state\n self.loop.draw_screen()\n File \"/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/main_loop.py\", line 578, in draw_screen\n canvas = self._topmost_widget.render(self.screen_size, focus=True)\n File \"/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/widget.py\", line 141, in cached_render\n canv = fn(self, size, focus=focus)\n File \"/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/container.py\", line 1083, in render\n focus and self.focus_part == 'body')\n File \"/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/widget.py\", line 141, in cached_render\n canv = fn(self, size, focus=focus)\n File \"/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/decoration.py\", line 225, in render\n canv = self._original_widget.render(size, focus=focus)\n File \"/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/widget.py\", line 141, in cached_render\n canv = fn(self, size, focus=focus)\n File \"/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/widget.py\", line 1751, in render\n canv = get_delegate(self).render(size, focus=focus)\n File \"/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/widget.py\", line 141, in cached_render\n canv = fn(self, size, focus=focus)\n File \"/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/container.py\", line 1083, in render\n focus and self.focus_part == 'body')\n File \"/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/widget.py\", line 141, in cached_render\n canv = fn(self, size, focus=focus)\n File \"/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/listbox.py\", line 457, in render\n (maxcol, maxrow), focus=focus)\n File \"/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/listbox.py\", line 339, in calculate_visible\n self._set_focus_complete( (maxcol, maxrow), focus )\n File \"/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/listbox.py\", line 704, in _set_focus_complete\n (maxcol,maxrow), focus)\n File \"/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/listbox.py\", line 674, in _set_focus_first_selectable\n (maxcol, maxrow), focus=focus)\n File \"/home/dufferzafar/dev/mitmproxy/env/lib/python2.7/site-packages/urwid/listbox.py\", line 402, in calculate_visible\n next, pos = self.body.get_next( pos )\n File \"/home/dufferzafar/dev/mitmproxy/mitmproxy/console/select.py\", line 57, in get_next\n return self.options[pos + 1].render(False), pos + 1\n File \"/home/dufferzafar/dev/mitmproxy/mitmproxy/console/select.py\", line 94, in render\n self.getstate(),\n File \"/home/dufferzafar/dev/mitmproxy/mitmproxy/console/options.py\", line 97, in <lambda>\n lambda: master.server.config.ssl_insecure,\nAttributeError: ProxyConfig instance has no attribute 'ssl_insecure'\n\nmitmproxy has crashed!\nPlease lodge a bug report at:\n https://github.com/mitmproxy/mitmproxy\nShutting down...\n```\n\n", "before_files": [{"content": "from __future__ import absolute_import, print_function, division\n\nimport base64\nimport collections\nimport os\nimport re\nfrom netlib import strutils\n\nimport six\nfrom OpenSSL import SSL, crypto\n\nfrom mitmproxy import exceptions\nfrom netlib import certutils\nfrom netlib import tcp\nfrom netlib.http import authentication\nfrom netlib.http import url\n\nCONF_BASENAME = \"mitmproxy\"\n\n\nclass HostMatcher(object):\n\n def __init__(self, patterns=tuple()):\n self.patterns = list(patterns)\n self.regexes = [re.compile(p, re.IGNORECASE) for p in self.patterns]\n\n def __call__(self, address):\n if not address:\n return False\n address = tcp.Address.wrap(address)\n host = \"%s:%s\" % (address.host, address.port)\n if any(rex.search(host) for rex in self.regexes):\n return True\n else:\n return False\n\n def __bool__(self):\n return bool(self.patterns)\n\n if six.PY2:\n __nonzero__ = __bool__\n\n\nServerSpec = collections.namedtuple(\"ServerSpec\", \"scheme address\")\n\n\ndef parse_server_spec(spec):\n try:\n p = url.parse(spec)\n if p[0] not in (b\"http\", b\"https\"):\n raise ValueError()\n except ValueError:\n raise exceptions.OptionsError(\n \"Invalid server specification: %s\" % spec\n )\n host, port = p[1:3]\n address = tcp.Address((host.decode(\"ascii\"), port))\n scheme = p[0].decode(\"ascii\").lower()\n return ServerSpec(scheme, address)\n\n\ndef parse_upstream_auth(auth):\n pattern = re.compile(\".+:\")\n if pattern.search(auth) is None:\n raise exceptions.OptionsError(\n \"Invalid upstream auth specification: %s\" % auth\n )\n return b\"Basic\" + b\" \" + base64.b64encode(strutils.always_bytes(auth))\n\n\nclass ProxyConfig:\n\n def __init__(self, options):\n self.options = options\n\n self.authenticator = None\n self.check_ignore = None\n self.check_tcp = None\n self.certstore = None\n self.clientcerts = None\n self.openssl_verification_mode_server = None\n self.configure(options, set(options.keys()))\n options.changed.connect(self.configure)\n\n def configure(self, options, updated):\n # type: (mitmproxy.options.Options, Any) -> None\n if options.add_upstream_certs_to_client_chain and not options.ssl_insecure:\n raise exceptions.OptionsError(\n \"The verify-upstream-cert requires certificate verification to be disabled. \"\n \"If upstream certificates are verified then extra upstream certificates are \"\n \"not available for inclusion to the client chain.\"\n )\n\n if options.ssl_insecure:\n self.openssl_verification_mode_server = SSL.VERIFY_NONE\n else:\n self.openssl_verification_mode_server = SSL.VERIFY_PEER\n\n self.check_ignore = HostMatcher(options.ignore_hosts)\n self.check_tcp = HostMatcher(options.tcp_hosts)\n\n self.openssl_method_client, self.openssl_options_client = \\\n tcp.sslversion_choices[options.ssl_version_client]\n self.openssl_method_server, self.openssl_options_server = \\\n tcp.sslversion_choices[options.ssl_version_server]\n\n certstore_path = os.path.expanduser(options.cadir)\n if not os.path.exists(os.path.dirname(certstore_path)):\n raise exceptions.OptionsError(\n \"Certificate Authority parent directory does not exist: %s\" %\n os.path.dirname(options.cadir)\n )\n self.certstore = certutils.CertStore.from_store(\n certstore_path,\n CONF_BASENAME\n )\n\n if options.clientcerts:\n clientcerts = os.path.expanduser(options.clientcerts)\n if not os.path.exists(clientcerts):\n raise exceptions.OptionsError(\n \"Client certificate path does not exist: %s\" %\n options.clientcerts\n )\n self.clientcerts = clientcerts\n\n for spec, cert in options.certs:\n cert = os.path.expanduser(cert)\n if not os.path.exists(cert):\n raise exceptions.OptionsError(\n \"Certificate file does not exist: %s\" % cert\n )\n try:\n self.certstore.add_cert_file(spec, cert)\n except crypto.Error:\n raise exceptions.OptionsError(\n \"Invalid certificate format: %s\" % cert\n )\n\n self.upstream_server = None\n self.upstream_auth = None\n if options.upstream_server:\n self.upstream_server = parse_server_spec(options.upstream_server)\n if options.upstream_auth:\n self.upstream_auth = parse_upstream_auth(options.upstream_auth)\n\n self.authenticator = authentication.NullProxyAuth(None)\n needsauth = any(\n [\n options.auth_nonanonymous,\n options.auth_singleuser,\n options.auth_htpasswd\n ]\n )\n if needsauth:\n if options.mode == \"transparent\":\n raise exceptions.OptionsError(\n \"Proxy Authentication not supported in transparent mode.\"\n )\n elif options.mode == \"socks5\":\n raise exceptions.OptionsError(\n \"Proxy Authentication not supported in SOCKS mode. \"\n \"https://github.com/mitmproxy/mitmproxy/issues/738\"\n )\n elif options.auth_singleuser:\n parts = options.auth_singleuser.split(':')\n if len(parts) != 2:\n raise exceptions.OptionsError(\n \"Invalid single-user specification. \"\n \"Please use the format username:password\"\n )\n password_manager = authentication.PassManSingleUser(*parts)\n elif options.auth_nonanonymous:\n password_manager = authentication.PassManNonAnon()\n elif options.auth_htpasswd:\n try:\n password_manager = authentication.PassManHtpasswd(\n options.auth_htpasswd\n )\n except ValueError as v:\n raise exceptions.OptionsError(str(v))\n self.authenticator = authentication.BasicProxyAuth(\n password_manager,\n \"mitmproxy\"\n )\n", "path": "mitmproxy/proxy/config.py"}]}
| 3,863 | 109 |
gh_patches_debug_16130
|
rasdani/github-patches
|
git_diff
|
kubeflow__pipelines-6816
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[testing] v2 sample test failing at master
reported by @chensun at https://github.com/kubeflow/pipelines/pull/6804#issuecomment-952542710
UPDATE: after the investigations below, it seems to me that v2 sample test is not flaky, it's basically broken at master.
The error message is https://4e18c21c9d33d20f-dot-datalab-vm-staging.googleusercontent.com/#/runs/details/bea48911-71d1-42ee-9dca-530bfee1f08e
```
Traceback (most recent call last):
File "/usr/local/lib/python3.7/runpy.py", line 183, in _run_module_as_main
mod_name, mod_spec, code = _get_module_details(mod_name, _Error)
File "/usr/local/lib/python3.7/runpy.py", line 109, in _get_module_details
__import__(pkg_name)
File "/usr/local/lib/python3.7/site-packages/kfp/__init__.py", line 23, in <module>
from . import dsl
File "/usr/local/lib/python3.7/site-packages/kfp/dsl/__init__.py", line 16, in <module>
from ._pipeline import Pipeline, PipelineExecutionMode, pipeline, get_pipeline_conf, PipelineConf
File "/usr/local/lib/python3.7/site-packages/kfp/dsl/_pipeline.py", line 22, in <module>
from kfp.dsl import _component_bridge
File "/usr/local/lib/python3.7/site-packages/kfp/dsl/_component_bridge.py", line 30, in <module>
from kfp.dsl import component_spec as dsl_component_spec
File "/usr/local/lib/python3.7/site-packages/kfp/dsl/component_spec.py", line 21, in <module>
from kfp.v2.components.types import type_utils
File "/usr/local/lib/python3.7/site-packages/kfp/v2/components/__init__.py", line 15, in <module>
from kfp.v2.components.experimental.yaml_component import load_component_from_text
File "/usr/local/lib/python3.7/site-packages/kfp/v2/components/experimental/yaml_component.py", line 16, in <module>
from kfp.v2.components.experimental import base_component
File "/usr/local/lib/python3.7/site-packages/kfp/v2/components/experimental/base_component.py", line 19, in <module>
from kfp.v2.components.experimental import pipeline_task
File "/usr/local/lib/python3.7/site-packages/kfp/v2/components/experimental/pipeline_task.py", line 21, in <module>
from kfp.v2.components.experimental import pipeline_channel
File "/usr/local/lib/python3.7/site-packages/kfp/v2/components/experimental/pipeline_channel.py", line 22, in <module>
from kfp.v2.components.types.experimental import type_utils
ModuleNotFoundError: No module named 'kfp.v2.components.types.experimental'
F1027 12:43:37.163580 1 main.go:50] Failed to execute component: exit status 1
```
</issue>
<code>
[start of sdk/python/setup.py]
1 # Copyright 2018 The Kubeflow Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import os
16 import re
17
18 from setuptools import setup
19
20 NAME = 'kfp'
21 #VERSION = .... Change the version in kfp/__init__.py
22
23 # NOTICE, after any updates to the following, ./requirements.in should be updated
24 # accordingly.
25 REQUIRES = [
26 'absl-py>=0.9,<=0.11',
27 'PyYAML>=5.3,<6',
28 # `Blob.from_string` was introduced in google-cloud-storage 1.20.0
29 # https://github.com/googleapis/python-storage/blob/master/CHANGELOG.md#1200
30 'google-cloud-storage>=1.20.0,<2',
31 'kubernetes>=8.0.0,<19',
32 # google-api-python-client v2 doesn't work for private dicovery by default:
33 # https://github.com/googleapis/google-api-python-client/issues/1225#issuecomment-791058235
34 'google-api-python-client>=1.7.8,<2',
35 'google-auth>=1.6.1,<2',
36 'requests-toolbelt>=0.8.0,<1',
37 'cloudpickle>=2.0.0,<3',
38 # Update the upper version whenever a new major version of the
39 # kfp-server-api package is released.
40 # Update the lower version when kfp sdk depends on new apis/fields in
41 # kfp-server-api.
42 # Note, please also update ./requirements.in
43 'kfp-server-api>=1.1.2,<2.0.0',
44 'jsonschema>=3.0.1,<4',
45 'tabulate>=0.8.6,<1',
46 'click>=7.1.2,<9',
47 'Deprecated>=1.2.7,<2',
48 'strip-hints>=0.1.8,<1',
49 'docstring-parser>=0.7.3,<1',
50 'kfp-pipeline-spec>=0.1.13,<0.2.0',
51 'fire>=0.3.1,<1',
52 'protobuf>=3.13.0,<4',
53 'uritemplate>=3.0.1,<4',
54 'pydantic>=1.8.2,<2',
55 # Standard library backports
56 'dataclasses;python_version<"3.7"',
57 'typer>=0.3.2,<1.0',
58 'typing-extensions>=3.7.4,<4;python_version<"3.9"',
59 ]
60
61 TESTS_REQUIRE = [
62 'frozendict',
63 ]
64
65 EXTRAS_REQUIRE = {
66 'all': ['docker'],
67 }
68
69
70 def find_version(*file_path_parts):
71 here = os.path.abspath(os.path.dirname(__file__))
72 with open(os.path.join(here, *file_path_parts), 'r') as fp:
73 version_file_text = fp.read()
74
75 version_match = re.search(
76 r"^__version__ = ['\"]([^'\"]*)['\"]",
77 version_file_text,
78 re.M,
79 )
80 if version_match:
81 return version_match.group(1)
82
83 raise RuntimeError('Unable to find version string.')
84
85
86 setup(
87 name=NAME,
88 version=find_version('kfp', '__init__.py'),
89 description='KubeFlow Pipelines SDK',
90 author='The Kubeflow Authors',
91 url="https://github.com/kubeflow/pipelines",
92 project_urls={
93 "Documentation":
94 "https://kubeflow-pipelines.readthedocs.io/en/stable/",
95 "Bug Tracker":
96 "https://github.com/kubeflow/pipelines/issues",
97 "Source":
98 "https://github.com/kubeflow/pipelines/tree/master/sdk",
99 "Changelog":
100 "https://github.com/kubeflow/pipelines/blob/master/sdk/RELEASE.md",
101 },
102 install_requires=REQUIRES,
103 tests_require=TESTS_REQUIRE,
104 extras_require=EXTRAS_REQUIRE,
105 packages=[
106 'kfp',
107 'kfp.auth',
108 'kfp.cli',
109 'kfp.cli.diagnose_me',
110 'kfp.compiler',
111 'kfp.components',
112 'kfp.components.structures',
113 'kfp.containers',
114 'kfp.dsl',
115 'kfp.dsl.extensions',
116 'kfp.notebook',
117 'kfp.v2',
118 'kfp.v2.compiler',
119 'kfp.v2.components',
120 'kfp.v2.components.types',
121 'kfp.v2.components.experimental',
122 'kfp.v2.dsl',
123 'kfp.v2.google.client',
124 'kfp.v2.google.experimental',
125 ],
126 classifiers=[
127 'Intended Audience :: Developers',
128 'Intended Audience :: Education',
129 'Intended Audience :: Science/Research',
130 'License :: OSI Approved :: Apache Software License',
131 'Programming Language :: Python :: 3',
132 'Programming Language :: Python :: 3.6',
133 'Programming Language :: Python :: 3.7',
134 'Programming Language :: Python :: 3.8',
135 'Programming Language :: Python :: 3.9',
136 'Topic :: Scientific/Engineering',
137 'Topic :: Scientific/Engineering :: Artificial Intelligence',
138 'Topic :: Software Development',
139 'Topic :: Software Development :: Libraries',
140 'Topic :: Software Development :: Libraries :: Python Modules',
141 ],
142 python_requires='>=3.6.1',
143 include_package_data=True,
144 entry_points={
145 'console_scripts': [
146 'dsl-compile = kfp.compiler.main:main',
147 'dsl-compile-v2 = kfp.v2.compiler.main:main',
148 'kfp=kfp.__main__:main'
149 ]
150 })
151
[end of sdk/python/setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sdk/python/setup.py b/sdk/python/setup.py
--- a/sdk/python/setup.py
+++ b/sdk/python/setup.py
@@ -52,9 +52,9 @@
'protobuf>=3.13.0,<4',
'uritemplate>=3.0.1,<4',
'pydantic>=1.8.2,<2',
+ 'typer>=0.3.2,<1.0',
# Standard library backports
'dataclasses;python_version<"3.7"',
- 'typer>=0.3.2,<1.0',
'typing-extensions>=3.7.4,<4;python_version<"3.9"',
]
@@ -118,6 +118,7 @@
'kfp.v2.compiler',
'kfp.v2.components',
'kfp.v2.components.types',
+ 'kfp.v2.components.types.experimental',
'kfp.v2.components.experimental',
'kfp.v2.dsl',
'kfp.v2.google.client',
|
{"golden_diff": "diff --git a/sdk/python/setup.py b/sdk/python/setup.py\n--- a/sdk/python/setup.py\n+++ b/sdk/python/setup.py\n@@ -52,9 +52,9 @@\n 'protobuf>=3.13.0,<4',\n 'uritemplate>=3.0.1,<4',\n 'pydantic>=1.8.2,<2',\n+ 'typer>=0.3.2,<1.0',\n # Standard library backports\n 'dataclasses;python_version<\"3.7\"',\n- 'typer>=0.3.2,<1.0',\n 'typing-extensions>=3.7.4,<4;python_version<\"3.9\"',\n ]\n \n@@ -118,6 +118,7 @@\n 'kfp.v2.compiler',\n 'kfp.v2.components',\n 'kfp.v2.components.types',\n+ 'kfp.v2.components.types.experimental',\n 'kfp.v2.components.experimental',\n 'kfp.v2.dsl',\n 'kfp.v2.google.client',\n", "issue": "[testing] v2 sample test failing at master\nreported by @chensun at https://github.com/kubeflow/pipelines/pull/6804#issuecomment-952542710\r\n\r\nUPDATE: after the investigations below, it seems to me that v2 sample test is not flaky, it's basically broken at master.\r\nThe error message is https://4e18c21c9d33d20f-dot-datalab-vm-staging.googleusercontent.com/#/runs/details/bea48911-71d1-42ee-9dca-530bfee1f08e\r\n```\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.7/runpy.py\", line 183, in _run_module_as_main\r\n mod_name, mod_spec, code = _get_module_details(mod_name, _Error)\r\n File \"/usr/local/lib/python3.7/runpy.py\", line 109, in _get_module_details\r\n __import__(pkg_name)\r\n File \"/usr/local/lib/python3.7/site-packages/kfp/__init__.py\", line 23, in <module>\r\n from . import dsl\r\n File \"/usr/local/lib/python3.7/site-packages/kfp/dsl/__init__.py\", line 16, in <module>\r\n from ._pipeline import Pipeline, PipelineExecutionMode, pipeline, get_pipeline_conf, PipelineConf\r\n File \"/usr/local/lib/python3.7/site-packages/kfp/dsl/_pipeline.py\", line 22, in <module>\r\n from kfp.dsl import _component_bridge\r\n File \"/usr/local/lib/python3.7/site-packages/kfp/dsl/_component_bridge.py\", line 30, in <module>\r\n from kfp.dsl import component_spec as dsl_component_spec\r\n File \"/usr/local/lib/python3.7/site-packages/kfp/dsl/component_spec.py\", line 21, in <module>\r\n from kfp.v2.components.types import type_utils\r\n File \"/usr/local/lib/python3.7/site-packages/kfp/v2/components/__init__.py\", line 15, in <module>\r\n from kfp.v2.components.experimental.yaml_component import load_component_from_text\r\n File \"/usr/local/lib/python3.7/site-packages/kfp/v2/components/experimental/yaml_component.py\", line 16, in <module>\r\n from kfp.v2.components.experimental import base_component\r\n File \"/usr/local/lib/python3.7/site-packages/kfp/v2/components/experimental/base_component.py\", line 19, in <module>\r\n from kfp.v2.components.experimental import pipeline_task\r\n File \"/usr/local/lib/python3.7/site-packages/kfp/v2/components/experimental/pipeline_task.py\", line 21, in <module>\r\n from kfp.v2.components.experimental import pipeline_channel\r\n File \"/usr/local/lib/python3.7/site-packages/kfp/v2/components/experimental/pipeline_channel.py\", line 22, in <module>\r\n from kfp.v2.components.types.experimental import type_utils\r\nModuleNotFoundError: No module named 'kfp.v2.components.types.experimental'\r\nF1027 12:43:37.163580 1 main.go:50] Failed to execute component: exit status 1\r\n```\n", "before_files": [{"content": "# Copyright 2018 The Kubeflow Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\nimport re\n\nfrom setuptools import setup\n\nNAME = 'kfp'\n#VERSION = .... Change the version in kfp/__init__.py\n\n# NOTICE, after any updates to the following, ./requirements.in should be updated\n# accordingly.\nREQUIRES = [\n 'absl-py>=0.9,<=0.11',\n 'PyYAML>=5.3,<6',\n # `Blob.from_string` was introduced in google-cloud-storage 1.20.0\n # https://github.com/googleapis/python-storage/blob/master/CHANGELOG.md#1200\n 'google-cloud-storage>=1.20.0,<2',\n 'kubernetes>=8.0.0,<19',\n # google-api-python-client v2 doesn't work for private dicovery by default:\n # https://github.com/googleapis/google-api-python-client/issues/1225#issuecomment-791058235\n 'google-api-python-client>=1.7.8,<2',\n 'google-auth>=1.6.1,<2',\n 'requests-toolbelt>=0.8.0,<1',\n 'cloudpickle>=2.0.0,<3',\n # Update the upper version whenever a new major version of the\n # kfp-server-api package is released.\n # Update the lower version when kfp sdk depends on new apis/fields in\n # kfp-server-api.\n # Note, please also update ./requirements.in\n 'kfp-server-api>=1.1.2,<2.0.0',\n 'jsonschema>=3.0.1,<4',\n 'tabulate>=0.8.6,<1',\n 'click>=7.1.2,<9',\n 'Deprecated>=1.2.7,<2',\n 'strip-hints>=0.1.8,<1',\n 'docstring-parser>=0.7.3,<1',\n 'kfp-pipeline-spec>=0.1.13,<0.2.0',\n 'fire>=0.3.1,<1',\n 'protobuf>=3.13.0,<4',\n 'uritemplate>=3.0.1,<4',\n 'pydantic>=1.8.2,<2',\n # Standard library backports\n 'dataclasses;python_version<\"3.7\"',\n 'typer>=0.3.2,<1.0',\n 'typing-extensions>=3.7.4,<4;python_version<\"3.9\"',\n]\n\nTESTS_REQUIRE = [\n 'frozendict',\n]\n\nEXTRAS_REQUIRE = {\n 'all': ['docker'],\n}\n\n\ndef find_version(*file_path_parts):\n here = os.path.abspath(os.path.dirname(__file__))\n with open(os.path.join(here, *file_path_parts), 'r') as fp:\n version_file_text = fp.read()\n\n version_match = re.search(\n r\"^__version__ = ['\\\"]([^'\\\"]*)['\\\"]\",\n version_file_text,\n re.M,\n )\n if version_match:\n return version_match.group(1)\n\n raise RuntimeError('Unable to find version string.')\n\n\nsetup(\n name=NAME,\n version=find_version('kfp', '__init__.py'),\n description='KubeFlow Pipelines SDK',\n author='The Kubeflow Authors',\n url=\"https://github.com/kubeflow/pipelines\",\n project_urls={\n \"Documentation\":\n \"https://kubeflow-pipelines.readthedocs.io/en/stable/\",\n \"Bug Tracker\":\n \"https://github.com/kubeflow/pipelines/issues\",\n \"Source\":\n \"https://github.com/kubeflow/pipelines/tree/master/sdk\",\n \"Changelog\":\n \"https://github.com/kubeflow/pipelines/blob/master/sdk/RELEASE.md\",\n },\n install_requires=REQUIRES,\n tests_require=TESTS_REQUIRE,\n extras_require=EXTRAS_REQUIRE,\n packages=[\n 'kfp',\n 'kfp.auth',\n 'kfp.cli',\n 'kfp.cli.diagnose_me',\n 'kfp.compiler',\n 'kfp.components',\n 'kfp.components.structures',\n 'kfp.containers',\n 'kfp.dsl',\n 'kfp.dsl.extensions',\n 'kfp.notebook',\n 'kfp.v2',\n 'kfp.v2.compiler',\n 'kfp.v2.components',\n 'kfp.v2.components.types',\n 'kfp.v2.components.experimental',\n 'kfp.v2.dsl',\n 'kfp.v2.google.client',\n 'kfp.v2.google.experimental',\n ],\n classifiers=[\n 'Intended Audience :: Developers',\n 'Intended Audience :: Education',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: Apache Software License',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: 3.9',\n 'Topic :: Scientific/Engineering',\n 'Topic :: Scientific/Engineering :: Artificial Intelligence',\n 'Topic :: Software Development',\n 'Topic :: Software Development :: Libraries',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n ],\n python_requires='>=3.6.1',\n include_package_data=True,\n entry_points={\n 'console_scripts': [\n 'dsl-compile = kfp.compiler.main:main',\n 'dsl-compile-v2 = kfp.v2.compiler.main:main',\n 'kfp=kfp.__main__:main'\n ]\n })\n", "path": "sdk/python/setup.py"}]}
| 2,966 | 231 |
gh_patches_debug_17956
|
rasdani/github-patches
|
git_diff
|
beetbox__beets-2952
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
play: Configuration option to include a UTF-8-BOM (and possibly use .m3u8 extension)
### Problem
Currently, the play plugin's generated m3u files don't behave with foobar2000 if they have special characters (i.e. [en dash](https://unicode-table.com/en/2013/) "–"). If I modify the m3u file to have an m3u8 extension and add the appropriate [BOM](https://en.wikipedia.org/wiki/Byte_order_mark), it works just fine.
Running this command in verbose (`-vv`) mode:
```sh
λ beet -vv play -a 009
user configuration: C:\Users\mikey\AppData\Roaming\beets\config.yaml
data directory: C:\Users\mikey\AppData\Roaming\beets
plugin paths:
Sending event: pluginload
library database: D:\beets.db
library directory: D:\Music
Sending event: library_opened
Playing 1 album.
play: executing command: foobar2000 ['C:\\Users\\mikey\\AppData\\Local\\Temp\\tmp911i_r7f.m3u']
```
Led to this problem:
```
Foobar can't find the files specified in the m3u file.
```
The file path attempting to be played is "D:\Music\Compilations\Monstercat 009 – Reunion"
### Setup
* OS: Windows 10 Pro 1803
* Python version: 3.6.4
* beets version: 1.4.6
* Turning off plugins made problem go away (yes/no): N/A
My configuration (output of `beet config`) is:
```yaml
directory: D:\\Music
library: D:\\beets.db
plugins: chroma fetchart mbsync fromfilename web play
import:
move: yes
write: yes
replace:
'[\\/]': _
^\.: _
'[\x00-\x1f]': _
'[<>:"\?\*\|]': _
\.$: _
\s+$: ''
^\s+: ''
^-: _
play:
command: foobar2000
use_folders: no
relative_to:
raw: no
warning_threshold: 100
sort_item: album+ disc+ track+ artist+
fetchart:
auto: yes
minwidth: 0
maxwidth: 0
enforce_ratio: no
cautious: no
cover_names:
- cover
- front
- art
- album
- folder
sources:
- filesystem
- coverart
- itunes
- amazon
- albumart
google_key: REDACTED
google_engine: 001442825323518660753:hrh5ch1gjzm
fanarttv_key: REDACTED
store_source: no
web:
host: 127.0.0.1
port: 8337
cors: ''
reverse_proxy: no
include_paths: no
chroma:
auto: yes
```
</issue>
<code>
[start of beetsplug/play.py]
1 # -*- coding: utf-8 -*-
2 # This file is part of beets.
3 # Copyright 2016, David Hamp-Gonsalves
4 #
5 # Permission is hereby granted, free of charge, to any person obtaining
6 # a copy of this software and associated documentation files (the
7 # "Software"), to deal in the Software without restriction, including
8 # without limitation the rights to use, copy, modify, merge, publish,
9 # distribute, sublicense, and/or sell copies of the Software, and to
10 # permit persons to whom the Software is furnished to do so, subject to
11 # the following conditions:
12 #
13 # The above copyright notice and this permission notice shall be
14 # included in all copies or substantial portions of the Software.
15
16 """Send the results of a query to the configured music player as a playlist.
17 """
18 from __future__ import division, absolute_import, print_function
19
20 from beets.plugins import BeetsPlugin
21 from beets.ui import Subcommand
22 from beets.ui.commands import PromptChoice
23 from beets import config
24 from beets import ui
25 from beets import util
26 from os.path import relpath
27 from tempfile import NamedTemporaryFile
28 import subprocess
29
30 # Indicate where arguments should be inserted into the command string.
31 # If this is missing, they're placed at the end.
32 ARGS_MARKER = '$args'
33
34
35 def play(command_str, selection, paths, open_args, log, item_type='track',
36 keep_open=False):
37 """Play items in paths with command_str and optional arguments. If
38 keep_open, return to beets, otherwise exit once command runs.
39 """
40 # Print number of tracks or albums to be played, log command to be run.
41 item_type += 's' if len(selection) > 1 else ''
42 ui.print_(u'Playing {0} {1}.'.format(len(selection), item_type))
43 log.debug(u'executing command: {} {!r}', command_str, open_args)
44
45 try:
46 if keep_open:
47 command = util.shlex_split(command_str)
48 command = command + open_args
49 subprocess.call(command)
50 else:
51 util.interactive_open(open_args, command_str)
52 except OSError as exc:
53 raise ui.UserError(
54 "Could not play the query: {0}".format(exc))
55
56
57 class PlayPlugin(BeetsPlugin):
58
59 def __init__(self):
60 super(PlayPlugin, self).__init__()
61
62 config['play'].add({
63 'command': None,
64 'use_folders': False,
65 'relative_to': None,
66 'raw': False,
67 'warning_threshold': 100,
68 })
69
70 self.register_listener('before_choose_candidate',
71 self.before_choose_candidate_listener)
72
73 def commands(self):
74 play_command = Subcommand(
75 'play',
76 help=u'send music to a player as a playlist'
77 )
78 play_command.parser.add_album_option()
79 play_command.parser.add_option(
80 u'-A', u'--args',
81 action='store',
82 help=u'add additional arguments to the command',
83 )
84 play_command.parser.add_option(
85 u'-y', u'--yes',
86 action="store_true",
87 help=u'skip the warning threshold',
88 )
89 play_command.func = self._play_command
90 return [play_command]
91
92 def _play_command(self, lib, opts, args):
93 """The CLI command function for `beet play`. Create a list of paths
94 from query, determine if tracks or albums are to be played.
95 """
96 use_folders = config['play']['use_folders'].get(bool)
97 relative_to = config['play']['relative_to'].get()
98 if relative_to:
99 relative_to = util.normpath(relative_to)
100 # Perform search by album and add folders rather than tracks to
101 # playlist.
102 if opts.album:
103 selection = lib.albums(ui.decargs(args))
104 paths = []
105
106 sort = lib.get_default_album_sort()
107 for album in selection:
108 if use_folders:
109 paths.append(album.item_dir())
110 else:
111 paths.extend(item.path
112 for item in sort.sort(album.items()))
113 item_type = 'album'
114
115 # Perform item query and add tracks to playlist.
116 else:
117 selection = lib.items(ui.decargs(args))
118 paths = [item.path for item in selection]
119 item_type = 'track'
120
121 if relative_to:
122 paths = [relpath(path, relative_to) for path in paths]
123
124 if not selection:
125 ui.print_(ui.colorize('text_warning',
126 u'No {0} to play.'.format(item_type)))
127 return
128
129 open_args = self._playlist_or_paths(paths)
130 command_str = self._command_str(opts.args)
131
132 # Check if the selection exceeds configured threshold. If True,
133 # cancel, otherwise proceed with play command.
134 if opts.yes or not self._exceeds_threshold(
135 selection, command_str, open_args, item_type):
136 play(command_str, selection, paths, open_args, self._log,
137 item_type)
138
139 def _command_str(self, args=None):
140 """Create a command string from the config command and optional args.
141 """
142 command_str = config['play']['command'].get()
143 if not command_str:
144 return util.open_anything()
145 # Add optional arguments to the player command.
146 if args:
147 if ARGS_MARKER in command_str:
148 return command_str.replace(ARGS_MARKER, args)
149 else:
150 return u"{} {}".format(command_str, args)
151 else:
152 # Don't include the marker in the command.
153 return command_str.replace(" " + ARGS_MARKER, "")
154
155 def _playlist_or_paths(self, paths):
156 """Return either the raw paths of items or a playlist of the items.
157 """
158 if config['play']['raw']:
159 return paths
160 else:
161 return [self._create_tmp_playlist(paths)]
162
163 def _exceeds_threshold(self, selection, command_str, open_args,
164 item_type='track'):
165 """Prompt user whether to abort if playlist exceeds threshold. If
166 True, cancel playback. If False, execute play command.
167 """
168 warning_threshold = config['play']['warning_threshold'].get(int)
169
170 # Warn user before playing any huge playlists.
171 if warning_threshold and len(selection) > warning_threshold:
172 if len(selection) > 1:
173 item_type += 's'
174
175 ui.print_(ui.colorize(
176 'text_warning',
177 u'You are about to queue {0} {1}.'.format(
178 len(selection), item_type)))
179
180 if ui.input_options((u'Continue', u'Abort')) == 'a':
181 return True
182
183 return False
184
185 def _create_tmp_playlist(self, paths_list):
186 """Create a temporary .m3u file. Return the filename.
187 """
188 m3u = NamedTemporaryFile('wb', suffix='.m3u', delete=False)
189 for item in paths_list:
190 m3u.write(item + b'\n')
191 m3u.close()
192 return m3u.name
193
194 def before_choose_candidate_listener(self, session, task):
195 """Append a "Play" choice to the interactive importer prompt.
196 """
197 return [PromptChoice('y', 'plaY', self.importer_play)]
198
199 def importer_play(self, session, task):
200 """Get items from current import task and send to play function.
201 """
202 selection = task.items
203 paths = [item.path for item in selection]
204
205 open_args = self._playlist_or_paths(paths)
206 command_str = self._command_str()
207
208 if not self._exceeds_threshold(selection, command_str, open_args):
209 play(command_str, selection, paths, open_args, self._log,
210 keep_open=True)
211
[end of beetsplug/play.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/beetsplug/play.py b/beetsplug/play.py
--- a/beetsplug/play.py
+++ b/beetsplug/play.py
@@ -65,6 +65,7 @@
'relative_to': None,
'raw': False,
'warning_threshold': 100,
+ 'bom': False,
})
self.register_listener('before_choose_candidate',
@@ -185,7 +186,12 @@
def _create_tmp_playlist(self, paths_list):
"""Create a temporary .m3u file. Return the filename.
"""
+ utf8_bom = config['play']['bom'].get(bool)
m3u = NamedTemporaryFile('wb', suffix='.m3u', delete=False)
+
+ if utf8_bom:
+ m3u.write(b'\xEF\xBB\xBF')
+
for item in paths_list:
m3u.write(item + b'\n')
m3u.close()
|
{"golden_diff": "diff --git a/beetsplug/play.py b/beetsplug/play.py\n--- a/beetsplug/play.py\n+++ b/beetsplug/play.py\n@@ -65,6 +65,7 @@\n 'relative_to': None,\n 'raw': False,\n 'warning_threshold': 100,\n+ 'bom': False,\n })\n \n self.register_listener('before_choose_candidate',\n@@ -185,7 +186,12 @@\n def _create_tmp_playlist(self, paths_list):\n \"\"\"Create a temporary .m3u file. Return the filename.\n \"\"\"\n+ utf8_bom = config['play']['bom'].get(bool)\n m3u = NamedTemporaryFile('wb', suffix='.m3u', delete=False)\n+\n+ if utf8_bom:\n+ m3u.write(b'\\xEF\\xBB\\xBF')\n+\n for item in paths_list:\n m3u.write(item + b'\\n')\n m3u.close()\n", "issue": "play: Configuration option to include a UTF-8-BOM (and possibly use .m3u8 extension)\n### Problem\r\nCurrently, the play plugin's generated m3u files don't behave with foobar2000 if they have special characters (i.e. [en dash](https://unicode-table.com/en/2013/) \"\u2013\"). If I modify the m3u file to have an m3u8 extension and add the appropriate [BOM](https://en.wikipedia.org/wiki/Byte_order_mark), it works just fine.\r\n\r\nRunning this command in verbose (`-vv`) mode:\r\n\r\n```sh\r\n\u03bb beet -vv play -a 009 \r\nuser configuration: C:\\Users\\mikey\\AppData\\Roaming\\beets\\config.yaml \r\ndata directory: C:\\Users\\mikey\\AppData\\Roaming\\beets \r\nplugin paths: \r\nSending event: pluginload \r\nlibrary database: D:\\beets.db \r\nlibrary directory: D:\\Music \r\nSending event: library_opened \r\nPlaying 1 album. \r\nplay: executing command: foobar2000 ['C:\\\\Users\\\\mikey\\\\AppData\\\\Local\\\\Temp\\\\tmp911i_r7f.m3u']\r\n \r\n```\r\n\r\nLed to this problem:\r\n\r\n```\r\nFoobar can't find the files specified in the m3u file.\r\n```\r\nThe file path attempting to be played is \"D:\\Music\\Compilations\\Monstercat 009 \u2013 Reunion\"\r\n\r\n\r\n### Setup\r\n\r\n* OS: Windows 10 Pro 1803\r\n* Python version: 3.6.4\r\n* beets version: 1.4.6\r\n* Turning off plugins made problem go away (yes/no): N/A\r\n\r\nMy configuration (output of `beet config`) is:\r\n\r\n```yaml\r\ndirectory: D:\\\\Music\r\nlibrary: D:\\\\beets.db\r\n\r\nplugins: chroma fetchart mbsync fromfilename web play\r\n\r\nimport:\r\n move: yes\r\n write: yes\r\n\r\nreplace:\r\n '[\\\\/]': _\r\n ^\\.: _\r\n '[\\x00-\\x1f]': _\r\n '[<>:\"\\?\\*\\|]': _\r\n \\.$: _\r\n \\s+$: ''\r\n ^\\s+: ''\r\n ^-: _\r\nplay:\r\n command: foobar2000\r\n use_folders: no\r\n relative_to:\r\n raw: no\r\n warning_threshold: 100\r\nsort_item: album+ disc+ track+ artist+\r\nfetchart:\r\n auto: yes\r\n minwidth: 0\r\n maxwidth: 0\r\n enforce_ratio: no\r\n cautious: no\r\n cover_names:\r\n - cover\r\n - front\r\n - art\r\n - album\r\n - folder\r\n sources:\r\n - filesystem\r\n - coverart\r\n - itunes\r\n - amazon\r\n - albumart\r\n google_key: REDACTED\r\n google_engine: 001442825323518660753:hrh5ch1gjzm\r\n fanarttv_key: REDACTED\r\n store_source: no\r\nweb:\r\n host: 127.0.0.1\r\n port: 8337\r\n cors: ''\r\n reverse_proxy: no\r\n include_paths: no\r\nchroma:\r\n auto: yes\r\n```\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# This file is part of beets.\n# Copyright 2016, David Hamp-Gonsalves\n#\n# Permission is hereby granted, free of charge, to any person obtaining\n# a copy of this software and associated documentation files (the\n# \"Software\"), to deal in the Software without restriction, including\n# without limitation the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the Software, and to\n# permit persons to whom the Software is furnished to do so, subject to\n# the following conditions:\n#\n# The above copyright notice and this permission notice shall be\n# included in all copies or substantial portions of the Software.\n\n\"\"\"Send the results of a query to the configured music player as a playlist.\n\"\"\"\nfrom __future__ import division, absolute_import, print_function\n\nfrom beets.plugins import BeetsPlugin\nfrom beets.ui import Subcommand\nfrom beets.ui.commands import PromptChoice\nfrom beets import config\nfrom beets import ui\nfrom beets import util\nfrom os.path import relpath\nfrom tempfile import NamedTemporaryFile\nimport subprocess\n\n# Indicate where arguments should be inserted into the command string.\n# If this is missing, they're placed at the end.\nARGS_MARKER = '$args'\n\n\ndef play(command_str, selection, paths, open_args, log, item_type='track',\n keep_open=False):\n \"\"\"Play items in paths with command_str and optional arguments. If\n keep_open, return to beets, otherwise exit once command runs.\n \"\"\"\n # Print number of tracks or albums to be played, log command to be run.\n item_type += 's' if len(selection) > 1 else ''\n ui.print_(u'Playing {0} {1}.'.format(len(selection), item_type))\n log.debug(u'executing command: {} {!r}', command_str, open_args)\n\n try:\n if keep_open:\n command = util.shlex_split(command_str)\n command = command + open_args\n subprocess.call(command)\n else:\n util.interactive_open(open_args, command_str)\n except OSError as exc:\n raise ui.UserError(\n \"Could not play the query: {0}\".format(exc))\n\n\nclass PlayPlugin(BeetsPlugin):\n\n def __init__(self):\n super(PlayPlugin, self).__init__()\n\n config['play'].add({\n 'command': None,\n 'use_folders': False,\n 'relative_to': None,\n 'raw': False,\n 'warning_threshold': 100,\n })\n\n self.register_listener('before_choose_candidate',\n self.before_choose_candidate_listener)\n\n def commands(self):\n play_command = Subcommand(\n 'play',\n help=u'send music to a player as a playlist'\n )\n play_command.parser.add_album_option()\n play_command.parser.add_option(\n u'-A', u'--args',\n action='store',\n help=u'add additional arguments to the command',\n )\n play_command.parser.add_option(\n u'-y', u'--yes',\n action=\"store_true\",\n help=u'skip the warning threshold',\n )\n play_command.func = self._play_command\n return [play_command]\n\n def _play_command(self, lib, opts, args):\n \"\"\"The CLI command function for `beet play`. Create a list of paths\n from query, determine if tracks or albums are to be played.\n \"\"\"\n use_folders = config['play']['use_folders'].get(bool)\n relative_to = config['play']['relative_to'].get()\n if relative_to:\n relative_to = util.normpath(relative_to)\n # Perform search by album and add folders rather than tracks to\n # playlist.\n if opts.album:\n selection = lib.albums(ui.decargs(args))\n paths = []\n\n sort = lib.get_default_album_sort()\n for album in selection:\n if use_folders:\n paths.append(album.item_dir())\n else:\n paths.extend(item.path\n for item in sort.sort(album.items()))\n item_type = 'album'\n\n # Perform item query and add tracks to playlist.\n else:\n selection = lib.items(ui.decargs(args))\n paths = [item.path for item in selection]\n item_type = 'track'\n\n if relative_to:\n paths = [relpath(path, relative_to) for path in paths]\n\n if not selection:\n ui.print_(ui.colorize('text_warning',\n u'No {0} to play.'.format(item_type)))\n return\n\n open_args = self._playlist_or_paths(paths)\n command_str = self._command_str(opts.args)\n\n # Check if the selection exceeds configured threshold. If True,\n # cancel, otherwise proceed with play command.\n if opts.yes or not self._exceeds_threshold(\n selection, command_str, open_args, item_type):\n play(command_str, selection, paths, open_args, self._log,\n item_type)\n\n def _command_str(self, args=None):\n \"\"\"Create a command string from the config command and optional args.\n \"\"\"\n command_str = config['play']['command'].get()\n if not command_str:\n return util.open_anything()\n # Add optional arguments to the player command.\n if args:\n if ARGS_MARKER in command_str:\n return command_str.replace(ARGS_MARKER, args)\n else:\n return u\"{} {}\".format(command_str, args)\n else:\n # Don't include the marker in the command.\n return command_str.replace(\" \" + ARGS_MARKER, \"\")\n\n def _playlist_or_paths(self, paths):\n \"\"\"Return either the raw paths of items or a playlist of the items.\n \"\"\"\n if config['play']['raw']:\n return paths\n else:\n return [self._create_tmp_playlist(paths)]\n\n def _exceeds_threshold(self, selection, command_str, open_args,\n item_type='track'):\n \"\"\"Prompt user whether to abort if playlist exceeds threshold. If\n True, cancel playback. If False, execute play command.\n \"\"\"\n warning_threshold = config['play']['warning_threshold'].get(int)\n\n # Warn user before playing any huge playlists.\n if warning_threshold and len(selection) > warning_threshold:\n if len(selection) > 1:\n item_type += 's'\n\n ui.print_(ui.colorize(\n 'text_warning',\n u'You are about to queue {0} {1}.'.format(\n len(selection), item_type)))\n\n if ui.input_options((u'Continue', u'Abort')) == 'a':\n return True\n\n return False\n\n def _create_tmp_playlist(self, paths_list):\n \"\"\"Create a temporary .m3u file. Return the filename.\n \"\"\"\n m3u = NamedTemporaryFile('wb', suffix='.m3u', delete=False)\n for item in paths_list:\n m3u.write(item + b'\\n')\n m3u.close()\n return m3u.name\n\n def before_choose_candidate_listener(self, session, task):\n \"\"\"Append a \"Play\" choice to the interactive importer prompt.\n \"\"\"\n return [PromptChoice('y', 'plaY', self.importer_play)]\n\n def importer_play(self, session, task):\n \"\"\"Get items from current import task and send to play function.\n \"\"\"\n selection = task.items\n paths = [item.path for item in selection]\n\n open_args = self._playlist_or_paths(paths)\n command_str = self._command_str()\n\n if not self._exceeds_threshold(selection, command_str, open_args):\n play(command_str, selection, paths, open_args, self._log,\n keep_open=True)\n", "path": "beetsplug/play.py"}]}
| 3,447 | 215 |
gh_patches_debug_29702
|
rasdani/github-patches
|
git_diff
|
sunpy__sunpy-4901
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Simplify semi_circular_loop function in asdf coordinates example
In the [example that shows how to save a coordinate into an asdf file](https://docs.sunpy.org/en/stable/generated/gallery/saving_and_loading_data/coordinates_in_asdf.html#sphx-glr-generated-gallery-saving-and-loading-data-coordinates-in-asdf-py), there is a function called `semi_circular_loop` that is needlessly complicated.
To make this example more straightforward, it would be better to replace it with,
```python
@u.quantity_input
def semi_circular_loop(length: u.cm, latitude: u.deg = 0*u.deg):
"""
Return HGS coordinates for a semi-circular loop
"""
s = np.linspace(0, length, 1000)
z = length / np.pi * np.sin(np.pi * u.rad * s/length)
x = np.sqrt((length / np.pi)**2 - z**2)
x = np.where(s < length/2, -x, x)
hcc_frame = frames.Heliocentric(
observer=frames.HeliographicStonyhurst(lon=0 * u.deg, lat=latitude, radius=const.au))
)
return SkyCoord(x= x, y=np.zeros(x.shape)*u.cm, z=z + const.R_sun, frame=hcc_frame)
```
</issue>
<code>
[start of examples/saving_and_loading_data/coordinates_in_asdf.py]
1 """
2 ========================================
3 Saving and loading coordinates with asdf
4 ========================================
5
6 In this example we are going to look at saving and loading collections of
7 coordinates with `asdf <https://asdf.readthedocs.io/en/latest/>`__.
8
9 asdf is a modern file format designed to meet the needs of the astronomy
10 community. It has deep integration with Python and SunPy and Astropy as well as
11 implementations in other languages. It can be used to store known Python
12 objects in a portable, well defined file format. It is primarily useful for
13 storing complex Astropy and SunPy objects in a way that can be loaded back into
14 the same form as they were saved.
15
16 .. note::
17 This example requires Astropy 3.2 and asdf 2.3.0
18
19 """
20
21 import matplotlib.pyplot as plt
22 import numpy as np
23 import scipy.optimize
24
25 import asdf
26 import astropy.units as u
27 from astropy.coordinates import SkyCoord
28
29 import sunpy.map
30 from sunpy.coordinates import frames
31 from sunpy.data.sample import AIA_171_IMAGE
32 from sunpy.sun import constants
33
34 ################################################################################
35 # To get started let's use a function to get the coordinates of a semi-circular
36 # loop from
37 # `this <https://sunpy.org/posts/2018/2018-07-21-coronal-loop-coordinates.html>`__
38 # blog post by Will Barnes to generate ourselves some coordinates.
39
40
41 @u.quantity_input
42 def semi_circular_loop(length: u.m, latitude: u.deg = 0*u.deg):
43 """
44 Return a Heliographic Stonyhurst coordinate object with points of a semi circular loop in it.
45 """
46 r_sun = constants.radius
47
48 def r_2_func(x):
49 return np.arccos(0.5 * x / r_sun.to(u.cm).value) - np.pi + length.to(u.cm).value / 2. / x
50
51 # Find the loop radius corresponding to the loop length
52 r_2 = scipy.optimize.bisect(r_2_func,
53 length.to(u.cm).value / (2 * np.pi),
54 length.to(u.cm).value / np.pi) * u.cm
55 alpha = np.arccos(0.5 * (r_2 / r_sun))
56 phi = np.linspace(-np.pi * u.rad + alpha, np.pi * u.rad - alpha, 2000)
57
58 hcc_frame = frames.Heliocentric(
59 observer=frames.HeliographicStonyhurst(lon=0 * u.deg, lat=latitude, radius=1 * u.AU))
60
61 return SkyCoord(
62 x=r_2 * np.sin(phi),
63 y=0 * u.cm,
64 z=r_2 * np.cos(phi) + r_sun,
65 frame=hcc_frame).transform_to('heliographic_stonyhurst')
66
67
68 ################################################################################
69 # Use this function to generate a `~astropy.coordinates.SkyCoord` object.
70 loop_coords = semi_circular_loop(500*u.Mm, 30*u.deg)
71 print(loop_coords.shape)
72 # print the first and last coordinate point
73 print(loop_coords[[0, -1]])
74
75
76 ################################################################################
77 # This is a regular coordinate object that can be transformed to other frames
78 # or overplotted on images. For instance we could overplot it on an AIA image
79
80 aiamap = sunpy.map.Map(AIA_171_IMAGE)
81
82 ax = plt.subplot(projection=aiamap)
83 aiamap.plot(axes=ax, clip_interval=(1, 99.5) * u.percent)
84 ax.plot_coord(loop_coords, 'r')
85
86 plt.show()
87
88
89 ################################################################################
90 # We can now save these loop points to an asdf file to use later. The advantage
91 # of saving them to asdf is that all the metadata about the coordinates will be
92 # preserved, and when we load the asdf, we will get back an identical
93 # `~astropy.coordinates.SkyCoord` object.
94 #
95 # asdf files save a dictionary to a file, so to save the loop coordinates we
96 # need to put them into a dictionary. This becomes what asdf calls a tree.
97
98 tree = {'loop_points': loop_coords}
99
100 with asdf.AsdfFile(tree) as asdf_file:
101 asdf_file.write_to("loop_coords.asdf")
102
103
104 ################################################################################
105 # This asdf file is a portable file and can be safely loaded by anyone with
106 # Astropy and SunPy installed. We can reload the file like so:
107
108 with asdf.open("loop_coords.asdf") as input_asdf:
109 new_coords = input_asdf['loop_points']
110
111 print(new_coords.shape)
112 # print the first and last coordinate point
113 print(new_coords[[0, -1]])
114
[end of examples/saving_and_loading_data/coordinates_in_asdf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/saving_and_loading_data/coordinates_in_asdf.py b/examples/saving_and_loading_data/coordinates_in_asdf.py
--- a/examples/saving_and_loading_data/coordinates_in_asdf.py
+++ b/examples/saving_and_loading_data/coordinates_in_asdf.py
@@ -20,7 +20,6 @@
import matplotlib.pyplot as plt
import numpy as np
-import scipy.optimize
import asdf
import astropy.units as u
@@ -39,30 +38,21 @@
@u.quantity_input
-def semi_circular_loop(length: u.m, latitude: u.deg = 0*u.deg):
+def semi_circular_loop(length: u.cm, latitude: u.deg = 0*u.deg):
"""
- Return a Heliographic Stonyhurst coordinate object with points of a semi circular loop in it.
+ Return HGS coordinates for a semi-circular loop
"""
- r_sun = constants.radius
-
- def r_2_func(x):
- return np.arccos(0.5 * x / r_sun.to(u.cm).value) - np.pi + length.to(u.cm).value / 2. / x
-
- # Find the loop radius corresponding to the loop length
- r_2 = scipy.optimize.bisect(r_2_func,
- length.to(u.cm).value / (2 * np.pi),
- length.to(u.cm).value / np.pi) * u.cm
- alpha = np.arccos(0.5 * (r_2 / r_sun))
- phi = np.linspace(-np.pi * u.rad + alpha, np.pi * u.rad - alpha, 2000)
-
+ angles = np.linspace(0, 1, 1000) * np.pi * u.rad
+ z = length / np.pi * np.sin(angles)
+ x = length / np.pi * np.cos(angles)
hcc_frame = frames.Heliocentric(
- observer=frames.HeliographicStonyhurst(lon=0 * u.deg, lat=latitude, radius=1 * u.AU))
+ observer=frames.HeliographicStonyhurst(lon=0 * u.deg, lat=latitude, radius=constants.au))
return SkyCoord(
- x=r_2 * np.sin(phi),
- y=0 * u.cm,
- z=r_2 * np.cos(phi) + r_sun,
- frame=hcc_frame).transform_to('heliographic_stonyhurst')
+ x=x,
+ y=np.zeros_like(x),
+ z=z + constants.radius,
+ frame=hcc_frame)
################################################################################
|
{"golden_diff": "diff --git a/examples/saving_and_loading_data/coordinates_in_asdf.py b/examples/saving_and_loading_data/coordinates_in_asdf.py\n--- a/examples/saving_and_loading_data/coordinates_in_asdf.py\n+++ b/examples/saving_and_loading_data/coordinates_in_asdf.py\n@@ -20,7 +20,6 @@\n \n import matplotlib.pyplot as plt\n import numpy as np\n-import scipy.optimize\n \n import asdf\n import astropy.units as u\n@@ -39,30 +38,21 @@\n \n \n @u.quantity_input\n-def semi_circular_loop(length: u.m, latitude: u.deg = 0*u.deg):\n+def semi_circular_loop(length: u.cm, latitude: u.deg = 0*u.deg):\n \"\"\"\n- Return a Heliographic Stonyhurst coordinate object with points of a semi circular loop in it.\n+ Return HGS coordinates for a semi-circular loop\n \"\"\"\n- r_sun = constants.radius\n-\n- def r_2_func(x):\n- return np.arccos(0.5 * x / r_sun.to(u.cm).value) - np.pi + length.to(u.cm).value / 2. / x\n-\n- # Find the loop radius corresponding to the loop length\n- r_2 = scipy.optimize.bisect(r_2_func,\n- length.to(u.cm).value / (2 * np.pi),\n- length.to(u.cm).value / np.pi) * u.cm\n- alpha = np.arccos(0.5 * (r_2 / r_sun))\n- phi = np.linspace(-np.pi * u.rad + alpha, np.pi * u.rad - alpha, 2000)\n-\n+ angles = np.linspace(0, 1, 1000) * np.pi * u.rad\n+ z = length / np.pi * np.sin(angles)\n+ x = length / np.pi * np.cos(angles)\n hcc_frame = frames.Heliocentric(\n- observer=frames.HeliographicStonyhurst(lon=0 * u.deg, lat=latitude, radius=1 * u.AU))\n+ observer=frames.HeliographicStonyhurst(lon=0 * u.deg, lat=latitude, radius=constants.au))\n \n return SkyCoord(\n- x=r_2 * np.sin(phi),\n- y=0 * u.cm,\n- z=r_2 * np.cos(phi) + r_sun,\n- frame=hcc_frame).transform_to('heliographic_stonyhurst')\n+ x=x,\n+ y=np.zeros_like(x),\n+ z=z + constants.radius,\n+ frame=hcc_frame)\n \n \n ################################################################################\n", "issue": "Simplify semi_circular_loop function in asdf coordinates example\nIn the [example that shows how to save a coordinate into an asdf file](https://docs.sunpy.org/en/stable/generated/gallery/saving_and_loading_data/coordinates_in_asdf.html#sphx-glr-generated-gallery-saving-and-loading-data-coordinates-in-asdf-py), there is a function called `semi_circular_loop` that is needlessly complicated.\r\n\r\nTo make this example more straightforward, it would be better to replace it with,\r\n\r\n```python\r\[email protected]_input\r\ndef semi_circular_loop(length: u.cm, latitude: u.deg = 0*u.deg):\r\n \"\"\"\r\n Return HGS coordinates for a semi-circular loop\r\n \"\"\"\r\n s = np.linspace(0, length, 1000)\r\n z = length / np.pi * np.sin(np.pi * u.rad * s/length)\r\n x = np.sqrt((length / np.pi)**2 - z**2)\r\n x = np.where(s < length/2, -x, x)\r\n hcc_frame = frames.Heliocentric(\r\n observer=frames.HeliographicStonyhurst(lon=0 * u.deg, lat=latitude, radius=const.au))\r\n )\r\n return SkyCoord(x= x, y=np.zeros(x.shape)*u.cm, z=z + const.R_sun, frame=hcc_frame)\r\n```\n", "before_files": [{"content": "\"\"\"\n========================================\nSaving and loading coordinates with asdf\n========================================\n\nIn this example we are going to look at saving and loading collections of\ncoordinates with `asdf <https://asdf.readthedocs.io/en/latest/>`__.\n\nasdf is a modern file format designed to meet the needs of the astronomy\ncommunity. It has deep integration with Python and SunPy and Astropy as well as\nimplementations in other languages. It can be used to store known Python\nobjects in a portable, well defined file format. It is primarily useful for\nstoring complex Astropy and SunPy objects in a way that can be loaded back into\nthe same form as they were saved.\n\n.. note::\n This example requires Astropy 3.2 and asdf 2.3.0\n\n\"\"\"\n\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport scipy.optimize\n\nimport asdf\nimport astropy.units as u\nfrom astropy.coordinates import SkyCoord\n\nimport sunpy.map\nfrom sunpy.coordinates import frames\nfrom sunpy.data.sample import AIA_171_IMAGE\nfrom sunpy.sun import constants\n\n################################################################################\n# To get started let's use a function to get the coordinates of a semi-circular\n# loop from\n# `this <https://sunpy.org/posts/2018/2018-07-21-coronal-loop-coordinates.html>`__\n# blog post by Will Barnes to generate ourselves some coordinates.\n\n\[email protected]_input\ndef semi_circular_loop(length: u.m, latitude: u.deg = 0*u.deg):\n \"\"\"\n Return a Heliographic Stonyhurst coordinate object with points of a semi circular loop in it.\n \"\"\"\n r_sun = constants.radius\n\n def r_2_func(x):\n return np.arccos(0.5 * x / r_sun.to(u.cm).value) - np.pi + length.to(u.cm).value / 2. / x\n\n # Find the loop radius corresponding to the loop length\n r_2 = scipy.optimize.bisect(r_2_func,\n length.to(u.cm).value / (2 * np.pi),\n length.to(u.cm).value / np.pi) * u.cm\n alpha = np.arccos(0.5 * (r_2 / r_sun))\n phi = np.linspace(-np.pi * u.rad + alpha, np.pi * u.rad - alpha, 2000)\n\n hcc_frame = frames.Heliocentric(\n observer=frames.HeliographicStonyhurst(lon=0 * u.deg, lat=latitude, radius=1 * u.AU))\n\n return SkyCoord(\n x=r_2 * np.sin(phi),\n y=0 * u.cm,\n z=r_2 * np.cos(phi) + r_sun,\n frame=hcc_frame).transform_to('heliographic_stonyhurst')\n\n\n################################################################################\n# Use this function to generate a `~astropy.coordinates.SkyCoord` object.\nloop_coords = semi_circular_loop(500*u.Mm, 30*u.deg)\nprint(loop_coords.shape)\n# print the first and last coordinate point\nprint(loop_coords[[0, -1]])\n\n\n################################################################################\n# This is a regular coordinate object that can be transformed to other frames\n# or overplotted on images. For instance we could overplot it on an AIA image\n\naiamap = sunpy.map.Map(AIA_171_IMAGE)\n\nax = plt.subplot(projection=aiamap)\naiamap.plot(axes=ax, clip_interval=(1, 99.5) * u.percent)\nax.plot_coord(loop_coords, 'r')\n\nplt.show()\n\n\n################################################################################\n# We can now save these loop points to an asdf file to use later. The advantage\n# of saving them to asdf is that all the metadata about the coordinates will be\n# preserved, and when we load the asdf, we will get back an identical\n# `~astropy.coordinates.SkyCoord` object.\n#\n# asdf files save a dictionary to a file, so to save the loop coordinates we\n# need to put them into a dictionary. This becomes what asdf calls a tree.\n\ntree = {'loop_points': loop_coords}\n\nwith asdf.AsdfFile(tree) as asdf_file:\n asdf_file.write_to(\"loop_coords.asdf\")\n\n\n################################################################################\n# This asdf file is a portable file and can be safely loaded by anyone with\n# Astropy and SunPy installed. We can reload the file like so:\n\nwith asdf.open(\"loop_coords.asdf\") as input_asdf:\n new_coords = input_asdf['loop_points']\n\nprint(new_coords.shape)\n# print the first and last coordinate point\nprint(new_coords[[0, -1]])\n", "path": "examples/saving_and_loading_data/coordinates_in_asdf.py"}]}
| 2,089 | 578 |
gh_patches_debug_9176
|
rasdani/github-patches
|
git_diff
|
nerfstudio-project__nerfstudio-871
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Relative data paths result in hidden output directories
Running `ns-train` with a relative path to the data results in an output directory that is hidden because the experiment name includes components of the relative path. For example, running: `ns-train nerfacto --data ../nerf_datasets/tum_fr1desk` results in an output directory `outputs/..-nerf_datasets-tum-fr1desk`.
**To Reproduce**
Steps to reproduce the behavior:
1. Run `ns-train nerfacto --data ../[path to data]`
**Expected behavior**
The expected behavior should probably be to remove any `"../"` from the data path when generating the experiment name.
</issue>
<code>
[start of nerfstudio/configs/base_config.py]
1 # Copyright 2022 The Nerfstudio Team. All rights reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Base Configs"""
16
17 # pylint: disable=wrong-import-position
18
19 from __future__ import annotations
20
21 from dataclasses import dataclass
22 from datetime import datetime
23 from pathlib import Path
24 from typing import Any, Dict, List, Optional, Tuple, Type
25
26 import yaml
27 from rich.console import Console
28 from typing_extensions import Literal
29
30 from nerfstudio.configs.config_utils import to_immutable_dict
31
32 # model instances
33 from nerfstudio.utils import writer
34
35 CONSOLE = Console(width=120)
36
37 # Pretty printing class
38 class PrintableConfig: # pylint: disable=too-few-public-methods
39 """Printable Config defining str function"""
40
41 def __str__(self):
42 lines = [self.__class__.__name__ + ":"]
43 for key, val in vars(self).items():
44 if isinstance(val, Tuple):
45 flattened_val = "["
46 for item in val:
47 flattened_val += str(item) + "\n"
48 flattened_val = flattened_val.rstrip("\n")
49 val = flattened_val + "]"
50 lines += f"{key}: {str(val)}".split("\n")
51 return "\n ".join(lines)
52
53
54 # Base instantiate configs
55 @dataclass
56 class InstantiateConfig(PrintableConfig): # pylint: disable=too-few-public-methods
57 """Config class for instantiating an the class specified in the _target attribute."""
58
59 _target: Type
60
61 def setup(self, **kwargs) -> Any:
62 """Returns the instantiated object using the config."""
63 return self._target(self, **kwargs)
64
65
66 # Machine related configs
67 @dataclass
68 class MachineConfig(PrintableConfig):
69 """Configuration of machine setup"""
70
71 seed: int = 42
72 """random seed initilization"""
73 num_gpus: int = 1
74 """total number of gpus available for train/eval"""
75 num_machines: int = 1
76 """total number of distributed machines available (for DDP)"""
77 machine_rank: int = 0
78 """current machine's rank (for DDP)"""
79 dist_url: str = "auto"
80 """distributed connection point (for DDP)"""
81
82
83 @dataclass
84 class LocalWriterConfig(InstantiateConfig):
85 """Local Writer config"""
86
87 _target: Type = writer.LocalWriter
88 """target class to instantiate"""
89 enable: bool = False
90 """if True enables local logging, else disables"""
91 stats_to_track: Tuple[writer.EventName, ...] = (
92 writer.EventName.ITER_TRAIN_TIME,
93 writer.EventName.TRAIN_RAYS_PER_SEC,
94 writer.EventName.CURR_TEST_PSNR,
95 writer.EventName.VIS_RAYS_PER_SEC,
96 writer.EventName.TEST_RAYS_PER_SEC,
97 )
98 """specifies which stats will be logged/printed to terminal"""
99 max_log_size: int = 10
100 """maximum number of rows to print before wrapping. if 0, will print everything."""
101
102 def setup(self, banner_messages: Optional[List[str]] = None, **kwargs) -> Any:
103 """Instantiate local writer
104
105 Args:
106 banner_messages: List of strings that always print at the bottom of screen.
107 """
108 return self._target(self, banner_messages=banner_messages, **kwargs)
109
110
111 @dataclass
112 class LoggingConfig(PrintableConfig):
113 """Configuration of loggers and profilers"""
114
115 relative_log_dir: Path = Path("./")
116 """relative path to save all logged events"""
117 steps_per_log: int = 10
118 """number of steps between logging stats"""
119 max_buffer_size: int = 20
120 """maximum history size to keep for computing running averages of stats.
121 e.g. if 20, averages will be computed over past 20 occurances."""
122 local_writer: LocalWriterConfig = LocalWriterConfig(enable=True)
123 """if provided, will print stats locally. if None, will disable printing"""
124 enable_profiler: bool = True
125 """whether to enable profiling code; prints speed of functions at the end of a program.
126 profiler logs run times of functions and prints at end of training"""
127
128
129 # Trainer related configs
130 @dataclass
131 class TrainerConfig(PrintableConfig):
132 """Configuration for training regimen"""
133
134 steps_per_save: int = 1000
135 """Number of steps between saves."""
136 steps_per_eval_batch: int = 500
137 """Number of steps between randomly sampled batches of rays."""
138 steps_per_eval_image: int = 500
139 """Number of steps between single eval images."""
140 steps_per_eval_all_images: int = 25000
141 """Number of steps between eval all images."""
142 max_num_iterations: int = 1000000
143 """Maximum number of iterations to run."""
144 mixed_precision: bool = False
145 """Whether or not to use mixed precision for training."""
146 relative_model_dir: Path = Path("nerfstudio_models/")
147 """Relative path to save all checkpoints."""
148 save_only_latest_checkpoint: bool = True
149 """Whether to only save the latest checkpoint or all checkpoints."""
150 # optional parameters if we want to resume training
151 load_dir: Optional[Path] = None
152 """Optionally specify a pre-trained model directory to load from."""
153 load_step: Optional[int] = None
154 """Optionally specify model step to load from; if none, will find most recent model in load_dir."""
155 load_config: Optional[Path] = None
156
157
158 # Viewer related configs
159 @dataclass
160 class ViewerConfig(PrintableConfig):
161 """Configuration for viewer instantiation"""
162
163 relative_log_filename: str = "viewer_log_filename.txt"
164 """Filename to use for the log file."""
165 start_train: bool = True
166 """whether to immediately start training upon loading viewer
167 if False, will just visualize dataset but you can toggle training in viewer"""
168 zmq_port: Optional[int] = None
169 """The zmq port to connect to for communication. If None, find an available port."""
170 launch_bridge_server: bool = True
171 """whether or not to launch the bridge server"""
172 websocket_port: Optional[int] = 7007
173 """the default websocket port to connect to"""
174 ip_address: str = "127.0.0.1"
175 """the ip address where the bridge server is running"""
176 num_rays_per_chunk: int = 32768
177 """number of rays per chunk to render with viewer"""
178 max_num_display_images: int = 512
179 """Maximum number of training images to display in the viewer, to avoid lag. This does not change which images are
180 actually used in training/evaluation. If -1, display all."""
181
182
183 from nerfstudio.engine.optimizers import OptimizerConfig
184 from nerfstudio.engine.schedulers import SchedulerConfig
185 from nerfstudio.pipelines.base_pipeline import VanillaPipelineConfig
186
187
188 @dataclass
189 class Config(PrintableConfig):
190 """Full config contents"""
191
192 output_dir: Path = Path("outputs")
193 """relative or absolute output directory to save all checkpoints and logging"""
194 method_name: Optional[str] = None
195 """Method name. Required to set in python or via cli"""
196 experiment_name: Optional[str] = None
197 """Experiment name. If None, will automatically be set to dataset name"""
198 timestamp: str = "{timestamp}"
199 """Experiment timestamp."""
200 machine: MachineConfig = MachineConfig()
201 """Machine configuration"""
202 logging: LoggingConfig = LoggingConfig()
203 """Logging configuration"""
204 viewer: ViewerConfig = ViewerConfig()
205 """Viewer configuration"""
206 trainer: TrainerConfig = TrainerConfig()
207 """Trainer configuration"""
208 pipeline: VanillaPipelineConfig = VanillaPipelineConfig()
209 """Pipeline configuration"""
210 optimizers: Dict[str, Any] = to_immutable_dict(
211 {
212 "fields": {
213 "optimizer": OptimizerConfig(),
214 "scheduler": SchedulerConfig(),
215 }
216 }
217 )
218 """Dictionary of optimizer groups and their schedulers"""
219 vis: Literal["viewer", "wandb", "tensorboard"] = "wandb"
220 """Which visualizer to use."""
221 data: Optional[Path] = None
222 """Alias for --pipeline.datamanager.dataparser.data"""
223
224 def is_viewer_enabled(self) -> bool:
225 """Checks if a viewer is enabled."""
226 return "viewer" == self.vis
227
228 def is_wandb_enabled(self) -> bool:
229 """Checks if wandb is enabled."""
230 return "wandb" == self.vis
231
232 def is_tensorboard_enabled(self) -> bool:
233 """Checks if tensorboard is enabled."""
234 return "tensorboard" == self.vis
235
236 def set_timestamp(self) -> None:
237 """Dynamically set the experiment timestamp"""
238 if self.timestamp == "{timestamp}":
239 self.timestamp = datetime.now().strftime("%Y-%m-%d_%H%M%S")
240
241 def set_experiment_name(self) -> None:
242 """Dynamically set the experiment name"""
243 if self.experiment_name is None:
244 self.experiment_name = str(self.pipeline.datamanager.dataparser.data).replace("/", "-")
245
246 def get_base_dir(self) -> Path:
247 """Retrieve the base directory to set relative paths"""
248 # check the experiment and method names
249 assert self.method_name is not None, "Please set method name in config or via the cli"
250 self.set_experiment_name()
251 return Path(f"{self.output_dir}/{self.experiment_name}/{self.method_name}/{self.timestamp}")
252
253 def get_checkpoint_dir(self) -> Path:
254 """Retrieve the checkpoint directory"""
255 return Path(self.get_base_dir() / self.trainer.relative_model_dir)
256
257 def print_to_terminal(self) -> None:
258 """Helper to pretty print config to terminal"""
259 CONSOLE.rule("Config")
260 CONSOLE.print(self)
261 CONSOLE.rule("")
262
263 def save_config(self) -> None:
264 """Save config to base directory"""
265 base_dir = self.get_base_dir()
266 assert base_dir is not None
267 base_dir.mkdir(parents=True, exist_ok=True)
268 config_yaml_path = base_dir / "config.yml"
269 CONSOLE.log(f"Saving config to: {config_yaml_path}")
270 config_yaml_path.write_text(yaml.dump(self), "utf8")
271
[end of nerfstudio/configs/base_config.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/nerfstudio/configs/base_config.py b/nerfstudio/configs/base_config.py
--- a/nerfstudio/configs/base_config.py
+++ b/nerfstudio/configs/base_config.py
@@ -241,7 +241,7 @@
def set_experiment_name(self) -> None:
"""Dynamically set the experiment name"""
if self.experiment_name is None:
- self.experiment_name = str(self.pipeline.datamanager.dataparser.data).replace("/", "-")
+ self.experiment_name = str(self.pipeline.datamanager.dataparser.data).replace("../", "").replace("/", "-")
def get_base_dir(self) -> Path:
"""Retrieve the base directory to set relative paths"""
|
{"golden_diff": "diff --git a/nerfstudio/configs/base_config.py b/nerfstudio/configs/base_config.py\n--- a/nerfstudio/configs/base_config.py\n+++ b/nerfstudio/configs/base_config.py\n@@ -241,7 +241,7 @@\n def set_experiment_name(self) -> None:\n \"\"\"Dynamically set the experiment name\"\"\"\n if self.experiment_name is None:\n- self.experiment_name = str(self.pipeline.datamanager.dataparser.data).replace(\"/\", \"-\")\n+ self.experiment_name = str(self.pipeline.datamanager.dataparser.data).replace(\"../\", \"\").replace(\"/\", \"-\")\n \n def get_base_dir(self) -> Path:\n \"\"\"Retrieve the base directory to set relative paths\"\"\"\n", "issue": "Relative data paths result in hidden output directories\nRunning `ns-train` with a relative path to the data results in an output directory that is hidden because the experiment name includes components of the relative path. For example, running: `ns-train nerfacto --data ../nerf_datasets/tum_fr1desk` results in an output directory `outputs/..-nerf_datasets-tum-fr1desk`.\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Run `ns-train nerfacto --data ../[path to data]`\r\n\r\n**Expected behavior**\r\nThe expected behavior should probably be to remove any `\"../\"` from the data path when generating the experiment name.\r\n\n", "before_files": [{"content": "# Copyright 2022 The Nerfstudio Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Base Configs\"\"\"\n\n# pylint: disable=wrong-import-position\n\nfrom __future__ import annotations\n\nfrom dataclasses import dataclass\nfrom datetime import datetime\nfrom pathlib import Path\nfrom typing import Any, Dict, List, Optional, Tuple, Type\n\nimport yaml\nfrom rich.console import Console\nfrom typing_extensions import Literal\n\nfrom nerfstudio.configs.config_utils import to_immutable_dict\n\n# model instances\nfrom nerfstudio.utils import writer\n\nCONSOLE = Console(width=120)\n\n# Pretty printing class\nclass PrintableConfig: # pylint: disable=too-few-public-methods\n \"\"\"Printable Config defining str function\"\"\"\n\n def __str__(self):\n lines = [self.__class__.__name__ + \":\"]\n for key, val in vars(self).items():\n if isinstance(val, Tuple):\n flattened_val = \"[\"\n for item in val:\n flattened_val += str(item) + \"\\n\"\n flattened_val = flattened_val.rstrip(\"\\n\")\n val = flattened_val + \"]\"\n lines += f\"{key}: {str(val)}\".split(\"\\n\")\n return \"\\n \".join(lines)\n\n\n# Base instantiate configs\n@dataclass\nclass InstantiateConfig(PrintableConfig): # pylint: disable=too-few-public-methods\n \"\"\"Config class for instantiating an the class specified in the _target attribute.\"\"\"\n\n _target: Type\n\n def setup(self, **kwargs) -> Any:\n \"\"\"Returns the instantiated object using the config.\"\"\"\n return self._target(self, **kwargs)\n\n\n# Machine related configs\n@dataclass\nclass MachineConfig(PrintableConfig):\n \"\"\"Configuration of machine setup\"\"\"\n\n seed: int = 42\n \"\"\"random seed initilization\"\"\"\n num_gpus: int = 1\n \"\"\"total number of gpus available for train/eval\"\"\"\n num_machines: int = 1\n \"\"\"total number of distributed machines available (for DDP)\"\"\"\n machine_rank: int = 0\n \"\"\"current machine's rank (for DDP)\"\"\"\n dist_url: str = \"auto\"\n \"\"\"distributed connection point (for DDP)\"\"\"\n\n\n@dataclass\nclass LocalWriterConfig(InstantiateConfig):\n \"\"\"Local Writer config\"\"\"\n\n _target: Type = writer.LocalWriter\n \"\"\"target class to instantiate\"\"\"\n enable: bool = False\n \"\"\"if True enables local logging, else disables\"\"\"\n stats_to_track: Tuple[writer.EventName, ...] = (\n writer.EventName.ITER_TRAIN_TIME,\n writer.EventName.TRAIN_RAYS_PER_SEC,\n writer.EventName.CURR_TEST_PSNR,\n writer.EventName.VIS_RAYS_PER_SEC,\n writer.EventName.TEST_RAYS_PER_SEC,\n )\n \"\"\"specifies which stats will be logged/printed to terminal\"\"\"\n max_log_size: int = 10\n \"\"\"maximum number of rows to print before wrapping. if 0, will print everything.\"\"\"\n\n def setup(self, banner_messages: Optional[List[str]] = None, **kwargs) -> Any:\n \"\"\"Instantiate local writer\n\n Args:\n banner_messages: List of strings that always print at the bottom of screen.\n \"\"\"\n return self._target(self, banner_messages=banner_messages, **kwargs)\n\n\n@dataclass\nclass LoggingConfig(PrintableConfig):\n \"\"\"Configuration of loggers and profilers\"\"\"\n\n relative_log_dir: Path = Path(\"./\")\n \"\"\"relative path to save all logged events\"\"\"\n steps_per_log: int = 10\n \"\"\"number of steps between logging stats\"\"\"\n max_buffer_size: int = 20\n \"\"\"maximum history size to keep for computing running averages of stats.\n e.g. if 20, averages will be computed over past 20 occurances.\"\"\"\n local_writer: LocalWriterConfig = LocalWriterConfig(enable=True)\n \"\"\"if provided, will print stats locally. if None, will disable printing\"\"\"\n enable_profiler: bool = True\n \"\"\"whether to enable profiling code; prints speed of functions at the end of a program.\n profiler logs run times of functions and prints at end of training\"\"\"\n\n\n# Trainer related configs\n@dataclass\nclass TrainerConfig(PrintableConfig):\n \"\"\"Configuration for training regimen\"\"\"\n\n steps_per_save: int = 1000\n \"\"\"Number of steps between saves.\"\"\"\n steps_per_eval_batch: int = 500\n \"\"\"Number of steps between randomly sampled batches of rays.\"\"\"\n steps_per_eval_image: int = 500\n \"\"\"Number of steps between single eval images.\"\"\"\n steps_per_eval_all_images: int = 25000\n \"\"\"Number of steps between eval all images.\"\"\"\n max_num_iterations: int = 1000000\n \"\"\"Maximum number of iterations to run.\"\"\"\n mixed_precision: bool = False\n \"\"\"Whether or not to use mixed precision for training.\"\"\"\n relative_model_dir: Path = Path(\"nerfstudio_models/\")\n \"\"\"Relative path to save all checkpoints.\"\"\"\n save_only_latest_checkpoint: bool = True\n \"\"\"Whether to only save the latest checkpoint or all checkpoints.\"\"\"\n # optional parameters if we want to resume training\n load_dir: Optional[Path] = None\n \"\"\"Optionally specify a pre-trained model directory to load from.\"\"\"\n load_step: Optional[int] = None\n \"\"\"Optionally specify model step to load from; if none, will find most recent model in load_dir.\"\"\"\n load_config: Optional[Path] = None\n\n\n# Viewer related configs\n@dataclass\nclass ViewerConfig(PrintableConfig):\n \"\"\"Configuration for viewer instantiation\"\"\"\n\n relative_log_filename: str = \"viewer_log_filename.txt\"\n \"\"\"Filename to use for the log file.\"\"\"\n start_train: bool = True\n \"\"\"whether to immediately start training upon loading viewer\n if False, will just visualize dataset but you can toggle training in viewer\"\"\"\n zmq_port: Optional[int] = None\n \"\"\"The zmq port to connect to for communication. If None, find an available port.\"\"\"\n launch_bridge_server: bool = True\n \"\"\"whether or not to launch the bridge server\"\"\"\n websocket_port: Optional[int] = 7007\n \"\"\"the default websocket port to connect to\"\"\"\n ip_address: str = \"127.0.0.1\"\n \"\"\"the ip address where the bridge server is running\"\"\"\n num_rays_per_chunk: int = 32768\n \"\"\"number of rays per chunk to render with viewer\"\"\"\n max_num_display_images: int = 512\n \"\"\"Maximum number of training images to display in the viewer, to avoid lag. This does not change which images are\n actually used in training/evaluation. If -1, display all.\"\"\"\n\n\nfrom nerfstudio.engine.optimizers import OptimizerConfig\nfrom nerfstudio.engine.schedulers import SchedulerConfig\nfrom nerfstudio.pipelines.base_pipeline import VanillaPipelineConfig\n\n\n@dataclass\nclass Config(PrintableConfig):\n \"\"\"Full config contents\"\"\"\n\n output_dir: Path = Path(\"outputs\")\n \"\"\"relative or absolute output directory to save all checkpoints and logging\"\"\"\n method_name: Optional[str] = None\n \"\"\"Method name. Required to set in python or via cli\"\"\"\n experiment_name: Optional[str] = None\n \"\"\"Experiment name. If None, will automatically be set to dataset name\"\"\"\n timestamp: str = \"{timestamp}\"\n \"\"\"Experiment timestamp.\"\"\"\n machine: MachineConfig = MachineConfig()\n \"\"\"Machine configuration\"\"\"\n logging: LoggingConfig = LoggingConfig()\n \"\"\"Logging configuration\"\"\"\n viewer: ViewerConfig = ViewerConfig()\n \"\"\"Viewer configuration\"\"\"\n trainer: TrainerConfig = TrainerConfig()\n \"\"\"Trainer configuration\"\"\"\n pipeline: VanillaPipelineConfig = VanillaPipelineConfig()\n \"\"\"Pipeline configuration\"\"\"\n optimizers: Dict[str, Any] = to_immutable_dict(\n {\n \"fields\": {\n \"optimizer\": OptimizerConfig(),\n \"scheduler\": SchedulerConfig(),\n }\n }\n )\n \"\"\"Dictionary of optimizer groups and their schedulers\"\"\"\n vis: Literal[\"viewer\", \"wandb\", \"tensorboard\"] = \"wandb\"\n \"\"\"Which visualizer to use.\"\"\"\n data: Optional[Path] = None\n \"\"\"Alias for --pipeline.datamanager.dataparser.data\"\"\"\n\n def is_viewer_enabled(self) -> bool:\n \"\"\"Checks if a viewer is enabled.\"\"\"\n return \"viewer\" == self.vis\n\n def is_wandb_enabled(self) -> bool:\n \"\"\"Checks if wandb is enabled.\"\"\"\n return \"wandb\" == self.vis\n\n def is_tensorboard_enabled(self) -> bool:\n \"\"\"Checks if tensorboard is enabled.\"\"\"\n return \"tensorboard\" == self.vis\n\n def set_timestamp(self) -> None:\n \"\"\"Dynamically set the experiment timestamp\"\"\"\n if self.timestamp == \"{timestamp}\":\n self.timestamp = datetime.now().strftime(\"%Y-%m-%d_%H%M%S\")\n\n def set_experiment_name(self) -> None:\n \"\"\"Dynamically set the experiment name\"\"\"\n if self.experiment_name is None:\n self.experiment_name = str(self.pipeline.datamanager.dataparser.data).replace(\"/\", \"-\")\n\n def get_base_dir(self) -> Path:\n \"\"\"Retrieve the base directory to set relative paths\"\"\"\n # check the experiment and method names\n assert self.method_name is not None, \"Please set method name in config or via the cli\"\n self.set_experiment_name()\n return Path(f\"{self.output_dir}/{self.experiment_name}/{self.method_name}/{self.timestamp}\")\n\n def get_checkpoint_dir(self) -> Path:\n \"\"\"Retrieve the checkpoint directory\"\"\"\n return Path(self.get_base_dir() / self.trainer.relative_model_dir)\n\n def print_to_terminal(self) -> None:\n \"\"\"Helper to pretty print config to terminal\"\"\"\n CONSOLE.rule(\"Config\")\n CONSOLE.print(self)\n CONSOLE.rule(\"\")\n\n def save_config(self) -> None:\n \"\"\"Save config to base directory\"\"\"\n base_dir = self.get_base_dir()\n assert base_dir is not None\n base_dir.mkdir(parents=True, exist_ok=True)\n config_yaml_path = base_dir / \"config.yml\"\n CONSOLE.log(f\"Saving config to: {config_yaml_path}\")\n config_yaml_path.write_text(yaml.dump(self), \"utf8\")\n", "path": "nerfstudio/configs/base_config.py"}]}
| 3,726 | 161 |
gh_patches_debug_17372
|
rasdani/github-patches
|
git_diff
|
sublimelsp__LSP-1142
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Provide a context key to check if LSP has a specific capability
<del>
Possible use case of the context key is to define custom keybind for go to definitions.
