
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.71k
18.9k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 465
23.6k
| num_tokens_prompt
int64 556
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_43113
|
rasdani/github-patches
|
git_diff
|
astronomer__astro-sdk-1257
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
CI: Fix Snowflake temp tables filling up
@utkarsharma2 @sunank200 - Can one of you add more details to this -- we need to investigate and fix the tests that is filling up our Snowflake instances with tables
</issue>
<code>
[start of python-sdk/example_dags/example_amazon_s3_snowflake_transform.py]
1 import os
2 import time
3 from datetime import datetime, timedelta
4
5 import pandas as pd
6
7 # Uses data from https://www.kaggle.com/c/shelter-animal-outcomes
8 from airflow.decorators import dag
9
10 from astro import sql as aql
11 from astro.files import File
12 from astro.table import Metadata, Table
13
14
15 @aql.transform()
16 def combine_data(center_1: Table, center_2: Table):
17 return """SELECT * FROM {{center_1}}
18 UNION SELECT * FROM {{center_2}}"""
19
20
21 @aql.transform()
22 def clean_data(input_table: Table):
23 return """SELECT *
24 FROM {{input_table}} WHERE type NOT LIKE 'Guinea Pig'
25 """
26
27
28 # [START dataframe_example_1]
29 @aql.dataframe(columns_names_capitalization="original")
30 def aggregate_data(df: pd.DataFrame):
31 new_df = df.pivot_table(index="date", values="name", columns=["type"], aggfunc="count").reset_index()
32 new_df.columns = new_df.columns.str.lower()
33 return new_df
34
35
36 # [END dataframe_example_1]
37
38
39 @dag(
40 start_date=datetime(2021, 1, 1),
41 max_active_runs=1,
42 schedule_interval="@daily",
43 default_args={
44 "email_on_failure": False,
45 "retries": 0,
46 "retry_delay": timedelta(minutes=5),
47 },
48 catchup=False,
49 )
50 def example_amazon_s3_snowflake_transform():
51
52 s3_bucket = os.getenv("S3_BUCKET", "s3://tmp9")
53
54 input_table_1 = Table(
55 name="ADOPTION_CENTER_1",
56 metadata=Metadata(
57 database=os.environ["SNOWFLAKE_DATABASE"],
58 schema=os.environ["SNOWFLAKE_SCHEMA"],
59 ),
60 conn_id="snowflake_conn",
61 )
62 # [START metadata_example_snowflake]
63 input_table_2 = Table(
64 name="ADOPTION_CENTER_2",
65 metadata=Metadata(
66 database=os.environ["SNOWFLAKE_DATABASE"],
67 schema=os.environ["SNOWFLAKE_SCHEMA"],
68 ),
69 conn_id="snowflake_conn",
70 )
71 # [END metadata_example_snowflake]
72
73 temp_table_1 = aql.load_file(
74 input_file=File(path=f"{s3_bucket}/ADOPTION_CENTER_1_unquoted.csv"),
75 output_table=input_table_1,
76 )
77 temp_table_2 = aql.load_file(
78 input_file=File(path=f"{s3_bucket}/ADOPTION_CENTER_2_unquoted.csv"),
79 output_table=input_table_2,
80 )
81
82 combined_data = combine_data(
83 center_1=temp_table_1,
84 center_2=temp_table_2,
85 )
86
87 cleaned_data = clean_data(combined_data)
88 # [START dataframe_example_2]
89 aggregate_data(
90 cleaned_data,
91 output_table=Table(
92 name="aggregated_adoptions_" + str(int(time.time())),
93 metadata=Metadata(
94 schema=os.environ["SNOWFLAKE_SCHEMA"],
95 database=os.environ["SNOWFLAKE_DATABASE"],
96 ),
97 conn_id="snowflake_conn",
98 ),
99 )
100 # [END dataframe_example_2]
101 aql.cleanup()
102
103
104 dag = example_amazon_s3_snowflake_transform()
105
[end of python-sdk/example_dags/example_amazon_s3_snowflake_transform.py]
[start of python-sdk/example_dags/example_snowflake_partial_table_with_append.py]
1 """
2 Example ETL DAG highlighting Astro functionality
3 DAG requires 2 "Homes" csv's (found in this repo), and a supported database
4 General flow of the DAG is to extract the data from csv's and combine using SQL,
5 then switch to Python for a melt transformation, then back to SQL for final
6 filtering. The data is then loaded by appending to an existing reporting table.
7
8 This example DAG creates the reporting table & truncates it by the end of the execution.
9 """
10
11 import os
12 from datetime import datetime
13
14 import pandas as pd
15 from airflow.decorators import dag
16
17 from astro.files import File
18 from astro.sql import append, cleanup, dataframe, load_file, run_raw_sql, transform
19 from astro.table import Metadata, Table
20
21 SNOWFLAKE_CONN_ID = "snowflake_conn"
22 dir_path = os.path.dirname(os.path.realpath(__file__))
23
24 FILE_PATH = dir_path + "/data/"
25
26
27 # The first transformation combines data from the two source csv's
28 @transform
29 def extract_data(homes1: Table, homes2: Table):
30 return """
31 SELECT *
32 FROM {{homes1}}
33 UNION
34 SELECT *
35 FROM {{homes2}}
36 """
37
38
39 # Switch to Python (Pandas) for melting transformation to get data into long format
40 @dataframe
41 def transform_data(df: pd.DataFrame):
42 df.columns = df.columns.str.lower()
43 melted_df = df.melt(id_vars=["sell", "list"], value_vars=["living", "rooms", "beds", "baths", "age"])
44
45 return melted_df
46
47
48 # Back to SQL to filter data
49 @transform
50 def filter_data(homes_long: Table):
51 return """
52 SELECT *
53 FROM {{homes_long}}
54 WHERE SELL > 200
55 """
56
57
58 # [START howto_run_raw_sql_snowflake_1]
59 @run_raw_sql
60 def create_table(table: Table):
61 """Create the reporting data which will be the target of the append method"""
62 return """
63 CREATE TABLE IF NOT EXISTS {{table}} (
64 sell number,
65 list number,
66 variable varchar,
67 value number
68 );
69 """
70
71
72 @dag(start_date=datetime(2021, 12, 1), schedule_interval="@daily", catchup=False)
73 def example_snowflake_partial_table_with_append():
74 homes_reporting = Table(conn_id=SNOWFLAKE_CONN_ID)
75 create_results_table = create_table(table=homes_reporting, conn_id=SNOWFLAKE_CONN_ID)
76 # [END howto_run_raw_sql_snowflake_1]
77
78 # Initial load of homes data csv's into Snowflake
79 homes_data1 = load_file(
80 input_file=File(path=FILE_PATH + "homes.csv"),
81 output_table=Table(
82 conn_id=SNOWFLAKE_CONN_ID,
83 metadata=Metadata(
84 database=os.getenv("SNOWFLAKE_DATABASE"),
85 schema=os.getenv("SNOWFLAKE_SCHEMA"),
86 ),
87 ),
88 )
89
90 homes_data2 = load_file(
91 input_file=File(path=FILE_PATH + "homes2.csv"),
92 output_table=Table(
93 conn_id=SNOWFLAKE_CONN_ID,
94 metadata=Metadata(
95 database=os.getenv("SNOWFLAKE_DATABASE"),
96 schema=os.getenv("SNOWFLAKE_SCHEMA"),
97 ),
98 ),
99 )
100
101 # Define task dependencies
102 extracted_data = extract_data(
103 homes1=homes_data1,
104 homes2=homes_data2,
105 output_table=Table(name="combined_homes_data"),
106 )
107
108 transformed_data = transform_data(df=extracted_data, output_table=Table(name="homes_data_long"))
109
110 filtered_data = filter_data(
111 homes_long=transformed_data,
112 output_table=Table(),
113 )
114
115 # Append transformed & filtered data to reporting table
116 # Dependency is inferred by passing the previous `filtered_data` task to `append_table` param
117 # [START append_example_with_columns_list]
118 record_results = append(
119 source_table=filtered_data,
120 target_table=homes_reporting,
121 columns=["sell", "list", "variable", "value"],
122 )
123 # [END append_example_with_columns_list]
124 record_results.set_upstream(create_results_table)
125
126 cleanup()
127
128
129 example_snowflake_partial_table_dag = example_snowflake_partial_table_with_append()
130
[end of python-sdk/example_dags/example_snowflake_partial_table_with_append.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/python-sdk/example_dags/example_amazon_s3_snowflake_transform.py b/python-sdk/example_dags/example_amazon_s3_snowflake_transform.py
--- a/python-sdk/example_dags/example_amazon_s3_snowflake_transform.py
+++ b/python-sdk/example_dags/example_amazon_s3_snowflake_transform.py
@@ -52,21 +52,23 @@
s3_bucket = os.getenv("S3_BUCKET", "s3://tmp9")
input_table_1 = Table(
- name="ADOPTION_CENTER_1",
+ name="ADOPTION_CENTER_1_" + str(int(time.time())),
metadata=Metadata(
database=os.environ["SNOWFLAKE_DATABASE"],
schema=os.environ["SNOWFLAKE_SCHEMA"],
),
conn_id="snowflake_conn",
+ temp=True,
)
# [START metadata_example_snowflake]
input_table_2 = Table(
- name="ADOPTION_CENTER_2",
+ name="ADOPTION_CENTER_2_" + str(int(time.time())),
metadata=Metadata(
database=os.environ["SNOWFLAKE_DATABASE"],
schema=os.environ["SNOWFLAKE_SCHEMA"],
),
conn_id="snowflake_conn",
+ temp=True,
)
# [END metadata_example_snowflake]
@@ -86,16 +88,18 @@
cleaned_data = clean_data(combined_data)
# [START dataframe_example_2]
+ snowflake_output_table = Table(
+ name="aggregated_adoptions_" + str(int(time.time())),
+ metadata=Metadata(
+ schema=os.environ["SNOWFLAKE_SCHEMA"],
+ database=os.environ["SNOWFLAKE_DATABASE"],
+ ),
+ conn_id="snowflake_conn",
+ temp=True,
+ )
aggregate_data(
cleaned_data,
- output_table=Table(
- name="aggregated_adoptions_" + str(int(time.time())),
- metadata=Metadata(
- schema=os.environ["SNOWFLAKE_SCHEMA"],
- database=os.environ["SNOWFLAKE_DATABASE"],
- ),
- conn_id="snowflake_conn",
- ),
+ output_table=snowflake_output_table,
)
# [END dataframe_example_2]
aql.cleanup()
diff --git a/python-sdk/example_dags/example_snowflake_partial_table_with_append.py b/python-sdk/example_dags/example_snowflake_partial_table_with_append.py
--- a/python-sdk/example_dags/example_snowflake_partial_table_with_append.py
+++ b/python-sdk/example_dags/example_snowflake_partial_table_with_append.py
@@ -9,6 +9,7 @@
"""
import os
+import time
from datetime import datetime
import pandas as pd
@@ -60,7 +61,7 @@
def create_table(table: Table):
"""Create the reporting data which will be the target of the append method"""
return """
- CREATE TABLE IF NOT EXISTS {{table}} (
+ CREATE OR REPLACE TABLE {{table}} (
sell number,
list number,
variable varchar,
@@ -71,7 +72,7 @@
@dag(start_date=datetime(2021, 12, 1), schedule_interval="@daily", catchup=False)
def example_snowflake_partial_table_with_append():
- homes_reporting = Table(conn_id=SNOWFLAKE_CONN_ID)
+ homes_reporting = Table(name="homes_reporting_data", temp=True, conn_id=SNOWFLAKE_CONN_ID)
create_results_table = create_table(table=homes_reporting, conn_id=SNOWFLAKE_CONN_ID)
# [END howto_run_raw_sql_snowflake_1]
@@ -102,10 +103,12 @@
extracted_data = extract_data(
homes1=homes_data1,
homes2=homes_data2,
- output_table=Table(name="combined_homes_data"),
+ output_table=Table(name="combined_homes_data_" + str(int(time.time())), temp=True),
)
- transformed_data = transform_data(df=extracted_data, output_table=Table(name="homes_data_long"))
+ transformed_data = transform_data(
+ df=extracted_data, output_table=Table(name="homes_data_long_" + str(int(time.time())), temp=True)
+ )
filtered_data = filter_data(
homes_long=transformed_data,
|
{"golden_diff": "diff --git a/python-sdk/example_dags/example_amazon_s3_snowflake_transform.py b/python-sdk/example_dags/example_amazon_s3_snowflake_transform.py\n--- a/python-sdk/example_dags/example_amazon_s3_snowflake_transform.py\n+++ b/python-sdk/example_dags/example_amazon_s3_snowflake_transform.py\n@@ -52,21 +52,23 @@\n s3_bucket = os.getenv(\"S3_BUCKET\", \"s3://tmp9\")\n \n input_table_1 = Table(\n- name=\"ADOPTION_CENTER_1\",\n+ name=\"ADOPTION_CENTER_1_\" + str(int(time.time())),\n metadata=Metadata(\n database=os.environ[\"SNOWFLAKE_DATABASE\"],\n schema=os.environ[\"SNOWFLAKE_SCHEMA\"],\n ),\n conn_id=\"snowflake_conn\",\n+ temp=True,\n )\n # [START metadata_example_snowflake]\n input_table_2 = Table(\n- name=\"ADOPTION_CENTER_2\",\n+ name=\"ADOPTION_CENTER_2_\" + str(int(time.time())),\n metadata=Metadata(\n database=os.environ[\"SNOWFLAKE_DATABASE\"],\n schema=os.environ[\"SNOWFLAKE_SCHEMA\"],\n ),\n conn_id=\"snowflake_conn\",\n+ temp=True,\n )\n # [END metadata_example_snowflake]\n \n@@ -86,16 +88,18 @@\n \n cleaned_data = clean_data(combined_data)\n # [START dataframe_example_2]\n+ snowflake_output_table = Table(\n+ name=\"aggregated_adoptions_\" + str(int(time.time())),\n+ metadata=Metadata(\n+ schema=os.environ[\"SNOWFLAKE_SCHEMA\"],\n+ database=os.environ[\"SNOWFLAKE_DATABASE\"],\n+ ),\n+ conn_id=\"snowflake_conn\",\n+ temp=True,\n+ )\n aggregate_data(\n cleaned_data,\n- output_table=Table(\n- name=\"aggregated_adoptions_\" + str(int(time.time())),\n- metadata=Metadata(\n- schema=os.environ[\"SNOWFLAKE_SCHEMA\"],\n- database=os.environ[\"SNOWFLAKE_DATABASE\"],\n- ),\n- conn_id=\"snowflake_conn\",\n- ),\n+ output_table=snowflake_output_table,\n )\n # [END dataframe_example_2]\n aql.cleanup()\ndiff --git a/python-sdk/example_dags/example_snowflake_partial_table_with_append.py b/python-sdk/example_dags/example_snowflake_partial_table_with_append.py\n--- a/python-sdk/example_dags/example_snowflake_partial_table_with_append.py\n+++ b/python-sdk/example_dags/example_snowflake_partial_table_with_append.py\n@@ -9,6 +9,7 @@\n \"\"\"\n \n import os\n+import time\n from datetime import datetime\n \n import pandas as pd\n@@ -60,7 +61,7 @@\n def create_table(table: Table):\n \"\"\"Create the reporting data which will be the target of the append method\"\"\"\n return \"\"\"\n- CREATE TABLE IF NOT EXISTS {{table}} (\n+ CREATE OR REPLACE TABLE {{table}} (\n sell number,\n list number,\n variable varchar,\n@@ -71,7 +72,7 @@\n \n @dag(start_date=datetime(2021, 12, 1), schedule_interval=\"@daily\", catchup=False)\n def example_snowflake_partial_table_with_append():\n- homes_reporting = Table(conn_id=SNOWFLAKE_CONN_ID)\n+ homes_reporting = Table(name=\"homes_reporting_data\", temp=True, conn_id=SNOWFLAKE_CONN_ID)\n create_results_table = create_table(table=homes_reporting, conn_id=SNOWFLAKE_CONN_ID)\n # [END howto_run_raw_sql_snowflake_1]\n \n@@ -102,10 +103,12 @@\n extracted_data = extract_data(\n homes1=homes_data1,\n homes2=homes_data2,\n- output_table=Table(name=\"combined_homes_data\"),\n+ output_table=Table(name=\"combined_homes_data_\" + str(int(time.time())), temp=True),\n )\n \n- transformed_data = transform_data(df=extracted_data, output_table=Table(name=\"homes_data_long\"))\n+ transformed_data = transform_data(\n+ df=extracted_data, output_table=Table(name=\"homes_data_long_\" + str(int(time.time())), temp=True)\n+ )\n \n filtered_data = filter_data(\n homes_long=transformed_data,\n", "issue": "CI: Fix Snowflake temp tables filling up\n@utkarsharma2 @sunank200 - Can one of you add more details to this -- we need to investigate and fix the tests that is filling up our Snowflake instances with tables\n", "before_files": [{"content": "import os\nimport time\nfrom datetime import datetime, timedelta\n\nimport pandas as pd\n\n# Uses data from https://www.kaggle.com/c/shelter-animal-outcomes\nfrom airflow.decorators import dag\n\nfrom astro import sql as aql\nfrom astro.files import File\nfrom astro.table import Metadata, Table\n\n\[email protected]()\ndef combine_data(center_1: Table, center_2: Table):\n return \"\"\"SELECT * FROM {{center_1}}\n UNION SELECT * FROM {{center_2}}\"\"\"\n\n\[email protected]()\ndef clean_data(input_table: Table):\n return \"\"\"SELECT *\n FROM {{input_table}} WHERE type NOT LIKE 'Guinea Pig'\n \"\"\"\n\n\n# [START dataframe_example_1]\[email protected](columns_names_capitalization=\"original\")\ndef aggregate_data(df: pd.DataFrame):\n new_df = df.pivot_table(index=\"date\", values=\"name\", columns=[\"type\"], aggfunc=\"count\").reset_index()\n new_df.columns = new_df.columns.str.lower()\n return new_df\n\n\n# [END dataframe_example_1]\n\n\n@dag(\n start_date=datetime(2021, 1, 1),\n max_active_runs=1,\n schedule_interval=\"@daily\",\n default_args={\n \"email_on_failure\": False,\n \"retries\": 0,\n \"retry_delay\": timedelta(minutes=5),\n },\n catchup=False,\n)\ndef example_amazon_s3_snowflake_transform():\n\n s3_bucket = os.getenv(\"S3_BUCKET\", \"s3://tmp9\")\n\n input_table_1 = Table(\n name=\"ADOPTION_CENTER_1\",\n metadata=Metadata(\n database=os.environ[\"SNOWFLAKE_DATABASE\"],\n schema=os.environ[\"SNOWFLAKE_SCHEMA\"],\n ),\n conn_id=\"snowflake_conn\",\n )\n # [START metadata_example_snowflake]\n input_table_2 = Table(\n name=\"ADOPTION_CENTER_2\",\n metadata=Metadata(\n database=os.environ[\"SNOWFLAKE_DATABASE\"],\n schema=os.environ[\"SNOWFLAKE_SCHEMA\"],\n ),\n conn_id=\"snowflake_conn\",\n )\n # [END metadata_example_snowflake]\n\n temp_table_1 = aql.load_file(\n input_file=File(path=f\"{s3_bucket}/ADOPTION_CENTER_1_unquoted.csv\"),\n output_table=input_table_1,\n )\n temp_table_2 = aql.load_file(\n input_file=File(path=f\"{s3_bucket}/ADOPTION_CENTER_2_unquoted.csv\"),\n output_table=input_table_2,\n )\n\n combined_data = combine_data(\n center_1=temp_table_1,\n center_2=temp_table_2,\n )\n\n cleaned_data = clean_data(combined_data)\n # [START dataframe_example_2]\n aggregate_data(\n cleaned_data,\n output_table=Table(\n name=\"aggregated_adoptions_\" + str(int(time.time())),\n metadata=Metadata(\n schema=os.environ[\"SNOWFLAKE_SCHEMA\"],\n database=os.environ[\"SNOWFLAKE_DATABASE\"],\n ),\n conn_id=\"snowflake_conn\",\n ),\n )\n # [END dataframe_example_2]\n aql.cleanup()\n\n\ndag = example_amazon_s3_snowflake_transform()\n", "path": "python-sdk/example_dags/example_amazon_s3_snowflake_transform.py"}, {"content": "\"\"\"\nExample ETL DAG highlighting Astro functionality\nDAG requires 2 \"Homes\" csv's (found in this repo), and a supported database\nGeneral flow of the DAG is to extract the data from csv's and combine using SQL,\nthen switch to Python for a melt transformation, then back to SQL for final\nfiltering. The data is then loaded by appending to an existing reporting table.\n\nThis example DAG creates the reporting table & truncates it by the end of the execution.\n\"\"\"\n\nimport os\nfrom datetime import datetime\n\nimport pandas as pd\nfrom airflow.decorators import dag\n\nfrom astro.files import File\nfrom astro.sql import append, cleanup, dataframe, load_file, run_raw_sql, transform\nfrom astro.table import Metadata, Table\n\nSNOWFLAKE_CONN_ID = \"snowflake_conn\"\ndir_path = os.path.dirname(os.path.realpath(__file__))\n\nFILE_PATH = dir_path + \"/data/\"\n\n\n# The first transformation combines data from the two source csv's\n@transform\ndef extract_data(homes1: Table, homes2: Table):\n return \"\"\"\n SELECT *\n FROM {{homes1}}\n UNION\n SELECT *\n FROM {{homes2}}\n \"\"\"\n\n\n# Switch to Python (Pandas) for melting transformation to get data into long format\n@dataframe\ndef transform_data(df: pd.DataFrame):\n df.columns = df.columns.str.lower()\n melted_df = df.melt(id_vars=[\"sell\", \"list\"], value_vars=[\"living\", \"rooms\", \"beds\", \"baths\", \"age\"])\n\n return melted_df\n\n\n# Back to SQL to filter data\n@transform\ndef filter_data(homes_long: Table):\n return \"\"\"\n SELECT *\n FROM {{homes_long}}\n WHERE SELL > 200\n \"\"\"\n\n\n# [START howto_run_raw_sql_snowflake_1]\n@run_raw_sql\ndef create_table(table: Table):\n \"\"\"Create the reporting data which will be the target of the append method\"\"\"\n return \"\"\"\n CREATE TABLE IF NOT EXISTS {{table}} (\n sell number,\n list number,\n variable varchar,\n value number\n );\n \"\"\"\n\n\n@dag(start_date=datetime(2021, 12, 1), schedule_interval=\"@daily\", catchup=False)\ndef example_snowflake_partial_table_with_append():\n homes_reporting = Table(conn_id=SNOWFLAKE_CONN_ID)\n create_results_table = create_table(table=homes_reporting, conn_id=SNOWFLAKE_CONN_ID)\n # [END howto_run_raw_sql_snowflake_1]\n\n # Initial load of homes data csv's into Snowflake\n homes_data1 = load_file(\n input_file=File(path=FILE_PATH + \"homes.csv\"),\n output_table=Table(\n conn_id=SNOWFLAKE_CONN_ID,\n metadata=Metadata(\n database=os.getenv(\"SNOWFLAKE_DATABASE\"),\n schema=os.getenv(\"SNOWFLAKE_SCHEMA\"),\n ),\n ),\n )\n\n homes_data2 = load_file(\n input_file=File(path=FILE_PATH + \"homes2.csv\"),\n output_table=Table(\n conn_id=SNOWFLAKE_CONN_ID,\n metadata=Metadata(\n database=os.getenv(\"SNOWFLAKE_DATABASE\"),\n schema=os.getenv(\"SNOWFLAKE_SCHEMA\"),\n ),\n ),\n )\n\n # Define task dependencies\n extracted_data = extract_data(\n homes1=homes_data1,\n homes2=homes_data2,\n output_table=Table(name=\"combined_homes_data\"),\n )\n\n transformed_data = transform_data(df=extracted_data, output_table=Table(name=\"homes_data_long\"))\n\n filtered_data = filter_data(\n homes_long=transformed_data,\n output_table=Table(),\n )\n\n # Append transformed & filtered data to reporting table\n # Dependency is inferred by passing the previous `filtered_data` task to `append_table` param\n # [START append_example_with_columns_list]\n record_results = append(\n source_table=filtered_data,\n target_table=homes_reporting,\n columns=[\"sell\", \"list\", \"variable\", \"value\"],\n )\n # [END append_example_with_columns_list]\n record_results.set_upstream(create_results_table)\n\n cleanup()\n\n\nexample_snowflake_partial_table_dag = example_snowflake_partial_table_with_append()\n", "path": "python-sdk/example_dags/example_snowflake_partial_table_with_append.py"}]}
| 2,747 | 945 |
gh_patches_debug_2450
|
rasdani/github-patches
|
git_diff
|
MAKENTNU__web-204
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fix delete permissions for course registration
</issue>
<code>
[start of make_queue/views/admin/course.py]
1 import io
2
3 import xlsxwriter
4 from django.contrib.auth.mixins import PermissionRequiredMixin
5 from django.db.models import Q
6 from django.http import HttpResponse
7 from django.shortcuts import redirect
8 from django.urls import reverse
9 from django.views.generic import TemplateView, View, CreateView, UpdateView, DeleteView
10
11 from make_queue.forms import Printer3DCourseForm
12 from make_queue.models.course import Printer3DCourse
13
14
15 class CourseView(TemplateView):
16 template_name = "make_queue/course/course_panel.html"
17
18 def get_context_data(self, **kwargs):
19 context_data = super().get_context_data(**kwargs)
20 context_data.update({
21 "registrations": Printer3DCourse.objects.order_by("name"),
22 "possible_statuses": Printer3DCourse.STATUS_CHOICES,
23 })
24 return context_data
25
26
27 class CreateRegistrationView(PermissionRequiredMixin, CreateView):
28 is_next = False
29 model = Printer3DCourse
30 form_class = Printer3DCourseForm
31 template_name = "make_queue/course/registration_create.html"
32 permission_required = (
33 "make_queue.add_printer3dcourse",
34 )
35
36 def get_context_data(self, **kwargs):
37 context_data = super().get_context_data(**kwargs)
38 if self.is_next:
39 context_data["is_next"] = True
40 return context_data
41
42 def get_success_url(self):
43 return reverse("create_course_registration_success")
44
45
46 class EditRegistrationView(PermissionRequiredMixin, UpdateView):
47 model = Printer3DCourse
48 form_class = Printer3DCourseForm
49 template_name = "make_queue/course/registration_edit.html"
50 permission_required = (
51 "make_queue.change_printer3dcourse",
52 )
53
54 def get_success_url(self):
55 return reverse("course_panel")
56
57
58 class DeleteRegistrationView(PermissionRequiredMixin, DeleteView):
59 model = Printer3DCourse
60 permission_required = (
61 "make_queue.delete_printer3d_course",
62 )
63
64 def get_success_url(self):
65 return reverse("course_panel")
66
67
68 class BulkStatusUpdate(View):
69 """
70 Provides a method for bulk updating the status of course registrations
71 """
72
73 def post(self, request):
74 status = request.POST.get("status")
75 registrations = list(map(int, request.POST.getlist("users")))
76 Printer3DCourse.objects.filter(pk__in=registrations).update(status=status)
77
78 return redirect("course_panel")
79
80
81 class CourseXLSXView(View):
82
83 def post(self, request):
84 search_string = request.POST.get("search_text")
85 status_filter = request.POST.get("status_filter")
86
87 course_registrations = Printer3DCourse.objects.filter(
88 Q(username__icontains=search_string) | Q(name__icontains=search_string), status__icontains=status_filter)
89
90 # Use an in-memory output file, to avoid having to clean up the disk
91 output_file = io.BytesIO()
92
93 workbook = xlsxwriter.Workbook(output_file, {"in_memory": True})
94 worksheet = workbook.add_worksheet("Kursdeltagere")
95
96 # Styles
97 format_header = workbook.add_format({
98 "bold": True,
99 "font_size": 10,
100 "font_name": "Arial",
101 "font_color": "#000000",
102 "bg_color": "#f8c700",
103 "border": 1,
104 "border_color": "#000000",
105 })
106
107 format_row = workbook.add_format({
108 "font_size": 10,
109 "font_name": "Arial",
110 "font_color": "#000000",
111 "bg_color": "#fff2cc",
112 "border": 1,
113 "border_color": "#000000",
114 })
115
116 # Set column width
117 worksheet.set_column("A:A", 40)
118 worksheet.set_column("B:B", 20)
119 worksheet.set_column("C:C", 15)
120 worksheet.set_column("D:D", 10)
121
122 # Header
123 worksheet.write(0, 0, "Navn", format_header)
124 worksheet.write(0, 1, "Brukernavn", format_header)
125 worksheet.write(0, 2, "Kortnummer", format_header)
126 worksheet.write(0, 3, "Dato", format_header)
127
128 for index, registration in enumerate(course_registrations):
129 worksheet.write(index + 1, 0, registration.name, format_row)
130 worksheet.write(index + 1, 1, registration.username, format_row)
131 worksheet.write(index + 1, 2, registration.card_number if registration.card_number is not None else "",
132 format_row)
133 worksheet.write(index + 1, 3, registration.date.strftime("%Y-%m-%d"), format_row)
134
135 workbook.close()
136 output_file.seek(0)
137
138 response = HttpResponse(output_file.read(),
139 content_type="application/vnd.openxmlformats-officedocument.spreadsheetml.sheet")
140
141 response['Content-Disposition'] = 'attachment; filename="Kursdeltagere.xlsx"'
142
143 return response
144
[end of make_queue/views/admin/course.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/make_queue/views/admin/course.py b/make_queue/views/admin/course.py
--- a/make_queue/views/admin/course.py
+++ b/make_queue/views/admin/course.py
@@ -58,7 +58,7 @@
class DeleteRegistrationView(PermissionRequiredMixin, DeleteView):
model = Printer3DCourse
permission_required = (
- "make_queue.delete_printer3d_course",
+ "make_queue.delete_printer3dcourse",
)
def get_success_url(self):
|
{"golden_diff": "diff --git a/make_queue/views/admin/course.py b/make_queue/views/admin/course.py\n--- a/make_queue/views/admin/course.py\n+++ b/make_queue/views/admin/course.py\n@@ -58,7 +58,7 @@\n class DeleteRegistrationView(PermissionRequiredMixin, DeleteView):\n model = Printer3DCourse\n permission_required = (\n- \"make_queue.delete_printer3d_course\",\n+ \"make_queue.delete_printer3dcourse\",\n )\n \n def get_success_url(self):\n", "issue": "Fix delete permissions for course registration\n\n", "before_files": [{"content": "import io\n\nimport xlsxwriter\nfrom django.contrib.auth.mixins import PermissionRequiredMixin\nfrom django.db.models import Q\nfrom django.http import HttpResponse\nfrom django.shortcuts import redirect\nfrom django.urls import reverse\nfrom django.views.generic import TemplateView, View, CreateView, UpdateView, DeleteView\n\nfrom make_queue.forms import Printer3DCourseForm\nfrom make_queue.models.course import Printer3DCourse\n\n\nclass CourseView(TemplateView):\n template_name = \"make_queue/course/course_panel.html\"\n\n def get_context_data(self, **kwargs):\n context_data = super().get_context_data(**kwargs)\n context_data.update({\n \"registrations\": Printer3DCourse.objects.order_by(\"name\"),\n \"possible_statuses\": Printer3DCourse.STATUS_CHOICES,\n })\n return context_data\n\n\nclass CreateRegistrationView(PermissionRequiredMixin, CreateView):\n is_next = False\n model = Printer3DCourse\n form_class = Printer3DCourseForm\n template_name = \"make_queue/course/registration_create.html\"\n permission_required = (\n \"make_queue.add_printer3dcourse\",\n )\n\n def get_context_data(self, **kwargs):\n context_data = super().get_context_data(**kwargs)\n if self.is_next:\n context_data[\"is_next\"] = True\n return context_data\n\n def get_success_url(self):\n return reverse(\"create_course_registration_success\")\n\n\nclass EditRegistrationView(PermissionRequiredMixin, UpdateView):\n model = Printer3DCourse\n form_class = Printer3DCourseForm\n template_name = \"make_queue/course/registration_edit.html\"\n permission_required = (\n \"make_queue.change_printer3dcourse\",\n )\n\n def get_success_url(self):\n return reverse(\"course_panel\")\n\n\nclass DeleteRegistrationView(PermissionRequiredMixin, DeleteView):\n model = Printer3DCourse\n permission_required = (\n \"make_queue.delete_printer3d_course\",\n )\n\n def get_success_url(self):\n return reverse(\"course_panel\")\n\n\nclass BulkStatusUpdate(View):\n \"\"\"\n Provides a method for bulk updating the status of course registrations\n \"\"\"\n\n def post(self, request):\n status = request.POST.get(\"status\")\n registrations = list(map(int, request.POST.getlist(\"users\")))\n Printer3DCourse.objects.filter(pk__in=registrations).update(status=status)\n\n return redirect(\"course_panel\")\n\n\nclass CourseXLSXView(View):\n\n def post(self, request):\n search_string = request.POST.get(\"search_text\")\n status_filter = request.POST.get(\"status_filter\")\n\n course_registrations = Printer3DCourse.objects.filter(\n Q(username__icontains=search_string) | Q(name__icontains=search_string), status__icontains=status_filter)\n\n # Use an in-memory output file, to avoid having to clean up the disk\n output_file = io.BytesIO()\n\n workbook = xlsxwriter.Workbook(output_file, {\"in_memory\": True})\n worksheet = workbook.add_worksheet(\"Kursdeltagere\")\n\n # Styles\n format_header = workbook.add_format({\n \"bold\": True,\n \"font_size\": 10,\n \"font_name\": \"Arial\",\n \"font_color\": \"#000000\",\n \"bg_color\": \"#f8c700\",\n \"border\": 1,\n \"border_color\": \"#000000\",\n })\n\n format_row = workbook.add_format({\n \"font_size\": 10,\n \"font_name\": \"Arial\",\n \"font_color\": \"#000000\",\n \"bg_color\": \"#fff2cc\",\n \"border\": 1,\n \"border_color\": \"#000000\",\n })\n\n # Set column width\n worksheet.set_column(\"A:A\", 40)\n worksheet.set_column(\"B:B\", 20)\n worksheet.set_column(\"C:C\", 15)\n worksheet.set_column(\"D:D\", 10)\n\n # Header\n worksheet.write(0, 0, \"Navn\", format_header)\n worksheet.write(0, 1, \"Brukernavn\", format_header)\n worksheet.write(0, 2, \"Kortnummer\", format_header)\n worksheet.write(0, 3, \"Dato\", format_header)\n\n for index, registration in enumerate(course_registrations):\n worksheet.write(index + 1, 0, registration.name, format_row)\n worksheet.write(index + 1, 1, registration.username, format_row)\n worksheet.write(index + 1, 2, registration.card_number if registration.card_number is not None else \"\",\n format_row)\n worksheet.write(index + 1, 3, registration.date.strftime(\"%Y-%m-%d\"), format_row)\n\n workbook.close()\n output_file.seek(0)\n\n response = HttpResponse(output_file.read(),\n content_type=\"application/vnd.openxmlformats-officedocument.spreadsheetml.sheet\")\n\n response['Content-Disposition'] = 'attachment; filename=\"Kursdeltagere.xlsx\"'\n\n return response\n", "path": "make_queue/views/admin/course.py"}]}
| 1,957 | 108 |
gh_patches_debug_10211
|
rasdani/github-patches
|
git_diff
|
google__clusterfuzz-189
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
linting in CI works differently than locally
I'm pretty sure it is pylint 1.9.4.
See https://github.com/google/clusterfuzz/pull/185 for a discrepancy I noticed between running pylint locally and running it in CI.
When I upgraded my local copy of pylint to 1.9.4 I was able to discover the issue showing up in CI.
</issue>
<code>
[start of src/local/butler/lint.py]
1 # Copyright 2019 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 """Lint changed code in current branch."""
15
16 import os
17 import sys
18
19 from local.butler import common
20
21
22 def execute(_):
23 """Lint changed code."""
24 if "GOOGLE_CLOUDBUILD" in os.environ:
25 # Explicitly compare against master if we're running on the CI
26 _, output = common.execute('git diff --name-only master FETCH_HEAD')
27 else:
28 _, output = common.execute('git diff --name-only FETCH_HEAD')
29
30 py_changed_file_paths = [
31 f for f in output.splitlines() if f.endswith('.py') and
32 # Exclude auto-generated files.
33 not f.endswith('_pb2.py') and not f.endswith('_pb2_grpc.py')
34 ]
35 go_changed_file_paths = [f for f in output.splitlines() if f.endswith('.go')]
36
37 for file_path in py_changed_file_paths:
38 if os.path.exists(file_path):
39 common.execute('pylint ' + file_path)
40 common.execute('yapf -d ' + file_path)
41
42 golint_path = os.path.join('local', 'bin', 'golint')
43 for file_path in go_changed_file_paths:
44 if os.path.exists(file_path):
45 common.execute(golint_path + ' ' + file_path)
46
47 _, output = common.execute('gofmt -d ' + file_path)
48 if output.strip():
49 sys.exit(1)
50
[end of src/local/butler/lint.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/local/butler/lint.py b/src/local/butler/lint.py
--- a/src/local/butler/lint.py
+++ b/src/local/butler/lint.py
@@ -16,11 +16,15 @@
import os
import sys
+from local.butler import appengine
from local.butler import common
def execute(_):
"""Lint changed code."""
+ pythonpath = os.getenv('PYTHONPATH', '')
+ os.environ['PYTHONPATH'] = appengine.find_sdk_path() + ':' + pythonpath
+
if "GOOGLE_CLOUDBUILD" in os.environ:
# Explicitly compare against master if we're running on the CI
_, output = common.execute('git diff --name-only master FETCH_HEAD')
|
{"golden_diff": "diff --git a/src/local/butler/lint.py b/src/local/butler/lint.py\n--- a/src/local/butler/lint.py\n+++ b/src/local/butler/lint.py\n@@ -16,11 +16,15 @@\n import os\n import sys\n \n+from local.butler import appengine\n from local.butler import common\n \n \n def execute(_):\n \"\"\"Lint changed code.\"\"\"\n+ pythonpath = os.getenv('PYTHONPATH', '')\n+ os.environ['PYTHONPATH'] = appengine.find_sdk_path() + ':' + pythonpath\n+\n if \"GOOGLE_CLOUDBUILD\" in os.environ:\n # Explicitly compare against master if we're running on the CI\n _, output = common.execute('git diff --name-only master FETCH_HEAD')\n", "issue": "linting in CI works differently than locally\nI'm pretty sure it is pylint 1.9.4.\r\nSee https://github.com/google/clusterfuzz/pull/185 for a discrepancy I noticed between running pylint locally and running it in CI.\r\n\r\nWhen I upgraded my local copy of pylint to 1.9.4 I was able to discover the issue showing up in CI.\n", "before_files": [{"content": "# Copyright 2019 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Lint changed code in current branch.\"\"\"\n\nimport os\nimport sys\n\nfrom local.butler import common\n\n\ndef execute(_):\n \"\"\"Lint changed code.\"\"\"\n if \"GOOGLE_CLOUDBUILD\" in os.environ:\n # Explicitly compare against master if we're running on the CI\n _, output = common.execute('git diff --name-only master FETCH_HEAD')\n else:\n _, output = common.execute('git diff --name-only FETCH_HEAD')\n\n py_changed_file_paths = [\n f for f in output.splitlines() if f.endswith('.py') and\n # Exclude auto-generated files.\n not f.endswith('_pb2.py') and not f.endswith('_pb2_grpc.py')\n ]\n go_changed_file_paths = [f for f in output.splitlines() if f.endswith('.go')]\n\n for file_path in py_changed_file_paths:\n if os.path.exists(file_path):\n common.execute('pylint ' + file_path)\n common.execute('yapf -d ' + file_path)\n\n golint_path = os.path.join('local', 'bin', 'golint')\n for file_path in go_changed_file_paths:\n if os.path.exists(file_path):\n common.execute(golint_path + ' ' + file_path)\n\n _, output = common.execute('gofmt -d ' + file_path)\n if output.strip():\n sys.exit(1)\n", "path": "src/local/butler/lint.py"}]}
| 1,142 | 171 |
gh_patches_debug_23546
|
rasdani/github-patches
|
git_diff
|
feast-dev__feast-1550
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
feast cli minor bug
## Expected Behavior
`feast teardown --help` should list the options to this subcommand like
> (feast) ➜ examples git:(br_jsd_mlflow_feast_example) ✗ feast init --help
> Usage: feast init [OPTIONS] [PROJECT_DIRECTORY]
>
> Create a new Feast repository
>
> Options:
> -m, --minimal Create an empty project repository
> -t, --template [local|gcp] Specify a template for the created project
> --help Show this message and exit.
## Current Behavior
> (base) ➜ delta-lake git:(master) ✗ feast teardown --help
> Usage: feast teardown [OPTIONS]
>
> Tear down deployed feature store infrastructure
>
> Options:
> --help Show this message and exit.
I reckon this is a generic message if the subcommand has not options. For example, `feast apply --help` exhibits similar
behavior.
## Steps to reproduce
`feast teardown --help`
### Specifications
- Version: 0.10.3
- Platform: MacOS Mojave
- Subsystem:
</issue>
<code>
[start of sdk/python/feast/cli.py]
1 # Copyright 2019 The Feast Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import logging
16 from datetime import datetime
17 from pathlib import Path
18 from typing import List
19
20 import click
21 import pkg_resources
22 import yaml
23
24 from feast.errors import FeastObjectNotFoundException, FeastProviderLoginError
25 from feast.feature_store import FeatureStore
26 from feast.repo_config import load_repo_config
27 from feast.repo_operations import (
28 apply_total,
29 cli_check_repo,
30 generate_project_name,
31 init_repo,
32 registry_dump,
33 teardown,
34 )
35 from feast.telemetry import Telemetry
36
37 _logger = logging.getLogger(__name__)
38 DATETIME_ISO = "%Y-%m-%dT%H:%M:%s"
39
40
41 @click.group()
42 @click.option(
43 "--chdir",
44 "-c",
45 help="Switch to a different feature repository directory before executing the given subcommand.",
46 )
47 @click.pass_context
48 def cli(ctx: click.Context, chdir: str):
49 """
50 Feast CLI
51
52 For more information, see our public docs at https://docs.feast.dev/
53
54 For any questions, you can reach us at https://slack.feast.dev/
55 """
56 ctx.ensure_object(dict)
57 ctx.obj["CHDIR"] = Path.cwd() if chdir is None else Path(chdir).absolute()
58 pass
59
60
61 @cli.command()
62 def version():
63 """
64 Display Feast SDK version
65 """
66 print(f'Feast SDK Version: "{pkg_resources.get_distribution("feast")}"')
67
68
69 @cli.group(name="entities")
70 def entities_cmd():
71 """
72 Access entities
73 """
74 pass
75
76
77 @entities_cmd.command("describe")
78 @click.argument("name", type=click.STRING)
79 @click.pass_context
80 def entity_describe(ctx: click.Context, name: str):
81 """
82 Describe an entity
83 """
84 repo = ctx.obj["CHDIR"]
85 cli_check_repo(repo)
86 store = FeatureStore(repo_path=str(repo))
87
88 try:
89 entity = store.get_entity(name)
90 except FeastObjectNotFoundException as e:
91 print(e)
92 exit(1)
93
94 print(
95 yaml.dump(
96 yaml.safe_load(str(entity)), default_flow_style=False, sort_keys=False
97 )
98 )
99
100
101 @entities_cmd.command(name="list")
102 @click.pass_context
103 def entity_list(ctx: click.Context):
104 """
105 List all entities
106 """
107 repo = ctx.obj["CHDIR"]
108 cli_check_repo(repo)
109 store = FeatureStore(repo_path=str(repo))
110 table = []
111 for entity in store.list_entities():
112 table.append([entity.name, entity.description, entity.value_type])
113
114 from tabulate import tabulate
115
116 print(tabulate(table, headers=["NAME", "DESCRIPTION", "TYPE"], tablefmt="plain"))
117
118
119 @cli.group(name="feature-views")
120 def feature_views_cmd():
121 """
122 Access feature views
123 """
124 pass
125
126
127 @feature_views_cmd.command("describe")
128 @click.argument("name", type=click.STRING)
129 @click.pass_context
130 def feature_view_describe(ctx: click.Context, name: str):
131 """
132 Describe a feature view
133 """
134 repo = ctx.obj["CHDIR"]
135 cli_check_repo(repo)
136 store = FeatureStore(repo_path=str(repo))
137
138 try:
139 feature_view = store.get_feature_view(name)
140 except FeastObjectNotFoundException as e:
141 print(e)
142 exit(1)
143
144 print(
145 yaml.dump(
146 yaml.safe_load(str(feature_view)), default_flow_style=False, sort_keys=False
147 )
148 )
149
150
151 @feature_views_cmd.command(name="list")
152 @click.pass_context
153 def feature_view_list(ctx: click.Context):
154 """
155 List all feature views
156 """
157 repo = ctx.obj["CHDIR"]
158 cli_check_repo(repo)
159 store = FeatureStore(repo_path=str(repo))
160 table = []
161 for feature_view in store.list_feature_views():
162 table.append([feature_view.name, feature_view.entities])
163
164 from tabulate import tabulate
165
166 print(tabulate(table, headers=["NAME", "ENTITIES"], tablefmt="plain"))
167
168
169 @cli.command("apply")
170 @click.pass_context
171 def apply_total_command(ctx: click.Context):
172 """
173 Create or update a feature store deployment
174 """
175 repo = ctx.obj["CHDIR"]
176 cli_check_repo(repo)
177 repo_config = load_repo_config(repo)
178 tele = Telemetry()
179 tele.log("apply")
180 try:
181 apply_total(repo_config, repo)
182 except FeastProviderLoginError as e:
183 print(str(e))
184
185
186 @cli.command("teardown")
187 @click.pass_context
188 def teardown_command(ctx: click.Context):
189 """
190 Tear down deployed feature store infrastructure
191 """
192 repo = ctx.obj["CHDIR"]
193 cli_check_repo(repo)
194 repo_config = load_repo_config(repo)
195 tele = Telemetry()
196 tele.log("teardown")
197
198 teardown(repo_config, repo)
199
200
201 @cli.command("registry-dump")
202 @click.pass_context
203 def registry_dump_command(ctx: click.Context):
204 """
205 Print contents of the metadata registry
206 """
207 repo = ctx.obj["CHDIR"]
208 cli_check_repo(repo)
209 repo_config = load_repo_config(repo)
210 tele = Telemetry()
211 tele.log("registry-dump")
212
213 registry_dump(repo_config, repo_path=repo)
214
215
216 @cli.command("materialize")
217 @click.argument("start_ts")
218 @click.argument("end_ts")
219 @click.option(
220 "--views", "-v", help="Feature views to materialize", multiple=True,
221 )
222 @click.pass_context
223 def materialize_command(
224 ctx: click.Context, start_ts: str, end_ts: str, views: List[str]
225 ):
226 """
227 Run a (non-incremental) materialization job to ingest data into the online store. Feast
228 will read all data between START_TS and END_TS from the offline store and write it to the
229 online store. If you don't specify feature view names using --views, all registered Feature
230 Views will be materialized.
231
232 START_TS and END_TS should be in ISO 8601 format, e.g. '2021-07-16T19:20:01'
233 """
234 repo = ctx.obj["CHDIR"]
235 cli_check_repo(repo)
236 store = FeatureStore(repo_path=str(repo))
237 store.materialize(
238 feature_views=None if not views else views,
239 start_date=datetime.fromisoformat(start_ts),
240 end_date=datetime.fromisoformat(end_ts),
241 )
242
243
244 @cli.command("materialize-incremental")
245 @click.argument("end_ts")
246 @click.option(
247 "--views", "-v", help="Feature views to incrementally materialize", multiple=True,
248 )
249 @click.pass_context
250 def materialize_incremental_command(ctx: click.Context, end_ts: str, views: List[str]):
251 """
252 Run an incremental materialization job to ingest new data into the online store. Feast will read
253 all data from the previously ingested point to END_TS from the offline store and write it to the
254 online store. If you don't specify feature view names using --views, all registered Feature
255 Views will be incrementally materialized.
256
257 END_TS should be in ISO 8601 format, e.g. '2021-07-16T19:20:01'
258 """
259 repo = ctx.obj["CHDIR"]
260 cli_check_repo(repo)
261 store = FeatureStore(repo_path=str(repo))
262 store.materialize_incremental(
263 feature_views=None if not views else views,
264 end_date=datetime.fromisoformat(end_ts),
265 )
266
267
268 @cli.command("init")
269 @click.argument("PROJECT_DIRECTORY", required=False)
270 @click.option(
271 "--minimal", "-m", is_flag=True, help="Create an empty project repository"
272 )
273 @click.option(
274 "--template",
275 "-t",
276 type=click.Choice(["local", "gcp"], case_sensitive=False),
277 help="Specify a template for the created project",
278 default="local",
279 )
280 def init_command(project_directory, minimal: bool, template: str):
281 """Create a new Feast repository"""
282 if not project_directory:
283 project_directory = generate_project_name()
284
285 if minimal:
286 template = "minimal"
287
288 tele = Telemetry()
289 tele.log("init")
290 init_repo(project_directory, template)
291
292
293 if __name__ == "__main__":
294 cli()
295
[end of sdk/python/feast/cli.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sdk/python/feast/cli.py b/sdk/python/feast/cli.py
--- a/sdk/python/feast/cli.py
+++ b/sdk/python/feast/cli.py
@@ -38,6 +38,19 @@
DATETIME_ISO = "%Y-%m-%dT%H:%M:%s"
+class NoOptionDefaultFormat(click.Command):
+ def format_options(self, ctx: click.Context, formatter: click.HelpFormatter):
+ """Writes all the options into the formatter if they exist."""
+ opts = []
+ for param in self.get_params(ctx):
+ rv = param.get_help_record(ctx)
+ if rv is not None:
+ opts.append(rv)
+ if opts:
+ with formatter.section("Options(No current command options)"):
+ formatter.write_dl(opts)
+
+
@click.group()
@click.option(
"--chdir",
@@ -166,7 +179,7 @@
print(tabulate(table, headers=["NAME", "ENTITIES"], tablefmt="plain"))
[email protected]("apply")
[email protected]("apply", cls=NoOptionDefaultFormat)
@click.pass_context
def apply_total_command(ctx: click.Context):
"""
@@ -183,7 +196,7 @@
print(str(e))
[email protected]("teardown")
[email protected]("teardown", cls=NoOptionDefaultFormat)
@click.pass_context
def teardown_command(ctx: click.Context):
"""
|
{"golden_diff": "diff --git a/sdk/python/feast/cli.py b/sdk/python/feast/cli.py\n--- a/sdk/python/feast/cli.py\n+++ b/sdk/python/feast/cli.py\n@@ -38,6 +38,19 @@\n DATETIME_ISO = \"%Y-%m-%dT%H:%M:%s\"\n \n \n+class NoOptionDefaultFormat(click.Command):\n+ def format_options(self, ctx: click.Context, formatter: click.HelpFormatter):\n+ \"\"\"Writes all the options into the formatter if they exist.\"\"\"\n+ opts = []\n+ for param in self.get_params(ctx):\n+ rv = param.get_help_record(ctx)\n+ if rv is not None:\n+ opts.append(rv)\n+ if opts:\n+ with formatter.section(\"Options(No current command options)\"):\n+ formatter.write_dl(opts)\n+\n+\n @click.group()\n @click.option(\n \"--chdir\",\n@@ -166,7 +179,7 @@\n print(tabulate(table, headers=[\"NAME\", \"ENTITIES\"], tablefmt=\"plain\"))\n \n \[email protected](\"apply\")\[email protected](\"apply\", cls=NoOptionDefaultFormat)\n @click.pass_context\n def apply_total_command(ctx: click.Context):\n \"\"\"\n@@ -183,7 +196,7 @@\n print(str(e))\n \n \[email protected](\"teardown\")\[email protected](\"teardown\", cls=NoOptionDefaultFormat)\n @click.pass_context\n def teardown_command(ctx: click.Context):\n \"\"\"\n", "issue": "feast cli minor bug\n## Expected Behavior \r\n\r\n`feast teardown --help` should list the options to this subcommand like\r\n\r\n> (feast) \u279c examples git:(br_jsd_mlflow_feast_example) \u2717 feast init --help\r\n> Usage: feast init [OPTIONS] [PROJECT_DIRECTORY]\r\n> \r\n> Create a new Feast repository\r\n> \r\n> Options:\r\n> -m, --minimal Create an empty project repository\r\n> -t, --template [local|gcp] Specify a template for the created project\r\n> --help Show this message and exit.\r\n\r\n## Current Behavior\r\n\r\n> (base) \u279c delta-lake git:(master) \u2717 feast teardown --help\r\n> Usage: feast teardown [OPTIONS]\r\n> \r\n> Tear down deployed feature store infrastructure\r\n> \r\n> Options:\r\n> --help Show this message and exit.\r\n\r\nI reckon this is a generic message if the subcommand has not options. For example, `feast apply --help` exhibits similar \r\nbehavior.\r\n\r\n## Steps to reproduce\r\n\r\n`feast teardown --help`\r\n\r\n### Specifications\r\n\r\n- Version: 0.10.3\r\n- Platform: MacOS Mojave\r\n- Subsystem:\r\n\r\n\n", "before_files": [{"content": "# Copyright 2019 The Feast Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport logging\nfrom datetime import datetime\nfrom pathlib import Path\nfrom typing import List\n\nimport click\nimport pkg_resources\nimport yaml\n\nfrom feast.errors import FeastObjectNotFoundException, FeastProviderLoginError\nfrom feast.feature_store import FeatureStore\nfrom feast.repo_config import load_repo_config\nfrom feast.repo_operations import (\n apply_total,\n cli_check_repo,\n generate_project_name,\n init_repo,\n registry_dump,\n teardown,\n)\nfrom feast.telemetry import Telemetry\n\n_logger = logging.getLogger(__name__)\nDATETIME_ISO = \"%Y-%m-%dT%H:%M:%s\"\n\n\[email protected]()\[email protected](\n \"--chdir\",\n \"-c\",\n help=\"Switch to a different feature repository directory before executing the given subcommand.\",\n)\[email protected]_context\ndef cli(ctx: click.Context, chdir: str):\n \"\"\"\n Feast CLI\n\n For more information, see our public docs at https://docs.feast.dev/\n\n For any questions, you can reach us at https://slack.feast.dev/\n \"\"\"\n ctx.ensure_object(dict)\n ctx.obj[\"CHDIR\"] = Path.cwd() if chdir is None else Path(chdir).absolute()\n pass\n\n\[email protected]()\ndef version():\n \"\"\"\n Display Feast SDK version\n \"\"\"\n print(f'Feast SDK Version: \"{pkg_resources.get_distribution(\"feast\")}\"')\n\n\[email protected](name=\"entities\")\ndef entities_cmd():\n \"\"\"\n Access entities\n \"\"\"\n pass\n\n\n@entities_cmd.command(\"describe\")\[email protected](\"name\", type=click.STRING)\[email protected]_context\ndef entity_describe(ctx: click.Context, name: str):\n \"\"\"\n Describe an entity\n \"\"\"\n repo = ctx.obj[\"CHDIR\"]\n cli_check_repo(repo)\n store = FeatureStore(repo_path=str(repo))\n\n try:\n entity = store.get_entity(name)\n except FeastObjectNotFoundException as e:\n print(e)\n exit(1)\n\n print(\n yaml.dump(\n yaml.safe_load(str(entity)), default_flow_style=False, sort_keys=False\n )\n )\n\n\n@entities_cmd.command(name=\"list\")\[email protected]_context\ndef entity_list(ctx: click.Context):\n \"\"\"\n List all entities\n \"\"\"\n repo = ctx.obj[\"CHDIR\"]\n cli_check_repo(repo)\n store = FeatureStore(repo_path=str(repo))\n table = []\n for entity in store.list_entities():\n table.append([entity.name, entity.description, entity.value_type])\n\n from tabulate import tabulate\n\n print(tabulate(table, headers=[\"NAME\", \"DESCRIPTION\", \"TYPE\"], tablefmt=\"plain\"))\n\n\[email protected](name=\"feature-views\")\ndef feature_views_cmd():\n \"\"\"\n Access feature views\n \"\"\"\n pass\n\n\n@feature_views_cmd.command(\"describe\")\[email protected](\"name\", type=click.STRING)\[email protected]_context\ndef feature_view_describe(ctx: click.Context, name: str):\n \"\"\"\n Describe a feature view\n \"\"\"\n repo = ctx.obj[\"CHDIR\"]\n cli_check_repo(repo)\n store = FeatureStore(repo_path=str(repo))\n\n try:\n feature_view = store.get_feature_view(name)\n except FeastObjectNotFoundException as e:\n print(e)\n exit(1)\n\n print(\n yaml.dump(\n yaml.safe_load(str(feature_view)), default_flow_style=False, sort_keys=False\n )\n )\n\n\n@feature_views_cmd.command(name=\"list\")\[email protected]_context\ndef feature_view_list(ctx: click.Context):\n \"\"\"\n List all feature views\n \"\"\"\n repo = ctx.obj[\"CHDIR\"]\n cli_check_repo(repo)\n store = FeatureStore(repo_path=str(repo))\n table = []\n for feature_view in store.list_feature_views():\n table.append([feature_view.name, feature_view.entities])\n\n from tabulate import tabulate\n\n print(tabulate(table, headers=[\"NAME\", \"ENTITIES\"], tablefmt=\"plain\"))\n\n\[email protected](\"apply\")\[email protected]_context\ndef apply_total_command(ctx: click.Context):\n \"\"\"\n Create or update a feature store deployment\n \"\"\"\n repo = ctx.obj[\"CHDIR\"]\n cli_check_repo(repo)\n repo_config = load_repo_config(repo)\n tele = Telemetry()\n tele.log(\"apply\")\n try:\n apply_total(repo_config, repo)\n except FeastProviderLoginError as e:\n print(str(e))\n\n\[email protected](\"teardown\")\[email protected]_context\ndef teardown_command(ctx: click.Context):\n \"\"\"\n Tear down deployed feature store infrastructure\n \"\"\"\n repo = ctx.obj[\"CHDIR\"]\n cli_check_repo(repo)\n repo_config = load_repo_config(repo)\n tele = Telemetry()\n tele.log(\"teardown\")\n\n teardown(repo_config, repo)\n\n\[email protected](\"registry-dump\")\[email protected]_context\ndef registry_dump_command(ctx: click.Context):\n \"\"\"\n Print contents of the metadata registry\n \"\"\"\n repo = ctx.obj[\"CHDIR\"]\n cli_check_repo(repo)\n repo_config = load_repo_config(repo)\n tele = Telemetry()\n tele.log(\"registry-dump\")\n\n registry_dump(repo_config, repo_path=repo)\n\n\[email protected](\"materialize\")\[email protected](\"start_ts\")\[email protected](\"end_ts\")\[email protected](\n \"--views\", \"-v\", help=\"Feature views to materialize\", multiple=True,\n)\[email protected]_context\ndef materialize_command(\n ctx: click.Context, start_ts: str, end_ts: str, views: List[str]\n):\n \"\"\"\n Run a (non-incremental) materialization job to ingest data into the online store. Feast\n will read all data between START_TS and END_TS from the offline store and write it to the\n online store. If you don't specify feature view names using --views, all registered Feature\n Views will be materialized.\n\n START_TS and END_TS should be in ISO 8601 format, e.g. '2021-07-16T19:20:01'\n \"\"\"\n repo = ctx.obj[\"CHDIR\"]\n cli_check_repo(repo)\n store = FeatureStore(repo_path=str(repo))\n store.materialize(\n feature_views=None if not views else views,\n start_date=datetime.fromisoformat(start_ts),\n end_date=datetime.fromisoformat(end_ts),\n )\n\n\[email protected](\"materialize-incremental\")\[email protected](\"end_ts\")\[email protected](\n \"--views\", \"-v\", help=\"Feature views to incrementally materialize\", multiple=True,\n)\[email protected]_context\ndef materialize_incremental_command(ctx: click.Context, end_ts: str, views: List[str]):\n \"\"\"\n Run an incremental materialization job to ingest new data into the online store. Feast will read\n all data from the previously ingested point to END_TS from the offline store and write it to the\n online store. If you don't specify feature view names using --views, all registered Feature\n Views will be incrementally materialized.\n\n END_TS should be in ISO 8601 format, e.g. '2021-07-16T19:20:01'\n \"\"\"\n repo = ctx.obj[\"CHDIR\"]\n cli_check_repo(repo)\n store = FeatureStore(repo_path=str(repo))\n store.materialize_incremental(\n feature_views=None if not views else views,\n end_date=datetime.fromisoformat(end_ts),\n )\n\n\[email protected](\"init\")\[email protected](\"PROJECT_DIRECTORY\", required=False)\[email protected](\n \"--minimal\", \"-m\", is_flag=True, help=\"Create an empty project repository\"\n)\[email protected](\n \"--template\",\n \"-t\",\n type=click.Choice([\"local\", \"gcp\"], case_sensitive=False),\n help=\"Specify a template for the created project\",\n default=\"local\",\n)\ndef init_command(project_directory, minimal: bool, template: str):\n \"\"\"Create a new Feast repository\"\"\"\n if not project_directory:\n project_directory = generate_project_name()\n\n if minimal:\n template = \"minimal\"\n\n tele = Telemetry()\n tele.log(\"init\")\n init_repo(project_directory, template)\n\n\nif __name__ == \"__main__\":\n cli()\n", "path": "sdk/python/feast/cli.py"}]}
| 3,469 | 320 |
gh_patches_debug_38451
|
rasdani/github-patches
|
git_diff
|
getsentry__sentry-56054
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add subscription for team in `endpoints/group_notes.py`
A few changes we will need to make here
1) Update `extract_user_ids_from_mentions` to no longer unpack teams into `user_id`
2) Update the call to `bulk_subscribe` to handle the new output of the function above
</issue>
<code>
[start of src/sentry/api/serializers/rest_framework/mentions.py]
1 from __future__ import annotations
2
3 from typing import Sequence
4
5 from rest_framework import serializers
6
7 from sentry.models import ActorTuple, OrganizationMember, OrganizationMemberTeam, Team, User
8 from sentry.services.hybrid_cloud.user import RpcUser
9
10
11 def extract_user_ids_from_mentions(organization_id, mentions):
12 """
13 Extracts user ids from a set of mentions. Mentions should be a list of
14 `ActorTuple` instances. Returns a dictionary with 'users' and 'team_users' keys.
15 'users' is the user ids for all explicitly mentioned users, and 'team_users'
16 is all user ids from explicitly mentioned teams, excluding any already
17 mentioned users.
18 """
19 actors: Sequence[RpcUser | Team] = ActorTuple.resolve_many(mentions)
20 actor_mentions = separate_resolved_actors(actors)
21
22 team_user_ids = set(
23 OrganizationMemberTeam.objects.filter(
24 team_id__in=[t.id for t in actor_mentions["teams"]],
25 organizationmember__user_id__isnull=False,
26 organizationmember__user_is_active=True,
27 organizationmember__organization_id=organization_id,
28 is_active=True,
29 ).values_list("organizationmember__user_id", flat=True)
30 )
31 mentioned_team_users = team_user_ids - set({u.id for u in actor_mentions["users"]})
32
33 return {
34 "users": {user.id for user in actor_mentions["users"]},
35 "team_users": set(mentioned_team_users),
36 }
37
38
39 def separate_actors(actors):
40 users = [actor for actor in actors if actor.type is User]
41 teams = [actor for actor in actors if actor.type is Team]
42
43 return {"users": users, "teams": teams}
44
45
46 def separate_resolved_actors(actors: Sequence[RpcUser | Team]):
47 users = [actor for actor in actors if actor.class_name() == "User"]
48 teams = [actor for actor in actors if isinstance(actor, Team)]
49
50 return {"users": users, "teams": teams}
51
52
53 class MentionsMixin:
54 def validate_mentions(self, mentions):
55 if mentions and "projects" in self.context:
56
57 separated_actors = separate_actors(mentions)
58 # Validate that all mentioned users exist and are on the project.
59 users = separated_actors["users"]
60
61 mentioned_user_ids = {user.id for user in users}
62
63 projects = self.context["projects"]
64 user_ids = list(
65 OrganizationMember.objects.filter(
66 teams__projectteam__project__in=[p.id for p in projects],
67 user_id__in=mentioned_user_ids,
68 ).values_list("user_id", flat=True)
69 )
70
71 if len(mentioned_user_ids) > len(user_ids):
72 raise serializers.ValidationError("Cannot mention a non team member")
73
74 # Validate that all mentioned teams exist and are on the project.
75 teams = separated_actors["teams"]
76 mentioned_team_ids = {team.id for team in teams}
77 if (
78 len(mentioned_team_ids)
79 > Team.objects.filter(
80 id__in=mentioned_team_ids, projectteam__project__in=projects
81 ).count()
82 ):
83 raise serializers.ValidationError(
84 "Mentioned team not found or not associated with project"
85 )
86
87 return mentions
88
[end of src/sentry/api/serializers/rest_framework/mentions.py]
[start of src/sentry/api/endpoints/group_notes.py]
1 from datetime import timedelta
2
3 from django.utils import timezone
4 from rest_framework import status
5 from rest_framework.request import Request
6 from rest_framework.response import Response
7
8 from sentry.api.api_publish_status import ApiPublishStatus
9 from sentry.api.base import region_silo_endpoint
10 from sentry.api.bases.group import GroupEndpoint
11 from sentry.api.paginator import DateTimePaginator
12 from sentry.api.serializers import serialize
13 from sentry.api.serializers.rest_framework.group_notes import NoteSerializer
14 from sentry.api.serializers.rest_framework.mentions import extract_user_ids_from_mentions
15 from sentry.models import Activity, GroupSubscription
16 from sentry.notifications.types import GroupSubscriptionReason
17 from sentry.signals import comment_created
18 from sentry.types.activity import ActivityType
19
20
21 @region_silo_endpoint
22 class GroupNotesEndpoint(GroupEndpoint):
23 publish_status = {
24 "GET": ApiPublishStatus.UNKNOWN,
25 "POST": ApiPublishStatus.UNKNOWN,
26 }
27
28 def get(self, request: Request, group) -> Response:
29 notes = Activity.objects.filter(group=group, type=ActivityType.NOTE.value)
30
31 return self.paginate(
32 request=request,
33 queryset=notes,
34 paginator_cls=DateTimePaginator,
35 order_by="-datetime",
36 on_results=lambda x: serialize(x, request.user),
37 )
38
39 def post(self, request: Request, group) -> Response:
40 serializer = NoteSerializer(
41 data=request.data,
42 context={
43 "organization": group.organization,
44 "organization_id": group.organization.id,
45 "projects": [group.project],
46 },
47 )
48
49 if not serializer.is_valid():
50 return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
51
52 data = dict(serializer.validated_data)
53
54 mentions = data.pop("mentions", [])
55
56 if Activity.objects.filter(
57 group=group,
58 type=ActivityType.NOTE.value,
59 user_id=request.user.id,
60 data=data,
61 datetime__gte=timezone.now() - timedelta(hours=1),
62 ).exists():
63 return Response(
64 '{"detail": "You have already posted that comment."}',
65 status=status.HTTP_400_BAD_REQUEST,
66 )
67
68 GroupSubscription.objects.subscribe(
69 group=group, subscriber=request.user, reason=GroupSubscriptionReason.comment
70 )
71
72 mentioned_users = extract_user_ids_from_mentions(group.organization.id, mentions)
73 GroupSubscription.objects.bulk_subscribe(
74 group=group, user_ids=mentioned_users["users"], reason=GroupSubscriptionReason.mentioned
75 )
76
77 GroupSubscription.objects.bulk_subscribe(
78 group=group,
79 user_ids=mentioned_users["team_users"],
80 reason=GroupSubscriptionReason.team_mentioned,
81 )
82
83 activity = Activity.objects.create_group_activity(
84 group, ActivityType.NOTE, user_id=request.user.id, data=data
85 )
86
87 self.create_external_comment(request, group, activity)
88
89 webhook_data = {
90 "comment_id": activity.id,
91 "timestamp": activity.datetime,
92 "comment": activity.data.get("text"),
93 "project_slug": activity.project.slug,
94 }
95
96 comment_created.send_robust(
97 project=group.project,
98 user=request.user,
99 group=group,
100 data=webhook_data,
101 sender="post",
102 )
103 return Response(serialize(activity, request.user), status=201)
104
[end of src/sentry/api/endpoints/group_notes.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/sentry/api/endpoints/group_notes.py b/src/sentry/api/endpoints/group_notes.py
--- a/src/sentry/api/endpoints/group_notes.py
+++ b/src/sentry/api/endpoints/group_notes.py
@@ -5,6 +5,7 @@
from rest_framework.request import Request
from rest_framework.response import Response
+from sentry import features
from sentry.api.api_publish_status import ApiPublishStatus
from sentry.api.base import region_silo_endpoint
from sentry.api.bases.group import GroupEndpoint
@@ -74,11 +75,18 @@
group=group, user_ids=mentioned_users["users"], reason=GroupSubscriptionReason.mentioned
)
- GroupSubscription.objects.bulk_subscribe(
- group=group,
- user_ids=mentioned_users["team_users"],
- reason=GroupSubscriptionReason.team_mentioned,
- )
+ if features.has("organizations:team-workflow-notifications", group.organization):
+ GroupSubscription.objects.bulk_subscribe(
+ group=group,
+ team_ids=mentioned_users["teams"],
+ reason=GroupSubscriptionReason.team_mentioned,
+ )
+ else:
+ GroupSubscription.objects.bulk_subscribe(
+ group=group,
+ user_ids=mentioned_users["team_users"],
+ reason=GroupSubscriptionReason.team_mentioned,
+ )
activity = Activity.objects.create_group_activity(
group, ActivityType.NOTE, user_id=request.user.id, data=data
diff --git a/src/sentry/api/serializers/rest_framework/mentions.py b/src/sentry/api/serializers/rest_framework/mentions.py
--- a/src/sentry/api/serializers/rest_framework/mentions.py
+++ b/src/sentry/api/serializers/rest_framework/mentions.py
@@ -11,10 +11,10 @@
def extract_user_ids_from_mentions(organization_id, mentions):
"""
Extracts user ids from a set of mentions. Mentions should be a list of
- `ActorTuple` instances. Returns a dictionary with 'users' and 'team_users' keys.
- 'users' is the user ids for all explicitly mentioned users, and 'team_users'
+ `ActorTuple` instances. Returns a dictionary with 'users', 'team_users', and 'teams' keys.
+ 'users' is the user ids for all explicitly mentioned users, 'team_users'
is all user ids from explicitly mentioned teams, excluding any already
- mentioned users.
+ mentioned users, and 'teams' is the team ids for all explicitly mentioned teams.
"""
actors: Sequence[RpcUser | Team] = ActorTuple.resolve_many(mentions)
actor_mentions = separate_resolved_actors(actors)
@@ -33,6 +33,7 @@
return {
"users": {user.id for user in actor_mentions["users"]},
"team_users": set(mentioned_team_users),
+ "teams": {team.id for team in actor_mentions["teams"]},
}
|
{"golden_diff": "diff --git a/src/sentry/api/endpoints/group_notes.py b/src/sentry/api/endpoints/group_notes.py\n--- a/src/sentry/api/endpoints/group_notes.py\n+++ b/src/sentry/api/endpoints/group_notes.py\n@@ -5,6 +5,7 @@\n from rest_framework.request import Request\n from rest_framework.response import Response\n \n+from sentry import features\n from sentry.api.api_publish_status import ApiPublishStatus\n from sentry.api.base import region_silo_endpoint\n from sentry.api.bases.group import GroupEndpoint\n@@ -74,11 +75,18 @@\n group=group, user_ids=mentioned_users[\"users\"], reason=GroupSubscriptionReason.mentioned\n )\n \n- GroupSubscription.objects.bulk_subscribe(\n- group=group,\n- user_ids=mentioned_users[\"team_users\"],\n- reason=GroupSubscriptionReason.team_mentioned,\n- )\n+ if features.has(\"organizations:team-workflow-notifications\", group.organization):\n+ GroupSubscription.objects.bulk_subscribe(\n+ group=group,\n+ team_ids=mentioned_users[\"teams\"],\n+ reason=GroupSubscriptionReason.team_mentioned,\n+ )\n+ else:\n+ GroupSubscription.objects.bulk_subscribe(\n+ group=group,\n+ user_ids=mentioned_users[\"team_users\"],\n+ reason=GroupSubscriptionReason.team_mentioned,\n+ )\n \n activity = Activity.objects.create_group_activity(\n group, ActivityType.NOTE, user_id=request.user.id, data=data\ndiff --git a/src/sentry/api/serializers/rest_framework/mentions.py b/src/sentry/api/serializers/rest_framework/mentions.py\n--- a/src/sentry/api/serializers/rest_framework/mentions.py\n+++ b/src/sentry/api/serializers/rest_framework/mentions.py\n@@ -11,10 +11,10 @@\n def extract_user_ids_from_mentions(organization_id, mentions):\n \"\"\"\n Extracts user ids from a set of mentions. Mentions should be a list of\n- `ActorTuple` instances. Returns a dictionary with 'users' and 'team_users' keys.\n- 'users' is the user ids for all explicitly mentioned users, and 'team_users'\n+ `ActorTuple` instances. Returns a dictionary with 'users', 'team_users', and 'teams' keys.\n+ 'users' is the user ids for all explicitly mentioned users, 'team_users'\n is all user ids from explicitly mentioned teams, excluding any already\n- mentioned users.\n+ mentioned users, and 'teams' is the team ids for all explicitly mentioned teams.\n \"\"\"\n actors: Sequence[RpcUser | Team] = ActorTuple.resolve_many(mentions)\n actor_mentions = separate_resolved_actors(actors)\n@@ -33,6 +33,7 @@\n return {\n \"users\": {user.id for user in actor_mentions[\"users\"]},\n \"team_users\": set(mentioned_team_users),\n+ \"teams\": {team.id for team in actor_mentions[\"teams\"]},\n }\n", "issue": "Add subscription for team in `endpoints/group_notes.py`\nA few changes we will need to make here\r\n1) Update `extract_user_ids_from_mentions` to no longer unpack teams into `user_id`\r\n2) Update the call to `bulk_subscribe` to handle the new output of the function above\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom typing import Sequence\n\nfrom rest_framework import serializers\n\nfrom sentry.models import ActorTuple, OrganizationMember, OrganizationMemberTeam, Team, User\nfrom sentry.services.hybrid_cloud.user import RpcUser\n\n\ndef extract_user_ids_from_mentions(organization_id, mentions):\n \"\"\"\n Extracts user ids from a set of mentions. Mentions should be a list of\n `ActorTuple` instances. Returns a dictionary with 'users' and 'team_users' keys.\n 'users' is the user ids for all explicitly mentioned users, and 'team_users'\n is all user ids from explicitly mentioned teams, excluding any already\n mentioned users.\n \"\"\"\n actors: Sequence[RpcUser | Team] = ActorTuple.resolve_many(mentions)\n actor_mentions = separate_resolved_actors(actors)\n\n team_user_ids = set(\n OrganizationMemberTeam.objects.filter(\n team_id__in=[t.id for t in actor_mentions[\"teams\"]],\n organizationmember__user_id__isnull=False,\n organizationmember__user_is_active=True,\n organizationmember__organization_id=organization_id,\n is_active=True,\n ).values_list(\"organizationmember__user_id\", flat=True)\n )\n mentioned_team_users = team_user_ids - set({u.id for u in actor_mentions[\"users\"]})\n\n return {\n \"users\": {user.id for user in actor_mentions[\"users\"]},\n \"team_users\": set(mentioned_team_users),\n }\n\n\ndef separate_actors(actors):\n users = [actor for actor in actors if actor.type is User]\n teams = [actor for actor in actors if actor.type is Team]\n\n return {\"users\": users, \"teams\": teams}\n\n\ndef separate_resolved_actors(actors: Sequence[RpcUser | Team]):\n users = [actor for actor in actors if actor.class_name() == \"User\"]\n teams = [actor for actor in actors if isinstance(actor, Team)]\n\n return {\"users\": users, \"teams\": teams}\n\n\nclass MentionsMixin:\n def validate_mentions(self, mentions):\n if mentions and \"projects\" in self.context:\n\n separated_actors = separate_actors(mentions)\n # Validate that all mentioned users exist and are on the project.\n users = separated_actors[\"users\"]\n\n mentioned_user_ids = {user.id for user in users}\n\n projects = self.context[\"projects\"]\n user_ids = list(\n OrganizationMember.objects.filter(\n teams__projectteam__project__in=[p.id for p in projects],\n user_id__in=mentioned_user_ids,\n ).values_list(\"user_id\", flat=True)\n )\n\n if len(mentioned_user_ids) > len(user_ids):\n raise serializers.ValidationError(\"Cannot mention a non team member\")\n\n # Validate that all mentioned teams exist and are on the project.\n teams = separated_actors[\"teams\"]\n mentioned_team_ids = {team.id for team in teams}\n if (\n len(mentioned_team_ids)\n > Team.objects.filter(\n id__in=mentioned_team_ids, projectteam__project__in=projects\n ).count()\n ):\n raise serializers.ValidationError(\n \"Mentioned team not found or not associated with project\"\n )\n\n return mentions\n", "path": "src/sentry/api/serializers/rest_framework/mentions.py"}, {"content": "from datetime import timedelta\n\nfrom django.utils import timezone\nfrom rest_framework import status\nfrom rest_framework.request import Request\nfrom rest_framework.response import Response\n\nfrom sentry.api.api_publish_status import ApiPublishStatus\nfrom sentry.api.base import region_silo_endpoint\nfrom sentry.api.bases.group import GroupEndpoint\nfrom sentry.api.paginator import DateTimePaginator\nfrom sentry.api.serializers import serialize\nfrom sentry.api.serializers.rest_framework.group_notes import NoteSerializer\nfrom sentry.api.serializers.rest_framework.mentions import extract_user_ids_from_mentions\nfrom sentry.models import Activity, GroupSubscription\nfrom sentry.notifications.types import GroupSubscriptionReason\nfrom sentry.signals import comment_created\nfrom sentry.types.activity import ActivityType\n\n\n@region_silo_endpoint\nclass GroupNotesEndpoint(GroupEndpoint):\n publish_status = {\n \"GET\": ApiPublishStatus.UNKNOWN,\n \"POST\": ApiPublishStatus.UNKNOWN,\n }\n\n def get(self, request: Request, group) -> Response:\n notes = Activity.objects.filter(group=group, type=ActivityType.NOTE.value)\n\n return self.paginate(\n request=request,\n queryset=notes,\n paginator_cls=DateTimePaginator,\n order_by=\"-datetime\",\n on_results=lambda x: serialize(x, request.user),\n )\n\n def post(self, request: Request, group) -> Response:\n serializer = NoteSerializer(\n data=request.data,\n context={\n \"organization\": group.organization,\n \"organization_id\": group.organization.id,\n \"projects\": [group.project],\n },\n )\n\n if not serializer.is_valid():\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n data = dict(serializer.validated_data)\n\n mentions = data.pop(\"mentions\", [])\n\n if Activity.objects.filter(\n group=group,\n type=ActivityType.NOTE.value,\n user_id=request.user.id,\n data=data,\n datetime__gte=timezone.now() - timedelta(hours=1),\n ).exists():\n return Response(\n '{\"detail\": \"You have already posted that comment.\"}',\n status=status.HTTP_400_BAD_REQUEST,\n )\n\n GroupSubscription.objects.subscribe(\n group=group, subscriber=request.user, reason=GroupSubscriptionReason.comment\n )\n\n mentioned_users = extract_user_ids_from_mentions(group.organization.id, mentions)\n GroupSubscription.objects.bulk_subscribe(\n group=group, user_ids=mentioned_users[\"users\"], reason=GroupSubscriptionReason.mentioned\n )\n\n GroupSubscription.objects.bulk_subscribe(\n group=group,\n user_ids=mentioned_users[\"team_users\"],\n reason=GroupSubscriptionReason.team_mentioned,\n )\n\n activity = Activity.objects.create_group_activity(\n group, ActivityType.NOTE, user_id=request.user.id, data=data\n )\n\n self.create_external_comment(request, group, activity)\n\n webhook_data = {\n \"comment_id\": activity.id,\n \"timestamp\": activity.datetime,\n \"comment\": activity.data.get(\"text\"),\n \"project_slug\": activity.project.slug,\n }\n\n comment_created.send_robust(\n project=group.project,\n user=request.user,\n group=group,\n data=webhook_data,\n sender=\"post\",\n )\n return Response(serialize(activity, request.user), status=201)\n", "path": "src/sentry/api/endpoints/group_notes.py"}]}
| 2,396 | 639 |
gh_patches_debug_281
|
rasdani/github-patches
|
git_diff
|
vega__altair-3387
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
minimum pyarrow version enforced even if pandas is installed
The error we are facing in an environment says:
```python
RuntimeError: The pyarrow package must be version 11.0.0 or greater. Found version 6.0.1
```
And is caused by these lines:
https://github.com/altair-viz/altair/blob/main/altair/utils/core.py#L591-L592
```python
# if data is specified and type is not, infer type from data
if "type" not in attrs:
if pyarrow_available() and data is not None and isinstance(data, DataFrameLike):
...
elif isinstance(data, pd.DataFrame):
# Fallback if pyarrow is not installed or if pandas is older than 1.5
```
In that particular environment pandas is installed by default and we are not able to upgrade pyarrow.
Now the altair specifications errors as the code never tries the pandas approach as it has found a pyarrow version that is too old.
</issue>
<code>
[start of altair/utils/_importers.py]
1 from types import ModuleType
2 from packaging.version import Version
3 from importlib.metadata import version as importlib_version
4
5
6 def import_vegafusion() -> ModuleType:
7 min_version = "1.5.0"
8 try:
9 version = importlib_version("vegafusion")
10 embed_version = importlib_version("vegafusion-python-embed")
11 if version != embed_version or Version(version) < Version(min_version):
12 raise RuntimeError(
13 "The versions of the vegafusion and vegafusion-python-embed packages must match\n"
14 f"and must be version {min_version} or greater.\n"
15 f"Found:\n"
16 f" - vegafusion=={version}\n"
17 f" - vegafusion-python-embed=={embed_version}\n"
18 )
19 import vegafusion as vf # type: ignore
20
21 return vf
22 except ImportError as err:
23 raise ImportError(
24 'The "vegafusion" data transformer and chart.transformed_data feature requires\n'
25 f"version {min_version} or greater of the 'vegafusion-python-embed' and 'vegafusion' packages.\n"
26 "These can be installed with pip using:\n"
27 f' pip install "vegafusion[embed]>={min_version}"\n'
28 "Or with conda using:\n"
29 f' conda install -c conda-forge "vegafusion-python-embed>={min_version}" '
30 f'"vegafusion>={min_version}"\n\n'
31 f"ImportError: {err.args[0]}"
32 ) from err
33
34
35 def import_vl_convert() -> ModuleType:
36 min_version = "1.3.0"
37 try:
38 version = importlib_version("vl-convert-python")
39 if Version(version) < Version(min_version):
40 raise RuntimeError(
41 f"The vl-convert-python package must be version {min_version} or greater. "
42 f"Found version {version}"
43 )
44 import vl_convert as vlc
45
46 return vlc
47 except ImportError as err:
48 raise ImportError(
49 f"The vl-convert Vega-Lite compiler and file export feature requires\n"
50 f"version {min_version} or greater of the 'vl-convert-python' package. \n"
51 f"This can be installed with pip using:\n"
52 f' pip install "vl-convert-python>={min_version}"\n'
53 "or conda:\n"
54 f' conda install -c conda-forge "vl-convert-python>={min_version}"\n\n'
55 f"ImportError: {err.args[0]}"
56 ) from err
57
58
59 def vl_version_for_vl_convert() -> str:
60 from ..vegalite import SCHEMA_VERSION
61
62 # Compute VlConvert's vl_version string (of the form 'v5_2')
63 # from SCHEMA_VERSION (of the form 'v5.2.0')
64 return "_".join(SCHEMA_VERSION.split(".")[:2])
65
66
67 def import_pyarrow_interchange() -> ModuleType:
68 min_version = "11.0.0"
69 try:
70 version = importlib_version("pyarrow")
71
72 if Version(version) < Version(min_version):
73 raise RuntimeError(
74 f"The pyarrow package must be version {min_version} or greater. "
75 f"Found version {version}"
76 )
77 import pyarrow.interchange as pi
78
79 return pi
80 except ImportError as err:
81 raise ImportError(
82 f"Usage of the DataFrame Interchange Protocol requires\n"
83 f"version {min_version} or greater of the pyarrow package. \n"
84 f"This can be installed with pip using:\n"
85 f' pip install "pyarrow>={min_version}"\n'
86 "or conda:\n"
87 f' conda install -c conda-forge "pyarrow>={min_version}"\n\n'
88 f"ImportError: {err.args[0]}"
89 ) from err
90
91
92 def pyarrow_available() -> bool:
93 try:
94 import_pyarrow_interchange()
95 return True
96 except ImportError:
97 return False
98
[end of altair/utils/_importers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/altair/utils/_importers.py b/altair/utils/_importers.py
--- a/altair/utils/_importers.py
+++ b/altair/utils/_importers.py
@@ -93,5 +93,5 @@
try:
import_pyarrow_interchange()
return True
- except ImportError:
+ except (ImportError, RuntimeError):
return False
|
{"golden_diff": "diff --git a/altair/utils/_importers.py b/altair/utils/_importers.py\n--- a/altair/utils/_importers.py\n+++ b/altair/utils/_importers.py\n@@ -93,5 +93,5 @@\n try:\n import_pyarrow_interchange()\n return True\n- except ImportError:\n+ except (ImportError, RuntimeError):\n return False\n", "issue": "minimum pyarrow version enforced even if pandas is installed\nThe error we are facing in an environment says:\r\n```python\r\nRuntimeError: The pyarrow package must be version 11.0.0 or greater. Found version 6.0.1\r\n```\r\n\r\nAnd is caused by these lines:\r\nhttps://github.com/altair-viz/altair/blob/main/altair/utils/core.py#L591-L592\r\n\r\n```python\r\n # if data is specified and type is not, infer type from data\r\n if \"type\" not in attrs:\r\n if pyarrow_available() and data is not None and isinstance(data, DataFrameLike):\r\n ...\r\n\r\n elif isinstance(data, pd.DataFrame):\r\n # Fallback if pyarrow is not installed or if pandas is older than 1.5\r\n```\r\nIn that particular environment pandas is installed by default and we are not able to upgrade pyarrow. \r\n\r\nNow the altair specifications errors as the code never tries the pandas approach as it has found a pyarrow version that is too old. \r\n\n", "before_files": [{"content": "from types import ModuleType\nfrom packaging.version import Version\nfrom importlib.metadata import version as importlib_version\n\n\ndef import_vegafusion() -> ModuleType:\n min_version = \"1.5.0\"\n try:\n version = importlib_version(\"vegafusion\")\n embed_version = importlib_version(\"vegafusion-python-embed\")\n if version != embed_version or Version(version) < Version(min_version):\n raise RuntimeError(\n \"The versions of the vegafusion and vegafusion-python-embed packages must match\\n\"\n f\"and must be version {min_version} or greater.\\n\"\n f\"Found:\\n\"\n f\" - vegafusion=={version}\\n\"\n f\" - vegafusion-python-embed=={embed_version}\\n\"\n )\n import vegafusion as vf # type: ignore\n\n return vf\n except ImportError as err:\n raise ImportError(\n 'The \"vegafusion\" data transformer and chart.transformed_data feature requires\\n'\n f\"version {min_version} or greater of the 'vegafusion-python-embed' and 'vegafusion' packages.\\n\"\n \"These can be installed with pip using:\\n\"\n f' pip install \"vegafusion[embed]>={min_version}\"\\n'\n \"Or with conda using:\\n\"\n f' conda install -c conda-forge \"vegafusion-python-embed>={min_version}\" '\n f'\"vegafusion>={min_version}\"\\n\\n'\n f\"ImportError: {err.args[0]}\"\n ) from err\n\n\ndef import_vl_convert() -> ModuleType:\n min_version = \"1.3.0\"\n try:\n version = importlib_version(\"vl-convert-python\")\n if Version(version) < Version(min_version):\n raise RuntimeError(\n f\"The vl-convert-python package must be version {min_version} or greater. \"\n f\"Found version {version}\"\n )\n import vl_convert as vlc\n\n return vlc\n except ImportError as err:\n raise ImportError(\n f\"The vl-convert Vega-Lite compiler and file export feature requires\\n\"\n f\"version {min_version} or greater of the 'vl-convert-python' package. \\n\"\n f\"This can be installed with pip using:\\n\"\n f' pip install \"vl-convert-python>={min_version}\"\\n'\n \"or conda:\\n\"\n f' conda install -c conda-forge \"vl-convert-python>={min_version}\"\\n\\n'\n f\"ImportError: {err.args[0]}\"\n ) from err\n\n\ndef vl_version_for_vl_convert() -> str:\n from ..vegalite import SCHEMA_VERSION\n\n # Compute VlConvert's vl_version string (of the form 'v5_2')\n # from SCHEMA_VERSION (of the form 'v5.2.0')\n return \"_\".join(SCHEMA_VERSION.split(\".\")[:2])\n\n\ndef import_pyarrow_interchange() -> ModuleType:\n min_version = \"11.0.0\"\n try:\n version = importlib_version(\"pyarrow\")\n\n if Version(version) < Version(min_version):\n raise RuntimeError(\n f\"The pyarrow package must be version {min_version} or greater. \"\n f\"Found version {version}\"\n )\n import pyarrow.interchange as pi\n\n return pi\n except ImportError as err:\n raise ImportError(\n f\"Usage of the DataFrame Interchange Protocol requires\\n\"\n f\"version {min_version} or greater of the pyarrow package. \\n\"\n f\"This can be installed with pip using:\\n\"\n f' pip install \"pyarrow>={min_version}\"\\n'\n \"or conda:\\n\"\n f' conda install -c conda-forge \"pyarrow>={min_version}\"\\n\\n'\n f\"ImportError: {err.args[0]}\"\n ) from err\n\n\ndef pyarrow_available() -> bool:\n try:\n import_pyarrow_interchange()\n return True\n except ImportError:\n return False\n", "path": "altair/utils/_importers.py"}]}
| 1,855 | 88 |
gh_patches_debug_24245
|
rasdani/github-patches
|
git_diff
|
nonebot__nonebot2-407
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bug:Mirai 邀请入群和入群操作报错
**描述问题:**
Mirai 邀请机器人入群报错
**如何复现?**
1. 邀请机器人入群
2. approve(bot)
**期望的结果**
**环境信息:**
- OS: [windows]
- Python Version: [3.8.8]
- Nonebot Version: [2.0.0a13.post1]
**截图**
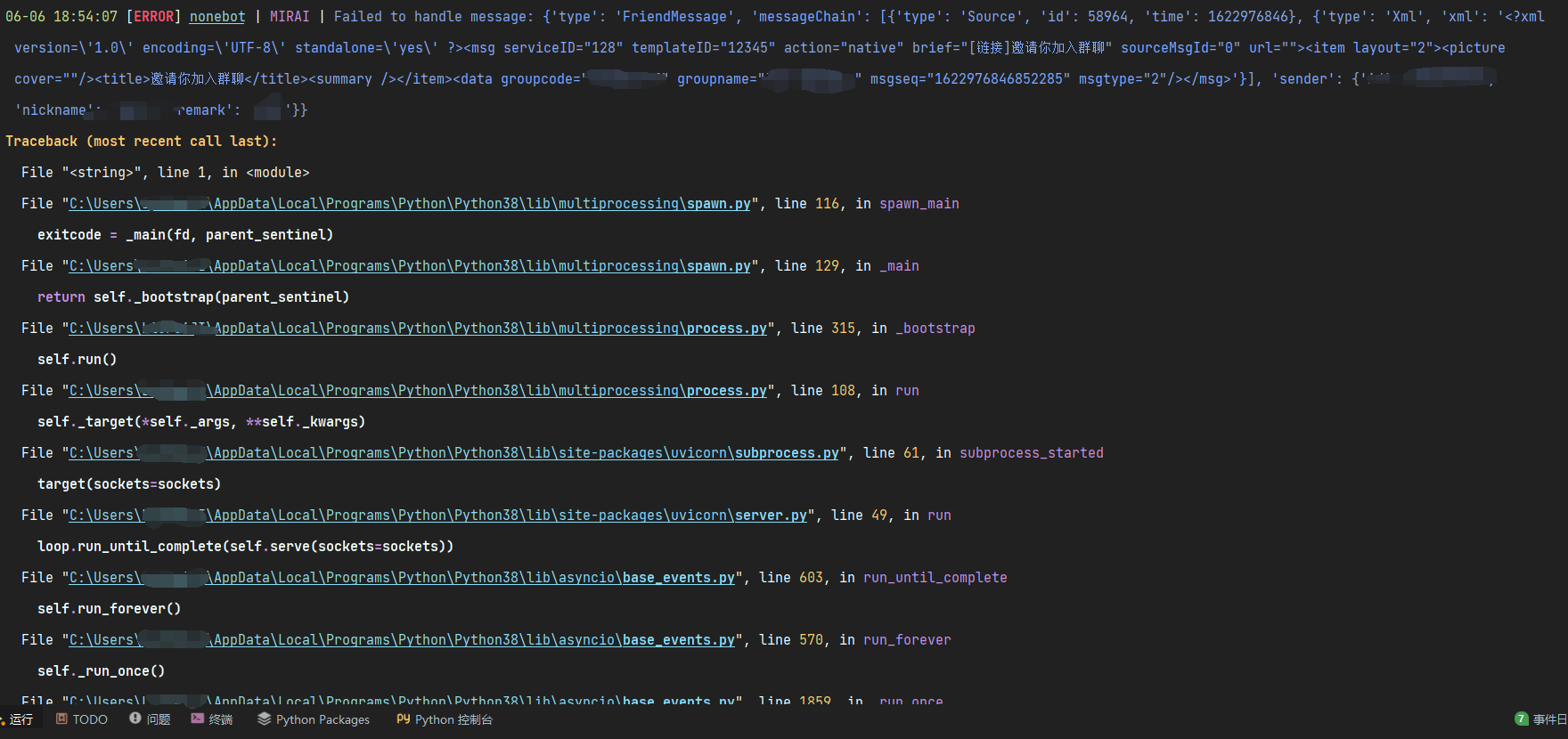
Bug:Mirai 邀请入群和入群操作报错
**描述问题:**
Mirai 邀请机器人入群报错
**如何复现?**
1. 邀请机器人入群
2. approve(bot)
**期望的结果**
**环境信息:**
- OS: [windows]
- Python Version: [3.8.8]
- Nonebot Version: [2.0.0a13.post1]
**截图**

</issue>
<code>
[start of packages/nonebot-adapter-mirai/nonebot/adapters/mirai/event/request.py]
1 from typing import TYPE_CHECKING
2
3 from pydantic import Field
4 from typing_extensions import Literal
5
6 from .base import Event
7
8 if TYPE_CHECKING:
9 from ..bot import Bot
10
11
12 class RequestEvent(Event):
13 """请求事件基类"""
14 event_id: int = Field(alias='eventId')
15 message: str
16 nick: str
17
18
19 class NewFriendRequestEvent(RequestEvent):
20 """添加好友申请"""
21 from_id: int = Field(alias='fromId')
22 group_id: int = Field(0, alias='groupId')
23
24 async def approve(self, bot: "Bot"):
25 """
26 :说明:
27
28 通过此人的好友申请
29
30 :参数:
31
32 * ``bot: Bot``: 当前的 ``Bot`` 对象
33 """
34 return await bot.api.post('/resp/newFriendRequestEvent',
35 params={
36 'eventId': self.event_id,
37 'groupId': self.group_id,
38 'fromId': self.from_id,
39 'operate': 0,
40 'message': ''
41 })
42
43 async def reject(self,
44 bot: "Bot",
45 operate: Literal[1, 2] = 1,
46 message: str = ''):
47 """
48 :说明:
49
50 拒绝此人的好友申请
51
52 :参数:
53
54 * ``bot: Bot``: 当前的 ``Bot`` 对象
55 * ``operate: Literal[1, 2]``: 响应的操作类型
56
57 * ``1``: 拒绝添加好友
58 * ``2``: 拒绝添加好友并添加黑名单,不再接收该用户的好友申请
59
60 * ``message: str``: 回复的信息
61 """
62 assert operate > 0
63 return await bot.api.post('/resp/newFriendRequestEvent',
64 params={
65 'eventId': self.event_id,
66 'groupId': self.group_id,
67 'fromId': self.from_id,
68 'operate': operate,
69 'message': message
70 })
71
72
73 class MemberJoinRequestEvent(RequestEvent):
74 """用户入群申请(Bot需要有管理员权限)"""
75 from_id: int = Field(alias='fromId')
76 group_id: int = Field(alias='groupId')
77 group_name: str = Field(alias='groupName')
78
79 async def approve(self, bot: "Bot"):
80 """
81 :说明:
82
83 通过此人的加群申请
84
85 :参数:
86
87 * ``bot: Bot``: 当前的 ``Bot`` 对象
88 """
89 return await bot.api.post('/resp/memberJoinRequestEvent',
90 params={
91 'eventId': self.event_id,
92 'groupId': self.group_id,
93 'fromId': self.from_id,
94 'operate': 0
95 })
96
97 async def reject(self,
98 bot: "Bot",
99 operate: Literal[1, 2, 3, 4] = 1,
100 message: str = ''):
101 """
102 :说明:
103
104 拒绝(忽略)此人的加群申请
105
106 :参数:
107
108 * ``bot: Bot``: 当前的 ``Bot`` 对象
109 * ``operate: Literal[1, 2, 3, 4]``: 响应的操作类型
110
111 * ``1``: 拒绝入群
112 * ``2``: 忽略请求
113 * ``3``: 拒绝入群并添加黑名单,不再接收该用户的入群申请
114 * ``4``: 忽略入群并添加黑名单,不再接收该用户的入群申请
115
116 * ``message: str``: 回复的信息
117 """
118 assert operate > 0
119 return await bot.api.post('/resp/memberJoinRequestEvent',
120 params={
121 'eventId': self.event_id,
122 'groupId': self.group_id,
123 'fromId': self.from_id,
124 'operate': operate,
125 'message': message
126 })
127
128
129 class BotInvitedJoinGroupRequestEvent(RequestEvent):
130 """Bot被邀请入群申请"""
131 from_id: int = Field(alias='fromId')
132 group_id: int = Field(alias='groupId')
133 group_name: str = Field(alias='groupName')
134
135 async def approve(self, bot: "Bot"):
136 """
137 :说明:
138
139 通过这份被邀请入群申请
140
141 :参数:
142
143 * ``bot: Bot``: 当前的 ``Bot`` 对象
144 """
145 return await bot.api.post('/resp/botInvitedJoinGroupRequestEvent',
146 params={
147 'eventId': self.event_id,
148 'groupId': self.group_id,
149 'fromId': self.from_id,
150 'operate': 0
151 })
152
153 async def reject(self, bot: "Bot", message: str = ""):
154 """
155 :说明:
156
157 拒绝这份被邀请入群申请
158
159 :参数:
160
161 * ``bot: Bot``: 当前的 ``Bot`` 对象
162 * ``message: str``: 邀请消息
163 """
164 return await bot.api.post('/resp/botInvitedJoinGroupRequestEvent',
165 params={
166 'eventId': self.event_id,
167 'groupId': self.group_id,
168 'fromId': self.from_id,
169 'operate': 1,
170 'message': message
171 })
172
[end of packages/nonebot-adapter-mirai/nonebot/adapters/mirai/event/request.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/packages/nonebot-adapter-mirai/nonebot/adapters/mirai/event/request.py b/packages/nonebot-adapter-mirai/nonebot/adapters/mirai/event/request.py
--- a/packages/nonebot-adapter-mirai/nonebot/adapters/mirai/event/request.py
+++ b/packages/nonebot-adapter-mirai/nonebot/adapters/mirai/event/request.py
@@ -91,7 +91,8 @@
'eventId': self.event_id,
'groupId': self.group_id,
'fromId': self.from_id,
- 'operate': 0
+ 'operate': 0,
+ 'message': ''
})
async def reject(self,
@@ -147,7 +148,8 @@
'eventId': self.event_id,
'groupId': self.group_id,
'fromId': self.from_id,
- 'operate': 0
+ 'operate': 0,
+ 'message': ''
})
async def reject(self, bot: "Bot", message: str = ""):
|
{"golden_diff": "diff --git a/packages/nonebot-adapter-mirai/nonebot/adapters/mirai/event/request.py b/packages/nonebot-adapter-mirai/nonebot/adapters/mirai/event/request.py\n--- a/packages/nonebot-adapter-mirai/nonebot/adapters/mirai/event/request.py\n+++ b/packages/nonebot-adapter-mirai/nonebot/adapters/mirai/event/request.py\n@@ -91,7 +91,8 @@\n 'eventId': self.event_id,\n 'groupId': self.group_id,\n 'fromId': self.from_id,\n- 'operate': 0\n+ 'operate': 0,\n+ 'message': ''\n })\n \n async def reject(self,\n@@ -147,7 +148,8 @@\n 'eventId': self.event_id,\n 'groupId': self.group_id,\n 'fromId': self.from_id,\n- 'operate': 0\n+ 'operate': 0,\n+ 'message': ''\n })\n \n async def reject(self, bot: \"Bot\", message: str = \"\"):\n", "issue": "Bug:Mirai \u9080\u8bf7\u5165\u7fa4\u548c\u5165\u7fa4\u64cd\u4f5c\u62a5\u9519\n**\u63cf\u8ff0\u95ee\u9898\uff1a**\r\n\r\nMirai \u9080\u8bf7\u673a\u5668\u4eba\u5165\u7fa4\u62a5\u9519\r\n\r\n**\u5982\u4f55\u590d\u73b0\uff1f**\r\n\r\n1. \u9080\u8bf7\u673a\u5668\u4eba\u5165\u7fa4\r\n2. approve(bot)\r\n\r\n**\u671f\u671b\u7684\u7ed3\u679c**\r\n\r\n\r\n\r\n**\u73af\u5883\u4fe1\u606f\uff1a**\r\n\r\n - OS: [windows]\r\n - Python Version: [3.8.8]\r\n - Nonebot Version: [2.0.0a13.post1]\r\n\r\n**\u622a\u56fe**\r\n\r\n\r\n\nBug:Mirai \u9080\u8bf7\u5165\u7fa4\u548c\u5165\u7fa4\u64cd\u4f5c\u62a5\u9519\n**\u63cf\u8ff0\u95ee\u9898\uff1a**\r\n\r\nMirai \u9080\u8bf7\u673a\u5668\u4eba\u5165\u7fa4\u62a5\u9519\r\n\r\n**\u5982\u4f55\u590d\u73b0\uff1f**\r\n\r\n1. \u9080\u8bf7\u673a\u5668\u4eba\u5165\u7fa4\r\n2. approve(bot)\r\n\r\n**\u671f\u671b\u7684\u7ed3\u679c**\r\n\r\n\r\n\r\n**\u73af\u5883\u4fe1\u606f\uff1a**\r\n\r\n - OS: [windows]\r\n - Python Version: [3.8.8]\r\n - Nonebot Version: [2.0.0a13.post1]\r\n\r\n**\u622a\u56fe**\r\n\r\n\r\n\n", "before_files": [{"content": "from typing import TYPE_CHECKING\n\nfrom pydantic import Field\nfrom typing_extensions import Literal\n\nfrom .base import Event\n\nif TYPE_CHECKING:\n from ..bot import Bot\n\n\nclass RequestEvent(Event):\n \"\"\"\u8bf7\u6c42\u4e8b\u4ef6\u57fa\u7c7b\"\"\"\n event_id: int = Field(alias='eventId')\n message: str\n nick: str\n\n\nclass NewFriendRequestEvent(RequestEvent):\n \"\"\"\u6dfb\u52a0\u597d\u53cb\u7533\u8bf7\"\"\"\n from_id: int = Field(alias='fromId')\n group_id: int = Field(0, alias='groupId')\n\n async def approve(self, bot: \"Bot\"):\n \"\"\"\n :\u8bf4\u660e:\n\n \u901a\u8fc7\u6b64\u4eba\u7684\u597d\u53cb\u7533\u8bf7\n\n :\u53c2\u6570:\n\n * ``bot: Bot``: \u5f53\u524d\u7684 ``Bot`` \u5bf9\u8c61\n \"\"\"\n return await bot.api.post('/resp/newFriendRequestEvent',\n params={\n 'eventId': self.event_id,\n 'groupId': self.group_id,\n 'fromId': self.from_id,\n 'operate': 0,\n 'message': ''\n })\n\n async def reject(self,\n bot: \"Bot\",\n operate: Literal[1, 2] = 1,\n message: str = ''):\n \"\"\"\n :\u8bf4\u660e:\n\n \u62d2\u7edd\u6b64\u4eba\u7684\u597d\u53cb\u7533\u8bf7\n\n :\u53c2\u6570:\n\n * ``bot: Bot``: \u5f53\u524d\u7684 ``Bot`` \u5bf9\u8c61\n * ``operate: Literal[1, 2]``: \u54cd\u5e94\u7684\u64cd\u4f5c\u7c7b\u578b\n\n * ``1``: \u62d2\u7edd\u6dfb\u52a0\u597d\u53cb\n * ``2``: \u62d2\u7edd\u6dfb\u52a0\u597d\u53cb\u5e76\u6dfb\u52a0\u9ed1\u540d\u5355\uff0c\u4e0d\u518d\u63a5\u6536\u8be5\u7528\u6237\u7684\u597d\u53cb\u7533\u8bf7\n\n * ``message: str``: \u56de\u590d\u7684\u4fe1\u606f\n \"\"\"\n assert operate > 0\n return await bot.api.post('/resp/newFriendRequestEvent',\n params={\n 'eventId': self.event_id,\n 'groupId': self.group_id,\n 'fromId': self.from_id,\n 'operate': operate,\n 'message': message\n })\n\n\nclass MemberJoinRequestEvent(RequestEvent):\n \"\"\"\u7528\u6237\u5165\u7fa4\u7533\u8bf7\uff08Bot\u9700\u8981\u6709\u7ba1\u7406\u5458\u6743\u9650\uff09\"\"\"\n from_id: int = Field(alias='fromId')\n group_id: int = Field(alias='groupId')\n group_name: str = Field(alias='groupName')\n\n async def approve(self, bot: \"Bot\"):\n \"\"\"\n :\u8bf4\u660e:\n\n \u901a\u8fc7\u6b64\u4eba\u7684\u52a0\u7fa4\u7533\u8bf7\n\n :\u53c2\u6570:\n\n * ``bot: Bot``: \u5f53\u524d\u7684 ``Bot`` \u5bf9\u8c61\n \"\"\"\n return await bot.api.post('/resp/memberJoinRequestEvent',\n params={\n 'eventId': self.event_id,\n 'groupId': self.group_id,\n 'fromId': self.from_id,\n 'operate': 0\n })\n\n async def reject(self,\n bot: \"Bot\",\n operate: Literal[1, 2, 3, 4] = 1,\n message: str = ''):\n \"\"\"\n :\u8bf4\u660e:\n\n \u62d2\u7edd(\u5ffd\u7565)\u6b64\u4eba\u7684\u52a0\u7fa4\u7533\u8bf7\n\n :\u53c2\u6570:\n\n * ``bot: Bot``: \u5f53\u524d\u7684 ``Bot`` \u5bf9\u8c61\n * ``operate: Literal[1, 2, 3, 4]``: \u54cd\u5e94\u7684\u64cd\u4f5c\u7c7b\u578b\n\n * ``1``: \u62d2\u7edd\u5165\u7fa4\n * ``2``: \u5ffd\u7565\u8bf7\u6c42\n * ``3``: \u62d2\u7edd\u5165\u7fa4\u5e76\u6dfb\u52a0\u9ed1\u540d\u5355\uff0c\u4e0d\u518d\u63a5\u6536\u8be5\u7528\u6237\u7684\u5165\u7fa4\u7533\u8bf7\n * ``4``: \u5ffd\u7565\u5165\u7fa4\u5e76\u6dfb\u52a0\u9ed1\u540d\u5355\uff0c\u4e0d\u518d\u63a5\u6536\u8be5\u7528\u6237\u7684\u5165\u7fa4\u7533\u8bf7\n\n * ``message: str``: \u56de\u590d\u7684\u4fe1\u606f\n \"\"\"\n assert operate > 0\n return await bot.api.post('/resp/memberJoinRequestEvent',\n params={\n 'eventId': self.event_id,\n 'groupId': self.group_id,\n 'fromId': self.from_id,\n 'operate': operate,\n 'message': message\n })\n\n\nclass BotInvitedJoinGroupRequestEvent(RequestEvent):\n \"\"\"Bot\u88ab\u9080\u8bf7\u5165\u7fa4\u7533\u8bf7\"\"\"\n from_id: int = Field(alias='fromId')\n group_id: int = Field(alias='groupId')\n group_name: str = Field(alias='groupName')\n\n async def approve(self, bot: \"Bot\"):\n \"\"\"\n :\u8bf4\u660e:\n\n \u901a\u8fc7\u8fd9\u4efd\u88ab\u9080\u8bf7\u5165\u7fa4\u7533\u8bf7\n\n :\u53c2\u6570:\n\n * ``bot: Bot``: \u5f53\u524d\u7684 ``Bot`` \u5bf9\u8c61\n \"\"\"\n return await bot.api.post('/resp/botInvitedJoinGroupRequestEvent',\n params={\n 'eventId': self.event_id,\n 'groupId': self.group_id,\n 'fromId': self.from_id,\n 'operate': 0\n })\n\n async def reject(self, bot: \"Bot\", message: str = \"\"):\n \"\"\"\n :\u8bf4\u660e:\n\n \u62d2\u7edd\u8fd9\u4efd\u88ab\u9080\u8bf7\u5165\u7fa4\u7533\u8bf7\n\n :\u53c2\u6570:\n\n * ``bot: Bot``: \u5f53\u524d\u7684 ``Bot`` \u5bf9\u8c61\n * ``message: str``: \u9080\u8bf7\u6d88\u606f\n \"\"\"\n return await bot.api.post('/resp/botInvitedJoinGroupRequestEvent',\n params={\n 'eventId': self.event_id,\n 'groupId': self.group_id,\n 'fromId': self.from_id,\n 'operate': 1,\n 'message': message\n })\n", "path": "packages/nonebot-adapter-mirai/nonebot/adapters/mirai/event/request.py"}]}
| 2,466 | 241 |
gh_patches_debug_12557
|
rasdani/github-patches
|
git_diff
|
GeotrekCE__Geotrek-admin-1541
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Infrastructure CONDITION - Should not be mandatory
Many will just localize their infrastructures.
</issue>
<code>
[start of geotrek/infrastructure/models.py]
1 from django.db import models
2 from django.utils.translation import ugettext_lazy as _
3 from django.contrib.gis.db import models as gismodels
4
5 from extended_choices import Choices
6 from mapentity.models import MapEntityMixin
7
8 from geotrek.common.utils import classproperty
9 from geotrek.core.models import Topology, Path
10 from geotrek.authent.models import StructureRelatedManager, StructureRelated
11
12
13 INFRASTRUCTURE_TYPES = Choices(
14 ('BUILDING', 'A', _("Building")),
15 ('FACILITY', 'E', _("Facility")),
16 ('SIGNAGE', 'S', _("Signage")),
17 )
18
19
20 class InfrastructureTypeQuerySet(models.query.QuerySet):
21 def for_infrastructures(self):
22 return self.exclude(type__exact=INFRASTRUCTURE_TYPES.SIGNAGE)
23
24 def for_signages(self):
25 return self.filter(type__exact=INFRASTRUCTURE_TYPES.SIGNAGE)
26
27
28 class InfrastructureTypeManager(models.Manager):
29 def get_queryset(self):
30 return InfrastructureTypeQuerySet(self.model, using=self._db)
31
32 def for_signages(self):
33 return self.get_queryset().for_signages()
34
35 def for_infrastructures(self):
36 return self.get_queryset().for_infrastructures()
37
38
39 class InfrastructureType(StructureRelated):
40 """ Types of infrastructures (bridge, WC, stairs, ...) """
41 label = models.CharField(db_column="nom", max_length=128)
42 type = models.CharField(db_column="type", max_length=1, choices=INFRASTRUCTURE_TYPES)
43
44 objects = InfrastructureTypeManager()
45
46 class Meta:
47 db_table = 'a_b_amenagement'
48 verbose_name = _(u"Infrastructure Type")
49 verbose_name_plural = _(u"Infrastructure Types")
50 ordering = ['label', 'type']
51
52 def __unicode__(self):
53 return self.label
54
55
56 class InfrastructureCondition(StructureRelated):
57 label = models.CharField(verbose_name=_(u"Name"), db_column="etat", max_length=250)
58
59 class Meta:
60 verbose_name = _(u"Infrastructure Condition")
61 verbose_name_plural = _(u"Infrastructure Conditions")
62 db_table = "a_b_etat"
63
64 def __unicode__(self):
65 return self.label
66
67
68 class BaseInfrastructure(MapEntityMixin, Topology, StructureRelated):
69 """ A generic infrastructure in the park """
70 topo_object = models.OneToOneField(Topology, parent_link=True,
71 db_column='evenement')
72
73 name = models.CharField(db_column="nom", max_length=128,
74 help_text=_(u"Reference, code, ..."), verbose_name=_("Name"))
75 description = models.TextField(blank=True, db_column='description',
76 verbose_name=_("Description"), help_text=_(u"Specificites"))
77 type = models.ForeignKey(InfrastructureType, db_column='type', verbose_name=_("Type"))
78 condition = models.ForeignKey(InfrastructureCondition, db_column='etat',
79 verbose_name=_("Condition"), null=True,
80 on_delete=models.PROTECT)
81
82 class Meta:
83 db_table = 'a_t_amenagement'
84
85 def __unicode__(self):
86 return self.name
87
88 @property
89 def name_display(self):
90 return '<a href="%s" title="%s" >%s</a>' % (self.get_detail_url(),
91 self,
92 self)
93
94 @property
95 def name_csv_display(self):
96 return unicode(self)
97
98 @property
99 def type_display(self):
100 return unicode(self.type)
101
102 @property
103 def cities_display(self):
104 if hasattr(self, 'cities'):
105 return [unicode(c) for c in self.cities]
106 return []
107
108 @classproperty
109 def cities_verbose_name(cls):
110 return _("Cities")
111
112
113 class InfrastructureGISManager(gismodels.GeoManager):
114 """ Overide default typology mixin manager, and filter by type. """
115 def get_queryset(self):
116 return super(InfrastructureGISManager, self).get_queryset().exclude(type__type=INFRASTRUCTURE_TYPES.SIGNAGE)
117
118
119 class InfrastructureStructureManager(StructureRelatedManager):
120 """ Overide default structure related manager, and filter by type. """
121 def get_queryset(self):
122 return super(InfrastructureStructureManager, self).get_queryset().exclude(type__type=INFRASTRUCTURE_TYPES.SIGNAGE)
123
124
125 class Infrastructure(BaseInfrastructure):
126 """ An infrastructure in the park, which is not of type SIGNAGE """
127 objects = BaseInfrastructure.get_manager_cls(InfrastructureGISManager)()
128 in_structure = InfrastructureStructureManager()
129
130 class Meta:
131 proxy = True
132 verbose_name = _(u"Infrastructure")
133 verbose_name_plural = _(u"Infrastructures")
134
135 @classmethod
136 def path_infrastructures(cls, path):
137 return cls.objects.existing().filter(aggregations__path=path).distinct('pk')
138
139 @classmethod
140 def topology_infrastructures(cls, topology):
141 return cls.overlapping(topology)
142
143 Path.add_property('infrastructures', lambda self: Infrastructure.path_infrastructures(self), _(u"Infrastructures"))
144 Topology.add_property('infrastructures', lambda self: Infrastructure.topology_infrastructures(self), _(u"Infrastructures"))
145
146
147 class SignageGISManager(gismodels.GeoManager):
148 """ Overide default typology mixin manager, and filter by type. """
149 def get_queryset(self):
150 return super(SignageGISManager, self).get_queryset().filter(type__type=INFRASTRUCTURE_TYPES.SIGNAGE)
151
152
153 class SignageStructureManager(StructureRelatedManager):
154 """ Overide default structure related manager, and filter by type. """
155 def get_queryset(self):
156 return super(SignageStructureManager, self).get_queryset().filter(type__type=INFRASTRUCTURE_TYPES.SIGNAGE)
157
158
159 class Signage(BaseInfrastructure):
160 """ An infrastructure in the park, which is of type SIGNAGE """
161 objects = BaseInfrastructure.get_manager_cls(SignageGISManager)()
162 in_structure = SignageStructureManager()
163
164 class Meta:
165 proxy = True
166 verbose_name = _(u"Signage")
167 verbose_name_plural = _(u"Signages")
168
169 @classmethod
170 def path_signages(cls, path):
171 return cls.objects.existing().filter(aggregations__path=path).distinct('pk')
172
173 @classmethod
174 def topology_signages(cls, topology):
175 return cls.overlapping(topology)
176
177 Path.add_property('signages', lambda self: Signage.path_signages(self), _(u"Signages"))
178 Topology.add_property('signages', lambda self: Signage.topology_signages(self), _(u"Signages"))
179
[end of geotrek/infrastructure/models.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/geotrek/infrastructure/models.py b/geotrek/infrastructure/models.py
--- a/geotrek/infrastructure/models.py
+++ b/geotrek/infrastructure/models.py
@@ -76,7 +76,7 @@
verbose_name=_("Description"), help_text=_(u"Specificites"))
type = models.ForeignKey(InfrastructureType, db_column='type', verbose_name=_("Type"))
condition = models.ForeignKey(InfrastructureCondition, db_column='etat',
- verbose_name=_("Condition"), null=True,
+ verbose_name=_("Condition"), blank=True, null=True,
on_delete=models.PROTECT)
class Meta:
|
{"golden_diff": "diff --git a/geotrek/infrastructure/models.py b/geotrek/infrastructure/models.py\n--- a/geotrek/infrastructure/models.py\n+++ b/geotrek/infrastructure/models.py\n@@ -76,7 +76,7 @@\n verbose_name=_(\"Description\"), help_text=_(u\"Specificites\"))\n type = models.ForeignKey(InfrastructureType, db_column='type', verbose_name=_(\"Type\"))\n condition = models.ForeignKey(InfrastructureCondition, db_column='etat',\n- verbose_name=_(\"Condition\"), null=True,\n+ verbose_name=_(\"Condition\"), blank=True, null=True,\n on_delete=models.PROTECT)\n \n class Meta:\n", "issue": "Infrastructure CONDITION - Should not be mandatory\nMany will just localize their infrastructures. \n\n", "before_files": [{"content": "from django.db import models\nfrom django.utils.translation import ugettext_lazy as _\nfrom django.contrib.gis.db import models as gismodels\n\nfrom extended_choices import Choices\nfrom mapentity.models import MapEntityMixin\n\nfrom geotrek.common.utils import classproperty\nfrom geotrek.core.models import Topology, Path\nfrom geotrek.authent.models import StructureRelatedManager, StructureRelated\n\n\nINFRASTRUCTURE_TYPES = Choices(\n ('BUILDING', 'A', _(\"Building\")),\n ('FACILITY', 'E', _(\"Facility\")),\n ('SIGNAGE', 'S', _(\"Signage\")),\n)\n\n\nclass InfrastructureTypeQuerySet(models.query.QuerySet):\n def for_infrastructures(self):\n return self.exclude(type__exact=INFRASTRUCTURE_TYPES.SIGNAGE)\n\n def for_signages(self):\n return self.filter(type__exact=INFRASTRUCTURE_TYPES.SIGNAGE)\n\n\nclass InfrastructureTypeManager(models.Manager):\n def get_queryset(self):\n return InfrastructureTypeQuerySet(self.model, using=self._db)\n\n def for_signages(self):\n return self.get_queryset().for_signages()\n\n def for_infrastructures(self):\n return self.get_queryset().for_infrastructures()\n\n\nclass InfrastructureType(StructureRelated):\n \"\"\" Types of infrastructures (bridge, WC, stairs, ...) \"\"\"\n label = models.CharField(db_column=\"nom\", max_length=128)\n type = models.CharField(db_column=\"type\", max_length=1, choices=INFRASTRUCTURE_TYPES)\n\n objects = InfrastructureTypeManager()\n\n class Meta:\n db_table = 'a_b_amenagement'\n verbose_name = _(u\"Infrastructure Type\")\n verbose_name_plural = _(u\"Infrastructure Types\")\n ordering = ['label', 'type']\n\n def __unicode__(self):\n return self.label\n\n\nclass InfrastructureCondition(StructureRelated):\n label = models.CharField(verbose_name=_(u\"Name\"), db_column=\"etat\", max_length=250)\n\n class Meta:\n verbose_name = _(u\"Infrastructure Condition\")\n verbose_name_plural = _(u\"Infrastructure Conditions\")\n db_table = \"a_b_etat\"\n\n def __unicode__(self):\n return self.label\n\n\nclass BaseInfrastructure(MapEntityMixin, Topology, StructureRelated):\n \"\"\" A generic infrastructure in the park \"\"\"\n topo_object = models.OneToOneField(Topology, parent_link=True,\n db_column='evenement')\n\n name = models.CharField(db_column=\"nom\", max_length=128,\n help_text=_(u\"Reference, code, ...\"), verbose_name=_(\"Name\"))\n description = models.TextField(blank=True, db_column='description',\n verbose_name=_(\"Description\"), help_text=_(u\"Specificites\"))\n type = models.ForeignKey(InfrastructureType, db_column='type', verbose_name=_(\"Type\"))\n condition = models.ForeignKey(InfrastructureCondition, db_column='etat',\n verbose_name=_(\"Condition\"), null=True,\n on_delete=models.PROTECT)\n\n class Meta:\n db_table = 'a_t_amenagement'\n\n def __unicode__(self):\n return self.name\n\n @property\n def name_display(self):\n return '<a href=\"%s\" title=\"%s\" >%s</a>' % (self.get_detail_url(),\n self,\n self)\n\n @property\n def name_csv_display(self):\n return unicode(self)\n\n @property\n def type_display(self):\n return unicode(self.type)\n\n @property\n def cities_display(self):\n if hasattr(self, 'cities'):\n return [unicode(c) for c in self.cities]\n return []\n\n @classproperty\n def cities_verbose_name(cls):\n return _(\"Cities\")\n\n\nclass InfrastructureGISManager(gismodels.GeoManager):\n \"\"\" Overide default typology mixin manager, and filter by type. \"\"\"\n def get_queryset(self):\n return super(InfrastructureGISManager, self).get_queryset().exclude(type__type=INFRASTRUCTURE_TYPES.SIGNAGE)\n\n\nclass InfrastructureStructureManager(StructureRelatedManager):\n \"\"\" Overide default structure related manager, and filter by type. \"\"\"\n def get_queryset(self):\n return super(InfrastructureStructureManager, self).get_queryset().exclude(type__type=INFRASTRUCTURE_TYPES.SIGNAGE)\n\n\nclass Infrastructure(BaseInfrastructure):\n \"\"\" An infrastructure in the park, which is not of type SIGNAGE \"\"\"\n objects = BaseInfrastructure.get_manager_cls(InfrastructureGISManager)()\n in_structure = InfrastructureStructureManager()\n\n class Meta:\n proxy = True\n verbose_name = _(u\"Infrastructure\")\n verbose_name_plural = _(u\"Infrastructures\")\n\n @classmethod\n def path_infrastructures(cls, path):\n return cls.objects.existing().filter(aggregations__path=path).distinct('pk')\n\n @classmethod\n def topology_infrastructures(cls, topology):\n return cls.overlapping(topology)\n\nPath.add_property('infrastructures', lambda self: Infrastructure.path_infrastructures(self), _(u\"Infrastructures\"))\nTopology.add_property('infrastructures', lambda self: Infrastructure.topology_infrastructures(self), _(u\"Infrastructures\"))\n\n\nclass SignageGISManager(gismodels.GeoManager):\n \"\"\" Overide default typology mixin manager, and filter by type. \"\"\"\n def get_queryset(self):\n return super(SignageGISManager, self).get_queryset().filter(type__type=INFRASTRUCTURE_TYPES.SIGNAGE)\n\n\nclass SignageStructureManager(StructureRelatedManager):\n \"\"\" Overide default structure related manager, and filter by type. \"\"\"\n def get_queryset(self):\n return super(SignageStructureManager, self).get_queryset().filter(type__type=INFRASTRUCTURE_TYPES.SIGNAGE)\n\n\nclass Signage(BaseInfrastructure):\n \"\"\" An infrastructure in the park, which is of type SIGNAGE \"\"\"\n objects = BaseInfrastructure.get_manager_cls(SignageGISManager)()\n in_structure = SignageStructureManager()\n\n class Meta:\n proxy = True\n verbose_name = _(u\"Signage\")\n verbose_name_plural = _(u\"Signages\")\n\n @classmethod\n def path_signages(cls, path):\n return cls.objects.existing().filter(aggregations__path=path).distinct('pk')\n\n @classmethod\n def topology_signages(cls, topology):\n return cls.overlapping(topology)\n\nPath.add_property('signages', lambda self: Signage.path_signages(self), _(u\"Signages\"))\nTopology.add_property('signages', lambda self: Signage.topology_signages(self), _(u\"Signages\"))\n", "path": "geotrek/infrastructure/models.py"}]}
| 2,392 | 139 |
gh_patches_debug_24403
|
rasdani/github-patches
|
git_diff
|
mitmproxy__mitmproxy-2674
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Mitmproxy odd UI behaviour
##### Steps to reproduce the problem:
1. Run `mitmproxy` and start intercepting flows.
2. Let the UI fill with flows and then goto the last flow.

3. Press up key to go one flow above.
4. The UI shifts one flow downwards instead of marker going one flow upwards.

##### Any other comments? What have you tried so far?
This is not a deal breaker or anything but a bit annoying. This seems to happen only with the last flow in UI.
##### System information
<!-- Paste the output of "mitmproxy --version" here. -->
```
Mitmproxy: 3.0.0
Python: 3.6.2
OpenSSL: OpenSSL 1.0.2g 1 Mar 2016
Platform: Linux-4.8.0-53-generic-x86_64-with-debian-stretch-sid
```
<!-- Please use the mitmproxy forums (https://discourse.mitmproxy.org/) for support/how-to questions. Thanks! :) -->
Mitmproxy odd UI behaviour
##### Steps to reproduce the problem:
1. Run `mitmproxy` and start intercepting flows.
2. Let the UI fill with flows and then goto the last flow.

3. Press up key to go one flow above.
4. The UI shifts one flow downwards instead of marker going one flow upwards.

##### Any other comments? What have you tried so far?
This is not a deal breaker or anything but a bit annoying. This seems to happen only with the last flow in UI.
##### System information
<!-- Paste the output of "mitmproxy --version" here. -->
```
Mitmproxy: 3.0.0
Python: 3.6.2
OpenSSL: OpenSSL 1.0.2g 1 Mar 2016
Platform: Linux-4.8.0-53-generic-x86_64-with-debian-stretch-sid
```
<!-- Please use the mitmproxy forums (https://discourse.mitmproxy.org/) for support/how-to questions. Thanks! :) -->
</issue>
<code>
[start of mitmproxy/tools/console/window.py]
1 import re
2
3 import urwid
4 from mitmproxy.tools.console import common
5 from mitmproxy.tools.console import signals
6 from mitmproxy.tools.console import statusbar
7 from mitmproxy.tools.console import flowlist
8 from mitmproxy.tools.console import flowview
9 from mitmproxy.tools.console import commands
10 from mitmproxy.tools.console import keybindings
11 from mitmproxy.tools.console import options
12 from mitmproxy.tools.console import overlay
13 from mitmproxy.tools.console import help
14 from mitmproxy.tools.console import grideditor
15 from mitmproxy.tools.console import eventlog
16
17
18 class Header(urwid.Frame):
19 def __init__(self, widget, title, focus):
20 super().__init__(
21 widget,
22 header = urwid.AttrWrap(
23 urwid.Text(title),
24 "heading" if focus else "heading_inactive"
25 )
26 )
27
28
29 class WindowStack:
30 def __init__(self, master, base):
31 self.master = master
32 self.windows = dict(
33 flowlist = flowlist.FlowListBox(master),
34 flowview = flowview.FlowView(master),
35 commands = commands.Commands(master),
36 keybindings = keybindings.KeyBindings(master),
37 options = options.Options(master),
38 help = help.HelpView(master),
39 eventlog = eventlog.EventLog(master),
40
41 edit_focus_query = grideditor.QueryEditor(master),
42 edit_focus_cookies = grideditor.CookieEditor(master),
43 edit_focus_setcookies = grideditor.SetCookieEditor(master),
44 edit_focus_form = grideditor.RequestFormEditor(master),
45 edit_focus_path = grideditor.PathEditor(master),
46 edit_focus_request_headers = grideditor.RequestHeaderEditor(master),
47 edit_focus_response_headers = grideditor.ResponseHeaderEditor(master),
48 )
49 self.stack = [base]
50 self.overlay = None
51
52 def set_overlay(self, o, **kwargs):
53 self.overlay = overlay.SimpleOverlay(
54 self, o, self.top_widget(), o.width, **kwargs,
55 )
56
57 def top_window(self):
58 """
59 The current top window, ignoring overlays.
60 """
61 return self.windows[self.stack[-1]]
62
63 def top_widget(self):
64 """
65 The current top widget - either a window or the active overlay.
66 """
67 if self.overlay:
68 return self.overlay
69 return self.top_window()
70
71 def push(self, wname):
72 if self.stack[-1] == wname:
73 return
74 prev = self.top_window()
75 self.stack.append(wname)
76 self.call("layout_pushed", prev)
77
78 def pop(self, *args, **kwargs):
79 """
80 Pop off the stack, return True if we're already at the top.
81 """
82 if not self.overlay and len(self.stack) == 1:
83 return True
84 self.call("layout_popping")
85 if self.overlay:
86 self.overlay = None
87 else:
88 self.stack.pop()
89
90 def call(self, name, *args, **kwargs):
91 """
92 Call a function on both the top window, and the overlay if there is
93 one. If the widget has a key_responder, we call the function on the
94 responder instead.
95 """
96 getattr(self.top_window(), name)(*args, **kwargs)
97 if self.overlay:
98 getattr(self.overlay, name)(*args, **kwargs)
99
100
101 class Window(urwid.Frame):
102 def __init__(self, master):
103 self.statusbar = statusbar.StatusBar(master)
104 super().__init__(
105 None,
106 header = None,
107 footer = urwid.AttrWrap(self.statusbar, "background")
108 )
109 self.master = master
110 self.master.view.sig_view_refresh.connect(self.view_changed)
111 self.master.view.sig_view_add.connect(self.view_changed)
112 self.master.view.sig_view_remove.connect(self.view_changed)
113 self.master.view.sig_view_update.connect(self.view_changed)
114 self.master.view.focus.sig_change.connect(self.view_changed)
115 self.master.view.focus.sig_change.connect(self.focus_changed)
116
117 signals.focus.connect(self.sig_focus)
118 signals.flow_change.connect(self.flow_changed)
119 signals.pop_view_state.connect(self.pop)
120 signals.push_view_state.connect(self.push)
121
122 self.master.options.subscribe(self.configure, ["console_layout"])
123 self.master.options.subscribe(self.configure, ["console_layout_headers"])
124 self.pane = 0
125 self.stacks = [
126 WindowStack(master, "flowlist"),
127 WindowStack(master, "eventlog")
128 ]
129
130 def focus_stack(self):
131 return self.stacks[self.pane]
132
133 def configure(self, otions, updated):
134 self.refresh()
135
136 def refresh(self):
137 """
138 Redraw the layout.
139 """
140 c = self.master.options.console_layout
141 if c == "single":
142 self.pane = 0
143
144 def wrapped(idx):
145 window = self.stacks[idx].top_window()
146 widget = self.stacks[idx].top_widget()
147 if self.master.options.console_layout_headers and window.title:
148 return Header(widget, window.title, self.pane == idx)
149 else:
150 return widget
151
152 w = None
153 if c == "single":
154 w = wrapped(0)
155 elif c == "vertical":
156 w = urwid.Pile(
157 [
158 wrapped(i) for i, s in enumerate(self.stacks)
159 ]
160 )
161 else:
162 w = urwid.Columns(
163 [wrapped(i) for i, s in enumerate(self.stacks)],
164 dividechars=1
165 )
166
167 self.body = urwid.AttrWrap(w, "background")
168
169 def flow_changed(self, sender, flow):
170 if self.master.view.focus.flow:
171 if flow.id == self.master.view.focus.flow.id:
172 self.focus_changed()
173
174 def focus_changed(self, *args, **kwargs):
175 """
176 Triggered when the focus changes - either when it's modified, or
177 when it changes to a different flow altogether.
178 """
179 for i in self.stacks:
180 i.call("focus_changed")
181
182 def view_changed(self, *args, **kwargs):
183 """
184 Triggered when the view list has changed.
185 """
186 for i in self.stacks:
187 i.call("view_changed")
188
189 def set_overlay(self, o, **kwargs):
190 """
191 Set an overlay on the currently focused stack.
192 """
193 self.focus_stack().set_overlay(o, **kwargs)
194 self.refresh()
195
196 def push(self, wname):
197 """
198 Push a window onto the currently focused stack.
199 """
200 self.focus_stack().push(wname)
201 self.refresh()
202 self.view_changed()
203 self.focus_changed()
204
205 def pop(self, *args, **kwargs):
206 """
207 Pop a window from the currently focused stack. If there is only one
208 window on the stack, this prompts for exit.
209 """
210 if self.focus_stack().pop():
211 self.master.prompt_for_exit()
212 else:
213 self.refresh()
214 self.view_changed()
215 self.focus_changed()
216
217 def current(self, keyctx):
218 """
219 Returns the active widget, but only the current focus or overlay has
220 a matching key context.
221 """
222 t = self.focus_stack().top_widget()
223 if t.keyctx == keyctx:
224 return t
225
226 def current_window(self, keyctx):
227 """
228 Returns the active window, ignoring overlays.
229 """
230 t = self.focus_stack().top_window()
231 if t.keyctx == keyctx:
232 return t
233
234 def any(self, keyctx):
235 """
236 Returns the top window of either stack if they match the context.
237 """
238 for t in [x.top_window() for x in self.stacks]:
239 if t.keyctx == keyctx:
240 return t
241
242 def sig_focus(self, sender, section):
243 self.focus_position = section
244
245 def switch(self):
246 """
247 Switch between the two panes.
248 """
249 if self.master.options.console_layout == "single":
250 self.pane = 0
251 else:
252 self.pane = (self.pane + 1) % len(self.stacks)
253 self.refresh()
254
255 def mouse_event(self, *args, **kwargs):
256 # args: (size, event, button, col, row)
257 k = super().mouse_event(*args, **kwargs)
258 if not k:
259 if args[1] == "mouse drag":
260 signals.status_message.send(
261 message = "Hold down fn, shift, alt or ctrl to select text or use the --no-mouse parameter.",
262 expire = 1
263 )
264 elif args[1] == "mouse press" and args[2] == 4:
265 self.keypress(args[0], "up")
266 elif args[1] == "mouse press" and args[2] == 5:
267 self.keypress(args[0], "down")
268 else:
269 return False
270 return True
271
272 def keypress(self, size, k):
273 if self.focus_part == "footer":
274 return super().keypress(size, k)
275 else:
276 fs = self.focus_stack().top_widget()
277 k = fs.keypress(size, k)
278 if k:
279 return self.master.keymap.handle(fs.keyctx, k)
280
281
282 class Screen(urwid.raw_display.Screen):
283
284 def write(self, data):
285 if common.IS_WSL:
286 # replace urwid's SI/SO, which produce artifacts under WSL.
287 # at some point we may figure out what they actually do.
288 data = re.sub("[\x0e\x0f]", "", data)
289 super().write(data)
290
[end of mitmproxy/tools/console/window.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mitmproxy/tools/console/window.py b/mitmproxy/tools/console/window.py
--- a/mitmproxy/tools/console/window.py
+++ b/mitmproxy/tools/console/window.py
@@ -156,12 +156,14 @@
w = urwid.Pile(
[
wrapped(i) for i, s in enumerate(self.stacks)
- ]
+ ],
+ focus_item=self.pane
)
else:
w = urwid.Columns(
[wrapped(i) for i, s in enumerate(self.stacks)],
- dividechars=1
+ dividechars=1,
+ focus_column=self.pane
)
self.body = urwid.AttrWrap(w, "background")
@@ -270,13 +272,12 @@
return True
def keypress(self, size, k):
- if self.focus_part == "footer":
- return super().keypress(size, k)
- else:
- fs = self.focus_stack().top_widget()
- k = fs.keypress(size, k)
- if k:
- return self.master.keymap.handle(fs.keyctx, k)
+ k = super().keypress(size, k)
+ if k:
+ return self.master.keymap.handle(
+ self.focus_stack().top_widget().keyctx,
+ k
+ )
class Screen(urwid.raw_display.Screen):
|
{"golden_diff": "diff --git a/mitmproxy/tools/console/window.py b/mitmproxy/tools/console/window.py\n--- a/mitmproxy/tools/console/window.py\n+++ b/mitmproxy/tools/console/window.py\n@@ -156,12 +156,14 @@\n w = urwid.Pile(\n [\n wrapped(i) for i, s in enumerate(self.stacks)\n- ]\n+ ],\n+ focus_item=self.pane\n )\n else:\n w = urwid.Columns(\n [wrapped(i) for i, s in enumerate(self.stacks)],\n- dividechars=1\n+ dividechars=1,\n+ focus_column=self.pane\n )\n \n self.body = urwid.AttrWrap(w, \"background\")\n@@ -270,13 +272,12 @@\n return True\n \n def keypress(self, size, k):\n- if self.focus_part == \"footer\":\n- return super().keypress(size, k)\n- else:\n- fs = self.focus_stack().top_widget()\n- k = fs.keypress(size, k)\n- if k:\n- return self.master.keymap.handle(fs.keyctx, k)\n+ k = super().keypress(size, k)\n+ if k:\n+ return self.master.keymap.handle(\n+ self.focus_stack().top_widget().keyctx,\n+ k\n+ )\n \n \n class Screen(urwid.raw_display.Screen):\n", "issue": "Mitmproxy odd UI behaviour\n##### Steps to reproduce the problem:\r\n\r\n1. Run `mitmproxy` and start intercepting flows.\r\n\r\n2. Let the UI fill with flows and then goto the last flow.\r\n\r\n\r\n\r\n3. Press up key to go one flow above.\r\n\r\n4. The UI shifts one flow downwards instead of marker going one flow upwards.\r\n\r\n\r\n\r\n\r\n##### Any other comments? What have you tried so far?\r\n\r\nThis is not a deal breaker or anything but a bit annoying. This seems to happen only with the last flow in UI.\r\n\r\n##### System information\r\n\r\n<!-- Paste the output of \"mitmproxy --version\" here. -->\r\n\r\n```\r\nMitmproxy: 3.0.0 \r\nPython: 3.6.2\r\nOpenSSL: OpenSSL 1.0.2g 1 Mar 2016\r\nPlatform: Linux-4.8.0-53-generic-x86_64-with-debian-stretch-sid\r\n```\r\n\r\n<!-- Please use the mitmproxy forums (https://discourse.mitmproxy.org/) for support/how-to questions. Thanks! :) -->\r\n\nMitmproxy odd UI behaviour\n##### Steps to reproduce the problem:\r\n\r\n1. Run `mitmproxy` and start intercepting flows.\r\n\r\n2. Let the UI fill with flows and then goto the last flow.\r\n\r\n\r\n\r\n3. Press up key to go one flow above.\r\n\r\n4. The UI shifts one flow downwards instead of marker going one flow upwards.\r\n\r\n\r\n\r\n\r\n##### Any other comments? What have you tried so far?\r\n\r\nThis is not a deal breaker or anything but a bit annoying. This seems to happen only with the last flow in UI.\r\n\r\n##### System information\r\n\r\n<!-- Paste the output of \"mitmproxy --version\" here. -->\r\n\r\n```\r\nMitmproxy: 3.0.0 \r\nPython: 3.6.2\r\nOpenSSL: OpenSSL 1.0.2g 1 Mar 2016\r\nPlatform: Linux-4.8.0-53-generic-x86_64-with-debian-stretch-sid\r\n```\r\n\r\n<!-- Please use the mitmproxy forums (https://discourse.mitmproxy.org/) for support/how-to questions. Thanks! :) -->\r\n\n", "before_files": [{"content": "import re\n\nimport urwid\nfrom mitmproxy.tools.console import common\nfrom mitmproxy.tools.console import signals\nfrom mitmproxy.tools.console import statusbar\nfrom mitmproxy.tools.console import flowlist\nfrom mitmproxy.tools.console import flowview\nfrom mitmproxy.tools.console import commands\nfrom mitmproxy.tools.console import keybindings\nfrom mitmproxy.tools.console import options\nfrom mitmproxy.tools.console import overlay\nfrom mitmproxy.tools.console import help\nfrom mitmproxy.tools.console import grideditor\nfrom mitmproxy.tools.console import eventlog\n\n\nclass Header(urwid.Frame):\n def __init__(self, widget, title, focus):\n super().__init__(\n widget,\n header = urwid.AttrWrap(\n urwid.Text(title),\n \"heading\" if focus else \"heading_inactive\"\n )\n )\n\n\nclass WindowStack:\n def __init__(self, master, base):\n self.master = master\n self.windows = dict(\n flowlist = flowlist.FlowListBox(master),\n flowview = flowview.FlowView(master),\n commands = commands.Commands(master),\n keybindings = keybindings.KeyBindings(master),\n options = options.Options(master),\n help = help.HelpView(master),\n eventlog = eventlog.EventLog(master),\n\n edit_focus_query = grideditor.QueryEditor(master),\n edit_focus_cookies = grideditor.CookieEditor(master),\n edit_focus_setcookies = grideditor.SetCookieEditor(master),\n edit_focus_form = grideditor.RequestFormEditor(master),\n edit_focus_path = grideditor.PathEditor(master),\n edit_focus_request_headers = grideditor.RequestHeaderEditor(master),\n edit_focus_response_headers = grideditor.ResponseHeaderEditor(master),\n )\n self.stack = [base]\n self.overlay = None\n\n def set_overlay(self, o, **kwargs):\n self.overlay = overlay.SimpleOverlay(\n self, o, self.top_widget(), o.width, **kwargs,\n )\n\n def top_window(self):\n \"\"\"\n The current top window, ignoring overlays.\n \"\"\"\n return self.windows[self.stack[-1]]\n\n def top_widget(self):\n \"\"\"\n The current top widget - either a window or the active overlay.\n \"\"\"\n if self.overlay:\n return self.overlay\n return self.top_window()\n\n def push(self, wname):\n if self.stack[-1] == wname:\n return\n prev = self.top_window()\n self.stack.append(wname)\n self.call(\"layout_pushed\", prev)\n\n def pop(self, *args, **kwargs):\n \"\"\"\n Pop off the stack, return True if we're already at the top.\n \"\"\"\n if not self.overlay and len(self.stack) == 1:\n return True\n self.call(\"layout_popping\")\n if self.overlay:\n self.overlay = None\n else:\n self.stack.pop()\n\n def call(self, name, *args, **kwargs):\n \"\"\"\n Call a function on both the top window, and the overlay if there is\n one. If the widget has a key_responder, we call the function on the\n responder instead.\n \"\"\"\n getattr(self.top_window(), name)(*args, **kwargs)\n if self.overlay:\n getattr(self.overlay, name)(*args, **kwargs)\n\n\nclass Window(urwid.Frame):\n def __init__(self, master):\n self.statusbar = statusbar.StatusBar(master)\n super().__init__(\n None,\n header = None,\n footer = urwid.AttrWrap(self.statusbar, \"background\")\n )\n self.master = master\n self.master.view.sig_view_refresh.connect(self.view_changed)\n self.master.view.sig_view_add.connect(self.view_changed)\n self.master.view.sig_view_remove.connect(self.view_changed)\n self.master.view.sig_view_update.connect(self.view_changed)\n self.master.view.focus.sig_change.connect(self.view_changed)\n self.master.view.focus.sig_change.connect(self.focus_changed)\n\n signals.focus.connect(self.sig_focus)\n signals.flow_change.connect(self.flow_changed)\n signals.pop_view_state.connect(self.pop)\n signals.push_view_state.connect(self.push)\n\n self.master.options.subscribe(self.configure, [\"console_layout\"])\n self.master.options.subscribe(self.configure, [\"console_layout_headers\"])\n self.pane = 0\n self.stacks = [\n WindowStack(master, \"flowlist\"),\n WindowStack(master, \"eventlog\")\n ]\n\n def focus_stack(self):\n return self.stacks[self.pane]\n\n def configure(self, otions, updated):\n self.refresh()\n\n def refresh(self):\n \"\"\"\n Redraw the layout.\n \"\"\"\n c = self.master.options.console_layout\n if c == \"single\":\n self.pane = 0\n\n def wrapped(idx):\n window = self.stacks[idx].top_window()\n widget = self.stacks[idx].top_widget()\n if self.master.options.console_layout_headers and window.title:\n return Header(widget, window.title, self.pane == idx)\n else:\n return widget\n\n w = None\n if c == \"single\":\n w = wrapped(0)\n elif c == \"vertical\":\n w = urwid.Pile(\n [\n wrapped(i) for i, s in enumerate(self.stacks)\n ]\n )\n else:\n w = urwid.Columns(\n [wrapped(i) for i, s in enumerate(self.stacks)],\n dividechars=1\n )\n\n self.body = urwid.AttrWrap(w, \"background\")\n\n def flow_changed(self, sender, flow):\n if self.master.view.focus.flow:\n if flow.id == self.master.view.focus.flow.id:\n self.focus_changed()\n\n def focus_changed(self, *args, **kwargs):\n \"\"\"\n Triggered when the focus changes - either when it's modified, or\n when it changes to a different flow altogether.\n \"\"\"\n for i in self.stacks:\n i.call(\"focus_changed\")\n\n def view_changed(self, *args, **kwargs):\n \"\"\"\n Triggered when the view list has changed.\n \"\"\"\n for i in self.stacks:\n i.call(\"view_changed\")\n\n def set_overlay(self, o, **kwargs):\n \"\"\"\n Set an overlay on the currently focused stack.\n \"\"\"\n self.focus_stack().set_overlay(o, **kwargs)\n self.refresh()\n\n def push(self, wname):\n \"\"\"\n Push a window onto the currently focused stack.\n \"\"\"\n self.focus_stack().push(wname)\n self.refresh()\n self.view_changed()\n self.focus_changed()\n\n def pop(self, *args, **kwargs):\n \"\"\"\n Pop a window from the currently focused stack. If there is only one\n window on the stack, this prompts for exit.\n \"\"\"\n if self.focus_stack().pop():\n self.master.prompt_for_exit()\n else:\n self.refresh()\n self.view_changed()\n self.focus_changed()\n\n def current(self, keyctx):\n \"\"\"\n Returns the active widget, but only the current focus or overlay has\n a matching key context.\n \"\"\"\n t = self.focus_stack().top_widget()\n if t.keyctx == keyctx:\n return t\n\n def current_window(self, keyctx):\n \"\"\"\n Returns the active window, ignoring overlays.\n \"\"\"\n t = self.focus_stack().top_window()\n if t.keyctx == keyctx:\n return t\n\n def any(self, keyctx):\n \"\"\"\n Returns the top window of either stack if they match the context.\n \"\"\"\n for t in [x.top_window() for x in self.stacks]:\n if t.keyctx == keyctx:\n return t\n\n def sig_focus(self, sender, section):\n self.focus_position = section\n\n def switch(self):\n \"\"\"\n Switch between the two panes.\n \"\"\"\n if self.master.options.console_layout == \"single\":\n self.pane = 0\n else:\n self.pane = (self.pane + 1) % len(self.stacks)\n self.refresh()\n\n def mouse_event(self, *args, **kwargs):\n # args: (size, event, button, col, row)\n k = super().mouse_event(*args, **kwargs)\n if not k:\n if args[1] == \"mouse drag\":\n signals.status_message.send(\n message = \"Hold down fn, shift, alt or ctrl to select text or use the --no-mouse parameter.\",\n expire = 1\n )\n elif args[1] == \"mouse press\" and args[2] == 4:\n self.keypress(args[0], \"up\")\n elif args[1] == \"mouse press\" and args[2] == 5:\n self.keypress(args[0], \"down\")\n else:\n return False\n return True\n\n def keypress(self, size, k):\n if self.focus_part == \"footer\":\n return super().keypress(size, k)\n else:\n fs = self.focus_stack().top_widget()\n k = fs.keypress(size, k)\n if k:\n return self.master.keymap.handle(fs.keyctx, k)\n\n\nclass Screen(urwid.raw_display.Screen):\n\n def write(self, data):\n if common.IS_WSL:\n # replace urwid's SI/SO, which produce artifacts under WSL.\n # at some point we may figure out what they actually do.\n data = re.sub(\"[\\x0e\\x0f]\", \"\", data)\n super().write(data)\n", "path": "mitmproxy/tools/console/window.py"}]}
| 4,038 | 308 |
gh_patches_debug_2526
|
rasdani/github-patches
|
git_diff
|
scikit-hep__pyhf-1049
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fix Fixture use in pytest
# Description
In pytest `v4.0.0` the [direct call of a fixture results in an error](https://travis-ci.org/diana-hep/pyhf/jobs/455364238#L661-L669).
```
==================================== ERRORS ====================================
__________________ ERROR collecting tests/test_validation.py ___________________
tests/test_validation.py:13: in <module>
def spec_1bin_shapesys(source=source_1bin_example1()):
E _pytest.warning_types.RemovedInPytest4Warning: Fixture "source_1bin_example1" called directly. Fixtures are not meant to be called directly, are created automatically when test functions request them as parameters. See https://docs.pytest.org/en/latest/fixture.html for more information.
__________________ ERROR collecting tests/test_validation.py ___________________
tests/test_validation.py:13: in <module>
def spec_1bin_shapesys(source=source_1bin_example1()):
E _pytest.warning_types.RemovedInPytest4Warning: Fixture "source_1bin_example1" called directly. Fixtures are not meant to be called directly, are created automatically when test functions request them as parameters. See https://docs.pytest.org/en/latest/fixture.html for more information.
```
This requires changing the way that pytest is used a bit.
This was noticed in preparation of PR #369
# Checklist
- [x] Run `git fetch` to get the most up to date version of `master`
- [x] Searched through existing Issues to confirm this is not a duplicate issue
- [x] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue
</issue>
<code>
[start of setup.py]
1 from setuptools import setup
2
3 extras_require = {
4 'shellcomplete': ['click_completion'],
5 'tensorflow': [
6 'tensorflow~=2.2.0', # TensorFlow minor releases are as volatile as major
7 'tensorflow-probability~=0.10.0',
8 ],
9 'torch': ['torch~=1.2'],
10 'jax': ['jax~=0.1,>0.1.51', 'jaxlib~=0.1,>0.1.33'],
11 'xmlio': ['uproot~=3.6'], # Future proof against uproot4 API changes
12 'minuit': ['iminuit~=1.4,>=1.4.3'], # Use "name" keyword in MINUIT optimizer
13 }
14 extras_require['backends'] = sorted(
15 set(
16 extras_require['tensorflow']
17 + extras_require['torch']
18 + extras_require['jax']
19 + extras_require['minuit']
20 )
21 )
22 extras_require['contrib'] = sorted(set(['matplotlib']))
23 extras_require['lint'] = sorted(set(['pyflakes', 'black']))
24
25 extras_require['test'] = sorted(
26 set(
27 extras_require['backends']
28 + extras_require['xmlio']
29 + extras_require['contrib']
30 + extras_require['shellcomplete']
31 + [
32 'pytest~=3.5',
33 'pytest-cov>=2.5.1',
34 'pytest-mock',
35 'pytest-benchmark[histogram]',
36 'pytest-console-scripts',
37 'pytest-mpl',
38 'pydocstyle',
39 'coverage>=4.0', # coveralls
40 'papermill~=2.0',
41 'nteract-scrapbook~=0.2',
42 'jupyter',
43 'uproot~=3.3',
44 'graphviz',
45 'jsonpatch',
46 ]
47 )
48 )
49 extras_require['docs'] = sorted(
50 set(
51 [
52 'sphinx>=3.1.2',
53 'sphinxcontrib-bibtex',
54 'sphinx-click',
55 'sphinx_rtd_theme',
56 'nbsphinx',
57 'ipywidgets',
58 'sphinx-issues',
59 'sphinx-copybutton>0.2.9',
60 ]
61 )
62 )
63 extras_require['develop'] = sorted(
64 set(
65 extras_require['docs']
66 + extras_require['lint']
67 + extras_require['test']
68 + ['nbdime', 'bumpversion', 'ipython', 'pre-commit', 'check-manifest', 'twine']
69 )
70 )
71 extras_require['complete'] = sorted(set(sum(extras_require.values(), [])))
72
73
74 setup(
75 extras_require=extras_require,
76 use_scm_version=lambda: {'local_scheme': lambda version: ''},
77 )
78
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -29,7 +29,7 @@
+ extras_require['contrib']
+ extras_require['shellcomplete']
+ [
- 'pytest~=3.5',
+ 'pytest~=6.0',
'pytest-cov>=2.5.1',
'pytest-mock',
'pytest-benchmark[histogram]',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -29,7 +29,7 @@\n + extras_require['contrib']\n + extras_require['shellcomplete']\n + [\n- 'pytest~=3.5',\n+ 'pytest~=6.0',\n 'pytest-cov>=2.5.1',\n 'pytest-mock',\n 'pytest-benchmark[histogram]',\n", "issue": "Fix Fixture use in pytest\n# Description\r\n\r\nIn pytest `v4.0.0` the [direct call of a fixture results in an error](https://travis-ci.org/diana-hep/pyhf/jobs/455364238#L661-L669). \r\n\r\n```\r\n==================================== ERRORS ====================================\r\n__________________ ERROR collecting tests/test_validation.py ___________________\r\ntests/test_validation.py:13: in <module>\r\n def spec_1bin_shapesys(source=source_1bin_example1()):\r\nE _pytest.warning_types.RemovedInPytest4Warning: Fixture \"source_1bin_example1\" called directly. Fixtures are not meant to be called directly, are created automatically when test functions request them as parameters. See https://docs.pytest.org/en/latest/fixture.html for more information.\r\n__________________ ERROR collecting tests/test_validation.py ___________________\r\ntests/test_validation.py:13: in <module>\r\n def spec_1bin_shapesys(source=source_1bin_example1()):\r\nE _pytest.warning_types.RemovedInPytest4Warning: Fixture \"source_1bin_example1\" called directly. Fixtures are not meant to be called directly, are created automatically when test functions request them as parameters. See https://docs.pytest.org/en/latest/fixture.html for more information.\r\n```\r\n\r\nThis requires changing the way that pytest is used a bit.\r\n\r\nThis was noticed in preparation of PR #369 \r\n\r\n# Checklist\r\n\r\n- [x] Run `git fetch` to get the most up to date version of `master`\r\n- [x] Searched through existing Issues to confirm this is not a duplicate issue\r\n- [x] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue\r\n\n", "before_files": [{"content": "from setuptools import setup\n\nextras_require = {\n 'shellcomplete': ['click_completion'],\n 'tensorflow': [\n 'tensorflow~=2.2.0', # TensorFlow minor releases are as volatile as major\n 'tensorflow-probability~=0.10.0',\n ],\n 'torch': ['torch~=1.2'],\n 'jax': ['jax~=0.1,>0.1.51', 'jaxlib~=0.1,>0.1.33'],\n 'xmlio': ['uproot~=3.6'], # Future proof against uproot4 API changes\n 'minuit': ['iminuit~=1.4,>=1.4.3'], # Use \"name\" keyword in MINUIT optimizer\n}\nextras_require['backends'] = sorted(\n set(\n extras_require['tensorflow']\n + extras_require['torch']\n + extras_require['jax']\n + extras_require['minuit']\n )\n)\nextras_require['contrib'] = sorted(set(['matplotlib']))\nextras_require['lint'] = sorted(set(['pyflakes', 'black']))\n\nextras_require['test'] = sorted(\n set(\n extras_require['backends']\n + extras_require['xmlio']\n + extras_require['contrib']\n + extras_require['shellcomplete']\n + [\n 'pytest~=3.5',\n 'pytest-cov>=2.5.1',\n 'pytest-mock',\n 'pytest-benchmark[histogram]',\n 'pytest-console-scripts',\n 'pytest-mpl',\n 'pydocstyle',\n 'coverage>=4.0', # coveralls\n 'papermill~=2.0',\n 'nteract-scrapbook~=0.2',\n 'jupyter',\n 'uproot~=3.3',\n 'graphviz',\n 'jsonpatch',\n ]\n )\n)\nextras_require['docs'] = sorted(\n set(\n [\n 'sphinx>=3.1.2',\n 'sphinxcontrib-bibtex',\n 'sphinx-click',\n 'sphinx_rtd_theme',\n 'nbsphinx',\n 'ipywidgets',\n 'sphinx-issues',\n 'sphinx-copybutton>0.2.9',\n ]\n )\n)\nextras_require['develop'] = sorted(\n set(\n extras_require['docs']\n + extras_require['lint']\n + extras_require['test']\n + ['nbdime', 'bumpversion', 'ipython', 'pre-commit', 'check-manifest', 'twine']\n )\n)\nextras_require['complete'] = sorted(set(sum(extras_require.values(), [])))\n\n\nsetup(\n extras_require=extras_require,\n use_scm_version=lambda: {'local_scheme': lambda version: ''},\n)\n", "path": "setup.py"}]}
| 1,651 | 95 |
gh_patches_debug_33893
|
rasdani/github-patches
|
git_diff
|
paperless-ngx__paperless-ngx-5783
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Security] Open Redirect on Login page
### Description
The application currently has a security vulnerability known as an "Open Redirect" on its login page. This issue arises because the application fails to properly check and validate the URLs provided in the next parameter during the login process. As a result, attackers can exploit this by inserting an external URL into the next parameter. When a user logs in, instead of being redirected to an internal page, they are unwittingly sent to a potentially malicious external website. This vulnerability can be used for phishing attacks, where users are redirected to fake websites that steal their personal information, or for spreading malware. It's crucial to address this vulnerability to protect users from being redirected to unsafe and untrusted websites.
### Steps to reproduce
1. In the browser's address bar, modify the URL by adding a next parameter with a value pointing to an external website. For example, change it to /accounts/login/?next=//evil.com
2. Log in using valid credentials.
3. Observe that after a successful login, instead of being directed to an internal page of the application, you are redirected to the external website specified in the next parameter.
### Webserver logs
```bash
n/a
```
### Browser logs
_No response_
### Paperless-ngx version
v 2.5.2
### Host OS
Ubuntu 22.04.3
### Installation method
Docker - official image
### Browser
_No response_
### Configuration changes
_No response_
### Other
_No response_
### Please confirm the following
- [X] I believe this issue is a bug that affects all users of Paperless-ngx, not something specific to my installation.
- [X] I have already searched for relevant existing issues and discussions before opening this report.
- [X] I have updated the title field above with a concise description.
</issue>
<code>
[start of src/paperless/urls.py]
1 import os
2
3 from django.conf import settings
4 from django.conf.urls import include
5 from django.contrib import admin
6 from django.contrib.auth.decorators import login_required
7 from django.urls import path
8 from django.urls import re_path
9 from django.utils.translation import gettext_lazy as _
10 from django.views.decorators.csrf import csrf_exempt
11 from django.views.decorators.csrf import ensure_csrf_cookie
12 from django.views.generic import RedirectView
13 from django.views.static import serve
14 from rest_framework.authtoken import views
15 from rest_framework.routers import DefaultRouter
16
17 from documents.views import AcknowledgeTasksView
18 from documents.views import BulkDownloadView
19 from documents.views import BulkEditObjectsView
20 from documents.views import BulkEditView
21 from documents.views import CorrespondentViewSet
22 from documents.views import CustomFieldViewSet
23 from documents.views import DocumentTypeViewSet
24 from documents.views import IndexView
25 from documents.views import LogViewSet
26 from documents.views import PostDocumentView
27 from documents.views import RemoteVersionView
28 from documents.views import SavedViewViewSet
29 from documents.views import SearchAutoCompleteView
30 from documents.views import SelectionDataView
31 from documents.views import SharedLinkView
32 from documents.views import ShareLinkViewSet
33 from documents.views import StatisticsView
34 from documents.views import StoragePathViewSet
35 from documents.views import TagViewSet
36 from documents.views import TasksViewSet
37 from documents.views import UiSettingsView
38 from documents.views import UnifiedSearchViewSet
39 from documents.views import WorkflowActionViewSet
40 from documents.views import WorkflowTriggerViewSet
41 from documents.views import WorkflowViewSet
42 from paperless.consumers import StatusConsumer
43 from paperless.views import ApplicationConfigurationViewSet
44 from paperless.views import DisconnectSocialAccountView
45 from paperless.views import FaviconView
46 from paperless.views import GenerateAuthTokenView
47 from paperless.views import GroupViewSet
48 from paperless.views import ProfileView
49 from paperless.views import SocialAccountProvidersView
50 from paperless.views import UserViewSet
51 from paperless_mail.views import MailAccountTestView
52 from paperless_mail.views import MailAccountViewSet
53 from paperless_mail.views import MailRuleViewSet
54
55 api_router = DefaultRouter()
56 api_router.register(r"correspondents", CorrespondentViewSet)
57 api_router.register(r"document_types", DocumentTypeViewSet)
58 api_router.register(r"documents", UnifiedSearchViewSet)
59 api_router.register(r"logs", LogViewSet, basename="logs")
60 api_router.register(r"tags", TagViewSet)
61 api_router.register(r"saved_views", SavedViewViewSet)
62 api_router.register(r"storage_paths", StoragePathViewSet)
63 api_router.register(r"tasks", TasksViewSet, basename="tasks")
64 api_router.register(r"users", UserViewSet, basename="users")
65 api_router.register(r"groups", GroupViewSet, basename="groups")
66 api_router.register(r"mail_accounts", MailAccountViewSet)
67 api_router.register(r"mail_rules", MailRuleViewSet)
68 api_router.register(r"share_links", ShareLinkViewSet)
69 api_router.register(r"workflow_triggers", WorkflowTriggerViewSet)
70 api_router.register(r"workflow_actions", WorkflowActionViewSet)
71 api_router.register(r"workflows", WorkflowViewSet)
72 api_router.register(r"custom_fields", CustomFieldViewSet)
73 api_router.register(r"config", ApplicationConfigurationViewSet)
74
75
76 urlpatterns = [
77 re_path(
78 r"^api/",
79 include(
80 [
81 re_path(
82 "^auth/",
83 include(
84 ("rest_framework.urls", "rest_framework"),
85 namespace="rest_framework",
86 ),
87 ),
88 re_path(
89 "^search/autocomplete/",
90 SearchAutoCompleteView.as_view(),
91 name="autocomplete",
92 ),
93 re_path("^statistics/", StatisticsView.as_view(), name="statistics"),
94 re_path(
95 "^documents/post_document/",
96 PostDocumentView.as_view(),
97 name="post_document",
98 ),
99 re_path(
100 "^documents/bulk_edit/",
101 BulkEditView.as_view(),
102 name="bulk_edit",
103 ),
104 re_path(
105 "^documents/selection_data/",
106 SelectionDataView.as_view(),
107 name="selection_data",
108 ),
109 re_path(
110 "^documents/bulk_download/",
111 BulkDownloadView.as_view(),
112 name="bulk_download",
113 ),
114 re_path(
115 "^remote_version/",
116 RemoteVersionView.as_view(),
117 name="remoteversion",
118 ),
119 re_path("^ui_settings/", UiSettingsView.as_view(), name="ui_settings"),
120 re_path(
121 "^acknowledge_tasks/",
122 AcknowledgeTasksView.as_view(),
123 name="acknowledge_tasks",
124 ),
125 re_path(
126 "^mail_accounts/test/",
127 MailAccountTestView.as_view(),
128 name="mail_accounts_test",
129 ),
130 path("token/", views.obtain_auth_token),
131 re_path(
132 "^bulk_edit_objects/",
133 BulkEditObjectsView.as_view(),
134 name="bulk_edit_objects",
135 ),
136 path("profile/generate_auth_token/", GenerateAuthTokenView.as_view()),
137 path(
138 "profile/disconnect_social_account/",
139 DisconnectSocialAccountView.as_view(),
140 ),
141 path(
142 "profile/social_account_providers/",
143 SocialAccountProvidersView.as_view(),
144 ),
145 re_path(
146 "^profile/",
147 ProfileView.as_view(),
148 name="profile_view",
149 ),
150 *api_router.urls,
151 ],
152 ),
153 ),
154 re_path(r"share/(?P<slug>\w+)/?$", SharedLinkView.as_view()),
155 re_path(r"^favicon.ico$", FaviconView.as_view(), name="favicon"),
156 re_path(r"admin/", admin.site.urls),
157 re_path(
158 r"^fetch/",
159 include(
160 [
161 re_path(
162 r"^doc/(?P<pk>\d+)$",
163 RedirectView.as_view(
164 url=settings.BASE_URL + "api/documents/%(pk)s/download/",
165 ),
166 ),
167 re_path(
168 r"^thumb/(?P<pk>\d+)$",
169 RedirectView.as_view(
170 url=settings.BASE_URL + "api/documents/%(pk)s/thumb/",
171 ),
172 ),
173 re_path(
174 r"^preview/(?P<pk>\d+)$",
175 RedirectView.as_view(
176 url=settings.BASE_URL + "api/documents/%(pk)s/preview/",
177 ),
178 ),
179 ],
180 ),
181 ),
182 re_path(
183 r"^push$",
184 csrf_exempt(
185 RedirectView.as_view(
186 url=settings.BASE_URL + "api/documents/post_document/",
187 ),
188 ),
189 ),
190 # Frontend assets TODO: this is pretty bad, but it works.
191 path(
192 "assets/<path:path>",
193 RedirectView.as_view(
194 url=settings.STATIC_URL + "frontend/en-US/assets/%(path)s",
195 ),
196 ),
197 # App logo
198 re_path(
199 r"^logo(?P<path>.*)$",
200 serve,
201 kwargs={"document_root": os.path.join(settings.MEDIA_ROOT, "logo")},
202 ),
203 # TODO: with localization, this is even worse! :/
204 # login, logout
205 path("accounts/", include("allauth.urls")),
206 # Root of the Frontend
207 re_path(
208 r".*",
209 login_required(ensure_csrf_cookie(IndexView.as_view())),
210 name="base",
211 ),
212 ]
213
214
215 websocket_urlpatterns = [
216 path(settings.BASE_URL.lstrip("/") + "ws/status/", StatusConsumer.as_asgi()),
217 ]
218
219 # Text in each page's <h1> (and above login form).
220 admin.site.site_header = "Paperless-ngx"
221 # Text at the end of each page's <title>.
222 admin.site.site_title = "Paperless-ngx"
223 # Text at the top of the admin index page.
224 admin.site.index_title = _("Paperless-ngx administration")
225
[end of src/paperless/urls.py]
[start of src/paperless/adapter.py]
1 from allauth.account.adapter import DefaultAccountAdapter
2 from allauth.socialaccount.adapter import DefaultSocialAccountAdapter
3 from django.conf import settings
4 from django.urls import reverse
5
6
7 class CustomAccountAdapter(DefaultAccountAdapter):
8 def is_open_for_signup(self, request):
9 allow_signups = super().is_open_for_signup(request)
10 # Override with setting, otherwise default to super.
11 return getattr(settings, "ACCOUNT_ALLOW_SIGNUPS", allow_signups)
12
13
14 class CustomSocialAccountAdapter(DefaultSocialAccountAdapter):
15 def is_open_for_signup(self, request, sociallogin):
16 allow_signups = super().is_open_for_signup(request, sociallogin)
17 # Override with setting, otherwise default to super.
18 return getattr(settings, "SOCIALACCOUNT_ALLOW_SIGNUPS", allow_signups)
19
20 def get_connect_redirect_url(self, request, socialaccount):
21 """
22 Returns the default URL to redirect to after successfully
23 connecting a social account.
24 """
25 url = reverse("base")
26 return url
27
28 def populate_user(self, request, sociallogin, data):
29 # TODO: If default global permissions are implemented, should also be here
30 return super().populate_user(request, sociallogin, data) # pragma: no cover
31
[end of src/paperless/adapter.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/paperless/adapter.py b/src/paperless/adapter.py
--- a/src/paperless/adapter.py
+++ b/src/paperless/adapter.py
@@ -1,4 +1,5 @@
from allauth.account.adapter import DefaultAccountAdapter
+from allauth.core import context
from allauth.socialaccount.adapter import DefaultSocialAccountAdapter
from django.conf import settings
from django.urls import reverse
@@ -10,6 +11,21 @@
# Override with setting, otherwise default to super.
return getattr(settings, "ACCOUNT_ALLOW_SIGNUPS", allow_signups)
+ def is_safe_url(self, url):
+ # see https://github.com/paperless-ngx/paperless-ngx/issues/5780
+ from django.utils.http import url_has_allowed_host_and_scheme
+
+ # get_host already validates the given host, so no need to check it again
+ allowed_hosts = {context.request.get_host()} | set(settings.ALLOWED_HOSTS)
+
+ if "*" in allowed_hosts:
+ # dont allow wildcard to allow urls from any host
+ allowed_hosts.remove("*")
+ allowed_hosts.add(context.request.get_host())
+ return url_has_allowed_host_and_scheme(url, allowed_hosts=allowed_hosts)
+
+ return url_has_allowed_host_and_scheme(url, allowed_hosts=allowed_hosts)
+
class CustomSocialAccountAdapter(DefaultSocialAccountAdapter):
def is_open_for_signup(self, request, sociallogin):
diff --git a/src/paperless/urls.py b/src/paperless/urls.py
--- a/src/paperless/urls.py
+++ b/src/paperless/urls.py
@@ -193,6 +193,7 @@
RedirectView.as_view(
url=settings.STATIC_URL + "frontend/en-US/assets/%(path)s",
),
+ # TODO: with localization, this is even worse! :/
),
# App logo
re_path(
@@ -200,7 +201,6 @@
serve,
kwargs={"document_root": os.path.join(settings.MEDIA_ROOT, "logo")},
),
- # TODO: with localization, this is even worse! :/
# login, logout
path("accounts/", include("allauth.urls")),
# Root of the Frontend
|
{"golden_diff": "diff --git a/src/paperless/adapter.py b/src/paperless/adapter.py\n--- a/src/paperless/adapter.py\n+++ b/src/paperless/adapter.py\n@@ -1,4 +1,5 @@\n from allauth.account.adapter import DefaultAccountAdapter\n+from allauth.core import context\n from allauth.socialaccount.adapter import DefaultSocialAccountAdapter\n from django.conf import settings\n from django.urls import reverse\n@@ -10,6 +11,21 @@\n # Override with setting, otherwise default to super.\n return getattr(settings, \"ACCOUNT_ALLOW_SIGNUPS\", allow_signups)\n \n+ def is_safe_url(self, url):\n+ # see https://github.com/paperless-ngx/paperless-ngx/issues/5780\n+ from django.utils.http import url_has_allowed_host_and_scheme\n+\n+ # get_host already validates the given host, so no need to check it again\n+ allowed_hosts = {context.request.get_host()} | set(settings.ALLOWED_HOSTS)\n+\n+ if \"*\" in allowed_hosts:\n+ # dont allow wildcard to allow urls from any host\n+ allowed_hosts.remove(\"*\")\n+ allowed_hosts.add(context.request.get_host())\n+ return url_has_allowed_host_and_scheme(url, allowed_hosts=allowed_hosts)\n+\n+ return url_has_allowed_host_and_scheme(url, allowed_hosts=allowed_hosts)\n+\n \n class CustomSocialAccountAdapter(DefaultSocialAccountAdapter):\n def is_open_for_signup(self, request, sociallogin):\ndiff --git a/src/paperless/urls.py b/src/paperless/urls.py\n--- a/src/paperless/urls.py\n+++ b/src/paperless/urls.py\n@@ -193,6 +193,7 @@\n RedirectView.as_view(\n url=settings.STATIC_URL + \"frontend/en-US/assets/%(path)s\",\n ),\n+ # TODO: with localization, this is even worse! :/\n ),\n # App logo\n re_path(\n@@ -200,7 +201,6 @@\n serve,\n kwargs={\"document_root\": os.path.join(settings.MEDIA_ROOT, \"logo\")},\n ),\n- # TODO: with localization, this is even worse! :/\n # login, logout\n path(\"accounts/\", include(\"allauth.urls\")),\n # Root of the Frontend\n", "issue": "[Security] Open Redirect on Login page\n### Description\n\nThe application currently has a security vulnerability known as an \"Open Redirect\" on its login page. This issue arises because the application fails to properly check and validate the URLs provided in the next parameter during the login process. As a result, attackers can exploit this by inserting an external URL into the next parameter. When a user logs in, instead of being redirected to an internal page, they are unwittingly sent to a potentially malicious external website. This vulnerability can be used for phishing attacks, where users are redirected to fake websites that steal their personal information, or for spreading malware. It's crucial to address this vulnerability to protect users from being redirected to unsafe and untrusted websites.\n\n### Steps to reproduce\n\n1. In the browser's address bar, modify the URL by adding a next parameter with a value pointing to an external website. For example, change it to /accounts/login/?next=//evil.com\r\n2. Log in using valid credentials.\r\n3. Observe that after a successful login, instead of being directed to an internal page of the application, you are redirected to the external website specified in the next parameter.\n\n### Webserver logs\n\n```bash\nn/a\n```\n\n\n### Browser logs\n\n_No response_\n\n### Paperless-ngx version\n\nv 2.5.2\n\n### Host OS\n\nUbuntu 22.04.3 \n\n### Installation method\n\nDocker - official image\n\n### Browser\n\n_No response_\n\n### Configuration changes\n\n_No response_\n\n### Other\n\n_No response_\n\n### Please confirm the following\n\n- [X] I believe this issue is a bug that affects all users of Paperless-ngx, not something specific to my installation.\n- [X] I have already searched for relevant existing issues and discussions before opening this report.\n- [X] I have updated the title field above with a concise description.\n", "before_files": [{"content": "import os\n\nfrom django.conf import settings\nfrom django.conf.urls import include\nfrom django.contrib import admin\nfrom django.contrib.auth.decorators import login_required\nfrom django.urls import path\nfrom django.urls import re_path\nfrom django.utils.translation import gettext_lazy as _\nfrom django.views.decorators.csrf import csrf_exempt\nfrom django.views.decorators.csrf import ensure_csrf_cookie\nfrom django.views.generic import RedirectView\nfrom django.views.static import serve\nfrom rest_framework.authtoken import views\nfrom rest_framework.routers import DefaultRouter\n\nfrom documents.views import AcknowledgeTasksView\nfrom documents.views import BulkDownloadView\nfrom documents.views import BulkEditObjectsView\nfrom documents.views import BulkEditView\nfrom documents.views import CorrespondentViewSet\nfrom documents.views import CustomFieldViewSet\nfrom documents.views import DocumentTypeViewSet\nfrom documents.views import IndexView\nfrom documents.views import LogViewSet\nfrom documents.views import PostDocumentView\nfrom documents.views import RemoteVersionView\nfrom documents.views import SavedViewViewSet\nfrom documents.views import SearchAutoCompleteView\nfrom documents.views import SelectionDataView\nfrom documents.views import SharedLinkView\nfrom documents.views import ShareLinkViewSet\nfrom documents.views import StatisticsView\nfrom documents.views import StoragePathViewSet\nfrom documents.views import TagViewSet\nfrom documents.views import TasksViewSet\nfrom documents.views import UiSettingsView\nfrom documents.views import UnifiedSearchViewSet\nfrom documents.views import WorkflowActionViewSet\nfrom documents.views import WorkflowTriggerViewSet\nfrom documents.views import WorkflowViewSet\nfrom paperless.consumers import StatusConsumer\nfrom paperless.views import ApplicationConfigurationViewSet\nfrom paperless.views import DisconnectSocialAccountView\nfrom paperless.views import FaviconView\nfrom paperless.views import GenerateAuthTokenView\nfrom paperless.views import GroupViewSet\nfrom paperless.views import ProfileView\nfrom paperless.views import SocialAccountProvidersView\nfrom paperless.views import UserViewSet\nfrom paperless_mail.views import MailAccountTestView\nfrom paperless_mail.views import MailAccountViewSet\nfrom paperless_mail.views import MailRuleViewSet\n\napi_router = DefaultRouter()\napi_router.register(r\"correspondents\", CorrespondentViewSet)\napi_router.register(r\"document_types\", DocumentTypeViewSet)\napi_router.register(r\"documents\", UnifiedSearchViewSet)\napi_router.register(r\"logs\", LogViewSet, basename=\"logs\")\napi_router.register(r\"tags\", TagViewSet)\napi_router.register(r\"saved_views\", SavedViewViewSet)\napi_router.register(r\"storage_paths\", StoragePathViewSet)\napi_router.register(r\"tasks\", TasksViewSet, basename=\"tasks\")\napi_router.register(r\"users\", UserViewSet, basename=\"users\")\napi_router.register(r\"groups\", GroupViewSet, basename=\"groups\")\napi_router.register(r\"mail_accounts\", MailAccountViewSet)\napi_router.register(r\"mail_rules\", MailRuleViewSet)\napi_router.register(r\"share_links\", ShareLinkViewSet)\napi_router.register(r\"workflow_triggers\", WorkflowTriggerViewSet)\napi_router.register(r\"workflow_actions\", WorkflowActionViewSet)\napi_router.register(r\"workflows\", WorkflowViewSet)\napi_router.register(r\"custom_fields\", CustomFieldViewSet)\napi_router.register(r\"config\", ApplicationConfigurationViewSet)\n\n\nurlpatterns = [\n re_path(\n r\"^api/\",\n include(\n [\n re_path(\n \"^auth/\",\n include(\n (\"rest_framework.urls\", \"rest_framework\"),\n namespace=\"rest_framework\",\n ),\n ),\n re_path(\n \"^search/autocomplete/\",\n SearchAutoCompleteView.as_view(),\n name=\"autocomplete\",\n ),\n re_path(\"^statistics/\", StatisticsView.as_view(), name=\"statistics\"),\n re_path(\n \"^documents/post_document/\",\n PostDocumentView.as_view(),\n name=\"post_document\",\n ),\n re_path(\n \"^documents/bulk_edit/\",\n BulkEditView.as_view(),\n name=\"bulk_edit\",\n ),\n re_path(\n \"^documents/selection_data/\",\n SelectionDataView.as_view(),\n name=\"selection_data\",\n ),\n re_path(\n \"^documents/bulk_download/\",\n BulkDownloadView.as_view(),\n name=\"bulk_download\",\n ),\n re_path(\n \"^remote_version/\",\n RemoteVersionView.as_view(),\n name=\"remoteversion\",\n ),\n re_path(\"^ui_settings/\", UiSettingsView.as_view(), name=\"ui_settings\"),\n re_path(\n \"^acknowledge_tasks/\",\n AcknowledgeTasksView.as_view(),\n name=\"acknowledge_tasks\",\n ),\n re_path(\n \"^mail_accounts/test/\",\n MailAccountTestView.as_view(),\n name=\"mail_accounts_test\",\n ),\n path(\"token/\", views.obtain_auth_token),\n re_path(\n \"^bulk_edit_objects/\",\n BulkEditObjectsView.as_view(),\n name=\"bulk_edit_objects\",\n ),\n path(\"profile/generate_auth_token/\", GenerateAuthTokenView.as_view()),\n path(\n \"profile/disconnect_social_account/\",\n DisconnectSocialAccountView.as_view(),\n ),\n path(\n \"profile/social_account_providers/\",\n SocialAccountProvidersView.as_view(),\n ),\n re_path(\n \"^profile/\",\n ProfileView.as_view(),\n name=\"profile_view\",\n ),\n *api_router.urls,\n ],\n ),\n ),\n re_path(r\"share/(?P<slug>\\w+)/?$\", SharedLinkView.as_view()),\n re_path(r\"^favicon.ico$\", FaviconView.as_view(), name=\"favicon\"),\n re_path(r\"admin/\", admin.site.urls),\n re_path(\n r\"^fetch/\",\n include(\n [\n re_path(\n r\"^doc/(?P<pk>\\d+)$\",\n RedirectView.as_view(\n url=settings.BASE_URL + \"api/documents/%(pk)s/download/\",\n ),\n ),\n re_path(\n r\"^thumb/(?P<pk>\\d+)$\",\n RedirectView.as_view(\n url=settings.BASE_URL + \"api/documents/%(pk)s/thumb/\",\n ),\n ),\n re_path(\n r\"^preview/(?P<pk>\\d+)$\",\n RedirectView.as_view(\n url=settings.BASE_URL + \"api/documents/%(pk)s/preview/\",\n ),\n ),\n ],\n ),\n ),\n re_path(\n r\"^push$\",\n csrf_exempt(\n RedirectView.as_view(\n url=settings.BASE_URL + \"api/documents/post_document/\",\n ),\n ),\n ),\n # Frontend assets TODO: this is pretty bad, but it works.\n path(\n \"assets/<path:path>\",\n RedirectView.as_view(\n url=settings.STATIC_URL + \"frontend/en-US/assets/%(path)s\",\n ),\n ),\n # App logo\n re_path(\n r\"^logo(?P<path>.*)$\",\n serve,\n kwargs={\"document_root\": os.path.join(settings.MEDIA_ROOT, \"logo\")},\n ),\n # TODO: with localization, this is even worse! :/\n # login, logout\n path(\"accounts/\", include(\"allauth.urls\")),\n # Root of the Frontend\n re_path(\n r\".*\",\n login_required(ensure_csrf_cookie(IndexView.as_view())),\n name=\"base\",\n ),\n]\n\n\nwebsocket_urlpatterns = [\n path(settings.BASE_URL.lstrip(\"/\") + \"ws/status/\", StatusConsumer.as_asgi()),\n]\n\n# Text in each page's <h1> (and above login form).\nadmin.site.site_header = \"Paperless-ngx\"\n# Text at the end of each page's <title>.\nadmin.site.site_title = \"Paperless-ngx\"\n# Text at the top of the admin index page.\nadmin.site.index_title = _(\"Paperless-ngx administration\")\n", "path": "src/paperless/urls.py"}, {"content": "from allauth.account.adapter import DefaultAccountAdapter\nfrom allauth.socialaccount.adapter import DefaultSocialAccountAdapter\nfrom django.conf import settings\nfrom django.urls import reverse\n\n\nclass CustomAccountAdapter(DefaultAccountAdapter):\n def is_open_for_signup(self, request):\n allow_signups = super().is_open_for_signup(request)\n # Override with setting, otherwise default to super.\n return getattr(settings, \"ACCOUNT_ALLOW_SIGNUPS\", allow_signups)\n\n\nclass CustomSocialAccountAdapter(DefaultSocialAccountAdapter):\n def is_open_for_signup(self, request, sociallogin):\n allow_signups = super().is_open_for_signup(request, sociallogin)\n # Override with setting, otherwise default to super.\n return getattr(settings, \"SOCIALACCOUNT_ALLOW_SIGNUPS\", allow_signups)\n\n def get_connect_redirect_url(self, request, socialaccount):\n \"\"\"\n Returns the default URL to redirect to after successfully\n connecting a social account.\n \"\"\"\n url = reverse(\"base\")\n return url\n\n def populate_user(self, request, sociallogin, data):\n # TODO: If default global permissions are implemented, should also be here\n return super().populate_user(request, sociallogin, data) # pragma: no cover\n", "path": "src/paperless/adapter.py"}]}
| 3,383 | 500 |
gh_patches_debug_37312
|
rasdani/github-patches
|
git_diff
|
vyperlang__vyper-2392
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Compiler error when function returns tuple containing structs
In Ethereum Python Community Discord group, fubuloubu asked me to create this issue.
### Version Information
* vyper: 0.2.12
* OS: OSX
* Python: 3.9.6
### What's your issue about?
When a function in a contract is returning a tuple of two structs, It will not compile. Here is the error:
`AttributeError: 'StructType' object has no attribute 'typ'`
Here is sample code if you want to replicate the error:
```
struct Animal:
location: address
fur: uint256
struct Human:
location: address
height: uint256
@external
def thisDoesNotWork(_animal: Animal, _human: Human) -> (Animal, Human):
animal: Animal = _animal
human: Human = _human
# do stuff, edit the structs
animal.fur += 1
human.height += 1
return animal, human
```
### How can it be fixed?
fubuloubu says it's a compiler error. I don't know exactly how to fix it.
</issue>
<code>
[start of vyper/old_codegen/return_.py]
1 from vyper import ast as vy_ast
2 from vyper.old_codegen.lll_node import LLLnode
3 from vyper.old_codegen.parser_utils import getpos, make_setter
4 from vyper.old_codegen.types import (
5 BaseType,
6 ListType,
7 TupleType,
8 get_size_of_type,
9 )
10 from vyper.old_codegen.types.check import check_assign
11 from vyper.utils import MemoryPositions
12
13 from .abi import abi_encode, abi_type_of, ensure_tuple
14
15
16 # Generate return code for stmt
17 def make_return_stmt(stmt, context, begin_pos, _size, loop_memory_position=None):
18 # TODO check this out
19 from vyper.old_codegen.function_definitions.utils import (
20 get_nonreentrant_lock,
21 )
22
23 func_type = stmt.get_ancestor(vy_ast.FunctionDef)._metadata["type"]
24 _, nonreentrant_post = get_nonreentrant_lock(func_type, context.global_ctx)
25
26 if context.is_internal:
27 if loop_memory_position is None:
28 loop_memory_position = context.new_internal_variable(BaseType("uint256"))
29
30 # Make label for stack push loop.
31 label_id = "_".join([str(x) for x in (context.method_id, stmt.lineno, stmt.col_offset)])
32 exit_label = f"make_return_loop_exit_{label_id}"
33 start_label = f"make_return_loop_start_{label_id}"
34
35 # Push prepared data onto the stack,
36 # in reverse order so it can be popped of in order.
37 if isinstance(begin_pos, int) and isinstance(_size, int):
38 # static values, unroll the mloads instead.
39 mloads = [["mload", pos] for pos in range(begin_pos, _size, 32)]
40 else:
41 mloads = [
42 "seq_unchecked",
43 ["mstore", loop_memory_position, _size],
44 ["label", start_label],
45 [ # maybe exit loop / break.
46 "if",
47 ["le", ["mload", loop_memory_position], 0],
48 ["goto", exit_label],
49 ],
50 [ # push onto stack
51 "mload",
52 ["add", begin_pos, ["sub", ["mload", loop_memory_position], 32]],
53 ],
54 [ # decrement i by 32.
55 "mstore",
56 loop_memory_position,
57 ["sub", ["mload", loop_memory_position], 32],
58 ],
59 ["goto", start_label],
60 ["label", exit_label],
61 ]
62
63 # if we are in a for loop, we have to exit prior to returning
64 exit_repeater = ["exit_repeater"] if context.forvars else []
65
66 return (
67 ["seq_unchecked"]
68 + exit_repeater
69 + mloads
70 + nonreentrant_post
71 + [["jump", ["mload", context.callback_ptr]]]
72 )
73 else:
74 return ["seq_unchecked"] + nonreentrant_post + [["return", begin_pos, _size]]
75
76
77 # Generate code for returning a tuple or struct.
78 def gen_tuple_return(stmt, context, sub):
79 abi_typ = abi_type_of(context.return_type)
80 # according to the ABI, return types are ALWAYS tuples even if
81 # only one element is being returned.
82 # https://solidity.readthedocs.io/en/latest/abi-spec.html#function-selector-and-argument-encoding
83 # "and the return values v_1, ..., v_k of f are encoded as
84 #
85 # enc((v_1, ..., v_k))
86 # i.e. the values are combined into a tuple and encoded.
87 # "
88 # therefore, wrap it in a tuple if it's not already a tuple.
89 # (big difference between returning `(bytes,)` and `bytes`.
90 abi_typ = ensure_tuple(abi_typ)
91 abi_bytes_needed = abi_typ.static_size() + abi_typ.dynamic_size_bound()
92 dst = context.memory_allocator.expand_memory(abi_bytes_needed)
93 return_buffer = LLLnode(
94 dst, location="memory", annotation="return_buffer", typ=context.return_type
95 )
96
97 check_assign(return_buffer, sub, pos=getpos(stmt))
98
99 if sub.value == "multi":
100
101 if isinstance(context.return_type, TupleType) and not abi_typ.dynamic_size_bound():
102 # for tuples where every value is of the same type and a fixed length,
103 # we can simplify the encoding by treating it as though it were an array
104 base_types = set()
105 for typ in context.return_type.members:
106 while isinstance(typ, ListType):
107 typ = typ.subtype
108 base_types.add(typ.typ)
109
110 if len(base_types) == 1:
111 new_sub = LLLnode.from_list(
112 context.new_internal_variable(context.return_type),
113 typ=context.return_type,
114 location="memory",
115 )
116 setter = make_setter(new_sub, sub, "memory", pos=getpos(stmt))
117 return LLLnode.from_list(
118 [
119 "seq",
120 setter,
121 make_return_stmt(
122 stmt, context, new_sub, get_size_of_type(context.return_type) * 32,
123 ),
124 ],
125 typ=None,
126 pos=getpos(stmt),
127 )
128
129 # in case of multi we can't create a variable to store location of the return expression
130 # as multi can have data from multiple location like store, calldata etc
131 encode_out = abi_encode(return_buffer, sub, pos=getpos(stmt), returns=True)
132 load_return_len = ["mload", MemoryPositions.FREE_VAR_SPACE]
133 os = [
134 "seq",
135 ["mstore", MemoryPositions.FREE_VAR_SPACE, encode_out],
136 make_return_stmt(stmt, context, return_buffer, load_return_len),
137 ]
138 return LLLnode.from_list(os, typ=None, pos=getpos(stmt), valency=0)
139
140 # for tuple return types where a function is called inside the tuple, we
141 # process the calls prior to encoding the return data
142 if sub.value == "seq_unchecked" and sub.args[-1].value == "multi":
143 encode_out = abi_encode(return_buffer, sub.args[-1], pos=getpos(stmt), returns=True)
144 load_return_len = ["mload", MemoryPositions.FREE_VAR_SPACE]
145 os = (
146 ["seq"]
147 + sub.args[:-1]
148 + [
149 ["mstore", MemoryPositions.FREE_VAR_SPACE, encode_out],
150 make_return_stmt(stmt, context, return_buffer, load_return_len),
151 ]
152 )
153 return LLLnode.from_list(os, typ=None, pos=getpos(stmt), valency=0)
154
155 # for all othe cases we are creating a stack variable named sub_loc to store the location
156 # of the return expression. This is done so that the return expression does not get evaluated
157 # abi-encode uses a function named o_list which evaluate the expression multiple times
158 sub_loc = LLLnode("sub_loc", typ=sub.typ, location=sub.location)
159 encode_out = abi_encode(return_buffer, sub_loc, pos=getpos(stmt), returns=True)
160 load_return_len = ["mload", MemoryPositions.FREE_VAR_SPACE]
161 os = [
162 "with",
163 "sub_loc",
164 sub,
165 [
166 "seq",
167 ["mstore", MemoryPositions.FREE_VAR_SPACE, encode_out],
168 make_return_stmt(stmt, context, return_buffer, load_return_len),
169 ],
170 ]
171 return LLLnode.from_list(os, typ=None, pos=getpos(stmt), valency=0)
172
[end of vyper/old_codegen/return_.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/vyper/old_codegen/return_.py b/vyper/old_codegen/return_.py
--- a/vyper/old_codegen/return_.py
+++ b/vyper/old_codegen/return_.py
@@ -1,12 +1,7 @@
from vyper import ast as vy_ast
from vyper.old_codegen.lll_node import LLLnode
from vyper.old_codegen.parser_utils import getpos, make_setter
-from vyper.old_codegen.types import (
- BaseType,
- ListType,
- TupleType,
- get_size_of_type,
-)
+from vyper.old_codegen.types import BaseType, TupleType, get_size_of_type
from vyper.old_codegen.types.check import check_assign
from vyper.utils import MemoryPositions
@@ -100,31 +95,26 @@
if isinstance(context.return_type, TupleType) and not abi_typ.dynamic_size_bound():
# for tuples where every value is of the same type and a fixed length,
- # we can simplify the encoding by treating it as though it were an array
- base_types = set()
- for typ in context.return_type.members:
- while isinstance(typ, ListType):
- typ = typ.subtype
- base_types.add(typ.typ)
-
- if len(base_types) == 1:
- new_sub = LLLnode.from_list(
- context.new_internal_variable(context.return_type),
- typ=context.return_type,
- location="memory",
- )
- setter = make_setter(new_sub, sub, "memory", pos=getpos(stmt))
- return LLLnode.from_list(
- [
- "seq",
- setter,
- make_return_stmt(
- stmt, context, new_sub, get_size_of_type(context.return_type) * 32,
- ),
- ],
- typ=None,
- pos=getpos(stmt),
- )
+ # we can simplify the encoding by using make_setter, since
+ # our memory encoding happens to be identical to the ABI
+ # encoding.
+ new_sub = LLLnode.from_list(
+ context.new_internal_variable(context.return_type),
+ typ=context.return_type,
+ location="memory",
+ )
+ setter = make_setter(new_sub, sub, "memory", pos=getpos(stmt))
+ return LLLnode.from_list(
+ [
+ "seq",
+ setter,
+ make_return_stmt(
+ stmt, context, new_sub, get_size_of_type(context.return_type) * 32,
+ ),
+ ],
+ typ=None,
+ pos=getpos(stmt),
+ )
# in case of multi we can't create a variable to store location of the return expression
# as multi can have data from multiple location like store, calldata etc
|
{"golden_diff": "diff --git a/vyper/old_codegen/return_.py b/vyper/old_codegen/return_.py\n--- a/vyper/old_codegen/return_.py\n+++ b/vyper/old_codegen/return_.py\n@@ -1,12 +1,7 @@\n from vyper import ast as vy_ast\n from vyper.old_codegen.lll_node import LLLnode\n from vyper.old_codegen.parser_utils import getpos, make_setter\n-from vyper.old_codegen.types import (\n- BaseType,\n- ListType,\n- TupleType,\n- get_size_of_type,\n-)\n+from vyper.old_codegen.types import BaseType, TupleType, get_size_of_type\n from vyper.old_codegen.types.check import check_assign\n from vyper.utils import MemoryPositions\n \n@@ -100,31 +95,26 @@\n \n if isinstance(context.return_type, TupleType) and not abi_typ.dynamic_size_bound():\n # for tuples where every value is of the same type and a fixed length,\n- # we can simplify the encoding by treating it as though it were an array\n- base_types = set()\n- for typ in context.return_type.members:\n- while isinstance(typ, ListType):\n- typ = typ.subtype\n- base_types.add(typ.typ)\n-\n- if len(base_types) == 1:\n- new_sub = LLLnode.from_list(\n- context.new_internal_variable(context.return_type),\n- typ=context.return_type,\n- location=\"memory\",\n- )\n- setter = make_setter(new_sub, sub, \"memory\", pos=getpos(stmt))\n- return LLLnode.from_list(\n- [\n- \"seq\",\n- setter,\n- make_return_stmt(\n- stmt, context, new_sub, get_size_of_type(context.return_type) * 32,\n- ),\n- ],\n- typ=None,\n- pos=getpos(stmt),\n- )\n+ # we can simplify the encoding by using make_setter, since\n+ # our memory encoding happens to be identical to the ABI\n+ # encoding.\n+ new_sub = LLLnode.from_list(\n+ context.new_internal_variable(context.return_type),\n+ typ=context.return_type,\n+ location=\"memory\",\n+ )\n+ setter = make_setter(new_sub, sub, \"memory\", pos=getpos(stmt))\n+ return LLLnode.from_list(\n+ [\n+ \"seq\",\n+ setter,\n+ make_return_stmt(\n+ stmt, context, new_sub, get_size_of_type(context.return_type) * 32,\n+ ),\n+ ],\n+ typ=None,\n+ pos=getpos(stmt),\n+ )\n \n # in case of multi we can't create a variable to store location of the return expression\n # as multi can have data from multiple location like store, calldata etc\n", "issue": "Compiler error when function returns tuple containing structs\nIn Ethereum Python Community Discord group, fubuloubu asked me to create this issue.\r\n\r\n### Version Information\r\n\r\n* vyper: 0.2.12\r\n* OS: OSX\r\n* Python: 3.9.6\r\n\r\n### What's your issue about?\r\n\r\nWhen a function in a contract is returning a tuple of two structs, It will not compile. Here is the error: \r\n\r\n`AttributeError: 'StructType' object has no attribute 'typ'`\r\n\r\nHere is sample code if you want to replicate the error:\r\n```\r\nstruct Animal:\r\n location: address\r\n fur: uint256\r\n\r\nstruct Human:\r\n location: address\r\n height: uint256\r\n\r\n@external\r\ndef thisDoesNotWork(_animal: Animal, _human: Human) -> (Animal, Human):\r\n animal: Animal = _animal\r\n human: Human = _human\r\n\r\n # do stuff, edit the structs\r\n animal.fur += 1\r\n human.height += 1\r\n\r\n return animal, human\r\n```\r\n\r\n### How can it be fixed?\r\n\r\nfubuloubu says it's a compiler error. I don't know exactly how to fix it.\r\n\n", "before_files": [{"content": "from vyper import ast as vy_ast\nfrom vyper.old_codegen.lll_node import LLLnode\nfrom vyper.old_codegen.parser_utils import getpos, make_setter\nfrom vyper.old_codegen.types import (\n BaseType,\n ListType,\n TupleType,\n get_size_of_type,\n)\nfrom vyper.old_codegen.types.check import check_assign\nfrom vyper.utils import MemoryPositions\n\nfrom .abi import abi_encode, abi_type_of, ensure_tuple\n\n\n# Generate return code for stmt\ndef make_return_stmt(stmt, context, begin_pos, _size, loop_memory_position=None):\n # TODO check this out\n from vyper.old_codegen.function_definitions.utils import (\n get_nonreentrant_lock,\n )\n\n func_type = stmt.get_ancestor(vy_ast.FunctionDef)._metadata[\"type\"]\n _, nonreentrant_post = get_nonreentrant_lock(func_type, context.global_ctx)\n\n if context.is_internal:\n if loop_memory_position is None:\n loop_memory_position = context.new_internal_variable(BaseType(\"uint256\"))\n\n # Make label for stack push loop.\n label_id = \"_\".join([str(x) for x in (context.method_id, stmt.lineno, stmt.col_offset)])\n exit_label = f\"make_return_loop_exit_{label_id}\"\n start_label = f\"make_return_loop_start_{label_id}\"\n\n # Push prepared data onto the stack,\n # in reverse order so it can be popped of in order.\n if isinstance(begin_pos, int) and isinstance(_size, int):\n # static values, unroll the mloads instead.\n mloads = [[\"mload\", pos] for pos in range(begin_pos, _size, 32)]\n else:\n mloads = [\n \"seq_unchecked\",\n [\"mstore\", loop_memory_position, _size],\n [\"label\", start_label],\n [ # maybe exit loop / break.\n \"if\",\n [\"le\", [\"mload\", loop_memory_position], 0],\n [\"goto\", exit_label],\n ],\n [ # push onto stack\n \"mload\",\n [\"add\", begin_pos, [\"sub\", [\"mload\", loop_memory_position], 32]],\n ],\n [ # decrement i by 32.\n \"mstore\",\n loop_memory_position,\n [\"sub\", [\"mload\", loop_memory_position], 32],\n ],\n [\"goto\", start_label],\n [\"label\", exit_label],\n ]\n\n # if we are in a for loop, we have to exit prior to returning\n exit_repeater = [\"exit_repeater\"] if context.forvars else []\n\n return (\n [\"seq_unchecked\"]\n + exit_repeater\n + mloads\n + nonreentrant_post\n + [[\"jump\", [\"mload\", context.callback_ptr]]]\n )\n else:\n return [\"seq_unchecked\"] + nonreentrant_post + [[\"return\", begin_pos, _size]]\n\n\n# Generate code for returning a tuple or struct.\ndef gen_tuple_return(stmt, context, sub):\n abi_typ = abi_type_of(context.return_type)\n # according to the ABI, return types are ALWAYS tuples even if\n # only one element is being returned.\n # https://solidity.readthedocs.io/en/latest/abi-spec.html#function-selector-and-argument-encoding\n # \"and the return values v_1, ..., v_k of f are encoded as\n #\n # enc((v_1, ..., v_k))\n # i.e. the values are combined into a tuple and encoded.\n # \"\n # therefore, wrap it in a tuple if it's not already a tuple.\n # (big difference between returning `(bytes,)` and `bytes`.\n abi_typ = ensure_tuple(abi_typ)\n abi_bytes_needed = abi_typ.static_size() + abi_typ.dynamic_size_bound()\n dst = context.memory_allocator.expand_memory(abi_bytes_needed)\n return_buffer = LLLnode(\n dst, location=\"memory\", annotation=\"return_buffer\", typ=context.return_type\n )\n\n check_assign(return_buffer, sub, pos=getpos(stmt))\n\n if sub.value == \"multi\":\n\n if isinstance(context.return_type, TupleType) and not abi_typ.dynamic_size_bound():\n # for tuples where every value is of the same type and a fixed length,\n # we can simplify the encoding by treating it as though it were an array\n base_types = set()\n for typ in context.return_type.members:\n while isinstance(typ, ListType):\n typ = typ.subtype\n base_types.add(typ.typ)\n\n if len(base_types) == 1:\n new_sub = LLLnode.from_list(\n context.new_internal_variable(context.return_type),\n typ=context.return_type,\n location=\"memory\",\n )\n setter = make_setter(new_sub, sub, \"memory\", pos=getpos(stmt))\n return LLLnode.from_list(\n [\n \"seq\",\n setter,\n make_return_stmt(\n stmt, context, new_sub, get_size_of_type(context.return_type) * 32,\n ),\n ],\n typ=None,\n pos=getpos(stmt),\n )\n\n # in case of multi we can't create a variable to store location of the return expression\n # as multi can have data from multiple location like store, calldata etc\n encode_out = abi_encode(return_buffer, sub, pos=getpos(stmt), returns=True)\n load_return_len = [\"mload\", MemoryPositions.FREE_VAR_SPACE]\n os = [\n \"seq\",\n [\"mstore\", MemoryPositions.FREE_VAR_SPACE, encode_out],\n make_return_stmt(stmt, context, return_buffer, load_return_len),\n ]\n return LLLnode.from_list(os, typ=None, pos=getpos(stmt), valency=0)\n\n # for tuple return types where a function is called inside the tuple, we\n # process the calls prior to encoding the return data\n if sub.value == \"seq_unchecked\" and sub.args[-1].value == \"multi\":\n encode_out = abi_encode(return_buffer, sub.args[-1], pos=getpos(stmt), returns=True)\n load_return_len = [\"mload\", MemoryPositions.FREE_VAR_SPACE]\n os = (\n [\"seq\"]\n + sub.args[:-1]\n + [\n [\"mstore\", MemoryPositions.FREE_VAR_SPACE, encode_out],\n make_return_stmt(stmt, context, return_buffer, load_return_len),\n ]\n )\n return LLLnode.from_list(os, typ=None, pos=getpos(stmt), valency=0)\n\n # for all othe cases we are creating a stack variable named sub_loc to store the location\n # of the return expression. This is done so that the return expression does not get evaluated\n # abi-encode uses a function named o_list which evaluate the expression multiple times\n sub_loc = LLLnode(\"sub_loc\", typ=sub.typ, location=sub.location)\n encode_out = abi_encode(return_buffer, sub_loc, pos=getpos(stmt), returns=True)\n load_return_len = [\"mload\", MemoryPositions.FREE_VAR_SPACE]\n os = [\n \"with\",\n \"sub_loc\",\n sub,\n [\n \"seq\",\n [\"mstore\", MemoryPositions.FREE_VAR_SPACE, encode_out],\n make_return_stmt(stmt, context, return_buffer, load_return_len),\n ],\n ]\n return LLLnode.from_list(os, typ=None, pos=getpos(stmt), valency=0)\n", "path": "vyper/old_codegen/return_.py"}]}
| 2,800 | 614 |
gh_patches_debug_10876
|
rasdani/github-patches
|
git_diff
|
privacyidea__privacyidea-2280
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Support other keytypes with SSHKey Token
We would like to import other public key types like ecdsa into the SSHKey token type.
