
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.1k
25.4k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 582
39.1k
| num_tokens
int64 271
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_1207
|
rasdani/github-patches
|
git_diff
|
pytorch__vision-2933
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Change default value of eps in FrozenBatchNorm to match BatchNorm
## ❓ Questions and Help
Hello
Loss is nan error occurs when I learn fast rcnn with resnext101 backbone
My code is as follows
```python
backbone = resnet_fpn_backbone('resnext101_32x8d', pretrained=True)
model = FasterRCNN(backbone, num_classes)
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
```
error message
```
Epoch: [0] [ 0/7208] eta: 1:27:42 lr: 0.000040 loss: 40613806080.0000 (40613806080.0000) loss_box_reg: 7979147264.0000 (7979147264.0000) loss_classifier: 11993160704.0000 (11993160704.0000) loss_objectness: 9486380032.0000 (9486380032.0000) loss_rpn_box_reg: 11155118080.0000 (11155118080.0000) time: 0.7301 data: 0.4106 max mem: 1241
Loss is nan, stopping training
```
When i change the backbone to resnet50 and resnet152, no error occrus.
### Please note that this issue tracker is not a help form and this issue will be closed.
We have a set of [listed resources available on the website](https://pytorch.org/resources). Our primary means of support is our discussion forum:
- [Discussion Forum](https://discuss.pytorch.org/)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `torchvision/ops/misc.py`
Content:
```
1 """
2 helper class that supports empty tensors on some nn functions.
3
4 Ideally, add support directly in PyTorch to empty tensors in
5 those functions.
6
7 This can be removed once https://github.com/pytorch/pytorch/issues/12013
8 is implemented
9 """
10
11 import warnings
12 import torch
13 from torch import Tensor, Size
14 from torch.jit.annotations import List, Optional, Tuple
15
16
17 class Conv2d(torch.nn.Conv2d):
18 def __init__(self, *args, **kwargs):
19 super().__init__(*args, **kwargs)
20 warnings.warn(
21 "torchvision.ops.misc.Conv2d is deprecated and will be "
22 "removed in future versions, use torch.nn.Conv2d instead.", FutureWarning)
23
24
25 class ConvTranspose2d(torch.nn.ConvTranspose2d):
26 def __init__(self, *args, **kwargs):
27 super().__init__(*args, **kwargs)
28 warnings.warn(
29 "torchvision.ops.misc.ConvTranspose2d is deprecated and will be "
30 "removed in future versions, use torch.nn.ConvTranspose2d instead.", FutureWarning)
31
32
33 class BatchNorm2d(torch.nn.BatchNorm2d):
34 def __init__(self, *args, **kwargs):
35 super().__init__(*args, **kwargs)
36 warnings.warn(
37 "torchvision.ops.misc.BatchNorm2d is deprecated and will be "
38 "removed in future versions, use torch.nn.BatchNorm2d instead.", FutureWarning)
39
40
41 interpolate = torch.nn.functional.interpolate
42
43
44 # This is not in nn
45 class FrozenBatchNorm2d(torch.nn.Module):
46 """
47 BatchNorm2d where the batch statistics and the affine parameters
48 are fixed
49 """
50
51 def __init__(
52 self,
53 num_features: int,
54 eps: float = 0.,
55 n: Optional[int] = None,
56 ):
57 # n=None for backward-compatibility
58 if n is not None:
59 warnings.warn("`n` argument is deprecated and has been renamed `num_features`",
60 DeprecationWarning)
61 num_features = n
62 super(FrozenBatchNorm2d, self).__init__()
63 self.eps = eps
64 self.register_buffer("weight", torch.ones(num_features))
65 self.register_buffer("bias", torch.zeros(num_features))
66 self.register_buffer("running_mean", torch.zeros(num_features))
67 self.register_buffer("running_var", torch.ones(num_features))
68
69 def _load_from_state_dict(
70 self,
71 state_dict: dict,
72 prefix: str,
73 local_metadata: dict,
74 strict: bool,
75 missing_keys: List[str],
76 unexpected_keys: List[str],
77 error_msgs: List[str],
78 ):
79 num_batches_tracked_key = prefix + 'num_batches_tracked'
80 if num_batches_tracked_key in state_dict:
81 del state_dict[num_batches_tracked_key]
82
83 super(FrozenBatchNorm2d, self)._load_from_state_dict(
84 state_dict, prefix, local_metadata, strict,
85 missing_keys, unexpected_keys, error_msgs)
86
87 def forward(self, x: Tensor) -> Tensor:
88 # move reshapes to the beginning
89 # to make it fuser-friendly
90 w = self.weight.reshape(1, -1, 1, 1)
91 b = self.bias.reshape(1, -1, 1, 1)
92 rv = self.running_var.reshape(1, -1, 1, 1)
93 rm = self.running_mean.reshape(1, -1, 1, 1)
94 scale = w * (rv + self.eps).rsqrt()
95 bias = b - rm * scale
96 return x * scale + bias
97
98 def __repr__(self) -> str:
99 return f"{self.__class__.__name__}({self.weight.shape[0]}, eps={self.eps})"
100
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/torchvision/ops/misc.py b/torchvision/ops/misc.py
--- a/torchvision/ops/misc.py
+++ b/torchvision/ops/misc.py
@@ -51,7 +51,7 @@
def __init__(
self,
num_features: int,
- eps: float = 0.,
+ eps: float = 1e-5,
n: Optional[int] = None,
):
# n=None for backward-compatibility
|
{"golden_diff": "diff --git a/torchvision/ops/misc.py b/torchvision/ops/misc.py\n--- a/torchvision/ops/misc.py\n+++ b/torchvision/ops/misc.py\n@@ -51,7 +51,7 @@\n def __init__(\n self,\n num_features: int,\n- eps: float = 0.,\n+ eps: float = 1e-5,\n n: Optional[int] = None,\n ):\n # n=None for backward-compatibility\n", "issue": "Change default value of eps in FrozenBatchNorm to match BatchNorm\n## \u2753 Questions and Help\r\nHello\r\nLoss is nan error occurs when I learn fast rcnn with resnext101 backbone\r\nMy code is as follows\r\n```python\r\nbackbone = resnet_fpn_backbone('resnext101_32x8d', pretrained=True)\r\nmodel = FasterRCNN(backbone, num_classes)\r\nin_features = model.roi_heads.box_predictor.cls_score.in_features\r\nmodel.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)\r\n```\r\n\r\nerror message\r\n```\r\nEpoch: [0] [ 0/7208] eta: 1:27:42 lr: 0.000040 loss: 40613806080.0000 (40613806080.0000) loss_box_reg: 7979147264.0000 (7979147264.0000) loss_classifier: 11993160704.0000 (11993160704.0000) loss_objectness: 9486380032.0000 (9486380032.0000) loss_rpn_box_reg: 11155118080.0000 (11155118080.0000) time: 0.7301 data: 0.4106 max mem: 1241\r\nLoss is nan, stopping training\r\n```\r\n\r\nWhen i change the backbone to resnet50 and resnet152, no error occrus.\r\n### Please note that this issue tracker is not a help form and this issue will be closed.\r\n\r\nWe have a set of [listed resources available on the website](https://pytorch.org/resources). Our primary means of support is our discussion forum:\r\n\r\n- [Discussion Forum](https://discuss.pytorch.org/)\r\n\n", "before_files": [{"content": "\"\"\"\nhelper class that supports empty tensors on some nn functions.\n\nIdeally, add support directly in PyTorch to empty tensors in\nthose functions.\n\nThis can be removed once https://github.com/pytorch/pytorch/issues/12013\nis implemented\n\"\"\"\n\nimport warnings\nimport torch\nfrom torch import Tensor, Size\nfrom torch.jit.annotations import List, Optional, Tuple\n\n\nclass Conv2d(torch.nn.Conv2d):\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n warnings.warn(\n \"torchvision.ops.misc.Conv2d is deprecated and will be \"\n \"removed in future versions, use torch.nn.Conv2d instead.\", FutureWarning)\n\n\nclass ConvTranspose2d(torch.nn.ConvTranspose2d):\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n warnings.warn(\n \"torchvision.ops.misc.ConvTranspose2d is deprecated and will be \"\n \"removed in future versions, use torch.nn.ConvTranspose2d instead.\", FutureWarning)\n\n\nclass BatchNorm2d(torch.nn.BatchNorm2d):\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n warnings.warn(\n \"torchvision.ops.misc.BatchNorm2d is deprecated and will be \"\n \"removed in future versions, use torch.nn.BatchNorm2d instead.\", FutureWarning)\n\n\ninterpolate = torch.nn.functional.interpolate\n\n\n# This is not in nn\nclass FrozenBatchNorm2d(torch.nn.Module):\n \"\"\"\n BatchNorm2d where the batch statistics and the affine parameters\n are fixed\n \"\"\"\n\n def __init__(\n self,\n num_features: int,\n eps: float = 0.,\n n: Optional[int] = None,\n ):\n # n=None for backward-compatibility\n if n is not None:\n warnings.warn(\"`n` argument is deprecated and has been renamed `num_features`\",\n DeprecationWarning)\n num_features = n\n super(FrozenBatchNorm2d, self).__init__()\n self.eps = eps\n self.register_buffer(\"weight\", torch.ones(num_features))\n self.register_buffer(\"bias\", torch.zeros(num_features))\n self.register_buffer(\"running_mean\", torch.zeros(num_features))\n self.register_buffer(\"running_var\", torch.ones(num_features))\n\n def _load_from_state_dict(\n self,\n state_dict: dict,\n prefix: str,\n local_metadata: dict,\n strict: bool,\n missing_keys: List[str],\n unexpected_keys: List[str],\n error_msgs: List[str],\n ):\n num_batches_tracked_key = prefix + 'num_batches_tracked'\n if num_batches_tracked_key in state_dict:\n del state_dict[num_batches_tracked_key]\n\n super(FrozenBatchNorm2d, self)._load_from_state_dict(\n state_dict, prefix, local_metadata, strict,\n missing_keys, unexpected_keys, error_msgs)\n\n def forward(self, x: Tensor) -> Tensor:\n # move reshapes to the beginning\n # to make it fuser-friendly\n w = self.weight.reshape(1, -1, 1, 1)\n b = self.bias.reshape(1, -1, 1, 1)\n rv = self.running_var.reshape(1, -1, 1, 1)\n rm = self.running_mean.reshape(1, -1, 1, 1)\n scale = w * (rv + self.eps).rsqrt()\n bias = b - rm * scale\n return x * scale + bias\n\n def __repr__(self) -> str:\n return f\"{self.__class__.__name__}({self.weight.shape[0]}, eps={self.eps})\"\n", "path": "torchvision/ops/misc.py"}], "after_files": [{"content": "\"\"\"\nhelper class that supports empty tensors on some nn functions.\n\nIdeally, add support directly in PyTorch to empty tensors in\nthose functions.\n\nThis can be removed once https://github.com/pytorch/pytorch/issues/12013\nis implemented\n\"\"\"\n\nimport warnings\nimport torch\nfrom torch import Tensor, Size\nfrom torch.jit.annotations import List, Optional, Tuple\n\n\nclass Conv2d(torch.nn.Conv2d):\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n warnings.warn(\n \"torchvision.ops.misc.Conv2d is deprecated and will be \"\n \"removed in future versions, use torch.nn.Conv2d instead.\", FutureWarning)\n\n\nclass ConvTranspose2d(torch.nn.ConvTranspose2d):\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n warnings.warn(\n \"torchvision.ops.misc.ConvTranspose2d is deprecated and will be \"\n \"removed in future versions, use torch.nn.ConvTranspose2d instead.\", FutureWarning)\n\n\nclass BatchNorm2d(torch.nn.BatchNorm2d):\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n warnings.warn(\n \"torchvision.ops.misc.BatchNorm2d is deprecated and will be \"\n \"removed in future versions, use torch.nn.BatchNorm2d instead.\", FutureWarning)\n\n\ninterpolate = torch.nn.functional.interpolate\n\n\n# This is not in nn\nclass FrozenBatchNorm2d(torch.nn.Module):\n \"\"\"\n BatchNorm2d where the batch statistics and the affine parameters\n are fixed\n \"\"\"\n\n def __init__(\n self,\n num_features: int,\n eps: float = 1e-5,\n n: Optional[int] = None,\n ):\n # n=None for backward-compatibility\n if n is not None:\n warnings.warn(\"`n` argument is deprecated and has been renamed `num_features`\",\n DeprecationWarning)\n num_features = n\n super(FrozenBatchNorm2d, self).__init__()\n self.eps = eps\n self.register_buffer(\"weight\", torch.ones(num_features))\n self.register_buffer(\"bias\", torch.zeros(num_features))\n self.register_buffer(\"running_mean\", torch.zeros(num_features))\n self.register_buffer(\"running_var\", torch.ones(num_features))\n\n def _load_from_state_dict(\n self,\n state_dict: dict,\n prefix: str,\n local_metadata: dict,\n strict: bool,\n missing_keys: List[str],\n unexpected_keys: List[str],\n error_msgs: List[str],\n ):\n num_batches_tracked_key = prefix + 'num_batches_tracked'\n if num_batches_tracked_key in state_dict:\n del state_dict[num_batches_tracked_key]\n\n super(FrozenBatchNorm2d, self)._load_from_state_dict(\n state_dict, prefix, local_metadata, strict,\n missing_keys, unexpected_keys, error_msgs)\n\n def forward(self, x: Tensor) -> Tensor:\n # move reshapes to the beginning\n # to make it fuser-friendly\n w = self.weight.reshape(1, -1, 1, 1)\n b = self.bias.reshape(1, -1, 1, 1)\n rv = self.running_var.reshape(1, -1, 1, 1)\n rm = self.running_mean.reshape(1, -1, 1, 1)\n scale = w * (rv + self.eps).rsqrt()\n bias = b - rm * scale\n return x * scale + bias\n\n def __repr__(self) -> str:\n return f\"{self.__class__.__name__}({self.weight.shape[0]}, eps={self.eps})\"\n", "path": "torchvision/ops/misc.py"}]}
| 1,742 | 107 |
gh_patches_debug_17358
|
rasdani/github-patches
|
git_diff
|
weecology__retriever-548
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
download_only w/path fails to use path argument when checking for file
When `download_only` checks to see if the file already exists before copying it, it ignores the path argument. This means that:
```
retriever download MoM2003 -p testdata
```
will keep overwriting the file in `testdata` if it exists, and it will not copy the file to `testdata` if the file exists in `.`.
Fixes this is probably just a little logic improvement in the `final_cleanup` function of `download_only`.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `engines/download_only.py`
Content:
```
1 from __future__ import print_function
2 from builtins import object
3 import os
4 import platform
5 import shutil
6 import inspect
7
8 from retriever.lib.engine import filename_from_url
9 from retriever.lib.models import Engine, no_cleanup
10 from retriever import DATA_DIR, HOME_DIR
11
12
13 class DummyConnection(object):
14
15 def cursor(self):
16 pass
17
18 def commit(self):
19 pass
20
21 def rollback(self):
22 pass
23
24 def close(self):
25 pass
26
27
28 class DummyCursor(DummyConnection):
29 pass
30
31
32 class engine(Engine):
33 """Engine instance for writing data to a CSV file."""
34 name = "Download Only"
35 abbreviation = "download"
36 required_opts = [("path",
37 "File path to copy data files",
38 "./"),
39 ("subdir",
40 "Keep the subdirectories for archived files",
41 False)
42 ]
43
44 def table_exists(self, dbname, tablename):
45 """Checks if the file to be downloaded already exists"""
46 try:
47 tablename = self.table_name(name=tablename, dbname=dbname)
48 return os.path.exists(tablename)
49 except:
50 return False
51
52 def get_connection(self):
53 """Gets the db connection."""
54 self.get_input()
55 return DummyConnection()
56
57 def final_cleanup(self):
58 """Copies downloaded files to desired directory
59
60 Copies the downloaded files into the chosen directory unless files with the same
61 name already exist in the directory.
62
63 """
64 if hasattr(self, "all_files"):
65 for file_name in self.all_files:
66 file_path, file_name_nopath = os.path.split(file_name)
67 subdir = os.path.split(file_path)[1] if self.opts['subdir'] else ''
68 dest_path = os.path.join(self.opts['path'], subdir)
69 if os.path.abspath(file_path) == os.path.abspath(os.path.join(DATA_DIR, subdir)):
70 print ("%s is already in the working directory" %
71 file_name_nopath)
72 print("Keeping existing copy.")
73 else:
74 print("Copying %s from %s" % (file_name_nopath, file_path))
75 if os.path.isdir(dest_path):
76 try:
77 shutil.copy(file_name, dest_path)
78 except:
79 print("Couldn't copy file to %s" % dest_path)
80 else:
81 try:
82 print("Creating directory %s" % dest_path)
83 os.makedirs(dest_path)
84 shutil.copy(file_name, dest_path)
85 except:
86 print("Couldn't create directory %s" % dest_path)
87 self.all_files = set()
88
89 def auto_create_table(self, table, url=None, filename=None, pk=None):
90 """Download the file if it doesn't exist"""
91 if url and not filename:
92 filename = filename_from_url(url)
93
94 if url and not self.find_file(filename):
95 # If the file doesn't exist, download it
96 self.download_file(url, filename)
97
98 def insert_data_from_url(self, url):
99 """Insert data from a web resource"""
100 filename = filename_from_url(url)
101 find = self.find_file(filename)
102 if not find:
103 self.create_raw_data_dir()
104 self.download_file(url, filename)
105
106 def find_file(self, filename):
107 """Checks for the given file and adds it to the list of all files"""
108 result = Engine.find_file(self, filename)
109 if not hasattr(self, "all_files"):
110 self.all_files = set()
111 if result:
112 self.all_files.add(result)
113 return result
114
115 def register_files(self, filenames):
116 """Identify a list of files to be moved by the download
117
118 When downloading archives with multiple files the engine needs to be
119 informed of all of the file names so that it can move them.
120
121 """
122 full_filenames = {self.find_file(filename) for filename in filenames
123 if self.find_file(filename)}
124 self.all_files = self.all_files.union(full_filenames)
125
126
127 # replace all other methods with a function that does nothing
128 def dummy_method(self, *args, **kwargs):
129 pass
130
131
132 methods = inspect.getmembers(engine, predicate=inspect.ismethod)
133 keep_methods = {'table_exists',
134 'get_connection',
135 'final_cleanup',
136 'auto_create_table',
137 'insert_data_from_url',
138 }
139 remove_methods = ['insert_data_from_file']
140 for name, method in methods:
141 if (name not in keep_methods and
142 'download' not in name and
143 'file' not in name and
144 'dir' not in name):
145 setattr(engine, name, dummy_method)
146 for name in remove_methods:
147 setattr(engine, name, dummy_method)
148
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/engines/download_only.py b/engines/download_only.py
--- a/engines/download_only.py
+++ b/engines/download_only.py
@@ -66,7 +66,9 @@
file_path, file_name_nopath = os.path.split(file_name)
subdir = os.path.split(file_path)[1] if self.opts['subdir'] else ''
dest_path = os.path.join(self.opts['path'], subdir)
- if os.path.abspath(file_path) == os.path.abspath(os.path.join(DATA_DIR, subdir)):
+ if os.path.isfile(os.path.join(dest_path, file_name_nopath)):
+ print ("File already exists at specified location")
+ elif os.path.abspath(file_path) == os.path.abspath(os.path.join(DATA_DIR, subdir)):
print ("%s is already in the working directory" %
file_name_nopath)
print("Keeping existing copy.")
|
{"golden_diff": "diff --git a/engines/download_only.py b/engines/download_only.py\n--- a/engines/download_only.py\n+++ b/engines/download_only.py\n@@ -66,7 +66,9 @@\n file_path, file_name_nopath = os.path.split(file_name)\n subdir = os.path.split(file_path)[1] if self.opts['subdir'] else ''\n dest_path = os.path.join(self.opts['path'], subdir)\n- if os.path.abspath(file_path) == os.path.abspath(os.path.join(DATA_DIR, subdir)):\n+ if os.path.isfile(os.path.join(dest_path, file_name_nopath)):\n+ print (\"File already exists at specified location\")\n+ elif os.path.abspath(file_path) == os.path.abspath(os.path.join(DATA_DIR, subdir)):\n print (\"%s is already in the working directory\" %\n file_name_nopath)\n print(\"Keeping existing copy.\")\n", "issue": "download_only w/path fails to use path argument when checking for file\nWhen `download_only` checks to see if the file already exists before copying it, it ignores the path argument. This means that:\n\n```\nretriever download MoM2003 -p testdata\n```\n\nwill keep overwriting the file in `testdata` if it exists, and it will not copy the file to `testdata` if the file exists in `.`.\n\nFixes this is probably just a little logic improvement in the `final_cleanup` function of `download_only`.\n\n", "before_files": [{"content": "from __future__ import print_function\nfrom builtins import object\nimport os\nimport platform\nimport shutil\nimport inspect\n\nfrom retriever.lib.engine import filename_from_url\nfrom retriever.lib.models import Engine, no_cleanup\nfrom retriever import DATA_DIR, HOME_DIR\n\n\nclass DummyConnection(object):\n\n def cursor(self):\n pass\n\n def commit(self):\n pass\n\n def rollback(self):\n pass\n\n def close(self):\n pass\n\n\nclass DummyCursor(DummyConnection):\n pass\n\n\nclass engine(Engine):\n \"\"\"Engine instance for writing data to a CSV file.\"\"\"\n name = \"Download Only\"\n abbreviation = \"download\"\n required_opts = [(\"path\",\n \"File path to copy data files\",\n \"./\"),\n (\"subdir\",\n \"Keep the subdirectories for archived files\",\n False)\n ]\n\n def table_exists(self, dbname, tablename):\n \"\"\"Checks if the file to be downloaded already exists\"\"\"\n try:\n tablename = self.table_name(name=tablename, dbname=dbname)\n return os.path.exists(tablename)\n except:\n return False\n\n def get_connection(self):\n \"\"\"Gets the db connection.\"\"\"\n self.get_input()\n return DummyConnection()\n\n def final_cleanup(self):\n \"\"\"Copies downloaded files to desired directory\n\n Copies the downloaded files into the chosen directory unless files with the same\n name already exist in the directory.\n\n \"\"\"\n if hasattr(self, \"all_files\"):\n for file_name in self.all_files:\n file_path, file_name_nopath = os.path.split(file_name)\n subdir = os.path.split(file_path)[1] if self.opts['subdir'] else ''\n dest_path = os.path.join(self.opts['path'], subdir)\n if os.path.abspath(file_path) == os.path.abspath(os.path.join(DATA_DIR, subdir)):\n print (\"%s is already in the working directory\" %\n file_name_nopath)\n print(\"Keeping existing copy.\")\n else:\n print(\"Copying %s from %s\" % (file_name_nopath, file_path))\n if os.path.isdir(dest_path):\n try:\n shutil.copy(file_name, dest_path)\n except:\n print(\"Couldn't copy file to %s\" % dest_path)\n else:\n try:\n print(\"Creating directory %s\" % dest_path)\n os.makedirs(dest_path)\n shutil.copy(file_name, dest_path)\n except:\n print(\"Couldn't create directory %s\" % dest_path)\n self.all_files = set()\n\n def auto_create_table(self, table, url=None, filename=None, pk=None):\n \"\"\"Download the file if it doesn't exist\"\"\"\n if url and not filename:\n filename = filename_from_url(url)\n\n if url and not self.find_file(filename):\n # If the file doesn't exist, download it\n self.download_file(url, filename)\n\n def insert_data_from_url(self, url):\n \"\"\"Insert data from a web resource\"\"\"\n filename = filename_from_url(url)\n find = self.find_file(filename)\n if not find:\n self.create_raw_data_dir()\n self.download_file(url, filename)\n\n def find_file(self, filename):\n \"\"\"Checks for the given file and adds it to the list of all files\"\"\"\n result = Engine.find_file(self, filename)\n if not hasattr(self, \"all_files\"):\n self.all_files = set()\n if result:\n self.all_files.add(result)\n return result\n\n def register_files(self, filenames):\n \"\"\"Identify a list of files to be moved by the download\n\n When downloading archives with multiple files the engine needs to be\n informed of all of the file names so that it can move them.\n\n \"\"\"\n full_filenames = {self.find_file(filename) for filename in filenames\n if self.find_file(filename)}\n self.all_files = self.all_files.union(full_filenames)\n\n\n# replace all other methods with a function that does nothing\ndef dummy_method(self, *args, **kwargs):\n pass\n\n\nmethods = inspect.getmembers(engine, predicate=inspect.ismethod)\nkeep_methods = {'table_exists',\n 'get_connection',\n 'final_cleanup',\n 'auto_create_table',\n 'insert_data_from_url',\n }\nremove_methods = ['insert_data_from_file']\nfor name, method in methods:\n if (name not in keep_methods and\n 'download' not in name and\n 'file' not in name and\n 'dir' not in name):\n setattr(engine, name, dummy_method)\nfor name in remove_methods:\n setattr(engine, name, dummy_method)\n", "path": "engines/download_only.py"}], "after_files": [{"content": "from __future__ import print_function\nfrom builtins import object\nimport os\nimport platform\nimport shutil\nimport inspect\n\nfrom retriever.lib.engine import filename_from_url\nfrom retriever.lib.models import Engine, no_cleanup\nfrom retriever import DATA_DIR, HOME_DIR\n\n\nclass DummyConnection(object):\n\n def cursor(self):\n pass\n\n def commit(self):\n pass\n\n def rollback(self):\n pass\n\n def close(self):\n pass\n\n\nclass DummyCursor(DummyConnection):\n pass\n\n\nclass engine(Engine):\n \"\"\"Engine instance for writing data to a CSV file.\"\"\"\n name = \"Download Only\"\n abbreviation = \"download\"\n required_opts = [(\"path\",\n \"File path to copy data files\",\n \"./\"),\n (\"subdir\",\n \"Keep the subdirectories for archived files\",\n False)\n ]\n\n def table_exists(self, dbname, tablename):\n \"\"\"Checks if the file to be downloaded already exists\"\"\"\n try:\n tablename = self.table_name(name=tablename, dbname=dbname)\n return os.path.exists(tablename)\n except:\n return False\n\n def get_connection(self):\n \"\"\"Gets the db connection.\"\"\"\n self.get_input()\n return DummyConnection()\n\n def final_cleanup(self):\n \"\"\"Copies downloaded files to desired directory\n\n Copies the downloaded files into the chosen directory unless files with the same\n name already exist in the directory.\n\n \"\"\"\n if hasattr(self, \"all_files\"):\n for file_name in self.all_files:\n file_path, file_name_nopath = os.path.split(file_name)\n subdir = os.path.split(file_path)[1] if self.opts['subdir'] else ''\n dest_path = os.path.join(self.opts['path'], subdir)\n if os.path.isfile(os.path.join(dest_path, file_name_nopath)):\n print (\"File already exists at specified location\")\n elif os.path.abspath(file_path) == os.path.abspath(os.path.join(DATA_DIR, subdir)):\n print (\"%s is already in the working directory\" %\n file_name_nopath)\n print(\"Keeping existing copy.\")\n else:\n print(\"Copying %s from %s\" % (file_name_nopath, file_path))\n if os.path.isdir(dest_path):\n try:\n shutil.copy(file_name, dest_path)\n except:\n print(\"Couldn't copy file to %s\" % dest_path)\n else:\n try:\n print(\"Creating directory %s\" % dest_path)\n os.makedirs(dest_path)\n shutil.copy(file_name, dest_path)\n except:\n print(\"Couldn't create directory %s\" % dest_path)\n self.all_files = set()\n\n def auto_create_table(self, table, url=None, filename=None, pk=None):\n \"\"\"Download the file if it doesn't exist\"\"\"\n if url and not filename:\n filename = filename_from_url(url)\n\n if url and not self.find_file(filename):\n # If the file doesn't exist, download it\n self.download_file(url, filename)\n\n def insert_data_from_url(self, url):\n \"\"\"Insert data from a web resource\"\"\"\n filename = filename_from_url(url)\n find = self.find_file(filename)\n if not find:\n self.create_raw_data_dir()\n self.download_file(url, filename)\n\n def find_file(self, filename):\n \"\"\"Checks for the given file and adds it to the list of all files\"\"\"\n result = Engine.find_file(self, filename)\n if not hasattr(self, \"all_files\"):\n self.all_files = set()\n if result:\n self.all_files.add(result)\n return result\n\n def register_files(self, filenames):\n \"\"\"Identify a list of files to be moved by the download\n\n When downloading archives with multiple files the engine needs to be\n informed of all of the file names so that it can move them.\n\n \"\"\"\n full_filenames = {self.find_file(filename) for filename in filenames\n if self.find_file(filename)}\n self.all_files = self.all_files.union(full_filenames)\n\n\n# replace all other methods with a function that does nothing\ndef dummy_method(self, *args, **kwargs):\n pass\n\n\nmethods = inspect.getmembers(engine, predicate=inspect.ismethod)\nkeep_methods = {'table_exists',\n 'get_connection',\n 'final_cleanup',\n 'auto_create_table',\n 'insert_data_from_url',\n }\nremove_methods = ['insert_data_from_file']\nfor name, method in methods:\n if (name not in keep_methods and\n 'download' not in name and\n 'file' not in name and\n 'dir' not in name):\n setattr(engine, name, dummy_method)\nfor name in remove_methods:\n setattr(engine, name, dummy_method)\n", "path": "engines/download_only.py"}]}
| 1,689 | 192 |
gh_patches_debug_20458
|
rasdani/github-patches
|
git_diff
|
Zeroto521__my-data-toolkit-444
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
BUG: fix jupyer notebook can’t render
<!--
Thanks for contributing a pull request!
Please follow these standard acronyms to start the commit message:
- ENH: enhancement
- BUG: bug fix
- DOC: documentation
- TYP: type annotations
- TST: addition or modification of tests
- MAINT: maintenance commit (refactoring, typos, etc.)
- BLD: change related to building
- REL: related to releasing
- API: an (incompatible) API change
- DEP: deprecate something, or remove a deprecated object
- DEV: development tool or utility
- REV: revert an earlier commit
- PERF: performance improvement
- BOT: always commit via a bot
- CI: related to CI or CD
- CLN: Code cleanup
-->
- [x] closes #436 and https://my-data-toolkit.readthedocs.io/en/v0.0.10/guide/tips_about_getattr.html
- [ ] whatsnew entry
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `doc/source/conf.py`
Content:
```
1 # Configuration file for the Sphinx documentation builder.
2 #
3 # This file only contains a selection of the most common options.
4 # For a full list see the documentation:
5 # https://www.sphinx-doc.org/en/master/usage/configuration.html
6
7
8 # -- Project information -----------------------------------------------------
9
10 # The version info for the project you're documenting, acts as replacement for
11 # |version| and |release|, also used in various other places throughout the
12 # built documents.
13 from __future__ import annotations
14
15 import inspect
16 import os
17 import sys
18 from datetime import datetime
19
20 import dtoolkit
21
22 version = release = dtoolkit.__version__
23 version = version.replace(".dev0", "")
24 version = version.replace(".post0", "")
25
26
27 project = "DToolKit"
28 author = "Zero <@Zeroto521>"
29 copyright = f"2021-{datetime.now().year}, {author}" # pylint: disable=redefined-builtin
30 github_url = "https://github.com/Zeroto521/my-data-toolkit"
31
32
33 # -- General configuration ---------------------------------------------------
34
35 # Add any Sphinx extension module names here, as strings. They can be
36 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
37 # ones.
38 extensions = [
39 "myst_parser",
40 "numpydoc",
41 "sphinx.ext.autodoc",
42 "sphinx.ext.autosummary",
43 "sphinx.ext.autosectionlabel",
44 "sphinx.ext.extlinks",
45 "sphinx.ext.intersphinx",
46 "sphinx.ext.linkcode",
47 "sphinx_toggleprompt",
48 "IPython.sphinxext.ipython_console_highlighting",
49 "IPython.sphinxext.ipython_directive",
50 "nbsphinx",
51 ]
52
53 # The suffix of source filenames.
54 source_suffix = [".rst", ".md"]
55
56 # Add any paths that contain templates here, relative to this directory.
57 templates_path = ["_templates"]
58
59 # List of patterns, relative to source directory, that match files and
60 # directories to ignore when looking for source files.
61 # This pattern also affects html_static_path and html_extra_path.
62 exclude_patterns = []
63
64
65 # -- Options for HTML output -------------------------------------------------
66
67 # The theme to use for HTML and HTML Help pages. See the documentation for
68 # a list of builtin themes.
69 html_theme = "pydata_sphinx_theme"
70
71 # Theme options are theme-specific and customize the look and feel of a theme
72 # further. For a list of options available for each theme, see the
73 # documentation.
74 html_theme_options = {
75 "search_bar_position": "sidebar",
76 "github_url": github_url,
77 "icon_links": [
78 {
79 "name": "PyPI",
80 "url": "https://pypi.org/project/my-data-toolkit",
81 "icon": "fas fa-box",
82 },
83 ],
84 }
85
86 # Add any paths that contain custom static files (such as style sheets) here,
87 # relative to this directory. They are copied after the builtin static files,
88 # so a file named "default.css" will overwrite the builtin "default.css".
89 html_static_path = ["_static"]
90
91
92 # Add redirect for previously existing pages, each item is like `(from_old, to_new)`
93
94 moved_pages = [
95 ("py-modindex", "reference"),
96 ]
97
98 html_additional_pages = {page[0]: "redirect.html" for page in moved_pages}
99
100 html_context = {"redirects": dict(moved_pages)}
101
102
103 nbsphinx_prolog = r"""
104 {% set docname = env.doc2path(env.docname, base=None) %}
105
106 .. tip::
107
108 This page was generated from `{{ docname }}`__.
109
110 __ :ghlink:`my-data-toolkit/blob/main/doc/source/{{ docname }}`
111 """
112
113
114 # --Options for sphinx extensions -----------------------------------------------
115
116 # connect docs in other projects
117 intersphinx_mapping = {
118 "python": ("http://docs.python.org/", None),
119 "pandas": ("https://pandas.pydata.org/pandas-docs/stable/", None),
120 "numpy": ("https://numpy.org/doc/stable/", None),
121 "sklearn": ("https://scikit-learn.org/stable/", None),
122 "geopandas": ("https://geopandas.readthedocs.io/en/stable/", None),
123 "shapely": ("https://shapely.readthedocs.io/en/stable/", None),
124 "pyproj": ("https://pyproj4.github.io/pyproj/stable/", None),
125 "pygeos": ("https://pygeos.readthedocs.io/en/stable/", None),
126 }
127
128 # extlinks alias
129 extlinks = {
130 "issue": (f"{github_url}/issues/%s", "issue#"),
131 "pr": (f"{github_url}/issues/%s", "pr#"),
132 "user": (r"https://github.com/%s", "@"),
133 # github's link
134 "ghlink": (r"https://github.com/%s", None),
135 }
136
137 myst_enable_extensions = [
138 "colon_fence",
139 ]
140
141 autosummary_generate = True
142
143 nbsphinx_execute = "always"
144 nbsphinx_allow_errors = True
145
146
147 # based on pandas doc/source/conf.py
148 def linkcode_resolve(domain: str, info: dict[str, str]) -> str | None:
149 """
150 Determine the URL corresponding to Python object
151 """
152
153 if domain != "py":
154 return None
155
156 modname = info["module"]
157 fullname = info["fullname"]
158
159 submod = sys.modules.get(modname)
160 if submod is None:
161 return None
162
163 obj = submod
164 for part in fullname.split("."):
165 try:
166 obj = getattr(obj, part)
167 except AttributeError:
168 return None
169
170 try:
171 fn = inspect.getsourcefile(inspect.unwrap(obj))
172 except TypeError:
173 fn = None
174
175 if not fn:
176 return None
177
178 # to fix these doc doesn't exist in dtoolkit
179 if project.lower() not in fn:
180 return None
181
182 try:
183 source, lineno = inspect.getsourcelines(obj)
184 except OSError:
185 lineno = None
186
187 linespec = f"#L{lineno}-L{lineno + len(source) - 1}" if lineno else ""
188 fn = os.path.relpath(fn, start=os.path.dirname(dtoolkit.__file__))
189
190 base_link = f"{github_url}/blob/" + "{branch}" + f"/dtoolkit/{fn}{linespec}"
191 if "post" in version:
192 return base_link.format(branch="main")
193
194 return base_link.format(branch=f"v{version}")
195
```
Path: `dtoolkit/geoaccessor/accessor.py`
Content:
```
1 import geopandas as gpd
2 from pandas.core.accessor import _register_accessor
3 from pandas.util._decorators import doc
4
5
6 @doc(klass=":class:`~geopandas.GeoSeries`")
7 def register_geoseries_accessor(name: str):
8 """
9 Register a custom accessor on {klass} objects.
10
11 This is a temparatory solution to hook method into
12 :class:`~geopandas.GeoSeries` or :class:`~geopandas.GeoDataFrame`.
13 If `geopandas#1952`_ done, it would be removed from
14 :mod:`dtoolkit.geoaccessor`.
15
16 .. _geopandas#1952: :ghlink:`geopandas/geopandas/pull/1952`
17
18 Parameters
19 ----------
20 name : str
21 Name under which the accessor should be registered. A warning is issued
22 if this name conflicts with a preexisting attribute.
23
24 Returns
25 -------
26 callable
27 A class decorator.
28
29 See Also
30 --------
31 register_geoseries_accessor
32 register_geodataframe_accessor
33 dtoolkit.geoaccessor.register_geoseries_method
34 dtoolkit.geoaccessor.register_geodataframe_method
35
36 Notes
37 -----
38 When accessed, your accessor will be initialized with the geopandas object
39 the user is interacting with. So the signature must be::
40
41 def __init__(self, geopandas_object): # noqa: E999
42 ...
43
44 For consistency with geopandas methods, you should raise an
45 ``AttributeError`` if the data passed to your accessor has an incorrect
46 dtype.
47
48 >>> import geopandas as gpd
49 >>> gpd.GeoSeries().dt
50 Traceback (most recent call last):
51 ...
52 AttributeError: Can only use .dt accessor with datetimelike values
53
54 Examples
55 --------
56 In your library code::
57
58 from pygeos import count_coordinates, from_shapely
59
60 @register_geodataframe_accessor("coords")
61 @register_geoseries_accessor("coords")
62 class CoordinateAccessor:
63 def __init__(self, gpd_obj):
64 self._obj = gpd_obj
65 self.geometry = gpd_obj.geometry
66
67 @property
68 def count_coordinates(self):
69 # Counts the number of coordinate pairs in geometry
70
71 return self.geometry.apply(count_coordinates(from_shapely(x)))
72
73 Back in an interactive IPython session:
74
75 .. code-block:: ipython
76
77 In [1]: import geopandas as gpd
78
79 In [2]: s = gpd.GeoSeries.from_wkt(["POINT (0 0)", "POINT (1 1)", None])
80
81 In [3]: s
82 Out[3]:
83 0 POINT (0.00000 0.00000)
84 1 POINT (1.00000 1.00000)
85 2 None
86 dtype: geometry
87
88 In [4]: s.coords.count_coordinates
89 Out[4]:
90 0 1
91 1 1
92 2 0
93 dtype: int64
94
95 In [5]: d = s.to_frame("geometry")
96 Out[5]:
97 geometry
98 0 POINT (0.00000 0.00000)
99 1 POINT (1.00000 1.00000)
100 2 None
101
102 In [6]: d.coords.count_coordinates
103 Out[6]:
104 0 1
105 1 1
106 2 0
107 Name: geometry, dtype: int64
108 """
109
110 return _register_accessor(name, gpd.GeoSeries)
111
112
113 @doc(register_geoseries_accessor, klass=":class:`~geopandas.GeoDataFrame`")
114 def register_geodataframe_accessor(name: str):
115
116 return _register_accessor(name, gpd.GeoDataFrame)
117
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/doc/source/conf.py b/doc/source/conf.py
--- a/doc/source/conf.py
+++ b/doc/source/conf.py
@@ -107,7 +107,7 @@
This page was generated from `{{ docname }}`__.
- __ :ghlink:`my-data-toolkit/blob/main/doc/source/{{ docname }}`
+ __ https://github.com/zeroto521/my-data-toolkit/blob/main/doc/source/{{ docname }}
"""
@@ -130,8 +130,6 @@
"issue": (f"{github_url}/issues/%s", "issue#"),
"pr": (f"{github_url}/issues/%s", "pr#"),
"user": (r"https://github.com/%s", "@"),
- # github's link
- "ghlink": (r"https://github.com/%s", None),
}
myst_enable_extensions = [
diff --git a/dtoolkit/geoaccessor/accessor.py b/dtoolkit/geoaccessor/accessor.py
--- a/dtoolkit/geoaccessor/accessor.py
+++ b/dtoolkit/geoaccessor/accessor.py
@@ -13,7 +13,7 @@
If `geopandas#1952`_ done, it would be removed from
:mod:`dtoolkit.geoaccessor`.
- .. _geopandas#1952: :ghlink:`geopandas/geopandas/pull/1952`
+ .. _geopandas#1952: https://github.com/geopandas/geopandas/pull/1952
Parameters
----------
|
{"golden_diff": "diff --git a/doc/source/conf.py b/doc/source/conf.py\n--- a/doc/source/conf.py\n+++ b/doc/source/conf.py\n@@ -107,7 +107,7 @@\n \n This page was generated from `{{ docname }}`__.\n \n- __ :ghlink:`my-data-toolkit/blob/main/doc/source/{{ docname }}`\n+ __ https://github.com/zeroto521/my-data-toolkit/blob/main/doc/source/{{ docname }}\n \"\"\"\n \n \n@@ -130,8 +130,6 @@\n \"issue\": (f\"{github_url}/issues/%s\", \"issue#\"),\n \"pr\": (f\"{github_url}/issues/%s\", \"pr#\"),\n \"user\": (r\"https://github.com/%s\", \"@\"),\n- # github's link\n- \"ghlink\": (r\"https://github.com/%s\", None),\n }\n \n myst_enable_extensions = [\ndiff --git a/dtoolkit/geoaccessor/accessor.py b/dtoolkit/geoaccessor/accessor.py\n--- a/dtoolkit/geoaccessor/accessor.py\n+++ b/dtoolkit/geoaccessor/accessor.py\n@@ -13,7 +13,7 @@\n If `geopandas#1952`_ done, it would be removed from\n :mod:`dtoolkit.geoaccessor`.\n \n- .. _geopandas#1952: :ghlink:`geopandas/geopandas/pull/1952`\n+ .. _geopandas#1952: https://github.com/geopandas/geopandas/pull/1952\n \n Parameters\n ----------\n", "issue": "BUG: fix jupyer notebook can\u2019t render\n<!--\r\nThanks for contributing a pull request!\r\n\r\nPlease follow these standard acronyms to start the commit message:\r\n\r\n- ENH: enhancement\r\n- BUG: bug fix\r\n- DOC: documentation\r\n- TYP: type annotations\r\n- TST: addition or modification of tests\r\n- MAINT: maintenance commit (refactoring, typos, etc.)\r\n- BLD: change related to building\r\n- REL: related to releasing\r\n- API: an (incompatible) API change\r\n- DEP: deprecate something, or remove a deprecated object\r\n- DEV: development tool or utility\r\n- REV: revert an earlier commit\r\n- PERF: performance improvement\r\n- BOT: always commit via a bot\r\n- CI: related to CI or CD\r\n- CLN: Code cleanup\r\n-->\r\n\r\n- [x] closes #436 and https://my-data-toolkit.readthedocs.io/en/v0.0.10/guide/tips_about_getattr.html\r\n- [ ] whatsnew entry\r\n\n", "before_files": [{"content": "# Configuration file for the Sphinx documentation builder.\n#\n# This file only contains a selection of the most common options.\n# For a full list see the documentation:\n# https://www.sphinx-doc.org/en/master/usage/configuration.html\n\n\n# -- Project information -----------------------------------------------------\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\nfrom __future__ import annotations\n\nimport inspect\nimport os\nimport sys\nfrom datetime import datetime\n\nimport dtoolkit\n\nversion = release = dtoolkit.__version__\nversion = version.replace(\".dev0\", \"\")\nversion = version.replace(\".post0\", \"\")\n\n\nproject = \"DToolKit\"\nauthor = \"Zero <@Zeroto521>\"\ncopyright = f\"2021-{datetime.now().year}, {author}\" # pylint: disable=redefined-builtin\ngithub_url = \"https://github.com/Zeroto521/my-data-toolkit\"\n\n\n# -- General configuration ---------------------------------------------------\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n \"myst_parser\",\n \"numpydoc\",\n \"sphinx.ext.autodoc\",\n \"sphinx.ext.autosummary\",\n \"sphinx.ext.autosectionlabel\",\n \"sphinx.ext.extlinks\",\n \"sphinx.ext.intersphinx\",\n \"sphinx.ext.linkcode\",\n \"sphinx_toggleprompt\",\n \"IPython.sphinxext.ipython_console_highlighting\",\n \"IPython.sphinxext.ipython_directive\",\n \"nbsphinx\",\n]\n\n# The suffix of source filenames.\nsource_suffix = [\".rst\", \".md\"]\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = [\"_templates\"]\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path.\nexclude_patterns = []\n\n\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\nhtml_theme = \"pydata_sphinx_theme\"\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\nhtml_theme_options = {\n \"search_bar_position\": \"sidebar\",\n \"github_url\": github_url,\n \"icon_links\": [\n {\n \"name\": \"PyPI\",\n \"url\": \"https://pypi.org/project/my-data-toolkit\",\n \"icon\": \"fas fa-box\",\n },\n ],\n}\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = [\"_static\"]\n\n\n# Add redirect for previously existing pages, each item is like `(from_old, to_new)`\n\nmoved_pages = [\n (\"py-modindex\", \"reference\"),\n]\n\nhtml_additional_pages = {page[0]: \"redirect.html\" for page in moved_pages}\n\nhtml_context = {\"redirects\": dict(moved_pages)}\n\n\nnbsphinx_prolog = r\"\"\"\n{% set docname = env.doc2path(env.docname, base=None) %}\n\n.. tip::\n\n This page was generated from `{{ docname }}`__.\n\n __ :ghlink:`my-data-toolkit/blob/main/doc/source/{{ docname }}`\n\"\"\"\n\n\n# --Options for sphinx extensions -----------------------------------------------\n\n# connect docs in other projects\nintersphinx_mapping = {\n \"python\": (\"http://docs.python.org/\", None),\n \"pandas\": (\"https://pandas.pydata.org/pandas-docs/stable/\", None),\n \"numpy\": (\"https://numpy.org/doc/stable/\", None),\n \"sklearn\": (\"https://scikit-learn.org/stable/\", None),\n \"geopandas\": (\"https://geopandas.readthedocs.io/en/stable/\", None),\n \"shapely\": (\"https://shapely.readthedocs.io/en/stable/\", None),\n \"pyproj\": (\"https://pyproj4.github.io/pyproj/stable/\", None),\n \"pygeos\": (\"https://pygeos.readthedocs.io/en/stable/\", None),\n}\n\n# extlinks alias\nextlinks = {\n \"issue\": (f\"{github_url}/issues/%s\", \"issue#\"),\n \"pr\": (f\"{github_url}/issues/%s\", \"pr#\"),\n \"user\": (r\"https://github.com/%s\", \"@\"),\n # github's link\n \"ghlink\": (r\"https://github.com/%s\", None),\n}\n\nmyst_enable_extensions = [\n \"colon_fence\",\n]\n\nautosummary_generate = True\n\nnbsphinx_execute = \"always\"\nnbsphinx_allow_errors = True\n\n\n# based on pandas doc/source/conf.py\ndef linkcode_resolve(domain: str, info: dict[str, str]) -> str | None:\n \"\"\"\n Determine the URL corresponding to Python object\n \"\"\"\n\n if domain != \"py\":\n return None\n\n modname = info[\"module\"]\n fullname = info[\"fullname\"]\n\n submod = sys.modules.get(modname)\n if submod is None:\n return None\n\n obj = submod\n for part in fullname.split(\".\"):\n try:\n obj = getattr(obj, part)\n except AttributeError:\n return None\n\n try:\n fn = inspect.getsourcefile(inspect.unwrap(obj))\n except TypeError:\n fn = None\n\n if not fn:\n return None\n\n # to fix these doc doesn't exist in dtoolkit\n if project.lower() not in fn:\n return None\n\n try:\n source, lineno = inspect.getsourcelines(obj)\n except OSError:\n lineno = None\n\n linespec = f\"#L{lineno}-L{lineno + len(source) - 1}\" if lineno else \"\"\n fn = os.path.relpath(fn, start=os.path.dirname(dtoolkit.__file__))\n\n base_link = f\"{github_url}/blob/\" + \"{branch}\" + f\"/dtoolkit/{fn}{linespec}\"\n if \"post\" in version:\n return base_link.format(branch=\"main\")\n\n return base_link.format(branch=f\"v{version}\")\n", "path": "doc/source/conf.py"}, {"content": "import geopandas as gpd\nfrom pandas.core.accessor import _register_accessor\nfrom pandas.util._decorators import doc\n\n\n@doc(klass=\":class:`~geopandas.GeoSeries`\")\ndef register_geoseries_accessor(name: str):\n \"\"\"\n Register a custom accessor on {klass} objects.\n\n This is a temparatory solution to hook method into\n :class:`~geopandas.GeoSeries` or :class:`~geopandas.GeoDataFrame`.\n If `geopandas#1952`_ done, it would be removed from\n :mod:`dtoolkit.geoaccessor`.\n\n .. _geopandas#1952: :ghlink:`geopandas/geopandas/pull/1952`\n\n Parameters\n ----------\n name : str\n Name under which the accessor should be registered. A warning is issued\n if this name conflicts with a preexisting attribute.\n\n Returns\n -------\n callable\n A class decorator.\n\n See Also\n --------\n register_geoseries_accessor\n register_geodataframe_accessor\n dtoolkit.geoaccessor.register_geoseries_method\n dtoolkit.geoaccessor.register_geodataframe_method\n\n Notes\n -----\n When accessed, your accessor will be initialized with the geopandas object\n the user is interacting with. So the signature must be::\n\n def __init__(self, geopandas_object): # noqa: E999\n ...\n\n For consistency with geopandas methods, you should raise an\n ``AttributeError`` if the data passed to your accessor has an incorrect\n dtype.\n\n >>> import geopandas as gpd\n >>> gpd.GeoSeries().dt\n Traceback (most recent call last):\n ...\n AttributeError: Can only use .dt accessor with datetimelike values\n\n Examples\n --------\n In your library code::\n\n from pygeos import count_coordinates, from_shapely\n\n @register_geodataframe_accessor(\"coords\")\n @register_geoseries_accessor(\"coords\")\n class CoordinateAccessor:\n def __init__(self, gpd_obj):\n self._obj = gpd_obj\n self.geometry = gpd_obj.geometry\n\n @property\n def count_coordinates(self):\n # Counts the number of coordinate pairs in geometry\n\n return self.geometry.apply(count_coordinates(from_shapely(x)))\n\n Back in an interactive IPython session:\n\n .. code-block:: ipython\n\n In [1]: import geopandas as gpd\n\n In [2]: s = gpd.GeoSeries.from_wkt([\"POINT (0 0)\", \"POINT (1 1)\", None])\n\n In [3]: s\n Out[3]:\n 0 POINT (0.00000 0.00000)\n 1 POINT (1.00000 1.00000)\n 2 None\n dtype: geometry\n\n In [4]: s.coords.count_coordinates\n Out[4]:\n 0 1\n 1 1\n 2 0\n dtype: int64\n\n In [5]: d = s.to_frame(\"geometry\")\n Out[5]:\n geometry\n 0 POINT (0.00000 0.00000)\n 1 POINT (1.00000 1.00000)\n 2 None\n\n In [6]: d.coords.count_coordinates\n Out[6]:\n 0 1\n 1 1\n 2 0\n Name: geometry, dtype: int64\n \"\"\"\n\n return _register_accessor(name, gpd.GeoSeries)\n\n\n@doc(register_geoseries_accessor, klass=\":class:`~geopandas.GeoDataFrame`\")\ndef register_geodataframe_accessor(name: str):\n\n return _register_accessor(name, gpd.GeoDataFrame)\n", "path": "dtoolkit/geoaccessor/accessor.py"}], "after_files": [{"content": "# Configuration file for the Sphinx documentation builder.\n#\n# This file only contains a selection of the most common options.\n# For a full list see the documentation:\n# https://www.sphinx-doc.org/en/master/usage/configuration.html\n\n\n# -- Project information -----------------------------------------------------\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\nfrom __future__ import annotations\n\nimport inspect\nimport os\nimport sys\nfrom datetime import datetime\n\nimport dtoolkit\n\nversion = release = dtoolkit.__version__\nversion = version.replace(\".dev0\", \"\")\nversion = version.replace(\".post0\", \"\")\n\n\nproject = \"DToolKit\"\nauthor = \"Zero <@Zeroto521>\"\ncopyright = f\"2021-{datetime.now().year}, {author}\" # pylint: disable=redefined-builtin\ngithub_url = \"https://github.com/Zeroto521/my-data-toolkit\"\n\n\n# -- General configuration ---------------------------------------------------\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n \"myst_parser\",\n \"numpydoc\",\n \"sphinx.ext.autodoc\",\n \"sphinx.ext.autosummary\",\n \"sphinx.ext.autosectionlabel\",\n \"sphinx.ext.extlinks\",\n \"sphinx.ext.intersphinx\",\n \"sphinx.ext.linkcode\",\n \"sphinx_toggleprompt\",\n \"IPython.sphinxext.ipython_console_highlighting\",\n \"IPython.sphinxext.ipython_directive\",\n \"nbsphinx\",\n]\n\n# The suffix of source filenames.\nsource_suffix = [\".rst\", \".md\"]\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = [\"_templates\"]\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path.\nexclude_patterns = []\n\n\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\nhtml_theme = \"pydata_sphinx_theme\"\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\nhtml_theme_options = {\n \"search_bar_position\": \"sidebar\",\n \"github_url\": github_url,\n \"icon_links\": [\n {\n \"name\": \"PyPI\",\n \"url\": \"https://pypi.org/project/my-data-toolkit\",\n \"icon\": \"fas fa-box\",\n },\n ],\n}\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = [\"_static\"]\n\n\n# Add redirect for previously existing pages, each item is like `(from_old, to_new)`\n\nmoved_pages = [\n (\"py-modindex\", \"reference\"),\n]\n\nhtml_additional_pages = {page[0]: \"redirect.html\" for page in moved_pages}\n\nhtml_context = {\"redirects\": dict(moved_pages)}\n\n\nnbsphinx_prolog = r\"\"\"\n{% set docname = env.doc2path(env.docname, base=None) %}\n\n.. tip::\n\n This page was generated from `{{ docname }}`__.\n\n __ https://github.com/zeroto521/my-data-toolkit/blob/main/doc/source/{{ docname }}\n\"\"\"\n\n\n# --Options for sphinx extensions -----------------------------------------------\n\n# connect docs in other projects\nintersphinx_mapping = {\n \"python\": (\"http://docs.python.org/\", None),\n \"pandas\": (\"https://pandas.pydata.org/pandas-docs/stable/\", None),\n \"numpy\": (\"https://numpy.org/doc/stable/\", None),\n \"sklearn\": (\"https://scikit-learn.org/stable/\", None),\n \"geopandas\": (\"https://geopandas.readthedocs.io/en/stable/\", None),\n \"shapely\": (\"https://shapely.readthedocs.io/en/stable/\", None),\n \"pyproj\": (\"https://pyproj4.github.io/pyproj/stable/\", None),\n \"pygeos\": (\"https://pygeos.readthedocs.io/en/stable/\", None),\n}\n\n# extlinks alias\nextlinks = {\n \"issue\": (f\"{github_url}/issues/%s\", \"issue#\"),\n \"pr\": (f\"{github_url}/issues/%s\", \"pr#\"),\n \"user\": (r\"https://github.com/%s\", \"@\"),\n}\n\nmyst_enable_extensions = [\n \"colon_fence\",\n]\n\nautosummary_generate = True\n\nnbsphinx_execute = \"always\"\nnbsphinx_allow_errors = True\n\n\n# based on pandas doc/source/conf.py\ndef linkcode_resolve(domain: str, info: dict[str, str]) -> str | None:\n \"\"\"\n Determine the URL corresponding to Python object\n \"\"\"\n\n if domain != \"py\":\n return None\n\n modname = info[\"module\"]\n fullname = info[\"fullname\"]\n\n submod = sys.modules.get(modname)\n if submod is None:\n return None\n\n obj = submod\n for part in fullname.split(\".\"):\n try:\n obj = getattr(obj, part)\n except AttributeError:\n return None\n\n try:\n fn = inspect.getsourcefile(inspect.unwrap(obj))\n except TypeError:\n fn = None\n\n if not fn:\n return None\n\n # to fix these doc doesn't exist in dtoolkit\n if project.lower() not in fn:\n return None\n\n try:\n source, lineno = inspect.getsourcelines(obj)\n except OSError:\n lineno = None\n\n linespec = f\"#L{lineno}-L{lineno + len(source) - 1}\" if lineno else \"\"\n fn = os.path.relpath(fn, start=os.path.dirname(dtoolkit.__file__))\n\n base_link = f\"{github_url}/blob/\" + \"{branch}\" + f\"/dtoolkit/{fn}{linespec}\"\n if \"post\" in version:\n return base_link.format(branch=\"main\")\n\n return base_link.format(branch=f\"v{version}\")\n", "path": "doc/source/conf.py"}, {"content": "import geopandas as gpd\nfrom pandas.core.accessor import _register_accessor\nfrom pandas.util._decorators import doc\n\n\n@doc(klass=\":class:`~geopandas.GeoSeries`\")\ndef register_geoseries_accessor(name: str):\n \"\"\"\n Register a custom accessor on {klass} objects.\n\n This is a temparatory solution to hook method into\n :class:`~geopandas.GeoSeries` or :class:`~geopandas.GeoDataFrame`.\n If `geopandas#1952`_ done, it would be removed from\n :mod:`dtoolkit.geoaccessor`.\n\n .. _geopandas#1952: https://github.com/geopandas/geopandas/pull/1952\n\n Parameters\n ----------\n name : str\n Name under which the accessor should be registered. A warning is issued\n if this name conflicts with a preexisting attribute.\n\n Returns\n -------\n callable\n A class decorator.\n\n See Also\n --------\n register_geoseries_accessor\n register_geodataframe_accessor\n dtoolkit.geoaccessor.register_geoseries_method\n dtoolkit.geoaccessor.register_geodataframe_method\n\n Notes\n -----\n When accessed, your accessor will be initialized with the geopandas object\n the user is interacting with. So the signature must be::\n\n def __init__(self, geopandas_object): # noqa: E999\n ...\n\n For consistency with geopandas methods, you should raise an\n ``AttributeError`` if the data passed to your accessor has an incorrect\n dtype.\n\n >>> import geopandas as gpd\n >>> gpd.GeoSeries().dt\n Traceback (most recent call last):\n ...\n AttributeError: Can only use .dt accessor with datetimelike values\n\n Examples\n --------\n In your library code::\n\n from pygeos import count_coordinates, from_shapely\n\n @register_geodataframe_accessor(\"coords\")\n @register_geoseries_accessor(\"coords\")\n class CoordinateAccessor:\n def __init__(self, gpd_obj):\n self._obj = gpd_obj\n self.geometry = gpd_obj.geometry\n\n @property\n def count_coordinates(self):\n # Counts the number of coordinate pairs in geometry\n\n return self.geometry.apply(count_coordinates(from_shapely(x)))\n\n Back in an interactive IPython session:\n\n .. code-block:: ipython\n\n In [1]: import geopandas as gpd\n\n In [2]: s = gpd.GeoSeries.from_wkt([\"POINT (0 0)\", \"POINT (1 1)\", None])\n\n In [3]: s\n Out[3]:\n 0 POINT (0.00000 0.00000)\n 1 POINT (1.00000 1.00000)\n 2 None\n dtype: geometry\n\n In [4]: s.coords.count_coordinates\n Out[4]:\n 0 1\n 1 1\n 2 0\n dtype: int64\n\n In [5]: d = s.to_frame(\"geometry\")\n Out[5]:\n geometry\n 0 POINT (0.00000 0.00000)\n 1 POINT (1.00000 1.00000)\n 2 None\n\n In [6]: d.coords.count_coordinates\n Out[6]:\n 0 1\n 1 1\n 2 0\n Name: geometry, dtype: int64\n \"\"\"\n\n return _register_accessor(name, gpd.GeoSeries)\n\n\n@doc(register_geoseries_accessor, klass=\":class:`~geopandas.GeoDataFrame`\")\ndef register_geodataframe_accessor(name: str):\n\n return _register_accessor(name, gpd.GeoDataFrame)\n", "path": "dtoolkit/geoaccessor/accessor.py"}]}
| 3,524 | 365 |
gh_patches_debug_6830
|
rasdani/github-patches
|
git_diff
|
platformsh__platformsh-docs-2432
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
🐛 Allow searching for code strings with separators
### Where on docs.platform.sh should be changed?
The search
### What exactly should be updated?
Searching for strings with separators like `X-Frame-Options` and `memory_ratio` don't show the results for pages that have those strings directly. Putting quotes around the strings doesn't help.
We'd like people to be able to get info on specific properties and strings, so the search should return these results.
### Additional context
_No response_
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `search/main.py`
Content:
```
1 import os
2 import glob
3 import json
4 import meilisearch
5 from platformshconfig import Config
6
7 class Search:
8 def __init__(self):
9 self.default = {
10 "host": "http://127.0.0.1",
11 "key": None,
12 "port": 7700
13 }
14
15 self.scrape_dir = "output"
16 self.scrape_config = "config/scrape.json"
17 self.docs_index = "docs"
18 self.primaryKey = "documentId"
19 self.index_name = "Docs"
20
21 # Below are Platform.sh custom settings for how the search engine functions.
22
23 # Data available to the dropdown React app in docs, used to fill out autocomplete results.
24 self.displayed_attributes = ['keywords', 'title', 'text', 'url', 'site', 'section']
25 # Data actually searchable by our queries.
26 self.searchable_attributes = ['keywords', 'title', 'pageUrl', 'section', 'text', 'url']
27
28 # Show results for one query with the listed pages, when they by default would not show up as best results.
29 # Note: these aren't automatically two-way, which is why they're all defined twice.
30 self.synonyms = {
31 "cron": ["crons"],
32 "crons": ["cron tasks", "cron jobs"],
33 "e-mail": ["email"],
34 "routes.yaml": ["routes"],
35 "routes": ["routes.yaml"],
36 "services": ["services.yaml"],
37 "services.yaml": ["services"],
38 "application": [".platform.app.yaml", "app.yaml", "applications.yaml"],
39 ".platform.app.yaml": ["application"],
40 "app.yaml": ["application"],
41 "applications.yaml": ["application", "multi-app"],
42 "multi-app": ["applications.yaml"],
43 "regions": ["public ip addresses"],
44 "public ip addresses": ["regions"],
45 "ssl": ["https", "tls"],
46 "https": ["ssl"],
47 "auth": ["authentication", "access control"], # Only needs to be one way since we don't use "auth" in the docs
48 }
49
50 # Ranking rules:
51 #
52 # - Default order: ["words", "typo", "proximity", "attribute", "sort", "exactness"]
53 #
54 # - words: number of times query is in document (greater number gets priority)
55 # - typo: fewer typos > more typos
56 # - proximity: smaller distance between multiple occurences of query in same document > larger distances
57 # - attribute: sorted according to order of importance of attributes (searchable_attributes). terms in
58 # more important attributes first.
59 # - sort: queries are sorted at query time
60 # - exactness: similarity of matched words in document with query
61
62 self.ranking_rules = ["rank:asc", "attribute", "typo", "words", "proximity", "exactness"]
63
64 self.updated_settings = {
65 "rankingRules": self.ranking_rules,
66 "searchableAttributes": self.searchable_attributes,
67 "displayedAttributes": self.displayed_attributes
68 }
69
70 # Group results by page
71 self.distinct_attribute = "pageUrl"
72
73 def getConnectionString(self):
74 """
75 Sets the Meilisearch host string, depending on the environment.
76
77 Returns:
78 string: Meilisearch host string.
79 """
80 if os.environ.get('PORT'):
81 return "{}:{}".format(self.default["host"], os.environ['PORT'])
82 else:
83 return "{}:{}".format(self.default["host"], self.default["port"])
84
85 def getMasterKey(self):
86 """
87 Retrieves the Meilisearch master key, either from the Platform.sh environment or locally.
88 """
89 config = Config()
90 if config.is_valid_platform():
91 return config.projectEntropy
92 elif os.environ.get("MEILI_MASTER_KEY"):
93 return os.environ["MEILI_MASTER_KEY"]
94 else:
95 return self.default["key"]
96
97 def add_documents(self, index):
98 """
99 Cycle through the individual site indexes in /outputs so their individual documents can be added to Meilisearch.
100 """
101 documents = [f for f in glob.glob("{}/*.json".format(self.scrape_dir))]
102 for doc in documents:
103 self.add(doc, index)
104
105 def add(self, doc, index):
106 """
107 Add an individual site's index to the Meilisearch service.
108 """
109 with open(doc) as scraped_index:
110 data = json.load(scraped_index)
111 index.add_documents(data)
112
113 def update(self):
114 """
115 Updates the Meilisearch index.
116 """
117 # Create a Meilisearch client.
118 client = meilisearch.Client(self.getConnectionString(), self.getMasterKey())
119
120 # Delete previous index
121 if len(client.get_indexes()):
122 client.index(self.docs_index).delete()
123
124 # Create a new index
125 create_index_task = client.create_index(uid=self.docs_index, options={'primaryKey': self.primaryKey, 'uid': self.index_name})
126
127 client.wait_for_task(create_index_task['uid'])
128
129 index = client.get_index(create_index_task['indexUid'])
130
131 # Add synonyms for the index
132 index.update_synonyms(self.synonyms)
133
134 # Update its settings: what can be searched, what's displayable, and how results should be ranked.
135 index.update_settings(self.updated_settings)
136
137 # Update distinct attribute.
138 index.update_distinct_attribute(self.distinct_attribute)
139
140 # Add documents to the index
141 self.add_documents(index)
142
143 if __name__ == "__main__":
144 meili = Search()
145 meili.update()
146
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/search/main.py b/search/main.py
--- a/search/main.py
+++ b/search/main.py
@@ -59,7 +59,7 @@
# - sort: queries are sorted at query time
# - exactness: similarity of matched words in document with query
- self.ranking_rules = ["rank:asc", "attribute", "typo", "words", "proximity", "exactness"]
+ self.ranking_rules = ["rank:asc", "exactness", "attribute", "proximity", "typo", "words"]
self.updated_settings = {
"rankingRules": self.ranking_rules,
|
{"golden_diff": "diff --git a/search/main.py b/search/main.py\n--- a/search/main.py\n+++ b/search/main.py\n@@ -59,7 +59,7 @@\n # - sort: queries are sorted at query time\n # - exactness: similarity of matched words in document with query\n \n- self.ranking_rules = [\"rank:asc\", \"attribute\", \"typo\", \"words\", \"proximity\", \"exactness\"]\n+ self.ranking_rules = [\"rank:asc\", \"exactness\", \"attribute\", \"proximity\", \"typo\", \"words\"]\n \n self.updated_settings = {\n \"rankingRules\": self.ranking_rules,\n", "issue": "\ud83d\udc1b Allow searching for code strings with separators\n### Where on docs.platform.sh should be changed?\r\n\r\nThe search\r\n\r\n### What exactly should be updated?\r\n\r\nSearching for strings with separators like `X-Frame-Options` and `memory_ratio` don't show the results for pages that have those strings directly. Putting quotes around the strings doesn't help.\r\n\r\nWe'd like people to be able to get info on specific properties and strings, so the search should return these results.\r\n\r\n### Additional context\r\n\r\n_No response_\n", "before_files": [{"content": "import os\nimport glob\nimport json\nimport meilisearch\nfrom platformshconfig import Config\n\nclass Search:\n def __init__(self):\n self.default = {\n \"host\": \"http://127.0.0.1\",\n \"key\": None,\n \"port\": 7700\n }\n\n self.scrape_dir = \"output\"\n self.scrape_config = \"config/scrape.json\"\n self.docs_index = \"docs\"\n self.primaryKey = \"documentId\"\n self.index_name = \"Docs\"\n\n # Below are Platform.sh custom settings for how the search engine functions.\n\n # Data available to the dropdown React app in docs, used to fill out autocomplete results.\n self.displayed_attributes = ['keywords', 'title', 'text', 'url', 'site', 'section']\n # Data actually searchable by our queries.\n self.searchable_attributes = ['keywords', 'title', 'pageUrl', 'section', 'text', 'url']\n\n # Show results for one query with the listed pages, when they by default would not show up as best results.\n # Note: these aren't automatically two-way, which is why they're all defined twice.\n self.synonyms = {\n \"cron\": [\"crons\"],\n \"crons\": [\"cron tasks\", \"cron jobs\"],\n \"e-mail\": [\"email\"],\n \"routes.yaml\": [\"routes\"],\n \"routes\": [\"routes.yaml\"],\n \"services\": [\"services.yaml\"],\n \"services.yaml\": [\"services\"],\n \"application\": [\".platform.app.yaml\", \"app.yaml\", \"applications.yaml\"],\n \".platform.app.yaml\": [\"application\"],\n \"app.yaml\": [\"application\"],\n \"applications.yaml\": [\"application\", \"multi-app\"],\n \"multi-app\": [\"applications.yaml\"],\n \"regions\": [\"public ip addresses\"],\n \"public ip addresses\": [\"regions\"],\n \"ssl\": [\"https\", \"tls\"],\n \"https\": [\"ssl\"],\n \"auth\": [\"authentication\", \"access control\"], # Only needs to be one way since we don't use \"auth\" in the docs\n }\n\n # Ranking rules:\n #\n # - Default order: [\"words\", \"typo\", \"proximity\", \"attribute\", \"sort\", \"exactness\"]\n #\n # - words: number of times query is in document (greater number gets priority)\n # - typo: fewer typos > more typos\n # - proximity: smaller distance between multiple occurences of query in same document > larger distances\n # - attribute: sorted according to order of importance of attributes (searchable_attributes). terms in\n # more important attributes first.\n # - sort: queries are sorted at query time\n # - exactness: similarity of matched words in document with query\n\n self.ranking_rules = [\"rank:asc\", \"attribute\", \"typo\", \"words\", \"proximity\", \"exactness\"]\n\n self.updated_settings = {\n \"rankingRules\": self.ranking_rules,\n \"searchableAttributes\": self.searchable_attributes,\n \"displayedAttributes\": self.displayed_attributes\n }\n\n # Group results by page\n self.distinct_attribute = \"pageUrl\"\n\n def getConnectionString(self):\n \"\"\"\n Sets the Meilisearch host string, depending on the environment.\n\n Returns:\n string: Meilisearch host string.\n \"\"\"\n if os.environ.get('PORT'):\n return \"{}:{}\".format(self.default[\"host\"], os.environ['PORT'])\n else:\n return \"{}:{}\".format(self.default[\"host\"], self.default[\"port\"])\n\n def getMasterKey(self):\n \"\"\"\n Retrieves the Meilisearch master key, either from the Platform.sh environment or locally.\n \"\"\"\n config = Config()\n if config.is_valid_platform():\n return config.projectEntropy\n elif os.environ.get(\"MEILI_MASTER_KEY\"):\n return os.environ[\"MEILI_MASTER_KEY\"]\n else:\n return self.default[\"key\"]\n\n def add_documents(self, index):\n \"\"\"\n Cycle through the individual site indexes in /outputs so their individual documents can be added to Meilisearch.\n \"\"\"\n documents = [f for f in glob.glob(\"{}/*.json\".format(self.scrape_dir))]\n for doc in documents:\n self.add(doc, index)\n\n def add(self, doc, index):\n \"\"\"\n Add an individual site's index to the Meilisearch service.\n \"\"\"\n with open(doc) as scraped_index:\n data = json.load(scraped_index)\n index.add_documents(data)\n\n def update(self):\n \"\"\"\n Updates the Meilisearch index.\n \"\"\"\n # Create a Meilisearch client.\n client = meilisearch.Client(self.getConnectionString(), self.getMasterKey())\n\n # Delete previous index\n if len(client.get_indexes()):\n client.index(self.docs_index).delete()\n\n # Create a new index\n create_index_task = client.create_index(uid=self.docs_index, options={'primaryKey': self.primaryKey, 'uid': self.index_name})\n\n client.wait_for_task(create_index_task['uid'])\n\n index = client.get_index(create_index_task['indexUid'])\n\n # Add synonyms for the index\n index.update_synonyms(self.synonyms)\n\n # Update its settings: what can be searched, what's displayable, and how results should be ranked.\n index.update_settings(self.updated_settings)\n\n # Update distinct attribute.\n index.update_distinct_attribute(self.distinct_attribute)\n\n # Add documents to the index\n self.add_documents(index)\n\nif __name__ == \"__main__\":\n meili = Search()\n meili.update()\n", "path": "search/main.py"}], "after_files": [{"content": "import os\nimport glob\nimport json\nimport meilisearch\nfrom platformshconfig import Config\n\nclass Search:\n def __init__(self):\n self.default = {\n \"host\": \"http://127.0.0.1\",\n \"key\": None,\n \"port\": 7700\n }\n\n self.scrape_dir = \"output\"\n self.scrape_config = \"config/scrape.json\"\n self.docs_index = \"docs\"\n self.primaryKey = \"documentId\"\n self.index_name = \"Docs\"\n\n # Below are Platform.sh custom settings for how the search engine functions.\n\n # Data available to the dropdown React app in docs, used to fill out autocomplete results.\n self.displayed_attributes = ['keywords', 'title', 'text', 'url', 'site', 'section']\n # Data actually searchable by our queries.\n self.searchable_attributes = ['keywords', 'title', 'pageUrl', 'section', 'text', 'url']\n\n # Show results for one query with the listed pages, when they by default would not show up as best results.\n # Note: these aren't automatically two-way, which is why they're all defined twice.\n self.synonyms = {\n \"cron\": [\"crons\"],\n \"crons\": [\"cron tasks\", \"cron jobs\"],\n \"e-mail\": [\"email\"],\n \"routes.yaml\": [\"routes\"],\n \"routes\": [\"routes.yaml\"],\n \"services\": [\"services.yaml\"],\n \"services.yaml\": [\"services\"],\n \"application\": [\".platform.app.yaml\", \"app.yaml\", \"applications.yaml\"],\n \".platform.app.yaml\": [\"application\"],\n \"app.yaml\": [\"application\"],\n \"applications.yaml\": [\"application\", \"multi-app\"],\n \"multi-app\": [\"applications.yaml\"],\n \"regions\": [\"public ip addresses\"],\n \"public ip addresses\": [\"regions\"],\n \"ssl\": [\"https\", \"tls\"],\n \"https\": [\"ssl\"],\n \"auth\": [\"authentication\", \"access control\"], # Only needs to be one way since we don't use \"auth\" in the docs\n }\n\n # Ranking rules:\n #\n # - Default order: [\"words\", \"typo\", \"proximity\", \"attribute\", \"sort\", \"exactness\"]\n #\n # - words: number of times query is in document (greater number gets priority)\n # - typo: fewer typos > more typos\n # - proximity: smaller distance between multiple occurences of query in same document > larger distances\n # - attribute: sorted according to order of importance of attributes (searchable_attributes). terms in\n # more important attributes first.\n # - sort: queries are sorted at query time\n # - exactness: similarity of matched words in document with query\n\n self.ranking_rules = [\"rank:asc\", \"exactness\", \"attribute\", \"proximity\", \"typo\", \"words\"]\n\n self.updated_settings = {\n \"rankingRules\": self.ranking_rules,\n \"searchableAttributes\": self.searchable_attributes,\n \"displayedAttributes\": self.displayed_attributes\n }\n\n # Group results by page\n self.distinct_attribute = \"pageUrl\"\n\n def getConnectionString(self):\n \"\"\"\n Sets the Meilisearch host string, depending on the environment.\n\n Returns:\n string: Meilisearch host string.\n \"\"\"\n if os.environ.get('PORT'):\n return \"{}:{}\".format(self.default[\"host\"], os.environ['PORT'])\n else:\n return \"{}:{}\".format(self.default[\"host\"], self.default[\"port\"])\n\n def getMasterKey(self):\n \"\"\"\n Retrieves the Meilisearch master key, either from the Platform.sh environment or locally.\n \"\"\"\n config = Config()\n if config.is_valid_platform():\n return config.projectEntropy\n elif os.environ.get(\"MEILI_MASTER_KEY\"):\n return os.environ[\"MEILI_MASTER_KEY\"]\n else:\n return self.default[\"key\"]\n\n def add_documents(self, index):\n \"\"\"\n Cycle through the individual site indexes in /outputs so their individual documents can be added to Meilisearch.\n \"\"\"\n documents = [f for f in glob.glob(\"{}/*.json\".format(self.scrape_dir))]\n for doc in documents:\n self.add(doc, index)\n\n def add(self, doc, index):\n \"\"\"\n Add an individual site's index to the Meilisearch service.\n \"\"\"\n with open(doc) as scraped_index:\n data = json.load(scraped_index)\n index.add_documents(data)\n\n def update(self):\n \"\"\"\n Updates the Meilisearch index.\n \"\"\"\n # Create a Meilisearch client.\n client = meilisearch.Client(self.getConnectionString(), self.getMasterKey())\n\n # Delete previous index\n if len(client.get_indexes()):\n client.index(self.docs_index).delete()\n\n # Create a new index\n create_index_task = client.create_index(uid=self.docs_index, options={'primaryKey': self.primaryKey, 'uid': self.index_name})\n\n client.wait_for_task(create_index_task['uid'])\n\n index = client.get_index(create_index_task['indexUid'])\n\n # Add synonyms for the index\n index.update_synonyms(self.synonyms)\n\n # Update its settings: what can be searched, what's displayable, and how results should be ranked.\n index.update_settings(self.updated_settings)\n\n # Update distinct attribute.\n index.update_distinct_attribute(self.distinct_attribute)\n\n # Add documents to the index\n self.add_documents(index)\n\nif __name__ == \"__main__\":\n meili = Search()\n meili.update()\n", "path": "search/main.py"}]}
| 1,899 | 142 |
gh_patches_debug_7495
|
rasdani/github-patches
|
git_diff
|
kymatio__kymatio-890
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Make NumPy the default frontend
Since we promised earlier:
```
/home/jenkins/workspace/kymatio_dev/kymatio/frontend/entry.py:20: DeprecationWarning: Torch frontend is currently the default, but NumPy will become the default in the next version.
warnings.warn("Torch frontend is currently the default, but NumPy will become the default in the next"
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kymatio/frontend/entry.py`
Content:
```
1 import logging
2 import warnings
3 import importlib
4
5
6 class ScatteringEntry(object):
7 def __init__(self, *args, **kwargs):
8 self.name = kwargs['name']
9 self.class_name = kwargs['class_name']
10 kwargs.pop('name')
11 kwargs.pop('class_name')
12
13 frontend_suffixes = {'torch' : 'Torch',
14 'numpy' : 'NumPy',
15 'tensorflow' : 'TensorFlow',
16 'keras': 'Keras',
17 'sklearn': 'Transformer'}
18
19 if 'frontend' not in kwargs:
20 warnings.warn("Torch frontend is currently the default, but NumPy will become the default in the next"
21 " version.", DeprecationWarning)
22 frontend = 'torch'
23 else:
24 frontend = kwargs['frontend'].lower()
25 kwargs.pop('frontend')
26
27 frontends = list(frontend_suffixes.keys())
28
29 if frontend not in frontends:
30 raise RuntimeError('The frontend \'%s\" is not valid. Must be '
31 'one of \'%s\', or \'%s\'.' %
32 (frontend, '\', \''.join(frontends[:-1]),
33 frontends[-1]))
34
35 try:
36 module = importlib.import_module('kymatio.' + self.class_name + '.frontend.' + frontend + '_frontend')
37
38 # Create frontend-specific class name by inserting frontend name
39 # after `Scattering`.
40 frontend = frontend_suffixes[frontend]
41
42 class_name = self.__class__.__name__
43
44 base_name = class_name[:-len('Entry*D')]
45 dim_suffix = class_name[-len('*D'):]
46
47 class_name = base_name + frontend + dim_suffix
48
49 self.__class__ = getattr(module, class_name)
50 self.__init__(*args, **kwargs)
51 except Exception as e:
52 raise e from RuntimeError('\nThe frontend \'' + frontend + '\' could not be correctly imported.')
53
54 logging.info('The ' + self.name + ' frontend ' + frontend + ' was imported.')
55
56
57 __all__ = ['ScatteringEntry']
58
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kymatio/frontend/entry.py b/kymatio/frontend/entry.py
--- a/kymatio/frontend/entry.py
+++ b/kymatio/frontend/entry.py
@@ -17,9 +17,7 @@
'sklearn': 'Transformer'}
if 'frontend' not in kwargs:
- warnings.warn("Torch frontend is currently the default, but NumPy will become the default in the next"
- " version.", DeprecationWarning)
- frontend = 'torch'
+ frontend = 'numpy'
else:
frontend = kwargs['frontend'].lower()
kwargs.pop('frontend')
|
{"golden_diff": "diff --git a/kymatio/frontend/entry.py b/kymatio/frontend/entry.py\n--- a/kymatio/frontend/entry.py\n+++ b/kymatio/frontend/entry.py\n@@ -17,9 +17,7 @@\n 'sklearn': 'Transformer'}\n \n if 'frontend' not in kwargs:\n- warnings.warn(\"Torch frontend is currently the default, but NumPy will become the default in the next\"\n- \" version.\", DeprecationWarning)\n- frontend = 'torch'\n+ frontend = 'numpy'\n else:\n frontend = kwargs['frontend'].lower()\n kwargs.pop('frontend')\n", "issue": "Make NumPy the default frontend\nSince we promised earlier:\r\n\r\n```\r\n /home/jenkins/workspace/kymatio_dev/kymatio/frontend/entry.py:20: DeprecationWarning: Torch frontend is currently the default, but NumPy will become the default in the next version.\r\n warnings.warn(\"Torch frontend is currently the default, but NumPy will become the default in the next\"\r\n```\n", "before_files": [{"content": "import logging\nimport warnings\nimport importlib\n\n\nclass ScatteringEntry(object):\n def __init__(self, *args, **kwargs):\n self.name = kwargs['name']\n self.class_name = kwargs['class_name']\n kwargs.pop('name')\n kwargs.pop('class_name')\n\n frontend_suffixes = {'torch' : 'Torch',\n 'numpy' : 'NumPy',\n 'tensorflow' : 'TensorFlow',\n 'keras': 'Keras',\n 'sklearn': 'Transformer'}\n\n if 'frontend' not in kwargs:\n warnings.warn(\"Torch frontend is currently the default, but NumPy will become the default in the next\"\n \" version.\", DeprecationWarning)\n frontend = 'torch'\n else:\n frontend = kwargs['frontend'].lower()\n kwargs.pop('frontend')\n\n frontends = list(frontend_suffixes.keys())\n\n if frontend not in frontends:\n raise RuntimeError('The frontend \\'%s\\\" is not valid. Must be '\n 'one of \\'%s\\', or \\'%s\\'.' %\n (frontend, '\\', \\''.join(frontends[:-1]),\n frontends[-1]))\n\n try:\n module = importlib.import_module('kymatio.' + self.class_name + '.frontend.' + frontend + '_frontend')\n\n # Create frontend-specific class name by inserting frontend name\n # after `Scattering`.\n frontend = frontend_suffixes[frontend]\n\n class_name = self.__class__.__name__\n\n base_name = class_name[:-len('Entry*D')]\n dim_suffix = class_name[-len('*D'):]\n\n class_name = base_name + frontend + dim_suffix\n\n self.__class__ = getattr(module, class_name)\n self.__init__(*args, **kwargs)\n except Exception as e:\n raise e from RuntimeError('\\nThe frontend \\'' + frontend + '\\' could not be correctly imported.')\n\n logging.info('The ' + self.name + ' frontend ' + frontend + ' was imported.')\n\n\n__all__ = ['ScatteringEntry']\n", "path": "kymatio/frontend/entry.py"}], "after_files": [{"content": "import logging\nimport warnings\nimport importlib\n\n\nclass ScatteringEntry(object):\n def __init__(self, *args, **kwargs):\n self.name = kwargs['name']\n self.class_name = kwargs['class_name']\n kwargs.pop('name')\n kwargs.pop('class_name')\n\n frontend_suffixes = {'torch' : 'Torch',\n 'numpy' : 'NumPy',\n 'tensorflow' : 'TensorFlow',\n 'keras': 'Keras',\n 'sklearn': 'Transformer'}\n\n if 'frontend' not in kwargs:\n frontend = 'numpy'\n else:\n frontend = kwargs['frontend'].lower()\n kwargs.pop('frontend')\n\n frontends = list(frontend_suffixes.keys())\n\n if frontend not in frontends:\n raise RuntimeError('The frontend \\'%s\\\" is not valid. Must be '\n 'one of \\'%s\\', or \\'%s\\'.' %\n (frontend, '\\', \\''.join(frontends[:-1]),\n frontends[-1]))\n\n try:\n module = importlib.import_module('kymatio.' + self.class_name + '.frontend.' + frontend + '_frontend')\n\n # Create frontend-specific class name by inserting frontend name\n # after `Scattering`.\n frontend = frontend_suffixes[frontend]\n\n class_name = self.__class__.__name__\n\n base_name = class_name[:-len('Entry*D')]\n dim_suffix = class_name[-len('*D'):]\n\n class_name = base_name + frontend + dim_suffix\n\n self.__class__ = getattr(module, class_name)\n self.__init__(*args, **kwargs)\n except Exception as e:\n raise e from RuntimeError('\\nThe frontend \\'' + frontend + '\\' could not be correctly imported.')\n\n logging.info('The ' + self.name + ' frontend ' + frontend + ' was imported.')\n\n\n__all__ = ['ScatteringEntry']\n", "path": "kymatio/frontend/entry.py"}]}
| 890 | 136 |
gh_patches_debug_14010
|
rasdani/github-patches
|
git_diff
|
vaexio__vaex-404
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Failing to open arrow file format & misleading error message
Vaex fails to open arrow file format. It confusingly expects a file written not in the arrow file-format but in arrow stream-format.
If this is a non-negotiable vaex constraint, a less misleading error message might help very confused novices...
```
import pandas as pd
import pyarrow as pa
import numpy as np
import vaex
df = pd.DataFrame(
{
'col1': range(5)
}
)
table = pa.Table.from_pandas(df)
with pa.OSFile('test2.arrow', 'wb') as sink:
with pa.RecordBatchFileWriter(sink, table.schema) as writer:
writer.write_table(table)
with pa.OSFile('test2.arrow', 'rb') as source:
df = pa.ipc.open_file(source).read_pandas()
df = vaex.open('test2.arrow')
```
Error messages:
```
ERROR:MainThread:vaex:error opening 'test2.arrow'
---------------------------------------------------------------------------
ArrowInvalid Traceback (most recent call last)
in
16 with pa.OSFile('test2.arrow', 'rb') as source:
17 df = pa.ipc.open_file(source).read_pandas()
---> 18 df = vaex.open('test2.arrow')
Z:\Systemdateien\Miniconda3\envs\finance\lib\site-packages\vaex\__init__.py in open(path, convert, shuffle, copy_index, *args, **kwargs)
189 ds = from_csv(path, copy_index=copy_index, **kwargs)
190 else:
--> 191 ds = vaex.file.open(path, *args, **kwargs)
192 if convert and ds:
193 ds.export_hdf5(filename_hdf5, shuffle=shuffle)
Z:\Systemdateien\Miniconda3\envs\finance\lib\site-packages\vaex\file\__init__.py in open(path, *args, **kwargs)
28 for opener in opener_classes:
29 if opener.can_open(path, *args, **kwargs):
---> 30 return opener.open(path, *args, **kwargs)
31 if hdf5:
32 openers.extend(hdf5.dataset.dataset_type_map.items())
Z:\Systemdateien\Miniconda3\envs\finance\lib\site-packages\vaex_arrow\opener.py in open(path, *args, **kwargs)
9 def open(path, *args, **kwargs):
10 from .dataset import DatasetArrow
---> 11 return DatasetArrow(path, *args, **kwargs)
12
13 class ParquetOpener:
Z:\Systemdateien\Miniconda3\envs\finance\lib\site-packages\vaex_arrow\dataset.py in __init__(self, filename, table, write)
18 self._write = write
19 if table is None:
---> 20 self._load()
21 else:
22 self._load_table(table)
Z:\Systemdateien\Miniconda3\envs\finance\lib\site-packages\vaex_arrow\dataset.py in _load(self)
24 def _load(self):
25 source = pa.memory_map(self.path)
---> 26 reader = pa.ipc.open_stream(source)
27 table = pa.Table.from_batches([b for b in reader])
28 self._load_table(table)
Z:\Systemdateien\Miniconda3\envs\finance\lib\site-packages\pyarrow\ipc.py in open_stream(source)
123 reader : RecordBatchStreamReader
124 """
--> 125 return RecordBatchStreamReader(source)
126
127
Z:\Systemdateien\Miniconda3\envs\finance\lib\site-packages\pyarrow\ipc.py in __init__(self, source)
58 """
59 def __init__(self, source):
---> 60 self._open(source)
61
62
Z:\Systemdateien\Miniconda3\envs\finance\lib\site-packages\pyarrow\ipc.pxi in pyarrow.lib._RecordBatchStreamReader._open()
Z:\Systemdateien\Miniconda3\envs\finance\lib\site-packages\pyarrow\error.pxi in pyarrow.lib.check_status()
ArrowInvalid: Expected to read 1330795073 metadata bytes, but only read 1474
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `packages/vaex-arrow/vaex_arrow/dataset.py`
Content:
```
1 __author__ = 'maartenbreddels'
2 import logging
3
4 import pyarrow as pa
5 import pyarrow.parquet as pq
6
7 import vaex.dataset
8 import vaex.file.other
9 from .convert import column_from_arrow_array
10 logger = logging.getLogger("vaex_arrow")
11
12
13 class DatasetArrow(vaex.dataset.DatasetLocal):
14 """Implements storage using arrow"""
15
16 def __init__(self, filename=None, table=None, write=False):
17 super(DatasetArrow, self).__init__(name=filename, path=filename, column_names=[])
18 self._write = write
19 if table is None:
20 self._load()
21 else:
22 self._load_table(table)
23
24 def _load(self):
25 source = pa.memory_map(self.path)
26 reader = pa.ipc.open_stream(source)
27 table = pa.Table.from_batches([b for b in reader])
28 self._load_table(table)
29
30 def _load_table(self, table):
31 self._length_unfiltered = self._length_original = table.num_rows
32 self._index_end = self._length_original = table.num_rows
33 for col in table.columns:
34 name = col.name
35 # TODO: keep the arrow columns, and support and test chunks
36 arrow_array = col.data.chunks[0]
37 column = column_from_arrow_array(arrow_array)
38
39 self.columns[name] = column
40 self.column_names.append(name)
41 self._save_assign_expression(name, vaex.expression.Expression(self, name))
42
43
44 @classmethod
45 def can_open(cls, path, *args, **kwargs):
46 return path.rpartition('.')[2] == 'arrow'
47
48 @classmethod
49 def get_options(cls, path):
50 return []
51
52 @classmethod
53 def option_to_args(cls, option):
54 return []
55
56 class DatasetParquet(DatasetArrow):
57 def _load(self):
58 # might not be optimal, but it works, we can always see if we can
59 # do mmapping later on
60 table = pq.read_table(self.path)
61 self._load_table(table)
62
63 vaex.file.other.dataset_type_map["arrow"] = DatasetArrow
64 vaex.file.other.dataset_type_map["parquet"] = DatasetParquet
65
66
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/packages/vaex-arrow/vaex_arrow/dataset.py b/packages/vaex-arrow/vaex_arrow/dataset.py
--- a/packages/vaex-arrow/vaex_arrow/dataset.py
+++ b/packages/vaex-arrow/vaex_arrow/dataset.py
@@ -23,8 +23,18 @@
def _load(self):
source = pa.memory_map(self.path)
- reader = pa.ipc.open_stream(source)
- table = pa.Table.from_batches([b for b in reader])
+ try:
+ # first we try if it opens as stream
+ reader = pa.ipc.open_stream(source)
+ except pa.lib.ArrowInvalid:
+ # if not, we open as file
+ reader = pa.ipc.open_file(source)
+ # for some reason this reader is not iterable
+ batches = [reader.get_batch(i) for i in range(reader.num_record_batches)]
+ else:
+ # if a stream, we're good
+ batches = reader # this reader is iterable
+ table = pa.Table.from_batches(batches)
self._load_table(table)
def _load_table(self, table):
|
{"golden_diff": "diff --git a/packages/vaex-arrow/vaex_arrow/dataset.py b/packages/vaex-arrow/vaex_arrow/dataset.py\n--- a/packages/vaex-arrow/vaex_arrow/dataset.py\n+++ b/packages/vaex-arrow/vaex_arrow/dataset.py\n@@ -23,8 +23,18 @@\n \n def _load(self):\n source = pa.memory_map(self.path)\n- reader = pa.ipc.open_stream(source)\n- table = pa.Table.from_batches([b for b in reader])\n+ try:\n+ # first we try if it opens as stream\n+ reader = pa.ipc.open_stream(source)\n+ except pa.lib.ArrowInvalid:\n+ # if not, we open as file\n+ reader = pa.ipc.open_file(source)\n+ # for some reason this reader is not iterable\n+ batches = [reader.get_batch(i) for i in range(reader.num_record_batches)]\n+ else:\n+ # if a stream, we're good\n+ batches = reader # this reader is iterable\n+ table = pa.Table.from_batches(batches)\n self._load_table(table)\n \n def _load_table(self, table):\n", "issue": "Failing to open arrow file format & misleading error message\nVaex fails to open arrow file format. It confusingly expects a file written not in the arrow file-format but in arrow stream-format.\r\n\r\nIf this is a non-negotiable vaex constraint, a less misleading error message might help very confused novices...\r\n\r\n```\r\n\r\nimport pandas as pd\r\nimport pyarrow as pa\r\nimport numpy as np\r\nimport vaex\r\ndf = pd.DataFrame(\r\n {\r\n 'col1': range(5)\r\n }\r\n)\r\ntable = pa.Table.from_pandas(df)\r\n\r\nwith pa.OSFile('test2.arrow', 'wb') as sink:\r\n with pa.RecordBatchFileWriter(sink, table.schema) as writer:\r\n writer.write_table(table)\r\n\r\nwith pa.OSFile('test2.arrow', 'rb') as source:\r\n df = pa.ipc.open_file(source).read_pandas()\r\ndf = vaex.open('test2.arrow')\r\n```\r\n\r\nError messages:\r\n```\r\nERROR:MainThread:vaex:error opening 'test2.arrow'\r\n---------------------------------------------------------------------------\r\nArrowInvalid Traceback (most recent call last)\r\n in \r\n 16 with pa.OSFile('test2.arrow', 'rb') as source:\r\n 17 df = pa.ipc.open_file(source).read_pandas()\r\n---> 18 df = vaex.open('test2.arrow')\r\n\r\nZ:\\Systemdateien\\Miniconda3\\envs\\finance\\lib\\site-packages\\vaex\\__init__.py in open(path, convert, shuffle, copy_index, *args, **kwargs)\r\n 189 ds = from_csv(path, copy_index=copy_index, **kwargs)\r\n 190 else:\r\n--> 191 ds = vaex.file.open(path, *args, **kwargs)\r\n 192 if convert and ds:\r\n 193 ds.export_hdf5(filename_hdf5, shuffle=shuffle)\r\n\r\nZ:\\Systemdateien\\Miniconda3\\envs\\finance\\lib\\site-packages\\vaex\\file\\__init__.py in open(path, *args, **kwargs)\r\n 28 for opener in opener_classes:\r\n 29 if opener.can_open(path, *args, **kwargs):\r\n---> 30 return opener.open(path, *args, **kwargs)\r\n 31 if hdf5:\r\n 32 openers.extend(hdf5.dataset.dataset_type_map.items())\r\n\r\nZ:\\Systemdateien\\Miniconda3\\envs\\finance\\lib\\site-packages\\vaex_arrow\\opener.py in open(path, *args, **kwargs)\r\n 9 def open(path, *args, **kwargs):\r\n 10 from .dataset import DatasetArrow\r\n---> 11 return DatasetArrow(path, *args, **kwargs)\r\n 12 \r\n 13 class ParquetOpener:\r\n\r\nZ:\\Systemdateien\\Miniconda3\\envs\\finance\\lib\\site-packages\\vaex_arrow\\dataset.py in __init__(self, filename, table, write)\r\n 18 self._write = write\r\n 19 if table is None:\r\n---> 20 self._load()\r\n 21 else:\r\n 22 self._load_table(table)\r\n\r\nZ:\\Systemdateien\\Miniconda3\\envs\\finance\\lib\\site-packages\\vaex_arrow\\dataset.py in _load(self)\r\n 24 def _load(self):\r\n 25 source = pa.memory_map(self.path)\r\n---> 26 reader = pa.ipc.open_stream(source)\r\n 27 table = pa.Table.from_batches([b for b in reader])\r\n 28 self._load_table(table)\r\n\r\nZ:\\Systemdateien\\Miniconda3\\envs\\finance\\lib\\site-packages\\pyarrow\\ipc.py in open_stream(source)\r\n 123 reader : RecordBatchStreamReader\r\n 124 \"\"\"\r\n--> 125 return RecordBatchStreamReader(source)\r\n 126 \r\n 127 \r\n\r\nZ:\\Systemdateien\\Miniconda3\\envs\\finance\\lib\\site-packages\\pyarrow\\ipc.py in __init__(self, source)\r\n 58 \"\"\"\r\n 59 def __init__(self, source):\r\n---> 60 self._open(source)\r\n 61 \r\n 62 \r\n\r\nZ:\\Systemdateien\\Miniconda3\\envs\\finance\\lib\\site-packages\\pyarrow\\ipc.pxi in pyarrow.lib._RecordBatchStreamReader._open()\r\n\r\nZ:\\Systemdateien\\Miniconda3\\envs\\finance\\lib\\site-packages\\pyarrow\\error.pxi in pyarrow.lib.check_status()\r\n\r\nArrowInvalid: Expected to read 1330795073 metadata bytes, but only read 1474\r\n```\n", "before_files": [{"content": "__author__ = 'maartenbreddels'\nimport logging\n\nimport pyarrow as pa\nimport pyarrow.parquet as pq\n\nimport vaex.dataset\nimport vaex.file.other\nfrom .convert import column_from_arrow_array\nlogger = logging.getLogger(\"vaex_arrow\")\n\n\nclass DatasetArrow(vaex.dataset.DatasetLocal):\n \"\"\"Implements storage using arrow\"\"\"\n\n def __init__(self, filename=None, table=None, write=False):\n super(DatasetArrow, self).__init__(name=filename, path=filename, column_names=[])\n self._write = write\n if table is None:\n self._load()\n else:\n self._load_table(table)\n\n def _load(self):\n source = pa.memory_map(self.path)\n reader = pa.ipc.open_stream(source)\n table = pa.Table.from_batches([b for b in reader])\n self._load_table(table)\n \n def _load_table(self, table):\n self._length_unfiltered = self._length_original = table.num_rows\n self._index_end = self._length_original = table.num_rows\n for col in table.columns:\n name = col.name\n # TODO: keep the arrow columns, and support and test chunks\n arrow_array = col.data.chunks[0]\n column = column_from_arrow_array(arrow_array)\n\n self.columns[name] = column\n self.column_names.append(name)\n self._save_assign_expression(name, vaex.expression.Expression(self, name))\n\n\n @classmethod\n def can_open(cls, path, *args, **kwargs):\n return path.rpartition('.')[2] == 'arrow'\n\n @classmethod\n def get_options(cls, path):\n return []\n\n @classmethod\n def option_to_args(cls, option):\n return []\n\nclass DatasetParquet(DatasetArrow):\n def _load(self):\n # might not be optimal, but it works, we can always see if we can\n # do mmapping later on\n table = pq.read_table(self.path)\n self._load_table(table)\n\nvaex.file.other.dataset_type_map[\"arrow\"] = DatasetArrow\nvaex.file.other.dataset_type_map[\"parquet\"] = DatasetParquet\n\n", "path": "packages/vaex-arrow/vaex_arrow/dataset.py"}], "after_files": [{"content": "__author__ = 'maartenbreddels'\nimport logging\n\nimport pyarrow as pa\nimport pyarrow.parquet as pq\n\nimport vaex.dataset\nimport vaex.file.other\nfrom .convert import column_from_arrow_array\nlogger = logging.getLogger(\"vaex_arrow\")\n\n\nclass DatasetArrow(vaex.dataset.DatasetLocal):\n \"\"\"Implements storage using arrow\"\"\"\n\n def __init__(self, filename=None, table=None, write=False):\n super(DatasetArrow, self).__init__(name=filename, path=filename, column_names=[])\n self._write = write\n if table is None:\n self._load()\n else:\n self._load_table(table)\n\n def _load(self):\n source = pa.memory_map(self.path)\n try:\n # first we try if it opens as stream\n reader = pa.ipc.open_stream(source)\n except pa.lib.ArrowInvalid:\n # if not, we open as file\n reader = pa.ipc.open_file(source)\n # for some reason this reader is not iterable\n batches = [reader.get_batch(i) for i in range(reader.num_record_batches)]\n else:\n # if a stream, we're good\n batches = reader # this reader is iterable\n table = pa.Table.from_batches(batches)\n self._load_table(table)\n \n def _load_table(self, table):\n self._length_unfiltered = self._length_original = table.num_rows\n self._index_end = self._length_original = table.num_rows\n for col in table.columns:\n name = col.name\n # TODO: keep the arrow columns, and support and test chunks\n arrow_array = col.data.chunks[0]\n column = column_from_arrow_array(arrow_array)\n\n self.columns[name] = column\n self.column_names.append(name)\n self._save_assign_expression(name, vaex.expression.Expression(self, name))\n\n\n @classmethod\n def can_open(cls, path, *args, **kwargs):\n return path.rpartition('.')[2] == 'arrow'\n\n @classmethod\n def get_options(cls, path):\n return []\n\n @classmethod\n def option_to_args(cls, option):\n return []\n\nclass DatasetParquet(DatasetArrow):\n def _load(self):\n # might not be optimal, but it works, we can always see if we can\n # do mmapping later on\n table = pq.read_table(self.path)\n self._load_table(table)\n\nvaex.file.other.dataset_type_map[\"arrow\"] = DatasetArrow\nvaex.file.other.dataset_type_map[\"parquet\"] = DatasetParquet\n\n", "path": "packages/vaex-arrow/vaex_arrow/dataset.py"}]}
| 1,909 | 259 |
gh_patches_debug_42783
|
rasdani/github-patches
|
git_diff
|
conda-forge__conda-smithy-1372
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
search for teams by handle/slug and not name
I think this is a simple as using `team.slug` instead of `team.name` in the relevant code.
cc @isuruf
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conda_smithy/github.py`
Content:
```
1 import os
2 from random import choice
3
4 from git import Repo
5
6 from github import Github
7 from github.GithubException import GithubException
8 from github.Organization import Organization
9 from github.Team import Team
10 import github
11
12 import conda_build.api
13 from conda_smithy.utils import get_feedstock_name_from_meta
14
15
16 def gh_token():
17 try:
18 with open(
19 os.path.expanduser("~/.conda-smithy/github.token"), "r"
20 ) as fh:
21 token = fh.read().strip()
22 if not token:
23 raise ValueError()
24 except (IOError, ValueError):
25 msg = (
26 "No github token. Go to https://github.com/settings/tokens/new and generate\n"
27 "a token with repo access. Put it in ~/.conda-smithy/github.token"
28 )
29 raise RuntimeError(msg)
30 return token
31
32
33 def create_team(org, name, description, repo_names=[]):
34 # PyGithub creates secret teams, and has no way of turning that off! :(
35 post_parameters = {
36 "name": name,
37 "description": description,
38 "privacy": "closed",
39 "permission": "push",
40 "repo_names": repo_names,
41 }
42 headers, data = org._requester.requestJsonAndCheck(
43 "POST", org.url + "/teams", input=post_parameters
44 )
45 return Team(org._requester, headers, data, completed=True)
46
47
48 def add_membership(team, member):
49 headers, data = team._requester.requestJsonAndCheck(
50 "PUT", team.url + "/memberships/" + member
51 )
52 return (headers, data)
53
54
55 def remove_membership(team, member):
56 headers, data = team._requester.requestJsonAndCheck(
57 "DELETE", team.url + "/memberships/" + member
58 )
59 return (headers, data)
60
61
62 def has_in_members(team, member):
63 status, headers, data = team._requester.requestJson(
64 "GET", team.url + "/members/" + member
65 )
66 return status == 204
67
68
69 def get_cached_team(org, team_name, description=""):
70 cached_file = os.path.expanduser(
71 "~/.conda-smithy/{}-{}-team".format(org.login, team_name)
72 )
73 try:
74 with open(cached_file, "r") as fh:
75 team_id = int(fh.read().strip())
76 return org.get_team(team_id)
77 except IOError:
78 pass
79
80 try:
81 repo = org.get_repo("{}-feedstock".format(team_name))
82 team = next(
83 (team for team in repo.get_teams() if team.name == team_name), None
84 )
85 if team:
86 return team
87 except GithubException:
88 pass
89
90 team = next(
91 (team for team in org.get_teams() if team.name == team_name), None
92 )
93 if not team:
94 if description:
95 team = create_team(org, team_name, description, [])
96 else:
97 raise RuntimeError("Couldn't find team {}".format(team_name))
98
99 with open(cached_file, "w") as fh:
100 fh.write(str(team.id))
101
102 return team
103
104
105 def create_github_repo(args):
106 token = gh_token()
107 meta = conda_build.api.render(
108 args.feedstock_directory,
109 permit_undefined_jinja=True,
110 finalize=False,
111 bypass_env_check=True,
112 trim_skip=False,
113 )[0][0]
114
115 feedstock_name = get_feedstock_name_from_meta(meta)
116
117 gh = Github(token)
118 user_or_org = None
119 if args.user is not None:
120 pass
121 # User has been defined, and organization has not.
122 user_or_org = gh.get_user()
123 else:
124 # Use the organization provided.
125 user_or_org = gh.get_organization(args.organization)
126
127 repo_name = "{}-feedstock".format(feedstock_name)
128 try:
129 gh_repo = user_or_org.create_repo(
130 repo_name,
131 has_wiki=False,
132 private=args.private,
133 description="A conda-smithy repository for {}.".format(
134 feedstock_name
135 ),
136 )
137 print("Created {} on github".format(gh_repo.full_name))
138 except GithubException as gh_except:
139 if (
140 gh_except.data.get("errors", [{}])[0].get("message", "")
141 != u"name already exists on this account"
142 ):
143 raise
144 gh_repo = user_or_org.get_repo(repo_name)
145 print("Github repository already exists.")
146
147 # Now add this new repo as a remote on the local clone.
148 repo = Repo(args.feedstock_directory)
149 remote_name = args.remote_name.strip()
150 if remote_name:
151 if remote_name in [remote.name for remote in repo.remotes]:
152 existing_remote = repo.remotes[remote_name]
153 if existing_remote.url != gh_repo.ssh_url:
154 print(
155 "Remote {} already exists, and doesn't point to {} "
156 "(it points to {}).".format(
157 remote_name, gh_repo.ssh_url, existing_remote.url
158 )
159 )
160 else:
161 repo.create_remote(remote_name, gh_repo.ssh_url)
162
163 if args.extra_admin_users is not None:
164 for user in args.extra_admin_users:
165 gh_repo.add_to_collaborators(user, "admin")
166
167 if args.add_teams:
168 if isinstance(user_or_org, Organization):
169 configure_github_team(meta, gh_repo, user_or_org, feedstock_name)
170
171
172 def accept_all_repository_invitations(gh):
173 user = gh.get_user()
174 invitations = github.PaginatedList.PaginatedList(
175 github.Invitation.Invitation,
176 user._requester,
177 user.url + "/repository_invitations",
178 None,
179 )
180 for invite in invitations:
181 invite._requester.requestJsonAndCheck("PATCH", invite.url)
182
183
184 def remove_from_project(gh, org, project):
185 user = gh.get_user()
186 repo = gh.get_repo("{}/{}".format(org, project))
187 repo.remove_from_collaborators(user.login)
188
189
190 def configure_github_team(meta, gh_repo, org, feedstock_name):
191
192 # Add a team for this repo and add the maintainers to it.
193 superlative = [
194 "awesome",
195 "slick",
196 "formidable",
197 "awe-inspiring",
198 "breathtaking",
199 "magnificent",
200 "wonderous",
201 "stunning",
202 "astonishing",
203 "superb",
204 "splendid",
205 "impressive",
206 "unbeatable",
207 "excellent",
208 "top",
209 "outstanding",
210 "exalted",
211 "standout",
212 "smashing",
213 ]
214
215 maintainers = set(meta.meta.get("extra", {}).get("recipe-maintainers", []))
216 maintainers = set(maintainer.lower() for maintainer in maintainers)
217 maintainer_teams = set(m for m in maintainers if "/" in m)
218 maintainers = set(m for m in maintainers if "/" not in m)
219
220 # Try to get team or create it if it doesn't exist.
221 team_name = feedstock_name
222 current_maintainer_teams = list(gh_repo.get_teams())
223 team = next(
224 (team for team in current_maintainer_teams if team.name == team_name),
225 None,
226 )
227 current_maintainers = set()
228 if not team:
229 team = create_team(
230 org,
231 team_name,
232 "The {} {} contributors!".format(choice(superlative), team_name),
233 )
234 team.add_to_repos(gh_repo)
235 else:
236 current_maintainers = set(
237 [e.login.lower() for e in team.get_members()]
238 )
239
240 # Get the all-members team
241 description = "All of the awesome {} contributors!".format(org.login)
242 all_members_team = get_cached_team(org, "all-members", description)
243 new_org_members = set()
244
245 # Add only the new maintainers to the team.
246 # Also add the new maintainers to all-members if not already included.
247 for new_maintainer in maintainers - current_maintainers:
248 add_membership(team, new_maintainer)
249
250 if not has_in_members(all_members_team, new_maintainer):
251 print(
252 "Adding a new member ({}) to {}. Welcome! :)".format(
253 new_maintainer, org.login
254 )
255 )
256 add_membership(all_members_team, new_maintainer)
257 new_org_members.add(new_maintainer)
258
259 # Mention any maintainers that need to be removed (unlikely here).
260 for old_maintainer in current_maintainers - maintainers:
261 print(
262 "AN OLD MEMBER ({}) NEEDS TO BE REMOVED FROM {}".format(
263 old_maintainer, gh_repo
264 )
265 )
266
267 # Add any new maintainer team
268 maintainer_teams = set(
269 m.split("/")[1]
270 for m in maintainer_teams
271 if m.startswith(str(org.login))
272 )
273 current_maintainer_teams = [team.name for team in current_maintainer_teams]
274 for maintainer_team in maintainer_teams - set(current_maintainer_teams):
275 print(
276 "Adding a new team ({}) to {}. Welcome! :)".format(
277 maintainer_team, org.login
278 )
279 )
280
281 team = get_cached_team(org, maintainer_team)
282 team.add_to_repos(gh_repo)
283
284 return maintainers, current_maintainers, new_org_members
285
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/conda_smithy/github.py b/conda_smithy/github.py
--- a/conda_smithy/github.py
+++ b/conda_smithy/github.py
@@ -187,7 +187,7 @@
repo.remove_from_collaborators(user.login)
-def configure_github_team(meta, gh_repo, org, feedstock_name):
+def configure_github_team(meta, gh_repo, org, feedstock_name, remove=True):
# Add a team for this repo and add the maintainers to it.
superlative = [
@@ -220,21 +220,21 @@
# Try to get team or create it if it doesn't exist.
team_name = feedstock_name
current_maintainer_teams = list(gh_repo.get_teams())
- team = next(
+ fs_team = next(
(team for team in current_maintainer_teams if team.name == team_name),
None,
)
current_maintainers = set()
- if not team:
- team = create_team(
+ if not fs_team:
+ fs_team = create_team(
org,
team_name,
"The {} {} contributors!".format(choice(superlative), team_name),
)
- team.add_to_repos(gh_repo)
+ fs_team.add_to_repos(gh_repo)
else:
current_maintainers = set(
- [e.login.lower() for e in team.get_members()]
+ [e.login.lower() for e in fs_team.get_members()]
)
# Get the all-members team
@@ -245,40 +245,41 @@
# Add only the new maintainers to the team.
# Also add the new maintainers to all-members if not already included.
for new_maintainer in maintainers - current_maintainers:
- add_membership(team, new_maintainer)
+ add_membership(fs_team, new_maintainer)
if not has_in_members(all_members_team, new_maintainer):
- print(
- "Adding a new member ({}) to {}. Welcome! :)".format(
- new_maintainer, org.login
- )
- )
add_membership(all_members_team, new_maintainer)
new_org_members.add(new_maintainer)
- # Mention any maintainers that need to be removed (unlikely here).
- for old_maintainer in current_maintainers - maintainers:
- print(
- "AN OLD MEMBER ({}) NEEDS TO BE REMOVED FROM {}".format(
- old_maintainer, gh_repo
- )
- )
+ # Remove any maintainers that need to be removed (unlikely here).
+ if remove:
+ for old_maintainer in current_maintainers - maintainers:
+ remove_membership(fs_team, old_maintainer)
- # Add any new maintainer team
+ # Add any new maintainer teams
maintainer_teams = set(
m.split("/")[1]
for m in maintainer_teams
if m.startswith(str(org.login))
)
- current_maintainer_teams = [team.name for team in current_maintainer_teams]
- for maintainer_team in maintainer_teams - set(current_maintainer_teams):
- print(
- "Adding a new team ({}) to {}. Welcome! :)".format(
- maintainer_team, org.login
- )
- )
-
- team = get_cached_team(org, maintainer_team)
+ current_maintainer_team_objs = {
+ team.slug: team for team in current_maintainer_teams
+ }
+ current_maintainer_teams = set(
+ [team.slug for team in current_maintainer_teams]
+ )
+ for new_team in maintainer_teams - current_maintainer_teams:
+ team = org.get_team_by_slug(new_team)
team.add_to_repos(gh_repo)
+ # remove any old teams
+ if remove:
+ for old_team in current_maintainer_teams - maintainer_teams:
+ team = current_maintainer_team_objs.get(
+ old_team, org.get_team_by_slug(old_team)
+ )
+ if team.name == fs_team.name:
+ continue
+ team.remove_from_repos(gh_repo)
+
return maintainers, current_maintainers, new_org_members
|
{"golden_diff": "diff --git a/conda_smithy/github.py b/conda_smithy/github.py\n--- a/conda_smithy/github.py\n+++ b/conda_smithy/github.py\n@@ -187,7 +187,7 @@\n repo.remove_from_collaborators(user.login)\n \n \n-def configure_github_team(meta, gh_repo, org, feedstock_name):\n+def configure_github_team(meta, gh_repo, org, feedstock_name, remove=True):\n \n # Add a team for this repo and add the maintainers to it.\n superlative = [\n@@ -220,21 +220,21 @@\n # Try to get team or create it if it doesn't exist.\n team_name = feedstock_name\n current_maintainer_teams = list(gh_repo.get_teams())\n- team = next(\n+ fs_team = next(\n (team for team in current_maintainer_teams if team.name == team_name),\n None,\n )\n current_maintainers = set()\n- if not team:\n- team = create_team(\n+ if not fs_team:\n+ fs_team = create_team(\n org,\n team_name,\n \"The {} {} contributors!\".format(choice(superlative), team_name),\n )\n- team.add_to_repos(gh_repo)\n+ fs_team.add_to_repos(gh_repo)\n else:\n current_maintainers = set(\n- [e.login.lower() for e in team.get_members()]\n+ [e.login.lower() for e in fs_team.get_members()]\n )\n \n # Get the all-members team\n@@ -245,40 +245,41 @@\n # Add only the new maintainers to the team.\n # Also add the new maintainers to all-members if not already included.\n for new_maintainer in maintainers - current_maintainers:\n- add_membership(team, new_maintainer)\n+ add_membership(fs_team, new_maintainer)\n \n if not has_in_members(all_members_team, new_maintainer):\n- print(\n- \"Adding a new member ({}) to {}. Welcome! :)\".format(\n- new_maintainer, org.login\n- )\n- )\n add_membership(all_members_team, new_maintainer)\n new_org_members.add(new_maintainer)\n \n- # Mention any maintainers that need to be removed (unlikely here).\n- for old_maintainer in current_maintainers - maintainers:\n- print(\n- \"AN OLD MEMBER ({}) NEEDS TO BE REMOVED FROM {}\".format(\n- old_maintainer, gh_repo\n- )\n- )\n+ # Remove any maintainers that need to be removed (unlikely here).\n+ if remove:\n+ for old_maintainer in current_maintainers - maintainers:\n+ remove_membership(fs_team, old_maintainer)\n \n- # Add any new maintainer team\n+ # Add any new maintainer teams\n maintainer_teams = set(\n m.split(\"/\")[1]\n for m in maintainer_teams\n if m.startswith(str(org.login))\n )\n- current_maintainer_teams = [team.name for team in current_maintainer_teams]\n- for maintainer_team in maintainer_teams - set(current_maintainer_teams):\n- print(\n- \"Adding a new team ({}) to {}. Welcome! :)\".format(\n- maintainer_team, org.login\n- )\n- )\n-\n- team = get_cached_team(org, maintainer_team)\n+ current_maintainer_team_objs = {\n+ team.slug: team for team in current_maintainer_teams\n+ }\n+ current_maintainer_teams = set(\n+ [team.slug for team in current_maintainer_teams]\n+ )\n+ for new_team in maintainer_teams - current_maintainer_teams:\n+ team = org.get_team_by_slug(new_team)\n team.add_to_repos(gh_repo)\n \n+ # remove any old teams\n+ if remove:\n+ for old_team in current_maintainer_teams - maintainer_teams:\n+ team = current_maintainer_team_objs.get(\n+ old_team, org.get_team_by_slug(old_team)\n+ )\n+ if team.name == fs_team.name:\n+ continue\n+ team.remove_from_repos(gh_repo)\n+\n return maintainers, current_maintainers, new_org_members\n", "issue": "search for teams by handle/slug and not name\nI think this is a simple as using `team.slug` instead of `team.name` in the relevant code.\r\n\r\ncc @isuruf \n", "before_files": [{"content": "import os\nfrom random import choice\n\nfrom git import Repo\n\nfrom github import Github\nfrom github.GithubException import GithubException\nfrom github.Organization import Organization\nfrom github.Team import Team\nimport github\n\nimport conda_build.api\nfrom conda_smithy.utils import get_feedstock_name_from_meta\n\n\ndef gh_token():\n try:\n with open(\n os.path.expanduser(\"~/.conda-smithy/github.token\"), \"r\"\n ) as fh:\n token = fh.read().strip()\n if not token:\n raise ValueError()\n except (IOError, ValueError):\n msg = (\n \"No github token. Go to https://github.com/settings/tokens/new and generate\\n\"\n \"a token with repo access. Put it in ~/.conda-smithy/github.token\"\n )\n raise RuntimeError(msg)\n return token\n\n\ndef create_team(org, name, description, repo_names=[]):\n # PyGithub creates secret teams, and has no way of turning that off! :(\n post_parameters = {\n \"name\": name,\n \"description\": description,\n \"privacy\": \"closed\",\n \"permission\": \"push\",\n \"repo_names\": repo_names,\n }\n headers, data = org._requester.requestJsonAndCheck(\n \"POST\", org.url + \"/teams\", input=post_parameters\n )\n return Team(org._requester, headers, data, completed=True)\n\n\ndef add_membership(team, member):\n headers, data = team._requester.requestJsonAndCheck(\n \"PUT\", team.url + \"/memberships/\" + member\n )\n return (headers, data)\n\n\ndef remove_membership(team, member):\n headers, data = team._requester.requestJsonAndCheck(\n \"DELETE\", team.url + \"/memberships/\" + member\n )\n return (headers, data)\n\n\ndef has_in_members(team, member):\n status, headers, data = team._requester.requestJson(\n \"GET\", team.url + \"/members/\" + member\n )\n return status == 204\n\n\ndef get_cached_team(org, team_name, description=\"\"):\n cached_file = os.path.expanduser(\n \"~/.conda-smithy/{}-{}-team\".format(org.login, team_name)\n )\n try:\n with open(cached_file, \"r\") as fh:\n team_id = int(fh.read().strip())\n return org.get_team(team_id)\n except IOError:\n pass\n\n try:\n repo = org.get_repo(\"{}-feedstock\".format(team_name))\n team = next(\n (team for team in repo.get_teams() if team.name == team_name), None\n )\n if team:\n return team\n except GithubException:\n pass\n\n team = next(\n (team for team in org.get_teams() if team.name == team_name), None\n )\n if not team:\n if description:\n team = create_team(org, team_name, description, [])\n else:\n raise RuntimeError(\"Couldn't find team {}\".format(team_name))\n\n with open(cached_file, \"w\") as fh:\n fh.write(str(team.id))\n\n return team\n\n\ndef create_github_repo(args):\n token = gh_token()\n meta = conda_build.api.render(\n args.feedstock_directory,\n permit_undefined_jinja=True,\n finalize=False,\n bypass_env_check=True,\n trim_skip=False,\n )[0][0]\n\n feedstock_name = get_feedstock_name_from_meta(meta)\n\n gh = Github(token)\n user_or_org = None\n if args.user is not None:\n pass\n # User has been defined, and organization has not.\n user_or_org = gh.get_user()\n else:\n # Use the organization provided.\n user_or_org = gh.get_organization(args.organization)\n\n repo_name = \"{}-feedstock\".format(feedstock_name)\n try:\n gh_repo = user_or_org.create_repo(\n repo_name,\n has_wiki=False,\n private=args.private,\n description=\"A conda-smithy repository for {}.\".format(\n feedstock_name\n ),\n )\n print(\"Created {} on github\".format(gh_repo.full_name))\n except GithubException as gh_except:\n if (\n gh_except.data.get(\"errors\", [{}])[0].get(\"message\", \"\")\n != u\"name already exists on this account\"\n ):\n raise\n gh_repo = user_or_org.get_repo(repo_name)\n print(\"Github repository already exists.\")\n\n # Now add this new repo as a remote on the local clone.\n repo = Repo(args.feedstock_directory)\n remote_name = args.remote_name.strip()\n if remote_name:\n if remote_name in [remote.name for remote in repo.remotes]:\n existing_remote = repo.remotes[remote_name]\n if existing_remote.url != gh_repo.ssh_url:\n print(\n \"Remote {} already exists, and doesn't point to {} \"\n \"(it points to {}).\".format(\n remote_name, gh_repo.ssh_url, existing_remote.url\n )\n )\n else:\n repo.create_remote(remote_name, gh_repo.ssh_url)\n\n if args.extra_admin_users is not None:\n for user in args.extra_admin_users:\n gh_repo.add_to_collaborators(user, \"admin\")\n\n if args.add_teams:\n if isinstance(user_or_org, Organization):\n configure_github_team(meta, gh_repo, user_or_org, feedstock_name)\n\n\ndef accept_all_repository_invitations(gh):\n user = gh.get_user()\n invitations = github.PaginatedList.PaginatedList(\n github.Invitation.Invitation,\n user._requester,\n user.url + \"/repository_invitations\",\n None,\n )\n for invite in invitations:\n invite._requester.requestJsonAndCheck(\"PATCH\", invite.url)\n\n\ndef remove_from_project(gh, org, project):\n user = gh.get_user()\n repo = gh.get_repo(\"{}/{}\".format(org, project))\n repo.remove_from_collaborators(user.login)\n\n\ndef configure_github_team(meta, gh_repo, org, feedstock_name):\n\n # Add a team for this repo and add the maintainers to it.\n superlative = [\n \"awesome\",\n \"slick\",\n \"formidable\",\n \"awe-inspiring\",\n \"breathtaking\",\n \"magnificent\",\n \"wonderous\",\n \"stunning\",\n \"astonishing\",\n \"superb\",\n \"splendid\",\n \"impressive\",\n \"unbeatable\",\n \"excellent\",\n \"top\",\n \"outstanding\",\n \"exalted\",\n \"standout\",\n \"smashing\",\n ]\n\n maintainers = set(meta.meta.get(\"extra\", {}).get(\"recipe-maintainers\", []))\n maintainers = set(maintainer.lower() for maintainer in maintainers)\n maintainer_teams = set(m for m in maintainers if \"/\" in m)\n maintainers = set(m for m in maintainers if \"/\" not in m)\n\n # Try to get team or create it if it doesn't exist.\n team_name = feedstock_name\n current_maintainer_teams = list(gh_repo.get_teams())\n team = next(\n (team for team in current_maintainer_teams if team.name == team_name),\n None,\n )\n current_maintainers = set()\n if not team:\n team = create_team(\n org,\n team_name,\n \"The {} {} contributors!\".format(choice(superlative), team_name),\n )\n team.add_to_repos(gh_repo)\n else:\n current_maintainers = set(\n [e.login.lower() for e in team.get_members()]\n )\n\n # Get the all-members team\n description = \"All of the awesome {} contributors!\".format(org.login)\n all_members_team = get_cached_team(org, \"all-members\", description)\n new_org_members = set()\n\n # Add only the new maintainers to the team.\n # Also add the new maintainers to all-members if not already included.\n for new_maintainer in maintainers - current_maintainers:\n add_membership(team, new_maintainer)\n\n if not has_in_members(all_members_team, new_maintainer):\n print(\n \"Adding a new member ({}) to {}. Welcome! :)\".format(\n new_maintainer, org.login\n )\n )\n add_membership(all_members_team, new_maintainer)\n new_org_members.add(new_maintainer)\n\n # Mention any maintainers that need to be removed (unlikely here).\n for old_maintainer in current_maintainers - maintainers:\n print(\n \"AN OLD MEMBER ({}) NEEDS TO BE REMOVED FROM {}\".format(\n old_maintainer, gh_repo\n )\n )\n\n # Add any new maintainer team\n maintainer_teams = set(\n m.split(\"/\")[1]\n for m in maintainer_teams\n if m.startswith(str(org.login))\n )\n current_maintainer_teams = [team.name for team in current_maintainer_teams]\n for maintainer_team in maintainer_teams - set(current_maintainer_teams):\n print(\n \"Adding a new team ({}) to {}. Welcome! :)\".format(\n maintainer_team, org.login\n )\n )\n\n team = get_cached_team(org, maintainer_team)\n team.add_to_repos(gh_repo)\n\n return maintainers, current_maintainers, new_org_members\n", "path": "conda_smithy/github.py"}], "after_files": [{"content": "import os\nfrom random import choice\n\nfrom git import Repo\n\nfrom github import Github\nfrom github.GithubException import GithubException\nfrom github.Organization import Organization\nfrom github.Team import Team\nimport github\n\nimport conda_build.api\nfrom conda_smithy.utils import get_feedstock_name_from_meta\n\n\ndef gh_token():\n try:\n with open(\n os.path.expanduser(\"~/.conda-smithy/github.token\"), \"r\"\n ) as fh:\n token = fh.read().strip()\n if not token:\n raise ValueError()\n except (IOError, ValueError):\n msg = (\n \"No github token. Go to https://github.com/settings/tokens/new and generate\\n\"\n \"a token with repo access. Put it in ~/.conda-smithy/github.token\"\n )\n raise RuntimeError(msg)\n return token\n\n\ndef create_team(org, name, description, repo_names=[]):\n # PyGithub creates secret teams, and has no way of turning that off! :(\n post_parameters = {\n \"name\": name,\n \"description\": description,\n \"privacy\": \"closed\",\n \"permission\": \"push\",\n \"repo_names\": repo_names,\n }\n headers, data = org._requester.requestJsonAndCheck(\n \"POST\", org.url + \"/teams\", input=post_parameters\n )\n return Team(org._requester, headers, data, completed=True)\n\n\ndef add_membership(team, member):\n headers, data = team._requester.requestJsonAndCheck(\n \"PUT\", team.url + \"/memberships/\" + member\n )\n return (headers, data)\n\n\ndef remove_membership(team, member):\n headers, data = team._requester.requestJsonAndCheck(\n \"DELETE\", team.url + \"/memberships/\" + member\n )\n return (headers, data)\n\n\ndef has_in_members(team, member):\n status, headers, data = team._requester.requestJson(\n \"GET\", team.url + \"/members/\" + member\n )\n return status == 204\n\n\ndef get_cached_team(org, team_name, description=\"\"):\n cached_file = os.path.expanduser(\n \"~/.conda-smithy/{}-{}-team\".format(org.login, team_name)\n )\n try:\n with open(cached_file, \"r\") as fh:\n team_id = int(fh.read().strip())\n return org.get_team(team_id)\n except IOError:\n pass\n\n try:\n repo = org.get_repo(\"{}-feedstock\".format(team_name))\n team = next(\n (team for team in repo.get_teams() if team.name == team_name), None\n )\n if team:\n return team\n except GithubException:\n pass\n\n team = next(\n (team for team in org.get_teams() if team.name == team_name), None\n )\n if not team:\n if description:\n team = create_team(org, team_name, description, [])\n else:\n raise RuntimeError(\"Couldn't find team {}\".format(team_name))\n\n with open(cached_file, \"w\") as fh:\n fh.write(str(team.id))\n\n return team\n\n\ndef create_github_repo(args):\n token = gh_token()\n meta = conda_build.api.render(\n args.feedstock_directory,\n permit_undefined_jinja=True,\n finalize=False,\n bypass_env_check=True,\n trim_skip=False,\n )[0][0]\n\n feedstock_name = get_feedstock_name_from_meta(meta)\n\n gh = Github(token)\n user_or_org = None\n if args.user is not None:\n pass\n # User has been defined, and organization has not.\n user_or_org = gh.get_user()\n else:\n # Use the organization provided.\n user_or_org = gh.get_organization(args.organization)\n\n repo_name = \"{}-feedstock\".format(feedstock_name)\n try:\n gh_repo = user_or_org.create_repo(\n repo_name,\n has_wiki=False,\n private=args.private,\n description=\"A conda-smithy repository for {}.\".format(\n feedstock_name\n ),\n )\n print(\"Created {} on github\".format(gh_repo.full_name))\n except GithubException as gh_except:\n if (\n gh_except.data.get(\"errors\", [{}])[0].get(\"message\", \"\")\n != u\"name already exists on this account\"\n ):\n raise\n gh_repo = user_or_org.get_repo(repo_name)\n print(\"Github repository already exists.\")\n\n # Now add this new repo as a remote on the local clone.\n repo = Repo(args.feedstock_directory)\n remote_name = args.remote_name.strip()\n if remote_name:\n if remote_name in [remote.name for remote in repo.remotes]:\n existing_remote = repo.remotes[remote_name]\n if existing_remote.url != gh_repo.ssh_url:\n print(\n \"Remote {} already exists, and doesn't point to {} \"\n \"(it points to {}).\".format(\n remote_name, gh_repo.ssh_url, existing_remote.url\n )\n )\n else:\n repo.create_remote(remote_name, gh_repo.ssh_url)\n\n if args.extra_admin_users is not None:\n for user in args.extra_admin_users:\n gh_repo.add_to_collaborators(user, \"admin\")\n\n if args.add_teams:\n if isinstance(user_or_org, Organization):\n configure_github_team(meta, gh_repo, user_or_org, feedstock_name)\n\n\ndef accept_all_repository_invitations(gh):\n user = gh.get_user()\n invitations = github.PaginatedList.PaginatedList(\n github.Invitation.Invitation,\n user._requester,\n user.url + \"/repository_invitations\",\n None,\n )\n for invite in invitations:\n invite._requester.requestJsonAndCheck(\"PATCH\", invite.url)\n\n\ndef remove_from_project(gh, org, project):\n user = gh.get_user()\n repo = gh.get_repo(\"{}/{}\".format(org, project))\n repo.remove_from_collaborators(user.login)\n\n\ndef configure_github_team(meta, gh_repo, org, feedstock_name, remove=True):\n\n # Add a team for this repo and add the maintainers to it.\n superlative = [\n \"awesome\",\n \"slick\",\n \"formidable\",\n \"awe-inspiring\",\n \"breathtaking\",\n \"magnificent\",\n \"wonderous\",\n \"stunning\",\n \"astonishing\",\n \"superb\",\n \"splendid\",\n \"impressive\",\n \"unbeatable\",\n \"excellent\",\n \"top\",\n \"outstanding\",\n \"exalted\",\n \"standout\",\n \"smashing\",\n ]\n\n maintainers = set(meta.meta.get(\"extra\", {}).get(\"recipe-maintainers\", []))\n maintainers = set(maintainer.lower() for maintainer in maintainers)\n maintainer_teams = set(m for m in maintainers if \"/\" in m)\n maintainers = set(m for m in maintainers if \"/\" not in m)\n\n # Try to get team or create it if it doesn't exist.\n team_name = feedstock_name\n current_maintainer_teams = list(gh_repo.get_teams())\n fs_team = next(\n (team for team in current_maintainer_teams if team.name == team_name),\n None,\n )\n current_maintainers = set()\n if not fs_team:\n fs_team = create_team(\n org,\n team_name,\n \"The {} {} contributors!\".format(choice(superlative), team_name),\n )\n fs_team.add_to_repos(gh_repo)\n else:\n current_maintainers = set(\n [e.login.lower() for e in fs_team.get_members()]\n )\n\n # Get the all-members team\n description = \"All of the awesome {} contributors!\".format(org.login)\n all_members_team = get_cached_team(org, \"all-members\", description)\n new_org_members = set()\n\n # Add only the new maintainers to the team.\n # Also add the new maintainers to all-members if not already included.\n for new_maintainer in maintainers - current_maintainers:\n add_membership(fs_team, new_maintainer)\n\n if not has_in_members(all_members_team, new_maintainer):\n add_membership(all_members_team, new_maintainer)\n new_org_members.add(new_maintainer)\n\n # Remove any maintainers that need to be removed (unlikely here).\n if remove:\n for old_maintainer in current_maintainers - maintainers:\n remove_membership(fs_team, old_maintainer)\n\n # Add any new maintainer teams\n maintainer_teams = set(\n m.split(\"/\")[1]\n for m in maintainer_teams\n if m.startswith(str(org.login))\n )\n current_maintainer_team_objs = {\n team.slug: team for team in current_maintainer_teams\n }\n current_maintainer_teams = set(\n [team.slug for team in current_maintainer_teams]\n )\n for new_team in maintainer_teams - current_maintainer_teams:\n team = org.get_team_by_slug(new_team)\n team.add_to_repos(gh_repo)\n\n # remove any old teams\n if remove:\n for old_team in current_maintainer_teams - maintainer_teams:\n team = current_maintainer_team_objs.get(\n old_team, org.get_team_by_slug(old_team)\n )\n if team.name == fs_team.name:\n continue\n team.remove_from_repos(gh_repo)\n\n return maintainers, current_maintainers, new_org_members\n", "path": "conda_smithy/github.py"}]}
| 3,081 | 958 |
gh_patches_debug_8010
|
rasdani/github-patches
|
git_diff
|
wagtail__wagtail-7538
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Preview error when using StreamField with EditHandler on per-request basis
### Issue Summary
We're using `EditHandler`s, which show/hide fields depending on the user's permission. This is based on the example in wagtail's tests (see https://github.com/wagtail/wagtail/blob/main/wagtail/tests/testapp/models.py#L1418).
**Problem:**
Unfortunately, there are multiple places in wagtail's codebase, where `BaseFormEditHandler.get_form_class()` is called, without binding the current request (and also instance etc). One example is the preview-mode (see [preview.py](https://github.com/wagtail/wagtail/blob/main/wagtail/admin/views/pages/preview.py#L51)).
As a result, a user which can only view a subset of the full admin form of a page for example, actually validates his POST-data (which only contains a subset of the fields) with the full form, since the logic that would hide some fields based on the request isn't called.
This probably works for simple cases like [wagtail's test](https://github.com/wagtail/wagtail/blob/main/wagtail/tests/testapp/models.py#L1442) and described in multiple tickets (e.g. https://github.com/wagtail/wagtail/issues/5546), but in our case it results in crashes when showing/hiding `StreamField`s.
**Solution:**
At least bind `instance` and `request` before `get_form_class()` is called, where possible, similar to how the normal edit-view does it: https://github.com/wagtail/wagtail/blob/main/wagtail/admin/views/pages/edit.py#L311
I will try to add those calls to all the places I can find and let the tests run and I hope this can be fixed quickly.
### Steps to Reproduce
I don't have a simple example available yet, but basically we have a custom `BaseCompositeEditHandler` which may skip some of its children, if the user is not a superuser. This is very similar to the [sample](https://github.com/wagtail/wagtail/blob/main/wagtail/tests/testapp/models.py#L1393) in wagtail's tests, but instead of switching between two panel-lists, we have one default list, and based on the field-keys we may exclude some of those fields.
So this all works for the superuser, since he can edit all of the fields. But if one of those excluded fields is a `StreamField` and the non-superuser clicks on the preview button, the server crashes with something like that:
2021-09-24 11:43:13 ERROR django.request: Internal Server Error: /admin/content/pages/add/base/testpage/1337/preview/ (log.py:224)
Traceback (most recent call last):
File "/****/lib/python3.8/site-packages/django/utils/datastructures.py", line 76, in __getitem__
list_ = super().__getitem__(key)
KeyError: 'form_element_blocks-count'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
...****...
return view_func(request, *args, **kwargs)
File "/****/lib/python3.8/site-packages/django/views/decorators/cache.py", line 44, in _wrapped_view_func
response = view_func(request, *args, **kwargs)
File "/****/lib/python3.8/site-packages/wagtail/admin/urls/__init__.py", line 121, in wrapper
return view_func(request, *args, **kwargs)
File "/****/lib/python3.8/site-packages/wagtail/admin/auth.py", line 193, in decorated_view
return view_func(request, *args, **kwargs)
File "/****/lib/python3.8/site-packages/django/views/generic/base.py", line 70, in view
return self.dispatch(request, *args, **kwargs)
File "/****/lib/python3.8/site-packages/django/views/generic/base.py", line 98, in dispatch
return handler(request, *args, **kwargs)
File "/****/lib/python3.8/site-packages/wagtail/admin/views/pages/preview.py", line 64, in post
form = self.get_form(self.get_page(), request.POST)
File "/****/lib/python3.8/site-packages/wagtail/admin/views/pages/preview.py", line 129, in get_form
if form.is_valid():
File "/****/lib/python3.8/site-packages/wagtail/admin/forms/pages.py", line 150, in is_valid
return super().is_valid()
File "/****/lib/python3.8/site-packages/modelcluster/forms.py", line 316, in is_valid
form_is_valid = super(ClusterForm, self).is_valid()
File "/****/lib/python3.8/site-packages/django/forms/forms.py", line 175, in is_valid
return self.is_bound and not self.errors
File "/****/lib/python3.8/site-packages/django/forms/forms.py", line 170, in errors
self.full_clean()
File "/****/lib/python3.8/site-packages/django/forms/forms.py", line 372, in full_clean
self._clean_fields()
File "/****/lib/python3.8/site-packages/django/forms/forms.py", line 384, in _clean_fields
value = field.widget.value_from_datadict(self.data, self.files, self.add_prefix(name))
File "/****/lib/python3.8/site-packages/wagtail/core/blocks/base.py", line 535, in value_from_datadict
return self.block_def.value_from_datadict(data, files, name)
File "/****/lib/python3.8/site-packages/wagtail/core/blocks/stream_block.py", line 97, in value_from_datadict
count = int(data['%s-count' % prefix])
File "/****/lib/python3.8/site-packages/django/utils/datastructures.py", line 78, in __getitem__
raise MultiValueDictKeyError(key)
django.utils.datastructures.MultiValueDictKeyError: 'form_element_blocks-count'
2021-09-24 11:43:13 ERROR django.channels.server: HTTP POST /admin/content/pages/add/base/testpage/1337/preview/ 500 [0.15, 127.0.0.1:44074] (runserver.py:160)
In the above stacktrace, the `form_element_blocks` (which is a `StreamField`) are not visible to the non-superuser user in the frontend. But the preview-request actually creates a form with the `StreamField` (because our code in `on_request_bound()` isn't called), which fails when validating against the POST-data, which doesn't contain any of the `StreamField`'s POST-data.
### Technical details
* Python version: 3.8.10
* Django version: 3.2.7
* Wagtail version: 2.14.1
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `wagtail/admin/views/pages/preview.py`
Content:
```
1 from time import time
2
3 from django.contrib.contenttypes.models import ContentType
4 from django.core.exceptions import PermissionDenied
5 from django.http import Http404, JsonResponse
6 from django.http.request import QueryDict
7 from django.shortcuts import get_object_or_404
8 from django.template.response import TemplateResponse
9 from django.views.generic import View
10
11 from wagtail.core.models import Page
12
13
14 def view_draft(request, page_id):
15 page = get_object_or_404(Page, id=page_id).get_latest_revision_as_page()
16 perms = page.permissions_for_user(request.user)
17 if not (perms.can_publish() or perms.can_edit()):
18 raise PermissionDenied
19
20 try:
21 preview_mode = page.default_preview_mode
22 except IndexError:
23 raise PermissionDenied
24
25 return page.make_preview_request(request, preview_mode)
26
27
28 class PreviewOnEdit(View):
29 http_method_names = ('post', 'get')
30 preview_expiration_timeout = 60 * 60 * 24 # seconds
31 session_key_prefix = 'wagtail-preview-'
32
33 def remove_old_preview_data(self):
34 expiration = time() - self.preview_expiration_timeout
35 expired_keys = [
36 k for k, v in self.request.session.items()
37 if k.startswith(self.session_key_prefix) and v[1] < expiration]
38 # Removes the session key gracefully
39 for k in expired_keys:
40 self.request.session.pop(k)
41
42 @property
43 def session_key(self):
44 return '{}{}'.format(self.session_key_prefix, self.kwargs['page_id'])
45
46 def get_page(self):
47 return get_object_or_404(Page,
48 id=self.kwargs["page_id"]).get_latest_revision_as_page()
49
50 def get_form(self, page, query_dict):
51 form_class = page.get_edit_handler().get_form_class()
52 parent_page = page.get_parent().specific
53
54 if self.session_key not in self.request.session:
55 # Session key not in session, returning null form
56 return form_class(instance=page, parent_page=parent_page)
57
58 return form_class(query_dict, instance=page, parent_page=parent_page)
59
60 def post(self, request, *args, **kwargs):
61 # TODO: Handle request.FILES.
62 request.session[self.session_key] = request.POST.urlencode(), time()
63 self.remove_old_preview_data()
64 form = self.get_form(self.get_page(), request.POST)
65 return JsonResponse({'is_valid': form.is_valid()})
66
67 def error_response(self, page):
68 return TemplateResponse(
69 self.request, 'wagtailadmin/pages/preview_error.html',
70 {'page': page}
71 )
72
73 def get(self, request, *args, **kwargs):
74 page = self.get_page()
75
76 post_data, timestamp = self.request.session.get(self.session_key,
77 (None, None))
78 if not isinstance(post_data, str):
79 post_data = ''
80 form = self.get_form(page, QueryDict(post_data))
81
82 if not form.is_valid():
83 return self.error_response(page)
84
85 form.save(commit=False)
86
87 try:
88 preview_mode = request.GET.get('mode', page.default_preview_mode)
89 except IndexError:
90 raise PermissionDenied
91
92 return page.make_preview_request(request, preview_mode)
93
94
95 class PreviewOnCreate(PreviewOnEdit):
96 @property
97 def session_key(self):
98 return '{}{}-{}-{}'.format(
99 self.session_key_prefix,
100 self.kwargs['content_type_app_name'],
101 self.kwargs['content_type_model_name'],
102 self.kwargs['parent_page_id'],
103 )
104
105 def get_page(self):
106 content_type_app_name = self.kwargs["content_type_app_name"]
107 content_type_model_name = self.kwargs["content_type_model_name"]
108 parent_page_id = self.kwargs["parent_page_id"]
109 try:
110 content_type = ContentType.objects.get_by_natural_key(
111 content_type_app_name, content_type_model_name)
112 except ContentType.DoesNotExist:
113 raise Http404
114
115 page = content_type.model_class()()
116 parent_page = get_object_or_404(Page, id=parent_page_id).specific
117 # We need to populate treebeard's path / depth fields in order to
118 # pass validation. We can't make these 100% consistent with the rest
119 # of the tree without making actual database changes (such as
120 # incrementing the parent's numchild field), but by calling treebeard's
121 # internal _get_path method, we can set a 'realistic' value that will
122 # hopefully enable tree traversal operations
123 # to at least partially work.
124 page.depth = parent_page.depth + 1
125 # Puts the page at the next available path
126 # for a child of `parent_page`.
127 if parent_page.is_leaf():
128 # set the path as the first child of parent_page
129 page.path = page._get_path(parent_page.path, page.depth, 1)
130 else:
131 # add the new page after the last child of parent_page
132 page.path = parent_page.get_last_child()._inc_path()
133
134 return page
135
136 def get_form(self, page, query_dict):
137 form = super().get_form(page, query_dict)
138 if form.is_valid():
139 # Ensures our unsaved page has a suitable url.
140 form.instance.set_url_path(form.parent_page)
141
142 form.instance.full_clean()
143 return form
144
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/wagtail/admin/views/pages/preview.py b/wagtail/admin/views/pages/preview.py
--- a/wagtail/admin/views/pages/preview.py
+++ b/wagtail/admin/views/pages/preview.py
@@ -48,7 +48,7 @@
id=self.kwargs["page_id"]).get_latest_revision_as_page()
def get_form(self, page, query_dict):
- form_class = page.get_edit_handler().get_form_class()
+ form_class = page.get_edit_handler().bind_to(instance=page, request=self.request).get_form_class()
parent_page = page.get_parent().specific
if self.session_key not in self.request.session:
|
{"golden_diff": "diff --git a/wagtail/admin/views/pages/preview.py b/wagtail/admin/views/pages/preview.py\n--- a/wagtail/admin/views/pages/preview.py\n+++ b/wagtail/admin/views/pages/preview.py\n@@ -48,7 +48,7 @@\n id=self.kwargs[\"page_id\"]).get_latest_revision_as_page()\n \n def get_form(self, page, query_dict):\n- form_class = page.get_edit_handler().get_form_class()\n+ form_class = page.get_edit_handler().bind_to(instance=page, request=self.request).get_form_class()\n parent_page = page.get_parent().specific\n \n if self.session_key not in self.request.session:\n", "issue": "Preview error when using StreamField with EditHandler on per-request basis\n### Issue Summary\r\n\r\nWe're using `EditHandler`s, which show/hide fields depending on the user's permission. This is based on the example in wagtail's tests (see https://github.com/wagtail/wagtail/blob/main/wagtail/tests/testapp/models.py#L1418).\r\n\r\n**Problem:**\r\nUnfortunately, there are multiple places in wagtail's codebase, where `BaseFormEditHandler.get_form_class()` is called, without binding the current request (and also instance etc). One example is the preview-mode (see [preview.py](https://github.com/wagtail/wagtail/blob/main/wagtail/admin/views/pages/preview.py#L51)).\r\n\r\nAs a result, a user which can only view a subset of the full admin form of a page for example, actually validates his POST-data (which only contains a subset of the fields) with the full form, since the logic that would hide some fields based on the request isn't called.\r\n\r\nThis probably works for simple cases like [wagtail's test](https://github.com/wagtail/wagtail/blob/main/wagtail/tests/testapp/models.py#L1442) and described in multiple tickets (e.g. https://github.com/wagtail/wagtail/issues/5546), but in our case it results in crashes when showing/hiding `StreamField`s.\r\n\r\n**Solution:**\r\nAt least bind `instance` and `request` before `get_form_class()` is called, where possible, similar to how the normal edit-view does it: https://github.com/wagtail/wagtail/blob/main/wagtail/admin/views/pages/edit.py#L311\r\n\r\nI will try to add those calls to all the places I can find and let the tests run and I hope this can be fixed quickly.\r\n\r\n\r\n### Steps to Reproduce\r\n\r\nI don't have a simple example available yet, but basically we have a custom `BaseCompositeEditHandler` which may skip some of its children, if the user is not a superuser. This is very similar to the [sample](https://github.com/wagtail/wagtail/blob/main/wagtail/tests/testapp/models.py#L1393) in wagtail's tests, but instead of switching between two panel-lists, we have one default list, and based on the field-keys we may exclude some of those fields.\r\n\r\nSo this all works for the superuser, since he can edit all of the fields. But if one of those excluded fields is a `StreamField` and the non-superuser clicks on the preview button, the server crashes with something like that:\r\n\r\n 2021-09-24 11:43:13 ERROR django.request: Internal Server Error: /admin/content/pages/add/base/testpage/1337/preview/ (log.py:224)\r\n Traceback (most recent call last):\r\n File \"/****/lib/python3.8/site-packages/django/utils/datastructures.py\", line 76, in __getitem__\r\n list_ = super().__getitem__(key)\r\n KeyError: 'form_element_blocks-count'\r\n\r\n During handling of the above exception, another exception occurred:\r\n\r\n Traceback (most recent call last):\r\n ...****...\r\n return view_func(request, *args, **kwargs)\r\n File \"/****/lib/python3.8/site-packages/django/views/decorators/cache.py\", line 44, in _wrapped_view_func\r\n response = view_func(request, *args, **kwargs)\r\n File \"/****/lib/python3.8/site-packages/wagtail/admin/urls/__init__.py\", line 121, in wrapper\r\n return view_func(request, *args, **kwargs)\r\n File \"/****/lib/python3.8/site-packages/wagtail/admin/auth.py\", line 193, in decorated_view\r\n return view_func(request, *args, **kwargs)\r\n File \"/****/lib/python3.8/site-packages/django/views/generic/base.py\", line 70, in view\r\n return self.dispatch(request, *args, **kwargs)\r\n File \"/****/lib/python3.8/site-packages/django/views/generic/base.py\", line 98, in dispatch\r\n return handler(request, *args, **kwargs)\r\n File \"/****/lib/python3.8/site-packages/wagtail/admin/views/pages/preview.py\", line 64, in post\r\n form = self.get_form(self.get_page(), request.POST)\r\n File \"/****/lib/python3.8/site-packages/wagtail/admin/views/pages/preview.py\", line 129, in get_form\r\n if form.is_valid():\r\n File \"/****/lib/python3.8/site-packages/wagtail/admin/forms/pages.py\", line 150, in is_valid\r\n return super().is_valid()\r\n File \"/****/lib/python3.8/site-packages/modelcluster/forms.py\", line 316, in is_valid\r\n form_is_valid = super(ClusterForm, self).is_valid()\r\n File \"/****/lib/python3.8/site-packages/django/forms/forms.py\", line 175, in is_valid\r\n return self.is_bound and not self.errors\r\n File \"/****/lib/python3.8/site-packages/django/forms/forms.py\", line 170, in errors\r\n self.full_clean()\r\n File \"/****/lib/python3.8/site-packages/django/forms/forms.py\", line 372, in full_clean\r\n self._clean_fields()\r\n File \"/****/lib/python3.8/site-packages/django/forms/forms.py\", line 384, in _clean_fields\r\n value = field.widget.value_from_datadict(self.data, self.files, self.add_prefix(name))\r\n File \"/****/lib/python3.8/site-packages/wagtail/core/blocks/base.py\", line 535, in value_from_datadict\r\n return self.block_def.value_from_datadict(data, files, name)\r\n File \"/****/lib/python3.8/site-packages/wagtail/core/blocks/stream_block.py\", line 97, in value_from_datadict\r\n count = int(data['%s-count' % prefix])\r\n File \"/****/lib/python3.8/site-packages/django/utils/datastructures.py\", line 78, in __getitem__\r\n raise MultiValueDictKeyError(key)\r\n django.utils.datastructures.MultiValueDictKeyError: 'form_element_blocks-count'\r\n 2021-09-24 11:43:13 ERROR django.channels.server: HTTP POST /admin/content/pages/add/base/testpage/1337/preview/ 500 [0.15, 127.0.0.1:44074] (runserver.py:160)\r\n\r\nIn the above stacktrace, the `form_element_blocks` (which is a `StreamField`) are not visible to the non-superuser user in the frontend. But the preview-request actually creates a form with the `StreamField` (because our code in `on_request_bound()` isn't called), which fails when validating against the POST-data, which doesn't contain any of the `StreamField`'s POST-data.\r\n\r\n\r\n### Technical details\r\n\r\n* Python version: 3.8.10\r\n* Django version: 3.2.7\r\n* Wagtail version: 2.14.1\r\n\n", "before_files": [{"content": "from time import time\n\nfrom django.contrib.contenttypes.models import ContentType\nfrom django.core.exceptions import PermissionDenied\nfrom django.http import Http404, JsonResponse\nfrom django.http.request import QueryDict\nfrom django.shortcuts import get_object_or_404\nfrom django.template.response import TemplateResponse\nfrom django.views.generic import View\n\nfrom wagtail.core.models import Page\n\n\ndef view_draft(request, page_id):\n page = get_object_or_404(Page, id=page_id).get_latest_revision_as_page()\n perms = page.permissions_for_user(request.user)\n if not (perms.can_publish() or perms.can_edit()):\n raise PermissionDenied\n\n try:\n preview_mode = page.default_preview_mode\n except IndexError:\n raise PermissionDenied\n\n return page.make_preview_request(request, preview_mode)\n\n\nclass PreviewOnEdit(View):\n http_method_names = ('post', 'get')\n preview_expiration_timeout = 60 * 60 * 24 # seconds\n session_key_prefix = 'wagtail-preview-'\n\n def remove_old_preview_data(self):\n expiration = time() - self.preview_expiration_timeout\n expired_keys = [\n k for k, v in self.request.session.items()\n if k.startswith(self.session_key_prefix) and v[1] < expiration]\n # Removes the session key gracefully\n for k in expired_keys:\n self.request.session.pop(k)\n\n @property\n def session_key(self):\n return '{}{}'.format(self.session_key_prefix, self.kwargs['page_id'])\n\n def get_page(self):\n return get_object_or_404(Page,\n id=self.kwargs[\"page_id\"]).get_latest_revision_as_page()\n\n def get_form(self, page, query_dict):\n form_class = page.get_edit_handler().get_form_class()\n parent_page = page.get_parent().specific\n\n if self.session_key not in self.request.session:\n # Session key not in session, returning null form\n return form_class(instance=page, parent_page=parent_page)\n\n return form_class(query_dict, instance=page, parent_page=parent_page)\n\n def post(self, request, *args, **kwargs):\n # TODO: Handle request.FILES.\n request.session[self.session_key] = request.POST.urlencode(), time()\n self.remove_old_preview_data()\n form = self.get_form(self.get_page(), request.POST)\n return JsonResponse({'is_valid': form.is_valid()})\n\n def error_response(self, page):\n return TemplateResponse(\n self.request, 'wagtailadmin/pages/preview_error.html',\n {'page': page}\n )\n\n def get(self, request, *args, **kwargs):\n page = self.get_page()\n\n post_data, timestamp = self.request.session.get(self.session_key,\n (None, None))\n if not isinstance(post_data, str):\n post_data = ''\n form = self.get_form(page, QueryDict(post_data))\n\n if not form.is_valid():\n return self.error_response(page)\n\n form.save(commit=False)\n\n try:\n preview_mode = request.GET.get('mode', page.default_preview_mode)\n except IndexError:\n raise PermissionDenied\n\n return page.make_preview_request(request, preview_mode)\n\n\nclass PreviewOnCreate(PreviewOnEdit):\n @property\n def session_key(self):\n return '{}{}-{}-{}'.format(\n self.session_key_prefix,\n self.kwargs['content_type_app_name'],\n self.kwargs['content_type_model_name'],\n self.kwargs['parent_page_id'],\n )\n\n def get_page(self):\n content_type_app_name = self.kwargs[\"content_type_app_name\"]\n content_type_model_name = self.kwargs[\"content_type_model_name\"]\n parent_page_id = self.kwargs[\"parent_page_id\"]\n try:\n content_type = ContentType.objects.get_by_natural_key(\n content_type_app_name, content_type_model_name)\n except ContentType.DoesNotExist:\n raise Http404\n\n page = content_type.model_class()()\n parent_page = get_object_or_404(Page, id=parent_page_id).specific\n # We need to populate treebeard's path / depth fields in order to\n # pass validation. We can't make these 100% consistent with the rest\n # of the tree without making actual database changes (such as\n # incrementing the parent's numchild field), but by calling treebeard's\n # internal _get_path method, we can set a 'realistic' value that will\n # hopefully enable tree traversal operations\n # to at least partially work.\n page.depth = parent_page.depth + 1\n # Puts the page at the next available path\n # for a child of `parent_page`.\n if parent_page.is_leaf():\n # set the path as the first child of parent_page\n page.path = page._get_path(parent_page.path, page.depth, 1)\n else:\n # add the new page after the last child of parent_page\n page.path = parent_page.get_last_child()._inc_path()\n\n return page\n\n def get_form(self, page, query_dict):\n form = super().get_form(page, query_dict)\n if form.is_valid():\n # Ensures our unsaved page has a suitable url.\n form.instance.set_url_path(form.parent_page)\n\n form.instance.full_clean()\n return form\n", "path": "wagtail/admin/views/pages/preview.py"}], "after_files": [{"content": "from time import time\n\nfrom django.contrib.contenttypes.models import ContentType\nfrom django.core.exceptions import PermissionDenied\nfrom django.http import Http404, JsonResponse\nfrom django.http.request import QueryDict\nfrom django.shortcuts import get_object_or_404\nfrom django.template.response import TemplateResponse\nfrom django.views.generic import View\n\nfrom wagtail.core.models import Page\n\n\ndef view_draft(request, page_id):\n page = get_object_or_404(Page, id=page_id).get_latest_revision_as_page()\n perms = page.permissions_for_user(request.user)\n if not (perms.can_publish() or perms.can_edit()):\n raise PermissionDenied\n\n try:\n preview_mode = page.default_preview_mode\n except IndexError:\n raise PermissionDenied\n\n return page.make_preview_request(request, preview_mode)\n\n\nclass PreviewOnEdit(View):\n http_method_names = ('post', 'get')\n preview_expiration_timeout = 60 * 60 * 24 # seconds\n session_key_prefix = 'wagtail-preview-'\n\n def remove_old_preview_data(self):\n expiration = time() - self.preview_expiration_timeout\n expired_keys = [\n k for k, v in self.request.session.items()\n if k.startswith(self.session_key_prefix) and v[1] < expiration]\n # Removes the session key gracefully\n for k in expired_keys:\n self.request.session.pop(k)\n\n @property\n def session_key(self):\n return '{}{}'.format(self.session_key_prefix, self.kwargs['page_id'])\n\n def get_page(self):\n return get_object_or_404(Page,\n id=self.kwargs[\"page_id\"]).get_latest_revision_as_page()\n\n def get_form(self, page, query_dict):\n form_class = page.get_edit_handler().bind_to(instance=page, request=self.request).get_form_class()\n parent_page = page.get_parent().specific\n\n if self.session_key not in self.request.session:\n # Session key not in session, returning null form\n return form_class(instance=page, parent_page=parent_page)\n\n return form_class(query_dict, instance=page, parent_page=parent_page)\n\n def post(self, request, *args, **kwargs):\n # TODO: Handle request.FILES.\n request.session[self.session_key] = request.POST.urlencode(), time()\n self.remove_old_preview_data()\n form = self.get_form(self.get_page(), request.POST)\n return JsonResponse({'is_valid': form.is_valid()})\n\n def error_response(self, page):\n return TemplateResponse(\n self.request, 'wagtailadmin/pages/preview_error.html',\n {'page': page}\n )\n\n def get(self, request, *args, **kwargs):\n page = self.get_page()\n\n post_data, timestamp = self.request.session.get(self.session_key,\n (None, None))\n if not isinstance(post_data, str):\n post_data = ''\n form = self.get_form(page, QueryDict(post_data))\n\n if not form.is_valid():\n return self.error_response(page)\n\n form.save(commit=False)\n\n try:\n preview_mode = request.GET.get('mode', page.default_preview_mode)\n except IndexError:\n raise PermissionDenied\n\n return page.make_preview_request(request, preview_mode)\n\n\nclass PreviewOnCreate(PreviewOnEdit):\n @property\n def session_key(self):\n return '{}{}-{}-{}'.format(\n self.session_key_prefix,\n self.kwargs['content_type_app_name'],\n self.kwargs['content_type_model_name'],\n self.kwargs['parent_page_id'],\n )\n\n def get_page(self):\n content_type_app_name = self.kwargs[\"content_type_app_name\"]\n content_type_model_name = self.kwargs[\"content_type_model_name\"]\n parent_page_id = self.kwargs[\"parent_page_id\"]\n try:\n content_type = ContentType.objects.get_by_natural_key(\n content_type_app_name, content_type_model_name)\n except ContentType.DoesNotExist:\n raise Http404\n\n page = content_type.model_class()()\n parent_page = get_object_or_404(Page, id=parent_page_id).specific\n # We need to populate treebeard's path / depth fields in order to\n # pass validation. We can't make these 100% consistent with the rest\n # of the tree without making actual database changes (such as\n # incrementing the parent's numchild field), but by calling treebeard's\n # internal _get_path method, we can set a 'realistic' value that will\n # hopefully enable tree traversal operations\n # to at least partially work.\n page.depth = parent_page.depth + 1\n # Puts the page at the next available path\n # for a child of `parent_page`.\n if parent_page.is_leaf():\n # set the path as the first child of parent_page\n page.path = page._get_path(parent_page.path, page.depth, 1)\n else:\n # add the new page after the last child of parent_page\n page.path = parent_page.get_last_child()._inc_path()\n\n return page\n\n def get_form(self, page, query_dict):\n form = super().get_form(page, query_dict)\n if form.is_valid():\n # Ensures our unsaved page has a suitable url.\n form.instance.set_url_path(form.parent_page)\n\n form.instance.full_clean()\n return form\n", "path": "wagtail/admin/views/pages/preview.py"}]}
| 3,323 | 145 |
gh_patches_debug_30712
|
rasdani/github-patches
|
git_diff
|
nvaccess__nvda-11841
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Visual Studio: IntelliSense tooltips reported twice
### Steps to reproduce:
1. Open Visual Studio 2019
2. Open a C# project
3. Enable reporting of Tooltips
4. Trigger an IntelliSense autocomplete suggestion by typing something.
5. Arrow through the suggestions
### Actual behavior:
The selected item is announced, followed by twice the tooltip.
### Expected behavior:
The selected item is announced, followed by once the tooltip.
### System configuration
#### NVDA installed/portable/running from source:
Installed
#### NVDA version:
alpha-20957
#### Windows version:
Windows 10 2004
#### Name and version of other software in use when reproducing the issue:
Visual Studio 2019 16.7.3 Enterprise
### Other questions
#### Does the issue still occur after restarting your computer?
Yes
#### Have you tried any other versions of NVDA? If so, please report their behaviors.
No
#### If addons are disabled, is your problem still occuring?
Yes
#### Did you try to run the COM registry fixing tool in NVDA menu / tools?
Yes
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `source/NVDAObjects/UIA/VisualStudio.py`
Content:
```
1 # This file is covered by the GNU General Public License.
2 # See the file COPYING for more details.
3 # Copyright (C) 2020 NV Access Limited, Leonard de Ruijter
4
5 """
6 Object overlay classes for Visual Studio components
7 available in Visual Studio and SQL Server Management Studio.
8 """
9
10 from . import UIA
11 import speech
12 import braille
13 import api
14
15
16 class IntelliSenseItem(UIA):
17
18 def _get_name(self):
19 return self.UIAElement.cachedAutomationID
20
21 def event_UIA_elementSelected(self):
22 # Cancel speech to have speech announce the selection as soon as possible.
23 # This is needed because L{reportFocus} does not cancel speech.
24 # Therefore, if speech wouldn't be cancelled,
25 # selection announcements would queue up when changing selection rapidly.
26 speech.cancelSpeech()
27 api.setNavigatorObject(self, isFocus=True)
28 self.reportFocus()
29 # Display results as flash messages.
30 braille.handler.message(braille.getPropertiesBraille(
31 name=self.name, role=self.role, positionInfo=self.positionInfo, description=self.description
32 ))
33
34
35 class IntelliSenseList(UIA):
36 ...
37
38
39 class IntelliSenseLiveRegion(UIA):
40 """
41 Visual Studio uses both Intellisense menu item objects and a live region
42 to communicate Intellisense selections.
43 NVDA uses the menu item approach and therefore the live region provides doubled information
44 and is disabled.
45 """
46
47 _shouldAllowUIALiveRegionChangeEvent = False
48
49
50 _INTELLISENSE_LIST_AUTOMATION_IDS = {
51 "listBoxCompletions",
52 "CompletionList"
53 }
54
55
56 def findExtraOverlayClasses(obj, clsList):
57 if obj.UIAAutomationId in _INTELLISENSE_LIST_AUTOMATION_IDS:
58 clsList.insert(0, IntelliSenseList)
59 elif isinstance(obj.parent, IntelliSenseList) and obj.UIAElement.cachedClassName == "IntellisenseMenuItem":
60 clsList.insert(0, IntelliSenseItem)
61 elif (
62 obj.UIAElement.cachedClassName == "LiveTextBlock"
63 and obj.previous
64 and isinstance(obj.previous.previous, IntelliSenseList)
65 ):
66 clsList.insert(0, IntelliSenseLiveRegion)
67
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/source/NVDAObjects/UIA/VisualStudio.py b/source/NVDAObjects/UIA/VisualStudio.py
--- a/source/NVDAObjects/UIA/VisualStudio.py
+++ b/source/NVDAObjects/UIA/VisualStudio.py
@@ -7,10 +7,11 @@
available in Visual Studio and SQL Server Management Studio.
"""
-from . import UIA
+from . import UIA, ToolTip
import speech
import braille
import api
+import time
class IntelliSenseItem(UIA):
@@ -53,6 +54,34 @@
}
+class CompletionToolTip(ToolTip):
+ """ A tool tip for which duplicate open events can be fired.
+ """
+
+ #: Keeps track of the last ToolTipOpened event (text, time)
+ _lastToolTipOpenedInfo = (None, None)
+ #: The duplicate tooltip events will be dropped within this time window
+ _preventDuplicateToolTipSeconds = 0.2
+
+ def event_UIA_toolTipOpened(self):
+ oldText, oldTime = self._lastToolTipOpenedInfo
+ newText = self.name
+ newTime = time.time()
+ self.__class__._lastToolTipOpenedInfo = (newText, newTime)
+ withinPossibleDupToolTipTimeWindow = (
+ oldTime is not None
+ and (newTime - oldTime) < self._preventDuplicateToolTipSeconds
+ )
+ if newText == oldText and withinPossibleDupToolTipTimeWindow:
+ # Tool-tip event suspected to be a duplicate, drop the event.
+ # - Users attempting to rapidly re-announce tool-tips may
+ # have the announcement erroneously suppressed
+ # - Users on slower systems (or systems under load) may still
+ # receive duplicate announcements
+ return
+ super().event_UIA_toolTipOpened()
+
+
def findExtraOverlayClasses(obj, clsList):
if obj.UIAAutomationId in _INTELLISENSE_LIST_AUTOMATION_IDS:
clsList.insert(0, IntelliSenseList)
@@ -64,3 +93,5 @@
and isinstance(obj.previous.previous, IntelliSenseList)
):
clsList.insert(0, IntelliSenseLiveRegion)
+ elif obj.UIAAutomationId == "completion tooltip":
+ clsList.insert(0, CompletionToolTip)
|
{"golden_diff": "diff --git a/source/NVDAObjects/UIA/VisualStudio.py b/source/NVDAObjects/UIA/VisualStudio.py\n--- a/source/NVDAObjects/UIA/VisualStudio.py\n+++ b/source/NVDAObjects/UIA/VisualStudio.py\n@@ -7,10 +7,11 @@\n available in Visual Studio and SQL Server Management Studio.\n \"\"\"\n \n-from . import UIA\n+from . import UIA, ToolTip\n import speech\n import braille\n import api\n+import time\n \n \n class IntelliSenseItem(UIA):\n@@ -53,6 +54,34 @@\n }\n \n \n+class CompletionToolTip(ToolTip):\n+\t\"\"\" A tool tip for which duplicate open events can be fired.\n+\t\"\"\"\n+\n+\t#: Keeps track of the last ToolTipOpened event (text, time)\n+\t_lastToolTipOpenedInfo = (None, None)\n+\t#: The duplicate tooltip events will be dropped within this time window\n+\t_preventDuplicateToolTipSeconds = 0.2\n+\n+\tdef event_UIA_toolTipOpened(self):\n+\t\toldText, oldTime = self._lastToolTipOpenedInfo\n+\t\tnewText = self.name\n+\t\tnewTime = time.time()\n+\t\tself.__class__._lastToolTipOpenedInfo = (newText, newTime)\n+\t\twithinPossibleDupToolTipTimeWindow = (\n+\t\t\toldTime is not None\n+\t\t\tand (newTime - oldTime) < self._preventDuplicateToolTipSeconds\n+\t\t)\n+\t\tif newText == oldText and withinPossibleDupToolTipTimeWindow:\n+\t\t\t# Tool-tip event suspected to be a duplicate, drop the event.\n+\t\t\t# - Users attempting to rapidly re-announce tool-tips may\n+\t\t\t# have the announcement erroneously suppressed\n+\t\t\t# - Users on slower systems (or systems under load) may still\n+\t\t\t# receive duplicate announcements\n+\t\t\treturn\n+\t\tsuper().event_UIA_toolTipOpened()\n+\n+\n def findExtraOverlayClasses(obj, clsList):\n \tif obj.UIAAutomationId in _INTELLISENSE_LIST_AUTOMATION_IDS:\n \t\tclsList.insert(0, IntelliSenseList)\n@@ -64,3 +93,5 @@\n \t\tand isinstance(obj.previous.previous, IntelliSenseList)\n \t):\n \t\tclsList.insert(0, IntelliSenseLiveRegion)\n+\telif obj.UIAAutomationId == \"completion tooltip\":\n+\t\tclsList.insert(0, CompletionToolTip)\n", "issue": "Visual Studio: IntelliSense tooltips reported twice\n### Steps to reproduce:\r\n1. Open Visual Studio 2019\r\n2. Open a C# project\r\n3. Enable reporting of Tooltips\r\n4. Trigger an IntelliSense autocomplete suggestion by typing something.\r\n5. Arrow through the suggestions\r\n\r\n### Actual behavior:\r\nThe selected item is announced, followed by twice the tooltip.\r\n\r\n### Expected behavior:\r\nThe selected item is announced, followed by once the tooltip.\r\n\r\n### System configuration\r\n#### NVDA installed/portable/running from source:\r\nInstalled\r\n\r\n#### NVDA version:\r\nalpha-20957\r\n\r\n#### Windows version:\r\nWindows 10 2004\r\n\r\n#### Name and version of other software in use when reproducing the issue:\r\nVisual Studio 2019 16.7.3 Enterprise\r\n\r\n### Other questions\r\n#### Does the issue still occur after restarting your computer?\r\nYes\r\n\r\n#### Have you tried any other versions of NVDA? If so, please report their behaviors.\r\nNo\r\n\r\n#### If addons are disabled, is your problem still occuring?\r\nYes\r\n\r\n#### Did you try to run the COM registry fixing tool in NVDA menu / tools?\r\nYes\n", "before_files": [{"content": "# This file is covered by the GNU General Public License.\n# See the file COPYING for more details.\n# Copyright (C) 2020 NV Access Limited, Leonard de Ruijter\n\n\"\"\"\nObject overlay classes for Visual Studio components\navailable in Visual Studio and SQL Server Management Studio.\n\"\"\"\n\nfrom . import UIA\nimport speech\nimport braille\nimport api\n\n\nclass IntelliSenseItem(UIA):\n\n\tdef _get_name(self):\n\t\treturn self.UIAElement.cachedAutomationID\n\n\tdef event_UIA_elementSelected(self):\n\t\t# Cancel speech to have speech announce the selection as soon as possible.\n\t\t# This is needed because L{reportFocus} does not cancel speech.\n\t\t# Therefore, if speech wouldn't be cancelled,\n\t\t# selection announcements would queue up when changing selection rapidly.\n\t\tspeech.cancelSpeech()\n\t\tapi.setNavigatorObject(self, isFocus=True)\n\t\tself.reportFocus()\n\t\t# Display results as flash messages.\n\t\tbraille.handler.message(braille.getPropertiesBraille(\n\t\t\tname=self.name, role=self.role, positionInfo=self.positionInfo, description=self.description\n\t\t))\n\n\nclass IntelliSenseList(UIA):\n\t...\n\n\nclass IntelliSenseLiveRegion(UIA):\n\t\"\"\"\n\tVisual Studio uses both Intellisense menu item objects and a live region\n\tto communicate Intellisense selections.\n\tNVDA uses the menu item approach and therefore the live region provides doubled information\n\tand is disabled.\n\t\"\"\"\n\n\t_shouldAllowUIALiveRegionChangeEvent = False\n\n\n_INTELLISENSE_LIST_AUTOMATION_IDS = {\n\t\"listBoxCompletions\",\n\t\"CompletionList\"\n}\n\n\ndef findExtraOverlayClasses(obj, clsList):\n\tif obj.UIAAutomationId in _INTELLISENSE_LIST_AUTOMATION_IDS:\n\t\tclsList.insert(0, IntelliSenseList)\n\telif isinstance(obj.parent, IntelliSenseList) and obj.UIAElement.cachedClassName == \"IntellisenseMenuItem\":\n\t\tclsList.insert(0, IntelliSenseItem)\n\telif (\n\t\tobj.UIAElement.cachedClassName == \"LiveTextBlock\"\n\t\tand obj.previous\n\t\tand isinstance(obj.previous.previous, IntelliSenseList)\n\t):\n\t\tclsList.insert(0, IntelliSenseLiveRegion)\n", "path": "source/NVDAObjects/UIA/VisualStudio.py"}], "after_files": [{"content": "# This file is covered by the GNU General Public License.\n# See the file COPYING for more details.\n# Copyright (C) 2020 NV Access Limited, Leonard de Ruijter\n\n\"\"\"\nObject overlay classes for Visual Studio components\navailable in Visual Studio and SQL Server Management Studio.\n\"\"\"\n\nfrom . import UIA, ToolTip\nimport speech\nimport braille\nimport api\nimport time\n\n\nclass IntelliSenseItem(UIA):\n\n\tdef _get_name(self):\n\t\treturn self.UIAElement.cachedAutomationID\n\n\tdef event_UIA_elementSelected(self):\n\t\t# Cancel speech to have speech announce the selection as soon as possible.\n\t\t# This is needed because L{reportFocus} does not cancel speech.\n\t\t# Therefore, if speech wouldn't be cancelled,\n\t\t# selection announcements would queue up when changing selection rapidly.\n\t\tspeech.cancelSpeech()\n\t\tapi.setNavigatorObject(self, isFocus=True)\n\t\tself.reportFocus()\n\t\t# Display results as flash messages.\n\t\tbraille.handler.message(braille.getPropertiesBraille(\n\t\t\tname=self.name, role=self.role, positionInfo=self.positionInfo, description=self.description\n\t\t))\n\n\nclass IntelliSenseList(UIA):\n\t...\n\n\nclass IntelliSenseLiveRegion(UIA):\n\t\"\"\"\n\tVisual Studio uses both Intellisense menu item objects and a live region\n\tto communicate Intellisense selections.\n\tNVDA uses the menu item approach and therefore the live region provides doubled information\n\tand is disabled.\n\t\"\"\"\n\n\t_shouldAllowUIALiveRegionChangeEvent = False\n\n\n_INTELLISENSE_LIST_AUTOMATION_IDS = {\n\t\"listBoxCompletions\",\n\t\"CompletionList\"\n}\n\n\nclass CompletionToolTip(ToolTip):\n\t\"\"\" A tool tip for which duplicate open events can be fired.\n\t\"\"\"\n\n\t#: Keeps track of the last ToolTipOpened event (text, time)\n\t_lastToolTipOpenedInfo = (None, None)\n\t#: The duplicate tooltip events will be dropped within this time window\n\t_preventDuplicateToolTipSeconds = 0.2\n\n\tdef event_UIA_toolTipOpened(self):\n\t\toldText, oldTime = self._lastToolTipOpenedInfo\n\t\tnewText = self.name\n\t\tnewTime = time.time()\n\t\tself.__class__._lastToolTipOpenedInfo = (newText, newTime)\n\t\twithinPossibleDupToolTipTimeWindow = (\n\t\t\toldTime is not None\n\t\t\tand (newTime - oldTime) < self._preventDuplicateToolTipSeconds\n\t\t)\n\t\tif newText == oldText and withinPossibleDupToolTipTimeWindow:\n\t\t\t# Tool-tip event suspected to be a duplicate, drop the event.\n\t\t\t# - Users attempting to rapidly re-announce tool-tips may\n\t\t\t# have the announcement erroneously suppressed\n\t\t\t# - Users on slower systems (or systems under load) may still\n\t\t\t# receive duplicate announcements\n\t\t\treturn\n\t\tsuper().event_UIA_toolTipOpened()\n\n\ndef findExtraOverlayClasses(obj, clsList):\n\tif obj.UIAAutomationId in _INTELLISENSE_LIST_AUTOMATION_IDS:\n\t\tclsList.insert(0, IntelliSenseList)\n\telif isinstance(obj.parent, IntelliSenseList) and obj.UIAElement.cachedClassName == \"IntellisenseMenuItem\":\n\t\tclsList.insert(0, IntelliSenseItem)\n\telif (\n\t\tobj.UIAElement.cachedClassName == \"LiveTextBlock\"\n\t\tand obj.previous\n\t\tand isinstance(obj.previous.previous, IntelliSenseList)\n\t):\n\t\tclsList.insert(0, IntelliSenseLiveRegion)\n\telif obj.UIAAutomationId == \"completion tooltip\":\n\t\tclsList.insert(0, CompletionToolTip)\n", "path": "source/NVDAObjects/UIA/VisualStudio.py"}]}
| 1,123 | 529 |
gh_patches_debug_35620
|
rasdani/github-patches
|
git_diff
|
mitmproxy__mitmproxy-4741
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
GZIP request body encoding falling back to raw
#### Problem Description
GZIP requests are not decoded correctly.
This only occurs in the request and not in the response. In the response I see the body as uncompromised gzip but not in the request.
I created a own content view to test the gzip decompression:
```python
from typing import Optional
from mitmproxy import contentviews, flow
from mitmproxy import http
import gzip
class ViewGZIPCase(contentviews.View):
name = "GZIP"
def __call__(self, data, **metadata) -> contentviews.TViewResult:
return "gzip", contentviews.format_text(gzip.decompress(data))
def render_priority(
self,
data: bytes,
*,
content_type: Optional[str] = None,
flow: Optional[flow.Flow] = None,
http_message: Optional[http.Message] = None,
**unknown_metadata,
) -> float:
if http_message.headers["content-encoding"] == "GZIP":
return 1
else:
return 0
view = ViewGZIPCase()
def load(l):
contentviews.add(view)
def done():
contentviews.remove(view)
```
##### request
with selected self-made view
<img width="1637" alt="Screenshot 2021-08-05 at 16 42 57" src="https://user-images.githubusercontent.com/1338331/128370647-68c5af49-dfca-4862-a3ff-b3413c4226fd.png">
without any special view
<img width="1637" alt="Screenshot 2021-08-05 at 16 42 42" src="https://user-images.githubusercontent.com/1338331/128370652-e2001fd6-0909-491a-8c77-19cfa226b7d6.png">
##### response
Mitmproxy standalone decompression and json parsing in the response but why not in the request?
<img width="1637" alt="Screenshot 2021-08-05 at 16 47 55" src="https://user-images.githubusercontent.com/1338331/128370639-75287a4f-5c54-47e9-a126-3ff95a1dc90f.png">
#### Steps to reproduce the behavior:
1. start Mitmproxy
2. wait for requests ( iPhone 12 as client is connected)
3. open the request
#### System Information
Mitmproxy: 7.0.2
Python: 3.9.6
OpenSSL: OpenSSL 1.1.1k 25 Mar 2021
Platform: macOS-11.5.1-x86_64-i386-64bit
GZIP request body encoding falling back to raw
#### Problem Description
GZIP requests are not decoded correctly.
This only occurs in the request and not in the response. In the response I see the body as uncompromised gzip but not in the request.
I created a own content view to test the gzip decompression:
```python
from typing import Optional
from mitmproxy import contentviews, flow
from mitmproxy import http
import gzip
class ViewGZIPCase(contentviews.View):
name = "GZIP"
def __call__(self, data, **metadata) -> contentviews.TViewResult:
return "gzip", contentviews.format_text(gzip.decompress(data))
def render_priority(
self,
data: bytes,
*,
content_type: Optional[str] = None,
flow: Optional[flow.Flow] = None,
http_message: Optional[http.Message] = None,
**unknown_metadata,
) -> float:
if http_message.headers["content-encoding"] == "GZIP":
return 1
else:
return 0
view = ViewGZIPCase()
def load(l):
contentviews.add(view)
def done():
contentviews.remove(view)
```
##### request
with selected self-made view
<img width="1637" alt="Screenshot 2021-08-05 at 16 42 57" src="https://user-images.githubusercontent.com/1338331/128370647-68c5af49-dfca-4862-a3ff-b3413c4226fd.png">
without any special view
<img width="1637" alt="Screenshot 2021-08-05 at 16 42 42" src="https://user-images.githubusercontent.com/1338331/128370652-e2001fd6-0909-491a-8c77-19cfa226b7d6.png">
##### response
Mitmproxy standalone decompression and json parsing in the response but why not in the request?
<img width="1637" alt="Screenshot 2021-08-05 at 16 47 55" src="https://user-images.githubusercontent.com/1338331/128370639-75287a4f-5c54-47e9-a126-3ff95a1dc90f.png">
#### Steps to reproduce the behavior:
1. start Mitmproxy
2. wait for requests ( iPhone 12 as client is connected)
3. open the request
#### System Information
Mitmproxy: 7.0.2
Python: 3.9.6
OpenSSL: OpenSSL 1.1.1k 25 Mar 2021
Platform: macOS-11.5.1-x86_64-i386-64bit
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mitmproxy/net/encoding.py`
Content:
```
1 """
2 Utility functions for decoding response bodies.
3 """
4
5 import codecs
6 import collections
7 from io import BytesIO
8
9 import gzip
10 import zlib
11 import brotli
12 import zstandard as zstd
13
14 from typing import Union, Optional, AnyStr, overload # noqa
15
16 # We have a shared single-element cache for encoding and decoding.
17 # This is quite useful in practice, e.g.
18 # flow.request.content = flow.request.content.replace(b"foo", b"bar")
19 # does not require an .encode() call if content does not contain b"foo"
20 CachedDecode = collections.namedtuple(
21 "CachedDecode", "encoded encoding errors decoded"
22 )
23 _cache = CachedDecode(None, None, None, None)
24
25
26 @overload
27 def decode(encoded: None, encoding: str, errors: str = 'strict') -> None:
28 ...
29
30
31 @overload
32 def decode(encoded: str, encoding: str, errors: str = 'strict') -> str:
33 ...
34
35
36 @overload
37 def decode(encoded: bytes, encoding: str, errors: str = 'strict') -> Union[str, bytes]:
38 ...
39
40
41 def decode(
42 encoded: Union[None, str, bytes], encoding: str, errors: str = 'strict'
43 ) -> Union[None, str, bytes]:
44 """
45 Decode the given input object
46
47 Returns:
48 The decoded value
49
50 Raises:
51 ValueError, if decoding fails.
52 """
53 if encoded is None:
54 return None
55
56 global _cache
57 cached = (
58 isinstance(encoded, bytes) and
59 _cache.encoded == encoded and
60 _cache.encoding == encoding and
61 _cache.errors == errors
62 )
63 if cached:
64 return _cache.decoded
65 try:
66 try:
67 decoded = custom_decode[encoding](encoded)
68 except KeyError:
69 decoded = codecs.decode(encoded, encoding, errors) # type: ignore
70 if encoding in ("gzip", "deflate", "br", "zstd"):
71 _cache = CachedDecode(encoded, encoding, errors, decoded)
72 return decoded
73 except TypeError:
74 raise
75 except Exception as e:
76 raise ValueError("{} when decoding {} with {}: {}".format(
77 type(e).__name__,
78 repr(encoded)[:10],
79 repr(encoding),
80 repr(e),
81 ))
82
83
84 @overload
85 def encode(decoded: None, encoding: str, errors: str = 'strict') -> None:
86 ...
87
88
89 @overload
90 def encode(decoded: str, encoding: str, errors: str = 'strict') -> Union[str, bytes]:
91 ...
92
93
94 @overload
95 def encode(decoded: bytes, encoding: str, errors: str = 'strict') -> bytes:
96 ...
97
98
99 def encode(decoded: Union[None, str, bytes], encoding, errors='strict') -> Union[None, str, bytes]:
100 """
101 Encode the given input object
102
103 Returns:
104 The encoded value
105
106 Raises:
107 ValueError, if encoding fails.
108 """
109 if decoded is None:
110 return None
111
112 global _cache
113 cached = (
114 isinstance(decoded, bytes) and
115 _cache.decoded == decoded and
116 _cache.encoding == encoding and
117 _cache.errors == errors
118 )
119 if cached:
120 return _cache.encoded
121 try:
122 try:
123 encoded = custom_encode[encoding](decoded)
124 except KeyError:
125 encoded = codecs.encode(decoded, encoding, errors) # type: ignore
126 if encoding in ("gzip", "deflate", "br", "zstd"):
127 _cache = CachedDecode(encoded, encoding, errors, decoded)
128 return encoded
129 except TypeError:
130 raise
131 except Exception as e:
132 raise ValueError("{} when encoding {} with {}: {}".format(
133 type(e).__name__,
134 repr(decoded)[:10],
135 repr(encoding),
136 repr(e),
137 ))
138
139
140 def identity(content):
141 """
142 Returns content unchanged. Identity is the default value of
143 Accept-Encoding headers.
144 """
145 return content
146
147
148 def decode_gzip(content: bytes) -> bytes:
149 if not content:
150 return b""
151 gfile = gzip.GzipFile(fileobj=BytesIO(content))
152 return gfile.read()
153
154
155 def encode_gzip(content: bytes) -> bytes:
156 s = BytesIO()
157 gf = gzip.GzipFile(fileobj=s, mode='wb')
158 gf.write(content)
159 gf.close()
160 return s.getvalue()
161
162
163 def decode_brotli(content: bytes) -> bytes:
164 if not content:
165 return b""
166 return brotli.decompress(content)
167
168
169 def encode_brotli(content: bytes) -> bytes:
170 return brotli.compress(content)
171
172
173 def decode_zstd(content: bytes) -> bytes:
174 if not content:
175 return b""
176 zstd_ctx = zstd.ZstdDecompressor()
177 try:
178 return zstd_ctx.decompress(content)
179 except zstd.ZstdError:
180 # If the zstd stream is streamed without a size header,
181 # try decoding with a 10MiB output buffer
182 return zstd_ctx.decompress(content, max_output_size=10 * 2 ** 20)
183
184
185 def encode_zstd(content: bytes) -> bytes:
186 zstd_ctx = zstd.ZstdCompressor()
187 return zstd_ctx.compress(content)
188
189
190 def decode_deflate(content: bytes) -> bytes:
191 """
192 Returns decompressed data for DEFLATE. Some servers may respond with
193 compressed data without a zlib header or checksum. An undocumented
194 feature of zlib permits the lenient decompression of data missing both
195 values.
196
197 http://bugs.python.org/issue5784
198 """
199 if not content:
200 return b""
201 try:
202 return zlib.decompress(content)
203 except zlib.error:
204 return zlib.decompress(content, -15)
205
206
207 def encode_deflate(content: bytes) -> bytes:
208 """
209 Returns compressed content, always including zlib header and checksum.
210 """
211 return zlib.compress(content)
212
213
214 custom_decode = {
215 "none": identity,
216 "identity": identity,
217 "gzip": decode_gzip,
218 "deflate": decode_deflate,
219 "deflateRaw": decode_deflate,
220 "br": decode_brotli,
221 "zstd": decode_zstd,
222 }
223 custom_encode = {
224 "none": identity,
225 "identity": identity,
226 "gzip": encode_gzip,
227 "deflate": encode_deflate,
228 "deflateRaw": encode_deflate,
229 "br": encode_brotli,
230 "zstd": encode_zstd,
231 }
232
233 __all__ = ["encode", "decode"]
234
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mitmproxy/net/encoding.py b/mitmproxy/net/encoding.py
--- a/mitmproxy/net/encoding.py
+++ b/mitmproxy/net/encoding.py
@@ -52,6 +52,7 @@
"""
if encoded is None:
return None
+ encoding = encoding.lower()
global _cache
cached = (
@@ -67,7 +68,7 @@
decoded = custom_decode[encoding](encoded)
except KeyError:
decoded = codecs.decode(encoded, encoding, errors) # type: ignore
- if encoding in ("gzip", "deflate", "br", "zstd"):
+ if encoding in ("gzip", "deflate", "deflateraw", "br", "zstd"):
_cache = CachedDecode(encoded, encoding, errors, decoded)
return decoded
except TypeError:
@@ -108,6 +109,7 @@
"""
if decoded is None:
return None
+ encoding = encoding.lower()
global _cache
cached = (
@@ -123,7 +125,7 @@
encoded = custom_encode[encoding](decoded)
except KeyError:
encoded = codecs.encode(decoded, encoding, errors) # type: ignore
- if encoding in ("gzip", "deflate", "br", "zstd"):
+ if encoding in ("gzip", "deflate", "deflateraw", "br", "zstd"):
_cache = CachedDecode(encoded, encoding, errors, decoded)
return encoded
except TypeError:
@@ -216,7 +218,7 @@
"identity": identity,
"gzip": decode_gzip,
"deflate": decode_deflate,
- "deflateRaw": decode_deflate,
+ "deflateraw": decode_deflate,
"br": decode_brotli,
"zstd": decode_zstd,
}
@@ -225,7 +227,7 @@
"identity": identity,
"gzip": encode_gzip,
"deflate": encode_deflate,
- "deflateRaw": encode_deflate,
+ "deflateraw": encode_deflate,
"br": encode_brotli,
"zstd": encode_zstd,
}
|
{"golden_diff": "diff --git a/mitmproxy/net/encoding.py b/mitmproxy/net/encoding.py\n--- a/mitmproxy/net/encoding.py\n+++ b/mitmproxy/net/encoding.py\n@@ -52,6 +52,7 @@\n \"\"\"\n if encoded is None:\n return None\n+ encoding = encoding.lower()\n \n global _cache\n cached = (\n@@ -67,7 +68,7 @@\n decoded = custom_decode[encoding](encoded)\n except KeyError:\n decoded = codecs.decode(encoded, encoding, errors) # type: ignore\n- if encoding in (\"gzip\", \"deflate\", \"br\", \"zstd\"):\n+ if encoding in (\"gzip\", \"deflate\", \"deflateraw\", \"br\", \"zstd\"):\n _cache = CachedDecode(encoded, encoding, errors, decoded)\n return decoded\n except TypeError:\n@@ -108,6 +109,7 @@\n \"\"\"\n if decoded is None:\n return None\n+ encoding = encoding.lower()\n \n global _cache\n cached = (\n@@ -123,7 +125,7 @@\n encoded = custom_encode[encoding](decoded)\n except KeyError:\n encoded = codecs.encode(decoded, encoding, errors) # type: ignore\n- if encoding in (\"gzip\", \"deflate\", \"br\", \"zstd\"):\n+ if encoding in (\"gzip\", \"deflate\", \"deflateraw\", \"br\", \"zstd\"):\n _cache = CachedDecode(encoded, encoding, errors, decoded)\n return encoded\n except TypeError:\n@@ -216,7 +218,7 @@\n \"identity\": identity,\n \"gzip\": decode_gzip,\n \"deflate\": decode_deflate,\n- \"deflateRaw\": decode_deflate,\n+ \"deflateraw\": decode_deflate,\n \"br\": decode_brotli,\n \"zstd\": decode_zstd,\n }\n@@ -225,7 +227,7 @@\n \"identity\": identity,\n \"gzip\": encode_gzip,\n \"deflate\": encode_deflate,\n- \"deflateRaw\": encode_deflate,\n+ \"deflateraw\": encode_deflate,\n \"br\": encode_brotli,\n \"zstd\": encode_zstd,\n }\n", "issue": "GZIP request body encoding falling back to raw\n#### Problem Description\r\nGZIP requests are not decoded correctly.\r\nThis only occurs in the request and not in the response. In the response I see the body as uncompromised gzip but not in the request. \r\n\r\nI created a own content view to test the gzip decompression:\r\n\r\n```python\r\nfrom typing import Optional\r\nfrom mitmproxy import contentviews, flow\r\nfrom mitmproxy import http\r\nimport gzip\r\n\r\n\r\nclass ViewGZIPCase(contentviews.View):\r\n name = \"GZIP\"\r\n\r\n def __call__(self, data, **metadata) -> contentviews.TViewResult:\r\n return \"gzip\", contentviews.format_text(gzip.decompress(data))\r\n\r\n def render_priority(\r\n self,\r\n data: bytes,\r\n *,\r\n content_type: Optional[str] = None,\r\n flow: Optional[flow.Flow] = None,\r\n http_message: Optional[http.Message] = None,\r\n **unknown_metadata,\r\n ) -> float:\r\n\r\n if http_message.headers[\"content-encoding\"] == \"GZIP\":\r\n return 1\r\n\r\n else:\r\n return 0\r\n\r\n\r\nview = ViewGZIPCase()\r\n\r\n\r\ndef load(l):\r\n contentviews.add(view)\r\n\r\n\r\ndef done():\r\n contentviews.remove(view)\r\n```\r\n\r\n##### request\r\n\r\nwith selected self-made view\r\n<img width=\"1637\" alt=\"Screenshot 2021-08-05 at 16 42 57\" src=\"https://user-images.githubusercontent.com/1338331/128370647-68c5af49-dfca-4862-a3ff-b3413c4226fd.png\">\r\n\r\nwithout any special view\r\n<img width=\"1637\" alt=\"Screenshot 2021-08-05 at 16 42 42\" src=\"https://user-images.githubusercontent.com/1338331/128370652-e2001fd6-0909-491a-8c77-19cfa226b7d6.png\">\r\n\r\n\r\n##### response\r\n\r\nMitmproxy standalone decompression and json parsing in the response but why not in the request?\r\n<img width=\"1637\" alt=\"Screenshot 2021-08-05 at 16 47 55\" src=\"https://user-images.githubusercontent.com/1338331/128370639-75287a4f-5c54-47e9-a126-3ff95a1dc90f.png\">\r\n\r\n\r\n#### Steps to reproduce the behavior:\r\n1. start Mitmproxy \r\n2. wait for requests ( iPhone 12 as client is connected)\r\n3. open the request\r\n\r\n#### System Information\r\nMitmproxy: 7.0.2\r\nPython: 3.9.6\r\nOpenSSL: OpenSSL 1.1.1k 25 Mar 2021\r\nPlatform: macOS-11.5.1-x86_64-i386-64bit\r\n\r\n\r\n\nGZIP request body encoding falling back to raw\n#### Problem Description\r\nGZIP requests are not decoded correctly.\r\nThis only occurs in the request and not in the response. In the response I see the body as uncompromised gzip but not in the request. \r\n\r\nI created a own content view to test the gzip decompression:\r\n\r\n```python\r\nfrom typing import Optional\r\nfrom mitmproxy import contentviews, flow\r\nfrom mitmproxy import http\r\nimport gzip\r\n\r\n\r\nclass ViewGZIPCase(contentviews.View):\r\n name = \"GZIP\"\r\n\r\n def __call__(self, data, **metadata) -> contentviews.TViewResult:\r\n return \"gzip\", contentviews.format_text(gzip.decompress(data))\r\n\r\n def render_priority(\r\n self,\r\n data: bytes,\r\n *,\r\n content_type: Optional[str] = None,\r\n flow: Optional[flow.Flow] = None,\r\n http_message: Optional[http.Message] = None,\r\n **unknown_metadata,\r\n ) -> float:\r\n\r\n if http_message.headers[\"content-encoding\"] == \"GZIP\":\r\n return 1\r\n\r\n else:\r\n return 0\r\n\r\n\r\nview = ViewGZIPCase()\r\n\r\n\r\ndef load(l):\r\n contentviews.add(view)\r\n\r\n\r\ndef done():\r\n contentviews.remove(view)\r\n```\r\n\r\n##### request\r\n\r\nwith selected self-made view\r\n<img width=\"1637\" alt=\"Screenshot 2021-08-05 at 16 42 57\" src=\"https://user-images.githubusercontent.com/1338331/128370647-68c5af49-dfca-4862-a3ff-b3413c4226fd.png\">\r\n\r\nwithout any special view\r\n<img width=\"1637\" alt=\"Screenshot 2021-08-05 at 16 42 42\" src=\"https://user-images.githubusercontent.com/1338331/128370652-e2001fd6-0909-491a-8c77-19cfa226b7d6.png\">\r\n\r\n\r\n##### response\r\n\r\nMitmproxy standalone decompression and json parsing in the response but why not in the request?\r\n<img width=\"1637\" alt=\"Screenshot 2021-08-05 at 16 47 55\" src=\"https://user-images.githubusercontent.com/1338331/128370639-75287a4f-5c54-47e9-a126-3ff95a1dc90f.png\">\r\n\r\n\r\n#### Steps to reproduce the behavior:\r\n1. start Mitmproxy \r\n2. wait for requests ( iPhone 12 as client is connected)\r\n3. open the request\r\n\r\n#### System Information\r\nMitmproxy: 7.0.2\r\nPython: 3.9.6\r\nOpenSSL: OpenSSL 1.1.1k 25 Mar 2021\r\nPlatform: macOS-11.5.1-x86_64-i386-64bit\r\n\r\n\r\n\n", "before_files": [{"content": "\"\"\"\nUtility functions for decoding response bodies.\n\"\"\"\n\nimport codecs\nimport collections\nfrom io import BytesIO\n\nimport gzip\nimport zlib\nimport brotli\nimport zstandard as zstd\n\nfrom typing import Union, Optional, AnyStr, overload # noqa\n\n# We have a shared single-element cache for encoding and decoding.\n# This is quite useful in practice, e.g.\n# flow.request.content = flow.request.content.replace(b\"foo\", b\"bar\")\n# does not require an .encode() call if content does not contain b\"foo\"\nCachedDecode = collections.namedtuple(\n \"CachedDecode\", \"encoded encoding errors decoded\"\n)\n_cache = CachedDecode(None, None, None, None)\n\n\n@overload\ndef decode(encoded: None, encoding: str, errors: str = 'strict') -> None:\n ...\n\n\n@overload\ndef decode(encoded: str, encoding: str, errors: str = 'strict') -> str:\n ...\n\n\n@overload\ndef decode(encoded: bytes, encoding: str, errors: str = 'strict') -> Union[str, bytes]:\n ...\n\n\ndef decode(\n encoded: Union[None, str, bytes], encoding: str, errors: str = 'strict'\n) -> Union[None, str, bytes]:\n \"\"\"\n Decode the given input object\n\n Returns:\n The decoded value\n\n Raises:\n ValueError, if decoding fails.\n \"\"\"\n if encoded is None:\n return None\n\n global _cache\n cached = (\n isinstance(encoded, bytes) and\n _cache.encoded == encoded and\n _cache.encoding == encoding and\n _cache.errors == errors\n )\n if cached:\n return _cache.decoded\n try:\n try:\n decoded = custom_decode[encoding](encoded)\n except KeyError:\n decoded = codecs.decode(encoded, encoding, errors) # type: ignore\n if encoding in (\"gzip\", \"deflate\", \"br\", \"zstd\"):\n _cache = CachedDecode(encoded, encoding, errors, decoded)\n return decoded\n except TypeError:\n raise\n except Exception as e:\n raise ValueError(\"{} when decoding {} with {}: {}\".format(\n type(e).__name__,\n repr(encoded)[:10],\n repr(encoding),\n repr(e),\n ))\n\n\n@overload\ndef encode(decoded: None, encoding: str, errors: str = 'strict') -> None:\n ...\n\n\n@overload\ndef encode(decoded: str, encoding: str, errors: str = 'strict') -> Union[str, bytes]:\n ...\n\n\n@overload\ndef encode(decoded: bytes, encoding: str, errors: str = 'strict') -> bytes:\n ...\n\n\ndef encode(decoded: Union[None, str, bytes], encoding, errors='strict') -> Union[None, str, bytes]:\n \"\"\"\n Encode the given input object\n\n Returns:\n The encoded value\n\n Raises:\n ValueError, if encoding fails.\n \"\"\"\n if decoded is None:\n return None\n\n global _cache\n cached = (\n isinstance(decoded, bytes) and\n _cache.decoded == decoded and\n _cache.encoding == encoding and\n _cache.errors == errors\n )\n if cached:\n return _cache.encoded\n try:\n try:\n encoded = custom_encode[encoding](decoded)\n except KeyError:\n encoded = codecs.encode(decoded, encoding, errors) # type: ignore\n if encoding in (\"gzip\", \"deflate\", \"br\", \"zstd\"):\n _cache = CachedDecode(encoded, encoding, errors, decoded)\n return encoded\n except TypeError:\n raise\n except Exception as e:\n raise ValueError(\"{} when encoding {} with {}: {}\".format(\n type(e).__name__,\n repr(decoded)[:10],\n repr(encoding),\n repr(e),\n ))\n\n\ndef identity(content):\n \"\"\"\n Returns content unchanged. Identity is the default value of\n Accept-Encoding headers.\n \"\"\"\n return content\n\n\ndef decode_gzip(content: bytes) -> bytes:\n if not content:\n return b\"\"\n gfile = gzip.GzipFile(fileobj=BytesIO(content))\n return gfile.read()\n\n\ndef encode_gzip(content: bytes) -> bytes:\n s = BytesIO()\n gf = gzip.GzipFile(fileobj=s, mode='wb')\n gf.write(content)\n gf.close()\n return s.getvalue()\n\n\ndef decode_brotli(content: bytes) -> bytes:\n if not content:\n return b\"\"\n return brotli.decompress(content)\n\n\ndef encode_brotli(content: bytes) -> bytes:\n return brotli.compress(content)\n\n\ndef decode_zstd(content: bytes) -> bytes:\n if not content:\n return b\"\"\n zstd_ctx = zstd.ZstdDecompressor()\n try:\n return zstd_ctx.decompress(content)\n except zstd.ZstdError:\n # If the zstd stream is streamed without a size header,\n # try decoding with a 10MiB output buffer\n return zstd_ctx.decompress(content, max_output_size=10 * 2 ** 20)\n\n\ndef encode_zstd(content: bytes) -> bytes:\n zstd_ctx = zstd.ZstdCompressor()\n return zstd_ctx.compress(content)\n\n\ndef decode_deflate(content: bytes) -> bytes:\n \"\"\"\n Returns decompressed data for DEFLATE. Some servers may respond with\n compressed data without a zlib header or checksum. An undocumented\n feature of zlib permits the lenient decompression of data missing both\n values.\n\n http://bugs.python.org/issue5784\n \"\"\"\n if not content:\n return b\"\"\n try:\n return zlib.decompress(content)\n except zlib.error:\n return zlib.decompress(content, -15)\n\n\ndef encode_deflate(content: bytes) -> bytes:\n \"\"\"\n Returns compressed content, always including zlib header and checksum.\n \"\"\"\n return zlib.compress(content)\n\n\ncustom_decode = {\n \"none\": identity,\n \"identity\": identity,\n \"gzip\": decode_gzip,\n \"deflate\": decode_deflate,\n \"deflateRaw\": decode_deflate,\n \"br\": decode_brotli,\n \"zstd\": decode_zstd,\n}\ncustom_encode = {\n \"none\": identity,\n \"identity\": identity,\n \"gzip\": encode_gzip,\n \"deflate\": encode_deflate,\n \"deflateRaw\": encode_deflate,\n \"br\": encode_brotli,\n \"zstd\": encode_zstd,\n}\n\n__all__ = [\"encode\", \"decode\"]\n", "path": "mitmproxy/net/encoding.py"}], "after_files": [{"content": "\"\"\"\nUtility functions for decoding response bodies.\n\"\"\"\n\nimport codecs\nimport collections\nfrom io import BytesIO\n\nimport gzip\nimport zlib\nimport brotli\nimport zstandard as zstd\n\nfrom typing import Union, Optional, AnyStr, overload # noqa\n\n# We have a shared single-element cache for encoding and decoding.\n# This is quite useful in practice, e.g.\n# flow.request.content = flow.request.content.replace(b\"foo\", b\"bar\")\n# does not require an .encode() call if content does not contain b\"foo\"\nCachedDecode = collections.namedtuple(\n \"CachedDecode\", \"encoded encoding errors decoded\"\n)\n_cache = CachedDecode(None, None, None, None)\n\n\n@overload\ndef decode(encoded: None, encoding: str, errors: str = 'strict') -> None:\n ...\n\n\n@overload\ndef decode(encoded: str, encoding: str, errors: str = 'strict') -> str:\n ...\n\n\n@overload\ndef decode(encoded: bytes, encoding: str, errors: str = 'strict') -> Union[str, bytes]:\n ...\n\n\ndef decode(\n encoded: Union[None, str, bytes], encoding: str, errors: str = 'strict'\n) -> Union[None, str, bytes]:\n \"\"\"\n Decode the given input object\n\n Returns:\n The decoded value\n\n Raises:\n ValueError, if decoding fails.\n \"\"\"\n if encoded is None:\n return None\n encoding = encoding.lower()\n\n global _cache\n cached = (\n isinstance(encoded, bytes) and\n _cache.encoded == encoded and\n _cache.encoding == encoding and\n _cache.errors == errors\n )\n if cached:\n return _cache.decoded\n try:\n try:\n decoded = custom_decode[encoding](encoded)\n except KeyError:\n decoded = codecs.decode(encoded, encoding, errors) # type: ignore\n if encoding in (\"gzip\", \"deflate\", \"deflateraw\", \"br\", \"zstd\"):\n _cache = CachedDecode(encoded, encoding, errors, decoded)\n return decoded\n except TypeError:\n raise\n except Exception as e:\n raise ValueError(\"{} when decoding {} with {}: {}\".format(\n type(e).__name__,\n repr(encoded)[:10],\n repr(encoding),\n repr(e),\n ))\n\n\n@overload\ndef encode(decoded: None, encoding: str, errors: str = 'strict') -> None:\n ...\n\n\n@overload\ndef encode(decoded: str, encoding: str, errors: str = 'strict') -> Union[str, bytes]:\n ...\n\n\n@overload\ndef encode(decoded: bytes, encoding: str, errors: str = 'strict') -> bytes:\n ...\n\n\ndef encode(decoded: Union[None, str, bytes], encoding, errors='strict') -> Union[None, str, bytes]:\n \"\"\"\n Encode the given input object\n\n Returns:\n The encoded value\n\n Raises:\n ValueError, if encoding fails.\n \"\"\"\n if decoded is None:\n return None\n encoding = encoding.lower()\n\n global _cache\n cached = (\n isinstance(decoded, bytes) and\n _cache.decoded == decoded and\n _cache.encoding == encoding and\n _cache.errors == errors\n )\n if cached:\n return _cache.encoded\n try:\n try:\n encoded = custom_encode[encoding](decoded)\n except KeyError:\n encoded = codecs.encode(decoded, encoding, errors) # type: ignore\n if encoding in (\"gzip\", \"deflate\", \"deflateraw\", \"br\", \"zstd\"):\n _cache = CachedDecode(encoded, encoding, errors, decoded)\n return encoded\n except TypeError:\n raise\n except Exception as e:\n raise ValueError(\"{} when encoding {} with {}: {}\".format(\n type(e).__name__,\n repr(decoded)[:10],\n repr(encoding),\n repr(e),\n ))\n\n\ndef identity(content):\n \"\"\"\n Returns content unchanged. Identity is the default value of\n Accept-Encoding headers.\n \"\"\"\n return content\n\n\ndef decode_gzip(content: bytes) -> bytes:\n if not content:\n return b\"\"\n gfile = gzip.GzipFile(fileobj=BytesIO(content))\n return gfile.read()\n\n\ndef encode_gzip(content: bytes) -> bytes:\n s = BytesIO()\n gf = gzip.GzipFile(fileobj=s, mode='wb')\n gf.write(content)\n gf.close()\n return s.getvalue()\n\n\ndef decode_brotli(content: bytes) -> bytes:\n if not content:\n return b\"\"\n return brotli.decompress(content)\n\n\ndef encode_brotli(content: bytes) -> bytes:\n return brotli.compress(content)\n\n\ndef decode_zstd(content: bytes) -> bytes:\n if not content:\n return b\"\"\n zstd_ctx = zstd.ZstdDecompressor()\n try:\n return zstd_ctx.decompress(content)\n except zstd.ZstdError:\n # If the zstd stream is streamed without a size header,\n # try decoding with a 10MiB output buffer\n return zstd_ctx.decompress(content, max_output_size=10 * 2 ** 20)\n\n\ndef encode_zstd(content: bytes) -> bytes:\n zstd_ctx = zstd.ZstdCompressor()\n return zstd_ctx.compress(content)\n\n\ndef decode_deflate(content: bytes) -> bytes:\n \"\"\"\n Returns decompressed data for DEFLATE. Some servers may respond with\n compressed data without a zlib header or checksum. An undocumented\n feature of zlib permits the lenient decompression of data missing both\n values.\n\n http://bugs.python.org/issue5784\n \"\"\"\n if not content:\n return b\"\"\n try:\n return zlib.decompress(content)\n except zlib.error:\n return zlib.decompress(content, -15)\n\n\ndef encode_deflate(content: bytes) -> bytes:\n \"\"\"\n Returns compressed content, always including zlib header and checksum.\n \"\"\"\n return zlib.compress(content)\n\n\ncustom_decode = {\n \"none\": identity,\n \"identity\": identity,\n \"gzip\": decode_gzip,\n \"deflate\": decode_deflate,\n \"deflateraw\": decode_deflate,\n \"br\": decode_brotli,\n \"zstd\": decode_zstd,\n}\ncustom_encode = {\n \"none\": identity,\n \"identity\": identity,\n \"gzip\": encode_gzip,\n \"deflate\": encode_deflate,\n \"deflateraw\": encode_deflate,\n \"br\": encode_brotli,\n \"zstd\": encode_zstd,\n}\n\n__all__ = [\"encode\", \"decode\"]\n", "path": "mitmproxy/net/encoding.py"}]}
| 3,655 | 498 |
gh_patches_debug_17450
|
rasdani/github-patches
|
git_diff
|
DataBiosphere__toil-2931
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Toil fails on python 3.7 due to dependency
Toil has an indirect dependency on http_parser package which is no longer maintained on pypi (last update 2013). This package does not compile with python 3.7. It is required by pymesos
However, it does not appear that pymesos has released a version that corrects this.
┆Issue is synchronized with this [Jira Task](https://ucsc-cgl.atlassian.net/browse/TOIL-489)
┆Issue Number: TOIL-489
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 # Copyright (C) 2015-2016 Regents of the University of California
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from setuptools import find_packages, setup
16 import sys
17
18 def runSetup():
19 """
20 Calls setup(). This function exists so the setup() invocation preceded more internal
21 functionality. The `version` module is imported dynamically by importVersion() below.
22 """
23 boto = 'boto==2.48.0'
24 boto3 = 'boto3>=1.7.50, <2.0'
25 futures = 'futures==3.1.1'
26 pycryptodome = 'pycryptodome==3.5.1'
27 pymesos = 'pymesos==0.3.7'
28 psutil = 'psutil >= 3.0.1, <6'
29 pynacl = 'pynacl==1.1.2'
30 gcs = 'google-cloud-storage==1.6.0'
31 gcs_oauth2_boto_plugin = 'gcs_oauth2_boto_plugin==1.14'
32 apacheLibcloud = 'apache-libcloud==2.2.1'
33 cwltool = 'cwltool==1.0.20190906054215'
34 schemaSalad = 'schema-salad<5,>=4.5.20190815125611'
35 galaxyLib = 'galaxy-lib==18.9.2'
36 htcondor = 'htcondor>=8.6.0'
37 kubernetes = 'kubernetes>=10, <11'
38 pytx = 'pytz>=2012'
39 dill = 'dill==0.2.7.1'
40 six = 'six>=1.10.0'
41 future = 'future'
42 requests = 'requests>=2, <3'
43 docker = 'docker==2.5.1'
44 subprocess32 = 'subprocess32<=3.5.2'
45 dateutil = 'python-dateutil'
46 addict = 'addict<=2.2.0'
47 sphinx = 'sphinx==1.7.5'
48 pathlib2 = 'pathlib2==2.3.2'
49
50 core_reqs = [
51 dill,
52 six,
53 future,
54 requests,
55 docker,
56 dateutil,
57 psutil,
58 subprocess32,
59 addict,
60 sphinx,
61 pathlib2]
62
63 aws_reqs = [
64 boto,
65 boto3,
66 futures,
67 pycryptodome]
68 cwl_reqs = [
69 cwltool,
70 schemaSalad,
71 galaxyLib]
72 encryption_reqs = [
73 pynacl]
74 google_reqs = [
75 gcs_oauth2_boto_plugin, # is this being used??
76 apacheLibcloud,
77 gcs]
78 htcondor_reqs = [
79 htcondor]
80 kubernetes_reqs = [
81 kubernetes]
82 mesos_reqs = [
83 pymesos,
84 psutil]
85 wdl_reqs = []
86
87
88 # htcondor is not supported by apple
89 # this is tricky to conditionally support in 'all' due
90 # to how wheels work, so it is not included in all and
91 # must be explicitly installed as an extra
92 all_reqs = \
93 aws_reqs + \
94 cwl_reqs + \
95 encryption_reqs + \
96 google_reqs + \
97 kubernetes_reqs + \
98 mesos_reqs
99
100 # remove the subprocess32 backport if not python2
101 if not sys.version_info[0] == 2:
102 core_reqs.remove(subprocess32)
103
104 setup(
105 name='toil',
106 version=version.distVersion,
107 description='Pipeline management software for clusters.',
108 author='Benedict Paten',
109 author_email='[email protected]',
110 url="https://github.com/BD2KGenomics/toil",
111 classifiers=[
112 'Development Status :: 5 - Production/Stable',
113 'Environment :: Console',
114 'Intended Audience :: Developers',
115 'Intended Audience :: Science/Research',
116 'Intended Audience :: Healthcare Industry',
117 'License :: OSI Approved :: Apache Software License',
118 'Natural Language :: English',
119 'Operating System :: MacOS :: MacOS X',
120 'Operating System :: POSIX',
121 'Operating System :: POSIX :: Linux',
122 'Programming Language :: Python :: 2.7',
123 'Programming Language :: Python :: 3.5',
124 'Programming Language :: Python :: 3.6',
125 'Topic :: Scientific/Engineering',
126 'Topic :: Scientific/Engineering :: Bio-Informatics',
127 'Topic :: Scientific/Engineering :: Astronomy',
128 'Topic :: Scientific/Engineering :: Atmospheric Science',
129 'Topic :: Scientific/Engineering :: Information Analysis',
130 'Topic :: Scientific/Engineering :: Medical Science Apps.',
131 'Topic :: System :: Distributed Computing',
132 'Topic :: Utilities'],
133 license="Apache License v2.0",
134 install_requires=core_reqs,
135 extras_require={
136 'aws': aws_reqs,
137 'cwl': cwl_reqs,
138 'encryption': encryption_reqs,
139 'google': google_reqs,
140 'htcondor:sys_platform!="darwin"': htcondor_reqs,
141 'kubernetes': kubernetes_reqs,
142 'mesos': mesos_reqs,
143 'wdl': wdl_reqs,
144 'all': all_reqs},
145 package_dir={'': 'src'},
146 packages=find_packages(where='src',
147 # Note that we intentionally include the top-level `test` package for
148 # functionality like the @experimental and @integrative decoratorss:
149 exclude=['*.test.*']),
150 package_data = {
151 '': ['*.yml', 'cloud-config'],
152 },
153 # Unfortunately, the names of the entry points are hard-coded elsewhere in the code base so
154 # you can't just change them here. Luckily, most of them are pretty unique strings, and thus
155 # easy to search for.
156 entry_points={
157 'console_scripts': [
158 'toil = toil.utils.toilMain:main',
159 '_toil_worker = toil.worker:main',
160 'cwltoil = toil.cwl.cwltoil:main [cwl]',
161 'toil-cwl-runner = toil.cwl.cwltoil:main [cwl]',
162 'toil-wdl-runner = toil.wdl.toilwdl:main',
163 '_toil_mesos_executor = toil.batchSystems.mesos.executor:main [mesos]',
164 '_toil_kubernetes_executor = toil.batchSystems.kubernetes:executor [kubernetes]']})
165
166
167 def importVersion():
168 """
169 Load and return the module object for src/toil/version.py, generating it from the template if
170 required.
171 """
172 import imp
173 try:
174 # Attempt to load the template first. It only exists in a working copy cloned via git.
175 import version_template
176 except ImportError:
177 # If loading the template fails we must be in a unpacked source distribution and
178 # src/toil/version.py will already exist.
179 pass
180 else:
181 # Use the template to generate src/toil/version.py
182 import os
183 import errno
184 from tempfile import NamedTemporaryFile
185
186 new = version_template.expand_()
187 try:
188 with open('src/toil/version.py') as f:
189 old = f.read()
190 except IOError as e:
191 if e.errno == errno.ENOENT:
192 old = None
193 else:
194 raise
195
196 if old != new:
197 with NamedTemporaryFile(mode='w',dir='src/toil', prefix='version.py.', delete=False) as f:
198 f.write(new)
199 os.rename(f.name, 'src/toil/version.py')
200 # Unfortunately, we can't use a straight import here because that would also load the stuff
201 # defined in src/toil/__init__.py which imports modules from external dependencies that may
202 # yet to be installed when setup.py is invoked.
203 return imp.load_source('toil.version', 'src/toil/version.py')
204
205
206 version = importVersion()
207 runSetup()
208
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -25,6 +25,11 @@
futures = 'futures==3.1.1'
pycryptodome = 'pycryptodome==3.5.1'
pymesos = 'pymesos==0.3.7'
+ # We need this specific http-parser that still claims to be version 0.8.3
+ # but which builds on Python 3.7+, to satisfy pymesos
+ http_parser = 'http-parser' + \
+ '@https://github.com/adamnovak/http-parser/archive/190a17839ba229c635b59d960579451a81fe73f3.zip' + \
+ '#sha256=3d30c84a426627e468657c44de199daee9d3210a48e392d4ad2e7497c5010949'
psutil = 'psutil >= 3.0.1, <6'
pynacl = 'pynacl==1.1.2'
gcs = 'google-cloud-storage==1.6.0'
@@ -80,6 +85,7 @@
kubernetes_reqs = [
kubernetes]
mesos_reqs = [
+ http_parser,
pymesos,
psutil]
wdl_reqs = []
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -25,6 +25,11 @@\n futures = 'futures==3.1.1'\n pycryptodome = 'pycryptodome==3.5.1'\n pymesos = 'pymesos==0.3.7'\n+ # We need this specific http-parser that still claims to be version 0.8.3\n+ # but which builds on Python 3.7+, to satisfy pymesos\n+ http_parser = 'http-parser' + \\\n+ '@https://github.com/adamnovak/http-parser/archive/190a17839ba229c635b59d960579451a81fe73f3.zip' + \\\n+ '#sha256=3d30c84a426627e468657c44de199daee9d3210a48e392d4ad2e7497c5010949'\n psutil = 'psutil >= 3.0.1, <6'\n pynacl = 'pynacl==1.1.2'\n gcs = 'google-cloud-storage==1.6.0'\n@@ -80,6 +85,7 @@\n kubernetes_reqs = [\n kubernetes]\n mesos_reqs = [\n+ http_parser,\n pymesos,\n psutil]\n wdl_reqs = []\n", "issue": "Toil fails on python 3.7 due to dependency\nToil has an indirect dependency on http_parser package which is no longer maintained on pypi (last update 2013). This package does not compile with python 3.7. It is required by pymesos\n\nHowever, it does not appear that pymesos has released a version that corrects this.\n\n\u2506Issue is synchronized with this [Jira Task](https://ucsc-cgl.atlassian.net/browse/TOIL-489)\n\u2506Issue Number: TOIL-489\n\n", "before_files": [{"content": "# Copyright (C) 2015-2016 Regents of the University of California\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom setuptools import find_packages, setup\nimport sys\n\ndef runSetup():\n \"\"\"\n Calls setup(). This function exists so the setup() invocation preceded more internal\n functionality. The `version` module is imported dynamically by importVersion() below.\n \"\"\"\n boto = 'boto==2.48.0'\n boto3 = 'boto3>=1.7.50, <2.0'\n futures = 'futures==3.1.1'\n pycryptodome = 'pycryptodome==3.5.1'\n pymesos = 'pymesos==0.3.7'\n psutil = 'psutil >= 3.0.1, <6'\n pynacl = 'pynacl==1.1.2'\n gcs = 'google-cloud-storage==1.6.0'\n gcs_oauth2_boto_plugin = 'gcs_oauth2_boto_plugin==1.14'\n apacheLibcloud = 'apache-libcloud==2.2.1'\n cwltool = 'cwltool==1.0.20190906054215'\n schemaSalad = 'schema-salad<5,>=4.5.20190815125611'\n galaxyLib = 'galaxy-lib==18.9.2'\n htcondor = 'htcondor>=8.6.0'\n kubernetes = 'kubernetes>=10, <11'\n pytx = 'pytz>=2012'\n dill = 'dill==0.2.7.1'\n six = 'six>=1.10.0'\n future = 'future'\n requests = 'requests>=2, <3'\n docker = 'docker==2.5.1'\n subprocess32 = 'subprocess32<=3.5.2'\n dateutil = 'python-dateutil'\n addict = 'addict<=2.2.0'\n sphinx = 'sphinx==1.7.5'\n pathlib2 = 'pathlib2==2.3.2'\n\n core_reqs = [\n dill,\n six,\n future,\n requests,\n docker,\n dateutil,\n psutil,\n subprocess32,\n addict,\n sphinx,\n pathlib2]\n\n aws_reqs = [\n boto,\n boto3,\n futures,\n pycryptodome]\n cwl_reqs = [\n cwltool,\n schemaSalad,\n galaxyLib]\n encryption_reqs = [\n pynacl]\n google_reqs = [\n gcs_oauth2_boto_plugin, # is this being used??\n apacheLibcloud,\n gcs]\n htcondor_reqs = [\n htcondor]\n kubernetes_reqs = [\n kubernetes]\n mesos_reqs = [\n pymesos,\n psutil]\n wdl_reqs = []\n \n\n # htcondor is not supported by apple\n # this is tricky to conditionally support in 'all' due\n # to how wheels work, so it is not included in all and\n # must be explicitly installed as an extra\n all_reqs = \\\n aws_reqs + \\\n cwl_reqs + \\\n encryption_reqs + \\\n google_reqs + \\\n kubernetes_reqs + \\\n mesos_reqs\n\n # remove the subprocess32 backport if not python2\n if not sys.version_info[0] == 2:\n core_reqs.remove(subprocess32)\n\n setup(\n name='toil',\n version=version.distVersion,\n description='Pipeline management software for clusters.',\n author='Benedict Paten',\n author_email='[email protected]',\n url=\"https://github.com/BD2KGenomics/toil\",\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Console',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Science/Research',\n 'Intended Audience :: Healthcare Industry',\n 'License :: OSI Approved :: Apache Software License',\n 'Natural Language :: English',\n 'Operating System :: MacOS :: MacOS X',\n 'Operating System :: POSIX',\n 'Operating System :: POSIX :: Linux',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Topic :: Scientific/Engineering',\n 'Topic :: Scientific/Engineering :: Bio-Informatics',\n 'Topic :: Scientific/Engineering :: Astronomy',\n 'Topic :: Scientific/Engineering :: Atmospheric Science',\n 'Topic :: Scientific/Engineering :: Information Analysis',\n 'Topic :: Scientific/Engineering :: Medical Science Apps.',\n 'Topic :: System :: Distributed Computing',\n 'Topic :: Utilities'],\n license=\"Apache License v2.0\",\n install_requires=core_reqs,\n extras_require={\n 'aws': aws_reqs,\n 'cwl': cwl_reqs,\n 'encryption': encryption_reqs,\n 'google': google_reqs,\n 'htcondor:sys_platform!=\"darwin\"': htcondor_reqs,\n 'kubernetes': kubernetes_reqs,\n 'mesos': mesos_reqs,\n 'wdl': wdl_reqs,\n 'all': all_reqs},\n package_dir={'': 'src'},\n packages=find_packages(where='src',\n # Note that we intentionally include the top-level `test` package for\n # functionality like the @experimental and @integrative decoratorss:\n exclude=['*.test.*']),\n package_data = {\n '': ['*.yml', 'cloud-config'],\n },\n # Unfortunately, the names of the entry points are hard-coded elsewhere in the code base so\n # you can't just change them here. Luckily, most of them are pretty unique strings, and thus\n # easy to search for.\n entry_points={\n 'console_scripts': [\n 'toil = toil.utils.toilMain:main',\n '_toil_worker = toil.worker:main',\n 'cwltoil = toil.cwl.cwltoil:main [cwl]',\n 'toil-cwl-runner = toil.cwl.cwltoil:main [cwl]',\n 'toil-wdl-runner = toil.wdl.toilwdl:main',\n '_toil_mesos_executor = toil.batchSystems.mesos.executor:main [mesos]',\n '_toil_kubernetes_executor = toil.batchSystems.kubernetes:executor [kubernetes]']})\n\n\ndef importVersion():\n \"\"\"\n Load and return the module object for src/toil/version.py, generating it from the template if\n required.\n \"\"\"\n import imp\n try:\n # Attempt to load the template first. It only exists in a working copy cloned via git.\n import version_template\n except ImportError:\n # If loading the template fails we must be in a unpacked source distribution and\n # src/toil/version.py will already exist.\n pass\n else:\n # Use the template to generate src/toil/version.py\n import os\n import errno\n from tempfile import NamedTemporaryFile\n\n new = version_template.expand_()\n try:\n with open('src/toil/version.py') as f:\n old = f.read()\n except IOError as e:\n if e.errno == errno.ENOENT:\n old = None\n else:\n raise\n\n if old != new:\n with NamedTemporaryFile(mode='w',dir='src/toil', prefix='version.py.', delete=False) as f:\n f.write(new)\n os.rename(f.name, 'src/toil/version.py')\n # Unfortunately, we can't use a straight import here because that would also load the stuff\n # defined in src/toil/__init__.py which imports modules from external dependencies that may\n # yet to be installed when setup.py is invoked.\n return imp.load_source('toil.version', 'src/toil/version.py')\n\n\nversion = importVersion()\nrunSetup()\n", "path": "setup.py"}], "after_files": [{"content": "# Copyright (C) 2015-2016 Regents of the University of California\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom setuptools import find_packages, setup\nimport sys\n\ndef runSetup():\n \"\"\"\n Calls setup(). This function exists so the setup() invocation preceded more internal\n functionality. The `version` module is imported dynamically by importVersion() below.\n \"\"\"\n boto = 'boto==2.48.0'\n boto3 = 'boto3>=1.7.50, <2.0'\n futures = 'futures==3.1.1'\n pycryptodome = 'pycryptodome==3.5.1'\n pymesos = 'pymesos==0.3.7'\n # We need this specific http-parser that still claims to be version 0.8.3\n # but which builds on Python 3.7+, to satisfy pymesos\n http_parser = 'http-parser' + \\\n '@https://github.com/adamnovak/http-parser/archive/190a17839ba229c635b59d960579451a81fe73f3.zip' + \\\n '#sha256=3d30c84a426627e468657c44de199daee9d3210a48e392d4ad2e7497c5010949'\n psutil = 'psutil >= 3.0.1, <6'\n pynacl = 'pynacl==1.1.2'\n gcs = 'google-cloud-storage==1.6.0'\n gcs_oauth2_boto_plugin = 'gcs_oauth2_boto_plugin==1.14'\n apacheLibcloud = 'apache-libcloud==2.2.1'\n cwltool = 'cwltool==1.0.20190906054215'\n schemaSalad = 'schema-salad<5,>=4.5.20190815125611'\n galaxyLib = 'galaxy-lib==18.9.2'\n htcondor = 'htcondor>=8.6.0'\n kubernetes = 'kubernetes>=10, <11'\n pytx = 'pytz>=2012'\n dill = 'dill==0.2.7.1'\n six = 'six>=1.10.0'\n future = 'future'\n requests = 'requests>=2, <3'\n docker = 'docker==2.5.1'\n subprocess32 = 'subprocess32<=3.5.2'\n dateutil = 'python-dateutil'\n addict = 'addict<=2.2.0'\n sphinx = 'sphinx==1.7.5'\n pathlib2 = 'pathlib2==2.3.2'\n\n core_reqs = [\n dill,\n six,\n future,\n requests,\n docker,\n dateutil,\n psutil,\n subprocess32,\n addict,\n sphinx,\n pathlib2]\n\n aws_reqs = [\n boto,\n boto3,\n futures,\n pycryptodome]\n cwl_reqs = [\n cwltool,\n schemaSalad,\n galaxyLib]\n encryption_reqs = [\n pynacl]\n google_reqs = [\n gcs_oauth2_boto_plugin, # is this being used??\n apacheLibcloud,\n gcs]\n htcondor_reqs = [\n htcondor]\n kubernetes_reqs = [\n kubernetes]\n mesos_reqs = [\n http_parser,\n pymesos,\n psutil]\n wdl_reqs = []\n \n\n # htcondor is not supported by apple\n # this is tricky to conditionally support in 'all' due\n # to how wheels work, so it is not included in all and\n # must be explicitly installed as an extra\n all_reqs = \\\n aws_reqs + \\\n cwl_reqs + \\\n encryption_reqs + \\\n google_reqs + \\\n kubernetes_reqs + \\\n mesos_reqs\n\n # remove the subprocess32 backport if not python2\n if not sys.version_info[0] == 2:\n core_reqs.remove(subprocess32)\n\n setup(\n name='toil',\n version=version.distVersion,\n description='Pipeline management software for clusters.',\n author='Benedict Paten',\n author_email='[email protected]',\n url=\"https://github.com/BD2KGenomics/toil\",\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Console',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Science/Research',\n 'Intended Audience :: Healthcare Industry',\n 'License :: OSI Approved :: Apache Software License',\n 'Natural Language :: English',\n 'Operating System :: MacOS :: MacOS X',\n 'Operating System :: POSIX',\n 'Operating System :: POSIX :: Linux',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Topic :: Scientific/Engineering',\n 'Topic :: Scientific/Engineering :: Bio-Informatics',\n 'Topic :: Scientific/Engineering :: Astronomy',\n 'Topic :: Scientific/Engineering :: Atmospheric Science',\n 'Topic :: Scientific/Engineering :: Information Analysis',\n 'Topic :: Scientific/Engineering :: Medical Science Apps.',\n 'Topic :: System :: Distributed Computing',\n 'Topic :: Utilities'],\n license=\"Apache License v2.0\",\n install_requires=core_reqs,\n extras_require={\n 'aws': aws_reqs,\n 'cwl': cwl_reqs,\n 'encryption': encryption_reqs,\n 'google': google_reqs,\n 'htcondor:sys_platform!=\"darwin\"': htcondor_reqs,\n 'kubernetes': kubernetes_reqs,\n 'mesos': mesos_reqs,\n 'wdl': wdl_reqs,\n 'all': all_reqs},\n package_dir={'': 'src'},\n packages=find_packages(where='src',\n # Note that we intentionally include the top-level `test` package for\n # functionality like the @experimental and @integrative decoratorss:\n exclude=['*.test.*']),\n package_data = {\n '': ['*.yml', 'cloud-config'],\n },\n # Unfortunately, the names of the entry points are hard-coded elsewhere in the code base so\n # you can't just change them here. Luckily, most of them are pretty unique strings, and thus\n # easy to search for.\n entry_points={\n 'console_scripts': [\n 'toil = toil.utils.toilMain:main',\n '_toil_worker = toil.worker:main',\n 'cwltoil = toil.cwl.cwltoil:main [cwl]',\n 'toil-cwl-runner = toil.cwl.cwltoil:main [cwl]',\n 'toil-wdl-runner = toil.wdl.toilwdl:main',\n '_toil_mesos_executor = toil.batchSystems.mesos.executor:main [mesos]',\n '_toil_kubernetes_executor = toil.batchSystems.kubernetes:executor [kubernetes]']})\n\n\ndef importVersion():\n \"\"\"\n Load and return the module object for src/toil/version.py, generating it from the template if\n required.\n \"\"\"\n import imp\n try:\n # Attempt to load the template first. It only exists in a working copy cloned via git.\n import version_template\n except ImportError:\n # If loading the template fails we must be in a unpacked source distribution and\n # src/toil/version.py will already exist.\n pass\n else:\n # Use the template to generate src/toil/version.py\n import os\n import errno\n from tempfile import NamedTemporaryFile\n\n new = version_template.expand_()\n try:\n with open('src/toil/version.py') as f:\n old = f.read()\n except IOError as e:\n if e.errno == errno.ENOENT:\n old = None\n else:\n raise\n\n if old != new:\n with NamedTemporaryFile(mode='w',dir='src/toil', prefix='version.py.', delete=False) as f:\n f.write(new)\n os.rename(f.name, 'src/toil/version.py')\n # Unfortunately, we can't use a straight import here because that would also load the stuff\n # defined in src/toil/__init__.py which imports modules from external dependencies that may\n # yet to be installed when setup.py is invoked.\n return imp.load_source('toil.version', 'src/toil/version.py')\n\n\nversion = importVersion()\nrunSetup()\n", "path": "setup.py"}]}
| 2,800 | 359 |
gh_patches_debug_34356
|
rasdani/github-patches
|
git_diff
|
ansible-collections__community.general-6369
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
idrac_redfish_command module - requesting job_id on the output
### Summary
idrac_redfish_command CreateBiosConfigJob command doesn't return job id now. I'm trying to check if job is completed before moving to next steps. This will ensure system is consistent state before next steps are executed.
### Issue Type
Feature Idea
### Component Name
idrac_redfish_command
### Additional Information
<!--- Paste example playbooks or commands between quotes below -->
```yaml (paste below)
- name: Create BIOS Config job
community.general.idrac_redfish_command:
baseuri: "{{ baseuri }}"
username: "{{ username }}"
password: "{{ password }}"
category: Systems
command: CreateBiosConfigJob
register: bios_job
- debug:
msg: "{{ bios_job.job_id }}
```
### Code of Conduct
- [X] I agree to follow the Ansible Code of Conduct
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `plugins/modules/idrac_redfish_command.py`
Content:
```
1 #!/usr/bin/python
2 # -*- coding: utf-8 -*-
3
4 # Copyright (c) 2018 Dell EMC Inc.
5 # GNU General Public License v3.0+ (see LICENSES/GPL-3.0-or-later.txt or https://www.gnu.org/licenses/gpl-3.0.txt)
6 # SPDX-License-Identifier: GPL-3.0-or-later
7
8 from __future__ import absolute_import, division, print_function
9 __metaclass__ = type
10
11 DOCUMENTATION = '''
12 ---
13 module: idrac_redfish_command
14 short_description: Manages Out-Of-Band controllers using iDRAC OEM Redfish APIs
15 description:
16 - Builds Redfish URIs locally and sends them to remote OOB controllers to
17 perform an action.
18 - For use with Dell iDRAC operations that require Redfish OEM extensions.
19 extends_documentation_fragment:
20 - community.general.attributes
21 attributes:
22 check_mode:
23 support: none
24 diff_mode:
25 support: none
26 options:
27 category:
28 required: true
29 description:
30 - Category to execute on iDRAC.
31 type: str
32 command:
33 required: true
34 description:
35 - List of commands to execute on iDRAC.
36 type: list
37 elements: str
38 baseuri:
39 required: true
40 description:
41 - Base URI of iDRAC.
42 type: str
43 username:
44 description:
45 - Username for authenticating to iDRAC.
46 type: str
47 password:
48 description:
49 - Password for authenticating to iDRAC.
50 type: str
51 auth_token:
52 description:
53 - Security token for authenticating to iDRAC.
54 type: str
55 version_added: 2.3.0
56 timeout:
57 description:
58 - Timeout in seconds for HTTP requests to iDRAC.
59 default: 10
60 type: int
61 resource_id:
62 required: false
63 description:
64 - ID of the System, Manager or Chassis to modify.
65 type: str
66 version_added: '0.2.0'
67
68 author: "Jose Delarosa (@jose-delarosa)"
69 '''
70
71 EXAMPLES = '''
72 - name: Create BIOS configuration job (schedule BIOS setting update)
73 community.general.idrac_redfish_command:
74 category: Systems
75 command: CreateBiosConfigJob
76 resource_id: System.Embedded.1
77 baseuri: "{{ baseuri }}"
78 username: "{{ username }}"
79 password: "{{ password }}"
80 '''
81
82 RETURN = '''
83 msg:
84 description: Message with action result or error description
85 returned: always
86 type: str
87 sample: "Action was successful"
88 '''
89
90 import re
91 from ansible.module_utils.basic import AnsibleModule
92 from ansible_collections.community.general.plugins.module_utils.redfish_utils import RedfishUtils
93 from ansible.module_utils.common.text.converters import to_native
94
95
96 class IdracRedfishUtils(RedfishUtils):
97
98 def create_bios_config_job(self):
99 result = {}
100 key = "Bios"
101 jobs = "Jobs"
102
103 # Search for 'key' entry and extract URI from it
104 response = self.get_request(self.root_uri + self.systems_uris[0])
105 if response['ret'] is False:
106 return response
107 result['ret'] = True
108 data = response['data']
109
110 if key not in data:
111 return {'ret': False, 'msg': "Key %s not found" % key}
112
113 bios_uri = data[key]["@odata.id"]
114
115 # Extract proper URI
116 response = self.get_request(self.root_uri + bios_uri)
117 if response['ret'] is False:
118 return response
119 result['ret'] = True
120 data = response['data']
121 set_bios_attr_uri = data["@Redfish.Settings"]["SettingsObject"][
122 "@odata.id"]
123
124 payload = {"TargetSettingsURI": set_bios_attr_uri}
125 response = self.post_request(
126 self.root_uri + self.manager_uri + "/" + jobs, payload)
127 if response['ret'] is False:
128 return response
129
130 response_output = response['resp'].__dict__
131 job_id = response_output["headers"]["Location"]
132 job_id = re.search("JID_.+", job_id).group()
133 # Currently not passing job_id back to user but patch is coming
134 return {'ret': True, 'msg': "Config job %s created" % job_id}
135
136
137 CATEGORY_COMMANDS_ALL = {
138 "Systems": ["CreateBiosConfigJob"],
139 "Accounts": [],
140 "Manager": []
141 }
142
143
144 def main():
145 result = {}
146 module = AnsibleModule(
147 argument_spec=dict(
148 category=dict(required=True),
149 command=dict(required=True, type='list', elements='str'),
150 baseuri=dict(required=True),
151 username=dict(),
152 password=dict(no_log=True),
153 auth_token=dict(no_log=True),
154 timeout=dict(type='int', default=10),
155 resource_id=dict()
156 ),
157 required_together=[
158 ('username', 'password'),
159 ],
160 required_one_of=[
161 ('username', 'auth_token'),
162 ],
163 mutually_exclusive=[
164 ('username', 'auth_token'),
165 ],
166 supports_check_mode=False
167 )
168
169 category = module.params['category']
170 command_list = module.params['command']
171
172 # admin credentials used for authentication
173 creds = {'user': module.params['username'],
174 'pswd': module.params['password'],
175 'token': module.params['auth_token']}
176
177 # timeout
178 timeout = module.params['timeout']
179
180 # System, Manager or Chassis ID to modify
181 resource_id = module.params['resource_id']
182
183 # Build root URI
184 root_uri = "https://" + module.params['baseuri']
185 rf_utils = IdracRedfishUtils(creds, root_uri, timeout, module,
186 resource_id=resource_id, data_modification=True)
187
188 # Check that Category is valid
189 if category not in CATEGORY_COMMANDS_ALL:
190 module.fail_json(msg=to_native("Invalid Category '%s'. Valid Categories = %s" % (category, list(CATEGORY_COMMANDS_ALL.keys()))))
191
192 # Check that all commands are valid
193 for cmd in command_list:
194 # Fail if even one command given is invalid
195 if cmd not in CATEGORY_COMMANDS_ALL[category]:
196 module.fail_json(msg=to_native("Invalid Command '%s'. Valid Commands = %s" % (cmd, CATEGORY_COMMANDS_ALL[category])))
197
198 # Organize by Categories / Commands
199
200 if category == "Systems":
201 # execute only if we find a System resource
202 result = rf_utils._find_systems_resource()
203 if result['ret'] is False:
204 module.fail_json(msg=to_native(result['msg']))
205
206 for command in command_list:
207 if command == "CreateBiosConfigJob":
208 # execute only if we find a Managers resource
209 result = rf_utils._find_managers_resource()
210 if result['ret'] is False:
211 module.fail_json(msg=to_native(result['msg']))
212 result = rf_utils.create_bios_config_job()
213
214 # Return data back or fail with proper message
215 if result['ret'] is True:
216 del result['ret']
217 module.exit_json(changed=True, msg='Action was successful')
218 else:
219 module.fail_json(msg=to_native(result['msg']))
220
221
222 if __name__ == '__main__':
223 main()
224
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/plugins/modules/idrac_redfish_command.py b/plugins/modules/idrac_redfish_command.py
--- a/plugins/modules/idrac_redfish_command.py
+++ b/plugins/modules/idrac_redfish_command.py
@@ -85,6 +85,14 @@
returned: always
type: str
sample: "Action was successful"
+return_values:
+ description: Dictionary containing command-specific response data from the action.
+ returned: on success
+ type: dict
+ version_added: 6.6.0
+ sample: {
+ "job_id": "/redfish/v1/Managers/iDRAC.Embedded.1/Jobs/JID_471269252011"
+ }
'''
import re
@@ -128,10 +136,9 @@
return response
response_output = response['resp'].__dict__
- job_id = response_output["headers"]["Location"]
- job_id = re.search("JID_.+", job_id).group()
- # Currently not passing job_id back to user but patch is coming
- return {'ret': True, 'msg': "Config job %s created" % job_id}
+ job_id_full = response_output["headers"]["Location"]
+ job_id = re.search("JID_.+", job_id_full).group()
+ return {'ret': True, 'msg': "Config job %s created" % job_id, 'job_id': job_id_full}
CATEGORY_COMMANDS_ALL = {
@@ -143,6 +150,7 @@
def main():
result = {}
+ return_values = {}
module = AnsibleModule(
argument_spec=dict(
category=dict(required=True),
@@ -210,11 +218,13 @@
if result['ret'] is False:
module.fail_json(msg=to_native(result['msg']))
result = rf_utils.create_bios_config_job()
+ if 'job_id' in result:
+ return_values['job_id'] = result['job_id']
# Return data back or fail with proper message
if result['ret'] is True:
del result['ret']
- module.exit_json(changed=True, msg='Action was successful')
+ module.exit_json(changed=True, msg='Action was successful', return_values=return_values)
else:
module.fail_json(msg=to_native(result['msg']))
|
{"golden_diff": "diff --git a/plugins/modules/idrac_redfish_command.py b/plugins/modules/idrac_redfish_command.py\n--- a/plugins/modules/idrac_redfish_command.py\n+++ b/plugins/modules/idrac_redfish_command.py\n@@ -85,6 +85,14 @@\n returned: always\n type: str\n sample: \"Action was successful\"\n+return_values:\n+ description: Dictionary containing command-specific response data from the action.\n+ returned: on success\n+ type: dict\n+ version_added: 6.6.0\n+ sample: {\n+ \"job_id\": \"/redfish/v1/Managers/iDRAC.Embedded.1/Jobs/JID_471269252011\"\n+ }\n '''\n \n import re\n@@ -128,10 +136,9 @@\n return response\n \n response_output = response['resp'].__dict__\n- job_id = response_output[\"headers\"][\"Location\"]\n- job_id = re.search(\"JID_.+\", job_id).group()\n- # Currently not passing job_id back to user but patch is coming\n- return {'ret': True, 'msg': \"Config job %s created\" % job_id}\n+ job_id_full = response_output[\"headers\"][\"Location\"]\n+ job_id = re.search(\"JID_.+\", job_id_full).group()\n+ return {'ret': True, 'msg': \"Config job %s created\" % job_id, 'job_id': job_id_full}\n \n \n CATEGORY_COMMANDS_ALL = {\n@@ -143,6 +150,7 @@\n \n def main():\n result = {}\n+ return_values = {}\n module = AnsibleModule(\n argument_spec=dict(\n category=dict(required=True),\n@@ -210,11 +218,13 @@\n if result['ret'] is False:\n module.fail_json(msg=to_native(result['msg']))\n result = rf_utils.create_bios_config_job()\n+ if 'job_id' in result:\n+ return_values['job_id'] = result['job_id']\n \n # Return data back or fail with proper message\n if result['ret'] is True:\n del result['ret']\n- module.exit_json(changed=True, msg='Action was successful')\n+ module.exit_json(changed=True, msg='Action was successful', return_values=return_values)\n else:\n module.fail_json(msg=to_native(result['msg']))\n", "issue": "idrac_redfish_command module - requesting job_id on the output\n### Summary\n\nidrac_redfish_command CreateBiosConfigJob command doesn't return job id now. I'm trying to check if job is completed before moving to next steps. This will ensure system is consistent state before next steps are executed.\n\n### Issue Type\n\nFeature Idea\n\n### Component Name\n\nidrac_redfish_command\n\n### Additional Information\n\n<!--- Paste example playbooks or commands between quotes below -->\r\n```yaml (paste below)\r\n- name: Create BIOS Config job\r\n community.general.idrac_redfish_command:\r\n baseuri: \"{{ baseuri }}\"\r\n username: \"{{ username }}\"\r\n password: \"{{ password }}\"\r\n category: Systems\r\n command: CreateBiosConfigJob\r\n register: bios_job\r\n\r\n- debug:\r\n msg: \"{{ bios_job.job_id }}\r\n\r\n\r\n```\r\n\n\n### Code of Conduct\n\n- [X] I agree to follow the Ansible Code of Conduct\n", "before_files": [{"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n# Copyright (c) 2018 Dell EMC Inc.\n# GNU General Public License v3.0+ (see LICENSES/GPL-3.0-or-later.txt or https://www.gnu.org/licenses/gpl-3.0.txt)\n# SPDX-License-Identifier: GPL-3.0-or-later\n\nfrom __future__ import absolute_import, division, print_function\n__metaclass__ = type\n\nDOCUMENTATION = '''\n---\nmodule: idrac_redfish_command\nshort_description: Manages Out-Of-Band controllers using iDRAC OEM Redfish APIs\ndescription:\n - Builds Redfish URIs locally and sends them to remote OOB controllers to\n perform an action.\n - For use with Dell iDRAC operations that require Redfish OEM extensions.\nextends_documentation_fragment:\n - community.general.attributes\nattributes:\n check_mode:\n support: none\n diff_mode:\n support: none\noptions:\n category:\n required: true\n description:\n - Category to execute on iDRAC.\n type: str\n command:\n required: true\n description:\n - List of commands to execute on iDRAC.\n type: list\n elements: str\n baseuri:\n required: true\n description:\n - Base URI of iDRAC.\n type: str\n username:\n description:\n - Username for authenticating to iDRAC.\n type: str\n password:\n description:\n - Password for authenticating to iDRAC.\n type: str\n auth_token:\n description:\n - Security token for authenticating to iDRAC.\n type: str\n version_added: 2.3.0\n timeout:\n description:\n - Timeout in seconds for HTTP requests to iDRAC.\n default: 10\n type: int\n resource_id:\n required: false\n description:\n - ID of the System, Manager or Chassis to modify.\n type: str\n version_added: '0.2.0'\n\nauthor: \"Jose Delarosa (@jose-delarosa)\"\n'''\n\nEXAMPLES = '''\n - name: Create BIOS configuration job (schedule BIOS setting update)\n community.general.idrac_redfish_command:\n category: Systems\n command: CreateBiosConfigJob\n resource_id: System.Embedded.1\n baseuri: \"{{ baseuri }}\"\n username: \"{{ username }}\"\n password: \"{{ password }}\"\n'''\n\nRETURN = '''\nmsg:\n description: Message with action result or error description\n returned: always\n type: str\n sample: \"Action was successful\"\n'''\n\nimport re\nfrom ansible.module_utils.basic import AnsibleModule\nfrom ansible_collections.community.general.plugins.module_utils.redfish_utils import RedfishUtils\nfrom ansible.module_utils.common.text.converters import to_native\n\n\nclass IdracRedfishUtils(RedfishUtils):\n\n def create_bios_config_job(self):\n result = {}\n key = \"Bios\"\n jobs = \"Jobs\"\n\n # Search for 'key' entry and extract URI from it\n response = self.get_request(self.root_uri + self.systems_uris[0])\n if response['ret'] is False:\n return response\n result['ret'] = True\n data = response['data']\n\n if key not in data:\n return {'ret': False, 'msg': \"Key %s not found\" % key}\n\n bios_uri = data[key][\"@odata.id\"]\n\n # Extract proper URI\n response = self.get_request(self.root_uri + bios_uri)\n if response['ret'] is False:\n return response\n result['ret'] = True\n data = response['data']\n set_bios_attr_uri = data[\"@Redfish.Settings\"][\"SettingsObject\"][\n \"@odata.id\"]\n\n payload = {\"TargetSettingsURI\": set_bios_attr_uri}\n response = self.post_request(\n self.root_uri + self.manager_uri + \"/\" + jobs, payload)\n if response['ret'] is False:\n return response\n\n response_output = response['resp'].__dict__\n job_id = response_output[\"headers\"][\"Location\"]\n job_id = re.search(\"JID_.+\", job_id).group()\n # Currently not passing job_id back to user but patch is coming\n return {'ret': True, 'msg': \"Config job %s created\" % job_id}\n\n\nCATEGORY_COMMANDS_ALL = {\n \"Systems\": [\"CreateBiosConfigJob\"],\n \"Accounts\": [],\n \"Manager\": []\n}\n\n\ndef main():\n result = {}\n module = AnsibleModule(\n argument_spec=dict(\n category=dict(required=True),\n command=dict(required=True, type='list', elements='str'),\n baseuri=dict(required=True),\n username=dict(),\n password=dict(no_log=True),\n auth_token=dict(no_log=True),\n timeout=dict(type='int', default=10),\n resource_id=dict()\n ),\n required_together=[\n ('username', 'password'),\n ],\n required_one_of=[\n ('username', 'auth_token'),\n ],\n mutually_exclusive=[\n ('username', 'auth_token'),\n ],\n supports_check_mode=False\n )\n\n category = module.params['category']\n command_list = module.params['command']\n\n # admin credentials used for authentication\n creds = {'user': module.params['username'],\n 'pswd': module.params['password'],\n 'token': module.params['auth_token']}\n\n # timeout\n timeout = module.params['timeout']\n\n # System, Manager or Chassis ID to modify\n resource_id = module.params['resource_id']\n\n # Build root URI\n root_uri = \"https://\" + module.params['baseuri']\n rf_utils = IdracRedfishUtils(creds, root_uri, timeout, module,\n resource_id=resource_id, data_modification=True)\n\n # Check that Category is valid\n if category not in CATEGORY_COMMANDS_ALL:\n module.fail_json(msg=to_native(\"Invalid Category '%s'. Valid Categories = %s\" % (category, list(CATEGORY_COMMANDS_ALL.keys()))))\n\n # Check that all commands are valid\n for cmd in command_list:\n # Fail if even one command given is invalid\n if cmd not in CATEGORY_COMMANDS_ALL[category]:\n module.fail_json(msg=to_native(\"Invalid Command '%s'. Valid Commands = %s\" % (cmd, CATEGORY_COMMANDS_ALL[category])))\n\n # Organize by Categories / Commands\n\n if category == \"Systems\":\n # execute only if we find a System resource\n result = rf_utils._find_systems_resource()\n if result['ret'] is False:\n module.fail_json(msg=to_native(result['msg']))\n\n for command in command_list:\n if command == \"CreateBiosConfigJob\":\n # execute only if we find a Managers resource\n result = rf_utils._find_managers_resource()\n if result['ret'] is False:\n module.fail_json(msg=to_native(result['msg']))\n result = rf_utils.create_bios_config_job()\n\n # Return data back or fail with proper message\n if result['ret'] is True:\n del result['ret']\n module.exit_json(changed=True, msg='Action was successful')\n else:\n module.fail_json(msg=to_native(result['msg']))\n\n\nif __name__ == '__main__':\n main()\n", "path": "plugins/modules/idrac_redfish_command.py"}], "after_files": [{"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n# Copyright (c) 2018 Dell EMC Inc.\n# GNU General Public License v3.0+ (see LICENSES/GPL-3.0-or-later.txt or https://www.gnu.org/licenses/gpl-3.0.txt)\n# SPDX-License-Identifier: GPL-3.0-or-later\n\nfrom __future__ import absolute_import, division, print_function\n__metaclass__ = type\n\nDOCUMENTATION = '''\n---\nmodule: idrac_redfish_command\nshort_description: Manages Out-Of-Band controllers using iDRAC OEM Redfish APIs\ndescription:\n - Builds Redfish URIs locally and sends them to remote OOB controllers to\n perform an action.\n - For use with Dell iDRAC operations that require Redfish OEM extensions.\nextends_documentation_fragment:\n - community.general.attributes\nattributes:\n check_mode:\n support: none\n diff_mode:\n support: none\noptions:\n category:\n required: true\n description:\n - Category to execute on iDRAC.\n type: str\n command:\n required: true\n description:\n - List of commands to execute on iDRAC.\n type: list\n elements: str\n baseuri:\n required: true\n description:\n - Base URI of iDRAC.\n type: str\n username:\n description:\n - Username for authenticating to iDRAC.\n type: str\n password:\n description:\n - Password for authenticating to iDRAC.\n type: str\n auth_token:\n description:\n - Security token for authenticating to iDRAC.\n type: str\n version_added: 2.3.0\n timeout:\n description:\n - Timeout in seconds for HTTP requests to iDRAC.\n default: 10\n type: int\n resource_id:\n required: false\n description:\n - ID of the System, Manager or Chassis to modify.\n type: str\n version_added: '0.2.0'\n\nauthor: \"Jose Delarosa (@jose-delarosa)\"\n'''\n\nEXAMPLES = '''\n - name: Create BIOS configuration job (schedule BIOS setting update)\n community.general.idrac_redfish_command:\n category: Systems\n command: CreateBiosConfigJob\n resource_id: System.Embedded.1\n baseuri: \"{{ baseuri }}\"\n username: \"{{ username }}\"\n password: \"{{ password }}\"\n'''\n\nRETURN = '''\nmsg:\n description: Message with action result or error description\n returned: always\n type: str\n sample: \"Action was successful\"\nreturn_values:\n description: Dictionary containing command-specific response data from the action.\n returned: on success\n type: dict\n version_added: 6.6.0\n sample: {\n \"job_id\": \"/redfish/v1/Managers/iDRAC.Embedded.1/Jobs/JID_471269252011\"\n }\n'''\n\nimport re\nfrom ansible.module_utils.basic import AnsibleModule\nfrom ansible_collections.community.general.plugins.module_utils.redfish_utils import RedfishUtils\nfrom ansible.module_utils.common.text.converters import to_native\n\n\nclass IdracRedfishUtils(RedfishUtils):\n\n def create_bios_config_job(self):\n result = {}\n key = \"Bios\"\n jobs = \"Jobs\"\n\n # Search for 'key' entry and extract URI from it\n response = self.get_request(self.root_uri + self.systems_uris[0])\n if response['ret'] is False:\n return response\n result['ret'] = True\n data = response['data']\n\n if key not in data:\n return {'ret': False, 'msg': \"Key %s not found\" % key}\n\n bios_uri = data[key][\"@odata.id\"]\n\n # Extract proper URI\n response = self.get_request(self.root_uri + bios_uri)\n if response['ret'] is False:\n return response\n result['ret'] = True\n data = response['data']\n set_bios_attr_uri = data[\"@Redfish.Settings\"][\"SettingsObject\"][\n \"@odata.id\"]\n\n payload = {\"TargetSettingsURI\": set_bios_attr_uri}\n response = self.post_request(\n self.root_uri + self.manager_uri + \"/\" + jobs, payload)\n if response['ret'] is False:\n return response\n\n response_output = response['resp'].__dict__\n job_id_full = response_output[\"headers\"][\"Location\"]\n job_id = re.search(\"JID_.+\", job_id_full).group()\n return {'ret': True, 'msg': \"Config job %s created\" % job_id, 'job_id': job_id_full}\n\n\nCATEGORY_COMMANDS_ALL = {\n \"Systems\": [\"CreateBiosConfigJob\"],\n \"Accounts\": [],\n \"Manager\": []\n}\n\n\ndef main():\n result = {}\n return_values = {}\n module = AnsibleModule(\n argument_spec=dict(\n category=dict(required=True),\n command=dict(required=True, type='list', elements='str'),\n baseuri=dict(required=True),\n username=dict(),\n password=dict(no_log=True),\n auth_token=dict(no_log=True),\n timeout=dict(type='int', default=10),\n resource_id=dict()\n ),\n required_together=[\n ('username', 'password'),\n ],\n required_one_of=[\n ('username', 'auth_token'),\n ],\n mutually_exclusive=[\n ('username', 'auth_token'),\n ],\n supports_check_mode=False\n )\n\n category = module.params['category']\n command_list = module.params['command']\n\n # admin credentials used for authentication\n creds = {'user': module.params['username'],\n 'pswd': module.params['password'],\n 'token': module.params['auth_token']}\n\n # timeout\n timeout = module.params['timeout']\n\n # System, Manager or Chassis ID to modify\n resource_id = module.params['resource_id']\n\n # Build root URI\n root_uri = \"https://\" + module.params['baseuri']\n rf_utils = IdracRedfishUtils(creds, root_uri, timeout, module,\n resource_id=resource_id, data_modification=True)\n\n # Check that Category is valid\n if category not in CATEGORY_COMMANDS_ALL:\n module.fail_json(msg=to_native(\"Invalid Category '%s'. Valid Categories = %s\" % (category, list(CATEGORY_COMMANDS_ALL.keys()))))\n\n # Check that all commands are valid\n for cmd in command_list:\n # Fail if even one command given is invalid\n if cmd not in CATEGORY_COMMANDS_ALL[category]:\n module.fail_json(msg=to_native(\"Invalid Command '%s'. Valid Commands = %s\" % (cmd, CATEGORY_COMMANDS_ALL[category])))\n\n # Organize by Categories / Commands\n\n if category == \"Systems\":\n # execute only if we find a System resource\n result = rf_utils._find_systems_resource()\n if result['ret'] is False:\n module.fail_json(msg=to_native(result['msg']))\n\n for command in command_list:\n if command == \"CreateBiosConfigJob\":\n # execute only if we find a Managers resource\n result = rf_utils._find_managers_resource()\n if result['ret'] is False:\n module.fail_json(msg=to_native(result['msg']))\n result = rf_utils.create_bios_config_job()\n if 'job_id' in result:\n return_values['job_id'] = result['job_id']\n\n # Return data back or fail with proper message\n if result['ret'] is True:\n del result['ret']\n module.exit_json(changed=True, msg='Action was successful', return_values=return_values)\n else:\n module.fail_json(msg=to_native(result['msg']))\n\n\nif __name__ == '__main__':\n main()\n", "path": "plugins/modules/idrac_redfish_command.py"}]}
| 2,617 | 531 |
gh_patches_debug_1740
|
rasdani/github-patches
|
git_diff
|
flairNLP__flair-239
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bug in tokenizer?
Here's a minimum viable code to reproduce:
```
from flair.data import Sentence
from flair.models import SequenceTagger
model = SequenceTagger.load("ner-ontonotes-fast")
full_text = "\"In the 1960s and 1970s...\" Then came Thierry Mugler and Gianni Versace."
sentence = Sentence(full_text, use_tokenizer=True)
model.predict(sentence)
print(f"full text : {full_text}")
print(f"text length: {len(full_text)}")
print("tag\tstart\tend\tto_original_text()")
for entity in sentence.get_spans('ner'):
print(f"{entity.tag}\t{entity.start_pos}\t{entity.end_pos}\t{entity.to_original_text()}")
```
Output:
``` $ python predict.py
full text : "In the 1960s and 1970s..." Then came Thierry Mugler and Gianni Versace.
text length: 72
tag start end to_original_text()
DATE 8 13 1960s
DATE 18 23 1970s
PERSON 81 94 ThierryMugler
PERSON 97 110 GianniVersace
```
Seems the resulting tokens have start_pos and end_pos indexes larger than the real text length. Note also that the method to_original_text() is eating the spaces, so I suppose it is related.
Any ideas about what is causing the trouble?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 from setuptools import setup, find_packages
2
3 setup(
4 name='flair',
5 version='0.3.2',
6 description='A very simple framework for state-of-the-art NLP',
7 long_description=open("README.md", encoding='utf-8').read(),
8 long_description_content_type="text/markdown",
9 author='Alan Akbik',
10 author_email='[email protected]',
11 url='https://github.com/zalandoresearch/flair',
12 packages=find_packages(exclude='test'), # same as name
13 license='MIT',
14 install_requires=[
15 'torch==0.4.1',
16 'gensim==3.4.0',
17 'typing==3.6.4',
18 'tqdm==4.23.4',
19 'segtok==1.5.6',
20 'matplotlib==3.0.0',
21 'mpld3==0.3',
22 'sklearn',
23 'sqlitedict==1.6.0',
24 'deprecated==1.2.4',
25 ],
26 include_package_data=True,
27 python_requires='>=3.6',
28 )
29
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -15,8 +15,8 @@
'torch==0.4.1',
'gensim==3.4.0',
'typing==3.6.4',
- 'tqdm==4.23.4',
- 'segtok==1.5.6',
+ 'tqdm==4.26.0',
+ 'segtok==1.5.7',
'matplotlib==3.0.0',
'mpld3==0.3',
'sklearn',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -15,8 +15,8 @@\n 'torch==0.4.1',\n 'gensim==3.4.0',\n 'typing==3.6.4',\n- 'tqdm==4.23.4',\n- 'segtok==1.5.6',\n+ 'tqdm==4.26.0',\n+ 'segtok==1.5.7',\n 'matplotlib==3.0.0',\n 'mpld3==0.3',\n 'sklearn',\n", "issue": "Bug in tokenizer?\nHere's a minimum viable code to reproduce:\r\n\r\n```\r\nfrom flair.data import Sentence\r\nfrom flair.models import SequenceTagger\r\n\r\nmodel = SequenceTagger.load(\"ner-ontonotes-fast\")\r\nfull_text = \"\\\"In the 1960s and 1970s...\\\" Then came Thierry Mugler and Gianni Versace.\"\r\nsentence = Sentence(full_text, use_tokenizer=True)\r\nmodel.predict(sentence)\r\nprint(f\"full text : {full_text}\")\r\nprint(f\"text length: {len(full_text)}\")\r\nprint(\"tag\\tstart\\tend\\tto_original_text()\")\r\nfor entity in sentence.get_spans('ner'):\r\n print(f\"{entity.tag}\\t{entity.start_pos}\\t{entity.end_pos}\\t{entity.to_original_text()}\")\r\n```\r\n\r\nOutput:\r\n\r\n``` $ python predict.py \r\nfull text : \"In the 1960s and 1970s...\" Then came Thierry Mugler and Gianni Versace.\r\ntext length: 72\r\ntag\tstart\tend\tto_original_text()\r\nDATE\t8\t13\t1960s\r\nDATE\t18\t23\t1970s\r\nPERSON\t81\t94\tThierryMugler\r\nPERSON\t97\t110\tGianniVersace\r\n```\r\nSeems the resulting tokens have start_pos and end_pos indexes larger than the real text length. Note also that the method to_original_text() is eating the spaces, so I suppose it is related.\r\n\r\nAny ideas about what is causing the trouble?\n", "before_files": [{"content": "from setuptools import setup, find_packages\n\nsetup(\n name='flair',\n version='0.3.2',\n description='A very simple framework for state-of-the-art NLP',\n long_description=open(\"README.md\", encoding='utf-8').read(),\n long_description_content_type=\"text/markdown\",\n author='Alan Akbik',\n author_email='[email protected]',\n url='https://github.com/zalandoresearch/flair',\n packages=find_packages(exclude='test'), # same as name\n license='MIT',\n install_requires=[\n 'torch==0.4.1',\n 'gensim==3.4.0',\n 'typing==3.6.4',\n 'tqdm==4.23.4',\n 'segtok==1.5.6',\n 'matplotlib==3.0.0',\n 'mpld3==0.3',\n 'sklearn',\n 'sqlitedict==1.6.0',\n 'deprecated==1.2.4',\n ],\n include_package_data=True,\n python_requires='>=3.6',\n)\n", "path": "setup.py"}], "after_files": [{"content": "from setuptools import setup, find_packages\n\nsetup(\n name='flair',\n version='0.3.2',\n description='A very simple framework for state-of-the-art NLP',\n long_description=open(\"README.md\", encoding='utf-8').read(),\n long_description_content_type=\"text/markdown\",\n author='Alan Akbik',\n author_email='[email protected]',\n url='https://github.com/zalandoresearch/flair',\n packages=find_packages(exclude='test'), # same as name\n license='MIT',\n install_requires=[\n 'torch==0.4.1',\n 'gensim==3.4.0',\n 'typing==3.6.4',\n 'tqdm==4.26.0',\n 'segtok==1.5.7',\n 'matplotlib==3.0.0',\n 'mpld3==0.3',\n 'sklearn',\n 'sqlitedict==1.6.0',\n 'deprecated==1.2.4',\n ],\n include_package_data=True,\n python_requires='>=3.6',\n)\n", "path": "setup.py"}]}
| 881 | 142 |
gh_patches_debug_21620
|
rasdani/github-patches
|
git_diff
|
openfun__marsha-98
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Integrate sentry
## Purpose
[Sentry](https://sentry.io) is a great tool to track and report application errors. Looks like a requirement for any Django project.
## Proposal
Add raven as a project requirement and configure sentry.
Reference documentation: https://docs.sentry.io/platforms/python/django/
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `marsha/settings.py`
Content:
```
1 """Django settings for marsha project.
2
3 Uses django-configurations to manage environments inheritance and the loading of some
4 config from the environment
5
6 """
7
8 from datetime import timedelta
9 import os
10
11 from django.utils.translation import gettext_lazy as _
12
13 from configurations import Configuration, values
14
15
16 class Base(Configuration):
17 """Base configuration every configuration (aka environment) should inherit from.
18
19 It depends on an environment variable that SHOULD be defined:
20 - DJANGO_SECRET_KEY
21
22 You may also want to override default configuration by setting the following
23 environment variables:
24 - DJANGO_DEBUG
25 - DATABASE_URL
26 """
27
28 BASE_DIR = os.path.dirname(__file__)
29 DATA_DIR = values.Value(os.path.join("/", "data"))
30
31 # Static files (CSS, JavaScript, Images)
32 STATICFILES_DIRS = (os.path.join(BASE_DIR, "static"),)
33 STATIC_URL = "/static/"
34 MEDIA_URL = "/media/"
35 # Allow to configure location of static/media files for non-Docker installation
36 MEDIA_ROOT = values.Value(os.path.join(str(DATA_DIR), "media"))
37 STATIC_ROOT = values.Value(os.path.join(str(DATA_DIR), "static"))
38
39 SECRET_KEY = values.SecretValue()
40
41 DEBUG = values.BooleanValue(False)
42
43 DATABASES = {
44 "default": {
45 "ENGINE": values.Value(
46 "django.db.backends.postgresql_psycopg2",
47 environ_name="DATABASE_ENGINE",
48 environ_prefix=None,
49 ),
50 "NAME": values.Value(
51 "marsha", environ_name="POSTGRES_DB", environ_prefix=None
52 ),
53 "USER": values.Value(
54 "marsha_user", environ_name="POSTGRES_USER", environ_prefix=None
55 ),
56 "PASSWORD": values.Value(
57 "pass", environ_name="POSTGRES_PASSWORD", environ_prefix=None
58 ),
59 "HOST": values.Value(
60 "localhost", environ_name="POSTGRES_HOST", environ_prefix=None
61 ),
62 "PORT": values.Value(
63 5432, environ_name="POSTGRES_PORT", environ_prefix=None
64 ),
65 }
66 }
67
68 ALLOWED_HOSTS = []
69
70 # Application definition
71
72 INSTALLED_APPS = [
73 "django.contrib.admin.apps.SimpleAdminConfig",
74 "django.contrib.auth",
75 "django.contrib.contenttypes",
76 "django.contrib.sessions",
77 "django.contrib.messages",
78 "django.contrib.staticfiles",
79 "django_extensions",
80 "rest_framework",
81 "marsha.core.apps.CoreConfig",
82 ]
83
84 MIDDLEWARE = [
85 "django.middleware.security.SecurityMiddleware",
86 "django.contrib.sessions.middleware.SessionMiddleware",
87 "django.middleware.common.CommonMiddleware",
88 "django.middleware.csrf.CsrfViewMiddleware",
89 "django.contrib.auth.middleware.AuthenticationMiddleware",
90 "django.contrib.messages.middleware.MessageMiddleware",
91 "django.middleware.clickjacking.XFrameOptionsMiddleware",
92 ]
93
94 ROOT_URLCONF = "marsha.urls"
95
96 TEMPLATES = [
97 {
98 "BACKEND": "django.template.backends.django.DjangoTemplates",
99 "DIRS": [],
100 "APP_DIRS": True,
101 "OPTIONS": {
102 "context_processors": [
103 "django.template.context_processors.debug",
104 "django.template.context_processors.request",
105 "django.contrib.auth.context_processors.auth",
106 "django.contrib.messages.context_processors.messages",
107 ]
108 },
109 }
110 ]
111
112 AUTH_USER_MODEL = "core.User"
113
114 WSGI_APPLICATION = "marsha.wsgi.application"
115
116 REST_FRAMEWORK = {
117 "DEFAULT_AUTHENTICATION_CLASSES": (
118 "rest_framework_simplejwt.authentication.JWTTokenUserAuthentication",
119 )
120 }
121
122 # Password validation
123 # https://docs.djangoproject.com/en/2.0/ref/settings/#auth-password-validators
124 AUTH_PASSWORD_VALIDATORS = [
125 {
126 "NAME": "django.contrib.auth.password_validation.UserAttributeSimilarityValidator"
127 },
128 {"NAME": "django.contrib.auth.password_validation.MinimumLengthValidator"},
129 {"NAME": "django.contrib.auth.password_validation.CommonPasswordValidator"},
130 {"NAME": "django.contrib.auth.password_validation.NumericPasswordValidator"},
131 ]
132
133 JWT_SIGNING_KEY = values.SecretValue()
134
135 # Internationalization
136 # https://docs.djangoproject.com/en/2.0/topics/i18n/
137
138 LANGUAGE_CODE = "en-us"
139
140 LANGUAGES = [("en", _("english")), ("fr", _("french"))]
141
142 # Internationalization
143 TIME_ZONE = "UTC"
144 USE_I18N = True
145 USE_L10N = True
146 USE_TZ = True
147
148 VIDEO_RESOLUTIONS = [144, 240, 480, 720, 1080]
149
150 # AWS
151 AWS_ACCESS_KEY_ID = values.SecretValue()
152 AWS_SECRET_ACCESS_KEY = values.SecretValue()
153 AWS_DEFAULT_REGION = values.Value("eu-west-1")
154 UPDATE_STATE_SHARED_SECRETS = values.ListValue()
155
156 # Cloud Front key pair for signed urls
157 CLOUDFRONT_URL = values.SecretValue()
158 CLOUDFRONT_ACCESS_KEY_ID = values.Value(None)
159 CLOUDFRONT_PRIVATE_KEY_PATH = values.Value(
160 os.path.join(BASE_DIR, "..", ".ssh", "cloudfront_private_key")
161 )
162 CLOUDFRONT_SIGNED_URLS_ACTIVE = True
163 CLOUDFRONT_SIGNED_URLS_VALIDITY = 2 * 60 * 60 # 2 hours
164
165 # pylint: disable=invalid-name
166 @property
167 def SIMPLE_JWT(self):
168 """Define settings for `djangorestframework_simplejwt`.