With the context key, it allows me to bind `super+alt+down` to both `goto_definition` and `lsp_symbol_definition`.
```js
{
// this is the default key for `goto_definition`
"keys": ["super+alt+down"], "command": "goto_definition"
},
{
"keys": ["super+alt+down"], "command": "lsp_symbol_definition" ,
"context": [
{ "key": "lsp.is.active", "operator": "equal", "operand": true }
]
}
```
</del>
Update: @rwols pointed out that there is `lsp_active` to check, so this issue is now requesting a key for checking more specific capability.
</issue>
<code>
[start of plugin/core/documents.py]
1 from .registry import get_position
2 from .registry import LSPViewEventListener
3 from .session_view import SessionView
4 from .sessions import Session
5 from .typing import Any, Callable, Optional, Dict, Generator, Iterable
6 from .windows import AbstractViewListener
7 import sublime
8 import threading
9
10
11 SUBLIME_WORD_MASK = 515
12
13
14 def is_at_word(view: sublime.View, event: Optional[dict]) -> bool:
15 pos = get_position(view, event)
16 return position_is_word(view, pos)
17
18
19 def position_is_word(view: sublime.View, position: int) -> bool:
20 point_classification = view.classify(position)
21 if point_classification & SUBLIME_WORD_MASK:
22 return True
23 else:
24 return False
25
26
27 def is_transient_view(view: sublime.View) -> bool:
28 window = view.window()
29 if window:
30 if window.get_view_index(view)[1] == -1:
31 return True # Quick panel transient views
32 return view == window.transient_view_in_group(window.active_group())
33 else:
34 return True
35
36
37 def _clear_async(lock: threading.Lock, session_views: Dict[str, SessionView]) -> Callable[[], None]:
38
39 def run() -> None:
40 with lock:
41 session_views.clear()
42
43 return run
44
45
46 class DocumentSyncListener(LSPViewEventListener, AbstractViewListener):
47
48 @classmethod
49 def applies_to_primary_view_only(cls) -> bool:
50 return False
51
52 def __init__(self, view: sublime.View) -> None:
53 super().__init__(view)
54 self._file_name = ''
55 self._session_views = {} # type: Dict[str, SessionView]
56 self._session_views_lock = threading.Lock()
57
58 def __del__(self) -> None:
59 self._clear_async()
60
61 def _clear_async(self) -> None:
62 sublime.set_timeout_async(_clear_async(self._session_views_lock, self._session_views))
63
64 def on_session_initialized_async(self, session: Session) -> None:
65 assert not self.view.is_loading()
66 with self._session_views_lock:
67 if session.config.name not in self._session_views:
68 self._session_views[session.config.name] = SessionView(self, session)
69 self.view.settings().set("lsp_active", True)
70
71 def on_session_shutdown_async(self, session: Session) -> None:
72 with self._session_views_lock:
73 self._session_views.pop(session.config.name, None)
74 if not self._session_views:
75 self.view.settings().erase("lsp_active")
76
77 def session_views(self) -> Generator[SessionView, None, None]:
78 yield from self._session_views.values()
79
80 def _register_async(self) -> None:
81 file_name = self.view.file_name()
82 if file_name:
83 self._file_name = file_name
84 self.manager.register_listener_async(self)
85
86 def _is_regular_view(self) -> bool:
87 v = self.view
88 # Not from the quick panel (CTRL+P), must have a filename on-disk, and not a special view like a console,
89 # output panel or find-in-files panels.
90 return not is_transient_view(v) and bool(v.file_name()) and v.element() is None
91
92 def on_load_async(self) -> None:
93 if self._is_regular_view():
94 self._register_async()
95
96 def on_activated_async(self) -> None:
97 if self._is_regular_view() and not self.view.is_loading():
98 self._register_async()
99
100 def purge_changes(self) -> None:
101 with self._session_views_lock:
102 for sv in self.session_views():
103 sv.purge_changes()
104
105 def on_text_changed(self, changes: Iterable[sublime.TextChange]) -> None:
106 if self.view.is_primary():
107 with self._session_views_lock:
108 for sv in self.session_views():
109 sv.on_text_changed(changes)
110
111 def on_pre_save(self) -> None:
112 with self._session_views_lock:
113 for sv in self.session_views():
114 sv.on_pre_save()
115
116 def on_post_save(self) -> None:
117 if self.view.file_name() != self._file_name:
118 self._file_name = ''
119 self._clear_async()
120 sublime.set_timeout_async(self._register_async)
121 return
122 with self._session_views_lock:
123 for sv in self.session_views():
124 sv.on_post_save()
125
126 def on_close(self) -> None:
127 self._clear_async()
128
129 def on_query_context(self, key: str, operator: str, operand: Any, match_all: bool) -> bool:
130 capability_prefix = "lsp.capabilities."
131 if key.startswith(capability_prefix):
132 return isinstance(self.view.settings().get(key[len(capability_prefix):]), dict)
133 elif key in ("lsp.sessions", "setting.lsp_active"):
134 return bool(self._session_views)
135 else:
136 return False
137
138 def __str__(self) -> str:
139 return str(self.view.id())
140
[end of plugin/core/documents.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/plugin/core/documents.py b/plugin/core/documents.py
--- a/plugin/core/documents.py
+++ b/plugin/core/documents.py
@@ -126,10 +126,14 @@
def on_close(self) -> None:
self._clear_async()
- def on_query_context(self, key: str, operator: str, operand: Any, match_all: bool) -> bool:
- capability_prefix = "lsp.capabilities."
- if key.startswith(capability_prefix):
- return isinstance(self.view.settings().get(key[len(capability_prefix):]), dict)
+ def on_query_context(self, key: str, operator: int, operand: Any, match_all: bool) -> bool:
+ if key == "lsp.session_with_capability" and operator == sublime.OP_EQUAL and isinstance(operand, str):
+ capabilities = [s.strip() for s in operand.split("|")]
+ get = self.view.settings().get
+ for capability in capabilities:
+ if isinstance(get(capability), dict):
+ return True
+ return False
elif key in ("lsp.sessions", "setting.lsp_active"):
return bool(self._session_views)
else:
|
{"golden_diff": "diff --git a/plugin/core/documents.py b/plugin/core/documents.py\n--- a/plugin/core/documents.py\n+++ b/plugin/core/documents.py\n@@ -126,10 +126,14 @@\n def on_close(self) -> None:\n self._clear_async()\n \n- def on_query_context(self, key: str, operator: str, operand: Any, match_all: bool) -> bool:\n- capability_prefix = \"lsp.capabilities.\"\n- if key.startswith(capability_prefix):\n- return isinstance(self.view.settings().get(key[len(capability_prefix):]), dict)\n+ def on_query_context(self, key: str, operator: int, operand: Any, match_all: bool) -> bool:\n+ if key == \"lsp.session_with_capability\" and operator == sublime.OP_EQUAL and isinstance(operand, str):\n+ capabilities = [s.strip() for s in operand.split(\"|\")]\n+ get = self.view.settings().get\n+ for capability in capabilities:\n+ if isinstance(get(capability), dict):\n+ return True\n+ return False\n elif key in (\"lsp.sessions\", \"setting.lsp_active\"):\n return bool(self._session_views)\n else:\n", "issue": "Provide a context key to check if LSP has a specific capability\n<del>\r\nPossible use case of the context key is to define custom keybind for go to definitions.\r\nWith the context key, it allows me to bind `super+alt+down` to both `goto_definition` and `lsp_symbol_definition`.\r\n\r\n\r\n```js\r\n{ \r\n // this is the default key for `goto_definition`\r\n \"keys\": [\"super+alt+down\"], \"command\": \"goto_definition\" \r\n},\r\n{ \r\n \"keys\": [\"super+alt+down\"], \"command\": \"lsp_symbol_definition\" ,\r\n \"context\": [\r\n\t\t\t{ \"key\": \"lsp.is.active\", \"operator\": \"equal\", \"operand\": true }\r\n\t\t]\r\n}\r\n```\r\n</del>\r\n\r\n\r\nUpdate: @rwols pointed out that there is `lsp_active` to check, so this issue is now requesting a key for checking more specific capability.\n", "before_files": [{"content": "from .registry import get_position\nfrom .registry import LSPViewEventListener\nfrom .session_view import SessionView\nfrom .sessions import Session\nfrom .typing import Any, Callable, Optional, Dict, Generator, Iterable\nfrom .windows import AbstractViewListener\nimport sublime\nimport threading\n\n\nSUBLIME_WORD_MASK = 515\n\n\ndef is_at_word(view: sublime.View, event: Optional[dict]) -> bool:\n pos = get_position(view, event)\n return position_is_word(view, pos)\n\n\ndef position_is_word(view: sublime.View, position: int) -> bool:\n point_classification = view.classify(position)\n if point_classification & SUBLIME_WORD_MASK:\n return True\n else:\n return False\n\n\ndef is_transient_view(view: sublime.View) -> bool:\n window = view.window()\n if window:\n if window.get_view_index(view)[1] == -1:\n return True # Quick panel transient views\n return view == window.transient_view_in_group(window.active_group())\n else:\n return True\n\n\ndef _clear_async(lock: threading.Lock, session_views: Dict[str, SessionView]) -> Callable[[], None]:\n\n def run() -> None:\n with lock:\n session_views.clear()\n\n return run\n\n\nclass DocumentSyncListener(LSPViewEventListener, AbstractViewListener):\n\n @classmethod\n def applies_to_primary_view_only(cls) -> bool:\n return False\n\n def __init__(self, view: sublime.View) -> None:\n super().__init__(view)\n self._file_name = ''\n self._session_views = {} # type: Dict[str, SessionView]\n self._session_views_lock = threading.Lock()\n\n def __del__(self) -> None:\n self._clear_async()\n\n def _clear_async(self) -> None:\n sublime.set_timeout_async(_clear_async(self._session_views_lock, self._session_views))\n\n def on_session_initialized_async(self, session: Session) -> None:\n assert not self.view.is_loading()\n with self._session_views_lock:\n if session.config.name not in self._session_views:\n self._session_views[session.config.name] = SessionView(self, session)\n self.view.settings().set(\"lsp_active\", True)\n\n def on_session_shutdown_async(self, session: Session) -> None:\n with self._session_views_lock:\n self._session_views.pop(session.config.name, None)\n if not self._session_views:\n self.view.settings().erase(\"lsp_active\")\n\n def session_views(self) -> Generator[SessionView, None, None]:\n yield from self._session_views.values()\n\n def _register_async(self) -> None:\n file_name = self.view.file_name()\n if file_name:\n self._file_name = file_name\n self.manager.register_listener_async(self)\n\n def _is_regular_view(self) -> bool:\n v = self.view\n # Not from the quick panel (CTRL+P), must have a filename on-disk, and not a special view like a console,\n # output panel or find-in-files panels.\n return not is_transient_view(v) and bool(v.file_name()) and v.element() is None\n\n def on_load_async(self) -> None:\n if self._is_regular_view():\n self._register_async()\n\n def on_activated_async(self) -> None:\n if self._is_regular_view() and not self.view.is_loading():\n self._register_async()\n\n def purge_changes(self) -> None:\n with self._session_views_lock:\n for sv in self.session_views():\n sv.purge_changes()\n\n def on_text_changed(self, changes: Iterable[sublime.TextChange]) -> None:\n if self.view.is_primary():\n with self._session_views_lock:\n for sv in self.session_views():\n sv.on_text_changed(changes)\n\n def on_pre_save(self) -> None:\n with self._session_views_lock:\n for sv in self.session_views():\n sv.on_pre_save()\n\n def on_post_save(self) -> None:\n if self.view.file_name() != self._file_name:\n self._file_name = ''\n self._clear_async()\n sublime.set_timeout_async(self._register_async)\n return\n with self._session_views_lock:\n for sv in self.session_views():\n sv.on_post_save()\n\n def on_close(self) -> None:\n self._clear_async()\n\n def on_query_context(self, key: str, operator: str, operand: Any, match_all: bool) -> bool:\n capability_prefix = \"lsp.capabilities.\"\n if key.startswith(capability_prefix):\n return isinstance(self.view.settings().get(key[len(capability_prefix):]), dict)\n elif key in (\"lsp.sessions\", \"setting.lsp_active\"):\n return bool(self._session_views)\n else:\n return False\n\n def __str__(self) -> str:\n return str(self.view.id())\n", "path": "plugin/core/documents.py"}]}
| 2,103 | 257 |
gh_patches_debug_11234
|
rasdani/github-patches
|
git_diff
|
Mailu__Mailu-1184
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Mailu 1.7 : Issue when moving mail to the Junk folder
When I move a mail to the Junk Folder, i see the following in the logs:
imap_1 | Sep 22 16:51:26 imap: Error: cannot stat file mailu
imap_1 | Sep 22 16:51:26 imap: Error: cannot stat file mailu
imap_1 | Sep 22 16:51:26 imap: Error: tee: /dev/fd/63: I/O error
imap_1 | Sep 22 16:51:26 imap([email protected])<27629><hn93GCeTsresEgAC>: Info: program exec:/conf/bin/spam (27655): Terminated with non-zero exit code 1
imap_1 | Sep 22 16:51:26 imap([email protected])<27629><hn93GCeTsresEgAC>: Info: sieve: left message in mailbox 'Junk'
</issue>
<code>
[start of core/dovecot/start.py]
1 #!/usr/bin/python3
2
3 import os
4 import glob
5 import multiprocessing
6 import logging as log
7 import sys
8
9 from podop import run_server
10 from socrate import system, conf
11
12 log.basicConfig(stream=sys.stderr, level=os.environ.get("LOG_LEVEL", "WARNING"))
13
14 def start_podop():
15 os.setuid(8)
16 url = "http://" + os.environ["ADMIN_ADDRESS"] + "/internal/dovecot/§"
17 run_server(0, "dovecot", "/tmp/podop.socket", [
18 ("quota", "url", url ),
19 ("auth", "url", url),
20 ("sieve", "url", url),
21 ])
22
23 # Actual startup script
24 os.environ["FRONT_ADDRESS"] = system.resolve_address(os.environ.get("HOST_FRONT", "front"))
25 os.environ["REDIS_ADDRESS"] = system.resolve_address(os.environ.get("HOST_REDIS", "redis"))
26 os.environ["ADMIN_ADDRESS"] = system.resolve_address(os.environ.get("HOST_ADMIN", "admin"))
27 os.environ["ANTISPAM_ADDRESS"] = system.resolve_address(os.environ.get("HOST_ANTISPAM", "antispam:11334"))
28 if os.environ["WEBMAIL"] != "none":
29 os.environ["WEBMAIL_ADDRESS"] = system.resolve_address(os.environ.get("HOST_WEBMAIL", "webmail"))
30
31 for dovecot_file in glob.glob("/conf/*.conf"):
32 conf.jinja(dovecot_file, os.environ, os.path.join("/etc/dovecot", os.path.basename(dovecot_file)))
33
34 # Run Podop, then postfix
35 multiprocessing.Process(target=start_podop).start()
36 os.system("chown mail:mail /mail")
37 os.system("chown -R mail:mail /var/lib/dovecot /conf")
38 os.execv("/usr/sbin/dovecot", ["dovecot", "-c", "/etc/dovecot/dovecot.conf", "-F"])
39
[end of core/dovecot/start.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/core/dovecot/start.py b/core/dovecot/start.py
--- a/core/dovecot/start.py
+++ b/core/dovecot/start.py
@@ -31,6 +31,12 @@
for dovecot_file in glob.glob("/conf/*.conf"):
conf.jinja(dovecot_file, os.environ, os.path.join("/etc/dovecot", os.path.basename(dovecot_file)))
+os.makedirs("/conf/bin", exist_ok=True)
+for script_file in glob.glob("/conf/*.script"):
+ out_file = os.path.join("/conf/bin/", os.path.basename(script_file).replace('.script',''))
+ conf.jinja(script_file, os.environ, out_file)
+ os.chmod(out_file, 0o555)
+
# Run Podop, then postfix
multiprocessing.Process(target=start_podop).start()
os.system("chown mail:mail /mail")
|
{"golden_diff": "diff --git a/core/dovecot/start.py b/core/dovecot/start.py\n--- a/core/dovecot/start.py\n+++ b/core/dovecot/start.py\n@@ -31,6 +31,12 @@\n for dovecot_file in glob.glob(\"/conf/*.conf\"):\n conf.jinja(dovecot_file, os.environ, os.path.join(\"/etc/dovecot\", os.path.basename(dovecot_file)))\n \n+os.makedirs(\"/conf/bin\", exist_ok=True)\n+for script_file in glob.glob(\"/conf/*.script\"):\n+ out_file = os.path.join(\"/conf/bin/\", os.path.basename(script_file).replace('.script',''))\n+ conf.jinja(script_file, os.environ, out_file)\n+ os.chmod(out_file, 0o555)\n+\n # Run Podop, then postfix\n multiprocessing.Process(target=start_podop).start()\n os.system(\"chown mail:mail /mail\")\n", "issue": "Mailu 1.7 : Issue when moving mail to the Junk folder\nWhen I move a mail to the Junk Folder, i see the following in the logs:\r\nimap_1 | Sep 22 16:51:26 imap: Error: cannot stat file mailu\r\nimap_1 | Sep 22 16:51:26 imap: Error: cannot stat file mailu\r\nimap_1 | Sep 22 16:51:26 imap: Error: tee: /dev/fd/63: I/O error\r\nimap_1 | Sep 22 16:51:26 imap([email protected])<27629><hn93GCeTsresEgAC>: Info: program exec:/conf/bin/spam (27655): Terminated with non-zero exit code 1\r\nimap_1 | Sep 22 16:51:26 imap([email protected])<27629><hn93GCeTsresEgAC>: Info: sieve: left message in mailbox 'Junk'\n", "before_files": [{"content": "#!/usr/bin/python3\n\nimport os\nimport glob\nimport multiprocessing\nimport logging as log\nimport sys\n\nfrom podop import run_server\nfrom socrate import system, conf\n\nlog.basicConfig(stream=sys.stderr, level=os.environ.get(\"LOG_LEVEL\", \"WARNING\"))\n\ndef start_podop():\n os.setuid(8)\n url = \"http://\" + os.environ[\"ADMIN_ADDRESS\"] + \"/internal/dovecot/\u00a7\"\n run_server(0, \"dovecot\", \"/tmp/podop.socket\", [\n\t\t(\"quota\", \"url\", url ),\n\t\t(\"auth\", \"url\", url),\n\t\t(\"sieve\", \"url\", url),\n ])\n\n# Actual startup script\nos.environ[\"FRONT_ADDRESS\"] = system.resolve_address(os.environ.get(\"HOST_FRONT\", \"front\"))\nos.environ[\"REDIS_ADDRESS\"] = system.resolve_address(os.environ.get(\"HOST_REDIS\", \"redis\"))\nos.environ[\"ADMIN_ADDRESS\"] = system.resolve_address(os.environ.get(\"HOST_ADMIN\", \"admin\"))\nos.environ[\"ANTISPAM_ADDRESS\"] = system.resolve_address(os.environ.get(\"HOST_ANTISPAM\", \"antispam:11334\"))\nif os.environ[\"WEBMAIL\"] != \"none\":\n os.environ[\"WEBMAIL_ADDRESS\"] = system.resolve_address(os.environ.get(\"HOST_WEBMAIL\", \"webmail\"))\n\nfor dovecot_file in glob.glob(\"/conf/*.conf\"):\n conf.jinja(dovecot_file, os.environ, os.path.join(\"/etc/dovecot\", os.path.basename(dovecot_file)))\n\n# Run Podop, then postfix\nmultiprocessing.Process(target=start_podop).start()\nos.system(\"chown mail:mail /mail\")\nos.system(\"chown -R mail:mail /var/lib/dovecot /conf\")\nos.execv(\"/usr/sbin/dovecot\", [\"dovecot\", \"-c\", \"/etc/dovecot/dovecot.conf\", \"-F\"])\n", "path": "core/dovecot/start.py"}]}
| 1,259 | 196 |
gh_patches_debug_33370
|
rasdani/github-patches
|
git_diff
|
pytorch__ignite-2034
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add args/kwargs to `BaseLogger.attach` method
## 🚀 Feature
Following this question: https://github.com/pytorch/ignite/discussions/2031 we can easily propagate args/kwargs for custom handlers:
```diff
def attach(
- self, engine: Engine, log_handler: Callable, event_name: Union[str, Events, CallableEventWithFilter, EventsList]
+ self, engine: Engine, log_handler: Callable, event_name: Union[str, Events, CallableEventWithFilter, EventsList], *args, **kwargs
):
...
- engine.add_event_handler(event_name, log_handler, self, event_name)
+ engine.add_event_handler(event_name, log_handler, self, event_name, *args, **kwargs)
```
</issue>
<code>
[start of ignite/contrib/handlers/base_logger.py]
1 """Base logger and its helper handlers."""
2 import numbers
3 import warnings
4 from abc import ABCMeta, abstractmethod
5 from collections import OrderedDict
6 from typing import Any, Callable, Dict, List, Optional, Sequence, Union
7
8 import torch
9 import torch.nn as nn
10 from torch.optim import Optimizer
11
12 from ignite.engine import Engine, Events, EventsList, State
13 from ignite.engine.events import CallableEventWithFilter, RemovableEventHandle
14
15
16 class BaseHandler(metaclass=ABCMeta):
17 """Base handler for defining various useful handlers."""
18
19 @abstractmethod
20 def __call__(self, engine: Engine, logger: Any, event_name: Union[str, Events]) -> None:
21 pass
22
23
24 class BaseOptimizerParamsHandler(BaseHandler):
25 """
26 Base handler for logging optimizer parameters
27 """
28
29 def __init__(self, optimizer: Optimizer, param_name: str = "lr", tag: Optional[str] = None):
30 if not (
31 isinstance(optimizer, Optimizer)
32 or (hasattr(optimizer, "param_groups") and isinstance(optimizer.param_groups, Sequence))
33 ):
34 raise TypeError(
35 "Argument optimizer should be torch.optim.Optimizer or has attribute 'param_groups' as list/tuple, "
36 f"but given {type(optimizer)}"
37 )
38
39 self.optimizer = optimizer
40 self.param_name = param_name
41 self.tag = tag
42
43
44 class BaseOutputHandler(BaseHandler):
45 """
46 Helper handler to log engine's output and/or metrics
47 """
48
49 def __init__(
50 self,
51 tag: str,
52 metric_names: Optional[Union[str, List[str]]] = None,
53 output_transform: Optional[Callable] = None,
54 global_step_transform: Optional[Callable] = None,
55 ):
56
57 if metric_names is not None:
58 if not (isinstance(metric_names, list) or (isinstance(metric_names, str) and metric_names == "all")):
59 raise TypeError(
60 f"metric_names should be either a list or equal 'all', got {type(metric_names)} instead."
61 )
62
63 if output_transform is not None and not callable(output_transform):
64 raise TypeError(f"output_transform should be a function, got {type(output_transform)} instead.")
65
66 if output_transform is None and metric_names is None:
67 raise ValueError("Either metric_names or output_transform should be defined")
68
69 if global_step_transform is not None and not callable(global_step_transform):
70 raise TypeError(f"global_step_transform should be a function, got {type(global_step_transform)} instead.")
71
72 if global_step_transform is None:
73
74 def global_step_transform(engine: Engine, event_name: Union[str, Events]) -> int:
75 return engine.state.get_event_attrib_value(event_name)
76
77 self.tag = tag
78 self.metric_names = metric_names
79 self.output_transform = output_transform
80 self.global_step_transform = global_step_transform
81
82 def _setup_output_metrics(self, engine: Engine) -> Dict[str, Any]:
83 """Helper method to setup metrics to log
84 """
85 metrics = OrderedDict()
86 if self.metric_names is not None:
87 if isinstance(self.metric_names, str) and self.metric_names == "all":
88 metrics = OrderedDict(engine.state.metrics)
89 else:
90 for name in self.metric_names:
91 if name not in engine.state.metrics:
92 warnings.warn(
93 f"Provided metric name '{name}' is missing "
94 f"in engine's state metrics: {list(engine.state.metrics.keys())}"
95 )
96 continue
97 metrics[name] = engine.state.metrics[name]
98
99 if self.output_transform is not None:
100 output_dict = self.output_transform(engine.state.output)
101
102 if not isinstance(output_dict, dict):
103 output_dict = {"output": output_dict}
104
105 metrics.update({name: value for name, value in output_dict.items()})
106 return metrics
107
108
109 class BaseWeightsScalarHandler(BaseHandler):
110 """
111 Helper handler to log model's weights as scalars.
112 """
113
114 def __init__(self, model: nn.Module, reduction: Callable = torch.norm, tag: Optional[str] = None):
115 if not isinstance(model, torch.nn.Module):
116 raise TypeError(f"Argument model should be of type torch.nn.Module, but given {type(model)}")
117
118 if not callable(reduction):
119 raise TypeError(f"Argument reduction should be callable, but given {type(reduction)}")
120
121 def _is_0D_tensor(t: torch.Tensor) -> bool:
122 return isinstance(t, torch.Tensor) and t.ndimension() == 0
123
124 # Test reduction function on a tensor
125 o = reduction(torch.ones(4, 2))
126 if not (isinstance(o, numbers.Number) or _is_0D_tensor(o)):
127 raise TypeError(f"Output of the reduction function should be a scalar, but got {type(o)}")
128
129 self.model = model
130 self.reduction = reduction
131 self.tag = tag
132
133
134 class BaseWeightsHistHandler(BaseHandler):
135 """
136 Helper handler to log model's weights as histograms.
137 """
138
139 def __init__(self, model: nn.Module, tag: Optional[str] = None):
140 if not isinstance(model, torch.nn.Module):
141 raise TypeError(f"Argument model should be of type torch.nn.Module, but given {type(model)}")
142
143 self.model = model
144 self.tag = tag
145
146
147 class BaseLogger(metaclass=ABCMeta):
148 """
149 Base logger handler. See implementations: TensorboardLogger, VisdomLogger, PolyaxonLogger, MLflowLogger, ...
150
151 """
152
153 def attach(
154 self, engine: Engine, log_handler: Callable, event_name: Union[str, Events, CallableEventWithFilter, EventsList]
155 ) -> RemovableEventHandle:
156 """Attach the logger to the engine and execute `log_handler` function at `event_name` events.
157
158 Args:
159 engine: engine object.
160 log_handler: a logging handler to execute
161 event_name: event to attach the logging handler to. Valid events are from
162 :class:`~ignite.engine.events.Events` or :class:`~ignite.engine.events.EventsList` or any `event_name`
163 added by :meth:`~ignite.engine.engine.Engine.register_events`.
164
165 Returns:
166 :class:`~ignite.engine.events.RemovableEventHandle`, which can be used to remove the handler.
167 """
168 if isinstance(event_name, EventsList):
169 for name in event_name:
170 if name not in State.event_to_attr:
171 raise RuntimeError(f"Unknown event name '{name}'")
172 engine.add_event_handler(name, log_handler, self, name)
173
174 return RemovableEventHandle(event_name, log_handler, engine)
175
176 else:
177
178 if event_name not in State.event_to_attr:
179 raise RuntimeError(f"Unknown event name '{event_name}'")
180
181 return engine.add_event_handler(event_name, log_handler, self, event_name)
182
183 def attach_output_handler(self, engine: Engine, event_name: Any, *args: Any, **kwargs: Any) -> RemovableEventHandle:
184 """Shortcut method to attach `OutputHandler` to the logger.
185
186 Args:
187 engine: engine object.
188 event_name: event to attach the logging handler to. Valid events are from
189 :class:`~ignite.engine.events.Events` or any `event_name` added by
190 :meth:`~ignite.engine.engine.Engine.register_events`.
191 args: args to initialize `OutputHandler`
192 kwargs: kwargs to initialize `OutputHandler`
193
194 Returns:
195 :class:`~ignite.engine.events.RemovableEventHandle`, which can be used to remove the handler.
196 """
197 return self.attach(engine, self._create_output_handler(*args, **kwargs), event_name=event_name)
198
199 def attach_opt_params_handler(
200 self, engine: Engine, event_name: Any, *args: Any, **kwargs: Any
201 ) -> RemovableEventHandle:
202 """Shortcut method to attach `OptimizerParamsHandler` to the logger.
203
204 Args:
205 engine: engine object.
206 event_name: event to attach the logging handler to. Valid events are from
207 :class:`~ignite.engine.events.Events` or any `event_name` added by
208 :meth:`~ignite.engine.engine.Engine.register_events`.
209 args: args to initialize `OptimizerParamsHandler`
210 kwargs: kwargs to initialize `OptimizerParamsHandler`
211
212 Returns:
213 :class:`~ignite.engine.events.RemovableEventHandle`, which can be used to remove the handler.
214
215 .. versionchanged:: 0.4.3
216 Added missing return statement.
217 """
218 return self.attach(engine, self._create_opt_params_handler(*args, **kwargs), event_name=event_name)
219
220 @abstractmethod
221 def _create_output_handler(self, engine: Engine, *args: Any, **kwargs: Any) -> Callable:
222 pass
223
224 @abstractmethod
225 def _create_opt_params_handler(self, *args: Any, **kwargs: Any) -> Callable:
226 pass
227
228 def __enter__(self) -> "BaseLogger":
229 return self
230
231 def __exit__(self, type: Any, value: Any, traceback: Any) -> None:
232 self.close()
233
234 def close(self) -> None:
235 pass
236
[end of ignite/contrib/handlers/base_logger.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ignite/contrib/handlers/base_logger.py b/ignite/contrib/handlers/base_logger.py
--- a/ignite/contrib/handlers/base_logger.py
+++ b/ignite/contrib/handlers/base_logger.py
@@ -151,7 +151,12 @@
"""
def attach(
- self, engine: Engine, log_handler: Callable, event_name: Union[str, Events, CallableEventWithFilter, EventsList]
+ self,
+ engine: Engine,
+ log_handler: Callable,
+ event_name: Union[str, Events, CallableEventWithFilter, EventsList],
+ *args: Any,
+ **kwargs: Any,
) -> RemovableEventHandle:
"""Attach the logger to the engine and execute `log_handler` function at `event_name` events.
@@ -161,6 +166,8 @@
event_name: event to attach the logging handler to. Valid events are from
:class:`~ignite.engine.events.Events` or :class:`~ignite.engine.events.EventsList` or any `event_name`
added by :meth:`~ignite.engine.engine.Engine.register_events`.
+ args: args forwarded to the `log_handler` method
+ kwargs: kwargs forwarded to the `log_handler` method
Returns:
:class:`~ignite.engine.events.RemovableEventHandle`, which can be used to remove the handler.
@@ -178,7 +185,7 @@
if event_name not in State.event_to_attr:
raise RuntimeError(f"Unknown event name '{event_name}'")
- return engine.add_event_handler(event_name, log_handler, self, event_name)
+ return engine.add_event_handler(event_name, log_handler, self, event_name, *args, **kwargs)
def attach_output_handler(self, engine: Engine, event_name: Any, *args: Any, **kwargs: Any) -> RemovableEventHandle:
"""Shortcut method to attach `OutputHandler` to the logger.
|
{"golden_diff": "diff --git a/ignite/contrib/handlers/base_logger.py b/ignite/contrib/handlers/base_logger.py\n--- a/ignite/contrib/handlers/base_logger.py\n+++ b/ignite/contrib/handlers/base_logger.py\n@@ -151,7 +151,12 @@\n \"\"\"\n \n def attach(\n- self, engine: Engine, log_handler: Callable, event_name: Union[str, Events, CallableEventWithFilter, EventsList]\n+ self,\n+ engine: Engine,\n+ log_handler: Callable,\n+ event_name: Union[str, Events, CallableEventWithFilter, EventsList],\n+ *args: Any,\n+ **kwargs: Any,\n ) -> RemovableEventHandle:\n \"\"\"Attach the logger to the engine and execute `log_handler` function at `event_name` events.\n \n@@ -161,6 +166,8 @@\n event_name: event to attach the logging handler to. Valid events are from\n :class:`~ignite.engine.events.Events` or :class:`~ignite.engine.events.EventsList` or any `event_name`\n added by :meth:`~ignite.engine.engine.Engine.register_events`.\n+ args: args forwarded to the `log_handler` method\n+ kwargs: kwargs forwarded to the `log_handler` method\n \n Returns:\n :class:`~ignite.engine.events.RemovableEventHandle`, which can be used to remove the handler.\n@@ -178,7 +185,7 @@\n if event_name not in State.event_to_attr:\n raise RuntimeError(f\"Unknown event name '{event_name}'\")\n \n- return engine.add_event_handler(event_name, log_handler, self, event_name)\n+ return engine.add_event_handler(event_name, log_handler, self, event_name, *args, **kwargs)\n \n def attach_output_handler(self, engine: Engine, event_name: Any, *args: Any, **kwargs: Any) -> RemovableEventHandle:\n \"\"\"Shortcut method to attach `OutputHandler` to the logger.\n", "issue": "Add args/kwargs to `BaseLogger.attach` method\n## \ud83d\ude80 Feature\r\n\r\nFollowing this question: https://github.com/pytorch/ignite/discussions/2031 we can easily propagate args/kwargs for custom handlers:\r\n```diff\r\ndef attach(\r\n- self, engine: Engine, log_handler: Callable, event_name: Union[str, Events, CallableEventWithFilter, EventsList]\r\n+ self, engine: Engine, log_handler: Callable, event_name: Union[str, Events, CallableEventWithFilter, EventsList], *args, **kwargs\r\n):\r\n...\r\n\r\n- engine.add_event_handler(event_name, log_handler, self, event_name)\r\n+ engine.add_event_handler(event_name, log_handler, self, event_name, *args, **kwargs)\r\n```\n", "before_files": [{"content": "\"\"\"Base logger and its helper handlers.\"\"\"\nimport numbers\nimport warnings\nfrom abc import ABCMeta, abstractmethod\nfrom collections import OrderedDict\nfrom typing import Any, Callable, Dict, List, Optional, Sequence, Union\n\nimport torch\nimport torch.nn as nn\nfrom torch.optim import Optimizer\n\nfrom ignite.engine import Engine, Events, EventsList, State\nfrom ignite.engine.events import CallableEventWithFilter, RemovableEventHandle\n\n\nclass BaseHandler(metaclass=ABCMeta):\n \"\"\"Base handler for defining various useful handlers.\"\"\"\n\n @abstractmethod\n def __call__(self, engine: Engine, logger: Any, event_name: Union[str, Events]) -> None:\n pass\n\n\nclass BaseOptimizerParamsHandler(BaseHandler):\n \"\"\"\n Base handler for logging optimizer parameters\n \"\"\"\n\n def __init__(self, optimizer: Optimizer, param_name: str = \"lr\", tag: Optional[str] = None):\n if not (\n isinstance(optimizer, Optimizer)\n or (hasattr(optimizer, \"param_groups\") and isinstance(optimizer.param_groups, Sequence))\n ):\n raise TypeError(\n \"Argument optimizer should be torch.optim.Optimizer or has attribute 'param_groups' as list/tuple, \"\n f\"but given {type(optimizer)}\"\n )\n\n self.optimizer = optimizer\n self.param_name = param_name\n self.tag = tag\n\n\nclass BaseOutputHandler(BaseHandler):\n \"\"\"\n Helper handler to log engine's output and/or metrics\n \"\"\"\n\n def __init__(\n self,\n tag: str,\n metric_names: Optional[Union[str, List[str]]] = None,\n output_transform: Optional[Callable] = None,\n global_step_transform: Optional[Callable] = None,\n ):\n\n if metric_names is not None:\n if not (isinstance(metric_names, list) or (isinstance(metric_names, str) and metric_names == \"all\")):\n raise TypeError(\n f\"metric_names should be either a list or equal 'all', got {type(metric_names)} instead.\"\n )\n\n if output_transform is not None and not callable(output_transform):\n raise TypeError(f\"output_transform should be a function, got {type(output_transform)} instead.\")\n\n if output_transform is None and metric_names is None:\n raise ValueError(\"Either metric_names or output_transform should be defined\")\n\n if global_step_transform is not None and not callable(global_step_transform):\n raise TypeError(f\"global_step_transform should be a function, got {type(global_step_transform)} instead.\")\n\n if global_step_transform is None:\n\n def global_step_transform(engine: Engine, event_name: Union[str, Events]) -> int:\n return engine.state.get_event_attrib_value(event_name)\n\n self.tag = tag\n self.metric_names = metric_names\n self.output_transform = output_transform\n self.global_step_transform = global_step_transform\n\n def _setup_output_metrics(self, engine: Engine) -> Dict[str, Any]:\n \"\"\"Helper method to setup metrics to log\n \"\"\"\n metrics = OrderedDict()\n if self.metric_names is not None:\n if isinstance(self.metric_names, str) and self.metric_names == \"all\":\n metrics = OrderedDict(engine.state.metrics)\n else:\n for name in self.metric_names:\n if name not in engine.state.metrics:\n warnings.warn(\n f\"Provided metric name '{name}' is missing \"\n f\"in engine's state metrics: {list(engine.state.metrics.keys())}\"\n )\n continue\n metrics[name] = engine.state.metrics[name]\n\n if self.output_transform is not None:\n output_dict = self.output_transform(engine.state.output)\n\n if not isinstance(output_dict, dict):\n output_dict = {\"output\": output_dict}\n\n metrics.update({name: value for name, value in output_dict.items()})\n return metrics\n\n\nclass BaseWeightsScalarHandler(BaseHandler):\n \"\"\"\n Helper handler to log model's weights as scalars.\n \"\"\"\n\n def __init__(self, model: nn.Module, reduction: Callable = torch.norm, tag: Optional[str] = None):\n if not isinstance(model, torch.nn.Module):\n raise TypeError(f\"Argument model should be of type torch.nn.Module, but given {type(model)}\")\n\n if not callable(reduction):\n raise TypeError(f\"Argument reduction should be callable, but given {type(reduction)}\")\n\n def _is_0D_tensor(t: torch.Tensor) -> bool:\n return isinstance(t, torch.Tensor) and t.ndimension() == 0\n\n # Test reduction function on a tensor\n o = reduction(torch.ones(4, 2))\n if not (isinstance(o, numbers.Number) or _is_0D_tensor(o)):\n raise TypeError(f\"Output of the reduction function should be a scalar, but got {type(o)}\")\n\n self.model = model\n self.reduction = reduction\n self.tag = tag\n\n\nclass BaseWeightsHistHandler(BaseHandler):\n \"\"\"\n Helper handler to log model's weights as histograms.\n \"\"\"\n\n def __init__(self, model: nn.Module, tag: Optional[str] = None):\n if not isinstance(model, torch.nn.Module):\n raise TypeError(f\"Argument model should be of type torch.nn.Module, but given {type(model)}\")\n\n self.model = model\n self.tag = tag\n\n\nclass BaseLogger(metaclass=ABCMeta):\n \"\"\"\n Base logger handler. See implementations: TensorboardLogger, VisdomLogger, PolyaxonLogger, MLflowLogger, ...\n\n \"\"\"\n\n def attach(\n self, engine: Engine, log_handler: Callable, event_name: Union[str, Events, CallableEventWithFilter, EventsList]\n ) -> RemovableEventHandle:\n \"\"\"Attach the logger to the engine and execute `log_handler` function at `event_name` events.\n\n Args:\n engine: engine object.\n log_handler: a logging handler to execute\n event_name: event to attach the logging handler to. Valid events are from\n :class:`~ignite.engine.events.Events` or :class:`~ignite.engine.events.EventsList` or any `event_name`\n added by :meth:`~ignite.engine.engine.Engine.register_events`.\n\n Returns:\n :class:`~ignite.engine.events.RemovableEventHandle`, which can be used to remove the handler.\n \"\"\"\n if isinstance(event_name, EventsList):\n for name in event_name:\n if name not in State.event_to_attr:\n raise RuntimeError(f\"Unknown event name '{name}'\")\n engine.add_event_handler(name, log_handler, self, name)\n\n return RemovableEventHandle(event_name, log_handler, engine)\n\n else:\n\n if event_name not in State.event_to_attr:\n raise RuntimeError(f\"Unknown event name '{event_name}'\")\n\n return engine.add_event_handler(event_name, log_handler, self, event_name)\n\n def attach_output_handler(self, engine: Engine, event_name: Any, *args: Any, **kwargs: Any) -> RemovableEventHandle:\n \"\"\"Shortcut method to attach `OutputHandler` to the logger.\n\n Args:\n engine: engine object.\n event_name: event to attach the logging handler to. Valid events are from\n :class:`~ignite.engine.events.Events` or any `event_name` added by\n :meth:`~ignite.engine.engine.Engine.register_events`.\n args: args to initialize `OutputHandler`\n kwargs: kwargs to initialize `OutputHandler`\n\n Returns:\n :class:`~ignite.engine.events.RemovableEventHandle`, which can be used to remove the handler.\n \"\"\"\n return self.attach(engine, self._create_output_handler(*args, **kwargs), event_name=event_name)\n\n def attach_opt_params_handler(\n self, engine: Engine, event_name: Any, *args: Any, **kwargs: Any\n ) -> RemovableEventHandle:\n \"\"\"Shortcut method to attach `OptimizerParamsHandler` to the logger.\n\n Args:\n engine: engine object.\n event_name: event to attach the logging handler to. Valid events are from\n :class:`~ignite.engine.events.Events` or any `event_name` added by\n :meth:`~ignite.engine.engine.Engine.register_events`.\n args: args to initialize `OptimizerParamsHandler`\n kwargs: kwargs to initialize `OptimizerParamsHandler`\n\n Returns:\n :class:`~ignite.engine.events.RemovableEventHandle`, which can be used to remove the handler.\n\n .. versionchanged:: 0.4.3\n Added missing return statement.\n \"\"\"\n return self.attach(engine, self._create_opt_params_handler(*args, **kwargs), event_name=event_name)\n\n @abstractmethod\n def _create_output_handler(self, engine: Engine, *args: Any, **kwargs: Any) -> Callable:\n pass\n\n @abstractmethod\n def _create_opt_params_handler(self, *args: Any, **kwargs: Any) -> Callable:\n pass\n\n def __enter__(self) -> \"BaseLogger\":\n return self\n\n def __exit__(self, type: Any, value: Any, traceback: Any) -> None:\n self.close()\n\n def close(self) -> None:\n pass\n", "path": "ignite/contrib/handlers/base_logger.py"}]}
| 3,249 | 433 |
gh_patches_debug_42573
|
rasdani/github-patches
|
git_diff
|
getpelican__pelican-2035
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
flake8 PEP8 violations
With the latest upstream clone:
```
(pep8=) ~/work/omiday/pelican/pelican $ git log -1 HEAD
commit b2231c40f7ddcf01dcb301ba599b517fb23102de
Merge: 0942fcb f803120
Author: Justin Mayer <[email protected]>
Date: Fri Oct 7 12:28:10 2016 -0600
Merge pull request #2016 from jerryasher/copy_file_metadata
Python's shutil.copy2 fails on Android
```
I'm seeing:
```
(pep8=) ~/work/omiday/pelican/pelican $ flake8
./setup.py:3:1: F401 'os.path.dirname' imported but unused
./setup.py:3:1: I101 Imported names are in the wrong order. Should be dirname, join, relpath
./setup.py:34:80: E501 line too long (93 > 79 characters)
./setup.py:35:80: E501 line too long (86 > 79 characters)
./setup.py:39:80: E501 line too long (83 > 79 characters)
./setup.py:43:80: E501 line too long (95 > 79 characters)
./setup.py:50:10: E131 continuation line unaligned for hanging indent
./docs/conf.py:3:11: E401 multiple imports on one line
./docs/conf.py:9:1: E402 module level import not at top of file
./docs/conf.py:11:80: E501 line too long (80 > 79 characters)
./docs/conf.py:13:80: E501 line too long (81 > 79 characters)
./docs/conf.py:33:80: E501 line too long (80 > 79 characters)
./docs/conf.py:66:80: E501 line too long (80 > 79 characters)
./docs/conf.py:69:4: E128 continuation line under-indented for visual indent
./docs/conf.py:72:80: E501 line too long (80 > 79 characters)
```
Got the go ahead from @justinmayer on IRC so I'm gonna try fixing those.
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2 from os import walk
3 from os.path import join, relpath, dirname
4
5 from setuptools import setup
6
7 requires = ['feedgenerator >= 1.9', 'jinja2 >= 2.7', 'pygments', 'docutils',
8 'pytz >= 0a', 'blinker', 'unidecode', 'six >= 1.4',
9 'python-dateutil']
10
11 entry_points = {
12 'console_scripts': [
13 'pelican = pelican:main',
14 'pelican-import = pelican.tools.pelican_import:main',
15 'pelican-quickstart = pelican.tools.pelican_quickstart:main',
16 'pelican-themes = pelican.tools.pelican_themes:main'
17 ]
18 }
19
20 README = open('README.rst').read()
21 CHANGELOG = open('docs/changelog.rst').read()
22
23 setup(
24 name="pelican",
25 version="3.6.4.dev0",
26 url='http://getpelican.com/',
27 author='Alexis Metaireau',
28 author_email='[email protected]',
29 description="A tool to generate a static blog from reStructuredText or "
30 "Markdown input files.",
31 long_description=README + '\n' + CHANGELOG,
32 packages=['pelican', 'pelican.tools'],
33 package_data={
34 # we manually collect the package data, as opposed to using include_package_data=True
35 # because we don't want the tests to be included automatically as package data
36 # (MANIFEST.in is too greedy)
37 'pelican': [
38 relpath(join(root, name), 'pelican')
39 for root, _, names in walk(join('pelican', 'themes')) for name in names
40 ],
41 'pelican.tools': [
42 relpath(join(root, name), join('pelican', 'tools'))
43 for root, _, names in walk(join('pelican', 'tools', 'templates')) for name in names
44 ],
45 },
46 install_requires=requires,
47 entry_points=entry_points,
48 classifiers=[
49 'Development Status :: 5 - Production/Stable',
50 'Environment :: Console',
51 'License :: OSI Approved :: GNU Affero General Public License v3',
52 'Operating System :: OS Independent',
53 'Programming Language :: Python :: 2',
54 'Programming Language :: Python :: 2.7',
55 'Programming Language :: Python :: 3',
56 'Programming Language :: Python :: 3.3',
57 'Programming Language :: Python :: 3.4',
58 'Programming Language :: Python :: 3.5',
59 'Topic :: Internet :: WWW/HTTP',
60 'Topic :: Software Development :: Libraries :: Python Modules',
61 ],
62 test_suite='pelican.tests',
63 )
64
[end of setup.py]
[start of docs/conf.py]
1 # -*- coding: utf-8 -*-
2 from __future__ import unicode_literals
3 import sys, os
4
5 on_rtd = os.environ.get('READTHEDOCS', None) == 'True'
6
7 sys.path.append(os.path.abspath(os.pardir))
8
9 from pelican import __version__
10
11 # -- General configuration -----------------------------------------------------
12 templates_path = ['_templates']
13 extensions = ['sphinx.ext.autodoc', 'sphinx.ext.ifconfig', 'sphinx.ext.extlinks']
14 source_suffix = '.rst'
15 master_doc = 'index'
16 project = 'Pelican'
17 copyright = '2015, Alexis Metaireau and contributors'
18 exclude_patterns = ['_build']
19 release = __version__
20 version = '.'.join(release.split('.')[:1])
21 last_stable = '3.6.3'
22 rst_prolog = '''
23 .. |last_stable| replace:: :pelican-doc:`{0}`
24 '''.format(last_stable)
25
26 # The name of the Pygments (syntax highlighting) style to use.
27 pygments_style = 'sphinx'
28
29 extlinks = {
30 'pelican-doc': ('http://docs.getpelican.com/%s/', '')
31 }
32
33 # -- Options for HTML output ---------------------------------------------------
34
35 html_theme = 'default'
36 if not on_rtd:
37 try:
38 import sphinx_rtd_theme
39 html_theme = 'sphinx_rtd_theme'
40 html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]
41 except ImportError:
42 pass
43
44 html_static_path = ['_static']
45
46 # Output file base name for HTML help builder.
47 htmlhelp_basename = 'Pelicandoc'
48
49 html_use_smartypants = True
50
51 # If false, no module index is generated.
52 html_use_modindex = False
53
54 # If false, no index is generated.
55 html_use_index = False
56
57 # If true, links to the reST sources are added to the pages.
58 html_show_sourcelink = False
59
60
61 def setup(app):
62 # overrides for wide tables in RTD theme
63 app.add_stylesheet('theme_overrides.css') # path relative to _static
64
65
66 # -- Options for LaTeX output --------------------------------------------------
67 latex_documents = [
68 ('index', 'Pelican.tex', 'Pelican Documentation',
69 'Alexis Métaireau', 'manual'),
70 ]
71
72 # -- Options for manual page output --------------------------------------------
73 man_pages = [
74 ('index', 'pelican', 'pelican documentation',
75 ['Alexis Métaireau'], 1),
76 ('pelican-themes', 'pelican-themes', 'A theme manager for Pelican',
77 ['Mickaël Raybaud'], 1),
78 ('themes', 'pelican-theming', 'How to create themes for Pelican',
79 ['The Pelican contributors'], 1)
80 ]
81
[end of docs/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -1,16 +1,19 @@
# -*- coding: utf-8 -*-
from __future__ import unicode_literals
-import sys, os
+import os
+import sys
+
+from pelican import __version__
on_rtd = os.environ.get('READTHEDOCS', None) == 'True'
sys.path.append(os.path.abspath(os.pardir))
-from pelican import __version__
-
-# -- General configuration -----------------------------------------------------
+# -- General configuration ----------------------------------------------------
templates_path = ['_templates']
-extensions = ['sphinx.ext.autodoc', 'sphinx.ext.ifconfig', 'sphinx.ext.extlinks']
+extensions = ['sphinx.ext.autodoc',
+ 'sphinx.ext.ifconfig',
+ 'sphinx.ext.extlinks']
source_suffix = '.rst'
master_doc = 'index'
project = 'Pelican'
@@ -30,7 +33,7 @@
'pelican-doc': ('http://docs.getpelican.com/%s/', '')
}
-# -- Options for HTML output ---------------------------------------------------
+# -- Options for HTML output --------------------------------------------------
html_theme = 'default'
if not on_rtd:
@@ -63,13 +66,13 @@
app.add_stylesheet('theme_overrides.css') # path relative to _static
-# -- Options for LaTeX output --------------------------------------------------
+# -- Options for LaTeX output -------------------------------------------------
latex_documents = [
- ('index', 'Pelican.tex', 'Pelican Documentation',
- 'Alexis Métaireau', 'manual'),
+ ('index', 'Pelican.tex', 'Pelican Documentation', 'Alexis Métaireau',
+ 'manual'),
]
-# -- Options for manual page output --------------------------------------------
+# -- Options for manual page output -------------------------------------------
man_pages = [
('index', 'pelican', 'pelican documentation',
['Alexis Métaireau'], 1),
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -1,6 +1,6 @@
#!/usr/bin/env python
from os import walk
-from os.path import join, relpath, dirname
+from os.path import join, relpath
from setuptools import setup
@@ -31,22 +31,22 @@
long_description=README + '\n' + CHANGELOG,
packages=['pelican', 'pelican.tools'],
package_data={
- # we manually collect the package data, as opposed to using include_package_data=True
- # because we don't want the tests to be included automatically as package data
- # (MANIFEST.in is too greedy)
- 'pelican': [
- relpath(join(root, name), 'pelican')
- for root, _, names in walk(join('pelican', 'themes')) for name in names
- ],
- 'pelican.tools': [
- relpath(join(root, name), join('pelican', 'tools'))
- for root, _, names in walk(join('pelican', 'tools', 'templates')) for name in names
- ],
+ # we manually collect the package data, as opposed to using,
+ # include_package_data=True because we don't want the tests to be
+ # included automatically as package data (MANIFEST.in is too greedy)
+ 'pelican': [relpath(join(root, name), 'pelican')
+ for root, _, names in walk(join('pelican', 'themes'))
+ for name in names],
+ 'pelican.tools': [relpath(join(root, name), join('pelican', 'tools'))
+ for root, _, names in walk(join('pelican',
+ 'tools',
+ 'templates'))
+ for name in names],
},
install_requires=requires,
entry_points=entry_points,
classifiers=[
- 'Development Status :: 5 - Production/Stable',
+ 'Development Status :: 5 - Production/Stable',
'Environment :: Console',
'License :: OSI Approved :: GNU Affero General Public License v3',
'Operating System :: OS Independent',
|
{"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -1,16 +1,19 @@\n # -*- coding: utf-8 -*-\n from __future__ import unicode_literals\n-import sys, os\n+import os\n+import sys\n+\n+from pelican import __version__\n \n on_rtd = os.environ.get('READTHEDOCS', None) == 'True'\n \n sys.path.append(os.path.abspath(os.pardir))\n \n-from pelican import __version__\n-\n-# -- General configuration -----------------------------------------------------\n+# -- General configuration ----------------------------------------------------\n templates_path = ['_templates']\n-extensions = ['sphinx.ext.autodoc', 'sphinx.ext.ifconfig', 'sphinx.ext.extlinks']\n+extensions = ['sphinx.ext.autodoc',\n+ 'sphinx.ext.ifconfig',\n+ 'sphinx.ext.extlinks']\n source_suffix = '.rst'\n master_doc = 'index'\n project = 'Pelican'\n@@ -30,7 +33,7 @@\n 'pelican-doc': ('http://docs.getpelican.com/%s/', '')\n }\n \n-# -- Options for HTML output ---------------------------------------------------\n+# -- Options for HTML output --------------------------------------------------\n \n html_theme = 'default'\n if not on_rtd:\n@@ -63,13 +66,13 @@\n app.add_stylesheet('theme_overrides.css') # path relative to _static\n \n \n-# -- Options for LaTeX output --------------------------------------------------\n+# -- Options for LaTeX output -------------------------------------------------\n latex_documents = [\n- ('index', 'Pelican.tex', 'Pelican Documentation',\n- 'Alexis M\u00e9taireau', 'manual'),\n+ ('index', 'Pelican.tex', 'Pelican Documentation', 'Alexis M\u00e9taireau',\n+ 'manual'),\n ]\n \n-# -- Options for manual page output --------------------------------------------\n+# -- Options for manual page output -------------------------------------------\n man_pages = [\n ('index', 'pelican', 'pelican documentation',\n ['Alexis M\u00e9taireau'], 1),\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -1,6 +1,6 @@\n #!/usr/bin/env python\n from os import walk\n-from os.path import join, relpath, dirname\n+from os.path import join, relpath\n \n from setuptools import setup\n \n@@ -31,22 +31,22 @@\n long_description=README + '\\n' + CHANGELOG,\n packages=['pelican', 'pelican.tools'],\n package_data={\n- # we manually collect the package data, as opposed to using include_package_data=True\n- # because we don't want the tests to be included automatically as package data\n- # (MANIFEST.in is too greedy)\n- 'pelican': [\n- relpath(join(root, name), 'pelican')\n- for root, _, names in walk(join('pelican', 'themes')) for name in names\n- ],\n- 'pelican.tools': [\n- relpath(join(root, name), join('pelican', 'tools'))\n- for root, _, names in walk(join('pelican', 'tools', 'templates')) for name in names\n- ],\n+ # we manually collect the package data, as opposed to using,\n+ # include_package_data=True because we don't want the tests to be\n+ # included automatically as package data (MANIFEST.in is too greedy)\n+ 'pelican': [relpath(join(root, name), 'pelican')\n+ for root, _, names in walk(join('pelican', 'themes'))\n+ for name in names],\n+ 'pelican.tools': [relpath(join(root, name), join('pelican', 'tools'))\n+ for root, _, names in walk(join('pelican',\n+ 'tools',\n+ 'templates'))\n+ for name in names],\n },\n install_requires=requires,\n entry_points=entry_points,\n classifiers=[\n- 'Development Status :: 5 - Production/Stable',\n+ 'Development Status :: 5 - Production/Stable',\n 'Environment :: Console',\n 'License :: OSI Approved :: GNU Affero General Public License v3',\n 'Operating System :: OS Independent',\n", "issue": "flake8 PEP8 violations\nWith the latest upstream clone:\n\n```\n(pep8=) ~/work/omiday/pelican/pelican $ git log -1 HEAD\ncommit b2231c40f7ddcf01dcb301ba599b517fb23102de\nMerge: 0942fcb f803120\nAuthor: Justin Mayer <[email protected]>\nDate: Fri Oct 7 12:28:10 2016 -0600\n\n Merge pull request #2016 from jerryasher/copy_file_metadata\n\n Python's shutil.copy2 fails on Android\n```\n\nI'm seeing:\n\n```\n(pep8=) ~/work/omiday/pelican/pelican $ flake8\n./setup.py:3:1: F401 'os.path.dirname' imported but unused\n./setup.py:3:1: I101 Imported names are in the wrong order. Should be dirname, join, relpath\n./setup.py:34:80: E501 line too long (93 > 79 characters)\n./setup.py:35:80: E501 line too long (86 > 79 characters)\n./setup.py:39:80: E501 line too long (83 > 79 characters)\n./setup.py:43:80: E501 line too long (95 > 79 characters)\n./setup.py:50:10: E131 continuation line unaligned for hanging indent\n./docs/conf.py:3:11: E401 multiple imports on one line\n./docs/conf.py:9:1: E402 module level import not at top of file\n./docs/conf.py:11:80: E501 line too long (80 > 79 characters)\n./docs/conf.py:13:80: E501 line too long (81 > 79 characters)\n./docs/conf.py:33:80: E501 line too long (80 > 79 characters)\n./docs/conf.py:66:80: E501 line too long (80 > 79 characters)\n./docs/conf.py:69:4: E128 continuation line under-indented for visual indent\n./docs/conf.py:72:80: E501 line too long (80 > 79 characters)\n```\n\nGot the go ahead from @justinmayer on IRC so I'm gonna try fixing those. \n\n", "before_files": [{"content": "#!/usr/bin/env python\nfrom os import walk\nfrom os.path import join, relpath, dirname\n\nfrom setuptools import setup\n\nrequires = ['feedgenerator >= 1.9', 'jinja2 >= 2.7', 'pygments', 'docutils',\n 'pytz >= 0a', 'blinker', 'unidecode', 'six >= 1.4',\n 'python-dateutil']\n\nentry_points = {\n 'console_scripts': [\n 'pelican = pelican:main',\n 'pelican-import = pelican.tools.pelican_import:main',\n 'pelican-quickstart = pelican.tools.pelican_quickstart:main',\n 'pelican-themes = pelican.tools.pelican_themes:main'\n ]\n}\n\nREADME = open('README.rst').read()\nCHANGELOG = open('docs/changelog.rst').read()\n\nsetup(\n name=\"pelican\",\n version=\"3.6.4.dev0\",\n url='http://getpelican.com/',\n author='Alexis Metaireau',\n author_email='[email protected]',\n description=\"A tool to generate a static blog from reStructuredText or \"\n \"Markdown input files.\",\n long_description=README + '\\n' + CHANGELOG,\n packages=['pelican', 'pelican.tools'],\n package_data={\n # we manually collect the package data, as opposed to using include_package_data=True\n # because we don't want the tests to be included automatically as package data\n # (MANIFEST.in is too greedy)\n 'pelican': [\n relpath(join(root, name), 'pelican')\n for root, _, names in walk(join('pelican', 'themes')) for name in names\n ],\n 'pelican.tools': [\n relpath(join(root, name), join('pelican', 'tools'))\n for root, _, names in walk(join('pelican', 'tools', 'templates')) for name in names\n ],\n },\n install_requires=requires,\n entry_points=entry_points,\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Console',\n 'License :: OSI Approved :: GNU Affero General Public License v3',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Topic :: Internet :: WWW/HTTP',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n ],\n test_suite='pelican.tests',\n)\n", "path": "setup.py"}, {"content": "# -*- coding: utf-8 -*-\nfrom __future__ import unicode_literals\nimport sys, os\n\non_rtd = os.environ.get('READTHEDOCS', None) == 'True'\n\nsys.path.append(os.path.abspath(os.pardir))\n\nfrom pelican import __version__\n\n# -- General configuration -----------------------------------------------------\ntemplates_path = ['_templates']\nextensions = ['sphinx.ext.autodoc', 'sphinx.ext.ifconfig', 'sphinx.ext.extlinks']\nsource_suffix = '.rst'\nmaster_doc = 'index'\nproject = 'Pelican'\ncopyright = '2015, Alexis Metaireau and contributors'\nexclude_patterns = ['_build']\nrelease = __version__\nversion = '.'.join(release.split('.')[:1])\nlast_stable = '3.6.3'\nrst_prolog = '''\n.. |last_stable| replace:: :pelican-doc:`{0}`\n'''.format(last_stable)\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\nextlinks = {\n 'pelican-doc': ('http://docs.getpelican.com/%s/', '')\n}\n\n# -- Options for HTML output ---------------------------------------------------\n\nhtml_theme = 'default'\nif not on_rtd:\n try:\n import sphinx_rtd_theme\n html_theme = 'sphinx_rtd_theme'\n html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]\n except ImportError:\n pass\n\nhtml_static_path = ['_static']\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'Pelicandoc'\n\nhtml_use_smartypants = True\n\n# If false, no module index is generated.\nhtml_use_modindex = False\n\n# If false, no index is generated.\nhtml_use_index = False\n\n# If true, links to the reST sources are added to the pages.\nhtml_show_sourcelink = False\n\n\ndef setup(app):\n # overrides for wide tables in RTD theme\n app.add_stylesheet('theme_overrides.css') # path relative to _static\n\n\n# -- Options for LaTeX output --------------------------------------------------\nlatex_documents = [\n ('index', 'Pelican.tex', 'Pelican Documentation',\n 'Alexis M\u00e9taireau', 'manual'),\n]\n\n# -- Options for manual page output --------------------------------------------\nman_pages = [\n ('index', 'pelican', 'pelican documentation',\n ['Alexis M\u00e9taireau'], 1),\n ('pelican-themes', 'pelican-themes', 'A theme manager for Pelican',\n ['Micka\u00ebl Raybaud'], 1),\n ('themes', 'pelican-theming', 'How to create themes for Pelican',\n ['The Pelican contributors'], 1)\n]\n", "path": "docs/conf.py"}]}
| 2,574 | 901 |
gh_patches_debug_15379
|
rasdani/github-patches
|
git_diff
|
biolab__orange3-5851
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
BUG: UI annoyance - Predictions Widget measures grid squashing
This is not a classic bug, but rather big visual annoyance: Predictions Widget squashes the grid with measures every time I retrain anything that sends data to it - like NN or LR. It seems that it chooses column widths based on the header text width and ignores the text in the cells below. Once I click on the model column heading or any other column to sort it, it unsquashes it - that is, it considers cells text width as well. Can we have that not squashed every time retraining is requested? It seems that it does remember its column order although sort column does not have that triangle shown after being squashed, thus I do not know which column was used for sorting in the first place. Thank you n advance for fixing this.
[1] Sqaushed
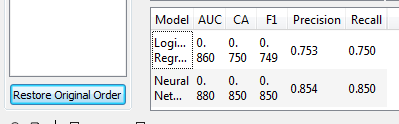
[2] Unsqaushed
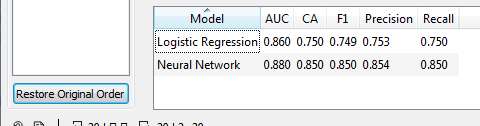
</issue>
<code>
[start of Orange/widgets/evaluate/utils.py]
1 import warnings
2 from functools import partial
3 from itertools import chain
4
5 import numpy as np
6
7 from AnyQt.QtWidgets import QHeaderView, QStyledItemDelegate, QMenu, \
8 QApplication
9 from AnyQt.QtGui import QStandardItemModel, QStandardItem, QClipboard
10 from AnyQt.QtCore import Qt, QSize, QObject, pyqtSignal as Signal, \
11 QSortFilterProxyModel
12 from sklearn.exceptions import UndefinedMetricWarning
13
14 from Orange.data import Variable, DiscreteVariable, ContinuousVariable
15 from Orange.evaluation import scoring
16 from Orange.widgets import gui
17 from Orange.widgets.utils.tableview import table_selection_to_mime_data
18 from Orange.widgets.gui import OWComponent
19 from Orange.widgets.settings import Setting
20
21
22 def check_results_adequacy(results, error_group, check_nan=True):
23 error_group.add_message("invalid_results")
24 error_group.invalid_results.clear()
25
26 def anynan(a):
27 return np.any(np.isnan(a))
28
29 if results is None:
30 return None
31 if results.data is None:
32 error_group.invalid_results(
33 "Results do not include information on test data.")
34 elif not results.data.domain.has_discrete_class:
35 error_group.invalid_results(
36 "Categorical target variable is required.")
37 elif not results.actual.size:
38 error_group.invalid_results(
39 "Empty result on input. Nothing to display.")
40 elif check_nan and (anynan(results.actual) or
41 anynan(results.predicted) or
42 (results.probabilities is not None and
43 anynan(results.probabilities))):
44 error_group.invalid_results(
45 "Results contain invalid values.")
46 else:
47 return results
48
49
50 def results_for_preview(data_name=""):
51 from Orange.data import Table
52 from Orange.evaluation import CrossValidation
53 from Orange.classification import \
54 LogisticRegressionLearner, SVMLearner, NuSVMLearner
55
56 data = Table(data_name or "heart_disease")
57 results = CrossValidation(
58 data,
59 [LogisticRegressionLearner(penalty="l2"),
60 LogisticRegressionLearner(penalty="l1"),
61 SVMLearner(probability=True),
62 NuSVMLearner(probability=True)
63 ],
64 store_data=True
65 )
66 results.learner_names = ["LR l2", "LR l1", "SVM", "Nu SVM"]
67 return results
68
69
70 BUILTIN_SCORERS_ORDER = {
71 DiscreteVariable: ("AUC", "CA", "F1", "Precision", "Recall"),
72 ContinuousVariable: ("MSE", "RMSE", "MAE", "R2")}
73
74
75 def learner_name(learner):
76 """Return the value of `learner.name` if it exists, or the learner's type
77 name otherwise"""
78 return getattr(learner, "name", type(learner).__name__)
79
80
81 def usable_scorers(target: Variable):
82 order = {name: i
83 for i, name in enumerate(BUILTIN_SCORERS_ORDER[type(target)])}
84 # 'abstract' is retrieved from __dict__ to avoid inheriting
85 usable = (cls for cls in scoring.Score.registry.values()
86 if cls.is_scalar and not cls.__dict__.get("abstract")
87 and isinstance(target, cls.class_types))
88 return sorted(usable, key=lambda cls: order.get(cls.name, 99))
89
90
91 def scorer_caller(scorer, ovr_results, target=None):
92 def thunked():
93 with warnings.catch_warnings():
94 # F-score and Precision return 0 for labels with no predicted
95 # samples. We're OK with that.
96 warnings.filterwarnings(
97 "ignore", "((F-score|Precision)) is ill-defined.*",
98 UndefinedMetricWarning)
99 if scorer.is_binary:
100 return scorer(ovr_results, target=target, average='weighted')
101 else:
102 return scorer(ovr_results)
103
104 return thunked
105
106
107 class ScoreModel(QSortFilterProxyModel):
108 def lessThan(self, left, right):
109 def is_bad(x):
110 return not isinstance(x, (int, float, str)) \
111 or isinstance(x, float) and np.isnan(x)
112
113 left = left.data()
114 right = right.data()
115 is_ascending = self.sortOrder() == Qt.AscendingOrder
116
117 # bad entries go below; if both are bad, left remains above
118 if is_bad(left) or is_bad(right):
119 return is_bad(right) == is_ascending
120
121 # for data of different types, numbers are at the top
122 if type(left) is not type(right):
123 return isinstance(left, float) == is_ascending
124
125 # case insensitive comparison for strings
126 if isinstance(left, str):
127 return left.upper() < right.upper()
128
129 # otherwise, compare numbers
130 return left < right
131
132
133 class ScoreTable(OWComponent, QObject):
134 shown_scores = \
135 Setting(set(chain(*BUILTIN_SCORERS_ORDER.values())))
136
137 shownScoresChanged = Signal()
138
139 class ItemDelegate(QStyledItemDelegate):
140 def sizeHint(self, *args):
141 size = super().sizeHint(*args)
142 return QSize(size.width(), size.height() + 6)
143
144 def displayText(self, value, locale):
145 if isinstance(value, float):
146 return f"{value:.3f}"
147 else:
148 return super().displayText(value, locale)
149
150 def __init__(self, master):
151 QObject.__init__(self)
152 OWComponent.__init__(self, master)
153
154 self.view = gui.TableView(
155 wordWrap=True, editTriggers=gui.TableView.NoEditTriggers
156 )
157 header = self.view.horizontalHeader()
158 header.setSectionResizeMode(QHeaderView.ResizeToContents)
159 header.setDefaultAlignment(Qt.AlignCenter)
160 header.setStretchLastSection(False)
161 header.setContextMenuPolicy(Qt.CustomContextMenu)
162 header.customContextMenuRequested.connect(self.show_column_chooser)
163
164 self.model = QStandardItemModel(master)
165 self.model.setHorizontalHeaderLabels(["Method"])
166 self.sorted_model = ScoreModel()
167 self.sorted_model.setSourceModel(self.model)
168 self.view.setModel(self.sorted_model)
169 self.view.setItemDelegate(self.ItemDelegate())
170
171 def _column_names(self):
172 return (self.model.horizontalHeaderItem(section).data(Qt.DisplayRole)
173 for section in range(1, self.model.columnCount()))
174
175 def show_column_chooser(self, pos):
176 # pylint doesn't know that self.shown_scores is a set, not a Setting
177 # pylint: disable=unsupported-membership-test
178 def update(col_name, checked):
179 if checked:
180 self.shown_scores.add(col_name)
181 else:
182 self.shown_scores.remove(col_name)
183 self._update_shown_columns()
184
185 menu = QMenu()
186 header = self.view.horizontalHeader()
187 for col_name in self._column_names():
188 action = menu.addAction(col_name)
189 action.setCheckable(True)
190 action.setChecked(col_name in self.shown_scores)
191 action.triggered.connect(partial(update, col_name))
192 menu.exec(header.mapToGlobal(pos))
193
194 def _update_shown_columns(self):
195 # pylint doesn't know that self.shown_scores is a set, not a Setting
196 # pylint: disable=unsupported-membership-test
197 header = self.view.horizontalHeader()
198 for section, col_name in enumerate(self._column_names(), start=1):
199 header.setSectionHidden(section, col_name not in self.shown_scores)
200 self.view.resizeColumnsToContents()
201 self.shownScoresChanged.emit()
202
203 def update_header(self, scorers):
204 # Set the correct horizontal header labels on the results_model.