* [x] The UI and the /token/init API needs to allow this.
* [x] We also need to check, if the keytype is saved and returned correctly by GET /authitem
</issue>
<code>
[start of privacyidea/lib/tokens/sshkeytoken.py]
1 # -*- coding: utf-8 -*-
2 #
3 # privacyIDEA
4 # Jul 18, 2014 Cornelius Kölbel
5 # License: AGPLv3
6 # contact: http://www.privacyidea.org
7 #
8 # This code is free software; you can redistribute it and/or
9 # modify it under the terms of the GNU AFFERO GENERAL PUBLIC LICENSE
10 # License as published by the Free Software Foundation; either
11 # version 3 of the License, or any later version.
12 #
13 # This code is distributed in the hope that it will be useful,
14 # but WITHOUT ANY WARRANTY; without even the implied warranty of
15 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
16 # GNU AFFERO GENERAL PUBLIC LICENSE for more details.
17 #
18 # You should have received a copy of the GNU Affero General Public
19 # License along with this program. If not, see <http://www.gnu.org/licenses/>.
20 #
21 __doc__="""The SSHKeyTokenClass provides a TokenClass that stores the public
22 SSH key and can give the public SSH key via the getotp function.
23 This can be used to manage SSH keys and retrieve the public ssh key
24 to import it to authorized keys files.
25
26 The code is tested in tests/test_lib_tokens_ssh
27 """
28
29 import logging
30 from privacyidea.lib import _
31 from privacyidea.api.lib.utils import getParam
32 from privacyidea.lib.log import log_with
33 from privacyidea.lib.tokenclass import TokenClass
34 from privacyidea.lib.policy import SCOPE, ACTION, GROUP
35
36 log = logging.getLogger(__name__)
37
38
39 optional = True
40 required = False
41
42
43 ##TODO: We should save a fingerprint of the SSH Key in the encrypted OTP
44 # field, so that we can be sure, that the public ssh key was not changed in
45 # the database!
46
47
48 class SSHkeyTokenClass(TokenClass):
49 """
50 The SSHKeyTokenClass provides a TokenClass that stores the public
51 SSH key and can give the public SSH key via the getotp function.
52 This can be used to manage SSH keys and retrieve the public ssh key
53 to import it to authorized keys files.
54 """
55 mode = ['authenticate']
56 using_pin = False
57
58 def __init__(self, db_token):
59 TokenClass.__init__(self, db_token)
60 self.set_type(u"sshkey")
61
62 @staticmethod
63 def get_class_type():
64 return "sshkey"
65
66 @staticmethod
67 def get_class_prefix():
68 return "SSHK"
69
70 @staticmethod
71 @log_with(log)
72 def get_class_info(key=None, ret='all'):
73 """
74 returns a subtree of the token definition
75
76 :param key: subsection identifier
77 :type key: string
78 :param ret: default return value, if nothing is found
79 :type ret: user defined
80 :return: subsection if key exists or user defined
81 :rtype: dictionary
82 """
83 res = {'type': 'sshkey',
84 'title': 'SSHkey Token',
85 'description': _('SSH Public Key: The public SSH key.'),
86 'config': {},
87 'user': ['enroll'],
88 # This tokentype is enrollable in the UI for...
89 'ui_enroll': ["admin", "user"],
90 'policy': {
91 SCOPE.ENROLL: {
92 ACTION.MAXTOKENUSER: {
93 'type': 'int',
94 'desc': _("The user may only have this maximum number of SSH keys assigned."),
95 'group': GROUP.TOKEN
96 },
97 ACTION.MAXACTIVETOKENUSER: {
98 'type': 'int',
99 'desc': _(
100 "The user may only have this maximum number of active SSH keys assigned."),
101 'group': GROUP.TOKEN
102 }
103 }
104 },
105 }
106 if key:
107 ret = res.get(key, {})
108 else:
109 if ret == 'all':
110 ret = res
111
112 return ret
113
114 def update(self, param):
115 """
116 The key holds the public ssh key and this is required
117
118 The key probably is of the form "ssh-rsa BASE64 comment"
119 """
120 # We need to save the token, so that we can later add the tokeninfo
121 # Otherwise we might not have created the DB entry, yet and we would
122 # be missing the token.id
123 self.token.save()
124
125 getParam(param, "sshkey", required)
126
127 key_elem = param.get("sshkey").split(" ", 2)
128 if len(key_elem) != 3 or key_elem[0] != "ssh-rsa":
129 raise Exception("The key must consist of 'ssh-rsa BASE64 comment'")
130
131 key_type = key_elem[0]
132 key = key_elem[1]
133 key_comment = key_elem[2]
134
135 # convert key to hex
136 self.add_tokeninfo("ssh_key", key, value_type="password")
137 self.add_tokeninfo("ssh_type", key_type)
138 self.add_tokeninfo("ssh_comment", key_comment)
139
140 # call the parents function
141 TokenClass.update(self, param)
142
143 @log_with(log)
144 def get_sshkey(self):
145 """
146 returns the public SSH key
147
148 :return: SSH pub key
149 :rtype: string
150 """
151 ti = self.get_tokeninfo()
152 key_type = ti.get("ssh_type")
153 key_comment = ti.get("ssh_comment")
154 # get the ssh key directly, otherwise it will not be decrypted
155 sshkey = self.get_tokeninfo("ssh_key")
156 return u"{0!s} {1!s} {2!s}".format(key_type, sshkey, key_comment)
157
[end of privacyidea/lib/tokens/sshkeytoken.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/privacyidea/lib/tokens/sshkeytoken.py b/privacyidea/lib/tokens/sshkeytoken.py
--- a/privacyidea/lib/tokens/sshkeytoken.py
+++ b/privacyidea/lib/tokens/sshkeytoken.py
@@ -125,8 +125,10 @@
getParam(param, "sshkey", required)
key_elem = param.get("sshkey").split(" ", 2)
- if len(key_elem) != 3 or key_elem[0] != "ssh-rsa":
- raise Exception("The key must consist of 'ssh-rsa BASE64 comment'")
+ if len(key_elem) != 3:
+ raise Exception("The key must consist of 'ssh-keytype BASE64 comment'")
+ if key_elem[0] not in ["ssh-rsa", "ssh-ed25519", "ecdsa-sha2-nistp256"]:
+ raise Exception("The keytype you specified is not supported.")
key_type = key_elem[0]
key = key_elem[1]
|
{"golden_diff": "diff --git a/privacyidea/lib/tokens/sshkeytoken.py b/privacyidea/lib/tokens/sshkeytoken.py\n--- a/privacyidea/lib/tokens/sshkeytoken.py\n+++ b/privacyidea/lib/tokens/sshkeytoken.py\n@@ -125,8 +125,10 @@\n getParam(param, \"sshkey\", required)\n \n key_elem = param.get(\"sshkey\").split(\" \", 2)\n- if len(key_elem) != 3 or key_elem[0] != \"ssh-rsa\":\n- raise Exception(\"The key must consist of 'ssh-rsa BASE64 comment'\")\n+ if len(key_elem) != 3:\n+ raise Exception(\"The key must consist of 'ssh-keytype BASE64 comment'\")\n+ if key_elem[0] not in [\"ssh-rsa\", \"ssh-ed25519\", \"ecdsa-sha2-nistp256\"]:\n+ raise Exception(\"The keytype you specified is not supported.\")\n \n key_type = key_elem[0]\n key = key_elem[1]\n", "issue": "Support other keytypes with SSHKey Token\nWe would like to import other public key types like ecdsa into the SSHKey token type.\r\n\r\n* [x] The UI and the /token/init API needs to allow this.\r\n* [x] We also need to check, if the keytype is saved and returned correctly by GET /authitem\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# privacyIDEA\n# Jul 18, 2014 Cornelius K\u00f6lbel\n# License: AGPLv3\n# contact: http://www.privacyidea.org\n#\n# This code is free software; you can redistribute it and/or\n# modify it under the terms of the GNU AFFERO GENERAL PUBLIC LICENSE\n# License as published by the Free Software Foundation; either\n# version 3 of the License, or any later version.\n#\n# This code is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU AFFERO GENERAL PUBLIC LICENSE for more details.\n#\n# You should have received a copy of the GNU Affero General Public\n# License along with this program. If not, see <http://www.gnu.org/licenses/>.\n#\n__doc__=\"\"\"The SSHKeyTokenClass provides a TokenClass that stores the public\nSSH key and can give the public SSH key via the getotp function.\nThis can be used to manage SSH keys and retrieve the public ssh key\nto import it to authorized keys files.\n\nThe code is tested in tests/test_lib_tokens_ssh\n\"\"\"\n\nimport logging\nfrom privacyidea.lib import _\nfrom privacyidea.api.lib.utils import getParam\nfrom privacyidea.lib.log import log_with\nfrom privacyidea.lib.tokenclass import TokenClass\nfrom privacyidea.lib.policy import SCOPE, ACTION, GROUP\n\nlog = logging.getLogger(__name__)\n\n\noptional = True\nrequired = False\n\n\n##TODO: We should save a fingerprint of the SSH Key in the encrypted OTP\n# field, so that we can be sure, that the public ssh key was not changed in\n# the database!\n\n\nclass SSHkeyTokenClass(TokenClass):\n \"\"\"\n The SSHKeyTokenClass provides a TokenClass that stores the public\n SSH key and can give the public SSH key via the getotp function.\n This can be used to manage SSH keys and retrieve the public ssh key\n to import it to authorized keys files.\n \"\"\"\n mode = ['authenticate']\n using_pin = False\n\n def __init__(self, db_token):\n TokenClass.__init__(self, db_token)\n self.set_type(u\"sshkey\")\n\n @staticmethod\n def get_class_type():\n return \"sshkey\"\n\n @staticmethod\n def get_class_prefix():\n return \"SSHK\"\n\n @staticmethod\n @log_with(log)\n def get_class_info(key=None, ret='all'):\n \"\"\"\n returns a subtree of the token definition\n\n :param key: subsection identifier\n :type key: string\n :param ret: default return value, if nothing is found\n :type ret: user defined\n :return: subsection if key exists or user defined\n :rtype: dictionary\n \"\"\"\n res = {'type': 'sshkey',\n 'title': 'SSHkey Token',\n 'description': _('SSH Public Key: The public SSH key.'),\n 'config': {},\n 'user': ['enroll'],\n # This tokentype is enrollable in the UI for...\n 'ui_enroll': [\"admin\", \"user\"],\n 'policy': {\n SCOPE.ENROLL: {\n ACTION.MAXTOKENUSER: {\n 'type': 'int',\n 'desc': _(\"The user may only have this maximum number of SSH keys assigned.\"),\n 'group': GROUP.TOKEN\n },\n ACTION.MAXACTIVETOKENUSER: {\n 'type': 'int',\n 'desc': _(\n \"The user may only have this maximum number of active SSH keys assigned.\"),\n 'group': GROUP.TOKEN\n }\n }\n },\n }\n if key:\n ret = res.get(key, {})\n else:\n if ret == 'all':\n ret = res\n\n return ret\n\n def update(self, param):\n \"\"\"\n The key holds the public ssh key and this is required\n \n The key probably is of the form \"ssh-rsa BASE64 comment\"\n \"\"\"\n # We need to save the token, so that we can later add the tokeninfo\n # Otherwise we might not have created the DB entry, yet and we would\n # be missing the token.id\n self.token.save()\n\n getParam(param, \"sshkey\", required)\n \n key_elem = param.get(\"sshkey\").split(\" \", 2)\n if len(key_elem) != 3 or key_elem[0] != \"ssh-rsa\":\n raise Exception(\"The key must consist of 'ssh-rsa BASE64 comment'\")\n\n key_type = key_elem[0]\n key = key_elem[1]\n key_comment = key_elem[2]\n \n # convert key to hex\n self.add_tokeninfo(\"ssh_key\", key, value_type=\"password\")\n self.add_tokeninfo(\"ssh_type\", key_type)\n self.add_tokeninfo(\"ssh_comment\", key_comment)\n\n # call the parents function\n TokenClass.update(self, param)\n \n @log_with(log)\n def get_sshkey(self):\n \"\"\"\n returns the public SSH key\n \n :return: SSH pub key\n :rtype: string\n \"\"\"\n ti = self.get_tokeninfo()\n key_type = ti.get(\"ssh_type\")\n key_comment = ti.get(\"ssh_comment\")\n # get the ssh key directly, otherwise it will not be decrypted\n sshkey = self.get_tokeninfo(\"ssh_key\")\n return u\"{0!s} {1!s} {2!s}\".format(key_type, sshkey, key_comment)\n", "path": "privacyidea/lib/tokens/sshkeytoken.py"}]}
| 2,189 | 239 |
gh_patches_debug_345
|
rasdani/github-patches
|
git_diff
|
NVIDIA__apex-564
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
RuntimeError: "GeluCUDAKernelImpl" not implemented for 'Half'
PyTorch 1.2 introduced the `gelu` activation function. Unfortunately, this leads to terminal errors when using with AMP.
Trace (`self.activation` is `gelu`):
```
Traceback (most recent call last):
File "predict.py", line 282, in <module>
predictor.predict()
File "predict.py", line 74, in predict
fig = trainer.train()
File "/home/bram/Python/projects/transformer-classifiers/transformer_classifiers/TransformerTrainer.py", line 232, in train
self._process('train', epoch)
File "/home/bram/Python/projects/transformer-classifiers/transformer_classifiers/TransformerTrainer.py", line 124, in _process
preds = self.model(input_ids, attention_mask=input_mask)
File "/home/bram/.local/share/virtualenvs/transformer-classifiers-x27iJBv7/lib/python3.7/site-packages/torch/nn/modules/module.py", line 541, in __call__
result = self.forward(*input, **kwargs)
File "/home/bram/.local/share/virtualenvs/transformer-classifiers-x27iJBv7/lib/python3.7/site-packages/torch/nn/parallel/distributed.py", line 442, in forward
output = self.module(*inputs[0], **kwargs[0])
File "/home/bram/.local/share/virtualenvs/transformer-classifiers-x27iJBv7/lib/python3.7/site-packages/torch/nn/modules/module.py", line 541, in __call__
result = self.forward(*input, **kwargs)
File "/home/bram/Python/projects/transformer-classifiers/transformer_classifiers/models.py", line 140, in forward
cls_output = self.activation(cls_output)
File "/home/bram/.local/share/virtualenvs/transformer-classifiers-x27iJBv7/lib/python3.7/site-packages/torch/nn/functional.py", line 1126, in gelu
return torch._C._nn.gelu(input)
RuntimeError: "GeluCUDAKernelImpl" not implemented for 'Half'
```
</issue>
<code>
[start of apex/amp/lists/functional_overrides.py]
1
2 # TODO: think about the following two. They do weird things.
3 # - torch.nn.utils.clip_grad (but it should always be fp32 anyway)
4 # - torch.nn.utils.weight_norm
5
6 # Notes:
7 # F.instance_norm uses batch_norm internally. Which correctly handles
8 # fp16 in/out with fp32 weights. So we shouldn't do anything for
9 # either of these.
10 # F.normalize calls `input.norm()` internally, so it's redundant, but
11 # kept here in case impl. changes.
12 # F.cosine_similarity is same: calls `x.norm()` internally.
13
14 import torch.nn.functional
15
16 MODULE = torch.nn.functional
17
18 FP16_FUNCS = [
19 'conv1d',
20 'conv2d',
21 'conv3d',
22 'conv_transpose1d',
23 'conv_transpose2d',
24 'conv_transpose3d',
25 'conv_tbc', # Undocumented / maybe new?
26 'linear',
27 ]
28
29 FP32_FUNCS = [
30
31 # Interpolation/Upsampling TODO: Remove for 1.2
32 'interpolate',
33 'grid_sample',
34
35 # Pointwise
36 'softplus',
37 'softmin',
38 'log_softmax',
39 'softmax',
40
41 # Normalization
42 'layer_norm',
43 'group_norm',
44 'local_response_norm',
45 'normalize',
46 'cosine_similarity',
47
48 # Loss functions
49 # TODO: which of these can be fp16?
50 'poisson_nll_loss',
51 'cosine_embedding_loss',
52 'cross_entropy',
53 'hinge_embedding_loss',
54 'kl_div',
55 'l1_loss',
56 'mse_loss',
57 'margin_ranking_loss',
58 'multilabel_margin_loss',
59 'multilabel_soft_margin_loss',
60 'multi_margin_loss',
61 'nll_loss',
62 'binary_cross_entropy_with_logits',
63 'smooth_l1_loss',
64 'soft_margin_loss',
65 'triplet_margin_loss'
66 ]
67
68 BANNED_FUNCS = [
69 ('binary_cross_entropy',
70 ("\namp does not work out-of-the-box with `F.binary_cross_entropy` or `torch.nn.BCELoss.` "
71 "It requires that the output of the previous function be already a FloatTensor. \n\n"
72 "Most models have a Sigmoid right before BCELoss. In that case, you can use\n"
73 " torch.nn.BCEWithLogitsLoss\nto combine Sigmoid+BCELoss into a single layer "
74 "that is compatible with amp.\nAnother option is to add\n"
75 " amp.register_float_function(torch, 'sigmoid')\nbefore calling `amp.init()`.\n"
76 "If you _really_ know what you are doing, you can disable this warning by passing "
77 "allow_banned=True to `amp.init()`."))
78 ]
79
[end of apex/amp/lists/functional_overrides.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/apex/amp/lists/functional_overrides.py b/apex/amp/lists/functional_overrides.py
--- a/apex/amp/lists/functional_overrides.py
+++ b/apex/amp/lists/functional_overrides.py
@@ -37,7 +37,8 @@
'softmin',
'log_softmax',
'softmax',
-
+ 'gelu',
+
# Normalization
'layer_norm',
'group_norm',
|
{"golden_diff": "diff --git a/apex/amp/lists/functional_overrides.py b/apex/amp/lists/functional_overrides.py\n--- a/apex/amp/lists/functional_overrides.py\n+++ b/apex/amp/lists/functional_overrides.py\n@@ -37,7 +37,8 @@\n 'softmin',\n 'log_softmax',\n 'softmax',\n-\n+ 'gelu',\n+ \n # Normalization\n 'layer_norm',\n 'group_norm',\n", "issue": "RuntimeError: \"GeluCUDAKernelImpl\" not implemented for 'Half'\nPyTorch 1.2 introduced the `gelu` activation function. Unfortunately, this leads to terminal errors when using with AMP.\r\n\r\nTrace (`self.activation` is `gelu`): \r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"predict.py\", line 282, in <module>\r\n predictor.predict()\r\n File \"predict.py\", line 74, in predict\r\n fig = trainer.train()\r\n File \"/home/bram/Python/projects/transformer-classifiers/transformer_classifiers/TransformerTrainer.py\", line 232, in train\r\n self._process('train', epoch)\r\n File \"/home/bram/Python/projects/transformer-classifiers/transformer_classifiers/TransformerTrainer.py\", line 124, in _process\r\n preds = self.model(input_ids, attention_mask=input_mask)\r\n File \"/home/bram/.local/share/virtualenvs/transformer-classifiers-x27iJBv7/lib/python3.7/site-packages/torch/nn/modules/module.py\", line 541, in __call__\r\n result = self.forward(*input, **kwargs)\r\n File \"/home/bram/.local/share/virtualenvs/transformer-classifiers-x27iJBv7/lib/python3.7/site-packages/torch/nn/parallel/distributed.py\", line 442, in forward\r\n output = self.module(*inputs[0], **kwargs[0])\r\n File \"/home/bram/.local/share/virtualenvs/transformer-classifiers-x27iJBv7/lib/python3.7/site-packages/torch/nn/modules/module.py\", line 541, in __call__\r\n result = self.forward(*input, **kwargs)\r\n File \"/home/bram/Python/projects/transformer-classifiers/transformer_classifiers/models.py\", line 140, in forward\r\n cls_output = self.activation(cls_output)\r\n File \"/home/bram/.local/share/virtualenvs/transformer-classifiers-x27iJBv7/lib/python3.7/site-packages/torch/nn/functional.py\", line 1126, in gelu\r\n return torch._C._nn.gelu(input)\r\nRuntimeError: \"GeluCUDAKernelImpl\" not implemented for 'Half'\r\n```\n", "before_files": [{"content": "\n# TODO: think about the following two. They do weird things.\n# - torch.nn.utils.clip_grad (but it should always be fp32 anyway)\n# - torch.nn.utils.weight_norm\n\n# Notes:\n# F.instance_norm uses batch_norm internally. Which correctly handles\n# fp16 in/out with fp32 weights. So we shouldn't do anything for\n# either of these.\n# F.normalize calls `input.norm()` internally, so it's redundant, but\n# kept here in case impl. changes.\n# F.cosine_similarity is same: calls `x.norm()` internally.\n\nimport torch.nn.functional\n\nMODULE = torch.nn.functional\n\nFP16_FUNCS = [\n 'conv1d',\n 'conv2d',\n 'conv3d',\n 'conv_transpose1d',\n 'conv_transpose2d',\n 'conv_transpose3d',\n 'conv_tbc', # Undocumented / maybe new?\n 'linear',\n]\n\nFP32_FUNCS = [\n\n # Interpolation/Upsampling TODO: Remove for 1.2\n 'interpolate',\n 'grid_sample',\n\n # Pointwise\n 'softplus',\n 'softmin',\n 'log_softmax',\n 'softmax',\n\n # Normalization\n 'layer_norm',\n 'group_norm',\n 'local_response_norm',\n 'normalize',\n 'cosine_similarity',\n\n # Loss functions\n # TODO: which of these can be fp16?\n 'poisson_nll_loss',\n 'cosine_embedding_loss',\n 'cross_entropy',\n 'hinge_embedding_loss',\n 'kl_div',\n 'l1_loss',\n 'mse_loss',\n 'margin_ranking_loss',\n 'multilabel_margin_loss',\n 'multilabel_soft_margin_loss',\n 'multi_margin_loss',\n 'nll_loss',\n 'binary_cross_entropy_with_logits',\n 'smooth_l1_loss',\n 'soft_margin_loss',\n 'triplet_margin_loss'\n]\n\nBANNED_FUNCS = [\n ('binary_cross_entropy',\n (\"\\namp does not work out-of-the-box with `F.binary_cross_entropy` or `torch.nn.BCELoss.` \"\n \"It requires that the output of the previous function be already a FloatTensor. \\n\\n\"\n \"Most models have a Sigmoid right before BCELoss. In that case, you can use\\n\"\n \" torch.nn.BCEWithLogitsLoss\\nto combine Sigmoid+BCELoss into a single layer \"\n \"that is compatible with amp.\\nAnother option is to add\\n\"\n \" amp.register_float_function(torch, 'sigmoid')\\nbefore calling `amp.init()`.\\n\"\n \"If you _really_ know what you are doing, you can disable this warning by passing \"\n \"allow_banned=True to `amp.init()`.\"))\n]\n", "path": "apex/amp/lists/functional_overrides.py"}]}
| 1,819 | 102 |
gh_patches_debug_23388
|
rasdani/github-patches
|
git_diff
|
cal-itp__benefits-1550
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bug: Grid-width issue
Related to #1545
Almost all instances of `col-lg-10` app should now be `col-lg-8`.
</issue>
<code>
[start of benefits/eligibility/forms.py]
1 """
2 The eligibility application: Form definition for the eligibility verification flow.
3 """
4 import logging
5
6 from django import forms
7 from django.utils.translation import gettext_lazy as _
8
9 from benefits.core import models, recaptcha, widgets
10
11
12 logger = logging.getLogger(__name__)
13
14
15 class EligibilityVerifierSelectionForm(forms.Form):
16 """Form to capture eligibility verifier selection."""
17
18 action_url = "eligibility:index"
19 id = "form-verifier-selection"
20 method = "POST"
21
22 verifier = forms.ChoiceField(label="", widget=widgets.VerifierRadioSelect)
23 # sets label to empty string so the radio_select template can override the label style
24 submit_value = _("eligibility.buttons.choose")
25
26 def __init__(self, agency: models.TransitAgency, *args, **kwargs):
27 super().__init__(*args, **kwargs)
28 verifiers = agency.eligibility_verifiers.all()
29
30 self.classes = "offset-lg-1 col-lg-9"
31 # second element is not used since we render the whole label using selection_label_template,
32 # therefore set to None
33 self.fields["verifier"].choices = [(v.id, None) for v in verifiers]
34 self.fields["verifier"].widget.selection_label_templates = {v.id: v.selection_label_template for v in verifiers}
35
36 def clean(self):
37 if not recaptcha.verify(self.data):
38 raise forms.ValidationError("reCAPTCHA failed")
39
40
41 class EligibilityVerificationForm(forms.Form):
42 """Form to collect eligibility verification details."""
43
44 action_url = "eligibility:confirm"
45 id = "form-eligibility-verification"
46 method = "POST"
47
48 submit_value = _("eligibility.forms.confirm.submit")
49 submitting_value = _("eligibility.forms.confirm.submitting")
50
51 _error_messages = {
52 "invalid": _("eligibility.forms.confirm.errors.invalid"),
53 "missing": _("eligibility.forms.confirm.errors.missing"),
54 }
55
56 def __init__(self, verifier: models.EligibilityVerifier, *args, **kwargs):
57 super().__init__(*args, **kwargs)
58
59 self.classes = "offset-lg-3 col-lg-6"
60 sub_widget = widgets.FormControlTextInput(placeholder=verifier.form_sub_placeholder)
61 if verifier.form_sub_pattern:
62 sub_widget.attrs.update({"pattern": verifier.form_sub_pattern})
63 if verifier.form_input_mode:
64 sub_widget.attrs.update({"inputmode": verifier.form_input_mode})
65 if verifier.form_max_length:
66 sub_widget.attrs.update({"maxlength": verifier.form_max_length})
67
68 self.fields["sub"] = forms.CharField(
69 label=_(verifier.form_sub_label),
70 widget=sub_widget,
71 help_text=_(verifier.form_sub_help_text),
72 )
73
74 name_widget = widgets.FormControlTextInput(placeholder=verifier.form_name_placeholder)
75 if verifier.form_name_max_length:
76 name_widget.attrs.update({"maxlength": verifier.form_name_max_length})
77
78 self.fields["name"] = forms.CharField(
79 label=_(verifier.form_name_label), widget=name_widget, help_text=_(verifier.form_name_help_text)
80 )
81
82 def clean(self):
83 if not recaptcha.verify(self.data):
84 raise forms.ValidationError("reCAPTCHA failed")
85
[end of benefits/eligibility/forms.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/benefits/eligibility/forms.py b/benefits/eligibility/forms.py
--- a/benefits/eligibility/forms.py
+++ b/benefits/eligibility/forms.py
@@ -27,7 +27,7 @@
super().__init__(*args, **kwargs)
verifiers = agency.eligibility_verifiers.all()
- self.classes = "offset-lg-1 col-lg-9"
+ self.classes = "col-lg-8"
# second element is not used since we render the whole label using selection_label_template,
# therefore set to None
self.fields["verifier"].choices = [(v.id, None) for v in verifiers]
@@ -56,7 +56,7 @@
def __init__(self, verifier: models.EligibilityVerifier, *args, **kwargs):
super().__init__(*args, **kwargs)
- self.classes = "offset-lg-3 col-lg-6"
+ self.classes = "col-lg-6"
sub_widget = widgets.FormControlTextInput(placeholder=verifier.form_sub_placeholder)
if verifier.form_sub_pattern:
sub_widget.attrs.update({"pattern": verifier.form_sub_pattern})
|
{"golden_diff": "diff --git a/benefits/eligibility/forms.py b/benefits/eligibility/forms.py\n--- a/benefits/eligibility/forms.py\n+++ b/benefits/eligibility/forms.py\n@@ -27,7 +27,7 @@\n super().__init__(*args, **kwargs)\n verifiers = agency.eligibility_verifiers.all()\n \n- self.classes = \"offset-lg-1 col-lg-9\"\n+ self.classes = \"col-lg-8\"\n # second element is not used since we render the whole label using selection_label_template,\n # therefore set to None\n self.fields[\"verifier\"].choices = [(v.id, None) for v in verifiers]\n@@ -56,7 +56,7 @@\n def __init__(self, verifier: models.EligibilityVerifier, *args, **kwargs):\n super().__init__(*args, **kwargs)\n \n- self.classes = \"offset-lg-3 col-lg-6\"\n+ self.classes = \"col-lg-6\"\n sub_widget = widgets.FormControlTextInput(placeholder=verifier.form_sub_placeholder)\n if verifier.form_sub_pattern:\n sub_widget.attrs.update({\"pattern\": verifier.form_sub_pattern})\n", "issue": "Bug: Grid-width issue\nRelated to #1545 \r\n\r\nAlmost all instances of `col-lg-10` app should now be `col-lg-8`.\n", "before_files": [{"content": "\"\"\"\nThe eligibility application: Form definition for the eligibility verification flow.\n\"\"\"\nimport logging\n\nfrom django import forms\nfrom django.utils.translation import gettext_lazy as _\n\nfrom benefits.core import models, recaptcha, widgets\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass EligibilityVerifierSelectionForm(forms.Form):\n \"\"\"Form to capture eligibility verifier selection.\"\"\"\n\n action_url = \"eligibility:index\"\n id = \"form-verifier-selection\"\n method = \"POST\"\n\n verifier = forms.ChoiceField(label=\"\", widget=widgets.VerifierRadioSelect)\n # sets label to empty string so the radio_select template can override the label style\n submit_value = _(\"eligibility.buttons.choose\")\n\n def __init__(self, agency: models.TransitAgency, *args, **kwargs):\n super().__init__(*args, **kwargs)\n verifiers = agency.eligibility_verifiers.all()\n\n self.classes = \"offset-lg-1 col-lg-9\"\n # second element is not used since we render the whole label using selection_label_template,\n # therefore set to None\n self.fields[\"verifier\"].choices = [(v.id, None) for v in verifiers]\n self.fields[\"verifier\"].widget.selection_label_templates = {v.id: v.selection_label_template for v in verifiers}\n\n def clean(self):\n if not recaptcha.verify(self.data):\n raise forms.ValidationError(\"reCAPTCHA failed\")\n\n\nclass EligibilityVerificationForm(forms.Form):\n \"\"\"Form to collect eligibility verification details.\"\"\"\n\n action_url = \"eligibility:confirm\"\n id = \"form-eligibility-verification\"\n method = \"POST\"\n\n submit_value = _(\"eligibility.forms.confirm.submit\")\n submitting_value = _(\"eligibility.forms.confirm.submitting\")\n\n _error_messages = {\n \"invalid\": _(\"eligibility.forms.confirm.errors.invalid\"),\n \"missing\": _(\"eligibility.forms.confirm.errors.missing\"),\n }\n\n def __init__(self, verifier: models.EligibilityVerifier, *args, **kwargs):\n super().__init__(*args, **kwargs)\n\n self.classes = \"offset-lg-3 col-lg-6\"\n sub_widget = widgets.FormControlTextInput(placeholder=verifier.form_sub_placeholder)\n if verifier.form_sub_pattern:\n sub_widget.attrs.update({\"pattern\": verifier.form_sub_pattern})\n if verifier.form_input_mode:\n sub_widget.attrs.update({\"inputmode\": verifier.form_input_mode})\n if verifier.form_max_length:\n sub_widget.attrs.update({\"maxlength\": verifier.form_max_length})\n\n self.fields[\"sub\"] = forms.CharField(\n label=_(verifier.form_sub_label),\n widget=sub_widget,\n help_text=_(verifier.form_sub_help_text),\n )\n\n name_widget = widgets.FormControlTextInput(placeholder=verifier.form_name_placeholder)\n if verifier.form_name_max_length:\n name_widget.attrs.update({\"maxlength\": verifier.form_name_max_length})\n\n self.fields[\"name\"] = forms.CharField(\n label=_(verifier.form_name_label), widget=name_widget, help_text=_(verifier.form_name_help_text)\n )\n\n def clean(self):\n if not recaptcha.verify(self.data):\n raise forms.ValidationError(\"reCAPTCHA failed\")\n", "path": "benefits/eligibility/forms.py"}]}
| 1,405 | 258 |
gh_patches_debug_30699
|
rasdani/github-patches
|
git_diff
|
plotly__dash-490
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Allow excluding file patterns when generating component definitions
Thanks a lot for making Dash -- we have found it very useful for building dashboards.
We ran into an issue migrating to the new `dash-generate-components` utility.
In [dash-bootstrap-components](https://github.com/ASIDataScience/dash-bootstrap-components), we keep the components in `src/components`. Besides components files, this also includes a few unit test files called, e.g. `src/components/__tests__/DropdownMenu.test.js`. When we run `dash-generate-components ./src/components <output>`, these test files also get picked up. This leads to a traceback in the build logs:
```
Error with path src/components/__tests__/DropdownMenu.test.jsError: No suitable component definition found.
Error: No suitable component definition found.
at parse (/project/pascal/dash-bootstrap-components/node_modules/react-docgen/dist/parse.js:84:9)
at Object.defaultParse [as parse] (/project/pascal/dash-bootstrap-components/node_modules/react-docgen/dist/main.js:66:30)
at parseFile (/opt/anaconda/envs/Python3/lib/python3.6/site-packages/dash/extract-meta.js:64:51)
at dirs.forEach.filename (/opt/anaconda/envs/Python3/lib/python3.6/site-packages/dash/extract-meta.js:84:17)
at Array.forEach (<anonymous>)
at collectMetadataRecursively (/opt/anaconda/envs/Python3/lib/python3.6/site-packages/dash/extract-meta.js:79:14)
at dirs.forEach.filename (/opt/anaconda/envs/Python3/lib/python3.6/site-packages/dash/extract-meta.js:82:17)
at Array.forEach (<anonymous>)
at collectMetadataRecursively (/opt/anaconda/envs/Python3/lib/python3.6/site-packages/dash/extract-meta.js:79:14)
at componentPaths.forEach.componentPath (/opt/anaconda/envs/Python3/lib/python3.6/site-packages/dash/extract-meta.js:15:5)
```
While the error is, of course, legitimate, it would be nice to be able to suppress these tracebacks. I can see three routes:
- do nothing -- after all, this doesn't stop us from building `metadata.json`, it just makes it slightly more confusing.
- in `dash/extract-meta.js`, we could explicitly blacklist `__tests__` directories in the same way that files that don't end in `jsx?` are black-listed. AFAICT, the `__tests__` directory structure is the default with [jest](https://jestjs.io/docs/en/configuration.html#testmatch-array-string). [react-docgen](https://github.com/reactjs/react-docgen#cli) ignores `node_modules`, `__tests__` and `__mocks__` by default, so there is definitely a precedent.
- add a `--ignore` argument to `dash-generate-components` that allows passing file globs to be excluded.
Very happy to submit a PR if you decide on what the best course of action is.
</issue>
<code>
[start of dash/development/component_generator.py]
1 from __future__ import print_function
2
3 import json
4 import sys
5 import subprocess
6 import shlex
7 import os
8 import argparse
9 import shutil
10
11 import pkg_resources
12
13 from ._py_components_generation import generate_class_file
14 from ._py_components_generation import generate_imports
15 from ._py_components_generation import generate_classes_files
16
17
18 class _CombinedFormatter(argparse.ArgumentDefaultsHelpFormatter,
19 argparse.RawDescriptionHelpFormatter):
20 pass
21
22
23 # pylint: disable=too-many-locals
24 def generate_components(components_source, project_shortname,
25 package_info_filename='package.json'):
26 is_windows = sys.platform == 'win32'
27
28 extract_path = pkg_resources.resource_filename('dash', 'extract-meta.js')
29
30 os.environ['NODE_PATH'] = 'node_modules'
31 cmd = shlex.split('node {} {}'.format(extract_path, components_source),
32 posix=not is_windows)
33
34 shutil.copyfile('package.json',
35 os.path.join(project_shortname, package_info_filename))
36
37 proc = subprocess.Popen(cmd,
38 stdout=subprocess.PIPE,
39 stderr=subprocess.PIPE,
40 shell=is_windows)
41 out, err = proc.communicate()
42 status = proc.poll()
43
44 if err:
45 print(err.decode(), file=sys.stderr)
46
47 if not out:
48 print(
49 'Error generating metadata in {} (status={})'.format(
50 project_shortname, status),
51 file=sys.stderr)
52 sys.exit(1)
53
54 metadata = json.loads(out.decode())
55
56 components = generate_classes_files(
57 project_shortname,
58 metadata,
59 generate_class_file
60 )
61
62 with open(os.path.join(project_shortname, 'metadata.json'), 'w') as f:
63 json.dump(metadata, f)
64
65 generate_imports(project_shortname, components)
66
67
68 def cli():
69 parser = argparse.ArgumentParser(
70 prog='dash-generate-components',
71 formatter_class=_CombinedFormatter,
72 description='Generate dash components by extracting the metadata '
73 'using react-docgen. Then map the metadata to python classes.'
74 )
75 parser.add_argument('components_source',
76 help='React components source directory.')
77 parser.add_argument(
78 'project_shortname',
79 help='Name of the project to export the classes files.'
80 )
81 parser.add_argument(
82 '-p', '--package-info-filename',
83 default='package.json',
84 help='The filename of the copied `package.json` to `project_shortname`'
85 )
86
87 args = parser.parse_args()
88 generate_components(args.components_source, args.project_shortname,
89 package_info_filename=args.package_info_filename)
90
91
92 if __name__ == '__main__':
93 cli()
94
[end of dash/development/component_generator.py]
[start of dash/version.py]
1 __version__ = '0.33.0'
2
[end of dash/version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/dash/development/component_generator.py b/dash/development/component_generator.py
--- a/dash/development/component_generator.py
+++ b/dash/development/component_generator.py
@@ -22,14 +22,17 @@
# pylint: disable=too-many-locals
def generate_components(components_source, project_shortname,
- package_info_filename='package.json'):
+ package_info_filename='package.json',
+ ignore='^_'):
is_windows = sys.platform == 'win32'
extract_path = pkg_resources.resource_filename('dash', 'extract-meta.js')
os.environ['NODE_PATH'] = 'node_modules'
- cmd = shlex.split('node {} {}'.format(extract_path, components_source),
- posix=not is_windows)
+ cmd = shlex.split(
+ 'node {} {} {}'.format(extract_path, ignore, components_source),
+ posix=not is_windows
+ )
shutil.copyfile('package.json',
os.path.join(project_shortname, package_info_filename))
@@ -83,10 +86,18 @@
default='package.json',
help='The filename of the copied `package.json` to `project_shortname`'
)
+ parser.add_argument(
+ '-i', '--ignore',
+ default='^_',
+ help='Files/directories matching the pattern will be ignored'
+ )
args = parser.parse_args()
- generate_components(args.components_source, args.project_shortname,
- package_info_filename=args.package_info_filename)
+ generate_components(
+ args.components_source, args.project_shortname,
+ package_info_filename=args.package_info_filename,
+ ignore=args.ignore
+ )
if __name__ == '__main__':
diff --git a/dash/version.py b/dash/version.py
--- a/dash/version.py
+++ b/dash/version.py
@@ -1 +1 @@
-__version__ = '0.33.0'
+__version__ = '0.34.0'
|
{"golden_diff": "diff --git a/dash/development/component_generator.py b/dash/development/component_generator.py\n--- a/dash/development/component_generator.py\n+++ b/dash/development/component_generator.py\n@@ -22,14 +22,17 @@\n \n # pylint: disable=too-many-locals\n def generate_components(components_source, project_shortname,\n- package_info_filename='package.json'):\n+ package_info_filename='package.json',\n+ ignore='^_'):\n is_windows = sys.platform == 'win32'\n \n extract_path = pkg_resources.resource_filename('dash', 'extract-meta.js')\n \n os.environ['NODE_PATH'] = 'node_modules'\n- cmd = shlex.split('node {} {}'.format(extract_path, components_source),\n- posix=not is_windows)\n+ cmd = shlex.split(\n+ 'node {} {} {}'.format(extract_path, ignore, components_source),\n+ posix=not is_windows\n+ )\n \n shutil.copyfile('package.json',\n os.path.join(project_shortname, package_info_filename))\n@@ -83,10 +86,18 @@\n default='package.json',\n help='The filename of the copied `package.json` to `project_shortname`'\n )\n+ parser.add_argument(\n+ '-i', '--ignore',\n+ default='^_',\n+ help='Files/directories matching the pattern will be ignored'\n+ )\n \n args = parser.parse_args()\n- generate_components(args.components_source, args.project_shortname,\n- package_info_filename=args.package_info_filename)\n+ generate_components(\n+ args.components_source, args.project_shortname,\n+ package_info_filename=args.package_info_filename,\n+ ignore=args.ignore\n+ )\n \n \n if __name__ == '__main__':\ndiff --git a/dash/version.py b/dash/version.py\n--- a/dash/version.py\n+++ b/dash/version.py\n@@ -1 +1 @@\n-__version__ = '0.33.0'\n+__version__ = '0.34.0'\n", "issue": "Allow excluding file patterns when generating component definitions \nThanks a lot for making Dash -- we have found it very useful for building dashboards.\r\n\r\nWe ran into an issue migrating to the new `dash-generate-components` utility.\r\n\r\nIn [dash-bootstrap-components](https://github.com/ASIDataScience/dash-bootstrap-components), we keep the components in `src/components`. Besides components files, this also includes a few unit test files called, e.g. `src/components/__tests__/DropdownMenu.test.js`. When we run `dash-generate-components ./src/components <output>`, these test files also get picked up. This leads to a traceback in the build logs: \r\n\r\n```\r\nError with path src/components/__tests__/DropdownMenu.test.jsError: No suitable component definition found.\r\nError: No suitable component definition found.\r\nat parse (/project/pascal/dash-bootstrap-components/node_modules/react-docgen/dist/parse.js:84:9)\r\nat Object.defaultParse [as parse] (/project/pascal/dash-bootstrap-components/node_modules/react-docgen/dist/main.js:66:30)\r\nat parseFile (/opt/anaconda/envs/Python3/lib/python3.6/site-packages/dash/extract-meta.js:64:51)\r\nat dirs.forEach.filename (/opt/anaconda/envs/Python3/lib/python3.6/site-packages/dash/extract-meta.js:84:17)\r\nat Array.forEach (<anonymous>)\r\nat collectMetadataRecursively (/opt/anaconda/envs/Python3/lib/python3.6/site-packages/dash/extract-meta.js:79:14)\r\nat dirs.forEach.filename (/opt/anaconda/envs/Python3/lib/python3.6/site-packages/dash/extract-meta.js:82:17)\r\nat Array.forEach (<anonymous>)\r\nat collectMetadataRecursively (/opt/anaconda/envs/Python3/lib/python3.6/site-packages/dash/extract-meta.js:79:14)\r\nat componentPaths.forEach.componentPath (/opt/anaconda/envs/Python3/lib/python3.6/site-packages/dash/extract-meta.js:15:5)\r\n```\r\n\r\nWhile the error is, of course, legitimate, it would be nice to be able to suppress these tracebacks. I can see three routes:\r\n- do nothing -- after all, this doesn't stop us from building `metadata.json`, it just makes it slightly more confusing.\r\n- in `dash/extract-meta.js`, we could explicitly blacklist `__tests__` directories in the same way that files that don't end in `jsx?` are black-listed. AFAICT, the `__tests__` directory structure is the default with [jest](https://jestjs.io/docs/en/configuration.html#testmatch-array-string). [react-docgen](https://github.com/reactjs/react-docgen#cli) ignores `node_modules`, `__tests__` and `__mocks__` by default, so there is definitely a precedent.\r\n- add a `--ignore` argument to `dash-generate-components` that allows passing file globs to be excluded. \r\n\r\nVery happy to submit a PR if you decide on what the best course of action is.\n", "before_files": [{"content": "from __future__ import print_function\n\nimport json\nimport sys\nimport subprocess\nimport shlex\nimport os\nimport argparse\nimport shutil\n\nimport pkg_resources\n\nfrom ._py_components_generation import generate_class_file\nfrom ._py_components_generation import generate_imports\nfrom ._py_components_generation import generate_classes_files\n\n\nclass _CombinedFormatter(argparse.ArgumentDefaultsHelpFormatter,\n argparse.RawDescriptionHelpFormatter):\n pass\n\n\n# pylint: disable=too-many-locals\ndef generate_components(components_source, project_shortname,\n package_info_filename='package.json'):\n is_windows = sys.platform == 'win32'\n\n extract_path = pkg_resources.resource_filename('dash', 'extract-meta.js')\n\n os.environ['NODE_PATH'] = 'node_modules'\n cmd = shlex.split('node {} {}'.format(extract_path, components_source),\n posix=not is_windows)\n\n shutil.copyfile('package.json',\n os.path.join(project_shortname, package_info_filename))\n\n proc = subprocess.Popen(cmd,\n stdout=subprocess.PIPE,\n stderr=subprocess.PIPE,\n shell=is_windows)\n out, err = proc.communicate()\n status = proc.poll()\n\n if err:\n print(err.decode(), file=sys.stderr)\n\n if not out:\n print(\n 'Error generating metadata in {} (status={})'.format(\n project_shortname, status),\n file=sys.stderr)\n sys.exit(1)\n\n metadata = json.loads(out.decode())\n\n components = generate_classes_files(\n project_shortname,\n metadata,\n generate_class_file\n )\n\n with open(os.path.join(project_shortname, 'metadata.json'), 'w') as f:\n json.dump(metadata, f)\n\n generate_imports(project_shortname, components)\n\n\ndef cli():\n parser = argparse.ArgumentParser(\n prog='dash-generate-components',\n formatter_class=_CombinedFormatter,\n description='Generate dash components by extracting the metadata '\n 'using react-docgen. Then map the metadata to python classes.'\n )\n parser.add_argument('components_source',\n help='React components source directory.')\n parser.add_argument(\n 'project_shortname',\n help='Name of the project to export the classes files.'\n )\n parser.add_argument(\n '-p', '--package-info-filename',\n default='package.json',\n help='The filename of the copied `package.json` to `project_shortname`'\n )\n\n args = parser.parse_args()\n generate_components(args.components_source, args.project_shortname,\n package_info_filename=args.package_info_filename)\n\n\nif __name__ == '__main__':\n cli()\n", "path": "dash/development/component_generator.py"}, {"content": "__version__ = '0.33.0'\n", "path": "dash/version.py"}]}
| 1,953 | 441 |
gh_patches_debug_22410
|
rasdani/github-patches
|
git_diff
|
ESMCI__cime-2298
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
query_config --component not working for E3SM
output from scripts_regression_tests:
```
======================================================================
ERROR: test_query_components (__main__.X_TestQueryConfig)
----------------------------------------------------------------------
Traceback (most recent call last):
File "./scripts_regression_tests.py", line 1452, in test_query_components
run_cmd_no_fail("{}/query_config --components".format(SCRIPT_DIR))
File "/lcrc/group/earthscience/jacob/cimeESMCI2/scripts/tests/../lib/CIME/utils.py", line 424, in run_cmd_no_fail
expect(False, "Command: '{}' failed with error '{}' from dir '{}'".format(cmd, errput.encode('utf-8'), os.getcwd() if from_dir is None else from_dir))
File "/lcrc/group/earthscience/jacob/cimeESMCI2/scripts/tests/../lib/CIME/utils.py", line 112, in expect
raise exc_type(msg)
SystemExit: ERROR: Command: '/lcrc/group/earthscience/jacob/cimeESMCI2/scripts/query_config --components' failed with error 'ERROR: Expected one child' from dir '/lcrc/group/earthscience/jacob/cimeESMCI2/scripts/tests'
```
</issue>
<code>
[start of scripts/lib/CIME/XML/files.py]
1 """
2 Interface to the config_files.xml file. This class inherits from EntryID.py
3 """
4 import re
5 from CIME.XML.standard_module_setup import *
6
7 from CIME.XML.entry_id import EntryID
8 from CIME.utils import expect, get_cime_root, get_model
9
10 logger = logging.getLogger(__name__)
11
12 class Files(EntryID):
13
14 def __init__(self):
15 """
16 initialize an object
17
18 >>> files = Files()
19 >>> files.get_value('CASEFILE_HEADERS',resolved=False)
20 '$CIMEROOT/config/config_headers.xml'
21 """
22 cimeroot = get_cime_root()
23 infile = os.path.join(cimeroot, "config", get_model(), "config_files.xml")
24 expect(os.path.isfile(infile), "Could not find or open file {}".format(infile))
25 schema = os.path.join(cimeroot, "config", "xml_schemas", "entry_id.xsd")
26 EntryID.__init__(self, infile, schema=schema)
27 config_files_override = os.path.join(os.path.dirname(cimeroot),".config_files.xml")
28 # variables COMP_ROOT_DIR_{} are mutable, all other variables are read only
29 self.COMP_ROOT_DIR = {}
30
31 # .config_file.xml at the top level may overwrite COMP_ROOT_DIR_ nodes in config_files
32
33 if os.path.isfile(config_files_override):
34 self.read(config_files_override)
35 self.overwrite_existing_entries()
36
37 def get_value(self, vid, attribute=None, resolved=True, subgroup=None):
38 if "COMP_ROOT_DIR" in vid:
39 if vid in self.COMP_ROOT_DIR:
40 if attribute is not None:
41 if vid+attribute["component"] in self.COMP_ROOT_DIR:
42 return self.COMP_ROOT_DIR[vid+attribute["component"]]
43 else:
44 return self.COMP_ROOT_DIR[vid]
45
46 value = super(Files, self).get_value(vid, attribute=attribute, resolved=False, subgroup=subgroup)
47 if value is None and attribute is not None:
48 value = super(Files, self).get_value(vid, attribute=None, resolved=False, subgroup=subgroup)
49
50 if "COMP_ROOT_DIR" not in vid and value is not None and "COMP_ROOT_DIR" in value:
51 m = re.search("(COMP_ROOT_DIR_[^/]+)/", value)
52 comp_root_dir_var_name = m.group(1)
53 comp_root_dir = self.get_value(comp_root_dir_var_name, attribute=attribute, resolved=False, subgroup=subgroup)
54 self.set_value(comp_root_dir_var_name, comp_root_dir,subgroup=attribute)
55 if resolved:
56 value = value.replace("$"+comp_root_dir_var_name, comp_root_dir)
57
58
59 if resolved and value is not None:
60 value = self.get_resolved_value(value)
61
62 return value
63
64 def set_value(self, vid, value,subgroup=None,ignore_type=False):
65 if "COMP_ROOT_DIR" in vid:
66 if subgroup is not None:
67 self.COMP_ROOT_DIR[vid+subgroup["component"]] = value
68 else:
69 self.COMP_ROOT_DIR[vid] = value
70
71 else:
72 expect(False, "Attempt to set a nonmutable variable {}".format(vid))
73 return value
74
75
76 def get_schema(self, nodename, attributes=None):
77 node = self.get_optional_child("entry", {"id":nodename})
78 schemanode = self.get_optional_child("schema", root=node, attributes=attributes)
79 if schemanode is not None:
80 logger.debug("Found schema for {}".format(nodename))
81 return self.get_resolved_value(self.text(schemanode))
82 return None
83
84 def get_components(self, nodename):
85 node = self.get_child("entry", {"id":nodename})
86 valnodes = self.get_children("value", root=self.get_child("values", root=node))
87 values = []
88 for valnode in valnodes:
89 value = self.get(valnode, "component")
90 values.append(value)
91 return values
92
[end of scripts/lib/CIME/XML/files.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scripts/lib/CIME/XML/files.py b/scripts/lib/CIME/XML/files.py
--- a/scripts/lib/CIME/XML/files.py
+++ b/scripts/lib/CIME/XML/files.py
@@ -67,7 +67,7 @@
self.COMP_ROOT_DIR[vid+subgroup["component"]] = value
else:
self.COMP_ROOT_DIR[vid] = value
-
+
else:
expect(False, "Attempt to set a nonmutable variable {}".format(vid))
return value
@@ -82,10 +82,13 @@
return None
def get_components(self, nodename):
- node = self.get_child("entry", {"id":nodename})
- valnodes = self.get_children("value", root=self.get_child("values", root=node))
- values = []
- for valnode in valnodes:
- value = self.get(valnode, "component")
- values.append(value)
- return values
+ node = self.get_optional_child("entry", {"id":nodename})
+ if node is not None:
+ valnodes = self.get_children("value", root=self.get_child("values", root=node))
+ values = []
+ for valnode in valnodes:
+ value = self.get(valnode, "component")
+ values.append(value)
+ return values
+
+ return None
|
{"golden_diff": "diff --git a/scripts/lib/CIME/XML/files.py b/scripts/lib/CIME/XML/files.py\n--- a/scripts/lib/CIME/XML/files.py\n+++ b/scripts/lib/CIME/XML/files.py\n@@ -67,7 +67,7 @@\n self.COMP_ROOT_DIR[vid+subgroup[\"component\"]] = value\n else:\n self.COMP_ROOT_DIR[vid] = value\n- \n+\n else:\n expect(False, \"Attempt to set a nonmutable variable {}\".format(vid))\n return value\n@@ -82,10 +82,13 @@\n return None\n \n def get_components(self, nodename):\n- node = self.get_child(\"entry\", {\"id\":nodename})\n- valnodes = self.get_children(\"value\", root=self.get_child(\"values\", root=node))\n- values = []\n- for valnode in valnodes:\n- value = self.get(valnode, \"component\")\n- values.append(value)\n- return values\n+ node = self.get_optional_child(\"entry\", {\"id\":nodename})\n+ if node is not None:\n+ valnodes = self.get_children(\"value\", root=self.get_child(\"values\", root=node))\n+ values = []\n+ for valnode in valnodes:\n+ value = self.get(valnode, \"component\")\n+ values.append(value)\n+ return values\n+\n+ return None\n", "issue": "query_config --component not working for E3SM\noutput from scripts_regression_tests:\r\n```\r\n======================================================================\r\nERROR: test_query_components (__main__.X_TestQueryConfig)\r\n----------------------------------------------------------------------\r\nTraceback (most recent call last):\r\n File \"./scripts_regression_tests.py\", line 1452, in test_query_components\r\n run_cmd_no_fail(\"{}/query_config --components\".format(SCRIPT_DIR))\r\n File \"/lcrc/group/earthscience/jacob/cimeESMCI2/scripts/tests/../lib/CIME/utils.py\", line 424, in run_cmd_no_fail\r\n expect(False, \"Command: '{}' failed with error '{}' from dir '{}'\".format(cmd, errput.encode('utf-8'), os.getcwd() if from_dir is None else from_dir))\r\n File \"/lcrc/group/earthscience/jacob/cimeESMCI2/scripts/tests/../lib/CIME/utils.py\", line 112, in expect\r\n raise exc_type(msg)\r\nSystemExit: ERROR: Command: '/lcrc/group/earthscience/jacob/cimeESMCI2/scripts/query_config --components' failed with error 'ERROR: Expected one child' from dir '/lcrc/group/earthscience/jacob/cimeESMCI2/scripts/tests'\r\n```\r\n\r\n\n", "before_files": [{"content": "\"\"\"\nInterface to the config_files.xml file. This class inherits from EntryID.py\n\"\"\"\nimport re\nfrom CIME.XML.standard_module_setup import *\n\nfrom CIME.XML.entry_id import EntryID\nfrom CIME.utils import expect, get_cime_root, get_model\n\nlogger = logging.getLogger(__name__)\n\nclass Files(EntryID):\n\n def __init__(self):\n \"\"\"\n initialize an object\n\n >>> files = Files()\n >>> files.get_value('CASEFILE_HEADERS',resolved=False)\n '$CIMEROOT/config/config_headers.xml'\n \"\"\"\n cimeroot = get_cime_root()\n infile = os.path.join(cimeroot, \"config\", get_model(), \"config_files.xml\")\n expect(os.path.isfile(infile), \"Could not find or open file {}\".format(infile))\n schema = os.path.join(cimeroot, \"config\", \"xml_schemas\", \"entry_id.xsd\")\n EntryID.__init__(self, infile, schema=schema)\n config_files_override = os.path.join(os.path.dirname(cimeroot),\".config_files.xml\")\n # variables COMP_ROOT_DIR_{} are mutable, all other variables are read only\n self.COMP_ROOT_DIR = {}\n\n # .config_file.xml at the top level may overwrite COMP_ROOT_DIR_ nodes in config_files\n\n if os.path.isfile(config_files_override):\n self.read(config_files_override)\n self.overwrite_existing_entries()\n\n def get_value(self, vid, attribute=None, resolved=True, subgroup=None):\n if \"COMP_ROOT_DIR\" in vid:\n if vid in self.COMP_ROOT_DIR:\n if attribute is not None:\n if vid+attribute[\"component\"] in self.COMP_ROOT_DIR:\n return self.COMP_ROOT_DIR[vid+attribute[\"component\"]]\n else:\n return self.COMP_ROOT_DIR[vid]\n\n value = super(Files, self).get_value(vid, attribute=attribute, resolved=False, subgroup=subgroup)\n if value is None and attribute is not None:\n value = super(Files, self).get_value(vid, attribute=None, resolved=False, subgroup=subgroup)\n\n if \"COMP_ROOT_DIR\" not in vid and value is not None and \"COMP_ROOT_DIR\" in value:\n m = re.search(\"(COMP_ROOT_DIR_[^/]+)/\", value)\n comp_root_dir_var_name = m.group(1)\n comp_root_dir = self.get_value(comp_root_dir_var_name, attribute=attribute, resolved=False, subgroup=subgroup)\n self.set_value(comp_root_dir_var_name, comp_root_dir,subgroup=attribute)\n if resolved:\n value = value.replace(\"$\"+comp_root_dir_var_name, comp_root_dir)\n\n\n if resolved and value is not None:\n value = self.get_resolved_value(value)\n\n return value\n\n def set_value(self, vid, value,subgroup=None,ignore_type=False):\n if \"COMP_ROOT_DIR\" in vid:\n if subgroup is not None:\n self.COMP_ROOT_DIR[vid+subgroup[\"component\"]] = value\n else:\n self.COMP_ROOT_DIR[vid] = value\n \n else:\n expect(False, \"Attempt to set a nonmutable variable {}\".format(vid))\n return value\n\n\n def get_schema(self, nodename, attributes=None):\n node = self.get_optional_child(\"entry\", {\"id\":nodename})\n schemanode = self.get_optional_child(\"schema\", root=node, attributes=attributes)\n if schemanode is not None:\n logger.debug(\"Found schema for {}\".format(nodename))\n return self.get_resolved_value(self.text(schemanode))\n return None\n\n def get_components(self, nodename):\n node = self.get_child(\"entry\", {\"id\":nodename})\n valnodes = self.get_children(\"value\", root=self.get_child(\"values\", root=node))\n values = []\n for valnode in valnodes:\n value = self.get(valnode, \"component\")\n values.append(value)\n return values\n", "path": "scripts/lib/CIME/XML/files.py"}]}
| 1,819 | 299 |
gh_patches_debug_39630
|
rasdani/github-patches
|
git_diff
|
Kinto__kinto-1250
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Accounts parent_id in records table not being set correctly
Ubuntu 16.04
From source Latest commit 5e2a13b
Postgres database
1. Change kinto.ini to enable accounts
2. Create admin user myadmin with
`kinto.account_create_principals = system.Everyone
`
3. Then change to
`kinto.account_create_principals = account:myadmin`
Final kinto.ini changes
```
multiauth.policies = account
multiauth.policy.account.use = kinto.plugins.accounts.authentication.AccountsAuthenticationPolicy
# Allow anyone to create accounts.
kinto.account_create_principals = account:myadmin
# Set user 'account:admin' as the administrator.
kinto.account_write_principals = account:myadmin
kinto.account_read_principals = account:myadmin
```
4. Create user using myadmin auth
echo '{"data": {"id": "zzz", "password": "test"}}' | http POST http://192.168.2.12:8888/v1/accounts --auth 'myadmin:test'
5. Try to delete user
`http DELETE http://192.168.2.12:8888/v1/accounts/zzz --verbose --auth 'myadmin:test'`
```
{
"code": 404,
"details": {
"id": "zzz",
"resource_name": "account"
},
"errno": 110,
"error": "Not Found"
}
```
6. If you change user zzz's password then Delete is a success
echo '{"data": {"password": "asdf"}}' | http PUT http://localhost:8888/v1/accounts/zzz --verbose --auth 'myadmin:test'
If you look at the records table in Postgres you will see that the initial creation of user zzz's parent_id is set to *
After changing zzz's password parent_id is set to zzz
Accounts parent_id in records table not being set correctly
Ubuntu 16.04
From source Latest commit 5e2a13b
Postgres database
1. Change kinto.ini to enable accounts
2. Create admin user myadmin with
`kinto.account_create_principals = system.Everyone
`
3. Then change to
`kinto.account_create_principals = account:myadmin`
Final kinto.ini changes
```
multiauth.policies = account
multiauth.policy.account.use = kinto.plugins.accounts.authentication.AccountsAuthenticationPolicy
# Allow anyone to create accounts.
kinto.account_create_principals = account:myadmin
# Set user 'account:admin' as the administrator.
kinto.account_write_principals = account:myadmin
kinto.account_read_principals = account:myadmin
```
4. Create user using myadmin auth
echo '{"data": {"id": "zzz", "password": "test"}}' | http POST http://192.168.2.12:8888/v1/accounts --auth 'myadmin:test'
5. Try to delete user
`http DELETE http://192.168.2.12:8888/v1/accounts/zzz --verbose --auth 'myadmin:test'`
```
{
"code": 404,
"details": {
"id": "zzz",
"resource_name": "account"
},
"errno": 110,
"error": "Not Found"
}
```
6. If you change user zzz's password then Delete is a success
echo '{"data": {"password": "asdf"}}' | http PUT http://localhost:8888/v1/accounts/zzz --verbose --auth 'myadmin:test'
If you look at the records table in Postgres you will see that the initial creation of user zzz's parent_id is set to *
After changing zzz's password parent_id is set to zzz
</issue>
<code>
[start of kinto/plugins/accounts/views.py]
1 import bcrypt
2 import colander
3 from pyramid import httpexceptions
4 from pyramid.decorator import reify
5 from pyramid.security import Authenticated, Everyone
6 from pyramid.settings import aslist
7
8 from kinto.views import NameGenerator
9 from kinto.core import resource
10 from kinto.core.errors import raise_invalid, http_error
11
12
13 class AccountSchema(resource.ResourceSchema):
14 password = colander.SchemaNode(colander.String())
15
16
17 @resource.register()
18 class Account(resource.ShareableResource):
19
20 schema = AccountSchema
21
22 def __init__(self, request, context):
23 # Store if current user is administrator (before accessing get_parent_id())
24 allowed_from_settings = request.registry.settings.get('account_write_principals', [])
25 context.is_administrator = len(set(aslist(allowed_from_settings)) &
26 set(request.prefixed_principals)) > 0
27 # Shortcut to check if current is anonymous (before get_parent_id()).
28 context.is_anonymous = Authenticated not in request.effective_principals
29
30 super().__init__(request, context)
31
32 # Overwrite the current principal set by ShareableResource.
33 if self.model.current_principal == Everyone:
34 # Creation is anonymous, but author with write perm is this:
35 # XXX: only works if policy name is account in settings.
36 self.model.current_principal = 'account:{}'.format(self.model.parent_id)
37
38 @reify
39 def id_generator(self):
40 # This generator is used for ID validation.
41 return NameGenerator()
42
43 def get_parent_id(self, request):
44 # The whole challenge here is that we want to isolate what
45 # authenticated users can list, but give access to everything to
46 # administrators.
47 # Plus when anonymous create accounts, we have to set their parent id
48 # to the same value they would obtain when authenticated.
49 if self.context.is_administrator:
50 if self.context.on_collection:
51 # Admin see all accounts.
52 return '*'
53 else:
54 # No pattern matching for admin on single record.
55 return request.matchdict['id']
56
57 if not self.context.is_anonymous:
58 # Authenticated users see their own account only.
59 return request.selected_userid
60
61 # Anonymous creation with PUT.
62 if 'id' in request.matchdict:
63 return request.matchdict['id']
64
65 try:
66 # Anonymous creation with POST.
67 return request.json['data']['id']
68 except (ValueError, KeyError):
69 # Bad POST data.
70 if request.method.lower() == 'post':
71 error_details = {
72 'name': 'data.id',
73 'description': 'data.id in body: Required'
74 }
75 raise_invalid(request, **error_details)
76 # Anonymous GET
77 error_msg = 'Cannot read accounts.'
78 raise http_error(httpexceptions.HTTPUnauthorized(), error=error_msg)
79
80 def collection_post(self):
81 result = super(Account, self).collection_post()
82 if self.context.is_anonymous and self.request.response.status_code == 200:
83 error_details = {
84 'message': 'Account ID %r already exists' % result['data']['id']
85 }
86 raise http_error(httpexceptions.HTTPForbidden(), **error_details)
87 return result
88
89 def process_record(self, new, old=None):
90 new = super(Account, self).process_record(new, old)
91
92 # Store password safely in database as str
93 # (bcrypt.hashpw returns base64 bytes).
94 pwd_str = new["password"].encode(encoding='utf-8')
95 hashed = bcrypt.hashpw(pwd_str, bcrypt.gensalt())
96 new["password"] = hashed.decode(encoding='utf-8')
97
98 # Administrators can reach other accounts and anonymous have no
99 # selected_userid. So do not try to enforce.
100 if self.context.is_administrator or self.context.is_anonymous:
101 return new
102
103 # Otherwise, we force the id to match the authenticated username.
104 if new[self.model.id_field] != self.request.selected_userid:
105 error_details = {
106 'name': 'data.id',
107 'description': 'Username and account ID do not match.',
108 }
109 raise_invalid(self.request, **error_details)
110
111 return new
112
[end of kinto/plugins/accounts/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kinto/plugins/accounts/views.py b/kinto/plugins/accounts/views.py
--- a/kinto/plugins/accounts/views.py
+++ b/kinto/plugins/accounts/views.py
@@ -10,6 +10,23 @@
from kinto.core.errors import raise_invalid, http_error
+def _extract_posted_body_id(request):
+ try:
+ # Anonymous creation with POST.
+ return request.json['data']['id']
+ except (ValueError, KeyError):
+ # Bad POST data.
+ if request.method.lower() == 'post':
+ error_details = {
+ 'name': 'data.id',
+ 'description': 'data.id in body: Required'
+ }
+ raise_invalid(request, **error_details)
+ # Anonymous GET
+ error_msg = 'Cannot read accounts.'
+ raise http_error(httpexceptions.HTTPUnauthorized(), error=error_msg)
+
+
class AccountSchema(resource.ResourceSchema):
password = colander.SchemaNode(colander.String())
@@ -30,7 +47,7 @@
super().__init__(request, context)
# Overwrite the current principal set by ShareableResource.
- if self.model.current_principal == Everyone:
+ if self.model.current_principal == Everyone or context.is_administrator:
# Creation is anonymous, but author with write perm is this:
# XXX: only works if policy name is account in settings.
self.model.current_principal = 'account:{}'.format(self.model.parent_id)
@@ -48,8 +65,12 @@
# to the same value they would obtain when authenticated.
if self.context.is_administrator:
if self.context.on_collection:
- # Admin see all accounts.
- return '*'
+ # Accounts created by admin should have userid as parent.
+ if request.method.lower() == 'post':
+ return _extract_posted_body_id(request)
+ else:
+ # Admin see all accounts.
+ return '*'
else:
# No pattern matching for admin on single record.
return request.matchdict['id']
@@ -62,20 +83,7 @@
if 'id' in request.matchdict:
return request.matchdict['id']
- try:
- # Anonymous creation with POST.
- return request.json['data']['id']
- except (ValueError, KeyError):
- # Bad POST data.
- if request.method.lower() == 'post':
- error_details = {
- 'name': 'data.id',
- 'description': 'data.id in body: Required'
- }
- raise_invalid(request, **error_details)
- # Anonymous GET
- error_msg = 'Cannot read accounts.'
- raise http_error(httpexceptions.HTTPUnauthorized(), error=error_msg)
+ return _extract_posted_body_id(request)
def collection_post(self):
result = super(Account, self).collection_post()
|
{"golden_diff": "diff --git a/kinto/plugins/accounts/views.py b/kinto/plugins/accounts/views.py\n--- a/kinto/plugins/accounts/views.py\n+++ b/kinto/plugins/accounts/views.py\n@@ -10,6 +10,23 @@\n from kinto.core.errors import raise_invalid, http_error\n \n \n+def _extract_posted_body_id(request):\n+ try:\n+ # Anonymous creation with POST.\n+ return request.json['data']['id']\n+ except (ValueError, KeyError):\n+ # Bad POST data.\n+ if request.method.lower() == 'post':\n+ error_details = {\n+ 'name': 'data.id',\n+ 'description': 'data.id in body: Required'\n+ }\n+ raise_invalid(request, **error_details)\n+ # Anonymous GET\n+ error_msg = 'Cannot read accounts.'\n+ raise http_error(httpexceptions.HTTPUnauthorized(), error=error_msg)\n+\n+\n class AccountSchema(resource.ResourceSchema):\n password = colander.SchemaNode(colander.String())\n \n@@ -30,7 +47,7 @@\n super().__init__(request, context)\n \n # Overwrite the current principal set by ShareableResource.\n- if self.model.current_principal == Everyone:\n+ if self.model.current_principal == Everyone or context.is_administrator:\n # Creation is anonymous, but author with write perm is this:\n # XXX: only works if policy name is account in settings.\n self.model.current_principal = 'account:{}'.format(self.model.parent_id)\n@@ -48,8 +65,12 @@\n # to the same value they would obtain when authenticated.\n if self.context.is_administrator:\n if self.context.on_collection:\n- # Admin see all accounts.\n- return '*'\n+ # Accounts created by admin should have userid as parent.\n+ if request.method.lower() == 'post':\n+ return _extract_posted_body_id(request)\n+ else:\n+ # Admin see all accounts.\n+ return '*'\n else:\n # No pattern matching for admin on single record.\n return request.matchdict['id']\n@@ -62,20 +83,7 @@\n if 'id' in request.matchdict:\n return request.matchdict['id']\n \n- try:\n- # Anonymous creation with POST.\n- return request.json['data']['id']\n- except (ValueError, KeyError):\n- # Bad POST data.\n- if request.method.lower() == 'post':\n- error_details = {\n- 'name': 'data.id',\n- 'description': 'data.id in body: Required'\n- }\n- raise_invalid(request, **error_details)\n- # Anonymous GET\n- error_msg = 'Cannot read accounts.'\n- raise http_error(httpexceptions.HTTPUnauthorized(), error=error_msg)\n+ return _extract_posted_body_id(request)\n \n def collection_post(self):\n result = super(Account, self).collection_post()\n", "issue": "Accounts parent_id in records table not being set correctly\nUbuntu 16.04\r\nFrom source Latest commit 5e2a13b\r\nPostgres database\r\n\r\n1. Change kinto.ini to enable accounts\r\n2. Create admin user myadmin with\r\n`kinto.account_create_principals = system.Everyone\r\n`\r\n3. Then change to\r\n`kinto.account_create_principals = account:myadmin`\r\n\r\nFinal kinto.ini changes\r\n```\r\nmultiauth.policies = account\r\nmultiauth.policy.account.use = kinto.plugins.accounts.authentication.AccountsAuthenticationPolicy\r\n# Allow anyone to create accounts.\r\nkinto.account_create_principals = account:myadmin\r\n# Set user 'account:admin' as the administrator.\r\nkinto.account_write_principals = account:myadmin\r\nkinto.account_read_principals = account:myadmin\r\n\r\n```\r\n\r\n4. Create user using myadmin auth\r\necho '{\"data\": {\"id\": \"zzz\", \"password\": \"test\"}}' | http POST http://192.168.2.12:8888/v1/accounts --auth 'myadmin:test'\r\n\r\n5. Try to delete user\r\n`http DELETE http://192.168.2.12:8888/v1/accounts/zzz --verbose --auth 'myadmin:test'`\r\n\r\n```\r\n{\r\n \"code\": 404,\r\n \"details\": {\r\n \"id\": \"zzz\",\r\n \"resource_name\": \"account\"\r\n },\r\n \"errno\": 110,\r\n \"error\": \"Not Found\"\r\n}\r\n```\r\n\r\n6. If you change user zzz's password then Delete is a success\r\necho '{\"data\": {\"password\": \"asdf\"}}' | http PUT http://localhost:8888/v1/accounts/zzz --verbose --auth 'myadmin:test'\r\n\r\nIf you look at the records table in Postgres you will see that the initial creation of user zzz's parent_id is set to *\r\n\r\nAfter changing zzz's password parent_id is set to zzz\r\n\nAccounts parent_id in records table not being set correctly\nUbuntu 16.04\r\nFrom source Latest commit 5e2a13b\r\nPostgres database\r\n\r\n1. Change kinto.ini to enable accounts\r\n2. Create admin user myadmin with\r\n`kinto.account_create_principals = system.Everyone\r\n`\r\n3. Then change to\r\n`kinto.account_create_principals = account:myadmin`\r\n\r\nFinal kinto.ini changes\r\n```\r\nmultiauth.policies = account\r\nmultiauth.policy.account.use = kinto.plugins.accounts.authentication.AccountsAuthenticationPolicy\r\n# Allow anyone to create accounts.\r\nkinto.account_create_principals = account:myadmin\r\n# Set user 'account:admin' as the administrator.\r\nkinto.account_write_principals = account:myadmin\r\nkinto.account_read_principals = account:myadmin\r\n\r\n```\r\n\r\n4. Create user using myadmin auth\r\necho '{\"data\": {\"id\": \"zzz\", \"password\": \"test\"}}' | http POST http://192.168.2.12:8888/v1/accounts --auth 'myadmin:test'\r\n\r\n5. Try to delete user\r\n`http DELETE http://192.168.2.12:8888/v1/accounts/zzz --verbose --auth 'myadmin:test'`\r\n\r\n```\r\n{\r\n \"code\": 404,\r\n \"details\": {\r\n \"id\": \"zzz\",\r\n \"resource_name\": \"account\"\r\n },\r\n \"errno\": 110,\r\n \"error\": \"Not Found\"\r\n}\r\n```\r\n\r\n6. If you change user zzz's password then Delete is a success\r\necho '{\"data\": {\"password\": \"asdf\"}}' | http PUT http://localhost:8888/v1/accounts/zzz --verbose --auth 'myadmin:test'\r\n\r\nIf you look at the records table in Postgres you will see that the initial creation of user zzz's parent_id is set to *\r\n\r\nAfter changing zzz's password parent_id is set to zzz\r\n\n", "before_files": [{"content": "import bcrypt\nimport colander\nfrom pyramid import httpexceptions\nfrom pyramid.decorator import reify\nfrom pyramid.security import Authenticated, Everyone\nfrom pyramid.settings import aslist\n\nfrom kinto.views import NameGenerator\nfrom kinto.core import resource\nfrom kinto.core.errors import raise_invalid, http_error\n\n\nclass AccountSchema(resource.ResourceSchema):\n password = colander.SchemaNode(colander.String())\n\n\[email protected]()\nclass Account(resource.ShareableResource):\n\n schema = AccountSchema\n\n def __init__(self, request, context):\n # Store if current user is administrator (before accessing get_parent_id())\n allowed_from_settings = request.registry.settings.get('account_write_principals', [])\n context.is_administrator = len(set(aslist(allowed_from_settings)) &\n set(request.prefixed_principals)) > 0\n # Shortcut to check if current is anonymous (before get_parent_id()).\n context.is_anonymous = Authenticated not in request.effective_principals\n\n super().__init__(request, context)\n\n # Overwrite the current principal set by ShareableResource.\n if self.model.current_principal == Everyone:\n # Creation is anonymous, but author with write perm is this:\n # XXX: only works if policy name is account in settings.\n self.model.current_principal = 'account:{}'.format(self.model.parent_id)\n\n @reify\n def id_generator(self):\n # This generator is used for ID validation.\n return NameGenerator()\n\n def get_parent_id(self, request):\n # The whole challenge here is that we want to isolate what\n # authenticated users can list, but give access to everything to\n # administrators.\n # Plus when anonymous create accounts, we have to set their parent id\n # to the same value they would obtain when authenticated.\n if self.context.is_administrator:\n if self.context.on_collection:\n # Admin see all accounts.\n return '*'\n else:\n # No pattern matching for admin on single record.\n return request.matchdict['id']\n\n if not self.context.is_anonymous:\n # Authenticated users see their own account only.\n return request.selected_userid\n\n # Anonymous creation with PUT.\n if 'id' in request.matchdict:\n return request.matchdict['id']\n\n try:\n # Anonymous creation with POST.\n return request.json['data']['id']\n except (ValueError, KeyError):\n # Bad POST data.\n if request.method.lower() == 'post':\n error_details = {\n 'name': 'data.id',\n 'description': 'data.id in body: Required'\n }\n raise_invalid(request, **error_details)\n # Anonymous GET\n error_msg = 'Cannot read accounts.'\n raise http_error(httpexceptions.HTTPUnauthorized(), error=error_msg)\n\n def collection_post(self):\n result = super(Account, self).collection_post()\n if self.context.is_anonymous and self.request.response.status_code == 200:\n error_details = {\n 'message': 'Account ID %r already exists' % result['data']['id']\n }\n raise http_error(httpexceptions.HTTPForbidden(), **error_details)\n return result\n\n def process_record(self, new, old=None):\n new = super(Account, self).process_record(new, old)\n\n # Store password safely in database as str\n # (bcrypt.hashpw returns base64 bytes).\n pwd_str = new[\"password\"].encode(encoding='utf-8')\n hashed = bcrypt.hashpw(pwd_str, bcrypt.gensalt())\n new[\"password\"] = hashed.decode(encoding='utf-8')\n\n # Administrators can reach other accounts and anonymous have no\n # selected_userid. So do not try to enforce.\n if self.context.is_administrator or self.context.is_anonymous:\n return new\n\n # Otherwise, we force the id to match the authenticated username.\n if new[self.model.id_field] != self.request.selected_userid:\n error_details = {\n 'name': 'data.id',\n 'description': 'Username and account ID do not match.',\n }\n raise_invalid(self.request, **error_details)\n\n return new\n", "path": "kinto/plugins/accounts/views.py"}]}
| 2,531 | 627 |
gh_patches_debug_8369
|
rasdani/github-patches
|
git_diff
|
Qiskit__qiskit-1089
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Default circuit names are not zero-based
<!-- ⚠️ If you do not respect this template, your issue will be closed -->
<!-- ⚠️ Make sure to browse the opened and closed issues -->
### Informations
- **Qiskit Terra version**: latest
- **Python version**: 3.7
- **Operating system**: OSX
### What is the current behavior?
When creating a quantum circuit with no name, the default name is set to `circuitX`. Currently, `X` starts from `1` rather than `0`, and can cause some confusion when trying to index circuits by name.
### Steps to reproduce the problem
```python
from qiskit import *
q = QuantumRegister(2, "q")
c = ClassicalRegister(2, "c")
# Create measurement subcircuit
qc = QuantumCircuit(q,c)
qc.name
```
gives `'circuit1'` for the initial circuit created. It should be `'circuit0'` to coincide with the the indexing in Python.
### What is the expected behavior?
### Suggested solutions
</issue>
<code>
[start of qiskit/_quantumcircuit.py]
1 # -*- coding: utf-8 -*-
2
3 # Copyright 2017, IBM.
4 #
5 # This source code is licensed under the Apache License, Version 2.0 found in
6 # the LICENSE.txt file in the root directory of this source tree.
7
8 """
9 Quantum circuit object.
10 """
11 import itertools
12 from collections import OrderedDict
13 from ._qiskiterror import QISKitError
14 from ._register import Register
15 from ._quantumregister import QuantumRegister
16 from ._classicalregister import ClassicalRegister
17 from ._measure import Measure
18 from ._reset import Reset
19 from ._instructionset import InstructionSet
20
21
22 class QuantumCircuit(object):
23 """Quantum circuit."""
24 instances = 0
25 prefix = 'circuit'
26
27 # Class variable OPENQASM header
28 header = "OPENQASM 2.0;"
29
30 # Class variable with gate definitions
31 # This is a dict whose values are dicts with the
32 # following keys:
33 # "print" = True or False
34 # "opaque" = True or False
35 # "n_args" = number of real parameters
36 # "n_bits" = number of qubits
37 # "args" = list of parameter names
38 # "bits" = list of qubit names
39 # "body" = GateBody AST node
40 definitions = OrderedDict()
41
42 def __init__(self, *regs, name=None):
43 """Create a new circuit.
44
45 Args:
46 *regs (Registers): registers to include in the circuit.
47 name (str or None): the name of the quantum circuit. If
48 None, an automatically generated identifier will be
49 assigned.
50
51 Raises:
52 QISKitError: if the circuit name, if given, is not valid.
53 """
54 self._increment_instances()
55 if name is None:
56 name = self.cls_prefix() + str(self.cls_instances())
57
58 if not isinstance(name, str):
59 raise QISKitError("The circuit name should be a string "
60 "(or None for autogenerate a name).")
61
62 self.name = name
63 # Data contains a list of instructions in the order they were applied.
64 self.data = []
65 # This is a map of registers bound to this circuit, by name.
66 self.regs = OrderedDict()
67 self.add(*regs)
68
69 @classmethod
70 def _increment_instances(cls):
71 cls.instances += 1
72
73 @classmethod
74 def cls_instances(cls):
75 """Return the current number of instances of this class,
76 useful for auto naming."""
77 return cls.instances
78
79 @classmethod
80 def cls_prefix(cls):
81 """Return the prefix to use for auto naming."""
82 return cls.prefix
83
84 def has_register(self, register):
85 """
86 Test if this circuit has the register r.
87
88 Return True or False.
89 """
90 if register.name in self.regs:
91 registers = self.regs[register.name]
92 if registers.size == register.size:
93 if ((isinstance(register, QuantumRegister) and
94 isinstance(registers, QuantumRegister)) or
95 (isinstance(register, ClassicalRegister) and
96 isinstance(registers, ClassicalRegister))):
97 return True
98 return False
99
100 def get_qregs(self):
101 """Get the qregs from the registers."""
102 qregs = OrderedDict()
103 for name, register in self.regs.items():
104 if isinstance(register, QuantumRegister):
105 qregs[name] = register
106 return qregs
107
108 def get_cregs(self):
109 """Get the cregs from the registers."""
110 cregs = OrderedDict()
111 for name, register in self.regs.items():
112 if isinstance(register, ClassicalRegister):
113 cregs[name] = register
114 return cregs
115
116 def combine(self, rhs):
117 """
118 Append rhs to self if self contains compatible registers.
119
120 Two circuits are compatible if they contain the same registers
121 or if they contain different registers with unique names. The
122 returned circuit will contain all unique registers between both
123 circuits.
124
125 Return self + rhs as a new object.
126 """
127 combined_registers = []
128 # Check registers in LHS are compatible with RHS
129 for name, register in self.regs.items():
130 if name in rhs.regs and register != rhs.regs[name]:
131 raise QISKitError("circuits are not compatible")
132 else:
133 combined_registers.append(register)
134 # Add registers in RHS not in LHS
135 complement_registers = set(rhs.regs) - set(self.regs)
136 for name in complement_registers:
137 combined_registers.append(rhs.regs[name])
138 # Make new circuit with combined registers
139 circuit = QuantumCircuit(*combined_registers)
140 for gate in itertools.chain(self.data, rhs.data):
141 gate.reapply(circuit)
142 return circuit
143
144 def extend(self, rhs):
145 """
146 Append rhs to self if self if it contains compatible registers.
147
148 Two circuits are compatible if they contain the same registers
149 or if they contain different registers with unique names. The
150 returned circuit will contain all unique registers between both
151 circuits.
152
153 Modify and return self.
154 """
155 # Check compatibility and add new registers
156 for name, register in rhs.regs.items():
157 if name not in self.regs:
158 self.add(register)
159 elif name in self.regs and register != self.regs[name]:
160 raise QISKitError("circuits are not compatible")
161
162 # Add new gates
163 for gate in rhs.data:
164 gate.reapply(self)
165 return self
166
167 def __add__(self, rhs):
168 """Overload + to implement self.concatenate."""
169 return self.combine(rhs)
170
171 def __iadd__(self, rhs):
172 """Overload += to implement self.extend."""
173 return self.extend(rhs)
174
175 def __len__(self):
176 """Return number of operations in circuit."""
177 return len(self.data)
178
179 def __getitem__(self, item):
180 """Return indexed operation."""
181 return self.data[item]
182
183 def _attach(self, gate):
184 """Attach a gate."""
185 self.data.append(gate)
186 return gate
187
188 def add(self, *regs):
189 """Add registers."""
190 for register in regs:
191 if not isinstance(register, Register):
192 raise QISKitError("expected a register")
193 if register.name not in self.regs:
194 self.regs[register.name] = register
195 else:
196 raise QISKitError("register name \"%s\" already exists"
197 % register.name)
198
199 def _check_qreg(self, register):
200 """Raise exception if r is not in this circuit or not qreg."""
201 if not isinstance(register, QuantumRegister):
202 raise QISKitError("expected quantum register")
203 if not self.has_register(register):
204 raise QISKitError(
205 "register '%s' not in this circuit" %
206 register.name)
207
208 def _check_qubit(self, qubit):
209 """Raise exception if qubit is not in this circuit or bad format."""
210 if not isinstance(qubit, tuple):
211 raise QISKitError("%s is not a tuple."
212 "A qubit should be formated as a tuple." % str(qubit))
213 if not len(qubit) == 2:
214 raise QISKitError("%s is not a tuple with two elements, but %i instead" % len(qubit))
215 if not isinstance(qubit[1], int):
216 raise QISKitError("The second element of a tuple defining a qubit should be an int:"
217 "%s was found instead" % type(qubit[1]).__name__)
218 self._check_qreg(qubit[0])
219 qubit[0].check_range(qubit[1])
220
221 def _check_creg(self, register):
222 """Raise exception if r is not in this circuit or not creg."""
223 if not isinstance(register, ClassicalRegister):
224 raise QISKitError("expected classical register")
225 if not self.has_register(register):
226 raise QISKitError(
227 "register '%s' not in this circuit" %
228 register.name)
229
230 def _check_dups(self, qubits):
231 """Raise exception if list of qubits contains duplicates."""
232 squbits = set(qubits)
233 if len(squbits) != len(qubits):
234 raise QISKitError("duplicate qubit arguments")
235
236 def _gate_string(self, name):
237 """Return a QASM string for the named gate."""
238 out = ""
239 if self.definitions[name]["opaque"]:
240 out = "opaque " + name
241 else:
242 out = "gate " + name
243 if self.definitions[name]["n_args"] > 0:
244 out += "(" + ",".join(self.definitions[name]["args"]) + ")"
245 out += " " + ",".join(self.definitions[name]["bits"])
246 if self.definitions[name]["opaque"]:
247 out += ";"
248 else:
249 out += "\n{\n" + self.definitions[name]["body"].qasm() + "}\n"
250 return out
251
252 def qasm(self):
253 """Return OPENQASM string."""
254 string_temp = self.header + "\n"
255 for gate_name in self.definitions:
256 if self.definitions[gate_name]["print"]:
257 string_temp += self._gate_string(gate_name)
258 for register in self.regs.values():
259 string_temp += register.qasm() + "\n"
260 for instruction in self.data:
261 string_temp += instruction.qasm() + "\n"
262 return string_temp
263
264 def measure(self, qubit, cbit):
265 """Measure quantum bit into classical bit (tuples).
266
267 Returns:
268 qiskit.Gate: the attached measure gate.
269
270 Raises:
271 QISKitError: if qubit is not in this circuit or bad format;
272 if cbit is not in this circuit or not creg.
273 """
274 if isinstance(qubit, QuantumRegister) and \
275 isinstance(cbit, ClassicalRegister) and len(qubit) == len(cbit):
276 instructions = InstructionSet()
277 for i in range(qubit.size):
278 instructions.add(self.measure((qubit, i), (cbit, i)))
279 return instructions
280
281 self._check_qubit(qubit)
282 self._check_creg(cbit[0])
283 cbit[0].check_range(cbit[1])
284 return self._attach(Measure(qubit, cbit, self))
285
286 def reset(self, quantum_register):
287 """Reset q."""
288 if isinstance(quantum_register, QuantumRegister):
289 instructions = InstructionSet()
290 for sizes in range(quantum_register.size):
291 instructions.add(self.reset((quantum_register, sizes)))
292 return instructions
293 self._check_qubit(quantum_register)
294 return self._attach(Reset(quantum_register, self))
295
[end of qiskit/_quantumcircuit.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/qiskit/_quantumcircuit.py b/qiskit/_quantumcircuit.py
--- a/qiskit/_quantumcircuit.py
+++ b/qiskit/_quantumcircuit.py
@@ -51,9 +51,9 @@
Raises:
QISKitError: if the circuit name, if given, is not valid.
"""
- self._increment_instances()
if name is None:
name = self.cls_prefix() + str(self.cls_instances())
+ self._increment_instances()
if not isinstance(name, str):
raise QISKitError("The circuit name should be a string "
|
{"golden_diff": "diff --git a/qiskit/_quantumcircuit.py b/qiskit/_quantumcircuit.py\n--- a/qiskit/_quantumcircuit.py\n+++ b/qiskit/_quantumcircuit.py\n@@ -51,9 +51,9 @@\n Raises:\n QISKitError: if the circuit name, if given, is not valid.\n \"\"\"\n- self._increment_instances()\n if name is None:\n name = self.cls_prefix() + str(self.cls_instances())\n+ self._increment_instances()\n \n if not isinstance(name, str):\n raise QISKitError(\"The circuit name should be a string \"\n", "issue": "Default circuit names are not zero-based\n<!-- \u26a0\ufe0f If you do not respect this template, your issue will be closed -->\r\n<!-- \u26a0\ufe0f Make sure to browse the opened and closed issues -->\r\n\r\n### Informations\r\n\r\n- **Qiskit Terra version**: latest\r\n- **Python version**: 3.7\r\n- **Operating system**: OSX\r\n\r\n### What is the current behavior?\r\nWhen creating a quantum circuit with no name, the default name is set to `circuitX`. Currently, `X` starts from `1` rather than `0`, and can cause some confusion when trying to index circuits by name.\r\n\r\n\r\n### Steps to reproduce the problem\r\n```python\r\nfrom qiskit import *\r\nq = QuantumRegister(2, \"q\")\r\nc = ClassicalRegister(2, \"c\")\r\n# Create measurement subcircuit\r\nqc = QuantumCircuit(q,c)\r\nqc.name\r\n```\r\ngives `'circuit1'` for the initial circuit created. It should be `'circuit0'` to coincide with the the indexing in Python.\r\n\r\n### What is the expected behavior?\r\n\r\n\r\n\r\n### Suggested solutions\r\n\r\n\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright 2017, IBM.\n#\n# This source code is licensed under the Apache License, Version 2.0 found in\n# the LICENSE.txt file in the root directory of this source tree.\n\n\"\"\"\nQuantum circuit object.\n\"\"\"\nimport itertools\nfrom collections import OrderedDict\nfrom ._qiskiterror import QISKitError\nfrom ._register import Register\nfrom ._quantumregister import QuantumRegister\nfrom ._classicalregister import ClassicalRegister\nfrom ._measure import Measure\nfrom ._reset import Reset\nfrom ._instructionset import InstructionSet\n\n\nclass QuantumCircuit(object):\n \"\"\"Quantum circuit.\"\"\"\n instances = 0\n prefix = 'circuit'\n\n # Class variable OPENQASM header\n header = \"OPENQASM 2.0;\"\n\n # Class variable with gate definitions\n # This is a dict whose values are dicts with the\n # following keys:\n # \"print\" = True or False\n # \"opaque\" = True or False\n # \"n_args\" = number of real parameters\n # \"n_bits\" = number of qubits\n # \"args\" = list of parameter names\n # \"bits\" = list of qubit names\n # \"body\" = GateBody AST node\n definitions = OrderedDict()\n\n def __init__(self, *regs, name=None):\n \"\"\"Create a new circuit.\n\n Args:\n *regs (Registers): registers to include in the circuit.\n name (str or None): the name of the quantum circuit. If\n None, an automatically generated identifier will be\n assigned.\n\n Raises:\n QISKitError: if the circuit name, if given, is not valid.\n \"\"\"\n self._increment_instances()\n if name is None:\n name = self.cls_prefix() + str(self.cls_instances())\n\n if not isinstance(name, str):\n raise QISKitError(\"The circuit name should be a string \"\n \"(or None for autogenerate a name).\")\n\n self.name = name\n # Data contains a list of instructions in the order they were applied.\n self.data = []\n # This is a map of registers bound to this circuit, by name.\n self.regs = OrderedDict()\n self.add(*regs)\n\n @classmethod\n def _increment_instances(cls):\n cls.instances += 1\n\n @classmethod\n def cls_instances(cls):\n \"\"\"Return the current number of instances of this class,\n useful for auto naming.\"\"\"\n return cls.instances\n\n @classmethod\n def cls_prefix(cls):\n \"\"\"Return the prefix to use for auto naming.\"\"\"\n return cls.prefix\n\n def has_register(self, register):\n \"\"\"\n Test if this circuit has the register r.\n\n Return True or False.\n \"\"\"\n if register.name in self.regs:\n registers = self.regs[register.name]\n if registers.size == register.size:\n if ((isinstance(register, QuantumRegister) and\n isinstance(registers, QuantumRegister)) or\n (isinstance(register, ClassicalRegister) and\n isinstance(registers, ClassicalRegister))):\n return True\n return False\n\n def get_qregs(self):\n \"\"\"Get the qregs from the registers.\"\"\"\n qregs = OrderedDict()\n for name, register in self.regs.items():\n if isinstance(register, QuantumRegister):\n qregs[name] = register\n return qregs\n\n def get_cregs(self):\n \"\"\"Get the cregs from the registers.\"\"\"\n cregs = OrderedDict()\n for name, register in self.regs.items():\n if isinstance(register, ClassicalRegister):\n cregs[name] = register\n return cregs\n\n def combine(self, rhs):\n \"\"\"\n Append rhs to self if self contains compatible registers.\n\n Two circuits are compatible if they contain the same registers\n or if they contain different registers with unique names. The\n returned circuit will contain all unique registers between both\n circuits.\n\n Return self + rhs as a new object.\n \"\"\"\n combined_registers = []\n # Check registers in LHS are compatible with RHS\n for name, register in self.regs.items():\n if name in rhs.regs and register != rhs.regs[name]:\n raise QISKitError(\"circuits are not compatible\")\n else:\n combined_registers.append(register)\n # Add registers in RHS not in LHS\n complement_registers = set(rhs.regs) - set(self.regs)\n for name in complement_registers:\n combined_registers.append(rhs.regs[name])\n # Make new circuit with combined registers\n circuit = QuantumCircuit(*combined_registers)\n for gate in itertools.chain(self.data, rhs.data):\n gate.reapply(circuit)\n return circuit\n\n def extend(self, rhs):\n \"\"\"\n Append rhs to self if self if it contains compatible registers.\n\n Two circuits are compatible if they contain the same registers\n or if they contain different registers with unique names. The\n returned circuit will contain all unique registers between both\n circuits.\n\n Modify and return self.\n \"\"\"\n # Check compatibility and add new registers\n for name, register in rhs.regs.items():\n if name not in self.regs:\n self.add(register)\n elif name in self.regs and register != self.regs[name]:\n raise QISKitError(\"circuits are not compatible\")\n\n # Add new gates\n for gate in rhs.data:\n gate.reapply(self)\n return self\n\n def __add__(self, rhs):\n \"\"\"Overload + to implement self.concatenate.\"\"\"\n return self.combine(rhs)\n\n def __iadd__(self, rhs):\n \"\"\"Overload += to implement self.extend.\"\"\"\n return self.extend(rhs)\n\n def __len__(self):\n \"\"\"Return number of operations in circuit.\"\"\"\n return len(self.data)\n\n def __getitem__(self, item):\n \"\"\"Return indexed operation.\"\"\"\n return self.data[item]\n\n def _attach(self, gate):\n \"\"\"Attach a gate.\"\"\"\n self.data.append(gate)\n return gate\n\n def add(self, *regs):\n \"\"\"Add registers.\"\"\"\n for register in regs:\n if not isinstance(register, Register):\n raise QISKitError(\"expected a register\")\n if register.name not in self.regs:\n self.regs[register.name] = register\n else:\n raise QISKitError(\"register name \\\"%s\\\" already exists\"\n % register.name)\n\n def _check_qreg(self, register):\n \"\"\"Raise exception if r is not in this circuit or not qreg.\"\"\"\n if not isinstance(register, QuantumRegister):\n raise QISKitError(\"expected quantum register\")\n if not self.has_register(register):\n raise QISKitError(\n \"register '%s' not in this circuit\" %\n register.name)\n\n def _check_qubit(self, qubit):\n \"\"\"Raise exception if qubit is not in this circuit or bad format.\"\"\"\n if not isinstance(qubit, tuple):\n raise QISKitError(\"%s is not a tuple.\"\n \"A qubit should be formated as a tuple.\" % str(qubit))\n if not len(qubit) == 2:\n raise QISKitError(\"%s is not a tuple with two elements, but %i instead\" % len(qubit))\n if not isinstance(qubit[1], int):\n raise QISKitError(\"The second element of a tuple defining a qubit should be an int:\"\n \"%s was found instead\" % type(qubit[1]).__name__)\n self._check_qreg(qubit[0])\n qubit[0].check_range(qubit[1])\n\n def _check_creg(self, register):\n \"\"\"Raise exception if r is not in this circuit or not creg.\"\"\"\n if not isinstance(register, ClassicalRegister):\n raise QISKitError(\"expected classical register\")\n if not self.has_register(register):\n raise QISKitError(\n \"register '%s' not in this circuit\" %\n register.name)\n\n def _check_dups(self, qubits):\n \"\"\"Raise exception if list of qubits contains duplicates.\"\"\"\n squbits = set(qubits)\n if len(squbits) != len(qubits):\n raise QISKitError(\"duplicate qubit arguments\")\n\n def _gate_string(self, name):\n \"\"\"Return a QASM string for the named gate.\"\"\"\n out = \"\"\n if self.definitions[name][\"opaque\"]:\n out = \"opaque \" + name\n else:\n out = \"gate \" + name\n if self.definitions[name][\"n_args\"] > 0:\n out += \"(\" + \",\".join(self.definitions[name][\"args\"]) + \")\"\n out += \" \" + \",\".join(self.definitions[name][\"bits\"])\n if self.definitions[name][\"opaque\"]:\n out += \";\"\n else:\n out += \"\\n{\\n\" + self.definitions[name][\"body\"].qasm() + \"}\\n\"\n return out\n\n def qasm(self):\n \"\"\"Return OPENQASM string.\"\"\"\n string_temp = self.header + \"\\n\"\n for gate_name in self.definitions:\n if self.definitions[gate_name][\"print\"]:\n string_temp += self._gate_string(gate_name)\n for register in self.regs.values():\n string_temp += register.qasm() + \"\\n\"\n for instruction in self.data:\n string_temp += instruction.qasm() + \"\\n\"\n return string_temp\n\n def measure(self, qubit, cbit):\n \"\"\"Measure quantum bit into classical bit (tuples).\n\n Returns:\n qiskit.Gate: the attached measure gate.\n\n Raises:\n QISKitError: if qubit is not in this circuit or bad format;\n if cbit is not in this circuit or not creg.\n \"\"\"\n if isinstance(qubit, QuantumRegister) and \\\n isinstance(cbit, ClassicalRegister) and len(qubit) == len(cbit):\n instructions = InstructionSet()\n for i in range(qubit.size):\n instructions.add(self.measure((qubit, i), (cbit, i)))\n return instructions\n\n self._check_qubit(qubit)\n self._check_creg(cbit[0])\n cbit[0].check_range(cbit[1])\n return self._attach(Measure(qubit, cbit, self))\n\n def reset(self, quantum_register):\n \"\"\"Reset q.\"\"\"\n if isinstance(quantum_register, QuantumRegister):\n instructions = InstructionSet()\n for sizes in range(quantum_register.size):\n instructions.add(self.reset((quantum_register, sizes)))\n return instructions\n self._check_qubit(quantum_register)\n return self._attach(Reset(quantum_register, self))\n", "path": "qiskit/_quantumcircuit.py"}]}
| 3,855 | 140 |
gh_patches_debug_6443
|
rasdani/github-patches
|
git_diff
|
learningequality__kolibri-6154
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Unselecting topic or resource sets size to import to 0
### Observed behavior
Tested the `0.13.0b2` release on Windows 7. Importing full channels works OK, but as soon as one subtopic or resource checkbox is unchecked, the total size of the content selected drops to zero ~(number is still apparently accurate)~, the number is inaccurate (104+55+14=173, not 219), and the subsequent import fails immediately, labeled as `Finished`.
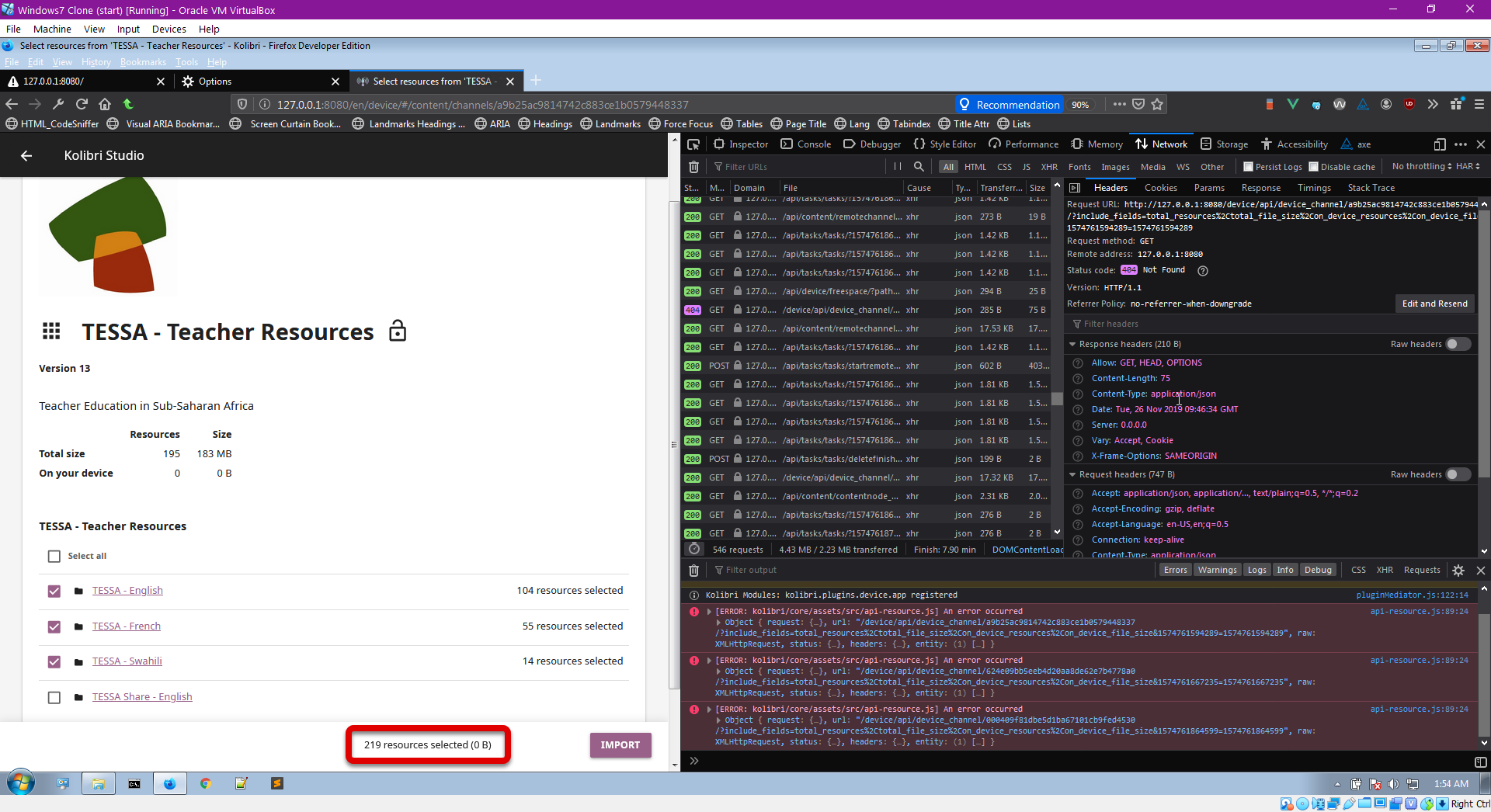
### Expected behavior
Size of the granular import correctly recalculated, and successful import.
### User-facing consequences
Impossibility to deselect and import just the selected content.
### Errors and logs
Nothing observable in the logs.
### Steps to reproduce
* select all
* then, unselect a topic
### Context
* Kolibri version: 0.13.0b2 release
* Operating system: Windows 7
* Browser: Firefox & Chrome
</issue>
<code>
[start of kolibri/core/content/utils/import_export_content.py]
1 import hashlib
2
3 from django.db.models import Sum
4 from requests.exceptions import ChunkedEncodingError
5 from requests.exceptions import ConnectionError
6 from requests.exceptions import HTTPError
7 from requests.exceptions import Timeout
8
9 from kolibri.core.content.models import ContentNode
10 from kolibri.core.content.models import LocalFile
11 from kolibri.core.content.utils.content_types_tools import (
12 renderable_contentnodes_q_filter,
13 )
14 from kolibri.core.content.utils.importability_annotation import (
15 get_channel_stats_from_disk,
16 )
17 from kolibri.core.content.utils.importability_annotation import (
18 get_channel_stats_from_peer,
19 )
20
21 try:
22 import OpenSSL
23
24 SSLERROR = OpenSSL.SSL.Error
25 except ImportError:
26 import requests
27
28 SSLERROR = requests.exceptions.SSLError
29
30 RETRY_STATUS_CODE = [502, 503, 504, 521, 522, 523, 524]
31
32
33 def get_nodes_to_transfer(
34 channel_id,
35 node_ids,
36 exclude_node_ids,
37 available,
38 renderable_only=True,
39 drive_id=None,
40 peer_id=None,
41 ):
42 nodes_to_include = ContentNode.objects.filter(channel_id=channel_id)
43
44 # if requested, filter down to only include particular topics/nodes
45 if node_ids:
46 nodes_to_include = nodes_to_include.filter(pk__in=node_ids).get_descendants(
47 include_self=True
48 )
49
50 # if requested, filter out nodes we're not able to render
51 if renderable_only:
52 nodes_to_include = nodes_to_include.filter(renderable_contentnodes_q_filter)
53
54 # filter down the query to remove files associated with nodes we've specifically been asked to exclude
55 if exclude_node_ids:
56 nodes_to_exclude = ContentNode.objects.filter(
57 pk__in=exclude_node_ids
58 ).get_descendants(include_self=True)
59
60 nodes_to_include = nodes_to_include.order_by().difference(
61 nodes_to_exclude.order_by()
62 )
63
64 # By default don't filter node ids by their underlying file importability
65 file_based_node_id_list = None
66 if drive_id:
67 file_based_node_id_list = get_channel_stats_from_disk(
68 channel_id, drive_id
69 ).keys()
70
71 if peer_id:
72 file_based_node_id_list = get_channel_stats_from_peer(
73 channel_id, peer_id
74 ).keys()
75 if file_based_node_id_list is not None:
76 nodes_to_include = nodes_to_include.filter(pk__in=file_based_node_id_list)
77 return nodes_to_include.filter(available=available).order_by()
78
79
80 def get_files_to_transfer(
81 channel_id,
82 node_ids,
83 exclude_node_ids,
84 available,
85 renderable_only=True,
86 drive_id=None,
87 peer_id=None,
88 ):
89
90 nodes_to_include = get_nodes_to_transfer(
91 channel_id,
92 node_ids,
93 exclude_node_ids,
94 available,
95 renderable_only=renderable_only,
96 drive_id=drive_id,
97 peer_id=peer_id,
98 )
99 return calculate_files_to_transfer(nodes_to_include, available)
100
101
102 def calculate_files_to_transfer(nodes_to_include, available):
103 files_to_transfer = LocalFile.objects.filter(
104 available=available, files__contentnode__in=nodes_to_include
105 )
106
107 # Make sure the files are unique, to avoid duplicating downloads
108 files_to_transfer = files_to_transfer.distinct()
109
110 # calculate the total file sizes across all files being returned in the queryset
111 total_bytes_to_transfer = (
112 files_to_transfer.aggregate(Sum("file_size"))["file_size__sum"] or 0
113 )
114
115 return files_to_transfer, total_bytes_to_transfer
116
117
118 def _get_node_ids(node_ids):
119
120 return (
121 ContentNode.objects.filter(pk__in=node_ids)
122 .get_descendants(include_self=True)
123 .values_list("id", flat=True)
124 )
125
126
127 def retry_import(e, **kwargs):
128 """
129 When an exception occurs during channel/content import, if
130 * there is an Internet connection error or timeout error,
131 or HTTPError where the error code is one of the RETRY_STATUS_CODE,
132 return return True to retry the file transfer
133 * the file does not exist on the server or disk, skip the file and return False.
134 This only applies to content import not channel import.
135 * otherwise, raise the exception.
136 return value:
137 * True - needs retry.
138 * False - file is skipped. Does not need retry.
139 """
140
141 skip_404 = kwargs.pop("skip_404")
142
143 if (
144 isinstance(e, ConnectionError)
145 or isinstance(e, Timeout)
146 or isinstance(e, ChunkedEncodingError)
147 or (isinstance(e, HTTPError) and e.response.status_code in RETRY_STATUS_CODE)
148 or (isinstance(e, SSLERROR) and "decryption failed or bad record mac" in str(e))
149 ):
150 return True
151
152 elif skip_404 and (
153 (isinstance(e, HTTPError) and e.response.status_code == 404)
154 or (isinstance(e, OSError) and e.errno == 2)
155 ):
156 return False
157
158 else:
159 raise e
160
161
162 def compare_checksums(file_name, file_id):
163 hasher = hashlib.md5()
164 with open(file_name, "rb") as f:
165 # Read chunks of 4096 bytes for memory efficiency
166 for chunk in iter(lambda: f.read(4096), b""):
167 hasher.update(chunk)
168 checksum = hasher.hexdigest()
169 return checksum == file_id
170
[end of kolibri/core/content/utils/import_export_content.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kolibri/core/content/utils/import_export_content.py b/kolibri/core/content/utils/import_export_content.py
--- a/kolibri/core/content/utils/import_export_content.py
+++ b/kolibri/core/content/utils/import_export_content.py
@@ -57,8 +57,8 @@
pk__in=exclude_node_ids
).get_descendants(include_self=True)
- nodes_to_include = nodes_to_include.order_by().difference(
- nodes_to_exclude.order_by()
+ nodes_to_include = nodes_to_include.order_by().exclude(
+ pk__in=nodes_to_exclude.values("pk")
)
# By default don't filter node ids by their underlying file importability
|
{"golden_diff": "diff --git a/kolibri/core/content/utils/import_export_content.py b/kolibri/core/content/utils/import_export_content.py\n--- a/kolibri/core/content/utils/import_export_content.py\n+++ b/kolibri/core/content/utils/import_export_content.py\n@@ -57,8 +57,8 @@\n pk__in=exclude_node_ids\n ).get_descendants(include_self=True)\n \n- nodes_to_include = nodes_to_include.order_by().difference(\n- nodes_to_exclude.order_by()\n+ nodes_to_include = nodes_to_include.order_by().exclude(\n+ pk__in=nodes_to_exclude.values(\"pk\")\n )\n \n # By default don't filter node ids by their underlying file importability\n", "issue": "Unselecting topic or resource sets size to import to 0\n### Observed behavior\r\nTested the `0.13.0b2` release on Windows 7. Importing full channels works OK, but as soon as one subtopic or resource checkbox is unchecked, the total size of the content selected drops to zero ~(number is still apparently accurate)~, the number is inaccurate (104+55+14=173, not 219), and the subsequent import fails immediately, labeled as `Finished`.\r\n\r\n\r\n\r\n\r\n### Expected behavior\r\nSize of the granular import correctly recalculated, and successful import.\r\n\r\n### User-facing consequences\r\nImpossibility to deselect and import just the selected content. \r\n\r\n### Errors and logs\r\nNothing observable in the logs.\r\n\r\n### Steps to reproduce\r\n\r\n* select all\r\n* then, unselect a topic\r\n\r\n### Context\r\n\r\n * Kolibri version: 0.13.0b2 release\r\n * Operating system: Windows 7\r\n * Browser: Firefox & Chrome\r\n\r\n\n", "before_files": [{"content": "import hashlib\n\nfrom django.db.models import Sum\nfrom requests.exceptions import ChunkedEncodingError\nfrom requests.exceptions import ConnectionError\nfrom requests.exceptions import HTTPError\nfrom requests.exceptions import Timeout\n\nfrom kolibri.core.content.models import ContentNode\nfrom kolibri.core.content.models import LocalFile\nfrom kolibri.core.content.utils.content_types_tools import (\n renderable_contentnodes_q_filter,\n)\nfrom kolibri.core.content.utils.importability_annotation import (\n get_channel_stats_from_disk,\n)\nfrom kolibri.core.content.utils.importability_annotation import (\n get_channel_stats_from_peer,\n)\n\ntry:\n import OpenSSL\n\n SSLERROR = OpenSSL.SSL.Error\nexcept ImportError:\n import requests\n\n SSLERROR = requests.exceptions.SSLError\n\nRETRY_STATUS_CODE = [502, 503, 504, 521, 522, 523, 524]\n\n\ndef get_nodes_to_transfer(\n channel_id,\n node_ids,\n exclude_node_ids,\n available,\n renderable_only=True,\n drive_id=None,\n peer_id=None,\n):\n nodes_to_include = ContentNode.objects.filter(channel_id=channel_id)\n\n # if requested, filter down to only include particular topics/nodes\n if node_ids:\n nodes_to_include = nodes_to_include.filter(pk__in=node_ids).get_descendants(\n include_self=True\n )\n\n # if requested, filter out nodes we're not able to render\n if renderable_only:\n nodes_to_include = nodes_to_include.filter(renderable_contentnodes_q_filter)\n\n # filter down the query to remove files associated with nodes we've specifically been asked to exclude\n if exclude_node_ids:\n nodes_to_exclude = ContentNode.objects.filter(\n pk__in=exclude_node_ids\n ).get_descendants(include_self=True)\n\n nodes_to_include = nodes_to_include.order_by().difference(\n nodes_to_exclude.order_by()\n )\n\n # By default don't filter node ids by their underlying file importability\n file_based_node_id_list = None\n if drive_id:\n file_based_node_id_list = get_channel_stats_from_disk(\n channel_id, drive_id\n ).keys()\n\n if peer_id:\n file_based_node_id_list = get_channel_stats_from_peer(\n channel_id, peer_id\n ).keys()\n if file_based_node_id_list is not None:\n nodes_to_include = nodes_to_include.filter(pk__in=file_based_node_id_list)\n return nodes_to_include.filter(available=available).order_by()\n\n\ndef get_files_to_transfer(\n channel_id,\n node_ids,\n exclude_node_ids,\n available,\n renderable_only=True,\n drive_id=None,\n peer_id=None,\n):\n\n nodes_to_include = get_nodes_to_transfer(\n channel_id,\n node_ids,\n exclude_node_ids,\n available,\n renderable_only=renderable_only,\n drive_id=drive_id,\n peer_id=peer_id,\n )\n return calculate_files_to_transfer(nodes_to_include, available)\n\n\ndef calculate_files_to_transfer(nodes_to_include, available):\n files_to_transfer = LocalFile.objects.filter(\n available=available, files__contentnode__in=nodes_to_include\n )\n\n # Make sure the files are unique, to avoid duplicating downloads\n files_to_transfer = files_to_transfer.distinct()\n\n # calculate the total file sizes across all files being returned in the queryset\n total_bytes_to_transfer = (\n files_to_transfer.aggregate(Sum(\"file_size\"))[\"file_size__sum\"] or 0\n )\n\n return files_to_transfer, total_bytes_to_transfer\n\n\ndef _get_node_ids(node_ids):\n\n return (\n ContentNode.objects.filter(pk__in=node_ids)\n .get_descendants(include_self=True)\n .values_list(\"id\", flat=True)\n )\n\n\ndef retry_import(e, **kwargs):\n \"\"\"\n When an exception occurs during channel/content import, if\n * there is an Internet connection error or timeout error,\n or HTTPError where the error code is one of the RETRY_STATUS_CODE,\n return return True to retry the file transfer\n * the file does not exist on the server or disk, skip the file and return False.\n This only applies to content import not channel import.\n * otherwise, raise the exception.\n return value:\n * True - needs retry.\n * False - file is skipped. Does not need retry.\n \"\"\"\n\n skip_404 = kwargs.pop(\"skip_404\")\n\n if (\n isinstance(e, ConnectionError)\n or isinstance(e, Timeout)\n or isinstance(e, ChunkedEncodingError)\n or (isinstance(e, HTTPError) and e.response.status_code in RETRY_STATUS_CODE)\n or (isinstance(e, SSLERROR) and \"decryption failed or bad record mac\" in str(e))\n ):\n return True\n\n elif skip_404 and (\n (isinstance(e, HTTPError) and e.response.status_code == 404)\n or (isinstance(e, OSError) and e.errno == 2)\n ):\n return False\n\n else:\n raise e\n\n\ndef compare_checksums(file_name, file_id):\n hasher = hashlib.md5()\n with open(file_name, \"rb\") as f:\n # Read chunks of 4096 bytes for memory efficiency\n for chunk in iter(lambda: f.read(4096), b\"\"):\n hasher.update(chunk)\n checksum = hasher.hexdigest()\n return checksum == file_id\n", "path": "kolibri/core/content/utils/import_export_content.py"}]}
| 2,426 | 151 |
gh_patches_debug_11870
|
rasdani/github-patches
|
git_diff
|
vllm-project__vllm-5077
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Remove EOS token before passing the tokenized input to model
How to remove eos token id before passing the input tokens to model. I'm trying for fine-tuned mistral model. Just because there is an eos token id at the end of sentence, model generates the results for a different input which is similar to original input
</issue>
<code>
[start of vllm/engine/output_processor/stop_checker.py]
1 from typing import Callable, Optional
2
3 from transformers import PreTrainedTokenizer
4
5 from vllm.lora.request import LoRARequest
6 from vllm.sampling_params import SamplingParams
7 from vllm.sequence import Sequence, SequenceStatus
8
9
10 class StopChecker:
11 """LLMEngine helper class which separates out the logic involving stop
12 checking. This checks things such as: whether the eos token was emitted,
13 whether the max_tokens has been consumed, whether a stop string has been
14 emitted, or if we have exceeded the max model len.
15 """
16
17 def __init__(self, max_model_len: int,
18 get_tokenizer_for_seq: Callable[[Sequence],
19 PreTrainedTokenizer]):
20 # Do not use it directly, but use `self._get_max_model_len`.
21 self._max_model_len = max_model_len
22 self.get_tokenizer_for_seq = get_tokenizer_for_seq
23
24 def _get_max_model_len(self, lora_req: Optional[LoRARequest]):
25 if lora_req and lora_req.long_lora_max_len:
26 return lora_req.long_lora_max_len
27 else:
28 return self._max_model_len
29
30 def maybe_stop_sequence(
31 self,
32 seq: Sequence,
33 new_char_count: int,
34 sampling_params: SamplingParams,
35 lora_req: Optional[LoRARequest] = None,
36 ) -> None:
37 """Stop the finished sequences.
38
39 new_char_count is the number of chars added to the
40 sequence's output text for the newly generated token
41 """
42
43 # Check if the minimum number of tokens has been generated yet;
44 # skip the stop string/token checks if not
45 if seq.get_output_len() < sampling_params.min_tokens:
46 return
47
48 # Check if the sequence has generated the EOS token.
49 if ((not sampling_params.ignore_eos)
50 and seq.get_last_token_id() == seq.eos_token_id):
51 seq.status = SequenceStatus.FINISHED_STOPPED
52 return
53
54 # Check if a stop token was encountered.
55 # This assumes a single token produced per step.
56 last_token_id = seq.get_last_token_id()
57 if last_token_id in sampling_params.stop_token_ids:
58 if new_char_count and (
59 not sampling_params.include_stop_str_in_output):
60 # Remove last token
61 seq.output_text = seq.output_text[:-new_char_count]
62 seq.status = SequenceStatus.FINISHED_STOPPED
63 seq.stop_reason = last_token_id
64 return
65
66 # Check if any stop strings are matched.
67 stop_str = self._check_stop_strings(seq, new_char_count,
68 sampling_params)
69 if stop_str is not None:
70 seq.status = SequenceStatus.FINISHED_STOPPED
71 seq.stop_reason = stop_str
72 return
73
74 # Check if the sequence has reached max_model_len.
75 if seq.get_len() > self._get_max_model_len(lora_req):
76 seq.status = SequenceStatus.FINISHED_LENGTH_CAPPED
77 return
78
79 # Check if the sequence has reached max_tokens.
80 if seq.get_output_len() == sampling_params.max_tokens:
81 seq.status = SequenceStatus.FINISHED_LENGTH_CAPPED
82 return
83
84 @staticmethod
85 def _check_stop_strings(seq: Sequence, new_char_count: int,
86 sampling_params: SamplingParams) -> Optional[str]:
87 """Check if any stop strings are matched and truncate sequence
88 output text accordingly.
89
90 Returns the stop string if matched or else None.
91 """
92 if not new_char_count:
93 return None
94
95 for stop_str in sampling_params.stop:
96 stop_string_len = len(stop_str)
97 # Avoid searching already-searched text.
98 stop_index = seq.output_text.find(
99 stop_str, -new_char_count - stop_string_len)
100 if stop_index == -1:
101 continue
102
103 if sampling_params.include_stop_str_in_output:
104 # Truncate to end of stop string.
105 stop_index += stop_string_len
106 if stop_index >= len(seq.output_text):
107 # No truncation required.
108 return stop_str
109
110 # Truncate the output text to either the beginning
111 # or end of the stop string.
112 seq.output_text = seq.output_text[:stop_index]
113 return stop_str
114 return None
115
[end of vllm/engine/output_processor/stop_checker.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/vllm/engine/output_processor/stop_checker.py b/vllm/engine/output_processor/stop_checker.py
--- a/vllm/engine/output_processor/stop_checker.py
+++ b/vllm/engine/output_processor/stop_checker.py
@@ -48,6 +48,11 @@
# Check if the sequence has generated the EOS token.
if ((not sampling_params.ignore_eos)
and seq.get_last_token_id() == seq.eos_token_id):
+ # Remove the last EOS token unless explicitly specified
+ # This prevents unintended exposure of the EOS token
+ if new_char_count and (
+ not sampling_params.include_stop_str_in_output):
+ seq.output_text = seq.output_text[:-new_char_count]
seq.status = SequenceStatus.FINISHED_STOPPED
return
|
{"golden_diff": "diff --git a/vllm/engine/output_processor/stop_checker.py b/vllm/engine/output_processor/stop_checker.py\n--- a/vllm/engine/output_processor/stop_checker.py\n+++ b/vllm/engine/output_processor/stop_checker.py\n@@ -48,6 +48,11 @@\n # Check if the sequence has generated the EOS token.\n if ((not sampling_params.ignore_eos)\n and seq.get_last_token_id() == seq.eos_token_id):\n+ # Remove the last EOS token unless explicitly specified\n+ # This prevents unintended exposure of the EOS token\n+ if new_char_count and (\n+ not sampling_params.include_stop_str_in_output):\n+ seq.output_text = seq.output_text[:-new_char_count]\n seq.status = SequenceStatus.FINISHED_STOPPED\n return\n", "issue": "Remove EOS token before passing the tokenized input to model\n\r\n\r\nHow to remove eos token id before passing the input tokens to model. I'm trying for fine-tuned mistral model. Just because there is an eos token id at the end of sentence, model generates the results for a different input which is similar to original input\n", "before_files": [{"content": "from typing import Callable, Optional\n\nfrom transformers import PreTrainedTokenizer\n\nfrom vllm.lora.request import LoRARequest\nfrom vllm.sampling_params import SamplingParams\nfrom vllm.sequence import Sequence, SequenceStatus\n\n\nclass StopChecker:\n \"\"\"LLMEngine helper class which separates out the logic involving stop\n checking. This checks things such as: whether the eos token was emitted,\n whether the max_tokens has been consumed, whether a stop string has been\n emitted, or if we have exceeded the max model len.\n \"\"\"\n\n def __init__(self, max_model_len: int,\n get_tokenizer_for_seq: Callable[[Sequence],\n PreTrainedTokenizer]):\n # Do not use it directly, but use `self._get_max_model_len`.\n self._max_model_len = max_model_len\n self.get_tokenizer_for_seq = get_tokenizer_for_seq\n\n def _get_max_model_len(self, lora_req: Optional[LoRARequest]):\n if lora_req and lora_req.long_lora_max_len:\n return lora_req.long_lora_max_len\n else:\n return self._max_model_len\n\n def maybe_stop_sequence(\n self,\n seq: Sequence,\n new_char_count: int,\n sampling_params: SamplingParams,\n lora_req: Optional[LoRARequest] = None,\n ) -> None:\n \"\"\"Stop the finished sequences.\n\n new_char_count is the number of chars added to the\n sequence's output text for the newly generated token\n \"\"\"\n\n # Check if the minimum number of tokens has been generated yet;\n # skip the stop string/token checks if not\n if seq.get_output_len() < sampling_params.min_tokens:\n return\n\n # Check if the sequence has generated the EOS token.\n if ((not sampling_params.ignore_eos)\n and seq.get_last_token_id() == seq.eos_token_id):\n seq.status = SequenceStatus.FINISHED_STOPPED\n return\n\n # Check if a stop token was encountered.\n # This assumes a single token produced per step.\n last_token_id = seq.get_last_token_id()\n if last_token_id in sampling_params.stop_token_ids:\n if new_char_count and (\n not sampling_params.include_stop_str_in_output):\n # Remove last token\n seq.output_text = seq.output_text[:-new_char_count]\n seq.status = SequenceStatus.FINISHED_STOPPED\n seq.stop_reason = last_token_id\n return\n\n # Check if any stop strings are matched.\n stop_str = self._check_stop_strings(seq, new_char_count,\n sampling_params)\n if stop_str is not None:\n seq.status = SequenceStatus.FINISHED_STOPPED\n seq.stop_reason = stop_str\n return\n\n # Check if the sequence has reached max_model_len.\n if seq.get_len() > self._get_max_model_len(lora_req):\n seq.status = SequenceStatus.FINISHED_LENGTH_CAPPED\n return\n\n # Check if the sequence has reached max_tokens.\n if seq.get_output_len() == sampling_params.max_tokens:\n seq.status = SequenceStatus.FINISHED_LENGTH_CAPPED\n return\n\n @staticmethod\n def _check_stop_strings(seq: Sequence, new_char_count: int,\n sampling_params: SamplingParams) -> Optional[str]:\n \"\"\"Check if any stop strings are matched and truncate sequence\n output text accordingly.\n\n Returns the stop string if matched or else None.\n \"\"\"\n if not new_char_count:\n return None\n\n for stop_str in sampling_params.stop:\n stop_string_len = len(stop_str)\n # Avoid searching already-searched text.\n stop_index = seq.output_text.find(\n stop_str, -new_char_count - stop_string_len)\n if stop_index == -1:\n continue\n\n if sampling_params.include_stop_str_in_output:\n # Truncate to end of stop string.\n stop_index += stop_string_len\n if stop_index >= len(seq.output_text):\n # No truncation required.\n return stop_str\n\n # Truncate the output text to either the beginning\n # or end of the stop string.\n seq.output_text = seq.output_text[:stop_index]\n return stop_str\n return None\n", "path": "vllm/engine/output_processor/stop_checker.py"}]}
| 1,759 | 174 |
gh_patches_debug_17122
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-2837
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
No colour option
**Describe the issue**
Checkov cli output is heavily targeted for a dark background. Using a light theme makes it very hard to read.
Is there a way to remove color or control the theme used?
**Version:**
- Checkov Version 2.0.1050
**Additional context**
Small search I found you use termcolor: https://github.com/bridgecrewio/checkov/blob/d55c68ff909c65e341e91938c13a155c99601f5f/checkov/common/output/report.py#L16
but I couldn't find a way to "mute" it. Maybe simply overwriting that function "colored" with a dummy lambda would do it.
</issue>
<code>
[start of checkov/common/output/record.py]
1 import os
2 import re
3 from pathlib import Path
4 from typing import Union, List, Tuple, Optional, Dict, Any
5
6 from colorama import init, Fore, Style
7 from termcolor import colored
8
9 from checkov.common.bridgecrew.severities import Severity
10 from checkov.common.models.enums import CheckResult
11 from checkov.common.typing import _CheckResult
12 from checkov.common.util.file_utils import convert_to_unix_path
13 from checkov.common.util.type_forcers import force_int
14
15 init(autoreset=True)
16
17 DEFAULT_SEVERITY = "none" # equivalent to a score of 0.0 in the CVSS v3.0 Ratings
18
19 OUTPUT_CODE_LINE_LIMIT = force_int(os.getenv('CHECKOV_OUTPUT_CODE_LINE_LIMIT')) or 50
20
21 class Record:
22 check_id = ""
23 check_name = ""
24 check_result = None
25 check_class = ""
26 code_block: List[Tuple[int, str]] = []
27 file_path = ""
28 file_line_range: List[int] = []
29 caller_file_path = None # When created from a module
30 caller_file_line_range = None # When created from a module
31 resource = ""
32 guideline = None
33 fixed_definition = None
34 entity_tags = None
35 severity = None
36 description = None # used by SARIF output
37 short_description = None # used by SARIF output
38 vulnerability_details = None # Stores package vulnerability details
39 connected_node = None
40
41 def __init__(
42 self,
43 check_id: str,
44 check_name: str,
45 check_result: _CheckResult,
46 code_block: List[Tuple[int, str]],
47 file_path: str,
48 file_line_range: List[int],
49 resource: str,
50 evaluations: Optional[Dict[str, Any]],
51 check_class: str,
52 file_abs_path: str,
53 entity_tags: Optional[Dict[str, str]] = None,
54 caller_file_path: Optional[str] = None,
55 caller_file_line_range: Optional[Tuple[int, int]] = None,
56 bc_check_id: Optional[str] = None,
57 resource_address: Optional[str] = None,
58 severity: Optional[Severity] = None,
59 bc_category: Optional[str] = None,
60 benchmarks: Optional[Dict[str, list]] = None,
61 description: Optional[str] = None,
62 short_description: Optional[str] = None,
63 vulnerability_details: Optional[Dict[str, Any]] = None,
64 connected_node: Optional[Dict[str, Any]] = None
65 ) -> None:
66 """
67 :param evaluations: A dict with the key being the variable name, value being a dict containing:
68 - 'var_file'
69 - 'value'
70 - 'definitions', a list of dicts which contain 'definition_expression'
71 """
72 self.check_id = check_id
73 self.bc_check_id = bc_check_id
74 self.check_name = check_name
75 self.check_result = check_result
76 self.code_block = code_block
77 self.file_path = file_path
78 self.file_abs_path = file_abs_path
79 self.repo_file_path = self._determine_repo_file_path(file_abs_path)
80 self.file_line_range = file_line_range
81 self.resource = resource
82 self.evaluations = evaluations
83 self.check_class = check_class
84 self.fixed_definition = None
85 self.entity_tags = entity_tags
86 self.caller_file_path = caller_file_path
87 self.caller_file_line_range = caller_file_line_range
88 self.resource_address = resource_address
89 self.severity = severity
90 self.bc_category = bc_category
91 self.benchmarks = benchmarks
92 self.description = description
93 self.short_description = short_description
94 self.vulnerability_details = vulnerability_details
95 self.connected_node = connected_node
96
97 @staticmethod
98 def _determine_repo_file_path(file_path: Union[str, "os.PathLike[str]"]) -> str:
99 # matches file paths given in the BC platform and should always be a unix path
100 repo_file_path = Path(file_path)
101 if Path.cwd().drive == repo_file_path.drive:
102 return convert_to_unix_path(f"/{os.path.relpath(repo_file_path)}").replace("/..", "")
103
104 return f"/{'/'.join(repo_file_path.parts[1:])}"
105
106 def set_guideline(self, guideline: Optional[str]) -> None:
107 self.guideline = guideline
108
109 @staticmethod
110 def _trim_special_chars(expression: str) -> str:
111 return "".join(re.findall(re.compile(r"[^ ${\}]+"), expression))
112
113 def _is_expression_in_code_lines(self, expression: str) -> bool:
114 stripped_expression = self._trim_special_chars(expression)
115 return any(stripped_expression in self._trim_special_chars(line) for (_, line) in self.code_block)
116
117 @staticmethod
118 def _code_line_string(code_block: List[Tuple[int, str]], colorized: bool = True) -> str:
119 code_output = []
120 color_codes = (Fore.WHITE if colorized else "", Fore.YELLOW if colorized else "")
121 last_line_number_len = len(str(code_block[-1][0]))
122
123 if len(code_block) >= OUTPUT_CODE_LINE_LIMIT:
124 return f'\t\t{color_codes[1]}Code lines for this resource are too many. ' \
125 f'Please use IDE of your choice to review the file.'
126
127 for line_num, line in code_block:
128 spaces = " " * (last_line_number_len - len(str(line_num)))
129 if line.lstrip().startswith("#"):
130 code_output.append(f"\t\t{color_codes[0]}{line_num}{spaces} | {line}")
131 else:
132 code_output.append(f"\t\t{color_codes[0]}{line_num}{spaces} | {color_codes[1]}{line}")
133 return "".join(code_output)
134
135 def to_string(self, compact: bool = False, use_bc_ids: bool = False) -> str:
136 status = ""
137 evaluation_message = ""
138 status_color = "white"
139 suppress_comment = ""
140 if self.check_result["result"] == CheckResult.PASSED:
141 status = CheckResult.PASSED.name
142 status_color = "green"
143 elif self.check_result["result"] == CheckResult.FAILED:
144 status = CheckResult.FAILED.name
145 status_color = "red"
146 elif self.check_result["result"] == CheckResult.SKIPPED:
147 status = CheckResult.SKIPPED.name
148 status_color = "blue"
149 suppress_comment = "\tSuppress comment: {}\n".format(self.check_result["suppress_comment"])
150
151 check_message = colored('Check: {}: "{}"\n'.format(self.get_output_id(use_bc_ids), self.check_name), "white")
152 guideline_message = ""
153 if self.guideline:
154 guideline_message = (
155 "\tGuide: "
156 + Style.BRIGHT
157 + colored(f"{self.guideline}\n", "blue", attrs=["underline"])
158 + Style.RESET_ALL
159 )
160
161 severity_message = f'\tSeverity: {self.severity.name}\n' if self.severity else ''
162
163 file_details = colored(
164 "\tFile: {}:{}\n".format(self.file_path, "-".join([str(x) for x in self.file_line_range])), "magenta"
165 )
166 code_lines = ""
167 if self.code_block:
168 code_lines = "\n{}\n".format("".join([self._code_line_string(self.code_block)]))
169 caller_file_details = ""
170 if self.caller_file_path and self.caller_file_line_range:
171 caller_file_details = colored(
172 "\tCalling File: {}:{}\n".format(
173 self.caller_file_path, "-".join([str(x) for x in self.caller_file_line_range])
174 ),
175 "magenta",
176 )
177 if self.evaluations:
178 for (var_name, var_evaluations) in self.evaluations.items():
179 var_file = var_evaluations["var_file"]
180 var_definitions = var_evaluations["definitions"]
181 for definition_obj in var_definitions:
182 definition_expression = definition_obj["definition_expression"]
183 if self._is_expression_in_code_lines(definition_expression):
184 evaluation_message = evaluation_message + colored(
185 f'\tVariable {colored(var_name, "yellow")} (of {var_file}) evaluated to value "{colored(var_evaluations["value"], "yellow")}" '
186 f'in expression: {colored(definition_obj["definition_name"] + " = ", "yellow")}{colored(definition_obj["definition_expression"], "yellow")}\n',
187 "white",
188 )
189
190 status_message = colored("\t{} for resource: {}\n".format(status, self.resource), status_color)
191 if self.check_result["result"] == CheckResult.FAILED and code_lines and not compact:
192 return f"{check_message}{status_message}{severity_message}{file_details}{caller_file_details}{guideline_message}{code_lines}{evaluation_message}"
193
194 if self.check_result["result"] == CheckResult.SKIPPED:
195 return f"{check_message}{status_message}{severity_message}{suppress_comment}{file_details}{caller_file_details}{guideline_message}"
196 else:
197 return f"{check_message}{status_message}{severity_message}{file_details}{caller_file_details}{evaluation_message}{guideline_message}"
198
199 def __str__(self) -> str:
200 return self.to_string()
201
202 def get_output_id(self, use_bc_ids: bool) -> str:
203 return self.bc_check_id if self.bc_check_id and use_bc_ids else self.check_id
204
205 def get_unique_string(self) -> str:
206 return f"{self.check_id}.{self.check_result}.{self.file_abs_path}.{self.file_line_range}.{self.resource}"
207
[end of checkov/common/output/record.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/checkov/common/output/record.py b/checkov/common/output/record.py
--- a/checkov/common/output/record.py
+++ b/checkov/common/output/record.py
@@ -18,6 +18,8 @@
OUTPUT_CODE_LINE_LIMIT = force_int(os.getenv('CHECKOV_OUTPUT_CODE_LINE_LIMIT')) or 50
+ANSI_COLORS_DISABLED = bool(os.getenv('ANSI_COLORS_DISABLED'))
+
class Record:
check_id = ""
check_name = ""
@@ -165,7 +167,7 @@
)
code_lines = ""
if self.code_block:
- code_lines = "\n{}\n".format("".join([self._code_line_string(self.code_block)]))
+ code_lines = "\n{}\n".format("".join([self._code_line_string(self.code_block, not(ANSI_COLORS_DISABLED))]))
caller_file_details = ""
if self.caller_file_path and self.caller_file_line_range:
caller_file_details = colored(
|
{"golden_diff": "diff --git a/checkov/common/output/record.py b/checkov/common/output/record.py\n--- a/checkov/common/output/record.py\n+++ b/checkov/common/output/record.py\n@@ -18,6 +18,8 @@\n \n OUTPUT_CODE_LINE_LIMIT = force_int(os.getenv('CHECKOV_OUTPUT_CODE_LINE_LIMIT')) or 50\n \n+ANSI_COLORS_DISABLED = bool(os.getenv('ANSI_COLORS_DISABLED'))\n+\n class Record:\n check_id = \"\"\n check_name = \"\"\n@@ -165,7 +167,7 @@\n )\n code_lines = \"\"\n if self.code_block:\n- code_lines = \"\\n{}\\n\".format(\"\".join([self._code_line_string(self.code_block)]))\n+ code_lines = \"\\n{}\\n\".format(\"\".join([self._code_line_string(self.code_block, not(ANSI_COLORS_DISABLED))]))\n caller_file_details = \"\"\n if self.caller_file_path and self.caller_file_line_range:\n caller_file_details = colored(\n", "issue": "No colour option\n**Describe the issue**\r\nCheckov cli output is heavily targeted for a dark background. Using a light theme makes it very hard to read.\r\nIs there a way to remove color or control the theme used?\r\n\r\n**Version:**\r\n - Checkov Version 2.0.1050\r\n\r\n**Additional context**\r\nSmall search I found you use termcolor: https://github.com/bridgecrewio/checkov/blob/d55c68ff909c65e341e91938c13a155c99601f5f/checkov/common/output/report.py#L16\r\nbut I couldn't find a way to \"mute\" it. Maybe simply overwriting that function \"colored\" with a dummy lambda would do it.\r\n\n", "before_files": [{"content": "import os\nimport re\nfrom pathlib import Path\nfrom typing import Union, List, Tuple, Optional, Dict, Any\n\nfrom colorama import init, Fore, Style\nfrom termcolor import colored\n\nfrom checkov.common.bridgecrew.severities import Severity\nfrom checkov.common.models.enums import CheckResult\nfrom checkov.common.typing import _CheckResult\nfrom checkov.common.util.file_utils import convert_to_unix_path\nfrom checkov.common.util.type_forcers import force_int\n\ninit(autoreset=True)\n\nDEFAULT_SEVERITY = \"none\" # equivalent to a score of 0.0 in the CVSS v3.0 Ratings\n\nOUTPUT_CODE_LINE_LIMIT = force_int(os.getenv('CHECKOV_OUTPUT_CODE_LINE_LIMIT')) or 50\n\nclass Record:\n check_id = \"\"\n check_name = \"\"\n check_result = None\n check_class = \"\"\n code_block: List[Tuple[int, str]] = []\n file_path = \"\"\n file_line_range: List[int] = []\n caller_file_path = None # When created from a module\n caller_file_line_range = None # When created from a module\n resource = \"\"\n guideline = None\n fixed_definition = None\n entity_tags = None\n severity = None\n description = None # used by SARIF output\n short_description = None # used by SARIF output\n vulnerability_details = None # Stores package vulnerability details\n connected_node = None\n\n def __init__(\n self,\n check_id: str,\n check_name: str,\n check_result: _CheckResult,\n code_block: List[Tuple[int, str]],\n file_path: str,\n file_line_range: List[int],\n resource: str,\n evaluations: Optional[Dict[str, Any]],\n check_class: str,\n file_abs_path: str,\n entity_tags: Optional[Dict[str, str]] = None,\n caller_file_path: Optional[str] = None,\n caller_file_line_range: Optional[Tuple[int, int]] = None,\n bc_check_id: Optional[str] = None,\n resource_address: Optional[str] = None,\n severity: Optional[Severity] = None,\n bc_category: Optional[str] = None,\n benchmarks: Optional[Dict[str, list]] = None,\n description: Optional[str] = None,\n short_description: Optional[str] = None,\n vulnerability_details: Optional[Dict[str, Any]] = None,\n connected_node: Optional[Dict[str, Any]] = None\n ) -> None:\n \"\"\"\n :param evaluations: A dict with the key being the variable name, value being a dict containing:\n - 'var_file'\n - 'value'\n - 'definitions', a list of dicts which contain 'definition_expression'\n \"\"\"\n self.check_id = check_id\n self.bc_check_id = bc_check_id\n self.check_name = check_name\n self.check_result = check_result\n self.code_block = code_block\n self.file_path = file_path\n self.file_abs_path = file_abs_path\n self.repo_file_path = self._determine_repo_file_path(file_abs_path)\n self.file_line_range = file_line_range\n self.resource = resource\n self.evaluations = evaluations\n self.check_class = check_class\n self.fixed_definition = None\n self.entity_tags = entity_tags\n self.caller_file_path = caller_file_path\n self.caller_file_line_range = caller_file_line_range\n self.resource_address = resource_address\n self.severity = severity\n self.bc_category = bc_category\n self.benchmarks = benchmarks\n self.description = description\n self.short_description = short_description\n self.vulnerability_details = vulnerability_details\n self.connected_node = connected_node\n\n @staticmethod\n def _determine_repo_file_path(file_path: Union[str, \"os.PathLike[str]\"]) -> str:\n # matches file paths given in the BC platform and should always be a unix path\n repo_file_path = Path(file_path)\n if Path.cwd().drive == repo_file_path.drive:\n return convert_to_unix_path(f\"/{os.path.relpath(repo_file_path)}\").replace(\"/..\", \"\")\n\n return f\"/{'/'.join(repo_file_path.parts[1:])}\"\n\n def set_guideline(self, guideline: Optional[str]) -> None:\n self.guideline = guideline\n\n @staticmethod\n def _trim_special_chars(expression: str) -> str:\n return \"\".join(re.findall(re.compile(r\"[^ ${\\}]+\"), expression))\n\n def _is_expression_in_code_lines(self, expression: str) -> bool:\n stripped_expression = self._trim_special_chars(expression)\n return any(stripped_expression in self._trim_special_chars(line) for (_, line) in self.code_block)\n\n @staticmethod\n def _code_line_string(code_block: List[Tuple[int, str]], colorized: bool = True) -> str:\n code_output = []\n color_codes = (Fore.WHITE if colorized else \"\", Fore.YELLOW if colorized else \"\")\n last_line_number_len = len(str(code_block[-1][0]))\n\n if len(code_block) >= OUTPUT_CODE_LINE_LIMIT:\n return f'\\t\\t{color_codes[1]}Code lines for this resource are too many. ' \\\n f'Please use IDE of your choice to review the file.'\n\n for line_num, line in code_block:\n spaces = \" \" * (last_line_number_len - len(str(line_num)))\n if line.lstrip().startswith(\"#\"):\n code_output.append(f\"\\t\\t{color_codes[0]}{line_num}{spaces} | {line}\")\n else:\n code_output.append(f\"\\t\\t{color_codes[0]}{line_num}{spaces} | {color_codes[1]}{line}\")\n return \"\".join(code_output)\n\n def to_string(self, compact: bool = False, use_bc_ids: bool = False) -> str:\n status = \"\"\n evaluation_message = \"\"\n status_color = \"white\"\n suppress_comment = \"\"\n if self.check_result[\"result\"] == CheckResult.PASSED:\n status = CheckResult.PASSED.name\n status_color = \"green\"\n elif self.check_result[\"result\"] == CheckResult.FAILED:\n status = CheckResult.FAILED.name\n status_color = \"red\"\n elif self.check_result[\"result\"] == CheckResult.SKIPPED:\n status = CheckResult.SKIPPED.name\n status_color = \"blue\"\n suppress_comment = \"\\tSuppress comment: {}\\n\".format(self.check_result[\"suppress_comment\"])\n\n check_message = colored('Check: {}: \"{}\"\\n'.format(self.get_output_id(use_bc_ids), self.check_name), \"white\")\n guideline_message = \"\"\n if self.guideline:\n guideline_message = (\n \"\\tGuide: \"\n + Style.BRIGHT\n + colored(f\"{self.guideline}\\n\", \"blue\", attrs=[\"underline\"])\n + Style.RESET_ALL\n )\n\n severity_message = f'\\tSeverity: {self.severity.name}\\n' if self.severity else ''\n\n file_details = colored(\n \"\\tFile: {}:{}\\n\".format(self.file_path, \"-\".join([str(x) for x in self.file_line_range])), \"magenta\"\n )\n code_lines = \"\"\n if self.code_block:\n code_lines = \"\\n{}\\n\".format(\"\".join([self._code_line_string(self.code_block)]))\n caller_file_details = \"\"\n if self.caller_file_path and self.caller_file_line_range:\n caller_file_details = colored(\n \"\\tCalling File: {}:{}\\n\".format(\n self.caller_file_path, \"-\".join([str(x) for x in self.caller_file_line_range])\n ),\n \"magenta\",\n )\n if self.evaluations:\n for (var_name, var_evaluations) in self.evaluations.items():\n var_file = var_evaluations[\"var_file\"]\n var_definitions = var_evaluations[\"definitions\"]\n for definition_obj in var_definitions:\n definition_expression = definition_obj[\"definition_expression\"]\n if self._is_expression_in_code_lines(definition_expression):\n evaluation_message = evaluation_message + colored(\n f'\\tVariable {colored(var_name, \"yellow\")} (of {var_file}) evaluated to value \"{colored(var_evaluations[\"value\"], \"yellow\")}\" '\n f'in expression: {colored(definition_obj[\"definition_name\"] + \" = \", \"yellow\")}{colored(definition_obj[\"definition_expression\"], \"yellow\")}\\n',\n \"white\",\n )\n\n status_message = colored(\"\\t{} for resource: {}\\n\".format(status, self.resource), status_color)\n if self.check_result[\"result\"] == CheckResult.FAILED and code_lines and not compact:\n return f\"{check_message}{status_message}{severity_message}{file_details}{caller_file_details}{guideline_message}{code_lines}{evaluation_message}\"\n\n if self.check_result[\"result\"] == CheckResult.SKIPPED:\n return f\"{check_message}{status_message}{severity_message}{suppress_comment}{file_details}{caller_file_details}{guideline_message}\"\n else:\n return f\"{check_message}{status_message}{severity_message}{file_details}{caller_file_details}{evaluation_message}{guideline_message}\"\n\n def __str__(self) -> str:\n return self.to_string()\n\n def get_output_id(self, use_bc_ids: bool) -> str:\n return self.bc_check_id if self.bc_check_id and use_bc_ids else self.check_id\n\n def get_unique_string(self) -> str:\n return f\"{self.check_id}.{self.check_result}.{self.file_abs_path}.{self.file_line_range}.{self.resource}\"\n", "path": "checkov/common/output/record.py"}]}
| 3,291 | 216 |
gh_patches_debug_19928
|
rasdani/github-patches
|
git_diff
|
benoitc__gunicorn-900
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
proxy protocol info lost after first keep-alive request
env:
- python v2.7
- gunicorn v19.1.1
- gevent v1.0.1 worker type
- keep-alive proxy-protcol'd lb (aws elb) in front of gunicorn
for multiple reqs during keep-alive session:
- first parses `req.proxy_protocol_info`
- subsequent reqs do not
so workers see only proxy network info (`REMOTE_ADDR`, `REMOTE_PORT` ).
probably should save off from 1st and propagate to later requests.
proxy protocol info lost after first keep-alive request
env:
- python v2.7
- gunicorn v19.1.1
- gevent v1.0.1 worker type
- keep-alive proxy-protcol'd lb (aws elb) in front of gunicorn
for multiple reqs during keep-alive session:
- first parses `req.proxy_protocol_info`
- subsequent reqs do not
so workers see only proxy network info (`REMOTE_ADDR`, `REMOTE_PORT` ).
probably should save off from 1st and propagate to later requests.
</issue>
<code>
[start of gunicorn/workers/async.py]
1 # -*- coding: utf-8 -
2 #
3 # This file is part of gunicorn released under the MIT license.
4 # See the NOTICE for more information.
5
6 from datetime import datetime
7 import errno
8 import socket
9 import ssl
10 import sys
11
12 import gunicorn.http as http
13 import gunicorn.http.wsgi as wsgi
14 import gunicorn.util as util
15 import gunicorn.workers.base as base
16 from gunicorn import six
17
18 ALREADY_HANDLED = object()
19
20
21 class AsyncWorker(base.Worker):
22
23 def __init__(self, *args, **kwargs):
24 super(AsyncWorker, self).__init__(*args, **kwargs)
25 self.worker_connections = self.cfg.worker_connections
26
27 def timeout_ctx(self):
28 raise NotImplementedError()
29
30 def handle(self, listener, client, addr):
31 req = None
32 try:
33 parser = http.RequestParser(self.cfg, client)
34 try:
35 listener_name = listener.getsockname()
36 if not self.cfg.keepalive:
37 req = six.next(parser)
38 self.handle_request(listener_name, req, client, addr)
39 else:
40 # keepalive loop
41 while True:
42 req = None
43 with self.timeout_ctx():
44 req = six.next(parser)
45 if not req:
46 break
47 self.handle_request(listener_name, req, client, addr)
48 except http.errors.NoMoreData as e:
49 self.log.debug("Ignored premature client disconnection. %s", e)
50 except StopIteration as e:
51 self.log.debug("Closing connection. %s", e)
52 except ssl.SSLError:
53 exc_info = sys.exc_info()
54 # pass to next try-except level
55 six.reraise(exc_info[0], exc_info[1], exc_info[2])
56 except socket.error:
57 exc_info = sys.exc_info()
58 # pass to next try-except level
59 six.reraise(exc_info[0], exc_info[1], exc_info[2])
60 except Exception as e:
61 self.handle_error(req, client, addr, e)
62 except ssl.SSLError as e:
63 if e.args[0] == ssl.SSL_ERROR_EOF:
64 self.log.debug("ssl connection closed")
65 client.close()
66 else:
67 self.log.debug("Error processing SSL request.")
68 self.handle_error(req, client, addr, e)
69 except socket.error as e:
70 if e.args[0] not in (errno.EPIPE, errno.ECONNRESET):
71 self.log.exception("Socket error processing request.")
72 else:
73 if e.args[0] == errno.ECONNRESET:
74 self.log.debug("Ignoring connection reset")
75 else:
76 self.log.debug("Ignoring EPIPE")
77 except Exception as e:
78 self.handle_error(req, client, addr, e)
79 finally:
80 util.close(client)
81
82 def handle_request(self, listener_name, req, sock, addr):
83 request_start = datetime.now()
84 environ = {}
85 resp = None
86 try:
87 self.cfg.pre_request(self, req)
88 resp, environ = wsgi.create(req, sock, addr,
89 listener_name, self.cfg)
90 environ["wsgi.multithread"] = True
91 self.nr += 1
92 if self.alive and self.nr >= self.max_requests:
93 self.log.info("Autorestarting worker after current request.")
94 resp.force_close()
95 self.alive = False
96
97 if not self.cfg.keepalive:
98 resp.force_close()
99
100 respiter = self.wsgi(environ, resp.start_response)
101 if respiter == ALREADY_HANDLED:
102 return False
103 try:
104 if isinstance(respiter, environ['wsgi.file_wrapper']):
105 resp.write_file(respiter)
106 else:
107 for item in respiter:
108 resp.write(item)
109 resp.close()
110 request_time = datetime.now() - request_start
111 self.log.access(resp, req, environ, request_time)
112 finally:
113 if hasattr(respiter, "close"):
114 respiter.close()
115 if resp.should_close():
116 raise StopIteration()
117 except StopIteration:
118 raise
119 except Exception:
120 if resp and resp.headers_sent:
121 # If the requests have already been sent, we should close the
122 # connection to indicate the error.
123 self.log.exception("Error handling request")
124 try:
125 sock.shutdown(socket.SHUT_RDWR)
126 sock.close()
127 except socket.error:
128 pass
129 raise StopIteration()
130 raise
131 finally:
132 try:
133 self.cfg.post_request(self, req, environ, resp)
134 except Exception:
135 self.log.exception("Exception in post_request hook")
136 return True
137
[end of gunicorn/workers/async.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/gunicorn/workers/async.py b/gunicorn/workers/async.py
--- a/gunicorn/workers/async.py
+++ b/gunicorn/workers/async.py
@@ -38,12 +38,14 @@
self.handle_request(listener_name, req, client, addr)
else:
# keepalive loop
+ proxy_protocol_info = req.proxy_protocol_info
while True:
req = None
with self.timeout_ctx():
req = six.next(parser)
if not req:
break
+ req.proxy_protocol_info = proxy_protocol_info
self.handle_request(listener_name, req, client, addr)
except http.errors.NoMoreData as e:
self.log.debug("Ignored premature client disconnection. %s", e)
|
{"golden_diff": "diff --git a/gunicorn/workers/async.py b/gunicorn/workers/async.py\n--- a/gunicorn/workers/async.py\n+++ b/gunicorn/workers/async.py\n@@ -38,12 +38,14 @@\n self.handle_request(listener_name, req, client, addr)\n else:\n # keepalive loop\n+ proxy_protocol_info = req.proxy_protocol_info\n while True:\n req = None\n with self.timeout_ctx():\n req = six.next(parser)\n if not req:\n break\n+ req.proxy_protocol_info = proxy_protocol_info\n self.handle_request(listener_name, req, client, addr)\n except http.errors.NoMoreData as e:\n self.log.debug(\"Ignored premature client disconnection. %s\", e)\n", "issue": "proxy protocol info lost after first keep-alive request\nenv:\n- python v2.7\n- gunicorn v19.1.1\n- gevent v1.0.1 worker type\n- keep-alive proxy-protcol'd lb (aws elb) in front of gunicorn\n\nfor multiple reqs during keep-alive session:\n- first parses `req.proxy_protocol_info`\n- subsequent reqs do not\n so workers see only proxy network info (`REMOTE_ADDR`, `REMOTE_PORT` ).\n\nprobably should save off from 1st and propagate to later requests.\n\nproxy protocol info lost after first keep-alive request\nenv:\n- python v2.7\n- gunicorn v19.1.1\n- gevent v1.0.1 worker type\n- keep-alive proxy-protcol'd lb (aws elb) in front of gunicorn\n\nfor multiple reqs during keep-alive session:\n- first parses `req.proxy_protocol_info`\n- subsequent reqs do not\n so workers see only proxy network info (`REMOTE_ADDR`, `REMOTE_PORT` ).\n\nprobably should save off from 1st and propagate to later requests.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -\n#\n# This file is part of gunicorn released under the MIT license.\n# See the NOTICE for more information.\n\nfrom datetime import datetime\nimport errno\nimport socket\nimport ssl\nimport sys\n\nimport gunicorn.http as http\nimport gunicorn.http.wsgi as wsgi\nimport gunicorn.util as util\nimport gunicorn.workers.base as base\nfrom gunicorn import six\n\nALREADY_HANDLED = object()\n\n\nclass AsyncWorker(base.Worker):\n\n def __init__(self, *args, **kwargs):\n super(AsyncWorker, self).__init__(*args, **kwargs)\n self.worker_connections = self.cfg.worker_connections\n\n def timeout_ctx(self):\n raise NotImplementedError()\n\n def handle(self, listener, client, addr):\n req = None\n try:\n parser = http.RequestParser(self.cfg, client)\n try:\n listener_name = listener.getsockname()\n if not self.cfg.keepalive:\n req = six.next(parser)\n self.handle_request(listener_name, req, client, addr)\n else:\n # keepalive loop\n while True:\n req = None\n with self.timeout_ctx():\n req = six.next(parser)\n if not req:\n break\n self.handle_request(listener_name, req, client, addr)\n except http.errors.NoMoreData as e:\n self.log.debug(\"Ignored premature client disconnection. %s\", e)\n except StopIteration as e:\n self.log.debug(\"Closing connection. %s\", e)\n except ssl.SSLError:\n exc_info = sys.exc_info()\n # pass to next try-except level\n six.reraise(exc_info[0], exc_info[1], exc_info[2])\n except socket.error:\n exc_info = sys.exc_info()\n # pass to next try-except level\n six.reraise(exc_info[0], exc_info[1], exc_info[2])\n except Exception as e:\n self.handle_error(req, client, addr, e)\n except ssl.SSLError as e:\n if e.args[0] == ssl.SSL_ERROR_EOF:\n self.log.debug(\"ssl connection closed\")\n client.close()\n else:\n self.log.debug(\"Error processing SSL request.\")\n self.handle_error(req, client, addr, e)\n except socket.error as e:\n if e.args[0] not in (errno.EPIPE, errno.ECONNRESET):\n self.log.exception(\"Socket error processing request.\")\n else:\n if e.args[0] == errno.ECONNRESET:\n self.log.debug(\"Ignoring connection reset\")\n else:\n self.log.debug(\"Ignoring EPIPE\")\n except Exception as e:\n self.handle_error(req, client, addr, e)\n finally:\n util.close(client)\n\n def handle_request(self, listener_name, req, sock, addr):\n request_start = datetime.now()\n environ = {}\n resp = None\n try:\n self.cfg.pre_request(self, req)\n resp, environ = wsgi.create(req, sock, addr,\n listener_name, self.cfg)\n environ[\"wsgi.multithread\"] = True\n self.nr += 1\n if self.alive and self.nr >= self.max_requests:\n self.log.info(\"Autorestarting worker after current request.\")\n resp.force_close()\n self.alive = False\n\n if not self.cfg.keepalive:\n resp.force_close()\n\n respiter = self.wsgi(environ, resp.start_response)\n if respiter == ALREADY_HANDLED:\n return False\n try:\n if isinstance(respiter, environ['wsgi.file_wrapper']):\n resp.write_file(respiter)\n else:\n for item in respiter:\n resp.write(item)\n resp.close()\n request_time = datetime.now() - request_start\n self.log.access(resp, req, environ, request_time)\n finally:\n if hasattr(respiter, \"close\"):\n respiter.close()\n if resp.should_close():\n raise StopIteration()\n except StopIteration:\n raise\n except Exception:\n if resp and resp.headers_sent:\n # If the requests have already been sent, we should close the\n # connection to indicate the error.\n self.log.exception(\"Error handling request\")\n try:\n sock.shutdown(socket.SHUT_RDWR)\n sock.close()\n except socket.error:\n pass\n raise StopIteration()\n raise\n finally:\n try:\n self.cfg.post_request(self, req, environ, resp)\n except Exception:\n self.log.exception(\"Exception in post_request hook\")\n return True\n", "path": "gunicorn/workers/async.py"}]}
| 2,056 | 168 |
gh_patches_debug_2732
|
rasdani/github-patches
|
git_diff
|
oobabooga__text-generation-webui-3014
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Error when downloading model from UI
### Describe the bug
I just downloaded the latest version of text-generation-webui on Ubuntu and started the UI but it is not longer allowing me to download a model from the UI. I tried to downloading 'anon8231489123/vicuna-13b-GPTQ-4bit-128g' but got the following error:
Traceback (most recent call last): File “/home/squirol/ben2/oobabooga_linux/text-generation-webui/server.py”, line 134, in download_model_wrapper downloader = downloader_module.ModelDownloader() TypeError: ModelDownloader.init() missing 1 required positional argument: ‘max_retries’
### Is there an existing issue for this?
- [X] I have searched the existing issues
### Reproduction
1. Launch web UI using ./start_linux.sh
2. Open browser to http://127.0.0.1:7860/
3. Enter 'anon8231489123/vicuna-13b-GPTQ-4bit-128g' and select Download in UI
4. View exception under Download button
### Screenshot

### Logs
```shell
N/A
```
### System Info
```shell
Ubuntu
NVIDIA
```
</issue>
<code>
[start of download-model.py]
1 '''
2 Downloads models from Hugging Face to models/username_modelname.
3
4 Example:
5 python download-model.py facebook/opt-1.3b
6
7 '''
8
9 import argparse
10 import base64
11 import datetime
12 import hashlib
13 import json
14 import os
15 import re
16 import sys
17 from pathlib import Path
18
19 import requests
20 import tqdm
21 from requests.adapters import HTTPAdapter
22 from tqdm.contrib.concurrent import thread_map
23
24
25 class ModelDownloader:
26 def __init__(self, max_retries):
27 self.s = requests.Session()
28 if max_retries:
29 self.s.mount('https://cdn-lfs.huggingface.co', HTTPAdapter(max_retries=max_retries))
30 self.s.mount('https://huggingface.co', HTTPAdapter(max_retries=max_retries))
31 if os.getenv('HF_USER') is not None and os.getenv('HF_PASS') is not None:
32 self.s.auth = (os.getenv('HF_USER'), os.getenv('HF_PASS'))
33
34 def sanitize_model_and_branch_names(self, model, branch):
35 if model[-1] == '/':
36 model = model[:-1]
37
38 if branch is None:
39 branch = "main"
40 else:
41 pattern = re.compile(r"^[a-zA-Z0-9._-]+$")
42 if not pattern.match(branch):
43 raise ValueError(
44 "Invalid branch name. Only alphanumeric characters, period, underscore and dash are allowed.")
45
46 return model, branch
47
48 def get_download_links_from_huggingface(self, model, branch, text_only=False):
49 base = "https://huggingface.co"
50 page = f"/api/models/{model}/tree/{branch}"
51 cursor = b""
52
53 links = []
54 sha256 = []
55 classifications = []
56 has_pytorch = False
57 has_pt = False
58 # has_ggml = False
59 has_safetensors = False
60 is_lora = False
61 while True:
62 url = f"{base}{page}" + (f"?cursor={cursor.decode()}" if cursor else "")
63 r = self.s.get(url, timeout=20)
64 r.raise_for_status()
65 content = r.content
66
67 dict = json.loads(content)
68 if len(dict) == 0:
69 break
70
71 for i in range(len(dict)):
72 fname = dict[i]['path']
73 if not is_lora and fname.endswith(('adapter_config.json', 'adapter_model.bin')):
74 is_lora = True
75
76 is_pytorch = re.match("(pytorch|adapter)_model.*\.bin", fname)
77 is_safetensors = re.match(".*\.safetensors", fname)
78 is_pt = re.match(".*\.pt", fname)
79 is_ggml = re.match(".*ggml.*\.bin", fname)
80 is_tokenizer = re.match("(tokenizer|ice).*\.model", fname)
81 is_text = re.match(".*\.(txt|json|py|md)", fname) or is_tokenizer
82 if any((is_pytorch, is_safetensors, is_pt, is_ggml, is_tokenizer, is_text)):
83 if 'lfs' in dict[i]:
84 sha256.append([fname, dict[i]['lfs']['oid']])
85
86 if is_text:
87 links.append(f"https://huggingface.co/{model}/resolve/{branch}/{fname}")
88 classifications.append('text')
89 continue
90
91 if not text_only:
92 links.append(f"https://huggingface.co/{model}/resolve/{branch}/{fname}")
93 if is_safetensors:
94 has_safetensors = True
95 classifications.append('safetensors')
96 elif is_pytorch:
97 has_pytorch = True
98 classifications.append('pytorch')
99 elif is_pt:
100 has_pt = True
101 classifications.append('pt')
102 elif is_ggml:
103 # has_ggml = True
104 classifications.append('ggml')
105
106 cursor = base64.b64encode(f'{{"file_name":"{dict[-1]["path"]}"}}'.encode()) + b':50'
107 cursor = base64.b64encode(cursor)
108 cursor = cursor.replace(b'=', b'%3D')
109
110 # If both pytorch and safetensors are available, download safetensors only
111 if (has_pytorch or has_pt) and has_safetensors:
112 for i in range(len(classifications) - 1, -1, -1):
113 if classifications[i] in ['pytorch', 'pt']:
114 links.pop(i)
115
116 return links, sha256, is_lora
117
118 def get_output_folder(self, model, branch, is_lora, base_folder=None):
119 if base_folder is None:
120 base_folder = 'models' if not is_lora else 'loras'
121
122 output_folder = f"{'_'.join(model.split('/')[-2:])}"
123 if branch != 'main':
124 output_folder += f'_{branch}'
125
126 output_folder = Path(base_folder) / output_folder
127 return output_folder
128
129 def get_single_file(self, url, output_folder, start_from_scratch=False):
130 filename = Path(url.rsplit('/', 1)[1])
131 output_path = output_folder / filename
132 headers = {}
133 mode = 'wb'
134 if output_path.exists() and not start_from_scratch:
135
136 # Check if the file has already been downloaded completely
137 r = self.s.get(url, stream=True, timeout=20)
138 total_size = int(r.headers.get('content-length', 0))
139 if output_path.stat().st_size >= total_size:
140 return
141
142 # Otherwise, resume the download from where it left off
143 headers = {'Range': f'bytes={output_path.stat().st_size}-'}
144 mode = 'ab'
145
146 with self.s.get(url, stream=True, headers=headers, timeout=20) as r:
147 r.raise_for_status() # Do not continue the download if the request was unsuccessful
148 total_size = int(r.headers.get('content-length', 0))
149 block_size = 1024 * 1024 # 1MB
150 with open(output_path, mode) as f:
151 with tqdm.tqdm(total=total_size, unit='iB', unit_scale=True, bar_format='{l_bar}{bar}| {n_fmt:6}/{total_fmt:6} {rate_fmt:6}') as t:
152 count = 0
153 for data in r.iter_content(block_size):
154 t.update(len(data))
155 f.write(data)
156 if total_size != 0 and self.progress_bar is not None:
157 count += len(data)
158 self.progress_bar(float(count) / float(total_size), f"Downloading {filename}")
159
160 def start_download_threads(self, file_list, output_folder, start_from_scratch=False, threads=1):
161 thread_map(lambda url: self.get_single_file(url, output_folder, start_from_scratch=start_from_scratch), file_list, max_workers=threads, disable=True)
162
163 def download_model_files(self, model, branch, links, sha256, output_folder, progress_bar=None, start_from_scratch=False, threads=1):
164 self.progress_bar = progress_bar
165
166 # Creating the folder and writing the metadata
167 output_folder.mkdir(parents=True, exist_ok=True)
168 metadata = f'url: https://huggingface.co/{model}\n' \
169 f'branch: {branch}\n' \
170 f'download date: {datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")}\n'
171
172 sha256_str = '\n'.join([f' {item[1]} {item[0]}' for item in sha256])
173 if sha256_str:
174 metadata += f'sha256sum:\n{sha256_str}'
175
176 metadata += '\n'
177 (output_folder / 'huggingface-metadata.txt').write_text(metadata)
178
179 # Downloading the files
180 print(f"Downloading the model to {output_folder}")
181 self.start_download_threads(links, output_folder, start_from_scratch=start_from_scratch, threads=threads)
182
183 def check_model_files(self, model, branch, links, sha256, output_folder):
184 # Validate the checksums
185 validated = True
186 for i in range(len(sha256)):
187 fpath = (output_folder / sha256[i][0])
188
189 if not fpath.exists():
190 print(f"The following file is missing: {fpath}")
191 validated = False
192 continue
193
194 with open(output_folder / sha256[i][0], "rb") as f:
195 bytes = f.read()
196 file_hash = hashlib.sha256(bytes).hexdigest()
197 if file_hash != sha256[i][1]:
198 print(f'Checksum failed: {sha256[i][0]} {sha256[i][1]}')
199 validated = False
200 else:
201 print(f'Checksum validated: {sha256[i][0]} {sha256[i][1]}')
202
203 if validated:
204 print('[+] Validated checksums of all model files!')
205 else:
206 print('[-] Invalid checksums. Rerun download-model.py with the --clean flag.')
207
208
209 if __name__ == '__main__':
210
211 parser = argparse.ArgumentParser()
212 parser.add_argument('MODEL', type=str, default=None, nargs='?')
213 parser.add_argument('--branch', type=str, default='main', help='Name of the Git branch to download from.')
214 parser.add_argument('--threads', type=int, default=1, help='Number of files to download simultaneously.')
215 parser.add_argument('--text-only', action='store_true', help='Only download text files (txt/json).')
216 parser.add_argument('--output', type=str, default=None, help='The folder where the model should be saved.')
217 parser.add_argument('--clean', action='store_true', help='Does not resume the previous download.')
218 parser.add_argument('--check', action='store_true', help='Validates the checksums of model files.')
219 parser.add_argument('--max-retries', type=int, default=5, help='Max retries count when get error in download time.')
220 args = parser.parse_args()
221
222 branch = args.branch
223 model = args.MODEL
224
225 if model is None:
226 print("Error: Please specify the model you'd like to download (e.g. 'python download-model.py facebook/opt-1.3b').")
227 sys.exit()
228
229 downloader = ModelDownloader(max_retries=args.max_retries)
230 # Cleaning up the model/branch names
231 try:
232 model, branch = downloader.sanitize_model_and_branch_names(model, branch)
233 except ValueError as err_branch:
234 print(f"Error: {err_branch}")
235 sys.exit()
236
237 # Getting the download links from Hugging Face
238 links, sha256, is_lora = downloader.get_download_links_from_huggingface(model, branch, text_only=args.text_only)
239
240 # Getting the output folder
241 output_folder = downloader.get_output_folder(model, branch, is_lora, base_folder=args.output)
242
243 if args.check:
244 # Check previously downloaded files
245 downloader.check_model_files(model, branch, links, sha256, output_folder)
246 else:
247 # Download files
248 downloader.download_model_files(model, branch, links, sha256, output_folder, threads=args.threads)
249
[end of download-model.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/download-model.py b/download-model.py
--- a/download-model.py
+++ b/download-model.py
@@ -23,7 +23,7 @@
class ModelDownloader:
- def __init__(self, max_retries):
+ def __init__(self, max_retries = 5):
self.s = requests.Session()
if max_retries:
self.s.mount('https://cdn-lfs.huggingface.co', HTTPAdapter(max_retries=max_retries))
|
{"golden_diff": "diff --git a/download-model.py b/download-model.py\n--- a/download-model.py\n+++ b/download-model.py\n@@ -23,7 +23,7 @@\n \n \n class ModelDownloader:\n- def __init__(self, max_retries):\n+ def __init__(self, max_retries = 5):\n self.s = requests.Session()\n if max_retries:\n self.s.mount('https://cdn-lfs.huggingface.co', HTTPAdapter(max_retries=max_retries))\n", "issue": "Error when downloading model from UI\n### Describe the bug\n\nI just downloaded the latest version of text-generation-webui on Ubuntu and started the UI but it is not longer allowing me to download a model from the UI. I tried to downloading 'anon8231489123/vicuna-13b-GPTQ-4bit-128g' but got the following error:\r\n\r\nTraceback (most recent call last): File \u201c/home/squirol/ben2/oobabooga_linux/text-generation-webui/server.py\u201d, line 134, in download_model_wrapper downloader = downloader_module.ModelDownloader() TypeError: ModelDownloader.init() missing 1 required positional argument: \u2018max_retries\u2019\n\n### Is there an existing issue for this?\n\n- [X] I have searched the existing issues\n\n### Reproduction\n\n1. Launch web UI using ./start_linux.sh\r\n2. Open browser to http://127.0.0.1:7860/\r\n3. Enter 'anon8231489123/vicuna-13b-GPTQ-4bit-128g' and select Download in UI\r\n4. View exception under Download button\n\n### Screenshot\n\n\r\n\n\n### Logs\n\n```shell\nN/A\n```\n\n\n### System Info\n\n```shell\nUbuntu\r\nNVIDIA\n```\n\n", "before_files": [{"content": "'''\nDownloads models from Hugging Face to models/username_modelname.\n\nExample:\npython download-model.py facebook/opt-1.3b\n\n'''\n\nimport argparse\nimport base64\nimport datetime\nimport hashlib\nimport json\nimport os\nimport re\nimport sys\nfrom pathlib import Path\n\nimport requests\nimport tqdm\nfrom requests.adapters import HTTPAdapter\nfrom tqdm.contrib.concurrent import thread_map\n\n\nclass ModelDownloader:\n def __init__(self, max_retries):\n self.s = requests.Session()\n if max_retries:\n self.s.mount('https://cdn-lfs.huggingface.co', HTTPAdapter(max_retries=max_retries))\n self.s.mount('https://huggingface.co', HTTPAdapter(max_retries=max_retries))\n if os.getenv('HF_USER') is not None and os.getenv('HF_PASS') is not None:\n self.s.auth = (os.getenv('HF_USER'), os.getenv('HF_PASS'))\n\n def sanitize_model_and_branch_names(self, model, branch):\n if model[-1] == '/':\n model = model[:-1]\n\n if branch is None:\n branch = \"main\"\n else:\n pattern = re.compile(r\"^[a-zA-Z0-9._-]+$\")\n if not pattern.match(branch):\n raise ValueError(\n \"Invalid branch name. Only alphanumeric characters, period, underscore and dash are allowed.\")\n\n return model, branch\n\n def get_download_links_from_huggingface(self, model, branch, text_only=False):\n base = \"https://huggingface.co\"\n page = f\"/api/models/{model}/tree/{branch}\"\n cursor = b\"\"\n\n links = []\n sha256 = []\n classifications = []\n has_pytorch = False\n has_pt = False\n # has_ggml = False\n has_safetensors = False\n is_lora = False\n while True:\n url = f\"{base}{page}\" + (f\"?cursor={cursor.decode()}\" if cursor else \"\")\n r = self.s.get(url, timeout=20)\n r.raise_for_status()\n content = r.content\n\n dict = json.loads(content)\n if len(dict) == 0:\n break\n\n for i in range(len(dict)):\n fname = dict[i]['path']\n if not is_lora and fname.endswith(('adapter_config.json', 'adapter_model.bin')):\n is_lora = True\n\n is_pytorch = re.match(\"(pytorch|adapter)_model.*\\.bin\", fname)\n is_safetensors = re.match(\".*\\.safetensors\", fname)\n is_pt = re.match(\".*\\.pt\", fname)\n is_ggml = re.match(\".*ggml.*\\.bin\", fname)\n is_tokenizer = re.match(\"(tokenizer|ice).*\\.model\", fname)\n is_text = re.match(\".*\\.(txt|json|py|md)\", fname) or is_tokenizer\n if any((is_pytorch, is_safetensors, is_pt, is_ggml, is_tokenizer, is_text)):\n if 'lfs' in dict[i]:\n sha256.append([fname, dict[i]['lfs']['oid']])\n\n if is_text:\n links.append(f\"https://huggingface.co/{model}/resolve/{branch}/{fname}\")\n classifications.append('text')\n continue\n\n if not text_only:\n links.append(f\"https://huggingface.co/{model}/resolve/{branch}/{fname}\")\n if is_safetensors:\n has_safetensors = True\n classifications.append('safetensors')\n elif is_pytorch:\n has_pytorch = True\n classifications.append('pytorch')\n elif is_pt:\n has_pt = True\n classifications.append('pt')\n elif is_ggml:\n # has_ggml = True\n classifications.append('ggml')\n\n cursor = base64.b64encode(f'{{\"file_name\":\"{dict[-1][\"path\"]}\"}}'.encode()) + b':50'\n cursor = base64.b64encode(cursor)\n cursor = cursor.replace(b'=', b'%3D')\n\n # If both pytorch and safetensors are available, download safetensors only\n if (has_pytorch or has_pt) and has_safetensors:\n for i in range(len(classifications) - 1, -1, -1):\n if classifications[i] in ['pytorch', 'pt']:\n links.pop(i)\n\n return links, sha256, is_lora\n\n def get_output_folder(self, model, branch, is_lora, base_folder=None):\n if base_folder is None:\n base_folder = 'models' if not is_lora else 'loras'\n\n output_folder = f\"{'_'.join(model.split('/')[-2:])}\"\n if branch != 'main':\n output_folder += f'_{branch}'\n\n output_folder = Path(base_folder) / output_folder\n return output_folder\n\n def get_single_file(self, url, output_folder, start_from_scratch=False):\n filename = Path(url.rsplit('/', 1)[1])\n output_path = output_folder / filename\n headers = {}\n mode = 'wb'\n if output_path.exists() and not start_from_scratch:\n\n # Check if the file has already been downloaded completely\n r = self.s.get(url, stream=True, timeout=20)\n total_size = int(r.headers.get('content-length', 0))\n if output_path.stat().st_size >= total_size:\n return\n\n # Otherwise, resume the download from where it left off\n headers = {'Range': f'bytes={output_path.stat().st_size}-'}\n mode = 'ab'\n\n with self.s.get(url, stream=True, headers=headers, timeout=20) as r:\n r.raise_for_status() # Do not continue the download if the request was unsuccessful\n total_size = int(r.headers.get('content-length', 0))\n block_size = 1024 * 1024 # 1MB\n with open(output_path, mode) as f:\n with tqdm.tqdm(total=total_size, unit='iB', unit_scale=True, bar_format='{l_bar}{bar}| {n_fmt:6}/{total_fmt:6} {rate_fmt:6}') as t:\n count = 0\n for data in r.iter_content(block_size):\n t.update(len(data))\n f.write(data)\n if total_size != 0 and self.progress_bar is not None:\n count += len(data)\n self.progress_bar(float(count) / float(total_size), f\"Downloading {filename}\")\n\n def start_download_threads(self, file_list, output_folder, start_from_scratch=False, threads=1):\n thread_map(lambda url: self.get_single_file(url, output_folder, start_from_scratch=start_from_scratch), file_list, max_workers=threads, disable=True)\n\n def download_model_files(self, model, branch, links, sha256, output_folder, progress_bar=None, start_from_scratch=False, threads=1):\n self.progress_bar = progress_bar\n\n # Creating the folder and writing the metadata\n output_folder.mkdir(parents=True, exist_ok=True)\n metadata = f'url: https://huggingface.co/{model}\\n' \\\n f'branch: {branch}\\n' \\\n f'download date: {datetime.datetime.now().strftime(\"%Y-%m-%d %H:%M:%S\")}\\n'\n\n sha256_str = '\\n'.join([f' {item[1]} {item[0]}' for item in sha256])\n if sha256_str:\n metadata += f'sha256sum:\\n{sha256_str}'\n\n metadata += '\\n'\n (output_folder / 'huggingface-metadata.txt').write_text(metadata)\n\n # Downloading the files\n print(f\"Downloading the model to {output_folder}\")\n self.start_download_threads(links, output_folder, start_from_scratch=start_from_scratch, threads=threads)\n\n def check_model_files(self, model, branch, links, sha256, output_folder):\n # Validate the checksums\n validated = True\n for i in range(len(sha256)):\n fpath = (output_folder / sha256[i][0])\n\n if not fpath.exists():\n print(f\"The following file is missing: {fpath}\")\n validated = False\n continue\n\n with open(output_folder / sha256[i][0], \"rb\") as f:\n bytes = f.read()\n file_hash = hashlib.sha256(bytes).hexdigest()\n if file_hash != sha256[i][1]:\n print(f'Checksum failed: {sha256[i][0]} {sha256[i][1]}')\n validated = False\n else:\n print(f'Checksum validated: {sha256[i][0]} {sha256[i][1]}')\n\n if validated:\n print('[+] Validated checksums of all model files!')\n else:\n print('[-] Invalid checksums. Rerun download-model.py with the --clean flag.')\n\n\nif __name__ == '__main__':\n\n parser = argparse.ArgumentParser()\n parser.add_argument('MODEL', type=str, default=None, nargs='?')\n parser.add_argument('--branch', type=str, default='main', help='Name of the Git branch to download from.')\n parser.add_argument('--threads', type=int, default=1, help='Number of files to download simultaneously.')\n parser.add_argument('--text-only', action='store_true', help='Only download text files (txt/json).')\n parser.add_argument('--output', type=str, default=None, help='The folder where the model should be saved.')\n parser.add_argument('--clean', action='store_true', help='Does not resume the previous download.')\n parser.add_argument('--check', action='store_true', help='Validates the checksums of model files.')\n parser.add_argument('--max-retries', type=int, default=5, help='Max retries count when get error in download time.')\n args = parser.parse_args()\n\n branch = args.branch\n model = args.MODEL\n\n if model is None:\n print(\"Error: Please specify the model you'd like to download (e.g. 'python download-model.py facebook/opt-1.3b').\")\n sys.exit()\n\n downloader = ModelDownloader(max_retries=args.max_retries)\n # Cleaning up the model/branch names\n try:\n model, branch = downloader.sanitize_model_and_branch_names(model, branch)\n except ValueError as err_branch:\n print(f\"Error: {err_branch}\")\n sys.exit()\n\n # Getting the download links from Hugging Face\n links, sha256, is_lora = downloader.get_download_links_from_huggingface(model, branch, text_only=args.text_only)\n\n # Getting the output folder\n output_folder = downloader.get_output_folder(model, branch, is_lora, base_folder=args.output)\n\n if args.check:\n # Check previously downloaded files\n downloader.check_model_files(model, branch, links, sha256, output_folder)\n else:\n # Download files\n downloader.download_model_files(model, branch, links, sha256, output_folder, threads=args.threads)\n", "path": "download-model.py"}]}
| 3,977 | 104 |
gh_patches_debug_41955
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-contrib-2101
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ERROR: No matching distribution found for opentelemetry-instrumentation-aiohttp-server==0.42b0
Python Version - 3.8
**Steps to reproduce**
Using 'opentelemetry-bootstrap -a install' Command to Install the Dependencies for Auto Instrumentation.
**What is the expected behavior?**
package : opentelemetry-instrumentation-aiohttp-server==0.42b0 should be downloaded from pypi
**What is the actual behavior?**
ERROR: No matching distribution found for opentelemetry-instrumentation-aiohttp-server==0.42b0
</issue>
<code>
[start of opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py]
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 # DO NOT EDIT. THIS FILE WAS AUTOGENERATED FROM INSTRUMENTATION PACKAGES.
16 # RUN `python scripts/generate_instrumentation_bootstrap.py` TO REGENERATE.