169
170 The JWT_SIGNING_KEY must be evaluated late as the jwt library check for string type.
171 """
172 return {
173 "ACCESS_TOKEN_LIFETIME": timedelta(days=1),
174 "ALGORITHM": "HS256",
175 "SIGNING_KEY": str(self.JWT_SIGNING_KEY),
176 "USER_ID_CLAIM": "video_id",
177 "AUTH_TOKEN_CLASSES": ("rest_framework_simplejwt.tokens.AccessToken",),
178 }
179
180
181 class Development(Base):
182 """Development environment settings.
183
184 We set ``DEBUG`` to ``True`` by default, configure the server to respond to all hosts,
185 and use a local sqlite database by default.
186 """
187
188 DEBUG = values.BooleanValue(True)
189 ALLOWED_HOSTS = ["*"]
190
191 AWS_SOURCE_BUCKET_NAME = "development-marsha-source"
192
193
194 class Test(Base):
195 """Test environment settings."""
196
197 AWS_SOURCE_BUCKET_NAME = "test-marsha-source"
198
199 CLOUDFRONT_SIGNED_URLS_ACTIVE = False
200
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/marsha/settings.py b/marsha/settings.py
--- a/marsha/settings.py
+++ b/marsha/settings.py
@@ -11,6 +11,8 @@
from django.utils.translation import gettext_lazy as _
from configurations import Configuration, values
+import sentry_sdk
+from sentry_sdk.integrations.django import DjangoIntegration
class Base(Configuration):
@@ -177,6 +179,25 @@
"AUTH_TOKEN_CLASSES": ("rest_framework_simplejwt.tokens.AccessToken",),
}
+ @classmethod
+ def post_setup(cls):
+ """Post setup configuration.
+
+ This is the place where you can configure settings that require other
+ settings to be loaded.
+ """
+ super().post_setup()
+
+ # The DJANGO_SENTRY_DSN environment variable should be set to activate
+ # sentry for an environment
+ sentry_dsn = values.Value(None, environ_name="SENTRY_DSN")
+ if sentry_dsn is not None:
+ sentry_sdk.init(
+ dsn=sentry_dsn,
+ environment=cls.__name__.lower(),
+ integrations=[DjangoIntegration()],
+ )
+
class Development(Base):
"""Development environment settings.
|
{"golden_diff": "diff --git a/marsha/settings.py b/marsha/settings.py\n--- a/marsha/settings.py\n+++ b/marsha/settings.py\n@@ -11,6 +11,8 @@\n from django.utils.translation import gettext_lazy as _\n \n from configurations import Configuration, values\n+import sentry_sdk\n+from sentry_sdk.integrations.django import DjangoIntegration\n \n \n class Base(Configuration):\n@@ -177,6 +179,25 @@\n \"AUTH_TOKEN_CLASSES\": (\"rest_framework_simplejwt.tokens.AccessToken\",),\n }\n \n+ @classmethod\n+ def post_setup(cls):\n+ \"\"\"Post setup configuration.\n+\n+ This is the place where you can configure settings that require other\n+ settings to be loaded.\n+ \"\"\"\n+ super().post_setup()\n+\n+ # The DJANGO_SENTRY_DSN environment variable should be set to activate\n+ # sentry for an environment\n+ sentry_dsn = values.Value(None, environ_name=\"SENTRY_DSN\")\n+ if sentry_dsn is not None:\n+ sentry_sdk.init(\n+ dsn=sentry_dsn,\n+ environment=cls.__name__.lower(),\n+ integrations=[DjangoIntegration()],\n+ )\n+\n \n class Development(Base):\n \"\"\"Development environment settings.\n", "issue": "Integrate sentry\n## Purpose\r\n\r\n[Sentry](https://sentry.io) is a great tool to track and report application errors. Looks like a requirement for any Django project.\r\n\r\n## Proposal\r\n\r\nAdd raven as a project requirement and configure sentry.\r\n\r\nReference documentation: https://docs.sentry.io/platforms/python/django/\n", "before_files": [{"content": "\"\"\"Django settings for marsha project.\n\nUses django-configurations to manage environments inheritance and the loading of some\nconfig from the environment\n\n\"\"\"\n\nfrom datetime import timedelta\nimport os\n\nfrom django.utils.translation import gettext_lazy as _\n\nfrom configurations import Configuration, values\n\n\nclass Base(Configuration):\n \"\"\"Base configuration every configuration (aka environment) should inherit from.\n\n It depends on an environment variable that SHOULD be defined:\n - DJANGO_SECRET_KEY\n\n You may also want to override default configuration by setting the following\n environment variables:\n - DJANGO_DEBUG\n - DATABASE_URL\n \"\"\"\n\n BASE_DIR = os.path.dirname(__file__)\n DATA_DIR = values.Value(os.path.join(\"/\", \"data\"))\n\n # Static files (CSS, JavaScript, Images)\n STATICFILES_DIRS = (os.path.join(BASE_DIR, \"static\"),)\n STATIC_URL = \"/static/\"\n MEDIA_URL = \"/media/\"\n # Allow to configure location of static/media files for non-Docker installation\n MEDIA_ROOT = values.Value(os.path.join(str(DATA_DIR), \"media\"))\n STATIC_ROOT = values.Value(os.path.join(str(DATA_DIR), \"static\"))\n\n SECRET_KEY = values.SecretValue()\n\n DEBUG = values.BooleanValue(False)\n\n DATABASES = {\n \"default\": {\n \"ENGINE\": values.Value(\n \"django.db.backends.postgresql_psycopg2\",\n environ_name=\"DATABASE_ENGINE\",\n environ_prefix=None,\n ),\n \"NAME\": values.Value(\n \"marsha\", environ_name=\"POSTGRES_DB\", environ_prefix=None\n ),\n \"USER\": values.Value(\n \"marsha_user\", environ_name=\"POSTGRES_USER\", environ_prefix=None\n ),\n \"PASSWORD\": values.Value(\n \"pass\", environ_name=\"POSTGRES_PASSWORD\", environ_prefix=None\n ),\n \"HOST\": values.Value(\n \"localhost\", environ_name=\"POSTGRES_HOST\", environ_prefix=None\n ),\n \"PORT\": values.Value(\n 5432, environ_name=\"POSTGRES_PORT\", environ_prefix=None\n ),\n }\n }\n\n ALLOWED_HOSTS = []\n\n # Application definition\n\n INSTALLED_APPS = [\n \"django.contrib.admin.apps.SimpleAdminConfig\",\n \"django.contrib.auth\",\n \"django.contrib.contenttypes\",\n \"django.contrib.sessions\",\n \"django.contrib.messages\",\n \"django.contrib.staticfiles\",\n \"django_extensions\",\n \"rest_framework\",\n \"marsha.core.apps.CoreConfig\",\n ]\n\n MIDDLEWARE = [\n \"django.middleware.security.SecurityMiddleware\",\n \"django.contrib.sessions.middleware.SessionMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n \"django.middleware.csrf.CsrfViewMiddleware\",\n \"django.contrib.auth.middleware.AuthenticationMiddleware\",\n \"django.contrib.messages.middleware.MessageMiddleware\",\n \"django.middleware.clickjacking.XFrameOptionsMiddleware\",\n ]\n\n ROOT_URLCONF = \"marsha.urls\"\n\n TEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [],\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\n \"django.template.context_processors.debug\",\n \"django.template.context_processors.request\",\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n ]\n },\n }\n ]\n\n AUTH_USER_MODEL = \"core.User\"\n\n WSGI_APPLICATION = \"marsha.wsgi.application\"\n\n REST_FRAMEWORK = {\n \"DEFAULT_AUTHENTICATION_CLASSES\": (\n \"rest_framework_simplejwt.authentication.JWTTokenUserAuthentication\",\n )\n }\n\n # Password validation\n # https://docs.djangoproject.com/en/2.0/ref/settings/#auth-password-validators\n AUTH_PASSWORD_VALIDATORS = [\n {\n \"NAME\": \"django.contrib.auth.password_validation.UserAttributeSimilarityValidator\"\n },\n {\"NAME\": \"django.contrib.auth.password_validation.MinimumLengthValidator\"},\n {\"NAME\": \"django.contrib.auth.password_validation.CommonPasswordValidator\"},\n {\"NAME\": \"django.contrib.auth.password_validation.NumericPasswordValidator\"},\n ]\n\n JWT_SIGNING_KEY = values.SecretValue()\n\n # Internationalization\n # https://docs.djangoproject.com/en/2.0/topics/i18n/\n\n LANGUAGE_CODE = \"en-us\"\n\n LANGUAGES = [(\"en\", _(\"english\")), (\"fr\", _(\"french\"))]\n\n # Internationalization\n TIME_ZONE = \"UTC\"\n USE_I18N = True\n USE_L10N = True\n USE_TZ = True\n\n VIDEO_RESOLUTIONS = [144, 240, 480, 720, 1080]\n\n # AWS\n AWS_ACCESS_KEY_ID = values.SecretValue()\n AWS_SECRET_ACCESS_KEY = values.SecretValue()\n AWS_DEFAULT_REGION = values.Value(\"eu-west-1\")\n UPDATE_STATE_SHARED_SECRETS = values.ListValue()\n\n # Cloud Front key pair for signed urls\n CLOUDFRONT_URL = values.SecretValue()\n CLOUDFRONT_ACCESS_KEY_ID = values.Value(None)\n CLOUDFRONT_PRIVATE_KEY_PATH = values.Value(\n os.path.join(BASE_DIR, \"..\", \".ssh\", \"cloudfront_private_key\")\n )\n CLOUDFRONT_SIGNED_URLS_ACTIVE = True\n CLOUDFRONT_SIGNED_URLS_VALIDITY = 2 * 60 * 60 # 2 hours\n\n # pylint: disable=invalid-name\n @property\n def SIMPLE_JWT(self):\n \"\"\"Define settings for `djangorestframework_simplejwt`.\n\n The JWT_SIGNING_KEY must be evaluated late as the jwt library check for string type.\n \"\"\"\n return {\n \"ACCESS_TOKEN_LIFETIME\": timedelta(days=1),\n \"ALGORITHM\": \"HS256\",\n \"SIGNING_KEY\": str(self.JWT_SIGNING_KEY),\n \"USER_ID_CLAIM\": \"video_id\",\n \"AUTH_TOKEN_CLASSES\": (\"rest_framework_simplejwt.tokens.AccessToken\",),\n }\n\n\nclass Development(Base):\n \"\"\"Development environment settings.\n\n We set ``DEBUG`` to ``True`` by default, configure the server to respond to all hosts,\n and use a local sqlite database by default.\n \"\"\"\n\n DEBUG = values.BooleanValue(True)\n ALLOWED_HOSTS = [\"*\"]\n\n AWS_SOURCE_BUCKET_NAME = \"development-marsha-source\"\n\n\nclass Test(Base):\n \"\"\"Test environment settings.\"\"\"\n\n AWS_SOURCE_BUCKET_NAME = \"test-marsha-source\"\n\n CLOUDFRONT_SIGNED_URLS_ACTIVE = False\n", "path": "marsha/settings.py"}], "after_files": [{"content": "\"\"\"Django settings for marsha project.\n\nUses django-configurations to manage environments inheritance and the loading of some\nconfig from the environment\n\n\"\"\"\n\nfrom datetime import timedelta\nimport os\n\nfrom django.utils.translation import gettext_lazy as _\n\nfrom configurations import Configuration, values\nimport sentry_sdk\nfrom sentry_sdk.integrations.django import DjangoIntegration\n\n\nclass Base(Configuration):\n \"\"\"Base configuration every configuration (aka environment) should inherit from.\n\n It depends on an environment variable that SHOULD be defined:\n - DJANGO_SECRET_KEY\n\n You may also want to override default configuration by setting the following\n environment variables:\n - DJANGO_DEBUG\n - DATABASE_URL\n \"\"\"\n\n BASE_DIR = os.path.dirname(__file__)\n DATA_DIR = values.Value(os.path.join(\"/\", \"data\"))\n\n # Static files (CSS, JavaScript, Images)\n STATICFILES_DIRS = (os.path.join(BASE_DIR, \"static\"),)\n STATIC_URL = \"/static/\"\n MEDIA_URL = \"/media/\"\n # Allow to configure location of static/media files for non-Docker installation\n MEDIA_ROOT = values.Value(os.path.join(str(DATA_DIR), \"media\"))\n STATIC_ROOT = values.Value(os.path.join(str(DATA_DIR), \"static\"))\n\n SECRET_KEY = values.SecretValue()\n\n DEBUG = values.BooleanValue(False)\n\n DATABASES = {\n \"default\": {\n \"ENGINE\": values.Value(\n \"django.db.backends.postgresql_psycopg2\",\n environ_name=\"DATABASE_ENGINE\",\n environ_prefix=None,\n ),\n \"NAME\": values.Value(\n \"marsha\", environ_name=\"POSTGRES_DB\", environ_prefix=None\n ),\n \"USER\": values.Value(\n \"marsha_user\", environ_name=\"POSTGRES_USER\", environ_prefix=None\n ),\n \"PASSWORD\": values.Value(\n \"pass\", environ_name=\"POSTGRES_PASSWORD\", environ_prefix=None\n ),\n \"HOST\": values.Value(\n \"localhost\", environ_name=\"POSTGRES_HOST\", environ_prefix=None\n ),\n \"PORT\": values.Value(\n 5432, environ_name=\"POSTGRES_PORT\", environ_prefix=None\n ),\n }\n }\n\n ALLOWED_HOSTS = []\n\n # Application definition\n\n INSTALLED_APPS = [\n \"django.contrib.admin.apps.SimpleAdminConfig\",\n \"django.contrib.auth\",\n \"django.contrib.contenttypes\",\n \"django.contrib.sessions\",\n \"django.contrib.messages\",\n \"django.contrib.staticfiles\",\n \"django_extensions\",\n \"rest_framework\",\n \"marsha.core.apps.CoreConfig\",\n ]\n\n MIDDLEWARE = [\n \"django.middleware.security.SecurityMiddleware\",\n \"django.contrib.sessions.middleware.SessionMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n \"django.middleware.csrf.CsrfViewMiddleware\",\n \"django.contrib.auth.middleware.AuthenticationMiddleware\",\n \"django.contrib.messages.middleware.MessageMiddleware\",\n \"django.middleware.clickjacking.XFrameOptionsMiddleware\",\n ]\n\n ROOT_URLCONF = \"marsha.urls\"\n\n TEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [],\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\n \"django.template.context_processors.debug\",\n \"django.template.context_processors.request\",\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n ]\n },\n }\n ]\n\n AUTH_USER_MODEL = \"core.User\"\n\n WSGI_APPLICATION = \"marsha.wsgi.application\"\n\n REST_FRAMEWORK = {\n \"DEFAULT_AUTHENTICATION_CLASSES\": (\n \"rest_framework_simplejwt.authentication.JWTTokenUserAuthentication\",\n )\n }\n\n # Password validation\n # https://docs.djangoproject.com/en/2.0/ref/settings/#auth-password-validators\n AUTH_PASSWORD_VALIDATORS = [\n {\n \"NAME\": \"django.contrib.auth.password_validation.UserAttributeSimilarityValidator\"\n },\n {\"NAME\": \"django.contrib.auth.password_validation.MinimumLengthValidator\"},\n {\"NAME\": \"django.contrib.auth.password_validation.CommonPasswordValidator\"},\n {\"NAME\": \"django.contrib.auth.password_validation.NumericPasswordValidator\"},\n ]\n\n JWT_SIGNING_KEY = values.SecretValue()\n\n # Internationalization\n # https://docs.djangoproject.com/en/2.0/topics/i18n/\n\n LANGUAGE_CODE = \"en-us\"\n\n LANGUAGES = [(\"en\", _(\"english\")), (\"fr\", _(\"french\"))]\n\n # Internationalization\n TIME_ZONE = \"UTC\"\n USE_I18N = True\n USE_L10N = True\n USE_TZ = True\n\n VIDEO_RESOLUTIONS = [144, 240, 480, 720, 1080]\n\n # AWS\n AWS_ACCESS_KEY_ID = values.SecretValue()\n AWS_SECRET_ACCESS_KEY = values.SecretValue()\n AWS_DEFAULT_REGION = values.Value(\"eu-west-1\")\n UPDATE_STATE_SHARED_SECRETS = values.ListValue()\n\n # Cloud Front key pair for signed urls\n CLOUDFRONT_URL = values.SecretValue()\n CLOUDFRONT_ACCESS_KEY_ID = values.Value(None)\n CLOUDFRONT_PRIVATE_KEY_PATH = values.Value(\n os.path.join(BASE_DIR, \"..\", \".ssh\", \"cloudfront_private_key\")\n )\n CLOUDFRONT_SIGNED_URLS_ACTIVE = True\n CLOUDFRONT_SIGNED_URLS_VALIDITY = 2 * 60 * 60 # 2 hours\n\n # pylint: disable=invalid-name\n @property\n def SIMPLE_JWT(self):\n \"\"\"Define settings for `djangorestframework_simplejwt`.\n\n The JWT_SIGNING_KEY must be evaluated late as the jwt library check for string type.\n \"\"\"\n return {\n \"ACCESS_TOKEN_LIFETIME\": timedelta(days=1),\n \"ALGORITHM\": \"HS256\",\n \"SIGNING_KEY\": str(self.JWT_SIGNING_KEY),\n \"USER_ID_CLAIM\": \"video_id\",\n \"AUTH_TOKEN_CLASSES\": (\"rest_framework_simplejwt.tokens.AccessToken\",),\n }\n\n @classmethod\n def post_setup(cls):\n \"\"\"Post setup configuration.\n\n This is the place where you can configure settings that require other\n settings to be loaded.\n \"\"\"\n super().post_setup()\n\n # The DJANGO_SENTRY_DSN environment variable should be set to activate\n # sentry for an environment\n sentry_dsn = values.Value(None, environ_name=\"SENTRY_DSN\")\n if sentry_dsn is not None:\n sentry_sdk.init(\n dsn=sentry_dsn,\n environment=cls.__name__.lower(),\n integrations=[DjangoIntegration()],\n )\n\n\nclass Development(Base):\n \"\"\"Development environment settings.\n\n We set ``DEBUG`` to ``True`` by default, configure the server to respond to all hosts,\n and use a local sqlite database by default.\n \"\"\"\n\n DEBUG = values.BooleanValue(True)\n ALLOWED_HOSTS = [\"*\"]\n\n AWS_SOURCE_BUCKET_NAME = \"development-marsha-source\"\n\n\nclass Test(Base):\n \"\"\"Test environment settings.\"\"\"\n\n AWS_SOURCE_BUCKET_NAME = \"test-marsha-source\"\n\n CLOUDFRONT_SIGNED_URLS_ACTIVE = False\n", "path": "marsha/settings.py"}]}
| 2,199 | 281 |
gh_patches_debug_18422
|
rasdani/github-patches
|
git_diff
|
ansible__awx-7280
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Mattermost Notification fails on latest release
##### ISSUE TYPE
- Bug Report
##### SUMMARY
Trying to send a (test) notification to a Mattermost Channel fails with
```
mattermostinfo: Notification failed.
Error sending notification mattermost: {"id":"api.webhook.incoming.error","message":"Could not decode the multipart payload of incoming webhook.","detailed_error":"","request_id":"<request ID>","status_code":400}
```
##### ENVIRONMENT
* AWX version: 11.2.0
* AWX install method: docker on linux
* Ansible version: 2.9.7
* Operating System: CentOS 7.8
* Web Browser: Chrome,Chromium,Firefox
* Mattermost Server Version: 5.22.1
##### STEPS TO REPRODUCE
- Create an incomming webhook
- Create a mattermost notification
- Send a test notification
##### EXPECTED RESULTS
Having a notification in the Channel
##### ACTUAL RESULTS
Sending failed with above error message
##### ADDITIONAL INFORMATION
The error message in the mattermost log shows
```
{"level":"error","ts":1591342011.6592789,"caller":"mlog/log.go:175","msg":"Could not decode the multipart payload of incoming webhook.","path":"/
hooks/<hook ID>","request_id":"<request ID>","ip_addr":"<IP Address>","user_id":"","method":"POST","err_where":"
incomingWebhook","http_code":400,"err_details":"mime: no media type"}
```
---
edit: some ID removed in the log sample, mattermost server version added
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `awx/main/notifications/mattermost_backend.py`
Content:
```
1 # Copyright (c) 2016 Ansible, Inc.
2 # All Rights Reserved.
3
4 import logging
5 import requests
6 import json
7
8 from django.utils.encoding import smart_text
9 from django.utils.translation import ugettext_lazy as _
10
11 from awx.main.notifications.base import AWXBaseEmailBackend
12 from awx.main.notifications.custom_notification_base import CustomNotificationBase
13
14 logger = logging.getLogger('awx.main.notifications.mattermost_backend')
15
16
17 class MattermostBackend(AWXBaseEmailBackend, CustomNotificationBase):
18
19 init_parameters = {"mattermost_url": {"label": "Target URL", "type": "string"},
20 "mattermost_no_verify_ssl": {"label": "Verify SSL", "type": "bool"}}
21 recipient_parameter = "mattermost_url"
22 sender_parameter = None
23
24 def __init__(self, mattermost_no_verify_ssl=False, mattermost_channel=None, mattermost_username=None,
25 mattermost_icon_url=None, fail_silently=False, **kwargs):
26 super(MattermostBackend, self).__init__(fail_silently=fail_silently)
27 self.mattermost_channel = mattermost_channel
28 self.mattermost_username = mattermost_username
29 self.mattermost_icon_url = mattermost_icon_url
30 self.mattermost_no_verify_ssl = mattermost_no_verify_ssl
31
32 def format_body(self, body):
33 return body
34
35 def send_messages(self, messages):
36 sent_messages = 0
37 for m in messages:
38 payload = {}
39 for opt, optval in {'mattermost_icon_url':'icon_url',
40 'mattermost_channel': 'channel', 'mattermost_username': 'username'}.items():
41 optvalue = getattr(self, opt)
42 if optvalue is not None:
43 payload[optval] = optvalue.strip()
44
45 payload['text'] = m.subject
46
47 r = requests.post("{}".format(m.recipients()[0]),
48 data=json.dumps(payload), verify=(not self.mattermost_no_verify_ssl))
49 if r.status_code >= 400:
50 logger.error(smart_text(_("Error sending notification mattermost: {}").format(r.text)))
51 if not self.fail_silently:
52 raise Exception(smart_text(_("Error sending notification mattermost: {}").format(r.text)))
53 sent_messages += 1
54 return sent_messages
55
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/awx/main/notifications/mattermost_backend.py b/awx/main/notifications/mattermost_backend.py
--- a/awx/main/notifications/mattermost_backend.py
+++ b/awx/main/notifications/mattermost_backend.py
@@ -3,7 +3,6 @@
import logging
import requests
-import json
from django.utils.encoding import smart_text
from django.utils.translation import ugettext_lazy as _
@@ -45,7 +44,7 @@
payload['text'] = m.subject
r = requests.post("{}".format(m.recipients()[0]),
- data=json.dumps(payload), verify=(not self.mattermost_no_verify_ssl))
+ json=payload, verify=(not self.mattermost_no_verify_ssl))
if r.status_code >= 400:
logger.error(smart_text(_("Error sending notification mattermost: {}").format(r.text)))
if not self.fail_silently:
|
{"golden_diff": "diff --git a/awx/main/notifications/mattermost_backend.py b/awx/main/notifications/mattermost_backend.py\n--- a/awx/main/notifications/mattermost_backend.py\n+++ b/awx/main/notifications/mattermost_backend.py\n@@ -3,7 +3,6 @@\n \n import logging\n import requests\n-import json\n \n from django.utils.encoding import smart_text\n from django.utils.translation import ugettext_lazy as _\n@@ -45,7 +44,7 @@\n payload['text'] = m.subject\n \n r = requests.post(\"{}\".format(m.recipients()[0]),\n- data=json.dumps(payload), verify=(not self.mattermost_no_verify_ssl))\n+ json=payload, verify=(not self.mattermost_no_verify_ssl))\n if r.status_code >= 400:\n logger.error(smart_text(_(\"Error sending notification mattermost: {}\").format(r.text)))\n if not self.fail_silently:\n", "issue": "Mattermost Notification fails on latest release\n##### ISSUE TYPE\r\n - Bug Report\r\n\r\n##### SUMMARY\r\nTrying to send a (test) notification to a Mattermost Channel fails with\r\n```\r\n mattermostinfo: Notification failed.\r\nError sending notification mattermost: {\"id\":\"api.webhook.incoming.error\",\"message\":\"Could not decode the multipart payload of incoming webhook.\",\"detailed_error\":\"\",\"request_id\":\"<request ID>\",\"status_code\":400}\r\n```\r\n##### ENVIRONMENT\r\n* AWX version: 11.2.0\r\n* AWX install method: docker on linux\r\n* Ansible version: 2.9.7\r\n* Operating System: CentOS 7.8\r\n* Web Browser: Chrome,Chromium,Firefox\r\n* Mattermost Server Version: 5.22.1\r\n\r\n##### STEPS TO REPRODUCE\r\n- Create an incomming webhook\r\n- Create a mattermost notification\r\n- Send a test notification\r\n\r\n\r\n##### EXPECTED RESULTS\r\nHaving a notification in the Channel\r\n\r\n\r\n##### ACTUAL RESULTS\r\n\r\nSending failed with above error message\r\n\r\n##### ADDITIONAL INFORMATION\r\n\r\nThe error message in the mattermost log shows\r\n```\r\n{\"level\":\"error\",\"ts\":1591342011.6592789,\"caller\":\"mlog/log.go:175\",\"msg\":\"Could not decode the multipart payload of incoming webhook.\",\"path\":\"/\r\nhooks/<hook ID>\",\"request_id\":\"<request ID>\",\"ip_addr\":\"<IP Address>\",\"user_id\":\"\",\"method\":\"POST\",\"err_where\":\"\r\nincomingWebhook\",\"http_code\":400,\"err_details\":\"mime: no media type\"}\r\n```\r\n---\r\nedit: some ID removed in the log sample, mattermost server version added\n", "before_files": [{"content": "# Copyright (c) 2016 Ansible, Inc.\n# All Rights Reserved.\n\nimport logging\nimport requests\nimport json\n\nfrom django.utils.encoding import smart_text\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom awx.main.notifications.base import AWXBaseEmailBackend\nfrom awx.main.notifications.custom_notification_base import CustomNotificationBase\n\nlogger = logging.getLogger('awx.main.notifications.mattermost_backend')\n\n\nclass MattermostBackend(AWXBaseEmailBackend, CustomNotificationBase):\n\n init_parameters = {\"mattermost_url\": {\"label\": \"Target URL\", \"type\": \"string\"},\n \"mattermost_no_verify_ssl\": {\"label\": \"Verify SSL\", \"type\": \"bool\"}}\n recipient_parameter = \"mattermost_url\"\n sender_parameter = None\n\n def __init__(self, mattermost_no_verify_ssl=False, mattermost_channel=None, mattermost_username=None,\n mattermost_icon_url=None, fail_silently=False, **kwargs):\n super(MattermostBackend, self).__init__(fail_silently=fail_silently)\n self.mattermost_channel = mattermost_channel\n self.mattermost_username = mattermost_username\n self.mattermost_icon_url = mattermost_icon_url\n self.mattermost_no_verify_ssl = mattermost_no_verify_ssl\n\n def format_body(self, body):\n return body\n\n def send_messages(self, messages):\n sent_messages = 0\n for m in messages:\n payload = {}\n for opt, optval in {'mattermost_icon_url':'icon_url',\n 'mattermost_channel': 'channel', 'mattermost_username': 'username'}.items():\n optvalue = getattr(self, opt)\n if optvalue is not None:\n payload[optval] = optvalue.strip()\n\n payload['text'] = m.subject\n\n r = requests.post(\"{}\".format(m.recipients()[0]),\n data=json.dumps(payload), verify=(not self.mattermost_no_verify_ssl))\n if r.status_code >= 400:\n logger.error(smart_text(_(\"Error sending notification mattermost: {}\").format(r.text)))\n if not self.fail_silently:\n raise Exception(smart_text(_(\"Error sending notification mattermost: {}\").format(r.text)))\n sent_messages += 1\n return sent_messages\n", "path": "awx/main/notifications/mattermost_backend.py"}], "after_files": [{"content": "# Copyright (c) 2016 Ansible, Inc.\n# All Rights Reserved.\n\nimport logging\nimport requests\n\nfrom django.utils.encoding import smart_text\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom awx.main.notifications.base import AWXBaseEmailBackend\nfrom awx.main.notifications.custom_notification_base import CustomNotificationBase\n\nlogger = logging.getLogger('awx.main.notifications.mattermost_backend')\n\n\nclass MattermostBackend(AWXBaseEmailBackend, CustomNotificationBase):\n\n init_parameters = {\"mattermost_url\": {\"label\": \"Target URL\", \"type\": \"string\"},\n \"mattermost_no_verify_ssl\": {\"label\": \"Verify SSL\", \"type\": \"bool\"}}\n recipient_parameter = \"mattermost_url\"\n sender_parameter = None\n\n def __init__(self, mattermost_no_verify_ssl=False, mattermost_channel=None, mattermost_username=None,\n mattermost_icon_url=None, fail_silently=False, **kwargs):\n super(MattermostBackend, self).__init__(fail_silently=fail_silently)\n self.mattermost_channel = mattermost_channel\n self.mattermost_username = mattermost_username\n self.mattermost_icon_url = mattermost_icon_url\n self.mattermost_no_verify_ssl = mattermost_no_verify_ssl\n\n def format_body(self, body):\n return body\n\n def send_messages(self, messages):\n sent_messages = 0\n for m in messages:\n payload = {}\n for opt, optval in {'mattermost_icon_url':'icon_url',\n 'mattermost_channel': 'channel', 'mattermost_username': 'username'}.items():\n optvalue = getattr(self, opt)\n if optvalue is not None:\n payload[optval] = optvalue.strip()\n\n payload['text'] = m.subject\n\n r = requests.post(\"{}\".format(m.recipients()[0]),\n json=payload, verify=(not self.mattermost_no_verify_ssl))\n if r.status_code >= 400:\n logger.error(smart_text(_(\"Error sending notification mattermost: {}\").format(r.text)))\n if not self.fail_silently:\n raise Exception(smart_text(_(\"Error sending notification mattermost: {}\").format(r.text)))\n sent_messages += 1\n return sent_messages\n", "path": "awx/main/notifications/mattermost_backend.py"}]}
| 1,222 | 203 |
gh_patches_debug_8442
|
rasdani/github-patches
|
git_diff
|
PaddlePaddle__PaddleSeg-980
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
DecoupledSegNet错误
1.环境:(首先安装cpu版本,测试成功)

2.安装GPU版本
命令:python -m pip install paddlepaddle-gpu==2.0.0 -i https://mirror.baidu.com/pypi/simple
3.出现问题

4.解决方案
(1)env | grep cuda
(2)port LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64
(3) /usr/local/cuda/lib64
(4)ln -s libcusolver.so.10 libcusolver.so
5. 运行
Python./train.py -config ./configs/decoupled_segnet/decoupledsegnet_resnet50_os8_cityscapes_832x832_80k.yml
6.新问题

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `paddleseg/models/decoupled_segnet.py`
Content:
```
1 # Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import cv2
16 import numpy as np
17 import paddle
18 import paddle.nn as nn
19 import paddle.nn.functional as F
20
21 from paddleseg.cvlibs import manager
22 from paddleseg.models import layers
23 from paddleseg.models.backbones import resnet_vd
24 from paddleseg.models import deeplab
25 from paddleseg.utils import utils
26
27
28 @manager.MODELS.add_component
29 class DecoupledSegNet(nn.Layer):
30 """
31 The DecoupledSegNet implementation based on PaddlePaddle.
32
33 The original article refers to
34 Xiangtai Li, et, al. "Improving Semantic Segmentation via Decoupled Body and Edge Supervision"
35 (https://arxiv.org/pdf/2007.10035.pdf)
36
37 Args:
38 num_classes (int): The unique number of target classes.
39 backbone (paddle.nn.Layer): Backbone network, currently support Resnet50_vd/Resnet101_vd.
40 backbone_indices (tuple, optional): Two values in the tuple indicate the indices of output of backbone.
41 Default: (0, 3).
42 aspp_ratios (tuple, optional): The dilation rate using in ASSP module.
43 If output_stride=16, aspp_ratios should be set as (1, 6, 12, 18).
44 If output_stride=8, aspp_ratios is (1, 12, 24, 36).
45 Default: (1, 6, 12, 18).
46 aspp_out_channels (int, optional): The output channels of ASPP module. Default: 256.
47 align_corners (bool, optional): An argument of F.interpolate. It should be set to False when the feature size is even,
48 e.g. 1024x512, otherwise it is True, e.g. 769x769. Default: False.
49 pretrained (str, optional): The path or url of pretrained model. Default: None.
50 """
51
52 def __init__(self,
53 num_classes,
54 backbone,
55 backbone_indices=(0, 3),
56 aspp_ratios=(1, 6, 12, 18),
57 aspp_out_channels=256,
58 align_corners=False,
59 pretrained=None):
60 super().__init__()
61 self.backbone = backbone
62 backbone_channels = self.backbone.feat_channels
63 self.head = DecoupledSegNetHead(num_classes, backbone_indices,
64 backbone_channels, aspp_ratios,
65 aspp_out_channels, align_corners)
66 self.align_corners = align_corners
67 self.pretrained = pretrained
68 self.init_weight()
69
70 def forward(self, x):
71 feat_list = self.backbone(x)
72 logit_list = self.head(feat_list)
73
74 seg_logit, body_logit, edge_logit = [
75 F.interpolate(
76 logit,
77 paddle.shape(x)[2:],
78 mode='bilinear',
79 align_corners=self.align_corners) for logit in logit_list
80 ]
81
82 return [seg_logit, body_logit, edge_logit, (seg_logit, edge_logit)]
83
84 def init_weight(self):
85 if self.pretrained is not None:
86 utils.load_entire_model(self, self.pretrained)
87
88
89 class DecoupledSegNetHead(nn.Layer):
90 """
91 The DecoupledSegNetHead implementation based on PaddlePaddle.
92
93 Args:
94 num_classes (int): The unique number of target classes.
95 backbone_indices (tuple): Two values in the tuple indicate the indices of output of backbone.
96 the first index will be taken as a low-level feature in Edge presevation component;
97 the second one will be taken as input of ASPP component.
98 backbone_channels (tuple): The channels of output of backbone.
99 aspp_ratios (tuple): The dilation rates using in ASSP module.
100 aspp_out_channels (int): The output channels of ASPP module.
101 align_corners (bool): An argument of F.interpolate. It should be set to False when the output size of feature
102 is even, e.g. 1024x512, otherwise it is True, e.g. 769x769.
103 """
104
105 def __init__(self, num_classes, backbone_indices, backbone_channels,
106 aspp_ratios, aspp_out_channels, align_corners):
107 super().__init__()
108 self.backbone_indices = backbone_indices
109 self.align_corners = align_corners
110 self.aspp = layers.ASPPModule(
111 aspp_ratios=aspp_ratios,
112 in_channels=backbone_channels[backbone_indices[1]],
113 out_channels=aspp_out_channels,
114 align_corners=align_corners,
115 image_pooling=True)
116
117 self.bot_fine = nn.Conv2D(
118 backbone_channels[backbone_indices[0]], 48, 1, bias_attr=False)
119 # decoupled
120 self.squeeze_body_edge = SqueezeBodyEdge(
121 256, align_corners=self.align_corners)
122 self.edge_fusion = nn.Conv2D(256 + 48, 256, 1, bias_attr=False)
123 self.sigmoid_edge = nn.Sigmoid()
124 self.edge_out = nn.Sequential(
125 layers.ConvBNReLU(
126 in_channels=256,
127 out_channels=48,
128 kernel_size=3,
129 bias_attr=False), nn.Conv2D(48, 1, 1, bias_attr=False))
130 self.dsn_seg_body = nn.Sequential(
131 layers.ConvBNReLU(
132 in_channels=256,
133 out_channels=256,
134 kernel_size=3,
135 bias_attr=False), nn.Conv2D(
136 256, num_classes, 1, bias_attr=False))
137
138 self.final_seg = nn.Sequential(
139 layers.ConvBNReLU(
140 in_channels=512,
141 out_channels=256,
142 kernel_size=3,
143 bias_attr=False),
144 layers.ConvBNReLU(
145 in_channels=256,
146 out_channels=256,
147 kernel_size=3,
148 bias_attr=False),
149 nn.Conv2D(256, num_classes, kernel_size=1, bias_attr=False))
150
151 def forward(self, feat_list):
152 fine_fea = feat_list[self.backbone_indices[0]]
153 fine_size = paddle.shape(fine_fea)
154 x = feat_list[self.backbone_indices[1]]
155 aspp = self.aspp(x)
156
157 # decoupled
158 seg_body, seg_edge = self.squeeze_body_edge(aspp)
159 # Edge presevation and edge out
160 fine_fea = self.bot_fine(fine_fea)
161 seg_edge = F.interpolate(
162 seg_edge,
163 fine_size[2:],
164 mode='bilinear',
165 align_corners=self.align_corners)
166 seg_edge = self.edge_fusion(paddle.concat([seg_edge, fine_fea], axis=1))
167 seg_edge_out = self.edge_out(seg_edge)
168 seg_edge_out = self.sigmoid_edge(seg_edge_out) # seg_edge output
169 seg_body_out = self.dsn_seg_body(seg_body) # body out
170
171 # seg_final out
172 seg_out = seg_edge + F.interpolate(
173 seg_body,
174 fine_size[2:],
175 mode='bilinear',
176 align_corners=self.align_corners)
177 aspp = F.interpolate(
178 aspp,
179 fine_size[2:],
180 mode='bilinear',
181 align_corners=self.align_corners)
182 seg_out = paddle.concat([aspp, seg_out], axis=1)
183 seg_final_out = self.final_seg(seg_out)
184
185 return [seg_final_out, seg_body_out, seg_edge_out]
186
187
188 class SqueezeBodyEdge(nn.Layer):
189 def __init__(self, inplane, align_corners=False):
190 super().__init__()
191 self.align_corners = align_corners
192 self.down = nn.Sequential(
193 layers.ConvBNReLU(
194 inplane, inplane, kernel_size=3, groups=inplane, stride=2),
195 layers.ConvBNReLU(
196 inplane, inplane, kernel_size=3, groups=inplane, stride=2))
197 self.flow_make = nn.Conv2D(
198 inplane * 2, 2, kernel_size=3, padding='same', bias_attr=False)
199
200 def forward(self, x):
201 size = paddle.shape(x)[2:]
202 seg_down = self.down(x)
203 seg_down = F.interpolate(
204 seg_down,
205 size=size,
206 mode='bilinear',
207 align_corners=self.align_corners)
208 flow = self.flow_make(paddle.concat([x, seg_down], axis=1))
209 seg_flow_warp = self.flow_warp(x, flow, size)
210 seg_edge = x - seg_flow_warp
211 return seg_flow_warp, seg_edge
212
213 def flow_warp(self, input, flow, size):
214 input_shape = paddle.shape(input)
215 norm = size[::-1].reshape([1, 1, 1, -1])
216 h_grid = paddle.linspace(-1.0, 1.0, size[0]).reshape([-1, 1])
217 h_grid = h_grid.tile([size[1]])
218 w_grid = paddle.linspace(-1.0, 1.0, size[1]).reshape([-1, 1])
219 w_grid = w_grid.tile([size[0]]).transpose([1, 0])
220 grid = paddle.concat([w_grid.unsqueeze(2), h_grid.unsqueeze(2)], axis=2)
221 grid.unsqueeze(0).tile([input_shape[0], 1, 1, 1])
222 grid = grid + paddle.transpose(flow, (0, 2, 3, 1)) / norm
223
224 output = F.grid_sample(input, grid)
225 return output
226
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/paddleseg/models/decoupled_segnet.py b/paddleseg/models/decoupled_segnet.py
--- a/paddleseg/models/decoupled_segnet.py
+++ b/paddleseg/models/decoupled_segnet.py
@@ -213,6 +213,7 @@
def flow_warp(self, input, flow, size):
input_shape = paddle.shape(input)
norm = size[::-1].reshape([1, 1, 1, -1])
+ norm.stop_gradient = True
h_grid = paddle.linspace(-1.0, 1.0, size[0]).reshape([-1, 1])
h_grid = h_grid.tile([size[1]])
w_grid = paddle.linspace(-1.0, 1.0, size[1]).reshape([-1, 1])
|
{"golden_diff": "diff --git a/paddleseg/models/decoupled_segnet.py b/paddleseg/models/decoupled_segnet.py\n--- a/paddleseg/models/decoupled_segnet.py\n+++ b/paddleseg/models/decoupled_segnet.py\n@@ -213,6 +213,7 @@\n def flow_warp(self, input, flow, size):\n input_shape = paddle.shape(input)\n norm = size[::-1].reshape([1, 1, 1, -1])\n+ norm.stop_gradient = True\n h_grid = paddle.linspace(-1.0, 1.0, size[0]).reshape([-1, 1])\n h_grid = h_grid.tile([size[1]])\n w_grid = paddle.linspace(-1.0, 1.0, size[1]).reshape([-1, 1])\n", "issue": "DecoupledSegNet\u9519\u8bef\n1.\u73af\u5883\uff1a\uff08\u9996\u5148\u5b89\u88c5cpu\u7248\u672c\uff0c\u6d4b\u8bd5\u6210\u529f\uff09\r\n \r\n\r\n\r\n\r\n2.\u5b89\u88c5GPU\u7248\u672c\r\n\u547d\u4ee4\uff1apython -m pip install paddlepaddle-gpu==2.0.0 -i https://mirror.baidu.com/pypi/simple\r\n\r\n3.\u51fa\u73b0\u95ee\u9898\r\n \r\n\r\n\r\n4.\u89e3\u51b3\u65b9\u6848\r\n\uff081\uff09env | grep cuda\r\n\uff082\uff09port LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64\r\n\uff083\uff09 /usr/local/cuda/lib64\r\n\uff084\uff09ln -s libcusolver.so.10 libcusolver.so\r\n\r\n5. \u8fd0\u884c \r\nPython./train.py -config ./configs/decoupled_segnet/decoupledsegnet_resnet50_os8_cityscapes_832x832_80k.yml\r\n\r\n6.\u65b0\u95ee\u9898\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport cv2\nimport numpy as np\nimport paddle\nimport paddle.nn as nn\nimport paddle.nn.functional as F\n\nfrom paddleseg.cvlibs import manager\nfrom paddleseg.models import layers\nfrom paddleseg.models.backbones import resnet_vd\nfrom paddleseg.models import deeplab\nfrom paddleseg.utils import utils\n\n\[email protected]_component\nclass DecoupledSegNet(nn.Layer):\n \"\"\"\n The DecoupledSegNet implementation based on PaddlePaddle.\n\n The original article refers to\n Xiangtai Li, et, al. \"Improving Semantic Segmentation via Decoupled Body and Edge Supervision\"\n (https://arxiv.org/pdf/2007.10035.pdf)\n\n Args:\n num_classes (int): The unique number of target classes.\n backbone (paddle.nn.Layer): Backbone network, currently support Resnet50_vd/Resnet101_vd.\n backbone_indices (tuple, optional): Two values in the tuple indicate the indices of output of backbone.\n Default: (0, 3).\n aspp_ratios (tuple, optional): The dilation rate using in ASSP module.\n If output_stride=16, aspp_ratios should be set as (1, 6, 12, 18).\n If output_stride=8, aspp_ratios is (1, 12, 24, 36).\n Default: (1, 6, 12, 18).\n aspp_out_channels (int, optional): The output channels of ASPP module. Default: 256.\n align_corners (bool, optional): An argument of F.interpolate. It should be set to False when the feature size is even,\n e.g. 1024x512, otherwise it is True, e.g. 769x769. Default: False.\n pretrained (str, optional): The path or url of pretrained model. Default: None.\n \"\"\"\n\n def __init__(self,\n num_classes,\n backbone,\n backbone_indices=(0, 3),\n aspp_ratios=(1, 6, 12, 18),\n aspp_out_channels=256,\n align_corners=False,\n pretrained=None):\n super().__init__()\n self.backbone = backbone\n backbone_channels = self.backbone.feat_channels\n self.head = DecoupledSegNetHead(num_classes, backbone_indices,\n backbone_channels, aspp_ratios,\n aspp_out_channels, align_corners)\n self.align_corners = align_corners\n self.pretrained = pretrained\n self.init_weight()\n\n def forward(self, x):\n feat_list = self.backbone(x)\n logit_list = self.head(feat_list)\n\n seg_logit, body_logit, edge_logit = [\n F.interpolate(\n logit,\n paddle.shape(x)[2:],\n mode='bilinear',\n align_corners=self.align_corners) for logit in logit_list\n ]\n\n return [seg_logit, body_logit, edge_logit, (seg_logit, edge_logit)]\n\n def init_weight(self):\n if self.pretrained is not None:\n utils.load_entire_model(self, self.pretrained)\n\n\nclass DecoupledSegNetHead(nn.Layer):\n \"\"\"\n The DecoupledSegNetHead implementation based on PaddlePaddle.\n\n Args:\n num_classes (int): The unique number of target classes.\n backbone_indices (tuple): Two values in the tuple indicate the indices of output of backbone.\n the first index will be taken as a low-level feature in Edge presevation component;\n the second one will be taken as input of ASPP component.\n backbone_channels (tuple): The channels of output of backbone.\n aspp_ratios (tuple): The dilation rates using in ASSP module.\n aspp_out_channels (int): The output channels of ASPP module.\n align_corners (bool): An argument of F.interpolate. It should be set to False when the output size of feature\n is even, e.g. 1024x512, otherwise it is True, e.g. 769x769.\n \"\"\"\n\n def __init__(self, num_classes, backbone_indices, backbone_channels,\n aspp_ratios, aspp_out_channels, align_corners):\n super().__init__()\n self.backbone_indices = backbone_indices\n self.align_corners = align_corners\n self.aspp = layers.ASPPModule(\n aspp_ratios=aspp_ratios,\n in_channels=backbone_channels[backbone_indices[1]],\n out_channels=aspp_out_channels,\n align_corners=align_corners,\n image_pooling=True)\n\n self.bot_fine = nn.Conv2D(\n backbone_channels[backbone_indices[0]], 48, 1, bias_attr=False)\n # decoupled\n self.squeeze_body_edge = SqueezeBodyEdge(\n 256, align_corners=self.align_corners)\n self.edge_fusion = nn.Conv2D(256 + 48, 256, 1, bias_attr=False)\n self.sigmoid_edge = nn.Sigmoid()\n self.edge_out = nn.Sequential(\n layers.ConvBNReLU(\n in_channels=256,\n out_channels=48,\n kernel_size=3,\n bias_attr=False), nn.Conv2D(48, 1, 1, bias_attr=False))\n self.dsn_seg_body = nn.Sequential(\n layers.ConvBNReLU(\n in_channels=256,\n out_channels=256,\n kernel_size=3,\n bias_attr=False), nn.Conv2D(\n 256, num_classes, 1, bias_attr=False))\n\n self.final_seg = nn.Sequential(\n layers.ConvBNReLU(\n in_channels=512,\n out_channels=256,\n kernel_size=3,\n bias_attr=False),\n layers.ConvBNReLU(\n in_channels=256,\n out_channels=256,\n kernel_size=3,\n bias_attr=False),\n nn.Conv2D(256, num_classes, kernel_size=1, bias_attr=False))\n\n def forward(self, feat_list):\n fine_fea = feat_list[self.backbone_indices[0]]\n fine_size = paddle.shape(fine_fea)\n x = feat_list[self.backbone_indices[1]]\n aspp = self.aspp(x)\n\n # decoupled\n seg_body, seg_edge = self.squeeze_body_edge(aspp)\n # Edge presevation and edge out\n fine_fea = self.bot_fine(fine_fea)\n seg_edge = F.interpolate(\n seg_edge,\n fine_size[2:],\n mode='bilinear',\n align_corners=self.align_corners)\n seg_edge = self.edge_fusion(paddle.concat([seg_edge, fine_fea], axis=1))\n seg_edge_out = self.edge_out(seg_edge)\n seg_edge_out = self.sigmoid_edge(seg_edge_out) # seg_edge output\n seg_body_out = self.dsn_seg_body(seg_body) # body out\n\n # seg_final out\n seg_out = seg_edge + F.interpolate(\n seg_body,\n fine_size[2:],\n mode='bilinear',\n align_corners=self.align_corners)\n aspp = F.interpolate(\n aspp,\n fine_size[2:],\n mode='bilinear',\n align_corners=self.align_corners)\n seg_out = paddle.concat([aspp, seg_out], axis=1)\n seg_final_out = self.final_seg(seg_out)\n\n return [seg_final_out, seg_body_out, seg_edge_out]\n\n\nclass SqueezeBodyEdge(nn.Layer):\n def __init__(self, inplane, align_corners=False):\n super().__init__()\n self.align_corners = align_corners\n self.down = nn.Sequential(\n layers.ConvBNReLU(\n inplane, inplane, kernel_size=3, groups=inplane, stride=2),\n layers.ConvBNReLU(\n inplane, inplane, kernel_size=3, groups=inplane, stride=2))\n self.flow_make = nn.Conv2D(\n inplane * 2, 2, kernel_size=3, padding='same', bias_attr=False)\n\n def forward(self, x):\n size = paddle.shape(x)[2:]\n seg_down = self.down(x)\n seg_down = F.interpolate(\n seg_down,\n size=size,\n mode='bilinear',\n align_corners=self.align_corners)\n flow = self.flow_make(paddle.concat([x, seg_down], axis=1))\n seg_flow_warp = self.flow_warp(x, flow, size)\n seg_edge = x - seg_flow_warp\n return seg_flow_warp, seg_edge\n\n def flow_warp(self, input, flow, size):\n input_shape = paddle.shape(input)\n norm = size[::-1].reshape([1, 1, 1, -1])\n h_grid = paddle.linspace(-1.0, 1.0, size[0]).reshape([-1, 1])\n h_grid = h_grid.tile([size[1]])\n w_grid = paddle.linspace(-1.0, 1.0, size[1]).reshape([-1, 1])\n w_grid = w_grid.tile([size[0]]).transpose([1, 0])\n grid = paddle.concat([w_grid.unsqueeze(2), h_grid.unsqueeze(2)], axis=2)\n grid.unsqueeze(0).tile([input_shape[0], 1, 1, 1])\n grid = grid + paddle.transpose(flow, (0, 2, 3, 1)) / norm\n\n output = F.grid_sample(input, grid)\n return output\n", "path": "paddleseg/models/decoupled_segnet.py"}], "after_files": [{"content": "# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport cv2\nimport numpy as np\nimport paddle\nimport paddle.nn as nn\nimport paddle.nn.functional as F\n\nfrom paddleseg.cvlibs import manager\nfrom paddleseg.models import layers\nfrom paddleseg.models.backbones import resnet_vd\nfrom paddleseg.models import deeplab\nfrom paddleseg.utils import utils\n\n\[email protected]_component\nclass DecoupledSegNet(nn.Layer):\n \"\"\"\n The DecoupledSegNet implementation based on PaddlePaddle.\n\n The original article refers to\n Xiangtai Li, et, al. \"Improving Semantic Segmentation via Decoupled Body and Edge Supervision\"\n (https://arxiv.org/pdf/2007.10035.pdf)\n\n Args:\n num_classes (int): The unique number of target classes.\n backbone (paddle.nn.Layer): Backbone network, currently support Resnet50_vd/Resnet101_vd.\n backbone_indices (tuple, optional): Two values in the tuple indicate the indices of output of backbone.\n Default: (0, 3).\n aspp_ratios (tuple, optional): The dilation rate using in ASSP module.\n If output_stride=16, aspp_ratios should be set as (1, 6, 12, 18).\n If output_stride=8, aspp_ratios is (1, 12, 24, 36).\n Default: (1, 6, 12, 18).\n aspp_out_channels (int, optional): The output channels of ASPP module. Default: 256.\n align_corners (bool, optional): An argument of F.interpolate. It should be set to False when the feature size is even,\n e.g. 1024x512, otherwise it is True, e.g. 769x769. Default: False.\n pretrained (str, optional): The path or url of pretrained model. Default: None.\n \"\"\"\n\n def __init__(self,\n num_classes,\n backbone,\n backbone_indices=(0, 3),\n aspp_ratios=(1, 6, 12, 18),\n aspp_out_channels=256,\n align_corners=False,\n pretrained=None):\n super().__init__()\n self.backbone = backbone\n backbone_channels = self.backbone.feat_channels\n self.head = DecoupledSegNetHead(num_classes, backbone_indices,\n backbone_channels, aspp_ratios,\n aspp_out_channels, align_corners)\n self.align_corners = align_corners\n self.pretrained = pretrained\n self.init_weight()\n\n def forward(self, x):\n feat_list = self.backbone(x)\n logit_list = self.head(feat_list)\n\n seg_logit, body_logit, edge_logit = [\n F.interpolate(\n logit,\n paddle.shape(x)[2:],\n mode='bilinear',\n align_corners=self.align_corners) for logit in logit_list\n ]\n\n return [seg_logit, body_logit, edge_logit, (seg_logit, edge_logit)]\n\n def init_weight(self):\n if self.pretrained is not None:\n utils.load_entire_model(self, self.pretrained)\n\n\nclass DecoupledSegNetHead(nn.Layer):\n \"\"\"\n The DecoupledSegNetHead implementation based on PaddlePaddle.\n\n Args:\n num_classes (int): The unique number of target classes.\n backbone_indices (tuple): Two values in the tuple indicate the indices of output of backbone.\n the first index will be taken as a low-level feature in Edge presevation component;\n the second one will be taken as input of ASPP component.\n backbone_channels (tuple): The channels of output of backbone.\n aspp_ratios (tuple): The dilation rates using in ASSP module.\n aspp_out_channels (int): The output channels of ASPP module.\n align_corners (bool): An argument of F.interpolate. It should be set to False when the output size of feature\n is even, e.g. 1024x512, otherwise it is True, e.g. 769x769.\n \"\"\"\n\n def __init__(self, num_classes, backbone_indices, backbone_channels,\n aspp_ratios, aspp_out_channels, align_corners):\n super().__init__()\n self.backbone_indices = backbone_indices\n self.align_corners = align_corners\n self.aspp = layers.ASPPModule(\n aspp_ratios=aspp_ratios,\n in_channels=backbone_channels[backbone_indices[1]],\n out_channels=aspp_out_channels,\n align_corners=align_corners,\n image_pooling=True)\n\n self.bot_fine = nn.Conv2D(\n backbone_channels[backbone_indices[0]], 48, 1, bias_attr=False)\n # decoupled\n self.squeeze_body_edge = SqueezeBodyEdge(\n 256, align_corners=self.align_corners)\n self.edge_fusion = nn.Conv2D(256 + 48, 256, 1, bias_attr=False)\n self.sigmoid_edge = nn.Sigmoid()\n self.edge_out = nn.Sequential(\n layers.ConvBNReLU(\n in_channels=256,\n out_channels=48,\n kernel_size=3,\n bias_attr=False), nn.Conv2D(48, 1, 1, bias_attr=False))\n self.dsn_seg_body = nn.Sequential(\n layers.ConvBNReLU(\n in_channels=256,\n out_channels=256,\n kernel_size=3,\n bias_attr=False), nn.Conv2D(\n 256, num_classes, 1, bias_attr=False))\n\n self.final_seg = nn.Sequential(\n layers.ConvBNReLU(\n in_channels=512,\n out_channels=256,\n kernel_size=3,\n bias_attr=False),\n layers.ConvBNReLU(\n in_channels=256,\n out_channels=256,\n kernel_size=3,\n bias_attr=False),\n nn.Conv2D(256, num_classes, kernel_size=1, bias_attr=False))\n\n def forward(self, feat_list):\n fine_fea = feat_list[self.backbone_indices[0]]\n fine_size = paddle.shape(fine_fea)\n x = feat_list[self.backbone_indices[1]]\n aspp = self.aspp(x)\n\n # decoupled\n seg_body, seg_edge = self.squeeze_body_edge(aspp)\n # Edge presevation and edge out\n fine_fea = self.bot_fine(fine_fea)\n seg_edge = F.interpolate(\n seg_edge,\n fine_size[2:],\n mode='bilinear',\n align_corners=self.align_corners)\n seg_edge = self.edge_fusion(paddle.concat([seg_edge, fine_fea], axis=1))\n seg_edge_out = self.edge_out(seg_edge)\n seg_edge_out = self.sigmoid_edge(seg_edge_out) # seg_edge output\n seg_body_out = self.dsn_seg_body(seg_body) # body out\n\n # seg_final out\n seg_out = seg_edge + F.interpolate(\n seg_body,\n fine_size[2:],\n mode='bilinear',\n align_corners=self.align_corners)\n aspp = F.interpolate(\n aspp,\n fine_size[2:],\n mode='bilinear',\n align_corners=self.align_corners)\n seg_out = paddle.concat([aspp, seg_out], axis=1)\n seg_final_out = self.final_seg(seg_out)\n\n return [seg_final_out, seg_body_out, seg_edge_out]\n\n\nclass SqueezeBodyEdge(nn.Layer):\n def __init__(self, inplane, align_corners=False):\n super().__init__()\n self.align_corners = align_corners\n self.down = nn.Sequential(\n layers.ConvBNReLU(\n inplane, inplane, kernel_size=3, groups=inplane, stride=2),\n layers.ConvBNReLU(\n inplane, inplane, kernel_size=3, groups=inplane, stride=2))\n self.flow_make = nn.Conv2D(\n inplane * 2, 2, kernel_size=3, padding='same', bias_attr=False)\n\n def forward(self, x):\n size = paddle.shape(x)[2:]\n seg_down = self.down(x)\n seg_down = F.interpolate(\n seg_down,\n size=size,\n mode='bilinear',\n align_corners=self.align_corners)\n flow = self.flow_make(paddle.concat([x, seg_down], axis=1))\n seg_flow_warp = self.flow_warp(x, flow, size)\n seg_edge = x - seg_flow_warp\n return seg_flow_warp, seg_edge\n\n def flow_warp(self, input, flow, size):\n input_shape = paddle.shape(input)\n norm = size[::-1].reshape([1, 1, 1, -1])\n norm.stop_gradient = True\n h_grid = paddle.linspace(-1.0, 1.0, size[0]).reshape([-1, 1])\n h_grid = h_grid.tile([size[1]])\n w_grid = paddle.linspace(-1.0, 1.0, size[1]).reshape([-1, 1])\n w_grid = w_grid.tile([size[0]]).transpose([1, 0])\n grid = paddle.concat([w_grid.unsqueeze(2), h_grid.unsqueeze(2)], axis=2)\n grid.unsqueeze(0).tile([input_shape[0], 1, 1, 1])\n grid = grid + paddle.transpose(flow, (0, 2, 3, 1)) / norm\n\n output = F.grid_sample(input, grid)\n return output\n", "path": "paddleseg/models/decoupled_segnet.py"}]}
| 3,454 | 185 |
gh_patches_debug_10731
|
rasdani/github-patches
|
git_diff
|
litestar-org__litestar-2982
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bug: openapi schema generation fails for Union of/in msgspec.Struct models
### Description
Hello!
In the latest versions(s) (I think this originates from the changes regarding nested models in openapi generation) we cannot use Unions of `msgspec.Struct`s anymore. Neither as direct return types for routes nor nested within return types.
The result is a 500 Error. The MCVE below raises `'types.UnionType' object has no attribute '__qualname__'` internally. In our production app I get `typing.Union is not a module, class, method, or function.` instead.
Cheers
### URL to code causing the issue
_No response_
### MCVE
```python
import msgspec
import uvicorn
from litestar import Litestar, get
class SubStructA(msgspec.Struct):
a: int
class SubStructB(msgspec.Struct):
a: int
class StructyStruct(msgspec.Struct):
sub: SubStructA | SubStructB
@get("/subunion")
async def testSubUnion() -> StructyStruct:
return StructyStruct(SubStructA(0))
@get("/union")
async def testUnion() -> SubStructA | SubStructB:
return SubStructA(0)
app = Litestar(route_handlers=[test2]) # or test
uvicorn.run(app)
```
### Steps to reproduce
```bash
Run the example and browse to `localhost:8000/schema`
```
### Screenshots
_No response_
### Logs
_No response_
### Litestar Version
2.5.0
### Platform
- [X] Linux
- [ ] Mac
- [ ] Windows
- [ ] Other (Please specify in the description above)
<!-- POLAR PLEDGE BADGE START -->
---
> [!NOTE]
> While we are open for sponsoring on [GitHub Sponsors](https://github.com/sponsors/litestar-org/) and
> [OpenCollective](https://opencollective.com/litestar), we also utilize [Polar.sh](https://polar.sh/) to engage in pledge-based sponsorship.
>
> Check out all issues funded or available for funding [on our Polar.sh dashboard](https://polar.sh/litestar-org)
> * If you would like to see an issue prioritized, make a pledge towards it!
> * We receive the pledge once the issue is completed & verified
> * This, along with engagement in the community, helps us know which features are a priority to our users.
<a href="https://polar.sh/litestar-org/litestar/issues/2971">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://polar.sh/api/github/litestar-org/litestar/issues/2971/pledge.svg?darkmode=1">
<img alt="Fund with Polar" src="https://polar.sh/api/github/litestar-org/litestar/issues/2971/pledge.svg">
</picture>
</a>
<!-- POLAR PLEDGE BADGE END -->
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `litestar/_openapi/schema_generation/plugins/struct.py`
Content:
```
1 from __future__ import annotations
2
3 from typing import TYPE_CHECKING
4
5 from msgspec import Struct
6 from msgspec.structs import fields
7
8 from litestar.plugins import OpenAPISchemaPlugin
9 from litestar.types.empty import Empty
10 from litestar.typing import FieldDefinition
11 from litestar.utils.predicates import is_optional_union
12
13 if TYPE_CHECKING:
14 from msgspec.structs import FieldInfo
15
16 from litestar._openapi.schema_generation import SchemaCreator
17 from litestar.openapi.spec import Schema
18
19
20 class StructSchemaPlugin(OpenAPISchemaPlugin):
21 def is_plugin_supported_field(self, field_definition: FieldDefinition) -> bool:
22 return field_definition.is_subclass_of(Struct)
23
24 def to_openapi_schema(self, field_definition: FieldDefinition, schema_creator: SchemaCreator) -> Schema:
25 def is_field_required(field: FieldInfo) -> bool:
26 return field.required or field.default_factory is Empty
27
28 type_hints = field_definition.get_type_hints(include_extras=True, resolve_generics=True)
29 struct_fields = fields(field_definition.type_)
30
31 return schema_creator.create_component_schema(
32 field_definition,
33 required=sorted(
34 [
35 field.encode_name
36 for field in struct_fields
37 if is_field_required(field=field) and not is_optional_union(type_hints[field.name])
38 ]
39 ),
40 property_fields={
41 field.encode_name: FieldDefinition.from_kwarg(type_hints[field.name], field.encode_name)
42 for field in struct_fields
43 },
44 )
45
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/litestar/_openapi/schema_generation/plugins/struct.py b/litestar/_openapi/schema_generation/plugins/struct.py
--- a/litestar/_openapi/schema_generation/plugins/struct.py
+++ b/litestar/_openapi/schema_generation/plugins/struct.py
@@ -19,7 +19,7 @@
class StructSchemaPlugin(OpenAPISchemaPlugin):
def is_plugin_supported_field(self, field_definition: FieldDefinition) -> bool:
- return field_definition.is_subclass_of(Struct)
+ return not field_definition.is_union and field_definition.is_subclass_of(Struct)
def to_openapi_schema(self, field_definition: FieldDefinition, schema_creator: SchemaCreator) -> Schema:
def is_field_required(field: FieldInfo) -> bool:
|
{"golden_diff": "diff --git a/litestar/_openapi/schema_generation/plugins/struct.py b/litestar/_openapi/schema_generation/plugins/struct.py\n--- a/litestar/_openapi/schema_generation/plugins/struct.py\n+++ b/litestar/_openapi/schema_generation/plugins/struct.py\n@@ -19,7 +19,7 @@\n \n class StructSchemaPlugin(OpenAPISchemaPlugin):\n def is_plugin_supported_field(self, field_definition: FieldDefinition) -> bool:\n- return field_definition.is_subclass_of(Struct)\n+ return not field_definition.is_union and field_definition.is_subclass_of(Struct)\n \n def to_openapi_schema(self, field_definition: FieldDefinition, schema_creator: SchemaCreator) -> Schema:\n def is_field_required(field: FieldInfo) -> bool:\n", "issue": "Bug: openapi schema generation fails for Union of/in msgspec.Struct models\n### Description\r\n\r\nHello!\r\n\r\nIn the latest versions(s) (I think this originates from the changes regarding nested models in openapi generation) we cannot use Unions of `msgspec.Struct`s anymore. Neither as direct return types for routes nor nested within return types. \r\n\r\nThe result is a 500 Error. The MCVE below raises `'types.UnionType' object has no attribute '__qualname__'` internally. In our production app I get `typing.Union is not a module, class, method, or function.` instead.\r\n\r\nCheers\r\n\r\n### URL to code causing the issue\r\n\r\n_No response_\r\n\r\n### MCVE\r\n\r\n```python\r\nimport msgspec\r\nimport uvicorn\r\nfrom litestar import Litestar, get\r\n\r\n\r\nclass SubStructA(msgspec.Struct):\r\n a: int\r\n\r\n\r\nclass SubStructB(msgspec.Struct):\r\n a: int\r\n\r\n\r\nclass StructyStruct(msgspec.Struct):\r\n sub: SubStructA | SubStructB\r\n\r\n\r\n@get(\"/subunion\")\r\nasync def testSubUnion() -> StructyStruct:\r\n return StructyStruct(SubStructA(0))\r\n\r\n\r\n@get(\"/union\")\r\nasync def testUnion() -> SubStructA | SubStructB:\r\n return SubStructA(0)\r\n\r\n\r\napp = Litestar(route_handlers=[test2]) # or test\r\nuvicorn.run(app)\r\n```\r\n\r\n\r\n### Steps to reproduce\r\n\r\n```bash\r\nRun the example and browse to `localhost:8000/schema`\r\n```\r\n\r\n\r\n### Screenshots\r\n\r\n_No response_\r\n\r\n### Logs\r\n\r\n_No response_\r\n\r\n### Litestar Version\r\n\r\n2.5.0\r\n\r\n### Platform\r\n\r\n- [X] Linux\r\n- [ ] Mac\r\n- [ ] Windows\r\n- [ ] Other (Please specify in the description above)\r\n\r\n<!-- POLAR PLEDGE BADGE START -->\r\n---\r\n> [!NOTE] \r\n> While we are open for sponsoring on [GitHub Sponsors](https://github.com/sponsors/litestar-org/) and \r\n> [OpenCollective](https://opencollective.com/litestar), we also utilize [Polar.sh](https://polar.sh/) to engage in pledge-based sponsorship.\r\n>\r\n> Check out all issues funded or available for funding [on our Polar.sh dashboard](https://polar.sh/litestar-org)\r\n> * If you would like to see an issue prioritized, make a pledge towards it!\r\n> * We receive the pledge once the issue is completed & verified\r\n> * This, along with engagement in the community, helps us know which features are a priority to our users.\r\n\r\n<a href=\"https://polar.sh/litestar-org/litestar/issues/2971\">\r\n<picture>\r\n <source media=\"(prefers-color-scheme: dark)\" srcset=\"https://polar.sh/api/github/litestar-org/litestar/issues/2971/pledge.svg?darkmode=1\">\r\n <img alt=\"Fund with Polar\" src=\"https://polar.sh/api/github/litestar-org/litestar/issues/2971/pledge.svg\">\r\n</picture>\r\n</a>\r\n<!-- POLAR PLEDGE BADGE END -->\r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom typing import TYPE_CHECKING\n\nfrom msgspec import Struct\nfrom msgspec.structs import fields\n\nfrom litestar.plugins import OpenAPISchemaPlugin\nfrom litestar.types.empty import Empty\nfrom litestar.typing import FieldDefinition\nfrom litestar.utils.predicates import is_optional_union\n\nif TYPE_CHECKING:\n from msgspec.structs import FieldInfo\n\n from litestar._openapi.schema_generation import SchemaCreator\n from litestar.openapi.spec import Schema\n\n\nclass StructSchemaPlugin(OpenAPISchemaPlugin):\n def is_plugin_supported_field(self, field_definition: FieldDefinition) -> bool:\n return field_definition.is_subclass_of(Struct)\n\n def to_openapi_schema(self, field_definition: FieldDefinition, schema_creator: SchemaCreator) -> Schema:\n def is_field_required(field: FieldInfo) -> bool:\n return field.required or field.default_factory is Empty\n\n type_hints = field_definition.get_type_hints(include_extras=True, resolve_generics=True)\n struct_fields = fields(field_definition.type_)\n\n return schema_creator.create_component_schema(\n field_definition,\n required=sorted(\n [\n field.encode_name\n for field in struct_fields\n if is_field_required(field=field) and not is_optional_union(type_hints[field.name])\n ]\n ),\n property_fields={\n field.encode_name: FieldDefinition.from_kwarg(type_hints[field.name], field.encode_name)\n for field in struct_fields\n },\n )\n", "path": "litestar/_openapi/schema_generation/plugins/struct.py"}], "after_files": [{"content": "from __future__ import annotations\n\nfrom typing import TYPE_CHECKING\n\nfrom msgspec import Struct\nfrom msgspec.structs import fields\n\nfrom litestar.plugins import OpenAPISchemaPlugin\nfrom litestar.types.empty import Empty\nfrom litestar.typing import FieldDefinition\nfrom litestar.utils.predicates import is_optional_union\n\nif TYPE_CHECKING:\n from msgspec.structs import FieldInfo\n\n from litestar._openapi.schema_generation import SchemaCreator\n from litestar.openapi.spec import Schema\n\n\nclass StructSchemaPlugin(OpenAPISchemaPlugin):\n def is_plugin_supported_field(self, field_definition: FieldDefinition) -> bool:\n return not field_definition.is_union and field_definition.is_subclass_of(Struct)\n\n def to_openapi_schema(self, field_definition: FieldDefinition, schema_creator: SchemaCreator) -> Schema:\n def is_field_required(field: FieldInfo) -> bool:\n return field.required or field.default_factory is Empty\n\n type_hints = field_definition.get_type_hints(include_extras=True, resolve_generics=True)\n struct_fields = fields(field_definition.type_)\n\n return schema_creator.create_component_schema(\n field_definition,\n required=sorted(\n [\n field.encode_name\n for field in struct_fields\n if is_field_required(field=field) and not is_optional_union(type_hints[field.name])\n ]\n ),\n property_fields={\n field.encode_name: FieldDefinition.from_kwarg(type_hints[field.name], field.encode_name)\n for field in struct_fields\n },\n )\n", "path": "litestar/_openapi/schema_generation/plugins/struct.py"}]}
| 1,323 | 168 |
gh_patches_debug_6714
|
rasdani/github-patches
|
git_diff
|
open-mmlab__mmocr-570
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Write image name to pickle file
Hi MMOCR team,
Thank you for this awesome framework. I have a task to get coordinate of bounding box from Textsnake model, so I use --out argument in test.py to export to a pickle file. But when I load this pickle, I just got ‘boundary_result’ and don't know this ‘boundary_result’ belongs to which image. How can I get the image to write to the pickle file? Thank you.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mmocr/models/textdet/dense_heads/head_mixin.py`
Content:
```
1 # Copyright (c) OpenMMLab. All rights reserved.
2 import numpy as np
3
4 from mmocr.models.builder import HEADS
5 from mmocr.models.textdet.postprocess import decode
6 from mmocr.utils import check_argument
7
8
9 @HEADS.register_module()
10 class HeadMixin:
11 """The head minxin for dbnet and pannet heads."""
12
13 def resize_boundary(self, boundaries, scale_factor):
14 """Rescale boundaries via scale_factor.
15
16 Args:
17 boundaries (list[list[float]]): The boundary list. Each boundary
18 with size 2k+1 with k>=4.
19 scale_factor(ndarray): The scale factor of size (4,).
20
21 Returns:
22 boundaries (list[list[float]]): The scaled boundaries.
23 """
24 assert check_argument.is_2dlist(boundaries)
25 assert isinstance(scale_factor, np.ndarray)
26 assert scale_factor.shape[0] == 4
27
28 for b in boundaries:
29 sz = len(b)
30 check_argument.valid_boundary(b, True)
31 b[:sz -
32 1] = (np.array(b[:sz - 1]) *
33 (np.tile(scale_factor[:2], int(
34 (sz - 1) / 2)).reshape(1, sz - 1))).flatten().tolist()
35 return boundaries
36
37 def get_boundary(self, score_maps, img_metas, rescale):
38 """Compute text boundaries via post processing.
39
40 Args:
41 score_maps (Tensor): The text score map.
42 img_metas (dict): The image meta info.
43 rescale (bool): Rescale boundaries to the original image resolution
44 if true, and keep the score_maps resolution if false.
45
46 Returns:
47 results (dict): The result dict.
48 """
49
50 assert check_argument.is_type_list(img_metas, dict)
51 assert isinstance(rescale, bool)
52
53 score_maps = score_maps.squeeze()
54 boundaries = decode(
55 decoding_type=self.decoding_type,
56 preds=score_maps,
57 text_repr_type=self.text_repr_type)
58 if rescale:
59 boundaries = self.resize_boundary(
60 boundaries,
61 1.0 / self.downsample_ratio / img_metas[0]['scale_factor'])
62 results = dict(boundary_result=boundaries)
63 return results
64
65 def loss(self, pred_maps, **kwargs):
66 """Compute the loss for text detection.
67
68 Args:
69 pred_maps (tensor): The input score maps of NxCxHxW.
70
71 Returns:
72 losses (dict): The dict for losses.
73 """
74 losses = self.loss_module(pred_maps, self.downsample_ratio, **kwargs)
75 return losses
76
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mmocr/models/textdet/dense_heads/head_mixin.py b/mmocr/models/textdet/dense_heads/head_mixin.py
--- a/mmocr/models/textdet/dense_heads/head_mixin.py
+++ b/mmocr/models/textdet/dense_heads/head_mixin.py
@@ -59,7 +59,9 @@
boundaries = self.resize_boundary(
boundaries,
1.0 / self.downsample_ratio / img_metas[0]['scale_factor'])
- results = dict(boundary_result=boundaries)
+ results = dict(
+ boundary_result=boundaries, filename=img_metas[0]['filename'])
+
return results
def loss(self, pred_maps, **kwargs):
|
{"golden_diff": "diff --git a/mmocr/models/textdet/dense_heads/head_mixin.py b/mmocr/models/textdet/dense_heads/head_mixin.py\n--- a/mmocr/models/textdet/dense_heads/head_mixin.py\n+++ b/mmocr/models/textdet/dense_heads/head_mixin.py\n@@ -59,7 +59,9 @@\n boundaries = self.resize_boundary(\n boundaries,\n 1.0 / self.downsample_ratio / img_metas[0]['scale_factor'])\n- results = dict(boundary_result=boundaries)\n+ results = dict(\n+ boundary_result=boundaries, filename=img_metas[0]['filename'])\n+\n return results\n \n def loss(self, pred_maps, **kwargs):\n", "issue": "Write image name to pickle file\nHi MMOCR team,\nThank you for this awesome framework. I have a task to get coordinate of bounding box from Textsnake model, so I use --out argument in test.py to export to a pickle file. But when I load this pickle, I just got \u2018boundary_result\u2019 and don't know this \u2018boundary_result\u2019 belongs to which image. How can I get the image to write to the pickle file? Thank you.\n", "before_files": [{"content": "# Copyright (c) OpenMMLab. All rights reserved.\nimport numpy as np\n\nfrom mmocr.models.builder import HEADS\nfrom mmocr.models.textdet.postprocess import decode\nfrom mmocr.utils import check_argument\n\n\[email protected]_module()\nclass HeadMixin:\n \"\"\"The head minxin for dbnet and pannet heads.\"\"\"\n\n def resize_boundary(self, boundaries, scale_factor):\n \"\"\"Rescale boundaries via scale_factor.\n\n Args:\n boundaries (list[list[float]]): The boundary list. Each boundary\n with size 2k+1 with k>=4.\n scale_factor(ndarray): The scale factor of size (4,).\n\n Returns:\n boundaries (list[list[float]]): The scaled boundaries.\n \"\"\"\n assert check_argument.is_2dlist(boundaries)\n assert isinstance(scale_factor, np.ndarray)\n assert scale_factor.shape[0] == 4\n\n for b in boundaries:\n sz = len(b)\n check_argument.valid_boundary(b, True)\n b[:sz -\n 1] = (np.array(b[:sz - 1]) *\n (np.tile(scale_factor[:2], int(\n (sz - 1) / 2)).reshape(1, sz - 1))).flatten().tolist()\n return boundaries\n\n def get_boundary(self, score_maps, img_metas, rescale):\n \"\"\"Compute text boundaries via post processing.\n\n Args:\n score_maps (Tensor): The text score map.\n img_metas (dict): The image meta info.\n rescale (bool): Rescale boundaries to the original image resolution\n if true, and keep the score_maps resolution if false.\n\n Returns:\n results (dict): The result dict.\n \"\"\"\n\n assert check_argument.is_type_list(img_metas, dict)\n assert isinstance(rescale, bool)\n\n score_maps = score_maps.squeeze()\n boundaries = decode(\n decoding_type=self.decoding_type,\n preds=score_maps,\n text_repr_type=self.text_repr_type)\n if rescale:\n boundaries = self.resize_boundary(\n boundaries,\n 1.0 / self.downsample_ratio / img_metas[0]['scale_factor'])\n results = dict(boundary_result=boundaries)\n return results\n\n def loss(self, pred_maps, **kwargs):\n \"\"\"Compute the loss for text detection.\n\n Args:\n pred_maps (tensor): The input score maps of NxCxHxW.\n\n Returns:\n losses (dict): The dict for losses.\n \"\"\"\n losses = self.loss_module(pred_maps, self.downsample_ratio, **kwargs)\n return losses\n", "path": "mmocr/models/textdet/dense_heads/head_mixin.py"}], "after_files": [{"content": "# Copyright (c) OpenMMLab. All rights reserved.\nimport numpy as np\n\nfrom mmocr.models.builder import HEADS\nfrom mmocr.models.textdet.postprocess import decode\nfrom mmocr.utils import check_argument\n\n\[email protected]_module()\nclass HeadMixin:\n \"\"\"The head minxin for dbnet and pannet heads.\"\"\"\n\n def resize_boundary(self, boundaries, scale_factor):\n \"\"\"Rescale boundaries via scale_factor.\n\n Args:\n boundaries (list[list[float]]): The boundary list. Each boundary\n with size 2k+1 with k>=4.\n scale_factor(ndarray): The scale factor of size (4,).\n\n Returns:\n boundaries (list[list[float]]): The scaled boundaries.\n \"\"\"\n assert check_argument.is_2dlist(boundaries)\n assert isinstance(scale_factor, np.ndarray)\n assert scale_factor.shape[0] == 4\n\n for b in boundaries:\n sz = len(b)\n check_argument.valid_boundary(b, True)\n b[:sz -\n 1] = (np.array(b[:sz - 1]) *\n (np.tile(scale_factor[:2], int(\n (sz - 1) / 2)).reshape(1, sz - 1))).flatten().tolist()\n return boundaries\n\n def get_boundary(self, score_maps, img_metas, rescale):\n \"\"\"Compute text boundaries via post processing.\n\n Args:\n score_maps (Tensor): The text score map.\n img_metas (dict): The image meta info.\n rescale (bool): Rescale boundaries to the original image resolution\n if true, and keep the score_maps resolution if false.\n\n Returns:\n results (dict): The result dict.\n \"\"\"\n\n assert check_argument.is_type_list(img_metas, dict)\n assert isinstance(rescale, bool)\n\n score_maps = score_maps.squeeze()\n boundaries = decode(\n decoding_type=self.decoding_type,\n preds=score_maps,\n text_repr_type=self.text_repr_type)\n if rescale:\n boundaries = self.resize_boundary(\n boundaries,\n 1.0 / self.downsample_ratio / img_metas[0]['scale_factor'])\n results = dict(\n boundary_result=boundaries, filename=img_metas[0]['filename'])\n\n return results\n\n def loss(self, pred_maps, **kwargs):\n \"\"\"Compute the loss for text detection.\n\n Args:\n pred_maps (tensor): The input score maps of NxCxHxW.\n\n Returns:\n losses (dict): The dict for losses.\n \"\"\"\n losses = self.loss_module(pred_maps, self.downsample_ratio, **kwargs)\n return losses\n", "path": "mmocr/models/textdet/dense_heads/head_mixin.py"}]}
| 1,065 | 153 |
gh_patches_debug_12224
|
rasdani/github-patches
|
git_diff
|
Zeroto521__my-data-toolkit-413
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
DEV: rename master to main
https://github.com/github/renaming
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `doc/source/conf.py`
Content:
```
1 # Configuration file for the Sphinx documentation builder.
2 #
3 # This file only contains a selection of the most common options.
4 # For a full list see the documentation:
5 # https://www.sphinx-doc.org/en/master/usage/configuration.html
6
7
8 # -- Project information -----------------------------------------------------
9
10 # The version info for the project you're documenting, acts as replacement for
11 # |version| and |release|, also used in various other places throughout the
12 # built documents.
13 from __future__ import annotations
14
15 import inspect
16 import os
17 import sys
18 from datetime import datetime
19
20 import dtoolkit
21
22 version = release = dtoolkit.__version__
23 version = version.replace(".dev0", "")
24 version = version.replace(".post0", "")
25
26
27 project = "DToolKit"
28 author = "Zero <@Zeroto521>"
29 copyright = f"2021-{datetime.now().year}, {author}" # pylint: disable=redefined-builtin
30 github_url = "https://github.com/Zeroto521/my-data-toolkit"
31
32
33 # -- General configuration ---------------------------------------------------
34
35 # Add any Sphinx extension module names here, as strings. They can be
36 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
37 # ones.
38 extensions = [
39 "myst_parser",
40 "numpydoc",
41 "sphinx.ext.autodoc",
42 "sphinx.ext.autosummary",
43 "sphinx.ext.autosectionlabel",
44 "sphinx.ext.extlinks",
45 "sphinx.ext.intersphinx",
46 "sphinx.ext.linkcode",
47 "sphinx_toggleprompt",
48 "IPython.sphinxext.ipython_console_highlighting",
49 "IPython.sphinxext.ipython_directive",
50 "nbsphinx",
51 ]
52
53 # The suffix of source filenames.
54 source_suffix = [".rst", ".md"]
55
56 # Add any paths that contain templates here, relative to this directory.
57 templates_path = ["_templates"]
58
59 # List of patterns, relative to source directory, that match files and
60 # directories to ignore when looking for source files.
61 # This pattern also affects html_static_path and html_extra_path.
62 exclude_patterns = []
63
64
65 # -- Options for HTML output -------------------------------------------------
66
67 # The theme to use for HTML and HTML Help pages. See the documentation for
68 # a list of builtin themes.
69 html_theme = "pydata_sphinx_theme"
70
71 # Theme options are theme-specific and customize the look and feel of a theme
72 # further. For a list of options available for each theme, see the
73 # documentation.
74 html_theme_options = {
75 "search_bar_position": "sidebar",
76 "github_url": github_url,
77 "icon_links": [
78 {
79 "name": "PyPI",
80 "url": "https://pypi.org/project/my-data-toolkit",
81 "icon": "fas fa-box",
82 },
83 ],
84 }
85
86 # Add any paths that contain custom static files (such as style sheets) here,
87 # relative to this directory. They are copied after the builtin static files,
88 # so a file named "default.css" will overwrite the builtin "default.css".
89 html_static_path = ["_static"]
90
91
92 # Add redirect for previously existing pages, each item is like `(from_old, to_new)`
93
94 moved_pages = [
95 ("py-modindex", "reference"),
96 ]
97
98 html_additional_pages = {page[0]: "redirect.html" for page in moved_pages}
99
100 html_context = {"redirects": dict(moved_pages)}
101
102
103 nbsphinx_prolog = r"""
104 {% set docname = env.doc2path(env.docname, base=None) %}
105
106 .. tip::
107
108 This page was generated from `{{ docname }}`__.
109
110 __ https://github.com/zeroto521/my-data-toolkit/blob/master/doc/source/{{ docname }}
111 """
112
113
114 # --Options for sphinx extensions -----------------------------------------------
115
116 # connect docs in other projects
117 intersphinx_mapping = {
118 "python": ("http://docs.python.org/", None),
119 "pandas": ("https://pandas.pydata.org/pandas-docs/stable/", None),
120 "numpy": ("https://numpy.org/doc/stable/", None),
121 "sklearn": ("https://scikit-learn.org/stable/", None),
122 "geopandas": ("https://geopandas.readthedocs.io/en/stable/", None),
123 "shapely": ("https://shapely.readthedocs.io/en/stable/", None),
124 "pyproj": ("https://pyproj4.github.io/pyproj/stable/", None),
125 "pygeos": ("https://pygeos.readthedocs.io/en/stable/", None),
126 }
127
128 # extlinks alias
129 extlinks = {
130 "issue": (f"{github_url}/issues/%s", "issue#"),
131 "pr": (f"{github_url}/issues/%s", "pr#"),
132 "user": ("https://github.com/%s", "@"),
133 }
134
135 myst_enable_extensions = [
136 "colon_fence",
137 ]
138
139 autosummary_generate = True
140
141 nbsphinx_execute = "always"
142 nbsphinx_allow_errors = True
143
144
145 # based on pandas doc/source/conf.py
146 def linkcode_resolve(domain: str, info: dict[str, str]) -> str | None:
147 """
148 Determine the URL corresponding to Python object
149 """
150
151 if domain != "py":
152 return None
153
154 modname = info["module"]
155 fullname = info["fullname"]
156
157 submod = sys.modules.get(modname)
158 if submod is None:
159 return None
160
161 obj = submod
162 for part in fullname.split("."):
163 try:
164 obj = getattr(obj, part)
165 except AttributeError:
166 return None
167
168 try:
169 fn = inspect.getsourcefile(inspect.unwrap(obj))
170 except TypeError:
171 fn = None
172
173 if not fn:
174 return None
175
176 # to fix these doc doesn't exist in dtoolkit
177 if project.lower() not in fn:
178 return None
179
180 try:
181 source, lineno = inspect.getsourcelines(obj)
182 except OSError:
183 lineno = None
184
185 linespec = f"#L{lineno}-L{lineno + len(source) - 1}" if lineno else ""
186 fn = os.path.relpath(fn, start=os.path.dirname(dtoolkit.__file__))
187
188 base_link = f"{github_url}/blob/" + "{branch}" + f"/dtoolkit/{fn}{linespec}"
189 if "post" in version:
190 return base_link.format(branch="master")
191
192 return base_link.format(branch=f"v{version}")
193
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/doc/source/conf.py b/doc/source/conf.py
--- a/doc/source/conf.py
+++ b/doc/source/conf.py
@@ -107,7 +107,7 @@
This page was generated from `{{ docname }}`__.
- __ https://github.com/zeroto521/my-data-toolkit/blob/master/doc/source/{{ docname }}
+ __ https://github.com/zeroto521/my-data-toolkit/blob/main/doc/source/{{ docname }}
"""
@@ -187,6 +187,6 @@
base_link = f"{github_url}/blob/" + "{branch}" + f"/dtoolkit/{fn}{linespec}"
if "post" in version:
- return base_link.format(branch="master")
+ return base_link.format(branch="main")
return base_link.format(branch=f"v{version}")
|
{"golden_diff": "diff --git a/doc/source/conf.py b/doc/source/conf.py\n--- a/doc/source/conf.py\n+++ b/doc/source/conf.py\n@@ -107,7 +107,7 @@\n \n This page was generated from `{{ docname }}`__.\n \n- __ https://github.com/zeroto521/my-data-toolkit/blob/master/doc/source/{{ docname }}\n+ __ https://github.com/zeroto521/my-data-toolkit/blob/main/doc/source/{{ docname }}\n \"\"\"\n \n \n@@ -187,6 +187,6 @@\n \n base_link = f\"{github_url}/blob/\" + \"{branch}\" + f\"/dtoolkit/{fn}{linespec}\"\n if \"post\" in version:\n- return base_link.format(branch=\"master\")\n+ return base_link.format(branch=\"main\")\n \n return base_link.format(branch=f\"v{version}\")\n", "issue": "DEV: rename master to main\nhttps://github.com/github/renaming\n", "before_files": [{"content": "# Configuration file for the Sphinx documentation builder.\n#\n# This file only contains a selection of the most common options.\n# For a full list see the documentation:\n# https://www.sphinx-doc.org/en/master/usage/configuration.html\n\n\n# -- Project information -----------------------------------------------------\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\nfrom __future__ import annotations\n\nimport inspect\nimport os\nimport sys\nfrom datetime import datetime\n\nimport dtoolkit\n\nversion = release = dtoolkit.__version__\nversion = version.replace(\".dev0\", \"\")\nversion = version.replace(\".post0\", \"\")\n\n\nproject = \"DToolKit\"\nauthor = \"Zero <@Zeroto521>\"\ncopyright = f\"2021-{datetime.now().year}, {author}\" # pylint: disable=redefined-builtin\ngithub_url = \"https://github.com/Zeroto521/my-data-toolkit\"\n\n\n# -- General configuration ---------------------------------------------------\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n \"myst_parser\",\n \"numpydoc\",\n \"sphinx.ext.autodoc\",\n \"sphinx.ext.autosummary\",\n \"sphinx.ext.autosectionlabel\",\n \"sphinx.ext.extlinks\",\n \"sphinx.ext.intersphinx\",\n \"sphinx.ext.linkcode\",\n \"sphinx_toggleprompt\",\n \"IPython.sphinxext.ipython_console_highlighting\",\n \"IPython.sphinxext.ipython_directive\",\n \"nbsphinx\",\n]\n\n# The suffix of source filenames.\nsource_suffix = [\".rst\", \".md\"]\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = [\"_templates\"]\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path.\nexclude_patterns = []\n\n\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\nhtml_theme = \"pydata_sphinx_theme\"\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\nhtml_theme_options = {\n \"search_bar_position\": \"sidebar\",\n \"github_url\": github_url,\n \"icon_links\": [\n {\n \"name\": \"PyPI\",\n \"url\": \"https://pypi.org/project/my-data-toolkit\",\n \"icon\": \"fas fa-box\",\n },\n ],\n}\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = [\"_static\"]\n\n\n# Add redirect for previously existing pages, each item is like `(from_old, to_new)`\n\nmoved_pages = [\n (\"py-modindex\", \"reference\"),\n]\n\nhtml_additional_pages = {page[0]: \"redirect.html\" for page in moved_pages}\n\nhtml_context = {\"redirects\": dict(moved_pages)}\n\n\nnbsphinx_prolog = r\"\"\"\n{% set docname = env.doc2path(env.docname, base=None) %}\n\n.. tip::\n\n This page was generated from `{{ docname }}`__.\n\n __ https://github.com/zeroto521/my-data-toolkit/blob/master/doc/source/{{ docname }}\n\"\"\"\n\n\n# --Options for sphinx extensions -----------------------------------------------\n\n# connect docs in other projects\nintersphinx_mapping = {\n \"python\": (\"http://docs.python.org/\", None),\n \"pandas\": (\"https://pandas.pydata.org/pandas-docs/stable/\", None),\n \"numpy\": (\"https://numpy.org/doc/stable/\", None),\n \"sklearn\": (\"https://scikit-learn.org/stable/\", None),\n \"geopandas\": (\"https://geopandas.readthedocs.io/en/stable/\", None),\n \"shapely\": (\"https://shapely.readthedocs.io/en/stable/\", None),\n \"pyproj\": (\"https://pyproj4.github.io/pyproj/stable/\", None),\n \"pygeos\": (\"https://pygeos.readthedocs.io/en/stable/\", None),\n}\n\n# extlinks alias\nextlinks = {\n \"issue\": (f\"{github_url}/issues/%s\", \"issue#\"),\n \"pr\": (f\"{github_url}/issues/%s\", \"pr#\"),\n \"user\": (\"https://github.com/%s\", \"@\"),\n}\n\nmyst_enable_extensions = [\n \"colon_fence\",\n]\n\nautosummary_generate = True\n\nnbsphinx_execute = \"always\"\nnbsphinx_allow_errors = True\n\n\n# based on pandas doc/source/conf.py\ndef linkcode_resolve(domain: str, info: dict[str, str]) -> str | None:\n \"\"\"\n Determine the URL corresponding to Python object\n \"\"\"\n\n if domain != \"py\":\n return None\n\n modname = info[\"module\"]\n fullname = info[\"fullname\"]\n\n submod = sys.modules.get(modname)\n if submod is None:\n return None\n\n obj = submod\n for part in fullname.split(\".\"):\n try:\n obj = getattr(obj, part)\n except AttributeError:\n return None\n\n try:\n fn = inspect.getsourcefile(inspect.unwrap(obj))\n except TypeError:\n fn = None\n\n if not fn:\n return None\n\n # to fix these doc doesn't exist in dtoolkit\n if project.lower() not in fn:\n return None\n\n try:\n source, lineno = inspect.getsourcelines(obj)\n except OSError:\n lineno = None\n\n linespec = f\"#L{lineno}-L{lineno + len(source) - 1}\" if lineno else \"\"\n fn = os.path.relpath(fn, start=os.path.dirname(dtoolkit.__file__))\n\n base_link = f\"{github_url}/blob/\" + \"{branch}\" + f\"/dtoolkit/{fn}{linespec}\"\n if \"post\" in version:\n return base_link.format(branch=\"master\")\n\n return base_link.format(branch=f\"v{version}\")\n", "path": "doc/source/conf.py"}], "after_files": [{"content": "# Configuration file for the Sphinx documentation builder.\n#\n# This file only contains a selection of the most common options.\n# For a full list see the documentation:\n# https://www.sphinx-doc.org/en/master/usage/configuration.html\n\n\n# -- Project information -----------------------------------------------------\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\nfrom __future__ import annotations\n\nimport inspect\nimport os\nimport sys\nfrom datetime import datetime\n\nimport dtoolkit\n\nversion = release = dtoolkit.__version__\nversion = version.replace(\".dev0\", \"\")\nversion = version.replace(\".post0\", \"\")\n\n\nproject = \"DToolKit\"\nauthor = \"Zero <@Zeroto521>\"\ncopyright = f\"2021-{datetime.now().year}, {author}\" # pylint: disable=redefined-builtin\ngithub_url = \"https://github.com/Zeroto521/my-data-toolkit\"\n\n\n# -- General configuration ---------------------------------------------------\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n \"myst_parser\",\n \"numpydoc\",\n \"sphinx.ext.autodoc\",\n \"sphinx.ext.autosummary\",\n \"sphinx.ext.autosectionlabel\",\n \"sphinx.ext.extlinks\",\n \"sphinx.ext.intersphinx\",\n \"sphinx.ext.linkcode\",\n \"sphinx_toggleprompt\",\n \"IPython.sphinxext.ipython_console_highlighting\",\n \"IPython.sphinxext.ipython_directive\",\n \"nbsphinx\",\n]\n\n# The suffix of source filenames.\nsource_suffix = [\".rst\", \".md\"]\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = [\"_templates\"]\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path.\nexclude_patterns = []\n\n\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\nhtml_theme = \"pydata_sphinx_theme\"\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\nhtml_theme_options = {\n \"search_bar_position\": \"sidebar\",\n \"github_url\": github_url,\n \"icon_links\": [\n {\n \"name\": \"PyPI\",\n \"url\": \"https://pypi.org/project/my-data-toolkit\",\n \"icon\": \"fas fa-box\",\n },\n ],\n}\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = [\"_static\"]\n\n\n# Add redirect for previously existing pages, each item is like `(from_old, to_new)`\n\nmoved_pages = [\n (\"py-modindex\", \"reference\"),\n]\n\nhtml_additional_pages = {page[0]: \"redirect.html\" for page in moved_pages}\n\nhtml_context = {\"redirects\": dict(moved_pages)}\n\n\nnbsphinx_prolog = r\"\"\"\n{% set docname = env.doc2path(env.docname, base=None) %}\n\n.. tip::\n\n This page was generated from `{{ docname }}`__.\n\n __ https://github.com/zeroto521/my-data-toolkit/blob/main/doc/source/{{ docname }}\n\"\"\"\n\n\n# --Options for sphinx extensions -----------------------------------------------\n\n# connect docs in other projects\nintersphinx_mapping = {\n \"python\": (\"http://docs.python.org/\", None),\n \"pandas\": (\"https://pandas.pydata.org/pandas-docs/stable/\", None),\n \"numpy\": (\"https://numpy.org/doc/stable/\", None),\n \"sklearn\": (\"https://scikit-learn.org/stable/\", None),\n \"geopandas\": (\"https://geopandas.readthedocs.io/en/stable/\", None),\n \"shapely\": (\"https://shapely.readthedocs.io/en/stable/\", None),\n \"pyproj\": (\"https://pyproj4.github.io/pyproj/stable/\", None),\n \"pygeos\": (\"https://pygeos.readthedocs.io/en/stable/\", None),\n}\n\n# extlinks alias\nextlinks = {\n \"issue\": (f\"{github_url}/issues/%s\", \"issue#\"),\n \"pr\": (f\"{github_url}/issues/%s\", \"pr#\"),\n \"user\": (\"https://github.com/%s\", \"@\"),\n}\n\nmyst_enable_extensions = [\n \"colon_fence\",\n]\n\nautosummary_generate = True\n\nnbsphinx_execute = \"always\"\nnbsphinx_allow_errors = True\n\n\n# based on pandas doc/source/conf.py\ndef linkcode_resolve(domain: str, info: dict[str, str]) -> str | None:\n \"\"\"\n Determine the URL corresponding to Python object\n \"\"\"\n\n if domain != \"py\":\n return None\n\n modname = info[\"module\"]\n fullname = info[\"fullname\"]\n\n submod = sys.modules.get(modname)\n if submod is None:\n return None\n\n obj = submod\n for part in fullname.split(\".\"):\n try:\n obj = getattr(obj, part)\n except AttributeError:\n return None\n\n try:\n fn = inspect.getsourcefile(inspect.unwrap(obj))\n except TypeError:\n fn = None\n\n if not fn:\n return None\n\n # to fix these doc doesn't exist in dtoolkit\n if project.lower() not in fn:\n return None\n\n try:\n source, lineno = inspect.getsourcelines(obj)\n except OSError:\n lineno = None\n\n linespec = f\"#L{lineno}-L{lineno + len(source) - 1}\" if lineno else \"\"\n fn = os.path.relpath(fn, start=os.path.dirname(dtoolkit.__file__))\n\n base_link = f\"{github_url}/blob/\" + \"{branch}\" + f\"/dtoolkit/{fn}{linespec}\"\n if \"post\" in version:\n return base_link.format(branch=\"main\")\n\n return base_link.format(branch=f\"v{version}\")\n", "path": "doc/source/conf.py"}]}
| 2,149 | 193 |
gh_patches_debug_29188
|
rasdani/github-patches
|
git_diff
|
nilearn__nilearn-2670
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
check_paradigm should check for invalid keys in passed dict
Using the old `nipy` user logic, I passed `amplitude=somethx` instead of `modulation=somethx` in the `make_design_matrix`. I didn't crash but the values where ignored (e.g Error: unknown param, etc.). A default value of 1 was forced...
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nilearn/glm/first_level/experimental_paradigm.py`
Content:
```
1 """
2 An experimental protocol is handled as a pandas DataFrame
3 that includes an 'onset' field.
4
5 This yields the onset time of the events in the experimental paradigm.
6 It can also contain:
7
8 * a 'trial_type' field that yields the condition identifier.
9 * a 'duration' field that yields event duration (for so-called block
10 paradigms).
11 * a 'modulation' field that associated a scalar value to each event.
12
13 Author: Bertrand Thirion, 2015
14
15 """
16 import warnings
17
18 import numpy as np
19
20
21 def check_events(events):
22 """Test that the events data describes a valid experimental paradigm
23
24 It is valid if the events data has an 'onset' key.
25
26 Parameters
27 ----------
28 events : pandas DataFrame
29 Events data that describes a functional experimental paradigm.
30
31 Returns
32 -------
33 trial_type : array of shape (n_events,), dtype='s'
34 Per-event experimental conditions identifier.
35 Defaults to np.repeat('dummy', len(onsets)).
36
37 onset : array of shape (n_events,), dtype='f'
38 Per-event onset time (in seconds)
39
40 duration : array of shape (n_events,), dtype='f'
41 Per-event durantion, (in seconds)
42 defaults to zeros(n_events) when no duration is provided
43
44 modulation : array of shape (n_events,), dtype='f'
45 Per-event modulation, (in seconds)
46 defaults to ones(n_events) when no duration is provided.
47
48 """
49 if 'onset' not in events.keys():
50 raise ValueError('The provided events data has no onset column.')
51 if 'duration' not in events.keys():
52 raise ValueError('The provided events data has no duration column.')
53
54 onset = np.array(events['onset'])
55 duration = np.array(events['duration']).astype(np.float)
56 n_events = len(onset)
57 trial_type = np.array(events['trial_type'])
58 modulation = np.ones(n_events)
59 if 'trial_type' not in events.keys():
60 warnings.warn("'trial_type' column not found "
61 "in the given events data.")
62 trial_type = np.repeat('dummy', n_events)
63 if 'modulation' in events.keys():
64 warnings.warn("'modulation' column found in the given events data.")
65 modulation = np.array(events['modulation']).astype(np.float)
66 return trial_type, onset, duration, modulation
67
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nilearn/glm/first_level/experimental_paradigm.py b/nilearn/glm/first_level/experimental_paradigm.py
--- a/nilearn/glm/first_level/experimental_paradigm.py
+++ b/nilearn/glm/first_level/experimental_paradigm.py
@@ -17,6 +17,11 @@
import numpy as np
+VALID_FIELDS = set(["onset",
+ "duration",
+ "trial_type",
+ "modulation",
+ ])
def check_events(events):
"""Test that the events data describes a valid experimental paradigm
@@ -54,13 +59,19 @@
onset = np.array(events['onset'])
duration = np.array(events['duration']).astype(np.float)
n_events = len(onset)
- trial_type = np.array(events['trial_type'])
modulation = np.ones(n_events)
if 'trial_type' not in events.keys():
warnings.warn("'trial_type' column not found "
"in the given events data.")
trial_type = np.repeat('dummy', n_events)
+ else:
+ trial_type = np.array(events['trial_type'])
if 'modulation' in events.keys():
warnings.warn("'modulation' column found in the given events data.")
modulation = np.array(events['modulation']).astype(np.float)
+ for event,_ in events.items():
+ if event not in VALID_FIELDS:
+ warnings.warn("Unexpected key `{}` in events "
+ "will be ignored.".format(
+ event))
return trial_type, onset, duration, modulation
|
{"golden_diff": "diff --git a/nilearn/glm/first_level/experimental_paradigm.py b/nilearn/glm/first_level/experimental_paradigm.py\n--- a/nilearn/glm/first_level/experimental_paradigm.py\n+++ b/nilearn/glm/first_level/experimental_paradigm.py\n@@ -17,6 +17,11 @@\n \n import numpy as np\n \n+VALID_FIELDS = set([\"onset\",\n+ \"duration\",\n+ \"trial_type\",\n+ \"modulation\",\n+ ])\n \n def check_events(events):\n \"\"\"Test that the events data describes a valid experimental paradigm\n@@ -54,13 +59,19 @@\n onset = np.array(events['onset'])\n duration = np.array(events['duration']).astype(np.float)\n n_events = len(onset)\n- trial_type = np.array(events['trial_type'])\n modulation = np.ones(n_events)\n if 'trial_type' not in events.keys():\n warnings.warn(\"'trial_type' column not found \"\n \"in the given events data.\")\n trial_type = np.repeat('dummy', n_events)\n+ else:\n+ trial_type = np.array(events['trial_type'])\n if 'modulation' in events.keys():\n warnings.warn(\"'modulation' column found in the given events data.\")\n modulation = np.array(events['modulation']).astype(np.float)\n+ for event,_ in events.items():\n+ if event not in VALID_FIELDS:\n+ warnings.warn(\"Unexpected key `{}` in events \"\n+ \"will be ignored.\".format(\n+ event))\n return trial_type, onset, duration, modulation\n", "issue": "check_paradigm should check for invalid keys in passed dict\nUsing the old `nipy` user logic, I passed `amplitude=somethx` instead of `modulation=somethx` in the `make_design_matrix`. I didn't crash but the values where ignored (e.g Error: unknown param, etc.). A default value of 1 was forced...\n\n", "before_files": [{"content": "\"\"\"\nAn experimental protocol is handled as a pandas DataFrame\nthat includes an 'onset' field.\n\nThis yields the onset time of the events in the experimental paradigm.\nIt can also contain:\n\n * a 'trial_type' field that yields the condition identifier.\n * a 'duration' field that yields event duration (for so-called block\n paradigms).\n * a 'modulation' field that associated a scalar value to each event.\n\nAuthor: Bertrand Thirion, 2015\n\n\"\"\"\nimport warnings\n\nimport numpy as np\n\n\ndef check_events(events):\n \"\"\"Test that the events data describes a valid experimental paradigm\n\n It is valid if the events data has an 'onset' key.\n\n Parameters\n ----------\n events : pandas DataFrame\n Events data that describes a functional experimental paradigm.\n\n Returns\n -------\n trial_type : array of shape (n_events,), dtype='s'\n Per-event experimental conditions identifier.\n Defaults to np.repeat('dummy', len(onsets)).\n\n onset : array of shape (n_events,), dtype='f'\n Per-event onset time (in seconds)\n\n duration : array of shape (n_events,), dtype='f'\n Per-event durantion, (in seconds)\n defaults to zeros(n_events) when no duration is provided\n\n modulation : array of shape (n_events,), dtype='f'\n Per-event modulation, (in seconds)\n defaults to ones(n_events) when no duration is provided.\n\n \"\"\"\n if 'onset' not in events.keys():\n raise ValueError('The provided events data has no onset column.')\n if 'duration' not in events.keys():\n raise ValueError('The provided events data has no duration column.')\n\n onset = np.array(events['onset'])\n duration = np.array(events['duration']).astype(np.float)\n n_events = len(onset)\n trial_type = np.array(events['trial_type'])\n modulation = np.ones(n_events)\n if 'trial_type' not in events.keys():\n warnings.warn(\"'trial_type' column not found \"\n \"in the given events data.\")\n trial_type = np.repeat('dummy', n_events)\n if 'modulation' in events.keys():\n warnings.warn(\"'modulation' column found in the given events data.\")\n modulation = np.array(events['modulation']).astype(np.float)\n return trial_type, onset, duration, modulation\n", "path": "nilearn/glm/first_level/experimental_paradigm.py"}], "after_files": [{"content": "\"\"\"\nAn experimental protocol is handled as a pandas DataFrame\nthat includes an 'onset' field.\n\nThis yields the onset time of the events in the experimental paradigm.\nIt can also contain:\n\n * a 'trial_type' field that yields the condition identifier.\n * a 'duration' field that yields event duration (for so-called block\n paradigms).\n * a 'modulation' field that associated a scalar value to each event.\n\nAuthor: Bertrand Thirion, 2015\n\n\"\"\"\nimport warnings\n\nimport numpy as np\n\nVALID_FIELDS = set([\"onset\",\n \"duration\",\n \"trial_type\",\n \"modulation\",\n ])\n\ndef check_events(events):\n \"\"\"Test that the events data describes a valid experimental paradigm\n\n It is valid if the events data has an 'onset' key.\n\n Parameters\n ----------\n events : pandas DataFrame\n Events data that describes a functional experimental paradigm.\n\n Returns\n -------\n trial_type : array of shape (n_events,), dtype='s'\n Per-event experimental conditions identifier.\n Defaults to np.repeat('dummy', len(onsets)).\n\n onset : array of shape (n_events,), dtype='f'\n Per-event onset time (in seconds)\n\n duration : array of shape (n_events,), dtype='f'\n Per-event durantion, (in seconds)\n defaults to zeros(n_events) when no duration is provided\n\n modulation : array of shape (n_events,), dtype='f'\n Per-event modulation, (in seconds)\n defaults to ones(n_events) when no duration is provided.\n\n \"\"\"\n if 'onset' not in events.keys():\n raise ValueError('The provided events data has no onset column.')\n if 'duration' not in events.keys():\n raise ValueError('The provided events data has no duration column.')\n\n onset = np.array(events['onset'])\n duration = np.array(events['duration']).astype(np.float)\n n_events = len(onset)\n modulation = np.ones(n_events)\n if 'trial_type' not in events.keys():\n warnings.warn(\"'trial_type' column not found \"\n \"in the given events data.\")\n trial_type = np.repeat('dummy', n_events)\n else:\n trial_type = np.array(events['trial_type'])\n if 'modulation' in events.keys():\n warnings.warn(\"'modulation' column found in the given events data.\")\n modulation = np.array(events['modulation']).astype(np.float)\n for event,_ in events.items():\n if event not in VALID_FIELDS:\n warnings.warn(\"Unexpected key `{}` in events \"\n \"will be ignored.\".format(\n event))\n return trial_type, onset, duration, modulation\n", "path": "nilearn/glm/first_level/experimental_paradigm.py"}]}
| 983 | 351 |
gh_patches_debug_40978
|
rasdani/github-patches
|
git_diff
|
interlegis__sapl-1093
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Migração de Documentos: separar documentos por ano
Nas models de MateriaLegislativa, DocumentoAcessorio e NormaJurídica, seria bom alterar a estrutura de pastas para organizar os documentos migrados de acordo com o ano que foi criado.
Como exemplo, a mudança passaria de:
`media/sapl/{model_name}/{id}/{id}_nome_documento.pdf`
Para:
`media/sapl/{model_name}/{ano}/{id}/{id}_nome_documento.pdf`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sapl/legacy/migracao_documentos.py`
Content:
```
1 import mimetypes
2 import os
3 import re
4
5 import magic
6
7 from django.db.models.signals import post_delete, post_save
8 from sapl.base.models import CasaLegislativa
9 from sapl.materia.models import (DocumentoAcessorio, MateriaLegislativa,
10 Proposicao)
11 from sapl.norma.models import NormaJuridica
12 from sapl.parlamentares.models import Parlamentar
13 from sapl.protocoloadm.models import DocumentoAdministrativo
14 from sapl.protocoloadm.models import DocumentoAcessorioAdministrativo
15 from sapl.sessao.models import SessaoPlenaria
16 from sapl.settings import MEDIA_ROOT
17 from sapl.utils import delete_texto, save_texto
18
19
20 # MIGRAÇÃO DE DOCUMENTOS ###################################################
21 EXTENSOES = {
22 'application/msword': '.doc',
23 'application/pdf': '.pdf',
24 'application/vnd.oasis.opendocument.text': '.odt',
25 'application/vnd.openxmlformats-officedocument.wordprocessingml.document': '.docx', # noqa
26 'application/xml': '.xml',
27 'application/zip': '.zip',
28 'image/jpeg': '.jpeg',
29 'image/png': '.png',
30 'text/html': '.html',
31 'text/rtf': '.rtf',
32 'text/x-python': '.py',
33 'text/plain': '.ksh',
34 'text/plain': '.c',
35 'text/plain': '.h',
36 'text/plain': '.txt',
37 'text/plain': '.bat',
38 'text/plain': '.pl',
39 'text/plain': '.asc',
40 'text/plain': '.text',
41 'text/plain': '.pot',
42 'text/plain': '.brf',
43 'text/plain': '.srt',
44
45 # sem extensao
46 'application/octet-stream': '', # binário
47 'inode/x-empty': '', # vazio
48 }
49
50 DOCS = {
51 CasaLegislativa: [(
52 'logotipo',
53 'props_sapl/logo_casa.gif',
54 'casa/logotipo/logo_casa.gif')],
55 Parlamentar: [(
56 'fotografia',
57 'parlamentar/fotos/{}_foto_parlamentar',
58 'parlamentar/{0}/{0}_foto_parlamentar{1}')],
59 MateriaLegislativa: [(
60 'texto_original',
61 'materia/{}_texto_integral',
62 'materialegislativa/{0}/{0}_texto_integral{1}')],
63 DocumentoAcessorio: [(
64 'arquivo',
65 'materia/{}',
66 'documentoacessorio/{0}/{0}{1}')],
67 NormaJuridica: [(
68 'texto_integral',
69 'norma_juridica/{}_texto_integral',
70 'normajuridica/{0}/{0}_texto_integral{1}')],
71 SessaoPlenaria: [
72 ('upload_ata',
73 'ata_sessao/{}_ata_sessao',
74 'sessaoplenaria/{0}/ata/{0}_ata_sessao{1}'),
75 ('upload_anexo',
76 'anexo_sessao/{}_texto_anexado',
77 'sessaoplenaria/{0}/anexo/{0}_texto_anexado{1}')
78 ],
79 Proposicao: [(
80 'texto_original',
81 'proposicao/{}',
82 'proposicao/{0}/{0}{1}')],
83 DocumentoAdministrativo: [(
84 'texto_integral',
85 'administrativo/{}_texto_integral',
86 'documentoadministrativo/{0}/{0}_texto_integral{1}')
87 ],
88 DocumentoAcessorioAdministrativo: [(
89 'arquivo',
90 'administrativo/{}',
91 'documentoacessorioadministrativo/{0}/{0}_acessorio_administrativo{1}')
92 ],
93 }
94
95 DOCS = {tipo: [(campo,
96 os.path.join('sapl_documentos', origem),
97 os.path.join('sapl', destino))
98 for campo, origem, destino in campos]
99 for tipo, campos in DOCS.items()}
100
101
102 def em_media(caminho):
103 return os.path.join(MEDIA_ROOT, caminho)
104
105
106 def mover_documento(origem, destino):
107 origem, destino = [em_media(c) if not os.path.isabs(c) else c
108 for c in (origem, destino)]
109 os.makedirs(os.path.dirname(destino), exist_ok=True)
110 os.rename(origem, destino)
111
112
113 def get_casa_legislativa():
114 casa = CasaLegislativa.objects.first()
115 if not casa:
116 casa = CasaLegislativa.objects.create(**{k: 'PREENCHER...' for k in [
117 'codigo', 'nome', 'sigla', 'endereco', 'cep', 'municipio', 'uf',
118 ]})
119 return casa
120
121
122 def migrar_docs_logo():
123 print('#### Migrando logotipo da casa ####')
124 [(_, origem, destino)] = DOCS[CasaLegislativa]
125 props_sapl = os.path.dirname(origem)
126
127 # a pasta props_sapl deve conter apenas o origem e metadatas!
128 # Edit: Aparentemente há diretório que contém properties ao invés de
129 # metadata. O assert foi modificado para essa situação.
130 assert set(os.listdir(em_media(props_sapl))) < {
131 'logo_casa.gif', '.metadata', 'logo_casa.gif.metadata',
132 '.properties', 'logo_casa.gif.properties', '.objects'}
133
134 mover_documento(origem, destino)
135 casa = get_casa_legislativa()
136 casa.logotipo = destino
137 casa.save()
138
139
140 def get_extensao(caminho):
141 mime = magic.from_file(caminho, mime=True)
142 try:
143 return EXTENSOES[mime]
144 except KeyError as e:
145 raise Exception('\n'.join([
146 'Extensão não conhecida para o arquivo:',
147 caminho,
148 'E mimetype:',
149 mime,
150 ' Algumas possibilidades são:', ] +
151 [" '{}': '{}',".format(mime, ext)
152 for ext in mimetypes.guess_all_extensions(mime)] +
153 ['Atualize o código do dicionário EXTENSOES!']
154 )) from e
155
156
157 def migrar_docs_por_ids(tipo):
158 for campo, base_origem, base_destino in DOCS[tipo]:
159 print('#### Migrando {} de {} ####'.format(campo, tipo.__name__))
160
161 dir_origem, nome_origem = os.path.split(em_media(base_origem))
162 pat = re.compile('^{}$'.format(nome_origem.format('(\d+)')))
163
164 if not os.path.isdir(dir_origem):
165 print(' >>> O diretório {} não existe! Abortado.'.format(
166 dir_origem))
167 continue
168
169 for arq in os.listdir(dir_origem):
170 match = pat.match(arq)
171 if match:
172 origem = os.path.join(dir_origem, match.group(0))
173 id = match.group(1)
174 extensao = get_extensao(origem)
175 destino = base_destino.format(id, extensao)
176 mover_documento(origem, destino)
177
178 # associa documento ao objeto
179 try:
180 obj = tipo.objects.get(pk=id)
181 setattr(obj, campo, destino)
182 obj.save()
183 except tipo.DoesNotExist:
184 msg = ' {} (pk={}) não encontrado para documento em [{}]'
185 print(msg.format(
186 tipo.__name__, id, destino))
187
188
189 def desconecta_sinais_indexacao():
190 post_save.disconnect(save_texto, NormaJuridica)
191 post_save.disconnect(save_texto, DocumentoAcessorio)
192 post_save.disconnect(save_texto, MateriaLegislativa)
193 post_delete.disconnect(delete_texto, NormaJuridica)
194 post_delete.disconnect(delete_texto, DocumentoAcessorio)
195 post_delete.disconnect(delete_texto, MateriaLegislativa)
196
197
198 def conecta_sinais_indexacao():
199 post_save.connect(save_texto, NormaJuridica)
200 post_save.connect(save_texto, DocumentoAcessorio)
201 post_save.connect(save_texto, MateriaLegislativa)
202 post_delete.connect(delete_texto, NormaJuridica)
203 post_delete.connect(delete_texto, DocumentoAcessorio)
204 post_delete.connect(delete_texto, MateriaLegislativa)
205
206
207 def migrar_documentos():
208 # precisamos excluir os sinais de post_save e post_delete para não que o
209 # computador não trave com a criação de threads desnecessárias
210 desconecta_sinais_indexacao()
211
212 # aqui supomos que uma pasta chamada sapl_documentos está em MEDIA_ROOT
213 # com o conteúdo da pasta de mesmo nome do zope
214 # Os arquivos da pasta serão movidos para a nova estrutura e a pasta será
215 # apagada
216 migrar_docs_logo()
217 for tipo in [
218 Parlamentar,
219 MateriaLegislativa,
220 DocumentoAcessorio,
221 NormaJuridica,
222 SessaoPlenaria,
223 Proposicao,
224 DocumentoAdministrativo,
225 DocumentoAcessorioAdministrativo,
226 ]:
227 migrar_docs_por_ids(tipo)
228
229 sobrando = [os.path.join(dir, file)
230 for (dir, _, files) in os.walk(em_media('sapl_documentos'))
231 for file in files]
232 if sobrando:
233 print('\n#### Encerrado ####\n\n'
234 '{} documentos sobraram sem ser migrados!!!'.format(
235 len(sobrando)))
236 for doc in sobrando:
237 print(' {}'. format(doc))
238 #
239 # reconexão dos sinais desligados no inicio da migração de documentos
240 conecta_sinais_indexacao()
241
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sapl/legacy/migracao_documentos.py b/sapl/legacy/migracao_documentos.py
--- a/sapl/legacy/migracao_documentos.py
+++ b/sapl/legacy/migracao_documentos.py
@@ -55,40 +55,40 @@
Parlamentar: [(
'fotografia',
'parlamentar/fotos/{}_foto_parlamentar',
- 'parlamentar/{0}/{0}_foto_parlamentar{1}')],
+ 'public/parlamentar/{0}/{0}_foto_parlamentar{1}')],
MateriaLegislativa: [(
'texto_original',
'materia/{}_texto_integral',
- 'materialegislativa/{0}/{0}_texto_integral{1}')],
+ 'public/materialegislativa/{2}/{0}/{0}_texto_integral{1}')],
DocumentoAcessorio: [(
'arquivo',
'materia/{}',
- 'documentoacessorio/{0}/{0}{1}')],
+ 'public/documentoacessorio/{2}/{0}/{0}{1}')],
NormaJuridica: [(
'texto_integral',
'norma_juridica/{}_texto_integral',
- 'normajuridica/{0}/{0}_texto_integral{1}')],
+ 'public/normajuridica/{2}/{0}/{0}_texto_integral{1}')],
SessaoPlenaria: [
('upload_ata',
'ata_sessao/{}_ata_sessao',
- 'sessaoplenaria/{0}/ata/{0}_ata_sessao{1}'),
+ 'public/sessaoplenaria/{0}/ata/{0}_ata_sessao{1}'),
('upload_anexo',
'anexo_sessao/{}_texto_anexado',
- 'sessaoplenaria/{0}/anexo/{0}_texto_anexado{1}')
+ 'public/sessaoplenaria/{0}/anexo/{0}_texto_anexado{1}')
],
Proposicao: [(
'texto_original',
'proposicao/{}',
- 'proposicao/{0}/{0}{1}')],
+ 'private/proposicao/{0}/{0}{1}')],
DocumentoAdministrativo: [(
'texto_integral',
'administrativo/{}_texto_integral',
- 'documentoadministrativo/{0}/{0}_texto_integral{1}')
+ 'private/documentoadministrativo/{0}/{0}_texto_integral{1}')
],
DocumentoAcessorioAdministrativo: [(
- 'arquivo',
+ 'arquivo',
'administrativo/{}',
- 'documentoacessorioadministrativo/{0}/{0}_acessorio_administrativo{1}')
+ 'private/documentoacessorioadministrativo/{0}/{0}_acessorio_administrativo{1}')
],
}
@@ -169,15 +169,22 @@
for arq in os.listdir(dir_origem):
match = pat.match(arq)
if match:
- origem = os.path.join(dir_origem, match.group(0))
- id = match.group(1)
- extensao = get_extensao(origem)
- destino = base_destino.format(id, extensao)
- mover_documento(origem, destino)
-
# associa documento ao objeto
try:
+ origem = os.path.join(dir_origem, match.group(0))
+ id = match.group(1)
obj = tipo.objects.get(pk=id)
+
+ extensao = get_extensao(origem)
+ if hasattr(obj, "ano"):
+ destino = base_destino.format(id, extensao, obj.ano)
+ elif isinstance(obj, DocumentoAcessorio):
+ destino = base_destino.format(
+ id, extensao, obj.materia.ano)
+ else:
+ destino = base_destino.format(id, extensao)
+ mover_documento(origem, destino)
+
setattr(obj, campo, destino)
obj.save()
except tipo.DoesNotExist:
|
{"golden_diff": "diff --git a/sapl/legacy/migracao_documentos.py b/sapl/legacy/migracao_documentos.py\n--- a/sapl/legacy/migracao_documentos.py\n+++ b/sapl/legacy/migracao_documentos.py\n@@ -55,40 +55,40 @@\n Parlamentar: [(\n 'fotografia',\n 'parlamentar/fotos/{}_foto_parlamentar',\n- 'parlamentar/{0}/{0}_foto_parlamentar{1}')],\n+ 'public/parlamentar/{0}/{0}_foto_parlamentar{1}')],\n MateriaLegislativa: [(\n 'texto_original',\n 'materia/{}_texto_integral',\n- 'materialegislativa/{0}/{0}_texto_integral{1}')],\n+ 'public/materialegislativa/{2}/{0}/{0}_texto_integral{1}')],\n DocumentoAcessorio: [(\n 'arquivo',\n 'materia/{}',\n- 'documentoacessorio/{0}/{0}{1}')],\n+ 'public/documentoacessorio/{2}/{0}/{0}{1}')],\n NormaJuridica: [(\n 'texto_integral',\n 'norma_juridica/{}_texto_integral',\n- 'normajuridica/{0}/{0}_texto_integral{1}')],\n+ 'public/normajuridica/{2}/{0}/{0}_texto_integral{1}')],\n SessaoPlenaria: [\n ('upload_ata',\n 'ata_sessao/{}_ata_sessao',\n- 'sessaoplenaria/{0}/ata/{0}_ata_sessao{1}'),\n+ 'public/sessaoplenaria/{0}/ata/{0}_ata_sessao{1}'),\n ('upload_anexo',\n 'anexo_sessao/{}_texto_anexado',\n- 'sessaoplenaria/{0}/anexo/{0}_texto_anexado{1}')\n+ 'public/sessaoplenaria/{0}/anexo/{0}_texto_anexado{1}')\n ],\n Proposicao: [(\n 'texto_original',\n 'proposicao/{}',\n- 'proposicao/{0}/{0}{1}')],\n+ 'private/proposicao/{0}/{0}{1}')],\n DocumentoAdministrativo: [(\n 'texto_integral',\n 'administrativo/{}_texto_integral',\n- 'documentoadministrativo/{0}/{0}_texto_integral{1}') \n+ 'private/documentoadministrativo/{0}/{0}_texto_integral{1}')\n ],\n DocumentoAcessorioAdministrativo: [(\n- \t 'arquivo',\n+ 'arquivo',\n 'administrativo/{}',\n- 'documentoacessorioadministrativo/{0}/{0}_acessorio_administrativo{1}')\n+ 'private/documentoacessorioadministrativo/{0}/{0}_acessorio_administrativo{1}')\n ],\n }\n \n@@ -169,15 +169,22 @@\n for arq in os.listdir(dir_origem):\n match = pat.match(arq)\n if match:\n- origem = os.path.join(dir_origem, match.group(0))\n- id = match.group(1)\n- extensao = get_extensao(origem)\n- destino = base_destino.format(id, extensao)\n- mover_documento(origem, destino)\n-\n # associa documento ao objeto\n try:\n+ origem = os.path.join(dir_origem, match.group(0))\n+ id = match.group(1)\n obj = tipo.objects.get(pk=id)\n+\n+ extensao = get_extensao(origem)\n+ if hasattr(obj, \"ano\"):\n+ destino = base_destino.format(id, extensao, obj.ano)\n+ elif isinstance(obj, DocumentoAcessorio):\n+ destino = base_destino.format(\n+ id, extensao, obj.materia.ano)\n+ else:\n+ destino = base_destino.format(id, extensao)\n+ mover_documento(origem, destino)\n+\n setattr(obj, campo, destino)\n obj.save()\n except tipo.DoesNotExist:\n", "issue": "Migra\u00e7\u00e3o de Documentos: separar documentos por ano\nNas models de MateriaLegislativa, DocumentoAcessorio e NormaJur\u00eddica, seria bom alterar a estrutura de pastas para organizar os documentos migrados de acordo com o ano que foi criado.\r\n\r\nComo exemplo, a mudan\u00e7a passaria de:\r\n`media/sapl/{model_name}/{id}/{id}_nome_documento.pdf`\r\nPara:\r\n`media/sapl/{model_name}/{ano}/{id}/{id}_nome_documento.pdf`\n", "before_files": [{"content": "import mimetypes\nimport os\nimport re\n\nimport magic\n\nfrom django.db.models.signals import post_delete, post_save\nfrom sapl.base.models import CasaLegislativa\nfrom sapl.materia.models import (DocumentoAcessorio, MateriaLegislativa,\n Proposicao)\nfrom sapl.norma.models import NormaJuridica\nfrom sapl.parlamentares.models import Parlamentar\nfrom sapl.protocoloadm.models import DocumentoAdministrativo\nfrom sapl.protocoloadm.models import DocumentoAcessorioAdministrativo\nfrom sapl.sessao.models import SessaoPlenaria\nfrom sapl.settings import MEDIA_ROOT\nfrom sapl.utils import delete_texto, save_texto\n\n\n# MIGRA\u00c7\u00c3O DE DOCUMENTOS ###################################################\nEXTENSOES = {\n 'application/msword': '.doc',\n 'application/pdf': '.pdf',\n 'application/vnd.oasis.opendocument.text': '.odt',\n 'application/vnd.openxmlformats-officedocument.wordprocessingml.document': '.docx', # noqa\n 'application/xml': '.xml',\n 'application/zip': '.zip',\n 'image/jpeg': '.jpeg',\n 'image/png': '.png',\n 'text/html': '.html',\n 'text/rtf': '.rtf',\n 'text/x-python': '.py',\n 'text/plain': '.ksh',\n 'text/plain': '.c',\n 'text/plain': '.h',\n 'text/plain': '.txt',\n 'text/plain': '.bat',\n 'text/plain': '.pl',\n 'text/plain': '.asc',\n 'text/plain': '.text',\n 'text/plain': '.pot',\n 'text/plain': '.brf',\n 'text/plain': '.srt',\n\n # sem extensao\n 'application/octet-stream': '', # bin\u00e1rio\n 'inode/x-empty': '', # vazio\n}\n\nDOCS = {\n CasaLegislativa: [(\n 'logotipo',\n 'props_sapl/logo_casa.gif',\n 'casa/logotipo/logo_casa.gif')],\n Parlamentar: [(\n 'fotografia',\n 'parlamentar/fotos/{}_foto_parlamentar',\n 'parlamentar/{0}/{0}_foto_parlamentar{1}')],\n MateriaLegislativa: [(\n 'texto_original',\n 'materia/{}_texto_integral',\n 'materialegislativa/{0}/{0}_texto_integral{1}')],\n DocumentoAcessorio: [(\n 'arquivo',\n 'materia/{}',\n 'documentoacessorio/{0}/{0}{1}')],\n NormaJuridica: [(\n 'texto_integral',\n 'norma_juridica/{}_texto_integral',\n 'normajuridica/{0}/{0}_texto_integral{1}')],\n SessaoPlenaria: [\n ('upload_ata',\n 'ata_sessao/{}_ata_sessao',\n 'sessaoplenaria/{0}/ata/{0}_ata_sessao{1}'),\n ('upload_anexo',\n 'anexo_sessao/{}_texto_anexado',\n 'sessaoplenaria/{0}/anexo/{0}_texto_anexado{1}')\n ],\n Proposicao: [(\n 'texto_original',\n 'proposicao/{}',\n 'proposicao/{0}/{0}{1}')],\n DocumentoAdministrativo: [(\n 'texto_integral',\n 'administrativo/{}_texto_integral',\n 'documentoadministrativo/{0}/{0}_texto_integral{1}') \n ],\n DocumentoAcessorioAdministrativo: [(\n \t 'arquivo',\n 'administrativo/{}',\n 'documentoacessorioadministrativo/{0}/{0}_acessorio_administrativo{1}')\n ],\n}\n\nDOCS = {tipo: [(campo,\n os.path.join('sapl_documentos', origem),\n os.path.join('sapl', destino))\n for campo, origem, destino in campos]\n for tipo, campos in DOCS.items()}\n\n\ndef em_media(caminho):\n return os.path.join(MEDIA_ROOT, caminho)\n\n\ndef mover_documento(origem, destino):\n origem, destino = [em_media(c) if not os.path.isabs(c) else c\n for c in (origem, destino)]\n os.makedirs(os.path.dirname(destino), exist_ok=True)\n os.rename(origem, destino)\n\n\ndef get_casa_legislativa():\n casa = CasaLegislativa.objects.first()\n if not casa:\n casa = CasaLegislativa.objects.create(**{k: 'PREENCHER...' for k in [\n 'codigo', 'nome', 'sigla', 'endereco', 'cep', 'municipio', 'uf',\n ]})\n return casa\n\n\ndef migrar_docs_logo():\n print('#### Migrando logotipo da casa ####')\n [(_, origem, destino)] = DOCS[CasaLegislativa]\n props_sapl = os.path.dirname(origem)\n\n # a pasta props_sapl deve conter apenas o origem e metadatas!\n # Edit: Aparentemente h\u00e1 diret\u00f3rio que cont\u00e9m properties ao inv\u00e9s de\n # metadata. O assert foi modificado para essa situa\u00e7\u00e3o.\n assert set(os.listdir(em_media(props_sapl))) < {\n 'logo_casa.gif', '.metadata', 'logo_casa.gif.metadata',\n '.properties', 'logo_casa.gif.properties', '.objects'}\n\n mover_documento(origem, destino)\n casa = get_casa_legislativa()\n casa.logotipo = destino\n casa.save()\n\n\ndef get_extensao(caminho):\n mime = magic.from_file(caminho, mime=True)\n try:\n return EXTENSOES[mime]\n except KeyError as e:\n raise Exception('\\n'.join([\n 'Extens\u00e3o n\u00e3o conhecida para o arquivo:',\n caminho,\n 'E mimetype:',\n mime,\n ' Algumas possibilidades s\u00e3o:', ] +\n [\" '{}': '{}',\".format(mime, ext)\n for ext in mimetypes.guess_all_extensions(mime)] +\n ['Atualize o c\u00f3digo do dicion\u00e1rio EXTENSOES!']\n )) from e\n\n\ndef migrar_docs_por_ids(tipo):\n for campo, base_origem, base_destino in DOCS[tipo]:\n print('#### Migrando {} de {} ####'.format(campo, tipo.__name__))\n\n dir_origem, nome_origem = os.path.split(em_media(base_origem))\n pat = re.compile('^{}$'.format(nome_origem.format('(\\d+)')))\n\n if not os.path.isdir(dir_origem):\n print(' >>> O diret\u00f3rio {} n\u00e3o existe! Abortado.'.format(\n dir_origem))\n continue\n\n for arq in os.listdir(dir_origem):\n match = pat.match(arq)\n if match:\n origem = os.path.join(dir_origem, match.group(0))\n id = match.group(1)\n extensao = get_extensao(origem)\n destino = base_destino.format(id, extensao)\n mover_documento(origem, destino)\n\n # associa documento ao objeto\n try:\n obj = tipo.objects.get(pk=id)\n setattr(obj, campo, destino)\n obj.save()\n except tipo.DoesNotExist:\n msg = ' {} (pk={}) n\u00e3o encontrado para documento em [{}]'\n print(msg.format(\n tipo.__name__, id, destino))\n\n\ndef desconecta_sinais_indexacao():\n post_save.disconnect(save_texto, NormaJuridica)\n post_save.disconnect(save_texto, DocumentoAcessorio)\n post_save.disconnect(save_texto, MateriaLegislativa)\n post_delete.disconnect(delete_texto, NormaJuridica)\n post_delete.disconnect(delete_texto, DocumentoAcessorio)\n post_delete.disconnect(delete_texto, MateriaLegislativa)\n\n\ndef conecta_sinais_indexacao():\n post_save.connect(save_texto, NormaJuridica)\n post_save.connect(save_texto, DocumentoAcessorio)\n post_save.connect(save_texto, MateriaLegislativa)\n post_delete.connect(delete_texto, NormaJuridica)\n post_delete.connect(delete_texto, DocumentoAcessorio)\n post_delete.connect(delete_texto, MateriaLegislativa)\n\n\ndef migrar_documentos():\n # precisamos excluir os sinais de post_save e post_delete para n\u00e3o que o\n # computador n\u00e3o trave com a cria\u00e7\u00e3o de threads desnecess\u00e1rias\n desconecta_sinais_indexacao()\n\n # aqui supomos que uma pasta chamada sapl_documentos est\u00e1 em MEDIA_ROOT\n # com o conte\u00fado da pasta de mesmo nome do zope\n # Os arquivos da pasta ser\u00e3o movidos para a nova estrutura e a pasta ser\u00e1\n # apagada\n migrar_docs_logo()\n for tipo in [\n Parlamentar,\n MateriaLegislativa,\n DocumentoAcessorio,\n NormaJuridica,\n SessaoPlenaria,\n Proposicao,\n DocumentoAdministrativo,\n \tDocumentoAcessorioAdministrativo,\n ]:\n migrar_docs_por_ids(tipo)\n\n sobrando = [os.path.join(dir, file)\n for (dir, _, files) in os.walk(em_media('sapl_documentos'))\n for file in files]\n if sobrando:\n print('\\n#### Encerrado ####\\n\\n'\n '{} documentos sobraram sem ser migrados!!!'.format(\n len(sobrando)))\n for doc in sobrando:\n print(' {}'. format(doc))\n #\n # reconex\u00e3o dos sinais desligados no inicio da migra\u00e7\u00e3o de documentos\n conecta_sinais_indexacao()\n", "path": "sapl/legacy/migracao_documentos.py"}], "after_files": [{"content": "import mimetypes\nimport os\nimport re\n\nimport magic\n\nfrom django.db.models.signals import post_delete, post_save\nfrom sapl.base.models import CasaLegislativa\nfrom sapl.materia.models import (DocumentoAcessorio, MateriaLegislativa,\n Proposicao)\nfrom sapl.norma.models import NormaJuridica\nfrom sapl.parlamentares.models import Parlamentar\nfrom sapl.protocoloadm.models import DocumentoAdministrativo\nfrom sapl.protocoloadm.models import DocumentoAcessorioAdministrativo\nfrom sapl.sessao.models import SessaoPlenaria\nfrom sapl.settings import MEDIA_ROOT\nfrom sapl.utils import delete_texto, save_texto\n\n\n# MIGRA\u00c7\u00c3O DE DOCUMENTOS ###################################################\nEXTENSOES = {\n 'application/msword': '.doc',\n 'application/pdf': '.pdf',\n 'application/vnd.oasis.opendocument.text': '.odt',\n 'application/vnd.openxmlformats-officedocument.wordprocessingml.document': '.docx', # noqa\n 'application/xml': '.xml',\n 'application/zip': '.zip',\n 'image/jpeg': '.jpeg',\n 'image/png': '.png',\n 'text/html': '.html',\n 'text/rtf': '.rtf',\n 'text/x-python': '.py',\n 'text/plain': '.ksh',\n 'text/plain': '.c',\n 'text/plain': '.h',\n 'text/plain': '.txt',\n 'text/plain': '.bat',\n 'text/plain': '.pl',\n 'text/plain': '.asc',\n 'text/plain': '.text',\n 'text/plain': '.pot',\n 'text/plain': '.brf',\n 'text/plain': '.srt',\n\n # sem extensao\n 'application/octet-stream': '', # bin\u00e1rio\n 'inode/x-empty': '', # vazio\n}\n\nDOCS = {\n CasaLegislativa: [(\n 'logotipo',\n 'props_sapl/logo_casa.gif',\n 'casa/logotipo/logo_casa.gif')],\n Parlamentar: [(\n 'fotografia',\n 'parlamentar/fotos/{}_foto_parlamentar',\n 'public/parlamentar/{0}/{0}_foto_parlamentar{1}')],\n MateriaLegislativa: [(\n 'texto_original',\n 'materia/{}_texto_integral',\n 'public/materialegislativa/{2}/{0}/{0}_texto_integral{1}')],\n DocumentoAcessorio: [(\n 'arquivo',\n 'materia/{}',\n 'public/documentoacessorio/{2}/{0}/{0}{1}')],\n NormaJuridica: [(\n 'texto_integral',\n 'norma_juridica/{}_texto_integral',\n 'public/normajuridica/{2}/{0}/{0}_texto_integral{1}')],\n SessaoPlenaria: [\n ('upload_ata',\n 'ata_sessao/{}_ata_sessao',\n 'public/sessaoplenaria/{0}/ata/{0}_ata_sessao{1}'),\n ('upload_anexo',\n 'anexo_sessao/{}_texto_anexado',\n 'public/sessaoplenaria/{0}/anexo/{0}_texto_anexado{1}')\n ],\n Proposicao: [(\n 'texto_original',\n 'proposicao/{}',\n 'private/proposicao/{0}/{0}{1}')],\n DocumentoAdministrativo: [(\n 'texto_integral',\n 'administrativo/{}_texto_integral',\n 'private/documentoadministrativo/{0}/{0}_texto_integral{1}')\n ],\n DocumentoAcessorioAdministrativo: [(\n 'arquivo',\n 'administrativo/{}',\n 'private/documentoacessorioadministrativo/{0}/{0}_acessorio_administrativo{1}')\n ],\n}\n\nDOCS = {tipo: [(campo,\n os.path.join('sapl_documentos', origem),\n os.path.join('sapl', destino))\n for campo, origem, destino in campos]\n for tipo, campos in DOCS.items()}\n\n\ndef em_media(caminho):\n return os.path.join(MEDIA_ROOT, caminho)\n\n\ndef mover_documento(origem, destino):\n origem, destino = [em_media(c) if not os.path.isabs(c) else c\n for c in (origem, destino)]\n os.makedirs(os.path.dirname(destino), exist_ok=True)\n os.rename(origem, destino)\n\n\ndef get_casa_legislativa():\n casa = CasaLegislativa.objects.first()\n if not casa:\n casa = CasaLegislativa.objects.create(**{k: 'PREENCHER...' for k in [\n 'codigo', 'nome', 'sigla', 'endereco', 'cep', 'municipio', 'uf',\n ]})\n return casa\n\n\ndef migrar_docs_logo():\n print('#### Migrando logotipo da casa ####')\n [(_, origem, destino)] = DOCS[CasaLegislativa]\n props_sapl = os.path.dirname(origem)\n\n # a pasta props_sapl deve conter apenas o origem e metadatas!\n # Edit: Aparentemente h\u00e1 diret\u00f3rio que cont\u00e9m properties ao inv\u00e9s de\n # metadata. O assert foi modificado para essa situa\u00e7\u00e3o.\n assert set(os.listdir(em_media(props_sapl))) < {\n 'logo_casa.gif', '.metadata', 'logo_casa.gif.metadata',\n '.properties', 'logo_casa.gif.properties', '.objects'}\n\n mover_documento(origem, destino)\n casa = get_casa_legislativa()\n casa.logotipo = destino\n casa.save()\n\n\ndef get_extensao(caminho):\n mime = magic.from_file(caminho, mime=True)\n try:\n return EXTENSOES[mime]\n except KeyError as e:\n raise Exception('\\n'.join([\n 'Extens\u00e3o n\u00e3o conhecida para o arquivo:',\n caminho,\n 'E mimetype:',\n mime,\n ' Algumas possibilidades s\u00e3o:', ] +\n [\" '{}': '{}',\".format(mime, ext)\n for ext in mimetypes.guess_all_extensions(mime)] +\n ['Atualize o c\u00f3digo do dicion\u00e1rio EXTENSOES!']\n )) from e\n\n\ndef migrar_docs_por_ids(tipo):\n for campo, base_origem, base_destino in DOCS[tipo]:\n print('#### Migrando {} de {} ####'.format(campo, tipo.__name__))\n\n dir_origem, nome_origem = os.path.split(em_media(base_origem))\n pat = re.compile('^{}$'.format(nome_origem.format('(\\d+)')))\n\n if not os.path.isdir(dir_origem):\n print(' >>> O diret\u00f3rio {} n\u00e3o existe! Abortado.'.format(\n dir_origem))\n continue\n\n for arq in os.listdir(dir_origem):\n match = pat.match(arq)\n if match:\n # associa documento ao objeto\n try:\n origem = os.path.join(dir_origem, match.group(0))\n id = match.group(1)\n obj = tipo.objects.get(pk=id)\n\n extensao = get_extensao(origem)\n if hasattr(obj, \"ano\"):\n destino = base_destino.format(id, extensao, obj.ano)\n elif isinstance(obj, DocumentoAcessorio):\n destino = base_destino.format(\n id, extensao, obj.materia.ano)\n else:\n destino = base_destino.format(id, extensao)\n mover_documento(origem, destino)\n\n setattr(obj, campo, destino)\n obj.save()\n except tipo.DoesNotExist:\n msg = ' {} (pk={}) n\u00e3o encontrado para documento em [{}]'\n print(msg.format(\n tipo.__name__, id, destino))\n\n\ndef desconecta_sinais_indexacao():\n post_save.disconnect(save_texto, NormaJuridica)\n post_save.disconnect(save_texto, DocumentoAcessorio)\n post_save.disconnect(save_texto, MateriaLegislativa)\n post_delete.disconnect(delete_texto, NormaJuridica)\n post_delete.disconnect(delete_texto, DocumentoAcessorio)\n post_delete.disconnect(delete_texto, MateriaLegislativa)\n\n\ndef conecta_sinais_indexacao():\n post_save.connect(save_texto, NormaJuridica)\n post_save.connect(save_texto, DocumentoAcessorio)\n post_save.connect(save_texto, MateriaLegislativa)\n post_delete.connect(delete_texto, NormaJuridica)\n post_delete.connect(delete_texto, DocumentoAcessorio)\n post_delete.connect(delete_texto, MateriaLegislativa)\n\n\ndef migrar_documentos():\n # precisamos excluir os sinais de post_save e post_delete para n\u00e3o que o\n # computador n\u00e3o trave com a cria\u00e7\u00e3o de threads desnecess\u00e1rias\n desconecta_sinais_indexacao()\n\n # aqui supomos que uma pasta chamada sapl_documentos est\u00e1 em MEDIA_ROOT\n # com o conte\u00fado da pasta de mesmo nome do zope\n # Os arquivos da pasta ser\u00e3o movidos para a nova estrutura e a pasta ser\u00e1\n # apagada\n migrar_docs_logo()\n for tipo in [\n Parlamentar,\n MateriaLegislativa,\n DocumentoAcessorio,\n NormaJuridica,\n SessaoPlenaria,\n Proposicao,\n DocumentoAdministrativo,\n \tDocumentoAcessorioAdministrativo,\n ]:\n migrar_docs_por_ids(tipo)\n\n sobrando = [os.path.join(dir, file)\n for (dir, _, files) in os.walk(em_media('sapl_documentos'))\n for file in files]\n if sobrando:\n print('\\n#### Encerrado ####\\n\\n'\n '{} documentos sobraram sem ser migrados!!!'.format(\n len(sobrando)))\n for doc in sobrando:\n print(' {}'. format(doc))\n #\n # reconex\u00e3o dos sinais desligados no inicio da migra\u00e7\u00e3o de documentos\n conecta_sinais_indexacao()\n", "path": "sapl/legacy/migracao_documentos.py"}]}
| 3,149 | 931 |
gh_patches_debug_25318
|
rasdani/github-patches
|
git_diff
|
getsentry__sentry-python-484
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Celery - Queue object has no attribute 'all_tasks_done'
Hi all,
I'm integrating Sentry on a project in python that uses Celery. I'm getting this error when shutting down the worker:
```
Error in atexit._run_exitfuncs:
Traceback (most recent call last):
File "/Users/jibanez/API/.conda/envs/cimrender/lib/python3.6/site-packages/sentry_sdk/worker.py", line 84, in flush
self._wait_flush(timeout, callback)
File "/Users/jibanez/API/.conda/envs/cimrender/lib/python3.6/site-packages/sentry_sdk/worker.py", line 90, in _wait_flush
if not self._timed_queue_join(initial_timeout):
File "/Users/jibanez/API/.conda/envs/cimrender/lib/python3.6/site-packages/sentry_sdk/worker.py", line 48, in _timed_queue_join
queue.all_tasks_done.acquire() # type: ignore
AttributeError: 'Queue' object has no attribute 'all_tasks_done'
```
I'm using:
- Python 3.6
- Celery 4.3.0
- OSX Mojave
Any thoughts?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sentry_sdk/worker.py`
Content:
```
1 import os
2
3 from threading import Thread, Lock
4 from time import sleep, time
5 from sentry_sdk._compat import queue, check_thread_support
6 from sentry_sdk.utils import logger
7
8
9 from sentry_sdk._types import MYPY
10
11 if MYPY:
12 from queue import Queue
13 from typing import Any
14 from typing import Optional
15 from typing import Callable
16
17
18 _TERMINATOR = object()
19
20
21 class BackgroundWorker(object):
22 def __init__(self):
23 # type: () -> None
24 check_thread_support()
25 self._queue = queue.Queue(-1) # type: Queue[Any]
26 self._lock = Lock()
27 self._thread = None # type: Optional[Thread]
28 self._thread_for_pid = None # type: Optional[int]
29
30 @property
31 def is_alive(self):
32 # type: () -> bool
33 if self._thread_for_pid != os.getpid():
34 return False
35 if not self._thread:
36 return False
37 return self._thread.is_alive()
38
39 def _ensure_thread(self):
40 # type: () -> None
41 if not self.is_alive:
42 self.start()
43
44 def _timed_queue_join(self, timeout):
45 # type: (float) -> bool
46 deadline = time() + timeout
47 queue = self._queue
48 queue.all_tasks_done.acquire() # type: ignore
49 try:
50 while queue.unfinished_tasks: # type: ignore
51 delay = deadline - time()
52 if delay <= 0:
53 return False
54 queue.all_tasks_done.wait(timeout=delay) # type: ignore
55 return True
56 finally:
57 queue.all_tasks_done.release() # type: ignore
58
59 def start(self):
60 # type: () -> None
61 with self._lock:
62 if not self.is_alive:
63 self._thread = Thread(
64 target=self._target, name="raven-sentry.BackgroundWorker"
65 )
66 self._thread.setDaemon(True)
67 self._thread.start()
68 self._thread_for_pid = os.getpid()
69
70 def kill(self):
71 # type: () -> None
72 logger.debug("background worker got kill request")
73 with self._lock:
74 if self._thread:
75 self._queue.put_nowait(_TERMINATOR)
76 self._thread = None
77 self._thread_for_pid = None
78
79 def flush(self, timeout, callback=None):
80 # type: (float, Optional[Any]) -> None
81 logger.debug("background worker got flush request")
82 with self._lock:
83 if self.is_alive and timeout > 0.0:
84 self._wait_flush(timeout, callback)
85 logger.debug("background worker flushed")
86
87 def _wait_flush(self, timeout, callback):
88 # type: (float, Optional[Any]) -> None
89 initial_timeout = min(0.1, timeout)
90 if not self._timed_queue_join(initial_timeout):
91 pending = self._queue.qsize()
92 logger.debug("%d event(s) pending on flush", pending)
93 if callback is not None:
94 callback(pending, timeout)
95 self._timed_queue_join(timeout - initial_timeout)
96
97 def submit(self, callback):
98 # type: (Callable[[], None]) -> None
99 self._ensure_thread()
100 self._queue.put_nowait(callback)
101
102 def _target(self):
103 # type: () -> None
104 while True:
105 callback = self._queue.get()
106 try:
107 if callback is _TERMINATOR:
108 break
109 try:
110 callback()
111 except Exception:
112 logger.error("Failed processing job", exc_info=True)
113 finally:
114 self._queue.task_done()
115 sleep(0)
116
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sentry_sdk/worker.py b/sentry_sdk/worker.py
--- a/sentry_sdk/worker.py
+++ b/sentry_sdk/worker.py
@@ -45,16 +45,33 @@
# type: (float) -> bool
deadline = time() + timeout
queue = self._queue
- queue.all_tasks_done.acquire() # type: ignore
+
+ real_all_tasks_done = getattr(
+ queue, "all_tasks_done", None
+ ) # type: Optional[Any]
+ if real_all_tasks_done is not None:
+ real_all_tasks_done.acquire()
+ all_tasks_done = real_all_tasks_done # type: Optional[Any]
+ elif queue.__module__.startswith("eventlet."):
+ all_tasks_done = getattr(queue, "_cond", None)
+ else:
+ all_tasks_done = None
+
try:
while queue.unfinished_tasks: # type: ignore
delay = deadline - time()
if delay <= 0:
return False
- queue.all_tasks_done.wait(timeout=delay) # type: ignore
+ if all_tasks_done is not None:
+ all_tasks_done.wait(timeout=delay)
+ else:
+ # worst case, we just poll the number of remaining tasks
+ sleep(0.1)
+
return True
finally:
- queue.all_tasks_done.release() # type: ignore
+ if real_all_tasks_done is not None:
+ real_all_tasks_done.release() # type: ignore
def start(self):
# type: () -> None
|
{"golden_diff": "diff --git a/sentry_sdk/worker.py b/sentry_sdk/worker.py\n--- a/sentry_sdk/worker.py\n+++ b/sentry_sdk/worker.py\n@@ -45,16 +45,33 @@\n # type: (float) -> bool\n deadline = time() + timeout\n queue = self._queue\n- queue.all_tasks_done.acquire() # type: ignore\n+\n+ real_all_tasks_done = getattr(\n+ queue, \"all_tasks_done\", None\n+ ) # type: Optional[Any]\n+ if real_all_tasks_done is not None:\n+ real_all_tasks_done.acquire()\n+ all_tasks_done = real_all_tasks_done # type: Optional[Any]\n+ elif queue.__module__.startswith(\"eventlet.\"):\n+ all_tasks_done = getattr(queue, \"_cond\", None)\n+ else:\n+ all_tasks_done = None\n+\n try:\n while queue.unfinished_tasks: # type: ignore\n delay = deadline - time()\n if delay <= 0:\n return False\n- queue.all_tasks_done.wait(timeout=delay) # type: ignore\n+ if all_tasks_done is not None:\n+ all_tasks_done.wait(timeout=delay)\n+ else:\n+ # worst case, we just poll the number of remaining tasks\n+ sleep(0.1)\n+\n return True\n finally:\n- queue.all_tasks_done.release() # type: ignore\n+ if real_all_tasks_done is not None:\n+ real_all_tasks_done.release() # type: ignore\n \n def start(self):\n # type: () -> None\n", "issue": "Celery - Queue object has no attribute 'all_tasks_done'\nHi all, \r\n\r\nI'm integrating Sentry on a project in python that uses Celery. I'm getting this error when shutting down the worker: \r\n\r\n```\r\nError in atexit._run_exitfuncs:\r\nTraceback (most recent call last):\r\n File \"/Users/jibanez/API/.conda/envs/cimrender/lib/python3.6/site-packages/sentry_sdk/worker.py\", line 84, in flush\r\n self._wait_flush(timeout, callback)\r\n File \"/Users/jibanez/API/.conda/envs/cimrender/lib/python3.6/site-packages/sentry_sdk/worker.py\", line 90, in _wait_flush\r\n if not self._timed_queue_join(initial_timeout):\r\n File \"/Users/jibanez/API/.conda/envs/cimrender/lib/python3.6/site-packages/sentry_sdk/worker.py\", line 48, in _timed_queue_join\r\n queue.all_tasks_done.acquire() # type: ignore\r\nAttributeError: 'Queue' object has no attribute 'all_tasks_done'\r\n```\r\n\r\nI'm using: \r\n- Python 3.6\r\n- Celery 4.3.0\r\n- OSX Mojave\r\n\r\nAny thoughts? \n", "before_files": [{"content": "import os\n\nfrom threading import Thread, Lock\nfrom time import sleep, time\nfrom sentry_sdk._compat import queue, check_thread_support\nfrom sentry_sdk.utils import logger\n\n\nfrom sentry_sdk._types import MYPY\n\nif MYPY:\n from queue import Queue\n from typing import Any\n from typing import Optional\n from typing import Callable\n\n\n_TERMINATOR = object()\n\n\nclass BackgroundWorker(object):\n def __init__(self):\n # type: () -> None\n check_thread_support()\n self._queue = queue.Queue(-1) # type: Queue[Any]\n self._lock = Lock()\n self._thread = None # type: Optional[Thread]\n self._thread_for_pid = None # type: Optional[int]\n\n @property\n def is_alive(self):\n # type: () -> bool\n if self._thread_for_pid != os.getpid():\n return False\n if not self._thread:\n return False\n return self._thread.is_alive()\n\n def _ensure_thread(self):\n # type: () -> None\n if not self.is_alive:\n self.start()\n\n def _timed_queue_join(self, timeout):\n # type: (float) -> bool\n deadline = time() + timeout\n queue = self._queue\n queue.all_tasks_done.acquire() # type: ignore\n try:\n while queue.unfinished_tasks: # type: ignore\n delay = deadline - time()\n if delay <= 0:\n return False\n queue.all_tasks_done.wait(timeout=delay) # type: ignore\n return True\n finally:\n queue.all_tasks_done.release() # type: ignore\n\n def start(self):\n # type: () -> None\n with self._lock:\n if not self.is_alive:\n self._thread = Thread(\n target=self._target, name=\"raven-sentry.BackgroundWorker\"\n )\n self._thread.setDaemon(True)\n self._thread.start()\n self._thread_for_pid = os.getpid()\n\n def kill(self):\n # type: () -> None\n logger.debug(\"background worker got kill request\")\n with self._lock:\n if self._thread:\n self._queue.put_nowait(_TERMINATOR)\n self._thread = None\n self._thread_for_pid = None\n\n def flush(self, timeout, callback=None):\n # type: (float, Optional[Any]) -> None\n logger.debug(\"background worker got flush request\")\n with self._lock:\n if self.is_alive and timeout > 0.0:\n self._wait_flush(timeout, callback)\n logger.debug(\"background worker flushed\")\n\n def _wait_flush(self, timeout, callback):\n # type: (float, Optional[Any]) -> None\n initial_timeout = min(0.1, timeout)\n if not self._timed_queue_join(initial_timeout):\n pending = self._queue.qsize()\n logger.debug(\"%d event(s) pending on flush\", pending)\n if callback is not None:\n callback(pending, timeout)\n self._timed_queue_join(timeout - initial_timeout)\n\n def submit(self, callback):\n # type: (Callable[[], None]) -> None\n self._ensure_thread()\n self._queue.put_nowait(callback)\n\n def _target(self):\n # type: () -> None\n while True:\n callback = self._queue.get()\n try:\n if callback is _TERMINATOR:\n break\n try:\n callback()\n except Exception:\n logger.error(\"Failed processing job\", exc_info=True)\n finally:\n self._queue.task_done()\n sleep(0)\n", "path": "sentry_sdk/worker.py"}], "after_files": [{"content": "import os\n\nfrom threading import Thread, Lock\nfrom time import sleep, time\nfrom sentry_sdk._compat import queue, check_thread_support\nfrom sentry_sdk.utils import logger\n\n\nfrom sentry_sdk._types import MYPY\n\nif MYPY:\n from queue import Queue\n from typing import Any\n from typing import Optional\n from typing import Callable\n\n\n_TERMINATOR = object()\n\n\nclass BackgroundWorker(object):\n def __init__(self):\n # type: () -> None\n check_thread_support()\n self._queue = queue.Queue(-1) # type: Queue[Any]\n self._lock = Lock()\n self._thread = None # type: Optional[Thread]\n self._thread_for_pid = None # type: Optional[int]\n\n @property\n def is_alive(self):\n # type: () -> bool\n if self._thread_for_pid != os.getpid():\n return False\n if not self._thread:\n return False\n return self._thread.is_alive()\n\n def _ensure_thread(self):\n # type: () -> None\n if not self.is_alive:\n self.start()\n\n def _timed_queue_join(self, timeout):\n # type: (float) -> bool\n deadline = time() + timeout\n queue = self._queue\n\n real_all_tasks_done = getattr(\n queue, \"all_tasks_done\", None\n ) # type: Optional[Any]\n if real_all_tasks_done is not None:\n real_all_tasks_done.acquire()\n all_tasks_done = real_all_tasks_done # type: Optional[Any]\n elif queue.__module__.startswith(\"eventlet.\"):\n all_tasks_done = getattr(queue, \"_cond\", None)\n else:\n all_tasks_done = None\n\n try:\n while queue.unfinished_tasks: # type: ignore\n delay = deadline - time()\n if delay <= 0:\n return False\n if all_tasks_done is not None:\n all_tasks_done.wait(timeout=delay)\n else:\n # worst case, we just poll the number of remaining tasks\n sleep(0.1)\n\n return True\n finally:\n if real_all_tasks_done is not None:\n real_all_tasks_done.release() # type: ignore\n\n def start(self):\n # type: () -> None\n with self._lock:\n if not self.is_alive:\n self._thread = Thread(\n target=self._target, name=\"raven-sentry.BackgroundWorker\"\n )\n self._thread.setDaemon(True)\n self._thread.start()\n self._thread_for_pid = os.getpid()\n\n def kill(self):\n # type: () -> None\n logger.debug(\"background worker got kill request\")\n with self._lock:\n if self._thread:\n self._queue.put_nowait(_TERMINATOR)\n self._thread = None\n self._thread_for_pid = None\n\n def flush(self, timeout, callback=None):\n # type: (float, Optional[Any]) -> None\n logger.debug(\"background worker got flush request\")\n with self._lock:\n if self.is_alive and timeout > 0.0:\n self._wait_flush(timeout, callback)\n logger.debug(\"background worker flushed\")\n\n def _wait_flush(self, timeout, callback):\n # type: (float, Optional[Any]) -> None\n initial_timeout = min(0.1, timeout)\n if not self._timed_queue_join(initial_timeout):\n pending = self._queue.qsize()\n logger.debug(\"%d event(s) pending on flush\", pending)\n if callback is not None:\n callback(pending, timeout)\n self._timed_queue_join(timeout - initial_timeout)\n\n def submit(self, callback):\n # type: (Callable[[], None]) -> None\n self._ensure_thread()\n self._queue.put_nowait(callback)\n\n def _target(self):\n # type: () -> None\n while True:\n callback = self._queue.get()\n try:\n if callback is _TERMINATOR:\n break\n try:\n callback()\n except Exception:\n logger.error(\"Failed processing job\", exc_info=True)\n finally:\n self._queue.task_done()\n sleep(0)\n", "path": "sentry_sdk/worker.py"}]}
| 1,560 | 354 |
gh_patches_debug_9960
|
rasdani/github-patches
|
git_diff
|
RocketMap__RocketMap-243
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Error with JS
Recently I clone the repository and I get this errors:
> map.built.js:227 Uncaught ReferenceError: center_lat is not defined
>
> map.built.js:1082 Uncaught TypeError: Cannot read property 'setMapTypeId' of undefined
>
> 19 map.built.js:677 Uncaught TypeError: Cannot read property 'getBounds' of undefined
Error with JS
Recently I clone the repository and I get this errors:
> map.built.js:227 Uncaught ReferenceError: center_lat is not defined
>
> map.built.js:1082 Uncaught TypeError: Cannot read property 'setMapTypeId' of undefined
>
> 19 map.built.js:677 Uncaught TypeError: Cannot read property 'getBounds' of undefined
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `runserver.py`
Content:
```
1 #!/usr/bin/python
2 # -*- coding: utf-8 -*-
3
4 import os
5 import sys
6 import shutil
7 import logging
8 import time
9 import re
10 import requests
11
12 # Currently supported pgoapi
13 pgoapi_version = "1.1.6"
14
15 # Moved here so logger is configured at load time
16 logging.basicConfig(format='%(asctime)s [%(threadName)16s][%(module)14s][%(levelname)8s] %(message)s')
17 log = logging.getLogger()
18
19 # Make sure pogom/pgoapi is actually removed if it is an empty directory
20 # This is a leftover directory from the time pgoapi was embedded in PokemonGo-Map
21 # The empty directory will cause problems with `import pgoapi` so it needs to go
22 oldpgoapiPath = os.path.join(os.path.dirname(__file__), "pogom/pgoapi")
23 if os.path.isdir(oldpgoapiPath):
24 log.info("I found %s, but its no longer used. Going to remove it...", oldpgoapiPath)
25 shutil.rmtree(oldpgoapiPath)
26 log.info("Done!")
27
28 # Assert pgoapi is installed
29 try:
30 import pgoapi
31 except ImportError:
32 log.critical("It seems `pgoapi` is not installed. You must run pip install -r requirements.txt again")
33 sys.exit(1)
34
35 # Assert pgoapi >= 1.1.6 is installed
36 from distutils.version import StrictVersion
37 if not hasattr(pgoapi, "__version__") or StrictVersion(pgoapi.__version__) < StrictVersion(pgoapi_version):
38 log.critical("It seems `pgoapi` is not up-to-date. You must run pip install -r requirements.txt again")
39 sys.exit(1)
40
41 from threading import Thread, Event
42 from queue import Queue
43 from flask_cors import CORS
44
45 from pogom import config
46 from pogom.app import Pogom
47 from pogom.utils import get_args, insert_mock_data, get_encryption_lib_path
48
49 from pogom.search import search_overseer_thread, fake_search_loop
50 from pogom.models import init_database, create_tables, drop_tables, Pokemon, Pokestop, Gym
51
52 from pgoapi import utilities as util
53
54 if __name__ == '__main__':
55 # Check if we have the proper encryption library file and get its path
56 encryption_lib_path = get_encryption_lib_path()
57 if encryption_lib_path is "":
58 sys.exit(1)
59
60 args = get_args()
61
62 if args.debug:
63 log.setLevel(logging.DEBUG);
64 else:
65 log.setLevel(logging.INFO);
66
67 # Let's not forget to run Grunt / Only needed when running with webserver
68 if not args.no_server:
69 if not os.path.exists(os.path.join(os.path.dirname(__file__), 'static/dist')):
70 log.critical('Missing front-end assets (static/dist) -- please run "npm install && npm run build" before starting the server');
71 sys.exit();
72
73 # These are very noisey, let's shush them up a bit
74 logging.getLogger('peewee').setLevel(logging.INFO)
75 logging.getLogger('requests').setLevel(logging.WARNING)
76 logging.getLogger('pgoapi.pgoapi').setLevel(logging.WARNING)
77 logging.getLogger('pgoapi.rpc_api').setLevel(logging.INFO)
78 logging.getLogger('werkzeug').setLevel(logging.ERROR)
79
80 config['parse_pokemon'] = not args.no_pokemon
81 config['parse_pokestops'] = not args.no_pokestops
82 config['parse_gyms'] = not args.no_gyms
83
84 # Turn these back up if debugging
85 if args.debug:
86 logging.getLogger('requests').setLevel(logging.DEBUG)
87 logging.getLogger('pgoapi').setLevel(logging.DEBUG)
88 logging.getLogger('rpc_api').setLevel(logging.DEBUG)
89
90
91 # use lat/lng directly if matches such a pattern
92 prog = re.compile("^(\-?\d+\.\d+),?\s?(\-?\d+\.\d+)$")
93 res = prog.match(args.location)
94 if res:
95 log.debug('Using coordinates from CLI directly')
96 position = (float(res.group(1)), float(res.group(2)), 0)
97 else:
98 log.debug('Looking up coordinates in API')
99 position = util.get_pos_by_name(args.location)
100
101 # Use the latitude and longitude to get the local altitude from Google
102 try:
103 url = 'https://maps.googleapis.com/maps/api/elevation/json?locations={},{}'.format(
104 str(position[0]), str(position[1]))
105 altitude = requests.get(url).json()[u'results'][0][u'elevation']
106 log.debug('Local altitude is: %sm', altitude)
107 position = (position[0], position[1], altitude)
108 except requests.exceptions.RequestException:
109 log.error('Unable to retrieve altitude from Google APIs; setting to 0')
110
111 if not any(position):
112 log.error('Could not get a position by name, aborting')
113 sys.exit()
114
115 log.info('Parsed location is: %.4f/%.4f/%.4f (lat/lng/alt)',
116 position[0], position[1], position[2])
117
118 if args.no_pokemon:
119 log.info('Parsing of Pokemon disabled')
120 if args.no_pokestops:
121 log.info('Parsing of Pokestops disabled')
122 if args.no_gyms:
123 log.info('Parsing of Gyms disabled')
124
125 config['LOCALE'] = args.locale
126 config['CHINA'] = args.china
127
128 app = Pogom(__name__)
129 db = init_database(app)
130 if args.clear_db:
131 log.info('Clearing database')
132 if args.db_type == 'mysql':
133 drop_tables(db)
134 elif os.path.isfile(args.db):
135 os.remove(args.db)
136 create_tables(db)
137
138 app.set_current_location(position);
139
140 # Control the search status (running or not) across threads
141 pause_bit = Event()
142 pause_bit.clear()
143
144 # Setup the location tracking queue and push the first location on
145 new_location_queue = Queue()
146 new_location_queue.put(position)
147
148 if not args.only_server:
149 # Gather the pokemons!
150 if not args.mock:
151 log.debug('Starting a real search thread')
152 search_thread = Thread(target=search_overseer_thread, args=(args, new_location_queue, pause_bit, encryption_lib_path))
153 else:
154 log.debug('Starting a fake search thread')
155 insert_mock_data(position)
156 search_thread = Thread(target=fake_search_loop)
157
158 search_thread.daemon = True
159 search_thread.name = 'search_thread'
160 search_thread.start()
161
162 if args.cors:
163 CORS(app);
164
165 app.set_search_control(pause_bit)
166 app.set_location_queue(new_location_queue)
167
168 config['ROOT_PATH'] = app.root_path
169 config['GMAPS_KEY'] = args.gmaps_key
170
171 if args.no_server:
172 # This loop allows for ctrl-c interupts to work since flask won't be holding the program open
173 while search_thread.is_alive():
174 time.sleep(60)
175 else:
176 app.run(threaded=True, use_reloader=False, debug=args.debug, host=args.host, port=args.port)
177
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/runserver.py b/runserver.py
--- a/runserver.py
+++ b/runserver.py
@@ -41,6 +41,7 @@
from threading import Thread, Event
from queue import Queue
from flask_cors import CORS
+from flask.ext import cache_bust
from pogom import config
from pogom.app import Pogom
@@ -162,6 +163,9 @@
if args.cors:
CORS(app);
+ # No more stale JS
+ cache_bust.init_cache_busting(app)
+
app.set_search_control(pause_bit)
app.set_location_queue(new_location_queue)
|
{"golden_diff": "diff --git a/runserver.py b/runserver.py\n--- a/runserver.py\n+++ b/runserver.py\n@@ -41,6 +41,7 @@\n from threading import Thread, Event\n from queue import Queue\n from flask_cors import CORS\n+from flask.ext import cache_bust\n \n from pogom import config\n from pogom.app import Pogom\n@@ -162,6 +163,9 @@\n if args.cors:\n CORS(app);\n \n+ # No more stale JS\n+ cache_bust.init_cache_busting(app)\n+\n app.set_search_control(pause_bit)\n app.set_location_queue(new_location_queue)\n", "issue": "Error with JS\nRecently I clone the repository and I get this errors:\n\n> map.built.js:227 Uncaught ReferenceError: center_lat is not defined\n> \n> map.built.js:1082 Uncaught TypeError: Cannot read property 'setMapTypeId' of undefined\n> \n> 19 map.built.js:677 Uncaught TypeError: Cannot read property 'getBounds' of undefined\n\nError with JS\nRecently I clone the repository and I get this errors:\n\n> map.built.js:227 Uncaught ReferenceError: center_lat is not defined\n> \n> map.built.js:1082 Uncaught TypeError: Cannot read property 'setMapTypeId' of undefined\n> \n> 19 map.built.js:677 Uncaught TypeError: Cannot read property 'getBounds' of undefined\n\n", "before_files": [{"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\nimport os\nimport sys\nimport shutil\nimport logging\nimport time\nimport re\nimport requests\n\n# Currently supported pgoapi\npgoapi_version = \"1.1.6\"\n\n# Moved here so logger is configured at load time\nlogging.basicConfig(format='%(asctime)s [%(threadName)16s][%(module)14s][%(levelname)8s] %(message)s')\nlog = logging.getLogger()\n\n# Make sure pogom/pgoapi is actually removed if it is an empty directory\n# This is a leftover directory from the time pgoapi was embedded in PokemonGo-Map\n# The empty directory will cause problems with `import pgoapi` so it needs to go\noldpgoapiPath = os.path.join(os.path.dirname(__file__), \"pogom/pgoapi\")\nif os.path.isdir(oldpgoapiPath):\n log.info(\"I found %s, but its no longer used. Going to remove it...\", oldpgoapiPath)\n shutil.rmtree(oldpgoapiPath)\n log.info(\"Done!\")\n\n# Assert pgoapi is installed\ntry:\n import pgoapi\nexcept ImportError:\n log.critical(\"It seems `pgoapi` is not installed. You must run pip install -r requirements.txt again\")\n sys.exit(1)\n\n# Assert pgoapi >= 1.1.6 is installed\nfrom distutils.version import StrictVersion\nif not hasattr(pgoapi, \"__version__\") or StrictVersion(pgoapi.__version__) < StrictVersion(pgoapi_version):\n log.critical(\"It seems `pgoapi` is not up-to-date. You must run pip install -r requirements.txt again\")\n sys.exit(1)\n\nfrom threading import Thread, Event\nfrom queue import Queue\nfrom flask_cors import CORS\n\nfrom pogom import config\nfrom pogom.app import Pogom\nfrom pogom.utils import get_args, insert_mock_data, get_encryption_lib_path\n\nfrom pogom.search import search_overseer_thread, fake_search_loop\nfrom pogom.models import init_database, create_tables, drop_tables, Pokemon, Pokestop, Gym\n\nfrom pgoapi import utilities as util\n\nif __name__ == '__main__':\n # Check if we have the proper encryption library file and get its path\n encryption_lib_path = get_encryption_lib_path()\n if encryption_lib_path is \"\":\n sys.exit(1)\n\n args = get_args()\n\n if args.debug:\n log.setLevel(logging.DEBUG);\n else:\n log.setLevel(logging.INFO);\n\n # Let's not forget to run Grunt / Only needed when running with webserver\n if not args.no_server:\n if not os.path.exists(os.path.join(os.path.dirname(__file__), 'static/dist')):\n log.critical('Missing front-end assets (static/dist) -- please run \"npm install && npm run build\" before starting the server');\n sys.exit();\n\n # These are very noisey, let's shush them up a bit\n logging.getLogger('peewee').setLevel(logging.INFO)\n logging.getLogger('requests').setLevel(logging.WARNING)\n logging.getLogger('pgoapi.pgoapi').setLevel(logging.WARNING)\n logging.getLogger('pgoapi.rpc_api').setLevel(logging.INFO)\n logging.getLogger('werkzeug').setLevel(logging.ERROR)\n\n config['parse_pokemon'] = not args.no_pokemon\n config['parse_pokestops'] = not args.no_pokestops\n config['parse_gyms'] = not args.no_gyms\n\n # Turn these back up if debugging\n if args.debug:\n logging.getLogger('requests').setLevel(logging.DEBUG)\n logging.getLogger('pgoapi').setLevel(logging.DEBUG)\n logging.getLogger('rpc_api').setLevel(logging.DEBUG)\n\n\n # use lat/lng directly if matches such a pattern\n prog = re.compile(\"^(\\-?\\d+\\.\\d+),?\\s?(\\-?\\d+\\.\\d+)$\")\n res = prog.match(args.location)\n if res:\n log.debug('Using coordinates from CLI directly')\n position = (float(res.group(1)), float(res.group(2)), 0)\n else:\n log.debug('Looking up coordinates in API')\n position = util.get_pos_by_name(args.location)\n\n # Use the latitude and longitude to get the local altitude from Google\n try:\n url = 'https://maps.googleapis.com/maps/api/elevation/json?locations={},{}'.format(\n str(position[0]), str(position[1]))\n altitude = requests.get(url).json()[u'results'][0][u'elevation']\n log.debug('Local altitude is: %sm', altitude)\n position = (position[0], position[1], altitude)\n except requests.exceptions.RequestException:\n log.error('Unable to retrieve altitude from Google APIs; setting to 0')\n\n if not any(position):\n log.error('Could not get a position by name, aborting')\n sys.exit()\n\n log.info('Parsed location is: %.4f/%.4f/%.4f (lat/lng/alt)',\n position[0], position[1], position[2])\n\n if args.no_pokemon:\n log.info('Parsing of Pokemon disabled')\n if args.no_pokestops:\n log.info('Parsing of Pokestops disabled')\n if args.no_gyms:\n log.info('Parsing of Gyms disabled')\n\n config['LOCALE'] = args.locale\n config['CHINA'] = args.china\n\n app = Pogom(__name__)\n db = init_database(app)\n if args.clear_db:\n log.info('Clearing database')\n if args.db_type == 'mysql':\n drop_tables(db)\n elif os.path.isfile(args.db):\n os.remove(args.db)\n create_tables(db)\n\n app.set_current_location(position);\n\n # Control the search status (running or not) across threads\n pause_bit = Event()\n pause_bit.clear()\n\n # Setup the location tracking queue and push the first location on\n new_location_queue = Queue()\n new_location_queue.put(position)\n\n if not args.only_server:\n # Gather the pokemons!\n if not args.mock:\n log.debug('Starting a real search thread')\n search_thread = Thread(target=search_overseer_thread, args=(args, new_location_queue, pause_bit, encryption_lib_path))\n else:\n log.debug('Starting a fake search thread')\n insert_mock_data(position)\n search_thread = Thread(target=fake_search_loop)\n\n search_thread.daemon = True\n search_thread.name = 'search_thread'\n search_thread.start()\n\n if args.cors:\n CORS(app);\n\n app.set_search_control(pause_bit)\n app.set_location_queue(new_location_queue)\n\n config['ROOT_PATH'] = app.root_path\n config['GMAPS_KEY'] = args.gmaps_key\n\n if args.no_server:\n # This loop allows for ctrl-c interupts to work since flask won't be holding the program open\n while search_thread.is_alive():\n time.sleep(60)\n else:\n app.run(threaded=True, use_reloader=False, debug=args.debug, host=args.host, port=args.port)\n", "path": "runserver.py"}], "after_files": [{"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\nimport os\nimport sys\nimport shutil\nimport logging\nimport time\nimport re\nimport requests\n\n# Currently supported pgoapi\npgoapi_version = \"1.1.6\"\n\n# Moved here so logger is configured at load time\nlogging.basicConfig(format='%(asctime)s [%(threadName)16s][%(module)14s][%(levelname)8s] %(message)s')\nlog = logging.getLogger()\n\n# Make sure pogom/pgoapi is actually removed if it is an empty directory\n# This is a leftover directory from the time pgoapi was embedded in PokemonGo-Map\n# The empty directory will cause problems with `import pgoapi` so it needs to go\noldpgoapiPath = os.path.join(os.path.dirname(__file__), \"pogom/pgoapi\")\nif os.path.isdir(oldpgoapiPath):\n log.info(\"I found %s, but its no longer used. Going to remove it...\", oldpgoapiPath)\n shutil.rmtree(oldpgoapiPath)\n log.info(\"Done!\")\n\n# Assert pgoapi is installed\ntry:\n import pgoapi\nexcept ImportError:\n log.critical(\"It seems `pgoapi` is not installed. You must run pip install -r requirements.txt again\")\n sys.exit(1)\n\n# Assert pgoapi >= 1.1.6 is installed\nfrom distutils.version import StrictVersion\nif not hasattr(pgoapi, \"__version__\") or StrictVersion(pgoapi.__version__) < StrictVersion(pgoapi_version):\n log.critical(\"It seems `pgoapi` is not up-to-date. You must run pip install -r requirements.txt again\")\n sys.exit(1)\n\nfrom threading import Thread, Event\nfrom queue import Queue\nfrom flask_cors import CORS\nfrom flask.ext import cache_bust\n\nfrom pogom import config\nfrom pogom.app import Pogom\nfrom pogom.utils import get_args, insert_mock_data, get_encryption_lib_path\n\nfrom pogom.search import search_overseer_thread, fake_search_loop\nfrom pogom.models import init_database, create_tables, drop_tables, Pokemon, Pokestop, Gym\n\nfrom pgoapi import utilities as util\n\nif __name__ == '__main__':\n # Check if we have the proper encryption library file and get its path\n encryption_lib_path = get_encryption_lib_path()\n if encryption_lib_path is \"\":\n sys.exit(1)\n\n args = get_args()\n\n if args.debug:\n log.setLevel(logging.DEBUG);\n else:\n log.setLevel(logging.INFO);\n\n # Let's not forget to run Grunt / Only needed when running with webserver\n if not args.no_server:\n if not os.path.exists(os.path.join(os.path.dirname(__file__), 'static/dist')):\n log.critical('Missing front-end assets (static/dist) -- please run \"npm install && npm run build\" before starting the server');\n sys.exit();\n\n # These are very noisey, let's shush them up a bit\n logging.getLogger('peewee').setLevel(logging.INFO)\n logging.getLogger('requests').setLevel(logging.WARNING)\n logging.getLogger('pgoapi.pgoapi').setLevel(logging.WARNING)\n logging.getLogger('pgoapi.rpc_api').setLevel(logging.INFO)\n logging.getLogger('werkzeug').setLevel(logging.ERROR)\n\n config['parse_pokemon'] = not args.no_pokemon\n config['parse_pokestops'] = not args.no_pokestops\n config['parse_gyms'] = not args.no_gyms\n\n # Turn these back up if debugging\n if args.debug:\n logging.getLogger('requests').setLevel(logging.DEBUG)\n logging.getLogger('pgoapi').setLevel(logging.DEBUG)\n logging.getLogger('rpc_api').setLevel(logging.DEBUG)\n\n\n # use lat/lng directly if matches such a pattern\n prog = re.compile(\"^(\\-?\\d+\\.\\d+),?\\s?(\\-?\\d+\\.\\d+)$\")\n res = prog.match(args.location)\n if res:\n log.debug('Using coordinates from CLI directly')\n position = (float(res.group(1)), float(res.group(2)), 0)\n else:\n log.debug('Looking up coordinates in API')\n position = util.get_pos_by_name(args.location)\n\n # Use the latitude and longitude to get the local altitude from Google\n try:\n url = 'https://maps.googleapis.com/maps/api/elevation/json?locations={},{}'.format(\n str(position[0]), str(position[1]))\n altitude = requests.get(url).json()[u'results'][0][u'elevation']\n log.debug('Local altitude is: %sm', altitude)\n position = (position[0], position[1], altitude)\n except requests.exceptions.RequestException:\n log.error('Unable to retrieve altitude from Google APIs; setting to 0')\n\n if not any(position):\n log.error('Could not get a position by name, aborting')\n sys.exit()\n\n log.info('Parsed location is: %.4f/%.4f/%.4f (lat/lng/alt)',\n position[0], position[1], position[2])\n\n if args.no_pokemon:\n log.info('Parsing of Pokemon disabled')\n if args.no_pokestops:\n log.info('Parsing of Pokestops disabled')\n if args.no_gyms:\n log.info('Parsing of Gyms disabled')\n\n config['LOCALE'] = args.locale\n config['CHINA'] = args.china\n\n app = Pogom(__name__)\n db = init_database(app)\n if args.clear_db:\n log.info('Clearing database')\n if args.db_type == 'mysql':\n drop_tables(db)\n elif os.path.isfile(args.db):\n os.remove(args.db)\n create_tables(db)\n\n app.set_current_location(position);\n\n # Control the search status (running or not) across threads\n pause_bit = Event()\n pause_bit.clear()\n\n # Setup the location tracking queue and push the first location on\n new_location_queue = Queue()\n new_location_queue.put(position)\n\n if not args.only_server:\n # Gather the pokemons!\n if not args.mock:\n log.debug('Starting a real search thread')\n search_thread = Thread(target=search_overseer_thread, args=(args, new_location_queue, pause_bit, encryption_lib_path))\n else:\n log.debug('Starting a fake search thread')\n insert_mock_data(position)\n search_thread = Thread(target=fake_search_loop)\n\n search_thread.daemon = True\n search_thread.name = 'search_thread'\n search_thread.start()\n\n if args.cors:\n CORS(app);\n\n # No more stale JS\n cache_bust.init_cache_busting(app)\n\n app.set_search_control(pause_bit)\n app.set_location_queue(new_location_queue)\n\n config['ROOT_PATH'] = app.root_path\n config['GMAPS_KEY'] = args.gmaps_key\n\n if args.no_server:\n # This loop allows for ctrl-c interupts to work since flask won't be holding the program open\n while search_thread.is_alive():\n time.sleep(60)\n else:\n app.run(threaded=True, use_reloader=False, debug=args.debug, host=args.host, port=args.port)\n", "path": "runserver.py"}]}
| 2,412 | 142 |
gh_patches_debug_37737
|
rasdani/github-patches
|
git_diff
|
optuna__optuna-972
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Hyperband Usage Documentation
First many thanks for the new hyperband pruner.
I would like to request some more information on how to use it. I guess that it is necessary to tune the default parameters. Maybe you could provide some more information then just link to the papers. When should I set which parameter to what value?
The paper talks about an infinite horizon setting. Since I often do not set the number of iterations on optuna but stop it with KeyboardInterrupt is that relevant for me?
Many thanks
Philip
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `optuna/pruners/hyperband.py`
Content:
```
1 import math
2 from typing import List
3 from typing import Optional
4 import warnings
5
6 import optuna
7 from optuna._experimental import experimental
8 from optuna import logging
9 from optuna.pruners.base import BasePruner
10 from optuna.pruners.successive_halving import SuccessiveHalvingPruner
11 from optuna.trial import FrozenTrial
12
13 _logger = logging.get_logger(__name__)
14
15
16 @experimental("1.1.0")
17 class HyperbandPruner(BasePruner):
18 """Pruner using Hyperband.
19
20 As SuccessiveHalving (SHA) requires the number of configurations
21 :math:`n` as its hyperparameter. For a given finite budget :math:`B`,
22 all the configurations have the resources of :math:`B \\over n` on average.
23 As you can see, there will be a trade-off of :math:`B` and :math:`B \\over n`.
24 `Hyperband <http://www.jmlr.org/papers/volume18/16-558/16-558.pdf>`_ attacks this trade-off
25 by trying different :math:`n` values for a fixed budget.
26
27 .. note::
28 * In the Hyperband paper, the counterpart of :class:`~optuna.samplers.RandomSampler`
29 is used.
30 * Optuna uses :class:`~optuna.samplers.TPESampler` by default.
31 * `The benchmark result
32 <https://github.com/optuna/optuna/pull/828#issuecomment-575457360>`_
33 shows that :class:`optuna.pruners.HyperbandPruner` supports both samplers.
34
35 .. note::
36 If you use ``HyperbandPruner`` with :class:`~optuna.samplers.TPESampler`,
37 it's recommended to consider to set larger ``n_trials`` or ``timeout`` to make full use of
38 the characteristics of :class:`~optuna.samplers.TPESampler`
39 because :class:`~optuna.samplers.TPESampler` uses some (by default, :math:`10`)
40 :class:`~optuna.trial.Trial`\\ s for its startup.
41
42 As Hyperband runs multiple :class:`~optuna.pruners.SuccessiveHalvingPruner` and collect
43 trials based on the current :class:`~optuna.trial.Trial`\\ 's bracket ID, each bracket
44 needs to observe more than :math:`10` :class:`~optuna.trial.Trial`\\ s
45 for :class:`~optuna.samplers.TPESampler` to adapt its search space.
46
47 Thus, for example, if ``HyperbandPruner`` has :math:`4` pruners in it,
48 at least :math:`4 \\times 10` trials are consumed for startup.
49
50 .. note::
51 Hyperband has several :class:`~optuna.pruners.SuccessiveHalvingPruner`. Each
52 :class:`~optuna.pruners.SuccessiveHalvingPruner` is referred as "bracket" in the original
53 paper. The number of brackets is an important factor to control the early stopping behavior
54 of Hyperband and is automatically determined by ``max_resource`` and ``reduction_factor``
55 as `The number of brackets = floor(log(max_resource) / log(reduction_factor)) + 1`. Please
56 set ``reduction_factor`` so that the number of brackets is not too large (about 4 ~ 6 in
57 most use cases). Please see Section 3.6 of the `original paper
58 <http://www.jmlr.org/papers/volume18/16-558/16-558.pdf>`_ for the detail.
59
60 Args:
61 min_resource:
62 A parameter for specifying the minimum resource allocated to a trial noted as :math:`r`
63 in the paper.
64 See the details for :class:`~optuna.pruners.SuccessiveHalvingPruner`.
65 max_resource:
66 A parameter for specifying the maximum resource allocated to a trial noted as :math:`R`
67 in the paper. This value represents and should match the maximum iteration steps (e.g.,
68 the number of epochs for neural networks).
69 reduction_factor:
70 A parameter for specifying reduction factor of promotable trials noted as
71 :math:`\\eta` in the paper. See the details for
72 :class:`~optuna.pruners.SuccessiveHalvingPruner`.
73 n_brackets:
74
75 .. deprecated:: 1.4.0
76 This argument will be removed from :class:`~optuna.pruners.HyperbandPruner`. The
77 number of brackets are automatically determined based on ``max_resource`` and
78 ``reduction_factor``.
79
80 The number of :class:`~optuna.pruners.SuccessiveHalvingPruner`\\ s (brackets).
81 Defaults to :math:`4`.
82 min_early_stopping_rate_low:
83
84 .. deprecated:: 1.4.0
85 This argument will be removed from :class:`~optuna.pruners.HyperbandPruner`.
86
87 A parameter for specifying the minimum early-stopping rate.
88 This parameter is related to a parameter that is referred to as :math:`s` and used in
89 `Asynchronous SuccessiveHalving paper <http://arxiv.org/abs/1810.05934>`_.
90 The minimum early stopping rate for :math:`i` th bracket is :math:`i + s`.
91 """
92
93 def __init__(
94 self,
95 min_resource: int = 1,
96 max_resource: int = 80,
97 reduction_factor: int = 3,
98 n_brackets: Optional[int] = None,
99 min_early_stopping_rate_low: Optional[int] = None,
100 ) -> None:
101
102 self._pruners = [] # type: List[SuccessiveHalvingPruner]
103 self._reduction_factor = reduction_factor
104 self._total_trial_allocation_budget = 0
105
106 if n_brackets is None:
107 # In the original paper http://www.jmlr.org/papers/volume18/16-558/16-558.pdf, the
108 # inputs of Hyperband are `R`: max resource and `\eta`: reduction factor. The
109 # number of brackets (this is referred as `s_{max} + 1` in the paper) is calculated
110 # by s_{max} + 1 = \floor{\log_{\eta} (R)} + 1 in Algorithm 1 of the original paper.
111 self._n_brackets = (
112 math.floor(math.log2(max_resource) / math.log2(reduction_factor)) + 1
113 )
114 else:
115 message = (
116 "The argument of `n_brackets` is deprecated. "
117 "The number of brackets is automatically determined by `max_resource` and "
118 "`reduction_factor` as "
119 "`n_brackets = floor(log(max_resource) / log(reduction_factor)) + 1`. "
120 "Please specify `reduction_factor` appropriately."
121 )
122 warnings.warn(message, DeprecationWarning)
123 _logger.warning(message)
124 self._n_brackets = n_brackets
125
126 self._trial_allocation_budgets = [] # type: List[int]
127
128 _logger.debug("Hyperband has {} brackets".format(self._n_brackets))
129
130 for i in range(self._n_brackets):
131 trial_allocation_budget = self._calculate_trial_allocation_budget(i)
132 self._total_trial_allocation_budget += trial_allocation_budget
133 self._trial_allocation_budgets.append(trial_allocation_budget)
134
135 # N.B. (crcrpar): `min_early_stopping_rate` has the information of `bracket_index`.
136 if min_early_stopping_rate_low is None:
137 min_early_stopping_rate = i
138 else:
139 message = (
140 "The argument of `min_early_stopping_rate_low` is deprecated. "
141 "Please specify `min_resource` appropriately."
142 )
143 warnings.warn(message, DeprecationWarning)
144 _logger.warning(message)
145 min_early_stopping_rate = min_early_stopping_rate_low + i
146
147 _logger.debug(
148 "{}th bracket has minimum early stopping rate of {}".format(
149 i, min_early_stopping_rate
150 )
151 )
152
153 pruner = SuccessiveHalvingPruner(
154 min_resource=min_resource,
155 reduction_factor=reduction_factor,
156 min_early_stopping_rate=min_early_stopping_rate,
157 )
158 self._pruners.append(pruner)
159
160 def prune(self, study: "optuna.study.Study", trial: FrozenTrial) -> bool:
161 i = self._get_bracket_id(study, trial)
162 _logger.debug("{}th bracket is selected".format(i))
163 bracket_study = self._create_bracket_study(study, i)
164 return self._pruners[i].prune(bracket_study, trial)
165
166 def _calculate_trial_allocation_budget(self, pruner_index: int) -> int:
167 """Compute the trial allocated budget for a bracket of ``pruner_index``.
168
169 In the `original paper <http://www.jmlr.org/papers/volume18/16-558/16-558.pdf>`, the
170 number of trials per one bracket is referred as ``n`` in Algorithm 1. Since we do not know
171 the total number of trials in the leaning scheme of Optuna, we calculate the ratio of the
172 number of trials here instead.
173 """
174
175 s = self._n_brackets - 1 - pruner_index
176 return math.ceil(self._n_brackets * (self._reduction_factor ** s) / (s + 1))
177
178 def _get_bracket_id(self, study: "optuna.study.Study", trial: FrozenTrial) -> int:
179 """Compute the index of bracket for a trial of ``trial_number``.
180
181 The index of a bracket is noted as :math:`s` in
182 `Hyperband paper <http://www.jmlr.org/papers/volume18/16-558/16-558.pdf>`_.
183 """
184
185 n = (
186 hash("{}_{}".format(study.study_name, trial.number))
187 % self._total_trial_allocation_budget
188 )
189 for i in range(self._n_brackets):
190 n -= self._trial_allocation_budgets[i]
191 if n < 0:
192 return i
193
194 assert False, "This line should be unreachable."
195
196 def _create_bracket_study(
197 self, study: "optuna.study.Study", bracket_index: int
198 ) -> "optuna.study.Study":
199 # This class is assumed to be passed to
200 # `SuccessiveHalvingPruner.prune` in which `get_trials`,
201 # `direction`, and `storage` are used.
202 # But for safety, prohibit the other attributes explicitly.
203 class _BracketStudy(optuna.study.Study):
204
205 _VALID_ATTRS = (
206 "get_trials",
207 "direction",
208 "_storage",
209 "_study_id",
210 "pruner",
211 "study_name",
212 "_bracket_id",
213 "sampler",
214 )
215
216 def __init__(self, study: "optuna.study.Study", bracket_id: int) -> None:
217 super().__init__(
218 study_name=study.study_name,
219 storage=study._storage,
220 sampler=study.sampler,
221 pruner=study.pruner,
222 )
223 self._bracket_id = bracket_id
224
225 def get_trials(self, deepcopy: bool = True) -> List[FrozenTrial]:
226 trials = super().get_trials(deepcopy=deepcopy)
227 pruner = self.pruner
228 assert isinstance(pruner, HyperbandPruner)
229 return [t for t in trials if pruner._get_bracket_id(self, t) == self._bracket_id]
230
231 def __getattribute__(self, attr_name): # type: ignore
232 if attr_name not in _BracketStudy._VALID_ATTRS:
233 raise AttributeError(
234 "_BracketStudy does not have attribute of '{}'".format(attr_name)
235 )
236 else:
237 return object.__getattribute__(self, attr_name)
238
239 return _BracketStudy(study, bracket_index)
240
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/optuna/pruners/hyperband.py b/optuna/pruners/hyperband.py
--- a/optuna/pruners/hyperband.py
+++ b/optuna/pruners/hyperband.py
@@ -57,10 +57,58 @@
most use cases). Please see Section 3.6 of the `original paper
<http://www.jmlr.org/papers/volume18/16-558/16-558.pdf>`_ for the detail.
+ Example:
+
+ We minimize an objective function with Hyperband pruning algorithm.
+
+ .. testsetup::
+
+ import numpy as np
+ from sklearn.model_selection import train_test_split
+
+ np.random.seed(seed=0)
+ X = np.random.randn(200).reshape(-1, 1)
+ y = np.where(X[:, 0] < 0.5, 0, 1)
+ X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
+ classes = np.unique(y)
+
+ .. testcode::
+
+ import optuna
+ from sklearn.linear_model import SGDClassifier
+
+ n_train_iter = 100
+
+ def objective(trial):
+ alpha = trial.suggest_uniform('alpha', 0.0, 1.0)
+ clf = SGDClassifier(alpha=alpha)
+
+ for step in range(n_train_iter):
+ clf.partial_fit(X_train, y_train, classes=classes)
+
+ intermediate_value = clf.score(X_test, y_test)
+ trial.report(intermediate_value, step)
+
+ if trial.should_prune():
+ raise optuna.exceptions.TrialPruned()
+
+ return clf.score(X_test, y_test)
+
+ study = optuna.create_study(
+ direction='maximize',
+ pruner=optuna.pruners.HyperbandPruner(
+ min_resource=1,
+ max_resource=n_train_iter,
+ reduction_factor=3
+ )
+ )
+ study.optimize(objective, n_trials=20)
+
Args:
min_resource:
A parameter for specifying the minimum resource allocated to a trial noted as :math:`r`
- in the paper.
+ in the paper. A smaller :math:`r` will give a result faster, but a larger
+ :math:`r` will give a better guarantee of successful judging between configurations.
See the details for :class:`~optuna.pruners.SuccessiveHalvingPruner`.
max_resource:
A parameter for specifying the maximum resource allocated to a trial noted as :math:`R`
@@ -68,8 +116,8 @@
the number of epochs for neural networks).
reduction_factor:
A parameter for specifying reduction factor of promotable trials noted as
- :math:`\\eta` in the paper. See the details for
- :class:`~optuna.pruners.SuccessiveHalvingPruner`.
+ :math:`\\eta` in the paper.
+ See the details for :class:`~optuna.pruners.SuccessiveHalvingPruner`.
n_brackets:
.. deprecated:: 1.4.0
|
{"golden_diff": "diff --git a/optuna/pruners/hyperband.py b/optuna/pruners/hyperband.py\n--- a/optuna/pruners/hyperband.py\n+++ b/optuna/pruners/hyperband.py\n@@ -57,10 +57,58 @@\n most use cases).\u3000Please see Section 3.6 of the `original paper\n <http://www.jmlr.org/papers/volume18/16-558/16-558.pdf>`_ for the detail.\n \n+ Example:\n+\n+ We minimize an objective function with Hyperband pruning algorithm.\n+\n+ .. testsetup::\n+\n+ import numpy as np\n+ from sklearn.model_selection import train_test_split\n+\n+ np.random.seed(seed=0)\n+ X = np.random.randn(200).reshape(-1, 1)\n+ y = np.where(X[:, 0] < 0.5, 0, 1)\n+ X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)\n+ classes = np.unique(y)\n+\n+ .. testcode::\n+\n+ import optuna\n+ from sklearn.linear_model import SGDClassifier\n+\n+ n_train_iter = 100\n+\n+ def objective(trial):\n+ alpha = trial.suggest_uniform('alpha', 0.0, 1.0)\n+ clf = SGDClassifier(alpha=alpha)\n+\n+ for step in range(n_train_iter):\n+ clf.partial_fit(X_train, y_train, classes=classes)\n+\n+ intermediate_value = clf.score(X_test, y_test)\n+ trial.report(intermediate_value, step)\n+\n+ if trial.should_prune():\n+ raise optuna.exceptions.TrialPruned()\n+\n+ return clf.score(X_test, y_test)\n+\n+ study = optuna.create_study(\n+ direction='maximize',\n+ pruner=optuna.pruners.HyperbandPruner(\n+ min_resource=1,\n+ max_resource=n_train_iter,\n+ reduction_factor=3\n+ )\n+ )\n+ study.optimize(objective, n_trials=20)\n+\n Args:\n min_resource:\n A parameter for specifying the minimum resource allocated to a trial noted as :math:`r`\n- in the paper.\n+ in the paper. A smaller :math:`r` will give a result faster, but a larger\n+ :math:`r` will give a better guarantee of successful judging between configurations.\n See the details for :class:`~optuna.pruners.SuccessiveHalvingPruner`.\n max_resource:\n A parameter for specifying the maximum resource allocated to a trial noted as :math:`R`\n@@ -68,8 +116,8 @@\n the number of epochs for neural networks).\n reduction_factor:\n A parameter for specifying reduction factor of promotable trials noted as\n- :math:`\\\\eta` in the paper. See the details for\n- :class:`~optuna.pruners.SuccessiveHalvingPruner`.\n+ :math:`\\\\eta` in the paper.\n+ See the details for :class:`~optuna.pruners.SuccessiveHalvingPruner`.\n n_brackets:\n \n .. deprecated:: 1.4.0\n", "issue": "Hyperband Usage Documentation\nFirst many thanks for the new hyperband pruner.\r\n\r\nI would like to request some more information on how to use it. I guess that it is necessary to tune the default parameters. Maybe you could provide some more information then just link to the papers. When should I set which parameter to what value?\r\n\r\nThe paper talks about an infinite horizon setting. Since I often do not set the number of iterations on optuna but stop it with KeyboardInterrupt is that relevant for me?\r\n\r\nMany thanks\r\nPhilip\n", "before_files": [{"content": "import math\nfrom typing import List\nfrom typing import Optional\nimport warnings\n\nimport optuna\nfrom optuna._experimental import experimental\nfrom optuna import logging\nfrom optuna.pruners.base import BasePruner\nfrom optuna.pruners.successive_halving import SuccessiveHalvingPruner\nfrom optuna.trial import FrozenTrial\n\n_logger = logging.get_logger(__name__)\n\n\n@experimental(\"1.1.0\")\nclass HyperbandPruner(BasePruner):\n \"\"\"Pruner using Hyperband.\n\n As SuccessiveHalving (SHA) requires the number of configurations\n :math:`n` as its hyperparameter. For a given finite budget :math:`B`,\n all the configurations have the resources of :math:`B \\\\over n` on average.\n As you can see, there will be a trade-off of :math:`B` and :math:`B \\\\over n`.\n `Hyperband <http://www.jmlr.org/papers/volume18/16-558/16-558.pdf>`_ attacks this trade-off\n by trying different :math:`n` values for a fixed budget.\n\n .. note::\n * In the Hyperband paper, the counterpart of :class:`~optuna.samplers.RandomSampler`\n is used.\n * Optuna uses :class:`~optuna.samplers.TPESampler` by default.\n * `The benchmark result\n <https://github.com/optuna/optuna/pull/828#issuecomment-575457360>`_\n shows that :class:`optuna.pruners.HyperbandPruner` supports both samplers.\n\n .. note::\n If you use ``HyperbandPruner`` with :class:`~optuna.samplers.TPESampler`,\n it's recommended to consider to set larger ``n_trials`` or ``timeout`` to make full use of\n the characteristics of :class:`~optuna.samplers.TPESampler`\n because :class:`~optuna.samplers.TPESampler` uses some (by default, :math:`10`)\n :class:`~optuna.trial.Trial`\\\\ s for its startup.\n\n As Hyperband runs multiple :class:`~optuna.pruners.SuccessiveHalvingPruner` and collect\n trials based on the current :class:`~optuna.trial.Trial`\\\\ 's bracket ID, each bracket\n needs to observe more than :math:`10` :class:`~optuna.trial.Trial`\\\\ s\n for :class:`~optuna.samplers.TPESampler` to adapt its search space.\n\n Thus, for example, if ``HyperbandPruner`` has :math:`4` pruners in it,\n at least :math:`4 \\\\times 10` trials are consumed for startup.\n\n .. note::\n Hyperband has several :class:`~optuna.pruners.SuccessiveHalvingPruner`. Each\n :class:`~optuna.pruners.SuccessiveHalvingPruner` is referred as \"bracket\" in the original\n paper. The number of brackets is an important factor to control the early stopping behavior\n of Hyperband and is automatically determined by ``max_resource`` and ``reduction_factor``\n as `The number of brackets = floor(log(max_resource) / log(reduction_factor)) + 1`. Please\n set ``reduction_factor`` so that the number of brackets is not too large\u3000(about 4 ~ 6 in\n most use cases).\u3000Please see Section 3.6 of the `original paper\n <http://www.jmlr.org/papers/volume18/16-558/16-558.pdf>`_ for the detail.\n\n Args:\n min_resource:\n A parameter for specifying the minimum resource allocated to a trial noted as :math:`r`\n in the paper.\n See the details for :class:`~optuna.pruners.SuccessiveHalvingPruner`.\n max_resource:\n A parameter for specifying the maximum resource allocated to a trial noted as :math:`R`\n in the paper. This value represents and should match the maximum iteration steps (e.g.,\n the number of epochs for neural networks).\n reduction_factor:\n A parameter for specifying reduction factor of promotable trials noted as\n :math:`\\\\eta` in the paper. See the details for\n :class:`~optuna.pruners.SuccessiveHalvingPruner`.\n n_brackets:\n\n .. deprecated:: 1.4.0\n This argument will be removed from :class:`~optuna.pruners.HyperbandPruner`. The\n number of brackets are automatically determined based on ``max_resource`` and\n ``reduction_factor``.\n\n The number of :class:`~optuna.pruners.SuccessiveHalvingPruner`\\\\ s (brackets).\n Defaults to :math:`4`.\n min_early_stopping_rate_low:\n\n .. deprecated:: 1.4.0\n This argument will be removed from :class:`~optuna.pruners.HyperbandPruner`.\n\n A parameter for specifying the minimum early-stopping rate.\n This parameter is related to a parameter that is referred to as :math:`s` and used in\n `Asynchronous SuccessiveHalving paper <http://arxiv.org/abs/1810.05934>`_.\n The minimum early stopping rate for :math:`i` th bracket is :math:`i + s`.\n \"\"\"\n\n def __init__(\n self,\n min_resource: int = 1,\n max_resource: int = 80,\n reduction_factor: int = 3,\n n_brackets: Optional[int] = None,\n min_early_stopping_rate_low: Optional[int] = None,\n ) -> None:\n\n self._pruners = [] # type: List[SuccessiveHalvingPruner]\n self._reduction_factor = reduction_factor\n self._total_trial_allocation_budget = 0\n\n if n_brackets is None:\n # In the original paper http://www.jmlr.org/papers/volume18/16-558/16-558.pdf, the\n # inputs of Hyperband are `R`: max resource and `\\eta`: reduction factor. The\n # number of brackets (this is referred as `s_{max} + 1` in the paper) is calculated\n # by s_{max} + 1 = \\floor{\\log_{\\eta} (R)} + 1 in Algorithm 1 of the original paper.\n self._n_brackets = (\n math.floor(math.log2(max_resource) / math.log2(reduction_factor)) + 1\n )\n else:\n message = (\n \"The argument of `n_brackets` is deprecated. \"\n \"The number of brackets is automatically determined by `max_resource` and \"\n \"`reduction_factor` as \"\n \"`n_brackets = floor(log(max_resource) / log(reduction_factor)) + 1`. \"\n \"Please specify `reduction_factor` appropriately.\"\n )\n warnings.warn(message, DeprecationWarning)\n _logger.warning(message)\n self._n_brackets = n_brackets\n\n self._trial_allocation_budgets = [] # type: List[int]\n\n _logger.debug(\"Hyperband has {} brackets\".format(self._n_brackets))\n\n for i in range(self._n_brackets):\n trial_allocation_budget = self._calculate_trial_allocation_budget(i)\n self._total_trial_allocation_budget += trial_allocation_budget\n self._trial_allocation_budgets.append(trial_allocation_budget)\n\n # N.B. (crcrpar): `min_early_stopping_rate` has the information of `bracket_index`.\n if min_early_stopping_rate_low is None:\n min_early_stopping_rate = i\n else:\n message = (\n \"The argument of `min_early_stopping_rate_low` is deprecated. \"\n \"Please specify `min_resource` appropriately.\"\n )\n warnings.warn(message, DeprecationWarning)\n _logger.warning(message)\n min_early_stopping_rate = min_early_stopping_rate_low + i\n\n _logger.debug(\n \"{}th bracket has minimum early stopping rate of {}\".format(\n i, min_early_stopping_rate\n )\n )\n\n pruner = SuccessiveHalvingPruner(\n min_resource=min_resource,\n reduction_factor=reduction_factor,\n min_early_stopping_rate=min_early_stopping_rate,\n )\n self._pruners.append(pruner)\n\n def prune(self, study: \"optuna.study.Study\", trial: FrozenTrial) -> bool:\n i = self._get_bracket_id(study, trial)\n _logger.debug(\"{}th bracket is selected\".format(i))\n bracket_study = self._create_bracket_study(study, i)\n return self._pruners[i].prune(bracket_study, trial)\n\n def _calculate_trial_allocation_budget(self, pruner_index: int) -> int:\n \"\"\"Compute the trial allocated budget for a bracket of ``pruner_index``.\n\n In the `original paper <http://www.jmlr.org/papers/volume18/16-558/16-558.pdf>`, the\n number of trials per one bracket is referred as ``n`` in Algorithm 1. Since we do not know\n the total number of trials in the leaning scheme of Optuna, we calculate the ratio of the\n number of trials here instead.\n \"\"\"\n\n s = self._n_brackets - 1 - pruner_index\n return math.ceil(self._n_brackets * (self._reduction_factor ** s) / (s + 1))\n\n def _get_bracket_id(self, study: \"optuna.study.Study\", trial: FrozenTrial) -> int:\n \"\"\"Compute the index of bracket for a trial of ``trial_number``.\n\n The index of a bracket is noted as :math:`s` in\n `Hyperband paper <http://www.jmlr.org/papers/volume18/16-558/16-558.pdf>`_.\n \"\"\"\n\n n = (\n hash(\"{}_{}\".format(study.study_name, trial.number))\n % self._total_trial_allocation_budget\n )\n for i in range(self._n_brackets):\n n -= self._trial_allocation_budgets[i]\n if n < 0:\n return i\n\n assert False, \"This line should be unreachable.\"\n\n def _create_bracket_study(\n self, study: \"optuna.study.Study\", bracket_index: int\n ) -> \"optuna.study.Study\":\n # This class is assumed to be passed to\n # `SuccessiveHalvingPruner.prune` in which `get_trials`,\n # `direction`, and `storage` are used.\n # But for safety, prohibit the other attributes explicitly.\n class _BracketStudy(optuna.study.Study):\n\n _VALID_ATTRS = (\n \"get_trials\",\n \"direction\",\n \"_storage\",\n \"_study_id\",\n \"pruner\",\n \"study_name\",\n \"_bracket_id\",\n \"sampler\",\n )\n\n def __init__(self, study: \"optuna.study.Study\", bracket_id: int) -> None:\n super().__init__(\n study_name=study.study_name,\n storage=study._storage,\n sampler=study.sampler,\n pruner=study.pruner,\n )\n self._bracket_id = bracket_id\n\n def get_trials(self, deepcopy: bool = True) -> List[FrozenTrial]:\n trials = super().get_trials(deepcopy=deepcopy)\n pruner = self.pruner\n assert isinstance(pruner, HyperbandPruner)\n return [t for t in trials if pruner._get_bracket_id(self, t) == self._bracket_id]\n\n def __getattribute__(self, attr_name): # type: ignore\n if attr_name not in _BracketStudy._VALID_ATTRS:\n raise AttributeError(\n \"_BracketStudy does not have attribute of '{}'\".format(attr_name)\n )\n else:\n return object.__getattribute__(self, attr_name)\n\n return _BracketStudy(study, bracket_index)\n", "path": "optuna/pruners/hyperband.py"}], "after_files": [{"content": "import math\nfrom typing import List\nfrom typing import Optional\nimport warnings\n\nimport optuna\nfrom optuna._experimental import experimental\nfrom optuna import logging\nfrom optuna.pruners.base import BasePruner\nfrom optuna.pruners.successive_halving import SuccessiveHalvingPruner\nfrom optuna.trial import FrozenTrial\n\n_logger = logging.get_logger(__name__)\n\n\n@experimental(\"1.1.0\")\nclass HyperbandPruner(BasePruner):\n \"\"\"Pruner using Hyperband.\n\n As SuccessiveHalving (SHA) requires the number of configurations\n :math:`n` as its hyperparameter. For a given finite budget :math:`B`,\n all the configurations have the resources of :math:`B \\\\over n` on average.\n As you can see, there will be a trade-off of :math:`B` and :math:`B \\\\over n`.\n `Hyperband <http://www.jmlr.org/papers/volume18/16-558/16-558.pdf>`_ attacks this trade-off\n by trying different :math:`n` values for a fixed budget.\n\n .. note::\n * In the Hyperband paper, the counterpart of :class:`~optuna.samplers.RandomSampler`\n is used.\n * Optuna uses :class:`~optuna.samplers.TPESampler` by default.\n * `The benchmark result\n <https://github.com/optuna/optuna/pull/828#issuecomment-575457360>`_\n shows that :class:`optuna.pruners.HyperbandPruner` supports both samplers.\n\n .. note::\n If you use ``HyperbandPruner`` with :class:`~optuna.samplers.TPESampler`,\n it's recommended to consider to set larger ``n_trials`` or ``timeout`` to make full use of\n the characteristics of :class:`~optuna.samplers.TPESampler`\n because :class:`~optuna.samplers.TPESampler` uses some (by default, :math:`10`)\n :class:`~optuna.trial.Trial`\\\\ s for its startup.\n\n As Hyperband runs multiple :class:`~optuna.pruners.SuccessiveHalvingPruner` and collect\n trials based on the current :class:`~optuna.trial.Trial`\\\\ 's bracket ID, each bracket\n needs to observe more than :math:`10` :class:`~optuna.trial.Trial`\\\\ s\n for :class:`~optuna.samplers.TPESampler` to adapt its search space.\n\n Thus, for example, if ``HyperbandPruner`` has :math:`4` pruners in it,\n at least :math:`4 \\\\times 10` trials are consumed for startup.\n\n .. note::\n Hyperband has several :class:`~optuna.pruners.SuccessiveHalvingPruner`. Each\n :class:`~optuna.pruners.SuccessiveHalvingPruner` is referred as \"bracket\" in the original\n paper. The number of brackets is an important factor to control the early stopping behavior\n of Hyperband and is automatically determined by ``max_resource`` and ``reduction_factor``\n as `The number of brackets = floor(log(max_resource) / log(reduction_factor)) + 1`. Please\n set ``reduction_factor`` so that the number of brackets is not too large\u3000(about 4 ~ 6 in\n most use cases).\u3000Please see Section 3.6 of the `original paper\n <http://www.jmlr.org/papers/volume18/16-558/16-558.pdf>`_ for the detail.\n\n Example:\n\n We minimize an objective function with Hyperband pruning algorithm.\n\n .. testsetup::\n\n import numpy as np\n from sklearn.model_selection import train_test_split\n\n np.random.seed(seed=0)\n X = np.random.randn(200).reshape(-1, 1)\n y = np.where(X[:, 0] < 0.5, 0, 1)\n X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)\n classes = np.unique(y)\n\n .. testcode::\n\n import optuna\n from sklearn.linear_model import SGDClassifier\n\n n_train_iter = 100\n\n def objective(trial):\n alpha = trial.suggest_uniform('alpha', 0.0, 1.0)\n clf = SGDClassifier(alpha=alpha)\n\n for step in range(n_train_iter):\n clf.partial_fit(X_train, y_train, classes=classes)\n\n intermediate_value = clf.score(X_test, y_test)\n trial.report(intermediate_value, step)\n\n if trial.should_prune():\n raise optuna.exceptions.TrialPruned()\n\n return clf.score(X_test, y_test)\n\n study = optuna.create_study(\n direction='maximize',\n pruner=optuna.pruners.HyperbandPruner(\n min_resource=1,\n max_resource=n_train_iter,\n reduction_factor=3\n )\n )\n study.optimize(objective, n_trials=20)\n\n Args:\n min_resource:\n A parameter for specifying the minimum resource allocated to a trial noted as :math:`r`\n in the paper. A smaller :math:`r` will give a result faster, but a larger\n :math:`r` will give a better guarantee of successful judging between configurations.\n See the details for :class:`~optuna.pruners.SuccessiveHalvingPruner`.\n max_resource:\n A parameter for specifying the maximum resource allocated to a trial noted as :math:`R`\n in the paper. This value represents and should match the maximum iteration steps (e.g.,\n the number of epochs for neural networks).\n reduction_factor:\n A parameter for specifying reduction factor of promotable trials noted as\n :math:`\\\\eta` in the paper.\n See the details for :class:`~optuna.pruners.SuccessiveHalvingPruner`.\n n_brackets:\n\n .. deprecated:: 1.4.0\n This argument will be removed from :class:`~optuna.pruners.HyperbandPruner`. The\n number of brackets are automatically determined based on ``max_resource`` and\n ``reduction_factor``.\n\n The number of :class:`~optuna.pruners.SuccessiveHalvingPruner`\\\\ s (brackets).\n Defaults to :math:`4`.\n min_early_stopping_rate_low:\n\n .. deprecated:: 1.4.0\n This argument will be removed from :class:`~optuna.pruners.HyperbandPruner`.\n\n A parameter for specifying the minimum early-stopping rate.\n This parameter is related to a parameter that is referred to as :math:`s` and used in\n `Asynchronous SuccessiveHalving paper <http://arxiv.org/abs/1810.05934>`_.\n The minimum early stopping rate for :math:`i` th bracket is :math:`i + s`.\n \"\"\"\n\n def __init__(\n self,\n min_resource: int = 1,\n max_resource: int = 80,\n reduction_factor: int = 3,\n n_brackets: Optional[int] = None,\n min_early_stopping_rate_low: Optional[int] = None,\n ) -> None:\n\n self._pruners = [] # type: List[SuccessiveHalvingPruner]\n self._reduction_factor = reduction_factor\n self._total_trial_allocation_budget = 0\n\n if n_brackets is None:\n # In the original paper http://www.jmlr.org/papers/volume18/16-558/16-558.pdf, the\n # inputs of Hyperband are `R`: max resource and `\\eta`: reduction factor. The\n # number of brackets (this is referred as `s_{max} + 1` in the paper) is calculated\n # by s_{max} + 1 = \\floor{\\log_{\\eta} (R)} + 1 in Algorithm 1 of the original paper.\n self._n_brackets = (\n math.floor(math.log2(max_resource) / math.log2(reduction_factor)) + 1\n )\n else:\n message = (\n \"The argument of `n_brackets` is deprecated. \"\n \"The number of brackets is automatically determined by `max_resource` and \"\n \"`reduction_factor` as \"\n \"`n_brackets = floor(log(max_resource) / log(reduction_factor)) + 1`. \"\n \"Please specify `reduction_factor` appropriately.\"\n )\n warnings.warn(message, DeprecationWarning)\n _logger.warning(message)\n self._n_brackets = n_brackets\n\n self._trial_allocation_budgets = [] # type: List[int]\n\n _logger.debug(\"Hyperband has {} brackets\".format(self._n_brackets))\n\n for i in range(self._n_brackets):\n trial_allocation_budget = self._calculate_trial_allocation_budget(i)\n self._total_trial_allocation_budget += trial_allocation_budget\n self._trial_allocation_budgets.append(trial_allocation_budget)\n\n # N.B. (crcrpar): `min_early_stopping_rate` has the information of `bracket_index`.\n if min_early_stopping_rate_low is None:\n min_early_stopping_rate = i\n else:\n message = (\n \"The argument of `min_early_stopping_rate_low` is deprecated. \"\n \"Please specify `min_resource` appropriately.\"\n )\n warnings.warn(message, DeprecationWarning)\n _logger.warning(message)\n min_early_stopping_rate = min_early_stopping_rate_low + i\n\n _logger.debug(\n \"{}th bracket has minimum early stopping rate of {}\".format(\n i, min_early_stopping_rate\n )\n )\n\n pruner = SuccessiveHalvingPruner(\n min_resource=min_resource,\n reduction_factor=reduction_factor,\n min_early_stopping_rate=min_early_stopping_rate,\n )\n self._pruners.append(pruner)\n\n def prune(self, study: \"optuna.study.Study\", trial: FrozenTrial) -> bool:\n i = self._get_bracket_id(study, trial)\n _logger.debug(\"{}th bracket is selected\".format(i))\n bracket_study = self._create_bracket_study(study, i)\n return self._pruners[i].prune(bracket_study, trial)\n\n def _calculate_trial_allocation_budget(self, pruner_index: int) -> int:\n \"\"\"Compute the trial allocated budget for a bracket of ``pruner_index``.\n\n In the `original paper <http://www.jmlr.org/papers/volume18/16-558/16-558.pdf>`, the\n number of trials per one bracket is referred as ``n`` in Algorithm 1. Since we do not know\n the total number of trials in the leaning scheme of Optuna, we calculate the ratio of the\n number of trials here instead.\n \"\"\"\n\n s = self._n_brackets - 1 - pruner_index\n return math.ceil(self._n_brackets * (self._reduction_factor ** s) / (s + 1))\n\n def _get_bracket_id(self, study: \"optuna.study.Study\", trial: FrozenTrial) -> int:\n \"\"\"Compute the index of bracket for a trial of ``trial_number``.\n\n The index of a bracket is noted as :math:`s` in\n `Hyperband paper <http://www.jmlr.org/papers/volume18/16-558/16-558.pdf>`_.\n \"\"\"\n\n n = (\n hash(\"{}_{}\".format(study.study_name, trial.number))\n % self._total_trial_allocation_budget\n )\n for i in range(self._n_brackets):\n n -= self._trial_allocation_budgets[i]\n if n < 0:\n return i\n\n assert False, \"This line should be unreachable.\"\n\n def _create_bracket_study(\n self, study: \"optuna.study.Study\", bracket_index: int\n ) -> \"optuna.study.Study\":\n # This class is assumed to be passed to\n # `SuccessiveHalvingPruner.prune` in which `get_trials`,\n # `direction`, and `storage` are used.\n # But for safety, prohibit the other attributes explicitly.\n class _BracketStudy(optuna.study.Study):\n\n _VALID_ATTRS = (\n \"get_trials\",\n \"direction\",\n \"_storage\",\n \"_study_id\",\n \"pruner\",\n \"study_name\",\n \"_bracket_id\",\n \"sampler\",\n )\n\n def __init__(self, study: \"optuna.study.Study\", bracket_id: int) -> None:\n super().__init__(\n study_name=study.study_name,\n storage=study._storage,\n sampler=study.sampler,\n pruner=study.pruner,\n )\n self._bracket_id = bracket_id\n\n def get_trials(self, deepcopy: bool = True) -> List[FrozenTrial]:\n trials = super().get_trials(deepcopy=deepcopy)\n pruner = self.pruner\n assert isinstance(pruner, HyperbandPruner)\n return [t for t in trials if pruner._get_bracket_id(self, t) == self._bracket_id]\n\n def __getattribute__(self, attr_name): # type: ignore\n if attr_name not in _BracketStudy._VALID_ATTRS:\n raise AttributeError(\n \"_BracketStudy does not have attribute of '{}'\".format(attr_name)\n )\n else:\n return object.__getattribute__(self, attr_name)\n\n return _BracketStudy(study, bracket_index)\n", "path": "optuna/pruners/hyperband.py"}]}
| 3,649 | 720 |
gh_patches_debug_12533
|
rasdani/github-patches
|
git_diff
|
getnikola__nikola-2108
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
output/assets/css/code.css is orphaned?
```
~/blog$ nikola build
Scanning posts................done!
copy_assets:output/assets/css/base.css
Scanning posts................done!
~/blog$
~/blog$ nikola build
Scanning posts................done!
~/blog$ nikola check -f
Scanning posts................done!
WARNING: check: Files from unknown origins (orphans):
WARNING: check: output/assets/css/code.css
~/blog$ nikola build
Scanning posts................done!
copy_assets:output/assets/css/base.css
~/blog$ nikola check -f
Scanning posts................done!
WARNING: check: Files from unknown origins (orphans):
WARNING: check: output/assets/css/code.css
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nikola/plugins/task/copy_assets.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # Copyright © 2012-2015 Roberto Alsina and others.
4
5 # Permission is hereby granted, free of charge, to any
6 # person obtaining a copy of this software and associated
7 # documentation files (the "Software"), to deal in the
8 # Software without restriction, including without limitation
9 # the rights to use, copy, modify, merge, publish,
10 # distribute, sublicense, and/or sell copies of the
11 # Software, and to permit persons to whom the Software is
12 # furnished to do so, subject to the following conditions:
13 #
14 # The above copyright notice and this permission notice
15 # shall be included in all copies or substantial portions of
16 # the Software.
17 #
18 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY
19 # KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE
20 # WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR
21 # PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS
22 # OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR
23 # OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
24 # OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
25 # SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
26
27 """Copy theme assets into output."""
28
29 from __future__ import unicode_literals
30
31 import io
32 import os
33
34 from nikola.plugin_categories import Task
35 from nikola import utils
36
37
38 class CopyAssets(Task):
39
40 """Copy theme assets into output."""
41
42 name = "copy_assets"
43
44 def gen_tasks(self):
45 """Create tasks to copy the assets of the whole theme chain.
46
47 If a file is present on two themes, use the version
48 from the "youngest" theme.
49 """
50 kw = {
51 "themes": self.site.THEMES,
52 "files_folders": self.site.config['FILES_FOLDERS'],
53 "output_folder": self.site.config['OUTPUT_FOLDER'],
54 "filters": self.site.config['FILTERS'],
55 "code_color_scheme": self.site.config['CODE_COLOR_SCHEME'],
56 "code.css_selectors": 'pre.code',
57 "code.css_head": '/* code.css file generated by Nikola */\n',
58 "code.css_close": "\ntable.codetable { width: 100%;} td.linenos {text-align: right; width: 4em;}\n",
59 }
60 tasks = {}
61 code_css_path = os.path.join(kw['output_folder'], 'assets', 'css', 'code.css')
62 code_css_input = utils.get_asset_path('assets/css/code.css',
63 themes=kw['themes'],
64 files_folders=kw['files_folders'])
65
66 kw["code.css_input"] = code_css_input
67
68 yield self.group_task()
69
70 for theme_name in kw['themes']:
71 src = os.path.join(utils.get_theme_path(theme_name), 'assets')
72 dst = os.path.join(kw['output_folder'], 'assets')
73 for task in utils.copy_tree(src, dst):
74 if task['name'] in tasks:
75 continue
76 tasks[task['name']] = task
77 task['uptodate'] = [utils.config_changed(kw, 'nikola.plugins.task.copy_assets')]
78 task['basename'] = self.name
79 if code_css_input:
80 if 'file_dep' not in task:
81 task['file_dep'] = []
82 task['file_dep'].append(code_css_input)
83 yield utils.apply_filters(task, kw['filters'])
84
85 # Check whether or not there is a code.css file around.
86 if not code_css_input:
87 def create_code_css():
88 from pygments.formatters import get_formatter_by_name
89 formatter = get_formatter_by_name('html', style=kw["code_color_scheme"])
90 utils.makedirs(os.path.dirname(code_css_path))
91 with io.open(code_css_path, 'w+', encoding='utf8') as outf:
92 outf.write(kw["code.css_head"])
93 outf.write(formatter.get_style_defs(kw["code.css_selectors"]))
94 outf.write(kw["code.css_close"])
95
96 if os.path.exists(code_css_path):
97 with io.open(code_css_path, 'r', encoding='utf-8') as fh:
98 testcontents = fh.read(len(kw["code.css_head"])) == kw["code.css_head"]
99 else:
100 testcontents = False
101
102 task = {
103 'basename': self.name,
104 'name': code_css_path,
105 'targets': [code_css_path],
106 'uptodate': [utils.config_changed(kw, 'nikola.plugins.task.copy_assets'), testcontents],
107 'actions': [(create_code_css, [])],
108 'clean': True,
109 }
110 yield utils.apply_filters(task, kw['filters'])
111
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nikola/plugins/task/copy_assets.py b/nikola/plugins/task/copy_assets.py
--- a/nikola/plugins/task/copy_assets.py
+++ b/nikola/plugins/task/copy_assets.py
@@ -61,10 +61,7 @@
code_css_path = os.path.join(kw['output_folder'], 'assets', 'css', 'code.css')
code_css_input = utils.get_asset_path('assets/css/code.css',
themes=kw['themes'],
- files_folders=kw['files_folders'])
-
- kw["code.css_input"] = code_css_input
-
+ files_folders=kw['files_folders'], output_dir=None)
yield self.group_task()
for theme_name in kw['themes']:
|
{"golden_diff": "diff --git a/nikola/plugins/task/copy_assets.py b/nikola/plugins/task/copy_assets.py\n--- a/nikola/plugins/task/copy_assets.py\n+++ b/nikola/plugins/task/copy_assets.py\n@@ -61,10 +61,7 @@\n code_css_path = os.path.join(kw['output_folder'], 'assets', 'css', 'code.css')\n code_css_input = utils.get_asset_path('assets/css/code.css',\n themes=kw['themes'],\n- files_folders=kw['files_folders'])\n-\n- kw[\"code.css_input\"] = code_css_input\n-\n+ files_folders=kw['files_folders'], output_dir=None)\n yield self.group_task()\n \n for theme_name in kw['themes']:\n", "issue": "output/assets/css/code.css is orphaned?\n```\n~/blog$ nikola build\nScanning posts................done!\ncopy_assets:output/assets/css/base.css\nScanning posts................done!\n~/blog$ \n~/blog$ nikola build\nScanning posts................done!\n~/blog$ nikola check -f\nScanning posts................done!\nWARNING: check: Files from unknown origins (orphans):\nWARNING: check: output/assets/css/code.css\n~/blog$ nikola build\nScanning posts................done!\ncopy_assets:output/assets/css/base.css\n~/blog$ nikola check -f\nScanning posts................done!\nWARNING: check: Files from unknown origins (orphans):\nWARNING: check: output/assets/css/code.css\n```\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright \u00a9 2012-2015 Roberto Alsina and others.\n\n# Permission is hereby granted, free of charge, to any\n# person obtaining a copy of this software and associated\n# documentation files (the \"Software\"), to deal in the\n# Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the\n# Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice\n# shall be included in all copies or substantial portions of\n# the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY\n# KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE\n# WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR\n# PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS\n# OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR\n# OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR\n# OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\n\"\"\"Copy theme assets into output.\"\"\"\n\nfrom __future__ import unicode_literals\n\nimport io\nimport os\n\nfrom nikola.plugin_categories import Task\nfrom nikola import utils\n\n\nclass CopyAssets(Task):\n\n \"\"\"Copy theme assets into output.\"\"\"\n\n name = \"copy_assets\"\n\n def gen_tasks(self):\n \"\"\"Create tasks to copy the assets of the whole theme chain.\n\n If a file is present on two themes, use the version\n from the \"youngest\" theme.\n \"\"\"\n kw = {\n \"themes\": self.site.THEMES,\n \"files_folders\": self.site.config['FILES_FOLDERS'],\n \"output_folder\": self.site.config['OUTPUT_FOLDER'],\n \"filters\": self.site.config['FILTERS'],\n \"code_color_scheme\": self.site.config['CODE_COLOR_SCHEME'],\n \"code.css_selectors\": 'pre.code',\n \"code.css_head\": '/* code.css file generated by Nikola */\\n',\n \"code.css_close\": \"\\ntable.codetable { width: 100%;} td.linenos {text-align: right; width: 4em;}\\n\",\n }\n tasks = {}\n code_css_path = os.path.join(kw['output_folder'], 'assets', 'css', 'code.css')\n code_css_input = utils.get_asset_path('assets/css/code.css',\n themes=kw['themes'],\n files_folders=kw['files_folders'])\n\n kw[\"code.css_input\"] = code_css_input\n\n yield self.group_task()\n\n for theme_name in kw['themes']:\n src = os.path.join(utils.get_theme_path(theme_name), 'assets')\n dst = os.path.join(kw['output_folder'], 'assets')\n for task in utils.copy_tree(src, dst):\n if task['name'] in tasks:\n continue\n tasks[task['name']] = task\n task['uptodate'] = [utils.config_changed(kw, 'nikola.plugins.task.copy_assets')]\n task['basename'] = self.name\n if code_css_input:\n if 'file_dep' not in task:\n task['file_dep'] = []\n task['file_dep'].append(code_css_input)\n yield utils.apply_filters(task, kw['filters'])\n\n # Check whether or not there is a code.css file around.\n if not code_css_input:\n def create_code_css():\n from pygments.formatters import get_formatter_by_name\n formatter = get_formatter_by_name('html', style=kw[\"code_color_scheme\"])\n utils.makedirs(os.path.dirname(code_css_path))\n with io.open(code_css_path, 'w+', encoding='utf8') as outf:\n outf.write(kw[\"code.css_head\"])\n outf.write(formatter.get_style_defs(kw[\"code.css_selectors\"]))\n outf.write(kw[\"code.css_close\"])\n\n if os.path.exists(code_css_path):\n with io.open(code_css_path, 'r', encoding='utf-8') as fh:\n testcontents = fh.read(len(kw[\"code.css_head\"])) == kw[\"code.css_head\"]\n else:\n testcontents = False\n\n task = {\n 'basename': self.name,\n 'name': code_css_path,\n 'targets': [code_css_path],\n 'uptodate': [utils.config_changed(kw, 'nikola.plugins.task.copy_assets'), testcontents],\n 'actions': [(create_code_css, [])],\n 'clean': True,\n }\n yield utils.apply_filters(task, kw['filters'])\n", "path": "nikola/plugins/task/copy_assets.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright \u00a9 2012-2015 Roberto Alsina and others.\n\n# Permission is hereby granted, free of charge, to any\n# person obtaining a copy of this software and associated\n# documentation files (the \"Software\"), to deal in the\n# Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the\n# Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice\n# shall be included in all copies or substantial portions of\n# the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY\n# KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE\n# WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR\n# PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS\n# OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR\n# OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR\n# OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\n\"\"\"Copy theme assets into output.\"\"\"\n\nfrom __future__ import unicode_literals\n\nimport io\nimport os\n\nfrom nikola.plugin_categories import Task\nfrom nikola import utils\n\n\nclass CopyAssets(Task):\n\n \"\"\"Copy theme assets into output.\"\"\"\n\n name = \"copy_assets\"\n\n def gen_tasks(self):\n \"\"\"Create tasks to copy the assets of the whole theme chain.\n\n If a file is present on two themes, use the version\n from the \"youngest\" theme.\n \"\"\"\n kw = {\n \"themes\": self.site.THEMES,\n \"files_folders\": self.site.config['FILES_FOLDERS'],\n \"output_folder\": self.site.config['OUTPUT_FOLDER'],\n \"filters\": self.site.config['FILTERS'],\n \"code_color_scheme\": self.site.config['CODE_COLOR_SCHEME'],\n \"code.css_selectors\": 'pre.code',\n \"code.css_head\": '/* code.css file generated by Nikola */\\n',\n \"code.css_close\": \"\\ntable.codetable { width: 100%;} td.linenos {text-align: right; width: 4em;}\\n\",\n }\n tasks = {}\n code_css_path = os.path.join(kw['output_folder'], 'assets', 'css', 'code.css')\n code_css_input = utils.get_asset_path('assets/css/code.css',\n themes=kw['themes'],\n files_folders=kw['files_folders'], output_dir=None)\n yield self.group_task()\n\n for theme_name in kw['themes']:\n src = os.path.join(utils.get_theme_path(theme_name), 'assets')\n dst = os.path.join(kw['output_folder'], 'assets')\n for task in utils.copy_tree(src, dst):\n if task['name'] in tasks:\n continue\n tasks[task['name']] = task\n task['uptodate'] = [utils.config_changed(kw, 'nikola.plugins.task.copy_assets')]\n task['basename'] = self.name\n if code_css_input:\n if 'file_dep' not in task:\n task['file_dep'] = []\n task['file_dep'].append(code_css_input)\n yield utils.apply_filters(task, kw['filters'])\n\n # Check whether or not there is a code.css file around.\n if not code_css_input:\n def create_code_css():\n from pygments.formatters import get_formatter_by_name\n formatter = get_formatter_by_name('html', style=kw[\"code_color_scheme\"])\n utils.makedirs(os.path.dirname(code_css_path))\n with io.open(code_css_path, 'w+', encoding='utf8') as outf:\n outf.write(kw[\"code.css_head\"])\n outf.write(formatter.get_style_defs(kw[\"code.css_selectors\"]))\n outf.write(kw[\"code.css_close\"])\n\n if os.path.exists(code_css_path):\n with io.open(code_css_path, 'r', encoding='utf-8') as fh:\n testcontents = fh.read(len(kw[\"code.css_head\"])) == kw[\"code.css_head\"]\n else:\n testcontents = False\n\n task = {\n 'basename': self.name,\n 'name': code_css_path,\n 'targets': [code_css_path],\n 'uptodate': [utils.config_changed(kw, 'nikola.plugins.task.copy_assets'), testcontents],\n 'actions': [(create_code_css, [])],\n 'clean': True,\n }\n yield utils.apply_filters(task, kw['filters'])\n", "path": "nikola/plugins/task/copy_assets.py"}]}
| 1,638 | 162 |
gh_patches_debug_12867
|
rasdani/github-patches
|
git_diff
|
great-expectations__great_expectations-6650
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Use cleaner solution for non-truncating division in python 2
Prefer `from __future__ import division` to `1.*x/y`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `contrib/experimental/great_expectations_experimental/expectations/expect_queried_slowly_changing_table_to_have_no_gaps.py`
Content:
```
1 from datetime import datetime, timedelta
2 from typing import Optional, Union
3
4 from great_expectations.core.expectation_configuration import ExpectationConfiguration
5 from great_expectations.core.util import convert_to_json_serializable
6 from great_expectations.exceptions.exceptions import (
7 InvalidExpectationConfigurationError,
8 )
9 from great_expectations.execution_engine import ExecutionEngine
10 from great_expectations.expectations.expectation import (
11 ExpectationValidationResult,
12 QueryExpectation,
13 )
14
15
16 class ExpectQueriedSlowlyChangingTableToHaveNoGaps(QueryExpectation):
17 """Expect Slowly changing table type II to have no gaps between the 'end date' of each row, and the next 'start date' in the next row.
18
19 Args:
20 template_dict: dict with the following keys: \
21 primary_key (primary key column name or multiple columns, comma separated), \
22 open_date_column (name of the column representing open date), \
23 close_date_column (name of the column representing clode date)
24 threshold: an optional parameter - default is zero. \
25 if the ratio of "gaps" to total table rows is higher than threshold - error will be raised.
26 """
27
28 metric_dependencies = ("query.template_values",)
29
30 query = """
31 SELECT SUM(CASE WHEN {close_date_column} != COALESCE(next_start_date, {close_date_column}) THEN 1 ELSE 0 END),
32 COUNT(1)
33 FROM(SELECT {primary_key}, {close_date_column}, LEAD({open_date_column}) OVER(PARTITION BY {primary_key} ORDER BY
34 {open_date_column}) AS next_start_date
35 FROM {active_batch})
36 """
37
38 success_keys = (
39 "template_dict",
40 "threshold",
41 "query",
42 )
43
44 domain_keys = (
45 "template_dict",
46 "query",
47 "batch_id",
48 "row_condition",
49 "condition_parser",
50 )
51
52 default_kwarg_values = {
53 "result_format": "BASIC",
54 "include_config": True,
55 "catch_exceptions": False,
56 "meta": None,
57 "threshold": 0,
58 "query": query,
59 }
60
61 library_metadata = {"tags": ["query-based"], "contributors": ["@itaise"]}
62
63 def _validate(
64 self,
65 configuration: ExpectationConfiguration,
66 metrics: dict,
67 runtime_configuration: dict = None,
68 execution_engine: ExecutionEngine = None,
69 ) -> Union[ExpectationValidationResult, dict]:
70 threshold = configuration["kwargs"].get("threshold")
71 if not threshold:
72 threshold = self.default_kwarg_values["threshold"]
73
74 metrics = convert_to_json_serializable(data=metrics)
75 holes_count, total_count = list(
76 metrics.get("query.template_values")[0].values()
77 )[0]
78 error_rate = holes_count / total_count
79
80 return {
81 "success": error_rate <= threshold,
82 "result": {
83 "threshold": threshold,
84 "holes_count": holes_count,
85 "total_count": total_count,
86 },
87 }
88
89 today = datetime(year=2022, month=8, day=10)
90 one_day_ago = today - timedelta(days=1)
91 two_day_ago = today - timedelta(days=2)
92 three_day_ago = today - timedelta(days=3)
93 four_day_ago = today - timedelta(days=4)
94 five_day_ago = today - timedelta(days=5)
95 six_day_ago = today - timedelta(days=6)
96 seven_day_ago = today - timedelta(days=7)
97 eight_day_ago = today - timedelta(days=8)
98 nine_day_ago = today - timedelta(days=9)
99 ten_day_ago = today - timedelta(days=10)
100
101 examples = [
102 {
103 "data": [
104 {
105 "dataset_name": "test",
106 "data": {
107 "msid": [
108 "aaa",
109 "aaa",
110 "aaa",
111 "aaa",
112 "aaa",
113 "aaa",
114 "aaa",
115 "aaa",
116 "aaa",
117 ],
118 "uuid": [
119 "aaa",
120 "aaa",
121 "aaa",
122 "aaa",
123 "aaa",
124 "aaa",
125 "aaa",
126 "aaa",
127 "aaa",
128 ],
129 "col1": [1, 2, 2, 3, 4, 5, 6, 7, 8],
130 "col2": ["a", "a", "b", "b", "a", "a", "a", "a", "a"],
131 "start_date": [
132 ten_day_ago,
133 nine_day_ago,
134 eight_day_ago,
135 seven_day_ago,
136 six_day_ago,
137 five_day_ago,
138 four_day_ago,
139 three_day_ago,
140 two_day_ago,
141 ],
142 "end_date": [
143 nine_day_ago,
144 eight_day_ago,
145 seven_day_ago,
146 six_day_ago,
147 five_day_ago,
148 four_day_ago,
149 three_day_ago,
150 two_day_ago,
151 one_day_ago,
152 ],
153 "start_date_2": [
154 ten_day_ago,
155 seven_day_ago,
156 six_day_ago,
157 five_day_ago,
158 four_day_ago,
159 three_day_ago,
160 two_day_ago,
161 two_day_ago,
162 two_day_ago,
163 ],
164 "end_date_2": [
165 nine_day_ago,
166 six_day_ago,
167 six_day_ago,
168 five_day_ago,
169 four_day_ago,
170 three_day_ago,
171 two_day_ago,
172 two_day_ago,
173 two_day_ago,
174 ],
175 },
176 },
177 ],
178 "tests": [
179 {
180 "title": "basic_positive_test",
181 "exact_match_out": False,
182 "include_in_gallery": True,
183 "in": {
184 "template_dict": {
185 "primary_key": "msid,uuid",
186 "open_date_column": "start_date",
187 "close_date_column": "end_date",
188 }
189 },
190 "out": {"success": True},
191 "only_for": ["sqlite"],
192 },
193 {
194 "title": "basic_negative_test",
195 "exact_match_out": False,
196 "include_in_gallery": True,
197 "in": {
198 "template_dict": {
199 "primary_key": "msid,uuid",
200 "open_date_column": "start_date_2",
201 "close_date_column": "end_date_2",
202 },
203 "threshold": 0.1,
204 },
205 "out": {"success": False},
206 "only_for": ["sqlite"],
207 },
208 ],
209 "test_backends": [
210 {
211 "backend": "sqlalchemy",
212 "dialects": ["sqlite"],
213 }
214 ],
215 },
216 ]
217
218 def validate_configuration(
219 self, configuration: Optional[ExpectationConfiguration]
220 ) -> None:
221 super().validate_configuration(configuration)
222 threshold = configuration["kwargs"].get("threshold")
223 if not threshold:
224 threshold = self.default_kwarg_values["threshold"]
225
226 try:
227 assert isinstance(threshold, int) or isinstance(threshold, float)
228 assert threshold >= 0
229 assert threshold <= 1
230
231 except AssertionError as e:
232 raise InvalidExpectationConfigurationError(str(e))
233
234
235 if __name__ == "__main__":
236 ExpectQueriedSlowlyChangingTableToHaveNoGaps().print_diagnostic_checklist()
237
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/contrib/experimental/great_expectations_experimental/expectations/expect_queried_slowly_changing_table_to_have_no_gaps.py b/contrib/experimental/great_expectations_experimental/expectations/expect_queried_slowly_changing_table_to_have_no_gaps.py
--- a/contrib/experimental/great_expectations_experimental/expectations/expect_queried_slowly_changing_table_to_have_no_gaps.py
+++ b/contrib/experimental/great_expectations_experimental/expectations/expect_queried_slowly_changing_table_to_have_no_gaps.py
@@ -72,10 +72,12 @@
threshold = self.default_kwarg_values["threshold"]
metrics = convert_to_json_serializable(data=metrics)
+ holes_count: int
+ total_count: int
holes_count, total_count = list(
metrics.get("query.template_values")[0].values()
- )[0]
- error_rate = holes_count / total_count
+ )
+ error_rate = float(holes_count) / total_count
return {
"success": error_rate <= threshold,
|
{"golden_diff": "diff --git a/contrib/experimental/great_expectations_experimental/expectations/expect_queried_slowly_changing_table_to_have_no_gaps.py b/contrib/experimental/great_expectations_experimental/expectations/expect_queried_slowly_changing_table_to_have_no_gaps.py\n--- a/contrib/experimental/great_expectations_experimental/expectations/expect_queried_slowly_changing_table_to_have_no_gaps.py\n+++ b/contrib/experimental/great_expectations_experimental/expectations/expect_queried_slowly_changing_table_to_have_no_gaps.py\n@@ -72,10 +72,12 @@\n threshold = self.default_kwarg_values[\"threshold\"]\n \n metrics = convert_to_json_serializable(data=metrics)\n+ holes_count: int\n+ total_count: int\n holes_count, total_count = list(\n metrics.get(\"query.template_values\")[0].values()\n- )[0]\n- error_rate = holes_count / total_count\n+ )\n+ error_rate = float(holes_count) / total_count\n \n return {\n \"success\": error_rate <= threshold,\n", "issue": "Use cleaner solution for non-truncating division in python 2\nPrefer `from __future__ import division` to `1.*x/y`\n", "before_files": [{"content": "from datetime import datetime, timedelta\nfrom typing import Optional, Union\n\nfrom great_expectations.core.expectation_configuration import ExpectationConfiguration\nfrom great_expectations.core.util import convert_to_json_serializable\nfrom great_expectations.exceptions.exceptions import (\n InvalidExpectationConfigurationError,\n)\nfrom great_expectations.execution_engine import ExecutionEngine\nfrom great_expectations.expectations.expectation import (\n ExpectationValidationResult,\n QueryExpectation,\n)\n\n\nclass ExpectQueriedSlowlyChangingTableToHaveNoGaps(QueryExpectation):\n \"\"\"Expect Slowly changing table type II to have no gaps between the 'end date' of each row, and the next 'start date' in the next row.\n\n Args:\n template_dict: dict with the following keys: \\\n primary_key (primary key column name or multiple columns, comma separated), \\\n open_date_column (name of the column representing open date), \\\n close_date_column (name of the column representing clode date)\n threshold: an optional parameter - default is zero. \\\n if the ratio of \"gaps\" to total table rows is higher than threshold - error will be raised.\n \"\"\"\n\n metric_dependencies = (\"query.template_values\",)\n\n query = \"\"\"\n SELECT SUM(CASE WHEN {close_date_column} != COALESCE(next_start_date, {close_date_column}) THEN 1 ELSE 0 END),\n COUNT(1)\n FROM(SELECT {primary_key}, {close_date_column}, LEAD({open_date_column}) OVER(PARTITION BY {primary_key} ORDER BY\n {open_date_column}) AS next_start_date\n FROM {active_batch})\n \"\"\"\n\n success_keys = (\n \"template_dict\",\n \"threshold\",\n \"query\",\n )\n\n domain_keys = (\n \"template_dict\",\n \"query\",\n \"batch_id\",\n \"row_condition\",\n \"condition_parser\",\n )\n\n default_kwarg_values = {\n \"result_format\": \"BASIC\",\n \"include_config\": True,\n \"catch_exceptions\": False,\n \"meta\": None,\n \"threshold\": 0,\n \"query\": query,\n }\n\n library_metadata = {\"tags\": [\"query-based\"], \"contributors\": [\"@itaise\"]}\n\n def _validate(\n self,\n configuration: ExpectationConfiguration,\n metrics: dict,\n runtime_configuration: dict = None,\n execution_engine: ExecutionEngine = None,\n ) -> Union[ExpectationValidationResult, dict]:\n threshold = configuration[\"kwargs\"].get(\"threshold\")\n if not threshold:\n threshold = self.default_kwarg_values[\"threshold\"]\n\n metrics = convert_to_json_serializable(data=metrics)\n holes_count, total_count = list(\n metrics.get(\"query.template_values\")[0].values()\n )[0]\n error_rate = holes_count / total_count\n\n return {\n \"success\": error_rate <= threshold,\n \"result\": {\n \"threshold\": threshold,\n \"holes_count\": holes_count,\n \"total_count\": total_count,\n },\n }\n\n today = datetime(year=2022, month=8, day=10)\n one_day_ago = today - timedelta(days=1)\n two_day_ago = today - timedelta(days=2)\n three_day_ago = today - timedelta(days=3)\n four_day_ago = today - timedelta(days=4)\n five_day_ago = today - timedelta(days=5)\n six_day_ago = today - timedelta(days=6)\n seven_day_ago = today - timedelta(days=7)\n eight_day_ago = today - timedelta(days=8)\n nine_day_ago = today - timedelta(days=9)\n ten_day_ago = today - timedelta(days=10)\n\n examples = [\n {\n \"data\": [\n {\n \"dataset_name\": \"test\",\n \"data\": {\n \"msid\": [\n \"aaa\",\n \"aaa\",\n \"aaa\",\n \"aaa\",\n \"aaa\",\n \"aaa\",\n \"aaa\",\n \"aaa\",\n \"aaa\",\n ],\n \"uuid\": [\n \"aaa\",\n \"aaa\",\n \"aaa\",\n \"aaa\",\n \"aaa\",\n \"aaa\",\n \"aaa\",\n \"aaa\",\n \"aaa\",\n ],\n \"col1\": [1, 2, 2, 3, 4, 5, 6, 7, 8],\n \"col2\": [\"a\", \"a\", \"b\", \"b\", \"a\", \"a\", \"a\", \"a\", \"a\"],\n \"start_date\": [\n ten_day_ago,\n nine_day_ago,\n eight_day_ago,\n seven_day_ago,\n six_day_ago,\n five_day_ago,\n four_day_ago,\n three_day_ago,\n two_day_ago,\n ],\n \"end_date\": [\n nine_day_ago,\n eight_day_ago,\n seven_day_ago,\n six_day_ago,\n five_day_ago,\n four_day_ago,\n three_day_ago,\n two_day_ago,\n one_day_ago,\n ],\n \"start_date_2\": [\n ten_day_ago,\n seven_day_ago,\n six_day_ago,\n five_day_ago,\n four_day_ago,\n three_day_ago,\n two_day_ago,\n two_day_ago,\n two_day_ago,\n ],\n \"end_date_2\": [\n nine_day_ago,\n six_day_ago,\n six_day_ago,\n five_day_ago,\n four_day_ago,\n three_day_ago,\n two_day_ago,\n two_day_ago,\n two_day_ago,\n ],\n },\n },\n ],\n \"tests\": [\n {\n \"title\": \"basic_positive_test\",\n \"exact_match_out\": False,\n \"include_in_gallery\": True,\n \"in\": {\n \"template_dict\": {\n \"primary_key\": \"msid,uuid\",\n \"open_date_column\": \"start_date\",\n \"close_date_column\": \"end_date\",\n }\n },\n \"out\": {\"success\": True},\n \"only_for\": [\"sqlite\"],\n },\n {\n \"title\": \"basic_negative_test\",\n \"exact_match_out\": False,\n \"include_in_gallery\": True,\n \"in\": {\n \"template_dict\": {\n \"primary_key\": \"msid,uuid\",\n \"open_date_column\": \"start_date_2\",\n \"close_date_column\": \"end_date_2\",\n },\n \"threshold\": 0.1,\n },\n \"out\": {\"success\": False},\n \"only_for\": [\"sqlite\"],\n },\n ],\n \"test_backends\": [\n {\n \"backend\": \"sqlalchemy\",\n \"dialects\": [\"sqlite\"],\n }\n ],\n },\n ]\n\n def validate_configuration(\n self, configuration: Optional[ExpectationConfiguration]\n ) -> None:\n super().validate_configuration(configuration)\n threshold = configuration[\"kwargs\"].get(\"threshold\")\n if not threshold:\n threshold = self.default_kwarg_values[\"threshold\"]\n\n try:\n assert isinstance(threshold, int) or isinstance(threshold, float)\n assert threshold >= 0\n assert threshold <= 1\n\n except AssertionError as e:\n raise InvalidExpectationConfigurationError(str(e))\n\n\nif __name__ == \"__main__\":\n ExpectQueriedSlowlyChangingTableToHaveNoGaps().print_diagnostic_checklist()\n", "path": "contrib/experimental/great_expectations_experimental/expectations/expect_queried_slowly_changing_table_to_have_no_gaps.py"}], "after_files": [{"content": "from datetime import datetime, timedelta\nfrom typing import Optional, Union\n\nfrom great_expectations.core.expectation_configuration import ExpectationConfiguration\nfrom great_expectations.core.util import convert_to_json_serializable\nfrom great_expectations.exceptions.exceptions import (\n InvalidExpectationConfigurationError,\n)\nfrom great_expectations.execution_engine import ExecutionEngine\nfrom great_expectations.expectations.expectation import (\n ExpectationValidationResult,\n QueryExpectation,\n)\n\n\nclass ExpectQueriedSlowlyChangingTableToHaveNoGaps(QueryExpectation):\n \"\"\"Expect Slowly changing table type II to have no gaps between the 'end date' of each row, and the next 'start date' in the next row.\n\n Args:\n template_dict: dict with the following keys: \\\n primary_key (primary key column name or multiple columns, comma separated), \\\n open_date_column (name of the column representing open date), \\\n close_date_column (name of the column representing clode date)\n threshold: an optional parameter - default is zero. \\\n if the ratio of \"gaps\" to total table rows is higher than threshold - error will be raised.\n \"\"\"\n\n metric_dependencies = (\"query.template_values\",)\n\n query = \"\"\"\n SELECT SUM(CASE WHEN {close_date_column} != COALESCE(next_start_date, {close_date_column}) THEN 1 ELSE 0 END),\n COUNT(1)\n FROM(SELECT {primary_key}, {close_date_column}, LEAD({open_date_column}) OVER(PARTITION BY {primary_key} ORDER BY\n {open_date_column}) AS next_start_date\n FROM {active_batch})\n \"\"\"\n\n success_keys = (\n \"template_dict\",\n \"threshold\",\n \"query\",\n )\n\n domain_keys = (\n \"template_dict\",\n \"query\",\n \"batch_id\",\n \"row_condition\",\n \"condition_parser\",\n )\n\n default_kwarg_values = {\n \"result_format\": \"BASIC\",\n \"include_config\": True,\n \"catch_exceptions\": False,\n \"meta\": None,\n \"threshold\": 0,\n \"query\": query,\n }\n\n library_metadata = {\"tags\": [\"query-based\"], \"contributors\": [\"@itaise\"]}\n\n def _validate(\n self,\n configuration: ExpectationConfiguration,\n metrics: dict,\n runtime_configuration: dict = None,\n execution_engine: ExecutionEngine = None,\n ) -> Union[ExpectationValidationResult, dict]:\n threshold = configuration[\"kwargs\"].get(\"threshold\")\n if not threshold:\n threshold = self.default_kwarg_values[\"threshold\"]\n\n metrics = convert_to_json_serializable(data=metrics)\n holes_count: int\n total_count: int\n holes_count, total_count = list(\n metrics.get(\"query.template_values\")[0].values()\n )\n error_rate = float(holes_count) / total_count\n\n return {\n \"success\": error_rate <= threshold,\n \"result\": {\n \"threshold\": threshold,\n \"holes_count\": holes_count,\n \"total_count\": total_count,\n },\n }\n\n today = datetime(year=2022, month=8, day=10)\n one_day_ago = today - timedelta(days=1)\n two_day_ago = today - timedelta(days=2)\n three_day_ago = today - timedelta(days=3)\n four_day_ago = today - timedelta(days=4)\n five_day_ago = today - timedelta(days=5)\n six_day_ago = today - timedelta(days=6)\n seven_day_ago = today - timedelta(days=7)\n eight_day_ago = today - timedelta(days=8)\n nine_day_ago = today - timedelta(days=9)\n ten_day_ago = today - timedelta(days=10)\n\n examples = [\n {\n \"data\": [\n {\n \"dataset_name\": \"test\",\n \"data\": {\n \"msid\": [\n \"aaa\",\n \"aaa\",\n \"aaa\",\n \"aaa\",\n \"aaa\",\n \"aaa\",\n \"aaa\",\n \"aaa\",\n \"aaa\",\n ],\n \"uuid\": [\n \"aaa\",\n \"aaa\",\n \"aaa\",\n \"aaa\",\n \"aaa\",\n \"aaa\",\n \"aaa\",\n \"aaa\",\n \"aaa\",\n ],\n \"col1\": [1, 2, 2, 3, 4, 5, 6, 7, 8],\n \"col2\": [\"a\", \"a\", \"b\", \"b\", \"a\", \"a\", \"a\", \"a\", \"a\"],\n \"start_date\": [\n ten_day_ago,\n nine_day_ago,\n eight_day_ago,\n seven_day_ago,\n six_day_ago,\n five_day_ago,\n four_day_ago,\n three_day_ago,\n two_day_ago,\n ],\n \"end_date\": [\n nine_day_ago,\n eight_day_ago,\n seven_day_ago,\n six_day_ago,\n five_day_ago,\n four_day_ago,\n three_day_ago,\n two_day_ago,\n one_day_ago,\n ],\n \"start_date_2\": [\n ten_day_ago,\n seven_day_ago,\n six_day_ago,\n five_day_ago,\n four_day_ago,\n three_day_ago,\n two_day_ago,\n two_day_ago,\n two_day_ago,\n ],\n \"end_date_2\": [\n nine_day_ago,\n six_day_ago,\n six_day_ago,\n five_day_ago,\n four_day_ago,\n three_day_ago,\n two_day_ago,\n two_day_ago,\n two_day_ago,\n ],\n },\n },\n ],\n \"tests\": [\n {\n \"title\": \"basic_positive_test\",\n \"exact_match_out\": False,\n \"include_in_gallery\": True,\n \"in\": {\n \"template_dict\": {\n \"primary_key\": \"msid,uuid\",\n \"open_date_column\": \"start_date\",\n \"close_date_column\": \"end_date\",\n }\n },\n \"out\": {\"success\": True},\n \"only_for\": [\"sqlite\"],\n },\n {\n \"title\": \"basic_negative_test\",\n \"exact_match_out\": False,\n \"include_in_gallery\": True,\n \"in\": {\n \"template_dict\": {\n \"primary_key\": \"msid,uuid\",\n \"open_date_column\": \"start_date_2\",\n \"close_date_column\": \"end_date_2\",\n },\n \"threshold\": 0.1,\n },\n \"out\": {\"success\": False},\n \"only_for\": [\"sqlite\"],\n },\n ],\n \"test_backends\": [\n {\n \"backend\": \"sqlalchemy\",\n \"dialects\": [\"sqlite\"],\n }\n ],\n },\n ]\n\n def validate_configuration(\n self, configuration: Optional[ExpectationConfiguration]\n ) -> None:\n super().validate_configuration(configuration)\n threshold = configuration[\"kwargs\"].get(\"threshold\")\n if not threshold:\n threshold = self.default_kwarg_values[\"threshold\"]\n\n try:\n assert isinstance(threshold, int) or isinstance(threshold, float)\n assert threshold >= 0\n assert threshold <= 1\n\n except AssertionError as e:\n raise InvalidExpectationConfigurationError(str(e))\n\n\nif __name__ == \"__main__\":\n ExpectQueriedSlowlyChangingTableToHaveNoGaps().print_diagnostic_checklist()\n", "path": "contrib/experimental/great_expectations_experimental/expectations/expect_queried_slowly_changing_table_to_have_no_gaps.py"}]}
| 2,516 | 246 |
gh_patches_debug_28251
|
rasdani/github-patches
|
git_diff
|
Lightning-AI__pytorch-lightning-3684
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
DataModules should have a reference to the Trainer
## 🚀 Feature
The DataModule should have a reference to the Trainer, so attributes on the Trainer can be accessed during prepare_data, setup, and the dataloader methods.
cc @nateraw
### Motivation
Further uncouple datamodules and lightning modules. For instance, it can be useful for DataModules to know what the current epoch is during training. If I want to use the DataModules, I don't have access to this. However this is readily available if I define my `train_dataloader` in the LightningModule instead.
### Pitch
We can follow the same setup that LightningModules have and how the trainer is initialized for them
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pytorch_lightning/trainer/connectors/data_connector.py`
Content:
```
1 # Copyright The PyTorch Lightning team.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from pytorch_lightning.core.datamodule import LightningDataModule
16 from pytorch_lightning.utilities.exceptions import MisconfigurationException
17 from typing import List, Union
18 from torch.utils.data import DataLoader
19 from pytorch_lightning.utilities.model_utils import is_overridden
20
21
22 class DataConnector(object):
23
24 def __init__(self, trainer):
25 self.trainer = trainer
26
27 def on_trainer_init(self, check_val_every_n_epoch, reload_dataloaders_every_epoch, prepare_data_per_node):
28 self.trainer.datamodule = None
29 self.trainer.prepare_data_per_node = prepare_data_per_node
30
31 self.trainer.check_val_every_n_epoch = check_val_every_n_epoch
32 self.trainer.reload_dataloaders_every_epoch = reload_dataloaders_every_epoch
33 self.trainer._is_data_prepared = False
34
35 def get_profiled_train_dataloader(self, train_dataloader):
36 profiled_dl = self.trainer.profiler.profile_iterable(
37 enumerate(self._with_is_last(train_dataloader)),
38 "get_train_batch"
39 )
40 return profiled_dl
41
42 def _with_is_last(self, iterable):
43 """Pass through values from the given iterable with an added boolean indicating if this is the last item.
44 See `https://stackoverflow.com/a/1630350 <https://stackoverflow.com/a/1630350>`_"""
45 it = iter(iterable)
46 last = next(it)
47 for val in it:
48 # yield last and has next
49 yield last, False
50 last = val
51 # yield last, no longer has next
52 yield last, True
53
54 def prepare_data(self, model):
55 # on multi-gpu jobs we only want to manipulate (download, etc) on node_rank=0, local_rank=0
56 # or in the case where each node needs to do its own manipulation in which case just local_rank=0
57 if self.can_prepare_data():
58 if self.trainer.datamodule is not None:
59 self.trainer.datamodule.prepare_data()
60 model.prepare_data()
61 self.trainer._is_data_prepared = True
62
63 def can_prepare_data(self):
64 should_call_dm_prepare_data = True
65 if self.trainer.datamodule is not None and is_overridden('prepare_data', self.trainer.datamodule):
66 should_call_dm_prepare_data = not self.trainer.datamodule.has_prepared_data
67
68 if self.trainer.prepare_data_per_node:
69 return self.trainer.local_rank == 0 and should_call_dm_prepare_data
70 else:
71 return self.trainer.node_rank == 0 and self.trainer.local_rank == 0 and should_call_dm_prepare_data
72
73 def attach_data(self, model, train_dataloader, val_dataloaders, datamodule):
74 # if a datamodule comes in as the second arg, then fix it for the user
75 if isinstance(train_dataloader, LightningDataModule):
76 datamodule = train_dataloader
77 train_dataloader = None
78
79 self.__enforce_datamodule_dataloader_override(train_dataloader, val_dataloaders, datamodule)
80
81 # set up the passed in dataloaders (if needed)
82 self.attach_dataloaders(model, train_dataloader, val_dataloaders)
83 self.attach_datamodule(model, datamodule, 'fit')
84
85 def __enforce_datamodule_dataloader_override(self, train_dataloader, val_dataloaders, datamodule):
86 # If you supply a datamodule you can't supply train_dataloader or val_dataloaders
87 if (train_dataloader is not None or val_dataloaders is not None) and datamodule is not None:
88 raise MisconfigurationException(
89 'You cannot pass train_dataloader or val_dataloaders to trainer.fit if you supply a datamodule'
90 )
91
92 def attach_dataloaders(self, model, train_dataloader=None, val_dataloaders=None, test_dataloaders=None):
93 # when dataloader is passed via fit, patch the train_dataloader
94 # functions to overwrite with these implementations
95 if train_dataloader is not None:
96 model.train_dataloader = _PatchDataLoader(train_dataloader)
97
98 if val_dataloaders is not None:
99 model.val_dataloader = _PatchDataLoader(val_dataloaders)
100
101 if test_dataloaders is not None:
102 model.test_dataloader = _PatchDataLoader(test_dataloaders)
103
104 def attach_datamodule(self, model, datamodule, stage):
105
106 # We use datamodule if it's been provided on .fit or .test, otherwise we check model for it
107 datamodule = datamodule or getattr(model, 'datamodule', None)
108
109 # If we have a datamodule, attach necessary hooks + dataloaders
110 if datamodule:
111
112 # Override loader hooks
113 if is_overridden('train_dataloader', datamodule):
114 model.train_dataloader = datamodule.train_dataloader
115 if is_overridden('val_dataloader', datamodule):
116 model.val_dataloader = datamodule.val_dataloader
117 if is_overridden('test_dataloader', datamodule):
118 model.test_dataloader = datamodule.test_dataloader
119
120 # Override transfer_batch_to_device if dataset-specific to_device logic has been defined in datamodule
121 if is_overridden('transfer_batch_to_device', datamodule):
122 model.transfer_batch_to_device = datamodule.transfer_batch_to_device
123
124 self.trainer.datamodule = datamodule
125
126
127 class _PatchDataLoader(object):
128 r"""
129 Callable object for patching dataloaders passed into trainer.fit().
130 Use this class to override model.*_dataloader() and be pickle-compatible.
131
132 Args:
133 dataloader: Dataloader object to return when called.
134
135 """
136
137 def __init__(self, dataloader: Union[List[DataLoader], DataLoader]):
138 self.dataloader = dataloader
139
140 # cannot pickle __code__ so cannot verify if PatchDataloader
141 # exists which shows dataloader methods have been overwritten.