205 self.model.setColumnCount(3 + len(scorers))
206 self.model.setHorizontalHeaderItem(0, QStandardItem("Model"))
207 self.model.setHorizontalHeaderItem(1, QStandardItem("Train time [s]"))
208 self.model.setHorizontalHeaderItem(2, QStandardItem("Test time [s]"))
209 for col, score in enumerate(scorers, start=3):
210 item = QStandardItem(score.name)
211 item.setToolTip(score.long_name)
212 self.model.setHorizontalHeaderItem(col, item)
213 self._update_shown_columns()
214
215 def copy_selection_to_clipboard(self):
216 mime = table_selection_to_mime_data(self.view)
217 QApplication.clipboard().setMimeData(
218 mime, QClipboard.Clipboard
219 )
220
[end of Orange/widgets/evaluate/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/Orange/widgets/evaluate/utils.py b/Orange/widgets/evaluate/utils.py
--- a/Orange/widgets/evaluate/utils.py
+++ b/Orange/widgets/evaluate/utils.py
@@ -194,10 +194,10 @@
def _update_shown_columns(self):
# pylint doesn't know that self.shown_scores is a set, not a Setting
# pylint: disable=unsupported-membership-test
+ self.view.resizeColumnsToContents()
header = self.view.horizontalHeader()
for section, col_name in enumerate(self._column_names(), start=1):
header.setSectionHidden(section, col_name not in self.shown_scores)
- self.view.resizeColumnsToContents()
self.shownScoresChanged.emit()
def update_header(self, scorers):
|
{"golden_diff": "diff --git a/Orange/widgets/evaluate/utils.py b/Orange/widgets/evaluate/utils.py\n--- a/Orange/widgets/evaluate/utils.py\n+++ b/Orange/widgets/evaluate/utils.py\n@@ -194,10 +194,10 @@\n def _update_shown_columns(self):\n # pylint doesn't know that self.shown_scores is a set, not a Setting\n # pylint: disable=unsupported-membership-test\n+ self.view.resizeColumnsToContents()\n header = self.view.horizontalHeader()\n for section, col_name in enumerate(self._column_names(), start=1):\n header.setSectionHidden(section, col_name not in self.shown_scores)\n- self.view.resizeColumnsToContents()\n self.shownScoresChanged.emit()\n \n def update_header(self, scorers):\n", "issue": "BUG: UI annoyance - Predictions Widget measures grid squashing\nThis is not a classic bug, but rather big visual annoyance: Predictions Widget squashes the grid with measures every time I retrain anything that sends data to it - like NN or LR. It seems that it chooses column widths based on the header text width and ignores the text in the cells below. Once I click on the model column heading or any other column to sort it, it unsquashes it - that is, it considers cells text width as well. Can we have that not squashed every time retraining is requested? It seems that it does remember its column order although sort column does not have that triangle shown after being squashed, thus I do not know which column was used for sorting in the first place. Thank you n advance for fixing this.\r\n\r\n[1] Sqaushed\r\n\r\n\r\n[2] Unsqaushed\r\n\r\n\n", "before_files": [{"content": "import warnings\nfrom functools import partial\nfrom itertools import chain\n\nimport numpy as np\n\nfrom AnyQt.QtWidgets import QHeaderView, QStyledItemDelegate, QMenu, \\\n QApplication\nfrom AnyQt.QtGui import QStandardItemModel, QStandardItem, QClipboard\nfrom AnyQt.QtCore import Qt, QSize, QObject, pyqtSignal as Signal, \\\n QSortFilterProxyModel\nfrom sklearn.exceptions import UndefinedMetricWarning\n\nfrom Orange.data import Variable, DiscreteVariable, ContinuousVariable\nfrom Orange.evaluation import scoring\nfrom Orange.widgets import gui\nfrom Orange.widgets.utils.tableview import table_selection_to_mime_data\nfrom Orange.widgets.gui import OWComponent\nfrom Orange.widgets.settings import Setting\n\n\ndef check_results_adequacy(results, error_group, check_nan=True):\n error_group.add_message(\"invalid_results\")\n error_group.invalid_results.clear()\n\n def anynan(a):\n return np.any(np.isnan(a))\n\n if results is None:\n return None\n if results.data is None:\n error_group.invalid_results(\n \"Results do not include information on test data.\")\n elif not results.data.domain.has_discrete_class:\n error_group.invalid_results(\n \"Categorical target variable is required.\")\n elif not results.actual.size:\n error_group.invalid_results(\n \"Empty result on input. Nothing to display.\")\n elif check_nan and (anynan(results.actual) or\n anynan(results.predicted) or\n (results.probabilities is not None and\n anynan(results.probabilities))):\n error_group.invalid_results(\n \"Results contain invalid values.\")\n else:\n return results\n\n\ndef results_for_preview(data_name=\"\"):\n from Orange.data import Table\n from Orange.evaluation import CrossValidation\n from Orange.classification import \\\n LogisticRegressionLearner, SVMLearner, NuSVMLearner\n\n data = Table(data_name or \"heart_disease\")\n results = CrossValidation(\n data,\n [LogisticRegressionLearner(penalty=\"l2\"),\n LogisticRegressionLearner(penalty=\"l1\"),\n SVMLearner(probability=True),\n NuSVMLearner(probability=True)\n ],\n store_data=True\n )\n results.learner_names = [\"LR l2\", \"LR l1\", \"SVM\", \"Nu SVM\"]\n return results\n\n\nBUILTIN_SCORERS_ORDER = {\n DiscreteVariable: (\"AUC\", \"CA\", \"F1\", \"Precision\", \"Recall\"),\n ContinuousVariable: (\"MSE\", \"RMSE\", \"MAE\", \"R2\")}\n\n\ndef learner_name(learner):\n \"\"\"Return the value of `learner.name` if it exists, or the learner's type\n name otherwise\"\"\"\n return getattr(learner, \"name\", type(learner).__name__)\n\n\ndef usable_scorers(target: Variable):\n order = {name: i\n for i, name in enumerate(BUILTIN_SCORERS_ORDER[type(target)])}\n # 'abstract' is retrieved from __dict__ to avoid inheriting\n usable = (cls for cls in scoring.Score.registry.values()\n if cls.is_scalar and not cls.__dict__.get(\"abstract\")\n and isinstance(target, cls.class_types))\n return sorted(usable, key=lambda cls: order.get(cls.name, 99))\n\n\ndef scorer_caller(scorer, ovr_results, target=None):\n def thunked():\n with warnings.catch_warnings():\n # F-score and Precision return 0 for labels with no predicted\n # samples. We're OK with that.\n warnings.filterwarnings(\n \"ignore\", \"((F-score|Precision)) is ill-defined.*\",\n UndefinedMetricWarning)\n if scorer.is_binary:\n return scorer(ovr_results, target=target, average='weighted')\n else:\n return scorer(ovr_results)\n\n return thunked\n\n\nclass ScoreModel(QSortFilterProxyModel):\n def lessThan(self, left, right):\n def is_bad(x):\n return not isinstance(x, (int, float, str)) \\\n or isinstance(x, float) and np.isnan(x)\n\n left = left.data()\n right = right.data()\n is_ascending = self.sortOrder() == Qt.AscendingOrder\n\n # bad entries go below; if both are bad, left remains above\n if is_bad(left) or is_bad(right):\n return is_bad(right) == is_ascending\n\n # for data of different types, numbers are at the top\n if type(left) is not type(right):\n return isinstance(left, float) == is_ascending\n\n # case insensitive comparison for strings\n if isinstance(left, str):\n return left.upper() < right.upper()\n\n # otherwise, compare numbers\n return left < right\n\n\nclass ScoreTable(OWComponent, QObject):\n shown_scores = \\\n Setting(set(chain(*BUILTIN_SCORERS_ORDER.values())))\n\n shownScoresChanged = Signal()\n\n class ItemDelegate(QStyledItemDelegate):\n def sizeHint(self, *args):\n size = super().sizeHint(*args)\n return QSize(size.width(), size.height() + 6)\n\n def displayText(self, value, locale):\n if isinstance(value, float):\n return f\"{value:.3f}\"\n else:\n return super().displayText(value, locale)\n\n def __init__(self, master):\n QObject.__init__(self)\n OWComponent.__init__(self, master)\n\n self.view = gui.TableView(\n wordWrap=True, editTriggers=gui.TableView.NoEditTriggers\n )\n header = self.view.horizontalHeader()\n header.setSectionResizeMode(QHeaderView.ResizeToContents)\n header.setDefaultAlignment(Qt.AlignCenter)\n header.setStretchLastSection(False)\n header.setContextMenuPolicy(Qt.CustomContextMenu)\n header.customContextMenuRequested.connect(self.show_column_chooser)\n\n self.model = QStandardItemModel(master)\n self.model.setHorizontalHeaderLabels([\"Method\"])\n self.sorted_model = ScoreModel()\n self.sorted_model.setSourceModel(self.model)\n self.view.setModel(self.sorted_model)\n self.view.setItemDelegate(self.ItemDelegate())\n\n def _column_names(self):\n return (self.model.horizontalHeaderItem(section).data(Qt.DisplayRole)\n for section in range(1, self.model.columnCount()))\n\n def show_column_chooser(self, pos):\n # pylint doesn't know that self.shown_scores is a set, not a Setting\n # pylint: disable=unsupported-membership-test\n def update(col_name, checked):\n if checked:\n self.shown_scores.add(col_name)\n else:\n self.shown_scores.remove(col_name)\n self._update_shown_columns()\n\n menu = QMenu()\n header = self.view.horizontalHeader()\n for col_name in self._column_names():\n action = menu.addAction(col_name)\n action.setCheckable(True)\n action.setChecked(col_name in self.shown_scores)\n action.triggered.connect(partial(update, col_name))\n menu.exec(header.mapToGlobal(pos))\n\n def _update_shown_columns(self):\n # pylint doesn't know that self.shown_scores is a set, not a Setting\n # pylint: disable=unsupported-membership-test\n header = self.view.horizontalHeader()\n for section, col_name in enumerate(self._column_names(), start=1):\n header.setSectionHidden(section, col_name not in self.shown_scores)\n self.view.resizeColumnsToContents()\n self.shownScoresChanged.emit()\n\n def update_header(self, scorers):\n # Set the correct horizontal header labels on the results_model.\n self.model.setColumnCount(3 + len(scorers))\n self.model.setHorizontalHeaderItem(0, QStandardItem(\"Model\"))\n self.model.setHorizontalHeaderItem(1, QStandardItem(\"Train time [s]\"))\n self.model.setHorizontalHeaderItem(2, QStandardItem(\"Test time [s]\"))\n for col, score in enumerate(scorers, start=3):\n item = QStandardItem(score.name)\n item.setToolTip(score.long_name)\n self.model.setHorizontalHeaderItem(col, item)\n self._update_shown_columns()\n\n def copy_selection_to_clipboard(self):\n mime = table_selection_to_mime_data(self.view)\n QApplication.clipboard().setMimeData(\n mime, QClipboard.Clipboard\n )\n", "path": "Orange/widgets/evaluate/utils.py"}]}
| 3,163 | 172 |
gh_patches_debug_4027
|
rasdani/github-patches
|
git_diff
|
opsdroid__opsdroid-180
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Cannot use ~ in module paths
Modules specified in the configuration with a path that includes the `~` character do not import. This character needs to be expanded.
</issue>
<code>
[start of opsdroid/loader.py]
1 """Class for loading in modules to OpsDroid."""
2
3 import logging
4 import os
5 import sys
6 import shutil
7 import subprocess
8 import importlib
9 import yaml
10 from opsdroid.const import (
11 DEFAULT_GIT_URL, MODULES_DIRECTORY, DEFAULT_MODULES_PATH,
12 DEFAULT_MODULE_BRANCH, DEFAULT_CONFIG_PATH, EXAMPLE_CONFIG_FILE,
13 DEFAULT_MODULE_DEPS_PATH)
14
15
16 _LOGGER = logging.getLogger(__name__)
17
18
19 class Loader:
20 """Class to load in config and modules."""
21
22 def __init__(self, opsdroid):
23 """Create object with opsdroid instance."""
24 self.opsdroid = opsdroid
25 self.modules_directory = None
26 self.current_import_config = None
27 _LOGGER.debug("Loaded loader")
28
29 @staticmethod
30 def import_module(config):
31 """Import module namespace as variable and return it."""
32 try:
33 module = importlib.import_module(
34 config["module_path"] + "." + config["name"])
35 _LOGGER.debug("Loaded " + config["type"] + ": " +
36 config["module_path"])
37 return module
38 except ImportError as error:
39 _LOGGER.debug("Failed to load " + config["type"] +
40 " " + config["module_path"] + "." + config["name"])
41 _LOGGER.debug(error)
42
43 try:
44 module = importlib.import_module(
45 config["module_path"])
46 _LOGGER.debug("Loaded " + config["type"] + ": " +
47 config["module_path"])
48 return module
49 except ImportError as error:
50 _LOGGER.debug("Failed to load " + config["type"] +
51 " " + config["module_path"])
52 _LOGGER.debug(error)
53
54 _LOGGER.error("Failed to load " + config["type"] +
55 " " + config["module_path"])
56 return None
57
58 @staticmethod
59 def check_cache(config):
60 """Remove module if 'no-cache' set in config."""
61 if "no-cache" in config \
62 and config["no-cache"]:
63 _LOGGER.debug("'no-cache' set, removing " + config["install_path"])
64 if os.path.isdir(config["install_path"]):
65 shutil.rmtree(config["install_path"])
66 if os.path.isfile(config["install_path"] + ".py"):
67 os.remove(config["install_path"] + ".py")
68
69 def build_module_path(self, path_type, config):
70 """Generate the module path from name and type."""
71 if path_type == "import":
72 return MODULES_DIRECTORY + "." + config["type"] + \
73 "." + config["name"]
74 elif path_type == "install":
75 return self.modules_directory + "/" + config["type"] + \
76 "/" + config["name"]
77
78 @staticmethod
79 def git_clone(git_url, install_path, branch):
80 """Clone a git repo to a location and wait for finish."""
81 process = subprocess.Popen(["git", "clone", "-b", branch,
82 git_url, install_path], shell=False,
83 stdout=subprocess.PIPE,
84 stderr=subprocess.PIPE)
85 for output in process.communicate():
86 if output != "":
87 for line in output.splitlines():
88 _LOGGER.debug(str(line).strip())
89 process.wait()
90
91 @staticmethod
92 def pip_install_deps(requirements_path):
93 """Pip install a requirements.txt file and wait for finish."""
94 process = subprocess.Popen(["pip", "install",
95 "--target={}".format(
96 DEFAULT_MODULE_DEPS_PATH),
97 "--ignore-installed",
98 "-r", requirements_path],
99 shell=False,
100 stdout=subprocess.PIPE,
101 stderr=subprocess.PIPE)
102 for output in process.communicate():
103 if output != "":
104 for line in output.splitlines():
105 _LOGGER.debug(str(line).strip())
106 process.wait()
107
108 @staticmethod
109 def create_default_config(config_path):
110 """Create a default config file based on the included example."""
111 _LOGGER.info("Creating %s.", config_path)
112 config_dir, _ = os.path.split(config_path)
113 if not os.path.isdir(config_dir):
114 os.makedirs(config_dir)
115 shutil.copyfile(EXAMPLE_CONFIG_FILE, config_path)
116 return config_path
117
118 @staticmethod
119 def _reload_modules(modules):
120 for module in modules:
121 importlib.reload(module["module"])
122
123 def load_config_file(self, config_paths):
124 """Load a yaml config file from path."""
125 config_path = ""
126 for possible_path in config_paths:
127 if not os.path.isfile(possible_path):
128 _LOGGER.debug("Config file " + possible_path +
129 " not found")
130 else:
131 config_path = possible_path
132 break
133
134 if not config_path:
135 _LOGGER.info("No configuration files found.")
136 config_path = self.create_default_config(DEFAULT_CONFIG_PATH)
137
138 try:
139 with open(config_path, 'r') as stream:
140 _LOGGER.info("Loaded config from %s", config_path)
141 return yaml.load(stream)
142 except yaml.YAMLError as error:
143 self.opsdroid.critical(error, 1)
144 except FileNotFoundError as error:
145 self.opsdroid.critical(str(error), 1)
146
147 def setup_modules_directory(self, config):
148 """Create and configure the modules directory."""
149 module_path = os.path.expanduser(
150 config.get("module-path", DEFAULT_MODULES_PATH))
151 sys.path.append(module_path)
152
153 if not os.path.isdir(module_path):
154 os.makedirs(module_path, exist_ok=True)
155
156 self.modules_directory = os.path.join(module_path, MODULES_DIRECTORY)
157
158 # Create modules directory if doesn't exist
159 if not os.path.isdir(self.modules_directory):
160 os.makedirs(self.modules_directory)
161
162 def load_modules_from_config(self, config):
163 """Load all module types based on config."""
164 _LOGGER.debug("Loading modules from config")
165
166 self.setup_modules_directory(config)
167
168 connectors, databases, skills = None, None, None
169
170 if 'databases' in config.keys():
171 databases = self._load_modules('database', config['databases'])
172 else:
173 _LOGGER.warning("No databases in configuration")
174
175 if 'skills' in config.keys():
176 skills = self._load_modules('skill', config['skills'])
177 self.opsdroid.skills = []
178 self._reload_modules(skills)
179 else:
180 self.opsdroid.critical(
181 "No skills in configuration, at least 1 required", 1)
182
183 if 'connectors' in config.keys():
184 connectors = self._load_modules('connector', config['connectors'])
185 else:
186 self.opsdroid.critical(
187 "No connectors in configuration, at least 1 required", 1)
188
189 return connectors, databases, skills
190
191 def _load_modules(self, modules_type, modules):
192 """Install and load modules."""
193 _LOGGER.debug("Loading " + modules_type + " modules")
194 loaded_modules = []
195
196 if not os.path.isdir(DEFAULT_MODULE_DEPS_PATH):
197 os.makedirs(DEFAULT_MODULE_DEPS_PATH)
198 sys.path.append(DEFAULT_MODULE_DEPS_PATH)
199
200 for module in modules:
201
202 # Set up module config
203 config = module
204 config = {} if config is None else config
205 config["name"] = module["name"]
206 config["type"] = modules_type
207 config["module_path"] = self.build_module_path("import", config)
208 config["install_path"] = self.build_module_path("install", config)
209 if "branch" not in config:
210 config["branch"] = DEFAULT_MODULE_BRANCH
211
212 # Remove module for reinstall if no-cache set
213 self.check_cache(config)
214
215 # Install module
216 self._install_module(config)
217
218 # Import module
219 self.current_import_config = config
220 module = self.import_module(config)
221 if module is not None:
222 loaded_modules.append({
223 "module": module,
224 "config": config})
225 else:
226 _LOGGER.error(
227 "Module " + config["name"] + " failed to import")
228
229 return loaded_modules
230
231 def _install_module(self, config):
232 # pylint: disable=R0201
233 """Install a module."""
234 _LOGGER.debug("Installing " + config["name"])
235
236 if os.path.isdir(config["install_path"]) or \
237 os.path.isfile(config["install_path"] + ".py"):
238 # TODO Allow for updating or reinstalling of modules
239 _LOGGER.debug("Module " + config["name"] +
240 " already installed, skipping")
241 return
242
243 if "path" in config:
244 self._install_local_module(config)
245 else:
246 self._install_git_module(config)
247
248 if os.path.isdir(config["install_path"]):
249 _LOGGER.debug("Installed " + config["name"] +
250 " to " + config["install_path"])
251 else:
252 _LOGGER.debug("Install of " + config["name"] + " failed")
253
254 # Install module dependancies
255 if os.path.isfile(config["install_path"] + "/requirements.txt"):
256 self.pip_install_deps(config["install_path"] +
257 "/requirements.txt")
258
259 def _install_git_module(self, config):
260 """Install a module from a git repository."""
261 if config is not None and "repo" in config:
262 git_url = config["repo"]
263 else:
264 git_url = DEFAULT_GIT_URL + config["type"] + \
265 "-" + config["name"] + ".git"
266
267 if any(prefix in git_url for prefix in ["http", "https", "ssh"]):
268 # TODO Test if url or ssh path exists
269 # TODO Handle github authentication
270 _LOGGER.debug("Cloning from remote repository")
271 self.git_clone(git_url, config["install_path"],
272 config["branch"])
273 else:
274 if os.path.isdir(git_url):
275 _LOGGER.debug("Cloning from local repository")
276 self.git_clone(git_url, config["install_path"],
277 config["branch"])
278 else:
279 _LOGGER.debug("Could not find local git repo " + git_url)
280
281 @staticmethod
282 def _install_local_module(config):
283 """Install a module from a local path."""
284 installed = False
285
286 installdir, _ = os.path.split(config["install_path"])
287 if not os.path.isdir(installdir):
288 os.makedirs(installdir, exist_ok=True)
289
290 if os.path.isdir(config["path"]):
291 shutil.copytree(config["path"], config["install_path"])
292 installed = True
293
294 if os.path.isfile(config["path"]):
295 os.makedirs(config["install_path"], exist_ok=True)
296 shutil.copyfile(config["path"], config["install_path"] +
297 "/__init__.py")
298 installed = True
299
300 if not installed:
301 _LOGGER.error("Failed to install from " + config["path"])
302
[end of opsdroid/loader.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/opsdroid/loader.py b/opsdroid/loader.py
--- a/opsdroid/loader.py
+++ b/opsdroid/loader.py
@@ -282,6 +282,7 @@
def _install_local_module(config):
"""Install a module from a local path."""
installed = False
+ config["path"] = os.path.expanduser(config["path"])
installdir, _ = os.path.split(config["install_path"])
if not os.path.isdir(installdir):
|
{"golden_diff": "diff --git a/opsdroid/loader.py b/opsdroid/loader.py\n--- a/opsdroid/loader.py\n+++ b/opsdroid/loader.py\n@@ -282,6 +282,7 @@\n def _install_local_module(config):\n \"\"\"Install a module from a local path.\"\"\"\n installed = False\n+ config[\"path\"] = os.path.expanduser(config[\"path\"])\n \n installdir, _ = os.path.split(config[\"install_path\"])\n if not os.path.isdir(installdir):\n", "issue": "Cannot use ~ in module paths\nModules specified in the configuration with a path that includes the `~` character do not import. This character needs to be expanded.\n", "before_files": [{"content": "\"\"\"Class for loading in modules to OpsDroid.\"\"\"\n\nimport logging\nimport os\nimport sys\nimport shutil\nimport subprocess\nimport importlib\nimport yaml\nfrom opsdroid.const import (\n DEFAULT_GIT_URL, MODULES_DIRECTORY, DEFAULT_MODULES_PATH,\n DEFAULT_MODULE_BRANCH, DEFAULT_CONFIG_PATH, EXAMPLE_CONFIG_FILE,\n DEFAULT_MODULE_DEPS_PATH)\n\n\n_LOGGER = logging.getLogger(__name__)\n\n\nclass Loader:\n \"\"\"Class to load in config and modules.\"\"\"\n\n def __init__(self, opsdroid):\n \"\"\"Create object with opsdroid instance.\"\"\"\n self.opsdroid = opsdroid\n self.modules_directory = None\n self.current_import_config = None\n _LOGGER.debug(\"Loaded loader\")\n\n @staticmethod\n def import_module(config):\n \"\"\"Import module namespace as variable and return it.\"\"\"\n try:\n module = importlib.import_module(\n config[\"module_path\"] + \".\" + config[\"name\"])\n _LOGGER.debug(\"Loaded \" + config[\"type\"] + \": \" +\n config[\"module_path\"])\n return module\n except ImportError as error:\n _LOGGER.debug(\"Failed to load \" + config[\"type\"] +\n \" \" + config[\"module_path\"] + \".\" + config[\"name\"])\n _LOGGER.debug(error)\n\n try:\n module = importlib.import_module(\n config[\"module_path\"])\n _LOGGER.debug(\"Loaded \" + config[\"type\"] + \": \" +\n config[\"module_path\"])\n return module\n except ImportError as error:\n _LOGGER.debug(\"Failed to load \" + config[\"type\"] +\n \" \" + config[\"module_path\"])\n _LOGGER.debug(error)\n\n _LOGGER.error(\"Failed to load \" + config[\"type\"] +\n \" \" + config[\"module_path\"])\n return None\n\n @staticmethod\n def check_cache(config):\n \"\"\"Remove module if 'no-cache' set in config.\"\"\"\n if \"no-cache\" in config \\\n and config[\"no-cache\"]:\n _LOGGER.debug(\"'no-cache' set, removing \" + config[\"install_path\"])\n if os.path.isdir(config[\"install_path\"]):\n shutil.rmtree(config[\"install_path\"])\n if os.path.isfile(config[\"install_path\"] + \".py\"):\n os.remove(config[\"install_path\"] + \".py\")\n\n def build_module_path(self, path_type, config):\n \"\"\"Generate the module path from name and type.\"\"\"\n if path_type == \"import\":\n return MODULES_DIRECTORY + \".\" + config[\"type\"] + \\\n \".\" + config[\"name\"]\n elif path_type == \"install\":\n return self.modules_directory + \"/\" + config[\"type\"] + \\\n \"/\" + config[\"name\"]\n\n @staticmethod\n def git_clone(git_url, install_path, branch):\n \"\"\"Clone a git repo to a location and wait for finish.\"\"\"\n process = subprocess.Popen([\"git\", \"clone\", \"-b\", branch,\n git_url, install_path], shell=False,\n stdout=subprocess.PIPE,\n stderr=subprocess.PIPE)\n for output in process.communicate():\n if output != \"\":\n for line in output.splitlines():\n _LOGGER.debug(str(line).strip())\n process.wait()\n\n @staticmethod\n def pip_install_deps(requirements_path):\n \"\"\"Pip install a requirements.txt file and wait for finish.\"\"\"\n process = subprocess.Popen([\"pip\", \"install\",\n \"--target={}\".format(\n DEFAULT_MODULE_DEPS_PATH),\n \"--ignore-installed\",\n \"-r\", requirements_path],\n shell=False,\n stdout=subprocess.PIPE,\n stderr=subprocess.PIPE)\n for output in process.communicate():\n if output != \"\":\n for line in output.splitlines():\n _LOGGER.debug(str(line).strip())\n process.wait()\n\n @staticmethod\n def create_default_config(config_path):\n \"\"\"Create a default config file based on the included example.\"\"\"\n _LOGGER.info(\"Creating %s.\", config_path)\n config_dir, _ = os.path.split(config_path)\n if not os.path.isdir(config_dir):\n os.makedirs(config_dir)\n shutil.copyfile(EXAMPLE_CONFIG_FILE, config_path)\n return config_path\n\n @staticmethod\n def _reload_modules(modules):\n for module in modules:\n importlib.reload(module[\"module\"])\n\n def load_config_file(self, config_paths):\n \"\"\"Load a yaml config file from path.\"\"\"\n config_path = \"\"\n for possible_path in config_paths:\n if not os.path.isfile(possible_path):\n _LOGGER.debug(\"Config file \" + possible_path +\n \" not found\")\n else:\n config_path = possible_path\n break\n\n if not config_path:\n _LOGGER.info(\"No configuration files found.\")\n config_path = self.create_default_config(DEFAULT_CONFIG_PATH)\n\n try:\n with open(config_path, 'r') as stream:\n _LOGGER.info(\"Loaded config from %s\", config_path)\n return yaml.load(stream)\n except yaml.YAMLError as error:\n self.opsdroid.critical(error, 1)\n except FileNotFoundError as error:\n self.opsdroid.critical(str(error), 1)\n\n def setup_modules_directory(self, config):\n \"\"\"Create and configure the modules directory.\"\"\"\n module_path = os.path.expanduser(\n config.get(\"module-path\", DEFAULT_MODULES_PATH))\n sys.path.append(module_path)\n\n if not os.path.isdir(module_path):\n os.makedirs(module_path, exist_ok=True)\n\n self.modules_directory = os.path.join(module_path, MODULES_DIRECTORY)\n\n # Create modules directory if doesn't exist\n if not os.path.isdir(self.modules_directory):\n os.makedirs(self.modules_directory)\n\n def load_modules_from_config(self, config):\n \"\"\"Load all module types based on config.\"\"\"\n _LOGGER.debug(\"Loading modules from config\")\n\n self.setup_modules_directory(config)\n\n connectors, databases, skills = None, None, None\n\n if 'databases' in config.keys():\n databases = self._load_modules('database', config['databases'])\n else:\n _LOGGER.warning(\"No databases in configuration\")\n\n if 'skills' in config.keys():\n skills = self._load_modules('skill', config['skills'])\n self.opsdroid.skills = []\n self._reload_modules(skills)\n else:\n self.opsdroid.critical(\n \"No skills in configuration, at least 1 required\", 1)\n\n if 'connectors' in config.keys():\n connectors = self._load_modules('connector', config['connectors'])\n else:\n self.opsdroid.critical(\n \"No connectors in configuration, at least 1 required\", 1)\n\n return connectors, databases, skills\n\n def _load_modules(self, modules_type, modules):\n \"\"\"Install and load modules.\"\"\"\n _LOGGER.debug(\"Loading \" + modules_type + \" modules\")\n loaded_modules = []\n\n if not os.path.isdir(DEFAULT_MODULE_DEPS_PATH):\n os.makedirs(DEFAULT_MODULE_DEPS_PATH)\n sys.path.append(DEFAULT_MODULE_DEPS_PATH)\n\n for module in modules:\n\n # Set up module config\n config = module\n config = {} if config is None else config\n config[\"name\"] = module[\"name\"]\n config[\"type\"] = modules_type\n config[\"module_path\"] = self.build_module_path(\"import\", config)\n config[\"install_path\"] = self.build_module_path(\"install\", config)\n if \"branch\" not in config:\n config[\"branch\"] = DEFAULT_MODULE_BRANCH\n\n # Remove module for reinstall if no-cache set\n self.check_cache(config)\n\n # Install module\n self._install_module(config)\n\n # Import module\n self.current_import_config = config\n module = self.import_module(config)\n if module is not None:\n loaded_modules.append({\n \"module\": module,\n \"config\": config})\n else:\n _LOGGER.error(\n \"Module \" + config[\"name\"] + \" failed to import\")\n\n return loaded_modules\n\n def _install_module(self, config):\n # pylint: disable=R0201\n \"\"\"Install a module.\"\"\"\n _LOGGER.debug(\"Installing \" + config[\"name\"])\n\n if os.path.isdir(config[\"install_path\"]) or \\\n os.path.isfile(config[\"install_path\"] + \".py\"):\n # TODO Allow for updating or reinstalling of modules\n _LOGGER.debug(\"Module \" + config[\"name\"] +\n \" already installed, skipping\")\n return\n\n if \"path\" in config:\n self._install_local_module(config)\n else:\n self._install_git_module(config)\n\n if os.path.isdir(config[\"install_path\"]):\n _LOGGER.debug(\"Installed \" + config[\"name\"] +\n \" to \" + config[\"install_path\"])\n else:\n _LOGGER.debug(\"Install of \" + config[\"name\"] + \" failed\")\n\n # Install module dependancies\n if os.path.isfile(config[\"install_path\"] + \"/requirements.txt\"):\n self.pip_install_deps(config[\"install_path\"] +\n \"/requirements.txt\")\n\n def _install_git_module(self, config):\n \"\"\"Install a module from a git repository.\"\"\"\n if config is not None and \"repo\" in config:\n git_url = config[\"repo\"]\n else:\n git_url = DEFAULT_GIT_URL + config[\"type\"] + \\\n \"-\" + config[\"name\"] + \".git\"\n\n if any(prefix in git_url for prefix in [\"http\", \"https\", \"ssh\"]):\n # TODO Test if url or ssh path exists\n # TODO Handle github authentication\n _LOGGER.debug(\"Cloning from remote repository\")\n self.git_clone(git_url, config[\"install_path\"],\n config[\"branch\"])\n else:\n if os.path.isdir(git_url):\n _LOGGER.debug(\"Cloning from local repository\")\n self.git_clone(git_url, config[\"install_path\"],\n config[\"branch\"])\n else:\n _LOGGER.debug(\"Could not find local git repo \" + git_url)\n\n @staticmethod\n def _install_local_module(config):\n \"\"\"Install a module from a local path.\"\"\"\n installed = False\n\n installdir, _ = os.path.split(config[\"install_path\"])\n if not os.path.isdir(installdir):\n os.makedirs(installdir, exist_ok=True)\n\n if os.path.isdir(config[\"path\"]):\n shutil.copytree(config[\"path\"], config[\"install_path\"])\n installed = True\n\n if os.path.isfile(config[\"path\"]):\n os.makedirs(config[\"install_path\"], exist_ok=True)\n shutil.copyfile(config[\"path\"], config[\"install_path\"] +\n \"/__init__.py\")\n installed = True\n\n if not installed:\n _LOGGER.error(\"Failed to install from \" + config[\"path\"])\n", "path": "opsdroid/loader.py"}]}
| 3,631 | 115 |
gh_patches_debug_2118
|
rasdani/github-patches
|
git_diff
|
mdn__kuma-6978
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
SystemError: <method 'get' of 'dict' objects> returned a result with an error set
https://sentry.prod.mozaws.net/operations/mdn-prod/issues/6659909/
```
timeout: timeout
SystemError: <method 'get' of 'dict' objects> returned a result with an error set
File "meinheld/mlogging.py", line 187, in _access
'h': environ.get('REMOTE_ADDR', '-'),
SystemError: <method 'get' of 'dict' objects> returned a result with an error set
```
Low priority: 12x in 2yrs, but might worth looking into with spare time.
</issue>
<code>
[start of kuma/wiki/views/misc.py]
1 import newrelic.agent
2 from django.http import HttpResponseBadRequest, JsonResponse
3 from django.shortcuts import render
4 from django.utils.translation import gettext_lazy as _
5 from django.views.decorators.http import require_GET
6
7 from kuma.core.decorators import (
8 block_user_agents,
9 ensure_wiki_domain,
10 shared_cache_control,
11 )
12
13 from ..constants import ALLOWED_TAGS, REDIRECT_CONTENT
14 from ..decorators import allow_CORS_GET
15 from ..models import Document, EditorToolbar
16
17
18 @ensure_wiki_domain
19 @shared_cache_control
20 @require_GET
21 def ckeditor_config(request):
22 """
23 Return ckeditor config from database
24 """
25 default_config = EditorToolbar.objects.filter(name="default")
26 if default_config.exists():
27 code = default_config[0].code
28 else:
29 code = ""
30
31 context = {
32 "editor_config": code,
33 "redirect_pattern": REDIRECT_CONTENT,
34 "allowed_tags": " ".join(ALLOWED_TAGS),
35 }
36 return render(
37 request,
38 "wiki/ckeditor_config.js",
39 context,
40 content_type="application/x-javascript",
41 )
42
43
44 @shared_cache_control
45 @newrelic.agent.function_trace()
46 @block_user_agents
47 @require_GET
48 @allow_CORS_GET
49 def autosuggest_documents(request):
50 """
51 Returns the closest title matches for front-end autosuggests
52 """
53 partial_title = request.GET.get("term", "")
54 locale = request.GET.get("locale", False)
55 current_locale = request.GET.get("current_locale", False)
56 exclude_current_locale = request.GET.get("exclude_current_locale", False)
57
58 if not partial_title:
59 # Only handle actual autosuggest requests, not requests for a
60 # memory-busting list of all documents.
61 return HttpResponseBadRequest(
62 _(
63 "Autosuggest requires a partial "
64 "title. For a full document "
65 "index, see the main page."
66 )
67 )
68
69 # Retrieve all documents that aren't redirects
70 docs = (
71 Document.objects.extra(select={"length": "Length(slug)"})
72 .filter(title__icontains=partial_title, is_redirect=0)
73 .exclude(slug__icontains="Talk:") # Remove old talk pages
74 .order_by("title", "length")
75 )
76
77 # All locales are assumed, unless a specific locale is requested or banned
78 if locale:
79 docs = docs.filter(locale=locale)
80 if current_locale:
81 docs = docs.filter(locale=request.LANGUAGE_CODE)
82 if exclude_current_locale:
83 docs = docs.exclude(locale=request.LANGUAGE_CODE)
84
85 # Generates a list of acceptable docs
86 docs_list = []
87 for doc in docs:
88 data = doc.get_json_data()
89 data["label"] += " [" + doc.locale + "]"
90 docs_list.append(data)
91
92 return JsonResponse(docs_list, safe=False)
93
[end of kuma/wiki/views/misc.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kuma/wiki/views/misc.py b/kuma/wiki/views/misc.py
--- a/kuma/wiki/views/misc.py
+++ b/kuma/wiki/views/misc.py
@@ -84,7 +84,7 @@
# Generates a list of acceptable docs
docs_list = []
- for doc in docs:
+ for doc in docs[:100]:
data = doc.get_json_data()
data["label"] += " [" + doc.locale + "]"
docs_list.append(data)
|
{"golden_diff": "diff --git a/kuma/wiki/views/misc.py b/kuma/wiki/views/misc.py\n--- a/kuma/wiki/views/misc.py\n+++ b/kuma/wiki/views/misc.py\n@@ -84,7 +84,7 @@\n \n # Generates a list of acceptable docs\n docs_list = []\n- for doc in docs:\n+ for doc in docs[:100]:\n data = doc.get_json_data()\n data[\"label\"] += \" [\" + doc.locale + \"]\"\n docs_list.append(data)\n", "issue": "SystemError: <method 'get' of 'dict' objects> returned a result with an error set\nhttps://sentry.prod.mozaws.net/operations/mdn-prod/issues/6659909/\r\n\r\n```\r\ntimeout: timeout\r\nSystemError: <method 'get' of 'dict' objects> returned a result with an error set\r\n File \"meinheld/mlogging.py\", line 187, in _access\r\n 'h': environ.get('REMOTE_ADDR', '-'),\r\n\r\nSystemError: <method 'get' of 'dict' objects> returned a result with an error set\r\n```\r\n\r\nLow priority: 12x in 2yrs, but might worth looking into with spare time.\n", "before_files": [{"content": "import newrelic.agent\nfrom django.http import HttpResponseBadRequest, JsonResponse\nfrom django.shortcuts import render\nfrom django.utils.translation import gettext_lazy as _\nfrom django.views.decorators.http import require_GET\n\nfrom kuma.core.decorators import (\n block_user_agents,\n ensure_wiki_domain,\n shared_cache_control,\n)\n\nfrom ..constants import ALLOWED_TAGS, REDIRECT_CONTENT\nfrom ..decorators import allow_CORS_GET\nfrom ..models import Document, EditorToolbar\n\n\n@ensure_wiki_domain\n@shared_cache_control\n@require_GET\ndef ckeditor_config(request):\n \"\"\"\n Return ckeditor config from database\n \"\"\"\n default_config = EditorToolbar.objects.filter(name=\"default\")\n if default_config.exists():\n code = default_config[0].code\n else:\n code = \"\"\n\n context = {\n \"editor_config\": code,\n \"redirect_pattern\": REDIRECT_CONTENT,\n \"allowed_tags\": \" \".join(ALLOWED_TAGS),\n }\n return render(\n request,\n \"wiki/ckeditor_config.js\",\n context,\n content_type=\"application/x-javascript\",\n )\n\n\n@shared_cache_control\[email protected]_trace()\n@block_user_agents\n@require_GET\n@allow_CORS_GET\ndef autosuggest_documents(request):\n \"\"\"\n Returns the closest title matches for front-end autosuggests\n \"\"\"\n partial_title = request.GET.get(\"term\", \"\")\n locale = request.GET.get(\"locale\", False)\n current_locale = request.GET.get(\"current_locale\", False)\n exclude_current_locale = request.GET.get(\"exclude_current_locale\", False)\n\n if not partial_title:\n # Only handle actual autosuggest requests, not requests for a\n # memory-busting list of all documents.\n return HttpResponseBadRequest(\n _(\n \"Autosuggest requires a partial \"\n \"title. For a full document \"\n \"index, see the main page.\"\n )\n )\n\n # Retrieve all documents that aren't redirects\n docs = (\n Document.objects.extra(select={\"length\": \"Length(slug)\"})\n .filter(title__icontains=partial_title, is_redirect=0)\n .exclude(slug__icontains=\"Talk:\") # Remove old talk pages\n .order_by(\"title\", \"length\")\n )\n\n # All locales are assumed, unless a specific locale is requested or banned\n if locale:\n docs = docs.filter(locale=locale)\n if current_locale:\n docs = docs.filter(locale=request.LANGUAGE_CODE)\n if exclude_current_locale:\n docs = docs.exclude(locale=request.LANGUAGE_CODE)\n\n # Generates a list of acceptable docs\n docs_list = []\n for doc in docs:\n data = doc.get_json_data()\n data[\"label\"] += \" [\" + doc.locale + \"]\"\n docs_list.append(data)\n\n return JsonResponse(docs_list, safe=False)\n", "path": "kuma/wiki/views/misc.py"}]}
| 1,464 | 109 |
gh_patches_debug_24314
|
rasdani/github-patches
|
git_diff
|
psf__black-4346
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Create URL links to actual PRs rather than simply referencing the PR number
The change log is immensely useful, however it makes reference to specific Github PRs and only mentions the PR number without actually linking to the issue.
I would like for the changelog to actually include links to the issue. It would be of great help to readers to be able to see the contextual discussion for a change, particularly for style changes.
https://black.readthedocs.io/en/stable/change_log.html
</issue>
<code>
[start of docs/conf.py]
1 #
2 # Configuration file for the Sphinx documentation builder.
3 #
4 # This file does only contain a selection of the most common options. For a
5 # full list see the documentation:
6 # http://www.sphinx-doc.org/en/stable/config
7
8 # -- Path setup --------------------------------------------------------------
9
10 # If extensions (or modules to document with autodoc) are in another directory,
11 # add these directories to sys.path here. If the directory is relative to the
12 # documentation root, use os.path.abspath to make it absolute, like shown here.
13 #
14
15 import os
16 import string
17 from importlib.metadata import version
18 from pathlib import Path
19
20 CURRENT_DIR = Path(__file__).parent
21
22
23 def make_pypi_svg(version: str) -> None:
24 template: Path = CURRENT_DIR / "_static" / "pypi_template.svg"
25 target: Path = CURRENT_DIR / "_static" / "pypi.svg"
26 with open(str(template), encoding="utf8") as f:
27 svg: str = string.Template(f.read()).substitute(version=version)
28 with open(str(target), "w", encoding="utf8") as f:
29 f.write(svg)
30
31
32 # Necessary so Click doesn't hit an encode error when called by
33 # sphinxcontrib-programoutput on Windows.
34 os.putenv("pythonioencoding", "utf-8")
35
36 # -- Project information -----------------------------------------------------
37
38 project = "Black"
39 copyright = "2018-Present, Łukasz Langa and contributors to Black"
40 author = "Łukasz Langa and contributors to Black"
41
42 # Autopopulate version
43 # The version, including alpha/beta/rc tags, but not commit hash and datestamps
44 release = version("black").split("+")[0]
45 # The short X.Y version.
46 version = release
47 for sp in "abcfr":
48 version = version.split(sp)[0]
49
50 make_pypi_svg(release)
51
52
53 # -- General configuration ---------------------------------------------------
54
55 # If your documentation needs a minimal Sphinx version, state it here.
56 needs_sphinx = "4.4"
57
58 # Add any Sphinx extension module names here, as strings. They can be
59 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
60 # ones.
61 extensions = [
62 "sphinx.ext.autodoc",
63 "sphinx.ext.intersphinx",
64 "sphinx.ext.napoleon",
65 "myst_parser",
66 "sphinxcontrib.programoutput",
67 "sphinx_copybutton",
68 ]
69
70 # If you need extensions of a certain version or higher, list them here.
71 needs_extensions = {"myst_parser": "0.13.7"}
72
73 # Add any paths that contain templates here, relative to this directory.
74 templates_path = ["_templates"]
75
76 # The suffix(es) of source filenames.
77 # You can specify multiple suffix as a list of string:
78 source_suffix = [".rst", ".md"]
79
80 # The master toctree document.
81 master_doc = "index"
82
83 # The language for content autogenerated by Sphinx. Refer to documentation
84 # for a list of supported languages.
85 #
86 # This is also used if you do content translation via gettext catalogs.
87 # Usually you set "language" from the command line for these cases.
88 language = "en"
89
90 # List of patterns, relative to source directory, that match files and
91 # directories to ignore when looking for source files.
92 # This pattern also affects html_static_path and html_extra_path .
93
94 exclude_patterns = ["_build", "Thumbs.db", ".DS_Store"]
95
96 # The name of the Pygments (syntax highlighting) style to use.
97 pygments_style = "sphinx"
98
99 # We need headers to be linkable to so ask MyST-Parser to autogenerate anchor IDs for
100 # headers up to and including level 3.
101 myst_heading_anchors = 3
102
103 # Prettier support formatting some MyST syntax but not all, so let's disable the
104 # unsupported yet still enabled by default ones.
105 myst_disable_syntax = [
106 "colon_fence",
107 "myst_block_break",
108 "myst_line_comment",
109 "math_block",
110 ]
111
112 # Optional MyST Syntaxes
113 myst_enable_extensions = []
114
115 # -- Options for HTML output -------------------------------------------------
116
117 # The theme to use for HTML and HTML Help pages. See the documentation for
118 # a list of builtin themes.
119 #
120 html_theme = "furo"
121 html_logo = "_static/logo2-readme.png"
122
123 # Add any paths that contain custom static files (such as style sheets) here,
124 # relative to this directory. They are copied after the builtin static files,
125 # so a file named "default.css" will overwrite the builtin "default.css".
126 html_static_path = ["_static"]
127
128 # Custom sidebar templates, must be a dictionary that maps document names
129 # to template names.
130 #
131 # The default sidebars (for documents that don't match any pattern) are
132 # defined by theme itself. Builtin themes are using these templates by
133 # default: ``['localtoc.html', 'relations.html', 'sourcelink.html',
134 # 'searchbox.html']``.
135 #
136 # html_sidebars = {}
137
138
139 # -- Options for HTMLHelp output ---------------------------------------------
140
141 # Output file base name for HTML help builder.
142 htmlhelp_basename = "blackdoc"
143
144
145 # -- Options for LaTeX output ------------------------------------------------
146
147 # Grouping the document tree into LaTeX files. List of tuples
148 # (source start file, target name, title,
149 # author, documentclass [howto, manual, or own class]).
150 latex_documents = [(
151 master_doc,
152 "black.tex",
153 "Documentation for Black",
154 "Łukasz Langa and contributors to Black",
155 "manual",
156 )]
157
158
159 # -- Options for manual page output ------------------------------------------
160
161 # One entry per manual page. List of tuples
162 # (source start file, name, description, authors, manual section).
163 man_pages = [(master_doc, "black", "Documentation for Black", [author], 1)]
164
165
166 # -- Options for Texinfo output ----------------------------------------------
167
168 # Grouping the document tree into Texinfo files. List of tuples
169 # (source start file, target name, title, author,
170 # dir menu entry, description, category)
171 texinfo_documents = [(
172 master_doc,
173 "Black",
174 "Documentation for Black",
175 author,
176 "Black",
177 "The uncompromising Python code formatter",
178 "Miscellaneous",
179 )]
180
181
182 # -- Options for Epub output -------------------------------------------------
183
184 # Bibliographic Dublin Core info.
185 epub_title = project
186 epub_author = author
187 epub_publisher = author
188 epub_copyright = copyright
189
190 # The unique identifier of the text. This can be a ISBN number
191 # or the project homepage.
192 #
193 # epub_identifier = ''
194
195 # A unique identification for the text.
196 #
197 # epub_uid = ''
198
199 # A list of files that should not be packed into the epub file.
200 epub_exclude_files = ["search.html"]
201
202
203 # -- Extension configuration -------------------------------------------------
204
205 autodoc_member_order = "bysource"
206
207 # -- sphinx-copybutton configuration ----------------------------------------
208 copybutton_prompt_text = (
209 r">>> |\.\.\. |> |\$ |\# | In \[\d*\]: | {2,5}\.\.\.: | {5,8}: "
210 )
211 copybutton_prompt_is_regexp = True
212 copybutton_remove_prompts = True
213
214 # -- Options for intersphinx extension ---------------------------------------
215
216 # Example configuration for intersphinx: refer to the Python standard library.
217 intersphinx_mapping = {"<name>": ("https://docs.python.org/3/", None)}
218
[end of docs/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -13,10 +13,13 @@
#
import os
+import re
import string
from importlib.metadata import version
from pathlib import Path
+from sphinx.application import Sphinx
+
CURRENT_DIR = Path(__file__).parent
@@ -29,6 +32,36 @@
f.write(svg)
+def replace_pr_numbers_with_links(content: str) -> str:
+ """Replaces all PR numbers with the corresponding GitHub link."""
+
+ base_url = "https://github.com/psf/black/pull/"
+ pr_num_regex = re.compile(r"\(#(\d+)\)")
+
+ def num_to_link(match: re.Match[str]) -> str:
+ number = match.group(1)
+ url = f"{base_url}{number}"
+ return f"([#{number}]({url}))"
+
+ return pr_num_regex.sub(num_to_link, content)
+
+
+def handle_include_read(
+ app: Sphinx,
+ relative_path: Path,
+ parent_docname: str,
+ content: list[str],
+) -> None:
+ """Handler for the include-read sphinx event."""
+ if parent_docname == "change_log":
+ content[0] = replace_pr_numbers_with_links(content[0])
+
+
+def setup(app: Sphinx) -> None:
+ """Sets up a minimal sphinx extension."""
+ app.connect("include-read", handle_include_read)
+
+
# Necessary so Click doesn't hit an encode error when called by
# sphinxcontrib-programoutput on Windows.
os.putenv("pythonioencoding", "utf-8")
|
{"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -13,10 +13,13 @@\n #\n \n import os\n+import re\n import string\n from importlib.metadata import version\n from pathlib import Path\n \n+from sphinx.application import Sphinx\n+\n CURRENT_DIR = Path(__file__).parent\n \n \n@@ -29,6 +32,36 @@\n f.write(svg)\n \n \n+def replace_pr_numbers_with_links(content: str) -> str:\n+ \"\"\"Replaces all PR numbers with the corresponding GitHub link.\"\"\"\n+\n+ base_url = \"https://github.com/psf/black/pull/\"\n+ pr_num_regex = re.compile(r\"\\(#(\\d+)\\)\")\n+\n+ def num_to_link(match: re.Match[str]) -> str:\n+ number = match.group(1)\n+ url = f\"{base_url}{number}\"\n+ return f\"([#{number}]({url}))\"\n+\n+ return pr_num_regex.sub(num_to_link, content)\n+\n+\n+def handle_include_read(\n+ app: Sphinx,\n+ relative_path: Path,\n+ parent_docname: str,\n+ content: list[str],\n+) -> None:\n+ \"\"\"Handler for the include-read sphinx event.\"\"\"\n+ if parent_docname == \"change_log\":\n+ content[0] = replace_pr_numbers_with_links(content[0])\n+\n+\n+def setup(app: Sphinx) -> None:\n+ \"\"\"Sets up a minimal sphinx extension.\"\"\"\n+ app.connect(\"include-read\", handle_include_read)\n+\n+\n # Necessary so Click doesn't hit an encode error when called by\n # sphinxcontrib-programoutput on Windows.\n os.putenv(\"pythonioencoding\", \"utf-8\")\n", "issue": "Create URL links to actual PRs rather than simply referencing the PR number\nThe change log is immensely useful, however it makes reference to specific Github PRs and only mentions the PR number without actually linking to the issue.\r\n\r\nI would like for the changelog to actually include links to the issue. It would be of great help to readers to be able to see the contextual discussion for a change, particularly for style changes.\r\n\r\nhttps://black.readthedocs.io/en/stable/change_log.html\r\n\n", "before_files": [{"content": "#\n# Configuration file for the Sphinx documentation builder.\n#\n# This file does only contain a selection of the most common options. For a\n# full list see the documentation:\n# http://www.sphinx-doc.org/en/stable/config\n\n# -- Path setup --------------------------------------------------------------\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\n\nimport os\nimport string\nfrom importlib.metadata import version\nfrom pathlib import Path\n\nCURRENT_DIR = Path(__file__).parent\n\n\ndef make_pypi_svg(version: str) -> None:\n template: Path = CURRENT_DIR / \"_static\" / \"pypi_template.svg\"\n target: Path = CURRENT_DIR / \"_static\" / \"pypi.svg\"\n with open(str(template), encoding=\"utf8\") as f:\n svg: str = string.Template(f.read()).substitute(version=version)\n with open(str(target), \"w\", encoding=\"utf8\") as f:\n f.write(svg)\n\n\n# Necessary so Click doesn't hit an encode error when called by\n# sphinxcontrib-programoutput on Windows.\nos.putenv(\"pythonioencoding\", \"utf-8\")\n\n# -- Project information -----------------------------------------------------\n\nproject = \"Black\"\ncopyright = \"2018-Present, \u0141ukasz Langa and contributors to Black\"\nauthor = \"\u0141ukasz Langa and contributors to Black\"\n\n# Autopopulate version\n# The version, including alpha/beta/rc tags, but not commit hash and datestamps\nrelease = version(\"black\").split(\"+\")[0]\n# The short X.Y version.\nversion = release\nfor sp in \"abcfr\":\n version = version.split(sp)[0]\n\nmake_pypi_svg(release)\n\n\n# -- General configuration ---------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\nneeds_sphinx = \"4.4\"\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n \"sphinx.ext.autodoc\",\n \"sphinx.ext.intersphinx\",\n \"sphinx.ext.napoleon\",\n \"myst_parser\",\n \"sphinxcontrib.programoutput\",\n \"sphinx_copybutton\",\n]\n\n# If you need extensions of a certain version or higher, list them here.\nneeds_extensions = {\"myst_parser\": \"0.13.7\"}\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = [\"_templates\"]\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\nsource_suffix = [\".rst\", \".md\"]\n\n# The master toctree document.\nmaster_doc = \"index\"\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = \"en\"\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path .\n\nexclude_patterns = [\"_build\", \"Thumbs.db\", \".DS_Store\"]\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = \"sphinx\"\n\n# We need headers to be linkable to so ask MyST-Parser to autogenerate anchor IDs for\n# headers up to and including level 3.\nmyst_heading_anchors = 3\n\n# Prettier support formatting some MyST syntax but not all, so let's disable the\n# unsupported yet still enabled by default ones.\nmyst_disable_syntax = [\n \"colon_fence\",\n \"myst_block_break\",\n \"myst_line_comment\",\n \"math_block\",\n]\n\n# Optional MyST Syntaxes\nmyst_enable_extensions = []\n\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\nhtml_theme = \"furo\"\nhtml_logo = \"_static/logo2-readme.png\"\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = [\"_static\"]\n\n# Custom sidebar templates, must be a dictionary that maps document names\n# to template names.\n#\n# The default sidebars (for documents that don't match any pattern) are\n# defined by theme itself. Builtin themes are using these templates by\n# default: ``['localtoc.html', 'relations.html', 'sourcelink.html',\n# 'searchbox.html']``.\n#\n# html_sidebars = {}\n\n\n# -- Options for HTMLHelp output ---------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = \"blackdoc\"\n\n\n# -- Options for LaTeX output ------------------------------------------------\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [(\n master_doc,\n \"black.tex\",\n \"Documentation for Black\",\n \"\u0141ukasz Langa and contributors to Black\",\n \"manual\",\n)]\n\n\n# -- Options for manual page output ------------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [(master_doc, \"black\", \"Documentation for Black\", [author], 1)]\n\n\n# -- Options for Texinfo output ----------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [(\n master_doc,\n \"Black\",\n \"Documentation for Black\",\n author,\n \"Black\",\n \"The uncompromising Python code formatter\",\n \"Miscellaneous\",\n)]\n\n\n# -- Options for Epub output -------------------------------------------------\n\n# Bibliographic Dublin Core info.\nepub_title = project\nepub_author = author\nepub_publisher = author\nepub_copyright = copyright\n\n# The unique identifier of the text. This can be a ISBN number\n# or the project homepage.\n#\n# epub_identifier = ''\n\n# A unique identification for the text.\n#\n# epub_uid = ''\n\n# A list of files that should not be packed into the epub file.\nepub_exclude_files = [\"search.html\"]\n\n\n# -- Extension configuration -------------------------------------------------\n\nautodoc_member_order = \"bysource\"\n\n# -- sphinx-copybutton configuration ----------------------------------------\ncopybutton_prompt_text = (\n r\">>> |\\.\\.\\. |> |\\$ |\\# | In \\[\\d*\\]: | {2,5}\\.\\.\\.: | {5,8}: \"\n)\ncopybutton_prompt_is_regexp = True\ncopybutton_remove_prompts = True\n\n# -- Options for intersphinx extension ---------------------------------------\n\n# Example configuration for intersphinx: refer to the Python standard library.\nintersphinx_mapping = {\"<name>\": (\"https://docs.python.org/3/\", None)}\n", "path": "docs/conf.py"}]}
| 2,763 | 376 |
gh_patches_debug_34968
|
rasdani/github-patches
|
git_diff
|
pytorch__pytorch-2775
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Gradient of zero norm is nan
If a norm is zero, its gradient returns nan:
```python
x = Variable(torch.zeros(1), requires_grad=True)
x.norm().backward()
print x.grad
# Variable containing:
# nan
# [torch.FloatTensor of size 1]
```
Obviously just happening because the gradient divides by the norm, but the (sub)gradient here should probably be zero, or at least not nan, since that will propagate to make all updates nan. Probably low priority, as it's not going to be an issue in 99% of cases, but we're doing a few things with (exact) line searches where this caused a nan to appear, breaking everything downstream.
</issue>
<code>
[start of torch/autograd/_functions/reduce.py]
1 from functools import reduce
2
3 from ..function import Function
4 from ..variable import Variable
5 import torch
6
7
8 class Sum(Function):
9
10 @staticmethod
11 def forward(ctx, input, dim=None, keepdim=None):
12 ctx.dim = dim
13 ctx.keepdim = False if keepdim is None else keepdim
14 ctx.input_size = input.size()
15 if dim is None:
16 return input.new((input.sum(),))
17 else:
18 if keepdim is not None:
19 return input.sum(dim, keepdim=keepdim)
20 else:
21 return input.sum(dim)
22
23 @staticmethod
24 def backward(ctx, grad_output):
25 if ctx.dim is None:
26 return grad_output.expand(ctx.input_size), None, None
27 else:
28 if ctx.keepdim is False and len(ctx.input_size) != 1:
29 grad_output = grad_output.unsqueeze(ctx.dim)
30
31 repeats = [1 for _ in ctx.input_size]
32 repeats[ctx.dim] = ctx.input_size[ctx.dim]
33 return grad_output.repeat(*repeats), None, None
34
35
36 class Prod(Function):
37
38 @staticmethod
39 def forward(ctx, input, dim=None, keepdim=None):
40 ctx.dim = dim
41 ctx.keepdim = False if keepdim is None else keepdim
42 ctx.input_size = input.size()
43 if dim is None:
44 ctx.result = input.prod()
45 ctx.save_for_backward(input)
46 return input.new((ctx.result,))
47 else:
48 if keepdim is not None:
49 output = input.prod(dim, keepdim=keepdim)
50 else:
51 output = input.prod(dim)
52 ctx.save_for_backward(input, output)
53 return output
54
55 @staticmethod
56 def backward(ctx, grad_output):
57 def safe_zeros_backward(inp, dim):
58 # note that the gradient is equivalent to:
59 # cumprod(exclusive, normal) * cumprod(exclusive, reverse), e.g.:
60 # input: [ a, b, c]
61 # cumprod(exclusive, normal): [1 , a, a * b]
62 # cumprod(exclusive, reverse): [b * c, c, 1]
63 # product: [b * c, a * c, a * b]
64 # and this is safe under input with 0s.
65 if inp.size(dim) == 1:
66 return grad_output
67
68 ones_size = torch.Size((inp.size()[:dim] + (1,) + inp.size()[dim + 1:]))
69 ones = Variable(grad_output.data.new(ones_size).fill_(1))
70 exclusive_normal_nocp = torch.cat((ones, inp.narrow(dim, 0, inp.size(dim) - 1)), dim)
71 exclusive_normal = exclusive_normal_nocp.cumprod(dim)
72
73 def reverse_dim(var, dim):
74 index = Variable(torch.arange(var.size(dim) - 1, -1, -1, out=var.data.new().long()))
75 return var.index_select(dim, index)
76
77 narrow_reverse = reverse_dim(inp.narrow(dim, 1, inp.size(dim) - 1), dim)
78 exclusive_reverse_nocp = torch.cat((ones, narrow_reverse), dim)
79 exclusive_reverse = reverse_dim(exclusive_reverse_nocp.cumprod(dim), dim)
80
81 grad_input = grad_output.expand_as(exclusive_normal).mul(exclusive_normal.mul(exclusive_reverse))
82 return grad_input
83
84 if ctx.dim is None:
85 input, = ctx.saved_variables
86 zero_idx = (input.data == 0).nonzero()
87 if zero_idx.dim() == 0:
88 return grad_output.mul(ctx.result).expand_as(input).div(input), None, None
89 elif zero_idx.size(0) > 1:
90 return (grad_output * 0).expand_as(input), None, None
91 else:
92 return safe_zeros_backward(input.contiguous().view(-1), 0).view_as(input), None, None
93
94 else:
95 input, output = ctx.saved_variables
96 dim = ctx.dim if ctx.dim >= 0 else ctx.dim + input.dim()
97 if ctx.keepdim is False and len(ctx.input_size) != 1:
98 grad_output = grad_output.unsqueeze(dim)
99 output = output.unsqueeze(dim)
100
101 zero_mask = input == 0
102 slice_zero_count = zero_mask.sum(dim, True)
103 total_zeros = slice_zero_count.data.sum()
104 if total_zeros == 0:
105 grad_input = grad_output.mul(output).expand_as(input).div(input)
106 else:
107 grad_input = safe_zeros_backward(input, dim)
108
109 return grad_input, None, None
110
111
112 class Mean(Function):
113
114 @staticmethod
115 def forward(ctx, input, dim=None, keepdim=None):
116 ctx.dim = dim
117 ctx.keepdim = False if keepdim is None else keepdim
118 ctx.input_size = input.size()
119 if dim is None:
120 return input.new((input.mean(),))
121 else:
122 if keepdim is not None:
123 return input.mean(dim, keepdim=keepdim)
124 else:
125 return input.mean(dim)
126
127 @staticmethod
128 def backward(ctx, grad_output):
129 if ctx.dim is None:
130 grad_input_val = grad_output / reduce(lambda x, y: x * y, ctx.input_size, 1)
131 return grad_input_val.expand(ctx.input_size), None, None
132 else:
133 if ctx.keepdim is False and len(ctx.input_size) != 1:
134 grad_output = grad_output.unsqueeze(ctx.dim)
135
136 repeats = [1 for _ in ctx.input_size]
137 dim_size = ctx.input_size[ctx.dim]
138 repeats[ctx.dim] = dim_size
139 return grad_output.repeat(*repeats).div_(dim_size), None, None
140
141
142 class _SelectionFunction(Function):
143 has_all_reduce = True
144 # additional_args is prepended before dim when calling the tensor
145 # function. It's a no-op for subclasses other than kthvalue.
146 # kthvalue not only requires us to pass a dim, but also precede it with k.
147
148 @classmethod
149 def forward(cls, ctx, input, dim=None, keepdim=None, additional_args=tuple()):
150 fn = getattr(input, cls.__name__.lower())
151 ctx.dim = dim
152 ctx.keepdim = False if keepdim is None else keepdim
153 ctx.additional_args = additional_args
154 ctx.input_size = input.size()
155 if ctx.dim is None and cls.has_all_reduce:
156 value = fn(*additional_args)
157 ctx.indices_tuple = tuple(input.eq(value).nonzero()[0])
158 return input.new((value,))
159 else:
160 if ctx.dim is None:
161 dim = input.dim() - 1
162 else:
163 dim = ctx.dim
164 args = (dim,)
165 if additional_args:
166 args = additional_args + args
167 if keepdim is not None:
168 output, indices = fn(*args, keepdim=keepdim)
169 else:
170 output, indices = fn(*args)
171 ctx.save_for_backward(indices)
172 ctx.mark_non_differentiable(indices)
173 return output, indices
174
175 @classmethod
176 def backward(cls, ctx, grad_output, grad_indices=None):
177 grad_input = Variable(grad_output.data.new(*ctx.input_size).zero_())
178 if ctx.dim is None and cls.has_all_reduce:
179 grad_input[ctx.indices_tuple] = grad_output
180 else:
181 if ctx.dim is None:
182 dim = len(ctx.input_size) - 1
183 else:
184 dim = ctx.dim
185
186 indices, = ctx.saved_variables
187 if ctx.keepdim is False and len(ctx.input_size) != 1:
188 grad_output = grad_output.unsqueeze(dim)
189 grad_indices = grad_indices.unsqueeze(dim)
190 indices = indices.unsqueeze(dim)
191
192 grad_input.scatter_(dim, indices, grad_output)
193 return grad_input, None, None, None
194
195
196 class Max(_SelectionFunction):
197 pass
198
199
200 class Min(_SelectionFunction):
201 pass
202
203
204 class Mode(_SelectionFunction):
205 has_all_reduce = False
206
207
208 class Median(_SelectionFunction):
209 pass
210
211
212 class Kthvalue(_SelectionFunction):
213 has_all_reduce = False
214
215 @classmethod
216 def forward(cls, ctx, input, k, dim=None, keepdim=None):
217 return super(Kthvalue, cls).forward(ctx, input, dim, keepdim, (k,))
218
219
220 class Norm(Function):
221
222 @staticmethod
223 def forward(ctx, input, p=2, dim=None, keepdim=None):
224 ctx.p = p
225 ctx.dim = dim
226 ctx.keepdim = False if keepdim is None else keepdim
227
228 if dim is None:
229 ctx.norm = input.norm(p)
230 ctx.save_for_backward(input)
231 return input.new((ctx.norm,))
232 else:
233 if keepdim is not None:
234 output = input.norm(p, dim, keepdim=keepdim)
235 else:
236 output = input.norm(p, dim)
237 ctx.save_for_backward(input, output)
238 return output
239
240 @staticmethod
241 def backward(ctx, grad_output):
242 if ctx.dim is None:
243 input, = ctx.saved_variables
244 if ctx.p == 2:
245 scale_v = (grad_output / ctx.norm).expand_as(input)
246 return input.mul(scale_v), None, None, None
247 else:
248 pow = input.abs().pow(ctx.p - 2)
249 scale_v = (grad_output / ctx.norm ** (ctx.p - 1)).expand_as(input)
250 return input.mul(pow).mul(scale_v), None, None, None
251 else:
252 input, output = ctx.saved_variables
253
254 if ctx.keepdim is False and input.dim() != 1:
255 grad_output = grad_output.unsqueeze(ctx.dim)
256 output = output.unsqueeze(ctx.dim)
257
258 big_grad_output = grad_output.expand_as(input)
259 if ctx.p == 2:
260 big_output = output.expand_as(input)
261 return input.mul(big_grad_output).div(big_output), None, None, None
262 else:
263 pow = input.abs().pow(ctx.p - 2)
264 big_output = output.pow(ctx.p - 1).expand_as(input)
265 return input.mul(pow).mul(big_grad_output).div(big_output), None, None, None
266
267
268 # TODO: renorm
269 # TODO: std
270 # TODO: var
271
[end of torch/autograd/_functions/reduce.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/torch/autograd/_functions/reduce.py b/torch/autograd/_functions/reduce.py
--- a/torch/autograd/_functions/reduce.py
+++ b/torch/autograd/_functions/reduce.py
@@ -226,43 +226,34 @@
ctx.keepdim = False if keepdim is None else keepdim
if dim is None:
- ctx.norm = input.norm(p)
- ctx.save_for_backward(input)
- return input.new((ctx.norm,))
+ norm = input.norm(p)
+ output = input.new((norm,))
else:
if keepdim is not None:
output = input.norm(p, dim, keepdim=keepdim)
else:
output = input.norm(p, dim)
- ctx.save_for_backward(input, output)
- return output
+ ctx.save_for_backward(input, output)
+ return output
@staticmethod
def backward(ctx, grad_output):
- if ctx.dim is None:
- input, = ctx.saved_variables
- if ctx.p == 2:
- scale_v = (grad_output / ctx.norm).expand_as(input)
- return input.mul(scale_v), None, None, None
- else:
- pow = input.abs().pow(ctx.p - 2)
- scale_v = (grad_output / ctx.norm ** (ctx.p - 1)).expand_as(input)
- return input.mul(pow).mul(scale_v), None, None, None
+ input, output = ctx.saved_variables
+ if ctx.dim is not None and ctx.keepdim is False and input.dim() != 1:
+ grad_output = grad_output.unsqueeze(ctx.dim)
+ output = output.unsqueeze(ctx.dim)
+
+ if ctx.p == 2:
+ grad_input = input.mul(grad_output).div(output)
else:
- input, output = ctx.saved_variables
+ input_pow = input.abs().pow(ctx.p - 2)
+ output_pow = output.pow(ctx.p - 1)
+ grad_input = input.mul(input_pow).mul(grad_output).div(output_pow)
- if ctx.keepdim is False and input.dim() != 1:
- grad_output = grad_output.unsqueeze(ctx.dim)
- output = output.unsqueeze(ctx.dim)
+ # Special case at 0 where we return a subgradient containing 0
+ grad_input.masked_fill_(output == 0, 0)
- big_grad_output = grad_output.expand_as(input)
- if ctx.p == 2:
- big_output = output.expand_as(input)
- return input.mul(big_grad_output).div(big_output), None, None, None
- else:
- pow = input.abs().pow(ctx.p - 2)
- big_output = output.pow(ctx.p - 1).expand_as(input)
- return input.mul(pow).mul(big_grad_output).div(big_output), None, None, None
+ return grad_input, None, None, None
# TODO: renorm
|
{"golden_diff": "diff --git a/torch/autograd/_functions/reduce.py b/torch/autograd/_functions/reduce.py\n--- a/torch/autograd/_functions/reduce.py\n+++ b/torch/autograd/_functions/reduce.py\n@@ -226,43 +226,34 @@\n ctx.keepdim = False if keepdim is None else keepdim\n \n if dim is None:\n- ctx.norm = input.norm(p)\n- ctx.save_for_backward(input)\n- return input.new((ctx.norm,))\n+ norm = input.norm(p)\n+ output = input.new((norm,))\n else:\n if keepdim is not None:\n output = input.norm(p, dim, keepdim=keepdim)\n else:\n output = input.norm(p, dim)\n- ctx.save_for_backward(input, output)\n- return output\n+ ctx.save_for_backward(input, output)\n+ return output\n \n @staticmethod\n def backward(ctx, grad_output):\n- if ctx.dim is None:\n- input, = ctx.saved_variables\n- if ctx.p == 2:\n- scale_v = (grad_output / ctx.norm).expand_as(input)\n- return input.mul(scale_v), None, None, None\n- else:\n- pow = input.abs().pow(ctx.p - 2)\n- scale_v = (grad_output / ctx.norm ** (ctx.p - 1)).expand_as(input)\n- return input.mul(pow).mul(scale_v), None, None, None\n+ input, output = ctx.saved_variables\n+ if ctx.dim is not None and ctx.keepdim is False and input.dim() != 1:\n+ grad_output = grad_output.unsqueeze(ctx.dim)\n+ output = output.unsqueeze(ctx.dim)\n+\n+ if ctx.p == 2:\n+ grad_input = input.mul(grad_output).div(output)\n else:\n- input, output = ctx.saved_variables\n+ input_pow = input.abs().pow(ctx.p - 2)\n+ output_pow = output.pow(ctx.p - 1)\n+ grad_input = input.mul(input_pow).mul(grad_output).div(output_pow)\n \n- if ctx.keepdim is False and input.dim() != 1:\n- grad_output = grad_output.unsqueeze(ctx.dim)\n- output = output.unsqueeze(ctx.dim)\n+ # Special case at 0 where we return a subgradient containing 0\n+ grad_input.masked_fill_(output == 0, 0)\n \n- big_grad_output = grad_output.expand_as(input)\n- if ctx.p == 2:\n- big_output = output.expand_as(input)\n- return input.mul(big_grad_output).div(big_output), None, None, None\n- else:\n- pow = input.abs().pow(ctx.p - 2)\n- big_output = output.pow(ctx.p - 1).expand_as(input)\n- return input.mul(pow).mul(big_grad_output).div(big_output), None, None, None\n+ return grad_input, None, None, None\n \n \n # TODO: renorm\n", "issue": "Gradient of zero norm is nan\nIf a norm is zero, its gradient returns nan:\r\n\r\n```python\r\nx = Variable(torch.zeros(1), requires_grad=True)\r\nx.norm().backward()\r\nprint x.grad\r\n\r\n# Variable containing:\r\n# nan\r\n# [torch.FloatTensor of size 1]\r\n```\r\n\r\nObviously just happening because the gradient divides by the norm, but the (sub)gradient here should probably be zero, or at least not nan, since that will propagate to make all updates nan. Probably low priority, as it's not going to be an issue in 99% of cases, but we're doing a few things with (exact) line searches where this caused a nan to appear, breaking everything downstream.\r\n\n", "before_files": [{"content": "from functools import reduce\n\nfrom ..function import Function\nfrom ..variable import Variable\nimport torch\n\n\nclass Sum(Function):\n\n @staticmethod\n def forward(ctx, input, dim=None, keepdim=None):\n ctx.dim = dim\n ctx.keepdim = False if keepdim is None else keepdim\n ctx.input_size = input.size()\n if dim is None:\n return input.new((input.sum(),))\n else:\n if keepdim is not None:\n return input.sum(dim, keepdim=keepdim)\n else:\n return input.sum(dim)\n\n @staticmethod\n def backward(ctx, grad_output):\n if ctx.dim is None:\n return grad_output.expand(ctx.input_size), None, None\n else:\n if ctx.keepdim is False and len(ctx.input_size) != 1:\n grad_output = grad_output.unsqueeze(ctx.dim)\n\n repeats = [1 for _ in ctx.input_size]\n repeats[ctx.dim] = ctx.input_size[ctx.dim]\n return grad_output.repeat(*repeats), None, None\n\n\nclass Prod(Function):\n\n @staticmethod\n def forward(ctx, input, dim=None, keepdim=None):\n ctx.dim = dim\n ctx.keepdim = False if keepdim is None else keepdim\n ctx.input_size = input.size()\n if dim is None:\n ctx.result = input.prod()\n ctx.save_for_backward(input)\n return input.new((ctx.result,))\n else:\n if keepdim is not None:\n output = input.prod(dim, keepdim=keepdim)\n else:\n output = input.prod(dim)\n ctx.save_for_backward(input, output)\n return output\n\n @staticmethod\n def backward(ctx, grad_output):\n def safe_zeros_backward(inp, dim):\n # note that the gradient is equivalent to:\n # cumprod(exclusive, normal) * cumprod(exclusive, reverse), e.g.:\n # input: [ a, b, c]\n # cumprod(exclusive, normal): [1 , a, a * b]\n # cumprod(exclusive, reverse): [b * c, c, 1]\n # product: [b * c, a * c, a * b]\n # and this is safe under input with 0s.\n if inp.size(dim) == 1:\n return grad_output\n\n ones_size = torch.Size((inp.size()[:dim] + (1,) + inp.size()[dim + 1:]))\n ones = Variable(grad_output.data.new(ones_size).fill_(1))\n exclusive_normal_nocp = torch.cat((ones, inp.narrow(dim, 0, inp.size(dim) - 1)), dim)\n exclusive_normal = exclusive_normal_nocp.cumprod(dim)\n\n def reverse_dim(var, dim):\n index = Variable(torch.arange(var.size(dim) - 1, -1, -1, out=var.data.new().long()))\n return var.index_select(dim, index)\n\n narrow_reverse = reverse_dim(inp.narrow(dim, 1, inp.size(dim) - 1), dim)\n exclusive_reverse_nocp = torch.cat((ones, narrow_reverse), dim)\n exclusive_reverse = reverse_dim(exclusive_reverse_nocp.cumprod(dim), dim)\n\n grad_input = grad_output.expand_as(exclusive_normal).mul(exclusive_normal.mul(exclusive_reverse))\n return grad_input\n\n if ctx.dim is None:\n input, = ctx.saved_variables\n zero_idx = (input.data == 0).nonzero()\n if zero_idx.dim() == 0:\n return grad_output.mul(ctx.result).expand_as(input).div(input), None, None\n elif zero_idx.size(0) > 1:\n return (grad_output * 0).expand_as(input), None, None\n else:\n return safe_zeros_backward(input.contiguous().view(-1), 0).view_as(input), None, None\n\n else:\n input, output = ctx.saved_variables\n dim = ctx.dim if ctx.dim >= 0 else ctx.dim + input.dim()\n if ctx.keepdim is False and len(ctx.input_size) != 1:\n grad_output = grad_output.unsqueeze(dim)\n output = output.unsqueeze(dim)\n\n zero_mask = input == 0\n slice_zero_count = zero_mask.sum(dim, True)\n total_zeros = slice_zero_count.data.sum()\n if total_zeros == 0:\n grad_input = grad_output.mul(output).expand_as(input).div(input)\n else:\n grad_input = safe_zeros_backward(input, dim)\n\n return grad_input, None, None\n\n\nclass Mean(Function):\n\n @staticmethod\n def forward(ctx, input, dim=None, keepdim=None):\n ctx.dim = dim\n ctx.keepdim = False if keepdim is None else keepdim\n ctx.input_size = input.size()\n if dim is None:\n return input.new((input.mean(),))\n else:\n if keepdim is not None:\n return input.mean(dim, keepdim=keepdim)\n else:\n return input.mean(dim)\n\n @staticmethod\n def backward(ctx, grad_output):\n if ctx.dim is None:\n grad_input_val = grad_output / reduce(lambda x, y: x * y, ctx.input_size, 1)\n return grad_input_val.expand(ctx.input_size), None, None\n else:\n if ctx.keepdim is False and len(ctx.input_size) != 1:\n grad_output = grad_output.unsqueeze(ctx.dim)\n\n repeats = [1 for _ in ctx.input_size]\n dim_size = ctx.input_size[ctx.dim]\n repeats[ctx.dim] = dim_size\n return grad_output.repeat(*repeats).div_(dim_size), None, None\n\n\nclass _SelectionFunction(Function):\n has_all_reduce = True\n # additional_args is prepended before dim when calling the tensor\n # function. It's a no-op for subclasses other than kthvalue.\n # kthvalue not only requires us to pass a dim, but also precede it with k.\n\n @classmethod\n def forward(cls, ctx, input, dim=None, keepdim=None, additional_args=tuple()):\n fn = getattr(input, cls.__name__.lower())\n ctx.dim = dim\n ctx.keepdim = False if keepdim is None else keepdim\n ctx.additional_args = additional_args\n ctx.input_size = input.size()\n if ctx.dim is None and cls.has_all_reduce:\n value = fn(*additional_args)\n ctx.indices_tuple = tuple(input.eq(value).nonzero()[0])\n return input.new((value,))\n else:\n if ctx.dim is None:\n dim = input.dim() - 1\n else:\n dim = ctx.dim\n args = (dim,)\n if additional_args:\n args = additional_args + args\n if keepdim is not None:\n output, indices = fn(*args, keepdim=keepdim)\n else:\n output, indices = fn(*args)\n ctx.save_for_backward(indices)\n ctx.mark_non_differentiable(indices)\n return output, indices\n\n @classmethod\n def backward(cls, ctx, grad_output, grad_indices=None):\n grad_input = Variable(grad_output.data.new(*ctx.input_size).zero_())\n if ctx.dim is None and cls.has_all_reduce:\n grad_input[ctx.indices_tuple] = grad_output\n else:\n if ctx.dim is None:\n dim = len(ctx.input_size) - 1\n else:\n dim = ctx.dim\n\n indices, = ctx.saved_variables\n if ctx.keepdim is False and len(ctx.input_size) != 1:\n grad_output = grad_output.unsqueeze(dim)\n grad_indices = grad_indices.unsqueeze(dim)\n indices = indices.unsqueeze(dim)\n\n grad_input.scatter_(dim, indices, grad_output)\n return grad_input, None, None, None\n\n\nclass Max(_SelectionFunction):\n pass\n\n\nclass Min(_SelectionFunction):\n pass\n\n\nclass Mode(_SelectionFunction):\n has_all_reduce = False\n\n\nclass Median(_SelectionFunction):\n pass\n\n\nclass Kthvalue(_SelectionFunction):\n has_all_reduce = False\n\n @classmethod\n def forward(cls, ctx, input, k, dim=None, keepdim=None):\n return super(Kthvalue, cls).forward(ctx, input, dim, keepdim, (k,))\n\n\nclass Norm(Function):\n\n @staticmethod\n def forward(ctx, input, p=2, dim=None, keepdim=None):\n ctx.p = p\n ctx.dim = dim\n ctx.keepdim = False if keepdim is None else keepdim\n\n if dim is None:\n ctx.norm = input.norm(p)\n ctx.save_for_backward(input)\n return input.new((ctx.norm,))\n else:\n if keepdim is not None:\n output = input.norm(p, dim, keepdim=keepdim)\n else:\n output = input.norm(p, dim)\n ctx.save_for_backward(input, output)\n return output\n\n @staticmethod\n def backward(ctx, grad_output):\n if ctx.dim is None:\n input, = ctx.saved_variables\n if ctx.p == 2:\n scale_v = (grad_output / ctx.norm).expand_as(input)\n return input.mul(scale_v), None, None, None\n else:\n pow = input.abs().pow(ctx.p - 2)\n scale_v = (grad_output / ctx.norm ** (ctx.p - 1)).expand_as(input)\n return input.mul(pow).mul(scale_v), None, None, None\n else:\n input, output = ctx.saved_variables\n\n if ctx.keepdim is False and input.dim() != 1:\n grad_output = grad_output.unsqueeze(ctx.dim)\n output = output.unsqueeze(ctx.dim)\n\n big_grad_output = grad_output.expand_as(input)\n if ctx.p == 2:\n big_output = output.expand_as(input)\n return input.mul(big_grad_output).div(big_output), None, None, None\n else:\n pow = input.abs().pow(ctx.p - 2)\n big_output = output.pow(ctx.p - 1).expand_as(input)\n return input.mul(pow).mul(big_grad_output).div(big_output), None, None, None\n\n\n# TODO: renorm\n# TODO: std\n# TODO: var\n", "path": "torch/autograd/_functions/reduce.py"}]}
| 3,612 | 658 |
gh_patches_debug_50138
|
rasdani/github-patches
|
git_diff
|
archlinux__archinstall-1322
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Please remove packagekit from GNOME profile
Speaking as the maintainer of GNOME on Arch, please remove packagekit from the `gnome` profile.
It's split out from the rest of gnome-software for a reason - packagekit is utterly unsupported. I've never seen it work reliably and it breaks our assumptions about user attention during upgrades.
</issue>
<code>
[start of profiles/gnome.py]
1 # A desktop environment using "Gnome"
2
3 import archinstall
4
5 is_top_level_profile = False
6
7 # Note: GDM should be part of the gnome group, but adding it here for clarity
8 __packages__ = [
9 "gnome",
10 "gnome-tweaks",
11 "gdm",
12 "gnome-software-packagekit-plugin",
13 ]
14
15
16 def _prep_function(*args, **kwargs):
17 """
18 Magic function called by the importing installer
19 before continuing any further. It also avoids executing any
20 other code in this stage. So it's a safe way to ask the user
21 for more input before any other installer steps start.
22 """
23
24 # Gnome optionally supports xorg, we'll install it since it also
25 # includes graphic driver setups (this might change in the future)
26 profile = archinstall.Profile(None, 'xorg')
27 with profile.load_instructions(namespace='xorg.py') as imported:
28 if hasattr(imported, '_prep_function'):
29 return imported._prep_function()
30 else:
31 print('Deprecated (??): xorg profile has no _prep_function() anymore')
32
33
34 # Ensures that this code only gets executed if executed
35 # through importlib.util.spec_from_file_location("gnome", "/somewhere/gnome.py")
36 # or through conventional import gnome
37 if __name__ == 'gnome':
38 # Install dependency profiles
39 archinstall.storage['installation_session'].install_profile('xorg')
40
41 # Install the GNOME packages
42 archinstall.storage['installation_session'].add_additional_packages(__packages__)
43
44 archinstall.storage['installation_session'].enable_service('gdm') # Gnome Display Manager
45 # We could also start it via xinitrc since we do have Xorg,
46 # but for gnome that's deprecated and wayland is preferred.
47
[end of profiles/gnome.py]
[start of profiles/kde.py]
1 # A desktop environment using "KDE".
2
3 import archinstall
4
5 is_top_level_profile = False
6
7 __packages__ = [
8 "plasma-meta",
9 "konsole",
10 "kwrite",
11 "dolphin",
12 "ark",
13 "sddm",
14 "plasma-wayland-session",
15 "egl-wayland",
16 "packagekit-qt5",
17 ]
18
19
20 # TODO: Remove hard dependency of bash (due to .bash_profile)
21
22
23 def _prep_function(*args, **kwargs):
24 """
25 Magic function called by the importing installer
26 before continuing any further. It also avoids executing any
27 other code in this stage. So it's a safe way to ask the user
28 for more input before any other installer steps start.
29 """
30
31 # KDE requires a functioning Xorg installation.