17
18 libraries = [
19 {
20 "library": "aio_pika >= 7.2.0, < 10.0.0",
21 "instrumentation": "opentelemetry-instrumentation-aio-pika==0.46b0.dev",
22 },
23 {
24 "library": "aiohttp ~= 3.0",
25 "instrumentation": "opentelemetry-instrumentation-aiohttp-client==0.46b0.dev",
26 },
27 {
28 "library": "aiohttp ~= 3.0",
29 "instrumentation": "opentelemetry-instrumentation-aiohttp-server==0.46b0.dev",
30 },
31 {
32 "library": "aiopg >= 0.13.0, < 2.0.0",
33 "instrumentation": "opentelemetry-instrumentation-aiopg==0.46b0.dev",
34 },
35 {
36 "library": "asgiref ~= 3.0",
37 "instrumentation": "opentelemetry-instrumentation-asgi==0.46b0.dev",
38 },
39 {
40 "library": "asyncpg >= 0.12.0",
41 "instrumentation": "opentelemetry-instrumentation-asyncpg==0.46b0.dev",
42 },
43 {
44 "library": "boto~=2.0",
45 "instrumentation": "opentelemetry-instrumentation-boto==0.46b0.dev",
46 },
47 {
48 "library": "boto3 ~= 1.0",
49 "instrumentation": "opentelemetry-instrumentation-boto3sqs==0.46b0.dev",
50 },
51 {
52 "library": "botocore ~= 1.0",
53 "instrumentation": "opentelemetry-instrumentation-botocore==0.46b0.dev",
54 },
55 {
56 "library": "cassandra-driver ~= 3.25",
57 "instrumentation": "opentelemetry-instrumentation-cassandra==0.46b0.dev",
58 },
59 {
60 "library": "scylla-driver ~= 3.25",
61 "instrumentation": "opentelemetry-instrumentation-cassandra==0.46b0.dev",
62 },
63 {
64 "library": "celery >= 4.0, < 6.0",
65 "instrumentation": "opentelemetry-instrumentation-celery==0.46b0.dev",
66 },
67 {
68 "library": "confluent-kafka >= 1.8.2, <= 2.3.0",
69 "instrumentation": "opentelemetry-instrumentation-confluent-kafka==0.46b0.dev",
70 },
71 {
72 "library": "django >= 1.10",
73 "instrumentation": "opentelemetry-instrumentation-django==0.46b0.dev",
74 },
75 {
76 "library": "elasticsearch >= 6.0",
77 "instrumentation": "opentelemetry-instrumentation-elasticsearch==0.46b0.dev",
78 },
79 {
80 "library": "falcon >= 1.4.1, < 3.1.2",
81 "instrumentation": "opentelemetry-instrumentation-falcon==0.46b0.dev",
82 },
83 {
84 "library": "fastapi ~= 0.58",
85 "instrumentation": "opentelemetry-instrumentation-fastapi==0.46b0.dev",
86 },
87 {
88 "library": "flask >= 1.0",
89 "instrumentation": "opentelemetry-instrumentation-flask==0.46b0.dev",
90 },
91 {
92 "library": "grpcio ~= 1.27",
93 "instrumentation": "opentelemetry-instrumentation-grpc==0.46b0.dev",
94 },
95 {
96 "library": "httpx >= 0.18.0",
97 "instrumentation": "opentelemetry-instrumentation-httpx==0.46b0.dev",
98 },
99 {
100 "library": "jinja2 >= 2.7, < 4.0",
101 "instrumentation": "opentelemetry-instrumentation-jinja2==0.46b0.dev",
102 },
103 {
104 "library": "kafka-python >= 2.0",
105 "instrumentation": "opentelemetry-instrumentation-kafka-python==0.46b0.dev",
106 },
107 {
108 "library": "mysql-connector-python ~= 8.0",
109 "instrumentation": "opentelemetry-instrumentation-mysql==0.46b0.dev",
110 },
111 {
112 "library": "mysqlclient < 3",
113 "instrumentation": "opentelemetry-instrumentation-mysqlclient==0.46b0.dev",
114 },
115 {
116 "library": "pika >= 0.12.0",
117 "instrumentation": "opentelemetry-instrumentation-pika==0.46b0.dev",
118 },
119 {
120 "library": "psycopg >= 3.1.0",
121 "instrumentation": "opentelemetry-instrumentation-psycopg==0.46b0.dev",
122 },
123 {
124 "library": "psycopg2 >= 2.7.3.1",
125 "instrumentation": "opentelemetry-instrumentation-psycopg2==0.46b0.dev",
126 },
127 {
128 "library": "pymemcache >= 1.3.5, < 5",
129 "instrumentation": "opentelemetry-instrumentation-pymemcache==0.46b0.dev",
130 },
131 {
132 "library": "pymongo >= 3.1, < 5.0",
133 "instrumentation": "opentelemetry-instrumentation-pymongo==0.46b0.dev",
134 },
135 {
136 "library": "PyMySQL < 2",
137 "instrumentation": "opentelemetry-instrumentation-pymysql==0.46b0.dev",
138 },
139 {
140 "library": "pyramid >= 1.7",
141 "instrumentation": "opentelemetry-instrumentation-pyramid==0.46b0.dev",
142 },
143 {
144 "library": "redis >= 2.6",
145 "instrumentation": "opentelemetry-instrumentation-redis==0.46b0.dev",
146 },
147 {
148 "library": "remoulade >= 0.50",
149 "instrumentation": "opentelemetry-instrumentation-remoulade==0.46b0.dev",
150 },
151 {
152 "library": "requests ~= 2.0",
153 "instrumentation": "opentelemetry-instrumentation-requests==0.46b0.dev",
154 },
155 {
156 "library": "scikit-learn ~= 0.24.0",
157 "instrumentation": "opentelemetry-instrumentation-sklearn==0.46b0.dev",
158 },
159 {
160 "library": "sqlalchemy",
161 "instrumentation": "opentelemetry-instrumentation-sqlalchemy==0.46b0.dev",
162 },
163 {
164 "library": "starlette ~= 0.13.0",
165 "instrumentation": "opentelemetry-instrumentation-starlette==0.46b0.dev",
166 },
167 {
168 "library": "psutil >= 5",
169 "instrumentation": "opentelemetry-instrumentation-system-metrics==0.46b0.dev",
170 },
171 {
172 "library": "tornado >= 5.1.1",
173 "instrumentation": "opentelemetry-instrumentation-tornado==0.46b0.dev",
174 },
175 {
176 "library": "tortoise-orm >= 0.17.0",
177 "instrumentation": "opentelemetry-instrumentation-tortoiseorm==0.46b0.dev",
178 },
179 {
180 "library": "pydantic >= 1.10.2",
181 "instrumentation": "opentelemetry-instrumentation-tortoiseorm==0.46b0.dev",
182 },
183 {
184 "library": "urllib3 >= 1.0.0, < 3.0.0",
185 "instrumentation": "opentelemetry-instrumentation-urllib3==0.46b0.dev",
186 },
187 ]
188 default_instrumentations = [
189 "opentelemetry-instrumentation-asyncio==0.46b0.dev",
190 "opentelemetry-instrumentation-aws-lambda==0.46b0.dev",
191 "opentelemetry-instrumentation-dbapi==0.46b0.dev",
192 "opentelemetry-instrumentation-logging==0.46b0.dev",
193 "opentelemetry-instrumentation-sqlite3==0.46b0.dev",
194 "opentelemetry-instrumentation-threading==0.46b0.dev",
195 "opentelemetry-instrumentation-urllib==0.46b0.dev",
196 "opentelemetry-instrumentation-wsgi==0.46b0.dev",
197 ]
198
[end of opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py]
[start of scripts/otel_packaging.py]
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import os
16 import subprocess
17 from subprocess import CalledProcessError
18
19 import tomli
20
21 scripts_path = os.path.dirname(os.path.abspath(__file__))
22 root_path = os.path.dirname(scripts_path)
23 instrumentations_path = os.path.join(root_path, "instrumentation")
24
25
26 def get_instrumentation_packages():
27 for pkg in sorted(os.listdir(instrumentations_path)):
28 pkg_path = os.path.join(instrumentations_path, pkg)
29 if not os.path.isdir(pkg_path):
30 continue
31
32 try:
33 version = subprocess.check_output(
34 "hatch version",
35 shell=True,
36 cwd=pkg_path,
37 universal_newlines=True,
38 )
39 except CalledProcessError as exc:
40 print(f"Could not get hatch version from path {pkg_path}")
41 print(exc.output)
42 raise exc
43
44 pyproject_toml_path = os.path.join(pkg_path, "pyproject.toml")
45
46 with open(pyproject_toml_path, "rb") as file:
47 pyproject_toml = tomli.load(file)
48
49 instrumentation = {
50 "name": pyproject_toml["project"]["name"],
51 "version": version.strip(),
52 "instruments": pyproject_toml["project"]["optional-dependencies"][
53 "instruments"
54 ],
55 }
56 instrumentation["requirement"] = "==".join(
57 (
58 instrumentation["name"],
59 instrumentation["version"],
60 )
61 )
62 yield instrumentation
63
64
65 if __name__ == "__main__":
66 print(list(get_instrumentation_packages()))
67
[end of scripts/otel_packaging.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py b/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py
--- a/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py
+++ b/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py
@@ -24,10 +24,6 @@
"library": "aiohttp ~= 3.0",
"instrumentation": "opentelemetry-instrumentation-aiohttp-client==0.46b0.dev",
},
- {
- "library": "aiohttp ~= 3.0",
- "instrumentation": "opentelemetry-instrumentation-aiohttp-server==0.46b0.dev",
- },
{
"library": "aiopg >= 0.13.0, < 2.0.0",
"instrumentation": "opentelemetry-instrumentation-aiopg==0.46b0.dev",
@@ -191,7 +187,6 @@
"opentelemetry-instrumentation-dbapi==0.46b0.dev",
"opentelemetry-instrumentation-logging==0.46b0.dev",
"opentelemetry-instrumentation-sqlite3==0.46b0.dev",
- "opentelemetry-instrumentation-threading==0.46b0.dev",
"opentelemetry-instrumentation-urllib==0.46b0.dev",
"opentelemetry-instrumentation-wsgi==0.46b0.dev",
]
diff --git a/scripts/otel_packaging.py b/scripts/otel_packaging.py
--- a/scripts/otel_packaging.py
+++ b/scripts/otel_packaging.py
@@ -12,43 +12,55 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-import os
-import subprocess
-from subprocess import CalledProcessError
+from tomli import load
+from os import path, listdir
+from subprocess import check_output, CalledProcessError
+from requests import get
-import tomli
-
-scripts_path = os.path.dirname(os.path.abspath(__file__))
-root_path = os.path.dirname(scripts_path)
-instrumentations_path = os.path.join(root_path, "instrumentation")
+scripts_path = path.dirname(path.abspath(__file__))
+root_path = path.dirname(scripts_path)
+instrumentations_path = path.join(root_path, "instrumentation")
def get_instrumentation_packages():
- for pkg in sorted(os.listdir(instrumentations_path)):
- pkg_path = os.path.join(instrumentations_path, pkg)
- if not os.path.isdir(pkg_path):
+ for pkg in sorted(listdir(instrumentations_path)):
+ pkg_path = path.join(instrumentations_path, pkg)
+ if not path.isdir(pkg_path):
continue
+ error = f"Could not get version for package {pkg}"
+
try:
- version = subprocess.check_output(
+ hatch_version = check_output(
"hatch version",
shell=True,
cwd=pkg_path,
- universal_newlines=True,
+ universal_newlines=True
)
+
except CalledProcessError as exc:
print(f"Could not get hatch version from path {pkg_path}")
print(exc.output)
- raise exc
- pyproject_toml_path = os.path.join(pkg_path, "pyproject.toml")
+ try:
+ response = get(f"https://pypi.org/pypi/{pkg}/json", timeout=10)
+
+ except Exception:
+ print(error)
+ continue
+
+ if response.status_code != 200:
+ print(error)
+ continue
+
+ pyproject_toml_path = path.join(pkg_path, "pyproject.toml")
with open(pyproject_toml_path, "rb") as file:
- pyproject_toml = tomli.load(file)
+ pyproject_toml = load(file)
instrumentation = {
"name": pyproject_toml["project"]["name"],
- "version": version.strip(),
+ "version": hatch_version.strip(),
"instruments": pyproject_toml["project"]["optional-dependencies"][
"instruments"
],
|
{"golden_diff": "diff --git a/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py b/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py\n--- a/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py\n+++ b/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py\n@@ -24,10 +24,6 @@\n \"library\": \"aiohttp ~= 3.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-aiohttp-client==0.46b0.dev\",\n },\n- {\n- \"library\": \"aiohttp ~= 3.0\",\n- \"instrumentation\": \"opentelemetry-instrumentation-aiohttp-server==0.46b0.dev\",\n- },\n {\n \"library\": \"aiopg >= 0.13.0, < 2.0.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-aiopg==0.46b0.dev\",\n@@ -191,7 +187,6 @@\n \"opentelemetry-instrumentation-dbapi==0.46b0.dev\",\n \"opentelemetry-instrumentation-logging==0.46b0.dev\",\n \"opentelemetry-instrumentation-sqlite3==0.46b0.dev\",\n- \"opentelemetry-instrumentation-threading==0.46b0.dev\",\n \"opentelemetry-instrumentation-urllib==0.46b0.dev\",\n \"opentelemetry-instrumentation-wsgi==0.46b0.dev\",\n ]\ndiff --git a/scripts/otel_packaging.py b/scripts/otel_packaging.py\n--- a/scripts/otel_packaging.py\n+++ b/scripts/otel_packaging.py\n@@ -12,43 +12,55 @@\n # See the License for the specific language governing permissions and\n # limitations under the License.\n \n-import os\n-import subprocess\n-from subprocess import CalledProcessError\n+from tomli import load\n+from os import path, listdir\n+from subprocess import check_output, CalledProcessError\n+from requests import get\n \n-import tomli\n-\n-scripts_path = os.path.dirname(os.path.abspath(__file__))\n-root_path = os.path.dirname(scripts_path)\n-instrumentations_path = os.path.join(root_path, \"instrumentation\")\n+scripts_path = path.dirname(path.abspath(__file__))\n+root_path = path.dirname(scripts_path)\n+instrumentations_path = path.join(root_path, \"instrumentation\")\n \n \n def get_instrumentation_packages():\n- for pkg in sorted(os.listdir(instrumentations_path)):\n- pkg_path = os.path.join(instrumentations_path, pkg)\n- if not os.path.isdir(pkg_path):\n+ for pkg in sorted(listdir(instrumentations_path)):\n+ pkg_path = path.join(instrumentations_path, pkg)\n+ if not path.isdir(pkg_path):\n continue\n \n+ error = f\"Could not get version for package {pkg}\"\n+\n try:\n- version = subprocess.check_output(\n+ hatch_version = check_output(\n \"hatch version\",\n shell=True,\n cwd=pkg_path,\n- universal_newlines=True,\n+ universal_newlines=True\n )\n+\n except CalledProcessError as exc:\n print(f\"Could not get hatch version from path {pkg_path}\")\n print(exc.output)\n- raise exc\n \n- pyproject_toml_path = os.path.join(pkg_path, \"pyproject.toml\")\n+ try:\n+ response = get(f\"https://pypi.org/pypi/{pkg}/json\", timeout=10)\n+\n+ except Exception:\n+ print(error)\n+ continue\n+\n+ if response.status_code != 200:\n+ print(error)\n+ continue\n+\n+ pyproject_toml_path = path.join(pkg_path, \"pyproject.toml\")\n \n with open(pyproject_toml_path, \"rb\") as file:\n- pyproject_toml = tomli.load(file)\n+ pyproject_toml = load(file)\n \n instrumentation = {\n \"name\": pyproject_toml[\"project\"][\"name\"],\n- \"version\": version.strip(),\n+ \"version\": hatch_version.strip(),\n \"instruments\": pyproject_toml[\"project\"][\"optional-dependencies\"][\n \"instruments\"\n ],\n", "issue": "ERROR: No matching distribution found for opentelemetry-instrumentation-aiohttp-server==0.42b0\nPython Version - 3.8\r\n\r\n**Steps to reproduce**\r\nUsing 'opentelemetry-bootstrap -a install' Command to Install the Dependencies for Auto Instrumentation.\r\n\r\n**What is the expected behavior?**\r\npackage : opentelemetry-instrumentation-aiohttp-server==0.42b0 should be downloaded from pypi\r\n\r\n**What is the actual behavior?**\r\nERROR: No matching distribution found for opentelemetry-instrumentation-aiohttp-server==0.42b0\r\n\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n# DO NOT EDIT. THIS FILE WAS AUTOGENERATED FROM INSTRUMENTATION PACKAGES.\n# RUN `python scripts/generate_instrumentation_bootstrap.py` TO REGENERATE.\n\nlibraries = [\n {\n \"library\": \"aio_pika >= 7.2.0, < 10.0.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-aio-pika==0.46b0.dev\",\n },\n {\n \"library\": \"aiohttp ~= 3.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-aiohttp-client==0.46b0.dev\",\n },\n {\n \"library\": \"aiohttp ~= 3.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-aiohttp-server==0.46b0.dev\",\n },\n {\n \"library\": \"aiopg >= 0.13.0, < 2.0.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-aiopg==0.46b0.dev\",\n },\n {\n \"library\": \"asgiref ~= 3.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-asgi==0.46b0.dev\",\n },\n {\n \"library\": \"asyncpg >= 0.12.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-asyncpg==0.46b0.dev\",\n },\n {\n \"library\": \"boto~=2.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-boto==0.46b0.dev\",\n },\n {\n \"library\": \"boto3 ~= 1.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-boto3sqs==0.46b0.dev\",\n },\n {\n \"library\": \"botocore ~= 1.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-botocore==0.46b0.dev\",\n },\n {\n \"library\": \"cassandra-driver ~= 3.25\",\n \"instrumentation\": \"opentelemetry-instrumentation-cassandra==0.46b0.dev\",\n },\n {\n \"library\": \"scylla-driver ~= 3.25\",\n \"instrumentation\": \"opentelemetry-instrumentation-cassandra==0.46b0.dev\",\n },\n {\n \"library\": \"celery >= 4.0, < 6.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-celery==0.46b0.dev\",\n },\n {\n \"library\": \"confluent-kafka >= 1.8.2, <= 2.3.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-confluent-kafka==0.46b0.dev\",\n },\n {\n \"library\": \"django >= 1.10\",\n \"instrumentation\": \"opentelemetry-instrumentation-django==0.46b0.dev\",\n },\n {\n \"library\": \"elasticsearch >= 6.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-elasticsearch==0.46b0.dev\",\n },\n {\n \"library\": \"falcon >= 1.4.1, < 3.1.2\",\n \"instrumentation\": \"opentelemetry-instrumentation-falcon==0.46b0.dev\",\n },\n {\n \"library\": \"fastapi ~= 0.58\",\n \"instrumentation\": \"opentelemetry-instrumentation-fastapi==0.46b0.dev\",\n },\n {\n \"library\": \"flask >= 1.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-flask==0.46b0.dev\",\n },\n {\n \"library\": \"grpcio ~= 1.27\",\n \"instrumentation\": \"opentelemetry-instrumentation-grpc==0.46b0.dev\",\n },\n {\n \"library\": \"httpx >= 0.18.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-httpx==0.46b0.dev\",\n },\n {\n \"library\": \"jinja2 >= 2.7, < 4.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-jinja2==0.46b0.dev\",\n },\n {\n \"library\": \"kafka-python >= 2.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-kafka-python==0.46b0.dev\",\n },\n {\n \"library\": \"mysql-connector-python ~= 8.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-mysql==0.46b0.dev\",\n },\n {\n \"library\": \"mysqlclient < 3\",\n \"instrumentation\": \"opentelemetry-instrumentation-mysqlclient==0.46b0.dev\",\n },\n {\n \"library\": \"pika >= 0.12.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-pika==0.46b0.dev\",\n },\n {\n \"library\": \"psycopg >= 3.1.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-psycopg==0.46b0.dev\",\n },\n {\n \"library\": \"psycopg2 >= 2.7.3.1\",\n \"instrumentation\": \"opentelemetry-instrumentation-psycopg2==0.46b0.dev\",\n },\n {\n \"library\": \"pymemcache >= 1.3.5, < 5\",\n \"instrumentation\": \"opentelemetry-instrumentation-pymemcache==0.46b0.dev\",\n },\n {\n \"library\": \"pymongo >= 3.1, < 5.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-pymongo==0.46b0.dev\",\n },\n {\n \"library\": \"PyMySQL < 2\",\n \"instrumentation\": \"opentelemetry-instrumentation-pymysql==0.46b0.dev\",\n },\n {\n \"library\": \"pyramid >= 1.7\",\n \"instrumentation\": \"opentelemetry-instrumentation-pyramid==0.46b0.dev\",\n },\n {\n \"library\": \"redis >= 2.6\",\n \"instrumentation\": \"opentelemetry-instrumentation-redis==0.46b0.dev\",\n },\n {\n \"library\": \"remoulade >= 0.50\",\n \"instrumentation\": \"opentelemetry-instrumentation-remoulade==0.46b0.dev\",\n },\n {\n \"library\": \"requests ~= 2.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-requests==0.46b0.dev\",\n },\n {\n \"library\": \"scikit-learn ~= 0.24.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-sklearn==0.46b0.dev\",\n },\n {\n \"library\": \"sqlalchemy\",\n \"instrumentation\": \"opentelemetry-instrumentation-sqlalchemy==0.46b0.dev\",\n },\n {\n \"library\": \"starlette ~= 0.13.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-starlette==0.46b0.dev\",\n },\n {\n \"library\": \"psutil >= 5\",\n \"instrumentation\": \"opentelemetry-instrumentation-system-metrics==0.46b0.dev\",\n },\n {\n \"library\": \"tornado >= 5.1.1\",\n \"instrumentation\": \"opentelemetry-instrumentation-tornado==0.46b0.dev\",\n },\n {\n \"library\": \"tortoise-orm >= 0.17.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-tortoiseorm==0.46b0.dev\",\n },\n {\n \"library\": \"pydantic >= 1.10.2\",\n \"instrumentation\": \"opentelemetry-instrumentation-tortoiseorm==0.46b0.dev\",\n },\n {\n \"library\": \"urllib3 >= 1.0.0, < 3.0.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-urllib3==0.46b0.dev\",\n },\n]\ndefault_instrumentations = [\n \"opentelemetry-instrumentation-asyncio==0.46b0.dev\",\n \"opentelemetry-instrumentation-aws-lambda==0.46b0.dev\",\n \"opentelemetry-instrumentation-dbapi==0.46b0.dev\",\n \"opentelemetry-instrumentation-logging==0.46b0.dev\",\n \"opentelemetry-instrumentation-sqlite3==0.46b0.dev\",\n \"opentelemetry-instrumentation-threading==0.46b0.dev\",\n \"opentelemetry-instrumentation-urllib==0.46b0.dev\",\n \"opentelemetry-instrumentation-wsgi==0.46b0.dev\",\n]\n", "path": "opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py"}, {"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\nimport subprocess\nfrom subprocess import CalledProcessError\n\nimport tomli\n\nscripts_path = os.path.dirname(os.path.abspath(__file__))\nroot_path = os.path.dirname(scripts_path)\ninstrumentations_path = os.path.join(root_path, \"instrumentation\")\n\n\ndef get_instrumentation_packages():\n for pkg in sorted(os.listdir(instrumentations_path)):\n pkg_path = os.path.join(instrumentations_path, pkg)\n if not os.path.isdir(pkg_path):\n continue\n\n try:\n version = subprocess.check_output(\n \"hatch version\",\n shell=True,\n cwd=pkg_path,\n universal_newlines=True,\n )\n except CalledProcessError as exc:\n print(f\"Could not get hatch version from path {pkg_path}\")\n print(exc.output)\n raise exc\n\n pyproject_toml_path = os.path.join(pkg_path, \"pyproject.toml\")\n\n with open(pyproject_toml_path, \"rb\") as file:\n pyproject_toml = tomli.load(file)\n\n instrumentation = {\n \"name\": pyproject_toml[\"project\"][\"name\"],\n \"version\": version.strip(),\n \"instruments\": pyproject_toml[\"project\"][\"optional-dependencies\"][\n \"instruments\"\n ],\n }\n instrumentation[\"requirement\"] = \"==\".join(\n (\n instrumentation[\"name\"],\n instrumentation[\"version\"],\n )\n )\n yield instrumentation\n\n\nif __name__ == \"__main__\":\n print(list(get_instrumentation_packages()))\n", "path": "scripts/otel_packaging.py"}]}
| 3,943 | 948 |
gh_patches_debug_10196
|
rasdani/github-patches
|
git_diff
|
plotly__dash-1384
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
prevent_initial_call in callback throws exception [BUG]
Thank you so much for helping improve the quality of Dash!
We do our best to catch bugs during the release process, but we rely on your help to find the ones that slip through.
**Describe your context**
Please provide us your environment so we can easily reproduce the issue.
- replace the result of `pip list | grep dash` below
```
dash 1.15.0
dash-bootstrap-components 0.9.2
dash-core-components 1.11.0
dash-html-components 1.1.0
dash-renderer 1.7.0
dash-table 4.10.0
```
**Describe the bug**
With the release of Dash 1.15.0. Setting prevent_initial_call in a callback now throws an exception.
It appears prevent_initial_call must be explicitly provided as a named parameter ex. prevent_initial_call=True. This was not previously the case if all parameters (Output, Input, State, and prevent_initial_call) were provided.
File "C:\Program Files\Python36\lib\site-packages\dash\dash.py", line 980, in callback
_args, _kwargs
File "C:\Program Files\Python36\lib\site-packages\dash\dependencies.py", line 159, in handle_callback_args
prevent_initial_call = args.pop()
AttributeError: 'tuple' object has no attribute 'pop'
**Expected behavior**
An exception should not be thrown.
prevent_initial_call in callback throws exception [BUG]
Thank you so much for helping improve the quality of Dash!
We do our best to catch bugs during the release process, but we rely on your help to find the ones that slip through.
**Describe your context**
Please provide us your environment so we can easily reproduce the issue.
- replace the result of `pip list | grep dash` below
```
dash 1.15.0
dash-bootstrap-components 0.9.2
dash-core-components 1.11.0
dash-html-components 1.1.0
dash-renderer 1.7.0
dash-table 4.10.0
```
**Describe the bug**
With the release of Dash 1.15.0. Setting prevent_initial_call in a callback now throws an exception.
It appears prevent_initial_call must be explicitly provided as a named parameter ex. prevent_initial_call=True. This was not previously the case if all parameters (Output, Input, State, and prevent_initial_call) were provided.
File "C:\Program Files\Python36\lib\site-packages\dash\dash.py", line 980, in callback
_args, _kwargs
File "C:\Program Files\Python36\lib\site-packages\dash\dependencies.py", line 159, in handle_callback_args
prevent_initial_call = args.pop()
AttributeError: 'tuple' object has no attribute 'pop'
**Expected behavior**
An exception should not be thrown.
</issue>
<code>
[start of dash/dependencies.py]
1 import json
2
3 from ._validate import validate_callback
4
5
6 class _Wildcard: # pylint: disable=too-few-public-methods
7 def __init__(self, name):
8 self._name = name
9
10 def __str__(self):
11 return self._name
12
13 def __repr__(self):
14 return "<{}>".format(self)
15
16 def to_json(self):
17 # used in serializing wildcards - arrays are not allowed as
18 # id values, so make the wildcards look like length-1 arrays.
19 return '["{}"]'.format(self._name)
20
21
22 MATCH = _Wildcard("MATCH")
23 ALL = _Wildcard("ALL")
24 ALLSMALLER = _Wildcard("ALLSMALLER")
25
26
27 class DashDependency: # pylint: disable=too-few-public-methods
28 def __init__(self, component_id, component_property):
29 self.component_id = component_id
30 self.component_property = component_property
31
32 def __str__(self):
33 return "{}.{}".format(self.component_id_str(), self.component_property)
34
35 def __repr__(self):
36 return "<{} `{}`>".format(self.__class__.__name__, self)
37
38 def component_id_str(self):
39 i = self.component_id
40
41 def _dump(v):
42 return json.dumps(v, sort_keys=True, separators=(",", ":"))
43
44 def _json(k, v):
45 vstr = v.to_json() if hasattr(v, "to_json") else json.dumps(v)
46 return "{}:{}".format(json.dumps(k), vstr)
47
48 if isinstance(i, dict):
49 return "{" + ",".join(_json(k, i[k]) for k in sorted(i)) + "}"
50
51 return i
52
53 def to_dict(self):
54 return {"id": self.component_id_str(), "property": self.component_property}
55
56 def __eq__(self, other):
57 """
58 We use "==" to denote two deps that refer to the same prop on
59 the same component. In the case of wildcard deps, this means
60 the same prop on *at least one* of the same components.
61 """
62 return (
63 isinstance(other, DashDependency)
64 and self.component_property == other.component_property
65 and self._id_matches(other)
66 )
67
68 def _id_matches(self, other):
69 my_id = self.component_id
70 other_id = other.component_id
71 self_dict = isinstance(my_id, dict)
72 other_dict = isinstance(other_id, dict)
73
74 if self_dict != other_dict:
75 return False
76 if self_dict:
77 if set(my_id.keys()) != set(other_id.keys()):
78 return False
79
80 for k, v in my_id.items():
81 other_v = other_id[k]
82 if v == other_v:
83 continue
84 v_wild = isinstance(v, _Wildcard)
85 other_wild = isinstance(other_v, _Wildcard)
86 if v_wild or other_wild:
87 if not (v_wild and other_wild):
88 continue # one wild, one not
89 if v is ALL or other_v is ALL:
90 continue # either ALL
91 if v is MATCH or other_v is MATCH:
92 return False # one MATCH, one ALLSMALLER
93 else:
94 return False
95 return True
96
97 # both strings
98 return my_id == other_id
99
100 def __hash__(self):
101 return hash(str(self))
102
103
104 class Output(DashDependency): # pylint: disable=too-few-public-methods
105 """Output of a callback."""
106
107 allowed_wildcards = (MATCH, ALL)
108
109
110 class Input(DashDependency): # pylint: disable=too-few-public-methods
111 """Input of callback: trigger an update when it is updated."""
112
113 allowed_wildcards = (MATCH, ALL, ALLSMALLER)
114
115
116 class State(DashDependency): # pylint: disable=too-few-public-methods
117 """Use the value of a State in a callback but don't trigger updates."""
118
119 allowed_wildcards = (MATCH, ALL, ALLSMALLER)
120
121
122 class ClientsideFunction: # pylint: disable=too-few-public-methods
123 def __init__(self, namespace=None, function_name=None):
124
125 if namespace.startswith("_dashprivate_"):
126 raise ValueError("Namespaces cannot start with '_dashprivate_'.")
127
128 if namespace in ["PreventUpdate", "no_update"]:
129 raise ValueError(
130 '"{}" is a forbidden namespace in' " dash_clientside.".format(namespace)
131 )
132
133 self.namespace = namespace
134 self.function_name = function_name
135
136 def __repr__(self):
137 return "ClientsideFunction({}, {})".format(self.namespace, self.function_name)
138
139
140 def extract_callback_args(args, kwargs, name, type_):
141 """Extract arguments for callback from a name and type"""
142 parameters = kwargs.get(name, [])
143 if parameters:
144 if not isinstance(parameters, (list, tuple)):
145 # accept a single item, not wrapped in a list, for any of the
146 # categories as a named arg (even though previously only output
147 # could be given unwrapped)
148 return [parameters]
149 else:
150 while args and isinstance(args[0], type_):
151 parameters.append(args.pop(0))
152 return parameters
153
154
155 def handle_callback_args(args, kwargs):
156 """Split args into outputs, inputs and states"""
157 prevent_initial_call = kwargs.get("prevent_initial_call", None)
158 if prevent_initial_call is None and args and isinstance(args[-1], bool):
159 prevent_initial_call = args.pop()
160
161 # flatten args, to support the older syntax where outputs, inputs, and states
162 # each needed to be in their own list
163 flat_args = []
164 for arg in args:
165 flat_args += arg if isinstance(arg, (list, tuple)) else [arg]
166
167 outputs = extract_callback_args(flat_args, kwargs, "output", Output)
168 validate_outputs = outputs
169 if len(outputs) == 1:
170 out0 = kwargs.get("output", args[0] if args else None)
171 if not isinstance(out0, (list, tuple)):
172 # unless it was explicitly provided as a list, a single output
173 # should be unwrapped. That ensures the return value of the
174 # callback is also not expected to be wrapped in a list.
175 outputs = outputs[0]
176
177 inputs = extract_callback_args(flat_args, kwargs, "inputs", Input)
178 states = extract_callback_args(flat_args, kwargs, "state", State)
179
180 types = Input, Output, State
181 validate_callback(validate_outputs, inputs, states, flat_args, types)
182
183 return outputs, inputs, states, prevent_initial_call
184
[end of dash/dependencies.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/dash/dependencies.py b/dash/dependencies.py
--- a/dash/dependencies.py
+++ b/dash/dependencies.py
@@ -156,7 +156,7 @@
"""Split args into outputs, inputs and states"""
prevent_initial_call = kwargs.get("prevent_initial_call", None)
if prevent_initial_call is None and args and isinstance(args[-1], bool):
- prevent_initial_call = args.pop()
+ args, prevent_initial_call = args[:-1], args[-1]
# flatten args, to support the older syntax where outputs, inputs, and states
# each needed to be in their own list
|
{"golden_diff": "diff --git a/dash/dependencies.py b/dash/dependencies.py\n--- a/dash/dependencies.py\n+++ b/dash/dependencies.py\n@@ -156,7 +156,7 @@\n \"\"\"Split args into outputs, inputs and states\"\"\"\n prevent_initial_call = kwargs.get(\"prevent_initial_call\", None)\n if prevent_initial_call is None and args and isinstance(args[-1], bool):\n- prevent_initial_call = args.pop()\n+ args, prevent_initial_call = args[:-1], args[-1]\n \n # flatten args, to support the older syntax where outputs, inputs, and states\n # each needed to be in their own list\n", "issue": "prevent_initial_call in callback throws exception [BUG]\nThank you so much for helping improve the quality of Dash!\r\n\r\nWe do our best to catch bugs during the release process, but we rely on your help to find the ones that slip through.\r\n\r\n\r\n**Describe your context**\r\nPlease provide us your environment so we can easily reproduce the issue.\r\n\r\n- replace the result of `pip list | grep dash` below\r\n```\r\ndash 1.15.0\r\ndash-bootstrap-components 0.9.2\r\ndash-core-components 1.11.0\r\ndash-html-components 1.1.0\r\ndash-renderer 1.7.0\r\ndash-table 4.10.0\r\n```\r\n\r\n**Describe the bug**\r\n\r\nWith the release of Dash 1.15.0. Setting prevent_initial_call in a callback now throws an exception.\r\nIt appears prevent_initial_call must be explicitly provided as a named parameter ex. prevent_initial_call=True. This was not previously the case if all parameters (Output, Input, State, and prevent_initial_call) were provided.\r\n\r\n File \"C:\\Program Files\\Python36\\lib\\site-packages\\dash\\dash.py\", line 980, in callback\r\n _args, _kwargs\r\n File \"C:\\Program Files\\Python36\\lib\\site-packages\\dash\\dependencies.py\", line 159, in handle_callback_args\r\n prevent_initial_call = args.pop()\r\nAttributeError: 'tuple' object has no attribute 'pop' \r\n\r\n**Expected behavior**\r\n\r\nAn exception should not be thrown.\r\n\r\n\nprevent_initial_call in callback throws exception [BUG]\nThank you so much for helping improve the quality of Dash!\r\n\r\nWe do our best to catch bugs during the release process, but we rely on your help to find the ones that slip through.\r\n\r\n\r\n**Describe your context**\r\nPlease provide us your environment so we can easily reproduce the issue.\r\n\r\n- replace the result of `pip list | grep dash` below\r\n```\r\ndash 1.15.0\r\ndash-bootstrap-components 0.9.2\r\ndash-core-components 1.11.0\r\ndash-html-components 1.1.0\r\ndash-renderer 1.7.0\r\ndash-table 4.10.0\r\n```\r\n\r\n**Describe the bug**\r\n\r\nWith the release of Dash 1.15.0. Setting prevent_initial_call in a callback now throws an exception.\r\nIt appears prevent_initial_call must be explicitly provided as a named parameter ex. prevent_initial_call=True. This was not previously the case if all parameters (Output, Input, State, and prevent_initial_call) were provided.\r\n\r\n File \"C:\\Program Files\\Python36\\lib\\site-packages\\dash\\dash.py\", line 980, in callback\r\n _args, _kwargs\r\n File \"C:\\Program Files\\Python36\\lib\\site-packages\\dash\\dependencies.py\", line 159, in handle_callback_args\r\n prevent_initial_call = args.pop()\r\nAttributeError: 'tuple' object has no attribute 'pop' \r\n\r\n**Expected behavior**\r\n\r\nAn exception should not be thrown.\r\n\r\n\n", "before_files": [{"content": "import json\n\nfrom ._validate import validate_callback\n\n\nclass _Wildcard: # pylint: disable=too-few-public-methods\n def __init__(self, name):\n self._name = name\n\n def __str__(self):\n return self._name\n\n def __repr__(self):\n return \"<{}>\".format(self)\n\n def to_json(self):\n # used in serializing wildcards - arrays are not allowed as\n # id values, so make the wildcards look like length-1 arrays.\n return '[\"{}\"]'.format(self._name)\n\n\nMATCH = _Wildcard(\"MATCH\")\nALL = _Wildcard(\"ALL\")\nALLSMALLER = _Wildcard(\"ALLSMALLER\")\n\n\nclass DashDependency: # pylint: disable=too-few-public-methods\n def __init__(self, component_id, component_property):\n self.component_id = component_id\n self.component_property = component_property\n\n def __str__(self):\n return \"{}.{}\".format(self.component_id_str(), self.component_property)\n\n def __repr__(self):\n return \"<{} `{}`>\".format(self.__class__.__name__, self)\n\n def component_id_str(self):\n i = self.component_id\n\n def _dump(v):\n return json.dumps(v, sort_keys=True, separators=(\",\", \":\"))\n\n def _json(k, v):\n vstr = v.to_json() if hasattr(v, \"to_json\") else json.dumps(v)\n return \"{}:{}\".format(json.dumps(k), vstr)\n\n if isinstance(i, dict):\n return \"{\" + \",\".join(_json(k, i[k]) for k in sorted(i)) + \"}\"\n\n return i\n\n def to_dict(self):\n return {\"id\": self.component_id_str(), \"property\": self.component_property}\n\n def __eq__(self, other):\n \"\"\"\n We use \"==\" to denote two deps that refer to the same prop on\n the same component. In the case of wildcard deps, this means\n the same prop on *at least one* of the same components.\n \"\"\"\n return (\n isinstance(other, DashDependency)\n and self.component_property == other.component_property\n and self._id_matches(other)\n )\n\n def _id_matches(self, other):\n my_id = self.component_id\n other_id = other.component_id\n self_dict = isinstance(my_id, dict)\n other_dict = isinstance(other_id, dict)\n\n if self_dict != other_dict:\n return False\n if self_dict:\n if set(my_id.keys()) != set(other_id.keys()):\n return False\n\n for k, v in my_id.items():\n other_v = other_id[k]\n if v == other_v:\n continue\n v_wild = isinstance(v, _Wildcard)\n other_wild = isinstance(other_v, _Wildcard)\n if v_wild or other_wild:\n if not (v_wild and other_wild):\n continue # one wild, one not\n if v is ALL or other_v is ALL:\n continue # either ALL\n if v is MATCH or other_v is MATCH:\n return False # one MATCH, one ALLSMALLER\n else:\n return False\n return True\n\n # both strings\n return my_id == other_id\n\n def __hash__(self):\n return hash(str(self))\n\n\nclass Output(DashDependency): # pylint: disable=too-few-public-methods\n \"\"\"Output of a callback.\"\"\"\n\n allowed_wildcards = (MATCH, ALL)\n\n\nclass Input(DashDependency): # pylint: disable=too-few-public-methods\n \"\"\"Input of callback: trigger an update when it is updated.\"\"\"\n\n allowed_wildcards = (MATCH, ALL, ALLSMALLER)\n\n\nclass State(DashDependency): # pylint: disable=too-few-public-methods\n \"\"\"Use the value of a State in a callback but don't trigger updates.\"\"\"\n\n allowed_wildcards = (MATCH, ALL, ALLSMALLER)\n\n\nclass ClientsideFunction: # pylint: disable=too-few-public-methods\n def __init__(self, namespace=None, function_name=None):\n\n if namespace.startswith(\"_dashprivate_\"):\n raise ValueError(\"Namespaces cannot start with '_dashprivate_'.\")\n\n if namespace in [\"PreventUpdate\", \"no_update\"]:\n raise ValueError(\n '\"{}\" is a forbidden namespace in' \" dash_clientside.\".format(namespace)\n )\n\n self.namespace = namespace\n self.function_name = function_name\n\n def __repr__(self):\n return \"ClientsideFunction({}, {})\".format(self.namespace, self.function_name)\n\n\ndef extract_callback_args(args, kwargs, name, type_):\n \"\"\"Extract arguments for callback from a name and type\"\"\"\n parameters = kwargs.get(name, [])\n if parameters:\n if not isinstance(parameters, (list, tuple)):\n # accept a single item, not wrapped in a list, for any of the\n # categories as a named arg (even though previously only output\n # could be given unwrapped)\n return [parameters]\n else:\n while args and isinstance(args[0], type_):\n parameters.append(args.pop(0))\n return parameters\n\n\ndef handle_callback_args(args, kwargs):\n \"\"\"Split args into outputs, inputs and states\"\"\"\n prevent_initial_call = kwargs.get(\"prevent_initial_call\", None)\n if prevent_initial_call is None and args and isinstance(args[-1], bool):\n prevent_initial_call = args.pop()\n\n # flatten args, to support the older syntax where outputs, inputs, and states\n # each needed to be in their own list\n flat_args = []\n for arg in args:\n flat_args += arg if isinstance(arg, (list, tuple)) else [arg]\n\n outputs = extract_callback_args(flat_args, kwargs, \"output\", Output)\n validate_outputs = outputs\n if len(outputs) == 1:\n out0 = kwargs.get(\"output\", args[0] if args else None)\n if not isinstance(out0, (list, tuple)):\n # unless it was explicitly provided as a list, a single output\n # should be unwrapped. That ensures the return value of the\n # callback is also not expected to be wrapped in a list.\n outputs = outputs[0]\n\n inputs = extract_callback_args(flat_args, kwargs, \"inputs\", Input)\n states = extract_callback_args(flat_args, kwargs, \"state\", State)\n\n types = Input, Output, State\n validate_callback(validate_outputs, inputs, states, flat_args, types)\n\n return outputs, inputs, states, prevent_initial_call\n", "path": "dash/dependencies.py"}]}
| 3,085 | 143 |
gh_patches_debug_32610
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-center-index-3830
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[package] libuuid/1.0.3: apple_clang 12 build broken by patch
build of libuuid 1.0.3 is broken on macOS11 / apple-clang 12 due to applied patch
the define HAVE_SYS_TIME_H seems to be not defined but the include is valid
```
+#if defined(HAVE_SYS_TIME_H)
#include <sys/time.h>
+#endif
```
this can be fixed by
```
+#if defined(HAVE_SYS_TIME_H) || defined(__APPLE__)
#include <sys/time.h>
+#endif
```
but I guess there is a better way to ensure the define is set for apple platform
</issue>
<code>
[start of recipes/libuuid/all/conanfile.py]
1 from conans import ConanFile, AutoToolsBuildEnvironment, tools
2 from conans.errors import ConanInvalidConfiguration
3 import os
4
5
6 class LibuuidConan(ConanFile):
7 name = "libuuid"
8 description = "Portable uuid C library"
9 url = "https://github.com/conan-io/conan-center-index"
10 homepage = "https://sourceforge.net/projects/libuuid/"
11 license = "BSD-3-Clause"
12 topics = ("conan", "libuuid", "uuid", "unique-id", "unique-identifier")
13 settings = "os", "arch", "compiler", "build_type"
14 exports_sources = "patches/**"
15 options = {"shared": [True, False], "fPIC": [True, False]}
16 default_options = {"shared": False, "fPIC": True}
17 _source_subfolder = "source_subfolder"
18 _autotools = None
19
20 def source(self):
21 tools.get(**self.conan_data["sources"][self.version])
22 os.rename(self.name + "-" + self.version, self._source_subfolder)
23
24 def _patch_sources(self):
25 for patch in self.conan_data["patches"][self.version]:
26 tools.patch(**patch)
27
28 def config_options(self):
29 if self.settings.os == 'Windows':
30 del self.options.fPIC
31
32 def configure(self):
33 if self.settings.os == "Windows":
34 raise ConanInvalidConfiguration("libuuid is not supported on Windows")
35 del self.settings.compiler.libcxx
36 del self.settings.compiler.cppstd
37
38 def _configure_autotools(self):
39 if not self._autotools:
40 configure_args = [
41 "--enable-shared=%s" % ("yes" if self.options.shared else "no"),
42 "--enable-static=%s" % ("no" if self.options.shared else "yes")
43 ]
44 self._autotools = AutoToolsBuildEnvironment(self)
45 if "x86" in self.settings.arch:
46 self._autotools.flags.append('-mstackrealign')
47 self._autotools.configure(args=configure_args)
48 return self._autotools
49
50 def build(self):
51 self._patch_sources()
52 with tools.chdir(self._source_subfolder):
53 autotools = self._configure_autotools()
54 autotools.make()
55
56 def package(self):
57 self.copy("COPYING", dst="licenses", src=self._source_subfolder)
58 with tools.chdir(self._source_subfolder):
59 autotools = self._configure_autotools()
60 autotools.install()
61 la_file = os.path.join(self.package_folder, "lib", "libuuid.la")
62 if os.path.isfile(la_file):
63 os.unlink(la_file)
64 tools.rmdir(os.path.join(self.package_folder, "lib", "pkgconfig"))
65
66 def package_info(self):
67 self.cpp_info.libs = tools.collect_libs(self)
68 self.cpp_info.includedirs.append(os.path.join("include", "uuid"))
69
[end of recipes/libuuid/all/conanfile.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/recipes/libuuid/all/conanfile.py b/recipes/libuuid/all/conanfile.py
--- a/recipes/libuuid/all/conanfile.py
+++ b/recipes/libuuid/all/conanfile.py
@@ -35,29 +35,34 @@
del self.settings.compiler.libcxx
del self.settings.compiler.cppstd
+ def build_requirements(self):
+ self.build_requires("libtool/2.4.6")
+
def _configure_autotools(self):
- if not self._autotools:
- configure_args = [
- "--enable-shared=%s" % ("yes" if self.options.shared else "no"),
- "--enable-static=%s" % ("no" if self.options.shared else "yes")
- ]
- self._autotools = AutoToolsBuildEnvironment(self)
- if "x86" in self.settings.arch:
- self._autotools.flags.append('-mstackrealign')
- self._autotools.configure(args=configure_args)
+ if self._autotools:
+ return self._autotools
+ self._autotools = AutoToolsBuildEnvironment(self)
+ yes_no = lambda v: "yes" if v else "no"
+ configure_args = [
+ "--enable-shared={}".format(yes_no(self.options.shared)),
+ "--enable-static={}".format(yes_no(not self.options.shared)),
+ ]
+ if "x86" in self.settings.arch:
+ self._autotools.flags.append('-mstackrealign')
+ self._autotools.configure(args=configure_args, configure_dir=self._source_subfolder)
return self._autotools
def build(self):
self._patch_sources()
with tools.chdir(self._source_subfolder):
- autotools = self._configure_autotools()
- autotools.make()
+ self.run("autoreconf -fiv", run_environment=True)
+ autotools = self._configure_autotools()
+ autotools.make()
def package(self):
self.copy("COPYING", dst="licenses", src=self._source_subfolder)
- with tools.chdir(self._source_subfolder):
- autotools = self._configure_autotools()
- autotools.install()
+ autotools = self._configure_autotools()
+ autotools.install()
la_file = os.path.join(self.package_folder, "lib", "libuuid.la")
if os.path.isfile(la_file):
os.unlink(la_file)
|
{"golden_diff": "diff --git a/recipes/libuuid/all/conanfile.py b/recipes/libuuid/all/conanfile.py\n--- a/recipes/libuuid/all/conanfile.py\n+++ b/recipes/libuuid/all/conanfile.py\n@@ -35,29 +35,34 @@\n del self.settings.compiler.libcxx\n del self.settings.compiler.cppstd\n \n+ def build_requirements(self):\n+ self.build_requires(\"libtool/2.4.6\")\n+\n def _configure_autotools(self):\n- if not self._autotools:\n- configure_args = [\n- \"--enable-shared=%s\" % (\"yes\" if self.options.shared else \"no\"),\n- \"--enable-static=%s\" % (\"no\" if self.options.shared else \"yes\")\n- ]\n- self._autotools = AutoToolsBuildEnvironment(self)\n- if \"x86\" in self.settings.arch:\n- self._autotools.flags.append('-mstackrealign')\n- self._autotools.configure(args=configure_args)\n+ if self._autotools:\n+ return self._autotools\n+ self._autotools = AutoToolsBuildEnvironment(self)\n+ yes_no = lambda v: \"yes\" if v else \"no\"\n+ configure_args = [\n+ \"--enable-shared={}\".format(yes_no(self.options.shared)),\n+ \"--enable-static={}\".format(yes_no(not self.options.shared)),\n+ ]\n+ if \"x86\" in self.settings.arch:\n+ self._autotools.flags.append('-mstackrealign')\n+ self._autotools.configure(args=configure_args, configure_dir=self._source_subfolder)\n return self._autotools\n \n def build(self):\n self._patch_sources()\n with tools.chdir(self._source_subfolder):\n- autotools = self._configure_autotools()\n- autotools.make()\n+ self.run(\"autoreconf -fiv\", run_environment=True)\n+ autotools = self._configure_autotools()\n+ autotools.make()\n \n def package(self):\n self.copy(\"COPYING\", dst=\"licenses\", src=self._source_subfolder)\n- with tools.chdir(self._source_subfolder):\n- autotools = self._configure_autotools()\n- autotools.install()\n+ autotools = self._configure_autotools()\n+ autotools.install()\n la_file = os.path.join(self.package_folder, \"lib\", \"libuuid.la\")\n if os.path.isfile(la_file):\n os.unlink(la_file)\n", "issue": "[package] libuuid/1.0.3: apple_clang 12 build broken by patch\nbuild of libuuid 1.0.3 is broken on macOS11 / apple-clang 12 due to applied patch\r\nthe define HAVE_SYS_TIME_H seems to be not defined but the include is valid\r\n\r\n```\r\n+#if defined(HAVE_SYS_TIME_H)\r\n #include <sys/time.h>\r\n+#endif\r\n```\r\n\r\nthis can be fixed by \r\n\r\n```\r\n+#if defined(HAVE_SYS_TIME_H) || defined(__APPLE__)\r\n #include <sys/time.h>\r\n+#endif\r\n```\r\n\r\nbut I guess there is a better way to ensure the define is set for apple platform\r\n\n", "before_files": [{"content": "from conans import ConanFile, AutoToolsBuildEnvironment, tools\nfrom conans.errors import ConanInvalidConfiguration\nimport os\n\n\nclass LibuuidConan(ConanFile):\n name = \"libuuid\"\n description = \"Portable uuid C library\"\n url = \"https://github.com/conan-io/conan-center-index\"\n homepage = \"https://sourceforge.net/projects/libuuid/\"\n license = \"BSD-3-Clause\"\n topics = (\"conan\", \"libuuid\", \"uuid\", \"unique-id\", \"unique-identifier\")\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n exports_sources = \"patches/**\"\n options = {\"shared\": [True, False], \"fPIC\": [True, False]}\n default_options = {\"shared\": False, \"fPIC\": True}\n _source_subfolder = \"source_subfolder\"\n _autotools = None\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version])\n os.rename(self.name + \"-\" + self.version, self._source_subfolder)\n\n def _patch_sources(self):\n for patch in self.conan_data[\"patches\"][self.version]:\n tools.patch(**patch)\n\n def config_options(self):\n if self.settings.os == 'Windows':\n del self.options.fPIC\n\n def configure(self):\n if self.settings.os == \"Windows\":\n raise ConanInvalidConfiguration(\"libuuid is not supported on Windows\")\n del self.settings.compiler.libcxx\n del self.settings.compiler.cppstd\n\n def _configure_autotools(self):\n if not self._autotools:\n configure_args = [\n \"--enable-shared=%s\" % (\"yes\" if self.options.shared else \"no\"),\n \"--enable-static=%s\" % (\"no\" if self.options.shared else \"yes\")\n ]\n self._autotools = AutoToolsBuildEnvironment(self)\n if \"x86\" in self.settings.arch:\n self._autotools.flags.append('-mstackrealign')\n self._autotools.configure(args=configure_args)\n return self._autotools\n\n def build(self):\n self._patch_sources()\n with tools.chdir(self._source_subfolder):\n autotools = self._configure_autotools()\n autotools.make()\n\n def package(self):\n self.copy(\"COPYING\", dst=\"licenses\", src=self._source_subfolder)\n with tools.chdir(self._source_subfolder):\n autotools = self._configure_autotools()\n autotools.install()\n la_file = os.path.join(self.package_folder, \"lib\", \"libuuid.la\")\n if os.path.isfile(la_file):\n os.unlink(la_file)\n tools.rmdir(os.path.join(self.package_folder, \"lib\", \"pkgconfig\"))\n\n def package_info(self):\n self.cpp_info.libs = tools.collect_libs(self)\n self.cpp_info.includedirs.append(os.path.join(\"include\", \"uuid\"))\n", "path": "recipes/libuuid/all/conanfile.py"}]}
| 1,446 | 558 |
gh_patches_debug_61268
|
rasdani/github-patches
|
git_diff
|
lk-geimfari__mimesis-433
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fix mypy issues
There are several things to consider:
1. Fixing bugs like this one: https://travis-ci.org/lk-geimfari/mimesis/jobs/361128185#L600
2. Adding new options to `mypy` to make it stricter: https://github.com/wemake-services/wemake-django-template/blob/master/%7B%7Bcookiecutter.project_name%7D%7D/setup.cfg#L67
3. Add `tests` folder to be checked by `mypy` (not only `mimesis/` folder is checked)
I can do it, if @lk-geimfari does not have anything to add/comment.
</issue>
<code>
[start of mimesis/providers/payment.py]
1 """Provides data related to payment."""
2
3 import re
4 import string
5 from typing import Optional
6
7 from mimesis.data import CREDIT_CARD_NETWORKS
8 from mimesis.enums import CardType, Gender
9 from mimesis.exceptions import NonEnumerableError
10 from mimesis.helpers import get_random_item
11 from mimesis.providers.base import BaseDataProvider
12 from mimesis.providers.person import Person
13 from mimesis.utils import luhn_checksum
14
15 __all__ = ['Payment']
16
17
18 class Payment(BaseDataProvider):
19 """Class that provides data related to payments."""
20
21 def __init__(self, *args, **kwargs) -> None:
22 """Initialize attributes.
23
24 :param args: Arguments.
25 :param kwargs: Keyword arguments.
26 """
27 super().__init__(*args, **kwargs)
28 self.__person = Person('en', seed=self.seed)
29
30 def cid(self) -> int:
31 """Generate a random CID.
32
33 :return: CID code.
34
35 :Example:
36 7452
37 """
38 return self.random.randint(1000, 9999)
39
40 def paypal(self) -> str:
41 """Generate a random PayPal account.
42
43 :return: Email of PapPal user.
44
45 :Example:
46 [email protected]
47 """
48 return self.__person.email()
49
50 def bitcoin_address(self) -> str:
51 """Generate a random bitcoin address.
52
53 :return: Bitcoin address.
54
55 :Example:
56 3EktnHQD7RiAE6uzMj2ZifT9YgRrkSgzQX
57 """
58 type_ = self.random.choice(['1', '3'])
59 letters = string.ascii_letters + string.digits
60 return type_ + ''.join(
61 self.random.choice(letters) for _ in range(33))
62
63 def ethereum_address(self) -> str:
64 """Generate a random Ethereum address.
65
66 .. Note: The address will look like Ethereum address,
67 but keep in mind that it is not the valid address.
68
69 :return: Ethereum address.
70
71 :Example:
72 0xe8ece9e6ff7dba52d4c07d37418036a89af9698d
73 """
74 bits = self.random.getrandbits(160)
75 address = bits.to_bytes(20, byteorder='big')
76 return '0x' + address.hex()
77
78 def credit_card_network(self) -> str:
79 """Generate a random credit card network.
80
81 :return: Credit card network
82
83 :Example:
84 MasterCard
85 """
86 return self.random.choice(CREDIT_CARD_NETWORKS)
87
88 def credit_card_number(self, card_type: Optional[CardType] = None) -> str:
89 """Generate a random credit card number.
90
91 :param card_type: Issuing Network. Default is Visa.
92 :return: Credit card number.
93 :raises NotImplementedError: if cart_type is not supported.
94
95 :Example:
96 4455 5299 1152 2450
97 """
98 length = 16
99 regex = re.compile('(\d{4})(\d{4})(\d{4})(\d{4})')
100
101 if card_type is None:
102 card_type = get_random_item(CardType, rnd=self.random)
103
104 if card_type == CardType.VISA:
105 number = self.random.randint(4000, 4999)
106 elif card_type == CardType.MASTER_CARD:
107 number = self.random.choice([
108 self.random.randint(2221, 2720),
109 self.random.randint(5100, 5500),
110 ])
111 elif card_type == CardType.AMERICAN_EXPRESS:
112 number = self.random.choice([34, 37])
113 length = 15
114 regex = re.compile('(\d{4})(\d{6})(\d{5})')
115 else:
116 raise NonEnumerableError(CardType)
117
118 str_num = str(number)
119 while len(str_num) < length - 1:
120 str_num += self.random.choice(string.digits)
121
122 groups = regex.search(str_num + luhn_checksum(str_num)).groups()
123 card = ' '.join(groups)
124 return card
125
126 def credit_card_expiration_date(self, minimum: int = 16,
127 maximum: int = 25) -> str:
128 """Generate a random expiration date for credit card.
129
130 :param minimum: Date of issue.
131 :param maximum: Maximum of expiration_date.
132 :return: Expiration date of credit card.
133
134 :Example:
135 03/19.
136 """
137 month = self.random.randint(1, 12)
138 year = self.random.randint(minimum, maximum)
139 return '{0:02d}/{1}'.format(month, year)
140
141 def cvv(self) -> int:
142 """Generate a random CVV.
143
144 :return: CVV code.
145
146 :Example:
147 324
148 """
149 return self.random.randint(100, 999)
150
151 def credit_card_owner(self, gender: Optional[Gender] = None) -> dict:
152 """Generate credit card owner.
153
154 :param gender: Gender of credit card owner.
155 :type gender: Gender's enum object.
156 :return:
157 """
158 owner = {
159 'credit_card': self.credit_card_number(),
160 'expiration_date': self.credit_card_expiration_date(),
161 'owner': self.__person.full_name(gender=gender).upper(),
162 }
163 return owner
164
[end of mimesis/providers/payment.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mimesis/providers/payment.py b/mimesis/providers/payment.py
--- a/mimesis/providers/payment.py
+++ b/mimesis/providers/payment.py
@@ -119,7 +119,9 @@
while len(str_num) < length - 1:
str_num += self.random.choice(string.digits)
- groups = regex.search(str_num + luhn_checksum(str_num)).groups()
+ groups = regex.search( # type: ignore
+ str_num + luhn_checksum(str_num),
+ ).groups()
card = ' '.join(groups)
return card
|
{"golden_diff": "diff --git a/mimesis/providers/payment.py b/mimesis/providers/payment.py\n--- a/mimesis/providers/payment.py\n+++ b/mimesis/providers/payment.py\n@@ -119,7 +119,9 @@\n while len(str_num) < length - 1:\n str_num += self.random.choice(string.digits)\n \n- groups = regex.search(str_num + luhn_checksum(str_num)).groups()\n+ groups = regex.search( # type: ignore\n+ str_num + luhn_checksum(str_num),\n+ ).groups()\n card = ' '.join(groups)\n return card\n", "issue": "Fix mypy issues\nThere are several things to consider:\r\n\r\n1. Fixing bugs like this one: https://travis-ci.org/lk-geimfari/mimesis/jobs/361128185#L600\r\n2. Adding new options to `mypy` to make it stricter: https://github.com/wemake-services/wemake-django-template/blob/master/%7B%7Bcookiecutter.project_name%7D%7D/setup.cfg#L67\r\n3. Add `tests` folder to be checked by `mypy` (not only `mimesis/` folder is checked)\r\n\r\nI can do it, if @lk-geimfari does not have anything to add/comment.\n", "before_files": [{"content": "\"\"\"Provides data related to payment.\"\"\"\n\nimport re\nimport string\nfrom typing import Optional\n\nfrom mimesis.data import CREDIT_CARD_NETWORKS\nfrom mimesis.enums import CardType, Gender\nfrom mimesis.exceptions import NonEnumerableError\nfrom mimesis.helpers import get_random_item\nfrom mimesis.providers.base import BaseDataProvider\nfrom mimesis.providers.person import Person\nfrom mimesis.utils import luhn_checksum\n\n__all__ = ['Payment']\n\n\nclass Payment(BaseDataProvider):\n \"\"\"Class that provides data related to payments.\"\"\"\n\n def __init__(self, *args, **kwargs) -> None:\n \"\"\"Initialize attributes.\n\n :param args: Arguments.\n :param kwargs: Keyword arguments.\n \"\"\"\n super().__init__(*args, **kwargs)\n self.__person = Person('en', seed=self.seed)\n\n def cid(self) -> int:\n \"\"\"Generate a random CID.\n\n :return: CID code.\n\n :Example:\n 7452\n \"\"\"\n return self.random.randint(1000, 9999)\n\n def paypal(self) -> str:\n \"\"\"Generate a random PayPal account.\n\n :return: Email of PapPal user.\n\n :Example:\n [email protected]\n \"\"\"\n return self.__person.email()\n\n def bitcoin_address(self) -> str:\n \"\"\"Generate a random bitcoin address.\n\n :return: Bitcoin address.\n\n :Example:\n 3EktnHQD7RiAE6uzMj2ZifT9YgRrkSgzQX\n \"\"\"\n type_ = self.random.choice(['1', '3'])\n letters = string.ascii_letters + string.digits\n return type_ + ''.join(\n self.random.choice(letters) for _ in range(33))\n\n def ethereum_address(self) -> str:\n \"\"\"Generate a random Ethereum address.\n\n .. Note: The address will look like Ethereum address,\n but keep in mind that it is not the valid address.\n\n :return: Ethereum address.\n\n :Example:\n 0xe8ece9e6ff7dba52d4c07d37418036a89af9698d\n \"\"\"\n bits = self.random.getrandbits(160)\n address = bits.to_bytes(20, byteorder='big')\n return '0x' + address.hex()\n\n def credit_card_network(self) -> str:\n \"\"\"Generate a random credit card network.\n\n :return: Credit card network\n\n :Example:\n MasterCard\n \"\"\"\n return self.random.choice(CREDIT_CARD_NETWORKS)\n\n def credit_card_number(self, card_type: Optional[CardType] = None) -> str:\n \"\"\"Generate a random credit card number.\n\n :param card_type: Issuing Network. Default is Visa.\n :return: Credit card number.\n :raises NotImplementedError: if cart_type is not supported.\n\n :Example:\n 4455 5299 1152 2450\n \"\"\"\n length = 16\n regex = re.compile('(\\d{4})(\\d{4})(\\d{4})(\\d{4})')\n\n if card_type is None:\n card_type = get_random_item(CardType, rnd=self.random)\n\n if card_type == CardType.VISA:\n number = self.random.randint(4000, 4999)\n elif card_type == CardType.MASTER_CARD:\n number = self.random.choice([\n self.random.randint(2221, 2720),\n self.random.randint(5100, 5500),\n ])\n elif card_type == CardType.AMERICAN_EXPRESS:\n number = self.random.choice([34, 37])\n length = 15\n regex = re.compile('(\\d{4})(\\d{6})(\\d{5})')\n else:\n raise NonEnumerableError(CardType)\n\n str_num = str(number)\n while len(str_num) < length - 1:\n str_num += self.random.choice(string.digits)\n\n groups = regex.search(str_num + luhn_checksum(str_num)).groups()\n card = ' '.join(groups)\n return card\n\n def credit_card_expiration_date(self, minimum: int = 16,\n maximum: int = 25) -> str:\n \"\"\"Generate a random expiration date for credit card.\n\n :param minimum: Date of issue.\n :param maximum: Maximum of expiration_date.\n :return: Expiration date of credit card.\n\n :Example:\n 03/19.\n \"\"\"\n month = self.random.randint(1, 12)\n year = self.random.randint(minimum, maximum)\n return '{0:02d}/{1}'.format(month, year)\n\n def cvv(self) -> int:\n \"\"\"Generate a random CVV.\n\n :return: CVV code.\n\n :Example:\n 324\n \"\"\"\n return self.random.randint(100, 999)\n\n def credit_card_owner(self, gender: Optional[Gender] = None) -> dict:\n \"\"\"Generate credit card owner.\n\n :param gender: Gender of credit card owner.\n :type gender: Gender's enum object.\n :return:\n \"\"\"\n owner = {\n 'credit_card': self.credit_card_number(),\n 'expiration_date': self.credit_card_expiration_date(),\n 'owner': self.__person.full_name(gender=gender).upper(),\n }\n return owner\n", "path": "mimesis/providers/payment.py"}]}
| 2,304 | 132 |
gh_patches_debug_6525
|
rasdani/github-patches
|
git_diff
|
pre-commit__pre-commit-2323
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Pre-commit does not always automatically re-apply patch when stopped with Ctrl-C
As mentioned in this issue:
> if you can reproduce your findings where it doesn't re-apply I'd be more interested in that
_Originally posted by @asottile in https://github.com/pre-commit/pre-commit/issues/2251#issuecomment-1043529759_
----
I reproduced it once, although unfortunately I can't share the config since it is from a private repository in my organization, I do have a log which might provide a clue where this is happening.
In this case, the affected repo uses around 35 hooks, some custom and some from various upstreams. I was doing a `git commit --amend` but forgot to stage some changes, so I canceled to try a `git commit --amend -a` instead, when I hit the issue.
### version information
```
pre-commit version: 2.17.0
git --version: git version 2.32.0
sys.version:
3.6.8 (default, Dec 2 2020, 12:54:58)
[GCC Apple LLVM 12.0.0 (clang-1200.0.32.27)]
sys.executable: /Users/ichamberlain/.pyenv/versions/3.6.8/envs/i95-py3/bin/python
os.name: posix
sys.platform: darwin
```
### error information
```
Interrupted (^C): KeyboardInterrupt:
```
```
Traceback (most recent call last):
File "/Users/ichamberlain/.pyenv/versions/3.6.8/envs/i95-py3/lib/python3.6/site-packages/pre_commit/error_handler.py", line 70, in error_handler
yield
File "/Users/ichamberlain/.pyenv/versions/3.6.8/envs/i95-py3/lib/python3.6/site-packages/pre_commit/main.py", line 375, in main
args=args.rest[1:],
File "/Users/ichamberlain/.pyenv/versions/3.6.8/envs/i95-py3/lib/python3.6/site-packages/pre_commit/commands/hook_impl.py", line 237, in hook_impl
return retv | run(config, store, ns)
File "/Users/ichamberlain/.pyenv/versions/3.6.8/envs/i95-py3/lib/python3.6/site-packages/pre_commit/commands/run.py", line 398, in run
exit_stack.enter_context(staged_files_only(store.directory))
File "/Users/ichamberlain/.pyenv/versions/3.6.8/lib/python3.6/contextlib.py", line 330, in enter_context
result = _cm_type.__enter__(cm)
File "/Users/ichamberlain/.pyenv/versions/3.6.8/lib/python3.6/contextlib.py", line 81, in __enter__
return next(self.gen)
File "/Users/ichamberlain/.pyenv/versions/3.6.8/envs/i95-py3/lib/python3.6/site-packages/pre_commit/staged_files_only.py", line 98, in staged_files_only
with _intent_to_add_cleared(), _unstaged_changes_cleared(patch_dir):
File "/Users/ichamberlain/.pyenv/versions/3.6.8/lib/python3.6/contextlib.py", line 81, in __enter__
return next(self.gen)
File "/Users/ichamberlain/.pyenv/versions/3.6.8/envs/i95-py3/lib/python3.6/site-packages/pre_commit/staged_files_only.py", line 67, in _unstaged_changes_cleared
cmd_output_b(*_CHECKOUT_CMD, env=no_checkout_env)
File "/Users/ichamberlain/.pyenv/versions/3.6.8/envs/i95-py3/lib/python3.6/site-packages/pre_commit/util.py", line 150, in cmd_output_b
stdout_b, stderr_b = proc.communicate()
File "/Users/ichamberlain/.pyenv/versions/3.6.8/lib/python3.6/subprocess.py", line 863, in communicate
stdout, stderr = self._communicate(input, endtime, timeout)
File "/Users/ichamberlain/.pyenv/versions/3.6.8/lib/python3.6/subprocess.py", line 1534, in _communicate
ready = selector.select(timeout)
File "/Users/ichamberlain/.pyenv/versions/3.6.8/lib/python3.6/selectors.py", line 376, in select
fd_event_list = self._poll.poll(timeout)
KeyboardInterrupt
```
</issue>
<code>
[start of pre_commit/staged_files_only.py]
1 from __future__ import annotations
2
3 import contextlib
4 import logging
5 import os.path
6 import time
7 from typing import Generator
8
9 from pre_commit import git
10 from pre_commit.util import CalledProcessError
11 from pre_commit.util import cmd_output
12 from pre_commit.util import cmd_output_b
13 from pre_commit.xargs import xargs
14
15
16 logger = logging.getLogger('pre_commit')
17
18 # without forcing submodule.recurse=0, changes in nested submodules will be
19 # discarded if `submodule.recurse=1` is configured
20 # we choose this instead of `--no-recurse-submodules` because it works on
21 # versions of git before that option was added to `git checkout`
22 _CHECKOUT_CMD = ('git', '-c', 'submodule.recurse=0', 'checkout', '--', '.')
23
24
25 def _git_apply(patch: str) -> None:
26 args = ('apply', '--whitespace=nowarn', patch)
27 try:
28 cmd_output_b('git', *args)
29 except CalledProcessError:
30 # Retry with autocrlf=false -- see #570
31 cmd_output_b('git', '-c', 'core.autocrlf=false', *args)
32
33
34 @contextlib.contextmanager
35 def _intent_to_add_cleared() -> Generator[None, None, None]:
36 intent_to_add = git.intent_to_add_files()
37 if intent_to_add:
38 logger.warning('Unstaged intent-to-add files detected.')
39
40 xargs(('git', 'rm', '--cached', '--'), intent_to_add)
41 try:
42 yield
43 finally:
44 xargs(('git', 'add', '--intent-to-add', '--'), intent_to_add)
45 else:
46 yield
47
48
49 @contextlib.contextmanager
50 def _unstaged_changes_cleared(patch_dir: str) -> Generator[None, None, None]:
51 tree = cmd_output('git', 'write-tree')[1].strip()
52 retcode, diff_stdout_binary, _ = cmd_output_b(
53 'git', 'diff-index', '--ignore-submodules', '--binary',
54 '--exit-code', '--no-color', '--no-ext-diff', tree, '--',
55 retcode=None,
56 )
57 if retcode and diff_stdout_binary.strip():
58 patch_filename = f'patch{int(time.time())}-{os.getpid()}'
59 patch_filename = os.path.join(patch_dir, patch_filename)
60 logger.warning('Unstaged files detected.')
61 logger.info(f'Stashing unstaged files to {patch_filename}.')
62 # Save the current unstaged changes as a patch
63 os.makedirs(patch_dir, exist_ok=True)
64 with open(patch_filename, 'wb') as patch_file:
65 patch_file.write(diff_stdout_binary)
66
67 # prevent recursive post-checkout hooks (#1418)
68 no_checkout_env = dict(os.environ, _PRE_COMMIT_SKIP_POST_CHECKOUT='1')
69 cmd_output_b(*_CHECKOUT_CMD, env=no_checkout_env)
70
71 try:
72 yield
73 finally:
74 # Try to apply the patch we saved
75 try:
76 _git_apply(patch_filename)
77 except CalledProcessError:
78 logger.warning(
79 'Stashed changes conflicted with hook auto-fixes... '
80 'Rolling back fixes...',
81 )
82 # We failed to apply the patch, presumably due to fixes made
83 # by hooks.
84 # Roll back the changes made by hooks.
85 cmd_output_b(*_CHECKOUT_CMD, env=no_checkout_env)
86 _git_apply(patch_filename)
87
88 logger.info(f'Restored changes from {patch_filename}.')
89 else:
90 # There weren't any staged files so we don't need to do anything
91 # special
92 yield
93
94
95 @contextlib.contextmanager
96 def staged_files_only(patch_dir: str) -> Generator[None, None, None]:
97 """Clear any unstaged changes from the git working directory inside this
98 context.
99 """
100 with _intent_to_add_cleared(), _unstaged_changes_cleared(patch_dir):
101 yield
102
[end of pre_commit/staged_files_only.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pre_commit/staged_files_only.py b/pre_commit/staged_files_only.py
--- a/pre_commit/staged_files_only.py
+++ b/pre_commit/staged_files_only.py
@@ -66,9 +66,9 @@
# prevent recursive post-checkout hooks (#1418)
no_checkout_env = dict(os.environ, _PRE_COMMIT_SKIP_POST_CHECKOUT='1')
- cmd_output_b(*_CHECKOUT_CMD, env=no_checkout_env)
try:
+ cmd_output_b(*_CHECKOUT_CMD, env=no_checkout_env)
yield
finally:
# Try to apply the patch we saved
|
{"golden_diff": "diff --git a/pre_commit/staged_files_only.py b/pre_commit/staged_files_only.py\n--- a/pre_commit/staged_files_only.py\n+++ b/pre_commit/staged_files_only.py\n@@ -66,9 +66,9 @@\n \n # prevent recursive post-checkout hooks (#1418)\n no_checkout_env = dict(os.environ, _PRE_COMMIT_SKIP_POST_CHECKOUT='1')\n- cmd_output_b(*_CHECKOUT_CMD, env=no_checkout_env)\n \n try:\n+ cmd_output_b(*_CHECKOUT_CMD, env=no_checkout_env)\n yield\n finally:\n # Try to apply the patch we saved\n", "issue": "Pre-commit does not always automatically re-apply patch when stopped with Ctrl-C\nAs mentioned in this issue:\r\n\r\n> if you can reproduce your findings where it doesn't re-apply I'd be more interested in that\r\n\r\n_Originally posted by @asottile in https://github.com/pre-commit/pre-commit/issues/2251#issuecomment-1043529759_\r\n\r\n----\r\n\r\nI reproduced it once, although unfortunately I can't share the config since it is from a private repository in my organization, I do have a log which might provide a clue where this is happening.\r\n\r\nIn this case, the affected repo uses around 35 hooks, some custom and some from various upstreams. I was doing a `git commit --amend` but forgot to stage some changes, so I canceled to try a `git commit --amend -a` instead, when I hit the issue.\r\n\r\n### version information\r\n\r\n```\r\npre-commit version: 2.17.0\r\ngit --version: git version 2.32.0\r\nsys.version:\r\n 3.6.8 (default, Dec 2 2020, 12:54:58) \r\n [GCC Apple LLVM 12.0.0 (clang-1200.0.32.27)]\r\nsys.executable: /Users/ichamberlain/.pyenv/versions/3.6.8/envs/i95-py3/bin/python\r\nos.name: posix\r\nsys.platform: darwin\r\n```\r\n\r\n### error information\r\n\r\n```\r\nInterrupted (^C): KeyboardInterrupt: \r\n```\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/Users/ichamberlain/.pyenv/versions/3.6.8/envs/i95-py3/lib/python3.6/site-packages/pre_commit/error_handler.py\", line 70, in error_handler\r\n yield\r\n File \"/Users/ichamberlain/.pyenv/versions/3.6.8/envs/i95-py3/lib/python3.6/site-packages/pre_commit/main.py\", line 375, in main\r\n args=args.rest[1:],\r\n File \"/Users/ichamberlain/.pyenv/versions/3.6.8/envs/i95-py3/lib/python3.6/site-packages/pre_commit/commands/hook_impl.py\", line 237, in hook_impl\r\n return retv | run(config, store, ns)\r\n File \"/Users/ichamberlain/.pyenv/versions/3.6.8/envs/i95-py3/lib/python3.6/site-packages/pre_commit/commands/run.py\", line 398, in run\r\n exit_stack.enter_context(staged_files_only(store.directory))\r\n File \"/Users/ichamberlain/.pyenv/versions/3.6.8/lib/python3.6/contextlib.py\", line 330, in enter_context\r\n result = _cm_type.__enter__(cm)\r\n File \"/Users/ichamberlain/.pyenv/versions/3.6.8/lib/python3.6/contextlib.py\", line 81, in __enter__\r\n return next(self.gen)\r\n File \"/Users/ichamberlain/.pyenv/versions/3.6.8/envs/i95-py3/lib/python3.6/site-packages/pre_commit/staged_files_only.py\", line 98, in staged_files_only\r\n with _intent_to_add_cleared(), _unstaged_changes_cleared(patch_dir):\r\n File \"/Users/ichamberlain/.pyenv/versions/3.6.8/lib/python3.6/contextlib.py\", line 81, in __enter__\r\n return next(self.gen)\r\n File \"/Users/ichamberlain/.pyenv/versions/3.6.8/envs/i95-py3/lib/python3.6/site-packages/pre_commit/staged_files_only.py\", line 67, in _unstaged_changes_cleared\r\n cmd_output_b(*_CHECKOUT_CMD, env=no_checkout_env)\r\n File \"/Users/ichamberlain/.pyenv/versions/3.6.8/envs/i95-py3/lib/python3.6/site-packages/pre_commit/util.py\", line 150, in cmd_output_b\r\n stdout_b, stderr_b = proc.communicate()\r\n File \"/Users/ichamberlain/.pyenv/versions/3.6.8/lib/python3.6/subprocess.py\", line 863, in communicate\r\n stdout, stderr = self._communicate(input, endtime, timeout)\r\n File \"/Users/ichamberlain/.pyenv/versions/3.6.8/lib/python3.6/subprocess.py\", line 1534, in _communicate\r\n ready = selector.select(timeout)\r\n File \"/Users/ichamberlain/.pyenv/versions/3.6.8/lib/python3.6/selectors.py\", line 376, in select\r\n fd_event_list = self._poll.poll(timeout)\r\nKeyboardInterrupt\r\n```\n", "before_files": [{"content": "from __future__ import annotations\n\nimport contextlib\nimport logging\nimport os.path\nimport time\nfrom typing import Generator\n\nfrom pre_commit import git\nfrom pre_commit.util import CalledProcessError\nfrom pre_commit.util import cmd_output\nfrom pre_commit.util import cmd_output_b\nfrom pre_commit.xargs import xargs\n\n\nlogger = logging.getLogger('pre_commit')\n\n# without forcing submodule.recurse=0, changes in nested submodules will be\n# discarded if `submodule.recurse=1` is configured\n# we choose this instead of `--no-recurse-submodules` because it works on\n# versions of git before that option was added to `git checkout`\n_CHECKOUT_CMD = ('git', '-c', 'submodule.recurse=0', 'checkout', '--', '.')\n\n\ndef _git_apply(patch: str) -> None:\n args = ('apply', '--whitespace=nowarn', patch)\n try:\n cmd_output_b('git', *args)\n except CalledProcessError:\n # Retry with autocrlf=false -- see #570\n cmd_output_b('git', '-c', 'core.autocrlf=false', *args)\n\n\[email protected]\ndef _intent_to_add_cleared() -> Generator[None, None, None]:\n intent_to_add = git.intent_to_add_files()\n if intent_to_add:\n logger.warning('Unstaged intent-to-add files detected.')\n\n xargs(('git', 'rm', '--cached', '--'), intent_to_add)\n try:\n yield\n finally:\n xargs(('git', 'add', '--intent-to-add', '--'), intent_to_add)\n else:\n yield\n\n\[email protected]\ndef _unstaged_changes_cleared(patch_dir: str) -> Generator[None, None, None]:\n tree = cmd_output('git', 'write-tree')[1].strip()\n retcode, diff_stdout_binary, _ = cmd_output_b(\n 'git', 'diff-index', '--ignore-submodules', '--binary',\n '--exit-code', '--no-color', '--no-ext-diff', tree, '--',\n retcode=None,\n )\n if retcode and diff_stdout_binary.strip():\n patch_filename = f'patch{int(time.time())}-{os.getpid()}'\n patch_filename = os.path.join(patch_dir, patch_filename)\n logger.warning('Unstaged files detected.')\n logger.info(f'Stashing unstaged files to {patch_filename}.')\n # Save the current unstaged changes as a patch\n os.makedirs(patch_dir, exist_ok=True)\n with open(patch_filename, 'wb') as patch_file:\n patch_file.write(diff_stdout_binary)\n\n # prevent recursive post-checkout hooks (#1418)\n no_checkout_env = dict(os.environ, _PRE_COMMIT_SKIP_POST_CHECKOUT='1')\n cmd_output_b(*_CHECKOUT_CMD, env=no_checkout_env)\n\n try:\n yield\n finally:\n # Try to apply the patch we saved\n try:\n _git_apply(patch_filename)\n except CalledProcessError:\n logger.warning(\n 'Stashed changes conflicted with hook auto-fixes... '\n 'Rolling back fixes...',\n )\n # We failed to apply the patch, presumably due to fixes made\n # by hooks.\n # Roll back the changes made by hooks.\n cmd_output_b(*_CHECKOUT_CMD, env=no_checkout_env)\n _git_apply(patch_filename)\n\n logger.info(f'Restored changes from {patch_filename}.')\n else:\n # There weren't any staged files so we don't need to do anything\n # special\n yield\n\n\[email protected]\ndef staged_files_only(patch_dir: str) -> Generator[None, None, None]:\n \"\"\"Clear any unstaged changes from the git working directory inside this\n context.\n \"\"\"\n with _intent_to_add_cleared(), _unstaged_changes_cleared(patch_dir):\n yield\n", "path": "pre_commit/staged_files_only.py"}]}
| 2,666 | 138 |
gh_patches_debug_3365
|
rasdani/github-patches
|
git_diff
|
liberapay__liberapay.com-481
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Logging in has become more difficult
In #421 I optimized the sign-in template for new users, putting the sign-up form on top. This results in the sign-in page (<https://liberapay.com/sign-in>) impeding users that are simply trying to log in.
The solution is simple: use two separate templates.
</issue>
<code>
[start of liberapay/utils/__init__.py]
1 # encoding: utf8
2
3 from __future__ import absolute_import, division, print_function, unicode_literals
4
5 from base64 import b64decode, b64encode
6 from binascii import hexlify, unhexlify
7 from datetime import date, datetime, timedelta
8 import errno
9 import fnmatch
10 import os
11 import pickle
12 import re
13
14 from six import PY3
15 from six.moves.urllib.parse import quote as urlquote
16
17 from pando import Response, json
18 from pando.utils import to_rfc822, utcnow
19 from markupsafe import Markup
20 from postgres.cursors import SimpleCursorBase
21
22 from liberapay.exceptions import AccountSuspended, AuthRequired, LoginRequired
23 from liberapay.models.community import Community
24 from liberapay.utils.i18n import Money
25 from liberapay.website import website
26
27
28 BEGINNING_OF_EPOCH = to_rfc822(datetime(1970, 1, 1)).encode('ascii')
29
30
31 def get_participant(state, restrict=True, redirect_stub=True, allow_member=False,
32 block_suspended_user=False, redirect_canon=True):
33 """Given a Request, raise Response or return Participant.
34
35 If restrict is True then we'll restrict access to owners and admins.
36
37 """
38 request = state['request']
39 response = state['response']
40 user = state['user']
41 slug = request.line.uri.path['username']
42 _ = state['_']
43
44 if restrict and user.ANON:
45 raise LoginRequired
46
47 if slug.startswith('~'):
48 thing = 'id'
49 value = slug[1:]
50 participant = user if user and str(user.id) == value else None
51 else:
52 thing = 'lower(username)'
53 value = slug.lower()
54 participant = user if user and user.username.lower() == value else None
55
56 if participant is None:
57 from liberapay.models.participant import Participant # avoid circular import
58 participant = Participant._from_thing(thing, value) if value else None
59 if participant is None or participant.kind == 'community':
60 raise response.error(404)
61
62 if redirect_canon and request.method in ('GET', 'HEAD'):
63 if slug != participant.username:
64 canon = '/' + participant.username + request.line.uri[len(slug)+1:]
65 raise response.redirect(canon)
66
67 status = participant.status
68 if status == 'closed':
69 if user.is_admin:
70 return participant
71 response.html_template = 'templates/account-closed.html'
72 raise response.error(410)
73 elif status == 'stub':
74 if redirect_stub:
75 to = participant.resolve_stub()
76 assert to
77 raise response.redirect(to)
78
79 if restrict:
80 if participant != user:
81 if allow_member and participant.kind == 'group' and user.member_of(participant):
82 pass
83 elif not user.is_admin:
84 raise response.error(403, _("You are not authorized to access this page."))
85
86 if block_suspended_user and participant.is_suspended and participant == user:
87 raise AccountSuspended()
88
89 return participant
90
91
92 def get_community(state, restrict=False):
93 request, response = state['request'], state['response']
94 user = state['user']
95 name = request.path['name']
96
97 c = Community.from_name(name)
98 if request.method in ('GET', 'HEAD'):
99 if not c:
100 response.redirect('/for/new?name=' + urlquote(name))
101 if c.name != name:
102 response.redirect('/for/' + c.name + request.line.uri[5+len(name):])
103 elif not c:
104 raise response.error(404)
105 elif user.ANON:
106 raise AuthRequired
107
108 if restrict:
109 if user.ANON:
110 raise LoginRequired
111 if user.id != c.creator and not user.is_admin:
112 _ = state['_']
113 raise response.error(403, _("You are not authorized to access this page."))
114
115 return c
116
117
118 def b64decode_s(s, **kw):
119 def error():
120 if 'default' in kw:
121 return kw['default']
122 raise Response(400, "invalid base64 input")
123
124 try:
125 s = s.encode('ascii') if hasattr(s, 'encode') else s
126 except UnicodeError:
127 return error()
128
129 udecode = lambda a: a.decode('utf8')
130 if s[:1] == b'.':
131 udecode = lambda a: a
132 s = s[1:]
133 s = s.replace(b'~', b'=')
134 try:
135 return udecode(b64decode(s, '-_'))
136 except Exception:
137 try:
138 # For retrocompatibility
139 return udecode(b64decode(s))
140 except Exception:
141 pass
142 return error()
143
144
145 def b64encode_s(s):
146 prefix = b''
147 if not isinstance(s, bytes):
148 s = s.encode('utf8')
149 else:
150 # Check whether the string is binary or already utf8
151 try:
152 s.decode('utf8')
153 except UnicodeError:
154 prefix = b'.'
155 r = prefix + b64encode(s, b'-_').replace(b'=', b'~')
156 return r.decode('ascii') if PY3 else r
157
158
159 def update_global_stats(website):
160 website.gnusers = website.db.one("""
161 SELECT count(*)
162 FROM participants
163 WHERE status = 'active'
164 AND kind <> 'community';
165 """)
166 transfer_volume = website.db.one("""
167 SELECT coalesce(sum(amount), 0)
168 FROM current_tips
169 WHERE is_funded
170 """)
171 website.gmonthly_volume = Money(transfer_volume * 52 / 12, 'EUR')
172
173
174 def _execute(this, sql, params=[]):
175 print(sql.strip(), params)
176 super(SimpleCursorBase, this).execute(sql, params)
177
178 def log_cursor(f):
179 "Prints sql and params to stdout. Works globaly so watch for threaded use."
180 def wrapper(*a, **kw):
181 try:
182 SimpleCursorBase.execute = _execute
183 ret = f(*a, **kw)
184 finally:
185 del SimpleCursorBase.execute
186 return ret
187 return wrapper
188
189
190 def excerpt_intro(text, length=175, append='…'):
191 if not text:
192 return ''
193 if len(text) > length:
194 return text[:length] + append
195 return text
196
197
198 def is_card_expired(exp_year, exp_month):
199 today = date.today()
200 cur_year, cur_month = today.year, today.month
201 return exp_year < cur_year or exp_year == cur_year and exp_month < cur_month
202
203
204 def ensure_str(s):
205 if isinstance(s, str):
206 return s
207 return s.decode('ascii') if isinstance(s, bytes) else s.encode('ascii')
208
209
210 def set_cookie(cookies, key, value, expires=None, httponly=True, path='/'):
211 key = ensure_str(key)
212 cookies[key] = ensure_str(value)
213 cookie = cookies[key]
214 if expires:
215 if isinstance(expires, timedelta):
216 expires += utcnow()
217 if isinstance(expires, datetime):
218 expires = to_rfc822(expires)
219 cookie[str('expires')] = ensure_str(expires)
220 if httponly:
221 cookie[str('httponly')] = True
222 if path:
223 cookie[str('path')] = ensure_str(path)
224 if website.canonical_domain:
225 cookie[str('domain')] = ensure_str(website.canonical_domain)
226 if website.canonical_scheme == 'https':
227 cookie[str('secure')] = True
228
229
230 def erase_cookie(cookies, key, **kw):
231 set_cookie(cookies, key, '', BEGINNING_OF_EPOCH, **kw)
232
233
234 def to_javascript(obj):
235 """For when you want to inject an object into a <script> tag.
236 """
237 return json.dumps(obj).replace('</', '<\\/')
238
239
240 svg_attrs_re = re.compile(r'\s+(?:height|width|x|y|xmlns)=(["\']).*?\1')
241
242 def include_svg(svg, height, width, x=None, y=None):
243 """For when you want to include an SVG in an HTML page or in another SVG.
244 """
245 assert svg.startswith('<svg')
246 i = svg.find('>')
247 assert i != -1
248 d = locals()
249 attrs = svg_attrs_re.sub('', svg[4:i])
250 for a in ('height', 'width', 'x', 'y'):
251 v = d[a]
252 if v is None:
253 continue
254 attrs += ' %s="%s"' % (a, v)
255 return Markup(svg[:4] + attrs + svg[i:])
256
257
258 def group_by(iterable, key):
259 r = {}
260 for obj in iterable:
261 try:
262 k = obj[key]
263 except KeyError:
264 continue
265 r.setdefault(k, []).append(obj)
266 return r
267
268
269 def find_files(directory, pattern):
270 for root, dirs, files in os.walk(directory):
271 for filename in fnmatch.filter(files, pattern):
272 yield os.path.join(root, filename)
273
274
275 def serialize(context):
276 for k, v in context.items():
277 if str(type(v)) == "<class 'psycopg2.extras.Record'>":
278 context[k] = v._asdict()
279 return b'\\x' + hexlify(pickle.dumps(context, 2))
280
281
282 def deserialize(context):
283 if isinstance(context, memoryview) and context[:2].tobytes() == b'\\x':
284 context = unhexlify(context[2:])
285 return pickle.loads(context)
286
287
288 def pid_exists(pid):
289 """Check whether pid exists in the current process table. UNIX only.
290
291 Source: http://stackoverflow.com/a/6940314/2729778
292 """
293 if not pid > 0:
294 raise ValueError("bad PID %s" % pid)
295 try:
296 os.kill(pid, 0)
297 except OSError as err:
298 if err.errno == errno.ESRCH:
299 # ESRCH == No such process
300 return False
301 elif err.errno == errno.EPERM:
302 # EPERM clearly means there's a process to deny access to
303 return True
304 else:
305 # According to "man 2 kill" possible error values are
306 # (EINVAL, EPERM, ESRCH)
307 raise
308 else:
309 return True
310
[end of liberapay/utils/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/liberapay/utils/__init__.py b/liberapay/utils/__init__.py
--- a/liberapay/utils/__init__.py
+++ b/liberapay/utils/__init__.py
@@ -68,6 +68,7 @@
if status == 'closed':
if user.is_admin:
return participant
+ state['closed_account'] = participant
response.html_template = 'templates/account-closed.html'
raise response.error(410)
elif status == 'stub':
|
{"golden_diff": "diff --git a/liberapay/utils/__init__.py b/liberapay/utils/__init__.py\n--- a/liberapay/utils/__init__.py\n+++ b/liberapay/utils/__init__.py\n@@ -68,6 +68,7 @@\n if status == 'closed':\n if user.is_admin:\n return participant\n+ state['closed_account'] = participant\n response.html_template = 'templates/account-closed.html'\n raise response.error(410)\n elif status == 'stub':\n", "issue": "Logging in has become more difficult\nIn #421 I optimized the sign-in template for new users, putting the sign-up form on top. This results in the sign-in page (<https://liberapay.com/sign-in>) impeding users that are simply trying to log in.\r\n\r\nThe solution is simple: use two separate templates.\n", "before_files": [{"content": "# encoding: utf8\n\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nfrom base64 import b64decode, b64encode\nfrom binascii import hexlify, unhexlify\nfrom datetime import date, datetime, timedelta\nimport errno\nimport fnmatch\nimport os\nimport pickle\nimport re\n\nfrom six import PY3\nfrom six.moves.urllib.parse import quote as urlquote\n\nfrom pando import Response, json\nfrom pando.utils import to_rfc822, utcnow\nfrom markupsafe import Markup\nfrom postgres.cursors import SimpleCursorBase\n\nfrom liberapay.exceptions import AccountSuspended, AuthRequired, LoginRequired\nfrom liberapay.models.community import Community\nfrom liberapay.utils.i18n import Money\nfrom liberapay.website import website\n\n\nBEGINNING_OF_EPOCH = to_rfc822(datetime(1970, 1, 1)).encode('ascii')\n\n\ndef get_participant(state, restrict=True, redirect_stub=True, allow_member=False,\n block_suspended_user=False, redirect_canon=True):\n \"\"\"Given a Request, raise Response or return Participant.\n\n If restrict is True then we'll restrict access to owners and admins.\n\n \"\"\"\n request = state['request']\n response = state['response']\n user = state['user']\n slug = request.line.uri.path['username']\n _ = state['_']\n\n if restrict and user.ANON:\n raise LoginRequired\n\n if slug.startswith('~'):\n thing = 'id'\n value = slug[1:]\n participant = user if user and str(user.id) == value else None\n else:\n thing = 'lower(username)'\n value = slug.lower()\n participant = user if user and user.username.lower() == value else None\n\n if participant is None:\n from liberapay.models.participant import Participant # avoid circular import\n participant = Participant._from_thing(thing, value) if value else None\n if participant is None or participant.kind == 'community':\n raise response.error(404)\n\n if redirect_canon and request.method in ('GET', 'HEAD'):\n if slug != participant.username:\n canon = '/' + participant.username + request.line.uri[len(slug)+1:]\n raise response.redirect(canon)\n\n status = participant.status\n if status == 'closed':\n if user.is_admin:\n return participant\n response.html_template = 'templates/account-closed.html'\n raise response.error(410)\n elif status == 'stub':\n if redirect_stub:\n to = participant.resolve_stub()\n assert to\n raise response.redirect(to)\n\n if restrict:\n if participant != user:\n if allow_member and participant.kind == 'group' and user.member_of(participant):\n pass\n elif not user.is_admin:\n raise response.error(403, _(\"You are not authorized to access this page.\"))\n\n if block_suspended_user and participant.is_suspended and participant == user:\n raise AccountSuspended()\n\n return participant\n\n\ndef get_community(state, restrict=False):\n request, response = state['request'], state['response']\n user = state['user']\n name = request.path['name']\n\n c = Community.from_name(name)\n if request.method in ('GET', 'HEAD'):\n if not c:\n response.redirect('/for/new?name=' + urlquote(name))\n if c.name != name:\n response.redirect('/for/' + c.name + request.line.uri[5+len(name):])\n elif not c:\n raise response.error(404)\n elif user.ANON:\n raise AuthRequired\n\n if restrict:\n if user.ANON:\n raise LoginRequired\n if user.id != c.creator and not user.is_admin:\n _ = state['_']\n raise response.error(403, _(\"You are not authorized to access this page.\"))\n\n return c\n\n\ndef b64decode_s(s, **kw):\n def error():\n if 'default' in kw:\n return kw['default']\n raise Response(400, \"invalid base64 input\")\n\n try:\n s = s.encode('ascii') if hasattr(s, 'encode') else s\n except UnicodeError:\n return error()\n\n udecode = lambda a: a.decode('utf8')\n if s[:1] == b'.':\n udecode = lambda a: a\n s = s[1:]\n s = s.replace(b'~', b'=')\n try:\n return udecode(b64decode(s, '-_'))\n except Exception:\n try:\n # For retrocompatibility\n return udecode(b64decode(s))\n except Exception:\n pass\n return error()\n\n\ndef b64encode_s(s):\n prefix = b''\n if not isinstance(s, bytes):\n s = s.encode('utf8')\n else:\n # Check whether the string is binary or already utf8\n try:\n s.decode('utf8')\n except UnicodeError:\n prefix = b'.'\n r = prefix + b64encode(s, b'-_').replace(b'=', b'~')\n return r.decode('ascii') if PY3 else r\n\n\ndef update_global_stats(website):\n website.gnusers = website.db.one(\"\"\"\n SELECT count(*)\n FROM participants\n WHERE status = 'active'\n AND kind <> 'community';\n \"\"\")\n transfer_volume = website.db.one(\"\"\"\n SELECT coalesce(sum(amount), 0)\n FROM current_tips\n WHERE is_funded\n \"\"\")\n website.gmonthly_volume = Money(transfer_volume * 52 / 12, 'EUR')\n\n\ndef _execute(this, sql, params=[]):\n print(sql.strip(), params)\n super(SimpleCursorBase, this).execute(sql, params)\n\ndef log_cursor(f):\n \"Prints sql and params to stdout. Works globaly so watch for threaded use.\"\n def wrapper(*a, **kw):\n try:\n SimpleCursorBase.execute = _execute\n ret = f(*a, **kw)\n finally:\n del SimpleCursorBase.execute\n return ret\n return wrapper\n\n\ndef excerpt_intro(text, length=175, append='\u2026'):\n if not text:\n return ''\n if len(text) > length:\n return text[:length] + append\n return text\n\n\ndef is_card_expired(exp_year, exp_month):\n today = date.today()\n cur_year, cur_month = today.year, today.month\n return exp_year < cur_year or exp_year == cur_year and exp_month < cur_month\n\n\ndef ensure_str(s):\n if isinstance(s, str):\n return s\n return s.decode('ascii') if isinstance(s, bytes) else s.encode('ascii')\n\n\ndef set_cookie(cookies, key, value, expires=None, httponly=True, path='/'):\n key = ensure_str(key)\n cookies[key] = ensure_str(value)\n cookie = cookies[key]\n if expires:\n if isinstance(expires, timedelta):\n expires += utcnow()\n if isinstance(expires, datetime):\n expires = to_rfc822(expires)\n cookie[str('expires')] = ensure_str(expires)\n if httponly:\n cookie[str('httponly')] = True\n if path:\n cookie[str('path')] = ensure_str(path)\n if website.canonical_domain:\n cookie[str('domain')] = ensure_str(website.canonical_domain)\n if website.canonical_scheme == 'https':\n cookie[str('secure')] = True\n\n\ndef erase_cookie(cookies, key, **kw):\n set_cookie(cookies, key, '', BEGINNING_OF_EPOCH, **kw)\n\n\ndef to_javascript(obj):\n \"\"\"For when you want to inject an object into a <script> tag.\n \"\"\"\n return json.dumps(obj).replace('</', '<\\\\/')\n\n\nsvg_attrs_re = re.compile(r'\\s+(?:height|width|x|y|xmlns)=([\"\\']).*?\\1')\n\ndef include_svg(svg, height, width, x=None, y=None):\n \"\"\"For when you want to include an SVG in an HTML page or in another SVG.\n \"\"\"\n assert svg.startswith('<svg')\n i = svg.find('>')\n assert i != -1\n d = locals()\n attrs = svg_attrs_re.sub('', svg[4:i])\n for a in ('height', 'width', 'x', 'y'):\n v = d[a]\n if v is None:\n continue\n attrs += ' %s=\"%s\"' % (a, v)\n return Markup(svg[:4] + attrs + svg[i:])\n\n\ndef group_by(iterable, key):\n r = {}\n for obj in iterable:\n try:\n k = obj[key]\n except KeyError:\n continue\n r.setdefault(k, []).append(obj)\n return r\n\n\ndef find_files(directory, pattern):\n for root, dirs, files in os.walk(directory):\n for filename in fnmatch.filter(files, pattern):\n yield os.path.join(root, filename)\n\n\ndef serialize(context):\n for k, v in context.items():\n if str(type(v)) == \"<class 'psycopg2.extras.Record'>\":\n context[k] = v._asdict()\n return b'\\\\x' + hexlify(pickle.dumps(context, 2))\n\n\ndef deserialize(context):\n if isinstance(context, memoryview) and context[:2].tobytes() == b'\\\\x':\n context = unhexlify(context[2:])\n return pickle.loads(context)\n\n\ndef pid_exists(pid):\n \"\"\"Check whether pid exists in the current process table. UNIX only.\n\n Source: http://stackoverflow.com/a/6940314/2729778\n \"\"\"\n if not pid > 0:\n raise ValueError(\"bad PID %s\" % pid)\n try:\n os.kill(pid, 0)\n except OSError as err:\n if err.errno == errno.ESRCH:\n # ESRCH == No such process\n return False\n elif err.errno == errno.EPERM:\n # EPERM clearly means there's a process to deny access to\n return True\n else:\n # According to \"man 2 kill\" possible error values are\n # (EINVAL, EPERM, ESRCH)\n raise\n else:\n return True\n", "path": "liberapay/utils/__init__.py"}]}
| 3,691 | 115 |
gh_patches_debug_26598
|
rasdani/github-patches
|
git_diff
|
openstates__openstates-scrapers-1530
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
LA: "Total --" being saved as vote name
The [LA bill scraper](https://github.com/openstates/openstates/blame/master/openstates/la/bills.py#L180) is saving vote names as "Total --" instead of actual names.
Some examples:
Total -- 35, Total -- 0, Total -- 4, Total -- 34, Total -- 5
This is causing the vote to come back with a null leg_id, since the name cannot be matched back to a known legislator.
</issue>
<code>
[start of openstates/la/bills.py]
1 import datetime as dt
2 import lxml.html
3 import scrapelib
4 import tempfile
5 import os
6 import re
7 from billy.scrape import ScrapeError
8 from billy.scrape.bills import BillScraper, Bill
9 from billy.scrape.votes import Vote
10 from billy.scrape.utils import pdf_to_lxml
11 from openstates.utils import LXMLMixin
12
13
14 class LABillScraper(BillScraper, LXMLMixin):
15 jurisdiction = 'la'
16
17 _chambers = {
18 'S': 'upper',
19 'H': 'lower',
20 'J': 'joint',
21 }
22
23 _bill_types = {
24 'B': 'bill',
25 'R': 'resolution',
26 'CR': 'concurrent resolution',
27 'SR': 'study request',
28 'CSR': 'concurrent study request',
29 }
30
31 def _get_bill_abbreviations(self, session_id):
32 page = self.lxmlize('http://www.legis.la.gov/legis/BillSearch.aspx?'
33 'sid={}'.format(session_id))
34 select_options = page.xpath('//select[contains(@id, "InstTypes")]/option')
35
36 bill_abbreviations = {
37 'upper': [],
38 'lower': [],
39 }
40
41 for option in select_options:
42 type_text = option.text
43 if type_text.startswith('S'):
44 bill_abbreviations['upper'].append(type_text)
45 elif type_text.startswith('H'):
46 bill_abbreviations['lower'].append(type_text)
47
48 return bill_abbreviations
49
50 def do_post_back(self, page, event_target, event_argument):
51 form = page.xpath("//form[@id='aspnetForm']")[0]
52 block = {name: value for name, value in [(obj.name, obj.value)
53 for obj in form.xpath(".//input")]}
54 block['__EVENTTARGET'] = event_target
55 block['__EVENTARGUMENT'] = event_argument
56 if form.method == "GET":
57 ret = lxml.html.fromstring(self.get(form.action, data=block).text)
58 elif form.method == "POST":
59 ret = lxml.html.fromstring(self.post(form.action, data=block).text)
60 else:
61 raise AssertionError("Unrecognized request type found: {}".format(
62 form.method))
63
64 ret.make_links_absolute(form.action)
65 return ret
66
67 def bill_pages(self, session_id, bill_abbreviation):
68 url = 'http://www.legis.la.gov/Legis/BillSearchListQ.aspx?s={}&r={}1*'\
69 .format(session_id, bill_abbreviation)
70 page = self.lxmlize(url)
71 yield page
72
73 while True:
74 hrefs = page.xpath("//a[text()=' > ']")
75 if hrefs == [] or "disabled" in hrefs[0].attrib:
76 return
77
78 href = hrefs[0].attrib['href']
79 tokens = re.match(".*\(\'(?P<token>.*)\',\'.*", href).groupdict()
80
81 page = self.do_post_back(
82 page,
83 tokens['token'],
84 ""
85 )
86 if page:
87 yield page
88
89 def scrape_bare_page(self, url):
90 page = self.lxmlize(url)
91 return page.xpath("//a")
92
93 def scrape(self, chamber, session):
94 session_id = self.metadata['session_details'][session]['_id']
95
96 # Scan bill abbreviation list if necessary.
97 self._bill_abbreviations = self._get_bill_abbreviations(session_id)
98
99 for bill_abbreviation in self._bill_abbreviations[chamber]:
100 for bill_page in self.bill_pages(session_id, bill_abbreviation):
101 for bill in bill_page.xpath(
102 "//a[contains(@href, 'BillInfo.aspx') and text()='more...']"):
103 self.scrape_bill_page(chamber,
104 session,
105 bill.attrib['href'],
106 bill_abbreviation)
107
108 def get_one_xpath(self, page, xpath):
109 ret = page.xpath(xpath)
110 if len(ret) != 1:
111 raise Exception
112 return ret[0]
113
114 def scrape_votes(self, bill, url):
115 text = self.get(url).text
116 page = lxml.html.fromstring(text)
117 page.make_links_absolute(url)
118
119 for a in page.xpath("//a[contains(@href, 'ViewDocument.aspx')]"):
120 self.scrape_vote(bill, a.text, a.attrib['href'])
121
122 def scrape_vote(self, bill, name, url):
123 match = re.match('^(Senate|House) Vote on [^,]*,(.*)$', name)
124
125 if not match:
126 return
127
128 chamber = {'Senate': 'upper', 'House': 'lower'}[match.group(1)]
129 motion = match.group(2).strip()
130
131 if motion.startswith('FINAL PASSAGE'):
132 type = 'passage'
133 elif motion.startswith('AMENDMENT'):
134 type = 'amendment'
135 elif 'ON 3RD READING' in motion:
136 type = 'reading:3'
137 else:
138 type = 'other'
139
140 vote = Vote(chamber, None, motion, None,
141 None, None, None)
142 vote['type'] = type
143 vote.add_source(url)
144
145 (fd, temp_path) = tempfile.mkstemp()
146 self.urlretrieve(url, temp_path)
147
148 html = pdf_to_lxml(temp_path)
149 os.close(fd)
150 os.remove(temp_path)
151
152 vote_type = None
153 total_re = re.compile('^Total--(\d+)$')
154 body = html.xpath('string(/html/body)')
155
156 date_match = re.search('Date: (\d{1,2}/\d{1,2}/\d{4})', body)
157 try:
158 date = date_match.group(1)
159 except AttributeError:
160 self.warning("BAD VOTE: date error")
161 return
162
163 vote['date'] = dt.datetime.strptime(date, '%m/%d/%Y')
164
165 for line in body.replace(u'\xa0', '\n').split('\n'):
166 line = line.replace(' ', '').strip()
167 if not line:
168 continue
169
170 if line in ('YEAS', 'NAYS', 'ABSENT'):
171 vote_type = {'YEAS': 'yes', 'NAYS': 'no',
172 'ABSENT': 'other'}[line]
173 elif line in ('Total', '--'):
174 vote_type = None
175 elif vote_type:
176 match = total_re.match(line)
177 if match:
178 vote['%s_count' % vote_type] = int(match.group(1))
179 elif vote_type == 'yes':
180 vote.yes(line)
181 elif vote_type == 'no':
182 vote.no(line)
183 elif vote_type == 'other':
184 vote.other(line)
185
186 # tally counts
187 vote['yes_count'] = len(vote['yes_votes'])
188 vote['no_count'] = len(vote['no_votes'])
189 vote['other_count'] = len(vote['other_votes'])
190
191 # The PDFs oddly don't say whether a vote passed or failed.
192 # Hopefully passage just requires yes_votes > not_yes_votes
193 if vote['yes_count'] > (vote['no_count'] + vote['other_count']):
194 vote['passed'] = True
195 else:
196 vote['passed'] = False
197
198 bill.add_vote(vote)
199
200 def scrape_bill_page(self, chamber, session, bill_url, bill_abbreviation):
201 page = self.lxmlize(bill_url)
202 author = self.get_one_xpath(
203 page,
204 "//a[@id='ctl00_PageBody_LinkAuthor']/text()"
205 )
206
207 sbp = lambda x: self.scrape_bare_page(page.xpath(
208 "//a[contains(text(), '%s')]" % (x))[0].attrib['href'])
209
210 authors = [x.text for x in sbp("Authors")]
211
212 try:
213 digests = sbp("Digests")
214 except IndexError:
215 digests = []
216
217 try:
218 versions = sbp("Text")
219 except IndexError:
220 versions = []
221
222 try:
223 amendments = sbp("Amendments")
224 except IndexError:
225 amendments = []
226
227 title = page.xpath(
228 "//span[@id='ctl00_PageBody_LabelShortTitle']/text()")[0]
229 actions = page.xpath(
230 "//div[@id='ctl00_PageBody_PanelBillInfo']/"
231 "/table[@style='font-size:small']/tr")
232
233 bill_id = page.xpath(
234 "//span[@id='ctl00_PageBody_LabelBillID']/text()")[0]
235 bill_type = LABillScraper._bill_types[bill_abbreviation[1:]]
236 bill = Bill(session, chamber, bill_id, title, type=bill_type)
237 bill.add_source(bill_url)
238
239 authors.remove(author)
240 bill.add_sponsor('primary', author)
241 for author in authors:
242 bill.add_sponsor('cosponsor', author)
243
244 for digest in digests:
245 bill.add_document(digest.text,
246 digest.attrib['href'],
247 mimetype="application/pdf")
248
249 for version in versions:
250 bill.add_version(version.text,
251 version.attrib['href'],
252 mimetype="application/pdf")
253
254 for amendment in amendments:
255 bill.add_version(amendment.text,
256 amendment.attrib['href'],
257 mimetype="application/pdf")
258
259 flags = {
260 "prefiled": ["bill:filed"],
261 "referred to the committee": ["committee:referred"],
262 "sent to the house": ['bill:passed'],
263 "ordered returned to the house": ['bill:passed'],
264 "ordered to the senate": ['bill:passed'],
265 "signed by the governor": ['governor:signed'],
266 "sent to the governor": ['governor:received'],
267 }
268
269 try:
270 votes_link = page.xpath("//a[text() = 'Votes']")[0]
271 self.scrape_votes(bill, votes_link.attrib['href'])
272 except IndexError:
273 # Some bills don't have any votes
274 pass
275
276 for action in actions:
277 date, chamber, page, text = [x.text for x in action.xpath(".//td")]
278 session_year = self.metadata['session_details'][session]\
279 ['start_date'].year
280 # Session is April -> June. Prefiles look like they're in
281 # January at earliest.
282 date += '/{}'.format(session_year)
283 date = dt.datetime.strptime(date, '%m/%d/%Y')
284 chamber = LABillScraper._chambers[chamber]
285
286 cat = []
287 for flag in flags:
288 if flag in text.lower():
289 cat += flags[flag]
290
291 if cat == []:
292 cat = ["other"]
293 bill.add_action(chamber, text, date, cat)
294
295 self.save_bill(bill)
296
[end of openstates/la/bills.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/openstates/la/bills.py b/openstates/la/bills.py
--- a/openstates/la/bills.py
+++ b/openstates/la/bills.py
@@ -150,7 +150,6 @@
os.remove(temp_path)
vote_type = None
- total_re = re.compile('^Total--(\d+)$')
body = html.xpath('string(/html/body)')
date_match = re.search('Date: (\d{1,2}/\d{1,2}/\d{4})', body)
@@ -164,7 +163,8 @@
for line in body.replace(u'\xa0', '\n').split('\n'):
line = line.replace(' ', '').strip()
- if not line:
+ # Skip blank lines and "Total --"
+ if not line or 'Total --' in line:
continue
if line in ('YEAS', 'NAYS', 'ABSENT'):
@@ -173,10 +173,7 @@
elif line in ('Total', '--'):
vote_type = None
elif vote_type:
- match = total_re.match(line)
- if match:
- vote['%s_count' % vote_type] = int(match.group(1))
- elif vote_type == 'yes':
+ if vote_type == 'yes':
vote.yes(line)
elif vote_type == 'no':
vote.no(line)
|
{"golden_diff": "diff --git a/openstates/la/bills.py b/openstates/la/bills.py\n--- a/openstates/la/bills.py\n+++ b/openstates/la/bills.py\n@@ -150,7 +150,6 @@\n os.remove(temp_path)\n \n vote_type = None\n- total_re = re.compile('^Total--(\\d+)$')\n body = html.xpath('string(/html/body)')\n \n date_match = re.search('Date: (\\d{1,2}/\\d{1,2}/\\d{4})', body)\n@@ -164,7 +163,8 @@\n \n for line in body.replace(u'\\xa0', '\\n').split('\\n'):\n line = line.replace(' ', '').strip()\n- if not line:\n+ # Skip blank lines and \"Total --\"\n+ if not line or 'Total --' in line:\n continue\n \n if line in ('YEAS', 'NAYS', 'ABSENT'):\n@@ -173,10 +173,7 @@\n elif line in ('Total', '--'):\n vote_type = None\n elif vote_type:\n- match = total_re.match(line)\n- if match:\n- vote['%s_count' % vote_type] = int(match.group(1))\n- elif vote_type == 'yes':\n+ if vote_type == 'yes':\n vote.yes(line)\n elif vote_type == 'no':\n vote.no(line)\n", "issue": "LA: \"Total --\" being saved as vote name\nThe [LA bill scraper](https://github.com/openstates/openstates/blame/master/openstates/la/bills.py#L180) is saving vote names as \"Total --\" instead of actual names.\r\n\r\nSome examples:\r\nTotal -- 35, Total -- 0, Total -- 4, Total -- 34, Total -- 5\r\n\r\nThis is causing the vote to come back with a null leg_id, since the name cannot be matched back to a known legislator.\n", "before_files": [{"content": "import datetime as dt\nimport lxml.html\nimport scrapelib\nimport tempfile\nimport os\nimport re\nfrom billy.scrape import ScrapeError\nfrom billy.scrape.bills import BillScraper, Bill\nfrom billy.scrape.votes import Vote\nfrom billy.scrape.utils import pdf_to_lxml\nfrom openstates.utils import LXMLMixin\n\n\nclass LABillScraper(BillScraper, LXMLMixin):\n jurisdiction = 'la'\n\n _chambers = {\n 'S': 'upper',\n 'H': 'lower',\n 'J': 'joint',\n }\n\n _bill_types = {\n 'B': 'bill',\n 'R': 'resolution',\n 'CR': 'concurrent resolution',\n 'SR': 'study request',\n 'CSR': 'concurrent study request',\n }\n\n def _get_bill_abbreviations(self, session_id):\n page = self.lxmlize('http://www.legis.la.gov/legis/BillSearch.aspx?'\n 'sid={}'.format(session_id))\n select_options = page.xpath('//select[contains(@id, \"InstTypes\")]/option')\n\n bill_abbreviations = {\n 'upper': [],\n 'lower': [],\n }\n\n for option in select_options:\n type_text = option.text\n if type_text.startswith('S'):\n bill_abbreviations['upper'].append(type_text)\n elif type_text.startswith('H'):\n bill_abbreviations['lower'].append(type_text)\n\n return bill_abbreviations\n\n def do_post_back(self, page, event_target, event_argument):\n form = page.xpath(\"//form[@id='aspnetForm']\")[0]\n block = {name: value for name, value in [(obj.name, obj.value)\n for obj in form.xpath(\".//input\")]}\n block['__EVENTTARGET'] = event_target\n block['__EVENTARGUMENT'] = event_argument\n if form.method == \"GET\":\n ret = lxml.html.fromstring(self.get(form.action, data=block).text)\n elif form.method == \"POST\":\n ret = lxml.html.fromstring(self.post(form.action, data=block).text)\n else:\n raise AssertionError(\"Unrecognized request type found: {}\".format(\n form.method))\n\n ret.make_links_absolute(form.action)\n return ret\n\n def bill_pages(self, session_id, bill_abbreviation):\n url = 'http://www.legis.la.gov/Legis/BillSearchListQ.aspx?s={}&r={}1*'\\\n .format(session_id, bill_abbreviation)\n page = self.lxmlize(url)\n yield page\n\n while True:\n hrefs = page.xpath(\"//a[text()=' > ']\")\n if hrefs == [] or \"disabled\" in hrefs[0].attrib:\n return\n\n href = hrefs[0].attrib['href']\n tokens = re.match(\".*\\(\\'(?P<token>.*)\\',\\'.*\", href).groupdict()\n\n page = self.do_post_back(\n page,\n tokens['token'],\n \"\"\n )\n if page:\n yield page\n\n def scrape_bare_page(self, url):\n page = self.lxmlize(url)\n return page.xpath(\"//a\")\n\n def scrape(self, chamber, session):\n session_id = self.metadata['session_details'][session]['_id']\n\n # Scan bill abbreviation list if necessary.\n self._bill_abbreviations = self._get_bill_abbreviations(session_id)\n\n for bill_abbreviation in self._bill_abbreviations[chamber]:\n for bill_page in self.bill_pages(session_id, bill_abbreviation):\n for bill in bill_page.xpath(\n \"//a[contains(@href, 'BillInfo.aspx') and text()='more...']\"):\n self.scrape_bill_page(chamber,\n session,\n bill.attrib['href'],\n bill_abbreviation)\n\n def get_one_xpath(self, page, xpath):\n ret = page.xpath(xpath)\n if len(ret) != 1:\n raise Exception\n return ret[0]\n\n def scrape_votes(self, bill, url):\n text = self.get(url).text\n page = lxml.html.fromstring(text)\n page.make_links_absolute(url)\n\n for a in page.xpath(\"//a[contains(@href, 'ViewDocument.aspx')]\"):\n self.scrape_vote(bill, a.text, a.attrib['href'])\n\n def scrape_vote(self, bill, name, url):\n match = re.match('^(Senate|House) Vote on [^,]*,(.*)$', name)\n\n if not match:\n return\n\n chamber = {'Senate': 'upper', 'House': 'lower'}[match.group(1)]\n motion = match.group(2).strip()\n\n if motion.startswith('FINAL PASSAGE'):\n type = 'passage'\n elif motion.startswith('AMENDMENT'):\n type = 'amendment'\n elif 'ON 3RD READING' in motion:\n type = 'reading:3'\n else:\n type = 'other'\n\n vote = Vote(chamber, None, motion, None,\n None, None, None)\n vote['type'] = type\n vote.add_source(url)\n\n (fd, temp_path) = tempfile.mkstemp()\n self.urlretrieve(url, temp_path)\n\n html = pdf_to_lxml(temp_path)\n os.close(fd)\n os.remove(temp_path)\n\n vote_type = None\n total_re = re.compile('^Total--(\\d+)$')\n body = html.xpath('string(/html/body)')\n\n date_match = re.search('Date: (\\d{1,2}/\\d{1,2}/\\d{4})', body)\n try:\n date = date_match.group(1)\n except AttributeError:\n self.warning(\"BAD VOTE: date error\")\n return\n\n vote['date'] = dt.datetime.strptime(date, '%m/%d/%Y')\n\n for line in body.replace(u'\\xa0', '\\n').split('\\n'):\n line = line.replace(' ', '').strip()\n if not line:\n continue\n\n if line in ('YEAS', 'NAYS', 'ABSENT'):\n vote_type = {'YEAS': 'yes', 'NAYS': 'no',\n 'ABSENT': 'other'}[line]\n elif line in ('Total', '--'):\n vote_type = None\n elif vote_type:\n match = total_re.match(line)\n if match:\n vote['%s_count' % vote_type] = int(match.group(1))\n elif vote_type == 'yes':\n vote.yes(line)\n elif vote_type == 'no':\n vote.no(line)\n elif vote_type == 'other':\n vote.other(line)\n\n # tally counts\n vote['yes_count'] = len(vote['yes_votes'])\n vote['no_count'] = len(vote['no_votes'])\n vote['other_count'] = len(vote['other_votes'])\n\n # The PDFs oddly don't say whether a vote passed or failed.\n # Hopefully passage just requires yes_votes > not_yes_votes\n if vote['yes_count'] > (vote['no_count'] + vote['other_count']):\n vote['passed'] = True\n else:\n vote['passed'] = False\n\n bill.add_vote(vote)\n\n def scrape_bill_page(self, chamber, session, bill_url, bill_abbreviation):\n page = self.lxmlize(bill_url)\n author = self.get_one_xpath(\n page,\n \"//a[@id='ctl00_PageBody_LinkAuthor']/text()\"\n )\n\n sbp = lambda x: self.scrape_bare_page(page.xpath(\n \"//a[contains(text(), '%s')]\" % (x))[0].attrib['href'])\n\n authors = [x.text for x in sbp(\"Authors\")]\n\n try:\n digests = sbp(\"Digests\")\n except IndexError:\n digests = []\n\n try:\n versions = sbp(\"Text\")\n except IndexError:\n versions = []\n\n try:\n amendments = sbp(\"Amendments\")\n except IndexError:\n amendments = []\n\n title = page.xpath(\n \"//span[@id='ctl00_PageBody_LabelShortTitle']/text()\")[0]\n actions = page.xpath(\n \"//div[@id='ctl00_PageBody_PanelBillInfo']/\"\n \"/table[@style='font-size:small']/tr\")\n\n bill_id = page.xpath(\n \"//span[@id='ctl00_PageBody_LabelBillID']/text()\")[0]\n bill_type = LABillScraper._bill_types[bill_abbreviation[1:]]\n bill = Bill(session, chamber, bill_id, title, type=bill_type)\n bill.add_source(bill_url)\n\n authors.remove(author)\n bill.add_sponsor('primary', author)\n for author in authors:\n bill.add_sponsor('cosponsor', author)\n\n for digest in digests:\n bill.add_document(digest.text,\n digest.attrib['href'],\n mimetype=\"application/pdf\")\n\n for version in versions:\n bill.add_version(version.text,\n version.attrib['href'],\n mimetype=\"application/pdf\")\n\n for amendment in amendments:\n bill.add_version(amendment.text,\n amendment.attrib['href'],\n mimetype=\"application/pdf\")\n\n flags = {\n \"prefiled\": [\"bill:filed\"],\n \"referred to the committee\": [\"committee:referred\"],\n \"sent to the house\": ['bill:passed'],\n \"ordered returned to the house\": ['bill:passed'],\n \"ordered to the senate\": ['bill:passed'],\n \"signed by the governor\": ['governor:signed'],\n \"sent to the governor\": ['governor:received'],\n }\n\n try:\n votes_link = page.xpath(\"//a[text() = 'Votes']\")[0]\n self.scrape_votes(bill, votes_link.attrib['href'])\n except IndexError:\n # Some bills don't have any votes\n pass\n\n for action in actions:\n date, chamber, page, text = [x.text for x in action.xpath(\".//td\")]\n session_year = self.metadata['session_details'][session]\\\n ['start_date'].year\n # Session is April -> June. Prefiles look like they're in\n # January at earliest.\n date += '/{}'.format(session_year)\n date = dt.datetime.strptime(date, '%m/%d/%Y')\n chamber = LABillScraper._chambers[chamber]\n\n cat = []\n for flag in flags:\n if flag in text.lower():\n cat += flags[flag]\n\n if cat == []:\n cat = [\"other\"]\n bill.add_action(chamber, text, date, cat)\n\n self.save_bill(bill)\n", "path": "openstates/la/bills.py"}]}
| 3,744 | 323 |
gh_patches_debug_14391
|
rasdani/github-patches
|
git_diff
|
mozilla__kitsune-3307
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
monkeypatch_render should only be used in testing
https://github.com/mozilla/kitsune/blob/69253e763ada10422d3c88e681bcb4af00e1eb4f/kitsune/sumo/monkeypatch.py#L105 will always evaluate to True, so monkeypatch_render is always called by patch_all, but: https://github.com/mozilla/kitsune/blob/69253e763ada10422d3c88e681bcb4af00e1eb4f/kitsune/sumo/monkeypatch.py#L143
</issue>
<code>
[start of kitsune/sumo/monkeypatch.py]
1 from functools import wraps
2
3 from django.forms import fields
4 from django.forms import widgets
5
6 from elasticutils import get_es as base_get_es
7 from elasticutils.contrib import django as elasticutils_django
8
9
10 _has_been_patched = False
11
12
13 class DateWidget(fields.DateField.widget):
14 input_type = 'date'
15
16
17 class TimeWidget(fields.TimeField.widget):
18 input_type = 'time'
19
20
21 class URLWidget(fields.URLField.widget):
22 input_type = 'url'
23
24
25 class EmailWidget(fields.EmailField.widget):
26 input_type = 'email'
27
28
29 def patch():
30 global _has_been_patched, URLWidget
31
32 if _has_been_patched:
33 return
34
35 # Monkey patch preserves the old values, so we can pick up any changes
36 # in CharField.widget_attrs and Field.widget_attrs
37 # paulc filed a Django ticket for it, #14884
38 field_widget_attrs = fields.Field.widget_attrs
39 charfield_widget_attrs = fields.CharField.widget_attrs
40
41 def required_field_attrs(self, widget):
42 """This function is for use on the base Field class."""
43 attrs = field_widget_attrs(self, widget)
44 # required="required" isn't supported for groups of checkboxes.
45 if (self.required and
46 'required' not in attrs and
47 not widget.is_hidden and
48 not isinstance(widget, widgets.CheckboxSelectMultiple)):
49 attrs['required'] = 'required'
50 return attrs
51
52 def required_char_field_attrs(self, widget, *args, **kwargs):
53 """This function is for use on the CharField class."""
54 # We need to call super() here, since Django's CharField.widget_attrs
55 # doesn't call its super and thus won't use the required_field_attrs
56 # above.
57 attrs = super(fields.CharField, self).widget_attrs(widget, *args,
58 **kwargs)
59 original_attrs = charfield_widget_attrs(self, widget) or {}
60 attrs.update(original_attrs)
61 return attrs
62
63 fields.Field.widget_attrs = required_field_attrs
64 fields.CharField.widget_attrs = required_char_field_attrs
65 fields.DateField.widget = DateWidget
66 fields.TimeField.widget = TimeWidget
67 fields.URLField.widget = URLWidget
68 fields.EmailField.widget = EmailWidget
69
70 # Workaround until https://code.djangoproject.com/ticket/16920 gets fixed.
71 from django.contrib.admin import util
72 from django.contrib.admin.util import NestedObjects
73 from django.db import models
74
75 def _collect(self, objs, source_attr=None, **kwargs):
76 for obj in objs:
77 if source_attr:
78 # We just added a default of None below and that gets around
79 # the problem.
80 self.add_edge(getattr(obj, source_attr, None), obj)
81 else:
82 self.add_edge(None, obj)
83 try:
84 return super(NestedObjects, self).collect(
85 objs, source_attr=source_attr, **kwargs)
86 except models.ProtectedError as e:
87 self.protected.update(e.protected_objects)
88
89 util.NestedObjects.collect = _collect
90
91 # Monkey-patch admin site.
92 from django.contrib import admin
93 from adminplus.sites import AdminSitePlus
94
95 # Patch the admin
96 admin.site = AdminSitePlus()
97 admin.site.site_header = 'Kitsune Administration'
98 admin.site.site_title = 'Mozilla Support'
99
100 # Monkey patch django's csrf
101 import session_csrf
102 session_csrf.monkeypatch()
103
104 # In testing contexts, patch django.shortcuts.render
105 if 'TESTING' == 'TESTING':
106 monkeypatch_render()
107
108 # Monkey patch ES
109 def get_es(**overrides):
110 """Monkey patch elasticutils get_es to add use_ssl and http_auth settings."""
111 from django.conf import settings
112
113 defaults = {
114 'urls': settings.ES_URLS,
115 'timeout': getattr(settings, 'ES_TIMEOUT', 5),
116 'use_ssl': getattr(settings, 'ES_USE_SSL', False),
117 'http_auth': getattr(settings, 'ES_HTTP_AUTH', None),
118 'verify_certs': getattr(settings, 'ES_VERIFY_CERTS', True),
119 }
120
121 defaults.update(overrides)
122 return base_get_es(**defaults)
123 elasticutils_django.get_es = get_es
124
125 def S_get_es(self, default_builder=get_es):
126 """Returns the elasticsearch Elasticsearch object to use.
127
128 This uses the django get_es builder by default which takes
129 into account settings in ``settings.py``.
130
131 """
132 return super(elasticutils_django.S, self).get_es(default_builder=default_builder)
133 elasticutils_django.S.get_es = S_get_es
134
135 _has_been_patched = True
136
137
138 def monkeypatch_render():
139 """
140 Monkeypatches django.shortcuts.render for Jinja2 kung-fu action
141
142 .. Note::
143 Only call this in a testing context!
144 """
145 import django.shortcuts
146
147 def more_info(fun):
148 """Django's render shortcut, but captures information for testing
149 When using Django's render shortcut with Jinja2 templates, none of
150 the information is captured and thus you can't use it for testing.
151 This alleviates that somewhat by capturing some of the information
152 allowing you to test it.
153 Caveats:
154 * it does *not* capture all the Jinja2 templates used to render.
155 Only the topmost one requested by the render() function.
156 """
157 @wraps(fun)
158 def _more_info(request, template_name, *args, **kwargs):
159 resp = fun(request, template_name, *args, **kwargs)
160
161 resp.jinja_templates = [template_name]
162 if args:
163 resp.jinja_context = args[0]
164 elif 'context' in kwargs:
165 resp.jinja_context = kwargs['context']
166 else:
167 resp.jinja_context = {}
168
169 return resp
170 return _more_info
171
172 django.shortcuts.render = more_info(django.shortcuts.render)
173
[end of kitsune/sumo/monkeypatch.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kitsune/sumo/monkeypatch.py b/kitsune/sumo/monkeypatch.py
--- a/kitsune/sumo/monkeypatch.py
+++ b/kitsune/sumo/monkeypatch.py
@@ -1,3 +1,4 @@
+import sys
from functools import wraps
from django.forms import fields
@@ -8,6 +9,7 @@
_has_been_patched = False
+TESTING = (len(sys.argv) > 1 and sys.argv[1] == 'test') or sys.argv[0].endswith('py.test')
class DateWidget(fields.DateField.widget):
@@ -102,7 +104,7 @@
session_csrf.monkeypatch()
# In testing contexts, patch django.shortcuts.render
- if 'TESTING' == 'TESTING':
+ if TESTING:
monkeypatch_render()
# Monkey patch ES
|
{"golden_diff": "diff --git a/kitsune/sumo/monkeypatch.py b/kitsune/sumo/monkeypatch.py\n--- a/kitsune/sumo/monkeypatch.py\n+++ b/kitsune/sumo/monkeypatch.py\n@@ -1,3 +1,4 @@\n+import sys\n from functools import wraps\n \n from django.forms import fields\n@@ -8,6 +9,7 @@\n \n \n _has_been_patched = False\n+TESTING = (len(sys.argv) > 1 and sys.argv[1] == 'test') or sys.argv[0].endswith('py.test')\n \n \n class DateWidget(fields.DateField.widget):\n@@ -102,7 +104,7 @@\n session_csrf.monkeypatch()\n \n # In testing contexts, patch django.shortcuts.render\n- if 'TESTING' == 'TESTING':\n+ if TESTING:\n monkeypatch_render()\n \n # Monkey patch ES\n", "issue": "monkeypatch_render should only be used in testing\nhttps://github.com/mozilla/kitsune/blob/69253e763ada10422d3c88e681bcb4af00e1eb4f/kitsune/sumo/monkeypatch.py#L105 will always evaluate to True, so monkeypatch_render is always called by patch_all, but: https://github.com/mozilla/kitsune/blob/69253e763ada10422d3c88e681bcb4af00e1eb4f/kitsune/sumo/monkeypatch.py#L143\n", "before_files": [{"content": "from functools import wraps\n\nfrom django.forms import fields\nfrom django.forms import widgets\n\nfrom elasticutils import get_es as base_get_es\nfrom elasticutils.contrib import django as elasticutils_django\n\n\n_has_been_patched = False\n\n\nclass DateWidget(fields.DateField.widget):\n input_type = 'date'\n\n\nclass TimeWidget(fields.TimeField.widget):\n input_type = 'time'\n\n\nclass URLWidget(fields.URLField.widget):\n input_type = 'url'\n\n\nclass EmailWidget(fields.EmailField.widget):\n input_type = 'email'\n\n\ndef patch():\n global _has_been_patched, URLWidget\n\n if _has_been_patched:\n return\n\n # Monkey patch preserves the old values, so we can pick up any changes\n # in CharField.widget_attrs and Field.widget_attrs\n # paulc filed a Django ticket for it, #14884\n field_widget_attrs = fields.Field.widget_attrs\n charfield_widget_attrs = fields.CharField.widget_attrs\n\n def required_field_attrs(self, widget):\n \"\"\"This function is for use on the base Field class.\"\"\"\n attrs = field_widget_attrs(self, widget)\n # required=\"required\" isn't supported for groups of checkboxes.\n if (self.required and\n 'required' not in attrs and\n not widget.is_hidden and\n not isinstance(widget, widgets.CheckboxSelectMultiple)):\n attrs['required'] = 'required'\n return attrs\n\n def required_char_field_attrs(self, widget, *args, **kwargs):\n \"\"\"This function is for use on the CharField class.\"\"\"\n # We need to call super() here, since Django's CharField.widget_attrs\n # doesn't call its super and thus won't use the required_field_attrs\n # above.\n attrs = super(fields.CharField, self).widget_attrs(widget, *args,\n **kwargs)\n original_attrs = charfield_widget_attrs(self, widget) or {}\n attrs.update(original_attrs)\n return attrs\n\n fields.Field.widget_attrs = required_field_attrs\n fields.CharField.widget_attrs = required_char_field_attrs\n fields.DateField.widget = DateWidget\n fields.TimeField.widget = TimeWidget\n fields.URLField.widget = URLWidget\n fields.EmailField.widget = EmailWidget\n\n # Workaround until https://code.djangoproject.com/ticket/16920 gets fixed.\n from django.contrib.admin import util\n from django.contrib.admin.util import NestedObjects\n from django.db import models\n\n def _collect(self, objs, source_attr=None, **kwargs):\n for obj in objs:\n if source_attr:\n # We just added a default of None below and that gets around\n # the problem.\n self.add_edge(getattr(obj, source_attr, None), obj)\n else:\n self.add_edge(None, obj)\n try:\n return super(NestedObjects, self).collect(\n objs, source_attr=source_attr, **kwargs)\n except models.ProtectedError as e:\n self.protected.update(e.protected_objects)\n\n util.NestedObjects.collect = _collect\n\n # Monkey-patch admin site.\n from django.contrib import admin\n from adminplus.sites import AdminSitePlus\n\n # Patch the admin\n admin.site = AdminSitePlus()\n admin.site.site_header = 'Kitsune Administration'\n admin.site.site_title = 'Mozilla Support'\n\n # Monkey patch django's csrf\n import session_csrf\n session_csrf.monkeypatch()\n\n # In testing contexts, patch django.shortcuts.render\n if 'TESTING' == 'TESTING':\n monkeypatch_render()\n\n # Monkey patch ES\n def get_es(**overrides):\n \"\"\"Monkey patch elasticutils get_es to add use_ssl and http_auth settings.\"\"\"\n from django.conf import settings\n\n defaults = {\n 'urls': settings.ES_URLS,\n 'timeout': getattr(settings, 'ES_TIMEOUT', 5),\n 'use_ssl': getattr(settings, 'ES_USE_SSL', False),\n 'http_auth': getattr(settings, 'ES_HTTP_AUTH', None),\n 'verify_certs': getattr(settings, 'ES_VERIFY_CERTS', True),\n }\n\n defaults.update(overrides)\n return base_get_es(**defaults)\n elasticutils_django.get_es = get_es\n\n def S_get_es(self, default_builder=get_es):\n \"\"\"Returns the elasticsearch Elasticsearch object to use.\n\n This uses the django get_es builder by default which takes\n into account settings in ``settings.py``.\n\n \"\"\"\n return super(elasticutils_django.S, self).get_es(default_builder=default_builder)\n elasticutils_django.S.get_es = S_get_es\n\n _has_been_patched = True\n\n\ndef monkeypatch_render():\n \"\"\"\n Monkeypatches django.shortcuts.render for Jinja2 kung-fu action\n\n .. Note::\n Only call this in a testing context!\n \"\"\"\n import django.shortcuts\n\n def more_info(fun):\n \"\"\"Django's render shortcut, but captures information for testing\n When using Django's render shortcut with Jinja2 templates, none of\n the information is captured and thus you can't use it for testing.\n This alleviates that somewhat by capturing some of the information\n allowing you to test it.\n Caveats:\n * it does *not* capture all the Jinja2 templates used to render.\n Only the topmost one requested by the render() function.\n \"\"\"\n @wraps(fun)\n def _more_info(request, template_name, *args, **kwargs):\n resp = fun(request, template_name, *args, **kwargs)\n\n resp.jinja_templates = [template_name]\n if args:\n resp.jinja_context = args[0]\n elif 'context' in kwargs:\n resp.jinja_context = kwargs['context']\n else:\n resp.jinja_context = {}\n\n return resp\n return _more_info\n\n django.shortcuts.render = more_info(django.shortcuts.render)\n", "path": "kitsune/sumo/monkeypatch.py"}]}
| 2,385 | 202 |
gh_patches_debug_12141
|
rasdani/github-patches
|
git_diff
|
pyg-team__pytorch_geometric-7536
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Planetoid dtype mismatch for CiteSeer
### 🐛 Describe the bug
I find that I can't load the CiteSeer dataset with double precision
```python
import torch_geometric as tg
tg.datasets.Planetoid(root="/tmp", name="CiteSeer")
```
I get this error
```
File /user/work/pc22286/mambaforge/envs/dkm/lib/python3.11/site-packages/torch_geometric/io/planetoid.py:34, in read_planetoid_data(folder, prefix)
31 len_test_indices = (test_index.max() - test_index.min()).item() + 1
33 tx_ext = torch.zeros(len_test_indices, tx.size(1))
---> 34 tx_ext[sorted_test_index - test_index.min(), :] = tx
35 ty_ext = torch.zeros(len_test_indices, ty.size(1))
36 ty_ext[sorted_test_index - test_index.min(), :] = ty
RuntimeError: Index put requires the source and destination dtypes match, got Double for the destination and Float for the source.
```
Fortunately, there is a workaround if I set the default precision to single precision
```python
import torch as t
t.set_default_dtype(t.float32)
tg.datasets.Planetoid(root="/tmp", name="CiteSeer") ## success, this time
```
and then I will convert to double precision manually later. Not a bit problem, but I expected to be able to use float64
### Environment
* PyG version: 2.3.1
* PyTorch version: 2.0.1
* OS: CentOS 7
* Python version: 3.11.3
* CUDA/cuDNN version: 12.0
* How you installed PyTorch and PyG (`conda`, `pip`, source): installed torch by conda (mamba), PyG by pip
* Any other relevant information (*e.g.*, version of `torch-scatter`):
</issue>
<code>
[start of torch_geometric/io/planetoid.py]
1 import os.path as osp
2 import sys
3 import warnings
4 from itertools import repeat
5
6 import torch
7
8 from torch_geometric.data import Data
9 from torch_geometric.io import read_txt_array
10 from torch_geometric.typing import SparseTensor
11 from torch_geometric.utils import coalesce, index_to_mask, remove_self_loops
12
13 try:
14 import cPickle as pickle
15 except ImportError:
16 import pickle
17
18
19 def read_planetoid_data(folder, prefix):
20 names = ['x', 'tx', 'allx', 'y', 'ty', 'ally', 'graph', 'test.index']
21 items = [read_file(folder, prefix, name) for name in names]
22 x, tx, allx, y, ty, ally, graph, test_index = items
23 train_index = torch.arange(y.size(0), dtype=torch.long)
24 val_index = torch.arange(y.size(0), y.size(0) + 500, dtype=torch.long)
25 sorted_test_index = test_index.sort()[0]
26
27 if prefix.lower() == 'citeseer':
28 # There are some isolated nodes in the Citeseer graph, resulting in
29 # none consecutive test indices. We need to identify them and add them
30 # as zero vectors to `tx` and `ty`.
31 len_test_indices = (test_index.max() - test_index.min()).item() + 1
32
33 tx_ext = torch.zeros(len_test_indices, tx.size(1))
34 tx_ext[sorted_test_index - test_index.min(), :] = tx
35 ty_ext = torch.zeros(len_test_indices, ty.size(1))
36 ty_ext[sorted_test_index - test_index.min(), :] = ty
37
38 tx, ty = tx_ext, ty_ext
39
40 if prefix.lower() == 'nell.0.001':
41 tx_ext = torch.zeros(len(graph) - allx.size(0), x.size(1))
42 tx_ext[sorted_test_index - allx.size(0)] = tx
43
44 ty_ext = torch.zeros(len(graph) - ally.size(0), y.size(1))
45 ty_ext[sorted_test_index - ally.size(0)] = ty
46
47 tx, ty = tx_ext, ty_ext
48
49 x = torch.cat([allx, tx], dim=0)
50 x[test_index] = x[sorted_test_index]
51
52 # Creating feature vectors for relations.
53 row, col, value = SparseTensor.from_dense(x).coo()
54 rows, cols, values = [row], [col], [value]
55
56 mask1 = index_to_mask(test_index, size=len(graph))
57 mask2 = index_to_mask(torch.arange(allx.size(0), len(graph)),
58 size=len(graph))
59 mask = ~mask1 | ~mask2
60 isolated_index = mask.nonzero(as_tuple=False).view(-1)[allx.size(0):]
61
62 rows += [isolated_index]
63 cols += [torch.arange(isolated_index.size(0)) + x.size(1)]
64 values += [torch.ones(isolated_index.size(0))]
65
66 x = SparseTensor(row=torch.cat(rows), col=torch.cat(cols),
67 value=torch.cat(values))
68 else:
69 x = torch.cat([allx, tx], dim=0)
70 x[test_index] = x[sorted_test_index]
71
72 y = torch.cat([ally, ty], dim=0).max(dim=1)[1]
73 y[test_index] = y[sorted_test_index]
74
75 train_mask = index_to_mask(train_index, size=y.size(0))
76 val_mask = index_to_mask(val_index, size=y.size(0))
77 test_mask = index_to_mask(test_index, size=y.size(0))
78
79 edge_index = edge_index_from_dict(graph, num_nodes=y.size(0))
80
81 data = Data(x=x, edge_index=edge_index, y=y)
82 data.train_mask = train_mask
83 data.val_mask = val_mask
84 data.test_mask = test_mask
85
86 return data
87
88
89 def read_file(folder, prefix, name):
90 path = osp.join(folder, f'ind.{prefix.lower()}.{name}')
91
92 if name == 'test.index':
93 return read_txt_array(path, dtype=torch.long)
94
95 with open(path, 'rb') as f:
96 if sys.version_info > (3, 0):
97 warnings.filterwarnings('ignore', '.*`scipy.sparse.csr` name.*')
98 out = pickle.load(f, encoding='latin1')
99 else:
100 out = pickle.load(f)
101
102 if name == 'graph':
103 return out
104
105 out = out.todense() if hasattr(out, 'todense') else out
106 out = torch.from_numpy(out).to(torch.float)
107 return out
108
109
110 def edge_index_from_dict(graph_dict, num_nodes=None):
111 row, col = [], []
112 for key, value in graph_dict.items():
113 row += repeat(key, len(value))
114 col += value
115 edge_index = torch.stack([torch.tensor(row), torch.tensor(col)], dim=0)
116
117 # NOTE: There are some duplicated edges and self loops in the datasets.
118 # Other implementations do not remove them!
119 edge_index, _ = remove_self_loops(edge_index)
120 edge_index = coalesce(edge_index, num_nodes=num_nodes)
121
122 return edge_index
123
[end of torch_geometric/io/planetoid.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/torch_geometric/io/planetoid.py b/torch_geometric/io/planetoid.py
--- a/torch_geometric/io/planetoid.py
+++ b/torch_geometric/io/planetoid.py
@@ -30,9 +30,9 @@
# as zero vectors to `tx` and `ty`.
len_test_indices = (test_index.max() - test_index.min()).item() + 1
- tx_ext = torch.zeros(len_test_indices, tx.size(1))
+ tx_ext = torch.zeros(len_test_indices, tx.size(1), dtype=tx.dtype)
tx_ext[sorted_test_index - test_index.min(), :] = tx
- ty_ext = torch.zeros(len_test_indices, ty.size(1))
+ ty_ext = torch.zeros(len_test_indices, ty.size(1), dtype=ty.dtype)
ty_ext[sorted_test_index - test_index.min(), :] = ty
tx, ty = tx_ext, ty_ext
|
{"golden_diff": "diff --git a/torch_geometric/io/planetoid.py b/torch_geometric/io/planetoid.py\n--- a/torch_geometric/io/planetoid.py\n+++ b/torch_geometric/io/planetoid.py\n@@ -30,9 +30,9 @@\n # as zero vectors to `tx` and `ty`.\n len_test_indices = (test_index.max() - test_index.min()).item() + 1\n \n- tx_ext = torch.zeros(len_test_indices, tx.size(1))\n+ tx_ext = torch.zeros(len_test_indices, tx.size(1), dtype=tx.dtype)\n tx_ext[sorted_test_index - test_index.min(), :] = tx\n- ty_ext = torch.zeros(len_test_indices, ty.size(1))\n+ ty_ext = torch.zeros(len_test_indices, ty.size(1), dtype=ty.dtype)\n ty_ext[sorted_test_index - test_index.min(), :] = ty\n \n tx, ty = tx_ext, ty_ext\n", "issue": "Planetoid dtype mismatch for CiteSeer\n### \ud83d\udc1b Describe the bug\r\n\r\nI find that I can't load the CiteSeer dataset with double precision\r\n\r\n```python\r\nimport torch_geometric as tg\r\ntg.datasets.Planetoid(root=\"/tmp\", name=\"CiteSeer\")\r\n```\r\n\r\nI get this error\r\n\r\n```\r\nFile /user/work/pc22286/mambaforge/envs/dkm/lib/python3.11/site-packages/torch_geometric/io/planetoid.py:34, in read_planetoid_data(folder, prefix)\r\n 31 len_test_indices = (test_index.max() - test_index.min()).item() + 1\r\n 33 tx_ext = torch.zeros(len_test_indices, tx.size(1))\r\n---> 34 tx_ext[sorted_test_index - test_index.min(), :] = tx\r\n 35 ty_ext = torch.zeros(len_test_indices, ty.size(1))\r\n 36 ty_ext[sorted_test_index - test_index.min(), :] = ty\r\n\r\nRuntimeError: Index put requires the source and destination dtypes match, got Double for the destination and Float for the source.\r\n```\r\n\r\nFortunately, there is a workaround if I set the default precision to single precision\r\n\r\n```python\r\nimport torch as t\r\nt.set_default_dtype(t.float32)\r\ntg.datasets.Planetoid(root=\"/tmp\", name=\"CiteSeer\") ## success, this time\r\n```\r\n\r\nand then I will convert to double precision manually later. Not a bit problem, but I expected to be able to use float64\r\n\r\n### Environment\r\n\r\n* PyG version: 2.3.1\r\n* PyTorch version: 2.0.1\r\n* OS: CentOS 7\r\n* Python version: 3.11.3\r\n* CUDA/cuDNN version: 12.0\r\n* How you installed PyTorch and PyG (`conda`, `pip`, source): installed torch by conda (mamba), PyG by pip\r\n* Any other relevant information (*e.g.*, version of `torch-scatter`):\r\n\n", "before_files": [{"content": "import os.path as osp\nimport sys\nimport warnings\nfrom itertools import repeat\n\nimport torch\n\nfrom torch_geometric.data import Data\nfrom torch_geometric.io import read_txt_array\nfrom torch_geometric.typing import SparseTensor\nfrom torch_geometric.utils import coalesce, index_to_mask, remove_self_loops\n\ntry:\n import cPickle as pickle\nexcept ImportError:\n import pickle\n\n\ndef read_planetoid_data(folder, prefix):\n names = ['x', 'tx', 'allx', 'y', 'ty', 'ally', 'graph', 'test.index']\n items = [read_file(folder, prefix, name) for name in names]\n x, tx, allx, y, ty, ally, graph, test_index = items\n train_index = torch.arange(y.size(0), dtype=torch.long)\n val_index = torch.arange(y.size(0), y.size(0) + 500, dtype=torch.long)\n sorted_test_index = test_index.sort()[0]\n\n if prefix.lower() == 'citeseer':\n # There are some isolated nodes in the Citeseer graph, resulting in\n # none consecutive test indices. We need to identify them and add them\n # as zero vectors to `tx` and `ty`.\n len_test_indices = (test_index.max() - test_index.min()).item() + 1\n\n tx_ext = torch.zeros(len_test_indices, tx.size(1))\n tx_ext[sorted_test_index - test_index.min(), :] = tx\n ty_ext = torch.zeros(len_test_indices, ty.size(1))\n ty_ext[sorted_test_index - test_index.min(), :] = ty\n\n tx, ty = tx_ext, ty_ext\n\n if prefix.lower() == 'nell.0.001':\n tx_ext = torch.zeros(len(graph) - allx.size(0), x.size(1))\n tx_ext[sorted_test_index - allx.size(0)] = tx\n\n ty_ext = torch.zeros(len(graph) - ally.size(0), y.size(1))\n ty_ext[sorted_test_index - ally.size(0)] = ty\n\n tx, ty = tx_ext, ty_ext\n\n x = torch.cat([allx, tx], dim=0)\n x[test_index] = x[sorted_test_index]\n\n # Creating feature vectors for relations.\n row, col, value = SparseTensor.from_dense(x).coo()\n rows, cols, values = [row], [col], [value]\n\n mask1 = index_to_mask(test_index, size=len(graph))\n mask2 = index_to_mask(torch.arange(allx.size(0), len(graph)),\n size=len(graph))\n mask = ~mask1 | ~mask2\n isolated_index = mask.nonzero(as_tuple=False).view(-1)[allx.size(0):]\n\n rows += [isolated_index]\n cols += [torch.arange(isolated_index.size(0)) + x.size(1)]\n values += [torch.ones(isolated_index.size(0))]\n\n x = SparseTensor(row=torch.cat(rows), col=torch.cat(cols),\n value=torch.cat(values))\n else:\n x = torch.cat([allx, tx], dim=0)\n x[test_index] = x[sorted_test_index]\n\n y = torch.cat([ally, ty], dim=0).max(dim=1)[1]\n y[test_index] = y[sorted_test_index]\n\n train_mask = index_to_mask(train_index, size=y.size(0))\n val_mask = index_to_mask(val_index, size=y.size(0))\n test_mask = index_to_mask(test_index, size=y.size(0))\n\n edge_index = edge_index_from_dict(graph, num_nodes=y.size(0))\n\n data = Data(x=x, edge_index=edge_index, y=y)\n data.train_mask = train_mask\n data.val_mask = val_mask\n data.test_mask = test_mask\n\n return data\n\n\ndef read_file(folder, prefix, name):\n path = osp.join(folder, f'ind.{prefix.lower()}.{name}')\n\n if name == 'test.index':\n return read_txt_array(path, dtype=torch.long)\n\n with open(path, 'rb') as f:\n if sys.version_info > (3, 0):\n warnings.filterwarnings('ignore', '.*`scipy.sparse.csr` name.*')\n out = pickle.load(f, encoding='latin1')\n else:\n out = pickle.load(f)\n\n if name == 'graph':\n return out\n\n out = out.todense() if hasattr(out, 'todense') else out\n out = torch.from_numpy(out).to(torch.float)\n return out\n\n\ndef edge_index_from_dict(graph_dict, num_nodes=None):\n row, col = [], []\n for key, value in graph_dict.items():\n row += repeat(key, len(value))\n col += value\n edge_index = torch.stack([torch.tensor(row), torch.tensor(col)], dim=0)\n\n # NOTE: There are some duplicated edges and self loops in the datasets.\n # Other implementations do not remove them!\n edge_index, _ = remove_self_loops(edge_index)\n edge_index = coalesce(edge_index, num_nodes=num_nodes)\n\n return edge_index\n", "path": "torch_geometric/io/planetoid.py"}]}
| 2,383 | 211 |
gh_patches_debug_36404
|
rasdani/github-patches
|
git_diff
|
pytorch__ignite-2261
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Update sphinx to 3.5.4 or latest
## 📚 Documentation
Let's bump Sphinx version to 3.5.4 or later for our docs building.
</issue>
<code>
[start of docs/source/conf.py]
1 # -*- coding: utf-8 -*-
2 #
3 # Configuration file for the Sphinx documentation builder.
4 #
5 # This file does only contain a selection of the most common options. For a
6 # full list see the documentation:
7 # http://www.sphinx-doc.org/en/stable/config
8
9 # -- Path setup --------------------------------------------------------------
10
11 # If extensions (or modules to document with autodoc) are in another directory,
12 # add these directories to sys.path here. If the directory is relative to the
13 # documentation root, use os.path.abspath to make it absolute, like shown here.
14 #
15 import os
16 import sys
17
18 sys.path.insert(0, os.path.abspath("../.."))
19 import ignite
20 import pytorch_sphinx_theme
21
22 from datetime import datetime
23
24 # -- Project information -----------------------------------------------------
25
26 project = "PyTorch-Ignite"
27 author = "PyTorch-Ignite Contributors"
28 copyright = f"{datetime.now().year}, {author}"
29
30 # The short X.Y version
31 try:
32 version = os.environ["code_version"]
33 except KeyError:
34 version = ignite.__version__
35
36 # The full version, including alpha/beta/rc tags
37 release = version
38
39
40 # -- General configuration ---------------------------------------------------
41
42 # If your documentation needs a minimal Sphinx version, state it here.
43 #
44 # needs_sphinx = '1.0'
45
46 # Add any Sphinx extension module names here, as strings. They can be
47 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
48 # ones.
49 extensions = [
50 "sphinx.ext.autodoc",
51 "sphinx.ext.autosummary",
52 "sphinx.ext.doctest",
53 "sphinx.ext.intersphinx",
54 "sphinx.ext.todo",
55 "sphinx.ext.coverage",
56 "sphinxcontrib.katex",
57 "sphinx.ext.napoleon",
58 "sphinx.ext.viewcode",
59 "sphinx.ext.autosectionlabel",
60 "sphinx_copybutton",
61 ]
62
63 # katex options
64 katex_prerender = True
65
66 # Add any paths that contain templates here, relative to this directory.
67 templates_path = ["_templates"]
68
69 # The suffix(es) of source filenames.
70 # You can specify multiple suffix as a list of string:
71 #
72 # source_suffix = ['.rst', '.md']
73 source_suffix = ".rst"
74
75 # The master toctree document.
76 master_doc = "index"
77
78 # The language for content autogenerated by Sphinx. Refer to documentation
79 # for a list of supported languages.
80 #
81 # This is also used if you do content translation via gettext catalogs.
82 # Usually you set "language" from the command line for these cases.
83 language = "en"
84
85 # List of patterns, relative to source directory, that match files and
86 # directories to ignore when looking for source files.
87 # This pattern also affects html_static_path and html_extra_path .
88 exclude_patterns = []
89
90 # The name of the Pygments (syntax highlighting) style to use.
91 pygments_style = "sphinx"
92
93
94 # -- Options for HTML output -------------------------------------------------
95
96 # The theme to use for HTML and HTML Help pages. See the documentation for
97 # a list of builtin themes.
98
99 html_title = f"{project} {version} Documentation"
100 html_theme = "pytorch_sphinx_theme"
101 html_theme_path = [pytorch_sphinx_theme.get_html_theme_path()]
102
103 html_theme_options = {
104 "canonical_url": "https://pytorch.org/ignite/",
105 "collapse_navigation": False,
106 "display_version": True,
107 "logo_only": True,
108 "navigation_with_keys": True,
109 }
110
111 html_logo = "_templates/_static/img/ignite_logo.svg"
112
113 html_favicon = "_templates/_static/img/ignite_logomark.svg"
114
115 # Theme options are theme-specific and customize the look and feel of a theme
116 # further. For a list of options available for each theme, see the
117 # documentation.
118 #
119 # html_theme_options = {}
120
121 # Add any paths that contain custom static files (such as style sheets) here,
122 # relative to this directory. They are copied after the builtin static files,
123 # so a file named "default.css" will overwrite the builtin "default.css".
124 html_static_path = ["_static", "_templates/_static"]
125
126 html_context = {
127 "extra_css_files": [
128 # 'https://fonts.googleapis.com/css?family=Lato',
129 # '_static/css/pytorch_theme.css'
130 "_static/css/ignite_theme.css",
131 "https://cdn.jsdelivr.net/npm/@docsearch/[email protected]/dist/style.min.css",
132 ],
133 }
134
135 html_last_updated_fmt = "%m/%d/%Y, %X"
136 html_add_permalinks = "#"
137
138 # -- Options for HTMLHelp output ---------------------------------------------
139
140 # Output file base name for HTML help builder.
141 htmlhelp_basename = "ignitedoc"
142
143
144 # -- Options for LaTeX output ------------------------------------------------
145
146 latex_elements = {
147 # The paper size ('letterpaper' or 'a4paper').
148 #
149 # 'papersize': 'letterpaper',
150 # The font size ('10pt', '11pt' or '12pt').
151 #
152 # 'pointsize': '10pt',
153 # Additional stuff for the LaTeX preamble.
154 #
155 # 'preamble': '',
156 # Latex figure (float) alignment
157 #
158 # 'figure_align': 'htbp',
159 }
160
161 # Grouping the document tree into LaTeX files. List of tuples
162 # (source start file, target name, title,
163 # author, documentclass [howto, manual, or own class]).
164 latex_documents = [
165 (master_doc, "ignite.tex", "ignite Documentation", "Torch Contributors", "manual"),
166 ]
167
168
169 # -- Options for manual page output ------------------------------------------
170
171 # One entry per manual page. List of tuples
172 # (source start file, name, description, authors, manual section).
173 man_pages = [(master_doc, "ignite", "ignite Documentation", [author], 1)]
174
175
176 # -- Options for Texinfo output ----------------------------------------------
177
178 # Grouping the document tree into Texinfo files. List of tuples
179 # (source start file, target name, title, author,
180 # dir menu entry, description, category)
181 texinfo_documents = [
182 (
183 master_doc,
184 "ignite",
185 "ignite Documentation",
186 author,
187 "ignite",
188 "One line description of project.",
189 "Miscellaneous",
190 ),
191 ]
192
193
194 # -- Extension configuration -------------------------------------------------
195
196 # -- Options for intersphinx extension ---------------------------------------
197
198 # Example configuration for intersphinx: refer to the Python standard library.
199 intersphinx_mapping = {
200 "python": ("https://docs.python.org/3", None),
201 "torch": ("https://pytorch.org/docs/stable/", None),
202 }
203
204 # -- Options for todo extension ----------------------------------------------
205
206 # If true, `todo` and `todoList` produce output, else they produce nothing.
207 todo_include_todos = True
208
209 # -- Type hints configs ------------------------------------------------------
210
211 autodoc_inherit_docstrings = True
212 autoclass_content = "both"
213 autodoc_typehints = "description"
214 napoleon_attr_annotations = True
215
216 # -- A patch that turns-off cross refs for type annotations ------------------
217
218 import sphinx.domains.python
219 from docutils import nodes
220 from sphinx import addnodes
221
222 # replaces pending_xref node with desc_type for type annotations
223 sphinx.domains.python.type_to_xref = lambda t, e=None: addnodes.desc_type("", nodes.Text(t))
224
225 # -- Autosummary patch to get list of a classes, funcs automatically ----------
226
227 from importlib import import_module
228 from inspect import getmembers, isclass, isfunction
229 import sphinx.ext.autosummary
230 from sphinx.ext.autosummary import Autosummary
231 from docutils.parsers.rst import directives
232 from docutils.statemachine import StringList
233
234
235 class BetterAutosummary(Autosummary):
236 """Autosummary with autolisting for modules.
237
238 By default it tries to import all public names (__all__),
239 otherwise import all classes and/or functions in a module.
240
241 Options:
242 - :autolist: option to get list of classes and functions from currentmodule.
243 - :autolist-classes: option to get list of classes from currentmodule.
244 - :autolist-functions: option to get list of functions from currentmodule.
245
246 Example Usage:
247
248 .. currentmodule:: ignite.metrics
249
250 .. autosummary::
251 :nosignatures:
252 :autolist:
253 """
254
255 # Add new option
256 _option_spec = Autosummary.option_spec.copy()
257 _option_spec.update(
258 {
259 "autolist": directives.unchanged,
260 "autolist-classes": directives.unchanged,
261 "autolist-functions": directives.unchanged,
262 }
263 )
264 option_spec = _option_spec
265
266 def run(self):
267 for auto in ("autolist", "autolist-classes", "autolist-functions"):
268 if auto in self.options:
269 # Get current module name
270 module_name = self.env.ref_context.get("py:module")
271 # Import module
272 module = import_module(module_name)
273
274 # Get public names (if possible)
275 try:
276 names = getattr(module, "__all__")
277 except AttributeError:
278 # Get classes defined in the module
279 cls_names = [
280 name[0]
281 for name in getmembers(module, isclass)
282 if name[-1].__module__ == module_name and not (name[0].startswith("_"))
283 ]
284 # Get functions defined in the module
285 fn_names = [
286 name[0]
287 for name in getmembers(module, isfunction)
288 if (name[-1].__module__ == module_name) and not (name[0].startswith("_"))
289 ]
290 names = cls_names + fn_names
291 # It may happen that module doesn't have any defined class or func
292 if not names:
293 names = [name[0] for name in getmembers(module)]
294
295 # Filter out members w/o doc strings
296 names = [name for name in names if getattr(module, name).__doc__ is not None]
297
298 if auto == "autolist":
299 # Get list of all classes and functions inside module
300 names = [
301 name for name in names if (isclass(getattr(module, name)) or isfunction(getattr(module, name)))
302 ]
303 else:
304 if auto == "autolist-classes":
305 # Get only classes
306 check = isclass
307 elif auto == "autolist-functions":
308 # Get only functions
309 check = isfunction
310 else:
311 raise NotImplementedError
312
313 names = [name for name in names if check(getattr(module, name))]
314
315 # Update content
316 self.content = StringList(names)
317 return super().run()
318
319
320 # Patch original Autosummary
321 sphinx.ext.autosummary.Autosummary = BetterAutosummary
322
323 # --- autosummary config -----------------------------------------------------
324 autosummary_generate = True
325
326 # --- nitpicky config : check internal links are correct or not --------------
327 nitpicky = True
328 # ignore links which can't be referenced
329 nitpick_ignore = [
330 ("py:class", ".."),
331 ("py:class", "TextIO"),
332 ("py:class", "torch.device"),
333 ("py:class", "_MpDeviceLoader"),
334 ("py:class", "torch.nn.modules.module.Module"),
335 ("py:class", "torch.optim.optimizer.Optimizer"),
336 ("py:class", "torch.utils.data.dataset.Dataset"),
337 ("py:class", "torch.utils.data.sampler.BatchSampler"),
338 ("py:class", "torch.cuda.amp.grad_scaler.GradScaler"),
339 ("py:class", "torch.optim.lr_scheduler._LRScheduler"),
340 ("py:class", "torch.utils.data.dataloader.DataLoader"),
341 ]
342
343 # doctest config
344 doctest_global_setup = """
345 import torch
346 from torch import nn, optim
347
348 from ignite.engine import *
349 from ignite.handlers import *
350 from ignite.metrics import *
351 from ignite.utils import *
352
353 manual_seed(666)
354 """
355
[end of docs/source/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/source/conf.py b/docs/source/conf.py
--- a/docs/source/conf.py
+++ b/docs/source/conf.py
@@ -16,10 +16,11 @@
import sys
sys.path.insert(0, os.path.abspath("../.."))
-import ignite
+from datetime import datetime
+
import pytorch_sphinx_theme
-from datetime import datetime
+import ignite
# -- Project information -----------------------------------------------------
@@ -133,7 +134,8 @@
}
html_last_updated_fmt = "%m/%d/%Y, %X"
-html_add_permalinks = "#"
+html_permalinks = True
+html_permalinks_icon = "#"
# -- Options for HTMLHelp output ---------------------------------------------
@@ -213,26 +215,17 @@
autodoc_typehints = "description"
napoleon_attr_annotations = True
-# -- A patch that turns-off cross refs for type annotations ------------------
-
-import sphinx.domains.python
-from docutils import nodes
-from sphinx import addnodes
-
-# replaces pending_xref node with desc_type for type annotations
-sphinx.domains.python.type_to_xref = lambda t, e=None: addnodes.desc_type("", nodes.Text(t))
-
# -- Autosummary patch to get list of a classes, funcs automatically ----------
from importlib import import_module
from inspect import getmembers, isclass, isfunction
-import sphinx.ext.autosummary
-from sphinx.ext.autosummary import Autosummary
+
from docutils.parsers.rst import directives
from docutils.statemachine import StringList
+from sphinx.ext.autosummary import Autosummary
-class BetterAutosummary(Autosummary):
+class AutolistAutosummary(Autosummary):
"""Autosummary with autolisting for modules.
By default it tries to import all public names (__all__),
@@ -317,9 +310,6 @@
return super().run()
-# Patch original Autosummary
-sphinx.ext.autosummary.Autosummary = BetterAutosummary
-
# --- autosummary config -----------------------------------------------------
autosummary_generate = True
@@ -352,3 +342,7 @@
manual_seed(666)
"""
+
+
+def setup(app):
+ app.add_directive("autosummary", AutolistAutosummary, override=True)
|
{"golden_diff": "diff --git a/docs/source/conf.py b/docs/source/conf.py\n--- a/docs/source/conf.py\n+++ b/docs/source/conf.py\n@@ -16,10 +16,11 @@\n import sys\n \n sys.path.insert(0, os.path.abspath(\"../..\"))\n-import ignite\n+from datetime import datetime\n+\n import pytorch_sphinx_theme\n \n-from datetime import datetime\n+import ignite\n \n # -- Project information -----------------------------------------------------\n \n@@ -133,7 +134,8 @@\n }\n \n html_last_updated_fmt = \"%m/%d/%Y, %X\"\n-html_add_permalinks = \"#\"\n+html_permalinks = True\n+html_permalinks_icon = \"#\"\n \n # -- Options for HTMLHelp output ---------------------------------------------\n \n@@ -213,26 +215,17 @@\n autodoc_typehints = \"description\"\n napoleon_attr_annotations = True\n \n-# -- A patch that turns-off cross refs for type annotations ------------------\n-\n-import sphinx.domains.python\n-from docutils import nodes\n-from sphinx import addnodes\n-\n-# replaces pending_xref node with desc_type for type annotations\n-sphinx.domains.python.type_to_xref = lambda t, e=None: addnodes.desc_type(\"\", nodes.Text(t))\n-\n # -- Autosummary patch to get list of a classes, funcs automatically ----------\n \n from importlib import import_module\n from inspect import getmembers, isclass, isfunction\n-import sphinx.ext.autosummary\n-from sphinx.ext.autosummary import Autosummary\n+\n from docutils.parsers.rst import directives\n from docutils.statemachine import StringList\n+from sphinx.ext.autosummary import Autosummary\n \n \n-class BetterAutosummary(Autosummary):\n+class AutolistAutosummary(Autosummary):\n \"\"\"Autosummary with autolisting for modules.\n \n By default it tries to import all public names (__all__),\n@@ -317,9 +310,6 @@\n return super().run()\n \n \n-# Patch original Autosummary\n-sphinx.ext.autosummary.Autosummary = BetterAutosummary\n-\n # --- autosummary config -----------------------------------------------------\n autosummary_generate = True\n \n@@ -352,3 +342,7 @@\n \n manual_seed(666)\n \"\"\"\n+\n+\n+def setup(app):\n+ app.add_directive(\"autosummary\", AutolistAutosummary, override=True)\n", "issue": "Update sphinx to 3.5.4 or latest\n## \ud83d\udcda Documentation\r\n\r\nLet's bump Sphinx version to 3.5.4 or later for our docs building.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Configuration file for the Sphinx documentation builder.\n#\n# This file does only contain a selection of the most common options. For a\n# full list see the documentation:\n# http://www.sphinx-doc.org/en/stable/config\n\n# -- Path setup --------------------------------------------------------------\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\nimport os\nimport sys\n\nsys.path.insert(0, os.path.abspath(\"../..\"))\nimport ignite\nimport pytorch_sphinx_theme\n\nfrom datetime import datetime\n\n# -- Project information -----------------------------------------------------\n\nproject = \"PyTorch-Ignite\"\nauthor = \"PyTorch-Ignite Contributors\"\ncopyright = f\"{datetime.now().year}, {author}\"\n\n# The short X.Y version\ntry:\n version = os.environ[\"code_version\"]\nexcept KeyError:\n version = ignite.__version__\n\n# The full version, including alpha/beta/rc tags\nrelease = version\n\n\n# -- General configuration ---------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\n# needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n \"sphinx.ext.autodoc\",\n \"sphinx.ext.autosummary\",\n \"sphinx.ext.doctest\",\n \"sphinx.ext.intersphinx\",\n \"sphinx.ext.todo\",\n \"sphinx.ext.coverage\",\n \"sphinxcontrib.katex\",\n \"sphinx.ext.napoleon\",\n \"sphinx.ext.viewcode\",\n \"sphinx.ext.autosectionlabel\",\n \"sphinx_copybutton\",\n]\n\n# katex options\nkatex_prerender = True\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = [\"_templates\"]\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\n# source_suffix = ['.rst', '.md']\nsource_suffix = \".rst\"\n\n# The master toctree document.\nmaster_doc = \"index\"\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = \"en\"\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path .\nexclude_patterns = []\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = \"sphinx\"\n\n\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n\nhtml_title = f\"{project} {version} Documentation\"\nhtml_theme = \"pytorch_sphinx_theme\"\nhtml_theme_path = [pytorch_sphinx_theme.get_html_theme_path()]\n\nhtml_theme_options = {\n \"canonical_url\": \"https://pytorch.org/ignite/\",\n \"collapse_navigation\": False,\n \"display_version\": True,\n \"logo_only\": True,\n \"navigation_with_keys\": True,\n}\n\nhtml_logo = \"_templates/_static/img/ignite_logo.svg\"\n\nhtml_favicon = \"_templates/_static/img/ignite_logomark.svg\"\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#\n# html_theme_options = {}\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = [\"_static\", \"_templates/_static\"]\n\nhtml_context = {\n \"extra_css_files\": [\n # 'https://fonts.googleapis.com/css?family=Lato',\n # '_static/css/pytorch_theme.css'\n \"_static/css/ignite_theme.css\",\n \"https://cdn.jsdelivr.net/npm/@docsearch/[email protected]/dist/style.min.css\",\n ],\n}\n\nhtml_last_updated_fmt = \"%m/%d/%Y, %X\"\nhtml_add_permalinks = \"#\"\n\n# -- Options for HTMLHelp output ---------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = \"ignitedoc\"\n\n\n# -- Options for LaTeX output ------------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n #\n # 'papersize': 'letterpaper',\n # The font size ('10pt', '11pt' or '12pt').\n #\n # 'pointsize': '10pt',\n # Additional stuff for the LaTeX preamble.\n #\n # 'preamble': '',\n # Latex figure (float) alignment\n #\n # 'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (master_doc, \"ignite.tex\", \"ignite Documentation\", \"Torch Contributors\", \"manual\"),\n]\n\n\n# -- Options for manual page output ------------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [(master_doc, \"ignite\", \"ignite Documentation\", [author], 1)]\n\n\n# -- Options for Texinfo output ----------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (\n master_doc,\n \"ignite\",\n \"ignite Documentation\",\n author,\n \"ignite\",\n \"One line description of project.\",\n \"Miscellaneous\",\n ),\n]\n\n\n# -- Extension configuration -------------------------------------------------\n\n# -- Options for intersphinx extension ---------------------------------------\n\n# Example configuration for intersphinx: refer to the Python standard library.\nintersphinx_mapping = {\n \"python\": (\"https://docs.python.org/3\", None),\n \"torch\": (\"https://pytorch.org/docs/stable/\", None),\n}\n\n# -- Options for todo extension ----------------------------------------------\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = True\n\n# -- Type hints configs ------------------------------------------------------\n\nautodoc_inherit_docstrings = True\nautoclass_content = \"both\"\nautodoc_typehints = \"description\"\nnapoleon_attr_annotations = True\n\n# -- A patch that turns-off cross refs for type annotations ------------------\n\nimport sphinx.domains.python\nfrom docutils import nodes\nfrom sphinx import addnodes\n\n# replaces pending_xref node with desc_type for type annotations\nsphinx.domains.python.type_to_xref = lambda t, e=None: addnodes.desc_type(\"\", nodes.Text(t))\n\n# -- Autosummary patch to get list of a classes, funcs automatically ----------\n\nfrom importlib import import_module\nfrom inspect import getmembers, isclass, isfunction\nimport sphinx.ext.autosummary\nfrom sphinx.ext.autosummary import Autosummary\nfrom docutils.parsers.rst import directives\nfrom docutils.statemachine import StringList\n\n\nclass BetterAutosummary(Autosummary):\n \"\"\"Autosummary with autolisting for modules.\n\n By default it tries to import all public names (__all__),\n otherwise import all classes and/or functions in a module.\n\n Options:\n - :autolist: option to get list of classes and functions from currentmodule.\n - :autolist-classes: option to get list of classes from currentmodule.\n - :autolist-functions: option to get list of functions from currentmodule.\n\n Example Usage:\n\n .. currentmodule:: ignite.metrics\n\n .. autosummary::\n :nosignatures:\n :autolist:\n \"\"\"\n\n # Add new option\n _option_spec = Autosummary.option_spec.copy()\n _option_spec.update(\n {\n \"autolist\": directives.unchanged,\n \"autolist-classes\": directives.unchanged,\n \"autolist-functions\": directives.unchanged,\n }\n )\n option_spec = _option_spec\n\n def run(self):\n for auto in (\"autolist\", \"autolist-classes\", \"autolist-functions\"):\n if auto in self.options:\n # Get current module name\n module_name = self.env.ref_context.get(\"py:module\")\n # Import module\n module = import_module(module_name)\n\n # Get public names (if possible)\n try:\n names = getattr(module, \"__all__\")\n except AttributeError:\n # Get classes defined in the module\n cls_names = [\n name[0]\n for name in getmembers(module, isclass)\n if name[-1].__module__ == module_name and not (name[0].startswith(\"_\"))\n ]\n # Get functions defined in the module\n fn_names = [\n name[0]\n for name in getmembers(module, isfunction)\n if (name[-1].__module__ == module_name) and not (name[0].startswith(\"_\"))\n ]\n names = cls_names + fn_names\n # It may happen that module doesn't have any defined class or func\n if not names:\n names = [name[0] for name in getmembers(module)]\n\n # Filter out members w/o doc strings\n names = [name for name in names if getattr(module, name).__doc__ is not None]\n\n if auto == \"autolist\":\n # Get list of all classes and functions inside module\n names = [\n name for name in names if (isclass(getattr(module, name)) or isfunction(getattr(module, name)))\n ]\n else:\n if auto == \"autolist-classes\":\n # Get only classes\n check = isclass\n elif auto == \"autolist-functions\":\n # Get only functions\n check = isfunction\n else:\n raise NotImplementedError\n\n names = [name for name in names if check(getattr(module, name))]\n\n # Update content\n self.content = StringList(names)\n return super().run()\n\n\n# Patch original Autosummary\nsphinx.ext.autosummary.Autosummary = BetterAutosummary\n\n# --- autosummary config -----------------------------------------------------\nautosummary_generate = True\n\n# --- nitpicky config : check internal links are correct or not --------------\nnitpicky = True\n# ignore links which can't be referenced\nnitpick_ignore = [\n (\"py:class\", \"..\"),\n (\"py:class\", \"TextIO\"),\n (\"py:class\", \"torch.device\"),\n (\"py:class\", \"_MpDeviceLoader\"),\n (\"py:class\", \"torch.nn.modules.module.Module\"),\n (\"py:class\", \"torch.optim.optimizer.Optimizer\"),\n (\"py:class\", \"torch.utils.data.dataset.Dataset\"),\n (\"py:class\", \"torch.utils.data.sampler.BatchSampler\"),\n (\"py:class\", \"torch.cuda.amp.grad_scaler.GradScaler\"),\n (\"py:class\", \"torch.optim.lr_scheduler._LRScheduler\"),\n (\"py:class\", \"torch.utils.data.dataloader.DataLoader\"),\n]\n\n# doctest config\ndoctest_global_setup = \"\"\"\nimport torch\nfrom torch import nn, optim\n\nfrom ignite.engine import *\nfrom ignite.handlers import *\nfrom ignite.metrics import *\nfrom ignite.utils import *\n\nmanual_seed(666)\n\"\"\"\n", "path": "docs/source/conf.py"}]}
| 4,081 | 524 |
gh_patches_debug_4018
|
rasdani/github-patches
|
git_diff
|
ethereum__web3.py-2360
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Upgrade jsonschema to the latest 4.4
### What was wrong?
https://github.com/ethereum/web3.py/blob/16aff7e80a6bc089051c154b5079213317c27da8/setup.py#L86
I cannot combine `web3.py` with the latest `jsonschema` in a single app (without relying on ugly hacks)
### How can it be fixed?
Maybe just expand the range to `jsonschema>=3.2.0,<4.5` and let users test compatibility?
https://github.com/ethereum/web3.py/blob/16aff7e80a6bc089051c154b5079213317c27da8/docs/web3.pm.rst#L12
so the web3.py dev team shouldn't have to worry too much about maintaining compatibility
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2 from setuptools import (
3 find_packages,
4 setup,
5 )
6
7 extras_require = {
8 'tester': [
9 "eth-tester[py-evm]==v0.6.0-beta.6",
10 "py-geth>=3.7.0,<4",
11 ],
12 'linter': [
13 "flake8==3.8.3",
14 "isort>=4.2.15,<4.3.5",
15 "mypy==0.910",
16 "types-setuptools>=57.4.4,<58",
17 "types-requests>=2.26.1,<3",
18 "types-protobuf>=3.18.2,<4",
19 ],
20 'docs': [
21 "mock",
22 "sphinx-better-theme>=0.1.4",
23 "click>=5.1",
24 "configparser==3.5.0",
25 "contextlib2>=0.5.4",
26 "py-geth>=3.6.0,<4",
27 "py-solc>=0.4.0",
28 "pytest>=4.4.0,<5.0.0",
29 "sphinx>=3.0,<4",
30 "sphinx_rtd_theme>=0.1.9",
31 "toposort>=1.4",
32 "towncrier==18.5.0",
33 "urllib3",
34 "wheel"
35 ],
36 'dev': [
37 "bumpversion",
38 "flaky>=3.7.0,<4",
39 "hypothesis>=3.31.2,<6",
40 "pytest>=4.4.0,<5.0.0",
41 "pytest-asyncio>=0.10.0,<0.11",
42 "pytest-mock>=1.10,<2",
43 "pytest-pythonpath>=0.3",
44 "pytest-watch>=4.2,<5",
45 "pytest-xdist>=1.29,<2",
46 "setuptools>=38.6.0",
47 "tox>=1.8.0",
48 "tqdm>4.32,<5",
49 "twine>=1.13,<2",
50 "pluggy==0.13.1",
51 "when-changed>=0.3.0,<0.4"
52 ]
53 }
54
55 extras_require['dev'] = (
56 extras_require['tester']
57 + extras_require['linter']
58 + extras_require['docs']
59 + extras_require['dev']
60 )
61
62 with open('./README.md') as readme:
63 long_description = readme.read()
64
65 setup(
66 name='web3',
67 # *IMPORTANT*: Don't manually change the version here. Use the 'bumpversion' utility.
68 version='5.28.0',
69 description="""Web3.py""",
70 long_description_content_type='text/markdown',
71 long_description=long_description,
72 author='Piper Merriam',
73 author_email='[email protected]',
74 url='https://github.com/ethereum/web3.py',
75 include_package_data=True,
76 install_requires=[
77 "aiohttp>=3.7.4.post0,<4",
78 "eth-abi>=2.0.0b6,<3.0.0",
79 "eth-account>=0.5.7,<0.6.0",
80 "eth-hash[pycryptodome]>=0.2.0,<1.0.0",
81 "eth-typing>=2.0.0,<3.0.0",
82 "eth-utils>=1.9.5,<2.0.0",
83 "hexbytes>=0.1.0,<1.0.0",
84 "ipfshttpclient==0.8.0a2",
85 "jsonschema>=3.2.0,<4.0.0",
86 "lru-dict>=1.1.6,<2.0.0",
87 "protobuf>=3.10.0,<4",
88 "pywin32>=223;platform_system=='Windows'",
89 "requests>=2.16.0,<3.0.0",
90 # remove typing_extensions after python_requires>=3.8, see web3._utils.compat
91 "typing-extensions>=3.7.4.1,<5;python_version<'3.8'",
92 "websockets>=9.1,<10",
93 ],
94 python_requires='>=3.6,<4',
95 extras_require=extras_require,
96 py_modules=['web3', 'ens', 'ethpm'],
97 entry_points={"pytest11": ["pytest_ethereum = web3.tools.pytest_ethereum.plugins"]},
98 license="MIT",
99 zip_safe=False,
100 keywords='ethereum',
101 packages=find_packages(exclude=["tests", "tests.*"]),
102 package_data={"web3": ["py.typed"]},
103 classifiers=[
104 'Development Status :: 5 - Production/Stable',
105 'Intended Audience :: Developers',
106 'License :: OSI Approved :: MIT License',
107 'Natural Language :: English',
108 'Programming Language :: Python :: 3',
109 'Programming Language :: Python :: 3.6',
110 'Programming Language :: Python :: 3.7',
111 'Programming Language :: Python :: 3.8',
112 'Programming Language :: Python :: 3.9',
113 ],
114 )
115
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -82,7 +82,7 @@
"eth-utils>=1.9.5,<2.0.0",
"hexbytes>=0.1.0,<1.0.0",
"ipfshttpclient==0.8.0a2",
- "jsonschema>=3.2.0,<4.0.0",
+ "jsonschema>=3.2.0,<5",
"lru-dict>=1.1.6,<2.0.0",
"protobuf>=3.10.0,<4",
"pywin32>=223;platform_system=='Windows'",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -82,7 +82,7 @@\n \"eth-utils>=1.9.5,<2.0.0\",\n \"hexbytes>=0.1.0,<1.0.0\",\n \"ipfshttpclient==0.8.0a2\",\n- \"jsonschema>=3.2.0,<4.0.0\",\n+ \"jsonschema>=3.2.0,<5\",\n \"lru-dict>=1.1.6,<2.0.0\",\n \"protobuf>=3.10.0,<4\",\n \"pywin32>=223;platform_system=='Windows'\",\n", "issue": "Upgrade jsonschema to the latest 4.4\n### What was wrong?\r\n\r\nhttps://github.com/ethereum/web3.py/blob/16aff7e80a6bc089051c154b5079213317c27da8/setup.py#L86\r\n\r\nI cannot combine `web3.py` with the latest `jsonschema` in a single app (without relying on ugly hacks)\r\n\r\n### How can it be fixed?\r\n\r\nMaybe just expand the range to `jsonschema>=3.2.0,<4.5` and let users test compatibility?\r\n\r\nhttps://github.com/ethereum/web3.py/blob/16aff7e80a6bc089051c154b5079213317c27da8/docs/web3.pm.rst#L12\r\n\r\nso the web3.py dev team shouldn't have to worry too much about maintaining compatibility \n", "before_files": [{"content": "#!/usr/bin/env python\nfrom setuptools import (\n find_packages,\n setup,\n)\n\nextras_require = {\n 'tester': [\n \"eth-tester[py-evm]==v0.6.0-beta.6\",\n \"py-geth>=3.7.0,<4\",\n ],\n 'linter': [\n \"flake8==3.8.3\",\n \"isort>=4.2.15,<4.3.5\",\n \"mypy==0.910\",\n \"types-setuptools>=57.4.4,<58\",\n \"types-requests>=2.26.1,<3\",\n \"types-protobuf>=3.18.2,<4\",\n ],\n 'docs': [\n \"mock\",\n \"sphinx-better-theme>=0.1.4\",\n \"click>=5.1\",\n \"configparser==3.5.0\",\n \"contextlib2>=0.5.4\",\n \"py-geth>=3.6.0,<4\",\n \"py-solc>=0.4.0\",\n \"pytest>=4.4.0,<5.0.0\",\n \"sphinx>=3.0,<4\",\n \"sphinx_rtd_theme>=0.1.9\",\n \"toposort>=1.4\",\n \"towncrier==18.5.0\",\n \"urllib3\",\n \"wheel\"\n ],\n 'dev': [\n \"bumpversion\",\n \"flaky>=3.7.0,<4\",\n \"hypothesis>=3.31.2,<6\",\n \"pytest>=4.4.0,<5.0.0\",\n \"pytest-asyncio>=0.10.0,<0.11\",\n \"pytest-mock>=1.10,<2\",\n \"pytest-pythonpath>=0.3\",\n \"pytest-watch>=4.2,<5\",\n \"pytest-xdist>=1.29,<2\",\n \"setuptools>=38.6.0\",\n \"tox>=1.8.0\",\n \"tqdm>4.32,<5\",\n \"twine>=1.13,<2\",\n \"pluggy==0.13.1\",\n \"when-changed>=0.3.0,<0.4\"\n ]\n}\n\nextras_require['dev'] = (\n extras_require['tester']\n + extras_require['linter']\n + extras_require['docs']\n + extras_require['dev']\n)\n\nwith open('./README.md') as readme:\n long_description = readme.read()\n\nsetup(\n name='web3',\n # *IMPORTANT*: Don't manually change the version here. Use the 'bumpversion' utility.\n version='5.28.0',\n description=\"\"\"Web3.py\"\"\",\n long_description_content_type='text/markdown',\n long_description=long_description,\n author='Piper Merriam',\n author_email='[email protected]',\n url='https://github.com/ethereum/web3.py',\n include_package_data=True,\n install_requires=[\n \"aiohttp>=3.7.4.post0,<4\",\n \"eth-abi>=2.0.0b6,<3.0.0\",\n \"eth-account>=0.5.7,<0.6.0\",\n \"eth-hash[pycryptodome]>=0.2.0,<1.0.0\",\n \"eth-typing>=2.0.0,<3.0.0\",\n \"eth-utils>=1.9.5,<2.0.0\",\n \"hexbytes>=0.1.0,<1.0.0\",\n \"ipfshttpclient==0.8.0a2\",\n \"jsonschema>=3.2.0,<4.0.0\",\n \"lru-dict>=1.1.6,<2.0.0\",\n \"protobuf>=3.10.0,<4\",\n \"pywin32>=223;platform_system=='Windows'\",\n \"requests>=2.16.0,<3.0.0\",\n # remove typing_extensions after python_requires>=3.8, see web3._utils.compat\n \"typing-extensions>=3.7.4.1,<5;python_version<'3.8'\",\n \"websockets>=9.1,<10\",\n ],\n python_requires='>=3.6,<4',\n extras_require=extras_require,\n py_modules=['web3', 'ens', 'ethpm'],\n entry_points={\"pytest11\": [\"pytest_ethereum = web3.tools.pytest_ethereum.plugins\"]},\n license=\"MIT\",\n zip_safe=False,\n keywords='ethereum',\n packages=find_packages(exclude=[\"tests\", \"tests.*\"]),\n package_data={\"web3\": [\"py.typed\"]},\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: MIT License',\n 'Natural Language :: English',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: 3.9',\n ],\n)\n", "path": "setup.py"}]}
| 2,132 | 161 |
gh_patches_debug_28103
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-39
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
security_groups in aws_security_group rule not supported
**Describe the bug**
referencing a `security_group` instead of `cidr_block` in a security group rule causes an exception
**To Reproduce**
Steps to reproduce the behavior:
1. try to run checkov on the following resource:
```tf
resource "aws_security_group" "bar-sg" {
name = "sg-bar"
vpc_id = aws_vpc.main.id
ingress {
from_port = 22
to_port = 22
protocol = "tcp"
security_groups = [aws_security_group.foo-sg.id]
description = "foo"
}
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
}
```
result:
```
Traceback (most recent call last):
File "/path/tf-checks/bin/checkov", line 34, in <module>
report = Runner().run(root_folder, external_checks_dir=args.external_checks_dir)
File "/path/tf-checks/lib/python3.7/site-packages/checkov/terraform/runner.py", line 38, in run
results = resource_registry.scan(resource, scanned_file, skipped_checks)
File "/pathtf-checks/lib/python3.7/site-packages/checkov/terraform/checks/resource/registry.py", line 38, in scan
resource_name=resource_name, resource_type=resource, skip_info=skip_info)
File "/path/tf-checks/lib/python3.7/site-packages/checkov/terraform/checks/resource/base_check.py", line 31, in run
check_result['result'] = self.scan_resource_conf(resource_configuration)
File "/path/tf-checks/lib/python3.7/site-packages/checkov/terraform/checks/resource/aws/SecurityGroupUnrestrictedIngress22.py", line 25, in scan_resource_conf
if rule['from_port'] == [PORT] and rule['to_port'] == [PORT] and rule['cidr_blocks'] == [[
KeyError: 'cidr_blocks'
```
**Expected behavior**
such resource definition is perfectly valid
**Desktop (please complete the following information):**
- OS: Ubuntu `19.10`
- Python: `3.7.5`
- Checkov Version `1.0.99`
</issue>
<code>
[start of checkov/terraform/checks/resource/aws/SecurityGroupUnrestrictedIngress3389.py]
1 from checkov.terraform.models.enums import CheckResult, CheckCategories
2 from checkov.terraform.checks.resource.base_check import BaseResourceCheck
3
4 PORT = 3389
5
6
7 class SecurityGroupUnrestrictedIngress3389(BaseResourceCheck):
8 def __init__(self):
9 name = "Ensure no security groups allow ingress from 0.0.0.0:0 to port %d" % PORT
10 id = "CKV_AWS_25"
11 supported_resources = ['aws_security_group']
12 categories = [CheckCategories.NETWORKING]
13 super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
14
15 def scan_resource_conf(self, conf):
16 """
17 Looks for configuration at security group ingress rules :
18 https://www.terraform.io/docs/providers/aws/r/security_group.html
19 :param conf: aws_security_group configuration
20 :return: <CheckResult>
21 """
22 if 'ingress' in conf.keys():
23 ingress_conf = conf['ingress']
24 for rule in ingress_conf:
25 if rule['from_port'] == [PORT] and rule['to_port'] == [PORT] and rule['cidr_blocks'] == [
26 ["0.0.0.0/0"]] and 'self' not in rule.keys() and 'security_groups' not in rule.keys():
27 return CheckResult.FAILED
28
29 return CheckResult.PASSED
30
31
32 check = SecurityGroupUnrestrictedIngress3389()
33
[end of checkov/terraform/checks/resource/aws/SecurityGroupUnrestrictedIngress3389.py]
[start of checkov/terraform/checks/resource/aws/SecurityGroupUnrestrictedIngress22.py]
1 from checkov.terraform.models.enums import CheckResult, CheckCategories
2 from checkov.terraform.checks.resource.base_check import BaseResourceCheck
3
4 PORT = 22
5
6
7 class SecurityGroupUnrestrictedIngress22(BaseResourceCheck):
8 def __init__(self):
9 name = "Ensure no security groups allow ingress from 0.0.0.0:0 to port %d" % PORT
10 id = "CKV_AWS_24"
11 supported_resources = ['aws_security_group']
12 categories = [CheckCategories.NETWORKING]
13 super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
14
15 def scan_resource_conf(self, conf):
16 """
17 Looks for configuration at security group ingress rules :
18 https://www.terraform.io/docs/providers/aws/r/security_group.html
19 :param conf: aws_security_group configuration
20 :return: <CheckResult>
21 """
22 if 'ingress' in conf.keys():
23 ingress_conf = conf['ingress']
24 for rule in ingress_conf:
25 if rule['from_port'] == [PORT] and rule['to_port'] == [PORT] and rule['cidr_blocks'] == [[
26 "0.0.0.0/0"]] and 'self' not in rule.keys() and 'security_groups' not in rule.keys():
27 return CheckResult.FAILED
28
29 return CheckResult.PASSED
30
31
32 check = SecurityGroupUnrestrictedIngress22()
33
[end of checkov/terraform/checks/resource/aws/SecurityGroupUnrestrictedIngress22.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/checkov/terraform/checks/resource/aws/SecurityGroupUnrestrictedIngress22.py b/checkov/terraform/checks/resource/aws/SecurityGroupUnrestrictedIngress22.py
--- a/checkov/terraform/checks/resource/aws/SecurityGroupUnrestrictedIngress22.py
+++ b/checkov/terraform/checks/resource/aws/SecurityGroupUnrestrictedIngress22.py
@@ -22,9 +22,10 @@
if 'ingress' in conf.keys():
ingress_conf = conf['ingress']
for rule in ingress_conf:
- if rule['from_port'] == [PORT] and rule['to_port'] == [PORT] and rule['cidr_blocks'] == [[
- "0.0.0.0/0"]] and 'self' not in rule.keys() and 'security_groups' not in rule.keys():
- return CheckResult.FAILED
+ if rule['from_port'] == [PORT] and rule['to_port'] == [PORT]:
+ if 'cidr_blocks' in rule.keys():
+ if rule['cidr_blocks'] == [["0.0.0.0/0"]] and 'security_groups' not in rule.keys():
+ return CheckResult.FAILED
return CheckResult.PASSED
diff --git a/checkov/terraform/checks/resource/aws/SecurityGroupUnrestrictedIngress3389.py b/checkov/terraform/checks/resource/aws/SecurityGroupUnrestrictedIngress3389.py
--- a/checkov/terraform/checks/resource/aws/SecurityGroupUnrestrictedIngress3389.py
+++ b/checkov/terraform/checks/resource/aws/SecurityGroupUnrestrictedIngress3389.py
@@ -22,9 +22,11 @@
if 'ingress' in conf.keys():
ingress_conf = conf['ingress']
for rule in ingress_conf:
- if rule['from_port'] == [PORT] and rule['to_port'] == [PORT] and rule['cidr_blocks'] == [
- ["0.0.0.0/0"]] and 'self' not in rule.keys() and 'security_groups' not in rule.keys():
- return CheckResult.FAILED
+ if rule['from_port'] == [PORT] and rule['to_port'] == [PORT]:
+ if 'cidr_blocks' in rule.keys():
+ if rule['cidr_blocks'] == [["0.0.0.0/0"]] and 'security_groups' not in rule.keys():
+ return CheckResult.FAILED
+
return CheckResult.PASSED
|
{"golden_diff": "diff --git a/checkov/terraform/checks/resource/aws/SecurityGroupUnrestrictedIngress22.py b/checkov/terraform/checks/resource/aws/SecurityGroupUnrestrictedIngress22.py\n--- a/checkov/terraform/checks/resource/aws/SecurityGroupUnrestrictedIngress22.py\n+++ b/checkov/terraform/checks/resource/aws/SecurityGroupUnrestrictedIngress22.py\n@@ -22,9 +22,10 @@\n if 'ingress' in conf.keys():\n ingress_conf = conf['ingress']\n for rule in ingress_conf:\n- if rule['from_port'] == [PORT] and rule['to_port'] == [PORT] and rule['cidr_blocks'] == [[\n- \"0.0.0.0/0\"]] and 'self' not in rule.keys() and 'security_groups' not in rule.keys():\n- return CheckResult.FAILED\n+ if rule['from_port'] == [PORT] and rule['to_port'] == [PORT]:\n+ if 'cidr_blocks' in rule.keys():\n+ if rule['cidr_blocks'] == [[\"0.0.0.0/0\"]] and 'security_groups' not in rule.keys():\n+ return CheckResult.FAILED\n \n return CheckResult.PASSED\n \ndiff --git a/checkov/terraform/checks/resource/aws/SecurityGroupUnrestrictedIngress3389.py b/checkov/terraform/checks/resource/aws/SecurityGroupUnrestrictedIngress3389.py\n--- a/checkov/terraform/checks/resource/aws/SecurityGroupUnrestrictedIngress3389.py\n+++ b/checkov/terraform/checks/resource/aws/SecurityGroupUnrestrictedIngress3389.py\n@@ -22,9 +22,11 @@\n if 'ingress' in conf.keys():\n ingress_conf = conf['ingress']\n for rule in ingress_conf:\n- if rule['from_port'] == [PORT] and rule['to_port'] == [PORT] and rule['cidr_blocks'] == [\n- [\"0.0.0.0/0\"]] and 'self' not in rule.keys() and 'security_groups' not in rule.keys():\n- return CheckResult.FAILED\n+ if rule['from_port'] == [PORT] and rule['to_port'] == [PORT]:\n+ if 'cidr_blocks' in rule.keys():\n+ if rule['cidr_blocks'] == [[\"0.0.0.0/0\"]] and 'security_groups' not in rule.keys():\n+ return CheckResult.FAILED\n+\n \n return CheckResult.PASSED\n", "issue": "security_groups in aws_security_group rule not supported\n**Describe the bug**\r\nreferencing a `security_group` instead of `cidr_block` in a security group rule causes an exception\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. try to run checkov on the following resource:\r\n```tf\r\nresource \"aws_security_group\" \"bar-sg\" {\r\n name = \"sg-bar\"\r\n vpc_id = aws_vpc.main.id\r\n\r\n ingress {\r\n from_port = 22\r\n to_port = 22\r\n protocol = \"tcp\"\r\n security_groups = [aws_security_group.foo-sg.id]\r\n description = \"foo\"\r\n }\r\n\r\n egress {\r\n from_port = 0\r\n to_port = 0\r\n protocol = \"-1\"\r\n cidr_blocks = [\"0.0.0.0/0\"]\r\n }\r\n\r\n}\r\n\r\n```\r\nresult:\r\n```\r\nTraceback (most recent call last):\r\n File \"/path/tf-checks/bin/checkov\", line 34, in <module>\r\n report = Runner().run(root_folder, external_checks_dir=args.external_checks_dir)\r\n File \"/path/tf-checks/lib/python3.7/site-packages/checkov/terraform/runner.py\", line 38, in run\r\n results = resource_registry.scan(resource, scanned_file, skipped_checks)\r\n File \"/pathtf-checks/lib/python3.7/site-packages/checkov/terraform/checks/resource/registry.py\", line 38, in scan\r\n resource_name=resource_name, resource_type=resource, skip_info=skip_info)\r\n File \"/path/tf-checks/lib/python3.7/site-packages/checkov/terraform/checks/resource/base_check.py\", line 31, in run\r\n check_result['result'] = self.scan_resource_conf(resource_configuration)\r\n File \"/path/tf-checks/lib/python3.7/site-packages/checkov/terraform/checks/resource/aws/SecurityGroupUnrestrictedIngress22.py\", line 25, in scan_resource_conf\r\n if rule['from_port'] == [PORT] and rule['to_port'] == [PORT] and rule['cidr_blocks'] == [[\r\nKeyError: 'cidr_blocks'\r\n```\r\n\r\n**Expected behavior**\r\nsuch resource definition is perfectly valid\r\n\r\n\r\n**Desktop (please complete the following information):**\r\n - OS: Ubuntu `19.10`\r\n - Python: `3.7.5`\r\n - Checkov Version `1.0.99`\r\n\r\n\r\n\n", "before_files": [{"content": "from checkov.terraform.models.enums import CheckResult, CheckCategories\nfrom checkov.terraform.checks.resource.base_check import BaseResourceCheck\n\nPORT = 3389\n\n\nclass SecurityGroupUnrestrictedIngress3389(BaseResourceCheck):\n def __init__(self):\n name = \"Ensure no security groups allow ingress from 0.0.0.0:0 to port %d\" % PORT\n id = \"CKV_AWS_25\"\n supported_resources = ['aws_security_group']\n categories = [CheckCategories.NETWORKING]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def scan_resource_conf(self, conf):\n \"\"\"\n Looks for configuration at security group ingress rules :\n https://www.terraform.io/docs/providers/aws/r/security_group.html\n :param conf: aws_security_group configuration\n :return: <CheckResult>\n \"\"\"\n if 'ingress' in conf.keys():\n ingress_conf = conf['ingress']\n for rule in ingress_conf:\n if rule['from_port'] == [PORT] and rule['to_port'] == [PORT] and rule['cidr_blocks'] == [\n [\"0.0.0.0/0\"]] and 'self' not in rule.keys() and 'security_groups' not in rule.keys():\n return CheckResult.FAILED\n\n return CheckResult.PASSED\n\n\ncheck = SecurityGroupUnrestrictedIngress3389()\n", "path": "checkov/terraform/checks/resource/aws/SecurityGroupUnrestrictedIngress3389.py"}, {"content": "from checkov.terraform.models.enums import CheckResult, CheckCategories\nfrom checkov.terraform.checks.resource.base_check import BaseResourceCheck\n\nPORT = 22\n\n\nclass SecurityGroupUnrestrictedIngress22(BaseResourceCheck):\n def __init__(self):\n name = \"Ensure no security groups allow ingress from 0.0.0.0:0 to port %d\" % PORT\n id = \"CKV_AWS_24\"\n supported_resources = ['aws_security_group']\n categories = [CheckCategories.NETWORKING]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def scan_resource_conf(self, conf):\n \"\"\"\n Looks for configuration at security group ingress rules :\n https://www.terraform.io/docs/providers/aws/r/security_group.html\n :param conf: aws_security_group configuration\n :return: <CheckResult>\n \"\"\"\n if 'ingress' in conf.keys():\n ingress_conf = conf['ingress']\n for rule in ingress_conf:\n if rule['from_port'] == [PORT] and rule['to_port'] == [PORT] and rule['cidr_blocks'] == [[\n \"0.0.0.0/0\"]] and 'self' not in rule.keys() and 'security_groups' not in rule.keys():\n return CheckResult.FAILED\n\n return CheckResult.PASSED\n\n\ncheck = SecurityGroupUnrestrictedIngress22()\n", "path": "checkov/terraform/checks/resource/aws/SecurityGroupUnrestrictedIngress22.py"}]}
| 1,887 | 565 |
gh_patches_debug_32754
|
rasdani/github-patches
|
git_diff
|
Mailu__Mailu-1349
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Support for SRS
See https://en.wikipedia.org/wiki/Sender_Rewriting_Scheme and https://github.com/roehling/postsrsd
</issue>
<code>
[start of core/admin/mailu/internal/views/postfix.py]
1 from mailu import models
2 from mailu.internal import internal
3
4 import flask
5 import re
6
7
8 @internal.route("/postfix/domain/<domain_name>")
9 def postfix_mailbox_domain(domain_name):
10 if re.match("^\[.*\]$", domain_name):
11 return flask.abort(404)
12 domain = models.Domain.query.get(domain_name) or \
13 models.Alternative.query.get(domain_name) or \
14 flask.abort(404)
15 return flask.jsonify(domain.name)
16
17
18 @internal.route("/postfix/mailbox/<path:email>")
19 def postfix_mailbox_map(email):
20 user = models.User.query.get(email) or flask.abort(404)
21 return flask.jsonify(user.email)
22
23
24 @internal.route("/postfix/alias/<path:alias>")
25 def postfix_alias_map(alias):
26 localpart, domain_name = models.Email.resolve_domain(alias)
27 if localpart is None:
28 return flask.jsonify(domain_name)
29 destination = models.Email.resolve_destination(localpart, domain_name)
30 return flask.jsonify(",".join(destination)) if destination else flask.abort(404)
31
32
33 @internal.route("/postfix/transport/<path:email>")
34 def postfix_transport(email):
35 if email == '*' or re.match("(^|.*@)\[.*\]$", email):
36 return flask.abort(404)
37 localpart, domain_name = models.Email.resolve_domain(email)
38 relay = models.Relay.query.get(domain_name) or flask.abort(404)
39 return flask.jsonify("smtp:[{}]".format(relay.smtp))
40
41
42 @internal.route("/postfix/sender/login/<path:sender>")
43 def postfix_sender_login(sender):
44 localpart, domain_name = models.Email.resolve_domain(sender)
45 if localpart is None:
46 return flask.abort(404)
47 destination = models.Email.resolve_destination(localpart, domain_name, True)
48 return flask.jsonify(",".join(destination)) if destination else flask.abort(404)
49
50
51 @internal.route("/postfix/sender/access/<path:sender>")
52 def postfix_sender_access(sender):
53 """ Simply reject any sender that pretends to be from a local domain
54 """
55 if not is_void_address(sender):
56 localpart, domain_name = models.Email.resolve_domain(sender)
57 return flask.jsonify("REJECT") if models.Domain.query.get(domain_name) else flask.abort(404)
58 else:
59 return flask.abort(404)
60
61
62 def is_void_address(email):
63 '''True if the email is void (null) email address.
64 '''
65 if email.startswith('<') and email.endswith('>'):
66 email = email[1:-1]
67 # Some MTAs use things like '<MAILER-DAEMON>' instead of '<>'; so let's
68 # consider void any such thing.
69 return '@' not in email
70
[end of core/admin/mailu/internal/views/postfix.py]
[start of core/postfix/start.py]
1 #!/usr/bin/python3
2
3 import os
4 import glob
5 import shutil
6 import multiprocessing
7 import logging as log
8 import sys
9
10 from podop import run_server
11 from socrate import system, conf
12
13 log.basicConfig(stream=sys.stderr, level=os.environ.get("LOG_LEVEL", "WARNING"))
14
15 def start_podop():
16 os.setuid(100)
17 url = "http://" + os.environ["ADMIN_ADDRESS"] + "/internal/postfix/"
18 # TODO: Remove verbosity setting from Podop?
19 run_server(0, "postfix", "/tmp/podop.socket", [
20 ("transport", "url", url + "transport/§"),
21 ("alias", "url", url + "alias/§"),
22 ("domain", "url", url + "domain/§"),
23 ("mailbox", "url", url + "mailbox/§"),
24 ("senderaccess", "url", url + "sender/access/§"),
25 ("senderlogin", "url", url + "sender/login/§")
26 ])
27
28 # Actual startup script
29 os.environ["FRONT_ADDRESS"] = system.get_host_address_from_environment("FRONT", "front")
30 os.environ["ADMIN_ADDRESS"] = system.get_host_address_from_environment("ADMIN", "admin")
31 os.environ["ANTISPAM_MILTER_ADDRESS"] = system.get_host_address_from_environment("ANTISPAM_MILTER", "antispam:11332")
32 os.environ["LMTP_ADDRESS"] = system.get_host_address_from_environment("LMTP", "imap:2525")
33
34 for postfix_file in glob.glob("/conf/*.cf"):
35 conf.jinja(postfix_file, os.environ, os.path.join("/etc/postfix", os.path.basename(postfix_file)))
36
37 if os.path.exists("/overrides/postfix.cf"):
38 for line in open("/overrides/postfix.cf").read().strip().split("\n"):
39 os.system('postconf -e "{}"'.format(line))
40
41 if os.path.exists("/overrides/postfix.master"):
42 for line in open("/overrides/postfix.master").read().strip().split("\n"):
43 os.system('postconf -Me "{}"'.format(line))
44
45 for map_file in glob.glob("/overrides/*.map"):
46 destination = os.path.join("/etc/postfix", os.path.basename(map_file))
47 shutil.copyfile(map_file, destination)
48 os.system("postmap {}".format(destination))
49 os.remove(destination)
50
51 if "RELAYUSER" in os.environ:
52 path = "/etc/postfix/sasl_passwd"
53 conf.jinja("/conf/sasl_passwd", os.environ, path)
54 os.system("postmap {}".format(path))
55
56 # Run Podop and Postfix
57 multiprocessing.Process(target=start_podop).start()
58 os.system("/usr/libexec/postfix/post-install meta_directory=/etc/postfix create-missing")
59 os.system("postfix start-fg")
60
[end of core/postfix/start.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/core/admin/mailu/internal/views/postfix.py b/core/admin/mailu/internal/views/postfix.py
--- a/core/admin/mailu/internal/views/postfix.py
+++ b/core/admin/mailu/internal/views/postfix.py
@@ -3,6 +3,7 @@
import flask
import re
+import srslib
@internal.route("/postfix/domain/<domain_name>")
@@ -39,6 +40,38 @@
return flask.jsonify("smtp:[{}]".format(relay.smtp))
[email protected]("/postfix/recipient/map/<path:recipient>")
+def postfix_recipient_map(recipient):
+ """ Rewrite the envelope recipient if it is a valid SRS address.
+
+ This is meant for bounces to go back to the original sender.
+ """
+ srs = srslib.SRS(flask.current_app.config["SECRET_KEY"])
+ if srslib.SRS.is_srs_address(recipient):
+ try:
+ return flask.jsonify(srs.reverse(recipient))
+ except srslib.Error as error:
+ return flask.abort(404)
+ return flask.abort(404)
+
+
[email protected]("/postfix/sender/map/<path:sender>")
+def postfix_sender_map(sender):
+ """ Rewrite the envelope sender in case the mail was not emitted by us.
+
+ This is for bounces to come back the reverse path properly.