142 # so, we hack it by using the string representation
143 self.patch_loader_code = str(self.__call__.__code__)
144
145 def __call__(self) -> Union[List[DataLoader], DataLoader]:
146 return self.dataloader
147
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pytorch_lightning/trainer/connectors/data_connector.py b/pytorch_lightning/trainer/connectors/data_connector.py
--- a/pytorch_lightning/trainer/connectors/data_connector.py
+++ b/pytorch_lightning/trainer/connectors/data_connector.py
@@ -14,7 +14,7 @@
from pytorch_lightning.core.datamodule import LightningDataModule
from pytorch_lightning.utilities.exceptions import MisconfigurationException
-from typing import List, Union
+from typing import List, Optional, Union
from torch.utils.data import DataLoader
from pytorch_lightning.utilities.model_utils import is_overridden
@@ -101,7 +101,7 @@
if test_dataloaders is not None:
model.test_dataloader = _PatchDataLoader(test_dataloaders)
- def attach_datamodule(self, model, datamodule, stage):
+ def attach_datamodule(self, model, datamodule: Optional[LightningDataModule], stage: str) -> None:
# We use datamodule if it's been provided on .fit or .test, otherwise we check model for it
datamodule = datamodule or getattr(model, 'datamodule', None)
@@ -122,6 +122,7 @@
model.transfer_batch_to_device = datamodule.transfer_batch_to_device
self.trainer.datamodule = datamodule
+ datamodule.trainer = self.trainer
class _PatchDataLoader(object):
|
{"golden_diff": "diff --git a/pytorch_lightning/trainer/connectors/data_connector.py b/pytorch_lightning/trainer/connectors/data_connector.py\n--- a/pytorch_lightning/trainer/connectors/data_connector.py\n+++ b/pytorch_lightning/trainer/connectors/data_connector.py\n@@ -14,7 +14,7 @@\n \n from pytorch_lightning.core.datamodule import LightningDataModule\n from pytorch_lightning.utilities.exceptions import MisconfigurationException\n-from typing import List, Union\n+from typing import List, Optional, Union\n from torch.utils.data import DataLoader\n from pytorch_lightning.utilities.model_utils import is_overridden\n \n@@ -101,7 +101,7 @@\n if test_dataloaders is not None:\n model.test_dataloader = _PatchDataLoader(test_dataloaders)\n \n- def attach_datamodule(self, model, datamodule, stage):\n+ def attach_datamodule(self, model, datamodule: Optional[LightningDataModule], stage: str) -> None:\n \n # We use datamodule if it's been provided on .fit or .test, otherwise we check model for it\n datamodule = datamodule or getattr(model, 'datamodule', None)\n@@ -122,6 +122,7 @@\n model.transfer_batch_to_device = datamodule.transfer_batch_to_device\n \n self.trainer.datamodule = datamodule\n+ datamodule.trainer = self.trainer\n \n \n class _PatchDataLoader(object):\n", "issue": "DataModules should have a reference to the Trainer\n## \ud83d\ude80 Feature\r\nThe DataModule should have a reference to the Trainer, so attributes on the Trainer can be accessed during prepare_data, setup, and the dataloader methods. \r\n\r\ncc @nateraw \r\n\r\n### Motivation\r\nFurther uncouple datamodules and lightning modules. For instance, it can be useful for DataModules to know what the current epoch is during training. If I want to use the DataModules, I don't have access to this. However this is readily available if I define my `train_dataloader` in the LightningModule instead. \r\n\r\n\r\n### Pitch\r\nWe can follow the same setup that LightningModules have and how the trainer is initialized for them\r\n\n", "before_files": [{"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom pytorch_lightning.core.datamodule import LightningDataModule\nfrom pytorch_lightning.utilities.exceptions import MisconfigurationException\nfrom typing import List, Union\nfrom torch.utils.data import DataLoader\nfrom pytorch_lightning.utilities.model_utils import is_overridden\n\n\nclass DataConnector(object):\n\n def __init__(self, trainer):\n self.trainer = trainer\n\n def on_trainer_init(self, check_val_every_n_epoch, reload_dataloaders_every_epoch, prepare_data_per_node):\n self.trainer.datamodule = None\n self.trainer.prepare_data_per_node = prepare_data_per_node\n\n self.trainer.check_val_every_n_epoch = check_val_every_n_epoch\n self.trainer.reload_dataloaders_every_epoch = reload_dataloaders_every_epoch\n self.trainer._is_data_prepared = False\n\n def get_profiled_train_dataloader(self, train_dataloader):\n profiled_dl = self.trainer.profiler.profile_iterable(\n enumerate(self._with_is_last(train_dataloader)),\n \"get_train_batch\"\n )\n return profiled_dl\n\n def _with_is_last(self, iterable):\n \"\"\"Pass through values from the given iterable with an added boolean indicating if this is the last item.\n See `https://stackoverflow.com/a/1630350 <https://stackoverflow.com/a/1630350>`_\"\"\"\n it = iter(iterable)\n last = next(it)\n for val in it:\n # yield last and has next\n yield last, False\n last = val\n # yield last, no longer has next\n yield last, True\n\n def prepare_data(self, model):\n # on multi-gpu jobs we only want to manipulate (download, etc) on node_rank=0, local_rank=0\n # or in the case where each node needs to do its own manipulation in which case just local_rank=0\n if self.can_prepare_data():\n if self.trainer.datamodule is not None:\n self.trainer.datamodule.prepare_data()\n model.prepare_data()\n self.trainer._is_data_prepared = True\n\n def can_prepare_data(self):\n should_call_dm_prepare_data = True\n if self.trainer.datamodule is not None and is_overridden('prepare_data', self.trainer.datamodule):\n should_call_dm_prepare_data = not self.trainer.datamodule.has_prepared_data\n\n if self.trainer.prepare_data_per_node:\n return self.trainer.local_rank == 0 and should_call_dm_prepare_data\n else:\n return self.trainer.node_rank == 0 and self.trainer.local_rank == 0 and should_call_dm_prepare_data\n\n def attach_data(self, model, train_dataloader, val_dataloaders, datamodule):\n # if a datamodule comes in as the second arg, then fix it for the user\n if isinstance(train_dataloader, LightningDataModule):\n datamodule = train_dataloader\n train_dataloader = None\n\n self.__enforce_datamodule_dataloader_override(train_dataloader, val_dataloaders, datamodule)\n\n # set up the passed in dataloaders (if needed)\n self.attach_dataloaders(model, train_dataloader, val_dataloaders)\n self.attach_datamodule(model, datamodule, 'fit')\n\n def __enforce_datamodule_dataloader_override(self, train_dataloader, val_dataloaders, datamodule):\n # If you supply a datamodule you can't supply train_dataloader or val_dataloaders\n if (train_dataloader is not None or val_dataloaders is not None) and datamodule is not None:\n raise MisconfigurationException(\n 'You cannot pass train_dataloader or val_dataloaders to trainer.fit if you supply a datamodule'\n )\n\n def attach_dataloaders(self, model, train_dataloader=None, val_dataloaders=None, test_dataloaders=None):\n # when dataloader is passed via fit, patch the train_dataloader\n # functions to overwrite with these implementations\n if train_dataloader is not None:\n model.train_dataloader = _PatchDataLoader(train_dataloader)\n\n if val_dataloaders is not None:\n model.val_dataloader = _PatchDataLoader(val_dataloaders)\n\n if test_dataloaders is not None:\n model.test_dataloader = _PatchDataLoader(test_dataloaders)\n\n def attach_datamodule(self, model, datamodule, stage):\n\n # We use datamodule if it's been provided on .fit or .test, otherwise we check model for it\n datamodule = datamodule or getattr(model, 'datamodule', None)\n\n # If we have a datamodule, attach necessary hooks + dataloaders\n if datamodule:\n\n # Override loader hooks\n if is_overridden('train_dataloader', datamodule):\n model.train_dataloader = datamodule.train_dataloader\n if is_overridden('val_dataloader', datamodule):\n model.val_dataloader = datamodule.val_dataloader\n if is_overridden('test_dataloader', datamodule):\n model.test_dataloader = datamodule.test_dataloader\n\n # Override transfer_batch_to_device if dataset-specific to_device logic has been defined in datamodule\n if is_overridden('transfer_batch_to_device', datamodule):\n model.transfer_batch_to_device = datamodule.transfer_batch_to_device\n\n self.trainer.datamodule = datamodule\n\n\nclass _PatchDataLoader(object):\n r\"\"\"\n Callable object for patching dataloaders passed into trainer.fit().\n Use this class to override model.*_dataloader() and be pickle-compatible.\n\n Args:\n dataloader: Dataloader object to return when called.\n\n \"\"\"\n\n def __init__(self, dataloader: Union[List[DataLoader], DataLoader]):\n self.dataloader = dataloader\n\n # cannot pickle __code__ so cannot verify if PatchDataloader\n # exists which shows dataloader methods have been overwritten.\n # so, we hack it by using the string representation\n self.patch_loader_code = str(self.__call__.__code__)\n\n def __call__(self) -> Union[List[DataLoader], DataLoader]:\n return self.dataloader\n", "path": "pytorch_lightning/trainer/connectors/data_connector.py"}], "after_files": [{"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom pytorch_lightning.core.datamodule import LightningDataModule\nfrom pytorch_lightning.utilities.exceptions import MisconfigurationException\nfrom typing import List, Optional, Union\nfrom torch.utils.data import DataLoader\nfrom pytorch_lightning.utilities.model_utils import is_overridden\n\n\nclass DataConnector(object):\n\n def __init__(self, trainer):\n self.trainer = trainer\n\n def on_trainer_init(self, check_val_every_n_epoch, reload_dataloaders_every_epoch, prepare_data_per_node):\n self.trainer.datamodule = None\n self.trainer.prepare_data_per_node = prepare_data_per_node\n\n self.trainer.check_val_every_n_epoch = check_val_every_n_epoch\n self.trainer.reload_dataloaders_every_epoch = reload_dataloaders_every_epoch\n self.trainer._is_data_prepared = False\n\n def get_profiled_train_dataloader(self, train_dataloader):\n profiled_dl = self.trainer.profiler.profile_iterable(\n enumerate(self._with_is_last(train_dataloader)),\n \"get_train_batch\"\n )\n return profiled_dl\n\n def _with_is_last(self, iterable):\n \"\"\"Pass through values from the given iterable with an added boolean indicating if this is the last item.\n See `https://stackoverflow.com/a/1630350 <https://stackoverflow.com/a/1630350>`_\"\"\"\n it = iter(iterable)\n last = next(it)\n for val in it:\n # yield last and has next\n yield last, False\n last = val\n # yield last, no longer has next\n yield last, True\n\n def prepare_data(self, model):\n # on multi-gpu jobs we only want to manipulate (download, etc) on node_rank=0, local_rank=0\n # or in the case where each node needs to do its own manipulation in which case just local_rank=0\n if self.can_prepare_data():\n if self.trainer.datamodule is not None:\n self.trainer.datamodule.prepare_data()\n model.prepare_data()\n self.trainer._is_data_prepared = True\n\n def can_prepare_data(self):\n should_call_dm_prepare_data = True\n if self.trainer.datamodule is not None and is_overridden('prepare_data', self.trainer.datamodule):\n should_call_dm_prepare_data = not self.trainer.datamodule.has_prepared_data\n\n if self.trainer.prepare_data_per_node:\n return self.trainer.local_rank == 0 and should_call_dm_prepare_data\n else:\n return self.trainer.node_rank == 0 and self.trainer.local_rank == 0 and should_call_dm_prepare_data\n\n def attach_data(self, model, train_dataloader, val_dataloaders, datamodule):\n # if a datamodule comes in as the second arg, then fix it for the user\n if isinstance(train_dataloader, LightningDataModule):\n datamodule = train_dataloader\n train_dataloader = None\n\n self.__enforce_datamodule_dataloader_override(train_dataloader, val_dataloaders, datamodule)\n\n # set up the passed in dataloaders (if needed)\n self.attach_dataloaders(model, train_dataloader, val_dataloaders)\n self.attach_datamodule(model, datamodule, 'fit')\n\n def __enforce_datamodule_dataloader_override(self, train_dataloader, val_dataloaders, datamodule):\n # If you supply a datamodule you can't supply train_dataloader or val_dataloaders\n if (train_dataloader is not None or val_dataloaders is not None) and datamodule is not None:\n raise MisconfigurationException(\n 'You cannot pass train_dataloader or val_dataloaders to trainer.fit if you supply a datamodule'\n )\n\n def attach_dataloaders(self, model, train_dataloader=None, val_dataloaders=None, test_dataloaders=None):\n # when dataloader is passed via fit, patch the train_dataloader\n # functions to overwrite with these implementations\n if train_dataloader is not None:\n model.train_dataloader = _PatchDataLoader(train_dataloader)\n\n if val_dataloaders is not None:\n model.val_dataloader = _PatchDataLoader(val_dataloaders)\n\n if test_dataloaders is not None:\n model.test_dataloader = _PatchDataLoader(test_dataloaders)\n\n def attach_datamodule(self, model, datamodule: Optional[LightningDataModule], stage: str) -> None:\n\n # We use datamodule if it's been provided on .fit or .test, otherwise we check model for it\n datamodule = datamodule or getattr(model, 'datamodule', None)\n\n # If we have a datamodule, attach necessary hooks + dataloaders\n if datamodule:\n\n # Override loader hooks\n if is_overridden('train_dataloader', datamodule):\n model.train_dataloader = datamodule.train_dataloader\n if is_overridden('val_dataloader', datamodule):\n model.val_dataloader = datamodule.val_dataloader\n if is_overridden('test_dataloader', datamodule):\n model.test_dataloader = datamodule.test_dataloader\n\n # Override transfer_batch_to_device if dataset-specific to_device logic has been defined in datamodule\n if is_overridden('transfer_batch_to_device', datamodule):\n model.transfer_batch_to_device = datamodule.transfer_batch_to_device\n\n self.trainer.datamodule = datamodule\n datamodule.trainer = self.trainer\n\n\nclass _PatchDataLoader(object):\n r\"\"\"\n Callable object for patching dataloaders passed into trainer.fit().\n Use this class to override model.*_dataloader() and be pickle-compatible.\n\n Args:\n dataloader: Dataloader object to return when called.\n\n \"\"\"\n\n def __init__(self, dataloader: Union[List[DataLoader], DataLoader]):\n self.dataloader = dataloader\n\n # cannot pickle __code__ so cannot verify if PatchDataloader\n # exists which shows dataloader methods have been overwritten.\n # so, we hack it by using the string representation\n self.patch_loader_code = str(self.__call__.__code__)\n\n def __call__(self) -> Union[List[DataLoader], DataLoader]:\n return self.dataloader\n", "path": "pytorch_lightning/trainer/connectors/data_connector.py"}]}
| 2,261 | 327 |
gh_patches_debug_26319
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-center-index-5256
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[package] fontconfig/2.13.93: Please make gettext dependency optional
### Package and Environment Details (include every applicable attribute)
* Package Name/Version: **fontconfig/2.13.93**
* Operating System+version: **MacOs**
The current recipe adds an unconditional dependency on libgettext/0.20.1 on MacOs.
Since libgettext is licensed under GPLv3, it places an additional license restriction to an otherwise more liberally licensed library.
</details>
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `recipes/fontconfig/all/conanfile.py`
Content:
```
1 import os
2 import glob
3
4 from conans import ConanFile, tools, AutoToolsBuildEnvironment
5 from conans.errors import ConanInvalidConfiguration
6
7
8 class FontconfigConan(ConanFile):
9 name = "fontconfig"
10 license = "MIT"
11 url = "https://github.com/conan-io/conan-center-index"
12 description = "Fontconfig is a library for configuring and customizing font access"
13 homepage = "https://gitlab.freedesktop.org/fontconfig/fontconfig"
14 topics = ("conan", "fontconfig", "fonts", "freedesktop")
15 settings = "os", "compiler", "build_type", "arch"
16 options = {"shared": [True, False], "fPIC": [True, False]}
17 default_options = {"shared": False, "fPIC": True}
18 generators = "pkg_config"
19
20 _autotools = None
21
22 @property
23 def _source_subfolder(self):
24 return "source_subfolder"
25
26 def config_options(self):
27 if self.settings.os == "Windows":
28 del self.options.fPIC
29
30 def configure(self):
31 if self.settings.compiler == "Visual Studio":
32 raise ConanInvalidConfiguration("Visual Studio builds are not supported.")
33 if self.options.shared:
34 del self.options.fPIC
35 del self.settings.compiler.libcxx
36 del self.settings.compiler.cppstd
37
38 def requirements(self):
39 self.requires("freetype/2.10.4")
40 self.requires("expat/2.2.10")
41 if self.settings.os == "Linux":
42 self.requires("libuuid/1.0.3")
43 elif self.settings.os == "Macos":
44 self.requires("libgettext/0.20.1")
45
46 def build_requirements(self):
47 self.build_requires("gperf/3.1")
48 self.build_requires("pkgconf/1.7.3")
49 if tools.os_info.is_windows and not tools.get_env("CONAN_BASH_PATH"):
50 self.build_requires("msys2/20200517")
51
52 def source(self):
53 tools.get(**self.conan_data["sources"][self.version])
54 extrated_dir = self.name + "-" + self.version
55 os.rename(extrated_dir, self._source_subfolder)
56
57 def _configure_autotools(self):
58 if not self._autotools:
59 args = ["--enable-static=%s" % ("no" if self.options.shared else "yes"),
60 "--enable-shared=%s" % ("yes" if self.options.shared else "no"),
61 "--disable-docs"]
62 args.append("--sysconfdir=%s" % tools.unix_path(os.path.join(self.package_folder, "bin", "etc")))
63 args.append("--datadir=%s" % tools.unix_path(os.path.join(self.package_folder, "bin", "share")))
64 args.append("--datarootdir=%s" % tools.unix_path(os.path.join(self.package_folder, "bin", "share")))
65 args.append("--localstatedir=%s" % tools.unix_path(os.path.join(self.package_folder, "bin", "var")))
66 self._autotools = AutoToolsBuildEnvironment(self, win_bash=tools.os_info.is_windows)
67 self._autotools.libs = []
68 self._autotools.configure(configure_dir=self._source_subfolder, args=args)
69 tools.replace_in_file("Makefile", "po-conf test", "po-conf")
70 return self._autotools
71
72 def _patch_files(self):
73 # - fontconfig requires libtool version number, change it for the corresponding freetype one
74 tools.replace_in_file(os.path.join(self._source_subfolder, 'configure'), '21.0.15', '2.8.1')
75
76 def build(self):
77 # Patch files from dependencies
78 self._patch_files()
79 with tools.run_environment(self):
80 autotools = self._configure_autotools()
81 autotools.make()
82
83 def package(self):
84 self.copy("COPYING", dst="licenses", src=self._source_subfolder)
85 with tools.run_environment(self):
86 autotools = self._configure_autotools()
87 autotools.install()
88 os.unlink(os.path.join(self.package_folder, "lib", "libfontconfig.la"))
89 tools.rmdir(os.path.join(self.package_folder, "lib", "pkgconfig"))
90 for f in glob.glob(os.path.join(self.package_folder, "bin", "etc", "fonts", "conf.d", "*.conf")):
91 if os.path.islink(f):
92 os.unlink(f)
93 for def_file in glob.glob(os.path.join(self.package_folder, "lib", "*.def")):
94 os.remove(def_file)
95
96 def package_info(self):
97 self.cpp_info.libs = ["fontconfig"]
98 if self.settings.os in ["Linux", "FreeBSD"]:
99 self.cpp_info.system_libs.extend(["m", "pthread"])
100 self.cpp_info.names["cmake_find_package"] = "Fontconfig"
101 self.cpp_info.names["cmake_find_package_multi"] = "Fontconfig"
102
103 fontconfig_file = os.path.join(self.package_folder, "bin", "etc", "fonts", "fonts.conf")
104 self.output.info("Creating FONTCONFIG_FILE environment variable: {}".format(fontconfig_file))
105 self.env_info.FONTCONFIG_FILE = fontconfig_file
106 fontconfig_path = os.path.join(self.package_folder, "bin", "etc", "fonts")
107 self.output.info("Creating FONTCONFIG_PATH environment variable: {}".format(fontconfig_path))
108 self.env_info.FONTCONFIG_PATH = fontconfig_path
109
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/recipes/fontconfig/all/conanfile.py b/recipes/fontconfig/all/conanfile.py
--- a/recipes/fontconfig/all/conanfile.py
+++ b/recipes/fontconfig/all/conanfile.py
@@ -40,8 +40,6 @@
self.requires("expat/2.2.10")
if self.settings.os == "Linux":
self.requires("libuuid/1.0.3")
- elif self.settings.os == "Macos":
- self.requires("libgettext/0.20.1")
def build_requirements(self):
self.build_requires("gperf/3.1")
@@ -58,7 +56,9 @@
if not self._autotools:
args = ["--enable-static=%s" % ("no" if self.options.shared else "yes"),
"--enable-shared=%s" % ("yes" if self.options.shared else "no"),
- "--disable-docs"]
+ "--disable-docs",
+ "--disable-nls",
+ ]
args.append("--sysconfdir=%s" % tools.unix_path(os.path.join(self.package_folder, "bin", "etc")))
args.append("--datadir=%s" % tools.unix_path(os.path.join(self.package_folder, "bin", "share")))
args.append("--datarootdir=%s" % tools.unix_path(os.path.join(self.package_folder, "bin", "share")))
|
{"golden_diff": "diff --git a/recipes/fontconfig/all/conanfile.py b/recipes/fontconfig/all/conanfile.py\n--- a/recipes/fontconfig/all/conanfile.py\n+++ b/recipes/fontconfig/all/conanfile.py\n@@ -40,8 +40,6 @@\n self.requires(\"expat/2.2.10\")\n if self.settings.os == \"Linux\":\n self.requires(\"libuuid/1.0.3\")\n- elif self.settings.os == \"Macos\":\n- self.requires(\"libgettext/0.20.1\")\n \n def build_requirements(self):\n self.build_requires(\"gperf/3.1\")\n@@ -58,7 +56,9 @@\n if not self._autotools:\n args = [\"--enable-static=%s\" % (\"no\" if self.options.shared else \"yes\"),\n \"--enable-shared=%s\" % (\"yes\" if self.options.shared else \"no\"),\n- \"--disable-docs\"]\n+ \"--disable-docs\",\n+ \"--disable-nls\",\n+ ]\n args.append(\"--sysconfdir=%s\" % tools.unix_path(os.path.join(self.package_folder, \"bin\", \"etc\")))\n args.append(\"--datadir=%s\" % tools.unix_path(os.path.join(self.package_folder, \"bin\", \"share\")))\n args.append(\"--datarootdir=%s\" % tools.unix_path(os.path.join(self.package_folder, \"bin\", \"share\")))\n", "issue": "[package] fontconfig/2.13.93: Please make gettext dependency optional\n### Package and Environment Details (include every applicable attribute)\r\n * Package Name/Version: **fontconfig/2.13.93**\r\n * Operating System+version: **MacOs**\r\n\r\nThe current recipe adds an unconditional dependency on libgettext/0.20.1 on MacOs.\r\n\r\nSince libgettext is licensed under GPLv3, it places an additional license restriction to an otherwise more liberally licensed library.\r\n\r\n</details>\r\n\n", "before_files": [{"content": "import os\nimport glob\n\nfrom conans import ConanFile, tools, AutoToolsBuildEnvironment\nfrom conans.errors import ConanInvalidConfiguration\n\n\nclass FontconfigConan(ConanFile):\n name = \"fontconfig\"\n license = \"MIT\"\n url = \"https://github.com/conan-io/conan-center-index\"\n description = \"Fontconfig is a library for configuring and customizing font access\"\n homepage = \"https://gitlab.freedesktop.org/fontconfig/fontconfig\"\n topics = (\"conan\", \"fontconfig\", \"fonts\", \"freedesktop\")\n settings = \"os\", \"compiler\", \"build_type\", \"arch\"\n options = {\"shared\": [True, False], \"fPIC\": [True, False]}\n default_options = {\"shared\": False, \"fPIC\": True}\n generators = \"pkg_config\"\n\n _autotools = None\n\n @property\n def _source_subfolder(self):\n return \"source_subfolder\"\n\n def config_options(self):\n if self.settings.os == \"Windows\":\n del self.options.fPIC\n\n def configure(self):\n if self.settings.compiler == \"Visual Studio\":\n raise ConanInvalidConfiguration(\"Visual Studio builds are not supported.\")\n if self.options.shared:\n del self.options.fPIC\n del self.settings.compiler.libcxx\n del self.settings.compiler.cppstd\n\n def requirements(self):\n self.requires(\"freetype/2.10.4\")\n self.requires(\"expat/2.2.10\")\n if self.settings.os == \"Linux\":\n self.requires(\"libuuid/1.0.3\")\n elif self.settings.os == \"Macos\":\n self.requires(\"libgettext/0.20.1\")\n\n def build_requirements(self):\n self.build_requires(\"gperf/3.1\")\n self.build_requires(\"pkgconf/1.7.3\")\n if tools.os_info.is_windows and not tools.get_env(\"CONAN_BASH_PATH\"):\n self.build_requires(\"msys2/20200517\")\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version])\n extrated_dir = self.name + \"-\" + self.version\n os.rename(extrated_dir, self._source_subfolder)\n\n def _configure_autotools(self):\n if not self._autotools:\n args = [\"--enable-static=%s\" % (\"no\" if self.options.shared else \"yes\"),\n \"--enable-shared=%s\" % (\"yes\" if self.options.shared else \"no\"),\n \"--disable-docs\"]\n args.append(\"--sysconfdir=%s\" % tools.unix_path(os.path.join(self.package_folder, \"bin\", \"etc\")))\n args.append(\"--datadir=%s\" % tools.unix_path(os.path.join(self.package_folder, \"bin\", \"share\")))\n args.append(\"--datarootdir=%s\" % tools.unix_path(os.path.join(self.package_folder, \"bin\", \"share\")))\n args.append(\"--localstatedir=%s\" % tools.unix_path(os.path.join(self.package_folder, \"bin\", \"var\")))\n self._autotools = AutoToolsBuildEnvironment(self, win_bash=tools.os_info.is_windows)\n self._autotools.libs = []\n self._autotools.configure(configure_dir=self._source_subfolder, args=args)\n tools.replace_in_file(\"Makefile\", \"po-conf test\", \"po-conf\")\n return self._autotools\n\n def _patch_files(self):\n # - fontconfig requires libtool version number, change it for the corresponding freetype one\n tools.replace_in_file(os.path.join(self._source_subfolder, 'configure'), '21.0.15', '2.8.1')\n\n def build(self):\n # Patch files from dependencies\n self._patch_files()\n with tools.run_environment(self):\n autotools = self._configure_autotools()\n autotools.make()\n\n def package(self):\n self.copy(\"COPYING\", dst=\"licenses\", src=self._source_subfolder)\n with tools.run_environment(self):\n autotools = self._configure_autotools()\n autotools.install()\n os.unlink(os.path.join(self.package_folder, \"lib\", \"libfontconfig.la\"))\n tools.rmdir(os.path.join(self.package_folder, \"lib\", \"pkgconfig\"))\n for f in glob.glob(os.path.join(self.package_folder, \"bin\", \"etc\", \"fonts\", \"conf.d\", \"*.conf\")):\n if os.path.islink(f):\n os.unlink(f)\n for def_file in glob.glob(os.path.join(self.package_folder, \"lib\", \"*.def\")):\n os.remove(def_file)\n\n def package_info(self):\n self.cpp_info.libs = [\"fontconfig\"]\n if self.settings.os in [\"Linux\", \"FreeBSD\"]:\n self.cpp_info.system_libs.extend([\"m\", \"pthread\"])\n self.cpp_info.names[\"cmake_find_package\"] = \"Fontconfig\"\n self.cpp_info.names[\"cmake_find_package_multi\"] = \"Fontconfig\"\n\n fontconfig_file = os.path.join(self.package_folder, \"bin\", \"etc\", \"fonts\", \"fonts.conf\")\n self.output.info(\"Creating FONTCONFIG_FILE environment variable: {}\".format(fontconfig_file))\n self.env_info.FONTCONFIG_FILE = fontconfig_file\n fontconfig_path = os.path.join(self.package_folder, \"bin\", \"etc\", \"fonts\")\n self.output.info(\"Creating FONTCONFIG_PATH environment variable: {}\".format(fontconfig_path))\n self.env_info.FONTCONFIG_PATH = fontconfig_path\n", "path": "recipes/fontconfig/all/conanfile.py"}], "after_files": [{"content": "import os\nimport glob\n\nfrom conans import ConanFile, tools, AutoToolsBuildEnvironment\nfrom conans.errors import ConanInvalidConfiguration\n\n\nclass FontconfigConan(ConanFile):\n name = \"fontconfig\"\n license = \"MIT\"\n url = \"https://github.com/conan-io/conan-center-index\"\n description = \"Fontconfig is a library for configuring and customizing font access\"\n homepage = \"https://gitlab.freedesktop.org/fontconfig/fontconfig\"\n topics = (\"conan\", \"fontconfig\", \"fonts\", \"freedesktop\")\n settings = \"os\", \"compiler\", \"build_type\", \"arch\"\n options = {\"shared\": [True, False], \"fPIC\": [True, False]}\n default_options = {\"shared\": False, \"fPIC\": True}\n generators = \"pkg_config\"\n\n _autotools = None\n\n @property\n def _source_subfolder(self):\n return \"source_subfolder\"\n\n def config_options(self):\n if self.settings.os == \"Windows\":\n del self.options.fPIC\n\n def configure(self):\n if self.settings.compiler == \"Visual Studio\":\n raise ConanInvalidConfiguration(\"Visual Studio builds are not supported.\")\n if self.options.shared:\n del self.options.fPIC\n del self.settings.compiler.libcxx\n del self.settings.compiler.cppstd\n\n def requirements(self):\n self.requires(\"freetype/2.10.4\")\n self.requires(\"expat/2.2.10\")\n if self.settings.os == \"Linux\":\n self.requires(\"libuuid/1.0.3\")\n\n def build_requirements(self):\n self.build_requires(\"gperf/3.1\")\n self.build_requires(\"pkgconf/1.7.3\")\n if tools.os_info.is_windows and not tools.get_env(\"CONAN_BASH_PATH\"):\n self.build_requires(\"msys2/20200517\")\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version])\n extrated_dir = self.name + \"-\" + self.version\n os.rename(extrated_dir, self._source_subfolder)\n\n def _configure_autotools(self):\n if not self._autotools:\n args = [\"--enable-static=%s\" % (\"no\" if self.options.shared else \"yes\"),\n \"--enable-shared=%s\" % (\"yes\" if self.options.shared else \"no\"),\n \"--disable-docs\",\n \"--disable-nls\",\n ]\n args.append(\"--sysconfdir=%s\" % tools.unix_path(os.path.join(self.package_folder, \"bin\", \"etc\")))\n args.append(\"--datadir=%s\" % tools.unix_path(os.path.join(self.package_folder, \"bin\", \"share\")))\n args.append(\"--datarootdir=%s\" % tools.unix_path(os.path.join(self.package_folder, \"bin\", \"share\")))\n args.append(\"--localstatedir=%s\" % tools.unix_path(os.path.join(self.package_folder, \"bin\", \"var\")))\n self._autotools = AutoToolsBuildEnvironment(self, win_bash=tools.os_info.is_windows)\n self._autotools.libs = []\n self._autotools.configure(configure_dir=self._source_subfolder, args=args)\n tools.replace_in_file(\"Makefile\", \"po-conf test\", \"po-conf\")\n return self._autotools\n\n def _patch_files(self):\n # - fontconfig requires libtool version number, change it for the corresponding freetype one\n tools.replace_in_file(os.path.join(self._source_subfolder, 'configure'), '21.0.15', '2.8.1')\n\n def build(self):\n # Patch files from dependencies\n self._patch_files()\n with tools.run_environment(self):\n autotools = self._configure_autotools()\n autotools.make()\n\n def package(self):\n self.copy(\"COPYING\", dst=\"licenses\", src=self._source_subfolder)\n with tools.run_environment(self):\n autotools = self._configure_autotools()\n autotools.install()\n os.unlink(os.path.join(self.package_folder, \"lib\", \"libfontconfig.la\"))\n tools.rmdir(os.path.join(self.package_folder, \"lib\", \"pkgconfig\"))\n for f in glob.glob(os.path.join(self.package_folder, \"bin\", \"etc\", \"fonts\", \"conf.d\", \"*.conf\")):\n if os.path.islink(f):\n os.unlink(f)\n for def_file in glob.glob(os.path.join(self.package_folder, \"lib\", \"*.def\")):\n os.remove(def_file)\n\n def package_info(self):\n self.cpp_info.libs = [\"fontconfig\"]\n if self.settings.os in [\"Linux\", \"FreeBSD\"]:\n self.cpp_info.system_libs.extend([\"m\", \"pthread\"])\n self.cpp_info.names[\"cmake_find_package\"] = \"Fontconfig\"\n self.cpp_info.names[\"cmake_find_package_multi\"] = \"Fontconfig\"\n\n fontconfig_file = os.path.join(self.package_folder, \"bin\", \"etc\", \"fonts\", \"fonts.conf\")\n self.output.info(\"Creating FONTCONFIG_FILE environment variable: {}\".format(fontconfig_file))\n self.env_info.FONTCONFIG_FILE = fontconfig_file\n fontconfig_path = os.path.join(self.package_folder, \"bin\", \"etc\", \"fonts\")\n self.output.info(\"Creating FONTCONFIG_PATH environment variable: {}\".format(fontconfig_path))\n self.env_info.FONTCONFIG_PATH = fontconfig_path\n", "path": "recipes/fontconfig/all/conanfile.py"}]}
| 1,786 | 311 |
gh_patches_debug_2840
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-center-index-2625
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[package] libx265/3.2.1: hash of source tar.gz changed
### Package and Environment Details (include every applicable attribute)
* Package Name/Version: **libx265/3.2.1**
* Operating System+version: **Linux Ubuntu 18.04 and 20.04 **
* Compiler+version: **GCC 7.5 and 8**
* Conan version: **conan 1.28.1**
* Python version: **Python 3.6.8**
### Conan profile
```
Configuration for profile default:
[settings]
os=Linux
os_build=Linux
arch=x86_64
arch_build=x86_64
compiler=gcc
compiler.version=7.5
compiler.libcxx=libstdc++11
build_type=Release
[options]
[build_requires]
[env]
```
### Steps to reproduce (Include if Applicable)
Try to build libx265/3.2.1 from source.
### Logs (Include/Attach if Applicable)
<details><summary>Click to expand log</summary>
```
ERROR: libx265/3.2.1: Error in source() method, line 50
tools.get(**self.conan_data["sources"][self.version])
ConanException: sha256 signature failed for 'x265_3.2.1.tar.gz' file.
Provided signature: 7cf8ed2927fcb2914cdca51c974594770da705cb43288beea62b69c53725b5d7
Computed signature: fb9badcf92364fd3567f8b5aa0e5e952aeea7a39a2b864387cec31e3b58cbbcc (edited)
```
</details>
I'm surprised that this wasn't caught earlier. Indeed, when downloading the file manually and computing the sha256sum I get the same as the computed signature above. What's the best way to make a PR for this? Would we bump the recipe version or just overwrite the current 3.2.1?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `recipes/libx265/all/conanfile.py`
Content:
```
1 from conans import CMake, ConanFile, tools
2 import os
3 import shutil
4
5
6 class Libx265Conan(ConanFile):
7 name = "libx265"
8 description = "x265 is the leading H.265 / HEVC encoder software library"
9 topics = ("conan", "libx265", "codec", "video", "H.265")
10 url = "https://github.com/conan-io/conan-center-index"
11 homepage = " https://bitbucket.org/multicoreware/x265"
12 exports_sources = ["CMakeLists.txt", "patches/*"]
13 generators = "cmake"
14 license = ("GPL-2.0-only", "commercial") # https://bitbucket.org/multicoreware/x265/src/default/COPYING
15 settings = "os", "arch", "compiler", "build_type"
16 options = {
17 "shared": [True, False],
18 "fPIC": [True, False],
19 "bit_depth": [8, 10, 12],
20 "HDR10": [True, False],
21 "SVG_HEVC_encoder": [True, False],
22 }
23 default_options = {
24 "shared": False,
25 "fPIC": True,
26 "bit_depth": 8,
27 "HDR10": False,
28 "SVG_HEVC_encoder": False,
29 }
30
31 _cmake = None
32
33 @property
34 def _source_subfolder(self):
35 return "source_subfolder"
36
37 @property
38 def _build_subfolder(self):
39 return "build_subfolder"
40
41 def config_options(self):
42 if self.settings.os == "Windows":
43 del self.options.fPIC
44
45 def configure(self):
46 if self.options.shared:
47 del self.options.fPIC
48
49 def source(self):
50 tools.get(**self.conan_data["sources"][self.version])
51 os.rename("x265_{}".format(self.version), self._source_subfolder)
52
53 def _configure_cmake(self):
54 if self._cmake:
55 return self._cmake
56 self._cmake = CMake(self)
57 self._cmake.definitions["ENABLE_SHARED"] = self.options.shared
58 self._cmake.definitions["ENABLE_LIBNUMA"] = False
59 if self.settings.os == "Macos":
60 self._cmake.definitions["CMAKE_SHARED_LINKER_FLAGS"] = "-Wl,-read_only_relocs,suppress"
61 self._cmake.definitions["HIGH_BIT_DEPTH"] = self.options.bit_depth != 8
62 self._cmake.definitions["MAIN12"] = self.options.bit_depth == 12
63 self._cmake.definitions["ENABLE_HDR10_PLUS"] = self.options.HDR10
64 self._cmake.definitions["ENABLE_SVT_HEVC"] = self.options.SVG_HEVC_encoder
65 if self.settings.compiler == "Visual Studio":
66 self._cmake.definitions["STATIC_LINK_CRT"] = "T" in str(self.settings.compiler.runtime)
67 if self.settings.os == "Linux":
68 self._cmake.definitions["PLATFORM_LIBS"] = "dl"
69 self._cmake.configure(build_folder=self._build_subfolder)
70 return self._cmake
71
72 def _patch_sources(self):
73 cmakelists = os.path.join(self._source_subfolder, "source", "CMakeLists.txt")
74 tools.replace_in_file(cmakelists,
75 "if((WIN32 AND ENABLE_CLI) OR (WIN32 AND ENABLE_SHARED))",
76 "if(FALSE)")
77 if self.settings.os == "Android":
78 tools.replace_in_file(cmakelists,
79 "list(APPEND PLATFORM_LIBS pthread)", "")
80 tools.replace_in_file(cmakelists,
81 "list(APPEND PLATFORM_LIBS rt)", "")
82 for patch in self.conan_data.get("patches", {}).get(self.version, []):
83 tools.patch(**patch)
84
85 def build(self):
86 self._patch_sources()
87 cmake = self._configure_cmake()
88 cmake.build()
89
90 def package(self):
91 self.copy("COPYING", src=self._source_subfolder, dst="licenses")
92 cmake = self._configure_cmake()
93 cmake.install()
94
95 if self.options.shared:
96 if self.settings.compiler == "Visual Studio":
97 static_lib = "x265-static.lib"
98 else:
99 static_lib = "libx265.a"
100 os.unlink(os.path.join(self.package_folder, "lib", static_lib))
101
102 if self.settings.compiler == "Visual Studio":
103 name = "libx265.lib" if self.options.shared else "x265-static.lib"
104 shutil.move(os.path.join(self.package_folder, "lib", name),
105 os.path.join(self.package_folder, "lib", "x265.lib"))
106
107 if self.settings.os != "Windows" or not self.options.shared:
108 tools.rmdir(os.path.join(self.package_folder, "bin"))
109 else:
110 for file in os.listdir(os.path.join(self.package_folder, "bin")):
111 if not file.endswith(".dll"):
112 os.unlink(os.path.join(self.package_folder, "bin", file))
113 tools.rmdir(os.path.join(self.package_folder, "lib", "pkgconfig"))
114
115 def package_info(self):
116 self.cpp_info.names["pkg_config"] = "x265"
117 self.cpp_info.libs = ["x265"]
118 if self.settings.os == "Linux":
119 self.cpp_info.system_libs.extend(["dl", "pthread", "m"])
120 if self.settings.os == "Android":
121 self.cpp_info.libs.extend(["dl", "m"])
122 libcxx = self.settings.get_safe("compiler.libcxx")
123 if libcxx in ["libstdc++", "libstdc++11"]:
124 self.cpp_info.system_libs.append("stdc++")
125 elif libcxx == "libc++":
126 self.cpp_info.system_libs.append("c++")
127 elif libcxx in ["c++_static", "c++_shared"]:
128 self.cpp_info.system_libs.extend([libcxx, "c++abi"])
129
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/recipes/libx265/all/conanfile.py b/recipes/libx265/all/conanfile.py
--- a/recipes/libx265/all/conanfile.py
+++ b/recipes/libx265/all/conanfile.py
@@ -48,7 +48,7 @@
def source(self):
tools.get(**self.conan_data["sources"][self.version])
- os.rename("x265_{}".format(self.version), self._source_subfolder)
+ os.rename("x265-{}".format(self.version), self._source_subfolder)
def _configure_cmake(self):
if self._cmake:
|
{"golden_diff": "diff --git a/recipes/libx265/all/conanfile.py b/recipes/libx265/all/conanfile.py\n--- a/recipes/libx265/all/conanfile.py\n+++ b/recipes/libx265/all/conanfile.py\n@@ -48,7 +48,7 @@\n \n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version])\n- os.rename(\"x265_{}\".format(self.version), self._source_subfolder)\n+ os.rename(\"x265-{}\".format(self.version), self._source_subfolder)\n \n def _configure_cmake(self):\n if self._cmake:\n", "issue": "[package] libx265/3.2.1: hash of source tar.gz changed\n### Package and Environment Details (include every applicable attribute)\r\n * Package Name/Version: **libx265/3.2.1**\r\n * Operating System+version: **Linux Ubuntu 18.04 and 20.04 **\r\n * Compiler+version: **GCC 7.5 and 8**\r\n * Conan version: **conan 1.28.1**\r\n * Python version: **Python 3.6.8**\r\n\r\n\r\n### Conan profile\r\n```\r\nConfiguration for profile default:\r\n\r\n[settings]\r\nos=Linux\r\nos_build=Linux\r\narch=x86_64\r\narch_build=x86_64\r\ncompiler=gcc\r\ncompiler.version=7.5\r\ncompiler.libcxx=libstdc++11\r\nbuild_type=Release\r\n[options]\r\n[build_requires]\r\n[env]\r\n```\r\n\r\n\r\n### Steps to reproduce (Include if Applicable)\r\nTry to build libx265/3.2.1 from source. \r\n\r\n\r\n### Logs (Include/Attach if Applicable)\r\n<details><summary>Click to expand log</summary>\r\n\r\n```\r\nERROR: libx265/3.2.1: Error in source() method, line 50\r\n\ttools.get(**self.conan_data[\"sources\"][self.version])\r\n\tConanException: sha256 signature failed for 'x265_3.2.1.tar.gz' file. \r\n Provided signature: 7cf8ed2927fcb2914cdca51c974594770da705cb43288beea62b69c53725b5d7 \r\n Computed signature: fb9badcf92364fd3567f8b5aa0e5e952aeea7a39a2b864387cec31e3b58cbbcc (edited) \r\n```\r\n\r\n</details>\r\n\r\nI'm surprised that this wasn't caught earlier. Indeed, when downloading the file manually and computing the sha256sum I get the same as the computed signature above. What's the best way to make a PR for this? Would we bump the recipe version or just overwrite the current 3.2.1?\n", "before_files": [{"content": "from conans import CMake, ConanFile, tools\nimport os\nimport shutil\n\n\nclass Libx265Conan(ConanFile):\n name = \"libx265\"\n description = \"x265 is the leading H.265 / HEVC encoder software library\"\n topics = (\"conan\", \"libx265\", \"codec\", \"video\", \"H.265\")\n url = \"https://github.com/conan-io/conan-center-index\"\n homepage = \" https://bitbucket.org/multicoreware/x265\"\n exports_sources = [\"CMakeLists.txt\", \"patches/*\"]\n generators = \"cmake\"\n license = (\"GPL-2.0-only\", \"commercial\") # https://bitbucket.org/multicoreware/x265/src/default/COPYING\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n options = {\n \"shared\": [True, False],\n \"fPIC\": [True, False],\n \"bit_depth\": [8, 10, 12],\n \"HDR10\": [True, False],\n \"SVG_HEVC_encoder\": [True, False],\n }\n default_options = {\n \"shared\": False,\n \"fPIC\": True,\n \"bit_depth\": 8,\n \"HDR10\": False,\n \"SVG_HEVC_encoder\": False,\n }\n\n _cmake = None\n\n @property\n def _source_subfolder(self):\n return \"source_subfolder\"\n\n @property\n def _build_subfolder(self):\n return \"build_subfolder\"\n\n def config_options(self):\n if self.settings.os == \"Windows\":\n del self.options.fPIC\n\n def configure(self):\n if self.options.shared:\n del self.options.fPIC\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version])\n os.rename(\"x265_{}\".format(self.version), self._source_subfolder)\n\n def _configure_cmake(self):\n if self._cmake:\n return self._cmake\n self._cmake = CMake(self)\n self._cmake.definitions[\"ENABLE_SHARED\"] = self.options.shared\n self._cmake.definitions[\"ENABLE_LIBNUMA\"] = False\n if self.settings.os == \"Macos\":\n self._cmake.definitions[\"CMAKE_SHARED_LINKER_FLAGS\"] = \"-Wl,-read_only_relocs,suppress\"\n self._cmake.definitions[\"HIGH_BIT_DEPTH\"] = self.options.bit_depth != 8\n self._cmake.definitions[\"MAIN12\"] = self.options.bit_depth == 12\n self._cmake.definitions[\"ENABLE_HDR10_PLUS\"] = self.options.HDR10\n self._cmake.definitions[\"ENABLE_SVT_HEVC\"] = self.options.SVG_HEVC_encoder\n if self.settings.compiler == \"Visual Studio\":\n self._cmake.definitions[\"STATIC_LINK_CRT\"] = \"T\" in str(self.settings.compiler.runtime)\n if self.settings.os == \"Linux\":\n self._cmake.definitions[\"PLATFORM_LIBS\"] = \"dl\"\n self._cmake.configure(build_folder=self._build_subfolder)\n return self._cmake\n\n def _patch_sources(self):\n cmakelists = os.path.join(self._source_subfolder, \"source\", \"CMakeLists.txt\")\n tools.replace_in_file(cmakelists,\n \"if((WIN32 AND ENABLE_CLI) OR (WIN32 AND ENABLE_SHARED))\",\n \"if(FALSE)\")\n if self.settings.os == \"Android\":\n tools.replace_in_file(cmakelists,\n \"list(APPEND PLATFORM_LIBS pthread)\", \"\")\n tools.replace_in_file(cmakelists,\n \"list(APPEND PLATFORM_LIBS rt)\", \"\")\n for patch in self.conan_data.get(\"patches\", {}).get(self.version, []):\n tools.patch(**patch)\n\n def build(self):\n self._patch_sources()\n cmake = self._configure_cmake()\n cmake.build()\n\n def package(self):\n self.copy(\"COPYING\", src=self._source_subfolder, dst=\"licenses\")\n cmake = self._configure_cmake()\n cmake.install()\n\n if self.options.shared:\n if self.settings.compiler == \"Visual Studio\":\n static_lib = \"x265-static.lib\"\n else:\n static_lib = \"libx265.a\"\n os.unlink(os.path.join(self.package_folder, \"lib\", static_lib))\n\n if self.settings.compiler == \"Visual Studio\":\n name = \"libx265.lib\" if self.options.shared else \"x265-static.lib\"\n shutil.move(os.path.join(self.package_folder, \"lib\", name),\n os.path.join(self.package_folder, \"lib\", \"x265.lib\"))\n\n if self.settings.os != \"Windows\" or not self.options.shared:\n tools.rmdir(os.path.join(self.package_folder, \"bin\"))\n else:\n for file in os.listdir(os.path.join(self.package_folder, \"bin\")):\n if not file.endswith(\".dll\"):\n os.unlink(os.path.join(self.package_folder, \"bin\", file))\n tools.rmdir(os.path.join(self.package_folder, \"lib\", \"pkgconfig\"))\n\n def package_info(self):\n self.cpp_info.names[\"pkg_config\"] = \"x265\"\n self.cpp_info.libs = [\"x265\"]\n if self.settings.os == \"Linux\":\n self.cpp_info.system_libs.extend([\"dl\", \"pthread\", \"m\"])\n if self.settings.os == \"Android\":\n self.cpp_info.libs.extend([\"dl\", \"m\"])\n libcxx = self.settings.get_safe(\"compiler.libcxx\")\n if libcxx in [\"libstdc++\", \"libstdc++11\"]:\n self.cpp_info.system_libs.append(\"stdc++\")\n elif libcxx == \"libc++\":\n self.cpp_info.system_libs.append(\"c++\")\n elif libcxx in [\"c++_static\", \"c++_shared\"]:\n self.cpp_info.system_libs.extend([libcxx, \"c++abi\"])\n", "path": "recipes/libx265/all/conanfile.py"}], "after_files": [{"content": "from conans import CMake, ConanFile, tools\nimport os\nimport shutil\n\n\nclass Libx265Conan(ConanFile):\n name = \"libx265\"\n description = \"x265 is the leading H.265 / HEVC encoder software library\"\n topics = (\"conan\", \"libx265\", \"codec\", \"video\", \"H.265\")\n url = \"https://github.com/conan-io/conan-center-index\"\n homepage = \" https://bitbucket.org/multicoreware/x265\"\n exports_sources = [\"CMakeLists.txt\", \"patches/*\"]\n generators = \"cmake\"\n license = (\"GPL-2.0-only\", \"commercial\") # https://bitbucket.org/multicoreware/x265/src/default/COPYING\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n options = {\n \"shared\": [True, False],\n \"fPIC\": [True, False],\n \"bit_depth\": [8, 10, 12],\n \"HDR10\": [True, False],\n \"SVG_HEVC_encoder\": [True, False],\n }\n default_options = {\n \"shared\": False,\n \"fPIC\": True,\n \"bit_depth\": 8,\n \"HDR10\": False,\n \"SVG_HEVC_encoder\": False,\n }\n\n _cmake = None\n\n @property\n def _source_subfolder(self):\n return \"source_subfolder\"\n\n @property\n def _build_subfolder(self):\n return \"build_subfolder\"\n\n def config_options(self):\n if self.settings.os == \"Windows\":\n del self.options.fPIC\n\n def configure(self):\n if self.options.shared:\n del self.options.fPIC\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version])\n os.rename(\"x265-{}\".format(self.version), self._source_subfolder)\n\n def _configure_cmake(self):\n if self._cmake:\n return self._cmake\n self._cmake = CMake(self)\n self._cmake.definitions[\"ENABLE_SHARED\"] = self.options.shared\n self._cmake.definitions[\"ENABLE_LIBNUMA\"] = False\n if self.settings.os == \"Macos\":\n self._cmake.definitions[\"CMAKE_SHARED_LINKER_FLAGS\"] = \"-Wl,-read_only_relocs,suppress\"\n self._cmake.definitions[\"HIGH_BIT_DEPTH\"] = self.options.bit_depth != 8\n self._cmake.definitions[\"MAIN12\"] = self.options.bit_depth == 12\n self._cmake.definitions[\"ENABLE_HDR10_PLUS\"] = self.options.HDR10\n self._cmake.definitions[\"ENABLE_SVT_HEVC\"] = self.options.SVG_HEVC_encoder\n if self.settings.compiler == \"Visual Studio\":\n self._cmake.definitions[\"STATIC_LINK_CRT\"] = \"T\" in str(self.settings.compiler.runtime)\n if self.settings.os == \"Linux\":\n self._cmake.definitions[\"PLATFORM_LIBS\"] = \"dl\"\n self._cmake.configure(build_folder=self._build_subfolder)\n return self._cmake\n\n def _patch_sources(self):\n cmakelists = os.path.join(self._source_subfolder, \"source\", \"CMakeLists.txt\")\n tools.replace_in_file(cmakelists,\n \"if((WIN32 AND ENABLE_CLI) OR (WIN32 AND ENABLE_SHARED))\",\n \"if(FALSE)\")\n if self.settings.os == \"Android\":\n tools.replace_in_file(cmakelists,\n \"list(APPEND PLATFORM_LIBS pthread)\", \"\")\n tools.replace_in_file(cmakelists,\n \"list(APPEND PLATFORM_LIBS rt)\", \"\")\n for patch in self.conan_data.get(\"patches\", {}).get(self.version, []):\n tools.patch(**patch)\n\n def build(self):\n self._patch_sources()\n cmake = self._configure_cmake()\n cmake.build()\n\n def package(self):\n self.copy(\"COPYING\", src=self._source_subfolder, dst=\"licenses\")\n cmake = self._configure_cmake()\n cmake.install()\n\n if self.options.shared:\n if self.settings.compiler == \"Visual Studio\":\n static_lib = \"x265-static.lib\"\n else:\n static_lib = \"libx265.a\"\n os.unlink(os.path.join(self.package_folder, \"lib\", static_lib))\n\n if self.settings.compiler == \"Visual Studio\":\n name = \"libx265.lib\" if self.options.shared else \"x265-static.lib\"\n shutil.move(os.path.join(self.package_folder, \"lib\", name),\n os.path.join(self.package_folder, \"lib\", \"x265.lib\"))\n\n if self.settings.os != \"Windows\" or not self.options.shared:\n tools.rmdir(os.path.join(self.package_folder, \"bin\"))\n else:\n for file in os.listdir(os.path.join(self.package_folder, \"bin\")):\n if not file.endswith(\".dll\"):\n os.unlink(os.path.join(self.package_folder, \"bin\", file))\n tools.rmdir(os.path.join(self.package_folder, \"lib\", \"pkgconfig\"))\n\n def package_info(self):\n self.cpp_info.names[\"pkg_config\"] = \"x265\"\n self.cpp_info.libs = [\"x265\"]\n if self.settings.os == \"Linux\":\n self.cpp_info.system_libs.extend([\"dl\", \"pthread\", \"m\"])\n if self.settings.os == \"Android\":\n self.cpp_info.libs.extend([\"dl\", \"m\"])\n libcxx = self.settings.get_safe(\"compiler.libcxx\")\n if libcxx in [\"libstdc++\", \"libstdc++11\"]:\n self.cpp_info.system_libs.append(\"stdc++\")\n elif libcxx == \"libc++\":\n self.cpp_info.system_libs.append(\"c++\")\n elif libcxx in [\"c++_static\", \"c++_shared\"]:\n self.cpp_info.system_libs.extend([libcxx, \"c++abi\"])\n", "path": "recipes/libx265/all/conanfile.py"}]}
| 2,376 | 150 |
gh_patches_debug_12144
|
rasdani/github-patches
|
git_diff
|
apluslms__a-plus-1183
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Hide exercises in the maintenance mode from the course table of contents
Exercises in maintenance mode (LearningObject.status maintenance) should be hidden from course table of contents.
Exercises with the status hidden are already hidden in the table of contents. The maintenance mode could be handled in the code in the same way.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `exercise/cache/hierarchy.py`
Content:
```
1 from django.http.response import Http404
2 from course.models import CourseModule, LearningObjectCategory
3 from ..models import LearningObject
4
5
6 class NoSuchContent(Exception):
7 pass
8
9
10 class HierarchyIterator:
11 # pylint: disable-next=too-many-arguments
12 def __init__(self, children, idx=None, tree=None, visited=False, enclosed=True):
13 if idx is None:
14 self._default_start(children)
15 else:
16 self.idx = idx.copy()
17 self.levels = [children]
18 if tree and len(tree) > 1:
19 for entry in tree[:-1]:
20 self.levels.append(entry['children'])
21 self.visited = visited
22 self.enclose_begun = not enclosed
23 self.enclose_ended = not enclosed
24
25 def __iter__(self): # pylint: disable=non-iterator-returned
26 return self
27
28
29 class NextIterator(HierarchyIterator):
30
31 def _default_start(self, children):
32 self.idx = [0]
33 self.levels = [children]
34
35 def __next__(self):
36 if not self.enclose_begun:
37 self.enclose_begun = True
38 return {'type':'level','down':True}
39 i = self.idx[-1]
40 level = self.levels[-1]
41 if not self.visited:
42 if i < len(level):
43 self.visited = True
44 return level[i]
45 else:
46 children = level[i].get('children')
47 if children:
48 self.levels.append(children)
49 self.idx.append(0)
50 self.visited = False
51 return {'type':'level','down':True}
52 i += 1
53 if i < len(level):
54 self.idx[-1] = i
55 return level[i]
56 if len(self.idx) > 1:
57 self.idx = self.idx[:-1]
58 self.levels = self.levels[:-1]
59 self.idx[-1] += 1
60 self.visited = False
61 return {'type':'level','up':True}
62 if not self.enclose_ended:
63 self.enclose_ended = True
64 return {'type':'level','up':True}
65 raise StopIteration()
66
67
68 class PreviousIterator(HierarchyIterator):
69
70 def _default_start(self, children):
71 self.idx = []
72 self.levels = []
73 self._goto_last(children)
74
75 def _goto_last(self, children):
76 level = children
77 while level:
78 i = len(level) - 1
79 self.idx.append(i)
80 self.levels.append(level)
81 level = level[i].get('children')
82
83 def __next__(self):
84 i = self.idx[-1]
85 level = self.levels[-1]
86 if not self.visited:
87 self.visited = True
88 return level[i]
89 if i > 0:
90 i -= 1
91 self.idx[-1] = i
92 self._goto_last(level[i].get('children'))
93 return self.levels[-1][self.idx[-1]]
94 if len(self.idx) > 1:
95 self.idx = self.idx[:-1]
96 self.levels = self.levels[:-1]
97 return self.levels[-1][self.idx[-1]]
98 raise StopIteration()
99
100
101 class ContentMixin:
102
103 def created(self):
104 return self.data['created']
105
106 def total(self):
107 return self.data['total']
108
109 def modules(self):
110 return self.data['modules']
111
112 def modules_flatted(self):
113 for module in self.data['modules']:
114 module['flatted'] = self.flat_module(module)
115 return self.data['modules']
116
117 def categories(self):
118 categories = list(self.data['categories'].values())
119 categories.sort(key=lambda entry: entry['name'])
120 return categories
121
122 def flat_module(self, module, enclosed=True):
123 modules = self.modules()
124 idx = self._model_idx(module)
125 tree = self._by_idx(modules, idx)
126 return NextIterator(tree[0]['children'], enclosed=enclosed)
127
128 def flat_full(self):
129 return NextIterator(self.modules(), enclosed=False)
130
131 def begin(self):
132 for entry in self.flat_full():
133 if entry['type'] == 'exercise':
134 return entry
135 return None
136
137 def find_path(self, module_id, path):
138 paths = self.data['paths'].get(module_id, {})
139 if path in paths:
140 return paths[path]
141 raise NoSuchContent()
142
143 def find_number(self, number):
144 hit = None
145 search = self.modules()
146 parts = number.split('.')
147 for i in range(len(parts)):
148 number = '.'.join(parts[0:i+1])
149 for s in search:
150 if s['number'] == number:
151 hit = s
152 search = hit['children']
153 break
154 else:
155 raise NoSuchContent()
156 return hit
157
158 def find_category(self, category_id):
159 categories = self.data['categories']
160 if category_id in categories:
161 return categories[category_id]
162 raise NoSuchContent()
163
164 def find(self, model):
165 modules = self.modules()
166 idx = self._model_idx(model)
167 tree = self._by_idx(modules, idx)
168 return (
169 tree[-1],
170 tree,
171 self._previous(idx, tree),
172 self._next(idx, tree),
173 )
174
175 def search_exercises(self, **kwargs):
176 _, entries = self.search_entries(**kwargs)
177 return [e for e in entries if e['type'] == 'exercise']
178
179 def search_entries(self, number=None, category_id=None, module_id=None, # noqa: MC0001
180 exercise_id=None, filter_for_assistant=False, best=False, # pylint: disable=unused-argument
181 raise_404=True):
182 entry = None
183 if number:
184 try:
185 entry = self.find_number(number)
186 if entry['type'] == 'module':
187 module_id = entry['id']
188 elif entry['type'] == 'exercise':
189 exercise_id = entry['id']
190 except NoSuchContent:
191 if raise_404:
192 raise Http404() # pylint: disable=raise-missing-from
193 raise
194 search = None
195 if exercise_id is not None:
196 search = { 'type': 'exercise', 'id': int(exercise_id) }
197 elif module_id is not None:
198 search = { 'type': 'module', 'id': int(module_id) }
199 if search:
200 try:
201 idx = self._model_idx(search)
202 except NoSuchContent:
203 if raise_404:
204 raise Http404() # pylint: disable=raise-missing-from
205 raise
206 tree = self._by_idx(self.modules(), idx)
207 if not entry:
208 entry = tree[-1]
209 else:
210 tree = [{ 'type': 'all', 'children': self.modules() }]
211 exercises = []
212
213 def recursion(entry):
214 if (
215 entry['type'] == 'module' or ( # pylint: disable=too-many-boolean-expressions
216 entry['type'] == 'exercise' and
217 (category_id is None or entry['category_id'] == category_id) and
218 (not filter_for_assistant or entry['allow_assistant_viewing'])
219 )
220 ):
221 exercises.append(entry)
222 for child in entry['children']:
223 recursion(child)
224 recursion(tree[-1])
225 return entry, exercises
226
227 def _previous(self, idx, tree):
228 for entry in PreviousIterator(self.modules(), idx, tree, visited=True):
229 if self.is_listed(entry):
230 return entry
231 return None
232
233 def _next(self, idx, tree):
234 for entry in NextIterator(self.modules(), idx, tree, visited=True, enclosed=False):
235 if self.is_listed(entry):
236 return entry
237 return None
238
239 def _model_idx(self, model):
240 def find(index, search):
241 if search in index:
242 return index[search]
243 raise NoSuchContent()
244 entry_type = None
245 if isinstance(model, dict):
246 entry_type = model.get('type', None)
247 if entry_type == 'module':
248 return find(self.data['module_index'], model['id'])
249 if entry_type == 'exercise':
250 return find(self.data['exercise_index'], model['id'])
251 elif isinstance(model, CourseModule):
252 return find(self.data['module_index'], model.id)
253 elif isinstance(model, LearningObject):
254 return find(self.data['exercise_index'], model.id)
255 else:
256 raise NoSuchContent()
257
258 @classmethod
259 def _by_idx(cls, hierarchy, idx):
260 tree = []
261 for i in idx:
262 entry = hierarchy[i]
263 hierarchy = entry['children']
264 tree.append(entry)
265 return tree
266
267 @classmethod
268 def _add_by_difficulty(cls, to, difficulty, points):
269 if difficulty in to:
270 to[difficulty] += points
271 else:
272 to[difficulty] = points
273
274 @classmethod
275 def is_visible(cls, entry):
276 t = entry['type']
277 if t == 'exercise':
278 return (
279 entry.get('category_status') != LearningObjectCategory.STATUS.HIDDEN
280 and entry.get('module_status') != CourseModule.STATUS.HIDDEN
281 and not entry['status'] in (
282 LearningObject.STATUS.HIDDEN,
283 LearningObject.STATUS.ENROLLMENT,
284 LearningObject.STATUS.ENROLLMENT_EXTERNAL,
285 )
286 )
287 if t == 'module':
288 return entry['status'] != CourseModule.STATUS.HIDDEN
289 if t == 'category':
290 return not entry['status'] in (
291 LearningObjectCategory.STATUS.HIDDEN,
292 LearningObjectCategory.STATUS.NOTOTAL,
293 )
294 return False
295
296 @classmethod
297 def is_listed(cls, entry):
298 if not cls.is_visible(entry):
299 return False
300 t = entry['type']
301 if t == 'exercise':
302 return (
303 entry.get('category_status') != LearningObjectCategory.STATUS.HIDDEN
304 and entry.get('module_status') != CourseModule.STATUS.UNLISTED
305 and entry['status'] != LearningObject.STATUS.UNLISTED
306 )
307 if t == 'module':
308 return entry['status'] != CourseModule.STATUS.UNLISTED
309 if t == 'category':
310 return entry['status'] != LearningObjectCategory.STATUS.HIDDEN
311 return True
312
313 @classmethod
314 def is_in_maintenance(cls, entry):
315 t = entry['type']
316 if t == 'exercise':
317 return (
318 entry['module_status'] == CourseModule.STATUS.MAINTENANCE
319 or entry['status'] == LearningObject.STATUS.MAINTENANCE
320 )
321 if t == 'module':
322 return entry['status'] == CourseModule.STATUS.MAINTENANCE
323 return False
324
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/exercise/cache/hierarchy.py b/exercise/cache/hierarchy.py
--- a/exercise/cache/hierarchy.py
+++ b/exercise/cache/hierarchy.py
@@ -302,7 +302,10 @@
return (
entry.get('category_status') != LearningObjectCategory.STATUS.HIDDEN
and entry.get('module_status') != CourseModule.STATUS.UNLISTED
- and entry['status'] != LearningObject.STATUS.UNLISTED
+ and not entry['status'] in (
+ LearningObject.STATUS.UNLISTED,
+ LearningObject.STATUS.MAINTENANCE,
+ )
)
if t == 'module':
return entry['status'] != CourseModule.STATUS.UNLISTED
|
{"golden_diff": "diff --git a/exercise/cache/hierarchy.py b/exercise/cache/hierarchy.py\n--- a/exercise/cache/hierarchy.py\n+++ b/exercise/cache/hierarchy.py\n@@ -302,7 +302,10 @@\n return (\n entry.get('category_status') != LearningObjectCategory.STATUS.HIDDEN\n and entry.get('module_status') != CourseModule.STATUS.UNLISTED\n- and entry['status'] != LearningObject.STATUS.UNLISTED\n+ and not entry['status'] in (\n+ LearningObject.STATUS.UNLISTED,\n+ LearningObject.STATUS.MAINTENANCE,\n+ )\n )\n if t == 'module':\n return entry['status'] != CourseModule.STATUS.UNLISTED\n", "issue": "Hide exercises in the maintenance mode from the course table of contents\nExercises in maintenance mode (LearningObject.status maintenance) should be hidden from course table of contents.\r\n\r\nExercises with the status hidden are already hidden in the table of contents. The maintenance mode could be handled in the code in the same way.\r\n\n", "before_files": [{"content": "from django.http.response import Http404\nfrom course.models import CourseModule, LearningObjectCategory\nfrom ..models import LearningObject\n\n\nclass NoSuchContent(Exception):\n pass\n\n\nclass HierarchyIterator:\n # pylint: disable-next=too-many-arguments\n def __init__(self, children, idx=None, tree=None, visited=False, enclosed=True):\n if idx is None:\n self._default_start(children)\n else:\n self.idx = idx.copy()\n self.levels = [children]\n if tree and len(tree) > 1:\n for entry in tree[:-1]:\n self.levels.append(entry['children'])\n self.visited = visited\n self.enclose_begun = not enclosed\n self.enclose_ended = not enclosed\n\n def __iter__(self): # pylint: disable=non-iterator-returned\n return self\n\n\nclass NextIterator(HierarchyIterator):\n\n def _default_start(self, children):\n self.idx = [0]\n self.levels = [children]\n\n def __next__(self):\n if not self.enclose_begun:\n self.enclose_begun = True\n return {'type':'level','down':True}\n i = self.idx[-1]\n level = self.levels[-1]\n if not self.visited:\n if i < len(level):\n self.visited = True\n return level[i]\n else:\n children = level[i].get('children')\n if children:\n self.levels.append(children)\n self.idx.append(0)\n self.visited = False\n return {'type':'level','down':True}\n i += 1\n if i < len(level):\n self.idx[-1] = i\n return level[i]\n if len(self.idx) > 1:\n self.idx = self.idx[:-1]\n self.levels = self.levels[:-1]\n self.idx[-1] += 1\n self.visited = False\n return {'type':'level','up':True}\n if not self.enclose_ended:\n self.enclose_ended = True\n return {'type':'level','up':True}\n raise StopIteration()\n\n\nclass PreviousIterator(HierarchyIterator):\n\n def _default_start(self, children):\n self.idx = []\n self.levels = []\n self._goto_last(children)\n\n def _goto_last(self, children):\n level = children\n while level:\n i = len(level) - 1\n self.idx.append(i)\n self.levels.append(level)\n level = level[i].get('children')\n\n def __next__(self):\n i = self.idx[-1]\n level = self.levels[-1]\n if not self.visited:\n self.visited = True\n return level[i]\n if i > 0:\n i -= 1\n self.idx[-1] = i\n self._goto_last(level[i].get('children'))\n return self.levels[-1][self.idx[-1]]\n if len(self.idx) > 1:\n self.idx = self.idx[:-1]\n self.levels = self.levels[:-1]\n return self.levels[-1][self.idx[-1]]\n raise StopIteration()\n\n\nclass ContentMixin:\n\n def created(self):\n return self.data['created']\n\n def total(self):\n return self.data['total']\n\n def modules(self):\n return self.data['modules']\n\n def modules_flatted(self):\n for module in self.data['modules']:\n module['flatted'] = self.flat_module(module)\n return self.data['modules']\n\n def categories(self):\n categories = list(self.data['categories'].values())\n categories.sort(key=lambda entry: entry['name'])\n return categories\n\n def flat_module(self, module, enclosed=True):\n modules = self.modules()\n idx = self._model_idx(module)\n tree = self._by_idx(modules, idx)\n return NextIterator(tree[0]['children'], enclosed=enclosed)\n\n def flat_full(self):\n return NextIterator(self.modules(), enclosed=False)\n\n def begin(self):\n for entry in self.flat_full():\n if entry['type'] == 'exercise':\n return entry\n return None\n\n def find_path(self, module_id, path):\n paths = self.data['paths'].get(module_id, {})\n if path in paths:\n return paths[path]\n raise NoSuchContent()\n\n def find_number(self, number):\n hit = None\n search = self.modules()\n parts = number.split('.')\n for i in range(len(parts)):\n number = '.'.join(parts[0:i+1])\n for s in search:\n if s['number'] == number:\n hit = s\n search = hit['children']\n break\n else:\n raise NoSuchContent()\n return hit\n\n def find_category(self, category_id):\n categories = self.data['categories']\n if category_id in categories:\n return categories[category_id]\n raise NoSuchContent()\n\n def find(self, model):\n modules = self.modules()\n idx = self._model_idx(model)\n tree = self._by_idx(modules, idx)\n return (\n tree[-1],\n tree,\n self._previous(idx, tree),\n self._next(idx, tree),\n )\n\n def search_exercises(self, **kwargs):\n _, entries = self.search_entries(**kwargs)\n return [e for e in entries if e['type'] == 'exercise']\n\n def search_entries(self, number=None, category_id=None, module_id=None, # noqa: MC0001\n exercise_id=None, filter_for_assistant=False, best=False, # pylint: disable=unused-argument\n raise_404=True):\n entry = None\n if number:\n try:\n entry = self.find_number(number)\n if entry['type'] == 'module':\n module_id = entry['id']\n elif entry['type'] == 'exercise':\n exercise_id = entry['id']\n except NoSuchContent:\n if raise_404:\n raise Http404() # pylint: disable=raise-missing-from\n raise\n search = None\n if exercise_id is not None:\n search = { 'type': 'exercise', 'id': int(exercise_id) }\n elif module_id is not None:\n search = { 'type': 'module', 'id': int(module_id) }\n if search:\n try:\n idx = self._model_idx(search)\n except NoSuchContent:\n if raise_404:\n raise Http404() # pylint: disable=raise-missing-from\n raise\n tree = self._by_idx(self.modules(), idx)\n if not entry:\n entry = tree[-1]\n else:\n tree = [{ 'type': 'all', 'children': self.modules() }]\n exercises = []\n\n def recursion(entry):\n if (\n entry['type'] == 'module' or ( # pylint: disable=too-many-boolean-expressions\n entry['type'] == 'exercise' and\n (category_id is None or entry['category_id'] == category_id) and\n (not filter_for_assistant or entry['allow_assistant_viewing'])\n )\n ):\n exercises.append(entry)\n for child in entry['children']:\n recursion(child)\n recursion(tree[-1])\n return entry, exercises\n\n def _previous(self, idx, tree):\n for entry in PreviousIterator(self.modules(), idx, tree, visited=True):\n if self.is_listed(entry):\n return entry\n return None\n\n def _next(self, idx, tree):\n for entry in NextIterator(self.modules(), idx, tree, visited=True, enclosed=False):\n if self.is_listed(entry):\n return entry\n return None\n\n def _model_idx(self, model):\n def find(index, search):\n if search in index:\n return index[search]\n raise NoSuchContent()\n entry_type = None\n if isinstance(model, dict):\n entry_type = model.get('type', None)\n if entry_type == 'module':\n return find(self.data['module_index'], model['id'])\n if entry_type == 'exercise':\n return find(self.data['exercise_index'], model['id'])\n elif isinstance(model, CourseModule):\n return find(self.data['module_index'], model.id)\n elif isinstance(model, LearningObject):\n return find(self.data['exercise_index'], model.id)\n else:\n raise NoSuchContent()\n\n @classmethod\n def _by_idx(cls, hierarchy, idx):\n tree = []\n for i in idx:\n entry = hierarchy[i]\n hierarchy = entry['children']\n tree.append(entry)\n return tree\n\n @classmethod\n def _add_by_difficulty(cls, to, difficulty, points):\n if difficulty in to:\n to[difficulty] += points\n else:\n to[difficulty] = points\n\n @classmethod\n def is_visible(cls, entry):\n t = entry['type']\n if t == 'exercise':\n return (\n entry.get('category_status') != LearningObjectCategory.STATUS.HIDDEN\n and entry.get('module_status') != CourseModule.STATUS.HIDDEN\n and not entry['status'] in (\n LearningObject.STATUS.HIDDEN,\n LearningObject.STATUS.ENROLLMENT,\n LearningObject.STATUS.ENROLLMENT_EXTERNAL,\n )\n )\n if t == 'module':\n return entry['status'] != CourseModule.STATUS.HIDDEN\n if t == 'category':\n return not entry['status'] in (\n LearningObjectCategory.STATUS.HIDDEN,\n LearningObjectCategory.STATUS.NOTOTAL,\n )\n return False\n\n @classmethod\n def is_listed(cls, entry):\n if not cls.is_visible(entry):\n return False\n t = entry['type']\n if t == 'exercise':\n return (\n entry.get('category_status') != LearningObjectCategory.STATUS.HIDDEN\n and entry.get('module_status') != CourseModule.STATUS.UNLISTED\n and entry['status'] != LearningObject.STATUS.UNLISTED\n )\n if t == 'module':\n return entry['status'] != CourseModule.STATUS.UNLISTED\n if t == 'category':\n return entry['status'] != LearningObjectCategory.STATUS.HIDDEN\n return True\n\n @classmethod\n def is_in_maintenance(cls, entry):\n t = entry['type']\n if t == 'exercise':\n return (\n entry['module_status'] == CourseModule.STATUS.MAINTENANCE\n or entry['status'] == LearningObject.STATUS.MAINTENANCE\n )\n if t == 'module':\n return entry['status'] == CourseModule.STATUS.MAINTENANCE\n return False\n", "path": "exercise/cache/hierarchy.py"}], "after_files": [{"content": "from django.http.response import Http404\nfrom course.models import CourseModule, LearningObjectCategory\nfrom ..models import LearningObject\n\n\nclass NoSuchContent(Exception):\n pass\n\n\nclass HierarchyIterator:\n # pylint: disable-next=too-many-arguments\n def __init__(self, children, idx=None, tree=None, visited=False, enclosed=True):\n if idx is None:\n self._default_start(children)\n else:\n self.idx = idx.copy()\n self.levels = [children]\n if tree and len(tree) > 1:\n for entry in tree[:-1]:\n self.levels.append(entry['children'])\n self.visited = visited\n self.enclose_begun = not enclosed\n self.enclose_ended = not enclosed\n\n def __iter__(self): # pylint: disable=non-iterator-returned\n return self\n\n\nclass NextIterator(HierarchyIterator):\n\n def _default_start(self, children):\n self.idx = [0]\n self.levels = [children]\n\n def __next__(self):\n if not self.enclose_begun:\n self.enclose_begun = True\n return {'type':'level','down':True}\n i = self.idx[-1]\n level = self.levels[-1]\n if not self.visited:\n if i < len(level):\n self.visited = True\n return level[i]\n else:\n children = level[i].get('children')\n if children:\n self.levels.append(children)\n self.idx.append(0)\n self.visited = False\n return {'type':'level','down':True}\n i += 1\n if i < len(level):\n self.idx[-1] = i\n return level[i]\n if len(self.idx) > 1:\n self.idx = self.idx[:-1]\n self.levels = self.levels[:-1]\n self.idx[-1] += 1\n self.visited = False\n return {'type':'level','up':True}\n if not self.enclose_ended:\n self.enclose_ended = True\n return {'type':'level','up':True}\n raise StopIteration()\n\n\nclass PreviousIterator(HierarchyIterator):\n\n def _default_start(self, children):\n self.idx = []\n self.levels = []\n self._goto_last(children)\n\n def _goto_last(self, children):\n level = children\n while level:\n i = len(level) - 1\n self.idx.append(i)\n self.levels.append(level)\n level = level[i].get('children')\n\n def __next__(self):\n i = self.idx[-1]\n level = self.levels[-1]\n if not self.visited:\n self.visited = True\n return level[i]\n if i > 0:\n i -= 1\n self.idx[-1] = i\n self._goto_last(level[i].get('children'))\n return self.levels[-1][self.idx[-1]]\n if len(self.idx) > 1:\n self.idx = self.idx[:-1]\n self.levels = self.levels[:-1]\n return self.levels[-1][self.idx[-1]]\n raise StopIteration()\n\n\nclass ContentMixin:\n\n def created(self):\n return self.data['created']\n\n def total(self):\n return self.data['total']\n\n def modules(self):\n return self.data['modules']\n\n def modules_flatted(self):\n for module in self.data['modules']:\n module['flatted'] = self.flat_module(module)\n return self.data['modules']\n\n def categories(self):\n categories = list(self.data['categories'].values())\n categories.sort(key=lambda entry: entry['name'])\n return categories\n\n def flat_module(self, module, enclosed=True):\n modules = self.modules()\n idx = self._model_idx(module)\n tree = self._by_idx(modules, idx)\n return NextIterator(tree[0]['children'], enclosed=enclosed)\n\n def flat_full(self):\n return NextIterator(self.modules(), enclosed=False)\n\n def begin(self):\n for entry in self.flat_full():\n if entry['type'] == 'exercise':\n return entry\n return None\n\n def find_path(self, module_id, path):\n paths = self.data['paths'].get(module_id, {})\n if path in paths:\n return paths[path]\n raise NoSuchContent()\n\n def find_number(self, number):\n hit = None\n search = self.modules()\n parts = number.split('.')\n for i in range(len(parts)):\n number = '.'.join(parts[0:i+1])\n for s in search:\n if s['number'] == number:\n hit = s\n search = hit['children']\n break\n else:\n raise NoSuchContent()\n return hit\n\n def find_category(self, category_id):\n categories = self.data['categories']\n if category_id in categories:\n return categories[category_id]\n raise NoSuchContent()\n\n def find(self, model):\n modules = self.modules()\n idx = self._model_idx(model)\n tree = self._by_idx(modules, idx)\n return (\n tree[-1],\n tree,\n self._previous(idx, tree),\n self._next(idx, tree),\n )\n\n def search_exercises(self, **kwargs):\n _, entries = self.search_entries(**kwargs)\n return [e for e in entries if e['type'] == 'exercise']\n\n def search_entries(self, number=None, category_id=None, module_id=None, # noqa: MC0001\n exercise_id=None, filter_for_assistant=False, best=False, # pylint: disable=unused-argument\n raise_404=True):\n entry = None\n if number:\n try:\n entry = self.find_number(number)\n if entry['type'] == 'module':\n module_id = entry['id']\n elif entry['type'] == 'exercise':\n exercise_id = entry['id']\n except NoSuchContent:\n if raise_404:\n raise Http404() # pylint: disable=raise-missing-from\n raise\n search = None\n if exercise_id is not None:\n search = { 'type': 'exercise', 'id': int(exercise_id) }\n elif module_id is not None:\n search = { 'type': 'module', 'id': int(module_id) }\n if search:\n try:\n idx = self._model_idx(search)\n except NoSuchContent:\n if raise_404:\n raise Http404() # pylint: disable=raise-missing-from\n raise\n tree = self._by_idx(self.modules(), idx)\n if not entry:\n entry = tree[-1]\n else:\n tree = [{ 'type': 'all', 'children': self.modules() }]\n exercises = []\n\n def recursion(entry):\n if (\n entry['type'] == 'module' or ( # pylint: disable=too-many-boolean-expressions\n entry['type'] == 'exercise' and\n (category_id is None or entry['category_id'] == category_id) and\n (not filter_for_assistant or entry['allow_assistant_viewing'])\n )\n ):\n exercises.append(entry)\n for child in entry['children']:\n recursion(child)\n recursion(tree[-1])\n return entry, exercises\n\n def _previous(self, idx, tree):\n for entry in PreviousIterator(self.modules(), idx, tree, visited=True):\n if self.is_listed(entry):\n return entry\n return None\n\n def _next(self, idx, tree):\n for entry in NextIterator(self.modules(), idx, tree, visited=True, enclosed=False):\n if self.is_listed(entry):\n return entry\n return None\n\n def _model_idx(self, model):\n def find(index, search):\n if search in index:\n return index[search]\n raise NoSuchContent()\n entry_type = None\n if isinstance(model, dict):\n entry_type = model.get('type', None)\n if entry_type == 'module':\n return find(self.data['module_index'], model['id'])\n if entry_type == 'exercise':\n return find(self.data['exercise_index'], model['id'])\n elif isinstance(model, CourseModule):\n return find(self.data['module_index'], model.id)\n elif isinstance(model, LearningObject):\n return find(self.data['exercise_index'], model.id)\n else:\n raise NoSuchContent()\n\n @classmethod\n def _by_idx(cls, hierarchy, idx):\n tree = []\n for i in idx:\n entry = hierarchy[i]\n hierarchy = entry['children']\n tree.append(entry)\n return tree\n\n @classmethod\n def _add_by_difficulty(cls, to, difficulty, points):\n if difficulty in to:\n to[difficulty] += points\n else:\n to[difficulty] = points\n\n @classmethod\n def is_visible(cls, entry):\n t = entry['type']\n if t == 'exercise':\n return (\n entry.get('category_status') != LearningObjectCategory.STATUS.HIDDEN\n and entry.get('module_status') != CourseModule.STATUS.HIDDEN\n and not entry['status'] in (\n LearningObject.STATUS.HIDDEN,\n LearningObject.STATUS.ENROLLMENT,\n LearningObject.STATUS.ENROLLMENT_EXTERNAL,\n )\n )\n if t == 'module':\n return entry['status'] != CourseModule.STATUS.HIDDEN\n if t == 'category':\n return not entry['status'] in (\n LearningObjectCategory.STATUS.HIDDEN,\n LearningObjectCategory.STATUS.NOTOTAL,\n )\n return False\n\n @classmethod\n def is_listed(cls, entry):\n if not cls.is_visible(entry):\n return False\n t = entry['type']\n if t == 'exercise':\n return (\n entry.get('category_status') != LearningObjectCategory.STATUS.HIDDEN\n and entry.get('module_status') != CourseModule.STATUS.UNLISTED\n and not entry['status'] in (\n LearningObject.STATUS.UNLISTED,\n LearningObject.STATUS.MAINTENANCE,\n )\n )\n if t == 'module':\n return entry['status'] != CourseModule.STATUS.UNLISTED\n if t == 'category':\n return entry['status'] != LearningObjectCategory.STATUS.HIDDEN\n return True\n\n @classmethod\n def is_in_maintenance(cls, entry):\n t = entry['type']\n if t == 'exercise':\n return (\n entry['module_status'] == CourseModule.STATUS.MAINTENANCE\n or entry['status'] == LearningObject.STATUS.MAINTENANCE\n )\n if t == 'module':\n return entry['status'] == CourseModule.STATUS.MAINTENANCE\n return False\n", "path": "exercise/cache/hierarchy.py"}]}
| 3,481 | 156 |
gh_patches_debug_37168
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-center-index-2696
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[request] sentry-native/0.4.1
### Package Details
* Package Name/Version: **sentry-native/0.4.1**
* Changelog: **https://github.com/getsentry/sentry-native/blob/0.4.1/CHANGELOG.md**
https://github.com/getsentry/sentry-native/tree/0.4.1
The above mentioned version is newly released by the upstream project and not yet available as a recipe. Please add this version.
Also, **please add windows support.**
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `recipes/sentry-native/all/conanfile.py`
Content:
```
1 import os
2 from conans import ConanFile, CMake, tools
3 from conans.errors import ConanInvalidConfiguration
4
5
6 class SentryNativeConan(ConanFile):
7 name = "sentry-native"
8 description = "The Sentry Native SDK is an error and crash reporting client for native applications,\n" \
9 "optimized for C and C++. Sentry allows to add tags,\n" \
10 "breadcrumbs and arbitrary custom context to enrich error reports."
11 url = "https://github.com/conan-io/conan-center-index"
12 homepage = "https://github.com/getsentry/sentry-native"
13 license = "MIT"
14 topics = ("conan", "breakpad", "crashpad",
15 "error-reporting", "crash-reporting")
16 exports_sources = ["CMakeLists.txt"]
17 generators = "cmake", "cmake_find_package"
18 settings = "os", "arch", "compiler", "build_type"
19 options = {
20 "shared": [True, False],
21 "fPIC": [True, False],
22 "backend": ["none", "inproc", "crashpad", "breakpad"],
23 "transport": ["none", "curl", "winhttp"],
24 }
25 default_options = {
26 "shared": False,
27 "fPIC": True,
28 "backend": "inproc",
29 "transport": "curl"
30 }
31
32 @property
33 def _source_subfolder(self):
34 return "source_subfolder"
35
36 _cmake = None
37
38 def requirements(self):
39 if self.options.transport == "curl":
40 self.requires("libcurl/7.68.0")
41
42 if self.options.backend == "crashpad":
43 raise ConanInvalidConfiguration("crashpad not available yet in CCI")
44 if self.options.backend == "breakpad":
45 raise ConanInvalidConfiguration("breakpad not available yet in CCI")
46
47 def config_options(self):
48 if self.settings.os == "Windows":
49 del self.options.fPIC
50
51 def source(self):
52 tools.get(**self.conan_data["sources"][self.version])
53 extracted_dir = self.name + "-" + self.version
54 os.rename(extracted_dir, self._source_subfolder)
55
56 def configure(self):
57 if self.options.backend == "inproc" and self.settings.os == "Windows":
58 raise ConanInvalidConfiguration("The in-process backend is not supported on Windows")
59
60 def _configure_cmake(self):
61 if self._cmake:
62 return self._cmake
63 self._cmake = CMake(self)
64 self._cmake.definitions["SENTRY_BACKEND"] = self.options.backend
65 self._cmake.definitions["SENTRY_ENABLE_INSTALL"] = True
66 self._cmake.definitions["SENTRY_TRANSPORT"] = self.options.transport
67 self._cmake.definitions["SENTRY_PIC"] = self.options.get_safe("fPIC", False)
68 self._cmake.configure()
69 return self._cmake
70
71 def build(self):
72 cmake = self._configure_cmake()
73 cmake.build()
74
75 def package(self):
76 self.copy("LICENSE", dst="licenses", src=self._source_subfolder)
77 cmake = self._configure_cmake()
78 cmake.install()
79 tools.rmdir(os.path.join(self.package_folder, "lib", "cmake"))
80
81 def package_info(self):
82 self.cpp_info.libs = ["sentry"]
83 if self.settings.os in ("Android", "Windows"):
84 self.cpp_info.exelinkflags= ["--build-id=sha1"]
85 self.cpp_info.sharedlinkflags = ["--build-id=sha1"]
86 if self.settings.os == "Linux":
87 self.cpp_info.system_libs = ["pthread", "dl"]
88 elif self.settings.os == "Windows":
89 self.cpp_info.system_libs = ["winhttp", "dbghelp", "pathcch"]
90
91 if not self.options.shared:
92 self.cpp_info.defines = ["SENTRY_BUILD_STATIC"]
93
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/recipes/sentry-native/all/conanfile.py b/recipes/sentry-native/all/conanfile.py
--- a/recipes/sentry-native/all/conanfile.py
+++ b/recipes/sentry-native/all/conanfile.py
@@ -1,4 +1,5 @@
import os
+import glob
from conans import ConanFile, CMake, tools
from conans.errors import ConanInvalidConfiguration
@@ -37,8 +38,8 @@
def requirements(self):
if self.options.transport == "curl":
- self.requires("libcurl/7.68.0")
-
+ self.requires("libcurl/7.71.0")
+
if self.options.backend == "crashpad":
raise ConanInvalidConfiguration("crashpad not available yet in CCI")
if self.options.backend == "breakpad":
@@ -54,7 +55,7 @@
os.rename(extracted_dir, self._source_subfolder)
def configure(self):
- if self.options.backend == "inproc" and self.settings.os == "Windows":
+ if self.options.backend == "inproc" and self.settings.os == "Windows" and tools.Version(self.version) < "0.4":
raise ConanInvalidConfiguration("The in-process backend is not supported on Windows")
def _configure_cmake(self):
@@ -77,16 +78,18 @@
cmake = self._configure_cmake()
cmake.install()
tools.rmdir(os.path.join(self.package_folder, "lib", "cmake"))
+ for pdb in glob.glob(os.path.join(self.package_folder, "bin", "*.pdb")):
+ os.unlink(pdb)
def package_info(self):
self.cpp_info.libs = ["sentry"]
- if self.settings.os in ("Android", "Windows"):
- self.cpp_info.exelinkflags= ["--build-id=sha1"]
- self.cpp_info.sharedlinkflags = ["--build-id=sha1"]
+ if self.settings.os in ("Android", "Linux"):
+ self.cpp_info.exelinkflags = ["-Wl,-E,--build-id=sha1"]
+ self.cpp_info.sharedlinkflags = ["-Wl,-E,--build-id=sha1"]
if self.settings.os == "Linux":
self.cpp_info.system_libs = ["pthread", "dl"]
elif self.settings.os == "Windows":
- self.cpp_info.system_libs = ["winhttp", "dbghelp", "pathcch"]
+ self.cpp_info.system_libs = ["winhttp", "dbghelp", "pathcch", "shlwapi"]
if not self.options.shared:
self.cpp_info.defines = ["SENTRY_BUILD_STATIC"]
|
{"golden_diff": "diff --git a/recipes/sentry-native/all/conanfile.py b/recipes/sentry-native/all/conanfile.py\n--- a/recipes/sentry-native/all/conanfile.py\n+++ b/recipes/sentry-native/all/conanfile.py\n@@ -1,4 +1,5 @@\n import os\n+import glob\n from conans import ConanFile, CMake, tools\n from conans.errors import ConanInvalidConfiguration\n \n@@ -37,8 +38,8 @@\n \n def requirements(self):\n if self.options.transport == \"curl\":\n- self.requires(\"libcurl/7.68.0\")\n- \n+ self.requires(\"libcurl/7.71.0\")\n+\n if self.options.backend == \"crashpad\":\n raise ConanInvalidConfiguration(\"crashpad not available yet in CCI\")\n if self.options.backend == \"breakpad\":\n@@ -54,7 +55,7 @@\n os.rename(extracted_dir, self._source_subfolder)\n \n def configure(self):\n- if self.options.backend == \"inproc\" and self.settings.os == \"Windows\":\n+ if self.options.backend == \"inproc\" and self.settings.os == \"Windows\" and tools.Version(self.version) < \"0.4\":\n raise ConanInvalidConfiguration(\"The in-process backend is not supported on Windows\")\n \n def _configure_cmake(self):\n@@ -77,16 +78,18 @@\n cmake = self._configure_cmake()\n cmake.install()\n tools.rmdir(os.path.join(self.package_folder, \"lib\", \"cmake\"))\n+ for pdb in glob.glob(os.path.join(self.package_folder, \"bin\", \"*.pdb\")):\n+ os.unlink(pdb)\n \n def package_info(self):\n self.cpp_info.libs = [\"sentry\"]\n- if self.settings.os in (\"Android\", \"Windows\"):\n- self.cpp_info.exelinkflags= [\"--build-id=sha1\"]\n- self.cpp_info.sharedlinkflags = [\"--build-id=sha1\"]\n+ if self.settings.os in (\"Android\", \"Linux\"):\n+ self.cpp_info.exelinkflags = [\"-Wl,-E,--build-id=sha1\"]\n+ self.cpp_info.sharedlinkflags = [\"-Wl,-E,--build-id=sha1\"]\n if self.settings.os == \"Linux\":\n self.cpp_info.system_libs = [\"pthread\", \"dl\"]\n elif self.settings.os == \"Windows\":\n- self.cpp_info.system_libs = [\"winhttp\", \"dbghelp\", \"pathcch\"]\n+ self.cpp_info.system_libs = [\"winhttp\", \"dbghelp\", \"pathcch\", \"shlwapi\"]\n \n if not self.options.shared:\n self.cpp_info.defines = [\"SENTRY_BUILD_STATIC\"]\n", "issue": "[request] sentry-native/0.4.1\n### Package Details\r\n * Package Name/Version: **sentry-native/0.4.1**\r\n * Changelog: **https://github.com/getsentry/sentry-native/blob/0.4.1/CHANGELOG.md**\r\n\r\nhttps://github.com/getsentry/sentry-native/tree/0.4.1\r\n\r\nThe above mentioned version is newly released by the upstream project and not yet available as a recipe. Please add this version.\r\nAlso, **please add windows support.**\n", "before_files": [{"content": "import os\nfrom conans import ConanFile, CMake, tools\nfrom conans.errors import ConanInvalidConfiguration\n\n\nclass SentryNativeConan(ConanFile):\n name = \"sentry-native\"\n description = \"The Sentry Native SDK is an error and crash reporting client for native applications,\\n\" \\\n \"optimized for C and C++. Sentry allows to add tags,\\n\" \\\n \"breadcrumbs and arbitrary custom context to enrich error reports.\"\n url = \"https://github.com/conan-io/conan-center-index\"\n homepage = \"https://github.com/getsentry/sentry-native\"\n license = \"MIT\"\n topics = (\"conan\", \"breakpad\", \"crashpad\",\n \"error-reporting\", \"crash-reporting\")\n exports_sources = [\"CMakeLists.txt\"]\n generators = \"cmake\", \"cmake_find_package\"\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n options = {\n \"shared\": [True, False],\n \"fPIC\": [True, False],\n \"backend\": [\"none\", \"inproc\", \"crashpad\", \"breakpad\"],\n \"transport\": [\"none\", \"curl\", \"winhttp\"],\n }\n default_options = {\n \"shared\": False,\n \"fPIC\": True,\n \"backend\": \"inproc\",\n \"transport\": \"curl\"\n }\n\n @property\n def _source_subfolder(self):\n return \"source_subfolder\"\n\n _cmake = None\n\n def requirements(self):\n if self.options.transport == \"curl\":\n self.requires(\"libcurl/7.68.0\")\n \n if self.options.backend == \"crashpad\":\n raise ConanInvalidConfiguration(\"crashpad not available yet in CCI\")\n if self.options.backend == \"breakpad\":\n raise ConanInvalidConfiguration(\"breakpad not available yet in CCI\")\n\n def config_options(self):\n if self.settings.os == \"Windows\":\n del self.options.fPIC\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version])\n extracted_dir = self.name + \"-\" + self.version\n os.rename(extracted_dir, self._source_subfolder)\n\n def configure(self):\n if self.options.backend == \"inproc\" and self.settings.os == \"Windows\":\n raise ConanInvalidConfiguration(\"The in-process backend is not supported on Windows\")\n\n def _configure_cmake(self):\n if self._cmake:\n return self._cmake\n self._cmake = CMake(self)\n self._cmake.definitions[\"SENTRY_BACKEND\"] = self.options.backend\n self._cmake.definitions[\"SENTRY_ENABLE_INSTALL\"] = True\n self._cmake.definitions[\"SENTRY_TRANSPORT\"] = self.options.transport\n self._cmake.definitions[\"SENTRY_PIC\"] = self.options.get_safe(\"fPIC\", False)\n self._cmake.configure()\n return self._cmake\n\n def build(self):\n cmake = self._configure_cmake()\n cmake.build()\n\n def package(self):\n self.copy(\"LICENSE\", dst=\"licenses\", src=self._source_subfolder)\n cmake = self._configure_cmake()\n cmake.install()\n tools.rmdir(os.path.join(self.package_folder, \"lib\", \"cmake\"))\n\n def package_info(self):\n self.cpp_info.libs = [\"sentry\"]\n if self.settings.os in (\"Android\", \"Windows\"):\n self.cpp_info.exelinkflags= [\"--build-id=sha1\"]\n self.cpp_info.sharedlinkflags = [\"--build-id=sha1\"]\n if self.settings.os == \"Linux\":\n self.cpp_info.system_libs = [\"pthread\", \"dl\"]\n elif self.settings.os == \"Windows\":\n self.cpp_info.system_libs = [\"winhttp\", \"dbghelp\", \"pathcch\"]\n\n if not self.options.shared:\n self.cpp_info.defines = [\"SENTRY_BUILD_STATIC\"]\n", "path": "recipes/sentry-native/all/conanfile.py"}], "after_files": [{"content": "import os\nimport glob\nfrom conans import ConanFile, CMake, tools\nfrom conans.errors import ConanInvalidConfiguration\n\n\nclass SentryNativeConan(ConanFile):\n name = \"sentry-native\"\n description = \"The Sentry Native SDK is an error and crash reporting client for native applications,\\n\" \\\n \"optimized for C and C++. Sentry allows to add tags,\\n\" \\\n \"breadcrumbs and arbitrary custom context to enrich error reports.\"\n url = \"https://github.com/conan-io/conan-center-index\"\n homepage = \"https://github.com/getsentry/sentry-native\"\n license = \"MIT\"\n topics = (\"conan\", \"breakpad\", \"crashpad\",\n \"error-reporting\", \"crash-reporting\")\n exports_sources = [\"CMakeLists.txt\"]\n generators = \"cmake\", \"cmake_find_package\"\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n options = {\n \"shared\": [True, False],\n \"fPIC\": [True, False],\n \"backend\": [\"none\", \"inproc\", \"crashpad\", \"breakpad\"],\n \"transport\": [\"none\", \"curl\", \"winhttp\"],\n }\n default_options = {\n \"shared\": False,\n \"fPIC\": True,\n \"backend\": \"inproc\",\n \"transport\": \"curl\"\n }\n\n @property\n def _source_subfolder(self):\n return \"source_subfolder\"\n\n _cmake = None\n\n def requirements(self):\n if self.options.transport == \"curl\":\n self.requires(\"libcurl/7.71.0\")\n\n if self.options.backend == \"crashpad\":\n raise ConanInvalidConfiguration(\"crashpad not available yet in CCI\")\n if self.options.backend == \"breakpad\":\n raise ConanInvalidConfiguration(\"breakpad not available yet in CCI\")\n\n def config_options(self):\n if self.settings.os == \"Windows\":\n del self.options.fPIC\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version])\n extracted_dir = self.name + \"-\" + self.version\n os.rename(extracted_dir, self._source_subfolder)\n\n def configure(self):\n if self.options.backend == \"inproc\" and self.settings.os == \"Windows\" and tools.Version(self.version) < \"0.4\":\n raise ConanInvalidConfiguration(\"The in-process backend is not supported on Windows\")\n\n def _configure_cmake(self):\n if self._cmake:\n return self._cmake\n self._cmake = CMake(self)\n self._cmake.definitions[\"SENTRY_BACKEND\"] = self.options.backend\n self._cmake.definitions[\"SENTRY_ENABLE_INSTALL\"] = True\n self._cmake.definitions[\"SENTRY_TRANSPORT\"] = self.options.transport\n self._cmake.definitions[\"SENTRY_PIC\"] = self.options.get_safe(\"fPIC\", False)\n self._cmake.configure()\n return self._cmake\n\n def build(self):\n cmake = self._configure_cmake()\n cmake.build()\n\n def package(self):\n self.copy(\"LICENSE\", dst=\"licenses\", src=self._source_subfolder)\n cmake = self._configure_cmake()\n cmake.install()\n tools.rmdir(os.path.join(self.package_folder, \"lib\", \"cmake\"))\n for pdb in glob.glob(os.path.join(self.package_folder, \"bin\", \"*.pdb\")):\n os.unlink(pdb)\n\n def package_info(self):\n self.cpp_info.libs = [\"sentry\"]\n if self.settings.os in (\"Android\", \"Linux\"):\n self.cpp_info.exelinkflags = [\"-Wl,-E,--build-id=sha1\"]\n self.cpp_info.sharedlinkflags = [\"-Wl,-E,--build-id=sha1\"]\n if self.settings.os == \"Linux\":\n self.cpp_info.system_libs = [\"pthread\", \"dl\"]\n elif self.settings.os == \"Windows\":\n self.cpp_info.system_libs = [\"winhttp\", \"dbghelp\", \"pathcch\", \"shlwapi\"]\n\n if not self.options.shared:\n self.cpp_info.defines = [\"SENTRY_BUILD_STATIC\"]\n", "path": "recipes/sentry-native/all/conanfile.py"}]}
| 1,398 | 595 |
gh_patches_debug_32336
|
rasdani/github-patches
|
git_diff
|
opsdroid__opsdroid-988
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Fixing rasanlu parser : dict object has no attribute matchers issue #860
# Description
When using rasanlu parser with no intents file (no need to train the module, already done) an attribute issue error happened in function _get_all_intents(skills)
...
matchers = [matcher for skill in skills for matcher in skill.matchers]
File "/Users/IOBreaker/Developments/Bots/opsdroid/opsdroid/parsers/rasanlu.py", line 19, in <listcomp>
matchers = [matcher for skill in skills for matcher in skill.matchers]
AttributeError: 'dict' object has no attribute 'matchers'
Fixes #860
After discussion with @jacobtomlinson the decision was to go using intents provided directly by the skill dict.
Beside, an other correction was added to this fixes according to [rasa_nlu](https://github.com/RasaHQ/rasa_nlu/blob/master/docs/http.rst#post-train) documentation
```
The request should always be sent as application/x-yml regardless of wether you use json or md for the data format. Do not send json as application/json for example.
```
## Status
**READY** | **~UNDER DEVELOPMENT~** | **~ON HOLD~**
## Type of change
- Bug fix (non-breaking change which fixes an issue)
# How Has This Been Tested?
I tested the fix on my environment, no issue detected
# Checklist:
- [x] I have performed a self-review of my own code
- [ ] I have made corresponding changes to the documentation (if applicable)
- [x] I have added tests that prove my fix is effective or that my feature works (test file modification)
- [x] New and existing unit tests pass locally with my changes
- [x] Tox ok
rasanlu parser does not manage the new returned response after training request
# Description
This issue was initially detected by @jhofeditz when testing the fix #881.
The new rasanlu trainer instead of returning a json response after a model training, it return a zip file with all files generated by the trainer.
## Steps to Reproduce
1- Download docker image rasa/rasa_nlu:latest-spacy
2- Start docker image
3- Use a skill that interact with rasanlu and that need rasa to be trained using an intents.yml file
4- activate the skill in your opsdroid config file
5- Start opsdroid
## Expected Functionality
Opsdroid should be capable to manage json response and zip response
## Experienced Functionality
Crash of opsdroid due to parsing error
## Versions
- **Opsdroid version: v0.14.1+37.ge71ea43**
- **Rasanlu version: 0.15.0a1**
- **Python version: 3.7.2**
- **OS/Docker version: Docker version 18.09.2, build 6247962 **
## Additional Details
**From Rasa side :**
```
2019-03-30 11:37:34 INFO rasa_nlu.data_router - Logging of requests is disabled. (No 'request_log' directory configured)
2019-03-30 11:37:34 INFO __main__ - Started http server on port 5000
2019-03-30 11:37:34+0000 [-] Log opened.
2019-03-30 11:37:34+0000 [-] Site starting on 5000
2019-03-30 11:37:34+0000 [-] Starting factory <twisted.web.server.Site object at 0x7f65ffbff470>
2019-03-30 11:50:43+0000 [-] 2019-03-30 11:50:43 DEBUG rasa_nlu.data_router - New training queued
Fitting 2 folds for each of 6 candidates, totalling 12 fits
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 12 out of 12 | elapsed: 0.0s finished
2019-03-30 11:50:59+0000 [-] "172.17.0.1" - - [30/Mar/2019:11:50:58 +0000] "POST /train?project=ergo&fixed_model_name=1c0badaf3eb8c2bf6546465eadfd8492e7d79c1f0f3520d103d4bc39b4bfc&token=sfgz654zfg546qs4fg646rg64efg HTTP/1.1" 200 11767 "-" "Python/3.7 aiohttp/3.5.4"
2019-03-30 11:53:24+0000 [-] "172.17.0.1" - - [30/Mar/2019:11:53:23 +0000] "GET / HTTP/1.1" 200 29 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:65.0) Gecko/20100101 Firefox/65.0"
2019-03-30 11:53:24+0000 [-] "172.17.0.1" - - [30/Mar/2019:11:53:23 +0000] "GET /favicon.ico HTTP/1.1" 404 233 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:65.0) Gecko/20100101 Firefox/65.0"
2019-03-30 11:54:24+0000 [-] Timing out client: IPv4Address(type='TCP', host='172.17.0.1', port=59948)
```
**From Opsdroid side :**
```
INFO opsdroid.parsers.rasanlu: Starting Rasa NLU training.
INFO opsdroid.parsers.rasanlu: Now training the model. This may take a while...
DEBUG asyncio: Using selector: KqueueSelector
Traceback (most recent call last):
...
File "/Users/hicham/Developments/Bots/opsdroid-iobreaker/opsdroid/opsdroid/parsers/rasanlu.py", line 117, in train_rasanlu
result = await resp.json()
File "/Users/hicham/.virtualenvs/opsdroid/lib/python3.7/site-packages/aiohttp/client_reqrep.py", line 1027, in json
headers=self.headers)
aiohttp.client_exceptions.ContentTypeError: 0, message='Attempt to decode JSON with unexpected mimetype: application/zip'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `opsdroid/parsers/rasanlu.py`
Content:
```
1 """A helper function for training, parsing and executing Rasa NLU skills."""
2
3 import logging
4 import json
5 import unicodedata
6
7 from hashlib import sha256
8
9 import aiohttp
10 import arrow
11
12 from opsdroid.const import RASANLU_DEFAULT_URL, RASANLU_DEFAULT_PROJECT
13
14 _LOGGER = logging.getLogger(__name__)
15
16
17 async def _get_all_intents(skills):
18 """Get all skill intents and concatenate into a single markdown string."""
19 intents = [skill["intents"] for skill in skills if skill["intents"] is not None]
20 if not intents:
21 return None
22 intents = "\n\n".join(intents)
23 return unicodedata.normalize("NFKD", intents).encode("ascii")
24
25
26 async def _get_intents_fingerprint(intents):
27 """Return a hash of the intents."""
28 return sha256(intents).hexdigest()
29
30
31 async def _build_training_url(config):
32 """Build the url for training a Rasa NLU model."""
33 url = "{}/train?project={}&fixed_model_name={}".format(
34 config.get("url", RASANLU_DEFAULT_URL),
35 config.get("project", RASANLU_DEFAULT_PROJECT),
36 config["model"],
37 )
38
39 if "token" in config:
40 url += "&token={}".format(config["token"])
41
42 return url
43
44
45 async def _build_status_url(config):
46 """Build the url for getting the status of Rasa NLU."""
47 return "{}/status".format(config.get("url", RASANLU_DEFAULT_URL))
48
49
50 async def _init_model(config):
51 """Make a request to force Rasa NLU to load the model into memory."""
52 _LOGGER.info(_("Initialising Rasa NLU model."))
53
54 initialisation_start = arrow.now()
55 result = await call_rasanlu("", config)
56
57 if result is None:
58 _LOGGER.error(_("Initialisation failed, training failed.."))
59 return False
60
61 time_taken = int((arrow.now() - initialisation_start).total_seconds())
62 _LOGGER.info(_("Initialisation complete in %s seconds."), time_taken)
63
64 return True
65
66
67 async def _get_existing_models(config):
68 """Get a list of models already trained in the Rasa NLU project."""
69 project = config.get("project", RASANLU_DEFAULT_PROJECT)
70 async with aiohttp.ClientSession() as session:
71 try:
72 resp = await session.get(await _build_status_url(config))
73 if resp.status == 200:
74 result = await resp.json()
75 if project in result["available_projects"]:
76 project_models = result["available_projects"][project]
77 return project_models["available_models"]
78 except aiohttp.ClientOSError:
79 pass
80 return []
81
82
83 async def train_rasanlu(config, skills):
84 """Train a Rasa NLU model based on the loaded skills."""
85 _LOGGER.info(_("Starting Rasa NLU training."))
86 intents = await _get_all_intents(skills)
87 if intents is None:
88 _LOGGER.warning(_("No intents found, skipping training."))
89 return False
90
91 config["model"] = await _get_intents_fingerprint(intents)
92 if config["model"] in await _get_existing_models(config):
93 _LOGGER.info(_("This model already exists, skipping training..."))
94 await _init_model(config)
95 return True
96
97 async with aiohttp.ClientSession() as session:
98 _LOGGER.info(_("Now training the model. This may take a while..."))
99
100 url = await _build_training_url(config)
101
102 # https://github.com/RasaHQ/rasa_nlu/blob/master/docs/http.rst#post-train
103 # Note : The request should always be sent as
104 # application/x-yml regardless of wether you use
105 # json or md for the data format. Do not send json as
106 # application/json for example.+
107 headers = {"content-type": "application/x-yml"}
108
109 try:
110 training_start = arrow.now()
111 resp = await session.post(url, data=intents, headers=headers)
112 except aiohttp.client_exceptions.ClientConnectorError:
113 _LOGGER.error(_("Unable to connect to Rasa NLU, training failed."))
114 return False
115
116 if resp.status == 200:
117 result = await resp.json()
118 if "info" in result and "new model trained" in result["info"]:
119 time_taken = (arrow.now() - training_start).total_seconds()
120 _LOGGER.info(
121 _("Rasa NLU training completed in %s seconds."), int(time_taken)
122 )
123 await _init_model(config)
124 return True
125
126 _LOGGER.debug(result)
127
128 _LOGGER.error(_("Bad Rasa NLU response - %s"), await resp.text())
129 _LOGGER.error(_("Rasa NLU training failed."))
130 return False
131
132
133 async def call_rasanlu(text, config):
134 """Call the Rasa NLU api and return the response."""
135 async with aiohttp.ClientSession() as session:
136 headers = {}
137 data = {
138 "q": text,
139 "project": config.get("project", "default"),
140 "model": config.get("model", "fallback"),
141 }
142 if "token" in config:
143 data["token"] = config["token"]
144 url = config.get("url", RASANLU_DEFAULT_URL) + "/parse"
145 try:
146 resp = await session.post(url, data=json.dumps(data), headers=headers)
147 except aiohttp.client_exceptions.ClientConnectorError:
148 _LOGGER.error(_("Unable to connect to Rasa NLU"))
149 return None
150 if resp.status == 200:
151 result = await resp.json()
152 _LOGGER.debug(_("Rasa NLU response - %s"), json.dumps(result))
153 else:
154 result = await resp.text()
155 _LOGGER.error(_("Bad Rasa NLU response - %s"), result)
156
157 return result
158
159
160 async def parse_rasanlu(opsdroid, skills, message, config):
161 """Parse a message against all Rasa NLU skills."""
162 matched_skills = []
163 try:
164 result = await call_rasanlu(message.text, config)
165 except aiohttp.ClientOSError:
166 _LOGGER.error(_("No response from Rasa NLU, check your network."))
167 return matched_skills
168
169 if result == "unauthorized":
170 _LOGGER.error(_("Rasa NLU error - Unauthorised request." "Check your 'token'."))
171 return matched_skills
172
173 if result is None or "intent" not in result or result["intent"] is None:
174 _LOGGER.error(
175 _("Rasa NLU error - No intent found. Did you " "forget to create one?")
176 )
177 return matched_skills
178
179 confidence = result["intent"]["confidence"]
180 if "min-score" in config and confidence < config["min-score"]:
181 _LOGGER.info(_("Rasa NLU score lower than min-score"))
182 return matched_skills
183
184 if result:
185 for skill in skills:
186 for matcher in skill.matchers:
187 if "rasanlu_intent" in matcher:
188 if matcher["rasanlu_intent"] == result["intent"]["name"]:
189 message.rasanlu = result
190 matched_skills.append(
191 {
192 "score": confidence,
193 "skill": skill,
194 "config": skill.config,
195 "message": message,
196 }
197 )
198
199 return matched_skills
200
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/opsdroid/parsers/rasanlu.py b/opsdroid/parsers/rasanlu.py
--- a/opsdroid/parsers/rasanlu.py
+++ b/opsdroid/parsers/rasanlu.py
@@ -114,17 +114,41 @@
return False
if resp.status == 200:
- result = await resp.json()
- if "info" in result and "new model trained" in result["info"]:
+ if resp.content_type == "application/json":
+ result = await resp.json()
+ if "info" in result and "new model trained" in result["info"]:
+ time_taken = (arrow.now() - training_start).total_seconds()
+ _LOGGER.info(
+ _("Rasa NLU training completed in %s seconds."), int(time_taken)
+ )
+ await _init_model(config)
+ return True
+
+ _LOGGER.debug(result)
+ if (
+ resp.content_type == "application/zip"
+ and resp.content_disposition.type == "attachment"
+ ):
time_taken = (arrow.now() - training_start).total_seconds()
_LOGGER.info(
_("Rasa NLU training completed in %s seconds."), int(time_taken)
)
await _init_model(config)
+ """
+ As inditated in the issue #886, returned zip file is ignored, this can be changed
+ This can be changed in future release if needed
+ Saving model.zip file example :
+ try:
+ output_file = open("/target/directory/model.zip","wb")
+ data = await resp.read()
+ output_file.write(data)
+ output_file.close()
+ _LOGGER.debug("Rasa taining model file saved to /target/directory/model.zip")
+ except:
+ _LOGGER.error("Cannot save rasa taining model file to /target/directory/model.zip")
+ """
return True
- _LOGGER.debug(result)
-
_LOGGER.error(_("Bad Rasa NLU response - %s"), await resp.text())
_LOGGER.error(_("Rasa NLU training failed."))
return False
|
{"golden_diff": "diff --git a/opsdroid/parsers/rasanlu.py b/opsdroid/parsers/rasanlu.py\n--- a/opsdroid/parsers/rasanlu.py\n+++ b/opsdroid/parsers/rasanlu.py\n@@ -114,17 +114,41 @@\n return False\n \n if resp.status == 200:\n- result = await resp.json()\n- if \"info\" in result and \"new model trained\" in result[\"info\"]:\n+ if resp.content_type == \"application/json\":\n+ result = await resp.json()\n+ if \"info\" in result and \"new model trained\" in result[\"info\"]:\n+ time_taken = (arrow.now() - training_start).total_seconds()\n+ _LOGGER.info(\n+ _(\"Rasa NLU training completed in %s seconds.\"), int(time_taken)\n+ )\n+ await _init_model(config)\n+ return True\n+\n+ _LOGGER.debug(result)\n+ if (\n+ resp.content_type == \"application/zip\"\n+ and resp.content_disposition.type == \"attachment\"\n+ ):\n time_taken = (arrow.now() - training_start).total_seconds()\n _LOGGER.info(\n _(\"Rasa NLU training completed in %s seconds.\"), int(time_taken)\n )\n await _init_model(config)\n+ \"\"\"\n+ As inditated in the issue #886, returned zip file is ignored, this can be changed\n+ This can be changed in future release if needed\n+ Saving model.zip file example :\n+ try:\n+ output_file = open(\"/target/directory/model.zip\",\"wb\")\n+ data = await resp.read()\n+ output_file.write(data)\n+ output_file.close()\n+ _LOGGER.debug(\"Rasa taining model file saved to /target/directory/model.zip\")\n+ except:\n+ _LOGGER.error(\"Cannot save rasa taining model file to /target/directory/model.zip\")\n+ \"\"\"\n return True\n \n- _LOGGER.debug(result)\n-\n _LOGGER.error(_(\"Bad Rasa NLU response - %s\"), await resp.text())\n _LOGGER.error(_(\"Rasa NLU training failed.\"))\n return False\n", "issue": "Fixing rasanlu parser : dict object has no attribute matchers issue #860\n# Description\r\n\r\nWhen using rasanlu parser with no intents file (no need to train the module, already done) an attribute issue error happened in function _get_all_intents(skills)\r\n\r\n...\r\n matchers = [matcher for skill in skills for matcher in skill.matchers]\r\n File \"/Users/IOBreaker/Developments/Bots/opsdroid/opsdroid/parsers/rasanlu.py\", line 19, in <listcomp>\r\n matchers = [matcher for skill in skills for matcher in skill.matchers]\r\nAttributeError: 'dict' object has no attribute 'matchers'\r\n\r\nFixes #860\r\n\r\nAfter discussion with @jacobtomlinson the decision was to go using intents provided directly by the skill dict.\r\n\r\nBeside, an other correction was added to this fixes according to [rasa_nlu](https://github.com/RasaHQ/rasa_nlu/blob/master/docs/http.rst#post-train) documentation\r\n\r\n```\r\nThe request should always be sent as application/x-yml regardless of wether you use json or md for the data format. Do not send json as application/json for example.\r\n```\r\n\r\n## Status\r\n**READY** | **~UNDER DEVELOPMENT~** | **~ON HOLD~**\r\n\r\n\r\n## Type of change\r\n\r\n- Bug fix (non-breaking change which fixes an issue)\r\n\r\n# How Has This Been Tested?\r\n\r\nI tested the fix on my environment, no issue detected\r\n\r\n# Checklist:\r\n\r\n- [x] I have performed a self-review of my own code\r\n- [ ] I have made corresponding changes to the documentation (if applicable)\r\n- [x] I have added tests that prove my fix is effective or that my feature works (test file modification)\r\n- [x] New and existing unit tests pass locally with my changes\r\n- [x] Tox ok\r\n\nrasanlu parser does not manage the new returned response after training request\n# Description\r\n\r\nThis issue was initially detected by @jhofeditz when testing the fix #881.\r\nThe new rasanlu trainer instead of returning a json response after a model training, it return a zip file with all files generated by the trainer.\r\n\r\n## Steps to Reproduce\r\n1- Download docker image rasa/rasa_nlu:latest-spacy\r\n2- Start docker image\r\n3- Use a skill that interact with rasanlu and that need rasa to be trained using an intents.yml file\r\n4- activate the skill in your opsdroid config file\r\n5- Start opsdroid \r\n\r\n## Expected Functionality\r\nOpsdroid should be capable to manage json response and zip response\r\n\r\n## Experienced Functionality\r\n\r\nCrash of opsdroid due to parsing error\r\n\r\n\r\n\r\n## Versions\r\n- **Opsdroid version: v0.14.1+37.ge71ea43**\r\n- **Rasanlu version: 0.15.0a1**\r\n- **Python version: 3.7.2**\r\n- **OS/Docker version: Docker version 18.09.2, build 6247962 **\r\n\r\n## Additional Details\r\n\r\n**From Rasa side :**\r\n```\r\n2019-03-30 11:37:34 INFO rasa_nlu.data_router - Logging of requests is disabled. (No 'request_log' directory configured)\r\n2019-03-30 11:37:34 INFO __main__ - Started http server on port 5000\r\n2019-03-30 11:37:34+0000 [-] Log opened.\r\n2019-03-30 11:37:34+0000 [-] Site starting on 5000\r\n2019-03-30 11:37:34+0000 [-] Starting factory <twisted.web.server.Site object at 0x7f65ffbff470>\r\n2019-03-30 11:50:43+0000 [-] 2019-03-30 11:50:43 DEBUG rasa_nlu.data_router - New training queued\r\nFitting 2 folds for each of 6 candidates, totalling 12 fits\r\n[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.\r\n[Parallel(n_jobs=1)]: Done 12 out of 12 | elapsed: 0.0s finished\r\n2019-03-30 11:50:59+0000 [-] \"172.17.0.1\" - - [30/Mar/2019:11:50:58 +0000] \"POST /train?project=ergo&fixed_model_name=1c0badaf3eb8c2bf6546465eadfd8492e7d79c1f0f3520d103d4bc39b4bfc&token=sfgz654zfg546qs4fg646rg64efg HTTP/1.1\" 200 11767 \"-\" \"Python/3.7 aiohttp/3.5.4\"\r\n2019-03-30 11:53:24+0000 [-] \"172.17.0.1\" - - [30/Mar/2019:11:53:23 +0000] \"GET / HTTP/1.1\" 200 29 \"-\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:65.0) Gecko/20100101 Firefox/65.0\"\r\n2019-03-30 11:53:24+0000 [-] \"172.17.0.1\" - - [30/Mar/2019:11:53:23 +0000] \"GET /favicon.ico HTTP/1.1\" 404 233 \"-\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:65.0) Gecko/20100101 Firefox/65.0\"\r\n2019-03-30 11:54:24+0000 [-] Timing out client: IPv4Address(type='TCP', host='172.17.0.1', port=59948)\r\n```\r\n\r\n\r\n**From Opsdroid side :**\r\n```\r\nINFO opsdroid.parsers.rasanlu: Starting Rasa NLU training.\r\nINFO opsdroid.parsers.rasanlu: Now training the model. This may take a while...\r\nDEBUG asyncio: Using selector: KqueueSelector\r\nTraceback (most recent call last):\r\n...\r\n File \"/Users/hicham/Developments/Bots/opsdroid-iobreaker/opsdroid/opsdroid/parsers/rasanlu.py\", line 117, in train_rasanlu\r\n result = await resp.json()\r\n File \"/Users/hicham/.virtualenvs/opsdroid/lib/python3.7/site-packages/aiohttp/client_reqrep.py\", line 1027, in json\r\n headers=self.headers)\r\naiohttp.client_exceptions.ContentTypeError: 0, message='Attempt to decode JSON with unexpected mimetype: application/zip'\r\n```\r\n\n", "before_files": [{"content": "\"\"\"A helper function for training, parsing and executing Rasa NLU skills.\"\"\"\n\nimport logging\nimport json\nimport unicodedata\n\nfrom hashlib import sha256\n\nimport aiohttp\nimport arrow\n\nfrom opsdroid.const import RASANLU_DEFAULT_URL, RASANLU_DEFAULT_PROJECT\n\n_LOGGER = logging.getLogger(__name__)\n\n\nasync def _get_all_intents(skills):\n \"\"\"Get all skill intents and concatenate into a single markdown string.\"\"\"\n intents = [skill[\"intents\"] for skill in skills if skill[\"intents\"] is not None]\n if not intents:\n return None\n intents = \"\\n\\n\".join(intents)\n return unicodedata.normalize(\"NFKD\", intents).encode(\"ascii\")\n\n\nasync def _get_intents_fingerprint(intents):\n \"\"\"Return a hash of the intents.\"\"\"\n return sha256(intents).hexdigest()\n\n\nasync def _build_training_url(config):\n \"\"\"Build the url for training a Rasa NLU model.\"\"\"\n url = \"{}/train?project={}&fixed_model_name={}\".format(\n config.get(\"url\", RASANLU_DEFAULT_URL),\n config.get(\"project\", RASANLU_DEFAULT_PROJECT),\n config[\"model\"],\n )\n\n if \"token\" in config:\n url += \"&token={}\".format(config[\"token\"])\n\n return url\n\n\nasync def _build_status_url(config):\n \"\"\"Build the url for getting the status of Rasa NLU.\"\"\"\n return \"{}/status\".format(config.get(\"url\", RASANLU_DEFAULT_URL))\n\n\nasync def _init_model(config):\n \"\"\"Make a request to force Rasa NLU to load the model into memory.\"\"\"\n _LOGGER.info(_(\"Initialising Rasa NLU model.\"))\n\n initialisation_start = arrow.now()\n result = await call_rasanlu(\"\", config)\n\n if result is None:\n _LOGGER.error(_(\"Initialisation failed, training failed..\"))\n return False\n\n time_taken = int((arrow.now() - initialisation_start).total_seconds())\n _LOGGER.info(_(\"Initialisation complete in %s seconds.\"), time_taken)\n\n return True\n\n\nasync def _get_existing_models(config):\n \"\"\"Get a list of models already trained in the Rasa NLU project.\"\"\"\n project = config.get(\"project\", RASANLU_DEFAULT_PROJECT)\n async with aiohttp.ClientSession() as session:\n try:\n resp = await session.get(await _build_status_url(config))\n if resp.status == 200:\n result = await resp.json()\n if project in result[\"available_projects\"]:\n project_models = result[\"available_projects\"][project]\n return project_models[\"available_models\"]\n except aiohttp.ClientOSError:\n pass\n return []\n\n\nasync def train_rasanlu(config, skills):\n \"\"\"Train a Rasa NLU model based on the loaded skills.\"\"\"\n _LOGGER.info(_(\"Starting Rasa NLU training.\"))\n intents = await _get_all_intents(skills)\n if intents is None:\n _LOGGER.warning(_(\"No intents found, skipping training.\"))\n return False\n\n config[\"model\"] = await _get_intents_fingerprint(intents)\n if config[\"model\"] in await _get_existing_models(config):\n _LOGGER.info(_(\"This model already exists, skipping training...\"))\n await _init_model(config)\n return True\n\n async with aiohttp.ClientSession() as session:\n _LOGGER.info(_(\"Now training the model. This may take a while...\"))\n\n url = await _build_training_url(config)\n\n # https://github.com/RasaHQ/rasa_nlu/blob/master/docs/http.rst#post-train\n # Note : The request should always be sent as\n # application/x-yml regardless of wether you use\n # json or md for the data format. Do not send json as\n # application/json for example.+\n headers = {\"content-type\": \"application/x-yml\"}\n\n try:\n training_start = arrow.now()\n resp = await session.post(url, data=intents, headers=headers)\n except aiohttp.client_exceptions.ClientConnectorError:\n _LOGGER.error(_(\"Unable to connect to Rasa NLU, training failed.\"))\n return False\n\n if resp.status == 200:\n result = await resp.json()\n if \"info\" in result and \"new model trained\" in result[\"info\"]:\n time_taken = (arrow.now() - training_start).total_seconds()\n _LOGGER.info(\n _(\"Rasa NLU training completed in %s seconds.\"), int(time_taken)\n )\n await _init_model(config)\n return True\n\n _LOGGER.debug(result)\n\n _LOGGER.error(_(\"Bad Rasa NLU response - %s\"), await resp.text())\n _LOGGER.error(_(\"Rasa NLU training failed.\"))\n return False\n\n\nasync def call_rasanlu(text, config):\n \"\"\"Call the Rasa NLU api and return the response.\"\"\"\n async with aiohttp.ClientSession() as session:\n headers = {}\n data = {\n \"q\": text,\n \"project\": config.get(\"project\", \"default\"),\n \"model\": config.get(\"model\", \"fallback\"),\n }\n if \"token\" in config:\n data[\"token\"] = config[\"token\"]\n url = config.get(\"url\", RASANLU_DEFAULT_URL) + \"/parse\"\n try:\n resp = await session.post(url, data=json.dumps(data), headers=headers)\n except aiohttp.client_exceptions.ClientConnectorError:\n _LOGGER.error(_(\"Unable to connect to Rasa NLU\"))\n return None\n if resp.status == 200:\n result = await resp.json()\n _LOGGER.debug(_(\"Rasa NLU response - %s\"), json.dumps(result))\n else:\n result = await resp.text()\n _LOGGER.error(_(\"Bad Rasa NLU response - %s\"), result)\n\n return result\n\n\nasync def parse_rasanlu(opsdroid, skills, message, config):\n \"\"\"Parse a message against all Rasa NLU skills.\"\"\"\n matched_skills = []\n try:\n result = await call_rasanlu(message.text, config)\n except aiohttp.ClientOSError:\n _LOGGER.error(_(\"No response from Rasa NLU, check your network.\"))\n return matched_skills\n\n if result == \"unauthorized\":\n _LOGGER.error(_(\"Rasa NLU error - Unauthorised request.\" \"Check your 'token'.\"))\n return matched_skills\n\n if result is None or \"intent\" not in result or result[\"intent\"] is None:\n _LOGGER.error(\n _(\"Rasa NLU error - No intent found. Did you \" \"forget to create one?\")\n )\n return matched_skills\n\n confidence = result[\"intent\"][\"confidence\"]\n if \"min-score\" in config and confidence < config[\"min-score\"]:\n _LOGGER.info(_(\"Rasa NLU score lower than min-score\"))\n return matched_skills\n\n if result:\n for skill in skills:\n for matcher in skill.matchers:\n if \"rasanlu_intent\" in matcher:\n if matcher[\"rasanlu_intent\"] == result[\"intent\"][\"name\"]:\n message.rasanlu = result\n matched_skills.append(\n {\n \"score\": confidence,\n \"skill\": skill,\n \"config\": skill.config,\n \"message\": message,\n }\n )\n\n return matched_skills\n", "path": "opsdroid/parsers/rasanlu.py"}], "after_files": [{"content": "\"\"\"A helper function for training, parsing and executing Rasa NLU skills.\"\"\"\n\nimport logging\nimport json\nimport unicodedata\n\nfrom hashlib import sha256\n\nimport aiohttp\nimport arrow\n\nfrom opsdroid.const import RASANLU_DEFAULT_URL, RASANLU_DEFAULT_PROJECT\n\n_LOGGER = logging.getLogger(__name__)\n\n\nasync def _get_all_intents(skills):\n \"\"\"Get all skill intents and concatenate into a single markdown string.\"\"\"\n intents = [skill[\"intents\"] for skill in skills if skill[\"intents\"] is not None]\n if not intents:\n return None\n intents = \"\\n\\n\".join(intents)\n return unicodedata.normalize(\"NFKD\", intents).encode(\"ascii\")\n\n\nasync def _get_intents_fingerprint(intents):\n \"\"\"Return a hash of the intents.\"\"\"\n return sha256(intents).hexdigest()\n\n\nasync def _build_training_url(config):\n \"\"\"Build the url for training a Rasa NLU model.\"\"\"\n url = \"{}/train?project={}&fixed_model_name={}\".format(\n config.get(\"url\", RASANLU_DEFAULT_URL),\n config.get(\"project\", RASANLU_DEFAULT_PROJECT),\n config[\"model\"],\n )\n\n if \"token\" in config:\n url += \"&token={}\".format(config[\"token\"])\n\n return url\n\n\nasync def _build_status_url(config):\n \"\"\"Build the url for getting the status of Rasa NLU.\"\"\"\n return \"{}/status\".format(config.get(\"url\", RASANLU_DEFAULT_URL))\n\n\nasync def _init_model(config):\n \"\"\"Make a request to force Rasa NLU to load the model into memory.\"\"\"\n _LOGGER.info(_(\"Initialising Rasa NLU model.\"))\n\n initialisation_start = arrow.now()\n result = await call_rasanlu(\"\", config)\n\n if result is None:\n _LOGGER.error(_(\"Initialisation failed, training failed..\"))\n return False\n\n time_taken = int((arrow.now() - initialisation_start).total_seconds())\n _LOGGER.info(_(\"Initialisation complete in %s seconds.\"), time_taken)\n\n return True\n\n\nasync def _get_existing_models(config):\n \"\"\"Get a list of models already trained in the Rasa NLU project.\"\"\"\n project = config.get(\"project\", RASANLU_DEFAULT_PROJECT)\n async with aiohttp.ClientSession() as session:\n try:\n resp = await session.get(await _build_status_url(config))\n if resp.status == 200:\n result = await resp.json()\n if project in result[\"available_projects\"]:\n project_models = result[\"available_projects\"][project]\n return project_models[\"available_models\"]\n except aiohttp.ClientOSError:\n pass\n return []\n\n\nasync def train_rasanlu(config, skills):\n \"\"\"Train a Rasa NLU model based on the loaded skills.\"\"\"\n _LOGGER.info(_(\"Starting Rasa NLU training.\"))\n intents = await _get_all_intents(skills)\n if intents is None:\n _LOGGER.warning(_(\"No intents found, skipping training.\"))\n return False\n\n config[\"model\"] = await _get_intents_fingerprint(intents)\n if config[\"model\"] in await _get_existing_models(config):\n _LOGGER.info(_(\"This model already exists, skipping training...\"))\n await _init_model(config)\n return True\n\n async with aiohttp.ClientSession() as session:\n _LOGGER.info(_(\"Now training the model. This may take a while...\"))\n\n url = await _build_training_url(config)\n\n # https://github.com/RasaHQ/rasa_nlu/blob/master/docs/http.rst#post-train\n # Note : The request should always be sent as\n # application/x-yml regardless of wether you use\n # json or md for the data format. Do not send json as\n # application/json for example.+\n headers = {\"content-type\": \"application/x-yml\"}\n\n try:\n training_start = arrow.now()\n resp = await session.post(url, data=intents, headers=headers)\n except aiohttp.client_exceptions.ClientConnectorError:\n _LOGGER.error(_(\"Unable to connect to Rasa NLU, training failed.\"))\n return False\n\n if resp.status == 200:\n if resp.content_type == \"application/json\":\n result = await resp.json()\n if \"info\" in result and \"new model trained\" in result[\"info\"]:\n time_taken = (arrow.now() - training_start).total_seconds()\n _LOGGER.info(\n _(\"Rasa NLU training completed in %s seconds.\"), int(time_taken)\n )\n await _init_model(config)\n return True\n\n _LOGGER.debug(result)\n if (\n resp.content_type == \"application/zip\"\n and resp.content_disposition.type == \"attachment\"\n ):\n time_taken = (arrow.now() - training_start).total_seconds()\n _LOGGER.info(\n _(\"Rasa NLU training completed in %s seconds.\"), int(time_taken)\n )\n await _init_model(config)\n \"\"\"\n As inditated in the issue #886, returned zip file is ignored, this can be changed\n This can be changed in future release if needed\n Saving model.zip file example :\n try:\n output_file = open(\"/target/directory/model.zip\",\"wb\")\n data = await resp.read()\n output_file.write(data)\n output_file.close()\n _LOGGER.debug(\"Rasa taining model file saved to /target/directory/model.zip\")\n except:\n _LOGGER.error(\"Cannot save rasa taining model file to /target/directory/model.zip\")\n \"\"\"\n return True\n\n _LOGGER.error(_(\"Bad Rasa NLU response - %s\"), await resp.text())\n _LOGGER.error(_(\"Rasa NLU training failed.\"))\n return False\n\n\nasync def call_rasanlu(text, config):\n \"\"\"Call the Rasa NLU api and return the response.\"\"\"\n async with aiohttp.ClientSession() as session:\n headers = {}\n data = {\n \"q\": text,\n \"project\": config.get(\"project\", \"default\"),\n \"model\": config.get(\"model\", \"fallback\"),\n }\n if \"token\" in config:\n data[\"token\"] = config[\"token\"]\n url = config.get(\"url\", RASANLU_DEFAULT_URL) + \"/parse\"\n try:\n resp = await session.post(url, data=json.dumps(data), headers=headers)\n except aiohttp.client_exceptions.ClientConnectorError:\n _LOGGER.error(_(\"Unable to connect to Rasa NLU\"))\n return None\n if resp.status == 200:\n result = await resp.json()\n _LOGGER.debug(_(\"Rasa NLU response - %s\"), json.dumps(result))\n else:\n result = await resp.text()\n _LOGGER.error(_(\"Bad Rasa NLU response - %s\"), result)\n\n return result\n\n\nasync def parse_rasanlu(opsdroid, skills, message, config):\n \"\"\"Parse a message against all Rasa NLU skills.\"\"\"\n matched_skills = []\n try:\n result = await call_rasanlu(message.text, config)\n except aiohttp.ClientOSError:\n _LOGGER.error(_(\"No response from Rasa NLU, check your network.\"))\n return matched_skills\n\n if result == \"unauthorized\":\n _LOGGER.error(_(\"Rasa NLU error - Unauthorised request.\" \"Check your 'token'.\"))\n return matched_skills\n\n if result is None or \"intent\" not in result or result[\"intent\"] is None:\n _LOGGER.error(\n _(\"Rasa NLU error - No intent found. Did you \" \"forget to create one?\")\n )\n return matched_skills\n\n confidence = result[\"intent\"][\"confidence\"]\n if \"min-score\" in config and confidence < config[\"min-score\"]:\n _LOGGER.info(_(\"Rasa NLU score lower than min-score\"))\n return matched_skills\n\n if result:\n for skill in skills:\n for matcher in skill.matchers:\n if \"rasanlu_intent\" in matcher:\n if matcher[\"rasanlu_intent\"] == result[\"intent\"][\"name\"]:\n message.rasanlu = result\n matched_skills.append(\n {\n \"score\": confidence,\n \"skill\": skill,\n \"config\": skill.config,\n \"message\": message,\n }\n )\n\n return matched_skills\n", "path": "opsdroid/parsers/rasanlu.py"}]}
| 4,024 | 472 |
gh_patches_debug_4349
|
rasdani/github-patches
|
git_diff
|
dbt-labs__dbt-core-4890
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[CT-381] [HOTFIX] Homebrew Incident Resolution
### What Happened
dbt-core depends on the dbt-extractor package, and the dbt-extractor package depends on tree-sitter-jinja2. dbt-extractor specifies tree-sitter-jinja2 via a github link using the git protocol. Github security rules changed to require this link to use https which caused cargo to fail to build the dbt-extractor.
### Who Is Affected
Everyone attempting to build dbt-core from source after the github security rules took affect. This primarily affects homebrew users since homebrew builds dbt from source locally.
### Solution:
- release new dbt-extractor (0.4.1). The fix is already in main
- dbt-labs/dbt-extractor#51
- release new dbt-core patch from branch [1.0.4-hotfix](https://github.com/dbt-labs/dbt-core/tree/1.0.4-hotfix) which depends on this new version and accepts all future patch releases so we can skip this step in the future. This branch is only the 3 necessary commits ahead of 1.0.3 to fix this incident.
- main: #4890
- backport is directly on branch [1.0.4-hotfix](https://github.com/dbt-labs/dbt-core/tree/1.0.4-hotfix) because of complications with running the bump-version workflow for a hotfix branch.
Getting the release out has been delayed due to complications with github actions due to an [ongoing GitHub incident](https://www.githubstatus.com/incidents/dcnvr6zym66r).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `core/setup.py`
Content:
```
1 #!/usr/bin/env python
2 import os
3 import sys
4
5 if sys.version_info < (3, 7, 2):
6 print("Error: dbt does not support this version of Python.")
7 print("Please upgrade to Python 3.7.2 or higher.")
8 sys.exit(1)
9
10
11 from setuptools import setup
12
13 try:
14 from setuptools import find_namespace_packages
15 except ImportError:
16 # the user has a downlevel version of setuptools.
17 print("Error: dbt requires setuptools v40.1.0 or higher.")
18 print('Please upgrade setuptools with "pip install --upgrade setuptools" ' "and try again")
19 sys.exit(1)
20
21
22 this_directory = os.path.abspath(os.path.dirname(__file__))
23 with open(os.path.join(this_directory, "README.md")) as f:
24 long_description = f.read()
25
26
27 package_name = "dbt-core"
28 package_version = "1.0.1"
29 description = """With dbt, data analysts and engineers can build analytics \
30 the way engineers build applications."""
31
32
33 setup(
34 name=package_name,
35 version=package_version,
36 description=description,
37 long_description=long_description,
38 long_description_content_type="text/markdown",
39 author="dbt Labs",
40 author_email="[email protected]",
41 url="https://github.com/dbt-labs/dbt-core",
42 packages=find_namespace_packages(include=["dbt", "dbt.*"]),
43 include_package_data=True,
44 test_suite="test",
45 entry_points={
46 "console_scripts": [
47 "dbt = dbt.main:main",
48 ],
49 },
50 scripts=[
51 "scripts/dbt",
52 ],
53 install_requires=[
54 "Jinja2==2.11.3",
55 "MarkupSafe==2.0.1",
56 "agate>=1.6,<1.6.4",
57 "click>=7.0,<9",
58 "colorama>=0.3.9,<0.4.5",
59 "hologram==0.0.14",
60 "isodate>=0.6,<0.7",
61 "logbook>=1.5,<1.6",
62 "mashumaro==2.9",
63 "minimal-snowplow-tracker==0.0.2",
64 "networkx>=2.3,<3",
65 "packaging>=20.9,<22.0",
66 "sqlparse>=0.2.3,<0.5",
67 "dbt-extractor==0.4.0",
68 "typing-extensions>=3.7.4,<4.2",
69 "werkzeug>=1,<3",
70 # the following are all to match snowflake-connector-python
71 "requests<3.0.0",
72 "idna>=2.5,<4",
73 "cffi>=1.9,<2.0.0",
74 ],
75 zip_safe=False,
76 classifiers=[
77 "Development Status :: 5 - Production/Stable",
78 "License :: OSI Approved :: Apache Software License",
79 "Operating System :: Microsoft :: Windows",
80 "Operating System :: MacOS :: MacOS X",
81 "Operating System :: POSIX :: Linux",
82 "Programming Language :: Python :: 3.7",
83 "Programming Language :: Python :: 3.8",
84 "Programming Language :: Python :: 3.9",
85 ],
86 python_requires=">=3.7.2",
87 )
88
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/core/setup.py b/core/setup.py
--- a/core/setup.py
+++ b/core/setup.py
@@ -64,7 +64,7 @@
"networkx>=2.3,<3",
"packaging>=20.9,<22.0",
"sqlparse>=0.2.3,<0.5",
- "dbt-extractor==0.4.0",
+ "dbt-extractor~=0.4.1",
"typing-extensions>=3.7.4,<4.2",
"werkzeug>=1,<3",
# the following are all to match snowflake-connector-python
|
{"golden_diff": "diff --git a/core/setup.py b/core/setup.py\n--- a/core/setup.py\n+++ b/core/setup.py\n@@ -64,7 +64,7 @@\n \"networkx>=2.3,<3\",\n \"packaging>=20.9,<22.0\",\n \"sqlparse>=0.2.3,<0.5\",\n- \"dbt-extractor==0.4.0\",\n+ \"dbt-extractor~=0.4.1\",\n \"typing-extensions>=3.7.4,<4.2\",\n \"werkzeug>=1,<3\",\n # the following are all to match snowflake-connector-python\n", "issue": "[CT-381] [HOTFIX] Homebrew Incident Resolution\n### What Happened\r\n\r\ndbt-core depends on the dbt-extractor package, and the dbt-extractor package depends on tree-sitter-jinja2. dbt-extractor specifies tree-sitter-jinja2 via a github link using the git protocol. Github security rules changed to require this link to use https which caused cargo to fail to build the dbt-extractor.\r\n\r\n### Who Is Affected\r\n\r\nEveryone attempting to build dbt-core from source after the github security rules took affect. This primarily affects homebrew users since homebrew builds dbt from source locally.\r\n\r\n### Solution:\r\n- release new dbt-extractor (0.4.1). The fix is already in main\r\n - dbt-labs/dbt-extractor#51\r\n- release new dbt-core patch from branch [1.0.4-hotfix](https://github.com/dbt-labs/dbt-core/tree/1.0.4-hotfix) which depends on this new version and accepts all future patch releases so we can skip this step in the future. This branch is only the 3 necessary commits ahead of 1.0.3 to fix this incident.\r\n - main: #4890\r\n - backport is directly on branch [1.0.4-hotfix](https://github.com/dbt-labs/dbt-core/tree/1.0.4-hotfix) because of complications with running the bump-version workflow for a hotfix branch.\r\n \r\nGetting the release out has been delayed due to complications with github actions due to an [ongoing GitHub incident](https://www.githubstatus.com/incidents/dcnvr6zym66r).\r\n \n", "before_files": [{"content": "#!/usr/bin/env python\nimport os\nimport sys\n\nif sys.version_info < (3, 7, 2):\n print(\"Error: dbt does not support this version of Python.\")\n print(\"Please upgrade to Python 3.7.2 or higher.\")\n sys.exit(1)\n\n\nfrom setuptools import setup\n\ntry:\n from setuptools import find_namespace_packages\nexcept ImportError:\n # the user has a downlevel version of setuptools.\n print(\"Error: dbt requires setuptools v40.1.0 or higher.\")\n print('Please upgrade setuptools with \"pip install --upgrade setuptools\" ' \"and try again\")\n sys.exit(1)\n\n\nthis_directory = os.path.abspath(os.path.dirname(__file__))\nwith open(os.path.join(this_directory, \"README.md\")) as f:\n long_description = f.read()\n\n\npackage_name = \"dbt-core\"\npackage_version = \"1.0.1\"\ndescription = \"\"\"With dbt, data analysts and engineers can build analytics \\\nthe way engineers build applications.\"\"\"\n\n\nsetup(\n name=package_name,\n version=package_version,\n description=description,\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n author=\"dbt Labs\",\n author_email=\"[email protected]\",\n url=\"https://github.com/dbt-labs/dbt-core\",\n packages=find_namespace_packages(include=[\"dbt\", \"dbt.*\"]),\n include_package_data=True,\n test_suite=\"test\",\n entry_points={\n \"console_scripts\": [\n \"dbt = dbt.main:main\",\n ],\n },\n scripts=[\n \"scripts/dbt\",\n ],\n install_requires=[\n \"Jinja2==2.11.3\",\n \"MarkupSafe==2.0.1\",\n \"agate>=1.6,<1.6.4\",\n \"click>=7.0,<9\",\n \"colorama>=0.3.9,<0.4.5\",\n \"hologram==0.0.14\",\n \"isodate>=0.6,<0.7\",\n \"logbook>=1.5,<1.6\",\n \"mashumaro==2.9\",\n \"minimal-snowplow-tracker==0.0.2\",\n \"networkx>=2.3,<3\",\n \"packaging>=20.9,<22.0\",\n \"sqlparse>=0.2.3,<0.5\",\n \"dbt-extractor==0.4.0\",\n \"typing-extensions>=3.7.4,<4.2\",\n \"werkzeug>=1,<3\",\n # the following are all to match snowflake-connector-python\n \"requests<3.0.0\",\n \"idna>=2.5,<4\",\n \"cffi>=1.9,<2.0.0\",\n ],\n zip_safe=False,\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: Microsoft :: Windows\",\n \"Operating System :: MacOS :: MacOS X\",\n \"Operating System :: POSIX :: Linux\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n ],\n python_requires=\">=3.7.2\",\n)\n", "path": "core/setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\nimport os\nimport sys\n\nif sys.version_info < (3, 7, 2):\n print(\"Error: dbt does not support this version of Python.\")\n print(\"Please upgrade to Python 3.7.2 or higher.\")\n sys.exit(1)\n\n\nfrom setuptools import setup\n\ntry:\n from setuptools import find_namespace_packages\nexcept ImportError:\n # the user has a downlevel version of setuptools.\n print(\"Error: dbt requires setuptools v40.1.0 or higher.\")\n print('Please upgrade setuptools with \"pip install --upgrade setuptools\" ' \"and try again\")\n sys.exit(1)\n\n\nthis_directory = os.path.abspath(os.path.dirname(__file__))\nwith open(os.path.join(this_directory, \"README.md\")) as f:\n long_description = f.read()\n\n\npackage_name = \"dbt-core\"\npackage_version = \"1.0.1\"\ndescription = \"\"\"With dbt, data analysts and engineers can build analytics \\\nthe way engineers build applications.\"\"\"\n\n\nsetup(\n name=package_name,\n version=package_version,\n description=description,\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n author=\"dbt Labs\",\n author_email=\"[email protected]\",\n url=\"https://github.com/dbt-labs/dbt-core\",\n packages=find_namespace_packages(include=[\"dbt\", \"dbt.*\"]),\n include_package_data=True,\n test_suite=\"test\",\n entry_points={\n \"console_scripts\": [\n \"dbt = dbt.main:main\",\n ],\n },\n scripts=[\n \"scripts/dbt\",\n ],\n install_requires=[\n \"Jinja2==2.11.3\",\n \"MarkupSafe==2.0.1\",\n \"agate>=1.6,<1.6.4\",\n \"click>=7.0,<9\",\n \"colorama>=0.3.9,<0.4.5\",\n \"hologram==0.0.14\",\n \"isodate>=0.6,<0.7\",\n \"logbook>=1.5,<1.6\",\n \"mashumaro==2.9\",\n \"minimal-snowplow-tracker==0.0.2\",\n \"networkx>=2.3,<3\",\n \"packaging>=20.9,<22.0\",\n \"sqlparse>=0.2.3,<0.5\",\n \"dbt-extractor~=0.4.1\",\n \"typing-extensions>=3.7.4,<4.2\",\n \"werkzeug>=1,<3\",\n # the following are all to match snowflake-connector-python\n \"requests<3.0.0\",\n \"idna>=2.5,<4\",\n \"cffi>=1.9,<2.0.0\",\n ],\n zip_safe=False,\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: Microsoft :: Windows\",\n \"Operating System :: MacOS :: MacOS X\",\n \"Operating System :: POSIX :: Linux\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n ],\n python_requires=\">=3.7.2\",\n)\n", "path": "core/setup.py"}]}
| 1,511 | 144 |
gh_patches_debug_36247
|
rasdani/github-patches
|
git_diff
|
TabbycatDebate__tabbycat-840
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Include QR code in private URL distribution pages
It is a bit odd to hand people a physical item directing them to the internet, but typing a random string is not really user-friendly. QR codes that directs to the URL could be added to the URL sheets for ease of use. The type of barcode that is in use can't encode as long a string, but a QR code is recognized to be scanned to lead to a website and seems to be well supported by phones.
This may require another dependency to generate these codes; `jsBarcode` can't generate them.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `tabbycat/printing/views.py`
Content:
```
1 import json
2
3 from django.db.models import Q
4 from django.utils.translation import gettext as _
5 from django.views.generic.base import TemplateView
6
7 from adjfeedback.models import AdjudicatorFeedbackQuestion
8 from adjfeedback.utils import expected_feedback_targets
9 from checkins.models import DebateIdentifier
10 from checkins.utils import create_identifiers
11 from draw.models import Debate, DebateTeam
12 from options.utils import use_team_code_names
13 from participants.models import Person
14 from results.utils import side_and_position_names
15 from tournaments.mixins import (CurrentRoundMixin, OptionalAssistantTournamentPageMixin,
16 RoundMixin, TournamentMixin)
17 from tournaments.models import Tournament
18 from utils.mixins import AdministratorMixin
19 from venues.models import VenueCategory
20
21
22 class MasterSheetsListView(AdministratorMixin, RoundMixin, TemplateView):
23 template_name = 'division_sheets_list.html'
24
25 def get_context_data(self, **kwargs):
26 kwargs['standings'] = VenueCategory.objects.all()
27 kwargs['venue_categories'] = VenueCategory.objects.all()
28 return super().get_context_data(**kwargs)
29
30
31 class MasterSheetsView(AdministratorMixin, RoundMixin, TemplateView):
32 template_name = 'master_sheets_view.html'
33
34 def get_context_data(self, **kwargs):
35 venue_category_id = self.kwargs['venue_category_id']
36 base_venue_category = VenueCategory.objects.get(id=venue_category_id)
37 active_tournaments = Tournament.objects.filter(active=True)
38 for tournament in list(active_tournaments):
39 tournament.debates = Debate.objects.select_related(
40 'division', 'division__venue_category', 'round',
41 'round__tournament').filter(
42 # All Debates, with a matching round, at the same venue category name
43 round__seq=self.round.seq,
44 round__tournament=tournament,
45 # Hack - remove when venue category are unified
46 division__venue_category__name=base_venue_category.name
47 ).order_by('round', 'division__venue_category__name', 'division')
48
49 kwargs['base_venue_category'] = base_venue_category
50 kwargs['active_tournaments'] = active_tournaments
51 return super().get_context_data(**kwargs)
52
53
54 class RoomSheetsView(AdministratorMixin, RoundMixin, TemplateView):
55 template_name = 'room_sheets_view.html'
56
57 def get_context_data(self, **kwargs):
58 venue_category_id = self.kwargs['venue_category_id']
59 base_venue_category = VenueCategory.objects.get(id=venue_category_id)
60 venues_list = []
61
62 # Get a unique list of venue names (avoid getting duplicates across tournaments)
63 for venue in set(base_venue_category.venues.order_by('name').values_list('name', flat=True)):
64 venues_list.append({'name': venue, 'debates': []})
65 # All Debates, with a matching round, at the same venue category
66 venues_list[-1]['debates'] = Debate.objects.filter(
67 round__seq=self.round.seq, venue__name=venue).order_by('round__tournament__seq').all()
68 print(venues_list[-1])
69
70 kwargs['base_venue_category'] = base_venue_category
71 kwargs['venues'] = venues_list
72 return super().get_context_data(**kwargs)
73
74
75 class BasePrintFeedbackFormsView(RoundMixin, TemplateView):
76
77 template_name = 'feedback_list.html'
78
79 def add_defaults(self):
80 default_questions = []
81
82 if self.tournament.pref('feedback_introduction'):
83 default_scale_info = AdjudicatorFeedbackQuestion(
84 text=self.tournament.pref('feedback_introduction'), seq=0,
85 answer_type='comment', # Custom type just for print display
86 required=True, from_team=True, from_adj=True
87 )
88 default_questions.append(default_scale_info.serialize())
89
90 default_scale_question = AdjudicatorFeedbackQuestion(
91 text=_("Overall Score"), seq=0,
92 answer_type=AdjudicatorFeedbackQuestion.ANSWER_TYPE_INTEGER_SCALE,
93 required=True, from_team=True, from_adj=True,
94 min_value=self.tournament.pref('adj_min_score'),
95 max_value=self.tournament.pref('adj_max_score')
96 )
97 default_questions.append(default_scale_question.serialize())
98
99 return default_questions
100
101 def questions_dict(self):
102 questions = self.add_defaults()
103 for question in self.tournament.adj_feedback_questions:
104 questions.append(question.serialize())
105
106 return questions
107
108 def construct_info(self, venue, source, source_p, target, target_p):
109 if hasattr(source, 'name'):
110 source_n = source.name
111 elif use_team_code_names(self.tournament, False):
112 source_n = source.code_name
113 else:
114 source_n = source.short_name
115
116 return {
117 'venue': venue.serialize() if venue else '',
118 'authorInstitution': source.institution.code if source.institution else _("Unaffiliated"),
119 'author': source_n, 'authorPosition': source_p,
120 'target': target.name, 'targetPosition': target_p,
121 }
122
123 def get_team_feedbacks(self, debate, team):
124 if len(debate.adjudicators) is 0:
125 return []
126
127 team_paths = self.tournament.pref('feedback_from_teams')
128 ballots = []
129
130 if team_paths == 'orallist' and debate.adjudicators.chair:
131 ballots.append(self.construct_info(debate.venue, team, _("Team"),
132 debate.adjudicators.chair, ""))
133 elif team_paths == 'all-adjs':
134 for target in debate.adjudicators.all():
135 ballots.append(self.construct_info(debate.venue, team, _("Team"), target, ""))
136
137 return ballots
138
139 def get_adj_feedbacks(self, debate):
140 adj_paths = self.tournament.pref('feedback_paths')
141 ballots = []
142
143 debateadjs = debate.debateadjudicator_set.all()
144 for debateadj in debateadjs:
145 sadj = debateadj.adjudicator
146 spos = debate.adjudicators.get_position(sadj)
147 targets = expected_feedback_targets(debateadj, feedback_paths=adj_paths, debate=debate)
148 for tadj, tpos in targets:
149 ballots.append(self.construct_info(debate.venue, sadj, spos, tadj, tpos))
150
151 return ballots
152
153 def get_context_data(self, **kwargs):
154 draw = self.round.debate_set_with_prefetches(institutions=True)
155 draw = sorted(draw, key=lambda d: d.venue.display_name if d.venue else "")
156
157 ballots = []
158 for debate in draw:
159 for team in debate.teams:
160 ballots.extend(self.get_team_feedbacks(debate, team))
161 ballots.extend(self.get_adj_feedbacks(debate))
162
163 kwargs['ballots'] = json.dumps(ballots)
164 kwargs['questions'] = json.dumps(self.questions_dict())
165
166 kwargs['team_questions_exist'] = self.tournament.adjudicatorfeedbackquestion_set.filter(from_team=True).exists()
167 kwargs['adj_questions_exist'] = self.tournament.adjudicatorfeedbackquestion_set.filter(from_adj=True).exists()
168
169 return super().get_context_data(**kwargs)
170
171
172 class AdminPrintFeedbackFormsView(AdministratorMixin, BasePrintFeedbackFormsView):
173 pass
174
175
176 class AssistantPrintFeedbackFormsView(CurrentRoundMixin, OptionalAssistantTournamentPageMixin, BasePrintFeedbackFormsView):
177 assistant_page_permissions = ['all_areas', 'results_draw']
178
179
180 class BasePrintScoresheetsView(RoundMixin, TemplateView):
181
182 template_name = 'scoresheet_list.html'
183
184 def get_ballots_dicts(self):
185 draw = self.round.debate_set_with_prefetches()
186
187 # Create the DebateIdentifiers for the ballots if needed
188 create_identifiers(DebateIdentifier, draw)
189 identifiers = DebateIdentifier.objects.values('debate_id', 'barcode')
190
191 draw = sorted(draw, key=lambda d: d.venue.display_name if d.venue else "")
192 ballots_dicts = []
193
194 # Force translation before JSON serialization
195 sides_and_positions = [(side, [str(pos) for pos in positions])
196 for side, positions in side_and_position_names(self.tournament)]
197
198 for debate in draw:
199 debate_dict = {}
200
201 if debate.venue:
202 debate_dict['venue'] = {'display_name': debate.venue.display_name}
203 else:
204 debate_dict['venue'] = None
205
206 debate_dict['barcode'] = next((i['barcode'] for i in identifiers if i['debate_id'] == debate.id), None)
207
208 debate_dict['debateTeams'] = []
209 for side, (side_name, positions) in zip(self.tournament.sides, sides_and_positions):
210 dt_dict = {'side_name': side_name, 'positions': positions}
211 try:
212 team = debate.get_team(side)
213 dt_dict['team'] = {
214 'short_name': team.short_name,
215 'code_name': team.code_name,
216 'speakers': [{'name': s.name} for s in team.speakers],
217 }
218 except DebateTeam.DoesNotExist:
219 dt_dict['team'] = None
220 debate_dict['debateTeams'].append(dt_dict)
221
222 debate_dict['debateAdjudicators'] = []
223 for adj, pos in debate.adjudicators.with_positions():
224 da_dict = {'position': pos}
225 da_dict['adjudicator'] = {
226 'name': adj.name,
227 'institution': {'code': adj.institution.code if adj.institution else _("Unaffiliated")},
228 }
229 debate_dict['debateAdjudicators'].append(da_dict)
230
231 if self.round.ballots_per_debate == 'per-adj':
232 authors = list(debate.adjudicators.voting_with_positions())
233 else:
234 authors = [(debate.adjudicators.chair, debate.adjudicators.POSITION_CHAIR)]
235
236 blank_author_dict = {
237 'author': "_______________________________________________",
238 'authorInstitution': "",
239 'authorPosition': "",
240 }
241
242 # Add a ballot for each author
243 for author, pos in authors:
244 if author:
245 ballot_dict = {
246 'author': author.name,
247 'authorInstitution': author.institution.code if author.institution else _("Unaffiliated"),
248 'authorPosition': pos,
249 }
250 else:
251 ballot_dict = blank_author_dict
252
253 ballot_dict.update(debate_dict)
254 ballots_dicts.append(ballot_dict)
255
256 if len(authors) == 0:
257 ballot_dict = blank_author_dict
258 ballot_dict.update(debate_dict)
259 ballots_dicts.append(ballot_dict)
260
261 return ballots_dicts
262
263 def get_context_data(self, **kwargs):
264 kwargs['ballots'] = json.dumps(self.get_ballots_dicts())
265 motions = self.round.motion_set.order_by('seq')
266 kwargs['motions'] = json.dumps([{'seq': m.seq, 'text': m.text} for m in motions])
267 kwargs['use_team_code_names'] = use_team_code_names(self.tournament, False)
268 return super().get_context_data(**kwargs)
269
270
271 class AdminPrintScoresheetsView(AdministratorMixin, BasePrintScoresheetsView):
272 pass
273
274
275 class AssistantPrintScoresheetsView(CurrentRoundMixin, OptionalAssistantTournamentPageMixin, BasePrintScoresheetsView):
276 assistant_page_permissions = ['all_areas']
277
278
279 class PrintableRandomisedURLs(TournamentMixin, AdministratorMixin, TemplateView):
280
281 template_name = 'randomised_url_sheets.html'
282
283 def get_context_data(self, **kwargs):
284 kwargs['tournament_slug'] = self.tournament.slug
285
286 if not self.tournament.pref('share_adjs'):
287 kwargs['parts'] = self.tournament.participants.filter(
288 url_key__isnull=False).select_related(
289 'speaker', 'speaker__team', 'adjudicator__institution',
290 'adjudicator')
291 else:
292 kwargs['parts'] = Person.objects.filter(Q(speaker__team__tournament=self.tournament) | Q(adjudicator__tournament__isnull=True) & Q(url_key__isnull=False))
293
294 kwargs['exists'] = self.tournament.participants.filter(url_key__isnull=False).exists()
295
296 return super().get_context_data(**kwargs)
297
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/tabbycat/printing/views.py b/tabbycat/printing/views.py
--- a/tabbycat/printing/views.py
+++ b/tabbycat/printing/views.py
@@ -1,5 +1,8 @@
import json
+import qrcode
+from qrcode.image import svg
+
from django.db.models import Q
from django.utils.translation import gettext as _
from django.views.generic.base import TemplateView
@@ -15,6 +18,7 @@
from tournaments.mixins import (CurrentRoundMixin, OptionalAssistantTournamentPageMixin,
RoundMixin, TournamentMixin)
from tournaments.models import Tournament
+from utils.misc import reverse_tournament
from utils.mixins import AdministratorMixin
from venues.models import VenueCategory
@@ -280,16 +284,28 @@
template_name = 'randomised_url_sheets.html'
+ def add_urls(self, participants):
+ for participant in participants:
+ url = reverse_tournament('privateurls-person-index', self.tournament, kwargs={'url_key': participant['url_key']})
+ abs_url = self.request.build_absolute_uri(url)
+ qr_code = qrcode.make(abs_url, image_factory=svg.SvgPathImage)
+
+ participant['url'] = abs_url
+ participant['qr'] = ' '.join(qr_code._generate_subpaths())
+
+ return participants
+
def get_context_data(self, **kwargs):
- kwargs['tournament_slug'] = self.tournament.slug
if not self.tournament.pref('share_adjs'):
- kwargs['parts'] = self.tournament.participants.filter(
- url_key__isnull=False).select_related(
- 'speaker', 'speaker__team', 'adjudicator__institution',
- 'adjudicator')
+ participants = self.tournament.participants.filter(url_key__isnull=False)
else:
- kwargs['parts'] = Person.objects.filter(Q(speaker__team__tournament=self.tournament) | Q(adjudicator__tournament__isnull=True) & Q(url_key__isnull=False))
+ participants = Person.objects.filter(
+ Q(speaker__team__tournament=self.tournament) | Q(adjudicator__tournament__isnull=True) & Q(url_key__isnull=False))
+
+ participants_array = list(participants.select_related('speaker', 'speaker__team', 'adjudicator__institution', 'adjudicator')
+ .values('name', 'speaker__team__short_name', 'adjudicator__institution__code', 'url_key'))
+ kwargs['parts'] = self.add_urls(participants_array)
kwargs['exists'] = self.tournament.participants.filter(url_key__isnull=False).exists()
|
{"golden_diff": "diff --git a/tabbycat/printing/views.py b/tabbycat/printing/views.py\n--- a/tabbycat/printing/views.py\n+++ b/tabbycat/printing/views.py\n@@ -1,5 +1,8 @@\n import json\n \n+import qrcode\n+from qrcode.image import svg\n+\n from django.db.models import Q\n from django.utils.translation import gettext as _\n from django.views.generic.base import TemplateView\n@@ -15,6 +18,7 @@\n from tournaments.mixins import (CurrentRoundMixin, OptionalAssistantTournamentPageMixin,\n RoundMixin, TournamentMixin)\n from tournaments.models import Tournament\n+from utils.misc import reverse_tournament\n from utils.mixins import AdministratorMixin\n from venues.models import VenueCategory\n \n@@ -280,16 +284,28 @@\n \n template_name = 'randomised_url_sheets.html'\n \n+ def add_urls(self, participants):\n+ for participant in participants:\n+ url = reverse_tournament('privateurls-person-index', self.tournament, kwargs={'url_key': participant['url_key']})\n+ abs_url = self.request.build_absolute_uri(url)\n+ qr_code = qrcode.make(abs_url, image_factory=svg.SvgPathImage)\n+\n+ participant['url'] = abs_url\n+ participant['qr'] = ' '.join(qr_code._generate_subpaths())\n+\n+ return participants\n+\n def get_context_data(self, **kwargs):\n- kwargs['tournament_slug'] = self.tournament.slug\n \n if not self.tournament.pref('share_adjs'):\n- kwargs['parts'] = self.tournament.participants.filter(\n- url_key__isnull=False).select_related(\n- 'speaker', 'speaker__team', 'adjudicator__institution',\n- 'adjudicator')\n+ participants = self.tournament.participants.filter(url_key__isnull=False)\n else:\n- kwargs['parts'] = Person.objects.filter(Q(speaker__team__tournament=self.tournament) | Q(adjudicator__tournament__isnull=True) & Q(url_key__isnull=False))\n+ participants = Person.objects.filter(\n+ Q(speaker__team__tournament=self.tournament) | Q(adjudicator__tournament__isnull=True) & Q(url_key__isnull=False))\n+\n+ participants_array = list(participants.select_related('speaker', 'speaker__team', 'adjudicator__institution', 'adjudicator')\n+ .values('name', 'speaker__team__short_name', 'adjudicator__institution__code', 'url_key'))\n+ kwargs['parts'] = self.add_urls(participants_array)\n \n kwargs['exists'] = self.tournament.participants.filter(url_key__isnull=False).exists()\n", "issue": "Include QR code in private URL distribution pages\nIt is a bit odd to hand people a physical item directing them to the internet, but typing a random string is not really user-friendly. QR codes that directs to the URL could be added to the URL sheets for ease of use. The type of barcode that is in use can't encode as long a string, but a QR code is recognized to be scanned to lead to a website and seems to be well supported by phones.\r\n\r\nThis may require another dependency to generate these codes; `jsBarcode` can't generate them.\n", "before_files": [{"content": "import json\n\nfrom django.db.models import Q\nfrom django.utils.translation import gettext as _\nfrom django.views.generic.base import TemplateView\n\nfrom adjfeedback.models import AdjudicatorFeedbackQuestion\nfrom adjfeedback.utils import expected_feedback_targets\nfrom checkins.models import DebateIdentifier\nfrom checkins.utils import create_identifiers\nfrom draw.models import Debate, DebateTeam\nfrom options.utils import use_team_code_names\nfrom participants.models import Person\nfrom results.utils import side_and_position_names\nfrom tournaments.mixins import (CurrentRoundMixin, OptionalAssistantTournamentPageMixin,\n RoundMixin, TournamentMixin)\nfrom tournaments.models import Tournament\nfrom utils.mixins import AdministratorMixin\nfrom venues.models import VenueCategory\n\n\nclass MasterSheetsListView(AdministratorMixin, RoundMixin, TemplateView):\n template_name = 'division_sheets_list.html'\n\n def get_context_data(self, **kwargs):\n kwargs['standings'] = VenueCategory.objects.all()\n kwargs['venue_categories'] = VenueCategory.objects.all()\n return super().get_context_data(**kwargs)\n\n\nclass MasterSheetsView(AdministratorMixin, RoundMixin, TemplateView):\n template_name = 'master_sheets_view.html'\n\n def get_context_data(self, **kwargs):\n venue_category_id = self.kwargs['venue_category_id']\n base_venue_category = VenueCategory.objects.get(id=venue_category_id)\n active_tournaments = Tournament.objects.filter(active=True)\n for tournament in list(active_tournaments):\n tournament.debates = Debate.objects.select_related(\n 'division', 'division__venue_category', 'round',\n 'round__tournament').filter(\n # All Debates, with a matching round, at the same venue category name\n round__seq=self.round.seq,\n round__tournament=tournament,\n # Hack - remove when venue category are unified\n division__venue_category__name=base_venue_category.name\n ).order_by('round', 'division__venue_category__name', 'division')\n\n kwargs['base_venue_category'] = base_venue_category\n kwargs['active_tournaments'] = active_tournaments\n return super().get_context_data(**kwargs)\n\n\nclass RoomSheetsView(AdministratorMixin, RoundMixin, TemplateView):\n template_name = 'room_sheets_view.html'\n\n def get_context_data(self, **kwargs):\n venue_category_id = self.kwargs['venue_category_id']\n base_venue_category = VenueCategory.objects.get(id=venue_category_id)\n venues_list = []\n\n # Get a unique list of venue names (avoid getting duplicates across tournaments)\n for venue in set(base_venue_category.venues.order_by('name').values_list('name', flat=True)):\n venues_list.append({'name': venue, 'debates': []})\n # All Debates, with a matching round, at the same venue category\n venues_list[-1]['debates'] = Debate.objects.filter(\n round__seq=self.round.seq, venue__name=venue).order_by('round__tournament__seq').all()\n print(venues_list[-1])\n\n kwargs['base_venue_category'] = base_venue_category\n kwargs['venues'] = venues_list\n return super().get_context_data(**kwargs)\n\n\nclass BasePrintFeedbackFormsView(RoundMixin, TemplateView):\n\n template_name = 'feedback_list.html'\n\n def add_defaults(self):\n default_questions = []\n\n if self.tournament.pref('feedback_introduction'):\n default_scale_info = AdjudicatorFeedbackQuestion(\n text=self.tournament.pref('feedback_introduction'), seq=0,\n answer_type='comment', # Custom type just for print display\n required=True, from_team=True, from_adj=True\n )\n default_questions.append(default_scale_info.serialize())\n\n default_scale_question = AdjudicatorFeedbackQuestion(\n text=_(\"Overall Score\"), seq=0,\n answer_type=AdjudicatorFeedbackQuestion.ANSWER_TYPE_INTEGER_SCALE,\n required=True, from_team=True, from_adj=True,\n min_value=self.tournament.pref('adj_min_score'),\n max_value=self.tournament.pref('adj_max_score')\n )\n default_questions.append(default_scale_question.serialize())\n\n return default_questions\n\n def questions_dict(self):\n questions = self.add_defaults()\n for question in self.tournament.adj_feedback_questions:\n questions.append(question.serialize())\n\n return questions\n\n def construct_info(self, venue, source, source_p, target, target_p):\n if hasattr(source, 'name'):\n source_n = source.name\n elif use_team_code_names(self.tournament, False):\n source_n = source.code_name\n else:\n source_n = source.short_name\n\n return {\n 'venue': venue.serialize() if venue else '',\n 'authorInstitution': source.institution.code if source.institution else _(\"Unaffiliated\"),\n 'author': source_n, 'authorPosition': source_p,\n 'target': target.name, 'targetPosition': target_p,\n }\n\n def get_team_feedbacks(self, debate, team):\n if len(debate.adjudicators) is 0:\n return []\n\n team_paths = self.tournament.pref('feedback_from_teams')\n ballots = []\n\n if team_paths == 'orallist' and debate.adjudicators.chair:\n ballots.append(self.construct_info(debate.venue, team, _(\"Team\"),\n debate.adjudicators.chair, \"\"))\n elif team_paths == 'all-adjs':\n for target in debate.adjudicators.all():\n ballots.append(self.construct_info(debate.venue, team, _(\"Team\"), target, \"\"))\n\n return ballots\n\n def get_adj_feedbacks(self, debate):\n adj_paths = self.tournament.pref('feedback_paths')\n ballots = []\n\n debateadjs = debate.debateadjudicator_set.all()\n for debateadj in debateadjs:\n sadj = debateadj.adjudicator\n spos = debate.adjudicators.get_position(sadj)\n targets = expected_feedback_targets(debateadj, feedback_paths=adj_paths, debate=debate)\n for tadj, tpos in targets:\n ballots.append(self.construct_info(debate.venue, sadj, spos, tadj, tpos))\n\n return ballots\n\n def get_context_data(self, **kwargs):\n draw = self.round.debate_set_with_prefetches(institutions=True)\n draw = sorted(draw, key=lambda d: d.venue.display_name if d.venue else \"\")\n\n ballots = []\n for debate in draw:\n for team in debate.teams:\n ballots.extend(self.get_team_feedbacks(debate, team))\n ballots.extend(self.get_adj_feedbacks(debate))\n\n kwargs['ballots'] = json.dumps(ballots)\n kwargs['questions'] = json.dumps(self.questions_dict())\n\n kwargs['team_questions_exist'] = self.tournament.adjudicatorfeedbackquestion_set.filter(from_team=True).exists()\n kwargs['adj_questions_exist'] = self.tournament.adjudicatorfeedbackquestion_set.filter(from_adj=True).exists()\n\n return super().get_context_data(**kwargs)\n\n\nclass AdminPrintFeedbackFormsView(AdministratorMixin, BasePrintFeedbackFormsView):\n pass\n\n\nclass AssistantPrintFeedbackFormsView(CurrentRoundMixin, OptionalAssistantTournamentPageMixin, BasePrintFeedbackFormsView):\n assistant_page_permissions = ['all_areas', 'results_draw']\n\n\nclass BasePrintScoresheetsView(RoundMixin, TemplateView):\n\n template_name = 'scoresheet_list.html'\n\n def get_ballots_dicts(self):\n draw = self.round.debate_set_with_prefetches()\n\n # Create the DebateIdentifiers for the ballots if needed\n create_identifiers(DebateIdentifier, draw)\n identifiers = DebateIdentifier.objects.values('debate_id', 'barcode')\n\n draw = sorted(draw, key=lambda d: d.venue.display_name if d.venue else \"\")\n ballots_dicts = []\n\n # Force translation before JSON serialization\n sides_and_positions = [(side, [str(pos) for pos in positions])\n for side, positions in side_and_position_names(self.tournament)]\n\n for debate in draw:\n debate_dict = {}\n\n if debate.venue:\n debate_dict['venue'] = {'display_name': debate.venue.display_name}\n else:\n debate_dict['venue'] = None\n\n debate_dict['barcode'] = next((i['barcode'] for i in identifiers if i['debate_id'] == debate.id), None)\n\n debate_dict['debateTeams'] = []\n for side, (side_name, positions) in zip(self.tournament.sides, sides_and_positions):\n dt_dict = {'side_name': side_name, 'positions': positions}\n try:\n team = debate.get_team(side)\n dt_dict['team'] = {\n 'short_name': team.short_name,\n 'code_name': team.code_name,\n 'speakers': [{'name': s.name} for s in team.speakers],\n }\n except DebateTeam.DoesNotExist:\n dt_dict['team'] = None\n debate_dict['debateTeams'].append(dt_dict)\n\n debate_dict['debateAdjudicators'] = []\n for adj, pos in debate.adjudicators.with_positions():\n da_dict = {'position': pos}\n da_dict['adjudicator'] = {\n 'name': adj.name,\n 'institution': {'code': adj.institution.code if adj.institution else _(\"Unaffiliated\")},\n }\n debate_dict['debateAdjudicators'].append(da_dict)\n\n if self.round.ballots_per_debate == 'per-adj':\n authors = list(debate.adjudicators.voting_with_positions())\n else:\n authors = [(debate.adjudicators.chair, debate.adjudicators.POSITION_CHAIR)]\n\n blank_author_dict = {\n 'author': \"_______________________________________________\",\n 'authorInstitution': \"\",\n 'authorPosition': \"\",\n }\n\n # Add a ballot for each author\n for author, pos in authors:\n if author:\n ballot_dict = {\n 'author': author.name,\n 'authorInstitution': author.institution.code if author.institution else _(\"Unaffiliated\"),\n 'authorPosition': pos,\n }\n else:\n ballot_dict = blank_author_dict\n\n ballot_dict.update(debate_dict)\n ballots_dicts.append(ballot_dict)\n\n if len(authors) == 0:\n ballot_dict = blank_author_dict\n ballot_dict.update(debate_dict)\n ballots_dicts.append(ballot_dict)\n\n return ballots_dicts\n\n def get_context_data(self, **kwargs):\n kwargs['ballots'] = json.dumps(self.get_ballots_dicts())\n motions = self.round.motion_set.order_by('seq')\n kwargs['motions'] = json.dumps([{'seq': m.seq, 'text': m.text} for m in motions])\n kwargs['use_team_code_names'] = use_team_code_names(self.tournament, False)\n return super().get_context_data(**kwargs)\n\n\nclass AdminPrintScoresheetsView(AdministratorMixin, BasePrintScoresheetsView):\n pass\n\n\nclass AssistantPrintScoresheetsView(CurrentRoundMixin, OptionalAssistantTournamentPageMixin, BasePrintScoresheetsView):\n assistant_page_permissions = ['all_areas']\n\n\nclass PrintableRandomisedURLs(TournamentMixin, AdministratorMixin, TemplateView):\n\n template_name = 'randomised_url_sheets.html'\n\n def get_context_data(self, **kwargs):\n kwargs['tournament_slug'] = self.tournament.slug\n\n if not self.tournament.pref('share_adjs'):\n kwargs['parts'] = self.tournament.participants.filter(\n url_key__isnull=False).select_related(\n 'speaker', 'speaker__team', 'adjudicator__institution',\n 'adjudicator')\n else:\n kwargs['parts'] = Person.objects.filter(Q(speaker__team__tournament=self.tournament) | Q(adjudicator__tournament__isnull=True) & Q(url_key__isnull=False))\n\n kwargs['exists'] = self.tournament.participants.filter(url_key__isnull=False).exists()\n\n return super().get_context_data(**kwargs)\n", "path": "tabbycat/printing/views.py"}], "after_files": [{"content": "import json\n\nimport qrcode\nfrom qrcode.image import svg\n\nfrom django.db.models import Q\nfrom django.utils.translation import gettext as _\nfrom django.views.generic.base import TemplateView\n\nfrom adjfeedback.models import AdjudicatorFeedbackQuestion\nfrom adjfeedback.utils import expected_feedback_targets\nfrom checkins.models import DebateIdentifier\nfrom checkins.utils import create_identifiers\nfrom draw.models import Debate, DebateTeam\nfrom options.utils import use_team_code_names\nfrom participants.models import Person\nfrom results.utils import side_and_position_names\nfrom tournaments.mixins import (CurrentRoundMixin, OptionalAssistantTournamentPageMixin,\n RoundMixin, TournamentMixin)\nfrom tournaments.models import Tournament\nfrom utils.misc import reverse_tournament\nfrom utils.mixins import AdministratorMixin\nfrom venues.models import VenueCategory\n\n\nclass MasterSheetsListView(AdministratorMixin, RoundMixin, TemplateView):\n template_name = 'division_sheets_list.html'\n\n def get_context_data(self, **kwargs):\n kwargs['standings'] = VenueCategory.objects.all()\n kwargs['venue_categories'] = VenueCategory.objects.all()\n return super().get_context_data(**kwargs)\n\n\nclass MasterSheetsView(AdministratorMixin, RoundMixin, TemplateView):\n template_name = 'master_sheets_view.html'\n\n def get_context_data(self, **kwargs):\n venue_category_id = self.kwargs['venue_category_id']\n base_venue_category = VenueCategory.objects.get(id=venue_category_id)\n active_tournaments = Tournament.objects.filter(active=True)\n for tournament in list(active_tournaments):\n tournament.debates = Debate.objects.select_related(\n 'division', 'division__venue_category', 'round',\n 'round__tournament').filter(\n # All Debates, with a matching round, at the same venue category name\n round__seq=self.round.seq,\n round__tournament=tournament,\n # Hack - remove when venue category are unified\n division__venue_category__name=base_venue_category.name\n ).order_by('round', 'division__venue_category__name', 'division')\n\n kwargs['base_venue_category'] = base_venue_category\n kwargs['active_tournaments'] = active_tournaments\n return super().get_context_data(**kwargs)\n\n\nclass RoomSheetsView(AdministratorMixin, RoundMixin, TemplateView):\n template_name = 'room_sheets_view.html'\n\n def get_context_data(self, **kwargs):\n venue_category_id = self.kwargs['venue_category_id']\n base_venue_category = VenueCategory.objects.get(id=venue_category_id)\n venues_list = []\n\n # Get a unique list of venue names (avoid getting duplicates across tournaments)\n for venue in set(base_venue_category.venues.order_by('name').values_list('name', flat=True)):\n venues_list.append({'name': venue, 'debates': []})\n # All Debates, with a matching round, at the same venue category\n venues_list[-1]['debates'] = Debate.objects.filter(\n round__seq=self.round.seq, venue__name=venue).order_by('round__tournament__seq').all()\n print(venues_list[-1])\n\n kwargs['base_venue_category'] = base_venue_category\n kwargs['venues'] = venues_list\n return super().get_context_data(**kwargs)\n\n\nclass BasePrintFeedbackFormsView(RoundMixin, TemplateView):\n\n template_name = 'feedback_list.html'\n\n def add_defaults(self):\n default_questions = []\n\n if self.tournament.pref('feedback_introduction'):\n default_scale_info = AdjudicatorFeedbackQuestion(\n text=self.tournament.pref('feedback_introduction'), seq=0,\n answer_type='comment', # Custom type just for print display\n required=True, from_team=True, from_adj=True\n )\n default_questions.append(default_scale_info.serialize())\n\n default_scale_question = AdjudicatorFeedbackQuestion(\n text=_(\"Overall Score\"), seq=0,\n answer_type=AdjudicatorFeedbackQuestion.ANSWER_TYPE_INTEGER_SCALE,\n required=True, from_team=True, from_adj=True,\n min_value=self.tournament.pref('adj_min_score'),\n max_value=self.tournament.pref('adj_max_score')\n )\n default_questions.append(default_scale_question.serialize())\n\n return default_questions\n\n def questions_dict(self):\n questions = self.add_defaults()\n for question in self.tournament.adj_feedback_questions:\n questions.append(question.serialize())\n\n return questions\n\n def construct_info(self, venue, source, source_p, target, target_p):\n if hasattr(source, 'name'):\n source_n = source.name\n elif use_team_code_names(self.tournament, False):\n source_n = source.code_name\n else:\n source_n = source.short_name\n\n return {\n 'venue': venue.serialize() if venue else '',\n 'authorInstitution': source.institution.code if source.institution else _(\"Unaffiliated\"),\n 'author': source_n, 'authorPosition': source_p,\n 'target': target.name, 'targetPosition': target_p,\n }\n\n def get_team_feedbacks(self, debate, team):\n if len(debate.adjudicators) is 0:\n return []\n\n team_paths = self.tournament.pref('feedback_from_teams')\n ballots = []\n\n if team_paths == 'orallist' and debate.adjudicators.chair:\n ballots.append(self.construct_info(debate.venue, team, _(\"Team\"),\n debate.adjudicators.chair, \"\"))\n elif team_paths == 'all-adjs':\n for target in debate.adjudicators.all():\n ballots.append(self.construct_info(debate.venue, team, _(\"Team\"), target, \"\"))\n\n return ballots\n\n def get_adj_feedbacks(self, debate):\n adj_paths = self.tournament.pref('feedback_paths')\n ballots = []\n\n debateadjs = debate.debateadjudicator_set.all()\n for debateadj in debateadjs:\n sadj = debateadj.adjudicator\n spos = debate.adjudicators.get_position(sadj)\n targets = expected_feedback_targets(debateadj, feedback_paths=adj_paths, debate=debate)\n for tadj, tpos in targets:\n ballots.append(self.construct_info(debate.venue, sadj, spos, tadj, tpos))\n\n return ballots\n\n def get_context_data(self, **kwargs):\n draw = self.round.debate_set_with_prefetches(institutions=True)\n draw = sorted(draw, key=lambda d: d.venue.display_name if d.venue else \"\")\n\n ballots = []\n for debate in draw:\n for team in debate.teams:\n ballots.extend(self.get_team_feedbacks(debate, team))\n ballots.extend(self.get_adj_feedbacks(debate))\n\n kwargs['ballots'] = json.dumps(ballots)\n kwargs['questions'] = json.dumps(self.questions_dict())\n\n kwargs['team_questions_exist'] = self.tournament.adjudicatorfeedbackquestion_set.filter(from_team=True).exists()\n kwargs['adj_questions_exist'] = self.tournament.adjudicatorfeedbackquestion_set.filter(from_adj=True).exists()\n\n return super().get_context_data(**kwargs)\n\n\nclass AdminPrintFeedbackFormsView(AdministratorMixin, BasePrintFeedbackFormsView):\n pass\n\n\nclass AssistantPrintFeedbackFormsView(CurrentRoundMixin, OptionalAssistantTournamentPageMixin, BasePrintFeedbackFormsView):\n assistant_page_permissions = ['all_areas', 'results_draw']\n\n\nclass BasePrintScoresheetsView(RoundMixin, TemplateView):\n\n template_name = 'scoresheet_list.html'\n\n def get_ballots_dicts(self):\n draw = self.round.debate_set_with_prefetches()\n\n # Create the DebateIdentifiers for the ballots if needed\n create_identifiers(DebateIdentifier, draw)\n identifiers = DebateIdentifier.objects.values('debate_id', 'barcode')\n\n draw = sorted(draw, key=lambda d: d.venue.display_name if d.venue else \"\")\n ballots_dicts = []\n\n # Force translation before JSON serialization\n sides_and_positions = [(side, [str(pos) for pos in positions])\n for side, positions in side_and_position_names(self.tournament)]\n\n for debate in draw:\n debate_dict = {}\n\n if debate.venue:\n debate_dict['venue'] = {'display_name': debate.venue.display_name}\n else:\n debate_dict['venue'] = None\n\n debate_dict['barcode'] = next((i['barcode'] for i in identifiers if i['debate_id'] == debate.id), None)\n\n debate_dict['debateTeams'] = []\n for side, (side_name, positions) in zip(self.tournament.sides, sides_and_positions):\n dt_dict = {'side_name': side_name, 'positions': positions}\n try:\n team = debate.get_team(side)\n dt_dict['team'] = {\n 'short_name': team.short_name,\n 'code_name': team.code_name,\n 'speakers': [{'name': s.name} for s in team.speakers],\n }\n except DebateTeam.DoesNotExist:\n dt_dict['team'] = None\n debate_dict['debateTeams'].append(dt_dict)\n\n debate_dict['debateAdjudicators'] = []\n for adj, pos in debate.adjudicators.with_positions():\n da_dict = {'position': pos}\n da_dict['adjudicator'] = {\n 'name': adj.name,\n 'institution': {'code': adj.institution.code if adj.institution else _(\"Unaffiliated\")},\n }\n debate_dict['debateAdjudicators'].append(da_dict)\n\n if self.round.ballots_per_debate == 'per-adj':\n authors = list(debate.adjudicators.voting_with_positions())\n else:\n authors = [(debate.adjudicators.chair, debate.adjudicators.POSITION_CHAIR)]\n\n blank_author_dict = {\n 'author': \"_______________________________________________\",\n 'authorInstitution': \"\",\n 'authorPosition': \"\",\n }\n\n # Add a ballot for each author\n for author, pos in authors:\n if author:\n ballot_dict = {\n 'author': author.name,\n 'authorInstitution': author.institution.code if author.institution else _(\"Unaffiliated\"),\n 'authorPosition': pos,\n }\n else:\n ballot_dict = blank_author_dict\n\n ballot_dict.update(debate_dict)\n ballots_dicts.append(ballot_dict)\n\n if len(authors) == 0:\n ballot_dict = blank_author_dict\n ballot_dict.update(debate_dict)\n ballots_dicts.append(ballot_dict)\n\n return ballots_dicts\n\n def get_context_data(self, **kwargs):\n kwargs['ballots'] = json.dumps(self.get_ballots_dicts())\n motions = self.round.motion_set.order_by('seq')\n kwargs['motions'] = json.dumps([{'seq': m.seq, 'text': m.text} for m in motions])\n kwargs['use_team_code_names'] = use_team_code_names(self.tournament, False)\n return super().get_context_data(**kwargs)\n\n\nclass AdminPrintScoresheetsView(AdministratorMixin, BasePrintScoresheetsView):\n pass\n\n\nclass AssistantPrintScoresheetsView(CurrentRoundMixin, OptionalAssistantTournamentPageMixin, BasePrintScoresheetsView):\n assistant_page_permissions = ['all_areas']\n\n\nclass PrintableRandomisedURLs(TournamentMixin, AdministratorMixin, TemplateView):\n\n template_name = 'randomised_url_sheets.html'\n\n def add_urls(self, participants):\n for participant in participants:\n url = reverse_tournament('privateurls-person-index', self.tournament, kwargs={'url_key': participant['url_key']})\n abs_url = self.request.build_absolute_uri(url)\n qr_code = qrcode.make(abs_url, image_factory=svg.SvgPathImage)\n\n participant['url'] = abs_url\n participant['qr'] = ' '.join(qr_code._generate_subpaths())\n\n return participants\n\n def get_context_data(self, **kwargs):\n\n if not self.tournament.pref('share_adjs'):\n participants = self.tournament.participants.filter(url_key__isnull=False)\n else:\n participants = Person.objects.filter(\n Q(speaker__team__tournament=self.tournament) | Q(adjudicator__tournament__isnull=True) & Q(url_key__isnull=False))\n\n participants_array = list(participants.select_related('speaker', 'speaker__team', 'adjudicator__institution', 'adjudicator')\n .values('name', 'speaker__team__short_name', 'adjudicator__institution__code', 'url_key'))\n kwargs['parts'] = self.add_urls(participants_array)\n\n kwargs['exists'] = self.tournament.participants.filter(url_key__isnull=False).exists()\n\n return super().get_context_data(**kwargs)\n", "path": "tabbycat/printing/views.py"}]}
| 3,715 | 583 |
gh_patches_debug_30485
|
rasdani/github-patches
|
git_diff
|
googleapis__google-cloud-python-4819
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Runtimeconfig: Update time fails to parse
OS: Linux (Debian 4.9.65)
Python: 3.5.3 / 2.7.13
Version: google-cloud-runtimeconfig==0.28.0, google-cloud==0.32.0
Steps to reproduce:
1. Using gcloud, set a runtimeconfig variable.
2. In Python, load that variable
3. Try to access its update_time property.
```pycon
>>> from google.cloud import runtimeconfig
>>> client = runtimeconfig.Client()
>>> config = client.config('testconfig')
>>> var = config.get_variable('foo')
>>> var.update_time
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/redacted/lib/python3.5/site-packages/google/cloud/runtimeconfig/variable.py", line 160, in update_time
value = _rfc3339_to_datetime(value)
File "/redacted/lib/python3.5/site-packages/google/cloud/_helpers.py", line 274, in _rfc3339_to_datetime
dt_str, _RFC3339_MICROS).replace(tzinfo=UTC)
File "/usr/lib/python3.5/_strptime.py", line 510, in _strptime_datetime
tt, fraction = _strptime(data_string, format)
File "/usr/lib/python3.5/_strptime.py", line 343, in _strptime
(data_string, format))
ValueError: time data '2018-01-22T21:39:44.095040522Z' does not match format '%Y-%m-%dT%H:%M:%S.%fZ'
>>> var._properties
{'text': '43', 'updateTime': '2018-01-22T21:39:44.095040522Z'}
```
Observation: The `%f` format accepts microseconds, not fractions of arbitrary precision. That means six digits at most, but I see nine in the data.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `runtimeconfig/google/cloud/runtimeconfig/variable.py`
Content:
```
1 # Copyright 2016 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Create / interact with Google Cloud RuntimeConfig variables.
16
17 .. data:: STATE_UNSPECIFIED
18
19 The default variable state. See
20 https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs.variables#VariableState
21
22 .. data:: STATE_UPDATED
23
24 Indicates the variable was updated, while `variables.watch` was executing.
25 See
26 https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs.variables#VariableState
27
28 .. data:: STATE_DELETED
29
30 Indicates the variable was deleted, while `variables.watch`_ was executing.
31 See
32 https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs.variables#VariableState
33
34 .. _variables.watch:
35 https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs.variables/watch
36 """
37
38 import base64
39
40 from google.cloud._helpers import _rfc3339_to_datetime
41 from google.cloud.exceptions import NotFound
42 from google.cloud.runtimeconfig._helpers import variable_name_from_full_name
43
44
45 STATE_UNSPECIFIED = 'VARIABLE_STATE_UNSPECIFIED'
46 STATE_UPDATED = 'UPDATED'
47 STATE_DELETED = 'DELETED'
48
49
50 class Variable(object):
51 """A variable in the Cloud RuntimeConfig service.
52
53 See
54 https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs.variables
55
56 :type name: str
57 :param name: The name of the variable. This corresponds to the
58 unique path of the variable in the config.
59
60 :type config: :class:`google.cloud.runtimeconfig.config.Config`
61 :param config: The config to which this variable belongs.
62 """
63
64 def __init__(self, name, config):
65 self.name = name
66 self.config = config
67 self._properties = {}
68
69 @classmethod
70 def from_api_repr(cls, resource, config):
71 """Factory: construct a Variable given its API representation
72
73 :type resource: dict
74 :param resource: change set representation returned from the API.
75
76 :type config: :class:`google.cloud.runtimeconfig.config.Config`
77 :param config: The config to which this variable belongs.
78
79 :rtype: :class:`google.cloud.runtimeconfig.variable.Variable`
80 :returns: Variable parsed from ``resource``.
81 """
82 name = variable_name_from_full_name(resource.get('name'))
83 variable = cls(name=name, config=config)
84 variable._set_properties(resource=resource)
85 return variable
86
87 @property
88 def full_name(self):
89 """Fully-qualified name of this variable.
90
91 Example:
92 ``projects/my-project/configs/my-config/variables/my-var``
93
94 :rtype: str
95 :returns: The full name based on config and variable names.
96
97 :raises: :class:`ValueError` if the variable is missing a name.
98 """
99 if not self.name:
100 raise ValueError('Missing variable name.')
101 return '%s/variables/%s' % (self.config.full_name, self.name)
102
103 @property
104 def path(self):
105 """URL path for the variable's APIs.
106
107 :rtype: str
108 :returns: The URL path based on config and variable names.
109 """
110 return '/%s' % (self.full_name,)
111
112 @property
113 def client(self):
114 """The client bound to this variable."""
115 return self.config.client
116
117 @property
118 def value(self):
119 """Value of the variable, as bytes.
120
121 See
122 https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs.variables
123
124 :rtype: bytes or ``NoneType``
125 :returns: The value of the variable or ``None`` if the property
126 is not set locally.
127 """
128 value = self._properties.get('value')
129 if value is not None:
130 value = base64.b64decode(value)
131 return value
132
133 @property
134 def state(self):
135 """Retrieve the state of the variable.
136
137 See
138 https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs.variables#VariableState
139
140 :rtype: str
141 :returns:
142 If set, one of "UPDATED", "DELETED", or defaults to
143 "VARIABLE_STATE_UNSPECIFIED".
144 """
145 return self._properties.get('state', STATE_UNSPECIFIED)
146
147 @property
148 def update_time(self):
149 """Retrieve the timestamp at which the variable was updated.
150
151 See
152 https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs.variables
153
154 :rtype: :class:`datetime.datetime` or ``NoneType``
155 :returns: Datetime object parsed from RFC3339 valid timestamp, or
156 ``None`` if the property is not set locally.
157 """
158 value = self._properties.get('updateTime')
159 if value is not None:
160 value = _rfc3339_to_datetime(value)
161 return value
162
163 def _require_client(self, client):
164 """Check client or verify over-ride.
165
166 :type client: :class:`google.cloud.runtimconfig.client.Client`
167 :param client:
168 (Optional) The client to use. If not passed, falls back to the
169 ``client`` stored on the current zone.
170
171 :rtype: :class:`google.cloud.runtimeconfig.client.Client`
172 :returns: The client passed in or the currently bound client.
173 """
174 if client is None:
175 client = self.client
176 return client
177
178 def _set_properties(self, resource):
179 """Update properties from resource in body of ``api_response``
180
181 :type resource: dict
182 :param resource: variable representation returned from the API.
183 """
184 self._properties.clear()
185 cleaned = resource.copy()
186 if 'name' in cleaned:
187 self.name = variable_name_from_full_name(cleaned.pop('name'))
188 self._properties.update(cleaned)
189
190 def exists(self, client=None):
191 """API call: test for the existence of the variable via a GET request
192
193 See
194 https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs.variables/get
195
196 :type client: :class:`~google.cloud.runtimeconfig.client.Client`
197 :param client:
198 (Optional) The client to use. If not passed, falls back to the
199 ``client`` stored on the variable's config.
200
201 :rtype: bool
202 :returns: True if the variable exists in Cloud RuntimeConfig.
203 """
204 client = self._require_client(client)
205 try:
206 # We only need the status code (200 or not) so we seek to
207 # minimize the returned payload.
208 query_params = {'fields': 'name'}
209 client._connection.api_request(method='GET', path=self.path,
210 query_params=query_params)
211 return True
212 except NotFound:
213 return False
214
215 def reload(self, client=None):
216 """API call: reload the variable via a ``GET`` request.
217
218 This method will reload the newest data for the variable.
219
220 See
221 https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs/get
222
223 :type client: :class:`google.cloud.runtimeconfig.client.Client`
224 :param client:
225 (Optional) The client to use. If not passed, falls back to the
226 client stored on the current config.
227 """
228 client = self._require_client(client)
229
230 # We assume the variable exists. If it doesn't it will raise a NotFound
231 # exception.
232 resp = client._connection.api_request(method='GET', path=self.path)
233 self._set_properties(resource=resp)
234
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/runtimeconfig/google/cloud/runtimeconfig/variable.py b/runtimeconfig/google/cloud/runtimeconfig/variable.py
--- a/runtimeconfig/google/cloud/runtimeconfig/variable.py
+++ b/runtimeconfig/google/cloud/runtimeconfig/variable.py
@@ -36,8 +36,11 @@
"""
import base64
+import datetime
-from google.cloud._helpers import _rfc3339_to_datetime
+import pytz
+
+from google.api_core import datetime_helpers
from google.cloud.exceptions import NotFound
from google.cloud.runtimeconfig._helpers import variable_name_from_full_name
@@ -151,13 +154,28 @@
See
https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs.variables
- :rtype: :class:`datetime.datetime` or ``NoneType``
- :returns: Datetime object parsed from RFC3339 valid timestamp, or
- ``None`` if the property is not set locally.
+ Returns:
+ :class:`~api_core.datetime_helpers.DatetimeWithNanoseconds`,
+ :class:`datetime.datetime` or ``NoneType``:
+ Datetime object parsed from RFC3339 valid timestamp, or
+ ``None`` if the property is not set locally.
+
+ Raises:
+ ValueError: if value is not a valid RFC3339 timestamp
"""
value = self._properties.get('updateTime')
if value is not None:
- value = _rfc3339_to_datetime(value)
+ try:
+ value = datetime.datetime.strptime(
+ value, datetime_helpers._RFC3339_MICROS)
+ except ValueError:
+ DatetimeNS = datetime_helpers.DatetimeWithNanoseconds
+ value = DatetimeNS.from_rfc3339(value)
+ naive = (
+ value.tzinfo is None
+ or value.tzinfo.utcoffset(value) is None)
+ if naive:
+ value = pytz.utc.localize(value)
return value
def _require_client(self, client):
|
{"golden_diff": "diff --git a/runtimeconfig/google/cloud/runtimeconfig/variable.py b/runtimeconfig/google/cloud/runtimeconfig/variable.py\n--- a/runtimeconfig/google/cloud/runtimeconfig/variable.py\n+++ b/runtimeconfig/google/cloud/runtimeconfig/variable.py\n@@ -36,8 +36,11 @@\n \"\"\"\n \n import base64\n+import datetime\n \n-from google.cloud._helpers import _rfc3339_to_datetime\n+import pytz\n+\n+from google.api_core import datetime_helpers\n from google.cloud.exceptions import NotFound\n from google.cloud.runtimeconfig._helpers import variable_name_from_full_name\n \n@@ -151,13 +154,28 @@\n See\n https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs.variables\n \n- :rtype: :class:`datetime.datetime` or ``NoneType``\n- :returns: Datetime object parsed from RFC3339 valid timestamp, or\n- ``None`` if the property is not set locally.\n+ Returns:\n+ :class:`~api_core.datetime_helpers.DatetimeWithNanoseconds`,\n+ :class:`datetime.datetime` or ``NoneType``:\n+ Datetime object parsed from RFC3339 valid timestamp, or\n+ ``None`` if the property is not set locally.\n+\n+ Raises:\n+ ValueError: if value is not a valid RFC3339 timestamp\n \"\"\"\n value = self._properties.get('updateTime')\n if value is not None:\n- value = _rfc3339_to_datetime(value)\n+ try:\n+ value = datetime.datetime.strptime(\n+ value, datetime_helpers._RFC3339_MICROS)\n+ except ValueError:\n+ DatetimeNS = datetime_helpers.DatetimeWithNanoseconds\n+ value = DatetimeNS.from_rfc3339(value)\n+ naive = (\n+ value.tzinfo is None\n+ or value.tzinfo.utcoffset(value) is None)\n+ if naive:\n+ value = pytz.utc.localize(value)\n return value\n \n def _require_client(self, client):\n", "issue": "Runtimeconfig: Update time fails to parse\nOS: Linux (Debian 4.9.65)\r\nPython: 3.5.3 / 2.7.13\r\nVersion: google-cloud-runtimeconfig==0.28.0, google-cloud==0.32.0\r\n\r\nSteps to reproduce:\r\n1. Using gcloud, set a runtimeconfig variable.\r\n2. In Python, load that variable\r\n3. Try to access its update_time property.\r\n\r\n```pycon\r\n>>> from google.cloud import runtimeconfig\r\n>>> client = runtimeconfig.Client()\r\n>>> config = client.config('testconfig')\r\n>>> var = config.get_variable('foo')\r\n>>> var.update_time\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/redacted/lib/python3.5/site-packages/google/cloud/runtimeconfig/variable.py\", line 160, in update_time\r\n value = _rfc3339_to_datetime(value)\r\n File \"/redacted/lib/python3.5/site-packages/google/cloud/_helpers.py\", line 274, in _rfc3339_to_datetime\r\n dt_str, _RFC3339_MICROS).replace(tzinfo=UTC)\r\n File \"/usr/lib/python3.5/_strptime.py\", line 510, in _strptime_datetime\r\n tt, fraction = _strptime(data_string, format)\r\n File \"/usr/lib/python3.5/_strptime.py\", line 343, in _strptime\r\n (data_string, format))\r\nValueError: time data '2018-01-22T21:39:44.095040522Z' does not match format '%Y-%m-%dT%H:%M:%S.%fZ'\r\n>>> var._properties\r\n{'text': '43', 'updateTime': '2018-01-22T21:39:44.095040522Z'}\r\n```\r\n\r\nObservation: The `%f` format accepts microseconds, not fractions of arbitrary precision. That means six digits at most, but I see nine in the data.\n", "before_files": [{"content": "# Copyright 2016 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Create / interact with Google Cloud RuntimeConfig variables.\n\n.. data:: STATE_UNSPECIFIED\n\n The default variable state. See\n https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs.variables#VariableState\n\n.. data:: STATE_UPDATED\n\n Indicates the variable was updated, while `variables.watch` was executing.\n See\n https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs.variables#VariableState\n\n.. data:: STATE_DELETED\n\n Indicates the variable was deleted, while `variables.watch`_ was executing.\n See\n https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs.variables#VariableState\n\n.. _variables.watch:\n https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs.variables/watch\n\"\"\"\n\nimport base64\n\nfrom google.cloud._helpers import _rfc3339_to_datetime\nfrom google.cloud.exceptions import NotFound\nfrom google.cloud.runtimeconfig._helpers import variable_name_from_full_name\n\n\nSTATE_UNSPECIFIED = 'VARIABLE_STATE_UNSPECIFIED'\nSTATE_UPDATED = 'UPDATED'\nSTATE_DELETED = 'DELETED'\n\n\nclass Variable(object):\n \"\"\"A variable in the Cloud RuntimeConfig service.\n\n See\n https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs.variables\n\n :type name: str\n :param name: The name of the variable. This corresponds to the\n unique path of the variable in the config.\n\n :type config: :class:`google.cloud.runtimeconfig.config.Config`\n :param config: The config to which this variable belongs.\n \"\"\"\n\n def __init__(self, name, config):\n self.name = name\n self.config = config\n self._properties = {}\n\n @classmethod\n def from_api_repr(cls, resource, config):\n \"\"\"Factory: construct a Variable given its API representation\n\n :type resource: dict\n :param resource: change set representation returned from the API.\n\n :type config: :class:`google.cloud.runtimeconfig.config.Config`\n :param config: The config to which this variable belongs.\n\n :rtype: :class:`google.cloud.runtimeconfig.variable.Variable`\n :returns: Variable parsed from ``resource``.\n \"\"\"\n name = variable_name_from_full_name(resource.get('name'))\n variable = cls(name=name, config=config)\n variable._set_properties(resource=resource)\n return variable\n\n @property\n def full_name(self):\n \"\"\"Fully-qualified name of this variable.\n\n Example:\n ``projects/my-project/configs/my-config/variables/my-var``\n\n :rtype: str\n :returns: The full name based on config and variable names.\n\n :raises: :class:`ValueError` if the variable is missing a name.\n \"\"\"\n if not self.name:\n raise ValueError('Missing variable name.')\n return '%s/variables/%s' % (self.config.full_name, self.name)\n\n @property\n def path(self):\n \"\"\"URL path for the variable's APIs.\n\n :rtype: str\n :returns: The URL path based on config and variable names.\n \"\"\"\n return '/%s' % (self.full_name,)\n\n @property\n def client(self):\n \"\"\"The client bound to this variable.\"\"\"\n return self.config.client\n\n @property\n def value(self):\n \"\"\"Value of the variable, as bytes.\n\n See\n https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs.variables\n\n :rtype: bytes or ``NoneType``\n :returns: The value of the variable or ``None`` if the property\n is not set locally.\n \"\"\"\n value = self._properties.get('value')\n if value is not None:\n value = base64.b64decode(value)\n return value\n\n @property\n def state(self):\n \"\"\"Retrieve the state of the variable.\n\n See\n https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs.variables#VariableState\n\n :rtype: str\n :returns:\n If set, one of \"UPDATED\", \"DELETED\", or defaults to\n \"VARIABLE_STATE_UNSPECIFIED\".\n \"\"\"\n return self._properties.get('state', STATE_UNSPECIFIED)\n\n @property\n def update_time(self):\n \"\"\"Retrieve the timestamp at which the variable was updated.\n\n See\n https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs.variables\n\n :rtype: :class:`datetime.datetime` or ``NoneType``\n :returns: Datetime object parsed from RFC3339 valid timestamp, or\n ``None`` if the property is not set locally.\n \"\"\"\n value = self._properties.get('updateTime')\n if value is not None:\n value = _rfc3339_to_datetime(value)\n return value\n\n def _require_client(self, client):\n \"\"\"Check client or verify over-ride.\n\n :type client: :class:`google.cloud.runtimconfig.client.Client`\n :param client:\n (Optional) The client to use. If not passed, falls back to the\n ``client`` stored on the current zone.\n\n :rtype: :class:`google.cloud.runtimeconfig.client.Client`\n :returns: The client passed in or the currently bound client.\n \"\"\"\n if client is None:\n client = self.client\n return client\n\n def _set_properties(self, resource):\n \"\"\"Update properties from resource in body of ``api_response``\n\n :type resource: dict\n :param resource: variable representation returned from the API.\n \"\"\"\n self._properties.clear()\n cleaned = resource.copy()\n if 'name' in cleaned:\n self.name = variable_name_from_full_name(cleaned.pop('name'))\n self._properties.update(cleaned)\n\n def exists(self, client=None):\n \"\"\"API call: test for the existence of the variable via a GET request\n\n See\n https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs.variables/get\n\n :type client: :class:`~google.cloud.runtimeconfig.client.Client`\n :param client:\n (Optional) The client to use. If not passed, falls back to the\n ``client`` stored on the variable's config.\n\n :rtype: bool\n :returns: True if the variable exists in Cloud RuntimeConfig.\n \"\"\"\n client = self._require_client(client)\n try:\n # We only need the status code (200 or not) so we seek to\n # minimize the returned payload.\n query_params = {'fields': 'name'}\n client._connection.api_request(method='GET', path=self.path,\n query_params=query_params)\n return True\n except NotFound:\n return False\n\n def reload(self, client=None):\n \"\"\"API call: reload the variable via a ``GET`` request.\n\n This method will reload the newest data for the variable.\n\n See\n https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs/get\n\n :type client: :class:`google.cloud.runtimeconfig.client.Client`\n :param client:\n (Optional) The client to use. If not passed, falls back to the\n client stored on the current config.\n \"\"\"\n client = self._require_client(client)\n\n # We assume the variable exists. If it doesn't it will raise a NotFound\n # exception.\n resp = client._connection.api_request(method='GET', path=self.path)\n self._set_properties(resource=resp)\n", "path": "runtimeconfig/google/cloud/runtimeconfig/variable.py"}], "after_files": [{"content": "# Copyright 2016 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Create / interact with Google Cloud RuntimeConfig variables.\n\n.. data:: STATE_UNSPECIFIED\n\n The default variable state. See\n https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs.variables#VariableState\n\n.. data:: STATE_UPDATED\n\n Indicates the variable was updated, while `variables.watch` was executing.\n See\n https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs.variables#VariableState\n\n.. data:: STATE_DELETED\n\n Indicates the variable was deleted, while `variables.watch`_ was executing.\n See\n https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs.variables#VariableState\n\n.. _variables.watch:\n https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs.variables/watch\n\"\"\"\n\nimport base64\nimport datetime\n\nimport pytz\n\nfrom google.api_core import datetime_helpers\nfrom google.cloud.exceptions import NotFound\nfrom google.cloud.runtimeconfig._helpers import variable_name_from_full_name\n\n\nSTATE_UNSPECIFIED = 'VARIABLE_STATE_UNSPECIFIED'\nSTATE_UPDATED = 'UPDATED'\nSTATE_DELETED = 'DELETED'\n\n\nclass Variable(object):\n \"\"\"A variable in the Cloud RuntimeConfig service.\n\n See\n https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs.variables\n\n :type name: str\n :param name: The name of the variable. This corresponds to the\n unique path of the variable in the config.\n\n :type config: :class:`google.cloud.runtimeconfig.config.Config`\n :param config: The config to which this variable belongs.\n \"\"\"\n\n def __init__(self, name, config):\n self.name = name\n self.config = config\n self._properties = {}\n\n @classmethod\n def from_api_repr(cls, resource, config):\n \"\"\"Factory: construct a Variable given its API representation\n\n :type resource: dict\n :param resource: change set representation returned from the API.\n\n :type config: :class:`google.cloud.runtimeconfig.config.Config`\n :param config: The config to which this variable belongs.\n\n :rtype: :class:`google.cloud.runtimeconfig.variable.Variable`\n :returns: Variable parsed from ``resource``.\n \"\"\"\n name = variable_name_from_full_name(resource.get('name'))\n variable = cls(name=name, config=config)\n variable._set_properties(resource=resource)\n return variable\n\n @property\n def full_name(self):\n \"\"\"Fully-qualified name of this variable.\n\n Example:\n ``projects/my-project/configs/my-config/variables/my-var``\n\n :rtype: str\n :returns: The full name based on config and variable names.\n\n :raises: :class:`ValueError` if the variable is missing a name.\n \"\"\"\n if not self.name:\n raise ValueError('Missing variable name.')\n return '%s/variables/%s' % (self.config.full_name, self.name)\n\n @property\n def path(self):\n \"\"\"URL path for the variable's APIs.\n\n :rtype: str\n :returns: The URL path based on config and variable names.\n \"\"\"\n return '/%s' % (self.full_name,)\n\n @property\n def client(self):\n \"\"\"The client bound to this variable.\"\"\"\n return self.config.client\n\n @property\n def value(self):\n \"\"\"Value of the variable, as bytes.\n\n See\n https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs.variables\n\n :rtype: bytes or ``NoneType``\n :returns: The value of the variable or ``None`` if the property\n is not set locally.\n \"\"\"\n value = self._properties.get('value')\n if value is not None:\n value = base64.b64decode(value)\n return value\n\n @property\n def state(self):\n \"\"\"Retrieve the state of the variable.\n\n See\n https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs.variables#VariableState\n\n :rtype: str\n :returns:\n If set, one of \"UPDATED\", \"DELETED\", or defaults to\n \"VARIABLE_STATE_UNSPECIFIED\".\n \"\"\"\n return self._properties.get('state', STATE_UNSPECIFIED)\n\n @property\n def update_time(self):\n \"\"\"Retrieve the timestamp at which the variable was updated.\n\n See\n https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs.variables\n\n Returns:\n :class:`~api_core.datetime_helpers.DatetimeWithNanoseconds`,\n :class:`datetime.datetime` or ``NoneType``:\n Datetime object parsed from RFC3339 valid timestamp, or\n ``None`` if the property is not set locally.\n\n Raises:\n ValueError: if value is not a valid RFC3339 timestamp\n \"\"\"\n value = self._properties.get('updateTime')\n if value is not None:\n try:\n value = datetime.datetime.strptime(\n value, datetime_helpers._RFC3339_MICROS)\n except ValueError:\n DatetimeNS = datetime_helpers.DatetimeWithNanoseconds\n value = DatetimeNS.from_rfc3339(value)\n naive = (\n value.tzinfo is None\n or value.tzinfo.utcoffset(value) is None)\n if naive:\n value = pytz.utc.localize(value)\n return value\n\n def _require_client(self, client):\n \"\"\"Check client or verify over-ride.\n\n :type client: :class:`google.cloud.runtimconfig.client.Client`\n :param client:\n (Optional) The client to use. If not passed, falls back to the\n ``client`` stored on the current zone.\n\n :rtype: :class:`google.cloud.runtimeconfig.client.Client`\n :returns: The client passed in or the currently bound client.\n \"\"\"\n if client is None:\n client = self.client\n return client\n\n def _set_properties(self, resource):\n \"\"\"Update properties from resource in body of ``api_response``\n\n :type resource: dict\n :param resource: variable representation returned from the API.\n \"\"\"\n self._properties.clear()\n cleaned = resource.copy()\n if 'name' in cleaned:\n self.name = variable_name_from_full_name(cleaned.pop('name'))\n self._properties.update(cleaned)\n\n def exists(self, client=None):\n \"\"\"API call: test for the existence of the variable via a GET request\n\n See\n https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs.variables/get\n\n :type client: :class:`~google.cloud.runtimeconfig.client.Client`\n :param client:\n (Optional) The client to use. If not passed, falls back to the\n ``client`` stored on the variable's config.\n\n :rtype: bool\n :returns: True if the variable exists in Cloud RuntimeConfig.\n \"\"\"\n client = self._require_client(client)\n try:\n # We only need the status code (200 or not) so we seek to\n # minimize the returned payload.\n query_params = {'fields': 'name'}\n client._connection.api_request(method='GET', path=self.path,\n query_params=query_params)\n return True\n except NotFound:\n return False\n\n def reload(self, client=None):\n \"\"\"API call: reload the variable via a ``GET`` request.\n\n This method will reload the newest data for the variable.\n\n See\n https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs/get\n\n :type client: :class:`google.cloud.runtimeconfig.client.Client`\n :param client:\n (Optional) The client to use. If not passed, falls back to the\n client stored on the current config.\n \"\"\"\n client = self._require_client(client)\n\n # We assume the variable exists. If it doesn't it will raise a NotFound\n # exception.\n resp = client._connection.api_request(method='GET', path=self.path)\n self._set_properties(resource=resp)\n", "path": "runtimeconfig/google/cloud/runtimeconfig/variable.py"}]}
| 3,142 | 457 |
gh_patches_debug_12822
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-center-index-22763
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[question] Using redis-plus-plus with TLS/SSL on
### What is your question?
Hi, I'm having difficulty using Conan to include a version of redis-plus-plus built with TLS enabled in my project. It seems like redis-plus-plus's conan recipe has a `with_tls` option that should enable the support. However, this depends on hiredis being built with SSL enabled. The conan recipe for hiredis seems to have a `with_ssl` option that's supposed to do exactly that, but I could not get it to work.
Here's my conanfile.py:
```
from conan import ConanFile, tools
from conan.tools.cmake import CMake, CMakeDeps, CMakeToolchain, cmake_layout
class HelloConan(ConanFile):
name = "myproject"
version = "0.0.1"
settings = "os", "compiler", "build_type", "arch"
def layout(self):
cmake_layout(self)
def generate(self):
deps = CMakeDeps(self)
deps.generate()
tc = CMakeToolchain(self)
tc.generate()
def configure(self):
self.options["hiredis"]["with_ssl"] = True
self.options["redis-plus-plus"]["with_tls"] = True
def build(self):
cmake = CMake(self)
cmake.configure()
cmake.build()
def package(self):
cmake = CMake(self)
cmake.install()
def requirements(self):
self.requires("redis-plus-plus/1.3.11")
self.requires("hiredis/1.2.0")
```
The error message I get is
```
CMake Error at
/home/ago/.conan2/p/b/redis08573fb8e514a/b/build/Release/generators/cmakedeps_macros.cmake:67 (message):
Library 'hiredis_ssl' not found in package. If 'hiredis_ssl' is a system
library, declare it with 'cpp_info.system_libs' property
```
I also tried not including hiredis in the requirements and/or configure functions in my conanfile.py. The result was
```
ERROR: There are invalid packages:
redis-plus-plus/1.3.11: Invalid: redis-plus-plus:with_tls=True requires hiredis:with_ssl=True
```
I'd really appreciate if anyone could guide me in the right direction to get redis-plus-plus built with the with_tls option enabled.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `recipes/hiredis/all/conanfile.py`
Content:
```
1 from conan import ConanFile
2 from conan.tools.cmake import CMake, CMakeDeps, CMakeToolchain, cmake_layout
3 from conan.tools.files import apply_conandata_patches, copy, export_conandata_patches, get, rmdir, rm
4 from conan.tools.scm import Version
5 from conan.tools.microsoft import is_msvc
6 import os
7
8 required_conan_version = ">=1.53.0"
9
10
11 class HiredisConan(ConanFile):
12 name = "hiredis"
13 description = "Hiredis is a minimalistic C client library for the Redis database."
14 license = "BSD-3-Clause"
15 topics = ("hiredis", "redis", "client", "database")
16 homepage = "https://github.com/redis/hiredis"
17 url = "https://github.com/conan-io/conan-center-index"
18 package_type = "library"
19 settings = "os", "arch", "compiler", "build_type"
20 options = {
21 "shared": [True, False],
22 "fPIC": [True, False],
23 "with_ssl": [True, False],
24 }
25 default_options = {
26 "shared": False,
27 "fPIC": True,
28 "with_ssl": False,
29 }
30
31 def export_sources(self):
32 export_conandata_patches(self)
33
34 def config_options(self):
35 if self.settings.os == "Windows":
36 del self.options.fPIC
37
38 def configure(self):
39 if self.options.shared:
40 self.options.rm_safe("fPIC")
41 self.settings.compiler.rm_safe("libcxx")
42 self.settings.compiler.rm_safe("cppstd")
43
44 def layout(self):
45 cmake_layout(self, src_folder="src")
46
47 def requirements(self):
48 if self.options.with_ssl:
49 self.requires("openssl/[>=1.1 <4]")
50
51 def source(self):
52 get(self, **self.conan_data["sources"][self.version], strip_root=True)
53
54 def generate(self):
55 tc = CMakeToolchain(self)
56 # Since 1.2.0, BUILD_SHARED_LIBS has been defined by option()
57 if Version(self.version) >= "1.2.0":
58 tc.cache_variables["BUILD_SHARED_LIBS"] = self.options.shared
59 tc.variables["ENABLE_SSL"] = self.options.with_ssl
60 tc.variables["DISABLE_TESTS"] = True
61 tc.variables["ENABLE_EXAMPLES"] = False
62 tc.generate()
63 deps = CMakeDeps(self)
64 deps.generate()
65
66 def build(self):
67 apply_conandata_patches(self)
68 cmake = CMake(self)
69 cmake.configure()
70 cmake.build()
71
72 def package(self):
73 copy(self, "COPYING", src=self.source_folder, dst=os.path.join(self.package_folder, "licenses"))
74 cmake = CMake(self)
75 cmake.install()
76 rmdir(self, os.path.join(self.package_folder, "lib", "pkgconfig"))
77 rmdir(self, os.path.join(self.package_folder, "lib", "cmake"))
78 rmdir(self, os.path.join(self.package_folder, "share"))
79 rmdir(self, os.path.join(self.package_folder, "build"))
80 rm(self, "*.pdb", os.path.join(self.package_folder, "bin"))
81
82 def package_info(self):
83 self.cpp_info.set_property("cmake_file_name", "hiredis")
84
85 suffix = ""
86 if Version(self.version) >= "1.1.0":
87 if is_msvc(self) and not self.options.shared and Version(self.version) < "1.2.0":
88 suffix += "_static"
89 if self.settings.build_type == "Debug":
90 suffix += "d"
91
92 # hiredis
93 self.cpp_info.components["hiredislib"].set_property("cmake_target_name", "hiredis::hiredis")
94 self.cpp_info.components["hiredislib"].set_property("pkg_config_name", "hiredis")
95 self.cpp_info.components["hiredislib"].names["cmake_find_package"] = "hiredis"
96 self.cpp_info.components["hiredislib"].names["cmake_find_package_multi"] = "hiredis"
97 self.cpp_info.components["hiredislib"].libs = [f"hiredis{suffix}"]
98 if self.settings.os == "Windows":
99 self.cpp_info.components["hiredislib"].system_libs = ["ws2_32"]
100 # hiredis_ssl
101 if self.options.with_ssl:
102 self.cpp_info.components["hiredis_ssl"].set_property("cmake_target_name", "hiredis::hiredis_ssl")
103 self.cpp_info.components["hiredis_ssl"].set_property("pkg_config_name", "hiredis_ssl")
104 self.cpp_info.components["hiredis_ssl"].names["cmake_find_package"] = "hiredis_ssl"
105 self.cpp_info.components["hiredis_ssl"].names["cmake_find_package_multi"] = "hiredis_ssl"
106 self.cpp_info.components["hiredis_ssl"].libs = [f"hiredis_ssl{suffix}"]
107 self.cpp_info.components["hiredis_ssl"].requires = ["openssl::ssl"]
108 if self.settings.os == "Windows":
109 self.cpp_info.components["hiredis_ssl"].requires.append("hiredislib")
110
111 # These cmake_target_name and pkg_config_name are unofficial. It avoids conflicts
112 # in conan generators between global target/pkg-config and hiredislib component.
113 # TODO: eventually remove the cmake_target_name trick if conan can implement smarter logic
114 # in CMakeDeps when a downstream recipe requires another recipe globally
115 # (link to all components directly instead of global target)
116 self.cpp_info.set_property("cmake_target_name", "hiredis::hiredis_all_unofficial")
117 self.cpp_info.set_property("pkg_config_name", "hiredis_all_unofficial")
118
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/recipes/hiredis/all/conanfile.py b/recipes/hiredis/all/conanfile.py
--- a/recipes/hiredis/all/conanfile.py
+++ b/recipes/hiredis/all/conanfile.py
@@ -56,9 +56,9 @@
# Since 1.2.0, BUILD_SHARED_LIBS has been defined by option()
if Version(self.version) >= "1.2.0":
tc.cache_variables["BUILD_SHARED_LIBS"] = self.options.shared
- tc.variables["ENABLE_SSL"] = self.options.with_ssl
- tc.variables["DISABLE_TESTS"] = True
- tc.variables["ENABLE_EXAMPLES"] = False
+ tc.cache_variables["ENABLE_SSL"] = self.options.with_ssl
+ tc.cache_variables["DISABLE_TESTS"] = True
+ tc.cache_variables["ENABLE_EXAMPLES"] = False
tc.generate()
deps = CMakeDeps(self)
deps.generate()
|
{"golden_diff": "diff --git a/recipes/hiredis/all/conanfile.py b/recipes/hiredis/all/conanfile.py\n--- a/recipes/hiredis/all/conanfile.py\n+++ b/recipes/hiredis/all/conanfile.py\n@@ -56,9 +56,9 @@\n # Since 1.2.0, BUILD_SHARED_LIBS has been defined by option()\n if Version(self.version) >= \"1.2.0\":\n tc.cache_variables[\"BUILD_SHARED_LIBS\"] = self.options.shared\n- tc.variables[\"ENABLE_SSL\"] = self.options.with_ssl\n- tc.variables[\"DISABLE_TESTS\"] = True\n- tc.variables[\"ENABLE_EXAMPLES\"] = False\n+ tc.cache_variables[\"ENABLE_SSL\"] = self.options.with_ssl\n+ tc.cache_variables[\"DISABLE_TESTS\"] = True\n+ tc.cache_variables[\"ENABLE_EXAMPLES\"] = False\n tc.generate()\n deps = CMakeDeps(self)\n deps.generate()\n", "issue": "[question] Using redis-plus-plus with TLS/SSL on\n### What is your question?\n\nHi, I'm having difficulty using Conan to include a version of redis-plus-plus built with TLS enabled in my project. It seems like redis-plus-plus's conan recipe has a `with_tls` option that should enable the support. However, this depends on hiredis being built with SSL enabled. The conan recipe for hiredis seems to have a `with_ssl` option that's supposed to do exactly that, but I could not get it to work. \r\n\r\nHere's my conanfile.py:\r\n\r\n```\r\nfrom conan import ConanFile, tools\r\nfrom conan.tools.cmake import CMake, CMakeDeps, CMakeToolchain, cmake_layout\r\n\r\nclass HelloConan(ConanFile):\r\n name = \"myproject\"\r\n version = \"0.0.1\"\r\n settings = \"os\", \"compiler\", \"build_type\", \"arch\"\r\n\r\n\r\n def layout(self):\r\n cmake_layout(self)\r\n\r\n def generate(self):\r\n deps = CMakeDeps(self)\r\n deps.generate()\r\n tc = CMakeToolchain(self)\r\n tc.generate()\r\n\r\n def configure(self):\r\n self.options[\"hiredis\"][\"with_ssl\"] = True\r\n self.options[\"redis-plus-plus\"][\"with_tls\"] = True\r\n\r\n def build(self):\r\n cmake = CMake(self)\r\n cmake.configure()\r\n cmake.build()\r\n\r\n def package(self):\r\n cmake = CMake(self)\r\n cmake.install()\r\n\r\n def requirements(self):\r\n self.requires(\"redis-plus-plus/1.3.11\")\r\n self.requires(\"hiredis/1.2.0\")\r\n```\r\n\r\nThe error message I get is \r\n```\r\nCMake Error at \r\n/home/ago/.conan2/p/b/redis08573fb8e514a/b/build/Release/generators/cmakedeps_macros.cmake:67 (message):\r\n Library 'hiredis_ssl' not found in package. If 'hiredis_ssl' is a system\r\n library, declare it with 'cpp_info.system_libs' property\r\n```\r\n\r\nI also tried not including hiredis in the requirements and/or configure functions in my conanfile.py. The result was \r\n\r\n```\r\nERROR: There are invalid packages:\r\nredis-plus-plus/1.3.11: Invalid: redis-plus-plus:with_tls=True requires hiredis:with_ssl=True\r\n```\r\n\r\nI'd really appreciate if anyone could guide me in the right direction to get redis-plus-plus built with the with_tls option enabled.\n", "before_files": [{"content": "from conan import ConanFile\nfrom conan.tools.cmake import CMake, CMakeDeps, CMakeToolchain, cmake_layout\nfrom conan.tools.files import apply_conandata_patches, copy, export_conandata_patches, get, rmdir, rm\nfrom conan.tools.scm import Version\nfrom conan.tools.microsoft import is_msvc\nimport os\n\nrequired_conan_version = \">=1.53.0\"\n\n\nclass HiredisConan(ConanFile):\n name = \"hiredis\"\n description = \"Hiredis is a minimalistic C client library for the Redis database.\"\n license = \"BSD-3-Clause\"\n topics = (\"hiredis\", \"redis\", \"client\", \"database\")\n homepage = \"https://github.com/redis/hiredis\"\n url = \"https://github.com/conan-io/conan-center-index\"\n package_type = \"library\"\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n options = {\n \"shared\": [True, False],\n \"fPIC\": [True, False],\n \"with_ssl\": [True, False],\n }\n default_options = {\n \"shared\": False,\n \"fPIC\": True,\n \"with_ssl\": False,\n }\n\n def export_sources(self):\n export_conandata_patches(self)\n\n def config_options(self):\n if self.settings.os == \"Windows\":\n del self.options.fPIC\n\n def configure(self):\n if self.options.shared:\n self.options.rm_safe(\"fPIC\")\n self.settings.compiler.rm_safe(\"libcxx\")\n self.settings.compiler.rm_safe(\"cppstd\")\n\n def layout(self):\n cmake_layout(self, src_folder=\"src\")\n\n def requirements(self):\n if self.options.with_ssl:\n self.requires(\"openssl/[>=1.1 <4]\")\n\n def source(self):\n get(self, **self.conan_data[\"sources\"][self.version], strip_root=True)\n\n def generate(self):\n tc = CMakeToolchain(self)\n # Since 1.2.0, BUILD_SHARED_LIBS has been defined by option()\n if Version(self.version) >= \"1.2.0\":\n tc.cache_variables[\"BUILD_SHARED_LIBS\"] = self.options.shared\n tc.variables[\"ENABLE_SSL\"] = self.options.with_ssl\n tc.variables[\"DISABLE_TESTS\"] = True\n tc.variables[\"ENABLE_EXAMPLES\"] = False\n tc.generate()\n deps = CMakeDeps(self)\n deps.generate()\n\n def build(self):\n apply_conandata_patches(self)\n cmake = CMake(self)\n cmake.configure()\n cmake.build()\n\n def package(self):\n copy(self, \"COPYING\", src=self.source_folder, dst=os.path.join(self.package_folder, \"licenses\"))\n cmake = CMake(self)\n cmake.install()\n rmdir(self, os.path.join(self.package_folder, \"lib\", \"pkgconfig\"))\n rmdir(self, os.path.join(self.package_folder, \"lib\", \"cmake\"))\n rmdir(self, os.path.join(self.package_folder, \"share\"))\n rmdir(self, os.path.join(self.package_folder, \"build\"))\n rm(self, \"*.pdb\", os.path.join(self.package_folder, \"bin\"))\n\n def package_info(self):\n self.cpp_info.set_property(\"cmake_file_name\", \"hiredis\")\n\n suffix = \"\"\n if Version(self.version) >= \"1.1.0\":\n if is_msvc(self) and not self.options.shared and Version(self.version) < \"1.2.0\":\n suffix += \"_static\"\n if self.settings.build_type == \"Debug\":\n suffix += \"d\"\n\n # hiredis\n self.cpp_info.components[\"hiredislib\"].set_property(\"cmake_target_name\", \"hiredis::hiredis\")\n self.cpp_info.components[\"hiredislib\"].set_property(\"pkg_config_name\", \"hiredis\")\n self.cpp_info.components[\"hiredislib\"].names[\"cmake_find_package\"] = \"hiredis\"\n self.cpp_info.components[\"hiredislib\"].names[\"cmake_find_package_multi\"] = \"hiredis\"\n self.cpp_info.components[\"hiredislib\"].libs = [f\"hiredis{suffix}\"]\n if self.settings.os == \"Windows\":\n self.cpp_info.components[\"hiredislib\"].system_libs = [\"ws2_32\"]\n # hiredis_ssl\n if self.options.with_ssl:\n self.cpp_info.components[\"hiredis_ssl\"].set_property(\"cmake_target_name\", \"hiredis::hiredis_ssl\")\n self.cpp_info.components[\"hiredis_ssl\"].set_property(\"pkg_config_name\", \"hiredis_ssl\")\n self.cpp_info.components[\"hiredis_ssl\"].names[\"cmake_find_package\"] = \"hiredis_ssl\"\n self.cpp_info.components[\"hiredis_ssl\"].names[\"cmake_find_package_multi\"] = \"hiredis_ssl\"\n self.cpp_info.components[\"hiredis_ssl\"].libs = [f\"hiredis_ssl{suffix}\"]\n self.cpp_info.components[\"hiredis_ssl\"].requires = [\"openssl::ssl\"]\n if self.settings.os == \"Windows\":\n self.cpp_info.components[\"hiredis_ssl\"].requires.append(\"hiredislib\")\n\n # These cmake_target_name and pkg_config_name are unofficial. It avoids conflicts\n # in conan generators between global target/pkg-config and hiredislib component.\n # TODO: eventually remove the cmake_target_name trick if conan can implement smarter logic\n # in CMakeDeps when a downstream recipe requires another recipe globally\n # (link to all components directly instead of global target)\n self.cpp_info.set_property(\"cmake_target_name\", \"hiredis::hiredis_all_unofficial\")\n self.cpp_info.set_property(\"pkg_config_name\", \"hiredis_all_unofficial\")\n", "path": "recipes/hiredis/all/conanfile.py"}], "after_files": [{"content": "from conan import ConanFile\nfrom conan.tools.cmake import CMake, CMakeDeps, CMakeToolchain, cmake_layout\nfrom conan.tools.files import apply_conandata_patches, copy, export_conandata_patches, get, rmdir, rm\nfrom conan.tools.scm import Version\nfrom conan.tools.microsoft import is_msvc\nimport os\n\nrequired_conan_version = \">=1.53.0\"\n\n\nclass HiredisConan(ConanFile):\n name = \"hiredis\"\n description = \"Hiredis is a minimalistic C client library for the Redis database.\"\n license = \"BSD-3-Clause\"\n topics = (\"hiredis\", \"redis\", \"client\", \"database\")\n homepage = \"https://github.com/redis/hiredis\"\n url = \"https://github.com/conan-io/conan-center-index\"\n package_type = \"library\"\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n options = {\n \"shared\": [True, False],\n \"fPIC\": [True, False],\n \"with_ssl\": [True, False],\n }\n default_options = {\n \"shared\": False,\n \"fPIC\": True,\n \"with_ssl\": False,\n }\n\n def export_sources(self):\n export_conandata_patches(self)\n\n def config_options(self):\n if self.settings.os == \"Windows\":\n del self.options.fPIC\n\n def configure(self):\n if self.options.shared:\n self.options.rm_safe(\"fPIC\")\n self.settings.compiler.rm_safe(\"libcxx\")\n self.settings.compiler.rm_safe(\"cppstd\")\n\n def layout(self):\n cmake_layout(self, src_folder=\"src\")\n\n def requirements(self):\n if self.options.with_ssl:\n self.requires(\"openssl/[>=1.1 <4]\")\n\n def source(self):\n get(self, **self.conan_data[\"sources\"][self.version], strip_root=True)\n\n def generate(self):\n tc = CMakeToolchain(self)\n # Since 1.2.0, BUILD_SHARED_LIBS has been defined by option()\n if Version(self.version) >= \"1.2.0\":\n tc.cache_variables[\"BUILD_SHARED_LIBS\"] = self.options.shared\n tc.cache_variables[\"ENABLE_SSL\"] = self.options.with_ssl\n tc.cache_variables[\"DISABLE_TESTS\"] = True\n tc.cache_variables[\"ENABLE_EXAMPLES\"] = False\n tc.generate()\n deps = CMakeDeps(self)\n deps.generate()\n\n def build(self):\n apply_conandata_patches(self)\n cmake = CMake(self)\n cmake.configure()\n cmake.build()\n\n def package(self):\n copy(self, \"COPYING\", src=self.source_folder, dst=os.path.join(self.package_folder, \"licenses\"))\n cmake = CMake(self)\n cmake.install()\n rmdir(self, os.path.join(self.package_folder, \"lib\", \"pkgconfig\"))\n rmdir(self, os.path.join(self.package_folder, \"lib\", \"cmake\"))\n rmdir(self, os.path.join(self.package_folder, \"share\"))\n rmdir(self, os.path.join(self.package_folder, \"build\"))\n rm(self, \"*.pdb\", os.path.join(self.package_folder, \"bin\"))\n\n def package_info(self):\n self.cpp_info.set_property(\"cmake_file_name\", \"hiredis\")\n\n suffix = \"\"\n if Version(self.version) >= \"1.1.0\":\n if is_msvc(self) and not self.options.shared and Version(self.version) < \"1.2.0\":\n suffix += \"_static\"\n if self.settings.build_type == \"Debug\":\n suffix += \"d\"\n\n # hiredis\n self.cpp_info.components[\"hiredislib\"].set_property(\"cmake_target_name\", \"hiredis::hiredis\")\n self.cpp_info.components[\"hiredislib\"].set_property(\"pkg_config_name\", \"hiredis\")\n self.cpp_info.components[\"hiredislib\"].names[\"cmake_find_package\"] = \"hiredis\"\n self.cpp_info.components[\"hiredislib\"].names[\"cmake_find_package_multi\"] = \"hiredis\"\n self.cpp_info.components[\"hiredislib\"].libs = [f\"hiredis{suffix}\"]\n if self.settings.os == \"Windows\":\n self.cpp_info.components[\"hiredislib\"].system_libs = [\"ws2_32\"]\n # hiredis_ssl\n if self.options.with_ssl:\n self.cpp_info.components[\"hiredis_ssl\"].set_property(\"cmake_target_name\", \"hiredis::hiredis_ssl\")\n self.cpp_info.components[\"hiredis_ssl\"].set_property(\"pkg_config_name\", \"hiredis_ssl\")\n self.cpp_info.components[\"hiredis_ssl\"].names[\"cmake_find_package\"] = \"hiredis_ssl\"\n self.cpp_info.components[\"hiredis_ssl\"].names[\"cmake_find_package_multi\"] = \"hiredis_ssl\"\n self.cpp_info.components[\"hiredis_ssl\"].libs = [f\"hiredis_ssl{suffix}\"]\n self.cpp_info.components[\"hiredis_ssl\"].requires = [\"openssl::ssl\"]\n if self.settings.os == \"Windows\":\n self.cpp_info.components[\"hiredis_ssl\"].requires.append(\"hiredislib\")\n\n # These cmake_target_name and pkg_config_name are unofficial. It avoids conflicts\n # in conan generators between global target/pkg-config and hiredislib component.\n # TODO: eventually remove the cmake_target_name trick if conan can implement smarter logic\n # in CMakeDeps when a downstream recipe requires another recipe globally\n # (link to all components directly instead of global target)\n self.cpp_info.set_property(\"cmake_target_name\", \"hiredis::hiredis_all_unofficial\")\n self.cpp_info.set_property(\"pkg_config_name\", \"hiredis_all_unofficial\")\n", "path": "recipes/hiredis/all/conanfile.py"}]}
| 2,293 | 209 |
gh_patches_debug_36232
|
rasdani/github-patches
|
git_diff
|
pymeasure__pymeasure-350
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Error in examples/Notebook Experiments/script2.ipynb
script.ipynb runs fine but in script2.ipynb I hit the following error at `experiment = Experiment('test', procedure, analyse)`:
```python
C:\ProgramData\Anaconda3\lib\site-packages\matplotlib\__init__.py in __setitem__(self, key, val)
927 raise KeyError(
928 '%s is not a valid rc parameter. See rcParams.keys() for a '
--> 929 'list of valid parameters.' % (key,))
930
931 def __getitem__(self, key):
KeyError: 'axes.color_cycle is not a valid rc parameter. See rcParams.keys() for a list of valid parameters.'
```
Error in examples/Notebook Experiments/script2.ipynb
script.ipynb runs fine but in script2.ipynb I hit the following error at `experiment = Experiment('test', procedure, analyse)`:
```python
C:\ProgramData\Anaconda3\lib\site-packages\matplotlib\__init__.py in __setitem__(self, key, val)
927 raise KeyError(
928 '%s is not a valid rc parameter. See rcParams.keys() for a '
--> 929 'list of valid parameters.' % (key,))
930
931 def __getitem__(self, key):
KeyError: 'axes.color_cycle is not a valid rc parameter. See rcParams.keys() for a list of valid parameters.'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pymeasure/experiment/config.py`
Content:
```
1 #
2 # This file is part of the PyMeasure package.
3 #
4 # Copyright (c) 2013-2020 PyMeasure Developers
5 #
6 # Permission is hereby granted, free of charge, to any person obtaining a copy
7 # of this software and associated documentation files (the "Software"), to deal
8 # in the Software without restriction, including without limitation the rights
9 # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
10 # copies of the Software, and to permit persons to whom the Software is
11 # furnished to do so, subject to the following conditions:
12 #
13 # The above copyright notice and this permission notice shall be included in
14 # all copies or substantial portions of the Software.
15 #
16 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
17 # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
18 # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
19 # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
20 # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
21 # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
22 # THE SOFTWARE.
23 #
24
25 import configparser
26 import logging
27 import os
28
29 log = logging.getLogger(__name__)
30 log.addHandler(logging.NullHandler())
31
32
33 def set_file(filename):
34 os.environ['CONFIG'] = filename
35
36
37 def get_config(filename='default_config.ini'):
38 if 'CONFIG' in os.environ.keys():
39 filename = os.environ['CONFIG']
40 config = configparser.ConfigParser()
41 config.read(filename)
42 return config
43
44
45 # noinspection PyProtectedMember
46 def set_mpl_rcparams(config):
47 if 'matplotlib.rcParams' in config._sections.keys():
48 import matplotlib
49 for key in config._sections['matplotlib.rcParams']:
50 matplotlib.rcParams[key] = eval(config._sections['matplotlib.rcParams'][key])
51
```
Path: `examples/Notebook Experiments/procedures.py`
Content:
```
1 #
2 # This file is part of the PyMeasure package.
3 #
4 # Copyright (c) 2013-2016 PyMeasure Developers
5 #
6 # Permission is hereby granted, free of charge, to any person obtaining a copy
7 # of this software and associated documentation files (the "Software"), to deal
8 # in the Software without restriction, including without limitation the rights
9 # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
10 # copies of the Software, and to permit persons to whom the Software is
11 # furnished to do so, subject to the following conditions:
12 #
13 # The above copyright notice and this permission notice shall be included in
14 # all copies or substantial portions of the Software.
15 #
16 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
17 # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
18 # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
19 # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
20 # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
21 # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
22 # THE SOFTWARE.
23 #
24
25 import random
26 from time import sleep
27 from pymeasure.experiment import Procedure, IntegerParameter, Parameter, FloatParameter
28 import logging
29 log = logging.getLogger(__name__)
30 log.addHandler(logging.NullHandler())
31
32 class TestProcedure(Procedure):
33
34 iterations = IntegerParameter('Loop Iterations', default=100)
35 delay = FloatParameter('Delay Time', units='s', default=0.2)
36 seed = Parameter('Random Seed', default='12345')
37
38 DATA_COLUMNS = ['Iteration', 'Random Number']
39
40 def startup(self):
41 log.info("Setting up random number generator")
42 random.seed(self.seed)
43
44 def execute(self):
45 log.info("Starting to generate numbers")
46 for i in range(self.iterations):
47 data = {
48 'Iteration': i,
49 'Random Number': random.random()
50 }
51 log.debug("Produced numbers: %s" % data)
52 self.emit('results', data)
53 self.emit('progress', 100.*i/self.iterations)
54 sleep(self.delay)
55 if self.should_stop():
56 log.warning("Catch stop command in procedure")
57 break
58
59 def shutdown(self):
60 log.info("Finished")
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/Notebook Experiments/procedures.py b/examples/Notebook Experiments/procedures.py
deleted file mode 100644
--- a/examples/Notebook Experiments/procedures.py
+++ /dev/null
@@ -1,60 +0,0 @@
-#
-# This file is part of the PyMeasure package.
-#
-# Copyright (c) 2013-2016 PyMeasure Developers
-#
-# Permission is hereby granted, free of charge, to any person obtaining a copy
-# of this software and associated documentation files (the "Software"), to deal
-# in the Software without restriction, including without limitation the rights
-# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-# copies of the Software, and to permit persons to whom the Software is
-# furnished to do so, subject to the following conditions:
-#
-# The above copyright notice and this permission notice shall be included in
-# all copies or substantial portions of the Software.
-#
-# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
-# THE SOFTWARE.
-#
-
-import random
-from time import sleep
-from pymeasure.experiment import Procedure, IntegerParameter, Parameter, FloatParameter
-import logging
-log = logging.getLogger(__name__)
-log.addHandler(logging.NullHandler())
-
-class TestProcedure(Procedure):
-
- iterations = IntegerParameter('Loop Iterations', default=100)
- delay = FloatParameter('Delay Time', units='s', default=0.2)
- seed = Parameter('Random Seed', default='12345')
-
- DATA_COLUMNS = ['Iteration', 'Random Number']
-
- def startup(self):
- log.info("Setting up random number generator")
- random.seed(self.seed)
-
- def execute(self):
- log.info("Starting to generate numbers")
- for i in range(self.iterations):
- data = {
- 'Iteration': i,
- 'Random Number': random.random()
- }
- log.debug("Produced numbers: %s" % data)
- self.emit('results', data)
- self.emit('progress', 100.*i/self.iterations)
- sleep(self.delay)
- if self.should_stop():
- log.warning("Catch stop command in procedure")
- break
-
- def shutdown(self):
- log.info("Finished")
\ No newline at end of file
diff --git a/pymeasure/experiment/config.py b/pymeasure/experiment/config.py
--- a/pymeasure/experiment/config.py
+++ b/pymeasure/experiment/config.py
@@ -46,5 +46,6 @@
def set_mpl_rcparams(config):
if 'matplotlib.rcParams' in config._sections.keys():
import matplotlib
+ from cycler import cycler
for key in config._sections['matplotlib.rcParams']:
matplotlib.rcParams[key] = eval(config._sections['matplotlib.rcParams'][key])
|
{"golden_diff": "diff --git a/examples/Notebook Experiments/procedures.py b/examples/Notebook Experiments/procedures.py\ndeleted file mode 100644\n--- a/examples/Notebook Experiments/procedures.py\t\n+++ /dev/null\n@@ -1,60 +0,0 @@\n-#\n-# This file is part of the PyMeasure package.\n-#\n-# Copyright (c) 2013-2016 PyMeasure Developers\n-#\n-# Permission is hereby granted, free of charge, to any person obtaining a copy\n-# of this software and associated documentation files (the \"Software\"), to deal\n-# in the Software without restriction, including without limitation the rights\n-# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n-# copies of the Software, and to permit persons to whom the Software is\n-# furnished to do so, subject to the following conditions:\n-#\n-# The above copyright notice and this permission notice shall be included in\n-# all copies or substantial portions of the Software.\n-#\n-# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n-# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n-# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n-# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n-# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n-# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN\n-# THE SOFTWARE.\n-#\n-\n-import random\n-from time import sleep\n-from pymeasure.experiment import Procedure, IntegerParameter, Parameter, FloatParameter\n-import logging\n-log = logging.getLogger(__name__)\n-log.addHandler(logging.NullHandler())\n-\n-class TestProcedure(Procedure):\n-\n- iterations = IntegerParameter('Loop Iterations', default=100)\n- delay = FloatParameter('Delay Time', units='s', default=0.2)\n- seed = Parameter('Random Seed', default='12345')\n- \n- DATA_COLUMNS = ['Iteration', 'Random Number']\n-\n- def startup(self):\n- log.info(\"Setting up random number generator\")\n- random.seed(self.seed)\n-\n- def execute(self):\n- log.info(\"Starting to generate numbers\")\n- for i in range(self.iterations):\n- data = {\n- 'Iteration': i,\n- 'Random Number': random.random()\n- }\n- log.debug(\"Produced numbers: %s\" % data)\n- self.emit('results', data)\n- self.emit('progress', 100.*i/self.iterations)\n- sleep(self.delay)\n- if self.should_stop():\n- log.warning(\"Catch stop command in procedure\")\n- break\n-\n- def shutdown(self):\n- log.info(\"Finished\")\n\\ No newline at end of file\ndiff --git a/pymeasure/experiment/config.py b/pymeasure/experiment/config.py\n--- a/pymeasure/experiment/config.py\n+++ b/pymeasure/experiment/config.py\n@@ -46,5 +46,6 @@\n def set_mpl_rcparams(config):\n if 'matplotlib.rcParams' in config._sections.keys():\n import matplotlib\n+ from cycler import cycler\n for key in config._sections['matplotlib.rcParams']:\n matplotlib.rcParams[key] = eval(config._sections['matplotlib.rcParams'][key])\n", "issue": "Error in examples/Notebook Experiments/script2.ipynb\nscript.ipynb runs fine but in script2.ipynb I hit the following error at `experiment = Experiment('test', procedure, analyse)`:\r\n\r\n```python\r\n\r\nC:\\ProgramData\\Anaconda3\\lib\\site-packages\\matplotlib\\__init__.py in __setitem__(self, key, val)\r\n 927 raise KeyError(\r\n 928 '%s is not a valid rc parameter. See rcParams.keys() for a '\r\n--> 929 'list of valid parameters.' % (key,))\r\n 930 \r\n 931 def __getitem__(self, key):\r\n\r\nKeyError: 'axes.color_cycle is not a valid rc parameter. See rcParams.keys() for a list of valid parameters.'\r\n```\r\n\nError in examples/Notebook Experiments/script2.ipynb\nscript.ipynb runs fine but in script2.ipynb I hit the following error at `experiment = Experiment('test', procedure, analyse)`:\r\n\r\n```python\r\n\r\nC:\\ProgramData\\Anaconda3\\lib\\site-packages\\matplotlib\\__init__.py in __setitem__(self, key, val)\r\n 927 raise KeyError(\r\n 928 '%s is not a valid rc parameter. See rcParams.keys() for a '\r\n--> 929 'list of valid parameters.' % (key,))\r\n 930 \r\n 931 def __getitem__(self, key):\r\n\r\nKeyError: 'axes.color_cycle is not a valid rc parameter. See rcParams.keys() for a list of valid parameters.'\r\n```\r\n\n", "before_files": [{"content": "#\n# This file is part of the PyMeasure package.\n#\n# Copyright (c) 2013-2020 PyMeasure Developers\n#\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to deal\n# in the Software without restriction, including without limitation the rights\n# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n# copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN\n# THE SOFTWARE.\n#\n\nimport configparser\nimport logging\nimport os\n\nlog = logging.getLogger(__name__)\nlog.addHandler(logging.NullHandler())\n\n\ndef set_file(filename):\n os.environ['CONFIG'] = filename\n\n\ndef get_config(filename='default_config.ini'):\n if 'CONFIG' in os.environ.keys():\n filename = os.environ['CONFIG']\n config = configparser.ConfigParser()\n config.read(filename)\n return config\n\n\n# noinspection PyProtectedMember\ndef set_mpl_rcparams(config):\n if 'matplotlib.rcParams' in config._sections.keys():\n import matplotlib\n for key in config._sections['matplotlib.rcParams']:\n matplotlib.rcParams[key] = eval(config._sections['matplotlib.rcParams'][key])\n", "path": "pymeasure/experiment/config.py"}, {"content": "#\n# This file is part of the PyMeasure package.\n#\n# Copyright (c) 2013-2016 PyMeasure Developers\n#\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to deal\n# in the Software without restriction, including without limitation the rights\n# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n# copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN\n# THE SOFTWARE.\n#\n\nimport random\nfrom time import sleep\nfrom pymeasure.experiment import Procedure, IntegerParameter, Parameter, FloatParameter\nimport logging\nlog = logging.getLogger(__name__)\nlog.addHandler(logging.NullHandler())\n\nclass TestProcedure(Procedure):\n\n iterations = IntegerParameter('Loop Iterations', default=100)\n delay = FloatParameter('Delay Time', units='s', default=0.2)\n seed = Parameter('Random Seed', default='12345')\n \n DATA_COLUMNS = ['Iteration', 'Random Number']\n\n def startup(self):\n log.info(\"Setting up random number generator\")\n random.seed(self.seed)\n\n def execute(self):\n log.info(\"Starting to generate numbers\")\n for i in range(self.iterations):\n data = {\n 'Iteration': i,\n 'Random Number': random.random()\n }\n log.debug(\"Produced numbers: %s\" % data)\n self.emit('results', data)\n self.emit('progress', 100.*i/self.iterations)\n sleep(self.delay)\n if self.should_stop():\n log.warning(\"Catch stop command in procedure\")\n break\n\n def shutdown(self):\n log.info(\"Finished\")", "path": "examples/Notebook Experiments/procedures.py"}], "after_files": [{"content": "#\n# This file is part of the PyMeasure package.\n#\n# Copyright (c) 2013-2020 PyMeasure Developers\n#\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to deal\n# in the Software without restriction, including without limitation the rights\n# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n# copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN\n# THE SOFTWARE.\n#\n\nimport configparser\nimport logging\nimport os\n\nlog = logging.getLogger(__name__)\nlog.addHandler(logging.NullHandler())\n\n\ndef set_file(filename):\n os.environ['CONFIG'] = filename\n\n\ndef get_config(filename='default_config.ini'):\n if 'CONFIG' in os.environ.keys():\n filename = os.environ['CONFIG']\n config = configparser.ConfigParser()\n config.read(filename)\n return config\n\n\n# noinspection PyProtectedMember\ndef set_mpl_rcparams(config):\n if 'matplotlib.rcParams' in config._sections.keys():\n import matplotlib\n from cycler import cycler\n for key in config._sections['matplotlib.rcParams']:\n matplotlib.rcParams[key] = eval(config._sections['matplotlib.rcParams'][key])\n", "path": "pymeasure/experiment/config.py"}, {"content": null, "path": "examples/Notebook Experiments/procedures.py"}]}
| 1,743 | 736 |
gh_patches_debug_4412
|
rasdani/github-patches
|
git_diff
|
mytardis__mytardis-1134
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
/search/parameter_field_list/ failures with Unicode first/last names in Users table
This can occur:
```
Internal Server Error: /search/parameter_field_list/
Traceback (most recent call last):
File "/home/mytardis/virtualenvs/mytardis/local/lib/python2.7/site-packages/django/core/handlers/base.py", line 132, in get_response
response = wrapped_callback(request, *callback_args, **callback_kwargs)
File "/home/mytardis/mytardis/tardis/search/views.py", line 282, in retrieve_field_list
fieldList = '+'.join([str(fn) for fn in auto_list])
UnicodeEncodeError: 'ascii' codec can't encode character u'\xfc' in position 8: ordinal not in range(128)
```
if there's a user with a non-ASCII character in their first or last name. The relevant code in tardis/search/views.py is:
```
usernames = [u.first_name + ' ' + u.last_name + ':username' for u in users]
...
auto_list = usernames + searchableFields
fieldList = '+'.join([str(fn) for fn in auto_list])
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `tardis/search/views.py`
Content:
```
1 """
2 views relevant to search
3 """
4 import logging
5 import warnings
6
7 from django.contrib.auth.models import User
8 from django.http import HttpResponse
9 from haystack.generic_views import SearchView
10
11 from tardis.search.forms import GroupedSearchForm
12 from tardis.search.utils import SearchQueryString
13 from tardis.tardis_portal.auth import decorators as authz
14 from tardis.tardis_portal.deprecations import RemovedInMyTardis311Warning
15 from tardis.tardis_portal.forms import createSearchDatafileSelectionForm
16 from tardis.tardis_portal.hacks import oracle_dbops_hack
17 from tardis.tardis_portal.models import Experiment
18 from tardis.tardis_portal.shortcuts import render_response_search, \
19 render_response_index
20 from tardis.tardis_portal.views.utils import __forwardToSearchExperimentFormPage, \
21 __getSearchExperimentForm, __processExperimentParameters, \
22 __getSearchDatafileForm, __processDatafileParameters, \
23 __forwardToSearchDatafileFormPage
24
25 logger = logging.getLogger(__name__)
26
27
28 def getNewSearchDatafileSelectionForm(initial=None):
29 DatafileSelectionForm = createSearchDatafileSelectionForm(initial)
30 return DatafileSelectionForm()
31
32
33 @oracle_dbops_hack
34 def search_experiment(request):
35
36 """Either show the search experiment form or the result of the search
37 experiment query.
38
39 """
40
41 if not request.GET:
42 return __forwardToSearchExperimentFormPage(request)
43
44 form = __getSearchExperimentForm(request)
45 experiments = __processExperimentParameters(request, form)
46
47 # check if the submitted form is valid
48 if experiments is not None:
49 bodyclass = 'list'
50 else:
51 return __forwardToSearchExperimentFormPage(request)
52
53 # remove information from previous searches from session
54 if 'datafileResults' in request.session:
55 del request.session['datafileResults']
56
57 results = []
58 for e in experiments:
59 result = {}
60 result['sr'] = e
61 result['dataset_hit'] = False
62 result['datafile_hit'] = False
63 result['experiment_hit'] = True
64 results.append(result)
65 c = {'header': 'Search Experiment',
66 'experiments': results,
67 'bodyclass': bodyclass}
68 url = 'tardis_portal/search_experiment_results.html'
69 return HttpResponse(render_response_search(request, url, c))
70
71
72 def search_quick(request):
73 get = False
74 experiments = Experiment.objects.all().order_by('title')
75
76 if 'results' in request.GET:
77 get = True
78 if 'quicksearch' in request.GET and request.GET['quicksearch']:
79 experiments = \
80 experiments.filter(
81 title__icontains=request.GET['quicksearch']) | \
82 experiments.filter(
83 institution_name__icontains=request.GET['quicksearch']) | \
84 experiments.filter(
85 experimentauthor__author__name__icontains=request.GET[
86 'quicksearch']) | \
87 experiments.filter(
88 pdbid__pdbid__icontains=request.GET['quicksearch'])
89
90 experiments = experiments.distinct()
91
92 logger.debug(experiments)
93
94 c = {'submitted': get, 'experiments': experiments,
95 'subtitle': 'Search Experiments'}
96 return HttpResponse(render_response_index(request,
97 'tardis_portal/search_experiment.html', c))
98
99
100 def search_datafile(request): # too complex # noqa
101 """Either show the search datafile form or the result of the search
102 datafile query.
103
104 """
105 warnings.warn(
106 "The old DataFile search form (triggered by the /search/datafile/ "
107 "URL) was only useful for X-Ray Diffraction data. It needs to be "
108 "rewritten if it is to be useful for other data types.",
109 RemovedInMyTardis311Warning
110 )
111 if 'type' in request.GET:
112 searchQueryType = request.GET.get('type')
113 else:
114 # for now we'll default to MX if nothing is provided
115 # TODO: should we forward the page to experiment search page if
116 # nothing is provided in the future?
117 searchQueryType = 'mx'
118 logger.info('search_datafile: searchQueryType {0}'.format(searchQueryType))
119 # TODO: check if going to /search/datafile will flag an error in unit test
120 bodyclass = None
121
122 if 'page' not in request.GET and 'type' in request.GET and \
123 len(request.GET) > 1:
124 # display the 1st page of the results
125
126 form = __getSearchDatafileForm(request, searchQueryType)
127 datafile_results = __processDatafileParameters(
128 request, searchQueryType, form)
129 if datafile_results is not None:
130 bodyclass = 'list'
131 else:
132 return __forwardToSearchDatafileFormPage(
133 request, searchQueryType, form)
134
135 else:
136 if 'page' in request.GET:
137 # succeeding pages of pagination
138 if 'datafileResults' in request.session:
139 datafile_results = request.session['datafileResults']
140 else:
141 form = __getSearchDatafileForm(request, searchQueryType)
142 datafile_results = __processDatafileParameters(
143 request, searchQueryType, form)
144 if datafile_results is not None:
145 bodyclass = 'list'
146 else:
147 return __forwardToSearchDatafileFormPage(
148 request, searchQueryType, form)
149 else:
150 # display the form
151 if 'datafileResults' in request.session:
152 del request.session['datafileResults']
153 return __forwardToSearchDatafileFormPage(request, searchQueryType)
154
155 # process the files to be displayed by the paginator...
156 # paginator = Paginator(datafile_results,
157 # constants.DATAFILE_RESULTS_PER_PAGE)
158
159 # try:
160 # page = int(request.GET.get('page', '1'))
161 # except ValueError:
162 # page = 1
163
164 # If page request (9999) is out of :range, deliver last page of results.
165 # try:
166 # datafiles = paginator.page(page)
167 # except (EmptyPage, InvalidPage):
168 # datafiles = paginator.page(paginator.num_pages)
169
170 import re
171 cleanedUpQueryString = re.sub('&page=\d+', '',
172 request.META['QUERY_STRING'])
173
174 # get experiments associated with datafiles
175 if datafile_results:
176 experiment_pks = list(set(datafile_results.values_list(
177 'dataset__experiments', flat=True)))
178 experiments = Experiment.safe.in_bulk(experiment_pks)
179 else:
180 experiments = {}
181
182 results = []
183 for key, e in experiments.items():
184 result = {}
185 result['sr'] = e
186 result['dataset_hit'] = False
187 result['datafile_hit'] = True
188 result['experiment_hit'] = False
189 results.append(result)
190
191 c = {
192 'experiments': results,
193 'datafiles': datafile_results,
194 # 'paginator': paginator,
195 'query_string': cleanedUpQueryString,
196 'subtitle': 'Search Datafiles',
197 'nav': [{'name': 'Search Datafile', 'link': '/search/datafile/'}],
198 'bodyclass': bodyclass,
199 'search_pressed': True,
200 'searchDatafileSelectionForm': getNewSearchDatafileSelectionForm()}
201 url = 'tardis_portal/search_experiment_results.html'
202 return HttpResponse(render_response_search(request, url, c))
203
204
205 class ExperimentSearchView(SearchView):
206 def __name__(self):
207 return "ExperimentSearchView"
208
209 def extra_context(self):
210 extra = super(ExperimentSearchView, self).extra_context()
211 # Results may contain Experiments, Datasets and DataFiles.
212 # Group them into experiments, noting whether or not the search
213 # hits were in the Dataset(s) or DataFile(s)
214 results = self.results
215 facets = results.facet_counts()
216 if facets:
217 experiment_facets = facets['fields']['experiment_id_stored']
218 experiment_ids = [int(f[0])
219 for f in experiment_facets if int(f[1]) > 0]
220 else:
221 experiment_ids = []
222
223 access_list = []
224
225 if self.request.user.is_authenticated():
226 access_list.extend(
227 [e.pk for e in
228 authz.get_accessible_experiments(self.request)])
229
230 access_list.extend(
231 [e.pk for e in Experiment.objects
232 .exclude(public_access=Experiment.PUBLIC_ACCESS_NONE)
233 .exclude(public_access=Experiment.PUBLIC_ACCESS_EMBARGO)])
234
235 ids = list(set(experiment_ids) & set(access_list))
236 experiments = Experiment.objects.filter(pk__in=ids)\
237 .order_by('-update_time')
238
239 results = []
240 for e in experiments:
241 result = {'sr': e, 'dataset_hit': False, 'datafile_hit': False,
242 'experiment_hit': False}
243 results.append(result)
244
245 extra['experiments'] = results
246 return extra
247
248 # override SearchView's method in order to
249 # return a ResponseContext
250 def create_response(self):
251 (paginator, page) = self.build_page()
252
253 # Remove unnecessary whitespace
254 # TODO this should just be done in the form clean...
255 query = SearchQueryString(self.query)
256 context = {
257 'search_query': query,
258 'form': self.form,
259 'page': page,
260 'paginator': paginator,
261 }
262 context.update(self.extra_context())
263
264 return render_response_index(self.request, self.template, context)
265
266
267 def retrieve_field_list(request):
268
269 from tardis.search.search_indexes import DataFileIndex
270
271 # Get all of the fields in the indexes
272 #
273 # TODO: these should be onl read from registered indexes
274 #
275 allFields = DataFileIndex.fields.items()
276
277 users = User.objects.all()
278
279 usernames = [u.first_name + ' ' + u.last_name + ':username' for u in users]
280
281 # Collect all of the indexed (searchable) fields, except
282 # for the main search document ('text')
283 searchableFields = ([key + ':search_field' for key, f in allFields
284 if f.indexed is True and key != 'text'])
285
286 auto_list = usernames + searchableFields
287
288 fieldList = '+'.join([str(fn) for fn in auto_list])
289 return HttpResponse(fieldList)
290
291
292 class SingleSearchView(SearchView):
293 form_class = GroupedSearchForm
294 template_name = 'search/search.html'
295
296 def form_valid(self, form):
297 sqs = form.search(user=self.request.user)
298 context = self.get_context_data(**{
299 self.form_name: form,
300 'query': form.cleaned_data.get(self.search_field),
301 'object_list': sqs,
302 })
303 return self.render_to_response(context)
304
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/tardis/search/views.py b/tardis/search/views.py
--- a/tardis/search/views.py
+++ b/tardis/search/views.py
@@ -276,7 +276,11 @@
users = User.objects.all()
- usernames = [u.first_name + ' ' + u.last_name + ':username' for u in users]
+ usernames = [
+ u.first_name.encode('utf-8') +
+ ' ' +
+ u.last_name.encode('utf-8') +
+ ':username' for u in users]
# Collect all of the indexed (searchable) fields, except
# for the main search document ('text')
|
{"golden_diff": "diff --git a/tardis/search/views.py b/tardis/search/views.py\n--- a/tardis/search/views.py\n+++ b/tardis/search/views.py\n@@ -276,7 +276,11 @@\n \n users = User.objects.all()\n \n- usernames = [u.first_name + ' ' + u.last_name + ':username' for u in users]\n+ usernames = [\n+ u.first_name.encode('utf-8') +\n+ ' ' +\n+ u.last_name.encode('utf-8') +\n+ ':username' for u in users]\n \n # Collect all of the indexed (searchable) fields, except\n # for the main search document ('text')\n", "issue": "/search/parameter_field_list/ failures with Unicode first/last names in Users table\nThis can occur:\r\n```\r\nInternal Server Error: /search/parameter_field_list/\r\nTraceback (most recent call last):\r\n File \"/home/mytardis/virtualenvs/mytardis/local/lib/python2.7/site-packages/django/core/handlers/base.py\", line 132, in get_response\r\n response = wrapped_callback(request, *callback_args, **callback_kwargs)\r\n File \"/home/mytardis/mytardis/tardis/search/views.py\", line 282, in retrieve_field_list\r\n fieldList = '+'.join([str(fn) for fn in auto_list])\r\nUnicodeEncodeError: 'ascii' codec can't encode character u'\\xfc' in position 8: ordinal not in range(128)\r\n```\r\n\r\nif there's a user with a non-ASCII character in their first or last name. The relevant code in tardis/search/views.py is:\r\n\r\n```\r\nusernames = [u.first_name + ' ' + u.last_name + ':username' for u in users]\r\n...\r\nauto_list = usernames + searchableFields\r\nfieldList = '+'.join([str(fn) for fn in auto_list])\r\n```\r\n\n", "before_files": [{"content": "\"\"\"\nviews relevant to search\n\"\"\"\nimport logging\nimport warnings\n\nfrom django.contrib.auth.models import User\nfrom django.http import HttpResponse\nfrom haystack.generic_views import SearchView\n\nfrom tardis.search.forms import GroupedSearchForm\nfrom tardis.search.utils import SearchQueryString\nfrom tardis.tardis_portal.auth import decorators as authz\nfrom tardis.tardis_portal.deprecations import RemovedInMyTardis311Warning\nfrom tardis.tardis_portal.forms import createSearchDatafileSelectionForm\nfrom tardis.tardis_portal.hacks import oracle_dbops_hack\nfrom tardis.tardis_portal.models import Experiment\nfrom tardis.tardis_portal.shortcuts import render_response_search, \\\n render_response_index\nfrom tardis.tardis_portal.views.utils import __forwardToSearchExperimentFormPage, \\\n __getSearchExperimentForm, __processExperimentParameters, \\\n __getSearchDatafileForm, __processDatafileParameters, \\\n __forwardToSearchDatafileFormPage\n\nlogger = logging.getLogger(__name__)\n\n\ndef getNewSearchDatafileSelectionForm(initial=None):\n DatafileSelectionForm = createSearchDatafileSelectionForm(initial)\n return DatafileSelectionForm()\n\n\n@oracle_dbops_hack\ndef search_experiment(request):\n\n \"\"\"Either show the search experiment form or the result of the search\n experiment query.\n\n \"\"\"\n\n if not request.GET:\n return __forwardToSearchExperimentFormPage(request)\n\n form = __getSearchExperimentForm(request)\n experiments = __processExperimentParameters(request, form)\n\n # check if the submitted form is valid\n if experiments is not None:\n bodyclass = 'list'\n else:\n return __forwardToSearchExperimentFormPage(request)\n\n # remove information from previous searches from session\n if 'datafileResults' in request.session:\n del request.session['datafileResults']\n\n results = []\n for e in experiments:\n result = {}\n result['sr'] = e\n result['dataset_hit'] = False\n result['datafile_hit'] = False\n result['experiment_hit'] = True\n results.append(result)\n c = {'header': 'Search Experiment',\n 'experiments': results,\n 'bodyclass': bodyclass}\n url = 'tardis_portal/search_experiment_results.html'\n return HttpResponse(render_response_search(request, url, c))\n\n\ndef search_quick(request):\n get = False\n experiments = Experiment.objects.all().order_by('title')\n\n if 'results' in request.GET:\n get = True\n if 'quicksearch' in request.GET and request.GET['quicksearch']:\n experiments = \\\n experiments.filter(\n title__icontains=request.GET['quicksearch']) | \\\n experiments.filter(\n institution_name__icontains=request.GET['quicksearch']) | \\\n experiments.filter(\n experimentauthor__author__name__icontains=request.GET[\n 'quicksearch']) | \\\n experiments.filter(\n pdbid__pdbid__icontains=request.GET['quicksearch'])\n\n experiments = experiments.distinct()\n\n logger.debug(experiments)\n\n c = {'submitted': get, 'experiments': experiments,\n 'subtitle': 'Search Experiments'}\n return HttpResponse(render_response_index(request,\n 'tardis_portal/search_experiment.html', c))\n\n\ndef search_datafile(request): # too complex # noqa\n \"\"\"Either show the search datafile form or the result of the search\n datafile query.\n\n \"\"\"\n warnings.warn(\n \"The old DataFile search form (triggered by the /search/datafile/ \"\n \"URL) was only useful for X-Ray Diffraction data. It needs to be \"\n \"rewritten if it is to be useful for other data types.\",\n RemovedInMyTardis311Warning\n )\n if 'type' in request.GET:\n searchQueryType = request.GET.get('type')\n else:\n # for now we'll default to MX if nothing is provided\n # TODO: should we forward the page to experiment search page if\n # nothing is provided in the future?\n searchQueryType = 'mx'\n logger.info('search_datafile: searchQueryType {0}'.format(searchQueryType))\n # TODO: check if going to /search/datafile will flag an error in unit test\n bodyclass = None\n\n if 'page' not in request.GET and 'type' in request.GET and \\\n len(request.GET) > 1:\n # display the 1st page of the results\n\n form = __getSearchDatafileForm(request, searchQueryType)\n datafile_results = __processDatafileParameters(\n request, searchQueryType, form)\n if datafile_results is not None:\n bodyclass = 'list'\n else:\n return __forwardToSearchDatafileFormPage(\n request, searchQueryType, form)\n\n else:\n if 'page' in request.GET:\n # succeeding pages of pagination\n if 'datafileResults' in request.session:\n datafile_results = request.session['datafileResults']\n else:\n form = __getSearchDatafileForm(request, searchQueryType)\n datafile_results = __processDatafileParameters(\n request, searchQueryType, form)\n if datafile_results is not None:\n bodyclass = 'list'\n else:\n return __forwardToSearchDatafileFormPage(\n request, searchQueryType, form)\n else:\n # display the form\n if 'datafileResults' in request.session:\n del request.session['datafileResults']\n return __forwardToSearchDatafileFormPage(request, searchQueryType)\n\n # process the files to be displayed by the paginator...\n # paginator = Paginator(datafile_results,\n # constants.DATAFILE_RESULTS_PER_PAGE)\n\n # try:\n # page = int(request.GET.get('page', '1'))\n # except ValueError:\n # page = 1\n\n # If page request (9999) is out of :range, deliver last page of results.\n # try:\n # datafiles = paginator.page(page)\n # except (EmptyPage, InvalidPage):\n # datafiles = paginator.page(paginator.num_pages)\n\n import re\n cleanedUpQueryString = re.sub('&page=\\d+', '',\n request.META['QUERY_STRING'])\n\n # get experiments associated with datafiles\n if datafile_results:\n experiment_pks = list(set(datafile_results.values_list(\n 'dataset__experiments', flat=True)))\n experiments = Experiment.safe.in_bulk(experiment_pks)\n else:\n experiments = {}\n\n results = []\n for key, e in experiments.items():\n result = {}\n result['sr'] = e\n result['dataset_hit'] = False\n result['datafile_hit'] = True\n result['experiment_hit'] = False\n results.append(result)\n\n c = {\n 'experiments': results,\n 'datafiles': datafile_results,\n # 'paginator': paginator,\n 'query_string': cleanedUpQueryString,\n 'subtitle': 'Search Datafiles',\n 'nav': [{'name': 'Search Datafile', 'link': '/search/datafile/'}],\n 'bodyclass': bodyclass,\n 'search_pressed': True,\n 'searchDatafileSelectionForm': getNewSearchDatafileSelectionForm()}\n url = 'tardis_portal/search_experiment_results.html'\n return HttpResponse(render_response_search(request, url, c))\n\n\nclass ExperimentSearchView(SearchView):\n def __name__(self):\n return \"ExperimentSearchView\"\n\n def extra_context(self):\n extra = super(ExperimentSearchView, self).extra_context()\n # Results may contain Experiments, Datasets and DataFiles.\n # Group them into experiments, noting whether or not the search\n # hits were in the Dataset(s) or DataFile(s)\n results = self.results\n facets = results.facet_counts()\n if facets:\n experiment_facets = facets['fields']['experiment_id_stored']\n experiment_ids = [int(f[0])\n for f in experiment_facets if int(f[1]) > 0]\n else:\n experiment_ids = []\n\n access_list = []\n\n if self.request.user.is_authenticated():\n access_list.extend(\n [e.pk for e in\n authz.get_accessible_experiments(self.request)])\n\n access_list.extend(\n [e.pk for e in Experiment.objects\n .exclude(public_access=Experiment.PUBLIC_ACCESS_NONE)\n .exclude(public_access=Experiment.PUBLIC_ACCESS_EMBARGO)])\n\n ids = list(set(experiment_ids) & set(access_list))\n experiments = Experiment.objects.filter(pk__in=ids)\\\n .order_by('-update_time')\n\n results = []\n for e in experiments:\n result = {'sr': e, 'dataset_hit': False, 'datafile_hit': False,\n 'experiment_hit': False}\n results.append(result)\n\n extra['experiments'] = results\n return extra\n\n # override SearchView's method in order to\n # return a ResponseContext\n def create_response(self):\n (paginator, page) = self.build_page()\n\n # Remove unnecessary whitespace\n # TODO this should just be done in the form clean...\n query = SearchQueryString(self.query)\n context = {\n 'search_query': query,\n 'form': self.form,\n 'page': page,\n 'paginator': paginator,\n }\n context.update(self.extra_context())\n\n return render_response_index(self.request, self.template, context)\n\n\ndef retrieve_field_list(request):\n\n from tardis.search.search_indexes import DataFileIndex\n\n # Get all of the fields in the indexes\n #\n # TODO: these should be onl read from registered indexes\n #\n allFields = DataFileIndex.fields.items()\n\n users = User.objects.all()\n\n usernames = [u.first_name + ' ' + u.last_name + ':username' for u in users]\n\n # Collect all of the indexed (searchable) fields, except\n # for the main search document ('text')\n searchableFields = ([key + ':search_field' for key, f in allFields\n if f.indexed is True and key != 'text'])\n\n auto_list = usernames + searchableFields\n\n fieldList = '+'.join([str(fn) for fn in auto_list])\n return HttpResponse(fieldList)\n\n\nclass SingleSearchView(SearchView):\n form_class = GroupedSearchForm\n template_name = 'search/search.html'\n\n def form_valid(self, form):\n sqs = form.search(user=self.request.user)\n context = self.get_context_data(**{\n self.form_name: form,\n 'query': form.cleaned_data.get(self.search_field),\n 'object_list': sqs,\n })\n return self.render_to_response(context)\n", "path": "tardis/search/views.py"}], "after_files": [{"content": "\"\"\"\nviews relevant to search\n\"\"\"\nimport logging\nimport warnings\n\nfrom django.contrib.auth.models import User\nfrom django.http import HttpResponse\nfrom haystack.generic_views import SearchView\n\nfrom tardis.search.forms import GroupedSearchForm\nfrom tardis.search.utils import SearchQueryString\nfrom tardis.tardis_portal.auth import decorators as authz\nfrom tardis.tardis_portal.deprecations import RemovedInMyTardis311Warning\nfrom tardis.tardis_portal.forms import createSearchDatafileSelectionForm\nfrom tardis.tardis_portal.hacks import oracle_dbops_hack\nfrom tardis.tardis_portal.models import Experiment\nfrom tardis.tardis_portal.shortcuts import render_response_search, \\\n render_response_index\nfrom tardis.tardis_portal.views.utils import __forwardToSearchExperimentFormPage, \\\n __getSearchExperimentForm, __processExperimentParameters, \\\n __getSearchDatafileForm, __processDatafileParameters, \\\n __forwardToSearchDatafileFormPage\n\nlogger = logging.getLogger(__name__)\n\n\ndef getNewSearchDatafileSelectionForm(initial=None):\n DatafileSelectionForm = createSearchDatafileSelectionForm(initial)\n return DatafileSelectionForm()\n\n\n@oracle_dbops_hack\ndef search_experiment(request):\n\n \"\"\"Either show the search experiment form or the result of the search\n experiment query.\n\n \"\"\"\n\n if not request.GET:\n return __forwardToSearchExperimentFormPage(request)\n\n form = __getSearchExperimentForm(request)\n experiments = __processExperimentParameters(request, form)\n\n # check if the submitted form is valid\n if experiments is not None:\n bodyclass = 'list'\n else:\n return __forwardToSearchExperimentFormPage(request)\n\n # remove information from previous searches from session\n if 'datafileResults' in request.session:\n del request.session['datafileResults']\n\n results = []\n for e in experiments:\n result = {}\n result['sr'] = e\n result['dataset_hit'] = False\n result['datafile_hit'] = False\n result['experiment_hit'] = True\n results.append(result)\n c = {'header': 'Search Experiment',\n 'experiments': results,\n 'bodyclass': bodyclass}\n url = 'tardis_portal/search_experiment_results.html'\n return HttpResponse(render_response_search(request, url, c))\n\n\ndef search_quick(request):\n get = False\n experiments = Experiment.objects.all().order_by('title')\n\n if 'results' in request.GET:\n get = True\n if 'quicksearch' in request.GET and request.GET['quicksearch']:\n experiments = \\\n experiments.filter(\n title__icontains=request.GET['quicksearch']) | \\\n experiments.filter(\n institution_name__icontains=request.GET['quicksearch']) | \\\n experiments.filter(\n experimentauthor__author__name__icontains=request.GET[\n 'quicksearch']) | \\\n experiments.filter(\n pdbid__pdbid__icontains=request.GET['quicksearch'])\n\n experiments = experiments.distinct()\n\n logger.debug(experiments)\n\n c = {'submitted': get, 'experiments': experiments,\n 'subtitle': 'Search Experiments'}\n return HttpResponse(render_response_index(request,\n 'tardis_portal/search_experiment.html', c))\n\n\ndef search_datafile(request): # too complex # noqa\n \"\"\"Either show the search datafile form or the result of the search\n datafile query.\n\n \"\"\"\n warnings.warn(\n \"The old DataFile search form (triggered by the /search/datafile/ \"\n \"URL) was only useful for X-Ray Diffraction data. It needs to be \"\n \"rewritten if it is to be useful for other data types.\",\n RemovedInMyTardis311Warning\n )\n if 'type' in request.GET:\n searchQueryType = request.GET.get('type')\n else:\n # for now we'll default to MX if nothing is provided\n # TODO: should we forward the page to experiment search page if\n # nothing is provided in the future?\n searchQueryType = 'mx'\n logger.info('search_datafile: searchQueryType {0}'.format(searchQueryType))\n # TODO: check if going to /search/datafile will flag an error in unit test\n bodyclass = None\n\n if 'page' not in request.GET and 'type' in request.GET and \\\n len(request.GET) > 1:\n # display the 1st page of the results\n\n form = __getSearchDatafileForm(request, searchQueryType)\n datafile_results = __processDatafileParameters(\n request, searchQueryType, form)\n if datafile_results is not None:\n bodyclass = 'list'\n else:\n return __forwardToSearchDatafileFormPage(\n request, searchQueryType, form)\n\n else:\n if 'page' in request.GET:\n # succeeding pages of pagination\n if 'datafileResults' in request.session:\n datafile_results = request.session['datafileResults']\n else:\n form = __getSearchDatafileForm(request, searchQueryType)\n datafile_results = __processDatafileParameters(\n request, searchQueryType, form)\n if datafile_results is not None:\n bodyclass = 'list'\n else:\n return __forwardToSearchDatafileFormPage(\n request, searchQueryType, form)\n else:\n # display the form\n if 'datafileResults' in request.session:\n del request.session['datafileResults']\n return __forwardToSearchDatafileFormPage(request, searchQueryType)\n\n # process the files to be displayed by the paginator...\n # paginator = Paginator(datafile_results,\n # constants.DATAFILE_RESULTS_PER_PAGE)\n\n # try:\n # page = int(request.GET.get('page', '1'))\n # except ValueError:\n # page = 1\n\n # If page request (9999) is out of :range, deliver last page of results.\n # try:\n # datafiles = paginator.page(page)\n # except (EmptyPage, InvalidPage):\n # datafiles = paginator.page(paginator.num_pages)\n\n import re\n cleanedUpQueryString = re.sub('&page=\\d+', '',\n request.META['QUERY_STRING'])\n\n # get experiments associated with datafiles\n if datafile_results:\n experiment_pks = list(set(datafile_results.values_list(\n 'dataset__experiments', flat=True)))\n experiments = Experiment.safe.in_bulk(experiment_pks)\n else:\n experiments = {}\n\n results = []\n for key, e in experiments.items():\n result = {}\n result['sr'] = e\n result['dataset_hit'] = False\n result['datafile_hit'] = True\n result['experiment_hit'] = False\n results.append(result)\n\n c = {\n 'experiments': results,\n 'datafiles': datafile_results,\n # 'paginator': paginator,\n 'query_string': cleanedUpQueryString,\n 'subtitle': 'Search Datafiles',\n 'nav': [{'name': 'Search Datafile', 'link': '/search/datafile/'}],\n 'bodyclass': bodyclass,\n 'search_pressed': True,\n 'searchDatafileSelectionForm': getNewSearchDatafileSelectionForm()}\n url = 'tardis_portal/search_experiment_results.html'\n return HttpResponse(render_response_search(request, url, c))\n\n\nclass ExperimentSearchView(SearchView):\n def __name__(self):\n return \"ExperimentSearchView\"\n\n def extra_context(self):\n extra = super(ExperimentSearchView, self).extra_context()\n # Results may contain Experiments, Datasets and DataFiles.\n # Group them into experiments, noting whether or not the search\n # hits were in the Dataset(s) or DataFile(s)\n results = self.results\n facets = results.facet_counts()\n if facets:\n experiment_facets = facets['fields']['experiment_id_stored']\n experiment_ids = [int(f[0])\n for f in experiment_facets if int(f[1]) > 0]\n else:\n experiment_ids = []\n\n access_list = []\n\n if self.request.user.is_authenticated():\n access_list.extend(\n [e.pk for e in\n authz.get_accessible_experiments(self.request)])\n\n access_list.extend(\n [e.pk for e in Experiment.objects\n .exclude(public_access=Experiment.PUBLIC_ACCESS_NONE)\n .exclude(public_access=Experiment.PUBLIC_ACCESS_EMBARGO)])\n\n ids = list(set(experiment_ids) & set(access_list))\n experiments = Experiment.objects.filter(pk__in=ids)\\\n .order_by('-update_time')\n\n results = []\n for e in experiments:\n result = {'sr': e, 'dataset_hit': False, 'datafile_hit': False,\n 'experiment_hit': False}\n results.append(result)\n\n extra['experiments'] = results\n return extra\n\n # override SearchView's method in order to\n # return a ResponseContext\n def create_response(self):\n (paginator, page) = self.build_page()\n\n # Remove unnecessary whitespace\n # TODO this should just be done in the form clean...\n query = SearchQueryString(self.query)\n context = {\n 'search_query': query,\n 'form': self.form,\n 'page': page,\n 'paginator': paginator,\n }\n context.update(self.extra_context())\n\n return render_response_index(self.request, self.template, context)\n\n\ndef retrieve_field_list(request):\n\n from tardis.search.search_indexes import DataFileIndex\n\n # Get all of the fields in the indexes\n #\n # TODO: these should be onl read from registered indexes\n #\n allFields = DataFileIndex.fields.items()\n\n users = User.objects.all()\n\n usernames = [\n u.first_name.encode('utf-8') +\n ' ' +\n u.last_name.encode('utf-8') +\n ':username' for u in users]\n\n # Collect all of the indexed (searchable) fields, except\n # for the main search document ('text')\n searchableFields = ([key + ':search_field' for key, f in allFields\n if f.indexed is True and key != 'text'])\n\n auto_list = usernames + searchableFields\n\n fieldList = '+'.join([str(fn) for fn in auto_list])\n return HttpResponse(fieldList)\n\n\nclass SingleSearchView(SearchView):\n form_class = GroupedSearchForm\n template_name = 'search/search.html'\n\n def form_valid(self, form):\n sqs = form.search(user=self.request.user)\n context = self.get_context_data(**{\n self.form_name: form,\n 'query': form.cleaned_data.get(self.search_field),\n 'object_list': sqs,\n })\n return self.render_to_response(context)\n", "path": "tardis/search/views.py"}]}
| 3,646 | 154 |
gh_patches_debug_28969
|
rasdani/github-patches
|
git_diff
|
optuna__optuna-4077
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
The plot and report of Bayesmark scripts are inconsistent
### Expected behavior
Consistent results in the plots and `report.md`.