32 profile = archinstall.Profile(None, 'xorg')
33 with profile.load_instructions(namespace='xorg.py') as imported:
34 if hasattr(imported, '_prep_function'):
35 return imported._prep_function()
36 else:
37 print('Deprecated (??): xorg profile has no _prep_function() anymore')
38
39
40 """
41 def _post_install(*args, **kwargs):
42 if "nvidia" in _gfx_driver_packages:
43 print("Plasma Wayland has known compatibility issues with the proprietary Nvidia driver")
44 print("After booting, you can choose between Wayland and Xorg using the drop-down menu")
45 return True
46 """
47
48 # Ensures that this code only gets executed if executed
49 # through importlib.util.spec_from_file_location("kde", "/somewhere/kde.py")
50 # or through conventional import kde
51 if __name__ == 'kde':
52 # Install dependency profiles
53 archinstall.storage['installation_session'].install_profile('xorg')
54
55 # Install the KDE packages
56 archinstall.storage['installation_session'].add_additional_packages(__packages__)
57
58 # Enable autostart of KDE for all users
59 archinstall.storage['installation_session'].enable_service('sddm')
60
[end of profiles/kde.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/profiles/gnome.py b/profiles/gnome.py
--- a/profiles/gnome.py
+++ b/profiles/gnome.py
@@ -8,8 +8,7 @@
__packages__ = [
"gnome",
"gnome-tweaks",
- "gdm",
- "gnome-software-packagekit-plugin",
+ "gdm"
]
diff --git a/profiles/kde.py b/profiles/kde.py
--- a/profiles/kde.py
+++ b/profiles/kde.py
@@ -12,8 +12,7 @@
"ark",
"sddm",
"plasma-wayland-session",
- "egl-wayland",
- "packagekit-qt5",
+ "egl-wayland"
]
|
{"golden_diff": "diff --git a/profiles/gnome.py b/profiles/gnome.py\n--- a/profiles/gnome.py\n+++ b/profiles/gnome.py\n@@ -8,8 +8,7 @@\n __packages__ = [\n \t\"gnome\",\n \t\"gnome-tweaks\",\n-\t\"gdm\",\n-\t\"gnome-software-packagekit-plugin\",\n+\t\"gdm\"\n ]\n \n \ndiff --git a/profiles/kde.py b/profiles/kde.py\n--- a/profiles/kde.py\n+++ b/profiles/kde.py\n@@ -12,8 +12,7 @@\n \t\"ark\",\n \t\"sddm\",\n \t\"plasma-wayland-session\",\n-\t\"egl-wayland\",\n-\t\"packagekit-qt5\",\n+\t\"egl-wayland\"\n ]\n", "issue": "Please remove packagekit from GNOME profile\nSpeaking as the maintainer of GNOME on Arch, please remove packagekit from the `gnome` profile.\r\n\r\nIt's split out from the rest of gnome-software for a reason - packagekit is utterly unsupported. I've never seen it work reliably and it breaks our assumptions about user attention during upgrades.\n", "before_files": [{"content": "# A desktop environment using \"Gnome\"\n\nimport archinstall\n\nis_top_level_profile = False\n\n# Note: GDM should be part of the gnome group, but adding it here for clarity\n__packages__ = [\n\t\"gnome\",\n\t\"gnome-tweaks\",\n\t\"gdm\",\n\t\"gnome-software-packagekit-plugin\",\n]\n\n\ndef _prep_function(*args, **kwargs):\n\t\"\"\"\n\tMagic function called by the importing installer\n\tbefore continuing any further. It also avoids executing any\n\tother code in this stage. So it's a safe way to ask the user\n\tfor more input before any other installer steps start.\n\t\"\"\"\n\n\t# Gnome optionally supports xorg, we'll install it since it also\n\t# includes graphic driver setups (this might change in the future)\n\tprofile = archinstall.Profile(None, 'xorg')\n\twith profile.load_instructions(namespace='xorg.py') as imported:\n\t\tif hasattr(imported, '_prep_function'):\n\t\t\treturn imported._prep_function()\n\t\telse:\n\t\t\tprint('Deprecated (??): xorg profile has no _prep_function() anymore')\n\n\n# Ensures that this code only gets executed if executed\n# through importlib.util.spec_from_file_location(\"gnome\", \"/somewhere/gnome.py\")\n# or through conventional import gnome\nif __name__ == 'gnome':\n\t# Install dependency profiles\n\tarchinstall.storage['installation_session'].install_profile('xorg')\n\n\t# Install the GNOME packages\n\tarchinstall.storage['installation_session'].add_additional_packages(__packages__)\n\n\tarchinstall.storage['installation_session'].enable_service('gdm') # Gnome Display Manager\n# We could also start it via xinitrc since we do have Xorg,\n# but for gnome that's deprecated and wayland is preferred.\n", "path": "profiles/gnome.py"}, {"content": "# A desktop environment using \"KDE\".\n\nimport archinstall\n\nis_top_level_profile = False\n\n__packages__ = [\n\t\"plasma-meta\",\n\t\"konsole\",\n\t\"kwrite\",\n\t\"dolphin\",\n\t\"ark\",\n\t\"sddm\",\n\t\"plasma-wayland-session\",\n\t\"egl-wayland\",\n\t\"packagekit-qt5\",\n]\n\n\n# TODO: Remove hard dependency of bash (due to .bash_profile)\n\n\ndef _prep_function(*args, **kwargs):\n\t\"\"\"\n\tMagic function called by the importing installer\n\tbefore continuing any further. It also avoids executing any\n\tother code in this stage. So it's a safe way to ask the user\n\tfor more input before any other installer steps start.\n\t\"\"\"\n\n\t# KDE requires a functioning Xorg installation.\n\tprofile = archinstall.Profile(None, 'xorg')\n\twith profile.load_instructions(namespace='xorg.py') as imported:\n\t\tif hasattr(imported, '_prep_function'):\n\t\t\treturn imported._prep_function()\n\t\telse:\n\t\t\tprint('Deprecated (??): xorg profile has no _prep_function() anymore')\n\n\n\"\"\"\ndef _post_install(*args, **kwargs):\n\tif \"nvidia\" in _gfx_driver_packages:\n\t\tprint(\"Plasma Wayland has known compatibility issues with the proprietary Nvidia driver\")\n\tprint(\"After booting, you can choose between Wayland and Xorg using the drop-down menu\")\n\treturn True\n\"\"\"\n\n# Ensures that this code only gets executed if executed\n# through importlib.util.spec_from_file_location(\"kde\", \"/somewhere/kde.py\")\n# or through conventional import kde\nif __name__ == 'kde':\n\t# Install dependency profiles\n\tarchinstall.storage['installation_session'].install_profile('xorg')\n\n\t# Install the KDE packages\n\tarchinstall.storage['installation_session'].add_additional_packages(__packages__)\n\n\t# Enable autostart of KDE for all users\n\tarchinstall.storage['installation_session'].enable_service('sddm')\n", "path": "profiles/kde.py"}]}
| 1,659 | 173 |
gh_patches_debug_29673
|
rasdani/github-patches
|
git_diff
|
CTFd__CTFd-1308
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Re-enable jinja cache
```
@app.before_request
def disable_jinja_cache():
app.jinja_env.cache = {}
```
Explore how we can re-enable the Jinja cache by perhaps storing it on Redis. This may require very custom code.
</issue>
<code>
[start of CTFd/__init__.py]
1 import datetime
2 import os
3 import sys
4 from distutils.version import StrictVersion
5
6 from flask import Flask, Request
7 from flask_migrate import upgrade
8 from jinja2 import FileSystemLoader
9 from jinja2.sandbox import SandboxedEnvironment
10 from six.moves import input
11 from werkzeug.middleware.proxy_fix import ProxyFix
12 from werkzeug.utils import cached_property
13
14 from CTFd import utils
15 from CTFd.plugins import init_plugins
16 from CTFd.utils.crypto import sha256
17 from CTFd.utils.initialization import (
18 init_events,
19 init_logs,
20 init_request_processors,
21 init_template_filters,
22 init_template_globals,
23 )
24 from CTFd.utils.migrations import create_database, migrations, stamp_latest_revision
25 from CTFd.utils.sessions import CachingSessionInterface
26 from CTFd.utils.updates import update_check
27
28 # Hack to support Unicode in Python 2 properly
29 if sys.version_info[0] < 3:
30 reload(sys) # noqa: F821
31 sys.setdefaultencoding("utf-8")
32
33 __version__ = "2.3.2"
34
35
36 class CTFdRequest(Request):
37 @cached_property
38 def path(self):
39 """
40 Hijack the original Flask request path because it does not account for subdirectory deployments in an intuitive
41 manner. We append script_root so that the path always points to the full path as seen in the browser.
42 e.g. /subdirectory/path/route vs /path/route
43
44 :return: string
45 """
46 return self.script_root + super(CTFdRequest, self).path
47
48
49 class CTFdFlask(Flask):
50 def __init__(self, *args, **kwargs):
51 """Overriden Jinja constructor setting a custom jinja_environment"""
52 self.jinja_environment = SandboxedBaseEnvironment
53 self.session_interface = CachingSessionInterface(key_prefix="session")
54 self.request_class = CTFdRequest
55
56 # Store server start time
57 self.start_time = datetime.datetime.utcnow()
58
59 # Create generally unique run identifier
60 self.run_id = sha256(str(self.start_time))[0:8]
61 Flask.__init__(self, *args, **kwargs)
62
63 def create_jinja_environment(self):
64 """Overridden jinja environment constructor"""
65 return super(CTFdFlask, self).create_jinja_environment()
66
67
68 class SandboxedBaseEnvironment(SandboxedEnvironment):
69 """SandboxEnvironment that mimics the Flask BaseEnvironment"""
70
71 def __init__(self, app, **options):
72 if "loader" not in options:
73 options["loader"] = app.create_global_jinja_loader()
74 # Disable cache entirely so that themes can be switched (#662)
75 # If the cache is enabled, switching themes will cause odd rendering errors
76 SandboxedEnvironment.__init__(self, cache_size=0, **options)
77 self.app = app
78
79
80 class ThemeLoader(FileSystemLoader):
81 """Custom FileSystemLoader that switches themes based on the configuration value"""
82
83 def __init__(self, searchpath, encoding="utf-8", followlinks=False):
84 super(ThemeLoader, self).__init__(searchpath, encoding, followlinks)
85 self.overriden_templates = {}
86
87 def get_source(self, environment, template):
88 # Check if the template has been overriden
89 if template in self.overriden_templates:
90 return self.overriden_templates[template], template, True
91
92 # Check if the template requested is for the admin panel
93 if template.startswith("admin/"):
94 template = template[6:] # Strip out admin/
95 template = "/".join(["admin", "templates", template])
96 return super(ThemeLoader, self).get_source(environment, template)
97
98 # Load regular theme data
99 theme = str(utils.get_config("ctf_theme"))
100 template = "/".join([theme, "templates", template])
101 return super(ThemeLoader, self).get_source(environment, template)
102
103
104 def confirm_upgrade():
105 if sys.stdin.isatty():
106 print("/*\\ CTFd has updated and must update the database! /*\\")
107 print("/*\\ Please backup your database before proceeding! /*\\")
108 print("/*\\ CTFd maintainers are not responsible for any data loss! /*\\")
109 if input("Run database migrations (Y/N)").lower().strip() == "y":
110 return True
111 else:
112 print("/*\\ Ignored database migrations... /*\\")
113 return False
114 else:
115 return True
116
117
118 def run_upgrade():
119 upgrade()
120 utils.set_config("ctf_version", __version__)
121
122
123 def create_app(config="CTFd.config.Config"):
124 app = CTFdFlask(__name__)
125 with app.app_context():
126 app.config.from_object(config)
127
128 theme_loader = ThemeLoader(
129 os.path.join(app.root_path, "themes"), followlinks=True
130 )
131 app.jinja_loader = theme_loader
132
133 from CTFd.models import ( # noqa: F401
134 db,
135 Teams,
136 Solves,
137 Challenges,
138 Fails,
139 Flags,
140 Tags,
141 Files,
142 Tracking,
143 )
144
145 url = create_database()
146
147 # This allows any changes to the SQLALCHEMY_DATABASE_URI to get pushed back in
148 # This is mostly so we can force MySQL's charset
149 app.config["SQLALCHEMY_DATABASE_URI"] = str(url)
150
151 # Register database
152 db.init_app(app)
153
154 # Register Flask-Migrate
155 migrations.init_app(app, db)
156
157 # Alembic sqlite support is lacking so we should just create_all anyway
158 if url.drivername.startswith("sqlite"):
159 db.create_all()
160 stamp_latest_revision()
161 else:
162 # This creates tables instead of db.create_all()
163 # Allows migrations to happen properly
164 upgrade()
165
166 from CTFd.models import ma
167
168 ma.init_app(app)
169
170 app.db = db
171 app.VERSION = __version__
172
173 from CTFd.cache import cache
174
175 cache.init_app(app)
176 app.cache = cache
177
178 reverse_proxy = app.config.get("REVERSE_PROXY")
179 if reverse_proxy:
180 if type(reverse_proxy) is str and "," in reverse_proxy:
181 proxyfix_args = [int(i) for i in reverse_proxy.split(",")]
182 app.wsgi_app = ProxyFix(app.wsgi_app, None, *proxyfix_args)
183 else:
184 app.wsgi_app = ProxyFix(
185 app.wsgi_app,
186 num_proxies=None,
187 x_for=1,
188 x_proto=1,
189 x_host=1,
190 x_port=1,
191 x_prefix=1,
192 )
193
194 version = utils.get_config("ctf_version")
195
196 # Upgrading from an older version of CTFd
197 if version and (StrictVersion(version) < StrictVersion(__version__)):
198 if confirm_upgrade():
199 run_upgrade()
200 else:
201 exit()
202
203 if not version:
204 utils.set_config("ctf_version", __version__)
205
206 if not utils.get_config("ctf_theme"):
207 utils.set_config("ctf_theme", "core")
208
209 update_check(force=True)
210
211 init_request_processors(app)
212 init_template_filters(app)
213 init_template_globals(app)
214
215 # Importing here allows tests to use sensible names (e.g. api instead of api_bp)
216 from CTFd.views import views
217 from CTFd.teams import teams
218 from CTFd.users import users
219 from CTFd.challenges import challenges
220 from CTFd.scoreboard import scoreboard
221 from CTFd.auth import auth
222 from CTFd.admin import admin
223 from CTFd.api import api
224 from CTFd.events import events
225 from CTFd.errors import page_not_found, forbidden, general_error, gateway_error
226
227 app.register_blueprint(views)
228 app.register_blueprint(teams)
229 app.register_blueprint(users)
230 app.register_blueprint(challenges)
231 app.register_blueprint(scoreboard)
232 app.register_blueprint(auth)
233 app.register_blueprint(api)
234 app.register_blueprint(events)
235
236 app.register_blueprint(admin)
237
238 app.register_error_handler(404, page_not_found)
239 app.register_error_handler(403, forbidden)
240 app.register_error_handler(500, general_error)
241 app.register_error_handler(502, gateway_error)
242
243 init_logs(app)
244 init_events(app)
245 init_plugins(app)
246
247 return app
248
[end of CTFd/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/CTFd/__init__.py b/CTFd/__init__.py
--- a/CTFd/__init__.py
+++ b/CTFd/__init__.py
@@ -1,6 +1,7 @@
import datetime
import os
import sys
+import weakref
from distutils.version import StrictVersion
from flask import Flask, Request
@@ -71,11 +72,33 @@
def __init__(self, app, **options):
if "loader" not in options:
options["loader"] = app.create_global_jinja_loader()
- # Disable cache entirely so that themes can be switched (#662)
- # If the cache is enabled, switching themes will cause odd rendering errors
- SandboxedEnvironment.__init__(self, cache_size=0, **options)
+ SandboxedEnvironment.__init__(self, **options)
self.app = app
+ def _load_template(self, name, globals):
+ if self.loader is None:
+ raise TypeError("no loader for this environment specified")
+
+ # Add theme to the LRUCache cache key
+ cache_name = name
+ if name.startswith("admin/") is False:
+ theme = str(utils.get_config("ctf_theme"))
+ cache_name = theme + "/" + name
+
+ # Rest of this code is copied from Jinja
+ # https://github.com/pallets/jinja/blob/master/src/jinja2/environment.py#L802-L815
+ cache_key = (weakref.ref(self.loader), cache_name)
+ if self.cache is not None:
+ template = self.cache.get(cache_key)
+ if template is not None and (
+ not self.auto_reload or template.is_up_to_date
+ ):
+ return template
+ template = self.loader.load(self, name, globals)
+ if self.cache is not None:
+ self.cache[cache_key] = template
+ return template
+
class ThemeLoader(FileSystemLoader):
"""Custom FileSystemLoader that switches themes based on the configuration value"""
|
{"golden_diff": "diff --git a/CTFd/__init__.py b/CTFd/__init__.py\n--- a/CTFd/__init__.py\n+++ b/CTFd/__init__.py\n@@ -1,6 +1,7 @@\n import datetime\n import os\n import sys\n+import weakref\n from distutils.version import StrictVersion\n \n from flask import Flask, Request\n@@ -71,11 +72,33 @@\n def __init__(self, app, **options):\n if \"loader\" not in options:\n options[\"loader\"] = app.create_global_jinja_loader()\n- # Disable cache entirely so that themes can be switched (#662)\n- # If the cache is enabled, switching themes will cause odd rendering errors\n- SandboxedEnvironment.__init__(self, cache_size=0, **options)\n+ SandboxedEnvironment.__init__(self, **options)\n self.app = app\n \n+ def _load_template(self, name, globals):\n+ if self.loader is None:\n+ raise TypeError(\"no loader for this environment specified\")\n+\n+ # Add theme to the LRUCache cache key\n+ cache_name = name\n+ if name.startswith(\"admin/\") is False:\n+ theme = str(utils.get_config(\"ctf_theme\"))\n+ cache_name = theme + \"/\" + name\n+\n+ # Rest of this code is copied from Jinja\n+ # https://github.com/pallets/jinja/blob/master/src/jinja2/environment.py#L802-L815\n+ cache_key = (weakref.ref(self.loader), cache_name)\n+ if self.cache is not None:\n+ template = self.cache.get(cache_key)\n+ if template is not None and (\n+ not self.auto_reload or template.is_up_to_date\n+ ):\n+ return template\n+ template = self.loader.load(self, name, globals)\n+ if self.cache is not None:\n+ self.cache[cache_key] = template\n+ return template\n+\n \n class ThemeLoader(FileSystemLoader):\n \"\"\"Custom FileSystemLoader that switches themes based on the configuration value\"\"\"\n", "issue": "Re-enable jinja cache\n```\r\n @app.before_request\r\n def disable_jinja_cache():\r\n app.jinja_env.cache = {}\r\n```\r\n\r\nExplore how we can re-enable the Jinja cache by perhaps storing it on Redis. This may require very custom code. \n", "before_files": [{"content": "import datetime\nimport os\nimport sys\nfrom distutils.version import StrictVersion\n\nfrom flask import Flask, Request\nfrom flask_migrate import upgrade\nfrom jinja2 import FileSystemLoader\nfrom jinja2.sandbox import SandboxedEnvironment\nfrom six.moves import input\nfrom werkzeug.middleware.proxy_fix import ProxyFix\nfrom werkzeug.utils import cached_property\n\nfrom CTFd import utils\nfrom CTFd.plugins import init_plugins\nfrom CTFd.utils.crypto import sha256\nfrom CTFd.utils.initialization import (\n init_events,\n init_logs,\n init_request_processors,\n init_template_filters,\n init_template_globals,\n)\nfrom CTFd.utils.migrations import create_database, migrations, stamp_latest_revision\nfrom CTFd.utils.sessions import CachingSessionInterface\nfrom CTFd.utils.updates import update_check\n\n# Hack to support Unicode in Python 2 properly\nif sys.version_info[0] < 3:\n reload(sys) # noqa: F821\n sys.setdefaultencoding(\"utf-8\")\n\n__version__ = \"2.3.2\"\n\n\nclass CTFdRequest(Request):\n @cached_property\n def path(self):\n \"\"\"\n Hijack the original Flask request path because it does not account for subdirectory deployments in an intuitive\n manner. We append script_root so that the path always points to the full path as seen in the browser.\n e.g. /subdirectory/path/route vs /path/route\n\n :return: string\n \"\"\"\n return self.script_root + super(CTFdRequest, self).path\n\n\nclass CTFdFlask(Flask):\n def __init__(self, *args, **kwargs):\n \"\"\"Overriden Jinja constructor setting a custom jinja_environment\"\"\"\n self.jinja_environment = SandboxedBaseEnvironment\n self.session_interface = CachingSessionInterface(key_prefix=\"session\")\n self.request_class = CTFdRequest\n\n # Store server start time\n self.start_time = datetime.datetime.utcnow()\n\n # Create generally unique run identifier\n self.run_id = sha256(str(self.start_time))[0:8]\n Flask.__init__(self, *args, **kwargs)\n\n def create_jinja_environment(self):\n \"\"\"Overridden jinja environment constructor\"\"\"\n return super(CTFdFlask, self).create_jinja_environment()\n\n\nclass SandboxedBaseEnvironment(SandboxedEnvironment):\n \"\"\"SandboxEnvironment that mimics the Flask BaseEnvironment\"\"\"\n\n def __init__(self, app, **options):\n if \"loader\" not in options:\n options[\"loader\"] = app.create_global_jinja_loader()\n # Disable cache entirely so that themes can be switched (#662)\n # If the cache is enabled, switching themes will cause odd rendering errors\n SandboxedEnvironment.__init__(self, cache_size=0, **options)\n self.app = app\n\n\nclass ThemeLoader(FileSystemLoader):\n \"\"\"Custom FileSystemLoader that switches themes based on the configuration value\"\"\"\n\n def __init__(self, searchpath, encoding=\"utf-8\", followlinks=False):\n super(ThemeLoader, self).__init__(searchpath, encoding, followlinks)\n self.overriden_templates = {}\n\n def get_source(self, environment, template):\n # Check if the template has been overriden\n if template in self.overriden_templates:\n return self.overriden_templates[template], template, True\n\n # Check if the template requested is for the admin panel\n if template.startswith(\"admin/\"):\n template = template[6:] # Strip out admin/\n template = \"/\".join([\"admin\", \"templates\", template])\n return super(ThemeLoader, self).get_source(environment, template)\n\n # Load regular theme data\n theme = str(utils.get_config(\"ctf_theme\"))\n template = \"/\".join([theme, \"templates\", template])\n return super(ThemeLoader, self).get_source(environment, template)\n\n\ndef confirm_upgrade():\n if sys.stdin.isatty():\n print(\"/*\\\\ CTFd has updated and must update the database! /*\\\\\")\n print(\"/*\\\\ Please backup your database before proceeding! /*\\\\\")\n print(\"/*\\\\ CTFd maintainers are not responsible for any data loss! /*\\\\\")\n if input(\"Run database migrations (Y/N)\").lower().strip() == \"y\":\n return True\n else:\n print(\"/*\\\\ Ignored database migrations... /*\\\\\")\n return False\n else:\n return True\n\n\ndef run_upgrade():\n upgrade()\n utils.set_config(\"ctf_version\", __version__)\n\n\ndef create_app(config=\"CTFd.config.Config\"):\n app = CTFdFlask(__name__)\n with app.app_context():\n app.config.from_object(config)\n\n theme_loader = ThemeLoader(\n os.path.join(app.root_path, \"themes\"), followlinks=True\n )\n app.jinja_loader = theme_loader\n\n from CTFd.models import ( # noqa: F401\n db,\n Teams,\n Solves,\n Challenges,\n Fails,\n Flags,\n Tags,\n Files,\n Tracking,\n )\n\n url = create_database()\n\n # This allows any changes to the SQLALCHEMY_DATABASE_URI to get pushed back in\n # This is mostly so we can force MySQL's charset\n app.config[\"SQLALCHEMY_DATABASE_URI\"] = str(url)\n\n # Register database\n db.init_app(app)\n\n # Register Flask-Migrate\n migrations.init_app(app, db)\n\n # Alembic sqlite support is lacking so we should just create_all anyway\n if url.drivername.startswith(\"sqlite\"):\n db.create_all()\n stamp_latest_revision()\n else:\n # This creates tables instead of db.create_all()\n # Allows migrations to happen properly\n upgrade()\n\n from CTFd.models import ma\n\n ma.init_app(app)\n\n app.db = db\n app.VERSION = __version__\n\n from CTFd.cache import cache\n\n cache.init_app(app)\n app.cache = cache\n\n reverse_proxy = app.config.get(\"REVERSE_PROXY\")\n if reverse_proxy:\n if type(reverse_proxy) is str and \",\" in reverse_proxy:\n proxyfix_args = [int(i) for i in reverse_proxy.split(\",\")]\n app.wsgi_app = ProxyFix(app.wsgi_app, None, *proxyfix_args)\n else:\n app.wsgi_app = ProxyFix(\n app.wsgi_app,\n num_proxies=None,\n x_for=1,\n x_proto=1,\n x_host=1,\n x_port=1,\n x_prefix=1,\n )\n\n version = utils.get_config(\"ctf_version\")\n\n # Upgrading from an older version of CTFd\n if version and (StrictVersion(version) < StrictVersion(__version__)):\n if confirm_upgrade():\n run_upgrade()\n else:\n exit()\n\n if not version:\n utils.set_config(\"ctf_version\", __version__)\n\n if not utils.get_config(\"ctf_theme\"):\n utils.set_config(\"ctf_theme\", \"core\")\n\n update_check(force=True)\n\n init_request_processors(app)\n init_template_filters(app)\n init_template_globals(app)\n\n # Importing here allows tests to use sensible names (e.g. api instead of api_bp)\n from CTFd.views import views\n from CTFd.teams import teams\n from CTFd.users import users\n from CTFd.challenges import challenges\n from CTFd.scoreboard import scoreboard\n from CTFd.auth import auth\n from CTFd.admin import admin\n from CTFd.api import api\n from CTFd.events import events\n from CTFd.errors import page_not_found, forbidden, general_error, gateway_error\n\n app.register_blueprint(views)\n app.register_blueprint(teams)\n app.register_blueprint(users)\n app.register_blueprint(challenges)\n app.register_blueprint(scoreboard)\n app.register_blueprint(auth)\n app.register_blueprint(api)\n app.register_blueprint(events)\n\n app.register_blueprint(admin)\n\n app.register_error_handler(404, page_not_found)\n app.register_error_handler(403, forbidden)\n app.register_error_handler(500, general_error)\n app.register_error_handler(502, gateway_error)\n\n init_logs(app)\n init_events(app)\n init_plugins(app)\n\n return app\n", "path": "CTFd/__init__.py"}]}
| 3,044 | 455 |
gh_patches_debug_11001
|
rasdani/github-patches
|
git_diff
|
MycroftAI__mycroft-core-235
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
"Whats" is not parsed out when searching WolframAlpha
`what is a dog` results in `I am searching for a dog` whereas `Whats a dog` results in `I am searching for whats a dog`.
</issue>
<code>
[start of mycroft/skills/wolfram_alpha/__init__.py]
1 # Copyright 2016 Mycroft AI, Inc.
2 #
3 # This file is part of Mycroft Core.
4 #
5 # Mycroft Core is free software: you can redistribute it and/or modify
6 # it under the terms of the GNU General Public License as published by
7 # the Free Software Foundation, either version 3 of the License, or
8 # (at your option) any later version.
9 #
10 # Mycroft Core is distributed in the hope that it will be useful,
11 # but WITHOUT ANY WARRANTY; without even the implied warranty of
12 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
13 # GNU General Public License for more details.
14 #
15 # You should have received a copy of the GNU General Public License
16 # along with Mycroft Core. If not, see <http://www.gnu.org/licenses/>.
17
18
19 from StringIO import StringIO
20 from os.path import dirname
21
22 import re
23 import requests
24 import wolframalpha
25 from six.moves import urllib
26
27 from mycroft.identity import IdentityManager
28 from mycroft.skills.core import MycroftSkill
29 from mycroft.util import CerberusAccessDenied
30 from mycroft.util.log import getLogger
31
32 __author__ = 'seanfitz'
33
34 logger = getLogger(__name__)
35
36
37 class EnglishQuestionParser(object):
38 """
39 Poor-man's english question parser. Not even close to conclusive, but
40 appears to construct some decent w|a queries and responses.
41 """
42
43 def __init__(self):
44 self.regexes = [
45 re.compile(
46 ".*(?P<QuestionWord>who|what|when|where|why|which) "
47 "(?P<Query1>.*) (?P<QuestionVerb>is|are|was|were) "
48 "(?P<Query2>.*)"),
49 re.compile(
50 ".*(?P<QuestionWord>who|what|when|where|why|which) "
51 "(?P<QuestionVerb>\w+) (?P<Query>.*)")
52 ]
53
54 def _normalize(self, groupdict):
55 if 'Query' in groupdict:
56 return groupdict
57 elif 'Query1' and 'Query2' in groupdict:
58 return {
59 'QuestionWord': groupdict.get('QuestionWord'),
60 'QuestionVerb': groupdict.get('QuestionVerb'),
61 'Query': ' '.join([groupdict.get('Query1'), groupdict.get(
62 'Query2')])
63 }
64
65 def parse(self, utterance):
66 for regex in self.regexes:
67 match = regex.match(utterance)
68 if match:
69 return self._normalize(match.groupdict())
70 return None
71
72
73 class CerberusWolframAlphaClient(object):
74 """
75 Wolfram|Alpha v2.0 client
76 """
77
78 def query(self, query):
79 """
80 Query Wolfram|Alpha with query using the v2.0 API
81 """
82 identity = IdentityManager().get()
83 bearer_token = 'Bearer %s:%s' % (identity.device_id, identity.token)
84 query = urllib.parse.urlencode(dict(input=query))
85 url = 'https://cerberus.mycroft.ai/wolframalpha/v2/query?' + query
86 headers = {'Authorization': bearer_token}
87 response = requests.get(url, headers=headers)
88 if response.status_code == 401:
89 raise CerberusAccessDenied()
90 logger.debug(response.content)
91 return wolframalpha.Result(StringIO(response.content))
92
93
94 class WolframAlphaSkill(MycroftSkill):
95 def __init__(self):
96 MycroftSkill.__init__(self, name="WolframAlphaSkill")
97 self.__init_client()
98 self.question_parser = EnglishQuestionParser()
99
100 def __init_client(self):
101 key = self.config.get('api_key')
102 if key:
103 self.client = wolframalpha.Client(key)
104 else:
105 self.client = CerberusWolframAlphaClient()
106
107 def initialize(self):
108 self.init_dialog(dirname(__file__))
109 self.emitter.on('intent_failure', self.handle_fallback)
110
111 def get_result(self, res):
112 result = None
113 try:
114 result = next(res.results).text
115 return result
116 except:
117 try:
118 result = self.__find_pod_id(res.pods, 'Value')
119 if not result:
120 result = self.__find_pod_id(
121 res.pods, 'NotableFacts:PeopleData')
122 if not result:
123 result = self.__find_pod_id(
124 res.pods, 'BasicInformation:PeopleData')
125 if not result:
126 result = self.__find_pod_id(res.pods, 'Definition')
127 if not result:
128 result = self.__find_pod_id(
129 res.pods, 'DecimalApproximation')
130 if result:
131 result = result[:5]
132 else:
133 result = self.__find_num(
134 res.pods, '200')
135 return result
136 except:
137 return result
138
139 def handle_fallback(self, message):
140 logger.debug(
141 "Could not determine intent, falling back to WolframAlpha Skill!")
142 utterance = message.metadata.get('utterance')
143 parsed_question = self.question_parser.parse(utterance)
144
145 # biding some time
146 if parsed_question:
147 self.speak("I am searching for " + parsed_question.get('Query'))
148 else:
149 self.speak("I am searching for " + utterance)
150 query = utterance
151 if parsed_question:
152 query = "%s %s %s" % (parsed_question.get('QuestionWord'),
153 parsed_question.get('QuestionVerb'),
154 parsed_question.get('Query'))
155
156 try:
157 res = self.client.query(query)
158 result = self.get_result(res)
159 except CerberusAccessDenied as e:
160 self.speak_dialog('not.paired')
161 return
162 except Exception as e:
163 logger.exception(e)
164 self.speak("Sorry, I don't understand your request.")
165 return
166
167 if result:
168 input_interpretation = self.__find_pod_id(res.pods, 'Input')
169 verb = "is"
170 structured_syntax_regex = re.compile(".*(\||\[|\\\\|\]).*")
171 if parsed_question:
172 if not input_interpretation or structured_syntax_regex.match(
173 input_interpretation):
174 input_interpretation = parsed_question.get('Query')
175 verb = parsed_question.get('QuestionVerb')
176
177 if "|" in result: # Assuming "|" indicates a list of items
178 verb = ":"
179
180 result = self.process_wolfram_string(result)
181 input_interpretation = \
182 self.process_wolfram_string(input_interpretation)
183 response = "%s %s %s" % (input_interpretation, verb, result)
184
185 self.speak(response)
186 else:
187 self.speak("Sorry, I don't understand your request.")
188
189 @staticmethod
190 def __find_pod_id(pods, pod_id):
191 for pod in pods:
192 if pod_id in pod.id:
193 return pod.text
194 return None
195
196 @staticmethod
197 def process_wolfram_string(text):
198 # Remove extra whitespace
199 text = re.sub(r" \s+", r" ", text)
200
201 # Convert | symbols to commas
202 text = re.sub(r" \| ", r", ", text)
203
204 # Convert newlines to commas
205 text = re.sub(r"\n", r", ", text)
206
207 # Convert !s to factorial
208 text = re.sub(r"!", r",factorial", text)
209 return text
210
211 @staticmethod
212 def __find_num(pods, pod_num):
213 for pod in pods:
214 if pod.node.attrib['position'] == pod_num:
215 return pod.text
216 return None
217
218 def stop(self):
219 pass
220
221
222 def create_skill():
223 return WolframAlphaSkill()
224
[end of mycroft/skills/wolfram_alpha/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mycroft/skills/wolfram_alpha/__init__.py b/mycroft/skills/wolfram_alpha/__init__.py
--- a/mycroft/skills/wolfram_alpha/__init__.py
+++ b/mycroft/skills/wolfram_alpha/__init__.py
@@ -46,6 +46,9 @@
".*(?P<QuestionWord>who|what|when|where|why|which) "
"(?P<Query1>.*) (?P<QuestionVerb>is|are|was|were) "
"(?P<Query2>.*)"),
+ re.compile(
+ ".*(?P<QuestionWord>what)(?P<QuestionVerb>\'s|s) "
+ "(?P<Query>.*)"),
re.compile(
".*(?P<QuestionWord>who|what|when|where|why|which) "
"(?P<QuestionVerb>\w+) (?P<Query>.*)")
|
{"golden_diff": "diff --git a/mycroft/skills/wolfram_alpha/__init__.py b/mycroft/skills/wolfram_alpha/__init__.py\n--- a/mycroft/skills/wolfram_alpha/__init__.py\n+++ b/mycroft/skills/wolfram_alpha/__init__.py\n@@ -46,6 +46,9 @@\n \".*(?P<QuestionWord>who|what|when|where|why|which) \"\n \"(?P<Query1>.*) (?P<QuestionVerb>is|are|was|were) \"\n \"(?P<Query2>.*)\"),\n+ re.compile(\n+ \".*(?P<QuestionWord>what)(?P<QuestionVerb>\\'s|s) \"\n+ \"(?P<Query>.*)\"),\n re.compile(\n \".*(?P<QuestionWord>who|what|when|where|why|which) \"\n \"(?P<QuestionVerb>\\w+) (?P<Query>.*)\")\n", "issue": "\"Whats\" is not parsed out when searching WolframAlpha\n`what is a dog` results in `I am searching for a dog` whereas `Whats a dog` results in `I am searching for whats a dog`.\n\n", "before_files": [{"content": "# Copyright 2016 Mycroft AI, Inc.\n#\n# This file is part of Mycroft Core.\n#\n# Mycroft Core is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Mycroft Core is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Mycroft Core. If not, see <http://www.gnu.org/licenses/>.\n\n\nfrom StringIO import StringIO\nfrom os.path import dirname\n\nimport re\nimport requests\nimport wolframalpha\nfrom six.moves import urllib\n\nfrom mycroft.identity import IdentityManager\nfrom mycroft.skills.core import MycroftSkill\nfrom mycroft.util import CerberusAccessDenied\nfrom mycroft.util.log import getLogger\n\n__author__ = 'seanfitz'\n\nlogger = getLogger(__name__)\n\n\nclass EnglishQuestionParser(object):\n \"\"\"\n Poor-man's english question parser. Not even close to conclusive, but\n appears to construct some decent w|a queries and responses.\n \"\"\"\n\n def __init__(self):\n self.regexes = [\n re.compile(\n \".*(?P<QuestionWord>who|what|when|where|why|which) \"\n \"(?P<Query1>.*) (?P<QuestionVerb>is|are|was|were) \"\n \"(?P<Query2>.*)\"),\n re.compile(\n \".*(?P<QuestionWord>who|what|when|where|why|which) \"\n \"(?P<QuestionVerb>\\w+) (?P<Query>.*)\")\n ]\n\n def _normalize(self, groupdict):\n if 'Query' in groupdict:\n return groupdict\n elif 'Query1' and 'Query2' in groupdict:\n return {\n 'QuestionWord': groupdict.get('QuestionWord'),\n 'QuestionVerb': groupdict.get('QuestionVerb'),\n 'Query': ' '.join([groupdict.get('Query1'), groupdict.get(\n 'Query2')])\n }\n\n def parse(self, utterance):\n for regex in self.regexes:\n match = regex.match(utterance)\n if match:\n return self._normalize(match.groupdict())\n return None\n\n\nclass CerberusWolframAlphaClient(object):\n \"\"\"\n Wolfram|Alpha v2.0 client\n \"\"\"\n\n def query(self, query):\n \"\"\"\n Query Wolfram|Alpha with query using the v2.0 API\n \"\"\"\n identity = IdentityManager().get()\n bearer_token = 'Bearer %s:%s' % (identity.device_id, identity.token)\n query = urllib.parse.urlencode(dict(input=query))\n url = 'https://cerberus.mycroft.ai/wolframalpha/v2/query?' + query\n headers = {'Authorization': bearer_token}\n response = requests.get(url, headers=headers)\n if response.status_code == 401:\n raise CerberusAccessDenied()\n logger.debug(response.content)\n return wolframalpha.Result(StringIO(response.content))\n\n\nclass WolframAlphaSkill(MycroftSkill):\n def __init__(self):\n MycroftSkill.__init__(self, name=\"WolframAlphaSkill\")\n self.__init_client()\n self.question_parser = EnglishQuestionParser()\n\n def __init_client(self):\n key = self.config.get('api_key')\n if key:\n self.client = wolframalpha.Client(key)\n else:\n self.client = CerberusWolframAlphaClient()\n\n def initialize(self):\n self.init_dialog(dirname(__file__))\n self.emitter.on('intent_failure', self.handle_fallback)\n\n def get_result(self, res):\n result = None\n try:\n result = next(res.results).text\n return result\n except:\n try:\n result = self.__find_pod_id(res.pods, 'Value')\n if not result:\n result = self.__find_pod_id(\n res.pods, 'NotableFacts:PeopleData')\n if not result:\n result = self.__find_pod_id(\n res.pods, 'BasicInformation:PeopleData')\n if not result:\n result = self.__find_pod_id(res.pods, 'Definition')\n if not result:\n result = self.__find_pod_id(\n res.pods, 'DecimalApproximation')\n if result:\n result = result[:5]\n else:\n result = self.__find_num(\n res.pods, '200')\n return result\n except:\n return result\n\n def handle_fallback(self, message):\n logger.debug(\n \"Could not determine intent, falling back to WolframAlpha Skill!\")\n utterance = message.metadata.get('utterance')\n parsed_question = self.question_parser.parse(utterance)\n\n # biding some time\n if parsed_question:\n self.speak(\"I am searching for \" + parsed_question.get('Query'))\n else:\n self.speak(\"I am searching for \" + utterance)\n query = utterance\n if parsed_question:\n query = \"%s %s %s\" % (parsed_question.get('QuestionWord'),\n parsed_question.get('QuestionVerb'),\n parsed_question.get('Query'))\n\n try:\n res = self.client.query(query)\n result = self.get_result(res)\n except CerberusAccessDenied as e:\n self.speak_dialog('not.paired')\n return\n except Exception as e:\n logger.exception(e)\n self.speak(\"Sorry, I don't understand your request.\")\n return\n\n if result:\n input_interpretation = self.__find_pod_id(res.pods, 'Input')\n verb = \"is\"\n structured_syntax_regex = re.compile(\".*(\\||\\[|\\\\\\\\|\\]).*\")\n if parsed_question:\n if not input_interpretation or structured_syntax_regex.match(\n input_interpretation):\n input_interpretation = parsed_question.get('Query')\n verb = parsed_question.get('QuestionVerb')\n\n if \"|\" in result: # Assuming \"|\" indicates a list of items\n verb = \":\"\n\n result = self.process_wolfram_string(result)\n input_interpretation = \\\n self.process_wolfram_string(input_interpretation)\n response = \"%s %s %s\" % (input_interpretation, verb, result)\n\n self.speak(response)\n else:\n self.speak(\"Sorry, I don't understand your request.\")\n\n @staticmethod\n def __find_pod_id(pods, pod_id):\n for pod in pods:\n if pod_id in pod.id:\n return pod.text\n return None\n\n @staticmethod\n def process_wolfram_string(text):\n # Remove extra whitespace\n text = re.sub(r\" \\s+\", r\" \", text)\n\n # Convert | symbols to commas\n text = re.sub(r\" \\| \", r\", \", text)\n\n # Convert newlines to commas\n text = re.sub(r\"\\n\", r\", \", text)\n\n # Convert !s to factorial\n text = re.sub(r\"!\", r\",factorial\", text)\n return text\n\n @staticmethod\n def __find_num(pods, pod_num):\n for pod in pods:\n if pod.node.attrib['position'] == pod_num:\n return pod.text\n return None\n\n def stop(self):\n pass\n\n\ndef create_skill():\n return WolframAlphaSkill()\n", "path": "mycroft/skills/wolfram_alpha/__init__.py"}]}
| 2,825 | 210 |
gh_patches_debug_2200
|
rasdani/github-patches
|
git_diff
|
zigpy__zha-device-handlers-1205
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Support for LIDL Livarno home staande led lamp zigbee
**Feature request.**
This LED Lamp is discovered in HA as a generic light (no Quirk).
- ON/OFF works Okay
- DIM/Level works Okay
- RGB color capability is reported, but not supported by this lamp. it only CCT.
- Color temperaturedoes not work correct.
When i change the color temperature, the LED does change. but not correct.
when putting it to minimal it is cold white (with little bit warm) and putting it to MAX, it become full cold.
While i expect it to be warm (yellow, orange).
LAMP website: https://www.lidl.nl/p/livarno-home-staande-led-lamp-zigbee-smart-home/p100335194
**Describe the solution you'd like**
1. I like to have the RGB detection removed, so it does not show to change the color.
2. I like to have the Color temperature working as it should be.
For solution (1. I have added in the file **/zhaquirks/lidl/cct.py** the following signature:
signature = { MODELS_INFO: [ ("_TZ3000_8uaoilu9", "TS0502A")
That solves the RGB problem.
For solution (2, i have no idea where to even start.
**Device signature - this can be acquired by removing the device from ZHA and pairing it again from the add devices screen. Be sure to add the entire content of the log panel after pairing the device to a code block below this line.**
```{
"node_descriptor": "NodeDescriptor(logical_type=<LogicalType.Router: 1>, complex_descriptor_available=0, user_descriptor_available=0, reserved=0, aps_flags=0, frequency_band=<FrequencyBand.Freq2400MHz: 8>, mac_capability_flags=<MACCapabilityFlags.AllocateAddress|RxOnWhenIdle|MainsPowered|FullFunctionDevice: 142>, manufacturer_code=4098, maximum_buffer_size=82, maximum_incoming_transfer_size=82, server_mask=11264, maximum_outgoing_transfer_size=82, descriptor_capability_field=<DescriptorCapability.NONE: 0>, *allocate_address=True, *is_alternate_pan_coordinator=False, *is_coordinator=False, *is_end_device=False, *is_full_function_device=True, *is_mains_powered=True, *is_receiver_on_when_idle=True, *is_router=True, *is_security_capable=False)",
"endpoints": {
"1": {
"profile_id": 260,
"device_type": "0x010c",
"in_clusters": [
"0x0000",
"0x0003",
"0x0004",
"0x0005",
"0x0006",
"0x0008",
"0x0300",
"0x1000"
],
"out_clusters": [
"0x000a",
"0x0019"
]
},
"242": {
"profile_id": 41440,
"device_type": "0x0061",
"in_clusters": [],
"out_clusters": [
"0x0021"
]
}
},
"manufacturer": "_TZ3000_8uaoilu9",
"model": "TS0502A",
"class": "zhaquirks.lidl.cct.CCTLight"
}```
**Additional context**
If you need any other info / logging, just let me know.
</issue>
<code>
[start of zhaquirks/lidl/cct.py]
1 """Quirk for LIDL CCT bulb."""
2 from zigpy.profiles import zha
3 from zigpy.quirks import CustomCluster, CustomDevice
4 from zigpy.zcl.clusters.general import (
5 Basic,
6 GreenPowerProxy,
7 Groups,
8 Identify,
9 LevelControl,
10 OnOff,
11 Ota,
12 Scenes,
13 Time,
14 )
15 from zigpy.zcl.clusters.lighting import Color
16 from zigpy.zcl.clusters.lightlink import LightLink
17
18 from zhaquirks.const import (
19 DEVICE_TYPE,
20 ENDPOINTS,
21 INPUT_CLUSTERS,
22 MODELS_INFO,
23 OUTPUT_CLUSTERS,
24 PROFILE_ID,
25 )
26
27
28 class LidlCCTColorCluster(CustomCluster, Color):
29 """Lidl CCT Lighting custom cluster."""
30
31 # Remove RGB color wheel for CCT Lighting: only expose color temperature
32 # LIDL bulbs do not correctly report this attribute (comes back as None in Home Assistant)
33 _CONSTANT_ATTRIBUTES = {0x400A: 16}
34
35
36 class CCTLight(CustomDevice):
37 """Lidl CCT Lighting device."""
38
39 signature = {
40 MODELS_INFO: [
41 ("_TZ3000_49qchf10", "TS0502A"),
42 ("_TZ3000_oborybow", "TS0502A"),
43 ("_TZ3000_9evm3otq", "TS0502A"),
44 ("_TZ3000_rylaozuc", "TS0502A"),
45 ("_TZ3000_el5kt5im", "TS0502A"),
46 ("_TZ3000_oh7jddmx", "TS0502A"),
47 ],
48 ENDPOINTS: {
49 1: {
50 # <SimpleDescriptor endpoint=1 profile=260 device_type=268
51 # device_version=1
52 # input_clusters=[0, 3, 4, 5, 6, 8, 768, 4096]
53 # output_clusters=[10, 25]
54 PROFILE_ID: zha.PROFILE_ID,
55 DEVICE_TYPE: zha.DeviceType.COLOR_TEMPERATURE_LIGHT,
56 INPUT_CLUSTERS: [
57 Basic.cluster_id,
58 Identify.cluster_id,
59 Groups.cluster_id,
60 Scenes.cluster_id,
61 OnOff.cluster_id,
62 LevelControl.cluster_id,
63 Color.cluster_id,
64 LightLink.cluster_id,
65 ],
66 OUTPUT_CLUSTERS: [Time.cluster_id, Ota.cluster_id],
67 },
68 242: {
69 # <SimpleDescriptor endpoint=242 profile=41440 device_type=97
70 # device_version=0
71 # input_clusters=[]
72 # output_clusters=[33]
73 PROFILE_ID: 41440,
74 DEVICE_TYPE: 97,
75 INPUT_CLUSTERS: [],
76 OUTPUT_CLUSTERS: [GreenPowerProxy.cluster_id],
77 },
78 },
79 }
80
81 replacement = {
82 ENDPOINTS: {
83 1: {
84 PROFILE_ID: zha.PROFILE_ID,
85 DEVICE_TYPE: zha.DeviceType.COLOR_TEMPERATURE_LIGHT,
86 INPUT_CLUSTERS: [
87 Basic.cluster_id,
88 Identify.cluster_id,
89 Groups.cluster_id,
90 Scenes.cluster_id,
91 OnOff.cluster_id,
92 LevelControl.cluster_id,
93 LidlCCTColorCluster,
94 LightLink.cluster_id,
95 ],
96 OUTPUT_CLUSTERS: [Time.cluster_id, Ota.cluster_id],
97 },
98 242: {
99 PROFILE_ID: 41440,
100 DEVICE_TYPE: 97,
101 INPUT_CLUSTERS: [],
102 OUTPUT_CLUSTERS: [GreenPowerProxy.cluster_id],
103 },
104 }
105 }
106
[end of zhaquirks/lidl/cct.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/zhaquirks/lidl/cct.py b/zhaquirks/lidl/cct.py
--- a/zhaquirks/lidl/cct.py
+++ b/zhaquirks/lidl/cct.py
@@ -44,6 +44,7 @@
("_TZ3000_rylaozuc", "TS0502A"),
("_TZ3000_el5kt5im", "TS0502A"),
("_TZ3000_oh7jddmx", "TS0502A"),
+ ("_TZ3000_8uaoilu9", "TS0502A"),
],
ENDPOINTS: {
1: {
|
{"golden_diff": "diff --git a/zhaquirks/lidl/cct.py b/zhaquirks/lidl/cct.py\n--- a/zhaquirks/lidl/cct.py\n+++ b/zhaquirks/lidl/cct.py\n@@ -44,6 +44,7 @@\n (\"_TZ3000_rylaozuc\", \"TS0502A\"),\n (\"_TZ3000_el5kt5im\", \"TS0502A\"),\n (\"_TZ3000_oh7jddmx\", \"TS0502A\"),\n+ (\"_TZ3000_8uaoilu9\", \"TS0502A\"),\n ],\n ENDPOINTS: {\n 1: {\n", "issue": "Support for LIDL Livarno home staande led lamp zigbee\n**Feature request.**\r\n\r\nThis LED Lamp is discovered in HA as a generic light (no Quirk). \r\n- ON/OFF works Okay\r\n- DIM/Level works Okay\r\n- RGB color capability is reported, but not supported by this lamp. it only CCT. \r\n- Color temperaturedoes not work correct.\r\nWhen i change the color temperature, the LED does change. but not correct. \r\nwhen putting it to minimal it is cold white (with little bit warm) and putting it to MAX, it become full cold.\r\nWhile i expect it to be warm (yellow, orange). \r\n\r\nLAMP website: https://www.lidl.nl/p/livarno-home-staande-led-lamp-zigbee-smart-home/p100335194\r\n\r\n**Describe the solution you'd like**\r\n1. I like to have the RGB detection removed, so it does not show to change the color.\r\n2. I like to have the Color temperature working as it should be.\r\n\r\nFor solution (1. I have added in the file **/zhaquirks/lidl/cct.py** the following signature:\r\nsignature = { MODELS_INFO: [ (\"_TZ3000_8uaoilu9\", \"TS0502A\")\r\nThat solves the RGB problem.\r\n\r\nFor solution (2, i have no idea where to even start.\r\n\r\n**Device signature - this can be acquired by removing the device from ZHA and pairing it again from the add devices screen. Be sure to add the entire content of the log panel after pairing the device to a code block below this line.**\r\n\r\n```{\r\n \"node_descriptor\": \"NodeDescriptor(logical_type=<LogicalType.Router: 1>, complex_descriptor_available=0, user_descriptor_available=0, reserved=0, aps_flags=0, frequency_band=<FrequencyBand.Freq2400MHz: 8>, mac_capability_flags=<MACCapabilityFlags.AllocateAddress|RxOnWhenIdle|MainsPowered|FullFunctionDevice: 142>, manufacturer_code=4098, maximum_buffer_size=82, maximum_incoming_transfer_size=82, server_mask=11264, maximum_outgoing_transfer_size=82, descriptor_capability_field=<DescriptorCapability.NONE: 0>, *allocate_address=True, *is_alternate_pan_coordinator=False, *is_coordinator=False, *is_end_device=False, *is_full_function_device=True, *is_mains_powered=True, *is_receiver_on_when_idle=True, *is_router=True, *is_security_capable=False)\",\r\n \"endpoints\": {\r\n \"1\": {\r\n \"profile_id\": 260,\r\n \"device_type\": \"0x010c\",\r\n \"in_clusters\": [\r\n \"0x0000\",\r\n \"0x0003\",\r\n \"0x0004\",\r\n \"0x0005\",\r\n \"0x0006\",\r\n \"0x0008\",\r\n \"0x0300\",\r\n \"0x1000\"\r\n ],\r\n \"out_clusters\": [\r\n \"0x000a\",\r\n \"0x0019\"\r\n ]\r\n },\r\n \"242\": {\r\n \"profile_id\": 41440,\r\n \"device_type\": \"0x0061\",\r\n \"in_clusters\": [],\r\n \"out_clusters\": [\r\n \"0x0021\"\r\n ]\r\n }\r\n },\r\n \"manufacturer\": \"_TZ3000_8uaoilu9\",\r\n \"model\": \"TS0502A\",\r\n \"class\": \"zhaquirks.lidl.cct.CCTLight\"\r\n}```\r\n\r\n\r\n**Additional context**\r\nIf you need any other info / logging, just let me know.\r\n\r\n\r\n\n", "before_files": [{"content": "\"\"\"Quirk for LIDL CCT bulb.\"\"\"\nfrom zigpy.profiles import zha\nfrom zigpy.quirks import CustomCluster, CustomDevice\nfrom zigpy.zcl.clusters.general import (\n Basic,\n GreenPowerProxy,\n Groups,\n Identify,\n LevelControl,\n OnOff,\n Ota,\n Scenes,\n Time,\n)\nfrom zigpy.zcl.clusters.lighting import Color\nfrom zigpy.zcl.clusters.lightlink import LightLink\n\nfrom zhaquirks.const import (\n DEVICE_TYPE,\n ENDPOINTS,\n INPUT_CLUSTERS,\n MODELS_INFO,\n OUTPUT_CLUSTERS,\n PROFILE_ID,\n)\n\n\nclass LidlCCTColorCluster(CustomCluster, Color):\n \"\"\"Lidl CCT Lighting custom cluster.\"\"\"\n\n # Remove RGB color wheel for CCT Lighting: only expose color temperature\n # LIDL bulbs do not correctly report this attribute (comes back as None in Home Assistant)\n _CONSTANT_ATTRIBUTES = {0x400A: 16}\n\n\nclass CCTLight(CustomDevice):\n \"\"\"Lidl CCT Lighting device.\"\"\"\n\n signature = {\n MODELS_INFO: [\n (\"_TZ3000_49qchf10\", \"TS0502A\"),\n (\"_TZ3000_oborybow\", \"TS0502A\"),\n (\"_TZ3000_9evm3otq\", \"TS0502A\"),\n (\"_TZ3000_rylaozuc\", \"TS0502A\"),\n (\"_TZ3000_el5kt5im\", \"TS0502A\"),\n (\"_TZ3000_oh7jddmx\", \"TS0502A\"),\n ],\n ENDPOINTS: {\n 1: {\n # <SimpleDescriptor endpoint=1 profile=260 device_type=268\n # device_version=1\n # input_clusters=[0, 3, 4, 5, 6, 8, 768, 4096]\n # output_clusters=[10, 25]\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.COLOR_TEMPERATURE_LIGHT,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n Identify.cluster_id,\n Groups.cluster_id,\n Scenes.cluster_id,\n OnOff.cluster_id,\n LevelControl.cluster_id,\n Color.cluster_id,\n LightLink.cluster_id,\n ],\n OUTPUT_CLUSTERS: [Time.cluster_id, Ota.cluster_id],\n },\n 242: {\n # <SimpleDescriptor endpoint=242 profile=41440 device_type=97\n # device_version=0\n # input_clusters=[]\n # output_clusters=[33]\n PROFILE_ID: 41440,\n DEVICE_TYPE: 97,\n INPUT_CLUSTERS: [],\n OUTPUT_CLUSTERS: [GreenPowerProxy.cluster_id],\n },\n },\n }\n\n replacement = {\n ENDPOINTS: {\n 1: {\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.COLOR_TEMPERATURE_LIGHT,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n Identify.cluster_id,\n Groups.cluster_id,\n Scenes.cluster_id,\n OnOff.cluster_id,\n LevelControl.cluster_id,\n LidlCCTColorCluster,\n LightLink.cluster_id,\n ],\n OUTPUT_CLUSTERS: [Time.cluster_id, Ota.cluster_id],\n },\n 242: {\n PROFILE_ID: 41440,\n DEVICE_TYPE: 97,\n INPUT_CLUSTERS: [],\n OUTPUT_CLUSTERS: [GreenPowerProxy.cluster_id],\n },\n }\n }\n", "path": "zhaquirks/lidl/cct.py"}]}
| 2,391 | 165 |
gh_patches_debug_37379
|
rasdani/github-patches
|
git_diff
|
goauthentik__authentik-9094
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
API: Application Pagination only works when user is superuser and { superuser_full_list: true } is passed to the API
**Describe the bug**
This works:
`/api/v3/core/applications/?ordering=name&page=7&page_size=20&search=&superuser_full_list=true`
This does not:
`/api/v3/core/applications/?ordering=name&page=7&page_size=20&search=`
If you pass a page request and do not set `superuser_full_list` _or_ you are not an admin user, you will always only get the first page of results from the Application API for authentik.
**Expected behavior**
The `page=` argument should be respected by the API under all circumstances.
**Version and Deployment (please complete the following information):**
- authentik version: post-2024.2, commit 2196bde820c4f59a128483670960971df073b076
- Deployment: authentik [full development environment](https://docs.goauthentik.io/developer-docs/setup/full-dev-environment)
</issue>
<code>
[start of authentik/core/api/applications.py]
1 """Application API Views"""
2
3 from collections.abc import Iterator
4 from copy import copy
5 from datetime import timedelta
6
7 from django.core.cache import cache
8 from django.db.models import QuerySet
9 from django.db.models.functions import ExtractHour
10 from django.shortcuts import get_object_or_404
11 from drf_spectacular.types import OpenApiTypes
12 from drf_spectacular.utils import OpenApiParameter, OpenApiResponse, extend_schema
13 from guardian.shortcuts import get_objects_for_user
14 from rest_framework.decorators import action
15 from rest_framework.exceptions import ValidationError
16 from rest_framework.fields import CharField, ReadOnlyField, SerializerMethodField
17 from rest_framework.parsers import MultiPartParser
18 from rest_framework.request import Request
19 from rest_framework.response import Response
20 from rest_framework.serializers import ModelSerializer
21 from rest_framework.viewsets import ModelViewSet
22 from structlog.stdlib import get_logger
23
24 from authentik.admin.api.metrics import CoordinateSerializer
25 from authentik.blueprints.v1.importer import SERIALIZER_CONTEXT_BLUEPRINT
26 from authentik.core.api.providers import ProviderSerializer
27 from authentik.core.api.used_by import UsedByMixin
28 from authentik.core.models import Application, User
29 from authentik.events.logs import LogEventSerializer, capture_logs
30 from authentik.events.models import EventAction
31 from authentik.lib.utils.file import (
32 FilePathSerializer,
33 FileUploadSerializer,
34 set_file,
35 set_file_url,
36 )
37 from authentik.policies.api.exec import PolicyTestResultSerializer
38 from authentik.policies.engine import PolicyEngine
39 from authentik.policies.types import CACHE_PREFIX, PolicyResult
40 from authentik.rbac.decorators import permission_required
41 from authentik.rbac.filters import ObjectFilter
42
43 LOGGER = get_logger()
44
45
46 def user_app_cache_key(user_pk: str) -> str:
47 """Cache key where application list for user is saved"""
48 return f"{CACHE_PREFIX}/app_access/{user_pk}"
49
50
51 class ApplicationSerializer(ModelSerializer):
52 """Application Serializer"""
53
54 launch_url = SerializerMethodField()
55 provider_obj = ProviderSerializer(source="get_provider", required=False, read_only=True)
56 backchannel_providers_obj = ProviderSerializer(
57 source="backchannel_providers", required=False, read_only=True, many=True
58 )
59
60 meta_icon = ReadOnlyField(source="get_meta_icon")
61
62 def get_launch_url(self, app: Application) -> str | None:
63 """Allow formatting of launch URL"""
64 user = None
65 if "request" in self.context:
66 user = self.context["request"].user
67 return app.get_launch_url(user)
68
69 def __init__(self, *args, **kwargs) -> None:
70 super().__init__(*args, **kwargs)
71 if SERIALIZER_CONTEXT_BLUEPRINT in self.context:
72 self.fields["icon"] = CharField(source="meta_icon", required=False)
73
74 class Meta:
75 model = Application
76 fields = [
77 "pk",
78 "name",
79 "slug",
80 "provider",
81 "provider_obj",
82 "backchannel_providers",
83 "backchannel_providers_obj",
84 "launch_url",
85 "open_in_new_tab",
86 "meta_launch_url",
87 "meta_icon",
88 "meta_description",
89 "meta_publisher",
90 "policy_engine_mode",
91 "group",
92 ]
93 extra_kwargs = {
94 "meta_icon": {"read_only": True},
95 "backchannel_providers": {"required": False},
96 }
97
98
99 class ApplicationViewSet(UsedByMixin, ModelViewSet):
100 """Application Viewset"""
101
102 queryset = Application.objects.all().prefetch_related("provider")
103 serializer_class = ApplicationSerializer
104 search_fields = [
105 "name",
106 "slug",
107 "meta_launch_url",
108 "meta_description",
109 "meta_publisher",
110 "group",
111 ]
112 filterset_fields = [
113 "name",
114 "slug",
115 "meta_launch_url",
116 "meta_description",
117 "meta_publisher",
118 "group",
119 ]
120 lookup_field = "slug"
121 ordering = ["name"]
122
123 def _filter_queryset_for_list(self, queryset: QuerySet) -> QuerySet:
124 """Custom filter_queryset method which ignores guardian, but still supports sorting"""
125 for backend in list(self.filter_backends):
126 if backend == ObjectFilter:
127 continue
128 queryset = backend().filter_queryset(self.request, queryset, self)
129 return queryset
130
131 def _get_allowed_applications(
132 self, pagined_apps: Iterator[Application], user: User | None = None
133 ) -> list[Application]:
134 applications = []
135 request = self.request._request
136 if user:
137 request = copy(request)
138 request.user = user
139 for application in pagined_apps:
140 engine = PolicyEngine(application, request.user, request)
141 engine.build()
142 if engine.passing:
143 applications.append(application)
144 return applications
145
146 @extend_schema(
147 parameters=[
148 OpenApiParameter(
149 name="for_user",
150 location=OpenApiParameter.QUERY,
151 type=OpenApiTypes.INT,
152 )
153 ],
154 responses={
155 200: PolicyTestResultSerializer(),
156 },
157 )
158 @action(detail=True, methods=["GET"])
159 def check_access(self, request: Request, slug: str) -> Response:
160 """Check access to a single application by slug"""
161 # Don't use self.get_object as that checks for view_application permission
162 # which the user might not have, even if they have access
163 application = get_object_or_404(Application, slug=slug)
164 # If the current user is superuser, they can set `for_user`
165 for_user = request.user
166 if request.user.is_superuser and "for_user" in request.query_params:
167 try:
168 for_user = User.objects.filter(pk=request.query_params.get("for_user")).first()
169 except ValueError:
170 raise ValidationError({"for_user": "for_user must be numerical"}) from None
171 if not for_user:
172 raise ValidationError({"for_user": "User not found"})
173 engine = PolicyEngine(application, for_user, request)
174 engine.use_cache = False
175 with capture_logs() as logs:
176 engine.build()
177 result = engine.result
178 response = PolicyTestResultSerializer(PolicyResult(False))
179 if result.passing:
180 response = PolicyTestResultSerializer(PolicyResult(True))
181 if request.user.is_superuser:
182 log_messages = []
183 for log in logs:
184 if log.attributes.get("process", "") == "PolicyProcess":
185 continue
186 log_messages.append(LogEventSerializer(log).data)
187 result.log_messages = log_messages
188 response = PolicyTestResultSerializer(result)
189 return Response(response.data)
190
191 @extend_schema(
192 parameters=[
193 OpenApiParameter(
194 name="superuser_full_list",
195 location=OpenApiParameter.QUERY,
196 type=OpenApiTypes.BOOL,
197 ),
198 OpenApiParameter(
199 name="for_user",
200 location=OpenApiParameter.QUERY,
201 type=OpenApiTypes.INT,
202 ),
203 ]
204 )
205 def list(self, request: Request) -> Response:
206 """Custom list method that checks Policy based access instead of guardian"""
207 should_cache = request.query_params.get("search", "") == ""
208
209 superuser_full_list = (
210 str(request.query_params.get("superuser_full_list", "false")).lower() == "true"
211 )
212 if superuser_full_list and request.user.is_superuser:
213 return super().list(request)
214
215 queryset = self._filter_queryset_for_list(self.get_queryset())
216 paginated_apps = self.paginate_queryset(queryset)
217
218 if "for_user" in request.query_params:
219 try:
220 for_user: int = int(request.query_params.get("for_user", 0))
221 for_user = (
222 get_objects_for_user(request.user, "authentik_core.view_user_applications")
223 .filter(pk=for_user)
224 .first()
225 )
226 if not for_user:
227 raise ValidationError({"for_user": "User not found"})
228 except ValueError as exc:
229 raise ValidationError from exc
230 allowed_applications = self._get_allowed_applications(paginated_apps, user=for_user)
231 serializer = self.get_serializer(allowed_applications, many=True)
232 return self.get_paginated_response(serializer.data)
233
234 allowed_applications = []
235 if not should_cache:
236 allowed_applications = self._get_allowed_applications(paginated_apps)
237 if should_cache:
238 allowed_applications = cache.get(user_app_cache_key(self.request.user.pk))
239 if not allowed_applications:
240 LOGGER.debug("Caching allowed application list")
241 allowed_applications = self._get_allowed_applications(paginated_apps)
242 cache.set(
243 user_app_cache_key(self.request.user.pk),
244 allowed_applications,
245 timeout=86400,
246 )
247 serializer = self.get_serializer(allowed_applications, many=True)
248 return self.get_paginated_response(serializer.data)
249
250 @permission_required("authentik_core.change_application")
251 @extend_schema(
252 request={
253 "multipart/form-data": FileUploadSerializer,
254 },
255 responses={
256 200: OpenApiResponse(description="Success"),
257 400: OpenApiResponse(description="Bad request"),
258 },
259 )
260 @action(
261 detail=True,
262 pagination_class=None,
263 filter_backends=[],
264 methods=["POST"],
265 parser_classes=(MultiPartParser,),
266 )
267 def set_icon(self, request: Request, slug: str):
268 """Set application icon"""
269 app: Application = self.get_object()
270 return set_file(request, app, "meta_icon")
271
272 @permission_required("authentik_core.change_application")
273 @extend_schema(
274 request=FilePathSerializer,
275 responses={
276 200: OpenApiResponse(description="Success"),
277 400: OpenApiResponse(description="Bad request"),
278 },
279 )
280 @action(
281 detail=True,
282 pagination_class=None,
283 filter_backends=[],
284 methods=["POST"],
285 )
286 def set_icon_url(self, request: Request, slug: str):
287 """Set application icon (as URL)"""
288 app: Application = self.get_object()
289 return set_file_url(request, app, "meta_icon")
290
291 @permission_required("authentik_core.view_application", ["authentik_events.view_event"])
292 @extend_schema(responses={200: CoordinateSerializer(many=True)})
293 @action(detail=True, pagination_class=None, filter_backends=[])
294 def metrics(self, request: Request, slug: str):
295 """Metrics for application logins"""
296 app = self.get_object()
297 return Response(
298 get_objects_for_user(request.user, "authentik_events.view_event").filter(
299 action=EventAction.AUTHORIZE_APPLICATION,
300 context__authorized_application__pk=app.pk.hex,
301 )
302 # 3 data points per day, so 8 hour spans
303 .get_events_per(timedelta(days=7), ExtractHour, 7 * 3)
304 )
305
[end of authentik/core/api/applications.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/authentik/core/api/applications.py b/authentik/core/api/applications.py
--- a/authentik/core/api/applications.py
+++ b/authentik/core/api/applications.py
@@ -22,6 +22,7 @@
from structlog.stdlib import get_logger
from authentik.admin.api.metrics import CoordinateSerializer
+from authentik.api.pagination import Pagination
from authentik.blueprints.v1.importer import SERIALIZER_CONTEXT_BLUEPRINT
from authentik.core.api.providers import ProviderSerializer
from authentik.core.api.used_by import UsedByMixin
@@ -43,9 +44,12 @@
LOGGER = get_logger()
-def user_app_cache_key(user_pk: str) -> str:
+def user_app_cache_key(user_pk: str, page_number: int | None = None) -> str:
"""Cache key where application list for user is saved"""
- return f"{CACHE_PREFIX}/app_access/{user_pk}"
+ key = f"{CACHE_PREFIX}/app_access/{user_pk}"
+ if page_number:
+ key += f"/{page_number}"
+ return key
class ApplicationSerializer(ModelSerializer):
@@ -213,7 +217,8 @@
return super().list(request)
queryset = self._filter_queryset_for_list(self.get_queryset())
- paginated_apps = self.paginate_queryset(queryset)
+ paginator: Pagination = self.paginator
+ paginated_apps = paginator.paginate_queryset(queryset, request)
if "for_user" in request.query_params:
try:
@@ -235,12 +240,14 @@
if not should_cache:
allowed_applications = self._get_allowed_applications(paginated_apps)
if should_cache:
- allowed_applications = cache.get(user_app_cache_key(self.request.user.pk))
+ allowed_applications = cache.get(
+ user_app_cache_key(self.request.user.pk, paginator.page.number)
+ )
if not allowed_applications:
- LOGGER.debug("Caching allowed application list")
+ LOGGER.debug("Caching allowed application list", page=paginator.page.number)
allowed_applications = self._get_allowed_applications(paginated_apps)
cache.set(
- user_app_cache_key(self.request.user.pk),
+ user_app_cache_key(self.request.user.pk, paginator.page.number),
allowed_applications,
timeout=86400,
)
|
{"golden_diff": "diff --git a/authentik/core/api/applications.py b/authentik/core/api/applications.py\n--- a/authentik/core/api/applications.py\n+++ b/authentik/core/api/applications.py\n@@ -22,6 +22,7 @@\n from structlog.stdlib import get_logger\n \n from authentik.admin.api.metrics import CoordinateSerializer\n+from authentik.api.pagination import Pagination\n from authentik.blueprints.v1.importer import SERIALIZER_CONTEXT_BLUEPRINT\n from authentik.core.api.providers import ProviderSerializer\n from authentik.core.api.used_by import UsedByMixin\n@@ -43,9 +44,12 @@\n LOGGER = get_logger()\n \n \n-def user_app_cache_key(user_pk: str) -> str:\n+def user_app_cache_key(user_pk: str, page_number: int | None = None) -> str:\n \"\"\"Cache key where application list for user is saved\"\"\"\n- return f\"{CACHE_PREFIX}/app_access/{user_pk}\"\n+ key = f\"{CACHE_PREFIX}/app_access/{user_pk}\"\n+ if page_number:\n+ key += f\"/{page_number}\"\n+ return key\n \n \n class ApplicationSerializer(ModelSerializer):\n@@ -213,7 +217,8 @@\n return super().list(request)\n \n queryset = self._filter_queryset_for_list(self.get_queryset())\n- paginated_apps = self.paginate_queryset(queryset)\n+ paginator: Pagination = self.paginator\n+ paginated_apps = paginator.paginate_queryset(queryset, request)\n \n if \"for_user\" in request.query_params:\n try:\n@@ -235,12 +240,14 @@\n if not should_cache:\n allowed_applications = self._get_allowed_applications(paginated_apps)\n if should_cache:\n- allowed_applications = cache.get(user_app_cache_key(self.request.user.pk))\n+ allowed_applications = cache.get(\n+ user_app_cache_key(self.request.user.pk, paginator.page.number)\n+ )\n if not allowed_applications:\n- LOGGER.debug(\"Caching allowed application list\")\n+ LOGGER.debug(\"Caching allowed application list\", page=paginator.page.number)\n allowed_applications = self._get_allowed_applications(paginated_apps)\n cache.set(\n- user_app_cache_key(self.request.user.pk),\n+ user_app_cache_key(self.request.user.pk, paginator.page.number),\n allowed_applications,\n timeout=86400,\n )\n", "issue": "API: Application Pagination only works when user is superuser and { superuser_full_list: true } is passed to the API\n**Describe the bug**\r\n\r\nThis works:\r\n\r\n`/api/v3/core/applications/?ordering=name&page=7&page_size=20&search=&superuser_full_list=true`\r\n\r\nThis does not:\r\n\r\n`/api/v3/core/applications/?ordering=name&page=7&page_size=20&search=`\r\n\r\nIf you pass a page request and do not set `superuser_full_list` _or_ you are not an admin user, you will always only get the first page of results from the Application API for authentik.\r\n\r\n**Expected behavior**\r\n\r\nThe `page=` argument should be respected by the API under all circumstances.\r\n\r\n**Version and Deployment (please complete the following information):**\r\n\r\n- authentik version: post-2024.2, commit 2196bde820c4f59a128483670960971df073b076\r\n- Deployment: authentik [full development environment](https://docs.goauthentik.io/developer-docs/setup/full-dev-environment)\n", "before_files": [{"content": "\"\"\"Application API Views\"\"\"\n\nfrom collections.abc import Iterator\nfrom copy import copy\nfrom datetime import timedelta\n\nfrom django.core.cache import cache\nfrom django.db.models import QuerySet\nfrom django.db.models.functions import ExtractHour\nfrom django.shortcuts import get_object_or_404\nfrom drf_spectacular.types import OpenApiTypes\nfrom drf_spectacular.utils import OpenApiParameter, OpenApiResponse, extend_schema\nfrom guardian.shortcuts import get_objects_for_user\nfrom rest_framework.decorators import action\nfrom rest_framework.exceptions import ValidationError\nfrom rest_framework.fields import CharField, ReadOnlyField, SerializerMethodField\nfrom rest_framework.parsers import MultiPartParser\nfrom rest_framework.request import Request\nfrom rest_framework.response import Response\nfrom rest_framework.serializers import ModelSerializer\nfrom rest_framework.viewsets import ModelViewSet\nfrom structlog.stdlib import get_logger\n\nfrom authentik.admin.api.metrics import CoordinateSerializer\nfrom authentik.blueprints.v1.importer import SERIALIZER_CONTEXT_BLUEPRINT\nfrom authentik.core.api.providers import ProviderSerializer\nfrom authentik.core.api.used_by import UsedByMixin\nfrom authentik.core.models import Application, User\nfrom authentik.events.logs import LogEventSerializer, capture_logs\nfrom authentik.events.models import EventAction\nfrom authentik.lib.utils.file import (\n FilePathSerializer,\n FileUploadSerializer,\n set_file,\n set_file_url,\n)\nfrom authentik.policies.api.exec import PolicyTestResultSerializer\nfrom authentik.policies.engine import PolicyEngine\nfrom authentik.policies.types import CACHE_PREFIX, PolicyResult\nfrom authentik.rbac.decorators import permission_required\nfrom authentik.rbac.filters import ObjectFilter\n\nLOGGER = get_logger()\n\n\ndef user_app_cache_key(user_pk: str) -> str:\n \"\"\"Cache key where application list for user is saved\"\"\"\n return f\"{CACHE_PREFIX}/app_access/{user_pk}\"\n\n\nclass ApplicationSerializer(ModelSerializer):\n \"\"\"Application Serializer\"\"\"\n\n launch_url = SerializerMethodField()\n provider_obj = ProviderSerializer(source=\"get_provider\", required=False, read_only=True)\n backchannel_providers_obj = ProviderSerializer(\n source=\"backchannel_providers\", required=False, read_only=True, many=True\n )\n\n meta_icon = ReadOnlyField(source=\"get_meta_icon\")\n\n def get_launch_url(self, app: Application) -> str | None:\n \"\"\"Allow formatting of launch URL\"\"\"\n user = None\n if \"request\" in self.context:\n user = self.context[\"request\"].user\n return app.get_launch_url(user)\n\n def __init__(self, *args, **kwargs) -> None:\n super().__init__(*args, **kwargs)\n if SERIALIZER_CONTEXT_BLUEPRINT in self.context:\n self.fields[\"icon\"] = CharField(source=\"meta_icon\", required=False)\n\n class Meta:\n model = Application\n fields = [\n \"pk\",\n \"name\",\n \"slug\",\n \"provider\",\n \"provider_obj\",\n \"backchannel_providers\",\n \"backchannel_providers_obj\",\n \"launch_url\",\n \"open_in_new_tab\",\n \"meta_launch_url\",\n \"meta_icon\",\n \"meta_description\",\n \"meta_publisher\",\n \"policy_engine_mode\",\n \"group\",\n ]\n extra_kwargs = {\n \"meta_icon\": {\"read_only\": True},\n \"backchannel_providers\": {\"required\": False},\n }\n\n\nclass ApplicationViewSet(UsedByMixin, ModelViewSet):\n \"\"\"Application Viewset\"\"\"\n\n queryset = Application.objects.all().prefetch_related(\"provider\")\n serializer_class = ApplicationSerializer\n search_fields = [\n \"name\",\n \"slug\",\n \"meta_launch_url\",\n \"meta_description\",\n \"meta_publisher\",\n \"group\",\n ]\n filterset_fields = [\n \"name\",\n \"slug\",\n \"meta_launch_url\",\n \"meta_description\",\n \"meta_publisher\",\n \"group\",\n ]\n lookup_field = \"slug\"\n ordering = [\"name\"]\n\n def _filter_queryset_for_list(self, queryset: QuerySet) -> QuerySet:\n \"\"\"Custom filter_queryset method which ignores guardian, but still supports sorting\"\"\"\n for backend in list(self.filter_backends):\n if backend == ObjectFilter:\n continue\n queryset = backend().filter_queryset(self.request, queryset, self)\n return queryset\n\n def _get_allowed_applications(\n self, pagined_apps: Iterator[Application], user: User | None = None\n ) -> list[Application]:\n applications = []\n request = self.request._request\n if user:\n request = copy(request)\n request.user = user\n for application in pagined_apps:\n engine = PolicyEngine(application, request.user, request)\n engine.build()\n if engine.passing:\n applications.append(application)\n return applications\n\n @extend_schema(\n parameters=[\n OpenApiParameter(\n name=\"for_user\",\n location=OpenApiParameter.QUERY,\n type=OpenApiTypes.INT,\n )\n ],\n responses={\n 200: PolicyTestResultSerializer(),\n },\n )\n @action(detail=True, methods=[\"GET\"])\n def check_access(self, request: Request, slug: str) -> Response:\n \"\"\"Check access to a single application by slug\"\"\"\n # Don't use self.get_object as that checks for view_application permission\n # which the user might not have, even if they have access\n application = get_object_or_404(Application, slug=slug)\n # If the current user is superuser, they can set `for_user`\n for_user = request.user\n if request.user.is_superuser and \"for_user\" in request.query_params:\n try:\n for_user = User.objects.filter(pk=request.query_params.get(\"for_user\")).first()\n except ValueError:\n raise ValidationError({\"for_user\": \"for_user must be numerical\"}) from None\n if not for_user:\n raise ValidationError({\"for_user\": \"User not found\"})\n engine = PolicyEngine(application, for_user, request)\n engine.use_cache = False\n with capture_logs() as logs:\n engine.build()\n result = engine.result\n response = PolicyTestResultSerializer(PolicyResult(False))\n if result.passing:\n response = PolicyTestResultSerializer(PolicyResult(True))\n if request.user.is_superuser:\n log_messages = []\n for log in logs:\n if log.attributes.get(\"process\", \"\") == \"PolicyProcess\":\n continue\n log_messages.append(LogEventSerializer(log).data)\n result.log_messages = log_messages\n response = PolicyTestResultSerializer(result)\n return Response(response.data)\n\n @extend_schema(\n parameters=[\n OpenApiParameter(\n name=\"superuser_full_list\",\n location=OpenApiParameter.QUERY,\n type=OpenApiTypes.BOOL,\n ),\n OpenApiParameter(\n name=\"for_user\",\n location=OpenApiParameter.QUERY,\n type=OpenApiTypes.INT,\n ),\n ]\n )\n def list(self, request: Request) -> Response:\n \"\"\"Custom list method that checks Policy based access instead of guardian\"\"\"\n should_cache = request.query_params.get(\"search\", \"\") == \"\"\n\n superuser_full_list = (\n str(request.query_params.get(\"superuser_full_list\", \"false\")).lower() == \"true\"\n )\n if superuser_full_list and request.user.is_superuser:\n return super().list(request)\n\n queryset = self._filter_queryset_for_list(self.get_queryset())\n paginated_apps = self.paginate_queryset(queryset)\n\n if \"for_user\" in request.query_params:\n try:\n for_user: int = int(request.query_params.get(\"for_user\", 0))\n for_user = (\n get_objects_for_user(request.user, \"authentik_core.view_user_applications\")\n .filter(pk=for_user)\n .first()\n )\n if not for_user:\n raise ValidationError({\"for_user\": \"User not found\"})\n except ValueError as exc:\n raise ValidationError from exc\n allowed_applications = self._get_allowed_applications(paginated_apps, user=for_user)\n serializer = self.get_serializer(allowed_applications, many=True)\n return self.get_paginated_response(serializer.data)\n\n allowed_applications = []\n if not should_cache:\n allowed_applications = self._get_allowed_applications(paginated_apps)\n if should_cache:\n allowed_applications = cache.get(user_app_cache_key(self.request.user.pk))\n if not allowed_applications:\n LOGGER.debug(\"Caching allowed application list\")\n allowed_applications = self._get_allowed_applications(paginated_apps)\n cache.set(\n user_app_cache_key(self.request.user.pk),\n allowed_applications,\n timeout=86400,\n )\n serializer = self.get_serializer(allowed_applications, many=True)\n return self.get_paginated_response(serializer.data)\n\n @permission_required(\"authentik_core.change_application\")\n @extend_schema(\n request={\n \"multipart/form-data\": FileUploadSerializer,\n },\n responses={\n 200: OpenApiResponse(description=\"Success\"),\n 400: OpenApiResponse(description=\"Bad request\"),\n },\n )\n @action(\n detail=True,\n pagination_class=None,\n filter_backends=[],\n methods=[\"POST\"],\n parser_classes=(MultiPartParser,),\n )\n def set_icon(self, request: Request, slug: str):\n \"\"\"Set application icon\"\"\"\n app: Application = self.get_object()\n return set_file(request, app, \"meta_icon\")\n\n @permission_required(\"authentik_core.change_application\")\n @extend_schema(\n request=FilePathSerializer,\n responses={\n 200: OpenApiResponse(description=\"Success\"),\n 400: OpenApiResponse(description=\"Bad request\"),\n },\n )\n @action(\n detail=True,\n pagination_class=None,\n filter_backends=[],\n methods=[\"POST\"],\n )\n def set_icon_url(self, request: Request, slug: str):\n \"\"\"Set application icon (as URL)\"\"\"\n app: Application = self.get_object()\n return set_file_url(request, app, \"meta_icon\")\n\n @permission_required(\"authentik_core.view_application\", [\"authentik_events.view_event\"])\n @extend_schema(responses={200: CoordinateSerializer(many=True)})\n @action(detail=True, pagination_class=None, filter_backends=[])\n def metrics(self, request: Request, slug: str):\n \"\"\"Metrics for application logins\"\"\"\n app = self.get_object()\n return Response(\n get_objects_for_user(request.user, \"authentik_events.view_event\").filter(\n action=EventAction.AUTHORIZE_APPLICATION,\n context__authorized_application__pk=app.pk.hex,\n )\n # 3 data points per day, so 8 hour spans\n .get_events_per(timedelta(days=7), ExtractHour, 7 * 3)\n )\n", "path": "authentik/core/api/applications.py"}]}
| 3,913 | 523 |
gh_patches_debug_21785
|
rasdani/github-patches
|
git_diff
|
getsentry__sentry-python-892
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add PEP 561 support
It would be useful to be able to use the type hints defined in this library with mypy. This library needs to add support for PEP 561 for this to work.