+ """
+ srs = srslib.SRS(flask.current_app.config["SECRET_KEY"])
+ domain = flask.current_app.config["DOMAIN"]
+ try:
+ localpart, domain_name = models.Email.resolve_domain(sender)
+ except Exception as error:
+ return flask.abort(404)
+ if models.Domain.query.get(domain_name):
+ return flask.abort(404)
+ return flask.jsonify(srs.forward(sender, domain))
+
+
@internal.route("/postfix/sender/login/<path:sender>")
def postfix_sender_login(sender):
localpart, domain_name = models.Email.resolve_domain(sender)
diff --git a/core/postfix/start.py b/core/postfix/start.py
--- a/core/postfix/start.py
+++ b/core/postfix/start.py
@@ -21,6 +21,8 @@
("alias", "url", url + "alias/§"),
("domain", "url", url + "domain/§"),
("mailbox", "url", url + "mailbox/§"),
+ ("recipientmap", "url", url + "recipient/map/§"),
+ ("sendermap", "url", url + "sender/map/§"),
("senderaccess", "url", url + "sender/access/§"),
("senderlogin", "url", url + "sender/login/§")
])
|
{"golden_diff": "diff --git a/core/admin/mailu/internal/views/postfix.py b/core/admin/mailu/internal/views/postfix.py\n--- a/core/admin/mailu/internal/views/postfix.py\n+++ b/core/admin/mailu/internal/views/postfix.py\n@@ -3,6 +3,7 @@\n \n import flask\n import re\n+import srslib\n \n \n @internal.route(\"/postfix/domain/<domain_name>\")\n@@ -39,6 +40,38 @@\n return flask.jsonify(\"smtp:[{}]\".format(relay.smtp))\n \n \[email protected](\"/postfix/recipient/map/<path:recipient>\")\n+def postfix_recipient_map(recipient):\n+ \"\"\" Rewrite the envelope recipient if it is a valid SRS address.\n+\n+ This is meant for bounces to go back to the original sender.\n+ \"\"\"\n+ srs = srslib.SRS(flask.current_app.config[\"SECRET_KEY\"])\n+ if srslib.SRS.is_srs_address(recipient):\n+ try:\n+ return flask.jsonify(srs.reverse(recipient))\n+ except srslib.Error as error:\n+ return flask.abort(404)\n+ return flask.abort(404)\n+\n+\[email protected](\"/postfix/sender/map/<path:sender>\")\n+def postfix_sender_map(sender):\n+ \"\"\" Rewrite the envelope sender in case the mail was not emitted by us.\n+\n+ This is for bounces to come back the reverse path properly.\n+ \"\"\"\n+ srs = srslib.SRS(flask.current_app.config[\"SECRET_KEY\"])\n+ domain = flask.current_app.config[\"DOMAIN\"]\n+ try:\n+ localpart, domain_name = models.Email.resolve_domain(sender)\n+ except Exception as error:\n+ return flask.abort(404)\n+ if models.Domain.query.get(domain_name):\n+ return flask.abort(404)\n+ return flask.jsonify(srs.forward(sender, domain))\n+\n+\n @internal.route(\"/postfix/sender/login/<path:sender>\")\n def postfix_sender_login(sender):\n localpart, domain_name = models.Email.resolve_domain(sender)\ndiff --git a/core/postfix/start.py b/core/postfix/start.py\n--- a/core/postfix/start.py\n+++ b/core/postfix/start.py\n@@ -21,6 +21,8 @@\n \t\t(\"alias\", \"url\", url + \"alias/\u00a7\"),\n \t\t(\"domain\", \"url\", url + \"domain/\u00a7\"),\n (\"mailbox\", \"url\", url + \"mailbox/\u00a7\"),\n+ (\"recipientmap\", \"url\", url + \"recipient/map/\u00a7\"),\n+ (\"sendermap\", \"url\", url + \"sender/map/\u00a7\"),\n (\"senderaccess\", \"url\", url + \"sender/access/\u00a7\"),\n (\"senderlogin\", \"url\", url + \"sender/login/\u00a7\")\n ])\n", "issue": "Support for SRS\nSee https://en.wikipedia.org/wiki/Sender_Rewriting_Scheme and https://github.com/roehling/postsrsd\n", "before_files": [{"content": "from mailu import models\nfrom mailu.internal import internal\n\nimport flask\nimport re\n\n\[email protected](\"/postfix/domain/<domain_name>\")\ndef postfix_mailbox_domain(domain_name):\n if re.match(\"^\\[.*\\]$\", domain_name):\n return flask.abort(404)\n domain = models.Domain.query.get(domain_name) or \\\n models.Alternative.query.get(domain_name) or \\\n flask.abort(404)\n return flask.jsonify(domain.name)\n\n\[email protected](\"/postfix/mailbox/<path:email>\")\ndef postfix_mailbox_map(email):\n user = models.User.query.get(email) or flask.abort(404)\n return flask.jsonify(user.email)\n\n\[email protected](\"/postfix/alias/<path:alias>\")\ndef postfix_alias_map(alias):\n localpart, domain_name = models.Email.resolve_domain(alias)\n if localpart is None:\n return flask.jsonify(domain_name)\n destination = models.Email.resolve_destination(localpart, domain_name)\n return flask.jsonify(\",\".join(destination)) if destination else flask.abort(404)\n\n\[email protected](\"/postfix/transport/<path:email>\")\ndef postfix_transport(email):\n if email == '*' or re.match(\"(^|.*@)\\[.*\\]$\", email):\n return flask.abort(404)\n localpart, domain_name = models.Email.resolve_domain(email)\n relay = models.Relay.query.get(domain_name) or flask.abort(404)\n return flask.jsonify(\"smtp:[{}]\".format(relay.smtp))\n\n\[email protected](\"/postfix/sender/login/<path:sender>\")\ndef postfix_sender_login(sender):\n localpart, domain_name = models.Email.resolve_domain(sender)\n if localpart is None:\n return flask.abort(404)\n destination = models.Email.resolve_destination(localpart, domain_name, True)\n return flask.jsonify(\",\".join(destination)) if destination else flask.abort(404)\n\n\[email protected](\"/postfix/sender/access/<path:sender>\")\ndef postfix_sender_access(sender):\n \"\"\" Simply reject any sender that pretends to be from a local domain\n \"\"\"\n if not is_void_address(sender):\n localpart, domain_name = models.Email.resolve_domain(sender)\n return flask.jsonify(\"REJECT\") if models.Domain.query.get(domain_name) else flask.abort(404)\n else:\n return flask.abort(404)\n\n\ndef is_void_address(email):\n '''True if the email is void (null) email address.\n '''\n if email.startswith('<') and email.endswith('>'):\n email = email[1:-1]\n # Some MTAs use things like '<MAILER-DAEMON>' instead of '<>'; so let's\n # consider void any such thing.\n return '@' not in email\n", "path": "core/admin/mailu/internal/views/postfix.py"}, {"content": "#!/usr/bin/python3\n\nimport os\nimport glob\nimport shutil\nimport multiprocessing\nimport logging as log\nimport sys\n\nfrom podop import run_server\nfrom socrate import system, conf\n\nlog.basicConfig(stream=sys.stderr, level=os.environ.get(\"LOG_LEVEL\", \"WARNING\"))\n\ndef start_podop():\n os.setuid(100)\n url = \"http://\" + os.environ[\"ADMIN_ADDRESS\"] + \"/internal/postfix/\"\n # TODO: Remove verbosity setting from Podop?\n run_server(0, \"postfix\", \"/tmp/podop.socket\", [\n\t\t(\"transport\", \"url\", url + \"transport/\u00a7\"),\n\t\t(\"alias\", \"url\", url + \"alias/\u00a7\"),\n\t\t(\"domain\", \"url\", url + \"domain/\u00a7\"),\n (\"mailbox\", \"url\", url + \"mailbox/\u00a7\"),\n (\"senderaccess\", \"url\", url + \"sender/access/\u00a7\"),\n (\"senderlogin\", \"url\", url + \"sender/login/\u00a7\")\n ])\n\n# Actual startup script\nos.environ[\"FRONT_ADDRESS\"] = system.get_host_address_from_environment(\"FRONT\", \"front\")\nos.environ[\"ADMIN_ADDRESS\"] = system.get_host_address_from_environment(\"ADMIN\", \"admin\")\nos.environ[\"ANTISPAM_MILTER_ADDRESS\"] = system.get_host_address_from_environment(\"ANTISPAM_MILTER\", \"antispam:11332\")\nos.environ[\"LMTP_ADDRESS\"] = system.get_host_address_from_environment(\"LMTP\", \"imap:2525\")\n\nfor postfix_file in glob.glob(\"/conf/*.cf\"):\n conf.jinja(postfix_file, os.environ, os.path.join(\"/etc/postfix\", os.path.basename(postfix_file)))\n\nif os.path.exists(\"/overrides/postfix.cf\"):\n for line in open(\"/overrides/postfix.cf\").read().strip().split(\"\\n\"):\n os.system('postconf -e \"{}\"'.format(line))\n\nif os.path.exists(\"/overrides/postfix.master\"):\n for line in open(\"/overrides/postfix.master\").read().strip().split(\"\\n\"):\n os.system('postconf -Me \"{}\"'.format(line))\n\nfor map_file in glob.glob(\"/overrides/*.map\"):\n destination = os.path.join(\"/etc/postfix\", os.path.basename(map_file))\n shutil.copyfile(map_file, destination)\n os.system(\"postmap {}\".format(destination))\n os.remove(destination)\n\nif \"RELAYUSER\" in os.environ:\n path = \"/etc/postfix/sasl_passwd\"\n conf.jinja(\"/conf/sasl_passwd\", os.environ, path)\n os.system(\"postmap {}\".format(path))\n\n# Run Podop and Postfix\nmultiprocessing.Process(target=start_podop).start()\nos.system(\"/usr/libexec/postfix/post-install meta_directory=/etc/postfix create-missing\")\nos.system(\"postfix start-fg\")\n", "path": "core/postfix/start.py"}]}
| 2,031 | 601 |
gh_patches_debug_13905
|
rasdani/github-patches
|
git_diff
|
pytorch__vision-2960
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Replace assert with ValueError in AnchorGenerator
## 🐛 Bug
I think with the Retina Net PR, there was an update to anchor utils.
My old code still works fine on torchvision 0.7 and pytorch 1.6. But on upgrading to 0.8 it doesn't.
I am not sure if this was BC Breaking change.
## To Reproduce
Steps to reproduce the behavior:
1. Following is the code block to create FRCNN
```
import torchvision
import torchvision.transforms as T
from torchvision.models.detection.rpn import AnchorGenerator
from torchvision.models.detection import FasterRCNN
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
def create_model(num_classes, min_size=300, max_size=500, backbone="mobile_net"):
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
in_features = model.roi_heads.box_predictor.cls_score.in_features
ft_mean = [0.485, 0.456, 0.406]
ft_std = [0.229, 0.224, 0.225]
mobile_net = torchvision.models.mobilenet_v2(pretrained=True)
ft_backbone = mobile_net.features
ft_backbone.out_channels = 1280
ft_model = FasterRCNN(backbone=ft_backbone,
num_classes=num_classes,
image_mean=ft_mean,
image_std=ft_std,)
```
2. When I do These three function sequeantially
```
def load_model():
detector = model.create_model(num_classes=config.NUM_CLASSES)
detector.load_state_dict(torch.load(config.MODEL_SAVE_PATH, map_location=device))
detector.eval()
detector.to(device)
return detector
def load_image_tensor(image_path, device):
image_tensor = T.ToTensor() (Image.open(image_path))
input_images = [image_tensor.to(device)]
return input_images
def get_prediction(detector, images):
with torch.no_grad():
prediction = detector(images)
return prediction
```
I get an assertion error from [this ](https://github.com/pytorch/vision/blob/master/torchvision/models/detection/anchor_utils.py#L103)line
## Expected behavior
It should work fine, I think an upgrade to torchvision should not break Anchor utils for FRCNN.
## Environment
- PyTorch / torchvision Version (e.g., 1.0 / 0.4.0): PT -> 1.7 TV-> 0.8.1
- OS (e.g., Linux): Windows
- How you installed PyTorch / torchvision (`conda`, `pip`, source): conda
- Build command you used (if compiling from source):
- Python version: 3.7
- CUDA/cuDNN version: NA
- GPU models and configuration: NA
## Additional context
1. Maybe something has changed and I'm not aware of
2. Can we remove these assertions and raise `ValueError` with suitable messages ? I cannot debug at all with `assert` errors.
3. Slightly associated with #2955
</issue>
<code>
[start of torchvision/models/detection/anchor_utils.py]
1 # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
2 import torch
3 from torch import nn
4
5 from torch.jit.annotations import List, Optional, Dict
6 from .image_list import ImageList
7
8
9 class AnchorGenerator(nn.Module):
10 """
11 Module that generates anchors for a set of feature maps and
12 image sizes.
13
14 The module support computing anchors at multiple sizes and aspect ratios
15 per feature map. This module assumes aspect ratio = height / width for
16 each anchor.
17
18 sizes and aspect_ratios should have the same number of elements, and it should
19 correspond to the number of feature maps.
20
21 sizes[i] and aspect_ratios[i] can have an arbitrary number of elements,
22 and AnchorGenerator will output a set of sizes[i] * aspect_ratios[i] anchors
23 per spatial location for feature map i.
24
25 Arguments:
26 sizes (Tuple[Tuple[int]]):
27 aspect_ratios (Tuple[Tuple[float]]):
28 """
29
30 __annotations__ = {
31 "cell_anchors": Optional[List[torch.Tensor]],
32 "_cache": Dict[str, List[torch.Tensor]]
33 }
34
35 def __init__(
36 self,
37 sizes=((128, 256, 512),),
38 aspect_ratios=((0.5, 1.0, 2.0),),
39 ):
40 super(AnchorGenerator, self).__init__()
41
42 if not isinstance(sizes[0], (list, tuple)):
43 # TODO change this
44 sizes = tuple((s,) for s in sizes)
45 if not isinstance(aspect_ratios[0], (list, tuple)):
46 aspect_ratios = (aspect_ratios,) * len(sizes)
47
48 assert len(sizes) == len(aspect_ratios)
49
50 self.sizes = sizes
51 self.aspect_ratios = aspect_ratios
52 self.cell_anchors = None
53 self._cache = {}
54
55 # TODO: https://github.com/pytorch/pytorch/issues/26792
56 # For every (aspect_ratios, scales) combination, output a zero-centered anchor with those values.
57 # (scales, aspect_ratios) are usually an element of zip(self.scales, self.aspect_ratios)
58 # This method assumes aspect ratio = height / width for an anchor.
59 def generate_anchors(self, scales, aspect_ratios, dtype=torch.float32, device="cpu"):
60 # type: (List[int], List[float], int, Device) -> Tensor # noqa: F821
61 scales = torch.as_tensor(scales, dtype=dtype, device=device)
62 aspect_ratios = torch.as_tensor(aspect_ratios, dtype=dtype, device=device)
63 h_ratios = torch.sqrt(aspect_ratios)
64 w_ratios = 1 / h_ratios
65
66 ws = (w_ratios[:, None] * scales[None, :]).view(-1)
67 hs = (h_ratios[:, None] * scales[None, :]).view(-1)
68
69 base_anchors = torch.stack([-ws, -hs, ws, hs], dim=1) / 2
70 return base_anchors.round()
71
72 def set_cell_anchors(self, dtype, device):
73 # type: (int, Device) -> None # noqa: F821
74 if self.cell_anchors is not None:
75 cell_anchors = self.cell_anchors
76 assert cell_anchors is not None
77 # suppose that all anchors have the same device
78 # which is a valid assumption in the current state of the codebase
79 if cell_anchors[0].device == device:
80 return
81
82 cell_anchors = [
83 self.generate_anchors(
84 sizes,
85 aspect_ratios,
86 dtype,
87 device
88 )
89 for sizes, aspect_ratios in zip(self.sizes, self.aspect_ratios)
90 ]
91 self.cell_anchors = cell_anchors
92
93 def num_anchors_per_location(self):
94 return [len(s) * len(a) for s, a in zip(self.sizes, self.aspect_ratios)]
95
96 # For every combination of (a, (g, s), i) in (self.cell_anchors, zip(grid_sizes, strides), 0:2),
97 # output g[i] anchors that are s[i] distance apart in direction i, with the same dimensions as a.
98 def grid_anchors(self, grid_sizes, strides):
99 # type: (List[List[int]], List[List[Tensor]]) -> List[Tensor]
100 anchors = []
101 cell_anchors = self.cell_anchors
102 assert cell_anchors is not None
103 assert len(grid_sizes) == len(strides) == len(cell_anchors)
104
105 for size, stride, base_anchors in zip(
106 grid_sizes, strides, cell_anchors
107 ):
108 grid_height, grid_width = size
109 stride_height, stride_width = stride
110 device = base_anchors.device
111
112 # For output anchor, compute [x_center, y_center, x_center, y_center]
113 shifts_x = torch.arange(
114 0, grid_width, dtype=torch.float32, device=device
115 ) * stride_width
116 shifts_y = torch.arange(
117 0, grid_height, dtype=torch.float32, device=device
118 ) * stride_height
119 shift_y, shift_x = torch.meshgrid(shifts_y, shifts_x)
120 shift_x = shift_x.reshape(-1)
121 shift_y = shift_y.reshape(-1)
122 shifts = torch.stack((shift_x, shift_y, shift_x, shift_y), dim=1)
123
124 # For every (base anchor, output anchor) pair,
125 # offset each zero-centered base anchor by the center of the output anchor.
126 anchors.append(
127 (shifts.view(-1, 1, 4) + base_anchors.view(1, -1, 4)).reshape(-1, 4)
128 )
129
130 return anchors
131
132 def cached_grid_anchors(self, grid_sizes, strides):
133 # type: (List[List[int]], List[List[Tensor]]) -> List[Tensor]
134 key = str(grid_sizes) + str(strides)
135 if key in self._cache:
136 return self._cache[key]
137 anchors = self.grid_anchors(grid_sizes, strides)
138 self._cache[key] = anchors
139 return anchors
140
141 def forward(self, image_list, feature_maps):
142 # type: (ImageList, List[Tensor]) -> List[Tensor]
143 grid_sizes = list([feature_map.shape[-2:] for feature_map in feature_maps])
144 image_size = image_list.tensors.shape[-2:]
145 dtype, device = feature_maps[0].dtype, feature_maps[0].device
146 strides = [[torch.tensor(image_size[0] // g[0], dtype=torch.int64, device=device),
147 torch.tensor(image_size[1] // g[1], dtype=torch.int64, device=device)] for g in grid_sizes]
148 self.set_cell_anchors(dtype, device)
149 anchors_over_all_feature_maps = self.cached_grid_anchors(grid_sizes, strides)
150 anchors = torch.jit.annotate(List[List[torch.Tensor]], [])
151 for i, (image_height, image_width) in enumerate(image_list.image_sizes):
152 anchors_in_image = []
153 for anchors_per_feature_map in anchors_over_all_feature_maps:
154 anchors_in_image.append(anchors_per_feature_map)
155 anchors.append(anchors_in_image)
156 anchors = [torch.cat(anchors_per_image) for anchors_per_image in anchors]
157 # Clear the cache in case that memory leaks.
158 self._cache.clear()
159 return anchors
160
[end of torchvision/models/detection/anchor_utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/torchvision/models/detection/anchor_utils.py b/torchvision/models/detection/anchor_utils.py
--- a/torchvision/models/detection/anchor_utils.py
+++ b/torchvision/models/detection/anchor_utils.py
@@ -100,7 +100,12 @@
anchors = []
cell_anchors = self.cell_anchors
assert cell_anchors is not None
- assert len(grid_sizes) == len(strides) == len(cell_anchors)
+
+ if not (len(grid_sizes) == len(strides) == len(cell_anchors)):
+ raise ValueError("Achors should be Tuple[Tuple[int]] because each feature "
+ "map could potentially have different sizes and aspect ratios. "
+ "There needs to be a match between the number of "
+ "feature maps passed and the number of sizes / aspect ratios specified.")
for size, stride, base_anchors in zip(
grid_sizes, strides, cell_anchors
|
{"golden_diff": "diff --git a/torchvision/models/detection/anchor_utils.py b/torchvision/models/detection/anchor_utils.py\n--- a/torchvision/models/detection/anchor_utils.py\n+++ b/torchvision/models/detection/anchor_utils.py\n@@ -100,7 +100,12 @@\n anchors = []\n cell_anchors = self.cell_anchors\n assert cell_anchors is not None\n- assert len(grid_sizes) == len(strides) == len(cell_anchors)\n+\n+ if not (len(grid_sizes) == len(strides) == len(cell_anchors)):\n+ raise ValueError(\"Achors should be Tuple[Tuple[int]] because each feature \"\n+ \"map could potentially have different sizes and aspect ratios. \"\n+ \"There needs to be a match between the number of \"\n+ \"feature maps passed and the number of sizes / aspect ratios specified.\")\n \n for size, stride, base_anchors in zip(\n grid_sizes, strides, cell_anchors\n", "issue": "Replace assert with ValueError in AnchorGenerator\n## \ud83d\udc1b Bug\r\n\r\nI think with the Retina Net PR, there was an update to anchor utils.\r\nMy old code still works fine on torchvision 0.7 and pytorch 1.6. But on upgrading to 0.8 it doesn't.\r\nI am not sure if this was BC Breaking change.\r\n\r\n## To Reproduce\r\n\r\nSteps to reproduce the behavior:\r\n\r\n1. Following is the code block to create FRCNN\r\n```\r\nimport torchvision\r\nimport torchvision.transforms as T\r\nfrom torchvision.models.detection.rpn import AnchorGenerator\r\nfrom torchvision.models.detection import FasterRCNN\r\n\r\ndevice = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')\r\n\r\ndef create_model(num_classes, min_size=300, max_size=500, backbone=\"mobile_net\"):\r\n\r\n model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)\r\n in_features = model.roi_heads.box_predictor.cls_score.in_features\r\n\r\n ft_mean = [0.485, 0.456, 0.406]\r\n ft_std = [0.229, 0.224, 0.225]\r\n\r\n mobile_net = torchvision.models.mobilenet_v2(pretrained=True)\r\n\r\n ft_backbone = mobile_net.features\r\n ft_backbone.out_channels = 1280\r\n\r\n ft_model = FasterRCNN(backbone=ft_backbone,\r\n num_classes=num_classes, \r\n image_mean=ft_mean, \r\n image_std=ft_std,)\r\n```\r\n2. When I do These three function sequeantially\r\n```\r\n\r\ndef load_model():\r\n detector = model.create_model(num_classes=config.NUM_CLASSES)\r\n detector.load_state_dict(torch.load(config.MODEL_SAVE_PATH, map_location=device))\r\n detector.eval()\r\n detector.to(device)\r\n return detector\r\n\r\n\r\ndef load_image_tensor(image_path, device):\r\n image_tensor = T.ToTensor() (Image.open(image_path))\r\n input_images = [image_tensor.to(device)]\r\n return input_images\r\n\r\n\r\ndef get_prediction(detector, images):\r\n with torch.no_grad():\r\n prediction = detector(images)\r\n return prediction\r\n\r\n```\r\n\r\nI get an assertion error from [this ](https://github.com/pytorch/vision/blob/master/torchvision/models/detection/anchor_utils.py#L103)line\r\n\r\n## Expected behavior\r\n\r\nIt should work fine, I think an upgrade to torchvision should not break Anchor utils for FRCNN.\r\n\r\n## Environment\r\n\r\n\r\n - PyTorch / torchvision Version (e.g., 1.0 / 0.4.0): PT -> 1.7 TV-> 0.8.1\r\n - OS (e.g., Linux): Windows\r\n - How you installed PyTorch / torchvision (`conda`, `pip`, source): conda\r\n - Build command you used (if compiling from source):\r\n - Python version: 3.7\r\n - CUDA/cuDNN version: NA\r\n - GPU models and configuration: NA\r\n\r\n## Additional context\r\n\r\n1. Maybe something has changed and I'm not aware of\r\n2. Can we remove these assertions and raise `ValueError` with suitable messages ? I cannot debug at all with `assert` errors.\r\n3. Slightly associated with #2955 \n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.\nimport torch\nfrom torch import nn\n\nfrom torch.jit.annotations import List, Optional, Dict\nfrom .image_list import ImageList\n\n\nclass AnchorGenerator(nn.Module):\n \"\"\"\n Module that generates anchors for a set of feature maps and\n image sizes.\n\n The module support computing anchors at multiple sizes and aspect ratios\n per feature map. This module assumes aspect ratio = height / width for\n each anchor.\n\n sizes and aspect_ratios should have the same number of elements, and it should\n correspond to the number of feature maps.\n\n sizes[i] and aspect_ratios[i] can have an arbitrary number of elements,\n and AnchorGenerator will output a set of sizes[i] * aspect_ratios[i] anchors\n per spatial location for feature map i.\n\n Arguments:\n sizes (Tuple[Tuple[int]]):\n aspect_ratios (Tuple[Tuple[float]]):\n \"\"\"\n\n __annotations__ = {\n \"cell_anchors\": Optional[List[torch.Tensor]],\n \"_cache\": Dict[str, List[torch.Tensor]]\n }\n\n def __init__(\n self,\n sizes=((128, 256, 512),),\n aspect_ratios=((0.5, 1.0, 2.0),),\n ):\n super(AnchorGenerator, self).__init__()\n\n if not isinstance(sizes[0], (list, tuple)):\n # TODO change this\n sizes = tuple((s,) for s in sizes)\n if not isinstance(aspect_ratios[0], (list, tuple)):\n aspect_ratios = (aspect_ratios,) * len(sizes)\n\n assert len(sizes) == len(aspect_ratios)\n\n self.sizes = sizes\n self.aspect_ratios = aspect_ratios\n self.cell_anchors = None\n self._cache = {}\n\n # TODO: https://github.com/pytorch/pytorch/issues/26792\n # For every (aspect_ratios, scales) combination, output a zero-centered anchor with those values.\n # (scales, aspect_ratios) are usually an element of zip(self.scales, self.aspect_ratios)\n # This method assumes aspect ratio = height / width for an anchor.\n def generate_anchors(self, scales, aspect_ratios, dtype=torch.float32, device=\"cpu\"):\n # type: (List[int], List[float], int, Device) -> Tensor # noqa: F821\n scales = torch.as_tensor(scales, dtype=dtype, device=device)\n aspect_ratios = torch.as_tensor(aspect_ratios, dtype=dtype, device=device)\n h_ratios = torch.sqrt(aspect_ratios)\n w_ratios = 1 / h_ratios\n\n ws = (w_ratios[:, None] * scales[None, :]).view(-1)\n hs = (h_ratios[:, None] * scales[None, :]).view(-1)\n\n base_anchors = torch.stack([-ws, -hs, ws, hs], dim=1) / 2\n return base_anchors.round()\n\n def set_cell_anchors(self, dtype, device):\n # type: (int, Device) -> None # noqa: F821\n if self.cell_anchors is not None:\n cell_anchors = self.cell_anchors\n assert cell_anchors is not None\n # suppose that all anchors have the same device\n # which is a valid assumption in the current state of the codebase\n if cell_anchors[0].device == device:\n return\n\n cell_anchors = [\n self.generate_anchors(\n sizes,\n aspect_ratios,\n dtype,\n device\n )\n for sizes, aspect_ratios in zip(self.sizes, self.aspect_ratios)\n ]\n self.cell_anchors = cell_anchors\n\n def num_anchors_per_location(self):\n return [len(s) * len(a) for s, a in zip(self.sizes, self.aspect_ratios)]\n\n # For every combination of (a, (g, s), i) in (self.cell_anchors, zip(grid_sizes, strides), 0:2),\n # output g[i] anchors that are s[i] distance apart in direction i, with the same dimensions as a.\n def grid_anchors(self, grid_sizes, strides):\n # type: (List[List[int]], List[List[Tensor]]) -> List[Tensor]\n anchors = []\n cell_anchors = self.cell_anchors\n assert cell_anchors is not None\n assert len(grid_sizes) == len(strides) == len(cell_anchors)\n\n for size, stride, base_anchors in zip(\n grid_sizes, strides, cell_anchors\n ):\n grid_height, grid_width = size\n stride_height, stride_width = stride\n device = base_anchors.device\n\n # For output anchor, compute [x_center, y_center, x_center, y_center]\n shifts_x = torch.arange(\n 0, grid_width, dtype=torch.float32, device=device\n ) * stride_width\n shifts_y = torch.arange(\n 0, grid_height, dtype=torch.float32, device=device\n ) * stride_height\n shift_y, shift_x = torch.meshgrid(shifts_y, shifts_x)\n shift_x = shift_x.reshape(-1)\n shift_y = shift_y.reshape(-1)\n shifts = torch.stack((shift_x, shift_y, shift_x, shift_y), dim=1)\n\n # For every (base anchor, output anchor) pair,\n # offset each zero-centered base anchor by the center of the output anchor.\n anchors.append(\n (shifts.view(-1, 1, 4) + base_anchors.view(1, -1, 4)).reshape(-1, 4)\n )\n\n return anchors\n\n def cached_grid_anchors(self, grid_sizes, strides):\n # type: (List[List[int]], List[List[Tensor]]) -> List[Tensor]\n key = str(grid_sizes) + str(strides)\n if key in self._cache:\n return self._cache[key]\n anchors = self.grid_anchors(grid_sizes, strides)\n self._cache[key] = anchors\n return anchors\n\n def forward(self, image_list, feature_maps):\n # type: (ImageList, List[Tensor]) -> List[Tensor]\n grid_sizes = list([feature_map.shape[-2:] for feature_map in feature_maps])\n image_size = image_list.tensors.shape[-2:]\n dtype, device = feature_maps[0].dtype, feature_maps[0].device\n strides = [[torch.tensor(image_size[0] // g[0], dtype=torch.int64, device=device),\n torch.tensor(image_size[1] // g[1], dtype=torch.int64, device=device)] for g in grid_sizes]\n self.set_cell_anchors(dtype, device)\n anchors_over_all_feature_maps = self.cached_grid_anchors(grid_sizes, strides)\n anchors = torch.jit.annotate(List[List[torch.Tensor]], [])\n for i, (image_height, image_width) in enumerate(image_list.image_sizes):\n anchors_in_image = []\n for anchors_per_feature_map in anchors_over_all_feature_maps:\n anchors_in_image.append(anchors_per_feature_map)\n anchors.append(anchors_in_image)\n anchors = [torch.cat(anchors_per_image) for anchors_per_image in anchors]\n # Clear the cache in case that memory leaks.\n self._cache.clear()\n return anchors\n", "path": "torchvision/models/detection/anchor_utils.py"}]}
| 3,231 | 215 |
gh_patches_debug_32359
|
rasdani/github-patches
|
git_diff
|
saulpw__visidata-2257
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fixed width saver and loader don't round trip. (Columns expand with increasing number of spaces)
**Small description**
Open `test.csv`:
``` csv
colours,counts
red,3
green,5
blue,8
```
Then save it as `test.fixed`:
```
colours counts
red 3
green 5
blue 8
```
Each column is separated by three spaces.
Now, open the newly saved `test.fixed`, and save it as `test.fixed.csv`.
Upon inspection, you will see that the three spaces have been included as column data, rather than being discarded as a separator:
```
colours,counts
red ,3
green ,5
blue ,8
```
If you repeat this process, three spaces get appended to each column every time you repeat a round trip.
**Expected result**
I expect to be able to round trip from CSV to Fixed and back without extra spaces being added to the data.
**Steps to reproduce with sample data and a .vd**
[test-fixed-saver.zip](https://github.com/saulpw/visidata/files/13938788/test-fixed-saver.zip)
**Additional context**
- saul.pw/VisiData v3.0.1
- Python 3.10.12
</issue>
<code>
[start of visidata/loaders/fixed_width.py]
1
2 from visidata import VisiData, vd, Sheet, Column, Progress, SequenceSheet
3
4
5 vd.option('fixed_rows', 1000, 'number of rows to check for fixed width columns')
6 vd.option('fixed_maxcols', 0, 'max number of fixed-width columns to create (0 is no max)')
7
8 @VisiData.api
9 def open_fixed(vd, p):
10 return FixedWidthColumnsSheet(p.base_stem, source=p, headerlines=[])
11
12 class FixedWidthColumn(Column):
13 def __init__(self, name, i, j, **kwargs):
14 super().__init__(name, **kwargs)
15 self.i, self.j = i, j
16
17 def calcValue(self, row):
18 return row[0][self.i:self.j]
19
20 def putValue(self, row, value):
21 value = str(value)[:self.j-self.i]
22 j = self.j or len(row)
23 row[0] = row[0][:self.i] + '%-*s' % (j-self.i, value) + row[0][self.j:]
24
25 def columnize(rows):
26 'Generate (i,j) indexes for fixed-width columns found in rows'
27
28 ## find all character columns that are not spaces ever
29 allNonspaces = set()
30 for r in rows:
31 for i, ch in enumerate(r):
32 if not ch.isspace():
33 allNonspaces.add(i)
34
35 colstart = 0
36 prev = 0
37
38 # collapse fields
39 for i in allNonspaces:
40 if i > prev+1:
41 yield colstart, i
42 colstart = i
43 prev = i
44
45 yield colstart, prev+1 # final column gets rest of line
46
47
48 class FixedWidthColumnsSheet(SequenceSheet):
49 rowtype = 'lines' # rowdef: [line] (wrapping in list makes it unique and modifiable)
50 def addRow(self, row, index=None):
51 Sheet.addRow(self, row, index=index)
52
53 def iterload(self):
54 itsource = iter(self.source)
55
56 # compute fixed width columns from first fixed_rows lines
57 maxcols = self.options.fixed_maxcols
58 self.columns = []
59 fixedRows = list([x] for x in self.optlines(itsource, 'fixed_rows'))
60 for i, j in columnize(list(r[0] for r in fixedRows)):
61 if maxcols and self.nCols >= maxcols-1:
62 self.addColumn(FixedWidthColumn('', i, None))
63 break
64 else:
65 self.addColumn(FixedWidthColumn('', i, j))
66
67 yield from fixedRows
68
69 self.setColNames(self.headerlines)
70
71 yield from ([line] for line in itsource)
72
73 def setCols(self, headerlines):
74 self.headerlines = headerlines
75
76
77 @VisiData.api
78 def save_fixed(vd, p, *vsheets):
79 with p.open(mode='w', encoding=vsheets[0].options.save_encoding) as fp:
80 for sheet in vsheets:
81 if len(vsheets) > 1:
82 fp.write('%s\n\n' % sheet.name)
83
84 widths = {} # Column -> width:int
85 # headers
86 for col in Progress(sheet.visibleCols, gerund='sizing'):
87 widths[col] = col.getMaxWidth(sheet.rows) #1849
88 fp.write(('{0:%s} ' % widths[col]).format(col.name))
89 fp.write('\n')
90
91 # rows
92 with Progress(gerund='saving'):
93 for dispvals in sheet.iterdispvals(format=True):
94 for col, val in dispvals.items():
95 fp.write(('{0:%s%s.%s} ' % ('>' if vd.isNumeric(col) else '<', widths[col], widths[col])).format(val))
96 fp.write('\n')
97
[end of visidata/loaders/fixed_width.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/visidata/loaders/fixed_width.py b/visidata/loaders/fixed_width.py
--- a/visidata/loaders/fixed_width.py
+++ b/visidata/loaders/fixed_width.py
@@ -1,5 +1,5 @@
-from visidata import VisiData, vd, Sheet, Column, Progress, SequenceSheet
+from visidata import VisiData, vd, Sheet, Column, Progress, SequenceSheet, Column, dispwidth
vd.option('fixed_rows', 1000, 'number of rows to check for fixed width columns')
@@ -9,6 +9,22 @@
def open_fixed(vd, p):
return FixedWidthColumnsSheet(p.base_stem, source=p, headerlines=[])
[email protected]
+def getMaxDataWidth(col, rows): #2255 need real max width for fixed width saver
+ '''Return the maximum length of any cell in column or its header,
+ even if wider than window. (Slow for large cells!)'''
+
+ w = 0
+ nlen = dispwidth(col.name)
+ if len(rows) > 0:
+ w_max = 0
+ for r in rows:
+ row_w = dispwidth(col.getDisplayValue(r))
+ if w_max < row_w:
+ w_max = row_w
+ w = w_max
+ return max(w, nlen)
+
class FixedWidthColumn(Column):
def __init__(self, name, i, j, **kwargs):
super().__init__(name, **kwargs)
@@ -38,7 +54,7 @@
# collapse fields
for i in allNonspaces:
if i > prev+1:
- yield colstart, i
+ yield colstart, prev+1 #2255
colstart = i
prev = i
@@ -84,7 +100,7 @@
widths = {} # Column -> width:int
# headers
for col in Progress(sheet.visibleCols, gerund='sizing'):
- widths[col] = col.getMaxWidth(sheet.rows) #1849
+ widths[col] = col.getMaxDataWidth(sheet.rows) #1849 #2255
fp.write(('{0:%s} ' % widths[col]).format(col.name))
fp.write('\n')
|
{"golden_diff": "diff --git a/visidata/loaders/fixed_width.py b/visidata/loaders/fixed_width.py\n--- a/visidata/loaders/fixed_width.py\n+++ b/visidata/loaders/fixed_width.py\n@@ -1,5 +1,5 @@\n \n-from visidata import VisiData, vd, Sheet, Column, Progress, SequenceSheet\n+from visidata import VisiData, vd, Sheet, Column, Progress, SequenceSheet, Column, dispwidth\n \n \n vd.option('fixed_rows', 1000, 'number of rows to check for fixed width columns')\n@@ -9,6 +9,22 @@\n def open_fixed(vd, p):\n return FixedWidthColumnsSheet(p.base_stem, source=p, headerlines=[])\n \[email protected]\n+def getMaxDataWidth(col, rows): #2255 need real max width for fixed width saver\n+ '''Return the maximum length of any cell in column or its header,\n+ even if wider than window. (Slow for large cells!)'''\n+\n+ w = 0\n+ nlen = dispwidth(col.name)\n+ if len(rows) > 0:\n+ w_max = 0\n+ for r in rows:\n+ row_w = dispwidth(col.getDisplayValue(r))\n+ if w_max < row_w:\n+ w_max = row_w\n+ w = w_max\n+ return max(w, nlen)\n+\n class FixedWidthColumn(Column):\n def __init__(self, name, i, j, **kwargs):\n super().__init__(name, **kwargs)\n@@ -38,7 +54,7 @@\n # collapse fields\n for i in allNonspaces:\n if i > prev+1:\n- yield colstart, i\n+ yield colstart, prev+1 #2255\n colstart = i\n prev = i\n \n@@ -84,7 +100,7 @@\n widths = {} # Column -> width:int\n # headers\n for col in Progress(sheet.visibleCols, gerund='sizing'):\n- widths[col] = col.getMaxWidth(sheet.rows) #1849\n+ widths[col] = col.getMaxDataWidth(sheet.rows) #1849 #2255\n fp.write(('{0:%s} ' % widths[col]).format(col.name))\n fp.write('\\n')\n", "issue": "Fixed width saver and loader don't round trip. (Columns expand with increasing number of spaces)\n**Small description**\r\n\r\nOpen `test.csv`:\r\n\r\n``` csv\r\ncolours,counts\r\nred,3\r\ngreen,5\r\nblue,8\r\n```\r\n\r\nThen save it as `test.fixed`:\r\n\r\n```\r\ncolours counts \r\nred 3 \r\ngreen 5 \r\nblue 8 \r\n```\r\n\r\nEach column is separated by three spaces.\r\n\r\nNow, open the newly saved `test.fixed`, and save it as `test.fixed.csv`.\r\nUpon inspection, you will see that the three spaces have been included as column data, rather than being discarded as a separator:\r\n\r\n```\r\ncolours,counts\r\nred ,3 \r\ngreen ,5 \r\nblue ,8 \r\n```\r\n\r\nIf you repeat this process, three spaces get appended to each column every time you repeat a round trip.\r\n\r\n**Expected result**\r\n\r\nI expect to be able to round trip from CSV to Fixed and back without extra spaces being added to the data.\r\n\r\n\r\n**Steps to reproduce with sample data and a .vd**\r\n\r\n[test-fixed-saver.zip](https://github.com/saulpw/visidata/files/13938788/test-fixed-saver.zip)\r\n\r\n**Additional context**\r\n\r\n- saul.pw/VisiData v3.0.1\r\n- Python 3.10.12\r\n\n", "before_files": [{"content": "\nfrom visidata import VisiData, vd, Sheet, Column, Progress, SequenceSheet\n\n\nvd.option('fixed_rows', 1000, 'number of rows to check for fixed width columns')\nvd.option('fixed_maxcols', 0, 'max number of fixed-width columns to create (0 is no max)')\n\[email protected]\ndef open_fixed(vd, p):\n return FixedWidthColumnsSheet(p.base_stem, source=p, headerlines=[])\n\nclass FixedWidthColumn(Column):\n def __init__(self, name, i, j, **kwargs):\n super().__init__(name, **kwargs)\n self.i, self.j = i, j\n\n def calcValue(self, row):\n return row[0][self.i:self.j]\n\n def putValue(self, row, value):\n value = str(value)[:self.j-self.i]\n j = self.j or len(row)\n row[0] = row[0][:self.i] + '%-*s' % (j-self.i, value) + row[0][self.j:]\n\ndef columnize(rows):\n 'Generate (i,j) indexes for fixed-width columns found in rows'\n\n ## find all character columns that are not spaces ever\n allNonspaces = set()\n for r in rows:\n for i, ch in enumerate(r):\n if not ch.isspace():\n allNonspaces.add(i)\n\n colstart = 0\n prev = 0\n\n # collapse fields\n for i in allNonspaces:\n if i > prev+1:\n yield colstart, i\n colstart = i\n prev = i\n\n yield colstart, prev+1 # final column gets rest of line\n\n\nclass FixedWidthColumnsSheet(SequenceSheet):\n rowtype = 'lines' # rowdef: [line] (wrapping in list makes it unique and modifiable)\n def addRow(self, row, index=None):\n Sheet.addRow(self, row, index=index)\n\n def iterload(self):\n itsource = iter(self.source)\n\n # compute fixed width columns from first fixed_rows lines\n maxcols = self.options.fixed_maxcols\n self.columns = []\n fixedRows = list([x] for x in self.optlines(itsource, 'fixed_rows'))\n for i, j in columnize(list(r[0] for r in fixedRows)):\n if maxcols and self.nCols >= maxcols-1:\n self.addColumn(FixedWidthColumn('', i, None))\n break\n else:\n self.addColumn(FixedWidthColumn('', i, j))\n\n yield from fixedRows\n\n self.setColNames(self.headerlines)\n\n yield from ([line] for line in itsource)\n\n def setCols(self, headerlines):\n self.headerlines = headerlines\n\n\[email protected]\ndef save_fixed(vd, p, *vsheets):\n with p.open(mode='w', encoding=vsheets[0].options.save_encoding) as fp:\n for sheet in vsheets:\n if len(vsheets) > 1:\n fp.write('%s\\n\\n' % sheet.name)\n\n widths = {} # Column -> width:int\n # headers\n for col in Progress(sheet.visibleCols, gerund='sizing'):\n widths[col] = col.getMaxWidth(sheet.rows) #1849\n fp.write(('{0:%s} ' % widths[col]).format(col.name))\n fp.write('\\n')\n\n # rows\n with Progress(gerund='saving'):\n for dispvals in sheet.iterdispvals(format=True):\n for col, val in dispvals.items():\n fp.write(('{0:%s%s.%s} ' % ('>' if vd.isNumeric(col) else '<', widths[col], widths[col])).format(val))\n fp.write('\\n')\n", "path": "visidata/loaders/fixed_width.py"}]}
| 1,846 | 525 |
gh_patches_debug_13773
|
rasdani/github-patches
|
git_diff
|
googleapis__python-bigquery-164
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Remove redundant dependencies
I think we can remove the following from the dependencies list:
https://github.com/googleapis/python-bigquery/blob/dbaf3bdc35656fdfef2d4380befdcc2392c1ca83/setup.py#L31-L43
* `google-auth` is already required via [google-api-core](https://github.com/googleapis/python-api-core/blob/master/setup.py#L34)
* `protobuf` is already required via [google-api-core](https://github.com/googleapis/python-api-core/blob/master/setup.py#L33)
* `rsa` [google-auth](https://github.com/googleapis/google-auth-library-python/blob/master/setup.py#L25-L26) is pinning compatible versions now
</issue>
<code>
[start of setup.py]
1 # Copyright 2018 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import io
16 import os
17
18 import setuptools
19
20
21 # Package metadata.
22
23 name = "google-cloud-bigquery"
24 description = "Google BigQuery API client library"
25 version = "1.25.0"
26 # Should be one of:
27 # 'Development Status :: 3 - Alpha'
28 # 'Development Status :: 4 - Beta'
29 # 'Development Status :: 5 - Production/Stable'
30 release_status = "Development Status :: 5 - Production/Stable"
31 dependencies = [
32 'enum34; python_version < "3.4"',
33 "google-auth >= 1.9.0, < 2.0dev",
34 "google-api-core >= 1.15.0, < 2.0dev",
35 "google-cloud-core >= 1.1.0, < 2.0dev",
36 "google-resumable-media >= 0.5.0, < 0.6dev",
37 "protobuf >= 3.6.0",
38 "six >=1.13.0,< 2.0.0dev",
39 # rsa >= 4.1 is not compatible with Python 2
40 # https://github.com/sybrenstuvel/python-rsa/issues/152
41 'rsa <4.1; python_version < "3"',
42 'rsa >=3.1.4, <5; python_version >= "3"',
43 ]
44 extras = {
45 "bqstorage": [
46 "google-cloud-bigquery-storage >= 1.0.0, <2.0.0dev",
47 # Due to an issue in pip's dependency resolver, the `grpc` extra is not
48 # installed, even though `google-cloud-bigquery-storage` specifies it
49 # as `google-api-core[grpc]`. We thus need to explicitly specify it here.
50 # See: https://github.com/googleapis/python-bigquery/issues/83
51 "grpcio >= 1.8.2, < 2.0dev",
52 "pyarrow>=0.16.0, < 2.0dev",
53 ],
54 "pandas": ["pandas>=0.17.1"],
55 # Exclude PyArrow dependency from Windows Python 2.7.
56 'pyarrow: platform_system != "Windows" or python_version >= "3.4"': [
57 # Bad Linux release for 0.14.0.
58 # https://issues.apache.org/jira/browse/ARROW-5868
59 "pyarrow>=0.4.1, != 0.14.0"
60 ],
61 "tqdm": ["tqdm >= 4.0.0, <5.0.0dev"],
62 "fastparquet": [
63 "fastparquet",
64 "python-snappy",
65 # llvmlite >= 0.32.0 cannot be installed on Python 3.5 and below
66 # (building the wheel fails), thus needs to be restricted.
67 # See: https://github.com/googleapis/python-bigquery/issues/78
68 "llvmlite <= 0.31.0",
69 ],
70 }
71
72 all_extras = []
73
74 for extra in extras:
75 if extra == "fastparquet":
76 # Skip fastparquet from "all" because it is redundant with pyarrow and
77 # creates a dependency on pre-release versions of numpy. See:
78 # https://github.com/googleapis/google-cloud-python/issues/8549
79 continue
80 all_extras.extend(extras[extra])
81
82 extras["all"] = all_extras
83
84 # Setup boilerplate below this line.
85
86 package_root = os.path.abspath(os.path.dirname(__file__))
87
88 readme_filename = os.path.join(package_root, "README.rst")
89 with io.open(readme_filename, encoding="utf-8") as readme_file:
90 readme = readme_file.read()
91
92 # Only include packages under the 'google' namespace. Do not include tests,
93 # benchmarks, etc.
94 packages = [
95 package for package in setuptools.find_packages() if package.startswith("google")
96 ]
97
98 # Determine which namespaces are needed.
99 namespaces = ["google"]
100 if "google.cloud" in packages:
101 namespaces.append("google.cloud")
102
103
104 setuptools.setup(
105 name=name,
106 version=version,
107 description=description,
108 long_description=readme,
109 author="Google LLC",
110 author_email="[email protected]",
111 license="Apache 2.0",
112 url="https://github.com/googleapis/python-bigquery",
113 classifiers=[
114 release_status,
115 "Intended Audience :: Developers",
116 "License :: OSI Approved :: Apache Software License",
117 "Programming Language :: Python",
118 "Programming Language :: Python :: 2",
119 "Programming Language :: Python :: 2.7",
120 "Programming Language :: Python :: 3",
121 "Programming Language :: Python :: 3.5",
122 "Programming Language :: Python :: 3.6",
123 "Programming Language :: Python :: 3.7",
124 "Programming Language :: Python :: 3.8",
125 "Operating System :: OS Independent",
126 "Topic :: Internet",
127 ],
128 platforms="Posix; MacOS X; Windows",
129 packages=packages,
130 namespace_packages=namespaces,
131 install_requires=dependencies,
132 extras_require=extras,
133 python_requires=">=2.7,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*",
134 include_package_data=True,
135 zip_safe=False,
136 )
137
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -30,16 +30,10 @@
release_status = "Development Status :: 5 - Production/Stable"
dependencies = [
'enum34; python_version < "3.4"',
- "google-auth >= 1.9.0, < 2.0dev",
- "google-api-core >= 1.15.0, < 2.0dev",
+ "google-api-core >= 1.21.0, < 2.0dev",
"google-cloud-core >= 1.1.0, < 2.0dev",
"google-resumable-media >= 0.5.0, < 0.6dev",
- "protobuf >= 3.6.0",
"six >=1.13.0,< 2.0.0dev",
- # rsa >= 4.1 is not compatible with Python 2
- # https://github.com/sybrenstuvel/python-rsa/issues/152
- 'rsa <4.1; python_version < "3"',
- 'rsa >=3.1.4, <5; python_version >= "3"',
]
extras = {
"bqstorage": [
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -30,16 +30,10 @@\n release_status = \"Development Status :: 5 - Production/Stable\"\n dependencies = [\n 'enum34; python_version < \"3.4\"',\n- \"google-auth >= 1.9.0, < 2.0dev\",\n- \"google-api-core >= 1.15.0, < 2.0dev\",\n+ \"google-api-core >= 1.21.0, < 2.0dev\",\n \"google-cloud-core >= 1.1.0, < 2.0dev\",\n \"google-resumable-media >= 0.5.0, < 0.6dev\",\n- \"protobuf >= 3.6.0\",\n \"six >=1.13.0,< 2.0.0dev\",\n- # rsa >= 4.1 is not compatible with Python 2\n- # https://github.com/sybrenstuvel/python-rsa/issues/152\n- 'rsa <4.1; python_version < \"3\"',\n- 'rsa >=3.1.4, <5; python_version >= \"3\"',\n ]\n extras = {\n \"bqstorage\": [\n", "issue": "Remove redundant dependencies\nI think we can remove the following from the dependencies list:\r\n\r\nhttps://github.com/googleapis/python-bigquery/blob/dbaf3bdc35656fdfef2d4380befdcc2392c1ca83/setup.py#L31-L43\r\n\r\n* `google-auth` is already required via [google-api-core](https://github.com/googleapis/python-api-core/blob/master/setup.py#L34)\r\n* `protobuf` is already required via [google-api-core](https://github.com/googleapis/python-api-core/blob/master/setup.py#L33)\r\n* `rsa` [google-auth](https://github.com/googleapis/google-auth-library-python/blob/master/setup.py#L25-L26) is pinning compatible versions now \n", "before_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport io\nimport os\n\nimport setuptools\n\n\n# Package metadata.\n\nname = \"google-cloud-bigquery\"\ndescription = \"Google BigQuery API client library\"\nversion = \"1.25.0\"\n# Should be one of:\n# 'Development Status :: 3 - Alpha'\n# 'Development Status :: 4 - Beta'\n# 'Development Status :: 5 - Production/Stable'\nrelease_status = \"Development Status :: 5 - Production/Stable\"\ndependencies = [\n 'enum34; python_version < \"3.4\"',\n \"google-auth >= 1.9.0, < 2.0dev\",\n \"google-api-core >= 1.15.0, < 2.0dev\",\n \"google-cloud-core >= 1.1.0, < 2.0dev\",\n \"google-resumable-media >= 0.5.0, < 0.6dev\",\n \"protobuf >= 3.6.0\",\n \"six >=1.13.0,< 2.0.0dev\",\n # rsa >= 4.1 is not compatible with Python 2\n # https://github.com/sybrenstuvel/python-rsa/issues/152\n 'rsa <4.1; python_version < \"3\"',\n 'rsa >=3.1.4, <5; python_version >= \"3\"',\n]\nextras = {\n \"bqstorage\": [\n \"google-cloud-bigquery-storage >= 1.0.0, <2.0.0dev\",\n # Due to an issue in pip's dependency resolver, the `grpc` extra is not\n # installed, even though `google-cloud-bigquery-storage` specifies it\n # as `google-api-core[grpc]`. We thus need to explicitly specify it here.\n # See: https://github.com/googleapis/python-bigquery/issues/83\n \"grpcio >= 1.8.2, < 2.0dev\",\n \"pyarrow>=0.16.0, < 2.0dev\",\n ],\n \"pandas\": [\"pandas>=0.17.1\"],\n # Exclude PyArrow dependency from Windows Python 2.7.\n 'pyarrow: platform_system != \"Windows\" or python_version >= \"3.4\"': [\n # Bad Linux release for 0.14.0.\n # https://issues.apache.org/jira/browse/ARROW-5868\n \"pyarrow>=0.4.1, != 0.14.0\"\n ],\n \"tqdm\": [\"tqdm >= 4.0.0, <5.0.0dev\"],\n \"fastparquet\": [\n \"fastparquet\",\n \"python-snappy\",\n # llvmlite >= 0.32.0 cannot be installed on Python 3.5 and below\n # (building the wheel fails), thus needs to be restricted.\n # See: https://github.com/googleapis/python-bigquery/issues/78\n \"llvmlite <= 0.31.0\",\n ],\n}\n\nall_extras = []\n\nfor extra in extras:\n if extra == \"fastparquet\":\n # Skip fastparquet from \"all\" because it is redundant with pyarrow and\n # creates a dependency on pre-release versions of numpy. See:\n # https://github.com/googleapis/google-cloud-python/issues/8549\n continue\n all_extras.extend(extras[extra])\n\nextras[\"all\"] = all_extras\n\n# Setup boilerplate below this line.\n\npackage_root = os.path.abspath(os.path.dirname(__file__))\n\nreadme_filename = os.path.join(package_root, \"README.rst\")\nwith io.open(readme_filename, encoding=\"utf-8\") as readme_file:\n readme = readme_file.read()\n\n# Only include packages under the 'google' namespace. Do not include tests,\n# benchmarks, etc.\npackages = [\n package for package in setuptools.find_packages() if package.startswith(\"google\")\n]\n\n# Determine which namespaces are needed.\nnamespaces = [\"google\"]\nif \"google.cloud\" in packages:\n namespaces.append(\"google.cloud\")\n\n\nsetuptools.setup(\n name=name,\n version=version,\n description=description,\n long_description=readme,\n author=\"Google LLC\",\n author_email=\"[email protected]\",\n license=\"Apache 2.0\",\n url=\"https://github.com/googleapis/python-bigquery\",\n classifiers=[\n release_status,\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Operating System :: OS Independent\",\n \"Topic :: Internet\",\n ],\n platforms=\"Posix; MacOS X; Windows\",\n packages=packages,\n namespace_packages=namespaces,\n install_requires=dependencies,\n extras_require=extras,\n python_requires=\">=2.7,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*\",\n include_package_data=True,\n zip_safe=False,\n)\n", "path": "setup.py"}]}
| 2,294 | 286 |
gh_patches_debug_14178
|
rasdani/github-patches
|
git_diff
|
cowrie__cowrie-897
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Mysql output has incorrect sql query in line 121
line 120-121 of src/cowrie/output/mysql.py show:
```
elif entry["eventid"] == 'cowrie.login.failed':
self.simpleQuery('INSERT INTO `auth` (`session`, `success` `username`, `password`, `timestamp`) '
```
There is a missing comma between `success` & `username`. This results in failure to log failed login attempts to mysql.
</issue>
<code>
[start of src/cowrie/output/mysql.py]
1 """
2 MySQL output connector. Writes audit logs to MySQL database
3 """
4
5 from __future__ import absolute_import, division
6
7 import MySQLdb
8
9 from twisted.enterprise import adbapi
10 from twisted.internet import defer
11 from twisted.python import log
12
13 import cowrie.core.output
14 from cowrie.core.config import CONFIG
15
16
17 class ReconnectingConnectionPool(adbapi.ConnectionPool):
18 """
19 Reconnecting adbapi connection pool for MySQL.
20
21 This class improves on the solution posted at
22 http://www.gelens.org/2008/09/12/reinitializing-twisted-connectionpool/
23 by checking exceptions by error code and only disconnecting the current
24 connection instead of all of them.
25
26 Also see:
27 http://twistedmatrix.com/pipermail/twisted-python/2009-July/020007.html
28 """
29
30 def _runInteraction(self, interaction, *args, **kw):
31 try:
32 return adbapi.ConnectionPool._runInteraction(
33 self, interaction, *args, **kw)
34 except MySQLdb.OperationalError as e:
35 if e[0] not in (2003, 2006, 2013):
36 log.msg("RCP: got error {0}, retrying operation".format(e))
37 raise e
38 conn = self.connections.get(self.threadID())
39 self.disconnect(conn)
40 # Try the interaction again
41 return adbapi.ConnectionPool._runInteraction(
42 self, interaction, *args, **kw)
43
44
45 class Output(cowrie.core.output.Output):
46 db = None
47
48 def __init__(self):
49 try:
50 self.debug = CONFIG.getboolean('output_mysql', 'debug')
51 except Exception:
52 self.debug = False
53
54 cowrie.core.output.Output.__init__(self)
55
56 def start(self):
57 try:
58 port = CONFIG.getint('output_mysql', 'port')
59 except Exception:
60 port = 3306
61
62 try:
63 self.db = ReconnectingConnectionPool(
64 'MySQLdb',
65 host=CONFIG.get('output_mysql', 'host'),
66 db=CONFIG.get('output_mysql', 'database'),
67 user=CONFIG.get('output_mysql', 'username'),
68 passwd=CONFIG.get('output_mysql', 'password', raw=True),
69 port=port,
70 cp_min=1,
71 cp_max=1
72 )
73 except MySQLdb.Error as e:
74 log.msg("output_mysql: Error %d: %s" % (e.args[0], e.args[1]))
75
76 def stop(self):
77 self.db.close()
78
79 def sqlerror(self, error):
80 log.err('output_mysql: MySQL Error: {}'.format(error.value))
81
82 def simpleQuery(self, sql, args):
83 """
84 Just run a deferred sql query, only care about errors
85 """
86 if self.debug:
87 log.msg("output_mysql: MySQL query: {} {}".format(sql, repr(args)))
88 d = self.db.runQuery(sql, args)
89 d.addErrback(self.sqlerror)
90
91 @defer.inlineCallbacks
92 def write(self, entry):
93 if entry["eventid"] == 'cowrie.session.connect':
94 r = yield self.db.runQuery(
95 "SELECT `id`"
96 "FROM `sensors`"
97 "WHERE `ip` = %s",
98 (self.sensor,))
99
100 if r:
101 sensorid = r[0][0]
102 else:
103 yield self.db.runQuery(
104 'INSERT INTO `sensors` (`ip`) '
105 'VALUES (%s)',
106 (self.sensor,))
107
108 r = yield self.db.runQuery('SELECT LAST_INSERT_ID()')
109 sensorid = int(r[0][0])
110 self.simpleQuery(
111 "INSERT INTO `sessions` (`id`, `starttime`, `sensor`, `ip`) "
112 "VALUES (%s, FROM_UNIXTIME(%s), %s, %s)",
113 (entry["session"], entry["time"], sensorid, entry["src_ip"]))
114
115 elif entry["eventid"] == 'cowrie.login.success':
116 self.simpleQuery('INSERT INTO `auth` (`session`, `success`, `username`, `password`, `timestamp`) '
117 'VALUES (%s, %s, %s, %s, FROM_UNIXTIME(%s))',
118 (entry["session"], 1, entry['username'], entry['password'], entry["time"]))
119
120 elif entry["eventid"] == 'cowrie.login.failed':
121 self.simpleQuery('INSERT INTO `auth` (`session`, `success` `username`, `password`, `timestamp`) '
122 'VALUES (%s, %s, %s, %s, FROM_UNIXTIME(%s))',
123 (entry["session"], 0, entry['username'], entry['password'], entry["time"]))
124
125 elif entry["eventid"] == 'cowrie.session.params':
126 self.simpleQuery('INSERT INTO `params` (`session`, `arch`) '
127 'VALUES (%s, %s)',
128 (entry["session"], entry["arch"]))
129
130 elif entry["eventid"] == 'cowrie.command.input':
131 self.simpleQuery('INSERT INTO `input` (`session`, `timestamp`, `success`, `input`) '
132 'VALUES (%s, FROM_UNIXTIME(%s), %s , %s)',
133 (entry["session"], entry["time"], 1, entry["input"]))
134
135 elif entry["eventid"] == 'cowrie.command.failed':
136 self.simpleQuery('INSERT INTO `input` (`session`, `timestamp`, `success`, `input`) '
137 'VALUES (%s, FROM_UNIXTIME(%s), %s , %s)',
138 (entry["session"], entry["time"], 0, entry["input"]))
139
140 elif entry["eventid"] == 'cowrie.session.file_download':
141 self.simpleQuery('INSERT INTO `downloads` (`session`, `timestamp`, `url`, `outfile`, `shasum`) '
142 'VALUES (%s, FROM_UNIXTIME(%s), %s, %s, %s)',
143 (entry["session"], entry["time"], entry['url'], entry['outfile'], entry['shasum']))
144
145 elif entry["eventid"] == 'cowrie.session.file_download.failed':
146 self.simpleQuery('INSERT INTO `downloads` (`session`, `timestamp`, `url`, `outfile`, `shasum`) '
147 'VALUES (%s, FROM_UNIXTIME(%s), %s, %s, %s)',
148 (entry["session"], entry["time"], entry['url'], 'NULL', 'NULL'))
149
150 elif entry["eventid"] == 'cowrie.session.file_upload':
151 self.simpleQuery('INSERT INTO `downloads` (`session`, `timestamp`, `url`, `outfile`, `shasum`) '
152 'VALUES (%s, FROM_UNIXTIME(%s), %s, %s, %s)',
153 (entry["session"], entry["time"], '', entry['outfile'], entry['shasum']))
154
155 elif entry["eventid"] == 'cowrie.session.input':
156 self.simpleQuery('INSERT INTO `input` (`session`, `timestamp`, `realm`, `input`) '
157 'VALUES (%s, FROM_UNIXTIME(%s), %s , %s)',
158 (entry["session"], entry["time"], entry["realm"], entry["input"]))
159
160 elif entry["eventid"] == 'cowrie.client.version':
161 r = yield self.db.runQuery(
162 'SELECT `id` FROM `clients` '
163 'WHERE `version` = %s',
164 (entry['version'],))
165
166 if r:
167 id = int(r[0][0])
168 else:
169 yield self.db.runQuery(
170 'INSERT INTO `clients` (`version`) '
171 'VALUES (%s)',
172 (entry['version'],))
173
174 r = yield self.db.runQuery('SELECT LAST_INSERT_ID()')
175 id = int(r[0][0])
176 self.simpleQuery(
177 'UPDATE `sessions` '
178 'SET `client` = %s '
179 'WHERE `id` = %s',
180 (id, entry["session"]))
181
182 elif entry["eventid"] == 'cowrie.client.size':
183 self.simpleQuery(
184 'UPDATE `sessions` '
185 'SET `termsize` = %s '
186 'WHERE `id` = %s',
187 ('%sx%s' % (entry['width'], entry['height']), entry["session"]))
188
189 elif entry["eventid"] == 'cowrie.session.closed':
190 self.simpleQuery(
191 'UPDATE `sessions` '
192 'SET `endtime` = FROM_UNIXTIME(%s) '
193 'WHERE `id` = %s',
194 (entry["time"], entry["session"]))
195
196 elif entry["eventid"] == 'cowrie.log.closed':
197 self.simpleQuery(
198 'INSERT INTO `ttylog` (`session`, `ttylog`, `size`) '
199 'VALUES (%s, %s, %s)',
200 (entry["session"], entry["ttylog"], entry["size"]))
201
202 elif entry["eventid"] == 'cowrie.client.fingerprint':
203 self.simpleQuery(
204 'INSERT INTO `keyfingerprints` (`session`, `username`, `fingerprint`) '
205 'VALUES (%s, %s, %s)',
206 (entry["session"], entry["username"], entry["fingerprint"]))
207
[end of src/cowrie/output/mysql.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/cowrie/output/mysql.py b/src/cowrie/output/mysql.py
--- a/src/cowrie/output/mysql.py
+++ b/src/cowrie/output/mysql.py
@@ -118,7 +118,7 @@
(entry["session"], 1, entry['username'], entry['password'], entry["time"]))
elif entry["eventid"] == 'cowrie.login.failed':
- self.simpleQuery('INSERT INTO `auth` (`session`, `success` `username`, `password`, `timestamp`) '
+ self.simpleQuery('INSERT INTO `auth` (`session`, `success`, `username`, `password`, `timestamp`) '
'VALUES (%s, %s, %s, %s, FROM_UNIXTIME(%s))',
(entry["session"], 0, entry['username'], entry['password'], entry["time"]))
|
{"golden_diff": "diff --git a/src/cowrie/output/mysql.py b/src/cowrie/output/mysql.py\n--- a/src/cowrie/output/mysql.py\n+++ b/src/cowrie/output/mysql.py\n@@ -118,7 +118,7 @@\n (entry[\"session\"], 1, entry['username'], entry['password'], entry[\"time\"]))\n \n elif entry[\"eventid\"] == 'cowrie.login.failed':\n- self.simpleQuery('INSERT INTO `auth` (`session`, `success` `username`, `password`, `timestamp`) '\n+ self.simpleQuery('INSERT INTO `auth` (`session`, `success`, `username`, `password`, `timestamp`) '\n 'VALUES (%s, %s, %s, %s, FROM_UNIXTIME(%s))',\n (entry[\"session\"], 0, entry['username'], entry['password'], entry[\"time\"]))\n", "issue": "Mysql output has incorrect sql query in line 121\nline 120-121 of src/cowrie/output/mysql.py show:\r\n```\r\nelif entry[\"eventid\"] == 'cowrie.login.failed':\r\n self.simpleQuery('INSERT INTO `auth` (`session`, `success` `username`, `password`, `timestamp`) '\r\n```\r\nThere is a missing comma between `success` & `username`. This results in failure to log failed login attempts to mysql.\n", "before_files": [{"content": "\"\"\"\nMySQL output connector. Writes audit logs to MySQL database\n\"\"\"\n\nfrom __future__ import absolute_import, division\n\nimport MySQLdb\n\nfrom twisted.enterprise import adbapi\nfrom twisted.internet import defer\nfrom twisted.python import log\n\nimport cowrie.core.output\nfrom cowrie.core.config import CONFIG\n\n\nclass ReconnectingConnectionPool(adbapi.ConnectionPool):\n \"\"\"\n Reconnecting adbapi connection pool for MySQL.\n\n This class improves on the solution posted at\n http://www.gelens.org/2008/09/12/reinitializing-twisted-connectionpool/\n by checking exceptions by error code and only disconnecting the current\n connection instead of all of them.\n\n Also see:\n http://twistedmatrix.com/pipermail/twisted-python/2009-July/020007.html\n \"\"\"\n\n def _runInteraction(self, interaction, *args, **kw):\n try:\n return adbapi.ConnectionPool._runInteraction(\n self, interaction, *args, **kw)\n except MySQLdb.OperationalError as e:\n if e[0] not in (2003, 2006, 2013):\n log.msg(\"RCP: got error {0}, retrying operation\".format(e))\n raise e\n conn = self.connections.get(self.threadID())\n self.disconnect(conn)\n # Try the interaction again\n return adbapi.ConnectionPool._runInteraction(\n self, interaction, *args, **kw)\n\n\nclass Output(cowrie.core.output.Output):\n db = None\n\n def __init__(self):\n try:\n self.debug = CONFIG.getboolean('output_mysql', 'debug')\n except Exception:\n self.debug = False\n\n cowrie.core.output.Output.__init__(self)\n\n def start(self):\n try:\n port = CONFIG.getint('output_mysql', 'port')\n except Exception:\n port = 3306\n\n try:\n self.db = ReconnectingConnectionPool(\n 'MySQLdb',\n host=CONFIG.get('output_mysql', 'host'),\n db=CONFIG.get('output_mysql', 'database'),\n user=CONFIG.get('output_mysql', 'username'),\n passwd=CONFIG.get('output_mysql', 'password', raw=True),\n port=port,\n cp_min=1,\n cp_max=1\n )\n except MySQLdb.Error as e:\n log.msg(\"output_mysql: Error %d: %s\" % (e.args[0], e.args[1]))\n\n def stop(self):\n self.db.close()\n\n def sqlerror(self, error):\n log.err('output_mysql: MySQL Error: {}'.format(error.value))\n\n def simpleQuery(self, sql, args):\n \"\"\"\n Just run a deferred sql query, only care about errors\n \"\"\"\n if self.debug:\n log.msg(\"output_mysql: MySQL query: {} {}\".format(sql, repr(args)))\n d = self.db.runQuery(sql, args)\n d.addErrback(self.sqlerror)\n\n @defer.inlineCallbacks\n def write(self, entry):\n if entry[\"eventid\"] == 'cowrie.session.connect':\n r = yield self.db.runQuery(\n \"SELECT `id`\"\n \"FROM `sensors`\"\n \"WHERE `ip` = %s\",\n (self.sensor,))\n\n if r:\n sensorid = r[0][0]\n else:\n yield self.db.runQuery(\n 'INSERT INTO `sensors` (`ip`) '\n 'VALUES (%s)',\n (self.sensor,))\n\n r = yield self.db.runQuery('SELECT LAST_INSERT_ID()')\n sensorid = int(r[0][0])\n self.simpleQuery(\n \"INSERT INTO `sessions` (`id`, `starttime`, `sensor`, `ip`) \"\n \"VALUES (%s, FROM_UNIXTIME(%s), %s, %s)\",\n (entry[\"session\"], entry[\"time\"], sensorid, entry[\"src_ip\"]))\n\n elif entry[\"eventid\"] == 'cowrie.login.success':\n self.simpleQuery('INSERT INTO `auth` (`session`, `success`, `username`, `password`, `timestamp`) '\n 'VALUES (%s, %s, %s, %s, FROM_UNIXTIME(%s))',\n (entry[\"session\"], 1, entry['username'], entry['password'], entry[\"time\"]))\n\n elif entry[\"eventid\"] == 'cowrie.login.failed':\n self.simpleQuery('INSERT INTO `auth` (`session`, `success` `username`, `password`, `timestamp`) '\n 'VALUES (%s, %s, %s, %s, FROM_UNIXTIME(%s))',\n (entry[\"session\"], 0, entry['username'], entry['password'], entry[\"time\"]))\n\n elif entry[\"eventid\"] == 'cowrie.session.params':\n self.simpleQuery('INSERT INTO `params` (`session`, `arch`) '\n 'VALUES (%s, %s)',\n (entry[\"session\"], entry[\"arch\"]))\n\n elif entry[\"eventid\"] == 'cowrie.command.input':\n self.simpleQuery('INSERT INTO `input` (`session`, `timestamp`, `success`, `input`) '\n 'VALUES (%s, FROM_UNIXTIME(%s), %s , %s)',\n (entry[\"session\"], entry[\"time\"], 1, entry[\"input\"]))\n\n elif entry[\"eventid\"] == 'cowrie.command.failed':\n self.simpleQuery('INSERT INTO `input` (`session`, `timestamp`, `success`, `input`) '\n 'VALUES (%s, FROM_UNIXTIME(%s), %s , %s)',\n (entry[\"session\"], entry[\"time\"], 0, entry[\"input\"]))\n\n elif entry[\"eventid\"] == 'cowrie.session.file_download':\n self.simpleQuery('INSERT INTO `downloads` (`session`, `timestamp`, `url`, `outfile`, `shasum`) '\n 'VALUES (%s, FROM_UNIXTIME(%s), %s, %s, %s)',\n (entry[\"session\"], entry[\"time\"], entry['url'], entry['outfile'], entry['shasum']))\n\n elif entry[\"eventid\"] == 'cowrie.session.file_download.failed':\n self.simpleQuery('INSERT INTO `downloads` (`session`, `timestamp`, `url`, `outfile`, `shasum`) '\n 'VALUES (%s, FROM_UNIXTIME(%s), %s, %s, %s)',\n (entry[\"session\"], entry[\"time\"], entry['url'], 'NULL', 'NULL'))\n\n elif entry[\"eventid\"] == 'cowrie.session.file_upload':\n self.simpleQuery('INSERT INTO `downloads` (`session`, `timestamp`, `url`, `outfile`, `shasum`) '\n 'VALUES (%s, FROM_UNIXTIME(%s), %s, %s, %s)',\n (entry[\"session\"], entry[\"time\"], '', entry['outfile'], entry['shasum']))\n\n elif entry[\"eventid\"] == 'cowrie.session.input':\n self.simpleQuery('INSERT INTO `input` (`session`, `timestamp`, `realm`, `input`) '\n 'VALUES (%s, FROM_UNIXTIME(%s), %s , %s)',\n (entry[\"session\"], entry[\"time\"], entry[\"realm\"], entry[\"input\"]))\n\n elif entry[\"eventid\"] == 'cowrie.client.version':\n r = yield self.db.runQuery(\n 'SELECT `id` FROM `clients` '\n 'WHERE `version` = %s',\n (entry['version'],))\n\n if r:\n id = int(r[0][0])\n else:\n yield self.db.runQuery(\n 'INSERT INTO `clients` (`version`) '\n 'VALUES (%s)',\n (entry['version'],))\n\n r = yield self.db.runQuery('SELECT LAST_INSERT_ID()')\n id = int(r[0][0])\n self.simpleQuery(\n 'UPDATE `sessions` '\n 'SET `client` = %s '\n 'WHERE `id` = %s',\n (id, entry[\"session\"]))\n\n elif entry[\"eventid\"] == 'cowrie.client.size':\n self.simpleQuery(\n 'UPDATE `sessions` '\n 'SET `termsize` = %s '\n 'WHERE `id` = %s',\n ('%sx%s' % (entry['width'], entry['height']), entry[\"session\"]))\n\n elif entry[\"eventid\"] == 'cowrie.session.closed':\n self.simpleQuery(\n 'UPDATE `sessions` '\n 'SET `endtime` = FROM_UNIXTIME(%s) '\n 'WHERE `id` = %s',\n (entry[\"time\"], entry[\"session\"]))\n\n elif entry[\"eventid\"] == 'cowrie.log.closed':\n self.simpleQuery(\n 'INSERT INTO `ttylog` (`session`, `ttylog`, `size`) '\n 'VALUES (%s, %s, %s)',\n (entry[\"session\"], entry[\"ttylog\"], entry[\"size\"]))\n\n elif entry[\"eventid\"] == 'cowrie.client.fingerprint':\n self.simpleQuery(\n 'INSERT INTO `keyfingerprints` (`session`, `username`, `fingerprint`) '\n 'VALUES (%s, %s, %s)',\n (entry[\"session\"], entry[\"username\"], entry[\"fingerprint\"]))\n", "path": "src/cowrie/output/mysql.py"}]}
| 3,142 | 187 |
gh_patches_debug_19403
|
rasdani/github-patches
|
git_diff
|
xonsh__xonsh-3851
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
An exception in a completer crashes xonsh
<!--- Provide a general summary of the issue in the Title above -->
<!--- If you have a question along the lines of "How do I do this Bash command in xonsh"
please first look over the Bash to Xonsh translation guide: https://xon.sh/bash_to_xsh.html
If you don't find an answer there, please do open an issue! -->
## xonfig
<details>
```
+------------------+-----------------+
| xonsh | 0.9.20 |
| Python | 3.8.5 |
| PLY | 3.11 |
| have readline | True |
| prompt toolkit | 3.0.7 |
| shell type | prompt_toolkit |
| pygments | 2.7.1 |
| on posix | True |
| on linux | True |
| distro | unknown |
| on darwin | False |
| on windows | False |
| on cygwin | False |
| on msys2 | False |
| is superuser | False |
| default encoding | utf-8 |
| xonsh encoding | utf-8 |
| encoding errors | surrogateescape |
+------------------+-----------------+
```
</details>
## Expected Behavior
Falling back to `sh` is much better than completely losing your shell, but it is still disconcerting, especially for a new user first trying to write a completer. I think that when an exception is raised by a completer xonsh should skip over that completer when finding completion results. Possibly xonsh could prompt the user that completer X encountered an error.
I am not a xonsh expert, but based on the traceback I think it would suffice to put a blanket `except` clause here that calls `continue`, possibly after printing some warning to the user about a bad completer and logging the traceback in some way:
https://github.com/xonsh/xonsh/blob/68993e4b3df51c1972098232e327e1510cc86c4c/xonsh/completer.py#L34-L38
## Current Behavior
<!--- Tell us what happens instead of the expected behavior -->
<!--- If part of your bug report is a traceback, please first enter debug mode before triggering the error
To enter debug mode, set the environment variable `XONSH_DEBUG=1` _before_ starting `xonsh`.
On Linux and OSX, an easy way to to do this is to run `env XONSH_DEBUG=1 xonsh` -->
### Traceback (if applicable)
<details>
```
Traceback (most recent call last):
File "/home/user/conda/lib/python3.8/site-packages/xonsh/__amalgam__.py", line 24534, in main
sys.exit(main_xonsh(args))
File "/home/user/conda/lib/python3.8/site-packages/xonsh/__amalgam__.py", line 24565, in main_xonsh
shell.shell.cmdloop()
File "/home/user/conda/lib/python3.8/site-packages/xonsh/ptk_shell/shell.py", line 224, in cmdloop
line = self.singleline(auto_suggest=auto_suggest)
File "/home/user/conda/lib/python3.8/site-packages/xonsh/ptk_shell/shell.py", line 193, in singleline
line = self.prompter.prompt(**prompt_args)
File "/home/user/conda/lib/python3.8/site-packages/prompt_toolkit/shortcuts/prompt.py", line 1013, in prompt
return self.app.run(set_exception_handler=set_exception_handler)
File "/home/user/conda/lib/python3.8/site-packages/prompt_toolkit/application/application.py", line 814, in run
return loop.run_until_complete(
File "/home/user/conda/lib/python3.8/asyncio/base_events.py", line 616, in run_until_complete
return future.result()
File "/home/user/conda/lib/python3.8/site-packages/prompt_toolkit/application/application.py", line 781, in run_async
return await _run_async2()
File "/home/user/conda/lib/python3.8/site-packages/prompt_toolkit/application/application.py", line 769, in _run_async2
await self.cancel_and_wait_for_background_tasks()
File "/home/user/conda/lib/python3.8/site-packages/prompt_toolkit/application/application.py", line 870, in cancel_and_wait_for_background_tasks
await task
File "/home/user/conda/lib/python3.8/site-packages/prompt_toolkit/buffer.py", line 1854, in new_coroutine
await coroutine(*a, **kw)
File "/home/user/conda/lib/python3.8/site-packages/prompt_toolkit/buffer.py", line 1683, in async_completer
async for completion in self.completer.get_completions_async(
File "/home/user/conda/lib/python3.8/site-packages/prompt_toolkit/completion/base.py", line 269, in get_completions_async
async for completion in completer.get_completions_async(
File "/home/user/conda/lib/python3.8/site-packages/prompt_toolkit/completion/base.py", line 196, in get_completions_async
for item in self.get_completions(document, complete_event):
File "/home/user/conda/lib/python3.8/site-packages/xonsh/ptk_shell/completer.py", line 51, in get_completions
completions, l = self.completer.complete(
File "/home/user/conda/lib/python3.8/site-packages/xonsh/__amalgam__.py", line 125, in complete
out = func(prefix, line, begidx, endidx, ctx)
File "<xonsh-code>", line 2, in bad_completer
Exception
Xonsh encountered an issue during launch
Failback to /bin/sh
```
</details>
## Steps to Reproduce
<!--- Please try to write out a minimal reproducible snippet to trigger the bug, it will help us fix it! -->
Declare a bad completer:
```
def bad_completer(pref, line, *args):
raise Exception
completer add test bad_completer start
```
Then start typing a command and hit `Tab`. No completion will happen (that behavior is okay). When you hit enter, `xonsh` will crash and failback to `sh`.
## For community
⬇️ **Please click the 👍 reaction instead of leaving a `+1` or 👍 comment**
</issue>
<code>
[start of xonsh/completer.py]
1 # -*- coding: utf-8 -*-
2 """A (tab-)completer for xonsh."""
3 import builtins
4 import collections.abc as cabc
5
6
7 class Completer(object):
8 """This provides a list of optional completions for the xonsh shell."""
9
10 def complete(self, prefix, line, begidx, endidx, ctx=None):
11 """Complete the string, given a possible execution context.
12
13 Parameters
14 ----------
15 prefix : str
16 The string to match
17 line : str
18 The line that prefix appears on.
19 begidx : int
20 The index in line that prefix starts on.
21 endidx : int
22 The index in line that prefix ends on.
23 ctx : Iterable of str (ie dict, set, etc), optional
24 Names in the current execution context.
25
26 Returns
27 -------
28 rtn : list of str
29 Possible completions of prefix, sorted alphabetically.
30 lprefix : int
31 Length of the prefix to be replaced in the completion.
32 """
33 ctx = ctx or {}
34 for func in builtins.__xonsh__.completers.values():
35 try:
36 out = func(prefix, line, begidx, endidx, ctx)
37 except StopIteration:
38 return set(), len(prefix)
39 if isinstance(out, cabc.Sequence):
40 res, lprefix = out
41 else:
42 res = out
43 lprefix = len(prefix)
44 if res is not None and len(res) != 0:
45
46 def sortkey(s):
47 return s.lstrip(''''"''').lower()
48
49 return tuple(sorted(res, key=sortkey)), lprefix
50 return set(), lprefix
51
[end of xonsh/completer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/xonsh/completer.py b/xonsh/completer.py
--- a/xonsh/completer.py
+++ b/xonsh/completer.py
@@ -3,6 +3,8 @@
import builtins
import collections.abc as cabc
+from xonsh.tools import print_exception
+
class Completer(object):
"""This provides a list of optional completions for the xonsh shell."""
@@ -36,6 +38,13 @@
out = func(prefix, line, begidx, endidx, ctx)
except StopIteration:
return set(), len(prefix)
+ except Exception as e:
+ print_exception(
+ f"Completer {func.__name__} raises exception when get "
+ f"(prefix={repr(prefix)}, line={repr(line)}, begidx={repr(begidx)}, endidx={repr(endidx)}):\n"
+ f"{e}"
+ )
+ return set(), len(prefix)
if isinstance(out, cabc.Sequence):
res, lprefix = out
else:
|
{"golden_diff": "diff --git a/xonsh/completer.py b/xonsh/completer.py\n--- a/xonsh/completer.py\n+++ b/xonsh/completer.py\n@@ -3,6 +3,8 @@\n import builtins\n import collections.abc as cabc\n \n+from xonsh.tools import print_exception\n+\n \n class Completer(object):\n \"\"\"This provides a list of optional completions for the xonsh shell.\"\"\"\n@@ -36,6 +38,13 @@\n out = func(prefix, line, begidx, endidx, ctx)\n except StopIteration:\n return set(), len(prefix)\n+ except Exception as e:\n+ print_exception(\n+ f\"Completer {func.__name__} raises exception when get \"\n+ f\"(prefix={repr(prefix)}, line={repr(line)}, begidx={repr(begidx)}, endidx={repr(endidx)}):\\n\"\n+ f\"{e}\"\n+ )\n+ return set(), len(prefix)\n if isinstance(out, cabc.Sequence):\n res, lprefix = out\n else:\n", "issue": "An exception in a completer crashes xonsh\n<!--- Provide a general summary of the issue in the Title above -->\r\n<!--- If you have a question along the lines of \"How do I do this Bash command in xonsh\"\r\nplease first look over the Bash to Xonsh translation guide: https://xon.sh/bash_to_xsh.html\r\nIf you don't find an answer there, please do open an issue! -->\r\n\r\n## xonfig\r\n\r\n<details>\r\n\r\n```\r\n+------------------+-----------------+\r\n| xonsh | 0.9.20 |\r\n| Python | 3.8.5 |\r\n| PLY | 3.11 |\r\n| have readline | True |\r\n| prompt toolkit | 3.0.7 |\r\n| shell type | prompt_toolkit |\r\n| pygments | 2.7.1 |\r\n| on posix | True |\r\n| on linux | True |\r\n| distro | unknown |\r\n| on darwin | False |\r\n| on windows | False |\r\n| on cygwin | False |\r\n| on msys2 | False |\r\n| is superuser | False |\r\n| default encoding | utf-8 |\r\n| xonsh encoding | utf-8 |\r\n| encoding errors | surrogateescape |\r\n+------------------+-----------------+\r\n\r\n```\r\n\r\n</details>\r\n\r\n## Expected Behavior\r\nFalling back to `sh` is much better than completely losing your shell, but it is still disconcerting, especially for a new user first trying to write a completer. I think that when an exception is raised by a completer xonsh should skip over that completer when finding completion results. Possibly xonsh could prompt the user that completer X encountered an error.\r\n\r\nI am not a xonsh expert, but based on the traceback I think it would suffice to put a blanket `except` clause here that calls `continue`, possibly after printing some warning to the user about a bad completer and logging the traceback in some way:\r\n\r\nhttps://github.com/xonsh/xonsh/blob/68993e4b3df51c1972098232e327e1510cc86c4c/xonsh/completer.py#L34-L38\r\n\r\n## Current Behavior\r\n<!--- Tell us what happens instead of the expected behavior -->\r\n<!--- If part of your bug report is a traceback, please first enter debug mode before triggering the error\r\nTo enter debug mode, set the environment variable `XONSH_DEBUG=1` _before_ starting `xonsh`.\r\nOn Linux and OSX, an easy way to to do this is to run `env XONSH_DEBUG=1 xonsh` -->\r\n\r\n### Traceback (if applicable)\r\n\r\n<details>\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/home/user/conda/lib/python3.8/site-packages/xonsh/__amalgam__.py\", line 24534, in main\r\n sys.exit(main_xonsh(args))\r\n File \"/home/user/conda/lib/python3.8/site-packages/xonsh/__amalgam__.py\", line 24565, in main_xonsh\r\n shell.shell.cmdloop()\r\n File \"/home/user/conda/lib/python3.8/site-packages/xonsh/ptk_shell/shell.py\", line 224, in cmdloop\r\n line = self.singleline(auto_suggest=auto_suggest)\r\n File \"/home/user/conda/lib/python3.8/site-packages/xonsh/ptk_shell/shell.py\", line 193, in singleline\r\n line = self.prompter.prompt(**prompt_args)\r\n File \"/home/user/conda/lib/python3.8/site-packages/prompt_toolkit/shortcuts/prompt.py\", line 1013, in prompt\r\n return self.app.run(set_exception_handler=set_exception_handler)\r\n File \"/home/user/conda/lib/python3.8/site-packages/prompt_toolkit/application/application.py\", line 814, in run\r\n return loop.run_until_complete(\r\n File \"/home/user/conda/lib/python3.8/asyncio/base_events.py\", line 616, in run_until_complete\r\n return future.result()\r\n File \"/home/user/conda/lib/python3.8/site-packages/prompt_toolkit/application/application.py\", line 781, in run_async\r\n return await _run_async2()\r\n File \"/home/user/conda/lib/python3.8/site-packages/prompt_toolkit/application/application.py\", line 769, in _run_async2\r\n await self.cancel_and_wait_for_background_tasks()\r\n File \"/home/user/conda/lib/python3.8/site-packages/prompt_toolkit/application/application.py\", line 870, in cancel_and_wait_for_background_tasks\r\n await task\r\n File \"/home/user/conda/lib/python3.8/site-packages/prompt_toolkit/buffer.py\", line 1854, in new_coroutine\r\n await coroutine(*a, **kw)\r\n File \"/home/user/conda/lib/python3.8/site-packages/prompt_toolkit/buffer.py\", line 1683, in async_completer\r\n async for completion in self.completer.get_completions_async(\r\n File \"/home/user/conda/lib/python3.8/site-packages/prompt_toolkit/completion/base.py\", line 269, in get_completions_async\r\n async for completion in completer.get_completions_async(\r\n File \"/home/user/conda/lib/python3.8/site-packages/prompt_toolkit/completion/base.py\", line 196, in get_completions_async\r\n for item in self.get_completions(document, complete_event):\r\n File \"/home/user/conda/lib/python3.8/site-packages/xonsh/ptk_shell/completer.py\", line 51, in get_completions\r\n completions, l = self.completer.complete(\r\n File \"/home/user/conda/lib/python3.8/site-packages/xonsh/__amalgam__.py\", line 125, in complete\r\n out = func(prefix, line, begidx, endidx, ctx)\r\n File \"<xonsh-code>\", line 2, in bad_completer\r\nException\r\nXonsh encountered an issue during launch\r\nFailback to /bin/sh\r\n```\r\n\r\n</details>\r\n\r\n## Steps to Reproduce\r\n<!--- Please try to write out a minimal reproducible snippet to trigger the bug, it will help us fix it! -->\r\n\r\nDeclare a bad completer:\r\n\r\n```\r\ndef bad_completer(pref, line, *args):\r\n raise Exception\r\n\r\ncompleter add test bad_completer start\r\n```\r\n\r\nThen start typing a command and hit `Tab`. No completion will happen (that behavior is okay). When you hit enter, `xonsh` will crash and failback to `sh`.\r\n\r\n## For community\r\n\u2b07\ufe0f **Please click the \ud83d\udc4d reaction instead of leaving a `+1` or \ud83d\udc4d comment**\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"A (tab-)completer for xonsh.\"\"\"\nimport builtins\nimport collections.abc as cabc\n\n\nclass Completer(object):\n \"\"\"This provides a list of optional completions for the xonsh shell.\"\"\"\n\n def complete(self, prefix, line, begidx, endidx, ctx=None):\n \"\"\"Complete the string, given a possible execution context.\n\n Parameters\n ----------\n prefix : str\n The string to match\n line : str\n The line that prefix appears on.\n begidx : int\n The index in line that prefix starts on.\n endidx : int\n The index in line that prefix ends on.\n ctx : Iterable of str (ie dict, set, etc), optional\n Names in the current execution context.\n\n Returns\n -------\n rtn : list of str\n Possible completions of prefix, sorted alphabetically.\n lprefix : int\n Length of the prefix to be replaced in the completion.\n \"\"\"\n ctx = ctx or {}\n for func in builtins.__xonsh__.completers.values():\n try:\n out = func(prefix, line, begidx, endidx, ctx)\n except StopIteration:\n return set(), len(prefix)\n if isinstance(out, cabc.Sequence):\n res, lprefix = out\n else:\n res = out\n lprefix = len(prefix)\n if res is not None and len(res) != 0:\n\n def sortkey(s):\n return s.lstrip(''''\"''').lower()\n\n return tuple(sorted(res, key=sortkey)), lprefix\n return set(), lprefix\n", "path": "xonsh/completer.py"}]}
| 2,496 | 235 |
gh_patches_debug_32340
|
rasdani/github-patches
|
git_diff
|
litestar-org__litestar-3417
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bug: ResponseHeaders results in invalid OpenAPI schema
### Description
Use of `response_headers` on the Litestar object seems to result in invalid OpenAPI 3.1 schema generation.
The Header object on the response is invalid aiui according to the spec (see https://spec.openapis.org/oas/v3.1.0#header-object) and fails validation when using `redocly lint`, as it includes the `name` and `in` fields.
The schema is as follows,
```json
{
"info": {
"title": "Litestar API",
"version": "1.0.0"
},
"openapi": "3.1.0",
"servers": [
{
"url": "/"
}
],
"paths": {
"/": {
"get": {
"summary": "HelloWorld1",
"operationId": "HelloWorld1",
"responses": {
"200": {
"description": "Request fulfilled, document follows",
"headers": {
"X-Version": {
"schema": {
"type": "string"
},
"name": "X-Version",
"in": "header",
"description": "Test",
"required": false,
"deprecated": false,
"allowEmptyValue": false,
"allowReserved": false
}
}
}
},
"deprecated": false
}
}
},
"components": {
"schemas": {}
}
}
```
### URL to code causing the issue
_No response_
### MCVE
```python
from litestar import Litestar, Request, get
from litestar.datastructures import ResponseHeader
@get("/")
async def hello_world1(request: Request) -> None:
request.logger.info("inside request")
return None
app1 = Litestar(
route_handlers=[hello_world1],
response_headers=[ResponseHeader(name="X-Version", value="ABCD", description="Test")],
)
```
This endpoint works, but the resulting schema fails validation.
```bash
$ litestar schema openapi --output openapi_schema.json
$ npx @redocly/cli lint openapi_schema.json
...
[1] openapi_schema.json:25:33 at #/paths/~1/get/responses/200/headers/X-Version/name
Property `name` is not expected here.
23 | "type": "string"
24 | },
25 | "name": "X-Version",
26 | "in": "header",
27 | "description": "Test",
Error was generated by the spec rule.
[2] openapi_schema.json:26:33 at #/paths/~1/get/responses/200/headers/X-Version/in
Property `in` is not expected here.
24 | },
25 | "name": "X-Version",
26 | "in": "header",
27 | "description": "Test",
28 | "required": false,
...
```
### Steps to reproduce
_No response_
### Screenshots
_No response_
### Logs
_No response_
### Litestar Version
2.8.2, using Python 3.12.2
### Platform
- [ ] Linux
- [X] Mac
- [ ] Windows
- [ ] Other (Please specify in the description above)
<!-- POLAR PLEDGE BADGE START -->
---
> [!NOTE]
> While we are open for sponsoring on [GitHub Sponsors](https://github.com/sponsors/litestar-org/) and
> [OpenCollective](https://opencollective.com/litestar), we also utilize [Polar.sh](https://polar.sh/) to engage in pledge-based sponsorship.
>
> Check out all issues funded or available for funding [on our Polar.sh dashboard](https://polar.sh/litestar-org)
> * If you would like to see an issue prioritized, make a pledge towards it!
> * We receive the pledge once the issue is completed & verified
> * This, along with engagement in the community, helps us know which features are a priority to our users.
<a href="https://polar.sh/litestar-org/litestar/issues/3416">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://polar.sh/api/github/litestar-org/litestar/issues/3416/pledge.svg?darkmode=1">
<img alt="Fund with Polar" src="https://polar.sh/api/github/litestar-org/litestar/issues/3416/pledge.svg">
</picture>
</a>
<!-- POLAR PLEDGE BADGE END -->
</issue>
<code>
[start of litestar/openapi/spec/header.py]
1 from __future__ import annotations
2
3 from dataclasses import dataclass
4 from typing import TYPE_CHECKING, Any, Literal
5
6 from litestar.openapi.spec.base import BaseSchemaObject
7
8 if TYPE_CHECKING:
9 from litestar.openapi.spec.example import Example
10 from litestar.openapi.spec.media_type import OpenAPIMediaType
11 from litestar.openapi.spec.reference import Reference
12 from litestar.openapi.spec.schema import Schema
13
14 __all__ = ("OpenAPIHeader",)
15
16
17 @dataclass
18 class OpenAPIHeader(BaseSchemaObject):
19 """The Header Object follows the structure of the [Parameter
20 Object](https://spec.openapis.org/oas/v3.1.0#parameterObject) with the
21 following changes:
22
23 1. ``name`` MUST NOT be specified, it is given in the corresponding ``headers`` map.
24 2. ``in`` MUST NOT be specified, it is implicitly in ``header``.
25 3. All traits that are affected by the location MUST be applicable to a location of ``header``
26 (for example, `style <https://spec.openapis.org/oas/v3.1.0#parameterStyle>`__).
27 """
28
29 schema: Schema | Reference | None = None
30 """The schema defining the type used for the parameter."""
31
32 name: Literal[""] = ""
33 """MUST NOT be specified, it is given in the corresponding ``headers`` map."""
34
35 param_in: Literal["header"] = "header"
36 """MUST NOT be specified, it is implicitly in ``header``."""
37
38 description: str | None = None
39 """A brief description of the parameter. This could contain examples of
40 use.
41
42 `CommonMark syntax <https://spec.commonmark.org/>`_ MAY be used for rich text representation.
43 """
44
45 required: bool = False
46 """Determines whether this parameter is mandatory.
47
48 If the `parameter location <https://spec.openapis.org/oas/v3.1.0#parameterIn>`_ is ``"path"``, this property is
49 **REQUIRED** and its value MUST be ``True``. Otherwise, the property MAY be included and its default value is
50 ``False``.
51 """
52
53 deprecated: bool = False
54 """Specifies that a parameter is deprecated and SHOULD be transitioned out of usage. Default value is ``False``."""
55
56 allow_empty_value: bool = False
57 """Sets the ability to pass empty-valued parameters. This is valid only for ``query`` parameters and allows sending
58 a parameter with an empty value. Default value is ``False``. If
59 `style <https://spec.openapis.org/oas/v3.1.0#parameterStyle>`__ is used, and if behavior is ``n/a`` (cannot be
60 serialized), the value of ``allowEmptyValue`` SHALL be ignored. Use of this property is NOT RECOMMENDED, as it is
61 likely to be removed in a later revision.
62
63 The rules for serialization of the parameter are specified in one of two ways.For simpler scenarios, a
64 `schema <https://spec.openapis.org/oas/v3.1.0#parameterSchema>`_ and
65 `style <https://spec.openapis.org/oas/v3.1.0#parameterStyle>`__ can describe the structure and syntax of the
66 parameter.
67 """
68
69 style: str | None = None
70 """Describes how the parameter value will be serialized depending on the
71 type of the parameter value. Default values (based on value of ``in``):
72
73 - for ``query`` - ``form``;
74 - for ``path`` - ``simple``;
75 - for ``header`` - ``simple``;
76 - for ``cookie`` - ``form``.
77 """
78
79 explode: bool | None = None
80 """When this is true, parameter values of type ``array`` or ``object`` generate separate parameters for each value
81 of the array or key-value pair of the map.
82
83 For other types of parameters this property has no effect.When
84 `style <https://spec.openapis.org/oas/v3.1.0#parameterStyle>`__ is ``form``, the default value is ``True``. For all
85 other styles, the default value is ``False``.
86 """
87
88 allow_reserved: bool = False
89 """Determines whether the parameter value SHOULD allow reserved characters, as defined by. :rfc:`3986`
90 (``:/?#[]@!$&'()*+,;=``) to be included without percent-encoding.
91
92 This property only applies to parameters with an ``in`` value of ``query``. The default value is ``False``.
93 """
94
95 example: Any | None = None
96 """Example of the parameter's potential value.
97
98 The example SHOULD match the specified schema and encoding properties if present. The ``example`` field is mutually
99 exclusive of the ``examples`` field. Furthermore, if referencing a ``schema`` that contains an example, the
100 ``example`` value SHALL _override_ the example provided by the schema. To represent examples of media types that
101 cannot naturally be represented in JSON or YAML, a string value can contain the example with escaping where
102 necessary.
103 """
104
105 examples: dict[str, Example | Reference] | None = None
106 """Examples of the parameter's potential value. Each example SHOULD contain a value in the correct format as
107 specified in the parameter encoding. The ``examples`` field is mutually exclusive of the ``example`` field.
108 Furthermore, if referencing a ``schema`` that contains an example, the ``examples`` value SHALL _override_ the
109 example provided by the schema.
110
111 For more complex scenarios, the `content <https://spec.openapis.org/oas/v3.1.0#parameterContent>`_ property can
112 define the media type and schema of the parameter. A parameter MUST contain either a ``schema`` property, or a
113 ``content`` property, but not both. When ``example`` or ``examples`` are provided in conjunction with the ``schema``
114 object, the example MUST follow the prescribed serialization strategy for the parameter.
115 """
116
117 content: dict[str, OpenAPIMediaType] | None = None
118 """A map containing the representations for the parameter.
119
120 The key is the media type and the value describes it. The map MUST only contain one entry.
121 """
122
[end of litestar/openapi/spec/header.py]
[start of litestar/openapi/spec/base.py]
1 from __future__ import annotations
2
3 from dataclasses import asdict, dataclass, fields, is_dataclass
4 from enum import Enum
5 from typing import Any
6
7 __all__ = ("BaseSchemaObject",)
8
9
10 def _normalize_key(key: str) -> str:
11 if key.endswith("_in"):
12 return "in"
13 if key.startswith("schema_"):
14 return key.split("_")[1]
15 if "_" in key:
16 components = key.split("_")
17 return components[0] + "".join(component.title() for component in components[1:])
18 return "$ref" if key == "ref" else key
19
20
21 def _normalize_value(value: Any) -> Any:
22 if isinstance(value, BaseSchemaObject):
23 return value.to_schema()
24 if is_dataclass(value):
25 return {_normalize_value(k): _normalize_value(v) for k, v in asdict(value).items() if v is not None}
26 if isinstance(value, dict):
27 return {_normalize_value(k): _normalize_value(v) for k, v in value.items() if v is not None}
28 if isinstance(value, list):
29 return [_normalize_value(v) for v in value]
30 return value.value if isinstance(value, Enum) else value
31
32
33 @dataclass
34 class BaseSchemaObject:
35 """Base class for schema spec objects"""
36
37 def to_schema(self) -> dict[str, Any]:
38 """Transform the spec dataclass object into a string keyed dictionary. This method traverses all nested values
39 recursively.
40 """
41 result: dict[str, Any] = {}
42
43 for field in fields(self):
44 value = _normalize_value(getattr(self, field.name, None))
45
46 if value is not None:
47 if "alias" in field.metadata:
48 if not isinstance(field.metadata["alias"], str):
49 raise TypeError('metadata["alias"] must be a str')
50 key = field.metadata["alias"]
51 else:
52 key = _normalize_key(field.name)
53
54 result[key] = value
55
56 return result
57
[end of litestar/openapi/spec/base.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/litestar/openapi/spec/base.py b/litestar/openapi/spec/base.py
--- a/litestar/openapi/spec/base.py
+++ b/litestar/openapi/spec/base.py
@@ -2,7 +2,11 @@
from dataclasses import asdict, dataclass, fields, is_dataclass
from enum import Enum
-from typing import Any
+from typing import TYPE_CHECKING, Any
+
+if TYPE_CHECKING:
+ from collections.abc import Iterator
+ from dataclasses import Field
__all__ = ("BaseSchemaObject",)
@@ -34,13 +38,16 @@
class BaseSchemaObject:
"""Base class for schema spec objects"""
+ def _iter_fields(self) -> Iterator[Field[Any]]:
+ yield from fields(self)
+
def to_schema(self) -> dict[str, Any]:
"""Transform the spec dataclass object into a string keyed dictionary. This method traverses all nested values
recursively.
"""
result: dict[str, Any] = {}
- for field in fields(self):
+ for field in self._iter_fields():
value = _normalize_value(getattr(self, field.name, None))
if value is not None:
diff --git a/litestar/openapi/spec/header.py b/litestar/openapi/spec/header.py
--- a/litestar/openapi/spec/header.py
+++ b/litestar/openapi/spec/header.py
@@ -1,7 +1,9 @@
from __future__ import annotations
-from dataclasses import dataclass
-from typing import TYPE_CHECKING, Any, Literal
+from dataclasses import Field, dataclass
+from typing import TYPE_CHECKING, Any, Iterator, Literal
+
+from typing_extensions import override
from litestar.openapi.spec.base import BaseSchemaObject
@@ -119,3 +121,7 @@
The key is the media type and the value describes it. The map MUST only contain one entry.
"""
+
+ @override
+ def _iter_fields(self) -> Iterator[Field[Any]]:
+ yield from (f for f in super()._iter_fields() if f.name not in {"name", "param_in"})
|
{"golden_diff": "diff --git a/litestar/openapi/spec/base.py b/litestar/openapi/spec/base.py\n--- a/litestar/openapi/spec/base.py\n+++ b/litestar/openapi/spec/base.py\n@@ -2,7 +2,11 @@\n \n from dataclasses import asdict, dataclass, fields, is_dataclass\n from enum import Enum\n-from typing import Any\n+from typing import TYPE_CHECKING, Any\n+\n+if TYPE_CHECKING:\n+ from collections.abc import Iterator\n+ from dataclasses import Field\n \n __all__ = (\"BaseSchemaObject\",)\n \n@@ -34,13 +38,16 @@\n class BaseSchemaObject:\n \"\"\"Base class for schema spec objects\"\"\"\n \n+ def _iter_fields(self) -> Iterator[Field[Any]]:\n+ yield from fields(self)\n+\n def to_schema(self) -> dict[str, Any]:\n \"\"\"Transform the spec dataclass object into a string keyed dictionary. This method traverses all nested values\n recursively.\n \"\"\"\n result: dict[str, Any] = {}\n \n- for field in fields(self):\n+ for field in self._iter_fields():\n value = _normalize_value(getattr(self, field.name, None))\n \n if value is not None:\ndiff --git a/litestar/openapi/spec/header.py b/litestar/openapi/spec/header.py\n--- a/litestar/openapi/spec/header.py\n+++ b/litestar/openapi/spec/header.py\n@@ -1,7 +1,9 @@\n from __future__ import annotations\n \n-from dataclasses import dataclass\n-from typing import TYPE_CHECKING, Any, Literal\n+from dataclasses import Field, dataclass\n+from typing import TYPE_CHECKING, Any, Iterator, Literal\n+\n+from typing_extensions import override\n \n from litestar.openapi.spec.base import BaseSchemaObject\n \n@@ -119,3 +121,7 @@\n \n The key is the media type and the value describes it. The map MUST only contain one entry.\n \"\"\"\n+\n+ @override\n+ def _iter_fields(self) -> Iterator[Field[Any]]:\n+ yield from (f for f in super()._iter_fields() if f.name not in {\"name\", \"param_in\"})\n", "issue": "Bug: ResponseHeaders results in invalid OpenAPI schema\n### Description\r\n\r\nUse of `response_headers` on the Litestar object seems to result in invalid OpenAPI 3.1 schema generation.\r\n\r\nThe Header object on the response is invalid aiui according to the spec (see https://spec.openapis.org/oas/v3.1.0#header-object) and fails validation when using `redocly lint`, as it includes the `name` and `in` fields.\r\n\r\nThe schema is as follows,\r\n\r\n```json\r\n{\r\n \"info\": {\r\n \"title\": \"Litestar API\",\r\n \"version\": \"1.0.0\"\r\n },\r\n \"openapi\": \"3.1.0\",\r\n \"servers\": [\r\n {\r\n \"url\": \"/\"\r\n }\r\n ],\r\n \"paths\": {\r\n \"/\": {\r\n \"get\": {\r\n \"summary\": \"HelloWorld1\",\r\n \"operationId\": \"HelloWorld1\",\r\n \"responses\": {\r\n \"200\": {\r\n \"description\": \"Request fulfilled, document follows\",\r\n \"headers\": {\r\n \"X-Version\": {\r\n \"schema\": {\r\n \"type\": \"string\"\r\n },\r\n \"name\": \"X-Version\",\r\n \"in\": \"header\",\r\n \"description\": \"Test\",\r\n \"required\": false,\r\n \"deprecated\": false,\r\n \"allowEmptyValue\": false,\r\n \"allowReserved\": false\r\n }\r\n }\r\n }\r\n },\r\n \"deprecated\": false\r\n }\r\n }\r\n },\r\n \"components\": {\r\n \"schemas\": {}\r\n }\r\n}\r\n```\r\n\r\n\r\n### URL to code causing the issue\r\n\r\n_No response_\r\n\r\n### MCVE\r\n\r\n```python\r\nfrom litestar import Litestar, Request, get\r\nfrom litestar.datastructures import ResponseHeader\r\n\r\n@get(\"/\")\r\nasync def hello_world1(request: Request) -> None:\r\n request.logger.info(\"inside request\")\r\n return None\r\n\r\napp1 = Litestar(\r\n route_handlers=[hello_world1],\r\n response_headers=[ResponseHeader(name=\"X-Version\", value=\"ABCD\", description=\"Test\")],\r\n)\r\n```\r\n\r\nThis endpoint works, but the resulting schema fails validation.\r\n\r\n```bash\r\n$ litestar schema openapi --output openapi_schema.json\r\n$ npx @redocly/cli lint openapi_schema.json\r\n\r\n...\r\n[1] openapi_schema.json:25:33 at #/paths/~1/get/responses/200/headers/X-Version/name\r\n\r\nProperty `name` is not expected here.\r\n\r\n23 | \"type\": \"string\"\r\n24 | },\r\n25 | \"name\": \"X-Version\",\r\n26 | \"in\": \"header\",\r\n27 | \"description\": \"Test\",\r\n\r\nError was generated by the spec rule.\r\n\r\n\r\n[2] openapi_schema.json:26:33 at #/paths/~1/get/responses/200/headers/X-Version/in\r\n\r\nProperty `in` is not expected here.\r\n\r\n24 | },\r\n25 | \"name\": \"X-Version\",\r\n26 | \"in\": \"header\",\r\n27 | \"description\": \"Test\",\r\n28 | \"required\": false,\r\n...\r\n\r\n```\r\n\r\n\r\n### Steps to reproduce\r\n\r\n_No response_\r\n\r\n### Screenshots\r\n\r\n_No response_\r\n\r\n### Logs\r\n\r\n_No response_\r\n\r\n### Litestar Version\r\n\r\n2.8.2, using Python 3.12.2\r\n\r\n### Platform\r\n\r\n- [ ] Linux\r\n- [X] Mac\r\n- [ ] Windows\r\n- [ ] Other (Please specify in the description above)\r\n\r\n<!-- POLAR PLEDGE BADGE START -->\r\n---\r\n> [!NOTE] \r\n> While we are open for sponsoring on [GitHub Sponsors](https://github.com/sponsors/litestar-org/) and \r\n> [OpenCollective](https://opencollective.com/litestar), we also utilize [Polar.sh](https://polar.sh/) to engage in pledge-based sponsorship.\r\n>\r\n> Check out all issues funded or available for funding [on our Polar.sh dashboard](https://polar.sh/litestar-org)\r\n> * If you would like to see an issue prioritized, make a pledge towards it!\r\n> * We receive the pledge once the issue is completed & verified\r\n> * This, along with engagement in the community, helps us know which features are a priority to our users.\r\n\r\n<a href=\"https://polar.sh/litestar-org/litestar/issues/3416\">\r\n<picture>\r\n <source media=\"(prefers-color-scheme: dark)\" srcset=\"https://polar.sh/api/github/litestar-org/litestar/issues/3416/pledge.svg?darkmode=1\">\r\n <img alt=\"Fund with Polar\" src=\"https://polar.sh/api/github/litestar-org/litestar/issues/3416/pledge.svg\">\r\n</picture>\r\n</a>\r\n<!-- POLAR PLEDGE BADGE END -->\r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom dataclasses import dataclass\nfrom typing import TYPE_CHECKING, Any, Literal\n\nfrom litestar.openapi.spec.base import BaseSchemaObject\n\nif TYPE_CHECKING:\n from litestar.openapi.spec.example import Example\n from litestar.openapi.spec.media_type import OpenAPIMediaType\n from litestar.openapi.spec.reference import Reference\n from litestar.openapi.spec.schema import Schema\n\n__all__ = (\"OpenAPIHeader\",)\n\n\n@dataclass\nclass OpenAPIHeader(BaseSchemaObject):\n \"\"\"The Header Object follows the structure of the [Parameter\n Object](https://spec.openapis.org/oas/v3.1.0#parameterObject) with the\n following changes:\n\n 1. ``name`` MUST NOT be specified, it is given in the corresponding ``headers`` map.\n 2. ``in`` MUST NOT be specified, it is implicitly in ``header``.\n 3. All traits that are affected by the location MUST be applicable to a location of ``header``\n (for example, `style <https://spec.openapis.org/oas/v3.1.0#parameterStyle>`__).\n \"\"\"\n\n schema: Schema | Reference | None = None\n \"\"\"The schema defining the type used for the parameter.\"\"\"\n\n name: Literal[\"\"] = \"\"\n \"\"\"MUST NOT be specified, it is given in the corresponding ``headers`` map.\"\"\"\n\n param_in: Literal[\"header\"] = \"header\"\n \"\"\"MUST NOT be specified, it is implicitly in ``header``.\"\"\"\n\n description: str | None = None\n \"\"\"A brief description of the parameter. This could contain examples of\n use.\n\n `CommonMark syntax <https://spec.commonmark.org/>`_ MAY be used for rich text representation.\n \"\"\"\n\n required: bool = False\n \"\"\"Determines whether this parameter is mandatory.\n\n If the `parameter location <https://spec.openapis.org/oas/v3.1.0#parameterIn>`_ is ``\"path\"``, this property is\n **REQUIRED** and its value MUST be ``True``. Otherwise, the property MAY be included and its default value is\n ``False``.\n \"\"\"\n\n deprecated: bool = False\n \"\"\"Specifies that a parameter is deprecated and SHOULD be transitioned out of usage. Default value is ``False``.\"\"\"\n\n allow_empty_value: bool = False\n \"\"\"Sets the ability to pass empty-valued parameters. This is valid only for ``query`` parameters and allows sending\n a parameter with an empty value. Default value is ``False``. If\n `style <https://spec.openapis.org/oas/v3.1.0#parameterStyle>`__ is used, and if behavior is ``n/a`` (cannot be\n serialized), the value of ``allowEmptyValue`` SHALL be ignored. Use of this property is NOT RECOMMENDED, as it is\n likely to be removed in a later revision.\n\n The rules for serialization of the parameter are specified in one of two ways.For simpler scenarios, a\n `schema <https://spec.openapis.org/oas/v3.1.0#parameterSchema>`_ and\n `style <https://spec.openapis.org/oas/v3.1.0#parameterStyle>`__ can describe the structure and syntax of the\n parameter.\n \"\"\"\n\n style: str | None = None\n \"\"\"Describes how the parameter value will be serialized depending on the\n type of the parameter value. Default values (based on value of ``in``):\n\n - for ``query`` - ``form``;\n - for ``path`` - ``simple``;\n - for ``header`` - ``simple``;\n - for ``cookie`` - ``form``.\n \"\"\"\n\n explode: bool | None = None\n \"\"\"When this is true, parameter values of type ``array`` or ``object`` generate separate parameters for each value\n of the array or key-value pair of the map.\n\n For other types of parameters this property has no effect.When\n `style <https://spec.openapis.org/oas/v3.1.0#parameterStyle>`__ is ``form``, the default value is ``True``. For all\n other styles, the default value is ``False``.\n \"\"\"\n\n allow_reserved: bool = False\n \"\"\"Determines whether the parameter value SHOULD allow reserved characters, as defined by. :rfc:`3986`\n (``:/?#[]@!$&'()*+,;=``) to be included without percent-encoding.\n\n This property only applies to parameters with an ``in`` value of ``query``. The default value is ``False``.\n \"\"\"\n\n example: Any | None = None\n \"\"\"Example of the parameter's potential value.\n\n The example SHOULD match the specified schema and encoding properties if present. The ``example`` field is mutually\n exclusive of the ``examples`` field. Furthermore, if referencing a ``schema`` that contains an example, the\n ``example`` value SHALL _override_ the example provided by the schema. To represent examples of media types that\n cannot naturally be represented in JSON or YAML, a string value can contain the example with escaping where\n necessary.\n \"\"\"\n\n examples: dict[str, Example | Reference] | None = None\n \"\"\"Examples of the parameter's potential value. Each example SHOULD contain a value in the correct format as\n specified in the parameter encoding. The ``examples`` field is mutually exclusive of the ``example`` field.\n Furthermore, if referencing a ``schema`` that contains an example, the ``examples`` value SHALL _override_ the\n example provided by the schema.\n\n For more complex scenarios, the `content <https://spec.openapis.org/oas/v3.1.0#parameterContent>`_ property can\n define the media type and schema of the parameter. A parameter MUST contain either a ``schema`` property, or a\n ``content`` property, but not both. When ``example`` or ``examples`` are provided in conjunction with the ``schema``\n object, the example MUST follow the prescribed serialization strategy for the parameter.\n \"\"\"\n\n content: dict[str, OpenAPIMediaType] | None = None\n \"\"\"A map containing the representations for the parameter.\n\n The key is the media type and the value describes it. The map MUST only contain one entry.\n \"\"\"\n", "path": "litestar/openapi/spec/header.py"}, {"content": "from __future__ import annotations\n\nfrom dataclasses import asdict, dataclass, fields, is_dataclass\nfrom enum import Enum\nfrom typing import Any\n\n__all__ = (\"BaseSchemaObject\",)\n\n\ndef _normalize_key(key: str) -> str:\n if key.endswith(\"_in\"):\n return \"in\"\n if key.startswith(\"schema_\"):\n return key.split(\"_\")[1]\n if \"_\" in key:\n components = key.split(\"_\")\n return components[0] + \"\".join(component.title() for component in components[1:])\n return \"$ref\" if key == \"ref\" else key\n\n\ndef _normalize_value(value: Any) -> Any:\n if isinstance(value, BaseSchemaObject):\n return value.to_schema()\n if is_dataclass(value):\n return {_normalize_value(k): _normalize_value(v) for k, v in asdict(value).items() if v is not None}\n if isinstance(value, dict):\n return {_normalize_value(k): _normalize_value(v) for k, v in value.items() if v is not None}\n if isinstance(value, list):\n return [_normalize_value(v) for v in value]\n return value.value if isinstance(value, Enum) else value\n\n\n@dataclass\nclass BaseSchemaObject:\n \"\"\"Base class for schema spec objects\"\"\"\n\n def to_schema(self) -> dict[str, Any]:\n \"\"\"Transform the spec dataclass object into a string keyed dictionary. This method traverses all nested values\n recursively.\n \"\"\"\n result: dict[str, Any] = {}\n\n for field in fields(self):\n value = _normalize_value(getattr(self, field.name, None))\n\n if value is not None:\n if \"alias\" in field.metadata:\n if not isinstance(field.metadata[\"alias\"], str):\n raise TypeError('metadata[\"alias\"] must be a str')\n key = field.metadata[\"alias\"]\n else:\n key = _normalize_key(field.name)\n\n result[key] = value\n\n return result\n", "path": "litestar/openapi/spec/base.py"}]}
| 3,742 | 475 |
gh_patches_debug_38641
|
rasdani/github-patches
|
git_diff
|
abey79__vpype-507
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Remove deprecated APIs
</issue>
<code>
[start of vpype/_deprecated.py]
1 from __future__ import annotations
2
3 import logging
4
5 from .config import config_manager
6
7 # deprecated
8 CONFIG_MANAGER = config_manager
9
10
11 def block_processor(*args, **kwargs): # pragma: no cover
12 import vpype_cli
13
14 logging.warning(
15 "!!! `@vpype.block_processor` is deprecated, "
16 "use `@vpype_cli.block_processor` instead."
17 )
18 return vpype_cli.block_processor(*args, **kwargs)
19
20
21 def generator(*args, **kwargs): # pragma: no cover
22 import vpype_cli
23
24 logging.warning(
25 "!!! `@vpype.generator` is deprecated, use `@vpype_cli.generator` instead."
26 )
27 return vpype_cli.generator(*args, **kwargs)
28
29
30 def global_processor(*args, **kwargs): # pragma: no cover
31 import vpype_cli
32
33 logging.warning(
34 "!!! `@vpype.global_processor` is deprecated, "
35 "use `@vpype_cli.global_processor` instead."
36 )
37 return vpype_cli.global_processor(*args, **kwargs)
38
39
40 def layer_processor(*args, **kwargs): # pragma: no cover
41 import vpype_cli
42
43 logging.warning(
44 "!!! `@vpype.layer_processor` is deprecated, use `@vpype_cli.layer_processor` instead."
45 )
46 return vpype_cli.layer_processor(*args, **kwargs)
47
48
49 def pass_state(*args, **kwargs): # pragma: no cover
50 import vpype_cli
51
52 logging.warning(
53 "!!! `@vpype.pass_state` is deprecated, use `@vpype_cli.pass_state` instead."
54 )
55 return vpype_cli.pass_state(*args, **kwargs)
56
57
58 class AngleType: # pragma: no cover
59 def __new__(cls):
60 import vpype_cli
61
62 logging.warning(
63 "!!! `vpype.AngleType` is deprecated, use `vpype_cli.AngleType` instead."
64 )
65 return vpype_cli.AngleType()
66
67
68 class LayerType: # pragma: no cover
69 def __new__(cls, *args, **kwargs):
70 import vpype_cli
71
72 logging.warning(
73 "!!! `vpype.LayerType` is deprecated, use `vpype_cli.LayerType` instead."
74 )
75 return vpype_cli.LayerType(*args, **kwargs)
76
77
78 class LengthType: # pragma: no cover
79 def __new__(cls):
80 import vpype_cli
81
82 logging.warning(
83 "!!! `vpype.LengthType` is deprecated, use `vpype_cli.LengthType` instead."
84 )
85 return vpype_cli.LengthType()
86
87
88 class PageSizeType: # pragma: no cover
89 def __new__(cls):
90 import vpype_cli
91
92 logging.warning(
93 "!!! `vpype.PageSizeType` is deprecated, use `vpype_cli.PageSizeType` instead."
94 )
95 return vpype_cli.PageSizeType()
96
97
98 def multiple_to_layer_ids(*args, **kwargs): # pragma: no cover
99 import vpype_cli
100
101 logging.warning(
102 "!!! `vpype.multiple_to_layer_ids` is deprecated, "
103 "use `vpype_cli.multiple_to_layer_ids` instead."
104 )
105 return vpype_cli.multiple_to_layer_ids(*args, **kwargs)
106
107
108 def single_to_layer_id(*args, **kwargs): # pragma: no cover
109 import vpype_cli
110
111 logging.warning(
112 "!!! `vpype.single_to_layer_id` is deprecated, "
113 "use `vpype_cli.single_to_layer_id` instead."
114 )
115 return vpype_cli.single_to_layer_id(*args, **kwargs)
116
[end of vpype/_deprecated.py]
[start of vpype/__init__.py]
1 """This module contains vpype core and its API."""
2
3 from ._deprecated import *
4 from .config import *
5 from .filters import *
6 from .geometry import *
7 from .io import *
8 from .line_index import *
9 from .metadata import *
10 from .model import *
11 from .primitives import *
12 from .text import *
13 from .utils import *
14
15
16 def _get_version() -> str:
17 from importlib.metadata import version
18
19 return version(__name__)
20
21
22 __version__ = _get_version()
23
[end of vpype/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/vpype/__init__.py b/vpype/__init__.py
--- a/vpype/__init__.py
+++ b/vpype/__init__.py
@@ -1,6 +1,5 @@
"""This module contains vpype core and its API."""
-from ._deprecated import *
from .config import *
from .filters import *
from .geometry import *
diff --git a/vpype/_deprecated.py b/vpype/_deprecated.py
deleted file mode 100644
--- a/vpype/_deprecated.py
+++ /dev/null
@@ -1,115 +0,0 @@
-from __future__ import annotations
-
-import logging
-
-from .config import config_manager
-
-# deprecated
-CONFIG_MANAGER = config_manager
-
-
-def block_processor(*args, **kwargs): # pragma: no cover
- import vpype_cli
-
- logging.warning(
- "!!! `@vpype.block_processor` is deprecated, "
- "use `@vpype_cli.block_processor` instead."
- )
- return vpype_cli.block_processor(*args, **kwargs)
-
-
-def generator(*args, **kwargs): # pragma: no cover
- import vpype_cli
-
- logging.warning(
- "!!! `@vpype.generator` is deprecated, use `@vpype_cli.generator` instead."
- )
- return vpype_cli.generator(*args, **kwargs)
-
-
-def global_processor(*args, **kwargs): # pragma: no cover
- import vpype_cli
-
- logging.warning(
- "!!! `@vpype.global_processor` is deprecated, "
- "use `@vpype_cli.global_processor` instead."
- )
- return vpype_cli.global_processor(*args, **kwargs)
-
-
-def layer_processor(*args, **kwargs): # pragma: no cover
- import vpype_cli
-
- logging.warning(
- "!!! `@vpype.layer_processor` is deprecated, use `@vpype_cli.layer_processor` instead."
- )
- return vpype_cli.layer_processor(*args, **kwargs)
-
-
-def pass_state(*args, **kwargs): # pragma: no cover
- import vpype_cli
-
- logging.warning(
- "!!! `@vpype.pass_state` is deprecated, use `@vpype_cli.pass_state` instead."
- )
- return vpype_cli.pass_state(*args, **kwargs)
-
-
-class AngleType: # pragma: no cover
- def __new__(cls):
- import vpype_cli
-
- logging.warning(
- "!!! `vpype.AngleType` is deprecated, use `vpype_cli.AngleType` instead."
- )
- return vpype_cli.AngleType()
-
-
-class LayerType: # pragma: no cover
- def __new__(cls, *args, **kwargs):
- import vpype_cli
-
- logging.warning(
- "!!! `vpype.LayerType` is deprecated, use `vpype_cli.LayerType` instead."
- )
- return vpype_cli.LayerType(*args, **kwargs)
-
-
-class LengthType: # pragma: no cover
- def __new__(cls):
- import vpype_cli
-
- logging.warning(
- "!!! `vpype.LengthType` is deprecated, use `vpype_cli.LengthType` instead."
- )
- return vpype_cli.LengthType()
-
-
-class PageSizeType: # pragma: no cover
- def __new__(cls):
- import vpype_cli
-
- logging.warning(
- "!!! `vpype.PageSizeType` is deprecated, use `vpype_cli.PageSizeType` instead."
- )
- return vpype_cli.PageSizeType()
-
-
-def multiple_to_layer_ids(*args, **kwargs): # pragma: no cover
- import vpype_cli
-
- logging.warning(
- "!!! `vpype.multiple_to_layer_ids` is deprecated, "
- "use `vpype_cli.multiple_to_layer_ids` instead."
- )
- return vpype_cli.multiple_to_layer_ids(*args, **kwargs)
-
-
-def single_to_layer_id(*args, **kwargs): # pragma: no cover
- import vpype_cli
-
- logging.warning(
- "!!! `vpype.single_to_layer_id` is deprecated, "
- "use `vpype_cli.single_to_layer_id` instead."
- )
- return vpype_cli.single_to_layer_id(*args, **kwargs)
|
{"golden_diff": "diff --git a/vpype/__init__.py b/vpype/__init__.py\n--- a/vpype/__init__.py\n+++ b/vpype/__init__.py\n@@ -1,6 +1,5 @@\n \"\"\"This module contains vpype core and its API.\"\"\"\n \n-from ._deprecated import *\n from .config import *\n from .filters import *\n from .geometry import *\ndiff --git a/vpype/_deprecated.py b/vpype/_deprecated.py\ndeleted file mode 100644\n--- a/vpype/_deprecated.py\n+++ /dev/null\n@@ -1,115 +0,0 @@\n-from __future__ import annotations\n-\n-import logging\n-\n-from .config import config_manager\n-\n-# deprecated\n-CONFIG_MANAGER = config_manager\n-\n-\n-def block_processor(*args, **kwargs): # pragma: no cover\n- import vpype_cli\n-\n- logging.warning(\n- \"!!! `@vpype.block_processor` is deprecated, \"\n- \"use `@vpype_cli.block_processor` instead.\"\n- )\n- return vpype_cli.block_processor(*args, **kwargs)\n-\n-\n-def generator(*args, **kwargs): # pragma: no cover\n- import vpype_cli\n-\n- logging.warning(\n- \"!!! `@vpype.generator` is deprecated, use `@vpype_cli.generator` instead.\"\n- )\n- return vpype_cli.generator(*args, **kwargs)\n-\n-\n-def global_processor(*args, **kwargs): # pragma: no cover\n- import vpype_cli\n-\n- logging.warning(\n- \"!!! `@vpype.global_processor` is deprecated, \"\n- \"use `@vpype_cli.global_processor` instead.\"\n- )\n- return vpype_cli.global_processor(*args, **kwargs)\n-\n-\n-def layer_processor(*args, **kwargs): # pragma: no cover\n- import vpype_cli\n-\n- logging.warning(\n- \"!!! `@vpype.layer_processor` is deprecated, use `@vpype_cli.layer_processor` instead.\"\n- )\n- return vpype_cli.layer_processor(*args, **kwargs)\n-\n-\n-def pass_state(*args, **kwargs): # pragma: no cover\n- import vpype_cli\n-\n- logging.warning(\n- \"!!! `@vpype.pass_state` is deprecated, use `@vpype_cli.pass_state` instead.\"\n- )\n- return vpype_cli.pass_state(*args, **kwargs)\n-\n-\n-class AngleType: # pragma: no cover\n- def __new__(cls):\n- import vpype_cli\n-\n- logging.warning(\n- \"!!! `vpype.AngleType` is deprecated, use `vpype_cli.AngleType` instead.\"\n- )\n- return vpype_cli.AngleType()\n-\n-\n-class LayerType: # pragma: no cover\n- def __new__(cls, *args, **kwargs):\n- import vpype_cli\n-\n- logging.warning(\n- \"!!! `vpype.LayerType` is deprecated, use `vpype_cli.LayerType` instead.\"\n- )\n- return vpype_cli.LayerType(*args, **kwargs)\n-\n-\n-class LengthType: # pragma: no cover\n- def __new__(cls):\n- import vpype_cli\n-\n- logging.warning(\n- \"!!! `vpype.LengthType` is deprecated, use `vpype_cli.LengthType` instead.\"\n- )\n- return vpype_cli.LengthType()\n-\n-\n-class PageSizeType: # pragma: no cover\n- def __new__(cls):\n- import vpype_cli\n-\n- logging.warning(\n- \"!!! `vpype.PageSizeType` is deprecated, use `vpype_cli.PageSizeType` instead.\"\n- )\n- return vpype_cli.PageSizeType()\n-\n-\n-def multiple_to_layer_ids(*args, **kwargs): # pragma: no cover\n- import vpype_cli\n-\n- logging.warning(\n- \"!!! `vpype.multiple_to_layer_ids` is deprecated, \"\n- \"use `vpype_cli.multiple_to_layer_ids` instead.\"\n- )\n- return vpype_cli.multiple_to_layer_ids(*args, **kwargs)\n-\n-\n-def single_to_layer_id(*args, **kwargs): # pragma: no cover\n- import vpype_cli\n-\n- logging.warning(\n- \"!!! `vpype.single_to_layer_id` is deprecated, \"\n- \"use `vpype_cli.single_to_layer_id` instead.\"\n- )\n- return vpype_cli.single_to_layer_id(*args, **kwargs)\n", "issue": "Remove deprecated APIs\n\n", "before_files": [{"content": "from __future__ import annotations\n\nimport logging\n\nfrom .config import config_manager\n\n# deprecated\nCONFIG_MANAGER = config_manager\n\n\ndef block_processor(*args, **kwargs): # pragma: no cover\n import vpype_cli\n\n logging.warning(\n \"!!! `@vpype.block_processor` is deprecated, \"\n \"use `@vpype_cli.block_processor` instead.\"\n )\n return vpype_cli.block_processor(*args, **kwargs)\n\n\ndef generator(*args, **kwargs): # pragma: no cover\n import vpype_cli\n\n logging.warning(\n \"!!! `@vpype.generator` is deprecated, use `@vpype_cli.generator` instead.\"\n )\n return vpype_cli.generator(*args, **kwargs)\n\n\ndef global_processor(*args, **kwargs): # pragma: no cover\n import vpype_cli\n\n logging.warning(\n \"!!! `@vpype.global_processor` is deprecated, \"\n \"use `@vpype_cli.global_processor` instead.\"\n )\n return vpype_cli.global_processor(*args, **kwargs)\n\n\ndef layer_processor(*args, **kwargs): # pragma: no cover\n import vpype_cli\n\n logging.warning(\n \"!!! `@vpype.layer_processor` is deprecated, use `@vpype_cli.layer_processor` instead.\"\n )\n return vpype_cli.layer_processor(*args, **kwargs)\n\n\ndef pass_state(*args, **kwargs): # pragma: no cover\n import vpype_cli\n\n logging.warning(\n \"!!! `@vpype.pass_state` is deprecated, use `@vpype_cli.pass_state` instead.\"\n )\n return vpype_cli.pass_state(*args, **kwargs)\n\n\nclass AngleType: # pragma: no cover\n def __new__(cls):\n import vpype_cli\n\n logging.warning(\n \"!!! `vpype.AngleType` is deprecated, use `vpype_cli.AngleType` instead.\"\n )\n return vpype_cli.AngleType()\n\n\nclass LayerType: # pragma: no cover\n def __new__(cls, *args, **kwargs):\n import vpype_cli\n\n logging.warning(\n \"!!! `vpype.LayerType` is deprecated, use `vpype_cli.LayerType` instead.\"\n )\n return vpype_cli.LayerType(*args, **kwargs)\n\n\nclass LengthType: # pragma: no cover\n def __new__(cls):\n import vpype_cli\n\n logging.warning(\n \"!!! `vpype.LengthType` is deprecated, use `vpype_cli.LengthType` instead.\"\n )\n return vpype_cli.LengthType()\n\n\nclass PageSizeType: # pragma: no cover\n def __new__(cls):\n import vpype_cli\n\n logging.warning(\n \"!!! `vpype.PageSizeType` is deprecated, use `vpype_cli.PageSizeType` instead.\"\n )\n return vpype_cli.PageSizeType()\n\n\ndef multiple_to_layer_ids(*args, **kwargs): # pragma: no cover\n import vpype_cli\n\n logging.warning(\n \"!!! `vpype.multiple_to_layer_ids` is deprecated, \"\n \"use `vpype_cli.multiple_to_layer_ids` instead.\"\n )\n return vpype_cli.multiple_to_layer_ids(*args, **kwargs)\n\n\ndef single_to_layer_id(*args, **kwargs): # pragma: no cover\n import vpype_cli\n\n logging.warning(\n \"!!! `vpype.single_to_layer_id` is deprecated, \"\n \"use `vpype_cli.single_to_layer_id` instead.\"\n )\n return vpype_cli.single_to_layer_id(*args, **kwargs)\n", "path": "vpype/_deprecated.py"}, {"content": "\"\"\"This module contains vpype core and its API.\"\"\"\n\nfrom ._deprecated import *\nfrom .config import *\nfrom .filters import *\nfrom .geometry import *\nfrom .io import *\nfrom .line_index import *\nfrom .metadata import *\nfrom .model import *\nfrom .primitives import *\nfrom .text import *\nfrom .utils import *\n\n\ndef _get_version() -> str:\n from importlib.metadata import version\n\n return version(__name__)\n\n\n__version__ = _get_version()\n", "path": "vpype/__init__.py"}]}
| 1,730 | 993 |
gh_patches_debug_16084
|
rasdani/github-patches
|
git_diff
|
interactions-py__interactions.py-440
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[BUG] Development dependencies are included in install_requires
**Describe the bug**
Installing this library also installs all libraries used for local development (list below). This makes it impossible to use different versions of these tools in development. It also requires installing all of these tools in production for the bot to function, which unnecessarily bloats the installation size by over 80MB (on windows)
**Reproducing steps**
Install the library as directed in the documentation, `pip install discord-py-interactions`
**What's normally expected**
The library itself and only code necessary for running the bot is downloaded and installed.
**What actually happened**
Development tools for this project are also installed.
If pip is used, other local tools are overwritten with the specific versions used in this project. If poetry is used, the tools are either downgraded to the version pinned in this library, or an error is generated when there is a version conflict. Either way devs using this library cannot use their own tooling.
Output from pip:
```
Successfully installed Jinja2-3.0.3 MarkupSafe-2.0.1 Pygments-2.10.0 Sphinx-4.1.2 alabaster-0.7.12 babel-2.9.1 backports.entry-points-selectable-1.1.1 black-21.11b1 certifi-2021.10.8 cfgv-3.3.1 charset-normalizer-2.0.9 click-8.0.3 colorama-0.4.4 discord-py-interactions-4.0.1 distlib-0.3.4 docutils-0.17.1 filelock-3.4.0 identify-2.4.0 imagesize-1.3.0 isort-5.9.3 nodeenv-1.6.0 orjson-3.6.3 packaging-21.3 pathspec-0.9.0 platformdirs-2.4.0 pre-commit-2.16.0 pyparsing-3.0.6 regex-2021.11.10 requests-2.26.0 six-1.16.0 snowballstemmer-2.2.0 sphinx-hoverxref-1.0.0 sphinxcontrib-applehelp-1.0.2 sphinxcontrib-devhelp-1.0.2 sphinxcontrib-htmlhelp-2.0.0 sphinxcontrib-jsmath-1.0.1 sphinxcontrib-qthelp-1.0.3 sphinxcontrib-serializinghtml-1.1.5 tomli-1.2.3 urllib3-1.26.7 virtualenv-20.10.0
```
pipdeptree shows that only `aiohttp`, and `orjson` are necessary for this package to function, the rest of them should be removed and instead placed in an extra dependency (e.g. `pip install discord-interactions[dev]`):
```
discord-py-interactions==4.0.1
- aiohttp [required: ==3.7.4.post0, installed: 3.7.4.post0]
- async-timeout [required: >=3.0,<4.0, installed: 3.0.1]
- attrs [required: >=17.3.0, installed: 21.2.0]
- chardet [required: >=2.0,<5.0, installed: 4.0.0]
- multidict [required: >=4.5,<7.0, installed: 5.2.0]
- typing-extensions [required: >=3.6.5, installed: 3.10.0.2]
- yarl [required: >=1.0,<2.0, installed: 1.6.3]
- idna [required: >=2.0, installed: 3.2]
- multidict [required: >=4.0, installed: 5.2.0]
- black [required: ==21.11b1, installed: 21.11b1]
- click [required: >=7.1.2, installed: 8.0.3]
- colorama [required: Any, installed: 0.4.4]
- mypy-extensions [required: >=0.4.3, installed: 0.4.3]
- pathspec [required: >=0.9.0,<1, installed: 0.9.0]
- platformdirs [required: >=2, installed: 2.4.0]
- regex [required: >=2021.4.4, installed: 2021.11.10]
- tomli [required: >=0.2.6,<2.0.0, installed: 1.2.3]
- typing-extensions [required: >=3.10.0.0, installed: 3.10.0.2]
- typing-extensions [required: !=3.10.0.1, installed: 3.10.0.2]
- colorama [required: ==0.4.4, installed: 0.4.4]
- flake8 [required: ==3.9.2, installed: 3.9.2]
- mccabe [required: >=0.6.0,<0.7.0, installed: 0.6.1]
- pycodestyle [required: >=2.7.0,<2.8.0, installed: 2.7.0]
- pyflakes [required: >=2.3.0,<2.4.0, installed: 2.3.1]
- isort [required: ==5.9.3, installed: 5.9.3]
- orjson [required: ==3.6.3, installed: 3.6.3]
- pre-commit [required: ==2.16.0, installed: 2.16.0]
- cfgv [required: >=2.0.0, installed: 3.3.1]
- identify [required: >=1.0.0, installed: 2.4.0]
- nodeenv [required: >=0.11.1, installed: 1.6.0]
- pyyaml [required: >=5.1, installed: 5.4.1]
- toml [required: Any, installed: 0.10.2]
- virtualenv [required: >=20.0.8, installed: 20.10.0]
- backports.entry-points-selectable [required: >=1.0.4, installed: 1.1.1]
- distlib [required: >=0.3.1,<1, installed: 0.3.4]
- filelock [required: >=3.2,<4, installed: 3.4.0]
- platformdirs [required: >=2,<3, installed: 2.4.0]
- six [required: >=1.9.0,<2, installed: 1.16.0]
- Sphinx [required: ==4.1.2, installed: 4.1.2]
- alabaster [required: >=0.7,<0.8, installed: 0.7.12]
- babel [required: >=1.3, installed: 2.9.1]
- pytz [required: >=2015.7, installed: 2021.3]
- colorama [required: >=0.3.5, installed: 0.4.4]
- docutils [required: >=0.14,<0.18, installed: 0.17.1]
- imagesize [required: Any, installed: 1.3.0]
- Jinja2 [required: >=2.3, installed: 3.0.3]
- MarkupSafe [required: >=2.0, installed: 2.0.1]
- packaging [required: Any, installed: 21.3]
- pyparsing [required: >=2.0.2,!=3.0.5, installed: 3.0.6]
- Pygments [required: >=2.0, installed: 2.10.0]
- requests [required: >=2.5.0, installed: 2.26.0]
- certifi [required: >=2017.4.17, installed: 2021.10.8]
- charset-normalizer [required: ~=2.0.0, installed: 2.0.9]
- idna [required: >=2.5,<4, installed: 3.2]
- urllib3 [required: >=1.21.1,<1.27, installed: 1.26.7]
- setuptools [required: Any, installed: 58.3.0]
- snowballstemmer [required: >=1.1, installed: 2.2.0]
- sphinxcontrib-applehelp [required: Any, installed: 1.0.2]
- sphinxcontrib-devhelp [required: Any, installed: 1.0.2]
- sphinxcontrib-htmlhelp [required: >=2.0.0, installed: 2.0.0]
- sphinxcontrib-jsmath [required: Any, installed: 1.0.1]
- sphinxcontrib-qthelp [required: Any, installed: 1.0.3]
- sphinxcontrib-serializinghtml [required: >=1.1.5, installed: 1.1.5]
- sphinx-hoverxref [required: ==1.0.0, installed: 1.0.0]
```
**Versions**
- [ ] I am using discord.py versions 1.7 and below with my code.
- [ ] I am using 2.0 or higher, or a modified fork.
- [ ] I am using dis-snek with my code.
- [x] I am not using any of the listed above and am using the library code alone.
</issue>
<code>
[start of setup.py]
1 import re
2 from codecs import open
3 from os import path
4
5 from setuptools import find_packages, setup
6
7 PACKAGE_NAME = "interactions"
8 HERE = path.abspath(path.dirname(__file__))
9
10 with open("README.rst", "r", encoding="UTF-8") as f:
11 README = f.read()
12 with open(path.join(HERE, PACKAGE_NAME, "base.py"), encoding="utf-8") as fp:
13 VERSION = re.search('__version__ = "([^"]+)"', fp.read()).group(1)
14
15 extras = {
16 "lint": ["black", "flake8", "isort"],
17 "readthedocs": ["sphinx", "karma-sphinx-theme"],
18 }
19 extras["lint"] += extras["readthedocs"]
20 extras["dev"] = extras["lint"] + extras["readthedocs"]
21
22 requirements = open("requirements.txt").read().split("\n")[:-1]
23
24 setup(
25 name="discord-py-interactions",
26 version=VERSION,
27 author="goverfl0w",
28 author_email="[email protected]",
29 description="Easy, simple, scalable and modular: a Python API wrapper for interactions.",
30 extras_require=extras,
31 install_requires=requirements,
32 license="MIT License",
33 long_description=README,
34 long_description_content_type="text/x-rst",
35 url="https://github.com/goverfl0w/discord-interactions",
36 packages=find_packages(),
37 python_requires=">=3.8.6",
38 classifiers=[
39 "Development Status :: 4 - Beta",
40 "Intended Audience :: Developers",
41 "License :: OSI Approved :: MIT License",
42 "Natural Language :: English",
43 "Operating System :: OS Independent",
44 "Programming Language :: Python :: 3",
45 "Programming Language :: Python :: 3.9",
46 "Topic :: Internet",
47 "Topic :: Software Development :: Libraries :: Python Modules",
48 "Topic :: Software Development :: Libraries",
49 "Topic :: Utilities",
50 ],
51 )
52
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -12,14 +12,18 @@
with open(path.join(HERE, PACKAGE_NAME, "base.py"), encoding="utf-8") as fp:
VERSION = re.search('__version__ = "([^"]+)"', fp.read()).group(1)
+
+def read_requirements(filename):
+ with open(filename, "r", encoding="utf-8") as fp:
+ return fp.read().strip().splitlines()
+
+
extras = {
- "lint": ["black", "flake8", "isort"],
- "readthedocs": ["sphinx", "karma-sphinx-theme"],
+ "lint": read_requirements("requirements-lint.txt"),
+ "readthedocs": read_requirements("requirements-docs.txt"),
}
-extras["lint"] += extras["readthedocs"]
extras["dev"] = extras["lint"] + extras["readthedocs"]
-
-requirements = open("requirements.txt").read().split("\n")[:-1]
+requirements = read_requirements("requirements.txt")
setup(
name="discord-py-interactions",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -12,14 +12,18 @@\n with open(path.join(HERE, PACKAGE_NAME, \"base.py\"), encoding=\"utf-8\") as fp:\n VERSION = re.search('__version__ = \"([^\"]+)\"', fp.read()).group(1)\n \n+\n+def read_requirements(filename):\n+ with open(filename, \"r\", encoding=\"utf-8\") as fp:\n+ return fp.read().strip().splitlines()\n+\n+\n extras = {\n- \"lint\": [\"black\", \"flake8\", \"isort\"],\n- \"readthedocs\": [\"sphinx\", \"karma-sphinx-theme\"],\n+ \"lint\": read_requirements(\"requirements-lint.txt\"),\n+ \"readthedocs\": read_requirements(\"requirements-docs.txt\"),\n }\n-extras[\"lint\"] += extras[\"readthedocs\"]\n extras[\"dev\"] = extras[\"lint\"] + extras[\"readthedocs\"]\n-\n-requirements = open(\"requirements.txt\").read().split(\"\\n\")[:-1]\n+requirements = read_requirements(\"requirements.txt\")\n \n setup(\n name=\"discord-py-interactions\",\n", "issue": "[BUG] Development dependencies are included in install_requires\n**Describe the bug**\r\nInstalling this library also installs all libraries used for local development (list below). This makes it impossible to use different versions of these tools in development. It also requires installing all of these tools in production for the bot to function, which unnecessarily bloats the installation size by over 80MB (on windows)\r\n\r\n**Reproducing steps**\r\nInstall the library as directed in the documentation, `pip install discord-py-interactions`\r\n\r\n**What's normally expected**\r\nThe library itself and only code necessary for running the bot is downloaded and installed.\r\n\r\n**What actually happened**\r\nDevelopment tools for this project are also installed. \r\n\r\nIf pip is used, other local tools are overwritten with the specific versions used in this project. If poetry is used, the tools are either downgraded to the version pinned in this library, or an error is generated when there is a version conflict. Either way devs using this library cannot use their own tooling. \r\n\r\nOutput from pip:\r\n```\r\nSuccessfully installed Jinja2-3.0.3 MarkupSafe-2.0.1 Pygments-2.10.0 Sphinx-4.1.2 alabaster-0.7.12 babel-2.9.1 backports.entry-points-selectable-1.1.1 black-21.11b1 certifi-2021.10.8 cfgv-3.3.1 charset-normalizer-2.0.9 click-8.0.3 colorama-0.4.4 discord-py-interactions-4.0.1 distlib-0.3.4 docutils-0.17.1 filelock-3.4.0 identify-2.4.0 imagesize-1.3.0 isort-5.9.3 nodeenv-1.6.0 orjson-3.6.3 packaging-21.3 pathspec-0.9.0 platformdirs-2.4.0 pre-commit-2.16.0 pyparsing-3.0.6 regex-2021.11.10 requests-2.26.0 six-1.16.0 snowballstemmer-2.2.0 sphinx-hoverxref-1.0.0 sphinxcontrib-applehelp-1.0.2 sphinxcontrib-devhelp-1.0.2 sphinxcontrib-htmlhelp-2.0.0 sphinxcontrib-jsmath-1.0.1 sphinxcontrib-qthelp-1.0.3 sphinxcontrib-serializinghtml-1.1.5 tomli-1.2.3 urllib3-1.26.7 virtualenv-20.10.0\r\n```\r\n\r\npipdeptree shows that only `aiohttp`, and `orjson` are necessary for this package to function, the rest of them should be removed and instead placed in an extra dependency (e.g. `pip install discord-interactions[dev]`):\r\n```\r\ndiscord-py-interactions==4.0.1\r\n - aiohttp [required: ==3.7.4.post0, installed: 3.7.4.post0]\r\n - async-timeout [required: >=3.0,<4.0, installed: 3.0.1]\r\n - attrs [required: >=17.3.0, installed: 21.2.0]\r\n - chardet [required: >=2.0,<5.0, installed: 4.0.0]\r\n - multidict [required: >=4.5,<7.0, installed: 5.2.0]\r\n - typing-extensions [required: >=3.6.5, installed: 3.10.0.2]\r\n - yarl [required: >=1.0,<2.0, installed: 1.6.3]\r\n - idna [required: >=2.0, installed: 3.2]\r\n - multidict [required: >=4.0, installed: 5.2.0]\r\n - black [required: ==21.11b1, installed: 21.11b1]\r\n - click [required: >=7.1.2, installed: 8.0.3]\r\n - colorama [required: Any, installed: 0.4.4]\r\n - mypy-extensions [required: >=0.4.3, installed: 0.4.3]\r\n - pathspec [required: >=0.9.0,<1, installed: 0.9.0]\r\n - platformdirs [required: >=2, installed: 2.4.0]\r\n - regex [required: >=2021.4.4, installed: 2021.11.10]\r\n - tomli [required: >=0.2.6,<2.0.0, installed: 1.2.3]\r\n - typing-extensions [required: >=3.10.0.0, installed: 3.10.0.2]\r\n - typing-extensions [required: !=3.10.0.1, installed: 3.10.0.2]\r\n - colorama [required: ==0.4.4, installed: 0.4.4]\r\n - flake8 [required: ==3.9.2, installed: 3.9.2]\r\n - mccabe [required: >=0.6.0,<0.7.0, installed: 0.6.1]\r\n - pycodestyle [required: >=2.7.0,<2.8.0, installed: 2.7.0]\r\n - pyflakes [required: >=2.3.0,<2.4.0, installed: 2.3.1]\r\n - isort [required: ==5.9.3, installed: 5.9.3]\r\n - orjson [required: ==3.6.3, installed: 3.6.3]\r\n - pre-commit [required: ==2.16.0, installed: 2.16.0]\r\n - cfgv [required: >=2.0.0, installed: 3.3.1]\r\n - identify [required: >=1.0.0, installed: 2.4.0]\r\n - nodeenv [required: >=0.11.1, installed: 1.6.0]\r\n - pyyaml [required: >=5.1, installed: 5.4.1]\r\n - toml [required: Any, installed: 0.10.2]\r\n - virtualenv [required: >=20.0.8, installed: 20.10.0]\r\n - backports.entry-points-selectable [required: >=1.0.4, installed: 1.1.1]\r\n - distlib [required: >=0.3.1,<1, installed: 0.3.4]\r\n - filelock [required: >=3.2,<4, installed: 3.4.0]\r\n - platformdirs [required: >=2,<3, installed: 2.4.0]\r\n - six [required: >=1.9.0,<2, installed: 1.16.0]\r\n - Sphinx [required: ==4.1.2, installed: 4.1.2]\r\n - alabaster [required: >=0.7,<0.8, installed: 0.7.12]\r\n - babel [required: >=1.3, installed: 2.9.1]\r\n - pytz [required: >=2015.7, installed: 2021.3]\r\n - colorama [required: >=0.3.5, installed: 0.4.4]\r\n - docutils [required: >=0.14,<0.18, installed: 0.17.1]\r\n - imagesize [required: Any, installed: 1.3.0]\r\n - Jinja2 [required: >=2.3, installed: 3.0.3]\r\n - MarkupSafe [required: >=2.0, installed: 2.0.1]\r\n - packaging [required: Any, installed: 21.3]\r\n - pyparsing [required: >=2.0.2,!=3.0.5, installed: 3.0.6]\r\n - Pygments [required: >=2.0, installed: 2.10.0]\r\n - requests [required: >=2.5.0, installed: 2.26.0]\r\n - certifi [required: >=2017.4.17, installed: 2021.10.8]\r\n - charset-normalizer [required: ~=2.0.0, installed: 2.0.9]\r\n - idna [required: >=2.5,<4, installed: 3.2]\r\n - urllib3 [required: >=1.21.1,<1.27, installed: 1.26.7]\r\n - setuptools [required: Any, installed: 58.3.0]\r\n - snowballstemmer [required: >=1.1, installed: 2.2.0]\r\n - sphinxcontrib-applehelp [required: Any, installed: 1.0.2]\r\n - sphinxcontrib-devhelp [required: Any, installed: 1.0.2]\r\n - sphinxcontrib-htmlhelp [required: >=2.0.0, installed: 2.0.0]\r\n - sphinxcontrib-jsmath [required: Any, installed: 1.0.1]\r\n - sphinxcontrib-qthelp [required: Any, installed: 1.0.3]\r\n - sphinxcontrib-serializinghtml [required: >=1.1.5, installed: 1.1.5]\r\n - sphinx-hoverxref [required: ==1.0.0, installed: 1.0.0]\r\n```\r\n\r\n**Versions**\r\n- [ ] I am using discord.py versions 1.7 and below with my code.\r\n - [ ] I am using 2.0 or higher, or a modified fork.\r\n- [ ] I am using dis-snek with my code.\r\n- [x] I am not using any of the listed above and am using the library code alone.\r\n\n", "before_files": [{"content": "import re\nfrom codecs import open\nfrom os import path\n\nfrom setuptools import find_packages, setup\n\nPACKAGE_NAME = \"interactions\"\nHERE = path.abspath(path.dirname(__file__))\n\nwith open(\"README.rst\", \"r\", encoding=\"UTF-8\") as f:\n README = f.read()\nwith open(path.join(HERE, PACKAGE_NAME, \"base.py\"), encoding=\"utf-8\") as fp:\n VERSION = re.search('__version__ = \"([^\"]+)\"', fp.read()).group(1)\n\nextras = {\n \"lint\": [\"black\", \"flake8\", \"isort\"],\n \"readthedocs\": [\"sphinx\", \"karma-sphinx-theme\"],\n}\nextras[\"lint\"] += extras[\"readthedocs\"]\nextras[\"dev\"] = extras[\"lint\"] + extras[\"readthedocs\"]\n\nrequirements = open(\"requirements.txt\").read().split(\"\\n\")[:-1]\n\nsetup(\n name=\"discord-py-interactions\",\n version=VERSION,\n author=\"goverfl0w\",\n author_email=\"[email protected]\",\n description=\"Easy, simple, scalable and modular: a Python API wrapper for interactions.\",\n extras_require=extras,\n install_requires=requirements,\n license=\"MIT License\",\n long_description=README,\n long_description_content_type=\"text/x-rst\",\n url=\"https://github.com/goverfl0w/discord-interactions\",\n packages=find_packages(),\n python_requires=\">=3.8.6\",\n classifiers=[\n \"Development Status :: 4 - Beta\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: MIT License\",\n \"Natural Language :: English\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.9\",\n \"Topic :: Internet\",\n \"Topic :: Software Development :: Libraries :: Python Modules\",\n \"Topic :: Software Development :: Libraries\",\n \"Topic :: Utilities\",\n ],\n)\n", "path": "setup.py"}]}
| 3,331 | 251 |
gh_patches_debug_7388
|
rasdani/github-patches
|
git_diff
|
sunpy__sunpy-3194
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Using SunPy in two threads sometimes crashes when creating config
I test HelioPy on two threads at the same time, and when it comes to importing SunPy the following error happens sporadically:
```
heliopy\coordinates\test\test_transformations.py:1: in <module>
import heliopy.coordinates.frames as frames
heliopy\coordinates\frames.py:19: in <module>
import sunpy.coordinates.sun
c:\hostedtoolcache\windows\python\3.6.8\x64\lib\site-packages\sunpy\__init__.py:47: in <module>
config = load_config()
c:\hostedtoolcache\windows\python\3.6.8\x64\lib\site-packages\sunpy\util\config.py:30: in load_config
config_files = _find_config_files()
c:\hostedtoolcache\windows\python\3.6.8\x64\lib\site-packages\sunpy\util\config.py:69: in _find_config_files
config_path = Path(_get_user_configdir())
c:\hostedtoolcache\windows\python\3.6.8\x64\lib\site-packages\sunpy\util\config.py:137: in _get_user_configdir
if not _is_writable_dir(configdir):
c:\hostedtoolcache\windows\python\3.6.8\x64\lib\site-packages\sunpy\util\config.py:123: in _is_writable_dir
Path(p).mkdir(parents=True)
c:\hostedtoolcache\windows\python\3.6.8\x64\lib\pathlib.py:1253: in mkdir
self.mkdir(mode, parents=False, exist_ok=exist_ok)
c:\hostedtoolcache\windows\python\3.6.8\x64\lib\pathlib.py:1248: in mkdir
self._accessor.mkdir(self, mode)
c:\hostedtoolcache\windows\python\3.6.8\x64\lib\pathlib.py:387: in wrapped
return strfunc(str(pathobj), *args)
E FileExistsError: [WinError 183] Cannot create a file when that file already exists: 'C:\\Users\\VssAdministrator\\AppData\\Local\\sunpy\\sunpy'
```
I think the solution is to change `Path(p).mkdir(parents=True)` to `Path(p).mkdir(parents=True, exist_okay=True)`
</issue>
<code>
[start of sunpy/util/config.py]
1 """
2 This module provides SunPy's configuration file functionality.
3 """
4 import os
5 import configparser
6 from pathlib import Path
7
8 import sunpy
9 from sunpy.extern.appdirs import AppDirs
10
11 __all__ = ['load_config', 'print_config', 'CONFIG_DIR']
12
13 # This is to avoid creating a new config dir for each new dev version.
14 # We use AppDirs to locate and create the config directory.
15 dirs = AppDirs("sunpy", "sunpy")
16 # Default one set by AppDirs
17 CONFIG_DIR = dirs.user_config_dir
18
19
20 def load_config():
21 """
22 Read the "sunpyrc" configuration file.
23
24 If one does not exists in the user's home directory then read in the
25 defaults from "sunpy/data/sunpyrc".
26 """
27 config = configparser.RawConfigParser()
28
29 # Get locations of SunPy configuration files to be loaded
30 config_files = _find_config_files()
31
32 # Read in configuration files
33 config.read(config_files)
34
35 # Specify the working directory as a default so that the user's home
36 # directory can be located in an OS-independent manner
37 if not config.has_option('general', 'working_dir'):
38 config.set('general', 'working_dir', str(Path.home() / "sunpy"))
39
40 # Specify the database url as a default so that the user's home
41 # directory can be located in an OS-independent manner
42 if not config.has_option('database', 'url'):
43 config.set('database', 'url', "sqlite:///" + str(Path.home() / "sunpy" / "sunpydb.sqlite"))
44
45 # Set the download_dir to be relative to the working_dir
46 working_dir = Path(config.get('general', 'working_dir'))
47 download_dir = Path(config.get('downloads', 'download_dir'))
48 sample_dir = config.get('downloads', 'sample_dir', fallback=dirs.user_data_dir)
49 config.set('downloads', 'sample_dir', Path(sample_dir).expanduser().resolve().as_posix())
50 config.set('downloads', 'download_dir', (working_dir / download_dir).expanduser().resolve().as_posix())
51
52 return config
53
54
55 def _find_config_files():
56 """
57 Finds locations of SunPy configuration files.
58 """
59 config_files = []
60 config_filename = 'sunpyrc'
61
62 # find default configuration file
63 module_dir = Path(sunpy.__file__).parent
64 config_files.append(str(module_dir / 'data' / 'sunpyrc'))
65
66 # if a user configuration file exists, add that to list of files to read
67 # so that any values set there will override ones specified in the default
68 # config file
69 config_path = Path(_get_user_configdir())
70 if config_path.joinpath(config_filename).exists():
71 config_files.append(str(config_path.joinpath(config_filename)))
72
73 return config_files
74
75
76 def get_and_create_download_dir():
77 """
78 Get the config of download directory and create one if not present.
79 """
80 download_dir = os.environ.get('SUNPY_DOWNLOADDIR')
81 if download_dir:
82 return download_dir
83
84 download_dir = Path(sunpy.config.get('downloads', 'download_dir')).expanduser().resolve()
85 if not _is_writable_dir(download_dir):
86 raise RuntimeError(f'Could not write to SunPy downloads directory="{download_dir}"')
87
88 return sunpy.config.get('downloads', 'download_dir')
89
90
91 def get_and_create_sample_dir():
92 """
93 Get the config of download directory and create one if not present.
94 """
95 sample_dir = Path(sunpy.config.get('downloads', 'sample_dir')).expanduser().resolve()
96 if not _is_writable_dir(sample_dir):
97 raise RuntimeError(f'Could not write to SunPy sample data directory="{sample_dir}"')
98
99 return sunpy.config.get('downloads', 'sample_dir')
100
101
102 def print_config():
103 """
104 Print current configuration options.
105 """
106 print("FILES USED:")
107 for file_ in _find_config_files():
108 print(" " + file_)
109
110 print("\nCONFIGURATION:")
111 for section in sunpy.config.sections():
112 print(" [{0}]".format(section))
113 for option in sunpy.config.options(section):
114 print(" {} = {}".format(option, sunpy.config.get(section, option)))
115 print("")
116
117
118 def _is_writable_dir(p):
119 """
120 Checks to see if a directory is writable.
121 """
122 if not Path(p).exists():
123 Path(p).mkdir(parents=True)
124 return Path(p).is_dir() and os.access(p, os.W_OK)
125
126
127 def _get_user_configdir():
128 """
129 Return the string representing the configuration dir.
130
131 The default is set by "AppDirs" and can be accessed by importing
132 ``sunpy.util.config.CONFIG_DIR``. You can override this with the
133 "SUNPY_CONFIGDIR" environment variable.
134 """
135 configdir = os.environ.get('SUNPY_CONFIGDIR', CONFIG_DIR)
136
137 if not _is_writable_dir(configdir):
138 raise RuntimeError(f'Could not write to SUNPY_CONFIGDIR="{configdir}"')
139 return configdir
140
[end of sunpy/util/config.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sunpy/util/config.py b/sunpy/util/config.py
--- a/sunpy/util/config.py
+++ b/sunpy/util/config.py
@@ -119,9 +119,13 @@
"""
Checks to see if a directory is writable.
"""
- if not Path(p).exists():
- Path(p).mkdir(parents=True)
- return Path(p).is_dir() and os.access(p, os.W_OK)
+ # Worried about multiple threads creating the directory at the same time.
+ try:
+ Path(p).mkdir(parents=True, exist_ok=True)
+ except FileExistsError: # raised if there's an existing file instead of a directory
+ return False
+ else:
+ return Path(p).is_dir() and os.access(p, os.W_OK)
def _get_user_configdir():
|
{"golden_diff": "diff --git a/sunpy/util/config.py b/sunpy/util/config.py\n--- a/sunpy/util/config.py\n+++ b/sunpy/util/config.py\n@@ -119,9 +119,13 @@\n \"\"\"\n Checks to see if a directory is writable.\n \"\"\"\n- if not Path(p).exists():\n- Path(p).mkdir(parents=True)\n- return Path(p).is_dir() and os.access(p, os.W_OK)\n+ # Worried about multiple threads creating the directory at the same time.\n+ try:\n+ Path(p).mkdir(parents=True, exist_ok=True)\n+ except FileExistsError: # raised if there's an existing file instead of a directory\n+ return False\n+ else:\n+ return Path(p).is_dir() and os.access(p, os.W_OK)\n \n \n def _get_user_configdir():\n", "issue": "Using SunPy in two threads sometimes crashes when creating config\nI test HelioPy on two threads at the same time, and when it comes to importing SunPy the following error happens sporadically:\r\n\r\n```\r\nheliopy\\coordinates\\test\\test_transformations.py:1: in <module>\r\n import heliopy.coordinates.frames as frames\r\nheliopy\\coordinates\\frames.py:19: in <module>\r\n import sunpy.coordinates.sun\r\nc:\\hostedtoolcache\\windows\\python\\3.6.8\\x64\\lib\\site-packages\\sunpy\\__init__.py:47: in <module>\r\n config = load_config()\r\nc:\\hostedtoolcache\\windows\\python\\3.6.8\\x64\\lib\\site-packages\\sunpy\\util\\config.py:30: in load_config\r\n config_files = _find_config_files()\r\nc:\\hostedtoolcache\\windows\\python\\3.6.8\\x64\\lib\\site-packages\\sunpy\\util\\config.py:69: in _find_config_files\r\n config_path = Path(_get_user_configdir())\r\nc:\\hostedtoolcache\\windows\\python\\3.6.8\\x64\\lib\\site-packages\\sunpy\\util\\config.py:137: in _get_user_configdir\r\n if not _is_writable_dir(configdir):\r\nc:\\hostedtoolcache\\windows\\python\\3.6.8\\x64\\lib\\site-packages\\sunpy\\util\\config.py:123: in _is_writable_dir\r\n Path(p).mkdir(parents=True)\r\nc:\\hostedtoolcache\\windows\\python\\3.6.8\\x64\\lib\\pathlib.py:1253: in mkdir\r\n self.mkdir(mode, parents=False, exist_ok=exist_ok)\r\nc:\\hostedtoolcache\\windows\\python\\3.6.8\\x64\\lib\\pathlib.py:1248: in mkdir\r\n self._accessor.mkdir(self, mode)\r\nc:\\hostedtoolcache\\windows\\python\\3.6.8\\x64\\lib\\pathlib.py:387: in wrapped\r\n return strfunc(str(pathobj), *args)\r\nE FileExistsError: [WinError 183] Cannot create a file when that file already exists: 'C:\\\\Users\\\\VssAdministrator\\\\AppData\\\\Local\\\\sunpy\\\\sunpy'\r\n```\r\n\r\nI think the solution is to change `Path(p).mkdir(parents=True)` to `Path(p).mkdir(parents=True, exist_okay=True)`\n", "before_files": [{"content": "\"\"\"\nThis module provides SunPy's configuration file functionality.\n\"\"\"\nimport os\nimport configparser\nfrom pathlib import Path\n\nimport sunpy\nfrom sunpy.extern.appdirs import AppDirs\n\n__all__ = ['load_config', 'print_config', 'CONFIG_DIR']\n\n# This is to avoid creating a new config dir for each new dev version.\n# We use AppDirs to locate and create the config directory.\ndirs = AppDirs(\"sunpy\", \"sunpy\")\n# Default one set by AppDirs\nCONFIG_DIR = dirs.user_config_dir\n\n\ndef load_config():\n \"\"\"\n Read the \"sunpyrc\" configuration file.\n\n If one does not exists in the user's home directory then read in the\n defaults from \"sunpy/data/sunpyrc\".\n \"\"\"\n config = configparser.RawConfigParser()\n\n # Get locations of SunPy configuration files to be loaded\n config_files = _find_config_files()\n\n # Read in configuration files\n config.read(config_files)\n\n # Specify the working directory as a default so that the user's home\n # directory can be located in an OS-independent manner\n if not config.has_option('general', 'working_dir'):\n config.set('general', 'working_dir', str(Path.home() / \"sunpy\"))\n\n # Specify the database url as a default so that the user's home\n # directory can be located in an OS-independent manner\n if not config.has_option('database', 'url'):\n config.set('database', 'url', \"sqlite:///\" + str(Path.home() / \"sunpy\" / \"sunpydb.sqlite\"))\n\n # Set the download_dir to be relative to the working_dir\n working_dir = Path(config.get('general', 'working_dir'))\n download_dir = Path(config.get('downloads', 'download_dir'))\n sample_dir = config.get('downloads', 'sample_dir', fallback=dirs.user_data_dir)\n config.set('downloads', 'sample_dir', Path(sample_dir).expanduser().resolve().as_posix())\n config.set('downloads', 'download_dir', (working_dir / download_dir).expanduser().resolve().as_posix())\n\n return config\n\n\ndef _find_config_files():\n \"\"\"\n Finds locations of SunPy configuration files.\n \"\"\"\n config_files = []\n config_filename = 'sunpyrc'\n\n # find default configuration file\n module_dir = Path(sunpy.__file__).parent\n config_files.append(str(module_dir / 'data' / 'sunpyrc'))\n\n # if a user configuration file exists, add that to list of files to read\n # so that any values set there will override ones specified in the default\n # config file\n config_path = Path(_get_user_configdir())\n if config_path.joinpath(config_filename).exists():\n config_files.append(str(config_path.joinpath(config_filename)))\n\n return config_files\n\n\ndef get_and_create_download_dir():\n \"\"\"\n Get the config of download directory and create one if not present.\n \"\"\"\n download_dir = os.environ.get('SUNPY_DOWNLOADDIR')\n if download_dir:\n return download_dir\n\n download_dir = Path(sunpy.config.get('downloads', 'download_dir')).expanduser().resolve()\n if not _is_writable_dir(download_dir):\n raise RuntimeError(f'Could not write to SunPy downloads directory=\"{download_dir}\"')\n\n return sunpy.config.get('downloads', 'download_dir')\n\n\ndef get_and_create_sample_dir():\n \"\"\"\n Get the config of download directory and create one if not present.\n \"\"\"\n sample_dir = Path(sunpy.config.get('downloads', 'sample_dir')).expanduser().resolve()\n if not _is_writable_dir(sample_dir):\n raise RuntimeError(f'Could not write to SunPy sample data directory=\"{sample_dir}\"')\n\n return sunpy.config.get('downloads', 'sample_dir')\n\n\ndef print_config():\n \"\"\"\n Print current configuration options.\n \"\"\"\n print(\"FILES USED:\")\n for file_ in _find_config_files():\n print(\" \" + file_)\n\n print(\"\\nCONFIGURATION:\")\n for section in sunpy.config.sections():\n print(\" [{0}]\".format(section))\n for option in sunpy.config.options(section):\n print(\" {} = {}\".format(option, sunpy.config.get(section, option)))\n print(\"\")\n\n\ndef _is_writable_dir(p):\n \"\"\"\n Checks to see if a directory is writable.\n \"\"\"\n if not Path(p).exists():\n Path(p).mkdir(parents=True)\n return Path(p).is_dir() and os.access(p, os.W_OK)\n\n\ndef _get_user_configdir():\n \"\"\"\n Return the string representing the configuration dir.\n\n The default is set by \"AppDirs\" and can be accessed by importing\n ``sunpy.util.config.CONFIG_DIR``. You can override this with the\n \"SUNPY_CONFIGDIR\" environment variable.\n \"\"\"\n configdir = os.environ.get('SUNPY_CONFIGDIR', CONFIG_DIR)\n\n if not _is_writable_dir(configdir):\n raise RuntimeError(f'Could not write to SUNPY_CONFIGDIR=\"{configdir}\"')\n return configdir\n", "path": "sunpy/util/config.py"}]}
| 2,510 | 192 |
gh_patches_debug_485
|
rasdani/github-patches
|
git_diff
|
celery__kombu-487
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Oracle database backend throws exception
When celery is used with oracle(11g) as database backend. There is an exception thrown
```
[2015-04-29 06:48:36,608: DEBUG/MainProcess] (0.011) QUERY = 'SELECT * FROM (SELECT ROWNUM AS "_RN", "_SUB".* FROM (SELECT "DJKOMBU_MESSAGE"."ID", "DJKOMBU_MESSAGE"."VISIBLE", "DJKOMBU_MESSAGE"."SENT_AT", "DJKOMBU_MESSAGE"."PAYLOAD", "DJKOMBU_MESSAGE"."QUEUE_ID" FROM "DJKOMBU_MESSAGE" WHERE ("DJKOMBU_MESSAGE"."QUEUE_ID" = :arg0 AND "DJKOMBU_MESSAGE"."VISIBLE" = :arg1) ORDER BY "DJKOMBU_MESSAGE"."SENT_AT" ASC, "DJKOMBU_MESSAGE"."ID" ASC FOR UPDATE) "_SUB" WHERE ROWNUM <= 1) WHERE "_RN" > 0' - PARAMS = (1, True); args=(1, True)
[2015-04-29 06:48:36,617: ERROR/MainProcess] Unrecoverable error: DatabaseError(<cx_Oracle._Error object at 0x111105878>,)
Traceback (most recent call last):
File "/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/django/db/backends/utils.py", line 65, in execute
return self.cursor.execute(sql, params)
File "/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/django/db/backends/oracle/base.py", line 916, in execute
return self.cursor.execute(query, self._param_generator(params))
cx_Oracle.DatabaseError: ORA-00907: missing right parenthesis
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/celery/worker/__init__.py", line 206, in start
self.blueprint.start(self)
File "/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/celery/bootsteps.py", line 123, in start
step.start(parent)
File "/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/celery/bootsteps.py", line 374, in start
return self.obj.start()
File "/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/celery/worker/consumer.py", line 278, in start
blueprint.start(self)
File "/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/celery/bootsteps.py", line 123, in start
step.start(parent)
File "/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/celery/worker/consumer.py", line 821, in start
c.loop(*c.loop_args())
File "/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/celery/worker/loops.py", line 97, in synloop
connection.drain_events(timeout=2.0)
File "/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/kombu/connection.py", line 275, in drain_events
return self.transport.drain_events(self.connection, **kwargs)
File "/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/kombu/transport/virtual/__init__.py", line 830, in drain_events
item, channel = get(timeout=timeout)
File "/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/kombu/transport/virtual/scheduling.py", line 39, in get
return self.fun(resource, **kwargs), resource
File "/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/kombu/transport/virtual/__init__.py", line 850, in _drain_channel
return channel.drain_events(timeout=timeout)
File "/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/kombu/transport/virtual/__init__.py", line 642, in drain_events
return self._poll(self.cycle, timeout=timeout)
File "/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/kombu/transport/virtual/__init__.py", line 328, in _poll
return cycle.get()
File "/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/kombu/transport/virtual/scheduling.py", line 39, in get
return self.fun(resource, **kwargs), resource
File "/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/kombu/transport/django/__init__.py", line 49, in _get
m = Queue.objects.fetch(queue)
File "/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/kombu/transport/django/managers.py", line 37, in fetch
return queue.messages.pop()
File "/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/kombu/transport/django/managers.py", line 21, in _commit
return fun(*args, **kwargs)
File "/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/kombu/transport/django/managers.py", line 72, in pop
result = resultset[0:1].get()
File "/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/django/db/models/query.py", line 351, in get
num = len(clone)
File "/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/django/db/models/query.py", line 122, in __len__
self._fetch_all()
File "/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/django/db/models/query.py", line 966, in _fetch_all
self._result_cache = list(self.iterator())
File "/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/django/db/models/query.py", line 265, in iterator
for row in compiler.results_iter():
File "/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/django/db/models/sql/compiler.py", line 700, in results_iter
for rows in self.execute_sql(MULTI):
File "/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/django/db/models/sql/compiler.py", line 786, in execute_sql
cursor.execute(sql, params)
File "/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/django/db/backends/utils.py", line 81, in execute
return super(CursorDebugWrapper, self).execute(sql, params)
File "/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/django/db/backends/utils.py", line 65, in execute
return self.cursor.execute(sql, params)
File "/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/django/db/utils.py", line 94, in __exit__
six.reraise(dj_exc_type, dj_exc_value, traceback)
File "/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/django/utils/six.py", line 658, in reraise
raise value.with_traceback(tb)
File "/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/django/db/backends/utils.py", line 65, in execute
return self.cursor.execute(sql, params)
File "/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/django/db/backends/oracle/base.py", line 916, in execute
return self.cursor.execute(query, self._param_generator(params))
django.db.utils.DatabaseError: ORA-00907: missing right parenthesis
```
This is discussed in google groups : https://groups.google.com/forum/#!topic/celery-users/5NOsMsw_p8A
</issue>
<code>
[start of kombu/transport/django/managers.py]
1 from __future__ import absolute_import
2
3 from functools import wraps
4
5 from django.db import transaction, connection, models
6 try:
7 from django.db import connections, router
8 except ImportError: # pre-Django 1.2
9 connections = router = None # noqa
10
11
12 try:
13 transaction.atomic
14 except AttributeError:
15 commit_on_success = transaction.commit_on_success
16 else:
17 def commit_on_success(fun):
18 @wraps(fun)
19 def _commit(*args, **kwargs):
20 with transaction.atomic():
21 return fun(*args, **kwargs)
22 return _commit
23
24
25
26 class QueueManager(models.Manager):
27
28 def publish(self, queue_name, payload):
29 queue, created = self.get_or_create(name=queue_name)
30 queue.messages.create(payload=payload)
31
32 def fetch(self, queue_name):
33 try:
34 queue = self.get(name=queue_name)
35 except self.model.DoesNotExist:
36 return
37
38 return queue.messages.pop()
39
40 def size(self, queue_name):
41 return self.get(name=queue_name).messages.count()
42
43 def purge(self, queue_name):
44 try:
45 queue = self.get(name=queue_name)
46 except self.model.DoesNotExist:
47 return
48
49 messages = queue.messages.all()
50 count = messages.count()
51 messages.delete()
52 return count
53
54
55 def select_for_update(qs):
56 try:
57 return qs.select_for_update()
58 except AttributeError:
59 return qs
60
61
62 class MessageManager(models.Manager):
63 _messages_received = [0]
64 cleanup_every = 10
65
66 @commit_on_success
67 def pop(self):
68 try:
69 resultset = select_for_update(
70 self.filter(visible=True).order_by('sent_at', 'id')
71 )
72 result = resultset[0:1].get()
73 result.visible = False
74 result.save()
75 recv = self.__class__._messages_received
76 recv[0] += 1
77 if not recv[0] % self.cleanup_every:
78 self.cleanup()
79 return result.payload
80 except self.model.DoesNotExist:
81 pass
82
83 def cleanup(self):
84 cursor = self.connection_for_write().cursor()
85 cursor.execute(
86 'DELETE FROM %s WHERE visible=%%s' % (
87 self.model._meta.db_table, ),
88 (False, )
89 )
90
91 def connection_for_write(self):
92 if connections:
93 return connections[router.db_for_write(self.model)]
94 return connection
95
[end of kombu/transport/django/managers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kombu/transport/django/managers.py b/kombu/transport/django/managers.py
--- a/kombu/transport/django/managers.py
+++ b/kombu/transport/django/managers.py
@@ -53,6 +53,8 @@
def select_for_update(qs):
+ if connection.vendor == 'oracle':
+ return qs
try:
return qs.select_for_update()
except AttributeError:
|
{"golden_diff": "diff --git a/kombu/transport/django/managers.py b/kombu/transport/django/managers.py\n--- a/kombu/transport/django/managers.py\n+++ b/kombu/transport/django/managers.py\n@@ -53,6 +53,8 @@\n \n \n def select_for_update(qs):\n+ if connection.vendor == 'oracle':\n+ return qs\n try:\n return qs.select_for_update()\n except AttributeError:\n", "issue": "Oracle database backend throws exception\nWhen celery is used with oracle(11g) as database backend. There is an exception thrown\n\n```\n[2015-04-29 06:48:36,608: DEBUG/MainProcess] (0.011) QUERY = 'SELECT * FROM (SELECT ROWNUM AS \"_RN\", \"_SUB\".* FROM (SELECT \"DJKOMBU_MESSAGE\".\"ID\", \"DJKOMBU_MESSAGE\".\"VISIBLE\", \"DJKOMBU_MESSAGE\".\"SENT_AT\", \"DJKOMBU_MESSAGE\".\"PAYLOAD\", \"DJKOMBU_MESSAGE\".\"QUEUE_ID\" FROM \"DJKOMBU_MESSAGE\" WHERE (\"DJKOMBU_MESSAGE\".\"QUEUE_ID\" = :arg0 AND \"DJKOMBU_MESSAGE\".\"VISIBLE\" = :arg1) ORDER BY \"DJKOMBU_MESSAGE\".\"SENT_AT\" ASC, \"DJKOMBU_MESSAGE\".\"ID\" ASC FOR UPDATE) \"_SUB\" WHERE ROWNUM <= 1) WHERE \"_RN\" > 0' - PARAMS = (1, True); args=(1, True)\n[2015-04-29 06:48:36,617: ERROR/MainProcess] Unrecoverable error: DatabaseError(<cx_Oracle._Error object at 0x111105878>,)\nTraceback (most recent call last):\n File \"/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/django/db/backends/utils.py\", line 65, in execute\n return self.cursor.execute(sql, params)\n File \"/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/django/db/backends/oracle/base.py\", line 916, in execute\n return self.cursor.execute(query, self._param_generator(params))\ncx_Oracle.DatabaseError: ORA-00907: missing right parenthesis\n\n\nThe above exception was the direct cause of the following exception:\n\nTraceback (most recent call last):\n File \"/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/celery/worker/__init__.py\", line 206, in start\n self.blueprint.start(self)\n File \"/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/celery/bootsteps.py\", line 123, in start\n step.start(parent)\n File \"/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/celery/bootsteps.py\", line 374, in start\n return self.obj.start()\n File \"/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/celery/worker/consumer.py\", line 278, in start\n blueprint.start(self)\n File \"/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/celery/bootsteps.py\", line 123, in start\n step.start(parent)\n File \"/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/celery/worker/consumer.py\", line 821, in start\n c.loop(*c.loop_args())\n File \"/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/celery/worker/loops.py\", line 97, in synloop\n connection.drain_events(timeout=2.0)\n File \"/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/kombu/connection.py\", line 275, in drain_events\n return self.transport.drain_events(self.connection, **kwargs)\n File \"/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/kombu/transport/virtual/__init__.py\", line 830, in drain_events\n item, channel = get(timeout=timeout)\n File \"/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/kombu/transport/virtual/scheduling.py\", line 39, in get\n return self.fun(resource, **kwargs), resource\n File \"/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/kombu/transport/virtual/__init__.py\", line 850, in _drain_channel\n return channel.drain_events(timeout=timeout)\n File \"/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/kombu/transport/virtual/__init__.py\", line 642, in drain_events\n return self._poll(self.cycle, timeout=timeout)\n File \"/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/kombu/transport/virtual/__init__.py\", line 328, in _poll\n return cycle.get()\n File \"/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/kombu/transport/virtual/scheduling.py\", line 39, in get\n return self.fun(resource, **kwargs), resource\n File \"/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/kombu/transport/django/__init__.py\", line 49, in _get\n m = Queue.objects.fetch(queue)\n File \"/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/kombu/transport/django/managers.py\", line 37, in fetch\n return queue.messages.pop()\n File \"/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/kombu/transport/django/managers.py\", line 21, in _commit\n return fun(*args, **kwargs)\n File \"/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/kombu/transport/django/managers.py\", line 72, in pop\n result = resultset[0:1].get()\n File \"/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/django/db/models/query.py\", line 351, in get\n num = len(clone)\n File \"/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/django/db/models/query.py\", line 122, in __len__\n self._fetch_all()\n File \"/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/django/db/models/query.py\", line 966, in _fetch_all\n self._result_cache = list(self.iterator())\n File \"/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/django/db/models/query.py\", line 265, in iterator\n for row in compiler.results_iter():\n File \"/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/django/db/models/sql/compiler.py\", line 700, in results_iter\n for rows in self.execute_sql(MULTI):\n File \"/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/django/db/models/sql/compiler.py\", line 786, in execute_sql\n cursor.execute(sql, params)\n File \"/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/django/db/backends/utils.py\", line 81, in execute\n return super(CursorDebugWrapper, self).execute(sql, params)\n File \"/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/django/db/backends/utils.py\", line 65, in execute\n return self.cursor.execute(sql, params)\n File \"/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/django/db/utils.py\", line 94, in __exit__\n six.reraise(dj_exc_type, dj_exc_value, traceback)\n File \"/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/django/utils/six.py\", line 658, in reraise\n raise value.with_traceback(tb)\n File \"/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/django/db/backends/utils.py\", line 65, in execute\n return self.cursor.execute(sql, params)\n File \"/Users/deepakn/dev/myapp/.env/lib/python3.4/site-packages/django/db/backends/oracle/base.py\", line 916, in execute\n return self.cursor.execute(query, self._param_generator(params))\ndjango.db.utils.DatabaseError: ORA-00907: missing right parenthesis\n```\n\nThis is discussed in google groups : https://groups.google.com/forum/#!topic/celery-users/5NOsMsw_p8A\n\n", "before_files": [{"content": "from __future__ import absolute_import\n\nfrom functools import wraps\n\nfrom django.db import transaction, connection, models\ntry:\n from django.db import connections, router\nexcept ImportError: # pre-Django 1.2\n connections = router = None # noqa\n\n\ntry:\n transaction.atomic\nexcept AttributeError:\n commit_on_success = transaction.commit_on_success\nelse:\n def commit_on_success(fun):\n @wraps(fun)\n def _commit(*args, **kwargs):\n with transaction.atomic():\n return fun(*args, **kwargs)\n return _commit\n\n\n\nclass QueueManager(models.Manager):\n\n def publish(self, queue_name, payload):\n queue, created = self.get_or_create(name=queue_name)\n queue.messages.create(payload=payload)\n\n def fetch(self, queue_name):\n try:\n queue = self.get(name=queue_name)\n except self.model.DoesNotExist:\n return\n\n return queue.messages.pop()\n\n def size(self, queue_name):\n return self.get(name=queue_name).messages.count()\n\n def purge(self, queue_name):\n try:\n queue = self.get(name=queue_name)\n except self.model.DoesNotExist:\n return\n\n messages = queue.messages.all()\n count = messages.count()\n messages.delete()\n return count\n\n\ndef select_for_update(qs):\n try:\n return qs.select_for_update()\n except AttributeError:\n return qs\n\n\nclass MessageManager(models.Manager):\n _messages_received = [0]\n cleanup_every = 10\n\n @commit_on_success\n def pop(self):\n try:\n resultset = select_for_update(\n self.filter(visible=True).order_by('sent_at', 'id')\n )\n result = resultset[0:1].get()\n result.visible = False\n result.save()\n recv = self.__class__._messages_received\n recv[0] += 1\n if not recv[0] % self.cleanup_every:\n self.cleanup()\n return result.payload\n except self.model.DoesNotExist:\n pass\n\n def cleanup(self):\n cursor = self.connection_for_write().cursor()\n cursor.execute(\n 'DELETE FROM %s WHERE visible=%%s' % (\n self.model._meta.db_table, ),\n (False, )\n )\n\n def connection_for_write(self):\n if connections:\n return connections[router.db_for_write(self.model)]\n return connection\n", "path": "kombu/transport/django/managers.py"}]}
| 3,148 | 100 |
gh_patches_debug_4774
|
rasdani/github-patches
|
git_diff
|
cowrie__cowrie-1002
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ftpget on python2
```
File "/home/cowrie/cowrie/src/cowrie/commands/ftpget.py", line 200, in ftp_download
ftp = FTP(source_address=out_addr)
File "/home/cowrie/cowrie/src/cowrie/commands/ftpget.py", line 24, in __init__
super(FTP, self).__init__(*args, **kwargs)
exceptions.TypeError: super() argument 1 must be type, not classobj
```
</issue>
<code>
[start of src/cowrie/commands/ftpget.py]
1 # -*- coding: utf-8 -*-
2 # Author: Claud Xiao
3
4 from __future__ import absolute_import, division
5
6 import ftplib
7 import getopt
8 import os
9 import socket
10
11 from twisted.python import log
12
13 from cowrie.core.artifact import Artifact
14 from cowrie.core.config import CONFIG
15 from cowrie.shell.command import HoneyPotCommand
16
17 commands = {}
18
19
20 class FTP(ftplib.FTP):
21
22 def __init__(self, *args, **kwargs):
23 self.source_address = kwargs.pop("source_address", None)
24 super(FTP, self).__init__(*args, **kwargs)
25
26 def connect(self, host='', port=0, timeout=-999, source_address=None):
27 if host != '':
28 self.host = host
29 if port > 0:
30 self.port = port
31 if timeout != -999:
32 self.timeout = timeout
33 if source_address is not None:
34 self.source_address = source_address
35 self.sock = socket.create_connection((self.host, self.port), self.timeout,
36 self.source_address)
37 self.af = self.sock.family
38 self.file = self.sock.makefile('rb')
39 self.welcome = self.getresp()
40 return self.welcome
41
42 def ntransfercmd(self, cmd, rest=None):
43 size = None
44 if self.passiveserver:
45 host, port = self.makepasv()
46 conn = socket.create_connection((host, port), self.timeout,
47 self.source_address)
48 try:
49 if rest is not None:
50 self.sendcmd("REST %s" % rest)
51 resp = self.sendcmd(cmd)
52 if resp[0] == '2':
53 resp = self.getresp()
54 if resp[0] != '1':
55 raise ftplib.error_reply(resp)
56 except Exception:
57 conn.close()
58 raise
59 else:
60 sock = self.makeport()
61 try:
62 if rest is not None:
63 self.sendcmd("REST %s" % rest)
64 resp = self.sendcmd(cmd)
65 if resp[0] == '2':
66 resp = self.getresp()
67 if resp[0] != '1':
68 raise ftplib.error_reply(resp)
69 conn, sockaddr = sock.accept()
70 if self.timeout is not socket._GLOBAL_DEFAULT_TIMEOUT:
71 conn.settimeout(self.timeout)
72 finally:
73 sock.close()
74 if resp[:3] == '150':
75 size = ftplib.parse150(resp)
76 return conn, size
77
78
79 class command_ftpget(HoneyPotCommand):
80
81 def help(self):
82 self.write("""BusyBox v1.20.2 (2016-06-22 15:12:53 EDT) multi-call binary.
83
84 Usage: ftpget [OPTIONS] HOST [LOCAL_FILE] REMOTE_FILE
85
86 Download a file via FTP
87
88 -c Continue previous transfer
89 -v Verbose
90 -u USER Username
91 -p PASS Password
92 -P NUM Port\n\n""")
93
94 def start(self):
95 try:
96 optlist, args = getopt.getopt(self.args, 'cvu:p:P:')
97 except getopt.GetoptError:
98 self.help()
99 self.exit()
100 return
101
102 if len(args) < 2:
103 self.help()
104 self.exit()
105 return
106
107 self.verbose = False
108 self.username = ''
109 self.password = ''
110 self.port = 21
111 self.host = ''
112 self.local_file = ''
113 self.remote_path = ''
114
115 for opt in optlist:
116 if opt[0] == '-v':
117 self.verbose = True
118 elif opt[0] == '-u':
119 self.username = opt[1]
120 elif opt[0] == '-p':
121 self.password = opt[1]
122 elif opt[0] == '-P':
123 try:
124 self.port = int(opt[1])
125 except ValueError:
126 pass
127
128 if len(args) == 2:
129 self.host, self.remote_path = args
130 elif len(args) >= 3:
131 self.host, self.local_file, self.remote_path = args[:3]
132
133 self.remote_dir = os.path.dirname(self.remote_path)
134 self.remote_file = os.path.basename(self.remote_path)
135 if not self.local_file:
136 self.local_file = self.remote_file
137
138 fakeoutfile = self.fs.resolve_path(self.local_file, self.protocol.cwd)
139 path = os.path.dirname(fakeoutfile)
140 if not path or not self.fs.exists(path) or not self.fs.isdir(path):
141 self.write('ftpget: can\'t open \'%s\': No such file or directory' % self.local_file)
142 self.exit()
143 return
144
145 self.download_path = CONFIG.get('honeypot', 'download_path')
146
147 self.url_log = 'ftp://'
148 if self.username:
149 self.url_log = '{}{}'.format(self.url_log, self.username)
150 if self.password:
151 self.url_log = '{}:{}'.format(self.url_log, self.password)
152 self.url_log = '{}@'.format(self.url_log)
153 self.url_log = '{}{}'.format(self.url_log, self.host)
154 if self.port != 21:
155 self.url_log = '{}:{}'.format(self.url_log, self.port)
156 self.url_log = '{}/{}'.format(self.url_log, self.remote_path)
157
158 self.artifactFile = Artifact(self.local_file)
159
160 result = self.ftp_download()
161
162 self.artifactFile.close()
163
164 if not result:
165 # log to cowrie.log
166 log.msg(format='Attempt to download file(s) from URL (%(url)s) failed',
167 url=self.url_log)
168
169 self.protocol.logDispatch(eventid='cowrie.session.file_download.failed',
170 format='Attempt to download file(s) from URL (%(url)s) failed',
171 url=self.url_log)
172 self.exit()
173 return
174
175 # log to cowrie.log
176 log.msg(format='Downloaded URL (%(url)s) with SHA-256 %(shasum)s to %(outfile)s',
177 url=self.url_log,
178 outfile=self.artifactFile.shasumFilename,
179 shasum=self.artifactFile.shasum)
180
181 self.protocol.logDispatch(eventid='cowrie.session.file_download',
182 format='Downloaded URL (%(url)s) with SHA-256 %(shasum)s to %(outfile)s',
183 url=self.url_log,
184 outfile=self.artifactFile.shasumFilename,
185 shasum=self.artifactFile.shasum,
186 destfile=self.local_file)
187
188 # Update the honeyfs to point to downloaded file
189 self.fs.mkfile(fakeoutfile, 0, 0, os.path.getsize(self.artifactFile.shasumFilename), 33188)
190 self.fs.update_realfile(self.fs.getfile(fakeoutfile), self.artifactFile.shasumFilename)
191 self.fs.chown(fakeoutfile, self.protocol.user.uid, self.protocol.user.gid)
192
193 self.exit()
194
195 def ftp_download(self):
196 out_addr = ('', 0)
197 if CONFIG.has_option('honeypot', 'out_addr'):
198 out_addr = (CONFIG.get('honeypot', 'out_addr'), 0)
199
200 ftp = FTP(source_address=out_addr)
201
202 # connect
203 if self.verbose:
204 self.write('Connecting to %s\n' % self.host) # TODO: add its IP address after the host
205
206 try:
207 ftp.connect(host=self.host, port=self.port, timeout=30)
208 except Exception as e:
209 log.msg('FTP connect failed: host=%s, port=%s, err=%s' % (self.host, self.port, str(e)))
210 self.write('ftpget: can\'t connect to remote host: Connection refused\n')
211 return False
212
213 # login
214 if self.verbose:
215 self.write('ftpget: cmd (null) (null)\n')
216 if self.username:
217 self.write('ftpget: cmd USER %s\n' % self.username)
218 else:
219 self.write('ftpget: cmd USER anonymous\n')
220 if self.password:
221 self.write('ftpget: cmd PASS %s\n' % self.password)
222 else:
223 self.write('ftpget: cmd PASS busybox@\n')
224
225 try:
226 ftp.login(user=self.username, passwd=self.password)
227 except Exception as e:
228 log.msg('FTP login failed: user=%s, passwd=%s, err=%s' % (self.username, self.password, str(e)))
229 self.write('ftpget: unexpected server response to USER: %s\n' % str(e))
230 try:
231 ftp.quit()
232 except socket.timeout:
233 pass
234 return False
235
236 # download
237 if self.verbose:
238 self.write('ftpget: cmd TYPE I (null)\n')
239 self.write('ftpget: cmd PASV (null)\n')
240 self.write('ftpget: cmd SIZE %s\n' % self.remote_path)
241 self.write('ftpget: cmd RETR %s\n' % self.remote_path)
242
243 try:
244 ftp.cwd(self.remote_dir)
245 ftp.retrbinary('RETR %s' % self.remote_file, self.artifactFile.write)
246 except Exception as e:
247 log.msg('FTP retrieval failed: %s' % str(e))
248 self.write('ftpget: unexpected server response to USER: %s\n' % str(e))
249 try:
250 ftp.quit()
251 except socket.timeout:
252 pass
253 return False
254
255 # quit
256 if self.verbose:
257 self.write('ftpget: cmd (null) (null)\n')
258 self.write('ftpget: cmd QUIT (null)\n')
259
260 try:
261 ftp.quit()
262 except socket.timeout:
263 pass
264
265 return True
266
267
268 commands['/usr/bin/ftpget'] = command_ftpget
269 commands['ftpget'] = command_ftpget
270
[end of src/cowrie/commands/ftpget.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/cowrie/commands/ftpget.py b/src/cowrie/commands/ftpget.py
--- a/src/cowrie/commands/ftpget.py
+++ b/src/cowrie/commands/ftpget.py
@@ -21,7 +21,7 @@
def __init__(self, *args, **kwargs):
self.source_address = kwargs.pop("source_address", None)
- super(FTP, self).__init__(*args, **kwargs)
+ ftplib.FTP.__init__(self, *args, **kwargs)
def connect(self, host='', port=0, timeout=-999, source_address=None):
if host != '':
|
{"golden_diff": "diff --git a/src/cowrie/commands/ftpget.py b/src/cowrie/commands/ftpget.py\n--- a/src/cowrie/commands/ftpget.py\n+++ b/src/cowrie/commands/ftpget.py\n@@ -21,7 +21,7 @@\n \n def __init__(self, *args, **kwargs):\n self.source_address = kwargs.pop(\"source_address\", None)\n- super(FTP, self).__init__(*args, **kwargs)\n+ ftplib.FTP.__init__(self, *args, **kwargs)\n \n def connect(self, host='', port=0, timeout=-999, source_address=None):\n if host != '':\n", "issue": "ftpget on python2\n```\r\n File \"/home/cowrie/cowrie/src/cowrie/commands/ftpget.py\", line 200, in ftp_download\r\n ftp = FTP(source_address=out_addr)\r\n File \"/home/cowrie/cowrie/src/cowrie/commands/ftpget.py\", line 24, in __init__\r\n super(FTP, self).__init__(*args, **kwargs)\r\n exceptions.TypeError: super() argument 1 must be type, not classobj\r\n```\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Author: Claud Xiao\n\nfrom __future__ import absolute_import, division\n\nimport ftplib\nimport getopt\nimport os\nimport socket\n\nfrom twisted.python import log\n\nfrom cowrie.core.artifact import Artifact\nfrom cowrie.core.config import CONFIG\nfrom cowrie.shell.command import HoneyPotCommand\n\ncommands = {}\n\n\nclass FTP(ftplib.FTP):\n\n def __init__(self, *args, **kwargs):\n self.source_address = kwargs.pop(\"source_address\", None)\n super(FTP, self).__init__(*args, **kwargs)\n\n def connect(self, host='', port=0, timeout=-999, source_address=None):\n if host != '':\n self.host = host\n if port > 0:\n self.port = port\n if timeout != -999:\n self.timeout = timeout\n if source_address is not None:\n self.source_address = source_address\n self.sock = socket.create_connection((self.host, self.port), self.timeout,\n self.source_address)\n self.af = self.sock.family\n self.file = self.sock.makefile('rb')\n self.welcome = self.getresp()\n return self.welcome\n\n def ntransfercmd(self, cmd, rest=None):\n size = None\n if self.passiveserver:\n host, port = self.makepasv()\n conn = socket.create_connection((host, port), self.timeout,\n self.source_address)\n try:\n if rest is not None:\n self.sendcmd(\"REST %s\" % rest)\n resp = self.sendcmd(cmd)\n if resp[0] == '2':\n resp = self.getresp()\n if resp[0] != '1':\n raise ftplib.error_reply(resp)\n except Exception:\n conn.close()\n raise\n else:\n sock = self.makeport()\n try:\n if rest is not None:\n self.sendcmd(\"REST %s\" % rest)\n resp = self.sendcmd(cmd)\n if resp[0] == '2':\n resp = self.getresp()\n if resp[0] != '1':\n raise ftplib.error_reply(resp)\n conn, sockaddr = sock.accept()\n if self.timeout is not socket._GLOBAL_DEFAULT_TIMEOUT:\n conn.settimeout(self.timeout)\n finally:\n sock.close()\n if resp[:3] == '150':\n size = ftplib.parse150(resp)\n return conn, size\n\n\nclass command_ftpget(HoneyPotCommand):\n\n def help(self):\n self.write(\"\"\"BusyBox v1.20.2 (2016-06-22 15:12:53 EDT) multi-call binary.\n\nUsage: ftpget [OPTIONS] HOST [LOCAL_FILE] REMOTE_FILE\n\nDownload a file via FTP\n\n -c Continue previous transfer\n -v Verbose\n -u USER Username\n -p PASS Password\n -P NUM Port\\n\\n\"\"\")\n\n def start(self):\n try:\n optlist, args = getopt.getopt(self.args, 'cvu:p:P:')\n except getopt.GetoptError:\n self.help()\n self.exit()\n return\n\n if len(args) < 2:\n self.help()\n self.exit()\n return\n\n self.verbose = False\n self.username = ''\n self.password = ''\n self.port = 21\n self.host = ''\n self.local_file = ''\n self.remote_path = ''\n\n for opt in optlist:\n if opt[0] == '-v':\n self.verbose = True\n elif opt[0] == '-u':\n self.username = opt[1]\n elif opt[0] == '-p':\n self.password = opt[1]\n elif opt[0] == '-P':\n try:\n self.port = int(opt[1])\n except ValueError:\n pass\n\n if len(args) == 2:\n self.host, self.remote_path = args\n elif len(args) >= 3:\n self.host, self.local_file, self.remote_path = args[:3]\n\n self.remote_dir = os.path.dirname(self.remote_path)\n self.remote_file = os.path.basename(self.remote_path)\n if not self.local_file:\n self.local_file = self.remote_file\n\n fakeoutfile = self.fs.resolve_path(self.local_file, self.protocol.cwd)\n path = os.path.dirname(fakeoutfile)\n if not path or not self.fs.exists(path) or not self.fs.isdir(path):\n self.write('ftpget: can\\'t open \\'%s\\': No such file or directory' % self.local_file)\n self.exit()\n return\n\n self.download_path = CONFIG.get('honeypot', 'download_path')\n\n self.url_log = 'ftp://'\n if self.username:\n self.url_log = '{}{}'.format(self.url_log, self.username)\n if self.password:\n self.url_log = '{}:{}'.format(self.url_log, self.password)\n self.url_log = '{}@'.format(self.url_log)\n self.url_log = '{}{}'.format(self.url_log, self.host)\n if self.port != 21:\n self.url_log = '{}:{}'.format(self.url_log, self.port)\n self.url_log = '{}/{}'.format(self.url_log, self.remote_path)\n\n self.artifactFile = Artifact(self.local_file)\n\n result = self.ftp_download()\n\n self.artifactFile.close()\n\n if not result:\n # log to cowrie.log\n log.msg(format='Attempt to download file(s) from URL (%(url)s) failed',\n url=self.url_log)\n\n self.protocol.logDispatch(eventid='cowrie.session.file_download.failed',\n format='Attempt to download file(s) from URL (%(url)s) failed',\n url=self.url_log)\n self.exit()\n return\n\n # log to cowrie.log\n log.msg(format='Downloaded URL (%(url)s) with SHA-256 %(shasum)s to %(outfile)s',\n url=self.url_log,\n outfile=self.artifactFile.shasumFilename,\n shasum=self.artifactFile.shasum)\n\n self.protocol.logDispatch(eventid='cowrie.session.file_download',\n format='Downloaded URL (%(url)s) with SHA-256 %(shasum)s to %(outfile)s',\n url=self.url_log,\n outfile=self.artifactFile.shasumFilename,\n shasum=self.artifactFile.shasum,\n destfile=self.local_file)\n\n # Update the honeyfs to point to downloaded file\n self.fs.mkfile(fakeoutfile, 0, 0, os.path.getsize(self.artifactFile.shasumFilename), 33188)\n self.fs.update_realfile(self.fs.getfile(fakeoutfile), self.artifactFile.shasumFilename)\n self.fs.chown(fakeoutfile, self.protocol.user.uid, self.protocol.user.gid)\n\n self.exit()\n\n def ftp_download(self):\n out_addr = ('', 0)\n if CONFIG.has_option('honeypot', 'out_addr'):\n out_addr = (CONFIG.get('honeypot', 'out_addr'), 0)\n\n ftp = FTP(source_address=out_addr)\n\n # connect\n if self.verbose:\n self.write('Connecting to %s\\n' % self.host) # TODO: add its IP address after the host\n\n try:\n ftp.connect(host=self.host, port=self.port, timeout=30)\n except Exception as e:\n log.msg('FTP connect failed: host=%s, port=%s, err=%s' % (self.host, self.port, str(e)))\n self.write('ftpget: can\\'t connect to remote host: Connection refused\\n')\n return False\n\n # login\n if self.verbose:\n self.write('ftpget: cmd (null) (null)\\n')\n if self.username:\n self.write('ftpget: cmd USER %s\\n' % self.username)\n else:\n self.write('ftpget: cmd USER anonymous\\n')\n if self.password:\n self.write('ftpget: cmd PASS %s\\n' % self.password)\n else:\n self.write('ftpget: cmd PASS busybox@\\n')\n\n try:\n ftp.login(user=self.username, passwd=self.password)\n except Exception as e:\n log.msg('FTP login failed: user=%s, passwd=%s, err=%s' % (self.username, self.password, str(e)))\n self.write('ftpget: unexpected server response to USER: %s\\n' % str(e))\n try:\n ftp.quit()\n except socket.timeout:\n pass\n return False\n\n # download\n if self.verbose:\n self.write('ftpget: cmd TYPE I (null)\\n')\n self.write('ftpget: cmd PASV (null)\\n')\n self.write('ftpget: cmd SIZE %s\\n' % self.remote_path)\n self.write('ftpget: cmd RETR %s\\n' % self.remote_path)\n\n try:\n ftp.cwd(self.remote_dir)\n ftp.retrbinary('RETR %s' % self.remote_file, self.artifactFile.write)\n except Exception as e:\n log.msg('FTP retrieval failed: %s' % str(e))\n self.write('ftpget: unexpected server response to USER: %s\\n' % str(e))\n try:\n ftp.quit()\n except socket.timeout:\n pass\n return False\n\n # quit\n if self.verbose:\n self.write('ftpget: cmd (null) (null)\\n')\n self.write('ftpget: cmd QUIT (null)\\n')\n\n try:\n ftp.quit()\n except socket.timeout:\n pass\n\n return True\n\n\ncommands['/usr/bin/ftpget'] = command_ftpget\ncommands['ftpget'] = command_ftpget\n", "path": "src/cowrie/commands/ftpget.py"}]}
| 3,489 | 150 |
gh_patches_debug_18507
|
rasdani/github-patches
|
git_diff
|
arviz-devs__arviz-586
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
xlim of traceplot does not cover all range of values
## Description of your problem
xlim of traceplot may not cover all range of traces for discrete variables. For example, if I get two chains: one with mean 28, another one with mean 32. Then the traceplot will show only one bar at x=28 and xlim from 27.5 to 28.5.