### Environment
GitHub Actions: https://github.com/optuna/optuna/blob/1a520bd5daa9ff0af09fb060464bb157f8af891b/.github/workflows/performance-benchmarks-bayesmark.yml
### Error messages, stack traces, or logs
```shell
https://github.com/optuna/optuna/actions/runs/3143078497
(See Additional context)
```
### Steps to reproduce
Run `Actions -> Performance benchmarks with bayesmark` with the default arguments.
### Additional context (optional)
The values in the plots and `report.md` seem to be inconsistent.
Example:
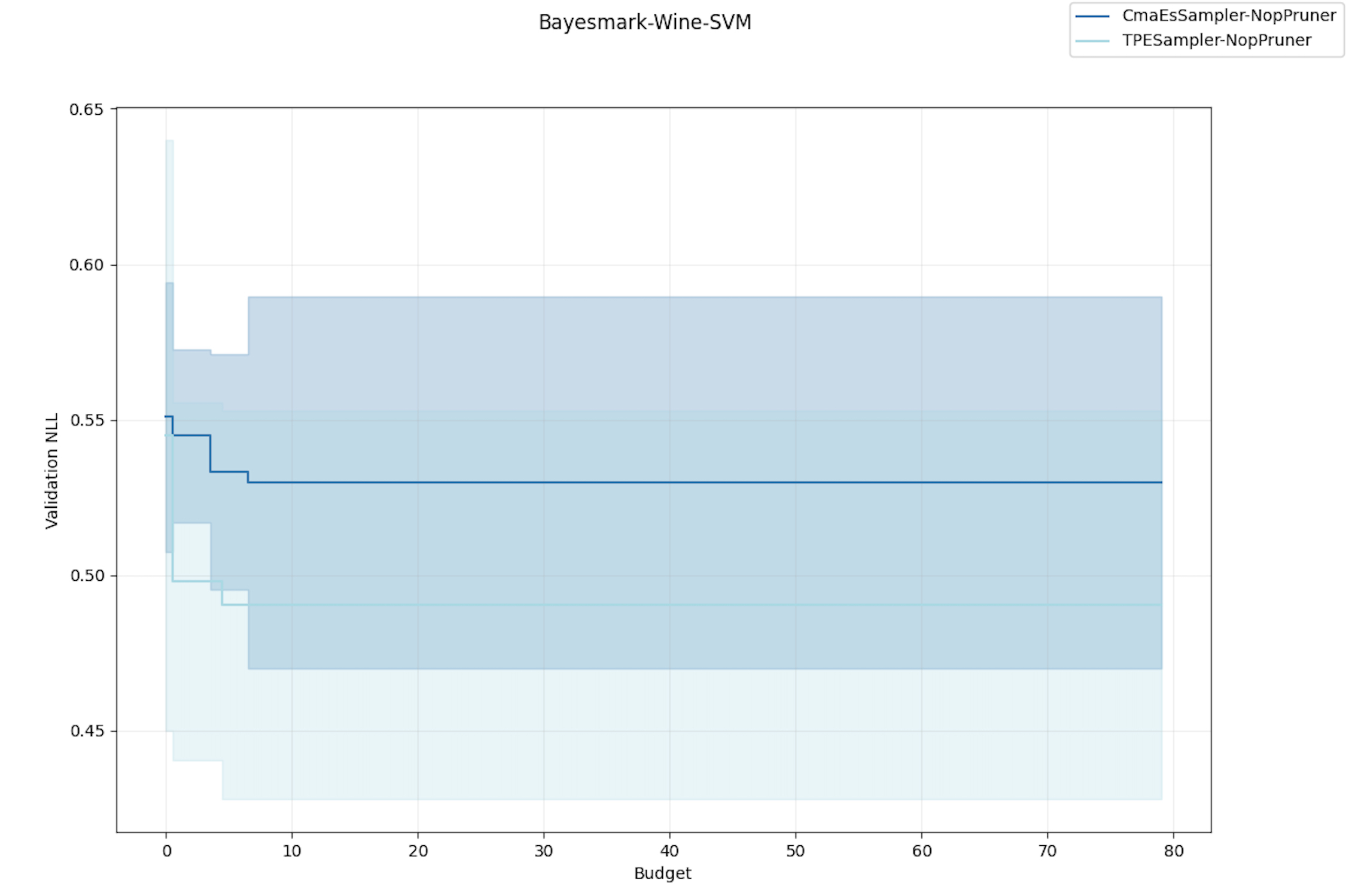

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `benchmarks/run_bayesmark.py`
Content:
```
1 import argparse
2 import json
3 import os
4 import subprocess
5 from typing import Dict
6 from typing import List
7
8 from matplotlib import cm
9 from matplotlib import colors
10 from matplotlib.axes import Axes
11 import matplotlib.pyplot as plt
12 import numpy as np
13 import pandas as pd
14 from xarray import Dataset
15
16
17 _DB = "bo_optuna_run"
18
19
20 def run_benchmark(args: argparse.Namespace) -> None:
21
22 sampler_list = args.sampler_list.split()
23 sampler_kwargs_list = args.sampler_kwargs_list.split()
24 pruner_list = args.pruner_list.split()
25 pruner_kwargs_list = args.pruner_kwargs_list.split()
26
27 config = dict()
28 for sampler, sampler_kwargs in zip(sampler_list, sampler_kwargs_list):
29 for pruner, pruner_kwargs in zip(pruner_list, pruner_kwargs_list):
30 optimizer_name = f"{sampler}-{pruner}"
31 optimizer_kwargs = {
32 "sampler": sampler,
33 "sampler_kwargs": json.loads(sampler_kwargs),
34 "pruner": pruner,
35 "pruner_kwargs": json.loads(pruner_kwargs),
36 }
37 # We need to dynamically generate config.json sice sampler pruner combos (solvers)
38 # are parametrized by user. Following sample config schema.
39 # https://github.com/uber/bayesmark/blob/master/example_opt_root/config.json
40 config[optimizer_name] = ["optuna_optimizer.py", optimizer_kwargs]
41
42 with open(os.path.join("benchmarks", "bayesmark", "config.json"), "w") as file:
43 json.dump(config, file, indent=4)
44
45 samplers = " ".join(config.keys())
46 metric = "nll" if args.dataset in ["breast", "iris", "wine", "digits"] else "mse"
47 cmd = (
48 f"bayesmark-launch -n {args.budget} -r {args.n_runs} "
49 f"-dir runs -b {_DB} "
50 f"-o {samplers} "
51 f"-c {args.model} -d {args.dataset} "
52 f"-m {metric} --opt-root benchmarks/bayesmark"
53 )
54 subprocess.run(cmd, shell=True)
55
56
57 def make_plots(args: argparse.Namespace) -> None:
58
59 filename = f"{args.dataset}-{args.model}-partial-report.json"
60 df = pd.read_json(os.path.join("partial", filename))
61 summaries = (
62 df.groupby(["opt", "iter"])
63 .generalization.agg(["mean", "std"])
64 .rename(columns={"mean": "best_mean", "std": "best_std"})
65 .reset_index()
66 )
67
68 fig, ax = plt.subplots()
69 fig.set_size_inches(12, 8)
70 warmup = json.loads(args.plot_warmup)
71 metric = df.metric[0]
72 color_lookup = build_color_dict(sorted(df["opt"].unique()))
73
74 for optimizer, summary in summaries.groupby("opt"):
75 color = color_lookup[optimizer]
76 make_plot(summary, ax, optimizer, metric, warmup, color)
77
78 handles, labels = ax.get_legend_handles_labels()
79 fig.legend(handles, labels)
80 fig.suptitle(f"Bayesmark-{args.dataset.capitalize()}-{args.model}")
81 fig.savefig(os.path.join("plots", f"optuna-{args.dataset}-{args.model}-sumamry.png"))
82
83
84 def make_plot(
85 summary: pd.DataFrame,
86 ax: Axes,
87 optimizer: str,
88 metric: str,
89 plot_warmup: bool,
90 color: np.ndarray,
91 ) -> None:
92
93 start = 0 if plot_warmup else 10
94 argpos = summary.best_mean.expanding().apply(np.argmin).astype(int)
95 best_found = summary.best_mean.values[argpos.values]
96 sdev = summary.best_std.values[argpos.values]
97
98 if len(best_found) <= start:
99 return
100
101 ax.fill_between(
102 np.arange(len(best_found))[start:],
103 (best_found - sdev)[start:],
104 (best_found + sdev)[start:],
105 color=color,
106 alpha=0.25,
107 step="mid",
108 )
109
110 ax.plot(
111 np.arange(len(best_found))[start:],
112 best_found[start:],
113 color=color,
114 label=optimizer,
115 drawstyle="steps-mid",
116 )
117
118 ax.set_xlabel("Budget", fontsize=10)
119 ax.set_ylabel(f"Validation {metric.upper()}", fontsize=10)
120 ax.grid(alpha=0.2)
121
122
123 def build_color_dict(names: List[str]) -> Dict[str, np.ndarray]:
124
125 norm = colors.Normalize(vmin=0, vmax=1)
126 m = cm.ScalarMappable(norm, cm.tab20)
127 color_dict = m.to_rgba(np.linspace(0, 1, len(names)))
128 color_dict = dict(zip(names, color_dict))
129
130 return color_dict
131
132
133 def partial_report(args: argparse.Namespace) -> None:
134
135 eval_path = os.path.join("runs", _DB, "eval")
136 time_path = os.path.join("runs", _DB, "time")
137 studies = os.listdir(eval_path)
138 summaries: List[pd.DataFrame] = []
139
140 for study in studies:
141 table_buffer: List[pd.DataFrame] = []
142 column_buffer: List[str] = []
143 for path in [eval_path, time_path]:
144 with open(os.path.join(path, study), "r") as file:
145 data = json.load(file)
146 df = Dataset.from_dict(data["data"]).to_dataframe()
147 df = df.droplevel("suggestion")
148
149 for argument, meatadata in data["meta"]["args"].items():
150 colname = argument[2:] if argument.startswith("--") else argument
151 if colname not in column_buffer:
152 df[colname] = meatadata
153 column_buffer.append(colname)
154
155 table_buffer.append(df)
156
157 summary = pd.merge(*table_buffer, left_index=True, right_index=True)
158 summaries.append(summary.reset_index())
159
160 filename = f"{args.dataset}-{args.model}-partial-report.json"
161 pd.concat(summaries).reset_index(drop=True).to_json(os.path.join("partial", filename))
162
163
164 if __name__ == "__main__":
165 parser = argparse.ArgumentParser()
166 parser.add_argument("--dataset", type=str, default="iris")
167 parser.add_argument("--model", type=str, default="kNN")
168 parser.add_argument("--budget", type=int, default=80)
169 parser.add_argument("--n-runs", type=int, default=10)
170 parser.add_argument("--sampler-list", type=str, default="TPESampler CmaEsSampler")
171 parser.add_argument(
172 "--sampler-kwargs-list",
173 type=str,
174 default='{"multivariate":true,"constant_liar":true} {}',
175 )
176 parser.add_argument("--pruner-list", type=str, default="NopPruner")
177 parser.add_argument("--pruner-kwargs-list", type=str, default="{}")
178 parser.add_argument("--plot-warmup", type=str, default="true")
179
180 args = parser.parse_args()
181 os.makedirs("runs", exist_ok=True)
182 os.makedirs("plots", exist_ok=True)
183 os.makedirs("partial", exist_ok=True)
184
185 run_benchmark(args)
186 partial_report(args)
187 make_plots(args)
188
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/benchmarks/run_bayesmark.py b/benchmarks/run_bayesmark.py
--- a/benchmarks/run_bayesmark.py
+++ b/benchmarks/run_bayesmark.py
@@ -58,9 +58,10 @@
filename = f"{args.dataset}-{args.model}-partial-report.json"
df = pd.read_json(os.path.join("partial", filename))
+ df["best_value"] = df.groupby(["opt", "uuid"]).generalization.cummin()
summaries = (
df.groupby(["opt", "iter"])
- .generalization.agg(["mean", "std"])
+ .best_value.agg(["mean", "std"])
.rename(columns={"mean": "best_mean", "std": "best_std"})
.reset_index()
)
@@ -91,25 +92,21 @@
) -> None:
start = 0 if plot_warmup else 10
- argpos = summary.best_mean.expanding().apply(np.argmin).astype(int)
- best_found = summary.best_mean.values[argpos.values]
- sdev = summary.best_std.values[argpos.values]
-
- if len(best_found) <= start:
+ if len(summary.best_mean) <= start:
return
ax.fill_between(
- np.arange(len(best_found))[start:],
- (best_found - sdev)[start:],
- (best_found + sdev)[start:],
+ np.arange(len(summary.best_mean))[start:],
+ (summary.best_mean - summary.best_std)[start:],
+ (summary.best_mean + summary.best_std)[start:],
color=color,
alpha=0.25,
step="mid",
)
ax.plot(
- np.arange(len(best_found))[start:],
- best_found[start:],
+ np.arange(len(summary.best_mean))[start:],
+ summary.best_mean[start:],
color=color,
label=optimizer,
drawstyle="steps-mid",
|
{"golden_diff": "diff --git a/benchmarks/run_bayesmark.py b/benchmarks/run_bayesmark.py\n--- a/benchmarks/run_bayesmark.py\n+++ b/benchmarks/run_bayesmark.py\n@@ -58,9 +58,10 @@\n \n filename = f\"{args.dataset}-{args.model}-partial-report.json\"\n df = pd.read_json(os.path.join(\"partial\", filename))\n+ df[\"best_value\"] = df.groupby([\"opt\", \"uuid\"]).generalization.cummin()\n summaries = (\n df.groupby([\"opt\", \"iter\"])\n- .generalization.agg([\"mean\", \"std\"])\n+ .best_value.agg([\"mean\", \"std\"])\n .rename(columns={\"mean\": \"best_mean\", \"std\": \"best_std\"})\n .reset_index()\n )\n@@ -91,25 +92,21 @@\n ) -> None:\n \n start = 0 if plot_warmup else 10\n- argpos = summary.best_mean.expanding().apply(np.argmin).astype(int)\n- best_found = summary.best_mean.values[argpos.values]\n- sdev = summary.best_std.values[argpos.values]\n-\n- if len(best_found) <= start:\n+ if len(summary.best_mean) <= start:\n return\n \n ax.fill_between(\n- np.arange(len(best_found))[start:],\n- (best_found - sdev)[start:],\n- (best_found + sdev)[start:],\n+ np.arange(len(summary.best_mean))[start:],\n+ (summary.best_mean - summary.best_std)[start:],\n+ (summary.best_mean + summary.best_std)[start:],\n color=color,\n alpha=0.25,\n step=\"mid\",\n )\n \n ax.plot(\n- np.arange(len(best_found))[start:],\n- best_found[start:],\n+ np.arange(len(summary.best_mean))[start:],\n+ summary.best_mean[start:],\n color=color,\n label=optimizer,\n drawstyle=\"steps-mid\",\n", "issue": "The plot and report of Bayesmark scripts are inconsistent\n### Expected behavior\r\n\r\nConsistent results in the plots and `report.md`.\r\n\r\n### Environment\r\n\r\nGitHub Actions: https://github.com/optuna/optuna/blob/1a520bd5daa9ff0af09fb060464bb157f8af891b/.github/workflows/performance-benchmarks-bayesmark.yml\r\n\r\n### Error messages, stack traces, or logs\r\n\r\n```shell\r\nhttps://github.com/optuna/optuna/actions/runs/3143078497\r\n\r\n(See Additional context)\r\n```\r\n\r\n\r\n### Steps to reproduce\r\n\r\nRun `Actions -> Performance benchmarks with bayesmark` with the default arguments.\r\n\r\n### Additional context (optional)\r\n\r\nThe values in the plots and `report.md` seem to be inconsistent.\r\nExample:\r\n\r\n\n", "before_files": [{"content": "import argparse\nimport json\nimport os\nimport subprocess\nfrom typing import Dict\nfrom typing import List\n\nfrom matplotlib import cm\nfrom matplotlib import colors\nfrom matplotlib.axes import Axes\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport pandas as pd\nfrom xarray import Dataset\n\n\n_DB = \"bo_optuna_run\"\n\n\ndef run_benchmark(args: argparse.Namespace) -> None:\n\n sampler_list = args.sampler_list.split()\n sampler_kwargs_list = args.sampler_kwargs_list.split()\n pruner_list = args.pruner_list.split()\n pruner_kwargs_list = args.pruner_kwargs_list.split()\n\n config = dict()\n for sampler, sampler_kwargs in zip(sampler_list, sampler_kwargs_list):\n for pruner, pruner_kwargs in zip(pruner_list, pruner_kwargs_list):\n optimizer_name = f\"{sampler}-{pruner}\"\n optimizer_kwargs = {\n \"sampler\": sampler,\n \"sampler_kwargs\": json.loads(sampler_kwargs),\n \"pruner\": pruner,\n \"pruner_kwargs\": json.loads(pruner_kwargs),\n }\n # We need to dynamically generate config.json sice sampler pruner combos (solvers)\n # are parametrized by user. Following sample config schema.\n # https://github.com/uber/bayesmark/blob/master/example_opt_root/config.json\n config[optimizer_name] = [\"optuna_optimizer.py\", optimizer_kwargs]\n\n with open(os.path.join(\"benchmarks\", \"bayesmark\", \"config.json\"), \"w\") as file:\n json.dump(config, file, indent=4)\n\n samplers = \" \".join(config.keys())\n metric = \"nll\" if args.dataset in [\"breast\", \"iris\", \"wine\", \"digits\"] else \"mse\"\n cmd = (\n f\"bayesmark-launch -n {args.budget} -r {args.n_runs} \"\n f\"-dir runs -b {_DB} \"\n f\"-o {samplers} \"\n f\"-c {args.model} -d {args.dataset} \"\n f\"-m {metric} --opt-root benchmarks/bayesmark\"\n )\n subprocess.run(cmd, shell=True)\n\n\ndef make_plots(args: argparse.Namespace) -> None:\n\n filename = f\"{args.dataset}-{args.model}-partial-report.json\"\n df = pd.read_json(os.path.join(\"partial\", filename))\n summaries = (\n df.groupby([\"opt\", \"iter\"])\n .generalization.agg([\"mean\", \"std\"])\n .rename(columns={\"mean\": \"best_mean\", \"std\": \"best_std\"})\n .reset_index()\n )\n\n fig, ax = plt.subplots()\n fig.set_size_inches(12, 8)\n warmup = json.loads(args.plot_warmup)\n metric = df.metric[0]\n color_lookup = build_color_dict(sorted(df[\"opt\"].unique()))\n\n for optimizer, summary in summaries.groupby(\"opt\"):\n color = color_lookup[optimizer]\n make_plot(summary, ax, optimizer, metric, warmup, color)\n\n handles, labels = ax.get_legend_handles_labels()\n fig.legend(handles, labels)\n fig.suptitle(f\"Bayesmark-{args.dataset.capitalize()}-{args.model}\")\n fig.savefig(os.path.join(\"plots\", f\"optuna-{args.dataset}-{args.model}-sumamry.png\"))\n\n\ndef make_plot(\n summary: pd.DataFrame,\n ax: Axes,\n optimizer: str,\n metric: str,\n plot_warmup: bool,\n color: np.ndarray,\n) -> None:\n\n start = 0 if plot_warmup else 10\n argpos = summary.best_mean.expanding().apply(np.argmin).astype(int)\n best_found = summary.best_mean.values[argpos.values]\n sdev = summary.best_std.values[argpos.values]\n\n if len(best_found) <= start:\n return\n\n ax.fill_between(\n np.arange(len(best_found))[start:],\n (best_found - sdev)[start:],\n (best_found + sdev)[start:],\n color=color,\n alpha=0.25,\n step=\"mid\",\n )\n\n ax.plot(\n np.arange(len(best_found))[start:],\n best_found[start:],\n color=color,\n label=optimizer,\n drawstyle=\"steps-mid\",\n )\n\n ax.set_xlabel(\"Budget\", fontsize=10)\n ax.set_ylabel(f\"Validation {metric.upper()}\", fontsize=10)\n ax.grid(alpha=0.2)\n\n\ndef build_color_dict(names: List[str]) -> Dict[str, np.ndarray]:\n\n norm = colors.Normalize(vmin=0, vmax=1)\n m = cm.ScalarMappable(norm, cm.tab20)\n color_dict = m.to_rgba(np.linspace(0, 1, len(names)))\n color_dict = dict(zip(names, color_dict))\n\n return color_dict\n\n\ndef partial_report(args: argparse.Namespace) -> None:\n\n eval_path = os.path.join(\"runs\", _DB, \"eval\")\n time_path = os.path.join(\"runs\", _DB, \"time\")\n studies = os.listdir(eval_path)\n summaries: List[pd.DataFrame] = []\n\n for study in studies:\n table_buffer: List[pd.DataFrame] = []\n column_buffer: List[str] = []\n for path in [eval_path, time_path]:\n with open(os.path.join(path, study), \"r\") as file:\n data = json.load(file)\n df = Dataset.from_dict(data[\"data\"]).to_dataframe()\n df = df.droplevel(\"suggestion\")\n\n for argument, meatadata in data[\"meta\"][\"args\"].items():\n colname = argument[2:] if argument.startswith(\"--\") else argument\n if colname not in column_buffer:\n df[colname] = meatadata\n column_buffer.append(colname)\n\n table_buffer.append(df)\n\n summary = pd.merge(*table_buffer, left_index=True, right_index=True)\n summaries.append(summary.reset_index())\n\n filename = f\"{args.dataset}-{args.model}-partial-report.json\"\n pd.concat(summaries).reset_index(drop=True).to_json(os.path.join(\"partial\", filename))\n\n\nif __name__ == \"__main__\":\n parser = argparse.ArgumentParser()\n parser.add_argument(\"--dataset\", type=str, default=\"iris\")\n parser.add_argument(\"--model\", type=str, default=\"kNN\")\n parser.add_argument(\"--budget\", type=int, default=80)\n parser.add_argument(\"--n-runs\", type=int, default=10)\n parser.add_argument(\"--sampler-list\", type=str, default=\"TPESampler CmaEsSampler\")\n parser.add_argument(\n \"--sampler-kwargs-list\",\n type=str,\n default='{\"multivariate\":true,\"constant_liar\":true} {}',\n )\n parser.add_argument(\"--pruner-list\", type=str, default=\"NopPruner\")\n parser.add_argument(\"--pruner-kwargs-list\", type=str, default=\"{}\")\n parser.add_argument(\"--plot-warmup\", type=str, default=\"true\")\n\n args = parser.parse_args()\n os.makedirs(\"runs\", exist_ok=True)\n os.makedirs(\"plots\", exist_ok=True)\n os.makedirs(\"partial\", exist_ok=True)\n\n run_benchmark(args)\n partial_report(args)\n make_plots(args)\n", "path": "benchmarks/run_bayesmark.py"}], "after_files": [{"content": "import argparse\nimport json\nimport os\nimport subprocess\nfrom typing import Dict\nfrom typing import List\n\nfrom matplotlib import cm\nfrom matplotlib import colors\nfrom matplotlib.axes import Axes\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport pandas as pd\nfrom xarray import Dataset\n\n\n_DB = \"bo_optuna_run\"\n\n\ndef run_benchmark(args: argparse.Namespace) -> None:\n\n sampler_list = args.sampler_list.split()\n sampler_kwargs_list = args.sampler_kwargs_list.split()\n pruner_list = args.pruner_list.split()\n pruner_kwargs_list = args.pruner_kwargs_list.split()\n\n config = dict()\n for sampler, sampler_kwargs in zip(sampler_list, sampler_kwargs_list):\n for pruner, pruner_kwargs in zip(pruner_list, pruner_kwargs_list):\n optimizer_name = f\"{sampler}-{pruner}\"\n optimizer_kwargs = {\n \"sampler\": sampler,\n \"sampler_kwargs\": json.loads(sampler_kwargs),\n \"pruner\": pruner,\n \"pruner_kwargs\": json.loads(pruner_kwargs),\n }\n # We need to dynamically generate config.json sice sampler pruner combos (solvers)\n # are parametrized by user. Following sample config schema.\n # https://github.com/uber/bayesmark/blob/master/example_opt_root/config.json\n config[optimizer_name] = [\"optuna_optimizer.py\", optimizer_kwargs]\n\n with open(os.path.join(\"benchmarks\", \"bayesmark\", \"config.json\"), \"w\") as file:\n json.dump(config, file, indent=4)\n\n samplers = \" \".join(config.keys())\n metric = \"nll\" if args.dataset in [\"breast\", \"iris\", \"wine\", \"digits\"] else \"mse\"\n cmd = (\n f\"bayesmark-launch -n {args.budget} -r {args.n_runs} \"\n f\"-dir runs -b {_DB} \"\n f\"-o {samplers} \"\n f\"-c {args.model} -d {args.dataset} \"\n f\"-m {metric} --opt-root benchmarks/bayesmark\"\n )\n subprocess.run(cmd, shell=True)\n\n\ndef make_plots(args: argparse.Namespace) -> None:\n\n filename = f\"{args.dataset}-{args.model}-partial-report.json\"\n df = pd.read_json(os.path.join(\"partial\", filename))\n df[\"best_value\"] = df.groupby([\"opt\", \"uuid\"]).generalization.cummin()\n summaries = (\n df.groupby([\"opt\", \"iter\"])\n .best_value.agg([\"mean\", \"std\"])\n .rename(columns={\"mean\": \"best_mean\", \"std\": \"best_std\"})\n .reset_index()\n )\n\n fig, ax = plt.subplots()\n fig.set_size_inches(12, 8)\n warmup = json.loads(args.plot_warmup)\n metric = df.metric[0]\n color_lookup = build_color_dict(sorted(df[\"opt\"].unique()))\n\n for optimizer, summary in summaries.groupby(\"opt\"):\n color = color_lookup[optimizer]\n make_plot(summary, ax, optimizer, metric, warmup, color)\n\n handles, labels = ax.get_legend_handles_labels()\n fig.legend(handles, labels)\n fig.suptitle(f\"Bayesmark-{args.dataset.capitalize()}-{args.model}\")\n fig.savefig(os.path.join(\"plots\", f\"optuna-{args.dataset}-{args.model}-sumamry.png\"))\n\n\ndef make_plot(\n summary: pd.DataFrame,\n ax: Axes,\n optimizer: str,\n metric: str,\n plot_warmup: bool,\n color: np.ndarray,\n) -> None:\n\n start = 0 if plot_warmup else 10\n if len(summary.best_mean) <= start:\n return\n\n ax.fill_between(\n np.arange(len(summary.best_mean))[start:],\n (summary.best_mean - summary.best_std)[start:],\n (summary.best_mean + summary.best_std)[start:],\n color=color,\n alpha=0.25,\n step=\"mid\",\n )\n\n ax.plot(\n np.arange(len(summary.best_mean))[start:],\n summary.best_mean[start:],\n color=color,\n label=optimizer,\n drawstyle=\"steps-mid\",\n )\n\n ax.set_xlabel(\"Budget\", fontsize=10)\n ax.set_ylabel(f\"Validation {metric.upper()}\", fontsize=10)\n ax.grid(alpha=0.2)\n\n\ndef build_color_dict(names: List[str]) -> Dict[str, np.ndarray]:\n\n norm = colors.Normalize(vmin=0, vmax=1)\n m = cm.ScalarMappable(norm, cm.tab20)\n color_dict = m.to_rgba(np.linspace(0, 1, len(names)))\n color_dict = dict(zip(names, color_dict))\n\n return color_dict\n\n\ndef partial_report(args: argparse.Namespace) -> None:\n\n eval_path = os.path.join(\"runs\", _DB, \"eval\")\n time_path = os.path.join(\"runs\", _DB, \"time\")\n studies = os.listdir(eval_path)\n summaries: List[pd.DataFrame] = []\n\n for study in studies:\n table_buffer: List[pd.DataFrame] = []\n column_buffer: List[str] = []\n for path in [eval_path, time_path]:\n with open(os.path.join(path, study), \"r\") as file:\n data = json.load(file)\n df = Dataset.from_dict(data[\"data\"]).to_dataframe()\n df = df.droplevel(\"suggestion\")\n\n for argument, meatadata in data[\"meta\"][\"args\"].items():\n colname = argument[2:] if argument.startswith(\"--\") else argument\n if colname not in column_buffer:\n df[colname] = meatadata\n column_buffer.append(colname)\n\n table_buffer.append(df)\n\n summary = pd.merge(*table_buffer, left_index=True, right_index=True)\n summaries.append(summary.reset_index())\n\n filename = f\"{args.dataset}-{args.model}-partial-report.json\"\n pd.concat(summaries).reset_index(drop=True).to_json(os.path.join(\"partial\", filename))\n\n\nif __name__ == \"__main__\":\n parser = argparse.ArgumentParser()\n parser.add_argument(\"--dataset\", type=str, default=\"iris\")\n parser.add_argument(\"--model\", type=str, default=\"kNN\")\n parser.add_argument(\"--budget\", type=int, default=80)\n parser.add_argument(\"--n-runs\", type=int, default=10)\n parser.add_argument(\"--sampler-list\", type=str, default=\"TPESampler CmaEsSampler\")\n parser.add_argument(\n \"--sampler-kwargs-list\",\n type=str,\n default='{\"multivariate\":true,\"constant_liar\":true} {}',\n )\n parser.add_argument(\"--pruner-list\", type=str, default=\"NopPruner\")\n parser.add_argument(\"--pruner-kwargs-list\", type=str, default=\"{}\")\n parser.add_argument(\"--plot-warmup\", type=str, default=\"true\")\n\n args = parser.parse_args()\n os.makedirs(\"runs\", exist_ok=True)\n os.makedirs(\"plots\", exist_ok=True)\n os.makedirs(\"partial\", exist_ok=True)\n\n run_benchmark(args)\n partial_report(args)\n make_plots(args)\n", "path": "benchmarks/run_bayesmark.py"}]}
| 2,586 | 439 |
gh_patches_debug_57667
|
rasdani/github-patches
|
git_diff
|
evennia__evennia-3042
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[BUG] "evennia xyzgrid help" causes TypeError: NoneType takes no arguments
#### Describe the bug
Fresh migration from git master to main and then installing xyzgrid prevents evennia xyzgrid commands from working. For example, "evennia xyzgrid help" causes TypeError: NoneType takes no arguments
#### To Reproduce
1. Migrated from git master branch to main branch for 1.x release of Evennia.
2. Installed [extra](use to be in requirements_extra).
At this point, I can run the server and log in.
3. Added the xyzgrid command set and restarted.
'path', 'goto', 'map' are seen in the command list. The Limbo room does not have a map. Everything appears to work fine.
4. Modify the server/conf/settings.py.
xyzgrid is now available.
When I use xyzgrid, such as 'evennia xyzgrid help', or any other xyzgrid command:
TypeError: NoneType takes no arguments
#### Expected behavior
'evennia xyzgrid <command>' should call the xyzgrid command.
#### Environment, Evennia version, OS etc
Evennia 1.0.1 (rev 38011cc48d)
OS: nt
Python: 3.11.1
Twisted: 22.10.0
Django: 4.1.4
#### Additional context
This is based off helix4's message in #general on discord. I added my current steps that seem to reproduce the same issue down below. Here is the original message from helix4, with steps for reproducing on the older version of the code.
I am trying to test XYZGrid on a brand new install but failing. 1. cloned the single branch of evennia-develop, and initiated an evennia game. 2. installed requirements_extra, and migrated. I can run the server and log in. 3. i added the command set and reloadead, i see path, goto, map ingame. the Limbo room does not have a map. seems to work well. 4. modify the server/conf/settings.py, xyzgrid is now available.
When I use xyzgrid, such as evennia xyzgrid help, or any other xyzgrid command:
from evennia.utils.eveditor import EvEditor
File "/home/ubuntu/3ProjectMUD/evennia/evennia/utils/eveditor.py", line 201, in <module>
class SaveYesNoCmdSet(CmdSet):
TypeError: NoneType takes no arguments
Original message
https://discord.com/channels/246323978879107073/246323978879107073/937578545704730624
Griatch's response
https://discord.com/channels/246323978879107073/246323978879107073/937610453184561183
Steps:
1. Migrated from git master branch to main branch for 1.x release of Evennia.
2. Installed [extra](use to be in requirements_extra).
At this point, I can run the server and log in.
3. Added the xyzgrid command set and restarted.
'path', 'goto', 'map' are seen in the command list. The Limbo room does not have a map. Everything appears to work fine.
4. Modify the server/conf/settings.py.
xyzgrid is now available.
When I use xyzgrid, such as 'evennia xyzgrid help', or any other xyzgrid command:
Traceback (most recent call last):
File "C:\muddev\evenv\Scripts\evennia_launcher.py", line 18, in <module>
main()
File "C:\muddev\evennia\evennia\server\evennia_launcher.py", line 2422, in main
if run_custom_commands(option, *unknown_args):
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\muddev\evennia\evennia\server\evennia_launcher.py", line 2023, in run_custom_commands
mod = importlib.import_module(modpath)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
...
File "<frozen importlib._bootstrap>", line 1206, in _gcd_import
File "<frozen importlib._bootstrap>", line 1178, in _find_and_load
File "<frozen importlib._bootstrap>", line 1128, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removed
File "<frozen importlib._bootstrap>", line 1206, in _gcd_import
File "<frozen importlib._bootstrap>", line 1178, in _find_and_load
File "<frozen importlib._bootstrap>", line 1149, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 690, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 940, in exec_module
File "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removed
File "C:\muddev\evennia\evennia\contrib\grid\xyzgrid\__init__.py", line 6, in <module>
from . import commands # noqa
^^^^^^^^^^^^^^^^^^^^^^
File "C:\muddev\evennia\evennia\contrib\grid\xyzgrid\commands.py", line 15, in <module>
from evennia.commands.default import building
File "C:\muddev\evennia\evennia\commands\default\building.py", line 14, in <module>
from evennia.prototypes import menus as olc_menus
File "C:\muddev\evennia\evennia\prototypes\menus.py", line 20, in <module>
from evennia.utils.evmenu import EvMenu, list_node
File "C:\muddev\evennia\evennia\utils\evmenu.py", line 350, in <module>
class CmdEvMenuNode(Command):
TypeError: NoneType takes no arguments
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `evennia/contrib/grid/xyzgrid/__init__.py`
Content:
```
1 """
2 XYZGrid - Griatch 2021
3
4 """
5
6 from . import commands # noqa
7 from . import example # noqa
8 from . import launchcmd # noqa
9 from . import prototypes # noqa
10 from . import tests # noqa
11 from . import utils # noqa
12 from . import xymap # noqa
13 from . import xymap_legend # noqa
14 from . import xyzgrid # noqa
15 from . import xyzroom # noqa
16
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/evennia/contrib/grid/xyzgrid/__init__.py b/evennia/contrib/grid/xyzgrid/__init__.py
--- a/evennia/contrib/grid/xyzgrid/__init__.py
+++ b/evennia/contrib/grid/xyzgrid/__init__.py
@@ -2,14 +2,15 @@
XYZGrid - Griatch 2021
"""
-
-from . import commands # noqa
-from . import example # noqa
-from . import launchcmd # noqa
-from . import prototypes # noqa
-from . import tests # noqa
-from . import utils # noqa
-from . import xymap # noqa
-from . import xymap_legend # noqa
-from . import xyzgrid # noqa
-from . import xyzroom # noqa
+from . import (
+ example,
+ launchcmd,
+ prototypes,
+ tests,
+ utils,
+ xymap,
+ xymap_legend,
+ xyzgrid,
+ xyzroom,
+ commands,
+)
|
{"golden_diff": "diff --git a/evennia/contrib/grid/xyzgrid/__init__.py b/evennia/contrib/grid/xyzgrid/__init__.py\n--- a/evennia/contrib/grid/xyzgrid/__init__.py\n+++ b/evennia/contrib/grid/xyzgrid/__init__.py\n@@ -2,14 +2,15 @@\n XYZGrid - Griatch 2021\n \n \"\"\"\n-\n-from . import commands # noqa\n-from . import example # noqa\n-from . import launchcmd # noqa\n-from . import prototypes # noqa\n-from . import tests # noqa\n-from . import utils # noqa\n-from . import xymap # noqa\n-from . import xymap_legend # noqa\n-from . import xyzgrid # noqa\n-from . import xyzroom # noqa\n+from . import (\n+ example,\n+ launchcmd,\n+ prototypes,\n+ tests,\n+ utils,\n+ xymap,\n+ xymap_legend,\n+ xyzgrid,\n+ xyzroom,\n+ commands,\n+)\n", "issue": "[BUG] \"evennia xyzgrid help\" causes TypeError: NoneType takes no arguments\n#### Describe the bug\r\nFresh migration from git master to main and then installing xyzgrid prevents evennia xyzgrid commands from working. For example, \"evennia xyzgrid help\" causes TypeError: NoneType takes no arguments\r\n\r\n#### To Reproduce\r\n1. Migrated from git master branch to main branch for 1.x release of Evennia.\r\n2. Installed [extra](use to be in requirements_extra). \r\n\r\nAt this point, I can run the server and log in.\r\n\r\n3. Added the xyzgrid command set and restarted. \r\n\r\n'path', 'goto', 'map' are seen in the command list. The Limbo room does not have a map. Everything appears to work fine.\r\n\r\n4. Modify the server/conf/settings.py.\r\n\r\nxyzgrid is now available.\r\n\r\nWhen I use xyzgrid, such as 'evennia xyzgrid help', or any other xyzgrid command:\r\nTypeError: NoneType takes no arguments\r\n\r\n#### Expected behavior\r\n'evennia xyzgrid <command>' should call the xyzgrid command.\r\n\r\n#### Environment, Evennia version, OS etc\r\n\r\n Evennia 1.0.1 (rev 38011cc48d)\r\n OS: nt\r\n Python: 3.11.1\r\n Twisted: 22.10.0\r\n Django: 4.1.4\r\n\r\n#### Additional context\r\n\r\nThis is based off helix4's message in #general on discord. I added my current steps that seem to reproduce the same issue down below. Here is the original message from helix4, with steps for reproducing on the older version of the code.\r\n\r\nI am trying to test XYZGrid on a brand new install but failing. 1. cloned the single branch of evennia-develop, and initiated an evennia game. 2. installed requirements_extra, and migrated. I can run the server and log in. 3. i added the command set and reloadead, i see path, goto, map ingame. the Limbo room does not have a map. seems to work well. 4. modify the server/conf/settings.py, xyzgrid is now available.\r\n\r\nWhen I use xyzgrid, such as evennia xyzgrid help, or any other xyzgrid command:\r\n from evennia.utils.eveditor import EvEditor\r\n File \"/home/ubuntu/3ProjectMUD/evennia/evennia/utils/eveditor.py\", line 201, in <module>\r\n class SaveYesNoCmdSet(CmdSet):\r\nTypeError: NoneType takes no arguments\r\n\r\nOriginal message\r\n\r\nhttps://discord.com/channels/246323978879107073/246323978879107073/937578545704730624\r\n\r\nGriatch's response\r\n\r\nhttps://discord.com/channels/246323978879107073/246323978879107073/937610453184561183\r\n\r\nSteps:\r\n\r\n1. Migrated from git master branch to main branch for 1.x release of Evennia.\r\n2. Installed [extra](use to be in requirements_extra). \r\n\r\nAt this point, I can run the server and log in.\r\n\r\n3. Added the xyzgrid command set and restarted. \r\n\r\n'path', 'goto', 'map' are seen in the command list. The Limbo room does not have a map. Everything appears to work fine.\r\n\r\n4. Modify the server/conf/settings.py.\r\n\r\nxyzgrid is now available.\r\n\r\nWhen I use xyzgrid, such as 'evennia xyzgrid help', or any other xyzgrid command:\r\n\r\nTraceback (most recent call last):\r\n File \"C:\\muddev\\evenv\\Scripts\\evennia_launcher.py\", line 18, in <module>\r\n main()\r\n File \"C:\\muddev\\evennia\\evennia\\server\\evennia_launcher.py\", line 2422, in main\r\n if run_custom_commands(option, *unknown_args):\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"C:\\muddev\\evennia\\evennia\\server\\evennia_launcher.py\", line 2023, in run_custom_commands\r\n mod = importlib.import_module(modpath)\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n...\r\n\r\n File \"<frozen importlib._bootstrap>\", line 1206, in _gcd_import\r\n File \"<frozen importlib._bootstrap>\", line 1178, in _find_and_load\r\n File \"<frozen importlib._bootstrap>\", line 1128, in _find_and_load_unlocked\r\n File \"<frozen importlib._bootstrap>\", line 241, in _call_with_frames_removed\r\n File \"<frozen importlib._bootstrap>\", line 1206, in _gcd_import\r\n File \"<frozen importlib._bootstrap>\", line 1178, in _find_and_load\r\n File \"<frozen importlib._bootstrap>\", line 1149, in _find_and_load_unlocked\r\n File \"<frozen importlib._bootstrap>\", line 690, in _load_unlocked\r\n File \"<frozen importlib._bootstrap_external>\", line 940, in exec_module\r\n File \"<frozen importlib._bootstrap>\", line 241, in _call_with_frames_removed\r\n File \"C:\\muddev\\evennia\\evennia\\contrib\\grid\\xyzgrid\\__init__.py\", line 6, in <module>\r\n from . import commands # noqa\r\n ^^^^^^^^^^^^^^^^^^^^^^\r\n File \"C:\\muddev\\evennia\\evennia\\contrib\\grid\\xyzgrid\\commands.py\", line 15, in <module>\r\n from evennia.commands.default import building\r\n File \"C:\\muddev\\evennia\\evennia\\commands\\default\\building.py\", line 14, in <module>\r\n from evennia.prototypes import menus as olc_menus\r\n File \"C:\\muddev\\evennia\\evennia\\prototypes\\menus.py\", line 20, in <module>\r\n from evennia.utils.evmenu import EvMenu, list_node\r\n File \"C:\\muddev\\evennia\\evennia\\utils\\evmenu.py\", line 350, in <module>\r\n class CmdEvMenuNode(Command):\r\nTypeError: NoneType takes no arguments\r\n\r\n\n", "before_files": [{"content": "\"\"\"\nXYZGrid - Griatch 2021\n\n\"\"\"\n\nfrom . import commands # noqa\nfrom . import example # noqa\nfrom . import launchcmd # noqa\nfrom . import prototypes # noqa\nfrom . import tests # noqa\nfrom . import utils # noqa\nfrom . import xymap # noqa\nfrom . import xymap_legend # noqa\nfrom . import xyzgrid # noqa\nfrom . import xyzroom # noqa\n", "path": "evennia/contrib/grid/xyzgrid/__init__.py"}], "after_files": [{"content": "\"\"\"\nXYZGrid - Griatch 2021\n\n\"\"\"\nfrom . import (\n example,\n launchcmd,\n prototypes,\n tests,\n utils,\n xymap,\n xymap_legend,\n xyzgrid,\n xyzroom,\n commands,\n)\n", "path": "evennia/contrib/grid/xyzgrid/__init__.py"}]}
| 1,817 | 232 |
gh_patches_debug_36164
|
rasdani/github-patches
|
git_diff
|
PaddlePaddle__models-1472
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ocr_recognition 的参数说明与代码不相符
说明中的 --train_images 与 --train_list 两个参数,在代码中并不存在;运行时,带上这两个参数会报错。
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `fluid/PaddleCV/ocr_recognition/train.py`
Content:
```
1 """Trainer for OCR CTC or attention model."""
2 from __future__ import absolute_import
3 from __future__ import division
4 from __future__ import print_function
5 import paddle.fluid as fluid
6 from utility import add_arguments, print_arguments, to_lodtensor, get_ctc_feeder_data, get_attention_feeder_data
7 import paddle.fluid.profiler as profiler
8 from crnn_ctc_model import ctc_train_net
9 from attention_model import attention_train_net
10 import data_reader
11 import argparse
12 import functools
13 import sys
14 import time
15 import os
16 import numpy as np
17
18 parser = argparse.ArgumentParser(description=__doc__)
19 add_arg = functools.partial(add_arguments, argparser=parser)
20 # yapf: disable
21 add_arg('batch_size', int, 32, "Minibatch size.")
22 add_arg('total_step', int, 720000, "The number of iterations. Zero or less means whole training set. More than 0 means the training set might be looped until # of iterations is reached.")
23 add_arg('log_period', int, 1000, "Log period.")
24 add_arg('save_model_period', int, 15000, "Save model period. '-1' means never saving the model.")
25 add_arg('eval_period', int, 15000, "Evaluate period. '-1' means never evaluating the model.")
26 add_arg('save_model_dir', str, "./models", "The directory the model to be saved to.")
27 add_arg('model', str, "crnn_ctc", "Which type of network to be used. 'crnn_ctc' or 'attention'")
28 add_arg('init_model', str, None, "The init model file of directory.")
29 add_arg('use_gpu', bool, True, "Whether use GPU to train.")
30 add_arg('min_average_window',int, 10000, "Min average window.")
31 add_arg('max_average_window',int, 12500, "Max average window. It is proposed to be set as the number of minibatch in a pass.")
32 add_arg('average_window', float, 0.15, "Average window.")
33 add_arg('parallel', bool, False, "Whether use parallel training.")
34 add_arg('profile', bool, False, "Whether to use profiling.")
35 add_arg('skip_batch_num', int, 0, "The number of first minibatches to skip as warm-up for better performance test.")
36 add_arg('skip_test', bool, False, "Whether to skip test phase.")
37 # yapf: enable
38
39
40 def train(args):
41 """OCR training"""
42
43 if args.model == "crnn_ctc":
44 train_net = ctc_train_net
45 get_feeder_data = get_ctc_feeder_data
46 else:
47 train_net = attention_train_net
48 get_feeder_data = get_attention_feeder_data
49
50 num_classes = None
51 train_images = None
52 train_list = None
53 test_images = None
54 test_list = None
55 num_classes = data_reader.num_classes(
56 ) if num_classes is None else num_classes
57 data_shape = data_reader.data_shape()
58 # define network
59 sum_cost, error_evaluator, inference_program, model_average = train_net(
60 args, data_shape, num_classes)
61
62 # data reader
63 train_reader = data_reader.train(
64 args.batch_size,
65 train_images_dir=train_images,
66 train_list_file=train_list,
67 cycle=args.total_step > 0,
68 model=args.model)
69 test_reader = data_reader.test(
70 test_images_dir=test_images, test_list_file=test_list, model=args.model)
71
72 # prepare environment
73 place = fluid.CPUPlace()
74 if args.use_gpu:
75 place = fluid.CUDAPlace(0)
76 exe = fluid.Executor(place)
77
78 if 'ce_mode' in os.environ:
79 fluid.default_startup_program().random_seed = 90
80
81 exe.run(fluid.default_startup_program())
82
83 # load init model
84 if args.init_model is not None:
85 model_dir = args.init_model
86 model_file_name = None
87 if not os.path.isdir(args.init_model):
88 model_dir = os.path.dirname(args.init_model)
89 model_file_name = os.path.basename(args.init_model)
90 fluid.io.load_params(exe, dirname=model_dir, filename=model_file_name)
91 print("Init model from: %s." % args.init_model)
92
93 train_exe = exe
94 error_evaluator.reset(exe)
95 if args.parallel:
96 train_exe = fluid.ParallelExecutor(
97 use_cuda=True if args.use_gpu else False, loss_name=sum_cost.name)
98
99 fetch_vars = [sum_cost] + error_evaluator.metrics
100
101 def train_one_batch(data):
102 var_names = [var.name for var in fetch_vars]
103 if args.parallel:
104 results = train_exe.run(var_names,
105 feed=get_feeder_data(data, place))
106 results = [np.array(result).sum() for result in results]
107 else:
108 results = train_exe.run(feed=get_feeder_data(data, place),
109 fetch_list=fetch_vars)
110 results = [result[0] for result in results]
111 return results
112
113 def test(iter_num):
114 error_evaluator.reset(exe)
115 for data in test_reader():
116 exe.run(inference_program, feed=get_feeder_data(data, place))
117 _, test_seq_error = error_evaluator.eval(exe)
118 print("\nTime: %s; Iter[%d]; Test seq error: %s.\n" % (
119 time.time(), iter_num, str(test_seq_error[0])))
120
121 #Note: The following logs are special for CE monitoring.
122 #Other situations do not need to care about these logs.
123 print("kpis test_acc %f" % (1 - test_seq_error[0]))
124
125 def save_model(args, exe, iter_num):
126 filename = "model_%05d" % iter_num
127 fluid.io.save_params(
128 exe, dirname=args.save_model_dir, filename=filename)
129 print("Saved model to: %s/%s." % (args.save_model_dir, filename))
130
131 iter_num = 0
132 stop = False
133 start_time = time.time()
134 while not stop:
135 total_loss = 0.0
136 total_seq_error = 0.0
137 batch_times = []
138 # train a pass
139 for data in train_reader():
140 if args.total_step > 0 and iter_num == args.total_step + args.skip_batch_num:
141 stop = True
142 break
143 if iter_num < args.skip_batch_num:
144 print("Warm-up iteration")
145 if iter_num == args.skip_batch_num:
146 profiler.reset_profiler()
147 start = time.time()
148 results = train_one_batch(data)
149 batch_time = time.time() - start
150 fps = args.batch_size / batch_time
151 batch_times.append(batch_time)
152 total_loss += results[0]
153 total_seq_error += results[2]
154
155 iter_num += 1
156 # training log
157 if iter_num % args.log_period == 0:
158 print("\nTime: %s; Iter[%d]; Avg loss: %.3f; Avg seq err: %.3f" % (
159 time.time(), iter_num,
160 total_loss / (args.log_period * args.batch_size),
161 total_seq_error / (args.log_period * args.batch_size)))
162 print("kpis train_cost %f" % (total_loss / (args.log_period *
163 args.batch_size)))
164 print("kpis train_acc %f" % (
165 1 - total_seq_error / (args.log_period * args.batch_size)))
166 total_loss = 0.0
167 total_seq_error = 0.0
168
169 # evaluate
170 if not args.skip_test and iter_num % args.eval_period == 0:
171 if model_average:
172 with model_average.apply(exe):
173 test(iter_num)
174 else:
175 test(iter_num)
176
177 # save model
178 if iter_num % args.save_model_period == 0:
179 if model_average:
180 with model_average.apply(exe):
181 save_model(args, exe, iter_num)
182 else:
183 save_model(args, exe, iter_num)
184 end_time = time.time()
185 print("kpis train_duration %f" % (end_time - start_time))
186 # Postprocess benchmark data
187 latencies = batch_times[args.skip_batch_num:]
188 latency_avg = np.average(latencies)
189 latency_pc99 = np.percentile(latencies, 99)
190 fpses = np.divide(args.batch_size, latencies)
191 fps_avg = np.average(fpses)
192 fps_pc99 = np.percentile(fpses, 1)
193
194 # Benchmark output
195 print('\nTotal examples (incl. warm-up): %d' %
196 (iter_num * args.batch_size))
197 print('average latency: %.5f s, 99pc latency: %.5f s' % (latency_avg,
198 latency_pc99))
199 print('average fps: %.5f, fps for 99pc latency: %.5f' % (fps_avg,
200 fps_pc99))
201
202
203 def main():
204 args = parser.parse_args()
205 print_arguments(args)
206 if args.profile:
207 if args.use_gpu:
208 with profiler.cuda_profiler("cuda_profiler.txt", 'csv') as nvprof:
209 train(args)
210 else:
211 with profiler.profiler("CPU", sorted_key='total') as cpuprof:
212 train(args)
213 else:
214 train(args)
215
216
217 if __name__ == "__main__":
218 main()
219
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/fluid/PaddleCV/ocr_recognition/train.py b/fluid/PaddleCV/ocr_recognition/train.py
--- a/fluid/PaddleCV/ocr_recognition/train.py
+++ b/fluid/PaddleCV/ocr_recognition/train.py
@@ -24,6 +24,10 @@
add_arg('save_model_period', int, 15000, "Save model period. '-1' means never saving the model.")
add_arg('eval_period', int, 15000, "Evaluate period. '-1' means never evaluating the model.")
add_arg('save_model_dir', str, "./models", "The directory the model to be saved to.")
+add_arg('train_images', str, None, "The directory of images to be used for training.")
+add_arg('train_list', str, None, "The list file of images to be used for training.")
+add_arg('test_images', str, None, "The directory of images to be used for test.")
+add_arg('test_list', str, None, "The list file of images to be used for training.")
add_arg('model', str, "crnn_ctc", "Which type of network to be used. 'crnn_ctc' or 'attention'")
add_arg('init_model', str, None, "The init model file of directory.")
add_arg('use_gpu', bool, True, "Whether use GPU to train.")
@@ -48,10 +52,6 @@
get_feeder_data = get_attention_feeder_data
num_classes = None
- train_images = None
- train_list = None
- test_images = None
- test_list = None
num_classes = data_reader.num_classes(
) if num_classes is None else num_classes
data_shape = data_reader.data_shape()
@@ -62,12 +62,12 @@
# data reader
train_reader = data_reader.train(
args.batch_size,
- train_images_dir=train_images,
- train_list_file=train_list,
+ train_images_dir=args.train_images,
+ train_list_file=args.train_list,
cycle=args.total_step > 0,
model=args.model)
test_reader = data_reader.test(
- test_images_dir=test_images, test_list_file=test_list, model=args.model)
+ test_images_dir=args.test_images, test_list_file=args.test_list, model=args.model)
# prepare environment
place = fluid.CPUPlace()
|
{"golden_diff": "diff --git a/fluid/PaddleCV/ocr_recognition/train.py b/fluid/PaddleCV/ocr_recognition/train.py\n--- a/fluid/PaddleCV/ocr_recognition/train.py\n+++ b/fluid/PaddleCV/ocr_recognition/train.py\n@@ -24,6 +24,10 @@\n add_arg('save_model_period', int, 15000, \"Save model period. '-1' means never saving the model.\")\n add_arg('eval_period', int, 15000, \"Evaluate period. '-1' means never evaluating the model.\")\n add_arg('save_model_dir', str, \"./models\", \"The directory the model to be saved to.\")\n+add_arg('train_images', str, None, \"The directory of images to be used for training.\")\n+add_arg('train_list', str, None, \"The list file of images to be used for training.\")\n+add_arg('test_images', str, None, \"The directory of images to be used for test.\")\n+add_arg('test_list', str, None, \"The list file of images to be used for training.\")\n add_arg('model', str, \"crnn_ctc\", \"Which type of network to be used. 'crnn_ctc' or 'attention'\")\n add_arg('init_model', str, None, \"The init model file of directory.\")\n add_arg('use_gpu', bool, True, \"Whether use GPU to train.\")\n@@ -48,10 +52,6 @@\n get_feeder_data = get_attention_feeder_data\n \n num_classes = None\n- train_images = None\n- train_list = None\n- test_images = None\n- test_list = None\n num_classes = data_reader.num_classes(\n ) if num_classes is None else num_classes\n data_shape = data_reader.data_shape()\n@@ -62,12 +62,12 @@\n # data reader\n train_reader = data_reader.train(\n args.batch_size,\n- train_images_dir=train_images,\n- train_list_file=train_list,\n+ train_images_dir=args.train_images,\n+ train_list_file=args.train_list,\n cycle=args.total_step > 0,\n model=args.model)\n test_reader = data_reader.test(\n- test_images_dir=test_images, test_list_file=test_list, model=args.model)\n+ test_images_dir=args.test_images, test_list_file=args.test_list, model=args.model)\n \n # prepare environment\n place = fluid.CPUPlace()\n", "issue": "ocr_recognition \u7684\u53c2\u6570\u8bf4\u660e\u4e0e\u4ee3\u7801\u4e0d\u76f8\u7b26\n\u8bf4\u660e\u4e2d\u7684 --train_images \u4e0e --train_list \u4e24\u4e2a\u53c2\u6570\uff0c\u5728\u4ee3\u7801\u4e2d\u5e76\u4e0d\u5b58\u5728\uff1b\u8fd0\u884c\u65f6\uff0c\u5e26\u4e0a\u8fd9\u4e24\u4e2a\u53c2\u6570\u4f1a\u62a5\u9519\u3002\n", "before_files": [{"content": "\"\"\"Trainer for OCR CTC or attention model.\"\"\"\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\nimport paddle.fluid as fluid\nfrom utility import add_arguments, print_arguments, to_lodtensor, get_ctc_feeder_data, get_attention_feeder_data\nimport paddle.fluid.profiler as profiler\nfrom crnn_ctc_model import ctc_train_net\nfrom attention_model import attention_train_net\nimport data_reader\nimport argparse\nimport functools\nimport sys\nimport time\nimport os\nimport numpy as np\n\nparser = argparse.ArgumentParser(description=__doc__)\nadd_arg = functools.partial(add_arguments, argparser=parser)\n# yapf: disable\nadd_arg('batch_size', int, 32, \"Minibatch size.\")\nadd_arg('total_step', int, 720000, \"The number of iterations. Zero or less means whole training set. More than 0 means the training set might be looped until # of iterations is reached.\")\nadd_arg('log_period', int, 1000, \"Log period.\")\nadd_arg('save_model_period', int, 15000, \"Save model period. '-1' means never saving the model.\")\nadd_arg('eval_period', int, 15000, \"Evaluate period. '-1' means never evaluating the model.\")\nadd_arg('save_model_dir', str, \"./models\", \"The directory the model to be saved to.\")\nadd_arg('model', str, \"crnn_ctc\", \"Which type of network to be used. 'crnn_ctc' or 'attention'\")\nadd_arg('init_model', str, None, \"The init model file of directory.\")\nadd_arg('use_gpu', bool, True, \"Whether use GPU to train.\")\nadd_arg('min_average_window',int, 10000, \"Min average window.\")\nadd_arg('max_average_window',int, 12500, \"Max average window. It is proposed to be set as the number of minibatch in a pass.\")\nadd_arg('average_window', float, 0.15, \"Average window.\")\nadd_arg('parallel', bool, False, \"Whether use parallel training.\")\nadd_arg('profile', bool, False, \"Whether to use profiling.\")\nadd_arg('skip_batch_num', int, 0, \"The number of first minibatches to skip as warm-up for better performance test.\")\nadd_arg('skip_test', bool, False, \"Whether to skip test phase.\")\n# yapf: enable\n\n\ndef train(args):\n \"\"\"OCR training\"\"\"\n\n if args.model == \"crnn_ctc\":\n train_net = ctc_train_net\n get_feeder_data = get_ctc_feeder_data\n else:\n train_net = attention_train_net\n get_feeder_data = get_attention_feeder_data\n\n num_classes = None\n train_images = None\n train_list = None\n test_images = None\n test_list = None\n num_classes = data_reader.num_classes(\n ) if num_classes is None else num_classes\n data_shape = data_reader.data_shape()\n # define network\n sum_cost, error_evaluator, inference_program, model_average = train_net(\n args, data_shape, num_classes)\n\n # data reader\n train_reader = data_reader.train(\n args.batch_size,\n train_images_dir=train_images,\n train_list_file=train_list,\n cycle=args.total_step > 0,\n model=args.model)\n test_reader = data_reader.test(\n test_images_dir=test_images, test_list_file=test_list, model=args.model)\n\n # prepare environment\n place = fluid.CPUPlace()\n if args.use_gpu:\n place = fluid.CUDAPlace(0)\n exe = fluid.Executor(place)\n\n if 'ce_mode' in os.environ:\n fluid.default_startup_program().random_seed = 90\n\n exe.run(fluid.default_startup_program())\n\n # load init model\n if args.init_model is not None:\n model_dir = args.init_model\n model_file_name = None\n if not os.path.isdir(args.init_model):\n model_dir = os.path.dirname(args.init_model)\n model_file_name = os.path.basename(args.init_model)\n fluid.io.load_params(exe, dirname=model_dir, filename=model_file_name)\n print(\"Init model from: %s.\" % args.init_model)\n\n train_exe = exe\n error_evaluator.reset(exe)\n if args.parallel:\n train_exe = fluid.ParallelExecutor(\n use_cuda=True if args.use_gpu else False, loss_name=sum_cost.name)\n\n fetch_vars = [sum_cost] + error_evaluator.metrics\n\n def train_one_batch(data):\n var_names = [var.name for var in fetch_vars]\n if args.parallel:\n results = train_exe.run(var_names,\n feed=get_feeder_data(data, place))\n results = [np.array(result).sum() for result in results]\n else:\n results = train_exe.run(feed=get_feeder_data(data, place),\n fetch_list=fetch_vars)\n results = [result[0] for result in results]\n return results\n\n def test(iter_num):\n error_evaluator.reset(exe)\n for data in test_reader():\n exe.run(inference_program, feed=get_feeder_data(data, place))\n _, test_seq_error = error_evaluator.eval(exe)\n print(\"\\nTime: %s; Iter[%d]; Test seq error: %s.\\n\" % (\n time.time(), iter_num, str(test_seq_error[0])))\n\n #Note: The following logs are special for CE monitoring.\n #Other situations do not need to care about these logs.\n print(\"kpis\ttest_acc\t%f\" % (1 - test_seq_error[0]))\n\n def save_model(args, exe, iter_num):\n filename = \"model_%05d\" % iter_num\n fluid.io.save_params(\n exe, dirname=args.save_model_dir, filename=filename)\n print(\"Saved model to: %s/%s.\" % (args.save_model_dir, filename))\n\n iter_num = 0\n stop = False\n start_time = time.time()\n while not stop:\n total_loss = 0.0\n total_seq_error = 0.0\n batch_times = []\n # train a pass\n for data in train_reader():\n if args.total_step > 0 and iter_num == args.total_step + args.skip_batch_num:\n stop = True\n break\n if iter_num < args.skip_batch_num:\n print(\"Warm-up iteration\")\n if iter_num == args.skip_batch_num:\n profiler.reset_profiler()\n start = time.time()\n results = train_one_batch(data)\n batch_time = time.time() - start\n fps = args.batch_size / batch_time\n batch_times.append(batch_time)\n total_loss += results[0]\n total_seq_error += results[2]\n\n iter_num += 1\n # training log\n if iter_num % args.log_period == 0:\n print(\"\\nTime: %s; Iter[%d]; Avg loss: %.3f; Avg seq err: %.3f\" % (\n time.time(), iter_num,\n total_loss / (args.log_period * args.batch_size),\n total_seq_error / (args.log_period * args.batch_size)))\n print(\"kpis\ttrain_cost\t%f\" % (total_loss / (args.log_period *\n args.batch_size)))\n print(\"kpis\ttrain_acc\t%f\" % (\n 1 - total_seq_error / (args.log_period * args.batch_size)))\n total_loss = 0.0\n total_seq_error = 0.0\n\n # evaluate\n if not args.skip_test and iter_num % args.eval_period == 0:\n if model_average:\n with model_average.apply(exe):\n test(iter_num)\n else:\n test(iter_num)\n\n # save model\n if iter_num % args.save_model_period == 0:\n if model_average:\n with model_average.apply(exe):\n save_model(args, exe, iter_num)\n else:\n save_model(args, exe, iter_num)\n end_time = time.time()\n print(\"kpis\ttrain_duration\t%f\" % (end_time - start_time))\n # Postprocess benchmark data\n latencies = batch_times[args.skip_batch_num:]\n latency_avg = np.average(latencies)\n latency_pc99 = np.percentile(latencies, 99)\n fpses = np.divide(args.batch_size, latencies)\n fps_avg = np.average(fpses)\n fps_pc99 = np.percentile(fpses, 1)\n\n # Benchmark output\n print('\\nTotal examples (incl. warm-up): %d' %\n (iter_num * args.batch_size))\n print('average latency: %.5f s, 99pc latency: %.5f s' % (latency_avg,\n latency_pc99))\n print('average fps: %.5f, fps for 99pc latency: %.5f' % (fps_avg,\n fps_pc99))\n\n\ndef main():\n args = parser.parse_args()\n print_arguments(args)\n if args.profile:\n if args.use_gpu:\n with profiler.cuda_profiler(\"cuda_profiler.txt\", 'csv') as nvprof:\n train(args)\n else:\n with profiler.profiler(\"CPU\", sorted_key='total') as cpuprof:\n train(args)\n else:\n train(args)\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "fluid/PaddleCV/ocr_recognition/train.py"}], "after_files": [{"content": "\"\"\"Trainer for OCR CTC or attention model.\"\"\"\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\nimport paddle.fluid as fluid\nfrom utility import add_arguments, print_arguments, to_lodtensor, get_ctc_feeder_data, get_attention_feeder_data\nimport paddle.fluid.profiler as profiler\nfrom crnn_ctc_model import ctc_train_net\nfrom attention_model import attention_train_net\nimport data_reader\nimport argparse\nimport functools\nimport sys\nimport time\nimport os\nimport numpy as np\n\nparser = argparse.ArgumentParser(description=__doc__)\nadd_arg = functools.partial(add_arguments, argparser=parser)\n# yapf: disable\nadd_arg('batch_size', int, 32, \"Minibatch size.\")\nadd_arg('total_step', int, 720000, \"The number of iterations. Zero or less means whole training set. More than 0 means the training set might be looped until # of iterations is reached.\")\nadd_arg('log_period', int, 1000, \"Log period.\")\nadd_arg('save_model_period', int, 15000, \"Save model period. '-1' means never saving the model.\")\nadd_arg('eval_period', int, 15000, \"Evaluate period. '-1' means never evaluating the model.\")\nadd_arg('save_model_dir', str, \"./models\", \"The directory the model to be saved to.\")\nadd_arg('train_images', str, None, \"The directory of images to be used for training.\")\nadd_arg('train_list', str, None, \"The list file of images to be used for training.\")\nadd_arg('test_images', str, None, \"The directory of images to be used for test.\")\nadd_arg('test_list', str, None, \"The list file of images to be used for training.\")\nadd_arg('model', str, \"crnn_ctc\", \"Which type of network to be used. 'crnn_ctc' or 'attention'\")\nadd_arg('init_model', str, None, \"The init model file of directory.\")\nadd_arg('use_gpu', bool, True, \"Whether use GPU to train.\")\nadd_arg('min_average_window',int, 10000, \"Min average window.\")\nadd_arg('max_average_window',int, 12500, \"Max average window. It is proposed to be set as the number of minibatch in a pass.\")\nadd_arg('average_window', float, 0.15, \"Average window.\")\nadd_arg('parallel', bool, False, \"Whether use parallel training.\")\nadd_arg('profile', bool, False, \"Whether to use profiling.\")\nadd_arg('skip_batch_num', int, 0, \"The number of first minibatches to skip as warm-up for better performance test.\")\nadd_arg('skip_test', bool, False, \"Whether to skip test phase.\")\n# yapf: enable\n\n\ndef train(args):\n \"\"\"OCR training\"\"\"\n\n if args.model == \"crnn_ctc\":\n train_net = ctc_train_net\n get_feeder_data = get_ctc_feeder_data\n else:\n train_net = attention_train_net\n get_feeder_data = get_attention_feeder_data\n\n num_classes = None\n num_classes = data_reader.num_classes(\n ) if num_classes is None else num_classes\n data_shape = data_reader.data_shape()\n # define network\n sum_cost, error_evaluator, inference_program, model_average = train_net(\n args, data_shape, num_classes)\n\n # data reader\n train_reader = data_reader.train(\n args.batch_size,\n train_images_dir=args.train_images,\n train_list_file=args.train_list,\n cycle=args.total_step > 0,\n model=args.model)\n test_reader = data_reader.test(\n test_images_dir=args.test_images, test_list_file=args.test_list, model=args.model)\n\n # prepare environment\n place = fluid.CPUPlace()\n if args.use_gpu:\n place = fluid.CUDAPlace(0)\n exe = fluid.Executor(place)\n\n if 'ce_mode' in os.environ:\n fluid.default_startup_program().random_seed = 90\n\n exe.run(fluid.default_startup_program())\n\n # load init model\n if args.init_model is not None:\n model_dir = args.init_model\n model_file_name = None\n if not os.path.isdir(args.init_model):\n model_dir = os.path.dirname(args.init_model)\n model_file_name = os.path.basename(args.init_model)\n fluid.io.load_params(exe, dirname=model_dir, filename=model_file_name)\n print(\"Init model from: %s.\" % args.init_model)\n\n train_exe = exe\n error_evaluator.reset(exe)\n if args.parallel:\n train_exe = fluid.ParallelExecutor(\n use_cuda=True if args.use_gpu else False, loss_name=sum_cost.name)\n\n fetch_vars = [sum_cost] + error_evaluator.metrics\n\n def train_one_batch(data):\n var_names = [var.name for var in fetch_vars]\n if args.parallel:\n results = train_exe.run(var_names,\n feed=get_feeder_data(data, place))\n results = [np.array(result).sum() for result in results]\n else:\n results = train_exe.run(feed=get_feeder_data(data, place),\n fetch_list=fetch_vars)\n results = [result[0] for result in results]\n return results\n\n def test(iter_num):\n error_evaluator.reset(exe)\n for data in test_reader():\n exe.run(inference_program, feed=get_feeder_data(data, place))\n _, test_seq_error = error_evaluator.eval(exe)\n print(\"\\nTime: %s; Iter[%d]; Test seq error: %s.\\n\" % (\n time.time(), iter_num, str(test_seq_error[0])))\n\n #Note: The following logs are special for CE monitoring.\n #Other situations do not need to care about these logs.\n print(\"kpis\ttest_acc\t%f\" % (1 - test_seq_error[0]))\n\n def save_model(args, exe, iter_num):\n filename = \"model_%05d\" % iter_num\n fluid.io.save_params(\n exe, dirname=args.save_model_dir, filename=filename)\n print(\"Saved model to: %s/%s.\" % (args.save_model_dir, filename))\n\n iter_num = 0\n stop = False\n start_time = time.time()\n while not stop:\n total_loss = 0.0\n total_seq_error = 0.0\n batch_times = []\n # train a pass\n for data in train_reader():\n if args.total_step > 0 and iter_num == args.total_step + args.skip_batch_num:\n stop = True\n break\n if iter_num < args.skip_batch_num:\n print(\"Warm-up iteration\")\n if iter_num == args.skip_batch_num:\n profiler.reset_profiler()\n start = time.time()\n results = train_one_batch(data)\n batch_time = time.time() - start\n fps = args.batch_size / batch_time\n batch_times.append(batch_time)\n total_loss += results[0]\n total_seq_error += results[2]\n\n iter_num += 1\n # training log\n if iter_num % args.log_period == 0:\n print(\"\\nTime: %s; Iter[%d]; Avg loss: %.3f; Avg seq err: %.3f\" % (\n time.time(), iter_num,\n total_loss / (args.log_period * args.batch_size),\n total_seq_error / (args.log_period * args.batch_size)))\n print(\"kpis\ttrain_cost\t%f\" % (total_loss / (args.log_period *\n args.batch_size)))\n print(\"kpis\ttrain_acc\t%f\" % (\n 1 - total_seq_error / (args.log_period * args.batch_size)))\n total_loss = 0.0\n total_seq_error = 0.0\n\n # evaluate\n if not args.skip_test and iter_num % args.eval_period == 0:\n if model_average:\n with model_average.apply(exe):\n test(iter_num)\n else:\n test(iter_num)\n\n # save model\n if iter_num % args.save_model_period == 0:\n if model_average:\n with model_average.apply(exe):\n save_model(args, exe, iter_num)\n else:\n save_model(args, exe, iter_num)\n end_time = time.time()\n print(\"kpis\ttrain_duration\t%f\" % (end_time - start_time))\n # Postprocess benchmark data\n latencies = batch_times[args.skip_batch_num:]\n latency_avg = np.average(latencies)\n latency_pc99 = np.percentile(latencies, 99)\n fpses = np.divide(args.batch_size, latencies)\n fps_avg = np.average(fpses)\n fps_pc99 = np.percentile(fpses, 1)\n\n # Benchmark output\n print('\\nTotal examples (incl. warm-up): %d' %\n (iter_num * args.batch_size))\n print('average latency: %.5f s, 99pc latency: %.5f s' % (latency_avg,\n latency_pc99))\n print('average fps: %.5f, fps for 99pc latency: %.5f' % (fps_avg,\n fps_pc99))\n\n\ndef main():\n args = parser.parse_args()\n print_arguments(args)\n if args.profile:\n if args.use_gpu:\n with profiler.cuda_profiler(\"cuda_profiler.txt\", 'csv') as nvprof:\n train(args)\n else:\n with profiler.profiler(\"CPU\", sorted_key='total') as cpuprof:\n train(args)\n else:\n train(args)\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "fluid/PaddleCV/ocr_recognition/train.py"}]}
| 2,949 | 562 |
gh_patches_debug_36868
|
rasdani/github-patches
|
git_diff
|
pyqtgraph__pyqtgraph-1410
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add fontSize kwarg to DockLabel constructor
Allows the font size of Dock title bars to be adjusted.
I need this for a project I'm writing -- the default font is quite small for what are significant graphical elements in a GUI.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pyqtgraph/dockarea/Dock.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 from ..Qt import QtCore, QtGui
3
4 from .DockDrop import *
5 from ..widgets.VerticalLabel import VerticalLabel
6 from ..python2_3 import asUnicode
7
8 class Dock(QtGui.QWidget, DockDrop):
9
10 sigStretchChanged = QtCore.Signal()
11 sigClosed = QtCore.Signal(object)
12
13 def __init__(self, name, area=None, size=(10, 10), widget=None, hideTitle=False, autoOrientation=True, closable=False):
14 QtGui.QWidget.__init__(self)
15 DockDrop.__init__(self)
16 self._container = None
17 self._name = name
18 self.area = area
19 self.label = DockLabel(name, self, closable)
20 if closable:
21 self.label.sigCloseClicked.connect(self.close)
22 self.labelHidden = False
23 self.moveLabel = True ## If false, the dock is no longer allowed to move the label.
24 self.autoOrient = autoOrientation
25 self.orientation = 'horizontal'
26 #self.label.setAlignment(QtCore.Qt.AlignHCenter)
27 self.topLayout = QtGui.QGridLayout()
28 self.topLayout.setContentsMargins(0, 0, 0, 0)
29 self.topLayout.setSpacing(0)
30 self.setLayout(self.topLayout)
31 self.topLayout.addWidget(self.label, 0, 1)
32 self.widgetArea = QtGui.QWidget()
33 self.topLayout.addWidget(self.widgetArea, 1, 1)
34 self.layout = QtGui.QGridLayout()
35 self.layout.setContentsMargins(0, 0, 0, 0)
36 self.layout.setSpacing(0)
37 self.widgetArea.setLayout(self.layout)
38 self.widgetArea.setSizePolicy(QtGui.QSizePolicy.Expanding, QtGui.QSizePolicy.Expanding)
39 self.widgets = []
40 self._container = None
41 self.currentRow = 0
42 #self.titlePos = 'top'
43 self.raiseOverlay()
44 self.hStyle = """
45 Dock > QWidget {
46 border: 1px solid #000;
47 border-radius: 5px;
48 border-top-left-radius: 0px;
49 border-top-right-radius: 0px;
50 border-top-width: 0px;
51 }"""
52 self.vStyle = """
53 Dock > QWidget {
54 border: 1px solid #000;
55 border-radius: 5px;
56 border-top-left-radius: 0px;
57 border-bottom-left-radius: 0px;
58 border-left-width: 0px;
59 }"""
60 self.nStyle = """
61 Dock > QWidget {
62 border: 1px solid #000;
63 border-radius: 5px;
64 }"""
65 self.dragStyle = """
66 Dock > QWidget {
67 border: 4px solid #00F;
68 border-radius: 5px;
69 }"""
70 self.setAutoFillBackground(False)
71 self.widgetArea.setStyleSheet(self.hStyle)
72
73 self.setStretch(*size)
74
75 if widget is not None:
76 self.addWidget(widget)
77
78 if hideTitle:
79 self.hideTitleBar()
80
81 def implements(self, name=None):
82 if name is None:
83 return ['dock']
84 else:
85 return name == 'dock'
86
87 def setStretch(self, x=None, y=None):
88 """
89 Set the 'target' size for this Dock.
90 The actual size will be determined by comparing this Dock's
91 stretch value to the rest of the docks it shares space with.
92 """
93 if x is None:
94 x = 0
95 if y is None:
96 y = 0
97 self._stretch = (x, y)
98 self.sigStretchChanged.emit()
99
100 def stretch(self):
101 return self._stretch
102
103 def hideTitleBar(self):
104 """
105 Hide the title bar for this Dock.
106 This will prevent the Dock being moved by the user.
107 """
108 self.label.hide()
109 self.labelHidden = True
110 if 'center' in self.allowedAreas:
111 self.allowedAreas.remove('center')
112 self.updateStyle()
113
114 def showTitleBar(self):
115 """
116 Show the title bar for this Dock.
117 """
118 self.label.show()
119 self.labelHidden = False
120 self.allowedAreas.add('center')
121 self.updateStyle()
122
123 def title(self):
124 """
125 Gets the text displayed in the title bar for this dock.
126 """
127 return asUnicode(self.label.text())
128
129 def setTitle(self, text):
130 """
131 Sets the text displayed in title bar for this Dock.
132 """
133 self.label.setText(text)
134
135 def setOrientation(self, o='auto', force=False):
136 """
137 Sets the orientation of the title bar for this Dock.
138 Must be one of 'auto', 'horizontal', or 'vertical'.
139 By default ('auto'), the orientation is determined
140 based on the aspect ratio of the Dock.
141 """
142 # setOrientation may be called before the container is set in some cases
143 # (via resizeEvent), so there's no need to do anything here until called
144 # again by containerChanged
145 if self.container() is None:
146 return
147
148 if o == 'auto' and self.autoOrient:
149 if self.container().type() == 'tab':
150 o = 'horizontal'
151 elif self.width() > self.height()*1.5:
152 o = 'vertical'
153 else:
154 o = 'horizontal'
155 if force or self.orientation != o:
156 self.orientation = o
157 self.label.setOrientation(o)
158 self.updateStyle()
159
160 def updateStyle(self):
161 ## updates orientation and appearance of title bar
162 if self.labelHidden:
163 self.widgetArea.setStyleSheet(self.nStyle)
164 elif self.orientation == 'vertical':
165 self.label.setOrientation('vertical')
166 if self.moveLabel:
167 self.topLayout.addWidget(self.label, 1, 0)
168 self.widgetArea.setStyleSheet(self.vStyle)
169 else:
170 self.label.setOrientation('horizontal')
171 if self.moveLabel:
172 self.topLayout.addWidget(self.label, 0, 1)
173 self.widgetArea.setStyleSheet(self.hStyle)
174
175 def resizeEvent(self, ev):
176 self.setOrientation()
177 self.resizeOverlay(self.size())
178
179 def name(self):
180 return self._name
181
182 def addWidget(self, widget, row=None, col=0, rowspan=1, colspan=1):
183 """
184 Add a new widget to the interior of this Dock.
185 Each Dock uses a QGridLayout to arrange widgets within.
186 """
187 if row is None:
188 row = self.currentRow
189 self.currentRow = max(row+1, self.currentRow)
190 self.widgets.append(widget)
191 self.layout.addWidget(widget, row, col, rowspan, colspan)
192 self.raiseOverlay()
193
194 def startDrag(self):
195 self.drag = QtGui.QDrag(self)
196 mime = QtCore.QMimeData()
197 self.drag.setMimeData(mime)
198 self.widgetArea.setStyleSheet(self.dragStyle)
199 self.update()
200 action = self.drag.exec_()
201 self.updateStyle()
202
203 def float(self):
204 self.area.floatDock(self)
205
206 def container(self):
207 return self._container
208
209 def containerChanged(self, c):
210 if self._container is not None:
211 # ask old container to close itself if it is no longer needed
212 self._container.apoptose()
213 self._container = c
214 if c is None:
215 self.area = None
216 else:
217 self.area = c.area
218 if c.type() != 'tab':
219 self.moveLabel = True
220 self.label.setDim(False)
221 else:
222 self.moveLabel = False
223
224 self.setOrientation(force=True)
225
226 def raiseDock(self):
227 """If this Dock is stacked underneath others, raise it to the top."""
228 self.container().raiseDock(self)
229
230 def close(self):
231 """Remove this dock from the DockArea it lives inside."""
232 self.setParent(None)
233 QtGui.QLabel.close(self.label)
234 self.label.setParent(None)
235 self._container.apoptose()
236 self._container = None
237 self.sigClosed.emit(self)
238
239 def __repr__(self):
240 return "<Dock %s %s>" % (self.name(), self.stretch())
241
242 ## PySide bug: We need to explicitly redefine these methods
243 ## or else drag/drop events will not be delivered.
244 def dragEnterEvent(self, *args):
245 DockDrop.dragEnterEvent(self, *args)
246
247 def dragMoveEvent(self, *args):
248 DockDrop.dragMoveEvent(self, *args)
249
250 def dragLeaveEvent(self, *args):
251 DockDrop.dragLeaveEvent(self, *args)
252
253 def dropEvent(self, *args):
254 DockDrop.dropEvent(self, *args)
255
256
257 class DockLabel(VerticalLabel):
258
259 sigClicked = QtCore.Signal(object, object)
260 sigCloseClicked = QtCore.Signal()
261
262 def __init__(self, text, dock, showCloseButton):
263 self.dim = False
264 self.fixedWidth = False
265 VerticalLabel.__init__(self, text, orientation='horizontal', forceWidth=False)
266 self.setAlignment(QtCore.Qt.AlignTop|QtCore.Qt.AlignHCenter)
267 self.dock = dock
268 self.updateStyle()
269 self.setAutoFillBackground(False)
270 self.mouseMoved = False
271
272 self.closeButton = None
273 if showCloseButton:
274 self.closeButton = QtGui.QToolButton(self)
275 self.closeButton.clicked.connect(self.sigCloseClicked)
276 self.closeButton.setIcon(QtGui.QApplication.style().standardIcon(QtGui.QStyle.SP_TitleBarCloseButton))
277
278 def updateStyle(self):
279 r = '3px'
280 if self.dim:
281 fg = '#aaa'
282 bg = '#44a'
283 border = '#339'
284 else:
285 fg = '#fff'
286 bg = '#66c'
287 border = '#55B'
288
289 if self.orientation == 'vertical':
290 self.vStyle = """DockLabel {
291 background-color : %s;
292 color : %s;
293 border-top-right-radius: 0px;
294 border-top-left-radius: %s;
295 border-bottom-right-radius: 0px;
296 border-bottom-left-radius: %s;
297 border-width: 0px;
298 border-right: 2px solid %s;
299 padding-top: 3px;
300 padding-bottom: 3px;
301 }""" % (bg, fg, r, r, border)
302 self.setStyleSheet(self.vStyle)
303 else:
304 self.hStyle = """DockLabel {
305 background-color : %s;
306 color : %s;
307 border-top-right-radius: %s;
308 border-top-left-radius: %s;
309 border-bottom-right-radius: 0px;
310 border-bottom-left-radius: 0px;
311 border-width: 0px;
312 border-bottom: 2px solid %s;
313 padding-left: 3px;
314 padding-right: 3px;
315 }""" % (bg, fg, r, r, border)
316 self.setStyleSheet(self.hStyle)
317
318 def setDim(self, d):
319 if self.dim != d:
320 self.dim = d
321 self.updateStyle()
322
323 def setOrientation(self, o):
324 VerticalLabel.setOrientation(self, o)
325 self.updateStyle()
326
327 def mousePressEvent(self, ev):
328 self.pressPos = ev.pos()
329 self.mouseMoved = False
330 ev.accept()
331
332 def mouseMoveEvent(self, ev):
333 if not self.mouseMoved:
334 self.mouseMoved = (ev.pos() - self.pressPos).manhattanLength() > QtGui.QApplication.startDragDistance()
335
336 if self.mouseMoved and ev.buttons() == QtCore.Qt.LeftButton:
337 self.dock.startDrag()
338 ev.accept()
339
340 def mouseReleaseEvent(self, ev):
341 ev.accept()
342 if not self.mouseMoved:
343 self.sigClicked.emit(self, ev)
344
345 def mouseDoubleClickEvent(self, ev):
346 if ev.button() == QtCore.Qt.LeftButton:
347 self.dock.float()
348
349 def resizeEvent (self, ev):
350 if self.closeButton:
351 if self.orientation == 'vertical':
352 size = ev.size().width()
353 pos = QtCore.QPoint(0, 0)
354 else:
355 size = ev.size().height()
356 pos = QtCore.QPoint(ev.size().width() - size, 0)
357 self.closeButton.setFixedSize(QtCore.QSize(size, size))
358 self.closeButton.move(pos)
359 super(DockLabel,self).resizeEvent(ev)
360
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pyqtgraph/dockarea/Dock.py b/pyqtgraph/dockarea/Dock.py
--- a/pyqtgraph/dockarea/Dock.py
+++ b/pyqtgraph/dockarea/Dock.py
@@ -10,13 +10,13 @@
sigStretchChanged = QtCore.Signal()
sigClosed = QtCore.Signal(object)
- def __init__(self, name, area=None, size=(10, 10), widget=None, hideTitle=False, autoOrientation=True, closable=False):
+ def __init__(self, name, area=None, size=(10, 10), widget=None, hideTitle=False, autoOrientation=True, closable=False, fontSize="12px"):
QtGui.QWidget.__init__(self)
DockDrop.__init__(self)
self._container = None
self._name = name
self.area = area
- self.label = DockLabel(name, self, closable)
+ self.label = DockLabel(name, self, closable, fontSize)
if closable:
self.label.sigCloseClicked.connect(self.close)
self.labelHidden = False
@@ -259,9 +259,10 @@
sigClicked = QtCore.Signal(object, object)
sigCloseClicked = QtCore.Signal()
- def __init__(self, text, dock, showCloseButton):
+ def __init__(self, text, dock, showCloseButton, fontSize):
self.dim = False
self.fixedWidth = False
+ self.fontSize = fontSize
VerticalLabel.__init__(self, text, orientation='horizontal', forceWidth=False)
self.setAlignment(QtCore.Qt.AlignTop|QtCore.Qt.AlignHCenter)
self.dock = dock
@@ -298,7 +299,8 @@
border-right: 2px solid %s;
padding-top: 3px;
padding-bottom: 3px;
- }""" % (bg, fg, r, r, border)
+ font-size: %s;
+ }""" % (bg, fg, r, r, border, self.fontSize)
self.setStyleSheet(self.vStyle)
else:
self.hStyle = """DockLabel {
@@ -312,7 +314,8 @@
border-bottom: 2px solid %s;
padding-left: 3px;
padding-right: 3px;
- }""" % (bg, fg, r, r, border)
+ font-size: %s;
+ }""" % (bg, fg, r, r, border, self.fontSize)
self.setStyleSheet(self.hStyle)
def setDim(self, d):
|
{"golden_diff": "diff --git a/pyqtgraph/dockarea/Dock.py b/pyqtgraph/dockarea/Dock.py\n--- a/pyqtgraph/dockarea/Dock.py\n+++ b/pyqtgraph/dockarea/Dock.py\n@@ -10,13 +10,13 @@\n sigStretchChanged = QtCore.Signal()\n sigClosed = QtCore.Signal(object)\n \n- def __init__(self, name, area=None, size=(10, 10), widget=None, hideTitle=False, autoOrientation=True, closable=False):\n+ def __init__(self, name, area=None, size=(10, 10), widget=None, hideTitle=False, autoOrientation=True, closable=False, fontSize=\"12px\"):\n QtGui.QWidget.__init__(self)\n DockDrop.__init__(self)\n self._container = None\n self._name = name\n self.area = area\n- self.label = DockLabel(name, self, closable)\n+ self.label = DockLabel(name, self, closable, fontSize)\n if closable:\n self.label.sigCloseClicked.connect(self.close)\n self.labelHidden = False\n@@ -259,9 +259,10 @@\n sigClicked = QtCore.Signal(object, object)\n sigCloseClicked = QtCore.Signal()\n \n- def __init__(self, text, dock, showCloseButton):\n+ def __init__(self, text, dock, showCloseButton, fontSize):\n self.dim = False\n self.fixedWidth = False\n+ self.fontSize = fontSize\n VerticalLabel.__init__(self, text, orientation='horizontal', forceWidth=False)\n self.setAlignment(QtCore.Qt.AlignTop|QtCore.Qt.AlignHCenter)\n self.dock = dock\n@@ -298,7 +299,8 @@\n border-right: 2px solid %s;\n padding-top: 3px;\n padding-bottom: 3px;\n- }\"\"\" % (bg, fg, r, r, border)\n+ font-size: %s;\n+ }\"\"\" % (bg, fg, r, r, border, self.fontSize)\n self.setStyleSheet(self.vStyle)\n else:\n self.hStyle = \"\"\"DockLabel {\n@@ -312,7 +314,8 @@\n border-bottom: 2px solid %s;\n padding-left: 3px;\n padding-right: 3px;\n- }\"\"\" % (bg, fg, r, r, border)\n+ font-size: %s;\n+ }\"\"\" % (bg, fg, r, r, border, self.fontSize)\n self.setStyleSheet(self.hStyle)\n \n def setDim(self, d):\n", "issue": "Add fontSize kwarg to DockLabel constructor\nAllows the font size of Dock title bars to be adjusted.\n\nI need this for a project I'm writing -- the default font is quite small for what are significant graphical elements in a GUI.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom ..Qt import QtCore, QtGui\n\nfrom .DockDrop import *\nfrom ..widgets.VerticalLabel import VerticalLabel\nfrom ..python2_3 import asUnicode\n\nclass Dock(QtGui.QWidget, DockDrop):\n\n sigStretchChanged = QtCore.Signal()\n sigClosed = QtCore.Signal(object)\n\n def __init__(self, name, area=None, size=(10, 10), widget=None, hideTitle=False, autoOrientation=True, closable=False):\n QtGui.QWidget.__init__(self)\n DockDrop.__init__(self)\n self._container = None\n self._name = name\n self.area = area\n self.label = DockLabel(name, self, closable)\n if closable:\n self.label.sigCloseClicked.connect(self.close)\n self.labelHidden = False\n self.moveLabel = True ## If false, the dock is no longer allowed to move the label.\n self.autoOrient = autoOrientation\n self.orientation = 'horizontal'\n #self.label.setAlignment(QtCore.Qt.AlignHCenter)\n self.topLayout = QtGui.QGridLayout()\n self.topLayout.setContentsMargins(0, 0, 0, 0)\n self.topLayout.setSpacing(0)\n self.setLayout(self.topLayout)\n self.topLayout.addWidget(self.label, 0, 1)\n self.widgetArea = QtGui.QWidget()\n self.topLayout.addWidget(self.widgetArea, 1, 1)\n self.layout = QtGui.QGridLayout()\n self.layout.setContentsMargins(0, 0, 0, 0)\n self.layout.setSpacing(0)\n self.widgetArea.setLayout(self.layout)\n self.widgetArea.setSizePolicy(QtGui.QSizePolicy.Expanding, QtGui.QSizePolicy.Expanding)\n self.widgets = []\n self._container = None\n self.currentRow = 0\n #self.titlePos = 'top'\n self.raiseOverlay()\n self.hStyle = \"\"\"\n Dock > QWidget {\n border: 1px solid #000;\n border-radius: 5px;\n border-top-left-radius: 0px;\n border-top-right-radius: 0px;\n border-top-width: 0px;\n }\"\"\"\n self.vStyle = \"\"\"\n Dock > QWidget {\n border: 1px solid #000;\n border-radius: 5px;\n border-top-left-radius: 0px;\n border-bottom-left-radius: 0px;\n border-left-width: 0px;\n }\"\"\"\n self.nStyle = \"\"\"\n Dock > QWidget {\n border: 1px solid #000;\n border-radius: 5px;\n }\"\"\"\n self.dragStyle = \"\"\"\n Dock > QWidget {\n border: 4px solid #00F;\n border-radius: 5px;\n }\"\"\"\n self.setAutoFillBackground(False)\n self.widgetArea.setStyleSheet(self.hStyle)\n\n self.setStretch(*size)\n\n if widget is not None:\n self.addWidget(widget)\n\n if hideTitle:\n self.hideTitleBar()\n\n def implements(self, name=None):\n if name is None:\n return ['dock']\n else:\n return name == 'dock'\n\n def setStretch(self, x=None, y=None):\n \"\"\"\n Set the 'target' size for this Dock.\n The actual size will be determined by comparing this Dock's\n stretch value to the rest of the docks it shares space with.\n \"\"\"\n if x is None:\n x = 0\n if y is None:\n y = 0\n self._stretch = (x, y)\n self.sigStretchChanged.emit()\n \n def stretch(self):\n return self._stretch\n\n def hideTitleBar(self):\n \"\"\"\n Hide the title bar for this Dock.\n This will prevent the Dock being moved by the user.\n \"\"\"\n self.label.hide()\n self.labelHidden = True\n if 'center' in self.allowedAreas:\n self.allowedAreas.remove('center')\n self.updateStyle()\n\n def showTitleBar(self):\n \"\"\"\n Show the title bar for this Dock.\n \"\"\"\n self.label.show()\n self.labelHidden = False\n self.allowedAreas.add('center')\n self.updateStyle()\n\n def title(self):\n \"\"\"\n Gets the text displayed in the title bar for this dock.\n \"\"\"\n return asUnicode(self.label.text())\n\n def setTitle(self, text):\n \"\"\"\n Sets the text displayed in title bar for this Dock.\n \"\"\"\n self.label.setText(text)\n\n def setOrientation(self, o='auto', force=False):\n \"\"\"\n Sets the orientation of the title bar for this Dock.\n Must be one of 'auto', 'horizontal', or 'vertical'.\n By default ('auto'), the orientation is determined\n based on the aspect ratio of the Dock.\n \"\"\"\n # setOrientation may be called before the container is set in some cases\n # (via resizeEvent), so there's no need to do anything here until called\n # again by containerChanged\n if self.container() is None:\n return\n\n if o == 'auto' and self.autoOrient:\n if self.container().type() == 'tab':\n o = 'horizontal'\n elif self.width() > self.height()*1.5:\n o = 'vertical'\n else:\n o = 'horizontal'\n if force or self.orientation != o:\n self.orientation = o\n self.label.setOrientation(o)\n self.updateStyle()\n\n def updateStyle(self):\n ## updates orientation and appearance of title bar\n if self.labelHidden:\n self.widgetArea.setStyleSheet(self.nStyle)\n elif self.orientation == 'vertical':\n self.label.setOrientation('vertical')\n if self.moveLabel:\n self.topLayout.addWidget(self.label, 1, 0)\n self.widgetArea.setStyleSheet(self.vStyle)\n else:\n self.label.setOrientation('horizontal')\n if self.moveLabel:\n self.topLayout.addWidget(self.label, 0, 1)\n self.widgetArea.setStyleSheet(self.hStyle)\n\n def resizeEvent(self, ev):\n self.setOrientation()\n self.resizeOverlay(self.size())\n\n def name(self):\n return self._name\n\n def addWidget(self, widget, row=None, col=0, rowspan=1, colspan=1):\n \"\"\"\n Add a new widget to the interior of this Dock.\n Each Dock uses a QGridLayout to arrange widgets within.\n \"\"\"\n if row is None:\n row = self.currentRow\n self.currentRow = max(row+1, self.currentRow)\n self.widgets.append(widget)\n self.layout.addWidget(widget, row, col, rowspan, colspan)\n self.raiseOverlay()\n \n def startDrag(self):\n self.drag = QtGui.QDrag(self)\n mime = QtCore.QMimeData()\n self.drag.setMimeData(mime)\n self.widgetArea.setStyleSheet(self.dragStyle)\n self.update()\n action = self.drag.exec_()\n self.updateStyle()\n\n def float(self):\n self.area.floatDock(self)\n \n def container(self):\n return self._container\n\n def containerChanged(self, c):\n if self._container is not None:\n # ask old container to close itself if it is no longer needed\n self._container.apoptose()\n self._container = c\n if c is None:\n self.area = None\n else:\n self.area = c.area\n if c.type() != 'tab':\n self.moveLabel = True\n self.label.setDim(False)\n else:\n self.moveLabel = False\n \n self.setOrientation(force=True)\n\n def raiseDock(self):\n \"\"\"If this Dock is stacked underneath others, raise it to the top.\"\"\"\n self.container().raiseDock(self)\n\n def close(self):\n \"\"\"Remove this dock from the DockArea it lives inside.\"\"\"\n self.setParent(None)\n QtGui.QLabel.close(self.label)\n self.label.setParent(None)\n self._container.apoptose()\n self._container = None\n self.sigClosed.emit(self)\n\n def __repr__(self):\n return \"<Dock %s %s>\" % (self.name(), self.stretch())\n\n ## PySide bug: We need to explicitly redefine these methods\n ## or else drag/drop events will not be delivered.\n def dragEnterEvent(self, *args):\n DockDrop.dragEnterEvent(self, *args)\n\n def dragMoveEvent(self, *args):\n DockDrop.dragMoveEvent(self, *args)\n\n def dragLeaveEvent(self, *args):\n DockDrop.dragLeaveEvent(self, *args)\n\n def dropEvent(self, *args):\n DockDrop.dropEvent(self, *args)\n\n\nclass DockLabel(VerticalLabel):\n\n sigClicked = QtCore.Signal(object, object)\n sigCloseClicked = QtCore.Signal()\n\n def __init__(self, text, dock, showCloseButton):\n self.dim = False\n self.fixedWidth = False\n VerticalLabel.__init__(self, text, orientation='horizontal', forceWidth=False)\n self.setAlignment(QtCore.Qt.AlignTop|QtCore.Qt.AlignHCenter)\n self.dock = dock\n self.updateStyle()\n self.setAutoFillBackground(False)\n self.mouseMoved = False\n\n self.closeButton = None\n if showCloseButton:\n self.closeButton = QtGui.QToolButton(self)\n self.closeButton.clicked.connect(self.sigCloseClicked)\n self.closeButton.setIcon(QtGui.QApplication.style().standardIcon(QtGui.QStyle.SP_TitleBarCloseButton))\n\n def updateStyle(self):\n r = '3px'\n if self.dim:\n fg = '#aaa'\n bg = '#44a'\n border = '#339'\n else:\n fg = '#fff'\n bg = '#66c'\n border = '#55B'\n\n if self.orientation == 'vertical':\n self.vStyle = \"\"\"DockLabel {\n background-color : %s;\n color : %s;\n border-top-right-radius: 0px;\n border-top-left-radius: %s;\n border-bottom-right-radius: 0px;\n border-bottom-left-radius: %s;\n border-width: 0px;\n border-right: 2px solid %s;\n padding-top: 3px;\n padding-bottom: 3px;\n }\"\"\" % (bg, fg, r, r, border)\n self.setStyleSheet(self.vStyle)\n else:\n self.hStyle = \"\"\"DockLabel {\n background-color : %s;\n color : %s;\n border-top-right-radius: %s;\n border-top-left-radius: %s;\n border-bottom-right-radius: 0px;\n border-bottom-left-radius: 0px;\n border-width: 0px;\n border-bottom: 2px solid %s;\n padding-left: 3px;\n padding-right: 3px;\n }\"\"\" % (bg, fg, r, r, border)\n self.setStyleSheet(self.hStyle)\n\n def setDim(self, d):\n if self.dim != d:\n self.dim = d\n self.updateStyle()\n\n def setOrientation(self, o):\n VerticalLabel.setOrientation(self, o)\n self.updateStyle()\n\n def mousePressEvent(self, ev):\n self.pressPos = ev.pos()\n self.mouseMoved = False\n ev.accept()\n\n def mouseMoveEvent(self, ev):\n if not self.mouseMoved:\n self.mouseMoved = (ev.pos() - self.pressPos).manhattanLength() > QtGui.QApplication.startDragDistance()\n\n if self.mouseMoved and ev.buttons() == QtCore.Qt.LeftButton:\n self.dock.startDrag()\n ev.accept()\n\n def mouseReleaseEvent(self, ev):\n ev.accept()\n if not self.mouseMoved:\n self.sigClicked.emit(self, ev)\n\n def mouseDoubleClickEvent(self, ev):\n if ev.button() == QtCore.Qt.LeftButton:\n self.dock.float()\n\n def resizeEvent (self, ev):\n if self.closeButton:\n if self.orientation == 'vertical':\n size = ev.size().width()\n pos = QtCore.QPoint(0, 0)\n else:\n size = ev.size().height()\n pos = QtCore.QPoint(ev.size().width() - size, 0)\n self.closeButton.setFixedSize(QtCore.QSize(size, size))\n self.closeButton.move(pos)\n super(DockLabel,self).resizeEvent(ev)\n", "path": "pyqtgraph/dockarea/Dock.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\nfrom ..Qt import QtCore, QtGui\n\nfrom .DockDrop import *\nfrom ..widgets.VerticalLabel import VerticalLabel\nfrom ..python2_3 import asUnicode\n\nclass Dock(QtGui.QWidget, DockDrop):\n\n sigStretchChanged = QtCore.Signal()\n sigClosed = QtCore.Signal(object)\n\n def __init__(self, name, area=None, size=(10, 10), widget=None, hideTitle=False, autoOrientation=True, closable=False, fontSize=\"12px\"):\n QtGui.QWidget.__init__(self)\n DockDrop.__init__(self)\n self._container = None\n self._name = name\n self.area = area\n self.label = DockLabel(name, self, closable, fontSize)\n if closable:\n self.label.sigCloseClicked.connect(self.close)\n self.labelHidden = False\n self.moveLabel = True ## If false, the dock is no longer allowed to move the label.\n self.autoOrient = autoOrientation\n self.orientation = 'horizontal'\n #self.label.setAlignment(QtCore.Qt.AlignHCenter)\n self.topLayout = QtGui.QGridLayout()\n self.topLayout.setContentsMargins(0, 0, 0, 0)\n self.topLayout.setSpacing(0)\n self.setLayout(self.topLayout)\n self.topLayout.addWidget(self.label, 0, 1)\n self.widgetArea = QtGui.QWidget()\n self.topLayout.addWidget(self.widgetArea, 1, 1)\n self.layout = QtGui.QGridLayout()\n self.layout.setContentsMargins(0, 0, 0, 0)\n self.layout.setSpacing(0)\n self.widgetArea.setLayout(self.layout)\n self.widgetArea.setSizePolicy(QtGui.QSizePolicy.Expanding, QtGui.QSizePolicy.Expanding)\n self.widgets = []\n self._container = None\n self.currentRow = 0\n #self.titlePos = 'top'\n self.raiseOverlay()\n self.hStyle = \"\"\"\n Dock > QWidget {\n border: 1px solid #000;\n border-radius: 5px;\n border-top-left-radius: 0px;\n border-top-right-radius: 0px;\n border-top-width: 0px;\n }\"\"\"\n self.vStyle = \"\"\"\n Dock > QWidget {\n border: 1px solid #000;\n border-radius: 5px;\n border-top-left-radius: 0px;\n border-bottom-left-radius: 0px;\n border-left-width: 0px;\n }\"\"\"\n self.nStyle = \"\"\"\n Dock > QWidget {\n border: 1px solid #000;\n border-radius: 5px;\n }\"\"\"\n self.dragStyle = \"\"\"\n Dock > QWidget {\n border: 4px solid #00F;\n border-radius: 5px;\n }\"\"\"\n self.setAutoFillBackground(False)\n self.widgetArea.setStyleSheet(self.hStyle)\n\n self.setStretch(*size)\n\n if widget is not None:\n self.addWidget(widget)\n\n if hideTitle:\n self.hideTitleBar()\n\n def implements(self, name=None):\n if name is None:\n return ['dock']\n else:\n return name == 'dock'\n\n def setStretch(self, x=None, y=None):\n \"\"\"\n Set the 'target' size for this Dock.\n The actual size will be determined by comparing this Dock's\n stretch value to the rest of the docks it shares space with.\n \"\"\"\n if x is None:\n x = 0\n if y is None:\n y = 0\n self._stretch = (x, y)\n self.sigStretchChanged.emit()\n \n def stretch(self):\n return self._stretch\n\n def hideTitleBar(self):\n \"\"\"\n Hide the title bar for this Dock.\n This will prevent the Dock being moved by the user.\n \"\"\"\n self.label.hide()\n self.labelHidden = True\n if 'center' in self.allowedAreas:\n self.allowedAreas.remove('center')\n self.updateStyle()\n\n def showTitleBar(self):\n \"\"\"\n Show the title bar for this Dock.\n \"\"\"\n self.label.show()\n self.labelHidden = False\n self.allowedAreas.add('center')\n self.updateStyle()\n\n def title(self):\n \"\"\"\n Gets the text displayed in the title bar for this dock.\n \"\"\"\n return asUnicode(self.label.text())\n\n def setTitle(self, text):\n \"\"\"\n Sets the text displayed in title bar for this Dock.\n \"\"\"\n self.label.setText(text)\n\n def setOrientation(self, o='auto', force=False):\n \"\"\"\n Sets the orientation of the title bar for this Dock.\n Must be one of 'auto', 'horizontal', or 'vertical'.\n By default ('auto'), the orientation is determined\n based on the aspect ratio of the Dock.\n \"\"\"\n # setOrientation may be called before the container is set in some cases\n # (via resizeEvent), so there's no need to do anything here until called\n # again by containerChanged\n if self.container() is None:\n return\n\n if o == 'auto' and self.autoOrient:\n if self.container().type() == 'tab':\n o = 'horizontal'\n elif self.width() > self.height()*1.5:\n o = 'vertical'\n else:\n o = 'horizontal'\n if force or self.orientation != o:\n self.orientation = o\n self.label.setOrientation(o)\n self.updateStyle()\n\n def updateStyle(self):\n ## updates orientation and appearance of title bar\n if self.labelHidden:\n self.widgetArea.setStyleSheet(self.nStyle)\n elif self.orientation == 'vertical':\n self.label.setOrientation('vertical')\n if self.moveLabel:\n self.topLayout.addWidget(self.label, 1, 0)\n self.widgetArea.setStyleSheet(self.vStyle)\n else:\n self.label.setOrientation('horizontal')\n if self.moveLabel:\n self.topLayout.addWidget(self.label, 0, 1)\n self.widgetArea.setStyleSheet(self.hStyle)\n\n def resizeEvent(self, ev):\n self.setOrientation()\n self.resizeOverlay(self.size())\n\n def name(self):\n return self._name\n\n def addWidget(self, widget, row=None, col=0, rowspan=1, colspan=1):\n \"\"\"\n Add a new widget to the interior of this Dock.\n Each Dock uses a QGridLayout to arrange widgets within.\n \"\"\"\n if row is None:\n row = self.currentRow\n self.currentRow = max(row+1, self.currentRow)\n self.widgets.append(widget)\n self.layout.addWidget(widget, row, col, rowspan, colspan)\n self.raiseOverlay()\n \n def startDrag(self):\n self.drag = QtGui.QDrag(self)\n mime = QtCore.QMimeData()\n self.drag.setMimeData(mime)\n self.widgetArea.setStyleSheet(self.dragStyle)\n self.update()\n action = self.drag.exec_()\n self.updateStyle()\n\n def float(self):\n self.area.floatDock(self)\n \n def container(self):\n return self._container\n\n def containerChanged(self, c):\n if self._container is not None:\n # ask old container to close itself if it is no longer needed\n self._container.apoptose()\n self._container = c\n if c is None:\n self.area = None\n else:\n self.area = c.area\n if c.type() != 'tab':\n self.moveLabel = True\n self.label.setDim(False)\n else:\n self.moveLabel = False\n \n self.setOrientation(force=True)\n\n def raiseDock(self):\n \"\"\"If this Dock is stacked underneath others, raise it to the top.\"\"\"\n self.container().raiseDock(self)\n\n def close(self):\n \"\"\"Remove this dock from the DockArea it lives inside.\"\"\"\n self.setParent(None)\n QtGui.QLabel.close(self.label)\n self.label.setParent(None)\n self._container.apoptose()\n self._container = None\n self.sigClosed.emit(self)\n\n def __repr__(self):\n return \"<Dock %s %s>\" % (self.name(), self.stretch())\n\n ## PySide bug: We need to explicitly redefine these methods\n ## or else drag/drop events will not be delivered.\n def dragEnterEvent(self, *args):\n DockDrop.dragEnterEvent(self, *args)\n\n def dragMoveEvent(self, *args):\n DockDrop.dragMoveEvent(self, *args)\n\n def dragLeaveEvent(self, *args):\n DockDrop.dragLeaveEvent(self, *args)\n\n def dropEvent(self, *args):\n DockDrop.dropEvent(self, *args)\n\n\nclass DockLabel(VerticalLabel):\n\n sigClicked = QtCore.Signal(object, object)\n sigCloseClicked = QtCore.Signal()\n\n def __init__(self, text, dock, showCloseButton, fontSize):\n self.dim = False\n self.fixedWidth = False\n self.fontSize = fontSize\n VerticalLabel.__init__(self, text, orientation='horizontal', forceWidth=False)\n self.setAlignment(QtCore.Qt.AlignTop|QtCore.Qt.AlignHCenter)\n self.dock = dock\n self.updateStyle()\n self.setAutoFillBackground(False)\n self.mouseMoved = False\n\n self.closeButton = None\n if showCloseButton:\n self.closeButton = QtGui.QToolButton(self)\n self.closeButton.clicked.connect(self.sigCloseClicked)\n self.closeButton.setIcon(QtGui.QApplication.style().standardIcon(QtGui.QStyle.SP_TitleBarCloseButton))\n\n def updateStyle(self):\n r = '3px'\n if self.dim:\n fg = '#aaa'\n bg = '#44a'\n border = '#339'\n else:\n fg = '#fff'\n bg = '#66c'\n border = '#55B'\n\n if self.orientation == 'vertical':\n self.vStyle = \"\"\"DockLabel {\n background-color : %s;\n color : %s;\n border-top-right-radius: 0px;\n border-top-left-radius: %s;\n border-bottom-right-radius: 0px;\n border-bottom-left-radius: %s;\n border-width: 0px;\n border-right: 2px solid %s;\n padding-top: 3px;\n padding-bottom: 3px;\n font-size: %s;\n }\"\"\" % (bg, fg, r, r, border, self.fontSize)\n self.setStyleSheet(self.vStyle)\n else:\n self.hStyle = \"\"\"DockLabel {\n background-color : %s;\n color : %s;\n border-top-right-radius: %s;\n border-top-left-radius: %s;\n border-bottom-right-radius: 0px;\n border-bottom-left-radius: 0px;\n border-width: 0px;\n border-bottom: 2px solid %s;\n padding-left: 3px;\n padding-right: 3px;\n font-size: %s;\n }\"\"\" % (bg, fg, r, r, border, self.fontSize)\n self.setStyleSheet(self.hStyle)\n\n def setDim(self, d):\n if self.dim != d:\n self.dim = d\n self.updateStyle()\n\n def setOrientation(self, o):\n VerticalLabel.setOrientation(self, o)\n self.updateStyle()\n\n def mousePressEvent(self, ev):\n self.pressPos = ev.pos()\n self.mouseMoved = False\n ev.accept()\n\n def mouseMoveEvent(self, ev):\n if not self.mouseMoved:\n self.mouseMoved = (ev.pos() - self.pressPos).manhattanLength() > QtGui.QApplication.startDragDistance()\n\n if self.mouseMoved and ev.buttons() == QtCore.Qt.LeftButton:\n self.dock.startDrag()\n ev.accept()\n\n def mouseReleaseEvent(self, ev):\n ev.accept()\n if not self.mouseMoved:\n self.sigClicked.emit(self, ev)\n\n def mouseDoubleClickEvent(self, ev):\n if ev.button() == QtCore.Qt.LeftButton:\n self.dock.float()\n\n def resizeEvent (self, ev):\n if self.closeButton:\n if self.orientation == 'vertical':\n size = ev.size().width()\n pos = QtCore.QPoint(0, 0)\n else:\n size = ev.size().height()\n pos = QtCore.QPoint(ev.size().width() - size, 0)\n self.closeButton.setFixedSize(QtCore.QSize(size, size))\n self.closeButton.move(pos)\n super(DockLabel,self).resizeEvent(ev)\n", "path": "pyqtgraph/dockarea/Dock.py"}]}
| 3,917 | 578 |
gh_patches_debug_12467
|
rasdani/github-patches
|
git_diff
|
deis__deis-571
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Make EC2 AMIs for 0.5.1 release
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `provider/ec2.py`
Content:
```
1 """
2 Deis cloud provider implementation for Amazon EC2.
3 """
4
5 from __future__ import unicode_literals
6
7 import json
8 import time
9
10 from boto import ec2
11 from boto.exception import EC2ResponseError
12
13 # from api.ssh import connect_ssh, exec_ssh
14 from deis import settings
15
16
17 # Deis-optimized EC2 amis -- with 3.8 kernel, chef 11 deps,
18 # and large docker images (e.g. buildstep) pre-installed
19 IMAGE_MAP = {
20 'ap-northeast-1': 'ami-5d432d5c',
21 'ap-southeast-1': 'ami-b4c493e6',
22 'ap-southeast-2': 'ami-d59d03ef',
23 'eu-west-1': 'ami-ce30c5b9',
24 'sa-east-1': 'ami-61b1117c',
25 'us-east-1': 'ami-8df9c9e4',
26 'us-west-1': 'ami-62477527',
27 'us-west-2': 'ami-ea6001da',
28 }
29
30
31 def seed_flavors():
32 """Seed the database with default flavors for each EC2 region.
33
34 :rtype: list of dicts containing flavor data
35 """
36 flavors = []
37 for r in ('us-east-1', 'us-west-1', 'us-west-2', 'eu-west-1',
38 'ap-northeast-1', 'ap-southeast-1', 'ap-southeast-2',
39 'sa-east-1'):
40 flavors.append({'id': 'ec2-{}'.format(r),
41 'provider': 'ec2',
42 'params': json.dumps({
43 'region': r,
44 'image': IMAGE_MAP[r],
45 'zone': 'any',
46 'size': 'm1.medium'})})
47 return flavors
48
49
50 def build_layer(layer):
51 """
52 Build a layer.
53
54 :param layer: a dict containing formation, id, params, and creds info
55 """
56 region = layer['params'].get('region', 'us-east-1')
57 conn = _create_ec2_connection(layer['creds'], region)
58 # create a new sg and authorize all ports
59 # use iptables on the host to firewall ports
60 name = "{formation}-{id}".format(**layer)
61 sg = conn.create_security_group(name, 'Created by Deis')
62 # import a new keypair using the layer key material
63 conn.import_key_pair(name, layer['ssh_public_key'])
64 # loop until the sg is *actually* there
65 for i in xrange(10):
66 try:
67 sg.authorize(ip_protocol='tcp', from_port=1, to_port=65535,
68 cidr_ip='0.0.0.0/0')
69 break
70 except EC2ResponseError:
71 if i < 10:
72 time.sleep(1.5)
73 continue
74 else:
75 raise RuntimeError('Failed to authorize security group')
76
77
78 def destroy_layer(layer):
79 """
80 Destroy a layer.
81
82 :param layer: a dict containing formation, id, params, and creds info
83 """
84 region = layer['params'].get('region', 'us-east-1')
85 name = "{formation}-{id}".format(**layer)
86 conn = _create_ec2_connection(layer['creds'], region)
87 conn.delete_key_pair(name)
88 # there's an ec2 race condition on instances terminating
89 # successfully but still holding a lock on the security group
90 for i in range(5):
91 # let's take a nap
92 time.sleep(i ** 1.25) # 1, 2.4, 3.9, 5.6, 7.4
93 try:
94 conn.delete_security_group(name)
95 return
96 except EC2ResponseError as err:
97 if err.code == 'InvalidGroup.NotFound':
98 return
99 elif err.code in ('InvalidGroup.InUse',
100 'DependencyViolation') and i < 4:
101 continue # retry
102 else:
103 raise
104
105
106 def build_node(node):
107 """
108 Build a node.
109
110 :param node: a dict containing formation, layer, params, and creds info.
111 :rtype: a tuple of (provider_id, fully_qualified_domain_name, metadata)
112 """
113 params, creds = node['params'], node['creds']
114 region = params.setdefault('region', 'us-east-1')
115 conn = _create_ec2_connection(creds, region)
116 name = "{formation}-{layer}".format(**node)
117 params['key_name'] = name
118 sg = conn.get_all_security_groups(name)[0]
119 params.setdefault('security_groups', []).append(sg.name)
120 image_id = params.get(
121 'image', getattr(settings, 'IMAGE_MAP', IMAGE_MAP)[region])
122 images = conn.get_all_images([image_id])
123 if len(images) != 1:
124 raise LookupError('Could not find AMI: %s' % image_id)
125 image = images[0]
126 kwargs = _prepare_run_kwargs(params)
127 reservation = image.run(**kwargs)
128 instances = reservation.instances
129 boto = instances[0]
130 # sleep before tagging
131 time.sleep(10)
132 boto.update()
133 boto.add_tag('Name', node['id'])
134 # loop until running
135 while(True):
136 time.sleep(2)
137 boto.update()
138 if boto.state == 'running':
139 break
140 # prepare return values
141 provider_id = boto.id
142 fqdn = boto.public_dns_name
143 metadata = _format_metadata(boto)
144 return provider_id, fqdn, metadata
145
146
147 def destroy_node(node):
148 """
149 Destroy a node.
150
151 :param node: a dict containing a node's provider_id, params, and creds
152 """
153 provider_id = node['provider_id']
154 region = node['params'].get('region', 'us-east-1')
155 conn = _create_ec2_connection(node['creds'], region)
156 if provider_id:
157 try:
158 conn.terminate_instances([provider_id])
159 i = conn.get_all_instances([provider_id])[0].instances[0]
160 while(True):
161 time.sleep(2)
162 i.update()
163 if i.state == "terminated":
164 break
165 except EC2ResponseError as e:
166 if e.code not in ('InvalidInstanceID.NotFound',):
167 raise
168
169
170 def _create_ec2_connection(creds, region):
171 """
172 Connect to an EC2 region with the given credentials.
173
174 :param creds: a dict containing an EC2 access_key and secret_key
175 :region: the name of an EC2 region, such as "us-west-2"
176 :rtype: a connected :class:`~boto.ec2.connection.EC2Connection`
177 :raises EnvironmentError: if no credentials are provided
178 """
179 if not creds:
180 raise EnvironmentError('No credentials provided')
181 return ec2.connect_to_region(region,
182 aws_access_key_id=creds['access_key'],
183 aws_secret_access_key=creds['secret_key'])
184
185
186 def _prepare_run_kwargs(params):
187 # start with sane defaults
188 kwargs = {
189 'min_count': 1, 'max_count': 1,
190 'user_data': None, 'addressing_type': None,
191 'instance_type': None, 'placement': None,
192 'kernel_id': None, 'ramdisk_id': None,
193 'monitoring_enabled': False, 'subnet_id': None,
194 'block_device_map': None,
195 }
196 # convert zone "any" to NoneType
197 requested_zone = params.get('zone')
198 if requested_zone and requested_zone.lower() == 'any':
199 requested_zone = None
200 # lookup kwargs from params
201 param_kwargs = {
202 'instance_type': params.get('size', 'm1.medium'),
203 'security_groups': params['security_groups'],
204 'placement': requested_zone,
205 'key_name': params['key_name'],
206 'kernel_id': params.get('kernel', None),
207 }
208 # add user_data if provided in params
209 user_data = params.get('user_data')
210 if user_data:
211 kwargs.update({'user_data': user_data})
212 # params override defaults
213 kwargs.update(param_kwargs)
214 return kwargs
215
216
217 def _format_metadata(boto):
218 return {
219 'architecture': boto.architecture,
220 'block_device_mapping': {
221 k: v.volume_id for k, v in boto.block_device_mapping.items()
222 },
223 'client_token': boto.client_token,
224 'dns_name': boto.dns_name,
225 'ebs_optimized': boto.ebs_optimized,
226 'eventsSet': boto.eventsSet,
227 'group_name': boto.group_name,
228 'groups': [g.id for g in boto.groups],
229 'hypervisor': boto.hypervisor,
230 'id': boto.id,
231 'image_id': boto.image_id,
232 'instance_profile': boto.instance_profile,
233 'instance_type': boto.instance_type,
234 'interfaces': list(boto.interfaces),
235 'ip_address': boto.ip_address,
236 'kernel': boto.kernel,
237 'key_name': boto.key_name,
238 'launch_time': boto.launch_time,
239 'monitored': boto.monitored,
240 'monitoring_state': boto.monitoring_state,
241 'persistent': boto.persistent,
242 'placement': boto.placement,
243 'placement_group': boto.placement_group,
244 'placement_tenancy': boto.placement_tenancy,
245 'previous_state': boto.previous_state,
246 'private_dns_name': boto.private_dns_name,
247 'private_ip_address': boto.private_ip_address,
248 'public_dns_name': boto.public_dns_name,
249 'ramdisk': boto.ramdisk,
250 'region': boto.region.name,
251 'root_device_name': boto.root_device_name,
252 'root_device_type': boto.root_device_type,
253 'spot_instance_request_id': boto.spot_instance_request_id,
254 'state': boto.state,
255 'state_code': boto.state_code,
256 'state_reason': boto.state_reason,
257 'subnet_id': boto.subnet_id,
258 'tags': dict(boto.tags),
259 'virtualization_type': boto.virtualization_type,
260 'vpc_id': boto.vpc_id,
261 }
262
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/provider/ec2.py b/provider/ec2.py
--- a/provider/ec2.py
+++ b/provider/ec2.py
@@ -17,14 +17,14 @@
# Deis-optimized EC2 amis -- with 3.8 kernel, chef 11 deps,
# and large docker images (e.g. buildstep) pre-installed
IMAGE_MAP = {
- 'ap-northeast-1': 'ami-5d432d5c',
- 'ap-southeast-1': 'ami-b4c493e6',
- 'ap-southeast-2': 'ami-d59d03ef',
- 'eu-west-1': 'ami-ce30c5b9',
- 'sa-east-1': 'ami-61b1117c',
- 'us-east-1': 'ami-8df9c9e4',
- 'us-west-1': 'ami-62477527',
- 'us-west-2': 'ami-ea6001da',
+ 'ap-northeast-1': 'ami-f37503f2',
+ 'ap-southeast-1': 'ami-7867362a',
+ 'ap-southeast-2': 'ami-71bb224b',
+ 'eu-west-1': 'ami-af31c3d8',
+ 'sa-east-1': 'ami-2b64c736',
+ 'us-east-1': 'ami-c1080aa8',
+ 'us-west-1': 'ami-1c8bb759',
+ 'us-west-2': 'ami-f282eec2',
}
|
{"golden_diff": "diff --git a/provider/ec2.py b/provider/ec2.py\n--- a/provider/ec2.py\n+++ b/provider/ec2.py\n@@ -17,14 +17,14 @@\n # Deis-optimized EC2 amis -- with 3.8 kernel, chef 11 deps,\n # and large docker images (e.g. buildstep) pre-installed\n IMAGE_MAP = {\n- 'ap-northeast-1': 'ami-5d432d5c',\n- 'ap-southeast-1': 'ami-b4c493e6',\n- 'ap-southeast-2': 'ami-d59d03ef',\n- 'eu-west-1': 'ami-ce30c5b9',\n- 'sa-east-1': 'ami-61b1117c',\n- 'us-east-1': 'ami-8df9c9e4',\n- 'us-west-1': 'ami-62477527',\n- 'us-west-2': 'ami-ea6001da',\n+ 'ap-northeast-1': 'ami-f37503f2',\n+ 'ap-southeast-1': 'ami-7867362a',\n+ 'ap-southeast-2': 'ami-71bb224b',\n+ 'eu-west-1': 'ami-af31c3d8',\n+ 'sa-east-1': 'ami-2b64c736',\n+ 'us-east-1': 'ami-c1080aa8',\n+ 'us-west-1': 'ami-1c8bb759',\n+ 'us-west-2': 'ami-f282eec2',\n }\n", "issue": "Make EC2 AMIs for 0.5.1 release\n\n", "before_files": [{"content": "\"\"\"\nDeis cloud provider implementation for Amazon EC2.\n\"\"\"\n\nfrom __future__ import unicode_literals\n\nimport json\nimport time\n\nfrom boto import ec2\nfrom boto.exception import EC2ResponseError\n\n# from api.ssh import connect_ssh, exec_ssh\nfrom deis import settings\n\n\n# Deis-optimized EC2 amis -- with 3.8 kernel, chef 11 deps,\n# and large docker images (e.g. buildstep) pre-installed\nIMAGE_MAP = {\n 'ap-northeast-1': 'ami-5d432d5c',\n 'ap-southeast-1': 'ami-b4c493e6',\n 'ap-southeast-2': 'ami-d59d03ef',\n 'eu-west-1': 'ami-ce30c5b9',\n 'sa-east-1': 'ami-61b1117c',\n 'us-east-1': 'ami-8df9c9e4',\n 'us-west-1': 'ami-62477527',\n 'us-west-2': 'ami-ea6001da',\n}\n\n\ndef seed_flavors():\n \"\"\"Seed the database with default flavors for each EC2 region.\n\n :rtype: list of dicts containing flavor data\n \"\"\"\n flavors = []\n for r in ('us-east-1', 'us-west-1', 'us-west-2', 'eu-west-1',\n 'ap-northeast-1', 'ap-southeast-1', 'ap-southeast-2',\n 'sa-east-1'):\n flavors.append({'id': 'ec2-{}'.format(r),\n 'provider': 'ec2',\n 'params': json.dumps({\n 'region': r,\n 'image': IMAGE_MAP[r],\n 'zone': 'any',\n 'size': 'm1.medium'})})\n return flavors\n\n\ndef build_layer(layer):\n \"\"\"\n Build a layer.\n\n :param layer: a dict containing formation, id, params, and creds info\n \"\"\"\n region = layer['params'].get('region', 'us-east-1')\n conn = _create_ec2_connection(layer['creds'], region)\n # create a new sg and authorize all ports\n # use iptables on the host to firewall ports\n name = \"{formation}-{id}\".format(**layer)\n sg = conn.create_security_group(name, 'Created by Deis')\n # import a new keypair using the layer key material\n conn.import_key_pair(name, layer['ssh_public_key'])\n # loop until the sg is *actually* there\n for i in xrange(10):\n try:\n sg.authorize(ip_protocol='tcp', from_port=1, to_port=65535,\n cidr_ip='0.0.0.0/0')\n break\n except EC2ResponseError:\n if i < 10:\n time.sleep(1.5)\n continue\n else:\n raise RuntimeError('Failed to authorize security group')\n\n\ndef destroy_layer(layer):\n \"\"\"\n Destroy a layer.\n\n :param layer: a dict containing formation, id, params, and creds info\n \"\"\"\n region = layer['params'].get('region', 'us-east-1')\n name = \"{formation}-{id}\".format(**layer)\n conn = _create_ec2_connection(layer['creds'], region)\n conn.delete_key_pair(name)\n # there's an ec2 race condition on instances terminating\n # successfully but still holding a lock on the security group\n for i in range(5):\n # let's take a nap\n time.sleep(i ** 1.25) # 1, 2.4, 3.9, 5.6, 7.4\n try:\n conn.delete_security_group(name)\n return\n except EC2ResponseError as err:\n if err.code == 'InvalidGroup.NotFound':\n return\n elif err.code in ('InvalidGroup.InUse',\n 'DependencyViolation') and i < 4:\n continue # retry\n else:\n raise\n\n\ndef build_node(node):\n \"\"\"\n Build a node.\n\n :param node: a dict containing formation, layer, params, and creds info.\n :rtype: a tuple of (provider_id, fully_qualified_domain_name, metadata)\n \"\"\"\n params, creds = node['params'], node['creds']\n region = params.setdefault('region', 'us-east-1')\n conn = _create_ec2_connection(creds, region)\n name = \"{formation}-{layer}\".format(**node)\n params['key_name'] = name\n sg = conn.get_all_security_groups(name)[0]\n params.setdefault('security_groups', []).append(sg.name)\n image_id = params.get(\n 'image', getattr(settings, 'IMAGE_MAP', IMAGE_MAP)[region])\n images = conn.get_all_images([image_id])\n if len(images) != 1:\n raise LookupError('Could not find AMI: %s' % image_id)\n image = images[0]\n kwargs = _prepare_run_kwargs(params)\n reservation = image.run(**kwargs)\n instances = reservation.instances\n boto = instances[0]\n # sleep before tagging\n time.sleep(10)\n boto.update()\n boto.add_tag('Name', node['id'])\n # loop until running\n while(True):\n time.sleep(2)\n boto.update()\n if boto.state == 'running':\n break\n # prepare return values\n provider_id = boto.id\n fqdn = boto.public_dns_name\n metadata = _format_metadata(boto)\n return provider_id, fqdn, metadata\n\n\ndef destroy_node(node):\n \"\"\"\n Destroy a node.\n\n :param node: a dict containing a node's provider_id, params, and creds\n \"\"\"\n provider_id = node['provider_id']\n region = node['params'].get('region', 'us-east-1')\n conn = _create_ec2_connection(node['creds'], region)\n if provider_id:\n try:\n conn.terminate_instances([provider_id])\n i = conn.get_all_instances([provider_id])[0].instances[0]\n while(True):\n time.sleep(2)\n i.update()\n if i.state == \"terminated\":\n break\n except EC2ResponseError as e:\n if e.code not in ('InvalidInstanceID.NotFound',):\n raise\n\n\ndef _create_ec2_connection(creds, region):\n \"\"\"\n Connect to an EC2 region with the given credentials.\n\n :param creds: a dict containing an EC2 access_key and secret_key\n :region: the name of an EC2 region, such as \"us-west-2\"\n :rtype: a connected :class:`~boto.ec2.connection.EC2Connection`\n :raises EnvironmentError: if no credentials are provided\n \"\"\"\n if not creds:\n raise EnvironmentError('No credentials provided')\n return ec2.connect_to_region(region,\n aws_access_key_id=creds['access_key'],\n aws_secret_access_key=creds['secret_key'])\n\n\ndef _prepare_run_kwargs(params):\n # start with sane defaults\n kwargs = {\n 'min_count': 1, 'max_count': 1,\n 'user_data': None, 'addressing_type': None,\n 'instance_type': None, 'placement': None,\n 'kernel_id': None, 'ramdisk_id': None,\n 'monitoring_enabled': False, 'subnet_id': None,\n 'block_device_map': None,\n }\n # convert zone \"any\" to NoneType\n requested_zone = params.get('zone')\n if requested_zone and requested_zone.lower() == 'any':\n requested_zone = None\n # lookup kwargs from params\n param_kwargs = {\n 'instance_type': params.get('size', 'm1.medium'),\n 'security_groups': params['security_groups'],\n 'placement': requested_zone,\n 'key_name': params['key_name'],\n 'kernel_id': params.get('kernel', None),\n }\n # add user_data if provided in params\n user_data = params.get('user_data')\n if user_data:\n kwargs.update({'user_data': user_data})\n # params override defaults\n kwargs.update(param_kwargs)\n return kwargs\n\n\ndef _format_metadata(boto):\n return {\n 'architecture': boto.architecture,\n 'block_device_mapping': {\n k: v.volume_id for k, v in boto.block_device_mapping.items()\n },\n 'client_token': boto.client_token,\n 'dns_name': boto.dns_name,\n 'ebs_optimized': boto.ebs_optimized,\n 'eventsSet': boto.eventsSet,\n 'group_name': boto.group_name,\n 'groups': [g.id for g in boto.groups],\n 'hypervisor': boto.hypervisor,\n 'id': boto.id,\n 'image_id': boto.image_id,\n 'instance_profile': boto.instance_profile,\n 'instance_type': boto.instance_type,\n 'interfaces': list(boto.interfaces),\n 'ip_address': boto.ip_address,\n 'kernel': boto.kernel,\n 'key_name': boto.key_name,\n 'launch_time': boto.launch_time,\n 'monitored': boto.monitored,\n 'monitoring_state': boto.monitoring_state,\n 'persistent': boto.persistent,\n 'placement': boto.placement,\n 'placement_group': boto.placement_group,\n 'placement_tenancy': boto.placement_tenancy,\n 'previous_state': boto.previous_state,\n 'private_dns_name': boto.private_dns_name,\n 'private_ip_address': boto.private_ip_address,\n 'public_dns_name': boto.public_dns_name,\n 'ramdisk': boto.ramdisk,\n 'region': boto.region.name,\n 'root_device_name': boto.root_device_name,\n 'root_device_type': boto.root_device_type,\n 'spot_instance_request_id': boto.spot_instance_request_id,\n 'state': boto.state,\n 'state_code': boto.state_code,\n 'state_reason': boto.state_reason,\n 'subnet_id': boto.subnet_id,\n 'tags': dict(boto.tags),\n 'virtualization_type': boto.virtualization_type,\n 'vpc_id': boto.vpc_id,\n }\n", "path": "provider/ec2.py"}], "after_files": [{"content": "\"\"\"\nDeis cloud provider implementation for Amazon EC2.\n\"\"\"\n\nfrom __future__ import unicode_literals\n\nimport json\nimport time\n\nfrom boto import ec2\nfrom boto.exception import EC2ResponseError\n\n# from api.ssh import connect_ssh, exec_ssh\nfrom deis import settings\n\n\n# Deis-optimized EC2 amis -- with 3.8 kernel, chef 11 deps,\n# and large docker images (e.g. buildstep) pre-installed\nIMAGE_MAP = {\n 'ap-northeast-1': 'ami-f37503f2',\n 'ap-southeast-1': 'ami-7867362a',\n 'ap-southeast-2': 'ami-71bb224b',\n 'eu-west-1': 'ami-af31c3d8',\n 'sa-east-1': 'ami-2b64c736',\n 'us-east-1': 'ami-c1080aa8',\n 'us-west-1': 'ami-1c8bb759',\n 'us-west-2': 'ami-f282eec2',\n}\n\n\ndef seed_flavors():\n \"\"\"Seed the database with default flavors for each EC2 region.\n\n :rtype: list of dicts containing flavor data\n \"\"\"\n flavors = []\n for r in ('us-east-1', 'us-west-1', 'us-west-2', 'eu-west-1',\n 'ap-northeast-1', 'ap-southeast-1', 'ap-southeast-2',\n 'sa-east-1'):\n flavors.append({'id': 'ec2-{}'.format(r),\n 'provider': 'ec2',\n 'params': json.dumps({\n 'region': r,\n 'image': IMAGE_MAP[r],\n 'zone': 'any',\n 'size': 'm1.medium'})})\n return flavors\n\n\ndef build_layer(layer):\n \"\"\"\n Build a layer.\n\n :param layer: a dict containing formation, id, params, and creds info\n \"\"\"\n region = layer['params'].get('region', 'us-east-1')\n conn = _create_ec2_connection(layer['creds'], region)\n # create a new sg and authorize all ports\n # use iptables on the host to firewall ports\n name = \"{formation}-{id}\".format(**layer)\n sg = conn.create_security_group(name, 'Created by Deis')\n # import a new keypair using the layer key material\n conn.import_key_pair(name, layer['ssh_public_key'])\n # loop until the sg is *actually* there\n for i in xrange(10):\n try:\n sg.authorize(ip_protocol='tcp', from_port=1, to_port=65535,\n cidr_ip='0.0.0.0/0')\n break\n except EC2ResponseError:\n if i < 10:\n time.sleep(1.5)\n continue\n else:\n raise RuntimeError('Failed to authorize security group')\n\n\ndef destroy_layer(layer):\n \"\"\"\n Destroy a layer.\n\n :param layer: a dict containing formation, id, params, and creds info\n \"\"\"\n region = layer['params'].get('region', 'us-east-1')\n name = \"{formation}-{id}\".format(**layer)\n conn = _create_ec2_connection(layer['creds'], region)\n conn.delete_key_pair(name)\n # there's an ec2 race condition on instances terminating\n # successfully but still holding a lock on the security group\n for i in range(5):\n # let's take a nap\n time.sleep(i ** 1.25) # 1, 2.4, 3.9, 5.6, 7.4\n try:\n conn.delete_security_group(name)\n return\n except EC2ResponseError as err:\n if err.code == 'InvalidGroup.NotFound':\n return\n elif err.code in ('InvalidGroup.InUse',\n 'DependencyViolation') and i < 4:\n continue # retry\n else:\n raise\n\n\ndef build_node(node):\n \"\"\"\n Build a node.\n\n :param node: a dict containing formation, layer, params, and creds info.\n :rtype: a tuple of (provider_id, fully_qualified_domain_name, metadata)\n \"\"\"\n params, creds = node['params'], node['creds']\n region = params.setdefault('region', 'us-east-1')\n conn = _create_ec2_connection(creds, region)\n name = \"{formation}-{layer}\".format(**node)\n params['key_name'] = name\n sg = conn.get_all_security_groups(name)[0]\n params.setdefault('security_groups', []).append(sg.name)\n image_id = params.get(\n 'image', getattr(settings, 'IMAGE_MAP', IMAGE_MAP)[region])\n images = conn.get_all_images([image_id])\n if len(images) != 1:\n raise LookupError('Could not find AMI: %s' % image_id)\n image = images[0]\n kwargs = _prepare_run_kwargs(params)\n reservation = image.run(**kwargs)\n instances = reservation.instances\n boto = instances[0]\n # sleep before tagging\n time.sleep(10)\n boto.update()\n boto.add_tag('Name', node['id'])\n # loop until running\n while(True):\n time.sleep(2)\n boto.update()\n if boto.state == 'running':\n break\n # prepare return values\n provider_id = boto.id\n fqdn = boto.public_dns_name\n metadata = _format_metadata(boto)\n return provider_id, fqdn, metadata\n\n\ndef destroy_node(node):\n \"\"\"\n Destroy a node.\n\n :param node: a dict containing a node's provider_id, params, and creds\n \"\"\"\n provider_id = node['provider_id']\n region = node['params'].get('region', 'us-east-1')\n conn = _create_ec2_connection(node['creds'], region)\n if provider_id:\n try:\n conn.terminate_instances([provider_id])\n i = conn.get_all_instances([provider_id])[0].instances[0]\n while(True):\n time.sleep(2)\n i.update()\n if i.state == \"terminated\":\n break\n except EC2ResponseError as e:\n if e.code not in ('InvalidInstanceID.NotFound',):\n raise\n\n\ndef _create_ec2_connection(creds, region):\n \"\"\"\n Connect to an EC2 region with the given credentials.\n\n :param creds: a dict containing an EC2 access_key and secret_key\n :region: the name of an EC2 region, such as \"us-west-2\"\n :rtype: a connected :class:`~boto.ec2.connection.EC2Connection`\n :raises EnvironmentError: if no credentials are provided\n \"\"\"\n if not creds:\n raise EnvironmentError('No credentials provided')\n return ec2.connect_to_region(region,\n aws_access_key_id=creds['access_key'],\n aws_secret_access_key=creds['secret_key'])\n\n\ndef _prepare_run_kwargs(params):\n # start with sane defaults\n kwargs = {\n 'min_count': 1, 'max_count': 1,\n 'user_data': None, 'addressing_type': None,\n 'instance_type': None, 'placement': None,\n 'kernel_id': None, 'ramdisk_id': None,\n 'monitoring_enabled': False, 'subnet_id': None,\n 'block_device_map': None,\n }\n # convert zone \"any\" to NoneType\n requested_zone = params.get('zone')\n if requested_zone and requested_zone.lower() == 'any':\n requested_zone = None\n # lookup kwargs from params\n param_kwargs = {\n 'instance_type': params.get('size', 'm1.medium'),\n 'security_groups': params['security_groups'],\n 'placement': requested_zone,\n 'key_name': params['key_name'],\n 'kernel_id': params.get('kernel', None),\n }\n # add user_data if provided in params\n user_data = params.get('user_data')\n if user_data:\n kwargs.update({'user_data': user_data})\n # params override defaults\n kwargs.update(param_kwargs)\n return kwargs\n\n\ndef _format_metadata(boto):\n return {\n 'architecture': boto.architecture,\n 'block_device_mapping': {\n k: v.volume_id for k, v in boto.block_device_mapping.items()\n },\n 'client_token': boto.client_token,\n 'dns_name': boto.dns_name,\n 'ebs_optimized': boto.ebs_optimized,\n 'eventsSet': boto.eventsSet,\n 'group_name': boto.group_name,\n 'groups': [g.id for g in boto.groups],\n 'hypervisor': boto.hypervisor,\n 'id': boto.id,\n 'image_id': boto.image_id,\n 'instance_profile': boto.instance_profile,\n 'instance_type': boto.instance_type,\n 'interfaces': list(boto.interfaces),\n 'ip_address': boto.ip_address,\n 'kernel': boto.kernel,\n 'key_name': boto.key_name,\n 'launch_time': boto.launch_time,\n 'monitored': boto.monitored,\n 'monitoring_state': boto.monitoring_state,\n 'persistent': boto.persistent,\n 'placement': boto.placement,\n 'placement_group': boto.placement_group,\n 'placement_tenancy': boto.placement_tenancy,\n 'previous_state': boto.previous_state,\n 'private_dns_name': boto.private_dns_name,\n 'private_ip_address': boto.private_ip_address,\n 'public_dns_name': boto.public_dns_name,\n 'ramdisk': boto.ramdisk,\n 'region': boto.region.name,\n 'root_device_name': boto.root_device_name,\n 'root_device_type': boto.root_device_type,\n 'spot_instance_request_id': boto.spot_instance_request_id,\n 'state': boto.state,\n 'state_code': boto.state_code,\n 'state_reason': boto.state_reason,\n 'subnet_id': boto.subnet_id,\n 'tags': dict(boto.tags),\n 'virtualization_type': boto.virtualization_type,\n 'vpc_id': boto.vpc_id,\n }\n", "path": "provider/ec2.py"}]}
| 3,163 | 400 |
gh_patches_debug_29525
|
rasdani/github-patches
|
git_diff
|
netbox-community__netbox-13826
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Validate all headers/fields when bulk import objects
### NetBox version
v3.4.3
### Python version
3.8
### Steps to Reproduce
1. Open Prefix Bulk Import
2. Specify all required field options and add some dummy data
`prefix,status,testa,testb`
`10.10.10.0/24,active,a,b`
4. Press Import
5. Import is done without any complains
### Expected Behavior
Fields which are not stated in Field Options should throw an error, or a warning that some data was ignored.
### Observed Behavior
Import is done without any complains, Looks like all data was imported correct, although some fields were ignored
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `netbox/utilities/forms/forms.py`
Content:
```
1 import re
2
3 from django import forms
4 from django.utils.translation import gettext as _
5 from .mixins import BootstrapMixin
6
7 __all__ = (
8 'BulkEditForm',
9 'BulkRenameForm',
10 'ConfirmationForm',
11 'CSVModelForm',
12 'FilterForm',
13 'TableConfigForm',
14 )
15
16
17 class ConfirmationForm(BootstrapMixin, forms.Form):
18 """
19 A generic confirmation form. The form is not valid unless the `confirm` field is checked.
20 """
21 return_url = forms.CharField(
22 required=False,
23 widget=forms.HiddenInput()
24 )
25 confirm = forms.BooleanField(
26 required=True,
27 widget=forms.HiddenInput(),
28 initial=True
29 )
30
31
32 class BulkEditForm(BootstrapMixin, forms.Form):
33 """
34 Provides bulk edit support for objects.
35 """
36 nullable_fields = ()
37
38
39 class BulkRenameForm(BootstrapMixin, forms.Form):
40 """
41 An extendable form to be used for renaming objects in bulk.
42 """
43 find = forms.CharField(
44 strip=False
45 )
46 replace = forms.CharField(
47 strip=False,
48 required=False
49 )
50 use_regex = forms.BooleanField(
51 required=False,
52 initial=True,
53 label=_('Use regular expressions')
54 )
55
56 def clean(self):
57 super().clean()
58
59 # Validate regular expression in "find" field
60 if self.cleaned_data['use_regex']:
61 try:
62 re.compile(self.cleaned_data['find'])
63 except re.error:
64 raise forms.ValidationError({
65 'find': "Invalid regular expression"
66 })
67
68
69 class CSVModelForm(forms.ModelForm):
70 """
71 ModelForm used for the import of objects in CSV format.
72 """
73 def __init__(self, *args, headers=None, fields=None, **kwargs):
74 headers = headers or {}
75 fields = fields or []
76 super().__init__(*args, **kwargs)
77
78 # Modify the model form to accommodate any customized to_field_name properties
79 for field, to_field in headers.items():
80 if to_field is not None:
81 self.fields[field].to_field_name = to_field
82
83 # Omit any fields not specified (e.g. because the form is being used to
84 # updated rather than create objects)
85 if fields:
86 for field in list(self.fields.keys()):
87 if field not in fields:
88 del self.fields[field]
89
90
91 class FilterForm(BootstrapMixin, forms.Form):
92 """
93 Base Form class for FilterSet forms.
94 """
95 q = forms.CharField(
96 required=False,
97 label=_('Search')
98 )
99
100
101 class TableConfigForm(BootstrapMixin, forms.Form):
102 """
103 Form for configuring user's table preferences.
104 """
105 available_columns = forms.MultipleChoiceField(
106 choices=[],
107 required=False,
108 widget=forms.SelectMultiple(
109 attrs={'size': 10, 'class': 'form-select'}
110 ),
111 label=_('Available Columns')
112 )
113 columns = forms.MultipleChoiceField(
114 choices=[],
115 required=False,
116 widget=forms.SelectMultiple(
117 attrs={'size': 10, 'class': 'form-select'}
118 ),
119 label=_('Selected Columns')
120 )
121
122 def __init__(self, table, *args, **kwargs):
123 self.table = table
124
125 super().__init__(*args, **kwargs)
126
127 # Initialize columns field based on table attributes
128 self.fields['available_columns'].choices = table.available_columns
129 self.fields['columns'].choices = table.selected_columns
130
131 @property
132 def table_name(self):
133 return self.table.__class__.__name__
134
```
Path: `netbox/utilities/forms/bulk_import.py`
Content:
```
1 import csv
2 import json
3 from io import StringIO
4
5 import yaml
6 from django import forms
7 from django.utils.translation import gettext as _
8
9 from core.forms.mixins import SyncedDataMixin
10 from utilities.choices import CSVDelimiterChoices, ImportFormatChoices, ImportMethodChoices
11 from utilities.constants import CSV_DELIMITERS
12 from utilities.forms.utils import parse_csv
13 from .mixins import BootstrapMixin
14
15
16 class BulkImportForm(BootstrapMixin, SyncedDataMixin, forms.Form):
17 import_method = forms.ChoiceField(
18 choices=ImportMethodChoices,
19 required=False
20 )
21 data = forms.CharField(
22 required=False,
23 widget=forms.Textarea(attrs={'class': 'font-monospace'}),
24 help_text=_("Enter object data in CSV, JSON or YAML format.")
25 )
26 upload_file = forms.FileField(
27 label=_("Data file"),
28 required=False
29 )
30 format = forms.ChoiceField(
31 choices=ImportFormatChoices,
32 initial=ImportFormatChoices.AUTO
33 )
34 csv_delimiter = forms.ChoiceField(
35 choices=CSVDelimiterChoices,
36 initial=CSVDelimiterChoices.AUTO,
37 label=_("CSV delimiter"),
38 help_text=_("The character which delimits CSV fields. Applies only to CSV format."),
39 required=False
40 )
41
42 data_field = 'data'
43
44 def clean(self):
45 super().clean()
46
47 # Determine import method
48 import_method = self.cleaned_data.get('import_method') or ImportMethodChoices.DIRECT
49
50 # Determine whether we're reading from form data or an uploaded file
51 if self.cleaned_data['data'] and import_method != ImportMethodChoices.DIRECT:
52 raise forms.ValidationError("Form data must be empty when uploading/selecting a file.")
53 if import_method == ImportMethodChoices.UPLOAD:
54 self.upload_file = 'upload_file'
55 file = self.files.get('upload_file')
56 data = file.read().decode('utf-8-sig')
57 elif import_method == ImportMethodChoices.DATA_FILE:
58 data = self.cleaned_data['data_file'].data_as_string
59 else:
60 data = self.cleaned_data['data']
61
62 # Determine the data format
63 if self.cleaned_data['format'] == ImportFormatChoices.AUTO:
64 if self.cleaned_data['csv_delimiter'] != CSVDelimiterChoices.AUTO:
65 # Specifying the CSV delimiter implies CSV format
66 format = ImportFormatChoices.CSV
67 else:
68 format = self._detect_format(data)
69 else:
70 format = self.cleaned_data['format']
71
72 # Process data according to the selected format
73 if format == ImportFormatChoices.CSV:
74 delimiter = self.cleaned_data.get('csv_delimiter', CSVDelimiterChoices.AUTO)
75 self.cleaned_data['data'] = self._clean_csv(data, delimiter=delimiter)
76 elif format == ImportFormatChoices.JSON:
77 self.cleaned_data['data'] = self._clean_json(data)
78 elif format == ImportFormatChoices.YAML:
79 self.cleaned_data['data'] = self._clean_yaml(data)
80 else:
81 raise forms.ValidationError(f"Unknown data format: {format}")
82
83 def _detect_format(self, data):
84 """
85 Attempt to automatically detect the format (CSV, JSON, or YAML) of the given data, or raise
86 a ValidationError.
87 """
88 try:
89 if data[0] in ('{', '['):
90 return ImportFormatChoices.JSON
91 if data.startswith('---') or data.startswith('- '):
92 return ImportFormatChoices.YAML
93 # Look for any of the CSV delimiters in the first line (ignoring the default 'auto' choice)
94 first_line = data.split('\n', 1)[0]
95 csv_delimiters = CSV_DELIMITERS.values()
96 if any(x in first_line for x in csv_delimiters):
97 return ImportFormatChoices.CSV
98 except IndexError:
99 pass
100 raise forms.ValidationError({
101 'format': _('Unable to detect data format. Please specify.')
102 })
103
104 def _clean_csv(self, data, delimiter=CSVDelimiterChoices.AUTO):
105 """
106 Clean CSV-formatted data. The first row will be treated as column headers.
107 """
108 # Determine the CSV dialect
109 if delimiter == CSVDelimiterChoices.AUTO:
110 # This uses a rough heuristic to detect the CSV dialect based on the presence of supported delimiting
111 # characters. If the data is malformed, we'll fall back to the default Excel dialect.
112 delimiters = ''.join(CSV_DELIMITERS.values())
113 try:
114 dialect = csv.Sniffer().sniff(data.strip(), delimiters=delimiters)
115 except csv.Error:
116 dialect = csv.excel
117 elif delimiter in (CSVDelimiterChoices.COMMA, CSVDelimiterChoices.SEMICOLON):
118 dialect = csv.excel
119 dialect.delimiter = delimiter
120 elif delimiter == CSVDelimiterChoices.TAB:
121 dialect = csv.excel_tab
122 else:
123 raise forms.ValidationError({
124 'csv_delimiter': _('Invalid CSV delimiter'),
125 })
126
127 stream = StringIO(data.strip())
128 reader = csv.reader(stream, dialect=dialect)
129 headers, records = parse_csv(reader)
130
131 # Set CSV headers for reference by the model form
132 self._csv_headers = headers
133
134 return records
135
136 def _clean_json(self, data):
137 """
138 Clean JSON-formatted data. If only a single object is defined, it will be encapsulated as a list.
139 """
140 try:
141 data = json.loads(data)
142 # Accommodate for users entering single objects
143 if type(data) is not list:
144 data = [data]
145 return data
146 except json.decoder.JSONDecodeError as err:
147 raise forms.ValidationError({
148 self.data_field: f"Invalid JSON data: {err}"
149 })
150
151 def _clean_yaml(self, data):
152 """
153 Clean YAML-formatted data. Data must be either
154 a) A single document comprising a list of dictionaries (each representing an object), or
155 b) Multiple documents, separated with the '---' token
156 """
157 records = []
158 try:
159 for data in yaml.load_all(data, Loader=yaml.SafeLoader):
160 if type(data) is list:
161 records.extend(data)
162 elif type(data) is dict:
163 records.append(data)
164 else:
165 raise forms.ValidationError({
166 self.data_field: _(
167 "Invalid YAML data. Data must be in the form of multiple documents, or a single document "
168 "comprising a list of dictionaries."
169 )
170 })
171 except yaml.error.YAMLError as err:
172 raise forms.ValidationError({
173 self.data_field: f"Invalid YAML data: {err}"
174 })
175
176 return records
177
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/netbox/utilities/forms/bulk_import.py b/netbox/utilities/forms/bulk_import.py
--- a/netbox/utilities/forms/bulk_import.py
+++ b/netbox/utilities/forms/bulk_import.py
@@ -129,6 +129,7 @@
headers, records = parse_csv(reader)
# Set CSV headers for reference by the model form
+ headers.pop('id', None)
self._csv_headers = headers
return records
diff --git a/netbox/utilities/forms/forms.py b/netbox/utilities/forms/forms.py
--- a/netbox/utilities/forms/forms.py
+++ b/netbox/utilities/forms/forms.py
@@ -70,22 +70,24 @@
"""
ModelForm used for the import of objects in CSV format.
"""
- def __init__(self, *args, headers=None, fields=None, **kwargs):
- headers = headers or {}
- fields = fields or []
+ def __init__(self, *args, headers=None, **kwargs):
+ self.headers = headers or {}
super().__init__(*args, **kwargs)
# Modify the model form to accommodate any customized to_field_name properties
- for field, to_field in headers.items():
+ for field, to_field in self.headers.items():
if to_field is not None:
self.fields[field].to_field_name = to_field
- # Omit any fields not specified (e.g. because the form is being used to
- # updated rather than create objects)
- if fields:
- for field in list(self.fields.keys()):
- if field not in fields:
- del self.fields[field]
+ def clean(self):
+ # Flag any invalid CSV headers
+ for header in self.headers:
+ if header not in self.fields:
+ raise forms.ValidationError(
+ _("Unrecognized header: {name}").format(name=header)
+ )
+
+ return super().clean()
class FilterForm(BootstrapMixin, forms.Form):
|
{"golden_diff": "diff --git a/netbox/utilities/forms/bulk_import.py b/netbox/utilities/forms/bulk_import.py\n--- a/netbox/utilities/forms/bulk_import.py\n+++ b/netbox/utilities/forms/bulk_import.py\n@@ -129,6 +129,7 @@\n headers, records = parse_csv(reader)\n \n # Set CSV headers for reference by the model form\n+ headers.pop('id', None)\n self._csv_headers = headers\n \n return records\ndiff --git a/netbox/utilities/forms/forms.py b/netbox/utilities/forms/forms.py\n--- a/netbox/utilities/forms/forms.py\n+++ b/netbox/utilities/forms/forms.py\n@@ -70,22 +70,24 @@\n \"\"\"\n ModelForm used for the import of objects in CSV format.\n \"\"\"\n- def __init__(self, *args, headers=None, fields=None, **kwargs):\n- headers = headers or {}\n- fields = fields or []\n+ def __init__(self, *args, headers=None, **kwargs):\n+ self.headers = headers or {}\n super().__init__(*args, **kwargs)\n \n # Modify the model form to accommodate any customized to_field_name properties\n- for field, to_field in headers.items():\n+ for field, to_field in self.headers.items():\n if to_field is not None:\n self.fields[field].to_field_name = to_field\n \n- # Omit any fields not specified (e.g. because the form is being used to\n- # updated rather than create objects)\n- if fields:\n- for field in list(self.fields.keys()):\n- if field not in fields:\n- del self.fields[field]\n+ def clean(self):\n+ # Flag any invalid CSV headers\n+ for header in self.headers:\n+ if header not in self.fields:\n+ raise forms.ValidationError(\n+ _(\"Unrecognized header: {name}\").format(name=header)\n+ )\n+\n+ return super().clean()\n \n \n class FilterForm(BootstrapMixin, forms.Form):\n", "issue": "Validate all headers/fields when bulk import objects\n### NetBox version\n\nv3.4.3\n\n### Python version\n\n3.8\n\n### Steps to Reproduce\n\n1. Open Prefix Bulk Import\r\n2. Specify all required field options and add some dummy data\r\n`prefix,status,testa,testb`\r\n`10.10.10.0/24,active,a,b`\r\n4. Press Import\r\n5. Import is done without any complains\r\n\n\n### Expected Behavior\n\nFields which are not stated in Field Options should throw an error, or a warning that some data was ignored.\r\n\n\n### Observed Behavior\n\nImport is done without any complains, Looks like all data was imported correct, although some fields were ignored\n", "before_files": [{"content": "import re\n\nfrom django import forms\nfrom django.utils.translation import gettext as _\nfrom .mixins import BootstrapMixin\n\n__all__ = (\n 'BulkEditForm',\n 'BulkRenameForm',\n 'ConfirmationForm',\n 'CSVModelForm',\n 'FilterForm',\n 'TableConfigForm',\n)\n\n\nclass ConfirmationForm(BootstrapMixin, forms.Form):\n \"\"\"\n A generic confirmation form. The form is not valid unless the `confirm` field is checked.\n \"\"\"\n return_url = forms.CharField(\n required=False,\n widget=forms.HiddenInput()\n )\n confirm = forms.BooleanField(\n required=True,\n widget=forms.HiddenInput(),\n initial=True\n )\n\n\nclass BulkEditForm(BootstrapMixin, forms.Form):\n \"\"\"\n Provides bulk edit support for objects.\n \"\"\"\n nullable_fields = ()\n\n\nclass BulkRenameForm(BootstrapMixin, forms.Form):\n \"\"\"\n An extendable form to be used for renaming objects in bulk.\n \"\"\"\n find = forms.CharField(\n strip=False\n )\n replace = forms.CharField(\n strip=False,\n required=False\n )\n use_regex = forms.BooleanField(\n required=False,\n initial=True,\n label=_('Use regular expressions')\n )\n\n def clean(self):\n super().clean()\n\n # Validate regular expression in \"find\" field\n if self.cleaned_data['use_regex']:\n try:\n re.compile(self.cleaned_data['find'])\n except re.error:\n raise forms.ValidationError({\n 'find': \"Invalid regular expression\"\n })\n\n\nclass CSVModelForm(forms.ModelForm):\n \"\"\"\n ModelForm used for the import of objects in CSV format.\n \"\"\"\n def __init__(self, *args, headers=None, fields=None, **kwargs):\n headers = headers or {}\n fields = fields or []\n super().__init__(*args, **kwargs)\n\n # Modify the model form to accommodate any customized to_field_name properties\n for field, to_field in headers.items():\n if to_field is not None:\n self.fields[field].to_field_name = to_field\n\n # Omit any fields not specified (e.g. because the form is being used to\n # updated rather than create objects)\n if fields:\n for field in list(self.fields.keys()):\n if field not in fields:\n del self.fields[field]\n\n\nclass FilterForm(BootstrapMixin, forms.Form):\n \"\"\"\n Base Form class for FilterSet forms.\n \"\"\"\n q = forms.CharField(\n required=False,\n label=_('Search')\n )\n\n\nclass TableConfigForm(BootstrapMixin, forms.Form):\n \"\"\"\n Form for configuring user's table preferences.\n \"\"\"\n available_columns = forms.MultipleChoiceField(\n choices=[],\n required=False,\n widget=forms.SelectMultiple(\n attrs={'size': 10, 'class': 'form-select'}\n ),\n label=_('Available Columns')\n )\n columns = forms.MultipleChoiceField(\n choices=[],\n required=False,\n widget=forms.SelectMultiple(\n attrs={'size': 10, 'class': 'form-select'}\n ),\n label=_('Selected Columns')\n )\n\n def __init__(self, table, *args, **kwargs):\n self.table = table\n\n super().__init__(*args, **kwargs)\n\n # Initialize columns field based on table attributes\n self.fields['available_columns'].choices = table.available_columns\n self.fields['columns'].choices = table.selected_columns\n\n @property\n def table_name(self):\n return self.table.__class__.__name__\n", "path": "netbox/utilities/forms/forms.py"}, {"content": "import csv\nimport json\nfrom io import StringIO\n\nimport yaml\nfrom django import forms\nfrom django.utils.translation import gettext as _\n\nfrom core.forms.mixins import SyncedDataMixin\nfrom utilities.choices import CSVDelimiterChoices, ImportFormatChoices, ImportMethodChoices\nfrom utilities.constants import CSV_DELIMITERS\nfrom utilities.forms.utils import parse_csv\nfrom .mixins import BootstrapMixin\n\n\nclass BulkImportForm(BootstrapMixin, SyncedDataMixin, forms.Form):\n import_method = forms.ChoiceField(\n choices=ImportMethodChoices,\n required=False\n )\n data = forms.CharField(\n required=False,\n widget=forms.Textarea(attrs={'class': 'font-monospace'}),\n help_text=_(\"Enter object data in CSV, JSON or YAML format.\")\n )\n upload_file = forms.FileField(\n label=_(\"Data file\"),\n required=False\n )\n format = forms.ChoiceField(\n choices=ImportFormatChoices,\n initial=ImportFormatChoices.AUTO\n )\n csv_delimiter = forms.ChoiceField(\n choices=CSVDelimiterChoices,\n initial=CSVDelimiterChoices.AUTO,\n label=_(\"CSV delimiter\"),\n help_text=_(\"The character which delimits CSV fields. Applies only to CSV format.\"),\n required=False\n )\n\n data_field = 'data'\n\n def clean(self):\n super().clean()\n\n # Determine import method\n import_method = self.cleaned_data.get('import_method') or ImportMethodChoices.DIRECT\n\n # Determine whether we're reading from form data or an uploaded file\n if self.cleaned_data['data'] and import_method != ImportMethodChoices.DIRECT:\n raise forms.ValidationError(\"Form data must be empty when uploading/selecting a file.\")\n if import_method == ImportMethodChoices.UPLOAD:\n self.upload_file = 'upload_file'\n file = self.files.get('upload_file')\n data = file.read().decode('utf-8-sig')\n elif import_method == ImportMethodChoices.DATA_FILE:\n data = self.cleaned_data['data_file'].data_as_string\n else:\n data = self.cleaned_data['data']\n\n # Determine the data format\n if self.cleaned_data['format'] == ImportFormatChoices.AUTO:\n if self.cleaned_data['csv_delimiter'] != CSVDelimiterChoices.AUTO:\n # Specifying the CSV delimiter implies CSV format\n format = ImportFormatChoices.CSV\n else:\n format = self._detect_format(data)\n else:\n format = self.cleaned_data['format']\n\n # Process data according to the selected format\n if format == ImportFormatChoices.CSV:\n delimiter = self.cleaned_data.get('csv_delimiter', CSVDelimiterChoices.AUTO)\n self.cleaned_data['data'] = self._clean_csv(data, delimiter=delimiter)\n elif format == ImportFormatChoices.JSON:\n self.cleaned_data['data'] = self._clean_json(data)\n elif format == ImportFormatChoices.YAML:\n self.cleaned_data['data'] = self._clean_yaml(data)\n else:\n raise forms.ValidationError(f\"Unknown data format: {format}\")\n\n def _detect_format(self, data):\n \"\"\"\n Attempt to automatically detect the format (CSV, JSON, or YAML) of the given data, or raise\n a ValidationError.\n \"\"\"\n try:\n if data[0] in ('{', '['):\n return ImportFormatChoices.JSON\n if data.startswith('---') or data.startswith('- '):\n return ImportFormatChoices.YAML\n # Look for any of the CSV delimiters in the first line (ignoring the default 'auto' choice)\n first_line = data.split('\\n', 1)[0]\n csv_delimiters = CSV_DELIMITERS.values()\n if any(x in first_line for x in csv_delimiters):\n return ImportFormatChoices.CSV\n except IndexError:\n pass\n raise forms.ValidationError({\n 'format': _('Unable to detect data format. Please specify.')\n })\n\n def _clean_csv(self, data, delimiter=CSVDelimiterChoices.AUTO):\n \"\"\"\n Clean CSV-formatted data. The first row will be treated as column headers.\n \"\"\"\n # Determine the CSV dialect\n if delimiter == CSVDelimiterChoices.AUTO:\n # This uses a rough heuristic to detect the CSV dialect based on the presence of supported delimiting\n # characters. If the data is malformed, we'll fall back to the default Excel dialect.\n delimiters = ''.join(CSV_DELIMITERS.values())\n try:\n dialect = csv.Sniffer().sniff(data.strip(), delimiters=delimiters)\n except csv.Error:\n dialect = csv.excel\n elif delimiter in (CSVDelimiterChoices.COMMA, CSVDelimiterChoices.SEMICOLON):\n dialect = csv.excel\n dialect.delimiter = delimiter\n elif delimiter == CSVDelimiterChoices.TAB:\n dialect = csv.excel_tab\n else:\n raise forms.ValidationError({\n 'csv_delimiter': _('Invalid CSV delimiter'),\n })\n\n stream = StringIO(data.strip())\n reader = csv.reader(stream, dialect=dialect)\n headers, records = parse_csv(reader)\n\n # Set CSV headers for reference by the model form\n self._csv_headers = headers\n\n return records\n\n def _clean_json(self, data):\n \"\"\"\n Clean JSON-formatted data. If only a single object is defined, it will be encapsulated as a list.\n \"\"\"\n try:\n data = json.loads(data)\n # Accommodate for users entering single objects\n if type(data) is not list:\n data = [data]\n return data\n except json.decoder.JSONDecodeError as err:\n raise forms.ValidationError({\n self.data_field: f\"Invalid JSON data: {err}\"\n })\n\n def _clean_yaml(self, data):\n \"\"\"\n Clean YAML-formatted data. Data must be either\n a) A single document comprising a list of dictionaries (each representing an object), or\n b) Multiple documents, separated with the '---' token\n \"\"\"\n records = []\n try:\n for data in yaml.load_all(data, Loader=yaml.SafeLoader):\n if type(data) is list:\n records.extend(data)\n elif type(data) is dict:\n records.append(data)\n else:\n raise forms.ValidationError({\n self.data_field: _(\n \"Invalid YAML data. Data must be in the form of multiple documents, or a single document \"\n \"comprising a list of dictionaries.\"\n )\n })\n except yaml.error.YAMLError as err:\n raise forms.ValidationError({\n self.data_field: f\"Invalid YAML data: {err}\"\n })\n\n return records\n", "path": "netbox/utilities/forms/bulk_import.py"}], "after_files": [{"content": "import re\n\nfrom django import forms\nfrom django.utils.translation import gettext as _\nfrom .mixins import BootstrapMixin\n\n__all__ = (\n 'BulkEditForm',\n 'BulkRenameForm',\n 'ConfirmationForm',\n 'CSVModelForm',\n 'FilterForm',\n 'TableConfigForm',\n)\n\n\nclass ConfirmationForm(BootstrapMixin, forms.Form):\n \"\"\"\n A generic confirmation form. The form is not valid unless the `confirm` field is checked.\n \"\"\"\n return_url = forms.CharField(\n required=False,\n widget=forms.HiddenInput()\n )\n confirm = forms.BooleanField(\n required=True,\n widget=forms.HiddenInput(),\n initial=True\n )\n\n\nclass BulkEditForm(BootstrapMixin, forms.Form):\n \"\"\"\n Provides bulk edit support for objects.\n \"\"\"\n nullable_fields = ()\n\n\nclass BulkRenameForm(BootstrapMixin, forms.Form):\n \"\"\"\n An extendable form to be used for renaming objects in bulk.\n \"\"\"\n find = forms.CharField(\n strip=False\n )\n replace = forms.CharField(\n strip=False,\n required=False\n )\n use_regex = forms.BooleanField(\n required=False,\n initial=True,\n label=_('Use regular expressions')\n )\n\n def clean(self):\n super().clean()\n\n # Validate regular expression in \"find\" field\n if self.cleaned_data['use_regex']:\n try:\n re.compile(self.cleaned_data['find'])\n except re.error:\n raise forms.ValidationError({\n 'find': \"Invalid regular expression\"\n })\n\n\nclass CSVModelForm(forms.ModelForm):\n \"\"\"\n ModelForm used for the import of objects in CSV format.\n \"\"\"\n def __init__(self, *args, headers=None, **kwargs):\n self.headers = headers or {}\n super().__init__(*args, **kwargs)\n\n # Modify the model form to accommodate any customized to_field_name properties\n for field, to_field in self.headers.items():\n if to_field is not None:\n self.fields[field].to_field_name = to_field\n\n def clean(self):\n # Flag any invalid CSV headers\n for header in self.headers:\n if header not in self.fields:\n raise forms.ValidationError(\n _(\"Unrecognized header: {name}\").format(name=header)\n )\n\n return super().clean()\n\n\nclass FilterForm(BootstrapMixin, forms.Form):\n \"\"\"\n Base Form class for FilterSet forms.\n \"\"\"\n q = forms.CharField(\n required=False,\n label=_('Search')\n )\n\n\nclass TableConfigForm(BootstrapMixin, forms.Form):\n \"\"\"\n Form for configuring user's table preferences.\n \"\"\"\n available_columns = forms.MultipleChoiceField(\n choices=[],\n required=False,\n widget=forms.SelectMultiple(\n attrs={'size': 10, 'class': 'form-select'}\n ),\n label=_('Available Columns')\n )\n columns = forms.MultipleChoiceField(\n choices=[],\n required=False,\n widget=forms.SelectMultiple(\n attrs={'size': 10, 'class': 'form-select'}\n ),\n label=_('Selected Columns')\n )\n\n def __init__(self, table, *args, **kwargs):\n self.table = table\n\n super().__init__(*args, **kwargs)\n\n # Initialize columns field based on table attributes\n self.fields['available_columns'].choices = table.available_columns\n self.fields['columns'].choices = table.selected_columns\n\n @property\n def table_name(self):\n return self.table.__class__.__name__\n", "path": "netbox/utilities/forms/forms.py"}, {"content": "import csv\nimport json\nfrom io import StringIO\n\nimport yaml\nfrom django import forms\nfrom django.utils.translation import gettext as _\n\nfrom core.forms.mixins import SyncedDataMixin\nfrom utilities.choices import CSVDelimiterChoices, ImportFormatChoices, ImportMethodChoices\nfrom utilities.constants import CSV_DELIMITERS\nfrom utilities.forms.utils import parse_csv\nfrom .mixins import BootstrapMixin\n\n\nclass BulkImportForm(BootstrapMixin, SyncedDataMixin, forms.Form):\n import_method = forms.ChoiceField(\n choices=ImportMethodChoices,\n required=False\n )\n data = forms.CharField(\n required=False,\n widget=forms.Textarea(attrs={'class': 'font-monospace'}),\n help_text=_(\"Enter object data in CSV, JSON or YAML format.\")\n )\n upload_file = forms.FileField(\n label=_(\"Data file\"),\n required=False\n )\n format = forms.ChoiceField(\n choices=ImportFormatChoices,\n initial=ImportFormatChoices.AUTO\n )\n csv_delimiter = forms.ChoiceField(\n choices=CSVDelimiterChoices,\n initial=CSVDelimiterChoices.AUTO,\n label=_(\"CSV delimiter\"),\n help_text=_(\"The character which delimits CSV fields. Applies only to CSV format.\"),\n required=False\n )\n\n data_field = 'data'\n\n def clean(self):\n super().clean()\n\n # Determine import method\n import_method = self.cleaned_data.get('import_method') or ImportMethodChoices.DIRECT\n\n # Determine whether we're reading from form data or an uploaded file\n if self.cleaned_data['data'] and import_method != ImportMethodChoices.DIRECT:\n raise forms.ValidationError(\"Form data must be empty when uploading/selecting a file.\")\n if import_method == ImportMethodChoices.UPLOAD:\n self.upload_file = 'upload_file'\n file = self.files.get('upload_file')\n data = file.read().decode('utf-8-sig')\n elif import_method == ImportMethodChoices.DATA_FILE:\n data = self.cleaned_data['data_file'].data_as_string\n else:\n data = self.cleaned_data['data']\n\n # Determine the data format\n if self.cleaned_data['format'] == ImportFormatChoices.AUTO:\n if self.cleaned_data['csv_delimiter'] != CSVDelimiterChoices.AUTO:\n # Specifying the CSV delimiter implies CSV format\n format = ImportFormatChoices.CSV\n else:\n format = self._detect_format(data)\n else:\n format = self.cleaned_data['format']\n\n # Process data according to the selected format\n if format == ImportFormatChoices.CSV:\n delimiter = self.cleaned_data.get('csv_delimiter', CSVDelimiterChoices.AUTO)\n self.cleaned_data['data'] = self._clean_csv(data, delimiter=delimiter)\n elif format == ImportFormatChoices.JSON:\n self.cleaned_data['data'] = self._clean_json(data)\n elif format == ImportFormatChoices.YAML:\n self.cleaned_data['data'] = self._clean_yaml(data)\n else:\n raise forms.ValidationError(f\"Unknown data format: {format}\")\n\n def _detect_format(self, data):\n \"\"\"\n Attempt to automatically detect the format (CSV, JSON, or YAML) of the given data, or raise\n a ValidationError.\n \"\"\"\n try:\n if data[0] in ('{', '['):\n return ImportFormatChoices.JSON\n if data.startswith('---') or data.startswith('- '):\n return ImportFormatChoices.YAML\n # Look for any of the CSV delimiters in the first line (ignoring the default 'auto' choice)\n first_line = data.split('\\n', 1)[0]\n csv_delimiters = CSV_DELIMITERS.values()\n if any(x in first_line for x in csv_delimiters):\n return ImportFormatChoices.CSV\n except IndexError:\n pass\n raise forms.ValidationError({\n 'format': _('Unable to detect data format. Please specify.')\n })\n\n def _clean_csv(self, data, delimiter=CSVDelimiterChoices.AUTO):\n \"\"\"\n Clean CSV-formatted data. The first row will be treated as column headers.\n \"\"\"\n # Determine the CSV dialect\n if delimiter == CSVDelimiterChoices.AUTO:\n # This uses a rough heuristic to detect the CSV dialect based on the presence of supported delimiting\n # characters. If the data is malformed, we'll fall back to the default Excel dialect.\n delimiters = ''.join(CSV_DELIMITERS.values())\n try:\n dialect = csv.Sniffer().sniff(data.strip(), delimiters=delimiters)\n except csv.Error:\n dialect = csv.excel\n elif delimiter in (CSVDelimiterChoices.COMMA, CSVDelimiterChoices.SEMICOLON):\n dialect = csv.excel\n dialect.delimiter = delimiter\n elif delimiter == CSVDelimiterChoices.TAB:\n dialect = csv.excel_tab\n else:\n raise forms.ValidationError({\n 'csv_delimiter': _('Invalid CSV delimiter'),\n })\n\n stream = StringIO(data.strip())\n reader = csv.reader(stream, dialect=dialect)\n headers, records = parse_csv(reader)\n\n # Set CSV headers for reference by the model form\n headers.pop('id', None)\n self._csv_headers = headers\n\n return records\n\n def _clean_json(self, data):\n \"\"\"\n Clean JSON-formatted data. If only a single object is defined, it will be encapsulated as a list.\n \"\"\"\n try:\n data = json.loads(data)\n # Accommodate for users entering single objects\n if type(data) is not list:\n data = [data]\n return data\n except json.decoder.JSONDecodeError as err:\n raise forms.ValidationError({\n self.data_field: f\"Invalid JSON data: {err}\"\n })\n\n def _clean_yaml(self, data):\n \"\"\"\n Clean YAML-formatted data. Data must be either\n a) A single document comprising a list of dictionaries (each representing an object), or\n b) Multiple documents, separated with the '---' token\n \"\"\"\n records = []\n try:\n for data in yaml.load_all(data, Loader=yaml.SafeLoader):\n if type(data) is list:\n records.extend(data)\n elif type(data) is dict:\n records.append(data)\n else:\n raise forms.ValidationError({\n self.data_field: _(\n \"Invalid YAML data. Data must be in the form of multiple documents, or a single document \"\n \"comprising a list of dictionaries.\"\n )\n })\n except yaml.error.YAMLError as err:\n raise forms.ValidationError({\n self.data_field: f\"Invalid YAML data: {err}\"\n })\n\n return records\n", "path": "netbox/utilities/forms/bulk_import.py"}]}
| 3,307 | 440 |
gh_patches_debug_34336
|
rasdani/github-patches
|
git_diff
|
CTFd__CTFd-461
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Optimize top10 call
https://github.com/CTFd/CTFd/blob/master/CTFd/scoreboard.py#L125-L127
This code seems pretty wasteful and is likely getting hit fairly often. Optimizing this to be a single database query is likely a good idea.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `CTFd/scoreboard.py`
Content:
```
1 from flask import render_template, jsonify, Blueprint, redirect, url_for, request
2 from sqlalchemy.sql.expression import union_all
3
4 from CTFd.models import db, Teams, Solves, Awards, Challenges
5
6 from CTFd import utils
7
8 scoreboard = Blueprint('scoreboard', __name__)
9
10
11 def get_standings(admin=False, count=None):
12 scores = db.session.query(
13 Solves.teamid.label('teamid'),
14 db.func.sum(Challenges.value).label('score'),
15 db.func.max(Solves.id).label('id'),
16 db.func.max(Solves.date).label('date')
17 ).join(Challenges).group_by(Solves.teamid)
18
19 awards = db.session.query(
20 Awards.teamid.label('teamid'),
21 db.func.sum(Awards.value).label('score'),
22 db.func.max(Awards.id).label('id'),
23 db.func.max(Awards.date).label('date')
24 ).group_by(Awards.teamid)
25
26 """
27 Filter out solves and awards that are before a specific time point.
28 """
29 freeze = utils.get_config('freeze')
30 if not admin and freeze:
31 scores = scores.filter(Solves.date < utils.unix_time_to_utc(freeze))
32 awards = awards.filter(Awards.date < utils.unix_time_to_utc(freeze))
33
34 """
35 Combine awards and solves with a union. They should have the same amount of columns
36 """
37 results = union_all(scores, awards).alias('results')
38
39 """
40 Sum each of the results by the team id to get their score.
41 """
42 sumscores = db.session.query(
43 results.columns.teamid,
44 db.func.sum(results.columns.score).label('score'),
45 db.func.max(results.columns.id).label('id'),
46 db.func.max(results.columns.date).label('date')
47 ).group_by(results.columns.teamid).subquery()
48
49 """
50 Admins can see scores for all users but the public cannot see banned users.
51
52 Filters out banned users.
53 Properly resolves value ties by ID.
54
55 Different databases treat time precision differently so resolve by the row ID instead.
56 """
57 if admin:
58 standings_query = db.session.query(
59 Teams.id.label('teamid'),
60 Teams.name.label('name'),
61 Teams.banned, sumscores.columns.score
62 )\
63 .join(sumscores, Teams.id == sumscores.columns.teamid) \
64 .order_by(sumscores.columns.score.desc(), sumscores.columns.id)
65 else:
66 standings_query = db.session.query(
67 Teams.id.label('teamid'),
68 Teams.name.label('name'),
69 sumscores.columns.score
70 )\
71 .join(sumscores, Teams.id == sumscores.columns.teamid) \
72 .filter(Teams.banned == False) \
73 .order_by(sumscores.columns.score.desc(), sumscores.columns.id)
74
75 """
76 Only select a certain amount of users if asked.
77 """
78 if count is None:
79 standings = standings_query.all()
80 else:
81 standings = standings_query.limit(count).all()
82 db.session.close()
83
84 return standings
85
86
87 @scoreboard.route('/scoreboard')
88 def scoreboard_view():
89 if utils.get_config('view_scoreboard_if_authed') and not utils.authed():
90 return redirect(url_for('auth.login', next=request.path))
91 if utils.hide_scores():
92 return render_template('scoreboard.html', errors=['Scores are currently hidden'])
93 standings = get_standings()
94 return render_template('scoreboard.html', teams=standings, score_frozen=utils.is_scoreboard_frozen())
95
96
97 @scoreboard.route('/scores')
98 def scores():
99 json = {'standings': []}
100 if utils.get_config('view_scoreboard_if_authed') and not utils.authed():
101 return redirect(url_for('auth.login', next=request.path))
102 if utils.hide_scores():
103 return jsonify(json)
104
105 standings = get_standings()
106
107 for i, x in enumerate(standings):
108 json['standings'].append({'pos': i + 1, 'id': x.teamid, 'team': x.name, 'score': int(x.score)})
109 return jsonify(json)
110
111
112 @scoreboard.route('/top/<int:count>')
113 def topteams(count):
114 json = {'places': {}}
115 if utils.get_config('view_scoreboard_if_authed') and not utils.authed():
116 return redirect(url_for('auth.login', next=request.path))
117 if utils.hide_scores():
118 return jsonify(json)
119
120 if count > 20 or count < 0:
121 count = 10
122
123 standings = get_standings(count=count)
124
125 for i, team in enumerate(standings):
126 solves = Solves.query.filter_by(teamid=team.teamid)
127 awards = Awards.query.filter_by(teamid=team.teamid)
128
129 freeze = utils.get_config('freeze')
130
131 if freeze:
132 solves = solves.filter(Solves.date < utils.unix_time_to_utc(freeze))
133 awards = awards.filter(Awards.date < utils.unix_time_to_utc(freeze))
134
135 solves = solves.all()
136 awards = awards.all()
137
138 json['places'][i + 1] = {
139 'id': team.teamid,
140 'name': team.name,
141 'solves': []
142 }
143 for x in solves:
144 json['places'][i + 1]['solves'].append({
145 'chal': x.chalid,
146 'team': x.teamid,
147 'value': x.chal.value,
148 'time': utils.unix_time(x.date)
149 })
150 for award in awards:
151 json['places'][i + 1]['solves'].append({
152 'chal': None,
153 'team': award.teamid,
154 'value': award.value,
155 'time': utils.unix_time(award.date)
156 })
157 json['places'][i + 1]['solves'] = sorted(json['places'][i + 1]['solves'], key=lambda k: k['time'])
158 return jsonify(json)
159
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/CTFd/scoreboard.py b/CTFd/scoreboard.py
--- a/CTFd/scoreboard.py
+++ b/CTFd/scoreboard.py
@@ -122,37 +122,42 @@
standings = get_standings(count=count)
- for i, team in enumerate(standings):
- solves = Solves.query.filter_by(teamid=team.teamid)
- awards = Awards.query.filter_by(teamid=team.teamid)
+ team_ids = [team.teamid for team in standings]
- freeze = utils.get_config('freeze')
+ solves = Solves.query.filter(Solves.teamid.in_(team_ids))
+ awards = Awards.query.filter(Awards.teamid.in_(team_ids))
- if freeze:
- solves = solves.filter(Solves.date < utils.unix_time_to_utc(freeze))
- awards = awards.filter(Awards.date < utils.unix_time_to_utc(freeze))
+ freeze = utils.get_config('freeze')
+
+ if freeze:
+ solves = solves.filter(Solves.date < utils.unix_time_to_utc(freeze))
+ awards = awards.filter(Awards.date < utils.unix_time_to_utc(freeze))
- solves = solves.all()
- awards = awards.all()
+ solves = solves.all()
+ awards = awards.all()
+ for i, team in enumerate(team_ids):
json['places'][i + 1] = {
- 'id': team.teamid,
- 'name': team.name,
+ 'id': standings[i].teamid,
+ 'name': standings[i].name,
'solves': []
}
- for x in solves:
- json['places'][i + 1]['solves'].append({
- 'chal': x.chalid,
- 'team': x.teamid,
- 'value': x.chal.value,
- 'time': utils.unix_time(x.date)
- })
+ for solve in solves:
+ if solve.teamid == team:
+ json['places'][i + 1]['solves'].append({
+ 'chal': solve.chalid,
+ 'team': solve.teamid,
+ 'value': solve.chal.value,
+ 'time': utils.unix_time(solve.date)
+ })
for award in awards:
- json['places'][i + 1]['solves'].append({
- 'chal': None,
- 'team': award.teamid,
- 'value': award.value,
- 'time': utils.unix_time(award.date)
- })
+ if award.teamid == team:
+ json['places'][i + 1]['solves'].append({
+ 'chal': None,
+ 'team': award.teamid,
+ 'value': award.value,
+ 'time': utils.unix_time(award.date)
+ })
json['places'][i + 1]['solves'] = sorted(json['places'][i + 1]['solves'], key=lambda k: k['time'])
+
return jsonify(json)
|
{"golden_diff": "diff --git a/CTFd/scoreboard.py b/CTFd/scoreboard.py\n--- a/CTFd/scoreboard.py\n+++ b/CTFd/scoreboard.py\n@@ -122,37 +122,42 @@\n \n standings = get_standings(count=count)\n \n- for i, team in enumerate(standings):\n- solves = Solves.query.filter_by(teamid=team.teamid)\n- awards = Awards.query.filter_by(teamid=team.teamid)\n+ team_ids = [team.teamid for team in standings]\n \n- freeze = utils.get_config('freeze')\n+ solves = Solves.query.filter(Solves.teamid.in_(team_ids))\n+ awards = Awards.query.filter(Awards.teamid.in_(team_ids))\n \n- if freeze:\n- solves = solves.filter(Solves.date < utils.unix_time_to_utc(freeze))\n- awards = awards.filter(Awards.date < utils.unix_time_to_utc(freeze))\n+ freeze = utils.get_config('freeze')\n+\n+ if freeze:\n+ solves = solves.filter(Solves.date < utils.unix_time_to_utc(freeze))\n+ awards = awards.filter(Awards.date < utils.unix_time_to_utc(freeze))\n \n- solves = solves.all()\n- awards = awards.all()\n+ solves = solves.all()\n+ awards = awards.all()\n \n+ for i, team in enumerate(team_ids):\n json['places'][i + 1] = {\n- 'id': team.teamid,\n- 'name': team.name,\n+ 'id': standings[i].teamid,\n+ 'name': standings[i].name,\n 'solves': []\n }\n- for x in solves:\n- json['places'][i + 1]['solves'].append({\n- 'chal': x.chalid,\n- 'team': x.teamid,\n- 'value': x.chal.value,\n- 'time': utils.unix_time(x.date)\n- })\n+ for solve in solves:\n+ if solve.teamid == team:\n+ json['places'][i + 1]['solves'].append({\n+ 'chal': solve.chalid,\n+ 'team': solve.teamid,\n+ 'value': solve.chal.value,\n+ 'time': utils.unix_time(solve.date)\n+ })\n for award in awards:\n- json['places'][i + 1]['solves'].append({\n- 'chal': None,\n- 'team': award.teamid,\n- 'value': award.value,\n- 'time': utils.unix_time(award.date)\n- })\n+ if award.teamid == team:\n+ json['places'][i + 1]['solves'].append({\n+ 'chal': None,\n+ 'team': award.teamid,\n+ 'value': award.value,\n+ 'time': utils.unix_time(award.date)\n+ })\n json['places'][i + 1]['solves'] = sorted(json['places'][i + 1]['solves'], key=lambda k: k['time'])\n+\n return jsonify(json)\n", "issue": "Optimize top10 call\nhttps://github.com/CTFd/CTFd/blob/master/CTFd/scoreboard.py#L125-L127\r\n\r\nThis code seems pretty wasteful and is likely getting hit fairly often. Optimizing this to be a single database query is likely a good idea. \n", "before_files": [{"content": "from flask import render_template, jsonify, Blueprint, redirect, url_for, request\nfrom sqlalchemy.sql.expression import union_all\n\nfrom CTFd.models import db, Teams, Solves, Awards, Challenges\n\nfrom CTFd import utils\n\nscoreboard = Blueprint('scoreboard', __name__)\n\n\ndef get_standings(admin=False, count=None):\n scores = db.session.query(\n Solves.teamid.label('teamid'),\n db.func.sum(Challenges.value).label('score'),\n db.func.max(Solves.id).label('id'),\n db.func.max(Solves.date).label('date')\n ).join(Challenges).group_by(Solves.teamid)\n\n awards = db.session.query(\n Awards.teamid.label('teamid'),\n db.func.sum(Awards.value).label('score'),\n db.func.max(Awards.id).label('id'),\n db.func.max(Awards.date).label('date')\n ).group_by(Awards.teamid)\n\n \"\"\"\n Filter out solves and awards that are before a specific time point.\n \"\"\"\n freeze = utils.get_config('freeze')\n if not admin and freeze:\n scores = scores.filter(Solves.date < utils.unix_time_to_utc(freeze))\n awards = awards.filter(Awards.date < utils.unix_time_to_utc(freeze))\n\n \"\"\"\n Combine awards and solves with a union. They should have the same amount of columns\n \"\"\"\n results = union_all(scores, awards).alias('results')\n\n \"\"\"\n Sum each of the results by the team id to get their score.\n \"\"\"\n sumscores = db.session.query(\n results.columns.teamid,\n db.func.sum(results.columns.score).label('score'),\n db.func.max(results.columns.id).label('id'),\n db.func.max(results.columns.date).label('date')\n ).group_by(results.columns.teamid).subquery()\n\n \"\"\"\n Admins can see scores for all users but the public cannot see banned users.\n\n Filters out banned users.\n Properly resolves value ties by ID.\n\n Different databases treat time precision differently so resolve by the row ID instead.\n \"\"\"\n if admin:\n standings_query = db.session.query(\n Teams.id.label('teamid'),\n Teams.name.label('name'),\n Teams.banned, sumscores.columns.score\n )\\\n .join(sumscores, Teams.id == sumscores.columns.teamid) \\\n .order_by(sumscores.columns.score.desc(), sumscores.columns.id)\n else:\n standings_query = db.session.query(\n Teams.id.label('teamid'),\n Teams.name.label('name'),\n sumscores.columns.score\n )\\\n .join(sumscores, Teams.id == sumscores.columns.teamid) \\\n .filter(Teams.banned == False) \\\n .order_by(sumscores.columns.score.desc(), sumscores.columns.id)\n\n \"\"\"\n Only select a certain amount of users if asked.\n \"\"\"\n if count is None:\n standings = standings_query.all()\n else:\n standings = standings_query.limit(count).all()\n db.session.close()\n\n return standings\n\n\[email protected]('/scoreboard')\ndef scoreboard_view():\n if utils.get_config('view_scoreboard_if_authed') and not utils.authed():\n return redirect(url_for('auth.login', next=request.path))\n if utils.hide_scores():\n return render_template('scoreboard.html', errors=['Scores are currently hidden'])\n standings = get_standings()\n return render_template('scoreboard.html', teams=standings, score_frozen=utils.is_scoreboard_frozen())\n\n\[email protected]('/scores')\ndef scores():\n json = {'standings': []}\n if utils.get_config('view_scoreboard_if_authed') and not utils.authed():\n return redirect(url_for('auth.login', next=request.path))\n if utils.hide_scores():\n return jsonify(json)\n\n standings = get_standings()\n\n for i, x in enumerate(standings):\n json['standings'].append({'pos': i + 1, 'id': x.teamid, 'team': x.name, 'score': int(x.score)})\n return jsonify(json)\n\n\[email protected]('/top/<int:count>')\ndef topteams(count):\n json = {'places': {}}\n if utils.get_config('view_scoreboard_if_authed') and not utils.authed():\n return redirect(url_for('auth.login', next=request.path))\n if utils.hide_scores():\n return jsonify(json)\n\n if count > 20 or count < 0:\n count = 10\n\n standings = get_standings(count=count)\n\n for i, team in enumerate(standings):\n solves = Solves.query.filter_by(teamid=team.teamid)\n awards = Awards.query.filter_by(teamid=team.teamid)\n\n freeze = utils.get_config('freeze')\n\n if freeze:\n solves = solves.filter(Solves.date < utils.unix_time_to_utc(freeze))\n awards = awards.filter(Awards.date < utils.unix_time_to_utc(freeze))\n\n solves = solves.all()\n awards = awards.all()\n\n json['places'][i + 1] = {\n 'id': team.teamid,\n 'name': team.name,\n 'solves': []\n }\n for x in solves:\n json['places'][i + 1]['solves'].append({\n 'chal': x.chalid,\n 'team': x.teamid,\n 'value': x.chal.value,\n 'time': utils.unix_time(x.date)\n })\n for award in awards:\n json['places'][i + 1]['solves'].append({\n 'chal': None,\n 'team': award.teamid,\n 'value': award.value,\n 'time': utils.unix_time(award.date)\n })\n json['places'][i + 1]['solves'] = sorted(json['places'][i + 1]['solves'], key=lambda k: k['time'])\n return jsonify(json)\n", "path": "CTFd/scoreboard.py"}], "after_files": [{"content": "from flask import render_template, jsonify, Blueprint, redirect, url_for, request\nfrom sqlalchemy.sql.expression import union_all\n\nfrom CTFd.models import db, Teams, Solves, Awards, Challenges\n\nfrom CTFd import utils\n\nscoreboard = Blueprint('scoreboard', __name__)\n\n\ndef get_standings(admin=False, count=None):\n scores = db.session.query(\n Solves.teamid.label('teamid'),\n db.func.sum(Challenges.value).label('score'),\n db.func.max(Solves.id).label('id'),\n db.func.max(Solves.date).label('date')\n ).join(Challenges).group_by(Solves.teamid)\n\n awards = db.session.query(\n Awards.teamid.label('teamid'),\n db.func.sum(Awards.value).label('score'),\n db.func.max(Awards.id).label('id'),\n db.func.max(Awards.date).label('date')\n ).group_by(Awards.teamid)\n\n \"\"\"\n Filter out solves and awards that are before a specific time point.\n \"\"\"\n freeze = utils.get_config('freeze')\n if not admin and freeze:\n scores = scores.filter(Solves.date < utils.unix_time_to_utc(freeze))\n awards = awards.filter(Awards.date < utils.unix_time_to_utc(freeze))\n\n \"\"\"\n Combine awards and solves with a union. They should have the same amount of columns\n \"\"\"\n results = union_all(scores, awards).alias('results')\n\n \"\"\"\n Sum each of the results by the team id to get their score.\n \"\"\"\n sumscores = db.session.query(\n results.columns.teamid,\n db.func.sum(results.columns.score).label('score'),\n db.func.max(results.columns.id).label('id'),\n db.func.max(results.columns.date).label('date')\n ).group_by(results.columns.teamid).subquery()\n\n \"\"\"\n Admins can see scores for all users but the public cannot see banned users.\n\n Filters out banned users.\n Properly resolves value ties by ID.\n\n Different databases treat time precision differently so resolve by the row ID instead.\n \"\"\"\n if admin:\n standings_query = db.session.query(\n Teams.id.label('teamid'),\n Teams.name.label('name'),\n Teams.banned, sumscores.columns.score\n )\\\n .join(sumscores, Teams.id == sumscores.columns.teamid) \\\n .order_by(sumscores.columns.score.desc(), sumscores.columns.id)\n else:\n standings_query = db.session.query(\n Teams.id.label('teamid'),\n Teams.name.label('name'),\n sumscores.columns.score\n )\\\n .join(sumscores, Teams.id == sumscores.columns.teamid) \\\n .filter(Teams.banned == False) \\\n .order_by(sumscores.columns.score.desc(), sumscores.columns.id)\n\n \"\"\"\n Only select a certain amount of users if asked.\n \"\"\"\n if count is None:\n standings = standings_query.all()\n else:\n standings = standings_query.limit(count).all()\n db.session.close()\n\n return standings\n\n\[email protected]('/scoreboard')\ndef scoreboard_view():\n if utils.get_config('view_scoreboard_if_authed') and not utils.authed():\n return redirect(url_for('auth.login', next=request.path))\n if utils.hide_scores():\n return render_template('scoreboard.html', errors=['Scores are currently hidden'])\n standings = get_standings()\n return render_template('scoreboard.html', teams=standings, score_frozen=utils.is_scoreboard_frozen())\n\n\[email protected]('/scores')\ndef scores():\n json = {'standings': []}\n if utils.get_config('view_scoreboard_if_authed') and not utils.authed():\n return redirect(url_for('auth.login', next=request.path))\n if utils.hide_scores():\n return jsonify(json)\n\n standings = get_standings()\n\n for i, x in enumerate(standings):\n json['standings'].append({'pos': i + 1, 'id': x.teamid, 'team': x.name, 'score': int(x.score)})\n return jsonify(json)\n\n\[email protected]('/top/<int:count>')\ndef topteams(count):\n json = {'places': {}}\n if utils.get_config('view_scoreboard_if_authed') and not utils.authed():\n return redirect(url_for('auth.login', next=request.path))\n if utils.hide_scores():\n return jsonify(json)\n\n if count > 20 or count < 0:\n count = 10\n\n standings = get_standings(count=count)\n\n team_ids = [team.teamid for team in standings]\n\n solves = Solves.query.filter(Solves.teamid.in_(team_ids))\n awards = Awards.query.filter(Awards.teamid.in_(team_ids))\n\n freeze = utils.get_config('freeze')\n\n if freeze:\n solves = solves.filter(Solves.date < utils.unix_time_to_utc(freeze))\n awards = awards.filter(Awards.date < utils.unix_time_to_utc(freeze))\n\n solves = solves.all()\n awards = awards.all()\n\n for i, team in enumerate(team_ids):\n json['places'][i + 1] = {\n 'id': standings[i].teamid,\n 'name': standings[i].name,\n 'solves': []\n }\n for solve in solves:\n if solve.teamid == team:\n json['places'][i + 1]['solves'].append({\n 'chal': solve.chalid,\n 'team': solve.teamid,\n 'value': solve.chal.value,\n 'time': utils.unix_time(solve.date)\n })\n for award in awards:\n if award.teamid == team:\n json['places'][i + 1]['solves'].append({\n 'chal': None,\n 'team': award.teamid,\n 'value': award.value,\n 'time': utils.unix_time(award.date)\n })\n json['places'][i + 1]['solves'] = sorted(json['places'][i + 1]['solves'], key=lambda k: k['time'])\n\n return jsonify(json)\n", "path": "CTFd/scoreboard.py"}]}
| 1,969 | 677 |
gh_patches_debug_25120
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-936
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ERROR:checkov.terraform.checks.resource.gcp.CloudStorageSelfLogging:Failed to run check: Bucket should not log to itself for configuration
**Describe the bug**
Error during check with rule CKV_GCP_63 (not clearly identify)
Here is the result of my terraform plan for my GCS resource using [terraform google storage module](https://github.com/terraform-google-modules/terraform-google-cloud-storage)
```
resource "google_storage_bucket" "buckets" {
bucket_policy_only = (known after apply)
force_destroy = false
id = (known after apply)
labels = {
"name" = "xxxxxxxx-bucket"
}
location = "EU"
name = "xxxxxxxx-bucket"
project = "xxxxxxxx-project"
self_link = (known after apply)
storage_class = "STANDARD"
uniform_bucket_level_access = true
url = (known after apply)
versioning {
enabled = true
}
}
```
```
ERROR:checkov.terraform.checks.resource.gcp.CloudStorageSelfLogging:Failed to run check: Bucket should not log to itself for configuration
[[]], 'default_event_based_hold': [None], 'encryption': [[]], 'force_destroy': [False], 'labels': [{'name': ['xxxxxxxx-bucket'], 'start_line': [158], 'end_line': [160]}], 'lifecycle_rule': [[]], 'location': ['EU'], 'logging': [[]], 'name': ['xxxxxxxx-bucket'], 'project': ['xxxxxxxx-project'], 'requester_pays': [None], 'retention_policy': [[]], 'storage_class': ['STANDARD'], 'uniform_bucket_level_access': [True], 'versioning': [{'enabled': [True], 'start_line': [171], 'end_line': [173]}], 'website': [[]], 'start_line': [153], 'end_line': [176]} at file: /checkov.tfplan.json
Traceback (most recent call last):
File "/usr/local/bin/checkov", line 5, in <module>
run()
File "/usr/local/lib/python3.8/site-packages/checkov/main.py", line 96, in run
scan_reports = runner_registry.run(external_checks_dir=external_checks_dir, files=args.file,
File "/usr/local/lib/python3.8/site-packages/checkov/common/runners/runner_registry.py", line 34, in run
scan_report = runner.run(root_folder, external_checks_dir=external_checks_dir, files=files,
File "/usr/local/lib/python3.8/site-packages/checkov/terraform/plan_runner.py", line 65, in run
self.check_tf_definition(report, runner_filter)
File "/usr/local/lib/python3.8/site-packages/checkov/terraform/plan_runner.py", line 79, in check_tf_definition
self.run_block(definition[block_type], full_file_path, report, scanned_file,
File "/usr/local/lib/python3.8/site-packages/checkov/terraform/plan_runner.py", line 95, in run_block
results = registry.scan(scanned_file, entity, [], runner_filter)
File "/usr/local/lib/python3.8/site-packages/checkov/common/checks/base_check_registry.py", line 109, in scan
result = self.run_check(check, entity_configuration, entity_name, entity_type, scanned_file, skip_info)
File "/usr/local/lib/python3.8/site-packages/checkov/common/checks/base_check_registry.py", line 115, in run_check
result = check.run(scanned_file=scanned_file, entity_configuration=entity_configuration,
File "/usr/local/lib/python3.8/site-packages/checkov/common/checks/base_check.py", line 62, in run
raise e
File "/usr/local/lib/python3.8/site-packages/checkov/common/checks/base_check.py", line 42, in run
check_result['result'] = self.scan_entity_conf(entity_configuration, entity_type)
File "/usr/local/lib/python3.8/site-packages/checkov/terraform/checks/resource/base_resource_check.py", line 17, in scan_entity_conf
return self.scan_resource_conf(conf, entity_type)
File "/usr/local/lib/python3.8/site-packages/checkov/terraform/checks/resource/base_resource_check.py", line 33, in wrapper
return wrapped(self, conf)
File "/usr/local/lib/python3.8/site-packages/checkov/terraform/checks/resource/gcp/CloudStorageSelfLogging.py", line 17, in scan_resource_conf
if conf['logging'][0]['log_bucket']:
TypeError: list indices must be integers or slices, not str
```
**To Reproduce**
Steps to reproduce the behavior:
1. Using [terraform GCS module](https://github.com/terraform-google-modules/terraform-google-cloud-storage) in your terraform
2. Run checkov scan
3. See error
**Informations**
- Checkov Version 1.0.799 (from docker image)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `checkov/terraform/checks/resource/gcp/CloudStorageLogging.py`
Content:
```
1 from checkov.common.models.enums import CheckResult, CheckCategories
2 from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck
3
4
5 class CloudStorageLogging(BaseResourceCheck):
6 def __init__(self):
7 name = "Bucket should log access"
8 id = "CKV_GCP_62"
9 supported_resources = ['google_storage_bucket']
10 categories = [CheckCategories.LOGGING]
11 super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
12
13 def scan_resource_conf(self, conf):
14 #check fot logging
15 if 'logging' in conf.keys():
16 if conf['logging'][0]['log_bucket']:
17 log_bucket_name = conf['logging'][0]['log_bucket']
18 if log_bucket_name != None:
19 return CheckResult.PASSED
20 else:
21 return CheckResult.FAILED
22 else:
23 return CheckResult.FAILED
24 return CheckResult.FAILED
25 else:
26 return CheckResult.FAILED
27 return CheckResult.FAILED
28
29 check = CloudStorageLogging()
30
```
Path: `checkov/terraform/checks/resource/gcp/CloudStorageSelfLogging.py`
Content:
```
1 from checkov.common.models.enums import CheckResult, CheckCategories
2 from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck
3
4
5 class CloudStorageSelfLogging(BaseResourceCheck):
6 def __init__(self):
7 name = "Bucket should not log to itself"
8 id = "CKV_GCP_63"
9 supported_resources = ['google_storage_bucket']
10 categories = [CheckCategories.LOGGING]
11 super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
12
13 def scan_resource_conf(self, conf):
14 bucket_name = conf['name']
15 #check fot logging
16 if 'logging' in conf.keys():
17 if conf['logging'][0]['log_bucket']:
18 log_bucket_name = conf['logging'][0]['log_bucket']
19 if log_bucket_name != bucket_name:
20 return CheckResult.PASSED
21 else:
22 return CheckResult.FAILED
23 else:
24 return CheckResult.FAILED
25 return CheckResult.FAILED
26 return CheckResult.UNKNOWN
27
28 check = CloudStorageSelfLogging()
29
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/checkov/terraform/checks/resource/gcp/CloudStorageLogging.py b/checkov/terraform/checks/resource/gcp/CloudStorageLogging.py
--- a/checkov/terraform/checks/resource/gcp/CloudStorageLogging.py
+++ b/checkov/terraform/checks/resource/gcp/CloudStorageLogging.py
@@ -11,9 +11,9 @@
super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
def scan_resource_conf(self, conf):
- #check fot logging
- if 'logging' in conf.keys():
- if conf['logging'][0]['log_bucket']:
+ #check for logging
+ if 'logging' in conf:
+ if conf['logging'][0]:
log_bucket_name = conf['logging'][0]['log_bucket']
if log_bucket_name != None:
return CheckResult.PASSED
diff --git a/checkov/terraform/checks/resource/gcp/CloudStorageSelfLogging.py b/checkov/terraform/checks/resource/gcp/CloudStorageSelfLogging.py
--- a/checkov/terraform/checks/resource/gcp/CloudStorageSelfLogging.py
+++ b/checkov/terraform/checks/resource/gcp/CloudStorageSelfLogging.py
@@ -12,9 +12,9 @@
def scan_resource_conf(self, conf):
bucket_name = conf['name']
- #check fot logging
- if 'logging' in conf.keys():
- if conf['logging'][0]['log_bucket']:
+ #check for logging
+ if 'logging' in conf:
+ if conf['logging'][0]:
log_bucket_name = conf['logging'][0]['log_bucket']
if log_bucket_name != bucket_name:
return CheckResult.PASSED
|
{"golden_diff": "diff --git a/checkov/terraform/checks/resource/gcp/CloudStorageLogging.py b/checkov/terraform/checks/resource/gcp/CloudStorageLogging.py\n--- a/checkov/terraform/checks/resource/gcp/CloudStorageLogging.py\n+++ b/checkov/terraform/checks/resource/gcp/CloudStorageLogging.py\n@@ -11,9 +11,9 @@\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n \n def scan_resource_conf(self, conf):\n- #check fot logging\n- if 'logging' in conf.keys():\n- if conf['logging'][0]['log_bucket']:\n+ #check for logging\n+ if 'logging' in conf:\n+ if conf['logging'][0]:\n log_bucket_name = conf['logging'][0]['log_bucket']\n if log_bucket_name != None:\n return CheckResult.PASSED\ndiff --git a/checkov/terraform/checks/resource/gcp/CloudStorageSelfLogging.py b/checkov/terraform/checks/resource/gcp/CloudStorageSelfLogging.py\n--- a/checkov/terraform/checks/resource/gcp/CloudStorageSelfLogging.py\n+++ b/checkov/terraform/checks/resource/gcp/CloudStorageSelfLogging.py\n@@ -12,9 +12,9 @@\n \n def scan_resource_conf(self, conf):\n bucket_name = conf['name']\n- #check fot logging\n- if 'logging' in conf.keys():\n- if conf['logging'][0]['log_bucket']:\n+ #check for logging\n+ if 'logging' in conf:\n+ if conf['logging'][0]:\n log_bucket_name = conf['logging'][0]['log_bucket']\n if log_bucket_name != bucket_name:\n return CheckResult.PASSED\n", "issue": "ERROR:checkov.terraform.checks.resource.gcp.CloudStorageSelfLogging:Failed to run check: Bucket should not log to itself for configuration\n**Describe the bug**\r\nError during check with rule CKV_GCP_63 (not clearly identify)\r\n\r\nHere is the result of my terraform plan for my GCS resource using [terraform google storage module](https://github.com/terraform-google-modules/terraform-google-cloud-storage)\r\n```\r\nresource \"google_storage_bucket\" \"buckets\" {\r\n bucket_policy_only = (known after apply)\r\n force_destroy = false\r\n id = (known after apply)\r\n labels = {\r\n \"name\" = \"xxxxxxxx-bucket\"\r\n }\r\n location = \"EU\"\r\n name = \"xxxxxxxx-bucket\"\r\n project = \"xxxxxxxx-project\"\r\n self_link = (known after apply)\r\n storage_class = \"STANDARD\"\r\n uniform_bucket_level_access = true\r\n url = (known after apply)\r\n versioning {\r\n enabled = true\r\n }\r\n }\r\n```\r\n\r\n```\r\nERROR:checkov.terraform.checks.resource.gcp.CloudStorageSelfLogging:Failed to run check: Bucket should not log to itself for configuration\r\n[[]], 'default_event_based_hold': [None], 'encryption': [[]], 'force_destroy': [False], 'labels': [{'name': ['xxxxxxxx-bucket'], 'start_line': [158], 'end_line': [160]}], 'lifecycle_rule': [[]], 'location': ['EU'], 'logging': [[]], 'name': ['xxxxxxxx-bucket'], 'project': ['xxxxxxxx-project'], 'requester_pays': [None], 'retention_policy': [[]], 'storage_class': ['STANDARD'], 'uniform_bucket_level_access': [True], 'versioning': [{'enabled': [True], 'start_line': [171], 'end_line': [173]}], 'website': [[]], 'start_line': [153], 'end_line': [176]} at file: /checkov.tfplan.json\r\nTraceback (most recent call last):\r\n File \"/usr/local/bin/checkov\", line 5, in <module>\r\n run()\r\n File \"/usr/local/lib/python3.8/site-packages/checkov/main.py\", line 96, in run\r\n scan_reports = runner_registry.run(external_checks_dir=external_checks_dir, files=args.file,\r\n File \"/usr/local/lib/python3.8/site-packages/checkov/common/runners/runner_registry.py\", line 34, in run\r\n scan_report = runner.run(root_folder, external_checks_dir=external_checks_dir, files=files,\r\n File \"/usr/local/lib/python3.8/site-packages/checkov/terraform/plan_runner.py\", line 65, in run\r\n self.check_tf_definition(report, runner_filter)\r\n File \"/usr/local/lib/python3.8/site-packages/checkov/terraform/plan_runner.py\", line 79, in check_tf_definition\r\n self.run_block(definition[block_type], full_file_path, report, scanned_file,\r\n File \"/usr/local/lib/python3.8/site-packages/checkov/terraform/plan_runner.py\", line 95, in run_block\r\n results = registry.scan(scanned_file, entity, [], runner_filter)\r\n File \"/usr/local/lib/python3.8/site-packages/checkov/common/checks/base_check_registry.py\", line 109, in scan\r\n result = self.run_check(check, entity_configuration, entity_name, entity_type, scanned_file, skip_info)\r\n File \"/usr/local/lib/python3.8/site-packages/checkov/common/checks/base_check_registry.py\", line 115, in run_check\r\n result = check.run(scanned_file=scanned_file, entity_configuration=entity_configuration,\r\n File \"/usr/local/lib/python3.8/site-packages/checkov/common/checks/base_check.py\", line 62, in run\r\n raise e\r\n File \"/usr/local/lib/python3.8/site-packages/checkov/common/checks/base_check.py\", line 42, in run\r\n check_result['result'] = self.scan_entity_conf(entity_configuration, entity_type)\r\n File \"/usr/local/lib/python3.8/site-packages/checkov/terraform/checks/resource/base_resource_check.py\", line 17, in scan_entity_conf\r\n return self.scan_resource_conf(conf, entity_type)\r\n File \"/usr/local/lib/python3.8/site-packages/checkov/terraform/checks/resource/base_resource_check.py\", line 33, in wrapper\r\n return wrapped(self, conf)\r\n File \"/usr/local/lib/python3.8/site-packages/checkov/terraform/checks/resource/gcp/CloudStorageSelfLogging.py\", line 17, in scan_resource_conf\r\n if conf['logging'][0]['log_bucket']:\r\nTypeError: list indices must be integers or slices, not str\r\n```\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Using [terraform GCS module](https://github.com/terraform-google-modules/terraform-google-cloud-storage) in your terraform\r\n2. Run checkov scan\r\n3. See error\r\n\r\n**Informations**\r\n - Checkov Version 1.0.799 (from docker image)\n", "before_files": [{"content": "from checkov.common.models.enums import CheckResult, CheckCategories\nfrom checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\n\n\nclass CloudStorageLogging(BaseResourceCheck):\n def __init__(self):\n name = \"Bucket should log access\"\n id = \"CKV_GCP_62\"\n supported_resources = ['google_storage_bucket']\n categories = [CheckCategories.LOGGING]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def scan_resource_conf(self, conf):\n #check fot logging\n if 'logging' in conf.keys():\n if conf['logging'][0]['log_bucket']:\n log_bucket_name = conf['logging'][0]['log_bucket']\n if log_bucket_name != None:\n return CheckResult.PASSED\n else:\n return CheckResult.FAILED\n else:\n return CheckResult.FAILED\n return CheckResult.FAILED\n else:\n return CheckResult.FAILED\n return CheckResult.FAILED\n\ncheck = CloudStorageLogging()\n", "path": "checkov/terraform/checks/resource/gcp/CloudStorageLogging.py"}, {"content": "from checkov.common.models.enums import CheckResult, CheckCategories\nfrom checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\n\n\nclass CloudStorageSelfLogging(BaseResourceCheck):\n def __init__(self):\n name = \"Bucket should not log to itself\"\n id = \"CKV_GCP_63\"\n supported_resources = ['google_storage_bucket']\n categories = [CheckCategories.LOGGING]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def scan_resource_conf(self, conf):\n bucket_name = conf['name']\n #check fot logging\n if 'logging' in conf.keys():\n if conf['logging'][0]['log_bucket']:\n log_bucket_name = conf['logging'][0]['log_bucket']\n if log_bucket_name != bucket_name:\n return CheckResult.PASSED\n else:\n return CheckResult.FAILED\n else:\n return CheckResult.FAILED\n return CheckResult.FAILED\n return CheckResult.UNKNOWN\n\ncheck = CloudStorageSelfLogging()\n", "path": "checkov/terraform/checks/resource/gcp/CloudStorageSelfLogging.py"}], "after_files": [{"content": "from checkov.common.models.enums import CheckResult, CheckCategories\nfrom checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\n\n\nclass CloudStorageLogging(BaseResourceCheck):\n def __init__(self):\n name = \"Bucket should log access\"\n id = \"CKV_GCP_62\"\n supported_resources = ['google_storage_bucket']\n categories = [CheckCategories.LOGGING]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def scan_resource_conf(self, conf):\n #check for logging\n if 'logging' in conf:\n if conf['logging'][0]:\n log_bucket_name = conf['logging'][0]['log_bucket']\n if log_bucket_name != None:\n return CheckResult.PASSED\n else:\n return CheckResult.FAILED\n else:\n return CheckResult.FAILED\n return CheckResult.FAILED\n else:\n return CheckResult.FAILED\n return CheckResult.FAILED\n\ncheck = CloudStorageLogging()\n", "path": "checkov/terraform/checks/resource/gcp/CloudStorageLogging.py"}, {"content": "from checkov.common.models.enums import CheckResult, CheckCategories\nfrom checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\n\n\nclass CloudStorageSelfLogging(BaseResourceCheck):\n def __init__(self):\n name = \"Bucket should not log to itself\"\n id = \"CKV_GCP_63\"\n supported_resources = ['google_storage_bucket']\n categories = [CheckCategories.LOGGING]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def scan_resource_conf(self, conf):\n bucket_name = conf['name']\n #check for logging\n if 'logging' in conf:\n if conf['logging'][0]:\n log_bucket_name = conf['logging'][0]['log_bucket']\n if log_bucket_name != bucket_name:\n return CheckResult.PASSED\n else:\n return CheckResult.FAILED\n else:\n return CheckResult.FAILED\n return CheckResult.FAILED\n return CheckResult.UNKNOWN\n\ncheck = CloudStorageSelfLogging()\n", "path": "checkov/terraform/checks/resource/gcp/CloudStorageSelfLogging.py"}]}
| 1,943 | 382 |
gh_patches_debug_38632
|
rasdani/github-patches
|
git_diff
|
kserve__kserve-549
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
XGBoost Model Perfomance Issue
/kind bug
XGboost model server perform poorly after deployed to k8s.
**What steps did you take and what happened:**
I did performance test for xgbserver using provided sample model.
`load.cfg`:
```
POST http://<target>/v1/models/default:predict
@request.json
```
`req.json`:
```
{"instances": [[1,2,3,4]]}
```
Running locally (on Mac OS, 8 core machine) with vegeta
```
cat load.cfg | vegeta attack -duration 1m -rate 1000 | vegeta report -type=text
```
I am able to hit 1000 RPS with good latencies result.
```
Requests [total, rate, throughput] 60000, 1000.02, 1000.00
Duration [total, attack, wait] 1m0.000012024s, 59.999069988s, 942.036µs
Latencies [mean, 50, 90, 95, 99, max] 1.070524ms, 946.443µs, 1.414653ms, 1.520775ms, 2.401196ms, 17.650717ms
Bytes In [total, mean] 1320000, 22.00
Bytes Out [total, mean] 1560000, 26.00
Success [ratio] 100.00%
Status Codes [code:count] 200:60000
```
But after deployed to K8S (with 4 core as CPU request and limit)
The performance deteriorates at 100 RPS
```
cat load-1.cfg | vegeta attack -rate 100 -duration 60s | vegeta report
```
```
Requests [total, rate, throughput] 6000, 100.02, 89.47
Duration [total, attack, wait] 1m7.064629048s, 59.989775627s, 7.074853421s
Latencies [mean, 50, 90, 95, 99, max] 1.524605151s, 3.683733ms, 5.575147148s, 7.007148666s, 7.789309456s, 8.606190814s
Bytes In [total, mean] 132000, 22.00
Bytes Out [total, mean] 192000, 32.00
Success [ratio] 100.00%
Status Codes [code:count] 200:6000
```
**What did you expect to happen:**
The performance should not be affected too much after deployed to K8S.
**Anything else you would like to add:**
I suspected the issue come from `nthread` in xgbserver are left to default (i.e. 0).
In:
https://github.com/kubeflow/kfserving/blob/c46a0da8c0cf168dccfcee3b79f306fea135faf4/python/xgbserver/xgbserver/model.py#L36
and
https://github.com/kubeflow/kfserving/blob/c46a0da8c0cf168dccfcee3b79f306fea135faf4/python/xgbserver/xgbserver/model.py#L42
Which will leave the decision of number of thread to use to xgboost by detecting number of cpu. However, possibly due to this https://bugs.python.org/issue36054, the `nthread` is incorrect and causing the performance issues.
I did a test with setting `nthread=1` :
```
class XGBoostModel(kfserving.KFModel):
def __init__(self, name: str, model_dir: str, booster: XGBModel = None):
super().__init__(name)
self.name = name
self.model_dir = model_dir
if not booster is None:
self._booster = booster
self.ready = True
def load(self):
model_file = os.path.join(
kfserving.Storage.download(self.model_dir), BOOSTER_FILE)
self._booster = xgb.Booster(params={"nthread" = 1},model_file=model_file)
self.ready = True
def predict(self, request: Dict) -> Dict:
try:
# Use of list as input is deprecated see https://github.com/dmlc/xgboost/pull/3970
dmatrix = xgb.DMatrix(request["instances"], nthread=1)
result: xgb.DMatrix = self._booster.predict(dmatrix)
return { "predictions": result.tolist() }
except Exception as e:
raise Exception("Failed to predict %s" % e)
```
```
cat load.cfg | vegeta attack -rate 1000 -duration 60s | vegeta report
```
and it performed much better:
```
Requests [total, rate, throughput] 60000, 1000.02, 999.99
Duration [total, attack, wait] 1m0.00064503s, 59.9988685s, 1.77653ms
Latencies [mean, 50, 90, 95, 99, max] 1.927362ms, 1.73989ms, 1.941139ms, 2.490536ms, 5.660895ms, 56.707145ms
Bytes In [total, mean] 1320000, 22.00
Bytes Out [total, mean] 1920000, 32.00
Success [ratio] 100.00%
Status Codes [code:count] 200:60000
```
The question here is:
1. Is setting `nthread=1` a good idea for other kind of workload?
2. Should this be configurable?
**Environment:**
- Istio Version: 1.1.7
- Knative Version: 0.8.1
- KFServing Version: 0.2.1
- Kubeflow version: NA
- Minikube version: NA
- Kubernetes version: (use `kubectl version`):
- OS (e.g. from `/etc/os-release`):
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `python/xgbserver/xgbserver/model.py`
Content:
```
1 # Copyright 2019 kubeflow.org.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import kfserving
16 import xgboost as xgb
17 from xgboost import XGBModel
18 import os
19 import numpy as np
20 from typing import List, Dict
21
22 BOOSTER_FILE = "model.bst"
23
24 class XGBoostModel(kfserving.KFModel):
25 def __init__(self, name: str, model_dir: str, booster: XGBModel = None):
26 super().__init__(name)
27 self.name = name
28 self.model_dir = model_dir
29 if not booster is None:
30 self._booster = booster
31 self.ready = True
32
33 def load(self):
34 model_file = os.path.join(
35 kfserving.Storage.download(self.model_dir), BOOSTER_FILE)
36 self._booster = xgb.Booster(model_file=model_file)
37 self.ready = True
38
39 def predict(self, request: Dict) -> Dict:
40 try:
41 # Use of list as input is deprecated see https://github.com/dmlc/xgboost/pull/3970
42 dmatrix = xgb.DMatrix(request["instances"])
43 result: xgb.DMatrix = self._booster.predict(dmatrix)
44 return { "predictions": result.tolist() }
45 except Exception as e:
46 raise Exception("Failed to predict %s" % e)
47
```
Path: `python/xgbserver/xgbserver/__main__.py`
Content:
```
1 # Copyright 2019 kubeflow.org.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import kfserving
16 import argparse
17
18 from xgbserver import XGBoostModel
19
20 DEFAULT_MODEL_NAME = "default"
21 DEFAULT_LOCAL_MODEL_DIR = "/tmp/model"
22
23 parser = argparse.ArgumentParser(parents=[kfserving.kfserver.parser]) #pylint:disable=c-extension-no-member
24 parser.add_argument('--model_dir', required=True,
25 help='A URI pointer to the model directory')
26 parser.add_argument('--model_name', default=DEFAULT_MODEL_NAME,
27 help='The name that the model is served under.')
28 args, _ = parser.parse_known_args()
29
30 if __name__ == "__main__":
31 model = XGBoostModel(args.model_name, args.model_dir)
32 model.load()
33 kfserving.KFServer().start([model]) #pylint:disable=c-extension-no-member
34
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/python/xgbserver/xgbserver/__main__.py b/python/xgbserver/xgbserver/__main__.py
--- a/python/xgbserver/xgbserver/__main__.py
+++ b/python/xgbserver/xgbserver/__main__.py
@@ -19,15 +19,18 @@
DEFAULT_MODEL_NAME = "default"
DEFAULT_LOCAL_MODEL_DIR = "/tmp/model"
+DEFAULT_NTHREAD = 1
parser = argparse.ArgumentParser(parents=[kfserving.kfserver.parser]) #pylint:disable=c-extension-no-member
parser.add_argument('--model_dir', required=True,
help='A URI pointer to the model directory')
parser.add_argument('--model_name', default=DEFAULT_MODEL_NAME,
help='The name that the model is served under.')
+parser.add_argument('--nthread', default=DEFAULT_NTHREAD,
+ help='Number of threads to use by XGBoost.')
args, _ = parser.parse_known_args()
if __name__ == "__main__":
- model = XGBoostModel(args.model_name, args.model_dir)
+ model = XGBoostModel(args.model_name, args.model_dir, args.nthread)
model.load()
kfserving.KFServer().start([model]) #pylint:disable=c-extension-no-member
diff --git a/python/xgbserver/xgbserver/model.py b/python/xgbserver/xgbserver/model.py
--- a/python/xgbserver/xgbserver/model.py
+++ b/python/xgbserver/xgbserver/model.py
@@ -22,10 +22,12 @@
BOOSTER_FILE = "model.bst"
class XGBoostModel(kfserving.KFModel):
- def __init__(self, name: str, model_dir: str, booster: XGBModel = None):
+ def __init__(self, name: str, model_dir: str, nthread: int, booster: \
+ XGBModel = None):
super().__init__(name)
self.name = name
self.model_dir = model_dir
+ self.nthread = nthread
if not booster is None:
self._booster = booster
self.ready = True
@@ -33,13 +35,14 @@
def load(self):
model_file = os.path.join(
kfserving.Storage.download(self.model_dir), BOOSTER_FILE)
- self._booster = xgb.Booster(model_file=model_file)
+ self._booster = xgb.Booster(params={"nthread" : self.nthread},
+ model_file=model_file)
self.ready = True
def predict(self, request: Dict) -> Dict:
try:
# Use of list as input is deprecated see https://github.com/dmlc/xgboost/pull/3970
- dmatrix = xgb.DMatrix(request["instances"])
+ dmatrix = xgb.DMatrix(request["instances"], nthread=self.nthread)
result: xgb.DMatrix = self._booster.predict(dmatrix)
return { "predictions": result.tolist() }
except Exception as e:
|
{"golden_diff": "diff --git a/python/xgbserver/xgbserver/__main__.py b/python/xgbserver/xgbserver/__main__.py\n--- a/python/xgbserver/xgbserver/__main__.py\n+++ b/python/xgbserver/xgbserver/__main__.py\n@@ -19,15 +19,18 @@\n \n DEFAULT_MODEL_NAME = \"default\"\n DEFAULT_LOCAL_MODEL_DIR = \"/tmp/model\"\n+DEFAULT_NTHREAD = 1\n \n parser = argparse.ArgumentParser(parents=[kfserving.kfserver.parser]) #pylint:disable=c-extension-no-member\n parser.add_argument('--model_dir', required=True,\n help='A URI pointer to the model directory')\n parser.add_argument('--model_name', default=DEFAULT_MODEL_NAME,\n help='The name that the model is served under.')\n+parser.add_argument('--nthread', default=DEFAULT_NTHREAD,\n+ help='Number of threads to use by XGBoost.')\n args, _ = parser.parse_known_args()\n \n if __name__ == \"__main__\":\n- model = XGBoostModel(args.model_name, args.model_dir)\n+ model = XGBoostModel(args.model_name, args.model_dir, args.nthread)\n model.load()\n kfserving.KFServer().start([model]) #pylint:disable=c-extension-no-member\ndiff --git a/python/xgbserver/xgbserver/model.py b/python/xgbserver/xgbserver/model.py\n--- a/python/xgbserver/xgbserver/model.py\n+++ b/python/xgbserver/xgbserver/model.py\n@@ -22,10 +22,12 @@\n BOOSTER_FILE = \"model.bst\"\n \n class XGBoostModel(kfserving.KFModel):\n- def __init__(self, name: str, model_dir: str, booster: XGBModel = None):\n+ def __init__(self, name: str, model_dir: str, nthread: int, booster: \\\n+ XGBModel = None):\n super().__init__(name)\n self.name = name\n self.model_dir = model_dir\n+ self.nthread = nthread\n if not booster is None:\n self._booster = booster\n self.ready = True\n@@ -33,13 +35,14 @@\n def load(self):\n model_file = os.path.join(\n kfserving.Storage.download(self.model_dir), BOOSTER_FILE)\n- self._booster = xgb.Booster(model_file=model_file)\n+ self._booster = xgb.Booster(params={\"nthread\" : self.nthread},\n+ model_file=model_file)\n self.ready = True\n \n def predict(self, request: Dict) -> Dict:\n try:\n # Use of list as input is deprecated see https://github.com/dmlc/xgboost/pull/3970\n- dmatrix = xgb.DMatrix(request[\"instances\"])\n+ dmatrix = xgb.DMatrix(request[\"instances\"], nthread=self.nthread)\n result: xgb.DMatrix = self._booster.predict(dmatrix)\n return { \"predictions\": result.tolist() }\n except Exception as e:\n", "issue": "XGBoost Model Perfomance Issue\n/kind bug\r\nXGboost model server perform poorly after deployed to k8s.\r\n\r\n**What steps did you take and what happened:**\r\nI did performance test for xgbserver using provided sample model.\r\n\r\n`load.cfg`:\r\n```\r\nPOST http://<target>/v1/models/default:predict\r\[email protected]\r\n```\r\n\r\n`req.json`:\r\n```\r\n{\"instances\": [[1,2,3,4]]}\r\n```\r\nRunning locally (on Mac OS, 8 core machine) with vegeta\r\n```\r\ncat load.cfg | vegeta attack -duration 1m -rate 1000 | vegeta report -type=text\r\n```\r\n\r\nI am able to hit 1000 RPS with good latencies result.\r\n\r\n```\r\nRequests [total, rate, throughput] 60000, 1000.02, 1000.00\r\nDuration [total, attack, wait] 1m0.000012024s, 59.999069988s, 942.036\u00b5s\r\nLatencies [mean, 50, 90, 95, 99, max] 1.070524ms, 946.443\u00b5s, 1.414653ms, 1.520775ms, 2.401196ms, 17.650717ms\r\nBytes In [total, mean] 1320000, 22.00\r\nBytes Out [total, mean] 1560000, 26.00\r\nSuccess [ratio] 100.00%\r\nStatus Codes [code:count] 200:60000 \r\n```\r\n\r\nBut after deployed to K8S (with 4 core as CPU request and limit)\r\n\r\nThe performance deteriorates at 100 RPS\r\n```\r\ncat load-1.cfg | vegeta attack -rate 100 -duration 60s | vegeta report\r\n```\r\n\r\n```\r\nRequests [total, rate, throughput] 6000, 100.02, 89.47\r\nDuration [total, attack, wait] 1m7.064629048s, 59.989775627s, 7.074853421s\r\nLatencies [mean, 50, 90, 95, 99, max] 1.524605151s, 3.683733ms, 5.575147148s, 7.007148666s, 7.789309456s, 8.606190814s\r\nBytes In [total, mean] 132000, 22.00\r\nBytes Out [total, mean] 192000, 32.00\r\nSuccess [ratio] 100.00%\r\nStatus Codes [code:count] 200:6000\r\n```\r\n\r\n**What did you expect to happen:**\r\n\r\nThe performance should not be affected too much after deployed to K8S.\r\n\r\n**Anything else you would like to add:**\r\nI suspected the issue come from `nthread` in xgbserver are left to default (i.e. 0). \r\nIn: \r\nhttps://github.com/kubeflow/kfserving/blob/c46a0da8c0cf168dccfcee3b79f306fea135faf4/python/xgbserver/xgbserver/model.py#L36\r\nand\r\nhttps://github.com/kubeflow/kfserving/blob/c46a0da8c0cf168dccfcee3b79f306fea135faf4/python/xgbserver/xgbserver/model.py#L42\r\n\r\nWhich will leave the decision of number of thread to use to xgboost by detecting number of cpu. However, possibly due to this https://bugs.python.org/issue36054, the `nthread` is incorrect and causing the performance issues.\r\n\r\nI did a test with setting `nthread=1` :\r\n```\r\nclass XGBoostModel(kfserving.KFModel):\r\n def __init__(self, name: str, model_dir: str, booster: XGBModel = None):\r\n super().__init__(name)\r\n self.name = name\r\n self.model_dir = model_dir\r\n if not booster is None:\r\n self._booster = booster\r\n self.ready = True\r\n\r\n def load(self):\r\n model_file = os.path.join(\r\n kfserving.Storage.download(self.model_dir), BOOSTER_FILE)\r\n self._booster = xgb.Booster(params={\"nthread\" = 1},model_file=model_file)\r\n self.ready = True\r\n\r\n def predict(self, request: Dict) -> Dict:\r\n try:\r\n # Use of list as input is deprecated see https://github.com/dmlc/xgboost/pull/3970\r\n dmatrix = xgb.DMatrix(request[\"instances\"], nthread=1)\r\n result: xgb.DMatrix = self._booster.predict(dmatrix)\r\n return { \"predictions\": result.tolist() }\r\n except Exception as e:\r\n raise Exception(\"Failed to predict %s\" % e)\r\n```\r\n\r\n```\r\ncat load.cfg | vegeta attack -rate 1000 -duration 60s | vegeta report\r\n```\r\n\r\nand it performed much better:\r\n\r\n```\r\nRequests [total, rate, throughput] 60000, 1000.02, 999.99\r\nDuration [total, attack, wait] 1m0.00064503s, 59.9988685s, 1.77653ms\r\nLatencies [mean, 50, 90, 95, 99, max] 1.927362ms, 1.73989ms, 1.941139ms, 2.490536ms, 5.660895ms, 56.707145ms\r\nBytes In [total, mean] 1320000, 22.00\r\nBytes Out [total, mean] 1920000, 32.00\r\nSuccess [ratio] 100.00%\r\nStatus Codes [code:count] 200:60000\r\n```\r\n\r\nThe question here is:\r\n1. Is setting `nthread=1` a good idea for other kind of workload?\r\n2. Should this be configurable?\r\n\r\n**Environment:**\r\n\r\n- Istio Version: 1.1.7\r\n- Knative Version: 0.8.1\r\n- KFServing Version: 0.2.1\r\n- Kubeflow version: NA\r\n- Minikube version: NA\r\n- Kubernetes version: (use `kubectl version`):\r\n- OS (e.g. from `/etc/os-release`):\r\n\n", "before_files": [{"content": "# Copyright 2019 kubeflow.org.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport kfserving\nimport xgboost as xgb\nfrom xgboost import XGBModel\nimport os\nimport numpy as np\nfrom typing import List, Dict\n\nBOOSTER_FILE = \"model.bst\"\n\nclass XGBoostModel(kfserving.KFModel):\n def __init__(self, name: str, model_dir: str, booster: XGBModel = None):\n super().__init__(name)\n self.name = name\n self.model_dir = model_dir\n if not booster is None:\n self._booster = booster\n self.ready = True\n\n def load(self):\n model_file = os.path.join(\n kfserving.Storage.download(self.model_dir), BOOSTER_FILE)\n self._booster = xgb.Booster(model_file=model_file)\n self.ready = True\n\n def predict(self, request: Dict) -> Dict:\n try:\n # Use of list as input is deprecated see https://github.com/dmlc/xgboost/pull/3970\n dmatrix = xgb.DMatrix(request[\"instances\"])\n result: xgb.DMatrix = self._booster.predict(dmatrix)\n return { \"predictions\": result.tolist() }\n except Exception as e:\n raise Exception(\"Failed to predict %s\" % e)\n", "path": "python/xgbserver/xgbserver/model.py"}, {"content": "# Copyright 2019 kubeflow.org.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport kfserving\nimport argparse\n\nfrom xgbserver import XGBoostModel\n\nDEFAULT_MODEL_NAME = \"default\"\nDEFAULT_LOCAL_MODEL_DIR = \"/tmp/model\"\n\nparser = argparse.ArgumentParser(parents=[kfserving.kfserver.parser]) #pylint:disable=c-extension-no-member\nparser.add_argument('--model_dir', required=True,\n help='A URI pointer to the model directory')\nparser.add_argument('--model_name', default=DEFAULT_MODEL_NAME,\n help='The name that the model is served under.')\nargs, _ = parser.parse_known_args()\n\nif __name__ == \"__main__\":\n model = XGBoostModel(args.model_name, args.model_dir)\n model.load()\n kfserving.KFServer().start([model]) #pylint:disable=c-extension-no-member\n", "path": "python/xgbserver/xgbserver/__main__.py"}], "after_files": [{"content": "# Copyright 2019 kubeflow.org.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport kfserving\nimport xgboost as xgb\nfrom xgboost import XGBModel\nimport os\nimport numpy as np\nfrom typing import List, Dict\n\nBOOSTER_FILE = \"model.bst\"\n\nclass XGBoostModel(kfserving.KFModel):\n def __init__(self, name: str, model_dir: str, nthread: int, booster: \\\n XGBModel = None):\n super().__init__(name)\n self.name = name\n self.model_dir = model_dir\n self.nthread = nthread\n if not booster is None:\n self._booster = booster\n self.ready = True\n\n def load(self):\n model_file = os.path.join(\n kfserving.Storage.download(self.model_dir), BOOSTER_FILE)\n self._booster = xgb.Booster(params={\"nthread\" : self.nthread},\n model_file=model_file)\n self.ready = True\n\n def predict(self, request: Dict) -> Dict:\n try:\n # Use of list as input is deprecated see https://github.com/dmlc/xgboost/pull/3970\n dmatrix = xgb.DMatrix(request[\"instances\"], nthread=self.nthread)\n result: xgb.DMatrix = self._booster.predict(dmatrix)\n return { \"predictions\": result.tolist() }\n except Exception as e:\n raise Exception(\"Failed to predict %s\" % e)\n", "path": "python/xgbserver/xgbserver/model.py"}, {"content": "# Copyright 2019 kubeflow.org.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport kfserving\nimport argparse\n\nfrom xgbserver import XGBoostModel\n\nDEFAULT_MODEL_NAME = \"default\"\nDEFAULT_LOCAL_MODEL_DIR = \"/tmp/model\"\nDEFAULT_NTHREAD = 1\n\nparser = argparse.ArgumentParser(parents=[kfserving.kfserver.parser]) #pylint:disable=c-extension-no-member\nparser.add_argument('--model_dir', required=True,\n help='A URI pointer to the model directory')\nparser.add_argument('--model_name', default=DEFAULT_MODEL_NAME,\n help='The name that the model is served under.')\nparser.add_argument('--nthread', default=DEFAULT_NTHREAD,\n help='Number of threads to use by XGBoost.')\nargs, _ = parser.parse_known_args()\n\nif __name__ == \"__main__\":\n model = XGBoostModel(args.model_name, args.model_dir, args.nthread)\n model.load()\n kfserving.KFServer().start([model]) #pylint:disable=c-extension-no-member\n", "path": "python/xgbserver/xgbserver/__main__.py"}]}
| 2,806 | 665 |
gh_patches_debug_18255
|
rasdani/github-patches
|
git_diff
|
xonsh__xonsh-1823
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Prompt `curr_branch` breaks when git config has status.short
If git config contains:
``` ini
[status]
short = true
```
then [the current method of getting the git branch](https://github.com/xonsh/xonsh/blob/619ae11486f2e4febfc2218c0d53c7b3f3c9ea49/xonsh/prompt/vc_branch.py#L16-L25) fails, even if `status.branch = true` is also set.
`git status` is a heavy-handed way of doing this anyway; better would be `git rev-parse --abbrev-ref HEAD` IMO. (PR to follow.)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `xonsh/prompt/vc_branch.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 """Prompt formatter for simple version control branchs"""
3
4 import os
5 import sys
6 import time
7 import queue
8 import builtins
9 import warnings
10 import threading
11 import subprocess
12
13 import xonsh.tools as xt
14
15
16 def _get_git_branch(q):
17 try:
18 status = subprocess.check_output(['git', 'status'],
19 stderr=subprocess.DEVNULL)
20 except (subprocess.CalledProcessError, OSError):
21 q.put(None)
22 else:
23 info = xt.decode_bytes(status)
24 branch = info.splitlines()[0].split()[-1]
25 q.put(branch)
26
27
28 def get_git_branch():
29 """Attempts to find the current git branch. If this could not
30 be determined (timeout, not in a git repo, etc.) then this returns None.
31 """
32 branch = None
33 timeout = builtins.__xonsh_env__.get('VC_BRANCH_TIMEOUT')
34 q = queue.Queue()
35
36 t = threading.Thread(target=_get_git_branch, args=(q,))
37 t.start()
38 t.join(timeout=timeout)
39 try:
40 branch = q.get_nowait()
41 except queue.Empty:
42 branch = None
43 return branch
44
45
46 def _get_parent_dir_for(path, dir_name, timeout):
47 # walk up the directory tree to see if we are inside an hg repo
48 # the timeout makes sure that we don't thrash the file system
49 previous_path = ''
50 t0 = time.time()
51 while path != previous_path and ((time.time() - t0) < timeout):
52 if os.path.isdir(os.path.join(path, dir_name)):
53 return path
54 previous_path = path
55 path, _ = os.path.split(path)
56 return (path == previous_path)
57
58
59 def get_hg_branch(cwd=None, root=None):
60 env = builtins.__xonsh_env__
61 cwd = env['PWD']
62 root = _get_parent_dir_for(cwd, '.hg', env['VC_BRANCH_TIMEOUT'])
63 if not isinstance(root, str):
64 # Bail if we are not in a repo or we timed out
65 if root:
66 return None
67 else:
68 return subprocess.TimeoutExpired(['hg'], env['VC_BRANCH_TIMEOUT'])
69 if env.get('VC_HG_SHOW_BRANCH') is True:
70 # get branch name
71 branch_path = os.path.sep.join([root, '.hg', 'branch'])
72 if os.path.exists(branch_path):
73 with open(branch_path, 'r') as branch_file:
74 branch = branch_file.read()
75 else:
76 branch = 'default'
77 else:
78 branch = ''
79 # add bookmark, if we can
80 bookmark_path = os.path.sep.join([root, '.hg', 'bookmarks.current'])
81 if os.path.exists(bookmark_path):
82 with open(bookmark_path, 'r') as bookmark_file:
83 active_bookmark = bookmark_file.read()
84 if env.get('VC_HG_SHOW_BRANCH') is True:
85 branch = "{0}, {1}".format(*(b.strip(os.linesep) for b in
86 (branch, active_bookmark)))
87 else:
88 branch = active_bookmark.strip(os.linesep)
89 else:
90 branch = branch.strip(os.linesep)
91 return branch
92
93
94 _FIRST_BRANCH_TIMEOUT = True
95
96
97 def _first_branch_timeout_message():
98 global _FIRST_BRANCH_TIMEOUT
99 sbtm = builtins.__xonsh_env__['SUPPRESS_BRANCH_TIMEOUT_MESSAGE']
100 if not _FIRST_BRANCH_TIMEOUT or sbtm:
101 return
102 _FIRST_BRANCH_TIMEOUT = False
103 print('xonsh: branch timeout: computing the branch name, color, or both '
104 'timed out while formatting the prompt. You may avoid this by '
105 'increaing the value of $VC_BRANCH_TIMEOUT or by removing branch '
106 'fields, like {curr_branch}, from your $PROMPT. See the FAQ '
107 'for more details. This message will be suppressed for the remainder '
108 'of this session. To suppress this message permanently, set '
109 '$SUPPRESS_BRANCH_TIMEOUT_MESSAGE = True in your xonshrc file.',
110 file=sys.stderr)
111
112
113 def current_branch(pad=NotImplemented):
114 """Gets the branch for a current working directory. Returns an empty string
115 if the cwd is not a repository. This currently only works for git and hg
116 and should be extended in the future. If a timeout occurred, the string
117 '<branch-timeout>' is returned.
118 """
119 if pad is not NotImplemented:
120 warnings.warn("The pad argument of current_branch has no effect now "
121 "and will be removed in the future")
122 branch = None
123 cmds = builtins.__xonsh_commands_cache__
124 if cmds.lazy_locate_binary('git') or cmds.is_empty():
125 branch = get_git_branch()
126 if (cmds.lazy_locate_binary('hg') or cmds.is_empty()) and not branch:
127 branch = get_hg_branch()
128 if isinstance(branch, subprocess.TimeoutExpired):
129 branch = '<branch-timeout>'
130 _first_branch_timeout_message()
131 return branch or None
132
133
134 def _git_dirty_working_directory(q, include_untracked):
135 status = None
136 try:
137 cmd = ['git', 'status', '--porcelain']
138 if include_untracked:
139 cmd.append('--untracked-files=normal')
140 else:
141 cmd.append('--untracked-files=no')
142 status = subprocess.check_output(cmd, stderr=subprocess.DEVNULL)
143 except (subprocess.CalledProcessError, OSError):
144 q.put(None)
145 if status is not None:
146 return q.put(bool(status))
147
148
149 def git_dirty_working_directory(include_untracked=False):
150 """Returns whether or not the git directory is dirty. If this could not
151 be determined (timeout, file not found, etc.) then this returns None.
152 """
153 timeout = builtins.__xonsh_env__.get("VC_BRANCH_TIMEOUT")
154 q = queue.Queue()
155 t = threading.Thread(target=_git_dirty_working_directory,
156 args=(q, include_untracked))
157 t.start()
158 t.join(timeout=timeout)
159 try:
160 return q.get_nowait()
161 except queue.Empty:
162 return None
163
164
165 def hg_dirty_working_directory():
166 """Computes whether or not the mercurial working directory is dirty or not.
167 If this cannot be deterimined, None is returned.
168 """
169 env = builtins.__xonsh_env__
170 cwd = env['PWD']
171 denv = env.detype()
172 vcbt = env['VC_BRANCH_TIMEOUT']
173 # Override user configurations settings and aliases
174 denv['HGRCPATH'] = ''
175 try:
176 s = subprocess.check_output(['hg', 'identify', '--id'],
177 stderr=subprocess.PIPE, cwd=cwd,
178 timeout=vcbt, universal_newlines=True,
179 env=denv)
180 return s.strip(os.linesep).endswith('+')
181 except (subprocess.CalledProcessError, subprocess.TimeoutExpired,
182 FileNotFoundError):
183 return None
184
185
186 def dirty_working_directory(cwd=None):
187 """Returns a boolean as to whether there are uncommitted files in version
188 control repository we are inside. If this cannot be determined, returns
189 None. Currently supports git and hg.
190 """
191 dwd = None
192 cmds = builtins.__xonsh_commands_cache__
193 if cmds.lazy_locate_binary('git') or cmds.is_empty():
194 dwd = git_dirty_working_directory()
195 if (cmds.lazy_locate_binary('hg') or cmds.is_empty()) and (dwd is None):
196 dwd = hg_dirty_working_directory()
197 return dwd
198
199
200 def branch_color():
201 """Return red if the current branch is dirty, yellow if the dirtiness can
202 not be determined, and green if it clean. These are bold, intense colors
203 for the foreground.
204 """
205 dwd = dirty_working_directory()
206 if dwd is None:
207 color = '{BOLD_INTENSE_YELLOW}'
208 elif dwd:
209 color = '{BOLD_INTENSE_RED}'
210 else:
211 color = '{BOLD_INTENSE_GREEN}'
212 return color
213
214
215 def branch_bg_color():
216 """Return red if the current branch is dirty, yellow if the dirtiness can
217 not be determined, and green if it clean. These are bacground colors.
218 """
219 dwd = dirty_working_directory()
220 if dwd is None:
221 color = '{BACKGROUND_YELLOW}'
222 elif dwd:
223 color = '{BACKGROUND_RED}'
224 else:
225 color = '{BACKGROUND_GREEN}'
226 return color
227
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/xonsh/prompt/vc_branch.py b/xonsh/prompt/vc_branch.py
--- a/xonsh/prompt/vc_branch.py
+++ b/xonsh/prompt/vc_branch.py
@@ -15,15 +15,25 @@
def _get_git_branch(q):
try:
- status = subprocess.check_output(['git', 'status'],
- stderr=subprocess.DEVNULL)
+ branches = xt.decode_bytes(subprocess.check_output(
+ ['git', 'branch'],
+ stderr=subprocess.DEVNULL
+ )).splitlines()
except (subprocess.CalledProcessError, OSError):
q.put(None)
else:
- info = xt.decode_bytes(status)
- branch = info.splitlines()[0].split()[-1]
- q.put(branch)
-
+ for branch in branches:
+ if not branch.startswith('* '):
+ continue
+ elif branch.endswith(')'):
+ branch = branch.split()[-1][:-1]
+ else:
+ branch = branch.split()[-1]
+
+ q.put(branch)
+ break
+ else:
+ q.put(None)
def get_git_branch():
"""Attempts to find the current git branch. If this could not
|
{"golden_diff": "diff --git a/xonsh/prompt/vc_branch.py b/xonsh/prompt/vc_branch.py\n--- a/xonsh/prompt/vc_branch.py\n+++ b/xonsh/prompt/vc_branch.py\n@@ -15,15 +15,25 @@\n \n def _get_git_branch(q):\n try:\n- status = subprocess.check_output(['git', 'status'],\n- stderr=subprocess.DEVNULL)\n+ branches = xt.decode_bytes(subprocess.check_output(\n+ ['git', 'branch'],\n+ stderr=subprocess.DEVNULL\n+ )).splitlines()\n except (subprocess.CalledProcessError, OSError):\n q.put(None)\n else:\n- info = xt.decode_bytes(status)\n- branch = info.splitlines()[0].split()[-1]\n- q.put(branch)\n-\n+ for branch in branches:\n+ if not branch.startswith('* '):\n+ continue\n+ elif branch.endswith(')'):\n+ branch = branch.split()[-1][:-1]\n+ else:\n+ branch = branch.split()[-1]\n+\n+ q.put(branch)\n+ break\n+ else:\n+ q.put(None)\n \n def get_git_branch():\n \"\"\"Attempts to find the current git branch. If this could not\n", "issue": "Prompt `curr_branch` breaks when git config has status.short\nIf git config contains:\n\n``` ini\n[status]\n short = true\n```\n\nthen [the current method of getting the git branch](https://github.com/xonsh/xonsh/blob/619ae11486f2e4febfc2218c0d53c7b3f3c9ea49/xonsh/prompt/vc_branch.py#L16-L25) fails, even if `status.branch = true` is also set.\n\n`git status` is a heavy-handed way of doing this anyway; better would be `git rev-parse --abbrev-ref HEAD` IMO. (PR to follow.)\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"Prompt formatter for simple version control branchs\"\"\"\n\nimport os\nimport sys\nimport time\nimport queue\nimport builtins\nimport warnings\nimport threading\nimport subprocess\n\nimport xonsh.tools as xt\n\n\ndef _get_git_branch(q):\n try:\n status = subprocess.check_output(['git', 'status'],\n stderr=subprocess.DEVNULL)\n except (subprocess.CalledProcessError, OSError):\n q.put(None)\n else:\n info = xt.decode_bytes(status)\n branch = info.splitlines()[0].split()[-1]\n q.put(branch)\n\n\ndef get_git_branch():\n \"\"\"Attempts to find the current git branch. If this could not\n be determined (timeout, not in a git repo, etc.) then this returns None.\n \"\"\"\n branch = None\n timeout = builtins.__xonsh_env__.get('VC_BRANCH_TIMEOUT')\n q = queue.Queue()\n\n t = threading.Thread(target=_get_git_branch, args=(q,))\n t.start()\n t.join(timeout=timeout)\n try:\n branch = q.get_nowait()\n except queue.Empty:\n branch = None\n return branch\n\n\ndef _get_parent_dir_for(path, dir_name, timeout):\n # walk up the directory tree to see if we are inside an hg repo\n # the timeout makes sure that we don't thrash the file system\n previous_path = ''\n t0 = time.time()\n while path != previous_path and ((time.time() - t0) < timeout):\n if os.path.isdir(os.path.join(path, dir_name)):\n return path\n previous_path = path\n path, _ = os.path.split(path)\n return (path == previous_path)\n\n\ndef get_hg_branch(cwd=None, root=None):\n env = builtins.__xonsh_env__\n cwd = env['PWD']\n root = _get_parent_dir_for(cwd, '.hg', env['VC_BRANCH_TIMEOUT'])\n if not isinstance(root, str):\n # Bail if we are not in a repo or we timed out\n if root:\n return None\n else:\n return subprocess.TimeoutExpired(['hg'], env['VC_BRANCH_TIMEOUT'])\n if env.get('VC_HG_SHOW_BRANCH') is True:\n # get branch name\n branch_path = os.path.sep.join([root, '.hg', 'branch'])\n if os.path.exists(branch_path):\n with open(branch_path, 'r') as branch_file:\n branch = branch_file.read()\n else:\n branch = 'default'\n else:\n branch = ''\n # add bookmark, if we can\n bookmark_path = os.path.sep.join([root, '.hg', 'bookmarks.current'])\n if os.path.exists(bookmark_path):\n with open(bookmark_path, 'r') as bookmark_file:\n active_bookmark = bookmark_file.read()\n if env.get('VC_HG_SHOW_BRANCH') is True:\n branch = \"{0}, {1}\".format(*(b.strip(os.linesep) for b in\n (branch, active_bookmark)))\n else:\n branch = active_bookmark.strip(os.linesep)\n else:\n branch = branch.strip(os.linesep)\n return branch\n\n\n_FIRST_BRANCH_TIMEOUT = True\n\n\ndef _first_branch_timeout_message():\n global _FIRST_BRANCH_TIMEOUT\n sbtm = builtins.__xonsh_env__['SUPPRESS_BRANCH_TIMEOUT_MESSAGE']\n if not _FIRST_BRANCH_TIMEOUT or sbtm:\n return\n _FIRST_BRANCH_TIMEOUT = False\n print('xonsh: branch timeout: computing the branch name, color, or both '\n 'timed out while formatting the prompt. You may avoid this by '\n 'increaing the value of $VC_BRANCH_TIMEOUT or by removing branch '\n 'fields, like {curr_branch}, from your $PROMPT. See the FAQ '\n 'for more details. This message will be suppressed for the remainder '\n 'of this session. To suppress this message permanently, set '\n '$SUPPRESS_BRANCH_TIMEOUT_MESSAGE = True in your xonshrc file.',\n file=sys.stderr)\n\n\ndef current_branch(pad=NotImplemented):\n \"\"\"Gets the branch for a current working directory. Returns an empty string\n if the cwd is not a repository. This currently only works for git and hg\n and should be extended in the future. If a timeout occurred, the string\n '<branch-timeout>' is returned.\n \"\"\"\n if pad is not NotImplemented:\n warnings.warn(\"The pad argument of current_branch has no effect now \"\n \"and will be removed in the future\")\n branch = None\n cmds = builtins.__xonsh_commands_cache__\n if cmds.lazy_locate_binary('git') or cmds.is_empty():\n branch = get_git_branch()\n if (cmds.lazy_locate_binary('hg') or cmds.is_empty()) and not branch:\n branch = get_hg_branch()\n if isinstance(branch, subprocess.TimeoutExpired):\n branch = '<branch-timeout>'\n _first_branch_timeout_message()\n return branch or None\n\n\ndef _git_dirty_working_directory(q, include_untracked):\n status = None\n try:\n cmd = ['git', 'status', '--porcelain']\n if include_untracked:\n cmd.append('--untracked-files=normal')\n else:\n cmd.append('--untracked-files=no')\n status = subprocess.check_output(cmd, stderr=subprocess.DEVNULL)\n except (subprocess.CalledProcessError, OSError):\n q.put(None)\n if status is not None:\n return q.put(bool(status))\n\n\ndef git_dirty_working_directory(include_untracked=False):\n \"\"\"Returns whether or not the git directory is dirty. If this could not\n be determined (timeout, file not found, etc.) then this returns None.\n \"\"\"\n timeout = builtins.__xonsh_env__.get(\"VC_BRANCH_TIMEOUT\")\n q = queue.Queue()\n t = threading.Thread(target=_git_dirty_working_directory,\n args=(q, include_untracked))\n t.start()\n t.join(timeout=timeout)\n try:\n return q.get_nowait()\n except queue.Empty:\n return None\n\n\ndef hg_dirty_working_directory():\n \"\"\"Computes whether or not the mercurial working directory is dirty or not.\n If this cannot be deterimined, None is returned.\n \"\"\"\n env = builtins.__xonsh_env__\n cwd = env['PWD']\n denv = env.detype()\n vcbt = env['VC_BRANCH_TIMEOUT']\n # Override user configurations settings and aliases\n denv['HGRCPATH'] = ''\n try:\n s = subprocess.check_output(['hg', 'identify', '--id'],\n stderr=subprocess.PIPE, cwd=cwd,\n timeout=vcbt, universal_newlines=True,\n env=denv)\n return s.strip(os.linesep).endswith('+')\n except (subprocess.CalledProcessError, subprocess.TimeoutExpired,\n FileNotFoundError):\n return None\n\n\ndef dirty_working_directory(cwd=None):\n \"\"\"Returns a boolean as to whether there are uncommitted files in version\n control repository we are inside. If this cannot be determined, returns\n None. Currently supports git and hg.\n \"\"\"\n dwd = None\n cmds = builtins.__xonsh_commands_cache__\n if cmds.lazy_locate_binary('git') or cmds.is_empty():\n dwd = git_dirty_working_directory()\n if (cmds.lazy_locate_binary('hg') or cmds.is_empty()) and (dwd is None):\n dwd = hg_dirty_working_directory()\n return dwd\n\n\ndef branch_color():\n \"\"\"Return red if the current branch is dirty, yellow if the dirtiness can\n not be determined, and green if it clean. These are bold, intense colors\n for the foreground.\n \"\"\"\n dwd = dirty_working_directory()\n if dwd is None:\n color = '{BOLD_INTENSE_YELLOW}'\n elif dwd:\n color = '{BOLD_INTENSE_RED}'\n else:\n color = '{BOLD_INTENSE_GREEN}'\n return color\n\n\ndef branch_bg_color():\n \"\"\"Return red if the current branch is dirty, yellow if the dirtiness can\n not be determined, and green if it clean. These are bacground colors.\n \"\"\"\n dwd = dirty_working_directory()\n if dwd is None:\n color = '{BACKGROUND_YELLOW}'\n elif dwd:\n color = '{BACKGROUND_RED}'\n else:\n color = '{BACKGROUND_GREEN}'\n return color\n", "path": "xonsh/prompt/vc_branch.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"Prompt formatter for simple version control branchs\"\"\"\n\nimport os\nimport sys\nimport time\nimport queue\nimport builtins\nimport warnings\nimport threading\nimport subprocess\n\nimport xonsh.tools as xt\n\n\ndef _get_git_branch(q):\n try:\n branches = xt.decode_bytes(subprocess.check_output(\n ['git', 'branch'],\n stderr=subprocess.DEVNULL\n )).splitlines()\n except (subprocess.CalledProcessError, OSError):\n q.put(None)\n else:\n for branch in branches:\n if not branch.startswith('* '):\n continue\n elif branch.endswith(')'):\n branch = branch.split()[-1][:-1]\n else:\n branch = branch.split()[-1]\n\n q.put(branch)\n break\n else:\n q.put(None)\n\ndef get_git_branch():\n \"\"\"Attempts to find the current git branch. If this could not\n be determined (timeout, not in a git repo, etc.) then this returns None.\n \"\"\"\n branch = None\n timeout = builtins.__xonsh_env__.get('VC_BRANCH_TIMEOUT')\n q = queue.Queue()\n\n t = threading.Thread(target=_get_git_branch, args=(q,))\n t.start()\n t.join(timeout=timeout)\n try:\n branch = q.get_nowait()\n except queue.Empty:\n branch = None\n return branch\n\n\ndef _get_parent_dir_for(path, dir_name, timeout):\n # walk up the directory tree to see if we are inside an hg repo\n # the timeout makes sure that we don't thrash the file system\n previous_path = ''\n t0 = time.time()\n while path != previous_path and ((time.time() - t0) < timeout):\n if os.path.isdir(os.path.join(path, dir_name)):\n return path\n previous_path = path\n path, _ = os.path.split(path)\n return (path == previous_path)\n\n\ndef get_hg_branch(cwd=None, root=None):\n env = builtins.__xonsh_env__\n cwd = env['PWD']\n root = _get_parent_dir_for(cwd, '.hg', env['VC_BRANCH_TIMEOUT'])\n if not isinstance(root, str):\n # Bail if we are not in a repo or we timed out\n if root:\n return None\n else:\n return subprocess.TimeoutExpired(['hg'], env['VC_BRANCH_TIMEOUT'])\n if env.get('VC_HG_SHOW_BRANCH') is True:\n # get branch name\n branch_path = os.path.sep.join([root, '.hg', 'branch'])\n if os.path.exists(branch_path):\n with open(branch_path, 'r') as branch_file:\n branch = branch_file.read()\n else:\n branch = 'default'\n else:\n branch = ''\n # add bookmark, if we can\n bookmark_path = os.path.sep.join([root, '.hg', 'bookmarks.current'])\n if os.path.exists(bookmark_path):\n with open(bookmark_path, 'r') as bookmark_file:\n active_bookmark = bookmark_file.read()\n if env.get('VC_HG_SHOW_BRANCH') is True:\n branch = \"{0}, {1}\".format(*(b.strip(os.linesep) for b in\n (branch, active_bookmark)))\n else:\n branch = active_bookmark.strip(os.linesep)\n else:\n branch = branch.strip(os.linesep)\n return branch\n\n\n_FIRST_BRANCH_TIMEOUT = True\n\n\ndef _first_branch_timeout_message():\n global _FIRST_BRANCH_TIMEOUT\n sbtm = builtins.__xonsh_env__['SUPPRESS_BRANCH_TIMEOUT_MESSAGE']\n if not _FIRST_BRANCH_TIMEOUT or sbtm:\n return\n _FIRST_BRANCH_TIMEOUT = False\n print('xonsh: branch timeout: computing the branch name, color, or both '\n 'timed out while formatting the prompt. You may avoid this by '\n 'increaing the value of $VC_BRANCH_TIMEOUT or by removing branch '\n 'fields, like {curr_branch}, from your $PROMPT. See the FAQ '\n 'for more details. This message will be suppressed for the remainder '\n 'of this session. To suppress this message permanently, set '\n '$SUPPRESS_BRANCH_TIMEOUT_MESSAGE = True in your xonshrc file.',\n file=sys.stderr)\n\n\ndef current_branch(pad=NotImplemented):\n \"\"\"Gets the branch for a current working directory. Returns an empty string\n if the cwd is not a repository. This currently only works for git and hg\n and should be extended in the future. If a timeout occurred, the string\n '<branch-timeout>' is returned.\n \"\"\"\n if pad is not NotImplemented:\n warnings.warn(\"The pad argument of current_branch has no effect now \"\n \"and will be removed in the future\")\n branch = None\n cmds = builtins.__xonsh_commands_cache__\n if cmds.lazy_locate_binary('git') or cmds.is_empty():\n branch = get_git_branch()\n if (cmds.lazy_locate_binary('hg') or cmds.is_empty()) and not branch:\n branch = get_hg_branch()\n if isinstance(branch, subprocess.TimeoutExpired):\n branch = '<branch-timeout>'\n _first_branch_timeout_message()\n return branch or None\n\n\ndef _git_dirty_working_directory(q, include_untracked):\n status = None\n try:\n cmd = ['git', 'status', '--porcelain']\n if include_untracked:\n cmd.append('--untracked-files=normal')\n else:\n cmd.append('--untracked-files=no')\n status = subprocess.check_output(cmd, stderr=subprocess.DEVNULL)\n except (subprocess.CalledProcessError, OSError):\n q.put(None)\n if status is not None:\n return q.put(bool(status))\n\n\ndef git_dirty_working_directory(include_untracked=False):\n \"\"\"Returns whether or not the git directory is dirty. If this could not\n be determined (timeout, file not found, etc.) then this returns None.\n \"\"\"\n timeout = builtins.__xonsh_env__.get(\"VC_BRANCH_TIMEOUT\")\n q = queue.Queue()\n t = threading.Thread(target=_git_dirty_working_directory,\n args=(q, include_untracked))\n t.start()\n t.join(timeout=timeout)\n try:\n return q.get_nowait()\n except queue.Empty:\n return None\n\n\ndef hg_dirty_working_directory():\n \"\"\"Computes whether or not the mercurial working directory is dirty or not.\n If this cannot be deterimined, None is returned.\n \"\"\"\n env = builtins.__xonsh_env__\n cwd = env['PWD']\n denv = env.detype()\n vcbt = env['VC_BRANCH_TIMEOUT']\n # Override user configurations settings and aliases\n denv['HGRCPATH'] = ''\n try:\n s = subprocess.check_output(['hg', 'identify', '--id'],\n stderr=subprocess.PIPE, cwd=cwd,\n timeout=vcbt, universal_newlines=True,\n env=denv)\n return s.strip(os.linesep).endswith('+')\n except (subprocess.CalledProcessError, subprocess.TimeoutExpired,\n FileNotFoundError):\n return None\n\n\ndef dirty_working_directory(cwd=None):\n \"\"\"Returns a boolean as to whether there are uncommitted files in version\n control repository we are inside. If this cannot be determined, returns\n None. Currently supports git and hg.\n \"\"\"\n dwd = None\n cmds = builtins.__xonsh_commands_cache__\n if cmds.lazy_locate_binary('git') or cmds.is_empty():\n dwd = git_dirty_working_directory()\n if (cmds.lazy_locate_binary('hg') or cmds.is_empty()) and (dwd is None):\n dwd = hg_dirty_working_directory()\n return dwd\n\n\ndef branch_color():\n \"\"\"Return red if the current branch is dirty, yellow if the dirtiness can\n not be determined, and green if it clean. These are bold, intense colors\n for the foreground.\n \"\"\"\n dwd = dirty_working_directory()\n if dwd is None:\n color = '{BOLD_INTENSE_YELLOW}'\n elif dwd:\n color = '{BOLD_INTENSE_RED}'\n else:\n color = '{BOLD_INTENSE_GREEN}'\n return color\n\n\ndef branch_bg_color():\n \"\"\"Return red if the current branch is dirty, yellow if the dirtiness can\n not be determined, and green if it clean. These are bacground colors.\n \"\"\"\n dwd = dirty_working_directory()\n if dwd is None:\n color = '{BACKGROUND_YELLOW}'\n elif dwd:\n color = '{BACKGROUND_RED}'\n else:\n color = '{BACKGROUND_GREEN}'\n return color\n", "path": "xonsh/prompt/vc_branch.py"}]}
| 2,794 | 277 |
gh_patches_debug_31071
|
rasdani/github-patches
|
git_diff
|
nonebot__nonebot2-772
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bug: Message.template format 问题
**描述问题:**
无法使用format
**如何复现?**
```py
from nonebot.adapters.onebot.v11 import Message
file_list = [
"file:///file1.image",
"file:///file2.image",
...