</issue>
<code>
[start of sentry_sdk/api.py]
1 import inspect
2
3 from sentry_sdk.hub import Hub
4 from sentry_sdk.scope import Scope
5
6 from sentry_sdk._types import MYPY
7
8 if MYPY:
9 from typing import Any
10 from typing import Dict
11 from typing import Optional
12 from typing import overload
13 from typing import Callable
14 from typing import TypeVar
15 from typing import ContextManager
16 from typing import Union
17
18 from sentry_sdk._types import Event, Hint, Breadcrumb, BreadcrumbHint, ExcInfo
19 from sentry_sdk.tracing import Span, Transaction
20
21 T = TypeVar("T")
22 F = TypeVar("F", bound=Callable[..., Any])
23 else:
24
25 def overload(x):
26 # type: (T) -> T
27 return x
28
29
30 __all__ = [
31 "capture_event",
32 "capture_message",
33 "capture_exception",
34 "add_breadcrumb",
35 "configure_scope",
36 "push_scope",
37 "flush",
38 "last_event_id",
39 "start_span",
40 "start_transaction",
41 "set_tag",
42 "set_context",
43 "set_extra",
44 "set_user",
45 "set_level",
46 ]
47
48
49 def hubmethod(f):
50 # type: (F) -> F
51 f.__doc__ = "%s\n\n%s" % (
52 "Alias for :py:meth:`sentry_sdk.Hub.%s`" % f.__name__,
53 inspect.getdoc(getattr(Hub, f.__name__)),
54 )
55 return f
56
57
58 def scopemethod(f):
59 # type: (F) -> F
60 f.__doc__ = "%s\n\n%s" % (
61 "Alias for :py:meth:`sentry_sdk.Scope.%s`" % f.__name__,
62 inspect.getdoc(getattr(Scope, f.__name__)),
63 )
64 return f
65
66
67 @hubmethod
68 def capture_event(
69 event, # type: Event
70 hint=None, # type: Optional[Hint]
71 scope=None, # type: Optional[Any]
72 **scope_args # type: Dict[str, Any]
73 ):
74 # type: (...) -> Optional[str]
75 return Hub.current.capture_event(event, hint, scope=scope, **scope_args)
76
77
78 @hubmethod
79 def capture_message(
80 message, # type: str
81 level=None, # type: Optional[str]
82 scope=None, # type: Optional[Any]
83 **scope_args # type: Dict[str, Any]
84 ):
85 # type: (...) -> Optional[str]
86 return Hub.current.capture_message(message, level, scope=scope, **scope_args)
87
88
89 @hubmethod
90 def capture_exception(
91 error=None, # type: Optional[Union[BaseException, ExcInfo]]
92 scope=None, # type: Optional[Any]
93 **scope_args # type: Dict[str, Any]
94 ):
95 # type: (...) -> Optional[str]
96 return Hub.current.capture_exception(error, scope=scope, **scope_args)
97
98
99 @hubmethod
100 def add_breadcrumb(
101 crumb=None, # type: Optional[Breadcrumb]
102 hint=None, # type: Optional[BreadcrumbHint]
103 **kwargs # type: Any
104 ):
105 # type: (...) -> None
106 return Hub.current.add_breadcrumb(crumb, hint, **kwargs)
107
108
109 @overload
110 def configure_scope(): # noqa: F811
111 # type: () -> ContextManager[Scope]
112 pass
113
114
115 @overload
116 def configure_scope( # noqa: F811
117 callback, # type: Callable[[Scope], None]
118 ):
119 # type: (...) -> None
120 pass
121
122
123 @hubmethod
124 def configure_scope( # noqa: F811
125 callback=None, # type: Optional[Callable[[Scope], None]]
126 ):
127 # type: (...) -> Optional[ContextManager[Scope]]
128 return Hub.current.configure_scope(callback)
129
130
131 @overload
132 def push_scope(): # noqa: F811
133 # type: () -> ContextManager[Scope]
134 pass
135
136
137 @overload
138 def push_scope( # noqa: F811
139 callback, # type: Callable[[Scope], None]
140 ):
141 # type: (...) -> None
142 pass
143
144
145 @hubmethod
146 def push_scope( # noqa: F811
147 callback=None, # type: Optional[Callable[[Scope], None]]
148 ):
149 # type: (...) -> Optional[ContextManager[Scope]]
150 return Hub.current.push_scope(callback)
151
152
153 @scopemethod # noqa
154 def set_tag(key, value):
155 # type: (str, Any) -> None
156 return Hub.current.scope.set_tag(key, value)
157
158
159 @scopemethod # noqa
160 def set_context(key, value):
161 # type: (str, Any) -> None
162 return Hub.current.scope.set_context(key, value)
163
164
165 @scopemethod # noqa
166 def set_extra(key, value):
167 # type: (str, Any) -> None
168 return Hub.current.scope.set_extra(key, value)
169
170
171 @scopemethod # noqa
172 def set_user(value):
173 # type: (Dict[str, Any]) -> None
174 return Hub.current.scope.set_user(value)
175
176
177 @scopemethod # noqa
178 def set_level(value):
179 # type: (str) -> None
180 return Hub.current.scope.set_level(value)
181
182
183 @hubmethod
184 def flush(
185 timeout=None, # type: Optional[float]
186 callback=None, # type: Optional[Callable[[int, float], None]]
187 ):
188 # type: (...) -> None
189 return Hub.current.flush(timeout=timeout, callback=callback)
190
191
192 @hubmethod
193 def last_event_id():
194 # type: () -> Optional[str]
195 return Hub.current.last_event_id()
196
197
198 @hubmethod
199 def start_span(
200 span=None, # type: Optional[Span]
201 **kwargs # type: Any
202 ):
203 # type: (...) -> Span
204 return Hub.current.start_span(span=span, **kwargs)
205
206
207 @hubmethod
208 def start_transaction(
209 transaction=None, # type: Optional[Transaction]
210 **kwargs # type: Any
211 ):
212 # type: (...) -> Transaction
213 return Hub.current.start_transaction(transaction, **kwargs)
214
[end of sentry_sdk/api.py]
[start of sentry_sdk/__init__.py]
1 from sentry_sdk.hub import Hub, init
2 from sentry_sdk.scope import Scope
3 from sentry_sdk.transport import Transport, HttpTransport
4 from sentry_sdk.client import Client
5
6 from sentry_sdk.api import * # noqa
7 from sentry_sdk.api import __all__ as api_all
8
9 from sentry_sdk.consts import VERSION # noqa
10
11 __all__ = api_all + [ # noqa
12 "Hub",
13 "Scope",
14 "Client",
15 "Transport",
16 "HttpTransport",
17 "init",
18 "integrations",
19 ]
20
21 # Initialize the debug support after everything is loaded
22 from sentry_sdk.debug import init_debug_support
23
24 init_debug_support()
25 del init_debug_support
26
[end of sentry_sdk/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sentry_sdk/__init__.py b/sentry_sdk/__init__.py
--- a/sentry_sdk/__init__.py
+++ b/sentry_sdk/__init__.py
@@ -4,11 +4,10 @@
from sentry_sdk.client import Client
from sentry_sdk.api import * # noqa
-from sentry_sdk.api import __all__ as api_all
from sentry_sdk.consts import VERSION # noqa
-__all__ = api_all + [ # noqa
+__all__ = [ # noqa
"Hub",
"Scope",
"Client",
@@ -16,6 +15,22 @@
"HttpTransport",
"init",
"integrations",
+ # From sentry_sdk.api
+ "capture_event",
+ "capture_message",
+ "capture_exception",
+ "add_breadcrumb",
+ "configure_scope",
+ "push_scope",
+ "flush",
+ "last_event_id",
+ "start_span",
+ "start_transaction",
+ "set_tag",
+ "set_context",
+ "set_extra",
+ "set_user",
+ "set_level",
]
# Initialize the debug support after everything is loaded
diff --git a/sentry_sdk/api.py b/sentry_sdk/api.py
--- a/sentry_sdk/api.py
+++ b/sentry_sdk/api.py
@@ -27,6 +27,7 @@
return x
+# When changing this, update __all__ in __init__.py too
__all__ = [
"capture_event",
"capture_message",
|
{"golden_diff": "diff --git a/sentry_sdk/__init__.py b/sentry_sdk/__init__.py\n--- a/sentry_sdk/__init__.py\n+++ b/sentry_sdk/__init__.py\n@@ -4,11 +4,10 @@\n from sentry_sdk.client import Client\n \n from sentry_sdk.api import * # noqa\n-from sentry_sdk.api import __all__ as api_all\n \n from sentry_sdk.consts import VERSION # noqa\n \n-__all__ = api_all + [ # noqa\n+__all__ = [ # noqa\n \"Hub\",\n \"Scope\",\n \"Client\",\n@@ -16,6 +15,22 @@\n \"HttpTransport\",\n \"init\",\n \"integrations\",\n+ # From sentry_sdk.api\n+ \"capture_event\",\n+ \"capture_message\",\n+ \"capture_exception\",\n+ \"add_breadcrumb\",\n+ \"configure_scope\",\n+ \"push_scope\",\n+ \"flush\",\n+ \"last_event_id\",\n+ \"start_span\",\n+ \"start_transaction\",\n+ \"set_tag\",\n+ \"set_context\",\n+ \"set_extra\",\n+ \"set_user\",\n+ \"set_level\",\n ]\n \n # Initialize the debug support after everything is loaded\ndiff --git a/sentry_sdk/api.py b/sentry_sdk/api.py\n--- a/sentry_sdk/api.py\n+++ b/sentry_sdk/api.py\n@@ -27,6 +27,7 @@\n return x\n \n \n+# When changing this, update __all__ in __init__.py too\n __all__ = [\n \"capture_event\",\n \"capture_message\",\n", "issue": "Add PEP 561 support\nIt would be useful to be able to use the type hints defined in this library with mypy. This library needs to add support for PEP 561 for this to work.\n", "before_files": [{"content": "import inspect\n\nfrom sentry_sdk.hub import Hub\nfrom sentry_sdk.scope import Scope\n\nfrom sentry_sdk._types import MYPY\n\nif MYPY:\n from typing import Any\n from typing import Dict\n from typing import Optional\n from typing import overload\n from typing import Callable\n from typing import TypeVar\n from typing import ContextManager\n from typing import Union\n\n from sentry_sdk._types import Event, Hint, Breadcrumb, BreadcrumbHint, ExcInfo\n from sentry_sdk.tracing import Span, Transaction\n\n T = TypeVar(\"T\")\n F = TypeVar(\"F\", bound=Callable[..., Any])\nelse:\n\n def overload(x):\n # type: (T) -> T\n return x\n\n\n__all__ = [\n \"capture_event\",\n \"capture_message\",\n \"capture_exception\",\n \"add_breadcrumb\",\n \"configure_scope\",\n \"push_scope\",\n \"flush\",\n \"last_event_id\",\n \"start_span\",\n \"start_transaction\",\n \"set_tag\",\n \"set_context\",\n \"set_extra\",\n \"set_user\",\n \"set_level\",\n]\n\n\ndef hubmethod(f):\n # type: (F) -> F\n f.__doc__ = \"%s\\n\\n%s\" % (\n \"Alias for :py:meth:`sentry_sdk.Hub.%s`\" % f.__name__,\n inspect.getdoc(getattr(Hub, f.__name__)),\n )\n return f\n\n\ndef scopemethod(f):\n # type: (F) -> F\n f.__doc__ = \"%s\\n\\n%s\" % (\n \"Alias for :py:meth:`sentry_sdk.Scope.%s`\" % f.__name__,\n inspect.getdoc(getattr(Scope, f.__name__)),\n )\n return f\n\n\n@hubmethod\ndef capture_event(\n event, # type: Event\n hint=None, # type: Optional[Hint]\n scope=None, # type: Optional[Any]\n **scope_args # type: Dict[str, Any]\n):\n # type: (...) -> Optional[str]\n return Hub.current.capture_event(event, hint, scope=scope, **scope_args)\n\n\n@hubmethod\ndef capture_message(\n message, # type: str\n level=None, # type: Optional[str]\n scope=None, # type: Optional[Any]\n **scope_args # type: Dict[str, Any]\n):\n # type: (...) -> Optional[str]\n return Hub.current.capture_message(message, level, scope=scope, **scope_args)\n\n\n@hubmethod\ndef capture_exception(\n error=None, # type: Optional[Union[BaseException, ExcInfo]]\n scope=None, # type: Optional[Any]\n **scope_args # type: Dict[str, Any]\n):\n # type: (...) -> Optional[str]\n return Hub.current.capture_exception(error, scope=scope, **scope_args)\n\n\n@hubmethod\ndef add_breadcrumb(\n crumb=None, # type: Optional[Breadcrumb]\n hint=None, # type: Optional[BreadcrumbHint]\n **kwargs # type: Any\n):\n # type: (...) -> None\n return Hub.current.add_breadcrumb(crumb, hint, **kwargs)\n\n\n@overload\ndef configure_scope(): # noqa: F811\n # type: () -> ContextManager[Scope]\n pass\n\n\n@overload\ndef configure_scope( # noqa: F811\n callback, # type: Callable[[Scope], None]\n):\n # type: (...) -> None\n pass\n\n\n@hubmethod\ndef configure_scope( # noqa: F811\n callback=None, # type: Optional[Callable[[Scope], None]]\n):\n # type: (...) -> Optional[ContextManager[Scope]]\n return Hub.current.configure_scope(callback)\n\n\n@overload\ndef push_scope(): # noqa: F811\n # type: () -> ContextManager[Scope]\n pass\n\n\n@overload\ndef push_scope( # noqa: F811\n callback, # type: Callable[[Scope], None]\n):\n # type: (...) -> None\n pass\n\n\n@hubmethod\ndef push_scope( # noqa: F811\n callback=None, # type: Optional[Callable[[Scope], None]]\n):\n # type: (...) -> Optional[ContextManager[Scope]]\n return Hub.current.push_scope(callback)\n\n\n@scopemethod # noqa\ndef set_tag(key, value):\n # type: (str, Any) -> None\n return Hub.current.scope.set_tag(key, value)\n\n\n@scopemethod # noqa\ndef set_context(key, value):\n # type: (str, Any) -> None\n return Hub.current.scope.set_context(key, value)\n\n\n@scopemethod # noqa\ndef set_extra(key, value):\n # type: (str, Any) -> None\n return Hub.current.scope.set_extra(key, value)\n\n\n@scopemethod # noqa\ndef set_user(value):\n # type: (Dict[str, Any]) -> None\n return Hub.current.scope.set_user(value)\n\n\n@scopemethod # noqa\ndef set_level(value):\n # type: (str) -> None\n return Hub.current.scope.set_level(value)\n\n\n@hubmethod\ndef flush(\n timeout=None, # type: Optional[float]\n callback=None, # type: Optional[Callable[[int, float], None]]\n):\n # type: (...) -> None\n return Hub.current.flush(timeout=timeout, callback=callback)\n\n\n@hubmethod\ndef last_event_id():\n # type: () -> Optional[str]\n return Hub.current.last_event_id()\n\n\n@hubmethod\ndef start_span(\n span=None, # type: Optional[Span]\n **kwargs # type: Any\n):\n # type: (...) -> Span\n return Hub.current.start_span(span=span, **kwargs)\n\n\n@hubmethod\ndef start_transaction(\n transaction=None, # type: Optional[Transaction]\n **kwargs # type: Any\n):\n # type: (...) -> Transaction\n return Hub.current.start_transaction(transaction, **kwargs)\n", "path": "sentry_sdk/api.py"}, {"content": "from sentry_sdk.hub import Hub, init\nfrom sentry_sdk.scope import Scope\nfrom sentry_sdk.transport import Transport, HttpTransport\nfrom sentry_sdk.client import Client\n\nfrom sentry_sdk.api import * # noqa\nfrom sentry_sdk.api import __all__ as api_all\n\nfrom sentry_sdk.consts import VERSION # noqa\n\n__all__ = api_all + [ # noqa\n \"Hub\",\n \"Scope\",\n \"Client\",\n \"Transport\",\n \"HttpTransport\",\n \"init\",\n \"integrations\",\n]\n\n# Initialize the debug support after everything is loaded\nfrom sentry_sdk.debug import init_debug_support\n\ninit_debug_support()\ndel init_debug_support\n", "path": "sentry_sdk/__init__.py"}]}
| 2,701 | 350 |
gh_patches_debug_20581
|
rasdani/github-patches
|
git_diff
|
searxng__searxng-2117
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Illegal version specifier according to pip
<!-- PLEASE FILL THESE FIELDS, IT REALLY HELPS THE MAINTAINERS OF SearXNG -->
**Version of SearXNG, commit number if you are using on master branch and stipulate if you forked SearXNG**
<!-- If you are running on master branch using git execute this command
in order to fetch the latest commit ID:
```
git log -1
```
If you are using searxng-docker then look at the bottom of the SearXNG page
and check for the version after "Powered by SearXNG"
Please also stipulate if you are using a forked version of SearXNG and
include a link to the fork source code.
-->
Commit 13b0c251c45c3d14700723b25b601be56178e8df
**How did you install SearXNG?**
<!-- Did you install SearXNG using the official wiki or using searxng-docker
or manually by executing the searx/webapp.py file? -->
Official wiki, install script.
**What happened?**
<!-- A clear and concise description of what the bug is. -->
Step `pip install -e .` fails with
```
Looking in indexes: https://pypi.org/simple, https://www.piwheels.org/simple
Obtaining file:///usr/local/searxng/searxng-src
Preparing metadata (setup.py) ... error
error: subprocess-exited-with-error
× python setup.py egg_info did not run successfully.
│ exit code: 1
╰─> [27 lines of output]
/usr/local/searxng/searx-pyenv/lib/python3.9/site-packages/setuptools/dist.py:543: UserWarning: The version specified ('2023.01.15-13b0c251') is an invalid version, this may not work as expected with newer versions of setuptools, pip, and PyPI. Please see PEP 440 for more details.
warnings.warn(
2023-01-16 13:17:41,865 INFO:root: running egg_info
Traceback (most recent call last):
File "<string>", line 2, in <module>
File "<pip-setuptools-caller>", line 34, in <module>
File "/usr/local/searxng/searxng-src/setup.py", line 19, in <module>
setup(
File "/usr/local/searxng/searx-pyenv/lib/python3.9/site-packages/setuptools/__init__.py", line 87, in setup
return distutils.core.setup(**attrs)
File "/usr/local/searxng/searx-pyenv/lib/python3.9/site-packages/setuptools/_distutils/core.py", line 185, in setup
return run_commands(dist)
File "/usr/local/searxng/searx-pyenv/lib/python3.9/site-packages/setuptools/_distutils/core.py", line 201, in run_commands
dist.run_commands()
File "/usr/local/searxng/searx-pyenv/lib/python3.9/site-packages/setuptools/_distutils/dist.py", line 969, in run_commands
self.run_command(cmd)
File "/usr/local/searxng/searx-pyenv/lib/python3.9/site-packages/setuptools/dist.py", line 1208, in run_command
super().run_command(command)
File "/usr/local/searxng/searx-pyenv/lib/python3.9/site-packages/setuptools/_distutils/dist.py", line 987, in run_command
cmd_obj.ensure_finalized()
File "/usr/local/searxng/searx-pyenv/lib/python3.9/site-packages/setuptools/_distutils/cmd.py", line 111, in ensure_finalized
self.finalize_options()
File "/usr/local/searxng/searx-pyenv/lib/python3.9/site-packages/setuptools/command/egg_info.py", line 219, in finalize_options
parsed_version = parse_version(self.egg_version)
File "/usr/local/searxng/searx-pyenv/lib/python3.9/site-packages/pkg_resources/_vendor/packaging/version.py", line 266, in __init__
raise InvalidVersion(f"Invalid version: '{version}'")
pkg_resources.extern.packaging.version.InvalidVersion: Invalid version: '2023.01.15-13b0c251'
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
error: metadata-generation-failed
× Encountered error while generating package metadata.
╰─> See above for output.
note: This is an issue with the package mentioned above, not pip.
hint: See above for details.
```
**How To Reproduce**
<!-- How can we reproduce this issue? (as minimally and as precisely as possible) -->
Follow instructions in https://docs.searxng.org/admin/installation-scripts.html#installation-scripts, in my case on a Raspberry Pi 4B, with following version info:
```
$ uname -a
Linux raspberrypi 5.15.32-v8+ #1538 SMP PREEMPT Thu Mar 31 19:40:39 BST 2022 aarch64 GNU/Linux
```
```
$ python --version
Python 3.9.2
```
```
$ pip --version
pip 22.3.1 from /usr/local/searxng/searx-pyenv/lib/python3.9/site-packages/pip (python 3.9)
```
**Expected behavior**
<!-- A clear and concise description of what you expected to happen. -->
Expected installation to succeed.
**Screenshots & Logs**
<!-- If applicable, add screenshots, logs to help explain your problem. -->
N/A
**Additional context**
<!-- Add any other context about the problem here. -->
N/A
</issue>
<code>
[start of searx/version.py]
1 # SPDX-License-Identifier: AGPL-3.0-or-later
2 # lint: pylint
3 # pylint: disable=,missing-module-docstring,missing-class-docstring
4
5 import os
6 import shlex
7 import subprocess
8 import logging
9 import importlib
10
11 # fallback values
12 # if there is searx.version_frozen module, and it is not possible to get the git tag
13 VERSION_STRING = "1.0.0"
14 VERSION_TAG = "1.0.0"
15 GIT_URL = "unknow"
16 GIT_BRANCH = "unknow"
17
18 logger = logging.getLogger("searx")
19
20 SUBPROCESS_RUN_ENV = {
21 "PATH": os.environ["PATH"],
22 "LC_ALL": "C",
23 "LANGUAGE": "",
24 }
25
26
27 def subprocess_run(args, **kwargs):
28 """Call :py:func:`subprocess.run` and return (striped) stdout. If returncode is
29 non-zero, raise a :py:func:`subprocess.CalledProcessError`.
30 """
31 if not isinstance(args, (list, tuple)):
32 args = shlex.split(args)
33
34 kwargs["env"] = kwargs.get("env", SUBPROCESS_RUN_ENV)
35 kwargs["encoding"] = kwargs.get("encoding", "utf-8")
36 kwargs["stdout"] = subprocess.PIPE
37 kwargs["stderr"] = subprocess.PIPE
38 # raise CalledProcessError if returncode is non-zero
39 kwargs["check"] = True
40 proc = subprocess.run(args, **kwargs) # pylint: disable=subprocess-run-check
41 return proc.stdout.strip()
42
43
44 def get_git_url_and_branch():
45 try:
46 ref = subprocess_run("git rev-parse --abbrev-ref @{upstream}")
47 except subprocess.CalledProcessError:
48 ref = subprocess_run("git rev-parse --abbrev-ref master@{upstream}")
49 origin, git_branch = ref.split("/", 1)
50 git_url = subprocess_run(["git", "remote", "get-url", origin])
51
52 # get https:// url from git@ url
53 if git_url.startswith("git@"):
54 git_url = git_url.replace(":", "/", 2).replace("git@", "https://", 1)
55 if git_url.endswith(".git"):
56 git_url = git_url.replace(".git", "", 1)
57
58 return git_url, git_branch
59
60
61 def get_git_version():
62 git_commit_date_hash = subprocess_run(r"git show -s --date='format:%Y.%m.%d' --format='%cd-%h'")
63 tag_version = git_version = git_commit_date_hash
64
65 # add "-dirty" suffix if there are uncommited changes except searx/settings.yml
66 try:
67 subprocess_run("git diff --quiet -- . ':!searx/settings.yml' ':!utils/brand.env'")
68 except subprocess.CalledProcessError as e:
69 if e.returncode == 1:
70 git_version += "-dirty"
71 else:
72 logger.warning('"%s" returns an unexpected return code %i', e.returncode, e.cmd)
73 return git_version, tag_version
74
75
76 try:
77 vf = importlib.import_module('searx.version_frozen')
78 VERSION_STRING, VERSION_TAG, GIT_URL, GIT_BRANCH = vf.VERSION_STRING, vf.VERSION_TAG, vf.GIT_URL, vf.GIT_BRANCH
79 except ImportError:
80 try:
81 try:
82 VERSION_STRING, VERSION_TAG = get_git_version()
83 except subprocess.CalledProcessError as ex:
84 logger.error("Error while getting the version: %s", ex.stderr)
85 try:
86 GIT_URL, GIT_BRANCH = get_git_url_and_branch()
87 except subprocess.CalledProcessError as ex:
88 logger.error("Error while getting the git URL & branch: %s", ex.stderr)
89 except FileNotFoundError as ex:
90 logger.error("%s is not found, fallback to the default version", ex.filename)
91
92
93 logger.info("version: %s", VERSION_STRING)
94
95 if __name__ == "__main__":
96 import sys
97
98 if len(sys.argv) >= 2 and sys.argv[1] == "freeze":
99 # freeze the version (to create an archive outside a git repository)
100 python_code = f"""# SPDX-License-Identifier: AGPL-3.0-or-later
101 # this file is generated automatically by searx/version.py
102
103 VERSION_STRING = "{VERSION_STRING}"
104 VERSION_TAG = "{VERSION_TAG}"
105 GIT_URL = "{GIT_URL}"
106 GIT_BRANCH = "{GIT_BRANCH}"
107 """
108 with open(os.path.join(os.path.dirname(__file__), "version_frozen.py"), "w", encoding="utf8") as f:
109 f.write(python_code)
110 print(f"{f.name} created")
111 else:
112 # output shell code to set the variables
113 # usage: eval "$(python -m searx.version)"
114 shell_code = f"""
115 VERSION_STRING="{VERSION_STRING}"
116 VERSION_TAG="{VERSION_TAG}"
117 GIT_URL="{GIT_URL}"
118 GIT_BRANCH="{GIT_BRANCH}"
119 """
120 print(shell_code)
121
[end of searx/version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/searx/version.py b/searx/version.py
--- a/searx/version.py
+++ b/searx/version.py
@@ -59,7 +59,7 @@
def get_git_version():
- git_commit_date_hash = subprocess_run(r"git show -s --date='format:%Y.%m.%d' --format='%cd-%h'")
+ git_commit_date_hash = subprocess_run(r"git show -s --date='format:%Y.%m.%d' --format='%cd+%h'")
tag_version = git_version = git_commit_date_hash
# add "-dirty" suffix if there are uncommited changes except searx/settings.yml
@@ -67,7 +67,7 @@
subprocess_run("git diff --quiet -- . ':!searx/settings.yml' ':!utils/brand.env'")
except subprocess.CalledProcessError as e:
if e.returncode == 1:
- git_version += "-dirty"
+ git_version += "+dirty"
else:
logger.warning('"%s" returns an unexpected return code %i', e.returncode, e.cmd)
return git_version, tag_version
|
{"golden_diff": "diff --git a/searx/version.py b/searx/version.py\n--- a/searx/version.py\n+++ b/searx/version.py\n@@ -59,7 +59,7 @@\n \n \n def get_git_version():\n- git_commit_date_hash = subprocess_run(r\"git show -s --date='format:%Y.%m.%d' --format='%cd-%h'\")\n+ git_commit_date_hash = subprocess_run(r\"git show -s --date='format:%Y.%m.%d' --format='%cd+%h'\")\n tag_version = git_version = git_commit_date_hash\n \n # add \"-dirty\" suffix if there are uncommited changes except searx/settings.yml\n@@ -67,7 +67,7 @@\n subprocess_run(\"git diff --quiet -- . ':!searx/settings.yml' ':!utils/brand.env'\")\n except subprocess.CalledProcessError as e:\n if e.returncode == 1:\n- git_version += \"-dirty\"\n+ git_version += \"+dirty\"\n else:\n logger.warning('\"%s\" returns an unexpected return code %i', e.returncode, e.cmd)\n return git_version, tag_version\n", "issue": "Illegal version specifier according to pip\n<!-- PLEASE FILL THESE FIELDS, IT REALLY HELPS THE MAINTAINERS OF SearXNG -->\r\n\r\n**Version of SearXNG, commit number if you are using on master branch and stipulate if you forked SearXNG**\r\n<!-- If you are running on master branch using git execute this command\r\nin order to fetch the latest commit ID:\r\n```\r\ngit log -1\r\n``` \r\nIf you are using searxng-docker then look at the bottom of the SearXNG page\r\nand check for the version after \"Powered by SearXNG\"\r\n\r\nPlease also stipulate if you are using a forked version of SearXNG and\r\ninclude a link to the fork source code.\r\n-->\r\n\r\nCommit 13b0c251c45c3d14700723b25b601be56178e8df\r\n\r\n**How did you install SearXNG?**\r\n<!-- Did you install SearXNG using the official wiki or using searxng-docker\r\nor manually by executing the searx/webapp.py file? -->\r\n\r\nOfficial wiki, install script.\r\n\r\n**What happened?**\r\n<!-- A clear and concise description of what the bug is. -->\r\n\r\nStep `pip install -e .` fails with\r\n\r\n```\r\nLooking in indexes: https://pypi.org/simple, https://www.piwheels.org/simple\r\nObtaining file:///usr/local/searxng/searxng-src\r\n Preparing metadata (setup.py) ... error\r\n error: subprocess-exited-with-error\r\n\r\n \u00d7 python setup.py egg_info did not run successfully.\r\n \u2502 exit code: 1\r\n \u2570\u2500> [27 lines of output]\r\n /usr/local/searxng/searx-pyenv/lib/python3.9/site-packages/setuptools/dist.py:543: UserWarning: The version specified ('2023.01.15-13b0c251') is an invalid version, this may not work as expected with newer versions of setuptools, pip, and PyPI. Please see PEP 440 for more details.\r\n warnings.warn(\r\n 2023-01-16 13:17:41,865 INFO:root: running egg_info\r\n Traceback (most recent call last):\r\n File \"<string>\", line 2, in <module>\r\n File \"<pip-setuptools-caller>\", line 34, in <module>\r\n File \"/usr/local/searxng/searxng-src/setup.py\", line 19, in <module>\r\n setup(\r\n File \"/usr/local/searxng/searx-pyenv/lib/python3.9/site-packages/setuptools/__init__.py\", line 87, in setup\r\n return distutils.core.setup(**attrs)\r\n File \"/usr/local/searxng/searx-pyenv/lib/python3.9/site-packages/setuptools/_distutils/core.py\", line 185, in setup\r\n return run_commands(dist)\r\n File \"/usr/local/searxng/searx-pyenv/lib/python3.9/site-packages/setuptools/_distutils/core.py\", line 201, in run_commands\r\n dist.run_commands()\r\n File \"/usr/local/searxng/searx-pyenv/lib/python3.9/site-packages/setuptools/_distutils/dist.py\", line 969, in run_commands\r\n self.run_command(cmd)\r\n File \"/usr/local/searxng/searx-pyenv/lib/python3.9/site-packages/setuptools/dist.py\", line 1208, in run_command\r\n super().run_command(command)\r\n File \"/usr/local/searxng/searx-pyenv/lib/python3.9/site-packages/setuptools/_distutils/dist.py\", line 987, in run_command\r\n cmd_obj.ensure_finalized()\r\n File \"/usr/local/searxng/searx-pyenv/lib/python3.9/site-packages/setuptools/_distutils/cmd.py\", line 111, in ensure_finalized\r\n self.finalize_options()\r\n File \"/usr/local/searxng/searx-pyenv/lib/python3.9/site-packages/setuptools/command/egg_info.py\", line 219, in finalize_options\r\n parsed_version = parse_version(self.egg_version)\r\n File \"/usr/local/searxng/searx-pyenv/lib/python3.9/site-packages/pkg_resources/_vendor/packaging/version.py\", line 266, in __init__\r\n raise InvalidVersion(f\"Invalid version: '{version}'\")\r\n pkg_resources.extern.packaging.version.InvalidVersion: Invalid version: '2023.01.15-13b0c251'\r\n [end of output]\r\n\r\n note: This error originates from a subprocess, and is likely not a problem with pip.\r\nerror: metadata-generation-failed\r\n\r\n\u00d7 Encountered error while generating package metadata.\r\n\u2570\u2500> See above for output.\r\n\r\nnote: This is an issue with the package mentioned above, not pip.\r\nhint: See above for details.\r\n```\r\n\r\n\r\n**How To Reproduce**\r\n<!-- How can we reproduce this issue? (as minimally and as precisely as possible) -->\r\n\r\nFollow instructions in https://docs.searxng.org/admin/installation-scripts.html#installation-scripts, in my case on a Raspberry Pi 4B, with following version info:\r\n\r\n```\r\n$ uname -a\r\nLinux raspberrypi 5.15.32-v8+ #1538 SMP PREEMPT Thu Mar 31 19:40:39 BST 2022 aarch64 GNU/Linux\r\n```\r\n```\r\n$ python --version\r\nPython 3.9.2\r\n```\r\n```\r\n$ pip --version\r\npip 22.3.1 from /usr/local/searxng/searx-pyenv/lib/python3.9/site-packages/pip (python 3.9)\r\n```\r\n\r\n**Expected behavior**\r\n<!-- A clear and concise description of what you expected to happen. -->\r\n\r\nExpected installation to succeed.\r\n\r\n**Screenshots & Logs**\r\n<!-- If applicable, add screenshots, logs to help explain your problem. -->\r\n\r\nN/A\r\n\r\n**Additional context**\r\n<!-- Add any other context about the problem here. -->\r\n\r\nN/A\n", "before_files": [{"content": "# SPDX-License-Identifier: AGPL-3.0-or-later\n# lint: pylint\n# pylint: disable=,missing-module-docstring,missing-class-docstring\n\nimport os\nimport shlex\nimport subprocess\nimport logging\nimport importlib\n\n# fallback values\n# if there is searx.version_frozen module, and it is not possible to get the git tag\nVERSION_STRING = \"1.0.0\"\nVERSION_TAG = \"1.0.0\"\nGIT_URL = \"unknow\"\nGIT_BRANCH = \"unknow\"\n\nlogger = logging.getLogger(\"searx\")\n\nSUBPROCESS_RUN_ENV = {\n \"PATH\": os.environ[\"PATH\"],\n \"LC_ALL\": \"C\",\n \"LANGUAGE\": \"\",\n}\n\n\ndef subprocess_run(args, **kwargs):\n \"\"\"Call :py:func:`subprocess.run` and return (striped) stdout. If returncode is\n non-zero, raise a :py:func:`subprocess.CalledProcessError`.\n \"\"\"\n if not isinstance(args, (list, tuple)):\n args = shlex.split(args)\n\n kwargs[\"env\"] = kwargs.get(\"env\", SUBPROCESS_RUN_ENV)\n kwargs[\"encoding\"] = kwargs.get(\"encoding\", \"utf-8\")\n kwargs[\"stdout\"] = subprocess.PIPE\n kwargs[\"stderr\"] = subprocess.PIPE\n # raise CalledProcessError if returncode is non-zero\n kwargs[\"check\"] = True\n proc = subprocess.run(args, **kwargs) # pylint: disable=subprocess-run-check\n return proc.stdout.strip()\n\n\ndef get_git_url_and_branch():\n try:\n ref = subprocess_run(\"git rev-parse --abbrev-ref @{upstream}\")\n except subprocess.CalledProcessError:\n ref = subprocess_run(\"git rev-parse --abbrev-ref master@{upstream}\")\n origin, git_branch = ref.split(\"/\", 1)\n git_url = subprocess_run([\"git\", \"remote\", \"get-url\", origin])\n\n # get https:// url from git@ url\n if git_url.startswith(\"git@\"):\n git_url = git_url.replace(\":\", \"/\", 2).replace(\"git@\", \"https://\", 1)\n if git_url.endswith(\".git\"):\n git_url = git_url.replace(\".git\", \"\", 1)\n\n return git_url, git_branch\n\n\ndef get_git_version():\n git_commit_date_hash = subprocess_run(r\"git show -s --date='format:%Y.%m.%d' --format='%cd-%h'\")\n tag_version = git_version = git_commit_date_hash\n\n # add \"-dirty\" suffix if there are uncommited changes except searx/settings.yml\n try:\n subprocess_run(\"git diff --quiet -- . ':!searx/settings.yml' ':!utils/brand.env'\")\n except subprocess.CalledProcessError as e:\n if e.returncode == 1:\n git_version += \"-dirty\"\n else:\n logger.warning('\"%s\" returns an unexpected return code %i', e.returncode, e.cmd)\n return git_version, tag_version\n\n\ntry:\n vf = importlib.import_module('searx.version_frozen')\n VERSION_STRING, VERSION_TAG, GIT_URL, GIT_BRANCH = vf.VERSION_STRING, vf.VERSION_TAG, vf.GIT_URL, vf.GIT_BRANCH\nexcept ImportError:\n try:\n try:\n VERSION_STRING, VERSION_TAG = get_git_version()\n except subprocess.CalledProcessError as ex:\n logger.error(\"Error while getting the version: %s\", ex.stderr)\n try:\n GIT_URL, GIT_BRANCH = get_git_url_and_branch()\n except subprocess.CalledProcessError as ex:\n logger.error(\"Error while getting the git URL & branch: %s\", ex.stderr)\n except FileNotFoundError as ex:\n logger.error(\"%s is not found, fallback to the default version\", ex.filename)\n\n\nlogger.info(\"version: %s\", VERSION_STRING)\n\nif __name__ == \"__main__\":\n import sys\n\n if len(sys.argv) >= 2 and sys.argv[1] == \"freeze\":\n # freeze the version (to create an archive outside a git repository)\n python_code = f\"\"\"# SPDX-License-Identifier: AGPL-3.0-or-later\n# this file is generated automatically by searx/version.py\n\nVERSION_STRING = \"{VERSION_STRING}\"\nVERSION_TAG = \"{VERSION_TAG}\"\nGIT_URL = \"{GIT_URL}\"\nGIT_BRANCH = \"{GIT_BRANCH}\"\n\"\"\"\n with open(os.path.join(os.path.dirname(__file__), \"version_frozen.py\"), \"w\", encoding=\"utf8\") as f:\n f.write(python_code)\n print(f\"{f.name} created\")\n else:\n # output shell code to set the variables\n # usage: eval \"$(python -m searx.version)\"\n shell_code = f\"\"\"\nVERSION_STRING=\"{VERSION_STRING}\"\nVERSION_TAG=\"{VERSION_TAG}\"\nGIT_URL=\"{GIT_URL}\"\nGIT_BRANCH=\"{GIT_BRANCH}\"\n\"\"\"\n print(shell_code)\n", "path": "searx/version.py"}]}
| 3,191 | 254 |
gh_patches_debug_18126
|
rasdani/github-patches
|
git_diff
|
scoutapp__scout_apm_python-504
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Support Django BASE_DIR being a pathlib.Path
As per [my blog post today](https://adamj.eu/tech/2020/03/16/use-pathlib-in-your-django-project/), this is changing in Django 3.1 but users may already be changing it now.
</issue>
<code>
[start of src/scout_apm/django/apps.py]
1 # coding=utf-8
2 from __future__ import absolute_import, division, print_function, unicode_literals
3
4 from django.apps import AppConfig
5 from django.conf import settings
6 from django.test.signals import setting_changed
7
8 import scout_apm.core
9 from scout_apm.core.config import scout_config
10 from scout_apm.django.instruments.huey import ensure_huey_instrumented
11 from scout_apm.django.instruments.sql import ensure_sql_instrumented
12 from scout_apm.django.instruments.template import ensure_templates_instrumented
13
14
15 class ScoutApmDjangoConfig(AppConfig):
16 name = "scout_apm"
17 verbose_name = "Scout Apm (Django)"
18
19 def ready(self):
20 self.update_scout_config_from_django_settings()
21 setting_changed.connect(self.on_setting_changed)
22
23 # Finish installing the agent. If the agent isn't installed for any
24 # reason, return without installing instruments
25 installed = scout_apm.core.install()
26 if not installed:
27 return
28
29 self.install_middleware()
30
31 # Setup Instruments
32 ensure_huey_instrumented()
33 ensure_sql_instrumented()
34 ensure_templates_instrumented()
35
36 def update_scout_config_from_django_settings(self, **kwargs):
37 for name in dir(settings):
38 self.on_setting_changed(name)
39
40 def on_setting_changed(self, setting, **kwargs):
41 if setting == "BASE_DIR":
42 scout_name = "application_root"
43 elif setting.startswith("SCOUT_"):
44 scout_name = setting.replace("SCOUT_", "").lower()
45 else:
46 return
47
48 try:
49 value = getattr(settings, setting)
50 except AttributeError:
51 # It was removed
52 scout_config.unset(scout_name)
53 else:
54 scout_config.set(**{scout_name: value})
55
56 def install_middleware(self):
57 """
58 Attempts to insert the ScoutApm middleware as the first middleware
59 (first on incoming requests, last on outgoing responses).
60 """
61 from django.conf import settings
62
63 # If MIDDLEWARE is set, update that, with handling of tuple vs array forms
64 if getattr(settings, "MIDDLEWARE", None) is not None:
65 timing_middleware = "scout_apm.django.middleware.MiddlewareTimingMiddleware"
66 view_middleware = "scout_apm.django.middleware.ViewTimingMiddleware"
67
68 if isinstance(settings.MIDDLEWARE, tuple):
69 if timing_middleware not in settings.MIDDLEWARE:
70 settings.MIDDLEWARE = (timing_middleware,) + settings.MIDDLEWARE
71 if view_middleware not in settings.MIDDLEWARE:
72 settings.MIDDLEWARE = settings.MIDDLEWARE + (view_middleware,)
73 else:
74 if timing_middleware not in settings.MIDDLEWARE:
75 settings.MIDDLEWARE.insert(0, timing_middleware)
76 if view_middleware not in settings.MIDDLEWARE:
77 settings.MIDDLEWARE.append(view_middleware)
78
79 # Otherwise, we're doing old style middleware, do the same thing with
80 # the same handling of tuple vs array forms
81 else:
82 timing_middleware = (
83 "scout_apm.django.middleware.OldStyleMiddlewareTimingMiddleware"
84 )
85 view_middleware = "scout_apm.django.middleware.OldStyleViewMiddleware"
86
87 if isinstance(settings.MIDDLEWARE_CLASSES, tuple):
88 if timing_middleware not in settings.MIDDLEWARE_CLASSES:
89 settings.MIDDLEWARE_CLASSES = (
90 timing_middleware,
91 ) + settings.MIDDLEWARE_CLASSES
92
93 if view_middleware not in settings.MIDDLEWARE_CLASSES:
94 settings.MIDDLEWARE_CLASSES = settings.MIDDLEWARE_CLASSES + (
95 view_middleware,
96 )
97 else:
98 if timing_middleware not in settings.MIDDLEWARE_CLASSES:
99 settings.MIDDLEWARE_CLASSES.insert(0, timing_middleware)
100 if view_middleware not in settings.MIDDLEWARE_CLASSES:
101 settings.MIDDLEWARE_CLASSES.append(view_middleware)
102
[end of src/scout_apm/django/apps.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/scout_apm/django/apps.py b/src/scout_apm/django/apps.py
--- a/src/scout_apm/django/apps.py
+++ b/src/scout_apm/django/apps.py
@@ -38,8 +38,10 @@
self.on_setting_changed(name)
def on_setting_changed(self, setting, **kwargs):
+ cast = None
if setting == "BASE_DIR":
scout_name = "application_root"
+ cast = str
elif setting.startswith("SCOUT_"):
scout_name = setting.replace("SCOUT_", "").lower()
else:
@@ -51,6 +53,8 @@
# It was removed
scout_config.unset(scout_name)
else:
+ if cast is not None:
+ value = cast(value)
scout_config.set(**{scout_name: value})
def install_middleware(self):
|
{"golden_diff": "diff --git a/src/scout_apm/django/apps.py b/src/scout_apm/django/apps.py\n--- a/src/scout_apm/django/apps.py\n+++ b/src/scout_apm/django/apps.py\n@@ -38,8 +38,10 @@\n self.on_setting_changed(name)\n \n def on_setting_changed(self, setting, **kwargs):\n+ cast = None\n if setting == \"BASE_DIR\":\n scout_name = \"application_root\"\n+ cast = str\n elif setting.startswith(\"SCOUT_\"):\n scout_name = setting.replace(\"SCOUT_\", \"\").lower()\n else:\n@@ -51,6 +53,8 @@\n # It was removed\n scout_config.unset(scout_name)\n else:\n+ if cast is not None:\n+ value = cast(value)\n scout_config.set(**{scout_name: value})\n \n def install_middleware(self):\n", "issue": "Support Django BASE_DIR being a pathlib.Path\nAs per [my blog post today](https://adamj.eu/tech/2020/03/16/use-pathlib-in-your-django-project/), this is changing in Django 3.1 but users may already be changing it now.\n", "before_files": [{"content": "# coding=utf-8\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nfrom django.apps import AppConfig\nfrom django.conf import settings\nfrom django.test.signals import setting_changed\n\nimport scout_apm.core\nfrom scout_apm.core.config import scout_config\nfrom scout_apm.django.instruments.huey import ensure_huey_instrumented\nfrom scout_apm.django.instruments.sql import ensure_sql_instrumented\nfrom scout_apm.django.instruments.template import ensure_templates_instrumented\n\n\nclass ScoutApmDjangoConfig(AppConfig):\n name = \"scout_apm\"\n verbose_name = \"Scout Apm (Django)\"\n\n def ready(self):\n self.update_scout_config_from_django_settings()\n setting_changed.connect(self.on_setting_changed)\n\n # Finish installing the agent. If the agent isn't installed for any\n # reason, return without installing instruments\n installed = scout_apm.core.install()\n if not installed:\n return\n\n self.install_middleware()\n\n # Setup Instruments\n ensure_huey_instrumented()\n ensure_sql_instrumented()\n ensure_templates_instrumented()\n\n def update_scout_config_from_django_settings(self, **kwargs):\n for name in dir(settings):\n self.on_setting_changed(name)\n\n def on_setting_changed(self, setting, **kwargs):\n if setting == \"BASE_DIR\":\n scout_name = \"application_root\"\n elif setting.startswith(\"SCOUT_\"):\n scout_name = setting.replace(\"SCOUT_\", \"\").lower()\n else:\n return\n\n try:\n value = getattr(settings, setting)\n except AttributeError:\n # It was removed\n scout_config.unset(scout_name)\n else:\n scout_config.set(**{scout_name: value})\n\n def install_middleware(self):\n \"\"\"\n Attempts to insert the ScoutApm middleware as the first middleware\n (first on incoming requests, last on outgoing responses).\n \"\"\"\n from django.conf import settings\n\n # If MIDDLEWARE is set, update that, with handling of tuple vs array forms\n if getattr(settings, \"MIDDLEWARE\", None) is not None:\n timing_middleware = \"scout_apm.django.middleware.MiddlewareTimingMiddleware\"\n view_middleware = \"scout_apm.django.middleware.ViewTimingMiddleware\"\n\n if isinstance(settings.MIDDLEWARE, tuple):\n if timing_middleware not in settings.MIDDLEWARE:\n settings.MIDDLEWARE = (timing_middleware,) + settings.MIDDLEWARE\n if view_middleware not in settings.MIDDLEWARE:\n settings.MIDDLEWARE = settings.MIDDLEWARE + (view_middleware,)\n else:\n if timing_middleware not in settings.MIDDLEWARE:\n settings.MIDDLEWARE.insert(0, timing_middleware)\n if view_middleware not in settings.MIDDLEWARE:\n settings.MIDDLEWARE.append(view_middleware)\n\n # Otherwise, we're doing old style middleware, do the same thing with\n # the same handling of tuple vs array forms\n else:\n timing_middleware = (\n \"scout_apm.django.middleware.OldStyleMiddlewareTimingMiddleware\"\n )\n view_middleware = \"scout_apm.django.middleware.OldStyleViewMiddleware\"\n\n if isinstance(settings.MIDDLEWARE_CLASSES, tuple):\n if timing_middleware not in settings.MIDDLEWARE_CLASSES:\n settings.MIDDLEWARE_CLASSES = (\n timing_middleware,\n ) + settings.MIDDLEWARE_CLASSES\n\n if view_middleware not in settings.MIDDLEWARE_CLASSES:\n settings.MIDDLEWARE_CLASSES = settings.MIDDLEWARE_CLASSES + (\n view_middleware,\n )\n else:\n if timing_middleware not in settings.MIDDLEWARE_CLASSES:\n settings.MIDDLEWARE_CLASSES.insert(0, timing_middleware)\n if view_middleware not in settings.MIDDLEWARE_CLASSES:\n settings.MIDDLEWARE_CLASSES.append(view_middleware)\n", "path": "src/scout_apm/django/apps.py"}]}
| 1,634 | 199 |
gh_patches_debug_19527
|
rasdani/github-patches
|
git_diff
|
twisted__twisted-512
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
twisted.internet._ssl is unused and can be deleted
|[<img alt="alex's avatar" src="https://avatars.githubusercontent.com/u/772?s=50" width="50" height="50">](https://github.com/alex)| @alex reported|
|-|-|
|Trac ID|trac#8775|
|Type|enhancement|
|Created|2016-08-20 12:51:20Z|
LGTM
<details><summary>Searchable metadata</summary>
```
trac-id__8775 8775
type__enhancement enhancement
reporter__alex alex
priority__normal normal
milestone__None None
branch__
branch_author__
status__closed closed
resolution__fixed fixed
component__core core
keywords__None None
time__1471697480022394 1471697480022394
changetime__1471699165043033 1471699165043033
version__None None
owner__hawkowl hawkowl
```
</details>
</issue>
<code>
[start of src/twisted/internet/_ssl.py]
1 # -*- test-case-name: twisted.test.test_ssl -*-
2 # Copyright (c) Twisted Matrix Laboratories.
3 # See LICENSE for details.
4
5 """
6 This module implements helpers for switching to TLS on an existing transport.
7
8 @since: 11.1
9 """
10
11 class _TLSDelayed(object):
12 """
13 State tracking record for TLS startup parameters. Used to remember how
14 TLS should be started when starting it is delayed to wait for the output
15 buffer to be flushed.
16
17 @ivar bufferedData: A C{list} which contains all the data which was
18 written to the transport after an attempt to start TLS was made but
19 before the buffers outstanding at that time could be flushed and TLS
20 could really be started. This is appended to by the transport's
21 write and writeSequence methods until it is possible to actually
22 start TLS, then it is written to the TLS-enabled transport.
23
24 @ivar context: An SSL context factory object to use to start TLS.
25
26 @ivar extra: An extra argument to pass to the transport's C{startTLS}
27 method.
28 """
29 def __init__(self, bufferedData, context, extra):
30 self.bufferedData = bufferedData
31 self.context = context
32 self.extra = extra
33
[end of src/twisted/internet/_ssl.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/twisted/internet/_ssl.py b/src/twisted/internet/_ssl.py
deleted file mode 100644
--- a/src/twisted/internet/_ssl.py
+++ /dev/null
@@ -1,32 +0,0 @@
-# -*- test-case-name: twisted.test.test_ssl -*-
-# Copyright (c) Twisted Matrix Laboratories.
-# See LICENSE for details.
-
-"""
-This module implements helpers for switching to TLS on an existing transport.
-
-@since: 11.1
-"""
-
-class _TLSDelayed(object):
- """
- State tracking record for TLS startup parameters. Used to remember how
- TLS should be started when starting it is delayed to wait for the output
- buffer to be flushed.
-
- @ivar bufferedData: A C{list} which contains all the data which was
- written to the transport after an attempt to start TLS was made but
- before the buffers outstanding at that time could be flushed and TLS
- could really be started. This is appended to by the transport's
- write and writeSequence methods until it is possible to actually
- start TLS, then it is written to the TLS-enabled transport.
-
- @ivar context: An SSL context factory object to use to start TLS.
-
- @ivar extra: An extra argument to pass to the transport's C{startTLS}
- method.
- """
- def __init__(self, bufferedData, context, extra):
- self.bufferedData = bufferedData
- self.context = context
- self.extra = extra
|
{"golden_diff": "diff --git a/src/twisted/internet/_ssl.py b/src/twisted/internet/_ssl.py\ndeleted file mode 100644\n--- a/src/twisted/internet/_ssl.py\n+++ /dev/null\n@@ -1,32 +0,0 @@\n-# -*- test-case-name: twisted.test.test_ssl -*-\n-# Copyright (c) Twisted Matrix Laboratories.\n-# See LICENSE for details.\n-\n-\"\"\"\n-This module implements helpers for switching to TLS on an existing transport.\n-\n-@since: 11.1\n-\"\"\"\n-\n-class _TLSDelayed(object):\n- \"\"\"\n- State tracking record for TLS startup parameters. Used to remember how\n- TLS should be started when starting it is delayed to wait for the output\n- buffer to be flushed.\n-\n- @ivar bufferedData: A C{list} which contains all the data which was\n- written to the transport after an attempt to start TLS was made but\n- before the buffers outstanding at that time could be flushed and TLS\n- could really be started. This is appended to by the transport's\n- write and writeSequence methods until it is possible to actually\n- start TLS, then it is written to the TLS-enabled transport.\n-\n- @ivar context: An SSL context factory object to use to start TLS.\n-\n- @ivar extra: An extra argument to pass to the transport's C{startTLS}\n- method.\n- \"\"\"\n- def __init__(self, bufferedData, context, extra):\n- self.bufferedData = bufferedData\n- self.context = context\n- self.extra = extra\n", "issue": "twisted.internet._ssl is unused and can be deleted\n|[<img alt=\"alex's avatar\" src=\"https://avatars.githubusercontent.com/u/772?s=50\" width=\"50\" height=\"50\">](https://github.com/alex)| @alex reported|\n|-|-|\n|Trac ID|trac#8775|\n|Type|enhancement|\n|Created|2016-08-20 12:51:20Z|\n\nLGTM\n\n<details><summary>Searchable metadata</summary>\n\n```\ntrac-id__8775 8775\ntype__enhancement enhancement\nreporter__alex alex\npriority__normal normal\nmilestone__None None\nbranch__ \nbranch_author__ \nstatus__closed closed\nresolution__fixed fixed\ncomponent__core core\nkeywords__None None\ntime__1471697480022394 1471697480022394\nchangetime__1471699165043033 1471699165043033\nversion__None None\nowner__hawkowl hawkowl\n\n```\n</details>\n\n", "before_files": [{"content": "# -*- test-case-name: twisted.test.test_ssl -*-\n# Copyright (c) Twisted Matrix Laboratories.\n# See LICENSE for details.\n\n\"\"\"\nThis module implements helpers for switching to TLS on an existing transport.\n\n@since: 11.1\n\"\"\"\n\nclass _TLSDelayed(object):\n \"\"\"\n State tracking record for TLS startup parameters. Used to remember how\n TLS should be started when starting it is delayed to wait for the output\n buffer to be flushed.\n\n @ivar bufferedData: A C{list} which contains all the data which was\n written to the transport after an attempt to start TLS was made but\n before the buffers outstanding at that time could be flushed and TLS\n could really be started. This is appended to by the transport's\n write and writeSequence methods until it is possible to actually\n start TLS, then it is written to the TLS-enabled transport.\n\n @ivar context: An SSL context factory object to use to start TLS.\n\n @ivar extra: An extra argument to pass to the transport's C{startTLS}\n method.\n \"\"\"\n def __init__(self, bufferedData, context, extra):\n self.bufferedData = bufferedData\n self.context = context\n self.extra = extra\n", "path": "src/twisted/internet/_ssl.py"}]}
| 1,147 | 358 |
gh_patches_debug_18885
|
rasdani/github-patches
|
git_diff
|
ansible-collections__community.general-2518
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
nmap inventory plugin error: local variable 'results' referenced before assignment
### Summary
Using the nmap inventory plugin from collection version 3.x and 2.x I am getting the following error when attempting to do the inventory sync in Ansible:
```
[WARNING]: * Failed to parse /tmp/awx_320_6c0cpe4z/project/hosts/nmap/nmap.yml
with ansible_collections.community.general.plugins.inventory.nmap plugin: local
variable 'results' referenced before assignment
```
I'm assuming the python code references the `results` variable before assignment.
This error did not exist in the previous version of the collection (version 1.x).
### Issue Type
Bug Report
### Component Name
nmap inventory plugin
### Ansible Version
From Ansible Tower job output:
```console (paste below)
ansible-inventory 2.9.17
config file = /tmp/awx_320_6c0cpe4z/project/ansible.cfg
configured module search path = ['/var/lib/awx/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']
ansible python module location = /usr/lib/python3.6/site-packages/ansible
executable location = /usr/bin/ansible-inventory
python version = 3.6.8 (default, Aug 18 2020, 08:33:21) [GCC 8.3.1 20191121 (Red Hat 8.3.1-5)]
Using /tmp/awx_320_6c0cpe4z/project/ansible.cfg as config file
[WARNING]: * Failed to parse /tmp/awx_320_6c0cpe4z/project/hosts/nmap/nmap.yml
with ansible_collections.community.general.plugins.inventory.nmap plugin: local
variable 'results' referenced before assignment
File "/usr/lib/python3.6/site-packages/ansible/inventory/manager.py", line 280, in parse_source
plugin.parse(self._inventory, self._loader, source, cache=cache)
File "/tmp/awx_320_6c0cpe4z/requirements_collections/ansible_collections/community/general/plugins/inventory/nmap.py", line 212, in parse
self._populate(results)
[WARNING]: Unable to parse /tmp/awx_320_6c0cpe4z/project/hosts/nmap/nmap.yml as
an inventory source
[WARNING]: Unable to parse /tmp/awx_320_6c0cpe4z/project/hosts/nmap as an
inventory source
ERROR! No inventory was parsed, please check your configuration and options.
```
### Configuration
The `nmap.yml` inventory plugin configuration.
```console (paste below)
# Inventory plugin type
plugin: community.general.nmap
# Invalid entries do not cause a fatal error and will be skipped
strict: False
# Network IP or range of IPs to scan, you can use a simple range (10.2.2.15-25) or CIDR notation.
address: 192.168.1.0/24
# list of addresses to exclude
exclude:
- '192.168.1.0'
# Enable/disable scanning for open ports; poor performance when scanning all ports
ports: False
# At least one of ipv4 or ipv6 is required to be True, both can be True, but they cannot both be False.
# Use IPv4 type addresses
ipv4: True
# Use IPv6 type addresses
ipv6: False
# # Create vars from jinja2 expressions. (dictionary)
# compose:
# open_ports_exist: "{{ ports | count }}"
# # Add hosts to group based on Jinja2 conditionals (dictionary)
# groups:
# 'ports_open': "{{ ports is defined }}"
# # Add hosts to group based on the values of a variable. (list)
# keyed_groups:
# - key: ports | default("none")
# parent_group: ports
```
### OS / Environment
RHEL8 server with Ansible Tower 3.8.x and Ansible Engine 2.9.x
### Steps to Reproduce
- Create `nmap.yml` inventory plugin yaml file
- Install `nmap` locally
- Run `ansible-inventory` to test nmap inventory plugin using collection
### Expected Results
Inventory sync succeeds.
### Actual Results
Error happens (as listed above)
### Code of Conduct
- [X] I agree to follow the Ansible Code of Conduct
</issue>
<code>
[start of plugins/inventory/nmap.py]
1 # Copyright (c) 2017 Ansible Project
2 # GNU General Public License v3.0+ (see COPYING or https://www.gnu.org/licenses/gpl-3.0.txt)
3
4 from __future__ import (absolute_import, division, print_function)
5 __metaclass__ = type
6
7 DOCUMENTATION = '''
8 author: Unknown (!UNKNOWN)
9 name: nmap
10 short_description: Uses nmap to find hosts to target
11 description:
12 - Uses a YAML configuration file with a valid YAML extension.
13 extends_documentation_fragment:
14 - constructed
15 - inventory_cache
16 requirements:
17 - nmap CLI installed
18 options:
19 plugin:
20 description: token that ensures this is a source file for the 'nmap' plugin.
21 required: True
22 choices: ['nmap', 'community.general.nmap']
23 address:
24 description: Network IP or range of IPs to scan, you can use a simple range (10.2.2.15-25) or CIDR notation.
25 required: True
26 exclude:
27 description: list of addresses to exclude
28 type: list
29 ports:
30 description: Enable/disable scanning for open ports
31 type: boolean
32 default: True
33 ipv4:
34 description: use IPv4 type addresses
35 type: boolean
36 default: True
37 ipv6:
38 description: use IPv6 type addresses
39 type: boolean
40 default: True
41 notes:
42 - At least one of ipv4 or ipv6 is required to be True, both can be True, but they cannot both be False.
43 - 'TODO: add OS fingerprinting'
44 '''
45 EXAMPLES = '''
46 # inventory.config file in YAML format
47 plugin: community.general.nmap
48 strict: False
49 address: 192.168.0.0/24
50 '''
51
52 import os
53 import re
54
55 from subprocess import Popen, PIPE
56
57 from ansible import constants as C
58 from ansible.errors import AnsibleParserError
59 from ansible.module_utils._text import to_native, to_text
60 from ansible.plugins.inventory import BaseInventoryPlugin, Constructable, Cacheable
61 from ansible.module_utils.common.process import get_bin_path
62
63
64 class InventoryModule(BaseInventoryPlugin, Constructable, Cacheable):
65
66 NAME = 'community.general.nmap'
67 find_host = re.compile(r'^Nmap scan report for ([\w,.,-]+)(?: \(([\w,.,:,\[,\]]+)\))?')
68 find_port = re.compile(r'^(\d+)/(\w+)\s+(\w+)\s+(\w+)')
69
70 def __init__(self):
71 self._nmap = None
72 super(InventoryModule, self).__init__()
73
74 def _populate(self, hosts):
75 # Use constructed if applicable
76 strict = self.get_option('strict')
77
78 for host in hosts:
79 hostname = host['name']
80 self.inventory.add_host(hostname)
81 for var, value in host.items():
82 self.inventory.set_variable(hostname, var, value)
83
84 # Composed variables
85 self._set_composite_vars(self.get_option('compose'), host, hostname, strict=strict)
86
87 # Complex groups based on jinja2 conditionals, hosts that meet the conditional are added to group
88 self._add_host_to_composed_groups(self.get_option('groups'), host, hostname, strict=strict)
89
90 # Create groups based on variable values and add the corresponding hosts to it
91 self._add_host_to_keyed_groups(self.get_option('keyed_groups'), host, hostname, strict=strict)
92
93 def verify_file(self, path):
94
95 valid = False
96 if super(InventoryModule, self).verify_file(path):
97 file_name, ext = os.path.splitext(path)
98
99 if not ext or ext in C.YAML_FILENAME_EXTENSIONS:
100 valid = True
101
102 return valid
103
104 def parse(self, inventory, loader, path, cache=True):
105
106 try:
107 self._nmap = get_bin_path('nmap')
108 except ValueError as e:
109 raise AnsibleParserError('nmap inventory plugin requires the nmap cli tool to work: {0}'.format(to_native(e)))
110
111 super(InventoryModule, self).parse(inventory, loader, path, cache=cache)
112
113 self._read_config_data(path)
114
115 cache_key = self.get_cache_key(path)
116
117 # cache may be True or False at this point to indicate if the inventory is being refreshed
118 # get the user's cache option too to see if we should save the cache if it is changing
119 user_cache_setting = self.get_option('cache')
120
121 # read if the user has caching enabled and the cache isn't being refreshed
122 attempt_to_read_cache = user_cache_setting and cache
123 # update if the user has caching enabled and the cache is being refreshed; update this value to True if the cache has expired below
124 cache_needs_update = user_cache_setting and not cache
125
126 if attempt_to_read_cache:
127 try:
128 results = self._cache[cache_key]
129 except KeyError:
130 # This occurs if the cache_key is not in the cache or if the cache_key expired, so the cache needs to be updated
131 cache_needs_update = True
132
133 if cache_needs_update:
134 # setup command
135 cmd = [self._nmap]
136 if not self._options['ports']:
137 cmd.append('-sP')
138
139 if self._options['ipv4'] and not self._options['ipv6']:
140 cmd.append('-4')
141 elif self._options['ipv6'] and not self._options['ipv4']:
142 cmd.append('-6')
143 elif not self._options['ipv6'] and not self._options['ipv4']:
144 raise AnsibleParserError('One of ipv4 or ipv6 must be enabled for this plugin')
145
146 if self._options['exclude']:
147 cmd.append('--exclude')
148 cmd.append(','.join(self._options['exclude']))
149
150 cmd.append(self._options['address'])
151 try:
152 # execute
153 p = Popen(cmd, stdout=PIPE, stderr=PIPE)
154 stdout, stderr = p.communicate()
155 if p.returncode != 0:
156 raise AnsibleParserError('Failed to run nmap, rc=%s: %s' % (p.returncode, to_native(stderr)))
157
158 # parse results
159 host = None
160 ip = None
161 ports = []
162 results = []
163
164 try:
165 t_stdout = to_text(stdout, errors='surrogate_or_strict')
166 except UnicodeError as e:
167 raise AnsibleParserError('Invalid (non unicode) input returned: %s' % to_native(e))
168
169 for line in t_stdout.splitlines():
170 hits = self.find_host.match(line)
171 if hits:
172 if host is not None and ports:
173 results[-1]['ports'] = ports
174
175 # if dns only shows arpa, just use ip instead as hostname
176 if hits.group(1).endswith('.in-addr.arpa'):
177 host = hits.group(2)
178 else:
179 host = hits.group(1)
180
181 # if no reverse dns exists, just use ip instead as hostname
182 if hits.group(2) is not None:
183 ip = hits.group(2)
184 else:
185 ip = hits.group(1)
186
187 if host is not None:
188 # update inventory
189 results.append(dict())
190 results[-1]['name'] = host
191 results[-1]['ip'] = ip
192 ports = []
193 continue
194
195 host_ports = self.find_port.match(line)
196 if host is not None and host_ports:
197 ports.append({'port': host_ports.group(1),
198 'protocol': host_ports.group(2),
199 'state': host_ports.group(3),
200 'service': host_ports.group(4)})
201 continue
202
203 # if any leftovers
204 if host and ports:
205 results[-1]['ports'] = ports
206
207 except Exception as e:
208 raise AnsibleParserError("failed to parse %s: %s " % (to_native(path), to_native(e)))
209
210 self._cache[cache_key] = results
211
212 self._populate(results)
213
[end of plugins/inventory/nmap.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/plugins/inventory/nmap.py b/plugins/inventory/nmap.py
--- a/plugins/inventory/nmap.py
+++ b/plugins/inventory/nmap.py
@@ -130,7 +130,7 @@
# This occurs if the cache_key is not in the cache or if the cache_key expired, so the cache needs to be updated
cache_needs_update = True
- if cache_needs_update:
+ if not user_cache_setting or cache_needs_update:
# setup command
cmd = [self._nmap]
if not self._options['ports']:
@@ -207,6 +207,7 @@
except Exception as e:
raise AnsibleParserError("failed to parse %s: %s " % (to_native(path), to_native(e)))
+ if cache_needs_update:
self._cache[cache_key] = results
self._populate(results)
|
{"golden_diff": "diff --git a/plugins/inventory/nmap.py b/plugins/inventory/nmap.py\n--- a/plugins/inventory/nmap.py\n+++ b/plugins/inventory/nmap.py\n@@ -130,7 +130,7 @@\n # This occurs if the cache_key is not in the cache or if the cache_key expired, so the cache needs to be updated\n cache_needs_update = True\n \n- if cache_needs_update:\n+ if not user_cache_setting or cache_needs_update:\n # setup command\n cmd = [self._nmap]\n if not self._options['ports']:\n@@ -207,6 +207,7 @@\n except Exception as e:\n raise AnsibleParserError(\"failed to parse %s: %s \" % (to_native(path), to_native(e)))\n \n+ if cache_needs_update:\n self._cache[cache_key] = results\n \n self._populate(results)\n", "issue": "nmap inventory plugin error: local variable 'results' referenced before assignment\n### Summary\n\nUsing the nmap inventory plugin from collection version 3.x and 2.x I am getting the following error when attempting to do the inventory sync in Ansible:\r\n\r\n```\r\n[WARNING]: * Failed to parse /tmp/awx_320_6c0cpe4z/project/hosts/nmap/nmap.yml\r\nwith ansible_collections.community.general.plugins.inventory.nmap plugin: local\r\nvariable 'results' referenced before assignment\r\n```\r\n\r\nI'm assuming the python code references the `results` variable before assignment. \r\n\r\nThis error did not exist in the previous version of the collection (version 1.x).\r\n\n\n### Issue Type\n\nBug Report\n\n### Component Name\n\nnmap inventory plugin\n\n### Ansible Version\n\nFrom Ansible Tower job output:\r\n\r\n```console (paste below)\r\nansible-inventory 2.9.17\r\n config file = /tmp/awx_320_6c0cpe4z/project/ansible.cfg\r\n configured module search path = ['/var/lib/awx/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']\r\n ansible python module location = /usr/lib/python3.6/site-packages/ansible\r\n executable location = /usr/bin/ansible-inventory\r\n python version = 3.6.8 (default, Aug 18 2020, 08:33:21) [GCC 8.3.1 20191121 (Red Hat 8.3.1-5)]\r\nUsing /tmp/awx_320_6c0cpe4z/project/ansible.cfg as config file\r\n[WARNING]: * Failed to parse /tmp/awx_320_6c0cpe4z/project/hosts/nmap/nmap.yml\r\nwith ansible_collections.community.general.plugins.inventory.nmap plugin: local\r\nvariable 'results' referenced before assignment\r\n File \"/usr/lib/python3.6/site-packages/ansible/inventory/manager.py\", line 280, in parse_source\r\n plugin.parse(self._inventory, self._loader, source, cache=cache)\r\n File \"/tmp/awx_320_6c0cpe4z/requirements_collections/ansible_collections/community/general/plugins/inventory/nmap.py\", line 212, in parse\r\n self._populate(results)\r\n[WARNING]: Unable to parse /tmp/awx_320_6c0cpe4z/project/hosts/nmap/nmap.yml as\r\nan inventory source\r\n[WARNING]: Unable to parse /tmp/awx_320_6c0cpe4z/project/hosts/nmap as an\r\ninventory source\r\nERROR! No inventory was parsed, please check your configuration and options.\r\n```\r\n\n\n### Configuration\n\nThe `nmap.yml` inventory plugin configuration.\r\n\r\n```console (paste below)\r\n# Inventory plugin type\r\nplugin: community.general.nmap\r\n# Invalid entries do not cause a fatal error and will be skipped\r\nstrict: False\r\n# Network IP or range of IPs to scan, you can use a simple range (10.2.2.15-25) or CIDR notation.\r\naddress: 192.168.1.0/24\r\n# list of addresses to exclude\r\nexclude:\r\n - '192.168.1.0'\r\n# Enable/disable scanning for open ports; poor performance when scanning all ports\r\nports: False\r\n\r\n# At least one of ipv4 or ipv6 is required to be True, both can be True, but they cannot both be False.\r\n# Use IPv4 type addresses\r\nipv4: True\r\n# Use IPv6 type addresses\r\nipv6: False\r\n\r\n# # Create vars from jinja2 expressions. (dictionary)\r\n# compose:\r\n# open_ports_exist: \"{{ ports | count }}\"\r\n# # Add hosts to group based on Jinja2 conditionals (dictionary)\r\n# groups:\r\n# 'ports_open': \"{{ ports is defined }}\"\r\n# # Add hosts to group based on the values of a variable. (list)\r\n# keyed_groups:\r\n# - key: ports | default(\"none\")\r\n# parent_group: ports\r\n```\r\n\n\n### OS / Environment\n\nRHEL8 server with Ansible Tower 3.8.x and Ansible Engine 2.9.x\n\n### Steps to Reproduce\n\n- Create `nmap.yml` inventory plugin yaml file\r\n- Install `nmap` locally\r\n- Run `ansible-inventory` to test nmap inventory plugin using collection\r\n\n\n### Expected Results\n\nInventory sync succeeds.\n\n### Actual Results\n\nError happens (as listed above)\n\n### Code of Conduct\n\n- [X] I agree to follow the Ansible Code of Conduct\n", "before_files": [{"content": "# Copyright (c) 2017 Ansible Project\n# GNU General Public License v3.0+ (see COPYING or https://www.gnu.org/licenses/gpl-3.0.txt)\n\nfrom __future__ import (absolute_import, division, print_function)\n__metaclass__ = type\n\nDOCUMENTATION = '''\n author: Unknown (!UNKNOWN)\n name: nmap\n short_description: Uses nmap to find hosts to target\n description:\n - Uses a YAML configuration file with a valid YAML extension.\n extends_documentation_fragment:\n - constructed\n - inventory_cache\n requirements:\n - nmap CLI installed\n options:\n plugin:\n description: token that ensures this is a source file for the 'nmap' plugin.\n required: True\n choices: ['nmap', 'community.general.nmap']\n address:\n description: Network IP or range of IPs to scan, you can use a simple range (10.2.2.15-25) or CIDR notation.\n required: True\n exclude:\n description: list of addresses to exclude\n type: list\n ports:\n description: Enable/disable scanning for open ports\n type: boolean\n default: True\n ipv4:\n description: use IPv4 type addresses\n type: boolean\n default: True\n ipv6:\n description: use IPv6 type addresses\n type: boolean\n default: True\n notes:\n - At least one of ipv4 or ipv6 is required to be True, both can be True, but they cannot both be False.\n - 'TODO: add OS fingerprinting'\n'''\nEXAMPLES = '''\n# inventory.config file in YAML format\nplugin: community.general.nmap\nstrict: False\naddress: 192.168.0.0/24\n'''\n\nimport os\nimport re\n\nfrom subprocess import Popen, PIPE\n\nfrom ansible import constants as C\nfrom ansible.errors import AnsibleParserError\nfrom ansible.module_utils._text import to_native, to_text\nfrom ansible.plugins.inventory import BaseInventoryPlugin, Constructable, Cacheable\nfrom ansible.module_utils.common.process import get_bin_path\n\n\nclass InventoryModule(BaseInventoryPlugin, Constructable, Cacheable):\n\n NAME = 'community.general.nmap'\n find_host = re.compile(r'^Nmap scan report for ([\\w,.,-]+)(?: \\(([\\w,.,:,\\[,\\]]+)\\))?')\n find_port = re.compile(r'^(\\d+)/(\\w+)\\s+(\\w+)\\s+(\\w+)')\n\n def __init__(self):\n self._nmap = None\n super(InventoryModule, self).__init__()\n\n def _populate(self, hosts):\n # Use constructed if applicable\n strict = self.get_option('strict')\n\n for host in hosts:\n hostname = host['name']\n self.inventory.add_host(hostname)\n for var, value in host.items():\n self.inventory.set_variable(hostname, var, value)\n\n # Composed variables\n self._set_composite_vars(self.get_option('compose'), host, hostname, strict=strict)\n\n # Complex groups based on jinja2 conditionals, hosts that meet the conditional are added to group\n self._add_host_to_composed_groups(self.get_option('groups'), host, hostname, strict=strict)\n\n # Create groups based on variable values and add the corresponding hosts to it\n self._add_host_to_keyed_groups(self.get_option('keyed_groups'), host, hostname, strict=strict)\n\n def verify_file(self, path):\n\n valid = False\n if super(InventoryModule, self).verify_file(path):\n file_name, ext = os.path.splitext(path)\n\n if not ext or ext in C.YAML_FILENAME_EXTENSIONS:\n valid = True\n\n return valid\n\n def parse(self, inventory, loader, path, cache=True):\n\n try:\n self._nmap = get_bin_path('nmap')\n except ValueError as e:\n raise AnsibleParserError('nmap inventory plugin requires the nmap cli tool to work: {0}'.format(to_native(e)))\n\n super(InventoryModule, self).parse(inventory, loader, path, cache=cache)\n\n self._read_config_data(path)\n\n cache_key = self.get_cache_key(path)\n\n # cache may be True or False at this point to indicate if the inventory is being refreshed\n # get the user's cache option too to see if we should save the cache if it is changing\n user_cache_setting = self.get_option('cache')\n\n # read if the user has caching enabled and the cache isn't being refreshed\n attempt_to_read_cache = user_cache_setting and cache\n # update if the user has caching enabled and the cache is being refreshed; update this value to True if the cache has expired below\n cache_needs_update = user_cache_setting and not cache\n\n if attempt_to_read_cache:\n try:\n results = self._cache[cache_key]\n except KeyError:\n # This occurs if the cache_key is not in the cache or if the cache_key expired, so the cache needs to be updated\n cache_needs_update = True\n\n if cache_needs_update:\n # setup command\n cmd = [self._nmap]\n if not self._options['ports']:\n cmd.append('-sP')\n\n if self._options['ipv4'] and not self._options['ipv6']:\n cmd.append('-4')\n elif self._options['ipv6'] and not self._options['ipv4']:\n cmd.append('-6')\n elif not self._options['ipv6'] and not self._options['ipv4']:\n raise AnsibleParserError('One of ipv4 or ipv6 must be enabled for this plugin')\n\n if self._options['exclude']:\n cmd.append('--exclude')\n cmd.append(','.join(self._options['exclude']))\n\n cmd.append(self._options['address'])\n try:\n # execute\n p = Popen(cmd, stdout=PIPE, stderr=PIPE)\n stdout, stderr = p.communicate()\n if p.returncode != 0:\n raise AnsibleParserError('Failed to run nmap, rc=%s: %s' % (p.returncode, to_native(stderr)))\n\n # parse results\n host = None\n ip = None\n ports = []\n results = []\n\n try:\n t_stdout = to_text(stdout, errors='surrogate_or_strict')\n except UnicodeError as e:\n raise AnsibleParserError('Invalid (non unicode) input returned: %s' % to_native(e))\n\n for line in t_stdout.splitlines():\n hits = self.find_host.match(line)\n if hits:\n if host is not None and ports:\n results[-1]['ports'] = ports\n\n # if dns only shows arpa, just use ip instead as hostname\n if hits.group(1).endswith('.in-addr.arpa'):\n host = hits.group(2)\n else:\n host = hits.group(1)\n\n # if no reverse dns exists, just use ip instead as hostname\n if hits.group(2) is not None:\n ip = hits.group(2)\n else:\n ip = hits.group(1)\n\n if host is not None:\n # update inventory\n results.append(dict())\n results[-1]['name'] = host\n results[-1]['ip'] = ip\n ports = []\n continue\n\n host_ports = self.find_port.match(line)\n if host is not None and host_ports:\n ports.append({'port': host_ports.group(1),\n 'protocol': host_ports.group(2),\n 'state': host_ports.group(3),\n 'service': host_ports.group(4)})\n continue\n\n # if any leftovers\n if host and ports:\n results[-1]['ports'] = ports\n\n except Exception as e:\n raise AnsibleParserError(\"failed to parse %s: %s \" % (to_native(path), to_native(e)))\n\n self._cache[cache_key] = results\n\n self._populate(results)\n", "path": "plugins/inventory/nmap.py"}]}
| 3,821 | 202 |
gh_patches_debug_5035
|
rasdani/github-patches
|
git_diff
|
wagtail__wagtail-1019
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Remove built dependencies
This commit removes libsass and Pillow from the setup.py dependency list. This greatly improves install performance and also means that the basic Wagtail installation is pure-python (so no build tools need to be on the end users host machine).