For discrete values I used DiscreteUniform:
```python
timestep=1.5
with pm.Model() as model_two_switches_11:
delaymean = pm.Uniform('delaymean',1,28,shape=3)
k = pm.Uniform('k',0.8,8,shape=3)
switch1 = pm.DiscreteUniform('switch1',df['T'].min()//7,df['T'].max()//7-timestep-1)
switch2 = pm.DiscreteUniform('switch2',switch1+timestep+1,df['T'].max()//7)
idx = tt.switch(df['t'].values>=(switch1*7),0,1)+tt.switch(df['t'].values>=(switch2*7),0,1)
θ = delaymean/tt.gamma(1+1/k)
delaysd = pm.Deterministic('delaysd',delaymean/tt.gamma(1+1/k)*tt.sqrt(tt.gamma(1+2/k)-tt.gamma(1+1/k)**2))
delay_p = (1-tt.exp(-(df['δt0'].values/θ[idx])**k[idx]))/(1-tt.exp(-(df['δt'].values/θ[idx])**k[idx]))
confirmed = pm.Poisson('confirmed',\
mu=df['confirmed'].values*delay_p+0.001,\
observed=df['confirmed0'].values)
start = {'switch1': 22, 'switch2': 28}
step = pm.Slice([switch1,switch2])
trace_two_switches_11 = pm.sample(number_of_iterations, tune=length_of_tunein, cores = number_of_jobs,
start=start, step=step)
model_two_switches_11.name = 'Two switches_11'
vrnames = ['switch1','switch2','delaymean','delaysd']
pm.traceplot(trace_two_switches_11,varnames=vrnames);
pm.summary(trace_two_switches_11)
```
ps: I assume that it's because the fraction of those points outside of chosen xlim-range is rather small, but it would be nice to see the consistent picture between left and right panels
## Versions and main components
* PyMC3 Version: 3.6
* Theano Version: 1.0.3
* Python Version: 3.7.1
* Operating system: linux
* How did you install PyMC3: (conda/pip) latest version from github
</issue>
<code>
[start of arviz/plots/traceplot.py]
1 """Plot histogram and values from MCMC samples."""
2 import matplotlib.pyplot as plt
3 import numpy as np
4
5 from ..data import convert_to_dataset
6 from .kdeplot import plot_kde
7 from .plot_utils import _scale_fig_size, get_bins, xarray_var_iter, make_label, get_coords
8 from ..utils import _var_names
9
10
11 def plot_trace(
12 data,
13 var_names=None,
14 coords=None,
15 divergences="bottom",
16 figsize=None,
17 textsize=None,
18 lines=None,
19 combined=False,
20 kde_kwargs=None,
21 hist_kwargs=None,
22 trace_kwargs=None,
23 ):
24 """Plot samples histograms and values.
25
26 If `divergences` data is available in `sample_stats`, will plot the location of divergences as
27 dashed vertical lines.
28
29 Parameters
30 ----------
31 data : obj
32 Any object that can be converted to an az.InferenceData object
33 Refer to documentation of az.convert_to_dataset for details
34 var_names : list of variable names
35 Variables to be plotted, two variables are required.
36 coords : mapping, optional
37 Coordinates of var_names to be plotted. Passed to `Dataset.sel`
38 divergences : {"bottom", "top", None, False}
39 Plot location of divergences on the traceplots. Options are "bottom", "top", or False-y.
40 figsize : figure size tuple
41 If None, size is (12, variables * 2)
42 textsize: float
43 Text size scaling factor for labels, titles and lines. If None it will be autoscaled based
44 on figsize.
45 lines : tuple
46 Tuple of (var_name, {'coord': selection}, [line, positions]) to be overplotted as
47 vertical lines on the density and horizontal lines on the trace.
48 combined : bool
49 Flag for combining multiple chains into a single line. If False (default), chains will be
50 plotted separately.
51 kde_kwargs : dict
52 Extra keyword arguments passed to `arviz.plot_kde`. Only affects continuous variables.
53 hist_kwargs : dict
54 Extra keyword arguments passed to `plt.hist`. Only affects discrete variables.
55 trace_kwargs : dict
56 Extra keyword arguments passed to `plt.plot`
57 Returns
58 -------
59 axes : matplotlib axes
60
61
62 Examples
63 --------
64 Plot a subset variables
65
66 .. plot::
67 :context: close-figs
68
69 >>> import arviz as az
70 >>> data = az.load_arviz_data('non_centered_eight')
71 >>> coords = {'theta_t_dim_0': [0, 1], 'school':['Lawrenceville']}
72 >>> az.plot_trace(data, var_names=('theta_t', 'theta'), coords=coords)
73
74 Combine all chains into one distribution and trace
75
76 .. plot::
77 :context: close-figs
78
79 >>> coords = {'theta_t_dim_0': [0, 1], 'school':['Lawrenceville']}
80 >>> az.plot_trace(data, var_names=('theta_t', 'theta'), coords=coords, combined=True)
81
82
83 Plot reference lines against distribution and trace
84
85 .. plot::
86 :context: close-figs
87
88 >>> lines = (('theta_t',{'theta_t_dim_0':0}, [-1]),)
89 >>> coords = {'theta_t_dim_0': [0, 1], 'school':['Lawrenceville']}
90 >>> az.plot_trace(data, var_names=('theta_t', 'theta'), coords=coords, lines=lines)
91 """
92 if divergences:
93 try:
94 divergence_data = convert_to_dataset(data, group="sample_stats").diverging
95 except (ValueError, AttributeError): # No sample_stats, or no `.diverging`
96 divergences = False
97
98 data = convert_to_dataset(data, group="posterior")
99 var_names = _var_names(var_names, data)
100
101 if coords is None:
102 coords = {}
103
104 if lines is None:
105 lines = ()
106
107 plotters = list(xarray_var_iter(get_coords(data, coords), var_names=var_names, combined=True))
108
109 if figsize is None:
110 figsize = (12, len(plotters) * 2)
111
112 if trace_kwargs is None:
113 trace_kwargs = {}
114
115 trace_kwargs.setdefault("alpha", 0.35)
116
117 if kde_kwargs is None:
118 kde_kwargs = {}
119
120 if hist_kwargs is None:
121 hist_kwargs = {}
122
123 hist_kwargs.setdefault("alpha", 0.35)
124
125 figsize, _, titlesize, xt_labelsize, linewidth, _ = _scale_fig_size(
126 figsize, textsize, rows=len(plotters), cols=2
127 )
128 trace_kwargs.setdefault("linewidth", linewidth)
129 kde_kwargs.setdefault("plot_kwargs", {"linewidth": linewidth})
130
131 _, axes = plt.subplots(
132 len(plotters), 2, squeeze=False, figsize=figsize, constrained_layout=True
133 )
134
135 colors = {}
136 for idx, (var_name, selection, value) in enumerate(plotters):
137 colors[idx] = []
138 if combined:
139 value = value.flatten()
140 value = np.atleast_2d(value)
141
142 for row in value:
143 axes[idx, 1].plot(np.arange(len(row)), row, **trace_kwargs)
144
145 colors[idx].append(axes[idx, 1].get_lines()[-1].get_color())
146 kde_kwargs["plot_kwargs"]["color"] = colors[idx][-1]
147 if row.dtype.kind == "i":
148 _histplot_op(axes[idx, 0], row, **hist_kwargs)
149 else:
150 plot_kde(row, textsize=xt_labelsize, ax=axes[idx, 0], **kde_kwargs)
151
152 axes[idx, 0].set_yticks([])
153 for col in (0, 1):
154 axes[idx, col].set_title(make_label(var_name, selection), fontsize=titlesize, wrap=True)
155 axes[idx, col].tick_params(labelsize=xt_labelsize)
156
157 xlims = [ax.get_xlim() for ax in axes[idx, :]]
158 ylims = [ax.get_ylim() for ax in axes[idx, :]]
159
160 if divergences:
161 div_selection = {k: v for k, v in selection.items() if k in divergence_data.dims}
162 divs = divergence_data.sel(**div_selection).values
163 if combined:
164 divs = divs.flatten()
165 divs = np.atleast_2d(divs)
166
167 for chain, chain_divs in enumerate(divs):
168 div_idxs = np.arange(len(chain_divs))[chain_divs]
169 if div_idxs.size > 0:
170 if divergences == "top":
171 ylocs = [ylim[1] for ylim in ylims]
172 else:
173 ylocs = [ylim[0] for ylim in ylims]
174 values = value[chain, div_idxs]
175 axes[idx, 1].plot(
176 div_idxs,
177 np.zeros_like(div_idxs) + ylocs[1],
178 marker="|",
179 color="black",
180 markeredgewidth=1.5,
181 markersize=30,
182 linestyle="None",
183 alpha=hist_kwargs["alpha"],
184 zorder=-5,
185 )
186 axes[idx, 1].set_ylim(*ylims[1])
187 axes[idx, 0].plot(
188 values,
189 np.zeros_like(values) + ylocs[0],
190 marker="|",
191 color="black",
192 markeredgewidth=1.5,
193 markersize=30,
194 linestyle="None",
195 alpha=trace_kwargs["alpha"],
196 zorder=-5,
197 )
198 axes[idx, 0].set_ylim(*ylims[0])
199
200 for _, _, vlines in (j for j in lines if j[0] == var_name and j[1] == selection):
201 if isinstance(vlines, (float, int)):
202 line_values = [vlines]
203 else:
204 line_values = np.atleast_1d(vlines).ravel()
205 axes[idx, 0].vlines(
206 line_values, *ylims[0], colors=colors[idx][0], linewidth=1.5, alpha=0.75
207 )
208 axes[idx, 1].hlines(
209 line_values,
210 *xlims[1],
211 colors=colors[idx][0],
212 linewidth=1.5,
213 alpha=trace_kwargs["alpha"]
214 )
215 axes[idx, 0].set_ylim(bottom=0, top=ylims[0][1])
216 axes[idx, 1].set_xlim(left=0, right=data.draw.max())
217 axes[idx, 1].set_ylim(*ylims[1])
218 return axes
219
220
221 def _histplot_op(ax, data, **kwargs):
222 """Add a histogram for the data to the axes."""
223 bins = get_bins(data)
224 ax.hist(data, bins=bins, align="left", density=True, **kwargs)
225 xticks = get_bins(data, max_bins=10, fenceposts=1)
226 ax.set_xticks(xticks)
227 return ax
228
[end of arviz/plots/traceplot.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/arviz/plots/traceplot.py b/arviz/plots/traceplot.py
--- a/arviz/plots/traceplot.py
+++ b/arviz/plots/traceplot.py
@@ -149,6 +149,9 @@
else:
plot_kde(row, textsize=xt_labelsize, ax=axes[idx, 0], **kde_kwargs)
+ if value[0].dtype.kind == "i":
+ xticks = get_bins(value, max_bins=10, fenceposts=1)
+ axes[idx, 0].set_xticks(xticks)
axes[idx, 0].set_yticks([])
for col in (0, 1):
axes[idx, col].set_title(make_label(var_name, selection), fontsize=titlesize, wrap=True)
@@ -222,6 +225,4 @@
"""Add a histogram for the data to the axes."""
bins = get_bins(data)
ax.hist(data, bins=bins, align="left", density=True, **kwargs)
- xticks = get_bins(data, max_bins=10, fenceposts=1)
- ax.set_xticks(xticks)
return ax
|
{"golden_diff": "diff --git a/arviz/plots/traceplot.py b/arviz/plots/traceplot.py\n--- a/arviz/plots/traceplot.py\n+++ b/arviz/plots/traceplot.py\n@@ -149,6 +149,9 @@\n else:\n plot_kde(row, textsize=xt_labelsize, ax=axes[idx, 0], **kde_kwargs)\n \n+ if value[0].dtype.kind == \"i\":\n+ xticks = get_bins(value, max_bins=10, fenceposts=1)\n+ axes[idx, 0].set_xticks(xticks)\n axes[idx, 0].set_yticks([])\n for col in (0, 1):\n axes[idx, col].set_title(make_label(var_name, selection), fontsize=titlesize, wrap=True)\n@@ -222,6 +225,4 @@\n \"\"\"Add a histogram for the data to the axes.\"\"\"\n bins = get_bins(data)\n ax.hist(data, bins=bins, align=\"left\", density=True, **kwargs)\n- xticks = get_bins(data, max_bins=10, fenceposts=1)\n- ax.set_xticks(xticks)\n return ax\n", "issue": "xlim of traceplot does not cover all range of values\n## Description of your problem\r\n\r\nxlim of traceplot may not cover all range of traces for discrete variables. For example, if I get two chains: one with mean 28, another one with mean 32. Then the traceplot will show only one bar at x=28 and xlim from 27.5 to 28.5.\r\n\r\n\r\n\r\nFor discrete values I used DiscreteUniform:\r\n```python\r\ntimestep=1.5\r\nwith pm.Model() as model_two_switches_11:\r\n delaymean = pm.Uniform('delaymean',1,28,shape=3)\r\n k = pm.Uniform('k',0.8,8,shape=3)\r\n \r\n switch1 = pm.DiscreteUniform('switch1',df['T'].min()//7,df['T'].max()//7-timestep-1)\r\n switch2 = pm.DiscreteUniform('switch2',switch1+timestep+1,df['T'].max()//7)\r\n \r\n idx = tt.switch(df['t'].values>=(switch1*7),0,1)+tt.switch(df['t'].values>=(switch2*7),0,1)\r\n \r\n \u03b8 = delaymean/tt.gamma(1+1/k)\r\n delaysd = pm.Deterministic('delaysd',delaymean/tt.gamma(1+1/k)*tt.sqrt(tt.gamma(1+2/k)-tt.gamma(1+1/k)**2))\r\n \r\n delay_p = (1-tt.exp(-(df['\u03b4t0'].values/\u03b8[idx])**k[idx]))/(1-tt.exp(-(df['\u03b4t'].values/\u03b8[idx])**k[idx]))\r\n \r\n confirmed = pm.Poisson('confirmed',\\\r\n mu=df['confirmed'].values*delay_p+0.001,\\\r\n observed=df['confirmed0'].values)\r\n \r\n start = {'switch1': 22, 'switch2': 28}\r\n step = pm.Slice([switch1,switch2])\r\n trace_two_switches_11 = pm.sample(number_of_iterations, tune=length_of_tunein, cores = number_of_jobs,\r\n start=start, step=step)\r\n\r\nmodel_two_switches_11.name = 'Two switches_11'\r\n\r\nvrnames = ['switch1','switch2','delaymean','delaysd']\r\npm.traceplot(trace_two_switches_11,varnames=vrnames);\r\npm.summary(trace_two_switches_11)\r\n```\r\n\r\nps: I assume that it's because the fraction of those points outside of chosen xlim-range is rather small, but it would be nice to see the consistent picture between left and right panels\r\n\r\n## Versions and main components\r\n\r\n* PyMC3 Version: 3.6\r\n* Theano Version: 1.0.3\r\n* Python Version: 3.7.1\r\n* Operating system: linux\r\n* How did you install PyMC3: (conda/pip) latest version from github\n", "before_files": [{"content": "\"\"\"Plot histogram and values from MCMC samples.\"\"\"\nimport matplotlib.pyplot as plt\nimport numpy as np\n\nfrom ..data import convert_to_dataset\nfrom .kdeplot import plot_kde\nfrom .plot_utils import _scale_fig_size, get_bins, xarray_var_iter, make_label, get_coords\nfrom ..utils import _var_names\n\n\ndef plot_trace(\n data,\n var_names=None,\n coords=None,\n divergences=\"bottom\",\n figsize=None,\n textsize=None,\n lines=None,\n combined=False,\n kde_kwargs=None,\n hist_kwargs=None,\n trace_kwargs=None,\n):\n \"\"\"Plot samples histograms and values.\n\n If `divergences` data is available in `sample_stats`, will plot the location of divergences as\n dashed vertical lines.\n\n Parameters\n ----------\n data : obj\n Any object that can be converted to an az.InferenceData object\n Refer to documentation of az.convert_to_dataset for details\n var_names : list of variable names\n Variables to be plotted, two variables are required.\n coords : mapping, optional\n Coordinates of var_names to be plotted. Passed to `Dataset.sel`\n divergences : {\"bottom\", \"top\", None, False}\n Plot location of divergences on the traceplots. Options are \"bottom\", \"top\", or False-y.\n figsize : figure size tuple\n If None, size is (12, variables * 2)\n textsize: float\n Text size scaling factor for labels, titles and lines. If None it will be autoscaled based\n on figsize.\n lines : tuple\n Tuple of (var_name, {'coord': selection}, [line, positions]) to be overplotted as\n vertical lines on the density and horizontal lines on the trace.\n combined : bool\n Flag for combining multiple chains into a single line. If False (default), chains will be\n plotted separately.\n kde_kwargs : dict\n Extra keyword arguments passed to `arviz.plot_kde`. Only affects continuous variables.\n hist_kwargs : dict\n Extra keyword arguments passed to `plt.hist`. Only affects discrete variables.\n trace_kwargs : dict\n Extra keyword arguments passed to `plt.plot`\n Returns\n -------\n axes : matplotlib axes\n\n\n Examples\n --------\n Plot a subset variables\n\n .. plot::\n :context: close-figs\n\n >>> import arviz as az\n >>> data = az.load_arviz_data('non_centered_eight')\n >>> coords = {'theta_t_dim_0': [0, 1], 'school':['Lawrenceville']}\n >>> az.plot_trace(data, var_names=('theta_t', 'theta'), coords=coords)\n\n Combine all chains into one distribution and trace\n\n .. plot::\n :context: close-figs\n\n >>> coords = {'theta_t_dim_0': [0, 1], 'school':['Lawrenceville']}\n >>> az.plot_trace(data, var_names=('theta_t', 'theta'), coords=coords, combined=True)\n\n\n Plot reference lines against distribution and trace\n\n .. plot::\n :context: close-figs\n\n >>> lines = (('theta_t',{'theta_t_dim_0':0}, [-1]),)\n >>> coords = {'theta_t_dim_0': [0, 1], 'school':['Lawrenceville']}\n >>> az.plot_trace(data, var_names=('theta_t', 'theta'), coords=coords, lines=lines)\n \"\"\"\n if divergences:\n try:\n divergence_data = convert_to_dataset(data, group=\"sample_stats\").diverging\n except (ValueError, AttributeError): # No sample_stats, or no `.diverging`\n divergences = False\n\n data = convert_to_dataset(data, group=\"posterior\")\n var_names = _var_names(var_names, data)\n\n if coords is None:\n coords = {}\n\n if lines is None:\n lines = ()\n\n plotters = list(xarray_var_iter(get_coords(data, coords), var_names=var_names, combined=True))\n\n if figsize is None:\n figsize = (12, len(plotters) * 2)\n\n if trace_kwargs is None:\n trace_kwargs = {}\n\n trace_kwargs.setdefault(\"alpha\", 0.35)\n\n if kde_kwargs is None:\n kde_kwargs = {}\n\n if hist_kwargs is None:\n hist_kwargs = {}\n\n hist_kwargs.setdefault(\"alpha\", 0.35)\n\n figsize, _, titlesize, xt_labelsize, linewidth, _ = _scale_fig_size(\n figsize, textsize, rows=len(plotters), cols=2\n )\n trace_kwargs.setdefault(\"linewidth\", linewidth)\n kde_kwargs.setdefault(\"plot_kwargs\", {\"linewidth\": linewidth})\n\n _, axes = plt.subplots(\n len(plotters), 2, squeeze=False, figsize=figsize, constrained_layout=True\n )\n\n colors = {}\n for idx, (var_name, selection, value) in enumerate(plotters):\n colors[idx] = []\n if combined:\n value = value.flatten()\n value = np.atleast_2d(value)\n\n for row in value:\n axes[idx, 1].plot(np.arange(len(row)), row, **trace_kwargs)\n\n colors[idx].append(axes[idx, 1].get_lines()[-1].get_color())\n kde_kwargs[\"plot_kwargs\"][\"color\"] = colors[idx][-1]\n if row.dtype.kind == \"i\":\n _histplot_op(axes[idx, 0], row, **hist_kwargs)\n else:\n plot_kde(row, textsize=xt_labelsize, ax=axes[idx, 0], **kde_kwargs)\n\n axes[idx, 0].set_yticks([])\n for col in (0, 1):\n axes[idx, col].set_title(make_label(var_name, selection), fontsize=titlesize, wrap=True)\n axes[idx, col].tick_params(labelsize=xt_labelsize)\n\n xlims = [ax.get_xlim() for ax in axes[idx, :]]\n ylims = [ax.get_ylim() for ax in axes[idx, :]]\n\n if divergences:\n div_selection = {k: v for k, v in selection.items() if k in divergence_data.dims}\n divs = divergence_data.sel(**div_selection).values\n if combined:\n divs = divs.flatten()\n divs = np.atleast_2d(divs)\n\n for chain, chain_divs in enumerate(divs):\n div_idxs = np.arange(len(chain_divs))[chain_divs]\n if div_idxs.size > 0:\n if divergences == \"top\":\n ylocs = [ylim[1] for ylim in ylims]\n else:\n ylocs = [ylim[0] for ylim in ylims]\n values = value[chain, div_idxs]\n axes[idx, 1].plot(\n div_idxs,\n np.zeros_like(div_idxs) + ylocs[1],\n marker=\"|\",\n color=\"black\",\n markeredgewidth=1.5,\n markersize=30,\n linestyle=\"None\",\n alpha=hist_kwargs[\"alpha\"],\n zorder=-5,\n )\n axes[idx, 1].set_ylim(*ylims[1])\n axes[idx, 0].plot(\n values,\n np.zeros_like(values) + ylocs[0],\n marker=\"|\",\n color=\"black\",\n markeredgewidth=1.5,\n markersize=30,\n linestyle=\"None\",\n alpha=trace_kwargs[\"alpha\"],\n zorder=-5,\n )\n axes[idx, 0].set_ylim(*ylims[0])\n\n for _, _, vlines in (j for j in lines if j[0] == var_name and j[1] == selection):\n if isinstance(vlines, (float, int)):\n line_values = [vlines]\n else:\n line_values = np.atleast_1d(vlines).ravel()\n axes[idx, 0].vlines(\n line_values, *ylims[0], colors=colors[idx][0], linewidth=1.5, alpha=0.75\n )\n axes[idx, 1].hlines(\n line_values,\n *xlims[1],\n colors=colors[idx][0],\n linewidth=1.5,\n alpha=trace_kwargs[\"alpha\"]\n )\n axes[idx, 0].set_ylim(bottom=0, top=ylims[0][1])\n axes[idx, 1].set_xlim(left=0, right=data.draw.max())\n axes[idx, 1].set_ylim(*ylims[1])\n return axes\n\n\ndef _histplot_op(ax, data, **kwargs):\n \"\"\"Add a histogram for the data to the axes.\"\"\"\n bins = get_bins(data)\n ax.hist(data, bins=bins, align=\"left\", density=True, **kwargs)\n xticks = get_bins(data, max_bins=10, fenceposts=1)\n ax.set_xticks(xticks)\n return ax\n", "path": "arviz/plots/traceplot.py"}]}
| 3,797 | 264 |
gh_patches_debug_19430
|
rasdani/github-patches
|
git_diff
|
pulp__pulpcore-236
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Update CI files for branch 3.21
Update CI files for branch 3.21
</issue>
<code>
[start of pulpcore/app/serializers/publication.py]
1 from gettext import gettext as _
2
3 from django.core import validators
4 from django.db.models import Q
5 from rest_framework import serializers
6 from rest_framework.validators import UniqueValidator
7
8 from pulpcore.app import models
9 from pulpcore.app.serializers import (
10 BaseURLField,
11 DetailIdentityField,
12 DetailRelatedField,
13 MasterModelSerializer,
14 ModelSerializer,
15 NestedRelatedField,
16 RelatedField,
17 validate_unknown_fields,
18 )
19
20
21 class PublicationSerializer(MasterModelSerializer):
22 _href = DetailIdentityField()
23 repository_version = NestedRelatedField(
24 view_name='versions-detail',
25 lookup_field='number',
26 parent_lookup_kwargs={'repository_pk': 'repository__pk'},
27 queryset=models.RepositoryVersion.objects.all(),
28 required=False,
29 )
30 repository = RelatedField(
31 help_text=_('A URI of the repository to be published.'),
32 required=False,
33 label=_('Repository'),
34 queryset=models.Repository.objects.all(),
35 view_name='repositories-detail',
36 write_only=True
37 )
38
39 def validate(self, data):
40 if hasattr(self, 'initial_data'):
41 validate_unknown_fields(self.initial_data, self.fields)
42
43 repository = data.pop('repository', None) # not an actual field on publication
44 repository_version = data.get('repository_version')
45 if not repository and not repository_version:
46 raise serializers.ValidationError(
47 _("Either the 'repository' or 'repository_version' need to be specified"))
48 elif not repository and repository_version:
49 return data
50 elif repository and not repository_version:
51 version = models.RepositoryVersion.latest(repository)
52 if version:
53 new_data = {'repository_version': version}
54 new_data.update(data)
55 return new_data
56 else:
57 raise serializers.ValidationError(
58 detail=_('Repository has no version available to create Publication from'))
59 raise serializers.ValidationError(
60 _("Either the 'repository' or 'repository_version' need to be specified "
61 "but not both.")
62 )
63
64 class Meta:
65 abstract = True
66 model = models.Publication
67 fields = MasterModelSerializer.Meta.fields + (
68 'publisher',
69 'repository_version',
70 'repository'
71 )
72
73
74 class ContentGuardSerializer(MasterModelSerializer):
75 _href = DetailIdentityField()
76
77 name = serializers.CharField(
78 help_text=_('The unique name.')
79 )
80 description = serializers.CharField(
81 help_text=_('An optional description.'),
82 allow_null=True,
83 required=False
84 )
85
86 class Meta:
87 model = models.ContentGuard
88 fields = MasterModelSerializer.Meta.fields + (
89 'name',
90 'description'
91 )
92
93
94 class BaseDistributionSerializer(MasterModelSerializer):
95 """
96 The Serializer for the BaseDistribution model.
97
98 The serializer deliberately omits the "remote" field, which is used for
99 pull-through caching only. Plugins implementing pull-through caching will
100 have to add the field in their derived serializer class like this::
101
102 remote = DetailRelatedField(
103 required=False,
104 help_text=_('Remote that can be used to fetch content when using pull-through caching.'),
105 queryset=models.Remote.objects.all(),
106 allow_null=True
107 )
108
109 """
110
111 _href = DetailIdentityField()
112 base_path = serializers.CharField(
113 help_text=_('The base (relative) path component of the published url. Avoid paths that \
114 overlap with other distribution base paths (e.g. "foo" and "foo/bar")'),
115 validators=[validators.MaxLengthValidator(
116 models.BaseDistribution._meta.get_field('base_path').max_length,
117 message=_('`base_path` length must be less than {} characters').format(
118 models.BaseDistribution._meta.get_field('base_path').max_length
119 )),
120 UniqueValidator(queryset=models.BaseDistribution.objects.all()),
121 ]
122 )
123 base_url = BaseURLField(
124 source='base_path', read_only=True,
125 help_text=_('The URL for accessing the publication as defined by this distribution.')
126 )
127 content_guard = DetailRelatedField(
128 required=False,
129 help_text=_('An optional content-guard.'),
130 queryset=models.ContentGuard.objects.all(),
131 allow_null=True
132 )
133 name = serializers.CharField(
134 help_text=_('A unique name. Ex, `rawhide` and `stable`.'),
135 validators=[validators.MaxLengthValidator(
136 models.BaseDistribution._meta.get_field('name').max_length,
137 message=_('`name` length must be less than {} characters').format(
138 models.BaseDistribution._meta.get_field('name').max_length
139 )),
140 UniqueValidator(queryset=models.BaseDistribution.objects.all())]
141 )
142
143 class Meta:
144 abstract = True
145 model = models.BaseDistribution
146 fields = ModelSerializer.Meta.fields + (
147 'base_path',
148 'base_url',
149 'content_guard',
150 'name',
151 )
152
153 def _validate_path_overlap(self, path):
154 # look for any base paths nested in path
155 search = path.split("/")[0]
156 q = Q(base_path=search)
157 for subdir in path.split("/")[1:]:
158 search = "/".join((search, subdir))
159 q |= Q(base_path=search)
160
161 # look for any base paths that nest path
162 q |= Q(base_path__startswith='{}/'.format(path))
163 qs = models.BaseDistribution.objects.filter(q)
164
165 if self.instance is not None:
166 qs = qs.exclude(pk=self.instance.pk)
167
168 match = qs.first()
169 if match:
170 raise serializers.ValidationError(detail=_("Overlaps with existing distribution '"
171 "{}'").format(match.name))
172
173 return path
174
175 def validate_base_path(self, path):
176 self._validate_relative_path(path)
177 return self._validate_path_overlap(path)
178
179
180 class PublicationDistributionSerializer(BaseDistributionSerializer):
181 publication = DetailRelatedField(
182 required=False,
183 help_text=_('Publication to be served'),
184 queryset=models.Publication.objects.exclude(complete=False),
185 allow_null=True
186 )
187
188 class Meta:
189 abstract = True
190 fields = BaseDistributionSerializer.Meta.fields + (
191 'publication',
192 )
193
194
195 class RepositoryVersionDistributionSerializer(BaseDistributionSerializer):
196 repository = RelatedField(
197 required=False,
198 help_text=_('The latest RepositoryVersion for this Repository will be served.'),
199 queryset=models.Repository.objects.all(),
200 view_name='repositories-detail',
201 allow_null=True
202 )
203 repository_version = NestedRelatedField(
204 required=False,
205 help_text=_('RepositoryVersion to be served'),
206 queryset=models.RepositoryVersion.objects.exclude(complete=False),
207 view_name='versions-detail',
208 allow_null=True,
209 lookup_field='number',
210 parent_lookup_kwargs={'repository_pk': 'repository__pk'},
211 )
212
213 class Meta:
214 abstract = True
215 fields = BaseDistributionSerializer.Meta.fields + (
216 'repository',
217 'repository_version',
218 )
219
220 def validate(self, data):
221 super().validate(data)
222
223 if 'repository' in data and 'repository_version' in data:
224 msg = _("The attributes 'repository' and 'repository_version' must be used"
225 "exclusively.")
226 raise serializers.ValidationError(msg)
227
228 return data
229
[end of pulpcore/app/serializers/publication.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pulpcore/app/serializers/publication.py b/pulpcore/app/serializers/publication.py
--- a/pulpcore/app/serializers/publication.py
+++ b/pulpcore/app/serializers/publication.py
@@ -220,9 +220,23 @@
def validate(self, data):
super().validate(data)
- if 'repository' in data and 'repository_version' in data:
+ repository_in_data = 'repository' in data
+ repository_version_in_data = 'repository_version' in data
+ repository_in_instance = self.instance.repository if self.instance else None
+ repository_version_in_instance = self.instance.repository_version if self.instance else None
+
+ if repository_in_data and repository_version_in_data:
+ error = True
+ elif repository_in_data and repository_version_in_instance:
+ error = True
+ elif repository_in_instance and repository_version_in_data:
+ error = True
+ else:
+ error = False
+
+ if error:
msg = _("The attributes 'repository' and 'repository_version' must be used"
- "exclusively.")
+ " exclusively.")
raise serializers.ValidationError(msg)
return data
|
{"golden_diff": "diff --git a/pulpcore/app/serializers/publication.py b/pulpcore/app/serializers/publication.py\n--- a/pulpcore/app/serializers/publication.py\n+++ b/pulpcore/app/serializers/publication.py\n@@ -220,9 +220,23 @@\n def validate(self, data):\n super().validate(data)\n \n- if 'repository' in data and 'repository_version' in data:\n+ repository_in_data = 'repository' in data\n+ repository_version_in_data = 'repository_version' in data\n+ repository_in_instance = self.instance.repository if self.instance else None\n+ repository_version_in_instance = self.instance.repository_version if self.instance else None\n+\n+ if repository_in_data and repository_version_in_data:\n+ error = True\n+ elif repository_in_data and repository_version_in_instance:\n+ error = True\n+ elif repository_in_instance and repository_version_in_data:\n+ error = True\n+ else:\n+ error = False\n+\n+ if error:\n msg = _(\"The attributes 'repository' and 'repository_version' must be used\"\n- \"exclusively.\")\n+ \" exclusively.\")\n raise serializers.ValidationError(msg)\n \n return data\n", "issue": "Update CI files for branch 3.21\n\nUpdate CI files for branch 3.21\n\n", "before_files": [{"content": "from gettext import gettext as _\n\nfrom django.core import validators\nfrom django.db.models import Q\nfrom rest_framework import serializers\nfrom rest_framework.validators import UniqueValidator\n\nfrom pulpcore.app import models\nfrom pulpcore.app.serializers import (\n BaseURLField,\n DetailIdentityField,\n DetailRelatedField,\n MasterModelSerializer,\n ModelSerializer,\n NestedRelatedField,\n RelatedField,\n validate_unknown_fields,\n)\n\n\nclass PublicationSerializer(MasterModelSerializer):\n _href = DetailIdentityField()\n repository_version = NestedRelatedField(\n view_name='versions-detail',\n lookup_field='number',\n parent_lookup_kwargs={'repository_pk': 'repository__pk'},\n queryset=models.RepositoryVersion.objects.all(),\n required=False,\n )\n repository = RelatedField(\n help_text=_('A URI of the repository to be published.'),\n required=False,\n label=_('Repository'),\n queryset=models.Repository.objects.all(),\n view_name='repositories-detail',\n write_only=True\n )\n\n def validate(self, data):\n if hasattr(self, 'initial_data'):\n validate_unknown_fields(self.initial_data, self.fields)\n\n repository = data.pop('repository', None) # not an actual field on publication\n repository_version = data.get('repository_version')\n if not repository and not repository_version:\n raise serializers.ValidationError(\n _(\"Either the 'repository' or 'repository_version' need to be specified\"))\n elif not repository and repository_version:\n return data\n elif repository and not repository_version:\n version = models.RepositoryVersion.latest(repository)\n if version:\n new_data = {'repository_version': version}\n new_data.update(data)\n return new_data\n else:\n raise serializers.ValidationError(\n detail=_('Repository has no version available to create Publication from'))\n raise serializers.ValidationError(\n _(\"Either the 'repository' or 'repository_version' need to be specified \"\n \"but not both.\")\n )\n\n class Meta:\n abstract = True\n model = models.Publication\n fields = MasterModelSerializer.Meta.fields + (\n 'publisher',\n 'repository_version',\n 'repository'\n )\n\n\nclass ContentGuardSerializer(MasterModelSerializer):\n _href = DetailIdentityField()\n\n name = serializers.CharField(\n help_text=_('The unique name.')\n )\n description = serializers.CharField(\n help_text=_('An optional description.'),\n allow_null=True,\n required=False\n )\n\n class Meta:\n model = models.ContentGuard\n fields = MasterModelSerializer.Meta.fields + (\n 'name',\n 'description'\n )\n\n\nclass BaseDistributionSerializer(MasterModelSerializer):\n \"\"\"\n The Serializer for the BaseDistribution model.\n\n The serializer deliberately omits the \"remote\" field, which is used for\n pull-through caching only. Plugins implementing pull-through caching will\n have to add the field in their derived serializer class like this::\n\n remote = DetailRelatedField(\n required=False,\n help_text=_('Remote that can be used to fetch content when using pull-through caching.'),\n queryset=models.Remote.objects.all(),\n allow_null=True\n )\n\n \"\"\"\n\n _href = DetailIdentityField()\n base_path = serializers.CharField(\n help_text=_('The base (relative) path component of the published url. Avoid paths that \\\n overlap with other distribution base paths (e.g. \"foo\" and \"foo/bar\")'),\n validators=[validators.MaxLengthValidator(\n models.BaseDistribution._meta.get_field('base_path').max_length,\n message=_('`base_path` length must be less than {} characters').format(\n models.BaseDistribution._meta.get_field('base_path').max_length\n )),\n UniqueValidator(queryset=models.BaseDistribution.objects.all()),\n ]\n )\n base_url = BaseURLField(\n source='base_path', read_only=True,\n help_text=_('The URL for accessing the publication as defined by this distribution.')\n )\n content_guard = DetailRelatedField(\n required=False,\n help_text=_('An optional content-guard.'),\n queryset=models.ContentGuard.objects.all(),\n allow_null=True\n )\n name = serializers.CharField(\n help_text=_('A unique name. Ex, `rawhide` and `stable`.'),\n validators=[validators.MaxLengthValidator(\n models.BaseDistribution._meta.get_field('name').max_length,\n message=_('`name` length must be less than {} characters').format(\n models.BaseDistribution._meta.get_field('name').max_length\n )),\n UniqueValidator(queryset=models.BaseDistribution.objects.all())]\n )\n\n class Meta:\n abstract = True\n model = models.BaseDistribution\n fields = ModelSerializer.Meta.fields + (\n 'base_path',\n 'base_url',\n 'content_guard',\n 'name',\n )\n\n def _validate_path_overlap(self, path):\n # look for any base paths nested in path\n search = path.split(\"/\")[0]\n q = Q(base_path=search)\n for subdir in path.split(\"/\")[1:]:\n search = \"/\".join((search, subdir))\n q |= Q(base_path=search)\n\n # look for any base paths that nest path\n q |= Q(base_path__startswith='{}/'.format(path))\n qs = models.BaseDistribution.objects.filter(q)\n\n if self.instance is not None:\n qs = qs.exclude(pk=self.instance.pk)\n\n match = qs.first()\n if match:\n raise serializers.ValidationError(detail=_(\"Overlaps with existing distribution '\"\n \"{}'\").format(match.name))\n\n return path\n\n def validate_base_path(self, path):\n self._validate_relative_path(path)\n return self._validate_path_overlap(path)\n\n\nclass PublicationDistributionSerializer(BaseDistributionSerializer):\n publication = DetailRelatedField(\n required=False,\n help_text=_('Publication to be served'),\n queryset=models.Publication.objects.exclude(complete=False),\n allow_null=True\n )\n\n class Meta:\n abstract = True\n fields = BaseDistributionSerializer.Meta.fields + (\n 'publication',\n )\n\n\nclass RepositoryVersionDistributionSerializer(BaseDistributionSerializer):\n repository = RelatedField(\n required=False,\n help_text=_('The latest RepositoryVersion for this Repository will be served.'),\n queryset=models.Repository.objects.all(),\n view_name='repositories-detail',\n allow_null=True\n )\n repository_version = NestedRelatedField(\n required=False,\n help_text=_('RepositoryVersion to be served'),\n queryset=models.RepositoryVersion.objects.exclude(complete=False),\n view_name='versions-detail',\n allow_null=True,\n lookup_field='number',\n parent_lookup_kwargs={'repository_pk': 'repository__pk'},\n )\n\n class Meta:\n abstract = True\n fields = BaseDistributionSerializer.Meta.fields + (\n 'repository',\n 'repository_version',\n )\n\n def validate(self, data):\n super().validate(data)\n\n if 'repository' in data and 'repository_version' in data:\n msg = _(\"The attributes 'repository' and 'repository_version' must be used\"\n \"exclusively.\")\n raise serializers.ValidationError(msg)\n\n return data\n", "path": "pulpcore/app/serializers/publication.py"}]}
| 2,609 | 267 |
gh_patches_debug_22779
|
rasdani/github-patches
|
git_diff
|
open-mmlab__mmcv-1905
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd3 in position 0: invalid continuation byte
在windows11上面,我使用`pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu113/torch1.11.0/index.html`安装了`mmcv-full 1.5.0`。
之后使用[测试脚本](https://github.com/open-mmlab/mmcv/blob/master/.dev_scripts/check_installation.py)测试是否安装成功,出现了如下错误:
```bash
C:\Users\ZhangQu\.conda\envs\mmlab\python.exe D:/masterResearch/envtest/check_mmcv.py
Start checking the installation of mmcv-full ...
CPU ops were compiled successfully.
CUDA ops were compiled successfully.
mmcv-full has been installed successfully.
Traceback (most recent call last):
File "D:\masterResearch\envtest\check_mmcv.py", line 40, in <module>
env_info_dict = collect_env()
File "C:\Users\ZhangQu\.conda\envs\mmlab\lib\site-packages\mmcv\utils\env.py", line 91, in collect_env
env_info['MSVC'] = cc.decode(encoding).partition('\n')[0].strip()
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd3 in position 0: invalid continuation byte
Process finished with exit code 1
```
</issue>
<code>
[start of mmcv/utils/env.py]
1 # Copyright (c) OpenMMLab. All rights reserved.
2 """This file holding some environment constant for sharing by other files."""
3
4 import os.path as osp
5 import subprocess
6 import sys
7 from collections import defaultdict
8
9 import cv2
10 import torch
11
12 import mmcv
13 from .parrots_wrapper import get_build_config
14
15
16 def collect_env():
17 """Collect the information of the running environments.
18
19 Returns:
20 dict: The environment information. The following fields are contained.
21
22 - sys.platform: The variable of ``sys.platform``.
23 - Python: Python version.
24 - CUDA available: Bool, indicating if CUDA is available.
25 - GPU devices: Device type of each GPU.
26 - CUDA_HOME (optional): The env var ``CUDA_HOME``.
27 - NVCC (optional): NVCC version.
28 - GCC: GCC version, "n/a" if GCC is not installed.
29 - MSVC: Microsoft Virtual C++ Compiler version, Windows only.
30 - PyTorch: PyTorch version.
31 - PyTorch compiling details: The output of \
32 ``torch.__config__.show()``.
33 - TorchVision (optional): TorchVision version.
34 - OpenCV: OpenCV version.
35 - MMCV: MMCV version.
36 - MMCV Compiler: The GCC version for compiling MMCV ops.
37 - MMCV CUDA Compiler: The CUDA version for compiling MMCV ops.
38 """
39 env_info = {}
40 env_info['sys.platform'] = sys.platform
41 env_info['Python'] = sys.version.replace('\n', '')
42
43 cuda_available = torch.cuda.is_available()
44 env_info['CUDA available'] = cuda_available
45
46 if cuda_available:
47 devices = defaultdict(list)
48 for k in range(torch.cuda.device_count()):
49 devices[torch.cuda.get_device_name(k)].append(str(k))
50 for name, device_ids in devices.items():
51 env_info['GPU ' + ','.join(device_ids)] = name
52
53 from mmcv.utils.parrots_wrapper import _get_cuda_home
54 CUDA_HOME = _get_cuda_home()
55 env_info['CUDA_HOME'] = CUDA_HOME
56
57 if CUDA_HOME is not None and osp.isdir(CUDA_HOME):
58 try:
59 nvcc = osp.join(CUDA_HOME, 'bin/nvcc')
60 nvcc = subprocess.check_output(f'"{nvcc}" -V', shell=True)
61 nvcc = nvcc.decode('utf-8').strip()
62 release = nvcc.rfind('Cuda compilation tools')
63 build = nvcc.rfind('Build ')
64 nvcc = nvcc[release:build].strip()
65 except subprocess.SubprocessError:
66 nvcc = 'Not Available'
67 env_info['NVCC'] = nvcc
68
69 try:
70 # Check C++ Compiler.
71 # For Unix-like, sysconfig has 'CC' variable like 'gcc -pthread ...',
72 # indicating the compiler used, we use this to get the compiler name
73 import sysconfig
74 cc = sysconfig.get_config_var('CC')
75 if cc:
76 cc = osp.basename(cc.split()[0])
77 cc_info = subprocess.check_output(f'{cc} --version', shell=True)
78 env_info['GCC'] = cc_info.decode('utf-8').partition(
79 '\n')[0].strip()
80 else:
81 # on Windows, cl.exe is not in PATH. We need to find the path.
82 # distutils.ccompiler.new_compiler() returns a msvccompiler
83 # object and after initialization, path to cl.exe is found.
84 import os
85 from distutils.ccompiler import new_compiler
86 ccompiler = new_compiler()
87 ccompiler.initialize()
88 cc = subprocess.check_output(
89 f'{ccompiler.cc}', stderr=subprocess.STDOUT, shell=True)
90 encoding = os.device_encoding(sys.stdout.fileno()) or 'utf-8'
91 env_info['MSVC'] = cc.decode(encoding).partition('\n')[0].strip()
92 env_info['GCC'] = 'n/a'
93 except subprocess.CalledProcessError:
94 env_info['GCC'] = 'n/a'
95
96 env_info['PyTorch'] = torch.__version__
97 env_info['PyTorch compiling details'] = get_build_config()
98
99 try:
100 import torchvision
101 env_info['TorchVision'] = torchvision.__version__
102 except ModuleNotFoundError:
103 pass
104
105 env_info['OpenCV'] = cv2.__version__
106
107 env_info['MMCV'] = mmcv.__version__
108
109 try:
110 from mmcv.ops import get_compiler_version, get_compiling_cuda_version
111 except ModuleNotFoundError:
112 env_info['MMCV Compiler'] = 'n/a'
113 env_info['MMCV CUDA Compiler'] = 'n/a'
114 else:
115 env_info['MMCV Compiler'] = get_compiler_version()
116 env_info['MMCV CUDA Compiler'] = get_compiling_cuda_version()
117
118 return env_info
119
[end of mmcv/utils/env.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mmcv/utils/env.py b/mmcv/utils/env.py
--- a/mmcv/utils/env.py
+++ b/mmcv/utils/env.py
@@ -81,13 +81,15 @@
# on Windows, cl.exe is not in PATH. We need to find the path.
# distutils.ccompiler.new_compiler() returns a msvccompiler
# object and after initialization, path to cl.exe is found.
+ import locale
import os
from distutils.ccompiler import new_compiler
ccompiler = new_compiler()
ccompiler.initialize()
cc = subprocess.check_output(
f'{ccompiler.cc}', stderr=subprocess.STDOUT, shell=True)
- encoding = os.device_encoding(sys.stdout.fileno()) or 'utf-8'
+ encoding = os.device_encoding(
+ sys.stdout.fileno()) or locale.getpreferredencoding()
env_info['MSVC'] = cc.decode(encoding).partition('\n')[0].strip()
env_info['GCC'] = 'n/a'
except subprocess.CalledProcessError:
|
{"golden_diff": "diff --git a/mmcv/utils/env.py b/mmcv/utils/env.py\n--- a/mmcv/utils/env.py\n+++ b/mmcv/utils/env.py\n@@ -81,13 +81,15 @@\n # on Windows, cl.exe is not in PATH. We need to find the path.\n # distutils.ccompiler.new_compiler() returns a msvccompiler\n # object and after initialization, path to cl.exe is found.\n+ import locale\n import os\n from distutils.ccompiler import new_compiler\n ccompiler = new_compiler()\n ccompiler.initialize()\n cc = subprocess.check_output(\n f'{ccompiler.cc}', stderr=subprocess.STDOUT, shell=True)\n- encoding = os.device_encoding(sys.stdout.fileno()) or 'utf-8'\n+ encoding = os.device_encoding(\n+ sys.stdout.fileno()) or locale.getpreferredencoding()\n env_info['MSVC'] = cc.decode(encoding).partition('\\n')[0].strip()\n env_info['GCC'] = 'n/a'\n except subprocess.CalledProcessError:\n", "issue": "UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd3 in position 0: invalid continuation byte\n\u5728windows11\u4e0a\u9762\uff0c\u6211\u4f7f\u7528`pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu113/torch1.11.0/index.html`\u5b89\u88c5\u4e86`mmcv-full 1.5.0`\u3002\r\n\u4e4b\u540e\u4f7f\u7528[\u6d4b\u8bd5\u811a\u672c](https://github.com/open-mmlab/mmcv/blob/master/.dev_scripts/check_installation.py)\u6d4b\u8bd5\u662f\u5426\u5b89\u88c5\u6210\u529f\uff0c\u51fa\u73b0\u4e86\u5982\u4e0b\u9519\u8bef:\r\n```bash\r\nC:\\Users\\ZhangQu\\.conda\\envs\\mmlab\\python.exe D:/masterResearch/envtest/check_mmcv.py\r\nStart checking the installation of mmcv-full ...\r\nCPU ops were compiled successfully.\r\nCUDA ops were compiled successfully.\r\nmmcv-full has been installed successfully.\r\n\r\nTraceback (most recent call last):\r\n File \"D:\\masterResearch\\envtest\\check_mmcv.py\", line 40, in <module>\r\n env_info_dict = collect_env()\r\n File \"C:\\Users\\ZhangQu\\.conda\\envs\\mmlab\\lib\\site-packages\\mmcv\\utils\\env.py\", line 91, in collect_env\r\n env_info['MSVC'] = cc.decode(encoding).partition('\\n')[0].strip()\r\nUnicodeDecodeError: 'utf-8' codec can't decode byte 0xd3 in position 0: invalid continuation byte\r\n\r\nProcess finished with exit code 1\r\n```\n", "before_files": [{"content": "# Copyright (c) OpenMMLab. All rights reserved.\n\"\"\"This file holding some environment constant for sharing by other files.\"\"\"\n\nimport os.path as osp\nimport subprocess\nimport sys\nfrom collections import defaultdict\n\nimport cv2\nimport torch\n\nimport mmcv\nfrom .parrots_wrapper import get_build_config\n\n\ndef collect_env():\n \"\"\"Collect the information of the running environments.\n\n Returns:\n dict: The environment information. The following fields are contained.\n\n - sys.platform: The variable of ``sys.platform``.\n - Python: Python version.\n - CUDA available: Bool, indicating if CUDA is available.\n - GPU devices: Device type of each GPU.\n - CUDA_HOME (optional): The env var ``CUDA_HOME``.\n - NVCC (optional): NVCC version.\n - GCC: GCC version, \"n/a\" if GCC is not installed.\n - MSVC: Microsoft Virtual C++ Compiler version, Windows only.\n - PyTorch: PyTorch version.\n - PyTorch compiling details: The output of \\\n ``torch.__config__.show()``.\n - TorchVision (optional): TorchVision version.\n - OpenCV: OpenCV version.\n - MMCV: MMCV version.\n - MMCV Compiler: The GCC version for compiling MMCV ops.\n - MMCV CUDA Compiler: The CUDA version for compiling MMCV ops.\n \"\"\"\n env_info = {}\n env_info['sys.platform'] = sys.platform\n env_info['Python'] = sys.version.replace('\\n', '')\n\n cuda_available = torch.cuda.is_available()\n env_info['CUDA available'] = cuda_available\n\n if cuda_available:\n devices = defaultdict(list)\n for k in range(torch.cuda.device_count()):\n devices[torch.cuda.get_device_name(k)].append(str(k))\n for name, device_ids in devices.items():\n env_info['GPU ' + ','.join(device_ids)] = name\n\n from mmcv.utils.parrots_wrapper import _get_cuda_home\n CUDA_HOME = _get_cuda_home()\n env_info['CUDA_HOME'] = CUDA_HOME\n\n if CUDA_HOME is not None and osp.isdir(CUDA_HOME):\n try:\n nvcc = osp.join(CUDA_HOME, 'bin/nvcc')\n nvcc = subprocess.check_output(f'\"{nvcc}\" -V', shell=True)\n nvcc = nvcc.decode('utf-8').strip()\n release = nvcc.rfind('Cuda compilation tools')\n build = nvcc.rfind('Build ')\n nvcc = nvcc[release:build].strip()\n except subprocess.SubprocessError:\n nvcc = 'Not Available'\n env_info['NVCC'] = nvcc\n\n try:\n # Check C++ Compiler.\n # For Unix-like, sysconfig has 'CC' variable like 'gcc -pthread ...',\n # indicating the compiler used, we use this to get the compiler name\n import sysconfig\n cc = sysconfig.get_config_var('CC')\n if cc:\n cc = osp.basename(cc.split()[0])\n cc_info = subprocess.check_output(f'{cc} --version', shell=True)\n env_info['GCC'] = cc_info.decode('utf-8').partition(\n '\\n')[0].strip()\n else:\n # on Windows, cl.exe is not in PATH. We need to find the path.\n # distutils.ccompiler.new_compiler() returns a msvccompiler\n # object and after initialization, path to cl.exe is found.\n import os\n from distutils.ccompiler import new_compiler\n ccompiler = new_compiler()\n ccompiler.initialize()\n cc = subprocess.check_output(\n f'{ccompiler.cc}', stderr=subprocess.STDOUT, shell=True)\n encoding = os.device_encoding(sys.stdout.fileno()) or 'utf-8'\n env_info['MSVC'] = cc.decode(encoding).partition('\\n')[0].strip()\n env_info['GCC'] = 'n/a'\n except subprocess.CalledProcessError:\n env_info['GCC'] = 'n/a'\n\n env_info['PyTorch'] = torch.__version__\n env_info['PyTorch compiling details'] = get_build_config()\n\n try:\n import torchvision\n env_info['TorchVision'] = torchvision.__version__\n except ModuleNotFoundError:\n pass\n\n env_info['OpenCV'] = cv2.__version__\n\n env_info['MMCV'] = mmcv.__version__\n\n try:\n from mmcv.ops import get_compiler_version, get_compiling_cuda_version\n except ModuleNotFoundError:\n env_info['MMCV Compiler'] = 'n/a'\n env_info['MMCV CUDA Compiler'] = 'n/a'\n else:\n env_info['MMCV Compiler'] = get_compiler_version()\n env_info['MMCV CUDA Compiler'] = get_compiling_cuda_version()\n\n return env_info\n", "path": "mmcv/utils/env.py"}]}
| 2,148 | 231 |
gh_patches_debug_20917
|
rasdani/github-patches
|
git_diff
|
open-mmlab__mmengine-695
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[bug] error when using `python tools/train.py` to train `ReDet` in MMRotate.
when the `self.distributed` equals to False, `revert_sync_batchnorm` function cannot work normally.
https://github.com/open-mmlab/mmengine/blob/bda92b49e751c721c11bb15623dabc7f7a9517e7/mmengine/runner/runner.py#L848
We argue this is caused by [ReDet](https://github.com/open-mmlab/mmrotate/blob/dev-1.x/configs/redet/redet_re50_refpn_1x_dota_le90.py) replacing ``torch.nn`` with ``e2cnn.nn``.
https://github.com/open-mmlab/mmrotate/blob/dev-1.x/mmrotate/models/backbones/re_resnet.py
</issue>
<code>
[start of mmengine/model/utils.py]
1 # Copyright (c) OpenMMLab. All rights reserved.
2 import logging
3 import warnings
4 from typing import List, Union
5
6 import torch
7 import torch.nn as nn
8 import torch.nn.functional as F
9
10 from mmengine.utils.dl_utils import mmcv_full_available
11
12
13 def stack_batch(tensor_list: List[torch.Tensor],
14 pad_size_divisor: int = 1,
15 pad_value: Union[int, float] = 0) -> torch.Tensor:
16 """Stack multiple tensors to form a batch and pad the tensor to the max
17 shape use the right bottom padding mode in these images. If
18 ``pad_size_divisor > 0``, add padding to ensure the shape of each dim is
19 divisible by ``pad_size_divisor``.
20
21 Args:
22 tensor_list (List[Tensor]): A list of tensors with the same dim.
23 pad_size_divisor (int): If ``pad_size_divisor > 0``, add padding
24 to ensure the shape of each dim is divisible by
25 ``pad_size_divisor``. This depends on the model, and many
26 models need to be divisible by 32. Defaults to 1
27 pad_value (int, float): The padding value. Defaults to 0.
28
29 Returns:
30 Tensor: The n dim tensor.
31 """
32 assert isinstance(
33 tensor_list,
34 list), (f'Expected input type to be list, but got {type(tensor_list)}')
35 assert tensor_list, '`tensor_list` could not be an empty list'
36 assert len({
37 tensor.ndim
38 for tensor in tensor_list
39 }) == 1, (f'Expected the dimensions of all tensors must be the same, '
40 f'but got {[tensor.ndim for tensor in tensor_list]}')
41
42 dim = tensor_list[0].dim()
43 num_img = len(tensor_list)
44 all_sizes: torch.Tensor = torch.Tensor(
45 [tensor.shape for tensor in tensor_list])
46 max_sizes = torch.ceil(
47 torch.max(all_sizes, dim=0)[0] / pad_size_divisor) * pad_size_divisor
48 padded_sizes = max_sizes - all_sizes
49 # The first dim normally means channel, which should not be padded.
50 padded_sizes[:, 0] = 0
51 if padded_sizes.sum() == 0:
52 return torch.stack(tensor_list)
53 # `pad` is the second arguments of `F.pad`. If pad is (1, 2, 3, 4),
54 # it means that padding the last dim with 1(left) 2(right), padding the
55 # penultimate dim to 3(top) 4(bottom). The order of `pad` is opposite of
56 # the `padded_sizes`. Therefore, the `padded_sizes` needs to be reversed,
57 # and only odd index of pad should be assigned to keep padding "right" and
58 # "bottom".
59 pad = torch.zeros(num_img, 2 * dim, dtype=torch.int)
60 pad[:, 1::2] = padded_sizes[:, range(dim - 1, -1, -1)]
61 batch_tensor = []
62 for idx, tensor in enumerate(tensor_list):
63 batch_tensor.append(
64 F.pad(tensor, tuple(pad[idx].tolist()), value=pad_value))
65 return torch.stack(batch_tensor)
66
67
68 def detect_anomalous_params(loss: torch.Tensor, model) -> None:
69 parameters_in_graph = set()
70 visited = set()
71
72 def traverse(grad_fn):
73 if grad_fn is None:
74 return
75 if grad_fn not in visited:
76 visited.add(grad_fn)
77 if hasattr(grad_fn, 'variable'):
78 parameters_in_graph.add(grad_fn.variable)
79 parents = grad_fn.next_functions
80 if parents is not None:
81 for parent in parents:
82 grad_fn = parent[0]
83 traverse(grad_fn)
84
85 traverse(loss.grad_fn)
86 from mmengine.logging import MMLogger
87 logger = MMLogger.get_current_instance()
88 for n, p in model.named_parameters():
89 if p not in parameters_in_graph and p.requires_grad:
90 logger.log(
91 level=logging.ERROR,
92 msg=f'{n} with shape {p.size()} is not '
93 f'in the computational graph \n')
94
95
96 def merge_dict(*args):
97 """Merge all dictionaries into one dictionary.
98
99 If pytorch version >= 1.8, ``merge_dict`` will be wrapped
100 by ``torch.fx.wrap``, which will make ``torch.fx.symbolic_trace`` skip
101 trace ``merge_dict``.
102
103 Note:
104 If a function needs to be traced by ``torch.fx.symbolic_trace``,
105 but inevitably needs to use ``update`` method of ``dict``(``update``
106 is not traceable). It should use ``merge_dict`` to replace
107 ``xxx.update``.
108
109 Args:
110 *args: dictionary needs to be merged.
111
112 Returns:
113 dict: Merged dict from args
114 """
115 output = dict()
116 for item in args:
117 assert isinstance(
118 item,
119 dict), (f'all arguments of merge_dict should be a dict, but got '
120 f'{type(item)}')
121 output.update(item)
122 return output
123
124
125 # torch.fx is only available when pytorch version >= 1.8.
126 # If the subclass of `BaseModel` has multiple submodules, and each module
127 # will return a loss dict during training process, i.e., `TwoStageDetector`
128 # in mmdet. It should use `merge_dict` to get the total loss, rather than
129 # `loss.update` to keep model traceable.
130 try:
131 import torch.fx
132
133 # make torch.fx skip trace `merge_dict`.
134 merge_dict = torch.fx.wrap(merge_dict)
135
136 except ImportError:
137 warnings.warn('Cannot import torch.fx, `merge_dict` is a simple function '
138 'to merge multiple dicts')
139
140
141 class _BatchNormXd(nn.modules.batchnorm._BatchNorm):
142 """A general BatchNorm layer without input dimension check.
143
144 Reproduced from @kapily's work:
145 (https://github.com/pytorch/pytorch/issues/41081#issuecomment-783961547)
146 The only difference between BatchNorm1d, BatchNorm2d, BatchNorm3d, etc
147 is `_check_input_dim` that is designed for tensor sanity checks.
148 The check has been bypassed in this class for the convenience of converting
149 SyncBatchNorm.
150 """
151
152 def _check_input_dim(self, input: torch.Tensor):
153 return
154
155
156 def revert_sync_batchnorm(module: nn.Module) -> nn.Module:
157 """Helper function to convert all `SyncBatchNorm` (SyncBN) and
158 `mmcv.ops.sync_bn.SyncBatchNorm`(MMSyncBN) layers in the model to
159 `BatchNormXd` layers.
160
161 Adapted from @kapily's work:
162 (https://github.com/pytorch/pytorch/issues/41081#issuecomment-783961547)
163
164 Args:
165 module (nn.Module): The module containing `SyncBatchNorm` layers.
166
167 Returns:
168 module_output: The converted module with `BatchNormXd` layers.
169 """
170 module_output = module
171 module_checklist = [torch.nn.modules.batchnorm.SyncBatchNorm]
172
173 if mmcv_full_available():
174 from mmcv.ops import SyncBatchNorm
175 module_checklist.append(SyncBatchNorm)
176
177 if isinstance(module, tuple(module_checklist)):
178 module_output = _BatchNormXd(module.num_features, module.eps,
179 module.momentum, module.affine,
180 module.track_running_stats)
181 if module.affine:
182 # no_grad() may not be needed here but
183 # just to be consistent with `convert_sync_batchnorm()`
184 with torch.no_grad():
185 module_output.weight = module.weight
186 module_output.bias = module.bias
187 module_output.running_mean = module.running_mean
188 module_output.running_var = module.running_var
189 module_output.num_batches_tracked = module.num_batches_tracked
190 module_output.training = module.training
191 # qconfig exists in quantized models
192 if hasattr(module, 'qconfig'):
193 module_output.qconfig = module.qconfig
194 for name, child in module.named_children():
195 module_output.add_module(name, revert_sync_batchnorm(child))
196 del module
197 return module_output
198
199
200 def convert_sync_batchnorm(module: nn.Module,
201 implementation='torch') -> nn.Module:
202 """Helper function to convert all `BatchNorm` layers in the model to
203 `SyncBatchNorm` (SyncBN) or `mmcv.ops.sync_bn.SyncBatchNorm`(MMSyncBN)
204 layers. Adapted from <https://pytorch.org/docs/stable/generated/torch.nn.Sy
205 ncBatchNorm.html#torch.nn.SyncBatchNorm.convert_sync_batchnorm>_.
206
207 Args:
208 module (nn.Module): The module containing `SyncBatchNorm` layers.
209 implementation (str): The type of `SyncBatchNorm` to convert to.
210
211 - 'torch': convert to `torch.nn.modules.batchnorm.SyncBatchNorm`.
212 - 'mmcv': convert to `mmcv.ops.sync_bn.SyncBatchNorm`.
213
214 Returns:
215 nn.Module: The converted module with `SyncBatchNorm` layers.
216 """ # noqa: E501
217 module_output = module
218
219 if isinstance(module, torch.nn.modules.batchnorm._BatchNorm):
220 if implementation == 'torch':
221 SyncBatchNorm = torch.nn.modules.batchnorm.SyncBatchNorm
222 elif implementation == 'mmcv':
223 from mmcv.ops import SyncBatchNorm # type: ignore
224 else:
225 raise ValueError('sync_bn should be "torch" or "mmcv", but got '
226 f'{implementation}')
227
228 module_output = SyncBatchNorm(module.num_features, module.eps,
229 module.momentum, module.affine,
230 module.track_running_stats)
231
232 if module.affine:
233 with torch.no_grad():
234 module_output.weight = module.weight
235 module_output.bias = module.bias
236 module_output.running_mean = module.running_mean
237 module_output.running_var = module.running_var
238 module_output.num_batches_tracked = module.num_batches_tracked
239 if hasattr(module, 'qconfig'):
240 module_output.qconfig = module.qconfig
241 for name, child in module.named_children():
242 module_output.add_module(name,
243 convert_sync_batchnorm(child, implementation))
244 del module
245 return module_output
246
[end of mmengine/model/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mmengine/model/utils.py b/mmengine/model/utils.py
--- a/mmengine/model/utils.py
+++ b/mmengine/model/utils.py
@@ -7,6 +7,7 @@
import torch.nn as nn
import torch.nn.functional as F
+from mmengine.logging import print_log
from mmengine.utils.dl_utils import mmcv_full_available
@@ -192,7 +193,17 @@
if hasattr(module, 'qconfig'):
module_output.qconfig = module.qconfig
for name, child in module.named_children():
- module_output.add_module(name, revert_sync_batchnorm(child))
+ # Some custom modules or 3rd party implemented modules may raise an
+ # error when calling `add_module`. Therefore, try to catch the error
+ # and do not raise it. See https://github.com/open-mmlab/mmengine/issues/638 # noqa: E501
+ # for more details.
+ try:
+ module_output.add_module(name, revert_sync_batchnorm(child))
+ except Exception:
+ print_log(
+ F'Failed to convert {child} from SyncBN to BN!',
+ logger='current',
+ level=logging.WARNING)
del module
return module_output
|
{"golden_diff": "diff --git a/mmengine/model/utils.py b/mmengine/model/utils.py\n--- a/mmengine/model/utils.py\n+++ b/mmengine/model/utils.py\n@@ -7,6 +7,7 @@\n import torch.nn as nn\n import torch.nn.functional as F\n \n+from mmengine.logging import print_log\n from mmengine.utils.dl_utils import mmcv_full_available\n \n \n@@ -192,7 +193,17 @@\n if hasattr(module, 'qconfig'):\n module_output.qconfig = module.qconfig\n for name, child in module.named_children():\n- module_output.add_module(name, revert_sync_batchnorm(child))\n+ # Some custom modules or 3rd party implemented modules may raise an\n+ # error when calling `add_module`. Therefore, try to catch the error\n+ # and do not raise it. See https://github.com/open-mmlab/mmengine/issues/638 # noqa: E501\n+ # for more details.\n+ try:\n+ module_output.add_module(name, revert_sync_batchnorm(child))\n+ except Exception:\n+ print_log(\n+ F'Failed to convert {child} from SyncBN to BN!',\n+ logger='current',\n+ level=logging.WARNING)\n del module\n return module_output\n", "issue": "[bug] error when using `python tools/train.py` to train `ReDet` in MMRotate.\nwhen the `self.distributed` equals to False, `revert_sync_batchnorm` function cannot work normally. \r\nhttps://github.com/open-mmlab/mmengine/blob/bda92b49e751c721c11bb15623dabc7f7a9517e7/mmengine/runner/runner.py#L848\r\n\r\nWe argue this is caused by [ReDet](https://github.com/open-mmlab/mmrotate/blob/dev-1.x/configs/redet/redet_re50_refpn_1x_dota_le90.py) replacing ``torch.nn`` with ``e2cnn.nn``.\r\n\r\nhttps://github.com/open-mmlab/mmrotate/blob/dev-1.x/mmrotate/models/backbones/re_resnet.py\r\n\r\n\n", "before_files": [{"content": "# Copyright (c) OpenMMLab. All rights reserved.\nimport logging\nimport warnings\nfrom typing import List, Union\n\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\n\nfrom mmengine.utils.dl_utils import mmcv_full_available\n\n\ndef stack_batch(tensor_list: List[torch.Tensor],\n pad_size_divisor: int = 1,\n pad_value: Union[int, float] = 0) -> torch.Tensor:\n \"\"\"Stack multiple tensors to form a batch and pad the tensor to the max\n shape use the right bottom padding mode in these images. If\n ``pad_size_divisor > 0``, add padding to ensure the shape of each dim is\n divisible by ``pad_size_divisor``.\n\n Args:\n tensor_list (List[Tensor]): A list of tensors with the same dim.\n pad_size_divisor (int): If ``pad_size_divisor > 0``, add padding\n to ensure the shape of each dim is divisible by\n ``pad_size_divisor``. This depends on the model, and many\n models need to be divisible by 32. Defaults to 1\n pad_value (int, float): The padding value. Defaults to 0.\n\n Returns:\n Tensor: The n dim tensor.\n \"\"\"\n assert isinstance(\n tensor_list,\n list), (f'Expected input type to be list, but got {type(tensor_list)}')\n assert tensor_list, '`tensor_list` could not be an empty list'\n assert len({\n tensor.ndim\n for tensor in tensor_list\n }) == 1, (f'Expected the dimensions of all tensors must be the same, '\n f'but got {[tensor.ndim for tensor in tensor_list]}')\n\n dim = tensor_list[0].dim()\n num_img = len(tensor_list)\n all_sizes: torch.Tensor = torch.Tensor(\n [tensor.shape for tensor in tensor_list])\n max_sizes = torch.ceil(\n torch.max(all_sizes, dim=0)[0] / pad_size_divisor) * pad_size_divisor\n padded_sizes = max_sizes - all_sizes\n # The first dim normally means channel, which should not be padded.\n padded_sizes[:, 0] = 0\n if padded_sizes.sum() == 0:\n return torch.stack(tensor_list)\n # `pad` is the second arguments of `F.pad`. If pad is (1, 2, 3, 4),\n # it means that padding the last dim with 1(left) 2(right), padding the\n # penultimate dim to 3(top) 4(bottom). The order of `pad` is opposite of\n # the `padded_sizes`. Therefore, the `padded_sizes` needs to be reversed,\n # and only odd index of pad should be assigned to keep padding \"right\" and\n # \"bottom\".\n pad = torch.zeros(num_img, 2 * dim, dtype=torch.int)\n pad[:, 1::2] = padded_sizes[:, range(dim - 1, -1, -1)]\n batch_tensor = []\n for idx, tensor in enumerate(tensor_list):\n batch_tensor.append(\n F.pad(tensor, tuple(pad[idx].tolist()), value=pad_value))\n return torch.stack(batch_tensor)\n\n\ndef detect_anomalous_params(loss: torch.Tensor, model) -> None:\n parameters_in_graph = set()\n visited = set()\n\n def traverse(grad_fn):\n if grad_fn is None:\n return\n if grad_fn not in visited:\n visited.add(grad_fn)\n if hasattr(grad_fn, 'variable'):\n parameters_in_graph.add(grad_fn.variable)\n parents = grad_fn.next_functions\n if parents is not None:\n for parent in parents:\n grad_fn = parent[0]\n traverse(grad_fn)\n\n traverse(loss.grad_fn)\n from mmengine.logging import MMLogger\n logger = MMLogger.get_current_instance()\n for n, p in model.named_parameters():\n if p not in parameters_in_graph and p.requires_grad:\n logger.log(\n level=logging.ERROR,\n msg=f'{n} with shape {p.size()} is not '\n f'in the computational graph \\n')\n\n\ndef merge_dict(*args):\n \"\"\"Merge all dictionaries into one dictionary.\n\n If pytorch version >= 1.8, ``merge_dict`` will be wrapped\n by ``torch.fx.wrap``, which will make ``torch.fx.symbolic_trace`` skip\n trace ``merge_dict``.\n\n Note:\n If a function needs to be traced by ``torch.fx.symbolic_trace``,\n but inevitably needs to use ``update`` method of ``dict``(``update``\n is not traceable). It should use ``merge_dict`` to replace\n ``xxx.update``.\n\n Args:\n *args: dictionary needs to be merged.\n\n Returns:\n dict: Merged dict from args\n \"\"\"\n output = dict()\n for item in args:\n assert isinstance(\n item,\n dict), (f'all arguments of merge_dict should be a dict, but got '\n f'{type(item)}')\n output.update(item)\n return output\n\n\n# torch.fx is only available when pytorch version >= 1.8.\n# If the subclass of `BaseModel` has multiple submodules, and each module\n# will return a loss dict during training process, i.e., `TwoStageDetector`\n# in mmdet. It should use `merge_dict` to get the total loss, rather than\n# `loss.update` to keep model traceable.\ntry:\n import torch.fx\n\n # make torch.fx skip trace `merge_dict`.\n merge_dict = torch.fx.wrap(merge_dict)\n\nexcept ImportError:\n warnings.warn('Cannot import torch.fx, `merge_dict` is a simple function '\n 'to merge multiple dicts')\n\n\nclass _BatchNormXd(nn.modules.batchnorm._BatchNorm):\n \"\"\"A general BatchNorm layer without input dimension check.\n\n Reproduced from @kapily's work:\n (https://github.com/pytorch/pytorch/issues/41081#issuecomment-783961547)\n The only difference between BatchNorm1d, BatchNorm2d, BatchNorm3d, etc\n is `_check_input_dim` that is designed for tensor sanity checks.\n The check has been bypassed in this class for the convenience of converting\n SyncBatchNorm.\n \"\"\"\n\n def _check_input_dim(self, input: torch.Tensor):\n return\n\n\ndef revert_sync_batchnorm(module: nn.Module) -> nn.Module:\n \"\"\"Helper function to convert all `SyncBatchNorm` (SyncBN) and\n `mmcv.ops.sync_bn.SyncBatchNorm`(MMSyncBN) layers in the model to\n `BatchNormXd` layers.\n\n Adapted from @kapily's work:\n (https://github.com/pytorch/pytorch/issues/41081#issuecomment-783961547)\n\n Args:\n module (nn.Module): The module containing `SyncBatchNorm` layers.\n\n Returns:\n module_output: The converted module with `BatchNormXd` layers.\n \"\"\"\n module_output = module\n module_checklist = [torch.nn.modules.batchnorm.SyncBatchNorm]\n\n if mmcv_full_available():\n from mmcv.ops import SyncBatchNorm\n module_checklist.append(SyncBatchNorm)\n\n if isinstance(module, tuple(module_checklist)):\n module_output = _BatchNormXd(module.num_features, module.eps,\n module.momentum, module.affine,\n module.track_running_stats)\n if module.affine:\n # no_grad() may not be needed here but\n # just to be consistent with `convert_sync_batchnorm()`\n with torch.no_grad():\n module_output.weight = module.weight\n module_output.bias = module.bias\n module_output.running_mean = module.running_mean\n module_output.running_var = module.running_var\n module_output.num_batches_tracked = module.num_batches_tracked\n module_output.training = module.training\n # qconfig exists in quantized models\n if hasattr(module, 'qconfig'):\n module_output.qconfig = module.qconfig\n for name, child in module.named_children():\n module_output.add_module(name, revert_sync_batchnorm(child))\n del module\n return module_output\n\n\ndef convert_sync_batchnorm(module: nn.Module,\n implementation='torch') -> nn.Module:\n \"\"\"Helper function to convert all `BatchNorm` layers in the model to\n `SyncBatchNorm` (SyncBN) or `mmcv.ops.sync_bn.SyncBatchNorm`(MMSyncBN)\n layers. Adapted from <https://pytorch.org/docs/stable/generated/torch.nn.Sy\n ncBatchNorm.html#torch.nn.SyncBatchNorm.convert_sync_batchnorm>_.\n\n Args:\n module (nn.Module): The module containing `SyncBatchNorm` layers.\n implementation (str): The type of `SyncBatchNorm` to convert to.\n\n - 'torch': convert to `torch.nn.modules.batchnorm.SyncBatchNorm`.\n - 'mmcv': convert to `mmcv.ops.sync_bn.SyncBatchNorm`.\n\n Returns:\n nn.Module: The converted module with `SyncBatchNorm` layers.\n \"\"\" # noqa: E501\n module_output = module\n\n if isinstance(module, torch.nn.modules.batchnorm._BatchNorm):\n if implementation == 'torch':\n SyncBatchNorm = torch.nn.modules.batchnorm.SyncBatchNorm\n elif implementation == 'mmcv':\n from mmcv.ops import SyncBatchNorm # type: ignore\n else:\n raise ValueError('sync_bn should be \"torch\" or \"mmcv\", but got '\n f'{implementation}')\n\n module_output = SyncBatchNorm(module.num_features, module.eps,\n module.momentum, module.affine,\n module.track_running_stats)\n\n if module.affine:\n with torch.no_grad():\n module_output.weight = module.weight\n module_output.bias = module.bias\n module_output.running_mean = module.running_mean\n module_output.running_var = module.running_var\n module_output.num_batches_tracked = module.num_batches_tracked\n if hasattr(module, 'qconfig'):\n module_output.qconfig = module.qconfig\n for name, child in module.named_children():\n module_output.add_module(name,\n convert_sync_batchnorm(child, implementation))\n del module\n return module_output\n", "path": "mmengine/model/utils.py"}]}
| 3,596 | 276 |
gh_patches_debug_3067
|
rasdani/github-patches
|
git_diff
|
celery__celery-2598
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
CELERY_RESULT_SERIALIZER = 'json' breaks Exception marshaling
Setting `CELERY_RESULT_SERIALIZER = json` and raising an exception in the worker leads to this:
```
/path/to/lib/python2.7/site-packages/celery/result.py in get(self, timeout, propagate, interval, no_ack, follow_parents, EXCEPTION_STATES, PROPAGATE_STATES)
173 status = meta['status']
174 if status in PROPAGATE_STATES and propagate:
--> 175 raise meta['result']
176 return meta['result']
177 wait = get # deprecated alias to :meth:`get`.
TypeError: exceptions must be old-style classes or derived from BaseException, not dict
```
where the contents of `meta['result']` are (in my case):
```
{u'exc_message': u'unknown keys: nam', u'exc_type': u'ValueError'}
```
so it _looks_ like celery could convert the dict to a real exception before raising, but it does not currently. Changing back to `pickle` works as expected.
bug can be reproduced with the following:
``` python
# jsonresults.py
from celery.app.base import Celery
CELERY_RESULT_SERIALIZER = 'json'
CELERY_RESULT_BACKEND = 'amqp'
app = Celery(config_source=__name__)
@app.task
def hello():
raise ValueError('go away')
```
worker:
```
# python -m celery --app=jsonresults:app worker
```
caller:
``` python
import jsonresults
jsonresults.hello.delay().get()
```
</issue>
<code>
[start of celery/backends/amqp.py]
1 # -*- coding: utf-8 -*-
2 """
3 celery.backends.amqp
4 ~~~~~~~~~~~~~~~~~~~~
5
6 The AMQP result backend.
7
8 This backend publishes results as messages.
9
10 """
11 from __future__ import absolute_import
12
13 import socket
14
15 from collections import deque
16 from operator import itemgetter
17
18 from kombu import Exchange, Queue, Producer, Consumer
19
20 from celery import states
21 from celery.exceptions import TimeoutError
22 from celery.five import range, monotonic
23 from celery.utils.functional import dictfilter
24 from celery.utils.log import get_logger
25 from celery.utils.timeutils import maybe_s_to_ms
26
27 from .base import BaseBackend
28
29 __all__ = ['BacklogLimitExceeded', 'AMQPBackend']
30
31 logger = get_logger(__name__)
32
33
34 class BacklogLimitExceeded(Exception):
35 """Too much state history to fast-forward."""
36
37
38 def repair_uuid(s):
39 # Historically the dashes in UUIDS are removed from AMQ entity names,
40 # but there is no known reason to. Hopefully we'll be able to fix
41 # this in v4.0.
42 return '%s-%s-%s-%s-%s' % (s[:8], s[8:12], s[12:16], s[16:20], s[20:])
43
44
45 class NoCacheQueue(Queue):
46 can_cache_declaration = False
47
48
49 class AMQPBackend(BaseBackend):
50 """Publishes results by sending messages."""
51 Exchange = Exchange
52 Queue = NoCacheQueue
53 Consumer = Consumer
54 Producer = Producer
55
56 BacklogLimitExceeded = BacklogLimitExceeded
57
58 persistent = True
59 supports_autoexpire = True
60 supports_native_join = True
61
62 retry_policy = {
63 'max_retries': 20,
64 'interval_start': 0,
65 'interval_step': 1,
66 'interval_max': 1,
67 }
68
69 def __init__(self, app, connection=None, exchange=None, exchange_type=None,
70 persistent=None, serializer=None, auto_delete=True, **kwargs):
71 super(AMQPBackend, self).__init__(app, **kwargs)
72 conf = self.app.conf
73 self._connection = connection
74 self.persistent = self.prepare_persistent(persistent)
75 self.delivery_mode = 2 if self.persistent else 1
76 exchange = exchange or conf.CELERY_RESULT_EXCHANGE
77 exchange_type = exchange_type or conf.CELERY_RESULT_EXCHANGE_TYPE
78 self.exchange = self._create_exchange(
79 exchange, exchange_type, self.delivery_mode,
80 )
81 self.serializer = serializer or conf.CELERY_RESULT_SERIALIZER
82 self.auto_delete = auto_delete
83 self.queue_arguments = dictfilter({
84 'x-expires': maybe_s_to_ms(self.expires),
85 })
86
87 def _create_exchange(self, name, type='direct', delivery_mode=2):
88 return self.Exchange(name=name,
89 type=type,
90 delivery_mode=delivery_mode,
91 durable=self.persistent,
92 auto_delete=False)
93
94 def _create_binding(self, task_id):
95 name = self.rkey(task_id)
96 return self.Queue(name=name,
97 exchange=self.exchange,
98 routing_key=name,
99 durable=self.persistent,
100 auto_delete=self.auto_delete,
101 queue_arguments=self.queue_arguments)
102
103 def revive(self, channel):
104 pass
105
106 def rkey(self, task_id):
107 return task_id.replace('-', '')
108
109 def destination_for(self, task_id, request):
110 if request:
111 return self.rkey(task_id), request.correlation_id or task_id
112 return self.rkey(task_id), task_id
113
114 def store_result(self, task_id, result, status,
115 traceback=None, request=None, **kwargs):
116 """Send task return value and status."""
117 routing_key, correlation_id = self.destination_for(task_id, request)
118 if not routing_key:
119 return
120 with self.app.amqp.producer_pool.acquire(block=True) as producer:
121 producer.publish(
122 {'task_id': task_id, 'status': status,
123 'result': self.encode_result(result, status),
124 'traceback': traceback,
125 'children': self.current_task_children(request)},
126 exchange=self.exchange,
127 routing_key=routing_key,
128 correlation_id=correlation_id,
129 serializer=self.serializer,
130 retry=True, retry_policy=self.retry_policy,
131 declare=self.on_reply_declare(task_id),
132 delivery_mode=self.delivery_mode,
133 )
134 return result
135
136 def on_reply_declare(self, task_id):
137 return [self._create_binding(task_id)]
138
139 def wait_for(self, task_id, timeout=None, cache=True,
140 no_ack=True, on_interval=None,
141 READY_STATES=states.READY_STATES,
142 PROPAGATE_STATES=states.PROPAGATE_STATES,
143 **kwargs):
144 cached_meta = self._cache.get(task_id)
145 if cache and cached_meta and \
146 cached_meta['status'] in READY_STATES:
147 return cached_meta
148 else:
149 try:
150 return self.consume(task_id, timeout=timeout, no_ack=no_ack,
151 on_interval=on_interval)
152 except socket.timeout:
153 raise TimeoutError('The operation timed out.')
154
155 def get_task_meta(self, task_id, backlog_limit=1000):
156 # Polling and using basic_get
157 with self.app.pool.acquire_channel(block=True) as (_, channel):
158 binding = self._create_binding(task_id)(channel)
159 binding.declare()
160
161 prev = latest = acc = None
162 for i in range(backlog_limit): # spool ffwd
163 acc = binding.get(
164 accept=self.accept, no_ack=False,
165 )
166 if not acc: # no more messages
167 break
168 if acc.payload['task_id'] == task_id:
169 prev, latest = latest, acc
170 if prev:
171 # backends are not expected to keep history,
172 # so we delete everything except the most recent state.
173 prev.ack()
174 prev = None
175 else:
176 raise self.BacklogLimitExceeded(task_id)
177
178 if latest:
179 payload = self._cache[task_id] = latest.payload
180 latest.requeue()
181 return payload
182 else:
183 # no new state, use previous
184 try:
185 return self._cache[task_id]
186 except KeyError:
187 # result probably pending.
188 return {'status': states.PENDING, 'result': None}
189 poll = get_task_meta # XXX compat
190
191 def drain_events(self, connection, consumer,
192 timeout=None, on_interval=None, now=monotonic, wait=None):
193 wait = wait or connection.drain_events
194 results = {}
195
196 def callback(meta, message):
197 if meta['status'] in states.READY_STATES:
198 results[meta['task_id']] = meta
199
200 consumer.callbacks[:] = [callback]
201 time_start = now()
202
203 while 1:
204 # Total time spent may exceed a single call to wait()
205 if timeout and now() - time_start >= timeout:
206 raise socket.timeout()
207 try:
208 wait(timeout=1)
209 except socket.timeout:
210 pass
211 if on_interval:
212 on_interval()
213 if results: # got event on the wanted channel.
214 break
215 self._cache.update(results)
216 return results
217
218 def consume(self, task_id, timeout=None, no_ack=True, on_interval=None):
219 wait = self.drain_events
220 with self.app.pool.acquire_channel(block=True) as (conn, channel):
221 binding = self._create_binding(task_id)
222 with self.Consumer(channel, binding,
223 no_ack=no_ack, accept=self.accept) as consumer:
224 while 1:
225 try:
226 return wait(
227 conn, consumer, timeout, on_interval)[task_id]
228 except KeyError:
229 continue
230
231 def _many_bindings(self, ids):
232 return [self._create_binding(task_id) for task_id in ids]
233
234 def get_many(self, task_ids, timeout=None, no_ack=True, on_message=None,
235 now=monotonic, getfields=itemgetter('status', 'task_id'),
236 READY_STATES=states.READY_STATES,
237 PROPAGATE_STATES=states.PROPAGATE_STATES, **kwargs):
238 with self.app.pool.acquire_channel(block=True) as (conn, channel):
239 ids = set(task_ids)
240 cached_ids = set()
241 mark_cached = cached_ids.add
242 for task_id in ids:
243 try:
244 cached = self._cache[task_id]
245 except KeyError:
246 pass
247 else:
248 if cached['status'] in READY_STATES:
249 yield task_id, cached
250 mark_cached(task_id)
251 ids.difference_update(cached_ids)
252 results = deque()
253 push_result = results.append
254 push_cache = self._cache.__setitem__
255 decode_result = self.meta_from_decoded
256
257 def _on_message(message):
258 body = decode_result(message.decode())
259 if on_message is not None:
260 on_message(body)
261 state, uid = getfields(body)
262 if state in READY_STATES:
263 push_result(body) \
264 if uid in task_ids else push_cache(uid, body)
265
266 bindings = self._many_bindings(task_ids)
267 with self.Consumer(channel, bindings, on_message=_on_message,
268 accept=self.accept, no_ack=no_ack):
269 wait = conn.drain_events
270 popleft = results.popleft
271 while ids:
272 wait(timeout=timeout)
273 while results:
274 state = popleft()
275 task_id = state['task_id']
276 ids.discard(task_id)
277 push_cache(task_id, state)
278 yield task_id, state
279
280 def reload_task_result(self, task_id):
281 raise NotImplementedError(
282 'reload_task_result is not supported by this backend.')
283
284 def reload_group_result(self, task_id):
285 """Reload group result, even if it has been previously fetched."""
286 raise NotImplementedError(
287 'reload_group_result is not supported by this backend.')
288
289 def save_group(self, group_id, result):
290 raise NotImplementedError(
291 'save_group is not supported by this backend.')
292
293 def restore_group(self, group_id, cache=True):
294 raise NotImplementedError(
295 'restore_group is not supported by this backend.')
296
297 def delete_group(self, group_id):
298 raise NotImplementedError(
299 'delete_group is not supported by this backend.')
300
301 def __reduce__(self, args=(), kwargs={}):
302 kwargs.update(
303 connection=self._connection,
304 exchange=self.exchange.name,
305 exchange_type=self.exchange.type,
306 persistent=self.persistent,
307 serializer=self.serializer,
308 auto_delete=self.auto_delete,
309 expires=self.expires,
310 )
311 return super(AMQPBackend, self).__reduce__(args, kwargs)
312
[end of celery/backends/amqp.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/celery/backends/amqp.py b/celery/backends/amqp.py
--- a/celery/backends/amqp.py
+++ b/celery/backends/amqp.py
@@ -195,7 +195,7 @@
def callback(meta, message):
if meta['status'] in states.READY_STATES:
- results[meta['task_id']] = meta
+ results[meta['task_id']] = self.meta_from_decoded(meta)
consumer.callbacks[:] = [callback]
time_start = now()
|
{"golden_diff": "diff --git a/celery/backends/amqp.py b/celery/backends/amqp.py\n--- a/celery/backends/amqp.py\n+++ b/celery/backends/amqp.py\n@@ -195,7 +195,7 @@\n \n def callback(meta, message):\n if meta['status'] in states.READY_STATES:\n- results[meta['task_id']] = meta\n+ results[meta['task_id']] = self.meta_from_decoded(meta)\n \n consumer.callbacks[:] = [callback]\n time_start = now()\n", "issue": "CELERY_RESULT_SERIALIZER = 'json' breaks Exception marshaling\nSetting `CELERY_RESULT_SERIALIZER = json` and raising an exception in the worker leads to this:\n\n```\n/path/to/lib/python2.7/site-packages/celery/result.py in get(self, timeout, propagate, interval, no_ack, follow_parents, EXCEPTION_STATES, PROPAGATE_STATES)\n 173 status = meta['status']\n 174 if status in PROPAGATE_STATES and propagate:\n--> 175 raise meta['result']\n 176 return meta['result']\n 177 wait = get # deprecated alias to :meth:`get`.\n\nTypeError: exceptions must be old-style classes or derived from BaseException, not dict\n```\n\nwhere the contents of `meta['result']` are (in my case):\n\n```\n{u'exc_message': u'unknown keys: nam', u'exc_type': u'ValueError'}\n```\n\nso it _looks_ like celery could convert the dict to a real exception before raising, but it does not currently. Changing back to `pickle` works as expected.\n\nbug can be reproduced with the following:\n\n``` python\n# jsonresults.py\nfrom celery.app.base import Celery\n\nCELERY_RESULT_SERIALIZER = 'json'\nCELERY_RESULT_BACKEND = 'amqp'\n\napp = Celery(config_source=__name__)\n\[email protected]\ndef hello():\n raise ValueError('go away')\n```\n\nworker:\n\n```\n# python -m celery --app=jsonresults:app worker\n```\n\ncaller:\n\n``` python\nimport jsonresults\njsonresults.hello.delay().get()\n```\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\n celery.backends.amqp\n ~~~~~~~~~~~~~~~~~~~~\n\n The AMQP result backend.\n\n This backend publishes results as messages.\n\n\"\"\"\nfrom __future__ import absolute_import\n\nimport socket\n\nfrom collections import deque\nfrom operator import itemgetter\n\nfrom kombu import Exchange, Queue, Producer, Consumer\n\nfrom celery import states\nfrom celery.exceptions import TimeoutError\nfrom celery.five import range, monotonic\nfrom celery.utils.functional import dictfilter\nfrom celery.utils.log import get_logger\nfrom celery.utils.timeutils import maybe_s_to_ms\n\nfrom .base import BaseBackend\n\n__all__ = ['BacklogLimitExceeded', 'AMQPBackend']\n\nlogger = get_logger(__name__)\n\n\nclass BacklogLimitExceeded(Exception):\n \"\"\"Too much state history to fast-forward.\"\"\"\n\n\ndef repair_uuid(s):\n # Historically the dashes in UUIDS are removed from AMQ entity names,\n # but there is no known reason to. Hopefully we'll be able to fix\n # this in v4.0.\n return '%s-%s-%s-%s-%s' % (s[:8], s[8:12], s[12:16], s[16:20], s[20:])\n\n\nclass NoCacheQueue(Queue):\n can_cache_declaration = False\n\n\nclass AMQPBackend(BaseBackend):\n \"\"\"Publishes results by sending messages.\"\"\"\n Exchange = Exchange\n Queue = NoCacheQueue\n Consumer = Consumer\n Producer = Producer\n\n BacklogLimitExceeded = BacklogLimitExceeded\n\n persistent = True\n supports_autoexpire = True\n supports_native_join = True\n\n retry_policy = {\n 'max_retries': 20,\n 'interval_start': 0,\n 'interval_step': 1,\n 'interval_max': 1,\n }\n\n def __init__(self, app, connection=None, exchange=None, exchange_type=None,\n persistent=None, serializer=None, auto_delete=True, **kwargs):\n super(AMQPBackend, self).__init__(app, **kwargs)\n conf = self.app.conf\n self._connection = connection\n self.persistent = self.prepare_persistent(persistent)\n self.delivery_mode = 2 if self.persistent else 1\n exchange = exchange or conf.CELERY_RESULT_EXCHANGE\n exchange_type = exchange_type or conf.CELERY_RESULT_EXCHANGE_TYPE\n self.exchange = self._create_exchange(\n exchange, exchange_type, self.delivery_mode,\n )\n self.serializer = serializer or conf.CELERY_RESULT_SERIALIZER\n self.auto_delete = auto_delete\n self.queue_arguments = dictfilter({\n 'x-expires': maybe_s_to_ms(self.expires),\n })\n\n def _create_exchange(self, name, type='direct', delivery_mode=2):\n return self.Exchange(name=name,\n type=type,\n delivery_mode=delivery_mode,\n durable=self.persistent,\n auto_delete=False)\n\n def _create_binding(self, task_id):\n name = self.rkey(task_id)\n return self.Queue(name=name,\n exchange=self.exchange,\n routing_key=name,\n durable=self.persistent,\n auto_delete=self.auto_delete,\n queue_arguments=self.queue_arguments)\n\n def revive(self, channel):\n pass\n\n def rkey(self, task_id):\n return task_id.replace('-', '')\n\n def destination_for(self, task_id, request):\n if request:\n return self.rkey(task_id), request.correlation_id or task_id\n return self.rkey(task_id), task_id\n\n def store_result(self, task_id, result, status,\n traceback=None, request=None, **kwargs):\n \"\"\"Send task return value and status.\"\"\"\n routing_key, correlation_id = self.destination_for(task_id, request)\n if not routing_key:\n return\n with self.app.amqp.producer_pool.acquire(block=True) as producer:\n producer.publish(\n {'task_id': task_id, 'status': status,\n 'result': self.encode_result(result, status),\n 'traceback': traceback,\n 'children': self.current_task_children(request)},\n exchange=self.exchange,\n routing_key=routing_key,\n correlation_id=correlation_id,\n serializer=self.serializer,\n retry=True, retry_policy=self.retry_policy,\n declare=self.on_reply_declare(task_id),\n delivery_mode=self.delivery_mode,\n )\n return result\n\n def on_reply_declare(self, task_id):\n return [self._create_binding(task_id)]\n\n def wait_for(self, task_id, timeout=None, cache=True,\n no_ack=True, on_interval=None,\n READY_STATES=states.READY_STATES,\n PROPAGATE_STATES=states.PROPAGATE_STATES,\n **kwargs):\n cached_meta = self._cache.get(task_id)\n if cache and cached_meta and \\\n cached_meta['status'] in READY_STATES:\n return cached_meta\n else:\n try:\n return self.consume(task_id, timeout=timeout, no_ack=no_ack,\n on_interval=on_interval)\n except socket.timeout:\n raise TimeoutError('The operation timed out.')\n\n def get_task_meta(self, task_id, backlog_limit=1000):\n # Polling and using basic_get\n with self.app.pool.acquire_channel(block=True) as (_, channel):\n binding = self._create_binding(task_id)(channel)\n binding.declare()\n\n prev = latest = acc = None\n for i in range(backlog_limit): # spool ffwd\n acc = binding.get(\n accept=self.accept, no_ack=False,\n )\n if not acc: # no more messages\n break\n if acc.payload['task_id'] == task_id:\n prev, latest = latest, acc\n if prev:\n # backends are not expected to keep history,\n # so we delete everything except the most recent state.\n prev.ack()\n prev = None\n else:\n raise self.BacklogLimitExceeded(task_id)\n\n if latest:\n payload = self._cache[task_id] = latest.payload\n latest.requeue()\n return payload\n else:\n # no new state, use previous\n try:\n return self._cache[task_id]\n except KeyError:\n # result probably pending.\n return {'status': states.PENDING, 'result': None}\n poll = get_task_meta # XXX compat\n\n def drain_events(self, connection, consumer,\n timeout=None, on_interval=None, now=monotonic, wait=None):\n wait = wait or connection.drain_events\n results = {}\n\n def callback(meta, message):\n if meta['status'] in states.READY_STATES:\n results[meta['task_id']] = meta\n\n consumer.callbacks[:] = [callback]\n time_start = now()\n\n while 1:\n # Total time spent may exceed a single call to wait()\n if timeout and now() - time_start >= timeout:\n raise socket.timeout()\n try:\n wait(timeout=1)\n except socket.timeout:\n pass\n if on_interval:\n on_interval()\n if results: # got event on the wanted channel.\n break\n self._cache.update(results)\n return results\n\n def consume(self, task_id, timeout=None, no_ack=True, on_interval=None):\n wait = self.drain_events\n with self.app.pool.acquire_channel(block=True) as (conn, channel):\n binding = self._create_binding(task_id)\n with self.Consumer(channel, binding,\n no_ack=no_ack, accept=self.accept) as consumer:\n while 1:\n try:\n return wait(\n conn, consumer, timeout, on_interval)[task_id]\n except KeyError:\n continue\n\n def _many_bindings(self, ids):\n return [self._create_binding(task_id) for task_id in ids]\n\n def get_many(self, task_ids, timeout=None, no_ack=True, on_message=None,\n now=monotonic, getfields=itemgetter('status', 'task_id'),\n READY_STATES=states.READY_STATES,\n PROPAGATE_STATES=states.PROPAGATE_STATES, **kwargs):\n with self.app.pool.acquire_channel(block=True) as (conn, channel):\n ids = set(task_ids)\n cached_ids = set()\n mark_cached = cached_ids.add\n for task_id in ids:\n try:\n cached = self._cache[task_id]\n except KeyError:\n pass\n else:\n if cached['status'] in READY_STATES:\n yield task_id, cached\n mark_cached(task_id)\n ids.difference_update(cached_ids)\n results = deque()\n push_result = results.append\n push_cache = self._cache.__setitem__\n decode_result = self.meta_from_decoded\n\n def _on_message(message):\n body = decode_result(message.decode())\n if on_message is not None:\n on_message(body)\n state, uid = getfields(body)\n if state in READY_STATES:\n push_result(body) \\\n if uid in task_ids else push_cache(uid, body)\n\n bindings = self._many_bindings(task_ids)\n with self.Consumer(channel, bindings, on_message=_on_message,\n accept=self.accept, no_ack=no_ack):\n wait = conn.drain_events\n popleft = results.popleft\n while ids:\n wait(timeout=timeout)\n while results:\n state = popleft()\n task_id = state['task_id']\n ids.discard(task_id)\n push_cache(task_id, state)\n yield task_id, state\n\n def reload_task_result(self, task_id):\n raise NotImplementedError(\n 'reload_task_result is not supported by this backend.')\n\n def reload_group_result(self, task_id):\n \"\"\"Reload group result, even if it has been previously fetched.\"\"\"\n raise NotImplementedError(\n 'reload_group_result is not supported by this backend.')\n\n def save_group(self, group_id, result):\n raise NotImplementedError(\n 'save_group is not supported by this backend.')\n\n def restore_group(self, group_id, cache=True):\n raise NotImplementedError(\n 'restore_group is not supported by this backend.')\n\n def delete_group(self, group_id):\n raise NotImplementedError(\n 'delete_group is not supported by this backend.')\n\n def __reduce__(self, args=(), kwargs={}):\n kwargs.update(\n connection=self._connection,\n exchange=self.exchange.name,\n exchange_type=self.exchange.type,\n persistent=self.persistent,\n serializer=self.serializer,\n auto_delete=self.auto_delete,\n expires=self.expires,\n )\n return super(AMQPBackend, self).__reduce__(args, kwargs)\n", "path": "celery/backends/amqp.py"}]}
| 3,982 | 122 |
gh_patches_debug_33327
|
rasdani/github-patches
|
git_diff
|
comfyanonymous__ComfyUI-2207
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
HyperTile node is nondeterministic across executions and messes with global randomness
The HyperTile node uses the random module and seeds the global random with its own counter variable.
Unfortunately, this counter variable is retained across executions if the HyperTile parameters don't change, and so every execution will have different results.
The effect on global random can be avoided just by using a `random.Random()` instance instead of a counter, but since ComfyUI doesn't provide any kind of after-exec function for nodes, there doesn't seem to be a way to reset it to its initial state after one prompt is executed.
I suppose you could work around this by setting having IS_CHANGED return something so that the node gets always executed, thus reinitializing randomness, but that might cause any nodes that come after the HyperTile node to needlessly re-execute.
</issue>
<code>
[start of comfy_extras/nodes_hypertile.py]
1 #Taken from: https://github.com/tfernd/HyperTile/
2
3 import math
4 from einops import rearrange
5 import random
6
7 def random_divisor(value: int, min_value: int, /, max_options: int = 1, counter = 0) -> int:
8 min_value = min(min_value, value)
9
10 # All big divisors of value (inclusive)
11 divisors = [i for i in range(min_value, value + 1) if value % i == 0]
12
13 ns = [value // i for i in divisors[:max_options]] # has at least 1 element
14
15 random.seed(counter)
16 idx = random.randint(0, len(ns) - 1)
17
18 return ns[idx]
19
20 class HyperTile:
21 @classmethod
22 def INPUT_TYPES(s):
23 return {"required": { "model": ("MODEL",),
24 "tile_size": ("INT", {"default": 256, "min": 1, "max": 2048}),
25 "swap_size": ("INT", {"default": 2, "min": 1, "max": 128}),
26 "max_depth": ("INT", {"default": 0, "min": 0, "max": 10}),
27 "scale_depth": ("BOOLEAN", {"default": False}),
28 }}
29 RETURN_TYPES = ("MODEL",)
30 FUNCTION = "patch"
31
32 CATEGORY = "_for_testing"
33
34 def patch(self, model, tile_size, swap_size, max_depth, scale_depth):
35 model_channels = model.model.model_config.unet_config["model_channels"]
36
37 apply_to = set()
38 temp = model_channels
39 for x in range(max_depth + 1):
40 apply_to.add(temp)
41 temp *= 2
42
43 latent_tile_size = max(32, tile_size) // 8
44 self.temp = None
45 self.counter = 1
46
47 def hypertile_in(q, k, v, extra_options):
48 if q.shape[-1] in apply_to:
49 shape = extra_options["original_shape"]
50 aspect_ratio = shape[-1] / shape[-2]
51
52 hw = q.size(1)
53 h, w = round(math.sqrt(hw * aspect_ratio)), round(math.sqrt(hw / aspect_ratio))
54
55 factor = 2**((q.shape[-1] // model_channels) - 1) if scale_depth else 1
56 nh = random_divisor(h, latent_tile_size * factor, swap_size, self.counter)
57 self.counter += 1
58 nw = random_divisor(w, latent_tile_size * factor, swap_size, self.counter)
59 self.counter += 1
60
61 if nh * nw > 1:
62 q = rearrange(q, "b (nh h nw w) c -> (b nh nw) (h w) c", h=h // nh, w=w // nw, nh=nh, nw=nw)
63 self.temp = (nh, nw, h, w)
64 return q, k, v
65
66 return q, k, v
67 def hypertile_out(out, extra_options):
68 if self.temp is not None:
69 nh, nw, h, w = self.temp
70 self.temp = None
71 out = rearrange(out, "(b nh nw) hw c -> b nh nw hw c", nh=nh, nw=nw)
72 out = rearrange(out, "b nh nw (h w) c -> b (nh h nw w) c", h=h // nh, w=w // nw)
73 return out
74
75
76 m = model.clone()
77 m.set_model_attn1_patch(hypertile_in)
78 m.set_model_attn1_output_patch(hypertile_out)
79 return (m, )
80
81 NODE_CLASS_MAPPINGS = {
82 "HyperTile": HyperTile,
83 }
84
[end of comfy_extras/nodes_hypertile.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/comfy_extras/nodes_hypertile.py b/comfy_extras/nodes_hypertile.py
--- a/comfy_extras/nodes_hypertile.py
+++ b/comfy_extras/nodes_hypertile.py
@@ -2,9 +2,10 @@
import math
from einops import rearrange
-import random
+# Use torch rng for consistency across generations
+from torch import randint
-def random_divisor(value: int, min_value: int, /, max_options: int = 1, counter = 0) -> int:
+def random_divisor(value: int, min_value: int, /, max_options: int = 1) -> int:
min_value = min(min_value, value)
# All big divisors of value (inclusive)
@@ -12,8 +13,7 @@
ns = [value // i for i in divisors[:max_options]] # has at least 1 element
- random.seed(counter)
- idx = random.randint(0, len(ns) - 1)
+ idx = randint(low=0, high=len(ns) - 1, size=(1,)).item()
return ns[idx]
@@ -42,7 +42,6 @@
latent_tile_size = max(32, tile_size) // 8
self.temp = None
- self.counter = 1
def hypertile_in(q, k, v, extra_options):
if q.shape[-1] in apply_to:
@@ -53,10 +52,8 @@
h, w = round(math.sqrt(hw * aspect_ratio)), round(math.sqrt(hw / aspect_ratio))
factor = 2**((q.shape[-1] // model_channels) - 1) if scale_depth else 1
- nh = random_divisor(h, latent_tile_size * factor, swap_size, self.counter)
- self.counter += 1
- nw = random_divisor(w, latent_tile_size * factor, swap_size, self.counter)
- self.counter += 1
+ nh = random_divisor(h, latent_tile_size * factor, swap_size)
+ nw = random_divisor(w, latent_tile_size * factor, swap_size)
if nh * nw > 1:
q = rearrange(q, "b (nh h nw w) c -> (b nh nw) (h w) c", h=h // nh, w=w // nw, nh=nh, nw=nw)
|
{"golden_diff": "diff --git a/comfy_extras/nodes_hypertile.py b/comfy_extras/nodes_hypertile.py\n--- a/comfy_extras/nodes_hypertile.py\n+++ b/comfy_extras/nodes_hypertile.py\n@@ -2,9 +2,10 @@\n \n import math\n from einops import rearrange\n-import random\n+# Use torch rng for consistency across generations\n+from torch import randint\n \n-def random_divisor(value: int, min_value: int, /, max_options: int = 1, counter = 0) -> int:\n+def random_divisor(value: int, min_value: int, /, max_options: int = 1) -> int:\n min_value = min(min_value, value)\n \n # All big divisors of value (inclusive)\n@@ -12,8 +13,7 @@\n \n ns = [value // i for i in divisors[:max_options]] # has at least 1 element\n \n- random.seed(counter)\n- idx = random.randint(0, len(ns) - 1)\n+ idx = randint(low=0, high=len(ns) - 1, size=(1,)).item()\n \n return ns[idx]\n \n@@ -42,7 +42,6 @@\n \n latent_tile_size = max(32, tile_size) // 8\n self.temp = None\n- self.counter = 1\n \n def hypertile_in(q, k, v, extra_options):\n if q.shape[-1] in apply_to:\n@@ -53,10 +52,8 @@\n h, w = round(math.sqrt(hw * aspect_ratio)), round(math.sqrt(hw / aspect_ratio))\n \n factor = 2**((q.shape[-1] // model_channels) - 1) if scale_depth else 1\n- nh = random_divisor(h, latent_tile_size * factor, swap_size, self.counter)\n- self.counter += 1\n- nw = random_divisor(w, latent_tile_size * factor, swap_size, self.counter)\n- self.counter += 1\n+ nh = random_divisor(h, latent_tile_size * factor, swap_size)\n+ nw = random_divisor(w, latent_tile_size * factor, swap_size)\n \n if nh * nw > 1:\n q = rearrange(q, \"b (nh h nw w) c -> (b nh nw) (h w) c\", h=h // nh, w=w // nw, nh=nh, nw=nw)\n", "issue": "HyperTile node is nondeterministic across executions and messes with global randomness\nThe HyperTile node uses the random module and seeds the global random with its own counter variable.\r\n\r\nUnfortunately, this counter variable is retained across executions if the HyperTile parameters don't change, and so every execution will have different results.\r\n\r\nThe effect on global random can be avoided just by using a `random.Random()` instance instead of a counter, but since ComfyUI doesn't provide any kind of after-exec function for nodes, there doesn't seem to be a way to reset it to its initial state after one prompt is executed.\r\n\r\nI suppose you could work around this by setting having IS_CHANGED return something so that the node gets always executed, thus reinitializing randomness, but that might cause any nodes that come after the HyperTile node to needlessly re-execute.\r\n\r\n\n", "before_files": [{"content": "#Taken from: https://github.com/tfernd/HyperTile/\n\nimport math\nfrom einops import rearrange\nimport random\n\ndef random_divisor(value: int, min_value: int, /, max_options: int = 1, counter = 0) -> int:\n min_value = min(min_value, value)\n\n # All big divisors of value (inclusive)\n divisors = [i for i in range(min_value, value + 1) if value % i == 0]\n\n ns = [value // i for i in divisors[:max_options]] # has at least 1 element\n\n random.seed(counter)\n idx = random.randint(0, len(ns) - 1)\n\n return ns[idx]\n\nclass HyperTile:\n @classmethod\n def INPUT_TYPES(s):\n return {\"required\": { \"model\": (\"MODEL\",),\n \"tile_size\": (\"INT\", {\"default\": 256, \"min\": 1, \"max\": 2048}),\n \"swap_size\": (\"INT\", {\"default\": 2, \"min\": 1, \"max\": 128}),\n \"max_depth\": (\"INT\", {\"default\": 0, \"min\": 0, \"max\": 10}),\n \"scale_depth\": (\"BOOLEAN\", {\"default\": False}),\n }}\n RETURN_TYPES = (\"MODEL\",)\n FUNCTION = \"patch\"\n\n CATEGORY = \"_for_testing\"\n\n def patch(self, model, tile_size, swap_size, max_depth, scale_depth):\n model_channels = model.model.model_config.unet_config[\"model_channels\"]\n\n apply_to = set()\n temp = model_channels\n for x in range(max_depth + 1):\n apply_to.add(temp)\n temp *= 2\n\n latent_tile_size = max(32, tile_size) // 8\n self.temp = None\n self.counter = 1\n\n def hypertile_in(q, k, v, extra_options):\n if q.shape[-1] in apply_to:\n shape = extra_options[\"original_shape\"]\n aspect_ratio = shape[-1] / shape[-2]\n\n hw = q.size(1)\n h, w = round(math.sqrt(hw * aspect_ratio)), round(math.sqrt(hw / aspect_ratio))\n\n factor = 2**((q.shape[-1] // model_channels) - 1) if scale_depth else 1\n nh = random_divisor(h, latent_tile_size * factor, swap_size, self.counter)\n self.counter += 1\n nw = random_divisor(w, latent_tile_size * factor, swap_size, self.counter)\n self.counter += 1\n\n if nh * nw > 1:\n q = rearrange(q, \"b (nh h nw w) c -> (b nh nw) (h w) c\", h=h // nh, w=w // nw, nh=nh, nw=nw)\n self.temp = (nh, nw, h, w)\n return q, k, v\n\n return q, k, v\n def hypertile_out(out, extra_options):\n if self.temp is not None:\n nh, nw, h, w = self.temp\n self.temp = None\n out = rearrange(out, \"(b nh nw) hw c -> b nh nw hw c\", nh=nh, nw=nw)\n out = rearrange(out, \"b nh nw (h w) c -> b (nh h nw w) c\", h=h // nh, w=w // nw)\n return out\n\n\n m = model.clone()\n m.set_model_attn1_patch(hypertile_in)\n m.set_model_attn1_output_patch(hypertile_out)\n return (m, )\n\nNODE_CLASS_MAPPINGS = {\n \"HyperTile\": HyperTile,\n}\n", "path": "comfy_extras/nodes_hypertile.py"}]}
| 1,702 | 548 |
gh_patches_debug_26976
|
rasdani/github-patches
|
git_diff
|
neptune-ai__neptune-client-197
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
experiment.get_system_properties() doesn't return "hostname"
I think there is some regression. For recent experiments `experiment.get_properties()` return either an empty dictionary or `{'key1': 'value1', 'key2': '17', 'key3': 'other-value'}` (whatever that is) in case of the sandbox project.
For older experiments, I still can get the properties.
This is probably a backend issue but there is no better place to put it.
</issue>
<code>
[start of neptune/internal/streams/channel_writer.py]
1 #
2 # Copyright (c) 2019, Neptune Labs Sp. z o.o.
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15 #
16
17 from __future__ import unicode_literals
18
19 import re
20 import time
21
22 from neptune.internal.channels.channels import ChannelNamespace, ChannelValue, ChannelType
23
24
25 class ChannelWriter(object):
26 __SPLIT_PATTERN = re.compile(r'[\n\r]{1,2}')
27
28 def __init__(self, experiment, channel_name, channel_namespace=ChannelNamespace.USER):
29 self.time_started_ms = time.time() * 1000
30 self._experiment = experiment
31 self._channel_name = channel_name
32 self._channel_namespace = channel_namespace
33 self._data = None
34
35 def write(self, data):
36 if self._data is None:
37 self._data = data
38 else:
39 self._data += data
40 lines = self.__SPLIT_PATTERN.split(self._data)
41 for line in lines[:-1]:
42 value = ChannelValue(
43 x=time.time() * 1000 - self.time_started_ms,
44 y=dict(text_value=str(line)),
45 ts=None
46 )
47 # pylint: disable=protected-access
48 self._experiment._channels_values_sender.send(
49 channel_name=self._channel_name,
50 channel_type=ChannelType.TEXT.value,
51 channel_value=value,
52 channel_namespace=self._channel_namespace
53 )
54
55 self._data = lines[-1]
56
[end of neptune/internal/streams/channel_writer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/neptune/internal/streams/channel_writer.py b/neptune/internal/streams/channel_writer.py
--- a/neptune/internal/streams/channel_writer.py
+++ b/neptune/internal/streams/channel_writer.py
@@ -16,8 +16,8 @@
from __future__ import unicode_literals
+from datetime import datetime
import re
-import time
from neptune.internal.channels.channels import ChannelNamespace, ChannelValue, ChannelType
@@ -26,7 +26,7 @@
__SPLIT_PATTERN = re.compile(r'[\n\r]{1,2}')
def __init__(self, experiment, channel_name, channel_namespace=ChannelNamespace.USER):
- self.time_started_ms = time.time() * 1000
+ self._time_started = experiment.get_system_properties()['created']
self._experiment = experiment
self._channel_name = channel_name
self._channel_namespace = channel_namespace
@@ -40,7 +40,7 @@
lines = self.__SPLIT_PATTERN.split(self._data)
for line in lines[:-1]:
value = ChannelValue(
- x=time.time() * 1000 - self.time_started_ms,
+ x=(datetime.now(tz=self._time_started.tzinfo) - self._time_started).total_seconds() * 1000,
y=dict(text_value=str(line)),
ts=None
)
|
{"golden_diff": "diff --git a/neptune/internal/streams/channel_writer.py b/neptune/internal/streams/channel_writer.py\n--- a/neptune/internal/streams/channel_writer.py\n+++ b/neptune/internal/streams/channel_writer.py\n@@ -16,8 +16,8 @@\n \n from __future__ import unicode_literals\n \n+from datetime import datetime\n import re\n-import time\n \n from neptune.internal.channels.channels import ChannelNamespace, ChannelValue, ChannelType\n \n@@ -26,7 +26,7 @@\n __SPLIT_PATTERN = re.compile(r'[\\n\\r]{1,2}')\n \n def __init__(self, experiment, channel_name, channel_namespace=ChannelNamespace.USER):\n- self.time_started_ms = time.time() * 1000\n+ self._time_started = experiment.get_system_properties()['created']\n self._experiment = experiment\n self._channel_name = channel_name\n self._channel_namespace = channel_namespace\n@@ -40,7 +40,7 @@\n lines = self.__SPLIT_PATTERN.split(self._data)\n for line in lines[:-1]:\n value = ChannelValue(\n- x=time.time() * 1000 - self.time_started_ms,\n+ x=(datetime.now(tz=self._time_started.tzinfo) - self._time_started).total_seconds() * 1000,\n y=dict(text_value=str(line)),\n ts=None\n )\n", "issue": "experiment.get_system_properties() doesn't return \"hostname\"\nI think there is some regression. For recent experiments `experiment.get_properties()` return either an empty dictionary or `{'key1': 'value1', 'key2': '17', 'key3': 'other-value'}` (whatever that is) in case of the sandbox project.\r\n\r\nFor older experiments, I still can get the properties. \r\n\r\nThis is probably a backend issue but there is no better place to put it.\n", "before_files": [{"content": "#\n# Copyright (c) 2019, Neptune Labs Sp. z o.o.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n\nfrom __future__ import unicode_literals\n\nimport re\nimport time\n\nfrom neptune.internal.channels.channels import ChannelNamespace, ChannelValue, ChannelType\n\n\nclass ChannelWriter(object):\n __SPLIT_PATTERN = re.compile(r'[\\n\\r]{1,2}')\n\n def __init__(self, experiment, channel_name, channel_namespace=ChannelNamespace.USER):\n self.time_started_ms = time.time() * 1000\n self._experiment = experiment\n self._channel_name = channel_name\n self._channel_namespace = channel_namespace\n self._data = None\n\n def write(self, data):\n if self._data is None:\n self._data = data\n else:\n self._data += data\n lines = self.__SPLIT_PATTERN.split(self._data)\n for line in lines[:-1]:\n value = ChannelValue(\n x=time.time() * 1000 - self.time_started_ms,\n y=dict(text_value=str(line)),\n ts=None\n )\n # pylint: disable=protected-access\n self._experiment._channels_values_sender.send(\n channel_name=self._channel_name,\n channel_type=ChannelType.TEXT.value,\n channel_value=value,\n channel_namespace=self._channel_namespace\n )\n\n self._data = lines[-1]\n", "path": "neptune/internal/streams/channel_writer.py"}]}
| 1,161 | 302 |
gh_patches_debug_34799
|
rasdani/github-patches
|
git_diff
|
PokemonGoF__PokemonGo-Bot-4556
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Feature Request] Differentiate Between Unlimited and "Purchased" Incubator use.
Blue incubators are difficult to get so I use it only for 10km eggs. Is there any configuration to prevent bot from using Blue Incubator?
</issue>
<code>
[start of pokemongo_bot/cell_workers/incubate_eggs.py]
1 from datetime import datetime, timedelta
2
3 from pokemongo_bot.human_behaviour import sleep
4 from pokemongo_bot.base_task import BaseTask
5
6
7 class IncubateEggs(BaseTask):
8 SUPPORTED_TASK_API_VERSION = 1
9
10 last_km_walked = 0
11
12 def initialize(self):
13 self.next_update = None
14 self.ready_incubators = []
15 self.used_incubators = []
16 self.eggs = []
17 self.km_walked = 0
18 self.hatching_animation_delay = 4.20
19 self.max_iv = 45.0
20
21 self._process_config()
22
23 def _process_config(self):
24 self.longer_eggs_first = self.config.get("longer_eggs_first", True)
25 self.min_interval = self.config.get('min_interval', 120)
26
27 def work(self):
28 try:
29 self._check_inventory()
30 except:
31 return
32
33 if self.used_incubators and IncubateEggs.last_km_walked != self.km_walked:
34 self.used_incubators.sort(key=lambda x: x.get("km"))
35 km_left = self.used_incubators[0]['km']-self.km_walked
36 if km_left <= 0:
37 self._hatch_eggs()
38 else:
39 self.bot.metrics.next_hatching_km(km_left)
40
41 if self._should_print():
42 self._print_eggs()
43 self._compute_next_update()
44
45 IncubateEggs.last_km_walked = self.km_walked
46
47 sorting = self.longer_eggs_first
48 self.eggs.sort(key=lambda x: x.get("km"), reverse=sorting)
49
50 if self.ready_incubators:
51 self._apply_incubators()
52
53 def _apply_incubators(self):
54 for incubator in self.ready_incubators:
55 if incubator.get('used', False):
56 continue
57 for egg in self.eggs:
58 if egg["used"] or egg["km"] == -1:
59 continue
60 self.emit_event(
61 'incubate_try',
62 level='debug',
63 formatted="Attempting to apply incubator {incubator_id} to egg {egg_id}",
64 data={
65 'incubator_id': incubator['id'],
66 'egg_id': egg['id']
67 }
68 )
69 ret = self.bot.api.use_item_egg_incubator(
70 item_id=incubator["id"],
71 pokemon_id=egg["id"]
72 )
73 if ret:
74 code = ret.get("responses", {}).get("USE_ITEM_EGG_INCUBATOR", {}).get("result", 0)
75 if code == 1:
76 self.emit_event(
77 'incubate',
78 formatted='Incubating a {distance_in_km} egg.',
79 data={
80 'distance_in_km': str(egg['km'])
81 }
82 )
83 egg["used"] = True
84 incubator["used"] = True
85 break
86 elif code == 5 or code == 7:
87 self.emit_event(
88 'incubator_already_used',
89 level='debug',
90 formatted='Incubator in use.',
91 )
92 incubator["used"] = True
93 break
94 elif code == 6:
95 self.emit_event(
96 'egg_already_incubating',
97 level='debug',
98 formatted='Egg already incubating',
99 )
100 egg["used"] = True
101
102 def _check_inventory(self, lookup_ids=[]):
103 inv = {}
104 response_dict = self.bot.api.get_inventory()
105 matched_pokemon = []
106 temp_eggs = []
107 temp_used_incubators = []
108 temp_ready_incubators = []
109 inv = reduce(
110 dict.__getitem__,
111 ["responses", "GET_INVENTORY", "inventory_delta", "inventory_items"],
112 response_dict
113 )
114 for inv_data in inv:
115 inv_data = inv_data.get("inventory_item_data", {})
116 if "egg_incubators" in inv_data:
117 temp_used_incubators = []
118 temp_ready_incubators = []
119 incubators = inv_data.get("egg_incubators", {}).get("egg_incubator",[])
120 if isinstance(incubators, basestring): # checking for old response
121 incubators = [incubators]
122 for incubator in incubators:
123 if 'pokemon_id' in incubator:
124 start_km = incubator.get('start_km_walked', 9001)
125 km_walked = incubator.get('target_km_walked', 9001)
126 temp_used_incubators.append({
127 "id": incubator.get('id', -1),
128 "km": km_walked,
129 "km_needed": (km_walked - start_km)
130 })
131 else:
132 temp_ready_incubators.append({
133 "id": incubator.get('id', -1)
134 })
135 continue
136 if "pokemon_data" in inv_data:
137 pokemon = inv_data.get("pokemon_data", {})
138 if pokemon.get("is_egg", False) and "egg_incubator_id" not in pokemon:
139 temp_eggs.append({
140 "id": pokemon.get("id", -1),
141 "km": pokemon.get("egg_km_walked_target", -1),
142 "used": False
143 })
144 elif 'is_egg' not in pokemon and pokemon['id'] in lookup_ids:
145 pokemon.update({
146 "iv": [
147 pokemon.get('individual_attack', 0),
148 pokemon.get('individual_defense', 0),
149 pokemon.get('individual_stamina', 0)
150 ]})
151 matched_pokemon.append(pokemon)
152 continue
153 if "player_stats" in inv_data:
154 self.km_walked = inv_data.get("player_stats", {}).get("km_walked", 0)
155 if temp_used_incubators:
156 self.used_incubators = temp_used_incubators
157 if temp_ready_incubators:
158 self.ready_incubators = temp_ready_incubators
159 if temp_eggs:
160 self.eggs = temp_eggs
161 return matched_pokemon
162
163 def _hatch_eggs(self):
164 response_dict = self.bot.api.get_hatched_eggs()
165 log_color = 'green'
166 try:
167 result = reduce(dict.__getitem__, ["responses", "GET_HATCHED_EGGS"], response_dict)
168 except KeyError:
169 return
170 pokemon_ids = []
171 if 'pokemon_id' in result:
172 pokemon_ids = [id for id in result['pokemon_id']]
173 stardust = result.get('stardust_awarded', "error")
174 candy = result.get('candy_awarded', "error")
175 xp = result.get('experience_awarded', "error")
176 sleep(self.hatching_animation_delay)
177 self.bot.latest_inventory = None
178 try:
179 pokemon_data = self._check_inventory(pokemon_ids)
180 for pokemon in pokemon_data:
181 # pokemon ids seem to be offset by one
182 if pokemon['pokemon_id']!=-1:
183 pokemon['name'] = self.bot.pokemon_list[(pokemon.get('pokemon_id')-1)]['Name']
184 else:
185 pokemon['name'] = "error"
186 except:
187 pokemon_data = [{"name":"error","cp":"error","iv":"error"}]
188 if not pokemon_ids or pokemon_data[0]['name'] == "error":
189 self.emit_event(
190 'egg_hatched',
191 data={
192 'pokemon': 'error',
193 'cp': 'error',
194 'iv': 'error',
195 'exp': 'error',
196 'stardust': 'error',
197 'candy': 'error',
198 }
199 )
200 return
201 for i in range(len(pokemon_data)):
202 msg = "Egg hatched with a {pokemon} (CP {cp} - IV {iv}), {exp} exp, {stardust} stardust and {candy} candies."
203 self.bot.metrics.hatched_eggs(1)
204 self.emit_event(
205 'egg_hatched',
206 formatted=msg,
207 data={
208 'pokemon': pokemon_data[i]['name'],
209 'cp': pokemon_data[i]['cp'],
210 'iv': "{} {}".format(
211 "/".join(map(str, pokemon_data[i]['iv'])),
212 round(sum(pokemon_data[i]['iv'])/self.max_iv, 2)
213 ),
214 'exp': xp[i],
215 'stardust': stardust[i],
216 'candy': candy[i],
217 }
218 )
219
220 def _print_eggs(self):
221 if not self.used_incubators:
222 return
223
224 self.used_incubators.sort(key=lambda x: x.get("km"))
225
226 eggs = ['{:.2f}/{} km'.format(e['km_needed']-e['km']+self.km_walked, e['km_needed']) for e in self.used_incubators]
227
228 self.emit_event(
229 'next_egg_incubates',
230 formatted='Eggs incubating: [{eggs}] (Eggs left: {eggs_left}, Incubating: {eggs_inc})',
231 data={
232 'eggs_left': len(self.eggs),
233 'eggs_inc': len(self.used_incubators),
234 'eggs': ', '.join(eggs)
235 }
236 )
237
238 def _should_print(self):
239 """
240 Returns a value indicating whether the eggs should be displayed.
241 :return: True if the stats should be displayed; otherwise, False.
242 :rtype: bool
243 """
244 return self.next_update is None or datetime.now() >= self.next_update
245
246 def _compute_next_update(self):
247 """
248 Computes the next update datetime based on the minimum update interval.
249 :return: Nothing.
250 :rtype: None
251 """
252 self.next_update = datetime.now() + timedelta(seconds=self.min_interval)
[end of pokemongo_bot/cell_workers/incubate_eggs.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pokemongo_bot/cell_workers/incubate_eggs.py b/pokemongo_bot/cell_workers/incubate_eggs.py
--- a/pokemongo_bot/cell_workers/incubate_eggs.py
+++ b/pokemongo_bot/cell_workers/incubate_eggs.py
@@ -23,7 +23,10 @@
def _process_config(self):
self.longer_eggs_first = self.config.get("longer_eggs_first", True)
self.min_interval = self.config.get('min_interval', 120)
-
+
+ self.breakable_incubator = self.config.get("breakable", [])
+ self.infinite_incubator = self.config.get("infinite", [])
+
def work(self):
try:
self._check_inventory()
@@ -57,6 +60,17 @@
for egg in self.eggs:
if egg["used"] or egg["km"] == -1:
continue
+
+ if self.breakable_incubator:
+ if incubator.get('uses_remaining') is not None: # test if the incubator is of type breakable
+ if egg["km"] not in self.breakable_incubator:
+ continue
+
+ if self.infinite_incubator:
+ if incubator.get('uses_remaining') is None: # test if the incubator is of type infinite
+ if egg["km"] not in self.infinite_incubator:
+ continue
+
self.emit_event(
'incubate_try',
level='debug',
@@ -119,7 +133,7 @@
incubators = inv_data.get("egg_incubators", {}).get("egg_incubator",[])
if isinstance(incubators, basestring): # checking for old response
incubators = [incubators]
- for incubator in incubators:
+ for incubator in incubators:
if 'pokemon_id' in incubator:
start_km = incubator.get('start_km_walked', 9001)
km_walked = incubator.get('target_km_walked', 9001)
|
{"golden_diff": "diff --git a/pokemongo_bot/cell_workers/incubate_eggs.py b/pokemongo_bot/cell_workers/incubate_eggs.py\n--- a/pokemongo_bot/cell_workers/incubate_eggs.py\n+++ b/pokemongo_bot/cell_workers/incubate_eggs.py\n@@ -23,7 +23,10 @@\n def _process_config(self):\n self.longer_eggs_first = self.config.get(\"longer_eggs_first\", True)\n self.min_interval = self.config.get('min_interval', 120)\n-\n+ \n+ self.breakable_incubator = self.config.get(\"breakable\", [])\n+ self.infinite_incubator = self.config.get(\"infinite\", [])\n+ \n def work(self):\n try:\n self._check_inventory()\n@@ -57,6 +60,17 @@\n for egg in self.eggs:\n if egg[\"used\"] or egg[\"km\"] == -1:\n continue\n+ \n+ if self.breakable_incubator:\n+ if incubator.get('uses_remaining') is not None: # test if the incubator is of type breakable\n+ if egg[\"km\"] not in self.breakable_incubator:\n+ continue\n+ \n+ if self.infinite_incubator:\n+ if incubator.get('uses_remaining') is None: # test if the incubator is of type infinite\n+ if egg[\"km\"] not in self.infinite_incubator:\n+ continue\n+ \n self.emit_event(\n 'incubate_try',\n level='debug',\n@@ -119,7 +133,7 @@\n incubators = inv_data.get(\"egg_incubators\", {}).get(\"egg_incubator\",[])\n if isinstance(incubators, basestring): # checking for old response\n incubators = [incubators]\n- for incubator in incubators:\n+ for incubator in incubators: \n if 'pokemon_id' in incubator:\n start_km = incubator.get('start_km_walked', 9001)\n km_walked = incubator.get('target_km_walked', 9001)\n", "issue": "[Feature Request] Differentiate Between Unlimited and \"Purchased\" Incubator use.\nBlue incubators are difficult to get so I use it only for 10km eggs. Is there any configuration to prevent bot from using Blue Incubator?\n\n", "before_files": [{"content": "from datetime import datetime, timedelta\n\nfrom pokemongo_bot.human_behaviour import sleep\nfrom pokemongo_bot.base_task import BaseTask\n\n\nclass IncubateEggs(BaseTask):\n SUPPORTED_TASK_API_VERSION = 1\n\n last_km_walked = 0\n\n def initialize(self):\n self.next_update = None\n self.ready_incubators = []\n self.used_incubators = []\n self.eggs = []\n self.km_walked = 0\n self.hatching_animation_delay = 4.20\n self.max_iv = 45.0\n\n self._process_config()\n\n def _process_config(self):\n self.longer_eggs_first = self.config.get(\"longer_eggs_first\", True)\n self.min_interval = self.config.get('min_interval', 120)\n\n def work(self):\n try:\n self._check_inventory()\n except:\n return\n\n if self.used_incubators and IncubateEggs.last_km_walked != self.km_walked:\n self.used_incubators.sort(key=lambda x: x.get(\"km\"))\n km_left = self.used_incubators[0]['km']-self.km_walked\n if km_left <= 0:\n self._hatch_eggs()\n else:\n self.bot.metrics.next_hatching_km(km_left)\n\n if self._should_print():\n self._print_eggs()\n self._compute_next_update()\n\n IncubateEggs.last_km_walked = self.km_walked\n\n sorting = self.longer_eggs_first\n self.eggs.sort(key=lambda x: x.get(\"km\"), reverse=sorting)\n\n if self.ready_incubators:\n self._apply_incubators()\n\n def _apply_incubators(self):\n for incubator in self.ready_incubators:\n if incubator.get('used', False):\n continue\n for egg in self.eggs:\n if egg[\"used\"] or egg[\"km\"] == -1:\n continue\n self.emit_event(\n 'incubate_try',\n level='debug',\n formatted=\"Attempting to apply incubator {incubator_id} to egg {egg_id}\",\n data={\n 'incubator_id': incubator['id'],\n 'egg_id': egg['id']\n }\n )\n ret = self.bot.api.use_item_egg_incubator(\n item_id=incubator[\"id\"],\n pokemon_id=egg[\"id\"]\n )\n if ret:\n code = ret.get(\"responses\", {}).get(\"USE_ITEM_EGG_INCUBATOR\", {}).get(\"result\", 0)\n if code == 1:\n self.emit_event(\n 'incubate',\n formatted='Incubating a {distance_in_km} egg.',\n data={\n 'distance_in_km': str(egg['km'])\n }\n )\n egg[\"used\"] = True\n incubator[\"used\"] = True\n break\n elif code == 5 or code == 7:\n self.emit_event(\n 'incubator_already_used',\n level='debug',\n formatted='Incubator in use.',\n )\n incubator[\"used\"] = True\n break\n elif code == 6:\n self.emit_event(\n 'egg_already_incubating',\n level='debug',\n formatted='Egg already incubating',\n )\n egg[\"used\"] = True\n\n def _check_inventory(self, lookup_ids=[]):\n inv = {}\n response_dict = self.bot.api.get_inventory()\n matched_pokemon = []\n temp_eggs = []\n temp_used_incubators = []\n temp_ready_incubators = []\n inv = reduce(\n dict.__getitem__,\n [\"responses\", \"GET_INVENTORY\", \"inventory_delta\", \"inventory_items\"],\n response_dict\n )\n for inv_data in inv:\n inv_data = inv_data.get(\"inventory_item_data\", {})\n if \"egg_incubators\" in inv_data:\n temp_used_incubators = []\n temp_ready_incubators = []\n incubators = inv_data.get(\"egg_incubators\", {}).get(\"egg_incubator\",[])\n if isinstance(incubators, basestring): # checking for old response\n incubators = [incubators]\n for incubator in incubators:\n if 'pokemon_id' in incubator:\n start_km = incubator.get('start_km_walked', 9001)\n km_walked = incubator.get('target_km_walked', 9001)\n temp_used_incubators.append({\n \"id\": incubator.get('id', -1),\n \"km\": km_walked,\n \"km_needed\": (km_walked - start_km)\n })\n else:\n temp_ready_incubators.append({\n \"id\": incubator.get('id', -1)\n })\n continue\n if \"pokemon_data\" in inv_data:\n pokemon = inv_data.get(\"pokemon_data\", {})\n if pokemon.get(\"is_egg\", False) and \"egg_incubator_id\" not in pokemon:\n temp_eggs.append({\n \"id\": pokemon.get(\"id\", -1),\n \"km\": pokemon.get(\"egg_km_walked_target\", -1),\n \"used\": False\n })\n elif 'is_egg' not in pokemon and pokemon['id'] in lookup_ids:\n pokemon.update({\n \"iv\": [\n pokemon.get('individual_attack', 0),\n pokemon.get('individual_defense', 0),\n pokemon.get('individual_stamina', 0)\n ]})\n matched_pokemon.append(pokemon)\n continue\n if \"player_stats\" in inv_data:\n self.km_walked = inv_data.get(\"player_stats\", {}).get(\"km_walked\", 0)\n if temp_used_incubators:\n self.used_incubators = temp_used_incubators\n if temp_ready_incubators:\n self.ready_incubators = temp_ready_incubators\n if temp_eggs:\n self.eggs = temp_eggs\n return matched_pokemon\n\n def _hatch_eggs(self):\n response_dict = self.bot.api.get_hatched_eggs()\n log_color = 'green'\n try:\n result = reduce(dict.__getitem__, [\"responses\", \"GET_HATCHED_EGGS\"], response_dict)\n except KeyError:\n return\n pokemon_ids = []\n if 'pokemon_id' in result:\n pokemon_ids = [id for id in result['pokemon_id']]\n stardust = result.get('stardust_awarded', \"error\")\n candy = result.get('candy_awarded', \"error\")\n xp = result.get('experience_awarded', \"error\")\n sleep(self.hatching_animation_delay)\n self.bot.latest_inventory = None\n try:\n pokemon_data = self._check_inventory(pokemon_ids)\n for pokemon in pokemon_data:\n # pokemon ids seem to be offset by one\n if pokemon['pokemon_id']!=-1:\n pokemon['name'] = self.bot.pokemon_list[(pokemon.get('pokemon_id')-1)]['Name']\n else:\n pokemon['name'] = \"error\"\n except:\n pokemon_data = [{\"name\":\"error\",\"cp\":\"error\",\"iv\":\"error\"}]\n if not pokemon_ids or pokemon_data[0]['name'] == \"error\":\n self.emit_event(\n 'egg_hatched',\n data={\n 'pokemon': 'error',\n 'cp': 'error',\n 'iv': 'error',\n 'exp': 'error',\n 'stardust': 'error',\n 'candy': 'error',\n }\n )\n return\n for i in range(len(pokemon_data)):\n msg = \"Egg hatched with a {pokemon} (CP {cp} - IV {iv}), {exp} exp, {stardust} stardust and {candy} candies.\"\n self.bot.metrics.hatched_eggs(1)\n self.emit_event(\n 'egg_hatched',\n formatted=msg,\n data={\n 'pokemon': pokemon_data[i]['name'],\n 'cp': pokemon_data[i]['cp'],\n 'iv': \"{} {}\".format(\n \"/\".join(map(str, pokemon_data[i]['iv'])),\n round(sum(pokemon_data[i]['iv'])/self.max_iv, 2)\n ),\n 'exp': xp[i],\n 'stardust': stardust[i],\n 'candy': candy[i],\n }\n )\n\n def _print_eggs(self):\n if not self.used_incubators:\n return\n\n self.used_incubators.sort(key=lambda x: x.get(\"km\"))\n \n eggs = ['{:.2f}/{} km'.format(e['km_needed']-e['km']+self.km_walked, e['km_needed']) for e in self.used_incubators]\n\n self.emit_event(\n 'next_egg_incubates',\n formatted='Eggs incubating: [{eggs}] (Eggs left: {eggs_left}, Incubating: {eggs_inc})',\n data={\n 'eggs_left': len(self.eggs),\n 'eggs_inc': len(self.used_incubators),\n 'eggs': ', '.join(eggs)\n }\n )\n \n def _should_print(self):\n \"\"\"\n Returns a value indicating whether the eggs should be displayed.\n :return: True if the stats should be displayed; otherwise, False.\n :rtype: bool\n \"\"\"\n return self.next_update is None or datetime.now() >= self.next_update\n\n def _compute_next_update(self):\n \"\"\"\n Computes the next update datetime based on the minimum update interval.\n :return: Nothing.\n :rtype: None\n \"\"\"\n self.next_update = datetime.now() + timedelta(seconds=self.min_interval)", "path": "pokemongo_bot/cell_workers/incubate_eggs.py"}]}
| 3,366 | 483 |
gh_patches_debug_44972
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-contrib-1177
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Redis] RedisCluster support
Redis instrumentation does not support RedisCluster ([redis.asyncio.cluster.RedisCluster](https://github.com/redis/redis-py/blob/master/redis/asyncio/cluster.py#L102)).
I tried to instrument RedisCluster using `opentelemetry-instrumentation-redis` as below, but the application did not export any traces related redis.
```python
from opentelemetry.instrumentation.redis import RedisInstrumentor
from redis.asyncio.cluster import RedisCluster as Redis
RedisInstrumentor().instrument()
client = await Redis(host=host, port=6379)
client.get("my-key")
```
It would be very helpful if redis instrumentation supports RedisCluster.
</issue>
<code>
[start of instrumentation/opentelemetry-instrumentation-redis/src/opentelemetry/instrumentation/redis/__init__.py]
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 #
15 """
16 Instrument `redis`_ to report Redis queries.
17
18 There are two options for instrumenting code. The first option is to use the
19 ``opentelemetry-instrumentation`` executable which will automatically
20 instrument your Redis client. The second is to programmatically enable
21 instrumentation via the following code:
22
23 .. _redis: https://pypi.org/project/redis/
24
25 Usage
26 -----
27
28 .. code:: python
29
30 from opentelemetry.instrumentation.redis import RedisInstrumentor
31 import redis
32
33
34 # Instrument redis
35 RedisInstrumentor().instrument()
36
37 # This will report a span with the default settings
38 client = redis.StrictRedis(host="localhost", port=6379)
39 client.get("my-key")
40
41 Async Redis clients (i.e. redis.asyncio.Redis) are also instrumented in the same way:
42
43 .. code:: python
44
45 from opentelemetry.instrumentation.redis import RedisInstrumentor
46 import redis.asyncio
47
48
49 # Instrument redis
50 RedisInstrumentor().instrument()
51
52 # This will report a span with the default settings
53 async def redis_get():
54 client = redis.asyncio.Redis(host="localhost", port=6379)
55 await client.get("my-key")
56
57 The `instrument` method accepts the following keyword args:
58
59 tracer_provider (TracerProvider) - an optional tracer provider
60
61 request_hook (Callable) - a function with extra user-defined logic to be performed before performing the request
62 this function signature is: def request_hook(span: Span, instance: redis.connection.Connection, args, kwargs) -> None
63
64 response_hook (Callable) - a function with extra user-defined logic to be performed after performing the request
65 this function signature is: def response_hook(span: Span, instance: redis.connection.Connection, response) -> None
66
67 for example:
68
69 .. code: python
70
71 from opentelemetry.instrumentation.redis import RedisInstrumentor
72 import redis
73
74 def request_hook(span, instance, args, kwargs):
75 if span and span.is_recording():
76 span.set_attribute("custom_user_attribute_from_request_hook", "some-value")
77
78 def response_hook(span, instance, response):
79 if span and span.is_recording():
80 span.set_attribute("custom_user_attribute_from_response_hook", "some-value")
81
82 # Instrument redis with hooks
83 RedisInstrumentor().instrument(request_hook=request_hook, response_hook=response_hook)
84
85 # This will report a span with the default settings and the custom attributes added from the hooks
86 client = redis.StrictRedis(host="localhost", port=6379)
87 client.get("my-key")
88
89 API
90 ---
91 """
92 import typing
93 from typing import Any, Collection
94
95 import redis
96 from wrapt import wrap_function_wrapper
97
98 from opentelemetry import trace
99 from opentelemetry.instrumentation.instrumentor import BaseInstrumentor
100 from opentelemetry.instrumentation.redis.package import _instruments
101 from opentelemetry.instrumentation.redis.util import (
102 _extract_conn_attributes,
103 _format_command_args,
104 )
105 from opentelemetry.instrumentation.redis.version import __version__
106 from opentelemetry.instrumentation.utils import unwrap
107 from opentelemetry.semconv.trace import SpanAttributes
108 from opentelemetry.trace import Span
109
110 _DEFAULT_SERVICE = "redis"
111
112 _RequestHookT = typing.Optional[
113 typing.Callable[
114 [Span, redis.connection.Connection, typing.List, typing.Dict], None
115 ]
116 ]
117 _ResponseHookT = typing.Optional[
118 typing.Callable[[Span, redis.connection.Connection, Any], None]
119 ]
120
121 _REDIS_ASYNCIO_VERSION = (4, 2, 0)
122 if redis.VERSION >= _REDIS_ASYNCIO_VERSION:
123 import redis.asyncio
124
125
126 def _set_connection_attributes(span, conn):
127 if not span.is_recording():
128 return
129 for key, value in _extract_conn_attributes(
130 conn.connection_pool.connection_kwargs
131 ).items():
132 span.set_attribute(key, value)
133
134
135 def _instrument(
136 tracer,
137 request_hook: _RequestHookT = None,
138 response_hook: _ResponseHookT = None,
139 ):
140 def _traced_execute_command(func, instance, args, kwargs):
141 query = _format_command_args(args)
142 name = ""
143 if len(args) > 0 and args[0]:
144 name = args[0]
145 else:
146 name = instance.connection_pool.connection_kwargs.get("db", 0)
147 with tracer.start_as_current_span(
148 name, kind=trace.SpanKind.CLIENT
149 ) as span:
150 if span.is_recording():
151 span.set_attribute(SpanAttributes.DB_STATEMENT, query)
152 _set_connection_attributes(span, instance)
153 span.set_attribute("db.redis.args_length", len(args))
154 if callable(request_hook):
155 request_hook(span, instance, args, kwargs)
156 response = func(*args, **kwargs)
157 if callable(response_hook):
158 response_hook(span, instance, response)
159 return response
160
161 def _traced_execute_pipeline(func, instance, args, kwargs):
162 cmds = [_format_command_args(c) for c, _ in instance.command_stack]
163 resource = "\n".join(cmds)
164
165 span_name = " ".join([args[0] for args, _ in instance.command_stack])
166
167 with tracer.start_as_current_span(
168 span_name, kind=trace.SpanKind.CLIENT
169 ) as span:
170 if span.is_recording():
171 span.set_attribute(SpanAttributes.DB_STATEMENT, resource)
172 _set_connection_attributes(span, instance)
173 span.set_attribute(
174 "db.redis.pipeline_length", len(instance.command_stack)
175 )
176 response = func(*args, **kwargs)
177 if callable(response_hook):
178 response_hook(span, instance, response)
179 return response
180
181 pipeline_class = (
182 "BasePipeline" if redis.VERSION < (3, 0, 0) else "Pipeline"
183 )
184 redis_class = "StrictRedis" if redis.VERSION < (3, 0, 0) else "Redis"
185
186 wrap_function_wrapper(
187 "redis", f"{redis_class}.execute_command", _traced_execute_command
188 )
189 wrap_function_wrapper(
190 "redis.client",
191 f"{pipeline_class}.execute",
192 _traced_execute_pipeline,
193 )
194 wrap_function_wrapper(
195 "redis.client",
196 f"{pipeline_class}.immediate_execute_command",
197 _traced_execute_command,
198 )
199 if redis.VERSION >= _REDIS_ASYNCIO_VERSION:
200 wrap_function_wrapper(
201 "redis.asyncio",
202 f"{redis_class}.execute_command",
203 _traced_execute_command,
204 )
205 wrap_function_wrapper(
206 "redis.asyncio.client",
207 f"{pipeline_class}.execute",
208 _traced_execute_pipeline,
209 )
210 wrap_function_wrapper(
211 "redis.asyncio.client",
212 f"{pipeline_class}.immediate_execute_command",
213 _traced_execute_command,
214 )
215
216
217 class RedisInstrumentor(BaseInstrumentor):
218 """An instrumentor for Redis
219 See `BaseInstrumentor`
220 """
221
222 def instrumentation_dependencies(self) -> Collection[str]:
223 return _instruments
224
225 def _instrument(self, **kwargs):
226 """Instruments the redis module
227
228 Args:
229 **kwargs: Optional arguments
230 ``tracer_provider``: a TracerProvider, defaults to global.
231 ``response_hook``: An optional callback which is invoked right before the span is finished processing a response.
232 """
233 tracer_provider = kwargs.get("tracer_provider")
234 tracer = trace.get_tracer(
235 __name__, __version__, tracer_provider=tracer_provider
236 )
237 _instrument(
238 tracer,
239 request_hook=kwargs.get("request_hook"),
240 response_hook=kwargs.get("response_hook"),
241 )
242
243 def _uninstrument(self, **kwargs):
244 if redis.VERSION < (3, 0, 0):
245 unwrap(redis.StrictRedis, "execute_command")
246 unwrap(redis.StrictRedis, "pipeline")
247 unwrap(redis.Redis, "pipeline")
248 unwrap(
249 redis.client.BasePipeline, # pylint:disable=no-member
250 "execute",
251 )
252 unwrap(
253 redis.client.BasePipeline, # pylint:disable=no-member
254 "immediate_execute_command",
255 )
256 else:
257 unwrap(redis.Redis, "execute_command")
258 unwrap(redis.Redis, "pipeline")
259 unwrap(redis.client.Pipeline, "execute")
260 unwrap(redis.client.Pipeline, "immediate_execute_command")
261 if redis.VERSION >= _REDIS_ASYNCIO_VERSION:
262 unwrap(redis.asyncio.Redis, "execute_command")
263 unwrap(redis.asyncio.Redis, "pipeline")
264 unwrap(redis.asyncio.client.Pipeline, "execute")
265 unwrap(redis.asyncio.client.Pipeline, "immediate_execute_command")
266
[end of instrumentation/opentelemetry-instrumentation-redis/src/opentelemetry/instrumentation/redis/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/instrumentation/opentelemetry-instrumentation-redis/src/opentelemetry/instrumentation/redis/__init__.py b/instrumentation/opentelemetry-instrumentation-redis/src/opentelemetry/instrumentation/redis/__init__.py
--- a/instrumentation/opentelemetry-instrumentation-redis/src/opentelemetry/instrumentation/redis/__init__.py
+++ b/instrumentation/opentelemetry-instrumentation-redis/src/opentelemetry/instrumentation/redis/__init__.py
@@ -122,9 +122,12 @@
if redis.VERSION >= _REDIS_ASYNCIO_VERSION:
import redis.asyncio
+_REDIS_CLUSTER_VERSION = (4, 1, 0)
+_REDIS_ASYNCIO_CLUSTER_VERSION = (4, 3, 0)
+
def _set_connection_attributes(span, conn):
- if not span.is_recording():
+ if not span.is_recording() or not hasattr(conn, "connection_pool"):
return
for key, value in _extract_conn_attributes(
conn.connection_pool.connection_kwargs
@@ -159,10 +162,29 @@
return response
def _traced_execute_pipeline(func, instance, args, kwargs):
- cmds = [_format_command_args(c) for c, _ in instance.command_stack]
- resource = "\n".join(cmds)
+ try:
+ command_stack = (
+ instance.command_stack
+ if hasattr(instance, "command_stack")
+ else instance._command_stack
+ )
- span_name = " ".join([args[0] for args, _ in instance.command_stack])
+ cmds = [
+ _format_command_args(c.args if hasattr(c, "args") else c[0])
+ for c in command_stack
+ ]
+ resource = "\n".join(cmds)
+
+ span_name = " ".join(
+ [
+ (c.args[0] if hasattr(c, "args") else c[0][0])
+ for c in command_stack
+ ]
+ )
+ except (AttributeError, IndexError):
+ command_stack = []
+ resource = ""
+ span_name = ""
with tracer.start_as_current_span(
span_name, kind=trace.SpanKind.CLIENT
@@ -171,7 +193,7 @@
span.set_attribute(SpanAttributes.DB_STATEMENT, resource)
_set_connection_attributes(span, instance)
span.set_attribute(
- "db.redis.pipeline_length", len(instance.command_stack)
+ "db.redis.pipeline_length", len(command_stack)
)
response = func(*args, **kwargs)
if callable(response_hook):
@@ -196,6 +218,17 @@
f"{pipeline_class}.immediate_execute_command",
_traced_execute_command,
)
+ if redis.VERSION >= _REDIS_CLUSTER_VERSION:
+ wrap_function_wrapper(
+ "redis.cluster",
+ "RedisCluster.execute_command",
+ _traced_execute_command,
+ )
+ wrap_function_wrapper(
+ "redis.cluster",
+ "ClusterPipeline.execute",
+ _traced_execute_pipeline,
+ )
if redis.VERSION >= _REDIS_ASYNCIO_VERSION:
wrap_function_wrapper(
"redis.asyncio",
@@ -212,6 +245,17 @@
f"{pipeline_class}.immediate_execute_command",
_traced_execute_command,
)
+ if redis.VERSION >= _REDIS_ASYNCIO_CLUSTER_VERSION:
+ wrap_function_wrapper(
+ "redis.asyncio.cluster",
+ "RedisCluster.execute_command",
+ _traced_execute_command,
+ )
+ wrap_function_wrapper(
+ "redis.asyncio.cluster",
+ "ClusterPipeline.execute",
+ _traced_execute_pipeline,
+ )
class RedisInstrumentor(BaseInstrumentor):
@@ -258,8 +302,14 @@
unwrap(redis.Redis, "pipeline")
unwrap(redis.client.Pipeline, "execute")
unwrap(redis.client.Pipeline, "immediate_execute_command")
+ if redis.VERSION >= _REDIS_CLUSTER_VERSION:
+ unwrap(redis.cluster.RedisCluster, "execute_command")
+ unwrap(redis.cluster.ClusterPipeline, "execute")
if redis.VERSION >= _REDIS_ASYNCIO_VERSION:
unwrap(redis.asyncio.Redis, "execute_command")
unwrap(redis.asyncio.Redis, "pipeline")
unwrap(redis.asyncio.client.Pipeline, "execute")
unwrap(redis.asyncio.client.Pipeline, "immediate_execute_command")
+ if redis.VERSION >= _REDIS_ASYNCIO_CLUSTER_VERSION:
+ unwrap(redis.asyncio.cluster.RedisCluster, "execute_command")
+ unwrap(redis.asyncio.cluster.ClusterPipeline, "execute")
|
{"golden_diff": "diff --git a/instrumentation/opentelemetry-instrumentation-redis/src/opentelemetry/instrumentation/redis/__init__.py b/instrumentation/opentelemetry-instrumentation-redis/src/opentelemetry/instrumentation/redis/__init__.py\n--- a/instrumentation/opentelemetry-instrumentation-redis/src/opentelemetry/instrumentation/redis/__init__.py\n+++ b/instrumentation/opentelemetry-instrumentation-redis/src/opentelemetry/instrumentation/redis/__init__.py\n@@ -122,9 +122,12 @@\n if redis.VERSION >= _REDIS_ASYNCIO_VERSION:\n import redis.asyncio\n \n+_REDIS_CLUSTER_VERSION = (4, 1, 0)\n+_REDIS_ASYNCIO_CLUSTER_VERSION = (4, 3, 0)\n+\n \n def _set_connection_attributes(span, conn):\n- if not span.is_recording():\n+ if not span.is_recording() or not hasattr(conn, \"connection_pool\"):\n return\n for key, value in _extract_conn_attributes(\n conn.connection_pool.connection_kwargs\n@@ -159,10 +162,29 @@\n return response\n \n def _traced_execute_pipeline(func, instance, args, kwargs):\n- cmds = [_format_command_args(c) for c, _ in instance.command_stack]\n- resource = \"\\n\".join(cmds)\n+ try:\n+ command_stack = (\n+ instance.command_stack\n+ if hasattr(instance, \"command_stack\")\n+ else instance._command_stack\n+ )\n \n- span_name = \" \".join([args[0] for args, _ in instance.command_stack])\n+ cmds = [\n+ _format_command_args(c.args if hasattr(c, \"args\") else c[0])\n+ for c in command_stack\n+ ]\n+ resource = \"\\n\".join(cmds)\n+\n+ span_name = \" \".join(\n+ [\n+ (c.args[0] if hasattr(c, \"args\") else c[0][0])\n+ for c in command_stack\n+ ]\n+ )\n+ except (AttributeError, IndexError):\n+ command_stack = []\n+ resource = \"\"\n+ span_name = \"\"\n \n with tracer.start_as_current_span(\n span_name, kind=trace.SpanKind.CLIENT\n@@ -171,7 +193,7 @@\n span.set_attribute(SpanAttributes.DB_STATEMENT, resource)\n _set_connection_attributes(span, instance)\n span.set_attribute(\n- \"db.redis.pipeline_length\", len(instance.command_stack)\n+ \"db.redis.pipeline_length\", len(command_stack)\n )\n response = func(*args, **kwargs)\n if callable(response_hook):\n@@ -196,6 +218,17 @@\n f\"{pipeline_class}.immediate_execute_command\",\n _traced_execute_command,\n )\n+ if redis.VERSION >= _REDIS_CLUSTER_VERSION:\n+ wrap_function_wrapper(\n+ \"redis.cluster\",\n+ \"RedisCluster.execute_command\",\n+ _traced_execute_command,\n+ )\n+ wrap_function_wrapper(\n+ \"redis.cluster\",\n+ \"ClusterPipeline.execute\",\n+ _traced_execute_pipeline,\n+ )\n if redis.VERSION >= _REDIS_ASYNCIO_VERSION:\n wrap_function_wrapper(\n \"redis.asyncio\",\n@@ -212,6 +245,17 @@\n f\"{pipeline_class}.immediate_execute_command\",\n _traced_execute_command,\n )\n+ if redis.VERSION >= _REDIS_ASYNCIO_CLUSTER_VERSION:\n+ wrap_function_wrapper(\n+ \"redis.asyncio.cluster\",\n+ \"RedisCluster.execute_command\",\n+ _traced_execute_command,\n+ )\n+ wrap_function_wrapper(\n+ \"redis.asyncio.cluster\",\n+ \"ClusterPipeline.execute\",\n+ _traced_execute_pipeline,\n+ )\n \n \n class RedisInstrumentor(BaseInstrumentor):\n@@ -258,8 +302,14 @@\n unwrap(redis.Redis, \"pipeline\")\n unwrap(redis.client.Pipeline, \"execute\")\n unwrap(redis.client.Pipeline, \"immediate_execute_command\")\n+ if redis.VERSION >= _REDIS_CLUSTER_VERSION:\n+ unwrap(redis.cluster.RedisCluster, \"execute_command\")\n+ unwrap(redis.cluster.ClusterPipeline, \"execute\")\n if redis.VERSION >= _REDIS_ASYNCIO_VERSION:\n unwrap(redis.asyncio.Redis, \"execute_command\")\n unwrap(redis.asyncio.Redis, \"pipeline\")\n unwrap(redis.asyncio.client.Pipeline, \"execute\")\n unwrap(redis.asyncio.client.Pipeline, \"immediate_execute_command\")\n+ if redis.VERSION >= _REDIS_ASYNCIO_CLUSTER_VERSION:\n+ unwrap(redis.asyncio.cluster.RedisCluster, \"execute_command\")\n+ unwrap(redis.asyncio.cluster.ClusterPipeline, \"execute\")\n", "issue": "[Redis] RedisCluster support\nRedis instrumentation does not support RedisCluster ([redis.asyncio.cluster.RedisCluster](https://github.com/redis/redis-py/blob/master/redis/asyncio/cluster.py#L102)).\r\n\r\nI tried to instrument RedisCluster using `opentelemetry-instrumentation-redis` as below, but the application did not export any traces related redis.\r\n```python\r\nfrom opentelemetry.instrumentation.redis import RedisInstrumentor\r\nfrom redis.asyncio.cluster import RedisCluster as Redis\r\n\r\nRedisInstrumentor().instrument()\r\n\r\nclient = await Redis(host=host, port=6379)\r\n\r\nclient.get(\"my-key\")\r\n```\r\n\r\nIt would be very helpful if redis instrumentation supports RedisCluster.\r\n\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n\"\"\"\nInstrument `redis`_ to report Redis queries.\n\nThere are two options for instrumenting code. The first option is to use the\n``opentelemetry-instrumentation`` executable which will automatically\ninstrument your Redis client. The second is to programmatically enable\ninstrumentation via the following code:\n\n.. _redis: https://pypi.org/project/redis/\n\nUsage\n-----\n\n.. code:: python\n\n from opentelemetry.instrumentation.redis import RedisInstrumentor\n import redis\n\n\n # Instrument redis\n RedisInstrumentor().instrument()\n\n # This will report a span with the default settings\n client = redis.StrictRedis(host=\"localhost\", port=6379)\n client.get(\"my-key\")\n\nAsync Redis clients (i.e. redis.asyncio.Redis) are also instrumented in the same way:\n\n.. code:: python\n\n from opentelemetry.instrumentation.redis import RedisInstrumentor\n import redis.asyncio\n\n\n # Instrument redis\n RedisInstrumentor().instrument()\n\n # This will report a span with the default settings\n async def redis_get():\n client = redis.asyncio.Redis(host=\"localhost\", port=6379)\n await client.get(\"my-key\")\n\nThe `instrument` method accepts the following keyword args:\n\ntracer_provider (TracerProvider) - an optional tracer provider\n\nrequest_hook (Callable) - a function with extra user-defined logic to be performed before performing the request\nthis function signature is: def request_hook(span: Span, instance: redis.connection.Connection, args, kwargs) -> None\n\nresponse_hook (Callable) - a function with extra user-defined logic to be performed after performing the request\nthis function signature is: def response_hook(span: Span, instance: redis.connection.Connection, response) -> None\n\nfor example:\n\n.. code: python\n\n from opentelemetry.instrumentation.redis import RedisInstrumentor\n import redis\n\n def request_hook(span, instance, args, kwargs):\n if span and span.is_recording():\n span.set_attribute(\"custom_user_attribute_from_request_hook\", \"some-value\")\n\n def response_hook(span, instance, response):\n if span and span.is_recording():\n span.set_attribute(\"custom_user_attribute_from_response_hook\", \"some-value\")\n\n # Instrument redis with hooks\n RedisInstrumentor().instrument(request_hook=request_hook, response_hook=response_hook)\n\n # This will report a span with the default settings and the custom attributes added from the hooks\n client = redis.StrictRedis(host=\"localhost\", port=6379)\n client.get(\"my-key\")\n\nAPI\n---\n\"\"\"\nimport typing\nfrom typing import Any, Collection\n\nimport redis\nfrom wrapt import wrap_function_wrapper\n\nfrom opentelemetry import trace\nfrom opentelemetry.instrumentation.instrumentor import BaseInstrumentor\nfrom opentelemetry.instrumentation.redis.package import _instruments\nfrom opentelemetry.instrumentation.redis.util import (\n _extract_conn_attributes,\n _format_command_args,\n)\nfrom opentelemetry.instrumentation.redis.version import __version__\nfrom opentelemetry.instrumentation.utils import unwrap\nfrom opentelemetry.semconv.trace import SpanAttributes\nfrom opentelemetry.trace import Span\n\n_DEFAULT_SERVICE = \"redis\"\n\n_RequestHookT = typing.Optional[\n typing.Callable[\n [Span, redis.connection.Connection, typing.List, typing.Dict], None\n ]\n]\n_ResponseHookT = typing.Optional[\n typing.Callable[[Span, redis.connection.Connection, Any], None]\n]\n\n_REDIS_ASYNCIO_VERSION = (4, 2, 0)\nif redis.VERSION >= _REDIS_ASYNCIO_VERSION:\n import redis.asyncio\n\n\ndef _set_connection_attributes(span, conn):\n if not span.is_recording():\n return\n for key, value in _extract_conn_attributes(\n conn.connection_pool.connection_kwargs\n ).items():\n span.set_attribute(key, value)\n\n\ndef _instrument(\n tracer,\n request_hook: _RequestHookT = None,\n response_hook: _ResponseHookT = None,\n):\n def _traced_execute_command(func, instance, args, kwargs):\n query = _format_command_args(args)\n name = \"\"\n if len(args) > 0 and args[0]:\n name = args[0]\n else:\n name = instance.connection_pool.connection_kwargs.get(\"db\", 0)\n with tracer.start_as_current_span(\n name, kind=trace.SpanKind.CLIENT\n ) as span:\n if span.is_recording():\n span.set_attribute(SpanAttributes.DB_STATEMENT, query)\n _set_connection_attributes(span, instance)\n span.set_attribute(\"db.redis.args_length\", len(args))\n if callable(request_hook):\n request_hook(span, instance, args, kwargs)\n response = func(*args, **kwargs)\n if callable(response_hook):\n response_hook(span, instance, response)\n return response\n\n def _traced_execute_pipeline(func, instance, args, kwargs):\n cmds = [_format_command_args(c) for c, _ in instance.command_stack]\n resource = \"\\n\".join(cmds)\n\n span_name = \" \".join([args[0] for args, _ in instance.command_stack])\n\n with tracer.start_as_current_span(\n span_name, kind=trace.SpanKind.CLIENT\n ) as span:\n if span.is_recording():\n span.set_attribute(SpanAttributes.DB_STATEMENT, resource)\n _set_connection_attributes(span, instance)\n span.set_attribute(\n \"db.redis.pipeline_length\", len(instance.command_stack)\n )\n response = func(*args, **kwargs)\n if callable(response_hook):\n response_hook(span, instance, response)\n return response\n\n pipeline_class = (\n \"BasePipeline\" if redis.VERSION < (3, 0, 0) else \"Pipeline\"\n )\n redis_class = \"StrictRedis\" if redis.VERSION < (3, 0, 0) else \"Redis\"\n\n wrap_function_wrapper(\n \"redis\", f\"{redis_class}.execute_command\", _traced_execute_command\n )\n wrap_function_wrapper(\n \"redis.client\",\n f\"{pipeline_class}.execute\",\n _traced_execute_pipeline,\n )\n wrap_function_wrapper(\n \"redis.client\",\n f\"{pipeline_class}.immediate_execute_command\",\n _traced_execute_command,\n )\n if redis.VERSION >= _REDIS_ASYNCIO_VERSION:\n wrap_function_wrapper(\n \"redis.asyncio\",\n f\"{redis_class}.execute_command\",\n _traced_execute_command,\n )\n wrap_function_wrapper(\n \"redis.asyncio.client\",\n f\"{pipeline_class}.execute\",\n _traced_execute_pipeline,\n )\n wrap_function_wrapper(\n \"redis.asyncio.client\",\n f\"{pipeline_class}.immediate_execute_command\",\n _traced_execute_command,\n )\n\n\nclass RedisInstrumentor(BaseInstrumentor):\n \"\"\"An instrumentor for Redis\n See `BaseInstrumentor`\n \"\"\"\n\n def instrumentation_dependencies(self) -> Collection[str]:\n return _instruments\n\n def _instrument(self, **kwargs):\n \"\"\"Instruments the redis module\n\n Args:\n **kwargs: Optional arguments\n ``tracer_provider``: a TracerProvider, defaults to global.\n ``response_hook``: An optional callback which is invoked right before the span is finished processing a response.\n \"\"\"\n tracer_provider = kwargs.get(\"tracer_provider\")\n tracer = trace.get_tracer(\n __name__, __version__, tracer_provider=tracer_provider\n )\n _instrument(\n tracer,\n request_hook=kwargs.get(\"request_hook\"),\n response_hook=kwargs.get(\"response_hook\"),\n )\n\n def _uninstrument(self, **kwargs):\n if redis.VERSION < (3, 0, 0):\n unwrap(redis.StrictRedis, \"execute_command\")\n unwrap(redis.StrictRedis, \"pipeline\")\n unwrap(redis.Redis, \"pipeline\")\n unwrap(\n redis.client.BasePipeline, # pylint:disable=no-member\n \"execute\",\n )\n unwrap(\n redis.client.BasePipeline, # pylint:disable=no-member\n \"immediate_execute_command\",\n )\n else:\n unwrap(redis.Redis, \"execute_command\")\n unwrap(redis.Redis, \"pipeline\")\n unwrap(redis.client.Pipeline, \"execute\")\n unwrap(redis.client.Pipeline, \"immediate_execute_command\")\n if redis.VERSION >= _REDIS_ASYNCIO_VERSION:\n unwrap(redis.asyncio.Redis, \"execute_command\")\n unwrap(redis.asyncio.Redis, \"pipeline\")\n unwrap(redis.asyncio.client.Pipeline, \"execute\")\n unwrap(redis.asyncio.client.Pipeline, \"immediate_execute_command\")\n", "path": "instrumentation/opentelemetry-instrumentation-redis/src/opentelemetry/instrumentation/redis/__init__.py"}]}
| 3,353 | 1,009 |
gh_patches_debug_41031
|
rasdani/github-patches
|
git_diff
|
zigpy__zha-device-handlers-715
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Device Support Request] Decoupled mode for ctrl_neutral (QBKG04LM/QBKG03LM/QBKG21LM/QBKG22LM)
**Is your feature request related to a problem? Please describe.**
Similar to #365, but for `ctrl_neutral` implementation. I think that once implemented it can be easily adapted.
In my case I want to implement QBKG04LM decoupled mode.
It can be done easily, following @albalaing indications (https://github.com/zigpy/zha-device-handlers/issues/365#issuecomment-636510316).
The problem is that without the click button events it is not useful, so it is necessary to also implement the generation of ZHA events.
**Describe the solution you'd like**
Before implement anything you can see that device generate 4 messages:
```
2021-01-09 21:46:29 DEBUG (MainThread) [zigpy.device] Ignoring message (b'18500a0000100000001001') on cluster 6: unknown endpoint or cluster id: 4
2021-01-09 21:46:31 DEBUG (MainThread) [zigpy.device] Ignoring message (b'18510a00001000') on cluster 6: unknown endpoint or cluster id: 4
2021-01-09 21:46:32 DEBUG (MainThread) [zigpy.device] Ignoring message (b'18520a00001001') on cluster 6: unknown endpoint or cluster id: 4
2021-01-09 21:46:32 DEBUG (MainThread) [zigpy.device] Ignoring message (b'18530a00001002') on cluster 6: unknown endpoint or cluster id: 4
```
This messages are (in order):
* click
* hold
* release
* double_click
You can see that the click message corresponds in some way to the hold+release messages (00001000+00001001)
I think I'm halfway done (the decoupled part is working as expected), but I'm not satisfied with the event generation part.
When a `replacement` for endpoint 4 (and 5) is implemented you can get the `on_off` attribute reported. But IMO this approach has the following problems:
* add a new entity in HA for click button events
* it is not possible to differentiate the `click` event from `hold` and `release`
* the `double_click` event cannot be handled (parse error)
Want I think that would be implemented is:
* no HA button entity
* full events control, not only hold and release
Any help in this regard is welcome.
**Device signature - this can be acquired by removing the device from ZHA and pairing it again from the add devices screen. Be sure to add the entire content of the log panel after pairing the device to a code block below this line.**
The device signature is known and correct.
**Additional context**
Although I am not sure if it can be done this way, I have tried without success to implement a replacement that transforms events from the `OnOff` cluster to the `MultistateInput` cluster.
My current implementation is as follows (only the relevant part):
```
class BasicClusterDecoupled(BasicCluster):
"""Adds attributes for decoupled mode"""
def __init__(self, *args, **kwargs):
"""Init."""
self.attributes = BasicCluster.attributes.copy()
self.attributes.update({ 0xFF22: ("left_decoupled_mode", t.uint8_t)})
self.attributes.update({ 0xFF23: ("right_decoupled_mode", t.uint8_t)})
super().__init__(*args, **kwargs)
class CustomOnOffCluster(OnOffCluster):
"""Fire ZHA events for on off cluster."""
cluster_id = OnOff.cluster_id
def __init__(self, *args, **kwargs):
"""Init."""
self._current_state = {}
super().__init__(*args, **kwargs)
def _update_attribute(self, attrid, value):
_LOGGER.info("%s: %s", attrid, value)
if attrid == 0:
self._current_state = PRESS_TYPES.get(value)
event_args = {
PRESS_TYPE: self._current_state,
VALUE: value,
}
self.listener_event(ZHA_SEND_EVENT, COMMAND_CLICK, event_args)
super()._update_attribute(attrid, self._current_state)
replacement = {
SKIP_CONFIGURATION: True,
ENDPOINTS: {
.../...
4: {
DEVICE_TYPE: zha.DeviceType.ON_OFF_SWITCH,
INPUT_CLUSTERS: [
MultistateInput.cluster_id,
CustomOnOffCluster,
],
OUTPUT_CLUSTERS: [],
},
5: {
DEVICE_TYPE: zha.DeviceType.ON_OFF_SWITCH,
INPUT_CLUSTERS: [
MultistateInput.cluster_id,
CustomOnOffCluster,
],
OUTPUT_CLUSTERS: [],
},
},
}
```
</issue>
<code>
[start of zhaquirks/xiaomi/aqara/ctrl_neutral.py]
1 """Xiaomi aqara single key wall switch devices."""
2 import logging
3
4 from zigpy.profiles import zha
5 from zigpy.zcl.clusters.general import (
6 AnalogInput,
7 Basic,
8 BinaryOutput,
9 DeviceTemperature,
10 Groups,
11 Identify,
12 MultistateInput,
13 OnOff,
14 Ota,
15 Scenes,
16 Time,
17 )
18
19 from .. import (
20 LUMI,
21 BasicCluster,
22 OnOffCluster,
23 XiaomiCustomDevice,
24 XiaomiPowerConfiguration,
25 )
26 from ...const import (
27 DEVICE_TYPE,
28 ENDPOINTS,
29 INPUT_CLUSTERS,
30 MODELS_INFO,
31 OUTPUT_CLUSTERS,
32 PROFILE_ID,
33 SKIP_CONFIGURATION,
34 )
35
36 DOUBLE = "double"
37 HOLD = "long press"
38 PRESS_TYPES = {0: "long press", 1: "single", 2: "double"}
39 SINGLE = "single"
40 STATUS_TYPE_ATTR = 0x0055 # decimal = 85
41 XIAOMI_CLUSTER_ID = 0xFFFF
42 XIAOMI_DEVICE_TYPE = 0x5F01
43 XIAOMI_DEVICE_TYPE2 = 0x5F02
44 XIAOMI_DEVICE_TYPE3 = 0x5F03
45
46 _LOGGER = logging.getLogger(__name__)
47
48 # click attr 0xF000
49 # single click 0x3FF1F00
50 # double click 0xCFF1F00
51
52
53 class CtrlNeutral(XiaomiCustomDevice):
54 """Aqara single and double key switch device."""
55
56 signature = {
57 MODELS_INFO: [
58 (LUMI, "lumi.ctrl_neutral1"),
59 (LUMI, "lumi.ctrl_neutral2"),
60 (LUMI, "lumi.switch.b1lacn02"),
61 (LUMI, "lumi.switch.b2lacn02"),
62 ],
63 ENDPOINTS: {
64 # <SimpleDescriptor endpoint=1 profile=260 device_type=6
65 # device_version=2
66 # input_clusters=[0, 3, 1, 2, 25, 10]
67 # output_clusters=[0, 10, 25]>
68 1: {
69 PROFILE_ID: zha.PROFILE_ID,
70 DEVICE_TYPE: zha.DeviceType.REMOTE_CONTROL,
71 INPUT_CLUSTERS: [
72 Basic.cluster_id,
73 Identify.cluster_id,
74 XiaomiPowerConfiguration.cluster_id,
75 DeviceTemperature.cluster_id,
76 Ota.cluster_id,
77 Time.cluster_id,
78 ],
79 OUTPUT_CLUSTERS: [Basic.cluster_id, Time.cluster_id, Ota.cluster_id],
80 },
81 # <SimpleDescriptor endpoint=2 profile=260 device_type=256
82 # device_version=2
83 # input_clusters=[16, 6, 4, 5]
84 # output_clusters=[]>
85 2: {
86 PROFILE_ID: zha.PROFILE_ID,
87 DEVICE_TYPE: zha.DeviceType.ON_OFF_LIGHT,
88 INPUT_CLUSTERS: [
89 BinaryOutput.cluster_id,
90 OnOff.cluster_id,
91 Groups.cluster_id,
92 Scenes.cluster_id,
93 ],
94 OUTPUT_CLUSTERS: [],
95 },
96 # <SimpleDescriptor endpoint=3 profile=260 device_type=256
97 # device_version=2
98 # input_clusters=[16, 6, 4, 5]
99 # output_clusters=[]
100 3: {
101 PROFILE_ID: zha.PROFILE_ID,
102 DEVICE_TYPE: zha.DeviceType.ON_OFF_LIGHT,
103 INPUT_CLUSTERS: [
104 BinaryOutput.cluster_id,
105 OnOff.cluster_id,
106 Groups.cluster_id,
107 Scenes.cluster_id,
108 ],
109 OUTPUT_CLUSTERS: [],
110 },
111 # <SimpleDescriptor endpoint=4 profile=260 device_type=0
112 # device_version=2
113 # input_clusters=[18, 6]
114 # output_clusters=[]>
115 4: {
116 PROFILE_ID: zha.PROFILE_ID,
117 DEVICE_TYPE: zha.DeviceType.ON_OFF_SWITCH,
118 INPUT_CLUSTERS: [MultistateInput.cluster_id, OnOff.cluster_id],
119 OUTPUT_CLUSTERS: [],
120 },
121 # <SimpleDescriptor endpoint=5 profile=260 device_type=0
122 # device_version=2
123 # input_clusters=[18, 6]
124 # output_clusters=[]>
125 5: {
126 PROFILE_ID: zha.PROFILE_ID,
127 DEVICE_TYPE: zha.DeviceType.ON_OFF_SWITCH,
128 INPUT_CLUSTERS: [MultistateInput.cluster_id, OnOff.cluster_id],
129 OUTPUT_CLUSTERS: [],
130 },
131 # <SimpleDescriptor endpoint=6 profile=260 device_type=0
132 # device_version=2
133 # input_clusters=[18, 6]
134 # output_clusters=[]>
135 6: {
136 PROFILE_ID: zha.PROFILE_ID,
137 DEVICE_TYPE: zha.DeviceType.ON_OFF_SWITCH,
138 INPUT_CLUSTERS: [MultistateInput.cluster_id, OnOff.cluster_id],
139 OUTPUT_CLUSTERS: [],
140 },
141 # <SimpleDescriptor endpoint=8 profile=260 device_type=83
142 # device_version=2
143 # input_clusters=[12]
144 # output_clusters=[]>
145 8: {
146 PROFILE_ID: zha.PROFILE_ID,
147 DEVICE_TYPE: zha.DeviceType.METER_INTERFACE,
148 INPUT_CLUSTERS: [AnalogInput.cluster_id],
149 OUTPUT_CLUSTERS: [],
150 },
151 },
152 }
153
154 replacement = {
155 SKIP_CONFIGURATION: True,
156 ENDPOINTS: {
157 1: {
158 DEVICE_TYPE: zha.DeviceType.REMOTE_CONTROL,
159 INPUT_CLUSTERS: [
160 BasicCluster,
161 Identify.cluster_id,
162 XiaomiPowerConfiguration.cluster_id,
163 DeviceTemperature.cluster_id,
164 Ota.cluster_id,
165 Time.cluster_id,
166 ],
167 OUTPUT_CLUSTERS: [Basic.cluster_id, Time.cluster_id, Ota.cluster_id],
168 },
169 2: {
170 DEVICE_TYPE: zha.DeviceType.ON_OFF_SWITCH,
171 INPUT_CLUSTERS: [
172 BinaryOutput.cluster_id,
173 OnOffCluster,
174 Groups.cluster_id,
175 Scenes.cluster_id,
176 ],
177 OUTPUT_CLUSTERS: [],
178 },
179 3: {
180 DEVICE_TYPE: zha.DeviceType.ON_OFF_SWITCH,
181 INPUT_CLUSTERS: [
182 BinaryOutput.cluster_id,
183 OnOffCluster,
184 Groups.cluster_id,
185 Scenes.cluster_id,
186 ],
187 OUTPUT_CLUSTERS: [],
188 },
189 },
190 }
191
[end of zhaquirks/xiaomi/aqara/ctrl_neutral.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/zhaquirks/xiaomi/aqara/ctrl_neutral.py b/zhaquirks/xiaomi/aqara/ctrl_neutral.py
--- a/zhaquirks/xiaomi/aqara/ctrl_neutral.py
+++ b/zhaquirks/xiaomi/aqara/ctrl_neutral.py
@@ -1,6 +1,7 @@
"""Xiaomi aqara single key wall switch devices."""
import logging
+from zigpy import types as t
from zigpy.profiles import zha
from zigpy.zcl.clusters.general import (
AnalogInput,
@@ -23,16 +24,30 @@
XiaomiCustomDevice,
XiaomiPowerConfiguration,
)
+from ... import EventableCluster
from ...const import (
+ ARGS,
+ ATTRIBUTE_ID,
+ ATTRIBUTE_NAME,
+ BUTTON,
+ CLUSTER_ID,
+ COMMAND,
+ COMMAND_ATTRIBUTE_UPDATED,
+ COMMAND_DOUBLE,
+ COMMAND_HOLD,
+ COMMAND_RELEASE,
DEVICE_TYPE,
+ ENDPOINT_ID,
ENDPOINTS,
INPUT_CLUSTERS,
MODELS_INFO,
OUTPUT_CLUSTERS,
PROFILE_ID,
SKIP_CONFIGURATION,
+ VALUE,
)
+ATTRIBUTE_ON_OFF = "on_off"
DOUBLE = "double"
HOLD = "long press"
PRESS_TYPES = {0: "long press", 1: "single", 2: "double"}
@@ -53,6 +68,20 @@
class CtrlNeutral(XiaomiCustomDevice):
"""Aqara single and double key switch device."""
+ class BasicClusterDecoupled(BasicCluster):
+ """Adds attributes for decoupled mode."""
+
+ # Known Options for 'decoupled_mode_<button>':
+ # * 254 (decoupled)
+ # * 18 (relay controlled)
+ manufacturer_attributes = {
+ 0xFF22: ("decoupled_mode_left", t.uint8_t),
+ 0xFF23: ("decoupled_mode_right", t.uint8_t),
+ }
+
+ class WallSwitchOnOffCluster(EventableCluster, OnOff):
+ """WallSwitchOnOffCluster: fire events corresponding to press type."""
+
signature = {
MODELS_INFO: [
(LUMI, "lumi.ctrl_neutral1"),
@@ -157,7 +186,7 @@
1: {
DEVICE_TYPE: zha.DeviceType.REMOTE_CONTROL,
INPUT_CLUSTERS: [
- BasicCluster,
+ BasicClusterDecoupled,
Identify.cluster_id,
XiaomiPowerConfiguration.cluster_id,
DeviceTemperature.cluster_id,
@@ -186,5 +215,34 @@
],
OUTPUT_CLUSTERS: [],
},
+ 4: {
+ DEVICE_TYPE: zha.DeviceType.ON_OFF_SWITCH,
+ INPUT_CLUSTERS: [
+ MultistateInput.cluster_id,
+ WallSwitchOnOffCluster,
+ ],
+ OUTPUT_CLUSTERS: [],
+ },
+ },
+ }
+
+ device_automation_triggers = {
+ (COMMAND_HOLD, BUTTON): {
+ ENDPOINT_ID: 4,
+ CLUSTER_ID: 6,
+ COMMAND: COMMAND_ATTRIBUTE_UPDATED,
+ ARGS: {ATTRIBUTE_ID: 0, ATTRIBUTE_NAME: ATTRIBUTE_ON_OFF, VALUE: 0},
+ },
+ (COMMAND_RELEASE, BUTTON): {
+ ENDPOINT_ID: 4,
+ CLUSTER_ID: 6,
+ COMMAND: COMMAND_ATTRIBUTE_UPDATED,
+ ARGS: {ATTRIBUTE_ID: 0, ATTRIBUTE_NAME: ATTRIBUTE_ON_OFF, VALUE: 1},
+ },
+ (COMMAND_DOUBLE, BUTTON): {
+ ENDPOINT_ID: 4,
+ CLUSTER_ID: 6,
+ COMMAND: COMMAND_ATTRIBUTE_UPDATED,
+ ARGS: {ATTRIBUTE_ID: 0, ATTRIBUTE_NAME: ATTRIBUTE_ON_OFF, VALUE: 2},
},
}
|
{"golden_diff": "diff --git a/zhaquirks/xiaomi/aqara/ctrl_neutral.py b/zhaquirks/xiaomi/aqara/ctrl_neutral.py\n--- a/zhaquirks/xiaomi/aqara/ctrl_neutral.py\n+++ b/zhaquirks/xiaomi/aqara/ctrl_neutral.py\n@@ -1,6 +1,7 @@\n \"\"\"Xiaomi aqara single key wall switch devices.\"\"\"\n import logging\n \n+from zigpy import types as t\n from zigpy.profiles import zha\n from zigpy.zcl.clusters.general import (\n AnalogInput,\n@@ -23,16 +24,30 @@\n XiaomiCustomDevice,\n XiaomiPowerConfiguration,\n )\n+from ... import EventableCluster\n from ...const import (\n+ ARGS,\n+ ATTRIBUTE_ID,\n+ ATTRIBUTE_NAME,\n+ BUTTON,\n+ CLUSTER_ID,\n+ COMMAND,\n+ COMMAND_ATTRIBUTE_UPDATED,\n+ COMMAND_DOUBLE,\n+ COMMAND_HOLD,\n+ COMMAND_RELEASE,\n DEVICE_TYPE,\n+ ENDPOINT_ID,\n ENDPOINTS,\n INPUT_CLUSTERS,\n MODELS_INFO,\n OUTPUT_CLUSTERS,\n PROFILE_ID,\n SKIP_CONFIGURATION,\n+ VALUE,\n )\n \n+ATTRIBUTE_ON_OFF = \"on_off\"\n DOUBLE = \"double\"\n HOLD = \"long press\"\n PRESS_TYPES = {0: \"long press\", 1: \"single\", 2: \"double\"}\n@@ -53,6 +68,20 @@\n class CtrlNeutral(XiaomiCustomDevice):\n \"\"\"Aqara single and double key switch device.\"\"\"\n \n+ class BasicClusterDecoupled(BasicCluster):\n+ \"\"\"Adds attributes for decoupled mode.\"\"\"\n+\n+ # Known Options for 'decoupled_mode_<button>':\n+ # * 254 (decoupled)\n+ # * 18 (relay controlled)\n+ manufacturer_attributes = {\n+ 0xFF22: (\"decoupled_mode_left\", t.uint8_t),\n+ 0xFF23: (\"decoupled_mode_right\", t.uint8_t),\n+ }\n+\n+ class WallSwitchOnOffCluster(EventableCluster, OnOff):\n+ \"\"\"WallSwitchOnOffCluster: fire events corresponding to press type.\"\"\"\n+\n signature = {\n MODELS_INFO: [\n (LUMI, \"lumi.ctrl_neutral1\"),\n@@ -157,7 +186,7 @@\n 1: {\n DEVICE_TYPE: zha.DeviceType.REMOTE_CONTROL,\n INPUT_CLUSTERS: [\n- BasicCluster,\n+ BasicClusterDecoupled,\n Identify.cluster_id,\n XiaomiPowerConfiguration.cluster_id,\n DeviceTemperature.cluster_id,\n@@ -186,5 +215,34 @@\n ],\n OUTPUT_CLUSTERS: [],\n },\n+ 4: {\n+ DEVICE_TYPE: zha.DeviceType.ON_OFF_SWITCH,\n+ INPUT_CLUSTERS: [\n+ MultistateInput.cluster_id,\n+ WallSwitchOnOffCluster,\n+ ],\n+ OUTPUT_CLUSTERS: [],\n+ },\n+ },\n+ }\n+\n+ device_automation_triggers = {\n+ (COMMAND_HOLD, BUTTON): {\n+ ENDPOINT_ID: 4,\n+ CLUSTER_ID: 6,\n+ COMMAND: COMMAND_ATTRIBUTE_UPDATED,\n+ ARGS: {ATTRIBUTE_ID: 0, ATTRIBUTE_NAME: ATTRIBUTE_ON_OFF, VALUE: 0},\n+ },\n+ (COMMAND_RELEASE, BUTTON): {\n+ ENDPOINT_ID: 4,\n+ CLUSTER_ID: 6,\n+ COMMAND: COMMAND_ATTRIBUTE_UPDATED,\n+ ARGS: {ATTRIBUTE_ID: 0, ATTRIBUTE_NAME: ATTRIBUTE_ON_OFF, VALUE: 1},\n+ },\n+ (COMMAND_DOUBLE, BUTTON): {\n+ ENDPOINT_ID: 4,\n+ CLUSTER_ID: 6,\n+ COMMAND: COMMAND_ATTRIBUTE_UPDATED,\n+ ARGS: {ATTRIBUTE_ID: 0, ATTRIBUTE_NAME: ATTRIBUTE_ON_OFF, VALUE: 2},\n },\n }\n", "issue": "[Device Support Request] Decoupled mode for ctrl_neutral (QBKG04LM/QBKG03LM/QBKG21LM/QBKG22LM)\n**Is your feature request related to a problem? Please describe.**\r\nSimilar to #365, but for `ctrl_neutral` implementation. I think that once implemented it can be easily adapted.\r\n\r\nIn my case I want to implement QBKG04LM decoupled mode.\r\nIt can be done easily, following @albalaing indications (https://github.com/zigpy/zha-device-handlers/issues/365#issuecomment-636510316).\r\n\r\nThe problem is that without the click button events it is not useful, so it is necessary to also implement the generation of ZHA events.\r\n\r\n**Describe the solution you'd like**\r\n\r\nBefore implement anything you can see that device generate 4 messages:\r\n```\r\n2021-01-09 21:46:29 DEBUG (MainThread) [zigpy.device] Ignoring message (b'18500a0000100000001001') on cluster 6: unknown endpoint or cluster id: 4\r\n2021-01-09 21:46:31 DEBUG (MainThread) [zigpy.device] Ignoring message (b'18510a00001000') on cluster 6: unknown endpoint or cluster id: 4\r\n2021-01-09 21:46:32 DEBUG (MainThread) [zigpy.device] Ignoring message (b'18520a00001001') on cluster 6: unknown endpoint or cluster id: 4\r\n2021-01-09 21:46:32 DEBUG (MainThread) [zigpy.device] Ignoring message (b'18530a00001002') on cluster 6: unknown endpoint or cluster id: 4\r\n```\r\n\r\nThis messages are (in order):\r\n* click\r\n* hold\r\n* release\r\n* double_click\r\n\r\nYou can see that the click message corresponds in some way to the hold+release messages (00001000+00001001)\r\n\r\n\r\nI think I'm halfway done (the decoupled part is working as expected), but I'm not satisfied with the event generation part. \r\n\r\n\r\nWhen a `replacement` for endpoint 4 (and 5) is implemented you can get the `on_off` attribute reported. But IMO this approach has the following problems:\r\n* add a new entity in HA for click button events\r\n* it is not possible to differentiate the `click` event from `hold` and `release`\r\n* the `double_click` event cannot be handled (parse error)\r\n\r\n\r\nWant I think that would be implemented is:\r\n* no HA button entity\r\n* full events control, not only hold and release\r\n\r\n\r\nAny help in this regard is welcome.\r\n\r\n\r\n**Device signature - this can be acquired by removing the device from ZHA and pairing it again from the add devices screen. Be sure to add the entire content of the log panel after pairing the device to a code block below this line.**\r\nThe device signature is known and correct.\r\n\r\n**Additional context**\r\nAlthough I am not sure if it can be done this way, I have tried without success to implement a replacement that transforms events from the `OnOff` cluster to the `MultistateInput` cluster.\r\n\r\nMy current implementation is as follows (only the relevant part):\r\n```\r\n class BasicClusterDecoupled(BasicCluster):\r\n \"\"\"Adds attributes for decoupled mode\"\"\"\r\n def __init__(self, *args, **kwargs):\r\n \"\"\"Init.\"\"\"\r\n self.attributes = BasicCluster.attributes.copy()\r\n self.attributes.update({ 0xFF22: (\"left_decoupled_mode\", t.uint8_t)})\r\n self.attributes.update({ 0xFF23: (\"right_decoupled_mode\", t.uint8_t)})\r\n super().__init__(*args, **kwargs)\r\n\r\n\r\n class CustomOnOffCluster(OnOffCluster):\r\n \"\"\"Fire ZHA events for on off cluster.\"\"\"\r\n\r\n cluster_id = OnOff.cluster_id\r\n\r\n def __init__(self, *args, **kwargs):\r\n \"\"\"Init.\"\"\"\r\n self._current_state = {}\r\n super().__init__(*args, **kwargs)\r\n\r\n def _update_attribute(self, attrid, value):\r\n _LOGGER.info(\"%s: %s\", attrid, value)\r\n if attrid == 0:\r\n self._current_state = PRESS_TYPES.get(value)\r\n event_args = {\r\n PRESS_TYPE: self._current_state,\r\n VALUE: value,\r\n }\r\n self.listener_event(ZHA_SEND_EVENT, COMMAND_CLICK, event_args)\r\n super()._update_attribute(attrid, self._current_state)\r\n\r\n\r\n replacement = {\r\n SKIP_CONFIGURATION: True,\r\n ENDPOINTS: {\r\n .../...\r\n 4: { \r\n DEVICE_TYPE: zha.DeviceType.ON_OFF_SWITCH, \r\n INPUT_CLUSTERS: [ \r\n MultistateInput.cluster_id, \r\n CustomOnOffCluster, \r\n ], \r\n OUTPUT_CLUSTERS: [], \r\n }, \r\n 5: { \r\n DEVICE_TYPE: zha.DeviceType.ON_OFF_SWITCH, \r\n INPUT_CLUSTERS: [ \r\n MultistateInput.cluster_id, \r\n CustomOnOffCluster, \r\n ], \r\n OUTPUT_CLUSTERS: [], \r\n }, \r\n },\r\n }\r\n```\r\n\r\n\n", "before_files": [{"content": "\"\"\"Xiaomi aqara single key wall switch devices.\"\"\"\nimport logging\n\nfrom zigpy.profiles import zha\nfrom zigpy.zcl.clusters.general import (\n AnalogInput,\n Basic,\n BinaryOutput,\n DeviceTemperature,\n Groups,\n Identify,\n MultistateInput,\n OnOff,\n Ota,\n Scenes,\n Time,\n)\n\nfrom .. import (\n LUMI,\n BasicCluster,\n OnOffCluster,\n XiaomiCustomDevice,\n XiaomiPowerConfiguration,\n)\nfrom ...const import (\n DEVICE_TYPE,\n ENDPOINTS,\n INPUT_CLUSTERS,\n MODELS_INFO,\n OUTPUT_CLUSTERS,\n PROFILE_ID,\n SKIP_CONFIGURATION,\n)\n\nDOUBLE = \"double\"\nHOLD = \"long press\"\nPRESS_TYPES = {0: \"long press\", 1: \"single\", 2: \"double\"}\nSINGLE = \"single\"\nSTATUS_TYPE_ATTR = 0x0055 # decimal = 85\nXIAOMI_CLUSTER_ID = 0xFFFF\nXIAOMI_DEVICE_TYPE = 0x5F01\nXIAOMI_DEVICE_TYPE2 = 0x5F02\nXIAOMI_DEVICE_TYPE3 = 0x5F03\n\n_LOGGER = logging.getLogger(__name__)\n\n# click attr 0xF000\n# single click 0x3FF1F00\n# double click 0xCFF1F00\n\n\nclass CtrlNeutral(XiaomiCustomDevice):\n \"\"\"Aqara single and double key switch device.\"\"\"\n\n signature = {\n MODELS_INFO: [\n (LUMI, \"lumi.ctrl_neutral1\"),\n (LUMI, \"lumi.ctrl_neutral2\"),\n (LUMI, \"lumi.switch.b1lacn02\"),\n (LUMI, \"lumi.switch.b2lacn02\"),\n ],\n ENDPOINTS: {\n # <SimpleDescriptor endpoint=1 profile=260 device_type=6\n # device_version=2\n # input_clusters=[0, 3, 1, 2, 25, 10]\n # output_clusters=[0, 10, 25]>\n 1: {\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.REMOTE_CONTROL,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n Identify.cluster_id,\n XiaomiPowerConfiguration.cluster_id,\n DeviceTemperature.cluster_id,\n Ota.cluster_id,\n Time.cluster_id,\n ],\n OUTPUT_CLUSTERS: [Basic.cluster_id, Time.cluster_id, Ota.cluster_id],\n },\n # <SimpleDescriptor endpoint=2 profile=260 device_type=256\n # device_version=2\n # input_clusters=[16, 6, 4, 5]\n # output_clusters=[]>\n 2: {\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.ON_OFF_LIGHT,\n INPUT_CLUSTERS: [\n BinaryOutput.cluster_id,\n OnOff.cluster_id,\n Groups.cluster_id,\n Scenes.cluster_id,\n ],\n OUTPUT_CLUSTERS: [],\n },\n # <SimpleDescriptor endpoint=3 profile=260 device_type=256\n # device_version=2\n # input_clusters=[16, 6, 4, 5]\n # output_clusters=[]\n 3: {\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.ON_OFF_LIGHT,\n INPUT_CLUSTERS: [\n BinaryOutput.cluster_id,\n OnOff.cluster_id,\n Groups.cluster_id,\n Scenes.cluster_id,\n ],\n OUTPUT_CLUSTERS: [],\n },\n # <SimpleDescriptor endpoint=4 profile=260 device_type=0\n # device_version=2\n # input_clusters=[18, 6]\n # output_clusters=[]>\n 4: {\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.ON_OFF_SWITCH,\n INPUT_CLUSTERS: [MultistateInput.cluster_id, OnOff.cluster_id],\n OUTPUT_CLUSTERS: [],\n },\n # <SimpleDescriptor endpoint=5 profile=260 device_type=0\n # device_version=2\n # input_clusters=[18, 6]\n # output_clusters=[]>\n 5: {\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.ON_OFF_SWITCH,\n INPUT_CLUSTERS: [MultistateInput.cluster_id, OnOff.cluster_id],\n OUTPUT_CLUSTERS: [],\n },\n # <SimpleDescriptor endpoint=6 profile=260 device_type=0\n # device_version=2\n # input_clusters=[18, 6]\n # output_clusters=[]>\n 6: {\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.ON_OFF_SWITCH,\n INPUT_CLUSTERS: [MultistateInput.cluster_id, OnOff.cluster_id],\n OUTPUT_CLUSTERS: [],\n },\n # <SimpleDescriptor endpoint=8 profile=260 device_type=83\n # device_version=2\n # input_clusters=[12]\n # output_clusters=[]>\n 8: {\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.METER_INTERFACE,\n INPUT_CLUSTERS: [AnalogInput.cluster_id],\n OUTPUT_CLUSTERS: [],\n },\n },\n }\n\n replacement = {\n SKIP_CONFIGURATION: True,\n ENDPOINTS: {\n 1: {\n DEVICE_TYPE: zha.DeviceType.REMOTE_CONTROL,\n INPUT_CLUSTERS: [\n BasicCluster,\n Identify.cluster_id,\n XiaomiPowerConfiguration.cluster_id,\n DeviceTemperature.cluster_id,\n Ota.cluster_id,\n Time.cluster_id,\n ],\n OUTPUT_CLUSTERS: [Basic.cluster_id, Time.cluster_id, Ota.cluster_id],\n },\n 2: {\n DEVICE_TYPE: zha.DeviceType.ON_OFF_SWITCH,\n INPUT_CLUSTERS: [\n BinaryOutput.cluster_id,\n OnOffCluster,\n Groups.cluster_id,\n Scenes.cluster_id,\n ],\n OUTPUT_CLUSTERS: [],\n },\n 3: {\n DEVICE_TYPE: zha.DeviceType.ON_OFF_SWITCH,\n INPUT_CLUSTERS: [\n BinaryOutput.cluster_id,\n OnOffCluster,\n Groups.cluster_id,\n Scenes.cluster_id,\n ],\n OUTPUT_CLUSTERS: [],\n },\n },\n }\n", "path": "zhaquirks/xiaomi/aqara/ctrl_neutral.py"}]}
| 3,616 | 861 |
gh_patches_debug_16917
|
rasdani/github-patches
|
git_diff
|
deeppavlov__DeepPavlov-100
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Files not found while running telegram bot
I run telegram bot interface (copy-paste from readme)
```
python -m deeppavlov.deep interactbot deeppavlov/configs/go_bot/gobot_dstc2.json -t TELEGRAM_TOKEN
```
But the error is given:
```
File "/home/ubuntu/work/ipavlov/DeepPavlov/deeppavlov/core/common/file.py", line 22, in read_json
with open(fpath) as fin:
FileNotFoundError: [Errno 2] No such file or directory: '../telegram_utils/models_info.json'
```
All files have been downloaded and successfully used in training.