]
text = "img1: {:image} img2: {:image} ..."
msg = Message.template(text).format(*file_list)
```
**期望的结果**
`msg` 为可以直接发送的 包含文字和图片的消息
**环境信息:**
- OS: Linux CentOS8
- Python Version: 3.9
- Nonebot Version: 2.0.0-beta.1
**截图或日志**
```log
Traceback (most recent call last):
File "/data/nb-test/test/re_test.py", line 23, in <module>
msg = Message.template(text).format(*file_list)
File "/root/.cache/pypoetry/virtualenvs/nb-test-NOSw4fD6-py3.9/lib/python3.9/site-packages/nonebot/adapters/_template.py", line 80, in format
msg += self.vformat(self.template, args, kwargs)
File "/root/.cache/pypoetry/virtualenvs/nb-test-NOSw4fD6-py3.9/lib/python3.9/site-packages/nonebot/adapters/_template.py", line 94, in vformat
result, _ = self._vformat(format_string, args, kwargs, used_args, 2)
File "/root/.cache/pypoetry/virtualenvs/nb-test-NOSw4fD6-py3.9/lib/python3.9/site-packages/nonebot/adapters/_template.py", line 165, in _vformat
formatted_text = self.format_field(obj, str(format_control))
File "/root/.cache/pypoetry/virtualenvs/nb-test-NOSw4fD6-py3.9/lib/python3.9/site-packages/nonebot/adapters/_template.py", line 181, in format_field
super().format_field(value, format_spec)
File "/root/miniconda3/lib/python3.9/string.py", line 235, in format_field
return format(value, format_spec)
ValueError: Invalid format specifier
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nonebot/internal/adapter/template.py`
Content:
```
1 import inspect
2 import functools
3 from string import Formatter
4 from typing import (
5 TYPE_CHECKING,
6 Any,
7 Set,
8 Dict,
9 List,
10 Type,
11 Tuple,
12 Union,
13 Generic,
14 Mapping,
15 TypeVar,
16 Callable,
17 Optional,
18 Sequence,
19 cast,
20 overload,
21 )
22
23 if TYPE_CHECKING:
24 from .message import Message, MessageSegment
25
26 TM = TypeVar("TM", bound="Message")
27 TF = TypeVar("TF", str, "Message")
28
29 FormatSpecFunc = Callable[[Any], str]
30 FormatSpecFunc_T = TypeVar("FormatSpecFunc_T", bound=FormatSpecFunc)
31
32
33 class MessageTemplate(Formatter, Generic[TF]):
34 """消息模板格式化实现类。
35
36 参数:
37 template: 模板
38 factory: 消息构造类型,默认为 `str`
39 """
40
41 @overload
42 def __init__(
43 self: "MessageTemplate[str]", template: str, factory: Type[str] = str
44 ) -> None:
45 ...
46
47 @overload
48 def __init__(
49 self: "MessageTemplate[TM]", template: Union[str, TM], factory: Type[TM]
50 ) -> None:
51 ...
52
53 def __init__(self, template, factory=str) -> None:
54 self.template: TF = template
55 self.factory: Type[TF] = factory
56 self.format_specs: Dict[str, FormatSpecFunc] = {}
57
58 def add_format_spec(
59 self, spec: FormatSpecFunc_T, name: Optional[str] = None
60 ) -> FormatSpecFunc_T:
61 name = name or spec.__name__
62 if name in self.format_specs:
63 raise ValueError(f"Format spec {name} already exists!")
64 self.format_specs[name] = spec
65 return spec
66
67 def format(self, *args: Any, **kwargs: Any) -> TF:
68 """根据模板和参数生成消息对象"""
69 msg = self.factory()
70 if isinstance(self.template, str):
71 msg += self.vformat(self.template, args, kwargs)
72 elif isinstance(self.template, self.factory):
73 template = cast("Message[MessageSegment]", self.template)
74 for seg in template:
75 msg += self.vformat(str(seg), args, kwargs) if seg.is_text() else seg
76 else:
77 raise TypeError("template must be a string or instance of Message!")
78
79 return msg # type:ignore
80
81 def vformat(
82 self, format_string: str, args: Sequence[Any], kwargs: Mapping[str, Any]
83 ) -> TF:
84 used_args = set()
85 result, _ = self._vformat(format_string, args, kwargs, used_args, 2)
86 self.check_unused_args(list(used_args), args, kwargs)
87 return result
88
89 def _vformat(
90 self,
91 format_string: str,
92 args: Sequence[Any],
93 kwargs: Mapping[str, Any],
94 used_args: Set[Union[int, str]],
95 recursion_depth: int,
96 auto_arg_index: int = 0,
97 ) -> Tuple[TF, int]:
98 if recursion_depth < 0:
99 raise ValueError("Max string recursion exceeded")
100
101 results: List[Any] = []
102
103 for (literal_text, field_name, format_spec, conversion) in self.parse(
104 format_string
105 ):
106
107 # output the literal text
108 if literal_text:
109 results.append(literal_text)
110
111 # if there's a field, output it
112 if field_name is not None:
113 # this is some markup, find the object and do
114 # the formatting
115
116 # handle arg indexing when empty field_names are given.
117 if field_name == "":
118 if auto_arg_index is False:
119 raise ValueError(
120 "cannot switch from manual field specification to "
121 "automatic field numbering"
122 )
123 field_name = str(auto_arg_index)
124 auto_arg_index += 1
125 elif field_name.isdigit():
126 if auto_arg_index:
127 raise ValueError(
128 "cannot switch from manual field specification to "
129 "automatic field numbering"
130 )
131 # disable auto arg incrementing, if it gets
132 # used later on, then an exception will be raised
133 auto_arg_index = False
134
135 # given the field_name, find the object it references
136 # and the argument it came from
137 obj, arg_used = self.get_field(field_name, args, kwargs)
138 used_args.add(arg_used)
139
140 assert format_spec is not None
141
142 # do any conversion on the resulting object
143 obj = self.convert_field(obj, conversion) if conversion else obj
144
145 # expand the format spec, if needed
146 format_control, auto_arg_index = self._vformat(
147 format_spec,
148 args,
149 kwargs,
150 used_args,
151 recursion_depth - 1,
152 auto_arg_index,
153 )
154
155 # format the object and append to the result
156 formatted_text = self.format_field(obj, str(format_control))
157 results.append(formatted_text)
158
159 return (
160 self.factory(functools.reduce(self._add, results or [""])),
161 auto_arg_index,
162 )
163
164 def format_field(self, value: Any, format_spec: str) -> Any:
165 formatter: Optional[FormatSpecFunc] = self.format_specs.get(format_spec)
166 if formatter is None and not issubclass(self.factory, str):
167 segment_class: Type["MessageSegment"] = self.factory.get_segment_class()
168 method = getattr(segment_class, format_spec, None)
169 if inspect.ismethod(method):
170 formatter = getattr(segment_class, format_spec)
171 return (
172 super().format_field(value, format_spec)
173 if formatter is None
174 else formatter(value)
175 )
176
177 def _add(self, a: Any, b: Any) -> Any:
178 try:
179 return a + b
180 except TypeError:
181 return a + str(b)
182
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nonebot/internal/adapter/template.py b/nonebot/internal/adapter/template.py
--- a/nonebot/internal/adapter/template.py
+++ b/nonebot/internal/adapter/template.py
@@ -1,4 +1,3 @@
-import inspect
import functools
from string import Formatter
from typing import (
@@ -35,7 +34,7 @@
参数:
template: 模板
- factory: 消息构造类型,默认为 `str`
+ factory: 消息类型工厂,默认为 `str`
"""
@overload
@@ -64,8 +63,15 @@
self.format_specs[name] = spec
return spec
- def format(self, *args: Any, **kwargs: Any) -> TF:
- """根据模板和参数生成消息对象"""
+ def format(self, *args, **kwargs):
+ """根据传入参数和模板生成消息对象"""
+ return self._format(args, kwargs)
+
+ def format_map(self, mapping: Mapping[str, Any]) -> TF:
+ """根据传入字典和模板生成消息对象, 在传入字段名不是有效标识符时有用"""
+ return self._format([], mapping)
+
+ def _format(self, args: Sequence[Any], kwargs: Mapping[str, Any]) -> TF:
msg = self.factory()
if isinstance(self.template, str):
msg += self.vformat(self.template, args, kwargs)
@@ -166,7 +172,7 @@
if formatter is None and not issubclass(self.factory, str):
segment_class: Type["MessageSegment"] = self.factory.get_segment_class()
method = getattr(segment_class, format_spec, None)
- if inspect.ismethod(method):
+ if callable(method) and not cast(str, method.__name__).startswith("_"):
formatter = getattr(segment_class, format_spec)
return (
super().format_field(value, format_spec)
|
{"golden_diff": "diff --git a/nonebot/internal/adapter/template.py b/nonebot/internal/adapter/template.py\n--- a/nonebot/internal/adapter/template.py\n+++ b/nonebot/internal/adapter/template.py\n@@ -1,4 +1,3 @@\n-import inspect\n import functools\n from string import Formatter\n from typing import (\n@@ -35,7 +34,7 @@\n \n \u53c2\u6570:\n template: \u6a21\u677f\n- factory: \u6d88\u606f\u6784\u9020\u7c7b\u578b\uff0c\u9ed8\u8ba4\u4e3a `str`\n+ factory: \u6d88\u606f\u7c7b\u578b\u5de5\u5382\uff0c\u9ed8\u8ba4\u4e3a `str`\n \"\"\"\n \n @overload\n@@ -64,8 +63,15 @@\n self.format_specs[name] = spec\n return spec\n \n- def format(self, *args: Any, **kwargs: Any) -> TF:\n- \"\"\"\u6839\u636e\u6a21\u677f\u548c\u53c2\u6570\u751f\u6210\u6d88\u606f\u5bf9\u8c61\"\"\"\n+ def format(self, *args, **kwargs):\n+ \"\"\"\u6839\u636e\u4f20\u5165\u53c2\u6570\u548c\u6a21\u677f\u751f\u6210\u6d88\u606f\u5bf9\u8c61\"\"\"\n+ return self._format(args, kwargs)\n+\n+ def format_map(self, mapping: Mapping[str, Any]) -> TF:\n+ \"\"\"\u6839\u636e\u4f20\u5165\u5b57\u5178\u548c\u6a21\u677f\u751f\u6210\u6d88\u606f\u5bf9\u8c61, \u5728\u4f20\u5165\u5b57\u6bb5\u540d\u4e0d\u662f\u6709\u6548\u6807\u8bc6\u7b26\u65f6\u6709\u7528\"\"\"\n+ return self._format([], mapping)\n+\n+ def _format(self, args: Sequence[Any], kwargs: Mapping[str, Any]) -> TF:\n msg = self.factory()\n if isinstance(self.template, str):\n msg += self.vformat(self.template, args, kwargs)\n@@ -166,7 +172,7 @@\n if formatter is None and not issubclass(self.factory, str):\n segment_class: Type[\"MessageSegment\"] = self.factory.get_segment_class()\n method = getattr(segment_class, format_spec, None)\n- if inspect.ismethod(method):\n+ if callable(method) and not cast(str, method.__name__).startswith(\"_\"):\n formatter = getattr(segment_class, format_spec)\n return (\n super().format_field(value, format_spec)\n", "issue": "Bug: Message.template format \u95ee\u9898\n**\u63cf\u8ff0\u95ee\u9898\uff1a**\r\n\r\n\u65e0\u6cd5\u4f7f\u7528format\r\n\r\n**\u5982\u4f55\u590d\u73b0\uff1f**\r\n\r\n```py\r\nfrom nonebot.adapters.onebot.v11 import Message\r\nfile_list = [\r\n \"file:///file1.image\",\r\n \"file:///file2.image\",\r\n ...\r\n]\r\ntext = \"img1: {:image} img2: {:image} ...\"\r\n\r\nmsg = Message.template(text).format(*file_list)\r\n```\r\n\r\n\r\n**\u671f\u671b\u7684\u7ed3\u679c**\r\n\r\n`msg` \u4e3a\u53ef\u4ee5\u76f4\u63a5\u53d1\u9001\u7684 \u5305\u542b\u6587\u5b57\u548c\u56fe\u7247\u7684\u6d88\u606f\r\n\r\n**\u73af\u5883\u4fe1\u606f\uff1a**\r\n\r\n - OS: Linux CentOS8\r\n - Python Version: 3.9\r\n - Nonebot Version: 2.0.0-beta.1\r\n\r\n\r\n**\u622a\u56fe\u6216\u65e5\u5fd7**\r\n```log\r\nTraceback (most recent call last):\r\n File \"/data/nb-test/test/re_test.py\", line 23, in <module>\r\n msg = Message.template(text).format(*file_list)\r\n File \"/root/.cache/pypoetry/virtualenvs/nb-test-NOSw4fD6-py3.9/lib/python3.9/site-packages/nonebot/adapters/_template.py\", line 80, in format\r\n msg += self.vformat(self.template, args, kwargs)\r\n File \"/root/.cache/pypoetry/virtualenvs/nb-test-NOSw4fD6-py3.9/lib/python3.9/site-packages/nonebot/adapters/_template.py\", line 94, in vformat\r\n result, _ = self._vformat(format_string, args, kwargs, used_args, 2)\r\n File \"/root/.cache/pypoetry/virtualenvs/nb-test-NOSw4fD6-py3.9/lib/python3.9/site-packages/nonebot/adapters/_template.py\", line 165, in _vformat\r\n formatted_text = self.format_field(obj, str(format_control))\r\n File \"/root/.cache/pypoetry/virtualenvs/nb-test-NOSw4fD6-py3.9/lib/python3.9/site-packages/nonebot/adapters/_template.py\", line 181, in format_field\r\n super().format_field(value, format_spec)\r\n File \"/root/miniconda3/lib/python3.9/string.py\", line 235, in format_field\r\n return format(value, format_spec)\r\nValueError: Invalid format specifier\r\n```\n", "before_files": [{"content": "import inspect\nimport functools\nfrom string import Formatter\nfrom typing import (\n TYPE_CHECKING,\n Any,\n Set,\n Dict,\n List,\n Type,\n Tuple,\n Union,\n Generic,\n Mapping,\n TypeVar,\n Callable,\n Optional,\n Sequence,\n cast,\n overload,\n)\n\nif TYPE_CHECKING:\n from .message import Message, MessageSegment\n\nTM = TypeVar(\"TM\", bound=\"Message\")\nTF = TypeVar(\"TF\", str, \"Message\")\n\nFormatSpecFunc = Callable[[Any], str]\nFormatSpecFunc_T = TypeVar(\"FormatSpecFunc_T\", bound=FormatSpecFunc)\n\n\nclass MessageTemplate(Formatter, Generic[TF]):\n \"\"\"\u6d88\u606f\u6a21\u677f\u683c\u5f0f\u5316\u5b9e\u73b0\u7c7b\u3002\n\n \u53c2\u6570:\n template: \u6a21\u677f\n factory: \u6d88\u606f\u6784\u9020\u7c7b\u578b\uff0c\u9ed8\u8ba4\u4e3a `str`\n \"\"\"\n\n @overload\n def __init__(\n self: \"MessageTemplate[str]\", template: str, factory: Type[str] = str\n ) -> None:\n ...\n\n @overload\n def __init__(\n self: \"MessageTemplate[TM]\", template: Union[str, TM], factory: Type[TM]\n ) -> None:\n ...\n\n def __init__(self, template, factory=str) -> None:\n self.template: TF = template\n self.factory: Type[TF] = factory\n self.format_specs: Dict[str, FormatSpecFunc] = {}\n\n def add_format_spec(\n self, spec: FormatSpecFunc_T, name: Optional[str] = None\n ) -> FormatSpecFunc_T:\n name = name or spec.__name__\n if name in self.format_specs:\n raise ValueError(f\"Format spec {name} already exists!\")\n self.format_specs[name] = spec\n return spec\n\n def format(self, *args: Any, **kwargs: Any) -> TF:\n \"\"\"\u6839\u636e\u6a21\u677f\u548c\u53c2\u6570\u751f\u6210\u6d88\u606f\u5bf9\u8c61\"\"\"\n msg = self.factory()\n if isinstance(self.template, str):\n msg += self.vformat(self.template, args, kwargs)\n elif isinstance(self.template, self.factory):\n template = cast(\"Message[MessageSegment]\", self.template)\n for seg in template:\n msg += self.vformat(str(seg), args, kwargs) if seg.is_text() else seg\n else:\n raise TypeError(\"template must be a string or instance of Message!\")\n\n return msg # type:ignore\n\n def vformat(\n self, format_string: str, args: Sequence[Any], kwargs: Mapping[str, Any]\n ) -> TF:\n used_args = set()\n result, _ = self._vformat(format_string, args, kwargs, used_args, 2)\n self.check_unused_args(list(used_args), args, kwargs)\n return result\n\n def _vformat(\n self,\n format_string: str,\n args: Sequence[Any],\n kwargs: Mapping[str, Any],\n used_args: Set[Union[int, str]],\n recursion_depth: int,\n auto_arg_index: int = 0,\n ) -> Tuple[TF, int]:\n if recursion_depth < 0:\n raise ValueError(\"Max string recursion exceeded\")\n\n results: List[Any] = []\n\n for (literal_text, field_name, format_spec, conversion) in self.parse(\n format_string\n ):\n\n # output the literal text\n if literal_text:\n results.append(literal_text)\n\n # if there's a field, output it\n if field_name is not None:\n # this is some markup, find the object and do\n # the formatting\n\n # handle arg indexing when empty field_names are given.\n if field_name == \"\":\n if auto_arg_index is False:\n raise ValueError(\n \"cannot switch from manual field specification to \"\n \"automatic field numbering\"\n )\n field_name = str(auto_arg_index)\n auto_arg_index += 1\n elif field_name.isdigit():\n if auto_arg_index:\n raise ValueError(\n \"cannot switch from manual field specification to \"\n \"automatic field numbering\"\n )\n # disable auto arg incrementing, if it gets\n # used later on, then an exception will be raised\n auto_arg_index = False\n\n # given the field_name, find the object it references\n # and the argument it came from\n obj, arg_used = self.get_field(field_name, args, kwargs)\n used_args.add(arg_used)\n\n assert format_spec is not None\n\n # do any conversion on the resulting object\n obj = self.convert_field(obj, conversion) if conversion else obj\n\n # expand the format spec, if needed\n format_control, auto_arg_index = self._vformat(\n format_spec,\n args,\n kwargs,\n used_args,\n recursion_depth - 1,\n auto_arg_index,\n )\n\n # format the object and append to the result\n formatted_text = self.format_field(obj, str(format_control))\n results.append(formatted_text)\n\n return (\n self.factory(functools.reduce(self._add, results or [\"\"])),\n auto_arg_index,\n )\n\n def format_field(self, value: Any, format_spec: str) -> Any:\n formatter: Optional[FormatSpecFunc] = self.format_specs.get(format_spec)\n if formatter is None and not issubclass(self.factory, str):\n segment_class: Type[\"MessageSegment\"] = self.factory.get_segment_class()\n method = getattr(segment_class, format_spec, None)\n if inspect.ismethod(method):\n formatter = getattr(segment_class, format_spec)\n return (\n super().format_field(value, format_spec)\n if formatter is None\n else formatter(value)\n )\n\n def _add(self, a: Any, b: Any) -> Any:\n try:\n return a + b\n except TypeError:\n return a + str(b)\n", "path": "nonebot/internal/adapter/template.py"}], "after_files": [{"content": "import functools\nfrom string import Formatter\nfrom typing import (\n TYPE_CHECKING,\n Any,\n Set,\n Dict,\n List,\n Type,\n Tuple,\n Union,\n Generic,\n Mapping,\n TypeVar,\n Callable,\n Optional,\n Sequence,\n cast,\n overload,\n)\n\nif TYPE_CHECKING:\n from .message import Message, MessageSegment\n\nTM = TypeVar(\"TM\", bound=\"Message\")\nTF = TypeVar(\"TF\", str, \"Message\")\n\nFormatSpecFunc = Callable[[Any], str]\nFormatSpecFunc_T = TypeVar(\"FormatSpecFunc_T\", bound=FormatSpecFunc)\n\n\nclass MessageTemplate(Formatter, Generic[TF]):\n \"\"\"\u6d88\u606f\u6a21\u677f\u683c\u5f0f\u5316\u5b9e\u73b0\u7c7b\u3002\n\n \u53c2\u6570:\n template: \u6a21\u677f\n factory: \u6d88\u606f\u7c7b\u578b\u5de5\u5382\uff0c\u9ed8\u8ba4\u4e3a `str`\n \"\"\"\n\n @overload\n def __init__(\n self: \"MessageTemplate[str]\", template: str, factory: Type[str] = str\n ) -> None:\n ...\n\n @overload\n def __init__(\n self: \"MessageTemplate[TM]\", template: Union[str, TM], factory: Type[TM]\n ) -> None:\n ...\n\n def __init__(self, template, factory=str) -> None:\n self.template: TF = template\n self.factory: Type[TF] = factory\n self.format_specs: Dict[str, FormatSpecFunc] = {}\n\n def add_format_spec(\n self, spec: FormatSpecFunc_T, name: Optional[str] = None\n ) -> FormatSpecFunc_T:\n name = name or spec.__name__\n if name in self.format_specs:\n raise ValueError(f\"Format spec {name} already exists!\")\n self.format_specs[name] = spec\n return spec\n\n def format(self, *args, **kwargs):\n \"\"\"\u6839\u636e\u4f20\u5165\u53c2\u6570\u548c\u6a21\u677f\u751f\u6210\u6d88\u606f\u5bf9\u8c61\"\"\"\n return self._format(args, kwargs)\n\n def format_map(self, mapping: Mapping[str, Any]) -> TF:\n \"\"\"\u6839\u636e\u4f20\u5165\u5b57\u5178\u548c\u6a21\u677f\u751f\u6210\u6d88\u606f\u5bf9\u8c61, \u5728\u4f20\u5165\u5b57\u6bb5\u540d\u4e0d\u662f\u6709\u6548\u6807\u8bc6\u7b26\u65f6\u6709\u7528\"\"\"\n return self._format([], mapping)\n\n def _format(self, args: Sequence[Any], kwargs: Mapping[str, Any]) -> TF:\n msg = self.factory()\n if isinstance(self.template, str):\n msg += self.vformat(self.template, args, kwargs)\n elif isinstance(self.template, self.factory):\n template = cast(\"Message[MessageSegment]\", self.template)\n for seg in template:\n msg += self.vformat(str(seg), args, kwargs) if seg.is_text() else seg\n else:\n raise TypeError(\"template must be a string or instance of Message!\")\n\n return msg # type:ignore\n\n def vformat(\n self, format_string: str, args: Sequence[Any], kwargs: Mapping[str, Any]\n ) -> TF:\n used_args = set()\n result, _ = self._vformat(format_string, args, kwargs, used_args, 2)\n self.check_unused_args(list(used_args), args, kwargs)\n return result\n\n def _vformat(\n self,\n format_string: str,\n args: Sequence[Any],\n kwargs: Mapping[str, Any],\n used_args: Set[Union[int, str]],\n recursion_depth: int,\n auto_arg_index: int = 0,\n ) -> Tuple[TF, int]:\n if recursion_depth < 0:\n raise ValueError(\"Max string recursion exceeded\")\n\n results: List[Any] = []\n\n for (literal_text, field_name, format_spec, conversion) in self.parse(\n format_string\n ):\n\n # output the literal text\n if literal_text:\n results.append(literal_text)\n\n # if there's a field, output it\n if field_name is not None:\n # this is some markup, find the object and do\n # the formatting\n\n # handle arg indexing when empty field_names are given.\n if field_name == \"\":\n if auto_arg_index is False:\n raise ValueError(\n \"cannot switch from manual field specification to \"\n \"automatic field numbering\"\n )\n field_name = str(auto_arg_index)\n auto_arg_index += 1\n elif field_name.isdigit():\n if auto_arg_index:\n raise ValueError(\n \"cannot switch from manual field specification to \"\n \"automatic field numbering\"\n )\n # disable auto arg incrementing, if it gets\n # used later on, then an exception will be raised\n auto_arg_index = False\n\n # given the field_name, find the object it references\n # and the argument it came from\n obj, arg_used = self.get_field(field_name, args, kwargs)\n used_args.add(arg_used)\n\n assert format_spec is not None\n\n # do any conversion on the resulting object\n obj = self.convert_field(obj, conversion) if conversion else obj\n\n # expand the format spec, if needed\n format_control, auto_arg_index = self._vformat(\n format_spec,\n args,\n kwargs,\n used_args,\n recursion_depth - 1,\n auto_arg_index,\n )\n\n # format the object and append to the result\n formatted_text = self.format_field(obj, str(format_control))\n results.append(formatted_text)\n\n return (\n self.factory(functools.reduce(self._add, results or [\"\"])),\n auto_arg_index,\n )\n\n def format_field(self, value: Any, format_spec: str) -> Any:\n formatter: Optional[FormatSpecFunc] = self.format_specs.get(format_spec)\n if formatter is None and not issubclass(self.factory, str):\n segment_class: Type[\"MessageSegment\"] = self.factory.get_segment_class()\n method = getattr(segment_class, format_spec, None)\n if callable(method) and not cast(str, method.__name__).startswith(\"_\"):\n formatter = getattr(segment_class, format_spec)\n return (\n super().format_field(value, format_spec)\n if formatter is None\n else formatter(value)\n )\n\n def _add(self, a: Any, b: Any) -> Any:\n try:\n return a + b\n except TypeError:\n return a + str(b)\n", "path": "nonebot/internal/adapter/template.py"}]}
| 2,472 | 427 |
gh_patches_debug_32582
|
rasdani/github-patches
|
git_diff
|
googleapis__google-auth-library-python-1243
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Password prompt opened by `google.auth.default()` when credentials have expired
When you have a reauthentication policy set in Google Cloud and your crendentials have expired, calling `google.auth.default()` will open a `Please enter your password:` password prompt, instead if raising a `DefaultCredentialsError` as I believe would be expected.
The password prompt interrupts the flow of the program, with no way to catch or handle it actively.
If credentials are _revoked_ (instead of expired), you don't get the password prompt, and instead get an exception as expected.
For example, when creating a `bigquery.Client`, its `__init__` calls `super(Client, self).__init__()` which in turn calls `google.auth.default()`, which in turn [calls the external program `gcloud config config-helper --format json` in a `subprocess`](https://github.com/googleapis/google-auth-library-python/blob/main/google/auth/_cloud_sdk.py#L108), which finally opens the prompt.
Full traceback after starting it with `python -m pdb ...` and hitting Ctrl-C from when the prompt is open:
```
Traceback (most recent call last):
".../code_under_test.py", line 90, in _bqclient
client = bigquery.Client(
File ".../.venv/lib/python3.10/site-packages/google/cloud/bigquery/client.py", line 244, in __init__
super(Client, self).__init__(
File ".../.venv/lib/python3.10/site-packages/google/cloud/client/__init__.py", line 321, in __init__
Client.__init__(
File ".../.venv/lib/python3.10/site-packages/google/cloud/client/__init__.py", line 178, in __init__
credentials, _ = google.auth.default(scopes=scopes)
File ".../.venv/lib/python3.10/site-packages/google/auth/_default.py", line 620, in default
credentials, project_id = checker()
File ".../.venv/lib/python3.10/site-packages/google/auth/_default.py", line 614, in <lambda>
lambda: _get_gcloud_sdk_credentials(quota_project_id=quota_project_id),
File ".../.venv/lib/python3.10/site-packages/google/auth/_default.py", line 205, in _get_gcloud_sdk_credentials
project_id = _cloud_sdk.get_project_id()
File ".../.venv/lib/python3.10/site-packages/google/auth/_cloud_sdk.py", line 108, in get_project_id
output = _run_subprocess_ignore_stderr((command,) + _CLOUD_SDK_CONFIG_COMMAND)
File ".../.venv/lib/python3.10/site-packages/google/auth/_cloud_sdk.py", line 90, in _run_subprocess_ignore_stderr
output = subprocess.check_output(command, stderr=devnull)
...
```
#### Environment details
- OS: macOS 13.2.1
- Python version: 3.10.8
- pip version: 23.0.1
- `google-auth` version: 2.16.1
#### Steps to reproduce
1. Set a [Reauthentication policy](https://admin.google.com/ac/security/reauth/admin-tools) in Google Cloud.
2. Authenticate using `gcloud auth login --update-adc`.
3. Let your access token expire.
4. Now, `python -c "import google.auth; google.auth.default()"` will prompt you with `Please enter your password:`.
If instead of letting your token expire, you actively revoke it with `gcloud auth application-default revoke` and `gcloud auth revoke`, then you get the following exception raised:
```
Traceback (most recent call last):
File "<string>", line 1, in <module>
File ".../.venv/lib/python3.10/site-packages/google/auth/_default.py", line 653, in default
raise exceptions.DefaultCredentialsError(_HELP_MESSAGE)
google.auth.exceptions.DefaultCredentialsError: Could not automatically determine credentials. Please set GOOGLE_APPLICATION_CREDENTIALS or explicitly create credentials and re-run the application. For more information, please see https://cloud.google.com/docs/authentication/getting-started
```
Also, for some reason the password prompt is **not** opened if you capture `stdin` like `subprocess.check_output(["gcloud", "config", "config-helper", "--format", "json"], stdin=subprocess.PIPE)`. This has the interesting effect that if you run code in `pytest`(that captures `stdin`), you don't get the password prompt, but if you run it with `pytest -s` you do.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `google/auth/_cloud_sdk.py`
Content:
```
1 # Copyright 2015 Google Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Helpers for reading the Google Cloud SDK's configuration."""
16
17 import json
18 import os
19 import subprocess
20
21 import six
22
23 from google.auth import environment_vars
24 from google.auth import exceptions
25
26
27 # The ~/.config subdirectory containing gcloud credentials.
28 _CONFIG_DIRECTORY = "gcloud"
29 # Windows systems store config at %APPDATA%\gcloud
30 _WINDOWS_CONFIG_ROOT_ENV_VAR = "APPDATA"
31 # The name of the file in the Cloud SDK config that contains default
32 # credentials.
33 _CREDENTIALS_FILENAME = "application_default_credentials.json"
34 # The name of the Cloud SDK shell script
35 _CLOUD_SDK_POSIX_COMMAND = "gcloud"
36 _CLOUD_SDK_WINDOWS_COMMAND = "gcloud.cmd"
37 # The command to get the Cloud SDK configuration
38 _CLOUD_SDK_CONFIG_COMMAND = ("config", "config-helper", "--format", "json")
39 # The command to get google user access token
40 _CLOUD_SDK_USER_ACCESS_TOKEN_COMMAND = ("auth", "print-access-token")
41 # Cloud SDK's application-default client ID
42 CLOUD_SDK_CLIENT_ID = (
43 "764086051850-6qr4p6gpi6hn506pt8ejuq83di341hur.apps.googleusercontent.com"
44 )
45
46
47 def get_config_path():
48 """Returns the absolute path the the Cloud SDK's configuration directory.
49
50 Returns:
51 str: The Cloud SDK config path.
52 """
53 # If the path is explicitly set, return that.
54 try:
55 return os.environ[environment_vars.CLOUD_SDK_CONFIG_DIR]
56 except KeyError:
57 pass
58
59 # Non-windows systems store this at ~/.config/gcloud
60 if os.name != "nt":
61 return os.path.join(os.path.expanduser("~"), ".config", _CONFIG_DIRECTORY)
62 # Windows systems store config at %APPDATA%\gcloud
63 else:
64 try:
65 return os.path.join(
66 os.environ[_WINDOWS_CONFIG_ROOT_ENV_VAR], _CONFIG_DIRECTORY
67 )
68 except KeyError:
69 # This should never happen unless someone is really
70 # messing with things, but we'll cover the case anyway.
71 drive = os.environ.get("SystemDrive", "C:")
72 return os.path.join(drive, "\\", _CONFIG_DIRECTORY)
73
74
75 def get_application_default_credentials_path():
76 """Gets the path to the application default credentials file.
77
78 The path may or may not exist.
79
80 Returns:
81 str: The full path to application default credentials.
82 """
83 config_path = get_config_path()
84 return os.path.join(config_path, _CREDENTIALS_FILENAME)
85
86
87 def _run_subprocess_ignore_stderr(command):
88 """ Return subprocess.check_output with the given command and ignores stderr."""
89 with open(os.devnull, "w") as devnull:
90 output = subprocess.check_output(command, stderr=devnull)
91 return output
92
93
94 def get_project_id():
95 """Gets the project ID from the Cloud SDK.
96
97 Returns:
98 Optional[str]: The project ID.
99 """
100 if os.name == "nt":
101 command = _CLOUD_SDK_WINDOWS_COMMAND
102 else:
103 command = _CLOUD_SDK_POSIX_COMMAND
104
105 try:
106 # Ignore the stderr coming from gcloud, so it won't be mixed into the output.
107 # https://github.com/googleapis/google-auth-library-python/issues/673
108 output = _run_subprocess_ignore_stderr((command,) + _CLOUD_SDK_CONFIG_COMMAND)
109 except (subprocess.CalledProcessError, OSError, IOError):
110 return None
111
112 try:
113 configuration = json.loads(output.decode("utf-8"))
114 except ValueError:
115 return None
116
117 try:
118 return configuration["configuration"]["properties"]["core"]["project"]
119 except KeyError:
120 return None
121
122
123 def get_auth_access_token(account=None):
124 """Load user access token with the ``gcloud auth print-access-token`` command.
125
126 Args:
127 account (Optional[str]): Account to get the access token for. If not
128 specified, the current active account will be used.
129
130 Returns:
131 str: The user access token.
132
133 Raises:
134 google.auth.exceptions.UserAccessTokenError: if failed to get access
135 token from gcloud.
136 """
137 if os.name == "nt":
138 command = _CLOUD_SDK_WINDOWS_COMMAND
139 else:
140 command = _CLOUD_SDK_POSIX_COMMAND
141
142 try:
143 if account:
144 command = (
145 (command,)
146 + _CLOUD_SDK_USER_ACCESS_TOKEN_COMMAND
147 + ("--account=" + account,)
148 )
149 else:
150 command = (command,) + _CLOUD_SDK_USER_ACCESS_TOKEN_COMMAND
151
152 access_token = subprocess.check_output(command, stderr=subprocess.STDOUT)
153 # remove the trailing "\n"
154 return access_token.decode("utf-8").strip()
155 except (subprocess.CalledProcessError, OSError, IOError) as caught_exc:
156 new_exc = exceptions.UserAccessTokenError(
157 "Failed to obtain access token", caught_exc
158 )
159 six.raise_from(new_exc, caught_exc)
160
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/google/auth/_cloud_sdk.py b/google/auth/_cloud_sdk.py
--- a/google/auth/_cloud_sdk.py
+++ b/google/auth/_cloud_sdk.py
@@ -14,12 +14,12 @@
"""Helpers for reading the Google Cloud SDK's configuration."""
-import json
import os
import subprocess
import six
+from google.auth import _helpers
from google.auth import environment_vars
from google.auth import exceptions
@@ -35,7 +35,7 @@
_CLOUD_SDK_POSIX_COMMAND = "gcloud"
_CLOUD_SDK_WINDOWS_COMMAND = "gcloud.cmd"
# The command to get the Cloud SDK configuration
-_CLOUD_SDK_CONFIG_COMMAND = ("config", "config-helper", "--format", "json")
+_CLOUD_SDK_CONFIG_GET_PROJECT_COMMAND = ("config", "get", "project")
# The command to get google user access token
_CLOUD_SDK_USER_ACCESS_TOKEN_COMMAND = ("auth", "print-access-token")
# Cloud SDK's application-default client ID
@@ -105,18 +105,14 @@
try:
# Ignore the stderr coming from gcloud, so it won't be mixed into the output.
# https://github.com/googleapis/google-auth-library-python/issues/673
- output = _run_subprocess_ignore_stderr((command,) + _CLOUD_SDK_CONFIG_COMMAND)
- except (subprocess.CalledProcessError, OSError, IOError):
- return None
-
- try:
- configuration = json.loads(output.decode("utf-8"))
- except ValueError:
- return None
+ project = _run_subprocess_ignore_stderr(
+ (command,) + _CLOUD_SDK_CONFIG_GET_PROJECT_COMMAND
+ )
- try:
- return configuration["configuration"]["properties"]["core"]["project"]
- except KeyError:
+ # Turn bytes into a string and remove "\n"
+ project = _helpers.from_bytes(project).strip()
+ return project if project else None
+ except (subprocess.CalledProcessError, OSError, IOError):
return None
|
{"golden_diff": "diff --git a/google/auth/_cloud_sdk.py b/google/auth/_cloud_sdk.py\n--- a/google/auth/_cloud_sdk.py\n+++ b/google/auth/_cloud_sdk.py\n@@ -14,12 +14,12 @@\n \n \"\"\"Helpers for reading the Google Cloud SDK's configuration.\"\"\"\n \n-import json\n import os\n import subprocess\n \n import six\n \n+from google.auth import _helpers\n from google.auth import environment_vars\n from google.auth import exceptions\n \n@@ -35,7 +35,7 @@\n _CLOUD_SDK_POSIX_COMMAND = \"gcloud\"\n _CLOUD_SDK_WINDOWS_COMMAND = \"gcloud.cmd\"\n # The command to get the Cloud SDK configuration\n-_CLOUD_SDK_CONFIG_COMMAND = (\"config\", \"config-helper\", \"--format\", \"json\")\n+_CLOUD_SDK_CONFIG_GET_PROJECT_COMMAND = (\"config\", \"get\", \"project\")\n # The command to get google user access token\n _CLOUD_SDK_USER_ACCESS_TOKEN_COMMAND = (\"auth\", \"print-access-token\")\n # Cloud SDK's application-default client ID\n@@ -105,18 +105,14 @@\n try:\n # Ignore the stderr coming from gcloud, so it won't be mixed into the output.\n # https://github.com/googleapis/google-auth-library-python/issues/673\n- output = _run_subprocess_ignore_stderr((command,) + _CLOUD_SDK_CONFIG_COMMAND)\n- except (subprocess.CalledProcessError, OSError, IOError):\n- return None\n-\n- try:\n- configuration = json.loads(output.decode(\"utf-8\"))\n- except ValueError:\n- return None\n+ project = _run_subprocess_ignore_stderr(\n+ (command,) + _CLOUD_SDK_CONFIG_GET_PROJECT_COMMAND\n+ )\n \n- try:\n- return configuration[\"configuration\"][\"properties\"][\"core\"][\"project\"]\n- except KeyError:\n+ # Turn bytes into a string and remove \"\\n\"\n+ project = _helpers.from_bytes(project).strip()\n+ return project if project else None\n+ except (subprocess.CalledProcessError, OSError, IOError):\n return None\n", "issue": "Password prompt opened by `google.auth.default()` when credentials have expired\nWhen you have a reauthentication policy set in Google Cloud and your crendentials have expired, calling `google.auth.default()` will open a `Please enter your password:` password prompt, instead if raising a `DefaultCredentialsError` as I believe would be expected.\r\n\r\nThe password prompt interrupts the flow of the program, with no way to catch or handle it actively.\r\n\r\nIf credentials are _revoked_ (instead of expired), you don't get the password prompt, and instead get an exception as expected.\r\n\r\nFor example, when creating a `bigquery.Client`, its `__init__` calls `super(Client, self).__init__()` which in turn calls `google.auth.default()`, which in turn [calls the external program `gcloud config config-helper --format json` in a `subprocess`](https://github.com/googleapis/google-auth-library-python/blob/main/google/auth/_cloud_sdk.py#L108), which finally opens the prompt.\r\n\r\nFull traceback after starting it with `python -m pdb ...` and hitting Ctrl-C from when the prompt is open:\r\n\r\n```\r\nTraceback (most recent call last):\r\n \".../code_under_test.py\", line 90, in _bqclient\r\n client = bigquery.Client(\r\n File \".../.venv/lib/python3.10/site-packages/google/cloud/bigquery/client.py\", line 244, in __init__\r\n super(Client, self).__init__(\r\n File \".../.venv/lib/python3.10/site-packages/google/cloud/client/__init__.py\", line 321, in __init__\r\n Client.__init__(\r\n File \".../.venv/lib/python3.10/site-packages/google/cloud/client/__init__.py\", line 178, in __init__\r\n credentials, _ = google.auth.default(scopes=scopes)\r\n File \".../.venv/lib/python3.10/site-packages/google/auth/_default.py\", line 620, in default\r\n credentials, project_id = checker()\r\n File \".../.venv/lib/python3.10/site-packages/google/auth/_default.py\", line 614, in <lambda>\r\n lambda: _get_gcloud_sdk_credentials(quota_project_id=quota_project_id),\r\n File \".../.venv/lib/python3.10/site-packages/google/auth/_default.py\", line 205, in _get_gcloud_sdk_credentials\r\n project_id = _cloud_sdk.get_project_id()\r\n File \".../.venv/lib/python3.10/site-packages/google/auth/_cloud_sdk.py\", line 108, in get_project_id\r\n output = _run_subprocess_ignore_stderr((command,) + _CLOUD_SDK_CONFIG_COMMAND)\r\n File \".../.venv/lib/python3.10/site-packages/google/auth/_cloud_sdk.py\", line 90, in _run_subprocess_ignore_stderr\r\n output = subprocess.check_output(command, stderr=devnull)\r\n ...\r\n```\r\n\r\n#### Environment details\r\n\r\n - OS: macOS 13.2.1\r\n - Python version: 3.10.8\r\n - pip version: 23.0.1\r\n - `google-auth` version: 2.16.1\r\n\r\n#### Steps to reproduce\r\n\r\n 1. Set a [Reauthentication policy](https://admin.google.com/ac/security/reauth/admin-tools) in Google Cloud.\r\n 2. Authenticate using `gcloud auth login --update-adc`.\r\n 3. Let your access token expire.\r\n 4. Now, `python -c \"import google.auth; google.auth.default()\"` will prompt you with `Please enter your password:`.\r\n\r\nIf instead of letting your token expire, you actively revoke it with `gcloud auth application-default revoke` and `gcloud auth revoke`, then you get the following exception raised:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"<string>\", line 1, in <module>\r\n File \".../.venv/lib/python3.10/site-packages/google/auth/_default.py\", line 653, in default\r\n raise exceptions.DefaultCredentialsError(_HELP_MESSAGE)\r\ngoogle.auth.exceptions.DefaultCredentialsError: Could not automatically determine credentials. Please set GOOGLE_APPLICATION_CREDENTIALS or explicitly create credentials and re-run the application. For more information, please see https://cloud.google.com/docs/authentication/getting-started\r\n```\r\n\r\nAlso, for some reason the password prompt is **not** opened if you capture `stdin` like `subprocess.check_output([\"gcloud\", \"config\", \"config-helper\", \"--format\", \"json\"], stdin=subprocess.PIPE)`. This has the interesting effect that if you run code in `pytest`(that captures `stdin`), you don't get the password prompt, but if you run it with `pytest -s` you do.\r\n\n", "before_files": [{"content": "# Copyright 2015 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Helpers for reading the Google Cloud SDK's configuration.\"\"\"\n\nimport json\nimport os\nimport subprocess\n\nimport six\n\nfrom google.auth import environment_vars\nfrom google.auth import exceptions\n\n\n# The ~/.config subdirectory containing gcloud credentials.\n_CONFIG_DIRECTORY = \"gcloud\"\n# Windows systems store config at %APPDATA%\\gcloud\n_WINDOWS_CONFIG_ROOT_ENV_VAR = \"APPDATA\"\n# The name of the file in the Cloud SDK config that contains default\n# credentials.\n_CREDENTIALS_FILENAME = \"application_default_credentials.json\"\n# The name of the Cloud SDK shell script\n_CLOUD_SDK_POSIX_COMMAND = \"gcloud\"\n_CLOUD_SDK_WINDOWS_COMMAND = \"gcloud.cmd\"\n# The command to get the Cloud SDK configuration\n_CLOUD_SDK_CONFIG_COMMAND = (\"config\", \"config-helper\", \"--format\", \"json\")\n# The command to get google user access token\n_CLOUD_SDK_USER_ACCESS_TOKEN_COMMAND = (\"auth\", \"print-access-token\")\n# Cloud SDK's application-default client ID\nCLOUD_SDK_CLIENT_ID = (\n \"764086051850-6qr4p6gpi6hn506pt8ejuq83di341hur.apps.googleusercontent.com\"\n)\n\n\ndef get_config_path():\n \"\"\"Returns the absolute path the the Cloud SDK's configuration directory.\n\n Returns:\n str: The Cloud SDK config path.\n \"\"\"\n # If the path is explicitly set, return that.\n try:\n return os.environ[environment_vars.CLOUD_SDK_CONFIG_DIR]\n except KeyError:\n pass\n\n # Non-windows systems store this at ~/.config/gcloud\n if os.name != \"nt\":\n return os.path.join(os.path.expanduser(\"~\"), \".config\", _CONFIG_DIRECTORY)\n # Windows systems store config at %APPDATA%\\gcloud\n else:\n try:\n return os.path.join(\n os.environ[_WINDOWS_CONFIG_ROOT_ENV_VAR], _CONFIG_DIRECTORY\n )\n except KeyError:\n # This should never happen unless someone is really\n # messing with things, but we'll cover the case anyway.\n drive = os.environ.get(\"SystemDrive\", \"C:\")\n return os.path.join(drive, \"\\\\\", _CONFIG_DIRECTORY)\n\n\ndef get_application_default_credentials_path():\n \"\"\"Gets the path to the application default credentials file.\n\n The path may or may not exist.\n\n Returns:\n str: The full path to application default credentials.\n \"\"\"\n config_path = get_config_path()\n return os.path.join(config_path, _CREDENTIALS_FILENAME)\n\n\ndef _run_subprocess_ignore_stderr(command):\n \"\"\" Return subprocess.check_output with the given command and ignores stderr.\"\"\"\n with open(os.devnull, \"w\") as devnull:\n output = subprocess.check_output(command, stderr=devnull)\n return output\n\n\ndef get_project_id():\n \"\"\"Gets the project ID from the Cloud SDK.\n\n Returns:\n Optional[str]: The project ID.\n \"\"\"\n if os.name == \"nt\":\n command = _CLOUD_SDK_WINDOWS_COMMAND\n else:\n command = _CLOUD_SDK_POSIX_COMMAND\n\n try:\n # Ignore the stderr coming from gcloud, so it won't be mixed into the output.\n # https://github.com/googleapis/google-auth-library-python/issues/673\n output = _run_subprocess_ignore_stderr((command,) + _CLOUD_SDK_CONFIG_COMMAND)\n except (subprocess.CalledProcessError, OSError, IOError):\n return None\n\n try:\n configuration = json.loads(output.decode(\"utf-8\"))\n except ValueError:\n return None\n\n try:\n return configuration[\"configuration\"][\"properties\"][\"core\"][\"project\"]\n except KeyError:\n return None\n\n\ndef get_auth_access_token(account=None):\n \"\"\"Load user access token with the ``gcloud auth print-access-token`` command.\n\n Args:\n account (Optional[str]): Account to get the access token for. If not\n specified, the current active account will be used.\n\n Returns:\n str: The user access token.\n\n Raises:\n google.auth.exceptions.UserAccessTokenError: if failed to get access\n token from gcloud.\n \"\"\"\n if os.name == \"nt\":\n command = _CLOUD_SDK_WINDOWS_COMMAND\n else:\n command = _CLOUD_SDK_POSIX_COMMAND\n\n try:\n if account:\n command = (\n (command,)\n + _CLOUD_SDK_USER_ACCESS_TOKEN_COMMAND\n + (\"--account=\" + account,)\n )\n else:\n command = (command,) + _CLOUD_SDK_USER_ACCESS_TOKEN_COMMAND\n\n access_token = subprocess.check_output(command, stderr=subprocess.STDOUT)\n # remove the trailing \"\\n\"\n return access_token.decode(\"utf-8\").strip()\n except (subprocess.CalledProcessError, OSError, IOError) as caught_exc:\n new_exc = exceptions.UserAccessTokenError(\n \"Failed to obtain access token\", caught_exc\n )\n six.raise_from(new_exc, caught_exc)\n", "path": "google/auth/_cloud_sdk.py"}], "after_files": [{"content": "# Copyright 2015 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Helpers for reading the Google Cloud SDK's configuration.\"\"\"\n\nimport os\nimport subprocess\n\nimport six\n\nfrom google.auth import _helpers\nfrom google.auth import environment_vars\nfrom google.auth import exceptions\n\n\n# The ~/.config subdirectory containing gcloud credentials.\n_CONFIG_DIRECTORY = \"gcloud\"\n# Windows systems store config at %APPDATA%\\gcloud\n_WINDOWS_CONFIG_ROOT_ENV_VAR = \"APPDATA\"\n# The name of the file in the Cloud SDK config that contains default\n# credentials.\n_CREDENTIALS_FILENAME = \"application_default_credentials.json\"\n# The name of the Cloud SDK shell script\n_CLOUD_SDK_POSIX_COMMAND = \"gcloud\"\n_CLOUD_SDK_WINDOWS_COMMAND = \"gcloud.cmd\"\n# The command to get the Cloud SDK configuration\n_CLOUD_SDK_CONFIG_GET_PROJECT_COMMAND = (\"config\", \"get\", \"project\")\n# The command to get google user access token\n_CLOUD_SDK_USER_ACCESS_TOKEN_COMMAND = (\"auth\", \"print-access-token\")\n# Cloud SDK's application-default client ID\nCLOUD_SDK_CLIENT_ID = (\n \"764086051850-6qr4p6gpi6hn506pt8ejuq83di341hur.apps.googleusercontent.com\"\n)\n\n\ndef get_config_path():\n \"\"\"Returns the absolute path the the Cloud SDK's configuration directory.\n\n Returns:\n str: The Cloud SDK config path.\n \"\"\"\n # If the path is explicitly set, return that.\n try:\n return os.environ[environment_vars.CLOUD_SDK_CONFIG_DIR]\n except KeyError:\n pass\n\n # Non-windows systems store this at ~/.config/gcloud\n if os.name != \"nt\":\n return os.path.join(os.path.expanduser(\"~\"), \".config\", _CONFIG_DIRECTORY)\n # Windows systems store config at %APPDATA%\\gcloud\n else:\n try:\n return os.path.join(\n os.environ[_WINDOWS_CONFIG_ROOT_ENV_VAR], _CONFIG_DIRECTORY\n )\n except KeyError:\n # This should never happen unless someone is really\n # messing with things, but we'll cover the case anyway.\n drive = os.environ.get(\"SystemDrive\", \"C:\")\n return os.path.join(drive, \"\\\\\", _CONFIG_DIRECTORY)\n\n\ndef get_application_default_credentials_path():\n \"\"\"Gets the path to the application default credentials file.\n\n The path may or may not exist.\n\n Returns:\n str: The full path to application default credentials.\n \"\"\"\n config_path = get_config_path()\n return os.path.join(config_path, _CREDENTIALS_FILENAME)\n\n\ndef _run_subprocess_ignore_stderr(command):\n \"\"\" Return subprocess.check_output with the given command and ignores stderr.\"\"\"\n with open(os.devnull, \"w\") as devnull:\n output = subprocess.check_output(command, stderr=devnull)\n return output\n\n\ndef get_project_id():\n \"\"\"Gets the project ID from the Cloud SDK.\n\n Returns:\n Optional[str]: The project ID.\n \"\"\"\n if os.name == \"nt\":\n command = _CLOUD_SDK_WINDOWS_COMMAND\n else:\n command = _CLOUD_SDK_POSIX_COMMAND\n\n try:\n # Ignore the stderr coming from gcloud, so it won't be mixed into the output.\n # https://github.com/googleapis/google-auth-library-python/issues/673\n project = _run_subprocess_ignore_stderr(\n (command,) + _CLOUD_SDK_CONFIG_GET_PROJECT_COMMAND\n )\n\n # Turn bytes into a string and remove \"\\n\"\n project = _helpers.from_bytes(project).strip()\n return project if project else None\n except (subprocess.CalledProcessError, OSError, IOError):\n return None\n\n\ndef get_auth_access_token(account=None):\n \"\"\"Load user access token with the ``gcloud auth print-access-token`` command.\n\n Args:\n account (Optional[str]): Account to get the access token for. If not\n specified, the current active account will be used.\n\n Returns:\n str: The user access token.\n\n Raises:\n google.auth.exceptions.UserAccessTokenError: if failed to get access\n token from gcloud.\n \"\"\"\n if os.name == \"nt\":\n command = _CLOUD_SDK_WINDOWS_COMMAND\n else:\n command = _CLOUD_SDK_POSIX_COMMAND\n\n try:\n if account:\n command = (\n (command,)\n + _CLOUD_SDK_USER_ACCESS_TOKEN_COMMAND\n + (\"--account=\" + account,)\n )\n else:\n command = (command,) + _CLOUD_SDK_USER_ACCESS_TOKEN_COMMAND\n\n access_token = subprocess.check_output(command, stderr=subprocess.STDOUT)\n # remove the trailing \"\\n\"\n return access_token.decode(\"utf-8\").strip()\n except (subprocess.CalledProcessError, OSError, IOError) as caught_exc:\n new_exc = exceptions.UserAccessTokenError(\n \"Failed to obtain access token\", caught_exc\n )\n six.raise_from(new_exc, caught_exc)\n", "path": "google/auth/_cloud_sdk.py"}]}
| 2,840 | 447 |
gh_patches_debug_38421
|
rasdani/github-patches
|
git_diff
|
Cloud-CV__EvalAI-1636
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Modify database seeding method
## Deliverables
- [ ] Modify the seed command to accept an argument `-nc` which denotes the number of challenges that a developer wants to create for testing.
- [ ] Modify the seed script in such a way that it can be run multiple times (right now, if you run it once and then you try to run it again, then it throws an error).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `apps/base/management/commands/seed.py`
Content:
```
1 from django.core.management import BaseCommand, call_command
2
3
4 class Command(BaseCommand):
5
6 help = "Seeds the database with random but sensible values."
7
8 def handle(self, *args, **options):
9 self.stdout.write(self.style.SUCCESS('Starting the database seeder. Hang on...'))
10 call_command('runscript', 'seed', '--settings', 'settings.dev')
11
```
Path: `scripts/seed.py`
Content:
```
1 # Command to run : python manage.py shell < scripts/seed.py
2 import os
3
4 from datetime import timedelta
5
6 from django.conf import settings
7 from django.contrib.auth.models import User
8 from django.core.files.uploadedfile import SimpleUploadedFile
9 from django.utils import timezone
10
11 from allauth.account.models import EmailAddress
12 from faker import Factory
13
14 from challenges.models import Challenge, ChallengePhase, DatasetSplit, Leaderboard, ChallengePhaseSplit
15 from hosts.models import ChallengeHostTeam, ChallengeHost
16 from participants.models import Participant, ParticipantTeam
17
18 fake = Factory.create()
19
20 NUMBER_OF_CHALLENGES = 1
21 NUMBER_OF_PHASES = 2
22 NUMBER_OF_DATASET_SPLITS = 2
23 DATASET_SPLIT_ITERATOR = 0
24
25 try:
26 xrange # Python 2
27 except NameError:
28 xrange = range # Python 3
29
30
31 def check_database():
32 if len(EmailAddress.objects.all()) > 0:
33 print("Are you sure you want to wipe the existing development database and reseed it? (Y/N)")
34 if raw_input().lower() == "y":
35 destroy_database()
36 else:
37 return False
38 else:
39 return True
40
41
42 def destroy_database():
43 print("Destroying existing database...")
44 print("Destroying Participant objects...")
45 Participant.objects.all().delete()
46 print("Destroying ParticipantTeam objects...")
47 ParticipantTeam.objects.all().delete()
48 print("Destroying ChallengePhaseSplit objects...")
49 ChallengePhaseSplit.objects.all().delete()
50 print("Destroying DatasetSplit objects...")
51 DatasetSplit.objects.all().delete()
52 print("Destroying ChallengePhase objects...")
53 ChallengePhase.objects.all().delete()
54 print("Destroying Leaderboard objects...")
55 Leaderboard.objects.all().delete()
56 print("Destroying Challenge objects...")
57 Challenge.objects.all().delete()
58 print("Destroying ChallengeHostTeam objects...")
59 ChallengeHostTeam.objects.all().delete()
60 print("Destroying ChallengeHost objects...")
61 ChallengeHost.objects.all().delete()
62 print("Destroying User objects...")
63 User.objects.all().delete()
64 print("Destroying EmailAddress objects...")
65 EmailAddress.objects.all().delete()
66 return True
67
68
69 def create_user(is_admin, username=""):
70 """
71 Creates superuser, participant user, host user and returns it.
72 """
73 if is_admin:
74 username = "admin"
75 email = "[email protected]"
76 else:
77 email = "%[email protected]" % (username)
78 user = User.objects.create_user(
79 email=email,
80 username=username,
81 password="password",
82 is_staff=is_admin,
83 is_superuser=is_admin,
84 )
85 EmailAddress.objects.create(user=user, email=email, verified=True, primary=True)
86 print("{} was created with username: {} password: password".format("Super user" if is_admin else "User", username))
87 return user
88
89
90 def create_challenge_host_team(user):
91 """
92 Creates challenge host team and returns it.
93 """
94 team_name = "{} Host Team".format(fake.city())
95 team = ChallengeHostTeam.objects.create(
96 team_name=team_name,
97 created_by=user,
98 )
99 print("Challenge Host Team created with team_name: {} created_by: {}".format(team_name, user.username))
100 ChallengeHost.objects.create(user=user, team_name=team, status=ChallengeHost.SELF, permissions=ChallengeHost.ADMIN)
101 print("Challenge Host created with user: {} team_name: {}".format(user.username, team_name))
102 return team
103
104
105 def create_challenges(number_of_challenges=3, host_team=None):
106 """
107 Creates past challenge, on-going challenge and upcoming challenge.
108 """
109 for i in xrange(number_of_challenges):
110 if (i % 3 == 0):
111 create_challenge("{} Challenge".format(fake.first_name()),
112 timezone.now() - timedelta(days=100),
113 timezone.now() + timedelta(days=500),
114 host_team
115 )
116 elif (i % 3 == 1):
117 create_challenge("{} Challenge" % (fake.first_name()),
118 timezone.now() - timedelta(days=500),
119 timezone.now() - timedelta(days=100),
120 host_team
121 )
122 elif (i % 3 == 2):
123 create_challenge("{} Challenge" % (fake.first_name()),
124 timezone.now() + timedelta(days=100),
125 timezone.now() + timedelta(days=500),
126 host_team
127 )
128
129
130 def create_challenge(title, start_date, end_date, host_team):
131 """
132 Creates a challenge.
133 """
134 evaluation_script = open(os.path.join(settings.BASE_DIR, 'examples', 'example1', 'string_matching.zip'), 'rb')
135 Challenge.objects.create(
136 title=title,
137 short_description=fake.paragraph(),
138 description=fake.paragraph(),
139 terms_and_conditions=fake.paragraph(),
140 submission_guidelines=fake.paragraph(),
141 evaluation_details=fake.paragraph(),
142 evaluation_script=SimpleUploadedFile(evaluation_script.name, evaluation_script.read()),
143 approved_by_admin=True,
144 creator=host_team,
145 published=True,
146 enable_forum=True,
147 anonymous_leaderboard=False,
148 start_date=start_date,
149 end_date=end_date,
150 )
151 print("Challenge created with title: {} creator: {} start_date: {} end_date: {}".format(title,
152 host_team.team_name,
153 start_date, end_date))
154
155
156 def create_challenge_phases(challenge, number_of_phases=1):
157 """
158 Creates challenge phases for the created challenges and returns it.
159 """
160 challenge_phases = []
161 for i in range(number_of_phases):
162 name = "{} Phase".format(fake.first_name())
163 with open(os.path.join(settings.BASE_DIR, 'examples', 'example1', 'test_annotation.txt'), 'rb') as data_file:
164 data = data_file.read()
165 data = data or None
166 challenge_phase = ChallengePhase.objects.create(
167 name=name,
168 description=fake.paragraph(),
169 leaderboard_public=True,
170 is_public=True,
171 start_date=challenge.start_date,
172 end_date=challenge.end_date,
173 challenge=challenge,
174 test_annotation=SimpleUploadedFile(fake.file_name(extension="txt"), data, content_type="text/plain"),
175 codename="{}{}".format("phase", i + 1),
176 )
177 challenge_phases.append(challenge_phase)
178 print("Challenge Phase created with name: {} challenge: {}".format(name, challenge.title))
179 return challenge_phases
180
181
182 def create_leaderboard():
183 """
184 Creates Leaderboard schema and returns it.
185 """
186 schema = {
187 'labels': ['score', ],
188 'default_order_by': 'score',
189 }
190 leaderboard = Leaderboard.objects.create(
191 schema=schema
192 )
193 print("Leaderboard created")
194 return leaderboard
195
196
197 def create_dataset_splits(number_of_splits):
198 """
199 Creates dataset splits and returns it.
200 """
201 dataset_splits = []
202 for i in range(number_of_splits):
203 global DATASET_SPLIT_ITERATOR
204 name = "Split {}".format(DATASET_SPLIT_ITERATOR + 1)
205 codename = "{}{}".format('split', DATASET_SPLIT_ITERATOR + 1)
206 dataset_split = DatasetSplit.objects.create(
207 name=name,
208 codename=codename,
209 )
210 dataset_splits.append(dataset_split)
211 DATASET_SPLIT_ITERATOR += 1
212 print("Dataset Split created with name: {} codename: {}".format(name, codename))
213 return dataset_splits
214
215
216 def create_challenge_phase_splits(challenge_phase, leaderboard, dataset_split):
217 """
218 Creates a challenge phase split.
219 """
220 ChallengePhaseSplit.objects.create(
221 challenge_phase=challenge_phase,
222 leaderboard=leaderboard,
223 dataset_split=dataset_split,
224 visibility=ChallengePhaseSplit.PUBLIC
225 )
226 print("Challenge Phase Split created with challenge_phase: {} dataset_split: {}".format(challenge_phase.name,
227 dataset_split.name))
228
229
230 def create_participant_team(user):
231 """
232 Creates participant team and returns it.
233 """
234 team_name = "{} Participant Team".format(fake.city())
235 team = ParticipantTeam.objects.create(
236 team_name=team_name,
237 created_by=user,
238 )
239 print("Participant Team created with team_name: {} created_by: {}".format(team_name, user.username))
240 Participant.objects.create(user=user, team=team, status="Self")
241 print("Participant created with user: {} team_name: {}".format(user.username, team_name))
242 return team
243
244
245 def run():
246 status = check_database()
247 if status is False:
248 print("Seeding aborted.")
249 return 0
250 print("Seeding...")
251 # Create superuser
252 create_user(is_admin=True)
253 # Create host user
254 host_user = create_user(is_admin=False, username="host")
255 # Create challenge host team with challenge host
256 challenge_host_team = create_challenge_host_team(user=host_user)
257 # Create challenge
258 create_challenges(number_of_challenges=NUMBER_OF_CHALLENGES, host_team=challenge_host_team)
259
260 # Fetch all the created challenges
261 challenges = Challenge.objects.all()
262 for challenge in challenges:
263 # Create a leaderboard object for each challenge
264 leaderboard = create_leaderboard()
265 # Create Phases for a challenge
266 challenge_phases = create_challenge_phases(challenge, number_of_phases=NUMBER_OF_PHASES)
267 # Create Dataset Split for each Challenge
268 dataset_splits = create_dataset_splits(number_of_splits=NUMBER_OF_DATASET_SPLITS)
269 # Create Challenge Phase Split for each Phase and Dataset Split
270 for challenge_phase in challenge_phases:
271 for dataset_split in dataset_splits:
272 create_challenge_phase_splits(challenge_phase, leaderboard, dataset_split)
273 participant_user = create_user(is_admin=False, username="participant")
274 create_participant_team(user=participant_user)
275 print('Database successfully seeded.')
276
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/apps/base/management/commands/seed.py b/apps/base/management/commands/seed.py
--- a/apps/base/management/commands/seed.py
+++ b/apps/base/management/commands/seed.py
@@ -5,6 +5,10 @@
help = "Seeds the database with random but sensible values."
+ def add_arguments(self, parser):
+ parser.add_argument('-nc', nargs='?', default=1, type=int, help='Number of challenges.')
+
def handle(self, *args, **options):
+ self.nc = options['nc']
self.stdout.write(self.style.SUCCESS('Starting the database seeder. Hang on...'))
- call_command('runscript', 'seed', '--settings', 'settings.dev')
+ call_command('runscript', 'seed', '--script-args', self.nc)
diff --git a/scripts/seed.py b/scripts/seed.py
--- a/scripts/seed.py
+++ b/scripts/seed.py
@@ -31,7 +31,7 @@
def check_database():
if len(EmailAddress.objects.all()) > 0:
print("Are you sure you want to wipe the existing development database and reseed it? (Y/N)")
- if raw_input().lower() == "y":
+ if settings.TEST or raw_input().lower() == "y":
destroy_database()
else:
return False
@@ -102,7 +102,7 @@
return team
-def create_challenges(number_of_challenges=3, host_team=None):
+def create_challenges(number_of_challenges, host_team=None):
"""
Creates past challenge, on-going challenge and upcoming challenge.
"""
@@ -114,13 +114,13 @@
host_team
)
elif (i % 3 == 1):
- create_challenge("{} Challenge" % (fake.first_name()),
+ create_challenge("{} Challenge".format(fake.first_name()),
timezone.now() - timedelta(days=500),
timezone.now() - timedelta(days=100),
host_team
)
elif (i % 3 == 2):
- create_challenge("{} Challenge" % (fake.first_name()),
+ create_challenge("{} Challenge".format(fake.first_name()),
timezone.now() + timedelta(days=100),
timezone.now() + timedelta(days=500),
host_team
@@ -242,7 +242,8 @@
return team
-def run():
+def run(*args):
+ NUMBER_OF_CHALLENGES = int(args[0])
status = check_database()
if status is False:
print("Seeding aborted.")
|
{"golden_diff": "diff --git a/apps/base/management/commands/seed.py b/apps/base/management/commands/seed.py\n--- a/apps/base/management/commands/seed.py\n+++ b/apps/base/management/commands/seed.py\n@@ -5,6 +5,10 @@\n \n help = \"Seeds the database with random but sensible values.\"\n \n+ def add_arguments(self, parser):\n+ parser.add_argument('-nc', nargs='?', default=1, type=int, help='Number of challenges.')\n+\n def handle(self, *args, **options):\n+ self.nc = options['nc']\n self.stdout.write(self.style.SUCCESS('Starting the database seeder. Hang on...'))\n- call_command('runscript', 'seed', '--settings', 'settings.dev')\n+ call_command('runscript', 'seed', '--script-args', self.nc)\ndiff --git a/scripts/seed.py b/scripts/seed.py\n--- a/scripts/seed.py\n+++ b/scripts/seed.py\n@@ -31,7 +31,7 @@\n def check_database():\n if len(EmailAddress.objects.all()) > 0:\n print(\"Are you sure you want to wipe the existing development database and reseed it? (Y/N)\")\n- if raw_input().lower() == \"y\":\n+ if settings.TEST or raw_input().lower() == \"y\":\n destroy_database()\n else:\n return False\n@@ -102,7 +102,7 @@\n return team\n \n \n-def create_challenges(number_of_challenges=3, host_team=None):\n+def create_challenges(number_of_challenges, host_team=None):\n \"\"\"\n Creates past challenge, on-going challenge and upcoming challenge.\n \"\"\"\n@@ -114,13 +114,13 @@\n host_team\n )\n elif (i % 3 == 1):\n- create_challenge(\"{} Challenge\" % (fake.first_name()),\n+ create_challenge(\"{} Challenge\".format(fake.first_name()),\n timezone.now() - timedelta(days=500),\n timezone.now() - timedelta(days=100),\n host_team\n )\n elif (i % 3 == 2):\n- create_challenge(\"{} Challenge\" % (fake.first_name()),\n+ create_challenge(\"{} Challenge\".format(fake.first_name()),\n timezone.now() + timedelta(days=100),\n timezone.now() + timedelta(days=500),\n host_team\n@@ -242,7 +242,8 @@\n return team\n \n \n-def run():\n+def run(*args):\n+ NUMBER_OF_CHALLENGES = int(args[0])\n status = check_database()\n if status is False:\n print(\"Seeding aborted.\")\n", "issue": "Modify database seeding method\n## Deliverables\r\n\r\n- [ ] Modify the seed command to accept an argument `-nc` which denotes the number of challenges that a developer wants to create for testing.\r\n- [ ] Modify the seed script in such a way that it can be run multiple times (right now, if you run it once and then you try to run it again, then it throws an error). \n", "before_files": [{"content": "from django.core.management import BaseCommand, call_command\n\n\nclass Command(BaseCommand):\n\n help = \"Seeds the database with random but sensible values.\"\n\n def handle(self, *args, **options):\n self.stdout.write(self.style.SUCCESS('Starting the database seeder. Hang on...'))\n call_command('runscript', 'seed', '--settings', 'settings.dev')\n", "path": "apps/base/management/commands/seed.py"}, {"content": "# Command to run : python manage.py shell < scripts/seed.py\nimport os\n\nfrom datetime import timedelta\n\nfrom django.conf import settings\nfrom django.contrib.auth.models import User\nfrom django.core.files.uploadedfile import SimpleUploadedFile\nfrom django.utils import timezone\n\nfrom allauth.account.models import EmailAddress\nfrom faker import Factory\n\nfrom challenges.models import Challenge, ChallengePhase, DatasetSplit, Leaderboard, ChallengePhaseSplit\nfrom hosts.models import ChallengeHostTeam, ChallengeHost\nfrom participants.models import Participant, ParticipantTeam\n\nfake = Factory.create()\n\nNUMBER_OF_CHALLENGES = 1\nNUMBER_OF_PHASES = 2\nNUMBER_OF_DATASET_SPLITS = 2\nDATASET_SPLIT_ITERATOR = 0\n\ntry:\n xrange # Python 2\nexcept NameError:\n xrange = range # Python 3\n\n\ndef check_database():\n if len(EmailAddress.objects.all()) > 0:\n print(\"Are you sure you want to wipe the existing development database and reseed it? (Y/N)\")\n if raw_input().lower() == \"y\":\n destroy_database()\n else:\n return False\n else:\n return True\n\n\ndef destroy_database():\n print(\"Destroying existing database...\")\n print(\"Destroying Participant objects...\")\n Participant.objects.all().delete()\n print(\"Destroying ParticipantTeam objects...\")\n ParticipantTeam.objects.all().delete()\n print(\"Destroying ChallengePhaseSplit objects...\")\n ChallengePhaseSplit.objects.all().delete()\n print(\"Destroying DatasetSplit objects...\")\n DatasetSplit.objects.all().delete()\n print(\"Destroying ChallengePhase objects...\")\n ChallengePhase.objects.all().delete()\n print(\"Destroying Leaderboard objects...\")\n Leaderboard.objects.all().delete()\n print(\"Destroying Challenge objects...\")\n Challenge.objects.all().delete()\n print(\"Destroying ChallengeHostTeam objects...\")\n ChallengeHostTeam.objects.all().delete()\n print(\"Destroying ChallengeHost objects...\")\n ChallengeHost.objects.all().delete()\n print(\"Destroying User objects...\")\n User.objects.all().delete()\n print(\"Destroying EmailAddress objects...\")\n EmailAddress.objects.all().delete()\n return True\n\n\ndef create_user(is_admin, username=\"\"):\n \"\"\"\n Creates superuser, participant user, host user and returns it.\n \"\"\"\n if is_admin:\n username = \"admin\"\n email = \"[email protected]\"\n else:\n email = \"%[email protected]\" % (username)\n user = User.objects.create_user(\n email=email,\n username=username,\n password=\"password\",\n is_staff=is_admin,\n is_superuser=is_admin,\n )\n EmailAddress.objects.create(user=user, email=email, verified=True, primary=True)\n print(\"{} was created with username: {} password: password\".format(\"Super user\" if is_admin else \"User\", username))\n return user\n\n\ndef create_challenge_host_team(user):\n \"\"\"\n Creates challenge host team and returns it.\n \"\"\"\n team_name = \"{} Host Team\".format(fake.city())\n team = ChallengeHostTeam.objects.create(\n team_name=team_name,\n created_by=user,\n )\n print(\"Challenge Host Team created with team_name: {} created_by: {}\".format(team_name, user.username))\n ChallengeHost.objects.create(user=user, team_name=team, status=ChallengeHost.SELF, permissions=ChallengeHost.ADMIN)\n print(\"Challenge Host created with user: {} team_name: {}\".format(user.username, team_name))\n return team\n\n\ndef create_challenges(number_of_challenges=3, host_team=None):\n \"\"\"\n Creates past challenge, on-going challenge and upcoming challenge.\n \"\"\"\n for i in xrange(number_of_challenges):\n if (i % 3 == 0):\n create_challenge(\"{} Challenge\".format(fake.first_name()),\n timezone.now() - timedelta(days=100),\n timezone.now() + timedelta(days=500),\n host_team\n )\n elif (i % 3 == 1):\n create_challenge(\"{} Challenge\" % (fake.first_name()),\n timezone.now() - timedelta(days=500),\n timezone.now() - timedelta(days=100),\n host_team\n )\n elif (i % 3 == 2):\n create_challenge(\"{} Challenge\" % (fake.first_name()),\n timezone.now() + timedelta(days=100),\n timezone.now() + timedelta(days=500),\n host_team\n )\n\n\ndef create_challenge(title, start_date, end_date, host_team):\n \"\"\"\n Creates a challenge.\n \"\"\"\n evaluation_script = open(os.path.join(settings.BASE_DIR, 'examples', 'example1', 'string_matching.zip'), 'rb')\n Challenge.objects.create(\n title=title,\n short_description=fake.paragraph(),\n description=fake.paragraph(),\n terms_and_conditions=fake.paragraph(),\n submission_guidelines=fake.paragraph(),\n evaluation_details=fake.paragraph(),\n evaluation_script=SimpleUploadedFile(evaluation_script.name, evaluation_script.read()),\n approved_by_admin=True,\n creator=host_team,\n published=True,\n enable_forum=True,\n anonymous_leaderboard=False,\n start_date=start_date,\n end_date=end_date,\n )\n print(\"Challenge created with title: {} creator: {} start_date: {} end_date: {}\".format(title,\n host_team.team_name,\n start_date, end_date))\n\n\ndef create_challenge_phases(challenge, number_of_phases=1):\n \"\"\"\n Creates challenge phases for the created challenges and returns it.\n \"\"\"\n challenge_phases = []\n for i in range(number_of_phases):\n name = \"{} Phase\".format(fake.first_name())\n with open(os.path.join(settings.BASE_DIR, 'examples', 'example1', 'test_annotation.txt'), 'rb') as data_file:\n data = data_file.read()\n data = data or None\n challenge_phase = ChallengePhase.objects.create(\n name=name,\n description=fake.paragraph(),\n leaderboard_public=True,\n is_public=True,\n start_date=challenge.start_date,\n end_date=challenge.end_date,\n challenge=challenge,\n test_annotation=SimpleUploadedFile(fake.file_name(extension=\"txt\"), data, content_type=\"text/plain\"),\n codename=\"{}{}\".format(\"phase\", i + 1),\n )\n challenge_phases.append(challenge_phase)\n print(\"Challenge Phase created with name: {} challenge: {}\".format(name, challenge.title))\n return challenge_phases\n\n\ndef create_leaderboard():\n \"\"\"\n Creates Leaderboard schema and returns it.\n \"\"\"\n schema = {\n 'labels': ['score', ],\n 'default_order_by': 'score',\n }\n leaderboard = Leaderboard.objects.create(\n schema=schema\n )\n print(\"Leaderboard created\")\n return leaderboard\n\n\ndef create_dataset_splits(number_of_splits):\n \"\"\"\n Creates dataset splits and returns it.\n \"\"\"\n dataset_splits = []\n for i in range(number_of_splits):\n global DATASET_SPLIT_ITERATOR\n name = \"Split {}\".format(DATASET_SPLIT_ITERATOR + 1)\n codename = \"{}{}\".format('split', DATASET_SPLIT_ITERATOR + 1)\n dataset_split = DatasetSplit.objects.create(\n name=name,\n codename=codename,\n )\n dataset_splits.append(dataset_split)\n DATASET_SPLIT_ITERATOR += 1\n print(\"Dataset Split created with name: {} codename: {}\".format(name, codename))\n return dataset_splits\n\n\ndef create_challenge_phase_splits(challenge_phase, leaderboard, dataset_split):\n \"\"\"\n Creates a challenge phase split.\n \"\"\"\n ChallengePhaseSplit.objects.create(\n challenge_phase=challenge_phase,\n leaderboard=leaderboard,\n dataset_split=dataset_split,\n visibility=ChallengePhaseSplit.PUBLIC\n )\n print(\"Challenge Phase Split created with challenge_phase: {} dataset_split: {}\".format(challenge_phase.name,\n dataset_split.name))\n\n\ndef create_participant_team(user):\n \"\"\"\n Creates participant team and returns it.\n \"\"\"\n team_name = \"{} Participant Team\".format(fake.city())\n team = ParticipantTeam.objects.create(\n team_name=team_name,\n created_by=user,\n )\n print(\"Participant Team created with team_name: {} created_by: {}\".format(team_name, user.username))\n Participant.objects.create(user=user, team=team, status=\"Self\")\n print(\"Participant created with user: {} team_name: {}\".format(user.username, team_name))\n return team\n\n\ndef run():\n status = check_database()\n if status is False:\n print(\"Seeding aborted.\")\n return 0\n print(\"Seeding...\")\n # Create superuser\n create_user(is_admin=True)\n # Create host user\n host_user = create_user(is_admin=False, username=\"host\")\n # Create challenge host team with challenge host\n challenge_host_team = create_challenge_host_team(user=host_user)\n # Create challenge\n create_challenges(number_of_challenges=NUMBER_OF_CHALLENGES, host_team=challenge_host_team)\n\n # Fetch all the created challenges\n challenges = Challenge.objects.all()\n for challenge in challenges:\n # Create a leaderboard object for each challenge\n leaderboard = create_leaderboard()\n # Create Phases for a challenge\n challenge_phases = create_challenge_phases(challenge, number_of_phases=NUMBER_OF_PHASES)\n # Create Dataset Split for each Challenge\n dataset_splits = create_dataset_splits(number_of_splits=NUMBER_OF_DATASET_SPLITS)\n # Create Challenge Phase Split for each Phase and Dataset Split\n for challenge_phase in challenge_phases:\n for dataset_split in dataset_splits:\n create_challenge_phase_splits(challenge_phase, leaderboard, dataset_split)\n participant_user = create_user(is_admin=False, username=\"participant\")\n create_participant_team(user=participant_user)\n print('Database successfully seeded.')\n", "path": "scripts/seed.py"}], "after_files": [{"content": "from django.core.management import BaseCommand, call_command\n\n\nclass Command(BaseCommand):\n\n help = \"Seeds the database with random but sensible values.\"\n\n def add_arguments(self, parser):\n parser.add_argument('-nc', nargs='?', default=1, type=int, help='Number of challenges.')\n\n def handle(self, *args, **options):\n self.nc = options['nc']\n self.stdout.write(self.style.SUCCESS('Starting the database seeder. Hang on...'))\n call_command('runscript', 'seed', '--script-args', self.nc)\n", "path": "apps/base/management/commands/seed.py"}, {"content": "# Command to run : python manage.py shell < scripts/seed.py\nimport os\n\nfrom datetime import timedelta\n\nfrom django.conf import settings\nfrom django.contrib.auth.models import User\nfrom django.core.files.uploadedfile import SimpleUploadedFile\nfrom django.utils import timezone\n\nfrom allauth.account.models import EmailAddress\nfrom faker import Factory\n\nfrom challenges.models import Challenge, ChallengePhase, DatasetSplit, Leaderboard, ChallengePhaseSplit\nfrom hosts.models import ChallengeHostTeam, ChallengeHost\nfrom participants.models import Participant, ParticipantTeam\n\nfake = Factory.create()\n\nNUMBER_OF_CHALLENGES = 1\nNUMBER_OF_PHASES = 2\nNUMBER_OF_DATASET_SPLITS = 2\nDATASET_SPLIT_ITERATOR = 0\n\ntry:\n xrange # Python 2\nexcept NameError:\n xrange = range # Python 3\n\n\ndef check_database():\n if len(EmailAddress.objects.all()) > 0:\n print(\"Are you sure you want to wipe the existing development database and reseed it? (Y/N)\")\n if settings.TEST or raw_input().lower() == \"y\":\n destroy_database()\n else:\n return False\n else:\n return True\n\n\ndef destroy_database():\n print(\"Destroying existing database...\")\n print(\"Destroying Participant objects...\")\n Participant.objects.all().delete()\n print(\"Destroying ParticipantTeam objects...\")\n ParticipantTeam.objects.all().delete()\n print(\"Destroying ChallengePhaseSplit objects...\")\n ChallengePhaseSplit.objects.all().delete()\n print(\"Destroying DatasetSplit objects...\")\n DatasetSplit.objects.all().delete()\n print(\"Destroying ChallengePhase objects...\")\n ChallengePhase.objects.all().delete()\n print(\"Destroying Leaderboard objects...\")\n Leaderboard.objects.all().delete()\n print(\"Destroying Challenge objects...\")\n Challenge.objects.all().delete()\n print(\"Destroying ChallengeHostTeam objects...\")\n ChallengeHostTeam.objects.all().delete()\n print(\"Destroying ChallengeHost objects...\")\n ChallengeHost.objects.all().delete()\n print(\"Destroying User objects...\")\n User.objects.all().delete()\n print(\"Destroying EmailAddress objects...\")\n EmailAddress.objects.all().delete()\n return True\n\n\ndef create_user(is_admin, username=\"\"):\n \"\"\"\n Creates superuser, participant user, host user and returns it.\n \"\"\"\n if is_admin:\n username = \"admin\"\n email = \"[email protected]\"\n else:\n email = \"%[email protected]\" % (username)\n user = User.objects.create_user(\n email=email,\n username=username,\n password=\"password\",\n is_staff=is_admin,\n is_superuser=is_admin,\n )\n EmailAddress.objects.create(user=user, email=email, verified=True, primary=True)\n print(\"{} was created with username: {} password: password\".format(\"Super user\" if is_admin else \"User\", username))\n return user\n\n\ndef create_challenge_host_team(user):\n \"\"\"\n Creates challenge host team and returns it.\n \"\"\"\n team_name = \"{} Host Team\".format(fake.city())\n team = ChallengeHostTeam.objects.create(\n team_name=team_name,\n created_by=user,\n )\n print(\"Challenge Host Team created with team_name: {} created_by: {}\".format(team_name, user.username))\n ChallengeHost.objects.create(user=user, team_name=team, status=ChallengeHost.SELF, permissions=ChallengeHost.ADMIN)\n print(\"Challenge Host created with user: {} team_name: {}\".format(user.username, team_name))\n return team\n\n\ndef create_challenges(number_of_challenges, host_team=None):\n \"\"\"\n Creates past challenge, on-going challenge and upcoming challenge.\n \"\"\"\n for i in xrange(number_of_challenges):\n if (i % 3 == 0):\n create_challenge(\"{} Challenge\".format(fake.first_name()),\n timezone.now() - timedelta(days=100),\n timezone.now() + timedelta(days=500),\n host_team\n )\n elif (i % 3 == 1):\n create_challenge(\"{} Challenge\".format(fake.first_name()),\n timezone.now() - timedelta(days=500),\n timezone.now() - timedelta(days=100),\n host_team\n )\n elif (i % 3 == 2):\n create_challenge(\"{} Challenge\".format(fake.first_name()),\n timezone.now() + timedelta(days=100),\n timezone.now() + timedelta(days=500),\n host_team\n )\n\n\ndef create_challenge(title, start_date, end_date, host_team):\n \"\"\"\n Creates a challenge.\n \"\"\"\n evaluation_script = open(os.path.join(settings.BASE_DIR, 'examples', 'example1', 'string_matching.zip'), 'rb')\n Challenge.objects.create(\n title=title,\n short_description=fake.paragraph(),\n description=fake.paragraph(),\n terms_and_conditions=fake.paragraph(),\n submission_guidelines=fake.paragraph(),\n evaluation_details=fake.paragraph(),\n evaluation_script=SimpleUploadedFile(evaluation_script.name, evaluation_script.read()),\n approved_by_admin=True,\n creator=host_team,\n published=True,\n enable_forum=True,\n anonymous_leaderboard=False,\n start_date=start_date,\n end_date=end_date,\n )\n print(\"Challenge created with title: {} creator: {} start_date: {} end_date: {}\".format(title,\n host_team.team_name,\n start_date, end_date))\n\n\ndef create_challenge_phases(challenge, number_of_phases=1):\n \"\"\"\n Creates challenge phases for the created challenges and returns it.\n \"\"\"\n challenge_phases = []\n for i in range(number_of_phases):\n name = \"{} Phase\".format(fake.first_name())\n with open(os.path.join(settings.BASE_DIR, 'examples', 'example1', 'test_annotation.txt'), 'rb') as data_file:\n data = data_file.read()\n data = data or None\n challenge_phase = ChallengePhase.objects.create(\n name=name,\n description=fake.paragraph(),\n leaderboard_public=True,\n is_public=True,\n start_date=challenge.start_date,\n end_date=challenge.end_date,\n challenge=challenge,\n test_annotation=SimpleUploadedFile(fake.file_name(extension=\"txt\"), data, content_type=\"text/plain\"),\n codename=\"{}{}\".format(\"phase\", i + 1),\n )\n challenge_phases.append(challenge_phase)\n print(\"Challenge Phase created with name: {} challenge: {}\".format(name, challenge.title))\n return challenge_phases\n\n\ndef create_leaderboard():\n \"\"\"\n Creates Leaderboard schema and returns it.\n \"\"\"\n schema = {\n 'labels': ['score', ],\n 'default_order_by': 'score',\n }\n leaderboard = Leaderboard.objects.create(\n schema=schema\n )\n print(\"Leaderboard created\")\n return leaderboard\n\n\ndef create_dataset_splits(number_of_splits):\n \"\"\"\n Creates dataset splits and returns it.\n \"\"\"\n dataset_splits = []\n for i in range(number_of_splits):\n global DATASET_SPLIT_ITERATOR\n name = \"Split {}\".format(DATASET_SPLIT_ITERATOR + 1)\n codename = \"{}{}\".format('split', DATASET_SPLIT_ITERATOR + 1)\n dataset_split = DatasetSplit.objects.create(\n name=name,\n codename=codename,\n )\n dataset_splits.append(dataset_split)\n DATASET_SPLIT_ITERATOR += 1\n print(\"Dataset Split created with name: {} codename: {}\".format(name, codename))\n return dataset_splits\n\n\ndef create_challenge_phase_splits(challenge_phase, leaderboard, dataset_split):\n \"\"\"\n Creates a challenge phase split.\n \"\"\"\n ChallengePhaseSplit.objects.create(\n challenge_phase=challenge_phase,\n leaderboard=leaderboard,\n dataset_split=dataset_split,\n visibility=ChallengePhaseSplit.PUBLIC\n )\n print(\"Challenge Phase Split created with challenge_phase: {} dataset_split: {}\".format(challenge_phase.name,\n dataset_split.name))\n\n\ndef create_participant_team(user):\n \"\"\"\n Creates participant team and returns it.\n \"\"\"\n team_name = \"{} Participant Team\".format(fake.city())\n team = ParticipantTeam.objects.create(\n team_name=team_name,\n created_by=user,\n )\n print(\"Participant Team created with team_name: {} created_by: {}\".format(team_name, user.username))\n Participant.objects.create(user=user, team=team, status=\"Self\")\n print(\"Participant created with user: {} team_name: {}\".format(user.username, team_name))\n return team\n\n\ndef run(*args):\n NUMBER_OF_CHALLENGES = int(args[0])\n status = check_database()\n if status is False:\n print(\"Seeding aborted.\")\n return 0\n print(\"Seeding...\")\n # Create superuser\n create_user(is_admin=True)\n # Create host user\n host_user = create_user(is_admin=False, username=\"host\")\n # Create challenge host team with challenge host\n challenge_host_team = create_challenge_host_team(user=host_user)\n # Create challenge\n create_challenges(number_of_challenges=NUMBER_OF_CHALLENGES, host_team=challenge_host_team)\n\n # Fetch all the created challenges\n challenges = Challenge.objects.all()\n for challenge in challenges:\n # Create a leaderboard object for each challenge\n leaderboard = create_leaderboard()\n # Create Phases for a challenge\n challenge_phases = create_challenge_phases(challenge, number_of_phases=NUMBER_OF_PHASES)\n # Create Dataset Split for each Challenge\n dataset_splits = create_dataset_splits(number_of_splits=NUMBER_OF_DATASET_SPLITS)\n # Create Challenge Phase Split for each Phase and Dataset Split\n for challenge_phase in challenge_phases:\n for dataset_split in dataset_splits:\n create_challenge_phase_splits(challenge_phase, leaderboard, dataset_split)\n participant_user = create_user(is_admin=False, username=\"participant\")\n create_participant_team(user=participant_user)\n print('Database successfully seeded.')\n", "path": "scripts/seed.py"}]}
| 3,244 | 577 |
gh_patches_debug_15645
|
rasdani/github-patches
|
git_diff
|
netbox-community__netbox-7928
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Don't fetch LDAP user and groups on all API request when FIND_GROUP_PERMS is disabled
### NetBox version
V3.0.9
### Feature type
Change to existing functionality
### Proposed functionality
Currently when using the LDAP backend for authentication, the AD is queried on every API request, regardless of other settings and regardless if the user is local or has been created by the LDAP backend. Additionally the LDAP cache built into django-auth-ldap does not function when using populate_user.
As the user is not actually authenticated against the AD when using the API (the token is used), I propose that the local user and it's group assignments are used when FIND_GROUP_PERMISSIONS is disabled.
I have a change ready for pull request if the issue is accepted.
For more info, please see the discussion I created: https://github.com/netbox-community/netbox/discussions/7708
This issue would also partly fix #6926 - it will not fix the caching, but the user who reported the issue is not using FIND_GROUP_PERMISSIONS.
### Use case
The end goal is vastly improved API performance when using the LDAP backend in most cases.
The above changes will result in the following changes for users:
**Not using the LDAP backend:**
No changes
**FIND_GROUP_PERMS = True:**
No changes
**MIRROR_GROUPS = True and FIND_GROUP_PERMS = True:**
No changes
**MIRROR_GROUPS = True and FIND_GROUP_PERMS = False:**
Local user and group assignments will be used when calling the API and the user and groups are never reloaded from the LDAP server during API calls. This means that LDAP users utilizing the API will have to login to the web ui to update group memberships. The change also allows one to use locally created users to call the API with querying the LDAP server.
**MIRROR_GROUPS = False and FIND_GROUP_PERMS = False:**
The user performing the API request has to be locally assigned groups or have local user object permissions.
### Database changes
No database changes
### External dependencies
_No response_
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `netbox/netbox/api/authentication.py`
Content:
```
1 from django.conf import settings
2 from rest_framework import authentication, exceptions
3 from rest_framework.permissions import BasePermission, DjangoObjectPermissions, SAFE_METHODS
4
5 from users.models import Token
6
7
8 class TokenAuthentication(authentication.TokenAuthentication):
9 """
10 A custom authentication scheme which enforces Token expiration times.
11 """
12 model = Token
13
14 def authenticate_credentials(self, key):
15 model = self.get_model()
16 try:
17 token = model.objects.prefetch_related('user').get(key=key)
18 except model.DoesNotExist:
19 raise exceptions.AuthenticationFailed("Invalid token")
20
21 # Enforce the Token's expiration time, if one has been set.
22 if token.is_expired:
23 raise exceptions.AuthenticationFailed("Token expired")
24
25 if not token.user.is_active:
26 raise exceptions.AuthenticationFailed("User inactive")
27
28 # When LDAP authentication is active try to load user data from LDAP directory
29 if settings.REMOTE_AUTH_BACKEND == 'netbox.authentication.LDAPBackend':
30 from netbox.authentication import LDAPBackend
31 ldap_backend = LDAPBackend()
32 user = ldap_backend.populate_user(token.user.username)
33 # If the user is found in the LDAP directory use it, if not fallback to the local user
34 if user:
35 return user, token
36
37 return token.user, token
38
39
40 class TokenPermissions(DjangoObjectPermissions):
41 """
42 Custom permissions handler which extends the built-in DjangoModelPermissions to validate a Token's write ability
43 for unsafe requests (POST/PUT/PATCH/DELETE).
44 """
45 # Override the stock perm_map to enforce view permissions
46 perms_map = {
47 'GET': ['%(app_label)s.view_%(model_name)s'],
48 'OPTIONS': [],
49 'HEAD': ['%(app_label)s.view_%(model_name)s'],
50 'POST': ['%(app_label)s.add_%(model_name)s'],
51 'PUT': ['%(app_label)s.change_%(model_name)s'],
52 'PATCH': ['%(app_label)s.change_%(model_name)s'],
53 'DELETE': ['%(app_label)s.delete_%(model_name)s'],
54 }
55
56 def __init__(self):
57
58 # LOGIN_REQUIRED determines whether read-only access is provided to anonymous users.
59 self.authenticated_users_only = settings.LOGIN_REQUIRED
60
61 super().__init__()
62
63 def _verify_write_permission(self, request):
64
65 # If token authentication is in use, verify that the token allows write operations (for unsafe methods).
66 if request.method in SAFE_METHODS or request.auth.write_enabled:
67 return True
68
69 def has_permission(self, request, view):
70
71 # Enforce Token write ability
72 if isinstance(request.auth, Token) and not self._verify_write_permission(request):
73 return False
74
75 return super().has_permission(request, view)
76
77 def has_object_permission(self, request, view, obj):
78
79 # Enforce Token write ability
80 if isinstance(request.auth, Token) and not self._verify_write_permission(request):
81 return False
82
83 return super().has_object_permission(request, view, obj)
84
85
86 class IsAuthenticatedOrLoginNotRequired(BasePermission):
87 """
88 Returns True if the user is authenticated or LOGIN_REQUIRED is False.
89 """
90 def has_permission(self, request, view):
91 if not settings.LOGIN_REQUIRED:
92 return True
93 return request.user.is_authenticated
94
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/netbox/netbox/api/authentication.py b/netbox/netbox/api/authentication.py
--- a/netbox/netbox/api/authentication.py
+++ b/netbox/netbox/api/authentication.py
@@ -29,10 +29,13 @@
if settings.REMOTE_AUTH_BACKEND == 'netbox.authentication.LDAPBackend':
from netbox.authentication import LDAPBackend
ldap_backend = LDAPBackend()
- user = ldap_backend.populate_user(token.user.username)
- # If the user is found in the LDAP directory use it, if not fallback to the local user
- if user:
- return user, token
+
+ # Load from LDAP if FIND_GROUP_PERMS is active
+ if ldap_backend.settings.FIND_GROUP_PERMS:
+ user = ldap_backend.populate_user(token.user.username)
+ # If the user is found in the LDAP directory use it, if not fallback to the local user
+ if user:
+ return user, token
return token.user, token
|
{"golden_diff": "diff --git a/netbox/netbox/api/authentication.py b/netbox/netbox/api/authentication.py\n--- a/netbox/netbox/api/authentication.py\n+++ b/netbox/netbox/api/authentication.py\n@@ -29,10 +29,13 @@\n if settings.REMOTE_AUTH_BACKEND == 'netbox.authentication.LDAPBackend':\n from netbox.authentication import LDAPBackend\n ldap_backend = LDAPBackend()\n- user = ldap_backend.populate_user(token.user.username)\n- # If the user is found in the LDAP directory use it, if not fallback to the local user\n- if user:\n- return user, token\n+\n+ # Load from LDAP if FIND_GROUP_PERMS is active\n+ if ldap_backend.settings.FIND_GROUP_PERMS:\n+ user = ldap_backend.populate_user(token.user.username)\n+ # If the user is found in the LDAP directory use it, if not fallback to the local user\n+ if user:\n+ return user, token\n \n return token.user, token\n", "issue": "Don't fetch LDAP user and groups on all API request when FIND_GROUP_PERMS is disabled\n### NetBox version\n\nV3.0.9\n\n### Feature type\n\nChange to existing functionality\n\n### Proposed functionality\n\nCurrently when using the LDAP backend for authentication, the AD is queried on every API request, regardless of other settings and regardless if the user is local or has been created by the LDAP backend. Additionally the LDAP cache built into django-auth-ldap does not function when using populate_user.\r\n\r\nAs the user is not actually authenticated against the AD when using the API (the token is used), I propose that the local user and it's group assignments are used when FIND_GROUP_PERMISSIONS is disabled.\r\n\r\nI have a change ready for pull request if the issue is accepted.\r\n\r\nFor more info, please see the discussion I created: https://github.com/netbox-community/netbox/discussions/7708\r\n\r\nThis issue would also partly fix #6926 - it will not fix the caching, but the user who reported the issue is not using FIND_GROUP_PERMISSIONS.\n\n### Use case\n\nThe end goal is vastly improved API performance when using the LDAP backend in most cases.\r\n\r\nThe above changes will result in the following changes for users:\r\n\r\n**Not using the LDAP backend:**\r\n\r\nNo changes\r\n\r\n**FIND_GROUP_PERMS = True:**\r\n\r\nNo changes\r\n\r\n**MIRROR_GROUPS = True and FIND_GROUP_PERMS = True:**\r\n\r\nNo changes\r\n\r\n**MIRROR_GROUPS = True and FIND_GROUP_PERMS = False:**\r\n\r\nLocal user and group assignments will be used when calling the API and the user and groups are never reloaded from the LDAP server during API calls. This means that LDAP users utilizing the API will have to login to the web ui to update group memberships. The change also allows one to use locally created users to call the API with querying the LDAP server.\r\n\r\n**MIRROR_GROUPS = False and FIND_GROUP_PERMS = False:**\r\n\r\nThe user performing the API request has to be locally assigned groups or have local user object permissions.\n\n### Database changes\n\nNo database changes\n\n### External dependencies\n\n_No response_\n", "before_files": [{"content": "from django.conf import settings\nfrom rest_framework import authentication, exceptions\nfrom rest_framework.permissions import BasePermission, DjangoObjectPermissions, SAFE_METHODS\n\nfrom users.models import Token\n\n\nclass TokenAuthentication(authentication.TokenAuthentication):\n \"\"\"\n A custom authentication scheme which enforces Token expiration times.\n \"\"\"\n model = Token\n\n def authenticate_credentials(self, key):\n model = self.get_model()\n try:\n token = model.objects.prefetch_related('user').get(key=key)\n except model.DoesNotExist:\n raise exceptions.AuthenticationFailed(\"Invalid token\")\n\n # Enforce the Token's expiration time, if one has been set.\n if token.is_expired:\n raise exceptions.AuthenticationFailed(\"Token expired\")\n\n if not token.user.is_active:\n raise exceptions.AuthenticationFailed(\"User inactive\")\n\n # When LDAP authentication is active try to load user data from LDAP directory\n if settings.REMOTE_AUTH_BACKEND == 'netbox.authentication.LDAPBackend':\n from netbox.authentication import LDAPBackend\n ldap_backend = LDAPBackend()\n user = ldap_backend.populate_user(token.user.username)\n # If the user is found in the LDAP directory use it, if not fallback to the local user\n if user:\n return user, token\n\n return token.user, token\n\n\nclass TokenPermissions(DjangoObjectPermissions):\n \"\"\"\n Custom permissions handler which extends the built-in DjangoModelPermissions to validate a Token's write ability\n for unsafe requests (POST/PUT/PATCH/DELETE).\n \"\"\"\n # Override the stock perm_map to enforce view permissions\n perms_map = {\n 'GET': ['%(app_label)s.view_%(model_name)s'],\n 'OPTIONS': [],\n 'HEAD': ['%(app_label)s.view_%(model_name)s'],\n 'POST': ['%(app_label)s.add_%(model_name)s'],\n 'PUT': ['%(app_label)s.change_%(model_name)s'],\n 'PATCH': ['%(app_label)s.change_%(model_name)s'],\n 'DELETE': ['%(app_label)s.delete_%(model_name)s'],\n }\n\n def __init__(self):\n\n # LOGIN_REQUIRED determines whether read-only access is provided to anonymous users.\n self.authenticated_users_only = settings.LOGIN_REQUIRED\n\n super().__init__()\n\n def _verify_write_permission(self, request):\n\n # If token authentication is in use, verify that the token allows write operations (for unsafe methods).\n if request.method in SAFE_METHODS or request.auth.write_enabled:\n return True\n\n def has_permission(self, request, view):\n\n # Enforce Token write ability\n if isinstance(request.auth, Token) and not self._verify_write_permission(request):\n return False\n\n return super().has_permission(request, view)\n\n def has_object_permission(self, request, view, obj):\n\n # Enforce Token write ability\n if isinstance(request.auth, Token) and not self._verify_write_permission(request):\n return False\n\n return super().has_object_permission(request, view, obj)\n\n\nclass IsAuthenticatedOrLoginNotRequired(BasePermission):\n \"\"\"\n Returns True if the user is authenticated or LOGIN_REQUIRED is False.\n \"\"\"\n def has_permission(self, request, view):\n if not settings.LOGIN_REQUIRED:\n return True\n return request.user.is_authenticated\n", "path": "netbox/netbox/api/authentication.py"}], "after_files": [{"content": "from django.conf import settings\nfrom rest_framework import authentication, exceptions\nfrom rest_framework.permissions import BasePermission, DjangoObjectPermissions, SAFE_METHODS\n\nfrom users.models import Token\n\n\nclass TokenAuthentication(authentication.TokenAuthentication):\n \"\"\"\n A custom authentication scheme which enforces Token expiration times.\n \"\"\"\n model = Token\n\n def authenticate_credentials(self, key):\n model = self.get_model()\n try:\n token = model.objects.prefetch_related('user').get(key=key)\n except model.DoesNotExist:\n raise exceptions.AuthenticationFailed(\"Invalid token\")\n\n # Enforce the Token's expiration time, if one has been set.\n if token.is_expired:\n raise exceptions.AuthenticationFailed(\"Token expired\")\n\n if not token.user.is_active:\n raise exceptions.AuthenticationFailed(\"User inactive\")\n\n # When LDAP authentication is active try to load user data from LDAP directory\n if settings.REMOTE_AUTH_BACKEND == 'netbox.authentication.LDAPBackend':\n from netbox.authentication import LDAPBackend\n ldap_backend = LDAPBackend()\n\n # Load from LDAP if FIND_GROUP_PERMS is active\n if ldap_backend.settings.FIND_GROUP_PERMS:\n user = ldap_backend.populate_user(token.user.username)\n # If the user is found in the LDAP directory use it, if not fallback to the local user\n if user:\n return user, token\n\n return token.user, token\n\n\nclass TokenPermissions(DjangoObjectPermissions):\n \"\"\"\n Custom permissions handler which extends the built-in DjangoModelPermissions to validate a Token's write ability\n for unsafe requests (POST/PUT/PATCH/DELETE).\n \"\"\"\n # Override the stock perm_map to enforce view permissions\n perms_map = {\n 'GET': ['%(app_label)s.view_%(model_name)s'],\n 'OPTIONS': [],\n 'HEAD': ['%(app_label)s.view_%(model_name)s'],\n 'POST': ['%(app_label)s.add_%(model_name)s'],\n 'PUT': ['%(app_label)s.change_%(model_name)s'],\n 'PATCH': ['%(app_label)s.change_%(model_name)s'],\n 'DELETE': ['%(app_label)s.delete_%(model_name)s'],\n }\n\n def __init__(self):\n\n # LOGIN_REQUIRED determines whether read-only access is provided to anonymous users.\n self.authenticated_users_only = settings.LOGIN_REQUIRED\n\n super().__init__()\n\n def _verify_write_permission(self, request):\n\n # If token authentication is in use, verify that the token allows write operations (for unsafe methods).\n if request.method in SAFE_METHODS or request.auth.write_enabled:\n return True\n\n def has_permission(self, request, view):\n\n # Enforce Token write ability\n if isinstance(request.auth, Token) and not self._verify_write_permission(request):\n return False\n\n return super().has_permission(request, view)\n\n def has_object_permission(self, request, view, obj):\n\n # Enforce Token write ability\n if isinstance(request.auth, Token) and not self._verify_write_permission(request):\n return False\n\n return super().has_object_permission(request, view, obj)\n\n\nclass IsAuthenticatedOrLoginNotRequired(BasePermission):\n \"\"\"\n Returns True if the user is authenticated or LOGIN_REQUIRED is False.\n \"\"\"\n def has_permission(self, request, view):\n if not settings.LOGIN_REQUIRED:\n return True\n return request.user.is_authenticated\n", "path": "netbox/netbox/api/authentication.py"}]}
| 1,561 | 215 |
gh_patches_debug_11790
|
rasdani/github-patches
|
git_diff
|
deepset-ai__haystack-4567
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Duplicate tests for WhisperTranscriber
`test_whisper_api_transcribe` and `test_whisper_api_transcribe_with_params` in `test/nodes/test_whisper.py` have the exact same code.
We should remove `test_whisper_api_transcribe_with_params`.
**Alternatives considered**
Change `transcribe_test_helper(w)` to `transcribe_test_helper(w, language="en")` in `test_whisper_api_transcribe_with_params`. This is probably how it was intended. However, we're only testing the API then and don't check the output taking into account that parameter.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `haystack/nodes/audio/whisper_transcriber.py`
Content:
```
1 import json
2
3 from typing import List, Optional, Dict, Any, Union, BinaryIO, Literal
4
5 import requests
6 import torch
7 from requests import PreparedRequest
8
9 from haystack import MultiLabel, Document
10 from haystack.errors import OpenAIError, OpenAIRateLimitError
11 from haystack.nodes.base import BaseComponent
12 from haystack.utils.import_utils import is_whisper_available
13
14 WhisperModel = Literal["tiny", "small", "medium", "large", "large-v2"]
15
16
17 class WhisperTranscriber(BaseComponent):
18 """
19 Transcribes audio files using OpenAI's Whisper. This class supports two underlying implementations:
20
21 - API (default): Uses the OpenAI API and requires an API key. See blog
22 [post](https://beta.openai.com/docs/api-reference/whisper for more details.) for more details.
23 - Local (requires installation of whisper): Uses the local installation
24 of [whisper](https://github.com/openai/whisper).
25
26 If you are using local installation of whisper, install whisper following the instructions available on
27 the Whisper [github repo](https://github.com/openai/whisper) and omit the api_key parameter.
28
29 If you are using the API implementation, you need to provide an api_key. You can get one by signing up
30 for an OpenAI account [here](https://beta.openai.com/).
31
32 For the supported audio formats, languages and other parameters, see the Whisper API
33 [documentation](https://platform.openai.com/docs/guides/speech-to-text) and the official Whisper
34 [github repo](https://github.com/openai/whisper).
35 """
36
37 # If it's not a decision component, there is only one outgoing edge
38 outgoing_edges = 1
39
40 def __init__(
41 self,
42 api_key: Optional[str] = None,
43 model_name_or_path: WhisperModel = "medium",
44 device: Optional[Union[str, torch.device]] = None,
45 ) -> None:
46 """
47 Creates a WhisperTranscriber instance.
48
49 :param api_key: OpenAI API key. If None, local installation of whisper is used.
50 :param model_name_or_path: Name of the model to use. If using local installation of whisper, this
51 value has to be one of the following: "tiny", "small", "medium", "large", "large-v2". If using
52 the API, this value has to be "whisper-1" (default).
53 :param device: Device to use for inference. This parameter is only used if you are using local
54 installation of whisper. If None, the device is automatically selected.
55 """
56 super().__init__()
57 self.api_key = api_key
58
59 self.use_local_whisper = is_whisper_available() and self.api_key is None
60
61 if self.use_local_whisper:
62 import whisper
63
64 self._model = whisper.load_model(model_name_or_path, device=device)
65 else:
66 if api_key is None:
67 raise ValueError(
68 "Please provide a valid api_key for OpenAI API. Alternatively, "
69 "install OpenAI whisper (see https://github.com/openai/whisper for more details)."
70 )
71
72 def transcribe(
73 self,
74 audio_file: Union[str, BinaryIO],
75 language: Optional[str] = None,
76 return_segments: bool = False,
77 translate: bool = False,
78 **kwargs,
79 ) -> Dict[str, Any]:
80 """
81 Transcribe audio file.
82
83 :param audio_file: Path to audio file or a binary file-like object.
84 :param language: Language of the audio file. If None, the language is automatically detected.
85 :param return_segments: If True, returns the transcription for each segment of the audio file.
86 :param translate: If True, translates the transcription to English.
87
88 """
89 transcript: Dict[str, Any] = {}
90
91 new_kwargs = {k: v for k, v in kwargs.items() if v is not None}
92 if language is not None:
93 new_kwargs["language"] = language
94
95 if self.use_local_whisper:
96 new_kwargs["return_segments"] = return_segments
97 transcript = self._invoke_local(audio_file, translate, **new_kwargs)
98 elif self.api_key:
99 transcript = self._invoke_api(audio_file, translate, **new_kwargs)
100 return transcript
101
102 def _invoke_api(
103 self, audio_file: Union[str, BinaryIO], translate: Optional[bool] = False, **kwargs
104 ) -> Dict[str, Any]:
105 if isinstance(audio_file, str):
106 with open(audio_file, "rb") as f:
107 return self._invoke_api(f, translate, **kwargs)
108 else:
109 headers = {"Authorization": f"Bearer {self.api_key}"}
110 request = PreparedRequest()
111 url: str = (
112 "https://api.openai.com/v1/audio/transcriptions"
113 if not translate
114 else "https://api.openai.com/v1/audio/translations"
115 )
116
117 request.prepare(
118 method="POST",
119 url=url,
120 headers=headers,
121 data={"model": "whisper-1", **kwargs},
122 files=[("file", (audio_file.name, audio_file, "application/octet-stream"))],
123 )
124 response = requests.post(url, data=request.body, headers=request.headers, timeout=600)
125
126 if response.status_code != 200:
127 openai_error: OpenAIError
128 if response.status_code == 429:
129 openai_error = OpenAIRateLimitError(f"API rate limit exceeded: {response.text}")
130 else:
131 openai_error = OpenAIError(
132 f"OpenAI returned an error.\n"
133 f"Status code: {response.status_code}\n"
134 f"Response body: {response.text}",
135 status_code=response.status_code,
136 )
137 raise openai_error
138
139 return json.loads(response.content)
140
141 def _invoke_local(
142 self, audio_file: Union[str, BinaryIO], translate: Optional[bool] = False, **kwargs
143 ) -> Dict[str, Any]:
144 if isinstance(audio_file, str):
145 with open(audio_file, "rb") as f:
146 return self._invoke_local(f, translate, **kwargs)
147 else:
148 return_segments = kwargs.pop("return_segments", None)
149 kwargs["task"] = "translate" if translate else "transcribe"
150 transcription = self._model.transcribe(audio_file.name, **kwargs)
151 if not return_segments:
152 transcription.pop("segments", None)
153
154 return transcription
155
156 def run(
157 self,
158 query: Optional[str] = None,
159 file_paths: Optional[List[str]] = None,
160 labels: Optional[MultiLabel] = None,
161 documents: Optional[List[Document]] = None,
162 meta: Optional[dict] = None,
163 ): # type: ignore
164 """
165 Transcribe audio files.
166
167 :param query: Ignored
168 :param file_paths: List of paths to audio files.
169 :param labels: Ignored
170 :param documents: Ignored
171 :param meta: Ignored
172 """
173 transcribed_documents: List[Document] = []
174 if file_paths:
175 for file_path in file_paths:
176 transcription = self.transcribe(file_path)
177 d = Document.from_dict(transcription, field_map={"text": "content"})
178 transcribed_documents.append(d)
179
180 output = {"documents": transcribed_documents}
181 return output, "output_1"
182
183 def run_batch(
184 self,
185 queries: Optional[Union[str, List[str]]] = None,
186 file_paths: Optional[List[str]] = None,
187 labels: Optional[Union[MultiLabel, List[MultiLabel]]] = None,
188 documents: Optional[Union[List[Document], List[List[Document]]]] = None,
189 meta: Optional[Union[Dict[str, Any], List[Dict[str, Any]]]] = None,
190 params: Optional[dict] = None,
191 debug: Optional[bool] = None,
192 ): # type: ignore
193 """
194 Transcribe audio files.
195
196 :param queries: Ignored
197 :param file_paths: List of paths to audio files.
198 :param labels: Ignored
199 :param documents: Ignored
200 :param meta: Ignored
201 :param params: Ignored
202 :param debug: Ignored
203 """
204 if file_paths and isinstance(file_paths[0], list):
205 all_files = []
206 for files_list in file_paths:
207 all_files += files_list
208 return self.run(file_paths=all_files)
209 return self.run(file_paths=file_paths)
210
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/haystack/nodes/audio/whisper_transcriber.py b/haystack/nodes/audio/whisper_transcriber.py
--- a/haystack/nodes/audio/whisper_transcriber.py
+++ b/haystack/nodes/audio/whisper_transcriber.py
@@ -82,7 +82,8 @@
:param audio_file: Path to audio file or a binary file-like object.
:param language: Language of the audio file. If None, the language is automatically detected.
- :param return_segments: If True, returns the transcription for each segment of the audio file.
+ :param return_segments: If True, returns the transcription for each segment of the audio file. Supported with
+ local installation of whisper only.
:param translate: If True, translates the transcription to English.
"""
|
{"golden_diff": "diff --git a/haystack/nodes/audio/whisper_transcriber.py b/haystack/nodes/audio/whisper_transcriber.py\n--- a/haystack/nodes/audio/whisper_transcriber.py\n+++ b/haystack/nodes/audio/whisper_transcriber.py\n@@ -82,7 +82,8 @@\n \n :param audio_file: Path to audio file or a binary file-like object.\n :param language: Language of the audio file. If None, the language is automatically detected.\n- :param return_segments: If True, returns the transcription for each segment of the audio file.\n+ :param return_segments: If True, returns the transcription for each segment of the audio file. Supported with\n+ local installation of whisper only.\n :param translate: If True, translates the transcription to English.\n \n \"\"\"\n", "issue": "Duplicate tests for WhisperTranscriber\n`test_whisper_api_transcribe` and `test_whisper_api_transcribe_with_params` in `test/nodes/test_whisper.py` have the exact same code.\r\nWe should remove `test_whisper_api_transcribe_with_params`.\r\n\r\n**Alternatives considered**\r\nChange `transcribe_test_helper(w)` to `transcribe_test_helper(w, language=\"en\")` in `test_whisper_api_transcribe_with_params`. This is probably how it was intended. However, we're only testing the API then and don't check the output taking into account that parameter.\r\n\n", "before_files": [{"content": "import json\n\nfrom typing import List, Optional, Dict, Any, Union, BinaryIO, Literal\n\nimport requests\nimport torch\nfrom requests import PreparedRequest\n\nfrom haystack import MultiLabel, Document\nfrom haystack.errors import OpenAIError, OpenAIRateLimitError\nfrom haystack.nodes.base import BaseComponent\nfrom haystack.utils.import_utils import is_whisper_available\n\nWhisperModel = Literal[\"tiny\", \"small\", \"medium\", \"large\", \"large-v2\"]\n\n\nclass WhisperTranscriber(BaseComponent):\n \"\"\"\n Transcribes audio files using OpenAI's Whisper. This class supports two underlying implementations:\n\n - API (default): Uses the OpenAI API and requires an API key. See blog\n [post](https://beta.openai.com/docs/api-reference/whisper for more details.) for more details.\n - Local (requires installation of whisper): Uses the local installation\n of [whisper](https://github.com/openai/whisper).\n\n If you are using local installation of whisper, install whisper following the instructions available on\n the Whisper [github repo](https://github.com/openai/whisper) and omit the api_key parameter.\n\n If you are using the API implementation, you need to provide an api_key. You can get one by signing up\n for an OpenAI account [here](https://beta.openai.com/).\n\n For the supported audio formats, languages and other parameters, see the Whisper API\n [documentation](https://platform.openai.com/docs/guides/speech-to-text) and the official Whisper\n [github repo](https://github.com/openai/whisper).\n \"\"\"\n\n # If it's not a decision component, there is only one outgoing edge\n outgoing_edges = 1\n\n def __init__(\n self,\n api_key: Optional[str] = None,\n model_name_or_path: WhisperModel = \"medium\",\n device: Optional[Union[str, torch.device]] = None,\n ) -> None:\n \"\"\"\n Creates a WhisperTranscriber instance.\n\n :param api_key: OpenAI API key. If None, local installation of whisper is used.\n :param model_name_or_path: Name of the model to use. If using local installation of whisper, this\n value has to be one of the following: \"tiny\", \"small\", \"medium\", \"large\", \"large-v2\". If using\n the API, this value has to be \"whisper-1\" (default).\n :param device: Device to use for inference. This parameter is only used if you are using local\n installation of whisper. If None, the device is automatically selected.\n \"\"\"\n super().__init__()\n self.api_key = api_key\n\n self.use_local_whisper = is_whisper_available() and self.api_key is None\n\n if self.use_local_whisper:\n import whisper\n\n self._model = whisper.load_model(model_name_or_path, device=device)\n else:\n if api_key is None:\n raise ValueError(\n \"Please provide a valid api_key for OpenAI API. Alternatively, \"\n \"install OpenAI whisper (see https://github.com/openai/whisper for more details).\"\n )\n\n def transcribe(\n self,\n audio_file: Union[str, BinaryIO],\n language: Optional[str] = None,\n return_segments: bool = False,\n translate: bool = False,\n **kwargs,\n ) -> Dict[str, Any]:\n \"\"\"\n Transcribe audio file.\n\n :param audio_file: Path to audio file or a binary file-like object.\n :param language: Language of the audio file. If None, the language is automatically detected.\n :param return_segments: If True, returns the transcription for each segment of the audio file.\n :param translate: If True, translates the transcription to English.\n\n \"\"\"\n transcript: Dict[str, Any] = {}\n\n new_kwargs = {k: v for k, v in kwargs.items() if v is not None}\n if language is not None:\n new_kwargs[\"language\"] = language\n\n if self.use_local_whisper:\n new_kwargs[\"return_segments\"] = return_segments\n transcript = self._invoke_local(audio_file, translate, **new_kwargs)\n elif self.api_key:\n transcript = self._invoke_api(audio_file, translate, **new_kwargs)\n return transcript\n\n def _invoke_api(\n self, audio_file: Union[str, BinaryIO], translate: Optional[bool] = False, **kwargs\n ) -> Dict[str, Any]:\n if isinstance(audio_file, str):\n with open(audio_file, \"rb\") as f:\n return self._invoke_api(f, translate, **kwargs)\n else:\n headers = {\"Authorization\": f\"Bearer {self.api_key}\"}\n request = PreparedRequest()\n url: str = (\n \"https://api.openai.com/v1/audio/transcriptions\"\n if not translate\n else \"https://api.openai.com/v1/audio/translations\"\n )\n\n request.prepare(\n method=\"POST\",\n url=url,\n headers=headers,\n data={\"model\": \"whisper-1\", **kwargs},\n files=[(\"file\", (audio_file.name, audio_file, \"application/octet-stream\"))],\n )\n response = requests.post(url, data=request.body, headers=request.headers, timeout=600)\n\n if response.status_code != 200:\n openai_error: OpenAIError\n if response.status_code == 429:\n openai_error = OpenAIRateLimitError(f\"API rate limit exceeded: {response.text}\")\n else:\n openai_error = OpenAIError(\n f\"OpenAI returned an error.\\n\"\n f\"Status code: {response.status_code}\\n\"\n f\"Response body: {response.text}\",\n status_code=response.status_code,\n )\n raise openai_error\n\n return json.loads(response.content)\n\n def _invoke_local(\n self, audio_file: Union[str, BinaryIO], translate: Optional[bool] = False, **kwargs\n ) -> Dict[str, Any]:\n if isinstance(audio_file, str):\n with open(audio_file, \"rb\") as f:\n return self._invoke_local(f, translate, **kwargs)\n else:\n return_segments = kwargs.pop(\"return_segments\", None)\n kwargs[\"task\"] = \"translate\" if translate else \"transcribe\"\n transcription = self._model.transcribe(audio_file.name, **kwargs)\n if not return_segments:\n transcription.pop(\"segments\", None)\n\n return transcription\n\n def run(\n self,\n query: Optional[str] = None,\n file_paths: Optional[List[str]] = None,\n labels: Optional[MultiLabel] = None,\n documents: Optional[List[Document]] = None,\n meta: Optional[dict] = None,\n ): # type: ignore\n \"\"\"\n Transcribe audio files.\n\n :param query: Ignored\n :param file_paths: List of paths to audio files.\n :param labels: Ignored\n :param documents: Ignored\n :param meta: Ignored\n \"\"\"\n transcribed_documents: List[Document] = []\n if file_paths:\n for file_path in file_paths:\n transcription = self.transcribe(file_path)\n d = Document.from_dict(transcription, field_map={\"text\": \"content\"})\n transcribed_documents.append(d)\n\n output = {\"documents\": transcribed_documents}\n return output, \"output_1\"\n\n def run_batch(\n self,\n queries: Optional[Union[str, List[str]]] = None,\n file_paths: Optional[List[str]] = None,\n labels: Optional[Union[MultiLabel, List[MultiLabel]]] = None,\n documents: Optional[Union[List[Document], List[List[Document]]]] = None,\n meta: Optional[Union[Dict[str, Any], List[Dict[str, Any]]]] = None,\n params: Optional[dict] = None,\n debug: Optional[bool] = None,\n ): # type: ignore\n \"\"\"\n Transcribe audio files.\n\n :param queries: Ignored\n :param file_paths: List of paths to audio files.\n :param labels: Ignored\n :param documents: Ignored\n :param meta: Ignored\n :param params: Ignored\n :param debug: Ignored\n \"\"\"\n if file_paths and isinstance(file_paths[0], list):\n all_files = []\n for files_list in file_paths:\n all_files += files_list\n return self.run(file_paths=all_files)\n return self.run(file_paths=file_paths)\n", "path": "haystack/nodes/audio/whisper_transcriber.py"}], "after_files": [{"content": "import json\n\nfrom typing import List, Optional, Dict, Any, Union, BinaryIO, Literal\n\nimport requests\nimport torch\nfrom requests import PreparedRequest\n\nfrom haystack import MultiLabel, Document\nfrom haystack.errors import OpenAIError, OpenAIRateLimitError\nfrom haystack.nodes.base import BaseComponent\nfrom haystack.utils.import_utils import is_whisper_available\n\nWhisperModel = Literal[\"tiny\", \"small\", \"medium\", \"large\", \"large-v2\"]\n\n\nclass WhisperTranscriber(BaseComponent):\n \"\"\"\n Transcribes audio files using OpenAI's Whisper. This class supports two underlying implementations:\n\n - API (default): Uses the OpenAI API and requires an API key. See blog\n [post](https://beta.openai.com/docs/api-reference/whisper for more details.) for more details.\n - Local (requires installation of whisper): Uses the local installation\n of [whisper](https://github.com/openai/whisper).\n\n If you are using local installation of whisper, install whisper following the instructions available on\n the Whisper [github repo](https://github.com/openai/whisper) and omit the api_key parameter.\n\n If you are using the API implementation, you need to provide an api_key. You can get one by signing up\n for an OpenAI account [here](https://beta.openai.com/).\n\n For the supported audio formats, languages and other parameters, see the Whisper API\n [documentation](https://platform.openai.com/docs/guides/speech-to-text) and the official Whisper\n [github repo](https://github.com/openai/whisper).\n \"\"\"\n\n # If it's not a decision component, there is only one outgoing edge\n outgoing_edges = 1\n\n def __init__(\n self,\n api_key: Optional[str] = None,\n model_name_or_path: WhisperModel = \"medium\",\n device: Optional[Union[str, torch.device]] = None,\n ) -> None:\n \"\"\"\n Creates a WhisperTranscriber instance.\n\n :param api_key: OpenAI API key. If None, local installation of whisper is used.\n :param model_name_or_path: Name of the model to use. If using local installation of whisper, this\n value has to be one of the following: \"tiny\", \"small\", \"medium\", \"large\", \"large-v2\". If using\n the API, this value has to be \"whisper-1\" (default).\n :param device: Device to use for inference. This parameter is only used if you are using local\n installation of whisper. If None, the device is automatically selected.\n \"\"\"\n super().__init__()\n self.api_key = api_key\n\n self.use_local_whisper = is_whisper_available() and self.api_key is None\n\n if self.use_local_whisper:\n import whisper\n\n self._model = whisper.load_model(model_name_or_path, device=device)\n else:\n if api_key is None:\n raise ValueError(\n \"Please provide a valid api_key for OpenAI API. Alternatively, \"\n \"install OpenAI whisper (see https://github.com/openai/whisper for more details).\"\n )\n\n def transcribe(\n self,\n audio_file: Union[str, BinaryIO],\n language: Optional[str] = None,\n return_segments: bool = False,\n translate: bool = False,\n **kwargs,\n ) -> Dict[str, Any]:\n \"\"\"\n Transcribe audio file.\n\n :param audio_file: Path to audio file or a binary file-like object.\n :param language: Language of the audio file. If None, the language is automatically detected.\n :param return_segments: If True, returns the transcription for each segment of the audio file. Supported with\n local installation of whisper only.\n :param translate: If True, translates the transcription to English.\n\n \"\"\"\n transcript: Dict[str, Any] = {}\n\n new_kwargs = {k: v for k, v in kwargs.items() if v is not None}\n if language is not None:\n new_kwargs[\"language\"] = language\n\n if self.use_local_whisper:\n new_kwargs[\"return_segments\"] = return_segments\n transcript = self._invoke_local(audio_file, translate, **new_kwargs)\n elif self.api_key:\n transcript = self._invoke_api(audio_file, translate, **new_kwargs)\n return transcript\n\n def _invoke_api(\n self, audio_file: Union[str, BinaryIO], translate: Optional[bool] = False, **kwargs\n ) -> Dict[str, Any]:\n if isinstance(audio_file, str):\n with open(audio_file, \"rb\") as f:\n return self._invoke_api(f, translate, **kwargs)\n else:\n headers = {\"Authorization\": f\"Bearer {self.api_key}\"}\n request = PreparedRequest()\n url: str = (\n \"https://api.openai.com/v1/audio/transcriptions\"\n if not translate\n else \"https://api.openai.com/v1/audio/translations\"\n )\n\n request.prepare(\n method=\"POST\",\n url=url,\n headers=headers,\n data={\"model\": \"whisper-1\", **kwargs},\n files=[(\"file\", (audio_file.name, audio_file, \"application/octet-stream\"))],\n )\n response = requests.post(url, data=request.body, headers=request.headers, timeout=600)\n\n if response.status_code != 200:\n openai_error: OpenAIError\n if response.status_code == 429:\n openai_error = OpenAIRateLimitError(f\"API rate limit exceeded: {response.text}\")\n else:\n openai_error = OpenAIError(\n f\"OpenAI returned an error.\\n\"\n f\"Status code: {response.status_code}\\n\"\n f\"Response body: {response.text}\",\n status_code=response.status_code,\n )\n raise openai_error\n\n return json.loads(response.content)\n\n def _invoke_local(\n self, audio_file: Union[str, BinaryIO], translate: Optional[bool] = False, **kwargs\n ) -> Dict[str, Any]:\n if isinstance(audio_file, str):\n with open(audio_file, \"rb\") as f:\n return self._invoke_local(f, translate, **kwargs)\n else:\n return_segments = kwargs.pop(\"return_segments\", None)\n kwargs[\"task\"] = \"translate\" if translate else \"transcribe\"\n transcription = self._model.transcribe(audio_file.name, **kwargs)\n if not return_segments:\n transcription.pop(\"segments\", None)\n\n return transcription\n\n def run(\n self,\n query: Optional[str] = None,\n file_paths: Optional[List[str]] = None,\n labels: Optional[MultiLabel] = None,\n documents: Optional[List[Document]] = None,\n meta: Optional[dict] = None,\n ): # type: ignore\n \"\"\"\n Transcribe audio files.\n\n :param query: Ignored\n :param file_paths: List of paths to audio files.\n :param labels: Ignored\n :param documents: Ignored\n :param meta: Ignored\n \"\"\"\n transcribed_documents: List[Document] = []\n if file_paths:\n for file_path in file_paths:\n transcription = self.transcribe(file_path)\n d = Document.from_dict(transcription, field_map={\"text\": \"content\"})\n transcribed_documents.append(d)\n\n output = {\"documents\": transcribed_documents}\n return output, \"output_1\"\n\n def run_batch(\n self,\n queries: Optional[Union[str, List[str]]] = None,\n file_paths: Optional[List[str]] = None,\n labels: Optional[Union[MultiLabel, List[MultiLabel]]] = None,\n documents: Optional[Union[List[Document], List[List[Document]]]] = None,\n meta: Optional[Union[Dict[str, Any], List[Dict[str, Any]]]] = None,\n params: Optional[dict] = None,\n debug: Optional[bool] = None,\n ): # type: ignore\n \"\"\"\n Transcribe audio files.\n\n :param queries: Ignored\n :param file_paths: List of paths to audio files.\n :param labels: Ignored\n :param documents: Ignored\n :param meta: Ignored\n :param params: Ignored\n :param debug: Ignored\n \"\"\"\n if file_paths and isinstance(file_paths[0], list):\n all_files = []\n for files_list in file_paths:\n all_files += files_list\n return self.run(file_paths=all_files)\n return self.run(file_paths=file_paths)\n", "path": "haystack/nodes/audio/whisper_transcriber.py"}]}
| 2,766 | 184 |
gh_patches_debug_31857
|
rasdani/github-patches
|
git_diff
|
projectmesa__mesa-301
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Documentation is not reflecting latest changes wrt width-height argument order in Grid()
As many people start with reading mesa on readthedocs, the documentation should be inline with the code changes wrt width-height argument order in Grid functions.This is not yet reflected.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mesa/visualization/modules/CanvasGridVisualization.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 """
3 Modular Canvas Rendering
4 ========================
5
6 Module for visualizing model objects in grid cells.
7
8 """
9 from collections import defaultdict
10 from mesa.visualization.ModularVisualization import VisualizationElement
11
12
13 class CanvasGrid(VisualizationElement):
14 """ A CanvasGrid object uses a user-provided portrayal method to generate a
15 portrayal for each object. A portrayal is a JSON-ready dictionary which
16 tells the relevant JavaScript code (GridDraw.js) where to draw what shape.
17
18 The render method returns a dictionary, keyed on layers, with values as
19 lists of portrayals to draw. Portrayals themselves are generated by the
20 user-provided portrayal_method, which accepts an object as an input and
21 produces a portrayal of it.
22
23 A portrayal as a dictionary with the following structure:
24 "x", "y": Coordinates for the cell in which the object is placed.
25 "Shape": Can be either "circle" or "rect"
26 For Circles:
27 "r": The radius, defined as a fraction of cell size. r=1 will
28 fill the entire cell.
29 For rectangles:
30 "w", "h": The width and height of the rectangle, which are in
31 fractions of cell width and height.
32 "Color": The color to draw the shape in; needs to be a valid HTML
33 color, e.g."Red" or "#AA08F8"
34 "Filled": either "true" or "false", and determines whether the shape is
35 filled or not.
36 "Layer": Layer number of 0 or above; higher-numbered layers are drawn
37 above lower-numbered layers.
38 "text": The text to be inscribed inside the Shape. Normally useful for
39 showing the unique_id of the agent.
40 "text_color": The color to draw the inscribed text. Should be given in
41 conjunction of "text" property.
42
43
44 Attributes:
45 portrayal_method: Function which generates portrayals from objects, as
46 described above.
47 grid_height, grid_width: Size of the grid to visualize, in cells.
48 canvas_height, canvas_width: Size, in pixels, of the grid visualization
49 to draw on the client.
50 template: "canvas_module.html" stores the module's HTML template.
51
52 """
53 package_includes = ["GridDraw.js", "CanvasModule.js"]
54 portrayal_method = None # Portrayal function
55 canvas_width = 500
56 canvas_height = 500
57
58 def __init__(self, portrayal_method, grid_width, grid_height,
59 canvas_width=500, canvas_height=500):
60 """ Instantiate a new CanvasGrid.
61
62 Args:
63 portrayal_method: function to convert each object on the grid to
64 a portrayal, as described above.
65 grid_width, grid_height: Size of the grid, in cells.
66 canvas_height, canvas_width: Size of the canvas to draw in the
67 client, in pixels. (default: 500x500)
68
69 """
70 self.portrayal_method = portrayal_method
71 self.grid_width = grid_width
72 self.grid_height = grid_height
73 self.canvas_width = canvas_width
74 self.canvas_height = canvas_height
75
76 new_element = ("new CanvasModule({}, {}, {}, {})"
77 .format(self.canvas_width, self.canvas_height,
78 self.grid_width, self.grid_height))
79
80 self.js_code = "elements.push(" + new_element + ");"
81
82 def render(self, model):
83 grid_state = defaultdict(list)
84 for x in range(model.grid.width):
85 for y in range(model.grid.height):
86 cell_objects = model.grid.get_cell_list_contents([(x, y)])
87 for obj in cell_objects:
88 portrayal = self.portrayal_method(obj)
89 if portrayal:
90 portrayal["x"] = x
91 portrayal["y"] = y
92 grid_state[portrayal["Layer"]].append(portrayal)
93
94 return grid_state
95
```
Path: `examples/Basic/basic/server.py`
Content:
```
1 import random
2
3 from mesa.visualization.modules import CanvasGrid
4 from mesa.visualization.ModularVisualization import ModularServer
5
6 from basic.model import Walker, ShapesModel
7
8
9 def agent_draw(agent):
10 portrayal = None
11 if agent is None:
12 # Actually this if part is unnecessary, but still keeping it for
13 # aesthetics
14 pass
15 elif isinstance(agent, Walker):
16 print("Uid: {0}, Heading: {1}".format(agent.unique_id, agent.heading))
17 portrayal = {"Shape": "arrowHead",
18 "Filled": "true",
19 "Layer": 2,
20 "Color": "green",
21 "Filled": "true",
22 "heading0": agent.heading[0],
23 "heading1": agent.heading[1],
24 "text": agent.unique_id,
25 "text_color": "white",
26 "scale": 0.8,
27 }
28 return portrayal
29
30
31 def launch_basic():
32 width = 15
33 height = 10
34 num_agents = 2
35 pixel_ratio = 50
36 grid = CanvasGrid(agent_draw, width, height,
37 width * pixel_ratio, height * pixel_ratio)
38 server = ModularServer(ShapesModel, [grid], "Basic Example",
39 num_agents, width, height)
40 server.max_steps = 0
41 server.port = 8888
42 server.launch()
43
44 if __name__ == "__main__":
45 random.seed(3)
46 launch_basic()
47
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/Basic/basic/server.py b/examples/Basic/basic/server.py
--- a/examples/Basic/basic/server.py
+++ b/examples/Basic/basic/server.py
@@ -19,8 +19,8 @@
"Layer": 2,
"Color": "green",
"Filled": "true",
- "heading0": agent.heading[0],
- "heading1": agent.heading[1],
+ "heading_x": agent.heading[0],
+ "heading_y": agent.heading[1],
"text": agent.unique_id,
"text_color": "white",
"scale": 0.8,
diff --git a/mesa/visualization/modules/CanvasGridVisualization.py b/mesa/visualization/modules/CanvasGridVisualization.py
--- a/mesa/visualization/modules/CanvasGridVisualization.py
+++ b/mesa/visualization/modules/CanvasGridVisualization.py
@@ -22,13 +22,17 @@
A portrayal as a dictionary with the following structure:
"x", "y": Coordinates for the cell in which the object is placed.
- "Shape": Can be either "circle" or "rect"
+ "Shape": Can be either "circle", "rect" or "arrowHead"
For Circles:
"r": The radius, defined as a fraction of cell size. r=1 will
fill the entire cell.
- For rectangles:
+ For Rectangles:
"w", "h": The width and height of the rectangle, which are in
fractions of cell width and height.
+ For arrowHead:
+ "scale": Proportion scaling as a fraction of cell size.
+ "heading_x": represents x direction unit vector.
+ "heading_y": represents y direction unit vector.
"Color": The color to draw the shape in; needs to be a valid HTML
color, e.g."Red" or "#AA08F8"
"Filled": either "true" or "false", and determines whether the shape is
|
{"golden_diff": "diff --git a/examples/Basic/basic/server.py b/examples/Basic/basic/server.py\n--- a/examples/Basic/basic/server.py\n+++ b/examples/Basic/basic/server.py\n@@ -19,8 +19,8 @@\n \"Layer\": 2,\n \"Color\": \"green\",\n \"Filled\": \"true\",\n- \"heading0\": agent.heading[0],\n- \"heading1\": agent.heading[1],\n+ \"heading_x\": agent.heading[0],\n+ \"heading_y\": agent.heading[1],\n \"text\": agent.unique_id,\n \"text_color\": \"white\",\n \"scale\": 0.8,\ndiff --git a/mesa/visualization/modules/CanvasGridVisualization.py b/mesa/visualization/modules/CanvasGridVisualization.py\n--- a/mesa/visualization/modules/CanvasGridVisualization.py\n+++ b/mesa/visualization/modules/CanvasGridVisualization.py\n@@ -22,13 +22,17 @@\n \n A portrayal as a dictionary with the following structure:\n \"x\", \"y\": Coordinates for the cell in which the object is placed.\n- \"Shape\": Can be either \"circle\" or \"rect\"\n+ \"Shape\": Can be either \"circle\", \"rect\" or \"arrowHead\"\n For Circles:\n \"r\": The radius, defined as a fraction of cell size. r=1 will\n fill the entire cell.\n- For rectangles:\n+ For Rectangles:\n \"w\", \"h\": The width and height of the rectangle, which are in\n fractions of cell width and height.\n+ For arrowHead:\n+ \"scale\": Proportion scaling as a fraction of cell size.\n+ \"heading_x\": represents x direction unit vector.\n+ \"heading_y\": represents y direction unit vector.\n \"Color\": The color to draw the shape in; needs to be a valid HTML\n color, e.g.\"Red\" or \"#AA08F8\"\n \"Filled\": either \"true\" or \"false\", and determines whether the shape is\n", "issue": "Documentation is not reflecting latest changes wrt width-height argument order in Grid()\nAs many people start with reading mesa on readthedocs, the documentation should be inline with the code changes wrt width-height argument order in Grid functions.This is not yet reflected.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\nModular Canvas Rendering\n========================\n\nModule for visualizing model objects in grid cells.\n\n\"\"\"\nfrom collections import defaultdict\nfrom mesa.visualization.ModularVisualization import VisualizationElement\n\n\nclass CanvasGrid(VisualizationElement):\n \"\"\" A CanvasGrid object uses a user-provided portrayal method to generate a\n portrayal for each object. A portrayal is a JSON-ready dictionary which\n tells the relevant JavaScript code (GridDraw.js) where to draw what shape.\n\n The render method returns a dictionary, keyed on layers, with values as\n lists of portrayals to draw. Portrayals themselves are generated by the\n user-provided portrayal_method, which accepts an object as an input and\n produces a portrayal of it.\n\n A portrayal as a dictionary with the following structure:\n \"x\", \"y\": Coordinates for the cell in which the object is placed.\n \"Shape\": Can be either \"circle\" or \"rect\"\n For Circles:\n \"r\": The radius, defined as a fraction of cell size. r=1 will\n fill the entire cell.\n For rectangles:\n \"w\", \"h\": The width and height of the rectangle, which are in\n fractions of cell width and height.\n \"Color\": The color to draw the shape in; needs to be a valid HTML\n color, e.g.\"Red\" or \"#AA08F8\"\n \"Filled\": either \"true\" or \"false\", and determines whether the shape is\n filled or not.\n \"Layer\": Layer number of 0 or above; higher-numbered layers are drawn\n above lower-numbered layers.\n \"text\": The text to be inscribed inside the Shape. Normally useful for\n showing the unique_id of the agent.\n \"text_color\": The color to draw the inscribed text. Should be given in\n conjunction of \"text\" property.\n\n\n Attributes:\n portrayal_method: Function which generates portrayals from objects, as\n described above.\n grid_height, grid_width: Size of the grid to visualize, in cells.\n canvas_height, canvas_width: Size, in pixels, of the grid visualization\n to draw on the client.\n template: \"canvas_module.html\" stores the module's HTML template.\n\n \"\"\"\n package_includes = [\"GridDraw.js\", \"CanvasModule.js\"]\n portrayal_method = None # Portrayal function\n canvas_width = 500\n canvas_height = 500\n\n def __init__(self, portrayal_method, grid_width, grid_height,\n canvas_width=500, canvas_height=500):\n \"\"\" Instantiate a new CanvasGrid.\n\n Args:\n portrayal_method: function to convert each object on the grid to\n a portrayal, as described above.\n grid_width, grid_height: Size of the grid, in cells.\n canvas_height, canvas_width: Size of the canvas to draw in the\n client, in pixels. (default: 500x500)\n\n \"\"\"\n self.portrayal_method = portrayal_method\n self.grid_width = grid_width\n self.grid_height = grid_height\n self.canvas_width = canvas_width\n self.canvas_height = canvas_height\n\n new_element = (\"new CanvasModule({}, {}, {}, {})\"\n .format(self.canvas_width, self.canvas_height,\n self.grid_width, self.grid_height))\n\n self.js_code = \"elements.push(\" + new_element + \");\"\n\n def render(self, model):\n grid_state = defaultdict(list)\n for x in range(model.grid.width):\n for y in range(model.grid.height):\n cell_objects = model.grid.get_cell_list_contents([(x, y)])\n for obj in cell_objects:\n portrayal = self.portrayal_method(obj)\n if portrayal:\n portrayal[\"x\"] = x\n portrayal[\"y\"] = y\n grid_state[portrayal[\"Layer\"]].append(portrayal)\n\n return grid_state\n", "path": "mesa/visualization/modules/CanvasGridVisualization.py"}, {"content": "import random\n\nfrom mesa.visualization.modules import CanvasGrid\nfrom mesa.visualization.ModularVisualization import ModularServer\n\nfrom basic.model import Walker, ShapesModel\n\n\ndef agent_draw(agent):\n portrayal = None\n if agent is None:\n # Actually this if part is unnecessary, but still keeping it for\n # aesthetics\n pass\n elif isinstance(agent, Walker):\n print(\"Uid: {0}, Heading: {1}\".format(agent.unique_id, agent.heading))\n portrayal = {\"Shape\": \"arrowHead\",\n \"Filled\": \"true\",\n \"Layer\": 2,\n \"Color\": \"green\",\n \"Filled\": \"true\",\n \"heading0\": agent.heading[0],\n \"heading1\": agent.heading[1],\n \"text\": agent.unique_id,\n \"text_color\": \"white\",\n \"scale\": 0.8,\n }\n return portrayal\n\n\ndef launch_basic():\n width = 15\n height = 10\n num_agents = 2\n pixel_ratio = 50\n grid = CanvasGrid(agent_draw, width, height,\n width * pixel_ratio, height * pixel_ratio)\n server = ModularServer(ShapesModel, [grid], \"Basic Example\",\n num_agents, width, height)\n server.max_steps = 0\n server.port = 8888\n server.launch()\n\nif __name__ == \"__main__\":\n random.seed(3)\n launch_basic()\n", "path": "examples/Basic/basic/server.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\nModular Canvas Rendering\n========================\n\nModule for visualizing model objects in grid cells.\n\n\"\"\"\nfrom collections import defaultdict\nfrom mesa.visualization.ModularVisualization import VisualizationElement\n\n\nclass CanvasGrid(VisualizationElement):\n \"\"\" A CanvasGrid object uses a user-provided portrayal method to generate a\n portrayal for each object. A portrayal is a JSON-ready dictionary which\n tells the relevant JavaScript code (GridDraw.js) where to draw what shape.\n\n The render method returns a dictionary, keyed on layers, with values as\n lists of portrayals to draw. Portrayals themselves are generated by the\n user-provided portrayal_method, which accepts an object as an input and\n produces a portrayal of it.\n\n A portrayal as a dictionary with the following structure:\n \"x\", \"y\": Coordinates for the cell in which the object is placed.\n \"Shape\": Can be either \"circle\", \"rect\" or \"arrowHead\"\n For Circles:\n \"r\": The radius, defined as a fraction of cell size. r=1 will\n fill the entire cell.\n For Rectangles:\n \"w\", \"h\": The width and height of the rectangle, which are in\n fractions of cell width and height.\n For arrowHead:\n \"scale\": Proportion scaling as a fraction of cell size.\n \"heading_x\": represents x direction unit vector.\n \"heading_y\": represents y direction unit vector.\n \"Color\": The color to draw the shape in; needs to be a valid HTML\n color, e.g.\"Red\" or \"#AA08F8\"\n \"Filled\": either \"true\" or \"false\", and determines whether the shape is\n filled or not.\n \"Layer\": Layer number of 0 or above; higher-numbered layers are drawn\n above lower-numbered layers.\n \"text\": The text to be inscribed inside the Shape. Normally useful for\n showing the unique_id of the agent.\n \"text_color\": The color to draw the inscribed text. Should be given in\n conjunction of \"text\" property.\n\n\n Attributes:\n portrayal_method: Function which generates portrayals from objects, as\n described above.\n grid_height, grid_width: Size of the grid to visualize, in cells.\n canvas_height, canvas_width: Size, in pixels, of the grid visualization\n to draw on the client.\n template: \"canvas_module.html\" stores the module's HTML template.\n\n \"\"\"\n package_includes = [\"GridDraw.js\", \"CanvasModule.js\"]\n portrayal_method = None # Portrayal function\n canvas_width = 500\n canvas_height = 500\n\n def __init__(self, portrayal_method, grid_width, grid_height,\n canvas_width=500, canvas_height=500):\n \"\"\" Instantiate a new CanvasGrid.\n\n Args:\n portrayal_method: function to convert each object on the grid to\n a portrayal, as described above.\n grid_width, grid_height: Size of the grid, in cells.\n canvas_height, canvas_width: Size of the canvas to draw in the\n client, in pixels. (default: 500x500)\n\n \"\"\"\n self.portrayal_method = portrayal_method\n self.grid_width = grid_width\n self.grid_height = grid_height\n self.canvas_width = canvas_width\n self.canvas_height = canvas_height\n\n new_element = (\"new CanvasModule({}, {}, {}, {})\"\n .format(self.canvas_width, self.canvas_height,\n self.grid_width, self.grid_height))\n\n self.js_code = \"elements.push(\" + new_element + \");\"\n\n def render(self, model):\n grid_state = defaultdict(list)\n for x in range(model.grid.width):\n for y in range(model.grid.height):\n cell_objects = model.grid.get_cell_list_contents([(x, y)])\n for obj in cell_objects:\n portrayal = self.portrayal_method(obj)\n if portrayal:\n portrayal[\"x\"] = x\n portrayal[\"y\"] = y\n grid_state[portrayal[\"Layer\"]].append(portrayal)\n\n return grid_state\n", "path": "mesa/visualization/modules/CanvasGridVisualization.py"}, {"content": "import random\n\nfrom mesa.visualization.modules import CanvasGrid\nfrom mesa.visualization.ModularVisualization import ModularServer\n\nfrom basic.model import Walker, ShapesModel\n\n\ndef agent_draw(agent):\n portrayal = None\n if agent is None:\n # Actually this if part is unnecessary, but still keeping it for\n # aesthetics\n pass\n elif isinstance(agent, Walker):\n print(\"Uid: {0}, Heading: {1}\".format(agent.unique_id, agent.heading))\n portrayal = {\"Shape\": \"arrowHead\",\n \"Filled\": \"true\",\n \"Layer\": 2,\n \"Color\": \"green\",\n \"Filled\": \"true\",\n \"heading_x\": agent.heading[0],\n \"heading_y\": agent.heading[1],\n \"text\": agent.unique_id,\n \"text_color\": \"white\",\n \"scale\": 0.8,\n }\n return portrayal\n\n\ndef launch_basic():\n width = 15\n height = 10\n num_agents = 2\n pixel_ratio = 50\n grid = CanvasGrid(agent_draw, width, height,\n width * pixel_ratio, height * pixel_ratio)\n server = ModularServer(ShapesModel, [grid], \"Basic Example\",\n num_agents, width, height)\n server.max_steps = 0\n server.port = 8888\n server.launch()\n\nif __name__ == \"__main__\":\n random.seed(3)\n launch_basic()\n", "path": "examples/Basic/basic/server.py"}]}
| 1,757 | 436 |
gh_patches_debug_44700
|
rasdani/github-patches
|
git_diff
|
feast-dev__feast-3702
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
performance issues of getting online features related to parsing protobuf data
**Is your feature request related to a problem? Please describe.**
The profiler of one application I am working on shows the `from_proto` method of the `FeatureView` class takes up 80% of the execution time. The result of cProfile is shown below.
```
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.003 0.003 78.931 78.931 profiler.py:53(main)
100 0.018 0.000 78.849 0.788 get_features.py:122(get_xxxx_features)
1100/400 0.020 0.000 77.077 0.193 usage.py:274(wrapper)
444200/9800 1.713 0.000 72.206 0.007 __init__.py:1030(wrapper)
200 0.078 0.000 68.913 0.345 feature_store.py:1527(get_online_features)
200 0.087 0.000 68.835 0.344 feature_store.py:1590(_get_online_features)
3500 5.634 0.002 62.442 0.018 feature_view.py:369(from_proto)
200 0.005 0.000 59.362 0.297 feature_store.py:2149(_get_feature_views_to_use)
200 0.002 0.000 58.501 0.293 feature_store.py:281(_list_feature_views)
200 0.001 0.000 58.499 0.292 registry.py:523(list_feature_views)
200 0.016 0.000 58.495 0.292 proto_registry_utils.py:150(list_feature_views)
```
There are 3 feature views accessed by `get_xxxx_features`, however 100 calls of `get_xxxx_features` lead to 3500 calls of `from_proto`. There are 17 feature views in the feature store of this application and 3 of them are used by `get_xxxx_features`.
Environment: `continuumio/miniconda3:4.11.0` (linux/amd64) base image, `python==3.9.7`, `feast=0.31.1`, `protobuf==4.23.2`
**Describe the solution you'd like**
Instead of caching the protobuf blob of `FeatureView`, cache the `FeatureView` python object in memory.
**Describe alternatives you've considered**
modify the `get_online_features` [method](https://github.com/feast-dev/feast/blob/v0.31.1/sdk/python/feast/feature_store.py#L1528) to
```python
def get_online_features(
self,
features: Union[List[str], List[FeatureView], FeatureService],
entity_rows: List[Dict[str, Any]],
full_feature_names: bool = False,
):
```
so that the application developer has the option to cache the `FeatureView` objects and use them to get features directly (by passing the `get_feature_views_to_use` [step](https://github.com/feast-dev/feast/blob/v0.31.1/sdk/python/feast/feature_store.py#L1606-L1613) )
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sdk/python/feast/infra/registry/proto_registry_utils.py`
Content:
```
1 import uuid
2 from typing import List, Optional
3
4 from feast import usage
5 from feast.data_source import DataSource
6 from feast.entity import Entity
7 from feast.errors import (
8 DataSourceObjectNotFoundException,
9 EntityNotFoundException,
10 FeatureServiceNotFoundException,
11 FeatureViewNotFoundException,
12 SavedDatasetNotFound,
13 ValidationReferenceNotFound,
14 )
15 from feast.feature_service import FeatureService
16 from feast.feature_view import FeatureView
17 from feast.on_demand_feature_view import OnDemandFeatureView
18 from feast.project_metadata import ProjectMetadata
19 from feast.protos.feast.core.Registry_pb2 import ProjectMetadata as ProjectMetadataProto
20 from feast.protos.feast.core.Registry_pb2 import Registry as RegistryProto
21 from feast.request_feature_view import RequestFeatureView
22 from feast.saved_dataset import SavedDataset, ValidationReference
23 from feast.stream_feature_view import StreamFeatureView
24
25
26 def init_project_metadata(cached_registry_proto: RegistryProto, project: str):
27 new_project_uuid = f"{uuid.uuid4()}"
28 usage.set_current_project_uuid(new_project_uuid)
29 cached_registry_proto.project_metadata.append(
30 ProjectMetadata(project_name=project, project_uuid=new_project_uuid).to_proto()
31 )
32
33
34 def get_project_metadata(
35 registry_proto: Optional[RegistryProto], project: str
36 ) -> Optional[ProjectMetadataProto]:
37 if not registry_proto:
38 return None
39 for pm in registry_proto.project_metadata:
40 if pm.project == project:
41 return pm
42 return None
43
44
45 def get_feature_service(
46 registry_proto: RegistryProto, name: str, project: str
47 ) -> FeatureService:
48 for feature_service_proto in registry_proto.feature_services:
49 if (
50 feature_service_proto.spec.project == project
51 and feature_service_proto.spec.name == name
52 ):
53 return FeatureService.from_proto(feature_service_proto)
54 raise FeatureServiceNotFoundException(name, project=project)
55
56
57 def get_feature_view(
58 registry_proto: RegistryProto, name: str, project: str
59 ) -> FeatureView:
60 for feature_view_proto in registry_proto.feature_views:
61 if (
62 feature_view_proto.spec.name == name
63 and feature_view_proto.spec.project == project
64 ):
65 return FeatureView.from_proto(feature_view_proto)
66 raise FeatureViewNotFoundException(name, project)
67
68
69 def get_stream_feature_view(
70 registry_proto: RegistryProto, name: str, project: str
71 ) -> StreamFeatureView:
72 for feature_view_proto in registry_proto.stream_feature_views:
73 if (
74 feature_view_proto.spec.name == name
75 and feature_view_proto.spec.project == project
76 ):
77 return StreamFeatureView.from_proto(feature_view_proto)
78 raise FeatureViewNotFoundException(name, project)
79
80
81 def get_request_feature_view(registry_proto: RegistryProto, name: str, project: str):
82 for feature_view_proto in registry_proto.feature_views:
83 if (
84 feature_view_proto.spec.name == name
85 and feature_view_proto.spec.project == project
86 ):
87 return RequestFeatureView.from_proto(feature_view_proto)
88 raise FeatureViewNotFoundException(name, project)
89
90
91 def get_on_demand_feature_view(
92 registry_proto: RegistryProto, name: str, project: str
93 ) -> OnDemandFeatureView:
94 for on_demand_feature_view in registry_proto.on_demand_feature_views:
95 if (
96 on_demand_feature_view.spec.project == project
97 and on_demand_feature_view.spec.name == name
98 ):
99 return OnDemandFeatureView.from_proto(on_demand_feature_view)
100 raise FeatureViewNotFoundException(name, project=project)
101
102
103 def get_data_source(
104 registry_proto: RegistryProto, name: str, project: str
105 ) -> DataSource:
106 for data_source in registry_proto.data_sources:
107 if data_source.project == project and data_source.name == name:
108 return DataSource.from_proto(data_source)
109 raise DataSourceObjectNotFoundException(name, project=project)
110
111
112 def get_entity(registry_proto: RegistryProto, name: str, project: str) -> Entity:
113 for entity_proto in registry_proto.entities:
114 if entity_proto.spec.name == name and entity_proto.spec.project == project:
115 return Entity.from_proto(entity_proto)
116 raise EntityNotFoundException(name, project=project)
117
118
119 def get_saved_dataset(
120 registry_proto: RegistryProto, name: str, project: str
121 ) -> SavedDataset:
122 for saved_dataset in registry_proto.saved_datasets:
123 if saved_dataset.spec.name == name and saved_dataset.spec.project == project:
124 return SavedDataset.from_proto(saved_dataset)
125 raise SavedDatasetNotFound(name, project=project)
126
127
128 def get_validation_reference(
129 registry_proto: RegistryProto, name: str, project: str
130 ) -> ValidationReference:
131 for validation_reference in registry_proto.validation_references:
132 if (
133 validation_reference.name == name
134 and validation_reference.project == project
135 ):
136 return ValidationReference.from_proto(validation_reference)
137 raise ValidationReferenceNotFound(name, project=project)
138
139
140 def list_feature_services(
141 registry_proto: RegistryProto, project: str, allow_cache: bool = False
142 ) -> List[FeatureService]:
143 feature_services = []
144 for feature_service_proto in registry_proto.feature_services:
145 if feature_service_proto.spec.project == project:
146 feature_services.append(FeatureService.from_proto(feature_service_proto))
147 return feature_services
148
149
150 def list_feature_views(
151 registry_proto: RegistryProto, project: str
152 ) -> List[FeatureView]:
153 feature_views: List[FeatureView] = []
154 for feature_view_proto in registry_proto.feature_views:
155 if feature_view_proto.spec.project == project:
156 feature_views.append(FeatureView.from_proto(feature_view_proto))
157 return feature_views
158
159
160 def list_request_feature_views(
161 registry_proto: RegistryProto, project: str
162 ) -> List[RequestFeatureView]:
163 feature_views: List[RequestFeatureView] = []
164 for request_feature_view_proto in registry_proto.request_feature_views:
165 if request_feature_view_proto.spec.project == project:
166 feature_views.append(
167 RequestFeatureView.from_proto(request_feature_view_proto)
168 )
169 return feature_views
170
171
172 def list_stream_feature_views(
173 registry_proto: RegistryProto, project: str
174 ) -> List[StreamFeatureView]:
175 stream_feature_views = []
176 for stream_feature_view in registry_proto.stream_feature_views:
177 if stream_feature_view.spec.project == project:
178 stream_feature_views.append(
179 StreamFeatureView.from_proto(stream_feature_view)
180 )
181 return stream_feature_views
182
183
184 def list_on_demand_feature_views(
185 registry_proto: RegistryProto, project: str
186 ) -> List[OnDemandFeatureView]:
187 on_demand_feature_views = []
188 for on_demand_feature_view in registry_proto.on_demand_feature_views:
189 if on_demand_feature_view.spec.project == project:
190 on_demand_feature_views.append(
191 OnDemandFeatureView.from_proto(on_demand_feature_view)
192 )
193 return on_demand_feature_views
194
195
196 def list_entities(registry_proto: RegistryProto, project: str) -> List[Entity]:
197 entities = []
198 for entity_proto in registry_proto.entities:
199 if entity_proto.spec.project == project:
200 entities.append(Entity.from_proto(entity_proto))
201 return entities
202
203
204 def list_data_sources(registry_proto: RegistryProto, project: str) -> List[DataSource]:
205 data_sources = []
206 for data_source_proto in registry_proto.data_sources:
207 if data_source_proto.project == project:
208 data_sources.append(DataSource.from_proto(data_source_proto))
209 return data_sources
210
211
212 def list_saved_datasets(
213 registry_proto: RegistryProto, project: str
214 ) -> List[SavedDataset]:
215 saved_datasets = []
216 for saved_dataset in registry_proto.saved_datasets:
217 if saved_dataset.project == project:
218 saved_datasets.append(SavedDataset.from_proto(saved_dataset))
219 return saved_datasets
220
221
222 def list_validation_references(
223 registry_proto: RegistryProto, project: str
224 ) -> List[ValidationReference]:
225 validation_references = []
226 for validation_reference in registry_proto.validation_references:
227 if validation_reference.project == project:
228 validation_references.append(
229 ValidationReference.from_proto(validation_reference)
230 )
231 return validation_references
232
233
234 def list_project_metadata(
235 registry_proto: RegistryProto, project: str
236 ) -> List[ProjectMetadata]:
237 return [
238 ProjectMetadata.from_proto(project_metadata)
239 for project_metadata in registry_proto.project_metadata
240 if project_metadata.project == project
241 ]
242
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sdk/python/feast/infra/registry/proto_registry_utils.py b/sdk/python/feast/infra/registry/proto_registry_utils.py
--- a/sdk/python/feast/infra/registry/proto_registry_utils.py
+++ b/sdk/python/feast/infra/registry/proto_registry_utils.py
@@ -1,4 +1,5 @@
import uuid
+from functools import wraps
from typing import List, Optional
from feast import usage
@@ -23,6 +24,26 @@
from feast.stream_feature_view import StreamFeatureView
+def registry_proto_cache(func):
+ cache_key = None
+ cache_value = None
+
+ @wraps(func)
+ def wrapper(registry_proto: RegistryProto, project: str):
+ nonlocal cache_key, cache_value
+
+ key = tuple([id(registry_proto), registry_proto.version_id, project])
+
+ if key == cache_key:
+ return cache_value
+ else:
+ cache_value = func(registry_proto, project)
+ cache_key = key
+ return cache_value
+
+ return wrapper
+
+
def init_project_metadata(cached_registry_proto: RegistryProto, project: str):
new_project_uuid = f"{uuid.uuid4()}"
usage.set_current_project_uuid(new_project_uuid)
@@ -137,8 +158,9 @@
raise ValidationReferenceNotFound(name, project=project)
+@registry_proto_cache
def list_feature_services(
- registry_proto: RegistryProto, project: str, allow_cache: bool = False
+ registry_proto: RegistryProto, project: str
) -> List[FeatureService]:
feature_services = []
for feature_service_proto in registry_proto.feature_services:
@@ -147,6 +169,7 @@
return feature_services
+@registry_proto_cache
def list_feature_views(
registry_proto: RegistryProto, project: str
) -> List[FeatureView]:
@@ -157,6 +180,7 @@
return feature_views
+@registry_proto_cache
def list_request_feature_views(
registry_proto: RegistryProto, project: str
) -> List[RequestFeatureView]:
@@ -169,6 +193,7 @@
return feature_views
+@registry_proto_cache
def list_stream_feature_views(
registry_proto: RegistryProto, project: str
) -> List[StreamFeatureView]:
@@ -181,6 +206,7 @@
return stream_feature_views
+@registry_proto_cache
def list_on_demand_feature_views(
registry_proto: RegistryProto, project: str
) -> List[OnDemandFeatureView]:
@@ -193,6 +219,7 @@
return on_demand_feature_views
+@registry_proto_cache
def list_entities(registry_proto: RegistryProto, project: str) -> List[Entity]:
entities = []
for entity_proto in registry_proto.entities:
@@ -201,6 +228,7 @@
return entities
+@registry_proto_cache
def list_data_sources(registry_proto: RegistryProto, project: str) -> List[DataSource]:
data_sources = []
for data_source_proto in registry_proto.data_sources:
@@ -209,6 +237,7 @@
return data_sources
+@registry_proto_cache
def list_saved_datasets(
registry_proto: RegistryProto, project: str
) -> List[SavedDataset]:
@@ -219,6 +248,7 @@
return saved_datasets
+@registry_proto_cache
def list_validation_references(
registry_proto: RegistryProto, project: str
) -> List[ValidationReference]:
@@ -231,6 +261,7 @@
return validation_references
+@registry_proto_cache
def list_project_metadata(
registry_proto: RegistryProto, project: str
) -> List[ProjectMetadata]:
|
{"golden_diff": "diff --git a/sdk/python/feast/infra/registry/proto_registry_utils.py b/sdk/python/feast/infra/registry/proto_registry_utils.py\n--- a/sdk/python/feast/infra/registry/proto_registry_utils.py\n+++ b/sdk/python/feast/infra/registry/proto_registry_utils.py\n@@ -1,4 +1,5 @@\n import uuid\n+from functools import wraps\n from typing import List, Optional\n \n from feast import usage\n@@ -23,6 +24,26 @@\n from feast.stream_feature_view import StreamFeatureView\n \n \n+def registry_proto_cache(func):\n+ cache_key = None\n+ cache_value = None\n+\n+ @wraps(func)\n+ def wrapper(registry_proto: RegistryProto, project: str):\n+ nonlocal cache_key, cache_value\n+\n+ key = tuple([id(registry_proto), registry_proto.version_id, project])\n+\n+ if key == cache_key:\n+ return cache_value\n+ else:\n+ cache_value = func(registry_proto, project)\n+ cache_key = key\n+ return cache_value\n+\n+ return wrapper\n+\n+\n def init_project_metadata(cached_registry_proto: RegistryProto, project: str):\n new_project_uuid = f\"{uuid.uuid4()}\"\n usage.set_current_project_uuid(new_project_uuid)\n@@ -137,8 +158,9 @@\n raise ValidationReferenceNotFound(name, project=project)\n \n \n+@registry_proto_cache\n def list_feature_services(\n- registry_proto: RegistryProto, project: str, allow_cache: bool = False\n+ registry_proto: RegistryProto, project: str\n ) -> List[FeatureService]:\n feature_services = []\n for feature_service_proto in registry_proto.feature_services:\n@@ -147,6 +169,7 @@\n return feature_services\n \n \n+@registry_proto_cache\n def list_feature_views(\n registry_proto: RegistryProto, project: str\n ) -> List[FeatureView]:\n@@ -157,6 +180,7 @@\n return feature_views\n \n \n+@registry_proto_cache\n def list_request_feature_views(\n registry_proto: RegistryProto, project: str\n ) -> List[RequestFeatureView]:\n@@ -169,6 +193,7 @@\n return feature_views\n \n \n+@registry_proto_cache\n def list_stream_feature_views(\n registry_proto: RegistryProto, project: str\n ) -> List[StreamFeatureView]:\n@@ -181,6 +206,7 @@\n return stream_feature_views\n \n \n+@registry_proto_cache\n def list_on_demand_feature_views(\n registry_proto: RegistryProto, project: str\n ) -> List[OnDemandFeatureView]:\n@@ -193,6 +219,7 @@\n return on_demand_feature_views\n \n \n+@registry_proto_cache\n def list_entities(registry_proto: RegistryProto, project: str) -> List[Entity]:\n entities = []\n for entity_proto in registry_proto.entities:\n@@ -201,6 +228,7 @@\n return entities\n \n \n+@registry_proto_cache\n def list_data_sources(registry_proto: RegistryProto, project: str) -> List[DataSource]:\n data_sources = []\n for data_source_proto in registry_proto.data_sources:\n@@ -209,6 +237,7 @@\n return data_sources\n \n \n+@registry_proto_cache\n def list_saved_datasets(\n registry_proto: RegistryProto, project: str\n ) -> List[SavedDataset]:\n@@ -219,6 +248,7 @@\n return saved_datasets\n \n \n+@registry_proto_cache\n def list_validation_references(\n registry_proto: RegistryProto, project: str\n ) -> List[ValidationReference]:\n@@ -231,6 +261,7 @@\n return validation_references\n \n \n+@registry_proto_cache\n def list_project_metadata(\n registry_proto: RegistryProto, project: str\n ) -> List[ProjectMetadata]:\n", "issue": "performance issues of getting online features related to parsing protobuf data\n**Is your feature request related to a problem? Please describe.**\r\n\r\nThe profiler of one application I am working on shows the `from_proto` method of the `FeatureView` class takes up 80% of the execution time. The result of cProfile is shown below.\r\n```\r\n ncalls tottime percall cumtime percall filename:lineno(function)\r\n 1 0.003 0.003 78.931 78.931 profiler.py:53(main)\r\n 100 0.018 0.000 78.849 0.788 get_features.py:122(get_xxxx_features)\r\n 1100/400 0.020 0.000 77.077 0.193 usage.py:274(wrapper)\r\n 444200/9800 1.713 0.000 72.206 0.007 __init__.py:1030(wrapper)\r\n 200 0.078 0.000 68.913 0.345 feature_store.py:1527(get_online_features)\r\n 200 0.087 0.000 68.835 0.344 feature_store.py:1590(_get_online_features)\r\n 3500 5.634 0.002 62.442 0.018 feature_view.py:369(from_proto)\r\n 200 0.005 0.000 59.362 0.297 feature_store.py:2149(_get_feature_views_to_use)\r\n 200 0.002 0.000 58.501 0.293 feature_store.py:281(_list_feature_views)\r\n 200 0.001 0.000 58.499 0.292 registry.py:523(list_feature_views)\r\n 200 0.016 0.000 58.495 0.292 proto_registry_utils.py:150(list_feature_views)\r\n```\r\nThere are 3 feature views accessed by `get_xxxx_features`, however 100 calls of `get_xxxx_features` lead to 3500 calls of `from_proto`. There are 17 feature views in the feature store of this application and 3 of them are used by `get_xxxx_features`.\r\n\r\nEnvironment: `continuumio/miniconda3:4.11.0` (linux/amd64) base image, `python==3.9.7`, `feast=0.31.1`, `protobuf==4.23.2`\r\n\r\n**Describe the solution you'd like**\r\n\r\nInstead of caching the protobuf blob of `FeatureView`, cache the `FeatureView` python object in memory.\r\n\r\n**Describe alternatives you've considered**\r\n\r\nmodify the `get_online_features` [method](https://github.com/feast-dev/feast/blob/v0.31.1/sdk/python/feast/feature_store.py#L1528) to\r\n```python\r\ndef get_online_features(\r\n self,\r\n features: Union[List[str], List[FeatureView], FeatureService],\r\n entity_rows: List[Dict[str, Any]],\r\n full_feature_names: bool = False,\r\n):\r\n``` \r\nso that the application developer has the option to cache the `FeatureView` objects and use them to get features directly (by passing the `get_feature_views_to_use` [step](https://github.com/feast-dev/feast/blob/v0.31.1/sdk/python/feast/feature_store.py#L1606-L1613) )\r\n \n", "before_files": [{"content": "import uuid\nfrom typing import List, Optional\n\nfrom feast import usage\nfrom feast.data_source import DataSource\nfrom feast.entity import Entity\nfrom feast.errors import (\n DataSourceObjectNotFoundException,\n EntityNotFoundException,\n FeatureServiceNotFoundException,\n FeatureViewNotFoundException,\n SavedDatasetNotFound,\n ValidationReferenceNotFound,\n)\nfrom feast.feature_service import FeatureService\nfrom feast.feature_view import FeatureView\nfrom feast.on_demand_feature_view import OnDemandFeatureView\nfrom feast.project_metadata import ProjectMetadata\nfrom feast.protos.feast.core.Registry_pb2 import ProjectMetadata as ProjectMetadataProto\nfrom feast.protos.feast.core.Registry_pb2 import Registry as RegistryProto\nfrom feast.request_feature_view import RequestFeatureView\nfrom feast.saved_dataset import SavedDataset, ValidationReference\nfrom feast.stream_feature_view import StreamFeatureView\n\n\ndef init_project_metadata(cached_registry_proto: RegistryProto, project: str):\n new_project_uuid = f\"{uuid.uuid4()}\"\n usage.set_current_project_uuid(new_project_uuid)\n cached_registry_proto.project_metadata.append(\n ProjectMetadata(project_name=project, project_uuid=new_project_uuid).to_proto()\n )\n\n\ndef get_project_metadata(\n registry_proto: Optional[RegistryProto], project: str\n) -> Optional[ProjectMetadataProto]:\n if not registry_proto:\n return None\n for pm in registry_proto.project_metadata:\n if pm.project == project:\n return pm\n return None\n\n\ndef get_feature_service(\n registry_proto: RegistryProto, name: str, project: str\n) -> FeatureService:\n for feature_service_proto in registry_proto.feature_services:\n if (\n feature_service_proto.spec.project == project\n and feature_service_proto.spec.name == name\n ):\n return FeatureService.from_proto(feature_service_proto)\n raise FeatureServiceNotFoundException(name, project=project)\n\n\ndef get_feature_view(\n registry_proto: RegistryProto, name: str, project: str\n) -> FeatureView:\n for feature_view_proto in registry_proto.feature_views:\n if (\n feature_view_proto.spec.name == name\n and feature_view_proto.spec.project == project\n ):\n return FeatureView.from_proto(feature_view_proto)\n raise FeatureViewNotFoundException(name, project)\n\n\ndef get_stream_feature_view(\n registry_proto: RegistryProto, name: str, project: str\n) -> StreamFeatureView:\n for feature_view_proto in registry_proto.stream_feature_views:\n if (\n feature_view_proto.spec.name == name\n and feature_view_proto.spec.project == project\n ):\n return StreamFeatureView.from_proto(feature_view_proto)\n raise FeatureViewNotFoundException(name, project)\n\n\ndef get_request_feature_view(registry_proto: RegistryProto, name: str, project: str):\n for feature_view_proto in registry_proto.feature_views:\n if (\n feature_view_proto.spec.name == name\n and feature_view_proto.spec.project == project\n ):\n return RequestFeatureView.from_proto(feature_view_proto)\n raise FeatureViewNotFoundException(name, project)\n\n\ndef get_on_demand_feature_view(\n registry_proto: RegistryProto, name: str, project: str\n) -> OnDemandFeatureView:\n for on_demand_feature_view in registry_proto.on_demand_feature_views:\n if (\n on_demand_feature_view.spec.project == project\n and on_demand_feature_view.spec.name == name\n ):\n return OnDemandFeatureView.from_proto(on_demand_feature_view)\n raise FeatureViewNotFoundException(name, project=project)\n\n\ndef get_data_source(\n registry_proto: RegistryProto, name: str, project: str\n) -> DataSource:\n for data_source in registry_proto.data_sources:\n if data_source.project == project and data_source.name == name:\n return DataSource.from_proto(data_source)\n raise DataSourceObjectNotFoundException(name, project=project)\n\n\ndef get_entity(registry_proto: RegistryProto, name: str, project: str) -> Entity:\n for entity_proto in registry_proto.entities:\n if entity_proto.spec.name == name and entity_proto.spec.project == project:\n return Entity.from_proto(entity_proto)\n raise EntityNotFoundException(name, project=project)\n\n\ndef get_saved_dataset(\n registry_proto: RegistryProto, name: str, project: str\n) -> SavedDataset:\n for saved_dataset in registry_proto.saved_datasets:\n if saved_dataset.spec.name == name and saved_dataset.spec.project == project:\n return SavedDataset.from_proto(saved_dataset)\n raise SavedDatasetNotFound(name, project=project)\n\n\ndef get_validation_reference(\n registry_proto: RegistryProto, name: str, project: str\n) -> ValidationReference:\n for validation_reference in registry_proto.validation_references:\n if (\n validation_reference.name == name\n and validation_reference.project == project\n ):\n return ValidationReference.from_proto(validation_reference)\n raise ValidationReferenceNotFound(name, project=project)\n\n\ndef list_feature_services(\n registry_proto: RegistryProto, project: str, allow_cache: bool = False\n) -> List[FeatureService]:\n feature_services = []\n for feature_service_proto in registry_proto.feature_services:\n if feature_service_proto.spec.project == project:\n feature_services.append(FeatureService.from_proto(feature_service_proto))\n return feature_services\n\n\ndef list_feature_views(\n registry_proto: RegistryProto, project: str\n) -> List[FeatureView]:\n feature_views: List[FeatureView] = []\n for feature_view_proto in registry_proto.feature_views:\n if feature_view_proto.spec.project == project:\n feature_views.append(FeatureView.from_proto(feature_view_proto))\n return feature_views\n\n\ndef list_request_feature_views(\n registry_proto: RegistryProto, project: str\n) -> List[RequestFeatureView]:\n feature_views: List[RequestFeatureView] = []\n for request_feature_view_proto in registry_proto.request_feature_views:\n if request_feature_view_proto.spec.project == project:\n feature_views.append(\n RequestFeatureView.from_proto(request_feature_view_proto)\n )\n return feature_views\n\n\ndef list_stream_feature_views(\n registry_proto: RegistryProto, project: str\n) -> List[StreamFeatureView]:\n stream_feature_views = []\n for stream_feature_view in registry_proto.stream_feature_views:\n if stream_feature_view.spec.project == project:\n stream_feature_views.append(\n StreamFeatureView.from_proto(stream_feature_view)\n )\n return stream_feature_views\n\n\ndef list_on_demand_feature_views(\n registry_proto: RegistryProto, project: str\n) -> List[OnDemandFeatureView]:\n on_demand_feature_views = []\n for on_demand_feature_view in registry_proto.on_demand_feature_views:\n if on_demand_feature_view.spec.project == project:\n on_demand_feature_views.append(\n OnDemandFeatureView.from_proto(on_demand_feature_view)\n )\n return on_demand_feature_views\n\n\ndef list_entities(registry_proto: RegistryProto, project: str) -> List[Entity]:\n entities = []\n for entity_proto in registry_proto.entities:\n if entity_proto.spec.project == project:\n entities.append(Entity.from_proto(entity_proto))\n return entities\n\n\ndef list_data_sources(registry_proto: RegistryProto, project: str) -> List[DataSource]:\n data_sources = []\n for data_source_proto in registry_proto.data_sources:\n if data_source_proto.project == project:\n data_sources.append(DataSource.from_proto(data_source_proto))\n return data_sources\n\n\ndef list_saved_datasets(\n registry_proto: RegistryProto, project: str\n) -> List[SavedDataset]:\n saved_datasets = []\n for saved_dataset in registry_proto.saved_datasets:\n if saved_dataset.project == project:\n saved_datasets.append(SavedDataset.from_proto(saved_dataset))\n return saved_datasets\n\n\ndef list_validation_references(\n registry_proto: RegistryProto, project: str\n) -> List[ValidationReference]:\n validation_references = []\n for validation_reference in registry_proto.validation_references:\n if validation_reference.project == project:\n validation_references.append(\n ValidationReference.from_proto(validation_reference)\n )\n return validation_references\n\n\ndef list_project_metadata(\n registry_proto: RegistryProto, project: str\n) -> List[ProjectMetadata]:\n return [\n ProjectMetadata.from_proto(project_metadata)\n for project_metadata in registry_proto.project_metadata\n if project_metadata.project == project\n ]\n", "path": "sdk/python/feast/infra/registry/proto_registry_utils.py"}], "after_files": [{"content": "import uuid\nfrom functools import wraps\nfrom typing import List, Optional\n\nfrom feast import usage\nfrom feast.data_source import DataSource\nfrom feast.entity import Entity\nfrom feast.errors import (\n DataSourceObjectNotFoundException,\n EntityNotFoundException,\n FeatureServiceNotFoundException,\n FeatureViewNotFoundException,\n SavedDatasetNotFound,\n ValidationReferenceNotFound,\n)\nfrom feast.feature_service import FeatureService\nfrom feast.feature_view import FeatureView\nfrom feast.on_demand_feature_view import OnDemandFeatureView\nfrom feast.project_metadata import ProjectMetadata\nfrom feast.protos.feast.core.Registry_pb2 import ProjectMetadata as ProjectMetadataProto\nfrom feast.protos.feast.core.Registry_pb2 import Registry as RegistryProto\nfrom feast.request_feature_view import RequestFeatureView\nfrom feast.saved_dataset import SavedDataset, ValidationReference\nfrom feast.stream_feature_view import StreamFeatureView\n\n\ndef registry_proto_cache(func):\n cache_key = None\n cache_value = None\n\n @wraps(func)\n def wrapper(registry_proto: RegistryProto, project: str):\n nonlocal cache_key, cache_value\n\n key = tuple([id(registry_proto), registry_proto.version_id, project])\n\n if key == cache_key:\n return cache_value\n else:\n cache_value = func(registry_proto, project)\n cache_key = key\n return cache_value\n\n return wrapper\n\n\ndef init_project_metadata(cached_registry_proto: RegistryProto, project: str):\n new_project_uuid = f\"{uuid.uuid4()}\"\n usage.set_current_project_uuid(new_project_uuid)\n cached_registry_proto.project_metadata.append(\n ProjectMetadata(project_name=project, project_uuid=new_project_uuid).to_proto()\n )\n\n\ndef get_project_metadata(\n registry_proto: Optional[RegistryProto], project: str\n) -> Optional[ProjectMetadataProto]:\n if not registry_proto:\n return None\n for pm in registry_proto.project_metadata:\n if pm.project == project:\n return pm\n return None\n\n\ndef get_feature_service(\n registry_proto: RegistryProto, name: str, project: str\n) -> FeatureService:\n for feature_service_proto in registry_proto.feature_services:\n if (\n feature_service_proto.spec.project == project\n and feature_service_proto.spec.name == name\n ):\n return FeatureService.from_proto(feature_service_proto)\n raise FeatureServiceNotFoundException(name, project=project)\n\n\ndef get_feature_view(\n registry_proto: RegistryProto, name: str, project: str\n) -> FeatureView:\n for feature_view_proto in registry_proto.feature_views:\n if (\n feature_view_proto.spec.name == name\n and feature_view_proto.spec.project == project\n ):\n return FeatureView.from_proto(feature_view_proto)\n raise FeatureViewNotFoundException(name, project)\n\n\ndef get_stream_feature_view(\n registry_proto: RegistryProto, name: str, project: str\n) -> StreamFeatureView:\n for feature_view_proto in registry_proto.stream_feature_views:\n if (\n feature_view_proto.spec.name == name\n and feature_view_proto.spec.project == project\n ):\n return StreamFeatureView.from_proto(feature_view_proto)\n raise FeatureViewNotFoundException(name, project)\n\n\ndef get_request_feature_view(registry_proto: RegistryProto, name: str, project: str):\n for feature_view_proto in registry_proto.feature_views:\n if (\n feature_view_proto.spec.name == name\n and feature_view_proto.spec.project == project\n ):\n return RequestFeatureView.from_proto(feature_view_proto)\n raise FeatureViewNotFoundException(name, project)\n\n\ndef get_on_demand_feature_view(\n registry_proto: RegistryProto, name: str, project: str\n) -> OnDemandFeatureView:\n for on_demand_feature_view in registry_proto.on_demand_feature_views:\n if (\n on_demand_feature_view.spec.project == project\n and on_demand_feature_view.spec.name == name\n ):\n return OnDemandFeatureView.from_proto(on_demand_feature_view)\n raise FeatureViewNotFoundException(name, project=project)\n\n\ndef get_data_source(\n registry_proto: RegistryProto, name: str, project: str\n) -> DataSource:\n for data_source in registry_proto.data_sources:\n if data_source.project == project and data_source.name == name:\n return DataSource.from_proto(data_source)\n raise DataSourceObjectNotFoundException(name, project=project)\n\n\ndef get_entity(registry_proto: RegistryProto, name: str, project: str) -> Entity:\n for entity_proto in registry_proto.entities:\n if entity_proto.spec.name == name and entity_proto.spec.project == project:\n return Entity.from_proto(entity_proto)\n raise EntityNotFoundException(name, project=project)\n\n\ndef get_saved_dataset(\n registry_proto: RegistryProto, name: str, project: str\n) -> SavedDataset:\n for saved_dataset in registry_proto.saved_datasets:\n if saved_dataset.spec.name == name and saved_dataset.spec.project == project:\n return SavedDataset.from_proto(saved_dataset)\n raise SavedDatasetNotFound(name, project=project)\n\n\ndef get_validation_reference(\n registry_proto: RegistryProto, name: str, project: str\n) -> ValidationReference:\n for validation_reference in registry_proto.validation_references:\n if (\n validation_reference.name == name\n and validation_reference.project == project\n ):\n return ValidationReference.from_proto(validation_reference)\n raise ValidationReferenceNotFound(name, project=project)\n\n\n@registry_proto_cache\ndef list_feature_services(\n registry_proto: RegistryProto, project: str\n) -> List[FeatureService]:\n feature_services = []\n for feature_service_proto in registry_proto.feature_services:\n if feature_service_proto.spec.project == project:\n feature_services.append(FeatureService.from_proto(feature_service_proto))\n return feature_services\n\n\n@registry_proto_cache\ndef list_feature_views(\n registry_proto: RegistryProto, project: str\n) -> List[FeatureView]:\n feature_views: List[FeatureView] = []\n for feature_view_proto in registry_proto.feature_views:\n if feature_view_proto.spec.project == project:\n feature_views.append(FeatureView.from_proto(feature_view_proto))\n return feature_views\n\n\n@registry_proto_cache\ndef list_request_feature_views(\n registry_proto: RegistryProto, project: str\n) -> List[RequestFeatureView]:\n feature_views: List[RequestFeatureView] = []\n for request_feature_view_proto in registry_proto.request_feature_views:\n if request_feature_view_proto.spec.project == project:\n feature_views.append(\n RequestFeatureView.from_proto(request_feature_view_proto)\n )\n return feature_views\n\n\n@registry_proto_cache\ndef list_stream_feature_views(\n registry_proto: RegistryProto, project: str\n) -> List[StreamFeatureView]:\n stream_feature_views = []\n for stream_feature_view in registry_proto.stream_feature_views:\n if stream_feature_view.spec.project == project:\n stream_feature_views.append(\n StreamFeatureView.from_proto(stream_feature_view)\n )\n return stream_feature_views\n\n\n@registry_proto_cache\ndef list_on_demand_feature_views(\n registry_proto: RegistryProto, project: str\n) -> List[OnDemandFeatureView]:\n on_demand_feature_views = []\n for on_demand_feature_view in registry_proto.on_demand_feature_views:\n if on_demand_feature_view.spec.project == project:\n on_demand_feature_views.append(\n OnDemandFeatureView.from_proto(on_demand_feature_view)\n )\n return on_demand_feature_views\n\n\n@registry_proto_cache\ndef list_entities(registry_proto: RegistryProto, project: str) -> List[Entity]:\n entities = []\n for entity_proto in registry_proto.entities:\n if entity_proto.spec.project == project:\n entities.append(Entity.from_proto(entity_proto))\n return entities\n\n\n@registry_proto_cache\ndef list_data_sources(registry_proto: RegistryProto, project: str) -> List[DataSource]:\n data_sources = []\n for data_source_proto in registry_proto.data_sources:\n if data_source_proto.project == project:\n data_sources.append(DataSource.from_proto(data_source_proto))\n return data_sources\n\n\n@registry_proto_cache\ndef list_saved_datasets(\n registry_proto: RegistryProto, project: str\n) -> List[SavedDataset]:\n saved_datasets = []\n for saved_dataset in registry_proto.saved_datasets:\n if saved_dataset.project == project:\n saved_datasets.append(SavedDataset.from_proto(saved_dataset))\n return saved_datasets\n\n\n@registry_proto_cache\ndef list_validation_references(\n registry_proto: RegistryProto, project: str\n) -> List[ValidationReference]:\n validation_references = []\n for validation_reference in registry_proto.validation_references:\n if validation_reference.project == project:\n validation_references.append(\n ValidationReference.from_proto(validation_reference)\n )\n return validation_references\n\n\n@registry_proto_cache\ndef list_project_metadata(\n registry_proto: RegistryProto, project: str\n) -> List[ProjectMetadata]:\n return [\n ProjectMetadata.from_proto(project_metadata)\n for project_metadata in registry_proto.project_metadata\n if project_metadata.project == project\n ]\n", "path": "sdk/python/feast/infra/registry/proto_registry_utils.py"}]}
| 3,544 | 846 |
gh_patches_debug_19757
|
rasdani/github-patches
|
git_diff
|
biopython__biopython-4328
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Biopython is not installable as a git repository with Poetry
### Setup
I am reporting a problem with Biopython version, Python version, and operating
system as follows:
```shell
❯ python -c 'import sys; print(sys.version)'
3.10.9 (main, Dec 7 2022, 01:12:00) [GCC 9.4.0]
```
```shell
❯ python -c 'import platform; print(platform.python_implementation()); print(platform.platform())'
CPython
Linux-5.15.90.1-microsoft-standard-WSL2-x86_64-with-glibc2.31
```
(This is an install issue, so certainly no install)
```shell
❯ python -c 'import Bio; print(Bio.__version__)'
Traceback (most recent call last):
File "<string>", line 1, in <module>
ModuleNotFoundError: No module named 'Bio'
```
### Expected behaviour
With the following in `pyproject.toml` under `[tool.poetry.dependencies]`:
```toml
biopython = { git = "https://github.com/biopython/biopython", rev="ca64586b1c6f6c8439c88e576fed091c923ad8f1" }
```
running `poetry lock` should update with the relevant biopython package.
### Actual behaviour
```shell
❯ poetry lock
Updating dependencies
Resolving dependencies... (0.0s)
Invalid version 'Undefined' on package biopython
```
### Steps to reproduce
Follow the above steps.
### Suggested Remediation
- Option A: Add a `setup.cfg` with version information as [here](https://packaging.python.org/en/latest/guides/single-sourcing-package-version/)
- Option B: Move to [PEP 518 pyproject.toml](https://peps.python.org/pep-0518/)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 """setuptools based setup script for Biopython.
2
3 This uses setuptools which is now the standard python mechanism for
4 installing packages. If you have downloaded and uncompressed the
5 Biopython source code, or fetched it from git, for the simplest
6 installation just type the command::
7
8 python setup.py install
9
10 However, you would normally install the latest Biopython release from
11 the PyPI archive with::
12
13 pip install biopython
14
15 For more in-depth instructions, see the installation section of the
16 Biopython manual, linked to from:
17
18 http://biopython.org/wiki/Documentation
19
20 Or, if all else fails, feel free to write to the sign up to the Biopython
21 mailing list and ask for help. See:
22
23 http://biopython.org/wiki/Mailing_lists
24 """
25
26 import sys
27 import os
28
29 try:
30 from setuptools import setup
31 from setuptools import Command
32 from setuptools import Extension
33 except ImportError:
34 sys.exit(
35 "We need the Python library setuptools to be installed. "
36 "Try running: python -m ensurepip"
37 )
38
39 if "bdist_wheel" in sys.argv:
40 try:
41 import wheel # noqa: F401
42 except ImportError:
43 sys.exit(
44 "We need both setuptools AND wheel packages installed "
45 "for bdist_wheel to work. Try running: pip install wheel"
46 )
47
48
49 # Make sure we have the right Python version.
50 MIN_PY_VER = (3, 8)
51 if sys.version_info[:2] < MIN_PY_VER:
52 sys.stderr.write(
53 ("ERROR: Biopython requires Python %i.%i or later. " % MIN_PY_VER)
54 + ("Python %d.%d detected.\n" % sys.version_info[:2])
55 )
56 sys.exit(1)
57
58
59 class test_biopython(Command):
60 """Run all of the tests for the package.
61
62 This is a automatic test run class to make distutils kind of act like
63 perl. With this you can do:
64
65 python setup.py build
66 python setup.py install
67 python setup.py test
68
69 """
70
71 description = "Automatically run the test suite for Biopython."
72 user_options = [("offline", None, "Don't run online tests")]
73
74 def initialize_options(self):
75 """No-op, initialise options."""
76 self.offline = None
77
78 def finalize_options(self):
79 """No-op, finalise options."""
80 pass
81
82 def run(self):
83 """Run the tests."""
84 this_dir = os.getcwd()
85
86 # change to the test dir and run the tests
87 os.chdir("Tests")
88 sys.path.insert(0, "")
89 import run_tests
90
91 if self.offline:
92 run_tests.main(["--offline"])
93 else:
94 run_tests.main([])
95
96 # change back to the current directory
97 os.chdir(this_dir)
98
99
100 def can_import(module_name):
101 """Check we can import the requested module."""
102 try:
103 return __import__(module_name)
104 except ImportError:
105 return None
106
107
108 # Using requirements.txt is preferred for an application
109 # (and likely will pin specific version numbers), using
110 # setup.py's install_requires is preferred for a library
111 # (and should try not to be overly narrow with versions).
112 REQUIRES = ["numpy"]
113
114 # --- set up the packages we are going to install
115 # standard biopython packages
116 PACKAGES = [
117 "Bio",
118 "Bio.Affy",
119 "Bio.Align",
120 "Bio.Align.Applications",
121 "Bio.Align.substitution_matrices",
122 "Bio.AlignIO",
123 "Bio.Alphabet",
124 "Bio.Application",
125 "Bio.Blast",
126 "Bio.CAPS",
127 "Bio.Cluster",
128 "Bio.codonalign",
129 "Bio.Compass",
130 "Bio.Data",
131 "Bio.Emboss",
132 "Bio.Entrez",
133 "Bio.ExPASy",
134 "Bio.GenBank",
135 "Bio.Geo",
136 "Bio.Graphics",
137 "Bio.Graphics.GenomeDiagram",
138 "Bio.HMM",
139 "Bio.KEGG",
140 "Bio.KEGG.Compound",
141 "Bio.KEGG.Enzyme",
142 "Bio.KEGG.Gene",
143 "Bio.KEGG.Map",
144 "Bio.PDB.mmtf",
145 "Bio.KEGG.KGML",
146 "Bio.Medline",
147 "Bio.motifs",
148 "Bio.motifs.applications",
149 "Bio.motifs.jaspar",
150 "Bio.Nexus",
151 "Bio.NMR",
152 "Bio.Pathway",
153 "Bio.Pathway.Rep",
154 "Bio.PDB",
155 "Bio.phenotype",
156 "Bio.PopGen",
157 "Bio.PopGen.GenePop",
158 "Bio.Restriction",
159 "Bio.SCOP",
160 "Bio.SearchIO",
161 "Bio.SearchIO._legacy",
162 "Bio.SearchIO._model",
163 "Bio.SearchIO.BlastIO",
164 "Bio.SearchIO.HHsuiteIO",
165 "Bio.SearchIO.HmmerIO",
166 "Bio.SearchIO.ExonerateIO",
167 "Bio.SearchIO.InterproscanIO",
168 "Bio.SeqIO",
169 "Bio.SeqUtils",
170 "Bio.Sequencing",
171 "Bio.Sequencing.Applications",
172 "Bio.SVDSuperimposer",
173 "Bio.PDB.QCPSuperimposer",
174 "Bio.SwissProt",
175 "Bio.TogoWS",
176 "Bio.Phylo",
177 "Bio.Phylo.Applications",
178 "Bio.Phylo.PAML",
179 "Bio.UniGene",
180 "Bio.UniProt",
181 "Bio.Wise",
182 # Other top level packages,
183 "BioSQL",
184 ]
185
186 EXTENSIONS = [
187 Extension("Bio.Align._aligners", ["Bio/Align/_aligners.c"]),
188 Extension("Bio.cpairwise2", ["Bio/cpairwise2module.c"]),
189 Extension("Bio.Nexus.cnexus", ["Bio/Nexus/cnexus.c"]),
190 Extension(
191 "Bio.PDB.QCPSuperimposer.qcprotmodule",
192 ["Bio/PDB/QCPSuperimposer/qcprotmodule.c"],
193 ),
194 Extension("Bio.motifs._pwm", ["Bio/motifs/_pwm.c"]),
195 Extension(
196 "Bio.Cluster._cluster", ["Bio/Cluster/cluster.c", "Bio/Cluster/clustermodule.c"]
197 ),
198 Extension("Bio.PDB.kdtrees", ["Bio/PDB/kdtrees.c"]),
199 Extension("Bio.PDB.ccealign", ["Bio/PDB/ccealignmodule.c"]),
200 Extension("Bio.SeqIO._twoBitIO", ["Bio/SeqIO/_twoBitIO.c"]),
201 ]
202
203 # We now define the Biopython version number in Bio/__init__.py
204 # Here we can't use "import Bio" then "Bio.__version__" as that would
205 # tell us the version of Biopython already installed (if any).
206 __version__ = "Undefined"
207 for line in open("Bio/__init__.py"):
208 if line.startswith("__version__"):
209 exec(line.strip())
210
211 # We now load in our reStructuredText README.rst file to pass explicitly in the
212 # metadata, since at time of writing PyPI did not do this for us.
213 #
214 # Must make encoding explicit to avoid any conflict with the local default.
215 # Currently keeping README as ASCII (might switch to UTF8 later if needed).
216 # If any invalid character does appear in README, this will fail and alert us.
217 with open("README.rst", encoding="ascii") as handle:
218 readme_rst = handle.read()
219
220 setup(
221 name="biopython",
222 version=__version__,
223 author="The Biopython Contributors",
224 author_email="[email protected]",
225 url="https://biopython.org/",
226 description="Freely available tools for computational molecular biology.",
227 long_description=readme_rst,
228 project_urls={
229 "Documentation": "https://biopython.org/wiki/Documentation",
230 "Source": "https://github.com/biopython/biopython/",
231 "Tracker": "https://github.com/biopython/biopython/issues",
232 },
233 classifiers=[
234 "Development Status :: 5 - Production/Stable",
235 "Intended Audience :: Developers",
236 "Intended Audience :: Science/Research",
237 "License :: Freely Distributable",
238 # Technically the "Biopython License Agreement" is not OSI approved,
239 # but is almost https://opensource.org/licenses/HPND so might put:
240 # 'License :: OSI Approved',
241 # To resolve this we are moving to dual-licensing with 3-clause BSD:
242 # 'License :: OSI Approved :: BSD License',
243 "Operating System :: OS Independent",
244 "Programming Language :: Python",
245 "Programming Language :: Python :: 3",
246 "Programming Language :: Python :: 3.8",
247 "Programming Language :: Python :: 3.9",
248 "Programming Language :: Python :: 3.10",
249 "Programming Language :: Python :: 3.11",
250 "Topic :: Scientific/Engineering",
251 "Topic :: Scientific/Engineering :: Bio-Informatics",
252 "Topic :: Software Development :: Libraries :: Python Modules",
253 ],
254 cmdclass={"test": test_biopython},
255 packages=PACKAGES,
256 ext_modules=EXTENSIONS,
257 include_package_data=True, # done via MANIFEST.in under setuptools
258 install_requires=REQUIRES,
259 python_requires=">=%i.%i" % MIN_PY_VER,
260 )
261
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -25,6 +25,7 @@
import sys
import os
+import ast
try:
from setuptools import setup
@@ -200,13 +201,16 @@
Extension("Bio.SeqIO._twoBitIO", ["Bio/SeqIO/_twoBitIO.c"]),
]
-# We now define the Biopython version number in Bio/__init__.py
-# Here we can't use "import Bio" then "Bio.__version__" as that would
-# tell us the version of Biopython already installed (if any).
-__version__ = "Undefined"
-for line in open("Bio/__init__.py"):
- if line.startswith("__version__"):
- exec(line.strip())
+
+def get_version():
+ """Get version number from __init__.py."""
+ for line in open("Bio/__init__.py"):
+ if line.startswith("__version__ = "):
+ return ast.literal_eval(line.split("=")[1].strip())
+ return "Undefined"
+
+
+__version__ = get_version()
# We now load in our reStructuredText README.rst file to pass explicitly in the
# metadata, since at time of writing PyPI did not do this for us.
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -25,6 +25,7 @@\n \n import sys\n import os\n+import ast\n \n try:\n from setuptools import setup\n@@ -200,13 +201,16 @@\n Extension(\"Bio.SeqIO._twoBitIO\", [\"Bio/SeqIO/_twoBitIO.c\"]),\n ]\n \n-# We now define the Biopython version number in Bio/__init__.py\n-# Here we can't use \"import Bio\" then \"Bio.__version__\" as that would\n-# tell us the version of Biopython already installed (if any).\n-__version__ = \"Undefined\"\n-for line in open(\"Bio/__init__.py\"):\n- if line.startswith(\"__version__\"):\n- exec(line.strip())\n+\n+def get_version():\n+ \"\"\"Get version number from __init__.py.\"\"\"\n+ for line in open(\"Bio/__init__.py\"):\n+ if line.startswith(\"__version__ = \"):\n+ return ast.literal_eval(line.split(\"=\")[1].strip())\n+ return \"Undefined\"\n+\n+\n+__version__ = get_version()\n \n # We now load in our reStructuredText README.rst file to pass explicitly in the\n # metadata, since at time of writing PyPI did not do this for us.\n", "issue": "Biopython is not installable as a git repository with Poetry\n### Setup\r\n\r\nI am reporting a problem with Biopython version, Python version, and operating\r\nsystem as follows:\r\n\r\n```shell\r\n\u276f python -c 'import sys; print(sys.version)'\r\n3.10.9 (main, Dec 7 2022, 01:12:00) [GCC 9.4.0]\r\n```\r\n\r\n```shell\r\n\u276f python -c 'import platform; print(platform.python_implementation()); print(platform.platform())'\r\nCPython\r\nLinux-5.15.90.1-microsoft-standard-WSL2-x86_64-with-glibc2.31\r\n```\r\n\r\n(This is an install issue, so certainly no install)\r\n```shell\r\n\u276f python -c 'import Bio; print(Bio.__version__)'\r\nTraceback (most recent call last):\r\n File \"<string>\", line 1, in <module>\r\nModuleNotFoundError: No module named 'Bio'\r\n```\r\n\r\n### Expected behaviour\r\n\r\nWith the following in `pyproject.toml` under `[tool.poetry.dependencies]`:\r\n\r\n```toml\r\nbiopython = { git = \"https://github.com/biopython/biopython\", rev=\"ca64586b1c6f6c8439c88e576fed091c923ad8f1\" }\r\n```\r\n\r\nrunning `poetry lock` should update with the relevant biopython package.\r\n\r\n### Actual behaviour\r\n\r\n```shell\r\n\u276f poetry lock\r\nUpdating dependencies\r\nResolving dependencies... (0.0s)\r\n\r\nInvalid version 'Undefined' on package biopython\r\n```\r\n\r\n### Steps to reproduce\r\n\r\nFollow the above steps.\r\n\r\n### Suggested Remediation\r\n\r\n- Option A: Add a `setup.cfg` with version information as [here](https://packaging.python.org/en/latest/guides/single-sourcing-package-version/)\r\n- Option B: Move to [PEP 518 pyproject.toml](https://peps.python.org/pep-0518/) \n", "before_files": [{"content": "\"\"\"setuptools based setup script for Biopython.\n\nThis uses setuptools which is now the standard python mechanism for\ninstalling packages. If you have downloaded and uncompressed the\nBiopython source code, or fetched it from git, for the simplest\ninstallation just type the command::\n\n python setup.py install\n\nHowever, you would normally install the latest Biopython release from\nthe PyPI archive with::\n\n pip install biopython\n\nFor more in-depth instructions, see the installation section of the\nBiopython manual, linked to from:\n\nhttp://biopython.org/wiki/Documentation\n\nOr, if all else fails, feel free to write to the sign up to the Biopython\nmailing list and ask for help. See:\n\nhttp://biopython.org/wiki/Mailing_lists\n\"\"\"\n\nimport sys\nimport os\n\ntry:\n from setuptools import setup\n from setuptools import Command\n from setuptools import Extension\nexcept ImportError:\n sys.exit(\n \"We need the Python library setuptools to be installed. \"\n \"Try running: python -m ensurepip\"\n )\n\nif \"bdist_wheel\" in sys.argv:\n try:\n import wheel # noqa: F401\n except ImportError:\n sys.exit(\n \"We need both setuptools AND wheel packages installed \"\n \"for bdist_wheel to work. Try running: pip install wheel\"\n )\n\n\n# Make sure we have the right Python version.\nMIN_PY_VER = (3, 8)\nif sys.version_info[:2] < MIN_PY_VER:\n sys.stderr.write(\n (\"ERROR: Biopython requires Python %i.%i or later. \" % MIN_PY_VER)\n + (\"Python %d.%d detected.\\n\" % sys.version_info[:2])\n )\n sys.exit(1)\n\n\nclass test_biopython(Command):\n \"\"\"Run all of the tests for the package.\n\n This is a automatic test run class to make distutils kind of act like\n perl. With this you can do:\n\n python setup.py build\n python setup.py install\n python setup.py test\n\n \"\"\"\n\n description = \"Automatically run the test suite for Biopython.\"\n user_options = [(\"offline\", None, \"Don't run online tests\")]\n\n def initialize_options(self):\n \"\"\"No-op, initialise options.\"\"\"\n self.offline = None\n\n def finalize_options(self):\n \"\"\"No-op, finalise options.\"\"\"\n pass\n\n def run(self):\n \"\"\"Run the tests.\"\"\"\n this_dir = os.getcwd()\n\n # change to the test dir and run the tests\n os.chdir(\"Tests\")\n sys.path.insert(0, \"\")\n import run_tests\n\n if self.offline:\n run_tests.main([\"--offline\"])\n else:\n run_tests.main([])\n\n # change back to the current directory\n os.chdir(this_dir)\n\n\ndef can_import(module_name):\n \"\"\"Check we can import the requested module.\"\"\"\n try:\n return __import__(module_name)\n except ImportError:\n return None\n\n\n# Using requirements.txt is preferred for an application\n# (and likely will pin specific version numbers), using\n# setup.py's install_requires is preferred for a library\n# (and should try not to be overly narrow with versions).\nREQUIRES = [\"numpy\"]\n\n# --- set up the packages we are going to install\n# standard biopython packages\nPACKAGES = [\n \"Bio\",\n \"Bio.Affy\",\n \"Bio.Align\",\n \"Bio.Align.Applications\",\n \"Bio.Align.substitution_matrices\",\n \"Bio.AlignIO\",\n \"Bio.Alphabet\",\n \"Bio.Application\",\n \"Bio.Blast\",\n \"Bio.CAPS\",\n \"Bio.Cluster\",\n \"Bio.codonalign\",\n \"Bio.Compass\",\n \"Bio.Data\",\n \"Bio.Emboss\",\n \"Bio.Entrez\",\n \"Bio.ExPASy\",\n \"Bio.GenBank\",\n \"Bio.Geo\",\n \"Bio.Graphics\",\n \"Bio.Graphics.GenomeDiagram\",\n \"Bio.HMM\",\n \"Bio.KEGG\",\n \"Bio.KEGG.Compound\",\n \"Bio.KEGG.Enzyme\",\n \"Bio.KEGG.Gene\",\n \"Bio.KEGG.Map\",\n \"Bio.PDB.mmtf\",\n \"Bio.KEGG.KGML\",\n \"Bio.Medline\",\n \"Bio.motifs\",\n \"Bio.motifs.applications\",\n \"Bio.motifs.jaspar\",\n \"Bio.Nexus\",\n \"Bio.NMR\",\n \"Bio.Pathway\",\n \"Bio.Pathway.Rep\",\n \"Bio.PDB\",\n \"Bio.phenotype\",\n \"Bio.PopGen\",\n \"Bio.PopGen.GenePop\",\n \"Bio.Restriction\",\n \"Bio.SCOP\",\n \"Bio.SearchIO\",\n \"Bio.SearchIO._legacy\",\n \"Bio.SearchIO._model\",\n \"Bio.SearchIO.BlastIO\",\n \"Bio.SearchIO.HHsuiteIO\",\n \"Bio.SearchIO.HmmerIO\",\n \"Bio.SearchIO.ExonerateIO\",\n \"Bio.SearchIO.InterproscanIO\",\n \"Bio.SeqIO\",\n \"Bio.SeqUtils\",\n \"Bio.Sequencing\",\n \"Bio.Sequencing.Applications\",\n \"Bio.SVDSuperimposer\",\n \"Bio.PDB.QCPSuperimposer\",\n \"Bio.SwissProt\",\n \"Bio.TogoWS\",\n \"Bio.Phylo\",\n \"Bio.Phylo.Applications\",\n \"Bio.Phylo.PAML\",\n \"Bio.UniGene\",\n \"Bio.UniProt\",\n \"Bio.Wise\",\n # Other top level packages,\n \"BioSQL\",\n]\n\nEXTENSIONS = [\n Extension(\"Bio.Align._aligners\", [\"Bio/Align/_aligners.c\"]),\n Extension(\"Bio.cpairwise2\", [\"Bio/cpairwise2module.c\"]),\n Extension(\"Bio.Nexus.cnexus\", [\"Bio/Nexus/cnexus.c\"]),\n Extension(\n \"Bio.PDB.QCPSuperimposer.qcprotmodule\",\n [\"Bio/PDB/QCPSuperimposer/qcprotmodule.c\"],\n ),\n Extension(\"Bio.motifs._pwm\", [\"Bio/motifs/_pwm.c\"]),\n Extension(\n \"Bio.Cluster._cluster\", [\"Bio/Cluster/cluster.c\", \"Bio/Cluster/clustermodule.c\"]\n ),\n Extension(\"Bio.PDB.kdtrees\", [\"Bio/PDB/kdtrees.c\"]),\n Extension(\"Bio.PDB.ccealign\", [\"Bio/PDB/ccealignmodule.c\"]),\n Extension(\"Bio.SeqIO._twoBitIO\", [\"Bio/SeqIO/_twoBitIO.c\"]),\n]\n\n# We now define the Biopython version number in Bio/__init__.py\n# Here we can't use \"import Bio\" then \"Bio.__version__\" as that would\n# tell us the version of Biopython already installed (if any).\n__version__ = \"Undefined\"\nfor line in open(\"Bio/__init__.py\"):\n if line.startswith(\"__version__\"):\n exec(line.strip())\n\n# We now load in our reStructuredText README.rst file to pass explicitly in the\n# metadata, since at time of writing PyPI did not do this for us.\n#\n# Must make encoding explicit to avoid any conflict with the local default.\n# Currently keeping README as ASCII (might switch to UTF8 later if needed).\n# If any invalid character does appear in README, this will fail and alert us.\nwith open(\"README.rst\", encoding=\"ascii\") as handle:\n readme_rst = handle.read()\n\nsetup(\n name=\"biopython\",\n version=__version__,\n author=\"The Biopython Contributors\",\n author_email=\"[email protected]\",\n url=\"https://biopython.org/\",\n description=\"Freely available tools for computational molecular biology.\",\n long_description=readme_rst,\n project_urls={\n \"Documentation\": \"https://biopython.org/wiki/Documentation\",\n \"Source\": \"https://github.com/biopython/biopython/\",\n \"Tracker\": \"https://github.com/biopython/biopython/issues\",\n },\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Science/Research\",\n \"License :: Freely Distributable\",\n # Technically the \"Biopython License Agreement\" is not OSI approved,\n # but is almost https://opensource.org/licenses/HPND so might put:\n # 'License :: OSI Approved',\n # To resolve this we are moving to dual-licensing with 3-clause BSD:\n # 'License :: OSI Approved :: BSD License',\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Programming Language :: Python :: 3.11\",\n \"Topic :: Scientific/Engineering\",\n \"Topic :: Scientific/Engineering :: Bio-Informatics\",\n \"Topic :: Software Development :: Libraries :: Python Modules\",\n ],\n cmdclass={\"test\": test_biopython},\n packages=PACKAGES,\n ext_modules=EXTENSIONS,\n include_package_data=True, # done via MANIFEST.in under setuptools\n install_requires=REQUIRES,\n python_requires=\">=%i.%i\" % MIN_PY_VER,\n)\n", "path": "setup.py"}], "after_files": [{"content": "\"\"\"setuptools based setup script for Biopython.\n\nThis uses setuptools which is now the standard python mechanism for\ninstalling packages. If you have downloaded and uncompressed the\nBiopython source code, or fetched it from git, for the simplest\ninstallation just type the command::\n\n python setup.py install\n\nHowever, you would normally install the latest Biopython release from\nthe PyPI archive with::\n\n pip install biopython\n\nFor more in-depth instructions, see the installation section of the\nBiopython manual, linked to from:\n\nhttp://biopython.org/wiki/Documentation\n\nOr, if all else fails, feel free to write to the sign up to the Biopython\nmailing list and ask for help. See:\n\nhttp://biopython.org/wiki/Mailing_lists\n\"\"\"\n\nimport sys\nimport os\nimport ast\n\ntry:\n from setuptools import setup\n from setuptools import Command\n from setuptools import Extension\nexcept ImportError:\n sys.exit(\n \"We need the Python library setuptools to be installed. \"\n \"Try running: python -m ensurepip\"\n )\n\nif \"bdist_wheel\" in sys.argv:\n try:\n import wheel # noqa: F401\n except ImportError:\n sys.exit(\n \"We need both setuptools AND wheel packages installed \"\n \"for bdist_wheel to work. Try running: pip install wheel\"\n )\n\n\n# Make sure we have the right Python version.\nMIN_PY_VER = (3, 8)\nif sys.version_info[:2] < MIN_PY_VER:\n sys.stderr.write(\n (\"ERROR: Biopython requires Python %i.%i or later. \" % MIN_PY_VER)\n + (\"Python %d.%d detected.\\n\" % sys.version_info[:2])\n )\n sys.exit(1)\n\n\nclass test_biopython(Command):\n \"\"\"Run all of the tests for the package.\n\n This is a automatic test run class to make distutils kind of act like\n perl. With this you can do:\n\n python setup.py build\n python setup.py install\n python setup.py test\n\n \"\"\"\n\n description = \"Automatically run the test suite for Biopython.\"\n user_options = [(\"offline\", None, \"Don't run online tests\")]\n\n def initialize_options(self):\n \"\"\"No-op, initialise options.\"\"\"\n self.offline = None\n\n def finalize_options(self):\n \"\"\"No-op, finalise options.\"\"\"\n pass\n\n def run(self):\n \"\"\"Run the tests.\"\"\"\n this_dir = os.getcwd()\n\n # change to the test dir and run the tests\n os.chdir(\"Tests\")\n sys.path.insert(0, \"\")\n import run_tests\n\n if self.offline:\n run_tests.main([\"--offline\"])\n else:\n run_tests.main([])\n\n # change back to the current directory\n os.chdir(this_dir)\n\n\ndef can_import(module_name):\n \"\"\"Check we can import the requested module.\"\"\"\n try:\n return __import__(module_name)\n except ImportError:\n return None\n\n\n# Using requirements.txt is preferred for an application\n# (and likely will pin specific version numbers), using\n# setup.py's install_requires is preferred for a library\n# (and should try not to be overly narrow with versions).\nREQUIRES = [\"numpy\"]\n\n# --- set up the packages we are going to install\n# standard biopython packages\nPACKAGES = [\n \"Bio\",\n \"Bio.Affy\",\n \"Bio.Align\",\n \"Bio.Align.Applications\",\n \"Bio.Align.substitution_matrices\",\n \"Bio.AlignIO\",\n \"Bio.Alphabet\",\n \"Bio.Application\",\n \"Bio.Blast\",\n \"Bio.CAPS\",\n \"Bio.Cluster\",\n \"Bio.codonalign\",\n \"Bio.Compass\",\n \"Bio.Data\",\n \"Bio.Emboss\",\n \"Bio.Entrez\",\n \"Bio.ExPASy\",\n \"Bio.GenBank\",\n \"Bio.Geo\",\n \"Bio.Graphics\",\n \"Bio.Graphics.GenomeDiagram\",\n \"Bio.HMM\",\n \"Bio.KEGG\",\n \"Bio.KEGG.Compound\",\n \"Bio.KEGG.Enzyme\",\n \"Bio.KEGG.Gene\",\n \"Bio.KEGG.Map\",\n \"Bio.PDB.mmtf\",\n \"Bio.KEGG.KGML\",\n \"Bio.Medline\",\n \"Bio.motifs\",\n \"Bio.motifs.applications\",\n \"Bio.motifs.jaspar\",\n \"Bio.Nexus\",\n \"Bio.NMR\",\n \"Bio.Pathway\",\n \"Bio.Pathway.Rep\",\n \"Bio.PDB\",\n \"Bio.phenotype\",\n \"Bio.PopGen\",\n \"Bio.PopGen.GenePop\",\n \"Bio.Restriction\",\n \"Bio.SCOP\",\n \"Bio.SearchIO\",\n \"Bio.SearchIO._legacy\",\n \"Bio.SearchIO._model\",\n \"Bio.SearchIO.BlastIO\",\n \"Bio.SearchIO.HHsuiteIO\",\n \"Bio.SearchIO.HmmerIO\",\n \"Bio.SearchIO.ExonerateIO\",\n \"Bio.SearchIO.InterproscanIO\",\n \"Bio.SeqIO\",\n \"Bio.SeqUtils\",\n \"Bio.Sequencing\",\n \"Bio.Sequencing.Applications\",\n \"Bio.SVDSuperimposer\",\n \"Bio.PDB.QCPSuperimposer\",\n \"Bio.SwissProt\",\n \"Bio.TogoWS\",\n \"Bio.Phylo\",\n \"Bio.Phylo.Applications\",\n \"Bio.Phylo.PAML\",\n \"Bio.UniGene\",\n \"Bio.UniProt\",\n \"Bio.Wise\",\n # Other top level packages,\n \"BioSQL\",\n]\n\nEXTENSIONS = [\n Extension(\"Bio.Align._aligners\", [\"Bio/Align/_aligners.c\"]),\n Extension(\"Bio.cpairwise2\", [\"Bio/cpairwise2module.c\"]),\n Extension(\"Bio.Nexus.cnexus\", [\"Bio/Nexus/cnexus.c\"]),\n Extension(\n \"Bio.PDB.QCPSuperimposer.qcprotmodule\",\n [\"Bio/PDB/QCPSuperimposer/qcprotmodule.c\"],\n ),\n Extension(\"Bio.motifs._pwm\", [\"Bio/motifs/_pwm.c\"]),\n Extension(\n \"Bio.Cluster._cluster\", [\"Bio/Cluster/cluster.c\", \"Bio/Cluster/clustermodule.c\"]\n ),\n Extension(\"Bio.PDB.kdtrees\", [\"Bio/PDB/kdtrees.c\"]),\n Extension(\"Bio.PDB.ccealign\", [\"Bio/PDB/ccealignmodule.c\"]),\n Extension(\"Bio.SeqIO._twoBitIO\", [\"Bio/SeqIO/_twoBitIO.c\"]),\n]\n\n\ndef get_version():\n \"\"\"Get version number from __init__.py.\"\"\"\n for line in open(\"Bio/__init__.py\"):\n if line.startswith(\"__version__ = \"):\n return ast.literal_eval(line.split(\"=\")[1].strip())\n return \"Undefined\"\n\n\n__version__ = get_version()\n\n# We now load in our reStructuredText README.rst file to pass explicitly in the\n# metadata, since at time of writing PyPI did not do this for us.\n#\n# Must make encoding explicit to avoid any conflict with the local default.\n# Currently keeping README as ASCII (might switch to UTF8 later if needed).\n# If any invalid character does appear in README, this will fail and alert us.\nwith open(\"README.rst\", encoding=\"ascii\") as handle:\n readme_rst = handle.read()\n\nsetup(\n name=\"biopython\",\n version=__version__,\n author=\"The Biopython Contributors\",\n author_email=\"[email protected]\",\n url=\"https://biopython.org/\",\n description=\"Freely available tools for computational molecular biology.\",\n long_description=readme_rst,\n project_urls={\n \"Documentation\": \"https://biopython.org/wiki/Documentation\",\n \"Source\": \"https://github.com/biopython/biopython/\",\n \"Tracker\": \"https://github.com/biopython/biopython/issues\",\n },\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Science/Research\",\n \"License :: Freely Distributable\",\n # Technically the \"Biopython License Agreement\" is not OSI approved,\n # but is almost https://opensource.org/licenses/HPND so might put:\n # 'License :: OSI Approved',\n # To resolve this we are moving to dual-licensing with 3-clause BSD:\n # 'License :: OSI Approved :: BSD License',\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Programming Language :: Python :: 3.11\",\n \"Topic :: Scientific/Engineering\",\n \"Topic :: Scientific/Engineering :: Bio-Informatics\",\n \"Topic :: Software Development :: Libraries :: Python Modules\",\n ],\n cmdclass={\"test\": test_biopython},\n packages=PACKAGES,\n ext_modules=EXTENSIONS,\n include_package_data=True, # done via MANIFEST.in under setuptools\n install_requires=REQUIRES,\n python_requires=\">=%i.%i\" % MIN_PY_VER,\n)\n", "path": "setup.py"}]}
| 3,413 | 291 |
gh_patches_debug_15
|
rasdani/github-patches
|
git_diff
|
OCHA-DAP__hdx-ckan-1748
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Shrink the spacing on the top line numbers
Proposed spacings shown here:

modified css:
.item-info {
border-top: 1px solid #cccccc;
border-bottom: 1px solid #cccccc;
padding: 20px 0;
margin-top: -1px;
color: #333333;
}
.item-info .item-info-title {
font-family: 'Gotham-Bold', sans-serif;
font-weight: 400;
font-size: 16px;
letter-spacing: 0.01em;
margin-bottom: 20px;
}
.item-info .item-info-number {
font-family: 'Gotham-Light', sans-serif;
font-size: 74px;
line-height: 1;
letter-spacing: 0.01em;
margin-bottom: 20px;
}
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ckanext-hdx_theme/ckanext/hdx_theme/version.py`
Content:
```
1 hdx_version = 'v0.4.9'
2
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ckanext-hdx_theme/ckanext/hdx_theme/version.py b/ckanext-hdx_theme/ckanext/hdx_theme/version.py
--- a/ckanext-hdx_theme/ckanext/hdx_theme/version.py
+++ b/ckanext-hdx_theme/ckanext/hdx_theme/version.py
@@ -1 +1 @@
-hdx_version = 'v0.4.9'
+hdx_version = 'v0.4.10'
|
{"golden_diff": "diff --git a/ckanext-hdx_theme/ckanext/hdx_theme/version.py b/ckanext-hdx_theme/ckanext/hdx_theme/version.py\n--- a/ckanext-hdx_theme/ckanext/hdx_theme/version.py\n+++ b/ckanext-hdx_theme/ckanext/hdx_theme/version.py\n@@ -1 +1 @@\n-hdx_version = 'v0.4.9'\n+hdx_version = 'v0.4.10'\n", "issue": "Shrink the spacing on the top line numbers\nProposed spacings shown here:\n\n\n\nmodified css:\n\n.item-info {\nborder-top: 1px solid #cccccc;\nborder-bottom: 1px solid #cccccc;\npadding: 20px 0;\nmargin-top: -1px;\ncolor: #333333;\n}\n\n.item-info .item-info-title {\nfont-family: 'Gotham-Bold', sans-serif;\nfont-weight: 400;\nfont-size: 16px;\nletter-spacing: 0.01em;\nmargin-bottom: 20px;\n}\n\n.item-info .item-info-number {\nfont-family: 'Gotham-Light', sans-serif;\nfont-size: 74px;\nline-height: 1;\nletter-spacing: 0.01em;\nmargin-bottom: 20px;\n}\n\n", "before_files": [{"content": "hdx_version = 'v0.4.9'\n", "path": "ckanext-hdx_theme/ckanext/hdx_theme/version.py"}], "after_files": [{"content": "hdx_version = 'v0.4.10'\n", "path": "ckanext-hdx_theme/ckanext/hdx_theme/version.py"}]}
| 526 | 107 |
gh_patches_debug_6535
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-2745
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
AttributeError: 'NoneType' object has no attribute 'attributes'
Run a slightly modified version of the [docs example](https://github.com/open-telemetry/opentelemetry-python/tree/main/docs/examples/metrics):
``` python
from typing import Iterable
from time import sleep
from opentelemetry.exporter.otlp.proto.grpc.metric_exporter import (
OTLPMetricExporter,
)
from opentelemetry.metrics import (
CallbackOptions,
Observation,
get_meter_provider,
set_meter_provider,
)
from opentelemetry.sdk.metrics import MeterProvider
from opentelemetry.sdk.metrics.export import PeriodicExportingMetricReader
exporter = OTLPMetricExporter(insecure=True)
reader = PeriodicExportingMetricReader(exporter, export_interval_millis=1000)
provider = MeterProvider(metric_readers=[reader])
set_meter_provider(provider)
def observable_counter_func(options: CallbackOptions) -> Iterable[Observation]:
yield Observation(1, {})
def observable_up_down_counter_func(
options: CallbackOptions,
) -> Iterable[Observation]:
yield Observation(-10, {})
def observable_gauge_func(options: CallbackOptions) -> Iterable[Observation]:
yield Observation(9, {})
meter = get_meter_provider().get_meter("getting-started", "0.1.2")
# Counter
counter = meter.create_counter("counter")
counter.add(1)
# Async Counter
observable_counter = meter.create_observable_counter(
"observable_counter",
[observable_counter_func],
)
# UpDownCounter
updown_counter = meter.create_up_down_counter("updown_counter")
updown_counter.add(1)
updown_counter.add(-5)
# Async UpDownCounter
observable_updown_counter = meter.create_observable_up_down_counter(
"observable_updown_counter", [observable_up_down_counter_func]
)
# Histogram
histogram = meter.create_histogram("histogram")
histogram.record(99.9)
# Async Gauge
gauge = meter.create_observable_gauge("gauge", [observable_gauge_func])
sleep(6)
```
running this script (after activating the collector via Docker) produces these errors:
```
Exception while exporting metrics 'NoneType' object has no attribute 'attributes'
Traceback (most recent call last):
File "/home/ocelotl/github/ocelotl/opentelemetry-python/opentelemetry-sdk/src/opentelemetry/sdk/metrics/_internal/export/__init__.py", line 412, in _receive_metrics
self._exporter.export(metrics_data, timeout_millis=timeout_millis)
File "/home/ocelotl/github/ocelotl/opentelemetry-python/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/metric_exporter/__init__.py", line 203, in export
return self._export(metrics_data)
File "/home/ocelotl/github/ocelotl/opentelemetry-python/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/exporter.py", line 293, in _export
request=self._translate_data(data),
File "/home/ocelotl/github/ocelotl/opentelemetry-python/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/metric_exporter/__init__.py", line 139, in _translate_data
data_point.attributes
AttributeError: 'NoneType' object has no attribute 'attributes'
Exception while exporting metrics 'NoneType' object has no attribute 'attributes'
Traceback (most recent call last):
File "/home/ocelotl/github/ocelotl/opentelemetry-python/opentelemetry-sdk/src/opentelemetry/sdk/metrics/_internal/export/__init__.py", line 412, in _receive_metrics
self._exporter.export(metrics_data, timeout_millis=timeout_millis)
File "/home/ocelotl/github/ocelotl/opentelemetry-python/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/metric_exporter/__init__.py", line 203, in export
return self._export(metrics_data)
File "/home/ocelotl/github/ocelotl/opentelemetry-python/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/exporter.py", line 293, in _export
request=self._translate_data(data),
File "/home/ocelotl/github/ocelotl/opentelemetry-python/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/metric_exporter/__init__.py", line 139, in _translate_data
data_point.attributes
AttributeError: 'NoneType' object has no attribute 'attributes'
Exception while exporting metrics 'NoneType' object has no attribute 'attributes'
Traceback (most recent call last):
File "/home/ocelotl/github/ocelotl/opentelemetry-python/opentelemetry-sdk/src/opentelemetry/sdk/metrics/_internal/export/__init__.py", line 412, in _receive_metrics
self._exporter.export(metrics_data, timeout_millis=timeout_millis)
File "/home/ocelotl/github/ocelotl/opentelemetry-python/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/metric_exporter/__init__.py", line 203, in export
return self._export(metrics_data)
File "/home/ocelotl/github/ocelotl/opentelemetry-python/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/exporter.py", line 293, in _export
request=self._translate_data(data),
File "/home/ocelotl/github/ocelotl/opentelemetry-python/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/metric_exporter/__init__.py", line 139, in _translate_data
data_point.attributes
AttributeError: 'NoneType' object has no attribute 'attributes'
Exception while exporting metrics 'NoneType' object has no attribute 'attributes'
Traceback (most recent call last):
File "/home/ocelotl/github/ocelotl/opentelemetry-python/opentelemetry-sdk/src/opentelemetry/sdk/metrics/_internal/export/__init__.py", line 412, in _receive_metrics
self._exporter.export(metrics_data, timeout_millis=timeout_millis)
File "/home/ocelotl/github/ocelotl/opentelemetry-python/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/metric_exporter/__init__.py", line 203, in export
return self._export(metrics_data)
File "/home/ocelotl/github/ocelotl/opentelemetry-python/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/exporter.py", line 293, in _export
request=self._translate_data(data),
File "/home/ocelotl/github/ocelotl/opentelemetry-python/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/metric_exporter/__init__.py", line 139, in _translate_data
data_point.attributes
AttributeError: 'NoneType' object has no attribute 'attributes'
Exception while exporting metrics 'NoneType' object has no attribute 'attributes'
Traceback (most recent call last):
File "/home/ocelotl/github/ocelotl/opentelemetry-python/opentelemetry-sdk/src/opentelemetry/sdk/metrics/_internal/export/__init__.py", line 412, in _receive_metrics
self._exporter.export(metrics_data, timeout_millis=timeout_millis)
File "/home/ocelotl/github/ocelotl/opentelemetry-python/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/metric_exporter/__init__.py", line 203, in export
return self._export(metrics_data)
File "/home/ocelotl/github/ocelotl/opentelemetry-python/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/exporter.py", line 293, in _export
request=self._translate_data(data),
File "/home/ocelotl/github/ocelotl/opentelemetry-python/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/metric_exporter/__init__.py", line 139, in _translate_data
data_point.attributes
AttributeError: 'NoneType' object has no attribute 'attributes'
shutdown
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `opentelemetry-sdk/src/opentelemetry/sdk/metrics/_internal/_view_instrument_match.py`
Content:
```
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15
16 from logging import getLogger
17 from threading import Lock
18 from typing import Dict, Iterable
19
20 from opentelemetry.metrics import Instrument
21 from opentelemetry.sdk.metrics._internal.aggregation import (
22 Aggregation,
23 DefaultAggregation,
24 _Aggregation,
25 _SumAggregation,
26 )
27 from opentelemetry.sdk.metrics._internal.export import AggregationTemporality
28 from opentelemetry.sdk.metrics._internal.measurement import Measurement
29 from opentelemetry.sdk.metrics._internal.point import DataPointT
30 from opentelemetry.sdk.metrics._internal.view import View
31 from opentelemetry.util._time import _time_ns
32
33 _logger = getLogger(__name__)
34
35
36 class _ViewInstrumentMatch:
37 def __init__(
38 self,
39 view: View,
40 instrument: Instrument,
41 instrument_class_aggregation: Dict[type, Aggregation],
42 ):
43 self._start_time_unix_nano = _time_ns()
44 self._view = view
45 self._instrument = instrument
46 self._attributes_aggregation: Dict[frozenset, _Aggregation] = {}
47 self._lock = Lock()
48 self._instrument_class_aggregation = instrument_class_aggregation
49 self._name = self._view._name or self._instrument.name
50 self._description = (
51 self._view._description or self._instrument.description
52 )
53 if not isinstance(self._view._aggregation, DefaultAggregation):
54 self._aggregation = self._view._aggregation._create_aggregation(
55 self._instrument, None, 0
56 )
57 else:
58 self._aggregation = self._instrument_class_aggregation[
59 self._instrument.__class__
60 ]._create_aggregation(self._instrument, None, 0)
61
62 def conflicts(self, other: "_ViewInstrumentMatch") -> bool:
63 # pylint: disable=protected-access
64
65 result = (
66 self._name == other._name
67 and self._instrument.unit == other._instrument.unit
68 # The aggregation class is being used here instead of data point
69 # type since they are functionally equivalent.
70 and self._aggregation.__class__ == other._aggregation.__class__
71 )
72 if isinstance(self._aggregation, _SumAggregation):
73 result = (
74 result
75 and self._aggregation._instrument_is_monotonic
76 == other._aggregation._instrument_is_monotonic
77 and self._aggregation._instrument_temporality
78 == other._aggregation._instrument_temporality
79 )
80
81 return result
82
83 # pylint: disable=protected-access
84 def consume_measurement(self, measurement: Measurement) -> None:
85
86 if self._view._attribute_keys is not None:
87
88 attributes = {}
89
90 for key, value in (measurement.attributes or {}).items():
91 if key in self._view._attribute_keys:
92 attributes[key] = value
93 elif measurement.attributes is not None:
94 attributes = measurement.attributes
95 else:
96 attributes = {}
97
98 aggr_key = frozenset(attributes.items())
99
100 if aggr_key not in self._attributes_aggregation:
101 with self._lock:
102 if aggr_key not in self._attributes_aggregation:
103 if not isinstance(
104 self._view._aggregation, DefaultAggregation
105 ):
106 aggregation = (
107 self._view._aggregation._create_aggregation(
108 self._instrument,
109 attributes,
110 self._start_time_unix_nano,
111 )
112 )
113 else:
114 aggregation = self._instrument_class_aggregation[
115 self._instrument.__class__
116 ]._create_aggregation(
117 self._instrument,
118 attributes,
119 self._start_time_unix_nano,
120 )
121 self._attributes_aggregation[aggr_key] = aggregation
122
123 self._attributes_aggregation[aggr_key].aggregate(measurement)
124
125 def collect(
126 self,
127 aggregation_temporality: AggregationTemporality,
128 collection_start_nanos: int,
129 ) -> Iterable[DataPointT]:
130
131 with self._lock:
132 for aggregation in self._attributes_aggregation.values():
133 yield aggregation.collect(
134 aggregation_temporality, collection_start_nanos
135 )
136
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/opentelemetry-sdk/src/opentelemetry/sdk/metrics/_internal/_view_instrument_match.py b/opentelemetry-sdk/src/opentelemetry/sdk/metrics/_internal/_view_instrument_match.py
--- a/opentelemetry-sdk/src/opentelemetry/sdk/metrics/_internal/_view_instrument_match.py
+++ b/opentelemetry-sdk/src/opentelemetry/sdk/metrics/_internal/_view_instrument_match.py
@@ -130,6 +130,8 @@
with self._lock:
for aggregation in self._attributes_aggregation.values():
- yield aggregation.collect(
+ data_point = aggregation.collect(
aggregation_temporality, collection_start_nanos
)
+ if data_point is not None:
+ yield data_point
|
{"golden_diff": "diff --git a/opentelemetry-sdk/src/opentelemetry/sdk/metrics/_internal/_view_instrument_match.py b/opentelemetry-sdk/src/opentelemetry/sdk/metrics/_internal/_view_instrument_match.py\n--- a/opentelemetry-sdk/src/opentelemetry/sdk/metrics/_internal/_view_instrument_match.py\n+++ b/opentelemetry-sdk/src/opentelemetry/sdk/metrics/_internal/_view_instrument_match.py\n@@ -130,6 +130,8 @@\n \n with self._lock:\n for aggregation in self._attributes_aggregation.values():\n- yield aggregation.collect(\n+ data_point = aggregation.collect(\n aggregation_temporality, collection_start_nanos\n )\n+ if data_point is not None:\n+ yield data_point\n", "issue": "AttributeError: 'NoneType' object has no attribute 'attributes'\nRun a slightly modified version of the [docs example](https://github.com/open-telemetry/opentelemetry-python/tree/main/docs/examples/metrics):\r\n\r\n``` python\r\nfrom typing import Iterable\r\nfrom time import sleep\r\n\r\nfrom opentelemetry.exporter.otlp.proto.grpc.metric_exporter import (\r\n OTLPMetricExporter,\r\n)\r\nfrom opentelemetry.metrics import (\r\n CallbackOptions,\r\n Observation,\r\n get_meter_provider,\r\n set_meter_provider,\r\n)\r\nfrom opentelemetry.sdk.metrics import MeterProvider\r\nfrom opentelemetry.sdk.metrics.export import PeriodicExportingMetricReader\r\n\r\nexporter = OTLPMetricExporter(insecure=True)\r\nreader = PeriodicExportingMetricReader(exporter, export_interval_millis=1000)\r\nprovider = MeterProvider(metric_readers=[reader])\r\nset_meter_provider(provider)\r\n\r\n\r\ndef observable_counter_func(options: CallbackOptions) -> Iterable[Observation]:\r\n yield Observation(1, {})\r\n\r\n\r\ndef observable_up_down_counter_func(\r\n options: CallbackOptions,\r\n) -> Iterable[Observation]:\r\n yield Observation(-10, {})\r\n\r\n\r\ndef observable_gauge_func(options: CallbackOptions) -> Iterable[Observation]:\r\n yield Observation(9, {})\r\n\r\n\r\nmeter = get_meter_provider().get_meter(\"getting-started\", \"0.1.2\")\r\n\r\n# Counter\r\ncounter = meter.create_counter(\"counter\")\r\ncounter.add(1)\r\n\r\n# Async Counter\r\nobservable_counter = meter.create_observable_counter(\r\n \"observable_counter\",\r\n [observable_counter_func],\r\n)\r\n\r\n# UpDownCounter\r\nupdown_counter = meter.create_up_down_counter(\"updown_counter\")\r\nupdown_counter.add(1)\r\nupdown_counter.add(-5)\r\n\r\n# Async UpDownCounter\r\nobservable_updown_counter = meter.create_observable_up_down_counter(\r\n \"observable_updown_counter\", [observable_up_down_counter_func]\r\n)\r\n\r\n# Histogram\r\nhistogram = meter.create_histogram(\"histogram\")\r\nhistogram.record(99.9)\r\n\r\n# Async Gauge\r\ngauge = meter.create_observable_gauge(\"gauge\", [observable_gauge_func])\r\n\r\nsleep(6)\r\n```\r\nrunning this script (after activating the collector via Docker) produces these errors:\r\n\r\n```\r\nException while exporting metrics 'NoneType' object has no attribute 'attributes'\r\nTraceback (most recent call last):\r\n File \"/home/ocelotl/github/ocelotl/opentelemetry-python/opentelemetry-sdk/src/opentelemetry/sdk/metrics/_internal/export/__init__.py\", line 412, in _receive_metrics\r\n self._exporter.export(metrics_data, timeout_millis=timeout_millis)\r\n File \"/home/ocelotl/github/ocelotl/opentelemetry-python/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/metric_exporter/__init__.py\", line 203, in export\r\n return self._export(metrics_data)\r\n File \"/home/ocelotl/github/ocelotl/opentelemetry-python/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/exporter.py\", line 293, in _export\r\n request=self._translate_data(data),\r\n File \"/home/ocelotl/github/ocelotl/opentelemetry-python/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/metric_exporter/__init__.py\", line 139, in _translate_data\r\n data_point.attributes\r\nAttributeError: 'NoneType' object has no attribute 'attributes'\r\nException while exporting metrics 'NoneType' object has no attribute 'attributes'\r\nTraceback (most recent call last):\r\n File \"/home/ocelotl/github/ocelotl/opentelemetry-python/opentelemetry-sdk/src/opentelemetry/sdk/metrics/_internal/export/__init__.py\", line 412, in _receive_metrics\r\n self._exporter.export(metrics_data, timeout_millis=timeout_millis)\r\n File \"/home/ocelotl/github/ocelotl/opentelemetry-python/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/metric_exporter/__init__.py\", line 203, in export\r\n return self._export(metrics_data)\r\n File \"/home/ocelotl/github/ocelotl/opentelemetry-python/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/exporter.py\", line 293, in _export\r\n request=self._translate_data(data),\r\n File \"/home/ocelotl/github/ocelotl/opentelemetry-python/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/metric_exporter/__init__.py\", line 139, in _translate_data\r\n data_point.attributes\r\nAttributeError: 'NoneType' object has no attribute 'attributes'\r\nException while exporting metrics 'NoneType' object has no attribute 'attributes'\r\nTraceback (most recent call last):\r\n File \"/home/ocelotl/github/ocelotl/opentelemetry-python/opentelemetry-sdk/src/opentelemetry/sdk/metrics/_internal/export/__init__.py\", line 412, in _receive_metrics\r\n self._exporter.export(metrics_data, timeout_millis=timeout_millis)\r\n File \"/home/ocelotl/github/ocelotl/opentelemetry-python/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/metric_exporter/__init__.py\", line 203, in export\r\n return self._export(metrics_data)\r\n File \"/home/ocelotl/github/ocelotl/opentelemetry-python/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/exporter.py\", line 293, in _export\r\n request=self._translate_data(data),\r\n File \"/home/ocelotl/github/ocelotl/opentelemetry-python/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/metric_exporter/__init__.py\", line 139, in _translate_data\r\n data_point.attributes\r\nAttributeError: 'NoneType' object has no attribute 'attributes'\r\nException while exporting metrics 'NoneType' object has no attribute 'attributes'\r\nTraceback (most recent call last):\r\n File \"/home/ocelotl/github/ocelotl/opentelemetry-python/opentelemetry-sdk/src/opentelemetry/sdk/metrics/_internal/export/__init__.py\", line 412, in _receive_metrics\r\n self._exporter.export(metrics_data, timeout_millis=timeout_millis)\r\n File \"/home/ocelotl/github/ocelotl/opentelemetry-python/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/metric_exporter/__init__.py\", line 203, in export\r\n return self._export(metrics_data)\r\n File \"/home/ocelotl/github/ocelotl/opentelemetry-python/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/exporter.py\", line 293, in _export\r\n request=self._translate_data(data),\r\n File \"/home/ocelotl/github/ocelotl/opentelemetry-python/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/metric_exporter/__init__.py\", line 139, in _translate_data\r\n data_point.attributes\r\nAttributeError: 'NoneType' object has no attribute 'attributes'\r\nException while exporting metrics 'NoneType' object has no attribute 'attributes'\r\nTraceback (most recent call last):\r\n File \"/home/ocelotl/github/ocelotl/opentelemetry-python/opentelemetry-sdk/src/opentelemetry/sdk/metrics/_internal/export/__init__.py\", line 412, in _receive_metrics\r\n self._exporter.export(metrics_data, timeout_millis=timeout_millis)\r\n File \"/home/ocelotl/github/ocelotl/opentelemetry-python/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/metric_exporter/__init__.py\", line 203, in export\r\n return self._export(metrics_data)\r\n File \"/home/ocelotl/github/ocelotl/opentelemetry-python/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/exporter.py\", line 293, in _export\r\n request=self._translate_data(data),\r\n File \"/home/ocelotl/github/ocelotl/opentelemetry-python/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/metric_exporter/__init__.py\", line 139, in _translate_data\r\n data_point.attributes\r\nAttributeError: 'NoneType' object has no attribute 'attributes'\r\nshutdown\r\n```\r\n\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\nfrom logging import getLogger\nfrom threading import Lock\nfrom typing import Dict, Iterable\n\nfrom opentelemetry.metrics import Instrument\nfrom opentelemetry.sdk.metrics._internal.aggregation import (\n Aggregation,\n DefaultAggregation,\n _Aggregation,\n _SumAggregation,\n)\nfrom opentelemetry.sdk.metrics._internal.export import AggregationTemporality\nfrom opentelemetry.sdk.metrics._internal.measurement import Measurement\nfrom opentelemetry.sdk.metrics._internal.point import DataPointT\nfrom opentelemetry.sdk.metrics._internal.view import View\nfrom opentelemetry.util._time import _time_ns\n\n_logger = getLogger(__name__)\n\n\nclass _ViewInstrumentMatch:\n def __init__(\n self,\n view: View,\n instrument: Instrument,\n instrument_class_aggregation: Dict[type, Aggregation],\n ):\n self._start_time_unix_nano = _time_ns()\n self._view = view\n self._instrument = instrument\n self._attributes_aggregation: Dict[frozenset, _Aggregation] = {}\n self._lock = Lock()\n self._instrument_class_aggregation = instrument_class_aggregation\n self._name = self._view._name or self._instrument.name\n self._description = (\n self._view._description or self._instrument.description\n )\n if not isinstance(self._view._aggregation, DefaultAggregation):\n self._aggregation = self._view._aggregation._create_aggregation(\n self._instrument, None, 0\n )\n else:\n self._aggregation = self._instrument_class_aggregation[\n self._instrument.__class__\n ]._create_aggregation(self._instrument, None, 0)\n\n def conflicts(self, other: \"_ViewInstrumentMatch\") -> bool:\n # pylint: disable=protected-access\n\n result = (\n self._name == other._name\n and self._instrument.unit == other._instrument.unit\n # The aggregation class is being used here instead of data point\n # type since they are functionally equivalent.\n and self._aggregation.__class__ == other._aggregation.__class__\n )\n if isinstance(self._aggregation, _SumAggregation):\n result = (\n result\n and self._aggregation._instrument_is_monotonic\n == other._aggregation._instrument_is_monotonic\n and self._aggregation._instrument_temporality\n == other._aggregation._instrument_temporality\n )\n\n return result\n\n # pylint: disable=protected-access\n def consume_measurement(self, measurement: Measurement) -> None:\n\n if self._view._attribute_keys is not None:\n\n attributes = {}\n\n for key, value in (measurement.attributes or {}).items():\n if key in self._view._attribute_keys:\n attributes[key] = value\n elif measurement.attributes is not None:\n attributes = measurement.attributes\n else:\n attributes = {}\n\n aggr_key = frozenset(attributes.items())\n\n if aggr_key not in self._attributes_aggregation:\n with self._lock:\n if aggr_key not in self._attributes_aggregation:\n if not isinstance(\n self._view._aggregation, DefaultAggregation\n ):\n aggregation = (\n self._view._aggregation._create_aggregation(\n self._instrument,\n attributes,\n self._start_time_unix_nano,\n )\n )\n else:\n aggregation = self._instrument_class_aggregation[\n self._instrument.__class__\n ]._create_aggregation(\n self._instrument,\n attributes,\n self._start_time_unix_nano,\n )\n self._attributes_aggregation[aggr_key] = aggregation\n\n self._attributes_aggregation[aggr_key].aggregate(measurement)\n\n def collect(\n self,\n aggregation_temporality: AggregationTemporality,\n collection_start_nanos: int,\n ) -> Iterable[DataPointT]:\n\n with self._lock:\n for aggregation in self._attributes_aggregation.values():\n yield aggregation.collect(\n aggregation_temporality, collection_start_nanos\n )\n", "path": "opentelemetry-sdk/src/opentelemetry/sdk/metrics/_internal/_view_instrument_match.py"}], "after_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\nfrom logging import getLogger\nfrom threading import Lock\nfrom typing import Dict, Iterable\n\nfrom opentelemetry.metrics import Instrument\nfrom opentelemetry.sdk.metrics._internal.aggregation import (\n Aggregation,\n DefaultAggregation,\n _Aggregation,\n _SumAggregation,\n)\nfrom opentelemetry.sdk.metrics._internal.export import AggregationTemporality\nfrom opentelemetry.sdk.metrics._internal.measurement import Measurement\nfrom opentelemetry.sdk.metrics._internal.point import DataPointT\nfrom opentelemetry.sdk.metrics._internal.view import View\nfrom opentelemetry.util._time import _time_ns\n\n_logger = getLogger(__name__)\n\n\nclass _ViewInstrumentMatch:\n def __init__(\n self,\n view: View,\n instrument: Instrument,\n instrument_class_aggregation: Dict[type, Aggregation],\n ):\n self._start_time_unix_nano = _time_ns()\n self._view = view\n self._instrument = instrument\n self._attributes_aggregation: Dict[frozenset, _Aggregation] = {}\n self._lock = Lock()\n self._instrument_class_aggregation = instrument_class_aggregation\n self._name = self._view._name or self._instrument.name\n self._description = (\n self._view._description or self._instrument.description\n )\n if not isinstance(self._view._aggregation, DefaultAggregation):\n self._aggregation = self._view._aggregation._create_aggregation(\n self._instrument, None, 0\n )\n else:\n self._aggregation = self._instrument_class_aggregation[\n self._instrument.__class__\n ]._create_aggregation(self._instrument, None, 0)\n\n def conflicts(self, other: \"_ViewInstrumentMatch\") -> bool:\n # pylint: disable=protected-access\n\n result = (\n self._name == other._name\n and self._instrument.unit == other._instrument.unit\n # The aggregation class is being used here instead of data point\n # type since they are functionally equivalent.\n and self._aggregation.__class__ == other._aggregation.__class__\n )\n if isinstance(self._aggregation, _SumAggregation):\n result = (\n result\n and self._aggregation._instrument_is_monotonic\n == other._aggregation._instrument_is_monotonic\n and self._aggregation._instrument_temporality\n == other._aggregation._instrument_temporality\n )\n\n return result\n\n # pylint: disable=protected-access\n def consume_measurement(self, measurement: Measurement) -> None:\n\n if self._view._attribute_keys is not None:\n\n attributes = {}\n\n for key, value in (measurement.attributes or {}).items():\n if key in self._view._attribute_keys:\n attributes[key] = value\n elif measurement.attributes is not None:\n attributes = measurement.attributes\n else:\n attributes = {}\n\n aggr_key = frozenset(attributes.items())\n\n if aggr_key not in self._attributes_aggregation:\n with self._lock:\n if aggr_key not in self._attributes_aggregation:\n if not isinstance(\n self._view._aggregation, DefaultAggregation\n ):\n aggregation = (\n self._view._aggregation._create_aggregation(\n self._instrument,\n attributes,\n self._start_time_unix_nano,\n )\n )\n else:\n aggregation = self._instrument_class_aggregation[\n self._instrument.__class__\n ]._create_aggregation(\n self._instrument,\n attributes,\n self._start_time_unix_nano,\n )\n self._attributes_aggregation[aggr_key] = aggregation\n\n self._attributes_aggregation[aggr_key].aggregate(measurement)\n\n def collect(\n self,\n aggregation_temporality: AggregationTemporality,\n collection_start_nanos: int,\n ) -> Iterable[DataPointT]:\n\n with self._lock:\n for aggregation in self._attributes_aggregation.values():\n data_point = aggregation.collect(\n aggregation_temporality, collection_start_nanos\n )\n if data_point is not None:\n yield data_point\n", "path": "opentelemetry-sdk/src/opentelemetry/sdk/metrics/_internal/_view_instrument_match.py"}]}
| 3,571 | 162 |
gh_patches_debug_24875
|
rasdani/github-patches
|
git_diff
|
coreproject-moe__CoreProject-Monorepo-3167
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[`Frontend`] : Move code to specific `web-component`
https://github.com/baseplate-admin/CoreProject/blob/cd436b876f4936b61397a0cc838aa88125527a78/backend/django_core/templates/anime/index.html#L123-L205
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `backend/django_core/apps/pages/views/anime.py`
Content:
```
1 from typing import TYPE_CHECKING
2
3 from django.http import HttpResponse
4 from django.shortcuts import render
5
6 from ..data.anime import (
7 anime,
8 anime_episode,
9 icons,
10 latest_animes,
11 latest_episodes,
12 my_list,
13 )
14
15 if TYPE_CHECKING:
16 from ..request import HtmxHttpRequest
17
18
19 async def anime_home_view_partial_slider_view(
20 request: "HtmxHttpRequest",
21 pk: int,
22 ) -> HttpResponse:
23 anime = latest_animes[pk]
24 next_index = (pk + 1) % len(latest_animes)
25 previous_index = (pk - 1) % len(latest_animes)
26
27 return render(
28 request,
29 "anime/_slider.html",
30 context={
31 "anime": anime,
32 "next_index": next_index,
33 "previous_index": previous_index,
34 "current_index": pk,
35 },
36 )
37
38
39 async def anime_home_view(request: "HtmxHttpRequest") -> HttpResponse:
40 if request.htmx:
41 return render(
42 request,
43 "anime/index.html",
44 context={
45 "latest_animes": latest_animes,
46 "my_list": my_list,
47 "latest_episodes": latest_episodes,
48 },
49 )
50
51 return render(
52 request,
53 "anime/_layout.html",
54 context={
55 "icons": icons,
56 "latest_animes": latest_animes,
57 "my_list": my_list,
58 "latest_episodes": latest_episodes,
59 },
60 )
61
62
63 async def anime_explore_view(request: "HtmxHttpRequest") -> HttpResponse:
64 if request.htmx:
65 return render(request, "anime/explore/index.html")
66
67 return render(request, "anime/_layout.html", context={"icons": icons})
68
69
70 async def anime_info_view(
71 request: "HtmxHttpRequest",
72 platform: str,
73 pk: int,
74 ) -> HttpResponse:
75 if request.htmx:
76 return render(
77 request,
78 "anime/info/index.html",
79 context={"anime": anime, "episode": anime_episode},
80 )
81
82 return render(request, "anime/_layout.html", context={"icons": icons})
83
84
85 async def anime_episode_view(
86 request: "HtmxHttpRequest", platform: str, mal_id: int, pk: int
87 ) -> HttpResponse:
88 if request.htmx:
89 return render(
90 request,
91 "anime/episode/index.html",
92 context={},
93 )
94
95 return render(request, "anime/_layout.html", context={"icons": icons})
96
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/backend/django_core/apps/pages/views/anime.py b/backend/django_core/apps/pages/views/anime.py
--- a/backend/django_core/apps/pages/views/anime.py
+++ b/backend/django_core/apps/pages/views/anime.py
@@ -1,3 +1,4 @@
+import json
from typing import TYPE_CHECKING
from django.http import HttpResponse
@@ -37,6 +38,9 @@
async def anime_home_view(request: "HtmxHttpRequest") -> HttpResponse:
+ # cant parse single quoted string
+ latest_episodes_json = json.dumps(latest_episodes)
+
if request.htmx:
return render(
request,
@@ -44,7 +48,7 @@
context={
"latest_animes": latest_animes,
"my_list": my_list,
- "latest_episodes": latest_episodes,
+ "latest_episodes": latest_episodes_json,
},
)
@@ -55,7 +59,7 @@
"icons": icons,
"latest_animes": latest_animes,
"my_list": my_list,
- "latest_episodes": latest_episodes,
+ "latest_episodes": latest_episodes_json,
},
)
|
{"golden_diff": "diff --git a/backend/django_core/apps/pages/views/anime.py b/backend/django_core/apps/pages/views/anime.py\n--- a/backend/django_core/apps/pages/views/anime.py\n+++ b/backend/django_core/apps/pages/views/anime.py\n@@ -1,3 +1,4 @@\n+import json\n from typing import TYPE_CHECKING\n \n from django.http import HttpResponse\n@@ -37,6 +38,9 @@\n \n \n async def anime_home_view(request: \"HtmxHttpRequest\") -> HttpResponse:\n+ # cant parse single quoted string\n+ latest_episodes_json = json.dumps(latest_episodes)\n+\n if request.htmx:\n return render(\n request,\n@@ -44,7 +48,7 @@\n context={\n \"latest_animes\": latest_animes,\n \"my_list\": my_list,\n- \"latest_episodes\": latest_episodes,\n+ \"latest_episodes\": latest_episodes_json,\n },\n )\n \n@@ -55,7 +59,7 @@\n \"icons\": icons,\n \"latest_animes\": latest_animes,\n \"my_list\": my_list,\n- \"latest_episodes\": latest_episodes,\n+ \"latest_episodes\": latest_episodes_json,\n },\n )\n", "issue": "[`Frontend`] : Move code to specific `web-component`\nhttps://github.com/baseplate-admin/CoreProject/blob/cd436b876f4936b61397a0cc838aa88125527a78/backend/django_core/templates/anime/index.html#L123-L205\n", "before_files": [{"content": "from typing import TYPE_CHECKING\n\nfrom django.http import HttpResponse\nfrom django.shortcuts import render\n\nfrom ..data.anime import (\n anime,\n anime_episode,\n icons,\n latest_animes,\n latest_episodes,\n my_list,\n)\n\nif TYPE_CHECKING:\n from ..request import HtmxHttpRequest\n\n\nasync def anime_home_view_partial_slider_view(\n request: \"HtmxHttpRequest\",\n pk: int,\n) -> HttpResponse:\n anime = latest_animes[pk]\n next_index = (pk + 1) % len(latest_animes)\n previous_index = (pk - 1) % len(latest_animes)\n\n return render(\n request,\n \"anime/_slider.html\",\n context={\n \"anime\": anime,\n \"next_index\": next_index,\n \"previous_index\": previous_index,\n \"current_index\": pk,\n },\n )\n\n\nasync def anime_home_view(request: \"HtmxHttpRequest\") -> HttpResponse:\n if request.htmx:\n return render(\n request,\n \"anime/index.html\",\n context={\n \"latest_animes\": latest_animes,\n \"my_list\": my_list,\n \"latest_episodes\": latest_episodes,\n },\n )\n\n return render(\n request,\n \"anime/_layout.html\",\n context={\n \"icons\": icons,\n \"latest_animes\": latest_animes,\n \"my_list\": my_list,\n \"latest_episodes\": latest_episodes,\n },\n )\n\n\nasync def anime_explore_view(request: \"HtmxHttpRequest\") -> HttpResponse:\n if request.htmx:\n return render(request, \"anime/explore/index.html\")\n\n return render(request, \"anime/_layout.html\", context={\"icons\": icons})\n\n\nasync def anime_info_view(\n request: \"HtmxHttpRequest\",\n platform: str,\n pk: int,\n) -> HttpResponse:\n if request.htmx:\n return render(\n request,\n \"anime/info/index.html\",\n context={\"anime\": anime, \"episode\": anime_episode},\n )\n\n return render(request, \"anime/_layout.html\", context={\"icons\": icons})\n\n\nasync def anime_episode_view(\n request: \"HtmxHttpRequest\", platform: str, mal_id: int, pk: int\n) -> HttpResponse:\n if request.htmx:\n return render(\n request,\n \"anime/episode/index.html\",\n context={},\n )\n\n return render(request, \"anime/_layout.html\", context={\"icons\": icons})\n", "path": "backend/django_core/apps/pages/views/anime.py"}], "after_files": [{"content": "import json\nfrom typing import TYPE_CHECKING\n\nfrom django.http import HttpResponse\nfrom django.shortcuts import render\n\nfrom ..data.anime import (\n anime,\n anime_episode,\n icons,\n latest_animes,\n latest_episodes,\n my_list,\n)\n\nif TYPE_CHECKING:\n from ..request import HtmxHttpRequest\n\n\nasync def anime_home_view_partial_slider_view(\n request: \"HtmxHttpRequest\",\n pk: int,\n) -> HttpResponse:\n anime = latest_animes[pk]\n next_index = (pk + 1) % len(latest_animes)\n previous_index = (pk - 1) % len(latest_animes)\n\n return render(\n request,\n \"anime/_slider.html\",\n context={\n \"anime\": anime,\n \"next_index\": next_index,\n \"previous_index\": previous_index,\n \"current_index\": pk,\n },\n )\n\n\nasync def anime_home_view(request: \"HtmxHttpRequest\") -> HttpResponse:\n # cant parse single quoted string\n latest_episodes_json = json.dumps(latest_episodes)\n\n if request.htmx:\n return render(\n request,\n \"anime/index.html\",\n context={\n \"latest_animes\": latest_animes,\n \"my_list\": my_list,\n \"latest_episodes\": latest_episodes_json,\n },\n )\n\n return render(\n request,\n \"anime/_layout.html\",\n context={\n \"icons\": icons,\n \"latest_animes\": latest_animes,\n \"my_list\": my_list,\n \"latest_episodes\": latest_episodes_json,\n },\n )\n\n\nasync def anime_explore_view(request: \"HtmxHttpRequest\") -> HttpResponse:\n if request.htmx:\n return render(request, \"anime/explore/index.html\")\n\n return render(request, \"anime/_layout.html\", context={\"icons\": icons})\n\n\nasync def anime_info_view(\n request: \"HtmxHttpRequest\",\n platform: str,\n pk: int,\n) -> HttpResponse:\n if request.htmx:\n return render(\n request,\n \"anime/info/index.html\",\n context={\"anime\": anime, \"episode\": anime_episode},\n )\n\n return render(request, \"anime/_layout.html\", context={\"icons\": icons})\n\n\nasync def anime_episode_view(\n request: \"HtmxHttpRequest\", platform: str, mal_id: int, pk: int\n) -> HttpResponse:\n if request.htmx:\n return render(\n request,\n \"anime/episode/index.html\",\n context={},\n )\n\n return render(request, \"anime/_layout.html\", context={\"icons\": icons})\n", "path": "backend/django_core/apps/pages/views/anime.py"}]}
| 1,061 | 259 |
gh_patches_debug_23236
|
rasdani/github-patches
|
git_diff
|
getpelican__pelican-964
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
{category} in URLs isn't slugified
When trying to save articles using:
```
CATEGORY_SAVE_AS = "{slug}/index.html"
ARTICLE_SAVE_AS = "{category}/{slug}/index.html"
```
the `{category}` in the second instance isn't slugified, so the URLs don't line up neatly and may end up with spaces or other URL-unfriendly characters in them. Ditto `{author}`.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pelican/contents.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 from __future__ import unicode_literals, print_function
3 import six
4
5 import copy
6 import locale
7 import logging
8 import functools
9 import os
10 import re
11 import sys
12
13 from datetime import datetime
14
15
16 from pelican import signals
17 from pelican.settings import DEFAULT_CONFIG
18 from pelican.utils import (slugify, truncate_html_words, memoized, strftime,
19 python_2_unicode_compatible, deprecated_attribute,
20 path_to_url)
21
22 # Import these so that they're avalaible when you import from pelican.contents.
23 from pelican.urlwrappers import (URLWrapper, Author, Category, Tag) # NOQA
24
25 logger = logging.getLogger(__name__)
26
27
28 class Content(object):
29 """Represents a content.
30
31 :param content: the string to parse, containing the original content.
32 :param metadata: the metadata associated to this page (optional).
33 :param settings: the settings dictionary (optional).
34 :param source_path: The location of the source of this content (if any).
35 :param context: The shared context between generators.
36
37 """
38 @deprecated_attribute(old='filename', new='source_path', since=(3, 2, 0))
39 def filename():
40 return None
41
42 def __init__(self, content, metadata=None, settings=None,
43 source_path=None, context=None):
44 if metadata is None:
45 metadata = {}
46 if settings is None:
47 settings = copy.deepcopy(DEFAULT_CONFIG)
48
49 self.settings = settings
50 self._content = content
51 if context is None:
52 context = {}
53 self._context = context
54 self.translations = []
55
56 local_metadata = dict(settings['DEFAULT_METADATA'])
57 local_metadata.update(metadata)
58
59 # set metadata as attributes
60 for key, value in local_metadata.items():
61 if key in ('save_as', 'url'):
62 key = 'override_' + key
63 setattr(self, key.lower(), value)
64
65 # also keep track of the metadata attributes available
66 self.metadata = local_metadata
67
68 #default template if it's not defined in page
69 self.template = self._get_template()
70
71 # default author to the one in settings if not defined
72 if not hasattr(self, 'author'):
73 if 'AUTHOR' in settings:
74 self.author = Author(settings['AUTHOR'], settings)
75
76 # XXX Split all the following code into pieces, there is too much here.
77
78 # manage languages
79 self.in_default_lang = True
80 if 'DEFAULT_LANG' in settings:
81 default_lang = settings['DEFAULT_LANG'].lower()
82 if not hasattr(self, 'lang'):
83 self.lang = default_lang
84
85 self.in_default_lang = (self.lang == default_lang)
86
87 # create the slug if not existing, from the title
88 if not hasattr(self, 'slug') and hasattr(self, 'title'):
89 self.slug = slugify(self.title,
90 settings.get('SLUG_SUBSTITUTIONS', ()))
91
92 self.source_path = source_path
93
94 # manage the date format
95 if not hasattr(self, 'date_format'):
96 if hasattr(self, 'lang') and self.lang in settings['DATE_FORMATS']:
97 self.date_format = settings['DATE_FORMATS'][self.lang]
98 else:
99 self.date_format = settings['DEFAULT_DATE_FORMAT']
100
101 if isinstance(self.date_format, tuple):
102 locale_string = self.date_format[0]
103 if sys.version_info < (3, ) and isinstance(locale_string,
104 six.text_type):
105 locale_string = locale_string.encode('ascii')
106 locale.setlocale(locale.LC_ALL, locale_string)
107 self.date_format = self.date_format[1]
108
109 if hasattr(self, 'date'):
110 self.locale_date = strftime(self.date, self.date_format)
111
112 # manage status
113 if not hasattr(self, 'status'):
114 self.status = settings['DEFAULT_STATUS']
115 if not settings['WITH_FUTURE_DATES']:
116 if hasattr(self, 'date') and self.date > datetime.now():
117 self.status = 'draft'
118
119 # store the summary metadata if it is set
120 if 'summary' in metadata:
121 self._summary = metadata['summary']
122
123 signals.content_object_init.send(self)
124
125 def __str__(self):
126 if self.source_path is None:
127 return repr(self)
128 elif six.PY3:
129 return self.source_path or repr(self)
130 else:
131 return str(self.source_path.encode('utf-8', 'replace'))
132
133 def check_properties(self):
134 """Test mandatory properties are set."""
135 for prop in self.mandatory_properties:
136 if not hasattr(self, prop):
137 raise NameError(prop)
138
139 @property
140 def url_format(self):
141 """Returns the URL, formatted with the proper values"""
142 metadata = copy.copy(self.metadata)
143 path = self.metadata.get('path', self.get_relative_source_path())
144 metadata.update({
145 'path': path_to_url(path),
146 'slug': getattr(self, 'slug', ''),
147 'lang': getattr(self, 'lang', 'en'),
148 'date': getattr(self, 'date', datetime.now()),
149 'author': getattr(self, 'author', ''),
150 'category': getattr(self, 'category',
151 self.settings['DEFAULT_CATEGORY']),
152 })
153 return metadata
154
155 def _expand_settings(self, key):
156 fq_key = ('%s_%s' % (self.__class__.__name__, key)).upper()
157 return self.settings[fq_key].format(**self.url_format)
158
159 def get_url_setting(self, key):
160 if hasattr(self, 'override_' + key):
161 return getattr(self, 'override_' + key)
162 key = key if self.in_default_lang else 'lang_%s' % key
163 return self._expand_settings(key)
164
165 def _update_content(self, content, siteurl):
166 """Update the content attribute.
167
168 Change all the relative paths of the content to relative paths
169 suitable for the ouput content.
170
171 :param content: content resource that will be passed to the templates.
172 :param siteurl: siteurl which is locally generated by the writer in
173 case of RELATIVE_URLS.
174 """
175 if not content:
176 return content
177
178 hrefs = re.compile(r"""
179 (?P<markup><\s*[^\>]* # match tag with src and href attr
180 (?:href|src)\s*=)
181
182 (?P<quote>["\']) # require value to be quoted
183 (?P<path>\|(?P<what>.*?)\|(?P<value>.*?)) # the url value
184 \2""", re.X)
185
186 def replacer(m):
187 what = m.group('what')
188 value = m.group('value')
189 origin = m.group('path')
190
191 # we support only filename for now. the plan is to support
192 # categories, tags, etc. in the future, but let's keep things
193 # simple for now.
194
195 # XXX Put this in a different location.
196 if what == 'filename':
197 if value.startswith('/'):
198 value = value[1:]
199 else:
200 # relative to the source path of this content
201 value = self.get_relative_source_path(
202 os.path.join(self.relative_dir, value)
203 )
204
205 if value in self._context['filenames']:
206 origin = '/'.join((siteurl,
207 self._context['filenames'][value].url))
208 origin = origin.replace('\\', '/') # Fow windows paths.
209 else:
210 logger.warning("Unable to find {fn}, skipping url"
211 " replacement".format(fn=value))
212
213 return ''.join((m.group('markup'), m.group('quote'), origin,
214 m.group('quote')))
215
216 return hrefs.sub(replacer, content)
217
218 @memoized
219 def get_content(self, siteurl):
220
221 if hasattr(self, '_get_content'):
222 content = self._get_content()
223 else:
224 content = self._content
225 return self._update_content(content, siteurl)
226
227 @property
228 def content(self):
229 return self.get_content(self._context.get('localsiteurl', ''))
230
231 def _get_summary(self):
232 """Returns the summary of an article.
233
234 This is based on the summary metadata if set, otherwise truncate the
235 content.
236 """
237 if hasattr(self, '_summary'):
238 return self._summary
239
240 if self.settings['SUMMARY_MAX_LENGTH'] is None:
241 return self.content
242
243 return truncate_html_words(self.content,
244 self.settings['SUMMARY_MAX_LENGTH'])
245
246 def _set_summary(self, summary):
247 """Dummy function"""
248 pass
249
250 summary = property(_get_summary, _set_summary, "Summary of the article."
251 "Based on the content. Can't be set")
252 url = property(functools.partial(get_url_setting, key='url'))
253 save_as = property(functools.partial(get_url_setting, key='save_as'))
254
255 def _get_template(self):
256 if hasattr(self, 'template') and self.template is not None:
257 return self.template
258 else:
259 return self.default_template
260
261 def get_relative_source_path(self, source_path=None):
262 """Return the relative path (from the content path) to the given
263 source_path.
264
265 If no source path is specified, use the source path of this
266 content object.