None of these dependencies are directly called from within Wagtail so the start project command continues to work correctly.
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2
3 import sys, os
4
5 from wagtail.wagtailcore import __version__
6
7
8 try:
9 from setuptools import setup, find_packages
10 except ImportError:
11 from distutils.core import setup
12
13
14 # Hack to prevent "TypeError: 'NoneType' object is not callable" error
15 # in multiprocessing/util.py _exit_function when setup.py exits
16 # (see http://www.eby-sarna.com/pipermail/peak/2010-May/003357.html)
17 try:
18 import multiprocessing
19 except ImportError:
20 pass
21
22
23 # Disable parallel builds, because Pillow 2.5.3 does some crazy monkeypatching of
24 # the build process on multicore systems, which breaks installation of libsass
25 os.environ['MAX_CONCURRENCY'] = '1'
26
27 PY3 = sys.version_info[0] == 3
28
29
30 install_requires = [
31 "Django>=1.7.0,<1.8",
32 "django-compressor>=1.4",
33 "django-libsass>=0.2",
34 "django-modelcluster>=0.5",
35 "django-taggit==0.12.2",
36 "django-treebeard==3.0",
37 "Pillow>=2.6.1",
38 "beautifulsoup4>=4.3.2",
39 "html5lib==0.999",
40 "Unidecode>=0.04.14",
41 "six>=1.7.0",
42 'requests>=2.0.0',
43 "Willow==0.1",
44 ]
45
46
47 if not PY3:
48 install_requires += [
49 "unicodecsv>=0.9.4"
50 ]
51
52
53 setup(
54 name='wagtail',
55 version=__version__,
56 description='A Django content management system focused on flexibility and user experience',
57 author='Matthew Westcott',
58 author_email='[email protected]',
59 url='http://wagtail.io/',
60 packages=find_packages(),
61 include_package_data=True,
62 license='BSD',
63 long_description=open('README.rst').read(),
64 classifiers=[
65 'Development Status :: 5 - Production/Stable',
66 'Environment :: Web Environment',
67 'Intended Audience :: Developers',
68 'License :: OSI Approved :: BSD License',
69 'Operating System :: OS Independent',
70 'Programming Language :: Python',
71 'Programming Language :: Python :: 2',
72 'Programming Language :: Python :: 2.7',
73 'Programming Language :: Python :: 3',
74 'Programming Language :: Python :: 3.3',
75 'Programming Language :: Python :: 3.4',
76 'Framework :: Django',
77 'Topic :: Internet :: WWW/HTTP :: Site Management',
78 ],
79 install_requires=install_requires,
80 entry_points="""
81 [console_scripts]
82 wagtail=wagtail.bin.wagtail:main
83 """,
84 zip_safe=False,
85 )
86
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -30,11 +30,9 @@
install_requires = [
"Django>=1.7.0,<1.8",
"django-compressor>=1.4",
- "django-libsass>=0.2",
"django-modelcluster>=0.5",
"django-taggit==0.12.2",
"django-treebeard==3.0",
- "Pillow>=2.6.1",
"beautifulsoup4>=4.3.2",
"html5lib==0.999",
"Unidecode>=0.04.14",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -30,11 +30,9 @@\n install_requires = [\n \"Django>=1.7.0,<1.8\",\n \"django-compressor>=1.4\",\n- \"django-libsass>=0.2\",\n \"django-modelcluster>=0.5\",\n \"django-taggit==0.12.2\",\n \"django-treebeard==3.0\",\n- \"Pillow>=2.6.1\",\n \"beautifulsoup4>=4.3.2\",\n \"html5lib==0.999\",\n \"Unidecode>=0.04.14\",\n", "issue": "Remove built dependencies\nThis commit removes libsass and Pillow from the setup.py dependency list. This greatly improves install performance and also means that the basic Wagtail installation is pure-python (so no build tools need to be on the end users host machine).\n\nNone of these dependencies are directly called from within Wagtail so the start project command continues to work correctly.\n\n", "before_files": [{"content": "#!/usr/bin/env python\n\nimport sys, os\n\nfrom wagtail.wagtailcore import __version__\n\n\ntry:\n from setuptools import setup, find_packages\nexcept ImportError:\n from distutils.core import setup\n\n\n# Hack to prevent \"TypeError: 'NoneType' object is not callable\" error\n# in multiprocessing/util.py _exit_function when setup.py exits\n# (see http://www.eby-sarna.com/pipermail/peak/2010-May/003357.html)\ntry:\n import multiprocessing\nexcept ImportError:\n pass\n\n\n# Disable parallel builds, because Pillow 2.5.3 does some crazy monkeypatching of\n# the build process on multicore systems, which breaks installation of libsass\nos.environ['MAX_CONCURRENCY'] = '1'\n\nPY3 = sys.version_info[0] == 3\n\n\ninstall_requires = [\n \"Django>=1.7.0,<1.8\",\n \"django-compressor>=1.4\",\n \"django-libsass>=0.2\",\n \"django-modelcluster>=0.5\",\n \"django-taggit==0.12.2\",\n \"django-treebeard==3.0\",\n \"Pillow>=2.6.1\",\n \"beautifulsoup4>=4.3.2\",\n \"html5lib==0.999\",\n \"Unidecode>=0.04.14\",\n \"six>=1.7.0\",\n 'requests>=2.0.0',\n \"Willow==0.1\",\n]\n\n\nif not PY3:\n install_requires += [\n \"unicodecsv>=0.9.4\"\n ]\n\n\nsetup(\n name='wagtail',\n version=__version__,\n description='A Django content management system focused on flexibility and user experience',\n author='Matthew Westcott',\n author_email='[email protected]',\n url='http://wagtail.io/',\n packages=find_packages(),\n include_package_data=True,\n license='BSD',\n long_description=open('README.rst').read(),\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Web Environment',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: BSD License',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Framework :: Django',\n 'Topic :: Internet :: WWW/HTTP :: Site Management',\n ],\n install_requires=install_requires,\n entry_points=\"\"\"\n [console_scripts]\n wagtail=wagtail.bin.wagtail:main\n \"\"\",\n zip_safe=False,\n)\n", "path": "setup.py"}]}
| 1,393 | 158 |
gh_patches_debug_20174
|
rasdani/github-patches
|
git_diff
|
google__openhtf-703
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
pypi release 1.2.0 is missing built proto files in openhtf/output/proto
pypi release 1.2.0 is missing built proto files in openhtf/output/proto. They are present in release 1.1.0. This is observed by downloading the tarball from pypi. Can this be corrected? Thanks
</issue>
<code>
[start of setup.py]
1 # Copyright 2014 Google Inc. All Rights Reserved.
2
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6
7 # http://www.apache.org/licenses/LICENSE-2.0
8
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 """Setup script for OpenHTF."""
15
16 import errno
17 import glob
18 import os
19 import platform
20 import subprocess
21 import sys
22
23 from distutils.command.build import build
24 from distutils.command.clean import clean
25 from distutils.cmd import Command
26 from setuptools import find_packages
27 from setuptools import setup
28 from setuptools.command.test import test
29
30
31 class CleanCommand(clean):
32 """Custom logic for the clean command."""
33
34 def run(self):
35 clean.run(self)
36 targets = [
37 './dist',
38 './*.egg-info',
39 './openhtf/output/proto/*_pb2.py',
40 './openhtf/**/*.pyc',
41 ]
42 os.system('shopt -s globstar; rm -vrf %s' % ' '.join(targets))
43
44
45 class BuildProtoCommand(Command):
46 """Custom setup command to build protocol buffers."""
47 description = 'Builds the proto files into python files.'
48 user_options = [('protoc=', None, 'Path to the protoc compiler.'),
49 ('protodir=', None, 'Path to protobuf install.'),
50 ('indir=', 'i', 'Directory containing input .proto files.'),
51 ('outdir=', 'o', 'Where to output .py files.')]
52
53 def initialize_options(self):
54 self.skip_proto = False
55 try:
56 prefix = subprocess.check_output(
57 'pkg-config --variable prefix protobuf'.split()).strip().decode('utf-8')
58 except (subprocess.CalledProcessError, OSError):
59 if platform.system() == 'Linux':
60 # Default to /usr?
61 prefix = '/usr'
62 elif platform.system() in ['Mac', 'Darwin']:
63 # Default to /usr/local for Homebrew
64 prefix = '/usr/local'
65 else:
66 print('Warning: mfg-inspector output is not fully implemented for '
67 'Windows. OpenHTF will be installed without it.')
68 self.skip_proto = True
69
70 maybe_protoc = os.path.join(prefix, 'bin', 'protoc')
71 if os.path.isfile(maybe_protoc) and os.access(maybe_protoc, os.X_OK):
72 self.protoc = maybe_protoc
73 else:
74 print('Warning: protoc not found at %s' % maybe_protoc)
75 print('setup will attempt to run protoc with no prefix.')
76 self.protoc = 'protoc'
77
78 self.protodir = os.path.join(prefix, 'include')
79 self.indir = os.getcwd()
80 self.outdir = os.getcwd()
81
82 def finalize_options(self):
83 pass
84
85 def run(self):
86 if self.skip_proto:
87 print('Skipping building protocol buffers.')
88 return
89
90 # Build regular proto files.
91 protos = glob.glob(
92 os.path.join(self.indir, 'openhtf', 'output', 'proto', '*.proto'))
93
94 if protos:
95 print('Attempting to build proto files:\n%s' % '\n'.join(protos))
96 cmd = [
97 self.protoc,
98 '--proto_path', self.indir,
99 '--proto_path', self.protodir,
100 '--python_out', self.outdir,
101 ] + protos
102 try:
103 subprocess.check_call(cmd)
104 except OSError as e:
105 if e.errno == errno.ENOENT:
106 print('Could not find the protobuf compiler at \'%s\'' % self.protoc)
107 if sys.platform.startswith('linux'):
108 print('On many Linux systems, this is fixed by installing the '
109 '"protobuf-compiler" and "libprotobuf-dev" packages.')
110 elif sys.platform == 'darwin':
111 print('On Mac, protobuf is often installed via homebrew.')
112 raise
113 except subprocess.CalledProcessError:
114 print('Could not build proto files.')
115 print('This could be due to missing helper files. On many Linux '
116 'systems, this is fixed by installing the '
117 '"libprotobuf-dev" package.')
118 raise
119 else:
120 print('Found no proto files to build.')
121
122
123 # Make building protos part of building overall.
124 build.sub_commands.insert(0, ('build_proto', None))
125
126
127 INSTALL_REQUIRES = [
128 'contextlib2>=0.5.1,<1.0',
129 'enum34>=1.1.2,<2.0;python_version<"3.4"',
130 'future>=0.16.0',
131 'mutablerecords>=0.4.1,<2.0',
132 'oauth2client>=1.5.2,<2.0',
133 'protobuf>=3.0.0,<4.0',
134 'pyaml>=15.3.1,<16.0',
135 'pyOpenSSL>=17.1.0,<18.0',
136 'sockjs-tornado>=1.0.3,<2.0',
137 'tornado>=4.3,<5.0',
138 ]
139
140
141 class PyTestCommand(test):
142 # Derived from
143 # https://github.com/chainreactionmfg/cara/blob/master/setup.py
144 user_options = [
145 ('pytest-args=', None, 'Arguments to pass to py.test'),
146 ('pytest-cov=', None, 'Enable coverage. Choose output type: '
147 'term, html, xml, annotate, or multiple with comma separation'),
148 ]
149
150 def initialize_options(self):
151 test.initialize_options(self)
152 self.pytest_args = 'test'
153 self.pytest_cov = None
154
155 def finalize_options(self):
156 test.finalize_options(self)
157 self.test_args = []
158 self.test_suite = True
159
160 def run_tests(self):
161 self.run_command('build_proto')
162
163 import pytest
164 cov = ''
165 if self.pytest_cov is not None:
166 outputs = ' '.join('--cov-report %s' % output
167 for output in self.pytest_cov.split(','))
168 cov = ' --cov openhtf ' + outputs
169
170 sys.argv = [sys.argv[0]]
171 print('invoking pytest.main with %s' % (self.pytest_args + cov))
172 sys.exit(pytest.main(self.pytest_args + cov))
173
174
175 setup(
176 name='openhtf',
177 version='1.2.0',
178 description='OpenHTF, the open hardware testing framework.',
179 author='John Hawley',
180 author_email='[email protected]',
181 maintainer='Joe Ethier',
182 maintainer_email='[email protected]',
183 packages=find_packages(exclude='examples'),
184 package_data={'openhtf': ['output/web_gui/prebuilt/**/*.*',
185 'output/web_gui/prebuilt/*.*']},
186 cmdclass={
187 'build_proto': BuildProtoCommand,
188 'clean': CleanCommand,
189 'test': PyTestCommand,
190 },
191 install_requires=INSTALL_REQUIRES,
192 extras_require={
193 'usb_plugs': [
194 'libusb1>=1.3.0,<2.0',
195 'M2Crypto>=0.22.3,<1.0',
196 ],
197 'update_units': [
198 'xlrd>=1.0.0,<2.0',
199 ],
200 },
201 setup_requires=[
202 'wheel>=0.29.0,<1.0',
203 ],
204 tests_require=[
205 'mock>=2.0.0',
206 'pytest>=2.9.2',
207 'pytest-cov>=2.2.1',
208 ],
209 )
210
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -126,7 +126,6 @@
INSTALL_REQUIRES = [
'contextlib2>=0.5.1,<1.0',
- 'enum34>=1.1.2,<2.0;python_version<"3.4"',
'future>=0.16.0',
'mutablerecords>=0.4.1,<2.0',
'oauth2client>=1.5.2,<2.0',
@@ -136,6 +135,11 @@
'sockjs-tornado>=1.0.3,<2.0',
'tornado>=4.3,<5.0',
]
+# Not all versions of setuptools support semicolon syntax for specifying
+# platform-specific dependencies, so we do it the old school way.
+if sys.version_info < (3,4):
+ INSTALL_REQUIRES.append('enum34>=1.1.2,<2.0')
+
class PyTestCommand(test):
@@ -174,7 +178,7 @@
setup(
name='openhtf',
- version='1.2.0',
+ version='1.2.1',
description='OpenHTF, the open hardware testing framework.',
author='John Hawley',
author_email='[email protected]',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -126,7 +126,6 @@\n \n INSTALL_REQUIRES = [\n 'contextlib2>=0.5.1,<1.0',\n- 'enum34>=1.1.2,<2.0;python_version<\"3.4\"',\n 'future>=0.16.0',\n 'mutablerecords>=0.4.1,<2.0',\n 'oauth2client>=1.5.2,<2.0',\n@@ -136,6 +135,11 @@\n 'sockjs-tornado>=1.0.3,<2.0',\n 'tornado>=4.3,<5.0',\n ]\n+# Not all versions of setuptools support semicolon syntax for specifying\n+# platform-specific dependencies, so we do it the old school way.\n+if sys.version_info < (3,4):\n+ INSTALL_REQUIRES.append('enum34>=1.1.2,<2.0')\n+\n \n \n class PyTestCommand(test):\n@@ -174,7 +178,7 @@\n \n setup(\n name='openhtf',\n- version='1.2.0',\n+ version='1.2.1',\n description='OpenHTF, the open hardware testing framework.',\n author='John Hawley',\n author_email='[email protected]',\n", "issue": "pypi release 1.2.0 is missing built proto files in openhtf/output/proto\npypi release 1.2.0 is missing built proto files in openhtf/output/proto. They are present in release 1.1.0. This is observed by downloading the tarball from pypi. Can this be corrected? Thanks\n", "before_files": [{"content": "# Copyright 2014 Google Inc. All Rights Reserved.\n\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n\n# http://www.apache.org/licenses/LICENSE-2.0\n\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Setup script for OpenHTF.\"\"\"\n\nimport errno\nimport glob\nimport os\nimport platform\nimport subprocess\nimport sys\n\nfrom distutils.command.build import build\nfrom distutils.command.clean import clean\nfrom distutils.cmd import Command\nfrom setuptools import find_packages\nfrom setuptools import setup\nfrom setuptools.command.test import test\n\n\nclass CleanCommand(clean):\n \"\"\"Custom logic for the clean command.\"\"\"\n\n def run(self):\n clean.run(self)\n targets = [\n './dist',\n './*.egg-info',\n './openhtf/output/proto/*_pb2.py',\n './openhtf/**/*.pyc',\n ]\n os.system('shopt -s globstar; rm -vrf %s' % ' '.join(targets))\n\n\nclass BuildProtoCommand(Command):\n \"\"\"Custom setup command to build protocol buffers.\"\"\"\n description = 'Builds the proto files into python files.'\n user_options = [('protoc=', None, 'Path to the protoc compiler.'),\n ('protodir=', None, 'Path to protobuf install.'),\n ('indir=', 'i', 'Directory containing input .proto files.'),\n ('outdir=', 'o', 'Where to output .py files.')]\n\n def initialize_options(self):\n self.skip_proto = False\n try:\n prefix = subprocess.check_output(\n 'pkg-config --variable prefix protobuf'.split()).strip().decode('utf-8')\n except (subprocess.CalledProcessError, OSError):\n if platform.system() == 'Linux':\n # Default to /usr?\n prefix = '/usr'\n elif platform.system() in ['Mac', 'Darwin']:\n # Default to /usr/local for Homebrew\n prefix = '/usr/local'\n else:\n print('Warning: mfg-inspector output is not fully implemented for '\n 'Windows. OpenHTF will be installed without it.')\n self.skip_proto = True\n\n maybe_protoc = os.path.join(prefix, 'bin', 'protoc')\n if os.path.isfile(maybe_protoc) and os.access(maybe_protoc, os.X_OK):\n self.protoc = maybe_protoc\n else:\n print('Warning: protoc not found at %s' % maybe_protoc)\n print('setup will attempt to run protoc with no prefix.')\n self.protoc = 'protoc'\n\n self.protodir = os.path.join(prefix, 'include')\n self.indir = os.getcwd()\n self.outdir = os.getcwd()\n\n def finalize_options(self):\n pass\n\n def run(self):\n if self.skip_proto:\n print('Skipping building protocol buffers.')\n return\n\n # Build regular proto files.\n protos = glob.glob(\n os.path.join(self.indir, 'openhtf', 'output', 'proto', '*.proto'))\n\n if protos:\n print('Attempting to build proto files:\\n%s' % '\\n'.join(protos))\n cmd = [\n self.protoc,\n '--proto_path', self.indir,\n '--proto_path', self.protodir,\n '--python_out', self.outdir,\n ] + protos\n try:\n subprocess.check_call(cmd)\n except OSError as e:\n if e.errno == errno.ENOENT:\n print('Could not find the protobuf compiler at \\'%s\\'' % self.protoc)\n if sys.platform.startswith('linux'):\n print('On many Linux systems, this is fixed by installing the '\n '\"protobuf-compiler\" and \"libprotobuf-dev\" packages.')\n elif sys.platform == 'darwin':\n print('On Mac, protobuf is often installed via homebrew.')\n raise\n except subprocess.CalledProcessError:\n print('Could not build proto files.')\n print('This could be due to missing helper files. On many Linux '\n 'systems, this is fixed by installing the '\n '\"libprotobuf-dev\" package.')\n raise\n else:\n print('Found no proto files to build.')\n\n\n# Make building protos part of building overall.\nbuild.sub_commands.insert(0, ('build_proto', None))\n\n\nINSTALL_REQUIRES = [\n 'contextlib2>=0.5.1,<1.0',\n 'enum34>=1.1.2,<2.0;python_version<\"3.4\"',\n 'future>=0.16.0',\n 'mutablerecords>=0.4.1,<2.0',\n 'oauth2client>=1.5.2,<2.0',\n 'protobuf>=3.0.0,<4.0',\n 'pyaml>=15.3.1,<16.0',\n 'pyOpenSSL>=17.1.0,<18.0',\n 'sockjs-tornado>=1.0.3,<2.0',\n 'tornado>=4.3,<5.0',\n]\n\n\nclass PyTestCommand(test):\n # Derived from\n # https://github.com/chainreactionmfg/cara/blob/master/setup.py\n user_options = [\n ('pytest-args=', None, 'Arguments to pass to py.test'),\n ('pytest-cov=', None, 'Enable coverage. Choose output type: '\n 'term, html, xml, annotate, or multiple with comma separation'),\n ]\n\n def initialize_options(self):\n test.initialize_options(self)\n self.pytest_args = 'test'\n self.pytest_cov = None\n\n def finalize_options(self):\n test.finalize_options(self)\n self.test_args = []\n self.test_suite = True\n\n def run_tests(self):\n self.run_command('build_proto')\n\n import pytest\n cov = ''\n if self.pytest_cov is not None:\n outputs = ' '.join('--cov-report %s' % output\n for output in self.pytest_cov.split(','))\n cov = ' --cov openhtf ' + outputs\n\n sys.argv = [sys.argv[0]]\n print('invoking pytest.main with %s' % (self.pytest_args + cov))\n sys.exit(pytest.main(self.pytest_args + cov))\n\n\nsetup(\n name='openhtf',\n version='1.2.0',\n description='OpenHTF, the open hardware testing framework.',\n author='John Hawley',\n author_email='[email protected]',\n maintainer='Joe Ethier',\n maintainer_email='[email protected]',\n packages=find_packages(exclude='examples'),\n package_data={'openhtf': ['output/web_gui/prebuilt/**/*.*',\n 'output/web_gui/prebuilt/*.*']},\n cmdclass={\n 'build_proto': BuildProtoCommand,\n 'clean': CleanCommand,\n 'test': PyTestCommand,\n },\n install_requires=INSTALL_REQUIRES,\n extras_require={\n 'usb_plugs': [\n 'libusb1>=1.3.0,<2.0',\n 'M2Crypto>=0.22.3,<1.0',\n ],\n 'update_units': [\n 'xlrd>=1.0.0,<2.0',\n ],\n },\n setup_requires=[\n 'wheel>=0.29.0,<1.0',\n ],\n tests_require=[\n 'mock>=2.0.0',\n 'pytest>=2.9.2',\n 'pytest-cov>=2.2.1',\n ],\n)\n", "path": "setup.py"}]}
| 2,835 | 312 |
gh_patches_debug_30697
|
rasdani/github-patches
|
git_diff
|
Pyomo__pyomo-996
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
TranformationFactory('core.fix_discrete') doesn't work for cloned models
# Summary
I have noticed that often times `TransformationFactory('core.fix_discrete')` doesn't work for a model, i.e. it doesn't actually fix the variables. I have found out that it happens to cloned models (whereas 'normal' models work as expected).
## Minimal working example
```python
from pyomo.environ import *
m = ConcreteModel()
m.y = Var(domain=Integers, bounds=(0,10), initialize=0)
m_clone = m.clone()
TransformationFactory('core.fix_discrete').apply_to(m_clone)
m_clone.pprint()
```
yields
```
1 Var Declarations
y : Size=1, Index=None
Key : Lower : Value : Upper : Fixed : Stale : Domain
None : 0 : 0 : 10 : False : False : Integers
1 Suffix Declarations
_fixed_discrete_vars : Direction=Suffix.LOCAL, Datatype=Suffix.FLOAT
Key : Value
None : []
2 Declarations: y _fixed_discrete_vars
```
Notice that the variable `y` didn't actually get fixed. If the `TranformationFactory` is intead applied to model `m`, the behaviour is as expected.
## Looking into the code
When diving into the code, the problem ends up being when the domain of the variable `y` is checked against a list of domains [here](https://github.com/Pyomo/pyomo/blob/ea161615a67b93c2540384eae4cce55e998dc8cc/pyomo/core/plugins/transform/discrete_vars.py#L116-L119)
The expression `var.domain in _discrete_relaxation_map` will yield `False`, even though `var` is an Integer.
</issue>
<code>
[start of pyomo/core/plugins/transform/discrete_vars.py]
1 # ___________________________________________________________________________
2 #
3 # Pyomo: Python Optimization Modeling Objects
4 # Copyright 2017 National Technology and Engineering Solutions of Sandia, LLC
5 # Under the terms of Contract DE-NA0003525 with National Technology and
6 # Engineering Solutions of Sandia, LLC, the U.S. Government retains certain
7 # rights in this software.
8 # This software is distributed under the 3-clause BSD License.
9 # ___________________________________________________________________________
10
11 import logging
12 logger = logging.getLogger('pyomo.core')
13
14 from six import itervalues
15
16 from pyomo.core.base import (
17 Transformation,
18 TransformationFactory,
19 Binary,
20 Boolean,
21 Integers,
22 Reals,
23 PositiveIntegers,
24 PositiveReals,
25 NonPositiveIntegers,
26 NonPositiveReals,
27 NegativeIntegers,
28 NegativeReals,
29 NonNegativeIntegers,
30 NonNegativeReals,
31 IntegerInterval,
32 RealInterval,
33 Var,
34 Suffix,
35 )
36
37 _discrete_relaxation_map = {
38 Binary : NonNegativeReals,
39 Boolean : NonNegativeReals,
40 Integers : Reals,
41 PositiveIntegers : PositiveReals,
42 NonPositiveIntegers : NonPositiveReals,
43 NegativeIntegers : NegativeReals,
44 NonNegativeIntegers : NonNegativeReals,
45 IntegerInterval : RealInterval,
46 }
47
48
49 #
50 # This transformation relaxes known discrete domains to their continuous
51 # counterparts
52 #
53 @TransformationFactory.register( 'core.relax_discrete',
54 doc="Relax known discrete domains to continuous counterparts" )
55 class RelaxDiscreteVars(Transformation):
56
57 def __init__(self):
58 super(RelaxDiscreteVars, self).__init__()
59
60 def _apply_to(self, model, **kwds):
61 options = kwds.pop('options', {})
62 if kwds.get('undo', options.get('undo', False)):
63 for v, d in itervalues(model._relaxed_discrete_vars[None]):
64 v.domain = d
65 model.del_component("_relaxed_discrete_vars")
66 return
67
68 # Relax the model
69 relaxed_vars = {}
70 _base_model_vars = model.component_data_objects(
71 Var, active=True, descend_into=True )
72 for var in _base_model_vars:
73 if var.domain in _discrete_relaxation_map:
74 if var.domain is Binary or var.domain is Boolean:
75 var.setlb(0)
76 var.setub(1)
77 # Note: some indexed components can only have their
78 # domain set on the parent component (the individual
79 # indices cannot be set independently)
80 _c = var.parent_component()
81 if id(_c) in _discrete_relaxation_map:
82 continue
83 try:
84 _domain = var.domain
85 var.domain = _discrete_relaxation_map[_domain]
86 relaxed_vars[id(var)] = (var, _domain)
87 except:
88 _domain = _c.domain
89 _c.domain = _discrete_relaxation_map[_domain]
90 relaxed_vars[id(_c)] = (_c, _domain)
91 model._relaxed_discrete_vars = Suffix(direction=Suffix.LOCAL)
92 model._relaxed_discrete_vars[None] = relaxed_vars
93
94
95 #
96 # This transformation fixes known discrete domains to their current values
97 #
98 @TransformationFactory.register('core.fix_discrete',
99 doc="Fix known discrete domains to continuous counterparts" )
100 class FixDiscreteVars(Transformation):
101
102 def __init__(self):
103 super(FixDiscreteVars, self).__init__()
104
105 def _apply_to(self, model, **kwds):
106 options = kwds.pop('options', {})
107 if kwds.get('undo', options.get('undo', False)):
108 for v in model._fixed_discrete_vars[None]:
109 v.unfix()
110 model.del_component("_fixed_discrete_vars")
111 return
112
113 fixed_vars = []
114 _base_model_vars = model.component_data_objects(
115 Var, active=True, descend_into=True )
116 for var in _base_model_vars:
117 if var.domain in _discrete_relaxation_map and not var.is_fixed():
118 fixed_vars.append(var)
119 var.fix()
120 model._fixed_discrete_vars = Suffix(direction=Suffix.LOCAL)
121 model._fixed_discrete_vars[None] = fixed_vars
122
123
[end of pyomo/core/plugins/transform/discrete_vars.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pyomo/core/plugins/transform/discrete_vars.py b/pyomo/core/plugins/transform/discrete_vars.py
--- a/pyomo/core/plugins/transform/discrete_vars.py
+++ b/pyomo/core/plugins/transform/discrete_vars.py
@@ -95,26 +95,29 @@
#
# This transformation fixes known discrete domains to their current values
#
[email protected]('core.fix_discrete',
- doc="Fix known discrete domains to continuous counterparts" )
[email protected]('core.fix_discrete',
+ doc="Fix known discrete domains to continuous counterparts")
class FixDiscreteVars(Transformation):
def __init__(self):
super(FixDiscreteVars, self).__init__()
- def _apply_to(self, model, **kwds):
+ def _apply_to(self, model, **kwds):
options = kwds.pop('options', {})
if kwds.get('undo', options.get('undo', False)):
for v in model._fixed_discrete_vars[None]:
v.unfix()
model.del_component("_fixed_discrete_vars")
return
-
+
fixed_vars = []
_base_model_vars = model.component_data_objects(
- Var, active=True, descend_into=True )
+ Var, active=True, descend_into=True)
for var in _base_model_vars:
- if var.domain in _discrete_relaxation_map and not var.is_fixed():
+ # Instead of checking against `_discrete_relaxation_map.keys()`
+ # we just check the item properties to fix #995
+ # When #326 has been resolved, we can check against the dict-keys again
+ if not var.is_continuous() and not var.is_fixed():
fixed_vars.append(var)
var.fix()
model._fixed_discrete_vars = Suffix(direction=Suffix.LOCAL)
|
{"golden_diff": "diff --git a/pyomo/core/plugins/transform/discrete_vars.py b/pyomo/core/plugins/transform/discrete_vars.py\n--- a/pyomo/core/plugins/transform/discrete_vars.py\n+++ b/pyomo/core/plugins/transform/discrete_vars.py\n@@ -95,26 +95,29 @@\n #\n # This transformation fixes known discrete domains to their current values\n #\[email protected]('core.fix_discrete', \n- doc=\"Fix known discrete domains to continuous counterparts\" )\[email protected]('core.fix_discrete',\n+ doc=\"Fix known discrete domains to continuous counterparts\")\n class FixDiscreteVars(Transformation):\n \n def __init__(self):\n super(FixDiscreteVars, self).__init__()\n \n- def _apply_to(self, model, **kwds): \n+ def _apply_to(self, model, **kwds):\n options = kwds.pop('options', {})\n if kwds.get('undo', options.get('undo', False)):\n for v in model._fixed_discrete_vars[None]:\n v.unfix()\n model.del_component(\"_fixed_discrete_vars\")\n return\n- \n+\n fixed_vars = []\n _base_model_vars = model.component_data_objects(\n- Var, active=True, descend_into=True )\n+ Var, active=True, descend_into=True)\n for var in _base_model_vars:\n- if var.domain in _discrete_relaxation_map and not var.is_fixed():\n+ # Instead of checking against `_discrete_relaxation_map.keys()` \n+ # we just check the item properties to fix #995 \n+ # When #326 has been resolved, we can check against the dict-keys again\n+ if not var.is_continuous() and not var.is_fixed():\n fixed_vars.append(var)\n var.fix()\n model._fixed_discrete_vars = Suffix(direction=Suffix.LOCAL)\n", "issue": "TranformationFactory('core.fix_discrete') doesn't work for cloned models\n# Summary\r\nI have noticed that often times `TransformationFactory('core.fix_discrete')` doesn't work for a model, i.e. it doesn't actually fix the variables. I have found out that it happens to cloned models (whereas 'normal' models work as expected).\r\n\r\n## Minimal working example\r\n```python\r\nfrom pyomo.environ import *\r\nm = ConcreteModel()\r\nm.y = Var(domain=Integers, bounds=(0,10), initialize=0)\r\nm_clone = m.clone()\r\nTransformationFactory('core.fix_discrete').apply_to(m_clone)\r\nm_clone.pprint()\r\n```\r\nyields\r\n```\r\n1 Var Declarations\r\n y : Size=1, Index=None\r\n Key : Lower : Value : Upper : Fixed : Stale : Domain\r\n None : 0 : 0 : 10 : False : False : Integers\r\n1 Suffix Declarations\r\n _fixed_discrete_vars : Direction=Suffix.LOCAL, Datatype=Suffix.FLOAT\r\n Key : Value\r\n None : []\r\n2 Declarations: y _fixed_discrete_vars\r\n```\r\nNotice that the variable `y` didn't actually get fixed. If the `TranformationFactory` is intead applied to model `m`, the behaviour is as expected.\r\n\r\n## Looking into the code\r\nWhen diving into the code, the problem ends up being when the domain of the variable `y` is checked against a list of domains [here](https://github.com/Pyomo/pyomo/blob/ea161615a67b93c2540384eae4cce55e998dc8cc/pyomo/core/plugins/transform/discrete_vars.py#L116-L119)\r\n\r\nThe expression `var.domain in _discrete_relaxation_map` will yield `False`, even though `var` is an Integer.\n", "before_files": [{"content": "# ___________________________________________________________________________\n#\n# Pyomo: Python Optimization Modeling Objects\n# Copyright 2017 National Technology and Engineering Solutions of Sandia, LLC\n# Under the terms of Contract DE-NA0003525 with National Technology and \n# Engineering Solutions of Sandia, LLC, the U.S. Government retains certain \n# rights in this software.\n# This software is distributed under the 3-clause BSD License.\n# ___________________________________________________________________________\n\nimport logging\nlogger = logging.getLogger('pyomo.core')\n\nfrom six import itervalues\n\nfrom pyomo.core.base import ( \n Transformation,\n TransformationFactory,\n Binary,\n Boolean,\n Integers,\n Reals, \n PositiveIntegers,\n PositiveReals, \n NonPositiveIntegers,\n NonPositiveReals, \n NegativeIntegers,\n NegativeReals,\n NonNegativeIntegers,\n NonNegativeReals,\n IntegerInterval,\n RealInterval,\n Var,\n Suffix,\n)\n\n_discrete_relaxation_map = {\n Binary : NonNegativeReals,\n Boolean : NonNegativeReals,\n Integers : Reals, \n PositiveIntegers : PositiveReals, \n NonPositiveIntegers : NonPositiveReals, \n NegativeIntegers : NegativeReals,\n NonNegativeIntegers : NonNegativeReals,\n IntegerInterval : RealInterval,\n}\n\n\n#\n# This transformation relaxes known discrete domains to their continuous\n# counterparts\n#\[email protected]( 'core.relax_discrete', \n doc=\"Relax known discrete domains to continuous counterparts\" )\nclass RelaxDiscreteVars(Transformation):\n\n def __init__(self):\n super(RelaxDiscreteVars, self).__init__()\n\n def _apply_to(self, model, **kwds): \n options = kwds.pop('options', {})\n if kwds.get('undo', options.get('undo', False)):\n for v, d in itervalues(model._relaxed_discrete_vars[None]):\n v.domain = d\n model.del_component(\"_relaxed_discrete_vars\")\n return\n \n # Relax the model\n relaxed_vars = {}\n _base_model_vars = model.component_data_objects(\n Var, active=True, descend_into=True )\n for var in _base_model_vars:\n if var.domain in _discrete_relaxation_map:\n if var.domain is Binary or var.domain is Boolean:\n var.setlb(0)\n var.setub(1)\n # Note: some indexed components can only have their\n # domain set on the parent component (the individual\n # indices cannot be set independently)\n _c = var.parent_component()\n if id(_c) in _discrete_relaxation_map:\n continue\n try:\n _domain = var.domain\n var.domain = _discrete_relaxation_map[_domain]\n relaxed_vars[id(var)] = (var, _domain)\n except:\n _domain = _c.domain\n _c.domain = _discrete_relaxation_map[_domain]\n relaxed_vars[id(_c)] = (_c, _domain)\n model._relaxed_discrete_vars = Suffix(direction=Suffix.LOCAL)\n model._relaxed_discrete_vars[None] = relaxed_vars\n\n\n#\n# This transformation fixes known discrete domains to their current values\n#\[email protected]('core.fix_discrete', \n doc=\"Fix known discrete domains to continuous counterparts\" )\nclass FixDiscreteVars(Transformation):\n\n def __init__(self):\n super(FixDiscreteVars, self).__init__()\n\n def _apply_to(self, model, **kwds): \n options = kwds.pop('options', {})\n if kwds.get('undo', options.get('undo', False)):\n for v in model._fixed_discrete_vars[None]:\n v.unfix()\n model.del_component(\"_fixed_discrete_vars\")\n return\n \n fixed_vars = []\n _base_model_vars = model.component_data_objects(\n Var, active=True, descend_into=True )\n for var in _base_model_vars:\n if var.domain in _discrete_relaxation_map and not var.is_fixed():\n fixed_vars.append(var)\n var.fix()\n model._fixed_discrete_vars = Suffix(direction=Suffix.LOCAL)\n model._fixed_discrete_vars[None] = fixed_vars\n\n", "path": "pyomo/core/plugins/transform/discrete_vars.py"}]}
| 2,154 | 405 |
gh_patches_debug_32672
|
rasdani/github-patches
|
git_diff
|
encode__uvicorn-591
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Proxy Middleware grabs the last IP in `x-forwarded-for`, not the first
https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/X-Forwarded-For says the first IP in is a client IP, but ProxyHeadersMiddleware grabs the last IP:
https://github.com/encode/uvicorn/blob/9d9f8820a8155e36dcb5e4d4023f470e51aa4e03/uvicorn/middleware/proxy_headers.py#L41
</issue>
<code>
[start of uvicorn/middleware/proxy_headers.py]
1 """
2 This middleware can be used when a known proxy is fronting the application,
3 and is trusted to be properly setting the `X-Forwarded-Proto` and
4 `X-Forwarded-For` headers with the connecting client information.
5
6 Modifies the `client` and `scheme` information so that they reference
7 the connecting client, rather that the connecting proxy.
8
9 https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers#Proxies
10 """
11
12
13 class ProxyHeadersMiddleware:
14 def __init__(self, app, trusted_hosts="127.0.0.1"):
15 self.app = app
16 if isinstance(trusted_hosts, str):
17 self.trusted_hosts = [item.strip() for item in trusted_hosts.split(",")]
18 else:
19 self.trusted_hosts = trusted_hosts
20 self.always_trust = "*" in self.trusted_hosts
21
22 async def __call__(self, scope, receive, send):
23 if scope["type"] in ("http", "websocket"):
24 client_addr = scope.get("client")
25 client_host = client_addr[0] if client_addr else None
26
27 if self.always_trust or client_host in self.trusted_hosts:
28 headers = dict(scope["headers"])
29
30 if b"x-forwarded-proto" in headers:
31 # Determine if the incoming request was http or https based on
32 # the X-Forwarded-Proto header.
33 x_forwarded_proto = headers[b"x-forwarded-proto"].decode("latin1")
34 scope["scheme"] = x_forwarded_proto.strip()
35
36 if b"x-forwarded-for" in headers:
37 # Determine the client address from the last trusted IP in the
38 # X-Forwarded-For header. We've lost the connecting client's port
39 # information by now, so only include the host.
40 x_forwarded_for = headers[b"x-forwarded-for"].decode("latin1")
41 host = x_forwarded_for.split(",")[-1].strip()
42 port = 0
43 scope["client"] = (host, port)
44
45 return await self.app(scope, receive, send)
46
[end of uvicorn/middleware/proxy_headers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/uvicorn/middleware/proxy_headers.py b/uvicorn/middleware/proxy_headers.py
--- a/uvicorn/middleware/proxy_headers.py
+++ b/uvicorn/middleware/proxy_headers.py
@@ -8,17 +8,28 @@
https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers#Proxies
"""
+from typing import List
class ProxyHeadersMiddleware:
def __init__(self, app, trusted_hosts="127.0.0.1"):
self.app = app
if isinstance(trusted_hosts, str):
- self.trusted_hosts = [item.strip() for item in trusted_hosts.split(",")]
+ self.trusted_hosts = {item.strip() for item in trusted_hosts.split(",")}
else:
- self.trusted_hosts = trusted_hosts
+ self.trusted_hosts = set(trusted_hosts)
self.always_trust = "*" in self.trusted_hosts
+ def get_trusted_client_host(
+ self, x_forwarded_for_hosts
+ ): # type: (List[str]) -> str
+ if self.always_trust:
+ return x_forwarded_for_hosts[0]
+
+ for host in reversed(x_forwarded_for_hosts):
+ if host not in self.trusted_hosts:
+ return host
+
async def __call__(self, scope, receive, send):
if scope["type"] in ("http", "websocket"):
client_addr = scope.get("client")
@@ -38,7 +49,10 @@
# X-Forwarded-For header. We've lost the connecting client's port
# information by now, so only include the host.
x_forwarded_for = headers[b"x-forwarded-for"].decode("latin1")
- host = x_forwarded_for.split(",")[-1].strip()
+ x_forwarded_for_hosts = [
+ item.strip() for item in x_forwarded_for.split(",")
+ ]
+ host = self.get_trusted_client_host(x_forwarded_for_hosts)
port = 0
scope["client"] = (host, port)
|
{"golden_diff": "diff --git a/uvicorn/middleware/proxy_headers.py b/uvicorn/middleware/proxy_headers.py\n--- a/uvicorn/middleware/proxy_headers.py\n+++ b/uvicorn/middleware/proxy_headers.py\n@@ -8,17 +8,28 @@\n \n https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers#Proxies\n \"\"\"\n+from typing import List\n \n \n class ProxyHeadersMiddleware:\n def __init__(self, app, trusted_hosts=\"127.0.0.1\"):\n self.app = app\n if isinstance(trusted_hosts, str):\n- self.trusted_hosts = [item.strip() for item in trusted_hosts.split(\",\")]\n+ self.trusted_hosts = {item.strip() for item in trusted_hosts.split(\",\")}\n else:\n- self.trusted_hosts = trusted_hosts\n+ self.trusted_hosts = set(trusted_hosts)\n self.always_trust = \"*\" in self.trusted_hosts\n \n+ def get_trusted_client_host(\n+ self, x_forwarded_for_hosts\n+ ): # type: (List[str]) -> str\n+ if self.always_trust:\n+ return x_forwarded_for_hosts[0]\n+\n+ for host in reversed(x_forwarded_for_hosts):\n+ if host not in self.trusted_hosts:\n+ return host\n+\n async def __call__(self, scope, receive, send):\n if scope[\"type\"] in (\"http\", \"websocket\"):\n client_addr = scope.get(\"client\")\n@@ -38,7 +49,10 @@\n # X-Forwarded-For header. We've lost the connecting client's port\n # information by now, so only include the host.\n x_forwarded_for = headers[b\"x-forwarded-for\"].decode(\"latin1\")\n- host = x_forwarded_for.split(\",\")[-1].strip()\n+ x_forwarded_for_hosts = [\n+ item.strip() for item in x_forwarded_for.split(\",\")\n+ ]\n+ host = self.get_trusted_client_host(x_forwarded_for_hosts)\n port = 0\n scope[\"client\"] = (host, port)\n", "issue": "Proxy Middleware grabs the last IP in `x-forwarded-for`, not the first\nhttps://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/X-Forwarded-For says the first IP in is a client IP, but ProxyHeadersMiddleware grabs the last IP:\r\nhttps://github.com/encode/uvicorn/blob/9d9f8820a8155e36dcb5e4d4023f470e51aa4e03/uvicorn/middleware/proxy_headers.py#L41\n", "before_files": [{"content": "\"\"\"\nThis middleware can be used when a known proxy is fronting the application,\nand is trusted to be properly setting the `X-Forwarded-Proto` and\n`X-Forwarded-For` headers with the connecting client information.\n\nModifies the `client` and `scheme` information so that they reference\nthe connecting client, rather that the connecting proxy.\n\nhttps://developer.mozilla.org/en-US/docs/Web/HTTP/Headers#Proxies\n\"\"\"\n\n\nclass ProxyHeadersMiddleware:\n def __init__(self, app, trusted_hosts=\"127.0.0.1\"):\n self.app = app\n if isinstance(trusted_hosts, str):\n self.trusted_hosts = [item.strip() for item in trusted_hosts.split(\",\")]\n else:\n self.trusted_hosts = trusted_hosts\n self.always_trust = \"*\" in self.trusted_hosts\n\n async def __call__(self, scope, receive, send):\n if scope[\"type\"] in (\"http\", \"websocket\"):\n client_addr = scope.get(\"client\")\n client_host = client_addr[0] if client_addr else None\n\n if self.always_trust or client_host in self.trusted_hosts:\n headers = dict(scope[\"headers\"])\n\n if b\"x-forwarded-proto\" in headers:\n # Determine if the incoming request was http or https based on\n # the X-Forwarded-Proto header.\n x_forwarded_proto = headers[b\"x-forwarded-proto\"].decode(\"latin1\")\n scope[\"scheme\"] = x_forwarded_proto.strip()\n\n if b\"x-forwarded-for\" in headers:\n # Determine the client address from the last trusted IP in the\n # X-Forwarded-For header. We've lost the connecting client's port\n # information by now, so only include the host.\n x_forwarded_for = headers[b\"x-forwarded-for\"].decode(\"latin1\")\n host = x_forwarded_for.split(\",\")[-1].strip()\n port = 0\n scope[\"client\"] = (host, port)\n\n return await self.app(scope, receive, send)\n", "path": "uvicorn/middleware/proxy_headers.py"}]}
| 1,190 | 461 |
gh_patches_debug_57180
|
rasdani/github-patches
|
git_diff
|
beeware__toga-1009
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Toga scrollbar breaks with macOS Natural Scrolling preference
## Expected Behavior
Scrolling in Toga windows should be reflected in the scrollbar.
## Current Behavior
When debugging the Toga ``DetailedList`` example in ``toga/examples/detailedlist``, I noticed that the scrolling direction was reversed from the trackpad direction (since I have macOS natural scrolling enabled), however the scroll bar moved in the reverse direction.
## Steps to reproduce
On a computer running macOS with Natural Scrolling enabled (set this in `System Preferences > Trackpad > Scroll & Zoom`):
```
cd toga/examples/detailedlist && python -m detailedlist
```
(this example will crash. this is already documented in issue #549.)
## My Environment
``toga-cocoa, running on Python 3.7.3, on macOS Mojave 10.14.4 (18E226)``
</issue>
<code>
[start of src/cocoa/toga_cocoa/widgets/internal/refresh.py]
1 from toga_cocoa.libs import (
2 SEL,
3 NSClipView,
4 NSEvent,
5 NSEventPhaseEnded,
6 NSLayoutAttributeCenterX,
7 NSLayoutAttributeCenterY,
8 NSLayoutAttributeHeight,
9 NSLayoutAttributeNotAnAttribute,
10 NSLayoutAttributeTop,
11 NSLayoutAttributeWidth,
12 NSLayoutConstraint,
13 NSLayoutRelationEqual,
14 NSMakePoint,
15 NSMakeRect,
16 NSNotificationCenter,
17 NSPoint,
18 NSProgressIndicator,
19 NSProgressIndicatorSpinningStyle,
20 NSRect,
21 NSScrollElasticityAllowed,
22 NSScrollView,
23 NSView,
24 NSViewBoundsDidChangeNotification,
25 ObjCInstance,
26 core_graphics,
27 kCGScrollEventUnitLine,
28 objc_method,
29 send_super
30 )
31
32 HEADER_HEIGHT = 45.0
33
34
35 class RefreshableClipView(NSClipView):
36 @objc_method
37 def constrainScrollPoint_(self, proposedNewOrigin: NSPoint) -> NSPoint:
38 constrained = send_super(
39 __class__, self, 'constrainScrollPoint:', proposedNewOrigin,
40 restype=NSPoint, argtypes=[NSPoint]
41 )
42
43 if self.superview and self.superview.refreshTriggered:
44 return NSMakePoint(
45 constrained.x,
46 max(proposedNewOrigin.y, -self.superview.refreshView.frame.size.height)
47 )
48
49 return constrained
50
51 @objc_method
52 def isFlipped(self):
53 return True
54
55 @objc_method
56 def documentRect(self) -> NSRect:
57 rect = send_super(__class__, self, 'documentRect', restype=NSRect, argtypes=[])
58
59 if self.superview and self.superview.refreshTriggered:
60 return NSMakeRect(
61 rect.origin.x, rect.origin.y - self.superview.refreshView.frame.size.height,
62 rect.size.width, rect.size.height + self.superview.refreshView.frame.size.height
63 )
64 return rect
65
66
67 class RefreshableScrollView(NSScrollView):
68 # Create Header View
69 @objc_method
70 def viewDidMoveToWindow(self) -> None:
71 self.refreshTriggered = False
72 self.isRefreshing = False
73 self.refreshView = None
74 self.refreshIndicator = None
75 self.createRefreshView()
76
77 @objc_method
78 def createContentView(self):
79 superClipView = ObjCInstance(send_super(__class__, self, 'contentView'))
80 if not isinstance(superClipView, RefreshableClipView):
81 # create new clipview
82 documentView = superClipView.documentView
83 clipView = RefreshableClipView.alloc().initWithFrame(superClipView.frame)
84
85 clipView.documentView = documentView
86 clipView.copiesOnScroll = False
87 clipView.drawsBackground = False
88
89 self.setContentView(clipView)
90 superClipView = ObjCInstance(send_super(__class__, self, 'contentView'))
91
92 return superClipView
93
94 @objc_method
95 def createRefreshView(self) -> None:
96 # delete old stuff if any
97 if self.refreshView:
98 self.refreshView.removeFromSuperview()
99 self.refreshView.release()
100 self.refreshView = None
101
102 self.verticalScrollElasticity = NSScrollElasticityAllowed
103
104 # create new content view
105 self.createContentView()
106
107 self.contentView.postsFrameChangedNotifications = True
108 self.contentView.postsBoundsChangedNotifications = True
109
110 NSNotificationCenter.defaultCenter.addObserver(
111 self,
112 selector=SEL('viewBoundsChanged:'),
113 name=NSViewBoundsDidChangeNotification,
114 object=self.contentView,
115 )
116
117 # Create view to hold the refresh widgets refreshview
118 contentRect = self.contentView.documentView.frame
119 self.refreshView = NSView.alloc().init()
120 self.refreshView.translatesAutoresizingMaskIntoConstraints = False
121
122 # Create spinner
123 self.refreshIndicator = NSProgressIndicator.alloc().init()
124 self.refreshIndicator.style = NSProgressIndicatorSpinningStyle
125 self.refreshIndicator.translatesAutoresizingMaskIntoConstraints = False
126 self.refreshIndicator.displayedWhenStopped = True
127 self.refreshIndicator.usesThreadedAnimation = True
128 self.refreshIndicator.indeterminate = True
129 self.refreshIndicator.bezeled = False
130 self.refreshIndicator.sizeToFit()
131
132 # Center the spinner in the header
133 self.refreshIndicator.setFrame(
134 NSMakeRect(
135 self.refreshView.bounds.size.width / 2 - self.refreshIndicator.frame.size.width / 2,
136 self.refreshView.bounds.size.height / 2 - self.refreshIndicator.frame.size.height / 2,
137 self.refreshIndicator.frame.size.width,
138 self.refreshIndicator.frame.size.height
139 )
140 )
141
142 # Put everything in place
143 self.refreshView.addSubview(self.refreshIndicator)
144 # self.refreshView.addSubview(self.refreshArrow)
145 self.contentView.addSubview(self.refreshView)
146
147 # set layout constraints
148 indicatorHCenter = NSLayoutConstraint.constraintWithItem_attribute_relatedBy_toItem_attribute_multiplier_constant_( # noqa: E501
149 self.refreshIndicator, NSLayoutAttributeCenterX,
150 NSLayoutRelationEqual,
151 self.refreshView, NSLayoutAttributeCenterX,
152 1.0, 0,
153 )
154 self.refreshView.addConstraint(indicatorHCenter)
155
156 indicatorVCenter = NSLayoutConstraint.constraintWithItem_attribute_relatedBy_toItem_attribute_multiplier_constant_( # noqa: E501
157 self.refreshIndicator, NSLayoutAttributeCenterY,
158 NSLayoutRelationEqual,
159 self.refreshView, NSLayoutAttributeCenterY,
160 1.0, 0,
161 )
162 self.refreshView.addConstraint(indicatorVCenter)
163
164 refreshWidth = NSLayoutConstraint.constraintWithItem_attribute_relatedBy_toItem_attribute_multiplier_constant_( # noqa: E501
165 self.refreshView, NSLayoutAttributeWidth,
166 NSLayoutRelationEqual,
167 self.contentView, NSLayoutAttributeWidth,
168 1.0, 0,
169 )
170 self.contentView.addConstraint(refreshWidth)
171
172 refreshHeight = NSLayoutConstraint.constraintWithItem_attribute_relatedBy_toItem_attribute_multiplier_constant_( # noqa: E501
173 self.refreshView, NSLayoutAttributeHeight,
174 NSLayoutRelationEqual,
175 None, NSLayoutAttributeNotAnAttribute,
176 1.0, HEADER_HEIGHT,
177 )
178 self.contentView.addConstraint(refreshHeight)
179
180 refreshHeight = NSLayoutConstraint.constraintWithItem_attribute_relatedBy_toItem_attribute_multiplier_constant_( # noqa: E501
181 self.refreshView, NSLayoutAttributeTop,
182 NSLayoutRelationEqual,
183 self.contentView, NSLayoutAttributeTop,
184 1.0, -HEADER_HEIGHT,
185 )
186 self.contentView.addConstraint(refreshHeight)
187
188 # Scroll to top
189 self.contentView.scrollToPoint(NSMakePoint(contentRect.origin.x, 0))
190 self.reflectScrolledClipView(self.contentView)
191
192 # Detecting scroll
193 @objc_method
194 def scrollWheel_(self, event) -> None:
195 if event.phase == NSEventPhaseEnded:
196 if self.refreshTriggered and not self.isRefreshing:
197 self.reload()
198
199 send_super(__class__, self, 'scrollWheel:', event)
200
201 @objc_method
202 def viewBoundsChanged_(self, note) -> None:
203 if self.isRefreshing:
204 return
205
206 if self.contentView.bounds.origin.y <= -self.refreshView.frame.size.height:
207 self.refreshTriggered = True
208
209 # Reload
210 @objc_method
211 def reload(self) -> None:
212 """Start a reload, starting the reload spinner"""
213 self.isRefreshing = True
214 self.refreshIndicator.startAnimation(self)
215 self.interface.on_refresh(self.interface)
216
217 @objc_method
218 def finishedLoading(self):
219 """Invoke to mark the end of a reload, stopping and hiding the reload spinner"""
220 self.isRefreshing = False
221 self.refreshTriggered = False
222 self.refreshIndicator.stopAnimation(self)
223 self.detailedlist.reloadData()
224
225 # Force a scroll event to make the scroll hide the reload
226 cgEvent = core_graphics.CGEventCreateScrollWheelEvent(None, kCGScrollEventUnitLine, 2, 1, 0)
227 scrollEvent = NSEvent.eventWithCGEvent(cgEvent)
228 self.scrollWheel(scrollEvent)
229
[end of src/cocoa/toga_cocoa/widgets/internal/refresh.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/cocoa/toga_cocoa/widgets/internal/refresh.py b/src/cocoa/toga_cocoa/widgets/internal/refresh.py
--- a/src/cocoa/toga_cocoa/widgets/internal/refresh.py
+++ b/src/cocoa/toga_cocoa/widgets/internal/refresh.py
@@ -48,10 +48,6 @@
return constrained
- @objc_method
- def isFlipped(self):
- return True
-
@objc_method
def documentRect(self) -> NSRect:
rect = send_super(__class__, self, 'documentRect', restype=NSRect, argtypes=[])
|
{"golden_diff": "diff --git a/src/cocoa/toga_cocoa/widgets/internal/refresh.py b/src/cocoa/toga_cocoa/widgets/internal/refresh.py\n--- a/src/cocoa/toga_cocoa/widgets/internal/refresh.py\n+++ b/src/cocoa/toga_cocoa/widgets/internal/refresh.py\n@@ -48,10 +48,6 @@\n \n return constrained\n \n- @objc_method\n- def isFlipped(self):\n- return True\n-\n @objc_method\n def documentRect(self) -> NSRect:\n rect = send_super(__class__, self, 'documentRect', restype=NSRect, argtypes=[])\n", "issue": "Toga scrollbar breaks with macOS Natural Scrolling preference\n## Expected Behavior\r\nScrolling in Toga windows should be reflected in the scrollbar.\r\n\r\n## Current Behavior\r\nWhen debugging the Toga ``DetailedList`` example in ``toga/examples/detailedlist``, I noticed that the scrolling direction was reversed from the trackpad direction (since I have macOS natural scrolling enabled), however the scroll bar moved in the reverse direction.\r\n\r\n## Steps to reproduce\r\n\r\nOn a computer running macOS with Natural Scrolling enabled (set this in `System Preferences > Trackpad > Scroll & Zoom`):\r\n```\r\ncd toga/examples/detailedlist && python -m detailedlist\r\n```\r\n\r\n(this example will crash. this is already documented in issue #549.)\r\n\r\n## My Environment\r\n\r\n``toga-cocoa, running on Python 3.7.3, on macOS Mojave 10.14.4 (18E226)``\n", "before_files": [{"content": "from toga_cocoa.libs import (\n SEL,\n NSClipView,\n NSEvent,\n NSEventPhaseEnded,\n NSLayoutAttributeCenterX,\n NSLayoutAttributeCenterY,\n NSLayoutAttributeHeight,\n NSLayoutAttributeNotAnAttribute,\n NSLayoutAttributeTop,\n NSLayoutAttributeWidth,\n NSLayoutConstraint,\n NSLayoutRelationEqual,\n NSMakePoint,\n NSMakeRect,\n NSNotificationCenter,\n NSPoint,\n NSProgressIndicator,\n NSProgressIndicatorSpinningStyle,\n NSRect,\n NSScrollElasticityAllowed,\n NSScrollView,\n NSView,\n NSViewBoundsDidChangeNotification,\n ObjCInstance,\n core_graphics,\n kCGScrollEventUnitLine,\n objc_method,\n send_super\n)\n\nHEADER_HEIGHT = 45.0\n\n\nclass RefreshableClipView(NSClipView):\n @objc_method\n def constrainScrollPoint_(self, proposedNewOrigin: NSPoint) -> NSPoint:\n constrained = send_super(\n __class__, self, 'constrainScrollPoint:', proposedNewOrigin,\n restype=NSPoint, argtypes=[NSPoint]\n )\n\n if self.superview and self.superview.refreshTriggered:\n return NSMakePoint(\n constrained.x,\n max(proposedNewOrigin.y, -self.superview.refreshView.frame.size.height)\n )\n\n return constrained\n\n @objc_method\n def isFlipped(self):\n return True\n\n @objc_method\n def documentRect(self) -> NSRect:\n rect = send_super(__class__, self, 'documentRect', restype=NSRect, argtypes=[])\n\n if self.superview and self.superview.refreshTriggered:\n return NSMakeRect(\n rect.origin.x, rect.origin.y - self.superview.refreshView.frame.size.height,\n rect.size.width, rect.size.height + self.superview.refreshView.frame.size.height\n )\n return rect\n\n\nclass RefreshableScrollView(NSScrollView):\n # Create Header View\n @objc_method\n def viewDidMoveToWindow(self) -> None:\n self.refreshTriggered = False\n self.isRefreshing = False\n self.refreshView = None\n self.refreshIndicator = None\n self.createRefreshView()\n\n @objc_method\n def createContentView(self):\n superClipView = ObjCInstance(send_super(__class__, self, 'contentView'))\n if not isinstance(superClipView, RefreshableClipView):\n # create new clipview\n documentView = superClipView.documentView\n clipView = RefreshableClipView.alloc().initWithFrame(superClipView.frame)\n\n clipView.documentView = documentView\n clipView.copiesOnScroll = False\n clipView.drawsBackground = False\n\n self.setContentView(clipView)\n superClipView = ObjCInstance(send_super(__class__, self, 'contentView'))\n\n return superClipView\n\n @objc_method\n def createRefreshView(self) -> None:\n # delete old stuff if any\n if self.refreshView:\n self.refreshView.removeFromSuperview()\n self.refreshView.release()\n self.refreshView = None\n\n self.verticalScrollElasticity = NSScrollElasticityAllowed\n\n # create new content view\n self.createContentView()\n\n self.contentView.postsFrameChangedNotifications = True\n self.contentView.postsBoundsChangedNotifications = True\n\n NSNotificationCenter.defaultCenter.addObserver(\n self,\n selector=SEL('viewBoundsChanged:'),\n name=NSViewBoundsDidChangeNotification,\n object=self.contentView,\n )\n\n # Create view to hold the refresh widgets refreshview\n contentRect = self.contentView.documentView.frame\n self.refreshView = NSView.alloc().init()\n self.refreshView.translatesAutoresizingMaskIntoConstraints = False\n\n # Create spinner\n self.refreshIndicator = NSProgressIndicator.alloc().init()\n self.refreshIndicator.style = NSProgressIndicatorSpinningStyle\n self.refreshIndicator.translatesAutoresizingMaskIntoConstraints = False\n self.refreshIndicator.displayedWhenStopped = True\n self.refreshIndicator.usesThreadedAnimation = True\n self.refreshIndicator.indeterminate = True\n self.refreshIndicator.bezeled = False\n self.refreshIndicator.sizeToFit()\n\n # Center the spinner in the header\n self.refreshIndicator.setFrame(\n NSMakeRect(\n self.refreshView.bounds.size.width / 2 - self.refreshIndicator.frame.size.width / 2,\n self.refreshView.bounds.size.height / 2 - self.refreshIndicator.frame.size.height / 2,\n self.refreshIndicator.frame.size.width,\n self.refreshIndicator.frame.size.height\n )\n )\n\n # Put everything in place\n self.refreshView.addSubview(self.refreshIndicator)\n # self.refreshView.addSubview(self.refreshArrow)\n self.contentView.addSubview(self.refreshView)\n\n # set layout constraints\n indicatorHCenter = NSLayoutConstraint.constraintWithItem_attribute_relatedBy_toItem_attribute_multiplier_constant_( # noqa: E501\n self.refreshIndicator, NSLayoutAttributeCenterX,\n NSLayoutRelationEqual,\n self.refreshView, NSLayoutAttributeCenterX,\n 1.0, 0,\n )\n self.refreshView.addConstraint(indicatorHCenter)\n\n indicatorVCenter = NSLayoutConstraint.constraintWithItem_attribute_relatedBy_toItem_attribute_multiplier_constant_( # noqa: E501\n self.refreshIndicator, NSLayoutAttributeCenterY,\n NSLayoutRelationEqual,\n self.refreshView, NSLayoutAttributeCenterY,\n 1.0, 0,\n )\n self.refreshView.addConstraint(indicatorVCenter)\n\n refreshWidth = NSLayoutConstraint.constraintWithItem_attribute_relatedBy_toItem_attribute_multiplier_constant_( # noqa: E501\n self.refreshView, NSLayoutAttributeWidth,\n NSLayoutRelationEqual,\n self.contentView, NSLayoutAttributeWidth,\n 1.0, 0,\n )\n self.contentView.addConstraint(refreshWidth)\n\n refreshHeight = NSLayoutConstraint.constraintWithItem_attribute_relatedBy_toItem_attribute_multiplier_constant_( # noqa: E501\n self.refreshView, NSLayoutAttributeHeight,\n NSLayoutRelationEqual,\n None, NSLayoutAttributeNotAnAttribute,\n 1.0, HEADER_HEIGHT,\n )\n self.contentView.addConstraint(refreshHeight)\n\n refreshHeight = NSLayoutConstraint.constraintWithItem_attribute_relatedBy_toItem_attribute_multiplier_constant_( # noqa: E501\n self.refreshView, NSLayoutAttributeTop,\n NSLayoutRelationEqual,\n self.contentView, NSLayoutAttributeTop,\n 1.0, -HEADER_HEIGHT,\n )\n self.contentView.addConstraint(refreshHeight)\n\n # Scroll to top\n self.contentView.scrollToPoint(NSMakePoint(contentRect.origin.x, 0))\n self.reflectScrolledClipView(self.contentView)\n\n # Detecting scroll\n @objc_method\n def scrollWheel_(self, event) -> None:\n if event.phase == NSEventPhaseEnded:\n if self.refreshTriggered and not self.isRefreshing:\n self.reload()\n\n send_super(__class__, self, 'scrollWheel:', event)\n\n @objc_method\n def viewBoundsChanged_(self, note) -> None:\n if self.isRefreshing:\n return\n\n if self.contentView.bounds.origin.y <= -self.refreshView.frame.size.height:\n self.refreshTriggered = True\n\n # Reload\n @objc_method\n def reload(self) -> None:\n \"\"\"Start a reload, starting the reload spinner\"\"\"\n self.isRefreshing = True\n self.refreshIndicator.startAnimation(self)\n self.interface.on_refresh(self.interface)\n\n @objc_method\n def finishedLoading(self):\n \"\"\"Invoke to mark the end of a reload, stopping and hiding the reload spinner\"\"\"\n self.isRefreshing = False\n self.refreshTriggered = False\n self.refreshIndicator.stopAnimation(self)\n self.detailedlist.reloadData()\n\n # Force a scroll event to make the scroll hide the reload\n cgEvent = core_graphics.CGEventCreateScrollWheelEvent(None, kCGScrollEventUnitLine, 2, 1, 0)\n scrollEvent = NSEvent.eventWithCGEvent(cgEvent)\n self.scrollWheel(scrollEvent)\n", "path": "src/cocoa/toga_cocoa/widgets/internal/refresh.py"}]}
| 3,037 | 137 |
gh_patches_debug_2617
|
rasdani/github-patches
|
git_diff
|
Bitmessage__PyBitmessage-1697
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fix backward compatibility in pickle_deserialize_old_knownnodes()
Hello!
#1662 is caused by changed package structure.
Here I've set up a minimal upgrade from v0.6.3 to reproduce the bug. Using v0.6.2 would be difficult, because it has no command line args.
</issue>
<code>
[start of src/network/knownnodes.py]
1 """
2 Manipulations with knownNodes dictionary.
3 """
4
5 import json
6 import logging
7 import os
8 import pickle
9 import threading
10 import time
11 try:
12 from collections.abc import Iterable
13 except ImportError:
14 from collections import Iterable
15
16 import state
17 from bmconfigparser import BMConfigParser
18 from network.node import Peer
19
20 knownNodesLock = threading.RLock()
21 """Thread lock for knownnodes modification"""
22 knownNodes = {stream: {} for stream in range(1, 4)}
23 """The dict of known nodes for each stream"""
24
25 knownNodesTrimAmount = 2000
26 """trim stream knownnodes dict to this length"""
27
28 knownNodesForgetRating = -0.5
29 """forget a node after rating is this low"""
30
31 knownNodesActual = False
32
33 logger = logging.getLogger('default')
34
35 DEFAULT_NODES = (
36 Peer('5.45.99.75', 8444),
37 Peer('75.167.159.54', 8444),
38 Peer('95.165.168.168', 8444),
39 Peer('85.180.139.241', 8444),
40 Peer('158.222.217.190', 8080),
41 Peer('178.62.12.187', 8448),
42 Peer('24.188.198.204', 8111),
43 Peer('109.147.204.113', 1195),
44 Peer('178.11.46.221', 8444)
45 )
46
47
48 def json_serialize_knownnodes(output):
49 """
50 Reorganize knownnodes dict and write it as JSON to output
51 """
52 _serialized = []
53 for stream, peers in knownNodes.iteritems():
54 for peer, info in peers.iteritems():
55 info.update(rating=round(info.get('rating', 0), 2))
56 _serialized.append({
57 'stream': stream, 'peer': peer._asdict(), 'info': info
58 })
59 json.dump(_serialized, output, indent=4)
60
61
62 def json_deserialize_knownnodes(source):
63 """
64 Read JSON from source and make knownnodes dict
65 """
66 global knownNodesActual # pylint: disable=global-statement
67 for node in json.load(source):
68 peer = node['peer']
69 info = node['info']
70 peer = Peer(str(peer['host']), peer.get('port', 8444))
71 knownNodes[node['stream']][peer] = info
72 if not (knownNodesActual
73 or info.get('self')) and peer not in DEFAULT_NODES:
74 knownNodesActual = True
75
76
77 def pickle_deserialize_old_knownnodes(source):
78 """
79 Unpickle source and reorganize knownnodes dict if it has old format
80 the old format was {Peer:lastseen, ...}
81 the new format is {Peer:{"lastseen":i, "rating":f}}
82 """
83 global knownNodes # pylint: disable=global-statement
84 knownNodes = pickle.load(source)
85 for stream in knownNodes.keys():
86 for node, params in knownNodes[stream].iteritems():
87 if isinstance(params, (float, int)):
88 addKnownNode(stream, node, params)
89
90
91 def saveKnownNodes(dirName=None):
92 """Save knownnodes to filesystem"""
93 if dirName is None:
94 dirName = state.appdata
95 with knownNodesLock:
96 with open(os.path.join(dirName, 'knownnodes.dat'), 'wb') as output:
97 json_serialize_knownnodes(output)
98
99
100 def addKnownNode(stream, peer, lastseen=None, is_self=False):
101 """
102 Add a new node to the dict or update lastseen if it already exists.
103 Do it for each stream number if *stream* is `Iterable`.
104 Returns True if added a new node.
105 """
106 # pylint: disable=too-many-branches
107 if isinstance(stream, Iterable):
108 with knownNodesLock:
109 for s in stream:
110 addKnownNode(s, peer, lastseen, is_self)
111 return
112
113 rating = 0.0
114 if not lastseen:
115 # FIXME: maybe about 28 days?
116 lastseen = int(time.time())
117 else:
118 lastseen = int(lastseen)
119 try:
120 info = knownNodes[stream].get(peer)
121 if lastseen > info['lastseen']:
122 info['lastseen'] = lastseen
123 except (KeyError, TypeError):
124 pass
125 else:
126 return
127
128 if not is_self:
129 if len(knownNodes[stream]) > BMConfigParser().safeGetInt(
130 "knownnodes", "maxnodes"):
131 return
132
133 knownNodes[stream][peer] = {
134 'lastseen': lastseen,
135 'rating': rating or 1 if is_self else 0,
136 'self': is_self,
137 }
138 return True
139
140
141 def createDefaultKnownNodes():
142 """Creating default Knownnodes"""
143 past = time.time() - 2418600 # 28 days - 10 min
144 for peer in DEFAULT_NODES:
145 addKnownNode(1, peer, past)
146 saveKnownNodes()
147
148
149 def readKnownNodes():
150 """Load knownnodes from filesystem"""
151 try:
152 with open(state.appdata + 'knownnodes.dat', 'rb') as source:
153 with knownNodesLock:
154 try:
155 json_deserialize_knownnodes(source)
156 except ValueError:
157 source.seek(0)
158 pickle_deserialize_old_knownnodes(source)
159 except (IOError, OSError, KeyError, EOFError):
160 logger.debug(
161 'Failed to read nodes from knownnodes.dat', exc_info=True)
162 createDefaultKnownNodes()
163
164 config = BMConfigParser()
165
166 # your own onion address, if setup
167 onionhostname = config.safeGet('bitmessagesettings', 'onionhostname')
168 if onionhostname and ".onion" in onionhostname:
169 onionport = config.safeGetInt('bitmessagesettings', 'onionport')
170 if onionport:
171 self_peer = Peer(onionhostname, onionport)
172 addKnownNode(1, self_peer, is_self=True)
173 state.ownAddresses[self_peer] = True
174
175
176 def increaseRating(peer):
177 """Increase rating of a peer node"""
178 increaseAmount = 0.1
179 maxRating = 1
180 with knownNodesLock:
181 for stream in knownNodes.keys():
182 try:
183 knownNodes[stream][peer]["rating"] = min(
184 knownNodes[stream][peer]["rating"] + increaseAmount,
185 maxRating
186 )
187 except KeyError:
188 pass
189
190
191 def decreaseRating(peer):
192 """Decrease rating of a peer node"""
193 decreaseAmount = 0.1
194 minRating = -1
195 with knownNodesLock:
196 for stream in knownNodes.keys():
197 try:
198 knownNodes[stream][peer]["rating"] = max(
199 knownNodes[stream][peer]["rating"] - decreaseAmount,
200 minRating
201 )
202 except KeyError:
203 pass
204
205
206 def trimKnownNodes(recAddrStream=1):
207 """Triming Knownnodes"""
208 if len(knownNodes[recAddrStream]) < \
209 BMConfigParser().safeGetInt("knownnodes", "maxnodes"):
210 return
211 with knownNodesLock:
212 oldestList = sorted(
213 knownNodes[recAddrStream],
214 key=lambda x: x['lastseen']
215 )[:knownNodesTrimAmount]
216 for oldest in oldestList:
217 del knownNodes[recAddrStream][oldest]
218
219
220 def dns():
221 """Add DNS names to knownnodes"""
222 for port in [8080, 8444]:
223 addKnownNode(
224 1, Peer('bootstrap%s.bitmessage.org' % port, port))
225
226
227 def cleanupKnownNodes():
228 """
229 Cleanup knownnodes: remove old nodes and nodes with low rating
230 """
231 now = int(time.time())
232 needToWriteKnownNodesToDisk = False
233
234 with knownNodesLock:
235 for stream in knownNodes:
236 if stream not in state.streamsInWhichIAmParticipating:
237 continue
238 keys = knownNodes[stream].keys()
239 for node in keys:
240 if len(knownNodes[stream]) <= 1: # leave at least one node
241 break
242 try:
243 age = now - knownNodes[stream][node]["lastseen"]
244 # scrap old nodes (age > 28 days)
245 if age > 2419200:
246 needToWriteKnownNodesToDisk = True
247 del knownNodes[stream][node]
248 continue
249 # scrap old nodes (age > 3 hours) with low rating
250 if (age > 10800 and knownNodes[stream][node]["rating"]
251 <= knownNodesForgetRating):
252 needToWriteKnownNodesToDisk = True
253 del knownNodes[stream][node]
254 continue
255 except TypeError:
256 logger.warning('Error in %s', node)
257 keys = []
258
259 # Let us write out the knowNodes to disk
260 # if there is anything new to write out.