</issue>
<code>
[start of telegram_utils/telegram_ui.py]
1 """
2 Copyright 2017 Neural Networks and Deep Learning lab, MIPT
3
4 Licensed under the Apache License, Version 2.0 (the "License");
5 you may not use this file except in compliance with the License.
6 You may obtain a copy of the License at
7
8 http://www.apache.org/licenses/LICENSE-2.0
9
10 Unless required by applicable law or agreed to in writing, software
11 distributed under the License is distributed on an "AS IS" BASIS,
12 WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 See the License for the specific language governing permissions and
14 limitations under the License.
15 """
16 import telebot
17
18 from deeppavlov.core.common.file import read_json
19 from deeppavlov.core.commands.infer import build_model_from_config
20
21
22 def init_bot_for_model(token, model):
23 bot = telebot.TeleBot(token)
24
25 model_name = type(model).__name__
26 models_info = read_json('../telegram_utils/models_info.json')
27 model_info = models_info[model_name] if model_name in models_info else models_info['@default']
28
29 @bot.message_handler(commands=['start'])
30 def send_start_message(message):
31 chat_id = message.chat.id
32 out_message = model_info['start_message']
33 if hasattr(model, 'reset'):
34 model.reset()
35 bot.send_message(chat_id, out_message)
36
37 @bot.message_handler(commands=['help'])
38 def send_help_message(message):
39 chat_id = message.chat.id
40 out_message = model_info['help_message']
41 bot.send_message(chat_id, out_message)
42
43 @bot.message_handler()
44 def handle_inference(message):
45 chat_id = message.chat.id
46 context = message.text
47
48 pred = model([context])
49 reply_message = str(pred[0])
50 bot.send_message(chat_id, reply_message)
51
52 bot.polling()
53
54
55 def interact_model_by_telegram(config_path, token):
56 config = read_json(config_path)
57 model = build_model_from_config(config)
58 init_bot_for_model(token, model)
59
[end of telegram_utils/telegram_ui.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/telegram_utils/telegram_ui.py b/telegram_utils/telegram_ui.py
--- a/telegram_utils/telegram_ui.py
+++ b/telegram_utils/telegram_ui.py
@@ -13,6 +13,8 @@
See the License for the specific language governing permissions and
limitations under the License.
"""
+from pathlib import Path
+
import telebot
from deeppavlov.core.common.file import read_json
@@ -23,7 +25,8 @@
bot = telebot.TeleBot(token)
model_name = type(model).__name__
- models_info = read_json('../telegram_utils/models_info.json')
+ config_path = Path(__file__).parent / 'models_info.json'
+ models_info = read_json(str(config_path))
model_info = models_info[model_name] if model_name in models_info else models_info['@default']
@bot.message_handler(commands=['start'])
|
{"golden_diff": "diff --git a/telegram_utils/telegram_ui.py b/telegram_utils/telegram_ui.py\n--- a/telegram_utils/telegram_ui.py\n+++ b/telegram_utils/telegram_ui.py\n@@ -13,6 +13,8 @@\n See the License for the specific language governing permissions and\n limitations under the License.\n \"\"\"\n+from pathlib import Path\n+\n import telebot\n \n from deeppavlov.core.common.file import read_json\n@@ -23,7 +25,8 @@\n bot = telebot.TeleBot(token)\n \n model_name = type(model).__name__\n- models_info = read_json('../telegram_utils/models_info.json')\n+ config_path = Path(__file__).parent / 'models_info.json'\n+ models_info = read_json(str(config_path))\n model_info = models_info[model_name] if model_name in models_info else models_info['@default']\n \n @bot.message_handler(commands=['start'])\n", "issue": "Files not found while running telegram bot \nI run telegram bot interface (copy-paste from readme)\r\n```\r\npython -m deeppavlov.deep interactbot deeppavlov/configs/go_bot/gobot_dstc2.json -t TELEGRAM_TOKEN\r\n```\r\n\r\nBut the error is given:\r\n\r\n``` \r\nFile \"/home/ubuntu/work/ipavlov/DeepPavlov/deeppavlov/core/common/file.py\", line 22, in read_json\r\n with open(fpath) as fin:\r\nFileNotFoundError: [Errno 2] No such file or directory: '../telegram_utils/models_info.json' \r\n```\r\n\r\nAll files have been downloaded and successfully used in training.\n", "before_files": [{"content": "\"\"\"\nCopyright 2017 Neural Networks and Deep Learning lab, MIPT\n\nLicensed under the Apache License, Version 2.0 (the \"License\");\nyou may not use this file except in compliance with the License.\nYou may obtain a copy of the License at\n\n http://www.apache.org/licenses/LICENSE-2.0\n\nUnless required by applicable law or agreed to in writing, software\ndistributed under the License is distributed on an \"AS IS\" BASIS,\nWITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\nSee the License for the specific language governing permissions and\nlimitations under the License.\n\"\"\"\nimport telebot\n\nfrom deeppavlov.core.common.file import read_json\nfrom deeppavlov.core.commands.infer import build_model_from_config\n\n\ndef init_bot_for_model(token, model):\n bot = telebot.TeleBot(token)\n\n model_name = type(model).__name__\n models_info = read_json('../telegram_utils/models_info.json')\n model_info = models_info[model_name] if model_name in models_info else models_info['@default']\n\n @bot.message_handler(commands=['start'])\n def send_start_message(message):\n chat_id = message.chat.id\n out_message = model_info['start_message']\n if hasattr(model, 'reset'):\n model.reset()\n bot.send_message(chat_id, out_message)\n\n @bot.message_handler(commands=['help'])\n def send_help_message(message):\n chat_id = message.chat.id\n out_message = model_info['help_message']\n bot.send_message(chat_id, out_message)\n\n @bot.message_handler()\n def handle_inference(message):\n chat_id = message.chat.id\n context = message.text\n\n pred = model([context])\n reply_message = str(pred[0])\n bot.send_message(chat_id, reply_message)\n\n bot.polling()\n\n\ndef interact_model_by_telegram(config_path, token):\n config = read_json(config_path)\n model = build_model_from_config(config)\n init_bot_for_model(token, model)\n", "path": "telegram_utils/telegram_ui.py"}]}
| 1,213 | 196 |
gh_patches_debug_15616
|
rasdani/github-patches
|
git_diff
|
pypi__warehouse-10459
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
DataError: No validator for user display name max length
https://sentry.io/organizations/python-software-foundation/issues/2847760761/?referrer=github_plugin
```
StringDataRightTruncation: value too long for type character varying(100)
File "sqlalchemy/engine/base.py", line 1802, in _execute_context
self.dialect.do_execute(
File "sqlalchemy/engine/default.py", line 719, in do_execute
cursor.execute(statement, parameters)
DataError: (raised as a result of Query-invoked autoflush; consider using a session.no_autoflush block if this flush is occurring prematurely)
(psycopg2.errors.StringDataRightTruncation) value too long for type character varying(100)
[SQL: UPDATE users SET name=%(name)s WHERE users.id = %(users_id)s]
[parameters: {'name': 'James is a marketing executive who excels in the development and execution of integrated marketing campaigns to drive brand awareness and drive customer loyalty. Links - https://www.amenify.com/...
(54 additional frame(s) were not displayed)
...
File "sqlalchemy/engine/base.py", line 1845, in _execute_context
self._handle_dbapi_exception(
File "sqlalchemy/engine/base.py", line 2026, in _handle_dbapi_exception
util.raise_(
File "sqlalchemy/util/compat.py", line 207, in raise_
raise exception
File "sqlalchemy/engine/base.py", line 1802, in _execute_context
self.dialect.do_execute(
File "sqlalchemy/engine/default.py", line 719, in do_execute
cursor.execute(statement, parameters)
```
</issue>
<code>
[start of warehouse/manage/forms.py]
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12
13 import json
14
15 import wtforms
16
17 import warehouse.utils.otp as otp
18 import warehouse.utils.webauthn as webauthn
19
20 from warehouse import forms
21 from warehouse.accounts.forms import (
22 NewEmailMixin,
23 NewPasswordMixin,
24 PasswordMixin,
25 TOTPValueMixin,
26 WebAuthnCredentialMixin,
27 )
28
29
30 class RoleNameMixin:
31
32 role_name = wtforms.SelectField(
33 "Select role",
34 choices=[("", "Select role"), ("Maintainer", "Maintainer"), ("Owner", "Owner")],
35 validators=[wtforms.validators.DataRequired(message="Select role")],
36 )
37
38
39 class UsernameMixin:
40
41 username = wtforms.StringField(
42 validators=[wtforms.validators.DataRequired(message="Specify username")]
43 )
44
45 def validate_username(self, field):
46 userid = self.user_service.find_userid(field.data)
47
48 if userid is None:
49 raise wtforms.validators.ValidationError(
50 "No user found with that username. Try again."
51 )
52
53
54 class CreateRoleForm(RoleNameMixin, UsernameMixin, forms.Form):
55 def __init__(self, *args, user_service, **kwargs):
56 super().__init__(*args, **kwargs)
57 self.user_service = user_service
58
59
60 class ChangeRoleForm(RoleNameMixin, forms.Form):
61 pass
62
63
64 class SaveAccountForm(forms.Form):
65
66 __params__ = ["name", "public_email"]
67
68 name = wtforms.StringField()
69 public_email = wtforms.SelectField(choices=[("", "Not displayed")])
70
71 def __init__(self, *args, user_service, user_id, **kwargs):
72 super().__init__(*args, **kwargs)
73 self.user_service = user_service
74 self.user_id = user_id
75 user = user_service.get_user(user_id)
76 self.public_email.choices.extend(
77 [(e.email, e.email) for e in user.emails if e.verified]
78 )
79
80 def validate_public_email(self, field):
81 if field.data:
82 user = self.user_service.get_user(self.user_id)
83 verified_emails = [e.email for e in user.emails if e.verified]
84 if field.data not in verified_emails:
85 raise wtforms.validators.ValidationError(
86 "%s is not a verified email for %s" % (field.data, user.username)
87 )
88
89
90 class AddEmailForm(NewEmailMixin, forms.Form):
91
92 __params__ = ["email"]
93
94 def __init__(self, *args, user_service, user_id, **kwargs):
95 super().__init__(*args, **kwargs)
96 self.user_service = user_service
97 self.user_id = user_id
98
99
100 class ChangePasswordForm(PasswordMixin, NewPasswordMixin, forms.Form):
101
102 __params__ = ["password", "new_password", "password_confirm"]
103
104 def __init__(self, *args, user_service, **kwargs):
105 super().__init__(*args, **kwargs)
106 self.user_service = user_service
107
108
109 class ConfirmPasswordForm(UsernameMixin, PasswordMixin, forms.Form):
110
111 __params__ = ["confirm_password"]
112
113 def __init__(self, *args, user_service, **kwargs):
114 super().__init__(*args, **kwargs)
115 self.user_service = user_service
116
117
118 class DeleteTOTPForm(ConfirmPasswordForm):
119 # TODO: delete?
120 pass
121
122
123 class ProvisionTOTPForm(TOTPValueMixin, forms.Form):
124
125 __params__ = ["totp_value"]
126
127 def __init__(self, *args, totp_secret, **kwargs):
128 super().__init__(*args, **kwargs)
129 self.totp_secret = totp_secret
130
131 def validate_totp_value(self, field):
132 totp_value = field.data.encode("utf8")
133 if not otp.verify_totp(self.totp_secret, totp_value):
134 raise wtforms.validators.ValidationError("Invalid TOTP code. Try again?")
135
136
137 class DeleteWebAuthnForm(forms.Form):
138 __params__ = ["confirm_device_name"]
139
140 label = wtforms.StringField(
141 validators=[
142 wtforms.validators.DataRequired(message="Specify a device name"),
143 wtforms.validators.Length(
144 max=64, message=("Label must be 64 characters or less")
145 ),
146 ]
147 )
148
149 def __init__(self, *args, user_service, user_id, **kwargs):
150 super().__init__(*args, **kwargs)
151 self.user_service = user_service
152 self.user_id = user_id
153
154 def validate_label(self, field):
155 label = field.data
156
157 webauthn = self.user_service.get_webauthn_by_label(self.user_id, label)
158 if webauthn is None:
159 raise wtforms.validators.ValidationError("No WebAuthn key with given label")
160 self.webauthn = webauthn
161
162
163 class ProvisionWebAuthnForm(WebAuthnCredentialMixin, forms.Form):
164 __params__ = ["label", "credential"]
165
166 label = wtforms.StringField(
167 validators=[
168 wtforms.validators.DataRequired(message="Specify a label"),
169 wtforms.validators.Length(
170 max=64, message=("Label must be 64 characters or less")
171 ),
172 ]
173 )
174
175 def __init__(
176 self, *args, user_service, user_id, challenge, rp_id, origin, **kwargs
177 ):
178 super().__init__(*args, **kwargs)
179 self.user_service = user_service
180 self.user_id = user_id
181 self.challenge = challenge
182 self.rp_id = rp_id
183 self.origin = origin
184
185 def validate_credential(self, field):
186 try:
187 credential_dict = json.loads(field.data.encode("utf8"))
188 except json.JSONDecodeError:
189 raise wtforms.validators.ValidationError(
190 "Invalid WebAuthn credential: Bad payload"
191 )
192
193 try:
194 validated_credential = self.user_service.verify_webauthn_credential(
195 credential_dict,
196 challenge=self.challenge,
197 rp_id=self.rp_id,
198 origin=self.origin,
199 )
200 except webauthn.RegistrationRejectedError as e:
201 raise wtforms.validators.ValidationError(str(e))
202
203 self.validated_credential = validated_credential
204
205 def validate_label(self, field):
206 label = field.data
207
208 if self.user_service.get_webauthn_by_label(self.user_id, label) is not None:
209 raise wtforms.validators.ValidationError(f"Label '{label}' already in use")
210
211
212 class CreateMacaroonForm(forms.Form):
213 __params__ = ["description", "token_scope"]
214
215 def __init__(self, *args, user_id, macaroon_service, project_names, **kwargs):
216 super().__init__(*args, **kwargs)
217 self.user_id = user_id
218 self.macaroon_service = macaroon_service
219 self.project_names = project_names
220
221 description = wtforms.StringField(
222 validators=[
223 wtforms.validators.DataRequired(message="Specify a token name"),
224 wtforms.validators.Length(
225 max=100, message="Description must be 100 characters or less"
226 ),
227 ]
228 )
229
230 token_scope = wtforms.StringField(
231 validators=[wtforms.validators.DataRequired(message="Specify the token scope")]
232 )
233
234 def validate_description(self, field):
235 description = field.data
236
237 if (
238 self.macaroon_service.get_macaroon_by_description(self.user_id, description)
239 is not None
240 ):
241 raise wtforms.validators.ValidationError("API token name already in use")
242
243 def validate_token_scope(self, field):
244 scope = field.data
245
246 try:
247 _, scope_kind = scope.split(":", 1)
248 except ValueError:
249 raise wtforms.ValidationError(f"Unknown token scope: {scope}")
250
251 if scope_kind == "unspecified":
252 raise wtforms.ValidationError("Specify the token scope")
253
254 if scope_kind == "user":
255 self.validated_scope = scope_kind
256 return
257
258 try:
259 scope_kind, scope_value = scope_kind.split(":", 1)
260 except ValueError:
261 raise wtforms.ValidationError(f"Unknown token scope: {scope}")
262
263 if scope_kind != "project":
264 raise wtforms.ValidationError(f"Unknown token scope: {scope}")
265 if scope_value not in self.project_names:
266 raise wtforms.ValidationError(
267 f"Unknown or invalid project name: {scope_value}"
268 )
269
270 self.validated_scope = {"projects": [scope_value]}
271
272
273 class DeleteMacaroonForm(UsernameMixin, PasswordMixin, forms.Form):
274 __params__ = ["confirm_password", "macaroon_id"]
275
276 macaroon_id = wtforms.StringField(
277 validators=[wtforms.validators.DataRequired(message="Identifier required")]
278 )
279
280 def __init__(self, *args, macaroon_service, user_service, **kwargs):
281 super().__init__(*args, **kwargs)
282 self.user_service = user_service
283 self.macaroon_service = macaroon_service
284
285 def validate_macaroon_id(self, field):
286 macaroon_id = field.data
287 if self.macaroon_service.find_macaroon(macaroon_id) is None:
288 raise wtforms.validators.ValidationError("No such macaroon")
289
[end of warehouse/manage/forms.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/warehouse/manage/forms.py b/warehouse/manage/forms.py
--- a/warehouse/manage/forms.py
+++ b/warehouse/manage/forms.py
@@ -25,6 +25,7 @@
TOTPValueMixin,
WebAuthnCredentialMixin,
)
+from warehouse.i18n import localize as _
class RoleNameMixin:
@@ -65,7 +66,17 @@
__params__ = ["name", "public_email"]
- name = wtforms.StringField()
+ name = wtforms.StringField(
+ validators=[
+ wtforms.validators.Length(
+ max=100,
+ message=_(
+ "The name is too long. "
+ "Choose a name with 100 characters or less."
+ ),
+ )
+ ]
+ )
public_email = wtforms.SelectField(choices=[("", "Not displayed")])
def __init__(self, *args, user_service, user_id, **kwargs):
|
{"golden_diff": "diff --git a/warehouse/manage/forms.py b/warehouse/manage/forms.py\n--- a/warehouse/manage/forms.py\n+++ b/warehouse/manage/forms.py\n@@ -25,6 +25,7 @@\n TOTPValueMixin,\n WebAuthnCredentialMixin,\n )\n+from warehouse.i18n import localize as _\n \n \n class RoleNameMixin:\n@@ -65,7 +66,17 @@\n \n __params__ = [\"name\", \"public_email\"]\n \n- name = wtforms.StringField()\n+ name = wtforms.StringField(\n+ validators=[\n+ wtforms.validators.Length(\n+ max=100,\n+ message=_(\n+ \"The name is too long. \"\n+ \"Choose a name with 100 characters or less.\"\n+ ),\n+ )\n+ ]\n+ )\n public_email = wtforms.SelectField(choices=[(\"\", \"Not displayed\")])\n \n def __init__(self, *args, user_service, user_id, **kwargs):\n", "issue": "DataError: No validator for user display name max length\nhttps://sentry.io/organizations/python-software-foundation/issues/2847760761/?referrer=github_plugin\n\n```\nStringDataRightTruncation: value too long for type character varying(100)\n\n File \"sqlalchemy/engine/base.py\", line 1802, in _execute_context\n self.dialect.do_execute(\n File \"sqlalchemy/engine/default.py\", line 719, in do_execute\n cursor.execute(statement, parameters)\n\nDataError: (raised as a result of Query-invoked autoflush; consider using a session.no_autoflush block if this flush is occurring prematurely)\n(psycopg2.errors.StringDataRightTruncation) value too long for type character varying(100)\n\n[SQL: UPDATE users SET name=%(name)s WHERE users.id = %(users_id)s]\n[parameters: {'name': 'James is a marketing executive who excels in the development and execution of integrated marketing campaigns to drive brand awareness and drive customer loyalty. Links - https://www.amenify.com/...\n(54 additional frame(s) were not displayed)\n...\n File \"sqlalchemy/engine/base.py\", line 1845, in _execute_context\n self._handle_dbapi_exception(\n File \"sqlalchemy/engine/base.py\", line 2026, in _handle_dbapi_exception\n util.raise_(\n File \"sqlalchemy/util/compat.py\", line 207, in raise_\n raise exception\n File \"sqlalchemy/engine/base.py\", line 1802, in _execute_context\n self.dialect.do_execute(\n File \"sqlalchemy/engine/default.py\", line 719, in do_execute\n cursor.execute(statement, parameters)\n```\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport json\n\nimport wtforms\n\nimport warehouse.utils.otp as otp\nimport warehouse.utils.webauthn as webauthn\n\nfrom warehouse import forms\nfrom warehouse.accounts.forms import (\n NewEmailMixin,\n NewPasswordMixin,\n PasswordMixin,\n TOTPValueMixin,\n WebAuthnCredentialMixin,\n)\n\n\nclass RoleNameMixin:\n\n role_name = wtforms.SelectField(\n \"Select role\",\n choices=[(\"\", \"Select role\"), (\"Maintainer\", \"Maintainer\"), (\"Owner\", \"Owner\")],\n validators=[wtforms.validators.DataRequired(message=\"Select role\")],\n )\n\n\nclass UsernameMixin:\n\n username = wtforms.StringField(\n validators=[wtforms.validators.DataRequired(message=\"Specify username\")]\n )\n\n def validate_username(self, field):\n userid = self.user_service.find_userid(field.data)\n\n if userid is None:\n raise wtforms.validators.ValidationError(\n \"No user found with that username. Try again.\"\n )\n\n\nclass CreateRoleForm(RoleNameMixin, UsernameMixin, forms.Form):\n def __init__(self, *args, user_service, **kwargs):\n super().__init__(*args, **kwargs)\n self.user_service = user_service\n\n\nclass ChangeRoleForm(RoleNameMixin, forms.Form):\n pass\n\n\nclass SaveAccountForm(forms.Form):\n\n __params__ = [\"name\", \"public_email\"]\n\n name = wtforms.StringField()\n public_email = wtforms.SelectField(choices=[(\"\", \"Not displayed\")])\n\n def __init__(self, *args, user_service, user_id, **kwargs):\n super().__init__(*args, **kwargs)\n self.user_service = user_service\n self.user_id = user_id\n user = user_service.get_user(user_id)\n self.public_email.choices.extend(\n [(e.email, e.email) for e in user.emails if e.verified]\n )\n\n def validate_public_email(self, field):\n if field.data:\n user = self.user_service.get_user(self.user_id)\n verified_emails = [e.email for e in user.emails if e.verified]\n if field.data not in verified_emails:\n raise wtforms.validators.ValidationError(\n \"%s is not a verified email for %s\" % (field.data, user.username)\n )\n\n\nclass AddEmailForm(NewEmailMixin, forms.Form):\n\n __params__ = [\"email\"]\n\n def __init__(self, *args, user_service, user_id, **kwargs):\n super().__init__(*args, **kwargs)\n self.user_service = user_service\n self.user_id = user_id\n\n\nclass ChangePasswordForm(PasswordMixin, NewPasswordMixin, forms.Form):\n\n __params__ = [\"password\", \"new_password\", \"password_confirm\"]\n\n def __init__(self, *args, user_service, **kwargs):\n super().__init__(*args, **kwargs)\n self.user_service = user_service\n\n\nclass ConfirmPasswordForm(UsernameMixin, PasswordMixin, forms.Form):\n\n __params__ = [\"confirm_password\"]\n\n def __init__(self, *args, user_service, **kwargs):\n super().__init__(*args, **kwargs)\n self.user_service = user_service\n\n\nclass DeleteTOTPForm(ConfirmPasswordForm):\n # TODO: delete?\n pass\n\n\nclass ProvisionTOTPForm(TOTPValueMixin, forms.Form):\n\n __params__ = [\"totp_value\"]\n\n def __init__(self, *args, totp_secret, **kwargs):\n super().__init__(*args, **kwargs)\n self.totp_secret = totp_secret\n\n def validate_totp_value(self, field):\n totp_value = field.data.encode(\"utf8\")\n if not otp.verify_totp(self.totp_secret, totp_value):\n raise wtforms.validators.ValidationError(\"Invalid TOTP code. Try again?\")\n\n\nclass DeleteWebAuthnForm(forms.Form):\n __params__ = [\"confirm_device_name\"]\n\n label = wtforms.StringField(\n validators=[\n wtforms.validators.DataRequired(message=\"Specify a device name\"),\n wtforms.validators.Length(\n max=64, message=(\"Label must be 64 characters or less\")\n ),\n ]\n )\n\n def __init__(self, *args, user_service, user_id, **kwargs):\n super().__init__(*args, **kwargs)\n self.user_service = user_service\n self.user_id = user_id\n\n def validate_label(self, field):\n label = field.data\n\n webauthn = self.user_service.get_webauthn_by_label(self.user_id, label)\n if webauthn is None:\n raise wtforms.validators.ValidationError(\"No WebAuthn key with given label\")\n self.webauthn = webauthn\n\n\nclass ProvisionWebAuthnForm(WebAuthnCredentialMixin, forms.Form):\n __params__ = [\"label\", \"credential\"]\n\n label = wtforms.StringField(\n validators=[\n wtforms.validators.DataRequired(message=\"Specify a label\"),\n wtforms.validators.Length(\n max=64, message=(\"Label must be 64 characters or less\")\n ),\n ]\n )\n\n def __init__(\n self, *args, user_service, user_id, challenge, rp_id, origin, **kwargs\n ):\n super().__init__(*args, **kwargs)\n self.user_service = user_service\n self.user_id = user_id\n self.challenge = challenge\n self.rp_id = rp_id\n self.origin = origin\n\n def validate_credential(self, field):\n try:\n credential_dict = json.loads(field.data.encode(\"utf8\"))\n except json.JSONDecodeError:\n raise wtforms.validators.ValidationError(\n \"Invalid WebAuthn credential: Bad payload\"\n )\n\n try:\n validated_credential = self.user_service.verify_webauthn_credential(\n credential_dict,\n challenge=self.challenge,\n rp_id=self.rp_id,\n origin=self.origin,\n )\n except webauthn.RegistrationRejectedError as e:\n raise wtforms.validators.ValidationError(str(e))\n\n self.validated_credential = validated_credential\n\n def validate_label(self, field):\n label = field.data\n\n if self.user_service.get_webauthn_by_label(self.user_id, label) is not None:\n raise wtforms.validators.ValidationError(f\"Label '{label}' already in use\")\n\n\nclass CreateMacaroonForm(forms.Form):\n __params__ = [\"description\", \"token_scope\"]\n\n def __init__(self, *args, user_id, macaroon_service, project_names, **kwargs):\n super().__init__(*args, **kwargs)\n self.user_id = user_id\n self.macaroon_service = macaroon_service\n self.project_names = project_names\n\n description = wtforms.StringField(\n validators=[\n wtforms.validators.DataRequired(message=\"Specify a token name\"),\n wtforms.validators.Length(\n max=100, message=\"Description must be 100 characters or less\"\n ),\n ]\n )\n\n token_scope = wtforms.StringField(\n validators=[wtforms.validators.DataRequired(message=\"Specify the token scope\")]\n )\n\n def validate_description(self, field):\n description = field.data\n\n if (\n self.macaroon_service.get_macaroon_by_description(self.user_id, description)\n is not None\n ):\n raise wtforms.validators.ValidationError(\"API token name already in use\")\n\n def validate_token_scope(self, field):\n scope = field.data\n\n try:\n _, scope_kind = scope.split(\":\", 1)\n except ValueError:\n raise wtforms.ValidationError(f\"Unknown token scope: {scope}\")\n\n if scope_kind == \"unspecified\":\n raise wtforms.ValidationError(\"Specify the token scope\")\n\n if scope_kind == \"user\":\n self.validated_scope = scope_kind\n return\n\n try:\n scope_kind, scope_value = scope_kind.split(\":\", 1)\n except ValueError:\n raise wtforms.ValidationError(f\"Unknown token scope: {scope}\")\n\n if scope_kind != \"project\":\n raise wtforms.ValidationError(f\"Unknown token scope: {scope}\")\n if scope_value not in self.project_names:\n raise wtforms.ValidationError(\n f\"Unknown or invalid project name: {scope_value}\"\n )\n\n self.validated_scope = {\"projects\": [scope_value]}\n\n\nclass DeleteMacaroonForm(UsernameMixin, PasswordMixin, forms.Form):\n __params__ = [\"confirm_password\", \"macaroon_id\"]\n\n macaroon_id = wtforms.StringField(\n validators=[wtforms.validators.DataRequired(message=\"Identifier required\")]\n )\n\n def __init__(self, *args, macaroon_service, user_service, **kwargs):\n super().__init__(*args, **kwargs)\n self.user_service = user_service\n self.macaroon_service = macaroon_service\n\n def validate_macaroon_id(self, field):\n macaroon_id = field.data\n if self.macaroon_service.find_macaroon(macaroon_id) is None:\n raise wtforms.validators.ValidationError(\"No such macaroon\")\n", "path": "warehouse/manage/forms.py"}]}
| 3,743 | 217 |
gh_patches_debug_15240
|
rasdani/github-patches
|
git_diff
|
Lightning-AI__pytorch-lightning-1654
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Allow keeping default save_dir in ModelCheckpointer
## Feature
Make `filepath` argument of `ModelCheckpointer` optional.
### Motivation
I'm pretty happy with all defaults of `ModelCheckpointer` except `save_top_k`. In case I want to override that parameter I have to write some awkward code related to figuring out the checkpointing path, which is normally only known at runtime:
```python
DEFROOT = Path('/data/models/lightning')
logger = WandbLogger(name=net.hparams.run_name, project=net.hparams.project, save_dir=str(DEFROOT))
logger.watch(net)
_ = logger.experiment # create an experiment to determine version
cp_template = str(DEFROOT / net.hparams.project / ('version_'+logger.version) / 'checkpoints' / '{epoch:04d}-{val_loss:.2f}-{other_metric:.2f}.pt')
checkpointer = ModelCheckpoint(
filepath=cp_template,
save_top_k=10,
verbose=True,
monitor='val_loss',
mode='min',
)
trainer = Trainer(
gpus=1,
logger=logger,
default_root_dir=DEFROOT,
checkpoint_callback=checkpointer,
**extra,
)
trainer.fit(net)
```
It would be nice to have an option to allow Lightning to determine runtime-valued save location instead. Additionally, it would be nice to have an option to override checkpoint filename without overriding the whole save path.
</issue>
<code>
[start of pytorch_lightning/callbacks/model_checkpoint.py]
1 """
2 Model Checkpointing
3 ===================
4
5 Automatically save model checkpoints during training.
6
7 """
8
9 import os
10 import re
11
12 import numpy as np
13 from typing import Optional
14
15 import torch
16 from pytorch_lightning import _logger as log
17 from pytorch_lightning.callbacks.base import Callback
18 from pytorch_lightning.utilities import rank_zero_warn, rank_zero_only
19
20
21 class ModelCheckpoint(Callback):
22 r"""
23 Save the model after every epoch.
24
25 Args:
26 filepath: path to save the model file.
27 Can contain named formatting options to be auto-filled.
28
29 Example::
30
31 # custom path
32 # saves a file like: my/path/epoch_0.ckpt
33 >>> checkpoint_callback = ModelCheckpoint('my/path/')
34
35 # save any arbitrary metrics like `val_loss`, etc. in name
36 # saves a file like: my/path/epoch=2-val_loss=0.2_other_metric=0.3.ckpt
37 >>> checkpoint_callback = ModelCheckpoint(
38 ... filepath='my/path/{epoch}-{val_loss:.2f}-{other_metric:.2f}'
39 ... )
40
41 Can also be set to `None`, then it will be set to default location
42 during trainer construction.
43
44 monitor: quantity to monitor.
45 verbose: verbosity mode. Default: ``False``.
46 save_top_k: if `save_top_k == k`,
47 the best k models according to
48 the quantity monitored will be saved.
49 if ``save_top_k == 0``, no models are saved.
50 if ``save_top_k == -1``, all models are saved.
51 Please note that the monitors are checked every `period` epochs.
52 if ``save_top_k >= 2`` and the callback is called multiple
53 times inside an epoch, the name of the saved file will be
54 appended with a version count starting with `v0`.
55 mode: one of {auto, min, max}.
56 If ``save_top_k != 0``, the decision
57 to overwrite the current save file is made
58 based on either the maximization or the
59 minimization of the monitored quantity. For `val_acc`,
60 this should be `max`, for `val_loss` this should
61 be `min`, etc. In `auto` mode, the direction is
62 automatically inferred from the name of the monitored quantity.
63 save_weights_only: if ``True``, then only the model's weights will be
64 saved (``model.save_weights(filepath)``), else the full model
65 is saved (``model.save(filepath)``).
66 period: Interval (number of epochs) between checkpoints.
67
68 Example::
69
70 >>> from pytorch_lightning import Trainer
71 >>> from pytorch_lightning.callbacks import ModelCheckpoint
72
73 # saves checkpoints to 'my/path/' whenever 'val_loss' has a new min
74 >>> checkpoint_callback = ModelCheckpoint(filepath='my/path/')
75 >>> trainer = Trainer(checkpoint_callback=checkpoint_callback)
76
77 # save epoch and val_loss in name
78 # saves a file like: my/path/sample-mnist_epoch=02_val_loss=0.32.ckpt
79 >>> checkpoint_callback = ModelCheckpoint(
80 ... filepath='my/path/sample-mnist_{epoch:02d}-{val_loss:.2f}'
81 ... )
82
83 """
84
85 def __init__(self, filepath: Optional[str] = None, monitor: str = 'val_loss', verbose: bool = False,
86 save_top_k: int = 1, save_weights_only: bool = False,
87 mode: str = 'auto', period: int = 1, prefix: str = ''):
88 super().__init__()
89 if save_top_k > 0 and os.path.isdir(filepath) and len(os.listdir(filepath)) > 0:
90 rank_zero_warn(
91 f"Checkpoint directory {filepath} exists and is not empty with save_top_k != 0."
92 "All files in this directory will be deleted when a checkpoint is saved!"
93 )
94 self._rank = 0
95
96 self.monitor = monitor
97 self.verbose = verbose
98 if filepath is None: # will be determined by trainer at runtime
99 self.dirpath, self.filename = None, None
100 else:
101 if os.path.isdir(filepath):
102 self.dirpath, self.filename = filepath, '{epoch}'
103 else:
104 self.dirpath, self.filename = os.path.split(filepath)
105 os.makedirs(self.dirpath, exist_ok=True)
106 self.save_top_k = save_top_k
107 self.save_weights_only = save_weights_only
108 self.period = period
109 self.epoch_last_check = None
110 self.prefix = prefix
111 self.best_k_models = {}
112 # {filename: monitor}
113 self.kth_best_model = ''
114 self.best = 0
115 self.save_function = None
116
117 torch_inf = torch.tensor(np.Inf)
118 mode_dict = {
119 'min': (torch_inf, 'min'),
120 'max': (-torch_inf, 'max'),
121 'auto': (-torch_inf, 'max') if 'acc' in self.monitor or self.monitor.startswith('fmeasure')
122 else (torch_inf, 'min'),
123 }
124
125 if mode not in mode_dict:
126 rank_zero_warn(f'ModelCheckpoint mode {mode} is unknown, '
127 f'fallback to auto mode.', RuntimeWarning)
128 mode = 'auto'
129
130 self.kth_value, self.mode = mode_dict[mode]
131
132 def _del_model(self, filepath):
133 if os.path.isfile(filepath):
134 os.remove(filepath)
135
136 def _save_model(self, filepath):
137 # make paths
138 os.makedirs(os.path.dirname(filepath), exist_ok=True)
139
140 # delegate the saving to the model
141 if self.save_function is not None:
142 self.save_function(filepath)
143 else:
144 raise ValueError(".save_function() not set")
145
146 def check_monitor_top_k(self, current):
147 less_than_k_models = len(self.best_k_models) < self.save_top_k
148 if less_than_k_models:
149 return True
150
151 if not isinstance(current, torch.Tensor):
152 current = torch.tensor(current)
153
154 monitor_op = {
155 "min": torch.lt,
156 "max": torch.gt,
157 }[self.mode]
158
159 return monitor_op(current, self.best_k_models[self.kth_best_model])
160
161 def format_checkpoint_name(self, epoch, metrics, ver=None):
162 """Generate a filename according to the defined template.
163
164 Example::
165
166 >>> tmpdir = os.path.dirname(__file__)
167 >>> ckpt = ModelCheckpoint(os.path.join(tmpdir, '{epoch}'))
168 >>> os.path.basename(ckpt.format_checkpoint_name(0, {}))
169 'epoch=0.ckpt'
170 >>> ckpt = ModelCheckpoint(os.path.join(tmpdir, '{epoch:03d}'))
171 >>> os.path.basename(ckpt.format_checkpoint_name(5, {}))
172 'epoch=005.ckpt'
173 >>> ckpt = ModelCheckpoint(os.path.join(tmpdir, '{epoch}-{val_loss:.2f}'))
174 >>> os.path.basename(ckpt.format_checkpoint_name(2, dict(val_loss=0.123456)))
175 'epoch=2-val_loss=0.12.ckpt'
176 >>> ckpt = ModelCheckpoint(os.path.join(tmpdir, '{missing:d}'))
177 >>> os.path.basename(ckpt.format_checkpoint_name(0, {}))
178 'missing=0.ckpt'
179 """
180 # check if user passed in keys to the string
181 groups = re.findall(r'(\{.*?)[:\}]', self.filename)
182
183 if len(groups) == 0:
184 # default name
185 filename = f'{self.prefix}_ckpt_epoch_{epoch}'
186 else:
187 metrics['epoch'] = epoch
188 filename = self.filename
189 for tmp in groups:
190 name = tmp[1:]
191 filename = filename.replace(tmp, name + '={' + name)
192 if name not in metrics:
193 metrics[name] = 0
194 filename = filename.format(**metrics)
195 str_ver = f'_v{ver}' if ver is not None else ''
196 filepath = os.path.join(self.dirpath, self.prefix + filename + str_ver + '.ckpt')
197 return filepath
198
199 @rank_zero_only
200 def on_validation_end(self, trainer, pl_module):
201 # only run on main process
202 if trainer.proc_rank != 0:
203 return
204
205 metrics = trainer.callback_metrics
206 epoch = trainer.current_epoch
207 if self.save_top_k == 0:
208 # no models are saved
209 return
210 if self.epoch_last_check is not None and (epoch - self.epoch_last_check) < self.period:
211 # skipping in this term
212 return
213
214 self.epoch_last_check = epoch
215
216 filepath = self.format_checkpoint_name(epoch, metrics)
217 version_cnt = 0
218 while os.path.isfile(filepath):
219 filepath = self.format_checkpoint_name(epoch, metrics, ver=version_cnt)
220 # this epoch called before
221 version_cnt += 1
222
223 if self.save_top_k != -1:
224 current = metrics.get(self.monitor)
225
226 if current is None:
227 rank_zero_warn(
228 f'Can save best model only with {self.monitor} available, skipping.', RuntimeWarning
229 )
230 elif self.check_monitor_top_k(current):
231 self._do_check_save(filepath, current, epoch)
232 elif self.verbose > 0:
233 log.info(f'\nEpoch {epoch:05d}: {self.monitor} was not in top {self.save_top_k}')
234
235 else:
236 if self.verbose > 0:
237 log.info(f'\nEpoch {epoch:05d}: saving model to {filepath}')
238 self._save_model(filepath)
239
240 def _do_check_save(self, filepath, current, epoch):
241 # remove kth
242
243 del_list = []
244 if len(self.best_k_models) == self.save_top_k and self.save_top_k > 0:
245 delpath = self.kth_best_model
246 self.best_k_models.pop(self.kth_best_model)
247 del_list.append(delpath)
248
249 self.best_k_models[filepath] = current
250 if len(self.best_k_models) == self.save_top_k:
251 # monitor dict has reached k elements
252 _op = max if self.mode == 'min' else min
253 self.kth_best_model = _op(self.best_k_models,
254 key=self.best_k_models.get)
255 self.kth_value = self.best_k_models[self.kth_best_model]
256
257 _op = min if self.mode == 'min' else max
258 self.best = _op(self.best_k_models.values())
259
260 if self.verbose > 0:
261 log.info(
262 f'\nEpoch {epoch:05d}: {self.monitor} reached'
263 f' {current:0.5f} (best {self.best:0.5f}), saving model to'
264 f' {filepath} as top {self.save_top_k}')
265 self._save_model(filepath)
266
267 for cur_path in del_list:
268 if cur_path != filepath:
269 self._del_model(cur_path)
270
[end of pytorch_lightning/callbacks/model_checkpoint.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pytorch_lightning/callbacks/model_checkpoint.py b/pytorch_lightning/callbacks/model_checkpoint.py
--- a/pytorch_lightning/callbacks/model_checkpoint.py
+++ b/pytorch_lightning/callbacks/model_checkpoint.py
@@ -86,7 +86,7 @@
save_top_k: int = 1, save_weights_only: bool = False,
mode: str = 'auto', period: int = 1, prefix: str = ''):
super().__init__()
- if save_top_k > 0 and os.path.isdir(filepath) and len(os.listdir(filepath)) > 0:
+ if save_top_k > 0 and filepath is not None and os.path.isdir(filepath) and len(os.listdir(filepath)) > 0:
rank_zero_warn(
f"Checkpoint directory {filepath} exists and is not empty with save_top_k != 0."
"All files in this directory will be deleted when a checkpoint is saved!"
|
{"golden_diff": "diff --git a/pytorch_lightning/callbacks/model_checkpoint.py b/pytorch_lightning/callbacks/model_checkpoint.py\n--- a/pytorch_lightning/callbacks/model_checkpoint.py\n+++ b/pytorch_lightning/callbacks/model_checkpoint.py\n@@ -86,7 +86,7 @@\n save_top_k: int = 1, save_weights_only: bool = False,\n mode: str = 'auto', period: int = 1, prefix: str = ''):\n super().__init__()\n- if save_top_k > 0 and os.path.isdir(filepath) and len(os.listdir(filepath)) > 0:\n+ if save_top_k > 0 and filepath is not None and os.path.isdir(filepath) and len(os.listdir(filepath)) > 0:\n rank_zero_warn(\n f\"Checkpoint directory {filepath} exists and is not empty with save_top_k != 0.\"\n \"All files in this directory will be deleted when a checkpoint is saved!\"\n", "issue": "Allow keeping default save_dir in ModelCheckpointer\n## Feature\r\nMake `filepath` argument of `ModelCheckpointer` optional.\r\n\r\n### Motivation\r\nI'm pretty happy with all defaults of `ModelCheckpointer` except `save_top_k`. In case I want to override that parameter I have to write some awkward code related to figuring out the checkpointing path, which is normally only known at runtime:\r\n\r\n```python\r\nDEFROOT = Path('/data/models/lightning')\r\nlogger = WandbLogger(name=net.hparams.run_name, project=net.hparams.project, save_dir=str(DEFROOT))\r\nlogger.watch(net)\r\n_ = logger.experiment # create an experiment to determine version\r\ncp_template = str(DEFROOT / net.hparams.project / ('version_'+logger.version) / 'checkpoints' / '{epoch:04d}-{val_loss:.2f}-{other_metric:.2f}.pt')\r\n\r\ncheckpointer = ModelCheckpoint(\r\n filepath=cp_template,\r\n save_top_k=10,\r\n verbose=True,\r\n monitor='val_loss',\r\n mode='min',\r\n)\r\n\r\ntrainer = Trainer(\r\n gpus=1,\r\n logger=logger,\r\n default_root_dir=DEFROOT,\r\n checkpoint_callback=checkpointer,\r\n **extra,\r\n)\r\ntrainer.fit(net)\r\n```\r\n\r\nIt would be nice to have an option to allow Lightning to determine runtime-valued save location instead. Additionally, it would be nice to have an option to override checkpoint filename without overriding the whole save path.\n", "before_files": [{"content": "\"\"\"\nModel Checkpointing\n===================\n\nAutomatically save model checkpoints during training.\n\n\"\"\"\n\nimport os\nimport re\n\nimport numpy as np\nfrom typing import Optional\n\nimport torch\nfrom pytorch_lightning import _logger as log\nfrom pytorch_lightning.callbacks.base import Callback\nfrom pytorch_lightning.utilities import rank_zero_warn, rank_zero_only\n\n\nclass ModelCheckpoint(Callback):\n r\"\"\"\n Save the model after every epoch.\n\n Args:\n filepath: path to save the model file.\n Can contain named formatting options to be auto-filled.\n\n Example::\n\n # custom path\n # saves a file like: my/path/epoch_0.ckpt\n >>> checkpoint_callback = ModelCheckpoint('my/path/')\n\n # save any arbitrary metrics like `val_loss`, etc. in name\n # saves a file like: my/path/epoch=2-val_loss=0.2_other_metric=0.3.ckpt\n >>> checkpoint_callback = ModelCheckpoint(\n ... filepath='my/path/{epoch}-{val_loss:.2f}-{other_metric:.2f}'\n ... )\n\n Can also be set to `None`, then it will be set to default location\n during trainer construction.\n\n monitor: quantity to monitor.\n verbose: verbosity mode. Default: ``False``.\n save_top_k: if `save_top_k == k`,\n the best k models according to\n the quantity monitored will be saved.\n if ``save_top_k == 0``, no models are saved.\n if ``save_top_k == -1``, all models are saved.\n Please note that the monitors are checked every `period` epochs.\n if ``save_top_k >= 2`` and the callback is called multiple\n times inside an epoch, the name of the saved file will be\n appended with a version count starting with `v0`.\n mode: one of {auto, min, max}.\n If ``save_top_k != 0``, the decision\n to overwrite the current save file is made\n based on either the maximization or the\n minimization of the monitored quantity. For `val_acc`,\n this should be `max`, for `val_loss` this should\n be `min`, etc. In `auto` mode, the direction is\n automatically inferred from the name of the monitored quantity.\n save_weights_only: if ``True``, then only the model's weights will be\n saved (``model.save_weights(filepath)``), else the full model\n is saved (``model.save(filepath)``).\n period: Interval (number of epochs) between checkpoints.\n\n Example::\n\n >>> from pytorch_lightning import Trainer\n >>> from pytorch_lightning.callbacks import ModelCheckpoint\n\n # saves checkpoints to 'my/path/' whenever 'val_loss' has a new min\n >>> checkpoint_callback = ModelCheckpoint(filepath='my/path/')\n >>> trainer = Trainer(checkpoint_callback=checkpoint_callback)\n\n # save epoch and val_loss in name\n # saves a file like: my/path/sample-mnist_epoch=02_val_loss=0.32.ckpt\n >>> checkpoint_callback = ModelCheckpoint(\n ... filepath='my/path/sample-mnist_{epoch:02d}-{val_loss:.2f}'\n ... )\n\n \"\"\"\n\n def __init__(self, filepath: Optional[str] = None, monitor: str = 'val_loss', verbose: bool = False,\n save_top_k: int = 1, save_weights_only: bool = False,\n mode: str = 'auto', period: int = 1, prefix: str = ''):\n super().__init__()\n if save_top_k > 0 and os.path.isdir(filepath) and len(os.listdir(filepath)) > 0:\n rank_zero_warn(\n f\"Checkpoint directory {filepath} exists and is not empty with save_top_k != 0.\"\n \"All files in this directory will be deleted when a checkpoint is saved!\"\n )\n self._rank = 0\n\n self.monitor = monitor\n self.verbose = verbose\n if filepath is None: # will be determined by trainer at runtime\n self.dirpath, self.filename = None, None\n else:\n if os.path.isdir(filepath):\n self.dirpath, self.filename = filepath, '{epoch}'\n else:\n self.dirpath, self.filename = os.path.split(filepath)\n os.makedirs(self.dirpath, exist_ok=True)\n self.save_top_k = save_top_k\n self.save_weights_only = save_weights_only\n self.period = period\n self.epoch_last_check = None\n self.prefix = prefix\n self.best_k_models = {}\n # {filename: monitor}\n self.kth_best_model = ''\n self.best = 0\n self.save_function = None\n\n torch_inf = torch.tensor(np.Inf)\n mode_dict = {\n 'min': (torch_inf, 'min'),\n 'max': (-torch_inf, 'max'),\n 'auto': (-torch_inf, 'max') if 'acc' in self.monitor or self.monitor.startswith('fmeasure')\n else (torch_inf, 'min'),\n }\n\n if mode not in mode_dict:\n rank_zero_warn(f'ModelCheckpoint mode {mode} is unknown, '\n f'fallback to auto mode.', RuntimeWarning)\n mode = 'auto'\n\n self.kth_value, self.mode = mode_dict[mode]\n\n def _del_model(self, filepath):\n if os.path.isfile(filepath):\n os.remove(filepath)\n\n def _save_model(self, filepath):\n # make paths\n os.makedirs(os.path.dirname(filepath), exist_ok=True)\n\n # delegate the saving to the model\n if self.save_function is not None:\n self.save_function(filepath)\n else:\n raise ValueError(\".save_function() not set\")\n\n def check_monitor_top_k(self, current):\n less_than_k_models = len(self.best_k_models) < self.save_top_k\n if less_than_k_models:\n return True\n\n if not isinstance(current, torch.Tensor):\n current = torch.tensor(current)\n\n monitor_op = {\n \"min\": torch.lt,\n \"max\": torch.gt,\n }[self.mode]\n\n return monitor_op(current, self.best_k_models[self.kth_best_model])\n\n def format_checkpoint_name(self, epoch, metrics, ver=None):\n \"\"\"Generate a filename according to the defined template.\n\n Example::\n\n >>> tmpdir = os.path.dirname(__file__)\n >>> ckpt = ModelCheckpoint(os.path.join(tmpdir, '{epoch}'))\n >>> os.path.basename(ckpt.format_checkpoint_name(0, {}))\n 'epoch=0.ckpt'\n >>> ckpt = ModelCheckpoint(os.path.join(tmpdir, '{epoch:03d}'))\n >>> os.path.basename(ckpt.format_checkpoint_name(5, {}))\n 'epoch=005.ckpt'\n >>> ckpt = ModelCheckpoint(os.path.join(tmpdir, '{epoch}-{val_loss:.2f}'))\n >>> os.path.basename(ckpt.format_checkpoint_name(2, dict(val_loss=0.123456)))\n 'epoch=2-val_loss=0.12.ckpt'\n >>> ckpt = ModelCheckpoint(os.path.join(tmpdir, '{missing:d}'))\n >>> os.path.basename(ckpt.format_checkpoint_name(0, {}))\n 'missing=0.ckpt'\n \"\"\"\n # check if user passed in keys to the string\n groups = re.findall(r'(\\{.*?)[:\\}]', self.filename)\n\n if len(groups) == 0:\n # default name\n filename = f'{self.prefix}_ckpt_epoch_{epoch}'\n else:\n metrics['epoch'] = epoch\n filename = self.filename\n for tmp in groups:\n name = tmp[1:]\n filename = filename.replace(tmp, name + '={' + name)\n if name not in metrics:\n metrics[name] = 0\n filename = filename.format(**metrics)\n str_ver = f'_v{ver}' if ver is not None else ''\n filepath = os.path.join(self.dirpath, self.prefix + filename + str_ver + '.ckpt')\n return filepath\n\n @rank_zero_only\n def on_validation_end(self, trainer, pl_module):\n # only run on main process\n if trainer.proc_rank != 0:\n return\n\n metrics = trainer.callback_metrics\n epoch = trainer.current_epoch\n if self.save_top_k == 0:\n # no models are saved\n return\n if self.epoch_last_check is not None and (epoch - self.epoch_last_check) < self.period:\n # skipping in this term\n return\n\n self.epoch_last_check = epoch\n\n filepath = self.format_checkpoint_name(epoch, metrics)\n version_cnt = 0\n while os.path.isfile(filepath):\n filepath = self.format_checkpoint_name(epoch, metrics, ver=version_cnt)\n # this epoch called before\n version_cnt += 1\n\n if self.save_top_k != -1:\n current = metrics.get(self.monitor)\n\n if current is None:\n rank_zero_warn(\n f'Can save best model only with {self.monitor} available, skipping.', RuntimeWarning\n )\n elif self.check_monitor_top_k(current):\n self._do_check_save(filepath, current, epoch)\n elif self.verbose > 0:\n log.info(f'\\nEpoch {epoch:05d}: {self.monitor} was not in top {self.save_top_k}')\n\n else:\n if self.verbose > 0:\n log.info(f'\\nEpoch {epoch:05d}: saving model to {filepath}')\n self._save_model(filepath)\n\n def _do_check_save(self, filepath, current, epoch):\n # remove kth\n\n del_list = []\n if len(self.best_k_models) == self.save_top_k and self.save_top_k > 0:\n delpath = self.kth_best_model\n self.best_k_models.pop(self.kth_best_model)\n del_list.append(delpath)\n\n self.best_k_models[filepath] = current\n if len(self.best_k_models) == self.save_top_k:\n # monitor dict has reached k elements\n _op = max if self.mode == 'min' else min\n self.kth_best_model = _op(self.best_k_models,\n key=self.best_k_models.get)\n self.kth_value = self.best_k_models[self.kth_best_model]\n\n _op = min if self.mode == 'min' else max\n self.best = _op(self.best_k_models.values())\n\n if self.verbose > 0:\n log.info(\n f'\\nEpoch {epoch:05d}: {self.monitor} reached'\n f' {current:0.5f} (best {self.best:0.5f}), saving model to'\n f' {filepath} as top {self.save_top_k}')\n self._save_model(filepath)\n\n for cur_path in del_list:\n if cur_path != filepath:\n self._del_model(cur_path)\n", "path": "pytorch_lightning/callbacks/model_checkpoint.py"}]}
| 3,903 | 201 |
gh_patches_debug_42952
|
rasdani/github-patches
|
git_diff
|
ansible__ansible-lint-2832
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
no-changelog: check_collection_changelog
check the collection structure to confirm if there is a changelog file present at the root of the directory.
rule should be optional and only enabled at users discretion. Error level should be Warn/Info (0)
based off of code found [here ](https://github.com/ansible/galaxy-importer/blob/master/galaxy_importer/loaders/collection.py#L119)
</issue>
<code>
[start of src/ansiblelint/rules/galaxy.py]
1 """Implementation of GalaxyRule."""
2 from __future__ import annotations
3
4 import sys
5 from functools import total_ordering
6 from typing import TYPE_CHECKING, Any
7
8 from ansiblelint.constants import LINE_NUMBER_KEY
9 from ansiblelint.errors import MatchError
10 from ansiblelint.rules import AnsibleLintRule
11
12 if TYPE_CHECKING:
13 from ansiblelint.file_utils import Lintable
14
15
16 class GalaxyRule(AnsibleLintRule):
17 """Rule for checking collection version is greater than 1.0.0."""
18
19 id = "galaxy"
20 description = "Confirm via galaxy.yml file if collection version is greater than or equal to 1.0.0"
21 severity = "MEDIUM"
22 tags = ["metadata", "opt-in", "experimental"]
23 version_added = "v6.6.0 (last update)"
24
25 def matchplay(self, file: Lintable, data: dict[str, Any]) -> list[MatchError]:
26 """Return matches found for a specific play (entry in playbook)."""
27 if file.kind != "galaxy": # type: ignore
28 return []
29 if "version" not in data:
30 return [
31 self.create_matcherror(
32 message="galaxy.yaml should have version tag.",
33 linenumber=data[LINE_NUMBER_KEY],
34 tag="galaxy[version-missing]",
35 filename=file,
36 )
37 ]
38 version = data.get("version")
39 if Version(version) < Version("1.0.0"):
40 return [
41 self.create_matcherror(
42 message="collection version should be greater than or equal to 1.0.0",
43 # pylint: disable=protected-access
44 linenumber=version._line_number,
45 tag="galaxy[version-incorrect]",
46 filename=file,
47 )
48 ]
49 return []
50
51
52 @total_ordering
53 class Version:
54 """Simple class to compare arbitrary versions."""
55
56 def __init__(self, version_string: str):
57 """Construct a Version object."""
58 self.components = version_string.split(".")
59
60 def __eq__(self, other: object) -> bool:
61 """Implement equality comparison."""
62 other = _coerce(other)
63 if not isinstance(other, Version):
64 return NotImplemented
65
66 return self.components == other.components
67
68 def __lt__(self, other: Version) -> bool:
69 """Implement lower-than operation."""
70 other = _coerce(other)
71 if not isinstance(other, Version):
72 return NotImplemented
73
74 return self.components < other.components
75
76
77 def _coerce(other: object) -> Version:
78 if isinstance(other, str):
79 other = Version(other)
80 if isinstance(other, (int, float)):
81 other = Version(str(other))
82 if isinstance(other, Version):
83 return other
84 raise NotImplementedError(f"Unable to coerce object type {type(other)} to Version")
85
86
87 if "pytest" in sys.modules: # noqa: C901
88
89 from ansiblelint.rules import RulesCollection
90 from ansiblelint.runner import Runner
91
92 def test_galaxy_collection_version_positive() -> None:
93 """Positive test for collection version in galaxy."""
94 collection = RulesCollection()
95 collection.register(GalaxyRule())
96 success = "examples/collection/galaxy.yml"
97 good_runner = Runner(success, rules=collection)
98 assert [] == good_runner.run()
99
100 def test_galaxy_collection_version_negative() -> None:
101 """Negative test for collection version in galaxy."""
102 collection = RulesCollection()
103 collection.register(GalaxyRule())
104 failure = "examples/meta/galaxy.yml"
105 bad_runner = Runner(failure, rules=collection)
106 errs = bad_runner.run()
107 assert len(errs) == 1
108
[end of src/ansiblelint/rules/galaxy.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/ansiblelint/rules/galaxy.py b/src/ansiblelint/rules/galaxy.py
--- a/src/ansiblelint/rules/galaxy.py
+++ b/src/ansiblelint/rules/galaxy.py
@@ -1,6 +1,7 @@
"""Implementation of GalaxyRule."""
from __future__ import annotations
+import os
import sys
from functools import total_ordering
from typing import TYPE_CHECKING, Any
@@ -14,10 +15,10 @@
class GalaxyRule(AnsibleLintRule):
- """Rule for checking collection version is greater than 1.0.0."""
+ """Rule for checking collection version is greater than 1.0.0 and checking for changelog."""
id = "galaxy"
- description = "Confirm via galaxy.yml file if collection version is greater than or equal to 1.0.0"
+ description = "Confirm via galaxy.yml file if collection version is greater than or equal to 1.0.0 and check for changelog."
severity = "MEDIUM"
tags = ["metadata", "opt-in", "experimental"]
version_added = "v6.6.0 (last update)"
@@ -26,18 +27,21 @@
"""Return matches found for a specific play (entry in playbook)."""
if file.kind != "galaxy": # type: ignore
return []
+
+ results = []
+
if "version" not in data:
- return [
+ results.append(
self.create_matcherror(
message="galaxy.yaml should have version tag.",
linenumber=data[LINE_NUMBER_KEY],
tag="galaxy[version-missing]",
filename=file,
)
- ]
+ )
version = data.get("version")
if Version(version) < Version("1.0.0"):
- return [
+ results.append(
self.create_matcherror(
message="collection version should be greater than or equal to 1.0.0",
# pylint: disable=protected-access
@@ -45,8 +49,33 @@
tag="galaxy[version-incorrect]",
filename=file,
)
- ]
- return []
+ )
+
+ # Changelog Check - building off Galaxy rule as there is no current way to check
+ # for a nonexistent file
+
+ base_path = os.path.split(str(file.abspath))[0]
+ changelog_found = 0
+ changelog_paths = [
+ os.path.join(base_path, "changelogs", "changelog.yaml"),
+ os.path.join(base_path, "CHANGELOG.rst"),
+ os.path.join(base_path, "CHANGELOG.md"),
+ ]
+
+ for path in changelog_paths:
+ if os.path.isfile(path):
+ changelog_found = 1
+
+ if not changelog_found:
+ results.append(
+ self.create_matcherror(
+ message="No changelog found. Please add a changelog file. Refer to the galaxy.md file for more info.",
+ tag="galaxy[no-changelog]",
+ filename=file,
+ )
+ )
+
+ return results
@total_ordering
@@ -105,3 +134,18 @@
bad_runner = Runner(failure, rules=collection)
errs = bad_runner.run()
assert len(errs) == 1
+
+ def test_changelog_present() -> None:
+ """Positive test for finding a changelog."""
+ collection = RulesCollection()
+ collection.register(GalaxyRule())
+ good_runner = Runner("examples/collection/galaxy.yml", rules=collection)
+ assert [] == good_runner.run()
+
+ def test_changelog_missing() -> None:
+ """Negative test for finding a changelog."""
+ collection = RulesCollection()
+ collection.register(GalaxyRule())
+ bad_runner = Runner("examples/no_changelog/galaxy.yml", rules=collection)
+ errs = bad_runner.run()
+ assert len(errs) == 1
|
{"golden_diff": "diff --git a/src/ansiblelint/rules/galaxy.py b/src/ansiblelint/rules/galaxy.py\n--- a/src/ansiblelint/rules/galaxy.py\n+++ b/src/ansiblelint/rules/galaxy.py\n@@ -1,6 +1,7 @@\n \"\"\"Implementation of GalaxyRule.\"\"\"\n from __future__ import annotations\n \n+import os\n import sys\n from functools import total_ordering\n from typing import TYPE_CHECKING, Any\n@@ -14,10 +15,10 @@\n \n \n class GalaxyRule(AnsibleLintRule):\n- \"\"\"Rule for checking collection version is greater than 1.0.0.\"\"\"\n+ \"\"\"Rule for checking collection version is greater than 1.0.0 and checking for changelog.\"\"\"\n \n id = \"galaxy\"\n- description = \"Confirm via galaxy.yml file if collection version is greater than or equal to 1.0.0\"\n+ description = \"Confirm via galaxy.yml file if collection version is greater than or equal to 1.0.0 and check for changelog.\"\n severity = \"MEDIUM\"\n tags = [\"metadata\", \"opt-in\", \"experimental\"]\n version_added = \"v6.6.0 (last update)\"\n@@ -26,18 +27,21 @@\n \"\"\"Return matches found for a specific play (entry in playbook).\"\"\"\n if file.kind != \"galaxy\": # type: ignore\n return []\n+\n+ results = []\n+\n if \"version\" not in data:\n- return [\n+ results.append(\n self.create_matcherror(\n message=\"galaxy.yaml should have version tag.\",\n linenumber=data[LINE_NUMBER_KEY],\n tag=\"galaxy[version-missing]\",\n filename=file,\n )\n- ]\n+ )\n version = data.get(\"version\")\n if Version(version) < Version(\"1.0.0\"):\n- return [\n+ results.append(\n self.create_matcherror(\n message=\"collection version should be greater than or equal to 1.0.0\",\n # pylint: disable=protected-access\n@@ -45,8 +49,33 @@\n tag=\"galaxy[version-incorrect]\",\n filename=file,\n )\n- ]\n- return []\n+ )\n+\n+ # Changelog Check - building off Galaxy rule as there is no current way to check\n+ # for a nonexistent file\n+\n+ base_path = os.path.split(str(file.abspath))[0]\n+ changelog_found = 0\n+ changelog_paths = [\n+ os.path.join(base_path, \"changelogs\", \"changelog.yaml\"),\n+ os.path.join(base_path, \"CHANGELOG.rst\"),\n+ os.path.join(base_path, \"CHANGELOG.md\"),\n+ ]\n+\n+ for path in changelog_paths:\n+ if os.path.isfile(path):\n+ changelog_found = 1\n+\n+ if not changelog_found:\n+ results.append(\n+ self.create_matcherror(\n+ message=\"No changelog found. Please add a changelog file. Refer to the galaxy.md file for more info.\",\n+ tag=\"galaxy[no-changelog]\",\n+ filename=file,\n+ )\n+ )\n+\n+ return results\n \n \n @total_ordering\n@@ -105,3 +134,18 @@\n bad_runner = Runner(failure, rules=collection)\n errs = bad_runner.run()\n assert len(errs) == 1\n+\n+ def test_changelog_present() -> None:\n+ \"\"\"Positive test for finding a changelog.\"\"\"\n+ collection = RulesCollection()\n+ collection.register(GalaxyRule())\n+ good_runner = Runner(\"examples/collection/galaxy.yml\", rules=collection)\n+ assert [] == good_runner.run()\n+\n+ def test_changelog_missing() -> None:\n+ \"\"\"Negative test for finding a changelog.\"\"\"\n+ collection = RulesCollection()\n+ collection.register(GalaxyRule())\n+ bad_runner = Runner(\"examples/no_changelog/galaxy.yml\", rules=collection)\n+ errs = bad_runner.run()\n+ assert len(errs) == 1\n", "issue": "no-changelog: check_collection_changelog\ncheck the collection structure to confirm if there is a changelog file present at the root of the directory. \r\n\r\nrule should be optional and only enabled at users discretion. Error level should be Warn/Info (0)\r\n\r\nbased off of code found [here ](https://github.com/ansible/galaxy-importer/blob/master/galaxy_importer/loaders/collection.py#L119)\n", "before_files": [{"content": "\"\"\"Implementation of GalaxyRule.\"\"\"\nfrom __future__ import annotations\n\nimport sys\nfrom functools import total_ordering\nfrom typing import TYPE_CHECKING, Any\n\nfrom ansiblelint.constants import LINE_NUMBER_KEY\nfrom ansiblelint.errors import MatchError\nfrom ansiblelint.rules import AnsibleLintRule\n\nif TYPE_CHECKING:\n from ansiblelint.file_utils import Lintable\n\n\nclass GalaxyRule(AnsibleLintRule):\n \"\"\"Rule for checking collection version is greater than 1.0.0.\"\"\"\n\n id = \"galaxy\"\n description = \"Confirm via galaxy.yml file if collection version is greater than or equal to 1.0.0\"\n severity = \"MEDIUM\"\n tags = [\"metadata\", \"opt-in\", \"experimental\"]\n version_added = \"v6.6.0 (last update)\"\n\n def matchplay(self, file: Lintable, data: dict[str, Any]) -> list[MatchError]:\n \"\"\"Return matches found for a specific play (entry in playbook).\"\"\"\n if file.kind != \"galaxy\": # type: ignore\n return []\n if \"version\" not in data:\n return [\n self.create_matcherror(\n message=\"galaxy.yaml should have version tag.\",\n linenumber=data[LINE_NUMBER_KEY],\n tag=\"galaxy[version-missing]\",\n filename=file,\n )\n ]\n version = data.get(\"version\")\n if Version(version) < Version(\"1.0.0\"):\n return [\n self.create_matcherror(\n message=\"collection version should be greater than or equal to 1.0.0\",\n # pylint: disable=protected-access\n linenumber=version._line_number,\n tag=\"galaxy[version-incorrect]\",\n filename=file,\n )\n ]\n return []\n\n\n@total_ordering\nclass Version:\n \"\"\"Simple class to compare arbitrary versions.\"\"\"\n\n def __init__(self, version_string: str):\n \"\"\"Construct a Version object.\"\"\"\n self.components = version_string.split(\".\")\n\n def __eq__(self, other: object) -> bool:\n \"\"\"Implement equality comparison.\"\"\"\n other = _coerce(other)\n if not isinstance(other, Version):\n return NotImplemented\n\n return self.components == other.components\n\n def __lt__(self, other: Version) -> bool:\n \"\"\"Implement lower-than operation.\"\"\"\n other = _coerce(other)\n if not isinstance(other, Version):\n return NotImplemented\n\n return self.components < other.components\n\n\ndef _coerce(other: object) -> Version:\n if isinstance(other, str):\n other = Version(other)\n if isinstance(other, (int, float)):\n other = Version(str(other))\n if isinstance(other, Version):\n return other\n raise NotImplementedError(f\"Unable to coerce object type {type(other)} to Version\")\n\n\nif \"pytest\" in sys.modules: # noqa: C901\n\n from ansiblelint.rules import RulesCollection\n from ansiblelint.runner import Runner\n\n def test_galaxy_collection_version_positive() -> None:\n \"\"\"Positive test for collection version in galaxy.\"\"\"\n collection = RulesCollection()\n collection.register(GalaxyRule())\n success = \"examples/collection/galaxy.yml\"\n good_runner = Runner(success, rules=collection)\n assert [] == good_runner.run()\n\n def test_galaxy_collection_version_negative() -> None:\n \"\"\"Negative test for collection version in galaxy.\"\"\"\n collection = RulesCollection()\n collection.register(GalaxyRule())\n failure = \"examples/meta/galaxy.yml\"\n bad_runner = Runner(failure, rules=collection)\n errs = bad_runner.run()\n assert len(errs) == 1\n", "path": "src/ansiblelint/rules/galaxy.py"}]}
| 1,631 | 888 |
gh_patches_debug_15507
|
rasdani/github-patches
|
git_diff
|
scikit-image__scikit-image-5395
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
metric.structural_similarity throws the wrong error for small sizes
## Description
when using `structural_similarity` when the images are small (<7 in any dimension) a `ValueError` gets thrown, but with the wrong text:
```
ValueError: win_size exceeds image extent. If the input is a multichannel (color) image, set multichannel=True.
```
Instead of misleading the user into thinking there's something wrong with the way they read in, or converted, their image data, this error should read:
```
ValueError: image data too small to perform SSIM analysis on, please ensure that your images are at least 7x7.
```
## Way to reproduce
```python
import cv2
from skimage.metrics import structural_similarity
def gray(img):
return cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
image = cv2.imread('test.jpg', cv2.IMREAD_COLOR)
# a 7x7 crop will work just fine
crop1 = image[0:7, 0:7]
crop2 = image[8:15, 8:15]
structural_similarity(gray(crop1), gray(crop2))
# a 6x6 crop will cause a ValueError, with the wrong message
crop1 = image[0:6, 0:6]
crop2 = image[8:14, 8:4]
structural_similarity(gray(crop1), gray(crop2))
```
## Version information
```python
# Paste the output of the following python commands
from __future__ import print_function
import sys; print(sys.version)
import platform; print(platform.platform())
import skimage; print("scikit-image version: {}".format(skimage.__version__))
import numpy; print("numpy version: {}".format(numpy.__version__))
```
```python
3.7.7 (tags/v3.7.7:d7c567b08f, Mar 10 2020, 10:41:24) [MSC v.1900 64 bit (AMD64)]
Windows-10-10.0.19041-SP0
scikit-image version: 0.18.1
numpy version: 1.20.2
```
</issue>
<code>
[start of skimage/metrics/_structural_similarity.py]
1 import functools
2
3 import numpy as np
4 from scipy.ndimage import uniform_filter, gaussian_filter
5
6 from .._shared import utils
7 from .._shared.utils import _supported_float_type, check_shape_equality, warn
8 from ..util.dtype import dtype_range
9 from ..util.arraycrop import crop
10
11
12 __all__ = ['structural_similarity']
13
14
15 @utils.deprecate_multichannel_kwarg()
16 def structural_similarity(im1, im2,
17 *,
18 win_size=None, gradient=False, data_range=None,
19 channel_axis=None, multichannel=False,
20 gaussian_weights=False, full=False, **kwargs):
21 """
22 Compute the mean structural similarity index between two images.
23
24 Parameters
25 ----------
26 im1, im2 : ndarray
27 Images. Any dimensionality with same shape.
28 win_size : int or None, optional
29 The side-length of the sliding window used in comparison. Must be an
30 odd value. If `gaussian_weights` is True, this is ignored and the
31 window size will depend on `sigma`.
32 gradient : bool, optional
33 If True, also return the gradient with respect to im2.
34 data_range : float, optional
35 The data range of the input image (distance between minimum and
36 maximum possible values). By default, this is estimated from the image
37 data-type.
38 channel_axis : int or None, optional
39 If None, the image is assumed to be a grayscale (single channel) image.
40 Otherwise, this parameter indicates which axis of the array corresponds
41 to channels.
42
43 .. versionadded:: 0.19
44 ``channel_axis`` was added in 0.19.
45 multichannel : bool, optional
46 If True, treat the last dimension of the array as channels. Similarity
47 calculations are done independently for each channel then averaged.
48 This argument is deprecated: specify `channel_axis` instead.
49 gaussian_weights : bool, optional
50 If True, each patch has its mean and variance spatially weighted by a
51 normalized Gaussian kernel of width sigma=1.5.
52 full : bool, optional
53 If True, also return the full structural similarity image.
54
55 Other Parameters
56 ----------------
57 use_sample_covariance : bool
58 If True, normalize covariances by N-1 rather than, N where N is the
59 number of pixels within the sliding window.
60 K1 : float
61 Algorithm parameter, K1 (small constant, see [1]_).
62 K2 : float
63 Algorithm parameter, K2 (small constant, see [1]_).
64 sigma : float
65 Standard deviation for the Gaussian when `gaussian_weights` is True.
66
67 Returns
68 -------
69 mssim : float
70 The mean structural similarity index over the image.
71 grad : ndarray
72 The gradient of the structural similarity between im1 and im2 [2]_.
73 This is only returned if `gradient` is set to True.
74 S : ndarray
75 The full SSIM image. This is only returned if `full` is set to True.
76
77 Notes
78 -----
79 To match the implementation of Wang et. al. [1]_, set `gaussian_weights`
80 to True, `sigma` to 1.5, and `use_sample_covariance` to False.
81
82 .. versionchanged:: 0.16
83 This function was renamed from ``skimage.measure.compare_ssim`` to
84 ``skimage.metrics.structural_similarity``.
85
86 References
87 ----------
88 .. [1] Wang, Z., Bovik, A. C., Sheikh, H. R., & Simoncelli, E. P.
89 (2004). Image quality assessment: From error visibility to
90 structural similarity. IEEE Transactions on Image Processing,
91 13, 600-612.
92 https://ece.uwaterloo.ca/~z70wang/publications/ssim.pdf,
93 :DOI:`10.1109/TIP.2003.819861`
94
95 .. [2] Avanaki, A. N. (2009). Exact global histogram specification
96 optimized for structural similarity. Optical Review, 16, 613-621.
97 :arxiv:`0901.0065`
98 :DOI:`10.1007/s10043-009-0119-z`
99
100 """
101 check_shape_equality(im1, im2)
102 float_type = _supported_float_type(im1.dtype)
103
104 if channel_axis is not None:
105 # loop over channels
106 args = dict(win_size=win_size,
107 gradient=gradient,
108 data_range=data_range,
109 channel_axis=None,
110 gaussian_weights=gaussian_weights,
111 full=full)
112 args.update(kwargs)
113 nch = im1.shape[channel_axis]
114 mssim = np.empty(nch, dtype=float_type)
115
116 if gradient:
117 G = np.empty(im1.shape, dtype=float_type)
118 if full:
119 S = np.empty(im1.shape, dtype=float_type)
120 channel_axis = channel_axis % im1.ndim
121 _at = functools.partial(utils.slice_at_axis, axis=channel_axis)
122 for ch in range(nch):
123 ch_result = structural_similarity(im1[_at(ch)],
124 im2[_at(ch)], **args)
125 if gradient and full:
126 mssim[ch], G[_at(ch)], S[_at(ch)] = ch_result
127 elif gradient:
128 mssim[ch], G[_at(ch)] = ch_result
129 elif full:
130 mssim[ch], S[_at(ch)] = ch_result
131 else:
132 mssim[ch] = ch_result
133 mssim = mssim.mean()
134 if gradient and full:
135 return mssim, G, S
136 elif gradient:
137 return mssim, G
138 elif full:
139 return mssim, S
140 else:
141 return mssim
142
143 K1 = kwargs.pop('K1', 0.01)
144 K2 = kwargs.pop('K2', 0.03)
145 sigma = kwargs.pop('sigma', 1.5)
146 if K1 < 0:
147 raise ValueError("K1 must be positive")
148 if K2 < 0:
149 raise ValueError("K2 must be positive")
150 if sigma < 0:
151 raise ValueError("sigma must be positive")
152 use_sample_covariance = kwargs.pop('use_sample_covariance', True)
153
154 if gaussian_weights:
155 # Set to give an 11-tap filter with the default sigma of 1.5 to match
156 # Wang et. al. 2004.
157 truncate = 3.5
158
159 if win_size is None:
160 if gaussian_weights:
161 # set win_size used by crop to match the filter size
162 r = int(truncate * sigma + 0.5) # radius as in ndimage
163 win_size = 2 * r + 1
164 else:
165 win_size = 7 # backwards compatibility
166
167 if np.any((np.asarray(im1.shape) - win_size) < 0):
168 raise ValueError(
169 "win_size exceeds image extent. If the input is a multichannel "
170 "(color) image, set channel_axis to the axis number corresponding "
171 "to the channels.")
172
173 if not (win_size % 2 == 1):
174 raise ValueError('Window size must be odd.')
175
176 if data_range is None:
177 if im1.dtype != im2.dtype:
178 warn("Inputs have mismatched dtype. Setting data_range based on "
179 "im1.dtype.", stacklevel=2)
180 dmin, dmax = dtype_range[im1.dtype.type]
181 data_range = dmax - dmin
182
183 ndim = im1.ndim
184
185 if gaussian_weights:
186 filter_func = gaussian_filter
187 filter_args = {'sigma': sigma, 'truncate': truncate}
188 else:
189 filter_func = uniform_filter
190 filter_args = {'size': win_size}
191
192 # ndimage filters need floating point data
193 im1 = im1.astype(float_type, copy=False)
194 im2 = im2.astype(float_type, copy=False)
195
196 NP = win_size ** ndim
197
198 # filter has already normalized by NP
199 if use_sample_covariance:
200 cov_norm = NP / (NP - 1) # sample covariance
201 else:
202 cov_norm = 1.0 # population covariance to match Wang et. al. 2004
203
204 # compute (weighted) means
205 ux = filter_func(im1, **filter_args)
206 uy = filter_func(im2, **filter_args)
207
208 # compute (weighted) variances and covariances
209 uxx = filter_func(im1 * im1, **filter_args)
210 uyy = filter_func(im2 * im2, **filter_args)
211 uxy = filter_func(im1 * im2, **filter_args)
212 vx = cov_norm * (uxx - ux * ux)
213 vy = cov_norm * (uyy - uy * uy)
214 vxy = cov_norm * (uxy - ux * uy)
215
216 R = data_range
217 C1 = (K1 * R) ** 2
218 C2 = (K2 * R) ** 2
219
220 A1, A2, B1, B2 = ((2 * ux * uy + C1,
221 2 * vxy + C2,
222 ux ** 2 + uy ** 2 + C1,
223 vx + vy + C2))
224 D = B1 * B2
225 S = (A1 * A2) / D
226
227 # to avoid edge effects will ignore filter radius strip around edges
228 pad = (win_size - 1) // 2
229
230 # compute (weighted) mean of ssim. Use float64 for accuracy.
231 mssim = crop(S, pad).mean(dtype=np.float64)
232
233 if gradient:
234 # The following is Eqs. 7-8 of Avanaki 2009.
235 grad = filter_func(A1 / D, **filter_args) * im1
236 grad += filter_func(-S / B2, **filter_args) * im2
237 grad += filter_func((ux * (A2 - A1) - uy * (B2 - B1) * S) / D,
238 **filter_args)
239 grad *= (2 / im1.size)
240
241 if full:
242 return mssim, grad, S
243 else:
244 return mssim, grad
245 else:
246 if full:
247 return mssim, S
248 else:
249 return mssim
250
[end of skimage/metrics/_structural_similarity.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/skimage/metrics/_structural_similarity.py b/skimage/metrics/_structural_similarity.py
--- a/skimage/metrics/_structural_similarity.py
+++ b/skimage/metrics/_structural_similarity.py
@@ -166,9 +166,14 @@
if np.any((np.asarray(im1.shape) - win_size) < 0):
raise ValueError(
- "win_size exceeds image extent. If the input is a multichannel "
- "(color) image, set channel_axis to the axis number corresponding "
- "to the channels.")
+ "win_size exceeds image extent. ",
+ "Either ensure that your images are ",
+ "at least 7x7; or pass win_size explicitly ",
+ "in the function call, with an odd value ",
+ "less than or equal to the smaller side of your ",
+ "images. If your images are multichannel ",
+ "(with color channels), set channel_axis to ",
+ "the axis number corresponding to the channels.")
if not (win_size % 2 == 1):
raise ValueError('Window size must be odd.')
|
{"golden_diff": "diff --git a/skimage/metrics/_structural_similarity.py b/skimage/metrics/_structural_similarity.py\n--- a/skimage/metrics/_structural_similarity.py\n+++ b/skimage/metrics/_structural_similarity.py\n@@ -166,9 +166,14 @@\n \n if np.any((np.asarray(im1.shape) - win_size) < 0):\n raise ValueError(\n- \"win_size exceeds image extent. If the input is a multichannel \"\n- \"(color) image, set channel_axis to the axis number corresponding \"\n- \"to the channels.\")\n+ \"win_size exceeds image extent. \",\n+ \"Either ensure that your images are \",\n+ \"at least 7x7; or pass win_size explicitly \",\n+ \"in the function call, with an odd value \",\n+ \"less than or equal to the smaller side of your \",\n+ \"images. If your images are multichannel \",\n+ \"(with color channels), set channel_axis to \",\n+ \"the axis number corresponding to the channels.\")\n \n if not (win_size % 2 == 1):\n raise ValueError('Window size must be odd.')\n", "issue": "metric.structural_similarity throws the wrong error for small sizes\n## Description\r\n\r\nwhen using `structural_similarity` when the images are small (<7 in any dimension) a `ValueError` gets thrown, but with the wrong text:\r\n\r\n```\r\nValueError: win_size exceeds image extent. If the input is a multichannel (color) image, set multichannel=True.\r\n```\r\n\r\nInstead of misleading the user into thinking there's something wrong with the way they read in, or converted, their image data, this error should read:\r\n\r\n```\r\nValueError: image data too small to perform SSIM analysis on, please ensure that your images are at least 7x7.\r\n```\r\n\r\n## Way to reproduce\r\n```python\r\nimport cv2\r\nfrom skimage.metrics import structural_similarity\r\n\r\ndef gray(img):\r\n\treturn cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)\r\n\r\nimage = cv2.imread('test.jpg', cv2.IMREAD_COLOR)\r\n\r\n# a 7x7 crop will work just fine\r\ncrop1 = image[0:7, 0:7]\r\ncrop2 = image[8:15, 8:15]\r\nstructural_similarity(gray(crop1), gray(crop2))\r\n\r\n# a 6x6 crop will cause a ValueError, with the wrong message\r\ncrop1 = image[0:6, 0:6]\r\ncrop2 = image[8:14, 8:4]\r\nstructural_similarity(gray(crop1), gray(crop2))\r\n```\r\n\r\n\r\n## Version information\r\n```python\r\n# Paste the output of the following python commands\r\nfrom __future__ import print_function\r\nimport sys; print(sys.version)\r\nimport platform; print(platform.platform())\r\nimport skimage; print(\"scikit-image version: {}\".format(skimage.__version__))\r\nimport numpy; print(\"numpy version: {}\".format(numpy.__version__))\r\n```\r\n\r\n```python\r\n3.7.7 (tags/v3.7.7:d7c567b08f, Mar 10 2020, 10:41:24) [MSC v.1900 64 bit (AMD64)]\r\nWindows-10-10.0.19041-SP0\r\nscikit-image version: 0.18.1\r\nnumpy version: 1.20.2\r\n```\r\n\n", "before_files": [{"content": "import functools\n\nimport numpy as np\nfrom scipy.ndimage import uniform_filter, gaussian_filter\n\nfrom .._shared import utils\nfrom .._shared.utils import _supported_float_type, check_shape_equality, warn\nfrom ..util.dtype import dtype_range\nfrom ..util.arraycrop import crop\n\n\n__all__ = ['structural_similarity']\n\n\[email protected]_multichannel_kwarg()\ndef structural_similarity(im1, im2,\n *,\n win_size=None, gradient=False, data_range=None,\n channel_axis=None, multichannel=False,\n gaussian_weights=False, full=False, **kwargs):\n \"\"\"\n Compute the mean structural similarity index between two images.\n\n Parameters\n ----------\n im1, im2 : ndarray\n Images. Any dimensionality with same shape.\n win_size : int or None, optional\n The side-length of the sliding window used in comparison. Must be an\n odd value. If `gaussian_weights` is True, this is ignored and the\n window size will depend on `sigma`.\n gradient : bool, optional\n If True, also return the gradient with respect to im2.\n data_range : float, optional\n The data range of the input image (distance between minimum and\n maximum possible values). By default, this is estimated from the image\n data-type.\n channel_axis : int or None, optional\n If None, the image is assumed to be a grayscale (single channel) image.\n Otherwise, this parameter indicates which axis of the array corresponds\n to channels.\n\n .. versionadded:: 0.19\n ``channel_axis`` was added in 0.19.\n multichannel : bool, optional\n If True, treat the last dimension of the array as channels. Similarity\n calculations are done independently for each channel then averaged.\n This argument is deprecated: specify `channel_axis` instead.\n gaussian_weights : bool, optional\n If True, each patch has its mean and variance spatially weighted by a\n normalized Gaussian kernel of width sigma=1.5.\n full : bool, optional\n If True, also return the full structural similarity image.\n\n Other Parameters\n ----------------\n use_sample_covariance : bool\n If True, normalize covariances by N-1 rather than, N where N is the\n number of pixels within the sliding window.\n K1 : float\n Algorithm parameter, K1 (small constant, see [1]_).\n K2 : float\n Algorithm parameter, K2 (small constant, see [1]_).\n sigma : float\n Standard deviation for the Gaussian when `gaussian_weights` is True.\n\n Returns\n -------\n mssim : float\n The mean structural similarity index over the image.\n grad : ndarray\n The gradient of the structural similarity between im1 and im2 [2]_.\n This is only returned if `gradient` is set to True.\n S : ndarray\n The full SSIM image. This is only returned if `full` is set to True.\n\n Notes\n -----\n To match the implementation of Wang et. al. [1]_, set `gaussian_weights`\n to True, `sigma` to 1.5, and `use_sample_covariance` to False.\n\n .. versionchanged:: 0.16\n This function was renamed from ``skimage.measure.compare_ssim`` to\n ``skimage.metrics.structural_similarity``.\n\n References\n ----------\n .. [1] Wang, Z., Bovik, A. C., Sheikh, H. R., & Simoncelli, E. P.\n (2004). Image quality assessment: From error visibility to\n structural similarity. IEEE Transactions on Image Processing,\n 13, 600-612.\n https://ece.uwaterloo.ca/~z70wang/publications/ssim.pdf,\n :DOI:`10.1109/TIP.2003.819861`\n\n .. [2] Avanaki, A. N. (2009). Exact global histogram specification\n optimized for structural similarity. Optical Review, 16, 613-621.\n :arxiv:`0901.0065`\n :DOI:`10.1007/s10043-009-0119-z`\n\n \"\"\"\n check_shape_equality(im1, im2)\n float_type = _supported_float_type(im1.dtype)\n\n if channel_axis is not None:\n # loop over channels\n args = dict(win_size=win_size,\n gradient=gradient,\n data_range=data_range,\n channel_axis=None,\n gaussian_weights=gaussian_weights,\n full=full)\n args.update(kwargs)\n nch = im1.shape[channel_axis]\n mssim = np.empty(nch, dtype=float_type)\n\n if gradient:\n G = np.empty(im1.shape, dtype=float_type)\n if full:\n S = np.empty(im1.shape, dtype=float_type)\n channel_axis = channel_axis % im1.ndim\n _at = functools.partial(utils.slice_at_axis, axis=channel_axis)\n for ch in range(nch):\n ch_result = structural_similarity(im1[_at(ch)],\n im2[_at(ch)], **args)\n if gradient and full:\n mssim[ch], G[_at(ch)], S[_at(ch)] = ch_result\n elif gradient:\n mssim[ch], G[_at(ch)] = ch_result\n elif full:\n mssim[ch], S[_at(ch)] = ch_result\n else:\n mssim[ch] = ch_result\n mssim = mssim.mean()\n if gradient and full:\n return mssim, G, S\n elif gradient:\n return mssim, G\n elif full:\n return mssim, S\n else:\n return mssim\n\n K1 = kwargs.pop('K1', 0.01)\n K2 = kwargs.pop('K2', 0.03)\n sigma = kwargs.pop('sigma', 1.5)\n if K1 < 0:\n raise ValueError(\"K1 must be positive\")\n if K2 < 0:\n raise ValueError(\"K2 must be positive\")\n if sigma < 0:\n raise ValueError(\"sigma must be positive\")\n use_sample_covariance = kwargs.pop('use_sample_covariance', True)\n\n if gaussian_weights:\n # Set to give an 11-tap filter with the default sigma of 1.5 to match\n # Wang et. al. 2004.\n truncate = 3.5\n\n if win_size is None:\n if gaussian_weights:\n # set win_size used by crop to match the filter size\n r = int(truncate * sigma + 0.5) # radius as in ndimage\n win_size = 2 * r + 1\n else:\n win_size = 7 # backwards compatibility\n\n if np.any((np.asarray(im1.shape) - win_size) < 0):\n raise ValueError(\n \"win_size exceeds image extent. If the input is a multichannel \"\n \"(color) image, set channel_axis to the axis number corresponding \"\n \"to the channels.\")\n\n if not (win_size % 2 == 1):\n raise ValueError('Window size must be odd.')\n\n if data_range is None:\n if im1.dtype != im2.dtype:\n warn(\"Inputs have mismatched dtype. Setting data_range based on \"\n \"im1.dtype.\", stacklevel=2)\n dmin, dmax = dtype_range[im1.dtype.type]\n data_range = dmax - dmin\n\n ndim = im1.ndim\n\n if gaussian_weights:\n filter_func = gaussian_filter\n filter_args = {'sigma': sigma, 'truncate': truncate}\n else:\n filter_func = uniform_filter\n filter_args = {'size': win_size}\n\n # ndimage filters need floating point data\n im1 = im1.astype(float_type, copy=False)\n im2 = im2.astype(float_type, copy=False)\n\n NP = win_size ** ndim\n\n # filter has already normalized by NP\n if use_sample_covariance:\n cov_norm = NP / (NP - 1) # sample covariance\n else:\n cov_norm = 1.0 # population covariance to match Wang et. al. 2004\n\n # compute (weighted) means\n ux = filter_func(im1, **filter_args)\n uy = filter_func(im2, **filter_args)\n\n # compute (weighted) variances and covariances\n uxx = filter_func(im1 * im1, **filter_args)\n uyy = filter_func(im2 * im2, **filter_args)\n uxy = filter_func(im1 * im2, **filter_args)\n vx = cov_norm * (uxx - ux * ux)\n vy = cov_norm * (uyy - uy * uy)\n vxy = cov_norm * (uxy - ux * uy)\n\n R = data_range\n C1 = (K1 * R) ** 2\n C2 = (K2 * R) ** 2\n\n A1, A2, B1, B2 = ((2 * ux * uy + C1,\n 2 * vxy + C2,\n ux ** 2 + uy ** 2 + C1,\n vx + vy + C2))\n D = B1 * B2\n S = (A1 * A2) / D\n\n # to avoid edge effects will ignore filter radius strip around edges\n pad = (win_size - 1) // 2\n\n # compute (weighted) mean of ssim. Use float64 for accuracy.\n mssim = crop(S, pad).mean(dtype=np.float64)\n\n if gradient:\n # The following is Eqs. 7-8 of Avanaki 2009.\n grad = filter_func(A1 / D, **filter_args) * im1\n grad += filter_func(-S / B2, **filter_args) * im2\n grad += filter_func((ux * (A2 - A1) - uy * (B2 - B1) * S) / D,\n **filter_args)\n grad *= (2 / im1.size)\n\n if full:\n return mssim, grad, S\n else:\n return mssim, grad\n else:\n if full:\n return mssim, S\n else:\n return mssim\n", "path": "skimage/metrics/_structural_similarity.py"}]}
| 4,002 | 252 |
gh_patches_debug_11363
|
rasdani/github-patches
|
git_diff
|
Cog-Creators__Red-DiscordBot-1221
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[V3 Context] Handle DMs properly during send_interactive
(*forwarded from @palmtree5*)
### Type:
- Bug
### Brief description of the problem
When a user in DM types `more` during a case of `ctx.send_interactive` (for example, a long response to `[p]debug`), an error occurs.
### Expected behavior
When a user types `more`, the bot's message *"type `more` to continue"* should be deleted.
### Actual behavior
```py
Exception in command 'debug'
Traceback (most recent call last):
File "/home/palm/redv3/lib/python3.5/site-packages/discord/ext/commands/core.py", line 62, in wrapped
ret = yield from coro(*args, **kwargs)
File "/home/palm/redv3/lib/python3.5/site-packages/redbot/core/dev_commands.py", line 124, in debug
await ctx.send_interactive(self.get_pages(result), box_lang="py")
File "/home/palm/redv3/lib/python3.5/site-packages/redbot/core/context.py", line 120, in send_interactive
await self.channel.delete_messages((query, resp))
AttributeError: 'DMChannel' object has no attribute 'delete_messages'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/palm/redv3/lib/python3.5/site-packages/discord/ext/commands/bot.py", line 886, in invoke
yield from ctx.command.invoke(ctx)
File "/home/palm/redv3/lib/python3.5/site-packages/discord/ext/commands/core.py", line 489, in invoke
yield from injected(*ctx.args, **ctx.kwargs)
File "/home/palm/redv3/lib/python3.5/site-packages/discord/ext/commands/core.py", line 71, in wrapped
raise CommandInvokeError(e) from e
discord.ext.commands.errors.CommandInvokeError: Command raised an exception: AttributeError: 'DMChannel' object has no attribute 'delete_messages'
```
### Steps to reproduce
1. Open a DM with the bot
2. Do `[p]debug dir(bot)`
3. Type `more` when queried
</issue>
<code>
[start of redbot/core/context.py]
1 """
2 The purpose of this module is to allow for Red to further customise the command
3 invocation context provided by discord.py.
4 """
5 import asyncio
6 from typing import Iterable, List
7
8 import discord
9 from discord.ext import commands
10
11 from redbot.core.utils.chat_formatting import box
12
13 __all__ = ["RedContext"]
14
15 TICK = "\N{WHITE HEAVY CHECK MARK}"
16
17
18 class RedContext(commands.Context):
19 """Command invocation context for Red.
20
21 All context passed into commands will be of this type.
22
23 This class inherits from `commands.Context <discord.ext.commands.Context>`.
24 """
25
26 async def send_help(self) -> List[discord.Message]:
27 """Send the command help message.
28
29 Returns
30 -------
31 `list` of `discord.Message`
32 A list of help messages which were sent to the user.
33
34 """
35 command = self.invoked_subcommand or self.command
36 embeds = await self.bot.formatter.format_help_for(self, command)
37 destination = self
38 ret = []
39 for embed in embeds:
40 try:
41 m = await destination.send(embed=embed)
42 except discord.HTTPException:
43 destination = self.author
44 m = await destination.send(embed=embed)
45 ret.append(m)
46
47 return ret
48
49 async def tick(self) -> bool:
50 """Add a tick reaction to the command message.
51
52 Returns
53 -------
54 bool
55 :code:`True` if adding the reaction succeeded.
56
57 """
58 try:
59 await self.message.add_reaction(TICK)
60 except discord.HTTPException:
61 return False
62 else:
63 return True
64
65 async def send_interactive(self,
66 messages: Iterable[str],
67 box_lang: str=None,
68 timeout: int=15) -> List[discord.Message]:
69 """Send multiple messages interactively.
70
71 The user will be prompted for whether or not they would like to view
72 the next message, one at a time. They will also be notified of how
73 many messages are remaining on each prompt.
74
75 Parameters
76 ----------
77 messages : `iterable` of `str`
78 The messages to send.
79 box_lang : str
80 If specified, each message will be contained within a codeblock of
81 this language.
82 timeout : int
83 How long the user has to respond to the prompt before it times out.
84 After timing out, the bot deletes its prompt message.
85
86 """
87 messages = tuple(messages)
88 ret = []
89
90 more_check = lambda m: (m.author == self.author and
91 m.channel == self.channel and
92 m.content.lower() == "more")
93
94 for idx, page in enumerate(messages, 1):
95 if box_lang is None:
96 msg = await self.send(page)
97 else:
98 msg = await self.send(box(page, lang=box_lang))
99 ret.append(msg)
100 n_remaining = len(messages) - idx
101 if n_remaining > 0:
102 if n_remaining == 1:
103 plural = ""
104 is_are = "is"
105 else:
106 plural = "s"
107 is_are = "are"
108 query = await self.send(
109 "There {} still {} message{} remaining. "
110 "Type `more` to continue."
111 "".format(is_are, n_remaining, plural))
112 try:
113 resp = await self.bot.wait_for(
114 'message', check=more_check, timeout=timeout)
115 except asyncio.TimeoutError:
116 await query.delete()
117 break
118 else:
119 try:
120 await self.channel.delete_messages((query, resp))
121 except discord.HTTPException:
122 # In case the bot can't delete other users' messages,
123 # or is not a bot account
124 await query.delete()
125 return ret
126
[end of redbot/core/context.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/redbot/core/context.py b/redbot/core/context.py
--- a/redbot/core/context.py
+++ b/redbot/core/context.py
@@ -118,8 +118,9 @@
else:
try:
await self.channel.delete_messages((query, resp))
- except discord.HTTPException:
+ except (discord.HTTPException, AttributeError):
# In case the bot can't delete other users' messages,
# or is not a bot account
+ # or chanel is a DM
await query.delete()
return ret
|
{"golden_diff": "diff --git a/redbot/core/context.py b/redbot/core/context.py\n--- a/redbot/core/context.py\n+++ b/redbot/core/context.py\n@@ -118,8 +118,9 @@\n else:\n try:\n await self.channel.delete_messages((query, resp))\n- except discord.HTTPException:\n+ except (discord.HTTPException, AttributeError):\n # In case the bot can't delete other users' messages,\n # or is not a bot account\n+ # or chanel is a DM\n await query.delete()\n return ret\n", "issue": "[V3 Context] Handle DMs properly during send_interactive\n(*forwarded from @palmtree5*)\r\n\r\n### Type:\r\n\r\n- Bug\r\n\r\n### Brief description of the problem\r\nWhen a user in DM types `more` during a case of `ctx.send_interactive` (for example, a long response to `[p]debug`), an error occurs.\r\n\r\n### Expected behavior\r\nWhen a user types `more`, the bot's message *\"type `more` to continue\"* should be deleted.\r\n\r\n### Actual behavior\r\n```py\r\nException in command 'debug'\r\nTraceback (most recent call last):\r\n File \"/home/palm/redv3/lib/python3.5/site-packages/discord/ext/commands/core.py\", line 62, in wrapped\r\n ret = yield from coro(*args, **kwargs)\r\n File \"/home/palm/redv3/lib/python3.5/site-packages/redbot/core/dev_commands.py\", line 124, in debug\r\n await ctx.send_interactive(self.get_pages(result), box_lang=\"py\")\r\n File \"/home/palm/redv3/lib/python3.5/site-packages/redbot/core/context.py\", line 120, in send_interactive\r\n await self.channel.delete_messages((query, resp))\r\nAttributeError: 'DMChannel' object has no attribute 'delete_messages'\r\n\r\nThe above exception was the direct cause of the following exception:\r\n\r\nTraceback (most recent call last):\r\n File \"/home/palm/redv3/lib/python3.5/site-packages/discord/ext/commands/bot.py\", line 886, in invoke\r\n yield from ctx.command.invoke(ctx)\r\n File \"/home/palm/redv3/lib/python3.5/site-packages/discord/ext/commands/core.py\", line 489, in invoke\r\n yield from injected(*ctx.args, **ctx.kwargs)\r\n File \"/home/palm/redv3/lib/python3.5/site-packages/discord/ext/commands/core.py\", line 71, in wrapped\r\n raise CommandInvokeError(e) from e\r\ndiscord.ext.commands.errors.CommandInvokeError: Command raised an exception: AttributeError: 'DMChannel' object has no attribute 'delete_messages'\r\n```\r\n\r\n### Steps to reproduce\r\n\r\n1. Open a DM with the bot\r\n2. Do `[p]debug dir(bot)`\r\n3. Type `more` when queried\r\n\n", "before_files": [{"content": "\"\"\"\nThe purpose of this module is to allow for Red to further customise the command\ninvocation context provided by discord.py.\n\"\"\"\nimport asyncio\nfrom typing import Iterable, List\n\nimport discord\nfrom discord.ext import commands\n\nfrom redbot.core.utils.chat_formatting import box\n\n__all__ = [\"RedContext\"]\n\nTICK = \"\\N{WHITE HEAVY CHECK MARK}\"\n\n\nclass RedContext(commands.Context):\n \"\"\"Command invocation context for Red.\n\n All context passed into commands will be of this type.\n\n This class inherits from `commands.Context <discord.ext.commands.Context>`.\n \"\"\"\n\n async def send_help(self) -> List[discord.Message]:\n \"\"\"Send the command help message.\n\n Returns\n -------\n `list` of `discord.Message`\n A list of help messages which were sent to the user.\n\n \"\"\"\n command = self.invoked_subcommand or self.command\n embeds = await self.bot.formatter.format_help_for(self, command)\n destination = self\n ret = []\n for embed in embeds:\n try:\n m = await destination.send(embed=embed)\n except discord.HTTPException:\n destination = self.author\n m = await destination.send(embed=embed)\n ret.append(m)\n\n return ret\n\n async def tick(self) -> bool:\n \"\"\"Add a tick reaction to the command message.\n\n Returns\n -------\n bool\n :code:`True` if adding the reaction succeeded.\n\n \"\"\"\n try:\n await self.message.add_reaction(TICK)\n except discord.HTTPException:\n return False\n else:\n return True\n\n async def send_interactive(self,\n messages: Iterable[str],\n box_lang: str=None,\n timeout: int=15) -> List[discord.Message]:\n \"\"\"Send multiple messages interactively.\n\n The user will be prompted for whether or not they would like to view\n the next message, one at a time. They will also be notified of how\n many messages are remaining on each prompt.\n\n Parameters\n ----------\n messages : `iterable` of `str`\n The messages to send.\n box_lang : str\n If specified, each message will be contained within a codeblock of\n this language.\n timeout : int\n How long the user has to respond to the prompt before it times out.\n After timing out, the bot deletes its prompt message.\n\n \"\"\"\n messages = tuple(messages)\n ret = []\n\n more_check = lambda m: (m.author == self.author and\n m.channel == self.channel and\n m.content.lower() == \"more\")\n\n for idx, page in enumerate(messages, 1):\n if box_lang is None:\n msg = await self.send(page)\n else:\n msg = await self.send(box(page, lang=box_lang))\n ret.append(msg)\n n_remaining = len(messages) - idx\n if n_remaining > 0:\n if n_remaining == 1:\n plural = \"\"\n is_are = \"is\"\n else:\n plural = \"s\"\n is_are = \"are\"\n query = await self.send(\n \"There {} still {} message{} remaining. \"\n \"Type `more` to continue.\"\n \"\".format(is_are, n_remaining, plural))\n try:\n resp = await self.bot.wait_for(\n 'message', check=more_check, timeout=timeout)\n except asyncio.TimeoutError:\n await query.delete()\n break\n else:\n try:\n await self.channel.delete_messages((query, resp))\n except discord.HTTPException:\n # In case the bot can't delete other users' messages,\n # or is not a bot account\n await query.delete()\n return ret\n", "path": "redbot/core/context.py"}]}
| 2,087 | 122 |
gh_patches_debug_14737
|
rasdani/github-patches
|
git_diff
|
opendatacube__datacube-core-1252
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Error message for missing file is confusing
### Expected behaviour
```bash
> datacube dataset add /no/such/file.yaml
ERROR: no such file "/no/such/file.yaml"
```
### Actual behaviour
```
ERROR No supported metadata docs found for dataset /no/such/file.yaml
```
### Steps to reproduce the behaviour
```
datacube dataset add /no/such/file.yaml
```
observe confusing message.
### Environment information
code in `develop` branch.
### Remediation Suggestions
Error message originates from here:
https://github.com/opendatacube/datacube-core/blob/80d466a2635ab37fbe33bb283b77df305e3c9236/datacube/ui/common.py#L91
There is some pretty involved logic in "locating actual metadata file", code accepts all sorts of inputs:
- directory
- some file in directory with a sibling file named `{base}.{agdc-md,agdc-metadata}.{yaml,yml,json}{,.tar.gz, .tgz}`.
Hence the error message, but really, if input is a "file path" and it is not a path that exists on the filesystem the error message should say just that: `"Supplied path '/no/such/file.yml' does not exist"`. And the current message should only be used when supplied path is an existing file/directory but is not a metadata file, say it is a `.tiff` image, but there is no metadata file next to it, or it's a directory and there are no metadata file in it.
Error message for missing file is confusing
### Expected behaviour
```bash
> datacube dataset add /no/such/file.yaml
ERROR: no such file "/no/such/file.yaml"
```
### Actual behaviour
```
ERROR No supported metadata docs found for dataset /no/such/file.yaml
```
### Steps to reproduce the behaviour
```
datacube dataset add /no/such/file.yaml
```
observe confusing message.
### Environment information
code in `develop` branch.
### Remediation Suggestions
Error message originates from here:
https://github.com/opendatacube/datacube-core/blob/80d466a2635ab37fbe33bb283b77df305e3c9236/datacube/ui/common.py#L91
There is some pretty involved logic in "locating actual metadata file", code accepts all sorts of inputs:
- directory
- some file in directory with a sibling file named `{base}.{agdc-md,agdc-metadata}.{yaml,yml,json}{,.tar.gz, .tgz}`.
Hence the error message, but really, if input is a "file path" and it is not a path that exists on the filesystem the error message should say just that: `"Supplied path '/no/such/file.yml' does not exist"`. And the current message should only be used when supplied path is an existing file/directory but is not a metadata file, say it is a `.tiff` image, but there is no metadata file next to it, or it's a directory and there are no metadata file in it.
</issue>
<code>
[start of datacube/ui/common.py]
1 # This file is part of the Open Data Cube, see https://opendatacube.org for more information
2 #
3 # Copyright (c) 2015-2020 ODC Contributors
4 # SPDX-License-Identifier: Apache-2.0
5 """
6 Common methods for UI code.
7 """
8 from pathlib import Path
9 from typing import Union, Optional
10
11 from toolz.functoolz import identity
12
13 from datacube.utils import read_documents, InvalidDocException, SimpleDocNav, is_supported_document_type, is_url
14
15
16 def get_metadata_path(possible_path: Union[str, Path]) -> str:
17 """
18 Find a metadata path for a given input/dataset path.
19
20 Needs to handle local files as well as remote URLs
21 """
22 # We require exact URLs, lets skip any sort of fancy investigation and mapping
23 if isinstance(possible_path, str) and is_url(possible_path):
24 return possible_path
25
26 dataset_path = Path(possible_path)
27
28 # They may have given us a metadata file directly.
29 if dataset_path.is_file() and is_supported_document_type(dataset_path):
30 return str(dataset_path)
31
32 # Otherwise there may be a sibling file with appended suffix '.agdc-md.yaml'.
33 expected_name = dataset_path.parent.joinpath('{}.agdc-md'.format(dataset_path.name))
34 found = _find_any_metadata_suffix(expected_name)
35 if found:
36 return str(found)
37
38 # Otherwise if it's a directory, there may be an 'agdc-metadata.yaml' file describing all contained datasets.
39 if dataset_path.is_dir():
40 expected_name = dataset_path.joinpath('agdc-metadata')
41 found = _find_any_metadata_suffix(expected_name)
42 if found:
43 return str(found)
44
45 raise ValueError('No metadata found for input %r' % dataset_path)
46
47
48 def _find_any_metadata_suffix(path: Path) -> Optional[Path]:
49 """
50 Find any supported metadata files that exist with the given file path stem.
51 (supported suffixes are tried on the name)
52
53 Eg. searching for '/tmp/ga-metadata' will find if any files such as '/tmp/ga-metadata.yaml' or
54 '/tmp/ga-metadata.json', or '/tmp/ga-metadata.yaml.gz' etc that exist: any suffix supported by read_documents()
55
56 :type path: pathlib.Path
57 """
58 existing_paths = list(filter(is_supported_document_type, path.parent.glob(path.name + '*')))
59 if not existing_paths:
60 return None
61
62 if len(existing_paths) > 1:
63 raise ValueError('Multiple matched metadata files: {!r}'.format(existing_paths))
64
65 return existing_paths[0]
66
67
68 def ui_path_doc_stream(paths, logger=None, uri=True, raw=False):
69 """Given a stream of URLs, or Paths that could be directories, generate a stream of
70 (path, doc) tuples.
71
72 For every path:
73 1. If directory find the metadata file or log error if not found
74
75 2. Load all documents from that path and return one at a time (parsing
76 errors are logged, but processing should continue)
77
78 :param paths: Filesystem paths
79
80 :param logger: Logger to use to report errors
81
82 :param uri: If True return path in uri format, else return it as filesystem path
83
84 :param raw: By default docs are wrapped in :class:`SimpleDocNav`, but you can
85 instead request them to be raw dictionaries
86
87 """
88
89 def on_error1(p, e):
90 if logger is not None:
91 logger.error('No supported metadata docs found for dataset %s', str(p))
92
93 def on_error2(p, e):
94 if logger is not None:
95 logger.error('Failed reading documents from %s', str(p))
96
97 yield from _path_doc_stream(_resolve_doc_files(paths, on_error=on_error1),
98 on_error=on_error2, uri=uri, raw=raw)
99
100
101 def _resolve_doc_files(paths, on_error):
102 for p in paths:
103 try:
104 yield get_metadata_path(p)
105 except ValueError as e:
106 on_error(p, e)
107
108
109 def _path_doc_stream(files, on_error, uri=True, raw=False):
110 """See :func:`ui_path_doc_stream` for documentation"""
111 maybe_wrap = identity if raw else SimpleDocNav
112
113 for fname in files:
114 try:
115 for p, doc in read_documents(fname, uri=uri):
116 yield p, maybe_wrap(doc)
117
118 except InvalidDocException as e:
119 on_error(fname, e)
120
[end of datacube/ui/common.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/datacube/ui/common.py b/datacube/ui/common.py
--- a/datacube/ui/common.py
+++ b/datacube/ui/common.py
@@ -42,7 +42,10 @@
if found:
return str(found)
- raise ValueError('No metadata found for input %r' % dataset_path)
+ if is_supported_document_type(dataset_path):
+ raise ValueError(f'No such file {dataset_path}')
+ else:
+ raise ValueError(f'No supported metadata docs found for dataset {dataset_path}')
def _find_any_metadata_suffix(path: Path) -> Optional[Path]:
@@ -88,7 +91,7 @@
def on_error1(p, e):
if logger is not None:
- logger.error('No supported metadata docs found for dataset %s', str(p))
+ logger.error(str(e))
def on_error2(p, e):
if logger is not None:
|
{"golden_diff": "diff --git a/datacube/ui/common.py b/datacube/ui/common.py\n--- a/datacube/ui/common.py\n+++ b/datacube/ui/common.py\n@@ -42,7 +42,10 @@\n if found:\n return str(found)\n \n- raise ValueError('No metadata found for input %r' % dataset_path)\n+ if is_supported_document_type(dataset_path):\n+ raise ValueError(f'No such file {dataset_path}')\n+ else:\n+ raise ValueError(f'No supported metadata docs found for dataset {dataset_path}')\n \n \n def _find_any_metadata_suffix(path: Path) -> Optional[Path]:\n@@ -88,7 +91,7 @@\n \n def on_error1(p, e):\n if logger is not None:\n- logger.error('No supported metadata docs found for dataset %s', str(p))\n+ logger.error(str(e))\n \n def on_error2(p, e):\n if logger is not None:\n", "issue": "Error message for missing file is confusing\n### Expected behaviour\r\n\r\n```bash\r\n> datacube dataset add /no/such/file.yaml\r\nERROR: no such file \"/no/such/file.yaml\"\r\n```\r\n\r\n### Actual behaviour\r\n\r\n```\r\nERROR No supported metadata docs found for dataset /no/such/file.yaml\r\n```\r\n\r\n### Steps to reproduce the behaviour\r\n\r\n```\r\ndatacube dataset add /no/such/file.yaml\r\n```\r\nobserve confusing message.\r\n\r\n\r\n### Environment information\r\n\r\ncode in `develop` branch.\r\n\r\n\r\n### Remediation Suggestions\r\n\r\nError message originates from here:\r\nhttps://github.com/opendatacube/datacube-core/blob/80d466a2635ab37fbe33bb283b77df305e3c9236/datacube/ui/common.py#L91\r\n\r\nThere is some pretty involved logic in \"locating actual metadata file\", code accepts all sorts of inputs:\r\n\r\n- directory\r\n- some file in directory with a sibling file named `{base}.{agdc-md,agdc-metadata}.{yaml,yml,json}{,.tar.gz, .tgz}`.\r\n\r\nHence the error message, but really, if input is a \"file path\" and it is not a path that exists on the filesystem the error message should say just that: `\"Supplied path '/no/such/file.yml' does not exist\"`. And the current message should only be used when supplied path is an existing file/directory but is not a metadata file, say it is a `.tiff` image, but there is no metadata file next to it, or it's a directory and there are no metadata file in it.\r\n\r\n\nError message for missing file is confusing\n### Expected behaviour\r\n\r\n```bash\r\n> datacube dataset add /no/such/file.yaml\r\nERROR: no such file \"/no/such/file.yaml\"\r\n```\r\n\r\n### Actual behaviour\r\n\r\n```\r\nERROR No supported metadata docs found for dataset /no/such/file.yaml\r\n```\r\n\r\n### Steps to reproduce the behaviour\r\n\r\n```\r\ndatacube dataset add /no/such/file.yaml\r\n```\r\nobserve confusing message.\r\n\r\n\r\n### Environment information\r\n\r\ncode in `develop` branch.\r\n\r\n\r\n### Remediation Suggestions\r\n\r\nError message originates from here:\r\nhttps://github.com/opendatacube/datacube-core/blob/80d466a2635ab37fbe33bb283b77df305e3c9236/datacube/ui/common.py#L91\r\n\r\nThere is some pretty involved logic in \"locating actual metadata file\", code accepts all sorts of inputs:\r\n\r\n- directory\r\n- some file in directory with a sibling file named `{base}.{agdc-md,agdc-metadata}.{yaml,yml,json}{,.tar.gz, .tgz}`.\r\n\r\nHence the error message, but really, if input is a \"file path\" and it is not a path that exists on the filesystem the error message should say just that: `\"Supplied path '/no/such/file.yml' does not exist\"`. And the current message should only be used when supplied path is an existing file/directory but is not a metadata file, say it is a `.tiff` image, but there is no metadata file next to it, or it's a directory and there are no metadata file in it.\r\n\r\n\n", "before_files": [{"content": "# This file is part of the Open Data Cube, see https://opendatacube.org for more information\n#\n# Copyright (c) 2015-2020 ODC Contributors\n# SPDX-License-Identifier: Apache-2.0\n\"\"\"\nCommon methods for UI code.\n\"\"\"\nfrom pathlib import Path\nfrom typing import Union, Optional\n\nfrom toolz.functoolz import identity\n\nfrom datacube.utils import read_documents, InvalidDocException, SimpleDocNav, is_supported_document_type, is_url\n\n\ndef get_metadata_path(possible_path: Union[str, Path]) -> str:\n \"\"\"\n Find a metadata path for a given input/dataset path.\n\n Needs to handle local files as well as remote URLs\n \"\"\"\n # We require exact URLs, lets skip any sort of fancy investigation and mapping\n if isinstance(possible_path, str) and is_url(possible_path):\n return possible_path\n\n dataset_path = Path(possible_path)\n\n # They may have given us a metadata file directly.\n if dataset_path.is_file() and is_supported_document_type(dataset_path):\n return str(dataset_path)\n\n # Otherwise there may be a sibling file with appended suffix '.agdc-md.yaml'.\n expected_name = dataset_path.parent.joinpath('{}.agdc-md'.format(dataset_path.name))\n found = _find_any_metadata_suffix(expected_name)\n if found:\n return str(found)\n\n # Otherwise if it's a directory, there may be an 'agdc-metadata.yaml' file describing all contained datasets.\n if dataset_path.is_dir():\n expected_name = dataset_path.joinpath('agdc-metadata')\n found = _find_any_metadata_suffix(expected_name)\n if found:\n return str(found)\n\n raise ValueError('No metadata found for input %r' % dataset_path)\n\n\ndef _find_any_metadata_suffix(path: Path) -> Optional[Path]:\n \"\"\"\n Find any supported metadata files that exist with the given file path stem.\n (supported suffixes are tried on the name)\n\n Eg. searching for '/tmp/ga-metadata' will find if any files such as '/tmp/ga-metadata.yaml' or\n '/tmp/ga-metadata.json', or '/tmp/ga-metadata.yaml.gz' etc that exist: any suffix supported by read_documents()\n\n :type path: pathlib.Path\n \"\"\"\n existing_paths = list(filter(is_supported_document_type, path.parent.glob(path.name + '*')))\n if not existing_paths:\n return None\n\n if len(existing_paths) > 1:\n raise ValueError('Multiple matched metadata files: {!r}'.format(existing_paths))\n\n return existing_paths[0]\n\n\ndef ui_path_doc_stream(paths, logger=None, uri=True, raw=False):\n \"\"\"Given a stream of URLs, or Paths that could be directories, generate a stream of\n (path, doc) tuples.\n\n For every path:\n 1. If directory find the metadata file or log error if not found\n\n 2. Load all documents from that path and return one at a time (parsing\n errors are logged, but processing should continue)\n\n :param paths: Filesystem paths\n\n :param logger: Logger to use to report errors\n\n :param uri: If True return path in uri format, else return it as filesystem path\n\n :param raw: By default docs are wrapped in :class:`SimpleDocNav`, but you can\n instead request them to be raw dictionaries\n\n \"\"\"\n\n def on_error1(p, e):\n if logger is not None:\n logger.error('No supported metadata docs found for dataset %s', str(p))\n\n def on_error2(p, e):\n if logger is not None:\n logger.error('Failed reading documents from %s', str(p))\n\n yield from _path_doc_stream(_resolve_doc_files(paths, on_error=on_error1),\n on_error=on_error2, uri=uri, raw=raw)\n\n\ndef _resolve_doc_files(paths, on_error):\n for p in paths:\n try:\n yield get_metadata_path(p)\n except ValueError as e:\n on_error(p, e)\n\n\ndef _path_doc_stream(files, on_error, uri=True, raw=False):\n \"\"\"See :func:`ui_path_doc_stream` for documentation\"\"\"\n maybe_wrap = identity if raw else SimpleDocNav\n\n for fname in files:\n try:\n for p, doc in read_documents(fname, uri=uri):\n yield p, maybe_wrap(doc)\n\n except InvalidDocException as e:\n on_error(fname, e)\n", "path": "datacube/ui/common.py"}]}
| 2,446 | 203 |
gh_patches_debug_4648
|
rasdani/github-patches
|
git_diff
|
kivy__kivy-2196
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[examples] installation of latest kivy-examples package fails
Looks like there is a simple syntax problem in an example...
Beleave it is not py3 compatible :/
Package: kivy-examples (1.8.1-daily0+201405040547-2023-testing42~ubuntu14.04.1)
```
File "/usr/share/kivy-examples/widgets/compound_selection.py", line 17
print [x.text for x in self.selected_nodes]
^
SyntaxError: invalid syntax
```
</issue>
<code>
[start of examples/widgets/compound_selection.py]
1 from kivy.uix.gridlayout import GridLayout
2 from kivy.uix.button import Button
3 from kivy.uix.behaviors import CompoundSelectionBehavior
4 from kivy.app import runTouchApp
5 from kivy.core.window import Window
6
7
8 class SelectableGrid(CompoundSelectionBehavior, GridLayout):
9
10 def __init__(self, **kwargs):
11 super(SelectableGrid, self).__init__(**kwargs)
12 keyboard = Window.request_keyboard(None, self)
13 keyboard.bind(on_key_down=self.select_with_key_down,
14 on_key_up=self.select_with_key_up)
15
16 def print_selection(*l):
17 print(x.text for x in self.selected_nodes)
18 self.bind(selected_nodes=print_selection)
19
20 def goto_node(self, key, last_node, last_node_idx):
21 ''' This function is used to go to the node by typing the number
22 of the text of the button.
23 '''
24 node, idx = super(SelectableGrid, self).goto_node(key, last_node,
25 last_node_idx)
26 if node == last_node:
27 children = self.children
28 for i in range(len(children)):
29 if children[i].text == key:
30 return children[i], i
31 return node, idx
32
33 def select_node(self, node):
34 node.background_color = (1, 0, 0, 1)
35 return super(SelectableGrid, self).select_node(node)
36
37 def deselect_node(self, node):
38 node.background_color = (1, 1, 1, 1)
39 super(SelectableGrid, self).deselect_node(node)
40
41 def do_touch(self, instance, touch):
42 if ('button' in touch.profile and touch.button in
43 ('scrollup', 'scrolldown', 'scrollleft', 'scrollright')) or\
44 instance.collide_point(*touch.pos):
45 self.select_with_touch(instance, touch)
46 else:
47 return False
48 return True
49
50
51 root = SelectableGrid(cols=5, up_count=5, multiselect=True, scroll_count=1)
52 for i in range(40):
53 c = Button(text=str(i))
54 c.bind(on_touch_down=root.do_touch)
55 root.add_widget(c)
56
57 runTouchApp(root)
58
[end of examples/widgets/compound_selection.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/widgets/compound_selection.py b/examples/widgets/compound_selection.py
--- a/examples/widgets/compound_selection.py
+++ b/examples/widgets/compound_selection.py
@@ -14,7 +14,7 @@
on_key_up=self.select_with_key_up)
def print_selection(*l):
- print(x.text for x in self.selected_nodes)
+ print([x.text for x in self.selected_nodes])
self.bind(selected_nodes=print_selection)
def goto_node(self, key, last_node, last_node_idx):
|
{"golden_diff": "diff --git a/examples/widgets/compound_selection.py b/examples/widgets/compound_selection.py\n--- a/examples/widgets/compound_selection.py\n+++ b/examples/widgets/compound_selection.py\n@@ -14,7 +14,7 @@\n on_key_up=self.select_with_key_up)\n \n def print_selection(*l):\n- print(x.text for x in self.selected_nodes)\n+ print([x.text for x in self.selected_nodes])\n self.bind(selected_nodes=print_selection)\n \n def goto_node(self, key, last_node, last_node_idx):\n", "issue": "[examples] installation of latest kivy-examples package fails\nLooks like there is a simple syntax problem in an example...\nBeleave it is not py3 compatible :/\n\nPackage: kivy-examples (1.8.1-daily0+201405040547-2023-testing42~ubuntu14.04.1)\n\n```\n File \"/usr/share/kivy-examples/widgets/compound_selection.py\", line 17\n print [x.text for x in self.selected_nodes]\n ^\nSyntaxError: invalid syntax\n```\n\n", "before_files": [{"content": "from kivy.uix.gridlayout import GridLayout\nfrom kivy.uix.button import Button\nfrom kivy.uix.behaviors import CompoundSelectionBehavior\nfrom kivy.app import runTouchApp\nfrom kivy.core.window import Window\n\n\nclass SelectableGrid(CompoundSelectionBehavior, GridLayout):\n\n def __init__(self, **kwargs):\n super(SelectableGrid, self).__init__(**kwargs)\n keyboard = Window.request_keyboard(None, self)\n keyboard.bind(on_key_down=self.select_with_key_down,\n on_key_up=self.select_with_key_up)\n\n def print_selection(*l):\n print(x.text for x in self.selected_nodes)\n self.bind(selected_nodes=print_selection)\n\n def goto_node(self, key, last_node, last_node_idx):\n ''' This function is used to go to the node by typing the number\n of the text of the button.\n '''\n node, idx = super(SelectableGrid, self).goto_node(key, last_node,\n last_node_idx)\n if node == last_node:\n children = self.children\n for i in range(len(children)):\n if children[i].text == key:\n return children[i], i\n return node, idx\n\n def select_node(self, node):\n node.background_color = (1, 0, 0, 1)\n return super(SelectableGrid, self).select_node(node)\n\n def deselect_node(self, node):\n node.background_color = (1, 1, 1, 1)\n super(SelectableGrid, self).deselect_node(node)\n\n def do_touch(self, instance, touch):\n if ('button' in touch.profile and touch.button in\n ('scrollup', 'scrolldown', 'scrollleft', 'scrollright')) or\\\n instance.collide_point(*touch.pos):\n self.select_with_touch(instance, touch)\n else:\n return False\n return True\n\n\nroot = SelectableGrid(cols=5, up_count=5, multiselect=True, scroll_count=1)\nfor i in range(40):\n c = Button(text=str(i))\n c.bind(on_touch_down=root.do_touch)\n root.add_widget(c)\n\nrunTouchApp(root)\n", "path": "examples/widgets/compound_selection.py"}]}
| 1,238 | 116 |
gh_patches_debug_19248
|
rasdani/github-patches
|
git_diff
|
Kinto__kinto-1765
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Exposed providers in openid capabilities are not filtered by `multiauth.policies`
For example, with:
```ini
kinto.includes = kinto.plugins.openid
multiauth.policies = google
multiauth.policy.google.use = kinto.plugins.openid.OpenIDConnectPolicy
multiauth.policy.google.issuer_url = https://accounts.google.com
multiauth.policy.google.client_id = a
multiauth.policy.google.client_secret = b
multiauth.policy.fxa.use = kinto.plugins.openid.OpenIDConnectPolicy
multiauth.policy.fxa.issuer_url = https://accounts.mozilla.org
multiauth.policy.fxa.client_id = a
multiauth.policy.fxa.client_secret = b
```
`fxa` provider should not be shown in capability.
See misbehaving code (OMG a `print()` statement!)
https://github.com/Kinto/kinto/blob/bf60689ae016a31b8c5bb1955397be46d7b4acca/kinto/plugins/openid/__init__.py#L89-L95
</issue>
<code>
[start of kinto/plugins/openid/__init__.py]
1 import re
2
3 import requests
4 from pyramid import authentication as base_auth
5 from pyramid.interfaces import IAuthenticationPolicy
6 from zope.interface import implementer
7
8 from kinto.core import logger
9 from kinto.core import utils as core_utils
10 from kinto.core.openapi import OpenAPI
11
12 from .utils import fetch_openid_config
13
14
15 @implementer(IAuthenticationPolicy)
16 class OpenIDConnectPolicy(base_auth.CallbackAuthenticationPolicy):
17 def __init__(self, issuer, client_id, realm='Realm', **kwargs):
18 self.realm = realm
19 self.issuer = issuer
20 self.client_id = client_id
21 self.client_secret = kwargs.get('client_secret', '')
22 self.header_type = kwargs.get('header_type', 'Bearer')
23 self.userid_field = kwargs.get('userid_field', 'sub')
24 self.verification_ttl = int(kwargs.get('verification_ttl_seconds', 86400))
25
26 # Fetch OpenID config (at instantiation, ie. startup)
27 self.oid_config = fetch_openid_config(issuer)
28
29 self._jwt_keys = None
30
31 def unauthenticated_userid(self, request):
32 """Return the userid or ``None`` if token could not be verified.
33 """
34 settings = request.registry.settings
35 hmac_secret = settings['userid_hmac_secret']
36
37 authorization = request.headers.get('Authorization', '')
38 try:
39 authmeth, access_token = authorization.split(' ', 1)
40 except ValueError:
41 return None
42
43 if authmeth.lower() != self.header_type.lower():
44 return None
45
46 # XXX JWT Access token
47 # https://auth0.com/docs/tokens/access-token#access-token-format
48
49 # Check cache if these tokens were already verified.
50 hmac_tokens = core_utils.hmac_digest(hmac_secret, access_token)
51 cache_key = 'openid:verify:{}'.format(hmac_tokens)
52 payload = request.registry.cache.get(cache_key)
53 if payload is None:
54 # This can take some time.
55 payload = self._verify_token(access_token)
56 if payload is None:
57 return None
58 # Save for next time / refresh ttl.
59 request.registry.cache.set(cache_key, payload, ttl=self.verification_ttl)
60 # Extract meaningful field from userinfo (eg. email or sub)
61 return payload.get(self.userid_field)
62
63 def forget(self, request):
64 """A no-op. Credentials are sent on every request.
65 Return WWW-Authenticate Realm header for Bearer token.
66 """
67 return [('WWW-Authenticate', '%s realm="%s"' % (self.header_type, self.realm))]
68
69 def _verify_token(self, access_token):
70 uri = self.oid_config['userinfo_endpoint']
71 # Opaque access token string. Fetch user info from profile.
72 try:
73 resp = requests.get(uri, headers={'Authorization': 'Bearer ' + access_token})
74 resp.raise_for_status()
75 userprofile = resp.json()
76 return userprofile
77
78 except (requests.exceptions.HTTPError, ValueError, KeyError) as e:
79 logger.debug('Unable to fetch user profile from %s (%s)' % (uri, e))
80 return None
81
82
83 def includeme(config):
84 # Activate end-points.
85 config.scan('kinto.plugins.openid.views')
86
87 settings = config.get_settings()
88
89 openid_policies = []
90 for k, v in settings.items():
91 m = re.match('multiauth\.policy\.(.*)\.use', k)
92 if m:
93 if v.endswith('OpenIDConnectPolicy'):
94 openid_policies.append(m.group(1))
95
96 if len(openid_policies) == 0:
97 # Do not add the capability if no policy is configured.
98 return
99
100 providers_infos = []
101 for name in openid_policies:
102 issuer = settings['multiauth.policy.%s.issuer' % name]
103 openid_config = fetch_openid_config(issuer)
104
105 client_id = settings['multiauth.policy.%s.client_id' % name]
106 header_type = settings.get('multiauth.policy.%s.header_type', 'Bearer')
107
108 providers_infos.append({
109 'name': name,
110 'issuer': openid_config['issuer'],
111 'auth_path': '/openid/%s/login' % name,
112 'client_id': client_id,
113 'header_type': header_type,
114 'userinfo_endpoint': openid_config['userinfo_endpoint'],
115 })
116
117 OpenAPI.expose_authentication_method(name, {
118 'type': 'oauth2',
119 'authorizationUrl': openid_config['authorization_endpoint'],
120 })
121
122 config.add_api_capability(
123 'openid',
124 description='OpenID connect support.',
125 url='http://kinto.readthedocs.io/en/stable/api/1.x/authentication.html',
126 providers=providers_infos)
127
[end of kinto/plugins/openid/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kinto/plugins/openid/__init__.py b/kinto/plugins/openid/__init__.py
--- a/kinto/plugins/openid/__init__.py
+++ b/kinto/plugins/openid/__init__.py
@@ -1,7 +1,7 @@
-import re
import requests
from pyramid import authentication as base_auth
+from pyramid.settings import aslist
from pyramid.interfaces import IAuthenticationPolicy
from zope.interface import implementer
@@ -87,11 +87,10 @@
settings = config.get_settings()
openid_policies = []
- for k, v in settings.items():
- m = re.match('multiauth\.policy\.(.*)\.use', k)
- if m:
- if v.endswith('OpenIDConnectPolicy'):
- openid_policies.append(m.group(1))
+ for policy in aslist(settings['multiauth.policies']):
+ v = settings.get('multiauth.policy.%s.use' % policy, '')
+ if v.endswith('OpenIDConnectPolicy'):
+ openid_policies.append(policy)
if len(openid_policies) == 0:
# Do not add the capability if no policy is configured.
|
{"golden_diff": "diff --git a/kinto/plugins/openid/__init__.py b/kinto/plugins/openid/__init__.py\n--- a/kinto/plugins/openid/__init__.py\n+++ b/kinto/plugins/openid/__init__.py\n@@ -1,7 +1,7 @@\n-import re\n \n import requests\n from pyramid import authentication as base_auth\n+from pyramid.settings import aslist\n from pyramid.interfaces import IAuthenticationPolicy\n from zope.interface import implementer\n \n@@ -87,11 +87,10 @@\n settings = config.get_settings()\n \n openid_policies = []\n- for k, v in settings.items():\n- m = re.match('multiauth\\.policy\\.(.*)\\.use', k)\n- if m:\n- if v.endswith('OpenIDConnectPolicy'):\n- openid_policies.append(m.group(1))\n+ for policy in aslist(settings['multiauth.policies']):\n+ v = settings.get('multiauth.policy.%s.use' % policy, '')\n+ if v.endswith('OpenIDConnectPolicy'):\n+ openid_policies.append(policy)\n \n if len(openid_policies) == 0:\n # Do not add the capability if no policy is configured.\n", "issue": "Exposed providers in openid capabilities are not filtered by `multiauth.policies`\nFor example, with:\r\n\r\n```ini\r\n\r\nkinto.includes = kinto.plugins.openid\r\n\r\nmultiauth.policies = google\r\n\r\nmultiauth.policy.google.use = kinto.plugins.openid.OpenIDConnectPolicy\r\nmultiauth.policy.google.issuer_url = https://accounts.google.com\r\nmultiauth.policy.google.client_id = a\r\nmultiauth.policy.google.client_secret = b\r\n\r\nmultiauth.policy.fxa.use = kinto.plugins.openid.OpenIDConnectPolicy\r\nmultiauth.policy.fxa.issuer_url = https://accounts.mozilla.org\r\nmultiauth.policy.fxa.client_id = a\r\nmultiauth.policy.fxa.client_secret = b\r\n```\r\n\r\n`fxa` provider should not be shown in capability.\r\n\r\nSee misbehaving code (OMG a `print()` statement!)\r\n\r\nhttps://github.com/Kinto/kinto/blob/bf60689ae016a31b8c5bb1955397be46d7b4acca/kinto/plugins/openid/__init__.py#L89-L95\n", "before_files": [{"content": "import re\n\nimport requests\nfrom pyramid import authentication as base_auth\nfrom pyramid.interfaces import IAuthenticationPolicy\nfrom zope.interface import implementer\n\nfrom kinto.core import logger\nfrom kinto.core import utils as core_utils\nfrom kinto.core.openapi import OpenAPI\n\nfrom .utils import fetch_openid_config\n\n\n@implementer(IAuthenticationPolicy)\nclass OpenIDConnectPolicy(base_auth.CallbackAuthenticationPolicy):\n def __init__(self, issuer, client_id, realm='Realm', **kwargs):\n self.realm = realm\n self.issuer = issuer\n self.client_id = client_id\n self.client_secret = kwargs.get('client_secret', '')\n self.header_type = kwargs.get('header_type', 'Bearer')\n self.userid_field = kwargs.get('userid_field', 'sub')\n self.verification_ttl = int(kwargs.get('verification_ttl_seconds', 86400))\n\n # Fetch OpenID config (at instantiation, ie. startup)\n self.oid_config = fetch_openid_config(issuer)\n\n self._jwt_keys = None\n\n def unauthenticated_userid(self, request):\n \"\"\"Return the userid or ``None`` if token could not be verified.\n \"\"\"\n settings = request.registry.settings\n hmac_secret = settings['userid_hmac_secret']\n\n authorization = request.headers.get('Authorization', '')\n try:\n authmeth, access_token = authorization.split(' ', 1)\n except ValueError:\n return None\n\n if authmeth.lower() != self.header_type.lower():\n return None\n\n # XXX JWT Access token\n # https://auth0.com/docs/tokens/access-token#access-token-format\n\n # Check cache if these tokens were already verified.\n hmac_tokens = core_utils.hmac_digest(hmac_secret, access_token)\n cache_key = 'openid:verify:{}'.format(hmac_tokens)\n payload = request.registry.cache.get(cache_key)\n if payload is None:\n # This can take some time.\n payload = self._verify_token(access_token)\n if payload is None:\n return None\n # Save for next time / refresh ttl.\n request.registry.cache.set(cache_key, payload, ttl=self.verification_ttl)\n # Extract meaningful field from userinfo (eg. email or sub)\n return payload.get(self.userid_field)\n\n def forget(self, request):\n \"\"\"A no-op. Credentials are sent on every request.\n Return WWW-Authenticate Realm header for Bearer token.\n \"\"\"\n return [('WWW-Authenticate', '%s realm=\"%s\"' % (self.header_type, self.realm))]\n\n def _verify_token(self, access_token):\n uri = self.oid_config['userinfo_endpoint']\n # Opaque access token string. Fetch user info from profile.\n try:\n resp = requests.get(uri, headers={'Authorization': 'Bearer ' + access_token})\n resp.raise_for_status()\n userprofile = resp.json()\n return userprofile\n\n except (requests.exceptions.HTTPError, ValueError, KeyError) as e:\n logger.debug('Unable to fetch user profile from %s (%s)' % (uri, e))\n return None\n\n\ndef includeme(config):\n # Activate end-points.\n config.scan('kinto.plugins.openid.views')\n\n settings = config.get_settings()\n\n openid_policies = []\n for k, v in settings.items():\n m = re.match('multiauth\\.policy\\.(.*)\\.use', k)\n if m:\n if v.endswith('OpenIDConnectPolicy'):\n openid_policies.append(m.group(1))\n\n if len(openid_policies) == 0:\n # Do not add the capability if no policy is configured.\n return\n\n providers_infos = []\n for name in openid_policies:\n issuer = settings['multiauth.policy.%s.issuer' % name]\n openid_config = fetch_openid_config(issuer)\n\n client_id = settings['multiauth.policy.%s.client_id' % name]\n header_type = settings.get('multiauth.policy.%s.header_type', 'Bearer')\n\n providers_infos.append({\n 'name': name,\n 'issuer': openid_config['issuer'],\n 'auth_path': '/openid/%s/login' % name,\n 'client_id': client_id,\n 'header_type': header_type,\n 'userinfo_endpoint': openid_config['userinfo_endpoint'],\n })\n\n OpenAPI.expose_authentication_method(name, {\n 'type': 'oauth2',\n 'authorizationUrl': openid_config['authorization_endpoint'],\n })\n\n config.add_api_capability(\n 'openid',\n description='OpenID connect support.',\n url='http://kinto.readthedocs.io/en/stable/api/1.x/authentication.html',\n providers=providers_infos)\n", "path": "kinto/plugins/openid/__init__.py"}]}
| 2,056 | 260 |
gh_patches_debug_24461
|
rasdani/github-patches
|
git_diff
|
pytorch__TensorRT-2375
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
🐛 [Bug] Issue in `ConstantFolder` where certain operators no longer exist in latest nightly
## Bug Description
[See here](https://github.com/pytorch/pytorch/blob/4b881b0da390c1290bb12850ef9daad6f6eb2cb6/torch/_inductor/constant_folding.py#L53-L63)
## To Reproduce
See recent PR
## Expected behavior
These tests should not fail.
## Environment
> Build information about Torch-TensorRT can be found by turning on debug messages
- Torch-TensorRT Version (e.g. 1.0.0): https://github.com/pytorch/TensorRT/commit/0ef47c78ce94f610ee2a3a5a62e6fb450d4a8b34
- PyTorch Version (e.g. 1.0): `2.2.0.dev20231009+cu121`
</issue>
<code>
[start of py/torch_tensorrt/dynamo/lowering/passes/constant_folding.py]
1 import logging
2 from typing import Sequence
3
4 import torch
5 from torch_tensorrt._utils import sanitized_torch_version
6 from torch_tensorrt.dynamo.lowering.passes.pass_utils import (
7 clean_up_graph_after_modifications,
8 )
9
10 from packaging import version
11
12 # Modify import location of utilities based on Torch version
13 if version.parse(sanitized_torch_version()) < version.parse("2.1.1"):
14 from torch._inductor.freezing import ConstantFolder, replace_node_with_constant
15 else:
16 from torch._inductor.constant_folding import (
17 ConstantFolder,
18 replace_node_with_constant,
19 )
20
21 logger = logging.getLogger(__name__)
22
23
24 @torch.utils._python_dispatch._disable_current_modes() # type: ignore
25 def constant_fold(
26 gm: torch.fx.GraphModule, sample_inputs: Sequence[torch.Tensor]
27 ) -> torch.fx.GraphModule:
28 """Adapted from:
29 https://github.com/pytorch/pytorch/blob/3a79621c9dce17f77fbddc06aab21f6bc477f313/torch/_inductor/freezing.py#L178-L197
30
31 Folds constants in the graph module, not skipping constructors
32
33 Modifies the graph in-place and replaces node with constants
34 """
35 cf = ConstantFolder(gm, skip_constructors=False)
36 cf.run()
37
38 for node, constant in cf.node_replacements.items():
39 replace_node_with_constant(gm, node, constant)
40
41 erased_params = []
42 for node in gm.graph.nodes:
43 # If get_attr node has no users, mark it for deletion
44 if node.op == "get_attr" and len(node.users) == 0:
45 # If the node's parameter is not a parameter of any other node, remove it
46 if not any(
47 other.target == node.target for other in gm.graph.nodes if other != node
48 ):
49 delattr(gm, node.target)
50 erased_params.append(node)
51
52 # Remove unused nodes from the graph
53 for node in erased_params:
54 gm.graph.erase_node(node)
55
56 gm = clean_up_graph_after_modifications(gm)
57
58 logger.debug(f"Graph after constant folding:\n{gm.graph}")
59
60 return gm
61
[end of py/torch_tensorrt/dynamo/lowering/passes/constant_folding.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/py/torch_tensorrt/dynamo/lowering/passes/constant_folding.py b/py/torch_tensorrt/dynamo/lowering/passes/constant_folding.py
--- a/py/torch_tensorrt/dynamo/lowering/passes/constant_folding.py
+++ b/py/torch_tensorrt/dynamo/lowering/passes/constant_folding.py
@@ -1,5 +1,5 @@
import logging
-from typing import Sequence
+from typing import Any, Sequence
import torch
from torch_tensorrt._utils import sanitized_torch_version
@@ -32,7 +32,7 @@
Modifies the graph in-place and replaces node with constants
"""
- cf = ConstantFolder(gm, skip_constructors=False)
+ cf = _TorchTensorRTConstantFolder(gm, skip_constructors=False)
cf.run()
for node, constant in cf.node_replacements.items():
@@ -58,3 +58,14 @@
logger.debug(f"Graph after constant folding:\n{gm.graph}")
return gm
+
+
+# TODO: Delete this class when the following code is fixed in nightly:
+# https://github.com/pytorch/pytorch/blob/4b881b0da390c1290bb12850ef9daad6f6eb2cb6/torch/_inductor/constant_folding.py#L53-L63
+class _TorchTensorRTConstantFolder(ConstantFolder): # type: ignore[misc]
+ def __init__(self, *args: Any, **kwargs: Any) -> None:
+ super().__init__(*args, **kwargs)
+
+ # TODO: Update this function when quantization is added
+ def is_impure(self, node: torch.fx.node.Node) -> bool:
+ return False
|
{"golden_diff": "diff --git a/py/torch_tensorrt/dynamo/lowering/passes/constant_folding.py b/py/torch_tensorrt/dynamo/lowering/passes/constant_folding.py\n--- a/py/torch_tensorrt/dynamo/lowering/passes/constant_folding.py\n+++ b/py/torch_tensorrt/dynamo/lowering/passes/constant_folding.py\n@@ -1,5 +1,5 @@\n import logging\n-from typing import Sequence\n+from typing import Any, Sequence\n \n import torch\n from torch_tensorrt._utils import sanitized_torch_version\n@@ -32,7 +32,7 @@\n \n Modifies the graph in-place and replaces node with constants\n \"\"\"\n- cf = ConstantFolder(gm, skip_constructors=False)\n+ cf = _TorchTensorRTConstantFolder(gm, skip_constructors=False)\n cf.run()\n \n for node, constant in cf.node_replacements.items():\n@@ -58,3 +58,14 @@\n logger.debug(f\"Graph after constant folding:\\n{gm.graph}\")\n \n return gm\n+\n+\n+# TODO: Delete this class when the following code is fixed in nightly:\n+# https://github.com/pytorch/pytorch/blob/4b881b0da390c1290bb12850ef9daad6f6eb2cb6/torch/_inductor/constant_folding.py#L53-L63\n+class _TorchTensorRTConstantFolder(ConstantFolder): # type: ignore[misc]\n+ def __init__(self, *args: Any, **kwargs: Any) -> None:\n+ super().__init__(*args, **kwargs)\n+\n+ # TODO: Update this function when quantization is added\n+ def is_impure(self, node: torch.fx.node.Node) -> bool:\n+ return False\n", "issue": "\ud83d\udc1b [Bug] Issue in `ConstantFolder` where certain operators no longer exist in latest nightly\n## Bug Description\r\n\r\n[See here](https://github.com/pytorch/pytorch/blob/4b881b0da390c1290bb12850ef9daad6f6eb2cb6/torch/_inductor/constant_folding.py#L53-L63)\r\n\r\n## To Reproduce\r\n\r\nSee recent PR \r\n\r\n## Expected behavior\r\n\r\nThese tests should not fail.\r\n\r\n## Environment\r\n\r\n> Build information about Torch-TensorRT can be found by turning on debug messages\r\n\r\n - Torch-TensorRT Version (e.g. 1.0.0): https://github.com/pytorch/TensorRT/commit/0ef47c78ce94f610ee2a3a5a62e6fb450d4a8b34\r\n - PyTorch Version (e.g. 1.0): `2.2.0.dev20231009+cu121`\r\n\n", "before_files": [{"content": "import logging\nfrom typing import Sequence\n\nimport torch\nfrom torch_tensorrt._utils import sanitized_torch_version\nfrom torch_tensorrt.dynamo.lowering.passes.pass_utils import (\n clean_up_graph_after_modifications,\n)\n\nfrom packaging import version\n\n# Modify import location of utilities based on Torch version\nif version.parse(sanitized_torch_version()) < version.parse(\"2.1.1\"):\n from torch._inductor.freezing import ConstantFolder, replace_node_with_constant\nelse:\n from torch._inductor.constant_folding import (\n ConstantFolder,\n replace_node_with_constant,\n )\n\nlogger = logging.getLogger(__name__)\n\n\[email protected]._python_dispatch._disable_current_modes() # type: ignore\ndef constant_fold(\n gm: torch.fx.GraphModule, sample_inputs: Sequence[torch.Tensor]\n) -> torch.fx.GraphModule:\n \"\"\"Adapted from:\n https://github.com/pytorch/pytorch/blob/3a79621c9dce17f77fbddc06aab21f6bc477f313/torch/_inductor/freezing.py#L178-L197\n\n Folds constants in the graph module, not skipping constructors\n\n Modifies the graph in-place and replaces node with constants\n \"\"\"\n cf = ConstantFolder(gm, skip_constructors=False)\n cf.run()\n\n for node, constant in cf.node_replacements.items():\n replace_node_with_constant(gm, node, constant)\n\n erased_params = []\n for node in gm.graph.nodes:\n # If get_attr node has no users, mark it for deletion\n if node.op == \"get_attr\" and len(node.users) == 0:\n # If the node's parameter is not a parameter of any other node, remove it\n if not any(\n other.target == node.target for other in gm.graph.nodes if other != node\n ):\n delattr(gm, node.target)\n erased_params.append(node)\n\n # Remove unused nodes from the graph\n for node in erased_params:\n gm.graph.erase_node(node)\n\n gm = clean_up_graph_after_modifications(gm)\n\n logger.debug(f\"Graph after constant folding:\\n{gm.graph}\")\n\n return gm\n", "path": "py/torch_tensorrt/dynamo/lowering/passes/constant_folding.py"}]}
| 1,388 | 397 |
gh_patches_debug_26365
|
rasdani/github-patches
|
git_diff
|
cisagov__manage.get.gov-1396
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Update error message on check availability section in the request form
### Issue description
To keep language consistent, we should update the error message in the check availability section in the request form from:
This
> That domain isn't available. Try entering another one. Contact us if you need help coming up with a domain.
To this
> That domain isn’t available. [Read more about choosing your .gov domain.](https://beta.get.gov/domains/choosing/)
Note that the hyperlink in the new message should open in a new tab so as to not take the user our of the request flow
### Acceptance criteria
- [ ] error message is updated
- [ ] link opens in new tab
### Additional context
_No response_
### Links to other issues
_No response_
</issue>
<code>
[start of src/api/views.py]
1 """Internal API views"""
2 from django.apps import apps
3 from django.views.decorators.http import require_http_methods
4 from django.http import JsonResponse
5
6 import requests
7
8 from login_required import login_not_required
9
10 from cachetools.func import ttl_cache
11
12
13 DOMAIN_FILE_URL = "https://raw.githubusercontent.com/cisagov/dotgov-data/main/current-full.csv"
14
15
16 DOMAIN_API_MESSAGES = {
17 "required": "Enter the .gov domain you want. Don’t include “www” or “.gov.”"
18 " For example, if you want www.city.gov, you would enter “city”"
19 " (without the quotes).",
20 "extra_dots": "Enter the .gov domain you want without any periods.",
21 "unavailable": "That domain isn’t available. Try entering another one."
22 " Contact us if you need help coming up with a domain.",
23 "invalid": "Enter a domain using only letters, numbers, or hyphens (though we don't recommend using hyphens).",
24 "success": "That domain is available!",
25 "error": "Error finding domain availability.",
26 }
27
28
29 # this file doesn't change that often, nor is it that big, so cache the result
30 # in memory for ten minutes
31 @ttl_cache(ttl=600)
32 def _domains():
33 """Return a list of the current .gov domains.
34
35 Fetch a file from DOMAIN_FILE_URL, parse the CSV for the domain,
36 lowercase everything and return the list.
37 """
38 DraftDomain = apps.get_model("registrar.DraftDomain")
39 # 5 second timeout
40 file_contents = requests.get(DOMAIN_FILE_URL, timeout=5).text
41 domains = set()
42 # skip the first line
43 for line in file_contents.splitlines()[1:]:
44 # get the domain before the first comma
45 domain = line.split(",", 1)[0]
46 # sanity-check the string we got from the file here
47 if DraftDomain.string_could_be_domain(domain):
48 # lowercase everything when we put it in domains
49 domains.add(domain.lower())
50 return domains
51
52
53 def check_domain_available(domain):
54 """Return true if the given domain is available.
55
56 The given domain is lowercased to match against the domains list. If the
57 given domain doesn't end with .gov, ".gov" is added when looking for
58 a match.
59 """
60 Domain = apps.get_model("registrar.Domain")
61 try:
62 if domain.endswith(".gov"):
63 return Domain.available(domain)
64 else:
65 # domain search string doesn't end with .gov, add it on here
66 return Domain.available(domain + ".gov")
67 except Exception:
68 return False
69
70
71 @require_http_methods(["GET"])
72 @login_not_required
73 def available(request, domain=""):
74 """Is a given domain available or not.
75
76 Response is a JSON dictionary with the key "available" and value true or
77 false.
78 """
79 DraftDomain = apps.get_model("registrar.DraftDomain")
80 # validate that the given domain could be a domain name and fail early if
81 # not.
82 if not (DraftDomain.string_could_be_domain(domain) or DraftDomain.string_could_be_domain(domain + ".gov")):
83 return JsonResponse({"available": False, "message": DOMAIN_API_MESSAGES["invalid"]})
84 # a domain is available if it is NOT in the list of current domains
85 try:
86 if check_domain_available(domain):
87 return JsonResponse({"available": True, "message": DOMAIN_API_MESSAGES["success"]})
88 else:
89 return JsonResponse({"available": False, "message": DOMAIN_API_MESSAGES["unavailable"]})
90 except Exception:
91 return JsonResponse({"available": False, "message": DOMAIN_API_MESSAGES["error"]})
92
[end of src/api/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/api/views.py b/src/api/views.py
--- a/src/api/views.py
+++ b/src/api/views.py
@@ -2,6 +2,9 @@
from django.apps import apps
from django.views.decorators.http import require_http_methods
from django.http import JsonResponse
+from django.utils.safestring import mark_safe
+
+from registrar.templatetags.url_helpers import public_site_url
import requests
@@ -18,8 +21,13 @@
" For example, if you want www.city.gov, you would enter “city”"
" (without the quotes).",
"extra_dots": "Enter the .gov domain you want without any periods.",
- "unavailable": "That domain isn’t available. Try entering another one."
- " Contact us if you need help coming up with a domain.",
+ # message below is considered safe; no user input can be inserted into the message
+ # body; public_site_url() function reads from local app settings and therefore safe
+ "unavailable": mark_safe( # nosec
+ "That domain isn’t available. "
+ "<a class='usa-link' href='{}' target='_blank'>"
+ "Read more about choosing your .gov domain.</a>".format(public_site_url("domains/choosing"))
+ ),
"invalid": "Enter a domain using only letters, numbers, or hyphens (though we don't recommend using hyphens).",
"success": "That domain is available!",
"error": "Error finding domain availability.",
|
{"golden_diff": "diff --git a/src/api/views.py b/src/api/views.py\n--- a/src/api/views.py\n+++ b/src/api/views.py\n@@ -2,6 +2,9 @@\n from django.apps import apps\n from django.views.decorators.http import require_http_methods\n from django.http import JsonResponse\n+from django.utils.safestring import mark_safe\n+\n+from registrar.templatetags.url_helpers import public_site_url\n \n import requests\n \n@@ -18,8 +21,13 @@\n \" For example, if you want www.city.gov, you would enter \u201ccity\u201d\"\n \" (without the quotes).\",\n \"extra_dots\": \"Enter the .gov domain you want without any periods.\",\n- \"unavailable\": \"That domain isn\u2019t available. Try entering another one.\"\n- \" Contact us if you need help coming up with a domain.\",\n+ # message below is considered safe; no user input can be inserted into the message\n+ # body; public_site_url() function reads from local app settings and therefore safe\n+ \"unavailable\": mark_safe( # nosec\n+ \"That domain isn\u2019t available. \"\n+ \"<a class='usa-link' href='{}' target='_blank'>\"\n+ \"Read more about choosing your .gov domain.</a>\".format(public_site_url(\"domains/choosing\"))\n+ ),\n \"invalid\": \"Enter a domain using only letters, numbers, or hyphens (though we don't recommend using hyphens).\",\n \"success\": \"That domain is available!\",\n \"error\": \"Error finding domain availability.\",\n", "issue": "Update error message on check availability section in the request form\n### Issue description\n\nTo keep language consistent, we should update the error message in the check availability section in the request form from:\r\n\r\nThis\r\n\r\n> That domain isn't available. Try entering another one. Contact us if you need help coming up with a domain. \r\n\r\n\r\nTo this\r\n\r\n> That domain isn\u2019t available. [Read more about choosing your .gov domain.](https://beta.get.gov/domains/choosing/) \r\n\r\n\r\nNote that the hyperlink in the new message should open in a new tab so as to not take the user our of the request flow\n\n### Acceptance criteria\n\n- [ ] error message is updated\r\n- [ ] link opens in new tab\n\n### Additional context\n\n_No response_\n\n### Links to other issues\n\n_No response_\n", "before_files": [{"content": "\"\"\"Internal API views\"\"\"\nfrom django.apps import apps\nfrom django.views.decorators.http import require_http_methods\nfrom django.http import JsonResponse\n\nimport requests\n\nfrom login_required import login_not_required\n\nfrom cachetools.func import ttl_cache\n\n\nDOMAIN_FILE_URL = \"https://raw.githubusercontent.com/cisagov/dotgov-data/main/current-full.csv\"\n\n\nDOMAIN_API_MESSAGES = {\n \"required\": \"Enter the .gov domain you want. Don\u2019t include \u201cwww\u201d or \u201c.gov.\u201d\"\n \" For example, if you want www.city.gov, you would enter \u201ccity\u201d\"\n \" (without the quotes).\",\n \"extra_dots\": \"Enter the .gov domain you want without any periods.\",\n \"unavailable\": \"That domain isn\u2019t available. Try entering another one.\"\n \" Contact us if you need help coming up with a domain.\",\n \"invalid\": \"Enter a domain using only letters, numbers, or hyphens (though we don't recommend using hyphens).\",\n \"success\": \"That domain is available!\",\n \"error\": \"Error finding domain availability.\",\n}\n\n\n# this file doesn't change that often, nor is it that big, so cache the result\n# in memory for ten minutes\n@ttl_cache(ttl=600)\ndef _domains():\n \"\"\"Return a list of the current .gov domains.\n\n Fetch a file from DOMAIN_FILE_URL, parse the CSV for the domain,\n lowercase everything and return the list.\n \"\"\"\n DraftDomain = apps.get_model(\"registrar.DraftDomain\")\n # 5 second timeout\n file_contents = requests.get(DOMAIN_FILE_URL, timeout=5).text\n domains = set()\n # skip the first line\n for line in file_contents.splitlines()[1:]:\n # get the domain before the first comma\n domain = line.split(\",\", 1)[0]\n # sanity-check the string we got from the file here\n if DraftDomain.string_could_be_domain(domain):\n # lowercase everything when we put it in domains\n domains.add(domain.lower())\n return domains\n\n\ndef check_domain_available(domain):\n \"\"\"Return true if the given domain is available.\n\n The given domain is lowercased to match against the domains list. If the\n given domain doesn't end with .gov, \".gov\" is added when looking for\n a match.\n \"\"\"\n Domain = apps.get_model(\"registrar.Domain\")\n try:\n if domain.endswith(\".gov\"):\n return Domain.available(domain)\n else:\n # domain search string doesn't end with .gov, add it on here\n return Domain.available(domain + \".gov\")\n except Exception:\n return False\n\n\n@require_http_methods([\"GET\"])\n@login_not_required\ndef available(request, domain=\"\"):\n \"\"\"Is a given domain available or not.\n\n Response is a JSON dictionary with the key \"available\" and value true or\n false.\n \"\"\"\n DraftDomain = apps.get_model(\"registrar.DraftDomain\")\n # validate that the given domain could be a domain name and fail early if\n # not.\n if not (DraftDomain.string_could_be_domain(domain) or DraftDomain.string_could_be_domain(domain + \".gov\")):\n return JsonResponse({\"available\": False, \"message\": DOMAIN_API_MESSAGES[\"invalid\"]})\n # a domain is available if it is NOT in the list of current domains\n try:\n if check_domain_available(domain):\n return JsonResponse({\"available\": True, \"message\": DOMAIN_API_MESSAGES[\"success\"]})\n else:\n return JsonResponse({\"available\": False, \"message\": DOMAIN_API_MESSAGES[\"unavailable\"]})\n except Exception:\n return JsonResponse({\"available\": False, \"message\": DOMAIN_API_MESSAGES[\"error\"]})\n", "path": "src/api/views.py"}]}
| 1,666 | 338 |
gh_patches_debug_1550
|
rasdani/github-patches
|
git_diff
|
pyca__cryptography-3711
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Empty subject or issuer in x.509 certificates throws Unknown OpenSSL error.
When trying to build a x509 certificate with an empty string as issuer or subject name, an unknown OpenSSL error is thrown. Maybe that should be handled differently.
**Tested on:**
```
Ubuntu 16.04.2 LTS
OpenSSL 1.0.2g 1 Mar 2016
cryptography 1.9
```
```
macOS Sierra 10.12.5
OpenSSL 0.9.8zh 14 Jan 2016
cryptography 1.9
```
**To reproduce:**
```
$ python openssl_error.py
```
```
Traceback (most recent call last):
File "openssl_error.py", line 19, in <module>
cert = builder.sign(private_key, hashes.SHA256(), default_backend())
File "/home/ubuntu/.local/lib/python2.7/site-packages/cryptography/x509/base.py", line 564, in sign
return backend.create_x509_certificate(self, private_key, algorithm)
File "/home/ubuntu/.local/lib/python2.7/site-packages/cryptography/hazmat/backends/openssl/backend.py", line 746, in create_x509_certificate
x509_cert, _encode_name_gc(self, builder._subject_name)
File "/home/ubuntu/.local/lib/python2.7/site-packages/cryptography/hazmat/backends/openssl/encode_asn1.py", line 103, in _encode_name_gc
subject = _encode_name(backend, attributes)
File "/home/ubuntu/.local/lib/python2.7/site-packages/cryptography/hazmat/backends/openssl/encode_asn1.py", line 97, in _encode_name
backend.openssl_assert(res == 1)
File "/home/ubuntu/.local/lib/python2.7/site-packages/cryptography/hazmat/backends/openssl/backend.py", line 107, in openssl_assert
return binding._openssl_assert(self._lib, ok)
File "/home/ubuntu/.local/lib/python2.7/site-packages/cryptography/hazmat/bindings/openssl/binding.py", line 75, in _openssl_assert
errors_with_text
cryptography.exceptions.InternalError: Unknown OpenSSL error. This error is commonly encountered when another library is not cleaning up the OpenSSL error stack. If you are using cryptography with another library that uses OpenSSL try disabling it before reporting a bug. Otherwise please file an issue at https://github.com/pyca/cryptography/issues with information on how to reproduce this. ([_OpenSSLErrorWithText(code=218603672L, lib=13, func=122, reason=152, reason_text='error:0D07A098:asn1 encoding routines:ASN1_mbstring_ncopy:string too short')])
```
**openssl_error.py**
```
import six
import datetime
from cryptography import x509
from cryptography.hazmat.backends import default_backend
from cryptography.hazmat.primitives.asymmetric import rsa
from cryptography.hazmat.primitives import hashes
builder = x509.CertificateBuilder()
builder = builder.serial_number(x509.random_serial_number())
builder = builder.not_valid_before(datetime.datetime.today())
builder = builder.not_valid_after(datetime.datetime.today())
# Empty strings here seems to make it crash.
builder = builder.subject_name(x509.Name([x509.NameAttribute(x509.oid.NameOID.COMMON_NAME, six.u('')), ]))
builder = builder.issuer_name(x509.Name([x509.NameAttribute(x509.oid.NameOID.COMMON_NAME, six.u('')), ]))
private_key = rsa.generate_private_key(65537, 2048, default_backend())
builder = builder.public_key(private_key.public_key())
cert = builder.sign(private_key, hashes.SHA256(), default_backend())
```
</issue>
<code>
[start of src/cryptography/x509/name.py]
1 # This file is dual licensed under the terms of the Apache License, Version
2 # 2.0, and the BSD License. See the LICENSE file in the root of this repository
3 # for complete details.
4
5 from __future__ import absolute_import, division, print_function
6
7 import six
8
9 from cryptography import utils
10 from cryptography.x509.oid import NameOID, ObjectIdentifier
11
12
13 class NameAttribute(object):
14 def __init__(self, oid, value):
15 if not isinstance(oid, ObjectIdentifier):
16 raise TypeError(
17 "oid argument must be an ObjectIdentifier instance."
18 )
19
20 if not isinstance(value, six.text_type):
21 raise TypeError(
22 "value argument must be a text type."
23 )
24
25 if oid == NameOID.COUNTRY_NAME and len(value.encode("utf8")) != 2:
26 raise ValueError(
27 "Country name must be a 2 character country code"
28 )
29
30 self._oid = oid
31 self._value = value
32
33 oid = utils.read_only_property("_oid")
34 value = utils.read_only_property("_value")
35
36 def __eq__(self, other):
37 if not isinstance(other, NameAttribute):
38 return NotImplemented
39
40 return (
41 self.oid == other.oid and
42 self.value == other.value
43 )
44
45 def __ne__(self, other):
46 return not self == other
47
48 def __hash__(self):
49 return hash((self.oid, self.value))
50
51 def __repr__(self):
52 return "<NameAttribute(oid={0.oid}, value={0.value!r})>".format(self)
53
54
55 class RelativeDistinguishedName(object):
56 def __init__(self, attributes):
57 attributes = frozenset(attributes)
58 if not attributes:
59 raise ValueError("a relative distinguished name cannot be empty")
60 if not all(isinstance(x, NameAttribute) for x in attributes):
61 raise TypeError("attributes must be an iterable of NameAttribute")
62
63 self._attributes = attributes
64
65 def get_attributes_for_oid(self, oid):
66 return [i for i in self if i.oid == oid]
67
68 def __eq__(self, other):
69 if not isinstance(other, RelativeDistinguishedName):
70 return NotImplemented
71
72 return self._attributes == other._attributes
73
74 def __ne__(self, other):
75 return not self == other
76
77 def __hash__(self):
78 return hash(self._attributes)
79
80 def __iter__(self):
81 return iter(self._attributes)
82
83 def __len__(self):
84 return len(self._attributes)
85
86 def __repr__(self):
87 return "<RelativeDistinguishedName({0!r})>".format(list(self))
88
89
90 class Name(object):
91 def __init__(self, attributes):
92 attributes = list(attributes)
93 if all(isinstance(x, NameAttribute) for x in attributes):
94 self._attributes = [
95 RelativeDistinguishedName([x]) for x in attributes
96 ]
97 elif all(isinstance(x, RelativeDistinguishedName) for x in attributes):
98 self._attributes = attributes
99 else:
100 raise TypeError(
101 "attributes must be a list of NameAttribute"
102 " or a list RelativeDistinguishedName"
103 )
104
105 def get_attributes_for_oid(self, oid):
106 return [i for i in self if i.oid == oid]
107
108 @property
109 def rdns(self):
110 return self._attributes
111
112 def public_bytes(self, backend):
113 return backend.x509_name_bytes(self)
114
115 def __eq__(self, other):
116 if not isinstance(other, Name):
117 return NotImplemented
118
119 return self._attributes == other._attributes
120
121 def __ne__(self, other):
122 return not self == other
123
124 def __hash__(self):
125 # TODO: this is relatively expensive, if this looks like a bottleneck
126 # for you, consider optimizing!
127 return hash(tuple(self._attributes))
128
129 def __iter__(self):
130 for rdn in self._attributes:
131 for ava in rdn:
132 yield ava
133
134 def __len__(self):
135 return sum(len(rdn) for rdn in self._attributes)
136
137 def __repr__(self):
138 return "<Name({0!r})>".format(list(self))
139
[end of src/cryptography/x509/name.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/cryptography/x509/name.py b/src/cryptography/x509/name.py
--- a/src/cryptography/x509/name.py
+++ b/src/cryptography/x509/name.py
@@ -27,6 +27,9 @@
"Country name must be a 2 character country code"
)
+ if len(value) == 0:
+ raise ValueError("Value cannot be an empty string")
+
self._oid = oid
self._value = value
|
{"golden_diff": "diff --git a/src/cryptography/x509/name.py b/src/cryptography/x509/name.py\n--- a/src/cryptography/x509/name.py\n+++ b/src/cryptography/x509/name.py\n@@ -27,6 +27,9 @@\n \"Country name must be a 2 character country code\"\n )\n \n+ if len(value) == 0:\n+ raise ValueError(\"Value cannot be an empty string\")\n+\n self._oid = oid\n self._value = value\n", "issue": "Empty subject or issuer in x.509 certificates throws Unknown OpenSSL error.\nWhen trying to build a x509 certificate with an empty string as issuer or subject name, an unknown OpenSSL error is thrown. Maybe that should be handled differently.\r\n\r\n**Tested on:**\r\n```\r\nUbuntu 16.04.2 LTS\r\nOpenSSL 1.0.2g 1 Mar 2016\r\ncryptography 1.9\r\n```\r\n```\r\nmacOS Sierra 10.12.5\r\nOpenSSL 0.9.8zh 14 Jan 2016\r\ncryptography 1.9\r\n```\r\n**To reproduce:**\r\n```\r\n$ python openssl_error.py\r\n```\r\n```\r\nTraceback (most recent call last):\r\n File \"openssl_error.py\", line 19, in <module>\r\n cert = builder.sign(private_key, hashes.SHA256(), default_backend())\r\n File \"/home/ubuntu/.local/lib/python2.7/site-packages/cryptography/x509/base.py\", line 564, in sign\r\n return backend.create_x509_certificate(self, private_key, algorithm)\r\n File \"/home/ubuntu/.local/lib/python2.7/site-packages/cryptography/hazmat/backends/openssl/backend.py\", line 746, in create_x509_certificate\r\n x509_cert, _encode_name_gc(self, builder._subject_name)\r\n File \"/home/ubuntu/.local/lib/python2.7/site-packages/cryptography/hazmat/backends/openssl/encode_asn1.py\", line 103, in _encode_name_gc\r\n subject = _encode_name(backend, attributes)\r\n File \"/home/ubuntu/.local/lib/python2.7/site-packages/cryptography/hazmat/backends/openssl/encode_asn1.py\", line 97, in _encode_name\r\n backend.openssl_assert(res == 1)\r\n File \"/home/ubuntu/.local/lib/python2.7/site-packages/cryptography/hazmat/backends/openssl/backend.py\", line 107, in openssl_assert\r\n return binding._openssl_assert(self._lib, ok)\r\n File \"/home/ubuntu/.local/lib/python2.7/site-packages/cryptography/hazmat/bindings/openssl/binding.py\", line 75, in _openssl_assert\r\n errors_with_text\r\ncryptography.exceptions.InternalError: Unknown OpenSSL error. This error is commonly encountered when another library is not cleaning up the OpenSSL error stack. If you are using cryptography with another library that uses OpenSSL try disabling it before reporting a bug. Otherwise please file an issue at https://github.com/pyca/cryptography/issues with information on how to reproduce this. ([_OpenSSLErrorWithText(code=218603672L, lib=13, func=122, reason=152, reason_text='error:0D07A098:asn1 encoding routines:ASN1_mbstring_ncopy:string too short')])\r\n```\r\n\r\n**openssl_error.py**\r\n```\r\nimport six\r\nimport datetime\r\nfrom cryptography import x509\r\nfrom cryptography.hazmat.backends import default_backend\r\nfrom cryptography.hazmat.primitives.asymmetric import rsa\r\nfrom cryptography.hazmat.primitives import hashes\r\n\r\nbuilder = x509.CertificateBuilder()\r\nbuilder = builder.serial_number(x509.random_serial_number())\r\nbuilder = builder.not_valid_before(datetime.datetime.today())\r\nbuilder = builder.not_valid_after(datetime.datetime.today())\r\n\r\n# Empty strings here seems to make it crash.\r\nbuilder = builder.subject_name(x509.Name([x509.NameAttribute(x509.oid.NameOID.COMMON_NAME, six.u('')), ]))\r\nbuilder = builder.issuer_name(x509.Name([x509.NameAttribute(x509.oid.NameOID.COMMON_NAME, six.u('')), ]))\r\n\r\nprivate_key = rsa.generate_private_key(65537, 2048, default_backend())\r\nbuilder = builder.public_key(private_key.public_key())\r\ncert = builder.sign(private_key, hashes.SHA256(), default_backend())\r\n```\n", "before_files": [{"content": "# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\nfrom __future__ import absolute_import, division, print_function\n\nimport six\n\nfrom cryptography import utils\nfrom cryptography.x509.oid import NameOID, ObjectIdentifier\n\n\nclass NameAttribute(object):\n def __init__(self, oid, value):\n if not isinstance(oid, ObjectIdentifier):\n raise TypeError(\n \"oid argument must be an ObjectIdentifier instance.\"\n )\n\n if not isinstance(value, six.text_type):\n raise TypeError(\n \"value argument must be a text type.\"\n )\n\n if oid == NameOID.COUNTRY_NAME and len(value.encode(\"utf8\")) != 2:\n raise ValueError(\n \"Country name must be a 2 character country code\"\n )\n\n self._oid = oid\n self._value = value\n\n oid = utils.read_only_property(\"_oid\")\n value = utils.read_only_property(\"_value\")\n\n def __eq__(self, other):\n if not isinstance(other, NameAttribute):\n return NotImplemented\n\n return (\n self.oid == other.oid and\n self.value == other.value\n )\n\n def __ne__(self, other):\n return not self == other\n\n def __hash__(self):\n return hash((self.oid, self.value))\n\n def __repr__(self):\n return \"<NameAttribute(oid={0.oid}, value={0.value!r})>\".format(self)\n\n\nclass RelativeDistinguishedName(object):\n def __init__(self, attributes):\n attributes = frozenset(attributes)\n if not attributes:\n raise ValueError(\"a relative distinguished name cannot be empty\")\n if not all(isinstance(x, NameAttribute) for x in attributes):\n raise TypeError(\"attributes must be an iterable of NameAttribute\")\n\n self._attributes = attributes\n\n def get_attributes_for_oid(self, oid):\n return [i for i in self if i.oid == oid]\n\n def __eq__(self, other):\n if not isinstance(other, RelativeDistinguishedName):\n return NotImplemented\n\n return self._attributes == other._attributes\n\n def __ne__(self, other):\n return not self == other\n\n def __hash__(self):\n return hash(self._attributes)\n\n def __iter__(self):\n return iter(self._attributes)\n\n def __len__(self):\n return len(self._attributes)\n\n def __repr__(self):\n return \"<RelativeDistinguishedName({0!r})>\".format(list(self))\n\n\nclass Name(object):\n def __init__(self, attributes):\n attributes = list(attributes)\n if all(isinstance(x, NameAttribute) for x in attributes):\n self._attributes = [\n RelativeDistinguishedName([x]) for x in attributes\n ]\n elif all(isinstance(x, RelativeDistinguishedName) for x in attributes):\n self._attributes = attributes\n else:\n raise TypeError(\n \"attributes must be a list of NameAttribute\"\n \" or a list RelativeDistinguishedName\"\n )\n\n def get_attributes_for_oid(self, oid):\n return [i for i in self if i.oid == oid]\n\n @property\n def rdns(self):\n return self._attributes\n\n def public_bytes(self, backend):\n return backend.x509_name_bytes(self)\n\n def __eq__(self, other):\n if not isinstance(other, Name):\n return NotImplemented\n\n return self._attributes == other._attributes\n\n def __ne__(self, other):\n return not self == other\n\n def __hash__(self):\n # TODO: this is relatively expensive, if this looks like a bottleneck\n # for you, consider optimizing!\n return hash(tuple(self._attributes))\n\n def __iter__(self):\n for rdn in self._attributes:\n for ava in rdn:\n yield ava\n\n def __len__(self):\n return sum(len(rdn) for rdn in self._attributes)\n\n def __repr__(self):\n return \"<Name({0!r})>\".format(list(self))\n", "path": "src/cryptography/x509/name.py"}]}
| 2,623 | 113 |
gh_patches_debug_34044
|
rasdani/github-patches
|
git_diff
|
TileDB-Inc__TileDB-Py-246
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
likely race condition in DenseArray.__new__
Test program below exposes (what I believe is a) race in class handling in DenseArray. The test program is completely artificial - it just spins up 5 threads, each of which open an S3 object and ask its shape. Without a sleep to sequence their execution, it fails inside the DenseArray.__new__ method.
Run with the sleep statement in worker(), I see:
```
python cctest.py
starting... 0
starting... 1
working... 0
ending... 0 (1305994, 972)
starting... 2
working... 1
ending... 1 (1305994, 972)
starting... 3
working... 2
ending... 2 (1305994, 972)
starting... 4
working... 3
ending... 3 (1305994, 972)
working... 4
ending... 4 (1305994, 972)
all done [(1305994, 972), (1305994, 972), (1305994, 972), (1305994, 972), (1305994, 972)]
```
Run with the sleep in worker removed/commented out:
```
$ python cctest.py
starting... 0
starting... 1
starting... 2
working... 0
ending... 0 (1305994, 972)
starting... 3
working... 2
ending... 2 (1305994, 972)
starting... 4
working... 3
ending... 3 (1305994, 972)
working... 4
ending... 4 (1305994, 972)
Traceback (most recent call last):
File "cctest.py", line 33, in <module>
main()
File "cctest.py", line 27, in main
res = [f.result() for f in concurrent.futures.as_completed(futures)]
File "cctest.py", line 27, in <listcomp>
res = [f.result() for f in concurrent.futures.as_completed(futures)]
File "/usr/lib64/python3.7/concurrent/futures/_base.py", line 428, in result
return self.__get_result()
File "/usr/lib64/python3.7/concurrent/futures/_base.py", line 384, in __get_result
raise self._exception
File "/usr/lib64/python3.7/concurrent/futures/thread.py", line 57, in run
result = self.fn(*self.args, **self.kwargs)
File "cctest.py", line 11, in worker
with tiledb.DenseArray(uri) as A:
File "/home/ec2-user/venv/lib64/python3.7/site-packages/tiledb/array.py", line 10, in __new__
DenseArray.__bases__ = DenseArray.__bases__ + (cloudarray.CloudArray,)
TypeError: duplicate base class CloudArray
```
Test case:
```
import tiledb
import time
import numpy as np
import concurrent.futures
def worker(n, uri):
print('starting...', n)
# time.sleep(n)
with tiledb.DenseArray(uri) as A:
print('working...', n)
res = A.shape
print('ending...', n, res)
return res
def main():
executor_cls = concurrent.futures.ThreadPoolExecutor
uri = "s3://tiledb-eval/10x_mouse_13MM_processed-Xr3zstd.cxg/X"
with executor_cls(max_workers=2) as executor:
futures = [executor.submit(worker, n, uri) for n in range(0, 5)]
res = [f.result() for f in concurrent.futures.as_completed(futures)]
print('all done', res)
if __name__ == '__main__':
main()
```
</issue>
<code>
[start of tiledb/array.py]
1 from .libtiledb import DenseArrayImpl, SparseArrayImpl
2
3 class DenseArray(DenseArrayImpl):
4 _mixin_init = False
5
6 def __new__(cls, *args, **kwargs):
7 if not cls._mixin_init:
8 try:
9 from tiledb.cloud import cloudarray
10 DenseArray.__bases__ = DenseArray.__bases__ + (cloudarray.CloudArray,)
11 except ImportError:
12 pass
13 finally:
14 cls._mixin_init = True
15
16 obj = super(DenseArray, cls).__new__(cls, *args, **kwargs)
17 return obj
18
19 class SparseArray(SparseArrayImpl):
20 _mixin_init = False
21
22 def __new__(cls, *args, **kwargs):
23 if not cls._mixin_init:
24 try:
25 from tiledb.cloud import cloudarray
26 SparseArray.__bases__ = SparseArray.__bases__ + (cloudarray.CloudArray,)
27 except ImportError:
28 pass
29 finally:
30 cls._mixin_init = True
31
32 obj = super(SparseArray, cls).__new__(cls, *args, **kwargs)
33 return obj
34
[end of tiledb/array.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/tiledb/array.py b/tiledb/array.py
--- a/tiledb/array.py
+++ b/tiledb/array.py
@@ -1,17 +1,29 @@
from .libtiledb import DenseArrayImpl, SparseArrayImpl
+# Extensible (pure Python) array class definitions inheriting from the
+# Cython implemention. The cloudarray mix-in adds optional functionality
+# for registering arrays and executing functions on the
+
+# NOTE: the mixin import must be inside the __new__ initializer because it
+# needs to be deferred. tiledb.cloud is not yet known to the importer
+# when this code is imported.
+# TODO: might be possible to work-around/simplify by using
+# import meta-hooks instead.
+
class DenseArray(DenseArrayImpl):
_mixin_init = False
def __new__(cls, *args, **kwargs):
if not cls._mixin_init:
+ # must set before importing, because import is not thread-safe
+ # https://github.com/TileDB-Inc/TileDB-Py/issues/244
+ cls._mixin_init = True
try:
from tiledb.cloud import cloudarray
DenseArray.__bases__ = DenseArray.__bases__ + (cloudarray.CloudArray,)
+ DenseArray.__doc__ = DenseArrayImpl.__doc__
except ImportError:
pass
- finally:
- cls._mixin_init = True
obj = super(DenseArray, cls).__new__(cls, *args, **kwargs)
return obj
@@ -21,13 +33,13 @@
def __new__(cls, *args, **kwargs):
if not cls._mixin_init:
+ cls._mixin_init = True
try:
from tiledb.cloud import cloudarray
SparseArray.__bases__ = SparseArray.__bases__ + (cloudarray.CloudArray,)
+ SparseArray.__doc__ = DenseArrayImpl.__doc__
except ImportError:
pass
- finally:
- cls._mixin_init = True
obj = super(SparseArray, cls).__new__(cls, *args, **kwargs)
return obj
|
{"golden_diff": "diff --git a/tiledb/array.py b/tiledb/array.py\n--- a/tiledb/array.py\n+++ b/tiledb/array.py\n@@ -1,17 +1,29 @@\n from .libtiledb import DenseArrayImpl, SparseArrayImpl\n \n+# Extensible (pure Python) array class definitions inheriting from the\n+# Cython implemention. The cloudarray mix-in adds optional functionality\n+# for registering arrays and executing functions on the\n+\n+# NOTE: the mixin import must be inside the __new__ initializer because it\n+# needs to be deferred. tiledb.cloud is not yet known to the importer\n+# when this code is imported.\n+# TODO: might be possible to work-around/simplify by using\n+# import meta-hooks instead.\n+\n class DenseArray(DenseArrayImpl):\n _mixin_init = False\n \n def __new__(cls, *args, **kwargs):\n if not cls._mixin_init:\n+ # must set before importing, because import is not thread-safe\n+ # https://github.com/TileDB-Inc/TileDB-Py/issues/244\n+ cls._mixin_init = True\n try:\n from tiledb.cloud import cloudarray\n DenseArray.__bases__ = DenseArray.__bases__ + (cloudarray.CloudArray,)\n+ DenseArray.__doc__ = DenseArrayImpl.__doc__\n except ImportError:\n pass\n- finally:\n- cls._mixin_init = True\n \n obj = super(DenseArray, cls).__new__(cls, *args, **kwargs)\n return obj\n@@ -21,13 +33,13 @@\n \n def __new__(cls, *args, **kwargs):\n if not cls._mixin_init:\n+ cls._mixin_init = True\n try:\n from tiledb.cloud import cloudarray\n SparseArray.__bases__ = SparseArray.__bases__ + (cloudarray.CloudArray,)\n+ SparseArray.__doc__ = DenseArrayImpl.__doc__\n except ImportError:\n pass\n- finally:\n- cls._mixin_init = True\n \n obj = super(SparseArray, cls).__new__(cls, *args, **kwargs)\n return obj\n", "issue": "likely race condition in DenseArray.__new__\n\r\nTest program below exposes (what I believe is a) race in class handling in DenseArray. The test program is completely artificial - it just spins up 5 threads, each of which open an S3 object and ask its shape. Without a sleep to sequence their execution, it fails inside the DenseArray.__new__ method.\r\n\r\nRun with the sleep statement in worker(), I see:\r\n```\r\npython cctest.py\r\nstarting... 0\r\nstarting... 1\r\nworking... 0\r\nending... 0 (1305994, 972)\r\nstarting... 2\r\nworking... 1\r\nending... 1 (1305994, 972)\r\nstarting... 3\r\nworking... 2\r\nending... 2 (1305994, 972)\r\nstarting... 4\r\nworking... 3\r\nending... 3 (1305994, 972)\r\nworking... 4\r\nending... 4 (1305994, 972)\r\nall done [(1305994, 972), (1305994, 972), (1305994, 972), (1305994, 972), (1305994, 972)]\r\n```\r\n\r\nRun with the sleep in worker removed/commented out:\r\n```\r\n$ python cctest.py\r\nstarting... 0\r\nstarting... 1\r\nstarting... 2\r\nworking... 0\r\nending... 0 (1305994, 972)\r\nstarting... 3\r\nworking... 2\r\nending... 2 (1305994, 972)\r\nstarting... 4\r\nworking... 3\r\nending... 3 (1305994, 972)\r\nworking... 4\r\nending... 4 (1305994, 972)\r\nTraceback (most recent call last):\r\n File \"cctest.py\", line 33, in <module>\r\n main()\r\n File \"cctest.py\", line 27, in main\r\n res = [f.result() for f in concurrent.futures.as_completed(futures)]\r\n File \"cctest.py\", line 27, in <listcomp>\r\n res = [f.result() for f in concurrent.futures.as_completed(futures)]\r\n File \"/usr/lib64/python3.7/concurrent/futures/_base.py\", line 428, in result\r\n return self.__get_result()\r\n File \"/usr/lib64/python3.7/concurrent/futures/_base.py\", line 384, in __get_result\r\n raise self._exception\r\n File \"/usr/lib64/python3.7/concurrent/futures/thread.py\", line 57, in run\r\n result = self.fn(*self.args, **self.kwargs)\r\n File \"cctest.py\", line 11, in worker\r\n with tiledb.DenseArray(uri) as A:\r\n File \"/home/ec2-user/venv/lib64/python3.7/site-packages/tiledb/array.py\", line 10, in __new__\r\n DenseArray.__bases__ = DenseArray.__bases__ + (cloudarray.CloudArray,)\r\nTypeError: duplicate base class CloudArray\r\n```\r\n\r\nTest case:\r\n```\r\nimport tiledb\r\nimport time\r\nimport numpy as np\r\nimport concurrent.futures\r\n\r\n\r\ndef worker(n, uri):\r\n print('starting...', n)\r\n # time.sleep(n)\r\n\r\n with tiledb.DenseArray(uri) as A:\r\n print('working...', n)\r\n res = A.shape\r\n\r\n print('ending...', n, res)\r\n return res\r\n\r\n\r\ndef main():\r\n executor_cls = concurrent.futures.ThreadPoolExecutor\r\n\r\n uri = \"s3://tiledb-eval/10x_mouse_13MM_processed-Xr3zstd.cxg/X\"\r\n\r\n with executor_cls(max_workers=2) as executor:\r\n futures = [executor.submit(worker, n, uri) for n in range(0, 5)]\r\n res = [f.result() for f in concurrent.futures.as_completed(futures)]\r\n\r\n print('all done', res)\r\n\r\n\r\nif __name__ == '__main__':\r\n main()\r\n```\n", "before_files": [{"content": "from .libtiledb import DenseArrayImpl, SparseArrayImpl\n\nclass DenseArray(DenseArrayImpl):\n _mixin_init = False\n\n def __new__(cls, *args, **kwargs):\n if not cls._mixin_init:\n try:\n from tiledb.cloud import cloudarray\n DenseArray.__bases__ = DenseArray.__bases__ + (cloudarray.CloudArray,)\n except ImportError:\n pass\n finally:\n cls._mixin_init = True\n\n obj = super(DenseArray, cls).__new__(cls, *args, **kwargs)\n return obj\n\nclass SparseArray(SparseArrayImpl):\n _mixin_init = False\n\n def __new__(cls, *args, **kwargs):\n if not cls._mixin_init:\n try:\n from tiledb.cloud import cloudarray\n SparseArray.__bases__ = SparseArray.__bases__ + (cloudarray.CloudArray,)\n except ImportError:\n pass\n finally:\n cls._mixin_init = True\n\n obj = super(SparseArray, cls).__new__(cls, *args, **kwargs)\n return obj\n", "path": "tiledb/array.py"}]}
| 1,771 | 477 |
gh_patches_debug_3779
|
rasdani/github-patches
|
git_diff
|
modin-project__modin-4515
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Logging mode leaves a hanging thread in interactive python session
### System information
- **OS Platform and Distribution (e.g., Linux Ubuntu 16.04)**: MacOS Monterey
- **Modin version** (`modin.__version__`): latest source
- **Python version**: 3.9.12
- **Code we can use to reproduce**:
In ipython, run
```python
from modin.config import LogMode
import modin.pandas as pd
LogMode.enable()
df = pd.DataFrame([[1]])
```
and try to exit. You have to control-c or control-d twice.
This bug came up in the discussion on #4372 but it wasn't fixed in that PR.
The problematic thread is started [here](https://github.com/modin-project/modin/blob/49fc2cf3733f20ac6cf8a7c61e42ef7aa5cf4b03/modin/logging/config.py#L127).
</issue>
<code>
[start of modin/logging/config.py]
1 # Licensed to Modin Development Team under one or more contributor license agreements.
2 # See the NOTICE file distributed with this work for additional information regarding
3 # copyright ownership. The Modin Development Team licenses this file to you under the
4 # Apache License, Version 2.0 (the "License"); you may not use this file except in
5 # compliance with the License. You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software distributed under
10 # the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF
11 # ANY KIND, either express or implied. See the License for the specific language
12 # governing permissions and limitations under the License.
13
14 """
15 Module contains ``ModinFormatter`` class.
16
17 ``ModinFormatter`` and the associated functions are used for logging configuration.
18 """
19
20 import logging
21 import datetime as dt
22 import os
23 import uuid
24 import platform
25 import psutil
26 import pkg_resources
27 import threading
28 import time
29 from modin.config import LogMemoryInterval, LogMode
30
31 __LOGGER_CONFIGURED__: bool = False
32
33
34 class ModinFormatter(logging.Formatter): # noqa: PR01
35 """Implement custom formatter to log at microsecond granularity."""
36
37 def formatTime(self, record, datefmt=None):
38 """
39 Return the creation time of the specified LogRecord as formatted text.
40
41 This custom logging formatter inherits from the logging module and
42 records timestamps at the microsecond level of granularity.
43
44 Parameters
45 ----------
46 record : LogRecord
47 The specified LogRecord object.
48 datefmt : str, default: None
49 Used with time.ststrftime() to format time record.
50
51 Returns
52 -------
53 datetime
54 Datetime object containing microsecond timestamp.
55 """
56 ct = dt.datetime.fromtimestamp(record.created)
57 if datefmt:
58 s = ct.strftime(datefmt)
59 else:
60 # Format datetime object ct to microseconds
61 t = ct.strftime("%Y-%m-%d %H:%M:%S")
62 s = f"{t},{record.msecs:03}"
63 return s
64
65
66 def bytes_int_to_str(num_bytes, suffix="B"):
67 """
68 Scale bytes to its human-readable format (e.g: 1253656678 => '1.17GB').
69
70 Parameters
71 ----------
72 num_bytes : int
73 Number of bytes.
74 suffix : str, default: "B"
75 Suffix to add to conversion of num_bytes.
76
77 Returns
78 -------
79 str
80 Human-readable string format.
81 """
82 factor = 1000
83 for unit in ["", "K", "M", "G", "T", "P"]:
84 if num_bytes < factor:
85 return f"{num_bytes:.2f}{unit}{suffix}"
86 num_bytes /= factor
87 return f"{num_bytes:.2f}{1000+P}{suffix}"
88
89
90 def configure_logging():
91 """Configure Modin logging by setting up directory structure and formatting."""
92 global __LOGGER_CONFIGURED__
93 logger = logging.getLogger("modin.logger")
94 job_id = uuid.uuid4().hex
95 log_filename = f".modin/logs/job_{job_id}.log"
96
97 os.makedirs(os.path.dirname(log_filename), exist_ok=True)
98
99 logfile = logging.FileHandler(log_filename, "a")
100 formatter = ModinFormatter(
101 fmt="%(process)d, %(thread)d, %(asctime)s, %(message)s",
102 datefmt="%Y-%m-%d,%H:%M:%S.%f",
103 )
104 logfile.setFormatter(formatter)
105 logger.addHandler(logfile)
106
107 if LogMode.get() == "enable_api_only":
108 logger.setLevel(logging.INFO)
109 logger.setLevel(logging.DEBUG)
110
111 logger = logging.getLogger("modin.logger")
112 logger.info(f"OS Version: {platform.platform()}")
113 logger.info(f"Python Version: {platform.python_version()}")
114 modin_version = pkg_resources.get_distribution("modin").version
115 pandas_version = pkg_resources.get_distribution("pandas").version
116 num_physical_cores = str(psutil.cpu_count(logical=False))
117 num_total_cores = str(psutil.cpu_count(logical=True))
118 svmem = psutil.virtual_memory()
119 logger.info(f"Modin Version: {modin_version}")
120 logger.info(f"Pandas Version: {pandas_version}")
121 logger.info(f"Physical Cores: {num_physical_cores}")
122 logger.info(f"Total Cores: {num_total_cores}")
123 logger.info(f"Memory Total: {bytes_int_to_str(svmem.total)}")
124 logger.info(f"Memory Available: {bytes_int_to_str(svmem.available)}")
125 logger.info(f"Memory Used: {bytes_int_to_str(svmem.used)}")
126
127 if LogMode.get() != "enable_api_only":
128 mem_sleep = LogMemoryInterval.get()
129 mem = threading.Thread(target=memory_thread, args=[logger, mem_sleep])
130 mem.start()
131
132 __LOGGER_CONFIGURED__ = True
133
134
135 def memory_thread(logger, sleep_time):
136 """
137 Configure Modin logging system memory profiling thread.
138
139 Parameters
140 ----------
141 logger : logging.Logger
142 The logger object.
143 sleep_time : int
144 The interval at which to profile system memory.
145 """
146 while True:
147 svmem = psutil.virtual_memory()
148 logger.info(f"Memory Percentage: {svmem.percent}%")
149 time.sleep(sleep_time)
150
151
152 def get_logger():
153 """
154 Configure Modin logger based on Modin config and returns the logger.
155
156 Returns
157 -------
158 logging.Logger
159 The Modin logger.
160 """
161 if not __LOGGER_CONFIGURED__ and LogMode.get() != "disable":
162 configure_logging()
163 return logging.getLogger("modin.logger")
164
[end of modin/logging/config.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/modin/logging/config.py b/modin/logging/config.py
--- a/modin/logging/config.py
+++ b/modin/logging/config.py
@@ -126,7 +126,9 @@
if LogMode.get() != "enable_api_only":
mem_sleep = LogMemoryInterval.get()
- mem = threading.Thread(target=memory_thread, args=[logger, mem_sleep])
+ mem = threading.Thread(
+ target=memory_thread, args=[logger, mem_sleep], daemon=True
+ )
mem.start()
__LOGGER_CONFIGURED__ = True
|
{"golden_diff": "diff --git a/modin/logging/config.py b/modin/logging/config.py\n--- a/modin/logging/config.py\n+++ b/modin/logging/config.py\n@@ -126,7 +126,9 @@\n \n if LogMode.get() != \"enable_api_only\":\n mem_sleep = LogMemoryInterval.get()\n- mem = threading.Thread(target=memory_thread, args=[logger, mem_sleep])\n+ mem = threading.Thread(\n+ target=memory_thread, args=[logger, mem_sleep], daemon=True\n+ )\n mem.start()\n \n __LOGGER_CONFIGURED__ = True\n", "issue": "Logging mode leaves a hanging thread in interactive python session\n### System information\r\n- **OS Platform and Distribution (e.g., Linux Ubuntu 16.04)**: MacOS Monterey\r\n- **Modin version** (`modin.__version__`): latest source\r\n- **Python version**: 3.9.12\r\n- **Code we can use to reproduce**:\r\n\r\nIn ipython, run \r\n\r\n```python\r\nfrom modin.config import LogMode\r\nimport modin.pandas as pd\r\n\r\nLogMode.enable()\r\ndf = pd.DataFrame([[1]])\r\n```\r\n\r\nand try to exit. You have to control-c or control-d twice.\r\n\r\nThis bug came up in the discussion on #4372 but it wasn't fixed in that PR.\r\n\r\nThe problematic thread is started [here](https://github.com/modin-project/modin/blob/49fc2cf3733f20ac6cf8a7c61e42ef7aa5cf4b03/modin/logging/config.py#L127).\r\n\n", "before_files": [{"content": "# Licensed to Modin Development Team under one or more contributor license agreements.\n# See the NOTICE file distributed with this work for additional information regarding\n# copyright ownership. The Modin Development Team licenses this file to you under the\n# Apache License, Version 2.0 (the \"License\"); you may not use this file except in\n# compliance with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software distributed under\n# the License is distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF\n# ANY KIND, either express or implied. See the License for the specific language\n# governing permissions and limitations under the License.\n\n\"\"\"\nModule contains ``ModinFormatter`` class.\n\n``ModinFormatter`` and the associated functions are used for logging configuration.\n\"\"\"\n\nimport logging\nimport datetime as dt\nimport os\nimport uuid\nimport platform\nimport psutil\nimport pkg_resources\nimport threading\nimport time\nfrom modin.config import LogMemoryInterval, LogMode\n\n__LOGGER_CONFIGURED__: bool = False\n\n\nclass ModinFormatter(logging.Formatter): # noqa: PR01\n \"\"\"Implement custom formatter to log at microsecond granularity.\"\"\"\n\n def formatTime(self, record, datefmt=None):\n \"\"\"\n Return the creation time of the specified LogRecord as formatted text.\n\n This custom logging formatter inherits from the logging module and\n records timestamps at the microsecond level of granularity.\n\n Parameters\n ----------\n record : LogRecord\n The specified LogRecord object.\n datefmt : str, default: None\n Used with time.ststrftime() to format time record.\n\n Returns\n -------\n datetime\n Datetime object containing microsecond timestamp.\n \"\"\"\n ct = dt.datetime.fromtimestamp(record.created)\n if datefmt:\n s = ct.strftime(datefmt)\n else:\n # Format datetime object ct to microseconds\n t = ct.strftime(\"%Y-%m-%d %H:%M:%S\")\n s = f\"{t},{record.msecs:03}\"\n return s\n\n\ndef bytes_int_to_str(num_bytes, suffix=\"B\"):\n \"\"\"\n Scale bytes to its human-readable format (e.g: 1253656678 => '1.17GB').\n\n Parameters\n ----------\n num_bytes : int\n Number of bytes.\n suffix : str, default: \"B\"\n Suffix to add to conversion of num_bytes.\n\n Returns\n -------\n str\n Human-readable string format.\n \"\"\"\n factor = 1000\n for unit in [\"\", \"K\", \"M\", \"G\", \"T\", \"P\"]:\n if num_bytes < factor:\n return f\"{num_bytes:.2f}{unit}{suffix}\"\n num_bytes /= factor\n return f\"{num_bytes:.2f}{1000+P}{suffix}\"\n\n\ndef configure_logging():\n \"\"\"Configure Modin logging by setting up directory structure and formatting.\"\"\"\n global __LOGGER_CONFIGURED__\n logger = logging.getLogger(\"modin.logger\")\n job_id = uuid.uuid4().hex\n log_filename = f\".modin/logs/job_{job_id}.log\"\n\n os.makedirs(os.path.dirname(log_filename), exist_ok=True)\n\n logfile = logging.FileHandler(log_filename, \"a\")\n formatter = ModinFormatter(\n fmt=\"%(process)d, %(thread)d, %(asctime)s, %(message)s\",\n datefmt=\"%Y-%m-%d,%H:%M:%S.%f\",\n )\n logfile.setFormatter(formatter)\n logger.addHandler(logfile)\n\n if LogMode.get() == \"enable_api_only\":\n logger.setLevel(logging.INFO)\n logger.setLevel(logging.DEBUG)\n\n logger = logging.getLogger(\"modin.logger\")\n logger.info(f\"OS Version: {platform.platform()}\")\n logger.info(f\"Python Version: {platform.python_version()}\")\n modin_version = pkg_resources.get_distribution(\"modin\").version\n pandas_version = pkg_resources.get_distribution(\"pandas\").version\n num_physical_cores = str(psutil.cpu_count(logical=False))\n num_total_cores = str(psutil.cpu_count(logical=True))\n svmem = psutil.virtual_memory()\n logger.info(f\"Modin Version: {modin_version}\")\n logger.info(f\"Pandas Version: {pandas_version}\")\n logger.info(f\"Physical Cores: {num_physical_cores}\")\n logger.info(f\"Total Cores: {num_total_cores}\")\n logger.info(f\"Memory Total: {bytes_int_to_str(svmem.total)}\")\n logger.info(f\"Memory Available: {bytes_int_to_str(svmem.available)}\")\n logger.info(f\"Memory Used: {bytes_int_to_str(svmem.used)}\")\n\n if LogMode.get() != \"enable_api_only\":\n mem_sleep = LogMemoryInterval.get()\n mem = threading.Thread(target=memory_thread, args=[logger, mem_sleep])\n mem.start()\n\n __LOGGER_CONFIGURED__ = True\n\n\ndef memory_thread(logger, sleep_time):\n \"\"\"\n Configure Modin logging system memory profiling thread.\n\n Parameters\n ----------\n logger : logging.Logger\n The logger object.\n sleep_time : int\n The interval at which to profile system memory.\n \"\"\"\n while True:\n svmem = psutil.virtual_memory()\n logger.info(f\"Memory Percentage: {svmem.percent}%\")\n time.sleep(sleep_time)\n\n\ndef get_logger():\n \"\"\"\n Configure Modin logger based on Modin config and returns the logger.\n\n Returns\n -------\n logging.Logger\n The Modin logger.\n \"\"\"\n if not __LOGGER_CONFIGURED__ and LogMode.get() != \"disable\":\n configure_logging()\n return logging.getLogger(\"modin.logger\")\n", "path": "modin/logging/config.py"}]}
| 2,380 | 127 |
gh_patches_debug_15408
|
rasdani/github-patches
|
git_diff
|
streamlit__streamlit-5023
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
UnhashableTypeError: Cannot hash object of type _json.Scanner...