267 """
268 if not source_path:
269 source_path = self.source_path
270 if source_path is None:
271 return None
272
273 return os.path.relpath(
274 os.path.abspath(os.path.join(self.settings['PATH'], source_path)),
275 os.path.abspath(self.settings['PATH'])
276 )
277
278 @property
279 def relative_dir(self):
280 return os.path.dirname(os.path.relpath(
281 os.path.abspath(self.source_path),
282 os.path.abspath(self.settings['PATH']))
283 )
284
285
286 class Page(Content):
287 mandatory_properties = ('title',)
288 default_template = 'page'
289
290
291 class Article(Page):
292 mandatory_properties = ('title', 'date', 'category')
293 default_template = 'article'
294
295
296 class Quote(Page):
297 base_properties = ('author', 'date')
298
299
300 @python_2_unicode_compatible
301 class Static(Page):
302 @deprecated_attribute(old='filepath', new='source_path', since=(3, 2, 0))
303 def filepath():
304 return None
305
306 @deprecated_attribute(old='src', new='source_path', since=(3, 2, 0))
307 def src():
308 return None
309
310 @deprecated_attribute(old='dst', new='save_as', since=(3, 2, 0))
311 def dst():
312 return None
313
314
315 def is_valid_content(content, f):
316 try:
317 content.check_properties()
318 return True
319 except NameError as e:
320 logger.error("Skipping %s: could not find information about "
321 "'%s'" % (f, e))
322 return False
323
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pelican/contents.py b/pelican/contents.py
--- a/pelican/contents.py
+++ b/pelican/contents.py
@@ -141,14 +141,21 @@
"""Returns the URL, formatted with the proper values"""
metadata = copy.copy(self.metadata)
path = self.metadata.get('path', self.get_relative_source_path())
+ default_category = self.settings['DEFAULT_CATEGORY']
+ slug_substitutions = self.settings.get('SLUG_SUBSTITUTIONS', ())
metadata.update({
'path': path_to_url(path),
'slug': getattr(self, 'slug', ''),
'lang': getattr(self, 'lang', 'en'),
'date': getattr(self, 'date', datetime.now()),
- 'author': getattr(self, 'author', ''),
- 'category': getattr(self, 'category',
- self.settings['DEFAULT_CATEGORY']),
+ 'author': slugify(
+ getattr(self, 'author', ''),
+ slug_substitutions
+ ),
+ 'category': slugify(
+ getattr(self, 'category', default_category),
+ slug_substitutions
+ )
})
return metadata
|
{"golden_diff": "diff --git a/pelican/contents.py b/pelican/contents.py\n--- a/pelican/contents.py\n+++ b/pelican/contents.py\n@@ -141,14 +141,21 @@\n \"\"\"Returns the URL, formatted with the proper values\"\"\"\n metadata = copy.copy(self.metadata)\n path = self.metadata.get('path', self.get_relative_source_path())\n+ default_category = self.settings['DEFAULT_CATEGORY']\n+ slug_substitutions = self.settings.get('SLUG_SUBSTITUTIONS', ())\n metadata.update({\n 'path': path_to_url(path),\n 'slug': getattr(self, 'slug', ''),\n 'lang': getattr(self, 'lang', 'en'),\n 'date': getattr(self, 'date', datetime.now()),\n- 'author': getattr(self, 'author', ''),\n- 'category': getattr(self, 'category',\n- self.settings['DEFAULT_CATEGORY']),\n+ 'author': slugify(\n+ getattr(self, 'author', ''),\n+ slug_substitutions\n+ ),\n+ 'category': slugify(\n+ getattr(self, 'category', default_category),\n+ slug_substitutions\n+ )\n })\n return metadata\n", "issue": "{category} in URLs isn't slugified\nWhen trying to save articles using:\n\n```\nCATEGORY_SAVE_AS = \"{slug}/index.html\" \nARTICLE_SAVE_AS = \"{category}/{slug}/index.html\"\n```\n\nthe `{category}` in the second instance isn't slugified, so the URLs don't line up neatly and may end up with spaces or other URL-unfriendly characters in them. Ditto `{author}`.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import unicode_literals, print_function\nimport six\n\nimport copy\nimport locale\nimport logging\nimport functools\nimport os\nimport re\nimport sys\n\nfrom datetime import datetime\n\n\nfrom pelican import signals\nfrom pelican.settings import DEFAULT_CONFIG\nfrom pelican.utils import (slugify, truncate_html_words, memoized, strftime,\n python_2_unicode_compatible, deprecated_attribute,\n path_to_url)\n\n# Import these so that they're avalaible when you import from pelican.contents.\nfrom pelican.urlwrappers import (URLWrapper, Author, Category, Tag) # NOQA\n\nlogger = logging.getLogger(__name__)\n\n\nclass Content(object):\n \"\"\"Represents a content.\n\n :param content: the string to parse, containing the original content.\n :param metadata: the metadata associated to this page (optional).\n :param settings: the settings dictionary (optional).\n :param source_path: The location of the source of this content (if any).\n :param context: The shared context between generators.\n\n \"\"\"\n @deprecated_attribute(old='filename', new='source_path', since=(3, 2, 0))\n def filename():\n return None\n\n def __init__(self, content, metadata=None, settings=None,\n source_path=None, context=None):\n if metadata is None:\n metadata = {}\n if settings is None:\n settings = copy.deepcopy(DEFAULT_CONFIG)\n\n self.settings = settings\n self._content = content\n if context is None:\n context = {}\n self._context = context\n self.translations = []\n\n local_metadata = dict(settings['DEFAULT_METADATA'])\n local_metadata.update(metadata)\n\n # set metadata as attributes\n for key, value in local_metadata.items():\n if key in ('save_as', 'url'):\n key = 'override_' + key\n setattr(self, key.lower(), value)\n\n # also keep track of the metadata attributes available\n self.metadata = local_metadata\n\n #default template if it's not defined in page\n self.template = self._get_template()\n\n # default author to the one in settings if not defined\n if not hasattr(self, 'author'):\n if 'AUTHOR' in settings:\n self.author = Author(settings['AUTHOR'], settings)\n\n # XXX Split all the following code into pieces, there is too much here.\n\n # manage languages\n self.in_default_lang = True\n if 'DEFAULT_LANG' in settings:\n default_lang = settings['DEFAULT_LANG'].lower()\n if not hasattr(self, 'lang'):\n self.lang = default_lang\n\n self.in_default_lang = (self.lang == default_lang)\n\n # create the slug if not existing, from the title\n if not hasattr(self, 'slug') and hasattr(self, 'title'):\n self.slug = slugify(self.title,\n settings.get('SLUG_SUBSTITUTIONS', ()))\n\n self.source_path = source_path\n\n # manage the date format\n if not hasattr(self, 'date_format'):\n if hasattr(self, 'lang') and self.lang in settings['DATE_FORMATS']:\n self.date_format = settings['DATE_FORMATS'][self.lang]\n else:\n self.date_format = settings['DEFAULT_DATE_FORMAT']\n\n if isinstance(self.date_format, tuple):\n locale_string = self.date_format[0]\n if sys.version_info < (3, ) and isinstance(locale_string,\n six.text_type):\n locale_string = locale_string.encode('ascii')\n locale.setlocale(locale.LC_ALL, locale_string)\n self.date_format = self.date_format[1]\n\n if hasattr(self, 'date'):\n self.locale_date = strftime(self.date, self.date_format)\n\n # manage status\n if not hasattr(self, 'status'):\n self.status = settings['DEFAULT_STATUS']\n if not settings['WITH_FUTURE_DATES']:\n if hasattr(self, 'date') and self.date > datetime.now():\n self.status = 'draft'\n\n # store the summary metadata if it is set\n if 'summary' in metadata:\n self._summary = metadata['summary']\n\n signals.content_object_init.send(self)\n\n def __str__(self):\n if self.source_path is None:\n return repr(self)\n elif six.PY3:\n return self.source_path or repr(self)\n else:\n return str(self.source_path.encode('utf-8', 'replace'))\n\n def check_properties(self):\n \"\"\"Test mandatory properties are set.\"\"\"\n for prop in self.mandatory_properties:\n if not hasattr(self, prop):\n raise NameError(prop)\n\n @property\n def url_format(self):\n \"\"\"Returns the URL, formatted with the proper values\"\"\"\n metadata = copy.copy(self.metadata)\n path = self.metadata.get('path', self.get_relative_source_path())\n metadata.update({\n 'path': path_to_url(path),\n 'slug': getattr(self, 'slug', ''),\n 'lang': getattr(self, 'lang', 'en'),\n 'date': getattr(self, 'date', datetime.now()),\n 'author': getattr(self, 'author', ''),\n 'category': getattr(self, 'category',\n self.settings['DEFAULT_CATEGORY']),\n })\n return metadata\n\n def _expand_settings(self, key):\n fq_key = ('%s_%s' % (self.__class__.__name__, key)).upper()\n return self.settings[fq_key].format(**self.url_format)\n\n def get_url_setting(self, key):\n if hasattr(self, 'override_' + key):\n return getattr(self, 'override_' + key)\n key = key if self.in_default_lang else 'lang_%s' % key\n return self._expand_settings(key)\n\n def _update_content(self, content, siteurl):\n \"\"\"Update the content attribute.\n\n Change all the relative paths of the content to relative paths\n suitable for the ouput content.\n\n :param content: content resource that will be passed to the templates.\n :param siteurl: siteurl which is locally generated by the writer in\n case of RELATIVE_URLS.\n \"\"\"\n if not content:\n return content\n\n hrefs = re.compile(r\"\"\"\n (?P<markup><\\s*[^\\>]* # match tag with src and href attr\n (?:href|src)\\s*=)\n\n (?P<quote>[\"\\']) # require value to be quoted\n (?P<path>\\|(?P<what>.*?)\\|(?P<value>.*?)) # the url value\n \\2\"\"\", re.X)\n\n def replacer(m):\n what = m.group('what')\n value = m.group('value')\n origin = m.group('path')\n\n # we support only filename for now. the plan is to support\n # categories, tags, etc. in the future, but let's keep things\n # simple for now.\n\n # XXX Put this in a different location.\n if what == 'filename':\n if value.startswith('/'):\n value = value[1:]\n else:\n # relative to the source path of this content\n value = self.get_relative_source_path(\n os.path.join(self.relative_dir, value)\n )\n\n if value in self._context['filenames']:\n origin = '/'.join((siteurl,\n self._context['filenames'][value].url))\n origin = origin.replace('\\\\', '/') # Fow windows paths.\n else:\n logger.warning(\"Unable to find {fn}, skipping url\"\n \" replacement\".format(fn=value))\n\n return ''.join((m.group('markup'), m.group('quote'), origin,\n m.group('quote')))\n\n return hrefs.sub(replacer, content)\n\n @memoized\n def get_content(self, siteurl):\n\n if hasattr(self, '_get_content'):\n content = self._get_content()\n else:\n content = self._content\n return self._update_content(content, siteurl)\n\n @property\n def content(self):\n return self.get_content(self._context.get('localsiteurl', ''))\n\n def _get_summary(self):\n \"\"\"Returns the summary of an article.\n\n This is based on the summary metadata if set, otherwise truncate the\n content.\n \"\"\"\n if hasattr(self, '_summary'):\n return self._summary\n\n if self.settings['SUMMARY_MAX_LENGTH'] is None:\n return self.content\n\n return truncate_html_words(self.content,\n self.settings['SUMMARY_MAX_LENGTH'])\n\n def _set_summary(self, summary):\n \"\"\"Dummy function\"\"\"\n pass\n\n summary = property(_get_summary, _set_summary, \"Summary of the article.\"\n \"Based on the content. Can't be set\")\n url = property(functools.partial(get_url_setting, key='url'))\n save_as = property(functools.partial(get_url_setting, key='save_as'))\n\n def _get_template(self):\n if hasattr(self, 'template') and self.template is not None:\n return self.template\n else:\n return self.default_template\n\n def get_relative_source_path(self, source_path=None):\n \"\"\"Return the relative path (from the content path) to the given\n source_path.\n\n If no source path is specified, use the source path of this\n content object.\n \"\"\"\n if not source_path:\n source_path = self.source_path\n if source_path is None:\n return None\n\n return os.path.relpath(\n os.path.abspath(os.path.join(self.settings['PATH'], source_path)),\n os.path.abspath(self.settings['PATH'])\n )\n\n @property\n def relative_dir(self):\n return os.path.dirname(os.path.relpath(\n os.path.abspath(self.source_path),\n os.path.abspath(self.settings['PATH']))\n )\n\n\nclass Page(Content):\n mandatory_properties = ('title',)\n default_template = 'page'\n\n\nclass Article(Page):\n mandatory_properties = ('title', 'date', 'category')\n default_template = 'article'\n\n\nclass Quote(Page):\n base_properties = ('author', 'date')\n\n\n@python_2_unicode_compatible\nclass Static(Page):\n @deprecated_attribute(old='filepath', new='source_path', since=(3, 2, 0))\n def filepath():\n return None\n\n @deprecated_attribute(old='src', new='source_path', since=(3, 2, 0))\n def src():\n return None\n\n @deprecated_attribute(old='dst', new='save_as', since=(3, 2, 0))\n def dst():\n return None\n\n\ndef is_valid_content(content, f):\n try:\n content.check_properties()\n return True\n except NameError as e:\n logger.error(\"Skipping %s: could not find information about \"\n \"'%s'\" % (f, e))\n return False\n", "path": "pelican/contents.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import unicode_literals, print_function\nimport six\n\nimport copy\nimport locale\nimport logging\nimport functools\nimport os\nimport re\nimport sys\n\nfrom datetime import datetime\n\n\nfrom pelican import signals\nfrom pelican.settings import DEFAULT_CONFIG\nfrom pelican.utils import (slugify, truncate_html_words, memoized, strftime,\n python_2_unicode_compatible, deprecated_attribute,\n path_to_url)\n\n# Import these so that they're avalaible when you import from pelican.contents.\nfrom pelican.urlwrappers import (URLWrapper, Author, Category, Tag) # NOQA\n\nlogger = logging.getLogger(__name__)\n\n\nclass Content(object):\n \"\"\"Represents a content.\n\n :param content: the string to parse, containing the original content.\n :param metadata: the metadata associated to this page (optional).\n :param settings: the settings dictionary (optional).\n :param source_path: The location of the source of this content (if any).\n :param context: The shared context between generators.\n\n \"\"\"\n @deprecated_attribute(old='filename', new='source_path', since=(3, 2, 0))\n def filename():\n return None\n\n def __init__(self, content, metadata=None, settings=None,\n source_path=None, context=None):\n if metadata is None:\n metadata = {}\n if settings is None:\n settings = copy.deepcopy(DEFAULT_CONFIG)\n\n self.settings = settings\n self._content = content\n if context is None:\n context = {}\n self._context = context\n self.translations = []\n\n local_metadata = dict(settings['DEFAULT_METADATA'])\n local_metadata.update(metadata)\n\n # set metadata as attributes\n for key, value in local_metadata.items():\n if key in ('save_as', 'url'):\n key = 'override_' + key\n setattr(self, key.lower(), value)\n\n # also keep track of the metadata attributes available\n self.metadata = local_metadata\n\n #default template if it's not defined in page\n self.template = self._get_template()\n\n # default author to the one in settings if not defined\n if not hasattr(self, 'author'):\n if 'AUTHOR' in settings:\n self.author = Author(settings['AUTHOR'], settings)\n\n # XXX Split all the following code into pieces, there is too much here.\n\n # manage languages\n self.in_default_lang = True\n if 'DEFAULT_LANG' in settings:\n default_lang = settings['DEFAULT_LANG'].lower()\n if not hasattr(self, 'lang'):\n self.lang = default_lang\n\n self.in_default_lang = (self.lang == default_lang)\n\n # create the slug if not existing, from the title\n if not hasattr(self, 'slug') and hasattr(self, 'title'):\n self.slug = slugify(self.title,\n settings.get('SLUG_SUBSTITUTIONS', ()))\n\n self.source_path = source_path\n\n # manage the date format\n if not hasattr(self, 'date_format'):\n if hasattr(self, 'lang') and self.lang in settings['DATE_FORMATS']:\n self.date_format = settings['DATE_FORMATS'][self.lang]\n else:\n self.date_format = settings['DEFAULT_DATE_FORMAT']\n\n if isinstance(self.date_format, tuple):\n locale_string = self.date_format[0]\n if sys.version_info < (3, ) and isinstance(locale_string,\n six.text_type):\n locale_string = locale_string.encode('ascii')\n locale.setlocale(locale.LC_ALL, locale_string)\n self.date_format = self.date_format[1]\n\n if hasattr(self, 'date'):\n self.locale_date = strftime(self.date, self.date_format)\n\n # manage status\n if not hasattr(self, 'status'):\n self.status = settings['DEFAULT_STATUS']\n if not settings['WITH_FUTURE_DATES']:\n if hasattr(self, 'date') and self.date > datetime.now():\n self.status = 'draft'\n\n # store the summary metadata if it is set\n if 'summary' in metadata:\n self._summary = metadata['summary']\n\n signals.content_object_init.send(self)\n\n def __str__(self):\n if self.source_path is None:\n return repr(self)\n elif six.PY3:\n return self.source_path or repr(self)\n else:\n return str(self.source_path.encode('utf-8', 'replace'))\n\n def check_properties(self):\n \"\"\"Test mandatory properties are set.\"\"\"\n for prop in self.mandatory_properties:\n if not hasattr(self, prop):\n raise NameError(prop)\n\n @property\n def url_format(self):\n \"\"\"Returns the URL, formatted with the proper values\"\"\"\n metadata = copy.copy(self.metadata)\n path = self.metadata.get('path', self.get_relative_source_path())\n default_category = self.settings['DEFAULT_CATEGORY']\n slug_substitutions = self.settings.get('SLUG_SUBSTITUTIONS', ())\n metadata.update({\n 'path': path_to_url(path),\n 'slug': getattr(self, 'slug', ''),\n 'lang': getattr(self, 'lang', 'en'),\n 'date': getattr(self, 'date', datetime.now()),\n 'author': slugify(\n getattr(self, 'author', ''),\n slug_substitutions\n ),\n 'category': slugify(\n getattr(self, 'category', default_category),\n slug_substitutions\n )\n })\n return metadata\n\n def _expand_settings(self, key):\n fq_key = ('%s_%s' % (self.__class__.__name__, key)).upper()\n return self.settings[fq_key].format(**self.url_format)\n\n def get_url_setting(self, key):\n if hasattr(self, 'override_' + key):\n return getattr(self, 'override_' + key)\n key = key if self.in_default_lang else 'lang_%s' % key\n return self._expand_settings(key)\n\n def _update_content(self, content, siteurl):\n \"\"\"Update the content attribute.\n\n Change all the relative paths of the content to relative paths\n suitable for the ouput content.\n\n :param content: content resource that will be passed to the templates.\n :param siteurl: siteurl which is locally generated by the writer in\n case of RELATIVE_URLS.\n \"\"\"\n if not content:\n return content\n\n hrefs = re.compile(r\"\"\"\n (?P<markup><\\s*[^\\>]* # match tag with src and href attr\n (?:href|src)\\s*=)\n\n (?P<quote>[\"\\']) # require value to be quoted\n (?P<path>\\|(?P<what>.*?)\\|(?P<value>.*?)) # the url value\n \\2\"\"\", re.X)\n\n def replacer(m):\n what = m.group('what')\n value = m.group('value')\n origin = m.group('path')\n\n # we support only filename for now. the plan is to support\n # categories, tags, etc. in the future, but let's keep things\n # simple for now.\n\n # XXX Put this in a different location.\n if what == 'filename':\n if value.startswith('/'):\n value = value[1:]\n else:\n # relative to the source path of this content\n value = self.get_relative_source_path(\n os.path.join(self.relative_dir, value)\n )\n\n if value in self._context['filenames']:\n origin = '/'.join((siteurl,\n self._context['filenames'][value].url))\n origin = origin.replace('\\\\', '/') # Fow windows paths.\n else:\n logger.warning(\"Unable to find {fn}, skipping url\"\n \" replacement\".format(fn=value))\n\n return ''.join((m.group('markup'), m.group('quote'), origin,\n m.group('quote')))\n\n return hrefs.sub(replacer, content)\n\n @memoized\n def get_content(self, siteurl):\n\n if hasattr(self, '_get_content'):\n content = self._get_content()\n else:\n content = self._content\n return self._update_content(content, siteurl)\n\n @property\n def content(self):\n return self.get_content(self._context.get('localsiteurl', ''))\n\n def _get_summary(self):\n \"\"\"Returns the summary of an article.\n\n This is based on the summary metadata if set, otherwise truncate the\n content.\n \"\"\"\n if hasattr(self, '_summary'):\n return self._summary\n\n if self.settings['SUMMARY_MAX_LENGTH'] is None:\n return self.content\n\n return truncate_html_words(self.content,\n self.settings['SUMMARY_MAX_LENGTH'])\n\n def _set_summary(self, summary):\n \"\"\"Dummy function\"\"\"\n pass\n\n summary = property(_get_summary, _set_summary, \"Summary of the article.\"\n \"Based on the content. Can't be set\")\n url = property(functools.partial(get_url_setting, key='url'))\n save_as = property(functools.partial(get_url_setting, key='save_as'))\n\n def _get_template(self):\n if hasattr(self, 'template') and self.template is not None:\n return self.template\n else:\n return self.default_template\n\n def get_relative_source_path(self, source_path=None):\n \"\"\"Return the relative path (from the content path) to the given\n source_path.\n\n If no source path is specified, use the source path of this\n content object.\n \"\"\"\n if not source_path:\n source_path = self.source_path\n if source_path is None:\n return None\n\n return os.path.relpath(\n os.path.abspath(os.path.join(self.settings['PATH'], source_path)),\n os.path.abspath(self.settings['PATH'])\n )\n\n @property\n def relative_dir(self):\n return os.path.dirname(os.path.relpath(\n os.path.abspath(self.source_path),\n os.path.abspath(self.settings['PATH']))\n )\n\n\nclass Page(Content):\n mandatory_properties = ('title',)\n default_template = 'page'\n\n\nclass Article(Page):\n mandatory_properties = ('title', 'date', 'category')\n default_template = 'article'\n\n\nclass Quote(Page):\n base_properties = ('author', 'date')\n\n\n@python_2_unicode_compatible\nclass Static(Page):\n @deprecated_attribute(old='filepath', new='source_path', since=(3, 2, 0))\n def filepath():\n return None\n\n @deprecated_attribute(old='src', new='source_path', since=(3, 2, 0))\n def src():\n return None\n\n @deprecated_attribute(old='dst', new='save_as', since=(3, 2, 0))\n def dst():\n return None\n\n\ndef is_valid_content(content, f):\n try:\n content.check_properties()\n return True\n except NameError as e:\n logger.error(\"Skipping %s: could not find information about \"\n \"'%s'\" % (f, e))\n return False\n", "path": "pelican/contents.py"}]}
| 3,536 | 257 |
gh_patches_debug_17192
|
rasdani/github-patches
|
git_diff
|
DataDog__dd-trace-py-3151
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
aioredis 1.3.x tracing does not correctly parent spans
### Which version of dd-trace-py are you using?
0.57.1
### Which version of pip are you using?
21.3.1
### Which version of the libraries are you using?
```
aioredis==1.3.1
async-timeout==4.0.2
attrs==21.4.0
coverage==6.2
-e git+ssh://[email protected]/jalaziz/dd-trace-py.git@7e36d871f2efec84c5e49f4a0f6320a9870d88c8#egg=ddtrace
hiredis==2.0.0
hypothesis==6.36.0
iniconfig==1.1.1
mock==4.0.3
opentracing==2.4.0
packaging==21.3
pluggy==1.0.0
protobuf==3.19.3
py==1.11.0
pyparsing==3.0.6
pytest==6.2.5
pytest-asyncio==0.17.2
pytest-cov==3.0.0
pytest-mock==3.6.1
six==1.16.0
sortedcontainers==2.4.0
tenacity==8.0.1
toml==0.10.2
tomli==2.0.0
```
### How can we reproduce your problem?
This test reproduces the problem:
```
@pytest.mark.asyncio
@pytest.mark.snapshot(variants={"": aioredis_version >= (2, 0), "13": aioredis_version < (2, 0)})
async def test_parenting(redis_client):
with tracer.trace("web-request", service="test"):
await redis_client.set("blah", "boo")
await redis_client.set("foo", "bar")
await redis_client.get("blah")
await redis_client.get("foo")
```
### What is the result that you get?
The redis command spans are not correctly parented to `web-request` for `aioredis` 1.3, but they are for 2.0.
### What is the result that you expected?
The redis command spans should be correctly reported as children of `web-request`.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ddtrace/contrib/aioredis/patch.py`
Content:
```
1 import asyncio
2 import sys
3
4 import aioredis
5
6 from ddtrace import config
7 from ddtrace.internal.utils.wrappers import unwrap as _u
8 from ddtrace.pin import Pin
9 from ddtrace.vendor.wrapt import wrap_function_wrapper as _w
10
11 from .. import trace_utils
12 from ...constants import ANALYTICS_SAMPLE_RATE_KEY
13 from ...constants import SPAN_MEASURED_KEY
14 from ...ext import SpanTypes
15 from ...ext import net
16 from ...ext import redis as redisx
17 from ..redis.util import _trace_redis_cmd
18 from ..redis.util import _trace_redis_execute_pipeline
19 from ..redis.util import format_command_args
20
21
22 try:
23 from aioredis.commands.transaction import _RedisBuffer
24 except ImportError:
25 _RedisBuffer = None
26
27 config._add("aioredis", dict(_default_service="redis"))
28
29 aioredis_version_str = getattr(aioredis, "__version__", "0.0.0")
30 aioredis_version = tuple([int(i) for i in aioredis_version_str.split(".")])
31
32
33 def patch():
34 if getattr(aioredis, "_datadog_patch", False):
35 return
36 setattr(aioredis, "_datadog_patch", True)
37 pin = Pin()
38 if aioredis_version >= (2, 0):
39 _w("aioredis.client", "Redis.execute_command", traced_execute_command)
40 _w("aioredis.client", "Redis.pipeline", traced_pipeline)
41 _w("aioredis.client", "Pipeline.execute", traced_execute_pipeline)
42 pin.onto(aioredis.client.Redis)
43 else:
44 _w("aioredis", "Redis.execute", traced_13_execute_command)
45 _w("aioredis", "Redis.pipeline", traced_13_pipeline)
46 _w("aioredis.commands.transaction", "Pipeline.execute", traced_13_execute_pipeline)
47 pin.onto(aioredis.Redis)
48
49
50 def unpatch():
51 if not getattr(aioredis, "_datadog_patch", False):
52 return
53
54 setattr(aioredis, "_datadog_patch", False)
55 if aioredis_version >= (2, 0):
56 _u(aioredis.client.Redis, "execute_command")
57 _u(aioredis.client.Redis, "pipeline")
58 _u(aioredis.client.Pipeline, "execute")
59 else:
60 _u(aioredis.Redis, "execute")
61 _u(aioredis.Redis, "pipeline")
62 _u(aioredis.commands.transaction.Pipeline, "execute")
63
64
65 async def traced_execute_command(func, instance, args, kwargs):
66 pin = Pin.get_from(instance)
67 if not pin or not pin.enabled():
68 return await func(*args, **kwargs)
69
70 with _trace_redis_cmd(pin, config.aioredis, instance, args):
71 return await func(*args, **kwargs)
72
73
74 def traced_pipeline(func, instance, args, kwargs):
75 pipeline = func(*args, **kwargs)
76 pin = Pin.get_from(instance)
77 if pin:
78 pin.onto(pipeline)
79 return pipeline
80
81
82 async def traced_execute_pipeline(func, instance, args, kwargs):
83 pin = Pin.get_from(instance)
84 if not pin or not pin.enabled():
85 return await func(*args, **kwargs)
86
87 cmds = [format_command_args(c) for c, _ in instance.command_stack]
88 resource = "\n".join(cmds)
89 with _trace_redis_execute_pipeline(pin, config.aioredis, resource, instance):
90 return await func(*args, **kwargs)
91
92
93 def traced_13_pipeline(func, instance, args, kwargs):
94 pipeline = func(*args, **kwargs)
95 pin = Pin.get_from(instance)
96 if pin:
97 pin.onto(pipeline)
98 return pipeline
99
100
101 def traced_13_execute_command(func, instance, args, kwargs):
102 # If we have a _RedisBuffer then we are in a pipeline
103 if isinstance(instance.connection, _RedisBuffer):
104 return func(*args, **kwargs)
105
106 pin = Pin.get_from(instance)
107 if not pin or not pin.enabled():
108 return func(*args, **kwargs)
109
110 # Don't activate the span since this operation is performed as a future which concludes sometime later on in
111 # execution so subsequent operations in the stack are not necessarily semantically related
112 # (we don't want this span to be the parent of all other spans created before the future is resolved)
113 span = pin.tracer.start_span(
114 redisx.CMD, service=trace_utils.ext_service(pin, config.aioredis), span_type=SpanTypes.REDIS, activate=False
115 )
116
117 span.set_tag(SPAN_MEASURED_KEY)
118 query = format_command_args(args)
119 span.resource = query
120 span.set_tag(redisx.RAWCMD, query)
121 if pin.tags:
122 span.set_tags(pin.tags)
123
124 span.set_tags(
125 {
126 net.TARGET_HOST: instance.address[0],
127 net.TARGET_PORT: instance.address[1],
128 redisx.DB: instance.db or 0,
129 }
130 )
131 span.set_metric(redisx.ARGS_LEN, len(args))
132 # set analytics sample rate if enabled
133 span.set_tag(ANALYTICS_SAMPLE_RATE_KEY, config.aioredis.get_analytics_sample_rate())
134
135 def _finish_span(future):
136 try:
137 # Accessing the result will raise an exception if:
138 # - The future was cancelled
139 # - There was an error executing the future (`future.exception()`)
140 # - The future is in an invalid state
141 future.result()
142 except Exception:
143 span.set_exc_info(*sys.exc_info())
144 finally:
145 span.finish()
146
147 task = func(*args, **kwargs)
148 # Execute command returns a coroutine when no free connections are available
149 # https://github.com/aio-libs/aioredis-py/blob/v1.3.1/aioredis/pool.py#L191
150 task = asyncio.ensure_future(task)
151 task.add_done_callback(_finish_span)
152 return task
153
154
155 async def traced_13_execute_pipeline(func, instance, args, kwargs):
156 pin = Pin.get_from(instance)
157 if not pin or not pin.enabled():
158 return await func(*args, **kwargs)
159
160 cmds = []
161 for _, cmd, cmd_args, _ in instance._pipeline:
162 parts = [cmd]
163 parts.extend(cmd_args)
164 cmds.append(format_command_args(parts))
165 resource = "\n".join(cmds)
166 with pin.tracer.trace(
167 redisx.CMD,
168 resource=resource,
169 service=trace_utils.ext_service(pin, config.aioredis),
170 span_type=SpanTypes.REDIS,
171 ) as span:
172
173 span.set_tags(
174 {
175 net.TARGET_HOST: instance._pool_or_conn.address[0],
176 net.TARGET_PORT: instance._pool_or_conn.address[1],
177 redisx.DB: instance._pool_or_conn.db or 0,
178 }
179 )
180
181 span.set_tag(SPAN_MEASURED_KEY)
182 span.set_tag(redisx.RAWCMD, resource)
183 span.set_metric(redisx.PIPELINE_LEN, len(instance._pipeline))
184 # set analytics sample rate if enabled
185 span.set_tag(ANALYTICS_SAMPLE_RATE_KEY, config.aioredis.get_analytics_sample_rate())
186
187 return await func(*args, **kwargs)
188
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ddtrace/contrib/aioredis/patch.py b/ddtrace/contrib/aioredis/patch.py
--- a/ddtrace/contrib/aioredis/patch.py
+++ b/ddtrace/contrib/aioredis/patch.py
@@ -110,8 +110,13 @@
# Don't activate the span since this operation is performed as a future which concludes sometime later on in
# execution so subsequent operations in the stack are not necessarily semantically related
# (we don't want this span to be the parent of all other spans created before the future is resolved)
+ parent = pin.tracer.current_span()
span = pin.tracer.start_span(
- redisx.CMD, service=trace_utils.ext_service(pin, config.aioredis), span_type=SpanTypes.REDIS, activate=False
+ redisx.CMD,
+ service=trace_utils.ext_service(pin, config.aioredis),
+ span_type=SpanTypes.REDIS,
+ activate=False,
+ child_of=parent,
)
span.set_tag(SPAN_MEASURED_KEY)
|
{"golden_diff": "diff --git a/ddtrace/contrib/aioredis/patch.py b/ddtrace/contrib/aioredis/patch.py\n--- a/ddtrace/contrib/aioredis/patch.py\n+++ b/ddtrace/contrib/aioredis/patch.py\n@@ -110,8 +110,13 @@\n # Don't activate the span since this operation is performed as a future which concludes sometime later on in\n # execution so subsequent operations in the stack are not necessarily semantically related\n # (we don't want this span to be the parent of all other spans created before the future is resolved)\n+ parent = pin.tracer.current_span()\n span = pin.tracer.start_span(\n- redisx.CMD, service=trace_utils.ext_service(pin, config.aioredis), span_type=SpanTypes.REDIS, activate=False\n+ redisx.CMD,\n+ service=trace_utils.ext_service(pin, config.aioredis),\n+ span_type=SpanTypes.REDIS,\n+ activate=False,\n+ child_of=parent,\n )\n \n span.set_tag(SPAN_MEASURED_KEY)\n", "issue": "aioredis 1.3.x tracing does not correctly parent spans\n### Which version of dd-trace-py are you using?\r\n\r\n0.57.1\r\n\r\n### Which version of pip are you using?\r\n\r\n21.3.1\r\n\r\n### Which version of the libraries are you using?\r\n\r\n```\r\naioredis==1.3.1\r\nasync-timeout==4.0.2\r\nattrs==21.4.0\r\ncoverage==6.2\r\n-e git+ssh://[email protected]/jalaziz/dd-trace-py.git@7e36d871f2efec84c5e49f4a0f6320a9870d88c8#egg=ddtrace\r\nhiredis==2.0.0\r\nhypothesis==6.36.0\r\niniconfig==1.1.1\r\nmock==4.0.3\r\nopentracing==2.4.0\r\npackaging==21.3\r\npluggy==1.0.0\r\nprotobuf==3.19.3\r\npy==1.11.0\r\npyparsing==3.0.6\r\npytest==6.2.5\r\npytest-asyncio==0.17.2\r\npytest-cov==3.0.0\r\npytest-mock==3.6.1\r\nsix==1.16.0\r\nsortedcontainers==2.4.0\r\ntenacity==8.0.1\r\ntoml==0.10.2\r\ntomli==2.0.0\r\n```\r\n\r\n### How can we reproduce your problem?\r\n\r\nThis test reproduces the problem:\r\n```\r\[email protected]\r\[email protected](variants={\"\": aioredis_version >= (2, 0), \"13\": aioredis_version < (2, 0)})\r\nasync def test_parenting(redis_client):\r\n with tracer.trace(\"web-request\", service=\"test\"):\r\n await redis_client.set(\"blah\", \"boo\")\r\n await redis_client.set(\"foo\", \"bar\")\r\n await redis_client.get(\"blah\")\r\n await redis_client.get(\"foo\")\r\n```\r\n\r\n### What is the result that you get?\r\n\r\nThe redis command spans are not correctly parented to `web-request` for `aioredis` 1.3, but they are for 2.0.\r\n\r\n### What is the result that you expected?\r\n\r\nThe redis command spans should be correctly reported as children of `web-request`.\n", "before_files": [{"content": "import asyncio\nimport sys\n\nimport aioredis\n\nfrom ddtrace import config\nfrom ddtrace.internal.utils.wrappers import unwrap as _u\nfrom ddtrace.pin import Pin\nfrom ddtrace.vendor.wrapt import wrap_function_wrapper as _w\n\nfrom .. import trace_utils\nfrom ...constants import ANALYTICS_SAMPLE_RATE_KEY\nfrom ...constants import SPAN_MEASURED_KEY\nfrom ...ext import SpanTypes\nfrom ...ext import net\nfrom ...ext import redis as redisx\nfrom ..redis.util import _trace_redis_cmd\nfrom ..redis.util import _trace_redis_execute_pipeline\nfrom ..redis.util import format_command_args\n\n\ntry:\n from aioredis.commands.transaction import _RedisBuffer\nexcept ImportError:\n _RedisBuffer = None\n\nconfig._add(\"aioredis\", dict(_default_service=\"redis\"))\n\naioredis_version_str = getattr(aioredis, \"__version__\", \"0.0.0\")\naioredis_version = tuple([int(i) for i in aioredis_version_str.split(\".\")])\n\n\ndef patch():\n if getattr(aioredis, \"_datadog_patch\", False):\n return\n setattr(aioredis, \"_datadog_patch\", True)\n pin = Pin()\n if aioredis_version >= (2, 0):\n _w(\"aioredis.client\", \"Redis.execute_command\", traced_execute_command)\n _w(\"aioredis.client\", \"Redis.pipeline\", traced_pipeline)\n _w(\"aioredis.client\", \"Pipeline.execute\", traced_execute_pipeline)\n pin.onto(aioredis.client.Redis)\n else:\n _w(\"aioredis\", \"Redis.execute\", traced_13_execute_command)\n _w(\"aioredis\", \"Redis.pipeline\", traced_13_pipeline)\n _w(\"aioredis.commands.transaction\", \"Pipeline.execute\", traced_13_execute_pipeline)\n pin.onto(aioredis.Redis)\n\n\ndef unpatch():\n if not getattr(aioredis, \"_datadog_patch\", False):\n return\n\n setattr(aioredis, \"_datadog_patch\", False)\n if aioredis_version >= (2, 0):\n _u(aioredis.client.Redis, \"execute_command\")\n _u(aioredis.client.Redis, \"pipeline\")\n _u(aioredis.client.Pipeline, \"execute\")\n else:\n _u(aioredis.Redis, \"execute\")\n _u(aioredis.Redis, \"pipeline\")\n _u(aioredis.commands.transaction.Pipeline, \"execute\")\n\n\nasync def traced_execute_command(func, instance, args, kwargs):\n pin = Pin.get_from(instance)\n if not pin or not pin.enabled():\n return await func(*args, **kwargs)\n\n with _trace_redis_cmd(pin, config.aioredis, instance, args):\n return await func(*args, **kwargs)\n\n\ndef traced_pipeline(func, instance, args, kwargs):\n pipeline = func(*args, **kwargs)\n pin = Pin.get_from(instance)\n if pin:\n pin.onto(pipeline)\n return pipeline\n\n\nasync def traced_execute_pipeline(func, instance, args, kwargs):\n pin = Pin.get_from(instance)\n if not pin or not pin.enabled():\n return await func(*args, **kwargs)\n\n cmds = [format_command_args(c) for c, _ in instance.command_stack]\n resource = \"\\n\".join(cmds)\n with _trace_redis_execute_pipeline(pin, config.aioredis, resource, instance):\n return await func(*args, **kwargs)\n\n\ndef traced_13_pipeline(func, instance, args, kwargs):\n pipeline = func(*args, **kwargs)\n pin = Pin.get_from(instance)\n if pin:\n pin.onto(pipeline)\n return pipeline\n\n\ndef traced_13_execute_command(func, instance, args, kwargs):\n # If we have a _RedisBuffer then we are in a pipeline\n if isinstance(instance.connection, _RedisBuffer):\n return func(*args, **kwargs)\n\n pin = Pin.get_from(instance)\n if not pin or not pin.enabled():\n return func(*args, **kwargs)\n\n # Don't activate the span since this operation is performed as a future which concludes sometime later on in\n # execution so subsequent operations in the stack are not necessarily semantically related\n # (we don't want this span to be the parent of all other spans created before the future is resolved)\n span = pin.tracer.start_span(\n redisx.CMD, service=trace_utils.ext_service(pin, config.aioredis), span_type=SpanTypes.REDIS, activate=False\n )\n\n span.set_tag(SPAN_MEASURED_KEY)\n query = format_command_args(args)\n span.resource = query\n span.set_tag(redisx.RAWCMD, query)\n if pin.tags:\n span.set_tags(pin.tags)\n\n span.set_tags(\n {\n net.TARGET_HOST: instance.address[0],\n net.TARGET_PORT: instance.address[1],\n redisx.DB: instance.db or 0,\n }\n )\n span.set_metric(redisx.ARGS_LEN, len(args))\n # set analytics sample rate if enabled\n span.set_tag(ANALYTICS_SAMPLE_RATE_KEY, config.aioredis.get_analytics_sample_rate())\n\n def _finish_span(future):\n try:\n # Accessing the result will raise an exception if:\n # - The future was cancelled\n # - There was an error executing the future (`future.exception()`)\n # - The future is in an invalid state\n future.result()\n except Exception:\n span.set_exc_info(*sys.exc_info())\n finally:\n span.finish()\n\n task = func(*args, **kwargs)\n # Execute command returns a coroutine when no free connections are available\n # https://github.com/aio-libs/aioredis-py/blob/v1.3.1/aioredis/pool.py#L191\n task = asyncio.ensure_future(task)\n task.add_done_callback(_finish_span)\n return task\n\n\nasync def traced_13_execute_pipeline(func, instance, args, kwargs):\n pin = Pin.get_from(instance)\n if not pin or not pin.enabled():\n return await func(*args, **kwargs)\n\n cmds = []\n for _, cmd, cmd_args, _ in instance._pipeline:\n parts = [cmd]\n parts.extend(cmd_args)\n cmds.append(format_command_args(parts))\n resource = \"\\n\".join(cmds)\n with pin.tracer.trace(\n redisx.CMD,\n resource=resource,\n service=trace_utils.ext_service(pin, config.aioredis),\n span_type=SpanTypes.REDIS,\n ) as span:\n\n span.set_tags(\n {\n net.TARGET_HOST: instance._pool_or_conn.address[0],\n net.TARGET_PORT: instance._pool_or_conn.address[1],\n redisx.DB: instance._pool_or_conn.db or 0,\n }\n )\n\n span.set_tag(SPAN_MEASURED_KEY)\n span.set_tag(redisx.RAWCMD, resource)\n span.set_metric(redisx.PIPELINE_LEN, len(instance._pipeline))\n # set analytics sample rate if enabled\n span.set_tag(ANALYTICS_SAMPLE_RATE_KEY, config.aioredis.get_analytics_sample_rate())\n\n return await func(*args, **kwargs)\n", "path": "ddtrace/contrib/aioredis/patch.py"}], "after_files": [{"content": "import asyncio\nimport sys\n\nimport aioredis\n\nfrom ddtrace import config\nfrom ddtrace.internal.utils.wrappers import unwrap as _u\nfrom ddtrace.pin import Pin\nfrom ddtrace.vendor.wrapt import wrap_function_wrapper as _w\n\nfrom .. import trace_utils\nfrom ...constants import ANALYTICS_SAMPLE_RATE_KEY\nfrom ...constants import SPAN_MEASURED_KEY\nfrom ...ext import SpanTypes\nfrom ...ext import net\nfrom ...ext import redis as redisx\nfrom ..redis.util import _trace_redis_cmd\nfrom ..redis.util import _trace_redis_execute_pipeline\nfrom ..redis.util import format_command_args\n\n\ntry:\n from aioredis.commands.transaction import _RedisBuffer\nexcept ImportError:\n _RedisBuffer = None\n\nconfig._add(\"aioredis\", dict(_default_service=\"redis\"))\n\naioredis_version_str = getattr(aioredis, \"__version__\", \"0.0.0\")\naioredis_version = tuple([int(i) for i in aioredis_version_str.split(\".\")])\n\n\ndef patch():\n if getattr(aioredis, \"_datadog_patch\", False):\n return\n setattr(aioredis, \"_datadog_patch\", True)\n pin = Pin()\n if aioredis_version >= (2, 0):\n _w(\"aioredis.client\", \"Redis.execute_command\", traced_execute_command)\n _w(\"aioredis.client\", \"Redis.pipeline\", traced_pipeline)\n _w(\"aioredis.client\", \"Pipeline.execute\", traced_execute_pipeline)\n pin.onto(aioredis.client.Redis)\n else:\n _w(\"aioredis\", \"Redis.execute\", traced_13_execute_command)\n _w(\"aioredis\", \"Redis.pipeline\", traced_13_pipeline)\n _w(\"aioredis.commands.transaction\", \"Pipeline.execute\", traced_13_execute_pipeline)\n pin.onto(aioredis.Redis)\n\n\ndef unpatch():\n if not getattr(aioredis, \"_datadog_patch\", False):\n return\n\n setattr(aioredis, \"_datadog_patch\", False)\n if aioredis_version >= (2, 0):\n _u(aioredis.client.Redis, \"execute_command\")\n _u(aioredis.client.Redis, \"pipeline\")\n _u(aioredis.client.Pipeline, \"execute\")\n else:\n _u(aioredis.Redis, \"execute\")\n _u(aioredis.Redis, \"pipeline\")\n _u(aioredis.commands.transaction.Pipeline, \"execute\")\n\n\nasync def traced_execute_command(func, instance, args, kwargs):\n pin = Pin.get_from(instance)\n if not pin or not pin.enabled():\n return await func(*args, **kwargs)\n\n with _trace_redis_cmd(pin, config.aioredis, instance, args):\n return await func(*args, **kwargs)\n\n\ndef traced_pipeline(func, instance, args, kwargs):\n pipeline = func(*args, **kwargs)\n pin = Pin.get_from(instance)\n if pin:\n pin.onto(pipeline)\n return pipeline\n\n\nasync def traced_execute_pipeline(func, instance, args, kwargs):\n pin = Pin.get_from(instance)\n if not pin or not pin.enabled():\n return await func(*args, **kwargs)\n\n cmds = [format_command_args(c) for c, _ in instance.command_stack]\n resource = \"\\n\".join(cmds)\n with _trace_redis_execute_pipeline(pin, config.aioredis, resource, instance):\n return await func(*args, **kwargs)\n\n\ndef traced_13_pipeline(func, instance, args, kwargs):\n pipeline = func(*args, **kwargs)\n pin = Pin.get_from(instance)\n if pin:\n pin.onto(pipeline)\n return pipeline\n\n\ndef traced_13_execute_command(func, instance, args, kwargs):\n # If we have a _RedisBuffer then we are in a pipeline\n if isinstance(instance.connection, _RedisBuffer):\n return func(*args, **kwargs)\n\n pin = Pin.get_from(instance)\n if not pin or not pin.enabled():\n return func(*args, **kwargs)\n\n # Don't activate the span since this operation is performed as a future which concludes sometime later on in\n # execution so subsequent operations in the stack are not necessarily semantically related\n # (we don't want this span to be the parent of all other spans created before the future is resolved)\n parent = pin.tracer.current_span()\n span = pin.tracer.start_span(\n redisx.CMD,\n service=trace_utils.ext_service(pin, config.aioredis),\n span_type=SpanTypes.REDIS,\n activate=False,\n child_of=parent,\n )\n\n span.set_tag(SPAN_MEASURED_KEY)\n query = format_command_args(args)\n span.resource = query\n span.set_tag(redisx.RAWCMD, query)\n if pin.tags:\n span.set_tags(pin.tags)\n\n span.set_tags(\n {\n net.TARGET_HOST: instance.address[0],\n net.TARGET_PORT: instance.address[1],\n redisx.DB: instance.db or 0,\n }\n )\n span.set_metric(redisx.ARGS_LEN, len(args))\n # set analytics sample rate if enabled\n span.set_tag(ANALYTICS_SAMPLE_RATE_KEY, config.aioredis.get_analytics_sample_rate())\n\n def _finish_span(future):\n try:\n # Accessing the result will raise an exception if:\n # - The future was cancelled\n # - There was an error executing the future (`future.exception()`)\n # - The future is in an invalid state\n future.result()\n except Exception:\n span.set_exc_info(*sys.exc_info())\n finally:\n span.finish()\n\n task = func(*args, **kwargs)\n # Execute command returns a coroutine when no free connections are available\n # https://github.com/aio-libs/aioredis-py/blob/v1.3.1/aioredis/pool.py#L191\n task = asyncio.ensure_future(task)\n task.add_done_callback(_finish_span)\n return task\n\n\nasync def traced_13_execute_pipeline(func, instance, args, kwargs):\n pin = Pin.get_from(instance)\n if not pin or not pin.enabled():\n return await func(*args, **kwargs)\n\n cmds = []\n for _, cmd, cmd_args, _ in instance._pipeline:\n parts = [cmd]\n parts.extend(cmd_args)\n cmds.append(format_command_args(parts))\n resource = \"\\n\".join(cmds)\n with pin.tracer.trace(\n redisx.CMD,\n resource=resource,\n service=trace_utils.ext_service(pin, config.aioredis),\n span_type=SpanTypes.REDIS,\n ) as span:\n\n span.set_tags(\n {\n net.TARGET_HOST: instance._pool_or_conn.address[0],\n net.TARGET_PORT: instance._pool_or_conn.address[1],\n redisx.DB: instance._pool_or_conn.db or 0,\n }\n )\n\n span.set_tag(SPAN_MEASURED_KEY)\n span.set_tag(redisx.RAWCMD, resource)\n span.set_metric(redisx.PIPELINE_LEN, len(instance._pipeline))\n # set analytics sample rate if enabled\n span.set_tag(ANALYTICS_SAMPLE_RATE_KEY, config.aioredis.get_analytics_sample_rate())\n\n return await func(*args, **kwargs)\n", "path": "ddtrace/contrib/aioredis/patch.py"}]}
| 2,824 | 241 |
gh_patches_debug_13729
|
rasdani/github-patches
|
git_diff
|
aws-cloudformation__cfn-lint-2765
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Invalid Property Resources/SESConfigurationSetDestination/Properties/EventDestination/SnsDestination
### CloudFormation Lint Version
0.77.8
### What operating system are you using?
Mac/Ubuntu
### Describe the bug
cfn-lint outputs:
Invalid Property Resources/SESConfigurationSetDestination/Properties/EventDestination/SnsDestination
But this is a valid property:
https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-ses-configurationseteventdestination-eventdestination.html#cfn-ses-configurationseteventdestination-eventdestination-snsdestination
### Expected behavior
cfn-lint doesn't output an error
### Reproduction template
```yaml
Resources:
SESConfigurationSetDestination:
Type: AWS::SES::ConfigurationSetEventDestination
Properties:
ConfigurationSetName: Name
EventDestination:
Name: DestinationName
Enabled: true
MatchingEventTypes:
- send
- reject
- bounce
- complaint
- delivery
SnsDestination:
TopicARN: Arn
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `scripts/update_specs_services_from_ssm.py`
Content:
```
1 #!/usr/bin/env python
2 """
3 Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
4 SPDX-License-Identifier: MIT-0
5 """
6 import json
7 import logging
8
9 import boto3
10
11 from cfnlint.helpers import REGIONS, get_url_content
12 from cfnlint.maintenance import SPEC_REGIONS
13
14 """
15 Updates our dynamic patches from SSM data
16 This script requires Boto3 and Credentials to call the SSM API
17 """
18
19 LOGGER = logging.getLogger("cfnlint")
20
21 service_map = {
22 "acm": ["AWS::CertificateManager::"],
23 "apigateway": ["AWS::ApiGateway::", "AWS::ApiGatewayV2::"],
24 # 'application-autoscaling': ['AWS::ApplicationAutoScaling::'], ## remove because SSM endpoints aren't correct
25 "appstream": ["AWS::AppStream::"],
26 "appsync": ["AWS::AppSync::"],
27 "athena": ["AWS::Athena::"],
28 "autoscaling": ["AWS::AutoScaling::"],
29 "batch": ["AWS::Batch::"],
30 "budgets": ["AWS::Budgets::"],
31 "cloud9": ["AWS::Cloud9::"],
32 "cloudfront": ["AWS::CloudFront::"],
33 "cloudtrail": ["AWS::CloudTrail::"],
34 "cloudwatch": ["AWS::CloudWatch::"],
35 "codebuild": ["AWS::CodeBuild::"],
36 "codecommit": ["AWS::CodeCommit::"],
37 "codedeploy": ["AWS::CodeDeploy::"],
38 "codepipeline": ["AWS::CodePipeline::"],
39 "cognito-identity": ["AWS::Cognito::"],
40 "config": ["AWS::Config::"],
41 "datapipeline": ["AWS::DataPipeline::"],
42 "dax": ["AWS::DAX::"],
43 "dms": ["AWS::DMS::"],
44 "docdb": ["AWS::DocDB::"],
45 "ds": ["AWS::DirectoryService::"],
46 "dynamodb": ["AWS::DynamoDB::"],
47 "ec2": ["AWS::EC2::"],
48 "ecr": ["AWS::ECR::"],
49 "ecs": ["AWS::ECS::"],
50 "efs": ["AWS::EFS::"],
51 "eks": ["AWS::EKS::"],
52 "elasticache": ["AWS::ElastiCache::"],
53 "elasticbeanstalk": ["AWS::ElasticBeanstalk::"],
54 "elb": ["AWS::ElasticLoadBalancing::", "AWS::ElasticLoadBalancingV2::"],
55 "emr": ["AWS::EMR::"],
56 "es": ["AWS::Elasticsearch::"],
57 "events": ["AWS::Events::"],
58 "firehose": ["AWS::KinesisFirehose::"],
59 "fsx": ["AWS::FSx::"],
60 "gamelift": ["AWS::GameLift::"],
61 "glue": ["AWS::Glue::"],
62 "greengrass": ["AWS::Greengrass::"],
63 "guardduty": ["AWS::GuardDuty::"],
64 "inspector": ["AWS::Inspector::"],
65 "iot": ["AWS::IoT::"],
66 "iot1click-projects": ["AWS::IoT1Click::"],
67 "iotanalytics": ["AWS::IoTAnalytics::"],
68 "kinesis": ["AWS::Kinesis::"],
69 "kinesisanalytics": ["AWS::KinesisAnalytics::", "AWS::KinesisAnalyticsV2::"],
70 "kms": ["AWS::KMS::"],
71 "lambda": ["AWS::Lambda::"],
72 "logs": ["AWS::Logs::"],
73 "mq": ["AWS::AmazonMQ::"],
74 "neptune": ["AWS::Neptune::"],
75 "opsworks": ["AWS::OpsWorks::"],
76 "opsworkscm": ["AWS::OpsWorksCM::"],
77 "ram": ["AWS::RAM::"],
78 "rds": ["AWS::RDS::"],
79 "redshift": ["AWS::Redshift::"],
80 "robomaker": ["AWS::RoboMaker::"],
81 "route53": ["AWS::Route53::"],
82 "route53resolver": [
83 "AWS::Route53Resolver::ResolverRule",
84 "AWS::Route53Resolver::ResolverEndpoint",
85 ],
86 "s3": ["AWS::S3::"],
87 "sagemaker": ["AWS::SageMaker::"],
88 "sdb": ["AWS::SDB::"],
89 "secretsmanager": ["AWS::SecretsManager::"],
90 "servicecatalog": ["AWS::ServiceCatalog::"],
91 "servicediscovery": ["AWS::ServiceDiscovery::"],
92 "ses": ["AWS::SES::"],
93 "sns": ["AWS::SNS::"],
94 "sqs": ["AWS::SQS::"],
95 "ssm": ["AWS::SSM::"],
96 "stepfunctions": ["AWS::StepFunctions::"],
97 "waf-regional": ["AWS::WAFRegional::"],
98 "workspaces": ["AWS::WorkSpaces::"],
99 }
100
101 session = boto3.session.Session()
102 client = session.client("ssm", region_name="us-east-1")
103
104
105 def configure_logging():
106 """Setup Logging"""
107 ch = logging.StreamHandler()
108 ch.setLevel(logging.INFO)
109
110 LOGGER.setLevel(logging.INFO)
111 log_formatter = logging.Formatter(
112 "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
113 )
114 ch.setFormatter(log_formatter)
115
116 # make sure all other log handlers are removed before adding it back
117 for handler in LOGGER.handlers:
118 LOGGER.removeHandler(handler)
119 LOGGER.addHandler(ch)
120
121
122 def update_outputs(region, resource_type, name, outputs):
123 """update outputs with appropriate results"""
124 element = {"op": "remove", "path": "/%s/%s" % (resource_type, name)}
125 outputs[region].append(element)
126
127 return outputs
128
129
130 def get_regions_for_service(service):
131 """get regions for a service"""
132 LOGGER.info("Get the regions for service %s", service)
133 results = []
134 paginator = client.get_paginator("get_parameters_by_path")
135 page_iterator = paginator.paginate(
136 Path="/aws/service/global-infrastructure/services/{}/regions".format(service),
137 )
138
139 for page in page_iterator:
140 for region in page.get("Parameters"):
141 results.append(region.get("Value"))
142
143 return results
144
145
146 def add_spec_patch(region, services):
147 """Go through spec and determine patching"""
148 LOGGER.info("Create 06_ssm_service_removal patch for region %s", region)
149 spec = json.loads(get_url_content(SPEC_REGIONS.get(region)))
150
151 patches = []
152
153 for spec_type in ["ResourceTypes", "PropertyTypes"]:
154 for resource in sorted(spec.get(spec_type).keys()):
155 for service in services:
156 for spec_name in service_map.get(service):
157 if resource.startswith(spec_name):
158 element = {
159 "op": "remove",
160 "path": "/%s/%s" % (spec_type, resource),
161 }
162 patches.append(element)
163
164 filename = "src/cfnlint/data/ExtendedSpecs/%s/06_ssm_service_removal.json" % region
165 with open(filename, "w+", encoding="utf-8") as f:
166 json.dump(patches, f, indent=1, sort_keys=True, separators=(",", ": "))
167
168
169 def add_spec_missing_services_patch(region, services):
170 """Go through spec and determine patching"""
171 LOGGER.info("Create 07_ssm_service_addition patch for region %s", region)
172 spec_string = get_url_content(SPEC_REGIONS.get(region))
173 spec_string_standard = get_url_content(SPEC_REGIONS.get("us-east-1"))
174
175 spec = json.loads(spec_string)
176 spec_standard = json.loads(spec_string_standard)
177
178 patches = []
179
180 for spec_type in ["ResourceTypes"]:
181 for service in services:
182 found = False
183 for resource in sorted(spec.get(spec_type).keys()):
184 for spec_name in service_map.get(service):
185 if resource.startswith(spec_name):
186 found = True
187 if found is False:
188 for standard_spec_type in ["ResourceTypes", "PropertyTypes"]:
189 for resource in sorted(
190 spec_standard.get(standard_spec_type).keys()
191 ):
192 for spec_name in service_map.get(service):
193 if resource.startswith(spec_name):
194 if spec_standard.get(standard_spec_type).get(resource):
195 element = {
196 "op": "add",
197 "path": "/%s/%s"
198 % (standard_spec_type, resource),
199 "value": spec_standard.get(
200 standard_spec_type
201 ).get(resource),
202 }
203 patches.append(element)
204 elif standard_spec_type == "ResourceTypes":
205 print("patch for %s not found" % service)
206
207 if patches:
208 filename = (
209 "src/cfnlint/data/ExtendedSpecs/%s/07_ssm_service_addition.json" % region
210 )
211 with open(filename, "w+", encoding="utf-8") as f:
212 json.dump(patches, f, indent=1, sort_keys=True, separators=(",", ": "))
213
214
215 def main():
216 """main function"""
217 configure_logging()
218
219 all_regions = list(set(REGIONS))
220 region_service_removal_map = {}
221 region_service_add_map = {}
222 for region in all_regions:
223 region_service_removal_map[region] = []
224 region_service_add_map[region] = []
225 for service in service_map:
226 regions = get_regions_for_service(service)
227 if regions:
228 for region in list(set(regions)):
229 region_service_add_map[region].append(service)
230 for region in list(set(all_regions) - set(regions)):
231 region_service_removal_map[region].append(service)
232
233 for region, services in region_service_removal_map.items():
234 if services:
235 add_spec_patch(region, services)
236 for region, services in region_service_add_map.items():
237 if services:
238 add_spec_missing_services_patch(region, services)
239
240
241 if __name__ == "__main__":
242 try:
243 main()
244 except (ValueError, TypeError):
245 LOGGER.error(ValueError)
246
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/scripts/update_specs_services_from_ssm.py b/scripts/update_specs_services_from_ssm.py
--- a/scripts/update_specs_services_from_ssm.py
+++ b/scripts/update_specs_services_from_ssm.py
@@ -204,12 +204,12 @@
elif standard_spec_type == "ResourceTypes":
print("patch for %s not found" % service)
- if patches:
- filename = (
- "src/cfnlint/data/ExtendedSpecs/%s/07_ssm_service_addition.json" % region
- )
- with open(filename, "w+", encoding="utf-8") as f:
- json.dump(patches, f, indent=1, sort_keys=True, separators=(",", ": "))
+ filename = (
+ "src/cfnlint/data/ExtendedSpecs/%s/07_ssm_service_addition.json" % region
+ )
+ with open(filename, "w+", encoding="utf-8") as f:
+ json.dump(patches, f, indent=1, sort_keys=True, separators=(",", ": "))
+
def main():
|
{"golden_diff": "diff --git a/scripts/update_specs_services_from_ssm.py b/scripts/update_specs_services_from_ssm.py\n--- a/scripts/update_specs_services_from_ssm.py\n+++ b/scripts/update_specs_services_from_ssm.py\n@@ -204,12 +204,12 @@\n elif standard_spec_type == \"ResourceTypes\":\n print(\"patch for %s not found\" % service)\n \n- if patches:\n- filename = (\n- \"src/cfnlint/data/ExtendedSpecs/%s/07_ssm_service_addition.json\" % region\n- )\n- with open(filename, \"w+\", encoding=\"utf-8\") as f:\n- json.dump(patches, f, indent=1, sort_keys=True, separators=(\",\", \": \"))\n+ filename = (\n+ \"src/cfnlint/data/ExtendedSpecs/%s/07_ssm_service_addition.json\" % region\n+ )\n+ with open(filename, \"w+\", encoding=\"utf-8\") as f:\n+ json.dump(patches, f, indent=1, sort_keys=True, separators=(\",\", \": \"))\n+ \n \n \n def main():\n", "issue": "Invalid Property Resources/SESConfigurationSetDestination/Properties/EventDestination/SnsDestination\n### CloudFormation Lint Version\r\n\r\n0.77.8\r\n\r\n### What operating system are you using?\r\n\r\nMac/Ubuntu\r\n\r\n### Describe the bug\r\n\r\ncfn-lint outputs:\r\n\r\nInvalid Property Resources/SESConfigurationSetDestination/Properties/EventDestination/SnsDestination\r\n\r\nBut this is a valid property:\r\n\r\nhttps://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-ses-configurationseteventdestination-eventdestination.html#cfn-ses-configurationseteventdestination-eventdestination-snsdestination\r\n\r\n### Expected behavior\r\n\r\ncfn-lint doesn't output an error\r\n\r\n### Reproduction template\r\n\r\n```yaml\r\nResources:\r\n SESConfigurationSetDestination:\r\n Type: AWS::SES::ConfigurationSetEventDestination\r\n Properties:\r\n ConfigurationSetName: Name\r\n EventDestination:\r\n Name: DestinationName\r\n Enabled: true\r\n MatchingEventTypes:\r\n - send\r\n - reject\r\n - bounce\r\n - complaint\r\n - delivery\r\n SnsDestination:\r\n TopicARN: Arn\r\n```\n", "before_files": [{"content": "#!/usr/bin/env python\n\"\"\"\nCopyright Amazon.com, Inc. or its affiliates. All Rights Reserved.\nSPDX-License-Identifier: MIT-0\n\"\"\"\nimport json\nimport logging\n\nimport boto3\n\nfrom cfnlint.helpers import REGIONS, get_url_content\nfrom cfnlint.maintenance import SPEC_REGIONS\n\n\"\"\"\n Updates our dynamic patches from SSM data\n This script requires Boto3 and Credentials to call the SSM API\n\"\"\"\n\nLOGGER = logging.getLogger(\"cfnlint\")\n\nservice_map = {\n \"acm\": [\"AWS::CertificateManager::\"],\n \"apigateway\": [\"AWS::ApiGateway::\", \"AWS::ApiGatewayV2::\"],\n # 'application-autoscaling': ['AWS::ApplicationAutoScaling::'], ## remove because SSM endpoints aren't correct\n \"appstream\": [\"AWS::AppStream::\"],\n \"appsync\": [\"AWS::AppSync::\"],\n \"athena\": [\"AWS::Athena::\"],\n \"autoscaling\": [\"AWS::AutoScaling::\"],\n \"batch\": [\"AWS::Batch::\"],\n \"budgets\": [\"AWS::Budgets::\"],\n \"cloud9\": [\"AWS::Cloud9::\"],\n \"cloudfront\": [\"AWS::CloudFront::\"],\n \"cloudtrail\": [\"AWS::CloudTrail::\"],\n \"cloudwatch\": [\"AWS::CloudWatch::\"],\n \"codebuild\": [\"AWS::CodeBuild::\"],\n \"codecommit\": [\"AWS::CodeCommit::\"],\n \"codedeploy\": [\"AWS::CodeDeploy::\"],\n \"codepipeline\": [\"AWS::CodePipeline::\"],\n \"cognito-identity\": [\"AWS::Cognito::\"],\n \"config\": [\"AWS::Config::\"],\n \"datapipeline\": [\"AWS::DataPipeline::\"],\n \"dax\": [\"AWS::DAX::\"],\n \"dms\": [\"AWS::DMS::\"],\n \"docdb\": [\"AWS::DocDB::\"],\n \"ds\": [\"AWS::DirectoryService::\"],\n \"dynamodb\": [\"AWS::DynamoDB::\"],\n \"ec2\": [\"AWS::EC2::\"],\n \"ecr\": [\"AWS::ECR::\"],\n \"ecs\": [\"AWS::ECS::\"],\n \"efs\": [\"AWS::EFS::\"],\n \"eks\": [\"AWS::EKS::\"],\n \"elasticache\": [\"AWS::ElastiCache::\"],\n \"elasticbeanstalk\": [\"AWS::ElasticBeanstalk::\"],\n \"elb\": [\"AWS::ElasticLoadBalancing::\", \"AWS::ElasticLoadBalancingV2::\"],\n \"emr\": [\"AWS::EMR::\"],\n \"es\": [\"AWS::Elasticsearch::\"],\n \"events\": [\"AWS::Events::\"],\n \"firehose\": [\"AWS::KinesisFirehose::\"],\n \"fsx\": [\"AWS::FSx::\"],\n \"gamelift\": [\"AWS::GameLift::\"],\n \"glue\": [\"AWS::Glue::\"],\n \"greengrass\": [\"AWS::Greengrass::\"],\n \"guardduty\": [\"AWS::GuardDuty::\"],\n \"inspector\": [\"AWS::Inspector::\"],\n \"iot\": [\"AWS::IoT::\"],\n \"iot1click-projects\": [\"AWS::IoT1Click::\"],\n \"iotanalytics\": [\"AWS::IoTAnalytics::\"],\n \"kinesis\": [\"AWS::Kinesis::\"],\n \"kinesisanalytics\": [\"AWS::KinesisAnalytics::\", \"AWS::KinesisAnalyticsV2::\"],\n \"kms\": [\"AWS::KMS::\"],\n \"lambda\": [\"AWS::Lambda::\"],\n \"logs\": [\"AWS::Logs::\"],\n \"mq\": [\"AWS::AmazonMQ::\"],\n \"neptune\": [\"AWS::Neptune::\"],\n \"opsworks\": [\"AWS::OpsWorks::\"],\n \"opsworkscm\": [\"AWS::OpsWorksCM::\"],\n \"ram\": [\"AWS::RAM::\"],\n \"rds\": [\"AWS::RDS::\"],\n \"redshift\": [\"AWS::Redshift::\"],\n \"robomaker\": [\"AWS::RoboMaker::\"],\n \"route53\": [\"AWS::Route53::\"],\n \"route53resolver\": [\n \"AWS::Route53Resolver::ResolverRule\",\n \"AWS::Route53Resolver::ResolverEndpoint\",\n ],\n \"s3\": [\"AWS::S3::\"],\n \"sagemaker\": [\"AWS::SageMaker::\"],\n \"sdb\": [\"AWS::SDB::\"],\n \"secretsmanager\": [\"AWS::SecretsManager::\"],\n \"servicecatalog\": [\"AWS::ServiceCatalog::\"],\n \"servicediscovery\": [\"AWS::ServiceDiscovery::\"],\n \"ses\": [\"AWS::SES::\"],\n \"sns\": [\"AWS::SNS::\"],\n \"sqs\": [\"AWS::SQS::\"],\n \"ssm\": [\"AWS::SSM::\"],\n \"stepfunctions\": [\"AWS::StepFunctions::\"],\n \"waf-regional\": [\"AWS::WAFRegional::\"],\n \"workspaces\": [\"AWS::WorkSpaces::\"],\n}\n\nsession = boto3.session.Session()\nclient = session.client(\"ssm\", region_name=\"us-east-1\")\n\n\ndef configure_logging():\n \"\"\"Setup Logging\"\"\"\n ch = logging.StreamHandler()\n ch.setLevel(logging.INFO)\n\n LOGGER.setLevel(logging.INFO)\n log_formatter = logging.Formatter(\n \"%(asctime)s - %(name)s - %(levelname)s - %(message)s\"\n )\n ch.setFormatter(log_formatter)\n\n # make sure all other log handlers are removed before adding it back\n for handler in LOGGER.handlers:\n LOGGER.removeHandler(handler)\n LOGGER.addHandler(ch)\n\n\ndef update_outputs(region, resource_type, name, outputs):\n \"\"\"update outputs with appropriate results\"\"\"\n element = {\"op\": \"remove\", \"path\": \"/%s/%s\" % (resource_type, name)}\n outputs[region].append(element)\n\n return outputs\n\n\ndef get_regions_for_service(service):\n \"\"\"get regions for a service\"\"\"\n LOGGER.info(\"Get the regions for service %s\", service)\n results = []\n paginator = client.get_paginator(\"get_parameters_by_path\")\n page_iterator = paginator.paginate(\n Path=\"/aws/service/global-infrastructure/services/{}/regions\".format(service),\n )\n\n for page in page_iterator:\n for region in page.get(\"Parameters\"):\n results.append(region.get(\"Value\"))\n\n return results\n\n\ndef add_spec_patch(region, services):\n \"\"\"Go through spec and determine patching\"\"\"\n LOGGER.info(\"Create 06_ssm_service_removal patch for region %s\", region)\n spec = json.loads(get_url_content(SPEC_REGIONS.get(region)))\n\n patches = []\n\n for spec_type in [\"ResourceTypes\", \"PropertyTypes\"]:\n for resource in sorted(spec.get(spec_type).keys()):\n for service in services:\n for spec_name in service_map.get(service):\n if resource.startswith(spec_name):\n element = {\n \"op\": \"remove\",\n \"path\": \"/%s/%s\" % (spec_type, resource),\n }\n patches.append(element)\n\n filename = \"src/cfnlint/data/ExtendedSpecs/%s/06_ssm_service_removal.json\" % region\n with open(filename, \"w+\", encoding=\"utf-8\") as f:\n json.dump(patches, f, indent=1, sort_keys=True, separators=(\",\", \": \"))\n\n\ndef add_spec_missing_services_patch(region, services):\n \"\"\"Go through spec and determine patching\"\"\"\n LOGGER.info(\"Create 07_ssm_service_addition patch for region %s\", region)\n spec_string = get_url_content(SPEC_REGIONS.get(region))\n spec_string_standard = get_url_content(SPEC_REGIONS.get(\"us-east-1\"))\n\n spec = json.loads(spec_string)\n spec_standard = json.loads(spec_string_standard)\n\n patches = []\n\n for spec_type in [\"ResourceTypes\"]:\n for service in services:\n found = False\n for resource in sorted(spec.get(spec_type).keys()):\n for spec_name in service_map.get(service):\n if resource.startswith(spec_name):\n found = True\n if found is False:\n for standard_spec_type in [\"ResourceTypes\", \"PropertyTypes\"]:\n for resource in sorted(\n spec_standard.get(standard_spec_type).keys()\n ):\n for spec_name in service_map.get(service):\n if resource.startswith(spec_name):\n if spec_standard.get(standard_spec_type).get(resource):\n element = {\n \"op\": \"add\",\n \"path\": \"/%s/%s\"\n % (standard_spec_type, resource),\n \"value\": spec_standard.get(\n standard_spec_type\n ).get(resource),\n }\n patches.append(element)\n elif standard_spec_type == \"ResourceTypes\":\n print(\"patch for %s not found\" % service)\n\n if patches:\n filename = (\n \"src/cfnlint/data/ExtendedSpecs/%s/07_ssm_service_addition.json\" % region\n )\n with open(filename, \"w+\", encoding=\"utf-8\") as f:\n json.dump(patches, f, indent=1, sort_keys=True, separators=(\",\", \": \"))\n\n\ndef main():\n \"\"\"main function\"\"\"\n configure_logging()\n\n all_regions = list(set(REGIONS))\n region_service_removal_map = {}\n region_service_add_map = {}\n for region in all_regions:\n region_service_removal_map[region] = []\n region_service_add_map[region] = []\n for service in service_map:\n regions = get_regions_for_service(service)\n if regions:\n for region in list(set(regions)):\n region_service_add_map[region].append(service)\n for region in list(set(all_regions) - set(regions)):\n region_service_removal_map[region].append(service)\n\n for region, services in region_service_removal_map.items():\n if services:\n add_spec_patch(region, services)\n for region, services in region_service_add_map.items():\n if services:\n add_spec_missing_services_patch(region, services)\n\n\nif __name__ == \"__main__\":\n try:\n main()\n except (ValueError, TypeError):\n LOGGER.error(ValueError)\n", "path": "scripts/update_specs_services_from_ssm.py"}], "after_files": [{"content": "#!/usr/bin/env python\n\"\"\"\nCopyright Amazon.com, Inc. or its affiliates. All Rights Reserved.\nSPDX-License-Identifier: MIT-0\n\"\"\"\nimport json\nimport logging\n\nimport boto3\n\nfrom cfnlint.helpers import REGIONS, get_url_content\nfrom cfnlint.maintenance import SPEC_REGIONS\n\n\"\"\"\n Updates our dynamic patches from SSM data\n This script requires Boto3 and Credentials to call the SSM API\n\"\"\"\n\nLOGGER = logging.getLogger(\"cfnlint\")\n\nservice_map = {\n \"acm\": [\"AWS::CertificateManager::\"],\n \"apigateway\": [\"AWS::ApiGateway::\", \"AWS::ApiGatewayV2::\"],\n # 'application-autoscaling': ['AWS::ApplicationAutoScaling::'], ## remove because SSM endpoints aren't correct\n \"appstream\": [\"AWS::AppStream::\"],\n \"appsync\": [\"AWS::AppSync::\"],\n \"athena\": [\"AWS::Athena::\"],\n \"autoscaling\": [\"AWS::AutoScaling::\"],\n \"batch\": [\"AWS::Batch::\"],\n \"budgets\": [\"AWS::Budgets::\"],\n \"cloud9\": [\"AWS::Cloud9::\"],\n \"cloudfront\": [\"AWS::CloudFront::\"],\n \"cloudtrail\": [\"AWS::CloudTrail::\"],\n \"cloudwatch\": [\"AWS::CloudWatch::\"],\n \"codebuild\": [\"AWS::CodeBuild::\"],\n \"codecommit\": [\"AWS::CodeCommit::\"],\n \"codedeploy\": [\"AWS::CodeDeploy::\"],\n \"codepipeline\": [\"AWS::CodePipeline::\"],\n \"cognito-identity\": [\"AWS::Cognito::\"],\n \"config\": [\"AWS::Config::\"],\n \"datapipeline\": [\"AWS::DataPipeline::\"],\n \"dax\": [\"AWS::DAX::\"],\n \"dms\": [\"AWS::DMS::\"],\n \"docdb\": [\"AWS::DocDB::\"],\n \"ds\": [\"AWS::DirectoryService::\"],\n \"dynamodb\": [\"AWS::DynamoDB::\"],\n \"ec2\": [\"AWS::EC2::\"],\n \"ecr\": [\"AWS::ECR::\"],\n \"ecs\": [\"AWS::ECS::\"],\n \"efs\": [\"AWS::EFS::\"],\n \"eks\": [\"AWS::EKS::\"],\n \"elasticache\": [\"AWS::ElastiCache::\"],\n \"elasticbeanstalk\": [\"AWS::ElasticBeanstalk::\"],\n \"elb\": [\"AWS::ElasticLoadBalancing::\", \"AWS::ElasticLoadBalancingV2::\"],\n \"emr\": [\"AWS::EMR::\"],\n \"es\": [\"AWS::Elasticsearch::\"],\n \"events\": [\"AWS::Events::\"],\n \"firehose\": [\"AWS::KinesisFirehose::\"],\n \"fsx\": [\"AWS::FSx::\"],\n \"gamelift\": [\"AWS::GameLift::\"],\n \"glue\": [\"AWS::Glue::\"],\n \"greengrass\": [\"AWS::Greengrass::\"],\n \"guardduty\": [\"AWS::GuardDuty::\"],\n \"inspector\": [\"AWS::Inspector::\"],\n \"iot\": [\"AWS::IoT::\"],\n \"iot1click-projects\": [\"AWS::IoT1Click::\"],\n \"iotanalytics\": [\"AWS::IoTAnalytics::\"],\n \"kinesis\": [\"AWS::Kinesis::\"],\n \"kinesisanalytics\": [\"AWS::KinesisAnalytics::\", \"AWS::KinesisAnalyticsV2::\"],\n \"kms\": [\"AWS::KMS::\"],\n \"lambda\": [\"AWS::Lambda::\"],\n \"logs\": [\"AWS::Logs::\"],\n \"mq\": [\"AWS::AmazonMQ::\"],\n \"neptune\": [\"AWS::Neptune::\"],\n \"opsworks\": [\"AWS::OpsWorks::\"],\n \"opsworkscm\": [\"AWS::OpsWorksCM::\"],\n \"ram\": [\"AWS::RAM::\"],\n \"rds\": [\"AWS::RDS::\"],\n \"redshift\": [\"AWS::Redshift::\"],\n \"robomaker\": [\"AWS::RoboMaker::\"],\n \"route53\": [\"AWS::Route53::\"],\n \"route53resolver\": [\n \"AWS::Route53Resolver::ResolverRule\",\n \"AWS::Route53Resolver::ResolverEndpoint\",\n ],\n \"s3\": [\"AWS::S3::\"],\n \"sagemaker\": [\"AWS::SageMaker::\"],\n \"sdb\": [\"AWS::SDB::\"],\n \"secretsmanager\": [\"AWS::SecretsManager::\"],\n \"servicecatalog\": [\"AWS::ServiceCatalog::\"],\n \"servicediscovery\": [\"AWS::ServiceDiscovery::\"],\n \"ses\": [\"AWS::SES::\"],\n \"sns\": [\"AWS::SNS::\"],\n \"sqs\": [\"AWS::SQS::\"],\n \"ssm\": [\"AWS::SSM::\"],\n \"stepfunctions\": [\"AWS::StepFunctions::\"],\n \"waf-regional\": [\"AWS::WAFRegional::\"],\n \"workspaces\": [\"AWS::WorkSpaces::\"],\n}\n\nsession = boto3.session.Session()\nclient = session.client(\"ssm\", region_name=\"us-east-1\")\n\n\ndef configure_logging():\n \"\"\"Setup Logging\"\"\"\n ch = logging.StreamHandler()\n ch.setLevel(logging.INFO)\n\n LOGGER.setLevel(logging.INFO)\n log_formatter = logging.Formatter(\n \"%(asctime)s - %(name)s - %(levelname)s - %(message)s\"\n )\n ch.setFormatter(log_formatter)\n\n # make sure all other log handlers are removed before adding it back\n for handler in LOGGER.handlers:\n LOGGER.removeHandler(handler)\n LOGGER.addHandler(ch)\n\n\ndef update_outputs(region, resource_type, name, outputs):\n \"\"\"update outputs with appropriate results\"\"\"\n element = {\"op\": \"remove\", \"path\": \"/%s/%s\" % (resource_type, name)}\n outputs[region].append(element)\n\n return outputs\n\n\ndef get_regions_for_service(service):\n \"\"\"get regions for a service\"\"\"\n LOGGER.info(\"Get the regions for service %s\", service)\n results = []\n paginator = client.get_paginator(\"get_parameters_by_path\")\n page_iterator = paginator.paginate(\n Path=\"/aws/service/global-infrastructure/services/{}/regions\".format(service),\n )\n\n for page in page_iterator:\n for region in page.get(\"Parameters\"):\n results.append(region.get(\"Value\"))\n\n return results\n\n\ndef add_spec_patch(region, services):\n \"\"\"Go through spec and determine patching\"\"\"\n LOGGER.info(\"Create 06_ssm_service_removal patch for region %s\", region)\n spec = json.loads(get_url_content(SPEC_REGIONS.get(region)))\n\n patches = []\n\n for spec_type in [\"ResourceTypes\", \"PropertyTypes\"]:\n for resource in sorted(spec.get(spec_type).keys()):\n for service in services:\n for spec_name in service_map.get(service):\n if resource.startswith(spec_name):\n element = {\n \"op\": \"remove\",\n \"path\": \"/%s/%s\" % (spec_type, resource),\n }\n patches.append(element)\n\n filename = \"src/cfnlint/data/ExtendedSpecs/%s/06_ssm_service_removal.json\" % region\n with open(filename, \"w+\", encoding=\"utf-8\") as f:\n json.dump(patches, f, indent=1, sort_keys=True, separators=(\",\", \": \"))\n\n\ndef add_spec_missing_services_patch(region, services):\n \"\"\"Go through spec and determine patching\"\"\"\n LOGGER.info(\"Create 07_ssm_service_addition patch for region %s\", region)\n spec_string = get_url_content(SPEC_REGIONS.get(region))\n spec_string_standard = get_url_content(SPEC_REGIONS.get(\"us-east-1\"))\n\n spec = json.loads(spec_string)\n spec_standard = json.loads(spec_string_standard)\n\n patches = []\n\n for spec_type in [\"ResourceTypes\"]:\n for service in services:\n found = False\n for resource in sorted(spec.get(spec_type).keys()):\n for spec_name in service_map.get(service):\n if resource.startswith(spec_name):\n found = True\n if found is False:\n for standard_spec_type in [\"ResourceTypes\", \"PropertyTypes\"]:\n for resource in sorted(\n spec_standard.get(standard_spec_type).keys()\n ):\n for spec_name in service_map.get(service):\n if resource.startswith(spec_name):\n if spec_standard.get(standard_spec_type).get(resource):\n element = {\n \"op\": \"add\",\n \"path\": \"/%s/%s\"\n % (standard_spec_type, resource),\n \"value\": spec_standard.get(\n standard_spec_type\n ).get(resource),\n }\n patches.append(element)\n elif standard_spec_type == \"ResourceTypes\":\n print(\"patch for %s not found\" % service)\n\n filename = (\n \"src/cfnlint/data/ExtendedSpecs/%s/07_ssm_service_addition.json\" % region\n )\n with open(filename, \"w+\", encoding=\"utf-8\") as f:\n json.dump(patches, f, indent=1, sort_keys=True, separators=(\",\", \": \"))\n \n\n\ndef main():\n \"\"\"main function\"\"\"\n configure_logging()\n\n all_regions = list(set(REGIONS))\n region_service_removal_map = {}\n region_service_add_map = {}\n for region in all_regions:\n region_service_removal_map[region] = []\n region_service_add_map[region] = []\n for service in service_map:\n regions = get_regions_for_service(service)\n if regions:\n for region in list(set(regions)):\n region_service_add_map[region].append(service)\n for region in list(set(all_regions) - set(regions)):\n region_service_removal_map[region].append(service)\n\n for region, services in region_service_removal_map.items():\n if services:\n add_spec_patch(region, services)\n for region, services in region_service_add_map.items():\n if services:\n add_spec_missing_services_patch(region, services)\n\n\nif __name__ == \"__main__\":\n try:\n main()\n except (ValueError, TypeError):\n LOGGER.error(ValueError)\n", "path": "scripts/update_specs_services_from_ssm.py"}]}
| 3,306 | 245 |
gh_patches_debug_7027
|
rasdani/github-patches
|
git_diff
|
conda__conda-10261
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`conda env remove --dry-run` actually deletes the env
## Current Behavior
Using the `--dry-run` flag doesn't do a dry-run at all.
### Steps to Reproduce
```
$ conda env list
# conda environments:
#
base * /usr
$ conda create -n foo
Collecting package metadata (current_repodata.json): done
Solving environment: done
## Package Plan ##
environment location: /home/eric/.conda/envs/foo
Proceed ([y]/n)? y
Preparing transaction: done
Verifying transaction: done
Executing transaction: done
#
# To activate this environment, use
#
# $ conda activate foo
#
# To deactivate an active environment, use
#
# $ conda deactivate
$ conda env list
# conda environments:
#
foo /home/eric/.conda/envs/foo
base * /usr
~ $ conda env remove --dry-run -n foo
Remove all packages in environment /home/eric/.conda/envs/foo:
$ conda env list
# conda environments:
#
base * /usr
$
```
## Expected Behavior
`--dry-run` is documented as `Only display what would have been done.`, but clearly that's not true :upside_down_face:
The expected behaviour here is obviously that the environment is **not** removed :slightly_smiling_face:
## Environment Information
<details open><summary><code>`conda info`</code></summary><p>
```
active environment : None
shell level : 0
user config file : /home/eric/.condarc
populated config files : /usr/share/conda/condarc.d/defaults.yaml
/home/eric/.condarc
conda version : 4.8.2
conda-build version : not installed
python version : 3.8.5.final.0
virtual packages : __glibc=2.31
base environment : /usr (read only)
channel URLs : https://conda.anaconda.org/conda-forge/linux-64
https://conda.anaconda.org/conda-forge/noarch
https://repo.anaconda.com/pkgs/main/linux-64
https://repo.anaconda.com/pkgs/main/noarch
https://repo.anaconda.com/pkgs/r/linux-64
https://repo.anaconda.com/pkgs/r/noarch
package cache : /var/cache/conda/pkgs
/home/eric/.conda/pkgs
envs directories : /home/eric/.conda/envs
/usr/envs
platform : linux-64
user-agent : conda/4.8.2 requests/2.22.0 CPython/3.8.5 Linux/5.8.6-201.fc32.x86_64 fedora/32 glibc/2.31
UID:GID : 1000:1000
netrc file : None
offline mode : False
```
</p></details>
<details open><summary><code>`conda config --show-sources`</code></summary><p>
```
==> /usr/share/conda/condarc.d/defaults.yaml <==
pkgs_dirs:
- /var/cache/conda/pkgs
- ~/.conda/pkgs
==> /home/eric/.condarc <==
channels:
- conda-forge
- defaults
```
</p></details>
<details><summary><code>`conda list --show-channel-urls`</code></summary><p>
<!-- between the ticks below, paste the output of 'conda list --show-channel-urls' -->
```
EnvironmentLocationNotFound: Not a conda environment: /usr
```
(I expect that might also be a bug, conda shouldn't crash like that here.)
</p></details>
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conda/cli/main_remove.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 # Copyright (C) 2012 Anaconda, Inc
3 # SPDX-License-Identifier: BSD-3-Clause
4 from __future__ import absolute_import, division, print_function, unicode_literals
5
6 import logging
7 from os.path import isfile, join
8 import sys
9
10 from .common import check_non_admin, specs_from_args
11 from .install import handle_txn
12 from ..base.context import context
13 from ..core.envs_manager import unregister_env
14 from ..core.link import PrefixSetup, UnlinkLinkTransaction
15 from ..core.prefix_data import PrefixData
16 from ..core.solve import Solver
17 from ..exceptions import CondaEnvironmentError, CondaValueError, DirectoryNotACondaEnvironmentError
18 from ..gateways.disk.delete import rm_rf, path_is_clean
19 from ..models.match_spec import MatchSpec
20 from ..exceptions import PackagesNotFoundError
21
22 log = logging.getLogger(__name__)
23
24
25 def execute(args, parser):
26
27 if not (args.all or args.package_names):
28 raise CondaValueError('no package names supplied,\n'
29 ' try "conda remove -h" for more details')
30
31 prefix = context.target_prefix
32 check_non_admin()
33
34 if args.all and prefix == context.default_prefix:
35 msg = "cannot remove current environment. deactivate and run conda remove again"
36 raise CondaEnvironmentError(msg)
37
38 if args.all and path_is_clean(prefix):
39 # full environment removal was requested, but environment doesn't exist anyway
40
41 # .. but you know what? If you call `conda remove --all` you'd expect the dir
42 # not to exist afterwards, would you not? If not (fine, I can see the argument
43 # about deleting people's work in envs being a very bad thing indeed), but if
44 # being careful is the goal it would still be nice if after `conda remove --all`
45 # to be able to do `conda create` on the same environment name.
46 #
47 # try:
48 # rm_rf(prefix, clean_empty_parents=True)
49 # except:
50 # log.warning("Failed rm_rf() of partially existent env {}".format(prefix))
51
52 return 0
53
54 if args.all:
55 if prefix == context.root_prefix:
56 raise CondaEnvironmentError('cannot remove root environment,\n'
57 ' add -n NAME or -p PREFIX option')
58 if not isfile(join(prefix, 'conda-meta', 'history')):
59 raise DirectoryNotACondaEnvironmentError(prefix)
60 print("\nRemove all packages in environment %s:\n" % prefix, file=sys.stderr)
61
62 if 'package_names' in args:
63 stp = PrefixSetup(
64 target_prefix=prefix,
65 unlink_precs=tuple(PrefixData(prefix).iter_records()),
66 link_precs=(),
67 remove_specs=(),
68 update_specs=(),
69 neutered_specs={},
70 )
71 txn = UnlinkLinkTransaction(stp)
72 try:
73 handle_txn(txn, prefix, args, False, True)
74 except PackagesNotFoundError:
75 print("No packages found in %s. Continuing environment removal" % prefix)
76 rm_rf(prefix, clean_empty_parents=True)
77 unregister_env(prefix)
78
79 return
80
81 else:
82 if args.features:
83 specs = tuple(MatchSpec(track_features=f) for f in set(args.package_names))
84 else:
85 specs = specs_from_args(args.package_names)
86 channel_urls = ()
87 subdirs = ()
88 solver = Solver(prefix, channel_urls, subdirs, specs_to_remove=specs)
89 txn = solver.solve_for_transaction()
90 handle_txn(txn, prefix, args, False, True)
91
92 # Keep this code for dev reference until private envs can be re-enabled in
93 # Solver.solve_for_transaction
94
95 # specs = None
96 # if args.features:
97 # specs = [MatchSpec(track_features=f) for f in set(args.package_names)]
98 # actions = remove_actions(prefix, specs, index, pinned=not context.ignore_pinned)
99 # actions['ACTION'] = 'REMOVE_FEATURE'
100 # action_groups = (actions, index),
101 # elif args.all:
102 # if prefix == context.root_prefix:
103 # raise CondaEnvironmentError('cannot remove root environment,\n'
104 # ' add -n NAME or -p PREFIX option')
105 # actions = defaultdict(list)
106 # actions[PREFIX] = prefix
107 # for dist in sorted(iterkeys(index)):
108 # add_unlink(actions, dist)
109 # actions['ACTION'] = 'REMOVE_ALL'
110 # action_groups = (actions, index),
111 # elif prefix == context.root_prefix and not context.prefix_specified:
112 # from ..core.envs_manager import EnvsDirectory
113 # ed = EnvsDirectory(join(context.root_prefix, 'envs'))
114 # get_env = lambda s: ed.get_registered_preferred_env(MatchSpec(s).name)
115 # specs = specs_from_args(args.package_names)
116 # env_spec_map = groupby(get_env, specs)
117 # action_groups = []
118 # for env_name, spcs in iteritems(env_spec_map):
119 # pfx = ed.to_prefix(env_name)
120 # r = get_resolve_object(index.copy(), pfx)
121 # specs_to_remove = tuple(MatchSpec(s) for s in spcs)
122 # prune = pfx != context.root_prefix
123 # dists_for_unlinking, dists_for_linking = solve_for_actions(
124 # pfx, r,
125 # specs_to_remove=specs_to_remove, prune=prune,
126 # )
127 # actions = get_blank_actions(pfx)
128 # actions['UNLINK'].extend(dists_for_unlinking)
129 # actions['LINK'].extend(dists_for_linking)
130 # actions['SPECS'].extend(text_type(s) for s in specs_to_remove)
131 # actions['ACTION'] = 'REMOVE'
132 # action_groups.append((actions, r.index))
133 # action_groups = tuple(action_groups)
134 # else:
135 # specs = specs_from_args(args.package_names)
136 # if sys.prefix == abspath(prefix) and names_in_specs(ROOT_NO_RM, specs) and not args.force: # NOQA
137 # raise CondaEnvironmentError('cannot remove %s from root environment' %
138 # ', '.join(ROOT_NO_RM))
139 # action_groups = (remove_actions(prefix, list(specs), index=index,
140 # force=args.force,
141 # pinned=not context.ignore_pinned,
142 # ), index),
143 #
144 #
145 # delete_trash()
146 # if any(nothing_to_do(x[0]) for x in action_groups):
147 # if args.all:
148 # print("\nRemove all packages in environment %s:\n" % prefix, file=sys.stderr)
149 # if not context.json:
150 # confirm_yn(args)
151 # rm_rf(prefix)
152 #
153 # if context.json:
154 # stdout_json({
155 # 'success': True,
156 # 'actions': tuple(x[0] for x in action_groups)
157 # })
158 # return
159 #
160 # pkg = str(args.package_names).replace("['", "")
161 # pkg = pkg.replace("']", "")
162 #
163 # error_message = "No packages named '%s' found to remove from environment." % pkg
164 # raise PackageNotFoundError(error_message)
165 # if not context.json:
166 # for actions, ndx in action_groups:
167 # print()
168 # print("Package plan for package removal in environment %s:" % actions["PREFIX"])
169 # display_actions(actions, ndx)
170 # elif context.json and args.dry_run:
171 # stdout_json({
172 # 'success': True,
173 # 'dry_run': True,
174 # 'actions': tuple(x[0] for x in action_groups),
175 # })
176 # return
177 #
178 # if not context.json:
179 # confirm_yn(args)
180 #
181 # for actions, ndx in action_groups:
182 # if context.json and not context.quiet:
183 # with json_progress_bars():
184 # execute_actions(actions, ndx, verbose=not context.quiet)
185 # else:
186 # execute_actions(actions, ndx, verbose=not context.quiet)
187 #
188 # target_prefix = actions["PREFIX"]
189 # if is_private_env_path(target_prefix) and linked_data(target_prefix) == {}:
190 # rm_rf(target_prefix)
191 #
192 # if args.all:
193 # rm_rf(prefix)
194 #
195 # if context.json:
196 # stdout_json({
197 # 'success': True,
198 # 'actions': tuple(x[0] for x in action_groups),
199 # })
200
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/conda/cli/main_remove.py b/conda/cli/main_remove.py
--- a/conda/cli/main_remove.py
+++ b/conda/cli/main_remove.py
@@ -73,8 +73,9 @@
handle_txn(txn, prefix, args, False, True)
except PackagesNotFoundError:
print("No packages found in %s. Continuing environment removal" % prefix)
- rm_rf(prefix, clean_empty_parents=True)
- unregister_env(prefix)
+ if not context.dry_run:
+ rm_rf(prefix, clean_empty_parents=True)
+ unregister_env(prefix)
return
|
{"golden_diff": "diff --git a/conda/cli/main_remove.py b/conda/cli/main_remove.py\n--- a/conda/cli/main_remove.py\n+++ b/conda/cli/main_remove.py\n@@ -73,8 +73,9 @@\n handle_txn(txn, prefix, args, False, True)\n except PackagesNotFoundError:\n print(\"No packages found in %s. Continuing environment removal\" % prefix)\n- rm_rf(prefix, clean_empty_parents=True)\n- unregister_env(prefix)\n+ if not context.dry_run:\n+ rm_rf(prefix, clean_empty_parents=True)\n+ unregister_env(prefix)\n \n return\n", "issue": "`conda env remove --dry-run` actually deletes the env\n## Current Behavior\r\nUsing the `--dry-run` flag doesn't do a dry-run at all.\r\n\r\n\r\n### Steps to Reproduce\r\n```\r\n$ conda env list\r\n# conda environments:\r\n#\r\nbase * /usr\r\n\r\n$ conda create -n foo\r\nCollecting package metadata (current_repodata.json): done\r\nSolving environment: done\r\n\r\n## Package Plan ##\r\n\r\n environment location: /home/eric/.conda/envs/foo\r\n\r\n\r\n\r\nProceed ([y]/n)? y\r\n\r\nPreparing transaction: done\r\nVerifying transaction: done\r\nExecuting transaction: done\r\n#\r\n# To activate this environment, use\r\n#\r\n# $ conda activate foo\r\n#\r\n# To deactivate an active environment, use\r\n#\r\n# $ conda deactivate\r\n\r\n$ conda env list\r\n# conda environments:\r\n#\r\nfoo /home/eric/.conda/envs/foo\r\nbase * /usr\r\n\r\n~ $ conda env remove --dry-run -n foo\r\n\r\nRemove all packages in environment /home/eric/.conda/envs/foo:\r\n\r\n$ conda env list\r\n# conda environments:\r\n#\r\nbase * /usr\r\n\r\n$ \r\n```\r\n\r\n\r\n## Expected Behavior\r\n`--dry-run` is documented as `Only display what would have been done.`, but clearly that's not true :upside_down_face: \r\n\r\nThe expected behaviour here is obviously that the environment is **not** removed :slightly_smiling_face: \r\n\r\n\r\n## Environment Information\r\n<details open><summary><code>`conda info`</code></summary><p>\r\n\r\n```\r\n active environment : None\r\n shell level : 0\r\n user config file : /home/eric/.condarc\r\n populated config files : /usr/share/conda/condarc.d/defaults.yaml\r\n /home/eric/.condarc\r\n conda version : 4.8.2\r\n conda-build version : not installed\r\n python version : 3.8.5.final.0\r\n virtual packages : __glibc=2.31\r\n base environment : /usr (read only)\r\n channel URLs : https://conda.anaconda.org/conda-forge/linux-64\r\n https://conda.anaconda.org/conda-forge/noarch\r\n https://repo.anaconda.com/pkgs/main/linux-64\r\n https://repo.anaconda.com/pkgs/main/noarch\r\n https://repo.anaconda.com/pkgs/r/linux-64\r\n https://repo.anaconda.com/pkgs/r/noarch\r\n package cache : /var/cache/conda/pkgs\r\n /home/eric/.conda/pkgs\r\n envs directories : /home/eric/.conda/envs\r\n /usr/envs\r\n platform : linux-64\r\n user-agent : conda/4.8.2 requests/2.22.0 CPython/3.8.5 Linux/5.8.6-201.fc32.x86_64 fedora/32 glibc/2.31\r\n UID:GID : 1000:1000\r\n netrc file : None\r\n offline mode : False\r\n```\r\n</p></details>\r\n\r\n\r\n<details open><summary><code>`conda config --show-sources`</code></summary><p>\r\n\r\n```\r\n==> /usr/share/conda/condarc.d/defaults.yaml <==\r\npkgs_dirs:\r\n - /var/cache/conda/pkgs\r\n - ~/.conda/pkgs\r\n\r\n==> /home/eric/.condarc <==\r\nchannels:\r\n - conda-forge\r\n - defaults\r\n```\r\n</p></details>\r\n\r\n\r\n<details><summary><code>`conda list --show-channel-urls`</code></summary><p>\r\n<!-- between the ticks below, paste the output of 'conda list --show-channel-urls' -->\r\n\r\n```\r\nEnvironmentLocationNotFound: Not a conda environment: /usr\r\n```\r\n(I expect that might also be a bug, conda shouldn't crash like that here.)\r\n</p></details>\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright (C) 2012 Anaconda, Inc\n# SPDX-License-Identifier: BSD-3-Clause\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport logging\nfrom os.path import isfile, join\nimport sys\n\nfrom .common import check_non_admin, specs_from_args\nfrom .install import handle_txn\nfrom ..base.context import context\nfrom ..core.envs_manager import unregister_env\nfrom ..core.link import PrefixSetup, UnlinkLinkTransaction\nfrom ..core.prefix_data import PrefixData\nfrom ..core.solve import Solver\nfrom ..exceptions import CondaEnvironmentError, CondaValueError, DirectoryNotACondaEnvironmentError\nfrom ..gateways.disk.delete import rm_rf, path_is_clean\nfrom ..models.match_spec import MatchSpec\nfrom ..exceptions import PackagesNotFoundError\n\nlog = logging.getLogger(__name__)\n\n\ndef execute(args, parser):\n\n if not (args.all or args.package_names):\n raise CondaValueError('no package names supplied,\\n'\n ' try \"conda remove -h\" for more details')\n\n prefix = context.target_prefix\n check_non_admin()\n\n if args.all and prefix == context.default_prefix:\n msg = \"cannot remove current environment. deactivate and run conda remove again\"\n raise CondaEnvironmentError(msg)\n\n if args.all and path_is_clean(prefix):\n # full environment removal was requested, but environment doesn't exist anyway\n\n # .. but you know what? If you call `conda remove --all` you'd expect the dir\n # not to exist afterwards, would you not? If not (fine, I can see the argument\n # about deleting people's work in envs being a very bad thing indeed), but if\n # being careful is the goal it would still be nice if after `conda remove --all`\n # to be able to do `conda create` on the same environment name.\n #\n # try:\n # rm_rf(prefix, clean_empty_parents=True)\n # except:\n # log.warning(\"Failed rm_rf() of partially existent env {}\".format(prefix))\n\n return 0\n\n if args.all:\n if prefix == context.root_prefix:\n raise CondaEnvironmentError('cannot remove root environment,\\n'\n ' add -n NAME or -p PREFIX option')\n if not isfile(join(prefix, 'conda-meta', 'history')):\n raise DirectoryNotACondaEnvironmentError(prefix)\n print(\"\\nRemove all packages in environment %s:\\n\" % prefix, file=sys.stderr)\n\n if 'package_names' in args:\n stp = PrefixSetup(\n target_prefix=prefix,\n unlink_precs=tuple(PrefixData(prefix).iter_records()),\n link_precs=(),\n remove_specs=(),\n update_specs=(),\n neutered_specs={},\n )\n txn = UnlinkLinkTransaction(stp)\n try:\n handle_txn(txn, prefix, args, False, True)\n except PackagesNotFoundError:\n print(\"No packages found in %s. Continuing environment removal\" % prefix)\n rm_rf(prefix, clean_empty_parents=True)\n unregister_env(prefix)\n\n return\n\n else:\n if args.features:\n specs = tuple(MatchSpec(track_features=f) for f in set(args.package_names))\n else:\n specs = specs_from_args(args.package_names)\n channel_urls = ()\n subdirs = ()\n solver = Solver(prefix, channel_urls, subdirs, specs_to_remove=specs)\n txn = solver.solve_for_transaction()\n handle_txn(txn, prefix, args, False, True)\n\n # Keep this code for dev reference until private envs can be re-enabled in\n # Solver.solve_for_transaction\n\n # specs = None\n # if args.features:\n # specs = [MatchSpec(track_features=f) for f in set(args.package_names)]\n # actions = remove_actions(prefix, specs, index, pinned=not context.ignore_pinned)\n # actions['ACTION'] = 'REMOVE_FEATURE'\n # action_groups = (actions, index),\n # elif args.all:\n # if prefix == context.root_prefix:\n # raise CondaEnvironmentError('cannot remove root environment,\\n'\n # ' add -n NAME or -p PREFIX option')\n # actions = defaultdict(list)\n # actions[PREFIX] = prefix\n # for dist in sorted(iterkeys(index)):\n # add_unlink(actions, dist)\n # actions['ACTION'] = 'REMOVE_ALL'\n # action_groups = (actions, index),\n # elif prefix == context.root_prefix and not context.prefix_specified:\n # from ..core.envs_manager import EnvsDirectory\n # ed = EnvsDirectory(join(context.root_prefix, 'envs'))\n # get_env = lambda s: ed.get_registered_preferred_env(MatchSpec(s).name)\n # specs = specs_from_args(args.package_names)\n # env_spec_map = groupby(get_env, specs)\n # action_groups = []\n # for env_name, spcs in iteritems(env_spec_map):\n # pfx = ed.to_prefix(env_name)\n # r = get_resolve_object(index.copy(), pfx)\n # specs_to_remove = tuple(MatchSpec(s) for s in spcs)\n # prune = pfx != context.root_prefix\n # dists_for_unlinking, dists_for_linking = solve_for_actions(\n # pfx, r,\n # specs_to_remove=specs_to_remove, prune=prune,\n # )\n # actions = get_blank_actions(pfx)\n # actions['UNLINK'].extend(dists_for_unlinking)\n # actions['LINK'].extend(dists_for_linking)\n # actions['SPECS'].extend(text_type(s) for s in specs_to_remove)\n # actions['ACTION'] = 'REMOVE'\n # action_groups.append((actions, r.index))\n # action_groups = tuple(action_groups)\n # else:\n # specs = specs_from_args(args.package_names)\n # if sys.prefix == abspath(prefix) and names_in_specs(ROOT_NO_RM, specs) and not args.force: # NOQA\n # raise CondaEnvironmentError('cannot remove %s from root environment' %\n # ', '.join(ROOT_NO_RM))\n # action_groups = (remove_actions(prefix, list(specs), index=index,\n # force=args.force,\n # pinned=not context.ignore_pinned,\n # ), index),\n #\n #\n # delete_trash()\n # if any(nothing_to_do(x[0]) for x in action_groups):\n # if args.all:\n # print(\"\\nRemove all packages in environment %s:\\n\" % prefix, file=sys.stderr)\n # if not context.json:\n # confirm_yn(args)\n # rm_rf(prefix)\n #\n # if context.json:\n # stdout_json({\n # 'success': True,\n # 'actions': tuple(x[0] for x in action_groups)\n # })\n # return\n #\n # pkg = str(args.package_names).replace(\"['\", \"\")\n # pkg = pkg.replace(\"']\", \"\")\n #\n # error_message = \"No packages named '%s' found to remove from environment.\" % pkg\n # raise PackageNotFoundError(error_message)\n # if not context.json:\n # for actions, ndx in action_groups:\n # print()\n # print(\"Package plan for package removal in environment %s:\" % actions[\"PREFIX\"])\n # display_actions(actions, ndx)\n # elif context.json and args.dry_run:\n # stdout_json({\n # 'success': True,\n # 'dry_run': True,\n # 'actions': tuple(x[0] for x in action_groups),\n # })\n # return\n #\n # if not context.json:\n # confirm_yn(args)\n #\n # for actions, ndx in action_groups:\n # if context.json and not context.quiet:\n # with json_progress_bars():\n # execute_actions(actions, ndx, verbose=not context.quiet)\n # else:\n # execute_actions(actions, ndx, verbose=not context.quiet)\n #\n # target_prefix = actions[\"PREFIX\"]\n # if is_private_env_path(target_prefix) and linked_data(target_prefix) == {}:\n # rm_rf(target_prefix)\n #\n # if args.all:\n # rm_rf(prefix)\n #\n # if context.json:\n # stdout_json({\n # 'success': True,\n # 'actions': tuple(x[0] for x in action_groups),\n # })\n", "path": "conda/cli/main_remove.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright (C) 2012 Anaconda, Inc\n# SPDX-License-Identifier: BSD-3-Clause\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport logging\nfrom os.path import isfile, join\nimport sys\n\nfrom .common import check_non_admin, specs_from_args\nfrom .install import handle_txn\nfrom ..base.context import context\nfrom ..core.envs_manager import unregister_env\nfrom ..core.link import PrefixSetup, UnlinkLinkTransaction\nfrom ..core.prefix_data import PrefixData\nfrom ..core.solve import Solver\nfrom ..exceptions import CondaEnvironmentError, CondaValueError, DirectoryNotACondaEnvironmentError\nfrom ..gateways.disk.delete import rm_rf, path_is_clean\nfrom ..models.match_spec import MatchSpec\nfrom ..exceptions import PackagesNotFoundError\n\nlog = logging.getLogger(__name__)\n\n\ndef execute(args, parser):\n\n if not (args.all or args.package_names):\n raise CondaValueError('no package names supplied,\\n'\n ' try \"conda remove -h\" for more details')\n\n prefix = context.target_prefix\n check_non_admin()\n\n if args.all and prefix == context.default_prefix:\n msg = \"cannot remove current environment. deactivate and run conda remove again\"\n raise CondaEnvironmentError(msg)\n\n if args.all and path_is_clean(prefix):\n # full environment removal was requested, but environment doesn't exist anyway\n\n # .. but you know what? If you call `conda remove --all` you'd expect the dir\n # not to exist afterwards, would you not? If not (fine, I can see the argument\n # about deleting people's work in envs being a very bad thing indeed), but if\n # being careful is the goal it would still be nice if after `conda remove --all`\n # to be able to do `conda create` on the same environment name.\n #\n # try:\n # rm_rf(prefix, clean_empty_parents=True)\n # except:\n # log.warning(\"Failed rm_rf() of partially existent env {}\".format(prefix))\n\n return 0\n\n if args.all:\n if prefix == context.root_prefix:\n raise CondaEnvironmentError('cannot remove root environment,\\n'\n ' add -n NAME or -p PREFIX option')\n if not isfile(join(prefix, 'conda-meta', 'history')):\n raise DirectoryNotACondaEnvironmentError(prefix)\n print(\"\\nRemove all packages in environment %s:\\n\" % prefix, file=sys.stderr)\n\n if 'package_names' in args:\n stp = PrefixSetup(\n target_prefix=prefix,\n unlink_precs=tuple(PrefixData(prefix).iter_records()),\n link_precs=(),\n remove_specs=(),\n update_specs=(),\n neutered_specs={},\n )\n txn = UnlinkLinkTransaction(stp)\n try:\n handle_txn(txn, prefix, args, False, True)\n except PackagesNotFoundError:\n print(\"No packages found in %s. Continuing environment removal\" % prefix)\n if not context.dry_run:\n rm_rf(prefix, clean_empty_parents=True)\n unregister_env(prefix)\n\n return\n\n else:\n if args.features:\n specs = tuple(MatchSpec(track_features=f) for f in set(args.package_names))\n else:\n specs = specs_from_args(args.package_names)\n channel_urls = ()\n subdirs = ()\n solver = Solver(prefix, channel_urls, subdirs, specs_to_remove=specs)\n txn = solver.solve_for_transaction()\n handle_txn(txn, prefix, args, False, True)\n\n # Keep this code for dev reference until private envs can be re-enabled in\n # Solver.solve_for_transaction\n\n # specs = None\n # if args.features:\n # specs = [MatchSpec(track_features=f) for f in set(args.package_names)]\n # actions = remove_actions(prefix, specs, index, pinned=not context.ignore_pinned)\n # actions['ACTION'] = 'REMOVE_FEATURE'\n # action_groups = (actions, index),\n # elif args.all:\n # if prefix == context.root_prefix:\n # raise CondaEnvironmentError('cannot remove root environment,\\n'\n # ' add -n NAME or -p PREFIX option')\n # actions = defaultdict(list)\n # actions[PREFIX] = prefix\n # for dist in sorted(iterkeys(index)):\n # add_unlink(actions, dist)\n # actions['ACTION'] = 'REMOVE_ALL'\n # action_groups = (actions, index),\n # elif prefix == context.root_prefix and not context.prefix_specified:\n # from ..core.envs_manager import EnvsDirectory\n # ed = EnvsDirectory(join(context.root_prefix, 'envs'))\n # get_env = lambda s: ed.get_registered_preferred_env(MatchSpec(s).name)\n # specs = specs_from_args(args.package_names)\n # env_spec_map = groupby(get_env, specs)\n # action_groups = []\n # for env_name, spcs in iteritems(env_spec_map):\n # pfx = ed.to_prefix(env_name)\n # r = get_resolve_object(index.copy(), pfx)\n # specs_to_remove = tuple(MatchSpec(s) for s in spcs)\n # prune = pfx != context.root_prefix\n # dists_for_unlinking, dists_for_linking = solve_for_actions(\n # pfx, r,\n # specs_to_remove=specs_to_remove, prune=prune,\n # )\n # actions = get_blank_actions(pfx)\n # actions['UNLINK'].extend(dists_for_unlinking)\n # actions['LINK'].extend(dists_for_linking)\n # actions['SPECS'].extend(text_type(s) for s in specs_to_remove)\n # actions['ACTION'] = 'REMOVE'\n # action_groups.append((actions, r.index))\n # action_groups = tuple(action_groups)\n # else:\n # specs = specs_from_args(args.package_names)\n # if sys.prefix == abspath(prefix) and names_in_specs(ROOT_NO_RM, specs) and not args.force: # NOQA\n # raise CondaEnvironmentError('cannot remove %s from root environment' %\n # ', '.join(ROOT_NO_RM))\n # action_groups = (remove_actions(prefix, list(specs), index=index,\n # force=args.force,\n # pinned=not context.ignore_pinned,\n # ), index),\n #\n #\n # delete_trash()\n # if any(nothing_to_do(x[0]) for x in action_groups):\n # if args.all:\n # print(\"\\nRemove all packages in environment %s:\\n\" % prefix, file=sys.stderr)\n # if not context.json:\n # confirm_yn(args)\n # rm_rf(prefix)\n #\n # if context.json:\n # stdout_json({\n # 'success': True,\n # 'actions': tuple(x[0] for x in action_groups)\n # })\n # return\n #\n # pkg = str(args.package_names).replace(\"['\", \"\")\n # pkg = pkg.replace(\"']\", \"\")\n #\n # error_message = \"No packages named '%s' found to remove from environment.\" % pkg\n # raise PackageNotFoundError(error_message)\n # if not context.json:\n # for actions, ndx in action_groups:\n # print()\n # print(\"Package plan for package removal in environment %s:\" % actions[\"PREFIX\"])\n # display_actions(actions, ndx)\n # elif context.json and args.dry_run:\n # stdout_json({\n # 'success': True,\n # 'dry_run': True,\n # 'actions': tuple(x[0] for x in action_groups),\n # })\n # return\n #\n # if not context.json:\n # confirm_yn(args)\n #\n # for actions, ndx in action_groups:\n # if context.json and not context.quiet:\n # with json_progress_bars():\n # execute_actions(actions, ndx, verbose=not context.quiet)\n # else:\n # execute_actions(actions, ndx, verbose=not context.quiet)\n #\n # target_prefix = actions[\"PREFIX\"]\n # if is_private_env_path(target_prefix) and linked_data(target_prefix) == {}:\n # rm_rf(target_prefix)\n #\n # if args.all:\n # rm_rf(prefix)\n #\n # if context.json:\n # stdout_json({\n # 'success': True,\n # 'actions': tuple(x[0] for x in action_groups),\n # })\n", "path": "conda/cli/main_remove.py"}]}
| 3,532 | 131 |
gh_patches_debug_21401
|
rasdani/github-patches
|
git_diff
|
ultrabug__py3status-551
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Runtime error (BrokenPipeError) helpers.py line 11
When restarting i3 using `i3 restart`, error bar pops up with message `py3status: Runtime error (BrokenPipeError) helpers.py line 11. Please try to fix this and reload i3wm (Mod+Shift+R)`
Everything appears to be functioning and the bar still shows.
Running Ubuntu 16.04
py3status 3.1
python 3.5.2
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `py3status/__init__.py`
Content:
```
1 import locale
2 import sys
3
4 from py3status.core import Py3statusWrapper
5
6 try:
7 from setproctitle import setproctitle
8 setproctitle('py3status')
9 except ImportError:
10 pass
11
12
13 def main():
14 try:
15 locale.setlocale(locale.LC_ALL, '')
16 except locale.Error:
17 print('No locale available')
18 sys.exit(2)
19
20 py3 = None
21 try:
22 py3 = Py3statusWrapper()
23 py3.setup()
24 except KeyboardInterrupt:
25 if py3:
26 py3.notify_user('Setup interrupted (KeyboardInterrupt).')
27 sys.exit(0)
28 except Exception as e:
29 if py3:
30 py3.report_exception('Setup error')
31 else:
32 # we cannot report this Exception
33 raise e
34 sys.exit(2)
35
36 try:
37 py3.run()
38 except Exception:
39 py3.report_exception('Runtime error')
40 sys.exit(3)
41 except KeyboardInterrupt:
42 pass
43 finally:
44 py3.stop()
45 sys.exit(0)
46
47
48 if __name__ == '__main__':
49 main()
50
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/py3status/__init__.py b/py3status/__init__.py
--- a/py3status/__init__.py
+++ b/py3status/__init__.py
@@ -9,6 +9,13 @@
except ImportError:
pass
+try:
+ # python3
+ IOPipeError = BrokenPipeError
+except NameError:
+ # python2
+ IOPipeError = IOError
+
def main():
try:
@@ -21,9 +28,9 @@
try:
py3 = Py3statusWrapper()
py3.setup()
- except KeyboardInterrupt:
+ except (IOPipeError, KeyboardInterrupt):
if py3:
- py3.notify_user('Setup interrupted (KeyboardInterrupt).')
+ py3.notify_user('Setup interrupted')
sys.exit(0)
except Exception as e:
if py3:
@@ -35,11 +42,11 @@
try:
py3.run()
+ except (IOPipeError, KeyboardInterrupt):
+ pass
except Exception:
py3.report_exception('Runtime error')
sys.exit(3)
- except KeyboardInterrupt:
- pass
finally:
py3.stop()
sys.exit(0)
|
{"golden_diff": "diff --git a/py3status/__init__.py b/py3status/__init__.py\n--- a/py3status/__init__.py\n+++ b/py3status/__init__.py\n@@ -9,6 +9,13 @@\n except ImportError:\n pass\n \n+try:\n+ # python3\n+ IOPipeError = BrokenPipeError\n+except NameError:\n+ # python2\n+ IOPipeError = IOError\n+\n \n def main():\n try:\n@@ -21,9 +28,9 @@\n try:\n py3 = Py3statusWrapper()\n py3.setup()\n- except KeyboardInterrupt:\n+ except (IOPipeError, KeyboardInterrupt):\n if py3:\n- py3.notify_user('Setup interrupted (KeyboardInterrupt).')\n+ py3.notify_user('Setup interrupted')\n sys.exit(0)\n except Exception as e:\n if py3:\n@@ -35,11 +42,11 @@\n \n try:\n py3.run()\n+ except (IOPipeError, KeyboardInterrupt):\n+ pass\n except Exception:\n py3.report_exception('Runtime error')\n sys.exit(3)\n- except KeyboardInterrupt:\n- pass\n finally:\n py3.stop()\n sys.exit(0)\n", "issue": "Runtime error (BrokenPipeError) helpers.py line 11\nWhen restarting i3 using `i3 restart`, error bar pops up with message `py3status: Runtime error (BrokenPipeError) helpers.py line 11. Please try to fix this and reload i3wm (Mod+Shift+R)`\n\nEverything appears to be functioning and the bar still shows.\n\nRunning Ubuntu 16.04\npy3status 3.1\npython 3.5.2\n\n", "before_files": [{"content": "import locale\nimport sys\n\nfrom py3status.core import Py3statusWrapper\n\ntry:\n from setproctitle import setproctitle\n setproctitle('py3status')\nexcept ImportError:\n pass\n\n\ndef main():\n try:\n locale.setlocale(locale.LC_ALL, '')\n except locale.Error:\n print('No locale available')\n sys.exit(2)\n\n py3 = None\n try:\n py3 = Py3statusWrapper()\n py3.setup()\n except KeyboardInterrupt:\n if py3:\n py3.notify_user('Setup interrupted (KeyboardInterrupt).')\n sys.exit(0)\n except Exception as e:\n if py3:\n py3.report_exception('Setup error')\n else:\n # we cannot report this Exception\n raise e\n sys.exit(2)\n\n try:\n py3.run()\n except Exception:\n py3.report_exception('Runtime error')\n sys.exit(3)\n except KeyboardInterrupt:\n pass\n finally:\n py3.stop()\n sys.exit(0)\n\n\nif __name__ == '__main__':\n main()\n", "path": "py3status/__init__.py"}], "after_files": [{"content": "import locale\nimport sys\n\nfrom py3status.core import Py3statusWrapper\n\ntry:\n from setproctitle import setproctitle\n setproctitle('py3status')\nexcept ImportError:\n pass\n\ntry:\n # python3\n IOPipeError = BrokenPipeError\nexcept NameError:\n # python2\n IOPipeError = IOError\n\n\ndef main():\n try:\n locale.setlocale(locale.LC_ALL, '')\n except locale.Error:\n print('No locale available')\n sys.exit(2)\n\n py3 = None\n try:\n py3 = Py3statusWrapper()\n py3.setup()\n except (IOPipeError, KeyboardInterrupt):\n if py3:\n py3.notify_user('Setup interrupted')\n sys.exit(0)\n except Exception as e:\n if py3:\n py3.report_exception('Setup error')\n else:\n # we cannot report this Exception\n raise e\n sys.exit(2)\n\n try:\n py3.run()\n except (IOPipeError, KeyboardInterrupt):\n pass\n except Exception:\n py3.report_exception('Runtime error')\n sys.exit(3)\n finally:\n py3.stop()\n sys.exit(0)\n\n\nif __name__ == '__main__':\n main()\n", "path": "py3status/__init__.py"}]}
| 695 | 276 |
gh_patches_debug_24621
|
rasdani/github-patches
|
git_diff
|
rlworkgroup__garage-2082
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Shape of env_info of HalfCheetah* environments not compatible with TrajectoryBatch
A trajectory of `HalfCheetahVel` and `HalfCheetahDir` should have an `env_info` dict of numpy array but they do not. The `task` in their `env_info` is instead a dict.
`env_info` is assumed by `TrajectoryBatch` to be a dict of numpy array.
This is a bug that will break an algorithm when it uses `HalfCheetah` together with `TrajectoryBatch`.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/garage/envs/mujoco/half_cheetah_vel_env.py`
Content:
```
1 """Variant of the HalfCheetahEnv with different target velocity."""
2 import numpy as np
3
4 from garage.envs.mujoco.half_cheetah_env_meta_base import (
5 HalfCheetahEnvMetaBase) # noqa: E501
6
7
8 class HalfCheetahVelEnv(HalfCheetahEnvMetaBase):
9 """Half-cheetah environment with target velocity, as described in [1].
10
11 The code is adapted from
12 https://github.com/cbfinn/maml_rl/blob/9c8e2ebd741cb0c7b8bf2d040c4caeeb8e06cc95/rllab/envs/mujoco/half_cheetah_env_rand.py
13
14 The half-cheetah follows the dynamics from MuJoCo [2], and receives at each
15 time step a reward composed of a control cost and a penalty equal to the
16 difference between its current velocity and the target velocity. The tasks
17 are generated by sampling the target velocities from the uniform
18 distribution on [0, 2].
19
20 [1] Chelsea Finn, Pieter Abbeel, Sergey Levine, "Model-Agnostic
21 Meta-Learning for Fast Adaptation of Deep Networks", 2017
22 (https://arxiv.org/abs/1703.03400)
23 [2] Emanuel Todorov, Tom Erez, Yuval Tassa, "MuJoCo: A physics engine for
24 model-based control", 2012
25 (https://homes.cs.washington.edu/~todorov/papers/TodorovIROS12.pdf)
26
27 Args:
28 task (dict or None):
29 velocity (float): Target velocity, usually between 0 and 2.
30
31 """
32
33 def __init__(self, task=None):
34 super().__init__(task or {'velocity': 0.})
35
36 def step(self, action):
37 """Take one step in the environment.
38
39 Equivalent to step in HalfCheetahEnv, but with different rewards.
40
41 Args:
42 action (np.ndarray): The action to take in the environment.
43
44 Returns:
45 tuple:
46 * observation (np.ndarray): The observation of the environment.
47 * reward (float): The reward acquired at this time step.
48 * done (boolean): Whether the environment was completed at this
49 time step. Always False for this environment.
50 * infos (dict):
51 * reward_forward (float): Reward for moving, ignoring the
52 control cost.
53 * reward_ctrl (float): The reward for acting i.e. the
54 control cost (always negative).
55 * task_vel (float): Target velocity.
56 Usually between 0 and 2.
57
58 """
59 xposbefore = self.sim.data.qpos[0]
60 self.do_simulation(action, self.frame_skip)
61 xposafter = self.sim.data.qpos[0]
62
63 forward_vel = (xposafter - xposbefore) / self.dt
64 forward_reward = -1.0 * abs(forward_vel - self._task['velocity'])
65 ctrl_cost = 0.5 * 1e-1 * np.sum(np.square(action))
66
67 observation = self._get_obs()
68 reward = forward_reward - ctrl_cost
69 done = False
70 infos = dict(reward_forward=forward_reward,
71 reward_ctrl=-ctrl_cost,
72 task_vel=self._task['velocity'])
73 return observation, reward, done, infos
74
75 def sample_tasks(self, num_tasks):
76 """Sample a list of `num_tasks` tasks.
77
78 Args:
79 num_tasks (int): Number of tasks to sample.
80
81 Returns:
82 list[dict[str, float]]: A list of "tasks," where each task is a
83 dictionary containing a single key, "velocity", mapping to a
84 value between 0 and 2.
85
86 """
87 velocities = self.np_random.uniform(0.0, 2.0, size=(num_tasks, ))
88 tasks = [{'velocity': velocity} for velocity in velocities]
89 return tasks
90
91 def set_task(self, task):
92 """Reset with a task.
93
94 Args:
95 task (dict[str, float]): A task (a dictionary containing a single
96 key, "velocity", usually between 0 and 2).
97
98 """
99 self._task = task
100
```
Path: `src/garage/envs/mujoco/half_cheetah_dir_env.py`
Content:
```
1 """Variant of the HalfCheetahEnv with different target directions."""
2 import numpy as np
3
4 from garage.envs.mujoco.half_cheetah_env_meta_base import (
5 HalfCheetahEnvMetaBase) # noqa: E501
6
7
8 class HalfCheetahDirEnv(HalfCheetahEnvMetaBase):
9 """Half-cheetah environment with target direction, as described in [1].
10
11 The code is adapted from
12 https://github.com/cbfinn/maml_rl/blob/9c8e2ebd741cb0c7b8bf2d040c4caeeb8e06cc95/rllab/envs/mujoco/half_cheetah_env_rand_direc.py
13
14 The half-cheetah follows the dynamics from MuJoCo [2], and receives at each
15 time step a reward composed of a control cost and a reward equal to its
16 velocity in the target direction. The tasks are generated by sampling the
17 target directions from a Bernoulli distribution on {-1, 1} with parameter
18 0.5 (-1: backward, +1: forward).
19
20 [1] Chelsea Finn, Pieter Abbeel, Sergey Levine, "Model-Agnostic
21 Meta-Learning for Fast Adaptation of Deep Networks", 2017
22 (https://arxiv.org/abs/1703.03400)
23 [2] Emanuel Todorov, Tom Erez, Yuval Tassa, "MuJoCo: A physics engine for
24 model-based control", 2012
25 (https://homes.cs.washington.edu/~todorov/papers/TodorovIROS12.pdf)
26
27 Args:
28 task (dict or None):
29 direction (float): Target direction, either -1 or 1.
30
31 """
32
33 def __init__(self, task=None):
34 super().__init__(task or {'direction': 1.})
35
36 def step(self, action):
37 """Take one step in the environment.
38
39 Equivalent to step in HalfCheetahEnv, but with different rewards.
40
41 Args:
42 action (np.ndarray): The action to take in the environment.
43
44 Raises:
45 ValueError: If the current direction is not 1.0 or -1.0.
46
47 Returns:
48 tuple:
49 * observation (np.ndarray): The observation of the environment.
50 * reward (float): The reward acquired at this time step.
51 * done (boolean): Whether the environment was completed at this
52 time step. Always False for this environment.
53 * infos (dict):
54 * reward_forward (float): Reward for moving, ignoring the
55 control cost.
56 * reward_ctrl (float): The reward for acting i.e. the
57 control cost (always negative).
58 * task_dir (float): Target direction. 1.0 for forwards,
59 -1.0 for backwards.
60
61 """
62 xposbefore = self.sim.data.qpos[0]
63 self.do_simulation(action, self.frame_skip)
64 xposafter = self.sim.data.qpos[0]
65
66 forward_vel = (xposafter - xposbefore) / self.dt
67 forward_reward = self._task['direction'] * forward_vel
68 ctrl_cost = 0.5 * 1e-1 * np.sum(np.square(action))
69
70 observation = self._get_obs()
71 reward = forward_reward - ctrl_cost
72 done = False
73 if self._task['direction'] == 1.:
74 task_name = 'fowrad'
75 elif self._task['direction'] == -1.:
76 task_name = 'backward'
77 else:
78 raise ValueError('task direction should be 1. or -1.')
79 infos = dict(reward_forward=forward_reward,
80 reward_ctrl=-ctrl_cost,
81 task_dir=self._task['direction'],
82 task_name=task_name)
83 return observation, reward, done, infos
84
85 def sample_tasks(self, num_tasks):
86 """Sample a list of `num_tasks` tasks.
87
88 Args:
89 num_tasks (int): Number of tasks to sample.
90
91 Returns:
92 list[dict[str, float]]: A list of "tasks," where each task is a
93 dictionary containing a single key, "direction", mapping to -1
94 or 1.
95
96 """
97 directions = (
98 2 * self.np_random.binomial(1, p=0.5, size=(num_tasks, )) - 1)
99 tasks = [{'direction': direction} for direction in directions]
100 return tasks
101
102 def set_task(self, task):
103 """Reset with a task.
104
105 Args:
106 task (dict[str, float]): A task (a dictionary containing a single
107 key, "direction", mapping to -1 or 1).
108
109 """
110 self._task = task
111
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/garage/envs/mujoco/half_cheetah_dir_env.py b/src/garage/envs/mujoco/half_cheetah_dir_env.py
--- a/src/garage/envs/mujoco/half_cheetah_dir_env.py
+++ b/src/garage/envs/mujoco/half_cheetah_dir_env.py
@@ -76,9 +76,9 @@
task_name = 'backward'
else:
raise ValueError('task direction should be 1. or -1.')
- infos = dict(reward_forward=forward_reward,
- reward_ctrl=-ctrl_cost,
- task_dir=self._task['direction'],
+ infos = dict(reward_forward=np.asarray([forward_reward]),
+ reward_ctrl=np.asarray([-ctrl_cost]),
+ task_dir=np.asarray([self._task['direction']]),
task_name=task_name)
return observation, reward, done, infos
diff --git a/src/garage/envs/mujoco/half_cheetah_vel_env.py b/src/garage/envs/mujoco/half_cheetah_vel_env.py
--- a/src/garage/envs/mujoco/half_cheetah_vel_env.py
+++ b/src/garage/envs/mujoco/half_cheetah_vel_env.py
@@ -67,9 +67,9 @@
observation = self._get_obs()
reward = forward_reward - ctrl_cost
done = False
- infos = dict(reward_forward=forward_reward,
- reward_ctrl=-ctrl_cost,
- task_vel=self._task['velocity'])
+ infos = dict(reward_forward=np.asarray([forward_reward]),
+ reward_ctrl=np.asarray([-ctrl_cost]),
+ task_vel=np.asarray([self._task['velocity']]))
return observation, reward, done, infos
def sample_tasks(self, num_tasks):
|
{"golden_diff": "diff --git a/src/garage/envs/mujoco/half_cheetah_dir_env.py b/src/garage/envs/mujoco/half_cheetah_dir_env.py\n--- a/src/garage/envs/mujoco/half_cheetah_dir_env.py\n+++ b/src/garage/envs/mujoco/half_cheetah_dir_env.py\n@@ -76,9 +76,9 @@\n task_name = 'backward'\n else:\n raise ValueError('task direction should be 1. or -1.')\n- infos = dict(reward_forward=forward_reward,\n- reward_ctrl=-ctrl_cost,\n- task_dir=self._task['direction'],\n+ infos = dict(reward_forward=np.asarray([forward_reward]),\n+ reward_ctrl=np.asarray([-ctrl_cost]),\n+ task_dir=np.asarray([self._task['direction']]),\n task_name=task_name)\n return observation, reward, done, infos\n \ndiff --git a/src/garage/envs/mujoco/half_cheetah_vel_env.py b/src/garage/envs/mujoco/half_cheetah_vel_env.py\n--- a/src/garage/envs/mujoco/half_cheetah_vel_env.py\n+++ b/src/garage/envs/mujoco/half_cheetah_vel_env.py\n@@ -67,9 +67,9 @@\n observation = self._get_obs()\n reward = forward_reward - ctrl_cost\n done = False\n- infos = dict(reward_forward=forward_reward,\n- reward_ctrl=-ctrl_cost,\n- task_vel=self._task['velocity'])\n+ infos = dict(reward_forward=np.asarray([forward_reward]),\n+ reward_ctrl=np.asarray([-ctrl_cost]),\n+ task_vel=np.asarray([self._task['velocity']]))\n return observation, reward, done, infos\n \n def sample_tasks(self, num_tasks):\n", "issue": "Shape of env_info of HalfCheetah* environments not compatible with TrajectoryBatch\nA trajectory of `HalfCheetahVel` and `HalfCheetahDir` should have an `env_info` dict of numpy array but they do not. The `task` in their `env_info` is instead a dict. \r\n\r\n`env_info` is assumed by `TrajectoryBatch` to be a dict of numpy array. \r\n\r\nThis is a bug that will break an algorithm when it uses `HalfCheetah` together with `TrajectoryBatch`.\n", "before_files": [{"content": "\"\"\"Variant of the HalfCheetahEnv with different target velocity.\"\"\"\nimport numpy as np\n\nfrom garage.envs.mujoco.half_cheetah_env_meta_base import (\n HalfCheetahEnvMetaBase) # noqa: E501\n\n\nclass HalfCheetahVelEnv(HalfCheetahEnvMetaBase):\n \"\"\"Half-cheetah environment with target velocity, as described in [1].\n\n The code is adapted from\n https://github.com/cbfinn/maml_rl/blob/9c8e2ebd741cb0c7b8bf2d040c4caeeb8e06cc95/rllab/envs/mujoco/half_cheetah_env_rand.py\n\n The half-cheetah follows the dynamics from MuJoCo [2], and receives at each\n time step a reward composed of a control cost and a penalty equal to the\n difference between its current velocity and the target velocity. The tasks\n are generated by sampling the target velocities from the uniform\n distribution on [0, 2].\n\n [1] Chelsea Finn, Pieter Abbeel, Sergey Levine, \"Model-Agnostic\n Meta-Learning for Fast Adaptation of Deep Networks\", 2017\n (https://arxiv.org/abs/1703.03400)\n [2] Emanuel Todorov, Tom Erez, Yuval Tassa, \"MuJoCo: A physics engine for\n model-based control\", 2012\n (https://homes.cs.washington.edu/~todorov/papers/TodorovIROS12.pdf)\n\n Args:\n task (dict or None):\n velocity (float): Target velocity, usually between 0 and 2.\n\n \"\"\"\n\n def __init__(self, task=None):\n super().__init__(task or {'velocity': 0.})\n\n def step(self, action):\n \"\"\"Take one step in the environment.\n\n Equivalent to step in HalfCheetahEnv, but with different rewards.\n\n Args:\n action (np.ndarray): The action to take in the environment.\n\n Returns:\n tuple:\n * observation (np.ndarray): The observation of the environment.\n * reward (float): The reward acquired at this time step.\n * done (boolean): Whether the environment was completed at this\n time step. Always False for this environment.\n * infos (dict):\n * reward_forward (float): Reward for moving, ignoring the\n control cost.\n * reward_ctrl (float): The reward for acting i.e. the\n control cost (always negative).\n * task_vel (float): Target velocity.\n Usually between 0 and 2.\n\n \"\"\"\n xposbefore = self.sim.data.qpos[0]\n self.do_simulation(action, self.frame_skip)\n xposafter = self.sim.data.qpos[0]\n\n forward_vel = (xposafter - xposbefore) / self.dt\n forward_reward = -1.0 * abs(forward_vel - self._task['velocity'])\n ctrl_cost = 0.5 * 1e-1 * np.sum(np.square(action))\n\n observation = self._get_obs()\n reward = forward_reward - ctrl_cost\n done = False\n infos = dict(reward_forward=forward_reward,\n reward_ctrl=-ctrl_cost,\n task_vel=self._task['velocity'])\n return observation, reward, done, infos\n\n def sample_tasks(self, num_tasks):\n \"\"\"Sample a list of `num_tasks` tasks.\n\n Args:\n num_tasks (int): Number of tasks to sample.\n\n Returns:\n list[dict[str, float]]: A list of \"tasks,\" where each task is a\n dictionary containing a single key, \"velocity\", mapping to a\n value between 0 and 2.\n\n \"\"\"\n velocities = self.np_random.uniform(0.0, 2.0, size=(num_tasks, ))\n tasks = [{'velocity': velocity} for velocity in velocities]\n return tasks\n\n def set_task(self, task):\n \"\"\"Reset with a task.\n\n Args:\n task (dict[str, float]): A task (a dictionary containing a single\n key, \"velocity\", usually between 0 and 2).\n\n \"\"\"\n self._task = task\n", "path": "src/garage/envs/mujoco/half_cheetah_vel_env.py"}, {"content": "\"\"\"Variant of the HalfCheetahEnv with different target directions.\"\"\"\nimport numpy as np\n\nfrom garage.envs.mujoco.half_cheetah_env_meta_base import (\n HalfCheetahEnvMetaBase) # noqa: E501\n\n\nclass HalfCheetahDirEnv(HalfCheetahEnvMetaBase):\n \"\"\"Half-cheetah environment with target direction, as described in [1].\n\n The code is adapted from\n https://github.com/cbfinn/maml_rl/blob/9c8e2ebd741cb0c7b8bf2d040c4caeeb8e06cc95/rllab/envs/mujoco/half_cheetah_env_rand_direc.py\n\n The half-cheetah follows the dynamics from MuJoCo [2], and receives at each\n time step a reward composed of a control cost and a reward equal to its\n velocity in the target direction. The tasks are generated by sampling the\n target directions from a Bernoulli distribution on {-1, 1} with parameter\n 0.5 (-1: backward, +1: forward).\n\n [1] Chelsea Finn, Pieter Abbeel, Sergey Levine, \"Model-Agnostic\n Meta-Learning for Fast Adaptation of Deep Networks\", 2017\n (https://arxiv.org/abs/1703.03400)\n [2] Emanuel Todorov, Tom Erez, Yuval Tassa, \"MuJoCo: A physics engine for\n model-based control\", 2012\n (https://homes.cs.washington.edu/~todorov/papers/TodorovIROS12.pdf)\n\n Args:\n task (dict or None):\n direction (float): Target direction, either -1 or 1.\n\n \"\"\"\n\n def __init__(self, task=None):\n super().__init__(task or {'direction': 1.})\n\n def step(self, action):\n \"\"\"Take one step in the environment.\n\n Equivalent to step in HalfCheetahEnv, but with different rewards.\n\n Args:\n action (np.ndarray): The action to take in the environment.\n\n Raises:\n ValueError: If the current direction is not 1.0 or -1.0.\n\n Returns:\n tuple:\n * observation (np.ndarray): The observation of the environment.\n * reward (float): The reward acquired at this time step.\n * done (boolean): Whether the environment was completed at this\n time step. Always False for this environment.\n * infos (dict):\n * reward_forward (float): Reward for moving, ignoring the\n control cost.\n * reward_ctrl (float): The reward for acting i.e. the\n control cost (always negative).\n * task_dir (float): Target direction. 1.0 for forwards,\n -1.0 for backwards.\n\n \"\"\"\n xposbefore = self.sim.data.qpos[0]\n self.do_simulation(action, self.frame_skip)\n xposafter = self.sim.data.qpos[0]\n\n forward_vel = (xposafter - xposbefore) / self.dt\n forward_reward = self._task['direction'] * forward_vel\n ctrl_cost = 0.5 * 1e-1 * np.sum(np.square(action))\n\n observation = self._get_obs()\n reward = forward_reward - ctrl_cost\n done = False\n if self._task['direction'] == 1.:\n task_name = 'fowrad'\n elif self._task['direction'] == -1.:\n task_name = 'backward'\n else:\n raise ValueError('task direction should be 1. or -1.')\n infos = dict(reward_forward=forward_reward,\n reward_ctrl=-ctrl_cost,\n task_dir=self._task['direction'],\n task_name=task_name)\n return observation, reward, done, infos\n\n def sample_tasks(self, num_tasks):\n \"\"\"Sample a list of `num_tasks` tasks.\n\n Args:\n num_tasks (int): Number of tasks to sample.\n\n Returns:\n list[dict[str, float]]: A list of \"tasks,\" where each task is a\n dictionary containing a single key, \"direction\", mapping to -1\n or 1.\n\n \"\"\"\n directions = (\n 2 * self.np_random.binomial(1, p=0.5, size=(num_tasks, )) - 1)\n tasks = [{'direction': direction} for direction in directions]\n return tasks\n\n def set_task(self, task):\n \"\"\"Reset with a task.\n\n Args:\n task (dict[str, float]): A task (a dictionary containing a single\n key, \"direction\", mapping to -1 or 1).\n\n \"\"\"\n self._task = task\n", "path": "src/garage/envs/mujoco/half_cheetah_dir_env.py"}], "after_files": [{"content": "\"\"\"Variant of the HalfCheetahEnv with different target velocity.\"\"\"\nimport numpy as np\n\nfrom garage.envs.mujoco.half_cheetah_env_meta_base import (\n HalfCheetahEnvMetaBase) # noqa: E501\n\n\nclass HalfCheetahVelEnv(HalfCheetahEnvMetaBase):\n \"\"\"Half-cheetah environment with target velocity, as described in [1].\n\n The code is adapted from\n https://github.com/cbfinn/maml_rl/blob/9c8e2ebd741cb0c7b8bf2d040c4caeeb8e06cc95/rllab/envs/mujoco/half_cheetah_env_rand.py\n\n The half-cheetah follows the dynamics from MuJoCo [2], and receives at each\n time step a reward composed of a control cost and a penalty equal to the\n difference between its current velocity and the target velocity. The tasks\n are generated by sampling the target velocities from the uniform\n distribution on [0, 2].\n\n [1] Chelsea Finn, Pieter Abbeel, Sergey Levine, \"Model-Agnostic\n Meta-Learning for Fast Adaptation of Deep Networks\", 2017\n (https://arxiv.org/abs/1703.03400)\n [2] Emanuel Todorov, Tom Erez, Yuval Tassa, \"MuJoCo: A physics engine for\n model-based control\", 2012\n (https://homes.cs.washington.edu/~todorov/papers/TodorovIROS12.pdf)\n\n Args:\n task (dict or None):\n velocity (float): Target velocity, usually between 0 and 2.\n\n \"\"\"\n\n def __init__(self, task=None):\n super().__init__(task or {'velocity': 0.})\n\n def step(self, action):\n \"\"\"Take one step in the environment.\n\n Equivalent to step in HalfCheetahEnv, but with different rewards.\n\n Args:\n action (np.ndarray): The action to take in the environment.\n\n Returns:\n tuple:\n * observation (np.ndarray): The observation of the environment.\n * reward (float): The reward acquired at this time step.\n * done (boolean): Whether the environment was completed at this\n time step. Always False for this environment.\n * infos (dict):\n * reward_forward (float): Reward for moving, ignoring the\n control cost.\n * reward_ctrl (float): The reward for acting i.e. the\n control cost (always negative).\n * task_vel (float): Target velocity.\n Usually between 0 and 2.\n\n \"\"\"\n xposbefore = self.sim.data.qpos[0]\n self.do_simulation(action, self.frame_skip)\n xposafter = self.sim.data.qpos[0]\n\n forward_vel = (xposafter - xposbefore) / self.dt\n forward_reward = -1.0 * abs(forward_vel - self._task['velocity'])\n ctrl_cost = 0.5 * 1e-1 * np.sum(np.square(action))\n\n observation = self._get_obs()\n reward = forward_reward - ctrl_cost\n done = False\n infos = dict(reward_forward=np.asarray([forward_reward]),\n reward_ctrl=np.asarray([-ctrl_cost]),\n task_vel=np.asarray([self._task['velocity']]))\n return observation, reward, done, infos\n\n def sample_tasks(self, num_tasks):\n \"\"\"Sample a list of `num_tasks` tasks.\n\n Args:\n num_tasks (int): Number of tasks to sample.\n\n Returns:\n list[dict[str, float]]: A list of \"tasks,\" where each task is a\n dictionary containing a single key, \"velocity\", mapping to a\n value between 0 and 2.\n\n \"\"\"\n velocities = self.np_random.uniform(0.0, 2.0, size=(num_tasks, ))\n tasks = [{'velocity': velocity} for velocity in velocities]\n return tasks\n\n def set_task(self, task):\n \"\"\"Reset with a task.\n\n Args:\n task (dict[str, float]): A task (a dictionary containing a single\n key, \"velocity\", usually between 0 and 2).\n\n \"\"\"\n self._task = task\n", "path": "src/garage/envs/mujoco/half_cheetah_vel_env.py"}, {"content": "\"\"\"Variant of the HalfCheetahEnv with different target directions.\"\"\"\nimport numpy as np\n\nfrom garage.envs.mujoco.half_cheetah_env_meta_base import (\n HalfCheetahEnvMetaBase) # noqa: E501\n\n\nclass HalfCheetahDirEnv(HalfCheetahEnvMetaBase):\n \"\"\"Half-cheetah environment with target direction, as described in [1].\n\n The code is adapted from\n https://github.com/cbfinn/maml_rl/blob/9c8e2ebd741cb0c7b8bf2d040c4caeeb8e06cc95/rllab/envs/mujoco/half_cheetah_env_rand_direc.py\n\n The half-cheetah follows the dynamics from MuJoCo [2], and receives at each\n time step a reward composed of a control cost and a reward equal to its\n velocity in the target direction. The tasks are generated by sampling the\n target directions from a Bernoulli distribution on {-1, 1} with parameter\n 0.5 (-1: backward, +1: forward).\n\n [1] Chelsea Finn, Pieter Abbeel, Sergey Levine, \"Model-Agnostic\n Meta-Learning for Fast Adaptation of Deep Networks\", 2017\n (https://arxiv.org/abs/1703.03400)\n [2] Emanuel Todorov, Tom Erez, Yuval Tassa, \"MuJoCo: A physics engine for\n model-based control\", 2012\n (https://homes.cs.washington.edu/~todorov/papers/TodorovIROS12.pdf)\n\n Args:\n task (dict or None):\n direction (float): Target direction, either -1 or 1.\n\n \"\"\"\n\n def __init__(self, task=None):\n super().__init__(task or {'direction': 1.})\n\n def step(self, action):\n \"\"\"Take one step in the environment.\n\n Equivalent to step in HalfCheetahEnv, but with different rewards.\n\n Args:\n action (np.ndarray): The action to take in the environment.\n\n Raises:\n ValueError: If the current direction is not 1.0 or -1.0.\n\n Returns:\n tuple:\n * observation (np.ndarray): The observation of the environment.\n * reward (float): The reward acquired at this time step.\n * done (boolean): Whether the environment was completed at this\n time step. Always False for this environment.\n * infos (dict):\n * reward_forward (float): Reward for moving, ignoring the\n control cost.\n * reward_ctrl (float): The reward for acting i.e. the\n control cost (always negative).\n * task_dir (float): Target direction. 1.0 for forwards,\n -1.0 for backwards.\n\n \"\"\"\n xposbefore = self.sim.data.qpos[0]\n self.do_simulation(action, self.frame_skip)\n xposafter = self.sim.data.qpos[0]\n\n forward_vel = (xposafter - xposbefore) / self.dt\n forward_reward = self._task['direction'] * forward_vel\n ctrl_cost = 0.5 * 1e-1 * np.sum(np.square(action))\n\n observation = self._get_obs()\n reward = forward_reward - ctrl_cost\n done = False\n if self._task['direction'] == 1.:\n task_name = 'fowrad'\n elif self._task['direction'] == -1.:\n task_name = 'backward'\n else:\n raise ValueError('task direction should be 1. or -1.')\n infos = dict(reward_forward=np.asarray([forward_reward]),\n reward_ctrl=np.asarray([-ctrl_cost]),\n task_dir=np.asarray([self._task['direction']]),\n task_name=task_name)\n return observation, reward, done, infos\n\n def sample_tasks(self, num_tasks):\n \"\"\"Sample a list of `num_tasks` tasks.\n\n Args:\n num_tasks (int): Number of tasks to sample.\n\n Returns:\n list[dict[str, float]]: A list of \"tasks,\" where each task is a\n dictionary containing a single key, \"direction\", mapping to -1\n or 1.\n\n \"\"\"\n directions = (\n 2 * self.np_random.binomial(1, p=0.5, size=(num_tasks, )) - 1)\n tasks = [{'direction': direction} for direction in directions]\n return tasks\n\n def set_task(self, task):\n \"\"\"Reset with a task.\n\n Args:\n task (dict[str, float]): A task (a dictionary containing a single\n key, \"direction\", mapping to -1 or 1).\n\n \"\"\"\n self._task = task\n", "path": "src/garage/envs/mujoco/half_cheetah_dir_env.py"}]}
| 2,822 | 403 |
gh_patches_debug_35140
|
rasdani/github-patches
|
git_diff
|
litestar-org__litestar-1669
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bug: Annotated Types not being rendered in OpenAPI schema
### Description
I've got a `msgspec.Struct` request object that uses an `typing.Annotated` type as one of it's field types.
When viewing routes request object, I'm only seeing a str or null allowed but no mention of the max length piece. This also happens when I exclude the `| None` from the type declaration as well.
### URL to code causing the issue
_No response_
### MCVE
```python
from typing import Annotated
import msgspec
IDType = Annotated[str, msgspec.Meta(max_length=16)]
class Lookup(msgspec.Struct):
id: IDType | None
```
### Steps to reproduce
```bash
1. Create route with the above request object.
2. View the route in the /schema endpoint.
```
### Screenshots
_No response_
### Logs
_No response_
### Litestar Version
2.0.0a5
### Platform
- [X] Linux
- [ ] Mac
- [ ] Windows
- [ ] Other (Please specify in the description above)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `litestar/_signature/field.py`
Content:
```
1 from __future__ import annotations
2
3 from dataclasses import dataclass
4 from typing import Any, Literal
5
6 from typing_extensions import get_args, get_origin
7
8 from litestar.constants import UNDEFINED_SENTINELS
9 from litestar.params import BodyKwarg, DependencyKwarg, ParameterKwarg
10 from litestar.types import Empty
11 from litestar.utils.predicates import (
12 is_any,
13 is_generic,
14 is_mapping,
15 is_non_string_iterable,
16 is_non_string_sequence,
17 is_optional_union,
18 is_union,
19 )
20 from litestar.utils.typing import make_non_optional_union
21
22 __all__ = ("SignatureField",)
23
24
25 @dataclass(unsafe_hash=True, frozen=True)
26 class SignatureField:
27 """Abstraction representing a model field. This class is meant to replace equivalent datastructures from other
28 libraries, for example, pydantic or msgspec.
29 """
30
31 __slots__ = (
32 "children",
33 "default_value",
34 "extra",
35 "field_type",
36 "kwarg_model",
37 "name",
38 )
39
40 children: tuple[SignatureField, ...] | None
41 """A mapping of subtypes, if any."""
42 default_value: Any
43 """Field name."""
44 extra: dict[str, Any]
45 """A mapping of extra values."""
46 field_type: Any
47 """The type of the kwarg."""
48 kwarg_model: ParameterKwarg | BodyKwarg | DependencyKwarg | None
49 """Kwarg Parameter."""
50 name: str
51 """Field name."""
52
53 @property
54 def is_empty(self) -> bool:
55 """Check if the default value is an empty type.
56
57 Returns:
58 True if the default_value is Empty or Ellipsis otherwise False.
59 """
60 return self.default_value is Empty or self.default_value is Ellipsis
61
62 @property
63 def is_optional(self) -> bool:
64 """Check if the field type is an Optional union.
65
66 Returns:
67 True if the field_type is an Optional union otherwise False.
68 """
69 return is_optional_union(self.field_type)
70
71 @property
72 def is_mapping(self) -> bool:
73 """Check if the field type is a Mapping."""
74 return is_mapping(self.field_type)
75
76 @property
77 def is_non_string_iterable(self) -> bool:
78 """Check if the field type is an Iterable.
79
80 If ``self.field_type`` is an optional union, only the non-optional members of the union are evaluated.
81
82 See: https://github.com/litestar-org/litestar/issues/1106
83 """
84 field_type = self.field_type
85 if self.is_optional:
86 field_type = make_non_optional_union(field_type)
87 return is_non_string_iterable(field_type)
88
89 @property
90 def is_non_string_sequence(self) -> bool:
91 """Check if the field type is a non-string Sequence.
92
93 If ``self.field_type`` is an optional union, only the non-optional members of the union are evaluated.
94
95 See: https://github.com/litestar-org/litestar/issues/1106
96 """
97 field_type = self.field_type
98 if self.is_optional:
99 field_type = make_non_optional_union(field_type)
100 return is_non_string_sequence(field_type)
101
102 @property
103 def is_any(self) -> bool:
104 """Check if the field type is Any."""
105 return is_any(self.field_type)
106
107 @property
108 def is_union(self) -> bool:
109 """Check if the field type is a Union."""
110 return is_union(self.field_type)
111
112 @property
113 def is_generic(self) -> bool:
114 """Check if the field type is a custom class extending Generic."""
115 return is_generic(self.field_type)
116
117 @property
118 def is_simple_type(self) -> bool:
119 """Check if the field type is a singleton value (e.g. int, str etc.)."""
120 return not (
121 self.is_generic or self.is_optional or self.is_union or self.is_mapping or self.is_non_string_iterable
122 )
123
124 @property
125 def is_parameter_field(self) -> bool:
126 """Check if the field type is a parameter kwarg value."""
127 return self.kwarg_model is not None and isinstance(self.kwarg_model, ParameterKwarg)
128
129 @property
130 def is_const(self) -> bool:
131 """Check if the field is defined as constant value."""
132 return bool(self.kwarg_model and getattr(self.kwarg_model, "const", False))
133
134 @property
135 def is_required(self) -> bool:
136 """Check if the field should be marked as a required parameter."""
137 if isinstance(self.kwarg_model, ParameterKwarg) and self.kwarg_model.required is not None:
138 return self.kwarg_model.required
139
140 return not (self.is_optional or self.is_any) and (self.is_empty or self.default_value is None)
141
142 @property
143 def is_literal(self) -> bool:
144 """Check if the field type is Literal."""
145 return get_origin(self.field_type) is Literal
146
147 @classmethod
148 def create(
149 cls,
150 field_type: Any,
151 name: str = "",
152 default_value: Any = Empty,
153 children: tuple[SignatureField, ...] | None = None,
154 kwarg_model: ParameterKwarg | BodyKwarg | DependencyKwarg | None = None,
155 extra: dict[str, Any] | None = None,
156 ) -> SignatureField:
157 """Create a new SignatureModel instance.
158
159 Args:
160 field_type: The type of the kwarg.
161 name: Field name.
162 default_value: A default value.
163 children: A mapping of subtypes, if any.
164 kwarg_model: Kwarg Parameter.
165 extra: A mapping of extra values.
166
167 Returns:
168 SignatureField instance.
169 """
170 if kwarg_model and default_value is Empty:
171 default_value = kwarg_model.default
172
173 if not children and get_origin(field_type) and (type_args := get_args(field_type)):
174 children = tuple(SignatureField.create(arg) for arg in type_args)
175
176 return SignatureField(
177 name=name,
178 field_type=field_type if field_type is not Empty else Any,
179 default_value=default_value if default_value not in UNDEFINED_SENTINELS else Empty,
180 children=children,
181 kwarg_model=kwarg_model,
182 extra=extra or {},
183 )
184
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/litestar/_signature/field.py b/litestar/_signature/field.py
--- a/litestar/_signature/field.py
+++ b/litestar/_signature/field.py
@@ -3,7 +3,8 @@
from dataclasses import dataclass
from typing import Any, Literal
-from typing_extensions import get_args, get_origin
+from msgspec import Meta
+from typing_extensions import Annotated, get_args, get_origin
from litestar.constants import UNDEFINED_SENTINELS
from litestar.params import BodyKwarg, DependencyKwarg, ParameterKwarg
@@ -22,6 +23,26 @@
__all__ = ("SignatureField",)
+def _create_metadata_from_type(
+ value: Any, model: type[ParameterKwarg] | type[BodyKwarg], field_type: Any
+) -> ParameterKwarg | BodyKwarg | None:
+ if isinstance(value, Meta):
+ is_sequence_container = is_non_string_sequence(field_type)
+ return model(
+ gt=value.gt,
+ ge=value.ge,
+ lt=value.lt,
+ le=value.le,
+ multiple_of=value.multiple_of,
+ regex=value.pattern,
+ min_length=value.min_length if not is_sequence_container else None,
+ max_length=value.max_length if not is_sequence_container else None,
+ min_items=value.min_length if is_sequence_container else None,
+ max_items=value.max_length if is_sequence_container else None,
+ )
+ return None
+
+
@dataclass(unsafe_hash=True, frozen=True)
class SignatureField:
"""Abstraction representing a model field. This class is meant to replace equivalent datastructures from other
@@ -170,8 +191,17 @@
if kwarg_model and default_value is Empty:
default_value = kwarg_model.default
- if not children and get_origin(field_type) and (type_args := get_args(field_type)):
- children = tuple(SignatureField.create(arg) for arg in type_args)
+ origin = get_origin(field_type)
+
+ if not children and origin and (type_args := get_args(field_type)):
+ if origin is Annotated:
+ field_type = type_args[0]
+ if not kwarg_model:
+ kwarg_model = _create_metadata_from_type(
+ type_args[1], BodyKwarg if name == "data" else ParameterKwarg, field_type=field_type
+ )
+ else:
+ children = tuple(SignatureField.create(arg) for arg in type_args)
return SignatureField(
name=name,
|
{"golden_diff": "diff --git a/litestar/_signature/field.py b/litestar/_signature/field.py\n--- a/litestar/_signature/field.py\n+++ b/litestar/_signature/field.py\n@@ -3,7 +3,8 @@\n from dataclasses import dataclass\n from typing import Any, Literal\n \n-from typing_extensions import get_args, get_origin\n+from msgspec import Meta\n+from typing_extensions import Annotated, get_args, get_origin\n \n from litestar.constants import UNDEFINED_SENTINELS\n from litestar.params import BodyKwarg, DependencyKwarg, ParameterKwarg\n@@ -22,6 +23,26 @@\n __all__ = (\"SignatureField\",)\n \n \n+def _create_metadata_from_type(\n+ value: Any, model: type[ParameterKwarg] | type[BodyKwarg], field_type: Any\n+) -> ParameterKwarg | BodyKwarg | None:\n+ if isinstance(value, Meta):\n+ is_sequence_container = is_non_string_sequence(field_type)\n+ return model(\n+ gt=value.gt,\n+ ge=value.ge,\n+ lt=value.lt,\n+ le=value.le,\n+ multiple_of=value.multiple_of,\n+ regex=value.pattern,\n+ min_length=value.min_length if not is_sequence_container else None,\n+ max_length=value.max_length if not is_sequence_container else None,\n+ min_items=value.min_length if is_sequence_container else None,\n+ max_items=value.max_length if is_sequence_container else None,\n+ )\n+ return None\n+\n+\n @dataclass(unsafe_hash=True, frozen=True)\n class SignatureField:\n \"\"\"Abstraction representing a model field. This class is meant to replace equivalent datastructures from other\n@@ -170,8 +191,17 @@\n if kwarg_model and default_value is Empty:\n default_value = kwarg_model.default\n \n- if not children and get_origin(field_type) and (type_args := get_args(field_type)):\n- children = tuple(SignatureField.create(arg) for arg in type_args)\n+ origin = get_origin(field_type)\n+\n+ if not children and origin and (type_args := get_args(field_type)):\n+ if origin is Annotated:\n+ field_type = type_args[0]\n+ if not kwarg_model:\n+ kwarg_model = _create_metadata_from_type(\n+ type_args[1], BodyKwarg if name == \"data\" else ParameterKwarg, field_type=field_type\n+ )\n+ else:\n+ children = tuple(SignatureField.create(arg) for arg in type_args)\n \n return SignatureField(\n name=name,\n", "issue": "Bug: Annotated Types not being rendered in OpenAPI schema\n### Description\n\nI've got a `msgspec.Struct` request object that uses an `typing.Annotated` type as one of it's field types.\r\n\r\nWhen viewing routes request object, I'm only seeing a str or null allowed but no mention of the max length piece. This also happens when I exclude the `| None` from the type declaration as well.\n\n### URL to code causing the issue\n\n_No response_\n\n### MCVE\n\n```python\nfrom typing import Annotated\r\nimport msgspec\r\n\r\nIDType = Annotated[str, msgspec.Meta(max_length=16)]\r\n\r\nclass Lookup(msgspec.Struct):\r\n id: IDType | None\n```\n\n\n### Steps to reproduce\n\n```bash\n1. Create route with the above request object.\r\n2. View the route in the /schema endpoint.\n```\n\n\n### Screenshots\n\n_No response_\n\n### Logs\n\n_No response_\n\n### Litestar Version\n\n2.0.0a5\n\n### Platform\n\n- [X] Linux\n- [ ] Mac\n- [ ] Windows\n- [ ] Other (Please specify in the description above)\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom dataclasses import dataclass\nfrom typing import Any, Literal\n\nfrom typing_extensions import get_args, get_origin\n\nfrom litestar.constants import UNDEFINED_SENTINELS\nfrom litestar.params import BodyKwarg, DependencyKwarg, ParameterKwarg\nfrom litestar.types import Empty\nfrom litestar.utils.predicates import (\n is_any,\n is_generic,\n is_mapping,\n is_non_string_iterable,\n is_non_string_sequence,\n is_optional_union,\n is_union,\n)\nfrom litestar.utils.typing import make_non_optional_union\n\n__all__ = (\"SignatureField\",)\n\n\n@dataclass(unsafe_hash=True, frozen=True)\nclass SignatureField:\n \"\"\"Abstraction representing a model field. This class is meant to replace equivalent datastructures from other\n libraries, for example, pydantic or msgspec.\n \"\"\"\n\n __slots__ = (\n \"children\",\n \"default_value\",\n \"extra\",\n \"field_type\",\n \"kwarg_model\",\n \"name\",\n )\n\n children: tuple[SignatureField, ...] | None\n \"\"\"A mapping of subtypes, if any.\"\"\"\n default_value: Any\n \"\"\"Field name.\"\"\"\n extra: dict[str, Any]\n \"\"\"A mapping of extra values.\"\"\"\n field_type: Any\n \"\"\"The type of the kwarg.\"\"\"\n kwarg_model: ParameterKwarg | BodyKwarg | DependencyKwarg | None\n \"\"\"Kwarg Parameter.\"\"\"\n name: str\n \"\"\"Field name.\"\"\"\n\n @property\n def is_empty(self) -> bool:\n \"\"\"Check if the default value is an empty type.\n\n Returns:\n True if the default_value is Empty or Ellipsis otherwise False.\n \"\"\"\n return self.default_value is Empty or self.default_value is Ellipsis\n\n @property\n def is_optional(self) -> bool:\n \"\"\"Check if the field type is an Optional union.\n\n Returns:\n True if the field_type is an Optional union otherwise False.\n \"\"\"\n return is_optional_union(self.field_type)\n\n @property\n def is_mapping(self) -> bool:\n \"\"\"Check if the field type is a Mapping.\"\"\"\n return is_mapping(self.field_type)\n\n @property\n def is_non_string_iterable(self) -> bool:\n \"\"\"Check if the field type is an Iterable.\n\n If ``self.field_type`` is an optional union, only the non-optional members of the union are evaluated.\n\n See: https://github.com/litestar-org/litestar/issues/1106\n \"\"\"\n field_type = self.field_type\n if self.is_optional:\n field_type = make_non_optional_union(field_type)\n return is_non_string_iterable(field_type)\n\n @property\n def is_non_string_sequence(self) -> bool:\n \"\"\"Check if the field type is a non-string Sequence.\n\n If ``self.field_type`` is an optional union, only the non-optional members of the union are evaluated.\n\n See: https://github.com/litestar-org/litestar/issues/1106\n \"\"\"\n field_type = self.field_type\n if self.is_optional:\n field_type = make_non_optional_union(field_type)\n return is_non_string_sequence(field_type)\n\n @property\n def is_any(self) -> bool:\n \"\"\"Check if the field type is Any.\"\"\"\n return is_any(self.field_type)\n\n @property\n def is_union(self) -> bool:\n \"\"\"Check if the field type is a Union.\"\"\"\n return is_union(self.field_type)\n\n @property\n def is_generic(self) -> bool:\n \"\"\"Check if the field type is a custom class extending Generic.\"\"\"\n return is_generic(self.field_type)\n\n @property\n def is_simple_type(self) -> bool:\n \"\"\"Check if the field type is a singleton value (e.g. int, str etc.).\"\"\"\n return not (\n self.is_generic or self.is_optional or self.is_union or self.is_mapping or self.is_non_string_iterable\n )\n\n @property\n def is_parameter_field(self) -> bool:\n \"\"\"Check if the field type is a parameter kwarg value.\"\"\"\n return self.kwarg_model is not None and isinstance(self.kwarg_model, ParameterKwarg)\n\n @property\n def is_const(self) -> bool:\n \"\"\"Check if the field is defined as constant value.\"\"\"\n return bool(self.kwarg_model and getattr(self.kwarg_model, \"const\", False))\n\n @property\n def is_required(self) -> bool:\n \"\"\"Check if the field should be marked as a required parameter.\"\"\"\n if isinstance(self.kwarg_model, ParameterKwarg) and self.kwarg_model.required is not None:\n return self.kwarg_model.required\n\n return not (self.is_optional or self.is_any) and (self.is_empty or self.default_value is None)\n\n @property\n def is_literal(self) -> bool:\n \"\"\"Check if the field type is Literal.\"\"\"\n return get_origin(self.field_type) is Literal\n\n @classmethod\n def create(\n cls,\n field_type: Any,\n name: str = \"\",\n default_value: Any = Empty,\n children: tuple[SignatureField, ...] | None = None,\n kwarg_model: ParameterKwarg | BodyKwarg | DependencyKwarg | None = None,\n extra: dict[str, Any] | None = None,\n ) -> SignatureField:\n \"\"\"Create a new SignatureModel instance.\n\n Args:\n field_type: The type of the kwarg.\n name: Field name.\n default_value: A default value.\n children: A mapping of subtypes, if any.\n kwarg_model: Kwarg Parameter.\n extra: A mapping of extra values.\n\n Returns:\n SignatureField instance.\n \"\"\"\n if kwarg_model and default_value is Empty:\n default_value = kwarg_model.default\n\n if not children and get_origin(field_type) and (type_args := get_args(field_type)):\n children = tuple(SignatureField.create(arg) for arg in type_args)\n\n return SignatureField(\n name=name,\n field_type=field_type if field_type is not Empty else Any,\n default_value=default_value if default_value not in UNDEFINED_SENTINELS else Empty,\n children=children,\n kwarg_model=kwarg_model,\n extra=extra or {},\n )\n", "path": "litestar/_signature/field.py"}], "after_files": [{"content": "from __future__ import annotations\n\nfrom dataclasses import dataclass\nfrom typing import Any, Literal\n\nfrom msgspec import Meta\nfrom typing_extensions import Annotated, get_args, get_origin\n\nfrom litestar.constants import UNDEFINED_SENTINELS\nfrom litestar.params import BodyKwarg, DependencyKwarg, ParameterKwarg\nfrom litestar.types import Empty\nfrom litestar.utils.predicates import (\n is_any,\n is_generic,\n is_mapping,\n is_non_string_iterable,\n is_non_string_sequence,\n is_optional_union,\n is_union,\n)\nfrom litestar.utils.typing import make_non_optional_union\n\n__all__ = (\"SignatureField\",)\n\n\ndef _create_metadata_from_type(\n value: Any, model: type[ParameterKwarg] | type[BodyKwarg], field_type: Any\n) -> ParameterKwarg | BodyKwarg | None:\n if isinstance(value, Meta):\n is_sequence_container = is_non_string_sequence(field_type)\n return model(\n gt=value.gt,\n ge=value.ge,\n lt=value.lt,\n le=value.le,\n multiple_of=value.multiple_of,\n regex=value.pattern,\n min_length=value.min_length if not is_sequence_container else None,\n max_length=value.max_length if not is_sequence_container else None,\n min_items=value.min_length if is_sequence_container else None,\n max_items=value.max_length if is_sequence_container else None,\n )\n return None\n\n\n@dataclass(unsafe_hash=True, frozen=True)\nclass SignatureField:\n \"\"\"Abstraction representing a model field. This class is meant to replace equivalent datastructures from other\n libraries, for example, pydantic or msgspec.\n \"\"\"\n\n __slots__ = (\n \"children\",\n \"default_value\",\n \"extra\",\n \"field_type\",\n \"kwarg_model\",\n \"name\",\n )\n\n children: tuple[SignatureField, ...] | None\n \"\"\"A mapping of subtypes, if any.\"\"\"\n default_value: Any\n \"\"\"Field name.\"\"\"\n extra: dict[str, Any]\n \"\"\"A mapping of extra values.\"\"\"\n field_type: Any\n \"\"\"The type of the kwarg.\"\"\"\n kwarg_model: ParameterKwarg | BodyKwarg | DependencyKwarg | None\n \"\"\"Kwarg Parameter.\"\"\"\n name: str\n \"\"\"Field name.\"\"\"\n\n @property\n def is_empty(self) -> bool:\n \"\"\"Check if the default value is an empty type.\n\n Returns:\n True if the default_value is Empty or Ellipsis otherwise False.\n \"\"\"\n return self.default_value is Empty or self.default_value is Ellipsis\n\n @property\n def is_optional(self) -> bool:\n \"\"\"Check if the field type is an Optional union.\n\n Returns:\n True if the field_type is an Optional union otherwise False.\n \"\"\"\n return is_optional_union(self.field_type)\n\n @property\n def is_mapping(self) -> bool:\n \"\"\"Check if the field type is a Mapping.\"\"\"\n return is_mapping(self.field_type)\n\n @property\n def is_non_string_iterable(self) -> bool:\n \"\"\"Check if the field type is an Iterable.\n\n If ``self.field_type`` is an optional union, only the non-optional members of the union are evaluated.\n\n See: https://github.com/litestar-org/litestar/issues/1106\n \"\"\"\n field_type = self.field_type\n if self.is_optional:\n field_type = make_non_optional_union(field_type)\n return is_non_string_iterable(field_type)\n\n @property\n def is_non_string_sequence(self) -> bool:\n \"\"\"Check if the field type is a non-string Sequence.\n\n If ``self.field_type`` is an optional union, only the non-optional members of the union are evaluated.\n\n See: https://github.com/litestar-org/litestar/issues/1106\n \"\"\"\n field_type = self.field_type\n if self.is_optional:\n field_type = make_non_optional_union(field_type)\n return is_non_string_sequence(field_type)\n\n @property\n def is_any(self) -> bool:\n \"\"\"Check if the field type is Any.\"\"\"\n return is_any(self.field_type)\n\n @property\n def is_union(self) -> bool:\n \"\"\"Check if the field type is a Union.\"\"\"\n return is_union(self.field_type)\n\n @property\n def is_generic(self) -> bool:\n \"\"\"Check if the field type is a custom class extending Generic.\"\"\"\n return is_generic(self.field_type)\n\n @property\n def is_simple_type(self) -> bool:\n \"\"\"Check if the field type is a singleton value (e.g. int, str etc.).\"\"\"\n return not (\n self.is_generic or self.is_optional or self.is_union or self.is_mapping or self.is_non_string_iterable\n )\n\n @property\n def is_parameter_field(self) -> bool:\n \"\"\"Check if the field type is a parameter kwarg value.\"\"\"\n return self.kwarg_model is not None and isinstance(self.kwarg_model, ParameterKwarg)\n\n @property\n def is_const(self) -> bool:\n \"\"\"Check if the field is defined as constant value.\"\"\"\n return bool(self.kwarg_model and getattr(self.kwarg_model, \"const\", False))\n\n @property\n def is_required(self) -> bool:\n \"\"\"Check if the field should be marked as a required parameter.\"\"\"\n if isinstance(self.kwarg_model, ParameterKwarg) and self.kwarg_model.required is not None:\n return self.kwarg_model.required\n\n return not (self.is_optional or self.is_any) and (self.is_empty or self.default_value is None)\n\n @property\n def is_literal(self) -> bool:\n \"\"\"Check if the field type is Literal.\"\"\"\n return get_origin(self.field_type) is Literal\n\n @classmethod\n def create(\n cls,\n field_type: Any,\n name: str = \"\",\n default_value: Any = Empty,\n children: tuple[SignatureField, ...] | None = None,\n kwarg_model: ParameterKwarg | BodyKwarg | DependencyKwarg | None = None,\n extra: dict[str, Any] | None = None,\n ) -> SignatureField:\n \"\"\"Create a new SignatureModel instance.\n\n Args:\n field_type: The type of the kwarg.\n name: Field name.\n default_value: A default value.\n children: A mapping of subtypes, if any.\n kwarg_model: Kwarg Parameter.\n extra: A mapping of extra values.\n\n Returns:\n SignatureField instance.\n \"\"\"\n if kwarg_model and default_value is Empty:\n default_value = kwarg_model.default\n\n origin = get_origin(field_type)\n\n if not children and origin and (type_args := get_args(field_type)):\n if origin is Annotated:\n field_type = type_args[0]\n if not kwarg_model:\n kwarg_model = _create_metadata_from_type(\n type_args[1], BodyKwarg if name == \"data\" else ParameterKwarg, field_type=field_type\n )\n else:\n children = tuple(SignatureField.create(arg) for arg in type_args)\n\n return SignatureField(\n name=name,\n field_type=field_type if field_type is not Empty else Any,\n default_value=default_value if default_value not in UNDEFINED_SENTINELS else Empty,\n children=children,\n kwarg_model=kwarg_model,\n extra=extra or {},\n )\n", "path": "litestar/_signature/field.py"}]}
| 2,327 | 575 |
gh_patches_debug_34970
|
rasdani/github-patches
|
git_diff
|
vyperlang__vyper-2235
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Cannot use empty for an array inside an event log
### What's your issue about?
The following code:
```python
event Foo:
a: bytes32[2]
@external
def test():
log Foo(empty(bytes32[2]))
```
Produces the following error:
```python
File "/home/computer/code/python/vyper/vyper/parser/events.py", line 208, in pack_args_by_32
for arg2 in arg.elements:
AttributeError: 'LLLnode' object has no attribute 'elements'
```
The issue happens with any array type.
### How can it be fixed?
I think that this code should compile, so we need to look at what's happening in parser that prevents it.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `vyper/parser/events.py`
Content:
```
1 from vyper import ast as vy_ast
2 from vyper.exceptions import TypeMismatch
3 from vyper.parser.expr import Expr
4 from vyper.parser.lll_node import LLLnode
5 from vyper.parser.parser_utils import (
6 base_type_conversion,
7 getpos,
8 make_byte_array_copier,
9 make_setter,
10 unwrap_location,
11 zero_pad,
12 )
13 from vyper.types.types import (
14 BaseType,
15 ByteArrayLike,
16 ListType,
17 get_size_of_type,
18 )
19 from vyper.utils import bytes_to_int, ceil32, keccak256
20
21
22 def pack_logging_topics(event_id, args, expected_topics, context, pos):
23 topics = [event_id]
24 code_pos = pos
25 for pos, expected_topic in enumerate(expected_topics):
26 expected_type = expected_topic.typ
27 arg = args[pos]
28 value = Expr(arg, context).lll_node
29 arg_type = value.typ
30
31 if isinstance(arg_type, ByteArrayLike) and isinstance(expected_type, ByteArrayLike):
32 if arg_type.maxlen > expected_type.maxlen:
33 raise TypeMismatch(
34 f"Topic input bytes are too big: {arg_type} {expected_type}", code_pos
35 )
36
37 if isinstance(arg, (vy_ast.Str, vy_ast.Bytes)):
38 # for literals, generate the topic at compile time
39 value = arg.value
40 if isinstance(value, str):
41 value = value.encode()
42 topics.append(bytes_to_int(keccak256(value)))
43
44 elif value.location == "memory":
45 topics.append(["sha3", ["add", value, 32], ["mload", value]])
46
47 else:
48 # storage or calldata
49 placeholder = context.new_internal_variable(value.typ)
50 placeholder_node = LLLnode.from_list(placeholder, typ=value.typ, location="memory")
51 copier = make_byte_array_copier(
52 placeholder_node,
53 LLLnode.from_list("_sub", typ=value.typ, location=value.location),
54 )
55 lll_node = [
56 "with",
57 "_sub",
58 value,
59 ["seq", copier, ["sha3", ["add", placeholder, 32], ["mload", placeholder]]],
60 ]
61 topics.append(lll_node)
62
63 elif isinstance(arg_type, ListType) and isinstance(expected_type, ListType):
64 size = get_size_of_type(value.typ) * 32
65 if value.location == "memory":
66 topics.append(["sha3", value, size])
67
68 else:
69 # storage or calldata
70 placeholder = context.new_internal_variable(value.typ)
71 placeholder_node = LLLnode.from_list(placeholder, typ=value.typ, location="memory")
72 setter = make_setter(placeholder_node, value, "memory", value.pos)
73 lll_node = ["seq", setter, ["sha3", placeholder, size]]
74 topics.append(lll_node)
75
76 else:
77 if arg_type != expected_type:
78 raise TypeMismatch(
79 f"Invalid type for logging topic, got {arg_type} expected {expected_type}",
80 value.pos,
81 )
82 value = unwrap_location(value)
83 value = base_type_conversion(value, arg_type, expected_type, pos=code_pos)
84 topics.append(value)
85
86 return topics
87
88
89 def pack_args_by_32(
90 holder,
91 maxlen,
92 arg,
93 typ,
94 context,
95 placeholder,
96 dynamic_offset_counter=None,
97 datamem_start=None,
98 pos=None,
99 ):
100 """
101 Copy necessary variables to pre-allocated memory section.
102
103 :param holder: Complete holder for all args
104 :param maxlen: Total length in bytes of the full arg section (static + dynamic).
105 :param arg: Current arg to pack
106 :param context: Context of arg
107 :param placeholder: Static placeholder for static argument part.
108 :param dynamic_offset_counter: position counter stored in static args.
109 :param dynamic_placeholder: pointer to current position in memory to write dynamic values to.
110 :param datamem_start: position where the whole datemem section starts.
111 """
112
113 if isinstance(typ, BaseType):
114 if isinstance(arg, LLLnode):
115 value = unwrap_location(arg)
116 else:
117 value = Expr(arg, context).lll_node
118 value = base_type_conversion(value, value.typ, typ, pos)
119 holder.append(LLLnode.from_list(["mstore", placeholder, value], typ=typ, location="memory"))
120 elif isinstance(typ, ByteArrayLike):
121
122 if isinstance(arg, LLLnode): # Is prealloacted variable.
123 source_lll = arg
124 else:
125 source_lll = Expr(arg, context).lll_node
126
127 # Set static offset, in arg slot.
128 holder.append(LLLnode.from_list(["mstore", placeholder, ["mload", dynamic_offset_counter]]))
129 # Get the biginning to write the ByteArray to.
130 dest_placeholder = LLLnode.from_list(
131 ["add", datamem_start, ["mload", dynamic_offset_counter]],
132 typ=typ,
133 location="memory",
134 annotation="pack_args_by_32:dest_placeholder",
135 )
136 copier = make_byte_array_copier(dest_placeholder, source_lll, pos=pos)
137 holder.append(copier)
138 # Add zero padding.
139 holder.append(zero_pad(dest_placeholder))
140
141 # Increment offset counter.
142 increment_counter = LLLnode.from_list(
143 [
144 "mstore",
145 dynamic_offset_counter,
146 [
147 "add",
148 [
149 "add",
150 ["mload", dynamic_offset_counter],
151 ["ceil32", ["mload", dest_placeholder]],
152 ],
153 32,
154 ],
155 ],
156 annotation="Increment dynamic offset counter",
157 )
158 holder.append(increment_counter)
159 elif isinstance(typ, ListType):
160 maxlen += (typ.count - 1) * 32
161 typ = typ.subtype
162
163 def check_list_type_match(provided): # Check list types match.
164 if provided != typ:
165 raise TypeMismatch(
166 f"Log list type '{provided}' does not match provided, expected '{typ}'"
167 )
168
169 # NOTE: Below code could be refactored into iterators/getter functions for each type of
170 # repetitive loop. But seeing how each one is a unique for loop, and in which way
171 # the sub value makes the difference in each type of list clearer.
172
173 # List from storage
174 if isinstance(arg, vy_ast.Attribute) and arg.value.id == "self":
175 stor_list = context.globals[arg.attr]
176 check_list_type_match(stor_list.typ.subtype)
177 size = stor_list.typ.count
178 mem_offset = 0
179 for i in range(0, size):
180 storage_offset = i
181 arg2 = LLLnode.from_list(
182 ["sload", ["add", ["sha3_32", Expr(arg, context).lll_node], storage_offset]],
183 typ=typ,
184 )
185 holder, maxlen = pack_args_by_32(
186 holder, maxlen, arg2, typ, context, placeholder + mem_offset, pos=pos,
187 )
188 mem_offset += get_size_of_type(typ) * 32
189
190 # List from variable.
191 elif isinstance(arg, vy_ast.Name):
192 size = context.vars[arg.id].size
193 pos = context.vars[arg.id].pos
194 check_list_type_match(context.vars[arg.id].typ.subtype)
195 mem_offset = 0
196 for _ in range(0, size):
197 arg2 = LLLnode.from_list(
198 pos + mem_offset, typ=typ, location=context.vars[arg.id].location
199 )
200 holder, maxlen = pack_args_by_32(
201 holder, maxlen, arg2, typ, context, placeholder + mem_offset, pos=pos,
202 )
203 mem_offset += get_size_of_type(typ) * 32
204
205 # List from list literal.
206 else:
207 mem_offset = 0
208 for arg2 in arg.elements:
209 holder, maxlen = pack_args_by_32(
210 holder, maxlen, arg2, typ, context, placeholder + mem_offset, pos=pos,
211 )
212 mem_offset += get_size_of_type(typ) * 32
213 return holder, maxlen
214
215
216 # Pack logging data arguments
217 def pack_logging_data(expected_data, args, context, pos):
218 # Checks to see if there's any data
219 if not args:
220 return ["seq"], 0, None, 0
221 holder = ["seq"]
222 maxlen = len(args) * 32 # total size of all packed args (upper limit)
223
224 # Unroll any function calls, to temp variables.
225 prealloacted = {}
226 for idx, (arg, _expected_arg) in enumerate(zip(args, expected_data)):
227
228 if isinstance(arg, (vy_ast.Str, vy_ast.Call)):
229 expr = Expr(arg, context)
230 source_lll = expr.lll_node
231 typ = source_lll.typ
232
233 if isinstance(arg, vy_ast.Str):
234 if len(arg.s) > typ.maxlen:
235 raise TypeMismatch(f"Data input bytes are to big: {len(arg.s)} {typ}", pos)
236
237 tmp_variable = context.new_internal_variable(source_lll.typ)
238 tmp_variable_node = LLLnode.from_list(
239 tmp_variable,
240 typ=source_lll.typ,
241 pos=getpos(arg),
242 location="memory",
243 annotation=f"log_prealloacted {source_lll.typ}",
244 )
245 # Store len.
246 # holder.append(['mstore', len_placeholder, ['mload', unwrap_location(source_lll)]])
247 # Copy bytes.
248
249 holder.append(
250 make_setter(tmp_variable_node, source_lll, pos=getpos(arg), location="memory")
251 )
252 prealloacted[idx] = tmp_variable_node
253
254 # Create internal variables for for dynamic and static args.
255 static_types = []
256 for data in expected_data:
257 static_types.append(data.typ if not isinstance(data.typ, ByteArrayLike) else BaseType(32))
258
259 requires_dynamic_offset = any(isinstance(data.typ, ByteArrayLike) for data in expected_data)
260
261 dynamic_offset_counter = None
262 if requires_dynamic_offset:
263 dynamic_offset_counter = context.new_internal_variable(BaseType(32))
264 dynamic_placeholder = context.new_internal_variable(BaseType(32))
265
266 static_vars = [context.new_internal_variable(i) for i in static_types]
267
268 # Populate static placeholders.
269 for i, (arg, data) in enumerate(zip(args, expected_data)):
270 typ = data.typ
271 placeholder = static_vars[i]
272 if not isinstance(typ, ByteArrayLike):
273 holder, maxlen = pack_args_by_32(
274 holder, maxlen, prealloacted.get(i, arg), typ, context, placeholder, pos=pos,
275 )
276
277 # Dynamic position starts right after the static args.
278 if requires_dynamic_offset:
279 holder.append(LLLnode.from_list(["mstore", dynamic_offset_counter, maxlen]))
280
281 # Calculate maximum dynamic offset placeholders, used for gas estimation.
282 for _arg, data in zip(args, expected_data):
283 typ = data.typ
284 if isinstance(typ, ByteArrayLike):
285 maxlen += 32 + ceil32(typ.maxlen)
286
287 if requires_dynamic_offset:
288 datamem_start = dynamic_placeholder + 32
289 else:
290 datamem_start = static_vars[0]
291
292 # Copy necessary data into allocated dynamic section.
293 for i, (arg, data) in enumerate(zip(args, expected_data)):
294 typ = data.typ
295 if isinstance(typ, ByteArrayLike):
296 pack_args_by_32(
297 holder=holder,
298 maxlen=maxlen,
299 arg=prealloacted.get(i, arg),
300 typ=typ,
301 context=context,
302 placeholder=static_vars[i],
303 datamem_start=datamem_start,
304 dynamic_offset_counter=dynamic_offset_counter,
305 pos=pos,
306 )
307
308 return holder, maxlen, dynamic_offset_counter, datamem_start
309
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/vyper/parser/events.py b/vyper/parser/events.py
--- a/vyper/parser/events.py
+++ b/vyper/parser/events.py
@@ -1,5 +1,5 @@
from vyper import ast as vy_ast
-from vyper.exceptions import TypeMismatch
+from vyper.exceptions import StructureException, TypeMismatch
from vyper.parser.expr import Expr
from vyper.parser.lll_node import LLLnode
from vyper.parser.parser_utils import (
@@ -7,6 +7,7 @@
getpos,
make_byte_array_copier,
make_setter,
+ mzero,
unwrap_location,
zero_pad,
)
@@ -157,6 +158,13 @@
)
holder.append(increment_counter)
elif isinstance(typ, ListType):
+
+ if isinstance(arg, vy_ast.Call) and arg.func.get("id") == "empty":
+ # special case for `empty()` with a static-sized array
+ holder.append(mzero(placeholder, get_size_of_type(typ) * 32))
+ maxlen += (get_size_of_type(typ) - 1) * 32
+ return holder, maxlen
+
maxlen += (typ.count - 1) * 32
typ = typ.subtype
@@ -225,7 +233,7 @@
prealloacted = {}
for idx, (arg, _expected_arg) in enumerate(zip(args, expected_data)):
- if isinstance(arg, (vy_ast.Str, vy_ast.Call)):
+ if isinstance(arg, (vy_ast.Str, vy_ast.Call)) and arg.get("func.id") != "empty":
expr = Expr(arg, context)
source_lll = expr.lll_node
typ = source_lll.typ
@@ -293,6 +301,11 @@
for i, (arg, data) in enumerate(zip(args, expected_data)):
typ = data.typ
if isinstance(typ, ByteArrayLike):
+ if isinstance(arg, vy_ast.Call) and arg.func.get("id") == "empty":
+ # TODO add support for this
+ raise StructureException(
+ "Cannot use `empty` on Bytes or String types within an event log", arg
+ )
pack_args_by_32(
holder=holder,
maxlen=maxlen,
|
{"golden_diff": "diff --git a/vyper/parser/events.py b/vyper/parser/events.py\n--- a/vyper/parser/events.py\n+++ b/vyper/parser/events.py\n@@ -1,5 +1,5 @@\n from vyper import ast as vy_ast\n-from vyper.exceptions import TypeMismatch\n+from vyper.exceptions import StructureException, TypeMismatch\n from vyper.parser.expr import Expr\n from vyper.parser.lll_node import LLLnode\n from vyper.parser.parser_utils import (\n@@ -7,6 +7,7 @@\n getpos,\n make_byte_array_copier,\n make_setter,\n+ mzero,\n unwrap_location,\n zero_pad,\n )\n@@ -157,6 +158,13 @@\n )\n holder.append(increment_counter)\n elif isinstance(typ, ListType):\n+\n+ if isinstance(arg, vy_ast.Call) and arg.func.get(\"id\") == \"empty\":\n+ # special case for `empty()` with a static-sized array\n+ holder.append(mzero(placeholder, get_size_of_type(typ) * 32))\n+ maxlen += (get_size_of_type(typ) - 1) * 32\n+ return holder, maxlen\n+\n maxlen += (typ.count - 1) * 32\n typ = typ.subtype\n \n@@ -225,7 +233,7 @@\n prealloacted = {}\n for idx, (arg, _expected_arg) in enumerate(zip(args, expected_data)):\n \n- if isinstance(arg, (vy_ast.Str, vy_ast.Call)):\n+ if isinstance(arg, (vy_ast.Str, vy_ast.Call)) and arg.get(\"func.id\") != \"empty\":\n expr = Expr(arg, context)\n source_lll = expr.lll_node\n typ = source_lll.typ\n@@ -293,6 +301,11 @@\n for i, (arg, data) in enumerate(zip(args, expected_data)):\n typ = data.typ\n if isinstance(typ, ByteArrayLike):\n+ if isinstance(arg, vy_ast.Call) and arg.func.get(\"id\") == \"empty\":\n+ # TODO add support for this\n+ raise StructureException(\n+ \"Cannot use `empty` on Bytes or String types within an event log\", arg\n+ )\n pack_args_by_32(\n holder=holder,\n maxlen=maxlen,\n", "issue": "Cannot use empty for an array inside an event log\n### What's your issue about?\r\n\r\nThe following code:\r\n\r\n```python\r\nevent Foo:\r\n a: bytes32[2]\r\n\r\n@external\r\ndef test():\r\n log Foo(empty(bytes32[2]))\r\n```\r\n\r\nProduces the following error:\r\n\r\n```python\r\nFile \"/home/computer/code/python/vyper/vyper/parser/events.py\", line 208, in pack_args_by_32\r\n for arg2 in arg.elements:\r\nAttributeError: 'LLLnode' object has no attribute 'elements'\r\n```\r\n\r\nThe issue happens with any array type.\r\n\r\n### How can it be fixed?\r\nI think that this code should compile, so we need to look at what's happening in parser that prevents it.\r\n\n", "before_files": [{"content": "from vyper import ast as vy_ast\nfrom vyper.exceptions import TypeMismatch\nfrom vyper.parser.expr import Expr\nfrom vyper.parser.lll_node import LLLnode\nfrom vyper.parser.parser_utils import (\n base_type_conversion,\n getpos,\n make_byte_array_copier,\n make_setter,\n unwrap_location,\n zero_pad,\n)\nfrom vyper.types.types import (\n BaseType,\n ByteArrayLike,\n ListType,\n get_size_of_type,\n)\nfrom vyper.utils import bytes_to_int, ceil32, keccak256\n\n\ndef pack_logging_topics(event_id, args, expected_topics, context, pos):\n topics = [event_id]\n code_pos = pos\n for pos, expected_topic in enumerate(expected_topics):\n expected_type = expected_topic.typ\n arg = args[pos]\n value = Expr(arg, context).lll_node\n arg_type = value.typ\n\n if isinstance(arg_type, ByteArrayLike) and isinstance(expected_type, ByteArrayLike):\n if arg_type.maxlen > expected_type.maxlen:\n raise TypeMismatch(\n f\"Topic input bytes are too big: {arg_type} {expected_type}\", code_pos\n )\n\n if isinstance(arg, (vy_ast.Str, vy_ast.Bytes)):\n # for literals, generate the topic at compile time\n value = arg.value\n if isinstance(value, str):\n value = value.encode()\n topics.append(bytes_to_int(keccak256(value)))\n\n elif value.location == \"memory\":\n topics.append([\"sha3\", [\"add\", value, 32], [\"mload\", value]])\n\n else:\n # storage or calldata\n placeholder = context.new_internal_variable(value.typ)\n placeholder_node = LLLnode.from_list(placeholder, typ=value.typ, location=\"memory\")\n copier = make_byte_array_copier(\n placeholder_node,\n LLLnode.from_list(\"_sub\", typ=value.typ, location=value.location),\n )\n lll_node = [\n \"with\",\n \"_sub\",\n value,\n [\"seq\", copier, [\"sha3\", [\"add\", placeholder, 32], [\"mload\", placeholder]]],\n ]\n topics.append(lll_node)\n\n elif isinstance(arg_type, ListType) and isinstance(expected_type, ListType):\n size = get_size_of_type(value.typ) * 32\n if value.location == \"memory\":\n topics.append([\"sha3\", value, size])\n\n else:\n # storage or calldata\n placeholder = context.new_internal_variable(value.typ)\n placeholder_node = LLLnode.from_list(placeholder, typ=value.typ, location=\"memory\")\n setter = make_setter(placeholder_node, value, \"memory\", value.pos)\n lll_node = [\"seq\", setter, [\"sha3\", placeholder, size]]\n topics.append(lll_node)\n\n else:\n if arg_type != expected_type:\n raise TypeMismatch(\n f\"Invalid type for logging topic, got {arg_type} expected {expected_type}\",\n value.pos,\n )\n value = unwrap_location(value)\n value = base_type_conversion(value, arg_type, expected_type, pos=code_pos)\n topics.append(value)\n\n return topics\n\n\ndef pack_args_by_32(\n holder,\n maxlen,\n arg,\n typ,\n context,\n placeholder,\n dynamic_offset_counter=None,\n datamem_start=None,\n pos=None,\n):\n \"\"\"\n Copy necessary variables to pre-allocated memory section.\n\n :param holder: Complete holder for all args\n :param maxlen: Total length in bytes of the full arg section (static + dynamic).\n :param arg: Current arg to pack\n :param context: Context of arg\n :param placeholder: Static placeholder for static argument part.\n :param dynamic_offset_counter: position counter stored in static args.\n :param dynamic_placeholder: pointer to current position in memory to write dynamic values to.\n :param datamem_start: position where the whole datemem section starts.\n \"\"\"\n\n if isinstance(typ, BaseType):\n if isinstance(arg, LLLnode):\n value = unwrap_location(arg)\n else:\n value = Expr(arg, context).lll_node\n value = base_type_conversion(value, value.typ, typ, pos)\n holder.append(LLLnode.from_list([\"mstore\", placeholder, value], typ=typ, location=\"memory\"))\n elif isinstance(typ, ByteArrayLike):\n\n if isinstance(arg, LLLnode): # Is prealloacted variable.\n source_lll = arg\n else:\n source_lll = Expr(arg, context).lll_node\n\n # Set static offset, in arg slot.\n holder.append(LLLnode.from_list([\"mstore\", placeholder, [\"mload\", dynamic_offset_counter]]))\n # Get the biginning to write the ByteArray to.\n dest_placeholder = LLLnode.from_list(\n [\"add\", datamem_start, [\"mload\", dynamic_offset_counter]],\n typ=typ,\n location=\"memory\",\n annotation=\"pack_args_by_32:dest_placeholder\",\n )\n copier = make_byte_array_copier(dest_placeholder, source_lll, pos=pos)\n holder.append(copier)\n # Add zero padding.\n holder.append(zero_pad(dest_placeholder))\n\n # Increment offset counter.\n increment_counter = LLLnode.from_list(\n [\n \"mstore\",\n dynamic_offset_counter,\n [\n \"add\",\n [\n \"add\",\n [\"mload\", dynamic_offset_counter],\n [\"ceil32\", [\"mload\", dest_placeholder]],\n ],\n 32,\n ],\n ],\n annotation=\"Increment dynamic offset counter\",\n )\n holder.append(increment_counter)\n elif isinstance(typ, ListType):\n maxlen += (typ.count - 1) * 32\n typ = typ.subtype\n\n def check_list_type_match(provided): # Check list types match.\n if provided != typ:\n raise TypeMismatch(\n f\"Log list type '{provided}' does not match provided, expected '{typ}'\"\n )\n\n # NOTE: Below code could be refactored into iterators/getter functions for each type of\n # repetitive loop. But seeing how each one is a unique for loop, and in which way\n # the sub value makes the difference in each type of list clearer.\n\n # List from storage\n if isinstance(arg, vy_ast.Attribute) and arg.value.id == \"self\":\n stor_list = context.globals[arg.attr]\n check_list_type_match(stor_list.typ.subtype)\n size = stor_list.typ.count\n mem_offset = 0\n for i in range(0, size):\n storage_offset = i\n arg2 = LLLnode.from_list(\n [\"sload\", [\"add\", [\"sha3_32\", Expr(arg, context).lll_node], storage_offset]],\n typ=typ,\n )\n holder, maxlen = pack_args_by_32(\n holder, maxlen, arg2, typ, context, placeholder + mem_offset, pos=pos,\n )\n mem_offset += get_size_of_type(typ) * 32\n\n # List from variable.\n elif isinstance(arg, vy_ast.Name):\n size = context.vars[arg.id].size\n pos = context.vars[arg.id].pos\n check_list_type_match(context.vars[arg.id].typ.subtype)\n mem_offset = 0\n for _ in range(0, size):\n arg2 = LLLnode.from_list(\n pos + mem_offset, typ=typ, location=context.vars[arg.id].location\n )\n holder, maxlen = pack_args_by_32(\n holder, maxlen, arg2, typ, context, placeholder + mem_offset, pos=pos,\n )\n mem_offset += get_size_of_type(typ) * 32\n\n # List from list literal.\n else:\n mem_offset = 0\n for arg2 in arg.elements:\n holder, maxlen = pack_args_by_32(\n holder, maxlen, arg2, typ, context, placeholder + mem_offset, pos=pos,\n )\n mem_offset += get_size_of_type(typ) * 32\n return holder, maxlen\n\n\n# Pack logging data arguments\ndef pack_logging_data(expected_data, args, context, pos):\n # Checks to see if there's any data\n if not args:\n return [\"seq\"], 0, None, 0\n holder = [\"seq\"]\n maxlen = len(args) * 32 # total size of all packed args (upper limit)\n\n # Unroll any function calls, to temp variables.\n prealloacted = {}\n for idx, (arg, _expected_arg) in enumerate(zip(args, expected_data)):\n\n if isinstance(arg, (vy_ast.Str, vy_ast.Call)):\n expr = Expr(arg, context)\n source_lll = expr.lll_node\n typ = source_lll.typ\n\n if isinstance(arg, vy_ast.Str):\n if len(arg.s) > typ.maxlen:\n raise TypeMismatch(f\"Data input bytes are to big: {len(arg.s)} {typ}\", pos)\n\n tmp_variable = context.new_internal_variable(source_lll.typ)\n tmp_variable_node = LLLnode.from_list(\n tmp_variable,\n typ=source_lll.typ,\n pos=getpos(arg),\n location=\"memory\",\n annotation=f\"log_prealloacted {source_lll.typ}\",\n )\n # Store len.\n # holder.append(['mstore', len_placeholder, ['mload', unwrap_location(source_lll)]])\n # Copy bytes.\n\n holder.append(\n make_setter(tmp_variable_node, source_lll, pos=getpos(arg), location=\"memory\")\n )\n prealloacted[idx] = tmp_variable_node\n\n # Create internal variables for for dynamic and static args.\n static_types = []\n for data in expected_data:\n static_types.append(data.typ if not isinstance(data.typ, ByteArrayLike) else BaseType(32))\n\n requires_dynamic_offset = any(isinstance(data.typ, ByteArrayLike) for data in expected_data)\n\n dynamic_offset_counter = None\n if requires_dynamic_offset:\n dynamic_offset_counter = context.new_internal_variable(BaseType(32))\n dynamic_placeholder = context.new_internal_variable(BaseType(32))\n\n static_vars = [context.new_internal_variable(i) for i in static_types]\n\n # Populate static placeholders.\n for i, (arg, data) in enumerate(zip(args, expected_data)):\n typ = data.typ\n placeholder = static_vars[i]\n if not isinstance(typ, ByteArrayLike):\n holder, maxlen = pack_args_by_32(\n holder, maxlen, prealloacted.get(i, arg), typ, context, placeholder, pos=pos,\n )\n\n # Dynamic position starts right after the static args.\n if requires_dynamic_offset:\n holder.append(LLLnode.from_list([\"mstore\", dynamic_offset_counter, maxlen]))\n\n # Calculate maximum dynamic offset placeholders, used for gas estimation.\n for _arg, data in zip(args, expected_data):\n typ = data.typ\n if isinstance(typ, ByteArrayLike):\n maxlen += 32 + ceil32(typ.maxlen)\n\n if requires_dynamic_offset:\n datamem_start = dynamic_placeholder + 32\n else:\n datamem_start = static_vars[0]\n\n # Copy necessary data into allocated dynamic section.\n for i, (arg, data) in enumerate(zip(args, expected_data)):\n typ = data.typ\n if isinstance(typ, ByteArrayLike):\n pack_args_by_32(\n holder=holder,\n maxlen=maxlen,\n arg=prealloacted.get(i, arg),\n typ=typ,\n context=context,\n placeholder=static_vars[i],\n datamem_start=datamem_start,\n dynamic_offset_counter=dynamic_offset_counter,\n pos=pos,\n )\n\n return holder, maxlen, dynamic_offset_counter, datamem_start\n", "path": "vyper/parser/events.py"}], "after_files": [{"content": "from vyper import ast as vy_ast\nfrom vyper.exceptions import StructureException, TypeMismatch\nfrom vyper.parser.expr import Expr\nfrom vyper.parser.lll_node import LLLnode\nfrom vyper.parser.parser_utils import (\n base_type_conversion,\n getpos,\n make_byte_array_copier,\n make_setter,\n mzero,\n unwrap_location,\n zero_pad,\n)\nfrom vyper.types.types import (\n BaseType,\n ByteArrayLike,\n ListType,\n get_size_of_type,\n)\nfrom vyper.utils import bytes_to_int, ceil32, keccak256\n\n\ndef pack_logging_topics(event_id, args, expected_topics, context, pos):\n topics = [event_id]\n code_pos = pos\n for pos, expected_topic in enumerate(expected_topics):\n expected_type = expected_topic.typ\n arg = args[pos]\n value = Expr(arg, context).lll_node\n arg_type = value.typ\n\n if isinstance(arg_type, ByteArrayLike) and isinstance(expected_type, ByteArrayLike):\n if arg_type.maxlen > expected_type.maxlen:\n raise TypeMismatch(\n f\"Topic input bytes are too big: {arg_type} {expected_type}\", code_pos\n )\n\n if isinstance(arg, (vy_ast.Str, vy_ast.Bytes)):\n # for literals, generate the topic at compile time\n value = arg.value\n if isinstance(value, str):\n value = value.encode()\n topics.append(bytes_to_int(keccak256(value)))\n\n elif value.location == \"memory\":\n topics.append([\"sha3\", [\"add\", value, 32], [\"mload\", value]])\n\n else:\n # storage or calldata\n placeholder = context.new_internal_variable(value.typ)\n placeholder_node = LLLnode.from_list(placeholder, typ=value.typ, location=\"memory\")\n copier = make_byte_array_copier(\n placeholder_node,\n LLLnode.from_list(\"_sub\", typ=value.typ, location=value.location),\n )\n lll_node = [\n \"with\",\n \"_sub\",\n value,\n [\"seq\", copier, [\"sha3\", [\"add\", placeholder, 32], [\"mload\", placeholder]]],\n ]\n topics.append(lll_node)\n\n elif isinstance(arg_type, ListType) and isinstance(expected_type, ListType):\n size = get_size_of_type(value.typ) * 32\n if value.location == \"memory\":\n topics.append([\"sha3\", value, size])\n\n else:\n # storage or calldata\n placeholder = context.new_internal_variable(value.typ)\n placeholder_node = LLLnode.from_list(placeholder, typ=value.typ, location=\"memory\")\n setter = make_setter(placeholder_node, value, \"memory\", value.pos)\n lll_node = [\"seq\", setter, [\"sha3\", placeholder, size]]\n topics.append(lll_node)\n\n else:\n if arg_type != expected_type:\n raise TypeMismatch(\n f\"Invalid type for logging topic, got {arg_type} expected {expected_type}\",\n value.pos,\n )\n value = unwrap_location(value)\n value = base_type_conversion(value, arg_type, expected_type, pos=code_pos)\n topics.append(value)\n\n return topics\n\n\ndef pack_args_by_32(\n holder,\n maxlen,\n arg,\n typ,\n context,\n placeholder,\n dynamic_offset_counter=None,\n datamem_start=None,\n pos=None,\n):\n \"\"\"\n Copy necessary variables to pre-allocated memory section.\n\n :param holder: Complete holder for all args\n :param maxlen: Total length in bytes of the full arg section (static + dynamic).\n :param arg: Current arg to pack\n :param context: Context of arg\n :param placeholder: Static placeholder for static argument part.\n :param dynamic_offset_counter: position counter stored in static args.\n :param dynamic_placeholder: pointer to current position in memory to write dynamic values to.\n :param datamem_start: position where the whole datemem section starts.\n \"\"\"\n\n if isinstance(typ, BaseType):\n if isinstance(arg, LLLnode):\n value = unwrap_location(arg)\n else:\n value = Expr(arg, context).lll_node\n value = base_type_conversion(value, value.typ, typ, pos)\n holder.append(LLLnode.from_list([\"mstore\", placeholder, value], typ=typ, location=\"memory\"))\n elif isinstance(typ, ByteArrayLike):\n\n if isinstance(arg, LLLnode): # Is prealloacted variable.\n source_lll = arg\n else:\n source_lll = Expr(arg, context).lll_node\n\n # Set static offset, in arg slot.\n holder.append(LLLnode.from_list([\"mstore\", placeholder, [\"mload\", dynamic_offset_counter]]))\n # Get the biginning to write the ByteArray to.\n dest_placeholder = LLLnode.from_list(\n [\"add\", datamem_start, [\"mload\", dynamic_offset_counter]],\n typ=typ,\n location=\"memory\",\n annotation=\"pack_args_by_32:dest_placeholder\",\n )\n copier = make_byte_array_copier(dest_placeholder, source_lll, pos=pos)\n holder.append(copier)\n # Add zero padding.\n holder.append(zero_pad(dest_placeholder))\n\n # Increment offset counter.\n increment_counter = LLLnode.from_list(\n [\n \"mstore\",\n dynamic_offset_counter,\n [\n \"add\",\n [\n \"add\",\n [\"mload\", dynamic_offset_counter],\n [\"ceil32\", [\"mload\", dest_placeholder]],\n ],\n 32,\n ],\n ],\n annotation=\"Increment dynamic offset counter\",\n )\n holder.append(increment_counter)\n elif isinstance(typ, ListType):\n\n if isinstance(arg, vy_ast.Call) and arg.func.get(\"id\") == \"empty\":\n # special case for `empty()` with a static-sized array\n holder.append(mzero(placeholder, get_size_of_type(typ) * 32))\n maxlen += (get_size_of_type(typ) - 1) * 32\n return holder, maxlen\n\n maxlen += (typ.count - 1) * 32\n typ = typ.subtype\n\n def check_list_type_match(provided): # Check list types match.\n if provided != typ:\n raise TypeMismatch(\n f\"Log list type '{provided}' does not match provided, expected '{typ}'\"\n )\n\n # NOTE: Below code could be refactored into iterators/getter functions for each type of\n # repetitive loop. But seeing how each one is a unique for loop, and in which way\n # the sub value makes the difference in each type of list clearer.\n\n # List from storage\n if isinstance(arg, vy_ast.Attribute) and arg.value.id == \"self\":\n stor_list = context.globals[arg.attr]\n check_list_type_match(stor_list.typ.subtype)\n size = stor_list.typ.count\n mem_offset = 0\n for i in range(0, size):\n storage_offset = i\n arg2 = LLLnode.from_list(\n [\"sload\", [\"add\", [\"sha3_32\", Expr(arg, context).lll_node], storage_offset]],\n typ=typ,\n )\n holder, maxlen = pack_args_by_32(\n holder, maxlen, arg2, typ, context, placeholder + mem_offset, pos=pos,\n )\n mem_offset += get_size_of_type(typ) * 32\n\n # List from variable.\n elif isinstance(arg, vy_ast.Name):\n size = context.vars[arg.id].size\n pos = context.vars[arg.id].pos\n check_list_type_match(context.vars[arg.id].typ.subtype)\n mem_offset = 0\n for _ in range(0, size):\n arg2 = LLLnode.from_list(\n pos + mem_offset, typ=typ, location=context.vars[arg.id].location\n )\n holder, maxlen = pack_args_by_32(\n holder, maxlen, arg2, typ, context, placeholder + mem_offset, pos=pos,\n )\n mem_offset += get_size_of_type(typ) * 32\n\n # List from list literal.\n else:\n mem_offset = 0\n for arg2 in arg.elements:\n holder, maxlen = pack_args_by_32(\n holder, maxlen, arg2, typ, context, placeholder + mem_offset, pos=pos,\n )\n mem_offset += get_size_of_type(typ) * 32\n return holder, maxlen\n\n\n# Pack logging data arguments\ndef pack_logging_data(expected_data, args, context, pos):\n # Checks to see if there's any data\n if not args:\n return [\"seq\"], 0, None, 0\n holder = [\"seq\"]\n maxlen = len(args) * 32 # total size of all packed args (upper limit)\n\n # Unroll any function calls, to temp variables.\n prealloacted = {}\n for idx, (arg, _expected_arg) in enumerate(zip(args, expected_data)):\n\n if isinstance(arg, (vy_ast.Str, vy_ast.Call)) and arg.get(\"func.id\") != \"empty\":\n expr = Expr(arg, context)\n source_lll = expr.lll_node\n typ = source_lll.typ\n\n if isinstance(arg, vy_ast.Str):\n if len(arg.s) > typ.maxlen:\n raise TypeMismatch(f\"Data input bytes are to big: {len(arg.s)} {typ}\", pos)\n\n tmp_variable = context.new_internal_variable(source_lll.typ)\n tmp_variable_node = LLLnode.from_list(\n tmp_variable,\n typ=source_lll.typ,\n pos=getpos(arg),\n location=\"memory\",\n annotation=f\"log_prealloacted {source_lll.typ}\",\n )\n # Store len.\n # holder.append(['mstore', len_placeholder, ['mload', unwrap_location(source_lll)]])\n # Copy bytes.\n\n holder.append(\n make_setter(tmp_variable_node, source_lll, pos=getpos(arg), location=\"memory\")\n )\n prealloacted[idx] = tmp_variable_node\n\n # Create internal variables for for dynamic and static args.\n static_types = []\n for data in expected_data:\n static_types.append(data.typ if not isinstance(data.typ, ByteArrayLike) else BaseType(32))\n\n requires_dynamic_offset = any(isinstance(data.typ, ByteArrayLike) for data in expected_data)\n\n dynamic_offset_counter = None\n if requires_dynamic_offset:\n dynamic_offset_counter = context.new_internal_variable(BaseType(32))\n dynamic_placeholder = context.new_internal_variable(BaseType(32))\n\n static_vars = [context.new_internal_variable(i) for i in static_types]\n\n # Populate static placeholders.\n for i, (arg, data) in enumerate(zip(args, expected_data)):\n typ = data.typ\n placeholder = static_vars[i]\n if not isinstance(typ, ByteArrayLike):\n holder, maxlen = pack_args_by_32(\n holder, maxlen, prealloacted.get(i, arg), typ, context, placeholder, pos=pos,\n )\n\n # Dynamic position starts right after the static args.\n if requires_dynamic_offset:\n holder.append(LLLnode.from_list([\"mstore\", dynamic_offset_counter, maxlen]))\n\n # Calculate maximum dynamic offset placeholders, used for gas estimation.\n for _arg, data in zip(args, expected_data):\n typ = data.typ\n if isinstance(typ, ByteArrayLike):\n maxlen += 32 + ceil32(typ.maxlen)\n\n if requires_dynamic_offset:\n datamem_start = dynamic_placeholder + 32\n else:\n datamem_start = static_vars[0]\n\n # Copy necessary data into allocated dynamic section.\n for i, (arg, data) in enumerate(zip(args, expected_data)):\n typ = data.typ\n if isinstance(typ, ByteArrayLike):\n if isinstance(arg, vy_ast.Call) and arg.func.get(\"id\") == \"empty\":\n # TODO add support for this\n raise StructureException(\n \"Cannot use `empty` on Bytes or String types within an event log\", arg\n )\n pack_args_by_32(\n holder=holder,\n maxlen=maxlen,\n arg=prealloacted.get(i, arg),\n typ=typ,\n context=context,\n placeholder=static_vars[i],\n datamem_start=datamem_start,\n dynamic_offset_counter=dynamic_offset_counter,\n pos=pos,\n )\n\n return holder, maxlen, dynamic_offset_counter, datamem_start\n", "path": "vyper/parser/events.py"}]}
| 3,788 | 509 |
gh_patches_debug_42561
|
rasdani/github-patches
|
git_diff
|
rasterio__rasterio-270
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add pixel size and center point to rio-info
Make these standard info properties as in gdalinfo.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `rasterio/warp.py`
Content:
```
1 """Raster warping and reprojection"""
2
3 from rasterio._warp import _reproject, _transform, _transform_geom, RESAMPLING
4 from rasterio.transform import guard_transform
5
6
7 def transform(src_crs, dst_crs, xs, ys, zs=None):
8 """
9 Transform vectors of x, y and optionally z from source
10 coordinate reference system into target.
11
12 Parameters
13 ------------
14 src_crs: dict
15 Source coordinate reference system, in rasterio dict format.
16 Example: {'init': 'EPSG:4326'}
17 dst_crs: dict
18 Target coordinate reference system.
19 xs: array_like
20 Contains x values. Will be cast to double floating point values.
21 ys: array_like
22 Contains y values.
23 zs: array_like, optional
24 Contains z values. Assumed to be all 0 if absent.
25
26 Returns
27 ---------
28 out: tuple of array_like, (xs, ys, [zs])
29 Tuple of x, y, and optionally z vectors, transformed into the target
30 coordinate reference system.
31 """
32 return _transform(src_crs, dst_crs, xs, ys, zs)
33
34
35 def transform_geom(
36 src_crs,
37 dst_crs,
38 geom,
39 antimeridian_cutting=False,
40 antimeridian_offset=10.0,
41 precision=-1):
42 """
43 Transform geometry from source coordinate reference system into target.
44
45 Parameters
46 ------------
47 src_crs: dict
48 Source coordinate reference system, in rasterio dict format.
49 Example: {'init': 'EPSG:4326'}
50 dst_crs: dict
51 Target coordinate reference system.
52 geom: GeoJSON like dict object
53 antimeridian_cutting: bool, optional
54 If True, cut geometries at the antimeridian, otherwise geometries will
55 not be cut (default).
56 antimeridian_offset: float
57 Offset from the antimeridian in degrees (default: 10) within which
58 any geometries will be split.
59 precision: float
60 If >= 0, geometry coordinates will be rounded to this number of decimal
61 places after the transform operation, otherwise original coordinate
62 values will be preserved (default).
63
64 Returns
65 ---------
66 out: GeoJSON like dict object
67 Transformed geometry in GeoJSON dict format
68 """
69
70 return _transform_geom(
71 src_crs,
72 dst_crs,
73 geom,
74 antimeridian_cutting,
75 antimeridian_offset,
76 precision)
77
78
79 def reproject(
80 source,
81 destination,
82 src_transform=None,
83 src_crs=None,
84 dst_transform=None,
85 dst_crs=None,
86 resampling=RESAMPLING.nearest,
87 **kwargs):
88 """
89 Reproject a source raster to a destination raster.
90
91 Parameters
92 ------------
93 source: ndarray or rasterio Band
94 Source raster.
95 destination: ndarray or rasterio Band
96 Target raster.
97 src_transform: affine transform object, optional
98 Source affine transformation. Required if source and destination
99 are ndarrays. Will be derived from source if it is a rasterio Band.
100 src_crs: dict, optional
101 Source coordinate reference system, in rasterio dict format.
102 Required if source and destination are ndarrays.
103 Will be derived from source if it is a rasterio Band.
104 Example: {'init': 'EPSG:4326'}
105 dst_transform: affine transform object, optional
106 Target affine transformation. Required if source and destination
107 are ndarrays. Will be derived from target if it is a rasterio Band.
108 dst_crs: dict, optional
109 Target coordinate reference system. Required if source and destination
110 are ndarrays. Will be derived from target if it is a rasterio Band.
111 resampling: int
112 Resampling method to use. One of the following:
113 RESAMPLING.nearest,
114 RESAMPLING.bilinear,
115 RESAMPLING.cubic,
116 RESAMPLING.cubic_spline,
117 RESAMPLING.lanczos,
118 RESAMPLING.average,
119 RESAMPLING.mode
120 kwargs: dict, optional
121 Additional arguments passed to transformation function.
122
123 Returns
124 ---------
125 out: None
126 Output is written to destination.
127 """
128
129 if src_transform:
130 src_transform = guard_transform(src_transform).to_gdal()
131 if dst_transform:
132 dst_transform = guard_transform(dst_transform).to_gdal()
133
134 _reproject(
135 source,
136 destination,
137 src_transform,
138 src_crs,
139 dst_transform,
140 dst_crs,
141 resampling,
142 **kwargs)
143
```
Path: `rasterio/rio/info.py`
Content:
```
1 # Info command.
2
3 import json
4 import logging
5 import os.path
6 import pprint
7 import sys
8
9 import click
10
11 import rasterio
12 import rasterio.crs
13 from rasterio.rio.cli import cli
14
15
16 @cli.command(short_help="Print information about the rio environment.")
17 @click.option('--formats', 'key', flag_value='formats', default=True,
18 help="Enumerate the available formats.")
19 @click.pass_context
20 def env(ctx, key):
21 """Print information about the Rasterio environment: available
22 formats, etc.
23 """
24 verbosity = (ctx.obj and ctx.obj.get('verbosity')) or 1
25 logger = logging.getLogger('rio')
26 stdout = click.get_text_stream('stdout')
27 with rasterio.drivers(CPL_DEBUG=(verbosity > 2)) as env:
28 if key == 'formats':
29 for k, v in sorted(env.drivers().items()):
30 stdout.write("%s: %s\n" % (k, v))
31 stdout.write('\n')
32
33
34 @cli.command(short_help="Print information about a data file.")
35 @click.argument('input', type=click.Path(exists=True))
36 @click.option('--meta', 'aspect', flag_value='meta', default=True,
37 help="Show data file structure (default).")
38 @click.option('--tags', 'aspect', flag_value='tags',
39 help="Show data file tags.")
40 @click.option('--namespace', help="Select a tag namespace.")
41 @click.option('--indent', default=None, type=int,
42 help="Indentation level for pretty printed output")
43 # Options to pick out a single metadata item and print it as
44 # a string.
45 @click.option('--count', 'meta_member', flag_value='count',
46 help="Print the count of bands.")
47 @click.option('--dtype', 'meta_member', flag_value='dtype',
48 help="Print the dtype name.")
49 @click.option('--nodata', 'meta_member', flag_value='nodata',
50 help="Print the nodata value.")
51 @click.option('-f', '--format', '--driver', 'meta_member', flag_value='driver',
52 help="Print the format driver.")
53 @click.option('--shape', 'meta_member', flag_value='shape',
54 help="Print the (height, width) shape.")
55 @click.option('--height', 'meta_member', flag_value='height',
56 help="Print the height (number of rows).")
57 @click.option('--width', 'meta_member', flag_value='width',
58 help="Print the width (number of columns).")
59 @click.option('--crs', 'meta_member', flag_value='crs',
60 help="Print the CRS as a PROJ.4 string.")
61 @click.option('--bounds', 'meta_member', flag_value='bounds',
62 help="Print the boundary coordinates "
63 "(left, bottom, right, top).")
64 @click.pass_context
65 def info(ctx, input, aspect, indent, namespace, meta_member):
66 """Print metadata about the dataset as JSON.
67
68 Optionally print a single metadata item as a string.
69 """
70 verbosity = (ctx.obj and ctx.obj.get('verbosity')) or 1
71 logger = logging.getLogger('rio')
72 stdout = click.get_text_stream('stdout')
73 try:
74 with rasterio.drivers(CPL_DEBUG=(verbosity > 2)):
75 with rasterio.open(input, 'r-') as src:
76 info = src.meta
77 del info['affine']
78 del info['transform']
79 info['shape'] = info['height'], info['width']
80 info['bounds'] = src.bounds
81 proj4 = rasterio.crs.to_string(src.crs)
82 if proj4.startswith('+init=epsg'):
83 proj4 = proj4.split('=')[1].upper()
84 info['crs'] = proj4
85 if aspect == 'meta':
86 if meta_member:
87 if isinstance(info[meta_member], (list, tuple)):
88 print(" ".join(map(str, info[meta_member])))
89 else:
90 print(info[meta_member])
91 else:
92 stdout.write(json.dumps(info, indent=indent))
93 stdout.write("\n")
94 elif aspect == 'tags':
95 stdout.write(json.dumps(src.tags(ns=namespace),
96 indent=indent))
97 stdout.write("\n")
98 sys.exit(0)
99 except Exception:
100 logger.exception("Failed. Exception caught")
101 sys.exit(1)
102
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/rasterio/rio/info.py b/rasterio/rio/info.py
--- a/rasterio/rio/info.py
+++ b/rasterio/rio/info.py
@@ -61,18 +61,29 @@
@click.option('--bounds', 'meta_member', flag_value='bounds',
help="Print the boundary coordinates "
"(left, bottom, right, top).")
[email protected]('--res', 'meta_member', flag_value='res',
+ help="Print pixel width and height.")
[email protected]('--lnglat', 'meta_member', flag_value='lnglat',
+ help="Print longitude and latitude at center.")
[email protected]('--stats', 'meta_member', flag_value='stats',
+ help="Print statistics (min, max, mean) of a single band "
+ "(use --bidx).")
[email protected]('-v', '--tell-me-more', '--verbose', is_flag=True,
+ help="Output extra information.")
[email protected]('--bidx', type=int, default=1,
+ help="Input file band index (default: 1).")
@click.pass_context
-def info(ctx, input, aspect, indent, namespace, meta_member):
+def info(ctx, input, aspect, indent, namespace, meta_member, verbose, bidx):
"""Print metadata about the dataset as JSON.
Optionally print a single metadata item as a string.
"""
verbosity = (ctx.obj and ctx.obj.get('verbosity')) or 1
logger = logging.getLogger('rio')
- stdout = click.get_text_stream('stdout')
+ mode = 'r' if (verbose or meta_member == 'stats') else 'r-'
try:
with rasterio.drivers(CPL_DEBUG=(verbosity > 2)):
- with rasterio.open(input, 'r-') as src:
+ with rasterio.open(input, mode) as src:
info = src.meta
del info['affine']
del info['transform']
@@ -82,19 +93,28 @@
if proj4.startswith('+init=epsg'):
proj4 = proj4.split('=')[1].upper()
info['crs'] = proj4
+ if verbose:
+ stats = [{'min': float(b.min()),
+ 'max': float(b.max()),
+ 'mean': float(b.mean())} for b in src.read()]
+ info['stats'] = stats
if aspect == 'meta':
- if meta_member:
+ if meta_member == 'stats':
+ band = src.read(bidx)
+ click.echo('%f %f %f' % (
+ float(band.min()),
+ float(band.max()),
+ float(band.mean())))
+ elif meta_member:
if isinstance(info[meta_member], (list, tuple)):
- print(" ".join(map(str, info[meta_member])))
+ click.echo(" ".join(map(str, info[meta_member])))
else:
- print(info[meta_member])
+ click.echo(info[meta_member])
else:
- stdout.write(json.dumps(info, indent=indent))
- stdout.write("\n")
+ click.echo(json.dumps(info, indent=indent))
elif aspect == 'tags':
- stdout.write(json.dumps(src.tags(ns=namespace),
+ click.echo(json.dumps(src.tags(ns=namespace),
indent=indent))
- stdout.write("\n")
sys.exit(0)
except Exception:
logger.exception("Failed. Exception caught")
diff --git a/rasterio/warp.py b/rasterio/warp.py
--- a/rasterio/warp.py
+++ b/rasterio/warp.py
@@ -1,6 +1,7 @@
"""Raster warping and reprojection"""
-from rasterio._warp import _reproject, _transform, _transform_geom, RESAMPLING
+from rasterio._base import _transform
+from rasterio._warp import _transform_geom, _reproject, RESAMPLING
from rasterio.transform import guard_transform
|
{"golden_diff": "diff --git a/rasterio/rio/info.py b/rasterio/rio/info.py\n--- a/rasterio/rio/info.py\n+++ b/rasterio/rio/info.py\n@@ -61,18 +61,29 @@\n @click.option('--bounds', 'meta_member', flag_value='bounds',\n help=\"Print the boundary coordinates \"\n \"(left, bottom, right, top).\")\[email protected]('--res', 'meta_member', flag_value='res',\n+ help=\"Print pixel width and height.\")\[email protected]('--lnglat', 'meta_member', flag_value='lnglat',\n+ help=\"Print longitude and latitude at center.\")\[email protected]('--stats', 'meta_member', flag_value='stats',\n+ help=\"Print statistics (min, max, mean) of a single band \"\n+ \"(use --bidx).\")\[email protected]('-v', '--tell-me-more', '--verbose', is_flag=True,\n+ help=\"Output extra information.\")\[email protected]('--bidx', type=int, default=1,\n+ help=\"Input file band index (default: 1).\")\n @click.pass_context\n-def info(ctx, input, aspect, indent, namespace, meta_member):\n+def info(ctx, input, aspect, indent, namespace, meta_member, verbose, bidx):\n \"\"\"Print metadata about the dataset as JSON.\n \n Optionally print a single metadata item as a string.\n \"\"\"\n verbosity = (ctx.obj and ctx.obj.get('verbosity')) or 1\n logger = logging.getLogger('rio')\n- stdout = click.get_text_stream('stdout')\n+ mode = 'r' if (verbose or meta_member == 'stats') else 'r-'\n try:\n with rasterio.drivers(CPL_DEBUG=(verbosity > 2)):\n- with rasterio.open(input, 'r-') as src:\n+ with rasterio.open(input, mode) as src:\n info = src.meta\n del info['affine']\n del info['transform']\n@@ -82,19 +93,28 @@\n if proj4.startswith('+init=epsg'):\n proj4 = proj4.split('=')[1].upper()\n info['crs'] = proj4\n+ if verbose:\n+ stats = [{'min': float(b.min()),\n+ 'max': float(b.max()),\n+ 'mean': float(b.mean())} for b in src.read()]\n+ info['stats'] = stats\n if aspect == 'meta':\n- if meta_member:\n+ if meta_member == 'stats':\n+ band = src.read(bidx)\n+ click.echo('%f %f %f' % (\n+ float(band.min()),\n+ float(band.max()),\n+ float(band.mean())))\n+ elif meta_member:\n if isinstance(info[meta_member], (list, tuple)):\n- print(\" \".join(map(str, info[meta_member])))\n+ click.echo(\" \".join(map(str, info[meta_member])))\n else:\n- print(info[meta_member])\n+ click.echo(info[meta_member])\n else:\n- stdout.write(json.dumps(info, indent=indent))\n- stdout.write(\"\\n\")\n+ click.echo(json.dumps(info, indent=indent))\n elif aspect == 'tags':\n- stdout.write(json.dumps(src.tags(ns=namespace), \n+ click.echo(json.dumps(src.tags(ns=namespace), \n indent=indent))\n- stdout.write(\"\\n\")\n sys.exit(0)\n except Exception:\n logger.exception(\"Failed. Exception caught\")\ndiff --git a/rasterio/warp.py b/rasterio/warp.py\n--- a/rasterio/warp.py\n+++ b/rasterio/warp.py\n@@ -1,6 +1,7 @@\n \"\"\"Raster warping and reprojection\"\"\"\n \n-from rasterio._warp import _reproject, _transform, _transform_geom, RESAMPLING\n+from rasterio._base import _transform\n+from rasterio._warp import _transform_geom, _reproject, RESAMPLING\n from rasterio.transform import guard_transform\n", "issue": "Add pixel size and center point to rio-info\nMake these standard info properties as in gdalinfo.\n\n", "before_files": [{"content": "\"\"\"Raster warping and reprojection\"\"\"\n\nfrom rasterio._warp import _reproject, _transform, _transform_geom, RESAMPLING\nfrom rasterio.transform import guard_transform\n\n\ndef transform(src_crs, dst_crs, xs, ys, zs=None):\n \"\"\"\n Transform vectors of x, y and optionally z from source\n coordinate reference system into target.\n\n Parameters\n ------------\n src_crs: dict\n Source coordinate reference system, in rasterio dict format.\n Example: {'init': 'EPSG:4326'}\n dst_crs: dict\n Target coordinate reference system.\n xs: array_like\n Contains x values. Will be cast to double floating point values.\n ys: array_like\n Contains y values.\n zs: array_like, optional\n Contains z values. Assumed to be all 0 if absent.\n\n Returns\n ---------\n out: tuple of array_like, (xs, ys, [zs])\n Tuple of x, y, and optionally z vectors, transformed into the target\n coordinate reference system.\n \"\"\"\n return _transform(src_crs, dst_crs, xs, ys, zs)\n\n\ndef transform_geom(\n src_crs,\n dst_crs,\n geom,\n antimeridian_cutting=False,\n antimeridian_offset=10.0,\n precision=-1):\n \"\"\"\n Transform geometry from source coordinate reference system into target.\n\n Parameters\n ------------\n src_crs: dict\n Source coordinate reference system, in rasterio dict format.\n Example: {'init': 'EPSG:4326'}\n dst_crs: dict\n Target coordinate reference system.\n geom: GeoJSON like dict object\n antimeridian_cutting: bool, optional\n If True, cut geometries at the antimeridian, otherwise geometries will\n not be cut (default).\n antimeridian_offset: float\n Offset from the antimeridian in degrees (default: 10) within which\n any geometries will be split.\n precision: float\n If >= 0, geometry coordinates will be rounded to this number of decimal\n places after the transform operation, otherwise original coordinate\n values will be preserved (default).\n\n Returns\n ---------\n out: GeoJSON like dict object\n Transformed geometry in GeoJSON dict format\n \"\"\"\n\n return _transform_geom(\n src_crs,\n dst_crs,\n geom,\n antimeridian_cutting,\n antimeridian_offset,\n precision)\n\n\ndef reproject(\n source,\n destination,\n src_transform=None,\n src_crs=None,\n dst_transform=None,\n dst_crs=None,\n resampling=RESAMPLING.nearest,\n **kwargs):\n \"\"\"\n Reproject a source raster to a destination raster.\n\n Parameters\n ------------\n source: ndarray or rasterio Band\n Source raster.\n destination: ndarray or rasterio Band\n Target raster.\n src_transform: affine transform object, optional\n Source affine transformation. Required if source and destination\n are ndarrays. Will be derived from source if it is a rasterio Band.\n src_crs: dict, optional\n Source coordinate reference system, in rasterio dict format.\n Required if source and destination are ndarrays.\n Will be derived from source if it is a rasterio Band.\n Example: {'init': 'EPSG:4326'}\n dst_transform: affine transform object, optional\n Target affine transformation. Required if source and destination\n are ndarrays. Will be derived from target if it is a rasterio Band.\n dst_crs: dict, optional\n Target coordinate reference system. Required if source and destination\n are ndarrays. Will be derived from target if it is a rasterio Band.\n resampling: int\n Resampling method to use. One of the following:\n RESAMPLING.nearest,\n RESAMPLING.bilinear,\n RESAMPLING.cubic,\n RESAMPLING.cubic_spline,\n RESAMPLING.lanczos,\n RESAMPLING.average,\n RESAMPLING.mode\n kwargs: dict, optional\n Additional arguments passed to transformation function.\n\n Returns\n ---------\n out: None\n Output is written to destination.\n \"\"\"\n\n if src_transform:\n src_transform = guard_transform(src_transform).to_gdal()\n if dst_transform:\n dst_transform = guard_transform(dst_transform).to_gdal()\n\n _reproject(\n source,\n destination,\n src_transform,\n src_crs,\n dst_transform,\n dst_crs,\n resampling,\n **kwargs)\n", "path": "rasterio/warp.py"}, {"content": "# Info command.\n\nimport json\nimport logging\nimport os.path\nimport pprint\nimport sys\n\nimport click\n\nimport rasterio\nimport rasterio.crs\nfrom rasterio.rio.cli import cli\n\n\[email protected](short_help=\"Print information about the rio environment.\")\[email protected]('--formats', 'key', flag_value='formats', default=True,\n help=\"Enumerate the available formats.\")\[email protected]_context\ndef env(ctx, key):\n \"\"\"Print information about the Rasterio environment: available\n formats, etc.\n \"\"\"\n verbosity = (ctx.obj and ctx.obj.get('verbosity')) or 1\n logger = logging.getLogger('rio')\n stdout = click.get_text_stream('stdout')\n with rasterio.drivers(CPL_DEBUG=(verbosity > 2)) as env:\n if key == 'formats':\n for k, v in sorted(env.drivers().items()):\n stdout.write(\"%s: %s\\n\" % (k, v))\n stdout.write('\\n')\n\n\[email protected](short_help=\"Print information about a data file.\")\[email protected]('input', type=click.Path(exists=True))\[email protected]('--meta', 'aspect', flag_value='meta', default=True,\n help=\"Show data file structure (default).\")\[email protected]('--tags', 'aspect', flag_value='tags',\n help=\"Show data file tags.\")\[email protected]('--namespace', help=\"Select a tag namespace.\")\[email protected]('--indent', default=None, type=int,\n help=\"Indentation level for pretty printed output\")\n# Options to pick out a single metadata item and print it as\n# a string.\[email protected]('--count', 'meta_member', flag_value='count',\n help=\"Print the count of bands.\")\[email protected]('--dtype', 'meta_member', flag_value='dtype',\n help=\"Print the dtype name.\")\[email protected]('--nodata', 'meta_member', flag_value='nodata',\n help=\"Print the nodata value.\")\[email protected]('-f', '--format', '--driver', 'meta_member', flag_value='driver',\n help=\"Print the format driver.\")\[email protected]('--shape', 'meta_member', flag_value='shape',\n help=\"Print the (height, width) shape.\")\[email protected]('--height', 'meta_member', flag_value='height',\n help=\"Print the height (number of rows).\")\[email protected]('--width', 'meta_member', flag_value='width',\n help=\"Print the width (number of columns).\")\[email protected]('--crs', 'meta_member', flag_value='crs',\n help=\"Print the CRS as a PROJ.4 string.\")\[email protected]('--bounds', 'meta_member', flag_value='bounds',\n help=\"Print the boundary coordinates \"\n \"(left, bottom, right, top).\")\[email protected]_context\ndef info(ctx, input, aspect, indent, namespace, meta_member):\n \"\"\"Print metadata about the dataset as JSON.\n\n Optionally print a single metadata item as a string.\n \"\"\"\n verbosity = (ctx.obj and ctx.obj.get('verbosity')) or 1\n logger = logging.getLogger('rio')\n stdout = click.get_text_stream('stdout')\n try:\n with rasterio.drivers(CPL_DEBUG=(verbosity > 2)):\n with rasterio.open(input, 'r-') as src:\n info = src.meta\n del info['affine']\n del info['transform']\n info['shape'] = info['height'], info['width']\n info['bounds'] = src.bounds\n proj4 = rasterio.crs.to_string(src.crs)\n if proj4.startswith('+init=epsg'):\n proj4 = proj4.split('=')[1].upper()\n info['crs'] = proj4\n if aspect == 'meta':\n if meta_member:\n if isinstance(info[meta_member], (list, tuple)):\n print(\" \".join(map(str, info[meta_member])))\n else:\n print(info[meta_member])\n else:\n stdout.write(json.dumps(info, indent=indent))\n stdout.write(\"\\n\")\n elif aspect == 'tags':\n stdout.write(json.dumps(src.tags(ns=namespace), \n indent=indent))\n stdout.write(\"\\n\")\n sys.exit(0)\n except Exception:\n logger.exception(\"Failed. Exception caught\")\n sys.exit(1)\n", "path": "rasterio/rio/info.py"}], "after_files": [{"content": "\"\"\"Raster warping and reprojection\"\"\"\n\nfrom rasterio._base import _transform\nfrom rasterio._warp import _transform_geom, _reproject, RESAMPLING\nfrom rasterio.transform import guard_transform\n\n\ndef transform(src_crs, dst_crs, xs, ys, zs=None):\n \"\"\"\n Transform vectors of x, y and optionally z from source\n coordinate reference system into target.\n\n Parameters\n ------------\n src_crs: dict\n Source coordinate reference system, in rasterio dict format.\n Example: {'init': 'EPSG:4326'}\n dst_crs: dict\n Target coordinate reference system.\n xs: array_like\n Contains x values. Will be cast to double floating point values.\n ys: array_like\n Contains y values.\n zs: array_like, optional\n Contains z values. Assumed to be all 0 if absent.\n\n Returns\n ---------\n out: tuple of array_like, (xs, ys, [zs])\n Tuple of x, y, and optionally z vectors, transformed into the target\n coordinate reference system.\n \"\"\"\n return _transform(src_crs, dst_crs, xs, ys, zs)\n\n\ndef transform_geom(\n src_crs,\n dst_crs,\n geom,\n antimeridian_cutting=False,\n antimeridian_offset=10.0,\n precision=-1):\n \"\"\"\n Transform geometry from source coordinate reference system into target.\n\n Parameters\n ------------\n src_crs: dict\n Source coordinate reference system, in rasterio dict format.\n Example: {'init': 'EPSG:4326'}\n dst_crs: dict\n Target coordinate reference system.\n geom: GeoJSON like dict object\n antimeridian_cutting: bool, optional\n If True, cut geometries at the antimeridian, otherwise geometries will\n not be cut (default).\n antimeridian_offset: float\n Offset from the antimeridian in degrees (default: 10) within which\n any geometries will be split.\n precision: float\n If >= 0, geometry coordinates will be rounded to this number of decimal\n places after the transform operation, otherwise original coordinate\n values will be preserved (default).\n\n Returns\n ---------\n out: GeoJSON like dict object\n Transformed geometry in GeoJSON dict format\n \"\"\"\n\n return _transform_geom(\n src_crs,\n dst_crs,\n geom,\n antimeridian_cutting,\n antimeridian_offset,\n precision)\n\n\ndef reproject(\n source,\n destination,\n src_transform=None,\n src_crs=None,\n dst_transform=None,\n dst_crs=None,\n resampling=RESAMPLING.nearest,\n **kwargs):\n \"\"\"\n Reproject a source raster to a destination raster.\n\n Parameters\n ------------\n source: ndarray or rasterio Band\n Source raster.\n destination: ndarray or rasterio Band\n Target raster.\n src_transform: affine transform object, optional\n Source affine transformation. Required if source and destination\n are ndarrays. Will be derived from source if it is a rasterio Band.\n src_crs: dict, optional\n Source coordinate reference system, in rasterio dict format.\n Required if source and destination are ndarrays.\n Will be derived from source if it is a rasterio Band.\n Example: {'init': 'EPSG:4326'}\n dst_transform: affine transform object, optional\n Target affine transformation. Required if source and destination\n are ndarrays. Will be derived from target if it is a rasterio Band.\n dst_crs: dict, optional\n Target coordinate reference system. Required if source and destination\n are ndarrays. Will be derived from target if it is a rasterio Band.\n resampling: int\n Resampling method to use. One of the following:\n RESAMPLING.nearest,\n RESAMPLING.bilinear,\n RESAMPLING.cubic,\n RESAMPLING.cubic_spline,\n RESAMPLING.lanczos,\n RESAMPLING.average,\n RESAMPLING.mode\n kwargs: dict, optional\n Additional arguments passed to transformation function.\n\n Returns\n ---------\n out: None\n Output is written to destination.\n \"\"\"\n\n if src_transform:\n src_transform = guard_transform(src_transform).to_gdal()\n if dst_transform:\n dst_transform = guard_transform(dst_transform).to_gdal()\n\n _reproject(\n source,\n destination,\n src_transform,\n src_crs,\n dst_transform,\n dst_crs,\n resampling,\n **kwargs)\n", "path": "rasterio/warp.py"}, {"content": "# Info command.\n\nimport json\nimport logging\nimport os.path\nimport pprint\nimport sys\n\nimport click\n\nimport rasterio\nimport rasterio.crs\nfrom rasterio.rio.cli import cli\n\n\[email protected](short_help=\"Print information about the rio environment.\")\[email protected]('--formats', 'key', flag_value='formats', default=True,\n help=\"Enumerate the available formats.\")\[email protected]_context\ndef env(ctx, key):\n \"\"\"Print information about the Rasterio environment: available\n formats, etc.\n \"\"\"\n verbosity = (ctx.obj and ctx.obj.get('verbosity')) or 1\n logger = logging.getLogger('rio')\n stdout = click.get_text_stream('stdout')\n with rasterio.drivers(CPL_DEBUG=(verbosity > 2)) as env:\n if key == 'formats':\n for k, v in sorted(env.drivers().items()):\n stdout.write(\"%s: %s\\n\" % (k, v))\n stdout.write('\\n')\n\n\[email protected](short_help=\"Print information about a data file.\")\[email protected]('input', type=click.Path(exists=True))\[email protected]('--meta', 'aspect', flag_value='meta', default=True,\n help=\"Show data file structure (default).\")\[email protected]('--tags', 'aspect', flag_value='tags',\n help=\"Show data file tags.\")\[email protected]('--namespace', help=\"Select a tag namespace.\")\[email protected]('--indent', default=None, type=int,\n help=\"Indentation level for pretty printed output\")\n# Options to pick out a single metadata item and print it as\n# a string.\[email protected]('--count', 'meta_member', flag_value='count',\n help=\"Print the count of bands.\")\[email protected]('--dtype', 'meta_member', flag_value='dtype',\n help=\"Print the dtype name.\")\[email protected]('--nodata', 'meta_member', flag_value='nodata',\n help=\"Print the nodata value.\")\[email protected]('-f', '--format', '--driver', 'meta_member', flag_value='driver',\n help=\"Print the format driver.\")\[email protected]('--shape', 'meta_member', flag_value='shape',\n help=\"Print the (height, width) shape.\")\[email protected]('--height', 'meta_member', flag_value='height',\n help=\"Print the height (number of rows).\")\[email protected]('--width', 'meta_member', flag_value='width',\n help=\"Print the width (number of columns).\")\[email protected]('--crs', 'meta_member', flag_value='crs',\n help=\"Print the CRS as a PROJ.4 string.\")\[email protected]('--bounds', 'meta_member', flag_value='bounds',\n help=\"Print the boundary coordinates \"\n \"(left, bottom, right, top).\")\[email protected]('--res', 'meta_member', flag_value='res',\n help=\"Print pixel width and height.\")\[email protected]('--lnglat', 'meta_member', flag_value='lnglat',\n help=\"Print longitude and latitude at center.\")\[email protected]('--stats', 'meta_member', flag_value='stats',\n help=\"Print statistics (min, max, mean) of a single band \"\n \"(use --bidx).\")\[email protected]('-v', '--tell-me-more', '--verbose', is_flag=True,\n help=\"Output extra information.\")\[email protected]('--bidx', type=int, default=1,\n help=\"Input file band index (default: 1).\")\[email protected]_context\ndef info(ctx, input, aspect, indent, namespace, meta_member, verbose, bidx):\n \"\"\"Print metadata about the dataset as JSON.\n\n Optionally print a single metadata item as a string.\n \"\"\"\n verbosity = (ctx.obj and ctx.obj.get('verbosity')) or 1\n logger = logging.getLogger('rio')\n mode = 'r' if (verbose or meta_member == 'stats') else 'r-'\n try:\n with rasterio.drivers(CPL_DEBUG=(verbosity > 2)):\n with rasterio.open(input, mode) as src:\n info = src.meta\n del info['affine']\n del info['transform']\n info['shape'] = info['height'], info['width']\n info['bounds'] = src.bounds\n proj4 = rasterio.crs.to_string(src.crs)\n if proj4.startswith('+init=epsg'):\n proj4 = proj4.split('=')[1].upper()\n info['crs'] = proj4\n if verbose:\n stats = [{'min': float(b.min()),\n 'max': float(b.max()),\n 'mean': float(b.mean())} for b in src.read()]\n info['stats'] = stats\n if aspect == 'meta':\n if meta_member == 'stats':\n band = src.read(bidx)\n click.echo('%f %f %f' % (\n float(band.min()),\n float(band.max()),\n float(band.mean())))\n elif meta_member:\n if isinstance(info[meta_member], (list, tuple)):\n click.echo(\" \".join(map(str, info[meta_member])))\n else:\n click.echo(info[meta_member])\n else:\n click.echo(json.dumps(info, indent=indent))\n elif aspect == 'tags':\n click.echo(json.dumps(src.tags(ns=namespace), \n indent=indent))\n sys.exit(0)\n except Exception:\n logger.exception(\"Failed. Exception caught\")\n sys.exit(1)\n", "path": "rasterio/rio/info.py"}]}
| 2,745 | 875 |
gh_patches_debug_4747
|
rasdani/github-patches
|
git_diff
|
scrapy__scrapy-5006
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Remove the use of parsel.Selector._default_type
Used at https://github.com/scrapy/scrapy/blob/58ca8bbf6d1589bd0c8cc1ebda52299346f55e8a/scrapy/selector/unified.py#L72
We should stop relying on this private class variable unless there’s a good reason for it.
[Noticed](https://github.com/scrapy/parsel/pull/181/files#r562118000) while trying out [JMESPath support for Parsel](https://github.com/scrapy/parsel/pull/181) in a real life project.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `scrapy/selector/unified.py`
Content:
```
1 """
2 XPath selectors based on lxml
3 """
4
5 from parsel import Selector as _ParselSelector
6 from scrapy.utils.trackref import object_ref
7 from scrapy.utils.python import to_bytes
8 from scrapy.http import HtmlResponse, XmlResponse
9
10
11 __all__ = ['Selector', 'SelectorList']
12
13
14 def _st(response, st):
15 if st is None:
16 return 'xml' if isinstance(response, XmlResponse) else 'html'
17 return st
18
19
20 def _response_from_text(text, st):
21 rt = XmlResponse if st == 'xml' else HtmlResponse
22 return rt(url='about:blank', encoding='utf-8',
23 body=to_bytes(text, 'utf-8'))
24
25
26 class SelectorList(_ParselSelector.selectorlist_cls, object_ref):
27 """
28 The :class:`SelectorList` class is a subclass of the builtin ``list``
29 class, which provides a few additional methods.
30 """
31
32
33 class Selector(_ParselSelector, object_ref):
34 """
35 An instance of :class:`Selector` is a wrapper over response to select
36 certain parts of its content.
37
38 ``response`` is an :class:`~scrapy.http.HtmlResponse` or an
39 :class:`~scrapy.http.XmlResponse` object that will be used for selecting
40 and extracting data.
41
42 ``text`` is a unicode string or utf-8 encoded text for cases when a
43 ``response`` isn't available. Using ``text`` and ``response`` together is
44 undefined behavior.
45
46 ``type`` defines the selector type, it can be ``"html"``, ``"xml"``
47 or ``None`` (default).
48
49 If ``type`` is ``None``, the selector automatically chooses the best type
50 based on ``response`` type (see below), or defaults to ``"html"`` in case it
51 is used together with ``text``.
52
53 If ``type`` is ``None`` and a ``response`` is passed, the selector type is
54 inferred from the response type as follows:
55
56 * ``"html"`` for :class:`~scrapy.http.HtmlResponse` type
57 * ``"xml"`` for :class:`~scrapy.http.XmlResponse` type
58 * ``"html"`` for anything else
59
60 Otherwise, if ``type`` is set, the selector type will be forced and no
61 detection will occur.
62 """
63
64 __slots__ = ['response']
65 selectorlist_cls = SelectorList
66
67 def __init__(self, response=None, text=None, type=None, root=None, **kwargs):
68 if response is not None and text is not None:
69 raise ValueError(f'{self.__class__.__name__}.__init__() received '
70 'both response and text')
71
72 st = _st(response, type or self._default_type)
73
74 if text is not None:
75 response = _response_from_text(text, st)
76
77 if response is not None:
78 text = response.text
79 kwargs.setdefault('base_url', response.url)
80
81 self.response = response
82 super().__init__(text=text, type=st, root=root, **kwargs)
83
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/scrapy/selector/unified.py b/scrapy/selector/unified.py
--- a/scrapy/selector/unified.py
+++ b/scrapy/selector/unified.py
@@ -69,7 +69,7 @@
raise ValueError(f'{self.__class__.__name__}.__init__() received '
'both response and text')
- st = _st(response, type or self._default_type)
+ st = _st(response, type)
if text is not None:
response = _response_from_text(text, st)
|
{"golden_diff": "diff --git a/scrapy/selector/unified.py b/scrapy/selector/unified.py\n--- a/scrapy/selector/unified.py\n+++ b/scrapy/selector/unified.py\n@@ -69,7 +69,7 @@\n raise ValueError(f'{self.__class__.__name__}.__init__() received '\n 'both response and text')\n \n- st = _st(response, type or self._default_type)\n+ st = _st(response, type)\n \n if text is not None:\n response = _response_from_text(text, st)\n", "issue": "Remove the use of parsel.Selector._default_type\nUsed at https://github.com/scrapy/scrapy/blob/58ca8bbf6d1589bd0c8cc1ebda52299346f55e8a/scrapy/selector/unified.py#L72\r\n\r\nWe should stop relying on this private class variable unless there\u2019s a good reason for it.\r\n\r\n[Noticed](https://github.com/scrapy/parsel/pull/181/files#r562118000) while trying out [JMESPath support for Parsel](https://github.com/scrapy/parsel/pull/181) in a real life project.\n", "before_files": [{"content": "\"\"\"\nXPath selectors based on lxml\n\"\"\"\n\nfrom parsel import Selector as _ParselSelector\nfrom scrapy.utils.trackref import object_ref\nfrom scrapy.utils.python import to_bytes\nfrom scrapy.http import HtmlResponse, XmlResponse\n\n\n__all__ = ['Selector', 'SelectorList']\n\n\ndef _st(response, st):\n if st is None:\n return 'xml' if isinstance(response, XmlResponse) else 'html'\n return st\n\n\ndef _response_from_text(text, st):\n rt = XmlResponse if st == 'xml' else HtmlResponse\n return rt(url='about:blank', encoding='utf-8',\n body=to_bytes(text, 'utf-8'))\n\n\nclass SelectorList(_ParselSelector.selectorlist_cls, object_ref):\n \"\"\"\n The :class:`SelectorList` class is a subclass of the builtin ``list``\n class, which provides a few additional methods.\n \"\"\"\n\n\nclass Selector(_ParselSelector, object_ref):\n \"\"\"\n An instance of :class:`Selector` is a wrapper over response to select\n certain parts of its content.\n\n ``response`` is an :class:`~scrapy.http.HtmlResponse` or an\n :class:`~scrapy.http.XmlResponse` object that will be used for selecting\n and extracting data.\n\n ``text`` is a unicode string or utf-8 encoded text for cases when a\n ``response`` isn't available. Using ``text`` and ``response`` together is\n undefined behavior.\n\n ``type`` defines the selector type, it can be ``\"html\"``, ``\"xml\"``\n or ``None`` (default).\n\n If ``type`` is ``None``, the selector automatically chooses the best type\n based on ``response`` type (see below), or defaults to ``\"html\"`` in case it\n is used together with ``text``.\n\n If ``type`` is ``None`` and a ``response`` is passed, the selector type is\n inferred from the response type as follows:\n\n * ``\"html\"`` for :class:`~scrapy.http.HtmlResponse` type\n * ``\"xml\"`` for :class:`~scrapy.http.XmlResponse` type\n * ``\"html\"`` for anything else\n\n Otherwise, if ``type`` is set, the selector type will be forced and no\n detection will occur.\n \"\"\"\n\n __slots__ = ['response']\n selectorlist_cls = SelectorList\n\n def __init__(self, response=None, text=None, type=None, root=None, **kwargs):\n if response is not None and text is not None:\n raise ValueError(f'{self.__class__.__name__}.__init__() received '\n 'both response and text')\n\n st = _st(response, type or self._default_type)\n\n if text is not None:\n response = _response_from_text(text, st)\n\n if response is not None:\n text = response.text\n kwargs.setdefault('base_url', response.url)\n\n self.response = response\n super().__init__(text=text, type=st, root=root, **kwargs)\n", "path": "scrapy/selector/unified.py"}], "after_files": [{"content": "\"\"\"\nXPath selectors based on lxml\n\"\"\"\n\nfrom parsel import Selector as _ParselSelector\nfrom scrapy.utils.trackref import object_ref\nfrom scrapy.utils.python import to_bytes\nfrom scrapy.http import HtmlResponse, XmlResponse\n\n\n__all__ = ['Selector', 'SelectorList']\n\n\ndef _st(response, st):\n if st is None:\n return 'xml' if isinstance(response, XmlResponse) else 'html'\n return st\n\n\ndef _response_from_text(text, st):\n rt = XmlResponse if st == 'xml' else HtmlResponse\n return rt(url='about:blank', encoding='utf-8',\n body=to_bytes(text, 'utf-8'))\n\n\nclass SelectorList(_ParselSelector.selectorlist_cls, object_ref):\n \"\"\"\n The :class:`SelectorList` class is a subclass of the builtin ``list``\n class, which provides a few additional methods.\n \"\"\"\n\n\nclass Selector(_ParselSelector, object_ref):\n \"\"\"\n An instance of :class:`Selector` is a wrapper over response to select\n certain parts of its content.\n\n ``response`` is an :class:`~scrapy.http.HtmlResponse` or an\n :class:`~scrapy.http.XmlResponse` object that will be used for selecting\n and extracting data.\n\n ``text`` is a unicode string or utf-8 encoded text for cases when a\n ``response`` isn't available. Using ``text`` and ``response`` together is\n undefined behavior.\n\n ``type`` defines the selector type, it can be ``\"html\"``, ``\"xml\"``\n or ``None`` (default).\n\n If ``type`` is ``None``, the selector automatically chooses the best type\n based on ``response`` type (see below), or defaults to ``\"html\"`` in case it\n is used together with ``text``.\n\n If ``type`` is ``None`` and a ``response`` is passed, the selector type is\n inferred from the response type as follows:\n\n * ``\"html\"`` for :class:`~scrapy.http.HtmlResponse` type\n * ``\"xml\"`` for :class:`~scrapy.http.XmlResponse` type\n * ``\"html\"`` for anything else\n\n Otherwise, if ``type`` is set, the selector type will be forced and no\n detection will occur.\n \"\"\"\n\n __slots__ = ['response']\n selectorlist_cls = SelectorList\n\n def __init__(self, response=None, text=None, type=None, root=None, **kwargs):\n if response is not None and text is not None:\n raise ValueError(f'{self.__class__.__name__}.__init__() received '\n 'both response and text')\n\n st = _st(response, type)\n\n if text is not None:\n response = _response_from_text(text, st)\n\n if response is not None:\n text = response.text\n kwargs.setdefault('base_url', response.url)\n\n self.response = response\n super().__init__(text=text, type=st, root=root, **kwargs)\n", "path": "scrapy/selector/unified.py"}]}
| 1,243 | 121 |
gh_patches_debug_41858
|
rasdani/github-patches
|
git_diff
|
pytorch__ignite-1265
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add option to replace bn by sync bn in auto_model
## 🚀 Feature
Idea is to add an option `sync_bn` (default, False) to apply [`convert_sync_batchnorm`](https://pytorch.org/docs/master/generated/torch.nn.SyncBatchNorm.html#torch.nn.SyncBatchNorm.convert_sync_batchnorm) on the input model if a DDP wrapper is used further.
- Check performances on PascalVOC
- Update ref examples
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ignite/distributed/auto.py`
Content:
```
1 import warnings
2
3 import torch
4 import torch.nn as nn
5 from torch.optim.optimizer import Optimizer
6 from torch.utils.data import DataLoader, Dataset
7 from torch.utils.data.distributed import DistributedSampler
8 from torch.utils.data.sampler import Sampler
9
10 from ignite.distributed import utils as idist
11 from ignite.distributed.comp_models import horovod as idist_hvd
12 from ignite.distributed.comp_models import native as idist_native
13 from ignite.distributed.comp_models import xla as idist_xla
14 from ignite.utils import setup_logger
15
16 __all__ = ["auto_dataloader", "auto_model", "auto_optim", "DistributedProxySampler"]
17
18
19 def auto_dataloader(dataset, **kwargs):
20 """Helper method to create a dataloader adapted for non-distributed and distributed configurations (supporting
21 all available backends from :meth:`~ignite.distributed.utils.available_backends()`).
22
23 Internally, we create a dataloader with provided kwargs while applying the following updates:
24
25 - batch size is scaled by world size: ``batch_size / world_size`` if larger or equal world size.
26 - number of workers is scaled by number of local processes: ``num_workers / nprocs`` if larger or equal world size.
27 - if no sampler provided by user, `torch DistributedSampler` is setup.
28 - if a sampler is provided by user, it is wrapped by :class:`~ignite.distributed.auto.DistributedProxySampler`.
29 - if the default device is 'cuda', `pin_memory` is automatically set to `True`.
30
31 .. warning::
32
33 Custom batch sampler is not adapted for distributed configuration. Please, make sure that provided batch
34 sampler is compatible with distributed configuration.
35
36 Examples:
37
38 .. code-block:: python
39
40 import ignite.distribted as idist
41
42 train_loader = idist.auto_dataloader(
43 train_dataset,
44 batch_size=32,
45 num_workers=4,
46 shuffle=True,
47 pin_memory="cuda" in idist.device().type,
48 drop_last=True,
49 )
50
51 Args:
52 dataset (Dataset): input torch dataset
53 **kwargs: keyword arguments for `torch DataLoader`_.
54
55 Returns:
56 `torch DataLoader`_ or `XLA MpDeviceLoader`_ for XLA devices
57
58 .. _torch DataLoader: https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader
59 .. _XLA MpDeviceLoader: https://github.com/pytorch/xla/blob/master/torch_xla/distributed/parallel_loader.py#L178
60 .. _torch DistributedSampler:
61 https://pytorch.org/docs/stable/data.html#torch.utils.data.distributed.DistributedSampler
62 """
63 rank = idist.get_rank()
64 world_size = idist.get_world_size()
65
66 logger = setup_logger(__name__ + ".auto_dataloader")
67 if world_size > 1:
68 if "batch_size" in kwargs and kwargs["batch_size"] >= world_size:
69 kwargs["batch_size"] //= world_size
70
71 nproc = idist.get_nproc_per_node()
72 if "num_workers" in kwargs and kwargs["num_workers"] >= nproc:
73 kwargs["num_workers"] = (kwargs["num_workers"] + nproc - 1) // nproc
74
75 if "batch_sampler" not in kwargs:
76 if kwargs.get("sampler", None) is not None:
77 sampler = DistributedProxySampler(kwargs["sampler"], num_replicas=world_size, rank=rank)
78 else:
79 sampler = DistributedSampler(
80 dataset, num_replicas=world_size, rank=rank, shuffle=kwargs.get("shuffle", True)
81 )
82 # we need to remove "shuffle" from kwargs if sampler is used
83 if "shuffle" in kwargs:
84 del kwargs["shuffle"]
85
86 kwargs["sampler"] = sampler
87 else:
88 warnings.warn(
89 "Found batch_sampler in provided kwargs. Please, make sure that it is compatible "
90 "with distributed configuration"
91 )
92
93 if idist.has_xla_support and idist.backend() == idist_xla.XLA_TPU and kwargs.get("pin_memory", False):
94 # TODO: How about XLA GPU ?
95 warnings.warn(
96 "Found incompatible options: xla support and pin_memory args equal True. "
97 "Argument `pin_memory=False` will be used to construct data loader."
98 )
99 kwargs["pin_memory"] = False
100 else:
101 kwargs["pin_memory"] = kwargs.get("pin_memory", "cuda" in idist.device().type)
102
103 logger.info("Use data loader kwargs for dataset '{}': \n\t{}".format(repr(dataset)[:20].strip(), kwargs))
104 dataloader = DataLoader(dataset, **kwargs)
105
106 if idist.has_xla_support and idist.backend() == idist_xla.XLA_TPU and world_size > 1:
107
108 logger.info("DataLoader is wrapped by `MpDeviceLoader` on XLA")
109
110 mp_device_loader_cls = _MpDeviceLoader
111 try:
112 from torch_xla.distributed.parallel_loader import MpDeviceLoader
113
114 mp_device_loader_cls = MpDeviceLoader
115 except ImportError:
116 pass
117
118 sampler = dataloader.sampler
119 dataloader = mp_device_loader_cls(dataloader, idist.device())
120 dataloader.sampler = sampler
121
122 return dataloader
123
124
125 def auto_model(model: nn.Module) -> nn.Module:
126 """Helper method to adapt provided model for non-distributed and distributed configurations (supporting
127 all available backends from :meth:`~ignite.distributed.utils.available_backends()`).
128
129 Internally, we perform to following:
130
131 - send model to current :meth:`~ignite.distributed.utils.device()` if model's parameters are not on the device.
132 - wrap the model to `torch DistributedDataParallel`_ for native torch distributed if world size is larger than 1.
133 - wrap the model to `torch DataParallel`_ if no distributed context found and more than one CUDA devices available.
134 - broadcast the initial variable states from rank 0 to all other processes if Horovod distributed framework is used.
135
136 Examples:
137
138 .. code-block:: python
139
140 import ignite.distribted as idist
141
142 model = idist.auto_model(model)
143
144 In addition with NVidia/Apex, it can be used in the following way:
145
146 .. code-block:: python
147
148 import ignite.distribted as idist
149
150 model, optimizer = amp.initialize(model, optimizer, opt_level=opt_level)
151 model = idist.auto_model(model)
152
153 Args:
154 model (torch.nn.Module): model to adapt.
155
156 Returns:
157 torch.nn.Module
158
159 .. _torch DistributedDataParallel: https://pytorch.org/docs/stable/nn.html#torch.nn.parallel.DistributedDataParallel
160 .. _torch DataParallel: https://pytorch.org/docs/stable/nn.html#torch.nn.DataParallel
161 """
162 logger = setup_logger(__name__ + ".auto_model")
163
164 # Put model's parameters to device if its parameters are not on the device
165 device = idist.device()
166 if not all([p.device == device for p in model.parameters()]):
167 model.to(device)
168
169 # distributed data parallel model
170 if idist.get_world_size() > 1:
171 bnd = idist.backend()
172 if idist.has_native_dist_support and bnd == idist_native.NCCL:
173 lrank = idist.get_local_rank()
174 logger.info("Apply torch DistributedDataParallel on model, device id: {}".format(lrank))
175 model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[lrank,])
176 elif idist.has_native_dist_support and bnd == idist_native.GLOO:
177 logger.info("Apply torch DistributedDataParallel on model")
178 model = torch.nn.parallel.DistributedDataParallel(model)
179 elif idist.has_hvd_support and bnd == idist_hvd.HOROVOD:
180 import horovod.torch as hvd
181
182 logger.info("Broadcast the initial variable states from rank 0 to all other processes")
183 hvd.broadcast_parameters(model.state_dict(), root_rank=0)
184
185 # not distributed but multiple GPUs reachable so data parallel model
186 elif torch.cuda.device_count() > 1 and "cuda" in idist.device().type:
187 logger.info("Apply torch DataParallel on model")
188 model = torch.nn.parallel.DataParallel(model)
189
190 return model
191
192
193 def auto_optim(optimizer: Optimizer) -> Optimizer:
194 """Helper method to adapt optimizer for non-distributed and distributed configurations (supporting
195 all available backends from :meth:`~ignite.distributed.utils.available_backends()`).
196
197 Internally, this method is no-op for non-distributed and torch native distributed configuration.
198
199 For XLA distributed configuration, we create a new class that inherits from provided optimizer.
200 The goal is to override the `step()` method with specific `xm.optimizer_step`_ implementation.
201
202 For Horovod distributed configuration, optimizer is wrapped with Horovod Distributed Optimizer and
203 its state is broadcasted from rank 0 to all other processes.
204
205 Examples:
206
207 .. code-block:: python
208
209 import ignite.distributed as idist
210
211 optimizer = idist.auto_optim(optimizer)
212
213
214 Args:
215 optimizer (Optimizer): input torch optimizer
216
217 Returns:
218 Optimizer
219
220 .. _xm.optimizer_step: http://pytorch.org/xla/release/1.5/index.html#torch_xla.core.xla_model.optimizer_step
221
222 """
223 bnd = idist.backend()
224 if idist.has_xla_support and bnd == idist_xla.XLA_TPU:
225 cls = type(optimizer.__class__.__name__, (optimizer.__class__,), dict(_XLADistributedOptimizer.__dict__))
226 return cls(optimizer)
227
228 if idist.has_hvd_support and bnd == idist_hvd.HOROVOD:
229 import horovod.torch as hvd
230
231 optimizer = hvd.DistributedOptimizer(optimizer)
232 hvd.broadcast_optimizer_state(optimizer, root_rank=0)
233 return optimizer
234
235 return optimizer
236
237
238 class DistributedProxySampler(DistributedSampler):
239 """Distributed sampler proxy to adapt user's sampler for distributed data parallelism configuration.
240
241 Code is based on https://github.com/pytorch/pytorch/issues/23430#issuecomment-562350407
242
243
244 .. note::
245 Input sampler is assumed to have a constant size.
246
247 Args:
248 sampler (Sampler): Input torch data sampler.
249 num_replicas (int, optional): Number of processes participating in distributed training.
250 rank (int, optional): Rank of the current process within ``num_replicas``.
251
252 """
253
254 def __init__(self, sampler: Sampler, num_replicas=None, rank=None):
255
256 if not isinstance(sampler, Sampler):
257 raise TypeError("Argument sampler should be instance of torch Sampler, but given: {}".format(type(sampler)))
258
259 if not hasattr(sampler, "__len__"):
260 raise TypeError("Argument sampler should have length")
261
262 super(DistributedProxySampler, self).__init__(sampler, num_replicas=num_replicas, rank=rank, shuffle=False)
263 self.sampler = sampler
264
265 def __iter__(self):
266 # deterministically shuffle based on epoch
267 torch.manual_seed(self.epoch)
268
269 indices = []
270 while len(indices) < self.total_size:
271 indices += list(self.sampler)
272
273 if len(indices) > self.total_size:
274 indices = indices[: self.total_size]
275
276 # subsample
277 indices = indices[self.rank : self.total_size : self.num_replicas]
278 if len(indices) != self.num_samples:
279 raise RuntimeError("{} vs {}".format(len(indices), self.num_samples))
280
281 return iter(indices)
282
283
284 if idist.has_xla_support:
285
286 import torch_xla.core.xla_model as xm
287 from torch_xla.distributed.parallel_loader import ParallelLoader
288
289 class _MpDeviceLoader:
290 # https://github.com/pytorch/xla/pull/2117
291 # From pytorch/xla if `torch_xla.distributed.parallel_loader.MpDeviceLoader` is not available
292 def __init__(self, loader, device, **kwargs):
293 self._loader = loader
294 self._device = device
295 self._parallel_loader_kwargs = kwargs
296
297 def __iter__(self):
298 parallel_loader = ParallelLoader(self._loader, [self._device], **self._parallel_loader_kwargs)
299 return parallel_loader.per_device_loader(self._device)
300
301 def __len__(self):
302 return len(self._loader)
303
304 class _XLADistributedOptimizer(Optimizer):
305 def __init__(self, optimizer):
306 super(self.__class__, self).__init__(optimizer.param_groups)
307 self.wrapped_optimizer = optimizer
308
309 def step(self, closure=None):
310 xm.optimizer_step(self.wrapped_optimizer, barrier=True)
311
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ignite/distributed/auto.py b/ignite/distributed/auto.py
--- a/ignite/distributed/auto.py
+++ b/ignite/distributed/auto.py
@@ -24,7 +24,7 @@
- batch size is scaled by world size: ``batch_size / world_size`` if larger or equal world size.
- number of workers is scaled by number of local processes: ``num_workers / nprocs`` if larger or equal world size.
- - if no sampler provided by user, `torch DistributedSampler` is setup.
+ - if no sampler provided by user, `torch DistributedSampler`_ is setup.
- if a sampler is provided by user, it is wrapped by :class:`~ignite.distributed.auto.DistributedProxySampler`.
- if the default device is 'cuda', `pin_memory` is automatically set to `True`.
@@ -122,7 +122,7 @@
return dataloader
-def auto_model(model: nn.Module) -> nn.Module:
+def auto_model(model: nn.Module, sync_bn: bool = False) -> nn.Module:
"""Helper method to adapt provided model for non-distributed and distributed configurations (supporting
all available backends from :meth:`~ignite.distributed.utils.available_backends()`).
@@ -152,12 +152,19 @@
Args:
model (torch.nn.Module): model to adapt.
+ sync_bn (bool): if True, applies `torch convert_sync_batchnorm`_ to the model for native torch
+ distributed only. Default, False. Note, if using Nvidia/Apex, batchnorm conversion should be
+ applied before calling ``amp.initialize``.
Returns:
torch.nn.Module
- .. _torch DistributedDataParallel: https://pytorch.org/docs/stable/nn.html#torch.nn.parallel.DistributedDataParallel
- .. _torch DataParallel: https://pytorch.org/docs/stable/nn.html#torch.nn.DataParallel
+ .. _torch DistributedDataParallel: https://pytorch.org/docs/stable/generated/torch.nn.parallel.