261 if needToWriteKnownNodesToDisk:
262 saveKnownNodes()
263
[end of src/network/knownnodes.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/network/knownnodes.py b/src/network/knownnodes.py
--- a/src/network/knownnodes.py
+++ b/src/network/knownnodes.py
@@ -17,6 +17,8 @@
from bmconfigparser import BMConfigParser
from network.node import Peer
+state.Peer = Peer
+
knownNodesLock = threading.RLock()
"""Thread lock for knownnodes modification"""
knownNodes = {stream: {} for stream in range(1, 4)}
|
{"golden_diff": "diff --git a/src/network/knownnodes.py b/src/network/knownnodes.py\n--- a/src/network/knownnodes.py\n+++ b/src/network/knownnodes.py\n@@ -17,6 +17,8 @@\n from bmconfigparser import BMConfigParser\n from network.node import Peer\n \n+state.Peer = Peer\n+\n knownNodesLock = threading.RLock()\n \"\"\"Thread lock for knownnodes modification\"\"\"\n knownNodes = {stream: {} for stream in range(1, 4)}\n", "issue": "Fix backward compatibility in pickle_deserialize_old_knownnodes()\nHello!\r\n\r\n#1662 is caused by changed package structure.\r\n\r\nHere I've set up a minimal upgrade from v0.6.3 to reproduce the bug. Using v0.6.2 would be difficult, because it has no command line args.\n", "before_files": [{"content": "\"\"\"\nManipulations with knownNodes dictionary.\n\"\"\"\n\nimport json\nimport logging\nimport os\nimport pickle\nimport threading\nimport time\ntry:\n from collections.abc import Iterable\nexcept ImportError:\n from collections import Iterable\n\nimport state\nfrom bmconfigparser import BMConfigParser\nfrom network.node import Peer\n\nknownNodesLock = threading.RLock()\n\"\"\"Thread lock for knownnodes modification\"\"\"\nknownNodes = {stream: {} for stream in range(1, 4)}\n\"\"\"The dict of known nodes for each stream\"\"\"\n\nknownNodesTrimAmount = 2000\n\"\"\"trim stream knownnodes dict to this length\"\"\"\n\nknownNodesForgetRating = -0.5\n\"\"\"forget a node after rating is this low\"\"\"\n\nknownNodesActual = False\n\nlogger = logging.getLogger('default')\n\nDEFAULT_NODES = (\n Peer('5.45.99.75', 8444),\n Peer('75.167.159.54', 8444),\n Peer('95.165.168.168', 8444),\n Peer('85.180.139.241', 8444),\n Peer('158.222.217.190', 8080),\n Peer('178.62.12.187', 8448),\n Peer('24.188.198.204', 8111),\n Peer('109.147.204.113', 1195),\n Peer('178.11.46.221', 8444)\n)\n\n\ndef json_serialize_knownnodes(output):\n \"\"\"\n Reorganize knownnodes dict and write it as JSON to output\n \"\"\"\n _serialized = []\n for stream, peers in knownNodes.iteritems():\n for peer, info in peers.iteritems():\n info.update(rating=round(info.get('rating', 0), 2))\n _serialized.append({\n 'stream': stream, 'peer': peer._asdict(), 'info': info\n })\n json.dump(_serialized, output, indent=4)\n\n\ndef json_deserialize_knownnodes(source):\n \"\"\"\n Read JSON from source and make knownnodes dict\n \"\"\"\n global knownNodesActual # pylint: disable=global-statement\n for node in json.load(source):\n peer = node['peer']\n info = node['info']\n peer = Peer(str(peer['host']), peer.get('port', 8444))\n knownNodes[node['stream']][peer] = info\n if not (knownNodesActual\n or info.get('self')) and peer not in DEFAULT_NODES:\n knownNodesActual = True\n\n\ndef pickle_deserialize_old_knownnodes(source):\n \"\"\"\n Unpickle source and reorganize knownnodes dict if it has old format\n the old format was {Peer:lastseen, ...}\n the new format is {Peer:{\"lastseen\":i, \"rating\":f}}\n \"\"\"\n global knownNodes # pylint: disable=global-statement\n knownNodes = pickle.load(source)\n for stream in knownNodes.keys():\n for node, params in knownNodes[stream].iteritems():\n if isinstance(params, (float, int)):\n addKnownNode(stream, node, params)\n\n\ndef saveKnownNodes(dirName=None):\n \"\"\"Save knownnodes to filesystem\"\"\"\n if dirName is None:\n dirName = state.appdata\n with knownNodesLock:\n with open(os.path.join(dirName, 'knownnodes.dat'), 'wb') as output:\n json_serialize_knownnodes(output)\n\n\ndef addKnownNode(stream, peer, lastseen=None, is_self=False):\n \"\"\"\n Add a new node to the dict or update lastseen if it already exists.\n Do it for each stream number if *stream* is `Iterable`.\n Returns True if added a new node.\n \"\"\"\n # pylint: disable=too-many-branches\n if isinstance(stream, Iterable):\n with knownNodesLock:\n for s in stream:\n addKnownNode(s, peer, lastseen, is_self)\n return\n\n rating = 0.0\n if not lastseen:\n # FIXME: maybe about 28 days?\n lastseen = int(time.time())\n else:\n lastseen = int(lastseen)\n try:\n info = knownNodes[stream].get(peer)\n if lastseen > info['lastseen']:\n info['lastseen'] = lastseen\n except (KeyError, TypeError):\n pass\n else:\n return\n\n if not is_self:\n if len(knownNodes[stream]) > BMConfigParser().safeGetInt(\n \"knownnodes\", \"maxnodes\"):\n return\n\n knownNodes[stream][peer] = {\n 'lastseen': lastseen,\n 'rating': rating or 1 if is_self else 0,\n 'self': is_self,\n }\n return True\n\n\ndef createDefaultKnownNodes():\n \"\"\"Creating default Knownnodes\"\"\"\n past = time.time() - 2418600 # 28 days - 10 min\n for peer in DEFAULT_NODES:\n addKnownNode(1, peer, past)\n saveKnownNodes()\n\n\ndef readKnownNodes():\n \"\"\"Load knownnodes from filesystem\"\"\"\n try:\n with open(state.appdata + 'knownnodes.dat', 'rb') as source:\n with knownNodesLock:\n try:\n json_deserialize_knownnodes(source)\n except ValueError:\n source.seek(0)\n pickle_deserialize_old_knownnodes(source)\n except (IOError, OSError, KeyError, EOFError):\n logger.debug(\n 'Failed to read nodes from knownnodes.dat', exc_info=True)\n createDefaultKnownNodes()\n\n config = BMConfigParser()\n\n # your own onion address, if setup\n onionhostname = config.safeGet('bitmessagesettings', 'onionhostname')\n if onionhostname and \".onion\" in onionhostname:\n onionport = config.safeGetInt('bitmessagesettings', 'onionport')\n if onionport:\n self_peer = Peer(onionhostname, onionport)\n addKnownNode(1, self_peer, is_self=True)\n state.ownAddresses[self_peer] = True\n\n\ndef increaseRating(peer):\n \"\"\"Increase rating of a peer node\"\"\"\n increaseAmount = 0.1\n maxRating = 1\n with knownNodesLock:\n for stream in knownNodes.keys():\n try:\n knownNodes[stream][peer][\"rating\"] = min(\n knownNodes[stream][peer][\"rating\"] + increaseAmount,\n maxRating\n )\n except KeyError:\n pass\n\n\ndef decreaseRating(peer):\n \"\"\"Decrease rating of a peer node\"\"\"\n decreaseAmount = 0.1\n minRating = -1\n with knownNodesLock:\n for stream in knownNodes.keys():\n try:\n knownNodes[stream][peer][\"rating\"] = max(\n knownNodes[stream][peer][\"rating\"] - decreaseAmount,\n minRating\n )\n except KeyError:\n pass\n\n\ndef trimKnownNodes(recAddrStream=1):\n \"\"\"Triming Knownnodes\"\"\"\n if len(knownNodes[recAddrStream]) < \\\n BMConfigParser().safeGetInt(\"knownnodes\", \"maxnodes\"):\n return\n with knownNodesLock:\n oldestList = sorted(\n knownNodes[recAddrStream],\n key=lambda x: x['lastseen']\n )[:knownNodesTrimAmount]\n for oldest in oldestList:\n del knownNodes[recAddrStream][oldest]\n\n\ndef dns():\n \"\"\"Add DNS names to knownnodes\"\"\"\n for port in [8080, 8444]:\n addKnownNode(\n 1, Peer('bootstrap%s.bitmessage.org' % port, port))\n\n\ndef cleanupKnownNodes():\n \"\"\"\n Cleanup knownnodes: remove old nodes and nodes with low rating\n \"\"\"\n now = int(time.time())\n needToWriteKnownNodesToDisk = False\n\n with knownNodesLock:\n for stream in knownNodes:\n if stream not in state.streamsInWhichIAmParticipating:\n continue\n keys = knownNodes[stream].keys()\n for node in keys:\n if len(knownNodes[stream]) <= 1: # leave at least one node\n break\n try:\n age = now - knownNodes[stream][node][\"lastseen\"]\n # scrap old nodes (age > 28 days)\n if age > 2419200:\n needToWriteKnownNodesToDisk = True\n del knownNodes[stream][node]\n continue\n # scrap old nodes (age > 3 hours) with low rating\n if (age > 10800 and knownNodes[stream][node][\"rating\"]\n <= knownNodesForgetRating):\n needToWriteKnownNodesToDisk = True\n del knownNodes[stream][node]\n continue\n except TypeError:\n logger.warning('Error in %s', node)\n keys = []\n\n # Let us write out the knowNodes to disk\n # if there is anything new to write out.\n if needToWriteKnownNodesToDisk:\n saveKnownNodes()\n", "path": "src/network/knownnodes.py"}]}
| 3,311 | 104 |
gh_patches_debug_29773
|
rasdani/github-patches
|
git_diff
|
streamlink__streamlink-3940
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
plugins.euronews: www.euronews.com and ru.euronews.com provide different APIs
### Checklist
- [X] This is a plugin issue and not a different kind of issue
- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)
- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)
- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)
### Streamlink version
Latest stable release
### Description
The main Euronews site has started using the new API some time ago, and the current streamlink's plugin, euronews.py, indeed works correctly with the main site. However, some (?) language specific subdomains, like https://ru.euronews.com/, still use the old API (compare, e.g., the following responses: https://www.euronews.com/api/watchlive.json vs. https://ru.euronews.com/api/watchlive.json).
[This previous version of euronews.py](https://github.com/streamlink/streamlink/blob/fcda5b681422718cc0a95b3de45d3fe2698d8e29/src/streamlink/plugins/euronews.py) works fine with the old API but obviously doesn't support the new one. Would be great if the plugin could support both versions.
### Debug log
```text
[cli][info] Found matching plugin euronews for URL https://ru.euronews.com/live
error: No playable streams found on this URL: https://ru.euronews.com/live
```
</issue>
<code>
[start of src/streamlink/plugins/euronews.py]
1 import re
2 from urllib.parse import urlparse
3
4 from streamlink.plugin import Plugin, pluginmatcher
5 from streamlink.plugin.api import validate
6 from streamlink.plugin.api.utils import itertags
7 from streamlink.stream import HTTPStream
8
9
10 @pluginmatcher(re.compile(
11 r'https?://(?:\w+\.)*euronews\.com/'
12 ))
13 class Euronews(Plugin):
14 def _get_vod_stream(self):
15 def find_video_url(content):
16 for elem in itertags(content, "meta"):
17 if elem.attributes.get("property") == "og:video":
18 return elem.attributes.get("content")
19
20 video_url = self.session.http.get(self.url, schema=validate.Schema(
21 validate.transform(find_video_url),
22 validate.any(None, validate.url())
23 ))
24
25 if video_url is not None:
26 return dict(vod=HTTPStream(self.session, video_url))
27
28 def _get_live_streams(self):
29 def find_video_id(content):
30 for elem in itertags(content, "div"):
31 if elem.attributes.get("id") == "pfpPlayer" and elem.attributes.get("data-google-src") is not None:
32 return elem.attributes.get("data-video-id")
33
34 video_id = self.session.http.get(self.url, schema=validate.Schema(
35 validate.transform(find_video_id),
36 validate.any(None, str)
37 ))
38
39 if video_id is not None:
40 return self.session.streams(f"https://www.youtube.com/watch?v={video_id}")
41
42 def _get_streams(self):
43 parsed = urlparse(self.url)
44
45 if parsed.path == "/live":
46 return self._get_live_streams()
47 else:
48 return self._get_vod_stream()
49
50
51 __plugin__ = Euronews
52
[end of src/streamlink/plugins/euronews.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/streamlink/plugins/euronews.py b/src/streamlink/plugins/euronews.py
--- a/src/streamlink/plugins/euronews.py
+++ b/src/streamlink/plugins/euronews.py
@@ -3,14 +3,17 @@
from streamlink.plugin import Plugin, pluginmatcher
from streamlink.plugin.api import validate
-from streamlink.plugin.api.utils import itertags
-from streamlink.stream import HTTPStream
+from streamlink.plugin.api.utils import itertags, parse_json
+from streamlink.stream import HLSStream, HTTPStream
+from streamlink.utils import update_scheme
@pluginmatcher(re.compile(
- r'https?://(?:\w+\.)*euronews\.com/'
+ r'https?://(?:(?P<subdomain>\w+)\.)?euronews\.com/'
))
class Euronews(Plugin):
+ API_URL = "https://{subdomain}.euronews.com/api/watchlive.json"
+
def _get_vod_stream(self):
def find_video_url(content):
for elem in itertags(content, "meta"):
@@ -39,6 +42,24 @@
if video_id is not None:
return self.session.streams(f"https://www.youtube.com/watch?v={video_id}")
+ info_url = self.session.http.get(self.API_URL.format(subdomain=self.match.group("subdomain")), schema=validate.Schema(
+ validate.transform(parse_json),
+ {"url": validate.url()},
+ validate.get("url"),
+ validate.transform(lambda url: update_scheme("https://", url))
+ ))
+ hls_url = self.session.http.get(info_url, schema=validate.Schema(
+ validate.transform(parse_json),
+ {
+ "status": "ok",
+ "protocol": "hls",
+ "primary": validate.url()
+ },
+ validate.get("primary")
+ ))
+
+ return HLSStream.parse_variant_playlist(self.session, hls_url)
+
def _get_streams(self):
parsed = urlparse(self.url)
|
{"golden_diff": "diff --git a/src/streamlink/plugins/euronews.py b/src/streamlink/plugins/euronews.py\n--- a/src/streamlink/plugins/euronews.py\n+++ b/src/streamlink/plugins/euronews.py\n@@ -3,14 +3,17 @@\n \n from streamlink.plugin import Plugin, pluginmatcher\n from streamlink.plugin.api import validate\n-from streamlink.plugin.api.utils import itertags\n-from streamlink.stream import HTTPStream\n+from streamlink.plugin.api.utils import itertags, parse_json\n+from streamlink.stream import HLSStream, HTTPStream\n+from streamlink.utils import update_scheme\n \n \n @pluginmatcher(re.compile(\n- r'https?://(?:\\w+\\.)*euronews\\.com/'\n+ r'https?://(?:(?P<subdomain>\\w+)\\.)?euronews\\.com/'\n ))\n class Euronews(Plugin):\n+ API_URL = \"https://{subdomain}.euronews.com/api/watchlive.json\"\n+\n def _get_vod_stream(self):\n def find_video_url(content):\n for elem in itertags(content, \"meta\"):\n@@ -39,6 +42,24 @@\n if video_id is not None:\n return self.session.streams(f\"https://www.youtube.com/watch?v={video_id}\")\n \n+ info_url = self.session.http.get(self.API_URL.format(subdomain=self.match.group(\"subdomain\")), schema=validate.Schema(\n+ validate.transform(parse_json),\n+ {\"url\": validate.url()},\n+ validate.get(\"url\"),\n+ validate.transform(lambda url: update_scheme(\"https://\", url))\n+ ))\n+ hls_url = self.session.http.get(info_url, schema=validate.Schema(\n+ validate.transform(parse_json),\n+ {\n+ \"status\": \"ok\",\n+ \"protocol\": \"hls\",\n+ \"primary\": validate.url()\n+ },\n+ validate.get(\"primary\")\n+ ))\n+\n+ return HLSStream.parse_variant_playlist(self.session, hls_url)\n+\n def _get_streams(self):\n parsed = urlparse(self.url)\n", "issue": "plugins.euronews: www.euronews.com and ru.euronews.com provide different APIs\n### Checklist\n\n- [X] This is a plugin issue and not a different kind of issue\n- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)\n- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)\n- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)\n\n### Streamlink version\n\nLatest stable release\n\n### Description\n\nThe main Euronews site has started using the new API some time ago, and the current streamlink's plugin, euronews.py, indeed works correctly with the main site. However, some (?) language specific subdomains, like https://ru.euronews.com/, still use the old API (compare, e.g., the following responses: https://www.euronews.com/api/watchlive.json vs. https://ru.euronews.com/api/watchlive.json).\r\n\r\n[This previous version of euronews.py](https://github.com/streamlink/streamlink/blob/fcda5b681422718cc0a95b3de45d3fe2698d8e29/src/streamlink/plugins/euronews.py) works fine with the old API but obviously doesn't support the new one. Would be great if the plugin could support both versions.\n\n### Debug log\n\n```text\n[cli][info] Found matching plugin euronews for URL https://ru.euronews.com/live\r\nerror: No playable streams found on this URL: https://ru.euronews.com/live\n```\n\n", "before_files": [{"content": "import re\nfrom urllib.parse import urlparse\n\nfrom streamlink.plugin import Plugin, pluginmatcher\nfrom streamlink.plugin.api import validate\nfrom streamlink.plugin.api.utils import itertags\nfrom streamlink.stream import HTTPStream\n\n\n@pluginmatcher(re.compile(\n r'https?://(?:\\w+\\.)*euronews\\.com/'\n))\nclass Euronews(Plugin):\n def _get_vod_stream(self):\n def find_video_url(content):\n for elem in itertags(content, \"meta\"):\n if elem.attributes.get(\"property\") == \"og:video\":\n return elem.attributes.get(\"content\")\n\n video_url = self.session.http.get(self.url, schema=validate.Schema(\n validate.transform(find_video_url),\n validate.any(None, validate.url())\n ))\n\n if video_url is not None:\n return dict(vod=HTTPStream(self.session, video_url))\n\n def _get_live_streams(self):\n def find_video_id(content):\n for elem in itertags(content, \"div\"):\n if elem.attributes.get(\"id\") == \"pfpPlayer\" and elem.attributes.get(\"data-google-src\") is not None:\n return elem.attributes.get(\"data-video-id\")\n\n video_id = self.session.http.get(self.url, schema=validate.Schema(\n validate.transform(find_video_id),\n validate.any(None, str)\n ))\n\n if video_id is not None:\n return self.session.streams(f\"https://www.youtube.com/watch?v={video_id}\")\n\n def _get_streams(self):\n parsed = urlparse(self.url)\n\n if parsed.path == \"/live\":\n return self._get_live_streams()\n else:\n return self._get_vod_stream()\n\n\n__plugin__ = Euronews\n", "path": "src/streamlink/plugins/euronews.py"}]}
| 1,405 | 444 |
gh_patches_debug_8386
|
rasdani/github-patches
|
git_diff
|
WeblateOrg__weblate-1471
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Provide example hooks in pip installations
### Steps to reproduce
1. `pip install Weblate`
2. `ls path/to/site-packages/weblate`
### Actual behaviour
Example hooks are missing. We have to download the examples manually and copy them where we want on the server.
### Expected behaviour
Example hooks should be in site-packages, packaged as data inside Weblate package. This would allow to use examples, even when Weblate is installed using pip.
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 #
4 # Copyright © 2012 - 2017 Michal Čihař <[email protected]>
5 #
6 # This file is part of Weblate <https://weblate.org/>
7 #
8 # This program is free software: you can redistribute it and/or modify
9 # it under the terms of the GNU General Public License as published by
10 # the Free Software Foundation, either version 3 of the License, or
11 # (at your option) any later version.
12 #
13 # This program is distributed in the hope that it will be useful,
14 # but WITHOUT ANY WARRANTY; without even the implied warranty of
15 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
16 # GNU General Public License for more details.
17 #
18 # You should have received a copy of the GNU General Public License
19 # along with this program. If not, see <https://www.gnu.org/licenses/>.
20 #
21
22 import os
23 import sys
24 from setuptools import setup
25
26 # allow setup.py to be run from any path
27 os.chdir(os.path.normpath(os.path.join(os.path.abspath(__file__), os.pardir)))
28
29 with open(os.path.join(os.path.dirname(__file__), 'README.rst')) as readme:
30 README = readme.read()
31
32 with open('requirements.txt') as requirements:
33 REQUIRES = requirements.read().splitlines()
34
35 setup(
36 name='Weblate',
37 version='2.14',
38 packages=[
39 'weblate',
40 'weblate.api',
41 'weblate.api.migrations',
42 'weblate.accounts',
43 'weblate.accounts.management',
44 'weblate.accounts.management.commands',
45 'weblate.accounts.migrations',
46 'weblate.accounts.templatetags',
47 'weblate.accounts.tests',
48 'weblate.billing',
49 'weblate.billing.management',
50 'weblate.billing.management.commands',
51 'weblate.billing.migrations',
52 'weblate.lang',
53 'weblate.lang.management',
54 'weblate.lang.management.commands',
55 'weblate.lang.migrations',
56 'weblate.trans',
57 'weblate.trans.autofixes',
58 'weblate.trans.checks',
59 'weblate.trans.machine',
60 'weblate.trans.management',
61 'weblate.trans.management.commands',
62 'weblate.trans.migrations',
63 'weblate.trans.models',
64 'weblate.trans.templatetags',
65 'weblate.trans.tests',
66 'weblate.trans.views',
67 ],
68 include_package_data=True,
69 license='GPLv3+',
70 description=(
71 'A web-based translation tool with tight version control integration'
72 ),
73 long_description=README,
74 keywords='i18n l10n gettext git mercurial translate',
75 url='https://weblate.org/',
76 download_url='https://weblate.org/download/',
77 bugtrack_url='https://github.com/WeblateOrg/weblate/issues',
78 author='Michal Čihař',
79 author_email='[email protected]',
80 install_requires=REQUIRES,
81 zip_safe=False,
82 extras_require={
83 'Mercurial': ['Mercurial>=2.8'],
84 'Unicode': ['pyuca>=1.1', 'python-bidi>=0.4.0', 'chardet'],
85 'Avatars': [
86 'pyLibravatar',
87 'pydns' if sys.version_info[0] == 2 else 'py3dns'
88 ],
89 'Android': ['Babel'],
90 'YAML': ['PyYAML>=3.0'],
91 'OCR': ['tesserocr>=1.2'],
92 },
93 classifiers=[
94 'Environment :: Web Environment',
95 'Framework :: Django',
96 'Intended Audience :: Developers',
97 'Intended Audience :: System Administrators',
98 'License :: OSI Approved :: '
99 'GNU General Public License v3 or later (GPLv3+)',
100 'Operating System :: OS Independent',
101 'Development Status :: 5 - Production/Stable',
102 'Programming Language :: Python',
103 'Programming Language :: Python :: 2',
104 'Programming Language :: Python :: 2.7',
105 'Programming Language :: Python :: 3',
106 'Programming Language :: Python :: 3.4',
107 'Programming Language :: Python :: 3.5',
108 'Topic :: Software Development :: Internationalization',
109 'Topic :: Software Development :: Localization',
110 'Topic :: Internet :: WWW/HTTP',
111 'Topic :: Internet :: WWW/HTTP :: Dynamic Content',
112 ],
113 entry_points={
114 'console_scripts': [
115 'weblate = weblate.runner:main',
116 ],
117 },
118 tests_require=(
119 'selenium',
120 'httpretty',
121 ),
122 test_suite='runtests.runtests',
123 )
124
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -32,6 +32,11 @@
with open('requirements.txt') as requirements:
REQUIRES = requirements.read().splitlines()
+DATA_FILES = [
+ ('share/weblate/' + root, [os.path.join(root, f) for f in files])
+ for root, dirs, files in os.walk('examples')
+]
+
setup(
name='Weblate',
version='2.14',
@@ -120,4 +125,5 @@
'httpretty',
),
test_suite='runtests.runtests',
+ data_files=DATA_FILES,
)
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -32,6 +32,11 @@\n with open('requirements.txt') as requirements:\n REQUIRES = requirements.read().splitlines()\n \n+DATA_FILES = [\n+ ('share/weblate/' + root, [os.path.join(root, f) for f in files])\n+ for root, dirs, files in os.walk('examples')\n+]\n+\n setup(\n name='Weblate',\n version='2.14',\n@@ -120,4 +125,5 @@\n 'httpretty',\n ),\n test_suite='runtests.runtests',\n+ data_files=DATA_FILES,\n )\n", "issue": "Provide example hooks in pip installations\n### Steps to reproduce\r\n1. `pip install Weblate`\r\n2. `ls path/to/site-packages/weblate`\r\n\r\n### Actual behaviour\r\nExample hooks are missing. We have to download the examples manually and copy them where we want on the server.\r\n\r\n### Expected behaviour\r\nExample hooks should be in site-packages, packaged as data inside Weblate package. This would allow to use examples, even when Weblate is installed using pip.\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n#\n# Copyright \u00a9 2012 - 2017 Michal \u010ciha\u0159 <[email protected]>\n#\n# This file is part of Weblate <https://weblate.org/>\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this program. If not, see <https://www.gnu.org/licenses/>.\n#\n\nimport os\nimport sys\nfrom setuptools import setup\n\n# allow setup.py to be run from any path\nos.chdir(os.path.normpath(os.path.join(os.path.abspath(__file__), os.pardir)))\n\nwith open(os.path.join(os.path.dirname(__file__), 'README.rst')) as readme:\n README = readme.read()\n\nwith open('requirements.txt') as requirements:\n REQUIRES = requirements.read().splitlines()\n\nsetup(\n name='Weblate',\n version='2.14',\n packages=[\n 'weblate',\n 'weblate.api',\n 'weblate.api.migrations',\n 'weblate.accounts',\n 'weblate.accounts.management',\n 'weblate.accounts.management.commands',\n 'weblate.accounts.migrations',\n 'weblate.accounts.templatetags',\n 'weblate.accounts.tests',\n 'weblate.billing',\n 'weblate.billing.management',\n 'weblate.billing.management.commands',\n 'weblate.billing.migrations',\n 'weblate.lang',\n 'weblate.lang.management',\n 'weblate.lang.management.commands',\n 'weblate.lang.migrations',\n 'weblate.trans',\n 'weblate.trans.autofixes',\n 'weblate.trans.checks',\n 'weblate.trans.machine',\n 'weblate.trans.management',\n 'weblate.trans.management.commands',\n 'weblate.trans.migrations',\n 'weblate.trans.models',\n 'weblate.trans.templatetags',\n 'weblate.trans.tests',\n 'weblate.trans.views',\n ],\n include_package_data=True,\n license='GPLv3+',\n description=(\n 'A web-based translation tool with tight version control integration'\n ),\n long_description=README,\n keywords='i18n l10n gettext git mercurial translate',\n url='https://weblate.org/',\n download_url='https://weblate.org/download/',\n bugtrack_url='https://github.com/WeblateOrg/weblate/issues',\n author='Michal \u010ciha\u0159',\n author_email='[email protected]',\n install_requires=REQUIRES,\n zip_safe=False,\n extras_require={\n 'Mercurial': ['Mercurial>=2.8'],\n 'Unicode': ['pyuca>=1.1', 'python-bidi>=0.4.0', 'chardet'],\n 'Avatars': [\n 'pyLibravatar',\n 'pydns' if sys.version_info[0] == 2 else 'py3dns'\n ],\n 'Android': ['Babel'],\n 'YAML': ['PyYAML>=3.0'],\n 'OCR': ['tesserocr>=1.2'],\n },\n classifiers=[\n 'Environment :: Web Environment',\n 'Framework :: Django',\n 'Intended Audience :: Developers',\n 'Intended Audience :: System Administrators',\n 'License :: OSI Approved :: '\n 'GNU General Public License v3 or later (GPLv3+)',\n 'Operating System :: OS Independent',\n 'Development Status :: 5 - Production/Stable',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Topic :: Software Development :: Internationalization',\n 'Topic :: Software Development :: Localization',\n 'Topic :: Internet :: WWW/HTTP',\n 'Topic :: Internet :: WWW/HTTP :: Dynamic Content',\n ],\n entry_points={\n 'console_scripts': [\n 'weblate = weblate.runner:main',\n ],\n },\n tests_require=(\n 'selenium',\n 'httpretty',\n ),\n test_suite='runtests.runtests',\n)\n", "path": "setup.py"}]}
| 1,943 | 155 |
gh_patches_debug_52237
|
rasdani/github-patches
|
git_diff
|
easybuilders__easybuild-framework-3584
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
-lpthtread is missing from $LIBBLAS_MT
when building with the `foss` toolchain, I noticed that `$LIBBLAS_MT` is defined identical to `$LIBBLAS` as `-lopenblas -lgfortran`
we should make sure `-lpthread` is included as well.
</issue>
<code>
[start of easybuild/toolchains/linalg/openblas.py]
1 ##
2 # Copyright 2013-2021 Ghent University
3 #
4 # This file is part of EasyBuild,
5 # originally created by the HPC team of Ghent University (http://ugent.be/hpc/en),
6 # with support of Ghent University (http://ugent.be/hpc),
7 # the Flemish Supercomputer Centre (VSC) (https://www.vscentrum.be),
8 # Flemish Research Foundation (FWO) (http://www.fwo.be/en)
9 # and the Department of Economy, Science and Innovation (EWI) (http://www.ewi-vlaanderen.be/en).
10 #
11 # https://github.com/easybuilders/easybuild
12 #
13 # EasyBuild is free software: you can redistribute it and/or modify
14 # it under the terms of the GNU General Public License as published by
15 # the Free Software Foundation v2.
16 #
17 # EasyBuild is distributed in the hope that it will be useful,
18 # but WITHOUT ANY WARRANTY; without even the implied warranty of
19 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
20 # GNU General Public License for more details.
21 #
22 # You should have received a copy of the GNU General Public License
23 # along with EasyBuild. If not, see <http://www.gnu.org/licenses/>.
24 ##
25 """
26 Support for OpenBLAS as toolchain linear algebra library.
27
28 :author: Kenneth Hoste (Ghent University)
29 """
30
31 from easybuild.tools.toolchain.linalg import LinAlg
32
33
34 TC_CONSTANT_OPENBLAS = 'OpenBLAS'
35
36
37 class OpenBLAS(LinAlg):
38 """
39 Trivial class, provides OpenBLAS support.
40 """
41 BLAS_MODULE_NAME = ['OpenBLAS']
42 BLAS_LIB = ['openblas']
43 BLAS_FAMILY = TC_CONSTANT_OPENBLAS
44
45 LAPACK_MODULE_NAME = ['OpenBLAS']
46 LAPACK_IS_BLAS = True
47 LAPACK_FAMILY = TC_CONSTANT_OPENBLAS
48
[end of easybuild/toolchains/linalg/openblas.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/easybuild/toolchains/linalg/openblas.py b/easybuild/toolchains/linalg/openblas.py
--- a/easybuild/toolchains/linalg/openblas.py
+++ b/easybuild/toolchains/linalg/openblas.py
@@ -40,6 +40,7 @@
"""
BLAS_MODULE_NAME = ['OpenBLAS']
BLAS_LIB = ['openblas']
+ BLAS_LIB_MT = ['openblas']
BLAS_FAMILY = TC_CONSTANT_OPENBLAS
LAPACK_MODULE_NAME = ['OpenBLAS']
|
{"golden_diff": "diff --git a/easybuild/toolchains/linalg/openblas.py b/easybuild/toolchains/linalg/openblas.py\n--- a/easybuild/toolchains/linalg/openblas.py\n+++ b/easybuild/toolchains/linalg/openblas.py\n@@ -40,6 +40,7 @@\n \"\"\"\n BLAS_MODULE_NAME = ['OpenBLAS']\n BLAS_LIB = ['openblas']\n+ BLAS_LIB_MT = ['openblas']\n BLAS_FAMILY = TC_CONSTANT_OPENBLAS\n \n LAPACK_MODULE_NAME = ['OpenBLAS']\n", "issue": "-lpthtread is missing from $LIBBLAS_MT\nwhen building with the `foss` toolchain, I noticed that `$LIBBLAS_MT` is defined identical to `$LIBBLAS` as `-lopenblas -lgfortran`\r\n\r\nwe should make sure `-lpthread` is included as well.\r\n\r\n\n", "before_files": [{"content": "##\n# Copyright 2013-2021 Ghent University\n#\n# This file is part of EasyBuild,\n# originally created by the HPC team of Ghent University (http://ugent.be/hpc/en),\n# with support of Ghent University (http://ugent.be/hpc),\n# the Flemish Supercomputer Centre (VSC) (https://www.vscentrum.be),\n# Flemish Research Foundation (FWO) (http://www.fwo.be/en)\n# and the Department of Economy, Science and Innovation (EWI) (http://www.ewi-vlaanderen.be/en).\n#\n# https://github.com/easybuilders/easybuild\n#\n# EasyBuild is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation v2.\n#\n# EasyBuild is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with EasyBuild. If not, see <http://www.gnu.org/licenses/>.\n##\n\"\"\"\nSupport for OpenBLAS as toolchain linear algebra library.\n\n:author: Kenneth Hoste (Ghent University)\n\"\"\"\n\nfrom easybuild.tools.toolchain.linalg import LinAlg\n\n\nTC_CONSTANT_OPENBLAS = 'OpenBLAS'\n\n\nclass OpenBLAS(LinAlg):\n \"\"\"\n Trivial class, provides OpenBLAS support.\n \"\"\"\n BLAS_MODULE_NAME = ['OpenBLAS']\n BLAS_LIB = ['openblas']\n BLAS_FAMILY = TC_CONSTANT_OPENBLAS\n\n LAPACK_MODULE_NAME = ['OpenBLAS']\n LAPACK_IS_BLAS = True\n LAPACK_FAMILY = TC_CONSTANT_OPENBLAS\n", "path": "easybuild/toolchains/linalg/openblas.py"}]}
| 1,105 | 119 |
gh_patches_debug_25082
|
rasdani/github-patches
|
git_diff
|
Zeroto521__my-data-toolkit-615
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
MAINT: Set only positional parameter for `(geo)accessor`
<!--
Thanks for contributing a pull request!
Please follow these standard acronyms to start the commit message:
- ENH: enhancement
- BUG: bug fix
- DOC: documentation
- TYP: type annotations
- TST: addition or modification of tests
- MAINT: maintenance commit (refactoring, typos, etc.)
- BLD: change related to building
- REL: related to releasing
- API: an (incompatible) API change
- DEP: deprecate something, or remove a deprecated object
- DEV: development tool or utility
- REV: revert an earlier commit
- PERF: performance improvement
- BOT: always commit via a bot
- CI: related to CI or CD
- CLN: Code cleanup
-->
- [ ] closes #xxxx
- [x] whatsnew entry
The first parameter of `(geo)accessor` methods must be set as only positional parameter.
</issue>
<code>
[start of dtoolkit/accessor/dataframe/repeat.py]
1 from __future__ import annotations
2
3 import numpy as np
4 import pandas as pd
5
6 from dtoolkit._typing import Axis
7 from dtoolkit.accessor.register import register_dataframe_method
8
9
10 @register_dataframe_method
11 def repeat(
12 df: pd.DataFrame,
13 repeat: int | list[int],
14 /,
15 axis: Axis = 0,
16 ) -> pd.DataFrame:
17 """
18 Repeat row or column of a :obj:`~pandas.DataFrame`.
19
20 Returns a new DataFrame where each row/column is repeated
21 consecutively a given number of times.
22
23 A sugary syntax wraps :meth:`numpy.repeat`.
24
25 Parameters
26 ----------
27 repeat : int or array of ints
28 The number of repetitions for each element. This should be a
29 non-negative integer. Repeating 0 times will return an empty
30 :obj:`~pandas.DataFrame`.
31
32 axis : {0 or 'index', 1 or 'columns'}, default 0
33 The axis along which to repeat.
34
35 * 0, or 'index' : Along the row to repeat.
36 * 1, or 'columns' : Along the column to repeat.
37
38 Returns
39 -------
40 DataFrame
41 Newly created DataFrame with repeated elements.
42
43 See Also
44 --------
45 numpy.repeat : This transformer's prototype method.
46
47 Examples
48 --------
49 >>> import pandas as pd
50 >>> import dtoolkit.accessor
51 >>> df = pd.DataFrame({'a': [1, 2], 'b':[3, 4]})
52 >>> df
53 a b
54 0 1 3
55 1 2 4
56
57 Each row repeat two times.
58
59 >>> df.repeat(2)
60 a b
61 0 1 3
62 0 1 3
63 1 2 4
64 1 2 4
65
66 Each column repeat two times.
67
68 >>> df.repeat(2, 1)
69 a a b b
70 0 1 1 3 3
71 1 2 2 4 4
72
73 ``a`` column repeat 1 times, ``b`` column repeat 2 times.
74
75 >>> df.repeat([1, 2], 1)
76 a b b
77 0 1 3 3
78 1 2 4 4
79 """
80
81 axis = df._get_axis_number(axis)
82 return pd.DataFrame(
83 np.repeat(
84 df._values,
85 repeat,
86 axis=axis,
87 ),
88 index=df.index.repeat(repeat) if axis == 0 else df.index,
89 columns=df.columns.repeat(repeat) if axis == 1 else df.columns,
90 )
91
[end of dtoolkit/accessor/dataframe/repeat.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/dtoolkit/accessor/dataframe/repeat.py b/dtoolkit/accessor/dataframe/repeat.py
--- a/dtoolkit/accessor/dataframe/repeat.py
+++ b/dtoolkit/accessor/dataframe/repeat.py
@@ -10,7 +10,7 @@
@register_dataframe_method
def repeat(
df: pd.DataFrame,
- repeat: int | list[int],
+ repeats: int | list[int],
/,
axis: Axis = 0,
) -> pd.DataFrame:
@@ -24,7 +24,7 @@
Parameters
----------
- repeat : int or array of ints
+ repeats : int or array of ints
The number of repetitions for each element. This should be a
non-negative integer. Repeating 0 times will return an empty
:obj:`~pandas.DataFrame`.
@@ -78,13 +78,12 @@
1 2 4 4
"""
- axis = df._get_axis_number(axis)
return pd.DataFrame(
np.repeat(
df._values,
- repeat,
- axis=axis,
+ repeats,
+ axis=df._get_axis_number(axis),
),
- index=df.index.repeat(repeat) if axis == 0 else df.index,
- columns=df.columns.repeat(repeat) if axis == 1 else df.columns,
+ index=df.index.repeat(repeats) if axis == 0 else df.index,
+ columns=df.columns.repeat(repeats) if axis == 1 else df.columns,
)
|
{"golden_diff": "diff --git a/dtoolkit/accessor/dataframe/repeat.py b/dtoolkit/accessor/dataframe/repeat.py\n--- a/dtoolkit/accessor/dataframe/repeat.py\n+++ b/dtoolkit/accessor/dataframe/repeat.py\n@@ -10,7 +10,7 @@\n @register_dataframe_method\n def repeat(\n df: pd.DataFrame,\n- repeat: int | list[int],\n+ repeats: int | list[int],\n /,\n axis: Axis = 0,\n ) -> pd.DataFrame:\n@@ -24,7 +24,7 @@\n \n Parameters\n ----------\n- repeat : int or array of ints\n+ repeats : int or array of ints\n The number of repetitions for each element. This should be a\n non-negative integer. Repeating 0 times will return an empty\n :obj:`~pandas.DataFrame`.\n@@ -78,13 +78,12 @@\n 1 2 4 4\n \"\"\"\n \n- axis = df._get_axis_number(axis)\n return pd.DataFrame(\n np.repeat(\n df._values,\n- repeat,\n- axis=axis,\n+ repeats,\n+ axis=df._get_axis_number(axis),\n ),\n- index=df.index.repeat(repeat) if axis == 0 else df.index,\n- columns=df.columns.repeat(repeat) if axis == 1 else df.columns,\n+ index=df.index.repeat(repeats) if axis == 0 else df.index,\n+ columns=df.columns.repeat(repeats) if axis == 1 else df.columns,\n )\n", "issue": "MAINT: Set only positional parameter for `(geo)accessor`\n<!--\r\nThanks for contributing a pull request!\r\n\r\nPlease follow these standard acronyms to start the commit message:\r\n\r\n- ENH: enhancement\r\n- BUG: bug fix\r\n- DOC: documentation\r\n- TYP: type annotations\r\n- TST: addition or modification of tests\r\n- MAINT: maintenance commit (refactoring, typos, etc.)\r\n- BLD: change related to building\r\n- REL: related to releasing\r\n- API: an (incompatible) API change\r\n- DEP: deprecate something, or remove a deprecated object\r\n- DEV: development tool or utility\r\n- REV: revert an earlier commit\r\n- PERF: performance improvement\r\n- BOT: always commit via a bot\r\n- CI: related to CI or CD\r\n- CLN: Code cleanup\r\n-->\r\n\r\n- [ ] closes #xxxx\r\n- [x] whatsnew entry\r\n\r\nThe first parameter of `(geo)accessor` methods must be set as only positional parameter.\n", "before_files": [{"content": "from __future__ import annotations\n\nimport numpy as np\nimport pandas as pd\n\nfrom dtoolkit._typing import Axis\nfrom dtoolkit.accessor.register import register_dataframe_method\n\n\n@register_dataframe_method\ndef repeat(\n df: pd.DataFrame,\n repeat: int | list[int],\n /,\n axis: Axis = 0,\n) -> pd.DataFrame:\n \"\"\"\n Repeat row or column of a :obj:`~pandas.DataFrame`.\n\n Returns a new DataFrame where each row/column is repeated\n consecutively a given number of times.\n\n A sugary syntax wraps :meth:`numpy.repeat`.\n\n Parameters\n ----------\n repeat : int or array of ints\n The number of repetitions for each element. This should be a\n non-negative integer. Repeating 0 times will return an empty\n :obj:`~pandas.DataFrame`.\n\n axis : {0 or 'index', 1 or 'columns'}, default 0\n The axis along which to repeat.\n\n * 0, or 'index' : Along the row to repeat.\n * 1, or 'columns' : Along the column to repeat.\n\n Returns\n -------\n DataFrame\n Newly created DataFrame with repeated elements.\n\n See Also\n --------\n numpy.repeat : This transformer's prototype method.\n\n Examples\n --------\n >>> import pandas as pd\n >>> import dtoolkit.accessor\n >>> df = pd.DataFrame({'a': [1, 2], 'b':[3, 4]})\n >>> df\n a b\n 0 1 3\n 1 2 4\n\n Each row repeat two times.\n\n >>> df.repeat(2)\n a b\n 0 1 3\n 0 1 3\n 1 2 4\n 1 2 4\n\n Each column repeat two times.\n\n >>> df.repeat(2, 1)\n a a b b\n 0 1 1 3 3\n 1 2 2 4 4\n\n ``a`` column repeat 1 times, ``b`` column repeat 2 times.\n\n >>> df.repeat([1, 2], 1)\n a b b\n 0 1 3 3\n 1 2 4 4\n \"\"\"\n\n axis = df._get_axis_number(axis)\n return pd.DataFrame(\n np.repeat(\n df._values,\n repeat,\n axis=axis,\n ),\n index=df.index.repeat(repeat) if axis == 0 else df.index,\n columns=df.columns.repeat(repeat) if axis == 1 else df.columns,\n )\n", "path": "dtoolkit/accessor/dataframe/repeat.py"}]}
| 1,544 | 342 |
gh_patches_debug_4871
|
rasdani/github-patches
|
git_diff
|
ansible__molecule-3521
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Missing `f` prefix on f-strings
Some strings looks like they're meant to be f-strings but are missing the `f` prefix meaning variable interpolation won't happen.
https://github.com/ansible-community/molecule/blob/19381a8a564f8013453b8dfb08b677fd81c2e358/src/molecule/scenarios.py#L85
I found this issue automatically. I'm a bot. Beep Boop 🦊. See other issues I found in your repo [here](https://codereview.doctor/ansible-community/molecule)
</issue>
<code>
[start of src/molecule/scenarios.py]
1 # Copyright (c) 2015-2018 Cisco Systems, Inc.
2 #
3 # Permission is hereby granted, free of charge, to any person obtaining a copy
4 # of this software and associated documentation files (the "Software"), to
5 # deal in the Software without restriction, including without limitation the
6 # rights to use, copy, modify, merge, publish, distribute, sublicense, and/or
7 # sell copies of the Software, and to permit persons to whom the Software is
8 # furnished to do so, subject to the following conditions:
9 #
10 # The above copyright notice and this permission notice shall be included in
11 # all copies or substantial portions of the Software.
12 #
13 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
14 # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
15 # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
16 # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
17 # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
18 # FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
19 # DEALINGS IN THE SOFTWARE.
20 """Scenarios Module."""
21 import logging
22 from typing import List
23
24 from molecule import util
25
26 LOG = logging.getLogger(__name__)
27
28
29 class Scenarios(object):
30 """The Scenarios groups one or more scenario objects Molecule will execute."""
31
32 def __init__(self, configs, scenario_name=None):
33 """
34 Initialize a new scenarios class and returns None.
35
36 :param configs: A list containing Molecule config instances.
37 :param scenario_name: A string containing the name of the scenario.
38 :return: None
39 """
40 self._configs = configs
41 self._scenario_name = scenario_name
42 self._scenarios = self.all
43
44 def next(self):
45 if not self._scenarios:
46 raise StopIteration
47 return self._scenarios.pop(0)
48
49 def __iter__(self):
50 """Make object iterable."""
51 return self
52
53 __next__ = next # Python 3.X compatibility
54
55 @property
56 def all(self):
57 """
58 Return a list containing all scenario objects.
59
60 :return: list
61 """
62 if self._scenario_name:
63 scenarios = self._filter_for_scenario()
64 self._verify()
65
66 return scenarios
67
68 scenarios = [c.scenario for c in self._configs]
69 scenarios.sort(key=lambda x: x.directory)
70 return scenarios
71
72 def print_matrix(self):
73 msg = "Test matrix"
74 LOG.info(msg)
75
76 tree = {}
77 for scenario in self.all:
78 tree[scenario.name] = [action for action in scenario.sequence]
79 util.print_as_yaml(tree)
80
81 def sequence(self, scenario_name: str) -> List[str]:
82 for scenario in self.all:
83 if scenario.name == scenario_name:
84 return [action for action in scenario.sequence]
85 raise RuntimeError("Unable to find sequence for {scenario_name} scenario.")
86
87 def _verify(self):
88 """
89 Verify the specified scenario was found and returns None.
90
91 :return: None
92 """
93 scenario_names = [c.scenario.name for c in self._configs]
94 if self._scenario_name not in scenario_names:
95 msg = f"Scenario '{self._scenario_name}' not found. Exiting."
96 util.sysexit_with_message(msg)
97
98 def _filter_for_scenario(self):
99 """
100 Find the scenario matching the provided scenario name and returns a \
101 list.
102
103 :return: list
104 """
105 return [
106 c.scenario for c in self._configs if c.scenario.name == self._scenario_name
107 ]
108
109 def _get_matrix(self):
110 """
111 Build a matrix of scenarios with sequence to include and returns a \
112 dict.
113
114 {
115 scenario_1: {
116 'subcommand': [
117 'action-1',
118 'action-2',
119 ],
120 },
121 scenario_2: {
122 'subcommand': [
123 'action-1',
124 ],
125 },
126 }
127
128 :returns: dict
129 """
130 return dict(
131 {
132 scenario.name: {
133 "check": scenario.check_sequence,
134 "cleanup": scenario.cleanup_sequence,
135 "converge": scenario.converge_sequence,
136 "create": scenario.create_sequence,
137 "dependency": scenario.dependency_sequence,
138 "destroy": scenario.destroy_sequence,
139 "idempotence": scenario.idempotence_sequence,
140 "lint": scenario.lint_sequence,
141 "prepare": scenario.prepare_sequence,
142 "side_effect": scenario.side_effect_sequence,
143 "syntax": scenario.syntax_sequence,
144 "test": scenario.test_sequence,
145 "verify": scenario.verify_sequence,
146 }
147 for scenario in self.all
148 }
149 )
150
[end of src/molecule/scenarios.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/molecule/scenarios.py b/src/molecule/scenarios.py
--- a/src/molecule/scenarios.py
+++ b/src/molecule/scenarios.py
@@ -82,7 +82,7 @@
for scenario in self.all:
if scenario.name == scenario_name:
return [action for action in scenario.sequence]
- raise RuntimeError("Unable to find sequence for {scenario_name} scenario.")
+ raise RuntimeError(f"Unable to find sequence for {scenario_name} scenario.")
def _verify(self):
"""
|
{"golden_diff": "diff --git a/src/molecule/scenarios.py b/src/molecule/scenarios.py\n--- a/src/molecule/scenarios.py\n+++ b/src/molecule/scenarios.py\n@@ -82,7 +82,7 @@\n for scenario in self.all:\n if scenario.name == scenario_name:\n return [action for action in scenario.sequence]\n- raise RuntimeError(\"Unable to find sequence for {scenario_name} scenario.\")\n+ raise RuntimeError(f\"Unable to find sequence for {scenario_name} scenario.\")\n \n def _verify(self):\n \"\"\"\n", "issue": "Missing `f` prefix on f-strings\nSome strings looks like they're meant to be f-strings but are missing the `f` prefix meaning variable interpolation won't happen.\n\nhttps://github.com/ansible-community/molecule/blob/19381a8a564f8013453b8dfb08b677fd81c2e358/src/molecule/scenarios.py#L85\n\nI found this issue automatically. I'm a bot. Beep Boop \ud83e\udd8a. See other issues I found in your repo [here](https://codereview.doctor/ansible-community/molecule)\n", "before_files": [{"content": "# Copyright (c) 2015-2018 Cisco Systems, Inc.\n#\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to\n# deal in the Software without restriction, including without limitation the\n# rights to use, copy, modify, merge, publish, distribute, sublicense, and/or\n# sell copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING\n# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER\n# DEALINGS IN THE SOFTWARE.\n\"\"\"Scenarios Module.\"\"\"\nimport logging\nfrom typing import List\n\nfrom molecule import util\n\nLOG = logging.getLogger(__name__)\n\n\nclass Scenarios(object):\n \"\"\"The Scenarios groups one or more scenario objects Molecule will execute.\"\"\"\n\n def __init__(self, configs, scenario_name=None):\n \"\"\"\n Initialize a new scenarios class and returns None.\n\n :param configs: A list containing Molecule config instances.\n :param scenario_name: A string containing the name of the scenario.\n :return: None\n \"\"\"\n self._configs = configs\n self._scenario_name = scenario_name\n self._scenarios = self.all\n\n def next(self):\n if not self._scenarios:\n raise StopIteration\n return self._scenarios.pop(0)\n\n def __iter__(self):\n \"\"\"Make object iterable.\"\"\"\n return self\n\n __next__ = next # Python 3.X compatibility\n\n @property\n def all(self):\n \"\"\"\n Return a list containing all scenario objects.\n\n :return: list\n \"\"\"\n if self._scenario_name:\n scenarios = self._filter_for_scenario()\n self._verify()\n\n return scenarios\n\n scenarios = [c.scenario for c in self._configs]\n scenarios.sort(key=lambda x: x.directory)\n return scenarios\n\n def print_matrix(self):\n msg = \"Test matrix\"\n LOG.info(msg)\n\n tree = {}\n for scenario in self.all:\n tree[scenario.name] = [action for action in scenario.sequence]\n util.print_as_yaml(tree)\n\n def sequence(self, scenario_name: str) -> List[str]:\n for scenario in self.all:\n if scenario.name == scenario_name:\n return [action for action in scenario.sequence]\n raise RuntimeError(\"Unable to find sequence for {scenario_name} scenario.\")\n\n def _verify(self):\n \"\"\"\n Verify the specified scenario was found and returns None.\n\n :return: None\n \"\"\"\n scenario_names = [c.scenario.name for c in self._configs]\n if self._scenario_name not in scenario_names:\n msg = f\"Scenario '{self._scenario_name}' not found. Exiting.\"\n util.sysexit_with_message(msg)\n\n def _filter_for_scenario(self):\n \"\"\"\n Find the scenario matching the provided scenario name and returns a \\\n list.\n\n :return: list\n \"\"\"\n return [\n c.scenario for c in self._configs if c.scenario.name == self._scenario_name\n ]\n\n def _get_matrix(self):\n \"\"\"\n Build a matrix of scenarios with sequence to include and returns a \\\n dict.\n\n {\n scenario_1: {\n 'subcommand': [\n 'action-1',\n 'action-2',\n ],\n },\n scenario_2: {\n 'subcommand': [\n 'action-1',\n ],\n },\n }\n\n :returns: dict\n \"\"\"\n return dict(\n {\n scenario.name: {\n \"check\": scenario.check_sequence,\n \"cleanup\": scenario.cleanup_sequence,\n \"converge\": scenario.converge_sequence,\n \"create\": scenario.create_sequence,\n \"dependency\": scenario.dependency_sequence,\n \"destroy\": scenario.destroy_sequence,\n \"idempotence\": scenario.idempotence_sequence,\n \"lint\": scenario.lint_sequence,\n \"prepare\": scenario.prepare_sequence,\n \"side_effect\": scenario.side_effect_sequence,\n \"syntax\": scenario.syntax_sequence,\n \"test\": scenario.test_sequence,\n \"verify\": scenario.verify_sequence,\n }\n for scenario in self.all\n }\n )\n", "path": "src/molecule/scenarios.py"}]}
| 2,045 | 115 |
gh_patches_debug_2101
|
rasdani/github-patches
|
git_diff
|
carpentries__amy-2028
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Update colors of progress states
The current color scheme for our progress states makes it hard to know when something needs further attention and when it does not. Previously we had three colors: Red-Failed, Yellow-Not evaluated yet and Green-Passed.
The new 'Asked to Repeat' progress state option is also yellow and so it conflicts with the 'Not Evaluated Yet' option.
**Please update the color for 'Asked to Repeat' to blue.. Any shade will do.**
Progress state colors can be viewed on the [More>Trainees page ](https://amy.carpentries.org/trainings/trainees/)
</issue>
<code>
[start of amy/workshops/templatetags/training_progress.py]
1 from django import template
2 from django.template.defaultfilters import escape
3 from django.utils.safestring import mark_safe
4
5 from workshops.models import TrainingProgress
6
7 register = template.Library()
8
9
10 @register.simple_tag
11 def progress_label(progress):
12 assert isinstance(progress, TrainingProgress)
13
14 if progress.discarded:
15 additional_label = "dark"
16
17 else:
18 switch = {
19 "n": "warning",
20 "f": "danger",
21 "a": "warning",
22 "p": "success",
23 }
24 additional_label = switch[progress.state]
25
26 fmt = "badge badge-{}".format(additional_label)
27 return mark_safe(fmt)
28
29
30 @register.simple_tag
31 def progress_description(progress):
32 assert isinstance(progress, TrainingProgress)
33
34 text = "{discarded}{state} {type}<br />{evaluated_by}<br />on {day}.{notes}".format(
35 discarded="discarded " if progress.discarded else "",
36 state=progress.get_state_display(),
37 type=progress.requirement,
38 evaluated_by=(
39 "evaluated by {}".format(progress.evaluated_by.full_name)
40 if progress.evaluated_by is not None
41 else "submitted"
42 ),
43 day=progress.created_at.strftime("%A %d %B %Y at %H:%M"),
44 notes="<br />Notes: {}".format(escape(progress.notes))
45 if progress.notes
46 else "",
47 )
48 text = text[0].upper() + text[1:]
49 return mark_safe(text)
50
[end of amy/workshops/templatetags/training_progress.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/amy/workshops/templatetags/training_progress.py b/amy/workshops/templatetags/training_progress.py
--- a/amy/workshops/templatetags/training_progress.py
+++ b/amy/workshops/templatetags/training_progress.py
@@ -18,7 +18,7 @@
switch = {
"n": "warning",
"f": "danger",
- "a": "warning",
+ "a": "info",
"p": "success",
}
additional_label = switch[progress.state]
|
{"golden_diff": "diff --git a/amy/workshops/templatetags/training_progress.py b/amy/workshops/templatetags/training_progress.py\n--- a/amy/workshops/templatetags/training_progress.py\n+++ b/amy/workshops/templatetags/training_progress.py\n@@ -18,7 +18,7 @@\n switch = {\n \"n\": \"warning\",\n \"f\": \"danger\",\n- \"a\": \"warning\",\n+ \"a\": \"info\",\n \"p\": \"success\",\n }\n additional_label = switch[progress.state]\n", "issue": "Update colors of progress states\nThe current color scheme for our progress states makes it hard to know when something needs further attention and when it does not. Previously we had three colors: Red-Failed, Yellow-Not evaluated yet and Green-Passed. \r\n\r\nThe new 'Asked to Repeat' progress state option is also yellow and so it conflicts with the 'Not Evaluated Yet' option.\r\n\r\n**Please update the color for 'Asked to Repeat' to blue.. Any shade will do.**\r\n\r\nProgress state colors can be viewed on the [More>Trainees page ](https://amy.carpentries.org/trainings/trainees/)\n", "before_files": [{"content": "from django import template\nfrom django.template.defaultfilters import escape\nfrom django.utils.safestring import mark_safe\n\nfrom workshops.models import TrainingProgress\n\nregister = template.Library()\n\n\[email protected]_tag\ndef progress_label(progress):\n assert isinstance(progress, TrainingProgress)\n\n if progress.discarded:\n additional_label = \"dark\"\n\n else:\n switch = {\n \"n\": \"warning\",\n \"f\": \"danger\",\n \"a\": \"warning\",\n \"p\": \"success\",\n }\n additional_label = switch[progress.state]\n\n fmt = \"badge badge-{}\".format(additional_label)\n return mark_safe(fmt)\n\n\[email protected]_tag\ndef progress_description(progress):\n assert isinstance(progress, TrainingProgress)\n\n text = \"{discarded}{state} {type}<br />{evaluated_by}<br />on {day}.{notes}\".format(\n discarded=\"discarded \" if progress.discarded else \"\",\n state=progress.get_state_display(),\n type=progress.requirement,\n evaluated_by=(\n \"evaluated by {}\".format(progress.evaluated_by.full_name)\n if progress.evaluated_by is not None\n else \"submitted\"\n ),\n day=progress.created_at.strftime(\"%A %d %B %Y at %H:%M\"),\n notes=\"<br />Notes: {}\".format(escape(progress.notes))\n if progress.notes\n else \"\",\n )\n text = text[0].upper() + text[1:]\n return mark_safe(text)\n", "path": "amy/workshops/templatetags/training_progress.py"}]}
| 1,084 | 128 |
gh_patches_debug_37112
|
rasdani/github-patches
|
git_diff
|
Lightning-AI__pytorch-lightning-2335
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Breaking compatibility with custom datatypes implementing `.to`
## 🚀 Feature
<!-- A clear and concise description of the feature proposal -->
Bring back compatibility for custom datatypes in collections implementing `.to` for transferring data.
### Motivation
<!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too -->
I am using Pytorch Lightning together with Pytorch Geometric. Pytorch Geometric implements several custom datatypes and dataloaders which is really useful for geometric deep learning. Everything worked well with pytorch lightning 0.7.6, as the custom datatypes implement a `.to` method for transferring the data to different devices.
However, with the recent 0.8.1 update, this is no longer possible and I had to scour the documentation to be able to implement a fix using `transfer_batch_to_device(batch, device)`. This is in my opinion not very pretty, as my batch looks like this
```
{"data": pytorch geometric batch object, "id": tensor, ...}
```
i.e. it is just a dictionary of types that all implement the `.to` method.
### Pitch
<!-- A clear and concise description of what you want to happen. -->
- Make it possible for classes implementing the `.to` method to be transferred automatically
- If part of the batch could not be transferred automatically output a warning letting the user know, that a custom transfer function for the batch might be required, or to implement the `.to` method for custom datatypes in the batch
- Add a note to the introduction guide about custom datatypes and handling for custom datatypes
### Alternatives
<!-- A clear and concise description of any alternative solutions or features you've considered, if any. -->
If this change was intentional and the behavior of trying to call the `.to` method is not desired, I think there should definitely be some more documentation about this, in a more obvious place.
### Additional context
<!-- Add any other context or screenshots about the feature request here. -->
</issue>
<code>
[start of pytorch_lightning/core/hooks.py]
1 from typing import Any
2
3 import torch
4 from torch import Tensor
5 from torch.nn import Module
6 from torch.optim.optimizer import Optimizer
7 from pytorch_lightning.utilities import move_data_to_device
8
9
10 try:
11 from apex import amp
12 except ImportError:
13 APEX_AVAILABLE = False
14 else:
15 APEX_AVAILABLE = True
16
17
18 class ModelHooks(Module):
19
20 def setup(self, stage: str):
21 """
22 Called at the beginning of fit and test.
23 This is a good hook when you need to build models dynamically or adjust something about them.
24 This hook is called on every process when using DDP.
25
26 Args:
27 stage: either 'fit' or 'test'
28
29 Example::
30
31 class LitModel(...):
32 def __init__(self):
33 self.l1 = None
34
35 def prepare_data(self):
36 download_data()
37 tokenize()
38
39 # don't do this
40 self.something = else
41
42 def setup(step):
43 data = Load_data(...)
44 self.l1 = nn.Linear(28, data.num_classes)
45
46 """
47
48 def teardown(self, stage: str):
49 """
50 Called at the end of fit and test.
51
52 Args:
53 stage: either 'fit' or 'test'
54 """
55
56 def on_fit_start(self):
57 """
58 Called at the very beginning of fit.
59 If on DDP it is called on every process
60 """
61
62 def on_fit_end(self):
63 """
64 Called at the very end of fit.
65 If on DDP it is called on every process
66 """
67
68 # TODO: remove in v0.9.0
69 def on_sanity_check_start(self):
70 """
71 Called before starting evaluation.
72
73 Warning:
74 Deprecated. Will be removed in v0.9.0.
75 """
76
77 def on_train_start(self) -> None:
78 """
79 Called at the beginning of training before sanity check.
80 """
81 # do something at the start of training
82
83 def on_train_end(self) -> None:
84 """
85 Called at the end of training before logger experiment is closed.
86 """
87 # do something at the end of training
88
89 def on_batch_start(self, batch: Any) -> None:
90 """
91 Called in the training loop before anything happens for that batch.
92
93 If you return -1 here, you will skip training for the rest of the current epoch.
94
95 Args:
96 batch: The batched data as it is returned by the training DataLoader.
97 """
98 # do something when the batch starts
99
100 def on_batch_end(self) -> None:
101 """
102 Called in the training loop after the batch.
103 """
104 # do something when the batch ends
105
106 def on_epoch_start(self) -> None:
107 """
108 Called in the training loop at the very beginning of the epoch.
109 """
110 # do something when the epoch starts
111
112 def on_epoch_end(self) -> None:
113 """
114 Called in the training loop at the very end of the epoch.
115 """
116 # do something when the epoch ends
117
118 def on_pre_performance_check(self) -> None:
119 """
120 Called at the very beginning of the validation loop.
121 """
122 # do something before validation starts
123
124 def on_post_performance_check(self) -> None:
125 """
126 Called at the very end of the validation loop.
127 """
128 # do something before validation end
129
130 def on_before_zero_grad(self, optimizer: Optimizer) -> None:
131 """
132 Called after optimizer.step() and before optimizer.zero_grad().
133
134 Called in the training loop after taking an optimizer step and before zeroing grads.
135 Good place to inspect weight information with weights updated.
136
137 This is where it is called::
138
139 for optimizer in optimizers:
140 optimizer.step()
141 model.on_before_zero_grad(optimizer) # < ---- called here
142 optimizer.zero_grad
143
144 Args:
145 optimizer: The optimizer for which grads should be zeroed.
146 """
147 # do something with the optimizer or inspect it.
148
149 def on_after_backward(self) -> None:
150 """
151 Called in the training loop after loss.backward() and before optimizers do anything.
152 This is the ideal place to inspect or log gradient information.
153
154 Example::
155
156 def on_after_backward(self):
157 # example to inspect gradient information in tensorboard
158 if self.trainer.global_step % 25 == 0: # don't make the tf file huge
159 params = self.state_dict()
160 for k, v in params.items():
161 grads = v
162 name = k
163 self.logger.experiment.add_histogram(tag=name, values=grads,
164 global_step=self.trainer.global_step)
165
166 """
167
168 def backward(self, trainer, loss: Tensor, optimizer: Optimizer, optimizer_idx: int) -> None:
169 """
170 Override backward with your own implementation if you need to.
171
172 Args:
173 trainer: Pointer to the trainer
174 loss: Loss is already scaled by accumulated grads
175 optimizer: Current optimizer being used
176 optimizer_idx: Index of the current optimizer being used
177
178 Called to perform backward step.
179 Feel free to override as needed.
180
181 The loss passed in has already been scaled for accumulated gradients if requested.
182
183 Example::
184
185 def backward(self, trainer, loss, optimizer, optimizer_idx):
186 loss.backward()
187
188 """
189 loss.backward()
190
191 def amp_scale_loss(self, unscaled_loss, optimizer, optimizer_idx):
192 if self.trainer.use_native_amp:
193 scaled_loss = self.trainer.scaler.scale(unscaled_loss)
194
195 else:
196 scaled_loss = amp.scale_loss(unscaled_loss, optimizer)
197
198 return scaled_loss
199
200 def transfer_batch_to_device(self, batch: Any, device: torch.device) -> Any:
201 """
202 Override this hook if your :class:`~torch.utils.data.DataLoader` returns tensors
203 wrapped in a custom data structure.
204
205 The data types listed below (and any arbitrary nesting of them) are supported out of the box:
206
207 - :class:`torch.Tensor`
208 - :class:`list`
209 - :class:`dict`
210 - :class:`tuple`
211 - ``torchtext.data.Batch`` (COMING SOON)
212
213 For anything else, you need to define how the data is moved to the target device (CPU, GPU, TPU, ...).
214
215 Example::
216
217 def transfer_batch_to_device(self, batch, device)
218 if isinstance(batch, CustomBatch):
219 # move all tensors in your custom data structure to the device
220 batch.samples = batch.samples.to(device)
221 batch.targets = batch.targets.to(device)
222 else:
223 batch = super().transfer_batch_to_device(data, device)
224 return batch
225
226 Args:
227 batch: A batch of data that needs to be transferred to a new device.
228 device: The target device as defined in PyTorch.
229
230 Returns:
231 A reference to the data on the new device.
232
233 Note:
234 This hook should only transfer the data and not modify it, nor should it move the data to
235 any other device than the one passed in as argument (unless you know what you are doing).
236 The :class:`~pytorch_lightning.trainer.trainer.Trainer` already takes care of splitting the
237 batch and determines the target devices.
238
239 See Also:
240 - :func:`~pytorch_lightning.utilities.apply_func.move_data_to_device`
241 - :func:`~pytorch_lightning.utilities.apply_func.apply_to_collection`
242 """
243 return move_data_to_device(batch, device)
244
[end of pytorch_lightning/core/hooks.py]
[start of pytorch_lightning/utilities/apply_func.py]
1 from collections import Mapping, Sequence
2 from typing import Any, Callable, Union
3
4 import torch
5
6
7 def apply_to_collection(data: Any, dtype: Union[type, tuple], function: Callable, *args, **kwargs) -> Any:
8 """
9 Recursively applies a function to all elements of a certain dtype.
10
11 Args:
12 data: the collection to apply the function to
13 dtype: the given function will be applied to all elements of this dtype
14 function: the function to apply
15 *args: positional arguments (will be forwarded to calls of ``function``)
16 **kwargs: keyword arguments (will be forwarded to calls of ``function``)
17
18 Returns:
19 the resulting collection
20
21 """
22 elem_type = type(data)
23
24 # Breaking condition
25 if isinstance(data, dtype):
26 return function(data, *args, **kwargs)
27
28 # Recursively apply to collection items
29 elif isinstance(data, Mapping):
30 return elem_type({k: apply_to_collection(v, dtype, function, *args, **kwargs)
31 for k, v in data.items()})
32 elif isinstance(data, tuple) and hasattr(data, '_fields'): # named tuple
33 return elem_type(*(apply_to_collection(d, dtype, function, *args, **kwargs) for d in data))
34 elif isinstance(data, Sequence) and not isinstance(data, str):
35 return elem_type([apply_to_collection(d, dtype, function, *args, **kwargs) for d in data])
36
37 # data is neither of dtype, nor a collection
38 return data
39
40
41 def move_data_to_device(batch: Any, device: torch.device):
42 """
43 Transfers a collection of tensors to the given device.
44
45 Args:
46 batch: A tensor or collection of tensors. See :func:`apply_to_collection`
47 for a list of supported collection types.
48 device: The device to which tensors should be moved
49
50 Return:
51 the same collection but with all contained tensors residing on the new device.
52
53 See Also:
54 - :meth:`torch.Tensor.to`
55 - :class:`torch.device`
56 """
57 def to(tensor):
58 return tensor.to(device, non_blocking=True)
59 return apply_to_collection(batch, dtype=torch.Tensor, function=to)
60
[end of pytorch_lightning/utilities/apply_func.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pytorch_lightning/core/hooks.py b/pytorch_lightning/core/hooks.py
--- a/pytorch_lightning/core/hooks.py
+++ b/pytorch_lightning/core/hooks.py
@@ -204,7 +204,7 @@
The data types listed below (and any arbitrary nesting of them) are supported out of the box:
- - :class:`torch.Tensor`
+ - :class:`torch.Tensor` or anything that implements `.to(...)`
- :class:`list`
- :class:`dict`
- :class:`tuple`
diff --git a/pytorch_lightning/utilities/apply_func.py b/pytorch_lightning/utilities/apply_func.py
--- a/pytorch_lightning/utilities/apply_func.py
+++ b/pytorch_lightning/utilities/apply_func.py
@@ -1,3 +1,4 @@
+from abc import ABC
from collections import Mapping, Sequence
from typing import Any, Callable, Union
@@ -38,14 +39,43 @@
return data
+class TransferableDataType(ABC):
+ """
+ A custom type for data that can be moved to a torch device via `.to(...)`.
+
+ Example:
+
+ >>> isinstance(dict, TransferableDataType)
+ False
+ >>> isinstance(torch.rand(2, 3), TransferableDataType)
+ True
+ >>> class CustomObject:
+ ... def __init__(self):
+ ... self.x = torch.rand(2, 2)
+ ... def to(self, device):
+ ... self.x = self.x.to(device)
+ ... return self
+ >>> isinstance(CustomObject(), TransferableDataType)
+ True
+ """
+
+ @classmethod
+ def __subclasshook__(cls, subclass):
+ if cls is TransferableDataType:
+ to = getattr(subclass, "to", None)
+ return callable(to)
+ return NotImplemented
+
+
def move_data_to_device(batch: Any, device: torch.device):
"""
- Transfers a collection of tensors to the given device.
+ Transfers a collection of data to the given device. Any object that defines a method
+ ``to(device)`` will be moved and all other objects in the collection will be left untouched.
Args:
- batch: A tensor or collection of tensors. See :func:`apply_to_collection`
- for a list of supported collection types.
- device: The device to which tensors should be moved
+ batch: A tensor or collection of tensors or anything that has a method `.to(...)`.
+ See :func:`apply_to_collection` for a list of supported collection types.
+ device: The device to which the data should be moved
Return:
the same collection but with all contained tensors residing on the new device.
@@ -54,6 +84,6 @@
- :meth:`torch.Tensor.to`
- :class:`torch.device`
"""
- def to(tensor):
- return tensor.to(device, non_blocking=True)
- return apply_to_collection(batch, dtype=torch.Tensor, function=to)
+ def to(data):
+ return data.to(device, non_blocking=True)
+ return apply_to_collection(batch, dtype=TransferableDataType, function=to)
|
{"golden_diff": "diff --git a/pytorch_lightning/core/hooks.py b/pytorch_lightning/core/hooks.py\n--- a/pytorch_lightning/core/hooks.py\n+++ b/pytorch_lightning/core/hooks.py\n@@ -204,7 +204,7 @@\n \n The data types listed below (and any arbitrary nesting of them) are supported out of the box:\n \n- - :class:`torch.Tensor`\n+ - :class:`torch.Tensor` or anything that implements `.to(...)`\n - :class:`list`\n - :class:`dict`\n - :class:`tuple`\ndiff --git a/pytorch_lightning/utilities/apply_func.py b/pytorch_lightning/utilities/apply_func.py\n--- a/pytorch_lightning/utilities/apply_func.py\n+++ b/pytorch_lightning/utilities/apply_func.py\n@@ -1,3 +1,4 @@\n+from abc import ABC\n from collections import Mapping, Sequence\n from typing import Any, Callable, Union\n \n@@ -38,14 +39,43 @@\n return data\n \n \n+class TransferableDataType(ABC):\n+ \"\"\"\n+ A custom type for data that can be moved to a torch device via `.to(...)`.\n+\n+ Example:\n+\n+ >>> isinstance(dict, TransferableDataType)\n+ False\n+ >>> isinstance(torch.rand(2, 3), TransferableDataType)\n+ True\n+ >>> class CustomObject:\n+ ... def __init__(self):\n+ ... self.x = torch.rand(2, 2)\n+ ... def to(self, device):\n+ ... self.x = self.x.to(device)\n+ ... return self\n+ >>> isinstance(CustomObject(), TransferableDataType)\n+ True\n+ \"\"\"\n+\n+ @classmethod\n+ def __subclasshook__(cls, subclass):\n+ if cls is TransferableDataType:\n+ to = getattr(subclass, \"to\", None)\n+ return callable(to)\n+ return NotImplemented\n+\n+\n def move_data_to_device(batch: Any, device: torch.device):\n \"\"\"\n- Transfers a collection of tensors to the given device.\n+ Transfers a collection of data to the given device. Any object that defines a method\n+ ``to(device)`` will be moved and all other objects in the collection will be left untouched.\n \n Args:\n- batch: A tensor or collection of tensors. See :func:`apply_to_collection`\n- for a list of supported collection types.\n- device: The device to which tensors should be moved\n+ batch: A tensor or collection of tensors or anything that has a method `.to(...)`.\n+ See :func:`apply_to_collection` for a list of supported collection types.\n+ device: The device to which the data should be moved\n \n Return:\n the same collection but with all contained tensors residing on the new device.\n@@ -54,6 +84,6 @@\n - :meth:`torch.Tensor.to`\n - :class:`torch.device`\n \"\"\"\n- def to(tensor):\n- return tensor.to(device, non_blocking=True)\n- return apply_to_collection(batch, dtype=torch.Tensor, function=to)\n+ def to(data):\n+ return data.to(device, non_blocking=True)\n+ return apply_to_collection(batch, dtype=TransferableDataType, function=to)\n", "issue": "Breaking compatibility with custom datatypes implementing `.to`\n## \ud83d\ude80 Feature\r\n<!-- A clear and concise description of the feature proposal -->\r\nBring back compatibility for custom datatypes in collections implementing `.to` for transferring data.\r\n\r\n### Motivation\r\n\r\n<!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too -->\r\nI am using Pytorch Lightning together with Pytorch Geometric. Pytorch Geometric implements several custom datatypes and dataloaders which is really useful for geometric deep learning. Everything worked well with pytorch lightning 0.7.6, as the custom datatypes implement a `.to` method for transferring the data to different devices.\r\nHowever, with the recent 0.8.1 update, this is no longer possible and I had to scour the documentation to be able to implement a fix using `transfer_batch_to_device(batch, device)`. This is in my opinion not very pretty, as my batch looks like this \r\n```\r\n{\"data\": pytorch geometric batch object, \"id\": tensor, ...}\r\n```\r\ni.e. it is just a dictionary of types that all implement the `.to` method.\r\n\r\n### Pitch\r\n\r\n<!-- A clear and concise description of what you want to happen. -->\r\n\r\n- Make it possible for classes implementing the `.to` method to be transferred automatically\r\n- If part of the batch could not be transferred automatically output a warning letting the user know, that a custom transfer function for the batch might be required, or to implement the `.to` method for custom datatypes in the batch\r\n- Add a note to the introduction guide about custom datatypes and handling for custom datatypes\r\n\r\n### Alternatives\r\n\r\n<!-- A clear and concise description of any alternative solutions or features you've considered, if any. -->\r\nIf this change was intentional and the behavior of trying to call the `.to` method is not desired, I think there should definitely be some more documentation about this, in a more obvious place.\r\n\r\n### Additional context\r\n\r\n<!-- Add any other context or screenshots about the feature request here. -->\r\n\n", "before_files": [{"content": "from typing import Any\n\nimport torch\nfrom torch import Tensor\nfrom torch.nn import Module\nfrom torch.optim.optimizer import Optimizer\nfrom pytorch_lightning.utilities import move_data_to_device\n\n\ntry:\n from apex import amp\nexcept ImportError:\n APEX_AVAILABLE = False\nelse:\n APEX_AVAILABLE = True\n\n\nclass ModelHooks(Module):\n\n def setup(self, stage: str):\n \"\"\"\n Called at the beginning of fit and test.\n This is a good hook when you need to build models dynamically or adjust something about them.\n This hook is called on every process when using DDP.\n\n Args:\n stage: either 'fit' or 'test'\n\n Example::\n\n class LitModel(...):\n def __init__(self):\n self.l1 = None\n\n def prepare_data(self):\n download_data()\n tokenize()\n\n # don't do this\n self.something = else\n\n def setup(step):\n data = Load_data(...)\n self.l1 = nn.Linear(28, data.num_classes)\n\n \"\"\"\n\n def teardown(self, stage: str):\n \"\"\"\n Called at the end of fit and test.\n\n Args:\n stage: either 'fit' or 'test'\n \"\"\"\n\n def on_fit_start(self):\n \"\"\"\n Called at the very beginning of fit.\n If on DDP it is called on every process\n \"\"\"\n\n def on_fit_end(self):\n \"\"\"\n Called at the very end of fit.\n If on DDP it is called on every process\n \"\"\"\n\n # TODO: remove in v0.9.0\n def on_sanity_check_start(self):\n \"\"\"\n Called before starting evaluation.\n\n Warning:\n Deprecated. Will be removed in v0.9.0.\n \"\"\"\n\n def on_train_start(self) -> None:\n \"\"\"\n Called at the beginning of training before sanity check.\n \"\"\"\n # do something at the start of training\n\n def on_train_end(self) -> None:\n \"\"\"\n Called at the end of training before logger experiment is closed.\n \"\"\"\n # do something at the end of training\n\n def on_batch_start(self, batch: Any) -> None:\n \"\"\"\n Called in the training loop before anything happens for that batch.\n\n If you return -1 here, you will skip training for the rest of the current epoch.\n\n Args:\n batch: The batched data as it is returned by the training DataLoader.\n \"\"\"\n # do something when the batch starts\n\n def on_batch_end(self) -> None:\n \"\"\"\n Called in the training loop after the batch.\n \"\"\"\n # do something when the batch ends\n\n def on_epoch_start(self) -> None:\n \"\"\"\n Called in the training loop at the very beginning of the epoch.\n \"\"\"\n # do something when the epoch starts\n\n def on_epoch_end(self) -> None:\n \"\"\"\n Called in the training loop at the very end of the epoch.\n \"\"\"\n # do something when the epoch ends\n\n def on_pre_performance_check(self) -> None:\n \"\"\"\n Called at the very beginning of the validation loop.\n \"\"\"\n # do something before validation starts\n\n def on_post_performance_check(self) -> None:\n \"\"\"\n Called at the very end of the validation loop.\n \"\"\"\n # do something before validation end\n\n def on_before_zero_grad(self, optimizer: Optimizer) -> None:\n \"\"\"\n Called after optimizer.step() and before optimizer.zero_grad().\n\n Called in the training loop after taking an optimizer step and before zeroing grads.\n Good place to inspect weight information with weights updated.\n\n This is where it is called::\n\n for optimizer in optimizers:\n optimizer.step()\n model.on_before_zero_grad(optimizer) # < ---- called here\n optimizer.zero_grad\n\n Args:\n optimizer: The optimizer for which grads should be zeroed.\n \"\"\"\n # do something with the optimizer or inspect it.\n\n def on_after_backward(self) -> None:\n \"\"\"\n Called in the training loop after loss.backward() and before optimizers do anything.\n This is the ideal place to inspect or log gradient information.\n\n Example::\n\n def on_after_backward(self):\n # example to inspect gradient information in tensorboard\n if self.trainer.global_step % 25 == 0: # don't make the tf file huge\n params = self.state_dict()\n for k, v in params.items():\n grads = v\n name = k\n self.logger.experiment.add_histogram(tag=name, values=grads,\n global_step=self.trainer.global_step)\n\n \"\"\"\n\n def backward(self, trainer, loss: Tensor, optimizer: Optimizer, optimizer_idx: int) -> None:\n \"\"\"\n Override backward with your own implementation if you need to.\n\n Args:\n trainer: Pointer to the trainer\n loss: Loss is already scaled by accumulated grads\n optimizer: Current optimizer being used\n optimizer_idx: Index of the current optimizer being used\n\n Called to perform backward step.\n Feel free to override as needed.\n\n The loss passed in has already been scaled for accumulated gradients if requested.\n\n Example::\n\n def backward(self, trainer, loss, optimizer, optimizer_idx):\n loss.backward()\n\n \"\"\"\n loss.backward()\n\n def amp_scale_loss(self, unscaled_loss, optimizer, optimizer_idx):\n if self.trainer.use_native_amp:\n scaled_loss = self.trainer.scaler.scale(unscaled_loss)\n\n else:\n scaled_loss = amp.scale_loss(unscaled_loss, optimizer)\n\n return scaled_loss\n\n def transfer_batch_to_device(self, batch: Any, device: torch.device) -> Any:\n \"\"\"\n Override this hook if your :class:`~torch.utils.data.DataLoader` returns tensors\n wrapped in a custom data structure.\n\n The data types listed below (and any arbitrary nesting of them) are supported out of the box:\n\n - :class:`torch.Tensor`\n - :class:`list`\n - :class:`dict`\n - :class:`tuple`\n - ``torchtext.data.Batch`` (COMING SOON)\n\n For anything else, you need to define how the data is moved to the target device (CPU, GPU, TPU, ...).\n\n Example::\n\n def transfer_batch_to_device(self, batch, device)\n if isinstance(batch, CustomBatch):\n # move all tensors in your custom data structure to the device\n batch.samples = batch.samples.to(device)\n batch.targets = batch.targets.to(device)\n else:\n batch = super().transfer_batch_to_device(data, device)\n return batch\n\n Args:\n batch: A batch of data that needs to be transferred to a new device.\n device: The target device as defined in PyTorch.\n\n Returns:\n A reference to the data on the new device.\n\n Note:\n This hook should only transfer the data and not modify it, nor should it move the data to\n any other device than the one passed in as argument (unless you know what you are doing).\n The :class:`~pytorch_lightning.trainer.trainer.Trainer` already takes care of splitting the\n batch and determines the target devices.\n\n See Also:\n - :func:`~pytorch_lightning.utilities.apply_func.move_data_to_device`\n - :func:`~pytorch_lightning.utilities.apply_func.apply_to_collection`\n \"\"\"\n return move_data_to_device(batch, device)\n", "path": "pytorch_lightning/core/hooks.py"}, {"content": "from collections import Mapping, Sequence\nfrom typing import Any, Callable, Union\n\nimport torch\n\n\ndef apply_to_collection(data: Any, dtype: Union[type, tuple], function: Callable, *args, **kwargs) -> Any:\n \"\"\"\n Recursively applies a function to all elements of a certain dtype.\n\n Args:\n data: the collection to apply the function to\n dtype: the given function will be applied to all elements of this dtype\n function: the function to apply\n *args: positional arguments (will be forwarded to calls of ``function``)\n **kwargs: keyword arguments (will be forwarded to calls of ``function``)\n\n Returns:\n the resulting collection\n\n \"\"\"\n elem_type = type(data)\n\n # Breaking condition\n if isinstance(data, dtype):\n return function(data, *args, **kwargs)\n\n # Recursively apply to collection items\n elif isinstance(data, Mapping):\n return elem_type({k: apply_to_collection(v, dtype, function, *args, **kwargs)\n for k, v in data.items()})\n elif isinstance(data, tuple) and hasattr(data, '_fields'): # named tuple\n return elem_type(*(apply_to_collection(d, dtype, function, *args, **kwargs) for d in data))\n elif isinstance(data, Sequence) and not isinstance(data, str):\n return elem_type([apply_to_collection(d, dtype, function, *args, **kwargs) for d in data])\n\n # data is neither of dtype, nor a collection\n return data\n\n\ndef move_data_to_device(batch: Any, device: torch.device):\n \"\"\"\n Transfers a collection of tensors to the given device.\n\n Args:\n batch: A tensor or collection of tensors. See :func:`apply_to_collection`\n for a list of supported collection types.\n device: The device to which tensors should be moved\n\n Return:\n the same collection but with all contained tensors residing on the new device.\n\n See Also:\n - :meth:`torch.Tensor.to`\n - :class:`torch.device`\n \"\"\"\n def to(tensor):\n return tensor.to(device, non_blocking=True)\n return apply_to_collection(batch, dtype=torch.Tensor, function=to)\n", "path": "pytorch_lightning/utilities/apply_func.py"}]}
| 3,818 | 716 |
gh_patches_debug_58217
|
rasdani/github-patches
|
git_diff
|
opsdroid__opsdroid-25
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Skill setup should be optional
You might not want to have a setup function in your skill.