### Summary
When attempting to use st.cache decorator (with streamlit 1.10.0) on a json data loader method, streamlit returns an unhashable error for a _json.Scanner. This behavior does not exist in the previous version (1.9.2).
### Steps to reproduce
1. Update streamlit to version 1.10.0
2. Use st.cache on any method that loads data from a json file
For example:
```python
@st.cache(allow_output_mutation=True)
def fetch_data_json(filename: str) -> Dict[str, Any]:
with open(filename, "r") as f:
config = json.load(f)
return config
```
Returns:
```
UnhashableTypeError: Cannot hash object of type _json.Scanner, found in the body of fetch_data_json().
While caching the body of fetch_data_json(), Streamlit encountered an object of type _json.Scanner, which it does not know how to hash.
To address this, please try helping Streamlit understand how to hash that type by passing the hash_funcs argument into @st.cache. For example:
@st.cache(hash_funcs={_json.Scanner: my_hash_func})
def my_func(...):
If you don't know where the object of type _json.Scanner is coming from, try looking at the hash chain below for an object that you do recognize, then pass that to hash_funcs instead:
Object of type _json.Scanner: <_json.Scanner object at 0x7fa22470b160>
Object of type builtins.method: <bound method JSONDecoder.raw_decode of <json.decoder.JSONDecoder object at 0x7fa2247b0760>>
Object of type builtins.method: <bound method JSONDecoder.decode of <json.decoder.JSONDecoder object at 0x7fa2247b0760>>
Object of type builtins.function: <function loads at 0x7fa22470e3a0>
Object of type builtins.function: <function load at 0x7fa22470e310>
Object of type builtins.function: <function fetch_data_json at 0x7fa22128cdc0>
Please see the hash_funcs [documentation] (https://docs.streamlit.io/library/advanced-features/caching#the-hash_funcs-parameter) for more details.
Traceback:
File "app.py", line 23, in <module>
json_file = fetch_data_json(TEST_CONFIG_FOLDER + "/test_config.json")
File "/usr/lib/python3.8/copyreg.py", line 66, in _reduce_ex
raise TypeError(f"cannot pickle {cls.__name__!r} object")
```
**Expected behavior:**
In version 1.9.2 the same code would produce valid parsed json data without @st.cache attempting to has an unhashable object. This image below is the method outlined above implemented in 1.10.0 and 1.9.2:

### Debug info
- Streamlit version: 1.10.0
- Python version: 3.8.12
- Using Conda? PipEnv? PyEnv? Pex? Pip via Poetry
- OS version: Ubuntu 20.04 (via Windows 11)
- Browser version: Chrome 102.0.5005.115
</issue>
<code>
[start of lib/streamlit/source_util.py]
1 # Copyright 2018-2022 Streamlit Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import re
16 import threading
17 from pathlib import Path
18 from typing import Any, Callable, cast, Dict, List, Optional, Tuple
19
20 from blinker import Signal
21
22 from streamlit.logger import get_logger
23 from streamlit.util import calc_md5
24
25 LOGGER = get_logger(__name__)
26
27
28 def open_python_file(filename):
29 """Open a read-only Python file taking proper care of its encoding.
30
31 In Python 3, we would like all files to be opened with utf-8 encoding.
32 However, some author like to specify PEP263 headers in their source files
33 with their own encodings. In that case, we should respect the author's
34 encoding.
35 """
36 import tokenize
37
38 if hasattr(tokenize, "open"): # Added in Python 3.2
39 # Open file respecting PEP263 encoding. If no encoding header is
40 # found, opens as utf-8.
41 return tokenize.open(filename)
42 else:
43 return open(filename, "r", encoding="utf-8")
44
45
46 PAGE_FILENAME_REGEX = re.compile(r"([0-9]*)[_ -]*(.*)\.py")
47 # Regex pattern to extract emoji taken from https://gist.github.com/Alex-Just/e86110836f3f93fe7932290526529cd1#gistcomment-3208085
48 # We may eventually want to swap this out for https://pypi.org/project/emoji,
49 # but I want to avoid adding a dependency if possible.
50 PAGE_ICON_REGEX = re.compile(
51 "(^[\U0001F1E0-\U0001F1FF"
52 "\U0001F300-\U0001F5FF"
53 "\U0001F600-\U0001F64F"
54 "\U0001F680-\U0001F6FF"
55 "\U0001F700-\U0001F77F"
56 "\U0001F780-\U0001F7FF"
57 "\U0001F800-\U0001F8FF"
58 "\U0001F900-\U0001F9FF"
59 "\U0001FA00-\U0001FA6F"
60 "\U0001FA70-\U0001FAFF"
61 "\U00002702-\U000027B0"
62 "\U000024C2-\U0001F251])[_-]*"
63 )
64
65
66 def page_sort_key(script_path: Path) -> Tuple[float, str]:
67 matches = re.findall(PAGE_FILENAME_REGEX, script_path.name)
68
69 # Failing this assert should only be possible if script_path isn't a Python
70 # file, which should never happen.
71 assert len(matches) > 0, f"{script_path} is not a Python file"
72
73 [(number, label)] = matches
74 label = label.lower()
75
76 if number == "":
77 return (float("inf"), label)
78
79 return (float(number), label)
80
81
82 def page_name_and_icon(script_path: Path) -> Tuple[str, str]:
83 """Compute the name of a page from its script path.
84
85 This is *almost* the page name displayed in the nav UI, but it has
86 underscores instead of spaces. The reason we do this is because having
87 spaces in URLs both looks bad and is hard to deal with due to the need to
88 URL-encode them. To solve this, we only swap the underscores for spaces
89 right before we render page names.
90 """
91 extraction = re.search(PAGE_FILENAME_REGEX, script_path.name)
92 if extraction is None:
93 return "", ""
94
95 # This cast to Any+type annotation weirdness is done because
96 # cast(re.Match[str], ...) explodes at runtime since Python interprets it
97 # as an attempt to index into re.Match instead of as a type annotation.
98 extraction: re.Match[str] = cast(Any, extraction)
99
100 name = re.sub(r"[_ ]+", "_", extraction.group(2)).strip()
101 if not name:
102 name = extraction.group(1)
103
104 extracted_icon = re.search(PAGE_ICON_REGEX, name)
105 if extracted_icon is not None:
106 icon = str(extracted_icon.group(1))
107 name = re.sub(PAGE_ICON_REGEX, "", name)
108 else:
109 icon = ""
110
111 return str(name), icon
112
113
114 _pages_cache_lock = threading.RLock()
115 _cached_pages: Optional[Dict[str, Dict[str, str]]] = None
116 _on_pages_changed = Signal(doc="Emitted when the pages directory is changed")
117
118
119 def invalidate_pages_cache():
120 global _cached_pages
121
122 LOGGER.debug("Pages directory changed")
123 with _pages_cache_lock:
124 _cached_pages = None
125
126 _on_pages_changed.send()
127
128
129 def get_pages(main_script_path_str: str) -> Dict[str, Dict[str, str]]:
130 global _cached_pages
131
132 # Avoid taking the lock if the pages cache hasn't been invalidated.
133 pages = _cached_pages
134 if pages is not None:
135 return pages
136
137 with _pages_cache_lock:
138 # The cache may have been repopulated while we were waiting to grab
139 # the lock.
140 if _cached_pages is not None:
141 return _cached_pages
142
143 main_script_path = Path(main_script_path_str)
144 main_page_name, main_page_icon = page_name_and_icon(main_script_path)
145 main_page_script_hash = calc_md5(main_script_path_str)
146
147 # NOTE: We include the page_script_hash in the dict even though it is
148 # already used as the key because that occasionally makes things
149 # easier for us when we need to iterate over pages.
150 pages = {
151 main_page_script_hash: {
152 "page_script_hash": main_page_script_hash,
153 "page_name": main_page_name,
154 "icon": main_page_icon,
155 "script_path": str(main_script_path),
156 }
157 }
158
159 pages_dir = main_script_path.parent / "pages"
160 page_scripts = sorted(
161 [f for f in pages_dir.glob("*.py") if not f.name.startswith(".")],
162 key=page_sort_key,
163 )
164
165 for script_path in page_scripts:
166 script_path_str = str(script_path)
167 pn, pi = page_name_and_icon(script_path)
168 psh = calc_md5(script_path_str)
169
170 pages[psh] = {
171 "page_script_hash": psh,
172 "page_name": pn,
173 "icon": pi,
174 "script_path": script_path_str,
175 }
176
177 _cached_pages = pages
178
179 return pages
180
181
182 def register_pages_changed_callback(
183 callback: Callable[[str], None],
184 ):
185 def disconnect():
186 _on_pages_changed.disconnect(callback)
187
188 # weak=False so that we have control of when the pages changed
189 # callback is deregistered.
190 _on_pages_changed.connect(callback, weak=False)
191
192 return disconnect
193
[end of lib/streamlit/source_util.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lib/streamlit/source_util.py b/lib/streamlit/source_util.py
--- a/lib/streamlit/source_util.py
+++ b/lib/streamlit/source_util.py
@@ -152,7 +152,7 @@
"page_script_hash": main_page_script_hash,
"page_name": main_page_name,
"icon": main_page_icon,
- "script_path": str(main_script_path),
+ "script_path": str(main_script_path.resolve()),
}
}
@@ -163,7 +163,7 @@
)
for script_path in page_scripts:
- script_path_str = str(script_path)
+ script_path_str = str(script_path.resolve())
pn, pi = page_name_and_icon(script_path)
psh = calc_md5(script_path_str)
|
{"golden_diff": "diff --git a/lib/streamlit/source_util.py b/lib/streamlit/source_util.py\n--- a/lib/streamlit/source_util.py\n+++ b/lib/streamlit/source_util.py\n@@ -152,7 +152,7 @@\n \"page_script_hash\": main_page_script_hash,\n \"page_name\": main_page_name,\n \"icon\": main_page_icon,\n- \"script_path\": str(main_script_path),\n+ \"script_path\": str(main_script_path.resolve()),\n }\n }\n \n@@ -163,7 +163,7 @@\n )\n \n for script_path in page_scripts:\n- script_path_str = str(script_path)\n+ script_path_str = str(script_path.resolve())\n pn, pi = page_name_and_icon(script_path)\n psh = calc_md5(script_path_str)\n", "issue": "UnhashableTypeError: Cannot hash object of type _json.Scanner...\n### Summary\r\n\r\nWhen attempting to use st.cache decorator (with streamlit 1.10.0) on a json data loader method, streamlit returns an unhashable error for a _json.Scanner. This behavior does not exist in the previous version (1.9.2). \r\n\r\n### Steps to reproduce\r\n\r\n1. Update streamlit to version 1.10.0\r\n2. Use st.cache on any method that loads data from a json file\r\n\r\nFor example:\r\n\r\n```python\r\[email protected](allow_output_mutation=True)\r\ndef fetch_data_json(filename: str) -> Dict[str, Any]:\r\n with open(filename, \"r\") as f:\r\n config = json.load(f)\r\n return config\r\n```\r\n\r\nReturns: \r\n\r\n```\r\nUnhashableTypeError: Cannot hash object of type _json.Scanner, found in the body of fetch_data_json().\r\n\r\nWhile caching the body of fetch_data_json(), Streamlit encountered an object of type _json.Scanner, which it does not know how to hash.\r\n\r\nTo address this, please try helping Streamlit understand how to hash that type by passing the hash_funcs argument into @st.cache. For example:\r\n\r\n\r\[email protected](hash_funcs={_json.Scanner: my_hash_func})\r\ndef my_func(...):\r\n \r\nIf you don't know where the object of type _json.Scanner is coming from, try looking at the hash chain below for an object that you do recognize, then pass that to hash_funcs instead:\r\n\r\n\r\nObject of type _json.Scanner: <_json.Scanner object at 0x7fa22470b160>\r\nObject of type builtins.method: <bound method JSONDecoder.raw_decode of <json.decoder.JSONDecoder object at 0x7fa2247b0760>>\r\nObject of type builtins.method: <bound method JSONDecoder.decode of <json.decoder.JSONDecoder object at 0x7fa2247b0760>>\r\nObject of type builtins.function: <function loads at 0x7fa22470e3a0>\r\nObject of type builtins.function: <function load at 0x7fa22470e310>\r\nObject of type builtins.function: <function fetch_data_json at 0x7fa22128cdc0>\r\nPlease see the hash_funcs [documentation] (https://docs.streamlit.io/library/advanced-features/caching#the-hash_funcs-parameter) for more details.\r\n\r\nTraceback:\r\nFile \"app.py\", line 23, in <module>\r\n json_file = fetch_data_json(TEST_CONFIG_FOLDER + \"/test_config.json\")\r\nFile \"/usr/lib/python3.8/copyreg.py\", line 66, in _reduce_ex\r\n raise TypeError(f\"cannot pickle {cls.__name__!r} object\")\r\n```\r\n\r\n**Expected behavior:**\r\n\r\nIn version 1.9.2 the same code would produce valid parsed json data without @st.cache attempting to has an unhashable object. This image below is the method outlined above implemented in 1.10.0 and 1.9.2:\r\n\r\n\r\n\r\n\r\n### Debug info\r\n\r\n- Streamlit version: 1.10.0\r\n- Python version: 3.8.12\r\n- Using Conda? PipEnv? PyEnv? Pex? Pip via Poetry\r\n- OS version: Ubuntu 20.04 (via Windows 11)\r\n- Browser version: Chrome 102.0.5005.115\r\n\r\n\r\n\n", "before_files": [{"content": "# Copyright 2018-2022 Streamlit Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport re\nimport threading\nfrom pathlib import Path\nfrom typing import Any, Callable, cast, Dict, List, Optional, Tuple\n\nfrom blinker import Signal\n\nfrom streamlit.logger import get_logger\nfrom streamlit.util import calc_md5\n\nLOGGER = get_logger(__name__)\n\n\ndef open_python_file(filename):\n \"\"\"Open a read-only Python file taking proper care of its encoding.\n\n In Python 3, we would like all files to be opened with utf-8 encoding.\n However, some author like to specify PEP263 headers in their source files\n with their own encodings. In that case, we should respect the author's\n encoding.\n \"\"\"\n import tokenize\n\n if hasattr(tokenize, \"open\"): # Added in Python 3.2\n # Open file respecting PEP263 encoding. If no encoding header is\n # found, opens as utf-8.\n return tokenize.open(filename)\n else:\n return open(filename, \"r\", encoding=\"utf-8\")\n\n\nPAGE_FILENAME_REGEX = re.compile(r\"([0-9]*)[_ -]*(.*)\\.py\")\n# Regex pattern to extract emoji taken from https://gist.github.com/Alex-Just/e86110836f3f93fe7932290526529cd1#gistcomment-3208085\n# We may eventually want to swap this out for https://pypi.org/project/emoji,\n# but I want to avoid adding a dependency if possible.\nPAGE_ICON_REGEX = re.compile(\n \"(^[\\U0001F1E0-\\U0001F1FF\"\n \"\\U0001F300-\\U0001F5FF\"\n \"\\U0001F600-\\U0001F64F\"\n \"\\U0001F680-\\U0001F6FF\"\n \"\\U0001F700-\\U0001F77F\"\n \"\\U0001F780-\\U0001F7FF\"\n \"\\U0001F800-\\U0001F8FF\"\n \"\\U0001F900-\\U0001F9FF\"\n \"\\U0001FA00-\\U0001FA6F\"\n \"\\U0001FA70-\\U0001FAFF\"\n \"\\U00002702-\\U000027B0\"\n \"\\U000024C2-\\U0001F251])[_-]*\"\n)\n\n\ndef page_sort_key(script_path: Path) -> Tuple[float, str]:\n matches = re.findall(PAGE_FILENAME_REGEX, script_path.name)\n\n # Failing this assert should only be possible if script_path isn't a Python\n # file, which should never happen.\n assert len(matches) > 0, f\"{script_path} is not a Python file\"\n\n [(number, label)] = matches\n label = label.lower()\n\n if number == \"\":\n return (float(\"inf\"), label)\n\n return (float(number), label)\n\n\ndef page_name_and_icon(script_path: Path) -> Tuple[str, str]:\n \"\"\"Compute the name of a page from its script path.\n\n This is *almost* the page name displayed in the nav UI, but it has\n underscores instead of spaces. The reason we do this is because having\n spaces in URLs both looks bad and is hard to deal with due to the need to\n URL-encode them. To solve this, we only swap the underscores for spaces\n right before we render page names.\n \"\"\"\n extraction = re.search(PAGE_FILENAME_REGEX, script_path.name)\n if extraction is None:\n return \"\", \"\"\n\n # This cast to Any+type annotation weirdness is done because\n # cast(re.Match[str], ...) explodes at runtime since Python interprets it\n # as an attempt to index into re.Match instead of as a type annotation.\n extraction: re.Match[str] = cast(Any, extraction)\n\n name = re.sub(r\"[_ ]+\", \"_\", extraction.group(2)).strip()\n if not name:\n name = extraction.group(1)\n\n extracted_icon = re.search(PAGE_ICON_REGEX, name)\n if extracted_icon is not None:\n icon = str(extracted_icon.group(1))\n name = re.sub(PAGE_ICON_REGEX, \"\", name)\n else:\n icon = \"\"\n\n return str(name), icon\n\n\n_pages_cache_lock = threading.RLock()\n_cached_pages: Optional[Dict[str, Dict[str, str]]] = None\n_on_pages_changed = Signal(doc=\"Emitted when the pages directory is changed\")\n\n\ndef invalidate_pages_cache():\n global _cached_pages\n\n LOGGER.debug(\"Pages directory changed\")\n with _pages_cache_lock:\n _cached_pages = None\n\n _on_pages_changed.send()\n\n\ndef get_pages(main_script_path_str: str) -> Dict[str, Dict[str, str]]:\n global _cached_pages\n\n # Avoid taking the lock if the pages cache hasn't been invalidated.\n pages = _cached_pages\n if pages is not None:\n return pages\n\n with _pages_cache_lock:\n # The cache may have been repopulated while we were waiting to grab\n # the lock.\n if _cached_pages is not None:\n return _cached_pages\n\n main_script_path = Path(main_script_path_str)\n main_page_name, main_page_icon = page_name_and_icon(main_script_path)\n main_page_script_hash = calc_md5(main_script_path_str)\n\n # NOTE: We include the page_script_hash in the dict even though it is\n # already used as the key because that occasionally makes things\n # easier for us when we need to iterate over pages.\n pages = {\n main_page_script_hash: {\n \"page_script_hash\": main_page_script_hash,\n \"page_name\": main_page_name,\n \"icon\": main_page_icon,\n \"script_path\": str(main_script_path),\n }\n }\n\n pages_dir = main_script_path.parent / \"pages\"\n page_scripts = sorted(\n [f for f in pages_dir.glob(\"*.py\") if not f.name.startswith(\".\")],\n key=page_sort_key,\n )\n\n for script_path in page_scripts:\n script_path_str = str(script_path)\n pn, pi = page_name_and_icon(script_path)\n psh = calc_md5(script_path_str)\n\n pages[psh] = {\n \"page_script_hash\": psh,\n \"page_name\": pn,\n \"icon\": pi,\n \"script_path\": script_path_str,\n }\n\n _cached_pages = pages\n\n return pages\n\n\ndef register_pages_changed_callback(\n callback: Callable[[str], None],\n):\n def disconnect():\n _on_pages_changed.disconnect(callback)\n\n # weak=False so that we have control of when the pages changed\n # callback is deregistered.\n _on_pages_changed.connect(callback, weak=False)\n\n return disconnect\n", "path": "lib/streamlit/source_util.py"}]}
| 3,524 | 175 |
gh_patches_debug_52453
|
rasdani/github-patches
|
git_diff
|
ipython__ipython-7492
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
nbformat v2 notebook with missing 'stream' key in stream outputs
@stefanv just sent me an nbformat 2 notebook which was missing the 'stream' keys in stream outputs, and failed to open in current master because of this.
@minrk , can you remember if that was ever a valid option in the notebook format? If so, we should support it. If not, we can write it off as having been saved by some broken development version of IPython.
</issue>
<code>
[start of IPython/nbformat/v4/convert.py]
1 """Code for converting notebooks to and from v3."""
2
3 # Copyright (c) IPython Development Team.
4 # Distributed under the terms of the Modified BSD License.
5
6 import json
7 import re
8
9 from .nbbase import (
10 nbformat, nbformat_minor,
11 NotebookNode,
12 )
13
14 from IPython.nbformat import v3
15 from IPython.utils.log import get_logger
16
17 def _warn_if_invalid(nb, version):
18 """Log validation errors, if there are any."""
19 from IPython.nbformat import validate, ValidationError
20 try:
21 validate(nb, version=version)
22 except ValidationError as e:
23 get_logger().error("Notebook JSON is not valid v%i: %s", version, e)
24
25 def upgrade(nb, from_version=3, from_minor=0):
26 """Convert a notebook to v4.
27
28 Parameters
29 ----------
30 nb : NotebookNode
31 The Python representation of the notebook to convert.
32 from_version : int
33 The original version of the notebook to convert.
34 from_minor : int
35 The original minor version of the notebook to convert (only relevant for v >= 3).
36 """
37 if from_version == 3:
38 # Validate the notebook before conversion
39 _warn_if_invalid(nb, from_version)
40
41 # Mark the original nbformat so consumers know it has been converted
42 orig_nbformat = nb.pop('orig_nbformat', None)
43 nb.metadata.orig_nbformat = orig_nbformat or 3
44
45 # Mark the new format
46 nb.nbformat = nbformat
47 nb.nbformat_minor = nbformat_minor
48
49 # remove worksheet(s)
50 nb['cells'] = cells = []
51 # In the unlikely event of multiple worksheets,
52 # they will be flattened
53 for ws in nb.pop('worksheets', []):
54 # upgrade each cell
55 for cell in ws['cells']:
56 cells.append(upgrade_cell(cell))
57 # upgrade metadata
58 nb.metadata.pop('name', '')
59 nb.metadata.pop('signature', '')
60 # Validate the converted notebook before returning it
61 _warn_if_invalid(nb, nbformat)
62 return nb
63 elif from_version == 4:
64 # nothing to do
65 if from_minor != nbformat_minor:
66 nb.metadata.orig_nbformat_minor = from_minor
67 nb.nbformat_minor = nbformat_minor
68
69 return nb
70 else:
71 raise ValueError('Cannot convert a notebook directly from v%s to v4. ' \
72 'Try using the IPython.nbformat.convert module.' % from_version)
73
74 def upgrade_cell(cell):
75 """upgrade a cell from v3 to v4
76
77 heading cell:
78 - -> markdown heading
79 code cell:
80 - remove language metadata
81 - cell.input -> cell.source
82 - cell.prompt_number -> cell.execution_count
83 - update outputs
84 """
85 cell.setdefault('metadata', NotebookNode())
86 if cell.cell_type == 'code':
87 cell.pop('language', '')
88 if 'collapsed' in cell:
89 cell.metadata['collapsed'] = cell.pop('collapsed')
90 cell.source = cell.pop('input', '')
91 cell.execution_count = cell.pop('prompt_number', None)
92 cell.outputs = upgrade_outputs(cell.outputs)
93 elif cell.cell_type == 'heading':
94 cell.cell_type = 'markdown'
95 level = cell.pop('level', 1)
96 cell.source = u'{hashes} {single_line}'.format(
97 hashes='#' * level,
98 single_line = ' '.join(cell.get('source', '').splitlines()),
99 )
100 elif cell.cell_type == 'html':
101 # Technically, this exists. It will never happen in practice.
102 cell.cell_type = 'markdown'
103 return cell
104
105 def downgrade_cell(cell):
106 """downgrade a cell from v4 to v3
107
108 code cell:
109 - set cell.language
110 - cell.input <- cell.source
111 - cell.prompt_number <- cell.execution_count
112 - update outputs
113 markdown cell:
114 - single-line heading -> heading cell
115 """
116 if cell.cell_type == 'code':
117 cell.language = 'python'
118 cell.input = cell.pop('source', '')
119 cell.prompt_number = cell.pop('execution_count', None)
120 cell.collapsed = cell.metadata.pop('collapsed', False)
121 cell.outputs = downgrade_outputs(cell.outputs)
122 elif cell.cell_type == 'markdown':
123 source = cell.get('source', '')
124 if '\n' not in source and source.startswith('#'):
125 prefix, text = re.match(r'(#+)\s*(.*)', source).groups()
126 cell.cell_type = 'heading'
127 cell.source = text
128 cell.level = len(prefix)
129 return cell
130
131 _mime_map = {
132 "text" : "text/plain",
133 "html" : "text/html",
134 "svg" : "image/svg+xml",
135 "png" : "image/png",
136 "jpeg" : "image/jpeg",
137 "latex" : "text/latex",
138 "json" : "application/json",
139 "javascript" : "application/javascript",
140 };
141
142 def to_mime_key(d):
143 """convert dict with v3 aliases to plain mime-type keys"""
144 for alias, mime in _mime_map.items():
145 if alias in d:
146 d[mime] = d.pop(alias)
147 return d
148
149 def from_mime_key(d):
150 """convert dict with mime-type keys to v3 aliases"""
151 for alias, mime in _mime_map.items():
152 if mime in d:
153 d[alias] = d.pop(mime)
154 return d
155
156 def upgrade_output(output):
157 """upgrade a single code cell output from v3 to v4
158
159 - pyout -> execute_result
160 - pyerr -> error
161 - output.type -> output.data.mime/type
162 - mime-type keys
163 - stream.stream -> stream.name
164 """
165 if output['output_type'] in {'pyout', 'display_data'}:
166 output.setdefault('metadata', NotebookNode())
167 if output['output_type'] == 'pyout':
168 output['output_type'] = 'execute_result'
169 output['execution_count'] = output.pop('prompt_number', None)
170
171 # move output data into data sub-dict
172 data = {}
173 for key in list(output):
174 if key in {'output_type', 'execution_count', 'metadata'}:
175 continue
176 data[key] = output.pop(key)
177 to_mime_key(data)
178 output['data'] = data
179 to_mime_key(output.metadata)
180 if 'application/json' in data:
181 data['application/json'] = json.loads(data['application/json'])
182 # promote ascii bytes (from v2) to unicode
183 for key in ('image/png', 'image/jpeg'):
184 if key in data and isinstance(data[key], bytes):
185 data[key] = data[key].decode('ascii')
186 elif output['output_type'] == 'pyerr':
187 output['output_type'] = 'error'
188 elif output['output_type'] == 'stream':
189 output['name'] = output.pop('stream')
190 return output
191
192 def downgrade_output(output):
193 """downgrade a single code cell output to v3 from v4
194
195 - pyout <- execute_result
196 - pyerr <- error
197 - output.data.mime/type -> output.type
198 - un-mime-type keys
199 - stream.stream <- stream.name
200 """
201 if output['output_type'] in {'execute_result', 'display_data'}:
202 if output['output_type'] == 'execute_result':
203 output['output_type'] = 'pyout'
204 output['prompt_number'] = output.pop('execution_count', None)
205
206 # promote data dict to top-level output namespace
207 data = output.pop('data', {})
208 if 'application/json' in data:
209 data['application/json'] = json.dumps(data['application/json'])
210 from_mime_key(data)
211 output.update(data)
212 from_mime_key(output.get('metadata', {}))
213 elif output['output_type'] == 'error':
214 output['output_type'] = 'pyerr'
215 elif output['output_type'] == 'stream':
216 output['stream'] = output.pop('name')
217 return output
218
219 def upgrade_outputs(outputs):
220 """upgrade outputs of a code cell from v3 to v4"""
221 return [upgrade_output(op) for op in outputs]
222
223 def downgrade_outputs(outputs):
224 """downgrade outputs of a code cell to v3 from v4"""
225 return [downgrade_output(op) for op in outputs]
226
227 def downgrade(nb):
228 """Convert a v4 notebook to v3.
229
230 Parameters
231 ----------
232 nb : NotebookNode
233 The Python representation of the notebook to convert.
234 """
235 if nb.nbformat != nbformat:
236 return nb
237
238 # Validate the notebook before conversion
239 _warn_if_invalid(nb, nbformat)
240
241 nb.nbformat = v3.nbformat
242 nb.nbformat_minor = v3.nbformat_minor
243 cells = [ downgrade_cell(cell) for cell in nb.pop('cells') ]
244 nb.worksheets = [v3.new_worksheet(cells=cells)]
245 nb.metadata.setdefault('name', '')
246
247 # Validate the converted notebook before returning it
248 _warn_if_invalid(nb, v3.nbformat)
249
250 nb.orig_nbformat = nb.metadata.pop('orig_nbformat', nbformat)
251 nb.orig_nbformat_minor = nb.metadata.pop('orig_nbformat_minor', nbformat_minor)
252
253 return nb
254
[end of IPython/nbformat/v4/convert.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/IPython/nbformat/v4/convert.py b/IPython/nbformat/v4/convert.py
--- a/IPython/nbformat/v4/convert.py
+++ b/IPython/nbformat/v4/convert.py
@@ -186,7 +186,7 @@
elif output['output_type'] == 'pyerr':
output['output_type'] = 'error'
elif output['output_type'] == 'stream':
- output['name'] = output.pop('stream')
+ output['name'] = output.pop('stream', 'stdout')
return output
def downgrade_output(output):
|
{"golden_diff": "diff --git a/IPython/nbformat/v4/convert.py b/IPython/nbformat/v4/convert.py\n--- a/IPython/nbformat/v4/convert.py\n+++ b/IPython/nbformat/v4/convert.py\n@@ -186,7 +186,7 @@\n elif output['output_type'] == 'pyerr':\n output['output_type'] = 'error'\n elif output['output_type'] == 'stream':\n- output['name'] = output.pop('stream')\n+ output['name'] = output.pop('stream', 'stdout')\n return output\n \n def downgrade_output(output):\n", "issue": "nbformat v2 notebook with missing 'stream' key in stream outputs\n@stefanv just sent me an nbformat 2 notebook which was missing the 'stream' keys in stream outputs, and failed to open in current master because of this.\n\n@minrk , can you remember if that was ever a valid option in the notebook format? If so, we should support it. If not, we can write it off as having been saved by some broken development version of IPython. \n\n", "before_files": [{"content": "\"\"\"Code for converting notebooks to and from v3.\"\"\"\n\n# Copyright (c) IPython Development Team.\n# Distributed under the terms of the Modified BSD License.\n\nimport json\nimport re\n\nfrom .nbbase import (\n nbformat, nbformat_minor,\n NotebookNode,\n)\n\nfrom IPython.nbformat import v3\nfrom IPython.utils.log import get_logger\n\ndef _warn_if_invalid(nb, version):\n \"\"\"Log validation errors, if there are any.\"\"\"\n from IPython.nbformat import validate, ValidationError\n try:\n validate(nb, version=version)\n except ValidationError as e:\n get_logger().error(\"Notebook JSON is not valid v%i: %s\", version, e)\n\ndef upgrade(nb, from_version=3, from_minor=0):\n \"\"\"Convert a notebook to v4.\n\n Parameters\n ----------\n nb : NotebookNode\n The Python representation of the notebook to convert.\n from_version : int\n The original version of the notebook to convert.\n from_minor : int\n The original minor version of the notebook to convert (only relevant for v >= 3).\n \"\"\"\n if from_version == 3:\n # Validate the notebook before conversion\n _warn_if_invalid(nb, from_version)\n\n # Mark the original nbformat so consumers know it has been converted\n orig_nbformat = nb.pop('orig_nbformat', None)\n nb.metadata.orig_nbformat = orig_nbformat or 3\n\n # Mark the new format\n nb.nbformat = nbformat\n nb.nbformat_minor = nbformat_minor\n\n # remove worksheet(s)\n nb['cells'] = cells = []\n # In the unlikely event of multiple worksheets,\n # they will be flattened\n for ws in nb.pop('worksheets', []):\n # upgrade each cell\n for cell in ws['cells']:\n cells.append(upgrade_cell(cell))\n # upgrade metadata\n nb.metadata.pop('name', '')\n nb.metadata.pop('signature', '')\n # Validate the converted notebook before returning it\n _warn_if_invalid(nb, nbformat)\n return nb\n elif from_version == 4:\n # nothing to do\n if from_minor != nbformat_minor:\n nb.metadata.orig_nbformat_minor = from_minor\n nb.nbformat_minor = nbformat_minor\n\n return nb\n else:\n raise ValueError('Cannot convert a notebook directly from v%s to v4. ' \\\n 'Try using the IPython.nbformat.convert module.' % from_version)\n\ndef upgrade_cell(cell):\n \"\"\"upgrade a cell from v3 to v4\n\n heading cell:\n - -> markdown heading\n code cell:\n - remove language metadata\n - cell.input -> cell.source\n - cell.prompt_number -> cell.execution_count\n - update outputs\n \"\"\"\n cell.setdefault('metadata', NotebookNode())\n if cell.cell_type == 'code':\n cell.pop('language', '')\n if 'collapsed' in cell:\n cell.metadata['collapsed'] = cell.pop('collapsed')\n cell.source = cell.pop('input', '')\n cell.execution_count = cell.pop('prompt_number', None)\n cell.outputs = upgrade_outputs(cell.outputs)\n elif cell.cell_type == 'heading':\n cell.cell_type = 'markdown'\n level = cell.pop('level', 1)\n cell.source = u'{hashes} {single_line}'.format(\n hashes='#' * level,\n single_line = ' '.join(cell.get('source', '').splitlines()),\n )\n elif cell.cell_type == 'html':\n # Technically, this exists. It will never happen in practice.\n cell.cell_type = 'markdown'\n return cell\n\ndef downgrade_cell(cell):\n \"\"\"downgrade a cell from v4 to v3\n\n code cell:\n - set cell.language\n - cell.input <- cell.source\n - cell.prompt_number <- cell.execution_count\n - update outputs\n markdown cell:\n - single-line heading -> heading cell\n \"\"\"\n if cell.cell_type == 'code':\n cell.language = 'python'\n cell.input = cell.pop('source', '')\n cell.prompt_number = cell.pop('execution_count', None)\n cell.collapsed = cell.metadata.pop('collapsed', False)\n cell.outputs = downgrade_outputs(cell.outputs)\n elif cell.cell_type == 'markdown':\n source = cell.get('source', '')\n if '\\n' not in source and source.startswith('#'):\n prefix, text = re.match(r'(#+)\\s*(.*)', source).groups()\n cell.cell_type = 'heading'\n cell.source = text\n cell.level = len(prefix)\n return cell\n\n_mime_map = {\n \"text\" : \"text/plain\",\n \"html\" : \"text/html\",\n \"svg\" : \"image/svg+xml\",\n \"png\" : \"image/png\",\n \"jpeg\" : \"image/jpeg\",\n \"latex\" : \"text/latex\",\n \"json\" : \"application/json\",\n \"javascript\" : \"application/javascript\",\n};\n\ndef to_mime_key(d):\n \"\"\"convert dict with v3 aliases to plain mime-type keys\"\"\"\n for alias, mime in _mime_map.items():\n if alias in d:\n d[mime] = d.pop(alias)\n return d\n\ndef from_mime_key(d):\n \"\"\"convert dict with mime-type keys to v3 aliases\"\"\"\n for alias, mime in _mime_map.items():\n if mime in d:\n d[alias] = d.pop(mime)\n return d\n\ndef upgrade_output(output):\n \"\"\"upgrade a single code cell output from v3 to v4\n\n - pyout -> execute_result\n - pyerr -> error\n - output.type -> output.data.mime/type\n - mime-type keys\n - stream.stream -> stream.name\n \"\"\"\n if output['output_type'] in {'pyout', 'display_data'}:\n output.setdefault('metadata', NotebookNode())\n if output['output_type'] == 'pyout':\n output['output_type'] = 'execute_result'\n output['execution_count'] = output.pop('prompt_number', None)\n\n # move output data into data sub-dict\n data = {}\n for key in list(output):\n if key in {'output_type', 'execution_count', 'metadata'}:\n continue\n data[key] = output.pop(key)\n to_mime_key(data)\n output['data'] = data\n to_mime_key(output.metadata)\n if 'application/json' in data:\n data['application/json'] = json.loads(data['application/json'])\n # promote ascii bytes (from v2) to unicode\n for key in ('image/png', 'image/jpeg'):\n if key in data and isinstance(data[key], bytes):\n data[key] = data[key].decode('ascii')\n elif output['output_type'] == 'pyerr':\n output['output_type'] = 'error'\n elif output['output_type'] == 'stream':\n output['name'] = output.pop('stream')\n return output\n\ndef downgrade_output(output):\n \"\"\"downgrade a single code cell output to v3 from v4\n\n - pyout <- execute_result\n - pyerr <- error\n - output.data.mime/type -> output.type\n - un-mime-type keys\n - stream.stream <- stream.name\n \"\"\"\n if output['output_type'] in {'execute_result', 'display_data'}:\n if output['output_type'] == 'execute_result':\n output['output_type'] = 'pyout'\n output['prompt_number'] = output.pop('execution_count', None)\n\n # promote data dict to top-level output namespace\n data = output.pop('data', {})\n if 'application/json' in data:\n data['application/json'] = json.dumps(data['application/json'])\n from_mime_key(data)\n output.update(data)\n from_mime_key(output.get('metadata', {}))\n elif output['output_type'] == 'error':\n output['output_type'] = 'pyerr'\n elif output['output_type'] == 'stream':\n output['stream'] = output.pop('name')\n return output\n\ndef upgrade_outputs(outputs):\n \"\"\"upgrade outputs of a code cell from v3 to v4\"\"\"\n return [upgrade_output(op) for op in outputs]\n\ndef downgrade_outputs(outputs):\n \"\"\"downgrade outputs of a code cell to v3 from v4\"\"\"\n return [downgrade_output(op) for op in outputs]\n\ndef downgrade(nb):\n \"\"\"Convert a v4 notebook to v3.\n\n Parameters\n ----------\n nb : NotebookNode\n The Python representation of the notebook to convert.\n \"\"\"\n if nb.nbformat != nbformat:\n return nb\n\n # Validate the notebook before conversion\n _warn_if_invalid(nb, nbformat)\n\n nb.nbformat = v3.nbformat\n nb.nbformat_minor = v3.nbformat_minor\n cells = [ downgrade_cell(cell) for cell in nb.pop('cells') ]\n nb.worksheets = [v3.new_worksheet(cells=cells)]\n nb.metadata.setdefault('name', '')\n \n # Validate the converted notebook before returning it\n _warn_if_invalid(nb, v3.nbformat)\n \n nb.orig_nbformat = nb.metadata.pop('orig_nbformat', nbformat)\n nb.orig_nbformat_minor = nb.metadata.pop('orig_nbformat_minor', nbformat_minor)\n \n return nb\n", "path": "IPython/nbformat/v4/convert.py"}]}
| 3,291 | 135 |
gh_patches_debug_29363
|
rasdani/github-patches
|
git_diff
|
TheAlgorithms__Python-7394
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[PYTEST WARNING] Decision tree
### Feature description
@nbrgr @hrishi84 @cclauss Please could you resolve this warning
```
machine_learning/decision_tree.py::machine_learning.decision_tree.DecisionTree.mean_squared_error
<doctest machine_learning.decision_tree.DecisionTree.mean_squared_error[2]>:1: DeprecationWarning: `np.float` is a deprecated alias for the builtin `float`. To silence this warning, use `float` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.float64` here.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
machine_learning/decision_tree.py::machine_learning.decision_tree.DecisionTree.mean_squared_error
machine_learning/decision_tree.py::machine_learning.decision_tree.DecisionTree.mean_squared_error
/home/runner/work/Python/Python/machine_learning/decision_tree.py:148: DeprecationWarning: `np.float` is a deprecated alias for the builtin `float`. To silence this warning, use `float` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.float64` here.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
squared_error_sum = np.float(0)
machine_learning/decision_tree.py::machine_learning.decision_tree.DecisionTree.mean_squared_error
machine_learning/decision_tree.py::machine_learning.decision_tree.DecisionTree.mean_squared_error
/home/runner/work/Python/Python/machine_learning/decision_tree.py:152: DeprecationWarning: `np.float` is a deprecated alias for the builtin `float`. To silence this warning, use `float` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.float64` here.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
return np.float(squared_error_sum / labels.size)
machine_learning/decision_tree.py::machine_learning.decision_tree.DecisionTree.mean_squared_error
<doctest machine_learning.decision_tree.DecisionTree.mean_squared_error[5]>:1: DeprecationWarning: `np.float` is a deprecated alias for the builtin `float`. To silence this warning, use `float` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.float64` here.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
```
origin: #7211
</issue>
<code>
[start of machine_learning/decision_tree.py]
1 """
2 Implementation of a basic regression decision tree.
3 Input data set: The input data set must be 1-dimensional with continuous labels.
4 Output: The decision tree maps a real number input to a real number output.
5 """
6 import numpy as np
7
8
9 class DecisionTree:
10 def __init__(self, depth=5, min_leaf_size=5):
11 self.depth = depth
12 self.decision_boundary = 0
13 self.left = None
14 self.right = None
15 self.min_leaf_size = min_leaf_size
16 self.prediction = None
17
18 def mean_squared_error(self, labels, prediction):
19 """
20 mean_squared_error:
21 @param labels: a one dimensional numpy array
22 @param prediction: a floating point value
23 return value: mean_squared_error calculates the error if prediction is used to
24 estimate the labels
25 >>> tester = DecisionTree()
26 >>> test_labels = np.array([1,2,3,4,5,6,7,8,9,10])
27 >>> test_prediction = np.float(6)
28 >>> tester.mean_squared_error(test_labels, test_prediction) == (
29 ... TestDecisionTree.helper_mean_squared_error_test(test_labels,
30 ... test_prediction))
31 True
32 >>> test_labels = np.array([1,2,3])
33 >>> test_prediction = np.float(2)
34 >>> tester.mean_squared_error(test_labels, test_prediction) == (
35 ... TestDecisionTree.helper_mean_squared_error_test(test_labels,
36 ... test_prediction))
37 True
38 """
39 if labels.ndim != 1:
40 print("Error: Input labels must be one dimensional")
41
42 return np.mean((labels - prediction) ** 2)
43
44 def train(self, x, y):
45 """
46 train:
47 @param x: a one dimensional numpy array
48 @param y: a one dimensional numpy array.
49 The contents of y are the labels for the corresponding X values
50
51 train does not have a return value
52 """
53
54 """
55 this section is to check that the inputs conform to our dimensionality
56 constraints
57 """
58 if x.ndim != 1:
59 print("Error: Input data set must be one dimensional")
60 return
61 if len(x) != len(y):
62 print("Error: X and y have different lengths")
63 return
64 if y.ndim != 1:
65 print("Error: Data set labels must be one dimensional")
66 return
67
68 if len(x) < 2 * self.min_leaf_size:
69 self.prediction = np.mean(y)
70 return
71
72 if self.depth == 1:
73 self.prediction = np.mean(y)
74 return
75
76 best_split = 0
77 min_error = self.mean_squared_error(x, np.mean(y)) * 2
78
79 """
80 loop over all possible splits for the decision tree. find the best split.
81 if no split exists that is less than 2 * error for the entire array
82 then the data set is not split and the average for the entire array is used as
83 the predictor
84 """
85 for i in range(len(x)):
86 if len(x[:i]) < self.min_leaf_size:
87 continue
88 elif len(x[i:]) < self.min_leaf_size:
89 continue
90 else:
91 error_left = self.mean_squared_error(x[:i], np.mean(y[:i]))
92 error_right = self.mean_squared_error(x[i:], np.mean(y[i:]))
93 error = error_left + error_right
94 if error < min_error:
95 best_split = i
96 min_error = error
97
98 if best_split != 0:
99 left_x = x[:best_split]
100 left_y = y[:best_split]
101 right_x = x[best_split:]
102 right_y = y[best_split:]
103
104 self.decision_boundary = x[best_split]
105 self.left = DecisionTree(
106 depth=self.depth - 1, min_leaf_size=self.min_leaf_size
107 )
108 self.right = DecisionTree(
109 depth=self.depth - 1, min_leaf_size=self.min_leaf_size
110 )
111 self.left.train(left_x, left_y)
112 self.right.train(right_x, right_y)
113 else:
114 self.prediction = np.mean(y)
115
116 return
117
118 def predict(self, x):
119 """
120 predict:
121 @param x: a floating point value to predict the label of
122 the prediction function works by recursively calling the predict function
123 of the appropriate subtrees based on the tree's decision boundary
124 """
125 if self.prediction is not None:
126 return self.prediction
127 elif self.left or self.right is not None:
128 if x >= self.decision_boundary:
129 return self.right.predict(x)
130 else:
131 return self.left.predict(x)
132 else:
133 print("Error: Decision tree not yet trained")
134 return None
135
136
137 class TestDecisionTree:
138 """Decision Tres test class"""
139
140 @staticmethod
141 def helper_mean_squared_error_test(labels, prediction):
142 """
143 helper_mean_squared_error_test:
144 @param labels: a one dimensional numpy array
145 @param prediction: a floating point value
146 return value: helper_mean_squared_error_test calculates the mean squared error
147 """
148 squared_error_sum = np.float(0)
149 for label in labels:
150 squared_error_sum += (label - prediction) ** 2
151
152 return np.float(squared_error_sum / labels.size)
153
154
155 def main():
156 """
157 In this demonstration we're generating a sample data set from the sin function in
158 numpy. We then train a decision tree on the data set and use the decision tree to
159 predict the label of 10 different test values. Then the mean squared error over
160 this test is displayed.
161 """
162 x = np.arange(-1.0, 1.0, 0.005)
163 y = np.sin(x)
164
165 tree = DecisionTree(depth=10, min_leaf_size=10)
166 tree.train(x, y)
167
168 test_cases = (np.random.rand(10) * 2) - 1
169 predictions = np.array([tree.predict(x) for x in test_cases])
170 avg_error = np.mean((predictions - test_cases) ** 2)
171
172 print("Test values: " + str(test_cases))
173 print("Predictions: " + str(predictions))
174 print("Average error: " + str(avg_error))
175
176
177 if __name__ == "__main__":
178 main()
179 import doctest
180
181 doctest.testmod(name="mean_squarred_error", verbose=True)
182
[end of machine_learning/decision_tree.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/machine_learning/decision_tree.py b/machine_learning/decision_tree.py
--- a/machine_learning/decision_tree.py
+++ b/machine_learning/decision_tree.py
@@ -24,13 +24,13 @@
estimate the labels
>>> tester = DecisionTree()
>>> test_labels = np.array([1,2,3,4,5,6,7,8,9,10])
- >>> test_prediction = np.float(6)
+ >>> test_prediction = float(6)
>>> tester.mean_squared_error(test_labels, test_prediction) == (
... TestDecisionTree.helper_mean_squared_error_test(test_labels,
... test_prediction))
True
>>> test_labels = np.array([1,2,3])
- >>> test_prediction = np.float(2)
+ >>> test_prediction = float(2)
>>> tester.mean_squared_error(test_labels, test_prediction) == (
... TestDecisionTree.helper_mean_squared_error_test(test_labels,
... test_prediction))
@@ -145,11 +145,11 @@
@param prediction: a floating point value
return value: helper_mean_squared_error_test calculates the mean squared error
"""
- squared_error_sum = np.float(0)
+ squared_error_sum = float(0)
for label in labels:
squared_error_sum += (label - prediction) ** 2
- return np.float(squared_error_sum / labels.size)
+ return float(squared_error_sum / labels.size)
def main():
|
{"golden_diff": "diff --git a/machine_learning/decision_tree.py b/machine_learning/decision_tree.py\n--- a/machine_learning/decision_tree.py\n+++ b/machine_learning/decision_tree.py\n@@ -24,13 +24,13 @@\n estimate the labels\n >>> tester = DecisionTree()\n >>> test_labels = np.array([1,2,3,4,5,6,7,8,9,10])\n- >>> test_prediction = np.float(6)\n+ >>> test_prediction = float(6)\n >>> tester.mean_squared_error(test_labels, test_prediction) == (\n ... TestDecisionTree.helper_mean_squared_error_test(test_labels,\n ... test_prediction))\n True\n >>> test_labels = np.array([1,2,3])\n- >>> test_prediction = np.float(2)\n+ >>> test_prediction = float(2)\n >>> tester.mean_squared_error(test_labels, test_prediction) == (\n ... TestDecisionTree.helper_mean_squared_error_test(test_labels,\n ... test_prediction))\n@@ -145,11 +145,11 @@\n @param prediction: a floating point value\n return value: helper_mean_squared_error_test calculates the mean squared error\n \"\"\"\n- squared_error_sum = np.float(0)\n+ squared_error_sum = float(0)\n for label in labels:\n squared_error_sum += (label - prediction) ** 2\n \n- return np.float(squared_error_sum / labels.size)\n+ return float(squared_error_sum / labels.size)\n \n \n def main():\n", "issue": "[PYTEST WARNING] Decision tree\n### Feature description\n\n@nbrgr @hrishi84 @cclauss Please could you resolve this warning\r\n```\r\nmachine_learning/decision_tree.py::machine_learning.decision_tree.DecisionTree.mean_squared_error\r\n <doctest machine_learning.decision_tree.DecisionTree.mean_squared_error[2]>:1: DeprecationWarning: `np.float` is a deprecated alias for the builtin `float`. To silence this warning, use `float` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.float64` here.\r\n Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations\r\n\r\nmachine_learning/decision_tree.py::machine_learning.decision_tree.DecisionTree.mean_squared_error\r\nmachine_learning/decision_tree.py::machine_learning.decision_tree.DecisionTree.mean_squared_error\r\n /home/runner/work/Python/Python/machine_learning/decision_tree.py:148: DeprecationWarning: `np.float` is a deprecated alias for the builtin `float`. To silence this warning, use `float` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.float64` here.\r\n Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations\r\n squared_error_sum = np.float(0)\r\n\r\nmachine_learning/decision_tree.py::machine_learning.decision_tree.DecisionTree.mean_squared_error\r\nmachine_learning/decision_tree.py::machine_learning.decision_tree.DecisionTree.mean_squared_error\r\n /home/runner/work/Python/Python/machine_learning/decision_tree.py:152: DeprecationWarning: `np.float` is a deprecated alias for the builtin `float`. To silence this warning, use `float` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.float64` here.\r\n Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations\r\n return np.float(squared_error_sum / labels.size)\r\n\r\nmachine_learning/decision_tree.py::machine_learning.decision_tree.DecisionTree.mean_squared_error\r\n <doctest machine_learning.decision_tree.DecisionTree.mean_squared_error[5]>:1: DeprecationWarning: `np.float` is a deprecated alias for the builtin `float`. To silence this warning, use `float` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.float64` here.\r\n Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations\r\n```\r\n\r\norigin: #7211\n", "before_files": [{"content": "\"\"\"\nImplementation of a basic regression decision tree.\nInput data set: The input data set must be 1-dimensional with continuous labels.\nOutput: The decision tree maps a real number input to a real number output.\n\"\"\"\nimport numpy as np\n\n\nclass DecisionTree:\n def __init__(self, depth=5, min_leaf_size=5):\n self.depth = depth\n self.decision_boundary = 0\n self.left = None\n self.right = None\n self.min_leaf_size = min_leaf_size\n self.prediction = None\n\n def mean_squared_error(self, labels, prediction):\n \"\"\"\n mean_squared_error:\n @param labels: a one dimensional numpy array\n @param prediction: a floating point value\n return value: mean_squared_error calculates the error if prediction is used to\n estimate the labels\n >>> tester = DecisionTree()\n >>> test_labels = np.array([1,2,3,4,5,6,7,8,9,10])\n >>> test_prediction = np.float(6)\n >>> tester.mean_squared_error(test_labels, test_prediction) == (\n ... TestDecisionTree.helper_mean_squared_error_test(test_labels,\n ... test_prediction))\n True\n >>> test_labels = np.array([1,2,3])\n >>> test_prediction = np.float(2)\n >>> tester.mean_squared_error(test_labels, test_prediction) == (\n ... TestDecisionTree.helper_mean_squared_error_test(test_labels,\n ... test_prediction))\n True\n \"\"\"\n if labels.ndim != 1:\n print(\"Error: Input labels must be one dimensional\")\n\n return np.mean((labels - prediction) ** 2)\n\n def train(self, x, y):\n \"\"\"\n train:\n @param x: a one dimensional numpy array\n @param y: a one dimensional numpy array.\n The contents of y are the labels for the corresponding X values\n\n train does not have a return value\n \"\"\"\n\n \"\"\"\n this section is to check that the inputs conform to our dimensionality\n constraints\n \"\"\"\n if x.ndim != 1:\n print(\"Error: Input data set must be one dimensional\")\n return\n if len(x) != len(y):\n print(\"Error: X and y have different lengths\")\n return\n if y.ndim != 1:\n print(\"Error: Data set labels must be one dimensional\")\n return\n\n if len(x) < 2 * self.min_leaf_size:\n self.prediction = np.mean(y)\n return\n\n if self.depth == 1:\n self.prediction = np.mean(y)\n return\n\n best_split = 0\n min_error = self.mean_squared_error(x, np.mean(y)) * 2\n\n \"\"\"\n loop over all possible splits for the decision tree. find the best split.\n if no split exists that is less than 2 * error for the entire array\n then the data set is not split and the average for the entire array is used as\n the predictor\n \"\"\"\n for i in range(len(x)):\n if len(x[:i]) < self.min_leaf_size:\n continue\n elif len(x[i:]) < self.min_leaf_size:\n continue\n else:\n error_left = self.mean_squared_error(x[:i], np.mean(y[:i]))\n error_right = self.mean_squared_error(x[i:], np.mean(y[i:]))\n error = error_left + error_right\n if error < min_error:\n best_split = i\n min_error = error\n\n if best_split != 0:\n left_x = x[:best_split]\n left_y = y[:best_split]\n right_x = x[best_split:]\n right_y = y[best_split:]\n\n self.decision_boundary = x[best_split]\n self.left = DecisionTree(\n depth=self.depth - 1, min_leaf_size=self.min_leaf_size\n )\n self.right = DecisionTree(\n depth=self.depth - 1, min_leaf_size=self.min_leaf_size\n )\n self.left.train(left_x, left_y)\n self.right.train(right_x, right_y)\n else:\n self.prediction = np.mean(y)\n\n return\n\n def predict(self, x):\n \"\"\"\n predict:\n @param x: a floating point value to predict the label of\n the prediction function works by recursively calling the predict function\n of the appropriate subtrees based on the tree's decision boundary\n \"\"\"\n if self.prediction is not None:\n return self.prediction\n elif self.left or self.right is not None:\n if x >= self.decision_boundary:\n return self.right.predict(x)\n else:\n return self.left.predict(x)\n else:\n print(\"Error: Decision tree not yet trained\")\n return None\n\n\nclass TestDecisionTree:\n \"\"\"Decision Tres test class\"\"\"\n\n @staticmethod\n def helper_mean_squared_error_test(labels, prediction):\n \"\"\"\n helper_mean_squared_error_test:\n @param labels: a one dimensional numpy array\n @param prediction: a floating point value\n return value: helper_mean_squared_error_test calculates the mean squared error\n \"\"\"\n squared_error_sum = np.float(0)\n for label in labels:\n squared_error_sum += (label - prediction) ** 2\n\n return np.float(squared_error_sum / labels.size)\n\n\ndef main():\n \"\"\"\n In this demonstration we're generating a sample data set from the sin function in\n numpy. We then train a decision tree on the data set and use the decision tree to\n predict the label of 10 different test values. Then the mean squared error over\n this test is displayed.\n \"\"\"\n x = np.arange(-1.0, 1.0, 0.005)\n y = np.sin(x)\n\n tree = DecisionTree(depth=10, min_leaf_size=10)\n tree.train(x, y)\n\n test_cases = (np.random.rand(10) * 2) - 1\n predictions = np.array([tree.predict(x) for x in test_cases])\n avg_error = np.mean((predictions - test_cases) ** 2)\n\n print(\"Test values: \" + str(test_cases))\n print(\"Predictions: \" + str(predictions))\n print(\"Average error: \" + str(avg_error))\n\n\nif __name__ == \"__main__\":\n main()\n import doctest\n\n doctest.testmod(name=\"mean_squarred_error\", verbose=True)\n", "path": "machine_learning/decision_tree.py"}]}
| 3,028 | 335 |
gh_patches_debug_45632
|
rasdani/github-patches
|
git_diff
|
kubeflow__pipelines-5250
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
BrokenPipe for ml engine train component
### What steps did you take:
ML engine train component throws BrokenPipe Error after around 30 minutes of continuous training. This is not a one-off situation but jobs keep failing.
### What happened:
### What did you expect to happen:
### Environment:
<!-- Please fill in those that seem relevant. -->
How did you deploy Kubeflow Pipelines (KFP)?
Kubeflow Pipelines was deployed using gcp "ai platform pipelines" tool.
Kubeflow Pipelines 1.0.4
Kubernetes: 1.17.14-gke.1600
```
ML_ENGINE_TRAIN_OP = comp.load_component_from_url(
"https://raw.githubusercontent.com/kubeflow/pipelines/1.3.0/components/gcp/ml_engine/train/component.yaml"
)
```
<!-- If you are not sure, here's [an introduction of all options](https://www.kubeflow.org/docs/pipelines/installation/overview/). -->
KFP version: 1.0.4
KFP SDK version: 1.3.0
### Anything else you would like to add:
[Miscellaneous information that will assist in solving the issue.]
/kind bug
<!-- Please include labels by uncommenting them to help us better triage issues, choose from the following -->
<!--
// /area frontend
// /area backend
// /area sdk
// /area testing
// /area engprod
-->
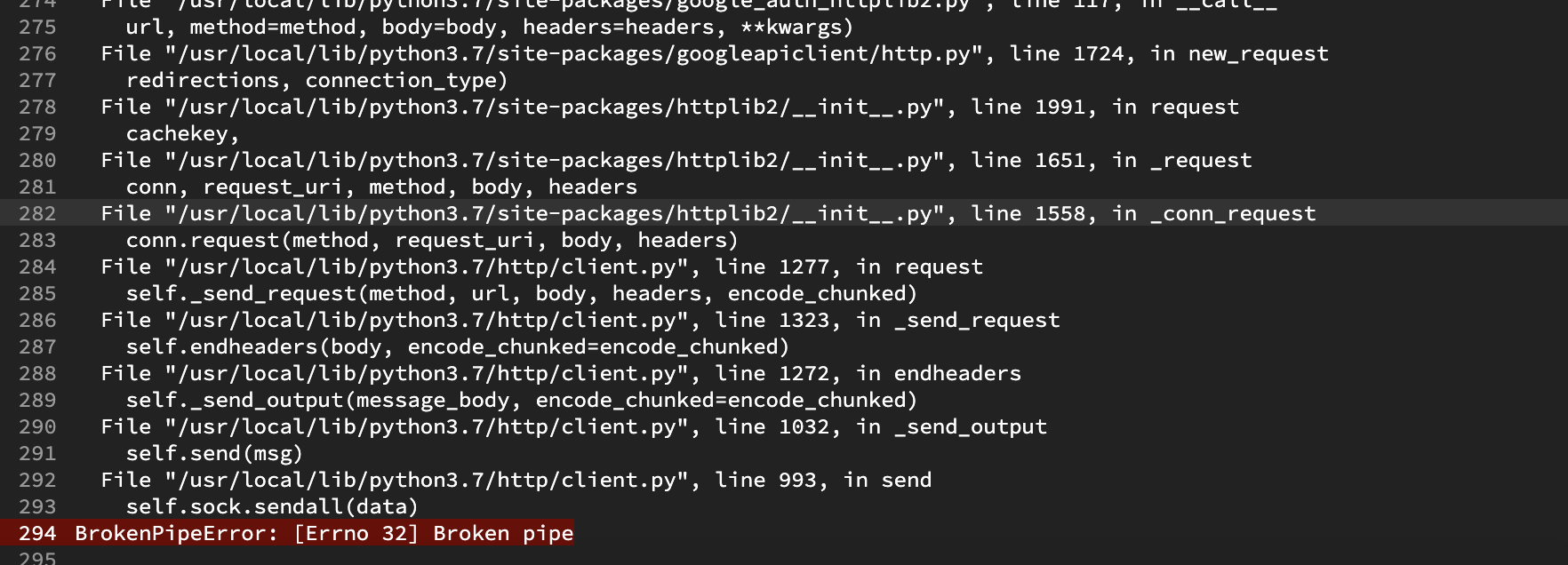
</issue>
<code>
[start of components/gcp/container/component_sdk/python/kfp_component/google/ml_engine/_client.py]
1 # Copyright 2018 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import logging
16 import time
17
18 import googleapiclient.discovery as discovery
19 from googleapiclient import errors
20 from ..common import wait_operation_done
21
22 class MLEngineClient:
23 """ Client for calling MLEngine APIs.
24 """
25 def __init__(self):
26 self._ml_client = discovery.build('ml', 'v1', cache_discovery=False)
27
28 def create_job(self, project_id, job):
29 """Create a new job.
30
31 Args:
32 project_id: the ID of the parent project.
33 job: the payload of the job.
34
35 Returns:
36 The created job.
37 """
38 return self._ml_client.projects().jobs().create(
39 parent = 'projects/{}'.format(project_id),
40 body = job
41 ).execute()
42
43 def cancel_job(self, project_id, job_id):
44 """Cancel the specified job.
45
46 Args:
47 project_id: the parent project ID of the job.
48 job_id: the ID of the job.
49 """
50 job_name = 'projects/{}/jobs/{}'.format(project_id, job_id)
51 self._ml_client.projects().jobs().cancel(
52 name = job_name,
53 body = {
54 'name': job_name
55 },
56 ).execute()
57
58 def get_job(self, project_id, job_id):
59 """Gets the job by ID.
60
61 Args:
62 project_id: the ID of the parent project.
63 job_id: the ID of the job to retrieve.
64 Returns:
65 The retrieved job payload.
66 """
67 job_name = 'projects/{}/jobs/{}'.format(project_id, job_id)
68 return self._ml_client.projects().jobs().get(
69 name=job_name).execute()
70
71 def create_model(self, project_id, model):
72 """Creates a new model.
73
74 Args:
75 project_id: the ID of the parent project.
76 model: the payload of the model.
77 Returns:
78 The created model.
79 """
80 return self._ml_client.projects().models().create(
81 parent = 'projects/{}'.format(project_id),
82 body = model
83 ).execute()
84
85 def get_model(self, model_name):
86 """Gets a model.
87
88 Args:
89 model_name: the name of the model.
90 Returns:
91 The retrieved model.
92 """
93 return self._ml_client.projects().models().get(
94 name = model_name
95 ).execute()
96
97 def create_version(self, model_name, version):
98 """Creates a new version.
99
100 Args:
101 model_name: the name of the parent model.
102 version: the payload of the version.
103
104 Returns:
105 The created version.
106 """
107 return self._ml_client.projects().models().versions().create(
108 parent = model_name,
109 body = version
110 ).execute()
111
112 def get_version(self, version_name):
113 """Gets a version.
114
115 Args:
116 version_name: the name of the version.
117
118 Returns:
119 The retrieved version. None if the version is not found.
120 """
121 try:
122 return self._ml_client.projects().models().versions().get(
123 name = version_name
124 ).execute()
125 except errors.HttpError as e:
126 if e.resp.status == 404:
127 return None
128 raise
129
130 def delete_version(self, version_name):
131 """Deletes a version.
132
133 Args:
134 version_name: the name of the version.
135
136 Returns:
137 The delete operation. None if the version is not found.
138 """
139 try:
140 return self._ml_client.projects().models().versions().delete(
141 name = version_name
142 ).execute()
143 except errors.HttpError as e:
144 if e.resp.status == 404:
145 logging.info('The version has already been deleted.')
146 return None
147 raise
148
149 def set_default_version(self, version_name):
150 return self._ml_client.projects().models().versions().setDefault(
151 name = version_name
152 ).execute()
153
154 def get_operation(self, operation_name):
155 """Gets an operation.
156
157 Args:
158 operation_name: the name of the operation.
159
160 Returns:
161 The retrieved operation.
162 """
163 return self._ml_client.projects().operations().get(
164 name = operation_name
165 ).execute()
166
167 def wait_for_operation_done(self, operation_name, wait_interval):
168 """Waits for an operation to be done.
169
170 Args:
171 operation_name: the name of the operation.
172 wait_interval: the wait interview between pulling job
173 status.
174
175 Returns:
176 The completed operation.
177 """
178 return wait_operation_done(
179 lambda: self.get_operation(operation_name), wait_interval)
180
181 def cancel_operation(self, operation_name):
182 """Cancels an operation.
183
184 Args:
185 operation_name: the name of the operation.
186 """
187 self._ml_client.projects().operations().cancel(
188 name = operation_name
189 ).execute()
190
[end of components/gcp/container/component_sdk/python/kfp_component/google/ml_engine/_client.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/components/gcp/container/component_sdk/python/kfp_component/google/ml_engine/_client.py b/components/gcp/container/component_sdk/python/kfp_component/google/ml_engine/_client.py
--- a/components/gcp/container/component_sdk/python/kfp_component/google/ml_engine/_client.py
+++ b/components/gcp/container/component_sdk/python/kfp_component/google/ml_engine/_client.py
@@ -12,6 +12,7 @@
# See the License for the specific language governing permissions and
# limitations under the License.
+from functools import wraps
import logging
import time
@@ -19,12 +20,53 @@
from googleapiclient import errors
from ..common import wait_operation_done
+
+def _retry(func, tries=5, delay=1):
+ """Retry decorator for methods in MLEngineClient class.
+
+ It bypasses the BrokenPipeError by directly accessing the `_build_client` method
+ and rebuilds `_ml_client` after `delay` seconds.
+
+ Args:
+ tries (int): Total number of retries if BrokenPipeError/IOError is raised.
+ delay (int): Number of seconds to wait between consecutive retries.
+ """
+
+ @wraps(func)
+ def wrapper(self, *args, **kwargs):
+ _tries, _delay = tries, delay
+ while _tries:
+ try:
+ return func(self, *args, **kwargs)
+ except (BrokenPipeError, IOError) as e:
+ _tries -= 1
+ if not _tries:
+ raise
+
+ logging.warning(
+ 'Caught {}. Retrying in {} seconds...'.format(
+ e._class__.__name__, _delay
+ )
+ )
+
+ time.sleep(_delay)
+ # access _build_client method and rebuild Http Client
+ self._build_client()
+
+ return wrapper
+
+
class MLEngineClient:
""" Client for calling MLEngine APIs.
"""
+
def __init__(self):
+ self._build_client()
+
+ def _build_client(self):
self._ml_client = discovery.build('ml', 'v1', cache_discovery=False)
+ @_retry
def create_job(self, project_id, job):
"""Create a new job.
@@ -40,6 +82,7 @@
body = job
).execute()
+ @_retry
def cancel_job(self, project_id, job_id):
"""Cancel the specified job.
@@ -55,6 +98,7 @@
},
).execute()
+ @_retry
def get_job(self, project_id, job_id):
"""Gets the job by ID.
@@ -68,6 +112,7 @@
return self._ml_client.projects().jobs().get(
name=job_name).execute()
+ @_retry
def create_model(self, project_id, model):
"""Creates a new model.
@@ -82,6 +127,7 @@
body = model
).execute()
+ @_retry
def get_model(self, model_name):
"""Gets a model.
@@ -94,6 +140,7 @@
name = model_name
).execute()
+ @_retry
def create_version(self, model_name, version):
"""Creates a new version.
@@ -109,6 +156,7 @@
body = version
).execute()
+ @_retry
def get_version(self, version_name):
"""Gets a version.
@@ -127,6 +175,7 @@
return None
raise
+ @_retry
def delete_version(self, version_name):
"""Deletes a version.
@@ -146,11 +195,13 @@
return None
raise
+ @_retry
def set_default_version(self, version_name):
return self._ml_client.projects().models().versions().setDefault(
name = version_name
).execute()
+ @_retry
def get_operation(self, operation_name):
"""Gets an operation.
@@ -178,6 +229,7 @@
return wait_operation_done(
lambda: self.get_operation(operation_name), wait_interval)
+ @_retry
def cancel_operation(self, operation_name):
"""Cancels an operation.
|
{"golden_diff": "diff --git a/components/gcp/container/component_sdk/python/kfp_component/google/ml_engine/_client.py b/components/gcp/container/component_sdk/python/kfp_component/google/ml_engine/_client.py\n--- a/components/gcp/container/component_sdk/python/kfp_component/google/ml_engine/_client.py\n+++ b/components/gcp/container/component_sdk/python/kfp_component/google/ml_engine/_client.py\n@@ -12,6 +12,7 @@\n # See the License for the specific language governing permissions and\n # limitations under the License.\n \n+from functools import wraps\n import logging\n import time\n \n@@ -19,12 +20,53 @@\n from googleapiclient import errors\n from ..common import wait_operation_done\n \n+\n+def _retry(func, tries=5, delay=1):\n+ \"\"\"Retry decorator for methods in MLEngineClient class.\n+\n+ It bypasses the BrokenPipeError by directly accessing the `_build_client` method\n+ and rebuilds `_ml_client` after `delay` seconds.\n+\n+ Args:\n+ tries (int): Total number of retries if BrokenPipeError/IOError is raised.\n+ delay (int): Number of seconds to wait between consecutive retries.\n+ \"\"\"\n+\n+ @wraps(func)\n+ def wrapper(self, *args, **kwargs):\n+ _tries, _delay = tries, delay\n+ while _tries:\n+ try:\n+ return func(self, *args, **kwargs)\n+ except (BrokenPipeError, IOError) as e:\n+ _tries -= 1\n+ if not _tries:\n+ raise\n+\n+ logging.warning(\n+ 'Caught {}. Retrying in {} seconds...'.format(\n+ e._class__.__name__, _delay\n+ )\n+ )\n+\n+ time.sleep(_delay)\n+ # access _build_client method and rebuild Http Client\n+ self._build_client()\n+\n+ return wrapper\n+\n+\n class MLEngineClient:\n \"\"\" Client for calling MLEngine APIs.\n \"\"\"\n+\n def __init__(self):\n+ self._build_client()\n+\n+ def _build_client(self):\n self._ml_client = discovery.build('ml', 'v1', cache_discovery=False)\n \n+ @_retry\n def create_job(self, project_id, job):\n \"\"\"Create a new job.\n \n@@ -40,6 +82,7 @@\n body = job\n ).execute()\n \n+ @_retry\n def cancel_job(self, project_id, job_id):\n \"\"\"Cancel the specified job.\n \n@@ -55,6 +98,7 @@\n },\n ).execute()\n \n+ @_retry\n def get_job(self, project_id, job_id):\n \"\"\"Gets the job by ID.\n \n@@ -68,6 +112,7 @@\n return self._ml_client.projects().jobs().get(\n name=job_name).execute()\n \n+ @_retry\n def create_model(self, project_id, model):\n \"\"\"Creates a new model.\n \n@@ -82,6 +127,7 @@\n body = model\n ).execute()\n \n+ @_retry\n def get_model(self, model_name):\n \"\"\"Gets a model.\n \n@@ -94,6 +140,7 @@\n name = model_name\n ).execute()\n \n+ @_retry\n def create_version(self, model_name, version):\n \"\"\"Creates a new version.\n \n@@ -109,6 +156,7 @@\n body = version\n ).execute()\n \n+ @_retry\n def get_version(self, version_name):\n \"\"\"Gets a version.\n \n@@ -127,6 +175,7 @@\n return None\n raise\n \n+ @_retry\n def delete_version(self, version_name):\n \"\"\"Deletes a version.\n \n@@ -146,11 +195,13 @@\n return None\n raise\n \n+ @_retry\n def set_default_version(self, version_name):\n return self._ml_client.projects().models().versions().setDefault(\n name = version_name\n ).execute()\n \n+ @_retry\n def get_operation(self, operation_name):\n \"\"\"Gets an operation.\n \n@@ -178,6 +229,7 @@\n return wait_operation_done(\n lambda: self.get_operation(operation_name), wait_interval)\n \n+ @_retry\n def cancel_operation(self, operation_name):\n \"\"\"Cancels an operation.\n", "issue": "BrokenPipe for ml engine train component\n### What steps did you take:\r\nML engine train component throws BrokenPipe Error after around 30 minutes of continuous training. This is not a one-off situation but jobs keep failing.\r\n### What happened:\r\n\r\n### What did you expect to happen:\r\n\r\n### Environment:\r\n<!-- Please fill in those that seem relevant. -->\r\n\r\nHow did you deploy Kubeflow Pipelines (KFP)?\r\nKubeflow Pipelines was deployed using gcp \"ai platform pipelines\" tool.\r\nKubeflow Pipelines 1.0.4\r\nKubernetes: 1.17.14-gke.1600\r\n\r\n```\r\nML_ENGINE_TRAIN_OP = comp.load_component_from_url(\r\n \"https://raw.githubusercontent.com/kubeflow/pipelines/1.3.0/components/gcp/ml_engine/train/component.yaml\"\r\n)\r\n```\r\n<!-- If you are not sure, here's [an introduction of all options](https://www.kubeflow.org/docs/pipelines/installation/overview/). -->\r\n\r\nKFP version: 1.0.4\r\n\r\nKFP SDK version: 1.3.0\r\n\r\n\r\n### Anything else you would like to add:\r\n[Miscellaneous information that will assist in solving the issue.]\r\n\r\n/kind bug\r\n<!-- Please include labels by uncommenting them to help us better triage issues, choose from the following -->\r\n<!--\r\n// /area frontend\r\n// /area backend\r\n// /area sdk\r\n// /area testing\r\n// /area engprod\r\n-->\r\n\r\n\n", "before_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport logging\nimport time\n\nimport googleapiclient.discovery as discovery\nfrom googleapiclient import errors\nfrom ..common import wait_operation_done\n\nclass MLEngineClient:\n \"\"\" Client for calling MLEngine APIs.\n \"\"\"\n def __init__(self):\n self._ml_client = discovery.build('ml', 'v1', cache_discovery=False)\n\n def create_job(self, project_id, job):\n \"\"\"Create a new job.\n\n Args:\n project_id: the ID of the parent project.\n job: the payload of the job.\n\n Returns:\n The created job.\n \"\"\"\n return self._ml_client.projects().jobs().create(\n parent = 'projects/{}'.format(project_id),\n body = job\n ).execute()\n\n def cancel_job(self, project_id, job_id):\n \"\"\"Cancel the specified job.\n\n Args:\n project_id: the parent project ID of the job.\n job_id: the ID of the job.\n \"\"\"\n job_name = 'projects/{}/jobs/{}'.format(project_id, job_id)\n self._ml_client.projects().jobs().cancel(\n name = job_name,\n body = {\n 'name': job_name\n },\n ).execute()\n\n def get_job(self, project_id, job_id):\n \"\"\"Gets the job by ID.\n\n Args:\n project_id: the ID of the parent project.\n job_id: the ID of the job to retrieve.\n Returns:\n The retrieved job payload.\n \"\"\"\n job_name = 'projects/{}/jobs/{}'.format(project_id, job_id)\n return self._ml_client.projects().jobs().get(\n name=job_name).execute()\n\n def create_model(self, project_id, model):\n \"\"\"Creates a new model.\n\n Args:\n project_id: the ID of the parent project.\n model: the payload of the model.\n Returns:\n The created model.\n \"\"\"\n return self._ml_client.projects().models().create(\n parent = 'projects/{}'.format(project_id),\n body = model\n ).execute()\n\n def get_model(self, model_name):\n \"\"\"Gets a model.\n\n Args:\n model_name: the name of the model.\n Returns:\n The retrieved model.\n \"\"\"\n return self._ml_client.projects().models().get(\n name = model_name\n ).execute()\n\n def create_version(self, model_name, version):\n \"\"\"Creates a new version.\n\n Args:\n model_name: the name of the parent model.\n version: the payload of the version.\n\n Returns:\n The created version.\n \"\"\"\n return self._ml_client.projects().models().versions().create(\n parent = model_name,\n body = version\n ).execute()\n\n def get_version(self, version_name):\n \"\"\"Gets a version.\n\n Args:\n version_name: the name of the version.\n\n Returns:\n The retrieved version. None if the version is not found.\n \"\"\"\n try:\n return self._ml_client.projects().models().versions().get(\n name = version_name\n ).execute()\n except errors.HttpError as e:\n if e.resp.status == 404:\n return None\n raise\n\n def delete_version(self, version_name):\n \"\"\"Deletes a version.\n\n Args:\n version_name: the name of the version.\n\n Returns:\n The delete operation. None if the version is not found.\n \"\"\"\n try:\n return self._ml_client.projects().models().versions().delete(\n name = version_name\n ).execute()\n except errors.HttpError as e:\n if e.resp.status == 404:\n logging.info('The version has already been deleted.')\n return None\n raise\n\n def set_default_version(self, version_name):\n return self._ml_client.projects().models().versions().setDefault(\n name = version_name\n ).execute()\n\n def get_operation(self, operation_name):\n \"\"\"Gets an operation.\n\n Args:\n operation_name: the name of the operation.\n\n Returns:\n The retrieved operation.\n \"\"\"\n return self._ml_client.projects().operations().get(\n name = operation_name\n ).execute()\n\n def wait_for_operation_done(self, operation_name, wait_interval):\n \"\"\"Waits for an operation to be done.\n\n Args:\n operation_name: the name of the operation.\n wait_interval: the wait interview between pulling job\n status.\n\n Returns:\n The completed operation.\n \"\"\"\n return wait_operation_done(\n lambda: self.get_operation(operation_name), wait_interval)\n\n def cancel_operation(self, operation_name):\n \"\"\"Cancels an operation.\n\n Args:\n operation_name: the name of the operation.\n \"\"\"\n self._ml_client.projects().operations().cancel(\n name = operation_name\n ).execute()\n", "path": "components/gcp/container/component_sdk/python/kfp_component/google/ml_engine/_client.py"}]}
| 2,566 | 970 |
gh_patches_debug_28522
|
rasdani/github-patches
|
git_diff
|
dynaconf__dynaconf-413
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[bug] Only one CombinedValidator is registered - subsequent are silently ignored
**Describe the bug**
If validators are added through `settings.validators.register()`, only first CombinedValidator is registered - subsequent are silently skipped.
**Analysis**
The root cause is `Validator.__eq__()` method. `ValidatorList.register()` will go through provided validators and add them, but only if they aren't already on the list (`validator not in self`). `in` will return "`True` if an item of *s* is equal to *x*" ([docs](https://docs.python.org/3.8/library/stdtypes.html#common-sequence-operations)). That logic was added in #256 .
When `Validator.__eq__()` compares different objects, it looks into various `Validator` properties and compares them in pair. If they are all the same, `__eq__()` will assume these are two instances of effectively the same validation rule.
The problem is, `CombinedValidator` doesn't have any of these properties, so two completely different `CombinedValidator` will appear to be the same for `__eq__()` method.
**To Reproduce**
In python shell:
```
>>> from dynaconf import Validator
>>> (Validator("foo.foo") | Validator("foo.bar")) == (Validator("bar.foo") & Validator("bar.bar"))
True
```
This should return False, as these two `CombinedValidator`s have nothing in common.
**Environment (please complete the following information):**
- OS: Linux/Fedora32
- Dynaconf master (6c568d687e29ca5ed9806a74f1f4fb7e4b96be2f), 3.0.1
**Additional context**
I might try working on patch, but I'm not sure about best approach. Perhaps we need type comparison inside `__eq__()` (so comparing AndValidator to OrValidator can return early). But how do we compare two `AndValidator`s? Look into combined validators properties recursively?
</issue>
<code>
[start of dynaconf/validator.py]
1 from itertools import chain
2 from types import MappingProxyType
3
4 from dynaconf import validator_conditions # noqa
5 from dynaconf.utils.functional import empty
6
7
8 class ValidationError(Exception):
9 pass
10
11
12 class Validator(object):
13 """Validators are conditions attached to settings variables names
14 or patterns::
15
16 Validator('MESSAGE', must_exist=True, eq='Hello World')
17
18 The above ensure MESSAGE is available in default env and
19 is equal to 'Hello World'
20
21 `names` are a one (or more) names or patterns::
22
23 Validator('NAME')
24 Validator('NAME', 'OTHER_NAME', 'EVEN_OTHER')
25 Validator(r'^NAME', r'OTHER./*')
26
27 The `operations` are::
28
29 eq: value == other
30 ne: value != other
31 gt: value > other
32 lt: value < other
33 gte: value >= other
34 lte: value <= other
35 is_type_of: isinstance(value, type)
36 is_in: value in sequence
37 is_not_in: value not in sequence
38 identity: value is other
39 cont: contain value in
40 len_eq: len(value) == other
41 len_ne: len(value) != other
42 len_min: len(value) > other
43 len_max: len(value) < other
44
45 `env` is which env to be checked, can be a list or
46 default is used.
47
48 `when` holds a validator and its return decides if validator runs or not::
49
50 Validator('NAME', must_exist=True, when=Validator('OTHER', eq=2))
51 # NAME is required only if OTHER eq to 2
52 # When the very first thing to be performed when passed.
53 # if no env is passed to `when` it is inherited
54
55 `must_exist` is alias to `required` requirement. (executed after when)::
56
57 settings.get(value, empty) returns non empty
58
59 condition is a callable to be executed and return boolean::
60
61 Validator('NAME', condition=lambda x: x == 1)
62 # it is executed before operations.
63
64 """
65
66 default_messages = MappingProxyType(
67 {
68 "must_exist_true": "{name} is required in env {env}",
69 "must_exist_false": "{name} cannot exists in env {env}",
70 "condition": "{name} invalid for {function}({value}) in env {env}",
71 "operations": (
72 "{name} must {operation} {op_value} "
73 "but it is {value} in env {env}"
74 ),
75 "combined": "combined validators failed {errors}",
76 }
77 )
78
79 def __init__(
80 self,
81 *names,
82 must_exist=None,
83 required=None, # this is alias for `must_exist`
84 condition=None,
85 when=None,
86 env=None,
87 messages=None,
88 cast=None,
89 default=empty, # Literal value or a callable
90 **operations
91 ):
92 # Copy immutable MappingProxyType as a mutable dict
93 self.messages = dict(self.default_messages)
94 if messages:
95 self.messages.update(messages)
96
97 if when is not None and not isinstance(when, Validator):
98 raise TypeError("when must be Validator instance")
99
100 if condition is not None and not callable(condition):
101 raise TypeError("condition must be callable")
102
103 self.names = names
104 self.must_exist = must_exist if must_exist is not None else required
105 self.condition = condition
106 self.when = when
107 self.cast = cast or (lambda value: value)
108 self.operations = operations
109 self.default = default
110
111 if isinstance(env, str):
112 self.envs = [env]
113 elif isinstance(env, (list, tuple)):
114 self.envs = env
115 else:
116 self.envs = None
117
118 def __or__(self, other):
119 return OrValidator(self, other)
120
121 def __and__(self, other):
122 return AndValidator(self, other)
123
124 def __eq__(self, other):
125 if self is other:
126 return True
127
128 identical_attrs = (
129 getattr(self, attr) == getattr(other, attr)
130 for attr in (
131 "names",
132 "must_exist",
133 "when",
134 "condition",
135 "operations",
136 "envs",
137 )
138 )
139 if all(identical_attrs):
140 return True
141
142 return False
143
144 def validate(self, settings):
145 """Raise ValidationError if invalid"""
146
147 if self.envs is None:
148 self.envs = [settings.current_env]
149
150 if self.when is not None:
151 try:
152 # inherit env if not defined
153 if self.when.envs is None:
154 self.when.envs = self.envs
155
156 self.when.validate(settings)
157 except ValidationError:
158 # if when is invalid, return canceling validation flow
159 return
160
161 # If only using current_env, skip using_env decoration (reload)
162 if (
163 len(self.envs) == 1
164 and self.envs[0].upper() == settings.current_env.upper()
165 ):
166 self._validate_items(settings, settings.current_env)
167 return
168
169 for env in self.envs:
170 self._validate_items(settings.from_env(env))
171
172 def _validate_items(self, settings, env=None):
173 env = env or settings.current_env
174 for name in self.names:
175 if self.default is not empty:
176 default_value = (
177 self.default(settings, self)
178 if callable(self.default)
179 else self.default
180 )
181 else:
182 default_value = empty
183
184 value = self.cast(settings.setdefault(name, default_value))
185
186 # is name required but not exists?
187 if self.must_exist is True and value is empty:
188 raise ValidationError(
189 self.messages["must_exist_true"].format(name=name, env=env)
190 )
191 elif self.must_exist is False and value is not empty:
192 raise ValidationError(
193 self.messages["must_exist_false"].format(
194 name=name, env=env
195 )
196 )
197 elif self.must_exist in (False, None) and value is empty:
198 continue
199
200 # is there a callable condition?
201 if self.condition is not None:
202 if not self.condition(value):
203 raise ValidationError(
204 self.messages["condition"].format(
205 name=name,
206 function=self.condition.__name__,
207 value=value,
208 env=env,
209 )
210 )
211
212 # operations
213 for op_name, op_value in self.operations.items():
214 op_function = getattr(validator_conditions, op_name)
215 if not op_function(value, op_value):
216 raise ValidationError(
217 self.messages["operations"].format(
218 name=name,
219 operation=op_function.__name__,
220 op_value=op_value,
221 value=value,
222 env=env,
223 )
224 )
225
226
227 class CombinedValidator(Validator):
228 def __init__(self, validator_a, validator_b, *args, **kwargs):
229 """Takes 2 validators and combines the validation"""
230 self.validators = (validator_a, validator_b)
231 super().__init__(*args, **kwargs)
232
233 def validate(self, settings): # pragma: no cover
234 raise NotImplementedError(
235 "subclasses OrValidator or AndValidator implements this method"
236 )
237
238
239 class OrValidator(CombinedValidator):
240 """Evaluates on Validator() | Validator()"""
241
242 def validate(self, settings):
243 """Ensure at least one of the validators are valid"""
244 errors = []
245 for validator in self.validators:
246 try:
247 validator.validate(settings)
248 except ValidationError as e:
249 errors.append(e)
250 continue
251 else:
252 return
253 raise ValidationError(
254 self.messages["combined"].format(
255 errors=" or ".join(str(e) for e in errors)
256 )
257 )
258
259
260 class AndValidator(CombinedValidator):
261 """Evaluates on Validator() & Validator()"""
262
263 def validate(self, settings):
264 """Ensure both the validators are valid"""
265 errors = []
266 for validator in self.validators:
267 try:
268 validator.validate(settings)
269 except ValidationError as e:
270 errors.append(e)
271 continue
272 if errors:
273 raise ValidationError(
274 self.messages["combined"].format(
275 errors=" and ".join(str(e) for e in errors)
276 )
277 )
278
279
280 class ValidatorList(list):
281 def __init__(self, settings, validators=None, *args, **kwargs):
282 if isinstance(validators, (list, tuple)):
283 args = list(args) + list(validators)
284 super(ValidatorList, self).__init__(args, **kwargs)
285 self.settings = settings
286
287 def register(self, *args, **kwargs):
288 validators = list(chain.from_iterable(kwargs.values()))
289 validators.extend(args)
290 for validator in validators:
291 if validator and validator not in self:
292 self.append(validator)
293
294 def validate(self):
295 for validator in self:
296 validator.validate(self.settings)
297
[end of dynaconf/validator.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/dynaconf/validator.py b/dynaconf/validator.py
--- a/dynaconf/validator.py
+++ b/dynaconf/validator.py
@@ -5,6 +5,16 @@
from dynaconf.utils.functional import empty
+EQUALITY_ATTRS = (
+ "names",
+ "must_exist",
+ "when",
+ "condition",
+ "operations",
+ "envs",
+)
+
+
class ValidationError(Exception):
pass
@@ -125,16 +135,12 @@
if self is other:
return True
+ if type(self).__name__ != type(other).__name__:
+ return False
+
identical_attrs = (
getattr(self, attr) == getattr(other, attr)
- for attr in (
- "names",
- "must_exist",
- "when",
- "condition",
- "operations",
- "envs",
- )
+ for attr in EQUALITY_ATTRS
)
if all(identical_attrs):
return True
@@ -229,6 +235,12 @@
"""Takes 2 validators and combines the validation"""
self.validators = (validator_a, validator_b)
super().__init__(*args, **kwargs)
+ for attr in EQUALITY_ATTRS:
+ if not getattr(self, attr, None):
+ value = tuple(
+ getattr(validator, attr) for validator in self.validators
+ )
+ setattr(self, attr, value)
def validate(self, settings): # pragma: no cover
raise NotImplementedError(
|
{"golden_diff": "diff --git a/dynaconf/validator.py b/dynaconf/validator.py\n--- a/dynaconf/validator.py\n+++ b/dynaconf/validator.py\n@@ -5,6 +5,16 @@\n from dynaconf.utils.functional import empty\n \n \n+EQUALITY_ATTRS = (\n+ \"names\",\n+ \"must_exist\",\n+ \"when\",\n+ \"condition\",\n+ \"operations\",\n+ \"envs\",\n+)\n+\n+\n class ValidationError(Exception):\n pass\n \n@@ -125,16 +135,12 @@\n if self is other:\n return True\n \n+ if type(self).__name__ != type(other).__name__:\n+ return False\n+\n identical_attrs = (\n getattr(self, attr) == getattr(other, attr)\n- for attr in (\n- \"names\",\n- \"must_exist\",\n- \"when\",\n- \"condition\",\n- \"operations\",\n- \"envs\",\n- )\n+ for attr in EQUALITY_ATTRS\n )\n if all(identical_attrs):\n return True\n@@ -229,6 +235,12 @@\n \"\"\"Takes 2 validators and combines the validation\"\"\"\n self.validators = (validator_a, validator_b)\n super().__init__(*args, **kwargs)\n+ for attr in EQUALITY_ATTRS:\n+ if not getattr(self, attr, None):\n+ value = tuple(\n+ getattr(validator, attr) for validator in self.validators\n+ )\n+ setattr(self, attr, value)\n \n def validate(self, settings): # pragma: no cover\n raise NotImplementedError(\n", "issue": "[bug] Only one CombinedValidator is registered - subsequent are silently ignored\n**Describe the bug**\r\nIf validators are added through `settings.validators.register()`, only first CombinedValidator is registered - subsequent are silently skipped.\r\n\r\n**Analysis**\r\nThe root cause is `Validator.__eq__()` method. `ValidatorList.register()` will go through provided validators and add them, but only if they aren't already on the list (`validator not in self`). `in` will return \"`True` if an item of *s* is equal to *x*\" ([docs](https://docs.python.org/3.8/library/stdtypes.html#common-sequence-operations)). That logic was added in #256 .\r\n\r\nWhen `Validator.__eq__()` compares different objects, it looks into various `Validator` properties and compares them in pair. If they are all the same, `__eq__()` will assume these are two instances of effectively the same validation rule.\r\n\r\nThe problem is, `CombinedValidator` doesn't have any of these properties, so two completely different `CombinedValidator` will appear to be the same for `__eq__()` method.\r\n\r\n\r\n**To Reproduce**\r\nIn python shell:\r\n```\r\n>>> from dynaconf import Validator\r\n>>> (Validator(\"foo.foo\") | Validator(\"foo.bar\")) == (Validator(\"bar.foo\") & Validator(\"bar.bar\"))\r\nTrue\r\n```\r\n\r\nThis should return False, as these two `CombinedValidator`s have nothing in common.\r\n\r\n**Environment (please complete the following information):**\r\n - OS: Linux/Fedora32\r\n - Dynaconf master (6c568d687e29ca5ed9806a74f1f4fb7e4b96be2f), 3.0.1\r\n\r\n**Additional context**\r\nI might try working on patch, but I'm not sure about best approach. Perhaps we need type comparison inside `__eq__()` (so comparing AndValidator to OrValidator can return early). But how do we compare two `AndValidator`s? Look into combined validators properties recursively?\n", "before_files": [{"content": "from itertools import chain\nfrom types import MappingProxyType\n\nfrom dynaconf import validator_conditions # noqa\nfrom dynaconf.utils.functional import empty\n\n\nclass ValidationError(Exception):\n pass\n\n\nclass Validator(object):\n \"\"\"Validators are conditions attached to settings variables names\n or patterns::\n\n Validator('MESSAGE', must_exist=True, eq='Hello World')\n\n The above ensure MESSAGE is available in default env and\n is equal to 'Hello World'\n\n `names` are a one (or more) names or patterns::\n\n Validator('NAME')\n Validator('NAME', 'OTHER_NAME', 'EVEN_OTHER')\n Validator(r'^NAME', r'OTHER./*')\n\n The `operations` are::\n\n eq: value == other\n ne: value != other\n gt: value > other\n lt: value < other\n gte: value >= other\n lte: value <= other\n is_type_of: isinstance(value, type)\n is_in: value in sequence\n is_not_in: value not in sequence\n identity: value is other\n cont: contain value in\n len_eq: len(value) == other\n len_ne: len(value) != other\n len_min: len(value) > other\n len_max: len(value) < other\n\n `env` is which env to be checked, can be a list or\n default is used.\n\n `when` holds a validator and its return decides if validator runs or not::\n\n Validator('NAME', must_exist=True, when=Validator('OTHER', eq=2))\n # NAME is required only if OTHER eq to 2\n # When the very first thing to be performed when passed.\n # if no env is passed to `when` it is inherited\n\n `must_exist` is alias to `required` requirement. (executed after when)::\n\n settings.get(value, empty) returns non empty\n\n condition is a callable to be executed and return boolean::\n\n Validator('NAME', condition=lambda x: x == 1)\n # it is executed before operations.\n\n \"\"\"\n\n default_messages = MappingProxyType(\n {\n \"must_exist_true\": \"{name} is required in env {env}\",\n \"must_exist_false\": \"{name} cannot exists in env {env}\",\n \"condition\": \"{name} invalid for {function}({value}) in env {env}\",\n \"operations\": (\n \"{name} must {operation} {op_value} \"\n \"but it is {value} in env {env}\"\n ),\n \"combined\": \"combined validators failed {errors}\",\n }\n )\n\n def __init__(\n self,\n *names,\n must_exist=None,\n required=None, # this is alias for `must_exist`\n condition=None,\n when=None,\n env=None,\n messages=None,\n cast=None,\n default=empty, # Literal value or a callable\n **operations\n ):\n # Copy immutable MappingProxyType as a mutable dict\n self.messages = dict(self.default_messages)\n if messages:\n self.messages.update(messages)\n\n if when is not None and not isinstance(when, Validator):\n raise TypeError(\"when must be Validator instance\")\n\n if condition is not None and not callable(condition):\n raise TypeError(\"condition must be callable\")\n\n self.names = names\n self.must_exist = must_exist if must_exist is not None else required\n self.condition = condition\n self.when = when\n self.cast = cast or (lambda value: value)\n self.operations = operations\n self.default = default\n\n if isinstance(env, str):\n self.envs = [env]\n elif isinstance(env, (list, tuple)):\n self.envs = env\n else:\n self.envs = None\n\n def __or__(self, other):\n return OrValidator(self, other)\n\n def __and__(self, other):\n return AndValidator(self, other)\n\n def __eq__(self, other):\n if self is other:\n return True\n\n identical_attrs = (\n getattr(self, attr) == getattr(other, attr)\n for attr in (\n \"names\",\n \"must_exist\",\n \"when\",\n \"condition\",\n \"operations\",\n \"envs\",\n )\n )\n if all(identical_attrs):\n return True\n\n return False\n\n def validate(self, settings):\n \"\"\"Raise ValidationError if invalid\"\"\"\n\n if self.envs is None:\n self.envs = [settings.current_env]\n\n if self.when is not None:\n try:\n # inherit env if not defined\n if self.when.envs is None:\n self.when.envs = self.envs\n\n self.when.validate(settings)\n except ValidationError:\n # if when is invalid, return canceling validation flow\n return\n\n # If only using current_env, skip using_env decoration (reload)\n if (\n len(self.envs) == 1\n and self.envs[0].upper() == settings.current_env.upper()\n ):\n self._validate_items(settings, settings.current_env)\n return\n\n for env in self.envs:\n self._validate_items(settings.from_env(env))\n\n def _validate_items(self, settings, env=None):\n env = env or settings.current_env\n for name in self.names:\n if self.default is not empty:\n default_value = (\n self.default(settings, self)\n if callable(self.default)\n else self.default\n )\n else:\n default_value = empty\n\n value = self.cast(settings.setdefault(name, default_value))\n\n # is name required but not exists?\n if self.must_exist is True and value is empty:\n raise ValidationError(\n self.messages[\"must_exist_true\"].format(name=name, env=env)\n )\n elif self.must_exist is False and value is not empty:\n raise ValidationError(\n self.messages[\"must_exist_false\"].format(\n name=name, env=env\n )\n )\n elif self.must_exist in (False, None) and value is empty:\n continue\n\n # is there a callable condition?\n if self.condition is not None:\n if not self.condition(value):\n raise ValidationError(\n self.messages[\"condition\"].format(\n name=name,\n function=self.condition.__name__,\n value=value,\n env=env,\n )\n )\n\n # operations\n for op_name, op_value in self.operations.items():\n op_function = getattr(validator_conditions, op_name)\n if not op_function(value, op_value):\n raise ValidationError(\n self.messages[\"operations\"].format(\n name=name,\n operation=op_function.__name__,\n op_value=op_value,\n value=value,\n env=env,\n )\n )\n\n\nclass CombinedValidator(Validator):\n def __init__(self, validator_a, validator_b, *args, **kwargs):\n \"\"\"Takes 2 validators and combines the validation\"\"\"\n self.validators = (validator_a, validator_b)\n super().__init__(*args, **kwargs)\n\n def validate(self, settings): # pragma: no cover\n raise NotImplementedError(\n \"subclasses OrValidator or AndValidator implements this method\"\n )\n\n\nclass OrValidator(CombinedValidator):\n \"\"\"Evaluates on Validator() | Validator()\"\"\"\n\n def validate(self, settings):\n \"\"\"Ensure at least one of the validators are valid\"\"\"\n errors = []\n for validator in self.validators:\n try:\n validator.validate(settings)\n except ValidationError as e:\n errors.append(e)\n continue\n else:\n return\n raise ValidationError(\n self.messages[\"combined\"].format(\n errors=\" or \".join(str(e) for e in errors)\n )\n )\n\n\nclass AndValidator(CombinedValidator):\n \"\"\"Evaluates on Validator() & Validator()\"\"\"\n\n def validate(self, settings):\n \"\"\"Ensure both the validators are valid\"\"\"\n errors = []\n for validator in self.validators:\n try:\n validator.validate(settings)\n except ValidationError as e:\n errors.append(e)\n continue\n if errors:\n raise ValidationError(\n self.messages[\"combined\"].format(\n errors=\" and \".join(str(e) for e in errors)\n )\n )\n\n\nclass ValidatorList(list):\n def __init__(self, settings, validators=None, *args, **kwargs):\n if isinstance(validators, (list, tuple)):\n args = list(args) + list(validators)\n super(ValidatorList, self).__init__(args, **kwargs)\n self.settings = settings\n\n def register(self, *args, **kwargs):\n validators = list(chain.from_iterable(kwargs.values()))\n validators.extend(args)\n for validator in validators:\n if validator and validator not in self:\n self.append(validator)\n\n def validate(self):\n for validator in self:\n validator.validate(self.settings)\n", "path": "dynaconf/validator.py"}]}
| 3,645 | 355 |
gh_patches_debug_18350
|
rasdani/github-patches
|
git_diff
|
beeware__toga-1243
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Change in label text doesn't trigger rehint and relayout
**Describe the bug**
Using `yield` in a function that gets triggered from an buttons `on_press` event is not responding on Windows.
**To Reproduce**
Steps to reproduce the behavior:
1. Click Button
2. See No Change
**Expected behavior**
The label should show "RUN1" and after 5s change to "RUN2"
**Screenshots**
If applicable, add screenshots to help explain your problem.
**Environment:**
- Operating System: Linux
- Python version: 3.9
- Software versions:
- Briefcase: 0.3.3
- Toga: 0.3.0.dev25
**Additional context**
The Installer is build with the following file:
```
# This workflow will install Python dependencies, run tests and lint with a single version of Python
# For more information see: https://help.github.com/actions/language-and-framework-guides/using-python-with-github-actions
name: Windows
on:
push:
branches: [ master, workflow-test, app-path, windows-yield ]
pull_request:
branches: [ master ]
jobs:
build:
runs-on: windows-latest
steps:
- uses: actions/checkout@v2
- name: Set up Python 3.8
uses: actions/setup-python@v2
with:
python-version: 3.8
- name: Install dependencies
run: |
#apt-get update
#sudo apt-get install git python3-dev python3-pip libgirepository1.0-dev libcairo2-dev libpango1.0-dev libwebkitgtk-3.0-0 gir1.2-webkit-3.0
- name: Beeware dependencies
run: |
# stop the build if there are Python syntax errors or undefined names
python -m pip install beeware
python -m pip install dhooks
- name: Run tests with pytest
run: |
cd src/
python -m unittest test_app.Test_Profile_Manager.test_swap_xml -v
python -m unittest test_app.Test_Profile_Manager.test_delete_profile -v
python -m unittest test_app.Test_Profile_Manager.test_create_profile -v
python -m unittest test_app.Test_Profile_Manager.test_load_profile -v
python -m unittest test_app.Test_Profile_Manager.test_get_ethnic -v
python -m unittest test_app.Test_Profile_Manager.test_switching_profiles_with_invalid_path -v
python -m unittest test_app.Test_Profile_Manager.test_migrate_function -v
python -m unittest test_app.Test_XML_Parser -v
python -m unittest test_app.Test_RTF_Parser -v
python -m unittest test_app.Test_Config_Manager -v
python -m unittest test_app.Test_Xml_Writing -v
python -m unittest test_mapper.Test_Mapper_Generate_Mapping -v
python -m unittest test_mapper.Test_Mapper_Preserve_Mapping -v
python -m unittest test_mapper.Test_Mapper_Overwrite_Mapping -v
- name: Build
run: |
briefcase create
briefcase build
briefcase package
- name: Save Installer
uses: actions/upload-artifact@v1
with:
name: NewGAN-Manager-Installer-Win
path: windows\NewGAN Manager-1.1.0.msi
```
The `app.py`
```
"""
Yield Test
"""
import toga
import time
class NewGANManager(toga.App):
def startup(self):
self.main_window = toga.MainWindow(self.name)
self.output = toga.Label("")
self.btn = toga.Button(label="Run", on_press=self.calc)
self.main_box = toga.Box()
self.main_box.add(self.output)
self.main_box.add(self.btn)
self.main_window.content = self.main_box
self.main_window.show()
def calc(self, widget):
self.output.text = "RUN1"
yield 0.1
time.sleep(3)
self.output.text = "RUN2"
yield 0.1
def main():
return NewGANManager('Toga Demo', 'org.beeware.toga-demo')
```
more info here: https://github.com/Maradonna90/NewGAN-Manager/tree/windows-yield
</issue>
<code>
[start of src/winforms/toga_winforms/libs/proactor.py]
1 import asyncio
2 import sys
3 import threading
4 from asyncio import events
5
6 from .winforms import Action, Task, WinForms, user32
7
8
9 class AsyncIOTickMessageFilter(WinForms.IMessageFilter):
10 """
11 A Winforms message filter that will catch the request to tick the Asyncio
12 event loop.
13 """
14 __namespace__ = 'System.Windows.Forms'
15
16 def __init__(self, loop, msg_id):
17 self.loop = loop
18 self.msg_id = msg_id
19
20 def PreFilterMessage(self, message):
21 print('ping', message)
22 if message.Msg == self.msg_id:
23 print("asyncio tick message!!")
24 self.loop.run_once_recurring()
25 return True
26 # print("Filter message", message)
27 return False
28
29
30 class WinformsProactorEventLoop(asyncio.ProactorEventLoop):
31 def run_forever(self, app_context):
32 """Set up the asyncio event loop, integrate it with the Winforms
33 event loop, and start the application.
34
35 This largely duplicates the setup behavior of the default Proactor
36 run_forever implementation.
37
38 :param app_context: The WinForms.ApplicationContext instance
39 controlling the lifecycle of the app.
40 """
41 # Python 3.8 added an implementation of run_forever() in
42 # ProactorEventLoop. The only part that actually matters is the
43 # refactoring that moved the initial call to stage _loop_self_reading;
44 # it now needs to be created as part of run_forever; otherwise the
45 # event loop locks up, because there won't be anything for the
46 # select call to process.
47 if sys.version_info >= (3, 8):
48 self.call_soon(self._loop_self_reading)
49
50 # Remember the application context.
51 self.app_context = app_context
52
53 # Register a custom user window message.
54 self.msg_id = user32.RegisterWindowMessageA("Python asyncio tick")
55 # Add a message filter to listen for the asyncio tick message
56 # FIXME: Actually install the message filter.
57 # msg_filter = AsyncIOTickMessageFilter(self, self.msg_id)
58 # WinForms.Application.AddMessageFilter(msg_filter)
59
60 # Setup the Proactor.
61 # The code between the following markers should be exactly the same as
62 # the official CPython implementation, up to the start of the
63 # `while True:` part of run_forever() (see BaseEventLoop.run_forever()
64 # in Lib/ascynio/base_events.py)
65 # === START BaseEventLoop.run_forever() setup ===
66 self._check_closed()
67 if self.is_running():
68 raise RuntimeError('This event loop is already running')
69 if events._get_running_loop() is not None:
70 raise RuntimeError(
71 'Cannot run the event loop while another loop is running')
72 self._set_coroutine_origin_tracking(self._debug)
73 self._thread_id = threading.get_ident()
74 try:
75 self._old_agen_hooks = sys.get_asyncgen_hooks()
76 sys.set_asyncgen_hooks(
77 firstiter=self._asyncgen_firstiter_hook,
78 finalizer=self._asyncgen_finalizer_hook
79 )
80 except AttributeError:
81 # Python < 3.6 didn't have sys.get_asyncgen_hooks();
82 # No action required for those versions.
83 pass
84
85 events._set_running_loop(self)
86 # === END BaseEventLoop.run_forever() setup ===
87
88 # Rather than going into a `while True:` loop, we're going to use the
89 # Winforms event loop to queue a tick() message that will cause a
90 # single iteration of the asyncio event loop to be executed. Each time
91 # we do this, we queue *another* tick() message in 5ms time. In this
92 # way, we'll get a continuous stream of tick() calls, without blocking
93 # the Winforms event loop.
94
95 # Queue the first asyncio tick.
96 self.enqueue_tick()
97
98 # Start the Winforms event loop.
99 WinForms.Application.Run(self.app_context)
100
101 def enqueue_tick(self):
102 # Queue a call to tick in 5ms.
103 self.task = Action[Task](self.tick)
104 Task.Delay(5).ContinueWith(self.task)
105
106 def tick(self, *args, **kwargs):
107 """
108 Cause a single iteration of the event loop to run on the main GUI thread.
109 """
110 # Post a userspace message that will trigger running an iteration
111 # of the asyncio event loop. This can't be done directly, because the
112 # tick() will be executing in a threadpool, and we need the asyncio
113 # handling to occur in the main GUI thread. However, by positing a
114 # message, it will be caught by the MessageFilter we installed on the
115 # Application thread.
116
117 if self.task:
118 self.task.Dispose()
119 del self.task
120 # The message is sent with:
121 # * HWND 0xfff (all windows),
122 # * MSG self.msg_id (a message ID in the WM_USER range)
123 # * LPARAM and WPARAM empty (no extra details needed; just tick!)
124 user32.PostMessageA(0xffff, self.msg_id, None, None)
125
126 # FIXME: Once we have a working message filter, this invoke call
127 # can be removed.
128 # If the app context has a main form, invoke run_once_recurring()
129 # on the thread associated with that form.
130 if self.app_context.MainForm:
131 action = Action(self.run_once_recurring)
132 self.app_context.MainForm.Invoke(action)
133 action.Dispose()
134 del action
135
136 def run_once_recurring(self):
137 """
138 Run one iteration of the event loop, and enqueue the next iteration
139 (if we're not stopping).
140
141 This largely duplicates the "finally" behavior of the default Proactor
142 run_forever implementation.
143 """
144 # Perform one tick of the event loop.
145 self._run_once()
146
147 if self._stopping:
148 # If we're stopping, we can do the "finally" handling from
149 # the BaseEventLoop run_forever().
150 # === START BaseEventLoop.run_forever() finally handling ===
151 self._stopping = False
152 self._thread_id = None
153 events._set_running_loop(None)
154 self._set_coroutine_origin_tracking(False)
155 try:
156 sys.set_asyncgen_hooks(*self._old_agen_hooks)
157 except AttributeError:
158 # Python < 3.6 didn't have set_asyncgen_hooks.
159 # No action required for those versions.
160 pass
161 # === END BaseEventLoop.run_forever() finally handling ===
162 else:
163 # Otherwise, live to tick another day. Enqueue the next tick,
164 # and make sure there will be *something* to be processed.
165 # If you don't ensure there is at least one message on the
166 # queue, the select() call will block, locking the app.
167 self.enqueue_tick()
168 self.call_soon(self._loop_self_reading)
169
170
171 # Python 3.7 changed the name of an internal wrapper function.
172 # Install an alias for the old name at the new name.
173 if sys.version_info < (3, 7):
174 WinformsProactorEventLoop._set_coroutine_origin_tracking = WinformsProactorEventLoop._set_coroutine_wrapper
175
[end of src/winforms/toga_winforms/libs/proactor.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/winforms/toga_winforms/libs/proactor.py b/src/winforms/toga_winforms/libs/proactor.py
--- a/src/winforms/toga_winforms/libs/proactor.py
+++ b/src/winforms/toga_winforms/libs/proactor.py
@@ -114,9 +114,6 @@
# message, it will be caught by the MessageFilter we installed on the
# Application thread.
- if self.task:
- self.task.Dispose()
- del self.task
# The message is sent with:
# * HWND 0xfff (all windows),
# * MSG self.msg_id (a message ID in the WM_USER range)
@@ -130,8 +127,6 @@
if self.app_context.MainForm:
action = Action(self.run_once_recurring)
self.app_context.MainForm.Invoke(action)
- action.Dispose()
- del action
def run_once_recurring(self):
"""
|
{"golden_diff": "diff --git a/src/winforms/toga_winforms/libs/proactor.py b/src/winforms/toga_winforms/libs/proactor.py\n--- a/src/winforms/toga_winforms/libs/proactor.py\n+++ b/src/winforms/toga_winforms/libs/proactor.py\n@@ -114,9 +114,6 @@\n # message, it will be caught by the MessageFilter we installed on the\n # Application thread.\n \n- if self.task:\n- self.task.Dispose()\n- del self.task\n # The message is sent with:\n # * HWND 0xfff (all windows),\n # * MSG self.msg_id (a message ID in the WM_USER range)\n@@ -130,8 +127,6 @@\n if self.app_context.MainForm:\n action = Action(self.run_once_recurring)\n self.app_context.MainForm.Invoke(action)\n- action.Dispose()\n- del action\n \n def run_once_recurring(self):\n \"\"\"\n", "issue": "Change in label text doesn't trigger rehint and relayout\n**Describe the bug**\r\nUsing `yield` in a function that gets triggered from an buttons `on_press` event is not responding on Windows.\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Click Button\r\n2. See No Change\r\n\r\n**Expected behavior**\r\nThe label should show \"RUN1\" and after 5s change to \"RUN2\"\r\n\r\n**Screenshots**\r\nIf applicable, add screenshots to help explain your problem.\r\n\r\n**Environment:**\r\n - Operating System: Linux\r\n - Python version: 3.9\r\n - Software versions:\r\n - Briefcase: 0.3.3 \r\n - Toga: 0.3.0.dev25\r\n**Additional context**\r\nThe Installer is build with the following file:\r\n```\r\n\r\n# This workflow will install Python dependencies, run tests and lint with a single version of Python\r\n# For more information see: https://help.github.com/actions/language-and-framework-guides/using-python-with-github-actions\r\n\r\nname: Windows\r\n\r\non:\r\n push:\r\n branches: [ master, workflow-test, app-path, windows-yield ]\r\n pull_request:\r\n branches: [ master ]\r\n\r\njobs:\r\n build:\r\n\r\n runs-on: windows-latest\r\n\r\n steps:\r\n - uses: actions/checkout@v2\r\n - name: Set up Python 3.8\r\n uses: actions/setup-python@v2\r\n with:\r\n python-version: 3.8\r\n - name: Install dependencies\r\n run: |\r\n #apt-get update\r\n #sudo apt-get install git python3-dev python3-pip libgirepository1.0-dev libcairo2-dev libpango1.0-dev libwebkitgtk-3.0-0 gir1.2-webkit-3.0\r\n - name: Beeware dependencies\r\n run: |\r\n # stop the build if there are Python syntax errors or undefined names\r\n python -m pip install beeware\r\n python -m pip install dhooks\r\n - name: Run tests with pytest\r\n run: |\r\n cd src/\r\n python -m unittest test_app.Test_Profile_Manager.test_swap_xml -v\r\n python -m unittest test_app.Test_Profile_Manager.test_delete_profile -v\r\n python -m unittest test_app.Test_Profile_Manager.test_create_profile -v\r\n python -m unittest test_app.Test_Profile_Manager.test_load_profile -v\r\n python -m unittest test_app.Test_Profile_Manager.test_get_ethnic -v\r\n python -m unittest test_app.Test_Profile_Manager.test_switching_profiles_with_invalid_path -v\r\n python -m unittest test_app.Test_Profile_Manager.test_migrate_function -v\r\n python -m unittest test_app.Test_XML_Parser -v\r\n python -m unittest test_app.Test_RTF_Parser -v\r\n python -m unittest test_app.Test_Config_Manager -v\r\n python -m unittest test_app.Test_Xml_Writing -v\r\n python -m unittest test_mapper.Test_Mapper_Generate_Mapping -v\r\n python -m unittest test_mapper.Test_Mapper_Preserve_Mapping -v\r\n python -m unittest test_mapper.Test_Mapper_Overwrite_Mapping -v\r\n - name: Build\r\n run: |\r\n briefcase create\r\n briefcase build\r\n briefcase package\r\n - name: Save Installer\r\n uses: actions/upload-artifact@v1\r\n with:\r\n name: NewGAN-Manager-Installer-Win\r\n path: windows\\NewGAN Manager-1.1.0.msi\r\n```\r\n\r\nThe `app.py`\r\n```\r\n\"\"\"\r\nYield Test\r\n\"\"\"\r\nimport toga\r\nimport time\r\n\r\n\r\nclass NewGANManager(toga.App):\r\n\r\n def startup(self):\r\n self.main_window = toga.MainWindow(self.name)\r\n self.output = toga.Label(\"\")\r\n self.btn = toga.Button(label=\"Run\", on_press=self.calc)\r\n self.main_box = toga.Box()\r\n self.main_box.add(self.output)\r\n self.main_box.add(self.btn)\r\n self.main_window.content = self.main_box\r\n self.main_window.show()\r\n def calc(self, widget):\r\n self.output.text = \"RUN1\"\r\n yield 0.1\r\n time.sleep(3)\r\n self.output.text = \"RUN2\"\r\n yield 0.1\r\n\r\ndef main():\r\n return NewGANManager('Toga Demo', 'org.beeware.toga-demo')\r\n```\r\n\r\nmore info here: https://github.com/Maradonna90/NewGAN-Manager/tree/windows-yield\n", "before_files": [{"content": "import asyncio\nimport sys\nimport threading\nfrom asyncio import events\n\nfrom .winforms import Action, Task, WinForms, user32\n\n\nclass AsyncIOTickMessageFilter(WinForms.IMessageFilter):\n \"\"\"\n A Winforms message filter that will catch the request to tick the Asyncio\n event loop.\n \"\"\"\n __namespace__ = 'System.Windows.Forms'\n\n def __init__(self, loop, msg_id):\n self.loop = loop\n self.msg_id = msg_id\n\n def PreFilterMessage(self, message):\n print('ping', message)\n if message.Msg == self.msg_id:\n print(\"asyncio tick message!!\")\n self.loop.run_once_recurring()\n return True\n # print(\"Filter message\", message)\n return False\n\n\nclass WinformsProactorEventLoop(asyncio.ProactorEventLoop):\n def run_forever(self, app_context):\n \"\"\"Set up the asyncio event loop, integrate it with the Winforms\n event loop, and start the application.\n\n This largely duplicates the setup behavior of the default Proactor\n run_forever implementation.\n\n :param app_context: The WinForms.ApplicationContext instance\n controlling the lifecycle of the app.\n \"\"\"\n # Python 3.8 added an implementation of run_forever() in\n # ProactorEventLoop. The only part that actually matters is the\n # refactoring that moved the initial call to stage _loop_self_reading;\n # it now needs to be created as part of run_forever; otherwise the\n # event loop locks up, because there won't be anything for the\n # select call to process.\n if sys.version_info >= (3, 8):\n self.call_soon(self._loop_self_reading)\n\n # Remember the application context.\n self.app_context = app_context\n\n # Register a custom user window message.\n self.msg_id = user32.RegisterWindowMessageA(\"Python asyncio tick\")\n # Add a message filter to listen for the asyncio tick message\n # FIXME: Actually install the message filter.\n # msg_filter = AsyncIOTickMessageFilter(self, self.msg_id)\n # WinForms.Application.AddMessageFilter(msg_filter)\n\n # Setup the Proactor.\n # The code between the following markers should be exactly the same as\n # the official CPython implementation, up to the start of the\n # `while True:` part of run_forever() (see BaseEventLoop.run_forever()\n # in Lib/ascynio/base_events.py)\n # === START BaseEventLoop.run_forever() setup ===\n self._check_closed()\n if self.is_running():\n raise RuntimeError('This event loop is already running')\n if events._get_running_loop() is not None:\n raise RuntimeError(\n 'Cannot run the event loop while another loop is running')\n self._set_coroutine_origin_tracking(self._debug)\n self._thread_id = threading.get_ident()\n try:\n self._old_agen_hooks = sys.get_asyncgen_hooks()\n sys.set_asyncgen_hooks(\n firstiter=self._asyncgen_firstiter_hook,\n finalizer=self._asyncgen_finalizer_hook\n )\n except AttributeError:\n # Python < 3.6 didn't have sys.get_asyncgen_hooks();\n # No action required for those versions.\n pass\n\n events._set_running_loop(self)\n # === END BaseEventLoop.run_forever() setup ===\n\n # Rather than going into a `while True:` loop, we're going to use the\n # Winforms event loop to queue a tick() message that will cause a\n # single iteration of the asyncio event loop to be executed. Each time\n # we do this, we queue *another* tick() message in 5ms time. In this\n # way, we'll get a continuous stream of tick() calls, without blocking\n # the Winforms event loop.\n\n # Queue the first asyncio tick.\n self.enqueue_tick()\n\n # Start the Winforms event loop.\n WinForms.Application.Run(self.app_context)\n\n def enqueue_tick(self):\n # Queue a call to tick in 5ms.\n self.task = Action[Task](self.tick)\n Task.Delay(5).ContinueWith(self.task)\n\n def tick(self, *args, **kwargs):\n \"\"\"\n Cause a single iteration of the event loop to run on the main GUI thread.\n \"\"\"\n # Post a userspace message that will trigger running an iteration\n # of the asyncio event loop. This can't be done directly, because the\n # tick() will be executing in a threadpool, and we need the asyncio\n # handling to occur in the main GUI thread. However, by positing a\n # message, it will be caught by the MessageFilter we installed on the\n # Application thread.\n\n if self.task:\n self.task.Dispose()\n del self.task\n # The message is sent with:\n # * HWND 0xfff (all windows),\n # * MSG self.msg_id (a message ID in the WM_USER range)\n # * LPARAM and WPARAM empty (no extra details needed; just tick!)\n user32.PostMessageA(0xffff, self.msg_id, None, None)\n\n # FIXME: Once we have a working message filter, this invoke call\n # can be removed.\n # If the app context has a main form, invoke run_once_recurring()\n # on the thread associated with that form.\n if self.app_context.MainForm:\n action = Action(self.run_once_recurring)\n self.app_context.MainForm.Invoke(action)\n action.Dispose()\n del action\n\n def run_once_recurring(self):\n \"\"\"\n Run one iteration of the event loop, and enqueue the next iteration\n (if we're not stopping).\n\n This largely duplicates the \"finally\" behavior of the default Proactor\n run_forever implementation.\n \"\"\"\n # Perform one tick of the event loop.\n self._run_once()\n\n if self._stopping:\n # If we're stopping, we can do the \"finally\" handling from\n # the BaseEventLoop run_forever().\n # === START BaseEventLoop.run_forever() finally handling ===\n self._stopping = False\n self._thread_id = None\n events._set_running_loop(None)\n self._set_coroutine_origin_tracking(False)\n try:\n sys.set_asyncgen_hooks(*self._old_agen_hooks)\n except AttributeError:\n # Python < 3.6 didn't have set_asyncgen_hooks.\n # No action required for those versions.\n pass\n # === END BaseEventLoop.run_forever() finally handling ===\n else:\n # Otherwise, live to tick another day. Enqueue the next tick,\n # and make sure there will be *something* to be processed.\n # If you don't ensure there is at least one message on the\n # queue, the select() call will block, locking the app.\n self.enqueue_tick()\n self.call_soon(self._loop_self_reading)\n\n\n# Python 3.7 changed the name of an internal wrapper function.\n# Install an alias for the old name at the new name.\nif sys.version_info < (3, 7):\n WinformsProactorEventLoop._set_coroutine_origin_tracking = WinformsProactorEventLoop._set_coroutine_wrapper\n", "path": "src/winforms/toga_winforms/libs/proactor.py"}]}
| 3,487 | 208 |
gh_patches_debug_13110
|
rasdani/github-patches
|
git_diff
|
Mailu__Mailu-1863
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Radicale password check fails (length limited?)
So far, the webdav radicale is protected with basic auth (apparently htaccess or similar).
If user password > 8 then it fails to connect.
we should remove this limitation to let use stong passwords
</issue>
<code>
[start of core/admin/mailu/internal/views/auth.py]
1 from mailu import models, utils
2 from mailu.internal import internal, nginx
3 from flask import current_app as app
4
5 import flask
6 import flask_login
7 import base64
8 import ipaddress
9
10
11 @internal.route("/auth/email")
12 def nginx_authentication():
13 """ Main authentication endpoint for Nginx email server
14 """
15 limiter = utils.limiter.get_limiter(app.config["AUTH_RATELIMIT"], "auth-ip")
16 client_ip = flask.request.headers["Client-Ip"]
17 if not limiter.test(client_ip):
18 response = flask.Response()
19 response.headers['Auth-Status'] = 'Authentication rate limit from one source exceeded'
20 response.headers['Auth-Error-Code'] = '451 4.3.2'
21 if int(flask.request.headers['Auth-Login-Attempt']) < 10:
22 response.headers['Auth-Wait'] = '3'
23 return response
24 headers = nginx.handle_authentication(flask.request.headers)
25 response = flask.Response()
26 for key, value in headers.items():
27 response.headers[key] = str(value)
28 if ("Auth-Status" not in headers) or (headers["Auth-Status"] != "OK"):
29 limit_subnet = str(app.config["AUTH_RATELIMIT_SUBNET"]) != 'False'
30 subnet = ipaddress.ip_network(app.config["SUBNET"])
31 if limit_subnet or ipaddress.ip_address(client_ip) not in subnet:
32 limiter.hit(flask.request.headers["Client-Ip"])
33 return response
34
35
36 @internal.route("/auth/admin")
37 def admin_authentication():
38 """ Fails if the user is not an authenticated admin.
39 """
40 if (not flask_login.current_user.is_anonymous
41 and flask_login.current_user.global_admin
42 and flask_login.current_user.enabled):
43 return ""
44 return flask.abort(403)
45
46
47 @internal.route("/auth/basic")
48 def basic_authentication():
49 """ Tries to authenticate using the Authorization header.
50 """
51 authorization = flask.request.headers.get("Authorization")
52 if authorization and authorization.startswith("Basic "):
53 encoded = authorization.replace("Basic ", "")
54 user_email, password = base64.b64decode(encoded).split(b":")
55 user = models.User.query.get(user_email.decode("utf8"))
56 if user and user.enabled and user.check_password(password.decode("utf8")):
57 response = flask.Response()
58 response.headers["X-User"] = user.email
59 return response
60 response = flask.Response(status=401)
61 response.headers["WWW-Authenticate"] = 'Basic realm="Login Required"'
62 return response
63
[end of core/admin/mailu/internal/views/auth.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/core/admin/mailu/internal/views/auth.py b/core/admin/mailu/internal/views/auth.py
--- a/core/admin/mailu/internal/views/auth.py
+++ b/core/admin/mailu/internal/views/auth.py
@@ -51,7 +51,7 @@
authorization = flask.request.headers.get("Authorization")
if authorization and authorization.startswith("Basic "):
encoded = authorization.replace("Basic ", "")
- user_email, password = base64.b64decode(encoded).split(b":")
+ user_email, password = base64.b64decode(encoded).split(b":", 1)
user = models.User.query.get(user_email.decode("utf8"))
if user and user.enabled and user.check_password(password.decode("utf8")):
response = flask.Response()
|
{"golden_diff": "diff --git a/core/admin/mailu/internal/views/auth.py b/core/admin/mailu/internal/views/auth.py\n--- a/core/admin/mailu/internal/views/auth.py\n+++ b/core/admin/mailu/internal/views/auth.py\n@@ -51,7 +51,7 @@\n authorization = flask.request.headers.get(\"Authorization\")\n if authorization and authorization.startswith(\"Basic \"):\n encoded = authorization.replace(\"Basic \", \"\")\n- user_email, password = base64.b64decode(encoded).split(b\":\")\n+ user_email, password = base64.b64decode(encoded).split(b\":\", 1)\n user = models.User.query.get(user_email.decode(\"utf8\"))\n if user and user.enabled and user.check_password(password.decode(\"utf8\")):\n response = flask.Response()\n", "issue": "Radicale password check fails (length limited?)\nSo far, the webdav radicale is protected with basic auth (apparently htaccess or similar).\r\nIf user password > 8 then it fails to connect. \r\nwe should remove this limitation to let use stong passwords\n", "before_files": [{"content": "from mailu import models, utils\nfrom mailu.internal import internal, nginx\nfrom flask import current_app as app\n\nimport flask\nimport flask_login\nimport base64\nimport ipaddress\n\n\[email protected](\"/auth/email\")\ndef nginx_authentication():\n \"\"\" Main authentication endpoint for Nginx email server\n \"\"\"\n limiter = utils.limiter.get_limiter(app.config[\"AUTH_RATELIMIT\"], \"auth-ip\")\n client_ip = flask.request.headers[\"Client-Ip\"]\n if not limiter.test(client_ip):\n response = flask.Response()\n response.headers['Auth-Status'] = 'Authentication rate limit from one source exceeded'\n response.headers['Auth-Error-Code'] = '451 4.3.2'\n if int(flask.request.headers['Auth-Login-Attempt']) < 10:\n response.headers['Auth-Wait'] = '3'\n return response\n headers = nginx.handle_authentication(flask.request.headers)\n response = flask.Response()\n for key, value in headers.items():\n response.headers[key] = str(value)\n if (\"Auth-Status\" not in headers) or (headers[\"Auth-Status\"] != \"OK\"):\n limit_subnet = str(app.config[\"AUTH_RATELIMIT_SUBNET\"]) != 'False'\n subnet = ipaddress.ip_network(app.config[\"SUBNET\"])\n if limit_subnet or ipaddress.ip_address(client_ip) not in subnet:\n limiter.hit(flask.request.headers[\"Client-Ip\"])\n return response\n\n\[email protected](\"/auth/admin\")\ndef admin_authentication():\n \"\"\" Fails if the user is not an authenticated admin.\n \"\"\"\n if (not flask_login.current_user.is_anonymous\n and flask_login.current_user.global_admin\n and flask_login.current_user.enabled):\n return \"\"\n return flask.abort(403)\n\n\[email protected](\"/auth/basic\")\ndef basic_authentication():\n \"\"\" Tries to authenticate using the Authorization header.\n \"\"\"\n authorization = flask.request.headers.get(\"Authorization\")\n if authorization and authorization.startswith(\"Basic \"):\n encoded = authorization.replace(\"Basic \", \"\")\n user_email, password = base64.b64decode(encoded).split(b\":\")\n user = models.User.query.get(user_email.decode(\"utf8\"))\n if user and user.enabled and user.check_password(password.decode(\"utf8\")):\n response = flask.Response()\n response.headers[\"X-User\"] = user.email\n return response\n response = flask.Response(status=401)\n response.headers[\"WWW-Authenticate\"] = 'Basic realm=\"Login Required\"'\n return response\n", "path": "core/admin/mailu/internal/views/auth.py"}]}
| 1,257 | 165 |
gh_patches_debug_1340
|
rasdani/github-patches
|
git_diff
|
nilearn__nilearn-3337
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Spelling Error
<!--Describe your proposed enhancement in detail.-->
I think the authors meant to describe ADHD but have written ADHD as AHDH. It is just a simple spelling or typographic error.
<!--List any pages that would be impacted by the enhancement.-->
### Affected pages
1. https://nilearn.github.io/dev/auto_examples/04_glm_first_level/plot_adhd_dmn.html#sphx-glr-auto-examples-04-glm-first-level-plot-adhd-dmn-py
2. https://nilearn.github.io/dev/glm/first_level_model.html#fitting-a-first-level-model
</issue>
<code>
[start of examples/04_glm_first_level/plot_adhd_dmn.py]
1 """Default Mode Network extraction of AHDH dataset
2 ===============================================
3
4 This example shows a full step-by-step workflow of fitting a GLM to data
5 extracted from a seed on the Posterior Cingulate Cortex and saving the results.
6
7 More specifically:
8
9 1. A sequence of fMRI volumes are loaded.
10 2. A design matrix with the Posterior Cingulate Cortex seed is defined.
11 3. A GLM is applied to the dataset (effect/covariance, then contrast estimation).
12 4. The Default Mode Network is displayed.
13
14 .. include:: ../../../examples/masker_note.rst
15
16 """
17 import numpy as np
18
19 from nilearn import datasets, plotting
20 from nilearn.maskers import NiftiSpheresMasker
21
22 from nilearn.glm.first_level import FirstLevelModel
23 from nilearn.glm.first_level import make_first_level_design_matrix
24
25 #########################################################################
26 # Prepare data and analysis parameters
27 # -------------------------------------
28 # Prepare the data.
29 adhd_dataset = datasets.fetch_adhd(n_subjects=1)
30
31 # Prepare timing
32 t_r = 2.
33 slice_time_ref = 0.
34 n_scans = 176
35
36 # Prepare seed
37 pcc_coords = (0, -53, 26)
38
39 #########################################################################
40 # Estimate contrasts
41 # ------------------
42 # Specify the contrasts.
43 seed_masker = NiftiSpheresMasker([pcc_coords], radius=10, detrend=True,
44 standardize=True, low_pass=0.1,
45 high_pass=0.01, t_r=2.,
46 memory='nilearn_cache',
47 memory_level=1, verbose=0)
48 seed_time_series = seed_masker.fit_transform(adhd_dataset.func[0])
49 frametimes = np.linspace(0, (n_scans - 1) * t_r, n_scans)
50 design_matrix = make_first_level_design_matrix(frametimes, hrf_model='spm',
51 add_regs=seed_time_series,
52 add_reg_names=["pcc_seed"])
53 dmn_contrast = np.array([1] + [0] * (design_matrix.shape[1] - 1))
54 contrasts = {'seed_based_glm': dmn_contrast}
55
56 #########################################################################
57 # Perform first level analysis
58 # ----------------------------
59 # Setup and fit GLM.
60 first_level_model = FirstLevelModel(t_r=t_r, slice_time_ref=slice_time_ref)
61 first_level_model = first_level_model.fit(run_imgs=adhd_dataset.func[0],
62 design_matrices=design_matrix)
63
64 #########################################################################
65 # Estimate the contrast.
66 print('Contrast seed_based_glm computed.')
67 z_map = first_level_model.compute_contrast(contrasts['seed_based_glm'],
68 output_type='z_score')
69
70 # Saving snapshots of the contrasts
71 filename = 'dmn_z_map.png'
72 display = plotting.plot_stat_map(z_map, threshold=3.0, title='Seed based GLM',
73 cut_coords=pcc_coords)
74 display.add_markers(marker_coords=[pcc_coords], marker_color='g',
75 marker_size=300)
76 display.savefig(filename)
77 print("Save z-map in '{0}'.".format(filename))
78
79 ###########################################################################
80 # Generating a report
81 # -------------------
82 # It can be useful to quickly generate a
83 # portable, ready-to-view report with most of the pertinent information.
84 # This is easy to do if you have a fitted model and the list of contrasts,
85 # which we do here.
86
87 from nilearn.reporting import make_glm_report
88
89 report = make_glm_report(first_level_model,
90 contrasts=contrasts,
91 title='ADHD DMN Report',
92 cluster_threshold=15,
93 min_distance=8.,
94 plot_type='glass',
95 )
96
97 #########################################################################
98 # We have several ways to access the report:
99
100 # report # This report can be viewed in a notebook
101 # report.save_as_html('report.html')
102 # report.open_in_browser()
103
[end of examples/04_glm_first_level/plot_adhd_dmn.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/04_glm_first_level/plot_adhd_dmn.py b/examples/04_glm_first_level/plot_adhd_dmn.py
--- a/examples/04_glm_first_level/plot_adhd_dmn.py
+++ b/examples/04_glm_first_level/plot_adhd_dmn.py
@@ -1,4 +1,4 @@
-"""Default Mode Network extraction of AHDH dataset
+"""Default Mode Network extraction of ADHD dataset
===============================================
This example shows a full step-by-step workflow of fitting a GLM to data
|
{"golden_diff": "diff --git a/examples/04_glm_first_level/plot_adhd_dmn.py b/examples/04_glm_first_level/plot_adhd_dmn.py\n--- a/examples/04_glm_first_level/plot_adhd_dmn.py\n+++ b/examples/04_glm_first_level/plot_adhd_dmn.py\n@@ -1,4 +1,4 @@\n-\"\"\"Default Mode Network extraction of AHDH dataset\n+\"\"\"Default Mode Network extraction of ADHD dataset\n ===============================================\n \n This example shows a full step-by-step workflow of fitting a GLM to data\n", "issue": "Spelling Error\n<!--Describe your proposed enhancement in detail.-->\r\nI think the authors meant to describe ADHD but have written ADHD as AHDH. It is just a simple spelling or typographic error.\r\n<!--List any pages that would be impacted by the enhancement.-->\r\n### Affected pages\r\n1. https://nilearn.github.io/dev/auto_examples/04_glm_first_level/plot_adhd_dmn.html#sphx-glr-auto-examples-04-glm-first-level-plot-adhd-dmn-py\r\n 2. https://nilearn.github.io/dev/glm/first_level_model.html#fitting-a-first-level-model\n", "before_files": [{"content": "\"\"\"Default Mode Network extraction of AHDH dataset\n===============================================\n\nThis example shows a full step-by-step workflow of fitting a GLM to data\nextracted from a seed on the Posterior Cingulate Cortex and saving the results.\n\nMore specifically:\n\n1. A sequence of fMRI volumes are loaded.\n2. A design matrix with the Posterior Cingulate Cortex seed is defined.\n3. A GLM is applied to the dataset (effect/covariance, then contrast estimation).\n4. The Default Mode Network is displayed.\n\n.. include:: ../../../examples/masker_note.rst\n\n\"\"\"\nimport numpy as np\n\nfrom nilearn import datasets, plotting\nfrom nilearn.maskers import NiftiSpheresMasker\n\nfrom nilearn.glm.first_level import FirstLevelModel\nfrom nilearn.glm.first_level import make_first_level_design_matrix\n\n#########################################################################\n# Prepare data and analysis parameters\n# -------------------------------------\n# Prepare the data.\nadhd_dataset = datasets.fetch_adhd(n_subjects=1)\n\n# Prepare timing\nt_r = 2.\nslice_time_ref = 0.\nn_scans = 176\n\n# Prepare seed\npcc_coords = (0, -53, 26)\n\n#########################################################################\n# Estimate contrasts\n# ------------------\n# Specify the contrasts.\nseed_masker = NiftiSpheresMasker([pcc_coords], radius=10, detrend=True,\n standardize=True, low_pass=0.1,\n high_pass=0.01, t_r=2.,\n memory='nilearn_cache',\n memory_level=1, verbose=0)\nseed_time_series = seed_masker.fit_transform(adhd_dataset.func[0])\nframetimes = np.linspace(0, (n_scans - 1) * t_r, n_scans)\ndesign_matrix = make_first_level_design_matrix(frametimes, hrf_model='spm',\n add_regs=seed_time_series,\n add_reg_names=[\"pcc_seed\"])\ndmn_contrast = np.array([1] + [0] * (design_matrix.shape[1] - 1))\ncontrasts = {'seed_based_glm': dmn_contrast}\n\n#########################################################################\n# Perform first level analysis\n# ----------------------------\n# Setup and fit GLM.\nfirst_level_model = FirstLevelModel(t_r=t_r, slice_time_ref=slice_time_ref)\nfirst_level_model = first_level_model.fit(run_imgs=adhd_dataset.func[0],\n design_matrices=design_matrix)\n\n#########################################################################\n# Estimate the contrast.\nprint('Contrast seed_based_glm computed.')\nz_map = first_level_model.compute_contrast(contrasts['seed_based_glm'],\n output_type='z_score')\n\n# Saving snapshots of the contrasts\nfilename = 'dmn_z_map.png'\ndisplay = plotting.plot_stat_map(z_map, threshold=3.0, title='Seed based GLM',\n cut_coords=pcc_coords)\ndisplay.add_markers(marker_coords=[pcc_coords], marker_color='g',\n marker_size=300)\ndisplay.savefig(filename)\nprint(\"Save z-map in '{0}'.\".format(filename))\n\n###########################################################################\n# Generating a report\n# -------------------\n# It can be useful to quickly generate a\n# portable, ready-to-view report with most of the pertinent information.\n# This is easy to do if you have a fitted model and the list of contrasts,\n# which we do here.\n\nfrom nilearn.reporting import make_glm_report\n\nreport = make_glm_report(first_level_model,\n contrasts=contrasts,\n title='ADHD DMN Report',\n cluster_threshold=15,\n min_distance=8.,\n plot_type='glass',\n )\n\n#########################################################################\n# We have several ways to access the report:\n\n# report # This report can be viewed in a notebook\n# report.save_as_html('report.html')\n# report.open_in_browser()\n", "path": "examples/04_glm_first_level/plot_adhd_dmn.py"}]}
| 1,710 | 124 |
gh_patches_debug_850
|
rasdani/github-patches
|
git_diff
|
dotkom__onlineweb4-1359
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Option to post video in article
Make it possible to post video in article from dashboard.
</issue>
<code>
[start of apps/article/dashboard/forms.py]
1 # -*- encoding: utf-8 -*-
2 from django import forms
3
4 from apps.article.models import Article
5 from apps.dashboard.widgets import DatetimePickerInput, multiple_widget_generator
6 from apps.gallery.widgets import SingleImageInput
7
8 from taggit.forms import TagWidget
9
10
11 class ArticleForm(forms.ModelForm):
12
13 class Meta(object):
14 """
15 Add fields that should have DTP activated in the datetimepicker_fields list
16 """
17
18 model = Article
19 fields = [
20 'heading',
21 'ingress_short',
22 'ingress',
23 'content',
24 'image',
25 'published_date',
26 'authors',
27 'tags',
28 'featured'
29 ]
30
31 # Fields should be a mapping between field name and an attribute dictionary
32 img_fields = [('image', {'id': 'responsive-image-id'})]
33 dtp_fields = [('published_date', {})]
34 widgetlist = [
35 (DatetimePickerInput, dtp_fields),
36 (SingleImageInput, img_fields)
37 ]
38
39 # Multiple widget generator merges results from regular widget_generator into a single widget dict
40 widgets = multiple_widget_generator(widgetlist)
41 widgets.update({'tags': TagWidget(attrs={'placeholder': 'Eksempel: åre, online, kjelleren'})})
42 labels = {
43 'tags': u'Tags'
44 }
45
[end of apps/article/dashboard/forms.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/apps/article/dashboard/forms.py b/apps/article/dashboard/forms.py
--- a/apps/article/dashboard/forms.py
+++ b/apps/article/dashboard/forms.py
@@ -22,6 +22,7 @@
'ingress',
'content',
'image',
+ 'video',
'published_date',
'authors',
'tags',
|
{"golden_diff": "diff --git a/apps/article/dashboard/forms.py b/apps/article/dashboard/forms.py\n--- a/apps/article/dashboard/forms.py\n+++ b/apps/article/dashboard/forms.py\n@@ -22,6 +22,7 @@\n 'ingress',\n 'content',\n 'image',\n+ 'video',\n 'published_date',\n 'authors',\n 'tags',\n", "issue": "Option to post video in article\nMake it possible to post video in article from dashboard.\n\n", "before_files": [{"content": "# -*- encoding: utf-8 -*-\nfrom django import forms\n\nfrom apps.article.models import Article\nfrom apps.dashboard.widgets import DatetimePickerInput, multiple_widget_generator\nfrom apps.gallery.widgets import SingleImageInput\n\nfrom taggit.forms import TagWidget\n\n\nclass ArticleForm(forms.ModelForm):\n\n class Meta(object):\n \"\"\"\n Add fields that should have DTP activated in the datetimepicker_fields list\n \"\"\"\n\n model = Article\n fields = [\n 'heading',\n 'ingress_short',\n 'ingress',\n 'content',\n 'image',\n 'published_date',\n 'authors',\n 'tags',\n 'featured'\n ]\n\n # Fields should be a mapping between field name and an attribute dictionary\n img_fields = [('image', {'id': 'responsive-image-id'})]\n dtp_fields = [('published_date', {})]\n widgetlist = [\n (DatetimePickerInput, dtp_fields),\n (SingleImageInput, img_fields)\n ]\n\n # Multiple widget generator merges results from regular widget_generator into a single widget dict\n widgets = multiple_widget_generator(widgetlist)\n widgets.update({'tags': TagWidget(attrs={'placeholder': 'Eksempel: \u00e5re, online, kjelleren'})})\n labels = {\n 'tags': u'Tags'\n }\n", "path": "apps/article/dashboard/forms.py"}]}
| 911 | 75 |
gh_patches_debug_26748
|
rasdani/github-patches
|
git_diff
|
pyjanitor-devs__pyjanitor-966
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Example of groupby_agg shows wrong output
# Brief Description of Fix
<!-- Please describe the fix in terms of a "before" and "after". In other words, what's not so good about the current docs
page, and what you would like to see it become.
Example starter wording is provided. -->
Currently, the docs for `groupby_agg` uses `new_column_name='count'` but the result shown in the docs has column name 'size'.
<img width="554" alt="image" src="https://user-images.githubusercontent.com/30731072/146632174-9b4a1022-d205-4ead-855e-76a3dccb7b7a.png">
The correct column name should be 'count'.
<img width="330" alt="image" src="https://user-images.githubusercontent.com/30731072/146632197-7607612a-8388-4383-846b-07ac3d7b522d.png">
```
group var1 count
0 1 1 4
1 1 1 4
2 1 1 4
3 1 1 4
4 1 2 1
5 2 1 1
6 2 2 3
7 2 2 3
8 2 2 3
9 2 3 1
```
Seems like a simple enough fix, I'm happy to open a PR if you'ld like
# Relevant Context
<!-- Please put here, in bullet points, links to the relevant docs page. A few starting template points are available
to get you started. -->
- [Link to documentation page](https://pyjanitor-devs.github.io/pyjanitor/api/functions/#janitor.functions.groupby_agg)
- [Link to exact file to be edited](https://github.com/pyjanitor-devs/pyjanitor/blob/dev/janitor/functions/groupby_agg.py)
</issue>
<code>
[start of janitor/functions/groupby_agg.py]
1 from typing import Callable, List, Union
2 import pandas_flavor as pf
3 import pandas as pd
4
5 from janitor.utils import deprecated_alias
6
7
8 @pf.register_dataframe_method
9 @deprecated_alias(new_column="new_column_name", agg_column="agg_column_name")
10 def groupby_agg(
11 df: pd.DataFrame,
12 by: Union[List, str],
13 new_column_name: str,
14 agg_column_name: str,
15 agg: Union[Callable, str],
16 dropna: bool = True,
17 ) -> pd.DataFrame:
18 """
19 Shortcut for assigning a groupby-transform to a new column.
20
21 This method does not mutate the original DataFrame.
22
23 Without this function, we would have to write a verbose line:
24
25 ```python
26 df = df.assign(...=df.groupby(...)[...].transform(...))
27 ```
28
29 Now, this function can be method-chained:
30
31 ```python
32 import pandas as pd
33 import janitor
34 df = pd.DataFrame(...).groupby_agg(by='group',
35 agg='mean',
36 agg_column_name="col1"
37 new_column_name='col1_mean_by_group',
38 dropna = True/False)
39 ```
40
41 Functional usage syntax:
42
43 ```python
44
45 import pandas as pd
46 import janitor as jn
47
48 jn.groupby_agg(
49 df,
50 by= column name/list of column names,
51 agg=aggregation function,
52 agg_column_name = col,
53 new_column_name= new column name,
54 dropna = True/False)
55 ```
56
57 Method chaining usage syntax:
58
59 ```python
60
61 df.groupby_agg(
62 by= column name/list of column names,
63 agg=aggregation function,
64 agg_column_name = col,
65 new_column_name= new column name,
66 dropna = True/False)
67 ```
68
69
70 :param df: A pandas DataFrame.
71 :param by: Column(s) to groupby on, either a `str` or
72 a `list` of `str`
73 :param new_column_name: Name of the aggregation output column.
74 :param agg_column_name: Name of the column to aggregate over.
75 :param agg: How to aggregate.
76 :param dropna: Whether or not to include null values,
77 if present in the `by` column(s). Default is True.
78 :returns: A pandas DataFrame.
79 """
80
81 return df.assign(
82 **{
83 new_column_name: df.groupby(by, dropna=dropna)[
84 agg_column_name
85 ].transform(agg)
86 }
87 )
88
[end of janitor/functions/groupby_agg.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/janitor/functions/groupby_agg.py b/janitor/functions/groupby_agg.py
--- a/janitor/functions/groupby_agg.py
+++ b/janitor/functions/groupby_agg.py
@@ -35,7 +35,7 @@
agg='mean',
agg_column_name="col1"
new_column_name='col1_mean_by_group',
- dropna = True/False)
+ dropna=True/False)
```
Functional usage syntax:
@@ -56,6 +56,41 @@
Method chaining usage syntax:
+ ```python
+ df.groupby_agg(
+ by=['group', 'var1'],
+ agg='size',
+ agg_column_name='var1',
+ new_column_name='count',
+ )
+ ```
+
+ group var1 count
+ 0 1 1 4
+ 1 1 1 4
+ 2 1 1 4
+ 3 1 1 4
+ 4 1 2 1
+ 5 2 1 1
+ 6 2 2 3
+ 7 2 2 3
+ 8 2 2 3
+ 9 2 3 1
+
+ If the data has null values,
+ you can include the null values by passing `False` to `dropna`;
+ this feature was introduced in Pandas 1.1:
+
+ name type num nulls
+ 0 black chair 4 1.0
+ 1 black chair 5 1.0
+ 2 black sofa 12 NaN
+ 3 red sofa 4 NaN
+ 4 red plate 3 3.0
+
+ Let's get the count, including the null values,
+ grouping on `nulls` column:
+
```python
df.groupby_agg(
|
{"golden_diff": "diff --git a/janitor/functions/groupby_agg.py b/janitor/functions/groupby_agg.py\n--- a/janitor/functions/groupby_agg.py\n+++ b/janitor/functions/groupby_agg.py\n@@ -35,7 +35,7 @@\n agg='mean',\n agg_column_name=\"col1\"\n new_column_name='col1_mean_by_group',\n- dropna = True/False)\n+ dropna=True/False)\n ```\n \n Functional usage syntax:\n@@ -56,6 +56,41 @@\n \n Method chaining usage syntax:\n \n+ ```python\n+ df.groupby_agg(\n+ by=['group', 'var1'],\n+ agg='size',\n+ agg_column_name='var1',\n+ new_column_name='count',\n+ )\n+ ```\n+\n+ group var1 count\n+ 0 1 1 4\n+ 1 1 1 4\n+ 2 1 1 4\n+ 3 1 1 4\n+ 4 1 2 1\n+ 5 2 1 1\n+ 6 2 2 3\n+ 7 2 2 3\n+ 8 2 2 3\n+ 9 2 3 1\n+\n+ If the data has null values,\n+ you can include the null values by passing `False` to `dropna`;\n+ this feature was introduced in Pandas 1.1:\n+\n+ name type num nulls\n+ 0 black chair 4 1.0\n+ 1 black chair 5 1.0\n+ 2 black sofa 12 NaN\n+ 3 red sofa 4 NaN\n+ 4 red plate 3 3.0\n+\n+ Let's get the count, including the null values,\n+ grouping on `nulls` column:\n+\n ```python\n \n df.groupby_agg(\n", "issue": "Example of groupby_agg shows wrong output\n# Brief Description of Fix\r\n\r\n<!-- Please describe the fix in terms of a \"before\" and \"after\". In other words, what's not so good about the current docs\r\npage, and what you would like to see it become.\r\n\r\nExample starter wording is provided. -->\r\n\r\nCurrently, the docs for `groupby_agg` uses `new_column_name='count'` but the result shown in the docs has column name 'size'.\r\n\r\n<img width=\"554\" alt=\"image\" src=\"https://user-images.githubusercontent.com/30731072/146632174-9b4a1022-d205-4ead-855e-76a3dccb7b7a.png\">\r\n\r\nThe correct column name should be 'count'.\r\n\r\n<img width=\"330\" alt=\"image\" src=\"https://user-images.githubusercontent.com/30731072/146632197-7607612a-8388-4383-846b-07ac3d7b522d.png\">\r\n\r\n```\r\n group var1 count\r\n0 1 1 4\r\n1 1 1 4\r\n2 1 1 4\r\n3 1 1 4\r\n4 1 2 1\r\n5 2 1 1\r\n6 2 2 3\r\n7 2 2 3\r\n8 2 2 3\r\n9 2 3 1\r\n```\r\n\r\nSeems like a simple enough fix, I'm happy to open a PR if you'ld like\r\n\r\n# Relevant Context\r\n\r\n<!-- Please put here, in bullet points, links to the relevant docs page. A few starting template points are available\r\nto get you started. -->\r\n\r\n- [Link to documentation page](https://pyjanitor-devs.github.io/pyjanitor/api/functions/#janitor.functions.groupby_agg)\r\n- [Link to exact file to be edited](https://github.com/pyjanitor-devs/pyjanitor/blob/dev/janitor/functions/groupby_agg.py)\r\n\n", "before_files": [{"content": "from typing import Callable, List, Union\nimport pandas_flavor as pf\nimport pandas as pd\n\nfrom janitor.utils import deprecated_alias\n\n\[email protected]_dataframe_method\n@deprecated_alias(new_column=\"new_column_name\", agg_column=\"agg_column_name\")\ndef groupby_agg(\n df: pd.DataFrame,\n by: Union[List, str],\n new_column_name: str,\n agg_column_name: str,\n agg: Union[Callable, str],\n dropna: bool = True,\n) -> pd.DataFrame:\n \"\"\"\n Shortcut for assigning a groupby-transform to a new column.\n\n This method does not mutate the original DataFrame.\n\n Without this function, we would have to write a verbose line:\n\n ```python\n df = df.assign(...=df.groupby(...)[...].transform(...))\n ```\n\n Now, this function can be method-chained:\n\n ```python\n import pandas as pd\n import janitor\n df = pd.DataFrame(...).groupby_agg(by='group',\n agg='mean',\n agg_column_name=\"col1\"\n new_column_name='col1_mean_by_group',\n dropna = True/False)\n ```\n\n Functional usage syntax:\n\n ```python\n\n import pandas as pd\n import janitor as jn\n\n jn.groupby_agg(\n df,\n by= column name/list of column names,\n agg=aggregation function,\n agg_column_name = col,\n new_column_name= new column name,\n dropna = True/False)\n ```\n\n Method chaining usage syntax:\n\n ```python\n\n df.groupby_agg(\n by= column name/list of column names,\n agg=aggregation function,\n agg_column_name = col,\n new_column_name= new column name,\n dropna = True/False)\n ```\n\n\n :param df: A pandas DataFrame.\n :param by: Column(s) to groupby on, either a `str` or\n a `list` of `str`\n :param new_column_name: Name of the aggregation output column.\n :param agg_column_name: Name of the column to aggregate over.\n :param agg: How to aggregate.\n :param dropna: Whether or not to include null values,\n if present in the `by` column(s). Default is True.\n :returns: A pandas DataFrame.\n \"\"\"\n\n return df.assign(\n **{\n new_column_name: df.groupby(by, dropna=dropna)[\n agg_column_name\n ].transform(agg)\n }\n )\n", "path": "janitor/functions/groupby_agg.py"}]}
| 1,748 | 494 |
gh_patches_debug_48464
|
rasdani/github-patches
|
git_diff
|
mirumee__ariadne-840
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Update Starlette dependency to 0.19
Starlette 0.19 has been released, we should bump Ariadne's version to it before releasing 0.15
</issue>
<code>
[start of setup.py]
1 #! /usr/bin/env python
2 import os
3 from setuptools import setup
4
5 CLASSIFIERS = [
6 "Development Status :: 4 - Beta",
7 "Intended Audience :: Developers",
8 "License :: OSI Approved :: BSD License",
9 "Operating System :: OS Independent",
10 "Programming Language :: Python",
11 "Programming Language :: Python :: 3.7",
12 "Programming Language :: Python :: 3.8",
13 "Programming Language :: Python :: 3.9",
14 "Programming Language :: Python :: 3.10",
15 "Topic :: Software Development :: Libraries :: Python Modules",
16 ]
17
18 README_PATH = os.path.join(os.path.dirname(os.path.abspath(__file__)), "README.md")
19 with open(README_PATH, "r", encoding="utf8") as f:
20 README = f.read()
21
22 setup(
23 name="ariadne",
24 author="Mirumee Software",
25 author_email="[email protected]",
26 description="Ariadne is a Python library for implementing GraphQL servers.",
27 long_description=README,
28 long_description_content_type="text/markdown",
29 license="BSD",
30 version="0.15.0.dev5",
31 url="https://github.com/mirumee/ariadne",
32 packages=["ariadne"],
33 include_package_data=True,
34 install_requires=[
35 "graphql-core>=3.2.0,<3.3",
36 "starlette<0.19",
37 "typing_extensions>=3.6.0",
38 ],
39 extras_require={"asgi-file-uploads": ["python-multipart>=0.0.5"]},
40 classifiers=CLASSIFIERS,
41 platforms=["any"],
42 zip_safe=False,
43 )
44
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -33,7 +33,7 @@
include_package_data=True,
install_requires=[
"graphql-core>=3.2.0,<3.3",
- "starlette<0.19",
+ "starlette>0.17<0.20",
"typing_extensions>=3.6.0",
],
extras_require={"asgi-file-uploads": ["python-multipart>=0.0.5"]},
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -33,7 +33,7 @@\n include_package_data=True,\n install_requires=[\n \"graphql-core>=3.2.0,<3.3\",\n- \"starlette<0.19\",\n+ \"starlette>0.17<0.20\",\n \"typing_extensions>=3.6.0\",\n ],\n extras_require={\"asgi-file-uploads\": [\"python-multipart>=0.0.5\"]},\n", "issue": "Update Starlette dependency to 0.19\nStarlette 0.19 has been released, we should bump Ariadne's version to it before releasing 0.15 \n", "before_files": [{"content": "#! /usr/bin/env python\nimport os\nfrom setuptools import setup\n\nCLASSIFIERS = [\n \"Development Status :: 4 - Beta\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: BSD License\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Topic :: Software Development :: Libraries :: Python Modules\",\n]\n\nREADME_PATH = os.path.join(os.path.dirname(os.path.abspath(__file__)), \"README.md\")\nwith open(README_PATH, \"r\", encoding=\"utf8\") as f:\n README = f.read()\n\nsetup(\n name=\"ariadne\",\n author=\"Mirumee Software\",\n author_email=\"[email protected]\",\n description=\"Ariadne is a Python library for implementing GraphQL servers.\",\n long_description=README,\n long_description_content_type=\"text/markdown\",\n license=\"BSD\",\n version=\"0.15.0.dev5\",\n url=\"https://github.com/mirumee/ariadne\",\n packages=[\"ariadne\"],\n include_package_data=True,\n install_requires=[\n \"graphql-core>=3.2.0,<3.3\",\n \"starlette<0.19\",\n \"typing_extensions>=3.6.0\",\n ],\n extras_require={\"asgi-file-uploads\": [\"python-multipart>=0.0.5\"]},\n classifiers=CLASSIFIERS,\n platforms=[\"any\"],\n zip_safe=False,\n)\n", "path": "setup.py"}]}
| 1,007 | 119 |
gh_patches_debug_43644
|
rasdani/github-patches
|
git_diff
|
crytic__slither-446
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
slither-flat: Translate all visibilities to internal
Similar to the `external` to `public` conversion, we can convert all visible functions to `internal`, and all `private` variables to `internal`.
This schema is useful when fuzzing a codebase with Echidna, to reduce the scope of the fuzzing and allow to access private elements.
slither-flat: Translate all visibilities to internal
Similar to the `external` to `public` conversion, we can convert all visible functions to `internal`, and all `private` variables to `internal`.
This schema is useful when fuzzing a codebase with Echidna, to reduce the scope of the fuzzing and allow to access private elements.
</issue>
<code>
[start of slither/tools/flattening/__main__.py]
1 import argparse
2 import logging
3 from slither import Slither
4 from crytic_compile import cryticparser
5 from .flattening import Flattening
6
7 logging.basicConfig()
8 logging.getLogger("Slither").setLevel(logging.INFO)
9 logger = logging.getLogger("Slither-flattening")
10 logger.setLevel(logging.INFO)
11
12 def parse_args():
13 """
14 Parse the underlying arguments for the program.
15 :return: Returns the arguments for the program.
16 """
17 parser = argparse.ArgumentParser(description='Contracts flattening',
18 usage='slither-flat filename')
19
20 parser.add_argument('filename',
21 help='The filename of the contract or project to analyze.')
22
23 parser.add_argument('--convert-external',
24 help='Convert external to public.',
25 action='store_true')
26
27 parser.add_argument('--remove-assert',
28 help='Remove call to assert().',
29 action='store_true')
30
31 parser.add_argument('--contract',
32 help='Flatten a specific contract (default: all most derived contracts).',
33 default=None)
34
35 # Add default arguments from crytic-compile
36 cryticparser.init(parser)
37
38 return parser.parse_args()
39
40
41 def main():
42 args = parse_args()
43
44 slither = Slither(args.filename, **vars(args))
45 flat = Flattening(slither, external_to_public=args.convert_external, remove_assert=args.remove_assert)
46
47 flat.export(target=args.contract)
48
49
50 if __name__ == '__main__':
51 main()
52
[end of slither/tools/flattening/__main__.py]
[start of slither/tools/flattening/flattening.py]
1 from pathlib import Path
2 import re
3 import logging
4 from collections import namedtuple
5
6 from slither.core.declarations import SolidityFunction
7 from slither.exceptions import SlitherException
8 from slither.core.solidity_types.user_defined_type import UserDefinedType
9 from slither.core.declarations.structure import Structure
10 from slither.core.declarations.enum import Enum
11 from slither.core.declarations.contract import Contract
12 from slither.slithir.operations import NewContract, TypeConversion, SolidityCall
13
14 logger = logging.getLogger("Slither-flattening")
15
16 # index: where to start
17 # patch_type:
18 # - public_to_external: public to external (external-to-public)
19 # - calldata_to_memory: calldata to memory (external-to-public)
20 # - line_removal: remove the line (remove-assert)
21 Patch = namedtuple('PatchExternal', ['index', 'patch_type'])
22
23 class Flattening:
24 DEFAULT_EXPORT_PATH = Path('crytic-export/flattening')
25
26 def __init__(self, slither, external_to_public=False, remove_assert=False):
27 self._source_codes = {}
28 self._slither = slither
29 self._external_to_public = external_to_public
30 self._remove_assert = remove_assert
31 self._use_abi_encoder_v2 = False
32
33 self._check_abi_encoder_v2()
34
35 for contract in slither.contracts:
36 self._get_source_code(contract)
37
38 def _check_abi_encoder_v2(self):
39 for p in self._slither.pragma_directives:
40 if 'ABIEncoderV2' in str(p.directive):
41 self._use_abi_encoder_v2 = True
42 return
43
44 def _get_source_code(self, contract):
45 src_mapping = contract.source_mapping
46 content = self._slither.source_code[src_mapping['filename_absolute']]
47 start = src_mapping['start']
48 end = src_mapping['start'] + src_mapping['length']
49 first_line = src_mapping['lines'][0]
50
51 to_patch = []
52 # interface must use external
53 if self._external_to_public and contract.contract_kind != "interface":
54 for f in contract.functions_declared:
55 # fallback must be external
56 if f.is_fallback or f.is_constructor_variables:
57 continue
58 if f.visibility == 'external':
59 attributes_start = (f.parameters_src.source_mapping['start'] +
60 f.parameters_src.source_mapping['length'])
61 attributes_end = f.returns_src.source_mapping['start']
62 attributes = content[attributes_start:attributes_end]
63 regex = re.search(r'((\sexternal)\s+)|(\sexternal)$|(\)external)$', attributes)
64 if regex:
65 to_patch.append(Patch(attributes_start + regex.span()[0] + 1, 'public_to_external'))
66 else:
67 raise SlitherException(f'External keyword not found {f.name} {attributes}')
68
69 for var in f.parameters:
70 if var.location == "calldata":
71 calldata_start = var.source_mapping['start']
72 calldata_end = calldata_start + var.source_mapping['length']
73 calldata_idx = content[calldata_start:calldata_end].find(' calldata ')
74 to_patch.append(Patch(calldata_start + calldata_idx + 1, 'calldata_to_memory'))
75
76 if self._remove_assert:
77 for function in contract.functions_and_modifiers_declared:
78 for node in function.nodes:
79 for ir in node.irs:
80 if isinstance(ir, SolidityCall) and ir.function == SolidityFunction('assert(bool)'):
81 to_patch.append(Patch(node.source_mapping['start'], 'line_removal'))
82 logger.info(f'Code commented: {node.expression} ({node.source_mapping_str})')
83
84 to_patch.sort(key=lambda x: x.index, reverse=True)
85
86 content = content[start:end]
87 for patch in to_patch:
88 patch_type = patch.patch_type
89 index = patch.index
90 index = index - start
91 if patch_type == 'public_to_external':
92 content = content[:index] + 'public' + content[index + len('external'):]
93 elif patch_type == 'calldata_to_memory':
94 content = content[:index] + 'memory' + content[index + len('calldata'):]
95 else:
96 assert patch_type == 'line_removal'
97 content = content[:index] + ' // ' + content[index:]
98
99 self._source_codes[contract] = content
100
101 def _export_from_type(self, t, contract, exported, list_contract):
102 if isinstance(t, UserDefinedType):
103 if isinstance(t.type, (Enum, Structure)):
104 if t.type.contract != contract and not t.type.contract in exported:
105 self._export_contract(t.type.contract, exported, list_contract)
106 else:
107 assert isinstance(t.type, Contract)
108 if t.type != contract and not t.type in exported:
109 self._export_contract(t.type, exported, list_contract)
110
111 def _export_contract(self, contract, exported, list_contract):
112 if contract.name in exported:
113 return
114 exported.add(contract.name)
115 for inherited in contract.inheritance:
116 self._export_contract(inherited, exported, list_contract)
117
118 # Find all the external contracts called
119 externals = contract.all_library_calls + contract.all_high_level_calls
120 # externals is a list of (contract, function)
121 # We also filter call to itself to avoid infilite loop
122 externals = list(set([e[0] for e in externals if e[0] != contract]))
123
124 for inherited in externals:
125 self._export_contract(inherited, exported, list_contract)
126
127 # Find all the external contracts use as a base type
128 local_vars = []
129 for f in contract.functions_declared:
130 local_vars += f.variables
131
132 for v in contract.variables + local_vars:
133 self._export_from_type(v.type, contract, exported, list_contract)
134
135 # Find all convert and "new" operation that can lead to use an external contract
136 for f in contract.functions_declared:
137 for ir in f.slithir_operations:
138 if isinstance(ir, NewContract):
139 if ir.contract_created != contract and not ir.contract_created in exported:
140 self._export_contract(ir.contract_created, exported, list_contract)
141 if isinstance(ir, TypeConversion):
142 self._export_from_type(ir.type, contract, exported, list_contract)
143 list_contract.append(self._source_codes[contract])
144
145 def _export(self, contract, ret):
146 self._export_contract(contract, set(), ret)
147 path = Path(self.DEFAULT_EXPORT_PATH, f'{contract.name}.sol')
148 logger.info(f'Export {path}')
149 with open(path, 'w') as f:
150 if self._slither.solc_version:
151 f.write(f'pragma solidity {self._slither.solc_version};\n')
152 if self._use_abi_encoder_v2:
153 f.write('pragma experimental ABIEncoderV2;\n')
154 f.write('\n'.join(ret))
155 f.write('\n')
156
157 def export(self, target=None):
158
159 if not self.DEFAULT_EXPORT_PATH.exists():
160 self.DEFAULT_EXPORT_PATH.mkdir(parents=True)
161
162 if target is None:
163 for contract in self._slither.contracts_derived:
164 ret = []
165 self._export(contract, ret)
166 else:
167 contract = self._slither.get_contract_from_name(target)
168 if contract is None:
169 logger.error(f'{target} not found')
170 else:
171 ret = []
172 self._export(contract, ret)
173
[end of slither/tools/flattening/flattening.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/slither/tools/flattening/__main__.py b/slither/tools/flattening/__main__.py
--- a/slither/tools/flattening/__main__.py
+++ b/slither/tools/flattening/__main__.py
@@ -24,6 +24,10 @@
help='Convert external to public.',
action='store_true')
+ parser.add_argument('--convert-private',
+ help='Convert private variables to internal.',
+ action='store_true')
+
parser.add_argument('--remove-assert',
help='Remove call to assert().',
action='store_true')
@@ -42,7 +46,10 @@
args = parse_args()
slither = Slither(args.filename, **vars(args))
- flat = Flattening(slither, external_to_public=args.convert_external, remove_assert=args.remove_assert)
+ flat = Flattening(slither,
+ external_to_public=args.convert_external,
+ remove_assert=args.remove_assert,
+ private_to_internal=args.convert_private)
flat.export(target=args.contract)
diff --git a/slither/tools/flattening/flattening.py b/slither/tools/flattening/flattening.py
--- a/slither/tools/flattening/flattening.py
+++ b/slither/tools/flattening/flattening.py
@@ -23,12 +23,13 @@
class Flattening:
DEFAULT_EXPORT_PATH = Path('crytic-export/flattening')
- def __init__(self, slither, external_to_public=False, remove_assert=False):
+ def __init__(self, slither, external_to_public=False, remove_assert=False, private_to_internal=False):
self._source_codes = {}
self._slither = slither
self._external_to_public = external_to_public
self._remove_assert = remove_assert
self._use_abi_encoder_v2 = False
+ self._private_to_internal = private_to_internal
self._check_abi_encoder_v2()
@@ -46,7 +47,6 @@
content = self._slither.source_code[src_mapping['filename_absolute']]
start = src_mapping['start']
end = src_mapping['start'] + src_mapping['length']
- first_line = src_mapping['lines'][0]
to_patch = []
# interface must use external
@@ -73,6 +73,20 @@
calldata_idx = content[calldata_start:calldata_end].find(' calldata ')
to_patch.append(Patch(calldata_start + calldata_idx + 1, 'calldata_to_memory'))
+ if self._private_to_internal:
+ for variable in contract.state_variables_declared:
+ if variable.visibility == 'private':
+ print(variable.source_mapping)
+ attributes_start = variable.source_mapping['start']
+ attributes_end = attributes_start + variable.source_mapping['length']
+ attributes = content[attributes_start:attributes_end]
+ print(attributes)
+ regex = re.search(r' private ', attributes)
+ if regex:
+ to_patch.append(Patch(attributes_start + regex.span()[0] + 1, 'private_to_internal'))
+ else:
+ raise SlitherException(f'private keyword not found {v.name} {attributes}')
+
if self._remove_assert:
for function in contract.functions_and_modifiers_declared:
for node in function.nodes:
@@ -90,6 +104,8 @@
index = index - start
if patch_type == 'public_to_external':
content = content[:index] + 'public' + content[index + len('external'):]
+ if patch_type == 'private_to_internal':
+ content = content[:index] + 'internal' + content[index + len('private'):]
elif patch_type == 'calldata_to_memory':
content = content[:index] + 'memory' + content[index + len('calldata'):]
else:
|
{"golden_diff": "diff --git a/slither/tools/flattening/__main__.py b/slither/tools/flattening/__main__.py\n--- a/slither/tools/flattening/__main__.py\n+++ b/slither/tools/flattening/__main__.py\n@@ -24,6 +24,10 @@\n help='Convert external to public.',\n action='store_true')\n \n+ parser.add_argument('--convert-private',\n+ help='Convert private variables to internal.',\n+ action='store_true')\n+\n parser.add_argument('--remove-assert',\n help='Remove call to assert().',\n action='store_true')\n@@ -42,7 +46,10 @@\n args = parse_args()\n \n slither = Slither(args.filename, **vars(args))\n- flat = Flattening(slither, external_to_public=args.convert_external, remove_assert=args.remove_assert)\n+ flat = Flattening(slither,\n+ external_to_public=args.convert_external,\n+ remove_assert=args.remove_assert,\n+ private_to_internal=args.convert_private)\n \n flat.export(target=args.contract)\n \ndiff --git a/slither/tools/flattening/flattening.py b/slither/tools/flattening/flattening.py\n--- a/slither/tools/flattening/flattening.py\n+++ b/slither/tools/flattening/flattening.py\n@@ -23,12 +23,13 @@\n class Flattening:\n DEFAULT_EXPORT_PATH = Path('crytic-export/flattening')\n \n- def __init__(self, slither, external_to_public=False, remove_assert=False):\n+ def __init__(self, slither, external_to_public=False, remove_assert=False, private_to_internal=False):\n self._source_codes = {}\n self._slither = slither\n self._external_to_public = external_to_public\n self._remove_assert = remove_assert\n self._use_abi_encoder_v2 = False\n+ self._private_to_internal = private_to_internal\n \n self._check_abi_encoder_v2()\n \n@@ -46,7 +47,6 @@\n content = self._slither.source_code[src_mapping['filename_absolute']]\n start = src_mapping['start']\n end = src_mapping['start'] + src_mapping['length']\n- first_line = src_mapping['lines'][0]\n \n to_patch = []\n # interface must use external\n@@ -73,6 +73,20 @@\n calldata_idx = content[calldata_start:calldata_end].find(' calldata ')\n to_patch.append(Patch(calldata_start + calldata_idx + 1, 'calldata_to_memory'))\n \n+ if self._private_to_internal:\n+ for variable in contract.state_variables_declared:\n+ if variable.visibility == 'private':\n+ print(variable.source_mapping)\n+ attributes_start = variable.source_mapping['start']\n+ attributes_end = attributes_start + variable.source_mapping['length']\n+ attributes = content[attributes_start:attributes_end]\n+ print(attributes)\n+ regex = re.search(r' private ', attributes)\n+ if regex:\n+ to_patch.append(Patch(attributes_start + regex.span()[0] + 1, 'private_to_internal'))\n+ else:\n+ raise SlitherException(f'private keyword not found {v.name} {attributes}')\n+\n if self._remove_assert:\n for function in contract.functions_and_modifiers_declared:\n for node in function.nodes:\n@@ -90,6 +104,8 @@\n index = index - start\n if patch_type == 'public_to_external':\n content = content[:index] + 'public' + content[index + len('external'):]\n+ if patch_type == 'private_to_internal':\n+ content = content[:index] + 'internal' + content[index + len('private'):]\n elif patch_type == 'calldata_to_memory':\n content = content[:index] + 'memory' + content[index + len('calldata'):]\n else:\n", "issue": "slither-flat: Translate all visibilities to internal\nSimilar to the `external` to `public` conversion, we can convert all visible functions to `internal`, and all `private` variables to `internal`.\r\n\r\nThis schema is useful when fuzzing a codebase with Echidna, to reduce the scope of the fuzzing and allow to access private elements.\nslither-flat: Translate all visibilities to internal\nSimilar to the `external` to `public` conversion, we can convert all visible functions to `internal`, and all `private` variables to `internal`.\r\n\r\nThis schema is useful when fuzzing a codebase with Echidna, to reduce the scope of the fuzzing and allow to access private elements.\n", "before_files": [{"content": "import argparse\nimport logging\nfrom slither import Slither\nfrom crytic_compile import cryticparser\nfrom .flattening import Flattening\n\nlogging.basicConfig()\nlogging.getLogger(\"Slither\").setLevel(logging.INFO)\nlogger = logging.getLogger(\"Slither-flattening\")\nlogger.setLevel(logging.INFO)\n\ndef parse_args():\n \"\"\"\n Parse the underlying arguments for the program.\n :return: Returns the arguments for the program.\n \"\"\"\n parser = argparse.ArgumentParser(description='Contracts flattening',\n usage='slither-flat filename')\n\n parser.add_argument('filename',\n help='The filename of the contract or project to analyze.')\n\n parser.add_argument('--convert-external',\n help='Convert external to public.',\n action='store_true')\n\n parser.add_argument('--remove-assert',\n help='Remove call to assert().',\n action='store_true')\n\n parser.add_argument('--contract',\n help='Flatten a specific contract (default: all most derived contracts).',\n default=None)\n\n # Add default arguments from crytic-compile\n cryticparser.init(parser)\n\n return parser.parse_args()\n\n\ndef main():\n args = parse_args()\n\n slither = Slither(args.filename, **vars(args))\n flat = Flattening(slither, external_to_public=args.convert_external, remove_assert=args.remove_assert)\n\n flat.export(target=args.contract)\n\n\nif __name__ == '__main__':\n main()\n", "path": "slither/tools/flattening/__main__.py"}, {"content": "from pathlib import Path\nimport re\nimport logging\nfrom collections import namedtuple\n\nfrom slither.core.declarations import SolidityFunction\nfrom slither.exceptions import SlitherException\nfrom slither.core.solidity_types.user_defined_type import UserDefinedType\nfrom slither.core.declarations.structure import Structure\nfrom slither.core.declarations.enum import Enum\nfrom slither.core.declarations.contract import Contract\nfrom slither.slithir.operations import NewContract, TypeConversion, SolidityCall\n\nlogger = logging.getLogger(\"Slither-flattening\")\n\n# index: where to start\n# patch_type:\n# - public_to_external: public to external (external-to-public)\n# - calldata_to_memory: calldata to memory (external-to-public)\n# - line_removal: remove the line (remove-assert)\nPatch = namedtuple('PatchExternal', ['index', 'patch_type'])\n\nclass Flattening:\n DEFAULT_EXPORT_PATH = Path('crytic-export/flattening')\n\n def __init__(self, slither, external_to_public=False, remove_assert=False):\n self._source_codes = {}\n self._slither = slither\n self._external_to_public = external_to_public\n self._remove_assert = remove_assert\n self._use_abi_encoder_v2 = False\n\n self._check_abi_encoder_v2()\n\n for contract in slither.contracts:\n self._get_source_code(contract)\n\n def _check_abi_encoder_v2(self):\n for p in self._slither.pragma_directives:\n if 'ABIEncoderV2' in str(p.directive):\n self._use_abi_encoder_v2 = True\n return\n\n def _get_source_code(self, contract):\n src_mapping = contract.source_mapping\n content = self._slither.source_code[src_mapping['filename_absolute']]\n start = src_mapping['start']\n end = src_mapping['start'] + src_mapping['length']\n first_line = src_mapping['lines'][0]\n\n to_patch = []\n # interface must use external\n if self._external_to_public and contract.contract_kind != \"interface\":\n for f in contract.functions_declared:\n # fallback must be external\n if f.is_fallback or f.is_constructor_variables:\n continue\n if f.visibility == 'external':\n attributes_start = (f.parameters_src.source_mapping['start'] +\n f.parameters_src.source_mapping['length'])\n attributes_end = f.returns_src.source_mapping['start']\n attributes = content[attributes_start:attributes_end]\n regex = re.search(r'((\\sexternal)\\s+)|(\\sexternal)$|(\\)external)$', attributes)\n if regex:\n to_patch.append(Patch(attributes_start + regex.span()[0] + 1, 'public_to_external'))\n else:\n raise SlitherException(f'External keyword not found {f.name} {attributes}')\n\n for var in f.parameters:\n if var.location == \"calldata\":\n calldata_start = var.source_mapping['start']\n calldata_end = calldata_start + var.source_mapping['length']\n calldata_idx = content[calldata_start:calldata_end].find(' calldata ')\n to_patch.append(Patch(calldata_start + calldata_idx + 1, 'calldata_to_memory'))\n\n if self._remove_assert:\n for function in contract.functions_and_modifiers_declared:\n for node in function.nodes:\n for ir in node.irs:\n if isinstance(ir, SolidityCall) and ir.function == SolidityFunction('assert(bool)'):\n to_patch.append(Patch(node.source_mapping['start'], 'line_removal'))\n logger.info(f'Code commented: {node.expression} ({node.source_mapping_str})')\n\n to_patch.sort(key=lambda x: x.index, reverse=True)\n\n content = content[start:end]\n for patch in to_patch:\n patch_type = patch.patch_type\n index = patch.index\n index = index - start\n if patch_type == 'public_to_external':\n content = content[:index] + 'public' + content[index + len('external'):]\n elif patch_type == 'calldata_to_memory':\n content = content[:index] + 'memory' + content[index + len('calldata'):]\n else:\n assert patch_type == 'line_removal'\n content = content[:index] + ' // ' + content[index:]\n\n self._source_codes[contract] = content\n\n def _export_from_type(self, t, contract, exported, list_contract):\n if isinstance(t, UserDefinedType):\n if isinstance(t.type, (Enum, Structure)):\n if t.type.contract != contract and not t.type.contract in exported:\n self._export_contract(t.type.contract, exported, list_contract)\n else:\n assert isinstance(t.type, Contract)\n if t.type != contract and not t.type in exported:\n self._export_contract(t.type, exported, list_contract)\n\n def _export_contract(self, contract, exported, list_contract):\n if contract.name in exported:\n return\n exported.add(contract.name)\n for inherited in contract.inheritance:\n self._export_contract(inherited, exported, list_contract)\n\n # Find all the external contracts called\n externals = contract.all_library_calls + contract.all_high_level_calls\n # externals is a list of (contract, function)\n # We also filter call to itself to avoid infilite loop\n externals = list(set([e[0] for e in externals if e[0] != contract]))\n\n for inherited in externals:\n self._export_contract(inherited, exported, list_contract)\n\n # Find all the external contracts use as a base type\n local_vars = []\n for f in contract.functions_declared:\n local_vars += f.variables\n\n for v in contract.variables + local_vars:\n self._export_from_type(v.type, contract, exported, list_contract)\n\n # Find all convert and \"new\" operation that can lead to use an external contract\n for f in contract.functions_declared:\n for ir in f.slithir_operations:\n if isinstance(ir, NewContract):\n if ir.contract_created != contract and not ir.contract_created in exported:\n self._export_contract(ir.contract_created, exported, list_contract)\n if isinstance(ir, TypeConversion):\n self._export_from_type(ir.type, contract, exported, list_contract)\n list_contract.append(self._source_codes[contract])\n\n def _export(self, contract, ret):\n self._export_contract(contract, set(), ret)\n path = Path(self.DEFAULT_EXPORT_PATH, f'{contract.name}.sol')\n logger.info(f'Export {path}')\n with open(path, 'w') as f:\n if self._slither.solc_version:\n f.write(f'pragma solidity {self._slither.solc_version};\\n')\n if self._use_abi_encoder_v2:\n f.write('pragma experimental ABIEncoderV2;\\n')\n f.write('\\n'.join(ret))\n f.write('\\n')\n\n def export(self, target=None):\n\n if not self.DEFAULT_EXPORT_PATH.exists():\n self.DEFAULT_EXPORT_PATH.mkdir(parents=True)\n\n if target is None:\n for contract in self._slither.contracts_derived:\n ret = []\n self._export(contract, ret)\n else:\n contract = self._slither.get_contract_from_name(target)\n if contract is None:\n logger.error(f'{target} not found')\n else:\n ret = []\n self._export(contract, ret)\n", "path": "slither/tools/flattening/flattening.py"}]}
| 3,142 | 851 |
gh_patches_debug_6633
|
rasdani/github-patches
|
git_diff
|
ESMCI__cime-544
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Get PFS test working.
PFS does not produce history files because it does not set HIST_N or HIST_OPTION. The test fails because it tries to move history files that aren't there.
</issue>
<code>
[start of utils/python/CIME/SystemTests/pfs.py]
1 """
2 CIME performance test This class inherits from SystemTestsCommon
3
4 20 days performance test, no restart files written
5 """
6
7 from CIME.XML.standard_module_setup import *
8 from CIME.SystemTests.system_tests_common import SystemTestsCommon
9
10 logger = logging.getLogger(__name__)
11
12 class PFS(SystemTestsCommon):
13
14 def __init__(self, case):
15 """
16 initialize an object interface to the PFS system test
17 """
18 SystemTestsCommon.__init__(self, case)
19
20 def run_phase(self):
21 self._case.set_value("STOP_OPTION", "ndays")
22 self._case.set_value("STOP_N", 20)
23 self._case.set_value("REST_OPTION","none")
24 self._case.set_value("CONTINUE_RUN", False)
25 self._case.flush()
26
27 logger.info("doing an 20 day initial test, no restarts written")
28 self.run_indv()
29
[end of utils/python/CIME/SystemTests/pfs.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/utils/python/CIME/SystemTests/pfs.py b/utils/python/CIME/SystemTests/pfs.py
--- a/utils/python/CIME/SystemTests/pfs.py
+++ b/utils/python/CIME/SystemTests/pfs.py
@@ -18,11 +18,5 @@
SystemTestsCommon.__init__(self, case)
def run_phase(self):
- self._case.set_value("STOP_OPTION", "ndays")
- self._case.set_value("STOP_N", 20)
- self._case.set_value("REST_OPTION","none")
- self._case.set_value("CONTINUE_RUN", False)
- self._case.flush()
-
logger.info("doing an 20 day initial test, no restarts written")
- self.run_indv()
+ self.run_indv(suffix=None)
|
{"golden_diff": "diff --git a/utils/python/CIME/SystemTests/pfs.py b/utils/python/CIME/SystemTests/pfs.py\n--- a/utils/python/CIME/SystemTests/pfs.py\n+++ b/utils/python/CIME/SystemTests/pfs.py\n@@ -18,11 +18,5 @@\n SystemTestsCommon.__init__(self, case)\n \n def run_phase(self):\n- self._case.set_value(\"STOP_OPTION\", \"ndays\")\n- self._case.set_value(\"STOP_N\", 20)\n- self._case.set_value(\"REST_OPTION\",\"none\")\n- self._case.set_value(\"CONTINUE_RUN\", False)\n- self._case.flush()\n-\n logger.info(\"doing an 20 day initial test, no restarts written\")\n- self.run_indv()\n+ self.run_indv(suffix=None)\n", "issue": "Get PFS test working.\nPFS does not produce history files because it does not set HIST_N or HIST_OPTION. The test fails because it tries to move history files that aren't there.\n\n", "before_files": [{"content": "\"\"\"\nCIME performance test This class inherits from SystemTestsCommon\n\n20 days performance test, no restart files written\n\"\"\"\n\nfrom CIME.XML.standard_module_setup import *\nfrom CIME.SystemTests.system_tests_common import SystemTestsCommon\n\nlogger = logging.getLogger(__name__)\n\nclass PFS(SystemTestsCommon):\n\n def __init__(self, case):\n \"\"\"\n initialize an object interface to the PFS system test\n \"\"\"\n SystemTestsCommon.__init__(self, case)\n\n def run_phase(self):\n self._case.set_value(\"STOP_OPTION\", \"ndays\")\n self._case.set_value(\"STOP_N\", 20)\n self._case.set_value(\"REST_OPTION\",\"none\")\n self._case.set_value(\"CONTINUE_RUN\", False)\n self._case.flush()\n\n logger.info(\"doing an 20 day initial test, no restarts written\")\n self.run_indv()\n", "path": "utils/python/CIME/SystemTests/pfs.py"}]}
| 828 | 178 |
gh_patches_debug_4430
|
rasdani/github-patches
|
git_diff
|
jupyter__docker-stacks-1412
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
We fail to push our multi-arch images
We successfully login with `docker login`, but we fail to push images. I'm unsure why, we only get 401 Unauthorized and that's it.
### From [CI run that failed](https://github.com/jupyter/docker-stacks/runs/3090573663?check_suite_focus=true)
```
#36 exporting to image
#36 exporting manifest sha256:f4885e2ee0a2d6f4484aa75b005e585414a56981e31ed2343f8a9f2dee27d2bf done
#36 exporting config sha256:125cf7a049b119220a812d64eeae4ed7e3c3fd61e92aed6fcb118251165062ba done
#36 exporting manifest sha256:e6b8d5dbd2a1cb3022cd214946f2290ac65aed7fc3787fa8fbdbd655c344ac28 done
#36 exporting config sha256:4ae4f82b528de65a8f301eef09d66007865189d8b405fe2f65ea6d10c7994760 done
#36 exporting manifest list sha256:30be78018e77875a79b18949ec26fcc8760399e82da17aefb0281bb177f0c2a0 done
#36 pushing layers
#36 ...
#38 [auth] library/40b549a81031:pull,push token for registry-1.docker.io
#38 DONE 0.0s
#39 [auth] library/40b549a81031:pull,push token for registry-1.docker.io
#39 DONE 0.0s
#40 [auth] library/40b549a81031:pull,push token for registry-1.docker.io
#40 DONE 0.0s
#41 [auth] library/40b549a81031:pull,push token for registry-1.docker.io
#41 DONE 0.0s
#42 [auth] library/40b549a81031:pull,push token for registry-1.docker.io
#42 DONE 0.0s
#43 [auth] library/40b549a81031:pull,push token for registry-1.docker.io
#43 DONE 0.0s
#36 exporting to image
#36 pushing layers 0.4s done
#36 ERROR: authorization status: 401: authorization failed
------
> exporting to image:
------
error: failed to solve: authorization status: 401: authorization failed
make: *** [Makefile:191: push-multi/base-notebook] Error 1
make: Leaving directory '/home/runner/work/docker-stacks/docker-stacks/main'
Error: Process completed with exit code 2.
```
</issue>
<code>
[start of tagging/tag_image.py]
1 #!/usr/bin/env python3
2 # Copyright (c) Jupyter Development Team.
3 # Distributed under the terms of the Modified BSD License.
4 import argparse
5 import logging
6 from plumbum.cmd import docker
7 from .docker_runner import DockerRunner
8 from .get_taggers_and_manifests import get_taggers_and_manifests
9 from .github_set_env import github_set_env
10
11
12 logger = logging.getLogger(__name__)
13
14
15 def tag_image(short_image_name: str, owner: str) -> None:
16 """
17 Tags <owner>/<short_image_name>:latest with the tags reported by all taggers
18 for the given image.
19
20 Tags are in a GitHub Actions environment also saved to environment variables
21 in a format making it easy to append them.
22 """
23 logger.info(f"Tagging image: {short_image_name}")
24 taggers, _ = get_taggers_and_manifests(short_image_name)
25
26 image = f"{owner}/{short_image_name}:latest"
27
28 with DockerRunner(image) as container:
29 tags = []
30 for tagger in taggers:
31 tagger_name = tagger.__name__
32 tag_value = tagger.tag_value(container)
33 tags.append(tag_value)
34 logger.info(
35 f"Applying tag tagger_name: {tagger_name} tag_value: {tag_value}"
36 )
37 docker["tag", image, f"{owner}/{short_image_name}:{tag_value}"]()
38
39 if tags:
40 env_name = f'{short_image_name.replace("-", "_")}_EXTRA_TAG_ARGS'
41 docker_build_tag_args = "-t " + " -t ".join(tags)
42 github_set_env(env_name, docker_build_tag_args)
43
44
45 if __name__ == "__main__":
46 logging.basicConfig(level=logging.INFO)
47
48 arg_parser = argparse.ArgumentParser()
49 arg_parser.add_argument(
50 "--short-image-name",
51 required=True,
52 help="Short image name to apply tags for",
53 )
54 arg_parser.add_argument("--owner", required=True, help="Owner of the image")
55 args = arg_parser.parse_args()
56
57 tag_image(args.short_image_name, args.owner)
58
[end of tagging/tag_image.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/tagging/tag_image.py b/tagging/tag_image.py
--- a/tagging/tag_image.py
+++ b/tagging/tag_image.py
@@ -38,7 +38,9 @@
if tags:
env_name = f'{short_image_name.replace("-", "_")}_EXTRA_TAG_ARGS'
- docker_build_tag_args = "-t " + " -t ".join(tags)
+ docker_build_tag_args = " ".join(
+ [f"-t {owner}/{short_image_name}:{tag}" for tag in tags]
+ )
github_set_env(env_name, docker_build_tag_args)
|
{"golden_diff": "diff --git a/tagging/tag_image.py b/tagging/tag_image.py\n--- a/tagging/tag_image.py\n+++ b/tagging/tag_image.py\n@@ -38,7 +38,9 @@\n \n if tags:\n env_name = f'{short_image_name.replace(\"-\", \"_\")}_EXTRA_TAG_ARGS'\n- docker_build_tag_args = \"-t \" + \" -t \".join(tags)\n+ docker_build_tag_args = \" \".join(\n+ [f\"-t {owner}/{short_image_name}:{tag}\" for tag in tags]\n+ )\n github_set_env(env_name, docker_build_tag_args)\n", "issue": "We fail to push our multi-arch images\nWe successfully login with `docker login`, but we fail to push images. I'm unsure why, we only get 401 Unauthorized and that's it.\r\n\r\n### From [CI run that failed](https://github.com/jupyter/docker-stacks/runs/3090573663?check_suite_focus=true)\r\n\r\n```\r\n #36 exporting to image\r\n #36 exporting manifest sha256:f4885e2ee0a2d6f4484aa75b005e585414a56981e31ed2343f8a9f2dee27d2bf done\r\n #36 exporting config sha256:125cf7a049b119220a812d64eeae4ed7e3c3fd61e92aed6fcb118251165062ba done\r\n #36 exporting manifest sha256:e6b8d5dbd2a1cb3022cd214946f2290ac65aed7fc3787fa8fbdbd655c344ac28 done\r\n #36 exporting config sha256:4ae4f82b528de65a8f301eef09d66007865189d8b405fe2f65ea6d10c7994760 done\r\n #36 exporting manifest list sha256:30be78018e77875a79b18949ec26fcc8760399e82da17aefb0281bb177f0c2a0 done\r\n #36 pushing layers\r\n #36 ...\r\n \r\n #38 [auth] library/40b549a81031:pull,push token for registry-1.docker.io\r\n #38 DONE 0.0s\r\n \r\n #39 [auth] library/40b549a81031:pull,push token for registry-1.docker.io\r\n #39 DONE 0.0s\r\n \r\n #40 [auth] library/40b549a81031:pull,push token for registry-1.docker.io\r\n #40 DONE 0.0s\r\n \r\n #41 [auth] library/40b549a81031:pull,push token for registry-1.docker.io\r\n #41 DONE 0.0s\r\n \r\n #42 [auth] library/40b549a81031:pull,push token for registry-1.docker.io\r\n #42 DONE 0.0s\r\n \r\n #43 [auth] library/40b549a81031:pull,push token for registry-1.docker.io\r\n #43 DONE 0.0s\r\n \r\n #36 exporting to image\r\n #36 pushing layers 0.4s done\r\n #36 ERROR: authorization status: 401: authorization failed\r\n ------\r\n > exporting to image:\r\n ------\r\n error: failed to solve: authorization status: 401: authorization failed\r\n make: *** [Makefile:191: push-multi/base-notebook] Error 1\r\n make: Leaving directory '/home/runner/work/docker-stacks/docker-stacks/main'\r\n Error: Process completed with exit code 2.\r\n```\n", "before_files": [{"content": "#!/usr/bin/env python3\n# Copyright (c) Jupyter Development Team.\n# Distributed under the terms of the Modified BSD License.\nimport argparse\nimport logging\nfrom plumbum.cmd import docker\nfrom .docker_runner import DockerRunner\nfrom .get_taggers_and_manifests import get_taggers_and_manifests\nfrom .github_set_env import github_set_env\n\n\nlogger = logging.getLogger(__name__)\n\n\ndef tag_image(short_image_name: str, owner: str) -> None:\n \"\"\"\n Tags <owner>/<short_image_name>:latest with the tags reported by all taggers\n for the given image.\n\n Tags are in a GitHub Actions environment also saved to environment variables\n in a format making it easy to append them.\n \"\"\"\n logger.info(f\"Tagging image: {short_image_name}\")\n taggers, _ = get_taggers_and_manifests(short_image_name)\n\n image = f\"{owner}/{short_image_name}:latest\"\n\n with DockerRunner(image) as container:\n tags = []\n for tagger in taggers:\n tagger_name = tagger.__name__\n tag_value = tagger.tag_value(container)\n tags.append(tag_value)\n logger.info(\n f\"Applying tag tagger_name: {tagger_name} tag_value: {tag_value}\"\n )\n docker[\"tag\", image, f\"{owner}/{short_image_name}:{tag_value}\"]()\n\n if tags:\n env_name = f'{short_image_name.replace(\"-\", \"_\")}_EXTRA_TAG_ARGS'\n docker_build_tag_args = \"-t \" + \" -t \".join(tags)\n github_set_env(env_name, docker_build_tag_args)\n\n\nif __name__ == \"__main__\":\n logging.basicConfig(level=logging.INFO)\n\n arg_parser = argparse.ArgumentParser()\n arg_parser.add_argument(\n \"--short-image-name\",\n required=True,\n help=\"Short image name to apply tags for\",\n )\n arg_parser.add_argument(\"--owner\", required=True, help=\"Owner of the image\")\n args = arg_parser.parse_args()\n\n tag_image(args.short_image_name, args.owner)\n", "path": "tagging/tag_image.py"}]}
| 1,923 | 132 |
gh_patches_debug_19274
|
rasdani/github-patches
|
git_diff
|
nautobot__nautobot-5223
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Custom field date-type objects AssertionError in GraphQL
<!--
NOTE: IF YOUR ISSUE DOES NOT FOLLOW THIS TEMPLATE, IT WILL BE CLOSED.
This form is only for reporting reproducible bugs. If you need assistance
with Nautobot installation, or if you have a general question, please start a
discussion instead: https://github.com/nautobot/nautobot/discussions
Please describe the environment in which you are running Nautobot. Be sure
that you are running an unmodified instance of the latest stable release
before submitting a bug report, and that any plugins have been disabled.
-->
### Environment
* Nautobot version (Docker tag too if applicable): 1.5.17b1, also tested in 1.5.8
* Python version: 3.9
* Database platform, version: psql 13.10
* Middleware(s): None
<!--
Describe in detail the exact steps that someone else can take to reproduce
this bug using the current stable release of Nautobot. Begin with the
creation of any necessary database objects and call out every operation
being performed explicitly. If reporting a bug in the REST API, be sure to
reconstruct the raw HTTP request(s) being made: Don't rely on a client
library such as pynautobot.
-->
### Steps to Reproduce
1. Create a [custom field object](https://demo.nautobot.com/extras/custom-fields/last_backup/?tab=main) for the Device type template with the type as Date
2. Set a date on a [device](https://demo.nautobot.com/dcim/devices/4d7aecac-addd-4f3c-8efc-e102872b54e5/?tab=main) in YYYY-MM-DD iso8601 format
3. You have to restart nautobot-server; we may need a post_save signal event for this as well, which would be a separate issue if so
4. Using GraphQL attempt to retrieve the value of this field from a device
`
{
devices (name: "ams01-dist-01") {
name,
cf_last_backup
}
}
`
<!-- What did you expect to happen? -->
### Expected Behavior
Query to return the value of the Date
<!-- What happened instead? -->
### Observed Behavior
* GrapQL returns `"message": "Received not compatible date \"'2023-04-26'\""`
* stdout from nautobot-server gets an exception
`[27/Apr/2023 17:20:01] "POST /graphql/ HTTP/1.1" 200 4437611
Traceback (most recent call last):
File "/home/meganerd/.cache/pypoetry/virtualenvs/nautobot-Sgl-QJQc-py3.9/lib/python3.9/site-packages/graphql/execution/executor.py", line 480, in complete_value_catching_error
completed = complete_value(
File "/home/meganerd/.cache/pypoetry/virtualenvs/nautobot-Sgl-QJQc-py3.9/lib/python3.9/site-packages/graphql/execution/executor.py", line 563, in complete_value
return complete_leaf_value(return_type, path, result)
File "/home/meganerd/.cache/pypoetry/virtualenvs/nautobot-Sgl-QJQc-py3.9/lib/python3.9/site-packages/graphql/execution/executor.py", line 626, in complete_leaf_value
serialized_result = return_type.serialize(result)
File "/home/meganerd/.cache/pypoetry/virtualenvs/nautobot-Sgl-QJQc-py3.9/lib/python3.9/site-packages/graphene/types/datetime.py", line 23, in serialize
assert isinstance(
AssertionError: Received not compatible date "'2023-04-26'"`
</issue>
<code>
[start of nautobot/core/graphql/types.py]
1 import datetime
2
3 from django.contrib.contenttypes.models import ContentType
4 import graphene
5 import graphene_django_optimizer as gql_optimizer
6
7
8 class OptimizedNautobotObjectType(gql_optimizer.OptimizedDjangoObjectType):
9 url = graphene.String()
10
11 def resolve_url(self, info):
12 return self.get_absolute_url(api=True)
13
14 class Meta:
15 abstract = True
16
17
18 class ContentTypeType(OptimizedNautobotObjectType):
19 """
20 Graphene-Django object type for ContentType records.
21
22 Needed because ContentType is a built-in model, not one that we own and can auto-generate types for.
23 """
24
25 class Meta:
26 model = ContentType
27
28
29 class DateType(graphene.Date):
30 """
31 Overriding the default serialize method from https://github.com/graphql-python/graphene/blob/master/graphene/types/datetime.py
32 to handle the case where the date object is passed as a str object.