+ DistributedDataParallel.html
+ .. _torch DataParallel: https://pytorch.org/docs/stable/generated/torch.nn.DataParallel.html
+ .. _torch convert_sync_batchnorm: https://pytorch.org/docs/stable/generated/torch.nn.SyncBatchNorm.html#
+ torch.nn.SyncBatchNorm.convert_sync_batchnorm
+
"""
logger = setup_logger(__name__ + ".auto_model")
@@ -170,10 +177,18 @@
if idist.get_world_size() > 1:
bnd = idist.backend()
if idist.has_native_dist_support and bnd == idist_native.NCCL:
+ if sync_bn:
+ logger.info("Convert batch norm to sync batch norm")
+ model = nn.SyncBatchNorm.convert_sync_batchnorm(model)
+
lrank = idist.get_local_rank()
logger.info("Apply torch DistributedDataParallel on model, device id: {}".format(lrank))
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[lrank,])
elif idist.has_native_dist_support and bnd == idist_native.GLOO:
+ if sync_bn:
+ logger.info("Convert batch norm to sync batch norm")
+ model = nn.SyncBatchNorm.convert_sync_batchnorm(model)
+
logger.info("Apply torch DistributedDataParallel on model")
model = torch.nn.parallel.DistributedDataParallel(model)
elif idist.has_hvd_support and bnd == idist_hvd.HOROVOD:
|
{"golden_diff": "diff --git a/ignite/distributed/auto.py b/ignite/distributed/auto.py\n--- a/ignite/distributed/auto.py\n+++ b/ignite/distributed/auto.py\n@@ -24,7 +24,7 @@\n \n - batch size is scaled by world size: ``batch_size / world_size`` if larger or equal world size.\n - number of workers is scaled by number of local processes: ``num_workers / nprocs`` if larger or equal world size.\n- - if no sampler provided by user, `torch DistributedSampler` is setup.\n+ - if no sampler provided by user, `torch DistributedSampler`_ is setup.\n - if a sampler is provided by user, it is wrapped by :class:`~ignite.distributed.auto.DistributedProxySampler`.\n - if the default device is 'cuda', `pin_memory` is automatically set to `True`.\n \n@@ -122,7 +122,7 @@\n return dataloader\n \n \n-def auto_model(model: nn.Module) -> nn.Module:\n+def auto_model(model: nn.Module, sync_bn: bool = False) -> nn.Module:\n \"\"\"Helper method to adapt provided model for non-distributed and distributed configurations (supporting\n all available backends from :meth:`~ignite.distributed.utils.available_backends()`).\n \n@@ -152,12 +152,19 @@\n \n Args:\n model (torch.nn.Module): model to adapt.\n+ sync_bn (bool): if True, applies `torch convert_sync_batchnorm`_ to the model for native torch\n+ distributed only. Default, False. Note, if using Nvidia/Apex, batchnorm conversion should be\n+ applied before calling ``amp.initialize``.\n \n Returns:\n torch.nn.Module\n \n- .. _torch DistributedDataParallel: https://pytorch.org/docs/stable/nn.html#torch.nn.parallel.DistributedDataParallel\n- .. _torch DataParallel: https://pytorch.org/docs/stable/nn.html#torch.nn.DataParallel\n+ .. _torch DistributedDataParallel: https://pytorch.org/docs/stable/generated/torch.nn.parallel.\n+ DistributedDataParallel.html\n+ .. _torch DataParallel: https://pytorch.org/docs/stable/generated/torch.nn.DataParallel.html\n+ .. _torch convert_sync_batchnorm: https://pytorch.org/docs/stable/generated/torch.nn.SyncBatchNorm.html#\n+ torch.nn.SyncBatchNorm.convert_sync_batchnorm\n+\n \"\"\"\n logger = setup_logger(__name__ + \".auto_model\")\n \n@@ -170,10 +177,18 @@\n if idist.get_world_size() > 1:\n bnd = idist.backend()\n if idist.has_native_dist_support and bnd == idist_native.NCCL:\n+ if sync_bn:\n+ logger.info(\"Convert batch norm to sync batch norm\")\n+ model = nn.SyncBatchNorm.convert_sync_batchnorm(model)\n+\n lrank = idist.get_local_rank()\n logger.info(\"Apply torch DistributedDataParallel on model, device id: {}\".format(lrank))\n model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[lrank,])\n elif idist.has_native_dist_support and bnd == idist_native.GLOO:\n+ if sync_bn:\n+ logger.info(\"Convert batch norm to sync batch norm\")\n+ model = nn.SyncBatchNorm.convert_sync_batchnorm(model)\n+\n logger.info(\"Apply torch DistributedDataParallel on model\")\n model = torch.nn.parallel.DistributedDataParallel(model)\n elif idist.has_hvd_support and bnd == idist_hvd.HOROVOD:\n", "issue": "Add option to replace bn by sync bn in auto_model\n## \ud83d\ude80 Feature\r\n\r\nIdea is to add an option `sync_bn` (default, False) to apply [`convert_sync_batchnorm`](https://pytorch.org/docs/master/generated/torch.nn.SyncBatchNorm.html#torch.nn.SyncBatchNorm.convert_sync_batchnorm) on the input model if a DDP wrapper is used further.\r\n\r\n- Check performances on PascalVOC\r\n- Update ref examples\r\n\n", "before_files": [{"content": "import warnings\n\nimport torch\nimport torch.nn as nn\nfrom torch.optim.optimizer import Optimizer\nfrom torch.utils.data import DataLoader, Dataset\nfrom torch.utils.data.distributed import DistributedSampler\nfrom torch.utils.data.sampler import Sampler\n\nfrom ignite.distributed import utils as idist\nfrom ignite.distributed.comp_models import horovod as idist_hvd\nfrom ignite.distributed.comp_models import native as idist_native\nfrom ignite.distributed.comp_models import xla as idist_xla\nfrom ignite.utils import setup_logger\n\n__all__ = [\"auto_dataloader\", \"auto_model\", \"auto_optim\", \"DistributedProxySampler\"]\n\n\ndef auto_dataloader(dataset, **kwargs):\n \"\"\"Helper method to create a dataloader adapted for non-distributed and distributed configurations (supporting\n all available backends from :meth:`~ignite.distributed.utils.available_backends()`).\n\n Internally, we create a dataloader with provided kwargs while applying the following updates:\n\n - batch size is scaled by world size: ``batch_size / world_size`` if larger or equal world size.\n - number of workers is scaled by number of local processes: ``num_workers / nprocs`` if larger or equal world size.\n - if no sampler provided by user, `torch DistributedSampler` is setup.\n - if a sampler is provided by user, it is wrapped by :class:`~ignite.distributed.auto.DistributedProxySampler`.\n - if the default device is 'cuda', `pin_memory` is automatically set to `True`.\n\n .. warning::\n\n Custom batch sampler is not adapted for distributed configuration. Please, make sure that provided batch\n sampler is compatible with distributed configuration.\n\n Examples:\n\n .. code-block:: python\n\n import ignite.distribted as idist\n\n train_loader = idist.auto_dataloader(\n train_dataset,\n batch_size=32,\n num_workers=4,\n shuffle=True,\n pin_memory=\"cuda\" in idist.device().type,\n drop_last=True,\n )\n\n Args:\n dataset (Dataset): input torch dataset\n **kwargs: keyword arguments for `torch DataLoader`_.\n\n Returns:\n `torch DataLoader`_ or `XLA MpDeviceLoader`_ for XLA devices\n\n .. _torch DataLoader: https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader\n .. _XLA MpDeviceLoader: https://github.com/pytorch/xla/blob/master/torch_xla/distributed/parallel_loader.py#L178\n .. _torch DistributedSampler:\n https://pytorch.org/docs/stable/data.html#torch.utils.data.distributed.DistributedSampler\n \"\"\"\n rank = idist.get_rank()\n world_size = idist.get_world_size()\n\n logger = setup_logger(__name__ + \".auto_dataloader\")\n if world_size > 1:\n if \"batch_size\" in kwargs and kwargs[\"batch_size\"] >= world_size:\n kwargs[\"batch_size\"] //= world_size\n\n nproc = idist.get_nproc_per_node()\n if \"num_workers\" in kwargs and kwargs[\"num_workers\"] >= nproc:\n kwargs[\"num_workers\"] = (kwargs[\"num_workers\"] + nproc - 1) // nproc\n\n if \"batch_sampler\" not in kwargs:\n if kwargs.get(\"sampler\", None) is not None:\n sampler = DistributedProxySampler(kwargs[\"sampler\"], num_replicas=world_size, rank=rank)\n else:\n sampler = DistributedSampler(\n dataset, num_replicas=world_size, rank=rank, shuffle=kwargs.get(\"shuffle\", True)\n )\n # we need to remove \"shuffle\" from kwargs if sampler is used\n if \"shuffle\" in kwargs:\n del kwargs[\"shuffle\"]\n\n kwargs[\"sampler\"] = sampler\n else:\n warnings.warn(\n \"Found batch_sampler in provided kwargs. Please, make sure that it is compatible \"\n \"with distributed configuration\"\n )\n\n if idist.has_xla_support and idist.backend() == idist_xla.XLA_TPU and kwargs.get(\"pin_memory\", False):\n # TODO: How about XLA GPU ?\n warnings.warn(\n \"Found incompatible options: xla support and pin_memory args equal True. \"\n \"Argument `pin_memory=False` will be used to construct data loader.\"\n )\n kwargs[\"pin_memory\"] = False\n else:\n kwargs[\"pin_memory\"] = kwargs.get(\"pin_memory\", \"cuda\" in idist.device().type)\n\n logger.info(\"Use data loader kwargs for dataset '{}': \\n\\t{}\".format(repr(dataset)[:20].strip(), kwargs))\n dataloader = DataLoader(dataset, **kwargs)\n\n if idist.has_xla_support and idist.backend() == idist_xla.XLA_TPU and world_size > 1:\n\n logger.info(\"DataLoader is wrapped by `MpDeviceLoader` on XLA\")\n\n mp_device_loader_cls = _MpDeviceLoader\n try:\n from torch_xla.distributed.parallel_loader import MpDeviceLoader\n\n mp_device_loader_cls = MpDeviceLoader\n except ImportError:\n pass\n\n sampler = dataloader.sampler\n dataloader = mp_device_loader_cls(dataloader, idist.device())\n dataloader.sampler = sampler\n\n return dataloader\n\n\ndef auto_model(model: nn.Module) -> nn.Module:\n \"\"\"Helper method to adapt provided model for non-distributed and distributed configurations (supporting\n all available backends from :meth:`~ignite.distributed.utils.available_backends()`).\n\n Internally, we perform to following:\n\n - send model to current :meth:`~ignite.distributed.utils.device()` if model's parameters are not on the device.\n - wrap the model to `torch DistributedDataParallel`_ for native torch distributed if world size is larger than 1.\n - wrap the model to `torch DataParallel`_ if no distributed context found and more than one CUDA devices available.\n - broadcast the initial variable states from rank 0 to all other processes if Horovod distributed framework is used.\n\n Examples:\n\n .. code-block:: python\n\n import ignite.distribted as idist\n\n model = idist.auto_model(model)\n\n In addition with NVidia/Apex, it can be used in the following way:\n\n .. code-block:: python\n\n import ignite.distribted as idist\n\n model, optimizer = amp.initialize(model, optimizer, opt_level=opt_level)\n model = idist.auto_model(model)\n\n Args:\n model (torch.nn.Module): model to adapt.\n\n Returns:\n torch.nn.Module\n\n .. _torch DistributedDataParallel: https://pytorch.org/docs/stable/nn.html#torch.nn.parallel.DistributedDataParallel\n .. _torch DataParallel: https://pytorch.org/docs/stable/nn.html#torch.nn.DataParallel\n \"\"\"\n logger = setup_logger(__name__ + \".auto_model\")\n\n # Put model's parameters to device if its parameters are not on the device\n device = idist.device()\n if not all([p.device == device for p in model.parameters()]):\n model.to(device)\n\n # distributed data parallel model\n if idist.get_world_size() > 1:\n bnd = idist.backend()\n if idist.has_native_dist_support and bnd == idist_native.NCCL:\n lrank = idist.get_local_rank()\n logger.info(\"Apply torch DistributedDataParallel on model, device id: {}\".format(lrank))\n model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[lrank,])\n elif idist.has_native_dist_support and bnd == idist_native.GLOO:\n logger.info(\"Apply torch DistributedDataParallel on model\")\n model = torch.nn.parallel.DistributedDataParallel(model)\n elif idist.has_hvd_support and bnd == idist_hvd.HOROVOD:\n import horovod.torch as hvd\n\n logger.info(\"Broadcast the initial variable states from rank 0 to all other processes\")\n hvd.broadcast_parameters(model.state_dict(), root_rank=0)\n\n # not distributed but multiple GPUs reachable so data parallel model\n elif torch.cuda.device_count() > 1 and \"cuda\" in idist.device().type:\n logger.info(\"Apply torch DataParallel on model\")\n model = torch.nn.parallel.DataParallel(model)\n\n return model\n\n\ndef auto_optim(optimizer: Optimizer) -> Optimizer:\n \"\"\"Helper method to adapt optimizer for non-distributed and distributed configurations (supporting\n all available backends from :meth:`~ignite.distributed.utils.available_backends()`).\n\n Internally, this method is no-op for non-distributed and torch native distributed configuration.\n\n For XLA distributed configuration, we create a new class that inherits from provided optimizer.\n The goal is to override the `step()` method with specific `xm.optimizer_step`_ implementation.\n\n For Horovod distributed configuration, optimizer is wrapped with Horovod Distributed Optimizer and\n its state is broadcasted from rank 0 to all other processes.\n\n Examples:\n\n .. code-block:: python\n\n import ignite.distributed as idist\n\n optimizer = idist.auto_optim(optimizer)\n\n\n Args:\n optimizer (Optimizer): input torch optimizer\n\n Returns:\n Optimizer\n\n .. _xm.optimizer_step: http://pytorch.org/xla/release/1.5/index.html#torch_xla.core.xla_model.optimizer_step\n\n \"\"\"\n bnd = idist.backend()\n if idist.has_xla_support and bnd == idist_xla.XLA_TPU:\n cls = type(optimizer.__class__.__name__, (optimizer.__class__,), dict(_XLADistributedOptimizer.__dict__))\n return cls(optimizer)\n\n if idist.has_hvd_support and bnd == idist_hvd.HOROVOD:\n import horovod.torch as hvd\n\n optimizer = hvd.DistributedOptimizer(optimizer)\n hvd.broadcast_optimizer_state(optimizer, root_rank=0)\n return optimizer\n\n return optimizer\n\n\nclass DistributedProxySampler(DistributedSampler):\n \"\"\"Distributed sampler proxy to adapt user's sampler for distributed data parallelism configuration.\n\n Code is based on https://github.com/pytorch/pytorch/issues/23430#issuecomment-562350407\n\n\n .. note::\n Input sampler is assumed to have a constant size.\n\n Args:\n sampler (Sampler): Input torch data sampler.\n num_replicas (int, optional): Number of processes participating in distributed training.\n rank (int, optional): Rank of the current process within ``num_replicas``.\n\n \"\"\"\n\n def __init__(self, sampler: Sampler, num_replicas=None, rank=None):\n\n if not isinstance(sampler, Sampler):\n raise TypeError(\"Argument sampler should be instance of torch Sampler, but given: {}\".format(type(sampler)))\n\n if not hasattr(sampler, \"__len__\"):\n raise TypeError(\"Argument sampler should have length\")\n\n super(DistributedProxySampler, self).__init__(sampler, num_replicas=num_replicas, rank=rank, shuffle=False)\n self.sampler = sampler\n\n def __iter__(self):\n # deterministically shuffle based on epoch\n torch.manual_seed(self.epoch)\n\n indices = []\n while len(indices) < self.total_size:\n indices += list(self.sampler)\n\n if len(indices) > self.total_size:\n indices = indices[: self.total_size]\n\n # subsample\n indices = indices[self.rank : self.total_size : self.num_replicas]\n if len(indices) != self.num_samples:\n raise RuntimeError(\"{} vs {}\".format(len(indices), self.num_samples))\n\n return iter(indices)\n\n\nif idist.has_xla_support:\n\n import torch_xla.core.xla_model as xm\n from torch_xla.distributed.parallel_loader import ParallelLoader\n\n class _MpDeviceLoader:\n # https://github.com/pytorch/xla/pull/2117\n # From pytorch/xla if `torch_xla.distributed.parallel_loader.MpDeviceLoader` is not available\n def __init__(self, loader, device, **kwargs):\n self._loader = loader\n self._device = device\n self._parallel_loader_kwargs = kwargs\n\n def __iter__(self):\n parallel_loader = ParallelLoader(self._loader, [self._device], **self._parallel_loader_kwargs)\n return parallel_loader.per_device_loader(self._device)\n\n def __len__(self):\n return len(self._loader)\n\n class _XLADistributedOptimizer(Optimizer):\n def __init__(self, optimizer):\n super(self.__class__, self).__init__(optimizer.param_groups)\n self.wrapped_optimizer = optimizer\n\n def step(self, closure=None):\n xm.optimizer_step(self.wrapped_optimizer, barrier=True)\n", "path": "ignite/distributed/auto.py"}], "after_files": [{"content": "import warnings\n\nimport torch\nimport torch.nn as nn\nfrom torch.optim.optimizer import Optimizer\nfrom torch.utils.data import DataLoader, Dataset\nfrom torch.utils.data.distributed import DistributedSampler\nfrom torch.utils.data.sampler import Sampler\n\nfrom ignite.distributed import utils as idist\nfrom ignite.distributed.comp_models import horovod as idist_hvd\nfrom ignite.distributed.comp_models import native as idist_native\nfrom ignite.distributed.comp_models import xla as idist_xla\nfrom ignite.utils import setup_logger\n\n__all__ = [\"auto_dataloader\", \"auto_model\", \"auto_optim\", \"DistributedProxySampler\"]\n\n\ndef auto_dataloader(dataset, **kwargs):\n \"\"\"Helper method to create a dataloader adapted for non-distributed and distributed configurations (supporting\n all available backends from :meth:`~ignite.distributed.utils.available_backends()`).\n\n Internally, we create a dataloader with provided kwargs while applying the following updates:\n\n - batch size is scaled by world size: ``batch_size / world_size`` if larger or equal world size.\n - number of workers is scaled by number of local processes: ``num_workers / nprocs`` if larger or equal world size.\n - if no sampler provided by user, `torch DistributedSampler`_ is setup.\n - if a sampler is provided by user, it is wrapped by :class:`~ignite.distributed.auto.DistributedProxySampler`.\n - if the default device is 'cuda', `pin_memory` is automatically set to `True`.\n\n .. warning::\n\n Custom batch sampler is not adapted for distributed configuration. Please, make sure that provided batch\n sampler is compatible with distributed configuration.\n\n Examples:\n\n .. code-block:: python\n\n import ignite.distribted as idist\n\n train_loader = idist.auto_dataloader(\n train_dataset,\n batch_size=32,\n num_workers=4,\n shuffle=True,\n pin_memory=\"cuda\" in idist.device().type,\n drop_last=True,\n )\n\n Args:\n dataset (Dataset): input torch dataset\n **kwargs: keyword arguments for `torch DataLoader`_.\n\n Returns:\n `torch DataLoader`_ or `XLA MpDeviceLoader`_ for XLA devices\n\n .. _torch DataLoader: https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader\n .. _XLA MpDeviceLoader: https://github.com/pytorch/xla/blob/master/torch_xla/distributed/parallel_loader.py#L178\n .. _torch DistributedSampler:\n https://pytorch.org/docs/stable/data.html#torch.utils.data.distributed.DistributedSampler\n \"\"\"\n rank = idist.get_rank()\n world_size = idist.get_world_size()\n\n logger = setup_logger(__name__ + \".auto_dataloader\")\n if world_size > 1:\n if \"batch_size\" in kwargs and kwargs[\"batch_size\"] >= world_size:\n kwargs[\"batch_size\"] //= world_size\n\n nproc = idist.get_nproc_per_node()\n if \"num_workers\" in kwargs and kwargs[\"num_workers\"] >= nproc:\n kwargs[\"num_workers\"] = (kwargs[\"num_workers\"] + nproc - 1) // nproc\n\n if \"batch_sampler\" not in kwargs:\n if kwargs.get(\"sampler\", None) is not None:\n sampler = DistributedProxySampler(kwargs[\"sampler\"], num_replicas=world_size, rank=rank)\n else:\n sampler = DistributedSampler(\n dataset, num_replicas=world_size, rank=rank, shuffle=kwargs.get(\"shuffle\", True)\n )\n # we need to remove \"shuffle\" from kwargs if sampler is used\n if \"shuffle\" in kwargs:\n del kwargs[\"shuffle\"]\n\n kwargs[\"sampler\"] = sampler\n else:\n warnings.warn(\n \"Found batch_sampler in provided kwargs. Please, make sure that it is compatible \"\n \"with distributed configuration\"\n )\n\n if idist.has_xla_support and idist.backend() == idist_xla.XLA_TPU and kwargs.get(\"pin_memory\", False):\n # TODO: How about XLA GPU ?\n warnings.warn(\n \"Found incompatible options: xla support and pin_memory args equal True. \"\n \"Argument `pin_memory=False` will be used to construct data loader.\"\n )\n kwargs[\"pin_memory\"] = False\n else:\n kwargs[\"pin_memory\"] = kwargs.get(\"pin_memory\", \"cuda\" in idist.device().type)\n\n logger.info(\"Use data loader kwargs for dataset '{}': \\n\\t{}\".format(repr(dataset)[:20].strip(), kwargs))\n dataloader = DataLoader(dataset, **kwargs)\n\n if idist.has_xla_support and idist.backend() == idist_xla.XLA_TPU and world_size > 1:\n\n logger.info(\"DataLoader is wrapped by `MpDeviceLoader` on XLA\")\n\n mp_device_loader_cls = _MpDeviceLoader\n try:\n from torch_xla.distributed.parallel_loader import MpDeviceLoader\n\n mp_device_loader_cls = MpDeviceLoader\n except ImportError:\n pass\n\n sampler = dataloader.sampler\n dataloader = mp_device_loader_cls(dataloader, idist.device())\n dataloader.sampler = sampler\n\n return dataloader\n\n\ndef auto_model(model: nn.Module, sync_bn: bool = False) -> nn.Module:\n \"\"\"Helper method to adapt provided model for non-distributed and distributed configurations (supporting\n all available backends from :meth:`~ignite.distributed.utils.available_backends()`).\n\n Internally, we perform to following:\n\n - send model to current :meth:`~ignite.distributed.utils.device()` if model's parameters are not on the device.\n - wrap the model to `torch DistributedDataParallel`_ for native torch distributed if world size is larger than 1.\n - wrap the model to `torch DataParallel`_ if no distributed context found and more than one CUDA devices available.\n - broadcast the initial variable states from rank 0 to all other processes if Horovod distributed framework is used.\n\n Examples:\n\n .. code-block:: python\n\n import ignite.distribted as idist\n\n model = idist.auto_model(model)\n\n In addition with NVidia/Apex, it can be used in the following way:\n\n .. code-block:: python\n\n import ignite.distribted as idist\n\n model, optimizer = amp.initialize(model, optimizer, opt_level=opt_level)\n model = idist.auto_model(model)\n\n Args:\n model (torch.nn.Module): model to adapt.\n sync_bn (bool): if True, applies `torch convert_sync_batchnorm`_ to the model for native torch\n distributed only. Default, False. Note, if using Nvidia/Apex, batchnorm conversion should be\n applied before calling ``amp.initialize``.\n\n Returns:\n torch.nn.Module\n\n .. _torch DistributedDataParallel: https://pytorch.org/docs/stable/generated/torch.nn.parallel.\n DistributedDataParallel.html\n .. _torch DataParallel: https://pytorch.org/docs/stable/generated/torch.nn.DataParallel.html\n .. _torch convert_sync_batchnorm: https://pytorch.org/docs/stable/generated/torch.nn.SyncBatchNorm.html#\n torch.nn.SyncBatchNorm.convert_sync_batchnorm\n\n \"\"\"\n logger = setup_logger(__name__ + \".auto_model\")\n\n # Put model's parameters to device if its parameters are not on the device\n device = idist.device()\n if not all([p.device == device for p in model.parameters()]):\n model.to(device)\n\n # distributed data parallel model\n if idist.get_world_size() > 1:\n bnd = idist.backend()\n if idist.has_native_dist_support and bnd == idist_native.NCCL:\n if sync_bn:\n logger.info(\"Convert batch norm to sync batch norm\")\n model = nn.SyncBatchNorm.convert_sync_batchnorm(model)\n\n lrank = idist.get_local_rank()\n logger.info(\"Apply torch DistributedDataParallel on model, device id: {}\".format(lrank))\n model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[lrank,])\n elif idist.has_native_dist_support and bnd == idist_native.GLOO:\n if sync_bn:\n logger.info(\"Convert batch norm to sync batch norm\")\n model = nn.SyncBatchNorm.convert_sync_batchnorm(model)\n\n logger.info(\"Apply torch DistributedDataParallel on model\")\n model = torch.nn.parallel.DistributedDataParallel(model)\n elif idist.has_hvd_support and bnd == idist_hvd.HOROVOD:\n import horovod.torch as hvd\n\n logger.info(\"Broadcast the initial variable states from rank 0 to all other processes\")\n hvd.broadcast_parameters(model.state_dict(), root_rank=0)\n\n # not distributed but multiple GPUs reachable so data parallel model\n elif torch.cuda.device_count() > 1 and \"cuda\" in idist.device().type:\n logger.info(\"Apply torch DataParallel on model\")\n model = torch.nn.parallel.DataParallel(model)\n\n return model\n\n\ndef auto_optim(optimizer: Optimizer) -> Optimizer:\n \"\"\"Helper method to adapt optimizer for non-distributed and distributed configurations (supporting\n all available backends from :meth:`~ignite.distributed.utils.available_backends()`).\n\n Internally, this method is no-op for non-distributed and torch native distributed configuration.\n\n For XLA distributed configuration, we create a new class that inherits from provided optimizer.\n The goal is to override the `step()` method with specific `xm.optimizer_step`_ implementation.\n\n For Horovod distributed configuration, optimizer is wrapped with Horovod Distributed Optimizer and\n its state is broadcasted from rank 0 to all other processes.\n\n Examples:\n\n .. code-block:: python\n\n import ignite.distributed as idist\n\n optimizer = idist.auto_optim(optimizer)\n\n\n Args:\n optimizer (Optimizer): input torch optimizer\n\n Returns:\n Optimizer\n\n .. _xm.optimizer_step: http://pytorch.org/xla/release/1.5/index.html#torch_xla.core.xla_model.optimizer_step\n\n \"\"\"\n bnd = idist.backend()\n if idist.has_xla_support and bnd == idist_xla.XLA_TPU:\n cls = type(optimizer.__class__.__name__, (optimizer.__class__,), dict(_XLADistributedOptimizer.__dict__))\n return cls(optimizer)\n\n if idist.has_hvd_support and bnd == idist_hvd.HOROVOD:\n import horovod.torch as hvd\n\n optimizer = hvd.DistributedOptimizer(optimizer)\n hvd.broadcast_optimizer_state(optimizer, root_rank=0)\n return optimizer\n\n return optimizer\n\n\nclass DistributedProxySampler(DistributedSampler):\n \"\"\"Distributed sampler proxy to adapt user's sampler for distributed data parallelism configuration.\n\n Code is based on https://github.com/pytorch/pytorch/issues/23430#issuecomment-562350407\n\n\n .. note::\n Input sampler is assumed to have a constant size.\n\n Args:\n sampler (Sampler): Input torch data sampler.\n num_replicas (int, optional): Number of processes participating in distributed training.\n rank (int, optional): Rank of the current process within ``num_replicas``.\n\n \"\"\"\n\n def __init__(self, sampler: Sampler, num_replicas=None, rank=None):\n\n if not isinstance(sampler, Sampler):\n raise TypeError(\"Argument sampler should be instance of torch Sampler, but given: {}\".format(type(sampler)))\n\n if not hasattr(sampler, \"__len__\"):\n raise TypeError(\"Argument sampler should have length\")\n\n super(DistributedProxySampler, self).__init__(sampler, num_replicas=num_replicas, rank=rank, shuffle=False)\n self.sampler = sampler\n\n def __iter__(self):\n # deterministically shuffle based on epoch\n torch.manual_seed(self.epoch)\n\n indices = []\n while len(indices) < self.total_size:\n indices += list(self.sampler)\n\n if len(indices) > self.total_size:\n indices = indices[: self.total_size]\n\n # subsample\n indices = indices[self.rank : self.total_size : self.num_replicas]\n if len(indices) != self.num_samples:\n raise RuntimeError(\"{} vs {}\".format(len(indices), self.num_samples))\n\n return iter(indices)\n\n\nif idist.has_xla_support:\n\n import torch_xla.core.xla_model as xm\n from torch_xla.distributed.parallel_loader import ParallelLoader\n\n class _MpDeviceLoader:\n # https://github.com/pytorch/xla/pull/2117\n # From pytorch/xla if `torch_xla.distributed.parallel_loader.MpDeviceLoader` is not available\n def __init__(self, loader, device, **kwargs):\n self._loader = loader\n self._device = device\n self._parallel_loader_kwargs = kwargs\n\n def __iter__(self):\n parallel_loader = ParallelLoader(self._loader, [self._device], **self._parallel_loader_kwargs)\n return parallel_loader.per_device_loader(self._device)\n\n def __len__(self):\n return len(self._loader)\n\n class _XLADistributedOptimizer(Optimizer):\n def __init__(self, optimizer):\n super(self.__class__, self).__init__(optimizer.param_groups)\n self.wrapped_optimizer = optimizer\n\n def step(self, closure=None):\n xm.optimizer_step(self.wrapped_optimizer, barrier=True)\n", "path": "ignite/distributed/auto.py"}]}
| 3,954 | 776 |
gh_patches_debug_2707
|
rasdani/github-patches
|
git_diff
|
DataDog__dd-trace-py-1582
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ddtrace.Pin() for multiple grpc channels doesn't work
Thanks for taking the time for reporting an issue!
Before reporting an issue on dd-trace-py, please be sure to provide all
necessary information.
If you're hitting a bug, make sure that you're using the latest version of this
library.
### Which version of dd-trace-py are you using?
0.38.2
I didn't find anything related to this issue in the release notes of the releases after this version.
### Which version of the libraries are you using?
datadog==0.36.0
### How can we reproduce your problem?
Approach 1:
servers is a list of grpc server addresses
```
for server in servers:
channel = grpc.insecure_channel(server)
Pin.override(channel, service=server)
# Do something with the channel
```
Since `Pin.override(grpc.Channel, service=server)` worked with one server, I also tried the following to see how it looks
Approach 2:
servers is a list of grpc server addresses
```
for server in servers:
Pin.override(grpc.Channel, service=server)
channel = grpc.insecure_channel(server)
# Do something with the channel
```
### What is the result that you get?
In Approach 1, Pin.override did not set the service name correctly. Everywhere in Datadog, I could see it as `grpc-client` which is the default value.
In Approach 2, since I I don't pass the channels corresponding to each server, all servers are overriden by Pin to the final server (probably because it's the last one in the loop)
### What is the result that you expected?
ddtrace.Pin() onto multiple grpc channels should work and I should be able to see the correct `service` in Datadog APM traces and Service Map
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ddtrace/contrib/grpc/patch.py`
Content:
```
1 import os
2
3 import grpc
4
5 from ddtrace.vendor.wrapt import wrap_function_wrapper as _w
6 from ddtrace import config, Pin
7
8 from ...utils.wrappers import unwrap as _u
9
10 from . import constants
11 from .client_interceptor import create_client_interceptor, intercept_channel
12 from .server_interceptor import create_server_interceptor
13
14
15 config._add('grpc_server', dict(
16 service_name=config._get_service(default=constants.GRPC_SERVICE_SERVER),
17 distributed_tracing_enabled=True,
18 ))
19
20
21 # Precedence for the service name:
22 # 1) DD_GRPC_SERVICE if defined; or
23 # 2) For compatibility, the globally set service + "-grpc-client"; or
24 # 3) The fall-back "grpc-client"
25 if "DD_GRPC_SERVICE" in os.environ:
26 service = os.getenv("DD_GRPC_SERVICE")
27 elif config._get_service():
28 service = "{}-{}".format(config._get_service(), constants.GRPC_SERVICE_CLIENT)
29 else:
30 service = constants.GRPC_SERVICE_CLIENT
31
32
33 # TODO[tbutt]: keeping name for client config unchanged to maintain backwards
34 # compatibility but should change in future
35 config._add('grpc', dict(
36 service_name=service,
37 distributed_tracing_enabled=True,
38 ))
39
40
41 def patch():
42 _patch_client()
43 _patch_server()
44
45
46 def unpatch():
47 _unpatch_client()
48 _unpatch_server()
49
50
51 def _patch_client():
52 if getattr(constants.GRPC_PIN_MODULE_CLIENT, '__datadog_patch', False):
53 return
54 setattr(constants.GRPC_PIN_MODULE_CLIENT, '__datadog_patch', True)
55
56 Pin().onto(constants.GRPC_PIN_MODULE_CLIENT)
57
58 _w('grpc', 'insecure_channel', _client_channel_interceptor)
59 _w('grpc', 'secure_channel', _client_channel_interceptor)
60 _w('grpc', 'intercept_channel', intercept_channel)
61
62
63 def _unpatch_client():
64 if not getattr(constants.GRPC_PIN_MODULE_CLIENT, '__datadog_patch', False):
65 return
66 setattr(constants.GRPC_PIN_MODULE_CLIENT, '__datadog_patch', False)
67
68 pin = Pin.get_from(constants.GRPC_PIN_MODULE_CLIENT)
69 if pin:
70 pin.remove_from(constants.GRPC_PIN_MODULE_CLIENT)
71
72 _u(grpc, 'secure_channel')
73 _u(grpc, 'insecure_channel')
74
75
76 def _patch_server():
77 if getattr(constants.GRPC_PIN_MODULE_SERVER, '__datadog_patch', False):
78 return
79 setattr(constants.GRPC_PIN_MODULE_SERVER, '__datadog_patch', True)
80
81 Pin().onto(constants.GRPC_PIN_MODULE_SERVER)
82
83 _w('grpc', 'server', _server_constructor_interceptor)
84
85
86 def _unpatch_server():
87 if not getattr(constants.GRPC_PIN_MODULE_SERVER, '__datadog_patch', False):
88 return
89 setattr(constants.GRPC_PIN_MODULE_SERVER, '__datadog_patch', False)
90
91 pin = Pin.get_from(constants.GRPC_PIN_MODULE_SERVER)
92 if pin:
93 pin.remove_from(constants.GRPC_PIN_MODULE_SERVER)
94
95 _u(grpc, 'server')
96
97
98 def _client_channel_interceptor(wrapped, instance, args, kwargs):
99 channel = wrapped(*args, **kwargs)
100
101 pin = Pin.get_from(constants.GRPC_PIN_MODULE_CLIENT)
102 if not pin or not pin.enabled():
103 return channel
104
105 (host, port) = _parse_target_from_arguments(args, kwargs)
106
107 interceptor_function = create_client_interceptor(pin, host, port)
108 return grpc.intercept_channel(channel, interceptor_function)
109
110
111 def _server_constructor_interceptor(wrapped, instance, args, kwargs):
112 # DEV: we clone the pin on the grpc module and configure it for the server
113 # interceptor
114
115 pin = Pin.get_from(constants.GRPC_PIN_MODULE_SERVER)
116 if not pin or not pin.enabled():
117 return wrapped(*args, **kwargs)
118
119 interceptor = create_server_interceptor(pin)
120
121 # DEV: Inject our tracing interceptor first in the list of interceptors
122 if 'interceptors' in kwargs:
123 kwargs['interceptors'] = (interceptor,) + tuple(kwargs['interceptors'])
124 else:
125 kwargs['interceptors'] = (interceptor,)
126
127 return wrapped(*args, **kwargs)
128
129
130 def _parse_target_from_arguments(args, kwargs):
131 if 'target' in kwargs:
132 target = kwargs['target']
133 else:
134 target = args[0]
135
136 split = target.rsplit(':', 2)
137
138 return (split[0], split[1] if len(split) > 1 else None)
139
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ddtrace/contrib/grpc/patch.py b/ddtrace/contrib/grpc/patch.py
--- a/ddtrace/contrib/grpc/patch.py
+++ b/ddtrace/contrib/grpc/patch.py
@@ -98,7 +98,7 @@
def _client_channel_interceptor(wrapped, instance, args, kwargs):
channel = wrapped(*args, **kwargs)
- pin = Pin.get_from(constants.GRPC_PIN_MODULE_CLIENT)
+ pin = Pin.get_from(channel)
if not pin or not pin.enabled():
return channel
|
{"golden_diff": "diff --git a/ddtrace/contrib/grpc/patch.py b/ddtrace/contrib/grpc/patch.py\n--- a/ddtrace/contrib/grpc/patch.py\n+++ b/ddtrace/contrib/grpc/patch.py\n@@ -98,7 +98,7 @@\n def _client_channel_interceptor(wrapped, instance, args, kwargs):\n channel = wrapped(*args, **kwargs)\n \n- pin = Pin.get_from(constants.GRPC_PIN_MODULE_CLIENT)\n+ pin = Pin.get_from(channel)\n if not pin or not pin.enabled():\n return channel\n", "issue": "ddtrace.Pin() for multiple grpc channels doesn't work\nThanks for taking the time for reporting an issue!\r\n\r\nBefore reporting an issue on dd-trace-py, please be sure to provide all\r\nnecessary information.\r\n\r\nIf you're hitting a bug, make sure that you're using the latest version of this\r\nlibrary.\r\n\r\n### Which version of dd-trace-py are you using?\r\n0.38.2\r\nI didn't find anything related to this issue in the release notes of the releases after this version.\r\n\r\n### Which version of the libraries are you using?\r\ndatadog==0.36.0\r\n\r\n### How can we reproduce your problem?\r\nApproach 1:\r\nservers is a list of grpc server addresses\r\n```\r\nfor server in servers:\r\n channel = grpc.insecure_channel(server)\r\n Pin.override(channel, service=server)\r\n # Do something with the channel\r\n```\r\n\r\nSince `Pin.override(grpc.Channel, service=server)` worked with one server, I also tried the following to see how it looks\r\nApproach 2:\r\nservers is a list of grpc server addresses\r\n```\r\nfor server in servers:\r\n Pin.override(grpc.Channel, service=server)\r\n channel = grpc.insecure_channel(server)\r\n # Do something with the channel\r\n```\r\n\r\n### What is the result that you get?\r\nIn Approach 1, Pin.override did not set the service name correctly. Everywhere in Datadog, I could see it as `grpc-client` which is the default value.\r\nIn Approach 2, since I I don't pass the channels corresponding to each server, all servers are overriden by Pin to the final server (probably because it's the last one in the loop)\r\n\r\n### What is the result that you expected?\r\nddtrace.Pin() onto multiple grpc channels should work and I should be able to see the correct `service` in Datadog APM traces and Service Map\n", "before_files": [{"content": "import os\n\nimport grpc\n\nfrom ddtrace.vendor.wrapt import wrap_function_wrapper as _w\nfrom ddtrace import config, Pin\n\nfrom ...utils.wrappers import unwrap as _u\n\nfrom . import constants\nfrom .client_interceptor import create_client_interceptor, intercept_channel\nfrom .server_interceptor import create_server_interceptor\n\n\nconfig._add('grpc_server', dict(\n service_name=config._get_service(default=constants.GRPC_SERVICE_SERVER),\n distributed_tracing_enabled=True,\n))\n\n\n# Precedence for the service name:\n# 1) DD_GRPC_SERVICE if defined; or\n# 2) For compatibility, the globally set service + \"-grpc-client\"; or\n# 3) The fall-back \"grpc-client\"\nif \"DD_GRPC_SERVICE\" in os.environ:\n service = os.getenv(\"DD_GRPC_SERVICE\")\nelif config._get_service():\n service = \"{}-{}\".format(config._get_service(), constants.GRPC_SERVICE_CLIENT)\nelse:\n service = constants.GRPC_SERVICE_CLIENT\n\n\n# TODO[tbutt]: keeping name for client config unchanged to maintain backwards\n# compatibility but should change in future\nconfig._add('grpc', dict(\n service_name=service,\n distributed_tracing_enabled=True,\n))\n\n\ndef patch():\n _patch_client()\n _patch_server()\n\n\ndef unpatch():\n _unpatch_client()\n _unpatch_server()\n\n\ndef _patch_client():\n if getattr(constants.GRPC_PIN_MODULE_CLIENT, '__datadog_patch', False):\n return\n setattr(constants.GRPC_PIN_MODULE_CLIENT, '__datadog_patch', True)\n\n Pin().onto(constants.GRPC_PIN_MODULE_CLIENT)\n\n _w('grpc', 'insecure_channel', _client_channel_interceptor)\n _w('grpc', 'secure_channel', _client_channel_interceptor)\n _w('grpc', 'intercept_channel', intercept_channel)\n\n\ndef _unpatch_client():\n if not getattr(constants.GRPC_PIN_MODULE_CLIENT, '__datadog_patch', False):\n return\n setattr(constants.GRPC_PIN_MODULE_CLIENT, '__datadog_patch', False)\n\n pin = Pin.get_from(constants.GRPC_PIN_MODULE_CLIENT)\n if pin:\n pin.remove_from(constants.GRPC_PIN_MODULE_CLIENT)\n\n _u(grpc, 'secure_channel')\n _u(grpc, 'insecure_channel')\n\n\ndef _patch_server():\n if getattr(constants.GRPC_PIN_MODULE_SERVER, '__datadog_patch', False):\n return\n setattr(constants.GRPC_PIN_MODULE_SERVER, '__datadog_patch', True)\n\n Pin().onto(constants.GRPC_PIN_MODULE_SERVER)\n\n _w('grpc', 'server', _server_constructor_interceptor)\n\n\ndef _unpatch_server():\n if not getattr(constants.GRPC_PIN_MODULE_SERVER, '__datadog_patch', False):\n return\n setattr(constants.GRPC_PIN_MODULE_SERVER, '__datadog_patch', False)\n\n pin = Pin.get_from(constants.GRPC_PIN_MODULE_SERVER)\n if pin:\n pin.remove_from(constants.GRPC_PIN_MODULE_SERVER)\n\n _u(grpc, 'server')\n\n\ndef _client_channel_interceptor(wrapped, instance, args, kwargs):\n channel = wrapped(*args, **kwargs)\n\n pin = Pin.get_from(constants.GRPC_PIN_MODULE_CLIENT)\n if not pin or not pin.enabled():\n return channel\n\n (host, port) = _parse_target_from_arguments(args, kwargs)\n\n interceptor_function = create_client_interceptor(pin, host, port)\n return grpc.intercept_channel(channel, interceptor_function)\n\n\ndef _server_constructor_interceptor(wrapped, instance, args, kwargs):\n # DEV: we clone the pin on the grpc module and configure it for the server\n # interceptor\n\n pin = Pin.get_from(constants.GRPC_PIN_MODULE_SERVER)\n if not pin or not pin.enabled():\n return wrapped(*args, **kwargs)\n\n interceptor = create_server_interceptor(pin)\n\n # DEV: Inject our tracing interceptor first in the list of interceptors\n if 'interceptors' in kwargs:\n kwargs['interceptors'] = (interceptor,) + tuple(kwargs['interceptors'])\n else:\n kwargs['interceptors'] = (interceptor,)\n\n return wrapped(*args, **kwargs)\n\n\ndef _parse_target_from_arguments(args, kwargs):\n if 'target' in kwargs:\n target = kwargs['target']\n else:\n target = args[0]\n\n split = target.rsplit(':', 2)\n\n return (split[0], split[1] if len(split) > 1 else None)\n", "path": "ddtrace/contrib/grpc/patch.py"}], "after_files": [{"content": "import os\n\nimport grpc\n\nfrom ddtrace.vendor.wrapt import wrap_function_wrapper as _w\nfrom ddtrace import config, Pin\n\nfrom ...utils.wrappers import unwrap as _u\n\nfrom . import constants\nfrom .client_interceptor import create_client_interceptor, intercept_channel\nfrom .server_interceptor import create_server_interceptor\n\n\nconfig._add('grpc_server', dict(\n service_name=config._get_service(default=constants.GRPC_SERVICE_SERVER),\n distributed_tracing_enabled=True,\n))\n\n\n# Precedence for the service name:\n# 1) DD_GRPC_SERVICE if defined; or\n# 2) For compatibility, the globally set service + \"-grpc-client\"; or\n# 3) The fall-back \"grpc-client\"\nif \"DD_GRPC_SERVICE\" in os.environ:\n service = os.getenv(\"DD_GRPC_SERVICE\")\nelif config._get_service():\n service = \"{}-{}\".format(config._get_service(), constants.GRPC_SERVICE_CLIENT)\nelse:\n service = constants.GRPC_SERVICE_CLIENT\n\n\n# TODO[tbutt]: keeping name for client config unchanged to maintain backwards\n# compatibility but should change in future\nconfig._add('grpc', dict(\n service_name=service,\n distributed_tracing_enabled=True,\n))\n\n\ndef patch():\n _patch_client()\n _patch_server()\n\n\ndef unpatch():\n _unpatch_client()\n _unpatch_server()\n\n\ndef _patch_client():\n if getattr(constants.GRPC_PIN_MODULE_CLIENT, '__datadog_patch', False):\n return\n setattr(constants.GRPC_PIN_MODULE_CLIENT, '__datadog_patch', True)\n\n Pin().onto(constants.GRPC_PIN_MODULE_CLIENT)\n\n _w('grpc', 'insecure_channel', _client_channel_interceptor)\n _w('grpc', 'secure_channel', _client_channel_interceptor)\n _w('grpc', 'intercept_channel', intercept_channel)\n\n\ndef _unpatch_client():\n if not getattr(constants.GRPC_PIN_MODULE_CLIENT, '__datadog_patch', False):\n return\n setattr(constants.GRPC_PIN_MODULE_CLIENT, '__datadog_patch', False)\n\n pin = Pin.get_from(constants.GRPC_PIN_MODULE_CLIENT)\n if pin:\n pin.remove_from(constants.GRPC_PIN_MODULE_CLIENT)\n\n _u(grpc, 'secure_channel')\n _u(grpc, 'insecure_channel')\n\n\ndef _patch_server():\n if getattr(constants.GRPC_PIN_MODULE_SERVER, '__datadog_patch', False):\n return\n setattr(constants.GRPC_PIN_MODULE_SERVER, '__datadog_patch', True)\n\n Pin().onto(constants.GRPC_PIN_MODULE_SERVER)\n\n _w('grpc', 'server', _server_constructor_interceptor)\n\n\ndef _unpatch_server():\n if not getattr(constants.GRPC_PIN_MODULE_SERVER, '__datadog_patch', False):\n return\n setattr(constants.GRPC_PIN_MODULE_SERVER, '__datadog_patch', False)\n\n pin = Pin.get_from(constants.GRPC_PIN_MODULE_SERVER)\n if pin:\n pin.remove_from(constants.GRPC_PIN_MODULE_SERVER)\n\n _u(grpc, 'server')\n\n\ndef _client_channel_interceptor(wrapped, instance, args, kwargs):\n channel = wrapped(*args, **kwargs)\n\n pin = Pin.get_from(channel)\n if not pin or not pin.enabled():\n return channel\n\n (host, port) = _parse_target_from_arguments(args, kwargs)\n\n interceptor_function = create_client_interceptor(pin, host, port)\n return grpc.intercept_channel(channel, interceptor_function)\n\n\ndef _server_constructor_interceptor(wrapped, instance, args, kwargs):\n # DEV: we clone the pin on the grpc module and configure it for the server\n # interceptor\n\n pin = Pin.get_from(constants.GRPC_PIN_MODULE_SERVER)\n if not pin or not pin.enabled():\n return wrapped(*args, **kwargs)\n\n interceptor = create_server_interceptor(pin)\n\n # DEV: Inject our tracing interceptor first in the list of interceptors\n if 'interceptors' in kwargs:\n kwargs['interceptors'] = (interceptor,) + tuple(kwargs['interceptors'])\n else:\n kwargs['interceptors'] = (interceptor,)\n\n return wrapped(*args, **kwargs)\n\n\ndef _parse_target_from_arguments(args, kwargs):\n if 'target' in kwargs:\n target = kwargs['target']\n else:\n target = args[0]\n\n split = target.rsplit(':', 2)\n\n return (split[0], split[1] if len(split) > 1 else None)\n", "path": "ddtrace/contrib/grpc/patch.py"}]}
| 1,938 | 118 |
gh_patches_debug_19885
|
rasdani/github-patches
|
git_diff
|
mlcommons__GaNDLF-498
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Per-label accuracy does not work for multiple batches
**Describe the bug**
When `batch_size > 1`, `per_label_accuracy` computation fails.
**To Reproduce**
Steps to reproduce the behavior:
1. Set `batch_size = 4` in any classification unit test
2. See error
**Expected behavior**
The function should compute multiple batches of accuracies.
**Screenshots**
N.A.
**GaNDLF Version**
<!-- Put the output of the following command:
python -c 'import GANDLF as g;print(g.__version__)'
-->
0.0.15-dev
**Desktop (please complete the following information):**
N.A.
**Additional context**
Reported by @brandon-edwards
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `GANDLF/metrics/regression.py`
Content:
```
1 """
2 All the metrics are to be called from here
3 """
4 import torch
5 from sklearn.metrics import balanced_accuracy_score
6 import numpy as np
7
8
9 def classification_accuracy(output, label, params):
10 """
11 This function computes the classification accuracy.
12
13 Args:
14 output (torch.Tensor): The output of the model.
15 label (torch.Tensor): The ground truth labels.
16 params (dict): The parameter dictionary containing training and data information.
17
18 Returns:
19 torch.Tensor: The classification accuracy.
20 """
21 if params["problem_type"] == "classification":
22 predicted_classes = torch.argmax(output, 1)
23 else:
24 predicted_classes = output
25
26 acc = torch.sum(predicted_classes == label.squeeze()) / len(label)
27 return acc
28
29
30 def balanced_acc_score(output, label, params):
31 """
32 This function computes the balanced accuracy.
33
34 Args:
35 output (torch.Tensor): The output of the model.
36 label (torch.Tensor): The ground truth labels.
37 params (dict): The parameter dictionary containing training and data information.
38
39 Returns:
40 torch.Tensor: The balanced accuracy.
41 """
42 if params["problem_type"] == "classification":
43 predicted_classes = torch.argmax(output, 1)
44 else:
45 predicted_classes = output
46
47 return torch.from_numpy(
48 np.array(balanced_accuracy_score(predicted_classes.cpu(), label.cpu()))
49 )
50
51
52 def per_label_accuracy(output, label, params):
53 """
54 This function computes the per class accuracy.
55
56 Args:
57 output (torch.Tensor): The output of the model.
58 label (torch.Tensor): The ground truth labels.
59 params (dict): The parameter dictionary containing training and data information.
60
61 Returns:
62 torch.Tensor: The per class accuracy.
63 """
64 if params["problem_type"] == "classification":
65 predicted_classes = np.array([0] * len(params["model"]["class_list"]))
66 label_cpu = np.array([0] * len(params["model"]["class_list"]))
67 predicted_classes[torch.argmax(output, 1).cpu().item()] = 1
68 label_cpu[label.cpu().item()] = 1
69 return torch.from_numpy((predicted_classes == label_cpu).astype(float))
70 else:
71 return balanced_acc_score(output, label, params)
72
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/GANDLF/metrics/regression.py b/GANDLF/metrics/regression.py
--- a/GANDLF/metrics/regression.py
+++ b/GANDLF/metrics/regression.py
@@ -62,10 +62,14 @@
torch.Tensor: The per class accuracy.
"""
if params["problem_type"] == "classification":
- predicted_classes = np.array([0] * len(params["model"]["class_list"]))
- label_cpu = np.array([0] * len(params["model"]["class_list"]))
- predicted_classes[torch.argmax(output, 1).cpu().item()] = 1
- label_cpu[label.cpu().item()] = 1
- return torch.from_numpy((predicted_classes == label_cpu).astype(float))
+ # ensure this works for multiple batches
+ output_accuracy = torch.zeros(len(params["model"]["class_list"]))
+ for output_batch, label_batch in zip(output, label):
+ predicted_classes = torch.Tensor([0] * len(params["model"]["class_list"]))
+ label_cpu = torch.Tensor([0] * len(params["model"]["class_list"]))
+ predicted_classes[torch.argmax(output_batch, 0).cpu().item()] = 1
+ label_cpu[label_batch.cpu().item()] = 1
+ output_accuracy += (predicted_classes == label_cpu).type(torch.float)
+ return output_accuracy / len(output)
else:
return balanced_acc_score(output, label, params)
|
{"golden_diff": "diff --git a/GANDLF/metrics/regression.py b/GANDLF/metrics/regression.py\n--- a/GANDLF/metrics/regression.py\n+++ b/GANDLF/metrics/regression.py\n@@ -62,10 +62,14 @@\n torch.Tensor: The per class accuracy.\n \"\"\"\n if params[\"problem_type\"] == \"classification\":\n- predicted_classes = np.array([0] * len(params[\"model\"][\"class_list\"]))\n- label_cpu = np.array([0] * len(params[\"model\"][\"class_list\"]))\n- predicted_classes[torch.argmax(output, 1).cpu().item()] = 1\n- label_cpu[label.cpu().item()] = 1\n- return torch.from_numpy((predicted_classes == label_cpu).astype(float))\n+ # ensure this works for multiple batches\n+ output_accuracy = torch.zeros(len(params[\"model\"][\"class_list\"]))\n+ for output_batch, label_batch in zip(output, label):\n+ predicted_classes = torch.Tensor([0] * len(params[\"model\"][\"class_list\"]))\n+ label_cpu = torch.Tensor([0] * len(params[\"model\"][\"class_list\"]))\n+ predicted_classes[torch.argmax(output_batch, 0).cpu().item()] = 1\n+ label_cpu[label_batch.cpu().item()] = 1\n+ output_accuracy += (predicted_classes == label_cpu).type(torch.float)\n+ return output_accuracy / len(output)\n else:\n return balanced_acc_score(output, label, params)\n", "issue": "Per-label accuracy does not work for multiple batches\n**Describe the bug**\r\nWhen `batch_size > 1`, `per_label_accuracy` computation fails.\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Set `batch_size = 4` in any classification unit test\r\n2. See error\r\n\r\n**Expected behavior**\r\nThe function should compute multiple batches of accuracies.\r\n\r\n**Screenshots**\r\nN.A.\r\n\r\n**GaNDLF Version**\r\n<!-- Put the output of the following command:\r\npython -c 'import GANDLF as g;print(g.__version__)'\r\n-->\r\n0.0.15-dev\r\n\r\n**Desktop (please complete the following information):**\r\nN.A.\r\n\r\n**Additional context**\r\nReported by @brandon-edwards\n", "before_files": [{"content": "\"\"\"\nAll the metrics are to be called from here\n\"\"\"\nimport torch\nfrom sklearn.metrics import balanced_accuracy_score\nimport numpy as np\n\n\ndef classification_accuracy(output, label, params):\n \"\"\"\n This function computes the classification accuracy.\n\n Args:\n output (torch.Tensor): The output of the model.\n label (torch.Tensor): The ground truth labels.\n params (dict): The parameter dictionary containing training and data information.\n\n Returns:\n torch.Tensor: The classification accuracy.\n \"\"\"\n if params[\"problem_type\"] == \"classification\":\n predicted_classes = torch.argmax(output, 1)\n else:\n predicted_classes = output\n\n acc = torch.sum(predicted_classes == label.squeeze()) / len(label)\n return acc\n\n\ndef balanced_acc_score(output, label, params):\n \"\"\"\n This function computes the balanced accuracy.\n\n Args:\n output (torch.Tensor): The output of the model.\n label (torch.Tensor): The ground truth labels.\n params (dict): The parameter dictionary containing training and data information.\n\n Returns:\n torch.Tensor: The balanced accuracy.\n \"\"\"\n if params[\"problem_type\"] == \"classification\":\n predicted_classes = torch.argmax(output, 1)\n else:\n predicted_classes = output\n\n return torch.from_numpy(\n np.array(balanced_accuracy_score(predicted_classes.cpu(), label.cpu()))\n )\n\n\ndef per_label_accuracy(output, label, params):\n \"\"\"\n This function computes the per class accuracy.\n\n Args:\n output (torch.Tensor): The output of the model.\n label (torch.Tensor): The ground truth labels.\n params (dict): The parameter dictionary containing training and data information.\n\n Returns:\n torch.Tensor: The per class accuracy.\n \"\"\"\n if params[\"problem_type\"] == \"classification\":\n predicted_classes = np.array([0] * len(params[\"model\"][\"class_list\"]))\n label_cpu = np.array([0] * len(params[\"model\"][\"class_list\"]))\n predicted_classes[torch.argmax(output, 1).cpu().item()] = 1\n label_cpu[label.cpu().item()] = 1\n return torch.from_numpy((predicted_classes == label_cpu).astype(float))\n else:\n return balanced_acc_score(output, label, params)\n", "path": "GANDLF/metrics/regression.py"}], "after_files": [{"content": "\"\"\"\nAll the metrics are to be called from here\n\"\"\"\nimport torch\nfrom sklearn.metrics import balanced_accuracy_score\nimport numpy as np\n\n\ndef classification_accuracy(output, label, params):\n \"\"\"\n This function computes the classification accuracy.\n\n Args:\n output (torch.Tensor): The output of the model.\n label (torch.Tensor): The ground truth labels.\n params (dict): The parameter dictionary containing training and data information.\n\n Returns:\n torch.Tensor: The classification accuracy.\n \"\"\"\n if params[\"problem_type\"] == \"classification\":\n predicted_classes = torch.argmax(output, 1)\n else:\n predicted_classes = output\n\n acc = torch.sum(predicted_classes == label.squeeze()) / len(label)\n return acc\n\n\ndef balanced_acc_score(output, label, params):\n \"\"\"\n This function computes the balanced accuracy.\n\n Args:\n output (torch.Tensor): The output of the model.\n label (torch.Tensor): The ground truth labels.\n params (dict): The parameter dictionary containing training and data information.\n\n Returns:\n torch.Tensor: The balanced accuracy.\n \"\"\"\n if params[\"problem_type\"] == \"classification\":\n predicted_classes = torch.argmax(output, 1)\n else:\n predicted_classes = output\n\n return torch.from_numpy(\n np.array(balanced_accuracy_score(predicted_classes.cpu(), label.cpu()))\n )\n\n\ndef per_label_accuracy(output, label, params):\n \"\"\"\n This function computes the per class accuracy.\n\n Args:\n output (torch.Tensor): The output of the model.\n label (torch.Tensor): The ground truth labels.\n params (dict): The parameter dictionary containing training and data information.\n\n Returns:\n torch.Tensor: The per class accuracy.\n \"\"\"\n if params[\"problem_type\"] == \"classification\":\n # ensure this works for multiple batches\n output_accuracy = torch.zeros(len(params[\"model\"][\"class_list\"]))\n for output_batch, label_batch in zip(output, label):\n predicted_classes = torch.Tensor([0] * len(params[\"model\"][\"class_list\"]))\n label_cpu = torch.Tensor([0] * len(params[\"model\"][\"class_list\"]))\n predicted_classes[torch.argmax(output_batch, 0).cpu().item()] = 1\n label_cpu[label_batch.cpu().item()] = 1\n output_accuracy += (predicted_classes == label_cpu).type(torch.float)\n return output_accuracy / len(output)\n else:\n return balanced_acc_score(output, label, params)\n", "path": "GANDLF/metrics/regression.py"}]}
| 1,023 | 318 |
gh_patches_debug_12330
|
rasdani/github-patches
|
git_diff
|
falconry__falcon-1883
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
deprecated() utility raises AttributeError under Meinheld
The inner function of our [`deprecated()`](https://falcon.readthedocs.io/en/latest/api/util.html#falcon.deprecated) utility generator grabs the current stack frame object via [`inspect.getcurrentframe()`](https://docs.python.org/3/library/inspect.html#inspect.currentframe), and then uses its attributes to provide a more informative deprecation warning.
However, as warned in the latter's docs, this function is not guaranteed to return a valid stack frame object on all Python implementations; it may also return `None`. It seems that running Gunicorn+Meinheld workers can trigger this situation even under CPython.
Discovered using the following command line under CPython 3.7 and 3.8:
```
gunicorn --workers=8 --worker-class="egg:meinheld#gunicorn_worker" test:app
```
For instance, assigning a value to the deprecated [`Response.body`](https://falcon.readthedocs.io/en/latest/api/request_and_response_wsgi.html#falcon.Response.body) yields
```
2021-03-11 23:31:42 [FALCON] [ERROR] GET /things => Traceback (most recent call last):
File "falcon/app.py", line 361, in falcon.app.App.__call__
File "/tmp/benchmark/test3.py", line 13, in on_get
resp.body = ('\nTwo things awe me most, the starry sky '
File "falcon/util/deprecation.py", line 67, in falcon.util.deprecation.deprecated.decorator.wrapper
AttributeError: 'NoneType' object has no attribute 'f_code'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `falcon/util/deprecation.py`
Content:
```
1 # Copyright 2013 by Rackspace Hosting, Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Miscellaneous deprecation utilities.
16
17 This module provides decorators to mark functions and classes as deprecated.
18 """
19
20 import functools
21 import inspect
22 import warnings
23
24
25 __all__ = (
26 'DeprecatedWarning',
27 'deprecated',
28 'deprecated_args',
29 )
30
31
32 # NOTE(kgriffs): We don't want our deprecations to be ignored by default,
33 # so create our own type.
34 #
35 # TODO(kgriffs): Revisit this decision if users complain.
36 class DeprecatedWarning(UserWarning):
37 pass
38
39
40 def deprecated(instructions, is_property=False):
41 """Flag a method as deprecated.
42
43 This function returns a decorator which can be used to mark deprecated
44 functions. Applying this decorator will result in a warning being
45 emitted when the function is used.
46
47 Args:
48 instructions (str): Specific guidance for the developer, e.g.:
49 'Please migrate to add_proxy(...)'
50 is_property (bool): If the deprecated object is a property. It
51 will omit the ``(...)`` from the generated documentation
52 """
53
54 def decorator(func):
55
56 object_name = 'property' if is_property else 'function'
57 post_name = '' if is_property else '(...)'
58 message = 'Call to deprecated {} {}{}. {}'.format(
59 object_name, func.__name__, post_name, instructions)
60
61 @functools.wraps(func)
62 def wrapper(*args, **kwargs):
63 frame = inspect.currentframe().f_back
64
65 warnings.warn_explicit(message,
66 category=DeprecatedWarning,
67 filename=inspect.getfile(frame.f_code),
68 lineno=frame.f_lineno)
69
70 return func(*args, **kwargs)
71
72 return wrapper
73
74 return decorator
75
76
77 def deprecated_args(*, allowed_positional, is_method=True):
78 """Flag a method call with positional args as deprecated.
79
80 Keyword Args:
81 allowed_positional (int): Number of allowed positional arguments
82 is_method (bool, optional): The decorated function is a method. Will
83 add one to the number of allowed positional args to account for
84 ``self``. Defaults to True.
85 """
86
87 template = (
88 'Calls with{} positional args are deprecated.'
89 ' Please specify them as keyword arguments instead.'
90 )
91 text = ' more than {}'.format(allowed_positional) if allowed_positional else ''
92 warn_text = template.format(text)
93 if is_method:
94 allowed_positional += 1
95
96 def deprecated_args(fn):
97 @functools.wraps(fn)
98 def wraps(*args, **kwargs):
99 if len(args) > allowed_positional:
100 warnings.warn(warn_text, DeprecatedWarning, stacklevel=2)
101 return fn(*args, **kwargs)
102
103 return wraps
104
105 return deprecated_args
106
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/falcon/util/deprecation.py b/falcon/util/deprecation.py
--- a/falcon/util/deprecation.py
+++ b/falcon/util/deprecation.py
@@ -18,7 +18,6 @@
"""
import functools
-import inspect
import warnings
@@ -60,12 +59,7 @@
@functools.wraps(func)
def wrapper(*args, **kwargs):
- frame = inspect.currentframe().f_back
-
- warnings.warn_explicit(message,
- category=DeprecatedWarning,
- filename=inspect.getfile(frame.f_code),
- lineno=frame.f_lineno)
+ warnings.warn(message, category=DeprecatedWarning, stacklevel=2)
return func(*args, **kwargs)
|
{"golden_diff": "diff --git a/falcon/util/deprecation.py b/falcon/util/deprecation.py\n--- a/falcon/util/deprecation.py\n+++ b/falcon/util/deprecation.py\n@@ -18,7 +18,6 @@\n \"\"\"\n \n import functools\n-import inspect\n import warnings\n \n \n@@ -60,12 +59,7 @@\n \n @functools.wraps(func)\n def wrapper(*args, **kwargs):\n- frame = inspect.currentframe().f_back\n-\n- warnings.warn_explicit(message,\n- category=DeprecatedWarning,\n- filename=inspect.getfile(frame.f_code),\n- lineno=frame.f_lineno)\n+ warnings.warn(message, category=DeprecatedWarning, stacklevel=2)\n \n return func(*args, **kwargs)\n", "issue": "deprecated() utility raises AttributeError under Meinheld\nThe inner function of our [`deprecated()`](https://falcon.readthedocs.io/en/latest/api/util.html#falcon.deprecated) utility generator grabs the current stack frame object via [`inspect.getcurrentframe()`](https://docs.python.org/3/library/inspect.html#inspect.currentframe), and then uses its attributes to provide a more informative deprecation warning.\r\n\r\nHowever, as warned in the latter's docs, this function is not guaranteed to return a valid stack frame object on all Python implementations; it may also return `None`. It seems that running Gunicorn+Meinheld workers can trigger this situation even under CPython.\r\n\r\nDiscovered using the following command line under CPython 3.7 and 3.8:\r\n```\r\ngunicorn --workers=8 --worker-class=\"egg:meinheld#gunicorn_worker\" test:app\r\n```\r\n\r\nFor instance, assigning a value to the deprecated [`Response.body`](https://falcon.readthedocs.io/en/latest/api/request_and_response_wsgi.html#falcon.Response.body) yields\r\n```\r\n2021-03-11 23:31:42 [FALCON] [ERROR] GET /things => Traceback (most recent call last):\r\n File \"falcon/app.py\", line 361, in falcon.app.App.__call__\r\n File \"/tmp/benchmark/test3.py\", line 13, in on_get\r\n resp.body = ('\\nTwo things awe me most, the starry sky '\r\n File \"falcon/util/deprecation.py\", line 67, in falcon.util.deprecation.deprecated.decorator.wrapper\r\nAttributeError: 'NoneType' object has no attribute 'f_code'\r\n```\n", "before_files": [{"content": "# Copyright 2013 by Rackspace Hosting, Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Miscellaneous deprecation utilities.\n\nThis module provides decorators to mark functions and classes as deprecated.\n\"\"\"\n\nimport functools\nimport inspect\nimport warnings\n\n\n__all__ = (\n 'DeprecatedWarning',\n 'deprecated',\n 'deprecated_args',\n)\n\n\n# NOTE(kgriffs): We don't want our deprecations to be ignored by default,\n# so create our own type.\n#\n# TODO(kgriffs): Revisit this decision if users complain.\nclass DeprecatedWarning(UserWarning):\n pass\n\n\ndef deprecated(instructions, is_property=False):\n \"\"\"Flag a method as deprecated.\n\n This function returns a decorator which can be used to mark deprecated\n functions. Applying this decorator will result in a warning being\n emitted when the function is used.\n\n Args:\n instructions (str): Specific guidance for the developer, e.g.:\n 'Please migrate to add_proxy(...)'\n is_property (bool): If the deprecated object is a property. It\n will omit the ``(...)`` from the generated documentation\n \"\"\"\n\n def decorator(func):\n\n object_name = 'property' if is_property else 'function'\n post_name = '' if is_property else '(...)'\n message = 'Call to deprecated {} {}{}. {}'.format(\n object_name, func.__name__, post_name, instructions)\n\n @functools.wraps(func)\n def wrapper(*args, **kwargs):\n frame = inspect.currentframe().f_back\n\n warnings.warn_explicit(message,\n category=DeprecatedWarning,\n filename=inspect.getfile(frame.f_code),\n lineno=frame.f_lineno)\n\n return func(*args, **kwargs)\n\n return wrapper\n\n return decorator\n\n\ndef deprecated_args(*, allowed_positional, is_method=True):\n \"\"\"Flag a method call with positional args as deprecated.\n\n Keyword Args:\n allowed_positional (int): Number of allowed positional arguments\n is_method (bool, optional): The decorated function is a method. Will\n add one to the number of allowed positional args to account for\n ``self``. Defaults to True.\n \"\"\"\n\n template = (\n 'Calls with{} positional args are deprecated.'\n ' Please specify them as keyword arguments instead.'\n )\n text = ' more than {}'.format(allowed_positional) if allowed_positional else ''\n warn_text = template.format(text)\n if is_method:\n allowed_positional += 1\n\n def deprecated_args(fn):\n @functools.wraps(fn)\n def wraps(*args, **kwargs):\n if len(args) > allowed_positional:\n warnings.warn(warn_text, DeprecatedWarning, stacklevel=2)\n return fn(*args, **kwargs)\n\n return wraps\n\n return deprecated_args\n", "path": "falcon/util/deprecation.py"}], "after_files": [{"content": "# Copyright 2013 by Rackspace Hosting, Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Miscellaneous deprecation utilities.\n\nThis module provides decorators to mark functions and classes as deprecated.\n\"\"\"\n\nimport functools\nimport warnings\n\n\n__all__ = (\n 'DeprecatedWarning',\n 'deprecated',\n 'deprecated_args',\n)\n\n\n# NOTE(kgriffs): We don't want our deprecations to be ignored by default,\n# so create our own type.\n#\n# TODO(kgriffs): Revisit this decision if users complain.\nclass DeprecatedWarning(UserWarning):\n pass\n\n\ndef deprecated(instructions, is_property=False):\n \"\"\"Flag a method as deprecated.\n\n This function returns a decorator which can be used to mark deprecated\n functions. Applying this decorator will result in a warning being\n emitted when the function is used.\n\n Args:\n instructions (str): Specific guidance for the developer, e.g.:\n 'Please migrate to add_proxy(...)'\n is_property (bool): If the deprecated object is a property. It\n will omit the ``(...)`` from the generated documentation\n \"\"\"\n\n def decorator(func):\n\n object_name = 'property' if is_property else 'function'\n post_name = '' if is_property else '(...)'\n message = 'Call to deprecated {} {}{}. {}'.format(\n object_name, func.__name__, post_name, instructions)\n\n @functools.wraps(func)\n def wrapper(*args, **kwargs):\n warnings.warn(message, category=DeprecatedWarning, stacklevel=2)\n\n return func(*args, **kwargs)\n\n return wrapper\n\n return decorator\n\n\ndef deprecated_args(*, allowed_positional, is_method=True):\n \"\"\"Flag a method call with positional args as deprecated.\n\n Keyword Args:\n allowed_positional (int): Number of allowed positional arguments\n is_method (bool, optional): The decorated function is a method. Will\n add one to the number of allowed positional args to account for\n ``self``. Defaults to True.\n \"\"\"\n\n template = (\n 'Calls with{} positional args are deprecated.'\n ' Please specify them as keyword arguments instead.'\n )\n text = ' more than {}'.format(allowed_positional) if allowed_positional else ''\n warn_text = template.format(text)\n if is_method:\n allowed_positional += 1\n\n def deprecated_args(fn):\n @functools.wraps(fn)\n def wraps(*args, **kwargs):\n if len(args) > allowed_positional:\n warnings.warn(warn_text, DeprecatedWarning, stacklevel=2)\n return fn(*args, **kwargs)\n\n return wraps\n\n return deprecated_args\n", "path": "falcon/util/deprecation.py"}]}
| 1,554 | 164 |
gh_patches_debug_44294
|
rasdani/github-patches
|
git_diff
|
readthedocs__readthedocs.org-7070
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Projects built with `htmldir` have invalid link for homepage in search results
Projects that are built with `htmldir` have invalid link in search results to homepage.
For example: https://2.python-requests.org/en/master/search/?q=%22The+Contributor%22
This is related to #5821.
We are using `processed_json.path` for the search results, but the correct path is present in `full_path`.
https://github.com/readthedocs/readthedocs.org/blob/3c04a96b3a9ea8b68ecf270670080285c73c689b/readthedocs/search/documents.py#L73-L74
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `readthedocs/search/api.py`
Content:
```
1 import itertools
2 import logging
3
4 from django.shortcuts import get_object_or_404
5 from django.utils import timezone
6 from rest_framework import generics, serializers
7 from rest_framework.exceptions import ValidationError
8 from rest_framework.pagination import PageNumberPagination
9
10 from readthedocs.api.v2.permissions import IsAuthorizedToViewVersion
11 from readthedocs.builds.models import Version
12 from readthedocs.projects.models import HTMLFile, Project
13 from readthedocs.search import tasks, utils
14 from readthedocs.search.faceted_search import PageSearch
15
16 log = logging.getLogger(__name__)
17
18
19 class SearchPagination(PageNumberPagination):
20 page_size = 50
21 page_size_query_param = 'page_size'
22 max_page_size = 100
23
24
25 class PageSearchSerializer(serializers.Serializer):
26 project = serializers.CharField()
27 version = serializers.CharField()
28 title = serializers.CharField()
29 path = serializers.CharField()
30 link = serializers.SerializerMethodField()
31 highlight = serializers.SerializerMethodField()
32 inner_hits = serializers.SerializerMethodField()
33
34 def get_link(self, obj):
35 projects_url = self.context.get('projects_url')
36 if projects_url:
37 docs_url = projects_url[obj.project]
38 return docs_url + obj.path
39
40 def get_highlight(self, obj):
41 highlight = getattr(obj.meta, 'highlight', None)
42 if highlight:
43 ret = highlight.to_dict()
44 log.debug('API Search highlight [Page title]: %s', ret)
45 return ret
46
47 def get_inner_hits(self, obj):
48 inner_hits = getattr(obj.meta, 'inner_hits', None)
49 if inner_hits:
50 sections = inner_hits.sections or []
51 domains = inner_hits.domains or []
52 all_results = itertools.chain(sections, domains)
53
54 sorted_results = utils._get_sorted_results(
55 results=all_results,
56 source_key='_source',
57 )
58
59 log.debug('[API] Sorted Results: %s', sorted_results)
60 return sorted_results
61
62
63 class PageSearchAPIView(generics.ListAPIView):
64
65 """
66 Main entry point to perform a search using Elasticsearch.
67
68 Required query params:
69 - q (search term)
70 - project
71 - version
72
73 .. note::
74
75 The methods `_get_project` and `_get_version`
76 are called many times, so a basic cache is implemented.
77 """
78
79 permission_classes = [IsAuthorizedToViewVersion]
80 pagination_class = SearchPagination
81 serializer_class = PageSearchSerializer
82
83 def _get_project(self):
84 cache_key = '_cached_project'
85 project = getattr(self, cache_key, None)
86
87 if not project:
88 project_slug = self.request.GET.get('project', None)
89 project = get_object_or_404(Project, slug=project_slug)
90 setattr(self, cache_key, project)
91
92 return project
93
94 def _get_version(self):
95 cache_key = '_cached_version'
96 version = getattr(self, cache_key, None)
97
98 if not version:
99 version_slug = self.request.GET.get('version', None)
100 project = self._get_project()
101 version = get_object_or_404(
102 project.versions.all(),
103 slug=version_slug,
104 )
105 setattr(self, cache_key, version)
106
107 return version
108
109 def get_queryset(self):
110 """
111 Return Elasticsearch DSL Search object instead of Django Queryset.
112
113 Django Queryset and elasticsearch-dsl ``Search`` object is similar pattern.
114 So for searching, its possible to return ``Search`` object instead of queryset.
115 The ``filter_backends`` and ``pagination_class`` is compatible with ``Search``
116 """
117 # Validate all the required params are there
118 self.validate_query_params()
119 query = self.request.query_params.get('q', '')
120 kwargs = {'filter_by_user': False, 'filters': {}}
121 kwargs['filters']['project'] = [p.slug for p in self.get_all_projects()]
122 kwargs['filters']['version'] = self._get_version().slug
123
124 # Check to avoid searching all projects in case these filters are empty.
125 if not kwargs['filters']['project']:
126 log.info("Unable to find a project to search")
127 return HTMLFile.objects.none()
128 if not kwargs['filters']['version']:
129 log.info("Unable to find a version to search")
130 return HTMLFile.objects.none()
131
132 user = self.request.user
133 queryset = PageSearch(
134 query=query, user=user, **kwargs
135 )
136 return queryset
137
138 def validate_query_params(self):
139 """
140 Validate all required query params are passed on the request.
141
142 Query params required are: ``q``, ``project`` and ``version``.
143
144 :rtype: None
145
146 :raises: ValidationError if one of them is missing.
147 """
148 required_query_params = {'q', 'project', 'version'} # python `set` literal is `{}`
149 request_params = set(self.request.query_params.keys())
150 missing_params = required_query_params - request_params
151 if missing_params:
152 errors = {}
153 for param in missing_params:
154 errors[param] = ["This query param is required"]
155
156 raise ValidationError(errors)
157
158 def get_serializer_context(self):
159 context = super().get_serializer_context()
160 context['projects_url'] = self.get_all_projects_url()
161 return context
162
163 def get_all_projects(self):
164 """
165 Return a list of the project itself and all its subprojects the user has permissions over.
166
167 :rtype: list
168 """
169 main_version = self._get_version()
170 main_project = self._get_project()
171
172 all_projects = [main_project]
173
174 subprojects = Project.objects.filter(
175 superprojects__parent_id=main_project.id,
176 )
177 for project in subprojects:
178 version = (
179 Version.internal
180 .public(user=self.request.user, project=project, include_hidden=False)
181 .filter(slug=main_version.slug)
182 .first()
183 )
184 if version:
185 all_projects.append(version.project)
186 return all_projects
187
188 def get_all_projects_url(self):
189 """
190 Return a dict containing the project slug and its version URL.
191
192 The dictionary contains the project and its subprojects . Each project's
193 slug is used as a key and the documentation URL for that project and
194 version as the value.
195
196 Example:
197
198 {
199 "requests": "https://requests.readthedocs.io/en/latest/",
200 "requests-oauth": "https://requests-oauth.readthedocs.io/en/latest/",
201 }
202
203 :rtype: dict
204 """
205 all_projects = self.get_all_projects()
206 version_slug = self._get_version().slug
207 projects_url = {}
208 for project in all_projects:
209 projects_url[project.slug] = project.get_docs_url(version_slug=version_slug)
210 return projects_url
211
212 def list(self, request, *args, **kwargs):
213 """Overriding ``list`` method to record query in database."""
214
215 response = super().list(request, *args, **kwargs)
216
217 project_slug = self._get_project().slug
218 version_slug = self._get_version().slug
219 total_results = response.data.get('count', 0)
220 time = timezone.now()
221
222 query = self.request.query_params.get('q', '')
223 query = query.lower().strip()
224
225 # record the search query with a celery task
226 tasks.record_search_query.delay(
227 project_slug,
228 version_slug,
229 query,
230 total_results,
231 time.isoformat(),
232 )
233
234 return response
235
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/readthedocs/search/api.py b/readthedocs/search/api.py
--- a/readthedocs/search/api.py
+++ b/readthedocs/search/api.py
@@ -1,5 +1,6 @@
import itertools
import logging
+import re
from django.shortcuts import get_object_or_404
from django.utils import timezone
@@ -9,6 +10,7 @@
from readthedocs.api.v2.permissions import IsAuthorizedToViewVersion
from readthedocs.builds.models import Version
+from readthedocs.projects.constants import MKDOCS, SPHINX_HTMLDIR
from readthedocs.projects.models import HTMLFile, Project
from readthedocs.search import tasks, utils
from readthedocs.search.faceted_search import PageSearch
@@ -27,15 +29,28 @@
version = serializers.CharField()
title = serializers.CharField()
path = serializers.CharField()
+ full_path = serializers.CharField()
link = serializers.SerializerMethodField()
highlight = serializers.SerializerMethodField()
inner_hits = serializers.SerializerMethodField()
def get_link(self, obj):
- projects_url = self.context.get('projects_url')
- if projects_url:
- docs_url = projects_url[obj.project]
- return docs_url + obj.path
+ project_data = self.context['projects_data'].get(obj.project)
+ if not project_data:
+ return None
+
+ docs_url, doctype = project_data
+ path = obj.full_path
+
+ # Generate an appropriate link for the doctypes that use htmldir,
+ # and always end it with / so it goes directly to proxito.
+ if doctype in {SPHINX_HTMLDIR, MKDOCS}:
+ new_path = re.sub('(^|/)index.html$', '/', path)
+ # docs_url already ends with /,
+ # so path doesn't need to start with /.
+ path = new_path.lstrip('/')
+
+ return docs_url + path
def get_highlight(self, obj):
highlight = getattr(obj.meta, 'highlight', None)
@@ -157,7 +172,7 @@
def get_serializer_context(self):
context = super().get_serializer_context()
- context['projects_url'] = self.get_all_projects_url()
+ context['projects_data'] = self.get_all_projects_data()
return context
def get_all_projects(self):
@@ -185,29 +200,44 @@
all_projects.append(version.project)
return all_projects
- def get_all_projects_url(self):
+ def get_all_projects_data(self):
"""
- Return a dict containing the project slug and its version URL.
-
- The dictionary contains the project and its subprojects . Each project's
- slug is used as a key and the documentation URL for that project and
- version as the value.
+ Return a dict containing the project slug and its version URL and version's doctype.
- Example:
+ The dictionary contains the project and its subprojects. Each project's
+ slug is used as a key and a tuple with the documentation URL and doctype
+ from the version. Example:
{
- "requests": "https://requests.readthedocs.io/en/latest/",
- "requests-oauth": "https://requests-oauth.readthedocs.io/en/latest/",
+ "requests": (
+ "https://requests.readthedocs.io/en/latest/",
+ "sphinx",
+ ),
+ "requests-oauth": (
+ "https://requests-oauth.readthedocs.io/en/latest/",
+ "sphinx_htmldir",
+ ),
}
:rtype: dict
"""
all_projects = self.get_all_projects()
version_slug = self._get_version().slug
- projects_url = {}
+ project_urls = {}
for project in all_projects:
- projects_url[project.slug] = project.get_docs_url(version_slug=version_slug)
- return projects_url
+ project_urls[project.slug] = project.get_docs_url(version_slug=version_slug)
+
+ versions_doctype = (
+ Version.objects
+ .filter(project__slug__in=project_urls.keys(), slug=version_slug)
+ .values_list('project__slug', 'documentation_type')
+ )
+
+ projects_data = {
+ project_slug: (project_urls[project_slug], doctype)
+ for project_slug, doctype in versions_doctype
+ }
+ return projects_data
def list(self, request, *args, **kwargs):
"""Overriding ``list`` method to record query in database."""
|
{"golden_diff": "diff --git a/readthedocs/search/api.py b/readthedocs/search/api.py\n--- a/readthedocs/search/api.py\n+++ b/readthedocs/search/api.py\n@@ -1,5 +1,6 @@\n import itertools\n import logging\n+import re\n \n from django.shortcuts import get_object_or_404\n from django.utils import timezone\n@@ -9,6 +10,7 @@\n \n from readthedocs.api.v2.permissions import IsAuthorizedToViewVersion\n from readthedocs.builds.models import Version\n+from readthedocs.projects.constants import MKDOCS, SPHINX_HTMLDIR\n from readthedocs.projects.models import HTMLFile, Project\n from readthedocs.search import tasks, utils\n from readthedocs.search.faceted_search import PageSearch\n@@ -27,15 +29,28 @@\n version = serializers.CharField()\n title = serializers.CharField()\n path = serializers.CharField()\n+ full_path = serializers.CharField()\n link = serializers.SerializerMethodField()\n highlight = serializers.SerializerMethodField()\n inner_hits = serializers.SerializerMethodField()\n \n def get_link(self, obj):\n- projects_url = self.context.get('projects_url')\n- if projects_url:\n- docs_url = projects_url[obj.project]\n- return docs_url + obj.path\n+ project_data = self.context['projects_data'].get(obj.project)\n+ if not project_data:\n+ return None\n+\n+ docs_url, doctype = project_data\n+ path = obj.full_path\n+\n+ # Generate an appropriate link for the doctypes that use htmldir,\n+ # and always end it with / so it goes directly to proxito.\n+ if doctype in {SPHINX_HTMLDIR, MKDOCS}:\n+ new_path = re.sub('(^|/)index.html$', '/', path)\n+ # docs_url already ends with /,\n+ # so path doesn't need to start with /.\n+ path = new_path.lstrip('/')\n+\n+ return docs_url + path\n \n def get_highlight(self, obj):\n highlight = getattr(obj.meta, 'highlight', None)\n@@ -157,7 +172,7 @@\n \n def get_serializer_context(self):\n context = super().get_serializer_context()\n- context['projects_url'] = self.get_all_projects_url()\n+ context['projects_data'] = self.get_all_projects_data()\n return context\n \n def get_all_projects(self):\n@@ -185,29 +200,44 @@\n all_projects.append(version.project)\n return all_projects\n \n- def get_all_projects_url(self):\n+ def get_all_projects_data(self):\n \"\"\"\n- Return a dict containing the project slug and its version URL.\n-\n- The dictionary contains the project and its subprojects . Each project's\n- slug is used as a key and the documentation URL for that project and\n- version as the value.\n+ Return a dict containing the project slug and its version URL and version's doctype.\n \n- Example:\n+ The dictionary contains the project and its subprojects. Each project's\n+ slug is used as a key and a tuple with the documentation URL and doctype\n+ from the version. Example:\n \n {\n- \"requests\": \"https://requests.readthedocs.io/en/latest/\",\n- \"requests-oauth\": \"https://requests-oauth.readthedocs.io/en/latest/\",\n+ \"requests\": (\n+ \"https://requests.readthedocs.io/en/latest/\",\n+ \"sphinx\",\n+ ),\n+ \"requests-oauth\": (\n+ \"https://requests-oauth.readthedocs.io/en/latest/\",\n+ \"sphinx_htmldir\",\n+ ),\n }\n \n :rtype: dict\n \"\"\"\n all_projects = self.get_all_projects()\n version_slug = self._get_version().slug\n- projects_url = {}\n+ project_urls = {}\n for project in all_projects:\n- projects_url[project.slug] = project.get_docs_url(version_slug=version_slug)\n- return projects_url\n+ project_urls[project.slug] = project.get_docs_url(version_slug=version_slug)\n+\n+ versions_doctype = (\n+ Version.objects\n+ .filter(project__slug__in=project_urls.keys(), slug=version_slug)\n+ .values_list('project__slug', 'documentation_type')\n+ )\n+\n+ projects_data = {\n+ project_slug: (project_urls[project_slug], doctype)\n+ for project_slug, doctype in versions_doctype\n+ }\n+ return projects_data\n \n def list(self, request, *args, **kwargs):\n \"\"\"Overriding ``list`` method to record query in database.\"\"\"\n", "issue": "Projects built with `htmldir` have invalid link for homepage in search results\nProjects that are built with `htmldir` have invalid link in search results to homepage.\r\nFor example: https://2.python-requests.org/en/master/search/?q=%22The+Contributor%22\r\n\r\nThis is related to #5821.\r\n\r\nWe are using `processed_json.path` for the search results, but the correct path is present in `full_path`.\r\n\r\nhttps://github.com/readthedocs/readthedocs.org/blob/3c04a96b3a9ea8b68ecf270670080285c73c689b/readthedocs/search/documents.py#L73-L74\n", "before_files": [{"content": "import itertools\nimport logging\n\nfrom django.shortcuts import get_object_or_404\nfrom django.utils import timezone\nfrom rest_framework import generics, serializers\nfrom rest_framework.exceptions import ValidationError\nfrom rest_framework.pagination import PageNumberPagination\n\nfrom readthedocs.api.v2.permissions import IsAuthorizedToViewVersion\nfrom readthedocs.builds.models import Version\nfrom readthedocs.projects.models import HTMLFile, Project\nfrom readthedocs.search import tasks, utils\nfrom readthedocs.search.faceted_search import PageSearch\n\nlog = logging.getLogger(__name__)\n\n\nclass SearchPagination(PageNumberPagination):\n page_size = 50\n page_size_query_param = 'page_size'\n max_page_size = 100\n\n\nclass PageSearchSerializer(serializers.Serializer):\n project = serializers.CharField()\n version = serializers.CharField()\n title = serializers.CharField()\n path = serializers.CharField()\n link = serializers.SerializerMethodField()\n highlight = serializers.SerializerMethodField()\n inner_hits = serializers.SerializerMethodField()\n\n def get_link(self, obj):\n projects_url = self.context.get('projects_url')\n if projects_url:\n docs_url = projects_url[obj.project]\n return docs_url + obj.path\n\n def get_highlight(self, obj):\n highlight = getattr(obj.meta, 'highlight', None)\n if highlight:\n ret = highlight.to_dict()\n log.debug('API Search highlight [Page title]: %s', ret)\n return ret\n\n def get_inner_hits(self, obj):\n inner_hits = getattr(obj.meta, 'inner_hits', None)\n if inner_hits:\n sections = inner_hits.sections or []\n domains = inner_hits.domains or []\n all_results = itertools.chain(sections, domains)\n\n sorted_results = utils._get_sorted_results(\n results=all_results,\n source_key='_source',\n )\n\n log.debug('[API] Sorted Results: %s', sorted_results)\n return sorted_results\n\n\nclass PageSearchAPIView(generics.ListAPIView):\n\n \"\"\"\n Main entry point to perform a search using Elasticsearch.\n\n Required query params:\n - q (search term)\n - project\n - version\n\n .. note::\n\n The methods `_get_project` and `_get_version`\n are called many times, so a basic cache is implemented.\n \"\"\"\n\n permission_classes = [IsAuthorizedToViewVersion]\n pagination_class = SearchPagination\n serializer_class = PageSearchSerializer\n\n def _get_project(self):\n cache_key = '_cached_project'\n project = getattr(self, cache_key, None)\n\n if not project:\n project_slug = self.request.GET.get('project', None)\n project = get_object_or_404(Project, slug=project_slug)\n setattr(self, cache_key, project)\n\n return project\n\n def _get_version(self):\n cache_key = '_cached_version'\n version = getattr(self, cache_key, None)\n\n if not version:\n version_slug = self.request.GET.get('version', None)\n project = self._get_project()\n version = get_object_or_404(\n project.versions.all(),\n slug=version_slug,\n )\n setattr(self, cache_key, version)\n\n return version\n\n def get_queryset(self):\n \"\"\"\n Return Elasticsearch DSL Search object instead of Django Queryset.\n\n Django Queryset and elasticsearch-dsl ``Search`` object is similar pattern.\n So for searching, its possible to return ``Search`` object instead of queryset.\n The ``filter_backends`` and ``pagination_class`` is compatible with ``Search``\n \"\"\"\n # Validate all the required params are there\n self.validate_query_params()\n query = self.request.query_params.get('q', '')\n kwargs = {'filter_by_user': False, 'filters': {}}\n kwargs['filters']['project'] = [p.slug for p in self.get_all_projects()]\n kwargs['filters']['version'] = self._get_version().slug\n\n # Check to avoid searching all projects in case these filters are empty.\n if not kwargs['filters']['project']:\n log.info(\"Unable to find a project to search\")\n return HTMLFile.objects.none()\n if not kwargs['filters']['version']:\n log.info(\"Unable to find a version to search\")\n return HTMLFile.objects.none()\n\n user = self.request.user\n queryset = PageSearch(\n query=query, user=user, **kwargs\n )\n return queryset\n\n def validate_query_params(self):\n \"\"\"\n Validate all required query params are passed on the request.\n\n Query params required are: ``q``, ``project`` and ``version``.\n\n :rtype: None\n\n :raises: ValidationError if one of them is missing.\n \"\"\"\n required_query_params = {'q', 'project', 'version'} # python `set` literal is `{}`\n request_params = set(self.request.query_params.keys())\n missing_params = required_query_params - request_params\n if missing_params:\n errors = {}\n for param in missing_params:\n errors[param] = [\"This query param is required\"]\n\n raise ValidationError(errors)\n\n def get_serializer_context(self):\n context = super().get_serializer_context()\n context['projects_url'] = self.get_all_projects_url()\n return context\n\n def get_all_projects(self):\n \"\"\"\n Return a list of the project itself and all its subprojects the user has permissions over.\n\n :rtype: list\n \"\"\"\n main_version = self._get_version()\n main_project = self._get_project()\n\n all_projects = [main_project]\n\n subprojects = Project.objects.filter(\n superprojects__parent_id=main_project.id,\n )\n for project in subprojects:\n version = (\n Version.internal\n .public(user=self.request.user, project=project, include_hidden=False)\n .filter(slug=main_version.slug)\n .first()\n )\n if version:\n all_projects.append(version.project)\n return all_projects\n\n def get_all_projects_url(self):\n \"\"\"\n Return a dict containing the project slug and its version URL.\n\n The dictionary contains the project and its subprojects . Each project's\n slug is used as a key and the documentation URL for that project and\n version as the value.\n\n Example:\n\n {\n \"requests\": \"https://requests.readthedocs.io/en/latest/\",\n \"requests-oauth\": \"https://requests-oauth.readthedocs.io/en/latest/\",\n }\n\n :rtype: dict\n \"\"\"\n all_projects = self.get_all_projects()\n version_slug = self._get_version().slug\n projects_url = {}\n for project in all_projects:\n projects_url[project.slug] = project.get_docs_url(version_slug=version_slug)\n return projects_url\n\n def list(self, request, *args, **kwargs):\n \"\"\"Overriding ``list`` method to record query in database.\"\"\"\n\n response = super().list(request, *args, **kwargs)\n\n project_slug = self._get_project().slug\n version_slug = self._get_version().slug\n total_results = response.data.get('count', 0)\n time = timezone.now()\n\n query = self.request.query_params.get('q', '')\n query = query.lower().strip()\n\n # record the search query with a celery task\n tasks.record_search_query.delay(\n project_slug,\n version_slug,\n query,\n total_results,\n time.isoformat(),\n )\n\n return response\n", "path": "readthedocs/search/api.py"}], "after_files": [{"content": "import itertools\nimport logging\nimport re\n\nfrom django.shortcuts import get_object_or_404\nfrom django.utils import timezone\nfrom rest_framework import generics, serializers\nfrom rest_framework.exceptions import ValidationError\nfrom rest_framework.pagination import PageNumberPagination\n\nfrom readthedocs.api.v2.permissions import IsAuthorizedToViewVersion\nfrom readthedocs.builds.models import Version\nfrom readthedocs.projects.constants import MKDOCS, SPHINX_HTMLDIR\nfrom readthedocs.projects.models import HTMLFile, Project\nfrom readthedocs.search import tasks, utils\nfrom readthedocs.search.faceted_search import PageSearch\n\nlog = logging.getLogger(__name__)\n\n\nclass SearchPagination(PageNumberPagination):\n page_size = 50\n page_size_query_param = 'page_size'\n max_page_size = 100\n\n\nclass PageSearchSerializer(serializers.Serializer):\n project = serializers.CharField()\n version = serializers.CharField()\n title = serializers.CharField()\n path = serializers.CharField()\n full_path = serializers.CharField()\n link = serializers.SerializerMethodField()\n highlight = serializers.SerializerMethodField()\n inner_hits = serializers.SerializerMethodField()\n\n def get_link(self, obj):\n project_data = self.context['projects_data'].get(obj.project)\n if not project_data:\n return None\n\n docs_url, doctype = project_data\n path = obj.full_path\n\n # Generate an appropriate link for the doctypes that use htmldir,\n # and always end it with / so it goes directly to proxito.\n if doctype in {SPHINX_HTMLDIR, MKDOCS}:\n new_path = re.sub('(^|/)index.html$', '/', path)\n # docs_url already ends with /,\n # so path doesn't need to start with /.\n path = new_path.lstrip('/')\n\n return docs_url + path\n\n def get_highlight(self, obj):\n highlight = getattr(obj.meta, 'highlight', None)\n if highlight:\n ret = highlight.to_dict()\n log.debug('API Search highlight [Page title]: %s', ret)\n return ret\n\n def get_inner_hits(self, obj):\n inner_hits = getattr(obj.meta, 'inner_hits', None)\n if inner_hits:\n sections = inner_hits.sections or []\n domains = inner_hits.domains or []\n all_results = itertools.chain(sections, domains)\n\n sorted_results = utils._get_sorted_results(\n results=all_results,\n source_key='_source',\n )\n\n log.debug('[API] Sorted Results: %s', sorted_results)\n return sorted_results\n\n\nclass PageSearchAPIView(generics.ListAPIView):\n\n \"\"\"\n Main entry point to perform a search using Elasticsearch.\n\n Required query params:\n - q (search term)\n - project\n - version\n\n .. note::\n\n The methods `_get_project` and `_get_version`\n are called many times, so a basic cache is implemented.\n \"\"\"\n\n permission_classes = [IsAuthorizedToViewVersion]\n pagination_class = SearchPagination\n serializer_class = PageSearchSerializer\n\n def _get_project(self):\n cache_key = '_cached_project'\n project = getattr(self, cache_key, None)\n\n if not project:\n project_slug = self.request.GET.get('project', None)\n project = get_object_or_404(Project, slug=project_slug)\n setattr(self, cache_key, project)\n\n return project\n\n def _get_version(self):\n cache_key = '_cached_version'\n version = getattr(self, cache_key, None)\n\n if not version:\n version_slug = self.request.GET.get('version', None)\n project = self._get_project()\n version = get_object_or_404(\n project.versions.all(),\n slug=version_slug,\n )\n setattr(self, cache_key, version)\n\n return version\n\n def get_queryset(self):\n \"\"\"\n Return Elasticsearch DSL Search object instead of Django Queryset.\n\n Django Queryset and elasticsearch-dsl ``Search`` object is similar pattern.\n So for searching, its possible to return ``Search`` object instead of queryset.\n The ``filter_backends`` and ``pagination_class`` is compatible with ``Search``\n \"\"\"\n # Validate all the required params are there\n self.validate_query_params()\n query = self.request.query_params.get('q', '')\n kwargs = {'filter_by_user': False, 'filters': {}}\n kwargs['filters']['project'] = [p.slug for p in self.get_all_projects()]\n kwargs['filters']['version'] = self._get_version().slug\n\n # Check to avoid searching all projects in case these filters are empty.\n if not kwargs['filters']['project']:\n log.info(\"Unable to find a project to search\")\n return HTMLFile.objects.none()\n if not kwargs['filters']['version']:\n log.info(\"Unable to find a version to search\")\n return HTMLFile.objects.none()\n\n user = self.request.user\n queryset = PageSearch(\n query=query, user=user, **kwargs\n )\n return queryset\n\n def validate_query_params(self):\n \"\"\"\n Validate all required query params are passed on the request.\n\n Query params required are: ``q``, ``project`` and ``version``.\n\n :rtype: None\n\n :raises: ValidationError if one of them is missing.\n \"\"\"\n required_query_params = {'q', 'project', 'version'} # python `set` literal is `{}`\n request_params = set(self.request.query_params.keys())\n missing_params = required_query_params - request_params\n if missing_params:\n errors = {}\n for param in missing_params:\n errors[param] = [\"This query param is required\"]\n\n raise ValidationError(errors)\n\n def get_serializer_context(self):\n context = super().get_serializer_context()\n context['projects_data'] = self.get_all_projects_data()\n return context\n\n def get_all_projects(self):\n \"\"\"\n Return a list of the project itself and all its subprojects the user has permissions over.\n\n :rtype: list\n \"\"\"\n main_version = self._get_version()\n main_project = self._get_project()\n\n all_projects = [main_project]\n\n subprojects = Project.objects.filter(\n superprojects__parent_id=main_project.id,\n )\n for project in subprojects:\n version = (\n Version.internal\n .public(user=self.request.user, project=project, include_hidden=False)\n .filter(slug=main_version.slug)\n .first()\n )\n if version:\n all_projects.append(version.project)\n return all_projects\n\n def get_all_projects_data(self):\n \"\"\"\n Return a dict containing the project slug and its version URL and version's doctype.\n\n The dictionary contains the project and its subprojects. Each project's\n slug is used as a key and a tuple with the documentation URL and doctype\n from the version. Example:\n\n {\n \"requests\": (\n \"https://requests.readthedocs.io/en/latest/\",\n \"sphinx\",\n ),\n \"requests-oauth\": (\n \"https://requests-oauth.readthedocs.io/en/latest/\",\n \"sphinx_htmldir\",\n ),\n }\n\n :rtype: dict\n \"\"\"\n all_projects = self.get_all_projects()\n version_slug = self._get_version().slug\n project_urls = {}\n for project in all_projects:\n project_urls[project.slug] = project.get_docs_url(version_slug=version_slug)\n\n versions_doctype = (\n Version.objects\n .filter(project__slug__in=project_urls.keys(), slug=version_slug)\n .values_list('project__slug', 'documentation_type')\n )\n\n projects_data = {\n project_slug: (project_urls[project_slug], doctype)\n for project_slug, doctype in versions_doctype\n }\n return projects_data\n\n def list(self, request, *args, **kwargs):\n \"\"\"Overriding ``list`` method to record query in database.\"\"\"\n\n response = super().list(request, *args, **kwargs)\n\n project_slug = self._get_project().slug\n version_slug = self._get_version().slug\n total_results = response.data.get('count', 0)\n time = timezone.now()\n\n query = self.request.query_params.get('q', '')\n query = query.lower().strip()\n\n # record the search query with a celery task\n tasks.record_search_query.delay(\n project_slug,\n version_slug,\n query,\n total_results,\n time.isoformat(),\n )\n\n return response\n", "path": "readthedocs/search/api.py"}]}
| 2,606 | 1,013 |
gh_patches_debug_12687
|
rasdani/github-patches
|
git_diff
|
Cloud-CV__EvalAI-1534
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add field submitted_at in leaderboard
In the leaderboard, add support for showing the field `submitted_at` for each entry on the leaderboard. This will help the participants to keep track of the challenge submissions.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `apps/jobs/views.py`
Content:
```
1 import datetime
2
3 from rest_framework import permissions, status
4 from rest_framework.decorators import (api_view,
5 authentication_classes,
6 permission_classes,
7 throttle_classes,)
8
9 from django.db.models.expressions import RawSQL
10 from django.db.models import FloatField
11 from django.utils import timezone
12
13 from rest_framework_expiring_authtoken.authentication import (
14 ExpiringTokenAuthentication,)
15 from rest_framework.response import Response
16 from rest_framework.throttling import UserRateThrottle, AnonRateThrottle
17
18 from accounts.permissions import HasVerifiedEmail
19 from base.utils import paginated_queryset, StandardResultSetPagination
20 from challenges.models import (
21 ChallengePhase,
22 Challenge,
23 ChallengePhaseSplit,
24 LeaderboardData,)
25 from challenges.utils import get_challenge_model, get_challenge_phase_model
26 from participants.models import (ParticipantTeam,)
27 from participants.utils import (
28 get_participant_team_id_of_user_for_a_challenge,)
29
30 from .models import Submission
31 from .sender import publish_submission_message
32 from .serializers import SubmissionSerializer
33
34
35 @throttle_classes([UserRateThrottle])
36 @api_view(['GET', 'POST'])
37 @permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))
38 @authentication_classes((ExpiringTokenAuthentication,))
39 def challenge_submission(request, challenge_id, challenge_phase_id):
40 """API Endpoint for making a submission to a challenge"""
41
42 # check if the challenge exists or not
43 try:
44 challenge = Challenge.objects.get(pk=challenge_id)
45 except Challenge.DoesNotExist:
46 response_data = {'error': 'Challenge does not exist'}
47 return Response(response_data, status=status.HTTP_400_BAD_REQUEST)
48
49 # check if the challenge phase exists or not
50 try:
51 challenge_phase = ChallengePhase.objects.get(
52 pk=challenge_phase_id, challenge=challenge)
53 except ChallengePhase.DoesNotExist:
54 response_data = {'error': 'Challenge Phase does not exist'}
55 return Response(response_data, status=status.HTTP_400_BAD_REQUEST)
56
57 if request.method == 'GET':
58 # getting participant team object for the user for a particular challenge.
59 participant_team_id = get_participant_team_id_of_user_for_a_challenge(
60 request.user, challenge_id)
61
62 # check if participant team exists or not.
63 try:
64 ParticipantTeam.objects.get(pk=participant_team_id)
65 except ParticipantTeam.DoesNotExist:
66 response_data = {'error': 'You haven\'t participated in the challenge'}
67 return Response(response_data, status=status.HTTP_403_FORBIDDEN)
68
69 submission = Submission.objects.filter(participant_team=participant_team_id,
70 challenge_phase=challenge_phase).order_by('-submitted_at')
71 paginator, result_page = paginated_queryset(submission, request)
72 try:
73 serializer = SubmissionSerializer(result_page, many=True, context={'request': request})
74 response_data = serializer.data
75 return paginator.get_paginated_response(response_data)
76 except:
77 return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
78
79 elif request.method == 'POST':
80
81 # check if the challenge is active or not
82 if not challenge.is_active:
83 response_data = {'error': 'Challenge is not active'}
84 return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)
85
86 # check if challenge phase is active
87 if not challenge_phase.is_active:
88 response_data = {
89 'error': 'Sorry, cannot accept submissions since challenge phase is not active'}
90 return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)
91
92 # check if challenge phase is public and accepting solutions
93 if not challenge_phase.is_public:
94 response_data = {
95 'error': 'Sorry, cannot accept submissions since challenge phase is not public'}
96 return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)
97
98 participant_team_id = get_participant_team_id_of_user_for_a_challenge(
99 request.user, challenge_id)
100 try:
101 participant_team = ParticipantTeam.objects.get(pk=participant_team_id)
102 except ParticipantTeam.DoesNotExist:
103 response_data = {'error': 'You haven\'t participated in the challenge'}
104 return Response(response_data, status=status.HTTP_403_FORBIDDEN)
105
106 serializer = SubmissionSerializer(data=request.data,
107 context={'participant_team': participant_team,
108 'challenge_phase': challenge_phase,
109 'request': request
110 })
111 if serializer.is_valid():
112 serializer.save()
113 response_data = serializer.data
114 submission = serializer.instance
115 # publish message in the queue
116 publish_submission_message(challenge_id, challenge_phase_id, submission.id)
117 return Response(response_data, status=status.HTTP_201_CREATED)
118 return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
119
120
121 @throttle_classes([UserRateThrottle])
122 @api_view(['PATCH'])
123 @permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))
124 @authentication_classes((ExpiringTokenAuthentication,))
125 def change_submission_data_and_visibility(request, challenge_pk, challenge_phase_pk, submission_pk):
126 """
127 API Endpoint for updating the submission meta data
128 and changing submission visibility.
129 """
130
131 # check if the challenge exists or not
132 challenge = get_challenge_model(challenge_pk)
133
134 # check if the challenge phase exists or not
135 challenge_phase = get_challenge_phase_model(challenge_phase_pk)
136
137 if not challenge.is_active:
138 response_data = {'error': 'Challenge is not active'}
139 return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)
140
141 # check if challenge phase is public and accepting solutions
142 if not challenge_phase.is_public:
143 response_data = {
144 'error': 'Sorry, cannot accept submissions since challenge phase is not public'}
145 return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)
146
147 participant_team_pk = get_participant_team_id_of_user_for_a_challenge(
148 request.user, challenge_pk)
149
150 try:
151 participant_team = ParticipantTeam.objects.get(pk=participant_team_pk)
152 except ParticipantTeam.DoesNotExist:
153 response_data = {'error': 'You haven\'t participated in the challenge'}
154 return Response(response_data, status=status.HTTP_403_FORBIDDEN)
155
156 try:
157 submission = Submission.objects.get(participant_team=participant_team,
158 challenge_phase=challenge_phase,
159 id=submission_pk)
160 except Submission.DoesNotExist:
161 response_data = {'error': 'Submission does not exist'}
162 return Response(response_data, status=status.HTTP_403_FORBIDDEN)
163
164 try:
165 is_public = request.data['is_public']
166 if is_public is True:
167 when_made_public = datetime.datetime.now()
168 request.data['when_made_public'] = when_made_public
169 except KeyError:
170 pass
171
172 serializer = SubmissionSerializer(submission,
173 data=request.data,
174 context={
175 'participant_team': participant_team,
176 'challenge_phase': challenge_phase,
177 'request': request
178 },
179 partial=True)
180
181 if serializer.is_valid():
182 serializer.save()
183 response_data = serializer.data
184 return Response(response_data, status=status.HTTP_200_OK)
185 else:
186 return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
187
188
189 @throttle_classes([AnonRateThrottle])
190 @api_view(['GET'])
191 def leaderboard(request, challenge_phase_split_id):
192 """Returns leaderboard for a corresponding Challenge Phase Split"""
193
194 # check if the challenge exists or not
195 try:
196 challenge_phase_split = ChallengePhaseSplit.objects.get(
197 pk=challenge_phase_split_id)
198 except ChallengePhaseSplit.DoesNotExist:
199 response_data = {'error': 'Challenge Phase Split does not exist'}
200 return Response(response_data, status=status.HTTP_400_BAD_REQUEST)
201
202 # Check if the Challenge Phase Split is publicly visible or not
203 if challenge_phase_split.visibility != ChallengePhaseSplit.PUBLIC:
204 response_data = {'error': 'Sorry, leaderboard is not public yet for this Challenge Phase Split!'}
205 return Response(response_data, status=status.HTTP_400_BAD_REQUEST)
206
207 # Get the leaderboard associated with the Challenge Phase Split
208 leaderboard = challenge_phase_split.leaderboard
209
210 # Get the default order by key to rank the entries on the leaderboard
211 try:
212 default_order_by = leaderboard.schema['default_order_by']
213 except:
214 response_data = {'error': 'Sorry, Default filtering key not found in leaderboard schema!'}
215 return Response(response_data, status=status.HTTP_400_BAD_REQUEST)
216
217 # Get all the successful submissions related to the challenge phase split
218 leaderboard_data = LeaderboardData.objects.filter(
219 challenge_phase_split=challenge_phase_split,
220 submission__is_public=True,
221 submission__is_flagged=False).order_by('created_at')
222 leaderboard_data = leaderboard_data.annotate(
223 filtering_score=RawSQL('result->>%s', (default_order_by, ), output_field=FloatField())).values(
224 'id', 'submission__participant_team__team_name',
225 'challenge_phase_split', 'result', 'filtering_score', 'leaderboard__schema')
226
227 sorted_leaderboard_data = sorted(leaderboard_data, key=lambda k: float(k['filtering_score']), reverse=True)
228
229 distinct_sorted_leaderboard_data = []
230 team_list = []
231
232 for data in sorted_leaderboard_data:
233 if data['submission__participant_team__team_name'] in team_list:
234 continue
235 else:
236 distinct_sorted_leaderboard_data.append(data)
237 team_list.append(data['submission__participant_team__team_name'])
238
239 leaderboard_labels = challenge_phase_split.leaderboard.schema['labels']
240 for item in distinct_sorted_leaderboard_data:
241 item['result'] = [item['result'][index.lower()] for index in leaderboard_labels]
242
243 paginator, result_page = paginated_queryset(
244 distinct_sorted_leaderboard_data,
245 request,
246 pagination_class=StandardResultSetPagination())
247 response_data = result_page
248 return paginator.get_paginated_response(response_data)
249
250
251 @throttle_classes([UserRateThrottle])
252 @api_view(['GET'])
253 @permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))
254 @authentication_classes((ExpiringTokenAuthentication,))
255 def get_remaining_submissions(request, challenge_phase_pk, challenge_pk):
256
257 get_challenge_model(challenge_pk)
258
259 challenge_phase = get_challenge_phase_model(challenge_phase_pk)
260
261 participant_team_pk = get_participant_team_id_of_user_for_a_challenge(
262 request.user, challenge_pk)
263
264 # Conditional check for the existence of participant team of the user.
265 if not participant_team_pk:
266 response_data = {'error': 'You haven\'t participated in the challenge'}
267 return Response(response_data, status=status.HTTP_403_FORBIDDEN)
268
269 max_submission_per_day = challenge_phase.max_submissions_per_day
270
271 max_submission = challenge_phase.max_submissions
272
273 submissions_done_today_count = Submission.objects.filter(
274 challenge_phase__challenge=challenge_pk,
275 challenge_phase=challenge_phase_pk,
276 participant_team=participant_team_pk,
277 submitted_at__gte=timezone.now().date()).count()
278
279 failed_submissions_count = Submission.objects.filter(
280 challenge_phase__challenge=challenge_pk,
281 challenge_phase=challenge_phase_pk,
282 participant_team=participant_team_pk,
283 status=Submission.FAILED,
284 submitted_at__gte=timezone.now().date()).count()
285
286 # Checks if today's successfull submission is greater than or equal to max submission per day.
287 if ((submissions_done_today_count - failed_submissions_count) >= max_submission_per_day
288 or (max_submission_per_day == 0)):
289 # Get the UTC time of the instant when the above condition is true.
290 date_time_now = timezone.now()
291 # Calculate the next day's date.
292 date_time_tomorrow = date_time_now.date() + datetime.timedelta(1)
293 utc = timezone.utc
294 # Get the midnight time of the day i.e. 12:00 AM of next day.
295 midnight = utc.localize(datetime.datetime.combine(
296 date_time_tomorrow, datetime.time()))
297 # Subtract the current time from the midnight time to get the remaining time for the next day's submissions.
298 remaining_time = midnight - date_time_now
299 # Return the remaining time with a message.
300 response_data = {'message': 'You have exhausted today\'s submission limit',
301 'remaining_time': remaining_time
302 }
303 return Response(response_data, status=status.HTTP_200_OK)
304 else:
305 # Calculate the remaining submissions for today.
306 remaining_submissions_today_count = (max_submission_per_day -
307 (submissions_done_today_count -
308 failed_submissions_count)
309 )
310 # calculate the remaining submissions from total submissions.
311 remaining_submission_count = max_submission - \
312 (submissions_done_today_count - failed_submissions_count)
313 # Return the above calculated data.
314 response_data = {'remaining_submissions_today_count': remaining_submissions_today_count,
315 'remaining_submissions': remaining_submission_count
316 }
317 return Response(response_data, status=status.HTTP_200_OK)
318
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/apps/jobs/views.py b/apps/jobs/views.py
--- a/apps/jobs/views.py
+++ b/apps/jobs/views.py
@@ -222,7 +222,7 @@
leaderboard_data = leaderboard_data.annotate(
filtering_score=RawSQL('result->>%s', (default_order_by, ), output_field=FloatField())).values(
'id', 'submission__participant_team__team_name',
- 'challenge_phase_split', 'result', 'filtering_score', 'leaderboard__schema')
+ 'challenge_phase_split', 'result', 'filtering_score', 'leaderboard__schema', 'submission__submitted_at')
sorted_leaderboard_data = sorted(leaderboard_data, key=lambda k: float(k['filtering_score']), reverse=True)
|
{"golden_diff": "diff --git a/apps/jobs/views.py b/apps/jobs/views.py\n--- a/apps/jobs/views.py\n+++ b/apps/jobs/views.py\n@@ -222,7 +222,7 @@\n leaderboard_data = leaderboard_data.annotate(\n filtering_score=RawSQL('result->>%s', (default_order_by, ), output_field=FloatField())).values(\n 'id', 'submission__participant_team__team_name',\n- 'challenge_phase_split', 'result', 'filtering_score', 'leaderboard__schema')\n+ 'challenge_phase_split', 'result', 'filtering_score', 'leaderboard__schema', 'submission__submitted_at')\n \n sorted_leaderboard_data = sorted(leaderboard_data, key=lambda k: float(k['filtering_score']), reverse=True)\n", "issue": "Add field submitted_at in leaderboard\nIn the leaderboard, add support for showing the field `submitted_at` for each entry on the leaderboard. This will help the participants to keep track of the challenge submissions. \n", "before_files": [{"content": "import datetime\n\nfrom rest_framework import permissions, status\nfrom rest_framework.decorators import (api_view,\n authentication_classes,\n permission_classes,\n throttle_classes,)\n\nfrom django.db.models.expressions import RawSQL\nfrom django.db.models import FloatField\nfrom django.utils import timezone\n\nfrom rest_framework_expiring_authtoken.authentication import (\n ExpiringTokenAuthentication,)\nfrom rest_framework.response import Response\nfrom rest_framework.throttling import UserRateThrottle, AnonRateThrottle\n\nfrom accounts.permissions import HasVerifiedEmail\nfrom base.utils import paginated_queryset, StandardResultSetPagination\nfrom challenges.models import (\n ChallengePhase,\n Challenge,\n ChallengePhaseSplit,\n LeaderboardData,)\nfrom challenges.utils import get_challenge_model, get_challenge_phase_model\nfrom participants.models import (ParticipantTeam,)\nfrom participants.utils import (\n get_participant_team_id_of_user_for_a_challenge,)\n\nfrom .models import Submission\nfrom .sender import publish_submission_message\nfrom .serializers import SubmissionSerializer\n\n\n@throttle_classes([UserRateThrottle])\n@api_view(['GET', 'POST'])\n@permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))\n@authentication_classes((ExpiringTokenAuthentication,))\ndef challenge_submission(request, challenge_id, challenge_phase_id):\n \"\"\"API Endpoint for making a submission to a challenge\"\"\"\n\n # check if the challenge exists or not\n try:\n challenge = Challenge.objects.get(pk=challenge_id)\n except Challenge.DoesNotExist:\n response_data = {'error': 'Challenge does not exist'}\n return Response(response_data, status=status.HTTP_400_BAD_REQUEST)\n\n # check if the challenge phase exists or not\n try:\n challenge_phase = ChallengePhase.objects.get(\n pk=challenge_phase_id, challenge=challenge)\n except ChallengePhase.DoesNotExist:\n response_data = {'error': 'Challenge Phase does not exist'}\n return Response(response_data, status=status.HTTP_400_BAD_REQUEST)\n\n if request.method == 'GET':\n # getting participant team object for the user for a particular challenge.\n participant_team_id = get_participant_team_id_of_user_for_a_challenge(\n request.user, challenge_id)\n\n # check if participant team exists or not.\n try:\n ParticipantTeam.objects.get(pk=participant_team_id)\n except ParticipantTeam.DoesNotExist:\n response_data = {'error': 'You haven\\'t participated in the challenge'}\n return Response(response_data, status=status.HTTP_403_FORBIDDEN)\n\n submission = Submission.objects.filter(participant_team=participant_team_id,\n challenge_phase=challenge_phase).order_by('-submitted_at')\n paginator, result_page = paginated_queryset(submission, request)\n try:\n serializer = SubmissionSerializer(result_page, many=True, context={'request': request})\n response_data = serializer.data\n return paginator.get_paginated_response(response_data)\n except:\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n elif request.method == 'POST':\n\n # check if the challenge is active or not\n if not challenge.is_active:\n response_data = {'error': 'Challenge is not active'}\n return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)\n\n # check if challenge phase is active\n if not challenge_phase.is_active:\n response_data = {\n 'error': 'Sorry, cannot accept submissions since challenge phase is not active'}\n return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)\n\n # check if challenge phase is public and accepting solutions\n if not challenge_phase.is_public:\n response_data = {\n 'error': 'Sorry, cannot accept submissions since challenge phase is not public'}\n return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)\n\n participant_team_id = get_participant_team_id_of_user_for_a_challenge(\n request.user, challenge_id)\n try:\n participant_team = ParticipantTeam.objects.get(pk=participant_team_id)\n except ParticipantTeam.DoesNotExist:\n response_data = {'error': 'You haven\\'t participated in the challenge'}\n return Response(response_data, status=status.HTTP_403_FORBIDDEN)\n\n serializer = SubmissionSerializer(data=request.data,\n context={'participant_team': participant_team,\n 'challenge_phase': challenge_phase,\n 'request': request\n })\n if serializer.is_valid():\n serializer.save()\n response_data = serializer.data\n submission = serializer.instance\n # publish message in the queue\n publish_submission_message(challenge_id, challenge_phase_id, submission.id)\n return Response(response_data, status=status.HTTP_201_CREATED)\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n\n@throttle_classes([UserRateThrottle])\n@api_view(['PATCH'])\n@permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))\n@authentication_classes((ExpiringTokenAuthentication,))\ndef change_submission_data_and_visibility(request, challenge_pk, challenge_phase_pk, submission_pk):\n \"\"\"\n API Endpoint for updating the submission meta data\n and changing submission visibility.\n \"\"\"\n\n # check if the challenge exists or not\n challenge = get_challenge_model(challenge_pk)\n\n # check if the challenge phase exists or not\n challenge_phase = get_challenge_phase_model(challenge_phase_pk)\n\n if not challenge.is_active:\n response_data = {'error': 'Challenge is not active'}\n return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)\n\n # check if challenge phase is public and accepting solutions\n if not challenge_phase.is_public:\n response_data = {\n 'error': 'Sorry, cannot accept submissions since challenge phase is not public'}\n return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)\n\n participant_team_pk = get_participant_team_id_of_user_for_a_challenge(\n request.user, challenge_pk)\n\n try:\n participant_team = ParticipantTeam.objects.get(pk=participant_team_pk)\n except ParticipantTeam.DoesNotExist:\n response_data = {'error': 'You haven\\'t participated in the challenge'}\n return Response(response_data, status=status.HTTP_403_FORBIDDEN)\n\n try:\n submission = Submission.objects.get(participant_team=participant_team,\n challenge_phase=challenge_phase,\n id=submission_pk)\n except Submission.DoesNotExist:\n response_data = {'error': 'Submission does not exist'}\n return Response(response_data, status=status.HTTP_403_FORBIDDEN)\n\n try:\n is_public = request.data['is_public']\n if is_public is True:\n when_made_public = datetime.datetime.now()\n request.data['when_made_public'] = when_made_public\n except KeyError:\n pass\n\n serializer = SubmissionSerializer(submission,\n data=request.data,\n context={\n 'participant_team': participant_team,\n 'challenge_phase': challenge_phase,\n 'request': request\n },\n partial=True)\n\n if serializer.is_valid():\n serializer.save()\n response_data = serializer.data\n return Response(response_data, status=status.HTTP_200_OK)\n else:\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n\n@throttle_classes([AnonRateThrottle])\n@api_view(['GET'])\ndef leaderboard(request, challenge_phase_split_id):\n \"\"\"Returns leaderboard for a corresponding Challenge Phase Split\"\"\"\n\n # check if the challenge exists or not\n try:\n challenge_phase_split = ChallengePhaseSplit.objects.get(\n pk=challenge_phase_split_id)\n except ChallengePhaseSplit.DoesNotExist:\n response_data = {'error': 'Challenge Phase Split does not exist'}\n return Response(response_data, status=status.HTTP_400_BAD_REQUEST)\n\n # Check if the Challenge Phase Split is publicly visible or not\n if challenge_phase_split.visibility != ChallengePhaseSplit.PUBLIC:\n response_data = {'error': 'Sorry, leaderboard is not public yet for this Challenge Phase Split!'}\n return Response(response_data, status=status.HTTP_400_BAD_REQUEST)\n\n # Get the leaderboard associated with the Challenge Phase Split\n leaderboard = challenge_phase_split.leaderboard\n\n # Get the default order by key to rank the entries on the leaderboard\n try:\n default_order_by = leaderboard.schema['default_order_by']\n except:\n response_data = {'error': 'Sorry, Default filtering key not found in leaderboard schema!'}\n return Response(response_data, status=status.HTTP_400_BAD_REQUEST)\n\n # Get all the successful submissions related to the challenge phase split\n leaderboard_data = LeaderboardData.objects.filter(\n challenge_phase_split=challenge_phase_split,\n submission__is_public=True,\n submission__is_flagged=False).order_by('created_at')\n leaderboard_data = leaderboard_data.annotate(\n filtering_score=RawSQL('result->>%s', (default_order_by, ), output_field=FloatField())).values(\n 'id', 'submission__participant_team__team_name',\n 'challenge_phase_split', 'result', 'filtering_score', 'leaderboard__schema')\n\n sorted_leaderboard_data = sorted(leaderboard_data, key=lambda k: float(k['filtering_score']), reverse=True)\n\n distinct_sorted_leaderboard_data = []\n team_list = []\n\n for data in sorted_leaderboard_data:\n if data['submission__participant_team__team_name'] in team_list:\n continue\n else:\n distinct_sorted_leaderboard_data.append(data)\n team_list.append(data['submission__participant_team__team_name'])\n\n leaderboard_labels = challenge_phase_split.leaderboard.schema['labels']\n for item in distinct_sorted_leaderboard_data:\n item['result'] = [item['result'][index.lower()] for index in leaderboard_labels]\n\n paginator, result_page = paginated_queryset(\n distinct_sorted_leaderboard_data,\n request,\n pagination_class=StandardResultSetPagination())\n response_data = result_page\n return paginator.get_paginated_response(response_data)\n\n\n@throttle_classes([UserRateThrottle])\n@api_view(['GET'])\n@permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))\n@authentication_classes((ExpiringTokenAuthentication,))\ndef get_remaining_submissions(request, challenge_phase_pk, challenge_pk):\n\n get_challenge_model(challenge_pk)\n\n challenge_phase = get_challenge_phase_model(challenge_phase_pk)\n\n participant_team_pk = get_participant_team_id_of_user_for_a_challenge(\n request.user, challenge_pk)\n\n # Conditional check for the existence of participant team of the user.\n if not participant_team_pk:\n response_data = {'error': 'You haven\\'t participated in the challenge'}\n return Response(response_data, status=status.HTTP_403_FORBIDDEN)\n\n max_submission_per_day = challenge_phase.max_submissions_per_day\n\n max_submission = challenge_phase.max_submissions\n\n submissions_done_today_count = Submission.objects.filter(\n challenge_phase__challenge=challenge_pk,\n challenge_phase=challenge_phase_pk,\n participant_team=participant_team_pk,\n submitted_at__gte=timezone.now().date()).count()\n\n failed_submissions_count = Submission.objects.filter(\n challenge_phase__challenge=challenge_pk,\n challenge_phase=challenge_phase_pk,\n participant_team=participant_team_pk,\n status=Submission.FAILED,\n submitted_at__gte=timezone.now().date()).count()\n\n # Checks if today's successfull submission is greater than or equal to max submission per day.\n if ((submissions_done_today_count - failed_submissions_count) >= max_submission_per_day\n or (max_submission_per_day == 0)):\n # Get the UTC time of the instant when the above condition is true.\n date_time_now = timezone.now()\n # Calculate the next day's date.\n date_time_tomorrow = date_time_now.date() + datetime.timedelta(1)\n utc = timezone.utc\n # Get the midnight time of the day i.e. 12:00 AM of next day.\n midnight = utc.localize(datetime.datetime.combine(\n date_time_tomorrow, datetime.time()))\n # Subtract the current time from the midnight time to get the remaining time for the next day's submissions.\n remaining_time = midnight - date_time_now\n # Return the remaining time with a message.\n response_data = {'message': 'You have exhausted today\\'s submission limit',\n 'remaining_time': remaining_time\n }\n return Response(response_data, status=status.HTTP_200_OK)\n else:\n # Calculate the remaining submissions for today.\n remaining_submissions_today_count = (max_submission_per_day -\n (submissions_done_today_count -\n failed_submissions_count)\n )\n # calculate the remaining submissions from total submissions.\n remaining_submission_count = max_submission - \\\n (submissions_done_today_count - failed_submissions_count)\n # Return the above calculated data.\n response_data = {'remaining_submissions_today_count': remaining_submissions_today_count,\n 'remaining_submissions': remaining_submission_count\n }\n return Response(response_data, status=status.HTTP_200_OK)\n", "path": "apps/jobs/views.py"}], "after_files": [{"content": "import datetime\n\nfrom rest_framework import permissions, status\nfrom rest_framework.decorators import (api_view,\n authentication_classes,\n permission_classes,\n throttle_classes,)\n\nfrom django.db.models.expressions import RawSQL\nfrom django.db.models import FloatField\nfrom django.utils import timezone\n\nfrom rest_framework_expiring_authtoken.authentication import (\n ExpiringTokenAuthentication,)\nfrom rest_framework.response import Response\nfrom rest_framework.throttling import UserRateThrottle, AnonRateThrottle\n\nfrom accounts.permissions import HasVerifiedEmail\nfrom base.utils import paginated_queryset, StandardResultSetPagination\nfrom challenges.models import (\n ChallengePhase,\n Challenge,\n ChallengePhaseSplit,\n LeaderboardData,)\nfrom challenges.utils import get_challenge_model, get_challenge_phase_model\nfrom participants.models import (ParticipantTeam,)\nfrom participants.utils import (\n get_participant_team_id_of_user_for_a_challenge,)\n\nfrom .models import Submission\nfrom .sender import publish_submission_message\nfrom .serializers import SubmissionSerializer\n\n\n@throttle_classes([UserRateThrottle])\n@api_view(['GET', 'POST'])\n@permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))\n@authentication_classes((ExpiringTokenAuthentication,))\ndef challenge_submission(request, challenge_id, challenge_phase_id):\n \"\"\"API Endpoint for making a submission to a challenge\"\"\"\n\n # check if the challenge exists or not\n try:\n challenge = Challenge.objects.get(pk=challenge_id)\n except Challenge.DoesNotExist:\n response_data = {'error': 'Challenge does not exist'}\n return Response(response_data, status=status.HTTP_400_BAD_REQUEST)\n\n # check if the challenge phase exists or not\n try:\n challenge_phase = ChallengePhase.objects.get(\n pk=challenge_phase_id, challenge=challenge)\n except ChallengePhase.DoesNotExist:\n response_data = {'error': 'Challenge Phase does not exist'}\n return Response(response_data, status=status.HTTP_400_BAD_REQUEST)\n\n if request.method == 'GET':\n # getting participant team object for the user for a particular challenge.\n participant_team_id = get_participant_team_id_of_user_for_a_challenge(\n request.user, challenge_id)\n\n # check if participant team exists or not.\n try:\n ParticipantTeam.objects.get(pk=participant_team_id)\n except ParticipantTeam.DoesNotExist:\n response_data = {'error': 'You haven\\'t participated in the challenge'}\n return Response(response_data, status=status.HTTP_403_FORBIDDEN)\n\n submission = Submission.objects.filter(participant_team=participant_team_id,\n challenge_phase=challenge_phase).order_by('-submitted_at')\n paginator, result_page = paginated_queryset(submission, request)\n try:\n serializer = SubmissionSerializer(result_page, many=True, context={'request': request})\n response_data = serializer.data\n return paginator.get_paginated_response(response_data)\n except:\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n elif request.method == 'POST':\n\n # check if the challenge is active or not\n if not challenge.is_active:\n response_data = {'error': 'Challenge is not active'}\n return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)\n\n # check if challenge phase is active\n if not challenge_phase.is_active:\n response_data = {\n 'error': 'Sorry, cannot accept submissions since challenge phase is not active'}\n return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)\n\n # check if challenge phase is public and accepting solutions\n if not challenge_phase.is_public:\n response_data = {\n 'error': 'Sorry, cannot accept submissions since challenge phase is not public'}\n return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)\n\n participant_team_id = get_participant_team_id_of_user_for_a_challenge(\n request.user, challenge_id)\n try:\n participant_team = ParticipantTeam.objects.get(pk=participant_team_id)\n except ParticipantTeam.DoesNotExist:\n response_data = {'error': 'You haven\\'t participated in the challenge'}\n return Response(response_data, status=status.HTTP_403_FORBIDDEN)\n\n serializer = SubmissionSerializer(data=request.data,\n context={'participant_team': participant_team,\n 'challenge_phase': challenge_phase,\n 'request': request\n })\n if serializer.is_valid():\n serializer.save()\n response_data = serializer.data\n submission = serializer.instance\n # publish message in the queue\n publish_submission_message(challenge_id, challenge_phase_id, submission.id)\n return Response(response_data, status=status.HTTP_201_CREATED)\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n\n@throttle_classes([UserRateThrottle])\n@api_view(['PATCH'])\n@permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))\n@authentication_classes((ExpiringTokenAuthentication,))\ndef change_submission_data_and_visibility(request, challenge_pk, challenge_phase_pk, submission_pk):\n \"\"\"\n API Endpoint for updating the submission meta data\n and changing submission visibility.\n \"\"\"\n\n # check if the challenge exists or not\n challenge = get_challenge_model(challenge_pk)\n\n # check if the challenge phase exists or not\n challenge_phase = get_challenge_phase_model(challenge_phase_pk)\n\n if not challenge.is_active:\n response_data = {'error': 'Challenge is not active'}\n return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)\n\n # check if challenge phase is public and accepting solutions\n if not challenge_phase.is_public:\n response_data = {\n 'error': 'Sorry, cannot accept submissions since challenge phase is not public'}\n return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)\n\n participant_team_pk = get_participant_team_id_of_user_for_a_challenge(\n request.user, challenge_pk)\n\n try:\n participant_team = ParticipantTeam.objects.get(pk=participant_team_pk)\n except ParticipantTeam.DoesNotExist:\n response_data = {'error': 'You haven\\'t participated in the challenge'}\n return Response(response_data, status=status.HTTP_403_FORBIDDEN)\n\n try:\n submission = Submission.objects.get(participant_team=participant_team,\n challenge_phase=challenge_phase,\n id=submission_pk)\n except Submission.DoesNotExist:\n response_data = {'error': 'Submission does not exist'}\n return Response(response_data, status=status.HTTP_403_FORBIDDEN)\n\n try:\n is_public = request.data['is_public']\n if is_public is True:\n when_made_public = datetime.datetime.now()\n request.data['when_made_public'] = when_made_public\n except KeyError:\n pass\n\n serializer = SubmissionSerializer(submission,\n data=request.data,\n context={\n 'participant_team': participant_team,\n 'challenge_phase': challenge_phase,\n 'request': request\n },\n partial=True)\n\n if serializer.is_valid():\n serializer.save()\n response_data = serializer.data\n return Response(response_data, status=status.HTTP_200_OK)\n else:\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n\n@throttle_classes([AnonRateThrottle])\n@api_view(['GET'])\ndef leaderboard(request, challenge_phase_split_id):\n \"\"\"Returns leaderboard for a corresponding Challenge Phase Split\"\"\"\n\n # check if the challenge exists or not\n try:\n challenge_phase_split = ChallengePhaseSplit.objects.get(\n pk=challenge_phase_split_id)\n except ChallengePhaseSplit.DoesNotExist:\n response_data = {'error': 'Challenge Phase Split does not exist'}\n return Response(response_data, status=status.HTTP_400_BAD_REQUEST)\n\n # Check if the Challenge Phase Split is publicly visible or not\n if challenge_phase_split.visibility != ChallengePhaseSplit.PUBLIC:\n response_data = {'error': 'Sorry, leaderboard is not public yet for this Challenge Phase Split!'}\n return Response(response_data, status=status.HTTP_400_BAD_REQUEST)\n\n # Get the leaderboard associated with the Challenge Phase Split\n leaderboard = challenge_phase_split.leaderboard\n\n # Get the default order by key to rank the entries on the leaderboard\n try:\n default_order_by = leaderboard.schema['default_order_by']\n except:\n response_data = {'error': 'Sorry, Default filtering key not found in leaderboard schema!'}\n return Response(response_data, status=status.HTTP_400_BAD_REQUEST)\n\n # Get all the successful submissions related to the challenge phase split\n leaderboard_data = LeaderboardData.objects.filter(\n challenge_phase_split=challenge_phase_split,\n submission__is_public=True,\n submission__is_flagged=False).order_by('created_at')\n leaderboard_data = leaderboard_data.annotate(\n filtering_score=RawSQL('result->>%s', (default_order_by, ), output_field=FloatField())).values(\n 'id', 'submission__participant_team__team_name',\n 'challenge_phase_split', 'result', 'filtering_score', 'leaderboard__schema', 'submission__submitted_at')\n\n sorted_leaderboard_data = sorted(leaderboard_data, key=lambda k: float(k['filtering_score']), reverse=True)\n\n distinct_sorted_leaderboard_data = []\n team_list = []\n\n for data in sorted_leaderboard_data:\n if data['submission__participant_team__team_name'] in team_list:\n continue\n else:\n distinct_sorted_leaderboard_data.append(data)\n team_list.append(data['submission__participant_team__team_name'])\n\n leaderboard_labels = challenge_phase_split.leaderboard.schema['labels']\n for item in distinct_sorted_leaderboard_data:\n item['result'] = [item['result'][index.lower()] for index in leaderboard_labels]\n\n paginator, result_page = paginated_queryset(\n distinct_sorted_leaderboard_data,\n request,\n pagination_class=StandardResultSetPagination())\n response_data = result_page\n return paginator.get_paginated_response(response_data)\n\n\n@throttle_classes([UserRateThrottle])\n@api_view(['GET'])\n@permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))\n@authentication_classes((ExpiringTokenAuthentication,))\ndef get_remaining_submissions(request, challenge_phase_pk, challenge_pk):\n\n get_challenge_model(challenge_pk)\n\n challenge_phase = get_challenge_phase_model(challenge_phase_pk)\n\n participant_team_pk = get_participant_team_id_of_user_for_a_challenge(\n request.user, challenge_pk)\n\n # Conditional check for the existence of participant team of the user.\n if not participant_team_pk:\n response_data = {'error': 'You haven\\'t participated in the challenge'}\n return Response(response_data, status=status.HTTP_403_FORBIDDEN)\n\n max_submission_per_day = challenge_phase.max_submissions_per_day\n\n max_submission = challenge_phase.max_submissions\n\n submissions_done_today_count = Submission.objects.filter(\n challenge_phase__challenge=challenge_pk,\n challenge_phase=challenge_phase_pk,\n participant_team=participant_team_pk,\n submitted_at__gte=timezone.now().date()).count()\n\n failed_submissions_count = Submission.objects.filter(\n challenge_phase__challenge=challenge_pk,\n challenge_phase=challenge_phase_pk,\n participant_team=participant_team_pk,\n status=Submission.FAILED,\n submitted_at__gte=timezone.now().date()).count()\n\n # Checks if today's successfull submission is greater than or equal to max submission per day.\n if ((submissions_done_today_count - failed_submissions_count) >= max_submission_per_day\n or (max_submission_per_day == 0)):\n # Get the UTC time of the instant when the above condition is true.\n date_time_now = timezone.now()\n # Calculate the next day's date.\n date_time_tomorrow = date_time_now.date() + datetime.timedelta(1)\n utc = timezone.utc\n # Get the midnight time of the day i.e. 12:00 AM of next day.\n midnight = utc.localize(datetime.datetime.combine(\n date_time_tomorrow, datetime.time()))\n # Subtract the current time from the midnight time to get the remaining time for the next day's submissions.\n remaining_time = midnight - date_time_now\n # Return the remaining time with a message.\n response_data = {'message': 'You have exhausted today\\'s submission limit',\n 'remaining_time': remaining_time\n }\n return Response(response_data, status=status.HTTP_200_OK)\n else:\n # Calculate the remaining submissions for today.\n remaining_submissions_today_count = (max_submission_per_day -\n (submissions_done_today_count -\n failed_submissions_count)\n )\n # calculate the remaining submissions from total submissions.\n remaining_submission_count = max_submission - \\\n (submissions_done_today_count - failed_submissions_count)\n # Return the above calculated data.\n response_data = {'remaining_submissions_today_count': remaining_submissions_today_count,\n 'remaining_submissions': remaining_submission_count\n }\n return Response(response_data, status=status.HTTP_200_OK)\n", "path": "apps/jobs/views.py"}]}
| 3,871 | 168 |
gh_patches_debug_1321
|
rasdani/github-patches
|
git_diff
|
pyodide__pyodide-717
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Calling yaml.load() without Loader=... is deprecated
For each built packages there is now the following deprecation warning ,
```
pyodide_build/common.py:27: YAMLLoadWarning: calling yaml.load() without Loader=... is deprecated, as the default Loader is unsafe. Please read https://msg.pyyaml.org/load for full details.
return yaml.load(fd)
```
it would be nice to fix this.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pyodide_build/common.py`
Content:
```
1 from pathlib import Path
2 from typing import Optional, Set
3
4
5 ROOTDIR = Path(__file__).parents[1].resolve() / "tools"
6 HOSTPYTHON = ROOTDIR / ".." / "cpython" / "build" / "3.8.2" / "host"
7 TARGETPYTHON = ROOTDIR / ".." / "cpython" / "installs" / "python-3.8.2"
8 DEFAULTCFLAGS = ""
9 DEFAULTLDFLAGS = " ".join(
10 [
11 "-O3",
12 "-s",
13 "BINARYEN_METHOD='native-wasm'",
14 "-Werror",
15 "-s",
16 "EMULATED_FUNCTION_POINTERS=1",
17 "-s",
18 "EMULATE_FUNCTION_POINTER_CASTS=1",
19 "-s",
20 "SIDE_MODULE=1",
21 "-s",
22 "WASM=1",
23 "--memory-init-file",
24 "0",
25 ]
26 )
27
28
29 def parse_package(package):
30 # Import yaml here because pywasmcross needs to run in the built native
31 # Python, which won't have PyYAML
32 import yaml
33
34 # TODO: Validate against a schema
35 with open(package) as fd:
36 return yaml.load(fd)
37
38
39 def _parse_package_subset(query: Optional[str]) -> Optional[Set[str]]:
40 """Parse the list of packages specified with PYODIDE_PACKAGES env var.
41
42 Also add the list of mandatory packages: ['micropip', 'distlib']
43
44 Returns:
45 a set of package names to build or None.
46 """
47 if query is None:
48 return None
49 packages = query.split(",")
50 packages = [el.strip() for el in packages]
51 packages = ["micropip", "distlib"] + packages
52 return set(packages)
53
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pyodide_build/common.py b/pyodide_build/common.py
--- a/pyodide_build/common.py
+++ b/pyodide_build/common.py
@@ -33,7 +33,7 @@
# TODO: Validate against a schema
with open(package) as fd:
- return yaml.load(fd)
+ return yaml.safe_load(fd)
def _parse_package_subset(query: Optional[str]) -> Optional[Set[str]]:
|
{"golden_diff": "diff --git a/pyodide_build/common.py b/pyodide_build/common.py\n--- a/pyodide_build/common.py\n+++ b/pyodide_build/common.py\n@@ -33,7 +33,7 @@\n \n # TODO: Validate against a schema\n with open(package) as fd:\n- return yaml.load(fd)\n+ return yaml.safe_load(fd)\n \n \n def _parse_package_subset(query: Optional[str]) -> Optional[Set[str]]:\n", "issue": "Calling yaml.load() without Loader=... is deprecated\nFor each built packages there is now the following deprecation warning ,\r\n```\r\npyodide_build/common.py:27: YAMLLoadWarning: calling yaml.load() without Loader=... is deprecated, as the default Loader is unsafe. Please read https://msg.pyyaml.org/load for full details.\r\n return yaml.load(fd)\r\n```\r\nit would be nice to fix this.\n", "before_files": [{"content": "from pathlib import Path\nfrom typing import Optional, Set\n\n\nROOTDIR = Path(__file__).parents[1].resolve() / \"tools\"\nHOSTPYTHON = ROOTDIR / \"..\" / \"cpython\" / \"build\" / \"3.8.2\" / \"host\"\nTARGETPYTHON = ROOTDIR / \"..\" / \"cpython\" / \"installs\" / \"python-3.8.2\"\nDEFAULTCFLAGS = \"\"\nDEFAULTLDFLAGS = \" \".join(\n [\n \"-O3\",\n \"-s\",\n \"BINARYEN_METHOD='native-wasm'\",\n \"-Werror\",\n \"-s\",\n \"EMULATED_FUNCTION_POINTERS=1\",\n \"-s\",\n \"EMULATE_FUNCTION_POINTER_CASTS=1\",\n \"-s\",\n \"SIDE_MODULE=1\",\n \"-s\",\n \"WASM=1\",\n \"--memory-init-file\",\n \"0\",\n ]\n)\n\n\ndef parse_package(package):\n # Import yaml here because pywasmcross needs to run in the built native\n # Python, which won't have PyYAML\n import yaml\n\n # TODO: Validate against a schema\n with open(package) as fd:\n return yaml.load(fd)\n\n\ndef _parse_package_subset(query: Optional[str]) -> Optional[Set[str]]:\n \"\"\"Parse the list of packages specified with PYODIDE_PACKAGES env var.\n\n Also add the list of mandatory packages: ['micropip', 'distlib']\n\n Returns:\n a set of package names to build or None.\n \"\"\"\n if query is None:\n return None\n packages = query.split(\",\")\n packages = [el.strip() for el in packages]\n packages = [\"micropip\", \"distlib\"] + packages\n return set(packages)\n", "path": "pyodide_build/common.py"}], "after_files": [{"content": "from pathlib import Path\nfrom typing import Optional, Set\n\n\nROOTDIR = Path(__file__).parents[1].resolve() / \"tools\"\nHOSTPYTHON = ROOTDIR / \"..\" / \"cpython\" / \"build\" / \"3.8.2\" / \"host\"\nTARGETPYTHON = ROOTDIR / \"..\" / \"cpython\" / \"installs\" / \"python-3.8.2\"\nDEFAULTCFLAGS = \"\"\nDEFAULTLDFLAGS = \" \".join(\n [\n \"-O3\",\n \"-s\",\n \"BINARYEN_METHOD='native-wasm'\",\n \"-Werror\",\n \"-s\",\n \"EMULATED_FUNCTION_POINTERS=1\",\n \"-s\",\n \"EMULATE_FUNCTION_POINTER_CASTS=1\",\n \"-s\",\n \"SIDE_MODULE=1\",\n \"-s\",\n \"WASM=1\",\n \"--memory-init-file\",\n \"0\",\n ]\n)\n\n\ndef parse_package(package):\n # Import yaml here because pywasmcross needs to run in the built native\n # Python, which won't have PyYAML\n import yaml\n\n # TODO: Validate against a schema\n with open(package) as fd:\n return yaml.safe_load(fd)\n\n\ndef _parse_package_subset(query: Optional[str]) -> Optional[Set[str]]:\n \"\"\"Parse the list of packages specified with PYODIDE_PACKAGES env var.\n\n Also add the list of mandatory packages: ['micropip', 'distlib']\n\n Returns:\n a set of package names to build or None.\n \"\"\"\n if query is None:\n return None\n packages = query.split(\",\")\n packages = [el.strip() for el in packages]\n packages = [\"micropip\", \"distlib\"] + packages\n return set(packages)\n", "path": "pyodide_build/common.py"}]}
| 827 | 98 |
gh_patches_debug_20517
|
rasdani/github-patches
|
git_diff
|
quantumlib__Cirq-1863
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Split cirq packages into with/without contrib
Otherwise there's no way to easily pip install the contrib-requirements
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 # Copyright 2018 The Cirq Developers
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import io
16 from setuptools import find_packages, setup
17
18 # This reads the __version__ variable from cirq/_version.py
19 __version__ = ''
20 exec(open('cirq/_version.py').read())
21
22 description = ('A framework for creating, editing, and invoking '
23 'Noisy Intermediate Scale Quantum (NISQ) circuits.')
24
25 # README file as long_description.
26 long_description = io.open('README.rst', encoding='utf-8').read()
27
28 # Read in requirements
29 requirements = open('requirements.txt').readlines()
30 requirements = [r.strip() for r in requirements]
31
32 cirq_packages = ['cirq'] + [
33 'cirq.' + package for package in find_packages(where='cirq')
34 ]
35
36 setup(name='cirq',
37 version=__version__,
38 url='http://github.com/quantumlib/cirq',
39 author='The Cirq Developers',
40 author_email='[email protected]',
41 python_requires=('>=3.6.0'),
42 install_requires=requirements,
43 license='Apache 2',
44 description=description,
45 long_description=long_description,
46 packages=cirq_packages,
47 package_data={
48 'cirq.api.google.v1': ['*.proto'],
49 'cirq.api.google.v2': ['*.proto'],
50 })
51
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -28,6 +28,10 @@
# Read in requirements
requirements = open('requirements.txt').readlines()
requirements = [r.strip() for r in requirements]
+contrib_requirements = open('cirq/contrib/contrib-requirements.txt').readlines()
+contrib_requirements = [r.strip() for r in contrib_requirements]
+dev_requirements = open('dev_tools/conf/pip-list-dev-tools.txt').readlines()
+dev_requirements = [r.strip() for r in dev_requirements]
cirq_packages = ['cirq'] + [
'cirq.' + package for package in find_packages(where='cirq')
@@ -40,6 +44,10 @@
author_email='[email protected]',
python_requires=('>=3.6.0'),
install_requires=requirements,
+ extras_require={
+ 'contrib': contrib_requirements,
+ 'dev': dev_requirements,
+ },
license='Apache 2',
description=description,
long_description=long_description,
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -28,6 +28,10 @@\n # Read in requirements\n requirements = open('requirements.txt').readlines()\n requirements = [r.strip() for r in requirements]\n+contrib_requirements = open('cirq/contrib/contrib-requirements.txt').readlines()\n+contrib_requirements = [r.strip() for r in contrib_requirements]\n+dev_requirements = open('dev_tools/conf/pip-list-dev-tools.txt').readlines()\n+dev_requirements = [r.strip() for r in dev_requirements]\n \n cirq_packages = ['cirq'] + [\n 'cirq.' + package for package in find_packages(where='cirq')\n@@ -40,6 +44,10 @@\n author_email='[email protected]',\n python_requires=('>=3.6.0'),\n install_requires=requirements,\n+ extras_require={\n+ 'contrib': contrib_requirements,\n+ 'dev': dev_requirements,\n+ },\n license='Apache 2',\n description=description,\n long_description=long_description,\n", "issue": "Split cirq packages into with/without contrib\nOtherwise there's no way to easily pip install the contrib-requirements\n", "before_files": [{"content": "# Copyright 2018 The Cirq Developers\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport io\nfrom setuptools import find_packages, setup\n\n# This reads the __version__ variable from cirq/_version.py\n__version__ = ''\nexec(open('cirq/_version.py').read())\n\ndescription = ('A framework for creating, editing, and invoking '\n 'Noisy Intermediate Scale Quantum (NISQ) circuits.')\n\n# README file as long_description.\nlong_description = io.open('README.rst', encoding='utf-8').read()\n\n# Read in requirements\nrequirements = open('requirements.txt').readlines()\nrequirements = [r.strip() for r in requirements]\n\ncirq_packages = ['cirq'] + [\n 'cirq.' + package for package in find_packages(where='cirq')\n]\n\nsetup(name='cirq',\n version=__version__,\n url='http://github.com/quantumlib/cirq',\n author='The Cirq Developers',\n author_email='[email protected]',\n python_requires=('>=3.6.0'),\n install_requires=requirements,\n license='Apache 2',\n description=description,\n long_description=long_description,\n packages=cirq_packages,\n package_data={\n 'cirq.api.google.v1': ['*.proto'],\n 'cirq.api.google.v2': ['*.proto'],\n })\n", "path": "setup.py"}], "after_files": [{"content": "# Copyright 2018 The Cirq Developers\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport io\nfrom setuptools import find_packages, setup\n\n# This reads the __version__ variable from cirq/_version.py\n__version__ = ''\nexec(open('cirq/_version.py').read())\n\ndescription = ('A framework for creating, editing, and invoking '\n 'Noisy Intermediate Scale Quantum (NISQ) circuits.')\n\n# README file as long_description.\nlong_description = io.open('README.rst', encoding='utf-8').read()\n\n# Read in requirements\nrequirements = open('requirements.txt').readlines()\nrequirements = [r.strip() for r in requirements]\ncontrib_requirements = open('cirq/contrib/contrib-requirements.txt').readlines()\ncontrib_requirements = [r.strip() for r in contrib_requirements]\ndev_requirements = open('dev_tools/conf/pip-list-dev-tools.txt').readlines()\ndev_requirements = [r.strip() for r in dev_requirements]\n\ncirq_packages = ['cirq'] + [\n 'cirq.' + package for package in find_packages(where='cirq')\n]\n\nsetup(name='cirq',\n version=__version__,\n url='http://github.com/quantumlib/cirq',\n author='The Cirq Developers',\n author_email='[email protected]',\n python_requires=('>=3.6.0'),\n install_requires=requirements,\n extras_require={\n 'contrib': contrib_requirements,\n 'dev': dev_requirements,\n },\n license='Apache 2',\n description=description,\n long_description=long_description,\n packages=cirq_packages,\n package_data={\n 'cirq.api.google.v1': ['*.proto'],\n 'cirq.api.google.v2': ['*.proto'],\n })\n", "path": "setup.py"}]}
| 779 | 238 |
gh_patches_debug_2369
|
rasdani/github-patches
|
git_diff
|
Pyomo__pyomo-2265
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Consistent semantic versioning
## Summary
The most recent version of Pyomo released was 6.2, as opposed to 6.2.0. It seems inconsistent with the way many other packages are versioned (e.g. NumFocus packages), although I am unaware if there is a standard specified anywhere. Is there a benefit to the former as opposed to the latter?
## Context
Managing our dependencies, we automate pulling in new versions of packages, running them through our CI prior to upgrading. We run this in two ways - one allowing all upgrades and one allowing only compatible upgrades (PEP 440). This always requires manual review because not all packages use semantic versioning (or the same semantic versioning). One manual override we had to apply this time was pinning `Pyomo ~= 6.2.0` instead of what our script automatically pulled in `Pyomo ~= 6.2`.
Consistent semantic versioning
## Summary
The most recent version of Pyomo released was 6.2, as opposed to 6.2.0. It seems inconsistent with the way many other packages are versioned (e.g. NumFocus packages), although I am unaware if there is a standard specified anywhere. Is there a benefit to the former as opposed to the latter?
## Context
Managing our dependencies, we automate pulling in new versions of packages, running them through our CI prior to upgrading. We run this in two ways - one allowing all upgrades and one allowing only compatible upgrades (PEP 440). This always requires manual review because not all packages use semantic versioning (or the same semantic versioning). One manual override we had to apply this time was pinning `Pyomo ~= 6.2.0` instead of what our script automatically pulled in `Pyomo ~= 6.2`.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pyomo/version/info.py`
Content:
```
1 # ___________________________________________________________________________
2 #
3 # Pyomo: Python Optimization Modeling Objects
4 # Copyright 2017 National Technology and Engineering Solutions of Sandia, LLC
5 # Under the terms of Contract DE-NA0003525 with National Technology and
6 # Engineering Solutions of Sandia, LLC, the U.S. Government retains certain
7 # rights in this software.
8 # This software is distributed under the 3-clause BSD License.
9 # ___________________________________________________________________________
10
11 _init_url="$URL$"
12
13 # NOTE: releaselevel should be left at 'invalid' for trunk development
14 # and set to 'final' for releases. During development, the
15 # major.minor.micro should point ot the NEXT release (generally, the
16 # next micro release after the current release).
17 #
18 # Note: When cutting a release, also update the major/minor/micro in
19 #
20 # pyomo/RELEASE.txt
21 #
22 # The VOTD zipbuilder will automatically change releaselevel to "VOTD
23 # {hash}" and set the serial number to YYMMDDhhmm. The serial number
24 # should generally be left at 0, unless a downstream package is tracking
25 # main and needs a hard reference to "suitably new" development.
26 major=6
27 minor=2
28 micro=1
29 releaselevel='invalid'
30 #releaselevel='final'
31 serial=0
32
33 if releaselevel == 'final':
34 pass
35 elif '/tags/' in _init_url: #pragma:nocover
36 releaselevel = 'final'
37 elif releaselevel == 'invalid':
38 from os.path import abspath, dirname, exists, join
39 if __file__.endswith('setup.py'):
40 # This file is being sources (exec'ed) from setup.py.
41 # dirname(__file__) setup.py's scope is the root sourec directory
42 _rootdir = os.path.dirname(__file__)
43 else:
44 # Eventually this should import PYOMO_ROOT_DIR from
45 # pyomo.common instead of reimplementing that logic here.
46 #
47 # __file__ fails if script is called in different ways on Windows
48 # __file__ fails if someone does os.chdir() before
49 # sys.argv[0] also fails because it doesn't not always contains the path
50 from inspect import getfile, currentframe
51 _rootdir = join(dirname(abspath(getfile(currentframe()))), '..', '..')
52
53 if exists(join(_rootdir, '.git')):
54 try:
55 with open(join(_rootdir, '.git', 'HEAD')) as _FILE:
56 _ref = _FILE.readline().strip() #pragma:nocover
57 releaselevel = 'devel {%s}' % (
58 _ref.split('/')[-1].split('\\')[-1], ) #pragma:nocover
59 except:
60 releaselevel = 'devel' #pragma:nocover
61 elif exists(join(_rootdir, '.svn')):
62 releaselevel = 'devel {svn}' #pragma:nocover
63 else:
64 releaselevel = 'VOTD' #pragma:nocover
65
66
67 version_info = (major, minor, micro, releaselevel, serial)
68
69 version = '.'.join(str(x) for x in version_info[:(3 if micro else 2)])
70 __version__ = version
71 if releaselevel != 'final':
72 version += ' ('+releaselevel+')'
73 if releaselevel.startswith('devel'):
74 __version__ += ".dev%d" % (serial,)
75 elif releaselevel.startswith('VOTD'):
76 __version__ += "a%d" % (serial,)
77
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pyomo/version/info.py b/pyomo/version/info.py
--- a/pyomo/version/info.py
+++ b/pyomo/version/info.py
@@ -66,7 +66,7 @@
version_info = (major, minor, micro, releaselevel, serial)
-version = '.'.join(str(x) for x in version_info[:(3 if micro else 2)])
+version = '.'.join(str(x) for x in version_info[:3])
__version__ = version
if releaselevel != 'final':
version += ' ('+releaselevel+')'
|
{"golden_diff": "diff --git a/pyomo/version/info.py b/pyomo/version/info.py\n--- a/pyomo/version/info.py\n+++ b/pyomo/version/info.py\n@@ -66,7 +66,7 @@\n \n version_info = (major, minor, micro, releaselevel, serial)\n \n-version = '.'.join(str(x) for x in version_info[:(3 if micro else 2)])\n+version = '.'.join(str(x) for x in version_info[:3])\n __version__ = version\n if releaselevel != 'final':\n version += ' ('+releaselevel+')'\n", "issue": "Consistent semantic versioning\n## Summary\r\n\r\nThe most recent version of Pyomo released was 6.2, as opposed to 6.2.0. It seems inconsistent with the way many other packages are versioned (e.g. NumFocus packages), although I am unaware if there is a standard specified anywhere. Is there a benefit to the former as opposed to the latter? \r\n\r\n## Context\r\n\r\nManaging our dependencies, we automate pulling in new versions of packages, running them through our CI prior to upgrading. We run this in two ways - one allowing all upgrades and one allowing only compatible upgrades (PEP 440). This always requires manual review because not all packages use semantic versioning (or the same semantic versioning). One manual override we had to apply this time was pinning `Pyomo ~= 6.2.0` instead of what our script automatically pulled in `Pyomo ~= 6.2`.\nConsistent semantic versioning\n## Summary\r\n\r\nThe most recent version of Pyomo released was 6.2, as opposed to 6.2.0. It seems inconsistent with the way many other packages are versioned (e.g. NumFocus packages), although I am unaware if there is a standard specified anywhere. Is there a benefit to the former as opposed to the latter? \r\n\r\n## Context\r\n\r\nManaging our dependencies, we automate pulling in new versions of packages, running them through our CI prior to upgrading. We run this in two ways - one allowing all upgrades and one allowing only compatible upgrades (PEP 440). This always requires manual review because not all packages use semantic versioning (or the same semantic versioning). One manual override we had to apply this time was pinning `Pyomo ~= 6.2.0` instead of what our script automatically pulled in `Pyomo ~= 6.2`.\n", "before_files": [{"content": "# ___________________________________________________________________________\n#\n# Pyomo: Python Optimization Modeling Objects\n# Copyright 2017 National Technology and Engineering Solutions of Sandia, LLC\n# Under the terms of Contract DE-NA0003525 with National Technology and \n# Engineering Solutions of Sandia, LLC, the U.S. Government retains certain \n# rights in this software.\n# This software is distributed under the 3-clause BSD License.\n# ___________________________________________________________________________\n\n_init_url=\"$URL$\"\n\n# NOTE: releaselevel should be left at 'invalid' for trunk development\n# and set to 'final' for releases. During development, the\n# major.minor.micro should point ot the NEXT release (generally, the\n# next micro release after the current release).\n#\n# Note: When cutting a release, also update the major/minor/micro in\n#\n# pyomo/RELEASE.txt\n#\n# The VOTD zipbuilder will automatically change releaselevel to \"VOTD\n# {hash}\" and set the serial number to YYMMDDhhmm. The serial number\n# should generally be left at 0, unless a downstream package is tracking\n# main and needs a hard reference to \"suitably new\" development.\nmajor=6\nminor=2\nmicro=1\nreleaselevel='invalid'\n#releaselevel='final'\nserial=0\n\nif releaselevel == 'final':\n pass\nelif '/tags/' in _init_url: #pragma:nocover\n releaselevel = 'final'\nelif releaselevel == 'invalid':\n from os.path import abspath, dirname, exists, join\n if __file__.endswith('setup.py'):\n # This file is being sources (exec'ed) from setup.py.\n # dirname(__file__) setup.py's scope is the root sourec directory\n _rootdir = os.path.dirname(__file__)\n else:\n # Eventually this should import PYOMO_ROOT_DIR from\n # pyomo.common instead of reimplementing that logic here.\n #\n # __file__ fails if script is called in different ways on Windows\n # __file__ fails if someone does os.chdir() before\n # sys.argv[0] also fails because it doesn't not always contains the path\n from inspect import getfile, currentframe\n _rootdir = join(dirname(abspath(getfile(currentframe()))), '..', '..')\n\n if exists(join(_rootdir, '.git')):\n try:\n with open(join(_rootdir, '.git', 'HEAD')) as _FILE:\n _ref = _FILE.readline().strip() #pragma:nocover\n releaselevel = 'devel {%s}' % (\n _ref.split('/')[-1].split('\\\\')[-1], ) #pragma:nocover\n except:\n releaselevel = 'devel' #pragma:nocover\n elif exists(join(_rootdir, '.svn')):\n releaselevel = 'devel {svn}' #pragma:nocover\n else:\n releaselevel = 'VOTD' #pragma:nocover\n\n\nversion_info = (major, minor, micro, releaselevel, serial)\n\nversion = '.'.join(str(x) for x in version_info[:(3 if micro else 2)])\n__version__ = version\nif releaselevel != 'final':\n version += ' ('+releaselevel+')'\nif releaselevel.startswith('devel'):\n __version__ += \".dev%d\" % (serial,)\nelif releaselevel.startswith('VOTD'):\n __version__ += \"a%d\" % (serial,)\n", "path": "pyomo/version/info.py"}], "after_files": [{"content": "# ___________________________________________________________________________\n#\n# Pyomo: Python Optimization Modeling Objects\n# Copyright 2017 National Technology and Engineering Solutions of Sandia, LLC\n# Under the terms of Contract DE-NA0003525 with National Technology and \n# Engineering Solutions of Sandia, LLC, the U.S. Government retains certain \n# rights in this software.\n# This software is distributed under the 3-clause BSD License.\n# ___________________________________________________________________________\n\n_init_url=\"$URL$\"\n\n# NOTE: releaselevel should be left at 'invalid' for trunk development\n# and set to 'final' for releases. During development, the\n# major.minor.micro should point ot the NEXT release (generally, the\n# next micro release after the current release).\n#\n# Note: When cutting a release, also update the major/minor/micro in\n#\n# pyomo/RELEASE.txt\n#\n# The VOTD zipbuilder will automatically change releaselevel to \"VOTD\n# {hash}\" and set the serial number to YYMMDDhhmm. The serial number\n# should generally be left at 0, unless a downstream package is tracking\n# main and needs a hard reference to \"suitably new\" development.\nmajor=6\nminor=2\nmicro=1\nreleaselevel='invalid'\n#releaselevel='final'\nserial=0\n\nif releaselevel == 'final':\n pass\nelif '/tags/' in _init_url: #pragma:nocover\n releaselevel = 'final'\nelif releaselevel == 'invalid':\n from os.path import abspath, dirname, exists, join\n if __file__.endswith('setup.py'):\n # This file is being sources (exec'ed) from setup.py.\n # dirname(__file__) setup.py's scope is the root sourec directory\n _rootdir = os.path.dirname(__file__)\n else:\n # Eventually this should import PYOMO_ROOT_DIR from\n # pyomo.common instead of reimplementing that logic here.\n #\n # __file__ fails if script is called in different ways on Windows\n # __file__ fails if someone does os.chdir() before\n # sys.argv[0] also fails because it doesn't not always contains the path\n from inspect import getfile, currentframe\n _rootdir = join(dirname(abspath(getfile(currentframe()))), '..', '..')\n\n if exists(join(_rootdir, '.git')):\n try:\n with open(join(_rootdir, '.git', 'HEAD')) as _FILE:\n _ref = _FILE.readline().strip() #pragma:nocover\n releaselevel = 'devel {%s}' % (\n _ref.split('/')[-1].split('\\\\')[-1], ) #pragma:nocover\n except:\n releaselevel = 'devel' #pragma:nocover\n elif exists(join(_rootdir, '.svn')):\n releaselevel = 'devel {svn}' #pragma:nocover\n else:\n releaselevel = 'VOTD' #pragma:nocover\n\n\nversion_info = (major, minor, micro, releaselevel, serial)\n\nversion = '.'.join(str(x) for x in version_info[:3])\n__version__ = version\nif releaselevel != 'final':\n version += ' ('+releaselevel+')'\nif releaselevel.startswith('devel'):\n __version__ += \".dev%d\" % (serial,)\nelif releaselevel.startswith('VOTD'):\n __version__ += \"a%d\" % (serial,)\n", "path": "pyomo/version/info.py"}]}
| 1,557 | 123 |
gh_patches_debug_36212
|
rasdani/github-patches
|
git_diff
|
strawberry-graphql__strawberry-403
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Error adding more than one implementation of an interface
**Observed Behaviour**: When i try to add two implementations of an interface, i get a duplicated type name exception
**Expected Behaviour**: Instead of trying to recreate the interface type again, reuse it.
**Steps to reproduce**:
1. Create an interface
2. Create two types which implement the interface
3. Launch `strawberry server app`
4. See it fails with ` Schema must contain uniquely named types but contains multiple types named '<InterfaceName>'`
**Snippet to reproduce the issue**
````python
from typing import List, Optional, Union
import strawberry
from strawberry import field
@strawberry.interface
class Person:
name: str
email: str
@strawberry.type
class Speaker(Person):
job: str
@strawberry.type
class Attendee(Person):
interests: List[str]
def get_people_by_name(name: str):
return []
@strawberry.type
class Query:
searchPeopleByName: List[Union[Speaker, Attendee]] = field(resolver=get_people_by_name)
schema = strawberry.Schema(query=Query)
````
**Full traceback:**
```
File "/mnt/c/Users/<User>/code/nerdearla/test_app.py", line 30, in <module>
schema = strawberry.Schema(query=Query)
File "/home/crow/.virtualenvs/venv/lib/python3.8/site-packages/strawberry/schema/schema.py", line 42, in __init__
self._schema = GraphQLSchema(
File "/home/crow/.virtualenvs/venv/lib/python3.8/site-packages/graphql/type/schema.py", line 240, in __init__
raise TypeError(
TypeError: Schema must contain uniquely named types but contains multiple types named 'Person'.
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `strawberry/schema/types/object_type.py`
Content:
```
1 from typing import Type, cast
2
3 from graphql import GraphQLInputObjectType, GraphQLObjectType
4 from graphql.type.definition import GraphQLInterfaceType
5 from strawberry.type import TypeDefinition
6
7 from .fields import get_field
8 from .types import ConcreteType, GraphQLType, TypeMap
9
10
11 def _get_object_type_for_type_definition(
12 type_definition: TypeDefinition, type_map: TypeMap
13 ) -> GraphQLType:
14
15 TypeClass: Type = GraphQLObjectType
16
17 kwargs = {}
18
19 if type_definition.is_input:
20 TypeClass = GraphQLInputObjectType
21 elif type_definition.is_interface:
22 TypeClass = GraphQLInterfaceType
23
24 if type_definition.interfaces:
25 kwargs["interfaces"] = [
26 _get_object_type_for_type_definition(interface, type_map)
27 for interface in type_definition.interfaces
28 ]
29
30 assert not type_definition.is_generic
31
32 return TypeClass(
33 name=type_definition.name,
34 fields=lambda: {
35 field.name: get_field(field, type_definition.is_input, type_map)
36 for field in type_definition.fields
37 },
38 description=type_definition.description,
39 **kwargs,
40 )
41
42
43 def get_object_type(origin: Type, type_map: TypeMap) -> GraphQLObjectType:
44 """Returns a root type (Query, Mutation, Subscription) from a decorated type"""
45
46 if not hasattr(origin, "_type_definition"):
47 raise ValueError(f"Wrong type passed to get object type {origin}")
48
49 type_definition: TypeDefinition = origin._type_definition
50
51 name = type_definition.name
52
53 if name not in type_map:
54 object_type = _get_object_type_for_type_definition(type_definition, type_map)
55
56 type_map[name] = ConcreteType(
57 definition=type_definition, implementation=object_type
58 )
59
60 return cast(GraphQLObjectType, type_map[name].implementation)
61
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/strawberry/schema/types/object_type.py b/strawberry/schema/types/object_type.py
--- a/strawberry/schema/types/object_type.py
+++ b/strawberry/schema/types/object_type.py
@@ -12,32 +12,43 @@
type_definition: TypeDefinition, type_map: TypeMap
) -> GraphQLType:
- TypeClass: Type = GraphQLObjectType
-
- kwargs = {}
-
- if type_definition.is_input:
- TypeClass = GraphQLInputObjectType
- elif type_definition.is_interface:
- TypeClass = GraphQLInterfaceType
-
- if type_definition.interfaces:
- kwargs["interfaces"] = [
- _get_object_type_for_type_definition(interface, type_map)
- for interface in type_definition.interfaces
- ]
-
- assert not type_definition.is_generic
-
- return TypeClass(
- name=type_definition.name,
- fields=lambda: {
- field.name: get_field(field, type_definition.is_input, type_map)
- for field in type_definition.fields
- },
- description=type_definition.description,
- **kwargs,
- )
+ if type_definition.name not in type_map:
+ TypeClass: Type = GraphQLObjectType
+
+ kwargs = {}
+
+ if type_definition.is_input:
+ TypeClass = GraphQLInputObjectType
+ elif type_definition.is_interface:
+ TypeClass = GraphQLInterfaceType
+
+ if type_definition.interfaces:
+ kwargs["interfaces"] = [
+ _get_object_type_for_type_definition(interface, type_map)
+ for interface in type_definition.interfaces
+ ]
+ # this tells GraphQL core what the returned object's actual type is
+ kwargs["is_type_of"] = lambda obj, _: isinstance( # type: ignore
+ obj, type_definition.origin
+ )
+
+ assert not type_definition.is_generic
+
+ object_type = TypeClass(
+ name=type_definition.name,
+ fields=lambda: {
+ field.name: get_field(field, type_definition.is_input, type_map)
+ for field in type_definition.fields
+ },
+ description=type_definition.description,
+ **kwargs,
+ )
+
+ type_map[type_definition.name] = ConcreteType(
+ definition=type_definition, implementation=object_type
+ )
+
+ return type_map[type_definition.name].implementation
def get_object_type(origin: Type, type_map: TypeMap) -> GraphQLObjectType:
@@ -48,13 +59,7 @@
type_definition: TypeDefinition = origin._type_definition
- name = type_definition.name
-
- if name not in type_map:
- object_type = _get_object_type_for_type_definition(type_definition, type_map)
-
- type_map[name] = ConcreteType(
- definition=type_definition, implementation=object_type
- )
-
- return cast(GraphQLObjectType, type_map[name].implementation)
+ return cast(
+ GraphQLObjectType,
+ _get_object_type_for_type_definition(type_definition, type_map),
+ )
|
{"golden_diff": "diff --git a/strawberry/schema/types/object_type.py b/strawberry/schema/types/object_type.py\n--- a/strawberry/schema/types/object_type.py\n+++ b/strawberry/schema/types/object_type.py\n@@ -12,32 +12,43 @@\n type_definition: TypeDefinition, type_map: TypeMap\n ) -> GraphQLType:\n \n- TypeClass: Type = GraphQLObjectType\n-\n- kwargs = {}\n-\n- if type_definition.is_input:\n- TypeClass = GraphQLInputObjectType\n- elif type_definition.is_interface:\n- TypeClass = GraphQLInterfaceType\n-\n- if type_definition.interfaces:\n- kwargs[\"interfaces\"] = [\n- _get_object_type_for_type_definition(interface, type_map)\n- for interface in type_definition.interfaces\n- ]\n-\n- assert not type_definition.is_generic\n-\n- return TypeClass(\n- name=type_definition.name,\n- fields=lambda: {\n- field.name: get_field(field, type_definition.is_input, type_map)\n- for field in type_definition.fields\n- },\n- description=type_definition.description,\n- **kwargs,\n- )\n+ if type_definition.name not in type_map:\n+ TypeClass: Type = GraphQLObjectType\n+\n+ kwargs = {}\n+\n+ if type_definition.is_input:\n+ TypeClass = GraphQLInputObjectType\n+ elif type_definition.is_interface:\n+ TypeClass = GraphQLInterfaceType\n+\n+ if type_definition.interfaces:\n+ kwargs[\"interfaces\"] = [\n+ _get_object_type_for_type_definition(interface, type_map)\n+ for interface in type_definition.interfaces\n+ ]\n+ # this tells GraphQL core what the returned object's actual type is\n+ kwargs[\"is_type_of\"] = lambda obj, _: isinstance( # type: ignore\n+ obj, type_definition.origin\n+ )\n+\n+ assert not type_definition.is_generic\n+\n+ object_type = TypeClass(\n+ name=type_definition.name,\n+ fields=lambda: {\n+ field.name: get_field(field, type_definition.is_input, type_map)\n+ for field in type_definition.fields\n+ },\n+ description=type_definition.description,\n+ **kwargs,\n+ )\n+\n+ type_map[type_definition.name] = ConcreteType(\n+ definition=type_definition, implementation=object_type\n+ )\n+\n+ return type_map[type_definition.name].implementation\n \n \n def get_object_type(origin: Type, type_map: TypeMap) -> GraphQLObjectType:\n@@ -48,13 +59,7 @@\n \n type_definition: TypeDefinition = origin._type_definition\n \n- name = type_definition.name\n-\n- if name not in type_map:\n- object_type = _get_object_type_for_type_definition(type_definition, type_map)\n-\n- type_map[name] = ConcreteType(\n- definition=type_definition, implementation=object_type\n- )\n-\n- return cast(GraphQLObjectType, type_map[name].implementation)\n+ return cast(\n+ GraphQLObjectType,\n+ _get_object_type_for_type_definition(type_definition, type_map),\n+ )\n", "issue": "Error adding more than one implementation of an interface\n**Observed Behaviour**: When i try to add two implementations of an interface, i get a duplicated type name exception\r\n\r\n**Expected Behaviour**: Instead of trying to recreate the interface type again, reuse it.\r\n\r\n**Steps to reproduce**:\r\n1. Create an interface\r\n2. Create two types which implement the interface\r\n3. Launch `strawberry server app`\r\n4. See it fails with ` Schema must contain uniquely named types but contains multiple types named '<InterfaceName>'`\r\n\r\n**Snippet to reproduce the issue**\r\n````python\r\nfrom typing import List, Optional, Union\r\nimport strawberry\r\nfrom strawberry import field\r\n\r\n\r\[email protected]\r\nclass Person:\r\n name: str\r\n email: str\r\n\r\n\r\[email protected]\r\nclass Speaker(Person):\r\n job: str \r\n\r\n\r\[email protected]\r\nclass Attendee(Person):\r\n interests: List[str]\r\n\r\n\r\ndef get_people_by_name(name: str): \r\n return []\r\n\r\n\r\[email protected]\r\nclass Query:\r\n searchPeopleByName: List[Union[Speaker, Attendee]] = field(resolver=get_people_by_name)\r\n\r\nschema = strawberry.Schema(query=Query)\r\n````\r\n**Full traceback:**\r\n```\r\n File \"/mnt/c/Users/<User>/code/nerdearla/test_app.py\", line 30, in <module>\r\n schema = strawberry.Schema(query=Query)\r\n File \"/home/crow/.virtualenvs/venv/lib/python3.8/site-packages/strawberry/schema/schema.py\", line 42, in __init__\r\n self._schema = GraphQLSchema(\r\n File \"/home/crow/.virtualenvs/venv/lib/python3.8/site-packages/graphql/type/schema.py\", line 240, in __init__\r\n raise TypeError(\r\nTypeError: Schema must contain uniquely named types but contains multiple types named 'Person'.\r\n```\n", "before_files": [{"content": "from typing import Type, cast\n\nfrom graphql import GraphQLInputObjectType, GraphQLObjectType\nfrom graphql.type.definition import GraphQLInterfaceType\nfrom strawberry.type import TypeDefinition\n\nfrom .fields import get_field\nfrom .types import ConcreteType, GraphQLType, TypeMap\n\n\ndef _get_object_type_for_type_definition(\n type_definition: TypeDefinition, type_map: TypeMap\n) -> GraphQLType:\n\n TypeClass: Type = GraphQLObjectType\n\n kwargs = {}\n\n if type_definition.is_input:\n TypeClass = GraphQLInputObjectType\n elif type_definition.is_interface:\n TypeClass = GraphQLInterfaceType\n\n if type_definition.interfaces:\n kwargs[\"interfaces\"] = [\n _get_object_type_for_type_definition(interface, type_map)\n for interface in type_definition.interfaces\n ]\n\n assert not type_definition.is_generic\n\n return TypeClass(\n name=type_definition.name,\n fields=lambda: {\n field.name: get_field(field, type_definition.is_input, type_map)\n for field in type_definition.fields\n },\n description=type_definition.description,\n **kwargs,\n )\n\n\ndef get_object_type(origin: Type, type_map: TypeMap) -> GraphQLObjectType:\n \"\"\"Returns a root type (Query, Mutation, Subscription) from a decorated type\"\"\"\n\n if not hasattr(origin, \"_type_definition\"):\n raise ValueError(f\"Wrong type passed to get object type {origin}\")\n\n type_definition: TypeDefinition = origin._type_definition\n\n name = type_definition.name\n\n if name not in type_map:\n object_type = _get_object_type_for_type_definition(type_definition, type_map)\n\n type_map[name] = ConcreteType(\n definition=type_definition, implementation=object_type\n )\n\n return cast(GraphQLObjectType, type_map[name].implementation)\n", "path": "strawberry/schema/types/object_type.py"}], "after_files": [{"content": "from typing import Type, cast\n\nfrom graphql import GraphQLInputObjectType, GraphQLObjectType\nfrom graphql.type.definition import GraphQLInterfaceType\nfrom strawberry.type import TypeDefinition\n\nfrom .fields import get_field\nfrom .types import ConcreteType, GraphQLType, TypeMap\n\n\ndef _get_object_type_for_type_definition(\n type_definition: TypeDefinition, type_map: TypeMap\n) -> GraphQLType:\n\n if type_definition.name not in type_map:\n TypeClass: Type = GraphQLObjectType\n\n kwargs = {}\n\n if type_definition.is_input:\n TypeClass = GraphQLInputObjectType\n elif type_definition.is_interface:\n TypeClass = GraphQLInterfaceType\n\n if type_definition.interfaces:\n kwargs[\"interfaces\"] = [\n _get_object_type_for_type_definition(interface, type_map)\n for interface in type_definition.interfaces\n ]\n # this tells GraphQL core what the returned object's actual type is\n kwargs[\"is_type_of\"] = lambda obj, _: isinstance( # type: ignore\n obj, type_definition.origin\n )\n\n assert not type_definition.is_generic\n\n object_type = TypeClass(\n name=type_definition.name,\n fields=lambda: {\n field.name: get_field(field, type_definition.is_input, type_map)\n for field in type_definition.fields\n },\n description=type_definition.description,\n **kwargs,\n )\n\n type_map[type_definition.name] = ConcreteType(\n definition=type_definition, implementation=object_type\n )\n\n return type_map[type_definition.name].implementation\n\n\ndef get_object_type(origin: Type, type_map: TypeMap) -> GraphQLObjectType:\n \"\"\"Returns a root type (Query, Mutation, Subscription) from a decorated type\"\"\"\n\n if not hasattr(origin, \"_type_definition\"):\n raise ValueError(f\"Wrong type passed to get object type {origin}\")\n\n type_definition: TypeDefinition = origin._type_definition\n\n return cast(\n GraphQLObjectType,\n _get_object_type_for_type_definition(type_definition, type_map),\n )\n", "path": "strawberry/schema/types/object_type.py"}]}
| 1,148 | 670 |
gh_patches_debug_26521
|
rasdani/github-patches
|
git_diff
|
internetarchive__openlibrary-7718
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Publisher search endpoint solr performance
<!-- What problem are we solving? What does the experience look like today? What are the symptoms? -->
Our /search/publishers endpoint is doing a strange roll-up and submitting many solr select queries causing performance issues. Solution presumably is to not make more than 1 solr query on /search/publishers.
### Proposal
Change the backend call for /search/publishers to make a single query to solr `publisher:(...)` query.
### Evidence / Screenshot (if possible)

<img width="775" alt="Screenshot 2023-03-23 at 12 18 55 PM" src="https://user-images.githubusercontent.com/978325/227324919-d19b91c5-d19b-4746-9908-43e0f7cf1cbd.png">
### Relevant url?
<!-- `https://openlibrary.org/...` -->
http://testing.openlibrary.org/search/publishers?q=Black%20Dolls%20And%20White%20Dolls%20From%201940%20Through%201970%3A%20Their%20Impact%20Then%20On%20Black%20And%20White%20Children%27s%20Development%20
### Related files
<!-- Files related to this issue; this is super useful for new contributors who might want to help! If you're not sure, leave this blank; a maintainer will add them. -->
https://github.com/internetarchive/openlibrary/blob/b897c8c51a79308e38f9825fac82864a5cc7d3ae/openlibrary/plugins/worksearch/publishers.py#L82
### Stakeholders
<!-- @ tag stakeholders of this bug -->
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `openlibrary/plugins/worksearch/publishers.py`
Content:
```
1 """Publisher pages
2 """
3 from infogami.utils import delegate, stats
4 from infogami.utils.view import render_template, safeint
5 import web
6 import logging
7
8 from . import subjects
9 from . import search
10
11 logger = logging.getLogger("openlibrary.worksearch")
12
13
14 class publishers(subjects.subjects):
15 path = '(/publishers/[^/]+)'
16
17 def GET(self, key):
18 key = key.replace("_", " ")
19 page = subjects.get_subject(key, details=True)
20
21 if not page or page.work_count == 0:
22 web.ctx.status = "404 Not Found"
23 return render_template('publishers/notfound.tmpl', key)
24
25 return render_template("publishers/view", page)
26
27 def is_enabled(self):
28 return "publishers" in web.ctx.features
29
30
31 class publishers_json(subjects.subjects_json):
32 path = '(/publishers/[^/]+)'
33 encoding = "json"
34
35 def is_enabled(self):
36 return "publishers" in web.ctx.features
37
38 def normalize_key(self, key):
39 return key
40
41 def process_key(self, key):
42 return key.replace("_", " ")
43
44
45 class index(delegate.page):
46 path = "/publishers"
47
48 def GET(self):
49 return render_template("publishers/index")
50
51 def is_enabled(self):
52 return "publishers" in web.ctx.features
53
54
55 class publisher_search(delegate.page):
56 path = '/search/publishers'
57
58 def GET(self):
59 i = web.input(q="")
60 solr = search.get_solr()
61 q = {"publisher": i.q}
62
63 result = solr.select(
64 q,
65 facets=["publisher_facet"],
66 fields=["publisher", "publisher_facet"],
67 rows=0,
68 )
69 result = self.process_result(result)
70 return render_template('search/publishers', i.q, result)
71
72 def process_result(self, result):
73 solr = search.get_solr()
74
75 def process(p):
76 return web.storage(
77 name=p.value,
78 key="/publishers/" + p.value.replace(" ", "_"),
79 count=solr.select({"publisher_facet": p.value}, rows=0)['num_found'],
80 )
81
82 publisher_facets = result['facets']['publisher_facet'][:25]
83 return [process(p) for p in publisher_facets]
84
85
86 class PublisherEngine(subjects.SubjectEngine):
87 def normalize_key(self, key):
88 return key
89
90 def get_ebook_count(self, name, value, publish_year):
91 # Query solr for this publish_year and publish_year combination and read the has_fulltext=true facet
92 solr = search.get_solr()
93 q = {"publisher_facet": value}
94
95 if isinstance(publish_year, list):
96 q['publish_year'] = tuple(publish_year) # range
97 elif publish_year:
98 q['publish_year'] = publish_year
99
100 result = solr.select(q, facets=["has_fulltext"], rows=0)
101 counts = {v.value: v.count for v in result["facets"]["has_fulltext"]}
102 return counts.get('true')
103
104
105 def setup():
106 subjects.SUBJECTS.append(
107 subjects.SubjectMeta(
108 name="publisher",
109 key="publishers",
110 prefix="/publishers/",
111 facet="publisher_facet",
112 facet_key="publisher_facet",
113 Engine=PublisherEngine,
114 )
115 )
116
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/openlibrary/plugins/worksearch/publishers.py b/openlibrary/plugins/worksearch/publishers.py
--- a/openlibrary/plugins/worksearch/publishers.py
+++ b/openlibrary/plugins/worksearch/publishers.py
@@ -57,30 +57,28 @@
def GET(self):
i = web.input(q="")
- solr = search.get_solr()
- q = {"publisher": i.q}
-
- result = solr.select(
- q,
+ result = search.get_solr().select(
+ {"publisher": i.q, "type": "work"},
facets=["publisher_facet"],
- fields=["publisher", "publisher_facet"],
+ facet_mincount=1,
+ facet_limit=25,
+ facet_contains=i.q,
+ facet_contains_ignoreCase='true',
rows=0,
)
result = self.process_result(result)
return render_template('search/publishers', i.q, result)
def process_result(self, result):
- solr = search.get_solr()
-
- def process(p):
- return web.storage(
+ publisher_facets = result['facets']['publisher_facet']
+ return [
+ web.storage(
name=p.value,
key="/publishers/" + p.value.replace(" ", "_"),
- count=solr.select({"publisher_facet": p.value}, rows=0)['num_found'],
+ count=p.count,
)
-
- publisher_facets = result['facets']['publisher_facet'][:25]
- return [process(p) for p in publisher_facets]
+ for p in publisher_facets
+ ]
class PublisherEngine(subjects.SubjectEngine):
|
{"golden_diff": "diff --git a/openlibrary/plugins/worksearch/publishers.py b/openlibrary/plugins/worksearch/publishers.py\n--- a/openlibrary/plugins/worksearch/publishers.py\n+++ b/openlibrary/plugins/worksearch/publishers.py\n@@ -57,30 +57,28 @@\n \n def GET(self):\n i = web.input(q=\"\")\n- solr = search.get_solr()\n- q = {\"publisher\": i.q}\n-\n- result = solr.select(\n- q,\n+ result = search.get_solr().select(\n+ {\"publisher\": i.q, \"type\": \"work\"},\n facets=[\"publisher_facet\"],\n- fields=[\"publisher\", \"publisher_facet\"],\n+ facet_mincount=1,\n+ facet_limit=25,\n+ facet_contains=i.q,\n+ facet_contains_ignoreCase='true',\n rows=0,\n )\n result = self.process_result(result)\n return render_template('search/publishers', i.q, result)\n \n def process_result(self, result):\n- solr = search.get_solr()\n-\n- def process(p):\n- return web.storage(\n+ publisher_facets = result['facets']['publisher_facet']\n+ return [\n+ web.storage(\n name=p.value,\n key=\"/publishers/\" + p.value.replace(\" \", \"_\"),\n- count=solr.select({\"publisher_facet\": p.value}, rows=0)['num_found'],\n+ count=p.count,\n )\n-\n- publisher_facets = result['facets']['publisher_facet'][:25]\n- return [process(p) for p in publisher_facets]\n+ for p in publisher_facets\n+ ]\n \n \n class PublisherEngine(subjects.SubjectEngine):\n", "issue": "Publisher search endpoint solr performance\n<!-- What problem are we solving? What does the experience look like today? What are the symptoms? -->\r\n\r\nOur /search/publishers endpoint is doing a strange roll-up and submitting many solr select queries causing performance issues. Solution presumably is to not make more than 1 solr query on /search/publishers.\r\n\r\n### Proposal\r\n\r\nChange the backend call for /search/publishers to make a single query to solr `publisher:(...)` query.\r\n\r\n### Evidence / Screenshot (if possible)\r\n\r\n<img width=\"775\" alt=\"Screenshot 2023-03-23 at 12 18 55 PM\" src=\"https://user-images.githubusercontent.com/978325/227324919-d19b91c5-d19b-4746-9908-43e0f7cf1cbd.png\">\r\n\r\n### Relevant url?\r\n<!-- `https://openlibrary.org/...` -->\r\n\r\nhttp://testing.openlibrary.org/search/publishers?q=Black%20Dolls%20And%20White%20Dolls%20From%201940%20Through%201970%3A%20Their%20Impact%20Then%20On%20Black%20And%20White%20Children%27s%20Development%20\r\n\r\n### Related files\r\n<!-- Files related to this issue; this is super useful for new contributors who might want to help! If you're not sure, leave this blank; a maintainer will add them. -->\r\n\r\nhttps://github.com/internetarchive/openlibrary/blob/b897c8c51a79308e38f9825fac82864a5cc7d3ae/openlibrary/plugins/worksearch/publishers.py#L82\r\n\r\n### Stakeholders\r\n<!-- @ tag stakeholders of this bug -->\r\n\n", "before_files": [{"content": "\"\"\"Publisher pages\n\"\"\"\nfrom infogami.utils import delegate, stats\nfrom infogami.utils.view import render_template, safeint\nimport web\nimport logging\n\nfrom . import subjects\nfrom . import search\n\nlogger = logging.getLogger(\"openlibrary.worksearch\")\n\n\nclass publishers(subjects.subjects):\n path = '(/publishers/[^/]+)'\n\n def GET(self, key):\n key = key.replace(\"_\", \" \")\n page = subjects.get_subject(key, details=True)\n\n if not page or page.work_count == 0:\n web.ctx.status = \"404 Not Found\"\n return render_template('publishers/notfound.tmpl', key)\n\n return render_template(\"publishers/view\", page)\n\n def is_enabled(self):\n return \"publishers\" in web.ctx.features\n\n\nclass publishers_json(subjects.subjects_json):\n path = '(/publishers/[^/]+)'\n encoding = \"json\"\n\n def is_enabled(self):\n return \"publishers\" in web.ctx.features\n\n def normalize_key(self, key):\n return key\n\n def process_key(self, key):\n return key.replace(\"_\", \" \")\n\n\nclass index(delegate.page):\n path = \"/publishers\"\n\n def GET(self):\n return render_template(\"publishers/index\")\n\n def is_enabled(self):\n return \"publishers\" in web.ctx.features\n\n\nclass publisher_search(delegate.page):\n path = '/search/publishers'\n\n def GET(self):\n i = web.input(q=\"\")\n solr = search.get_solr()\n q = {\"publisher\": i.q}\n\n result = solr.select(\n q,\n facets=[\"publisher_facet\"],\n fields=[\"publisher\", \"publisher_facet\"],\n rows=0,\n )\n result = self.process_result(result)\n return render_template('search/publishers', i.q, result)\n\n def process_result(self, result):\n solr = search.get_solr()\n\n def process(p):\n return web.storage(\n name=p.value,\n key=\"/publishers/\" + p.value.replace(\" \", \"_\"),\n count=solr.select({\"publisher_facet\": p.value}, rows=0)['num_found'],\n )\n\n publisher_facets = result['facets']['publisher_facet'][:25]\n return [process(p) for p in publisher_facets]\n\n\nclass PublisherEngine(subjects.SubjectEngine):\n def normalize_key(self, key):\n return key\n\n def get_ebook_count(self, name, value, publish_year):\n # Query solr for this publish_year and publish_year combination and read the has_fulltext=true facet\n solr = search.get_solr()\n q = {\"publisher_facet\": value}\n\n if isinstance(publish_year, list):\n q['publish_year'] = tuple(publish_year) # range\n elif publish_year:\n q['publish_year'] = publish_year\n\n result = solr.select(q, facets=[\"has_fulltext\"], rows=0)\n counts = {v.value: v.count for v in result[\"facets\"][\"has_fulltext\"]}\n return counts.get('true')\n\n\ndef setup():\n subjects.SUBJECTS.append(\n subjects.SubjectMeta(\n name=\"publisher\",\n key=\"publishers\",\n prefix=\"/publishers/\",\n facet=\"publisher_facet\",\n facet_key=\"publisher_facet\",\n Engine=PublisherEngine,\n )\n )\n", "path": "openlibrary/plugins/worksearch/publishers.py"}], "after_files": [{"content": "\"\"\"Publisher pages\n\"\"\"\nfrom infogami.utils import delegate, stats\nfrom infogami.utils.view import render_template, safeint\nimport web\nimport logging\n\nfrom . import subjects\nfrom . import search\n\nlogger = logging.getLogger(\"openlibrary.worksearch\")\n\n\nclass publishers(subjects.subjects):\n path = '(/publishers/[^/]+)'\n\n def GET(self, key):\n key = key.replace(\"_\", \" \")\n page = subjects.get_subject(key, details=True)\n\n if not page or page.work_count == 0:\n web.ctx.status = \"404 Not Found\"\n return render_template('publishers/notfound.tmpl', key)\n\n return render_template(\"publishers/view\", page)\n\n def is_enabled(self):\n return \"publishers\" in web.ctx.features\n\n\nclass publishers_json(subjects.subjects_json):\n path = '(/publishers/[^/]+)'\n encoding = \"json\"\n\n def is_enabled(self):\n return \"publishers\" in web.ctx.features\n\n def normalize_key(self, key):\n return key\n\n def process_key(self, key):\n return key.replace(\"_\", \" \")\n\n\nclass index(delegate.page):\n path = \"/publishers\"\n\n def GET(self):\n return render_template(\"publishers/index\")\n\n def is_enabled(self):\n return \"publishers\" in web.ctx.features\n\n\nclass publisher_search(delegate.page):\n path = '/search/publishers'\n\n def GET(self):\n i = web.input(q=\"\")\n result = search.get_solr().select(\n {\"publisher\": i.q, \"type\": \"work\"},\n facets=[\"publisher_facet\"],\n facet_mincount=1,\n facet_limit=25,\n facet_contains=i.q,\n facet_contains_ignoreCase='true',\n rows=0,\n )\n result = self.process_result(result)\n return render_template('search/publishers', i.q, result)\n\n def process_result(self, result):\n publisher_facets = result['facets']['publisher_facet']\n return [\n web.storage(\n name=p.value,\n key=\"/publishers/\" + p.value.replace(\" \", \"_\"),\n count=p.count,\n )\n for p in publisher_facets\n ]\n\n\nclass PublisherEngine(subjects.SubjectEngine):\n def normalize_key(self, key):\n return key\n\n def get_ebook_count(self, name, value, publish_year):\n # Query solr for this publish_year and publish_year combination and read the has_fulltext=true facet\n solr = search.get_solr()\n q = {\"publisher_facet\": value}\n\n if isinstance(publish_year, list):\n q['publish_year'] = tuple(publish_year) # range\n elif publish_year:\n q['publish_year'] = publish_year\n\n result = solr.select(q, facets=[\"has_fulltext\"], rows=0)\n counts = {v.value: v.count for v in result[\"facets\"][\"has_fulltext\"]}\n return counts.get('true')\n\n\ndef setup():\n subjects.SUBJECTS.append(\n subjects.SubjectMeta(\n name=\"publisher\",\n key=\"publishers\",\n prefix=\"/publishers/\",\n facet=\"publisher_facet\",\n facet_key=\"publisher_facet\",\n Engine=PublisherEngine,\n )\n )\n", "path": "openlibrary/plugins/worksearch/publishers.py"}]}
| 1,729 | 373 |
gh_patches_debug_18174
|
rasdani/github-patches
|
git_diff
|
ephios-dev__ephios-82
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Redirect anonymous users to login view instead of raising 403
this also raises 403 if users are not logged in. this is not what we want
_Originally posted by @jeriox in https://github.com/jeriox/jep/pull/48#discussion_r479789720_
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `jep/permissions.py`
Content:
```
1 import guardian.mixins
2 from django.contrib.auth.models import Permission, Group
3 from guardian.ctypes import get_content_type
4 from guardian.utils import get_group_obj_perms_model
5
6
7 def get_groups_with_perms(obj, only_with_perms_in):
8
9 ctype = get_content_type(obj)
10 group_model = get_group_obj_perms_model(obj)
11
12 group_rel_name = group_model.group.field.related_query_name()
13
14 if group_model.objects.is_generic():
15 group_filters = {
16 "%s__content_type" % group_rel_name: ctype,
17 "%s__object_pk" % group_rel_name: obj.pk,
18 }
19 else:
20 group_filters = {"%s__content_object" % group_rel_name: obj}
21
22 permission_ids = Permission.objects.filter(
23 content_type=ctype, codename__in=only_with_perms_in
24 ).values_list("id", flat=True)
25 group_filters.update(
26 {"%s__permission_id__in" % group_rel_name: permission_ids,}
27 )
28 return Group.objects.filter(**group_filters).distinct()
29
30
31 class CustomPermissionRequiredMixin(guardian.mixins.PermissionRequiredMixin):
32 raise_exception = True
33 accept_global_perms = True
34
35 # FIXME redirect non logged in users and raise Permission for others
36
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/jep/permissions.py b/jep/permissions.py
--- a/jep/permissions.py
+++ b/jep/permissions.py
@@ -1,8 +1,12 @@
import guardian.mixins
+from django.contrib.auth import REDIRECT_FIELD_NAME
from django.contrib.auth.models import Permission, Group
+from django.contrib.auth.views import redirect_to_login
from guardian.ctypes import get_content_type
from guardian.utils import get_group_obj_perms_model
+from jep import settings
+
def get_groups_with_perms(obj, only_with_perms_in):
@@ -32,4 +36,10 @@
raise_exception = True
accept_global_perms = True
- # FIXME redirect non logged in users and raise Permission for others
+ def on_permission_check_fail(self, request, response, obj=None):
+ if request.user.is_authenticated:
+ return response
+ else:
+ return redirect_to_login(
+ self.request.get_full_path(), settings.LOGIN_URL, REDIRECT_FIELD_NAME
+ )
|
{"golden_diff": "diff --git a/jep/permissions.py b/jep/permissions.py\n--- a/jep/permissions.py\n+++ b/jep/permissions.py\n@@ -1,8 +1,12 @@\n import guardian.mixins\n+from django.contrib.auth import REDIRECT_FIELD_NAME\n from django.contrib.auth.models import Permission, Group\n+from django.contrib.auth.views import redirect_to_login\n from guardian.ctypes import get_content_type\n from guardian.utils import get_group_obj_perms_model\n \n+from jep import settings\n+\n \n def get_groups_with_perms(obj, only_with_perms_in):\n \n@@ -32,4 +36,10 @@\n raise_exception = True\n accept_global_perms = True\n \n- # FIXME redirect non logged in users and raise Permission for others\n+ def on_permission_check_fail(self, request, response, obj=None):\n+ if request.user.is_authenticated:\n+ return response\n+ else:\n+ return redirect_to_login(\n+ self.request.get_full_path(), settings.LOGIN_URL, REDIRECT_FIELD_NAME\n+ )\n", "issue": "Redirect anonymous users to login view instead of raising 403\nthis also raises 403 if users are not logged in. this is not what we want\r\n\r\n_Originally posted by @jeriox in https://github.com/jeriox/jep/pull/48#discussion_r479789720_\n", "before_files": [{"content": "import guardian.mixins\nfrom django.contrib.auth.models import Permission, Group\nfrom guardian.ctypes import get_content_type\nfrom guardian.utils import get_group_obj_perms_model\n\n\ndef get_groups_with_perms(obj, only_with_perms_in):\n\n ctype = get_content_type(obj)\n group_model = get_group_obj_perms_model(obj)\n\n group_rel_name = group_model.group.field.related_query_name()\n\n if group_model.objects.is_generic():\n group_filters = {\n \"%s__content_type\" % group_rel_name: ctype,\n \"%s__object_pk\" % group_rel_name: obj.pk,\n }\n else:\n group_filters = {\"%s__content_object\" % group_rel_name: obj}\n\n permission_ids = Permission.objects.filter(\n content_type=ctype, codename__in=only_with_perms_in\n ).values_list(\"id\", flat=True)\n group_filters.update(\n {\"%s__permission_id__in\" % group_rel_name: permission_ids,}\n )\n return Group.objects.filter(**group_filters).distinct()\n\n\nclass CustomPermissionRequiredMixin(guardian.mixins.PermissionRequiredMixin):\n raise_exception = True\n accept_global_perms = True\n\n # FIXME redirect non logged in users and raise Permission for others\n", "path": "jep/permissions.py"}], "after_files": [{"content": "import guardian.mixins\nfrom django.contrib.auth import REDIRECT_FIELD_NAME\nfrom django.contrib.auth.models import Permission, Group\nfrom django.contrib.auth.views import redirect_to_login\nfrom guardian.ctypes import get_content_type\nfrom guardian.utils import get_group_obj_perms_model\n\nfrom jep import settings\n\n\ndef get_groups_with_perms(obj, only_with_perms_in):\n\n ctype = get_content_type(obj)\n group_model = get_group_obj_perms_model(obj)\n\n group_rel_name = group_model.group.field.related_query_name()\n\n if group_model.objects.is_generic():\n group_filters = {\n \"%s__content_type\" % group_rel_name: ctype,\n \"%s__object_pk\" % group_rel_name: obj.pk,\n }\n else:\n group_filters = {\"%s__content_object\" % group_rel_name: obj}\n\n permission_ids = Permission.objects.filter(\n content_type=ctype, codename__in=only_with_perms_in\n ).values_list(\"id\", flat=True)\n group_filters.update(\n {\"%s__permission_id__in\" % group_rel_name: permission_ids,}\n )\n return Group.objects.filter(**group_filters).distinct()\n\n\nclass CustomPermissionRequiredMixin(guardian.mixins.PermissionRequiredMixin):\n raise_exception = True\n accept_global_perms = True\n\n def on_permission_check_fail(self, request, response, obj=None):\n if request.user.is_authenticated:\n return response\n else:\n return redirect_to_login(\n self.request.get_full_path(), settings.LOGIN_URL, REDIRECT_FIELD_NAME\n )\n", "path": "jep/permissions.py"}]}
| 654 | 222 |
gh_patches_debug_65915
|
rasdani/github-patches
|
git_diff
|
ipython__ipython-2812
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Cython -la doesn't work
It's parsed as -l instead.
``` python
@magic_arguments.argument(
'-la', '--link-args', action='append', default=[],
help="Extra flags to pass to linker via the `extra_link_args` "
"Extension flag (can be specified multiple times)."
)
@magic_arguments.argument(
'-l', '--lib', action='append', default=[],
help="Add a library to link the extension against (can be specified "
"multiple times)."
)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `IPython/extensions/cythonmagic.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 """
3 =====================
4 Cython related magics
5 =====================
6
7 Usage
8 =====
9
10 ``%%cython``
11
12 {CYTHON_DOC}
13
14 ``%%cython_inline``
15
16 {CYTHON_INLINE_DOC}
17
18 ``%%cython_pyximport``
19
20 {CYTHON_PYXIMPORT_DOC}
21
22 Author:
23 * Brian Granger
24
25 Parts of this code were taken from Cython.inline.
26 """
27 #-----------------------------------------------------------------------------
28 # Copyright (C) 2010-2011, IPython Development Team.
29 #
30 # Distributed under the terms of the Modified BSD License.
31 #
32 # The full license is in the file COPYING.txt, distributed with this software.
33 #-----------------------------------------------------------------------------
34
35 from __future__ import print_function
36
37 import imp
38 import io
39 import os
40 import re
41 import sys
42 import time
43
44 try:
45 import hashlib
46 except ImportError:
47 import md5 as hashlib
48
49 from distutils.core import Distribution, Extension
50 from distutils.command.build_ext import build_ext
51
52 from IPython.core import display
53 from IPython.core import magic_arguments
54 from IPython.core.magic import Magics, magics_class, cell_magic
55 from IPython.testing.skipdoctest import skip_doctest
56 from IPython.utils import py3compat
57
58 import Cython
59 from Cython.Compiler.Errors import CompileError
60 from Cython.Build.Dependencies import cythonize
61
62
63 @magics_class
64 class CythonMagics(Magics):
65
66 def __init__(self, shell):
67 super(CythonMagics,self).__init__(shell)
68 self._reloads = {}
69 self._code_cache = {}
70
71 def _import_all(self, module):
72 for k,v in module.__dict__.items():
73 if not k.startswith('__'):
74 self.shell.push({k:v})
75
76 @cell_magic
77 def cython_inline(self, line, cell):
78 """Compile and run a Cython code cell using Cython.inline.
79
80 This magic simply passes the body of the cell to Cython.inline
81 and returns the result. If the variables `a` and `b` are defined
82 in the user's namespace, here is a simple example that returns
83 their sum::
84
85 %%cython_inline
86 return a+b
87
88 For most purposes, we recommend the usage of the `%%cython` magic.
89 """
90 locs = self.shell.user_global_ns
91 globs = self.shell.user_ns
92 return Cython.inline(cell, locals=locs, globals=globs)
93
94 @cell_magic
95 def cython_pyximport(self, line, cell):
96 """Compile and import a Cython code cell using pyximport.
97
98 The contents of the cell are written to a `.pyx` file in the current
99 working directory, which is then imported using `pyximport`. This
100 magic requires a module name to be passed::
101
102 %%cython_pyximport modulename
103 def f(x):
104 return 2.0*x
105
106 The compiled module is then imported and all of its symbols are
107 injected into the user's namespace. For most purposes, we recommend
108 the usage of the `%%cython` magic.
109 """
110 module_name = line.strip()
111 if not module_name:
112 raise ValueError('module name must be given')
113 fname = module_name + '.pyx'
114 with io.open(fname, 'w', encoding='utf-8') as f:
115 f.write(cell)
116 if 'pyximport' not in sys.modules:
117 import pyximport
118 pyximport.install(reload_support=True)
119 if module_name in self._reloads:
120 module = self._reloads[module_name]
121 reload(module)
122 else:
123 __import__(module_name)
124 module = sys.modules[module_name]
125 self._reloads[module_name] = module
126 self._import_all(module)
127
128 @magic_arguments.magic_arguments()
129 @magic_arguments.argument(
130 '-c', '--compile-args', action='append', default=[],
131 help="Extra flags to pass to compiler via the `extra_compile_args` "
132 "Extension flag (can be specified multiple times)."
133 )
134 @magic_arguments.argument(
135 '-la', '--link-args', action='append', default=[],
136 help="Extra flags to pass to linker via the `extra_link_args` "
137 "Extension flag (can be specified multiple times)."
138 )
139 @magic_arguments.argument(
140 '-l', '--lib', action='append', default=[],
141 help="Add a library to link the extension against (can be specified "
142 "multiple times)."
143 )
144 @magic_arguments.argument(
145 '-L', dest='library_dirs', metavar='dir', action='append', default=[],
146 help="Add a path to the list of libary directories (can be specified "
147 "multiple times)."
148 )
149 @magic_arguments.argument(
150 '-I', '--include', action='append', default=[],
151 help="Add a path to the list of include directories (can be specified "
152 "multiple times)."
153 )
154 @magic_arguments.argument(
155 '-+', '--cplus', action='store_true', default=False,
156 help="Output a C++ rather than C file."
157 )
158 @magic_arguments.argument(
159 '-f', '--force', action='store_true', default=False,
160 help="Force the compilation of a new module, even if the source has been "
161 "previously compiled."
162 )
163 @magic_arguments.argument(
164 '-a', '--annotate', action='store_true', default=False,
165 help="Produce a colorized HTML version of the source."
166 )
167 @cell_magic
168 def cython(self, line, cell):
169 """Compile and import everything from a Cython code cell.
170
171 The contents of the cell are written to a `.pyx` file in the
172 directory `IPYTHONDIR/cython` using a filename with the hash of the
173 code. This file is then cythonized and compiled. The resulting module
174 is imported and all of its symbols are injected into the user's
175 namespace. The usage is similar to that of `%%cython_pyximport` but
176 you don't have to pass a module name::
177
178 %%cython
179 def f(x):
180 return 2.0*x
181
182 To compile OpenMP codes, pass the required `--compile-args`
183 and `--link-args`. For example with gcc::
184
185 %%cython --compile-args=-fopenmp --link-args=-fopenmp
186 ...
187 """
188 args = magic_arguments.parse_argstring(self.cython, line)
189 code = cell if cell.endswith('\n') else cell+'\n'
190 lib_dir = os.path.join(self.shell.ipython_dir, 'cython')
191 quiet = True
192 key = code, sys.version_info, sys.executable, Cython.__version__
193
194 if not os.path.exists(lib_dir):
195 os.makedirs(lib_dir)
196
197 if args.force:
198 # Force a new module name by adding the current time to the
199 # key which is hashed to determine the module name.
200 key += time.time(),
201
202 module_name = "_cython_magic_" + hashlib.md5(str(key).encode('utf-8')).hexdigest()
203 module_path = os.path.join(lib_dir, module_name + self.so_ext)
204
205 have_module = os.path.isfile(module_path)
206 need_cythonize = not have_module
207
208 if args.annotate:
209 html_file = os.path.join(lib_dir, module_name + '.html')
210 if not os.path.isfile(html_file):
211 need_cythonize = True
212
213 if need_cythonize:
214 c_include_dirs = args.include
215 if 'numpy' in code:
216 import numpy
217 c_include_dirs.append(numpy.get_include())
218 pyx_file = os.path.join(lib_dir, module_name + '.pyx')
219 pyx_file = py3compat.cast_bytes_py2(pyx_file, encoding=sys.getfilesystemencoding())
220 with io.open(pyx_file, 'w', encoding='utf-8') as f:
221 f.write(code)
222 extension = Extension(
223 name = module_name,
224 sources = [pyx_file],
225 include_dirs = c_include_dirs,
226 library_dirs = args.library_dirs,
227 extra_compile_args = args.compile_args,
228 extra_link_args = args.link_args,
229 libraries = args.lib,
230 language = 'c++' if args.cplus else 'c',
231 )
232 build_extension = self._get_build_extension()
233 try:
234 opts = dict(
235 quiet=quiet,
236 annotate = args.annotate,
237 force = True,
238 )
239 build_extension.extensions = cythonize([extension], **opts)
240 except CompileError:
241 return
242
243 if not have_module:
244 build_extension.build_temp = os.path.dirname(pyx_file)
245 build_extension.build_lib = lib_dir
246 build_extension.run()
247 self._code_cache[key] = module_name
248
249 module = imp.load_dynamic(module_name, module_path)
250 self._import_all(module)
251
252 if args.annotate:
253 try:
254 with io.open(html_file, encoding='utf-8') as f:
255 annotated_html = f.read()
256 except IOError as e:
257 # File could not be opened. Most likely the user has a version
258 # of Cython before 0.15.1 (when `cythonize` learned the
259 # `force` keyword argument) and has already compiled this
260 # exact source without annotation.
261 print('Cython completed successfully but the annotated '
262 'source could not be read.', file=sys.stderr)
263 print(e, file=sys.stderr)
264 else:
265 return display.HTML(self.clean_annotated_html(annotated_html))
266
267 @property
268 def so_ext(self):
269 """The extension suffix for compiled modules."""
270 try:
271 return self._so_ext
272 except AttributeError:
273 self._so_ext = self._get_build_extension().get_ext_filename('')
274 return self._so_ext
275
276 def _get_build_extension(self):
277 dist = Distribution()
278 config_files = dist.find_config_files()
279 try:
280 config_files.remove('setup.cfg')
281 except ValueError:
282 pass
283 dist.parse_config_files(config_files)
284 build_extension = build_ext(dist)
285 build_extension.finalize_options()
286 return build_extension
287
288 @staticmethod
289 def clean_annotated_html(html):
290 """Clean up the annotated HTML source.
291
292 Strips the link to the generated C or C++ file, which we do not
293 present to the user.
294 """
295 r = re.compile('<p>Raw output: <a href="(.*)">(.*)</a>')
296 html = '\n'.join(l for l in html.splitlines() if not r.match(l))
297 return html
298
299 __doc__ = __doc__.format(
300 CYTHON_DOC = ' '*8 + CythonMagics.cython.__doc__,
301 CYTHON_INLINE_DOC = ' '*8 + CythonMagics.cython_inline.__doc__,
302 CYTHON_PYXIMPORT_DOC = ' '*8 + CythonMagics.cython_pyximport.__doc__,
303 )
304
305 def load_ipython_extension(ip):
306 """Load the extension in IPython."""
307 ip.register_magics(CythonMagics)
308
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/IPython/extensions/cythonmagic.py b/IPython/extensions/cythonmagic.py
--- a/IPython/extensions/cythonmagic.py
+++ b/IPython/extensions/cythonmagic.py
@@ -132,7 +132,7 @@
"Extension flag (can be specified multiple times)."
)
@magic_arguments.argument(
- '-la', '--link-args', action='append', default=[],
+ '--link-args', action='append', default=[],
help="Extra flags to pass to linker via the `extra_link_args` "
"Extension flag (can be specified multiple times)."
)
|
{"golden_diff": "diff --git a/IPython/extensions/cythonmagic.py b/IPython/extensions/cythonmagic.py\n--- a/IPython/extensions/cythonmagic.py\n+++ b/IPython/extensions/cythonmagic.py\n@@ -132,7 +132,7 @@\n \"Extension flag (can be specified multiple times).\"\n )\n @magic_arguments.argument(\n- '-la', '--link-args', action='append', default=[],\n+ '--link-args', action='append', default=[],\n help=\"Extra flags to pass to linker via the `extra_link_args` \"\n \"Extension flag (can be specified multiple times).\"\n )\n", "issue": "Cython -la doesn't work\nIt's parsed as -l instead.\n\n``` python\n @magic_arguments.argument(\n '-la', '--link-args', action='append', default=[],\n help=\"Extra flags to pass to linker via the `extra_link_args` \"\n \"Extension flag (can be specified multiple times).\"\n )\n @magic_arguments.argument(\n '-l', '--lib', action='append', default=[],\n help=\"Add a library to link the extension against (can be specified \"\n \"multiple times).\"\n )\n```\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\n=====================\nCython related magics\n=====================\n\nUsage\n=====\n\n``%%cython``\n\n{CYTHON_DOC}\n\n``%%cython_inline``\n\n{CYTHON_INLINE_DOC}\n\n``%%cython_pyximport``\n\n{CYTHON_PYXIMPORT_DOC}\n\nAuthor:\n* Brian Granger\n\nParts of this code were taken from Cython.inline.\n\"\"\"\n#-----------------------------------------------------------------------------\n# Copyright (C) 2010-2011, IPython Development Team.\n#\n# Distributed under the terms of the Modified BSD License.\n#\n# The full license is in the file COPYING.txt, distributed with this software.\n#-----------------------------------------------------------------------------\n\nfrom __future__ import print_function\n\nimport imp\nimport io\nimport os\nimport re\nimport sys\nimport time\n\ntry:\n import hashlib\nexcept ImportError:\n import md5 as hashlib\n\nfrom distutils.core import Distribution, Extension\nfrom distutils.command.build_ext import build_ext\n\nfrom IPython.core import display\nfrom IPython.core import magic_arguments\nfrom IPython.core.magic import Magics, magics_class, cell_magic\nfrom IPython.testing.skipdoctest import skip_doctest\nfrom IPython.utils import py3compat\n\nimport Cython\nfrom Cython.Compiler.Errors import CompileError\nfrom Cython.Build.Dependencies import cythonize\n\n\n@magics_class\nclass CythonMagics(Magics):\n\n def __init__(self, shell):\n super(CythonMagics,self).__init__(shell)\n self._reloads = {}\n self._code_cache = {}\n\n def _import_all(self, module):\n for k,v in module.__dict__.items():\n if not k.startswith('__'):\n self.shell.push({k:v})\n\n @cell_magic\n def cython_inline(self, line, cell):\n \"\"\"Compile and run a Cython code cell using Cython.inline.\n\n This magic simply passes the body of the cell to Cython.inline\n and returns the result. If the variables `a` and `b` are defined\n in the user's namespace, here is a simple example that returns\n their sum::\n\n %%cython_inline\n return a+b\n\n For most purposes, we recommend the usage of the `%%cython` magic.\n \"\"\"\n locs = self.shell.user_global_ns\n globs = self.shell.user_ns\n return Cython.inline(cell, locals=locs, globals=globs)\n\n @cell_magic\n def cython_pyximport(self, line, cell):\n \"\"\"Compile and import a Cython code cell using pyximport.\n\n The contents of the cell are written to a `.pyx` file in the current\n working directory, which is then imported using `pyximport`. This\n magic requires a module name to be passed::\n\n %%cython_pyximport modulename\n def f(x):\n return 2.0*x\n\n The compiled module is then imported and all of its symbols are\n injected into the user's namespace. For most purposes, we recommend\n the usage of the `%%cython` magic.\n \"\"\"\n module_name = line.strip()\n if not module_name:\n raise ValueError('module name must be given')\n fname = module_name + '.pyx'\n with io.open(fname, 'w', encoding='utf-8') as f:\n f.write(cell)\n if 'pyximport' not in sys.modules:\n import pyximport\n pyximport.install(reload_support=True)\n if module_name in self._reloads:\n module = self._reloads[module_name]\n reload(module)\n else:\n __import__(module_name)\n module = sys.modules[module_name]\n self._reloads[module_name] = module\n self._import_all(module)\n\n @magic_arguments.magic_arguments()\n @magic_arguments.argument(\n '-c', '--compile-args', action='append', default=[],\n help=\"Extra flags to pass to compiler via the `extra_compile_args` \"\n \"Extension flag (can be specified multiple times).\"\n )\n @magic_arguments.argument(\n '-la', '--link-args', action='append', default=[],\n help=\"Extra flags to pass to linker via the `extra_link_args` \"\n \"Extension flag (can be specified multiple times).\"\n )\n @magic_arguments.argument(\n '-l', '--lib', action='append', default=[],\n help=\"Add a library to link the extension against (can be specified \"\n \"multiple times).\"\n )\n @magic_arguments.argument(\n '-L', dest='library_dirs', metavar='dir', action='append', default=[],\n help=\"Add a path to the list of libary directories (can be specified \"\n \"multiple times).\"\n )\n @magic_arguments.argument(\n '-I', '--include', action='append', default=[],\n help=\"Add a path to the list of include directories (can be specified \"\n \"multiple times).\"\n )\n @magic_arguments.argument(\n '-+', '--cplus', action='store_true', default=False,\n help=\"Output a C++ rather than C file.\"\n )\n @magic_arguments.argument(\n '-f', '--force', action='store_true', default=False,\n help=\"Force the compilation of a new module, even if the source has been \"\n \"previously compiled.\"\n )\n @magic_arguments.argument(\n '-a', '--annotate', action='store_true', default=False,\n help=\"Produce a colorized HTML version of the source.\"\n )\n @cell_magic\n def cython(self, line, cell):\n \"\"\"Compile and import everything from a Cython code cell.\n\n The contents of the cell are written to a `.pyx` file in the\n directory `IPYTHONDIR/cython` using a filename with the hash of the\n code. This file is then cythonized and compiled. The resulting module\n is imported and all of its symbols are injected into the user's\n namespace. The usage is similar to that of `%%cython_pyximport` but\n you don't have to pass a module name::\n\n %%cython\n def f(x):\n return 2.0*x\n\n To compile OpenMP codes, pass the required `--compile-args`\n and `--link-args`. For example with gcc::\n\n %%cython --compile-args=-fopenmp --link-args=-fopenmp\n ...\n \"\"\"\n args = magic_arguments.parse_argstring(self.cython, line)\n code = cell if cell.endswith('\\n') else cell+'\\n'\n lib_dir = os.path.join(self.shell.ipython_dir, 'cython')\n quiet = True\n key = code, sys.version_info, sys.executable, Cython.__version__\n\n if not os.path.exists(lib_dir):\n os.makedirs(lib_dir)\n\n if args.force:\n # Force a new module name by adding the current time to the\n # key which is hashed to determine the module name.\n key += time.time(),\n\n module_name = \"_cython_magic_\" + hashlib.md5(str(key).encode('utf-8')).hexdigest()\n module_path = os.path.join(lib_dir, module_name + self.so_ext)\n\n have_module = os.path.isfile(module_path)\n need_cythonize = not have_module\n\n if args.annotate:\n html_file = os.path.join(lib_dir, module_name + '.html')\n if not os.path.isfile(html_file):\n need_cythonize = True\n\n if need_cythonize:\n c_include_dirs = args.include\n if 'numpy' in code:\n import numpy\n c_include_dirs.append(numpy.get_include())\n pyx_file = os.path.join(lib_dir, module_name + '.pyx')\n pyx_file = py3compat.cast_bytes_py2(pyx_file, encoding=sys.getfilesystemencoding())\n with io.open(pyx_file, 'w', encoding='utf-8') as f:\n f.write(code)\n extension = Extension(\n name = module_name,\n sources = [pyx_file],\n include_dirs = c_include_dirs,\n library_dirs = args.library_dirs,\n extra_compile_args = args.compile_args,\n extra_link_args = args.link_args,\n libraries = args.lib,\n language = 'c++' if args.cplus else 'c',\n )\n build_extension = self._get_build_extension()\n try:\n opts = dict(\n quiet=quiet,\n annotate = args.annotate,\n force = True,\n )\n build_extension.extensions = cythonize([extension], **opts)\n except CompileError:\n return\n\n if not have_module:\n build_extension.build_temp = os.path.dirname(pyx_file)\n build_extension.build_lib = lib_dir\n build_extension.run()\n self._code_cache[key] = module_name\n\n module = imp.load_dynamic(module_name, module_path)\n self._import_all(module)\n\n if args.annotate:\n try:\n with io.open(html_file, encoding='utf-8') as f:\n annotated_html = f.read()\n except IOError as e:\n # File could not be opened. Most likely the user has a version\n # of Cython before 0.15.1 (when `cythonize` learned the\n # `force` keyword argument) and has already compiled this\n # exact source without annotation.\n print('Cython completed successfully but the annotated '\n 'source could not be read.', file=sys.stderr)\n print(e, file=sys.stderr)\n else:\n return display.HTML(self.clean_annotated_html(annotated_html))\n\n @property\n def so_ext(self):\n \"\"\"The extension suffix for compiled modules.\"\"\"\n try:\n return self._so_ext\n except AttributeError:\n self._so_ext = self._get_build_extension().get_ext_filename('')\n return self._so_ext\n\n def _get_build_extension(self):\n dist = Distribution()\n config_files = dist.find_config_files()\n try:\n config_files.remove('setup.cfg')\n except ValueError:\n pass\n dist.parse_config_files(config_files)\n build_extension = build_ext(dist)\n build_extension.finalize_options()\n return build_extension\n\n @staticmethod\n def clean_annotated_html(html):\n \"\"\"Clean up the annotated HTML source.\n\n Strips the link to the generated C or C++ file, which we do not\n present to the user.\n \"\"\"\n r = re.compile('<p>Raw output: <a href=\"(.*)\">(.*)</a>')\n html = '\\n'.join(l for l in html.splitlines() if not r.match(l))\n return html\n\n__doc__ = __doc__.format(\n CYTHON_DOC = ' '*8 + CythonMagics.cython.__doc__,\n CYTHON_INLINE_DOC = ' '*8 + CythonMagics.cython_inline.__doc__,\n CYTHON_PYXIMPORT_DOC = ' '*8 + CythonMagics.cython_pyximport.__doc__,\n)\n\ndef load_ipython_extension(ip):\n \"\"\"Load the extension in IPython.\"\"\"\n ip.register_magics(CythonMagics)\n", "path": "IPython/extensions/cythonmagic.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\n=====================\nCython related magics\n=====================\n\nUsage\n=====\n\n``%%cython``\n\n{CYTHON_DOC}\n\n``%%cython_inline``\n\n{CYTHON_INLINE_DOC}\n\n``%%cython_pyximport``\n\n{CYTHON_PYXIMPORT_DOC}\n\nAuthor:\n* Brian Granger\n\nParts of this code were taken from Cython.inline.\n\"\"\"\n#-----------------------------------------------------------------------------\n# Copyright (C) 2010-2011, IPython Development Team.\n#\n# Distributed under the terms of the Modified BSD License.\n#\n# The full license is in the file COPYING.txt, distributed with this software.\n#-----------------------------------------------------------------------------\n\nfrom __future__ import print_function\n\nimport imp\nimport io\nimport os\nimport re\nimport sys\nimport time\n\ntry:\n import hashlib\nexcept ImportError:\n import md5 as hashlib\n\nfrom distutils.core import Distribution, Extension\nfrom distutils.command.build_ext import build_ext\n\nfrom IPython.core import display\nfrom IPython.core import magic_arguments\nfrom IPython.core.magic import Magics, magics_class, cell_magic\nfrom IPython.testing.skipdoctest import skip_doctest\nfrom IPython.utils import py3compat\n\nimport Cython\nfrom Cython.Compiler.Errors import CompileError\nfrom Cython.Build.Dependencies import cythonize\n\n\n@magics_class\nclass CythonMagics(Magics):\n\n def __init__(self, shell):\n super(CythonMagics,self).__init__(shell)\n self._reloads = {}\n self._code_cache = {}\n\n def _import_all(self, module):\n for k,v in module.__dict__.items():\n if not k.startswith('__'):\n self.shell.push({k:v})\n\n @cell_magic\n def cython_inline(self, line, cell):\n \"\"\"Compile and run a Cython code cell using Cython.inline.\n\n This magic simply passes the body of the cell to Cython.inline\n and returns the result. If the variables `a` and `b` are defined\n in the user's namespace, here is a simple example that returns\n their sum::\n\n %%cython_inline\n return a+b\n\n For most purposes, we recommend the usage of the `%%cython` magic.\n \"\"\"\n locs = self.shell.user_global_ns\n globs = self.shell.user_ns\n return Cython.inline(cell, locals=locs, globals=globs)\n\n @cell_magic\n def cython_pyximport(self, line, cell):\n \"\"\"Compile and import a Cython code cell using pyximport.\n\n The contents of the cell are written to a `.pyx` file in the current\n working directory, which is then imported using `pyximport`. This\n magic requires a module name to be passed::\n\n %%cython_pyximport modulename\n def f(x):\n return 2.0*x\n\n The compiled module is then imported and all of its symbols are\n injected into the user's namespace. For most purposes, we recommend\n the usage of the `%%cython` magic.\n \"\"\"\n module_name = line.strip()\n if not module_name:\n raise ValueError('module name must be given')\n fname = module_name + '.pyx'\n with io.open(fname, 'w', encoding='utf-8') as f:\n f.write(cell)\n if 'pyximport' not in sys.modules:\n import pyximport\n pyximport.install(reload_support=True)\n if module_name in self._reloads:\n module = self._reloads[module_name]\n reload(module)\n else:\n __import__(module_name)\n module = sys.modules[module_name]\n self._reloads[module_name] = module\n self._import_all(module)\n\n @magic_arguments.magic_arguments()\n @magic_arguments.argument(\n '-c', '--compile-args', action='append', default=[],\n help=\"Extra flags to pass to compiler via the `extra_compile_args` \"\n \"Extension flag (can be specified multiple times).\"\n )\n @magic_arguments.argument(\n '--link-args', action='append', default=[],\n help=\"Extra flags to pass to linker via the `extra_link_args` \"\n \"Extension flag (can be specified multiple times).\"\n )\n @magic_arguments.argument(\n '-l', '--lib', action='append', default=[],\n help=\"Add a library to link the extension against (can be specified \"\n \"multiple times).\"\n )\n @magic_arguments.argument(\n '-L', dest='library_dirs', metavar='dir', action='append', default=[],\n help=\"Add a path to the list of libary directories (can be specified \"\n \"multiple times).\"\n )\n @magic_arguments.argument(\n '-I', '--include', action='append', default=[],\n help=\"Add a path to the list of include directories (can be specified \"\n \"multiple times).\"\n )\n @magic_arguments.argument(\n '-+', '--cplus', action='store_true', default=False,\n help=\"Output a C++ rather than C file.\"\n )\n @magic_arguments.argument(\n '-f', '--force', action='store_true', default=False,\n help=\"Force the compilation of a new module, even if the source has been \"\n \"previously compiled.\"\n )\n @magic_arguments.argument(\n '-a', '--annotate', action='store_true', default=False,\n help=\"Produce a colorized HTML version of the source.\"\n )\n @cell_magic\n def cython(self, line, cell):\n \"\"\"Compile and import everything from a Cython code cell.\n\n The contents of the cell are written to a `.pyx` file in the\n directory `IPYTHONDIR/cython` using a filename with the hash of the\n code. This file is then cythonized and compiled. The resulting module\n is imported and all of its symbols are injected into the user's\n namespace. The usage is similar to that of `%%cython_pyximport` but\n you don't have to pass a module name::\n\n %%cython\n def f(x):\n return 2.0*x\n\n To compile OpenMP codes, pass the required `--compile-args`\n and `--link-args`. For example with gcc::\n\n %%cython --compile-args=-fopenmp --link-args=-fopenmp\n ...\n \"\"\"\n args = magic_arguments.parse_argstring(self.cython, line)\n code = cell if cell.endswith('\\n') else cell+'\\n'\n lib_dir = os.path.join(self.shell.ipython_dir, 'cython')\n quiet = True\n key = code, sys.version_info, sys.executable, Cython.__version__\n\n if not os.path.exists(lib_dir):\n os.makedirs(lib_dir)\n\n if args.force:\n # Force a new module name by adding the current time to the\n # key which is hashed to determine the module name.\n key += time.time(),\n\n module_name = \"_cython_magic_\" + hashlib.md5(str(key).encode('utf-8')).hexdigest()\n module_path = os.path.join(lib_dir, module_name + self.so_ext)\n\n have_module = os.path.isfile(module_path)\n need_cythonize = not have_module\n\n if args.annotate:\n html_file = os.path.join(lib_dir, module_name + '.html')\n if not os.path.isfile(html_file):\n need_cythonize = True\n\n if need_cythonize:\n c_include_dirs = args.include\n if 'numpy' in code:\n import numpy\n c_include_dirs.append(numpy.get_include())\n pyx_file = os.path.join(lib_dir, module_name + '.pyx')\n pyx_file = py3compat.cast_bytes_py2(pyx_file, encoding=sys.getfilesystemencoding())\n with io.open(pyx_file, 'w', encoding='utf-8') as f:\n f.write(code)\n extension = Extension(\n name = module_name,\n sources = [pyx_file],\n include_dirs = c_include_dirs,\n library_dirs = args.library_dirs,\n extra_compile_args = args.compile_args,\n extra_link_args = args.link_args,\n libraries = args.lib,\n language = 'c++' if args.cplus else 'c',\n )\n build_extension = self._get_build_extension()\n try:\n opts = dict(\n quiet=quiet,\n annotate = args.annotate,\n force = True,\n )\n build_extension.extensions = cythonize([extension], **opts)\n except CompileError:\n return\n\n if not have_module:\n build_extension.build_temp = os.path.dirname(pyx_file)\n build_extension.build_lib = lib_dir\n build_extension.run()\n self._code_cache[key] = module_name\n\n module = imp.load_dynamic(module_name, module_path)\n self._import_all(module)\n\n if args.annotate:\n try:\n with io.open(html_file, encoding='utf-8') as f:\n annotated_html = f.read()\n except IOError as e:\n # File could not be opened. Most likely the user has a version\n # of Cython before 0.15.1 (when `cythonize` learned the\n # `force` keyword argument) and has already compiled this\n # exact source without annotation.\n print('Cython completed successfully but the annotated '\n 'source could not be read.', file=sys.stderr)\n print(e, file=sys.stderr)\n else:\n return display.HTML(self.clean_annotated_html(annotated_html))\n\n @property\n def so_ext(self):\n \"\"\"The extension suffix for compiled modules.\"\"\"\n try:\n return self._so_ext\n except AttributeError:\n self._so_ext = self._get_build_extension().get_ext_filename('')\n return self._so_ext\n\n def _get_build_extension(self):\n dist = Distribution()\n config_files = dist.find_config_files()\n try:\n config_files.remove('setup.cfg')\n except ValueError:\n pass\n dist.parse_config_files(config_files)\n build_extension = build_ext(dist)\n build_extension.finalize_options()\n return build_extension\n\n @staticmethod\n def clean_annotated_html(html):\n \"\"\"Clean up the annotated HTML source.\n\n Strips the link to the generated C or C++ file, which we do not\n present to the user.\n \"\"\"\n r = re.compile('<p>Raw output: <a href=\"(.*)\">(.*)</a>')\n html = '\\n'.join(l for l in html.splitlines() if not r.match(l))\n return html\n\n__doc__ = __doc__.format(\n CYTHON_DOC = ' '*8 + CythonMagics.cython.__doc__,\n CYTHON_INLINE_DOC = ' '*8 + CythonMagics.cython_inline.__doc__,\n CYTHON_PYXIMPORT_DOC = ' '*8 + CythonMagics.cython_pyximport.__doc__,\n)\n\ndef load_ipython_extension(ip):\n \"\"\"Load the extension in IPython.\"\"\"\n ip.register_magics(CythonMagics)\n", "path": "IPython/extensions/cythonmagic.py"}]}
| 3,598 | 138 |
gh_patches_debug_15802
|
rasdani/github-patches
|
git_diff
|
lutris__lutris-1179
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Have logger scroll automatically only when at the bottom
Currently the logger scrolls whenever it outputs which makes scrolling up useless unless the game is stopped. This behavior is annoying.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lutris/gui/logwindow.py`
Content:
```
1 from gi.repository import Gtk
2 from lutris.gui.widgets.dialogs import Dialog
3
4
5 class LogTextView(Gtk.TextView):
6 def __init__(self, buffer):
7 super(LogTextView, self).__init__()
8
9 self.set_buffer(buffer)
10 self.set_editable(False)
11 self.set_monospace(True)
12 self.set_left_margin(10)
13 self.set_wrap_mode(Gtk.WrapMode.CHAR)
14 self.get_style_context().add_class('lutris-logview')
15 self.connect("size-allocate", self.autoscroll)
16
17 def autoscroll(self, *args):
18 adj = self.get_vadjustment()
19 adj.set_value(adj.get_upper() - adj.get_page_size())
20
21
22 class LogWindow(Dialog):
23 def __init__(self, title, buffer, parent):
24 super(LogWindow, self).__init__(title, parent, 0,
25 ('_OK', Gtk.ResponseType.OK))
26 self.set_size_request(640, 480)
27 self.grid = Gtk.Grid()
28 self.buffer = buffer
29 self.logtextview = LogTextView(self.buffer)
30
31 scrolledwindow = Gtk.ScrolledWindow(hexpand=True, vexpand=True,
32 child=self.logtextview)
33 self.vbox.add(scrolledwindow)
34 self.show_all()
35
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lutris/gui/logwindow.py b/lutris/gui/logwindow.py
--- a/lutris/gui/logwindow.py
+++ b/lutris/gui/logwindow.py
@@ -10,13 +10,16 @@
self.set_editable(False)
self.set_monospace(True)
self.set_left_margin(10)
+ self.scroll_max = 0
self.set_wrap_mode(Gtk.WrapMode.CHAR)
self.get_style_context().add_class('lutris-logview')
self.connect("size-allocate", self.autoscroll)
def autoscroll(self, *args):
adj = self.get_vadjustment()
- adj.set_value(adj.get_upper() - adj.get_page_size())
+ if adj.get_value() == self.scroll_max or self.scroll_max == 0:
+ adj.set_value(adj.get_upper() - adj.get_page_size())
+ self.scroll_max = adj.get_upper() - adj.get_page_size()
class LogWindow(Dialog):
|
{"golden_diff": "diff --git a/lutris/gui/logwindow.py b/lutris/gui/logwindow.py\n--- a/lutris/gui/logwindow.py\n+++ b/lutris/gui/logwindow.py\n@@ -10,13 +10,16 @@\n self.set_editable(False)\n self.set_monospace(True)\n self.set_left_margin(10)\n+ self.scroll_max = 0\n self.set_wrap_mode(Gtk.WrapMode.CHAR)\n self.get_style_context().add_class('lutris-logview')\n self.connect(\"size-allocate\", self.autoscroll)\n \n def autoscroll(self, *args):\n adj = self.get_vadjustment()\n- adj.set_value(adj.get_upper() - adj.get_page_size())\n+ if adj.get_value() == self.scroll_max or self.scroll_max == 0:\n+ adj.set_value(adj.get_upper() - adj.get_page_size())\n+ self.scroll_max = adj.get_upper() - adj.get_page_size()\n \n \n class LogWindow(Dialog):\n", "issue": "Have logger scroll automatically only when at the bottom\nCurrently the logger scrolls whenever it outputs which makes scrolling up useless unless the game is stopped. This behavior is annoying.\n", "before_files": [{"content": "from gi.repository import Gtk\nfrom lutris.gui.widgets.dialogs import Dialog\n\n\nclass LogTextView(Gtk.TextView):\n def __init__(self, buffer):\n super(LogTextView, self).__init__()\n\n self.set_buffer(buffer)\n self.set_editable(False)\n self.set_monospace(True)\n self.set_left_margin(10)\n self.set_wrap_mode(Gtk.WrapMode.CHAR)\n self.get_style_context().add_class('lutris-logview')\n self.connect(\"size-allocate\", self.autoscroll)\n\n def autoscroll(self, *args):\n adj = self.get_vadjustment()\n adj.set_value(adj.get_upper() - adj.get_page_size())\n\n\nclass LogWindow(Dialog):\n def __init__(self, title, buffer, parent):\n super(LogWindow, self).__init__(title, parent, 0,\n ('_OK', Gtk.ResponseType.OK))\n self.set_size_request(640, 480)\n self.grid = Gtk.Grid()\n self.buffer = buffer\n self.logtextview = LogTextView(self.buffer)\n\n scrolledwindow = Gtk.ScrolledWindow(hexpand=True, vexpand=True,\n child=self.logtextview)\n self.vbox.add(scrolledwindow)\n self.show_all()\n", "path": "lutris/gui/logwindow.py"}], "after_files": [{"content": "from gi.repository import Gtk\nfrom lutris.gui.widgets.dialogs import Dialog\n\n\nclass LogTextView(Gtk.TextView):\n def __init__(self, buffer):\n super(LogTextView, self).__init__()\n\n self.set_buffer(buffer)\n self.set_editable(False)\n self.set_monospace(True)\n self.set_left_margin(10)\n self.scroll_max = 0\n self.set_wrap_mode(Gtk.WrapMode.CHAR)\n self.get_style_context().add_class('lutris-logview')\n self.connect(\"size-allocate\", self.autoscroll)\n\n def autoscroll(self, *args):\n adj = self.get_vadjustment()\n if adj.get_value() == self.scroll_max or self.scroll_max == 0:\n adj.set_value(adj.get_upper() - adj.get_page_size())\n self.scroll_max = adj.get_upper() - adj.get_page_size()\n\n\nclass LogWindow(Dialog):\n def __init__(self, title, buffer, parent):\n super(LogWindow, self).__init__(title, parent, 0,\n ('_OK', Gtk.ResponseType.OK))\n self.set_size_request(640, 480)\n self.grid = Gtk.Grid()\n self.buffer = buffer\n self.logtextview = LogTextView(self.buffer)\n\n scrolledwindow = Gtk.ScrolledWindow(hexpand=True, vexpand=True,\n child=self.logtextview)\n self.vbox.add(scrolledwindow)\n self.show_all()\n", "path": "lutris/gui/logwindow.py"}]}
| 620 | 214 |
gh_patches_debug_16370
|
rasdani/github-patches
|
git_diff
|
open-mmlab__mmaction2-676
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Localizer train cfg & test cfg ?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `configs/_base_/models/bsn_tem.py`
Content:
```
1 # model settings
2 model = dict(
3 type='TEM',
4 temporal_dim=100,
5 boundary_ratio=0.1,
6 tem_feat_dim=400,
7 tem_hidden_dim=512,
8 tem_match_threshold=0.5)
9 # model training and testing settings
10 train_cfg = None
11 test_cfg = dict(average_clips='score')
12
```
Path: `configs/_base_/models/bsn_pem.py`
Content:
```
1 # model settings
2 model = dict(
3 type='PEM',
4 pem_feat_dim=32,
5 pem_hidden_dim=256,
6 pem_u_ratio_m=1,
7 pem_u_ratio_l=2,
8 pem_high_temporal_iou_threshold=0.6,
9 pem_low_temporal_iou_threshold=0.2,
10 soft_nms_alpha=0.75,
11 soft_nms_low_threshold=0.65,
12 soft_nms_high_threshold=0.9,
13 post_process_top_k=100)
14 # model training and testing settings
15 train_cfg = None
16 test_cfg = dict(average_clips='score')
17
```
Path: `configs/_base_/models/bmn_400x100.py`
Content:
```
1 # model settings
2 model = dict(
3 type='BMN',
4 temporal_dim=100,
5 boundary_ratio=0.5,
6 num_samples=32,
7 num_samples_per_bin=3,
8 feat_dim=400,
9 soft_nms_alpha=0.4,
10 soft_nms_low_threshold=0.5,
11 soft_nms_high_threshold=0.9,
12 post_process_top_k=100)
13 # model training and testing settings
14 train_cfg = None
15 test_cfg = dict(average_clips='score')
16
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/configs/_base_/models/bmn_400x100.py b/configs/_base_/models/bmn_400x100.py
--- a/configs/_base_/models/bmn_400x100.py
+++ b/configs/_base_/models/bmn_400x100.py
@@ -10,6 +10,3 @@
soft_nms_low_threshold=0.5,
soft_nms_high_threshold=0.9,
post_process_top_k=100)
-# model training and testing settings
-train_cfg = None
-test_cfg = dict(average_clips='score')
diff --git a/configs/_base_/models/bsn_pem.py b/configs/_base_/models/bsn_pem.py
--- a/configs/_base_/models/bsn_pem.py
+++ b/configs/_base_/models/bsn_pem.py
@@ -11,6 +11,3 @@
soft_nms_low_threshold=0.65,
soft_nms_high_threshold=0.9,
post_process_top_k=100)
-# model training and testing settings
-train_cfg = None
-test_cfg = dict(average_clips='score')
diff --git a/configs/_base_/models/bsn_tem.py b/configs/_base_/models/bsn_tem.py
--- a/configs/_base_/models/bsn_tem.py
+++ b/configs/_base_/models/bsn_tem.py
@@ -6,6 +6,3 @@
tem_feat_dim=400,
tem_hidden_dim=512,
tem_match_threshold=0.5)
-# model training and testing settings
-train_cfg = None
-test_cfg = dict(average_clips='score')
|
{"golden_diff": "diff --git a/configs/_base_/models/bmn_400x100.py b/configs/_base_/models/bmn_400x100.py\n--- a/configs/_base_/models/bmn_400x100.py\n+++ b/configs/_base_/models/bmn_400x100.py\n@@ -10,6 +10,3 @@\n soft_nms_low_threshold=0.5,\n soft_nms_high_threshold=0.9,\n post_process_top_k=100)\n-# model training and testing settings\n-train_cfg = None\n-test_cfg = dict(average_clips='score')\ndiff --git a/configs/_base_/models/bsn_pem.py b/configs/_base_/models/bsn_pem.py\n--- a/configs/_base_/models/bsn_pem.py\n+++ b/configs/_base_/models/bsn_pem.py\n@@ -11,6 +11,3 @@\n soft_nms_low_threshold=0.65,\n soft_nms_high_threshold=0.9,\n post_process_top_k=100)\n-# model training and testing settings\n-train_cfg = None\n-test_cfg = dict(average_clips='score')\ndiff --git a/configs/_base_/models/bsn_tem.py b/configs/_base_/models/bsn_tem.py\n--- a/configs/_base_/models/bsn_tem.py\n+++ b/configs/_base_/models/bsn_tem.py\n@@ -6,6 +6,3 @@\n tem_feat_dim=400,\n tem_hidden_dim=512,\n tem_match_threshold=0.5)\n-# model training and testing settings\n-train_cfg = None\n-test_cfg = dict(average_clips='score')\n", "issue": "Localizer train cfg & test cfg ?\n\n", "before_files": [{"content": "# model settings\nmodel = dict(\n type='TEM',\n temporal_dim=100,\n boundary_ratio=0.1,\n tem_feat_dim=400,\n tem_hidden_dim=512,\n tem_match_threshold=0.5)\n# model training and testing settings\ntrain_cfg = None\ntest_cfg = dict(average_clips='score')\n", "path": "configs/_base_/models/bsn_tem.py"}, {"content": "# model settings\nmodel = dict(\n type='PEM',\n pem_feat_dim=32,\n pem_hidden_dim=256,\n pem_u_ratio_m=1,\n pem_u_ratio_l=2,\n pem_high_temporal_iou_threshold=0.6,\n pem_low_temporal_iou_threshold=0.2,\n soft_nms_alpha=0.75,\n soft_nms_low_threshold=0.65,\n soft_nms_high_threshold=0.9,\n post_process_top_k=100)\n# model training and testing settings\ntrain_cfg = None\ntest_cfg = dict(average_clips='score')\n", "path": "configs/_base_/models/bsn_pem.py"}, {"content": "# model settings\nmodel = dict(\n type='BMN',\n temporal_dim=100,\n boundary_ratio=0.5,\n num_samples=32,\n num_samples_per_bin=3,\n feat_dim=400,\n soft_nms_alpha=0.4,\n soft_nms_low_threshold=0.5,\n soft_nms_high_threshold=0.9,\n post_process_top_k=100)\n# model training and testing settings\ntrain_cfg = None\ntest_cfg = dict(average_clips='score')\n", "path": "configs/_base_/models/bmn_400x100.py"}], "after_files": [{"content": "# model settings\nmodel = dict(\n type='TEM',\n temporal_dim=100,\n boundary_ratio=0.1,\n tem_feat_dim=400,\n tem_hidden_dim=512,\n tem_match_threshold=0.5)\n", "path": "configs/_base_/models/bsn_tem.py"}, {"content": "# model settings\nmodel = dict(\n type='PEM',\n pem_feat_dim=32,\n pem_hidden_dim=256,\n pem_u_ratio_m=1,\n pem_u_ratio_l=2,\n pem_high_temporal_iou_threshold=0.6,\n pem_low_temporal_iou_threshold=0.2,\n soft_nms_alpha=0.75,\n soft_nms_low_threshold=0.65,\n soft_nms_high_threshold=0.9,\n post_process_top_k=100)\n", "path": "configs/_base_/models/bsn_pem.py"}, {"content": "# model settings\nmodel = dict(\n type='BMN',\n temporal_dim=100,\n boundary_ratio=0.5,\n num_samples=32,\n num_samples_per_bin=3,\n feat_dim=400,\n soft_nms_alpha=0.4,\n soft_nms_low_threshold=0.5,\n soft_nms_high_threshold=0.9,\n post_process_top_k=100)\n", "path": "configs/_base_/models/bmn_400x100.py"}]}
| 722 | 397 |
gh_patches_debug_16280
|
rasdani/github-patches
|
git_diff
|
mirumee__ariadne-35
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
If value from resolver is callable, call it with **kwargs.
[Apollo doc](https://www.apollographql.com/docs/graphql-tools/resolvers) for default resolver says that if `field_name` resolves to function, it will be called with query arguments:
> Calls a function on obj with the relevant field name and passes the query arguments into that function
This can be useful for situations when parent resolver returned an object with getter functions.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ariadne/resolvers.py`
Content:
```
1 from graphql import GraphQLObjectType, GraphQLScalarType, GraphQLSchema
2 from graphql.execution.base import ResolveInfo
3
4
5 def resolve_parent_field(parent, name: str):
6 if isinstance(parent, dict):
7 return parent.get(name)
8 return getattr(parent, name, None)
9
10
11 def default_resolver(parent, info: ResolveInfo):
12 return resolve_parent_field(parent, info.field_name)
13
14
15 def resolve_to(name: str):
16 def resolver(parent, *_):
17 return resolve_parent_field(parent, name)
18
19 return resolver
20
21
22 def add_resolve_functions_to_schema(schema: GraphQLSchema, resolvers: dict):
23 for type_name, type_object in schema.get_type_map().items():
24 if isinstance(type_object, GraphQLObjectType):
25 add_resolve_functions_to_object(type_name, type_object, resolvers)
26 if isinstance(type_object, GraphQLScalarType):
27 add_resolve_functions_to_scalar(type_name, type_object, resolvers)
28
29
30 def add_resolve_functions_to_object(name: str, obj: GraphQLObjectType, resolvers: dict):
31 type_resolvers = resolvers.get(name, {})
32 for field_name, field_object in obj.fields.items():
33 field_resolver = type_resolvers.get(field_name)
34 if field_resolver:
35 field_object.resolver = field_resolver
36 elif field_object.resolver is None:
37 field_object.resolver = default_resolver
38
39
40 def add_resolve_functions_to_scalar(name: str, obj: GraphQLObjectType, resolvers: dict):
41 scalar_resolvers = resolvers.get(name, {})
42
43 serialize = scalar_resolvers.get("serialize", obj.serialize)
44 obj.serialize = serialize
45
46 parse_literal = scalar_resolvers.get("parse_literal", obj.parse_literal)
47 obj.parse_literal = parse_literal
48
49 parse_value = scalar_resolvers.get("parse_value", obj.parse_value)
50 obj.parse_value = parse_value
51
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ariadne/resolvers.py b/ariadne/resolvers.py
--- a/ariadne/resolvers.py
+++ b/ariadne/resolvers.py
@@ -2,19 +2,23 @@
from graphql.execution.base import ResolveInfo
-def resolve_parent_field(parent, name: str):
+def resolve_parent_field(parent, name: str, **kwargs: dict):
if isinstance(parent, dict):
- return parent.get(name)
- return getattr(parent, name, None)
+ value = parent.get(name)
+ else:
+ value = getattr(parent, name, None)
+ if callable(value):
+ return value(**kwargs)
+ return value
-def default_resolver(parent, info: ResolveInfo):
- return resolve_parent_field(parent, info.field_name)
+def default_resolver(parent, info: ResolveInfo, **kwargs):
+ return resolve_parent_field(parent, info.field_name, **kwargs)
def resolve_to(name: str):
- def resolver(parent, *_):
- return resolve_parent_field(parent, name)
+ def resolver(parent, *_, **kwargs):
+ return resolve_parent_field(parent, name, **kwargs)
return resolver
|
{"golden_diff": "diff --git a/ariadne/resolvers.py b/ariadne/resolvers.py\n--- a/ariadne/resolvers.py\n+++ b/ariadne/resolvers.py\n@@ -2,19 +2,23 @@\n from graphql.execution.base import ResolveInfo\n \n \n-def resolve_parent_field(parent, name: str):\n+def resolve_parent_field(parent, name: str, **kwargs: dict):\n if isinstance(parent, dict):\n- return parent.get(name)\n- return getattr(parent, name, None)\n+ value = parent.get(name)\n+ else:\n+ value = getattr(parent, name, None)\n+ if callable(value):\n+ return value(**kwargs)\n+ return value\n \n \n-def default_resolver(parent, info: ResolveInfo):\n- return resolve_parent_field(parent, info.field_name)\n+def default_resolver(parent, info: ResolveInfo, **kwargs):\n+ return resolve_parent_field(parent, info.field_name, **kwargs)\n \n \n def resolve_to(name: str):\n- def resolver(parent, *_):\n- return resolve_parent_field(parent, name)\n+ def resolver(parent, *_, **kwargs):\n+ return resolve_parent_field(parent, name, **kwargs)\n \n return resolver\n", "issue": "If value from resolver is callable, call it with **kwargs.\n[Apollo doc](https://www.apollographql.com/docs/graphql-tools/resolvers) for default resolver says that if `field_name` resolves to function, it will be called with query arguments:\r\n\r\n> Calls a function on obj with the relevant field name and passes the query arguments into that function\r\n\r\nThis can be useful for situations when parent resolver returned an object with getter functions.\n", "before_files": [{"content": "from graphql import GraphQLObjectType, GraphQLScalarType, GraphQLSchema\nfrom graphql.execution.base import ResolveInfo\n\n\ndef resolve_parent_field(parent, name: str):\n if isinstance(parent, dict):\n return parent.get(name)\n return getattr(parent, name, None)\n\n\ndef default_resolver(parent, info: ResolveInfo):\n return resolve_parent_field(parent, info.field_name)\n\n\ndef resolve_to(name: str):\n def resolver(parent, *_):\n return resolve_parent_field(parent, name)\n\n return resolver\n\n\ndef add_resolve_functions_to_schema(schema: GraphQLSchema, resolvers: dict):\n for type_name, type_object in schema.get_type_map().items():\n if isinstance(type_object, GraphQLObjectType):\n add_resolve_functions_to_object(type_name, type_object, resolvers)\n if isinstance(type_object, GraphQLScalarType):\n add_resolve_functions_to_scalar(type_name, type_object, resolvers)\n\n\ndef add_resolve_functions_to_object(name: str, obj: GraphQLObjectType, resolvers: dict):\n type_resolvers = resolvers.get(name, {})\n for field_name, field_object in obj.fields.items():\n field_resolver = type_resolvers.get(field_name)\n if field_resolver:\n field_object.resolver = field_resolver\n elif field_object.resolver is None:\n field_object.resolver = default_resolver\n\n\ndef add_resolve_functions_to_scalar(name: str, obj: GraphQLObjectType, resolvers: dict):\n scalar_resolvers = resolvers.get(name, {})\n\n serialize = scalar_resolvers.get(\"serialize\", obj.serialize)\n obj.serialize = serialize\n\n parse_literal = scalar_resolvers.get(\"parse_literal\", obj.parse_literal)\n obj.parse_literal = parse_literal\n\n parse_value = scalar_resolvers.get(\"parse_value\", obj.parse_value)\n obj.parse_value = parse_value\n", "path": "ariadne/resolvers.py"}], "after_files": [{"content": "from graphql import GraphQLObjectType, GraphQLScalarType, GraphQLSchema\nfrom graphql.execution.base import ResolveInfo\n\n\ndef resolve_parent_field(parent, name: str, **kwargs: dict):\n if isinstance(parent, dict):\n value = parent.get(name)\n else:\n value = getattr(parent, name, None)\n if callable(value):\n return value(**kwargs)\n return value\n\n\ndef default_resolver(parent, info: ResolveInfo, **kwargs):\n return resolve_parent_field(parent, info.field_name, **kwargs)\n\n\ndef resolve_to(name: str):\n def resolver(parent, *_, **kwargs):\n return resolve_parent_field(parent, name, **kwargs)\n\n return resolver\n\n\ndef add_resolve_functions_to_schema(schema: GraphQLSchema, resolvers: dict):\n for type_name, type_object in schema.get_type_map().items():\n if isinstance(type_object, GraphQLObjectType):\n add_resolve_functions_to_object(type_name, type_object, resolvers)\n if isinstance(type_object, GraphQLScalarType):\n add_resolve_functions_to_scalar(type_name, type_object, resolvers)\n\n\ndef add_resolve_functions_to_object(name: str, obj: GraphQLObjectType, resolvers: dict):\n type_resolvers = resolvers.get(name, {})\n for field_name, field_object in obj.fields.items():\n field_resolver = type_resolvers.get(field_name)\n if field_resolver:\n field_object.resolver = field_resolver\n elif field_object.resolver is None:\n field_object.resolver = default_resolver\n\n\ndef add_resolve_functions_to_scalar(name: str, obj: GraphQLObjectType, resolvers: dict):\n scalar_resolvers = resolvers.get(name, {})\n\n serialize = scalar_resolvers.get(\"serialize\", obj.serialize)\n obj.serialize = serialize\n\n parse_literal = scalar_resolvers.get(\"parse_literal\", obj.parse_literal)\n obj.parse_literal = parse_literal\n\n parse_value = scalar_resolvers.get(\"parse_value\", obj.parse_value)\n obj.parse_value = parse_value\n", "path": "ariadne/resolvers.py"}]}
| 824 | 259 |
gh_patches_debug_13586
|
rasdani/github-patches
|
git_diff
|
pwndbg__pwndbg-146
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
"show print elements 0" causes exceptions on stop
```
pwndbg> show print elements
Limit on string chars or array elements to print is unlimited.
Traceback (most recent call last):
File "/home/david/.pwndbg/pwndbg/events.py", line 111, in caller
func()
File "/home/david/.pwndbg/pwndbg/strings.py", line 34, in update_length
length = int(message)
File "/home/david/.pwndbg/pwndbg/inthook.py", line 44, in __new__
return _int(_int(value, *a, **kw))
ValueError: invalid literal for int() with base 10: 'unlimited'
Python Exception <class 'ValueError'> invalid literal for int() with base 10: 'unlimited':
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pwndbg/strings.py`
Content:
```
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 """
4 Functionality for resolving ASCII printable strings within
5 the debuggee's address space.
6 """
7 from __future__ import absolute_import
8 from __future__ import division
9 from __future__ import print_function
10 from __future__ import unicode_literals
11
12 import string
13
14 import gdb
15
16 import pwndbg.events
17 import pwndbg.memory
18 import pwndbg.typeinfo
19
20 length = 15
21
22 @pwndbg.events.stop
23 def update_length():
24 r"""
25 Unfortunately there's not a better way to get at this info.
26
27 >>> gdb.execute('show print elements', from_tty=False, to_string=True)
28 'Limit on string chars or array elements to print is 21.\n'
29 """
30 global length
31 message = gdb.execute('show print elements', from_tty=False, to_string=True)
32 message = message.split()[-1]
33 message = message.strip('.')
34 length = int(message)
35
36 def get(address, maxlen = None):
37 if maxlen is None:
38 maxlen = length
39
40 try:
41 sz = pwndbg.memory.string(address)
42 sz = sz.decode('latin-1', 'replace')
43
44 if not sz or not all(s in string.printable for s in sz):
45 return None
46 except Exception as e:
47 return None
48
49 if len(sz) < maxlen:
50 return sz
51
52 return sz[:maxlen] + '...'
53
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pwndbg/strings.py b/pwndbg/strings.py
--- a/pwndbg/strings.py
+++ b/pwndbg/strings.py
@@ -31,7 +31,10 @@
message = gdb.execute('show print elements', from_tty=False, to_string=True)
message = message.split()[-1]
message = message.strip('.')
- length = int(message)
+ if message == 'unlimited':
+ length = 0
+ else:
+ length = int(message)
def get(address, maxlen = None):
if maxlen is None:
@@ -46,7 +49,7 @@
except Exception as e:
return None
- if len(sz) < maxlen:
+ if len(sz) < maxlen or not maxlen:
return sz
return sz[:maxlen] + '...'
|
{"golden_diff": "diff --git a/pwndbg/strings.py b/pwndbg/strings.py\n--- a/pwndbg/strings.py\n+++ b/pwndbg/strings.py\n@@ -31,7 +31,10 @@\n message = gdb.execute('show print elements', from_tty=False, to_string=True)\n message = message.split()[-1]\n message = message.strip('.')\n- length = int(message)\n+ if message == 'unlimited':\n+ length = 0\n+ else:\n+ length = int(message)\n \n def get(address, maxlen = None):\n if maxlen is None:\n@@ -46,7 +49,7 @@\n except Exception as e:\n return None\n \n- if len(sz) < maxlen:\n+ if len(sz) < maxlen or not maxlen:\n return sz\n \n return sz[:maxlen] + '...'\n", "issue": "\"show print elements 0\" causes exceptions on stop\n```\r\npwndbg> show print elements\r\nLimit on string chars or array elements to print is unlimited.\r\nTraceback (most recent call last):\r\n File \"/home/david/.pwndbg/pwndbg/events.py\", line 111, in caller\r\n func()\r\n File \"/home/david/.pwndbg/pwndbg/strings.py\", line 34, in update_length\r\n length = int(message)\r\n File \"/home/david/.pwndbg/pwndbg/inthook.py\", line 44, in __new__\r\n return _int(_int(value, *a, **kw))\r\nValueError: invalid literal for int() with base 10: 'unlimited'\r\nPython Exception <class 'ValueError'> invalid literal for int() with base 10: 'unlimited': \r\n```\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"\nFunctionality for resolving ASCII printable strings within\nthe debuggee's address space.\n\"\"\"\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\nfrom __future__ import unicode_literals\n\nimport string\n\nimport gdb\n\nimport pwndbg.events\nimport pwndbg.memory\nimport pwndbg.typeinfo\n\nlength = 15\n\[email protected]\ndef update_length():\n r\"\"\"\n Unfortunately there's not a better way to get at this info.\n\n >>> gdb.execute('show print elements', from_tty=False, to_string=True)\n 'Limit on string chars or array elements to print is 21.\\n'\n \"\"\"\n global length\n message = gdb.execute('show print elements', from_tty=False, to_string=True)\n message = message.split()[-1]\n message = message.strip('.')\n length = int(message)\n\ndef get(address, maxlen = None):\n if maxlen is None:\n maxlen = length\n\n try:\n sz = pwndbg.memory.string(address)\n sz = sz.decode('latin-1', 'replace')\n\n if not sz or not all(s in string.printable for s in sz):\n return None\n except Exception as e:\n return None\n\n if len(sz) < maxlen:\n return sz\n\n return sz[:maxlen] + '...'\n", "path": "pwndbg/strings.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"\nFunctionality for resolving ASCII printable strings within\nthe debuggee's address space.\n\"\"\"\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\nfrom __future__ import unicode_literals\n\nimport string\n\nimport gdb\n\nimport pwndbg.events\nimport pwndbg.memory\nimport pwndbg.typeinfo\n\nlength = 15\n\[email protected]\ndef update_length():\n r\"\"\"\n Unfortunately there's not a better way to get at this info.\n\n >>> gdb.execute('show print elements', from_tty=False, to_string=True)\n 'Limit on string chars or array elements to print is 21.\\n'\n \"\"\"\n global length\n message = gdb.execute('show print elements', from_tty=False, to_string=True)\n message = message.split()[-1]\n message = message.strip('.')\n if message == 'unlimited':\n length = 0\n else:\n length = int(message)\n\ndef get(address, maxlen = None):\n if maxlen is None:\n maxlen = length\n\n try:\n sz = pwndbg.memory.string(address)\n sz = sz.decode('latin-1', 'replace')\n\n if not sz or not all(s in string.printable for s in sz):\n return None\n except Exception as e:\n return None\n\n if len(sz) < maxlen or not maxlen:\n return sz\n\n return sz[:maxlen] + '...'\n", "path": "pwndbg/strings.py"}]}
| 860 | 190 |
gh_patches_debug_1981
|
rasdani/github-patches
|
git_diff
|
vyperlang__vyper-2905
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Missing @view decorator for interface ERC20Detailed.py
### Version Information
* vyper Version (output of `vyper --version`): 0.3.3
* OS: linux
* Python Version (output of `python --version`): Python 3.9.5
### What's your issue about?
**Issue**
Error using `ERC20Detailed.py` as an interface to a vyper class. Trying to compile the following snippet produces the following error.
```
# @version 0.3.3
from vyper.interfaces import ERC20Detailed
@view
@external
def getSymbol() -> String[32]:
return ERC20Detailed(0x5f3b5DfEb7B28CDbD7FAba78963EE202a494e2A2).symbol()
```
**Error**
```
vyper.exceptions.StateAccessViolation: May not call state modifying function 'symbol' within a constant
function.vyper.exceptions.StateAccessViolation: May not call state modifying function 'symbol' within a constant function.
```
**Reason**
This issue occurs because `ERC20Detailed.py` does not contain `@view` decorator for its interfaces
### How can it be fixed?
Adding `@view` decorator to interface under `vyper.builtin_interfaces.ERC20Detailed.py`
```
@external
@view
def name() -> String[1]:
pass
@external
@view
def symbol() -> String[1]:
pass
@external
@view
def decimals() -> uint8:
pass
```
**Why?**
Running `vyper -f interface examples/tokens/ERC20.vy` generates the following
```
...
@view
@external
def name() -> String[32]:
pass
@view
@external
def symbol() -> String[32]:
pass
@view
@external
def decimals() -> uint8:
pass
...
```
Adding `@view` decorator to `vyper.builtin_interfaces.ERC20Detailed.py` would make interface consistent.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `vyper/builtin_interfaces/ERC20Detailed.py`
Content:
```
1 """
2 NOTE: interface uses `String[1]` where 1 is the lower bound of the string returned by the function.
3 For end-users this means they can't use `implements: ERC20Detailed` unless their implementation
4 uses a value n >= 1. Regardless this is fine as one can't do String[0] where n == 0.
5 """
6
7 interface_code = """
8 @external
9 def name() -> String[1]:
10 pass
11
12 @external
13 def symbol() -> String[1]:
14 pass
15
16 @external
17 def decimals() -> uint8:
18 pass
19 """
20
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/vyper/builtin_interfaces/ERC20Detailed.py b/vyper/builtin_interfaces/ERC20Detailed.py
--- a/vyper/builtin_interfaces/ERC20Detailed.py
+++ b/vyper/builtin_interfaces/ERC20Detailed.py
@@ -5,14 +5,17 @@
"""
interface_code = """
+@view
@external
def name() -> String[1]:
pass
+@view
@external
def symbol() -> String[1]:
pass
+@view
@external
def decimals() -> uint8:
pass
|
{"golden_diff": "diff --git a/vyper/builtin_interfaces/ERC20Detailed.py b/vyper/builtin_interfaces/ERC20Detailed.py\n--- a/vyper/builtin_interfaces/ERC20Detailed.py\n+++ b/vyper/builtin_interfaces/ERC20Detailed.py\n@@ -5,14 +5,17 @@\n \"\"\"\n \n interface_code = \"\"\"\n+@view\n @external\n def name() -> String[1]:\n pass\n \n+@view\n @external\n def symbol() -> String[1]:\n pass\n \n+@view\n @external\n def decimals() -> uint8:\n pass\n", "issue": "Missing @view decorator for interface ERC20Detailed.py\n### Version Information\r\n* vyper Version (output of `vyper --version`): 0.3.3\r\n* OS: linux\r\n* Python Version (output of `python --version`): Python 3.9.5\r\n### What's your issue about?\r\n**Issue**\r\nError using `ERC20Detailed.py` as an interface to a vyper class. Trying to compile the following snippet produces the following error.\r\n```\r\n# @version 0.3.3\r\n\r\nfrom vyper.interfaces import ERC20Detailed\r\n\r\n@view\r\n@external\r\ndef getSymbol() -> String[32]:\r\n return ERC20Detailed(0x5f3b5DfEb7B28CDbD7FAba78963EE202a494e2A2).symbol()\r\n```\r\n**Error**\r\n```\r\nvyper.exceptions.StateAccessViolation: May not call state modifying function 'symbol' within a constant\r\nfunction.vyper.exceptions.StateAccessViolation: May not call state modifying function 'symbol' within a constant function.\r\n```\r\n**Reason**\r\nThis issue occurs because `ERC20Detailed.py` does not contain `@view` decorator for its interfaces\r\n### How can it be fixed?\r\nAdding `@view` decorator to interface under `vyper.builtin_interfaces.ERC20Detailed.py`\r\n```\r\n@external\r\n@view\r\ndef name() -> String[1]:\r\n pass\r\n \r\n@external\r\n@view\r\ndef symbol() -> String[1]:\r\n pass\r\n \r\n@external\r\n@view\r\ndef decimals() -> uint8:\r\n pass\r\n```\r\n**Why?**\r\nRunning `vyper -f interface examples/tokens/ERC20.vy` generates the following\r\n```\r\n...\r\n@view\r\n@external\r\ndef name() -> String[32]:\r\n pass\r\n \r\n@view\r\n@external\r\ndef symbol() -> String[32]:\r\n pass\r\n \r\n@view\r\n@external\r\ndef decimals() -> uint8:\r\n pass\r\n...\r\n```\r\n\r\nAdding `@view` decorator to `vyper.builtin_interfaces.ERC20Detailed.py` would make interface consistent.\n", "before_files": [{"content": "\"\"\"\nNOTE: interface uses `String[1]` where 1 is the lower bound of the string returned by the function.\n For end-users this means they can't use `implements: ERC20Detailed` unless their implementation\n uses a value n >= 1. Regardless this is fine as one can't do String[0] where n == 0.\n\"\"\"\n\ninterface_code = \"\"\"\n@external\ndef name() -> String[1]:\n pass\n\n@external\ndef symbol() -> String[1]:\n pass\n\n@external\ndef decimals() -> uint8:\n pass\n\"\"\"\n", "path": "vyper/builtin_interfaces/ERC20Detailed.py"}], "after_files": [{"content": "\"\"\"\nNOTE: interface uses `String[1]` where 1 is the lower bound of the string returned by the function.\n For end-users this means they can't use `implements: ERC20Detailed` unless their implementation\n uses a value n >= 1. Regardless this is fine as one can't do String[0] where n == 0.\n\"\"\"\n\ninterface_code = \"\"\"\n@view\n@external\ndef name() -> String[1]:\n pass\n\n@view\n@external\ndef symbol() -> String[1]:\n pass\n\n@view\n@external\ndef decimals() -> uint8:\n pass\n\"\"\"\n", "path": "vyper/builtin_interfaces/ERC20Detailed.py"}]}
| 876 | 127 |
gh_patches_debug_22138
|
rasdani/github-patches
|
git_diff
|
mkdocs__mkdocs-2604
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
CVE-2021-40978 - Path Traversal.
Hey!
We have verified a security flaw in the current version of MKdocs, a path traversal failure affecting the built-in dev-server.
That flaw turns the server susceptible to providing data outside the scope of the application allowing anyone to request sensitive files.
If you need further information, don't hesitate to get in touch with me.
https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-40978
https://github.com/nisdn/CVE-2021-40978
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mkdocs/livereload/__init__.py`
Content:
```
1 import functools
2 import io
3 import logging
4 import mimetypes
5 import os
6 import os.path
7 import re
8 import socketserver
9 import threading
10 import time
11 import warnings
12 import wsgiref.simple_server
13
14 import watchdog.events
15 import watchdog.observers.polling
16
17
18 class _LoggerAdapter(logging.LoggerAdapter):
19 def process(self, msg, kwargs):
20 return time.strftime("[%H:%M:%S] ") + msg, kwargs
21
22
23 log = _LoggerAdapter(logging.getLogger(__name__), {})
24
25
26 class LiveReloadServer(socketserver.ThreadingMixIn, wsgiref.simple_server.WSGIServer):
27 daemon_threads = True
28 poll_response_timeout = 60
29
30 def __init__(
31 self,
32 builder,
33 host,
34 port,
35 root,
36 mount_path="/",
37 polling_interval=0.5,
38 shutdown_delay=0.25,
39 **kwargs,
40 ):
41 self.builder = builder
42 self.server_name = host
43 self.server_port = port
44 self.root = os.path.abspath(root)
45 self.mount_path = ("/" + mount_path.lstrip("/")).rstrip("/") + "/"
46 self.url = f"http://{self.server_name}:{self.server_port}{self.mount_path}"
47 self.build_delay = 0.1
48 self.shutdown_delay = shutdown_delay
49 # To allow custom error pages.
50 self.error_handler = lambda code: None
51
52 super().__init__((host, port), _Handler, **kwargs)
53 self.set_app(self.serve_request)
54
55 self._wanted_epoch = _timestamp() # The version of the site that started building.
56 self._visible_epoch = self._wanted_epoch # Latest fully built version of the site.
57 self._epoch_cond = threading.Condition() # Must be held when accessing _visible_epoch.
58
59 self._to_rebuild = {} # Used as an ordered set of functions to call.
60 self._rebuild_cond = threading.Condition() # Must be held when accessing _to_rebuild.
61
62 self._shutdown = False
63 self.serve_thread = threading.Thread(target=lambda: self.serve_forever(shutdown_delay))
64 self.observer = watchdog.observers.polling.PollingObserver(timeout=polling_interval)
65
66 def watch(self, path, func=None, recursive=True):
67 """Add the 'path' to watched paths, call the function and reload when any file changes under it."""
68 path = os.path.abspath(path)
69 if func in (None, self.builder):
70 func = self.builder
71 else:
72 warnings.warn(
73 "Plugins should not pass the 'func' parameter of watch(). "
74 "The ability to execute custom callbacks will be removed soon.",
75 DeprecationWarning,
76 stacklevel=2,
77 )
78
79 def callback(event):
80 if event.is_directory:
81 return
82 log.debug(str(event))
83 with self._rebuild_cond:
84 self._to_rebuild[func] = True
85 self._rebuild_cond.notify_all()
86
87 handler = watchdog.events.FileSystemEventHandler()
88 handler.on_any_event = callback
89 log.debug(f"Watching '{path}'")
90 self.observer.schedule(handler, path, recursive=recursive)
91
92 def serve(self):
93 self.observer.start()
94
95 log.info(f"Serving on {self.url}")
96 self.serve_thread.start()
97
98 self._build_loop()
99
100 def _build_loop(self):
101 while True:
102 with self._rebuild_cond:
103 while not self._rebuild_cond.wait_for(
104 lambda: self._to_rebuild or self._shutdown, timeout=self.shutdown_delay
105 ):
106 # We could have used just one wait instead of a loop + timeout, but we need
107 # occasional breaks, otherwise on Windows we can't receive KeyboardInterrupt.
108 pass
109 if self._shutdown:
110 break
111 log.info("Detected file changes")
112 while self._rebuild_cond.wait(timeout=self.build_delay):
113 log.debug("Waiting for file changes to stop happening")
114
115 self._wanted_epoch = _timestamp()
116 funcs = list(self._to_rebuild)
117 self._to_rebuild.clear()
118
119 for func in funcs:
120 func()
121
122 with self._epoch_cond:
123 log.info("Reloading browsers")
124 self._visible_epoch = self._wanted_epoch
125 self._epoch_cond.notify_all()
126
127 def shutdown(self):
128 self.observer.stop()
129 with self._rebuild_cond:
130 self._shutdown = True
131 self._rebuild_cond.notify_all()
132
133 if self.serve_thread.is_alive():
134 super().shutdown()
135 self.serve_thread.join()
136 self.observer.join()
137
138 def serve_request(self, environ, start_response):
139 try:
140 result = self._serve_request(environ, start_response)
141 except Exception:
142 code = 500
143 msg = "500 Internal Server Error"
144 log.exception(msg)
145 else:
146 if result is not None:
147 return result
148 code = 404
149 msg = "404 Not Found"
150
151 error_content = None
152 try:
153 error_content = self.error_handler(code)
154 except Exception:
155 log.exception("Failed to render an error message!")
156 if error_content is None:
157 error_content = msg.encode()
158
159 start_response(msg, [("Content-Type", "text/html")])
160 return [error_content]
161
162 def _serve_request(self, environ, start_response):
163 # https://bugs.python.org/issue16679
164 # https://github.com/bottlepy/bottle/blob/f9b1849db4/bottle.py#L984
165 path = environ["PATH_INFO"].encode("latin-1").decode("utf-8", "ignore")
166
167 m = re.fullmatch(r"/livereload/([0-9]+)/[0-9]+", path)
168 if m:
169 epoch = int(m[1])
170 start_response("200 OK", [("Content-Type", "text/plain")])
171
172 def condition():
173 return self._visible_epoch > epoch
174
175 with self._epoch_cond:
176 if not condition():
177 # Stall the browser, respond as soon as there's something new.
178 # If there's not, respond anyway after a minute.