</issue>
<code>
[start of opsdroid/loader.py]
1 """Class for loading in modules to OpsDroid."""
2
3 import logging
4 import os
5 import shutil
6 import subprocess
7 import importlib
8 import yaml
9 from opsdroid.const import (
10 DEFAULT_GIT_URL, MODULES_DIRECTORY, DEFAULT_MODULE_BRANCH)
11
12
13 def import_module(config):
14 """Import module namespace as variable and return it."""
15 try:
16 module = importlib.import_module(
17 config["path"] + "." + config["name"])
18 logging.debug("Loading " + config["type"] + ": " + config["name"])
19 return module
20 except ImportError as error:
21 logging.error("Failed to load " + config["type"] +
22 " " + config["name"])
23 logging.error(error)
24 return None
25
26
27 def check_cache(config):
28 """Remove module if 'no-cache' set in config."""
29 if "no-cache" in config \
30 and config["no-cache"] \
31 and os.path.isdir(config["install_path"]):
32 logging.debug("'no-cache' set, removing " + config["install_path"])
33 shutil.rmtree(config["install_path"])
34
35
36 def build_module_path(path_type, config):
37 """Generate the module path from name and type."""
38 if path_type == "import":
39 return MODULES_DIRECTORY + "." + config["type"] + "." + config["name"]
40 elif path_type == "install":
41 return MODULES_DIRECTORY + "/" + config["type"] + "/" + config["name"]
42
43
44 def git_clone(git_url, install_path, branch):
45 """Clone a git repo to a location and wait for finish."""
46 process = subprocess.Popen(["git", "clone", "-b", branch,
47 git_url, install_path], shell=False,
48 stdout=subprocess.PIPE,
49 stderr=subprocess.PIPE)
50 process.wait()
51
52
53 def pip_install_deps(requirements_path):
54 """Pip install a requirements.txt file and wait for finish."""
55 process = subprocess.Popen(["pip", "install", "-r", requirements_path],
56 shell=False,
57 stdout=subprocess.PIPE,
58 stderr=subprocess.PIPE)
59 for output in process.communicate():
60 if output != "":
61 for line in output.splitlines():
62 logging.debug(str(line).strip())
63 process.wait()
64
65
66 class Loader:
67 """Class to load in config and modules."""
68
69 def __init__(self, opsdroid):
70 """Setup object with opsdroid instance."""
71 self.opsdroid = opsdroid
72 logging.debug("Loaded loader")
73
74 def load_config_file(self, config_paths):
75 """Load a yaml config file from path."""
76 config_path = ""
77 for possible_path in config_paths:
78 if not os.path.isfile(possible_path):
79 logging.warning("Config file " + possible_path +
80 " not found", 1)
81 else:
82 config_path = possible_path
83 break
84
85 if not config_path:
86 self.opsdroid.critical("No configuration files found", 1)
87
88 try:
89 with open(config_path, 'r') as stream:
90 return yaml.load(stream)
91 except yaml.YAMLError as error:
92 self.opsdroid.critical(error, 1)
93 except FileNotFoundError as error:
94 self.opsdroid.critical(str(error), 1)
95
96 def load_config(self, config):
97 """Load all module types based on config."""
98 logging.debug("Loading modules from config")
99
100 if 'databases' in config.keys():
101 self.opsdroid.start_databases(
102 self._load_modules('database', config['databases']))
103 else:
104 logging.warning("No databases in configuration")
105
106 if 'skills' in config.keys():
107 self._setup_modules(
108 self._load_modules('skill', config['skills'])
109 )
110 else:
111 self.opsdroid.critical(
112 "No skills in configuration, at least 1 required", 1)
113
114 if 'connectors' in config.keys():
115 self.opsdroid.start_connectors(
116 self._load_modules('connector', config['connectors']))
117 else:
118 self.opsdroid.critical(
119 "No connectors in configuration, at least 1 required", 1)
120
121 def _load_modules(self, modules_type, modules):
122 """Install and load modules."""
123 logging.debug("Loading " + modules_type + " modules")
124 loaded_modules = []
125
126 # Create modules directory if doesn't exist
127 if not os.path.isdir(MODULES_DIRECTORY):
128 os.makedirs(MODULES_DIRECTORY)
129
130 for module_name in modules.keys():
131
132 # Set up module config
133 config = modules[module_name]
134 config = {} if config is None else config
135 config["name"] = module_name
136 config["type"] = modules_type
137 config["path"] = build_module_path("import", config)
138 config["install_path"] = build_module_path("install", config)
139 if "branch" not in config:
140 config["branch"] = DEFAULT_MODULE_BRANCH
141
142 # Remove module for reinstall if no-cache set
143 check_cache(config)
144
145 # Install module
146 self._install_module(config)
147
148 # Import module
149 module = import_module(config)
150 if module is not None:
151 loaded_modules.append({
152 "module": module,
153 "config": config})
154
155 return loaded_modules
156
157 def _setup_modules(self, modules):
158 """Call the setup function on the passed in modules."""
159 for module in modules:
160 module["module"].setup(self.opsdroid)
161
162 def _install_module(self, config):
163 # pylint: disable=R0201
164 """Install a module."""
165 logging.debug("Installing " + config["name"])
166
167 if os.path.isdir(config["install_path"]):
168 # TODO Allow for updating or reinstalling of modules
169 logging.debug("Module " + config["name"] +
170 " already installed, skipping")
171 else:
172 if config is not None and "repo" in config:
173 git_url = config["repo"]
174 else:
175 git_url = DEFAULT_GIT_URL + config["type"] + \
176 "-" + config["name"] + ".git"
177
178 if any(prefix in git_url for prefix in ["http", "https", "ssh"]):
179 # TODO Test if url or ssh path exists
180 # TODO Handle github authentication
181 git_clone(git_url, config["install_path"], config["branch"])
182 else:
183 if os.path.isdir(git_url):
184 git_clone(git_url, config["install_path"],
185 config["branch"])
186 else:
187 logging.debug("Could not find local git repo " + git_url)
188
189 if os.path.isdir(config["install_path"]):
190 logging.debug("Installed " + config["name"] +
191 " to " + config["install_path"])
192 else:
193 logging.debug("Install of " + config["name"] + " failed ")
194
195 # Install module dependancies
196 if os.path.isfile(config["install_path"] + "/requirements.txt"):
197 pip_install_deps(config["install_path"] + "/requirements.txt")
198
[end of opsdroid/loader.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/opsdroid/loader.py b/opsdroid/loader.py
--- a/opsdroid/loader.py
+++ b/opsdroid/loader.py
@@ -157,7 +157,10 @@
def _setup_modules(self, modules):
"""Call the setup function on the passed in modules."""
for module in modules:
- module["module"].setup(self.opsdroid)
+ try:
+ module["module"].setup(self.opsdroid)
+ except AttributeError:
+ pass
def _install_module(self, config):
# pylint: disable=R0201
|
{"golden_diff": "diff --git a/opsdroid/loader.py b/opsdroid/loader.py\n--- a/opsdroid/loader.py\n+++ b/opsdroid/loader.py\n@@ -157,7 +157,10 @@\n def _setup_modules(self, modules):\n \"\"\"Call the setup function on the passed in modules.\"\"\"\n for module in modules:\n- module[\"module\"].setup(self.opsdroid)\n+ try:\n+ module[\"module\"].setup(self.opsdroid)\n+ except AttributeError:\n+ pass\n \n def _install_module(self, config):\n # pylint: disable=R0201\n", "issue": "Skill setup should be optional\nYou might not want to have a setup function in your skill. \n\n", "before_files": [{"content": "\"\"\"Class for loading in modules to OpsDroid.\"\"\"\n\nimport logging\nimport os\nimport shutil\nimport subprocess\nimport importlib\nimport yaml\nfrom opsdroid.const import (\n DEFAULT_GIT_URL, MODULES_DIRECTORY, DEFAULT_MODULE_BRANCH)\n\n\ndef import_module(config):\n \"\"\"Import module namespace as variable and return it.\"\"\"\n try:\n module = importlib.import_module(\n config[\"path\"] + \".\" + config[\"name\"])\n logging.debug(\"Loading \" + config[\"type\"] + \": \" + config[\"name\"])\n return module\n except ImportError as error:\n logging.error(\"Failed to load \" + config[\"type\"] +\n \" \" + config[\"name\"])\n logging.error(error)\n return None\n\n\ndef check_cache(config):\n \"\"\"Remove module if 'no-cache' set in config.\"\"\"\n if \"no-cache\" in config \\\n and config[\"no-cache\"] \\\n and os.path.isdir(config[\"install_path\"]):\n logging.debug(\"'no-cache' set, removing \" + config[\"install_path\"])\n shutil.rmtree(config[\"install_path\"])\n\n\ndef build_module_path(path_type, config):\n \"\"\"Generate the module path from name and type.\"\"\"\n if path_type == \"import\":\n return MODULES_DIRECTORY + \".\" + config[\"type\"] + \".\" + config[\"name\"]\n elif path_type == \"install\":\n return MODULES_DIRECTORY + \"/\" + config[\"type\"] + \"/\" + config[\"name\"]\n\n\ndef git_clone(git_url, install_path, branch):\n \"\"\"Clone a git repo to a location and wait for finish.\"\"\"\n process = subprocess.Popen([\"git\", \"clone\", \"-b\", branch,\n git_url, install_path], shell=False,\n stdout=subprocess.PIPE,\n stderr=subprocess.PIPE)\n process.wait()\n\n\ndef pip_install_deps(requirements_path):\n \"\"\"Pip install a requirements.txt file and wait for finish.\"\"\"\n process = subprocess.Popen([\"pip\", \"install\", \"-r\", requirements_path],\n shell=False,\n stdout=subprocess.PIPE,\n stderr=subprocess.PIPE)\n for output in process.communicate():\n if output != \"\":\n for line in output.splitlines():\n logging.debug(str(line).strip())\n process.wait()\n\n\nclass Loader:\n \"\"\"Class to load in config and modules.\"\"\"\n\n def __init__(self, opsdroid):\n \"\"\"Setup object with opsdroid instance.\"\"\"\n self.opsdroid = opsdroid\n logging.debug(\"Loaded loader\")\n\n def load_config_file(self, config_paths):\n \"\"\"Load a yaml config file from path.\"\"\"\n config_path = \"\"\n for possible_path in config_paths:\n if not os.path.isfile(possible_path):\n logging.warning(\"Config file \" + possible_path +\n \" not found\", 1)\n else:\n config_path = possible_path\n break\n\n if not config_path:\n self.opsdroid.critical(\"No configuration files found\", 1)\n\n try:\n with open(config_path, 'r') as stream:\n return yaml.load(stream)\n except yaml.YAMLError as error:\n self.opsdroid.critical(error, 1)\n except FileNotFoundError as error:\n self.opsdroid.critical(str(error), 1)\n\n def load_config(self, config):\n \"\"\"Load all module types based on config.\"\"\"\n logging.debug(\"Loading modules from config\")\n\n if 'databases' in config.keys():\n self.opsdroid.start_databases(\n self._load_modules('database', config['databases']))\n else:\n logging.warning(\"No databases in configuration\")\n\n if 'skills' in config.keys():\n self._setup_modules(\n self._load_modules('skill', config['skills'])\n )\n else:\n self.opsdroid.critical(\n \"No skills in configuration, at least 1 required\", 1)\n\n if 'connectors' in config.keys():\n self.opsdroid.start_connectors(\n self._load_modules('connector', config['connectors']))\n else:\n self.opsdroid.critical(\n \"No connectors in configuration, at least 1 required\", 1)\n\n def _load_modules(self, modules_type, modules):\n \"\"\"Install and load modules.\"\"\"\n logging.debug(\"Loading \" + modules_type + \" modules\")\n loaded_modules = []\n\n # Create modules directory if doesn't exist\n if not os.path.isdir(MODULES_DIRECTORY):\n os.makedirs(MODULES_DIRECTORY)\n\n for module_name in modules.keys():\n\n # Set up module config\n config = modules[module_name]\n config = {} if config is None else config\n config[\"name\"] = module_name\n config[\"type\"] = modules_type\n config[\"path\"] = build_module_path(\"import\", config)\n config[\"install_path\"] = build_module_path(\"install\", config)\n if \"branch\" not in config:\n config[\"branch\"] = DEFAULT_MODULE_BRANCH\n\n # Remove module for reinstall if no-cache set\n check_cache(config)\n\n # Install module\n self._install_module(config)\n\n # Import module\n module = import_module(config)\n if module is not None:\n loaded_modules.append({\n \"module\": module,\n \"config\": config})\n\n return loaded_modules\n\n def _setup_modules(self, modules):\n \"\"\"Call the setup function on the passed in modules.\"\"\"\n for module in modules:\n module[\"module\"].setup(self.opsdroid)\n\n def _install_module(self, config):\n # pylint: disable=R0201\n \"\"\"Install a module.\"\"\"\n logging.debug(\"Installing \" + config[\"name\"])\n\n if os.path.isdir(config[\"install_path\"]):\n # TODO Allow for updating or reinstalling of modules\n logging.debug(\"Module \" + config[\"name\"] +\n \" already installed, skipping\")\n else:\n if config is not None and \"repo\" in config:\n git_url = config[\"repo\"]\n else:\n git_url = DEFAULT_GIT_URL + config[\"type\"] + \\\n \"-\" + config[\"name\"] + \".git\"\n\n if any(prefix in git_url for prefix in [\"http\", \"https\", \"ssh\"]):\n # TODO Test if url or ssh path exists\n # TODO Handle github authentication\n git_clone(git_url, config[\"install_path\"], config[\"branch\"])\n else:\n if os.path.isdir(git_url):\n git_clone(git_url, config[\"install_path\"],\n config[\"branch\"])\n else:\n logging.debug(\"Could not find local git repo \" + git_url)\n\n if os.path.isdir(config[\"install_path\"]):\n logging.debug(\"Installed \" + config[\"name\"] +\n \" to \" + config[\"install_path\"])\n else:\n logging.debug(\"Install of \" + config[\"name\"] + \" failed \")\n\n # Install module dependancies\n if os.path.isfile(config[\"install_path\"] + \"/requirements.txt\"):\n pip_install_deps(config[\"install_path\"] + \"/requirements.txt\")\n", "path": "opsdroid/loader.py"}]}
| 2,512 | 135 |
gh_patches_debug_34161
|
rasdani/github-patches
|
git_diff
|
ytdl-org__youtube-dl-3042
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
youtube-dl bug due to new ARD layout
youtube-dl --verbose http://www.ardmediathek.de/tv/14-Tageb%C3%BCcher-des-Ersten-Weltkriegs/Folge-4-Die-Entscheidung/Das-Erste/Video?documentId=21568646&bcastId=20282330
[1] 7470
[x@yhost ~]$ [debug] System config: []
[debug] User config: []
[debug] Command-line args: ['--verbose', 'http://www.ardmediathek.de/tv/14-Tageb%C3%BCcher-des-Ersten-Weltkriegs/Folge-4-Die-Entscheidung/Das-Erste/Video?documentId=21568646']
[debug] Encodings: locale UTF-8, fs utf-8, out UTF-8, pref UTF-8
[debug] youtube-dl version 2014.05.19
[debug] Python version 3.4.1 - Linux-3.14.4xxxxxx
[debug] Proxy map: {}
[ARD] 21568646: Downloading webpage
ERROR: Unable to extract title; please report this issue on https://yt-dl.org/bug . Be sure to call youtube-dl with the --verbose flag and include its complete output. Make sure you are using the latest version; type youtube-dl -U to update.
Traceback (most recent call last):
File "/usr/lib/python3.4/site-packages/youtube_dl/YoutubeDL.py", line 516, in extract_info
ie_result = ie.extract(url)
File "/usr/lib/python3.4/site-packages/youtube_dl/extractor/common.py", line 163, in extract
return self._real_extract(url)
File "/usr/lib/python3.4/site-packages/youtube_dl/extractor/ard.py", line 41, in _real_extract
r'<h1(?:\s+class="boxTopHeadline")?>(.*?)</h1>', webpage, 'title')
File "/usr/lib/python3.4/site-packages/youtube_dl/extractor/common.py", line 389, in _html_search_regex
res = self._search_regex(pattern, string, name, default, fatal, flags)
File "/usr/lib/python3.4/site-packages/youtube_dl/extractor/common.py", line 379, in _search_regex
raise RegexNotFoundError(u'Unable to extract %s' % _name)
youtube_dl.utils.RegexNotFoundError: Unable to extract title; please report this issue on https://yt-dl.org/bug . Be sure to call youtube-dl with the --verbose flag and include its complete output. Make sure you are using the latest version; type youtube-dl -U to update.
[1]+ Exit 1 youtube-dl --verbose http://www.ardmediathek.de/tv/14-Tageb%C3%BCcher-des-Ersten-Weltkriegs/Folge-4-Die-Entscheidung/Das-Erste/Video?documentId=21568646
</issue>
<code>
[start of youtube_dl/extractor/ard.py]
1 # coding: utf-8
2 from __future__ import unicode_literals
3
4 import re
5
6 from .common import InfoExtractor
7 from ..utils import (
8 determine_ext,
9 ExtractorError,
10 )
11
12
13 class ARDIE(InfoExtractor):
14 _VALID_URL = r'^https?://(?:(?:www\.)?ardmediathek\.de|mediathek\.daserste\.de)/(?:.*/)(?P<video_id>[^/\?]+)(?:\?.*)?'
15
16 _TEST = {
17 'url': 'http://www.ardmediathek.de/das-erste/guenther-jauch/edward-snowden-im-interview-held-oder-verraeter?documentId=19288786',
18 'file': '19288786.mp4',
19 'md5': '515bf47ce209fb3f5a61b7aad364634c',
20 'info_dict': {
21 'title': 'Edward Snowden im Interview - Held oder Verräter?',
22 'description': 'Edward Snowden hat alles aufs Spiel gesetzt, um die weltweite \xdcberwachung durch die Geheimdienste zu enttarnen. Nun stellt sich der ehemalige NSA-Mitarbeiter erstmals weltweit in einem TV-Interview den Fragen eines NDR-Journalisten. Die Sendung vom Sonntagabend.',
23 'thumbnail': 'http://www.ardmediathek.de/ard/servlet/contentblob/19/28/87/90/19288790/bild/2250037',
24 },
25 'skip': 'Blocked outside of Germany',
26 }
27
28 def _real_extract(self, url):
29 # determine video id from url
30 m = re.match(self._VALID_URL, url)
31
32 numid = re.search(r'documentId=([0-9]+)', url)
33 if numid:
34 video_id = numid.group(1)
35 else:
36 video_id = m.group('video_id')
37
38 webpage = self._download_webpage(url, video_id)
39
40 title = self._html_search_regex(
41 [r'<h1(?:\s+class="boxTopHeadline")?>(.*?)</h1>',
42 r'<h4 class="headline">(.*?)</h4>'],
43 webpage, 'title')
44 description = self._html_search_meta(
45 'dcterms.abstract', webpage, 'description')
46 thumbnail = self._og_search_thumbnail(webpage)
47
48 streams = [
49 mo.groupdict()
50 for mo in re.finditer(
51 r'mediaCollection\.addMediaStream\((?P<media_type>\d+), (?P<quality>\d+), "(?P<rtmp_url>[^"]*)", "(?P<video_url>[^"]*)", "[^"]*"\)', webpage)]
52 if not streams:
53 if '"fsk"' in webpage:
54 raise ExtractorError('This video is only available after 20:00')
55
56 formats = []
57 for s in streams:
58 format = {
59 'quality': int(s['quality']),
60 }
61 if s.get('rtmp_url'):
62 format['protocol'] = 'rtmp'
63 format['url'] = s['rtmp_url']
64 format['playpath'] = s['video_url']
65 else:
66 format['url'] = s['video_url']
67
68 quality_name = self._search_regex(
69 r'[,.]([a-zA-Z0-9_-]+),?\.mp4', format['url'],
70 'quality name', default='NA')
71 format['format_id'] = '%s-%s-%s-%s' % (
72 determine_ext(format['url']), quality_name, s['media_type'],
73 s['quality'])
74
75 formats.append(format)
76
77 self._sort_formats(formats)
78
79 return {
80 'id': video_id,
81 'title': title,
82 'description': description,
83 'formats': formats,
84 'thumbnail': thumbnail,
85 }
86
[end of youtube_dl/extractor/ard.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/youtube_dl/extractor/ard.py b/youtube_dl/extractor/ard.py
--- a/youtube_dl/extractor/ard.py
+++ b/youtube_dl/extractor/ard.py
@@ -39,16 +39,18 @@
title = self._html_search_regex(
[r'<h1(?:\s+class="boxTopHeadline")?>(.*?)</h1>',
+ r'<meta name="dcterms.title" content="(.*?)"/>',
r'<h4 class="headline">(.*?)</h4>'],
webpage, 'title')
description = self._html_search_meta(
'dcterms.abstract', webpage, 'description')
thumbnail = self._og_search_thumbnail(webpage)
- streams = [
- mo.groupdict()
- for mo in re.finditer(
- r'mediaCollection\.addMediaStream\((?P<media_type>\d+), (?P<quality>\d+), "(?P<rtmp_url>[^"]*)", "(?P<video_url>[^"]*)", "[^"]*"\)', webpage)]
+
+ media_info = self._download_json(
+ 'http://www.ardmediathek.de/play/media/%s' % video_id, video_id)
+ # The second element of the _mediaArray contains the standard http urls
+ streams = media_info['_mediaArray'][1]['_mediaStreamArray']
if not streams:
if '"fsk"' in webpage:
raise ExtractorError('This video is only available after 20:00')
@@ -56,21 +58,12 @@
formats = []
for s in streams:
format = {
- 'quality': int(s['quality']),
+ 'quality': s['_quality'],
+ 'url': s['_stream'],
}
- if s.get('rtmp_url'):
- format['protocol'] = 'rtmp'
- format['url'] = s['rtmp_url']
- format['playpath'] = s['video_url']
- else:
- format['url'] = s['video_url']
-
- quality_name = self._search_regex(
- r'[,.]([a-zA-Z0-9_-]+),?\.mp4', format['url'],
- 'quality name', default='NA')
- format['format_id'] = '%s-%s-%s-%s' % (
- determine_ext(format['url']), quality_name, s['media_type'],
- s['quality'])
+
+ format['format_id'] = '%s-%s' % (
+ determine_ext(format['url']), format['quality'])
formats.append(format)
|
{"golden_diff": "diff --git a/youtube_dl/extractor/ard.py b/youtube_dl/extractor/ard.py\n--- a/youtube_dl/extractor/ard.py\n+++ b/youtube_dl/extractor/ard.py\n@@ -39,16 +39,18 @@\n \n title = self._html_search_regex(\n [r'<h1(?:\\s+class=\"boxTopHeadline\")?>(.*?)</h1>',\n+ r'<meta name=\"dcterms.title\" content=\"(.*?)\"/>',\n r'<h4 class=\"headline\">(.*?)</h4>'],\n webpage, 'title')\n description = self._html_search_meta(\n 'dcterms.abstract', webpage, 'description')\n thumbnail = self._og_search_thumbnail(webpage)\n \n- streams = [\n- mo.groupdict()\n- for mo in re.finditer(\n- r'mediaCollection\\.addMediaStream\\((?P<media_type>\\d+), (?P<quality>\\d+), \"(?P<rtmp_url>[^\"]*)\", \"(?P<video_url>[^\"]*)\", \"[^\"]*\"\\)', webpage)]\n+\n+ media_info = self._download_json(\n+ 'http://www.ardmediathek.de/play/media/%s' % video_id, video_id)\n+ # The second element of the _mediaArray contains the standard http urls\n+ streams = media_info['_mediaArray'][1]['_mediaStreamArray']\n if not streams:\n if '\"fsk\"' in webpage:\n raise ExtractorError('This video is only available after 20:00')\n@@ -56,21 +58,12 @@\n formats = []\n for s in streams:\n format = {\n- 'quality': int(s['quality']),\n+ 'quality': s['_quality'],\n+ 'url': s['_stream'],\n }\n- if s.get('rtmp_url'):\n- format['protocol'] = 'rtmp'\n- format['url'] = s['rtmp_url']\n- format['playpath'] = s['video_url']\n- else:\n- format['url'] = s['video_url']\n-\n- quality_name = self._search_regex(\n- r'[,.]([a-zA-Z0-9_-]+),?\\.mp4', format['url'],\n- 'quality name', default='NA')\n- format['format_id'] = '%s-%s-%s-%s' % (\n- determine_ext(format['url']), quality_name, s['media_type'],\n- s['quality'])\n+\n+ format['format_id'] = '%s-%s' % (\n+ determine_ext(format['url']), format['quality'])\n \n formats.append(format)\n", "issue": "youtube-dl bug due to new ARD layout\n youtube-dl --verbose http://www.ardmediathek.de/tv/14-Tageb%C3%BCcher-des-Ersten-Weltkriegs/Folge-4-Die-Entscheidung/Das-Erste/Video?documentId=21568646&bcastId=20282330\n[1] 7470\n[x@yhost ~]$ [debug] System config: []\n[debug] User config: []\n[debug] Command-line args: ['--verbose', 'http://www.ardmediathek.de/tv/14-Tageb%C3%BCcher-des-Ersten-Weltkriegs/Folge-4-Die-Entscheidung/Das-Erste/Video?documentId=21568646']\n[debug] Encodings: locale UTF-8, fs utf-8, out UTF-8, pref UTF-8\n[debug] youtube-dl version 2014.05.19\n[debug] Python version 3.4.1 - Linux-3.14.4xxxxxx\n[debug] Proxy map: {}\n[ARD] 21568646: Downloading webpage\nERROR: Unable to extract title; please report this issue on https://yt-dl.org/bug . Be sure to call youtube-dl with the --verbose flag and include its complete output. Make sure you are using the latest version; type youtube-dl -U to update.\nTraceback (most recent call last):\n File \"/usr/lib/python3.4/site-packages/youtube_dl/YoutubeDL.py\", line 516, in extract_info\n ie_result = ie.extract(url)\n File \"/usr/lib/python3.4/site-packages/youtube_dl/extractor/common.py\", line 163, in extract\n return self._real_extract(url)\n File \"/usr/lib/python3.4/site-packages/youtube_dl/extractor/ard.py\", line 41, in _real_extract\n r'<h1(?:\\s+class=\"boxTopHeadline\")?>(.*?)</h1>', webpage, 'title')\n File \"/usr/lib/python3.4/site-packages/youtube_dl/extractor/common.py\", line 389, in _html_search_regex\n res = self._search_regex(pattern, string, name, default, fatal, flags)\n File \"/usr/lib/python3.4/site-packages/youtube_dl/extractor/common.py\", line 379, in _search_regex\n raise RegexNotFoundError(u'Unable to extract %s' % _name)\nyoutube_dl.utils.RegexNotFoundError: Unable to extract title; please report this issue on https://yt-dl.org/bug . Be sure to call youtube-dl with the --verbose flag and include its complete output. Make sure you are using the latest version; type youtube-dl -U to update.\n\n[1]+ Exit 1 youtube-dl --verbose http://www.ardmediathek.de/tv/14-Tageb%C3%BCcher-des-Ersten-Weltkriegs/Folge-4-Die-Entscheidung/Das-Erste/Video?documentId=21568646\n\n", "before_files": [{"content": "# coding: utf-8\nfrom __future__ import unicode_literals\n\nimport re\n\nfrom .common import InfoExtractor\nfrom ..utils import (\n determine_ext,\n ExtractorError,\n)\n\n\nclass ARDIE(InfoExtractor):\n _VALID_URL = r'^https?://(?:(?:www\\.)?ardmediathek\\.de|mediathek\\.daserste\\.de)/(?:.*/)(?P<video_id>[^/\\?]+)(?:\\?.*)?'\n\n _TEST = {\n 'url': 'http://www.ardmediathek.de/das-erste/guenther-jauch/edward-snowden-im-interview-held-oder-verraeter?documentId=19288786',\n 'file': '19288786.mp4',\n 'md5': '515bf47ce209fb3f5a61b7aad364634c',\n 'info_dict': {\n 'title': 'Edward Snowden im Interview - Held oder Verr\u00e4ter?',\n 'description': 'Edward Snowden hat alles aufs Spiel gesetzt, um die weltweite \\xdcberwachung durch die Geheimdienste zu enttarnen. Nun stellt sich der ehemalige NSA-Mitarbeiter erstmals weltweit in einem TV-Interview den Fragen eines NDR-Journalisten. Die Sendung vom Sonntagabend.',\n 'thumbnail': 'http://www.ardmediathek.de/ard/servlet/contentblob/19/28/87/90/19288790/bild/2250037',\n },\n 'skip': 'Blocked outside of Germany',\n }\n\n def _real_extract(self, url):\n # determine video id from url\n m = re.match(self._VALID_URL, url)\n\n numid = re.search(r'documentId=([0-9]+)', url)\n if numid:\n video_id = numid.group(1)\n else:\n video_id = m.group('video_id')\n\n webpage = self._download_webpage(url, video_id)\n\n title = self._html_search_regex(\n [r'<h1(?:\\s+class=\"boxTopHeadline\")?>(.*?)</h1>',\n r'<h4 class=\"headline\">(.*?)</h4>'],\n webpage, 'title')\n description = self._html_search_meta(\n 'dcterms.abstract', webpage, 'description')\n thumbnail = self._og_search_thumbnail(webpage)\n\n streams = [\n mo.groupdict()\n for mo in re.finditer(\n r'mediaCollection\\.addMediaStream\\((?P<media_type>\\d+), (?P<quality>\\d+), \"(?P<rtmp_url>[^\"]*)\", \"(?P<video_url>[^\"]*)\", \"[^\"]*\"\\)', webpage)]\n if not streams:\n if '\"fsk\"' in webpage:\n raise ExtractorError('This video is only available after 20:00')\n\n formats = []\n for s in streams:\n format = {\n 'quality': int(s['quality']),\n }\n if s.get('rtmp_url'):\n format['protocol'] = 'rtmp'\n format['url'] = s['rtmp_url']\n format['playpath'] = s['video_url']\n else:\n format['url'] = s['video_url']\n\n quality_name = self._search_regex(\n r'[,.]([a-zA-Z0-9_-]+),?\\.mp4', format['url'],\n 'quality name', default='NA')\n format['format_id'] = '%s-%s-%s-%s' % (\n determine_ext(format['url']), quality_name, s['media_type'],\n s['quality'])\n\n formats.append(format)\n\n self._sort_formats(formats)\n\n return {\n 'id': video_id,\n 'title': title,\n 'description': description,\n 'formats': formats,\n 'thumbnail': thumbnail,\n }\n", "path": "youtube_dl/extractor/ard.py"}]}
| 2,318 | 591 |
gh_patches_debug_4976
|
rasdani/github-patches
|
git_diff
|
instadeepai__Mava-627
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[TEST] Jax System Core Parameter Client
### What do you want to test?
Jax system core parameter client (in `mava/systems/jax/`)
### Outline of test structure
* Unit tests
* Test components and hooks
### Definition of done
Passing checks, cover all hooks, edge cases considered
### Mandatory checklist before making a PR
* [ ] The success criteria laid down in “Definition of done” are met.
* [ ] Test code is documented - docstrings for methods and classes, static types for arguments.
* [ ] Documentation is updated - README, CONTRIBUTING, or other documentation.
</issue>
<code>
[start of mava/systems/jax/parameter_client.py]
1 # python3
2 # Copyright 2021 InstaDeep Ltd. All rights reserved.
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15
16 """Parameter client for Jax system. Adapted from Deepmind's Acme library"""
17
18 from concurrent import futures
19 from typing import Any, Dict, List, Optional, Union
20
21 import jax
22 import numpy as np
23
24 from mava.systems.jax.parameter_server import ParameterServer
25 from mava.utils.sort_utils import sort_str_num
26
27
28 class ParameterClient:
29 """A parameter client for updating parameters from a remote server."""
30
31 def __init__(
32 self,
33 client: ParameterServer,
34 parameters: Dict[str, Any],
35 get_keys: List[str] = None,
36 set_keys: List[str] = None,
37 update_period: int = 1,
38 devices: Dict[str, Optional[Union[str, jax.xla.Device]]] = {},
39 ):
40 """Initialise the parameter server."""
41 self._all_keys = sort_str_num(list(parameters.keys()))
42 # TODO (dries): Is the below change correct?
43 self._get_keys = get_keys if get_keys is not None else []
44 self._set_keys = set_keys if set_keys is not None else []
45 self._parameters: Dict[str, Any] = parameters
46 self._get_call_counter = 0
47 self._set_call_counter = 0
48 self._set_get_call_counter = 0
49 self._update_period = update_period
50 self._client = client
51 self._devices = devices
52
53 # note below it is assumed that if one device is specified with a string
54 # they all are - need to test this works
55 # TODO: (Dries/Arnu): check this
56 if len(self._devices) and isinstance(list(self._devices.values())[0], str):
57 for key, device in self._devices.items():
58 self._devices[key] = jax.devices(device)[0] # type: ignore
59
60 self._request = lambda: client.get_parameters(self._get_keys)
61 self._request_all = lambda: client.get_parameters(self._all_keys)
62
63 self._adjust = lambda: client.set_parameters(
64 {key: self._parameters[key] for key in self._set_keys},
65 )
66
67 self._add = lambda params: client.add_to_parameters(params)
68
69 # Create a single background thread to fetch parameters without necessarily
70 # blocking the actor.
71 self._executor = futures.ThreadPoolExecutor(max_workers=1)
72 self._async_add_buffer: Dict[str, Any] = {}
73 self._async_request = lambda: self._executor.submit(self._request)
74 self._async_adjust = lambda: self._executor.submit(self._adjust)
75 self._async_adjust_and_request = lambda: self._executor.submit(
76 self._adjust_and_request
77 )
78 self._async_add: Any = lambda params: self._executor.submit(
79 self._add(params) # type: ignore
80 )
81
82 # Initialize this client's future to None to indicate to the `update()`
83 # method that there is no pending/running request.
84 self._get_future: Optional[futures.Future] = None
85 self._set_future: Optional[futures.Future] = None
86 self._set_get_future: Optional[futures.Future] = None
87 self._add_future: Optional[futures.Future] = None
88
89 def _adjust_and_request(self) -> None:
90 self._client.set_parameters(
91 {key: self._parameters[key] for key in self._set_keys},
92 )
93 self._copy(self._client.get_parameters(self._get_keys))
94
95 def get_async(self) -> None:
96 """Asynchronously updates the parameters with the latest copy from server."""
97
98 # Track the number of calls (we only update periodically).
99 if self._get_call_counter < self._update_period:
100 self._get_call_counter += 1
101
102 period_reached: bool = self._get_call_counter >= self._update_period
103 if period_reached and self._get_future is None:
104 # The update period has been reached and no request has been sent yet, so
105 # making an asynchronous request now.
106 self._get_future = self._async_request()
107 self._get_call_counter = 0
108
109 if self._get_future is not None and self._get_future.done():
110 # The active request is done so copy the result and remove the future.\
111 self._copy(self._get_future.result())
112 self._get_future = None
113
114 def set_async(self) -> None:
115 """Asynchronously updates server with the set parameters."""
116 # Track the number of calls (we only update periodically).
117 if self._set_call_counter < self._update_period:
118 self._set_call_counter += 1
119
120 period_reached: bool = self._set_call_counter >= self._update_period
121
122 if period_reached and self._set_future is None:
123 # The update period has been reached and no request has been sent yet, so
124 # making an asynchronous request now.
125 self._set_future = self._async_adjust()
126 self._set_call_counter = 0
127 return
128 if self._set_future is not None and self._set_future.done():
129 self._set_future = None
130
131 def set_and_get_async(self) -> None:
132 """Asynchronously updates server and gets from server."""
133 # Track the number of calls (we only update periodically).
134 if self._set_get_call_counter < self._update_period:
135 self._set_get_call_counter += 1
136 period_reached: bool = self._set_get_call_counter >= self._update_period
137
138 if period_reached and self._set_get_future is None:
139 # The update period has been reached and no request has been sent yet, so
140 # making an asynchronous request now.
141 self._set_get_future = self._async_adjust_and_request()
142 self._set_get_call_counter = 0
143 return
144 if self._set_get_future is not None and self._set_get_future.done():
145 self._set_get_future = None
146
147 def add_async(self, params: Dict[str, Any]) -> None:
148 """Asynchronously adds to server parameters."""
149 if self._add_future is not None and self._add_future.done():
150 self._add_future = None
151
152 names = params.keys()
153 if self._add_future is None:
154 # The update period has been reached and no request has been sent yet, so
155 # making an asynchronous request now.
156 if not self._async_add_buffer:
157 self._add_future = self._async_add(params)
158 else:
159 for name in names:
160 self._async_add_buffer[name] += params[name]
161
162 self._add_future = self._async_add(self._async_add_buffer)
163 self._async_add_buffer = {}
164 return
165 else:
166 # The trainers is going to fast to keep up! Adding
167 # all the values up and only writing them when the
168 # process is ready.
169 if self._async_add_buffer:
170 for name in names:
171 self._async_add_buffer[name] += params[name]
172 else:
173 for name in names:
174 self._async_add_buffer[name] = params[name]
175
176 def add_and_wait(self, params: Dict[str, Any]) -> None:
177 """Adds the specified parameters to the corresponding parameters in server \
178 and waits for the process to complete before continuing."""
179 self._client.add_to_parameters(params)
180
181 def get_and_wait(self) -> None:
182 """Updates the get parameters with the latest copy from server \
183 and waits for the process to complete before continuing."""
184 self._copy(self._request())
185
186 def get_all_and_wait(self) -> None:
187 """Updates all the parameters with the latest copy from server \
188 and waits for the process to complete before continuing."""
189 self._copy(self._request_all())
190
191 def set_and_wait(self) -> None:
192 """Updates server with the set parameters \
193 and waits for the process to complete before continuing."""
194 self._adjust()
195
196 # TODO(Dries/Arnu): this needs a bit of a cleanup
197 def _copy(self, new_parameters: Dict[str, Any]) -> None:
198 """Copies the new parameters to the old ones."""
199 for key in new_parameters.keys():
200 if isinstance(new_parameters[key], dict):
201 for type1_key in new_parameters[key].keys():
202 for type2_key in self._parameters[key][type1_key].keys():
203 if self._devices:
204 # Move variables to a proper device.
205 # self._parameters[key][type1_key][
206 # type2_key
207 # ] = jax.device_put( # type: ignore
208 # new_parameters[key][type1_key],
209 # self._devices[key][type1_key],
210 # )
211 raise NotImplementedError(
212 "Support for devices"
213 + "have not been implemented"
214 + "yet in the parameter client."
215 )
216 else:
217 self._parameters[key][type1_key][
218 type2_key
219 ] = new_parameters[key][type1_key][type2_key]
220 elif isinstance(new_parameters[key], np.ndarray):
221 if self._devices:
222 self._parameters[key] = jax.device_put(
223 new_parameters[key], self._devices[key] # type: ignore
224 )
225 else:
226 # Note (dries): These in-place operators are used instead
227 # of direct assignment to not lose reference to the numpy
228 # array.
229
230 self._parameters[key] *= 0
231 # Remove last dim of numpy array if needed
232 if new_parameters[key].shape != self._parameters[key].shape:
233 self._parameters[key] += new_parameters[key][0]
234 else:
235 self._parameters[key] += new_parameters[key]
236
237 elif isinstance(new_parameters[key], tuple):
238 for i in range(len(self._parameters[key])):
239 if self._devices:
240 self._parameters[key][i] = jax.device_put(
241 new_parameters[key][i],
242 self._devices[key][i], # type: ignore
243 )
244 else:
245 self._parameters[key][i] = new_parameters[key][i]
246 else:
247 NotImplementedError(
248 f"Parameter type of {type(new_parameters[key])} not implemented."
249 )
250
[end of mava/systems/jax/parameter_client.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mava/systems/jax/parameter_client.py b/mava/systems/jax/parameter_client.py
--- a/mava/systems/jax/parameter_client.py
+++ b/mava/systems/jax/parameter_client.py
@@ -244,6 +244,6 @@
else:
self._parameters[key][i] = new_parameters[key][i]
else:
- NotImplementedError(
+ raise NotImplementedError(
f"Parameter type of {type(new_parameters[key])} not implemented."
)
|
{"golden_diff": "diff --git a/mava/systems/jax/parameter_client.py b/mava/systems/jax/parameter_client.py\n--- a/mava/systems/jax/parameter_client.py\n+++ b/mava/systems/jax/parameter_client.py\n@@ -244,6 +244,6 @@\n else:\n self._parameters[key][i] = new_parameters[key][i]\n else:\n- NotImplementedError(\n+ raise NotImplementedError(\n f\"Parameter type of {type(new_parameters[key])} not implemented.\"\n )\n", "issue": "[TEST] Jax System Core Parameter Client\n### What do you want to test?\r\nJax system core parameter client (in `mava/systems/jax/`)\r\n\r\n### Outline of test structure\r\n* Unit tests\r\n* Test components and hooks\r\n\r\n### Definition of done\r\nPassing checks, cover all hooks, edge cases considered\r\n\r\n### Mandatory checklist before making a PR\r\n* [ ] The success criteria laid down in \u201cDefinition of done\u201d are met.\r\n* [ ] Test code is documented - docstrings for methods and classes, static types for arguments.\r\n* [ ] Documentation is updated - README, CONTRIBUTING, or other documentation.\n", "before_files": [{"content": "# python3\n# Copyright 2021 InstaDeep Ltd. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Parameter client for Jax system. Adapted from Deepmind's Acme library\"\"\"\n\nfrom concurrent import futures\nfrom typing import Any, Dict, List, Optional, Union\n\nimport jax\nimport numpy as np\n\nfrom mava.systems.jax.parameter_server import ParameterServer\nfrom mava.utils.sort_utils import sort_str_num\n\n\nclass ParameterClient:\n \"\"\"A parameter client for updating parameters from a remote server.\"\"\"\n\n def __init__(\n self,\n client: ParameterServer,\n parameters: Dict[str, Any],\n get_keys: List[str] = None,\n set_keys: List[str] = None,\n update_period: int = 1,\n devices: Dict[str, Optional[Union[str, jax.xla.Device]]] = {},\n ):\n \"\"\"Initialise the parameter server.\"\"\"\n self._all_keys = sort_str_num(list(parameters.keys()))\n # TODO (dries): Is the below change correct?\n self._get_keys = get_keys if get_keys is not None else []\n self._set_keys = set_keys if set_keys is not None else []\n self._parameters: Dict[str, Any] = parameters\n self._get_call_counter = 0\n self._set_call_counter = 0\n self._set_get_call_counter = 0\n self._update_period = update_period\n self._client = client\n self._devices = devices\n\n # note below it is assumed that if one device is specified with a string\n # they all are - need to test this works\n # TODO: (Dries/Arnu): check this\n if len(self._devices) and isinstance(list(self._devices.values())[0], str):\n for key, device in self._devices.items():\n self._devices[key] = jax.devices(device)[0] # type: ignore\n\n self._request = lambda: client.get_parameters(self._get_keys)\n self._request_all = lambda: client.get_parameters(self._all_keys)\n\n self._adjust = lambda: client.set_parameters(\n {key: self._parameters[key] for key in self._set_keys},\n )\n\n self._add = lambda params: client.add_to_parameters(params)\n\n # Create a single background thread to fetch parameters without necessarily\n # blocking the actor.\n self._executor = futures.ThreadPoolExecutor(max_workers=1)\n self._async_add_buffer: Dict[str, Any] = {}\n self._async_request = lambda: self._executor.submit(self._request)\n self._async_adjust = lambda: self._executor.submit(self._adjust)\n self._async_adjust_and_request = lambda: self._executor.submit(\n self._adjust_and_request\n )\n self._async_add: Any = lambda params: self._executor.submit(\n self._add(params) # type: ignore\n )\n\n # Initialize this client's future to None to indicate to the `update()`\n # method that there is no pending/running request.\n self._get_future: Optional[futures.Future] = None\n self._set_future: Optional[futures.Future] = None\n self._set_get_future: Optional[futures.Future] = None\n self._add_future: Optional[futures.Future] = None\n\n def _adjust_and_request(self) -> None:\n self._client.set_parameters(\n {key: self._parameters[key] for key in self._set_keys},\n )\n self._copy(self._client.get_parameters(self._get_keys))\n\n def get_async(self) -> None:\n \"\"\"Asynchronously updates the parameters with the latest copy from server.\"\"\"\n\n # Track the number of calls (we only update periodically).\n if self._get_call_counter < self._update_period:\n self._get_call_counter += 1\n\n period_reached: bool = self._get_call_counter >= self._update_period\n if period_reached and self._get_future is None:\n # The update period has been reached and no request has been sent yet, so\n # making an asynchronous request now.\n self._get_future = self._async_request()\n self._get_call_counter = 0\n\n if self._get_future is not None and self._get_future.done():\n # The active request is done so copy the result and remove the future.\\\n self._copy(self._get_future.result())\n self._get_future = None\n\n def set_async(self) -> None:\n \"\"\"Asynchronously updates server with the set parameters.\"\"\"\n # Track the number of calls (we only update periodically).\n if self._set_call_counter < self._update_period:\n self._set_call_counter += 1\n\n period_reached: bool = self._set_call_counter >= self._update_period\n\n if period_reached and self._set_future is None:\n # The update period has been reached and no request has been sent yet, so\n # making an asynchronous request now.\n self._set_future = self._async_adjust()\n self._set_call_counter = 0\n return\n if self._set_future is not None and self._set_future.done():\n self._set_future = None\n\n def set_and_get_async(self) -> None:\n \"\"\"Asynchronously updates server and gets from server.\"\"\"\n # Track the number of calls (we only update periodically).\n if self._set_get_call_counter < self._update_period:\n self._set_get_call_counter += 1\n period_reached: bool = self._set_get_call_counter >= self._update_period\n\n if period_reached and self._set_get_future is None:\n # The update period has been reached and no request has been sent yet, so\n # making an asynchronous request now.\n self._set_get_future = self._async_adjust_and_request()\n self._set_get_call_counter = 0\n return\n if self._set_get_future is not None and self._set_get_future.done():\n self._set_get_future = None\n\n def add_async(self, params: Dict[str, Any]) -> None:\n \"\"\"Asynchronously adds to server parameters.\"\"\"\n if self._add_future is not None and self._add_future.done():\n self._add_future = None\n\n names = params.keys()\n if self._add_future is None:\n # The update period has been reached and no request has been sent yet, so\n # making an asynchronous request now.\n if not self._async_add_buffer:\n self._add_future = self._async_add(params)\n else:\n for name in names:\n self._async_add_buffer[name] += params[name]\n\n self._add_future = self._async_add(self._async_add_buffer)\n self._async_add_buffer = {}\n return\n else:\n # The trainers is going to fast to keep up! Adding\n # all the values up and only writing them when the\n # process is ready.\n if self._async_add_buffer:\n for name in names:\n self._async_add_buffer[name] += params[name]\n else:\n for name in names:\n self._async_add_buffer[name] = params[name]\n\n def add_and_wait(self, params: Dict[str, Any]) -> None:\n \"\"\"Adds the specified parameters to the corresponding parameters in server \\\n and waits for the process to complete before continuing.\"\"\"\n self._client.add_to_parameters(params)\n\n def get_and_wait(self) -> None:\n \"\"\"Updates the get parameters with the latest copy from server \\\n and waits for the process to complete before continuing.\"\"\"\n self._copy(self._request())\n\n def get_all_and_wait(self) -> None:\n \"\"\"Updates all the parameters with the latest copy from server \\\n and waits for the process to complete before continuing.\"\"\"\n self._copy(self._request_all())\n\n def set_and_wait(self) -> None:\n \"\"\"Updates server with the set parameters \\\n and waits for the process to complete before continuing.\"\"\"\n self._adjust()\n\n # TODO(Dries/Arnu): this needs a bit of a cleanup\n def _copy(self, new_parameters: Dict[str, Any]) -> None:\n \"\"\"Copies the new parameters to the old ones.\"\"\"\n for key in new_parameters.keys():\n if isinstance(new_parameters[key], dict):\n for type1_key in new_parameters[key].keys():\n for type2_key in self._parameters[key][type1_key].keys():\n if self._devices:\n # Move variables to a proper device.\n # self._parameters[key][type1_key][\n # type2_key\n # ] = jax.device_put( # type: ignore\n # new_parameters[key][type1_key],\n # self._devices[key][type1_key],\n # )\n raise NotImplementedError(\n \"Support for devices\"\n + \"have not been implemented\"\n + \"yet in the parameter client.\"\n )\n else:\n self._parameters[key][type1_key][\n type2_key\n ] = new_parameters[key][type1_key][type2_key]\n elif isinstance(new_parameters[key], np.ndarray):\n if self._devices:\n self._parameters[key] = jax.device_put(\n new_parameters[key], self._devices[key] # type: ignore\n )\n else:\n # Note (dries): These in-place operators are used instead\n # of direct assignment to not lose reference to the numpy\n # array.\n\n self._parameters[key] *= 0\n # Remove last dim of numpy array if needed\n if new_parameters[key].shape != self._parameters[key].shape:\n self._parameters[key] += new_parameters[key][0]\n else:\n self._parameters[key] += new_parameters[key]\n\n elif isinstance(new_parameters[key], tuple):\n for i in range(len(self._parameters[key])):\n if self._devices:\n self._parameters[key][i] = jax.device_put(\n new_parameters[key][i],\n self._devices[key][i], # type: ignore\n )\n else:\n self._parameters[key][i] = new_parameters[key][i]\n else:\n NotImplementedError(\n f\"Parameter type of {type(new_parameters[key])} not implemented.\"\n )\n", "path": "mava/systems/jax/parameter_client.py"}]}
| 3,635 | 114 |
gh_patches_debug_11216
|
rasdani/github-patches
|
git_diff
|
OCA__server-tools-75
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[7.0] [base_optional_quick_create] AttributeError: 'NoneType' object has no attribute 'name_create'
Error at starting before a migration if a model has been removed
</issue>
<code>
[start of base_optional_quick_create/model.py]
1 # -*- coding: utf-8 -*-
2 ##############################################################################
3 #
4 # Copyright (C) 2013 Agile Business Group sagl (<http://www.agilebg.com>)
5 #
6 # This program is free software: you can redistribute it and/or modify
7 # it under the terms of the GNU Affero General Public License as published
8 # by the Free Software Foundation, either version 3 of the License, or
9 # (at your option) any later version.
10 #
11 # This program is distributed in the hope that it will be useful,
12 # but WITHOUT ANY WARRANTY; without even the implied warranty of
13 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
14 # GNU Affero General Public License for more details.
15 #
16 # You should have received a copy of the GNU Affero General Public License
17 # along with this program. If not, see <http://www.gnu.org/licenses/>.
18 #
19 ##############################################################################
20
21 from openerp.osv import orm, fields
22 from openerp import SUPERUSER_ID
23 from openerp.tools.translate import _
24
25
26 class ir_model(orm.Model):
27 _inherit = 'ir.model'
28
29 _columns = {
30 'avoid_quick_create': fields.boolean('Avoid quick create'),
31 }
32
33 def _wrap_name_create(self, old_create, model):
34 def wrapper(cr, uid, name, context=None):
35 raise orm.except_orm(
36 _('Error'),
37 _("Can't create quickly. Opening create form"))
38 return wrapper
39
40 def _register_hook(self, cr, ids=None):
41 if ids is None:
42 ids = self.search(cr, SUPERUSER_ID, [])
43 for model in self.browse(cr, SUPERUSER_ID, ids):
44 if model.avoid_quick_create:
45 model_name = model.model
46 model_obj = self.pool.get(model_name)
47 if not hasattr(model_obj, 'check_quick_create'):
48 model_obj.name_create = self._wrap_name_create(
49 model_obj.name_create, model_name)
50 model_obj.check_quick_create = True
51 return True
52
53 def create(self, cr, uid, vals, context=None):
54 res_id = super(ir_model, self).create(cr, uid, vals, context=context)
55 self._register_hook(cr, [res_id])
56 return res_id
57
58 def write(self, cr, uid, ids, vals, context=None):
59 if isinstance(ids, (int, long)):
60 ids = [ids]
61 res = super(ir_model, self).write(cr, uid, ids, vals, context=context)
62 self._register_hook(cr, ids)
63 return res
64
[end of base_optional_quick_create/model.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/base_optional_quick_create/model.py b/base_optional_quick_create/model.py
--- a/base_optional_quick_create/model.py
+++ b/base_optional_quick_create/model.py
@@ -44,7 +44,7 @@
if model.avoid_quick_create:
model_name = model.model
model_obj = self.pool.get(model_name)
- if not hasattr(model_obj, 'check_quick_create'):
+ if model_obj and not hasattr(model_obj, 'check_quick_create'):
model_obj.name_create = self._wrap_name_create(
model_obj.name_create, model_name)
model_obj.check_quick_create = True
|
{"golden_diff": "diff --git a/base_optional_quick_create/model.py b/base_optional_quick_create/model.py\n--- a/base_optional_quick_create/model.py\n+++ b/base_optional_quick_create/model.py\n@@ -44,7 +44,7 @@\n if model.avoid_quick_create:\n model_name = model.model\n model_obj = self.pool.get(model_name)\n- if not hasattr(model_obj, 'check_quick_create'):\n+ if model_obj and not hasattr(model_obj, 'check_quick_create'):\n model_obj.name_create = self._wrap_name_create(\n model_obj.name_create, model_name)\n model_obj.check_quick_create = True\n", "issue": "[7.0] [base_optional_quick_create] AttributeError: 'NoneType' object has no attribute 'name_create'\nError at starting before a migration if a model has been removed\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n##############################################################################\n#\n# Copyright (C) 2013 Agile Business Group sagl (<http://www.agilebg.com>)\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU Affero General Public License as published\n# by the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU Affero General Public License for more details.\n#\n# You should have received a copy of the GNU Affero General Public License\n# along with this program. If not, see <http://www.gnu.org/licenses/>.\n#\n##############################################################################\n\nfrom openerp.osv import orm, fields\nfrom openerp import SUPERUSER_ID\nfrom openerp.tools.translate import _\n\n\nclass ir_model(orm.Model):\n _inherit = 'ir.model'\n\n _columns = {\n 'avoid_quick_create': fields.boolean('Avoid quick create'),\n }\n\n def _wrap_name_create(self, old_create, model):\n def wrapper(cr, uid, name, context=None):\n raise orm.except_orm(\n _('Error'),\n _(\"Can't create quickly. Opening create form\"))\n return wrapper\n\n def _register_hook(self, cr, ids=None):\n if ids is None:\n ids = self.search(cr, SUPERUSER_ID, [])\n for model in self.browse(cr, SUPERUSER_ID, ids):\n if model.avoid_quick_create:\n model_name = model.model\n model_obj = self.pool.get(model_name)\n if not hasattr(model_obj, 'check_quick_create'):\n model_obj.name_create = self._wrap_name_create(\n model_obj.name_create, model_name)\n model_obj.check_quick_create = True\n return True\n\n def create(self, cr, uid, vals, context=None):\n res_id = super(ir_model, self).create(cr, uid, vals, context=context)\n self._register_hook(cr, [res_id])\n return res_id\n\n def write(self, cr, uid, ids, vals, context=None):\n if isinstance(ids, (int, long)):\n ids = [ids]\n res = super(ir_model, self).write(cr, uid, ids, vals, context=context)\n self._register_hook(cr, ids)\n return res\n", "path": "base_optional_quick_create/model.py"}]}
| 1,239 | 132 |
gh_patches_debug_53573
|
rasdani/github-patches
|
git_diff
|
yt-project__yt-2663
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
RecursionError while loading enzo_p dataset with cosmology
### Bug report
**Bug summary**
Loading a cosmological Enzo_p dataset raises `RecursionError`
**Code for reproduction**
```python
from yt.utilities.answer_testing.framework import data_dir_load
ep_cosmo = "ENZOP_DD0140/ENZOP_DD0140.block_list"
ds = data_dir_load(ep_cosmo)
```
**Actual outcome**
```
Traceback (most recent call last):
File "ala.py", line 7, in <module>
ds = data_dir_load(ep_cosmo)
File "/home/xarth/codes/xarthisius/yt/yt/utilities/answer_testing/framework.py", line 314, in data_dir_load
ds.index
File "/home/xarth/codes/xarthisius/yt/yt/data_objects/static_output.py", line 447, in index
self.create_field_info()
File "/home/xarth/codes/xarthisius/yt/yt/data_objects/static_output.py", line 494, in create_field_info
self.field_info.setup_particle_fields(ptype)
File "/home/xarth/codes/xarthisius/yt/yt/frontends/enzo_p/fields.py", line 50, in setup_particle_fields
self.setup_particle_mass_field(ptype)
File "/home/xarth/codes/xarthisius/yt/yt/frontends/enzo_p/fields.py", line 72, in setup_particle_mass_field
val /= self.ds.domain_dimensions.prod()
File "/home/xarth/codes/yt-project/unyt/unyt/array.py", line 1811, in __array_ufunc__
multiply(out, mul, out=out)
File "/home/xarth/codes/yt-project/unyt/unyt/array.py", line 1811, in __array_ufunc__
multiply(out, mul, out=out)
File "/home/xarth/codes/yt-project/unyt/unyt/array.py", line 1811, in __array_ufunc__
multiply(out, mul, out=out)
[Previous line repeated 323 more times]
File "/home/xarth/codes/yt-project/unyt/unyt/array.py", line 1800, in __array_ufunc__
out_arr = unyt_quantity(np.asarray(out_arr), unit)
File "/home/xarth/codes/yt-project/unyt/unyt/array.py", line 2023, in __new__
or isinstance(input_scalar, (numeric_type, np.number, np.ndarray))
File "/usr/lib/python3.6/abc.py", line 190, in __instancecheck__
subclass in cls._abc_negative_cache):
File "/usr/lib/python3.6/_weakrefset.py", line 75, in __contains__
return wr in self.data
RecursionError: maximum recursion depth exceeded in comparison
```
**Expected outcome**
Just happiness
**Version Information**
* Operating System: Ubuntu 18.04.4 LTS
* Python Version: 3.6.9
* yt version: b6d9463b287099685800353fd6293dffa4bace9d
* Other Libraries (if applicable): unyt==2.7.1
<!--Please tell us how you installed yt and python e.g., from source,
pip, conda. If you installed from conda, please specify which channel you used
if not the default-->
</issue>
<code>
[start of yt/frontends/enzo_p/fields.py]
1 from yt.fields.field_info_container import \
2 FieldInfoContainer
3 from yt.fields.particle_fields import \
4 add_union_field
5 from yt.frontends.enzo_p.misc import \
6 nested_dict_get
7
8 rho_units = "code_mass / code_length**3"
9 vel_units = "code_velocity"
10 acc_units = "code_velocity / code_time"
11 energy_units = "code_velocity**2"
12
13 known_species_names = {
14 }
15
16 class EnzoPFieldInfo(FieldInfoContainer):
17 known_other_fields = (
18 ("velocity_x", (vel_units, ["velocity_x"], None)),
19 ("velocity_y", (vel_units, ["velocity_y"], None)),
20 ("velocity_z", (vel_units, ["velocity_z"], None)),
21 ("acceleration_x", (acc_units, ["acceleration_x"], None)),
22 ("acceleration_y", (acc_units, ["acceleration_y"], None)),
23 ("acceleration_z", (acc_units, ["acceleration_z"], None)),
24 ("density", (rho_units, ["density"], None)),
25 ("density_total", (rho_units, ["total_density"], None)),
26 ("total_energy", (energy_units, ["total_energy"], None)),
27 ("internal_energy", (energy_units, ["internal_energy"], None)),
28 )
29
30 known_particle_fields = (
31 ("x", ("code_length", ["particle_position_x"], None)),
32 ("y", ("code_length", ["particle_position_y"], None)),
33 ("z", ("code_length", ["particle_position_z"], None)),
34 ("vx", (vel_units, ["particle_velocity_x"], None)),
35 ("vy", (vel_units, ["particle_velocity_y"], None)),
36 ("vz", (vel_units, ["particle_velocity_z"], None)),
37 ("ax", (acc_units, ["particle_acceleration_x"], None)),
38 ("ay", (acc_units, ["particle_acceleration_y"], None)),
39 ("az", (acc_units, ["particle_acceleration_z"], None)),
40 ("mass", ("code_mass", ["particle_mass"], None)),
41 )
42
43 def __init__(self, ds, field_list, slice_info = None):
44 super(EnzoPFieldInfo, self).__init__(
45 ds, field_list, slice_info=slice_info)
46
47 def setup_particle_fields(self, ptype, ftype='gas', num_neighbors=64):
48 super(EnzoPFieldInfo, self).setup_particle_fields(
49 ptype, ftype=ftype, num_neighbors=num_neighbors)
50 self.setup_particle_mass_field(ptype)
51
52 def setup_particle_mass_field(self, ptype):
53 name = "particle_mass"
54 if ptype in self.ds.particle_unions:
55 add_union_field(self, ptype, name, "code_mass")
56 return
57
58 constants = nested_dict_get(
59 self.ds.parameters, ("Particle", ptype, "constants"),
60 default=[])
61 if not constants:
62 names = []
63 else:
64 if not isinstance(constants[0], tuple):
65 constants = (constants,)
66 names = [c[0] for c in constants]
67
68 if "mass" in names:
69 val = constants[names.index("mass")][2]
70 val = self.ds.quan(val, self.ds.mass_unit)
71 if self.ds.cosmological_simulation:
72 val /= self.ds.domain_dimensions.prod()
73
74 def _pmass(field, data):
75 return val * data[ptype, "particle_ones"]
76 self.add_field((ptype, name),
77 function=_pmass, units="code_mass",
78 sampling_type="particle")
79
[end of yt/frontends/enzo_p/fields.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/yt/frontends/enzo_p/fields.py b/yt/frontends/enzo_p/fields.py
--- a/yt/frontends/enzo_p/fields.py
+++ b/yt/frontends/enzo_p/fields.py
@@ -69,7 +69,7 @@
val = constants[names.index("mass")][2]
val = self.ds.quan(val, self.ds.mass_unit)
if self.ds.cosmological_simulation:
- val /= self.ds.domain_dimensions.prod()
+ val = val / self.ds.domain_dimensions.prod()
def _pmass(field, data):
return val * data[ptype, "particle_ones"]
|
{"golden_diff": "diff --git a/yt/frontends/enzo_p/fields.py b/yt/frontends/enzo_p/fields.py\n--- a/yt/frontends/enzo_p/fields.py\n+++ b/yt/frontends/enzo_p/fields.py\n@@ -69,7 +69,7 @@\n val = constants[names.index(\"mass\")][2]\n val = self.ds.quan(val, self.ds.mass_unit)\n if self.ds.cosmological_simulation:\n- val /= self.ds.domain_dimensions.prod()\n+ val = val / self.ds.domain_dimensions.prod()\n \n def _pmass(field, data):\n return val * data[ptype, \"particle_ones\"]\n", "issue": "RecursionError while loading enzo_p dataset with cosmology\n### Bug report\r\n\r\n**Bug summary**\r\n\r\nLoading a cosmological Enzo_p dataset raises `RecursionError`\r\n\r\n**Code for reproduction**\r\n\r\n```python\r\nfrom yt.utilities.answer_testing.framework import data_dir_load \r\nep_cosmo = \"ENZOP_DD0140/ENZOP_DD0140.block_list\"\r\nds = data_dir_load(ep_cosmo)\r\n```\r\n\r\n**Actual outcome**\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"ala.py\", line 7, in <module>\r\n ds = data_dir_load(ep_cosmo)\r\n File \"/home/xarth/codes/xarthisius/yt/yt/utilities/answer_testing/framework.py\", line 314, in data_dir_load\r\n ds.index\r\n File \"/home/xarth/codes/xarthisius/yt/yt/data_objects/static_output.py\", line 447, in index\r\n self.create_field_info()\r\n File \"/home/xarth/codes/xarthisius/yt/yt/data_objects/static_output.py\", line 494, in create_field_info\r\n self.field_info.setup_particle_fields(ptype)\r\n File \"/home/xarth/codes/xarthisius/yt/yt/frontends/enzo_p/fields.py\", line 50, in setup_particle_fields\r\n self.setup_particle_mass_field(ptype)\r\n File \"/home/xarth/codes/xarthisius/yt/yt/frontends/enzo_p/fields.py\", line 72, in setup_particle_mass_field\r\n val /= self.ds.domain_dimensions.prod()\r\n File \"/home/xarth/codes/yt-project/unyt/unyt/array.py\", line 1811, in __array_ufunc__\r\n multiply(out, mul, out=out)\r\n File \"/home/xarth/codes/yt-project/unyt/unyt/array.py\", line 1811, in __array_ufunc__\r\n multiply(out, mul, out=out)\r\n File \"/home/xarth/codes/yt-project/unyt/unyt/array.py\", line 1811, in __array_ufunc__\r\n multiply(out, mul, out=out)\r\n [Previous line repeated 323 more times]\r\n File \"/home/xarth/codes/yt-project/unyt/unyt/array.py\", line 1800, in __array_ufunc__\r\n out_arr = unyt_quantity(np.asarray(out_arr), unit)\r\n File \"/home/xarth/codes/yt-project/unyt/unyt/array.py\", line 2023, in __new__\r\n or isinstance(input_scalar, (numeric_type, np.number, np.ndarray))\r\n File \"/usr/lib/python3.6/abc.py\", line 190, in __instancecheck__\r\n subclass in cls._abc_negative_cache):\r\n File \"/usr/lib/python3.6/_weakrefset.py\", line 75, in __contains__\r\n return wr in self.data\r\nRecursionError: maximum recursion depth exceeded in comparison\r\n```\r\n\r\n**Expected outcome**\r\n\r\nJust happiness\r\n\r\n**Version Information**\r\n\r\n * Operating System: Ubuntu 18.04.4 LTS\r\n * Python Version: 3.6.9\r\n * yt version: b6d9463b287099685800353fd6293dffa4bace9d\r\n * Other Libraries (if applicable): unyt==2.7.1\r\n\r\n<!--Please tell us how you installed yt and python e.g., from source,\r\npip, conda. If you installed from conda, please specify which channel you used\r\nif not the default-->\r\n\r\n\n", "before_files": [{"content": "from yt.fields.field_info_container import \\\n FieldInfoContainer\nfrom yt.fields.particle_fields import \\\n add_union_field\nfrom yt.frontends.enzo_p.misc import \\\n nested_dict_get\n\nrho_units = \"code_mass / code_length**3\"\nvel_units = \"code_velocity\"\nacc_units = \"code_velocity / code_time\"\nenergy_units = \"code_velocity**2\"\n\nknown_species_names = {\n}\n\nclass EnzoPFieldInfo(FieldInfoContainer):\n known_other_fields = (\n (\"velocity_x\", (vel_units, [\"velocity_x\"], None)),\n (\"velocity_y\", (vel_units, [\"velocity_y\"], None)),\n (\"velocity_z\", (vel_units, [\"velocity_z\"], None)),\n (\"acceleration_x\", (acc_units, [\"acceleration_x\"], None)),\n (\"acceleration_y\", (acc_units, [\"acceleration_y\"], None)),\n (\"acceleration_z\", (acc_units, [\"acceleration_z\"], None)),\n (\"density\", (rho_units, [\"density\"], None)),\n (\"density_total\", (rho_units, [\"total_density\"], None)),\n (\"total_energy\", (energy_units, [\"total_energy\"], None)),\n (\"internal_energy\", (energy_units, [\"internal_energy\"], None)),\n )\n\n known_particle_fields = (\n (\"x\", (\"code_length\", [\"particle_position_x\"], None)),\n (\"y\", (\"code_length\", [\"particle_position_y\"], None)),\n (\"z\", (\"code_length\", [\"particle_position_z\"], None)),\n (\"vx\", (vel_units, [\"particle_velocity_x\"], None)),\n (\"vy\", (vel_units, [\"particle_velocity_y\"], None)),\n (\"vz\", (vel_units, [\"particle_velocity_z\"], None)),\n (\"ax\", (acc_units, [\"particle_acceleration_x\"], None)),\n (\"ay\", (acc_units, [\"particle_acceleration_y\"], None)),\n (\"az\", (acc_units, [\"particle_acceleration_z\"], None)),\n (\"mass\", (\"code_mass\", [\"particle_mass\"], None)),\n )\n\n def __init__(self, ds, field_list, slice_info = None):\n super(EnzoPFieldInfo, self).__init__(\n ds, field_list, slice_info=slice_info)\n\n def setup_particle_fields(self, ptype, ftype='gas', num_neighbors=64):\n super(EnzoPFieldInfo, self).setup_particle_fields(\n ptype, ftype=ftype, num_neighbors=num_neighbors)\n self.setup_particle_mass_field(ptype)\n\n def setup_particle_mass_field(self, ptype):\n name = \"particle_mass\"\n if ptype in self.ds.particle_unions:\n add_union_field(self, ptype, name, \"code_mass\")\n return\n\n constants = nested_dict_get(\n self.ds.parameters, (\"Particle\", ptype, \"constants\"),\n default=[])\n if not constants:\n names = []\n else:\n if not isinstance(constants[0], tuple):\n constants = (constants,)\n names = [c[0] for c in constants]\n\n if \"mass\" in names:\n val = constants[names.index(\"mass\")][2]\n val = self.ds.quan(val, self.ds.mass_unit)\n if self.ds.cosmological_simulation:\n val /= self.ds.domain_dimensions.prod()\n\n def _pmass(field, data):\n return val * data[ptype, \"particle_ones\"]\n self.add_field((ptype, name),\n function=_pmass, units=\"code_mass\",\n sampling_type=\"particle\")\n", "path": "yt/frontends/enzo_p/fields.py"}]}
| 2,221 | 145 |
gh_patches_debug_33358
|
rasdani/github-patches
|
git_diff
|
vaexio__vaex-1299
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Displaying full integers instead of scientific notiation when printing out Vaex HDF5 data
Hi,
Can you help me:
my code:
`myfile = vaex.open('myfile.hdf5')`
`myfile['customer_id']`
output:
`Length: 4,259,376 dtype: int64 (column)`
`0 9.4618e+08`
` 1 9.43324e+08`
` 2 9.43325e+08`
` 3 9.43333e+08`
` 4 9.43333e+08`
...
How can get output with full integer instead of scientific notation? Thank you.
</issue>
<code>
[start of packages/vaex-core/vaex/formatting.py]
1 import numpy as np
2 import numbers
3 import six
4 import datetime
5 import pyarrow as pa
6
7
8 MAX_LENGTH = 50
9
10
11 def _format_value(value):
12 if isinstance(value, six.string_types):
13 value = str(value)
14 elif isinstance(value, pa.lib.Scalar):
15 value = value.as_py()
16 if value is None:
17 value = '--'
18 else:
19 value = repr(value)
20 elif isinstance(value, bytes):
21 value = repr(value)
22 elif isinstance(value, np.ma.core.MaskedConstant):
23 value = str(value)
24 if isinstance(value, np.datetime64):
25 if np.isnat(value):
26 value = 'NaT'
27 else:
28 value = ' '.join(str(value).split('T'))
29 if isinstance(value, np.timedelta64):
30 if np.isnat(value):
31 value = 'NaT'
32 else:
33 tmp = datetime.timedelta(seconds=value / np.timedelta64(1, 's'))
34 ms = tmp.microseconds
35 s = np.mod(tmp.seconds, 60)
36 m = np.mod(tmp.seconds//60, 60)
37 h = tmp.seconds // 3600
38 d = tmp.days
39 if ms:
40 value = str('%i days %+02i:%02i:%02i.%i' % (d,h,m,s,ms))
41 else:
42 value = str('%i days %+02i:%02i:%02i' % (d,h,m,s))
43 elif not isinstance(value, numbers.Number):
44 value = str(value)
45 if isinstance(value, float):
46 value = repr(value)
47 if isinstance(value, (str, bytes)):
48 if len(value) > MAX_LENGTH:
49 value = repr(value[:MAX_LENGTH-3])[:-1] + '...'
50 return value
51
[end of packages/vaex-core/vaex/formatting.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/packages/vaex-core/vaex/formatting.py b/packages/vaex-core/vaex/formatting.py
--- a/packages/vaex-core/vaex/formatting.py
+++ b/packages/vaex-core/vaex/formatting.py
@@ -8,25 +8,32 @@
MAX_LENGTH = 50
+def _trim_string(value):
+ if len(value) > MAX_LENGTH:
+ value = repr(value[:MAX_LENGTH-3])[:-1] + '...'
+ return value
+
def _format_value(value):
- if isinstance(value, six.string_types):
- value = str(value)
- elif isinstance(value, pa.lib.Scalar):
+ # print("value = ", value, type(value), isinstance(value, numbers.Number))
+ if isinstance(value, pa.lib.Scalar):
value = value.as_py()
if value is None:
- value = '--'
+ return '--'
else:
- value = repr(value)
+ return _trim_string(str(value))
+ if isinstance(value, str):
+ return _trim_string(str(value))
elif isinstance(value, bytes):
- value = repr(value)
+ value = _trim_string(repr(value))
elif isinstance(value, np.ma.core.MaskedConstant):
- value = str(value)
- if isinstance(value, np.datetime64):
+ return str(value)
+ elif isinstance(value, np.datetime64):
if np.isnat(value):
value = 'NaT'
else:
value = ' '.join(str(value).split('T'))
- if isinstance(value, np.timedelta64):
+ return value
+ elif isinstance(value, np.timedelta64):
if np.isnat(value):
value = 'NaT'
else:
@@ -40,11 +47,10 @@
value = str('%i days %+02i:%02i:%02i.%i' % (d,h,m,s,ms))
else:
value = str('%i days %+02i:%02i:%02i' % (d,h,m,s))
- elif not isinstance(value, numbers.Number):
+ return value
+ elif isinstance(value, numbers.Number):
value = str(value)
- if isinstance(value, float):
+ else:
value = repr(value)
- if isinstance(value, (str, bytes)):
- if len(value) > MAX_LENGTH:
- value = repr(value[:MAX_LENGTH-3])[:-1] + '...'
+ value = _trim_string(value)
return value
|
{"golden_diff": "diff --git a/packages/vaex-core/vaex/formatting.py b/packages/vaex-core/vaex/formatting.py\n--- a/packages/vaex-core/vaex/formatting.py\n+++ b/packages/vaex-core/vaex/formatting.py\n@@ -8,25 +8,32 @@\n MAX_LENGTH = 50\n \n \n+def _trim_string(value):\n+ if len(value) > MAX_LENGTH:\n+ value = repr(value[:MAX_LENGTH-3])[:-1] + '...'\n+ return value\n+\n def _format_value(value):\n- if isinstance(value, six.string_types):\n- value = str(value)\n- elif isinstance(value, pa.lib.Scalar):\n+ # print(\"value = \", value, type(value), isinstance(value, numbers.Number))\n+ if isinstance(value, pa.lib.Scalar):\n value = value.as_py()\n if value is None:\n- value = '--'\n+ return '--'\n else:\n- value = repr(value)\n+ return _trim_string(str(value))\n+ if isinstance(value, str):\n+ return _trim_string(str(value))\n elif isinstance(value, bytes):\n- value = repr(value)\n+ value = _trim_string(repr(value))\n elif isinstance(value, np.ma.core.MaskedConstant):\n- value = str(value)\n- if isinstance(value, np.datetime64):\n+ return str(value)\n+ elif isinstance(value, np.datetime64):\n if np.isnat(value):\n value = 'NaT'\n else:\n value = ' '.join(str(value).split('T'))\n- if isinstance(value, np.timedelta64):\n+ return value\n+ elif isinstance(value, np.timedelta64):\n if np.isnat(value):\n value = 'NaT'\n else:\n@@ -40,11 +47,10 @@\n value = str('%i days %+02i:%02i:%02i.%i' % (d,h,m,s,ms))\n else:\n value = str('%i days %+02i:%02i:%02i' % (d,h,m,s))\n- elif not isinstance(value, numbers.Number):\n+ return value\n+ elif isinstance(value, numbers.Number):\n value = str(value)\n- if isinstance(value, float):\n+ else:\n value = repr(value)\n- if isinstance(value, (str, bytes)):\n- if len(value) > MAX_LENGTH:\n- value = repr(value[:MAX_LENGTH-3])[:-1] + '...'\n+ value = _trim_string(value)\n return value\n", "issue": "Displaying full integers instead of scientific notiation when printing out Vaex HDF5 data\nHi,\r\nCan you help me:\r\nmy code:\r\n`myfile = vaex.open('myfile.hdf5')`\r\n`myfile['customer_id']`\r\n\r\noutput:\r\n`Length: 4,259,376 dtype: int64 (column)`\r\n`0 9.4618e+08`\r\n` 1 9.43324e+08`\r\n` 2 9.43325e+08`\r\n` 3 9.43333e+08`\r\n` 4 9.43333e+08`\r\n ...\r\n\r\nHow can get output with full integer instead of scientific notation? Thank you.\r\n\n", "before_files": [{"content": "import numpy as np\nimport numbers\nimport six\nimport datetime\nimport pyarrow as pa\n\n\nMAX_LENGTH = 50\n\n\ndef _format_value(value):\n if isinstance(value, six.string_types):\n value = str(value)\n elif isinstance(value, pa.lib.Scalar):\n value = value.as_py()\n if value is None:\n value = '--'\n else:\n value = repr(value)\n elif isinstance(value, bytes):\n value = repr(value)\n elif isinstance(value, np.ma.core.MaskedConstant):\n value = str(value)\n if isinstance(value, np.datetime64):\n if np.isnat(value):\n value = 'NaT'\n else:\n value = ' '.join(str(value).split('T'))\n if isinstance(value, np.timedelta64):\n if np.isnat(value):\n value = 'NaT'\n else:\n tmp = datetime.timedelta(seconds=value / np.timedelta64(1, 's'))\n ms = tmp.microseconds\n s = np.mod(tmp.seconds, 60)\n m = np.mod(tmp.seconds//60, 60)\n h = tmp.seconds // 3600\n d = tmp.days\n if ms:\n value = str('%i days %+02i:%02i:%02i.%i' % (d,h,m,s,ms))\n else:\n value = str('%i days %+02i:%02i:%02i' % (d,h,m,s))\n elif not isinstance(value, numbers.Number):\n value = str(value)\n if isinstance(value, float):\n value = repr(value)\n if isinstance(value, (str, bytes)):\n if len(value) > MAX_LENGTH:\n value = repr(value[:MAX_LENGTH-3])[:-1] + '...'\n return value\n", "path": "packages/vaex-core/vaex/formatting.py"}]}
| 1,208 | 562 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.