33 """
34
35 @staticmethod
36 def serialize(date):
37 if isinstance(date, datetime.datetime):
38 date = date.date()
39 return date.isoformat()
40 elif isinstance(date, str):
41 return date
42 else:
43 raise AssertionError(f'Received not compatible date "{date!r}"')
44
45
46 class JSON(graphene.Scalar):
47 @staticmethod
48 def serialize_data(dt):
49 return dt
50
51 serialize = serialize_data
52 parse_value = serialize_data
53 parse_literal = serialize_data
54
[end of nautobot/core/graphql/types.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/nautobot/core/graphql/types.py b/nautobot/core/graphql/types.py
--- a/nautobot/core/graphql/types.py
+++ b/nautobot/core/graphql/types.py
@@ -3,6 +3,7 @@
from django.contrib.contenttypes.models import ContentType
import graphene
import graphene_django_optimizer as gql_optimizer
+from graphql import GraphQLError
class OptimizedNautobotObjectType(gql_optimizer.OptimizedDjangoObjectType):
@@ -37,10 +38,12 @@
if isinstance(date, datetime.datetime):
date = date.date()
return date.isoformat()
+ elif isinstance(date, datetime.date):
+ return date.isoformat()
elif isinstance(date, str):
return date
else:
- raise AssertionError(f'Received not compatible date "{date!r}"')
+ raise GraphQLError(f'Received not compatible date "{date!r}"')
class JSON(graphene.Scalar):
|
{"golden_diff": "diff --git a/nautobot/core/graphql/types.py b/nautobot/core/graphql/types.py\n--- a/nautobot/core/graphql/types.py\n+++ b/nautobot/core/graphql/types.py\n@@ -3,6 +3,7 @@\n from django.contrib.contenttypes.models import ContentType\n import graphene\n import graphene_django_optimizer as gql_optimizer\n+from graphql import GraphQLError\n \n \n class OptimizedNautobotObjectType(gql_optimizer.OptimizedDjangoObjectType):\n@@ -37,10 +38,12 @@\n if isinstance(date, datetime.datetime):\n date = date.date()\n return date.isoformat()\n+ elif isinstance(date, datetime.date):\n+ return date.isoformat()\n elif isinstance(date, str):\n return date\n else:\n- raise AssertionError(f'Received not compatible date \"{date!r}\"')\n+ raise GraphQLError(f'Received not compatible date \"{date!r}\"')\n \n \n class JSON(graphene.Scalar):\n", "issue": "Custom field date-type objects AssertionError in GraphQL\n<!--\r\n NOTE: IF YOUR ISSUE DOES NOT FOLLOW THIS TEMPLATE, IT WILL BE CLOSED.\r\n\r\n This form is only for reporting reproducible bugs. If you need assistance\r\n with Nautobot installation, or if you have a general question, please start a\r\n discussion instead: https://github.com/nautobot/nautobot/discussions\r\n\r\n Please describe the environment in which you are running Nautobot. Be sure\r\n that you are running an unmodified instance of the latest stable release\r\n before submitting a bug report, and that any plugins have been disabled.\r\n-->\r\n### Environment\r\n* Nautobot version (Docker tag too if applicable): 1.5.17b1, also tested in 1.5.8\r\n* Python version: 3.9\r\n* Database platform, version: psql 13.10\r\n* Middleware(s): None\r\n\r\n<!--\r\n Describe in detail the exact steps that someone else can take to reproduce\r\n this bug using the current stable release of Nautobot. Begin with the\r\n creation of any necessary database objects and call out every operation\r\n being performed explicitly. If reporting a bug in the REST API, be sure to\r\n reconstruct the raw HTTP request(s) being made: Don't rely on a client\r\n library such as pynautobot.\r\n-->\r\n### Steps to Reproduce\r\n1. Create a [custom field object](https://demo.nautobot.com/extras/custom-fields/last_backup/?tab=main) for the Device type template with the type as Date\r\n2. Set a date on a [device](https://demo.nautobot.com/dcim/devices/4d7aecac-addd-4f3c-8efc-e102872b54e5/?tab=main) in YYYY-MM-DD iso8601 format\r\n3. You have to restart nautobot-server; we may need a post_save signal event for this as well, which would be a separate issue if so\r\n4. Using GraphQL attempt to retrieve the value of this field from a device\r\n`\r\n{\r\n devices (name: \"ams01-dist-01\") {\r\n name,\r\n cf_last_backup\r\n }\r\n}\r\n`\r\n\r\n<!-- What did you expect to happen? -->\r\n### Expected Behavior\r\nQuery to return the value of the Date\r\n\r\n<!-- What happened instead? -->\r\n### Observed Behavior\r\n* GrapQL returns `\"message\": \"Received not compatible date \\\"'2023-04-26'\\\"\"`\r\n* stdout from nautobot-server gets an exception\r\n\r\n`[27/Apr/2023 17:20:01] \"POST /graphql/ HTTP/1.1\" 200 4437611\r\nTraceback (most recent call last):\r\n File \"/home/meganerd/.cache/pypoetry/virtualenvs/nautobot-Sgl-QJQc-py3.9/lib/python3.9/site-packages/graphql/execution/executor.py\", line 480, in complete_value_catching_error\r\n completed = complete_value(\r\n File \"/home/meganerd/.cache/pypoetry/virtualenvs/nautobot-Sgl-QJQc-py3.9/lib/python3.9/site-packages/graphql/execution/executor.py\", line 563, in complete_value\r\n return complete_leaf_value(return_type, path, result)\r\n File \"/home/meganerd/.cache/pypoetry/virtualenvs/nautobot-Sgl-QJQc-py3.9/lib/python3.9/site-packages/graphql/execution/executor.py\", line 626, in complete_leaf_value\r\n serialized_result = return_type.serialize(result)\r\n File \"/home/meganerd/.cache/pypoetry/virtualenvs/nautobot-Sgl-QJQc-py3.9/lib/python3.9/site-packages/graphene/types/datetime.py\", line 23, in serialize\r\n assert isinstance(\r\nAssertionError: Received not compatible date \"'2023-04-26'\"`\r\n\r\n\n", "before_files": [{"content": "import datetime\n\nfrom django.contrib.contenttypes.models import ContentType\nimport graphene\nimport graphene_django_optimizer as gql_optimizer\n\n\nclass OptimizedNautobotObjectType(gql_optimizer.OptimizedDjangoObjectType):\n url = graphene.String()\n\n def resolve_url(self, info):\n return self.get_absolute_url(api=True)\n\n class Meta:\n abstract = True\n\n\nclass ContentTypeType(OptimizedNautobotObjectType):\n \"\"\"\n Graphene-Django object type for ContentType records.\n\n Needed because ContentType is a built-in model, not one that we own and can auto-generate types for.\n \"\"\"\n\n class Meta:\n model = ContentType\n\n\nclass DateType(graphene.Date):\n \"\"\"\n Overriding the default serialize method from https://github.com/graphql-python/graphene/blob/master/graphene/types/datetime.py\n to handle the case where the date object is passed as a str object.\n \"\"\"\n\n @staticmethod\n def serialize(date):\n if isinstance(date, datetime.datetime):\n date = date.date()\n return date.isoformat()\n elif isinstance(date, str):\n return date\n else:\n raise AssertionError(f'Received not compatible date \"{date!r}\"')\n\n\nclass JSON(graphene.Scalar):\n @staticmethod\n def serialize_data(dt):\n return dt\n\n serialize = serialize_data\n parse_value = serialize_data\n parse_literal = serialize_data\n", "path": "nautobot/core/graphql/types.py"}]}
| 1,808 | 203 |
gh_patches_debug_11157
|
rasdani/github-patches
|
git_diff
|
kivy__python-for-android-800
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Cryptography recipe does not compile
I'm trying to build Kivy app with:
- sdl2 bootstrap
- recipes python2,kivy,cryptography
- buildozer 0.32
- latest python-for-android master branch
In libffi recipe I had to replace [line](https://github.com/kivy/python-for-android/blob/master/pythonforandroid/recipes/libffi/__init__.py#L43) with:
`shprint(sh.Command('autoreconf'), '-vif', _env=env)`.
Without that change p4a was raising sh.CommandNotFound error.
Now running `buildozer android_new debug` produces the following error log: http://pastebin.com/22qjBJwL
buildozer.spec file: http://pastebin.com/aLe7nLHG
main.py file: http://pastebin.com/xSReYe6u
</issue>
<code>
[start of pythonforandroid/recipes/libffi/__init__.py]
1 from pythonforandroid.recipe import Recipe
2 from pythonforandroid.logger import shprint
3 from pythonforandroid.util import current_directory
4 from os.path import exists, join
5 import sh
6 import glob
7
8
9 class LibffiRecipe(Recipe):
10 name = 'libffi'
11 version = 'v3.2.1'
12 url = 'https://github.com/atgreen/libffi/archive/{version}.zip'
13
14 patches = ['remove-version-info.patch']
15
16 def get_host(self, arch):
17 with current_directory(self.get_build_dir(arch.arch)):
18 host = None
19 with open('Makefile') as f:
20 for line in f:
21 if line.startswith('host = '):
22 host = line.strip()[7:]
23 break
24
25 if not host or not exists(host):
26 raise RuntimeError('failed to find build output! ({})'
27 .format(host))
28
29 return host
30
31 def should_build(self, arch):
32 # return not bool(glob.glob(join(self.ctx.get_libs_dir(arch.arch),
33 # 'libffi.so*')))
34 return not exists(join(self.ctx.get_libs_dir(arch.arch), 'libffi.so'))
35 # return not exists(join(self.ctx.get_python_install_dir(), 'lib',
36 # 'libffi.so'))
37
38 def build_arch(self, arch):
39 env = self.get_recipe_env(arch)
40 with current_directory(self.get_build_dir(arch.arch)):
41 if not exists('configure'):
42 shprint(sh.Command('./autogen.sh'), _env=env)
43 shprint(sh.Command('autoreconf -vif'), _env=env)
44 shprint(sh.Command('./configure'), '--host=' + arch.toolchain_prefix,
45 '--prefix=' + self.ctx.get_python_install_dir(),
46 '--enable-shared', _env=env)
47 shprint(sh.make, '-j5', 'libffi.la', _env=env)
48
49
50 # dlname = None
51 # with open(join(host, 'libffi.la')) as f:
52 # for line in f:
53 # if line.startswith('dlname='):
54 # dlname = line.strip()[8:-1]
55 # break
56 #
57 # if not dlname or not exists(join(host, '.libs', dlname)):
58 # raise RuntimeError('failed to locate shared object! ({})'
59 # .format(dlname))
60
61 # shprint(sh.sed, '-i', 's/^dlname=.*$/dlname=\'libffi.so\'/', join(host, 'libffi.la'))
62
63 shprint(sh.cp, '-t', self.ctx.get_libs_dir(arch.arch),
64 join(self.get_host(arch), '.libs', 'libffi.so')) #,
65 # join(host, 'libffi.la'))
66
67 def get_include_dirs(self, arch):
68 return [join(self.get_build_dir(arch.arch), self.get_host(arch), 'include')]
69
70
71 recipe = LibffiRecipe()
72
[end of pythonforandroid/recipes/libffi/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pythonforandroid/recipes/libffi/__init__.py b/pythonforandroid/recipes/libffi/__init__.py
--- a/pythonforandroid/recipes/libffi/__init__.py
+++ b/pythonforandroid/recipes/libffi/__init__.py
@@ -40,7 +40,7 @@
with current_directory(self.get_build_dir(arch.arch)):
if not exists('configure'):
shprint(sh.Command('./autogen.sh'), _env=env)
- shprint(sh.Command('autoreconf -vif'), _env=env)
+ shprint(sh.Command('autoreconf'), '-vif', _env=env)
shprint(sh.Command('./configure'), '--host=' + arch.toolchain_prefix,
'--prefix=' + self.ctx.get_python_install_dir(),
'--enable-shared', _env=env)
|
{"golden_diff": "diff --git a/pythonforandroid/recipes/libffi/__init__.py b/pythonforandroid/recipes/libffi/__init__.py\n--- a/pythonforandroid/recipes/libffi/__init__.py\n+++ b/pythonforandroid/recipes/libffi/__init__.py\n@@ -40,7 +40,7 @@\n \t\twith current_directory(self.get_build_dir(arch.arch)):\n \t\t\tif not exists('configure'):\n \t\t\t\tshprint(sh.Command('./autogen.sh'), _env=env)\n-\t\t\tshprint(sh.Command('autoreconf -vif'), _env=env)\n+\t\t\tshprint(sh.Command('autoreconf'), '-vif', _env=env)\n \t\t\tshprint(sh.Command('./configure'), '--host=' + arch.toolchain_prefix,\n \t\t\t '--prefix=' + self.ctx.get_python_install_dir(),\n \t\t\t '--enable-shared', _env=env)\n", "issue": "Cryptography recipe does not compile\nI'm trying to build Kivy app with:\n- sdl2 bootstrap\n- recipes python2,kivy,cryptography \n- buildozer 0.32 \n- latest python-for-android master branch \n\nIn libffi recipe I had to replace [line](https://github.com/kivy/python-for-android/blob/master/pythonforandroid/recipes/libffi/__init__.py#L43) with:\n`shprint(sh.Command('autoreconf'), '-vif', _env=env)`.\nWithout that change p4a was raising sh.CommandNotFound error. \n\nNow running `buildozer android_new debug` produces the following error log: http://pastebin.com/22qjBJwL\nbuildozer.spec file: http://pastebin.com/aLe7nLHG\nmain.py file: http://pastebin.com/xSReYe6u\n\n", "before_files": [{"content": "from pythonforandroid.recipe import Recipe\nfrom pythonforandroid.logger import shprint\nfrom pythonforandroid.util import current_directory\nfrom os.path import exists, join\nimport sh\nimport glob\n\n\nclass LibffiRecipe(Recipe):\n\tname = 'libffi'\n\tversion = 'v3.2.1'\n\turl = 'https://github.com/atgreen/libffi/archive/{version}.zip'\n\n\tpatches = ['remove-version-info.patch']\n\n\tdef get_host(self, arch):\n\t\twith current_directory(self.get_build_dir(arch.arch)):\n\t\t\thost = None\n\t\t\twith open('Makefile') as f:\n\t\t\t\tfor line in f:\n\t\t\t\t\tif line.startswith('host = '):\n\t\t\t\t\t\thost = line.strip()[7:]\n\t\t\t\t\t\tbreak\n\n\t\t\tif not host or not exists(host):\n\t\t\t\traise RuntimeError('failed to find build output! ({})'\n\t\t\t\t .format(host))\n\t\t\t\n\t\t\treturn host\n\n\tdef should_build(self, arch):\n\t\t# return not bool(glob.glob(join(self.ctx.get_libs_dir(arch.arch),\n\t\t# 'libffi.so*')))\n\t\treturn not exists(join(self.ctx.get_libs_dir(arch.arch), 'libffi.so'))\n\t\t# return not exists(join(self.ctx.get_python_install_dir(), 'lib',\n\t\t# 'libffi.so'))\n\n\tdef build_arch(self, arch):\n\t\tenv = self.get_recipe_env(arch)\n\t\twith current_directory(self.get_build_dir(arch.arch)):\n\t\t\tif not exists('configure'):\n\t\t\t\tshprint(sh.Command('./autogen.sh'), _env=env)\n\t\t\tshprint(sh.Command('autoreconf -vif'), _env=env)\n\t\t\tshprint(sh.Command('./configure'), '--host=' + arch.toolchain_prefix,\n\t\t\t '--prefix=' + self.ctx.get_python_install_dir(),\n\t\t\t '--enable-shared', _env=env)\n\t\t\tshprint(sh.make, '-j5', 'libffi.la', _env=env)\n\n\n\t\t\t# dlname = None\n\t\t\t# with open(join(host, 'libffi.la')) as f:\n\t\t\t# \tfor line in f:\n\t\t\t# \t\tif line.startswith('dlname='):\n\t\t\t# \t\t\tdlname = line.strip()[8:-1]\n\t\t\t# \t\t\tbreak\n\t\t\t# \n\t\t\t# if not dlname or not exists(join(host, '.libs', dlname)):\n\t\t\t# \traise RuntimeError('failed to locate shared object! ({})'\n\t\t\t# \t .format(dlname))\n\n\t\t\t# shprint(sh.sed, '-i', 's/^dlname=.*$/dlname=\\'libffi.so\\'/', join(host, 'libffi.la'))\n\n\t\t\tshprint(sh.cp, '-t', self.ctx.get_libs_dir(arch.arch),\n\t\t\t join(self.get_host(arch), '.libs', 'libffi.so')) #,\n\t\t\t # join(host, 'libffi.la'))\n\n\tdef get_include_dirs(self, arch):\n\t\treturn [join(self.get_build_dir(arch.arch), self.get_host(arch), 'include')]\n\n\nrecipe = LibffiRecipe()\n", "path": "pythonforandroid/recipes/libffi/__init__.py"}]}
| 1,525 | 182 |
gh_patches_debug_20900
|
rasdani/github-patches
|
git_diff
|
opsdroid__opsdroid-1260
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Token based authentication for Webhook Matcher
<!-- Before you post an issue or if you are unsure about something join our matrix channel https://riot.im/app/#/room/#opsdroid-general:matrix.org and ask away! We are more than happy to help you. -->
# Description
The webhook matcher allows you to trigger the skill by calling a specific URL endpoint.
Currently, a skill with a webhook matcher would be called if you send a `POST` to `http://localhost:8080/skill/exampleskill/examplewebhook`.
This URL is public and does not have any form of authentication/authorization checks, which means it can be triggered by anyone. Adding an `Authorization` header with a token-based authentication would secure the webhook.
## Steps to Reproduce
1. Create a skill `exampleskill` with a webhook matcher `examplewebhook`.
2. Send a `POST` request to `http://localhost:8080/skill/exampleskill/examplewebhook` to trigger the bot.
## Expected Functionality
1. The webhook should check for the `Authorization` header and perform a token-based authentication.
2. The bot should be triggered based on the success/failure of the authentication.
## Experienced Functionality
The Bot gets triggered without any authentication/authorization.
## Versions
- **Opsdroid version:** master branch in git
- **Python version:** 3.6.8
- **OS/Docker version:** Ubuntu 18.04
<!-- Love opsdroid? Please consider supporting our collective:
+👉 https://opencollective.com/opsdroid/donate -->
</issue>
<code>
[start of opsdroid/web.py]
1 """Submodule to handle web requests in opsdroid."""
2
3 import json
4 import logging
5 import ssl
6
7 from aiohttp import web
8
9 from opsdroid import __version__
10
11
12 _LOGGER = logging.getLogger(__name__)
13
14
15 class Web:
16 """Create class for opsdroid Web server."""
17
18 def __init__(self, opsdroid):
19 """Create web object."""
20 self.opsdroid = opsdroid
21 try:
22 self.config = self.opsdroid.config["web"]
23 except KeyError:
24 self.config = {}
25 self.web_app = web.Application()
26 self.runner = web.AppRunner(self.web_app)
27 self.site = None
28 self.web_app.router.add_get("/", self.web_index_handler)
29 self.web_app.router.add_get("", self.web_index_handler)
30 self.web_app.router.add_get("/stats", self.web_stats_handler)
31 self.web_app.router.add_get("/stats/", self.web_stats_handler)
32
33 @property
34 def get_port(self):
35 """Return port from config or the default.
36
37 Args:
38 self: instance method
39
40 Returns:
41 int: returns value of port being used, config or default
42
43 """
44 try:
45 port = self.config["port"]
46 except KeyError:
47 if self.get_ssl_context is not None:
48 port = 8443
49 else:
50 port = 8080
51 return port
52
53 @property
54 def get_host(self):
55 """Return host from config or the default.
56
57 Args:
58 self: instance method
59
60 Returns:
61 string: returns address of host being used, config or default
62
63 """
64 try:
65 host = self.config["host"]
66 except KeyError:
67 host = "0.0.0.0"
68 return host
69
70 @property
71 def get_ssl_context(self):
72 """Return the ssl context or None.
73
74 Args:
75 self: instance method
76
77 Returns:
78 string (or NoneType): returns ssl context of None.
79
80 """
81 try:
82 ssl_config = self.config["ssl"]
83 sslcontext = ssl.SSLContext(ssl.PROTOCOL_TLSv1)
84 sslcontext.load_cert_chain(ssl_config["cert"], ssl_config["key"])
85 return sslcontext
86 except FileNotFoundError:
87 _LOGGER.error(_("Cannot find ssl cert or key."))
88 return None
89 except KeyError:
90 return None
91
92 async def start(self):
93 """Start web servers."""
94 _LOGGER.info(
95 _("Started web server on %s://%s%s"),
96 "http" if self.get_ssl_context is None else "https",
97 self.get_host,
98 ":{}".format(self.get_port) if self.get_port not in (80, 443) else "",
99 )
100 await self.runner.setup()
101 self.site = web.TCPSite(
102 self.runner,
103 host=self.get_host,
104 port=self.get_port,
105 ssl_context=self.get_ssl_context,
106 )
107 await self.site.start()
108
109 async def stop(self):
110 """Stop the web server."""
111 await self.runner.cleanup()
112
113 @staticmethod
114 def build_response(status, result):
115 """Build a json response object to power the bot reponses.
116
117 Args:
118 result: serialize obj as a JSON formated stream
119
120 Returns:
121 json: returns json object with list of responses for the bot
122
123 """
124 return web.Response(text=json.dumps(result), status=status)
125
126 def register_skill(self, opsdroid, skill, webhook):
127 """Register a new skill in the web app router."""
128
129 async def wrapper(req, opsdroid=opsdroid, config=skill.config):
130 """Wrap up the aiohttp handler."""
131 _LOGGER.info(_("Running skill %s via webhook"), webhook)
132 opsdroid.stats["webhooks_called"] = opsdroid.stats["webhooks_called"] + 1
133 resp = await opsdroid.run_skill(skill, config, req)
134 if isinstance(resp, web.Response):
135 return resp
136 return Web.build_response(200, {"called_skill": webhook})
137
138 self.web_app.router.add_post(
139 "/skill/{}/{}".format(skill.config["name"], webhook), wrapper
140 )
141 self.web_app.router.add_post(
142 "/skill/{}/{}/".format(skill.config["name"], webhook), wrapper
143 )
144
145 def setup_webhooks(self, skills):
146 """Add the webhooks for the webhook skills to the router."""
147 for skill in skills:
148 for matcher in skill.matchers:
149 if "webhook" in matcher:
150 self.register_skill(self.opsdroid, skill, matcher["webhook"])
151
152 async def web_index_handler(self, request):
153 """Handle root web request to opsdroid API.
154
155 Args:
156 request: web request to the root (index)
157
158 Returns:
159 dict: returns successful status code and greeting for the root page
160
161 """
162 return self.build_response(200, {"message": "Welcome to the opsdroid API"})
163
164 async def web_stats_handler(self, request):
165 """Handle stats request.
166
167 Args:
168 request: web request to render opsdroid stats
169
170 Returns:
171 dict: returns successful status code and dictionary with
172 stats requested
173
174 """
175 stats = self.opsdroid.stats
176 try:
177 stats["average_response_time"] = (
178 stats["total_response_time"] / stats["total_responses"]
179 )
180 except ZeroDivisionError:
181 stats["average_response_time"] = 0
182
183 return self.build_response(
184 200,
185 {
186 "version": __version__,
187 "messages": {
188 "total_parsed": stats["messages_parsed"],
189 "webhooks_called": stats["webhooks_called"],
190 "total_response_time": stats["total_response_time"],
191 "total_responses": stats["total_responses"],
192 "average_response_time": stats["average_response_time"],
193 },
194 "modules": {
195 "skills": len(self.opsdroid.skills),
196 "connectors": len(self.opsdroid.connectors),
197 "databases": len(self.opsdroid.memory.databases),
198 },
199 },
200 )
201
[end of opsdroid/web.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/opsdroid/web.py b/opsdroid/web.py
--- a/opsdroid/web.py
+++ b/opsdroid/web.py
@@ -128,6 +128,22 @@
async def wrapper(req, opsdroid=opsdroid, config=skill.config):
"""Wrap up the aiohttp handler."""
+ webhook_token = self.config.get("webhook-token", None)
+ authorization_header = []
+ if req is not None:
+ authorization_header = req.headers.get("Authorization", "").split()
+
+ if webhook_token is not None:
+ if not (
+ len(authorization_header) == 2
+ and authorization_header[0] == "Bearer"
+ and authorization_header[1] == webhook_token
+ ):
+ _LOGGER.error(
+ _("Unauthorized to run skill %s via webhook"), webhook
+ )
+ return Web.build_response(403, {"called_skill": webhook})
+
_LOGGER.info(_("Running skill %s via webhook"), webhook)
opsdroid.stats["webhooks_called"] = opsdroid.stats["webhooks_called"] + 1
resp = await opsdroid.run_skill(skill, config, req)
|
{"golden_diff": "diff --git a/opsdroid/web.py b/opsdroid/web.py\n--- a/opsdroid/web.py\n+++ b/opsdroid/web.py\n@@ -128,6 +128,22 @@\n \n async def wrapper(req, opsdroid=opsdroid, config=skill.config):\n \"\"\"Wrap up the aiohttp handler.\"\"\"\n+ webhook_token = self.config.get(\"webhook-token\", None)\n+ authorization_header = []\n+ if req is not None:\n+ authorization_header = req.headers.get(\"Authorization\", \"\").split()\n+\n+ if webhook_token is not None:\n+ if not (\n+ len(authorization_header) == 2\n+ and authorization_header[0] == \"Bearer\"\n+ and authorization_header[1] == webhook_token\n+ ):\n+ _LOGGER.error(\n+ _(\"Unauthorized to run skill %s via webhook\"), webhook\n+ )\n+ return Web.build_response(403, {\"called_skill\": webhook})\n+\n _LOGGER.info(_(\"Running skill %s via webhook\"), webhook)\n opsdroid.stats[\"webhooks_called\"] = opsdroid.stats[\"webhooks_called\"] + 1\n resp = await opsdroid.run_skill(skill, config, req)\n", "issue": "Token based authentication for Webhook Matcher\n<!-- Before you post an issue or if you are unsure about something join our matrix channel https://riot.im/app/#/room/#opsdroid-general:matrix.org and ask away! We are more than happy to help you. -->\r\n# Description\r\n\r\nThe webhook matcher allows you to trigger the skill by calling a specific URL endpoint.\r\n\r\nCurrently, a skill with a webhook matcher would be called if you send a `POST` to `http://localhost:8080/skill/exampleskill/examplewebhook`. \r\n\r\nThis URL is public and does not have any form of authentication/authorization checks, which means it can be triggered by anyone. Adding an `Authorization` header with a token-based authentication would secure the webhook.\r\n\r\n## Steps to Reproduce\r\n1. Create a skill `exampleskill` with a webhook matcher `examplewebhook`.\r\n\r\n2. Send a `POST` request to `http://localhost:8080/skill/exampleskill/examplewebhook` to trigger the bot.\r\n\r\n## Expected Functionality\r\n1. The webhook should check for the `Authorization` header and perform a token-based authentication.\r\n\r\n2. The bot should be triggered based on the success/failure of the authentication.\r\n\r\n## Experienced Functionality\r\nThe Bot gets triggered without any authentication/authorization.\r\n\r\n## Versions\r\n- **Opsdroid version:** master branch in git\r\n- **Python version:** 3.6.8\r\n- **OS/Docker version:** Ubuntu 18.04\r\n\r\n\r\n<!-- Love opsdroid? Please consider supporting our collective:\r\n +\ud83d\udc49 https://opencollective.com/opsdroid/donate -->\r\n\n", "before_files": [{"content": "\"\"\"Submodule to handle web requests in opsdroid.\"\"\"\n\nimport json\nimport logging\nimport ssl\n\nfrom aiohttp import web\n\nfrom opsdroid import __version__\n\n\n_LOGGER = logging.getLogger(__name__)\n\n\nclass Web:\n \"\"\"Create class for opsdroid Web server.\"\"\"\n\n def __init__(self, opsdroid):\n \"\"\"Create web object.\"\"\"\n self.opsdroid = opsdroid\n try:\n self.config = self.opsdroid.config[\"web\"]\n except KeyError:\n self.config = {}\n self.web_app = web.Application()\n self.runner = web.AppRunner(self.web_app)\n self.site = None\n self.web_app.router.add_get(\"/\", self.web_index_handler)\n self.web_app.router.add_get(\"\", self.web_index_handler)\n self.web_app.router.add_get(\"/stats\", self.web_stats_handler)\n self.web_app.router.add_get(\"/stats/\", self.web_stats_handler)\n\n @property\n def get_port(self):\n \"\"\"Return port from config or the default.\n\n Args:\n self: instance method\n\n Returns:\n int: returns value of port being used, config or default\n\n \"\"\"\n try:\n port = self.config[\"port\"]\n except KeyError:\n if self.get_ssl_context is not None:\n port = 8443\n else:\n port = 8080\n return port\n\n @property\n def get_host(self):\n \"\"\"Return host from config or the default.\n\n Args:\n self: instance method\n\n Returns:\n string: returns address of host being used, config or default\n\n \"\"\"\n try:\n host = self.config[\"host\"]\n except KeyError:\n host = \"0.0.0.0\"\n return host\n\n @property\n def get_ssl_context(self):\n \"\"\"Return the ssl context or None.\n\n Args:\n self: instance method\n\n Returns:\n string (or NoneType): returns ssl context of None.\n\n \"\"\"\n try:\n ssl_config = self.config[\"ssl\"]\n sslcontext = ssl.SSLContext(ssl.PROTOCOL_TLSv1)\n sslcontext.load_cert_chain(ssl_config[\"cert\"], ssl_config[\"key\"])\n return sslcontext\n except FileNotFoundError:\n _LOGGER.error(_(\"Cannot find ssl cert or key.\"))\n return None\n except KeyError:\n return None\n\n async def start(self):\n \"\"\"Start web servers.\"\"\"\n _LOGGER.info(\n _(\"Started web server on %s://%s%s\"),\n \"http\" if self.get_ssl_context is None else \"https\",\n self.get_host,\n \":{}\".format(self.get_port) if self.get_port not in (80, 443) else \"\",\n )\n await self.runner.setup()\n self.site = web.TCPSite(\n self.runner,\n host=self.get_host,\n port=self.get_port,\n ssl_context=self.get_ssl_context,\n )\n await self.site.start()\n\n async def stop(self):\n \"\"\"Stop the web server.\"\"\"\n await self.runner.cleanup()\n\n @staticmethod\n def build_response(status, result):\n \"\"\"Build a json response object to power the bot reponses.\n\n Args:\n result: serialize obj as a JSON formated stream\n\n Returns:\n json: returns json object with list of responses for the bot\n\n \"\"\"\n return web.Response(text=json.dumps(result), status=status)\n\n def register_skill(self, opsdroid, skill, webhook):\n \"\"\"Register a new skill in the web app router.\"\"\"\n\n async def wrapper(req, opsdroid=opsdroid, config=skill.config):\n \"\"\"Wrap up the aiohttp handler.\"\"\"\n _LOGGER.info(_(\"Running skill %s via webhook\"), webhook)\n opsdroid.stats[\"webhooks_called\"] = opsdroid.stats[\"webhooks_called\"] + 1\n resp = await opsdroid.run_skill(skill, config, req)\n if isinstance(resp, web.Response):\n return resp\n return Web.build_response(200, {\"called_skill\": webhook})\n\n self.web_app.router.add_post(\n \"/skill/{}/{}\".format(skill.config[\"name\"], webhook), wrapper\n )\n self.web_app.router.add_post(\n \"/skill/{}/{}/\".format(skill.config[\"name\"], webhook), wrapper\n )\n\n def setup_webhooks(self, skills):\n \"\"\"Add the webhooks for the webhook skills to the router.\"\"\"\n for skill in skills:\n for matcher in skill.matchers:\n if \"webhook\" in matcher:\n self.register_skill(self.opsdroid, skill, matcher[\"webhook\"])\n\n async def web_index_handler(self, request):\n \"\"\"Handle root web request to opsdroid API.\n\n Args:\n request: web request to the root (index)\n\n Returns:\n dict: returns successful status code and greeting for the root page\n\n \"\"\"\n return self.build_response(200, {\"message\": \"Welcome to the opsdroid API\"})\n\n async def web_stats_handler(self, request):\n \"\"\"Handle stats request.\n\n Args:\n request: web request to render opsdroid stats\n\n Returns:\n dict: returns successful status code and dictionary with\n stats requested\n\n \"\"\"\n stats = self.opsdroid.stats\n try:\n stats[\"average_response_time\"] = (\n stats[\"total_response_time\"] / stats[\"total_responses\"]\n )\n except ZeroDivisionError:\n stats[\"average_response_time\"] = 0\n\n return self.build_response(\n 200,\n {\n \"version\": __version__,\n \"messages\": {\n \"total_parsed\": stats[\"messages_parsed\"],\n \"webhooks_called\": stats[\"webhooks_called\"],\n \"total_response_time\": stats[\"total_response_time\"],\n \"total_responses\": stats[\"total_responses\"],\n \"average_response_time\": stats[\"average_response_time\"],\n },\n \"modules\": {\n \"skills\": len(self.opsdroid.skills),\n \"connectors\": len(self.opsdroid.connectors),\n \"databases\": len(self.opsdroid.memory.databases),\n },\n },\n )\n", "path": "opsdroid/web.py"}]}
| 2,677 | 270 |
gh_patches_debug_4752
|
rasdani/github-patches
|
git_diff
|
pymedusa__Medusa-3292
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[APP SUBMITTED]: TypeError: integer argument expected, got float
### INFO
**Python Version**: `2.7.13 (default, Apr 11 2017, 16:05:39) [GCC 4.8.4]`
**Operating System**: `Linux-4.2.8-x86_64-with-glibc2.2.5`
**Locale**: `UTF-8`
**Branch**: [master](../tree/master)
**Database**: `44.8`
**Commit**: pymedusa/Medusa@b16e0e5eb4ded727eebd2ab2cd9683ab597662f5
**Link to Log**: https://gist.github.com/28959ec35573f55afe29fc65ecbe8270
### ERROR
<pre>
2017-11-11 19:37:49 ERROR TORNADO :: [b16e0e5] API :: 'integer argument expected, got float'
Traceback (most recent call last):
File "/share/CACHEDEV1_DATA/.qpkg/Medusa/Medusa/<a href="../blob/b16e0e5eb4ded727eebd2ab2cd9683ab597662f5/medusa/server/api/v1/core.py#L126">medusa/server/api/v1/core.py</a>", line 126, in get
out_dict = _call_dispatcher(args, kwargs)
File "/share/CACHEDEV1_DATA/.qpkg/Medusa/Medusa/<a href="../blob/b16e0e5eb4ded727eebd2ab2cd9683ab597662f5/medusa/server/api/v1/core.py#L196">medusa/server/api/v1/core.py</a>", line 196, in call_dispatcher
cur_out_dict = func(cur_args, cur_kwargs).run() # call function and get response
File "/share/CACHEDEV1_DATA/.qpkg/Medusa/Medusa/<a href="../blob/b16e0e5eb4ded727eebd2ab2cd9683ab597662f5/medusa/server/api/v1/core.py#L1423">medusa/server/api/v1/core.py</a>", line 1423, in run
next_backlog = app.backlog_search_scheduler.next_run().strftime(dateFormat).decode(app.SYS_ENCODING)
File "/share/CACHEDEV1_DATA/.qpkg/Medusa/Medusa/<a href="../blob/b16e0e5eb4ded727eebd2ab2cd9683ab597662f5/medusa/search/backlog.py#L33">medusa/search/backlog.py</a>", line 33, in next_run
return datetime.date.fromordinal(self.action._last_backlog + self.action.cycleTime)
TypeError: integer argument expected, got float
</pre>
---
_STAFF NOTIFIED_: @pymedusa/support @pymedusa/moderators
</issue>
<code>
[start of medusa/search/backlog.py]
1 # coding=utf-8
2
3 """Backlog module."""
4
5 import datetime
6 import logging
7 import threading
8
9 from medusa import app, common, db, scheduler, ui
10 from medusa.helper.common import episode_num
11 from medusa.logger.adapters.style import BraceAdapter
12 from medusa.search.queue import BacklogQueueItem
13
14 from six import iteritems
15
16 log = BraceAdapter(logging.getLogger(__name__))
17 log.logger.addHandler(logging.NullHandler())
18
19
20 class BacklogSearchScheduler(scheduler.Scheduler):
21 """Backlog search scheduler class."""
22
23 def force_search(self):
24 """Set the last backlog in the DB."""
25 self.action._set_last_backlog(1)
26 self.lastRun = datetime.datetime.fromordinal(1)
27
28 def next_run(self):
29 """Return when backlog should run next."""
30 if self.action._last_backlog <= 1:
31 return datetime.date.today()
32 else:
33 return datetime.date.fromordinal(self.action._last_backlog + self.action.cycleTime)
34
35
36 class BacklogSearcher(object):
37 """Backlog Searcher class."""
38
39 def __init__(self):
40 """Initialize the class."""
41 self._last_backlog = self._get_last_backlog()
42 self.cycleTime = app.BACKLOG_FREQUENCY / 60.0 / 24
43 self.lock = threading.Lock()
44 self.amActive = False
45 self.amPaused = False
46 self.amWaiting = False
47 self.forced = False
48 self.currentSearchInfo = {}
49
50 self._reset_pi()
51
52 def _reset_pi(self):
53 """Reset percent done."""
54 self.percentDone = 0
55 self.currentSearchInfo = {'title': 'Initializing'}
56
57 def get_progress_indicator(self):
58 """Get backlog search progress indicator."""
59 if self.amActive:
60 return ui.ProgressIndicator(self.percentDone, self.currentSearchInfo)
61 else:
62 return None
63
64 def am_running(self):
65 """Check if backlog is running."""
66 log.debug(u'amWaiting: {0}, amActive: {1}', self.amWaiting, self.amActive)
67 return (not self.amWaiting) and self.amActive
68
69 def search_backlog(self, which_shows=None):
70 """Run the backlog search for given shows."""
71 if self.amActive:
72 log.debug(u'Backlog is still running, not starting it again')
73 return
74
75 if app.forced_search_queue_scheduler.action.is_forced_search_in_progress():
76 log.warning(u'Manual search is running. Unable to start Backlog Search')
77 return
78
79 self.amActive = True
80 self.amPaused = False
81
82 if which_shows:
83 show_list = which_shows
84 else:
85 show_list = app.showList
86
87 self._get_last_backlog()
88
89 cur_date = datetime.date.today().toordinal()
90 from_date = datetime.date.fromordinal(1)
91
92 if not which_shows and self.forced:
93 log.info(u'Running limited backlog search on missed episodes from last {0} days',
94 app.BACKLOG_DAYS)
95 from_date = datetime.date.today() - datetime.timedelta(days=app.BACKLOG_DAYS)
96 else:
97 log.info(u'Running full backlog search on missed episodes for selected shows')
98
99 # go through non air-by-date shows and see if they need any episodes
100 for cur_show in show_list:
101
102 if cur_show.paused:
103 continue
104
105 segments = self._get_segments(cur_show, from_date)
106
107 for season, segment in iteritems(segments):
108 self.currentSearchInfo = {'title': cur_show.name + ' Season ' + str(season)}
109
110 backlog_queue_item = BacklogQueueItem(cur_show, segment)
111 app.search_queue_scheduler.action.add_item(backlog_queue_item) # @UndefinedVariable
112
113 if not segments:
114 log.debug(u'Nothing needs to be downloaded for {0!r}, skipping', cur_show.name)
115
116 # don't consider this an actual backlog search if we only did recent eps
117 # or if we only did certain shows
118 if from_date == datetime.date.fromordinal(1) and not which_shows:
119 self._set_last_backlog(cur_date)
120
121 self.amActive = False
122 self._reset_pi()
123
124 def _get_last_backlog(self):
125 """Get the last time backloged runned."""
126 log.debug(u'Retrieving the last check time from the DB')
127
128 main_db_con = db.DBConnection()
129 sql_results = main_db_con.select('SELECT last_backlog '
130 'FROM info')
131
132 if not sql_results:
133 last_backlog = 1
134 elif sql_results[0]['last_backlog'] is None or sql_results[0]['last_backlog'] == '':
135 last_backlog = 1
136 else:
137 last_backlog = int(sql_results[0]['last_backlog'])
138 if last_backlog > datetime.date.today().toordinal():
139 last_backlog = 1
140
141 self._last_backlog = last_backlog
142 return self._last_backlog
143
144 @staticmethod
145 def _get_segments(show, from_date):
146 """Get episodes that should be backlog searched."""
147 wanted = {}
148 if show.paused:
149 log.debug(u'Skipping backlog for {0} because the show is paused', show.name)
150 return wanted
151
152 log.debug(u'Seeing if we need anything from {0}', show.name)
153
154 con = db.DBConnection()
155 sql_results = con.select(
156 'SELECT status, season, episode, manually_searched '
157 'FROM tv_episodes '
158 'WHERE airdate > ?'
159 ' AND showid = ?',
160 [from_date.toordinal(), show.indexerid]
161 )
162
163 # check through the list of statuses to see if we want any
164 for sql_result in sql_results:
165 should_search, shold_search_reason = common.Quality.should_search(sql_result['status'], show,
166 sql_result['manually_searched'])
167 if not should_search:
168 continue
169 log.debug(
170 u'Found needed backlog episodes for: {show} {ep}. Reason: {reason}', {
171 'show': show.name,
172 'ep': episode_num(sql_result['season'], sql_result['episode']),
173 'reason': shold_search_reason,
174 }
175 )
176 ep_obj = show.get_episode(sql_result['season'], sql_result['episode'])
177
178 if ep_obj.season not in wanted:
179 wanted[ep_obj.season] = [ep_obj]
180 else:
181 wanted[ep_obj.season].append(ep_obj)
182
183 return wanted
184
185 @staticmethod
186 def _set_last_backlog(when):
187 """Set the last backlog in the DB."""
188 log.debug(u'Setting the last backlog in the DB to {0}', when)
189
190 main_db_con = db.DBConnection()
191 sql_results = main_db_con.select('SELECT last_backlog '
192 'FROM info')
193
194 if not sql_results:
195 main_db_con.action('INSERT INTO info (last_backlog, last_indexer) '
196 'VALUES (?,?)', [str(when), 0])
197 else:
198 main_db_con.action('UPDATE info '
199 'SET last_backlog={0}'.format(when))
200
201 def run(self, force=False):
202 """Run the backlog."""
203 try:
204 if force:
205 self.forced = True
206 self.search_backlog()
207 except Exception:
208 self.amActive = False
209 raise
210
[end of medusa/search/backlog.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/medusa/search/backlog.py b/medusa/search/backlog.py
--- a/medusa/search/backlog.py
+++ b/medusa/search/backlog.py
@@ -30,7 +30,8 @@
if self.action._last_backlog <= 1:
return datetime.date.today()
else:
- return datetime.date.fromordinal(self.action._last_backlog + self.action.cycleTime)
+ backlog_frequency_in_days = int(self.action.cycleTime)
+ return datetime.date.fromordinal(self.action._last_backlog + backlog_frequency_in_days)
class BacklogSearcher(object):
|
{"golden_diff": "diff --git a/medusa/search/backlog.py b/medusa/search/backlog.py\n--- a/medusa/search/backlog.py\n+++ b/medusa/search/backlog.py\n@@ -30,7 +30,8 @@\n if self.action._last_backlog <= 1:\n return datetime.date.today()\n else:\n- return datetime.date.fromordinal(self.action._last_backlog + self.action.cycleTime)\n+ backlog_frequency_in_days = int(self.action.cycleTime)\n+ return datetime.date.fromordinal(self.action._last_backlog + backlog_frequency_in_days)\n \n \n class BacklogSearcher(object):\n", "issue": "[APP SUBMITTED]: TypeError: integer argument expected, got float\n### INFO\n**Python Version**: `2.7.13 (default, Apr 11 2017, 16:05:39) [GCC 4.8.4]`\n**Operating System**: `Linux-4.2.8-x86_64-with-glibc2.2.5`\n**Locale**: `UTF-8`\n**Branch**: [master](../tree/master)\n**Database**: `44.8`\n**Commit**: pymedusa/Medusa@b16e0e5eb4ded727eebd2ab2cd9683ab597662f5\n**Link to Log**: https://gist.github.com/28959ec35573f55afe29fc65ecbe8270\n### ERROR\n<pre>\n2017-11-11 19:37:49 ERROR TORNADO :: [b16e0e5] API :: 'integer argument expected, got float'\nTraceback (most recent call last):\n File \"/share/CACHEDEV1_DATA/.qpkg/Medusa/Medusa/<a href=\"../blob/b16e0e5eb4ded727eebd2ab2cd9683ab597662f5/medusa/server/api/v1/core.py#L126\">medusa/server/api/v1/core.py</a>\", line 126, in get\n out_dict = _call_dispatcher(args, kwargs)\n File \"/share/CACHEDEV1_DATA/.qpkg/Medusa/Medusa/<a href=\"../blob/b16e0e5eb4ded727eebd2ab2cd9683ab597662f5/medusa/server/api/v1/core.py#L196\">medusa/server/api/v1/core.py</a>\", line 196, in call_dispatcher\n cur_out_dict = func(cur_args, cur_kwargs).run() # call function and get response\n File \"/share/CACHEDEV1_DATA/.qpkg/Medusa/Medusa/<a href=\"../blob/b16e0e5eb4ded727eebd2ab2cd9683ab597662f5/medusa/server/api/v1/core.py#L1423\">medusa/server/api/v1/core.py</a>\", line 1423, in run\n next_backlog = app.backlog_search_scheduler.next_run().strftime(dateFormat).decode(app.SYS_ENCODING)\n File \"/share/CACHEDEV1_DATA/.qpkg/Medusa/Medusa/<a href=\"../blob/b16e0e5eb4ded727eebd2ab2cd9683ab597662f5/medusa/search/backlog.py#L33\">medusa/search/backlog.py</a>\", line 33, in next_run\n return datetime.date.fromordinal(self.action._last_backlog + self.action.cycleTime)\nTypeError: integer argument expected, got float\n</pre>\n---\n_STAFF NOTIFIED_: @pymedusa/support @pymedusa/moderators\n", "before_files": [{"content": "# coding=utf-8\n\n\"\"\"Backlog module.\"\"\"\n\nimport datetime\nimport logging\nimport threading\n\nfrom medusa import app, common, db, scheduler, ui\nfrom medusa.helper.common import episode_num\nfrom medusa.logger.adapters.style import BraceAdapter\nfrom medusa.search.queue import BacklogQueueItem\n\nfrom six import iteritems\n\nlog = BraceAdapter(logging.getLogger(__name__))\nlog.logger.addHandler(logging.NullHandler())\n\n\nclass BacklogSearchScheduler(scheduler.Scheduler):\n \"\"\"Backlog search scheduler class.\"\"\"\n\n def force_search(self):\n \"\"\"Set the last backlog in the DB.\"\"\"\n self.action._set_last_backlog(1)\n self.lastRun = datetime.datetime.fromordinal(1)\n\n def next_run(self):\n \"\"\"Return when backlog should run next.\"\"\"\n if self.action._last_backlog <= 1:\n return datetime.date.today()\n else:\n return datetime.date.fromordinal(self.action._last_backlog + self.action.cycleTime)\n\n\nclass BacklogSearcher(object):\n \"\"\"Backlog Searcher class.\"\"\"\n\n def __init__(self):\n \"\"\"Initialize the class.\"\"\"\n self._last_backlog = self._get_last_backlog()\n self.cycleTime = app.BACKLOG_FREQUENCY / 60.0 / 24\n self.lock = threading.Lock()\n self.amActive = False\n self.amPaused = False\n self.amWaiting = False\n self.forced = False\n self.currentSearchInfo = {}\n\n self._reset_pi()\n\n def _reset_pi(self):\n \"\"\"Reset percent done.\"\"\"\n self.percentDone = 0\n self.currentSearchInfo = {'title': 'Initializing'}\n\n def get_progress_indicator(self):\n \"\"\"Get backlog search progress indicator.\"\"\"\n if self.amActive:\n return ui.ProgressIndicator(self.percentDone, self.currentSearchInfo)\n else:\n return None\n\n def am_running(self):\n \"\"\"Check if backlog is running.\"\"\"\n log.debug(u'amWaiting: {0}, amActive: {1}', self.amWaiting, self.amActive)\n return (not self.amWaiting) and self.amActive\n\n def search_backlog(self, which_shows=None):\n \"\"\"Run the backlog search for given shows.\"\"\"\n if self.amActive:\n log.debug(u'Backlog is still running, not starting it again')\n return\n\n if app.forced_search_queue_scheduler.action.is_forced_search_in_progress():\n log.warning(u'Manual search is running. Unable to start Backlog Search')\n return\n\n self.amActive = True\n self.amPaused = False\n\n if which_shows:\n show_list = which_shows\n else:\n show_list = app.showList\n\n self._get_last_backlog()\n\n cur_date = datetime.date.today().toordinal()\n from_date = datetime.date.fromordinal(1)\n\n if not which_shows and self.forced:\n log.info(u'Running limited backlog search on missed episodes from last {0} days',\n app.BACKLOG_DAYS)\n from_date = datetime.date.today() - datetime.timedelta(days=app.BACKLOG_DAYS)\n else:\n log.info(u'Running full backlog search on missed episodes for selected shows')\n\n # go through non air-by-date shows and see if they need any episodes\n for cur_show in show_list:\n\n if cur_show.paused:\n continue\n\n segments = self._get_segments(cur_show, from_date)\n\n for season, segment in iteritems(segments):\n self.currentSearchInfo = {'title': cur_show.name + ' Season ' + str(season)}\n\n backlog_queue_item = BacklogQueueItem(cur_show, segment)\n app.search_queue_scheduler.action.add_item(backlog_queue_item) # @UndefinedVariable\n\n if not segments:\n log.debug(u'Nothing needs to be downloaded for {0!r}, skipping', cur_show.name)\n\n # don't consider this an actual backlog search if we only did recent eps\n # or if we only did certain shows\n if from_date == datetime.date.fromordinal(1) and not which_shows:\n self._set_last_backlog(cur_date)\n\n self.amActive = False\n self._reset_pi()\n\n def _get_last_backlog(self):\n \"\"\"Get the last time backloged runned.\"\"\"\n log.debug(u'Retrieving the last check time from the DB')\n\n main_db_con = db.DBConnection()\n sql_results = main_db_con.select('SELECT last_backlog '\n 'FROM info')\n\n if not sql_results:\n last_backlog = 1\n elif sql_results[0]['last_backlog'] is None or sql_results[0]['last_backlog'] == '':\n last_backlog = 1\n else:\n last_backlog = int(sql_results[0]['last_backlog'])\n if last_backlog > datetime.date.today().toordinal():\n last_backlog = 1\n\n self._last_backlog = last_backlog\n return self._last_backlog\n\n @staticmethod\n def _get_segments(show, from_date):\n \"\"\"Get episodes that should be backlog searched.\"\"\"\n wanted = {}\n if show.paused:\n log.debug(u'Skipping backlog for {0} because the show is paused', show.name)\n return wanted\n\n log.debug(u'Seeing if we need anything from {0}', show.name)\n\n con = db.DBConnection()\n sql_results = con.select(\n 'SELECT status, season, episode, manually_searched '\n 'FROM tv_episodes '\n 'WHERE airdate > ?'\n ' AND showid = ?',\n [from_date.toordinal(), show.indexerid]\n )\n\n # check through the list of statuses to see if we want any\n for sql_result in sql_results:\n should_search, shold_search_reason = common.Quality.should_search(sql_result['status'], show,\n sql_result['manually_searched'])\n if not should_search:\n continue\n log.debug(\n u'Found needed backlog episodes for: {show} {ep}. Reason: {reason}', {\n 'show': show.name,\n 'ep': episode_num(sql_result['season'], sql_result['episode']),\n 'reason': shold_search_reason,\n }\n )\n ep_obj = show.get_episode(sql_result['season'], sql_result['episode'])\n\n if ep_obj.season not in wanted:\n wanted[ep_obj.season] = [ep_obj]\n else:\n wanted[ep_obj.season].append(ep_obj)\n\n return wanted\n\n @staticmethod\n def _set_last_backlog(when):\n \"\"\"Set the last backlog in the DB.\"\"\"\n log.debug(u'Setting the last backlog in the DB to {0}', when)\n\n main_db_con = db.DBConnection()\n sql_results = main_db_con.select('SELECT last_backlog '\n 'FROM info')\n\n if not sql_results:\n main_db_con.action('INSERT INTO info (last_backlog, last_indexer) '\n 'VALUES (?,?)', [str(when), 0])\n else:\n main_db_con.action('UPDATE info '\n 'SET last_backlog={0}'.format(when))\n\n def run(self, force=False):\n \"\"\"Run the backlog.\"\"\"\n try:\n if force:\n self.forced = True\n self.search_backlog()\n except Exception:\n self.amActive = False\n raise\n", "path": "medusa/search/backlog.py"}]}
| 3,359 | 132 |
gh_patches_debug_18274
|
rasdani/github-patches
|
git_diff
|
openstates__openstates-scrapers-1304
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Louisiana is not yet available for 2017
State: LA
Louisiana's session starts on 4/10, we'll monitor the situation and update LA as soon as possible.
</issue>
<code>
[start of openstates/la/__init__.py]
1 import datetime
2 import re
3 from billy.scrape.utils import url_xpath
4 from billy.utils.fulltext import pdfdata_to_text, text_after_line_numbers
5 from .bills import LABillScraper
6 from .legislators import LALegislatorScraper
7 from .committees import LACommitteeScraper
8 from .events import LAEventScraper
9
10 metadata = {
11 'name': 'Louisiana',
12 'abbreviation': 'la',
13 'legislature_name': 'Louisiana Legislature',
14 'legislature_url': 'http://www.legis.la.gov/',
15 'capitol_timezone': 'America/Chicago',
16 'chambers': {
17 'upper': {'name': 'Senate', 'title': 'Senator'},
18 'lower': {'name': 'House', 'title': 'Representative'},
19 },
20 # Louisiana legislators serve four-year terms.
21 'terms': [
22 {
23 'name': '2008-2011',
24 'start_year': 2008,
25 'end_year': 2011,
26 'sessions': [
27 '2009',
28 '2010',
29 '2011 1st Extraordinary Session',
30 '2011',
31 ],
32 },
33 {
34 'name': '2012-2015',
35 'start_year': 2012,
36 'end_year': 2015,
37 'sessions': [
38 '2012',
39 '2013',
40 '2014',
41 '2015',
42 ],
43 },
44 {
45 'name': '2016-2019',
46 'start_year': 2016,
47 'end_year': 2019,
48 'sessions': [
49 '2016',
50 '2016 1st Extraordinary Session',
51 '2016 2nd Extraordinary Session',
52 ],
53 },
54 ],
55 'session_details': {
56 '2009': {
57 'type': 'primary',
58 'start_date': datetime.date(2010, 4, 27),
59 'end_date': datetime.date(2010, 6, 24),
60 'display_name': '2009 Regular Session',
61 '_id': '09RS',
62 '_scraped_name': '2009 Regular Session',
63 },
64 '2010': {
65 'type': 'primary',
66 'start_date': datetime.date(2010, 3, 29),
67 'end_date': datetime.date(2010, 6, 21),
68 'display_name': '2010 Regular Session',
69 '_id': '10RS',
70 '_scraped_name': '2010 Regular Session',
71 },
72 '2011 1st Extraordinary Session': {
73 'type': 'special',
74 'start_date': datetime.date(2011, 3, 20),
75 'end_date': datetime.date(2011, 4, 13),
76 'display_name': '2011, 1st Extraordinary Session',
77 '_id': '111ES',
78 '_scraped_name': '2011 First Extraordinary Session',
79 },
80 '2011': {
81 'type': 'primary',
82 'start_date': datetime.date(2011, 4, 25),
83 'end_date': datetime.date(2011, 6, 23),
84 'display_name': '2011 Regular Session',
85 '_id': '11RS',
86 '_scraped_name': '2011 Regular Session',
87 },
88 '2012': {
89 'type': 'primary',
90 'start_date': datetime.date(2012, 3, 12),
91 'end_date': datetime.date(2012, 6, 4),
92 'display_name': '2012 Regular Session',
93 '_id': '12RS',
94 '_scraped_name': '2012 Regular Session',
95 },
96 '2013': {
97 'type': 'primary',
98 'start_date': datetime.date(2013, 4, 8),
99 'end_date': datetime.date(2013, 6, 6),
100 'display_name': '2013 Regular Session',
101 '_id': '13RS',
102 '_scraped_name': '2013 Regular Session',
103 },
104 '2014': {
105 'type': 'primary',
106 'start_date': datetime.date(2014, 3, 10),
107 'end_date': datetime.date(2014, 6, 2),
108 'display_name': '2014 Regular Session',
109 '_id': '14RS',
110 '_scraped_name': '2014 Regular Session',
111 },
112 '2015': {
113 'type': 'primary',
114 'start_date': datetime.date(2015, 4, 13),
115 'end_date': datetime.date(2015, 6, 11),
116 'display_name': '2015 Regular Session',
117 '_id': '15RS',
118 '_scraped_name': '2015 Regular Session',
119 },
120 '2016': {
121 'type': 'primary',
122 'start_date': datetime.date(2016, 3, 14),
123 'end_date': datetime.date(2016, 6, 6),
124 'display_name': '2016 Regular Session',
125 '_id': '16RS',
126 '_scraped_name': '2016 Regular Session',
127 },
128 '2016 1st Extraordinary Session': {
129 'type': 'special',
130 'start_date': datetime.date(2016, 2, 14),
131 'end_date': datetime.date(2016, 3, 9),
132 'display_name': '2016, 1st Extraordinary Session',
133 '_id': '161ES',
134 '_scraped_name': '2016 First Extraordinary Session',
135 },
136 '2016 2nd Extraordinary Session': {
137 'type': 'special',
138 'start_date': datetime.date(2016, 6, 6),
139 'end_date': datetime.date(2016, 6, 23),
140 'display_name': '2016, 2nd Extraordinary Session',
141 '_id': '162ES',
142 '_scraped_name': '2016 Second Extraordinary Session',
143 },
144 },
145 'feature_flags': ['subjects', 'influenceexplorer', 'events'],
146 '_ignored_scraped_sessions': [
147 '2016 Organizational Session',
148 '2015 Regular Session',
149 '2014 Regular Session',
150 '2013 Regular Session',
151 '2012 Regular Session',
152 '2012 Organizational Session',
153 '2011 Regular Session',
154 '2011 First Extraordinary Session',
155 '2010 Regular Session',
156 '2009 Regular Session',
157 '2008 Regular Session',
158 '2008 Organizational Session',
159 '2008 Second Extraordinary Session',
160 '2008 First Extraordinary Session',
161 '2007 Regular Session',
162 '2006 Regular Session',
163 '2005 Regular Session',
164 '2004 Regular Session',
165 '2004 First Extraordinary Session',
166 '2004 1st Extraordinary Session',
167 '2003 Regular Session',
168 '2002 Regular Session',
169 '2001 Regular Session',
170 '2000 Regular Session',
171 '1999 Regular Session',
172 '1998 Regular Session',
173 '1997 Regular Session',
174 '2006 Second Extraordinary Session',
175 '2006 First Extraordinary Session',
176 '2005 First Extraordinary Session',
177 '2002 First Extraordinary Session',
178 '2001 Second Extraordinary Session',
179 '2001 First Extraordinary Session',
180 '2000 Second Extraordinary Session',
181 '2000 First Extraordinary Session',
182 '1998 First Extraordinary Session',
183 '2012 Organizational Session',
184 '2000 Organizational Session',
185 '2004 Organizational Session',
186 'Other Sessions',
187 'Other Sessions',
188 'Sessions',
189 ]
190 }
191
192
193 def session_list():
194 return url_xpath(
195 'http://www.legis.la.gov/Legis/SessionInfo/SessionInfo.aspx',
196 '//table[@id="ctl00_ctl00_PageBody_DataListSessions"]//a[contains'
197 '(text(), "Session")]/text()')
198
199
200 def extract_text(doc, data):
201 return text_after_line_numbers(pdfdata_to_text(data))
202
[end of openstates/la/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/openstates/la/__init__.py b/openstates/la/__init__.py
--- a/openstates/la/__init__.py
+++ b/openstates/la/__init__.py
@@ -49,6 +49,7 @@
'2016',
'2016 1st Extraordinary Session',
'2016 2nd Extraordinary Session',
+ '2017',
],
},
],
@@ -141,6 +142,14 @@
'_id': '162ES',
'_scraped_name': '2016 Second Extraordinary Session',
},
+ '2017': {
+ 'type': 'primary',
+ 'start_date': datetime.date(2017, 4, 10),
+ 'end_date': datetime.date(2017, 6, 8),
+ 'display_name': '2017 Regular Session',
+ '_id': '17RS',
+ '_scraped_name': '2017 Regular Session',
+ },
},
'feature_flags': ['subjects', 'influenceexplorer', 'events'],
'_ignored_scraped_sessions': [
|
{"golden_diff": "diff --git a/openstates/la/__init__.py b/openstates/la/__init__.py\n--- a/openstates/la/__init__.py\n+++ b/openstates/la/__init__.py\n@@ -49,6 +49,7 @@\n '2016',\n '2016 1st Extraordinary Session',\n '2016 2nd Extraordinary Session',\n+ '2017',\n ],\n },\n ],\n@@ -141,6 +142,14 @@\n '_id': '162ES',\n '_scraped_name': '2016 Second Extraordinary Session',\n },\n+ '2017': {\n+ 'type': 'primary',\n+ 'start_date': datetime.date(2017, 4, 10),\n+ 'end_date': datetime.date(2017, 6, 8),\n+ 'display_name': '2017 Regular Session',\n+ '_id': '17RS',\n+ '_scraped_name': '2017 Regular Session',\n+ },\n },\n 'feature_flags': ['subjects', 'influenceexplorer', 'events'],\n '_ignored_scraped_sessions': [\n", "issue": "Louisiana is not yet available for 2017\nState: LA\r\n\r\nLouisiana's session starts on 4/10, we'll monitor the situation and update LA as soon as possible.\r\n\n", "before_files": [{"content": "import datetime\nimport re\nfrom billy.scrape.utils import url_xpath\nfrom billy.utils.fulltext import pdfdata_to_text, text_after_line_numbers\nfrom .bills import LABillScraper\nfrom .legislators import LALegislatorScraper\nfrom .committees import LACommitteeScraper\nfrom .events import LAEventScraper\n\nmetadata = {\n 'name': 'Louisiana',\n 'abbreviation': 'la',\n 'legislature_name': 'Louisiana Legislature',\n 'legislature_url': 'http://www.legis.la.gov/',\n 'capitol_timezone': 'America/Chicago',\n 'chambers': {\n 'upper': {'name': 'Senate', 'title': 'Senator'},\n 'lower': {'name': 'House', 'title': 'Representative'},\n },\n # Louisiana legislators serve four-year terms.\n 'terms': [\n {\n 'name': '2008-2011',\n 'start_year': 2008,\n 'end_year': 2011,\n 'sessions': [\n '2009',\n '2010',\n '2011 1st Extraordinary Session',\n '2011',\n ],\n },\n {\n 'name': '2012-2015',\n 'start_year': 2012,\n 'end_year': 2015,\n 'sessions': [\n '2012',\n '2013',\n '2014',\n '2015',\n ],\n },\n {\n 'name': '2016-2019',\n 'start_year': 2016,\n 'end_year': 2019,\n 'sessions': [\n '2016',\n '2016 1st Extraordinary Session',\n '2016 2nd Extraordinary Session',\n ],\n },\n ],\n 'session_details': {\n '2009': {\n 'type': 'primary',\n 'start_date': datetime.date(2010, 4, 27),\n 'end_date': datetime.date(2010, 6, 24),\n 'display_name': '2009 Regular Session',\n '_id': '09RS',\n '_scraped_name': '2009 Regular Session',\n },\n '2010': {\n 'type': 'primary',\n 'start_date': datetime.date(2010, 3, 29),\n 'end_date': datetime.date(2010, 6, 21),\n 'display_name': '2010 Regular Session',\n '_id': '10RS',\n '_scraped_name': '2010 Regular Session',\n },\n '2011 1st Extraordinary Session': {\n 'type': 'special',\n 'start_date': datetime.date(2011, 3, 20),\n 'end_date': datetime.date(2011, 4, 13),\n 'display_name': '2011, 1st Extraordinary Session',\n '_id': '111ES',\n '_scraped_name': '2011 First Extraordinary Session',\n },\n '2011': {\n 'type': 'primary',\n 'start_date': datetime.date(2011, 4, 25),\n 'end_date': datetime.date(2011, 6, 23),\n 'display_name': '2011 Regular Session',\n '_id': '11RS',\n '_scraped_name': '2011 Regular Session',\n },\n '2012': {\n 'type': 'primary',\n 'start_date': datetime.date(2012, 3, 12),\n 'end_date': datetime.date(2012, 6, 4),\n 'display_name': '2012 Regular Session',\n '_id': '12RS',\n '_scraped_name': '2012 Regular Session',\n },\n '2013': {\n 'type': 'primary',\n 'start_date': datetime.date(2013, 4, 8),\n 'end_date': datetime.date(2013, 6, 6),\n 'display_name': '2013 Regular Session',\n '_id': '13RS',\n '_scraped_name': '2013 Regular Session',\n },\n '2014': {\n 'type': 'primary',\n 'start_date': datetime.date(2014, 3, 10),\n 'end_date': datetime.date(2014, 6, 2),\n 'display_name': '2014 Regular Session',\n '_id': '14RS',\n '_scraped_name': '2014 Regular Session',\n },\n '2015': {\n 'type': 'primary',\n 'start_date': datetime.date(2015, 4, 13),\n 'end_date': datetime.date(2015, 6, 11),\n 'display_name': '2015 Regular Session',\n '_id': '15RS',\n '_scraped_name': '2015 Regular Session',\n },\n '2016': {\n 'type': 'primary',\n 'start_date': datetime.date(2016, 3, 14),\n 'end_date': datetime.date(2016, 6, 6),\n 'display_name': '2016 Regular Session',\n '_id': '16RS',\n '_scraped_name': '2016 Regular Session',\n },\n '2016 1st Extraordinary Session': {\n 'type': 'special',\n 'start_date': datetime.date(2016, 2, 14),\n 'end_date': datetime.date(2016, 3, 9),\n 'display_name': '2016, 1st Extraordinary Session',\n '_id': '161ES',\n '_scraped_name': '2016 First Extraordinary Session',\n },\n '2016 2nd Extraordinary Session': {\n 'type': 'special',\n 'start_date': datetime.date(2016, 6, 6),\n 'end_date': datetime.date(2016, 6, 23),\n 'display_name': '2016, 2nd Extraordinary Session',\n '_id': '162ES',\n '_scraped_name': '2016 Second Extraordinary Session',\n },\n },\n 'feature_flags': ['subjects', 'influenceexplorer', 'events'],\n '_ignored_scraped_sessions': [\n '2016 Organizational Session',\n '2015 Regular Session',\n '2014 Regular Session',\n '2013 Regular Session',\n '2012 Regular Session',\n '2012 Organizational Session',\n '2011 Regular Session',\n '2011 First Extraordinary Session',\n '2010 Regular Session',\n '2009 Regular Session',\n '2008 Regular Session',\n '2008 Organizational Session',\n '2008 Second Extraordinary Session',\n '2008 First Extraordinary Session',\n '2007 Regular Session',\n '2006 Regular Session',\n '2005 Regular Session',\n '2004 Regular Session',\n '2004 First Extraordinary Session',\n '2004 1st Extraordinary Session',\n '2003 Regular Session',\n '2002 Regular Session',\n '2001 Regular Session',\n '2000 Regular Session',\n '1999 Regular Session',\n '1998 Regular Session',\n '1997 Regular Session',\n '2006 Second Extraordinary Session',\n '2006 First Extraordinary Session',\n '2005 First Extraordinary Session',\n '2002 First Extraordinary Session',\n '2001 Second Extraordinary Session',\n '2001 First Extraordinary Session',\n '2000 Second Extraordinary Session',\n '2000 First Extraordinary Session',\n '1998 First Extraordinary Session',\n '2012 Organizational Session',\n '2000 Organizational Session',\n '2004 Organizational Session',\n 'Other Sessions',\n 'Other Sessions',\n 'Sessions',\n ]\n}\n\n\ndef session_list():\n return url_xpath(\n 'http://www.legis.la.gov/Legis/SessionInfo/SessionInfo.aspx',\n '//table[@id=\"ctl00_ctl00_PageBody_DataListSessions\"]//a[contains'\n '(text(), \"Session\")]/text()')\n\n\ndef extract_text(doc, data):\n return text_after_line_numbers(pdfdata_to_text(data))\n", "path": "openstates/la/__init__.py"}]}
| 3,109 | 276 |
gh_patches_debug_19803
|
rasdani/github-patches
|
git_diff
|
mampfes__hacs_waste_collection_schedule-1678
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Braintree error when selecting address
I have had the follow error for the past couple of months:
> fetch failed for source Braintree District Council: Traceback (most recent call last): File "/config/custom_components/waste_collection_schedule/waste_collection_schedule/source_shell.py", line 134, in fetch entries = self._source.fetch() ^^^^^^^^^^^^^^^^^^^^ File "/config/custom_components/waste_collection_schedule/waste_collection_schedule/source/braintree_gov_uk.py", line 45, in fetch id = next( ^^^^^ StopIteration
I am seeing address["value"] on line 43 having a length of 11.
Removing this line cures the problem for me, and I am not sure what this line is achieving?
https://github.com/mampfes/hacs_waste_collection_schedule/blob/73baeef472c5db4c85db3a7b725df68f3a15a101/custom_components/waste_collection_schedule/waste_collection_schedule/source/braintree_gov_uk.py#L43
</issue>
<code>
[start of custom_components/waste_collection_schedule/waste_collection_schedule/source/braintree_gov_uk.py]
1 import requests
2 from bs4 import BeautifulSoup
3 from dateutil import parser
4 from waste_collection_schedule import Collection
5
6 TITLE = "Braintree District Council"
7 DESCRIPTION = "Braintree District Council, UK - Waste Collection"
8 URL = "https://www.braintree.gov.uk"
9 TEST_CASES = {
10 "30 Boars Tye Road": {"house_number": "30", "post_code": "CM8 3QE"},
11 "64 Silver Street": {"house_number": "64", "post_code": "CM8 3QG"},
12 "18 St Mary's Road": {"house_number": "1", "post_code": "CM8 3PE"},
13 "20 Peel Crescent": {"house_number": "20", "post_code": "CM7 2RS"},
14 }
15
16 ICON_MAP = {
17 "Grey Bin": "mdi:trash-can",
18 "Clear Sack": "mdi:recycle",
19 "Green Bin": "mdi:leaf",
20 "Food Bin": "mdi:food-apple",
21 }
22
23
24 class Source:
25 def __init__(self, post_code: str, house_number: str):
26 self.post_code = post_code
27 self.house_number = house_number
28 self.url = f"{URL}/xfp/form/554"
29 self.form_data = {
30 "qe15dda0155d237d1ea161004d1839e3369ed4831_0_0": (None, post_code),
31 "page": (None, 5730),
32 }
33
34 def fetch(self):
35 address_lookup = requests.post(
36 "https://www.braintree.gov.uk/xfp/form/554", files=self.form_data
37 )
38 address_lookup.raise_for_status()
39 addresses = {}
40 for address in BeautifulSoup(address_lookup.text, "html.parser").find_all(
41 "option"
42 ):
43 if len(address["value"]) == 12:
44 addresses[address["value"]] = address.text.strip()
45 id = next(
46 address
47 for address in addresses
48 if addresses[address].startswith(self.house_number)
49 )
50 self.form_data["qe15dda0155d237d1ea161004d1839e3369ed4831_1_0"] = (None, id)
51 self.form_data["next"] = (None, "Next")
52 collection_lookup = requests.post(
53 "https://www.braintree.gov.uk/xfp/form/554", files=self.form_data
54 )
55 collection_lookup.raise_for_status()
56 entries = []
57 for results in BeautifulSoup(collection_lookup.text, "html.parser").find_all(
58 "div", class_="date_display"
59 ):
60 try:
61 collection_type, collection_date = results.text.strip().split("\n")
62 entries.append(
63 Collection(
64 date=parser.parse(collection_date, dayfirst=True).date(),
65 t=collection_type,
66 icon=ICON_MAP.get(collection_type),
67 )
68 )
69 except (StopIteration, TypeError):
70 pass
71 return entries
72
[end of custom_components/waste_collection_schedule/waste_collection_schedule/source/braintree_gov_uk.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/custom_components/waste_collection_schedule/waste_collection_schedule/source/braintree_gov_uk.py b/custom_components/waste_collection_schedule/waste_collection_schedule/source/braintree_gov_uk.py
--- a/custom_components/waste_collection_schedule/waste_collection_schedule/source/braintree_gov_uk.py
+++ b/custom_components/waste_collection_schedule/waste_collection_schedule/source/braintree_gov_uk.py
@@ -1,7 +1,7 @@
import requests
from bs4 import BeautifulSoup
from dateutil import parser
-from waste_collection_schedule import Collection
+from waste_collection_schedule import Collection # type: ignore[attr-defined]
TITLE = "Braintree District Council"
DESCRIPTION = "Braintree District Council, UK - Waste Collection"
@@ -40,7 +40,7 @@
for address in BeautifulSoup(address_lookup.text, "html.parser").find_all(
"option"
):
- if len(address["value"]) == 12:
+ if len(address["value"]) > 5: # Skip the first option
addresses[address["value"]] = address.text.strip()
id = next(
address
|
{"golden_diff": "diff --git a/custom_components/waste_collection_schedule/waste_collection_schedule/source/braintree_gov_uk.py b/custom_components/waste_collection_schedule/waste_collection_schedule/source/braintree_gov_uk.py\n--- a/custom_components/waste_collection_schedule/waste_collection_schedule/source/braintree_gov_uk.py\n+++ b/custom_components/waste_collection_schedule/waste_collection_schedule/source/braintree_gov_uk.py\n@@ -1,7 +1,7 @@\n import requests\n from bs4 import BeautifulSoup\n from dateutil import parser\n-from waste_collection_schedule import Collection\n+from waste_collection_schedule import Collection # type: ignore[attr-defined]\n \n TITLE = \"Braintree District Council\"\n DESCRIPTION = \"Braintree District Council, UK - Waste Collection\"\n@@ -40,7 +40,7 @@\n for address in BeautifulSoup(address_lookup.text, \"html.parser\").find_all(\n \"option\"\n ):\n- if len(address[\"value\"]) == 12:\n+ if len(address[\"value\"]) > 5: # Skip the first option\n addresses[address[\"value\"]] = address.text.strip()\n id = next(\n address\n", "issue": "Braintree error when selecting address\nI have had the follow error for the past couple of months:\r\n\r\n> fetch failed for source Braintree District Council: Traceback (most recent call last): File \"/config/custom_components/waste_collection_schedule/waste_collection_schedule/source_shell.py\", line 134, in fetch entries = self._source.fetch() ^^^^^^^^^^^^^^^^^^^^ File \"/config/custom_components/waste_collection_schedule/waste_collection_schedule/source/braintree_gov_uk.py\", line 45, in fetch id = next( ^^^^^ StopIteration\r\n\r\nI am seeing address[\"value\"] on line 43 having a length of 11.\r\nRemoving this line cures the problem for me, and I am not sure what this line is achieving?\r\n\r\nhttps://github.com/mampfes/hacs_waste_collection_schedule/blob/73baeef472c5db4c85db3a7b725df68f3a15a101/custom_components/waste_collection_schedule/waste_collection_schedule/source/braintree_gov_uk.py#L43\n", "before_files": [{"content": "import requests\nfrom bs4 import BeautifulSoup\nfrom dateutil import parser\nfrom waste_collection_schedule import Collection\n\nTITLE = \"Braintree District Council\"\nDESCRIPTION = \"Braintree District Council, UK - Waste Collection\"\nURL = \"https://www.braintree.gov.uk\"\nTEST_CASES = {\n \"30 Boars Tye Road\": {\"house_number\": \"30\", \"post_code\": \"CM8 3QE\"},\n \"64 Silver Street\": {\"house_number\": \"64\", \"post_code\": \"CM8 3QG\"},\n \"18 St Mary's Road\": {\"house_number\": \"1\", \"post_code\": \"CM8 3PE\"},\n \"20 Peel Crescent\": {\"house_number\": \"20\", \"post_code\": \"CM7 2RS\"},\n}\n\nICON_MAP = {\n \"Grey Bin\": \"mdi:trash-can\",\n \"Clear Sack\": \"mdi:recycle\",\n \"Green Bin\": \"mdi:leaf\",\n \"Food Bin\": \"mdi:food-apple\",\n}\n\n\nclass Source:\n def __init__(self, post_code: str, house_number: str):\n self.post_code = post_code\n self.house_number = house_number\n self.url = f\"{URL}/xfp/form/554\"\n self.form_data = {\n \"qe15dda0155d237d1ea161004d1839e3369ed4831_0_0\": (None, post_code),\n \"page\": (None, 5730),\n }\n\n def fetch(self):\n address_lookup = requests.post(\n \"https://www.braintree.gov.uk/xfp/form/554\", files=self.form_data\n )\n address_lookup.raise_for_status()\n addresses = {}\n for address in BeautifulSoup(address_lookup.text, \"html.parser\").find_all(\n \"option\"\n ):\n if len(address[\"value\"]) == 12:\n addresses[address[\"value\"]] = address.text.strip()\n id = next(\n address\n for address in addresses\n if addresses[address].startswith(self.house_number)\n )\n self.form_data[\"qe15dda0155d237d1ea161004d1839e3369ed4831_1_0\"] = (None, id)\n self.form_data[\"next\"] = (None, \"Next\")\n collection_lookup = requests.post(\n \"https://www.braintree.gov.uk/xfp/form/554\", files=self.form_data\n )\n collection_lookup.raise_for_status()\n entries = []\n for results in BeautifulSoup(collection_lookup.text, \"html.parser\").find_all(\n \"div\", class_=\"date_display\"\n ):\n try:\n collection_type, collection_date = results.text.strip().split(\"\\n\")\n entries.append(\n Collection(\n date=parser.parse(collection_date, dayfirst=True).date(),\n t=collection_type,\n icon=ICON_MAP.get(collection_type),\n )\n )\n except (StopIteration, TypeError):\n pass\n return entries\n", "path": "custom_components/waste_collection_schedule/waste_collection_schedule/source/braintree_gov_uk.py"}]}
| 1,614 | 245 |
gh_patches_debug_19615
|
rasdani/github-patches
|
git_diff
|
rucio__rucio-4440
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
list-dids-extended with new metadata plugin currently fails
Motivation
----------
```
rucio set-metadata --did
CTA_LAPP_FREDERIC:cta_data_DL0_ObsId2021_02_22_15_49_11_975413919_TelId0.h
df5 --key ObsID --value 1
rucio get-metadata
CTA_LAPP_FREDERIC:cta_data_DL0_ObsId2021_02_22_15_49_11_975413919_TelId0.h
df5 --plugin ALL
bsID: 1
access_cnt: None
accessed_at: None
....
rucio list-dids-extended --filter ObsID=1 CTA_LAPP_FREDERIC:*
/usr/lib/python2.7/site-packages/paramiko/transport.py:33:
CryptographyDeprecationWarning: Python 2 is no longer supported by the
Python core team. Support for it is now deprecated in cryptography, and
will be removed in a future release.
from cryptography.hazmat.backends import default_backend
2021-02-22 15:58:35,693 ERROR An unknown exception occurred.
Details: no error information passed (http status code: 500
('internal_server_error', 'server_error', '/o\\', '\xe2\x9c\x97'))
```
</issue>
<code>
[start of lib/rucio/core/did_meta_plugins/json_meta.py]
1 # -*- coding: utf-8 -*-
2 # Copyright 2013-2021 CERN
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15 #
16 # Authors:
17 # - Vincent Garonne <[email protected]>, 2013-2018
18 # - Martin Barisits <[email protected]>, 2013-2019
19 # - Cedric Serfon <[email protected]>, 2013-2020
20 # - Ralph Vigne <[email protected]>, 2013
21 # - Mario Lassnig <[email protected]>, 2013-2019
22 # - Yun-Pin Sun <[email protected]>, 2013
23 # - Thomas Beermann <[email protected]>, 2013-2018
24 # - Joaquin Bogado <[email protected]>, 2014-2015
25 # - Wen Guan <[email protected]>, 2015
26 # - Hannes Hansen <[email protected]>, 2018-2019
27 # - Tobias Wegner <[email protected]>, 2019
28 # - Andrew Lister <[email protected]>, 2019
29 # - Ruturaj Gujar, <[email protected]>, 2019
30 # - Brandon White, <[email protected]>, 2019
31 # - Aristeidis Fkiaras <[email protected]>, 2020
32 # - Benedikt Ziemons <[email protected]>, 2020-2021
33
34 import json as json_lib
35
36 from six import iteritems
37 from sqlalchemy import String, cast, type_coerce, JSON
38 from sqlalchemy.orm.exc import NoResultFound
39 from sqlalchemy.sql.expression import text
40
41 from rucio.common import exception
42 from rucio.core.did_meta_plugins.did_meta_plugin_interface import DidMetaPlugin
43 from rucio.db.sqla import models
44 from rucio.db.sqla.session import read_session, transactional_session, stream_session
45 from rucio.db.sqla.util import json_implemented
46
47
48 class JSONDidMeta(DidMetaPlugin):
49 """
50 A plugin to store DID metadata on a table on the relational database, using JSON blobs
51 """
52
53 def __init__(self):
54 super(JSONDidMeta, self).__init__()
55 self.plugin_name = "JSON"
56
57 @read_session
58 def get_metadata(self, scope, name, session=None):
59 """
60 Get data identifier metadata (JSON)
61
62 :param scope: The scope name.
63 :param name: The data identifier name.
64 :param session: The database session in use.
65 """
66 if not json_implemented(session=session):
67 raise NotImplementedError
68
69 try:
70 row = session.query(models.DidMeta).filter_by(scope=scope, name=name).one()
71 meta = getattr(row, 'meta')
72 return json_lib.loads(meta) if session.bind.dialect.name in ['oracle', 'sqlite'] else meta
73 except NoResultFound:
74 raise exception.DataIdentifierNotFound("No generic metadata found for '%(scope)s:%(name)s'" % locals())
75
76 def set_metadata(self, scope, name, key, value, recursive=False, session=None):
77 self.set_metadata_bulk(scope=scope, name=name, meta={key: value}, recursive=recursive, session=session)
78
79 @transactional_session
80 def set_metadata_bulk(self, scope, name, meta, recursive=False, session=None):
81 if not json_implemented(session=session):
82 raise NotImplementedError
83
84 if session.query(models.DataIdentifier).filter_by(scope=scope, name=name).one_or_none() is None:
85 raise exception.DataIdentifierNotFound("Data identifier '%s:%s' not found" % (scope, name))
86
87 row_did_meta = session.query(models.DidMeta).filter_by(scope=scope, name=name).scalar()
88 if row_did_meta is None:
89 # Add metadata column to new table (if not already present)
90 row_did_meta = models.DidMeta(scope=scope, name=name)
91 row_did_meta.save(session=session, flush=False)
92
93 existing_meta = {}
94 if hasattr(row_did_meta, 'meta'):
95 if row_did_meta.meta:
96 existing_meta = row_did_meta.meta
97
98 # Oracle returns a string instead of a dict
99 if session.bind.dialect.name in ['oracle', 'sqlite'] and existing_meta:
100 existing_meta = json_lib.loads(existing_meta)
101
102 for key, value in meta.items():
103 existing_meta[key] = value
104
105 row_did_meta.meta = None
106 session.flush()
107
108 # Oracle insert takes a string as input
109 if session.bind.dialect.name in ['oracle', 'sqlite']:
110 existing_meta = json_lib.dumps(existing_meta)
111
112 row_did_meta.meta = existing_meta
113 row_did_meta.save(session=session, flush=True)
114
115 @transactional_session
116 def delete_metadata(self, scope, name, key, session=None):
117 """
118 Delete a key from the metadata column
119
120 :param scope: the scope of did
121 :param name: the name of the did
122 :param key: the key to be deleted
123 """
124 if not json_implemented(session=session):
125 raise NotImplementedError
126
127 try:
128 row = session.query(models.DidMeta).filter_by(scope=scope, name=name).one()
129 existing_meta = getattr(row, 'meta')
130 # Oracle returns a string instead of a dict
131 if session.bind.dialect.name in ['oracle', 'sqlite'] and existing_meta is not None:
132 existing_meta = json_lib.loads(existing_meta)
133
134 if key not in existing_meta:
135 raise exception.KeyNotFound(key)
136
137 existing_meta.pop(key, None)
138
139 row.meta = None
140 session.flush()
141
142 # Oracle insert takes a string as input
143 if session.bind.dialect.name in ['oracle', 'sqlite']:
144 existing_meta = json_lib.dumps(existing_meta)
145
146 row.meta = existing_meta
147 except NoResultFound:
148 raise exception.DataIdentifierNotFound("Key not found for data identifier '%(scope)s:%(name)s'" % locals())
149
150 @stream_session
151 def list_dids(self, scope, filters, type='collection', ignore_case=False, limit=None,
152 offset=None, long=False, recursive=False, session=None):
153 # Currently for sqlite only add, get and delete is implemented.
154 if not json_implemented(session=session):
155 raise NotImplementedError
156
157 query = session.query(models.DidMeta)
158 if scope is not None:
159 query = query.filter(models.DidMeta.scope == scope)
160 filters.pop('name', None)
161 for k, v in iteritems(filters):
162 if session.bind.dialect.name == 'oracle':
163 query = query.filter(text("json_exists(meta,'$.%s?(@==''%s'')')" % (k, v)))
164 else:
165 query = query.filter(cast(models.DidMeta.meta[k], String) == type_coerce(v, JSON))
166
167 if long:
168 for row in query.yield_per(5):
169 yield {
170 'scope': row.scope,
171 'name': row.name,
172 'did_type': 'Info not available in JSON Plugin',
173 'bytes': 'Info not available in JSON Plugin',
174 'length': 'Info not available in JSON Plugin'
175 }
176 else:
177 for row in query.yield_per(5):
178 yield row.name
179
180 @read_session
181 def manages_key(self, key, session=None):
182 return json_implemented(session=session)
183
184 def get_plugin_name(self):
185 """
186 Returns Plugins Name.
187 This can then be used when listing the metadata of did to only provide dids from this plugin.
188 """
189 return self.plugin_name
190
[end of lib/rucio/core/did_meta_plugins/json_meta.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lib/rucio/core/did_meta_plugins/json_meta.py b/lib/rucio/core/did_meta_plugins/json_meta.py
--- a/lib/rucio/core/did_meta_plugins/json_meta.py
+++ b/lib/rucio/core/did_meta_plugins/json_meta.py
@@ -30,6 +30,7 @@
# - Brandon White, <[email protected]>, 2019
# - Aristeidis Fkiaras <[email protected]>, 2020
# - Benedikt Ziemons <[email protected]>, 2020-2021
+# - Rizart Dona <[email protected]>, 2021
import json as json_lib
@@ -160,7 +161,7 @@
filters.pop('name', None)
for k, v in iteritems(filters):
if session.bind.dialect.name == 'oracle':
- query = query.filter(text("json_exists(meta,'$.%s?(@==''%s'')')" % (k, v)))
+ query = query.filter(text("json_exists(meta,'$?(@.{} == \"{}\")')".format(k, v)))
else:
query = query.filter(cast(models.DidMeta.meta[k], String) == type_coerce(v, JSON))
|
{"golden_diff": "diff --git a/lib/rucio/core/did_meta_plugins/json_meta.py b/lib/rucio/core/did_meta_plugins/json_meta.py\n--- a/lib/rucio/core/did_meta_plugins/json_meta.py\n+++ b/lib/rucio/core/did_meta_plugins/json_meta.py\n@@ -30,6 +30,7 @@\n # - Brandon White, <[email protected]>, 2019\n # - Aristeidis Fkiaras <[email protected]>, 2020\n # - Benedikt Ziemons <[email protected]>, 2020-2021\n+# - Rizart Dona <[email protected]>, 2021\n \n import json as json_lib\n \n@@ -160,7 +161,7 @@\n filters.pop('name', None)\n for k, v in iteritems(filters):\n if session.bind.dialect.name == 'oracle':\n- query = query.filter(text(\"json_exists(meta,'$.%s?(@==''%s'')')\" % (k, v)))\n+ query = query.filter(text(\"json_exists(meta,'$?(@.{} == \\\"{}\\\")')\".format(k, v)))\n else:\n query = query.filter(cast(models.DidMeta.meta[k], String) == type_coerce(v, JSON))\n", "issue": "list-dids-extended with new metadata plugin currently fails\nMotivation\r\n----------\r\n```\r\nrucio set-metadata --did\r\nCTA_LAPP_FREDERIC:cta_data_DL0_ObsId2021_02_22_15_49_11_975413919_TelId0.h\r\ndf5 --key ObsID --value 1\r\n\r\nrucio get-metadata\r\nCTA_LAPP_FREDERIC:cta_data_DL0_ObsId2021_02_22_15_49_11_975413919_TelId0.h\r\ndf5 --plugin ALL\r\nbsID: 1\r\naccess_cnt: None\r\naccessed_at: None\r\n....\r\n\r\nrucio list-dids-extended --filter ObsID=1 CTA_LAPP_FREDERIC:*\r\n/usr/lib/python2.7/site-packages/paramiko/transport.py:33:\r\nCryptographyDeprecationWarning: Python 2 is no longer supported by the\r\nPython core team. Support for it is now deprecated in cryptography, and\r\nwill be removed in a future release.\r\n from cryptography.hazmat.backends import default_backend\r\n2021-02-22 15:58:35,693 ERROR An unknown exception occurred.\r\nDetails: no error information passed (http status code: 500\r\n('internal_server_error', 'server_error', '/o\\\\', '\\xe2\\x9c\\x97'))\r\n```\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright 2013-2021 CERN\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n# Authors:\n# - Vincent Garonne <[email protected]>, 2013-2018\n# - Martin Barisits <[email protected]>, 2013-2019\n# - Cedric Serfon <[email protected]>, 2013-2020\n# - Ralph Vigne <[email protected]>, 2013\n# - Mario Lassnig <[email protected]>, 2013-2019\n# - Yun-Pin Sun <[email protected]>, 2013\n# - Thomas Beermann <[email protected]>, 2013-2018\n# - Joaquin Bogado <[email protected]>, 2014-2015\n# - Wen Guan <[email protected]>, 2015\n# - Hannes Hansen <[email protected]>, 2018-2019\n# - Tobias Wegner <[email protected]>, 2019\n# - Andrew Lister <[email protected]>, 2019\n# - Ruturaj Gujar, <[email protected]>, 2019\n# - Brandon White, <[email protected]>, 2019\n# - Aristeidis Fkiaras <[email protected]>, 2020\n# - Benedikt Ziemons <[email protected]>, 2020-2021\n\nimport json as json_lib\n\nfrom six import iteritems\nfrom sqlalchemy import String, cast, type_coerce, JSON\nfrom sqlalchemy.orm.exc import NoResultFound\nfrom sqlalchemy.sql.expression import text\n\nfrom rucio.common import exception\nfrom rucio.core.did_meta_plugins.did_meta_plugin_interface import DidMetaPlugin\nfrom rucio.db.sqla import models\nfrom rucio.db.sqla.session import read_session, transactional_session, stream_session\nfrom rucio.db.sqla.util import json_implemented\n\n\nclass JSONDidMeta(DidMetaPlugin):\n \"\"\"\n A plugin to store DID metadata on a table on the relational database, using JSON blobs\n \"\"\"\n\n def __init__(self):\n super(JSONDidMeta, self).__init__()\n self.plugin_name = \"JSON\"\n\n @read_session\n def get_metadata(self, scope, name, session=None):\n \"\"\"\n Get data identifier metadata (JSON)\n\n :param scope: The scope name.\n :param name: The data identifier name.\n :param session: The database session in use.\n \"\"\"\n if not json_implemented(session=session):\n raise NotImplementedError\n\n try:\n row = session.query(models.DidMeta).filter_by(scope=scope, name=name).one()\n meta = getattr(row, 'meta')\n return json_lib.loads(meta) if session.bind.dialect.name in ['oracle', 'sqlite'] else meta\n except NoResultFound:\n raise exception.DataIdentifierNotFound(\"No generic metadata found for '%(scope)s:%(name)s'\" % locals())\n\n def set_metadata(self, scope, name, key, value, recursive=False, session=None):\n self.set_metadata_bulk(scope=scope, name=name, meta={key: value}, recursive=recursive, session=session)\n\n @transactional_session\n def set_metadata_bulk(self, scope, name, meta, recursive=False, session=None):\n if not json_implemented(session=session):\n raise NotImplementedError\n\n if session.query(models.DataIdentifier).filter_by(scope=scope, name=name).one_or_none() is None:\n raise exception.DataIdentifierNotFound(\"Data identifier '%s:%s' not found\" % (scope, name))\n\n row_did_meta = session.query(models.DidMeta).filter_by(scope=scope, name=name).scalar()\n if row_did_meta is None:\n # Add metadata column to new table (if not already present)\n row_did_meta = models.DidMeta(scope=scope, name=name)\n row_did_meta.save(session=session, flush=False)\n\n existing_meta = {}\n if hasattr(row_did_meta, 'meta'):\n if row_did_meta.meta:\n existing_meta = row_did_meta.meta\n\n # Oracle returns a string instead of a dict\n if session.bind.dialect.name in ['oracle', 'sqlite'] and existing_meta:\n existing_meta = json_lib.loads(existing_meta)\n\n for key, value in meta.items():\n existing_meta[key] = value\n\n row_did_meta.meta = None\n session.flush()\n\n # Oracle insert takes a string as input\n if session.bind.dialect.name in ['oracle', 'sqlite']:\n existing_meta = json_lib.dumps(existing_meta)\n\n row_did_meta.meta = existing_meta\n row_did_meta.save(session=session, flush=True)\n\n @transactional_session\n def delete_metadata(self, scope, name, key, session=None):\n \"\"\"\n Delete a key from the metadata column\n\n :param scope: the scope of did\n :param name: the name of the did\n :param key: the key to be deleted\n \"\"\"\n if not json_implemented(session=session):\n raise NotImplementedError\n\n try:\n row = session.query(models.DidMeta).filter_by(scope=scope, name=name).one()\n existing_meta = getattr(row, 'meta')\n # Oracle returns a string instead of a dict\n if session.bind.dialect.name in ['oracle', 'sqlite'] and existing_meta is not None:\n existing_meta = json_lib.loads(existing_meta)\n\n if key not in existing_meta:\n raise exception.KeyNotFound(key)\n\n existing_meta.pop(key, None)\n\n row.meta = None\n session.flush()\n\n # Oracle insert takes a string as input\n if session.bind.dialect.name in ['oracle', 'sqlite']:\n existing_meta = json_lib.dumps(existing_meta)\n\n row.meta = existing_meta\n except NoResultFound:\n raise exception.DataIdentifierNotFound(\"Key not found for data identifier '%(scope)s:%(name)s'\" % locals())\n\n @stream_session\n def list_dids(self, scope, filters, type='collection', ignore_case=False, limit=None,\n offset=None, long=False, recursive=False, session=None):\n # Currently for sqlite only add, get and delete is implemented.\n if not json_implemented(session=session):\n raise NotImplementedError\n\n query = session.query(models.DidMeta)\n if scope is not None:\n query = query.filter(models.DidMeta.scope == scope)\n filters.pop('name', None)\n for k, v in iteritems(filters):\n if session.bind.dialect.name == 'oracle':\n query = query.filter(text(\"json_exists(meta,'$.%s?(@==''%s'')')\" % (k, v)))\n else:\n query = query.filter(cast(models.DidMeta.meta[k], String) == type_coerce(v, JSON))\n\n if long:\n for row in query.yield_per(5):\n yield {\n 'scope': row.scope,\n 'name': row.name,\n 'did_type': 'Info not available in JSON Plugin',\n 'bytes': 'Info not available in JSON Plugin',\n 'length': 'Info not available in JSON Plugin'\n }\n else:\n for row in query.yield_per(5):\n yield row.name\n\n @read_session\n def manages_key(self, key, session=None):\n return json_implemented(session=session)\n\n def get_plugin_name(self):\n \"\"\"\n Returns Plugins Name.\n This can then be used when listing the metadata of did to only provide dids from this plugin.\n \"\"\"\n return self.plugin_name\n", "path": "lib/rucio/core/did_meta_plugins/json_meta.py"}]}
| 3,198 | 301 |
gh_patches_debug_6877
|
rasdani/github-patches
|
git_diff
|
apache__airflow-36241
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
AirbyteTriggerSyncOperator should kill job upon timeout
### Apache Airflow version
2.7.3
### What happened
When calling in not asyncronous way the AirbyteTriggerSyncOperator ([here](https://github.com/apache/airflow/blob/main/airflow/providers/airbyte/operators/airbyte.py#L79)) and timeout is reached [here](https://github.com/apache/airflow/blob/main/airflow/providers/airbyte/hooks/airbyte.py#L66) the job should be killed otherwise the airbyte will keep running,
is just a matter of calling the cancel job which is already there https://github.com/apache/airflow/blob/main/airflow/providers/airbyte/hooks/airbyte.py#L110C9-L110C9
### What you think should happen instead
I think that if the airbyte operator has not finished within the defined timeout then the airbyte should also stop. Otherwise the airbyte job may continue to operate and even finish (after the timeout). This way the airflow will have failed but airbyte will look successful, which is inconsistency among airflow and airbyte
### How to reproduce
Its very easy to reproduce by calling a connection with very small timeout
```
from airflow import DAG
from airflow.utils.dates import days_ago
from airflow.providers.airbyte.operators.airbyte import AirbyteTriggerSyncOperator
with DAG(dag_id='trigger_airbyte_job_example',
default_args={'owner': 'airflow'},
schedule_interval='@daily',
start_date=days_ago(1)
) as dag:
money_to_json = AirbyteTriggerSyncOperator(
task_id='airbyte_money_json_example',
airbyte_conn_id='airbyte_conn_example',
connection_id='1e3b5a72-7bfd-4808-a13c-204505490110', # change this to something that works
asynchronous=False, # important to have this to False
timeout=10, # something really small
wait_seconds=3
)
```
### Operating System
Debian GNU/Linux 11 (bullseye)
### Versions of Apache Airflow Providers
apache-airflow-providers-airbyte 3.4.0
### Deployment
Docker-Compose
### Deployment details
_No response_
### Anything else
_No response_
### Are you willing to submit PR?
- [ ] Yes I am willing to submit a PR!
### Code of Conduct
- [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md)
</issue>
<code>
[start of airflow/providers/airbyte/hooks/airbyte.py]
1 #
2 # Licensed to the Apache Software Foundation (ASF) under one
3 # or more contributor license agreements. See the NOTICE file
4 # distributed with this work for additional information
5 # regarding copyright ownership. The ASF licenses this file
6 # to you under the Apache License, Version 2.0 (the
7 # "License"); you may not use this file except in compliance
8 # with the License. You may obtain a copy of the License at
9 #
10 # http://www.apache.org/licenses/LICENSE-2.0
11 #
12 # Unless required by applicable law or agreed to in writing,
13 # software distributed under the License is distributed on an
14 # "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
15 # KIND, either express or implied. See the License for the
16 # specific language governing permissions and limitations
17 # under the License.
18 from __future__ import annotations
19
20 import time
21 from typing import Any
22
23 from airflow.exceptions import AirflowException
24 from airflow.providers.http.hooks.http import HttpHook
25
26
27 class AirbyteHook(HttpHook):
28 """
29 Hook for Airbyte API.
30
31 :param airbyte_conn_id: Optional. The name of the Airflow connection to get
32 connection information for Airbyte. Defaults to "airbyte_default".
33 :param api_version: Optional. Airbyte API version. Defaults to "v1".
34 """
35
36 conn_name_attr = "airbyte_conn_id"
37 default_conn_name = "airbyte_default"
38 conn_type = "airbyte"
39 hook_name = "Airbyte"
40
41 RUNNING = "running"
42 SUCCEEDED = "succeeded"
43 CANCELLED = "cancelled"
44 PENDING = "pending"
45 FAILED = "failed"
46 ERROR = "error"
47 INCOMPLETE = "incomplete"
48
49 def __init__(self, airbyte_conn_id: str = "airbyte_default", api_version: str = "v1") -> None:
50 super().__init__(http_conn_id=airbyte_conn_id)
51 self.api_version: str = api_version
52
53 def wait_for_job(self, job_id: str | int, wait_seconds: float = 3, timeout: float | None = 3600) -> None:
54 """
55 Poll a job to check if it finishes.
56
57 :param job_id: Required. Id of the Airbyte job
58 :param wait_seconds: Optional. Number of seconds between checks.
59 :param timeout: Optional. How many seconds wait for job to be ready.
60 Used only if ``asynchronous`` is False.
61 """
62 state = None
63 start = time.monotonic()
64 while True:
65 if timeout and start + timeout < time.monotonic():
66 raise AirflowException(f"Timeout: Airbyte job {job_id} is not ready after {timeout}s")
67 time.sleep(wait_seconds)
68 try:
69 job = self.get_job(job_id=(int(job_id)))
70 state = job.json()["job"]["status"]
71 except AirflowException as err:
72 self.log.info("Retrying. Airbyte API returned server error when waiting for job: %s", err)
73 continue
74
75 if state in (self.RUNNING, self.PENDING, self.INCOMPLETE):
76 continue
77 if state == self.SUCCEEDED:
78 break
79 if state == self.ERROR:
80 raise AirflowException(f"Job failed:\n{job}")
81 elif state == self.CANCELLED:
82 raise AirflowException(f"Job was cancelled:\n{job}")
83 else:
84 raise Exception(f"Encountered unexpected state `{state}` for job_id `{job_id}`")
85
86 def submit_sync_connection(self, connection_id: str) -> Any:
87 """
88 Submit a job to a Airbyte server.
89
90 :param connection_id: Required. The ConnectionId of the Airbyte Connection.
91 """
92 return self.run(
93 endpoint=f"api/{self.api_version}/connections/sync",
94 json={"connectionId": connection_id},
95 headers={"accept": "application/json"},
96 )
97
98 def get_job(self, job_id: int) -> Any:
99 """
100 Get the resource representation for a job in Airbyte.
101
102 :param job_id: Required. Id of the Airbyte job
103 """
104 return self.run(
105 endpoint=f"api/{self.api_version}/jobs/get",
106 json={"id": job_id},
107 headers={"accept": "application/json"},
108 )
109
110 def cancel_job(self, job_id: int) -> Any:
111 """
112 Cancel the job when task is cancelled.
113
114 :param job_id: Required. Id of the Airbyte job
115 """
116 return self.run(
117 endpoint=f"api/{self.api_version}/jobs/cancel",
118 json={"id": job_id},
119 headers={"accept": "application/json"},
120 )
121
122 def test_connection(self):
123 """Tests the Airbyte connection by hitting the health API."""
124 self.method = "GET"
125 try:
126 res = self.run(
127 endpoint=f"api/{self.api_version}/health",
128 headers={"accept": "application/json"},
129 extra_options={"check_response": False},
130 )
131
132 if res.status_code == 200:
133 return True, "Connection successfully tested"
134 else:
135 return False, res.text
136 except Exception as e:
137 return False, str(e)
138 finally:
139 self.method = "POST"
140
[end of airflow/providers/airbyte/hooks/airbyte.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/airflow/providers/airbyte/hooks/airbyte.py b/airflow/providers/airbyte/hooks/airbyte.py
--- a/airflow/providers/airbyte/hooks/airbyte.py
+++ b/airflow/providers/airbyte/hooks/airbyte.py
@@ -63,6 +63,7 @@
start = time.monotonic()
while True:
if timeout and start + timeout < time.monotonic():
+ self.cancel_job(job_id=(int(job_id)))
raise AirflowException(f"Timeout: Airbyte job {job_id} is not ready after {timeout}s")
time.sleep(wait_seconds)
try:
|
{"golden_diff": "diff --git a/airflow/providers/airbyte/hooks/airbyte.py b/airflow/providers/airbyte/hooks/airbyte.py\n--- a/airflow/providers/airbyte/hooks/airbyte.py\n+++ b/airflow/providers/airbyte/hooks/airbyte.py\n@@ -63,6 +63,7 @@\n start = time.monotonic()\n while True:\n if timeout and start + timeout < time.monotonic():\n+ self.cancel_job(job_id=(int(job_id)))\n raise AirflowException(f\"Timeout: Airbyte job {job_id} is not ready after {timeout}s\")\n time.sleep(wait_seconds)\n try:\n", "issue": "AirbyteTriggerSyncOperator should kill job upon timeout \n### Apache Airflow version\n\n2.7.3\n\n### What happened\n\nWhen calling in not asyncronous way the AirbyteTriggerSyncOperator ([here](https://github.com/apache/airflow/blob/main/airflow/providers/airbyte/operators/airbyte.py#L79)) and timeout is reached [here](https://github.com/apache/airflow/blob/main/airflow/providers/airbyte/hooks/airbyte.py#L66) the job should be killed otherwise the airbyte will keep running,\r\n\r\nis just a matter of calling the cancel job which is already there https://github.com/apache/airflow/blob/main/airflow/providers/airbyte/hooks/airbyte.py#L110C9-L110C9\r\n\n\n### What you think should happen instead\n\nI think that if the airbyte operator has not finished within the defined timeout then the airbyte should also stop. Otherwise the airbyte job may continue to operate and even finish (after the timeout). This way the airflow will have failed but airbyte will look successful, which is inconsistency among airflow and airbyte\n\n### How to reproduce\n\nIts very easy to reproduce by calling a connection with very small timeout\r\n\r\n```\r\nfrom airflow import DAG\r\nfrom airflow.utils.dates import days_ago\r\nfrom airflow.providers.airbyte.operators.airbyte import AirbyteTriggerSyncOperator\r\n\r\nwith DAG(dag_id='trigger_airbyte_job_example',\r\n default_args={'owner': 'airflow'},\r\n schedule_interval='@daily',\r\n start_date=days_ago(1)\r\n ) as dag:\r\n\r\n money_to_json = AirbyteTriggerSyncOperator(\r\n task_id='airbyte_money_json_example',\r\n airbyte_conn_id='airbyte_conn_example',\r\n connection_id='1e3b5a72-7bfd-4808-a13c-204505490110', # change this to something that works\r\n asynchronous=False, # important to have this to False\r\n timeout=10, # something really small\r\n wait_seconds=3\r\n )\r\n```\n\n### Operating System\n\nDebian GNU/Linux 11 (bullseye)\n\n### Versions of Apache Airflow Providers\n\napache-airflow-providers-airbyte 3.4.0\n\n### Deployment\n\nDocker-Compose\n\n### Deployment details\n\n_No response_\n\n### Anything else\n\n_No response_\n\n### Are you willing to submit PR?\n\n- [ ] Yes I am willing to submit a PR!\n\n### Code of Conduct\n\n- [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md)\n\n", "before_files": [{"content": "#\n# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\nfrom __future__ import annotations\n\nimport time\nfrom typing import Any\n\nfrom airflow.exceptions import AirflowException\nfrom airflow.providers.http.hooks.http import HttpHook\n\n\nclass AirbyteHook(HttpHook):\n \"\"\"\n Hook for Airbyte API.\n\n :param airbyte_conn_id: Optional. The name of the Airflow connection to get\n connection information for Airbyte. Defaults to \"airbyte_default\".\n :param api_version: Optional. Airbyte API version. Defaults to \"v1\".\n \"\"\"\n\n conn_name_attr = \"airbyte_conn_id\"\n default_conn_name = \"airbyte_default\"\n conn_type = \"airbyte\"\n hook_name = \"Airbyte\"\n\n RUNNING = \"running\"\n SUCCEEDED = \"succeeded\"\n CANCELLED = \"cancelled\"\n PENDING = \"pending\"\n FAILED = \"failed\"\n ERROR = \"error\"\n INCOMPLETE = \"incomplete\"\n\n def __init__(self, airbyte_conn_id: str = \"airbyte_default\", api_version: str = \"v1\") -> None:\n super().__init__(http_conn_id=airbyte_conn_id)\n self.api_version: str = api_version\n\n def wait_for_job(self, job_id: str | int, wait_seconds: float = 3, timeout: float | None = 3600) -> None:\n \"\"\"\n Poll a job to check if it finishes.\n\n :param job_id: Required. Id of the Airbyte job\n :param wait_seconds: Optional. Number of seconds between checks.\n :param timeout: Optional. How many seconds wait for job to be ready.\n Used only if ``asynchronous`` is False.\n \"\"\"\n state = None\n start = time.monotonic()\n while True:\n if timeout and start + timeout < time.monotonic():\n raise AirflowException(f\"Timeout: Airbyte job {job_id} is not ready after {timeout}s\")\n time.sleep(wait_seconds)\n try:\n job = self.get_job(job_id=(int(job_id)))\n state = job.json()[\"job\"][\"status\"]\n except AirflowException as err:\n self.log.info(\"Retrying. Airbyte API returned server error when waiting for job: %s\", err)\n continue\n\n if state in (self.RUNNING, self.PENDING, self.INCOMPLETE):\n continue\n if state == self.SUCCEEDED:\n break\n if state == self.ERROR:\n raise AirflowException(f\"Job failed:\\n{job}\")\n elif state == self.CANCELLED:\n raise AirflowException(f\"Job was cancelled:\\n{job}\")\n else:\n raise Exception(f\"Encountered unexpected state `{state}` for job_id `{job_id}`\")\n\n def submit_sync_connection(self, connection_id: str) -> Any:\n \"\"\"\n Submit a job to a Airbyte server.\n\n :param connection_id: Required. The ConnectionId of the Airbyte Connection.\n \"\"\"\n return self.run(\n endpoint=f\"api/{self.api_version}/connections/sync\",\n json={\"connectionId\": connection_id},\n headers={\"accept\": \"application/json\"},\n )\n\n def get_job(self, job_id: int) -> Any:\n \"\"\"\n Get the resource representation for a job in Airbyte.\n\n :param job_id: Required. Id of the Airbyte job\n \"\"\"\n return self.run(\n endpoint=f\"api/{self.api_version}/jobs/get\",\n json={\"id\": job_id},\n headers={\"accept\": \"application/json\"},\n )\n\n def cancel_job(self, job_id: int) -> Any:\n \"\"\"\n Cancel the job when task is cancelled.\n\n :param job_id: Required. Id of the Airbyte job\n \"\"\"\n return self.run(\n endpoint=f\"api/{self.api_version}/jobs/cancel\",\n json={\"id\": job_id},\n headers={\"accept\": \"application/json\"},\n )\n\n def test_connection(self):\n \"\"\"Tests the Airbyte connection by hitting the health API.\"\"\"\n self.method = \"GET\"\n try:\n res = self.run(\n endpoint=f\"api/{self.api_version}/health\",\n headers={\"accept\": \"application/json\"},\n extra_options={\"check_response\": False},\n )\n\n if res.status_code == 200:\n return True, \"Connection successfully tested\"\n else:\n return False, res.text\n except Exception as e:\n return False, str(e)\n finally:\n self.method = \"POST\"\n", "path": "airflow/providers/airbyte/hooks/airbyte.py"}]}
| 2,557 | 142 |
gh_patches_debug_30483
|
rasdani/github-patches
|
git_diff
|
tobymao__sqlglot-975
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ClickHouse WITH statement
According to ClickHouse [docs](https://clickhouse.com/docs/en/sql-reference/statements/select/with/), `WITH` statement looks like `WITH <expression> AS <identifier>`. `sqlglot` expects that identifier precedes expression. So if I'll try to parse SQL like:
```sql
WITH '2019-08-01 15:23:00' as ts_upper_bound
SELECT *
FROM hits
WHERE
EventDate = toDate(ts_upper_bound) AND
EventTime <= ts_upper_bound
```
I have exception:
```python
sqlglot.errors.ParseError: Expected CTE to have alias. Line 2, Col: 6.
```
One more problem is SQL generation. If I try to generate something like:
```sql
WITH trim(' A ') AS val SELECT val
```
I expect to write something like:
```python
select("val").with_("val", as_="trim(' a ')").sql(dialect=Dialects.CLICKHOUSE)
```
but receive this SQL, which is invalid in ClickHouse:
```sql
WITH val AS (TRIM(' a ')) SELECT val
```
If I switch arguments of `with_` method, I'll almost achieve expected:
```python
select("val").with_(parse_one("trim(' a ')"), as_="val", dialect=Dialects.CLICKHOUSE).sql(dialect=Dialects.CLICKHOUSE)
```
But resulting SQL is also invalid due to parentheses around `val`:
```sql
WITH TRIM(' a ') AS (val) SELECT val
```
I guess ClickHouse dialect should have specified behaviour for `expressions.CTE` parsing/generation.
</issue>
<code>
[start of sqlglot/dialects/clickhouse.py]
1 from __future__ import annotations
2
3 import typing as t
4
5 from sqlglot import exp, generator, parser, tokens
6 from sqlglot.dialects.dialect import Dialect, inline_array_sql, var_map_sql
7 from sqlglot.parser import parse_var_map
8 from sqlglot.tokens import TokenType
9
10
11 def _lower_func(sql):
12 index = sql.index("(")
13 return sql[:index].lower() + sql[index:]
14
15
16 class ClickHouse(Dialect):
17 normalize_functions = None
18 null_ordering = "nulls_are_last"
19
20 class Tokenizer(tokens.Tokenizer):
21 COMMENTS = ["--", "#", "#!", ("/*", "*/")]
22 IDENTIFIERS = ['"', "`"]
23
24 KEYWORDS = {
25 **tokens.Tokenizer.KEYWORDS,
26 "ASOF": TokenType.ASOF,
27 "GLOBAL": TokenType.GLOBAL,
28 "DATETIME64": TokenType.DATETIME,
29 "FINAL": TokenType.FINAL,
30 "FLOAT32": TokenType.FLOAT,
31 "FLOAT64": TokenType.DOUBLE,
32 "INT16": TokenType.SMALLINT,
33 "INT32": TokenType.INT,
34 "INT64": TokenType.BIGINT,
35 "INT8": TokenType.TINYINT,
36 "TUPLE": TokenType.STRUCT,
37 }
38
39 class Parser(parser.Parser):
40 FUNCTIONS = {
41 **parser.Parser.FUNCTIONS, # type: ignore
42 "MAP": parse_var_map,
43 "QUANTILE": lambda params, args: exp.Quantile(this=args, quantile=params),
44 "QUANTILES": lambda params, args: exp.Quantiles(parameters=params, expressions=args),
45 "QUANTILEIF": lambda params, args: exp.QuantileIf(parameters=params, expressions=args),
46 }
47
48 RANGE_PARSERS = {
49 **parser.Parser.RANGE_PARSERS,
50 TokenType.GLOBAL: lambda self, this: self._match(TokenType.IN)
51 and self._parse_in(this, is_global=True),
52 }
53
54 JOIN_KINDS = {*parser.Parser.JOIN_KINDS, TokenType.ANY, TokenType.ASOF} # type: ignore
55
56 TABLE_ALIAS_TOKENS = {*parser.Parser.TABLE_ALIAS_TOKENS} - {TokenType.ANY} # type: ignore
57
58 def _parse_in(
59 self, this: t.Optional[exp.Expression], is_global: bool = False
60 ) -> exp.Expression:
61 this = super()._parse_in(this)
62 this.set("is_global", is_global)
63 return this
64
65 def _parse_table(
66 self, schema: bool = False, alias_tokens: t.Optional[t.Collection[TokenType]] = None
67 ) -> t.Optional[exp.Expression]:
68 this = super()._parse_table(schema=schema, alias_tokens=alias_tokens)
69
70 if self._match(TokenType.FINAL):
71 this = self.expression(exp.Final, this=this)
72
73 return this
74
75 def _parse_position(self) -> exp.Expression:
76 this = super()._parse_position()
77 # clickhouse position args are swapped
78 substr = this.this
79 this.args["this"] = this.args.get("substr")
80 this.args["substr"] = substr
81 return this
82
83 class Generator(generator.Generator):
84 STRUCT_DELIMITER = ("(", ")")
85
86 TYPE_MAPPING = {
87 **generator.Generator.TYPE_MAPPING, # type: ignore
88 exp.DataType.Type.NULLABLE: "Nullable",
89 exp.DataType.Type.DATETIME: "DateTime64",
90 exp.DataType.Type.MAP: "Map",
91 exp.DataType.Type.ARRAY: "Array",
92 exp.DataType.Type.STRUCT: "Tuple",
93 exp.DataType.Type.TINYINT: "Int8",
94 exp.DataType.Type.SMALLINT: "Int16",
95 exp.DataType.Type.INT: "Int32",
96 exp.DataType.Type.BIGINT: "Int64",
97 exp.DataType.Type.FLOAT: "Float32",
98 exp.DataType.Type.DOUBLE: "Float64",
99 }
100
101 TRANSFORMS = {
102 **generator.Generator.TRANSFORMS, # type: ignore
103 exp.Array: inline_array_sql,
104 exp.StrPosition: lambda self, e: f"position({self.format_args(e.this, e.args.get('substr'), e.args.get('position'))})",
105 exp.Final: lambda self, e: f"{self.sql(e, 'this')} FINAL",
106 exp.Map: lambda self, e: _lower_func(var_map_sql(self, e)),
107 exp.VarMap: lambda self, e: _lower_func(var_map_sql(self, e)),
108 exp.Quantile: lambda self, e: f"quantile{self._param_args_sql(e, 'quantile', 'this')}",
109 exp.Quantiles: lambda self, e: f"quantiles{self._param_args_sql(e, 'parameters', 'expressions')}",
110 exp.QuantileIf: lambda self, e: f"quantileIf{self._param_args_sql(e, 'parameters', 'expressions')}",
111 }
112
113 EXPLICIT_UNION = True
114
115 def _param_args_sql(
116 self, expression: exp.Expression, params_name: str, args_name: str
117 ) -> str:
118 params = self.format_args(self.expressions(expression, params_name))
119 args = self.format_args(self.expressions(expression, args_name))
120 return f"({params})({args})"
121
[end of sqlglot/dialects/clickhouse.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sqlglot/dialects/clickhouse.py b/sqlglot/dialects/clickhouse.py
--- a/sqlglot/dialects/clickhouse.py
+++ b/sqlglot/dialects/clickhouse.py
@@ -4,6 +4,7 @@
from sqlglot import exp, generator, parser, tokens
from sqlglot.dialects.dialect import Dialect, inline_array_sql, var_map_sql
+from sqlglot.errors import ParseError
from sqlglot.parser import parse_var_map
from sqlglot.tokens import TokenType
@@ -80,6 +81,22 @@
this.args["substr"] = substr
return this
+ # https://clickhouse.com/docs/en/sql-reference/statements/select/with/
+ def _parse_cte(self) -> exp.Expression:
+ index = self._index
+ try:
+ # WITH <identifier> AS <subquery expression>
+ return super()._parse_cte()
+ except ParseError:
+ # WITH <expression> AS <identifier>
+ self._retreat(index)
+ statement = self._parse_statement()
+
+ if statement and isinstance(statement.this, exp.Alias):
+ self.raise_error("Expected CTE to have alias")
+
+ return self.expression(exp.CTE, this=statement, alias=statement and statement.this)
+
class Generator(generator.Generator):
STRUCT_DELIMITER = ("(", ")")
@@ -118,3 +135,9 @@
params = self.format_args(self.expressions(expression, params_name))
args = self.format_args(self.expressions(expression, args_name))
return f"({params})({args})"
+
+ def cte_sql(self, expression: exp.CTE) -> str:
+ if isinstance(expression.this, exp.Alias):
+ return self.sql(expression, "this")
+
+ return super().cte_sql(expression)
|
{"golden_diff": "diff --git a/sqlglot/dialects/clickhouse.py b/sqlglot/dialects/clickhouse.py\n--- a/sqlglot/dialects/clickhouse.py\n+++ b/sqlglot/dialects/clickhouse.py\n@@ -4,6 +4,7 @@\n \n from sqlglot import exp, generator, parser, tokens\n from sqlglot.dialects.dialect import Dialect, inline_array_sql, var_map_sql\n+from sqlglot.errors import ParseError\n from sqlglot.parser import parse_var_map\n from sqlglot.tokens import TokenType\n \n@@ -80,6 +81,22 @@\n this.args[\"substr\"] = substr\n return this\n \n+ # https://clickhouse.com/docs/en/sql-reference/statements/select/with/\n+ def _parse_cte(self) -> exp.Expression:\n+ index = self._index\n+ try:\n+ # WITH <identifier> AS <subquery expression>\n+ return super()._parse_cte()\n+ except ParseError:\n+ # WITH <expression> AS <identifier>\n+ self._retreat(index)\n+ statement = self._parse_statement()\n+\n+ if statement and isinstance(statement.this, exp.Alias):\n+ self.raise_error(\"Expected CTE to have alias\")\n+\n+ return self.expression(exp.CTE, this=statement, alias=statement and statement.this)\n+\n class Generator(generator.Generator):\n STRUCT_DELIMITER = (\"(\", \")\")\n \n@@ -118,3 +135,9 @@\n params = self.format_args(self.expressions(expression, params_name))\n args = self.format_args(self.expressions(expression, args_name))\n return f\"({params})({args})\"\n+\n+ def cte_sql(self, expression: exp.CTE) -> str:\n+ if isinstance(expression.this, exp.Alias):\n+ return self.sql(expression, \"this\")\n+\n+ return super().cte_sql(expression)\n", "issue": "ClickHouse WITH statement\nAccording to ClickHouse [docs](https://clickhouse.com/docs/en/sql-reference/statements/select/with/), `WITH` statement looks like `WITH <expression> AS <identifier>`. `sqlglot` expects that identifier precedes expression. So if I'll try to parse SQL like:\r\n```sql\r\nWITH '2019-08-01 15:23:00' as ts_upper_bound\r\nSELECT *\r\nFROM hits\r\nWHERE\r\n EventDate = toDate(ts_upper_bound) AND\r\n EventTime <= ts_upper_bound\r\n```\r\nI have exception:\r\n```python\r\nsqlglot.errors.ParseError: Expected CTE to have alias. Line 2, Col: 6.\r\n```\r\nOne more problem is SQL generation. If I try to generate something like:\r\n```sql\r\nWITH trim(' A ') AS val SELECT val\r\n```\r\nI expect to write something like:\r\n```python\r\nselect(\"val\").with_(\"val\", as_=\"trim(' a ')\").sql(dialect=Dialects.CLICKHOUSE)\r\n```\r\nbut receive this SQL, which is invalid in ClickHouse:\r\n```sql\r\nWITH val AS (TRIM(' a ')) SELECT val\r\n```\r\nIf I switch arguments of `with_` method, I'll almost achieve expected:\r\n```python\r\nselect(\"val\").with_(parse_one(\"trim(' a ')\"), as_=\"val\", dialect=Dialects.CLICKHOUSE).sql(dialect=Dialects.CLICKHOUSE)\r\n```\r\nBut resulting SQL is also invalid due to parentheses around `val`:\r\n```sql\r\nWITH TRIM(' a ') AS (val) SELECT val\r\n```\r\nI guess ClickHouse dialect should have specified behaviour for `expressions.CTE` parsing/generation.\n", "before_files": [{"content": "from __future__ import annotations\n\nimport typing as t\n\nfrom sqlglot import exp, generator, parser, tokens\nfrom sqlglot.dialects.dialect import Dialect, inline_array_sql, var_map_sql\nfrom sqlglot.parser import parse_var_map\nfrom sqlglot.tokens import TokenType\n\n\ndef _lower_func(sql):\n index = sql.index(\"(\")\n return sql[:index].lower() + sql[index:]\n\n\nclass ClickHouse(Dialect):\n normalize_functions = None\n null_ordering = \"nulls_are_last\"\n\n class Tokenizer(tokens.Tokenizer):\n COMMENTS = [\"--\", \"#\", \"#!\", (\"/*\", \"*/\")]\n IDENTIFIERS = ['\"', \"`\"]\n\n KEYWORDS = {\n **tokens.Tokenizer.KEYWORDS,\n \"ASOF\": TokenType.ASOF,\n \"GLOBAL\": TokenType.GLOBAL,\n \"DATETIME64\": TokenType.DATETIME,\n \"FINAL\": TokenType.FINAL,\n \"FLOAT32\": TokenType.FLOAT,\n \"FLOAT64\": TokenType.DOUBLE,\n \"INT16\": TokenType.SMALLINT,\n \"INT32\": TokenType.INT,\n \"INT64\": TokenType.BIGINT,\n \"INT8\": TokenType.TINYINT,\n \"TUPLE\": TokenType.STRUCT,\n }\n\n class Parser(parser.Parser):\n FUNCTIONS = {\n **parser.Parser.FUNCTIONS, # type: ignore\n \"MAP\": parse_var_map,\n \"QUANTILE\": lambda params, args: exp.Quantile(this=args, quantile=params),\n \"QUANTILES\": lambda params, args: exp.Quantiles(parameters=params, expressions=args),\n \"QUANTILEIF\": lambda params, args: exp.QuantileIf(parameters=params, expressions=args),\n }\n\n RANGE_PARSERS = {\n **parser.Parser.RANGE_PARSERS,\n TokenType.GLOBAL: lambda self, this: self._match(TokenType.IN)\n and self._parse_in(this, is_global=True),\n }\n\n JOIN_KINDS = {*parser.Parser.JOIN_KINDS, TokenType.ANY, TokenType.ASOF} # type: ignore\n\n TABLE_ALIAS_TOKENS = {*parser.Parser.TABLE_ALIAS_TOKENS} - {TokenType.ANY} # type: ignore\n\n def _parse_in(\n self, this: t.Optional[exp.Expression], is_global: bool = False\n ) -> exp.Expression:\n this = super()._parse_in(this)\n this.set(\"is_global\", is_global)\n return this\n\n def _parse_table(\n self, schema: bool = False, alias_tokens: t.Optional[t.Collection[TokenType]] = None\n ) -> t.Optional[exp.Expression]:\n this = super()._parse_table(schema=schema, alias_tokens=alias_tokens)\n\n if self._match(TokenType.FINAL):\n this = self.expression(exp.Final, this=this)\n\n return this\n\n def _parse_position(self) -> exp.Expression:\n this = super()._parse_position()\n # clickhouse position args are swapped\n substr = this.this\n this.args[\"this\"] = this.args.get(\"substr\")\n this.args[\"substr\"] = substr\n return this\n\n class Generator(generator.Generator):\n STRUCT_DELIMITER = (\"(\", \")\")\n\n TYPE_MAPPING = {\n **generator.Generator.TYPE_MAPPING, # type: ignore\n exp.DataType.Type.NULLABLE: \"Nullable\",\n exp.DataType.Type.DATETIME: \"DateTime64\",\n exp.DataType.Type.MAP: \"Map\",\n exp.DataType.Type.ARRAY: \"Array\",\n exp.DataType.Type.STRUCT: \"Tuple\",\n exp.DataType.Type.TINYINT: \"Int8\",\n exp.DataType.Type.SMALLINT: \"Int16\",\n exp.DataType.Type.INT: \"Int32\",\n exp.DataType.Type.BIGINT: \"Int64\",\n exp.DataType.Type.FLOAT: \"Float32\",\n exp.DataType.Type.DOUBLE: \"Float64\",\n }\n\n TRANSFORMS = {\n **generator.Generator.TRANSFORMS, # type: ignore\n exp.Array: inline_array_sql,\n exp.StrPosition: lambda self, e: f\"position({self.format_args(e.this, e.args.get('substr'), e.args.get('position'))})\",\n exp.Final: lambda self, e: f\"{self.sql(e, 'this')} FINAL\",\n exp.Map: lambda self, e: _lower_func(var_map_sql(self, e)),\n exp.VarMap: lambda self, e: _lower_func(var_map_sql(self, e)),\n exp.Quantile: lambda self, e: f\"quantile{self._param_args_sql(e, 'quantile', 'this')}\",\n exp.Quantiles: lambda self, e: f\"quantiles{self._param_args_sql(e, 'parameters', 'expressions')}\",\n exp.QuantileIf: lambda self, e: f\"quantileIf{self._param_args_sql(e, 'parameters', 'expressions')}\",\n }\n\n EXPLICIT_UNION = True\n\n def _param_args_sql(\n self, expression: exp.Expression, params_name: str, args_name: str\n ) -> str:\n params = self.format_args(self.expressions(expression, params_name))\n args = self.format_args(self.expressions(expression, args_name))\n return f\"({params})({args})\"\n", "path": "sqlglot/dialects/clickhouse.py"}]}
| 2,317 | 418 |
gh_patches_debug_15643
|
rasdani/github-patches
|
git_diff
|
platformsh__platformsh-docs-1859
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Poor search results
If I search on https://docs.platform.sh for "routes", I get the following results:
* https://docs.platform.sh/administration/web/configure-environment.html#routes
* https://docs.platform.sh/gettingstarted/introduction/own-code/routes-configuration.html
* https://docs.platform.sh/configuration/app/upgrading.html#platformroutesyaml
* https://docs.platform.sh/guides/gatsby/headless/drupal.html#platformroutesyaml
* https://docs.platform.sh/guides/gatsby/headless/strapi.html#platformroutesyaml
* https://docs.platform.sh/guides/gatsby/headless/wordpress.html#platformroutesyaml
* https://docs.platform.sh/guides/drupal9/deploy/configure.html#requests-configuration-routesyaml
Note the absence of the main resource on this topic: https://docs.platform.sh/configuration/routes.html
I've also tried "routes.yaml" and "configure routes" neither of which return the main routing configuration page.
The same issue appears to afflict these pages as well which seem near-impossible to locate by search:
* https://docs.platform.sh/configuration/services.html
* https://docs.platform.sh/configuration/app.html
Doing a bit of digging if I make the same search query with 1000 results limit the routes URL does not show up in the results, so perhaps it's not being indexed.
</issue>
<code>
[start of search/main.py]
1 import os
2 import glob
3 import json
4 import meilisearch
5 from platformshconfig import Config
6
7 class Search:
8 def __init__(self):
9 self.default = {
10 "host": "http://127.0.0.1",
11 "key": None,
12 "port": 7700
13 }
14
15 self.scrape_dir = "output"
16 self.scrape_config = "config/scrape.json"
17 self.docs_index = "docs"
18 self.primaryKey = "documentId"
19 self.index_name = "Docs"
20
21 # Below are Platform.sh custom settings for how the search engine functions.
22
23 # Data available to the dropdown React app in docs, used to fill out autocomplete results.
24 self.displayed_attributes = ['title', 'text', 'url', 'site', 'section']
25 # Data actually searchable by our queries.
26 self.searchable_attributes = ['title', 'text', 'section']
27
28 # Show results for one query with the listed pages, when they by default would not show up as best results. Note: these
29 # are not automatically two-way, so that's why they all appear to be defined twice.
30 self.synonyms = {
31 "routes.yaml": ["routes"],
32 "routes": ["routes.yaml"],
33 "services": ["services.yaml"],
34 "services.yaml": ["services"],
35 "application": [".platform.app.yaml", "app.yaml", "applications.yaml"],
36 ".platform.app.yaml": ["application"],
37 "app.yaml": ["application"],
38 "applications.yaml": ["application", "multi-app"],
39 "multi-app": ["applications.yaml"],
40 "regions": ["public ip addresses"],
41 "public ip addresses": ["regions"],
42 "ssl": ["https", "tls"],
43 "https": ["ssl"],
44 }
45
46 # Ranking rules:
47 #
48 # - Default order: ["typo", "words", "proximity", "attribute", "wordsPosition", "exactness"]
49 #
50 # - typo: fewer typos > more typos
51 # - words: number of times query is in document (greater number gets priority)
52 # - proximity: smaller distance between multiple occurences of query in same document > larger distances
53 # - attribute: sorted according to order of importance of attributes (searchable_attributes). terms in
54 # more important attributes first.
55 # - wordsPosition: query terms earlier in document > later in document
56 # - exactness: similarity of matched words in document with query
57
58 self.ranking_rules = ["asc(rank)", "attribute", "typo", "words", "proximity", "wordsPosition", "exactness"]
59
60 self.updated_settings = {
61 "rankingRules": self.ranking_rules,
62 "searchableAttributes": self.searchable_attributes,
63 "displayedAttributes": self.displayed_attributes
64 }
65
66 self.distinct_attribute = "url"
67
68 def getConnectionString(self):
69 """
70 Sets the Meilisearch host string, depending on the environment.
71
72 Returns:
73 string: Meilisearch host string.
74 """
75 if os.environ.get('PORT'):
76 return "{}:{}".format(self.default["host"], os.environ['PORT'])
77 else:
78 return "{}:{}".format(self.default["host"], self.default["port"])
79
80 def getMasterKey(self):
81 """
82 Retrieves the Meilisearch master key, either from the Platform.sh environment or locally.
83 """
84 config = Config()
85 if config.is_valid_platform():
86 return config.projectEntropy
87 elif os.environ.get("MEILI_MASTER_KEY"):
88 return os.environ["MEILI_MASTER_KEY"]
89 else:
90 return self.default["key"]
91
92 def add_documents(self, index):
93 """
94 Cycle through the individual site indexes in /outputs so their individual documents can be added to Meilisearch.
95 """
96 documents = [f for f in glob.glob("{}/*.json".format(self.scrape_dir))]
97 for doc in documents:
98 self.add(doc, index)
99
100 def add(self, doc, index):
101 """
102 Add an individual site's index to the Meilisearch service.
103 """
104 with open(doc) as scraped_index:
105 data = json.load(scraped_index)
106 index.add_documents(data)
107
108 def update(self):
109 """
110 Updates the Meilisearch index.
111 """
112 # Create a Meilisearch client.
113 client = meilisearch.Client(self.getConnectionString(), self.getMasterKey())
114
115 # Delete previous index
116 if len(client.get_indexes()):
117 client.get_index(self.docs_index).delete()
118
119 # Create a new index
120 index = client.create_index(uid=self.docs_index, options={'primaryKey': self.primaryKey, 'name': self.index_name})
121
122 # Add synonyms for the index
123 index.update_synonyms(self.synonyms)
124
125 # Update its settings: what can be searched, what's displayable, and how results should be ranked.
126 index.update_settings(self.updated_settings)
127
128 # Update distinct attribute.
129 index.update_distinct_attribute(self.distinct_attribute)
130
131 # Add documents to the index
132 self.add_documents(index)
133
134 if __name__ == "__main__":
135 meili = Search()
136 meili.update()
137
[end of search/main.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/search/main.py b/search/main.py
--- a/search/main.py
+++ b/search/main.py
@@ -23,7 +23,7 @@
# Data available to the dropdown React app in docs, used to fill out autocomplete results.
self.displayed_attributes = ['title', 'text', 'url', 'site', 'section']
# Data actually searchable by our queries.
- self.searchable_attributes = ['title', 'text', 'section']
+ self.searchable_attributes = ['title', 'text', 'url', 'section']
# Show results for one query with the listed pages, when they by default would not show up as best results. Note: these
# are not automatically two-way, so that's why they all appear to be defined twice.
|
{"golden_diff": "diff --git a/search/main.py b/search/main.py\n--- a/search/main.py\n+++ b/search/main.py\n@@ -23,7 +23,7 @@\n # Data available to the dropdown React app in docs, used to fill out autocomplete results.\n self.displayed_attributes = ['title', 'text', 'url', 'site', 'section']\n # Data actually searchable by our queries.\n- self.searchable_attributes = ['title', 'text', 'section']\n+ self.searchable_attributes = ['title', 'text', 'url', 'section']\n \n # Show results for one query with the listed pages, when they by default would not show up as best results. Note: these\n # are not automatically two-way, so that's why they all appear to be defined twice.\n", "issue": "Poor search results\nIf I search on https://docs.platform.sh for \"routes\", I get the following results:\r\n\r\n* https://docs.platform.sh/administration/web/configure-environment.html#routes\r\n* https://docs.platform.sh/gettingstarted/introduction/own-code/routes-configuration.html\r\n* https://docs.platform.sh/configuration/app/upgrading.html#platformroutesyaml\r\n* https://docs.platform.sh/guides/gatsby/headless/drupal.html#platformroutesyaml\r\n* https://docs.platform.sh/guides/gatsby/headless/strapi.html#platformroutesyaml\r\n* https://docs.platform.sh/guides/gatsby/headless/wordpress.html#platformroutesyaml\r\n* https://docs.platform.sh/guides/drupal9/deploy/configure.html#requests-configuration-routesyaml\r\n\r\nNote the absence of the main resource on this topic: https://docs.platform.sh/configuration/routes.html\r\n\r\nI've also tried \"routes.yaml\" and \"configure routes\" neither of which return the main routing configuration page.\r\n\r\nThe same issue appears to afflict these pages as well which seem near-impossible to locate by search:\r\n* https://docs.platform.sh/configuration/services.html\r\n* https://docs.platform.sh/configuration/app.html\r\n\r\nDoing a bit of digging if I make the same search query with 1000 results limit the routes URL does not show up in the results, so perhaps it's not being indexed.\n", "before_files": [{"content": "import os\nimport glob\nimport json\nimport meilisearch\nfrom platformshconfig import Config\n\nclass Search:\n def __init__(self):\n self.default = {\n \"host\": \"http://127.0.0.1\",\n \"key\": None,\n \"port\": 7700\n }\n\n self.scrape_dir = \"output\"\n self.scrape_config = \"config/scrape.json\"\n self.docs_index = \"docs\"\n self.primaryKey = \"documentId\"\n self.index_name = \"Docs\"\n\n # Below are Platform.sh custom settings for how the search engine functions.\n\n # Data available to the dropdown React app in docs, used to fill out autocomplete results.\n self.displayed_attributes = ['title', 'text', 'url', 'site', 'section']\n # Data actually searchable by our queries.\n self.searchable_attributes = ['title', 'text', 'section']\n\n # Show results for one query with the listed pages, when they by default would not show up as best results. Note: these\n # are not automatically two-way, so that's why they all appear to be defined twice.\n self.synonyms = {\n \"routes.yaml\": [\"routes\"],\n \"routes\": [\"routes.yaml\"],\n \"services\": [\"services.yaml\"],\n \"services.yaml\": [\"services\"],\n \"application\": [\".platform.app.yaml\", \"app.yaml\", \"applications.yaml\"],\n \".platform.app.yaml\": [\"application\"],\n \"app.yaml\": [\"application\"],\n \"applications.yaml\": [\"application\", \"multi-app\"],\n \"multi-app\": [\"applications.yaml\"],\n \"regions\": [\"public ip addresses\"],\n \"public ip addresses\": [\"regions\"],\n \"ssl\": [\"https\", \"tls\"],\n \"https\": [\"ssl\"],\n }\n\n # Ranking rules:\n #\n # - Default order: [\"typo\", \"words\", \"proximity\", \"attribute\", \"wordsPosition\", \"exactness\"]\n #\n # - typo: fewer typos > more typos\n # - words: number of times query is in document (greater number gets priority)\n # - proximity: smaller distance between multiple occurences of query in same document > larger distances\n # - attribute: sorted according to order of importance of attributes (searchable_attributes). terms in\n # more important attributes first.\n # - wordsPosition: query terms earlier in document > later in document\n # - exactness: similarity of matched words in document with query\n\n self.ranking_rules = [\"asc(rank)\", \"attribute\", \"typo\", \"words\", \"proximity\", \"wordsPosition\", \"exactness\"]\n\n self.updated_settings = {\n \"rankingRules\": self.ranking_rules,\n \"searchableAttributes\": self.searchable_attributes,\n \"displayedAttributes\": self.displayed_attributes\n }\n\n self.distinct_attribute = \"url\"\n\n def getConnectionString(self):\n \"\"\"\n Sets the Meilisearch host string, depending on the environment.\n\n Returns:\n string: Meilisearch host string.\n \"\"\"\n if os.environ.get('PORT'):\n return \"{}:{}\".format(self.default[\"host\"], os.environ['PORT'])\n else:\n return \"{}:{}\".format(self.default[\"host\"], self.default[\"port\"])\n\n def getMasterKey(self):\n \"\"\"\n Retrieves the Meilisearch master key, either from the Platform.sh environment or locally.\n \"\"\"\n config = Config()\n if config.is_valid_platform():\n return config.projectEntropy\n elif os.environ.get(\"MEILI_MASTER_KEY\"):\n return os.environ[\"MEILI_MASTER_KEY\"]\n else:\n return self.default[\"key\"]\n\n def add_documents(self, index):\n \"\"\"\n Cycle through the individual site indexes in /outputs so their individual documents can be added to Meilisearch.\n \"\"\"\n documents = [f for f in glob.glob(\"{}/*.json\".format(self.scrape_dir))]\n for doc in documents:\n self.add(doc, index)\n\n def add(self, doc, index):\n \"\"\"\n Add an individual site's index to the Meilisearch service.\n \"\"\"\n with open(doc) as scraped_index:\n data = json.load(scraped_index)\n index.add_documents(data)\n\n def update(self):\n \"\"\"\n Updates the Meilisearch index.\n \"\"\"\n # Create a Meilisearch client.\n client = meilisearch.Client(self.getConnectionString(), self.getMasterKey())\n\n # Delete previous index\n if len(client.get_indexes()):\n client.get_index(self.docs_index).delete()\n\n # Create a new index\n index = client.create_index(uid=self.docs_index, options={'primaryKey': self.primaryKey, 'name': self.index_name})\n\n # Add synonyms for the index\n index.update_synonyms(self.synonyms)\n\n # Update its settings: what can be searched, what's displayable, and how results should be ranked.\n index.update_settings(self.updated_settings)\n\n # Update distinct attribute.\n index.update_distinct_attribute(self.distinct_attribute)\n\n # Add documents to the index\n self.add_documents(index)\n\nif __name__ == \"__main__\":\n meili = Search()\n meili.update()\n", "path": "search/main.py"}]}
| 2,235 | 169 |
gh_patches_debug_3310
|
rasdani/github-patches
|
git_diff
|
ansible-collections__community.general-6942
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
machinectl become plugin does not specify it requires a tty
### Summary
see https://github.com/ansible/ansible/issues/81254
if the plugin sets the class attribute:
```
require_tty = True
```
It would automatically disable pipelining and avoid such errors
### Issue Type
Bug Report
### Component Name
become/machinectl
### Ansible Version
```console (paste below)
$ ansible --version
```
all
### Community.general Version
```console (paste below)
$ ansible-galaxy collection list community.general
```
all
### Configuration
```console (paste below)
$ ansible-config dump --only-changed
```
N/A
### OS / Environment
N/A
### Steps to Reproduce
<!--- Paste example playbooks or commands between quotes below -->
```yaml (paste below)
```
Use machinectl become plugin + pipelining
### Expected Results
it works TM
### Actual Results
```console (paste below)
"msg": "MODULE FAILURE\nSee stdout/stderr for the exact error",
```
### Code of Conduct
- [X] I agree to follow the Ansible Code of Conduct
</issue>
<code>
[start of plugins/become/machinectl.py]
1 # -*- coding: utf-8 -*-
2 # Copyright (c) 2018, Ansible Project
3 # GNU General Public License v3.0+ (see LICENSES/GPL-3.0-or-later.txt or https://www.gnu.org/licenses/gpl-3.0.txt)
4 # SPDX-License-Identifier: GPL-3.0-or-later
5 from __future__ import (absolute_import, division, print_function)
6 __metaclass__ = type
7
8 DOCUMENTATION = '''
9 name: machinectl
10 short_description: Systemd's machinectl privilege escalation
11 description:
12 - This become plugins allows your remote/login user to execute commands as another user via the machinectl utility.
13 author: Ansible Core Team
14 options:
15 become_user:
16 description: User you 'become' to execute the task
17 default: ''
18 ini:
19 - section: privilege_escalation
20 key: become_user
21 - section: machinectl_become_plugin
22 key: user
23 vars:
24 - name: ansible_become_user
25 - name: ansible_machinectl_user
26 env:
27 - name: ANSIBLE_BECOME_USER
28 - name: ANSIBLE_MACHINECTL_USER
29 become_exe:
30 description: Machinectl executable
31 default: machinectl
32 ini:
33 - section: privilege_escalation
34 key: become_exe
35 - section: machinectl_become_plugin
36 key: executable
37 vars:
38 - name: ansible_become_exe
39 - name: ansible_machinectl_exe
40 env:
41 - name: ANSIBLE_BECOME_EXE
42 - name: ANSIBLE_MACHINECTL_EXE
43 become_flags:
44 description: Options to pass to machinectl
45 default: ''
46 ini:
47 - section: privilege_escalation
48 key: become_flags
49 - section: machinectl_become_plugin
50 key: flags
51 vars:
52 - name: ansible_become_flags
53 - name: ansible_machinectl_flags
54 env:
55 - name: ANSIBLE_BECOME_FLAGS
56 - name: ANSIBLE_MACHINECTL_FLAGS
57 become_pass:
58 description: Password for machinectl
59 required: false
60 vars:
61 - name: ansible_become_password
62 - name: ansible_become_pass
63 - name: ansible_machinectl_pass
64 env:
65 - name: ANSIBLE_BECOME_PASS
66 - name: ANSIBLE_MACHINECTL_PASS
67 ini:
68 - section: machinectl_become_plugin
69 key: password
70 notes:
71 - When not using this plugin with user V(root), it only works correctly with a polkit rule which will alter
72 the behaviour of machinectl. This rule must alter the prompt behaviour to ask directly for the user credentials,
73 if the user is allowed to perform the action (take a look at the examples section).
74 If such a rule is not present the plugin only work if it is used in context with the root user,
75 because then no further prompt will be shown by machinectl.
76 '''
77
78 EXAMPLES = r'''
79 # A polkit rule needed to use the module with a non-root user.
80 # See the Notes section for details.
81 60-machinectl-fast-user-auth.rules: |
82 polkit.addRule(function(action, subject) {
83 if(action.id == "org.freedesktop.machine1.host-shell" && subject.isInGroup("wheel")) {
84 return polkit.Result.AUTH_SELF_KEEP;
85 }
86 });
87 '''
88
89 from re import compile as re_compile
90
91 from ansible.plugins.become import BecomeBase
92 from ansible.module_utils._text import to_bytes
93
94
95 ansi_color_codes = re_compile(to_bytes(r'\x1B\[[0-9;]+m'))
96
97
98 class BecomeModule(BecomeBase):
99
100 name = 'community.general.machinectl'
101
102 prompt = 'Password: '
103 fail = ('==== AUTHENTICATION FAILED ====',)
104 success = ('==== AUTHENTICATION COMPLETE ====',)
105
106 @staticmethod
107 def remove_ansi_codes(line):
108 return ansi_color_codes.sub(b"", line)
109
110 def build_become_command(self, cmd, shell):
111 super(BecomeModule, self).build_become_command(cmd, shell)
112
113 if not cmd:
114 return cmd
115
116 become = self.get_option('become_exe')
117
118 flags = self.get_option('become_flags')
119 user = self.get_option('become_user')
120 return '%s -q shell %s %s@ %s' % (become, flags, user, self._build_success_command(cmd, shell))
121
122 def check_success(self, b_output):
123 b_output = self.remove_ansi_codes(b_output)
124 return super().check_success(b_output)
125
126 def check_incorrect_password(self, b_output):
127 b_output = self.remove_ansi_codes(b_output)
128 return super().check_incorrect_password(b_output)
129
130 def check_missing_password(self, b_output):
131 b_output = self.remove_ansi_codes(b_output)
132 return super().check_missing_password(b_output)
133
[end of plugins/become/machinectl.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/plugins/become/machinectl.py b/plugins/become/machinectl.py
--- a/plugins/become/machinectl.py
+++ b/plugins/become/machinectl.py
@@ -102,6 +102,7 @@
prompt = 'Password: '
fail = ('==== AUTHENTICATION FAILED ====',)
success = ('==== AUTHENTICATION COMPLETE ====',)
+ require_tty = True # see https://github.com/ansible-collections/community.general/issues/6932
@staticmethod
def remove_ansi_codes(line):
|
{"golden_diff": "diff --git a/plugins/become/machinectl.py b/plugins/become/machinectl.py\n--- a/plugins/become/machinectl.py\n+++ b/plugins/become/machinectl.py\n@@ -102,6 +102,7 @@\n prompt = 'Password: '\n fail = ('==== AUTHENTICATION FAILED ====',)\n success = ('==== AUTHENTICATION COMPLETE ====',)\n+ require_tty = True # see https://github.com/ansible-collections/community.general/issues/6932\n \n @staticmethod\n def remove_ansi_codes(line):\n", "issue": "machinectl become plugin does not specify it requires a tty\n### Summary\n\nsee https://github.com/ansible/ansible/issues/81254\r\n\r\nif the plugin sets the class attribute:\r\n\r\n```\r\n require_tty = True\r\n```\r\n\r\nIt would automatically disable pipelining and avoid such errors\n\n### Issue Type\n\nBug Report\n\n### Component Name\n\nbecome/machinectl\n\n### Ansible Version\n\n```console (paste below)\r\n$ ansible --version\r\n\r\n```\r\nall\n\n### Community.general Version\n\n```console (paste below)\r\n$ ansible-galaxy collection list community.general\r\n\r\n```\r\nall\n\n### Configuration\n\n```console (paste below)\r\n$ ansible-config dump --only-changed\r\n\r\n```\r\nN/A\n\n### OS / Environment\n\nN/A\n\n### Steps to Reproduce\n\n<!--- Paste example playbooks or commands between quotes below -->\r\n```yaml (paste below)\r\n\r\n```\r\nUse machinectl become plugin + pipelining\n\n### Expected Results\n\nit works TM\n\n### Actual Results\n\n```console (paste below)\r\n \"msg\": \"MODULE FAILURE\\nSee stdout/stderr for the exact error\",\r\n```\r\n\n\n### Code of Conduct\n\n- [X] I agree to follow the Ansible Code of Conduct\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright (c) 2018, Ansible Project\n# GNU General Public License v3.0+ (see LICENSES/GPL-3.0-or-later.txt or https://www.gnu.org/licenses/gpl-3.0.txt)\n# SPDX-License-Identifier: GPL-3.0-or-later\nfrom __future__ import (absolute_import, division, print_function)\n__metaclass__ = type\n\nDOCUMENTATION = '''\n name: machinectl\n short_description: Systemd's machinectl privilege escalation\n description:\n - This become plugins allows your remote/login user to execute commands as another user via the machinectl utility.\n author: Ansible Core Team\n options:\n become_user:\n description: User you 'become' to execute the task\n default: ''\n ini:\n - section: privilege_escalation\n key: become_user\n - section: machinectl_become_plugin\n key: user\n vars:\n - name: ansible_become_user\n - name: ansible_machinectl_user\n env:\n - name: ANSIBLE_BECOME_USER\n - name: ANSIBLE_MACHINECTL_USER\n become_exe:\n description: Machinectl executable\n default: machinectl\n ini:\n - section: privilege_escalation\n key: become_exe\n - section: machinectl_become_plugin\n key: executable\n vars:\n - name: ansible_become_exe\n - name: ansible_machinectl_exe\n env:\n - name: ANSIBLE_BECOME_EXE\n - name: ANSIBLE_MACHINECTL_EXE\n become_flags:\n description: Options to pass to machinectl\n default: ''\n ini:\n - section: privilege_escalation\n key: become_flags\n - section: machinectl_become_plugin\n key: flags\n vars:\n - name: ansible_become_flags\n - name: ansible_machinectl_flags\n env:\n - name: ANSIBLE_BECOME_FLAGS\n - name: ANSIBLE_MACHINECTL_FLAGS\n become_pass:\n description: Password for machinectl\n required: false\n vars:\n - name: ansible_become_password\n - name: ansible_become_pass\n - name: ansible_machinectl_pass\n env:\n - name: ANSIBLE_BECOME_PASS\n - name: ANSIBLE_MACHINECTL_PASS\n ini:\n - section: machinectl_become_plugin\n key: password\n notes:\n - When not using this plugin with user V(root), it only works correctly with a polkit rule which will alter\n the behaviour of machinectl. This rule must alter the prompt behaviour to ask directly for the user credentials,\n if the user is allowed to perform the action (take a look at the examples section).\n If such a rule is not present the plugin only work if it is used in context with the root user,\n because then no further prompt will be shown by machinectl.\n'''\n\nEXAMPLES = r'''\n# A polkit rule needed to use the module with a non-root user.\n# See the Notes section for details.\n60-machinectl-fast-user-auth.rules: |\n polkit.addRule(function(action, subject) {\n if(action.id == \"org.freedesktop.machine1.host-shell\" && subject.isInGroup(\"wheel\")) {\n return polkit.Result.AUTH_SELF_KEEP;\n }\n });\n'''\n\nfrom re import compile as re_compile\n\nfrom ansible.plugins.become import BecomeBase\nfrom ansible.module_utils._text import to_bytes\n\n\nansi_color_codes = re_compile(to_bytes(r'\\x1B\\[[0-9;]+m'))\n\n\nclass BecomeModule(BecomeBase):\n\n name = 'community.general.machinectl'\n\n prompt = 'Password: '\n fail = ('==== AUTHENTICATION FAILED ====',)\n success = ('==== AUTHENTICATION COMPLETE ====',)\n\n @staticmethod\n def remove_ansi_codes(line):\n return ansi_color_codes.sub(b\"\", line)\n\n def build_become_command(self, cmd, shell):\n super(BecomeModule, self).build_become_command(cmd, shell)\n\n if not cmd:\n return cmd\n\n become = self.get_option('become_exe')\n\n flags = self.get_option('become_flags')\n user = self.get_option('become_user')\n return '%s -q shell %s %s@ %s' % (become, flags, user, self._build_success_command(cmd, shell))\n\n def check_success(self, b_output):\n b_output = self.remove_ansi_codes(b_output)\n return super().check_success(b_output)\n\n def check_incorrect_password(self, b_output):\n b_output = self.remove_ansi_codes(b_output)\n return super().check_incorrect_password(b_output)\n\n def check_missing_password(self, b_output):\n b_output = self.remove_ansi_codes(b_output)\n return super().check_missing_password(b_output)\n", "path": "plugins/become/machinectl.py"}]}
| 2,182 | 126 |
gh_patches_debug_32539
|
rasdani/github-patches
|
git_diff
|
lnbits__lnbits-1117
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Usermanager: shows wrong key
Usermanager API sidebar shows invoice API keys for most operations but it should be the admin key.
</issue>
<code>
[start of lnbits/extensions/usermanager/views_api.py]
1 from http import HTTPStatus
2
3 from fastapi import Query
4 from fastapi.params import Depends
5 from starlette.exceptions import HTTPException
6
7 from lnbits.core import update_user_extension
8 from lnbits.core.crud import get_user
9 from lnbits.decorators import WalletTypeInfo, get_key_type, require_admin_key
10
11 from . import usermanager_ext
12 from .crud import (
13 create_usermanager_user,
14 create_usermanager_wallet,
15 delete_usermanager_user,
16 delete_usermanager_wallet,
17 get_usermanager_user,
18 get_usermanager_users,
19 get_usermanager_users_wallets,
20 get_usermanager_wallet,
21 get_usermanager_wallet_transactions,
22 get_usermanager_wallets,
23 )
24 from .models import CreateUserData, CreateUserWallet
25
26 # Users
27
28
29 @usermanager_ext.get("/api/v1/users", status_code=HTTPStatus.OK)
30 async def api_usermanager_users(wallet: WalletTypeInfo = Depends(require_admin_key)):
31 user_id = wallet.wallet.user
32 return [user.dict() for user in await get_usermanager_users(user_id)]
33
34
35 @usermanager_ext.get("/api/v1/users/{user_id}", status_code=HTTPStatus.OK)
36 async def api_usermanager_user(user_id, wallet: WalletTypeInfo = Depends(get_key_type)):
37 user = await get_usermanager_user(user_id)
38 return user.dict()
39
40
41 @usermanager_ext.post("/api/v1/users", status_code=HTTPStatus.CREATED)
42 async def api_usermanager_users_create(
43 data: CreateUserData, wallet: WalletTypeInfo = Depends(get_key_type)
44 ):
45 user = await create_usermanager_user(data)
46 full = user.dict()
47 full["wallets"] = [
48 wallet.dict() for wallet in await get_usermanager_users_wallets(user.id)
49 ]
50 return full
51
52
53 @usermanager_ext.delete("/api/v1/users/{user_id}")
54 async def api_usermanager_users_delete(
55 user_id, wallet: WalletTypeInfo = Depends(require_admin_key)
56 ):
57 user = await get_usermanager_user(user_id)
58 if not user:
59 raise HTTPException(
60 status_code=HTTPStatus.NOT_FOUND, detail="User does not exist."
61 )
62 await delete_usermanager_user(user_id)
63 raise HTTPException(status_code=HTTPStatus.NO_CONTENT)
64
65
66 # Activate Extension
67
68
69 @usermanager_ext.post("/api/v1/extensions")
70 async def api_usermanager_activate_extension(
71 extension: str = Query(...), userid: str = Query(...), active: bool = Query(...)
72 ):
73 user = await get_user(userid)
74 if not user:
75 raise HTTPException(
76 status_code=HTTPStatus.NOT_FOUND, detail="User does not exist."
77 )
78 await update_user_extension(user_id=userid, extension=extension, active=active)
79 return {"extension": "updated"}
80
81
82 # Wallets
83
84
85 @usermanager_ext.post("/api/v1/wallets")
86 async def api_usermanager_wallets_create(
87 data: CreateUserWallet, wallet: WalletTypeInfo = Depends(get_key_type)
88 ):
89 user = await create_usermanager_wallet(
90 user_id=data.user_id, wallet_name=data.wallet_name, admin_id=data.admin_id
91 )
92 return user.dict()
93
94
95 @usermanager_ext.get("/api/v1/wallets")
96 async def api_usermanager_wallets(wallet: WalletTypeInfo = Depends(require_admin_key)):
97 admin_id = wallet.wallet.user
98 return [wallet.dict() for wallet in await get_usermanager_wallets(admin_id)]
99
100
101 @usermanager_ext.get("/api/v1/transactions/{wallet_id}")
102 async def api_usermanager_wallet_transactions(
103 wallet_id, wallet: WalletTypeInfo = Depends(get_key_type)
104 ):
105 return await get_usermanager_wallet_transactions(wallet_id)
106
107
108 @usermanager_ext.get("/api/v1/wallets/{user_id}")
109 async def api_usermanager_users_wallets(
110 user_id, wallet: WalletTypeInfo = Depends(require_admin_key)
111 ):
112 return [
113 s_wallet.dict() for s_wallet in await get_usermanager_users_wallets(user_id)
114 ]
115
116
117 @usermanager_ext.delete("/api/v1/wallets/{wallet_id}")
118 async def api_usermanager_wallets_delete(
119 wallet_id, wallet: WalletTypeInfo = Depends(require_admin_key)
120 ):
121 get_wallet = await get_usermanager_wallet(wallet_id)
122 if not get_wallet:
123 raise HTTPException(
124 status_code=HTTPStatus.NOT_FOUND, detail="Wallet does not exist."
125 )
126 await delete_usermanager_wallet(wallet_id, get_wallet.user)
127 raise HTTPException(status_code=HTTPStatus.NO_CONTENT)
128
[end of lnbits/extensions/usermanager/views_api.py]
[start of lnbits/extensions/usermanager/crud.py]
1 from typing import List, Optional
2
3 from lnbits.core.crud import (
4 create_account,
5 create_wallet,
6 delete_wallet,
7 get_payments,
8 get_user,
9 )
10 from lnbits.core.models import Payment
11
12 from . import db
13 from .models import CreateUserData, Users, Wallets
14
15 ### Users
16
17
18 async def create_usermanager_user(data: CreateUserData) -> Users:
19 account = await create_account()
20 user = await get_user(account.id)
21 assert user, "Newly created user couldn't be retrieved"
22
23 wallet = await create_wallet(user_id=user.id, wallet_name=data.wallet_name)
24
25 await db.execute(
26 """
27 INSERT INTO usermanager.users (id, name, admin, email, password)
28 VALUES (?, ?, ?, ?, ?)
29 """,
30 (user.id, data.user_name, data.admin_id, data.email, data.password),
31 )
32
33 await db.execute(
34 """
35 INSERT INTO usermanager.wallets (id, admin, name, "user", adminkey, inkey)
36 VALUES (?, ?, ?, ?, ?, ?)
37 """,
38 (
39 wallet.id,
40 data.admin_id,
41 data.wallet_name,
42 user.id,
43 wallet.adminkey,
44 wallet.inkey,
45 ),
46 )
47
48 user_created = await get_usermanager_user(user.id)
49 assert user_created, "Newly created user couldn't be retrieved"
50 return user_created
51
52
53 async def get_usermanager_user(user_id: str) -> Optional[Users]:
54 row = await db.fetchone("SELECT * FROM usermanager.users WHERE id = ?", (user_id,))
55 return Users(**row) if row else None
56
57
58 async def get_usermanager_users(user_id: str) -> List[Users]:
59 rows = await db.fetchall(
60 "SELECT * FROM usermanager.users WHERE admin = ?", (user_id,)
61 )
62
63 return [Users(**row) for row in rows]
64
65
66 async def delete_usermanager_user(user_id: str) -> None:
67 wallets = await get_usermanager_wallets(user_id)
68 for wallet in wallets:
69 await delete_wallet(user_id=user_id, wallet_id=wallet.id)
70
71 await db.execute("DELETE FROM usermanager.users WHERE id = ?", (user_id,))
72 await db.execute("""DELETE FROM usermanager.wallets WHERE "user" = ?""", (user_id,))
73
74
75 ### Wallets
76
77
78 async def create_usermanager_wallet(
79 user_id: str, wallet_name: str, admin_id: str
80 ) -> Wallets:
81 wallet = await create_wallet(user_id=user_id, wallet_name=wallet_name)
82 await db.execute(
83 """
84 INSERT INTO usermanager.wallets (id, admin, name, "user", adminkey, inkey)
85 VALUES (?, ?, ?, ?, ?, ?)
86 """,
87 (wallet.id, admin_id, wallet_name, user_id, wallet.adminkey, wallet.inkey),
88 )
89 wallet_created = await get_usermanager_wallet(wallet.id)
90 assert wallet_created, "Newly created wallet couldn't be retrieved"
91 return wallet_created
92
93
94 async def get_usermanager_wallet(wallet_id: str) -> Optional[Wallets]:
95 row = await db.fetchone(
96 "SELECT * FROM usermanager.wallets WHERE id = ?", (wallet_id,)
97 )
98 return Wallets(**row) if row else None
99
100
101 async def get_usermanager_wallets(admin_id: str) -> Optional[Wallets]:
102 rows = await db.fetchall(
103 "SELECT * FROM usermanager.wallets WHERE admin = ?", (admin_id,)
104 )
105 return [Wallets(**row) for row in rows]
106
107
108 async def get_usermanager_users_wallets(user_id: str) -> Optional[Wallets]:
109 rows = await db.fetchall(
110 """SELECT * FROM usermanager.wallets WHERE "user" = ?""", (user_id,)
111 )
112 return [Wallets(**row) for row in rows]
113
114
115 async def get_usermanager_wallet_transactions(wallet_id: str) -> Optional[Payment]:
116 return await get_payments(
117 wallet_id=wallet_id, complete=True, pending=False, outgoing=True, incoming=True
118 )
119
120
121 async def delete_usermanager_wallet(wallet_id: str, user_id: str) -> None:
122 await delete_wallet(user_id=user_id, wallet_id=wallet_id)
123 await db.execute("DELETE FROM usermanager.wallets WHERE id = ?", (wallet_id,))
124
[end of lnbits/extensions/usermanager/crud.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lnbits/extensions/usermanager/crud.py b/lnbits/extensions/usermanager/crud.py
--- a/lnbits/extensions/usermanager/crud.py
+++ b/lnbits/extensions/usermanager/crud.py
@@ -63,10 +63,11 @@
return [Users(**row) for row in rows]
-async def delete_usermanager_user(user_id: str) -> None:
- wallets = await get_usermanager_wallets(user_id)
- for wallet in wallets:
- await delete_wallet(user_id=user_id, wallet_id=wallet.id)
+async def delete_usermanager_user(user_id: str, delete_core: bool = True) -> None:
+ if delete_core:
+ wallets = await get_usermanager_wallets(user_id)
+ for wallet in wallets:
+ await delete_wallet(user_id=user_id, wallet_id=wallet.id)
await db.execute("DELETE FROM usermanager.users WHERE id = ?", (user_id,))
await db.execute("""DELETE FROM usermanager.wallets WHERE "user" = ?""", (user_id,))
diff --git a/lnbits/extensions/usermanager/views_api.py b/lnbits/extensions/usermanager/views_api.py
--- a/lnbits/extensions/usermanager/views_api.py
+++ b/lnbits/extensions/usermanager/views_api.py
@@ -52,15 +52,17 @@
@usermanager_ext.delete("/api/v1/users/{user_id}")
async def api_usermanager_users_delete(
- user_id, wallet: WalletTypeInfo = Depends(require_admin_key)
+ user_id,
+ delete_core: bool = Query(True),
+ wallet: WalletTypeInfo = Depends(require_admin_key),
):
user = await get_usermanager_user(user_id)
if not user:
raise HTTPException(
status_code=HTTPStatus.NOT_FOUND, detail="User does not exist."
)
- await delete_usermanager_user(user_id)
- raise HTTPException(status_code=HTTPStatus.NO_CONTENT)
+ await delete_usermanager_user(user_id, delete_core)
+ return "", HTTPStatus.NO_CONTENT
# Activate Extension
@@ -124,4 +126,4 @@
status_code=HTTPStatus.NOT_FOUND, detail="Wallet does not exist."
)
await delete_usermanager_wallet(wallet_id, get_wallet.user)
- raise HTTPException(status_code=HTTPStatus.NO_CONTENT)
+ return "", HTTPStatus.NO_CONTENT
|
{"golden_diff": "diff --git a/lnbits/extensions/usermanager/crud.py b/lnbits/extensions/usermanager/crud.py\n--- a/lnbits/extensions/usermanager/crud.py\n+++ b/lnbits/extensions/usermanager/crud.py\n@@ -63,10 +63,11 @@\n return [Users(**row) for row in rows]\n \n \n-async def delete_usermanager_user(user_id: str) -> None:\n- wallets = await get_usermanager_wallets(user_id)\n- for wallet in wallets:\n- await delete_wallet(user_id=user_id, wallet_id=wallet.id)\n+async def delete_usermanager_user(user_id: str, delete_core: bool = True) -> None:\n+ if delete_core:\n+ wallets = await get_usermanager_wallets(user_id)\n+ for wallet in wallets:\n+ await delete_wallet(user_id=user_id, wallet_id=wallet.id)\n \n await db.execute(\"DELETE FROM usermanager.users WHERE id = ?\", (user_id,))\n await db.execute(\"\"\"DELETE FROM usermanager.wallets WHERE \"user\" = ?\"\"\", (user_id,))\ndiff --git a/lnbits/extensions/usermanager/views_api.py b/lnbits/extensions/usermanager/views_api.py\n--- a/lnbits/extensions/usermanager/views_api.py\n+++ b/lnbits/extensions/usermanager/views_api.py\n@@ -52,15 +52,17 @@\n \n @usermanager_ext.delete(\"/api/v1/users/{user_id}\")\n async def api_usermanager_users_delete(\n- user_id, wallet: WalletTypeInfo = Depends(require_admin_key)\n+ user_id,\n+ delete_core: bool = Query(True),\n+ wallet: WalletTypeInfo = Depends(require_admin_key),\n ):\n user = await get_usermanager_user(user_id)\n if not user:\n raise HTTPException(\n status_code=HTTPStatus.NOT_FOUND, detail=\"User does not exist.\"\n )\n- await delete_usermanager_user(user_id)\n- raise HTTPException(status_code=HTTPStatus.NO_CONTENT)\n+ await delete_usermanager_user(user_id, delete_core)\n+ return \"\", HTTPStatus.NO_CONTENT\n \n \n # Activate Extension\n@@ -124,4 +126,4 @@\n status_code=HTTPStatus.NOT_FOUND, detail=\"Wallet does not exist.\"\n )\n await delete_usermanager_wallet(wallet_id, get_wallet.user)\n- raise HTTPException(status_code=HTTPStatus.NO_CONTENT)\n+ return \"\", HTTPStatus.NO_CONTENT\n", "issue": "Usermanager: shows wrong key\nUsermanager API sidebar shows invoice API keys for most operations but it should be the admin key.\n", "before_files": [{"content": "from http import HTTPStatus\n\nfrom fastapi import Query\nfrom fastapi.params import Depends\nfrom starlette.exceptions import HTTPException\n\nfrom lnbits.core import update_user_extension\nfrom lnbits.core.crud import get_user\nfrom lnbits.decorators import WalletTypeInfo, get_key_type, require_admin_key\n\nfrom . import usermanager_ext\nfrom .crud import (\n create_usermanager_user,\n create_usermanager_wallet,\n delete_usermanager_user,\n delete_usermanager_wallet,\n get_usermanager_user,\n get_usermanager_users,\n get_usermanager_users_wallets,\n get_usermanager_wallet,\n get_usermanager_wallet_transactions,\n get_usermanager_wallets,\n)\nfrom .models import CreateUserData, CreateUserWallet\n\n# Users\n\n\n@usermanager_ext.get(\"/api/v1/users\", status_code=HTTPStatus.OK)\nasync def api_usermanager_users(wallet: WalletTypeInfo = Depends(require_admin_key)):\n user_id = wallet.wallet.user\n return [user.dict() for user in await get_usermanager_users(user_id)]\n\n\n@usermanager_ext.get(\"/api/v1/users/{user_id}\", status_code=HTTPStatus.OK)\nasync def api_usermanager_user(user_id, wallet: WalletTypeInfo = Depends(get_key_type)):\n user = await get_usermanager_user(user_id)\n return user.dict()\n\n\n@usermanager_ext.post(\"/api/v1/users\", status_code=HTTPStatus.CREATED)\nasync def api_usermanager_users_create(\n data: CreateUserData, wallet: WalletTypeInfo = Depends(get_key_type)\n):\n user = await create_usermanager_user(data)\n full = user.dict()\n full[\"wallets\"] = [\n wallet.dict() for wallet in await get_usermanager_users_wallets(user.id)\n ]\n return full\n\n\n@usermanager_ext.delete(\"/api/v1/users/{user_id}\")\nasync def api_usermanager_users_delete(\n user_id, wallet: WalletTypeInfo = Depends(require_admin_key)\n):\n user = await get_usermanager_user(user_id)\n if not user:\n raise HTTPException(\n status_code=HTTPStatus.NOT_FOUND, detail=\"User does not exist.\"\n )\n await delete_usermanager_user(user_id)\n raise HTTPException(status_code=HTTPStatus.NO_CONTENT)\n\n\n# Activate Extension\n\n\n@usermanager_ext.post(\"/api/v1/extensions\")\nasync def api_usermanager_activate_extension(\n extension: str = Query(...), userid: str = Query(...), active: bool = Query(...)\n):\n user = await get_user(userid)\n if not user:\n raise HTTPException(\n status_code=HTTPStatus.NOT_FOUND, detail=\"User does not exist.\"\n )\n await update_user_extension(user_id=userid, extension=extension, active=active)\n return {\"extension\": \"updated\"}\n\n\n# Wallets\n\n\n@usermanager_ext.post(\"/api/v1/wallets\")\nasync def api_usermanager_wallets_create(\n data: CreateUserWallet, wallet: WalletTypeInfo = Depends(get_key_type)\n):\n user = await create_usermanager_wallet(\n user_id=data.user_id, wallet_name=data.wallet_name, admin_id=data.admin_id\n )\n return user.dict()\n\n\n@usermanager_ext.get(\"/api/v1/wallets\")\nasync def api_usermanager_wallets(wallet: WalletTypeInfo = Depends(require_admin_key)):\n admin_id = wallet.wallet.user\n return [wallet.dict() for wallet in await get_usermanager_wallets(admin_id)]\n\n\n@usermanager_ext.get(\"/api/v1/transactions/{wallet_id}\")\nasync def api_usermanager_wallet_transactions(\n wallet_id, wallet: WalletTypeInfo = Depends(get_key_type)\n):\n return await get_usermanager_wallet_transactions(wallet_id)\n\n\n@usermanager_ext.get(\"/api/v1/wallets/{user_id}\")\nasync def api_usermanager_users_wallets(\n user_id, wallet: WalletTypeInfo = Depends(require_admin_key)\n):\n return [\n s_wallet.dict() for s_wallet in await get_usermanager_users_wallets(user_id)\n ]\n\n\n@usermanager_ext.delete(\"/api/v1/wallets/{wallet_id}\")\nasync def api_usermanager_wallets_delete(\n wallet_id, wallet: WalletTypeInfo = Depends(require_admin_key)\n):\n get_wallet = await get_usermanager_wallet(wallet_id)\n if not get_wallet:\n raise HTTPException(\n status_code=HTTPStatus.NOT_FOUND, detail=\"Wallet does not exist.\"\n )\n await delete_usermanager_wallet(wallet_id, get_wallet.user)\n raise HTTPException(status_code=HTTPStatus.NO_CONTENT)\n", "path": "lnbits/extensions/usermanager/views_api.py"}, {"content": "from typing import List, Optional\n\nfrom lnbits.core.crud import (\n create_account,\n create_wallet,\n delete_wallet,\n get_payments,\n get_user,\n)\nfrom lnbits.core.models import Payment\n\nfrom . import db\nfrom .models import CreateUserData, Users, Wallets\n\n### Users\n\n\nasync def create_usermanager_user(data: CreateUserData) -> Users:\n account = await create_account()\n user = await get_user(account.id)\n assert user, \"Newly created user couldn't be retrieved\"\n\n wallet = await create_wallet(user_id=user.id, wallet_name=data.wallet_name)\n\n await db.execute(\n \"\"\"\n INSERT INTO usermanager.users (id, name, admin, email, password)\n VALUES (?, ?, ?, ?, ?)\n \"\"\",\n (user.id, data.user_name, data.admin_id, data.email, data.password),\n )\n\n await db.execute(\n \"\"\"\n INSERT INTO usermanager.wallets (id, admin, name, \"user\", adminkey, inkey)\n VALUES (?, ?, ?, ?, ?, ?)\n \"\"\",\n (\n wallet.id,\n data.admin_id,\n data.wallet_name,\n user.id,\n wallet.adminkey,\n wallet.inkey,\n ),\n )\n\n user_created = await get_usermanager_user(user.id)\n assert user_created, \"Newly created user couldn't be retrieved\"\n return user_created\n\n\nasync def get_usermanager_user(user_id: str) -> Optional[Users]:\n row = await db.fetchone(\"SELECT * FROM usermanager.users WHERE id = ?\", (user_id,))\n return Users(**row) if row else None\n\n\nasync def get_usermanager_users(user_id: str) -> List[Users]:\n rows = await db.fetchall(\n \"SELECT * FROM usermanager.users WHERE admin = ?\", (user_id,)\n )\n\n return [Users(**row) for row in rows]\n\n\nasync def delete_usermanager_user(user_id: str) -> None:\n wallets = await get_usermanager_wallets(user_id)\n for wallet in wallets:\n await delete_wallet(user_id=user_id, wallet_id=wallet.id)\n\n await db.execute(\"DELETE FROM usermanager.users WHERE id = ?\", (user_id,))\n await db.execute(\"\"\"DELETE FROM usermanager.wallets WHERE \"user\" = ?\"\"\", (user_id,))\n\n\n### Wallets\n\n\nasync def create_usermanager_wallet(\n user_id: str, wallet_name: str, admin_id: str\n) -> Wallets:\n wallet = await create_wallet(user_id=user_id, wallet_name=wallet_name)\n await db.execute(\n \"\"\"\n INSERT INTO usermanager.wallets (id, admin, name, \"user\", adminkey, inkey)\n VALUES (?, ?, ?, ?, ?, ?)\n \"\"\",\n (wallet.id, admin_id, wallet_name, user_id, wallet.adminkey, wallet.inkey),\n )\n wallet_created = await get_usermanager_wallet(wallet.id)\n assert wallet_created, \"Newly created wallet couldn't be retrieved\"\n return wallet_created\n\n\nasync def get_usermanager_wallet(wallet_id: str) -> Optional[Wallets]:\n row = await db.fetchone(\n \"SELECT * FROM usermanager.wallets WHERE id = ?\", (wallet_id,)\n )\n return Wallets(**row) if row else None\n\n\nasync def get_usermanager_wallets(admin_id: str) -> Optional[Wallets]:\n rows = await db.fetchall(\n \"SELECT * FROM usermanager.wallets WHERE admin = ?\", (admin_id,)\n )\n return [Wallets(**row) for row in rows]\n\n\nasync def get_usermanager_users_wallets(user_id: str) -> Optional[Wallets]:\n rows = await db.fetchall(\n \"\"\"SELECT * FROM usermanager.wallets WHERE \"user\" = ?\"\"\", (user_id,)\n )\n return [Wallets(**row) for row in rows]\n\n\nasync def get_usermanager_wallet_transactions(wallet_id: str) -> Optional[Payment]:\n return await get_payments(\n wallet_id=wallet_id, complete=True, pending=False, outgoing=True, incoming=True\n )\n\n\nasync def delete_usermanager_wallet(wallet_id: str, user_id: str) -> None:\n await delete_wallet(user_id=user_id, wallet_id=wallet_id)\n await db.execute(\"DELETE FROM usermanager.wallets WHERE id = ?\", (wallet_id,))\n", "path": "lnbits/extensions/usermanager/crud.py"}]}
| 2,999 | 516 |
gh_patches_debug_22741
|
rasdani/github-patches
|
git_diff
|
aio-libs__aiohttp-5364
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Switch http_parser to llhttp
Nodejs decide to move from their hard-coded C parser to this one.
https://github.com/nodejs/http-parser/pull/285#issuecomment-456025694
*Upd:*
proposed parser is https://llhttp.org
</issue>
<code>
[start of setup.py]
1 import os
2 import pathlib
3 import re
4 import sys
5
6 from setuptools import Extension, setup
7
8 if sys.version_info < (3, 7):
9 raise RuntimeError("aiohttp 4.x requires Python 3.7+")
10
11
12 NO_EXTENSIONS = bool(os.environ.get("AIOHTTP_NO_EXTENSIONS")) # type: bool
13 HERE = pathlib.Path(__file__).parent
14 IS_GIT_REPO = (HERE / ".git").exists()
15
16
17 if sys.implementation.name != "cpython":
18 NO_EXTENSIONS = True
19
20
21 if IS_GIT_REPO and not (HERE / "vendor/http-parser/README.md").exists():
22 print("Install submodules when building from git clone", file=sys.stderr)
23 print("Hint:", file=sys.stderr)
24 print(" git submodule update --init", file=sys.stderr)
25 sys.exit(2)
26
27
28 # NOTE: makefile cythonizes all Cython modules
29
30 extensions = [
31 Extension("aiohttp._websocket", ["aiohttp/_websocket.c"]),
32 Extension(
33 "aiohttp._http_parser",
34 [
35 "aiohttp/_http_parser.c",
36 "vendor/http-parser/http_parser.c",
37 "aiohttp/_find_header.c",
38 ],
39 define_macros=[("HTTP_PARSER_STRICT", 0)],
40 ),
41 Extension("aiohttp._helpers", ["aiohttp/_helpers.c"]),
42 Extension("aiohttp._http_writer", ["aiohttp/_http_writer.c"]),
43 ]
44
45
46 txt = (HERE / "aiohttp" / "__init__.py").read_text("utf-8")
47 try:
48 version = re.findall(r'^__version__ = "([^"]+)"\r?$', txt, re.M)[0]
49 except IndexError:
50 raise RuntimeError("Unable to determine version.")
51
52 install_requires = [
53 "chardet>=2.0,<5.0",
54 "multidict>=4.5,<7.0",
55 "async_timeout>=4.0a2,<5.0",
56 'asynctest==0.13.0; python_version<"3.8"',
57 "yarl>=1.0,<2.0",
58 "typing_extensions>=3.7.4",
59 "frozenlist>=1.1.1",
60 "aiosignal>=1.1.2",
61 ]
62
63
64 def read(f):
65 return (HERE / f).read_text("utf-8").strip()
66
67
68 args = dict(
69 name="aiohttp",
70 version=version,
71 description="Async http client/server framework (asyncio)",
72 long_description="\n\n".join((read("README.rst"), read("CHANGES.rst"))),
73 long_description_content_type="text/x-rst",
74 classifiers=[
75 "License :: OSI Approved :: Apache Software License",
76 "Intended Audience :: Developers",
77 "Programming Language :: Python",
78 "Programming Language :: Python :: 3",
79 "Programming Language :: Python :: 3.7",
80 "Programming Language :: Python :: 3.8",
81 "Programming Language :: Python :: 3.9",
82 "Development Status :: 5 - Production/Stable",
83 "Operating System :: POSIX",
84 "Operating System :: MacOS :: MacOS X",
85 "Operating System :: Microsoft :: Windows",
86 "Topic :: Internet :: WWW/HTTP",
87 "Framework :: AsyncIO",
88 ],
89 author="Nikolay Kim",
90 author_email="[email protected]",
91 maintainer=", ".join(
92 (
93 "Nikolay Kim <[email protected]>",
94 "Andrew Svetlov <[email protected]>",
95 )
96 ),
97 maintainer_email="[email protected]",
98 url="https://github.com/aio-libs/aiohttp",
99 project_urls={
100 "Chat: Gitter": "https://gitter.im/aio-libs/Lobby",
101 "CI: GitHub Actions": "https://github.com/aio-libs/aiohttp/actions?query=workflow%3ACI", # noqa
102 "Coverage: codecov": "https://codecov.io/github/aio-libs/aiohttp",
103 "Docs: Changelog": "https://docs.aiohttp.org/en/stable/changes.html",
104 "Docs: RTD": "https://docs.aiohttp.org",
105 "GitHub: issues": "https://github.com/aio-libs/aiohttp/issues",
106 "GitHub: repo": "https://github.com/aio-libs/aiohttp",
107 },
108 license="Apache 2",
109 packages=["aiohttp"],
110 python_requires=">=3.7",
111 install_requires=install_requires,
112 extras_require={
113 "speedups": [
114 "aiodns>=1.1",
115 "Brotli",
116 "cchardet",
117 ],
118 },
119 include_package_data=True,
120 )
121
122 if not NO_EXTENSIONS:
123 print("*********************")
124 print("* Accelerated build *")
125 print("*********************")
126 setup(ext_modules=extensions, **args)
127 else:
128 print("*********************")
129 print("* Pure Python build *")
130 print("*********************")
131 setup(**args)
132
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -18,7 +18,7 @@
NO_EXTENSIONS = True
-if IS_GIT_REPO and not (HERE / "vendor/http-parser/README.md").exists():
+if IS_GIT_REPO and not (HERE / "vendor/llhttp/README.md").exists():
print("Install submodules when building from git clone", file=sys.stderr)
print("Hint:", file=sys.stderr)
print(" git submodule update --init", file=sys.stderr)
@@ -33,10 +33,13 @@
"aiohttp._http_parser",
[
"aiohttp/_http_parser.c",
- "vendor/http-parser/http_parser.c",
"aiohttp/_find_header.c",
+ "vendor/llhttp/build/c/llhttp.c",
+ "vendor/llhttp/src/native/api.c",
+ "vendor/llhttp/src/native/http.c",
],
- define_macros=[("HTTP_PARSER_STRICT", 0)],
+ define_macros=[("LLHTTP_STRICT_MODE", 0)],
+ include_dirs=["vendor/llhttp/build"],
),
Extension("aiohttp._helpers", ["aiohttp/_helpers.c"]),
Extension("aiohttp._http_writer", ["aiohttp/_http_writer.c"]),
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -18,7 +18,7 @@\n NO_EXTENSIONS = True\n \n \n-if IS_GIT_REPO and not (HERE / \"vendor/http-parser/README.md\").exists():\n+if IS_GIT_REPO and not (HERE / \"vendor/llhttp/README.md\").exists():\n print(\"Install submodules when building from git clone\", file=sys.stderr)\n print(\"Hint:\", file=sys.stderr)\n print(\" git submodule update --init\", file=sys.stderr)\n@@ -33,10 +33,13 @@\n \"aiohttp._http_parser\",\n [\n \"aiohttp/_http_parser.c\",\n- \"vendor/http-parser/http_parser.c\",\n \"aiohttp/_find_header.c\",\n+ \"vendor/llhttp/build/c/llhttp.c\",\n+ \"vendor/llhttp/src/native/api.c\",\n+ \"vendor/llhttp/src/native/http.c\",\n ],\n- define_macros=[(\"HTTP_PARSER_STRICT\", 0)],\n+ define_macros=[(\"LLHTTP_STRICT_MODE\", 0)],\n+ include_dirs=[\"vendor/llhttp/build\"],\n ),\n Extension(\"aiohttp._helpers\", [\"aiohttp/_helpers.c\"]),\n Extension(\"aiohttp._http_writer\", [\"aiohttp/_http_writer.c\"]),\n", "issue": "Switch http_parser to llhttp\nNodejs decide to move from their hard-coded C parser to this one.\r\n\r\nhttps://github.com/nodejs/http-parser/pull/285#issuecomment-456025694\r\n\r\n*Upd:* \r\nproposed parser is https://llhttp.org\r\n\n", "before_files": [{"content": "import os\nimport pathlib\nimport re\nimport sys\n\nfrom setuptools import Extension, setup\n\nif sys.version_info < (3, 7):\n raise RuntimeError(\"aiohttp 4.x requires Python 3.7+\")\n\n\nNO_EXTENSIONS = bool(os.environ.get(\"AIOHTTP_NO_EXTENSIONS\")) # type: bool\nHERE = pathlib.Path(__file__).parent\nIS_GIT_REPO = (HERE / \".git\").exists()\n\n\nif sys.implementation.name != \"cpython\":\n NO_EXTENSIONS = True\n\n\nif IS_GIT_REPO and not (HERE / \"vendor/http-parser/README.md\").exists():\n print(\"Install submodules when building from git clone\", file=sys.stderr)\n print(\"Hint:\", file=sys.stderr)\n print(\" git submodule update --init\", file=sys.stderr)\n sys.exit(2)\n\n\n# NOTE: makefile cythonizes all Cython modules\n\nextensions = [\n Extension(\"aiohttp._websocket\", [\"aiohttp/_websocket.c\"]),\n Extension(\n \"aiohttp._http_parser\",\n [\n \"aiohttp/_http_parser.c\",\n \"vendor/http-parser/http_parser.c\",\n \"aiohttp/_find_header.c\",\n ],\n define_macros=[(\"HTTP_PARSER_STRICT\", 0)],\n ),\n Extension(\"aiohttp._helpers\", [\"aiohttp/_helpers.c\"]),\n Extension(\"aiohttp._http_writer\", [\"aiohttp/_http_writer.c\"]),\n]\n\n\ntxt = (HERE / \"aiohttp\" / \"__init__.py\").read_text(\"utf-8\")\ntry:\n version = re.findall(r'^__version__ = \"([^\"]+)\"\\r?$', txt, re.M)[0]\nexcept IndexError:\n raise RuntimeError(\"Unable to determine version.\")\n\ninstall_requires = [\n \"chardet>=2.0,<5.0\",\n \"multidict>=4.5,<7.0\",\n \"async_timeout>=4.0a2,<5.0\",\n 'asynctest==0.13.0; python_version<\"3.8\"',\n \"yarl>=1.0,<2.0\",\n \"typing_extensions>=3.7.4\",\n \"frozenlist>=1.1.1\",\n \"aiosignal>=1.1.2\",\n]\n\n\ndef read(f):\n return (HERE / f).read_text(\"utf-8\").strip()\n\n\nargs = dict(\n name=\"aiohttp\",\n version=version,\n description=\"Async http client/server framework (asyncio)\",\n long_description=\"\\n\\n\".join((read(\"README.rst\"), read(\"CHANGES.rst\"))),\n long_description_content_type=\"text/x-rst\",\n classifiers=[\n \"License :: OSI Approved :: Apache Software License\",\n \"Intended Audience :: Developers\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Development Status :: 5 - Production/Stable\",\n \"Operating System :: POSIX\",\n \"Operating System :: MacOS :: MacOS X\",\n \"Operating System :: Microsoft :: Windows\",\n \"Topic :: Internet :: WWW/HTTP\",\n \"Framework :: AsyncIO\",\n ],\n author=\"Nikolay Kim\",\n author_email=\"[email protected]\",\n maintainer=\", \".join(\n (\n \"Nikolay Kim <[email protected]>\",\n \"Andrew Svetlov <[email protected]>\",\n )\n ),\n maintainer_email=\"[email protected]\",\n url=\"https://github.com/aio-libs/aiohttp\",\n project_urls={\n \"Chat: Gitter\": \"https://gitter.im/aio-libs/Lobby\",\n \"CI: GitHub Actions\": \"https://github.com/aio-libs/aiohttp/actions?query=workflow%3ACI\", # noqa\n \"Coverage: codecov\": \"https://codecov.io/github/aio-libs/aiohttp\",\n \"Docs: Changelog\": \"https://docs.aiohttp.org/en/stable/changes.html\",\n \"Docs: RTD\": \"https://docs.aiohttp.org\",\n \"GitHub: issues\": \"https://github.com/aio-libs/aiohttp/issues\",\n \"GitHub: repo\": \"https://github.com/aio-libs/aiohttp\",\n },\n license=\"Apache 2\",\n packages=[\"aiohttp\"],\n python_requires=\">=3.7\",\n install_requires=install_requires,\n extras_require={\n \"speedups\": [\n \"aiodns>=1.1\",\n \"Brotli\",\n \"cchardet\",\n ],\n },\n include_package_data=True,\n)\n\nif not NO_EXTENSIONS:\n print(\"*********************\")\n print(\"* Accelerated build *\")\n print(\"*********************\")\n setup(ext_modules=extensions, **args)\nelse:\n print(\"*********************\")\n print(\"* Pure Python build *\")\n print(\"*********************\")\n setup(**args)\n", "path": "setup.py"}]}
| 1,986 | 293 |
gh_patches_debug_5390
|
rasdani/github-patches
|
git_diff
|
scalableminds__webknossos-libs-47
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Tiled cubing doesn't convert last slice
Tiled cubing doesn't convert last slice
</issue>
<code>
[start of wkcuber/utils.py]
1 import time
2 import wkw
3 import numpy as np
4 import logging
5 from glob import iglob
6 from collections import namedtuple
7 from multiprocessing import cpu_count, Lock
8 from concurrent.futures import ProcessPoolExecutor
9 from os import path
10 from platform import python_version
11 from math import floor, ceil
12
13
14 from .knossos import KnossosDataset, CUBE_EDGE_LEN
15
16
17 WkwDatasetInfo = namedtuple(
18 "WkwDatasetInfo", ("dataset_path", "layer_name", "dtype", "mag")
19 )
20 KnossosDatasetInfo = namedtuple("KnossosDatasetInfo", ("dataset_path", "dtype"))
21
22
23 def _open_wkw(info, **kwargs):
24 header = wkw.Header(np.dtype(info.dtype), **kwargs)
25 ds = wkw.Dataset.open(
26 path.join(info.dataset_path, info.layer_name, str(info.mag)), header
27 )
28 return ds
29
30
31 def open_wkw(info, lock=None, **kwargs):
32 if lock is None:
33 # Create dummy lock
34 lock = Lock()
35
36 with lock:
37 return _open_wkw(info, **kwargs)
38
39
40 def open_knossos(info):
41 return KnossosDataset.open(info.dataset_path, np.dtype(info.dtype))
42
43
44 def add_verbose_flag(parser):
45 parser.add_argument(
46 "--verbose", "-v", help="Verbose output", dest="verbose", action="store_true"
47 )
48
49 parser.set_defaults(verbose=False)
50
51
52 def find_files(source_path, extensions):
53 # Find all files with a matching file extension
54 return (
55 f
56 for f in iglob(source_path, recursive=True)
57 if any([f.endswith(suffix) for suffix in extensions])
58 )
59
60
61 def get_chunks(arr, chunk_size):
62 for i in range(0, len(arr), chunk_size):
63 yield arr[i : i + chunk_size]
64
65
66 def get_regular_chunks(min_z, max_z, chunk_size):
67 i = floor(min_z / chunk_size) * chunk_size
68 while i < ceil(max_z / chunk_size) * chunk_size:
69 yield range(i, i + chunk_size)
70 i += chunk_size
71
72
73 def add_jobs_flag(parser):
74 parser.add_argument(
75 "--jobs", "-j", help="Parallel jobs", type=int, default=cpu_count()
76 )
77
78
79 def pool_init(lock):
80 global process_pool_lock
81 process_pool_lock = lock
82
83
84 def pool_get_lock():
85 global process_pool_lock
86 try:
87 return process_pool_lock
88 except NameError:
89 return None
90
91
92 class ParallelExecutor:
93 def __init__(self, jobs):
94 self.lock = Lock()
95 if python_version() >= "3.7.0":
96 self.exec = ProcessPoolExecutor(
97 jobs, initializer=pool_init, initargs=(self.lock,)
98 )
99 else:
100 self.exec = ProcessPoolExecutor(jobs)
101 self.futures = []
102
103 def submit(self, fn, *args):
104 future = self.exec.submit(fn, *args)
105 self.futures.append(future)
106 return future
107
108 def __enter__(self):
109 self.exec.__enter__()
110 return self
111
112 def __exit__(self, type, value, tb):
113 [f.result() for f in self.futures]
114 self.exec.__exit__(type, value, tb)
115
116
117 times = {}
118
119
120 def time_start(identifier):
121 times[identifier] = time.time()
122
123
124 def time_stop(identifier):
125 _time = times.pop(identifier)
126 logging.debug("{} took {:.8f}s".format(identifier, time.time() - _time))
127
[end of wkcuber/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/wkcuber/utils.py b/wkcuber/utils.py
--- a/wkcuber/utils.py
+++ b/wkcuber/utils.py
@@ -63,9 +63,10 @@
yield arr[i : i + chunk_size]
+# min_z and max_z are both inclusive
def get_regular_chunks(min_z, max_z, chunk_size):
i = floor(min_z / chunk_size) * chunk_size
- while i < ceil(max_z / chunk_size) * chunk_size:
+ while i < ceil((max_z + 1) / chunk_size) * chunk_size:
yield range(i, i + chunk_size)
i += chunk_size
|
{"golden_diff": "diff --git a/wkcuber/utils.py b/wkcuber/utils.py\n--- a/wkcuber/utils.py\n+++ b/wkcuber/utils.py\n@@ -63,9 +63,10 @@\n yield arr[i : i + chunk_size]\n \n \n+# min_z and max_z are both inclusive\n def get_regular_chunks(min_z, max_z, chunk_size):\n i = floor(min_z / chunk_size) * chunk_size\n- while i < ceil(max_z / chunk_size) * chunk_size:\n+ while i < ceil((max_z + 1) / chunk_size) * chunk_size:\n yield range(i, i + chunk_size)\n i += chunk_size\n", "issue": "Tiled cubing doesn't convert last slice\n\nTiled cubing doesn't convert last slice\n\n", "before_files": [{"content": "import time\nimport wkw\nimport numpy as np\nimport logging\nfrom glob import iglob\nfrom collections import namedtuple\nfrom multiprocessing import cpu_count, Lock\nfrom concurrent.futures import ProcessPoolExecutor\nfrom os import path\nfrom platform import python_version\nfrom math import floor, ceil\n\n\nfrom .knossos import KnossosDataset, CUBE_EDGE_LEN\n\n\nWkwDatasetInfo = namedtuple(\n \"WkwDatasetInfo\", (\"dataset_path\", \"layer_name\", \"dtype\", \"mag\")\n)\nKnossosDatasetInfo = namedtuple(\"KnossosDatasetInfo\", (\"dataset_path\", \"dtype\"))\n\n\ndef _open_wkw(info, **kwargs):\n header = wkw.Header(np.dtype(info.dtype), **kwargs)\n ds = wkw.Dataset.open(\n path.join(info.dataset_path, info.layer_name, str(info.mag)), header\n )\n return ds\n\n\ndef open_wkw(info, lock=None, **kwargs):\n if lock is None:\n # Create dummy lock\n lock = Lock()\n\n with lock:\n return _open_wkw(info, **kwargs)\n\n\ndef open_knossos(info):\n return KnossosDataset.open(info.dataset_path, np.dtype(info.dtype))\n\n\ndef add_verbose_flag(parser):\n parser.add_argument(\n \"--verbose\", \"-v\", help=\"Verbose output\", dest=\"verbose\", action=\"store_true\"\n )\n\n parser.set_defaults(verbose=False)\n\n\ndef find_files(source_path, extensions):\n # Find all files with a matching file extension\n return (\n f\n for f in iglob(source_path, recursive=True)\n if any([f.endswith(suffix) for suffix in extensions])\n )\n\n\ndef get_chunks(arr, chunk_size):\n for i in range(0, len(arr), chunk_size):\n yield arr[i : i + chunk_size]\n\n\ndef get_regular_chunks(min_z, max_z, chunk_size):\n i = floor(min_z / chunk_size) * chunk_size\n while i < ceil(max_z / chunk_size) * chunk_size:\n yield range(i, i + chunk_size)\n i += chunk_size\n\n\ndef add_jobs_flag(parser):\n parser.add_argument(\n \"--jobs\", \"-j\", help=\"Parallel jobs\", type=int, default=cpu_count()\n )\n\n\ndef pool_init(lock):\n global process_pool_lock\n process_pool_lock = lock\n\n\ndef pool_get_lock():\n global process_pool_lock\n try:\n return process_pool_lock\n except NameError:\n return None\n\n\nclass ParallelExecutor:\n def __init__(self, jobs):\n self.lock = Lock()\n if python_version() >= \"3.7.0\":\n self.exec = ProcessPoolExecutor(\n jobs, initializer=pool_init, initargs=(self.lock,)\n )\n else:\n self.exec = ProcessPoolExecutor(jobs)\n self.futures = []\n\n def submit(self, fn, *args):\n future = self.exec.submit(fn, *args)\n self.futures.append(future)\n return future\n\n def __enter__(self):\n self.exec.__enter__()\n return self\n\n def __exit__(self, type, value, tb):\n [f.result() for f in self.futures]\n self.exec.__exit__(type, value, tb)\n\n\ntimes = {}\n\n\ndef time_start(identifier):\n times[identifier] = time.time()\n\n\ndef time_stop(identifier):\n _time = times.pop(identifier)\n logging.debug(\"{} took {:.8f}s\".format(identifier, time.time() - _time))\n", "path": "wkcuber/utils.py"}]}
| 1,590 | 146 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.