179 self._log_poll_request(environ.get("HTTP_REFERER"), request_id=path)
180 self._epoch_cond.wait_for(condition, timeout=self.poll_response_timeout)
181 return [b"%d" % self._visible_epoch]
182
183 if path == "/js/livereload.js":
184 file_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), "livereload.js")
185 elif path.startswith(self.mount_path):
186 rel_file_path = path[len(self.mount_path):].lstrip("/")
187 if path.endswith("/"):
188 rel_file_path += "index.html"
189 file_path = os.path.join(self.root, rel_file_path)
190 elif path == "/":
191 start_response("302 Found", [("Location", self.mount_path)])
192 return []
193 else:
194 return None # Not found
195
196 # Wait until the ongoing rebuild (if any) finishes, so we're not serving a half-built site.
197 with self._epoch_cond:
198 self._epoch_cond.wait_for(lambda: self._visible_epoch == self._wanted_epoch)
199 epoch = self._visible_epoch
200
201 try:
202 file = open(file_path, "rb")
203 except OSError:
204 if not path.endswith("/") and os.path.isfile(os.path.join(file_path, "index.html")):
205 start_response("302 Found", [("Location", path + "/")])
206 return []
207 return None # Not found
208
209 if file_path.endswith(".html"):
210 with file:
211 content = file.read()
212 content = self._inject_js_into_html(content, epoch)
213 file = io.BytesIO(content)
214 content_length = len(content)
215 else:
216 content_length = os.path.getsize(file_path)
217
218 content_type = self._guess_type(file_path)
219 start_response(
220 "200 OK", [("Content-Type", content_type), ("Content-Length", str(content_length))]
221 )
222 return wsgiref.util.FileWrapper(file)
223
224 @classmethod
225 def _inject_js_into_html(cls, content, epoch):
226 try:
227 body_end = content.rindex(b"</body>")
228 except ValueError:
229 body_end = len(content)
230 # The page will reload if the livereload poller returns a newer epoch than what it knows.
231 # The other timestamp becomes just a unique identifier for the initiating page.
232 return (
233 b'%b<script src="/js/livereload.js"></script><script>livereload(%d, %d);</script>%b'
234 % (content[:body_end], epoch, _timestamp(), content[body_end:])
235 )
236
237 @classmethod
238 @functools.lru_cache() # "Cache" to not repeat the same message for the same browser tab.
239 def _log_poll_request(cls, url, request_id):
240 log.info(f"Browser connected: {url}")
241
242 def _guess_type(cls, path):
243 # MkDocs only ensures a few common types (as seen in livereload_tests.py::test_mime_types).
244 # Other uncommon types will not be accepted.
245 if path.endswith((".js", ".JS")):
246 return "application/javascript"
247 if path.endswith(".gz"):
248 return "application/gzip"
249
250 guess, _ = mimetypes.guess_type(path)
251 if guess:
252 return guess
253 return "application/octet-stream"
254
255
256 class _Handler(wsgiref.simple_server.WSGIRequestHandler):
257 def log_request(self, code="-", size="-"):
258 level = logging.DEBUG if str(code) == "200" else logging.WARNING
259 log.log(level, f'"{self.requestline}" code {code}')
260
261 def log_message(self, format, *args):
262 log.debug(format, *args)
263
264
265 def _timestamp():
266 return round(time.monotonic() * 1000)
267
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mkdocs/livereload/__init__.py b/mkdocs/livereload/__init__.py
--- a/mkdocs/livereload/__init__.py
+++ b/mkdocs/livereload/__init__.py
@@ -4,6 +4,7 @@
import mimetypes
import os
import os.path
+import posixpath
import re
import socketserver
import threading
@@ -183,9 +184,11 @@
if path == "/js/livereload.js":
file_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), "livereload.js")
elif path.startswith(self.mount_path):
- rel_file_path = path[len(self.mount_path):].lstrip("/")
+ rel_file_path = path[len(self.mount_path):]
if path.endswith("/"):
rel_file_path += "index.html"
+ # Prevent directory traversal - normalize the path.
+ rel_file_path = posixpath.normpath("/" + rel_file_path).lstrip("/")
file_path = os.path.join(self.root, rel_file_path)
elif path == "/":
start_response("302 Found", [("Location", self.mount_path)])
|
{"golden_diff": "diff --git a/mkdocs/livereload/__init__.py b/mkdocs/livereload/__init__.py\n--- a/mkdocs/livereload/__init__.py\n+++ b/mkdocs/livereload/__init__.py\n@@ -4,6 +4,7 @@\n import mimetypes\n import os\n import os.path\n+import posixpath\n import re\n import socketserver\n import threading\n@@ -183,9 +184,11 @@\n if path == \"/js/livereload.js\":\n file_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), \"livereload.js\")\n elif path.startswith(self.mount_path):\n- rel_file_path = path[len(self.mount_path):].lstrip(\"/\")\n+ rel_file_path = path[len(self.mount_path):]\n if path.endswith(\"/\"):\n rel_file_path += \"index.html\"\n+ # Prevent directory traversal - normalize the path.\n+ rel_file_path = posixpath.normpath(\"/\" + rel_file_path).lstrip(\"/\")\n file_path = os.path.join(self.root, rel_file_path)\n elif path == \"/\":\n start_response(\"302 Found\", [(\"Location\", self.mount_path)])\n", "issue": "CVE-2021-40978 - Path Traversal.\nHey!\r\n\r\nWe have verified a security flaw in the current version of MKdocs, a path traversal failure affecting the built-in dev-server.\r\n\r\nThat flaw turns the server susceptible to providing data outside the scope of the application allowing anyone to request sensitive files.\r\n\r\nIf you need further information, don't hesitate to get in touch with me.\r\n\r\nhttps://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-40978\r\nhttps://github.com/nisdn/CVE-2021-40978\r\n\n", "before_files": [{"content": "import functools\nimport io\nimport logging\nimport mimetypes\nimport os\nimport os.path\nimport re\nimport socketserver\nimport threading\nimport time\nimport warnings\nimport wsgiref.simple_server\n\nimport watchdog.events\nimport watchdog.observers.polling\n\n\nclass _LoggerAdapter(logging.LoggerAdapter):\n def process(self, msg, kwargs):\n return time.strftime(\"[%H:%M:%S] \") + msg, kwargs\n\n\nlog = _LoggerAdapter(logging.getLogger(__name__), {})\n\n\nclass LiveReloadServer(socketserver.ThreadingMixIn, wsgiref.simple_server.WSGIServer):\n daemon_threads = True\n poll_response_timeout = 60\n\n def __init__(\n self,\n builder,\n host,\n port,\n root,\n mount_path=\"/\",\n polling_interval=0.5,\n shutdown_delay=0.25,\n **kwargs,\n ):\n self.builder = builder\n self.server_name = host\n self.server_port = port\n self.root = os.path.abspath(root)\n self.mount_path = (\"/\" + mount_path.lstrip(\"/\")).rstrip(\"/\") + \"/\"\n self.url = f\"http://{self.server_name}:{self.server_port}{self.mount_path}\"\n self.build_delay = 0.1\n self.shutdown_delay = shutdown_delay\n # To allow custom error pages.\n self.error_handler = lambda code: None\n\n super().__init__((host, port), _Handler, **kwargs)\n self.set_app(self.serve_request)\n\n self._wanted_epoch = _timestamp() # The version of the site that started building.\n self._visible_epoch = self._wanted_epoch # Latest fully built version of the site.\n self._epoch_cond = threading.Condition() # Must be held when accessing _visible_epoch.\n\n self._to_rebuild = {} # Used as an ordered set of functions to call.\n self._rebuild_cond = threading.Condition() # Must be held when accessing _to_rebuild.\n\n self._shutdown = False\n self.serve_thread = threading.Thread(target=lambda: self.serve_forever(shutdown_delay))\n self.observer = watchdog.observers.polling.PollingObserver(timeout=polling_interval)\n\n def watch(self, path, func=None, recursive=True):\n \"\"\"Add the 'path' to watched paths, call the function and reload when any file changes under it.\"\"\"\n path = os.path.abspath(path)\n if func in (None, self.builder):\n func = self.builder\n else:\n warnings.warn(\n \"Plugins should not pass the 'func' parameter of watch(). \"\n \"The ability to execute custom callbacks will be removed soon.\",\n DeprecationWarning,\n stacklevel=2,\n )\n\n def callback(event):\n if event.is_directory:\n return\n log.debug(str(event))\n with self._rebuild_cond:\n self._to_rebuild[func] = True\n self._rebuild_cond.notify_all()\n\n handler = watchdog.events.FileSystemEventHandler()\n handler.on_any_event = callback\n log.debug(f\"Watching '{path}'\")\n self.observer.schedule(handler, path, recursive=recursive)\n\n def serve(self):\n self.observer.start()\n\n log.info(f\"Serving on {self.url}\")\n self.serve_thread.start()\n\n self._build_loop()\n\n def _build_loop(self):\n while True:\n with self._rebuild_cond:\n while not self._rebuild_cond.wait_for(\n lambda: self._to_rebuild or self._shutdown, timeout=self.shutdown_delay\n ):\n # We could have used just one wait instead of a loop + timeout, but we need\n # occasional breaks, otherwise on Windows we can't receive KeyboardInterrupt.\n pass\n if self._shutdown:\n break\n log.info(\"Detected file changes\")\n while self._rebuild_cond.wait(timeout=self.build_delay):\n log.debug(\"Waiting for file changes to stop happening\")\n\n self._wanted_epoch = _timestamp()\n funcs = list(self._to_rebuild)\n self._to_rebuild.clear()\n\n for func in funcs:\n func()\n\n with self._epoch_cond:\n log.info(\"Reloading browsers\")\n self._visible_epoch = self._wanted_epoch\n self._epoch_cond.notify_all()\n\n def shutdown(self):\n self.observer.stop()\n with self._rebuild_cond:\n self._shutdown = True\n self._rebuild_cond.notify_all()\n\n if self.serve_thread.is_alive():\n super().shutdown()\n self.serve_thread.join()\n self.observer.join()\n\n def serve_request(self, environ, start_response):\n try:\n result = self._serve_request(environ, start_response)\n except Exception:\n code = 500\n msg = \"500 Internal Server Error\"\n log.exception(msg)\n else:\n if result is not None:\n return result\n code = 404\n msg = \"404 Not Found\"\n\n error_content = None\n try:\n error_content = self.error_handler(code)\n except Exception:\n log.exception(\"Failed to render an error message!\")\n if error_content is None:\n error_content = msg.encode()\n\n start_response(msg, [(\"Content-Type\", \"text/html\")])\n return [error_content]\n\n def _serve_request(self, environ, start_response):\n # https://bugs.python.org/issue16679\n # https://github.com/bottlepy/bottle/blob/f9b1849db4/bottle.py#L984\n path = environ[\"PATH_INFO\"].encode(\"latin-1\").decode(\"utf-8\", \"ignore\")\n\n m = re.fullmatch(r\"/livereload/([0-9]+)/[0-9]+\", path)\n if m:\n epoch = int(m[1])\n start_response(\"200 OK\", [(\"Content-Type\", \"text/plain\")])\n\n def condition():\n return self._visible_epoch > epoch\n\n with self._epoch_cond:\n if not condition():\n # Stall the browser, respond as soon as there's something new.\n # If there's not, respond anyway after a minute.\n self._log_poll_request(environ.get(\"HTTP_REFERER\"), request_id=path)\n self._epoch_cond.wait_for(condition, timeout=self.poll_response_timeout)\n return [b\"%d\" % self._visible_epoch]\n\n if path == \"/js/livereload.js\":\n file_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), \"livereload.js\")\n elif path.startswith(self.mount_path):\n rel_file_path = path[len(self.mount_path):].lstrip(\"/\")\n if path.endswith(\"/\"):\n rel_file_path += \"index.html\"\n file_path = os.path.join(self.root, rel_file_path)\n elif path == \"/\":\n start_response(\"302 Found\", [(\"Location\", self.mount_path)])\n return []\n else:\n return None # Not found\n\n # Wait until the ongoing rebuild (if any) finishes, so we're not serving a half-built site.\n with self._epoch_cond:\n self._epoch_cond.wait_for(lambda: self._visible_epoch == self._wanted_epoch)\n epoch = self._visible_epoch\n\n try:\n file = open(file_path, \"rb\")\n except OSError:\n if not path.endswith(\"/\") and os.path.isfile(os.path.join(file_path, \"index.html\")):\n start_response(\"302 Found\", [(\"Location\", path + \"/\")])\n return []\n return None # Not found\n\n if file_path.endswith(\".html\"):\n with file:\n content = file.read()\n content = self._inject_js_into_html(content, epoch)\n file = io.BytesIO(content)\n content_length = len(content)\n else:\n content_length = os.path.getsize(file_path)\n\n content_type = self._guess_type(file_path)\n start_response(\n \"200 OK\", [(\"Content-Type\", content_type), (\"Content-Length\", str(content_length))]\n )\n return wsgiref.util.FileWrapper(file)\n\n @classmethod\n def _inject_js_into_html(cls, content, epoch):\n try:\n body_end = content.rindex(b\"</body>\")\n except ValueError:\n body_end = len(content)\n # The page will reload if the livereload poller returns a newer epoch than what it knows.\n # The other timestamp becomes just a unique identifier for the initiating page.\n return (\n b'%b<script src=\"/js/livereload.js\"></script><script>livereload(%d, %d);</script>%b'\n % (content[:body_end], epoch, _timestamp(), content[body_end:])\n )\n\n @classmethod\n @functools.lru_cache() # \"Cache\" to not repeat the same message for the same browser tab.\n def _log_poll_request(cls, url, request_id):\n log.info(f\"Browser connected: {url}\")\n\n def _guess_type(cls, path):\n # MkDocs only ensures a few common types (as seen in livereload_tests.py::test_mime_types).\n # Other uncommon types will not be accepted.\n if path.endswith((\".js\", \".JS\")):\n return \"application/javascript\"\n if path.endswith(\".gz\"):\n return \"application/gzip\"\n\n guess, _ = mimetypes.guess_type(path)\n if guess:\n return guess\n return \"application/octet-stream\"\n\n\nclass _Handler(wsgiref.simple_server.WSGIRequestHandler):\n def log_request(self, code=\"-\", size=\"-\"):\n level = logging.DEBUG if str(code) == \"200\" else logging.WARNING\n log.log(level, f'\"{self.requestline}\" code {code}')\n\n def log_message(self, format, *args):\n log.debug(format, *args)\n\n\ndef _timestamp():\n return round(time.monotonic() * 1000)\n", "path": "mkdocs/livereload/__init__.py"}], "after_files": [{"content": "import functools\nimport io\nimport logging\nimport mimetypes\nimport os\nimport os.path\nimport posixpath\nimport re\nimport socketserver\nimport threading\nimport time\nimport warnings\nimport wsgiref.simple_server\n\nimport watchdog.events\nimport watchdog.observers.polling\n\n\nclass _LoggerAdapter(logging.LoggerAdapter):\n def process(self, msg, kwargs):\n return time.strftime(\"[%H:%M:%S] \") + msg, kwargs\n\n\nlog = _LoggerAdapter(logging.getLogger(__name__), {})\n\n\nclass LiveReloadServer(socketserver.ThreadingMixIn, wsgiref.simple_server.WSGIServer):\n daemon_threads = True\n poll_response_timeout = 60\n\n def __init__(\n self,\n builder,\n host,\n port,\n root,\n mount_path=\"/\",\n polling_interval=0.5,\n shutdown_delay=0.25,\n **kwargs,\n ):\n self.builder = builder\n self.server_name = host\n self.server_port = port\n self.root = os.path.abspath(root)\n self.mount_path = (\"/\" + mount_path.lstrip(\"/\")).rstrip(\"/\") + \"/\"\n self.url = f\"http://{self.server_name}:{self.server_port}{self.mount_path}\"\n self.build_delay = 0.1\n self.shutdown_delay = shutdown_delay\n # To allow custom error pages.\n self.error_handler = lambda code: None\n\n super().__init__((host, port), _Handler, **kwargs)\n self.set_app(self.serve_request)\n\n self._wanted_epoch = _timestamp() # The version of the site that started building.\n self._visible_epoch = self._wanted_epoch # Latest fully built version of the site.\n self._epoch_cond = threading.Condition() # Must be held when accessing _visible_epoch.\n\n self._to_rebuild = {} # Used as an ordered set of functions to call.\n self._rebuild_cond = threading.Condition() # Must be held when accessing _to_rebuild.\n\n self._shutdown = False\n self.serve_thread = threading.Thread(target=lambda: self.serve_forever(shutdown_delay))\n self.observer = watchdog.observers.polling.PollingObserver(timeout=polling_interval)\n\n def watch(self, path, func=None, recursive=True):\n \"\"\"Add the 'path' to watched paths, call the function and reload when any file changes under it.\"\"\"\n path = os.path.abspath(path)\n if func in (None, self.builder):\n func = self.builder\n else:\n warnings.warn(\n \"Plugins should not pass the 'func' parameter of watch(). \"\n \"The ability to execute custom callbacks will be removed soon.\",\n DeprecationWarning,\n stacklevel=2,\n )\n\n def callback(event):\n if event.is_directory:\n return\n log.debug(str(event))\n with self._rebuild_cond:\n self._to_rebuild[func] = True\n self._rebuild_cond.notify_all()\n\n handler = watchdog.events.FileSystemEventHandler()\n handler.on_any_event = callback\n log.debug(f\"Watching '{path}'\")\n self.observer.schedule(handler, path, recursive=recursive)\n\n def serve(self):\n self.observer.start()\n\n log.info(f\"Serving on {self.url}\")\n self.serve_thread.start()\n\n self._build_loop()\n\n def _build_loop(self):\n while True:\n with self._rebuild_cond:\n while not self._rebuild_cond.wait_for(\n lambda: self._to_rebuild or self._shutdown, timeout=self.shutdown_delay\n ):\n # We could have used just one wait instead of a loop + timeout, but we need\n # occasional breaks, otherwise on Windows we can't receive KeyboardInterrupt.\n pass\n if self._shutdown:\n break\n log.info(\"Detected file changes\")\n while self._rebuild_cond.wait(timeout=self.build_delay):\n log.debug(\"Waiting for file changes to stop happening\")\n\n self._wanted_epoch = _timestamp()\n funcs = list(self._to_rebuild)\n self._to_rebuild.clear()\n\n for func in funcs:\n func()\n\n with self._epoch_cond:\n log.info(\"Reloading browsers\")\n self._visible_epoch = self._wanted_epoch\n self._epoch_cond.notify_all()\n\n def shutdown(self):\n self.observer.stop()\n with self._rebuild_cond:\n self._shutdown = True\n self._rebuild_cond.notify_all()\n\n if self.serve_thread.is_alive():\n super().shutdown()\n self.serve_thread.join()\n self.observer.join()\n\n def serve_request(self, environ, start_response):\n try:\n result = self._serve_request(environ, start_response)\n except Exception:\n code = 500\n msg = \"500 Internal Server Error\"\n log.exception(msg)\n else:\n if result is not None:\n return result\n code = 404\n msg = \"404 Not Found\"\n\n error_content = None\n try:\n error_content = self.error_handler(code)\n except Exception:\n log.exception(\"Failed to render an error message!\")\n if error_content is None:\n error_content = msg.encode()\n\n start_response(msg, [(\"Content-Type\", \"text/html\")])\n return [error_content]\n\n def _serve_request(self, environ, start_response):\n # https://bugs.python.org/issue16679\n # https://github.com/bottlepy/bottle/blob/f9b1849db4/bottle.py#L984\n path = environ[\"PATH_INFO\"].encode(\"latin-1\").decode(\"utf-8\", \"ignore\")\n\n m = re.fullmatch(r\"/livereload/([0-9]+)/[0-9]+\", path)\n if m:\n epoch = int(m[1])\n start_response(\"200 OK\", [(\"Content-Type\", \"text/plain\")])\n\n def condition():\n return self._visible_epoch > epoch\n\n with self._epoch_cond:\n if not condition():\n # Stall the browser, respond as soon as there's something new.\n # If there's not, respond anyway after a minute.\n self._log_poll_request(environ.get(\"HTTP_REFERER\"), request_id=path)\n self._epoch_cond.wait_for(condition, timeout=self.poll_response_timeout)\n return [b\"%d\" % self._visible_epoch]\n\n if path == \"/js/livereload.js\":\n file_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), \"livereload.js\")\n elif path.startswith(self.mount_path):\n rel_file_path = path[len(self.mount_path):]\n if path.endswith(\"/\"):\n rel_file_path += \"index.html\"\n # Prevent directory traversal - normalize the path.\n rel_file_path = posixpath.normpath(\"/\" + rel_file_path).lstrip(\"/\")\n file_path = os.path.join(self.root, rel_file_path)\n elif path == \"/\":\n start_response(\"302 Found\", [(\"Location\", self.mount_path)])\n return []\n else:\n return None # Not found\n\n # Wait until the ongoing rebuild (if any) finishes, so we're not serving a half-built site.\n with self._epoch_cond:\n self._epoch_cond.wait_for(lambda: self._visible_epoch == self._wanted_epoch)\n epoch = self._visible_epoch\n\n try:\n file = open(file_path, \"rb\")\n except OSError:\n if not path.endswith(\"/\") and os.path.isfile(os.path.join(file_path, \"index.html\")):\n start_response(\"302 Found\", [(\"Location\", path + \"/\")])\n return []\n return None # Not found\n\n if file_path.endswith(\".html\"):\n with file:\n content = file.read()\n content = self._inject_js_into_html(content, epoch)\n file = io.BytesIO(content)\n content_length = len(content)\n else:\n content_length = os.path.getsize(file_path)\n\n content_type = self._guess_type(file_path)\n start_response(\n \"200 OK\", [(\"Content-Type\", content_type), (\"Content-Length\", str(content_length))]\n )\n return wsgiref.util.FileWrapper(file)\n\n @classmethod\n def _inject_js_into_html(cls, content, epoch):\n try:\n body_end = content.rindex(b\"</body>\")\n except ValueError:\n body_end = len(content)\n # The page will reload if the livereload poller returns a newer epoch than what it knows.\n # The other timestamp becomes just a unique identifier for the initiating page.\n return (\n b'%b<script src=\"/js/livereload.js\"></script><script>livereload(%d, %d);</script>%b'\n % (content[:body_end], epoch, _timestamp(), content[body_end:])\n )\n\n @classmethod\n @functools.lru_cache() # \"Cache\" to not repeat the same message for the same browser tab.\n def _log_poll_request(cls, url, request_id):\n log.info(f\"Browser connected: {url}\")\n\n def _guess_type(cls, path):\n # MkDocs only ensures a few common types (as seen in livereload_tests.py::test_mime_types).\n # Other uncommon types will not be accepted.\n if path.endswith((\".js\", \".JS\")):\n return \"application/javascript\"\n if path.endswith(\".gz\"):\n return \"application/gzip\"\n\n guess, _ = mimetypes.guess_type(path)\n if guess:\n return guess\n return \"application/octet-stream\"\n\n\nclass _Handler(wsgiref.simple_server.WSGIRequestHandler):\n def log_request(self, code=\"-\", size=\"-\"):\n level = logging.DEBUG if str(code) == \"200\" else logging.WARNING\n log.log(level, f'\"{self.requestline}\" code {code}')\n\n def log_message(self, format, *args):\n log.debug(format, *args)\n\n\ndef _timestamp():\n return round(time.monotonic() * 1000)\n", "path": "mkdocs/livereload/__init__.py"}]}
| 3,218 | 256 |
gh_patches_debug_21290
|
rasdani/github-patches
|
git_diff
|
rucio__rucio-953
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
setup_clients.py classifiers needs to be a list, not tuples
Motivation
----------
Classifiers were changed to tuple, which does not work, needs to be a list.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup_rucio_client.py`
Content:
```
1 # Copyright 2014-2018 CERN for the benefit of the ATLAS collaboration.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 #
15 # Authors:
16 # - Vincent Garonne <[email protected]>, 2014-2018
17 # - Martin Barisits <[email protected]>, 2017
18
19 import os
20 import re
21 import shutil
22 import subprocess
23 import sys
24
25 from distutils.command.sdist import sdist as _sdist # pylint:disable=no-name-in-module,import-error
26 from setuptools import setup
27
28 sys.path.insert(0, os.path.abspath('lib/'))
29
30 from rucio import version # noqa
31
32 if sys.version_info < (2, 5):
33 print('ERROR: Rucio requires at least Python 2.6 to run.')
34 sys.exit(1)
35 sys.path.insert(0, os.path.abspath('lib/'))
36
37
38 # Arguments to the setup script to build Basic/Lite distributions
39 COPY_ARGS = sys.argv[1:]
40 NAME = 'rucio-clients'
41 IS_RELEASE = False
42 PACKAGES = ['rucio', 'rucio.client', 'rucio.common',
43 'rucio.rse.protocols', 'rucio.rse', 'rucio.tests']
44 REQUIREMENTS_FILES = ['tools/pip-requires-client']
45 DESCRIPTION = "Rucio Client Lite Package"
46 DATA_FILES = [('etc/', ['etc/rse-accounts.cfg.template', 'etc/rucio.cfg.template', 'etc/rucio.cfg.atlas.client.template']),
47 ('tools/', ['tools/pip-requires-client', ]), ]
48
49 SCRIPTS = ['bin/rucio', 'bin/rucio-admin']
50 if os.path.exists('build/'):
51 shutil.rmtree('build/')
52 if os.path.exists('lib/rucio_clients.egg-info/'):
53 shutil.rmtree('lib/rucio_clients.egg-info/')
54 if os.path.exists('lib/rucio.egg-info/'):
55 shutil.rmtree('lib/rucio.egg-info/')
56
57 SSH_EXTRAS = ['paramiko==1.18.4']
58 KERBEROS_EXTRAS = ['kerberos>=1.2.5', 'pykerberos>=1.1.14', 'requests-kerberos>=0.11.0']
59 SWIFT_EXTRAS = ['python-swiftclient>=3.5.0', ]
60 EXTRAS_REQUIRES = dict(ssh=SSH_EXTRAS,
61 kerberos=KERBEROS_EXTRAS,
62 swift=SWIFT_EXTRAS)
63
64 if '--release' in COPY_ARGS:
65 IS_RELEASE = True
66 COPY_ARGS.remove('--release')
67
68
69 # If Sphinx is installed on the box running setup.py,
70 # enable setup.py to build the documentation, otherwise,
71 # just ignore it
72 cmdclass = {}
73
74 try:
75 from sphinx.setup_command import BuildDoc
76
77 class local_BuildDoc(BuildDoc):
78 '''
79 local_BuildDoc
80 '''
81 def run(self):
82 '''
83 run
84 '''
85 for builder in ['html']: # 'man','latex'
86 self.builder = builder
87 self.finalize_options()
88 BuildDoc.run(self)
89 cmdclass['build_sphinx'] = local_BuildDoc
90 except Exception:
91 pass
92
93
94 def get_reqs_from_file(requirements_file):
95 '''
96 get_reqs_from_file
97 '''
98 if os.path.exists(requirements_file):
99 return open(requirements_file, 'r').read().split('\n')
100 return []
101
102
103 def parse_requirements(requirements_files):
104 '''
105 parse_requirements
106 '''
107 requirements = []
108 for requirements_file in requirements_files:
109 for line in get_reqs_from_file(requirements_file):
110 if re.match(r'\s*-e\s+', line):
111 requirements.append(re.sub(r'\s*-e\s+.*#egg=(.*)$', r'\1', line))
112 elif re.match(r'\s*-f\s+', line):
113 pass
114 else:
115 requirements.append(line)
116 return requirements
117
118
119 def parse_dependency_links(requirements_files):
120 '''
121 parse_dependency_links
122 '''
123 dependency_links = []
124 for requirements_file in requirements_files:
125 for line in get_reqs_from_file(requirements_file):
126 if re.match(r'(\s*#)|(\s*$)', line):
127 continue
128 if re.match(r'\s*-[ef]\s+', line):
129 dependency_links.append(re.sub(r'\s*-[ef]\s+', '', line))
130 return dependency_links
131
132
133 def write_requirements():
134 '''
135 write_requirements
136 '''
137 venv = os.environ.get('VIRTUAL_ENV', None)
138 if venv is not None:
139 req_file = open("requirements.txt", "w")
140 output = subprocess.Popen(["pip", "freeze", "-l"], stdout=subprocess.PIPE)
141 requirements = output.communicate()[0].strip()
142 req_file.write(requirements)
143 req_file.close()
144
145
146 REQUIRES = parse_requirements(requirements_files=REQUIREMENTS_FILES)
147 DEPEND_LINKS = parse_dependency_links(requirements_files=REQUIREMENTS_FILES)
148
149
150 class CustomSdist(_sdist):
151 '''
152 CustomSdist
153 '''
154 user_options = [
155 ('packaging=', None, "Some option to indicate what should be packaged")
156 ] + _sdist.user_options
157
158 def __init__(self, *args, **kwargs):
159 '''
160 __init__
161 '''
162 _sdist.__init__(self, *args, **kwargs)
163 self.packaging = "default value for this option"
164
165 def get_file_list(self):
166 '''
167 get_file_list
168 '''
169 print("Chosen packaging option: " + NAME)
170 self.distribution.data_files = DATA_FILES
171 _sdist.get_file_list(self)
172
173
174 cmdclass['sdist'] = CustomSdist
175
176 setup(
177 name=NAME,
178 version=version.version_string(),
179 packages=PACKAGES,
180 package_dir={'': 'lib'},
181 data_files=DATA_FILES,
182 script_args=COPY_ARGS,
183 cmdclass=cmdclass,
184 include_package_data=True,
185 scripts=SCRIPTS,
186 # doc=cmdclass,
187 author="Rucio",
188 author_email="[email protected]",
189 description=DESCRIPTION,
190 license="Apache License, Version 2.0",
191 url="http://rucio.cern.ch/",
192 python_requires=">=2.6, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*",
193 classifiers=(
194 'Development Status :: 5 - Production/Stable',
195 'License :: OSI Approved :: Apache Software License',
196 'Intended Audience :: Information Technology',
197 'Intended Audience :: System Administrators',
198 'Operating System :: POSIX :: Linux',
199 'Natural Language :: English',
200 'Programming Language :: Python',
201 'Programming Language :: Python :: 2.6',
202 'Programming Language :: Python :: 2.7',
203 'Programming Language :: Python :: 3',
204 'Programming Language :: Python :: 3.4',
205 'Programming Language :: Python :: 3.5',
206 'Programming Language :: Python :: 3.6',
207 'Programming Language :: Python :: Implementation :: CPython',
208 'Programming Language :: Python :: Implementation :: PyPy',
209 'Environment :: No Input/Output (Daemon)'
210 ),
211 install_requires=REQUIRES,
212 extras_require=EXTRAS_REQUIRES,
213 dependency_links=DEPEND_LINKS,
214 )
215
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup_rucio_client.py b/setup_rucio_client.py
--- a/setup_rucio_client.py
+++ b/setup_rucio_client.py
@@ -190,7 +190,7 @@
license="Apache License, Version 2.0",
url="http://rucio.cern.ch/",
python_requires=">=2.6, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*",
- classifiers=(
+ classifiers=[
'Development Status :: 5 - Production/Stable',
'License :: OSI Approved :: Apache Software License',
'Intended Audience :: Information Technology',
@@ -207,7 +207,7 @@
'Programming Language :: Python :: Implementation :: CPython',
'Programming Language :: Python :: Implementation :: PyPy',
'Environment :: No Input/Output (Daemon)'
- ),
+ ],
install_requires=REQUIRES,
extras_require=EXTRAS_REQUIRES,
dependency_links=DEPEND_LINKS,
|
{"golden_diff": "diff --git a/setup_rucio_client.py b/setup_rucio_client.py\n--- a/setup_rucio_client.py\n+++ b/setup_rucio_client.py\n@@ -190,7 +190,7 @@\n license=\"Apache License, Version 2.0\",\n url=\"http://rucio.cern.ch/\",\n python_requires=\">=2.6, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*\",\n- classifiers=(\n+ classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'License :: OSI Approved :: Apache Software License',\n 'Intended Audience :: Information Technology',\n@@ -207,7 +207,7 @@\n 'Programming Language :: Python :: Implementation :: CPython',\n 'Programming Language :: Python :: Implementation :: PyPy',\n 'Environment :: No Input/Output (Daemon)'\n- ),\n+ ],\n install_requires=REQUIRES,\n extras_require=EXTRAS_REQUIRES,\n dependency_links=DEPEND_LINKS,\n", "issue": "setup_clients.py classifiers needs to be a list, not tuples\nMotivation\r\n----------\r\nClassifiers were changed to tuple, which does not work, needs to be a list.\n", "before_files": [{"content": "# Copyright 2014-2018 CERN for the benefit of the ATLAS collaboration.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n# Authors:\n# - Vincent Garonne <[email protected]>, 2014-2018\n# - Martin Barisits <[email protected]>, 2017\n\nimport os\nimport re\nimport shutil\nimport subprocess\nimport sys\n\nfrom distutils.command.sdist import sdist as _sdist # pylint:disable=no-name-in-module,import-error\nfrom setuptools import setup\n\nsys.path.insert(0, os.path.abspath('lib/'))\n\nfrom rucio import version # noqa\n\nif sys.version_info < (2, 5):\n print('ERROR: Rucio requires at least Python 2.6 to run.')\n sys.exit(1)\nsys.path.insert(0, os.path.abspath('lib/'))\n\n\n# Arguments to the setup script to build Basic/Lite distributions\nCOPY_ARGS = sys.argv[1:]\nNAME = 'rucio-clients'\nIS_RELEASE = False\nPACKAGES = ['rucio', 'rucio.client', 'rucio.common',\n 'rucio.rse.protocols', 'rucio.rse', 'rucio.tests']\nREQUIREMENTS_FILES = ['tools/pip-requires-client']\nDESCRIPTION = \"Rucio Client Lite Package\"\nDATA_FILES = [('etc/', ['etc/rse-accounts.cfg.template', 'etc/rucio.cfg.template', 'etc/rucio.cfg.atlas.client.template']),\n ('tools/', ['tools/pip-requires-client', ]), ]\n\nSCRIPTS = ['bin/rucio', 'bin/rucio-admin']\nif os.path.exists('build/'):\n shutil.rmtree('build/')\nif os.path.exists('lib/rucio_clients.egg-info/'):\n shutil.rmtree('lib/rucio_clients.egg-info/')\nif os.path.exists('lib/rucio.egg-info/'):\n shutil.rmtree('lib/rucio.egg-info/')\n\nSSH_EXTRAS = ['paramiko==1.18.4']\nKERBEROS_EXTRAS = ['kerberos>=1.2.5', 'pykerberos>=1.1.14', 'requests-kerberos>=0.11.0']\nSWIFT_EXTRAS = ['python-swiftclient>=3.5.0', ]\nEXTRAS_REQUIRES = dict(ssh=SSH_EXTRAS,\n kerberos=KERBEROS_EXTRAS,\n swift=SWIFT_EXTRAS)\n\nif '--release' in COPY_ARGS:\n IS_RELEASE = True\n COPY_ARGS.remove('--release')\n\n\n# If Sphinx is installed on the box running setup.py,\n# enable setup.py to build the documentation, otherwise,\n# just ignore it\ncmdclass = {}\n\ntry:\n from sphinx.setup_command import BuildDoc\n\n class local_BuildDoc(BuildDoc):\n '''\n local_BuildDoc\n '''\n def run(self):\n '''\n run\n '''\n for builder in ['html']: # 'man','latex'\n self.builder = builder\n self.finalize_options()\n BuildDoc.run(self)\n cmdclass['build_sphinx'] = local_BuildDoc\nexcept Exception:\n pass\n\n\ndef get_reqs_from_file(requirements_file):\n '''\n get_reqs_from_file\n '''\n if os.path.exists(requirements_file):\n return open(requirements_file, 'r').read().split('\\n')\n return []\n\n\ndef parse_requirements(requirements_files):\n '''\n parse_requirements\n '''\n requirements = []\n for requirements_file in requirements_files:\n for line in get_reqs_from_file(requirements_file):\n if re.match(r'\\s*-e\\s+', line):\n requirements.append(re.sub(r'\\s*-e\\s+.*#egg=(.*)$', r'\\1', line))\n elif re.match(r'\\s*-f\\s+', line):\n pass\n else:\n requirements.append(line)\n return requirements\n\n\ndef parse_dependency_links(requirements_files):\n '''\n parse_dependency_links\n '''\n dependency_links = []\n for requirements_file in requirements_files:\n for line in get_reqs_from_file(requirements_file):\n if re.match(r'(\\s*#)|(\\s*$)', line):\n continue\n if re.match(r'\\s*-[ef]\\s+', line):\n dependency_links.append(re.sub(r'\\s*-[ef]\\s+', '', line))\n return dependency_links\n\n\ndef write_requirements():\n '''\n write_requirements\n '''\n venv = os.environ.get('VIRTUAL_ENV', None)\n if venv is not None:\n req_file = open(\"requirements.txt\", \"w\")\n output = subprocess.Popen([\"pip\", \"freeze\", \"-l\"], stdout=subprocess.PIPE)\n requirements = output.communicate()[0].strip()\n req_file.write(requirements)\n req_file.close()\n\n\nREQUIRES = parse_requirements(requirements_files=REQUIREMENTS_FILES)\nDEPEND_LINKS = parse_dependency_links(requirements_files=REQUIREMENTS_FILES)\n\n\nclass CustomSdist(_sdist):\n '''\n CustomSdist\n '''\n user_options = [\n ('packaging=', None, \"Some option to indicate what should be packaged\")\n ] + _sdist.user_options\n\n def __init__(self, *args, **kwargs):\n '''\n __init__\n '''\n _sdist.__init__(self, *args, **kwargs)\n self.packaging = \"default value for this option\"\n\n def get_file_list(self):\n '''\n get_file_list\n '''\n print(\"Chosen packaging option: \" + NAME)\n self.distribution.data_files = DATA_FILES\n _sdist.get_file_list(self)\n\n\ncmdclass['sdist'] = CustomSdist\n\nsetup(\n name=NAME,\n version=version.version_string(),\n packages=PACKAGES,\n package_dir={'': 'lib'},\n data_files=DATA_FILES,\n script_args=COPY_ARGS,\n cmdclass=cmdclass,\n include_package_data=True,\n scripts=SCRIPTS,\n # doc=cmdclass,\n author=\"Rucio\",\n author_email=\"[email protected]\",\n description=DESCRIPTION,\n license=\"Apache License, Version 2.0\",\n url=\"http://rucio.cern.ch/\",\n python_requires=\">=2.6, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*\",\n classifiers=(\n 'Development Status :: 5 - Production/Stable',\n 'License :: OSI Approved :: Apache Software License',\n 'Intended Audience :: Information Technology',\n 'Intended Audience :: System Administrators',\n 'Operating System :: POSIX :: Linux',\n 'Natural Language :: English',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2.6',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: Implementation :: CPython',\n 'Programming Language :: Python :: Implementation :: PyPy',\n 'Environment :: No Input/Output (Daemon)'\n ),\n install_requires=REQUIRES,\n extras_require=EXTRAS_REQUIRES,\n dependency_links=DEPEND_LINKS,\n)\n", "path": "setup_rucio_client.py"}], "after_files": [{"content": "# Copyright 2014-2018 CERN for the benefit of the ATLAS collaboration.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n# Authors:\n# - Vincent Garonne <[email protected]>, 2014-2018\n# - Martin Barisits <[email protected]>, 2017\n\nimport os\nimport re\nimport shutil\nimport subprocess\nimport sys\n\nfrom distutils.command.sdist import sdist as _sdist # pylint:disable=no-name-in-module,import-error\nfrom setuptools import setup\n\nsys.path.insert(0, os.path.abspath('lib/'))\n\nfrom rucio import version # noqa\n\nif sys.version_info < (2, 5):\n print('ERROR: Rucio requires at least Python 2.6 to run.')\n sys.exit(1)\nsys.path.insert(0, os.path.abspath('lib/'))\n\n\n# Arguments to the setup script to build Basic/Lite distributions\nCOPY_ARGS = sys.argv[1:]\nNAME = 'rucio-clients'\nIS_RELEASE = False\nPACKAGES = ['rucio', 'rucio.client', 'rucio.common',\n 'rucio.rse.protocols', 'rucio.rse', 'rucio.tests']\nREQUIREMENTS_FILES = ['tools/pip-requires-client']\nDESCRIPTION = \"Rucio Client Lite Package\"\nDATA_FILES = [('etc/', ['etc/rse-accounts.cfg.template', 'etc/rucio.cfg.template', 'etc/rucio.cfg.atlas.client.template']),\n ('tools/', ['tools/pip-requires-client', ]), ]\n\nSCRIPTS = ['bin/rucio', 'bin/rucio-admin']\nif os.path.exists('build/'):\n shutil.rmtree('build/')\nif os.path.exists('lib/rucio_clients.egg-info/'):\n shutil.rmtree('lib/rucio_clients.egg-info/')\nif os.path.exists('lib/rucio.egg-info/'):\n shutil.rmtree('lib/rucio.egg-info/')\n\nSSH_EXTRAS = ['paramiko==1.18.4']\nKERBEROS_EXTRAS = ['kerberos>=1.2.5', 'pykerberos>=1.1.14', 'requests-kerberos>=0.11.0']\nSWIFT_EXTRAS = ['python-swiftclient>=3.5.0', ]\nEXTRAS_REQUIRES = dict(ssh=SSH_EXTRAS,\n kerberos=KERBEROS_EXTRAS,\n swift=SWIFT_EXTRAS)\n\nif '--release' in COPY_ARGS:\n IS_RELEASE = True\n COPY_ARGS.remove('--release')\n\n\n# If Sphinx is installed on the box running setup.py,\n# enable setup.py to build the documentation, otherwise,\n# just ignore it\ncmdclass = {}\n\ntry:\n from sphinx.setup_command import BuildDoc\n\n class local_BuildDoc(BuildDoc):\n '''\n local_BuildDoc\n '''\n def run(self):\n '''\n run\n '''\n for builder in ['html']: # 'man','latex'\n self.builder = builder\n self.finalize_options()\n BuildDoc.run(self)\n cmdclass['build_sphinx'] = local_BuildDoc\nexcept Exception:\n pass\n\n\ndef get_reqs_from_file(requirements_file):\n '''\n get_reqs_from_file\n '''\n if os.path.exists(requirements_file):\n return open(requirements_file, 'r').read().split('\\n')\n return []\n\n\ndef parse_requirements(requirements_files):\n '''\n parse_requirements\n '''\n requirements = []\n for requirements_file in requirements_files:\n for line in get_reqs_from_file(requirements_file):\n if re.match(r'\\s*-e\\s+', line):\n requirements.append(re.sub(r'\\s*-e\\s+.*#egg=(.*)$', r'\\1', line))\n elif re.match(r'\\s*-f\\s+', line):\n pass\n else:\n requirements.append(line)\n return requirements\n\n\ndef parse_dependency_links(requirements_files):\n '''\n parse_dependency_links\n '''\n dependency_links = []\n for requirements_file in requirements_files:\n for line in get_reqs_from_file(requirements_file):\n if re.match(r'(\\s*#)|(\\s*$)', line):\n continue\n if re.match(r'\\s*-[ef]\\s+', line):\n dependency_links.append(re.sub(r'\\s*-[ef]\\s+', '', line))\n return dependency_links\n\n\ndef write_requirements():\n '''\n write_requirements\n '''\n venv = os.environ.get('VIRTUAL_ENV', None)\n if venv is not None:\n req_file = open(\"requirements.txt\", \"w\")\n output = subprocess.Popen([\"pip\", \"freeze\", \"-l\"], stdout=subprocess.PIPE)\n requirements = output.communicate()[0].strip()\n req_file.write(requirements)\n req_file.close()\n\n\nREQUIRES = parse_requirements(requirements_files=REQUIREMENTS_FILES)\nDEPEND_LINKS = parse_dependency_links(requirements_files=REQUIREMENTS_FILES)\n\n\nclass CustomSdist(_sdist):\n '''\n CustomSdist\n '''\n user_options = [\n ('packaging=', None, \"Some option to indicate what should be packaged\")\n ] + _sdist.user_options\n\n def __init__(self, *args, **kwargs):\n '''\n __init__\n '''\n _sdist.__init__(self, *args, **kwargs)\n self.packaging = \"default value for this option\"\n\n def get_file_list(self):\n '''\n get_file_list\n '''\n print(\"Chosen packaging option: \" + NAME)\n self.distribution.data_files = DATA_FILES\n _sdist.get_file_list(self)\n\n\ncmdclass['sdist'] = CustomSdist\n\nsetup(\n name=NAME,\n version=version.version_string(),\n packages=PACKAGES,\n package_dir={'': 'lib'},\n data_files=DATA_FILES,\n script_args=COPY_ARGS,\n cmdclass=cmdclass,\n include_package_data=True,\n scripts=SCRIPTS,\n # doc=cmdclass,\n author=\"Rucio\",\n author_email=\"[email protected]\",\n description=DESCRIPTION,\n license=\"Apache License, Version 2.0\",\n url=\"http://rucio.cern.ch/\",\n python_requires=\">=2.6, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*\",\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'License :: OSI Approved :: Apache Software License',\n 'Intended Audience :: Information Technology',\n 'Intended Audience :: System Administrators',\n 'Operating System :: POSIX :: Linux',\n 'Natural Language :: English',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2.6',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: Implementation :: CPython',\n 'Programming Language :: Python :: Implementation :: PyPy',\n 'Environment :: No Input/Output (Daemon)'\n ],\n install_requires=REQUIRES,\n extras_require=EXTRAS_REQUIRES,\n dependency_links=DEPEND_LINKS,\n)\n", "path": "setup_rucio_client.py"}]}
| 2,527 | 223 |
gh_patches_debug_41092
|
rasdani/github-patches
|
git_diff
|
jupyterhub__jupyterhub-4249
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
migrate remaining rst docs to myst
We still have several doc pages in .rst format, while most are .md.
@consideRatio proposed migrating to myst, which I agree we should do, and it may be good to get done before the docs-reorg internship gets underway in a few weeks.
The challenge is the following open PRs (mostly from the outreachy application period last month) touch these rst files:
- [x] #4209:
- docs/source/contributing/setup.rst
- [x] #4186:
- docs/source/getting-started/security-basics.rst
- [x] #4127:
- docs/source/contributing/docs.rst
- [x] #4119:
- docs/source/contributing/tests.rst
- [x] #4094:
- docs/source/admin/upgrading.rst
- docs/source/getting-started/security-basics.rst
- [x] #4084:
- docs/source/index.rst
- [ ] #4066:
- docs/source/contributing/index.rst
- docs/source/contributing/layout.rst
- [x] #4008:
- docs/source/index-admin.rst
- [x] #3053:
- docs/source/reference/index.rst
- [ ] #2726:
- docs/source/getting-started/index.rst
- docs/source/index.rst
<details>
<summary>PR list generated with</summary>
```python
from github import Github as GitHub
gh = GitHub()
repo = gh.get_repo("jupyterhub/jupyterhub")
for pull in repo.get_pulls(state="open"):
pull_files = [f.filename for f in list(pull.get_files())]
if any(f.endswith(".rst") for f in pull_files):
print(f"- [ ] #{pull.number}:")
for f in pull_files:
if f.endswith(".rst"):
print(f" - {f}")
continue
```
</details>
We should merge/close as many of these as we can to avoid conflicts (some that just touch an index are no big deal to resolve conflicts).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/generate-metrics.py`
Content:
```
1 import os
2
3 from pytablewriter import RstSimpleTableWriter
4 from pytablewriter.style import Style
5
6 import jupyterhub.metrics
7
8 HERE = os.path.abspath(os.path.dirname(__file__))
9
10
11 class Generator:
12 @classmethod
13 def create_writer(cls, table_name, headers, values):
14 writer = RstSimpleTableWriter()
15 writer.table_name = table_name
16 writer.headers = headers
17 writer.value_matrix = values
18 writer.margin = 1
19 [writer.set_style(header, Style(align="center")) for header in headers]
20 return writer
21
22 def _parse_metrics(self):
23 table_rows = []
24 for name in dir(jupyterhub.metrics):
25 obj = getattr(jupyterhub.metrics, name)
26 if obj.__class__.__module__.startswith('prometheus_client.'):
27 for metric in obj.describe():
28 table_rows.append([metric.type, metric.name, metric.documentation])
29 return table_rows
30
31 def prometheus_metrics(self):
32 generated_directory = f"{HERE}/source/reference"
33 if not os.path.exists(generated_directory):
34 os.makedirs(generated_directory)
35
36 filename = f"{generated_directory}/metrics.rst"
37 table_name = ""
38 headers = ["Type", "Name", "Description"]
39 values = self._parse_metrics()
40 writer = self.create_writer(table_name, headers, values)
41
42 title = "List of Prometheus Metrics"
43 underline = "============================"
44 content = f"{title}\n{underline}\n{writer.dumps()}"
45 with open(filename, 'w') as f:
46 f.write(content)
47 print(f"Generated {filename}.")
48
49
50 def main():
51 doc_generator = Generator()
52 doc_generator.prometheus_metrics()
53
54
55 if __name__ == "__main__":
56 main()
57
```
Path: `docs/source/conf.py`
Content:
```
1 # Configuration file for Sphinx to build our documentation to HTML.
2 #
3 # Configuration reference: https://www.sphinx-doc.org/en/master/usage/configuration.html
4 #
5 import contextlib
6 import datetime
7 import io
8 import os
9 import subprocess
10
11 from docutils import nodes
12 from sphinx.directives.other import SphinxDirective
13
14 import jupyterhub
15 from jupyterhub.app import JupyterHub
16
17 # -- Project information -----------------------------------------------------
18 # ref: https://www.sphinx-doc.org/en/master/usage/configuration.html#project-information
19 #
20 project = "JupyterHub"
21 author = "Project Jupyter Contributors"
22 copyright = f"{datetime.date.today().year}, {author}"
23 version = "%i.%i" % jupyterhub.version_info[:2]
24 release = jupyterhub.__version__
25
26
27 # -- General Sphinx configuration --------------------------------------------
28 # ref: https://www.sphinx-doc.org/en/master/usage/configuration.html#general-configuration
29 #
30 extensions = [
31 "sphinx.ext.autodoc",
32 "sphinx.ext.intersphinx",
33 "sphinx.ext.napoleon",
34 "autodoc_traits",
35 "sphinx_copybutton",
36 "sphinx-jsonschema",
37 "sphinxext.opengraph",
38 "sphinxext.rediraffe",
39 "myst_parser",
40 ]
41 root_doc = "index"
42 source_suffix = [".md", ".rst"]
43 # default_role let's use use `foo` instead of ``foo`` in rST
44 default_role = "literal"
45
46
47 # -- MyST configuration ------------------------------------------------------
48 # ref: https://myst-parser.readthedocs.io/en/latest/configuration.html
49 #
50 myst_heading_anchors = 2
51 myst_enable_extensions = [
52 "colon_fence",
53 "deflist",
54 ]
55
56
57 # -- Custom directives to generate documentation -----------------------------
58 # ref: https://myst-parser.readthedocs.io/en/latest/syntax/roles-and-directives.html
59 #
60 # We define custom directives to help us generate documentation using Python on
61 # demand when referenced from our documentation files.
62 #
63
64 # Create a temp instance of JupyterHub for use by two separate directive classes
65 # to get the output from using the "--generate-config" and "--help-all" CLI
66 # flags respectively.
67 #
68 jupyterhub_app = JupyterHub()
69
70
71 class ConfigDirective(SphinxDirective):
72 """Generate the configuration file output for use in the documentation."""
73
74 has_content = False
75 required_arguments = 0
76 optional_arguments = 0
77 final_argument_whitespace = False
78 option_spec = {}
79
80 def run(self):
81 # The generated configuration file for this version
82 generated_config = jupyterhub_app.generate_config_file()
83 # post-process output
84 home_dir = os.environ["HOME"]
85 generated_config = generated_config.replace(home_dir, "$HOME", 1)
86 par = nodes.literal_block(text=generated_config)
87 return [par]
88
89
90 class HelpAllDirective(SphinxDirective):
91 """Print the output of jupyterhub help --all for use in the documentation."""
92
93 has_content = False
94 required_arguments = 0
95 optional_arguments = 0
96 final_argument_whitespace = False
97 option_spec = {}
98
99 def run(self):
100 # The output of the help command for this version
101 buffer = io.StringIO()
102 with contextlib.redirect_stdout(buffer):
103 jupyterhub_app.print_help("--help-all")
104 all_help = buffer.getvalue()
105 # post-process output
106 home_dir = os.environ["HOME"]
107 all_help = all_help.replace(home_dir, "$HOME", 1)
108 par = nodes.literal_block(text=all_help)
109 return [par]
110
111
112 def setup(app):
113 app.add_css_file("custom.css")
114 app.add_directive("jupyterhub-generate-config", ConfigDirective)
115 app.add_directive("jupyterhub-help-all", HelpAllDirective)
116
117
118 # -- Read The Docs -----------------------------------------------------------
119 #
120 # Since RTD runs sphinx-build directly without running "make html", we run the
121 # pre-requisite steps for "make html" from here if needed.
122 #
123 if os.environ.get("READTHEDOCS"):
124 docs = os.path.dirname(os.path.dirname(__file__))
125 subprocess.check_call(["make", "metrics", "scopes"], cwd=docs)
126
127
128 # -- Spell checking ----------------------------------------------------------
129 # ref: https://sphinxcontrib-spelling.readthedocs.io/en/latest/customize.html#configuration-options
130 #
131 # The "sphinxcontrib.spelling" extension is optionally enabled if its available.
132 #
133 try:
134 import sphinxcontrib.spelling # noqa
135 except ImportError:
136 pass
137 else:
138 extensions.append("sphinxcontrib.spelling")
139 spelling_word_list_filename = "spelling_wordlist.txt"
140
141
142 # -- Options for HTML output -------------------------------------------------
143 # ref: https://www.sphinx-doc.org/en/master/usage/configuration.html#options-for-html-output
144 #
145 html_logo = "_static/images/logo/logo.png"
146 html_favicon = "_static/images/logo/favicon.ico"
147 html_static_path = ["_static"]
148
149 html_theme = "pydata_sphinx_theme"
150 html_theme_options = {
151 "icon_links": [
152 {
153 "name": "GitHub",
154 "url": "https://github.com/jupyterhub/jupyterhub",
155 "icon": "fab fa-github-square",
156 },
157 {
158 "name": "Discourse",
159 "url": "https://discourse.jupyter.org/c/jupyterhub/10",
160 "icon": "fab fa-discourse",
161 },
162 ],
163 "use_edit_page_button": True,
164 "navbar_align": "left",
165 }
166 html_context = {
167 "github_user": "jupyterhub",
168 "github_repo": "jupyterhub",
169 "github_version": "main",
170 "doc_path": "docs/source",
171 }
172
173
174 # -- Options for linkcheck builder -------------------------------------------
175 # ref: https://www.sphinx-doc.org/en/master/usage/configuration.html#options-for-the-linkcheck-builder
176 #
177 linkcheck_ignore = [
178 r"(.*)github\.com(.*)#", # javascript based anchors
179 r"(.*)/#%21(.*)/(.*)", # /#!forum/jupyter - encoded anchor edge case
180 r"https://github.com/[^/]*$", # too many github usernames / searches in changelog
181 "https://github.com/jupyterhub/jupyterhub/pull/", # too many PRs in changelog
182 "https://github.com/jupyterhub/jupyterhub/compare/", # too many comparisons in changelog
183 ]
184 linkcheck_anchors_ignore = [
185 "/#!",
186 "/#%21",
187 ]
188
189
190 # -- Intersphinx -------------------------------------------------------------
191 # ref: https://www.sphinx-doc.org/en/master/usage/extensions/intersphinx.html#configuration
192 #
193 intersphinx_mapping = {
194 "python": ("https://docs.python.org/3/", None),
195 "tornado": ("https://www.tornadoweb.org/en/stable/", None),
196 }
197 # -- Options for the opengraph extension -------------------------------------
198 # ref: https://github.com/wpilibsuite/sphinxext-opengraph#options
199 #
200 # ogp_site_url is set automatically by RTD
201 ogp_image = "_static/logo.png"
202 ogp_use_first_image = True
203
204
205 # -- Options for the rediraffe extension -------------------------------------
206 # ref: https://github.com/wpilibsuite/sphinxext-rediraffe#readme
207 #
208 # This extensions help us relocated content without breaking links. If a
209 # document is moved internally, a redirect like should be configured below to
210 # help us not break links.
211 #
212 rediraffe_branch = "main"
213 rediraffe_redirects = {
214 # "old-file": "new-folder/new-file-name",
215 }
216
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docs/generate-metrics.py b/docs/generate-metrics.py
--- a/docs/generate-metrics.py
+++ b/docs/generate-metrics.py
@@ -1,7 +1,6 @@
import os
-from pytablewriter import RstSimpleTableWriter
-from pytablewriter.style import Style
+from pytablewriter import MarkdownTableWriter
import jupyterhub.metrics
@@ -11,12 +10,11 @@
class Generator:
@classmethod
def create_writer(cls, table_name, headers, values):
- writer = RstSimpleTableWriter()
+ writer = MarkdownTableWriter()
writer.table_name = table_name
writer.headers = headers
writer.value_matrix = values
writer.margin = 1
- [writer.set_style(header, Style(align="center")) for header in headers]
return writer
def _parse_metrics(self):
@@ -33,18 +31,17 @@
if not os.path.exists(generated_directory):
os.makedirs(generated_directory)
- filename = f"{generated_directory}/metrics.rst"
+ filename = f"{generated_directory}/metrics.md"
table_name = ""
headers = ["Type", "Name", "Description"]
values = self._parse_metrics()
writer = self.create_writer(table_name, headers, values)
- title = "List of Prometheus Metrics"
- underline = "============================"
- content = f"{title}\n{underline}\n{writer.dumps()}"
with open(filename, 'w') as f:
- f.write(content)
- print(f"Generated {filename}.")
+ f.write("# List of Prometheus Metrics\n\n")
+ f.write(writer.dumps())
+ f.write("\n")
+ print(f"Generated {filename}")
def main():
diff --git a/docs/source/conf.py b/docs/source/conf.py
--- a/docs/source/conf.py
+++ b/docs/source/conf.py
@@ -20,8 +20,6 @@
project = "JupyterHub"
author = "Project Jupyter Contributors"
copyright = f"{datetime.date.today().year}, {author}"
-version = "%i.%i" % jupyterhub.version_info[:2]
-release = jupyterhub.__version__
# -- General Sphinx configuration --------------------------------------------
@@ -39,7 +37,7 @@
"myst_parser",
]
root_doc = "index"
-source_suffix = [".md", ".rst"]
+source_suffix = [".md"]
# default_role let's use use `foo` instead of ``foo`` in rST
default_role = "literal"
@@ -48,11 +46,21 @@
# ref: https://myst-parser.readthedocs.io/en/latest/configuration.html
#
myst_heading_anchors = 2
+
myst_enable_extensions = [
+ # available extensions: https://myst-parser.readthedocs.io/en/latest/syntax/optional.html
"colon_fence",
"deflist",
+ "fieldlist",
+ "substitution",
]
+myst_substitutions = {
+ # date example: Dev 07, 2022
+ "date": datetime.date.today().strftime("%b %d, %Y").title(),
+ "version": jupyterhub.__version__,
+}
+
# -- Custom directives to generate documentation -----------------------------
# ref: https://myst-parser.readthedocs.io/en/latest/syntax/roles-and-directives.html
|
{"golden_diff": "diff --git a/docs/generate-metrics.py b/docs/generate-metrics.py\n--- a/docs/generate-metrics.py\n+++ b/docs/generate-metrics.py\n@@ -1,7 +1,6 @@\n import os\n \n-from pytablewriter import RstSimpleTableWriter\n-from pytablewriter.style import Style\n+from pytablewriter import MarkdownTableWriter\n \n import jupyterhub.metrics\n \n@@ -11,12 +10,11 @@\n class Generator:\n @classmethod\n def create_writer(cls, table_name, headers, values):\n- writer = RstSimpleTableWriter()\n+ writer = MarkdownTableWriter()\n writer.table_name = table_name\n writer.headers = headers\n writer.value_matrix = values\n writer.margin = 1\n- [writer.set_style(header, Style(align=\"center\")) for header in headers]\n return writer\n \n def _parse_metrics(self):\n@@ -33,18 +31,17 @@\n if not os.path.exists(generated_directory):\n os.makedirs(generated_directory)\n \n- filename = f\"{generated_directory}/metrics.rst\"\n+ filename = f\"{generated_directory}/metrics.md\"\n table_name = \"\"\n headers = [\"Type\", \"Name\", \"Description\"]\n values = self._parse_metrics()\n writer = self.create_writer(table_name, headers, values)\n \n- title = \"List of Prometheus Metrics\"\n- underline = \"============================\"\n- content = f\"{title}\\n{underline}\\n{writer.dumps()}\"\n with open(filename, 'w') as f:\n- f.write(content)\n- print(f\"Generated {filename}.\")\n+ f.write(\"# List of Prometheus Metrics\\n\\n\")\n+ f.write(writer.dumps())\n+ f.write(\"\\n\")\n+ print(f\"Generated {filename}\")\n \n \n def main():\ndiff --git a/docs/source/conf.py b/docs/source/conf.py\n--- a/docs/source/conf.py\n+++ b/docs/source/conf.py\n@@ -20,8 +20,6 @@\n project = \"JupyterHub\"\n author = \"Project Jupyter Contributors\"\n copyright = f\"{datetime.date.today().year}, {author}\"\n-version = \"%i.%i\" % jupyterhub.version_info[:2]\n-release = jupyterhub.__version__\n \n \n # -- General Sphinx configuration --------------------------------------------\n@@ -39,7 +37,7 @@\n \"myst_parser\",\n ]\n root_doc = \"index\"\n-source_suffix = [\".md\", \".rst\"]\n+source_suffix = [\".md\"]\n # default_role let's use use `foo` instead of ``foo`` in rST\n default_role = \"literal\"\n \n@@ -48,11 +46,21 @@\n # ref: https://myst-parser.readthedocs.io/en/latest/configuration.html\n #\n myst_heading_anchors = 2\n+\n myst_enable_extensions = [\n+ # available extensions: https://myst-parser.readthedocs.io/en/latest/syntax/optional.html\n \"colon_fence\",\n \"deflist\",\n+ \"fieldlist\",\n+ \"substitution\",\n ]\n \n+myst_substitutions = {\n+ # date example: Dev 07, 2022\n+ \"date\": datetime.date.today().strftime(\"%b %d, %Y\").title(),\n+ \"version\": jupyterhub.__version__,\n+}\n+\n \n # -- Custom directives to generate documentation -----------------------------\n # ref: https://myst-parser.readthedocs.io/en/latest/syntax/roles-and-directives.html\n", "issue": "migrate remaining rst docs to myst\nWe still have several doc pages in .rst format, while most are .md.\r\n\r\n@consideRatio proposed migrating to myst, which I agree we should do, and it may be good to get done before the docs-reorg internship gets underway in a few weeks.\r\n\r\nThe challenge is the following open PRs (mostly from the outreachy application period last month) touch these rst files:\r\n\r\n- [x] #4209:\r\n - docs/source/contributing/setup.rst\r\n- [x] #4186:\r\n - docs/source/getting-started/security-basics.rst\r\n- [x] #4127:\r\n - docs/source/contributing/docs.rst\r\n- [x] #4119:\r\n - docs/source/contributing/tests.rst\r\n- [x] #4094:\r\n - docs/source/admin/upgrading.rst\r\n - docs/source/getting-started/security-basics.rst\r\n- [x] #4084:\r\n - docs/source/index.rst\r\n- [ ] #4066:\r\n - docs/source/contributing/index.rst\r\n - docs/source/contributing/layout.rst\r\n- [x] #4008:\r\n - docs/source/index-admin.rst\r\n- [x] #3053:\r\n - docs/source/reference/index.rst\r\n- [ ] #2726:\r\n - docs/source/getting-started/index.rst\r\n - docs/source/index.rst\r\n\r\n<details>\r\n<summary>PR list generated with</summary>\r\n\r\n```python\r\nfrom github import Github as GitHub\r\n\r\ngh = GitHub()\r\n\r\nrepo = gh.get_repo(\"jupyterhub/jupyterhub\")\r\nfor pull in repo.get_pulls(state=\"open\"):\r\n pull_files = [f.filename for f in list(pull.get_files())]\r\n if any(f.endswith(\".rst\") for f in pull_files):\r\n print(f\"- [ ] #{pull.number}:\")\r\n for f in pull_files:\r\n if f.endswith(\".rst\"):\r\n print(f\" - {f}\")\r\n continue\r\n```\r\n\r\n</details>\r\n\r\nWe should merge/close as many of these as we can to avoid conflicts (some that just touch an index are no big deal to resolve conflicts).\r\n\r\n\r\n\n", "before_files": [{"content": "import os\n\nfrom pytablewriter import RstSimpleTableWriter\nfrom pytablewriter.style import Style\n\nimport jupyterhub.metrics\n\nHERE = os.path.abspath(os.path.dirname(__file__))\n\n\nclass Generator:\n @classmethod\n def create_writer(cls, table_name, headers, values):\n writer = RstSimpleTableWriter()\n writer.table_name = table_name\n writer.headers = headers\n writer.value_matrix = values\n writer.margin = 1\n [writer.set_style(header, Style(align=\"center\")) for header in headers]\n return writer\n\n def _parse_metrics(self):\n table_rows = []\n for name in dir(jupyterhub.metrics):\n obj = getattr(jupyterhub.metrics, name)\n if obj.__class__.__module__.startswith('prometheus_client.'):\n for metric in obj.describe():\n table_rows.append([metric.type, metric.name, metric.documentation])\n return table_rows\n\n def prometheus_metrics(self):\n generated_directory = f\"{HERE}/source/reference\"\n if not os.path.exists(generated_directory):\n os.makedirs(generated_directory)\n\n filename = f\"{generated_directory}/metrics.rst\"\n table_name = \"\"\n headers = [\"Type\", \"Name\", \"Description\"]\n values = self._parse_metrics()\n writer = self.create_writer(table_name, headers, values)\n\n title = \"List of Prometheus Metrics\"\n underline = \"============================\"\n content = f\"{title}\\n{underline}\\n{writer.dumps()}\"\n with open(filename, 'w') as f:\n f.write(content)\n print(f\"Generated {filename}.\")\n\n\ndef main():\n doc_generator = Generator()\n doc_generator.prometheus_metrics()\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "docs/generate-metrics.py"}, {"content": "# Configuration file for Sphinx to build our documentation to HTML.\n#\n# Configuration reference: https://www.sphinx-doc.org/en/master/usage/configuration.html\n#\nimport contextlib\nimport datetime\nimport io\nimport os\nimport subprocess\n\nfrom docutils import nodes\nfrom sphinx.directives.other import SphinxDirective\n\nimport jupyterhub\nfrom jupyterhub.app import JupyterHub\n\n# -- Project information -----------------------------------------------------\n# ref: https://www.sphinx-doc.org/en/master/usage/configuration.html#project-information\n#\nproject = \"JupyterHub\"\nauthor = \"Project Jupyter Contributors\"\ncopyright = f\"{datetime.date.today().year}, {author}\"\nversion = \"%i.%i\" % jupyterhub.version_info[:2]\nrelease = jupyterhub.__version__\n\n\n# -- General Sphinx configuration --------------------------------------------\n# ref: https://www.sphinx-doc.org/en/master/usage/configuration.html#general-configuration\n#\nextensions = [\n \"sphinx.ext.autodoc\",\n \"sphinx.ext.intersphinx\",\n \"sphinx.ext.napoleon\",\n \"autodoc_traits\",\n \"sphinx_copybutton\",\n \"sphinx-jsonschema\",\n \"sphinxext.opengraph\",\n \"sphinxext.rediraffe\",\n \"myst_parser\",\n]\nroot_doc = \"index\"\nsource_suffix = [\".md\", \".rst\"]\n# default_role let's use use `foo` instead of ``foo`` in rST\ndefault_role = \"literal\"\n\n\n# -- MyST configuration ------------------------------------------------------\n# ref: https://myst-parser.readthedocs.io/en/latest/configuration.html\n#\nmyst_heading_anchors = 2\nmyst_enable_extensions = [\n \"colon_fence\",\n \"deflist\",\n]\n\n\n# -- Custom directives to generate documentation -----------------------------\n# ref: https://myst-parser.readthedocs.io/en/latest/syntax/roles-and-directives.html\n#\n# We define custom directives to help us generate documentation using Python on\n# demand when referenced from our documentation files.\n#\n\n# Create a temp instance of JupyterHub for use by two separate directive classes\n# to get the output from using the \"--generate-config\" and \"--help-all\" CLI\n# flags respectively.\n#\njupyterhub_app = JupyterHub()\n\n\nclass ConfigDirective(SphinxDirective):\n \"\"\"Generate the configuration file output for use in the documentation.\"\"\"\n\n has_content = False\n required_arguments = 0\n optional_arguments = 0\n final_argument_whitespace = False\n option_spec = {}\n\n def run(self):\n # The generated configuration file for this version\n generated_config = jupyterhub_app.generate_config_file()\n # post-process output\n home_dir = os.environ[\"HOME\"]\n generated_config = generated_config.replace(home_dir, \"$HOME\", 1)\n par = nodes.literal_block(text=generated_config)\n return [par]\n\n\nclass HelpAllDirective(SphinxDirective):\n \"\"\"Print the output of jupyterhub help --all for use in the documentation.\"\"\"\n\n has_content = False\n required_arguments = 0\n optional_arguments = 0\n final_argument_whitespace = False\n option_spec = {}\n\n def run(self):\n # The output of the help command for this version\n buffer = io.StringIO()\n with contextlib.redirect_stdout(buffer):\n jupyterhub_app.print_help(\"--help-all\")\n all_help = buffer.getvalue()\n # post-process output\n home_dir = os.environ[\"HOME\"]\n all_help = all_help.replace(home_dir, \"$HOME\", 1)\n par = nodes.literal_block(text=all_help)\n return [par]\n\n\ndef setup(app):\n app.add_css_file(\"custom.css\")\n app.add_directive(\"jupyterhub-generate-config\", ConfigDirective)\n app.add_directive(\"jupyterhub-help-all\", HelpAllDirective)\n\n\n# -- Read The Docs -----------------------------------------------------------\n#\n# Since RTD runs sphinx-build directly without running \"make html\", we run the\n# pre-requisite steps for \"make html\" from here if needed.\n#\nif os.environ.get(\"READTHEDOCS\"):\n docs = os.path.dirname(os.path.dirname(__file__))\n subprocess.check_call([\"make\", \"metrics\", \"scopes\"], cwd=docs)\n\n\n# -- Spell checking ----------------------------------------------------------\n# ref: https://sphinxcontrib-spelling.readthedocs.io/en/latest/customize.html#configuration-options\n#\n# The \"sphinxcontrib.spelling\" extension is optionally enabled if its available.\n#\ntry:\n import sphinxcontrib.spelling # noqa\nexcept ImportError:\n pass\nelse:\n extensions.append(\"sphinxcontrib.spelling\")\nspelling_word_list_filename = \"spelling_wordlist.txt\"\n\n\n# -- Options for HTML output -------------------------------------------------\n# ref: https://www.sphinx-doc.org/en/master/usage/configuration.html#options-for-html-output\n#\nhtml_logo = \"_static/images/logo/logo.png\"\nhtml_favicon = \"_static/images/logo/favicon.ico\"\nhtml_static_path = [\"_static\"]\n\nhtml_theme = \"pydata_sphinx_theme\"\nhtml_theme_options = {\n \"icon_links\": [\n {\n \"name\": \"GitHub\",\n \"url\": \"https://github.com/jupyterhub/jupyterhub\",\n \"icon\": \"fab fa-github-square\",\n },\n {\n \"name\": \"Discourse\",\n \"url\": \"https://discourse.jupyter.org/c/jupyterhub/10\",\n \"icon\": \"fab fa-discourse\",\n },\n ],\n \"use_edit_page_button\": True,\n \"navbar_align\": \"left\",\n}\nhtml_context = {\n \"github_user\": \"jupyterhub\",\n \"github_repo\": \"jupyterhub\",\n \"github_version\": \"main\",\n \"doc_path\": \"docs/source\",\n}\n\n\n# -- Options for linkcheck builder -------------------------------------------\n# ref: https://www.sphinx-doc.org/en/master/usage/configuration.html#options-for-the-linkcheck-builder\n#\nlinkcheck_ignore = [\n r\"(.*)github\\.com(.*)#\", # javascript based anchors\n r\"(.*)/#%21(.*)/(.*)\", # /#!forum/jupyter - encoded anchor edge case\n r\"https://github.com/[^/]*$\", # too many github usernames / searches in changelog\n \"https://github.com/jupyterhub/jupyterhub/pull/\", # too many PRs in changelog\n \"https://github.com/jupyterhub/jupyterhub/compare/\", # too many comparisons in changelog\n]\nlinkcheck_anchors_ignore = [\n \"/#!\",\n \"/#%21\",\n]\n\n\n# -- Intersphinx -------------------------------------------------------------\n# ref: https://www.sphinx-doc.org/en/master/usage/extensions/intersphinx.html#configuration\n#\nintersphinx_mapping = {\n \"python\": (\"https://docs.python.org/3/\", None),\n \"tornado\": (\"https://www.tornadoweb.org/en/stable/\", None),\n}\n# -- Options for the opengraph extension -------------------------------------\n# ref: https://github.com/wpilibsuite/sphinxext-opengraph#options\n#\n# ogp_site_url is set automatically by RTD\nogp_image = \"_static/logo.png\"\nogp_use_first_image = True\n\n\n# -- Options for the rediraffe extension -------------------------------------\n# ref: https://github.com/wpilibsuite/sphinxext-rediraffe#readme\n#\n# This extensions help us relocated content without breaking links. If a\n# document is moved internally, a redirect like should be configured below to\n# help us not break links.\n#\nrediraffe_branch = \"main\"\nrediraffe_redirects = {\n # \"old-file\": \"new-folder/new-file-name\",\n}\n", "path": "docs/source/conf.py"}], "after_files": [{"content": "import os\n\nfrom pytablewriter import MarkdownTableWriter\n\nimport jupyterhub.metrics\n\nHERE = os.path.abspath(os.path.dirname(__file__))\n\n\nclass Generator:\n @classmethod\n def create_writer(cls, table_name, headers, values):\n writer = MarkdownTableWriter()\n writer.table_name = table_name\n writer.headers = headers\n writer.value_matrix = values\n writer.margin = 1\n return writer\n\n def _parse_metrics(self):\n table_rows = []\n for name in dir(jupyterhub.metrics):\n obj = getattr(jupyterhub.metrics, name)\n if obj.__class__.__module__.startswith('prometheus_client.'):\n for metric in obj.describe():\n table_rows.append([metric.type, metric.name, metric.documentation])\n return table_rows\n\n def prometheus_metrics(self):\n generated_directory = f\"{HERE}/source/reference\"\n if not os.path.exists(generated_directory):\n os.makedirs(generated_directory)\n\n filename = f\"{generated_directory}/metrics.md\"\n table_name = \"\"\n headers = [\"Type\", \"Name\", \"Description\"]\n values = self._parse_metrics()\n writer = self.create_writer(table_name, headers, values)\n\n with open(filename, 'w') as f:\n f.write(\"# List of Prometheus Metrics\\n\\n\")\n f.write(writer.dumps())\n f.write(\"\\n\")\n print(f\"Generated {filename}\")\n\n\ndef main():\n doc_generator = Generator()\n doc_generator.prometheus_metrics()\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "docs/generate-metrics.py"}, {"content": "# Configuration file for Sphinx to build our documentation to HTML.\n#\n# Configuration reference: https://www.sphinx-doc.org/en/master/usage/configuration.html\n#\nimport contextlib\nimport datetime\nimport io\nimport os\nimport subprocess\n\nfrom docutils import nodes\nfrom sphinx.directives.other import SphinxDirective\n\nimport jupyterhub\nfrom jupyterhub.app import JupyterHub\n\n# -- Project information -----------------------------------------------------\n# ref: https://www.sphinx-doc.org/en/master/usage/configuration.html#project-information\n#\nproject = \"JupyterHub\"\nauthor = \"Project Jupyter Contributors\"\ncopyright = f\"{datetime.date.today().year}, {author}\"\n\n\n# -- General Sphinx configuration --------------------------------------------\n# ref: https://www.sphinx-doc.org/en/master/usage/configuration.html#general-configuration\n#\nextensions = [\n \"sphinx.ext.autodoc\",\n \"sphinx.ext.intersphinx\",\n \"sphinx.ext.napoleon\",\n \"autodoc_traits\",\n \"sphinx_copybutton\",\n \"sphinx-jsonschema\",\n \"sphinxext.opengraph\",\n \"sphinxext.rediraffe\",\n \"myst_parser\",\n]\nroot_doc = \"index\"\nsource_suffix = [\".md\"]\n# default_role let's use use `foo` instead of ``foo`` in rST\ndefault_role = \"literal\"\n\n\n# -- MyST configuration ------------------------------------------------------\n# ref: https://myst-parser.readthedocs.io/en/latest/configuration.html\n#\nmyst_heading_anchors = 2\n\nmyst_enable_extensions = [\n # available extensions: https://myst-parser.readthedocs.io/en/latest/syntax/optional.html\n \"colon_fence\",\n \"deflist\",\n \"fieldlist\",\n \"substitution\",\n]\n\nmyst_substitutions = {\n # date example: Dev 07, 2022\n \"date\": datetime.date.today().strftime(\"%b %d, %Y\").title(),\n \"version\": jupyterhub.__version__,\n}\n\n\n# -- Custom directives to generate documentation -----------------------------\n# ref: https://myst-parser.readthedocs.io/en/latest/syntax/roles-and-directives.html\n#\n# We define custom directives to help us generate documentation using Python on\n# demand when referenced from our documentation files.\n#\n\n# Create a temp instance of JupyterHub for use by two separate directive classes\n# to get the output from using the \"--generate-config\" and \"--help-all\" CLI\n# flags respectively.\n#\njupyterhub_app = JupyterHub()\n\n\nclass ConfigDirective(SphinxDirective):\n \"\"\"Generate the configuration file output for use in the documentation.\"\"\"\n\n has_content = False\n required_arguments = 0\n optional_arguments = 0\n final_argument_whitespace = False\n option_spec = {}\n\n def run(self):\n # The generated configuration file for this version\n generated_config = jupyterhub_app.generate_config_file()\n # post-process output\n home_dir = os.environ[\"HOME\"]\n generated_config = generated_config.replace(home_dir, \"$HOME\", 1)\n par = nodes.literal_block(text=generated_config)\n return [par]\n\n\nclass HelpAllDirective(SphinxDirective):\n \"\"\"Print the output of jupyterhub help --all for use in the documentation.\"\"\"\n\n has_content = False\n required_arguments = 0\n optional_arguments = 0\n final_argument_whitespace = False\n option_spec = {}\n\n def run(self):\n # The output of the help command for this version\n buffer = io.StringIO()\n with contextlib.redirect_stdout(buffer):\n jupyterhub_app.print_help(\"--help-all\")\n all_help = buffer.getvalue()\n # post-process output\n home_dir = os.environ[\"HOME\"]\n all_help = all_help.replace(home_dir, \"$HOME\", 1)\n par = nodes.literal_block(text=all_help)\n return [par]\n\n\ndef setup(app):\n app.add_css_file(\"custom.css\")\n app.add_directive(\"jupyterhub-generate-config\", ConfigDirective)\n app.add_directive(\"jupyterhub-help-all\", HelpAllDirective)\n\n\n# -- Read The Docs -----------------------------------------------------------\n#\n# Since RTD runs sphinx-build directly without running \"make html\", we run the\n# pre-requisite steps for \"make html\" from here if needed.\n#\nif os.environ.get(\"READTHEDOCS\"):\n docs = os.path.dirname(os.path.dirname(__file__))\n subprocess.check_call([\"make\", \"metrics\", \"scopes\"], cwd=docs)\n\n\n# -- Spell checking ----------------------------------------------------------\n# ref: https://sphinxcontrib-spelling.readthedocs.io/en/latest/customize.html#configuration-options\n#\n# The \"sphinxcontrib.spelling\" extension is optionally enabled if its available.\n#\ntry:\n import sphinxcontrib.spelling # noqa\nexcept ImportError:\n pass\nelse:\n extensions.append(\"sphinxcontrib.spelling\")\nspelling_word_list_filename = \"spelling_wordlist.txt\"\n\n\n# -- Options for HTML output -------------------------------------------------\n# ref: https://www.sphinx-doc.org/en/master/usage/configuration.html#options-for-html-output\n#\nhtml_logo = \"_static/images/logo/logo.png\"\nhtml_favicon = \"_static/images/logo/favicon.ico\"\nhtml_static_path = [\"_static\"]\n\nhtml_theme = \"pydata_sphinx_theme\"\nhtml_theme_options = {\n \"icon_links\": [\n {\n \"name\": \"GitHub\",\n \"url\": \"https://github.com/jupyterhub/jupyterhub\",\n \"icon\": \"fab fa-github-square\",\n },\n {\n \"name\": \"Discourse\",\n \"url\": \"https://discourse.jupyter.org/c/jupyterhub/10\",\n \"icon\": \"fab fa-discourse\",\n },\n ],\n \"use_edit_page_button\": True,\n \"navbar_align\": \"left\",\n}\nhtml_context = {\n \"github_user\": \"jupyterhub\",\n \"github_repo\": \"jupyterhub\",\n \"github_version\": \"main\",\n \"doc_path\": \"docs/source\",\n}\n\n\n# -- Options for linkcheck builder -------------------------------------------\n# ref: https://www.sphinx-doc.org/en/master/usage/configuration.html#options-for-the-linkcheck-builder\n#\nlinkcheck_ignore = [\n r\"(.*)github\\.com(.*)#\", # javascript based anchors\n r\"(.*)/#%21(.*)/(.*)\", # /#!forum/jupyter - encoded anchor edge case\n r\"https://github.com/[^/]*$\", # too many github usernames / searches in changelog\n \"https://github.com/jupyterhub/jupyterhub/pull/\", # too many PRs in changelog\n \"https://github.com/jupyterhub/jupyterhub/compare/\", # too many comparisons in changelog\n]\nlinkcheck_anchors_ignore = [\n \"/#!\",\n \"/#%21\",\n]\n\n\n# -- Intersphinx -------------------------------------------------------------\n# ref: https://www.sphinx-doc.org/en/master/usage/extensions/intersphinx.html#configuration\n#\nintersphinx_mapping = {\n \"python\": (\"https://docs.python.org/3/\", None),\n \"tornado\": (\"https://www.tornadoweb.org/en/stable/\", None),\n}\n# -- Options for the opengraph extension -------------------------------------\n# ref: https://github.com/wpilibsuite/sphinxext-opengraph#options\n#\n# ogp_site_url is set automatically by RTD\nogp_image = \"_static/logo.png\"\nogp_use_first_image = True\n\n\n# -- Options for the rediraffe extension -------------------------------------\n# ref: https://github.com/wpilibsuite/sphinxext-rediraffe#readme\n#\n# This extensions help us relocated content without breaking links. If a\n# document is moved internally, a redirect like should be configured below to\n# help us not break links.\n#\nrediraffe_branch = \"main\"\nrediraffe_redirects = {\n # \"old-file\": \"new-folder/new-file-name\",\n}\n", "path": "docs/source/conf.py"}]}
| 3,399 | 744 |
gh_patches_debug_7521
|
rasdani/github-patches
|
git_diff
|
sunpy__sunpy-780
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Database.query buggy with Time
Database.query works different using the Time attribute than VSO does.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sunpy/database/attrs.py`
Content:
```
1 # Author: Simon Liedtke <[email protected]>
2 #
3 # This module was developed with funding provided by
4 # the Google Summer of Code (2013).
5
6 from __future__ import absolute_import
7
8 from sqlalchemy import or_, and_, not_
9 from astropy.units import Unit, nm, equivalencies
10
11 from sunpy.time import parse_time
12 from sunpy.net.vso import attrs as vso_attrs
13 from sunpy.net.attr import AttrWalker, Attr, ValueAttr, AttrAnd, AttrOr
14 from sunpy.database.tables import DatabaseEntry, Tag as TableTag,\
15 FitsHeaderEntry as TableFitsHeaderEntry
16
17 __all__ = [
18 'Starred', 'Tag', 'Path', 'DownloadTime', 'FitsHeaderEntry', 'walker']
19
20
21 class _BooleanAttr(object):
22 def __init__(self, value, make):
23 self.value = bool(value)
24 self.make = make
25
26 def __and__(self, other):
27 if not isinstance(other, self.make):
28 return AttrAnd([self, other])
29 attr = self.make()
30 attr.value = self.value and other.value
31 return attr
32
33 def __or__(self, other):
34 if not isinstance(other, self.make):
35 return AttrOr([self, other])
36 attr = self.make()
37 attr.value = self.value or other.value
38 return attr
39
40 def __nonzero__(self):
41 return self.value
42
43 def __invert__(self):
44 attr = self.make()
45 attr.value = not self.value
46 return attr
47
48 def __eq__(self, other):
49 return isinstance(other, self.make) and self.value == other.value
50
51 def collides(self, other): # pragma: no cover
52 return False
53
54 def __repr__(self):
55 return '<{0}{1}()>'.format(
56 '~' if not self.value else '', self.__class__.__name__)
57
58
59 class Starred(_BooleanAttr, Attr):
60 def __init__(self):
61 _BooleanAttr.__init__(self, True, self.__class__)
62
63
64 class Tag(Attr):
65 def __init__(self, tagname):
66 self.tagname = tagname
67 self.inverted = False
68
69 def __invert__(self):
70 tag = self.__class__(self.tagname)
71 tag.inverted = True
72 return tag
73
74 def collides(self, other): # pragma: no cover
75 return False
76
77 def __repr__(self):
78 return '<{0}Tag({1!r})>'.format(
79 '~' if self.inverted else '', self.tagname)
80
81
82 class Path(Attr):
83 def __init__(self, value):
84 self.value = value
85 self.inverted = False
86
87 def __invert__(self):
88 path = self.__class__(self.value)
89 path.inverted = True
90 return path
91
92 def collides(self, other): # pragma: no cover
93 return isinstance(other, self.__class__)
94
95 def __repr__(self):
96 return '<{0}Path({1!r})>'.format(
97 '~' if self.inverted else '', self.value)
98
99
100 # TODO: support excluding ranges as soon as
101 # vso_attrs._Range.__xor__ is fixed / renamed
102 class DownloadTime(Attr, vso_attrs._Range):
103 def __init__(self, start, end):
104 self.start = parse_time(start)
105 self.end = parse_time(end)
106 self.inverted = False
107 vso_attrs._Range.__init__(self, start, end, self.__class__)
108
109 def __invert__(self):
110 download_time = self.__class__(self.start, self.end)
111 download_time.inverted = True
112 return download_time
113
114 def collides(self, other): # pragma: no cover
115 return isinstance(other, self.__class__)
116
117 def __repr__(self):
118 return '<{0}DownloadTime({1!r}, {2!r})>'.format(
119 '~' if self.inverted else '', self.start, self.end)
120
121
122 class FitsHeaderEntry(Attr):
123 def __init__(self, key, value):
124 self.key = key
125 self.value = value
126 self.inverted = False
127
128 def __invert__(self):
129 entry = self.__class__(self.key, self.value)
130 entry.inverted = True
131 return entry
132
133 def collides(self, other): # pragma: no cover
134 return False
135
136 def __repr__(self):
137 return '<{0}FitsHeaderEntry({1!r}, {2!r})>'.format(
138 '~' if self.inverted else '', self.key, self.value)
139
140
141 walker = AttrWalker()
142
143
144 @walker.add_creator(AttrOr)
145 def _create(wlk, root, session):
146 entries = set()
147 for attr in root.attrs:
148 # make sure to add only new entries to the set to avoid duplicates
149 entries.update(set(wlk.create(attr, session)) - entries)
150 return list(entries)
151
152
153 @walker.add_creator(AttrAnd)
154 def _create(wlk, root, session):
155 entries = [set(wlk.create(attr, session)) for attr in root.attrs]
156 return list(set.intersection(*entries))
157
158
159 @walker.add_creator(ValueAttr)
160 def _create(wlk, root, session):
161 query = session.query(DatabaseEntry)
162 for key, value in root.attrs.iteritems():
163 typ = key[0]
164 if typ == 'tag':
165 criterion = TableTag.name.in_([value])
166 # `key[1]` is here the `inverted` attribute of the tag. That means
167 # that if it is True, the given tag must not be included in the
168 # resulting entries.
169 if key[1]:
170 query = query.filter(~DatabaseEntry.tags.any(criterion))
171 else:
172 query = query.filter(DatabaseEntry.tags.any(criterion))
173 elif typ == 'fitsheaderentry':
174 key, val, inverted = value
175 key_criterion = TableFitsHeaderEntry.key == key
176 value_criterion = TableFitsHeaderEntry.value == val
177 if inverted:
178 query = query.filter(not_(and_(
179 DatabaseEntry.fits_header_entries.any(key_criterion),
180 DatabaseEntry.fits_header_entries.any(value_criterion))))
181 else:
182 query = query.filter(and_(
183 DatabaseEntry.fits_header_entries.any(key_criterion),
184 DatabaseEntry.fits_header_entries.any(value_criterion)))
185 elif typ == 'download time':
186 start, end, inverted = value
187 if inverted:
188 query = query.filter(
189 ~DatabaseEntry.download_time.between(start, end))
190 else:
191 query = query.filter(
192 DatabaseEntry.download_time.between(start, end))
193 elif typ == 'path':
194 path, inverted = value
195 if inverted:
196 query = query.filter(or_(
197 DatabaseEntry.path != path, DatabaseEntry.path == None))
198 else:
199 query = query.filter(DatabaseEntry.path == path)
200 elif typ == 'wave':
201 min_, max_, unit = value
202 waveunit = Unit(unit)
203 # convert min_ and max_ to nm from the unit `waveunit`
204 wavemin = waveunit.to(nm, min_, equivalencies.spectral())
205 wavemax = waveunit.to(nm, max_, equivalencies.spectral())
206 query = query.filter(and_(
207 DatabaseEntry.wavemin >= wavemin,
208 DatabaseEntry.wavemax <= wavemax))
209 elif typ == 'time':
210 start, end, near = value
211 query = query.filter(and_(
212 DatabaseEntry.observation_time_start >= start,
213 DatabaseEntry.observation_time_end <= end))
214 else:
215 query = query.filter_by(**{typ: value})
216 return query.all()
217
218
219 @walker.add_converter(Tag)
220 def _convert(attr):
221 return ValueAttr({('tag', attr.inverted): attr.tagname})
222
223
224 @walker.add_converter(Starred)
225 def _convert(attr):
226 return ValueAttr({('starred', ): attr.value})
227
228
229 @walker.add_converter(Path)
230 def _convert(attr):
231 return ValueAttr({('path', ): (attr.value, attr.inverted)})
232
233
234 @walker.add_converter(DownloadTime)
235 def _convert(attr):
236 return ValueAttr({
237 ('download time', ): (attr.start, attr.end, attr.inverted)})
238
239
240 @walker.add_converter(FitsHeaderEntry)
241 def _convert(attr):
242 return ValueAttr(
243 {('fitsheaderentry', ): (attr.key, attr.value, attr.inverted)})
244
245
246 @walker.add_converter(vso_attrs._VSOSimpleAttr)
247 def _convert(attr):
248 return ValueAttr({(attr.__class__.__name__.lower(), ): attr.value})
249
250
251 @walker.add_converter(vso_attrs.Wave)
252 def _convert(attr):
253 return ValueAttr({('wave', ): (attr.min, attr.max, attr.unit)})
254
255
256 @walker.add_converter(vso_attrs.Time)
257 def _convert(attr):
258 return ValueAttr({('time', ): (attr.start, attr.end, attr.near)})
259
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sunpy/database/attrs.py b/sunpy/database/attrs.py
--- a/sunpy/database/attrs.py
+++ b/sunpy/database/attrs.py
@@ -209,8 +209,8 @@
elif typ == 'time':
start, end, near = value
query = query.filter(and_(
- DatabaseEntry.observation_time_start >= start,
- DatabaseEntry.observation_time_end <= end))
+ DatabaseEntry.observation_time_start < end,
+ DatabaseEntry.observation_time_end > start))
else:
query = query.filter_by(**{typ: value})
return query.all()
|
{"golden_diff": "diff --git a/sunpy/database/attrs.py b/sunpy/database/attrs.py\n--- a/sunpy/database/attrs.py\n+++ b/sunpy/database/attrs.py\n@@ -209,8 +209,8 @@\n elif typ == 'time':\n start, end, near = value\n query = query.filter(and_(\n- DatabaseEntry.observation_time_start >= start,\n- DatabaseEntry.observation_time_end <= end))\n+ DatabaseEntry.observation_time_start < end,\n+ DatabaseEntry.observation_time_end > start))\n else:\n query = query.filter_by(**{typ: value})\n return query.all()\n", "issue": "Database.query buggy with Time\nDatabase.query works different using the Time attribute than VSO does.\n\n", "before_files": [{"content": "# Author: Simon Liedtke <[email protected]>\n#\n# This module was developed with funding provided by\n# the Google Summer of Code (2013).\n\nfrom __future__ import absolute_import\n\nfrom sqlalchemy import or_, and_, not_\nfrom astropy.units import Unit, nm, equivalencies\n\nfrom sunpy.time import parse_time\nfrom sunpy.net.vso import attrs as vso_attrs\nfrom sunpy.net.attr import AttrWalker, Attr, ValueAttr, AttrAnd, AttrOr\nfrom sunpy.database.tables import DatabaseEntry, Tag as TableTag,\\\n FitsHeaderEntry as TableFitsHeaderEntry\n\n__all__ = [\n 'Starred', 'Tag', 'Path', 'DownloadTime', 'FitsHeaderEntry', 'walker']\n\n\nclass _BooleanAttr(object):\n def __init__(self, value, make):\n self.value = bool(value)\n self.make = make\n\n def __and__(self, other):\n if not isinstance(other, self.make):\n return AttrAnd([self, other])\n attr = self.make()\n attr.value = self.value and other.value\n return attr\n\n def __or__(self, other):\n if not isinstance(other, self.make):\n return AttrOr([self, other])\n attr = self.make()\n attr.value = self.value or other.value\n return attr\n\n def __nonzero__(self):\n return self.value\n\n def __invert__(self):\n attr = self.make()\n attr.value = not self.value\n return attr\n\n def __eq__(self, other):\n return isinstance(other, self.make) and self.value == other.value\n\n def collides(self, other): # pragma: no cover\n return False\n\n def __repr__(self):\n return '<{0}{1}()>'.format(\n '~' if not self.value else '', self.__class__.__name__)\n\n\nclass Starred(_BooleanAttr, Attr):\n def __init__(self):\n _BooleanAttr.__init__(self, True, self.__class__)\n\n\nclass Tag(Attr):\n def __init__(self, tagname):\n self.tagname = tagname\n self.inverted = False\n\n def __invert__(self):\n tag = self.__class__(self.tagname)\n tag.inverted = True\n return tag\n\n def collides(self, other): # pragma: no cover\n return False\n\n def __repr__(self):\n return '<{0}Tag({1!r})>'.format(\n '~' if self.inverted else '', self.tagname)\n\n\nclass Path(Attr):\n def __init__(self, value):\n self.value = value\n self.inverted = False\n\n def __invert__(self):\n path = self.__class__(self.value)\n path.inverted = True\n return path\n\n def collides(self, other): # pragma: no cover\n return isinstance(other, self.__class__)\n\n def __repr__(self):\n return '<{0}Path({1!r})>'.format(\n '~' if self.inverted else '', self.value)\n\n\n# TODO: support excluding ranges as soon as\n# vso_attrs._Range.__xor__ is fixed / renamed\nclass DownloadTime(Attr, vso_attrs._Range):\n def __init__(self, start, end):\n self.start = parse_time(start)\n self.end = parse_time(end)\n self.inverted = False\n vso_attrs._Range.__init__(self, start, end, self.__class__)\n\n def __invert__(self):\n download_time = self.__class__(self.start, self.end)\n download_time.inverted = True\n return download_time\n\n def collides(self, other): # pragma: no cover\n return isinstance(other, self.__class__)\n\n def __repr__(self):\n return '<{0}DownloadTime({1!r}, {2!r})>'.format(\n '~' if self.inverted else '', self.start, self.end)\n\n\nclass FitsHeaderEntry(Attr):\n def __init__(self, key, value):\n self.key = key\n self.value = value\n self.inverted = False\n\n def __invert__(self):\n entry = self.__class__(self.key, self.value)\n entry.inverted = True\n return entry\n\n def collides(self, other): # pragma: no cover\n return False\n\n def __repr__(self):\n return '<{0}FitsHeaderEntry({1!r}, {2!r})>'.format(\n '~' if self.inverted else '', self.key, self.value)\n\n\nwalker = AttrWalker()\n\n\[email protected]_creator(AttrOr)\ndef _create(wlk, root, session):\n entries = set()\n for attr in root.attrs:\n # make sure to add only new entries to the set to avoid duplicates\n entries.update(set(wlk.create(attr, session)) - entries)\n return list(entries)\n\n\[email protected]_creator(AttrAnd)\ndef _create(wlk, root, session):\n entries = [set(wlk.create(attr, session)) for attr in root.attrs]\n return list(set.intersection(*entries))\n\n\[email protected]_creator(ValueAttr)\ndef _create(wlk, root, session):\n query = session.query(DatabaseEntry)\n for key, value in root.attrs.iteritems():\n typ = key[0]\n if typ == 'tag':\n criterion = TableTag.name.in_([value])\n # `key[1]` is here the `inverted` attribute of the tag. That means\n # that if it is True, the given tag must not be included in the\n # resulting entries.\n if key[1]:\n query = query.filter(~DatabaseEntry.tags.any(criterion))\n else:\n query = query.filter(DatabaseEntry.tags.any(criterion))\n elif typ == 'fitsheaderentry':\n key, val, inverted = value\n key_criterion = TableFitsHeaderEntry.key == key\n value_criterion = TableFitsHeaderEntry.value == val\n if inverted:\n query = query.filter(not_(and_(\n DatabaseEntry.fits_header_entries.any(key_criterion),\n DatabaseEntry.fits_header_entries.any(value_criterion))))\n else:\n query = query.filter(and_(\n DatabaseEntry.fits_header_entries.any(key_criterion),\n DatabaseEntry.fits_header_entries.any(value_criterion)))\n elif typ == 'download time':\n start, end, inverted = value\n if inverted:\n query = query.filter(\n ~DatabaseEntry.download_time.between(start, end))\n else:\n query = query.filter(\n DatabaseEntry.download_time.between(start, end))\n elif typ == 'path':\n path, inverted = value\n if inverted:\n query = query.filter(or_(\n DatabaseEntry.path != path, DatabaseEntry.path == None))\n else:\n query = query.filter(DatabaseEntry.path == path)\n elif typ == 'wave':\n min_, max_, unit = value\n waveunit = Unit(unit)\n # convert min_ and max_ to nm from the unit `waveunit`\n wavemin = waveunit.to(nm, min_, equivalencies.spectral())\n wavemax = waveunit.to(nm, max_, equivalencies.spectral())\n query = query.filter(and_(\n DatabaseEntry.wavemin >= wavemin,\n DatabaseEntry.wavemax <= wavemax))\n elif typ == 'time':\n start, end, near = value\n query = query.filter(and_(\n DatabaseEntry.observation_time_start >= start,\n DatabaseEntry.observation_time_end <= end))\n else:\n query = query.filter_by(**{typ: value})\n return query.all()\n\n\[email protected]_converter(Tag)\ndef _convert(attr):\n return ValueAttr({('tag', attr.inverted): attr.tagname})\n\n\[email protected]_converter(Starred)\ndef _convert(attr):\n return ValueAttr({('starred', ): attr.value})\n\n\[email protected]_converter(Path)\ndef _convert(attr):\n return ValueAttr({('path', ): (attr.value, attr.inverted)})\n\n\[email protected]_converter(DownloadTime)\ndef _convert(attr):\n return ValueAttr({\n ('download time', ): (attr.start, attr.end, attr.inverted)})\n\n\[email protected]_converter(FitsHeaderEntry)\ndef _convert(attr):\n return ValueAttr(\n {('fitsheaderentry', ): (attr.key, attr.value, attr.inverted)})\n\n\[email protected]_converter(vso_attrs._VSOSimpleAttr)\ndef _convert(attr):\n return ValueAttr({(attr.__class__.__name__.lower(), ): attr.value})\n\n\[email protected]_converter(vso_attrs.Wave)\ndef _convert(attr):\n return ValueAttr({('wave', ): (attr.min, attr.max, attr.unit)})\n\n\[email protected]_converter(vso_attrs.Time)\ndef _convert(attr):\n return ValueAttr({('time', ): (attr.start, attr.end, attr.near)})\n", "path": "sunpy/database/attrs.py"}], "after_files": [{"content": "# Author: Simon Liedtke <[email protected]>\n#\n# This module was developed with funding provided by\n# the Google Summer of Code (2013).\n\nfrom __future__ import absolute_import\n\nfrom sqlalchemy import or_, and_, not_\nfrom astropy.units import Unit, nm, equivalencies\n\nfrom sunpy.time import parse_time\nfrom sunpy.net.vso import attrs as vso_attrs\nfrom sunpy.net.attr import AttrWalker, Attr, ValueAttr, AttrAnd, AttrOr\nfrom sunpy.database.tables import DatabaseEntry, Tag as TableTag,\\\n FitsHeaderEntry as TableFitsHeaderEntry\n\n__all__ = [\n 'Starred', 'Tag', 'Path', 'DownloadTime', 'FitsHeaderEntry', 'walker']\n\n\nclass _BooleanAttr(object):\n def __init__(self, value, make):\n self.value = bool(value)\n self.make = make\n\n def __and__(self, other):\n if not isinstance(other, self.make):\n return AttrAnd([self, other])\n attr = self.make()\n attr.value = self.value and other.value\n return attr\n\n def __or__(self, other):\n if not isinstance(other, self.make):\n return AttrOr([self, other])\n attr = self.make()\n attr.value = self.value or other.value\n return attr\n\n def __nonzero__(self):\n return self.value\n\n def __invert__(self):\n attr = self.make()\n attr.value = not self.value\n return attr\n\n def __eq__(self, other):\n return isinstance(other, self.make) and self.value == other.value\n\n def collides(self, other): # pragma: no cover\n return False\n\n def __repr__(self):\n return '<{0}{1}()>'.format(\n '~' if not self.value else '', self.__class__.__name__)\n\n\nclass Starred(_BooleanAttr, Attr):\n def __init__(self):\n _BooleanAttr.__init__(self, True, self.__class__)\n\n\nclass Tag(Attr):\n def __init__(self, tagname):\n self.tagname = tagname\n self.inverted = False\n\n def __invert__(self):\n tag = self.__class__(self.tagname)\n tag.inverted = True\n return tag\n\n def collides(self, other): # pragma: no cover\n return False\n\n def __repr__(self):\n return '<{0}Tag({1!r})>'.format(\n '~' if self.inverted else '', self.tagname)\n\n\nclass Path(Attr):\n def __init__(self, value):\n self.value = value\n self.inverted = False\n\n def __invert__(self):\n path = self.__class__(self.value)\n path.inverted = True\n return path\n\n def collides(self, other): # pragma: no cover\n return isinstance(other, self.__class__)\n\n def __repr__(self):\n return '<{0}Path({1!r})>'.format(\n '~' if self.inverted else '', self.value)\n\n\n# TODO: support excluding ranges as soon as\n# vso_attrs._Range.__xor__ is fixed / renamed\nclass DownloadTime(Attr, vso_attrs._Range):\n def __init__(self, start, end):\n self.start = parse_time(start)\n self.end = parse_time(end)\n self.inverted = False\n vso_attrs._Range.__init__(self, start, end, self.__class__)\n\n def __invert__(self):\n download_time = self.__class__(self.start, self.end)\n download_time.inverted = True\n return download_time\n\n def collides(self, other): # pragma: no cover\n return isinstance(other, self.__class__)\n\n def __repr__(self):\n return '<{0}DownloadTime({1!r}, {2!r})>'.format(\n '~' if self.inverted else '', self.start, self.end)\n\n\nclass FitsHeaderEntry(Attr):\n def __init__(self, key, value):\n self.key = key\n self.value = value\n self.inverted = False\n\n def __invert__(self):\n entry = self.__class__(self.key, self.value)\n entry.inverted = True\n return entry\n\n def collides(self, other): # pragma: no cover\n return False\n\n def __repr__(self):\n return '<{0}FitsHeaderEntry({1!r}, {2!r})>'.format(\n '~' if self.inverted else '', self.key, self.value)\n\n\nwalker = AttrWalker()\n\n\[email protected]_creator(AttrOr)\ndef _create(wlk, root, session):\n entries = set()\n for attr in root.attrs:\n # make sure to add only new entries to the set to avoid duplicates\n entries.update(set(wlk.create(attr, session)) - entries)\n return list(entries)\n\n\[email protected]_creator(AttrAnd)\ndef _create(wlk, root, session):\n entries = [set(wlk.create(attr, session)) for attr in root.attrs]\n return list(set.intersection(*entries))\n\n\[email protected]_creator(ValueAttr)\ndef _create(wlk, root, session):\n query = session.query(DatabaseEntry)\n for key, value in root.attrs.iteritems():\n typ = key[0]\n if typ == 'tag':\n criterion = TableTag.name.in_([value])\n # `key[1]` is here the `inverted` attribute of the tag. That means\n # that if it is True, the given tag must not be included in the\n # resulting entries.\n if key[1]:\n query = query.filter(~DatabaseEntry.tags.any(criterion))\n else:\n query = query.filter(DatabaseEntry.tags.any(criterion))\n elif typ == 'fitsheaderentry':\n key, val, inverted = value\n key_criterion = TableFitsHeaderEntry.key == key\n value_criterion = TableFitsHeaderEntry.value == val\n if inverted:\n query = query.filter(not_(and_(\n DatabaseEntry.fits_header_entries.any(key_criterion),\n DatabaseEntry.fits_header_entries.any(value_criterion))))\n else:\n query = query.filter(and_(\n DatabaseEntry.fits_header_entries.any(key_criterion),\n DatabaseEntry.fits_header_entries.any(value_criterion)))\n elif typ == 'download time':\n start, end, inverted = value\n if inverted:\n query = query.filter(\n ~DatabaseEntry.download_time.between(start, end))\n else:\n query = query.filter(\n DatabaseEntry.download_time.between(start, end))\n elif typ == 'path':\n path, inverted = value\n if inverted:\n query = query.filter(or_(\n DatabaseEntry.path != path, DatabaseEntry.path == None))\n else:\n query = query.filter(DatabaseEntry.path == path)\n elif typ == 'wave':\n min_, max_, unit = value\n waveunit = Unit(unit)\n # convert min_ and max_ to nm from the unit `waveunit`\n wavemin = waveunit.to(nm, min_, equivalencies.spectral())\n wavemax = waveunit.to(nm, max_, equivalencies.spectral())\n query = query.filter(and_(\n DatabaseEntry.wavemin >= wavemin,\n DatabaseEntry.wavemax <= wavemax))\n elif typ == 'time':\n start, end, near = value\n query = query.filter(and_(\n DatabaseEntry.observation_time_start < end,\n DatabaseEntry.observation_time_end > start))\n else:\n query = query.filter_by(**{typ: value})\n return query.all()\n\n\[email protected]_converter(Tag)\ndef _convert(attr):\n return ValueAttr({('tag', attr.inverted): attr.tagname})\n\n\[email protected]_converter(Starred)\ndef _convert(attr):\n return ValueAttr({('starred', ): attr.value})\n\n\[email protected]_converter(Path)\ndef _convert(attr):\n return ValueAttr({('path', ): (attr.value, attr.inverted)})\n\n\[email protected]_converter(DownloadTime)\ndef _convert(attr):\n return ValueAttr({\n ('download time', ): (attr.start, attr.end, attr.inverted)})\n\n\[email protected]_converter(FitsHeaderEntry)\ndef _convert(attr):\n return ValueAttr(\n {('fitsheaderentry', ): (attr.key, attr.value, attr.inverted)})\n\n\[email protected]_converter(vso_attrs._VSOSimpleAttr)\ndef _convert(attr):\n return ValueAttr({(attr.__class__.__name__.lower(), ): attr.value})\n\n\[email protected]_converter(vso_attrs.Wave)\ndef _convert(attr):\n return ValueAttr({('wave', ): (attr.min, attr.max, attr.unit)})\n\n\[email protected]_converter(vso_attrs.Time)\ndef _convert(attr):\n return ValueAttr({('time', ): (attr.start, attr.end, attr.near)})\n", "path": "sunpy/database/attrs.py"}]}
| 2,893 | 142 |
gh_patches_debug_42442
|
rasdani/github-patches
|
git_diff
|
saulpw__visidata-2434
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[fec] opening rows in FEC files does not seem to work
**Small description**
FEC files can be opened, but rows cannot be browsed.
**Data to reproduce**
Using [a sample file 1326070.fec](https://docquery.fec.gov/dcdev/posted/1326070.fec).
**Steps to reproduce**
**Expected result**
When the user presses `Enter`, rows should open as in [jsvine's demo video at 13 seconds].(https://asciinema.org/a/Xyh2BFsUaOF0AlHTmMUbqQZPC)
**Actual result**
When the user presses `Enter`, `open-rows` runs, for example, opening the itemization row, as:
```
column | value
------------------------
component | itemization
size | 56958
```
**Configuration**
- Does this issue reproduce without any plugins or configuration (using the `-N` CLI flag)?
Yes, it reproduces with `-N`.
- Does this issue reproduce with either the [latest release](https://www.visidata.org/releases/), or with the [develop branch](https://www.visidata.org/install/#update-visidata-from-an-existing-installation)?
Yes, the latest develop.
**Additional context**
`fecfile` 0.8.0 installed via pip
Python 3.10.12
Ubuntu 22.04.4
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `visidata/loaders/fec.py`
Content:
```
1 """
2 Filename: vdfec.py
3 Last updated: 2019-04-21
4 Home: https://github.com/jsvine/visidata-plugins
5 Author: Jeremy Singer-Vine
6
7 # Installation
8
9 - Install fecfile: `pip install fecfile`
10 - Add vdfec.py to your ~/.visidata directory
11 - Add "import vdfec" to your ~/.visidatarc file
12
13 # Usage
14
15 vdfec.py enables VisiData to load .fec files from the Federal Election Commission.
16
17 Once saved to your ~/.visidata directory, and imported via your ~/.visidatarc file,
18 you should be able to interactively explore .fec files as you would any other
19 filetype in VisiData.
20
21 From the command line:
22
23 vd path/to/my/file.fec
24
25 # Thanks
26
27 vdfec.py depends heavily on Evan Sonderegger's `fecfile` Python library: https://esonderegger.github.io/fecfile/
28
29 ... which in turn is based on Derek Willis's `Fech` Ruby library: https://github.com/dwillis/Fech
30
31 ... and Chris Zubak-Skees' transformation of `Fech`'s form-and-field mappings: https://github.com/PublicI/fec-parse/blob/master/lib/renderedmaps.js
32
33 Thanks to all who have contributed to those projects.
34
35 """
36
37 from copy import copy
38 from visidata import (
39 vd,
40 Path,
41 Sheet,
42 TextSheet,
43 Column,
44 ColumnAttr,
45 ColumnItem,
46 ENTER,
47 asyncthread,
48 Progress,
49 addGlobals,
50 )
51
52 class DiveSheet(Sheet):
53 "A deeply-diveable, quick-diving sheet."
54
55 def reload(self):
56 mapping = self.source
57
58 self.columns = []
59 self.rows = []
60
61 self.key_type = str
62 self.size = len(mapping)
63
64 if self.size == 0:
65 return
66
67 if isinstance(mapping, list):
68 first = mapping[0]
69 if isinstance(first, dict):
70 colgetter = lambda x: x.keys()
71 elif isinstance(first, list):
72 colgetter = lambda x: list(range(len(x)))
73 else:
74 mapping = dict(enumerate(mapping))
75 self.key_type = int
76 self.size = len(mapping)
77
78 if isinstance(mapping, dict):
79 self.is_keyvalue = True
80 if self.size:
81 max_key_len = max(map(len, map(str, mapping.keys())))
82 key_width = min(50, max(max_key_len + 2, 6))
83 else:
84 key_width = None
85
86 self.addColumn(ColumnItem(
87 "key",
88 width = key_width,
89 type = self.key_type
90 ))
91 self.addColumn(ColumnItem("value"))
92 self.setKeys(self.columns[:1])
93
94 for k, v in mapping.items():
95 self.addRow({ "key": k, "value": v })
96
97 elif isinstance(mapping, list):
98 self.is_keyvalue = False
99 indices = []
100 for item in mapping:
101 try:
102 cols = colgetter(item)
103 for col in cols:
104 if col not in indices:
105 self.addColumn(ColumnItem(col))
106 indices.append(col)
107
108 self.addRow(item)
109
110 except Exception as e:
111 vd.warning("Can't dive on lists with heterogenous item types.")
112 return False
113
114 def dive(self):
115 if self.is_keyvalue:
116 cell = self.cursorRow["value"]
117 name = vd.joinSheetnames(self.name, self.cursorRow["key"])
118
119 if isinstance(cell, (list, dict)):
120 vs = self.__class__(name, source = cell)
121 else:
122 vd.warning("Nothing to dive into.")
123 return
124 else:
125 name = vd.joinSheetnames(self.name, "row")
126 vs = self.__class__(name, source = self.cursorRow)
127
128 success = vs.reload()
129 if success == False:
130 return
131
132 vd.push(vs)
133
134 DiveSheet.addCommand(
135 ENTER,
136 'dive-row',
137 'vd.sheet.dive()'
138 )
139
140 class FECItemizationSheet(Sheet):
141 "A sheet to display a list of FEC itemizations from a given form/schedule."
142
143 rowtype = "itemizations"
144
145 @asyncthread
146 def reload(self):
147 self.rows = []
148 self.columns = []
149
150 if len(self.source) == 0:
151 return
152
153 for i, row in enumerate(Progress(self.source, total = len(self.source))):
154 if i == 0:
155 self.set_columns_from_row(row)
156 self.addRow(row)
157
158 def set_columns_from_row(self, row):
159 self.columns.clear()
160 for i, name in enumerate(row.keys()):
161 self.addColumn(ColumnItem(name))
162 def dive(self):
163 vs = DiveSheet(
164 vd.joinSheetnames(self.name, "detail"),
165 source = self.cursorRow
166 )
167 vs.reload()
168 vd.push(vs)
169
170 FECItemizationSheet.addCommand(
171 ENTER,
172 'dive-row',
173 'vd.sheet.dive()'
174 )
175
176 class FECScheduleSheet(Sheet):
177 "A sheet to display the list of itemized schedules in a filing."
178
179 rowtype = "schedules"
180
181 columns = [
182 ColumnAttr("schedule", "schedule_name", width = 14),
183 ColumnAttr("name", width = 0),
184 ColumnAttr("size", type = int),
185 ]
186
187 nKeys = 1
188
189 @asyncthread
190 def reload(self):
191 self.rows = []
192
193 for schedule_name in self.source.keys():
194 vs = FECItemizationSheet(
195 vd.joinSheetnames(self.name, schedule_name),
196 schedule_name = schedule_name,
197 source = self.source[schedule_name],
198 size = len(self.source[schedule_name]),
199 )
200 self.addRow(vs)
201
202 FECScheduleSheet.addCommand(
203 ENTER,
204 'dive-row',
205 'vd.push(cursorRow)'
206 )
207
208 COMPONENT_SHEET_CLASSES = {
209 "header": DiveSheet,
210 "summary": DiveSheet,
211 "itemization": FECScheduleSheet,
212 "text": FECItemizationSheet,
213 "F99_text": TextSheet,
214 }
215
216 class FECFiling(Sheet):
217 "A sheet representing an entire .fec file."
218
219 rowtype = "components"
220 filing = None
221
222 columns = [
223 ColumnAttr("component", "component_name", width = 14),
224 ColumnAttr("name", width = 0),
225 ColumnAttr("size", type = int),
226 ]
227
228 nKeys = 1
229
230 @asyncthread
231 def reload(self):
232 from fecfile import fecparser
233 self.rows = []
234
235 row_dict = { }
236 itemization_subsheets = {}
237
238 def addSheetRow(component_name):
239 "On first encountering a component, add a row to the filing sheet"
240
241 cls = COMPONENT_SHEET_CLASSES[component_name]
242
243 source_cls = list if cls in [
244 FECItemizationSheet,
245 TextSheet
246 ] else dict
247
248 vs = cls(
249 vd.joinSheetnames(self.name, component_name),
250 component_name = component_name,
251 source = source_cls(),
252 size = 0,
253 )
254
255 vs.reload()
256 row_dict[component_name] = vs
257 self.addRow(vs)
258
259 src = Path(self.source.resolve())
260
261 item_iter = fecparser.iter_lines(src, { "as_strings": True })
262
263 for item in item_iter:
264 dtype = item.data_type
265 if dtype not in row_dict.keys():
266 addSheetRow(dtype)
267
268 sheet_row = row_dict[dtype]
269
270 if dtype in [ "header", "summary" ]:
271 sheet_row.source = item.data
272 sheet_row.reload()
273
274 elif dtype == "text":
275 if len(sheet_row.source) == 0:
276 sheet_row.set_columns_from_row(item.data)
277 sheet_row.source.append(item.data)
278 sheet_row.addRow(item.data)
279 sheet_row.size += 1
280
281 elif dtype == "F99_text":
282 sheet_row.source = item.data.split("\n")
283 sheet_row.size = len(sheet_row.source)
284
285 elif dtype == "itemization":
286 form_type = item.data["form_type"]
287
288 if form_type[0] == "S":
289 form_type = "Schedule " + item.data["form_type"][1]
290
291 if form_type not in sheet_row.source:
292 sheet_row.source[form_type] = [ ]
293 subsheet = FECItemizationSheet(
294 vd.joinSheetnames(sheet_row.name, form_type),
295 schedule_name = form_type,
296 source = [ ],
297 size = 0,
298 )
299 subsheet.reload()
300 subsheet.set_columns_from_row(item.data)
301 sheet_row.addRow(subsheet)
302 itemization_subsheets[form_type] = subsheet
303 else:
304 subsheet = itemization_subsheets[form_type]
305
306 subsheet.addRow(item.data)
307 subsheet.source.append(item.data)
308 subsheet.size += 1
309
310 sheet_row.source[form_type].append(item.data)
311 sheet_row.size += 1
312
313 FECFiling.addCommand(
314 ENTER,
315 'dive-row',
316 'vd.push(cursorRow)'
317 )
318
319 def open_fec(p):
320 return FECFiling(p.base_stem, source=p)
321
322 addGlobals({
323 "open_fec": open_fec,
324 "DiveSheet": DiveSheet
325 })
326
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/visidata/loaders/fec.py b/visidata/loaders/fec.py
--- a/visidata/loaders/fec.py
+++ b/visidata/loaders/fec.py
@@ -37,13 +37,12 @@
from copy import copy
from visidata import (
vd,
+ VisiData,
Path,
Sheet,
TextSheet,
- Column,
ColumnAttr,
ColumnItem,
- ENTER,
asyncthread,
Progress,
addGlobals,
@@ -111,10 +110,10 @@
vd.warning("Can't dive on lists with heterogenous item types.")
return False
- def dive(self):
+ def openRow(self, row):
if self.is_keyvalue:
- cell = self.cursorRow["value"]
- name = vd.joinSheetnames(self.name, self.cursorRow["key"])
+ cell = row["value"]
+ name = vd.joinSheetnames(self.name, row["key"])
if isinstance(cell, (list, dict)):
vs = self.__class__(name, source = cell)
@@ -123,19 +122,13 @@
return
else:
name = vd.joinSheetnames(self.name, "row")
- vs = self.__class__(name, source = self.cursorRow)
+ vs = self.__class__(name, source = self.row)
success = vs.reload()
if success == False:
- return
-
- vd.push(vs)
+ vd.fail('could not reload new sheet')
+ return vs
-DiveSheet.addCommand(
- ENTER,
- 'dive-row',
- 'vd.sheet.dive()'
-)
class FECItemizationSheet(Sheet):
"A sheet to display a list of FEC itemizations from a given form/schedule."
@@ -159,19 +152,9 @@
self.columns.clear()
for i, name in enumerate(row.keys()):
self.addColumn(ColumnItem(name))
- def dive(self):
- vs = DiveSheet(
- vd.joinSheetnames(self.name, "detail"),
- source = self.cursorRow
- )
- vs.reload()
- vd.push(vs)
-
-FECItemizationSheet.addCommand(
- ENTER,
- 'dive-row',
- 'vd.sheet.dive()'
-)
+
+ def openRow(self, row):
+ return row
class FECScheduleSheet(Sheet):
"A sheet to display the list of itemized schedules in a filing."
@@ -199,11 +182,8 @@
)
self.addRow(vs)
-FECScheduleSheet.addCommand(
- ENTER,
- 'dive-row',
- 'vd.push(cursorRow)'
-)
+ def openRow(self, row):
+ return row
COMPONENT_SHEET_CLASSES = {
"header": DiveSheet,
@@ -230,7 +210,7 @@
@asyncthread
def reload(self):
from fecfile import fecparser
- self.rows = []
+ self.rows = [] # rowdef: Sheet, of a type from COMPONENT_SHEET_CLASSES.values()
row_dict = { }
itemization_subsheets = {}
@@ -310,16 +290,13 @@
sheet_row.source[form_type].append(item.data)
sheet_row.size += 1
-FECFiling.addCommand(
- ENTER,
- 'dive-row',
- 'vd.push(cursorRow)'
-)
+ def openRow(self, row):
+ return row
-def open_fec(p):
[email protected]
+def open_fec(vd, p):
return FECFiling(p.base_stem, source=p)
addGlobals({
- "open_fec": open_fec,
"DiveSheet": DiveSheet
})
|
{"golden_diff": "diff --git a/visidata/loaders/fec.py b/visidata/loaders/fec.py\n--- a/visidata/loaders/fec.py\n+++ b/visidata/loaders/fec.py\n@@ -37,13 +37,12 @@\n from copy import copy\n from visidata import (\n vd,\n+ VisiData,\n Path,\n Sheet,\n TextSheet,\n- Column,\n ColumnAttr,\n ColumnItem,\n- ENTER,\n asyncthread,\n Progress,\n addGlobals,\n@@ -111,10 +110,10 @@\n vd.warning(\"Can't dive on lists with heterogenous item types.\")\n return False\n \n- def dive(self):\n+ def openRow(self, row):\n if self.is_keyvalue:\n- cell = self.cursorRow[\"value\"]\n- name = vd.joinSheetnames(self.name, self.cursorRow[\"key\"])\n+ cell = row[\"value\"]\n+ name = vd.joinSheetnames(self.name, row[\"key\"])\n \n if isinstance(cell, (list, dict)):\n vs = self.__class__(name, source = cell)\n@@ -123,19 +122,13 @@\n return\n else:\n name = vd.joinSheetnames(self.name, \"row\")\n- vs = self.__class__(name, source = self.cursorRow)\n+ vs = self.__class__(name, source = self.row)\n \n success = vs.reload()\n if success == False:\n- return\n-\n- vd.push(vs)\n+ vd.fail('could not reload new sheet')\n+ return vs\n \n-DiveSheet.addCommand(\n- ENTER,\n- 'dive-row',\n- 'vd.sheet.dive()'\n-)\n \n class FECItemizationSheet(Sheet):\n \"A sheet to display a list of FEC itemizations from a given form/schedule.\"\n@@ -159,19 +152,9 @@\n self.columns.clear()\n for i, name in enumerate(row.keys()):\n self.addColumn(ColumnItem(name))\n- def dive(self):\n- vs = DiveSheet(\n- vd.joinSheetnames(self.name, \"detail\"),\n- source = self.cursorRow\n- )\n- vs.reload()\n- vd.push(vs)\n-\n-FECItemizationSheet.addCommand(\n- ENTER,\n- 'dive-row',\n- 'vd.sheet.dive()'\n-)\n+\n+ def openRow(self, row):\n+ return row\n \n class FECScheduleSheet(Sheet):\n \"A sheet to display the list of itemized schedules in a filing.\"\n@@ -199,11 +182,8 @@\n )\n self.addRow(vs)\n \n-FECScheduleSheet.addCommand(\n- ENTER,\n- 'dive-row',\n- 'vd.push(cursorRow)'\n-)\n+ def openRow(self, row):\n+ return row\n \n COMPONENT_SHEET_CLASSES = {\n \"header\": DiveSheet,\n@@ -230,7 +210,7 @@\n @asyncthread\n def reload(self):\n from fecfile import fecparser\n- self.rows = []\n+ self.rows = [] # rowdef: Sheet, of a type from COMPONENT_SHEET_CLASSES.values()\n \n row_dict = { }\n itemization_subsheets = {}\n@@ -310,16 +290,13 @@\n sheet_row.source[form_type].append(item.data)\n sheet_row.size += 1\n \n-FECFiling.addCommand(\n- ENTER,\n- 'dive-row',\n- 'vd.push(cursorRow)'\n-)\n+ def openRow(self, row):\n+ return row\n \n-def open_fec(p):\[email protected]\n+def open_fec(vd, p):\n return FECFiling(p.base_stem, source=p)\n \n addGlobals({\n- \"open_fec\": open_fec,\n \"DiveSheet\": DiveSheet\n })\n", "issue": "[fec] opening rows in FEC files does not seem to work\n**Small description**\r\nFEC files can be opened, but rows cannot be browsed.\r\n\r\n**Data to reproduce**\r\nUsing [a sample file 1326070.fec](https://docquery.fec.gov/dcdev/posted/1326070.fec).\r\n\r\n**Steps to reproduce**\r\n\r\n**Expected result**\r\nWhen the user presses `Enter`, rows should open as in [jsvine's demo video at 13 seconds].(https://asciinema.org/a/Xyh2BFsUaOF0AlHTmMUbqQZPC)\r\n\r\n**Actual result**\r\nWhen the user presses `Enter`, `open-rows` runs, for example, opening the itemization row, as:\r\n```\r\ncolumn | value\r\n------------------------\r\ncomponent | itemization\r\nsize | 56958\r\n```\r\n\r\n**Configuration**\r\n- Does this issue reproduce without any plugins or configuration (using the `-N` CLI flag)?\r\nYes, it reproduces with `-N`.\r\n\r\n- Does this issue reproduce with either the [latest release](https://www.visidata.org/releases/), or with the [develop branch](https://www.visidata.org/install/#update-visidata-from-an-existing-installation)?\r\nYes, the latest develop.\r\n\r\n**Additional context**\r\n`fecfile` 0.8.0 installed via pip\r\nPython 3.10.12\r\nUbuntu 22.04.4\n", "before_files": [{"content": "\"\"\"\nFilename: vdfec.py\nLast updated: 2019-04-21\nHome: https://github.com/jsvine/visidata-plugins\nAuthor: Jeremy Singer-Vine\n\n# Installation\n\n- Install fecfile: `pip install fecfile`\n- Add vdfec.py to your ~/.visidata directory\n- Add \"import vdfec\" to your ~/.visidatarc file\n\n# Usage\n\nvdfec.py enables VisiData to load .fec files from the Federal Election Commission.\n\nOnce saved to your ~/.visidata directory, and imported via your ~/.visidatarc file,\nyou should be able to interactively explore .fec files as you would any other \nfiletype in VisiData.\n\nFrom the command line:\n\n vd path/to/my/file.fec\n\n# Thanks\n\nvdfec.py depends heavily on Evan Sonderegger's `fecfile` Python library: https://esonderegger.github.io/fecfile/\n\n... which in turn is based on Derek Willis's `Fech` Ruby library: https://github.com/dwillis/Fech\n\n... and Chris Zubak-Skees' transformation of `Fech`'s form-and-field mappings: https://github.com/PublicI/fec-parse/blob/master/lib/renderedmaps.js\n\nThanks to all who have contributed to those projects.\n\n\"\"\"\n\nfrom copy import copy\nfrom visidata import (\n vd,\n Path,\n Sheet,\n TextSheet,\n Column,\n ColumnAttr,\n ColumnItem,\n ENTER,\n asyncthread,\n Progress,\n addGlobals,\n)\n\nclass DiveSheet(Sheet):\n \"A deeply-diveable, quick-diving sheet.\"\n\n def reload(self):\n mapping = self.source\n\n self.columns = []\n self.rows = []\n\n self.key_type = str\n self.size = len(mapping)\n\n if self.size == 0:\n return\n\n if isinstance(mapping, list):\n first = mapping[0]\n if isinstance(first, dict):\n colgetter = lambda x: x.keys()\n elif isinstance(first, list):\n colgetter = lambda x: list(range(len(x)))\n else:\n mapping = dict(enumerate(mapping))\n self.key_type = int\n self.size = len(mapping)\n\n if isinstance(mapping, dict):\n self.is_keyvalue = True\n if self.size:\n max_key_len = max(map(len, map(str, mapping.keys())))\n key_width = min(50, max(max_key_len + 2, 6))\n else:\n key_width = None\n\n self.addColumn(ColumnItem(\n \"key\",\n width = key_width,\n type = self.key_type\n ))\n self.addColumn(ColumnItem(\"value\"))\n self.setKeys(self.columns[:1])\n\n for k, v in mapping.items():\n self.addRow({ \"key\": k, \"value\": v })\n\n elif isinstance(mapping, list):\n self.is_keyvalue = False\n indices = [] \n for item in mapping:\n try:\n cols = colgetter(item)\n for col in cols:\n if col not in indices:\n self.addColumn(ColumnItem(col))\n indices.append(col)\n\n self.addRow(item)\n\n except Exception as e:\n vd.warning(\"Can't dive on lists with heterogenous item types.\")\n return False\n\n def dive(self):\n if self.is_keyvalue:\n cell = self.cursorRow[\"value\"]\n name = vd.joinSheetnames(self.name, self.cursorRow[\"key\"])\n\n if isinstance(cell, (list, dict)):\n vs = self.__class__(name, source = cell)\n else:\n vd.warning(\"Nothing to dive into.\")\n return\n else:\n name = vd.joinSheetnames(self.name, \"row\")\n vs = self.__class__(name, source = self.cursorRow)\n\n success = vs.reload()\n if success == False:\n return\n\n vd.push(vs)\n\nDiveSheet.addCommand(\n ENTER,\n 'dive-row',\n 'vd.sheet.dive()'\n)\n\nclass FECItemizationSheet(Sheet):\n \"A sheet to display a list of FEC itemizations from a given form/schedule.\"\n\n rowtype = \"itemizations\"\n\n @asyncthread\n def reload(self):\n self.rows = []\n self.columns = []\n\n if len(self.source) == 0:\n return\n\n for i, row in enumerate(Progress(self.source, total = len(self.source))):\n if i == 0:\n self.set_columns_from_row(row)\n self.addRow(row)\n \n def set_columns_from_row(self, row):\n self.columns.clear()\n for i, name in enumerate(row.keys()):\n self.addColumn(ColumnItem(name))\n def dive(self):\n vs = DiveSheet(\n vd.joinSheetnames(self.name, \"detail\"),\n source = self.cursorRow\n )\n vs.reload()\n vd.push(vs)\n\nFECItemizationSheet.addCommand(\n ENTER,\n 'dive-row',\n 'vd.sheet.dive()'\n)\n\nclass FECScheduleSheet(Sheet):\n \"A sheet to display the list of itemized schedules in a filing.\"\n\n rowtype = \"schedules\"\n\n columns = [\n ColumnAttr(\"schedule\", \"schedule_name\", width = 14),\n ColumnAttr(\"name\", width = 0),\n ColumnAttr(\"size\", type = int),\n ]\n\n nKeys = 1\n\n @asyncthread\n def reload(self):\n self.rows = []\n\n for schedule_name in self.source.keys():\n vs = FECItemizationSheet(\n vd.joinSheetnames(self.name, schedule_name),\n schedule_name = schedule_name,\n source = self.source[schedule_name],\n size = len(self.source[schedule_name]),\n )\n self.addRow(vs)\n\nFECScheduleSheet.addCommand(\n ENTER,\n 'dive-row',\n 'vd.push(cursorRow)'\n)\n\nCOMPONENT_SHEET_CLASSES = {\n \"header\": DiveSheet,\n \"summary\": DiveSheet,\n \"itemization\": FECScheduleSheet,\n \"text\": FECItemizationSheet,\n \"F99_text\": TextSheet,\n}\n\nclass FECFiling(Sheet):\n \"A sheet representing an entire .fec file.\"\n\n rowtype = \"components\"\n filing = None\n\n columns = [\n ColumnAttr(\"component\", \"component_name\", width = 14),\n ColumnAttr(\"name\", width = 0),\n ColumnAttr(\"size\", type = int),\n ]\n\n nKeys = 1\n\n @asyncthread\n def reload(self):\n from fecfile import fecparser\n self.rows = []\n\n row_dict = { }\n itemization_subsheets = {}\n\n def addSheetRow(component_name):\n \"On first encountering a component, add a row to the filing sheet\"\n\n cls = COMPONENT_SHEET_CLASSES[component_name]\n\n source_cls = list if cls in [\n FECItemizationSheet,\n TextSheet\n ] else dict\n\n vs = cls(\n vd.joinSheetnames(self.name, component_name),\n component_name = component_name,\n source = source_cls(),\n size = 0,\n )\n\n vs.reload()\n row_dict[component_name] = vs\n self.addRow(vs)\n\n src = Path(self.source.resolve())\n\n item_iter = fecparser.iter_lines(src, { \"as_strings\": True })\n\n for item in item_iter:\n dtype = item.data_type \n if dtype not in row_dict.keys():\n addSheetRow(dtype)\n\n sheet_row = row_dict[dtype]\n\n if dtype in [ \"header\", \"summary\" ]:\n sheet_row.source = item.data\n sheet_row.reload()\n\n elif dtype == \"text\":\n if len(sheet_row.source) == 0:\n sheet_row.set_columns_from_row(item.data)\n sheet_row.source.append(item.data)\n sheet_row.addRow(item.data)\n sheet_row.size += 1\n\n elif dtype == \"F99_text\":\n sheet_row.source = item.data.split(\"\\n\")\n sheet_row.size = len(sheet_row.source)\n\n elif dtype == \"itemization\":\n form_type = item.data[\"form_type\"]\n\n if form_type[0] == \"S\":\n form_type = \"Schedule \" + item.data[\"form_type\"][1]\n\n if form_type not in sheet_row.source:\n sheet_row.source[form_type] = [ ] \n subsheet = FECItemizationSheet(\n vd.joinSheetnames(sheet_row.name, form_type),\n schedule_name = form_type,\n source = [ ],\n size = 0,\n )\n subsheet.reload()\n subsheet.set_columns_from_row(item.data)\n sheet_row.addRow(subsheet)\n itemization_subsheets[form_type] = subsheet\n else:\n subsheet = itemization_subsheets[form_type]\n\n subsheet.addRow(item.data)\n subsheet.source.append(item.data)\n subsheet.size += 1\n\n sheet_row.source[form_type].append(item.data)\n sheet_row.size += 1\n\nFECFiling.addCommand(\n ENTER,\n 'dive-row',\n 'vd.push(cursorRow)'\n)\n\ndef open_fec(p):\n return FECFiling(p.base_stem, source=p)\n\naddGlobals({\n \"open_fec\": open_fec,\n \"DiveSheet\": DiveSheet\n})\n", "path": "visidata/loaders/fec.py"}], "after_files": [{"content": "\"\"\"\nFilename: vdfec.py\nLast updated: 2019-04-21\nHome: https://github.com/jsvine/visidata-plugins\nAuthor: Jeremy Singer-Vine\n\n# Installation\n\n- Install fecfile: `pip install fecfile`\n- Add vdfec.py to your ~/.visidata directory\n- Add \"import vdfec\" to your ~/.visidatarc file\n\n# Usage\n\nvdfec.py enables VisiData to load .fec files from the Federal Election Commission.\n\nOnce saved to your ~/.visidata directory, and imported via your ~/.visidatarc file,\nyou should be able to interactively explore .fec files as you would any other \nfiletype in VisiData.\n\nFrom the command line:\n\n vd path/to/my/file.fec\n\n# Thanks\n\nvdfec.py depends heavily on Evan Sonderegger's `fecfile` Python library: https://esonderegger.github.io/fecfile/\n\n... which in turn is based on Derek Willis's `Fech` Ruby library: https://github.com/dwillis/Fech\n\n... and Chris Zubak-Skees' transformation of `Fech`'s form-and-field mappings: https://github.com/PublicI/fec-parse/blob/master/lib/renderedmaps.js\n\nThanks to all who have contributed to those projects.\n\n\"\"\"\n\nfrom copy import copy\nfrom visidata import (\n vd,\n VisiData,\n Path,\n Sheet,\n TextSheet,\n ColumnAttr,\n ColumnItem,\n asyncthread,\n Progress,\n addGlobals,\n)\n\nclass DiveSheet(Sheet):\n \"A deeply-diveable, quick-diving sheet.\"\n\n def reload(self):\n mapping = self.source\n\n self.columns = []\n self.rows = []\n\n self.key_type = str\n self.size = len(mapping)\n\n if self.size == 0:\n return\n\n if isinstance(mapping, list):\n first = mapping[0]\n if isinstance(first, dict):\n colgetter = lambda x: x.keys()\n elif isinstance(first, list):\n colgetter = lambda x: list(range(len(x)))\n else:\n mapping = dict(enumerate(mapping))\n self.key_type = int\n self.size = len(mapping)\n\n if isinstance(mapping, dict):\n self.is_keyvalue = True\n if self.size:\n max_key_len = max(map(len, map(str, mapping.keys())))\n key_width = min(50, max(max_key_len + 2, 6))\n else:\n key_width = None\n\n self.addColumn(ColumnItem(\n \"key\",\n width = key_width,\n type = self.key_type\n ))\n self.addColumn(ColumnItem(\"value\"))\n self.setKeys(self.columns[:1])\n\n for k, v in mapping.items():\n self.addRow({ \"key\": k, \"value\": v })\n\n elif isinstance(mapping, list):\n self.is_keyvalue = False\n indices = [] \n for item in mapping:\n try:\n cols = colgetter(item)\n for col in cols:\n if col not in indices:\n self.addColumn(ColumnItem(col))\n indices.append(col)\n\n self.addRow(item)\n\n except Exception as e:\n vd.warning(\"Can't dive on lists with heterogenous item types.\")\n return False\n\n def openRow(self, row):\n if self.is_keyvalue:\n cell = row[\"value\"]\n name = vd.joinSheetnames(self.name, row[\"key\"])\n\n if isinstance(cell, (list, dict)):\n vs = self.__class__(name, source = cell)\n else:\n vd.warning(\"Nothing to dive into.\")\n return\n else:\n name = vd.joinSheetnames(self.name, \"row\")\n vs = self.__class__(name, source = self.row)\n\n success = vs.reload()\n if success == False:\n vd.fail('could not reload new sheet')\n return vs\n\n\nclass FECItemizationSheet(Sheet):\n \"A sheet to display a list of FEC itemizations from a given form/schedule.\"\n\n rowtype = \"itemizations\"\n\n @asyncthread\n def reload(self):\n self.rows = []\n self.columns = []\n\n if len(self.source) == 0:\n return\n\n for i, row in enumerate(Progress(self.source, total = len(self.source))):\n if i == 0:\n self.set_columns_from_row(row)\n self.addRow(row)\n \n def set_columns_from_row(self, row):\n self.columns.clear()\n for i, name in enumerate(row.keys()):\n self.addColumn(ColumnItem(name))\n\n def openRow(self, row):\n return row\n\nclass FECScheduleSheet(Sheet):\n \"A sheet to display the list of itemized schedules in a filing.\"\n\n rowtype = \"schedules\"\n\n columns = [\n ColumnAttr(\"schedule\", \"schedule_name\", width = 14),\n ColumnAttr(\"name\", width = 0),\n ColumnAttr(\"size\", type = int),\n ]\n\n nKeys = 1\n\n @asyncthread\n def reload(self):\n self.rows = []\n\n for schedule_name in self.source.keys():\n vs = FECItemizationSheet(\n vd.joinSheetnames(self.name, schedule_name),\n schedule_name = schedule_name,\n source = self.source[schedule_name],\n size = len(self.source[schedule_name]),\n )\n self.addRow(vs)\n\n def openRow(self, row):\n return row\n\nCOMPONENT_SHEET_CLASSES = {\n \"header\": DiveSheet,\n \"summary\": DiveSheet,\n \"itemization\": FECScheduleSheet,\n \"text\": FECItemizationSheet,\n \"F99_text\": TextSheet,\n}\n\nclass FECFiling(Sheet):\n \"A sheet representing an entire .fec file.\"\n\n rowtype = \"components\"\n filing = None\n\n columns = [\n ColumnAttr(\"component\", \"component_name\", width = 14),\n ColumnAttr(\"name\", width = 0),\n ColumnAttr(\"size\", type = int),\n ]\n\n nKeys = 1\n\n @asyncthread\n def reload(self):\n from fecfile import fecparser\n self.rows = [] # rowdef: Sheet, of a type from COMPONENT_SHEET_CLASSES.values()\n\n row_dict = { }\n itemization_subsheets = {}\n\n def addSheetRow(component_name):\n \"On first encountering a component, add a row to the filing sheet\"\n\n cls = COMPONENT_SHEET_CLASSES[component_name]\n\n source_cls = list if cls in [\n FECItemizationSheet,\n TextSheet\n ] else dict\n\n vs = cls(\n vd.joinSheetnames(self.name, component_name),\n component_name = component_name,\n source = source_cls(),\n size = 0,\n )\n\n vs.reload()\n row_dict[component_name] = vs\n self.addRow(vs)\n\n src = Path(self.source.resolve())\n\n item_iter = fecparser.iter_lines(src, { \"as_strings\": True })\n\n for item in item_iter:\n dtype = item.data_type \n if dtype not in row_dict.keys():\n addSheetRow(dtype)\n\n sheet_row = row_dict[dtype]\n\n if dtype in [ \"header\", \"summary\" ]:\n sheet_row.source = item.data\n sheet_row.reload()\n\n elif dtype == \"text\":\n if len(sheet_row.source) == 0:\n sheet_row.set_columns_from_row(item.data)\n sheet_row.source.append(item.data)\n sheet_row.addRow(item.data)\n sheet_row.size += 1\n\n elif dtype == \"F99_text\":\n sheet_row.source = item.data.split(\"\\n\")\n sheet_row.size = len(sheet_row.source)\n\n elif dtype == \"itemization\":\n form_type = item.data[\"form_type\"]\n\n if form_type[0] == \"S\":\n form_type = \"Schedule \" + item.data[\"form_type\"][1]\n\n if form_type not in sheet_row.source:\n sheet_row.source[form_type] = [ ] \n subsheet = FECItemizationSheet(\n vd.joinSheetnames(sheet_row.name, form_type),\n schedule_name = form_type,\n source = [ ],\n size = 0,\n )\n subsheet.reload()\n subsheet.set_columns_from_row(item.data)\n sheet_row.addRow(subsheet)\n itemization_subsheets[form_type] = subsheet\n else:\n subsheet = itemization_subsheets[form_type]\n\n subsheet.addRow(item.data)\n subsheet.source.append(item.data)\n subsheet.size += 1\n\n sheet_row.source[form_type].append(item.data)\n sheet_row.size += 1\n\n def openRow(self, row):\n return row\n\[email protected]\ndef open_fec(vd, p):\n return FECFiling(p.base_stem, source=p)\n\naddGlobals({\n \"DiveSheet\": DiveSheet\n})\n", "path": "visidata/loaders/fec.py"}]}
| 3,465 | 859 |
gh_patches_debug_53192
|
rasdani/github-patches
|
git_diff
|
buildbot__buildbot-426
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Move to a ChangeHook in hgbuildbot.py (closes #2227)
Starting a Twisted reactor within a Mercurial hook is problematic
because a hook can get called multiple times (from the same Mercurial
process) which conflicts with the one-time only nature of the Twisted
reactor start/stop calls.
By moving to HTTP requests the hook is now re-entrant which fixes
ReactorNotRestartable exceptions being raised all the time.
The requests library is used to make the calls, since it has a
functional TLS implementation (unlike urllib/httplib in Python 2 until
recently).
Additionally, the codebase argument is added to the base ChangeHook, so
it can properly be used with a codebaseGenerator.
Finally, if a venv argument is used, it is now properly used to activate
the environment [1].
Possible improvements to this changeset are:
- send requests in parallel;
- switch back to urllib2 so the hook doesn't depend on anything;
- a few more cleanups.
[1] https://github.com/pypa/virtualenv/blob/master/virtualenv_embedded/activate_this.py
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `master/buildbot/steps/source/cvs.py`
Content:
```
1 # This file is part of Buildbot. Buildbot is free software: you can
2 # redistribute it and/or modify it under the terms of the GNU General Public
3 # License as published by the Free Software Foundation, version 2.
4 #
5 # This program is distributed in the hope that it will be useful, but WITHOUT
6 # ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
7 # FOR A PARTICULAR PURPOSE. See the GNU General Public License for more
8 # details.
9 #
10 # You should have received a copy of the GNU General Public License along with
11 # this program; if not, write to the Free Software Foundation, Inc., 51
12 # Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
13 #
14 # Copyright Buildbot Team Members
15
16 from email.Utils import formatdate
17 import time
18
19 from twisted.python import log
20 from twisted.internet import defer
21
22 from buildbot.process import buildstep
23 from buildbot.steps.shell import StringFileWriter
24 from buildbot.steps.source.base import Source
25 from buildbot.interfaces import BuildSlaveTooOldError
26
27 class CVS(Source):
28
29 name = "cvs"
30
31 renderables = [ "cvsroot" ]
32
33 def __init__(self, cvsroot=None, cvsmodule='', mode='incremental',
34 method=None, branch=None, global_options=[], extra_options=[],
35 login=None, **kwargs):
36
37 self.cvsroot = cvsroot
38 self.cvsmodule = cvsmodule
39 self.branch = branch
40 self.global_options = global_options
41 self.extra_options = extra_options
42 self.login = login
43 self.mode = mode
44 self.method = method
45 self.srcdir = 'source'
46 Source.__init__(self, **kwargs)
47
48 def startVC(self, branch, revision, patch):
49 self.revision = revision
50 self.stdio_log = self.addLog("stdio")
51 self.method = self._getMethod()
52 d = self.checkCvs()
53 def checkInstall(cvsInstalled):
54 if not cvsInstalled:
55 raise BuildSlaveTooOldError("CVS is not installed on slave")
56 return 0
57 d.addCallback(checkInstall)
58 d.addCallback(self.checkLogin)
59
60 if self.mode == 'incremental':
61 d.addCallback(lambda _: self.incremental())
62 elif self.mode == 'full':
63 d.addCallback(lambda _: self.full())
64
65 d.addCallback(self.parseGotRevision)
66 d.addCallback(self.finish)
67 d.addErrback(self.failed)
68 return d
69
70 @defer.inlineCallbacks
71 def incremental(self):
72 updatable = yield self._sourcedirIsUpdatable()
73 if updatable:
74 rv = yield self.doUpdate()
75 else:
76 rv = yield self.clobber()
77 defer.returnValue(rv)
78
79 @defer.inlineCallbacks
80 def full(self):
81 if self.method == 'clobber':
82 rv = yield self.clobber()
83 defer.returnValue(rv)
84 return
85
86 elif self.method == 'copy':
87 rv = yield self.copy()
88 defer.returnValue(rv)
89 return
90
91 updatable = yield self._sourcedirIsUpdatable()
92 if not updatable:
93 log.msg("CVS repo not present, making full checkout")
94 rv = yield self.doCheckout(self.workdir)
95 elif self.method == 'clean':
96 rv = yield self.clean()
97 elif self.method == 'fresh':
98 rv = yield self.fresh()
99 else:
100 raise ValueError("Unknown method, check your configuration")
101 defer.returnValue(rv)
102
103 def clobber(self):
104 cmd = buildstep.RemoteCommand('rmdir', {'dir': self.workdir,
105 'logEnviron': self.logEnviron})
106 cmd.useLog(self.stdio_log, False)
107 d = self.runCommand(cmd)
108 def checkRemoval(res):
109 if res != 0:
110 raise RuntimeError("Failed to delete directory")
111 return res
112 d.addCallback(lambda _: checkRemoval(cmd.rc))
113 d.addCallback(lambda _: self.doCheckout(self.workdir))
114 return d
115
116 def fresh(self, ):
117 d = self.purge(True)
118 d.addCallback(lambda _: self.doUpdate())
119 return d
120
121 def clean(self, ):
122 d = self.purge(False)
123 d.addCallback(lambda _: self.doUpdate())
124 return d
125
126 def copy(self):
127 cmd = buildstep.RemoteCommand('rmdir', {'dir': self.workdir,
128 'logEnviron': self.logEnviron})
129 cmd.useLog(self.stdio_log, False)
130 d = self.runCommand(cmd)
131 self.workdir = 'source'
132 d.addCallback(lambda _: self.incremental())
133 def copy(_):
134 cmd = buildstep.RemoteCommand('cpdir',
135 {'fromdir': 'source',
136 'todir':'build',
137 'logEnviron': self.logEnviron,})
138 cmd.useLog(self.stdio_log, False)
139 d = self.runCommand(cmd)
140 return d
141 d.addCallback(copy)
142 def resetWorkdir(_):
143 self.workdir = 'build'
144 return 0
145 d.addCallback(resetWorkdir)
146 return d
147
148 def purge(self, ignore_ignores):
149 command = ['cvsdiscard']
150 if ignore_ignores:
151 command += ['--ignore']
152 cmd = buildstep.RemoteShellCommand(self.workdir, command,
153 env=self.env,
154 logEnviron=self.logEnviron)
155 cmd.useLog(self.stdio_log, False)
156 d = self.runCommand(cmd)
157 def evaluate(rc):
158 if rc != 0:
159 raise buildstep.BuildStepFailed()
160 return rc
161 d.addCallback(lambda _: evaluate(cmd.rc))
162 return d
163
164 def doCheckout(self, dir):
165 command = ['-d', self.cvsroot, '-z3', 'checkout', '-d', dir ]
166 command = self.global_options + command + self.extra_options
167 if self.branch:
168 command += ['-r', self.branch]
169 if self.revision:
170 command += ['-D', self.revision]
171 command += [ self.cvsmodule ]
172 d = self._dovccmd(command, '')
173 return d
174
175 def doUpdate(self):
176 command = ['-z3', 'update', '-dP']
177 if self.branch:
178 command += ['-r', self.branch]
179 if self.revision:
180 command += ['-D', self.revision]
181 d = self._dovccmd(command)
182 return d
183
184 def finish(self, res):
185 d = defer.succeed(res)
186 def _gotResults(results):
187 self.setStatus(self.cmd, results)
188 return results
189 d.addCallback(_gotResults)
190 d.addCallbacks(self.finished, self.checkDisconnect)
191 return d
192
193 def checkLogin(self, _):
194 if self.login:
195 d = defer.succeed(0)
196 else:
197 d = self._dovccmd(['-d', self.cvsroot, 'login'])
198 def setLogin(res):
199 # this happens only if the login command succeeds.
200 self.login = True
201 return res
202 d.addCallback(setLogin)
203
204 return d
205
206 def _dovccmd(self, command, workdir=None):
207 if workdir is None:
208 workdir = self.workdir
209 if not command:
210 raise ValueError("No command specified")
211 cmd = buildstep.RemoteShellCommand(workdir, ['cvs'] +
212 command,
213 env=self.env,
214 logEnviron=self.logEnviron)
215 cmd.useLog(self.stdio_log, False)
216 d = self.runCommand(cmd)
217 def evaluateCommand(cmd):
218 if cmd.rc != 0:
219 log.msg("Source step failed while running command %s" % cmd)
220 raise buildstep.BuildStepFailed()
221 return cmd.rc
222 d.addCallback(lambda _: evaluateCommand(cmd))
223 return d
224
225 @defer.inlineCallbacks
226 def _sourcedirIsUpdatable(self):
227 myFileWriter = StringFileWriter()
228 args = {
229 'workdir': self.build.path_module.join(self.workdir, 'CVS'),
230 'writer': myFileWriter,
231 'maxsize': None,
232 'blocksize': 32*1024,
233 }
234
235 cmd = buildstep.RemoteCommand('uploadFile',
236 dict(slavesrc='Root', **args),
237 ignore_updates=True)
238 yield self.runCommand(cmd)
239 if cmd.rc is not None and cmd.rc != 0:
240 defer.returnValue(False)
241 return
242 if myFileWriter.buffer.strip() != self.cvsroot:
243 defer.returnValue(False)
244 return
245
246 myFileWriter.buffer = ""
247 cmd = buildstep.RemoteCommand('uploadFile',
248 dict(slavesrc='Repository', **args),
249 ignore_updates=True)
250 yield self.runCommand(cmd)
251 if cmd.rc is not None and cmd.rc != 0:
252 defer.returnValue(False)
253 return
254 if myFileWriter.buffer.strip() != self.cvsmodule:
255 defer.returnValue(False)
256 return
257
258 defer.returnValue(True)
259
260 def parseGotRevision(self, res):
261 revision = time.strftime("%Y-%m-%d %H:%M:%S +0000", time.gmtime())
262 self.setProperty('got_revision', revision, 'Source')
263 return res
264
265 def checkCvs(self):
266 d = self._dovccmd(['--version'])
267 def check(res):
268 if res == 0:
269 return True
270 return False
271 d.addCallback(check)
272 return d
273
274 def _getMethod(self):
275 if self.method is not None and self.mode != 'incremental':
276 return self.method
277 elif self.mode == 'incremental':
278 return None
279 elif self.method is None and self.mode == 'full':
280 return 'fresh'
281
282 def computeSourceRevision(self, changes):
283 if not changes:
284 return None
285 lastChange = max([c.when for c in changes])
286 lastSubmit = max([br.submittedAt for br in self.build.requests])
287 when = (lastChange + lastSubmit) / 2
288 return formatdate(when)
289
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/master/buildbot/steps/source/cvs.py b/master/buildbot/steps/source/cvs.py
--- a/master/buildbot/steps/source/cvs.py
+++ b/master/buildbot/steps/source/cvs.py
@@ -46,6 +46,7 @@
Source.__init__(self, **kwargs)
def startVC(self, branch, revision, patch):
+ self.branch = branch
self.revision = revision
self.stdio_log = self.addLog("stdio")
self.method = self._getMethod()
|
{"golden_diff": "diff --git a/master/buildbot/steps/source/cvs.py b/master/buildbot/steps/source/cvs.py\n--- a/master/buildbot/steps/source/cvs.py\n+++ b/master/buildbot/steps/source/cvs.py\n@@ -46,6 +46,7 @@\n Source.__init__(self, **kwargs)\n \n def startVC(self, branch, revision, patch):\n+ self.branch = branch\n self.revision = revision\n self.stdio_log = self.addLog(\"stdio\")\n self.method = self._getMethod()\n", "issue": "Move to a ChangeHook in hgbuildbot.py (closes #2227)\nStarting a Twisted reactor within a Mercurial hook is problematic\nbecause a hook can get called multiple times (from the same Mercurial\nprocess) which conflicts with the one-time only nature of the Twisted\nreactor start/stop calls.\n\nBy moving to HTTP requests the hook is now re-entrant which fixes\nReactorNotRestartable exceptions being raised all the time.\n\nThe requests library is used to make the calls, since it has a\nfunctional TLS implementation (unlike urllib/httplib in Python 2 until\nrecently).\n\nAdditionally, the codebase argument is added to the base ChangeHook, so\nit can properly be used with a codebaseGenerator.\n\nFinally, if a venv argument is used, it is now properly used to activate\nthe environment [1].\n\nPossible improvements to this changeset are:\n- send requests in parallel;\n- switch back to urllib2 so the hook doesn't depend on anything;\n- a few more cleanups.\n\n[1] https://github.com/pypa/virtualenv/blob/master/virtualenv_embedded/activate_this.py\n\n", "before_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\nfrom email.Utils import formatdate\nimport time\n\nfrom twisted.python import log\nfrom twisted.internet import defer\n\nfrom buildbot.process import buildstep\nfrom buildbot.steps.shell import StringFileWriter\nfrom buildbot.steps.source.base import Source\nfrom buildbot.interfaces import BuildSlaveTooOldError\n\nclass CVS(Source):\n\n name = \"cvs\"\n\n renderables = [ \"cvsroot\" ]\n\n def __init__(self, cvsroot=None, cvsmodule='', mode='incremental',\n method=None, branch=None, global_options=[], extra_options=[],\n login=None, **kwargs):\n\n self.cvsroot = cvsroot\n self.cvsmodule = cvsmodule\n self.branch = branch\n self.global_options = global_options\n self.extra_options = extra_options\n self.login = login\n self.mode = mode\n self.method = method\n self.srcdir = 'source'\n Source.__init__(self, **kwargs)\n\n def startVC(self, branch, revision, patch):\n self.revision = revision\n self.stdio_log = self.addLog(\"stdio\")\n self.method = self._getMethod()\n d = self.checkCvs()\n def checkInstall(cvsInstalled):\n if not cvsInstalled:\n raise BuildSlaveTooOldError(\"CVS is not installed on slave\")\n return 0\n d.addCallback(checkInstall)\n d.addCallback(self.checkLogin)\n\n if self.mode == 'incremental':\n d.addCallback(lambda _: self.incremental())\n elif self.mode == 'full':\n d.addCallback(lambda _: self.full())\n\n d.addCallback(self.parseGotRevision)\n d.addCallback(self.finish)\n d.addErrback(self.failed)\n return d\n\n @defer.inlineCallbacks\n def incremental(self):\n updatable = yield self._sourcedirIsUpdatable()\n if updatable:\n rv = yield self.doUpdate()\n else:\n rv = yield self.clobber()\n defer.returnValue(rv)\n\n @defer.inlineCallbacks\n def full(self):\n if self.method == 'clobber':\n rv = yield self.clobber()\n defer.returnValue(rv)\n return\n\n elif self.method == 'copy':\n rv = yield self.copy()\n defer.returnValue(rv)\n return\n\n updatable = yield self._sourcedirIsUpdatable()\n if not updatable:\n log.msg(\"CVS repo not present, making full checkout\")\n rv = yield self.doCheckout(self.workdir)\n elif self.method == 'clean':\n rv = yield self.clean()\n elif self.method == 'fresh':\n rv = yield self.fresh()\n else:\n raise ValueError(\"Unknown method, check your configuration\")\n defer.returnValue(rv)\n\n def clobber(self):\n cmd = buildstep.RemoteCommand('rmdir', {'dir': self.workdir,\n 'logEnviron': self.logEnviron})\n cmd.useLog(self.stdio_log, False)\n d = self.runCommand(cmd)\n def checkRemoval(res):\n if res != 0:\n raise RuntimeError(\"Failed to delete directory\")\n return res\n d.addCallback(lambda _: checkRemoval(cmd.rc))\n d.addCallback(lambda _: self.doCheckout(self.workdir))\n return d\n\n def fresh(self, ):\n d = self.purge(True)\n d.addCallback(lambda _: self.doUpdate())\n return d\n\n def clean(self, ):\n d = self.purge(False)\n d.addCallback(lambda _: self.doUpdate())\n return d\n\n def copy(self):\n cmd = buildstep.RemoteCommand('rmdir', {'dir': self.workdir,\n 'logEnviron': self.logEnviron})\n cmd.useLog(self.stdio_log, False)\n d = self.runCommand(cmd) \n self.workdir = 'source'\n d.addCallback(lambda _: self.incremental())\n def copy(_):\n cmd = buildstep.RemoteCommand('cpdir',\n {'fromdir': 'source',\n 'todir':'build',\n 'logEnviron': self.logEnviron,})\n cmd.useLog(self.stdio_log, False)\n d = self.runCommand(cmd)\n return d\n d.addCallback(copy)\n def resetWorkdir(_):\n self.workdir = 'build'\n return 0\n d.addCallback(resetWorkdir)\n return d\n \n def purge(self, ignore_ignores):\n command = ['cvsdiscard']\n if ignore_ignores:\n command += ['--ignore']\n cmd = buildstep.RemoteShellCommand(self.workdir, command,\n env=self.env,\n logEnviron=self.logEnviron)\n cmd.useLog(self.stdio_log, False)\n d = self.runCommand(cmd)\n def evaluate(rc):\n if rc != 0:\n raise buildstep.BuildStepFailed()\n return rc\n d.addCallback(lambda _: evaluate(cmd.rc))\n return d\n \n def doCheckout(self, dir):\n command = ['-d', self.cvsroot, '-z3', 'checkout', '-d', dir ]\n command = self.global_options + command + self.extra_options\n if self.branch:\n command += ['-r', self.branch]\n if self.revision:\n command += ['-D', self.revision]\n command += [ self.cvsmodule ]\n d = self._dovccmd(command, '')\n return d\n\n def doUpdate(self):\n command = ['-z3', 'update', '-dP']\n if self.branch:\n command += ['-r', self.branch]\n if self.revision:\n command += ['-D', self.revision]\n d = self._dovccmd(command)\n return d\n\n def finish(self, res):\n d = defer.succeed(res)\n def _gotResults(results):\n self.setStatus(self.cmd, results)\n return results\n d.addCallback(_gotResults)\n d.addCallbacks(self.finished, self.checkDisconnect)\n return d\n\n def checkLogin(self, _):\n if self.login:\n d = defer.succeed(0)\n else:\n d = self._dovccmd(['-d', self.cvsroot, 'login'])\n def setLogin(res):\n # this happens only if the login command succeeds.\n self.login = True\n return res\n d.addCallback(setLogin)\n\n return d\n\n def _dovccmd(self, command, workdir=None):\n if workdir is None:\n workdir = self.workdir\n if not command:\n raise ValueError(\"No command specified\")\n cmd = buildstep.RemoteShellCommand(workdir, ['cvs'] +\n command,\n env=self.env,\n logEnviron=self.logEnviron)\n cmd.useLog(self.stdio_log, False)\n d = self.runCommand(cmd)\n def evaluateCommand(cmd):\n if cmd.rc != 0:\n log.msg(\"Source step failed while running command %s\" % cmd)\n raise buildstep.BuildStepFailed()\n return cmd.rc\n d.addCallback(lambda _: evaluateCommand(cmd))\n return d\n\n @defer.inlineCallbacks\n def _sourcedirIsUpdatable(self):\n myFileWriter = StringFileWriter()\n args = {\n 'workdir': self.build.path_module.join(self.workdir, 'CVS'),\n 'writer': myFileWriter,\n 'maxsize': None,\n 'blocksize': 32*1024,\n }\n\n cmd = buildstep.RemoteCommand('uploadFile',\n dict(slavesrc='Root', **args),\n ignore_updates=True)\n yield self.runCommand(cmd)\n if cmd.rc is not None and cmd.rc != 0:\n defer.returnValue(False)\n return\n if myFileWriter.buffer.strip() != self.cvsroot:\n defer.returnValue(False)\n return\n\n myFileWriter.buffer = \"\"\n cmd = buildstep.RemoteCommand('uploadFile',\n dict(slavesrc='Repository', **args),\n ignore_updates=True)\n yield self.runCommand(cmd)\n if cmd.rc is not None and cmd.rc != 0:\n defer.returnValue(False)\n return\n if myFileWriter.buffer.strip() != self.cvsmodule:\n defer.returnValue(False)\n return\n\n defer.returnValue(True)\n\n def parseGotRevision(self, res):\n revision = time.strftime(\"%Y-%m-%d %H:%M:%S +0000\", time.gmtime())\n self.setProperty('got_revision', revision, 'Source')\n return res\n\n def checkCvs(self):\n d = self._dovccmd(['--version'])\n def check(res):\n if res == 0:\n return True\n return False\n d.addCallback(check)\n return d\n\n def _getMethod(self):\n if self.method is not None and self.mode != 'incremental':\n return self.method\n elif self.mode == 'incremental':\n return None\n elif self.method is None and self.mode == 'full':\n return 'fresh'\n\n def computeSourceRevision(self, changes):\n if not changes:\n return None\n lastChange = max([c.when for c in changes])\n lastSubmit = max([br.submittedAt for br in self.build.requests])\n when = (lastChange + lastSubmit) / 2\n return formatdate(when)\n", "path": "master/buildbot/steps/source/cvs.py"}], "after_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\nfrom email.Utils import formatdate\nimport time\n\nfrom twisted.python import log\nfrom twisted.internet import defer\n\nfrom buildbot.process import buildstep\nfrom buildbot.steps.shell import StringFileWriter\nfrom buildbot.steps.source.base import Source\nfrom buildbot.interfaces import BuildSlaveTooOldError\n\nclass CVS(Source):\n\n name = \"cvs\"\n\n renderables = [ \"cvsroot\" ]\n\n def __init__(self, cvsroot=None, cvsmodule='', mode='incremental',\n method=None, branch=None, global_options=[], extra_options=[],\n login=None, **kwargs):\n\n self.cvsroot = cvsroot\n self.cvsmodule = cvsmodule\n self.branch = branch\n self.global_options = global_options\n self.extra_options = extra_options\n self.login = login\n self.mode = mode\n self.method = method\n self.srcdir = 'source'\n Source.__init__(self, **kwargs)\n\n def startVC(self, branch, revision, patch):\n self.branch = branch\n self.revision = revision\n self.stdio_log = self.addLog(\"stdio\")\n self.method = self._getMethod()\n d = self.checkCvs()\n def checkInstall(cvsInstalled):\n if not cvsInstalled:\n raise BuildSlaveTooOldError(\"CVS is not installed on slave\")\n return 0\n d.addCallback(checkInstall)\n d.addCallback(self.checkLogin)\n\n if self.mode == 'incremental':\n d.addCallback(lambda _: self.incremental())\n elif self.mode == 'full':\n d.addCallback(lambda _: self.full())\n\n d.addCallback(self.parseGotRevision)\n d.addCallback(self.finish)\n d.addErrback(self.failed)\n return d\n\n @defer.inlineCallbacks\n def incremental(self):\n updatable = yield self._sourcedirIsUpdatable()\n if updatable:\n rv = yield self.doUpdate()\n else:\n rv = yield self.clobber()\n defer.returnValue(rv)\n\n @defer.inlineCallbacks\n def full(self):\n if self.method == 'clobber':\n rv = yield self.clobber()\n defer.returnValue(rv)\n return\n\n elif self.method == 'copy':\n rv = yield self.copy()\n defer.returnValue(rv)\n return\n\n updatable = yield self._sourcedirIsUpdatable()\n if not updatable:\n log.msg(\"CVS repo not present, making full checkout\")\n rv = yield self.doCheckout(self.workdir)\n elif self.method == 'clean':\n rv = yield self.clean()\n elif self.method == 'fresh':\n rv = yield self.fresh()\n else:\n raise ValueError(\"Unknown method, check your configuration\")\n defer.returnValue(rv)\n\n def clobber(self):\n cmd = buildstep.RemoteCommand('rmdir', {'dir': self.workdir,\n 'logEnviron': self.logEnviron})\n cmd.useLog(self.stdio_log, False)\n d = self.runCommand(cmd)\n def checkRemoval(res):\n if res != 0:\n raise RuntimeError(\"Failed to delete directory\")\n return res\n d.addCallback(lambda _: checkRemoval(cmd.rc))\n d.addCallback(lambda _: self.doCheckout(self.workdir))\n return d\n\n def fresh(self, ):\n d = self.purge(True)\n d.addCallback(lambda _: self.doUpdate())\n return d\n\n def clean(self, ):\n d = self.purge(False)\n d.addCallback(lambda _: self.doUpdate())\n return d\n\n def copy(self):\n cmd = buildstep.RemoteCommand('rmdir', {'dir': self.workdir,\n 'logEnviron': self.logEnviron})\n cmd.useLog(self.stdio_log, False)\n d = self.runCommand(cmd) \n self.workdir = 'source'\n d.addCallback(lambda _: self.incremental())\n def copy(_):\n cmd = buildstep.RemoteCommand('cpdir',\n {'fromdir': 'source',\n 'todir':'build',\n 'logEnviron': self.logEnviron,})\n cmd.useLog(self.stdio_log, False)\n d = self.runCommand(cmd)\n return d\n d.addCallback(copy)\n def resetWorkdir(_):\n self.workdir = 'build'\n return 0\n d.addCallback(resetWorkdir)\n return d\n \n def purge(self, ignore_ignores):\n command = ['cvsdiscard']\n if ignore_ignores:\n command += ['--ignore']\n cmd = buildstep.RemoteShellCommand(self.workdir, command,\n env=self.env,\n logEnviron=self.logEnviron)\n cmd.useLog(self.stdio_log, False)\n d = self.runCommand(cmd)\n def evaluate(rc):\n if rc != 0:\n raise buildstep.BuildStepFailed()\n return rc\n d.addCallback(lambda _: evaluate(cmd.rc))\n return d\n \n def doCheckout(self, dir):\n command = ['-d', self.cvsroot, '-z3', 'checkout', '-d', dir ]\n command = self.global_options + command + self.extra_options\n if self.branch:\n command += ['-r', self.branch]\n if self.revision:\n command += ['-D', self.revision]\n command += [ self.cvsmodule ]\n d = self._dovccmd(command, '')\n return d\n\n def doUpdate(self):\n command = ['-z3', 'update', '-dP']\n if self.branch:\n command += ['-r', self.branch]\n if self.revision:\n command += ['-D', self.revision]\n d = self._dovccmd(command)\n return d\n\n def finish(self, res):\n d = defer.succeed(res)\n def _gotResults(results):\n self.setStatus(self.cmd, results)\n return results\n d.addCallback(_gotResults)\n d.addCallbacks(self.finished, self.checkDisconnect)\n return d\n\n def checkLogin(self, _):\n if self.login:\n d = defer.succeed(0)\n else:\n d = self._dovccmd(['-d', self.cvsroot, 'login'])\n def setLogin(res):\n # this happens only if the login command succeeds.\n self.login = True\n return res\n d.addCallback(setLogin)\n\n return d\n\n def _dovccmd(self, command, workdir=None):\n if workdir is None:\n workdir = self.workdir\n if not command:\n raise ValueError(\"No command specified\")\n cmd = buildstep.RemoteShellCommand(workdir, ['cvs'] +\n command,\n env=self.env,\n logEnviron=self.logEnviron)\n cmd.useLog(self.stdio_log, False)\n d = self.runCommand(cmd)\n def evaluateCommand(cmd):\n if cmd.rc != 0:\n log.msg(\"Source step failed while running command %s\" % cmd)\n raise buildstep.BuildStepFailed()\n return cmd.rc\n d.addCallback(lambda _: evaluateCommand(cmd))\n return d\n\n @defer.inlineCallbacks\n def _sourcedirIsUpdatable(self):\n myFileWriter = StringFileWriter()\n args = {\n 'workdir': self.build.path_module.join(self.workdir, 'CVS'),\n 'writer': myFileWriter,\n 'maxsize': None,\n 'blocksize': 32*1024,\n }\n\n cmd = buildstep.RemoteCommand('uploadFile',\n dict(slavesrc='Root', **args),\n ignore_updates=True)\n yield self.runCommand(cmd)\n if cmd.rc is not None and cmd.rc != 0:\n defer.returnValue(False)\n return\n if myFileWriter.buffer.strip() != self.cvsroot:\n defer.returnValue(False)\n return\n\n myFileWriter.buffer = \"\"\n cmd = buildstep.RemoteCommand('uploadFile',\n dict(slavesrc='Repository', **args),\n ignore_updates=True)\n yield self.runCommand(cmd)\n if cmd.rc is not None and cmd.rc != 0:\n defer.returnValue(False)\n return\n if myFileWriter.buffer.strip() != self.cvsmodule:\n defer.returnValue(False)\n return\n\n defer.returnValue(True)\n\n def parseGotRevision(self, res):\n revision = time.strftime(\"%Y-%m-%d %H:%M:%S +0000\", time.gmtime())\n self.setProperty('got_revision', revision, 'Source')\n return res\n\n def checkCvs(self):\n d = self._dovccmd(['--version'])\n def check(res):\n if res == 0:\n return True\n return False\n d.addCallback(check)\n return d\n\n def _getMethod(self):\n if self.method is not None and self.mode != 'incremental':\n return self.method\n elif self.mode == 'incremental':\n return None\n elif self.method is None and self.mode == 'full':\n return 'fresh'\n\n def computeSourceRevision(self, changes):\n if not changes:\n return None\n lastChange = max([c.when for c in changes])\n lastSubmit = max([br.submittedAt for br in self.build.requests])\n when = (lastChange + lastSubmit) / 2\n return formatdate(when)\n", "path": "master/buildbot/steps/source/cvs.py"}]}
| 3,428 | 117 |
gh_patches_debug_19831
|
rasdani/github-patches
|
git_diff
|
akvo__akvo-rsr-1882
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Calculate updates from baseline, not from actual
## Test plan
There shouldn't be a difference from the original results framework. No specific testing needed.
## Issue description
Currently, the place of the updates on the slider is calculated by going back from the actual. However, this sometimes results in strange behaviour (e.g. the slider being before the baseline). We should calculate starting from the baseline and add up all the previous updates.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `akvo/rsr/models/project_update.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # Akvo RSR is covered by the GNU Affero General Public License.
4 # See more details in the license.txt file located at the root folder of the Akvo RSR module.
5 # For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.
6
7
8 from datetime import datetime, timedelta
9 from decimal import Decimal, InvalidOperation
10
11 from django.conf import settings
12 from django.core.exceptions import ValidationError
13 from django.db import models
14 from django.utils.translation import ugettext_lazy as _
15
16 from django_counter.models import ViewCounter
17
18 from sorl.thumbnail.fields import ImageField
19 from embed_video.fields import EmbedVideoField
20
21 from akvo.utils import rsr_image_path, to_gmt
22
23 from ..fields import ValidXMLCharField, ValidXMLTextField
24 from ..mixins import TimestampsMixin
25
26
27 def image_path(instance, file_name):
28 """Create a path like 'db/project/<update.project.id>/update/<update.id>/image_name.ext'"""
29 path = 'db/project/%d/update/%%(instance_pk)s/%%(file_name)s' % instance.project.pk
30 return rsr_image_path(instance, file_name, path)
31
32
33 class ProjectUpdate(TimestampsMixin, models.Model):
34 UPDATE_METHODS = (
35 ('W', _(u'web')),
36 ('E', _(u'e-mail')),
37 ('S', _(u'SMS')),
38 ('M', _(u'mobile')),
39 )
40
41 project = models.ForeignKey('Project', related_name='project_updates',
42 verbose_name=_(u'project'))
43 user = models.ForeignKey(settings.AUTH_USER_MODEL, verbose_name=_(u'user'))
44 title = ValidXMLCharField(_(u'title'), max_length=80, db_index=True,
45 help_text=_(u'80 characters'))
46 text = ValidXMLTextField(_(u'text'), blank=True)
47 language = ValidXMLCharField(max_length=2, choices=settings.LANGUAGES, default='en',
48 help_text=_(u'The language of the update'))
49 primary_location = models.ForeignKey('ProjectUpdateLocation', null=True, blank=True,
50 on_delete=models.SET_NULL)
51 photo = ImageField(_(u'photo'), blank=True, upload_to=image_path,
52 help_text=_(u'The image should have 4:3 height:width ratio for best '
53 u'displaying result'))
54 photo_caption = ValidXMLCharField(_(u'photo caption'), blank=True, max_length=75,
55 help_text=_(u'75 characters'))
56 photo_credit = ValidXMLCharField(_(u'photo credit'), blank=True, max_length=75,
57 help_text=_(u'75 characters'))
58 video = EmbedVideoField(_(u'video URL'), blank=True,
59 help_text=_(u'Supported providers: YouTube and Vimeo'))
60 video_caption = ValidXMLCharField(_(u'video caption'), blank=True, max_length=75,
61 help_text=_(u'75 characters'))
62 video_credit = ValidXMLCharField(_(u'video credit'), blank=True, max_length=75,
63 help_text=_(u'75 characters'))
64 update_method = ValidXMLCharField(_(u'update method'), blank=True, max_length=1,
65 choices=UPDATE_METHODS, db_index=True, default='W')
66 user_agent = ValidXMLCharField(_(u'user agent'), blank=True, max_length=200, default='')
67 uuid = ValidXMLCharField(_(u'uuid'), blank=True, max_length=40, default='', db_index=True,
68 help_text=_(u'Universally unique ID set by creating user agent'))
69 notes = ValidXMLTextField(verbose_name=_(u"Notes and comments"), blank=True, default='')
70
71 # Indicator updates
72 indicator_period = models.ForeignKey('IndicatorPeriod', related_name='updates',
73 verbose_name=_(u'indicator period'), blank=True, null=True)
74 period_update = models.DecimalField(_(u'period update'), blank=True, null=True, max_digits=14,
75 decimal_places=2)
76
77 class Meta:
78 app_label = 'rsr'
79 get_latest_by = "created_at"
80 verbose_name = _(u'project update')
81 verbose_name_plural = _(u'project updates')
82 ordering = ['-id', ]
83
84 def save(self, *args, **kwargs):
85 if self.indicator_period and self.period_update:
86 if not self.pk:
87 # Newly created update to indicator period, update the actual value.
88 self.indicator_period.update_actual_value(self.period_update)
89
90 else:
91 # Update to already existing indicator period, check if values have been changed.
92 orig_update = ProjectUpdate.objects.get(pk=self.pk)
93 if orig_update.indicator_period != self.indicator_period:
94 # Indicator period has changed. Substract value from old period, and add new
95 # value to new period.
96 try:
97 orig_update.update_actual_value(Decimal(orig_update.period_update) * -1)
98 except (InvalidOperation, TypeError):
99 pass
100 self.indicator_period.update_actual_value(self.period_update)
101
102 elif orig_update.period_update != self.period_update:
103 # Indicator value has changed. Add the difference to it.
104 try:
105 self.indicator_period.update_actual_value(
106 Decimal(self.period_update) - Decimal(orig_update.period_update)
107 )
108 except (InvalidOperation, TypeError):
109 self.indicator_period.update_actual_value(self.period_update)
110
111 super(ProjectUpdate, self).save(*args, **kwargs)
112
113 def delete(self, *args, **kwargs):
114 if self.indicator_period and self.period_update:
115 try:
116 self.indicator_period.update_actual_value(
117 Decimal(self.period_update) * -1
118 )
119 except (InvalidOperation, TypeError):
120 pass
121 super(ProjectUpdate, self).delete(*args, **kwargs)
122
123 def clean(self):
124 if hasattr(self, 'project') and hasattr(self, 'indicator_period') and \
125 hasattr(self, 'period_update'):
126 validation_errors = {}
127
128 # Don't allow an indicator period that belongs to a different project
129 if self.project and self.indicator_period:
130 if not self.indicator_period.indicator.result.project == self.project:
131 validation_errors['indicator_period'] = u'%s' % _(
132 u'Indicator period must be part of the same project'
133 )
134
135 # Don't allow an indicator update to a non-Impact project
136 if self.indicator_period and self.period_update and not self.project.is_impact_project:
137 validation_errors['project'] = u'%s' % _(
138 u'Project must be an Impact project to place indicator updates to it'
139 )
140
141 if validation_errors:
142 raise ValidationError(validation_errors)
143
144 def img(self, value=''):
145 try:
146 return self.photo.thumbnail_tag
147 except:
148 return value
149 img.allow_tags = True
150
151 def edit_window_has_expired(self):
152 """Determine whether or not update timeout window has expired.
153 The timeout is controlled by settings.PROJECT_UPDATE_TIMEOUT and
154 defaults to 30 minutes.
155 """
156 return (datetime.now() - self.created_at) > self.edit_timeout
157
158 @property
159 def expires_at(self):
160 return to_gmt(self.created_at + self.edit_timeout)
161
162 @property
163 def edit_timeout(self):
164 timeout_minutes = getattr(settings, 'PROJECT_UPDATE_TIMEOUT', 30)
165 return timedelta(minutes=timeout_minutes)
166
167 @property
168 def edit_time_remaining(self):
169 return self.edit_timeout - self.created_at
170
171 @property
172 def time_gmt(self):
173 return to_gmt(self.created_at)
174
175 @property
176 def time_last_updated_gmt(self):
177 return to_gmt(self.last_modified_at)
178
179 @property
180 def view_count(self):
181 counter = ViewCounter.objects.get_for_object(self)
182 return counter.count or 0
183
184 @models.permalink
185 def get_absolute_url(self):
186 return 'update-main', (), {'project_id': self.project.pk, 'update_id': self.pk}
187
188 def __unicode__(self):
189 return _(u'Project update for %(project_name)s') % {'project_name': self.project.title}
190
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/akvo/rsr/models/project_update.py b/akvo/rsr/models/project_update.py
--- a/akvo/rsr/models/project_update.py
+++ b/akvo/rsr/models/project_update.py
@@ -112,12 +112,19 @@
def delete(self, *args, **kwargs):
if self.indicator_period and self.period_update:
- try:
- self.indicator_period.update_actual_value(
- Decimal(self.period_update) * -1
- )
- except (InvalidOperation, TypeError):
- pass
+ # Subsctract the value of the update from the actual value of the indicator period
+ if ProjectUpdate.objects.filter(indicator_period=self.indicator_period).\
+ exclude(pk=self.pk).exists():
+ try:
+ self.indicator_period.update_actual_value(
+ Decimal(self.period_update) * -1
+ )
+ except (InvalidOperation, TypeError):
+ pass
+ else:
+ # There's no other updates for this indicator period, remove actual value
+ self.indicator_period.actual_value = ''
+ self.indicator_period.save()
super(ProjectUpdate, self).delete(*args, **kwargs)
def clean(self):
|
{"golden_diff": "diff --git a/akvo/rsr/models/project_update.py b/akvo/rsr/models/project_update.py\n--- a/akvo/rsr/models/project_update.py\n+++ b/akvo/rsr/models/project_update.py\n@@ -112,12 +112,19 @@\n \n def delete(self, *args, **kwargs):\n if self.indicator_period and self.period_update:\n- try:\n- self.indicator_period.update_actual_value(\n- Decimal(self.period_update) * -1\n- )\n- except (InvalidOperation, TypeError):\n- pass\n+ # Subsctract the value of the update from the actual value of the indicator period\n+ if ProjectUpdate.objects.filter(indicator_period=self.indicator_period).\\\n+ exclude(pk=self.pk).exists():\n+ try:\n+ self.indicator_period.update_actual_value(\n+ Decimal(self.period_update) * -1\n+ )\n+ except (InvalidOperation, TypeError):\n+ pass\n+ else:\n+ # There's no other updates for this indicator period, remove actual value\n+ self.indicator_period.actual_value = ''\n+ self.indicator_period.save()\n super(ProjectUpdate, self).delete(*args, **kwargs)\n \n def clean(self):\n", "issue": "Calculate updates from baseline, not from actual\n## Test plan\n\nThere shouldn't be a difference from the original results framework. No specific testing needed.\n## Issue description\n\nCurrently, the place of the updates on the slider is calculated by going back from the actual. However, this sometimes results in strange behaviour (e.g. the slider being before the baseline). We should calculate starting from the baseline and add up all the previous updates.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Akvo RSR is covered by the GNU Affero General Public License.\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\n\nfrom datetime import datetime, timedelta\nfrom decimal import Decimal, InvalidOperation\n\nfrom django.conf import settings\nfrom django.core.exceptions import ValidationError\nfrom django.db import models\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom django_counter.models import ViewCounter\n\nfrom sorl.thumbnail.fields import ImageField\nfrom embed_video.fields import EmbedVideoField\n\nfrom akvo.utils import rsr_image_path, to_gmt\n\nfrom ..fields import ValidXMLCharField, ValidXMLTextField\nfrom ..mixins import TimestampsMixin\n\n\ndef image_path(instance, file_name):\n \"\"\"Create a path like 'db/project/<update.project.id>/update/<update.id>/image_name.ext'\"\"\"\n path = 'db/project/%d/update/%%(instance_pk)s/%%(file_name)s' % instance.project.pk\n return rsr_image_path(instance, file_name, path)\n\n\nclass ProjectUpdate(TimestampsMixin, models.Model):\n UPDATE_METHODS = (\n ('W', _(u'web')),\n ('E', _(u'e-mail')),\n ('S', _(u'SMS')),\n ('M', _(u'mobile')),\n )\n\n project = models.ForeignKey('Project', related_name='project_updates',\n verbose_name=_(u'project'))\n user = models.ForeignKey(settings.AUTH_USER_MODEL, verbose_name=_(u'user'))\n title = ValidXMLCharField(_(u'title'), max_length=80, db_index=True,\n help_text=_(u'80 characters'))\n text = ValidXMLTextField(_(u'text'), blank=True)\n language = ValidXMLCharField(max_length=2, choices=settings.LANGUAGES, default='en',\n help_text=_(u'The language of the update'))\n primary_location = models.ForeignKey('ProjectUpdateLocation', null=True, blank=True,\n on_delete=models.SET_NULL)\n photo = ImageField(_(u'photo'), blank=True, upload_to=image_path,\n help_text=_(u'The image should have 4:3 height:width ratio for best '\n u'displaying result'))\n photo_caption = ValidXMLCharField(_(u'photo caption'), blank=True, max_length=75,\n help_text=_(u'75 characters'))\n photo_credit = ValidXMLCharField(_(u'photo credit'), blank=True, max_length=75,\n help_text=_(u'75 characters'))\n video = EmbedVideoField(_(u'video URL'), blank=True,\n help_text=_(u'Supported providers: YouTube and Vimeo'))\n video_caption = ValidXMLCharField(_(u'video caption'), blank=True, max_length=75,\n help_text=_(u'75 characters'))\n video_credit = ValidXMLCharField(_(u'video credit'), blank=True, max_length=75,\n help_text=_(u'75 characters'))\n update_method = ValidXMLCharField(_(u'update method'), blank=True, max_length=1,\n choices=UPDATE_METHODS, db_index=True, default='W')\n user_agent = ValidXMLCharField(_(u'user agent'), blank=True, max_length=200, default='')\n uuid = ValidXMLCharField(_(u'uuid'), blank=True, max_length=40, default='', db_index=True,\n help_text=_(u'Universally unique ID set by creating user agent'))\n notes = ValidXMLTextField(verbose_name=_(u\"Notes and comments\"), blank=True, default='')\n\n # Indicator updates\n indicator_period = models.ForeignKey('IndicatorPeriod', related_name='updates',\n verbose_name=_(u'indicator period'), blank=True, null=True)\n period_update = models.DecimalField(_(u'period update'), blank=True, null=True, max_digits=14,\n decimal_places=2)\n\n class Meta:\n app_label = 'rsr'\n get_latest_by = \"created_at\"\n verbose_name = _(u'project update')\n verbose_name_plural = _(u'project updates')\n ordering = ['-id', ]\n\n def save(self, *args, **kwargs):\n if self.indicator_period and self.period_update:\n if not self.pk:\n # Newly created update to indicator period, update the actual value.\n self.indicator_period.update_actual_value(self.period_update)\n\n else:\n # Update to already existing indicator period, check if values have been changed.\n orig_update = ProjectUpdate.objects.get(pk=self.pk)\n if orig_update.indicator_period != self.indicator_period:\n # Indicator period has changed. Substract value from old period, and add new\n # value to new period.\n try:\n orig_update.update_actual_value(Decimal(orig_update.period_update) * -1)\n except (InvalidOperation, TypeError):\n pass\n self.indicator_period.update_actual_value(self.period_update)\n\n elif orig_update.period_update != self.period_update:\n # Indicator value has changed. Add the difference to it.\n try:\n self.indicator_period.update_actual_value(\n Decimal(self.period_update) - Decimal(orig_update.period_update)\n )\n except (InvalidOperation, TypeError):\n self.indicator_period.update_actual_value(self.period_update)\n\n super(ProjectUpdate, self).save(*args, **kwargs)\n\n def delete(self, *args, **kwargs):\n if self.indicator_period and self.period_update:\n try:\n self.indicator_period.update_actual_value(\n Decimal(self.period_update) * -1\n )\n except (InvalidOperation, TypeError):\n pass\n super(ProjectUpdate, self).delete(*args, **kwargs)\n\n def clean(self):\n if hasattr(self, 'project') and hasattr(self, 'indicator_period') and \\\n hasattr(self, 'period_update'):\n validation_errors = {}\n\n # Don't allow an indicator period that belongs to a different project\n if self.project and self.indicator_period:\n if not self.indicator_period.indicator.result.project == self.project:\n validation_errors['indicator_period'] = u'%s' % _(\n u'Indicator period must be part of the same project'\n )\n\n # Don't allow an indicator update to a non-Impact project\n if self.indicator_period and self.period_update and not self.project.is_impact_project:\n validation_errors['project'] = u'%s' % _(\n u'Project must be an Impact project to place indicator updates to it'\n )\n\n if validation_errors:\n raise ValidationError(validation_errors)\n\n def img(self, value=''):\n try:\n return self.photo.thumbnail_tag\n except:\n return value\n img.allow_tags = True\n\n def edit_window_has_expired(self):\n \"\"\"Determine whether or not update timeout window has expired.\n The timeout is controlled by settings.PROJECT_UPDATE_TIMEOUT and\n defaults to 30 minutes.\n \"\"\"\n return (datetime.now() - self.created_at) > self.edit_timeout\n\n @property\n def expires_at(self):\n return to_gmt(self.created_at + self.edit_timeout)\n\n @property\n def edit_timeout(self):\n timeout_minutes = getattr(settings, 'PROJECT_UPDATE_TIMEOUT', 30)\n return timedelta(minutes=timeout_minutes)\n\n @property\n def edit_time_remaining(self):\n return self.edit_timeout - self.created_at\n\n @property\n def time_gmt(self):\n return to_gmt(self.created_at)\n\n @property\n def time_last_updated_gmt(self):\n return to_gmt(self.last_modified_at)\n\n @property\n def view_count(self):\n counter = ViewCounter.objects.get_for_object(self)\n return counter.count or 0\n\n @models.permalink\n def get_absolute_url(self):\n return 'update-main', (), {'project_id': self.project.pk, 'update_id': self.pk}\n\n def __unicode__(self):\n return _(u'Project update for %(project_name)s') % {'project_name': self.project.title}\n", "path": "akvo/rsr/models/project_update.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Akvo RSR is covered by the GNU Affero General Public License.\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\n\nfrom datetime import datetime, timedelta\nfrom decimal import Decimal, InvalidOperation\n\nfrom django.conf import settings\nfrom django.core.exceptions import ValidationError\nfrom django.db import models\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom django_counter.models import ViewCounter\n\nfrom sorl.thumbnail.fields import ImageField\nfrom embed_video.fields import EmbedVideoField\n\nfrom akvo.utils import rsr_image_path, to_gmt\n\nfrom ..fields import ValidXMLCharField, ValidXMLTextField\nfrom ..mixins import TimestampsMixin\n\n\ndef image_path(instance, file_name):\n \"\"\"Create a path like 'db/project/<update.project.id>/update/<update.id>/image_name.ext'\"\"\"\n path = 'db/project/%d/update/%%(instance_pk)s/%%(file_name)s' % instance.project.pk\n return rsr_image_path(instance, file_name, path)\n\n\nclass ProjectUpdate(TimestampsMixin, models.Model):\n UPDATE_METHODS = (\n ('W', _(u'web')),\n ('E', _(u'e-mail')),\n ('S', _(u'SMS')),\n ('M', _(u'mobile')),\n )\n\n project = models.ForeignKey('Project', related_name='project_updates',\n verbose_name=_(u'project'))\n user = models.ForeignKey(settings.AUTH_USER_MODEL, verbose_name=_(u'user'))\n title = ValidXMLCharField(_(u'title'), max_length=80, db_index=True,\n help_text=_(u'80 characters'))\n text = ValidXMLTextField(_(u'text'), blank=True)\n language = ValidXMLCharField(max_length=2, choices=settings.LANGUAGES, default='en',\n help_text=_(u'The language of the update'))\n primary_location = models.ForeignKey('ProjectUpdateLocation', null=True, blank=True,\n on_delete=models.SET_NULL)\n photo = ImageField(_(u'photo'), blank=True, upload_to=image_path,\n help_text=_(u'The image should have 4:3 height:width ratio for best '\n u'displaying result'))\n photo_caption = ValidXMLCharField(_(u'photo caption'), blank=True, max_length=75,\n help_text=_(u'75 characters'))\n photo_credit = ValidXMLCharField(_(u'photo credit'), blank=True, max_length=75,\n help_text=_(u'75 characters'))\n video = EmbedVideoField(_(u'video URL'), blank=True,\n help_text=_(u'Supported providers: YouTube and Vimeo'))\n video_caption = ValidXMLCharField(_(u'video caption'), blank=True, max_length=75,\n help_text=_(u'75 characters'))\n video_credit = ValidXMLCharField(_(u'video credit'), blank=True, max_length=75,\n help_text=_(u'75 characters'))\n update_method = ValidXMLCharField(_(u'update method'), blank=True, max_length=1,\n choices=UPDATE_METHODS, db_index=True, default='W')\n user_agent = ValidXMLCharField(_(u'user agent'), blank=True, max_length=200, default='')\n uuid = ValidXMLCharField(_(u'uuid'), blank=True, max_length=40, default='', db_index=True,\n help_text=_(u'Universally unique ID set by creating user agent'))\n notes = ValidXMLTextField(verbose_name=_(u\"Notes and comments\"), blank=True, default='')\n\n # Indicator updates\n indicator_period = models.ForeignKey('IndicatorPeriod', related_name='updates',\n verbose_name=_(u'indicator period'), blank=True, null=True)\n period_update = models.DecimalField(_(u'period update'), blank=True, null=True, max_digits=14,\n decimal_places=2)\n\n class Meta:\n app_label = 'rsr'\n get_latest_by = \"created_at\"\n verbose_name = _(u'project update')\n verbose_name_plural = _(u'project updates')\n ordering = ['-id', ]\n\n def save(self, *args, **kwargs):\n if self.indicator_period and self.period_update:\n if not self.pk:\n # Newly created update to indicator period, update the actual value.\n self.indicator_period.update_actual_value(self.period_update)\n\n else:\n # Update to already existing indicator period, check if values have been changed.\n orig_update = ProjectUpdate.objects.get(pk=self.pk)\n if orig_update.indicator_period != self.indicator_period:\n # Indicator period has changed. Substract value from old period, and add new\n # value to new period.\n try:\n orig_update.update_actual_value(Decimal(orig_update.period_update) * -1)\n except (InvalidOperation, TypeError):\n pass\n self.indicator_period.update_actual_value(self.period_update)\n\n elif orig_update.period_update != self.period_update:\n # Indicator value has changed. Add the difference to it.\n try:\n self.indicator_period.update_actual_value(\n Decimal(self.period_update) - Decimal(orig_update.period_update)\n )\n except (InvalidOperation, TypeError):\n self.indicator_period.update_actual_value(self.period_update)\n\n super(ProjectUpdate, self).save(*args, **kwargs)\n\n def delete(self, *args, **kwargs):\n if self.indicator_period and self.period_update:\n # Subsctract the value of the update from the actual value of the indicator period\n if ProjectUpdate.objects.filter(indicator_period=self.indicator_period).\\\n exclude(pk=self.pk).exists():\n try:\n self.indicator_period.update_actual_value(\n Decimal(self.period_update) * -1\n )\n except (InvalidOperation, TypeError):\n pass\n else:\n # There's no other updates for this indicator period, remove actual value\n self.indicator_period.actual_value = ''\n self.indicator_period.save()\n super(ProjectUpdate, self).delete(*args, **kwargs)\n\n def clean(self):\n if hasattr(self, 'project') and hasattr(self, 'indicator_period') and \\\n hasattr(self, 'period_update'):\n validation_errors = {}\n\n # Don't allow an indicator period that belongs to a different project\n if self.project and self.indicator_period:\n if not self.indicator_period.indicator.result.project == self.project:\n validation_errors['indicator_period'] = u'%s' % _(\n u'Indicator period must be part of the same project'\n )\n\n # Don't allow an indicator update to a non-Impact project\n if self.indicator_period and self.period_update and not self.project.is_impact_project:\n validation_errors['project'] = u'%s' % _(\n u'Project must be an Impact project to place indicator updates to it'\n )\n\n if validation_errors:\n raise ValidationError(validation_errors)\n\n def img(self, value=''):\n try:\n return self.photo.thumbnail_tag\n except:\n return value\n img.allow_tags = True\n\n def edit_window_has_expired(self):\n \"\"\"Determine whether or not update timeout window has expired.\n The timeout is controlled by settings.PROJECT_UPDATE_TIMEOUT and\n defaults to 30 minutes.\n \"\"\"\n return (datetime.now() - self.created_at) > self.edit_timeout\n\n @property\n def expires_at(self):\n return to_gmt(self.created_at + self.edit_timeout)\n\n @property\n def edit_timeout(self):\n timeout_minutes = getattr(settings, 'PROJECT_UPDATE_TIMEOUT', 30)\n return timedelta(minutes=timeout_minutes)\n\n @property\n def edit_time_remaining(self):\n return self.edit_timeout - self.created_at\n\n @property\n def time_gmt(self):\n return to_gmt(self.created_at)\n\n @property\n def time_last_updated_gmt(self):\n return to_gmt(self.last_modified_at)\n\n @property\n def view_count(self):\n counter = ViewCounter.objects.get_for_object(self)\n return counter.count or 0\n\n @models.permalink\n def get_absolute_url(self):\n return 'update-main', (), {'project_id': self.project.pk, 'update_id': self.pk}\n\n def __unicode__(self):\n return _(u'Project update for %(project_name)s') % {'project_name': self.project.title}\n", "path": "akvo/rsr/models/project_update.py"}]}
| 2,569 | 274 |
gh_patches_debug_1714
|
rasdani/github-patches
|
git_diff
|
networkx__networkx-1544
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Added implementation of SimRank matrix of the graph.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `networkx/relabel.py`
Content:
```
1 # Copyright (C) 2006-2013 by
2 # Aric Hagberg <[email protected]>
3 # Dan Schult <[email protected]>
4 # Pieter Swart <[email protected]>
5 # All rights reserved.
6 # BSD license.
7 import networkx as nx
8 __author__ = """\n""".join(['Aric Hagberg <[email protected]>',
9 'Pieter Swart ([email protected])',
10 'Dan Schult ([email protected])'])
11 __all__ = ['convert_node_labels_to_integers', 'relabel_nodes']
12
13 def relabel_nodes(G, mapping, copy=True):
14 """Relabel the nodes of the graph G.
15
16 Parameters
17 ----------
18 G : graph
19 A NetworkX graph
20
21 mapping : dictionary
22 A dictionary with the old labels as keys and new labels as values.
23 A partial mapping is allowed.
24
25 copy : bool (optional, default=True)
26 If True return a copy, or if False relabel the nodes in place.
27
28 Examples
29 --------
30 >>> G=nx.path_graph(3) # nodes 0-1-2
31 >>> mapping={0:'a',1:'b',2:'c'}
32 >>> H=nx.relabel_nodes(G,mapping)
33 >>> print(sorted(H.nodes()))
34 ['a', 'b', 'c']
35
36 >>> G=nx.path_graph(26) # nodes 0..25
37 >>> mapping=dict(zip(G.nodes(),"abcdefghijklmnopqrstuvwxyz"))
38 >>> H=nx.relabel_nodes(G,mapping) # nodes a..z
39 >>> mapping=dict(zip(G.nodes(),range(1,27)))
40 >>> G1=nx.relabel_nodes(G,mapping) # nodes 1..26
41
42 Partial in-place mapping:
43
44 >>> G=nx.path_graph(3) # nodes 0-1-2
45 >>> mapping={0:'a',1:'b'} # 0->'a' and 1->'b'
46 >>> G=nx.relabel_nodes(G,mapping, copy=False)
47
48 print(G.nodes())
49 [2, 'b', 'a']
50
51 Mapping as function:
52
53 >>> G=nx.path_graph(3)
54 >>> def mapping(x):
55 ... return x**2
56 >>> H=nx.relabel_nodes(G,mapping)
57 >>> print(H.nodes())
58 [0, 1, 4]
59
60 Notes
61 -----
62 Only the nodes specified in the mapping will be relabeled.
63
64 The keyword setting copy=False modifies the graph in place.
65 This is not always possible if the mapping is circular.
66 In that case use copy=True.
67
68 See Also
69 --------
70 convert_node_labels_to_integers
71 """
72 # you can pass a function f(old_label)->new_label
73 # but we'll just make a dictionary here regardless
74 if not hasattr(mapping,"__getitem__"):
75 m = dict((n, mapping(n)) for n in G)
76 else:
77 m = mapping
78 if copy:
79 return _relabel_copy(G, m)
80 else:
81 return _relabel_inplace(G, m)
82
83
84 def _relabel_inplace(G, mapping):
85 old_labels = set(mapping.keys())
86 new_labels = set(mapping.values())
87 if len(old_labels & new_labels) > 0:
88 # labels sets overlap
89 # can we topological sort and still do the relabeling?
90 D = nx.DiGraph(list(mapping.items()))
91 D.remove_edges_from(D.selfloop_edges())
92 try:
93 nodes = nx.topological_sort(D, reverse=True)
94 except nx.NetworkXUnfeasible:
95 raise nx.NetworkXUnfeasible('The node label sets are overlapping '
96 'and no ordering can resolve the '
97 'mapping. Use copy=True.')
98 else:
99 # non-overlapping label sets
100 nodes = old_labels
101
102 multigraph = G.is_multigraph()
103 directed = G.is_directed()
104
105 for old in nodes:
106 try:
107 new = mapping[old]
108 except KeyError:
109 continue
110 try:
111 G.add_node(new, attr_dict=G.node[old])
112 except KeyError:
113 raise KeyError("Node %s is not in the graph"%old)
114 if multigraph:
115 new_edges = [(new, new if old == target else target, key, data)
116 for (_,target,key,data)
117 in G.edges(old, data=True, keys=True)]
118 if directed:
119 new_edges += [(new if old == source else source, new, key, data)
120 for (source, _, key,data)
121 in G.in_edges(old, data=True, keys=True)]
122 else:
123 new_edges = [(new, new if old == target else target, data)
124 for (_,target,data) in G.edges(old, data=True)]
125 if directed:
126 new_edges += [(new if old == source else source,new,data)
127 for (source,_,data) in G.in_edges(old, data=True)]
128 G.remove_node(old)
129 G.add_edges_from(new_edges)
130 return G
131
132 def _relabel_copy(G, mapping):
133 H = G.__class__()
134 H.name = "(%s)" % G.name
135 if G.is_multigraph():
136 H.add_edges_from( (mapping.get(n1, n1),mapping.get(n2, n2),k,d.copy())
137 for (n1,n2,k,d) in G.edges_iter(keys=True, data=True))
138 else:
139 H.add_edges_from( (mapping.get(n1, n1),mapping.get(n2, n2),d.copy())
140 for (n1, n2, d) in G.edges_iter(data=True))
141
142 H.add_nodes_from(mapping.get(n, n) for n in G)
143 H.node.update(dict((mapping.get(n, n), d.copy()) for n,d in G.node.items()))
144 H.graph.update(G.graph.copy())
145
146 return H
147
148
149 def convert_node_labels_to_integers(G, first_label=0, ordering="default",
150 label_attribute=None):
151 """Return a copy of the graph G with the nodes relabeled using
152 consecutive integers.
153
154 Parameters
155 ----------
156 G : graph
157 A NetworkX graph
158
159 first_label : int, optional (default=0)
160 An integer specifying the starting offset in numbering nodes.
161 The new integer labels are numbered first_label, ..., n-1+first_label.
162
163 ordering : string
164 "default" : inherit node ordering from G.nodes()
165 "sorted" : inherit node ordering from sorted(G.nodes())
166 "increasing degree" : nodes are sorted by increasing degree
167 "decreasing degree" : nodes are sorted by decreasing degree
168
169 label_attribute : string, optional (default=None)
170 Name of node attribute to store old label. If None no attribute
171 is created.
172
173 Notes
174 -----
175 Node and edge attribute data are copied to the new (relabeled) graph.
176
177 See Also
178 --------
179 relabel_nodes
180 """
181 N = G.number_of_nodes()+first_label
182 if ordering == "default":
183 mapping = dict(zip(G.nodes(), range(first_label, N)))
184 elif ordering == "sorted":
185 nlist = G.nodes()
186 nlist.sort()
187 mapping = dict(zip(nlist, range(first_label, N)))
188 elif ordering == "increasing degree":
189 dv_pairs = [(d,n) for (n,d) in G.degree_iter()]
190 dv_pairs.sort() # in-place sort from lowest to highest degree
191 mapping = dict(zip([n for d,n in dv_pairs], range(first_label, N)))
192 elif ordering == "decreasing degree":
193 dv_pairs = [(d,n) for (n,d) in G.degree_iter()]
194 dv_pairs.sort() # in-place sort from lowest to highest degree
195 dv_pairs.reverse()
196 mapping = dict(zip([n for d,n in dv_pairs], range(first_label, N)))
197 else:
198 raise nx.NetworkXError('Unknown node ordering: %s'%ordering)
199 H = relabel_nodes(G, mapping)
200 H.name = "("+G.name+")_with_int_labels"
201 # create node attribute with the old label
202 if label_attribute is not None:
203 nx.set_node_attributes(H, label_attribute,
204 dict((v,k) for k,v in mapping.items()))
205 return H
206
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/networkx/relabel.py b/networkx/relabel.py
--- a/networkx/relabel.py
+++ b/networkx/relabel.py
@@ -107,6 +107,8 @@
new = mapping[old]
except KeyError:
continue
+ if new == old:
+ continue
try:
G.add_node(new, attr_dict=G.node[old])
except KeyError:
|
{"golden_diff": "diff --git a/networkx/relabel.py b/networkx/relabel.py\n--- a/networkx/relabel.py\n+++ b/networkx/relabel.py\n@@ -107,6 +107,8 @@\n new = mapping[old]\n except KeyError:\n continue\n+ if new == old:\n+ continue\n try:\n G.add_node(new, attr_dict=G.node[old])\n except KeyError:\n", "issue": "Added implementation of SimRank matrix of the graph.\n\n", "before_files": [{"content": "# Copyright (C) 2006-2013 by\n# Aric Hagberg <[email protected]>\n# Dan Schult <[email protected]>\n# Pieter Swart <[email protected]>\n# All rights reserved.\n# BSD license.\nimport networkx as nx\n__author__ = \"\"\"\\n\"\"\".join(['Aric Hagberg <[email protected]>',\n 'Pieter Swart ([email protected])',\n 'Dan Schult ([email protected])'])\n__all__ = ['convert_node_labels_to_integers', 'relabel_nodes']\n\ndef relabel_nodes(G, mapping, copy=True):\n \"\"\"Relabel the nodes of the graph G.\n\n Parameters\n ----------\n G : graph\n A NetworkX graph\n\n mapping : dictionary\n A dictionary with the old labels as keys and new labels as values.\n A partial mapping is allowed.\n\n copy : bool (optional, default=True)\n If True return a copy, or if False relabel the nodes in place.\n\n Examples\n --------\n >>> G=nx.path_graph(3) # nodes 0-1-2\n >>> mapping={0:'a',1:'b',2:'c'}\n >>> H=nx.relabel_nodes(G,mapping)\n >>> print(sorted(H.nodes()))\n ['a', 'b', 'c']\n\n >>> G=nx.path_graph(26) # nodes 0..25\n >>> mapping=dict(zip(G.nodes(),\"abcdefghijklmnopqrstuvwxyz\"))\n >>> H=nx.relabel_nodes(G,mapping) # nodes a..z\n >>> mapping=dict(zip(G.nodes(),range(1,27)))\n >>> G1=nx.relabel_nodes(G,mapping) # nodes 1..26\n\n Partial in-place mapping:\n\n >>> G=nx.path_graph(3) # nodes 0-1-2\n >>> mapping={0:'a',1:'b'} # 0->'a' and 1->'b'\n >>> G=nx.relabel_nodes(G,mapping, copy=False)\n\n print(G.nodes())\n [2, 'b', 'a']\n\n Mapping as function:\n\n >>> G=nx.path_graph(3)\n >>> def mapping(x):\n ... return x**2\n >>> H=nx.relabel_nodes(G,mapping)\n >>> print(H.nodes())\n [0, 1, 4]\n\n Notes\n -----\n Only the nodes specified in the mapping will be relabeled.\n\n The keyword setting copy=False modifies the graph in place.\n This is not always possible if the mapping is circular.\n In that case use copy=True.\n\n See Also\n --------\n convert_node_labels_to_integers\n \"\"\"\n # you can pass a function f(old_label)->new_label\n # but we'll just make a dictionary here regardless\n if not hasattr(mapping,\"__getitem__\"):\n m = dict((n, mapping(n)) for n in G)\n else:\n m = mapping\n if copy:\n return _relabel_copy(G, m)\n else:\n return _relabel_inplace(G, m)\n\n\ndef _relabel_inplace(G, mapping):\n old_labels = set(mapping.keys())\n new_labels = set(mapping.values())\n if len(old_labels & new_labels) > 0:\n # labels sets overlap\n # can we topological sort and still do the relabeling?\n D = nx.DiGraph(list(mapping.items()))\n D.remove_edges_from(D.selfloop_edges())\n try:\n nodes = nx.topological_sort(D, reverse=True)\n except nx.NetworkXUnfeasible:\n raise nx.NetworkXUnfeasible('The node label sets are overlapping '\n 'and no ordering can resolve the '\n 'mapping. Use copy=True.')\n else:\n # non-overlapping label sets\n nodes = old_labels\n\n multigraph = G.is_multigraph()\n directed = G.is_directed()\n\n for old in nodes:\n try:\n new = mapping[old]\n except KeyError:\n continue\n try:\n G.add_node(new, attr_dict=G.node[old])\n except KeyError:\n raise KeyError(\"Node %s is not in the graph\"%old)\n if multigraph:\n new_edges = [(new, new if old == target else target, key, data)\n for (_,target,key,data)\n in G.edges(old, data=True, keys=True)]\n if directed:\n new_edges += [(new if old == source else source, new, key, data)\n for (source, _, key,data)\n in G.in_edges(old, data=True, keys=True)]\n else:\n new_edges = [(new, new if old == target else target, data)\n for (_,target,data) in G.edges(old, data=True)]\n if directed:\n new_edges += [(new if old == source else source,new,data)\n for (source,_,data) in G.in_edges(old, data=True)]\n G.remove_node(old)\n G.add_edges_from(new_edges)\n return G\n\ndef _relabel_copy(G, mapping):\n H = G.__class__()\n H.name = \"(%s)\" % G.name\n if G.is_multigraph():\n H.add_edges_from( (mapping.get(n1, n1),mapping.get(n2, n2),k,d.copy())\n for (n1,n2,k,d) in G.edges_iter(keys=True, data=True))\n else:\n H.add_edges_from( (mapping.get(n1, n1),mapping.get(n2, n2),d.copy())\n for (n1, n2, d) in G.edges_iter(data=True))\n\n H.add_nodes_from(mapping.get(n, n) for n in G)\n H.node.update(dict((mapping.get(n, n), d.copy()) for n,d in G.node.items()))\n H.graph.update(G.graph.copy())\n\n return H\n\n\ndef convert_node_labels_to_integers(G, first_label=0, ordering=\"default\",\n label_attribute=None):\n \"\"\"Return a copy of the graph G with the nodes relabeled using\n consecutive integers.\n\n Parameters\n ----------\n G : graph\n A NetworkX graph\n\n first_label : int, optional (default=0)\n An integer specifying the starting offset in numbering nodes.\n The new integer labels are numbered first_label, ..., n-1+first_label.\n\n ordering : string\n \"default\" : inherit node ordering from G.nodes()\n \"sorted\" : inherit node ordering from sorted(G.nodes())\n \"increasing degree\" : nodes are sorted by increasing degree\n \"decreasing degree\" : nodes are sorted by decreasing degree\n\n label_attribute : string, optional (default=None)\n Name of node attribute to store old label. If None no attribute\n is created.\n\n Notes\n -----\n Node and edge attribute data are copied to the new (relabeled) graph.\n\n See Also\n --------\n relabel_nodes\n \"\"\"\n N = G.number_of_nodes()+first_label\n if ordering == \"default\":\n mapping = dict(zip(G.nodes(), range(first_label, N)))\n elif ordering == \"sorted\":\n nlist = G.nodes()\n nlist.sort()\n mapping = dict(zip(nlist, range(first_label, N)))\n elif ordering == \"increasing degree\":\n dv_pairs = [(d,n) for (n,d) in G.degree_iter()]\n dv_pairs.sort() # in-place sort from lowest to highest degree\n mapping = dict(zip([n for d,n in dv_pairs], range(first_label, N)))\n elif ordering == \"decreasing degree\":\n dv_pairs = [(d,n) for (n,d) in G.degree_iter()]\n dv_pairs.sort() # in-place sort from lowest to highest degree\n dv_pairs.reverse()\n mapping = dict(zip([n for d,n in dv_pairs], range(first_label, N)))\n else:\n raise nx.NetworkXError('Unknown node ordering: %s'%ordering)\n H = relabel_nodes(G, mapping)\n H.name = \"(\"+G.name+\")_with_int_labels\"\n # create node attribute with the old label\n if label_attribute is not None:\n nx.set_node_attributes(H, label_attribute,\n dict((v,k) for k,v in mapping.items()))\n return H\n", "path": "networkx/relabel.py"}], "after_files": [{"content": "# Copyright (C) 2006-2013 by\n# Aric Hagberg <[email protected]>\n# Dan Schult <[email protected]>\n# Pieter Swart <[email protected]>\n# All rights reserved.\n# BSD license.\nimport networkx as nx\n__author__ = \"\"\"\\n\"\"\".join(['Aric Hagberg <[email protected]>',\n 'Pieter Swart ([email protected])',\n 'Dan Schult ([email protected])'])\n__all__ = ['convert_node_labels_to_integers', 'relabel_nodes']\n\ndef relabel_nodes(G, mapping, copy=True):\n \"\"\"Relabel the nodes of the graph G.\n\n Parameters\n ----------\n G : graph\n A NetworkX graph\n\n mapping : dictionary\n A dictionary with the old labels as keys and new labels as values.\n A partial mapping is allowed.\n\n copy : bool (optional, default=True)\n If True return a copy, or if False relabel the nodes in place.\n\n Examples\n --------\n >>> G=nx.path_graph(3) # nodes 0-1-2\n >>> mapping={0:'a',1:'b',2:'c'}\n >>> H=nx.relabel_nodes(G,mapping)\n >>> print(sorted(H.nodes()))\n ['a', 'b', 'c']\n\n >>> G=nx.path_graph(26) # nodes 0..25\n >>> mapping=dict(zip(G.nodes(),\"abcdefghijklmnopqrstuvwxyz\"))\n >>> H=nx.relabel_nodes(G,mapping) # nodes a..z\n >>> mapping=dict(zip(G.nodes(),range(1,27)))\n >>> G1=nx.relabel_nodes(G,mapping) # nodes 1..26\n\n Partial in-place mapping:\n\n >>> G=nx.path_graph(3) # nodes 0-1-2\n >>> mapping={0:'a',1:'b'} # 0->'a' and 1->'b'\n >>> G=nx.relabel_nodes(G,mapping, copy=False)\n\n print(G.nodes())\n [2, 'b', 'a']\n\n Mapping as function:\n\n >>> G=nx.path_graph(3)\n >>> def mapping(x):\n ... return x**2\n >>> H=nx.relabel_nodes(G,mapping)\n >>> print(H.nodes())\n [0, 1, 4]\n\n Notes\n -----\n Only the nodes specified in the mapping will be relabeled.\n\n The keyword setting copy=False modifies the graph in place.\n This is not always possible if the mapping is circular.\n In that case use copy=True.\n\n See Also\n --------\n convert_node_labels_to_integers\n \"\"\"\n # you can pass a function f(old_label)->new_label\n # but we'll just make a dictionary here regardless\n if not hasattr(mapping,\"__getitem__\"):\n m = dict((n, mapping(n)) for n in G)\n else:\n m = mapping\n if copy:\n return _relabel_copy(G, m)\n else:\n return _relabel_inplace(G, m)\n\n\ndef _relabel_inplace(G, mapping):\n old_labels = set(mapping.keys())\n new_labels = set(mapping.values())\n if len(old_labels & new_labels) > 0:\n # labels sets overlap\n # can we topological sort and still do the relabeling?\n D = nx.DiGraph(list(mapping.items()))\n D.remove_edges_from(D.selfloop_edges())\n try:\n nodes = nx.topological_sort(D, reverse=True)\n except nx.NetworkXUnfeasible:\n raise nx.NetworkXUnfeasible('The node label sets are overlapping '\n 'and no ordering can resolve the '\n 'mapping. Use copy=True.')\n else:\n # non-overlapping label sets\n nodes = old_labels\n\n multigraph = G.is_multigraph()\n directed = G.is_directed()\n\n for old in nodes:\n try:\n new = mapping[old]\n except KeyError:\n continue\n if new == old:\n continue\n try:\n G.add_node(new, attr_dict=G.node[old])\n except KeyError:\n raise KeyError(\"Node %s is not in the graph\"%old)\n if multigraph:\n new_edges = [(new, new if old == target else target, key, data)\n for (_,target,key,data)\n in G.edges(old, data=True, keys=True)]\n if directed:\n new_edges += [(new if old == source else source, new, key, data)\n for (source, _, key,data)\n in G.in_edges(old, data=True, keys=True)]\n else:\n new_edges = [(new, new if old == target else target, data)\n for (_,target,data) in G.edges(old, data=True)]\n if directed:\n new_edges += [(new if old == source else source,new,data)\n for (source,_,data) in G.in_edges(old, data=True)]\n G.remove_node(old)\n G.add_edges_from(new_edges)\n return G\n\ndef _relabel_copy(G, mapping):\n H = G.__class__()\n H.name = \"(%s)\" % G.name\n if G.is_multigraph():\n H.add_edges_from( (mapping.get(n1, n1),mapping.get(n2, n2),k,d.copy())\n for (n1,n2,k,d) in G.edges_iter(keys=True, data=True))\n else:\n H.add_edges_from( (mapping.get(n1, n1),mapping.get(n2, n2),d.copy())\n for (n1, n2, d) in G.edges_iter(data=True))\n\n H.add_nodes_from(mapping.get(n, n) for n in G)\n H.node.update(dict((mapping.get(n, n), d.copy()) for n,d in G.node.items()))\n H.graph.update(G.graph.copy())\n\n return H\n\n\ndef convert_node_labels_to_integers(G, first_label=0, ordering=\"default\",\n label_attribute=None):\n \"\"\"Return a copy of the graph G with the nodes relabeled using\n consecutive integers.\n\n Parameters\n ----------\n G : graph\n A NetworkX graph\n\n first_label : int, optional (default=0)\n An integer specifying the starting offset in numbering nodes.\n The new integer labels are numbered first_label, ..., n-1+first_label.\n\n ordering : string\n \"default\" : inherit node ordering from G.nodes()\n \"sorted\" : inherit node ordering from sorted(G.nodes())\n \"increasing degree\" : nodes are sorted by increasing degree\n \"decreasing degree\" : nodes are sorted by decreasing degree\n\n label_attribute : string, optional (default=None)\n Name of node attribute to store old label. If None no attribute\n is created.\n\n Notes\n -----\n Node and edge attribute data are copied to the new (relabeled) graph.\n\n See Also\n --------\n relabel_nodes\n \"\"\"\n N = G.number_of_nodes()+first_label\n if ordering == \"default\":\n mapping = dict(zip(G.nodes(), range(first_label, N)))\n elif ordering == \"sorted\":\n nlist = G.nodes()\n nlist.sort()\n mapping = dict(zip(nlist, range(first_label, N)))\n elif ordering == \"increasing degree\":\n dv_pairs = [(d,n) for (n,d) in G.degree_iter()]\n dv_pairs.sort() # in-place sort from lowest to highest degree\n mapping = dict(zip([n for d,n in dv_pairs], range(first_label, N)))\n elif ordering == \"decreasing degree\":\n dv_pairs = [(d,n) for (n,d) in G.degree_iter()]\n dv_pairs.sort() # in-place sort from lowest to highest degree\n dv_pairs.reverse()\n mapping = dict(zip([n for d,n in dv_pairs], range(first_label, N)))\n else:\n raise nx.NetworkXError('Unknown node ordering: %s'%ordering)\n H = relabel_nodes(G, mapping)\n H.name = \"(\"+G.name+\")_with_int_labels\"\n # create node attribute with the old label\n if label_attribute is not None:\n nx.set_node_attributes(H, label_attribute,\n dict((v,k) for k,v in mapping.items()))\n return H\n", "path": "networkx/relabel.py"}]}
| 2,584 | 91 |
gh_patches_debug_15337
|
rasdani/github-patches
|
git_diff
|
weecology__retriever-952
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
install to msaccess error
When I try to install a dataset to msaccess I get the error:
Couldn't create table (no module named 'pypyodbc')
I've tried doing "pip install pypyodbc --upgrade" which seems to work, but doesn't help with the retriever error.
I'm on a windows 10 machine
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `retriever/engines/msaccess.py`
Content:
```
1 from __future__ import print_function
2 from builtins import str
3 import os
4 from retriever.lib.models import Engine, no_cleanup
5 from retriever import DATA_DIR, current_platform
6
7
8 class engine(Engine):
9 """Engine instance for Microsoft Access."""
10 name = "Microsoft Access"
11 instructions = """Create a database in Microsoft Access, close Access, then \nselect your database file using this dialog."""
12 abbreviation = "msaccess"
13 datatypes = {
14 "auto": "AUTOINCREMENT",
15 "int": "INTEGER",
16 "bigint": "INTEGER",
17 "double": "NUMERIC",
18 "decimal": "NUMERIC",
19 "char": "VARCHAR",
20 "bool": "BIT",
21 }
22 required_opts = [("file",
23 "Enter the filename of your Access database",
24 os.path.join(DATA_DIR, "access.mdb"),
25 "Access databases (*.mdb, *.accdb)|*.mdb;*.accdb"),
26 ("table_name",
27 "Format of table name",
28 "[{db} {table}]"),
29 ]
30
31 def convert_data_type(self, datatype):
32 """MS Access can't handle complex Decimal types"""
33 converted = Engine.convert_data_type(self, datatype)
34 if "NUMERIC" in converted:
35 converted = "NUMERIC"
36 elif "VARCHAR" in converted:
37 try:
38 length = int(converted.split('(')[1].split(')')[0].split(',')[0])
39 if length > 255:
40 converted = "TEXT"
41 except:
42 pass
43 return converted
44
45 def create_db(self):
46 """MS Access doesn't create databases."""
47 return None
48
49 def drop_statement(self, objecttype, objectname):
50 """Returns a drop table or database SQL statement."""
51 dropstatement = "DROP %s %s" % (objecttype, objectname)
52 return dropstatement
53
54 def insert_data_from_file(self, filename):
55 """Perform a bulk insert."""
56 self.get_cursor()
57 ct = len([True for c in self.table.columns if c[1][0][:3] == "ct-"]) != 0
58 if ((self.table.cleanup.function == no_cleanup and not self.table.fixed_width and
59 self.table.header_rows < 2)
60 and (self.table.delimiter in ["\t", ","])
61 and not ct
62 and (not hasattr(self.table, "do_not_bulk_insert") or not self.table.do_not_bulk_insert)
63 ):
64 print ("Inserting data from " + os.path.basename(filename) + "...")
65
66 if self.table.delimiter == "\t":
67 fmt = "TabDelimited"
68 elif self.table.delimiter == ",":
69 fmt = "CSVDelimited"
70
71 if self.table.header_rows == 1:
72 hdr = "Yes"
73 else:
74 hdr = "No"
75
76 columns = self.table.get_insert_columns()
77
78 need_to_delete = False
79 add_to_record_id = 0
80
81 if self.table.pk and not self.table.contains_pk:
82 if '.' in os.path.basename(filename):
83 proper_name = filename.split('.')
84 newfilename = '.'.join((proper_name[0:-1]) if len(proper_name) > 0 else proper_name[0]
85 ) + "_new." + filename.split(".")[-1]
86 else:
87 newfilename = filename + "_new"
88
89 if not os.path.isfile(newfilename):
90 print("Adding index to " + os.path.abspath(newfilename) + "...")
91 read = open(filename, "rb")
92 write = open(newfilename, "wb")
93 to_write = ""
94
95 for line in read:
96 to_write += str(id) + self.table.delimiter + line.replace("\n", "\r\n")
97 add_to_record_id += 1
98 self.table.record_id += add_to_record_id
99
100 write.write(to_write)
101 write.close()
102 read.close()
103 need_to_delete = True
104 columns = "record_id, " + columns
105 else:
106 newfilename = filename
107
108 newfilename = os.path.abspath(newfilename)
109 filename_length = (len(os.path.basename(newfilename)) * -1) - 1
110 filepath = newfilename[:filename_length]
111 statement = """
112 INSERT INTO """ + self.table_name() + " (" + columns + """)
113 SELECT * FROM [""" + os.path.basename(newfilename) + ''']
114 IN "''' + filepath + '''" "Text;FMT=''' + fmt + ''';HDR=''' + hdr + ''';"'''
115
116 try:
117 self.execute(statement)
118 except:
119 print("Couldn't bulk insert. Trying manual insert.")
120 self.connection.rollback()
121
122 self.table.record_id -= add_to_record_id
123
124 return Engine.insert_data_from_file(self, filename)
125
126 if need_to_delete:
127 os.remove(newfilename)
128
129 else:
130 return Engine.insert_data_from_file(self, filename)
131
132 def table_exists(self, dbname, tablename):
133 """Determine if the table already exists in the database"""
134 if not hasattr(self, 'existing_table_names'):
135 self.existing_table_names = set()
136 for row in self.cursor.tables():
137 tableinfo = row[2]
138 if not tableinfo.startswith("MSys"):
139 # ignore system tables
140 database, table = tableinfo.split()
141 self.existing_table_names.add((database, table))
142 return self.table_name(name=tablename, dbname=dbname).lower() in self.existing_table_names
143
144 def get_connection(self):
145 """Gets the db connection."""
146 if current_platform != "windows":
147 raise Exception("MS Access can only be used in Windows.")
148 import pypyodbc as dbapi
149 self.get_input()
150 if not os.path.exists(self.opts['file']) and self.opts['file'].endswith('.mdb'):
151 dbapi.win_create_mdb(self.opts['file'])
152 connection_string = ("DRIVER={Microsoft Access Driver (*.mdb, *.accdb)};DBQ=" +
153 os.path.abspath(self.opts["file"]).replace("/", "//") + ";")
154 return dbapi.connect(connection_string, autocommit=False)
155
```
Path: `setup.py`
Content:
```
1 """Use the following command to install retriever: python setup.py install"""
2 from __future__ import absolute_import
3 import platform
4 import os
5 from setuptools import setup
6 from pkg_resources import parse_version
7
8 current_platform = platform.system().lower()
9 extra_includes = []
10
11 if os.path.exists(".git/hooks"): # check if we are in git repo
12 os.system("cp hooks/pre-commit .git/hooks/pre-commit")
13 os.system("chmod +x .git/hooks/pre-commit")
14
15
16 __version__ = 'v2.1.dev'
17 with open(os.path.join("retriever", "_version.py"), "w") as version_file:
18 version_file.write("__version__ = " + "'" + __version__ + "'\n")
19 version_file.close()
20
21
22 def clean_version(v):
23 return parse_version(v).__repr__().lstrip("<Version('").rstrip("')>")
24
25 packages = [
26 'retriever.lib',
27 'retriever.engines',
28 'retriever',
29 ]
30
31 includes = [
32 'xlrd',
33 'future',
34 'argcomplete',
35 'pymysql',
36 'psycopg2',
37 'sqlite3',
38 ] + extra_includes
39
40 excludes = [
41 'pyreadline',
42 'doctest',
43 'pickle',
44 'pdb',
45 'pywin', 'pywin.debugger',
46 'pywin.debugger.dbgcon',
47 'pywin.dialogs', 'pywin.dialogs.list',
48 'Tkconstants', 'Tkinter', 'tcl', 'tk'
49 ]
50
51 setup(name='retriever',
52 version=clean_version(__version__),
53 description='Data Retriever',
54 author='Ben Morris, Akash Goel, Henry Senyondo, Ethan White',
55 author_email='[email protected]',
56 url='https://github.com/weecology/retriever',
57 classifiers=['Intended Audience :: Science/Research',
58 'License :: OSI Approved :: MIT License',
59 'Programming Language :: Python',
60 'Programming Language :: Python :: 2',
61 'Programming Language :: Python :: 3', ],
62 packages=packages,
63 package_dir={
64 'retriever': 'retriever'
65 },
66 entry_points={
67 'console_scripts': [
68 'retriever = retriever.__main__:main',
69 ],
70 },
71 install_requires=[
72 'xlrd',
73 'future',
74 'argcomplete'
75 ],
76
77 # py2app flags
78 app=['__main__.py'],
79 data_files=[('', ['CITATION'])],
80 setup_requires=[],
81 )
82
83 # windows doesn't have bash. No point in using bash-completion
84 if current_platform != "windows":
85 # if platform is OS X use "~/.bash_profile"
86 if current_platform == "darwin":
87 bash_file = "~/.bash_profile"
88 # if platform is Linux use "~/.bashrc
89 elif current_platform == "linux":
90 bash_file = "~/.bashrc"
91 # else write and discard
92 else:
93 bash_file = "/dev/null"
94
95 argcomplete_command = 'eval "$(register-python-argcomplete retriever)"'
96 with open(os.path.expanduser(bash_file), "a+") as bashrc:
97 bashrc.seek(0)
98 # register retriever for arg-completion if not already registered
99 # whenever a new shell is spawned
100 if argcomplete_command not in bashrc.read():
101 bashrc.write(argcomplete_command + "\n")
102 bashrc.close()
103 os.system("activate-global-python-argcomplete")
104 # register for the current shell
105 os.system(argcomplete_command)
106
107 try:
108 from retriever.compile import compile
109 from retriever.lib.repository import check_for_updates
110 compile()
111 check_for_updates()
112 except:
113 pass
114
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/retriever/engines/msaccess.py b/retriever/engines/msaccess.py
--- a/retriever/engines/msaccess.py
+++ b/retriever/engines/msaccess.py
@@ -27,6 +27,7 @@
"Format of table name",
"[{db} {table}]"),
]
+ placeholder = "?"
def convert_data_type(self, datatype):
"""MS Access can't handle complex Decimal types"""
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -7,6 +7,8 @@
current_platform = platform.system().lower()
extra_includes = []
+if current_platform == "windows":
+ extra_includes = ["pypyodbc"]
if os.path.exists(".git/hooks"): # check if we are in git repo
os.system("cp hooks/pre-commit .git/hooks/pre-commit")
|
{"golden_diff": "diff --git a/retriever/engines/msaccess.py b/retriever/engines/msaccess.py\n--- a/retriever/engines/msaccess.py\n+++ b/retriever/engines/msaccess.py\n@@ -27,6 +27,7 @@\n \"Format of table name\",\n \"[{db} {table}]\"),\n ]\n+ placeholder = \"?\"\n \n def convert_data_type(self, datatype):\n \"\"\"MS Access can't handle complex Decimal types\"\"\"\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -7,6 +7,8 @@\n \n current_platform = platform.system().lower()\n extra_includes = []\n+if current_platform == \"windows\":\n+ extra_includes = [\"pypyodbc\"]\n \n if os.path.exists(\".git/hooks\"): # check if we are in git repo\n os.system(\"cp hooks/pre-commit .git/hooks/pre-commit\")\n", "issue": "install to msaccess error\nWhen I try to install a dataset to msaccess I get the error:\r\nCouldn't create table (no module named 'pypyodbc')\r\n\r\nI've tried doing \"pip install pypyodbc --upgrade\" which seems to work, but doesn't help with the retriever error.\r\n\r\nI'm on a windows 10 machine\n", "before_files": [{"content": "from __future__ import print_function\nfrom builtins import str\nimport os\nfrom retriever.lib.models import Engine, no_cleanup\nfrom retriever import DATA_DIR, current_platform\n\n\nclass engine(Engine):\n \"\"\"Engine instance for Microsoft Access.\"\"\"\n name = \"Microsoft Access\"\n instructions = \"\"\"Create a database in Microsoft Access, close Access, then \\nselect your database file using this dialog.\"\"\"\n abbreviation = \"msaccess\"\n datatypes = {\n \"auto\": \"AUTOINCREMENT\",\n \"int\": \"INTEGER\",\n \"bigint\": \"INTEGER\",\n \"double\": \"NUMERIC\",\n \"decimal\": \"NUMERIC\",\n \"char\": \"VARCHAR\",\n \"bool\": \"BIT\",\n }\n required_opts = [(\"file\",\n \"Enter the filename of your Access database\",\n os.path.join(DATA_DIR, \"access.mdb\"),\n \"Access databases (*.mdb, *.accdb)|*.mdb;*.accdb\"),\n (\"table_name\",\n \"Format of table name\",\n \"[{db} {table}]\"),\n ]\n\n def convert_data_type(self, datatype):\n \"\"\"MS Access can't handle complex Decimal types\"\"\"\n converted = Engine.convert_data_type(self, datatype)\n if \"NUMERIC\" in converted:\n converted = \"NUMERIC\"\n elif \"VARCHAR\" in converted:\n try:\n length = int(converted.split('(')[1].split(')')[0].split(',')[0])\n if length > 255:\n converted = \"TEXT\"\n except:\n pass\n return converted\n\n def create_db(self):\n \"\"\"MS Access doesn't create databases.\"\"\"\n return None\n\n def drop_statement(self, objecttype, objectname):\n \"\"\"Returns a drop table or database SQL statement.\"\"\"\n dropstatement = \"DROP %s %s\" % (objecttype, objectname)\n return dropstatement\n\n def insert_data_from_file(self, filename):\n \"\"\"Perform a bulk insert.\"\"\"\n self.get_cursor()\n ct = len([True for c in self.table.columns if c[1][0][:3] == \"ct-\"]) != 0\n if ((self.table.cleanup.function == no_cleanup and not self.table.fixed_width and\n self.table.header_rows < 2)\n and (self.table.delimiter in [\"\\t\", \",\"])\n and not ct\n and (not hasattr(self.table, \"do_not_bulk_insert\") or not self.table.do_not_bulk_insert)\n ):\n print (\"Inserting data from \" + os.path.basename(filename) + \"...\")\n\n if self.table.delimiter == \"\\t\":\n fmt = \"TabDelimited\"\n elif self.table.delimiter == \",\":\n fmt = \"CSVDelimited\"\n\n if self.table.header_rows == 1:\n hdr = \"Yes\"\n else:\n hdr = \"No\"\n\n columns = self.table.get_insert_columns()\n\n need_to_delete = False\n add_to_record_id = 0\n\n if self.table.pk and not self.table.contains_pk:\n if '.' in os.path.basename(filename):\n proper_name = filename.split('.')\n newfilename = '.'.join((proper_name[0:-1]) if len(proper_name) > 0 else proper_name[0]\n ) + \"_new.\" + filename.split(\".\")[-1]\n else:\n newfilename = filename + \"_new\"\n\n if not os.path.isfile(newfilename):\n print(\"Adding index to \" + os.path.abspath(newfilename) + \"...\")\n read = open(filename, \"rb\")\n write = open(newfilename, \"wb\")\n to_write = \"\"\n\n for line in read:\n to_write += str(id) + self.table.delimiter + line.replace(\"\\n\", \"\\r\\n\")\n add_to_record_id += 1\n self.table.record_id += add_to_record_id\n\n write.write(to_write)\n write.close()\n read.close()\n need_to_delete = True\n columns = \"record_id, \" + columns\n else:\n newfilename = filename\n\n newfilename = os.path.abspath(newfilename)\n filename_length = (len(os.path.basename(newfilename)) * -1) - 1\n filepath = newfilename[:filename_length]\n statement = \"\"\"\nINSERT INTO \"\"\" + self.table_name() + \" (\" + columns + \"\"\")\nSELECT * FROM [\"\"\" + os.path.basename(newfilename) + ''']\nIN \"''' + filepath + '''\" \"Text;FMT=''' + fmt + ''';HDR=''' + hdr + ''';\"'''\n\n try:\n self.execute(statement)\n except:\n print(\"Couldn't bulk insert. Trying manual insert.\")\n self.connection.rollback()\n\n self.table.record_id -= add_to_record_id\n\n return Engine.insert_data_from_file(self, filename)\n\n if need_to_delete:\n os.remove(newfilename)\n\n else:\n return Engine.insert_data_from_file(self, filename)\n\n def table_exists(self, dbname, tablename):\n \"\"\"Determine if the table already exists in the database\"\"\"\n if not hasattr(self, 'existing_table_names'):\n self.existing_table_names = set()\n for row in self.cursor.tables():\n tableinfo = row[2]\n if not tableinfo.startswith(\"MSys\"):\n # ignore system tables\n database, table = tableinfo.split()\n self.existing_table_names.add((database, table))\n return self.table_name(name=tablename, dbname=dbname).lower() in self.existing_table_names\n\n def get_connection(self):\n \"\"\"Gets the db connection.\"\"\"\n if current_platform != \"windows\":\n raise Exception(\"MS Access can only be used in Windows.\")\n import pypyodbc as dbapi\n self.get_input()\n if not os.path.exists(self.opts['file']) and self.opts['file'].endswith('.mdb'):\n dbapi.win_create_mdb(self.opts['file'])\n connection_string = (\"DRIVER={Microsoft Access Driver (*.mdb, *.accdb)};DBQ=\" +\n os.path.abspath(self.opts[\"file\"]).replace(\"/\", \"//\") + \";\")\n return dbapi.connect(connection_string, autocommit=False)\n", "path": "retriever/engines/msaccess.py"}, {"content": "\"\"\"Use the following command to install retriever: python setup.py install\"\"\"\nfrom __future__ import absolute_import\nimport platform\nimport os\nfrom setuptools import setup\nfrom pkg_resources import parse_version\n\ncurrent_platform = platform.system().lower()\nextra_includes = []\n\nif os.path.exists(\".git/hooks\"): # check if we are in git repo\n os.system(\"cp hooks/pre-commit .git/hooks/pre-commit\")\n os.system(\"chmod +x .git/hooks/pre-commit\")\n\n\n__version__ = 'v2.1.dev'\nwith open(os.path.join(\"retriever\", \"_version.py\"), \"w\") as version_file:\n version_file.write(\"__version__ = \" + \"'\" + __version__ + \"'\\n\")\n version_file.close()\n\n\ndef clean_version(v):\n return parse_version(v).__repr__().lstrip(\"<Version('\").rstrip(\"')>\")\n\npackages = [\n 'retriever.lib',\n 'retriever.engines',\n 'retriever',\n]\n\nincludes = [\n 'xlrd',\n 'future',\n 'argcomplete',\n 'pymysql',\n 'psycopg2',\n 'sqlite3',\n] + extra_includes\n\nexcludes = [\n 'pyreadline',\n 'doctest',\n 'pickle',\n 'pdb',\n 'pywin', 'pywin.debugger',\n 'pywin.debugger.dbgcon',\n 'pywin.dialogs', 'pywin.dialogs.list',\n 'Tkconstants', 'Tkinter', 'tcl', 'tk'\n]\n\nsetup(name='retriever',\n version=clean_version(__version__),\n description='Data Retriever',\n author='Ben Morris, Akash Goel, Henry Senyondo, Ethan White',\n author_email='[email protected]',\n url='https://github.com/weecology/retriever',\n classifiers=['Intended Audience :: Science/Research',\n 'License :: OSI Approved :: MIT License',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 3', ],\n packages=packages,\n package_dir={\n 'retriever': 'retriever'\n },\n entry_points={\n 'console_scripts': [\n 'retriever = retriever.__main__:main',\n ],\n },\n install_requires=[\n 'xlrd',\n 'future',\n 'argcomplete'\n ],\n\n # py2app flags\n app=['__main__.py'],\n data_files=[('', ['CITATION'])],\n setup_requires=[],\n )\n\n# windows doesn't have bash. No point in using bash-completion\nif current_platform != \"windows\":\n # if platform is OS X use \"~/.bash_profile\"\n if current_platform == \"darwin\":\n bash_file = \"~/.bash_profile\"\n # if platform is Linux use \"~/.bashrc\n elif current_platform == \"linux\":\n bash_file = \"~/.bashrc\"\n # else write and discard\n else:\n bash_file = \"/dev/null\"\n\n argcomplete_command = 'eval \"$(register-python-argcomplete retriever)\"'\n with open(os.path.expanduser(bash_file), \"a+\") as bashrc:\n bashrc.seek(0)\n # register retriever for arg-completion if not already registered\n # whenever a new shell is spawned\n if argcomplete_command not in bashrc.read():\n bashrc.write(argcomplete_command + \"\\n\")\n bashrc.close()\n os.system(\"activate-global-python-argcomplete\")\n # register for the current shell\n os.system(argcomplete_command)\n\ntry:\n from retriever.compile import compile\n from retriever.lib.repository import check_for_updates\n compile()\n check_for_updates()\nexcept:\n pass\n", "path": "setup.py"}], "after_files": [{"content": "from __future__ import print_function\nfrom builtins import str\nimport os\nfrom retriever.lib.models import Engine, no_cleanup\nfrom retriever import DATA_DIR, current_platform\n\n\nclass engine(Engine):\n \"\"\"Engine instance for Microsoft Access.\"\"\"\n name = \"Microsoft Access\"\n instructions = \"\"\"Create a database in Microsoft Access, close Access, then \\nselect your database file using this dialog.\"\"\"\n abbreviation = \"msaccess\"\n datatypes = {\n \"auto\": \"AUTOINCREMENT\",\n \"int\": \"INTEGER\",\n \"bigint\": \"INTEGER\",\n \"double\": \"NUMERIC\",\n \"decimal\": \"NUMERIC\",\n \"char\": \"VARCHAR\",\n \"bool\": \"BIT\",\n }\n required_opts = [(\"file\",\n \"Enter the filename of your Access database\",\n os.path.join(DATA_DIR, \"access.mdb\"),\n \"Access databases (*.mdb, *.accdb)|*.mdb;*.accdb\"),\n (\"table_name\",\n \"Format of table name\",\n \"[{db} {table}]\"),\n ]\n placeholder = \"?\"\n\n def convert_data_type(self, datatype):\n \"\"\"MS Access can't handle complex Decimal types\"\"\"\n converted = Engine.convert_data_type(self, datatype)\n if \"NUMERIC\" in converted:\n converted = \"NUMERIC\"\n elif \"VARCHAR\" in converted:\n try:\n length = int(converted.split('(')[1].split(')')[0].split(',')[0])\n if length > 255:\n converted = \"TEXT\"\n except:\n pass\n return converted\n\n def create_db(self):\n \"\"\"MS Access doesn't create databases.\"\"\"\n return None\n\n def drop_statement(self, objecttype, objectname):\n \"\"\"Returns a drop table or database SQL statement.\"\"\"\n dropstatement = \"DROP %s %s\" % (objecttype, objectname)\n return dropstatement\n\n def insert_data_from_file(self, filename):\n \"\"\"Perform a bulk insert.\"\"\"\n self.get_cursor()\n ct = len([True for c in self.table.columns if c[1][0][:3] == \"ct-\"]) != 0\n if ((self.table.cleanup.function == no_cleanup and not self.table.fixed_width and\n self.table.header_rows < 2)\n and (self.table.delimiter in [\"\\t\", \",\"])\n and not ct\n and (not hasattr(self.table, \"do_not_bulk_insert\") or not self.table.do_not_bulk_insert)\n ):\n print (\"Inserting data from \" + os.path.basename(filename) + \"...\")\n\n if self.table.delimiter == \"\\t\":\n fmt = \"TabDelimited\"\n elif self.table.delimiter == \",\":\n fmt = \"CSVDelimited\"\n\n if self.table.header_rows == 1:\n hdr = \"Yes\"\n else:\n hdr = \"No\"\n\n columns = self.table.get_insert_columns()\n\n need_to_delete = False\n add_to_record_id = 0\n\n if self.table.pk and not self.table.contains_pk:\n if '.' in os.path.basename(filename):\n proper_name = filename.split('.')\n newfilename = '.'.join((proper_name[0:-1]) if len(proper_name) > 0 else proper_name[0]\n ) + \"_new.\" + filename.split(\".\")[-1]\n else:\n newfilename = filename + \"_new\"\n\n if not os.path.isfile(newfilename):\n print(\"Adding index to \" + os.path.abspath(newfilename) + \"...\")\n read = open(filename, \"rb\")\n write = open(newfilename, \"wb\")\n to_write = \"\"\n\n for line in read:\n to_write += str(id) + self.table.delimiter + line.replace(\"\\n\", \"\\r\\n\")\n add_to_record_id += 1\n self.table.record_id += add_to_record_id\n\n write.write(to_write)\n write.close()\n read.close()\n need_to_delete = True\n columns = \"record_id, \" + columns\n else:\n newfilename = filename\n\n newfilename = os.path.abspath(newfilename)\n filename_length = (len(os.path.basename(newfilename)) * -1) - 1\n filepath = newfilename[:filename_length]\n statement = \"\"\"\nINSERT INTO \"\"\" + self.table_name() + \" (\" + columns + \"\"\")\nSELECT * FROM [\"\"\" + os.path.basename(newfilename) + ''']\nIN \"''' + filepath + '''\" \"Text;FMT=''' + fmt + ''';HDR=''' + hdr + ''';\"'''\n\n try:\n self.execute(statement)\n except:\n print(\"Couldn't bulk insert. Trying manual insert.\")\n self.connection.rollback()\n\n self.table.record_id -= add_to_record_id\n\n return Engine.insert_data_from_file(self, filename)\n\n if need_to_delete:\n os.remove(newfilename)\n\n else:\n return Engine.insert_data_from_file(self, filename)\n\n def table_exists(self, dbname, tablename):\n \"\"\"Determine if the table already exists in the database\"\"\"\n if not hasattr(self, 'existing_table_names'):\n self.existing_table_names = set()\n for row in self.cursor.tables():\n tableinfo = row[2]\n if not tableinfo.startswith(\"MSys\"):\n # ignore system tables\n database, table = tableinfo.split()\n self.existing_table_names.add((database, table))\n return self.table_name(name=tablename, dbname=dbname).lower() in self.existing_table_names\n\n def get_connection(self):\n \"\"\"Gets the db connection.\"\"\"\n if current_platform != \"windows\":\n raise Exception(\"MS Access can only be used in Windows.\")\n import pypyodbc as dbapi\n self.get_input()\n if not os.path.exists(self.opts['file']) and self.opts['file'].endswith('.mdb'):\n dbapi.win_create_mdb(self.opts['file'])\n connection_string = (\"DRIVER={Microsoft Access Driver (*.mdb, *.accdb)};DBQ=\" +\n os.path.abspath(self.opts[\"file\"]).replace(\"/\", \"//\") + \";\")\n return dbapi.connect(connection_string, autocommit=False)\n", "path": "retriever/engines/msaccess.py"}, {"content": "\"\"\"Use the following command to install retriever: python setup.py install\"\"\"\nfrom __future__ import absolute_import\nimport platform\nimport os\nfrom setuptools import setup\nfrom pkg_resources import parse_version\n\ncurrent_platform = platform.system().lower()\nextra_includes = []\nif current_platform == \"windows\":\n extra_includes = [\"pypyodbc\"]\n\nif os.path.exists(\".git/hooks\"): # check if we are in git repo\n os.system(\"cp hooks/pre-commit .git/hooks/pre-commit\")\n os.system(\"chmod +x .git/hooks/pre-commit\")\n\n\n__version__ = 'v2.1.dev'\nwith open(os.path.join(\"retriever\", \"_version.py\"), \"w\") as version_file:\n version_file.write(\"__version__ = \" + \"'\" + __version__ + \"'\\n\")\n version_file.close()\n\n\ndef clean_version(v):\n return parse_version(v).__repr__().lstrip(\"<Version('\").rstrip(\"')>\")\n\npackages = [\n 'retriever.lib',\n 'retriever.engines',\n 'retriever',\n]\n\nincludes = [\n 'xlrd',\n 'future',\n 'argcomplete',\n 'pymysql',\n 'psycopg2',\n 'sqlite3',\n] + extra_includes\n\nexcludes = [\n 'pyreadline',\n 'doctest',\n 'pickle',\n 'pdb',\n 'pywin', 'pywin.debugger',\n 'pywin.debugger.dbgcon',\n 'pywin.dialogs', 'pywin.dialogs.list',\n 'Tkconstants', 'Tkinter', 'tcl', 'tk'\n]\n\nsetup(name='retriever',\n version=clean_version(__version__),\n description='Data Retriever',\n author='Ben Morris, Akash Goel, Henry Senyondo, Ethan White',\n author_email='[email protected]',\n url='https://github.com/weecology/retriever',\n classifiers=['Intended Audience :: Science/Research',\n 'License :: OSI Approved :: MIT License',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 3', ],\n packages=packages,\n package_dir={\n 'retriever': 'retriever'\n },\n entry_points={\n 'console_scripts': [\n 'retriever = retriever.__main__:main',\n ],\n },\n install_requires=[\n 'xlrd',\n 'future',\n 'argcomplete'\n ],\n\n # py2app flags\n app=['__main__.py'],\n data_files=[('', ['CITATION'])],\n setup_requires=[],\n )\n\n# windows doesn't have bash. No point in using bash-completion\nif current_platform != \"windows\":\n # if platform is OS X use \"~/.bash_profile\"\n if current_platform == \"darwin\":\n bash_file = \"~/.bash_profile\"\n # if platform is Linux use \"~/.bashrc\n elif current_platform == \"linux\":\n bash_file = \"~/.bashrc\"\n # else write and discard\n else:\n bash_file = \"/dev/null\"\n\n argcomplete_command = 'eval \"$(register-python-argcomplete retriever)\"'\n with open(os.path.expanduser(bash_file), \"a+\") as bashrc:\n bashrc.seek(0)\n # register retriever for arg-completion if not already registered\n # whenever a new shell is spawned\n if argcomplete_command not in bashrc.read():\n bashrc.write(argcomplete_command + \"\\n\")\n bashrc.close()\n os.system(\"activate-global-python-argcomplete\")\n # register for the current shell\n os.system(argcomplete_command)\n\ntry:\n from retriever.compile import compile\n from retriever.lib.repository import check_for_updates\n compile()\n check_for_updates()\nexcept:\n pass\n", "path": "setup.py"}]}
| 3,037 | 202 |
gh_patches_debug_2390
|
rasdani/github-patches
|
git_diff
|
Qiskit__qiskit-2448
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
No module named 'vcr': requirement is missing (vcrpy)
<!-- ⚠️ If you do not respect this template, your issue will be closed -->
<!-- ⚠️ Make sure to browse the opened and closed issues -->
### Information
- **Qiskit Terra version**: 0.10.1
- **Python version**: 3.7.3
- **Operating system**: windows 10
### What is the current behavior?
Fresh qiskit installation inside a new environment on windows 10.
In one of the terra tutorial (using_the_transpiler) `from qiskit.test.mock import FakeTokyo` is failing 'ModuleNotFoundError: No module named vcr'
### Suggested solutions
'pip install vcrpy'
'vcrpy' needs to be added in requirements.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `qiskit/util.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 # This code is part of Qiskit.
3 #
4 # (C) Copyright IBM 2017.
5 #
6 # This code is licensed under the Apache License, Version 2.0. You may
7 # obtain a copy of this license in the LICENSE.txt file in the root directory
8 # of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.
9 #
10 # Any modifications or derivative works of this code must retain this
11 # copyright notice, and modified files need to carry a notice indicating
12 # that they have been altered from the originals.
13
14 """Common utilities for Qiskit."""
15
16 import platform
17 import re
18 import socket
19 import sys
20 import warnings
21
22 import psutil
23 from marshmallow.warnings import ChangedInMarshmallow3Warning
24
25
26 def _check_python_version():
27 """Check for Python version 3.5+."""
28 if sys.version_info < (3, 5):
29 raise Exception('Qiskit requires Python version 3.5 or greater.')
30
31
32 def _filter_deprecation_warnings():
33 """Apply filters to deprecation warnings.
34
35 Force the `DeprecationWarning` warnings to be displayed for the qiskit
36 module, overriding the system configuration as they are ignored by default
37 [1] for end-users. Additionally, silence the `ChangedInMarshmallow3Warning`
38 messages.
39
40 TODO: on Python 3.7, this might not be needed due to PEP-0565 [2].
41
42 [1] https://docs.python.org/3/library/warnings.html#default-warning-filters
43 [2] https://www.python.org/dev/peps/pep-0565/
44 """
45 deprecation_filter = ('always', None, DeprecationWarning,
46 re.compile(r'^qiskit\.*', re.UNICODE), 0)
47
48 # Instead of using warnings.simple_filter() directly, the internal
49 # _add_filter() function is used for being able to match against the
50 # module.
51 try:
52 warnings._add_filter(*deprecation_filter, append=False)
53 except AttributeError:
54 # ._add_filter is internal and not available in some Python versions.
55 pass
56
57 # Add a filter for ignoring ChangedInMarshmallow3Warning, as we depend on
58 # marhsmallow 2 explicitly. 2.17.0 introduced new deprecation warnings that
59 # are useful for eventually migrating, but too verbose for our purposes.
60 warnings.simplefilter('ignore', category=ChangedInMarshmallow3Warning)
61
62
63 _check_python_version()
64 _filter_deprecation_warnings()
65
66
67 def local_hardware_info():
68 """Basic hardware information about the local machine.
69
70 Gives actual number of CPU's in the machine, even when hyperthreading is
71 turned on. CPU count defaults to 1 when true count can't be determined.
72
73 Returns:
74 dict: The hardware information.
75 """
76 results = {
77 'os': platform.system(),
78 'memory': psutil.virtual_memory().total / (1024 ** 3),
79 'cpus': psutil.cpu_count(logical=False) or 1
80 }
81 return results
82
83
84 def _has_connection(hostname, port):
85 """Checks if internet connection exists to host via specified port.
86
87 If any exception is raised while trying to open a socket this will return
88 false.
89
90 Args:
91 hostname (str): Hostname to connect to.
92 port (int): Port to connect to
93
94 Returns:
95 bool: Has connection or not
96
97 """
98 try:
99 host = socket.gethostbyname(hostname)
100 socket.create_connection((host, port), 2)
101 return True
102 except Exception: # pylint: disable=broad-except
103 return False
104
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/qiskit/util.py b/qiskit/util.py
--- a/qiskit/util.py
+++ b/qiskit/util.py
@@ -97,7 +97,7 @@
"""
try:
host = socket.gethostbyname(hostname)
- socket.create_connection((host, port), 2)
+ socket.create_connection((host, port), 2).close()
return True
except Exception: # pylint: disable=broad-except
return False
|
{"golden_diff": "diff --git a/qiskit/util.py b/qiskit/util.py\n--- a/qiskit/util.py\n+++ b/qiskit/util.py\n@@ -97,7 +97,7 @@\n \"\"\"\n try:\n host = socket.gethostbyname(hostname)\n- socket.create_connection((host, port), 2)\n+ socket.create_connection((host, port), 2).close()\n return True\n except Exception: # pylint: disable=broad-except\n return False\n", "issue": "No module named 'vcr': requirement is missing (vcrpy) \n<!-- \u26a0\ufe0f If you do not respect this template, your issue will be closed -->\r\n<!-- \u26a0\ufe0f Make sure to browse the opened and closed issues -->\r\n\r\n### Information\r\n\r\n- **Qiskit Terra version**: 0.10.1\r\n- **Python version**: 3.7.3\r\n- **Operating system**: windows 10\r\n\r\n### What is the current behavior?\r\nFresh qiskit installation inside a new environment on windows 10. \r\nIn one of the terra tutorial (using_the_transpiler) `from qiskit.test.mock import FakeTokyo` is failing 'ModuleNotFoundError: No module named vcr'\r\n\r\n### Suggested solutions\r\n'pip install vcrpy' \r\n'vcrpy' needs to be added in requirements.\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# This code is part of Qiskit.\n#\n# (C) Copyright IBM 2017.\n#\n# This code is licensed under the Apache License, Version 2.0. You may\n# obtain a copy of this license in the LICENSE.txt file in the root directory\n# of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.\n#\n# Any modifications or derivative works of this code must retain this\n# copyright notice, and modified files need to carry a notice indicating\n# that they have been altered from the originals.\n\n\"\"\"Common utilities for Qiskit.\"\"\"\n\nimport platform\nimport re\nimport socket\nimport sys\nimport warnings\n\nimport psutil\nfrom marshmallow.warnings import ChangedInMarshmallow3Warning\n\n\ndef _check_python_version():\n \"\"\"Check for Python version 3.5+.\"\"\"\n if sys.version_info < (3, 5):\n raise Exception('Qiskit requires Python version 3.5 or greater.')\n\n\ndef _filter_deprecation_warnings():\n \"\"\"Apply filters to deprecation warnings.\n\n Force the `DeprecationWarning` warnings to be displayed for the qiskit\n module, overriding the system configuration as they are ignored by default\n [1] for end-users. Additionally, silence the `ChangedInMarshmallow3Warning`\n messages.\n\n TODO: on Python 3.7, this might not be needed due to PEP-0565 [2].\n\n [1] https://docs.python.org/3/library/warnings.html#default-warning-filters\n [2] https://www.python.org/dev/peps/pep-0565/\n \"\"\"\n deprecation_filter = ('always', None, DeprecationWarning,\n re.compile(r'^qiskit\\.*', re.UNICODE), 0)\n\n # Instead of using warnings.simple_filter() directly, the internal\n # _add_filter() function is used for being able to match against the\n # module.\n try:\n warnings._add_filter(*deprecation_filter, append=False)\n except AttributeError:\n # ._add_filter is internal and not available in some Python versions.\n pass\n\n # Add a filter for ignoring ChangedInMarshmallow3Warning, as we depend on\n # marhsmallow 2 explicitly. 2.17.0 introduced new deprecation warnings that\n # are useful for eventually migrating, but too verbose for our purposes.\n warnings.simplefilter('ignore', category=ChangedInMarshmallow3Warning)\n\n\n_check_python_version()\n_filter_deprecation_warnings()\n\n\ndef local_hardware_info():\n \"\"\"Basic hardware information about the local machine.\n\n Gives actual number of CPU's in the machine, even when hyperthreading is\n turned on. CPU count defaults to 1 when true count can't be determined.\n\n Returns:\n dict: The hardware information.\n \"\"\"\n results = {\n 'os': platform.system(),\n 'memory': psutil.virtual_memory().total / (1024 ** 3),\n 'cpus': psutil.cpu_count(logical=False) or 1\n }\n return results\n\n\ndef _has_connection(hostname, port):\n \"\"\"Checks if internet connection exists to host via specified port.\n\n If any exception is raised while trying to open a socket this will return\n false.\n\n Args:\n hostname (str): Hostname to connect to.\n port (int): Port to connect to\n\n Returns:\n bool: Has connection or not\n\n \"\"\"\n try:\n host = socket.gethostbyname(hostname)\n socket.create_connection((host, port), 2)\n return True\n except Exception: # pylint: disable=broad-except\n return False\n", "path": "qiskit/util.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n# This code is part of Qiskit.\n#\n# (C) Copyright IBM 2017.\n#\n# This code is licensed under the Apache License, Version 2.0. You may\n# obtain a copy of this license in the LICENSE.txt file in the root directory\n# of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.\n#\n# Any modifications or derivative works of this code must retain this\n# copyright notice, and modified files need to carry a notice indicating\n# that they have been altered from the originals.\n\n\"\"\"Common utilities for Qiskit.\"\"\"\n\nimport platform\nimport re\nimport socket\nimport sys\nimport warnings\n\nimport psutil\nfrom marshmallow.warnings import ChangedInMarshmallow3Warning\n\n\ndef _check_python_version():\n \"\"\"Check for Python version 3.5+.\"\"\"\n if sys.version_info < (3, 5):\n raise Exception('Qiskit requires Python version 3.5 or greater.')\n\n\ndef _filter_deprecation_warnings():\n \"\"\"Apply filters to deprecation warnings.\n\n Force the `DeprecationWarning` warnings to be displayed for the qiskit\n module, overriding the system configuration as they are ignored by default\n [1] for end-users. Additionally, silence the `ChangedInMarshmallow3Warning`\n messages.\n\n TODO: on Python 3.7, this might not be needed due to PEP-0565 [2].\n\n [1] https://docs.python.org/3/library/warnings.html#default-warning-filters\n [2] https://www.python.org/dev/peps/pep-0565/\n \"\"\"\n deprecation_filter = ('always', None, DeprecationWarning,\n re.compile(r'^qiskit\\.*', re.UNICODE), 0)\n\n # Instead of using warnings.simple_filter() directly, the internal\n # _add_filter() function is used for being able to match against the\n # module.\n try:\n warnings._add_filter(*deprecation_filter, append=False)\n except AttributeError:\n # ._add_filter is internal and not available in some Python versions.\n pass\n\n # Add a filter for ignoring ChangedInMarshmallow3Warning, as we depend on\n # marhsmallow 2 explicitly. 2.17.0 introduced new deprecation warnings that\n # are useful for eventually migrating, but too verbose for our purposes.\n warnings.simplefilter('ignore', category=ChangedInMarshmallow3Warning)\n\n\n_check_python_version()\n_filter_deprecation_warnings()\n\n\ndef local_hardware_info():\n \"\"\"Basic hardware information about the local machine.\n\n Gives actual number of CPU's in the machine, even when hyperthreading is\n turned on. CPU count defaults to 1 when true count can't be determined.\n\n Returns:\n dict: The hardware information.\n \"\"\"\n results = {\n 'os': platform.system(),\n 'memory': psutil.virtual_memory().total / (1024 ** 3),\n 'cpus': psutil.cpu_count(logical=False) or 1\n }\n return results\n\n\ndef _has_connection(hostname, port):\n \"\"\"Checks if internet connection exists to host via specified port.\n\n If any exception is raised while trying to open a socket this will return\n false.\n\n Args:\n hostname (str): Hostname to connect to.\n port (int): Port to connect to\n\n Returns:\n bool: Has connection or not\n\n \"\"\"\n try:\n host = socket.gethostbyname(hostname)\n socket.create_connection((host, port), 2).close()\n return True\n except Exception: # pylint: disable=broad-except\n return False\n", "path": "qiskit/util.py"}]}
| 1,452 | 108 |
gh_patches_debug_34444
|
rasdani/github-patches
|
git_diff
|
google__osv.dev-439
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bulk query API
A bulk query API would allow developers to more easily query the API without hitting rate limits. It would also help with scenarios like #257, where an SBOM will contain many dependencies.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/build.py`
Content:
```
1 # Copyright 2021 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 """Documentation builder."""
15
16 import json
17 import os
18 import shutil
19 import subprocess
20
21 _ROOT_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
22 _GENERATED_FILENAME = 'v1/osv_service_v1.swagger.json'
23
24
25 def property_description_workaround(definition):
26 """Work around an OpenAPI limitation with a field descriptions getting
27 replaced by the object descriptions."""
28 # Workaround described in https://github.com/Redocly/redoc/issues/835.
29 for value in definition['properties'].values():
30 if '$ref' in value:
31 value['allOf'] = [{'$ref': value['$ref']}]
32 del value['$ref']
33
34
35 def replace_property_name(definition, key, replacement):
36 """Replace property name."""
37 definition['properties'][replacement] = definition['properties'][key]
38 del definition['properties'][key]
39
40
41 def main():
42 api_dir = os.path.join(_ROOT_DIR, 'gcp', 'api')
43 v1_api_dir = os.path.join(api_dir, 'v1')
44 googleapis_dir = os.path.join(api_dir, 'googleapis')
45 service_proto_path = os.path.join(v1_api_dir, 'osv_service_v1.proto')
46
47 # Add OSV dependencies.
48 osv_path = os.path.join(api_dir, 'osv')
49 if os.path.exists(osv_path):
50 shutil.rmtree(osv_path)
51
52 shutil.copytree(os.path.join(_ROOT_DIR, 'lib', 'osv'), osv_path)
53
54 subprocess.run([
55 'protoc',
56 '-I',
57 api_dir,
58 '-I',
59 v1_api_dir,
60 '-I',
61 googleapis_dir,
62 '--openapiv2_out',
63 '.',
64 '--openapiv2_opt',
65 'logtostderr=true',
66 service_proto_path,
67 ],
68 check=True)
69
70 with open(_GENERATED_FILENAME) as f:
71 spec = json.load(f)
72
73 spec['host'] = 'api.osv.dev'
74 spec['info']['title'] = 'OSV'
75 spec['info']['version'] = '1.0'
76 spec['tags'] = [{
77 'name': 'api',
78 'x-displayName': 'API',
79 'description': 'The API has 2 methods:'
80 }, {
81 'name': 'vulnerability_schema',
82 'x-displayName': 'Vulnerability schema',
83 'description': 'Please see the [OpenSSF Open Source Vulnerability spec]'
84 '(https://ossf.github.io/osv-schema/).',
85 }]
86
87 spec['x-tagGroups'] = [{
88 'name': 'API',
89 'tags': ['api']
90 }, {
91 'name': 'Schema',
92 'tags': ['vulnerability_schema']
93 }]
94
95 spec['paths']['/v1/query']['post']['tags'] = ['api']
96 spec['paths']['/v1/vulns/{id}']['get']['tags'] = ['api']
97
98 spec['paths']['/v1/query']['post']['x-code-samples'] = [{
99 'lang':
100 'Curl example',
101 'source':
102 ('curl -X POST -d \\\n'
103 ' \'{"commit": "6879efc2c1596d11a6a6ad296f80063b558d5e0f"}\' \\\n'
104 ' "https://api.osv.dev/v1/query"\n\n'
105 'curl -X POST -d \\\n'
106 ' \'{"package": {"name": "mruby"}, "version": "2.1.2rc"}\' \\\n'
107 ' "https://api.osv.dev/v1/query"')
108 }]
109
110 spec['paths']['/v1/vulns/{id}']['get']['x-code-samples'] = [{
111 'lang': 'Curl example',
112 'source': 'curl "https://api.osv.dev/v1/vulns/OSV-2020-111"'
113 }]
114
115 property_description_workaround(spec['definitions']['v1Query'])
116 property_description_workaround(spec['definitions']['osvVulnerability'])
117
118 replace_property_name(spec['definitions']['osvVulnerability'],
119 'databaseSpecific', 'database_specific')
120
121 with open('sections.md') as f:
122 spec['info']['description'] = f.read()
123
124 with open(_GENERATED_FILENAME, 'w') as f:
125 f.write(json.dumps(spec, indent=2))
126
127 shutil.move(_GENERATED_FILENAME, os.path.basename(_GENERATED_FILENAME))
128
129
130 if __name__ == '__main__':
131 main()
132
```
Path: `gcp/api/osv_service_v1_pb2_grpc.py`
Content:
```
1 # Generated by the gRPC Python protocol compiler plugin. DO NOT EDIT!
2 """Client and server classes corresponding to protobuf-defined services."""
3 import grpc
4
5 from osv import vulnerability_pb2 as osv_dot_vulnerability__pb2
6 import osv_service_v1_pb2 as osv__service__v1__pb2
7
8
9 class OSVStub(object):
10 """Open source vulnerability database.
11 """
12
13 def __init__(self, channel):
14 """Constructor.
15
16 Args:
17 channel: A grpc.Channel.
18 """
19 self.GetVulnById = channel.unary_unary(
20 '/osv.v1.OSV/GetVulnById',
21 request_serializer=osv__service__v1__pb2.GetVulnByIdParameters.SerializeToString,
22 response_deserializer=osv_dot_vulnerability__pb2.Vulnerability.FromString,
23 )
24 self.QueryAffected = channel.unary_unary(
25 '/osv.v1.OSV/QueryAffected',
26 request_serializer=osv__service__v1__pb2.QueryAffectedParameters.SerializeToString,
27 response_deserializer=osv__service__v1__pb2.VulnerabilityList.FromString,
28 )
29 self.QueryAffectedBatch = channel.unary_unary(
30 '/osv.v1.OSV/QueryAffectedBatch',
31 request_serializer=osv__service__v1__pb2.QueryAffectedBatchParameters.SerializeToString,
32 response_deserializer=osv__service__v1__pb2.BatchVulnerabilityList.FromString,
33 )
34
35
36 class OSVServicer(object):
37 """Open source vulnerability database.
38 """
39
40 def GetVulnById(self, request, context):
41 """Return a `Vulnerability` object for a given OSV ID.
42 """
43 context.set_code(grpc.StatusCode.UNIMPLEMENTED)
44 context.set_details('Method not implemented!')
45 raise NotImplementedError('Method not implemented!')
46
47 def QueryAffected(self, request, context):
48 """Query vulnerabilities for a particular project at a given commit or
49 version.
50 """
51 context.set_code(grpc.StatusCode.UNIMPLEMENTED)
52 context.set_details('Method not implemented!')
53 raise NotImplementedError('Method not implemented!')
54
55 def QueryAffectedBatch(self, request, context):
56 """Query vulnerabilities for a particular project at given commits and
57 versions.
58 """
59 context.set_code(grpc.StatusCode.UNIMPLEMENTED)
60 context.set_details('Method not implemented!')
61 raise NotImplementedError('Method not implemented!')
62
63
64 def add_OSVServicer_to_server(servicer, server):
65 rpc_method_handlers = {
66 'GetVulnById': grpc.unary_unary_rpc_method_handler(
67 servicer.GetVulnById,
68 request_deserializer=osv__service__v1__pb2.GetVulnByIdParameters.FromString,
69 response_serializer=osv_dot_vulnerability__pb2.Vulnerability.SerializeToString,
70 ),
71 'QueryAffected': grpc.unary_unary_rpc_method_handler(
72 servicer.QueryAffected,
73 request_deserializer=osv__service__v1__pb2.QueryAffectedParameters.FromString,
74 response_serializer=osv__service__v1__pb2.VulnerabilityList.SerializeToString,
75 ),
76 'QueryAffectedBatch': grpc.unary_unary_rpc_method_handler(
77 servicer.QueryAffectedBatch,
78 request_deserializer=osv__service__v1__pb2.QueryAffectedBatchParameters.FromString,
79 response_serializer=osv__service__v1__pb2.BatchVulnerabilityList.SerializeToString,
80 ),
81 }
82 generic_handler = grpc.method_handlers_generic_handler(
83 'osv.v1.OSV', rpc_method_handlers)
84 server.add_generic_rpc_handlers((generic_handler,))
85
86
87 # This class is part of an EXPERIMENTAL API.
88 class OSV(object):
89 """Open source vulnerability database.
90 """
91
92 @staticmethod
93 def GetVulnById(request,
94 target,
95 options=(),
96 channel_credentials=None,
97 call_credentials=None,
98 insecure=False,
99 compression=None,
100 wait_for_ready=None,
101 timeout=None,
102 metadata=None):
103 return grpc.experimental.unary_unary(request, target, '/osv.v1.OSV/GetVulnById',
104 osv__service__v1__pb2.GetVulnByIdParameters.SerializeToString,
105 osv_dot_vulnerability__pb2.Vulnerability.FromString,
106 options, channel_credentials,
107 insecure, call_credentials, compression, wait_for_ready, timeout, metadata)
108
109 @staticmethod
110 def QueryAffected(request,
111 target,
112 options=(),
113 channel_credentials=None,
114 call_credentials=None,
115 insecure=False,
116 compression=None,
117 wait_for_ready=None,
118 timeout=None,
119 metadata=None):
120 return grpc.experimental.unary_unary(request, target, '/osv.v1.OSV/QueryAffected',
121 osv__service__v1__pb2.QueryAffectedParameters.SerializeToString,
122 osv__service__v1__pb2.VulnerabilityList.FromString,
123 options, channel_credentials,
124 insecure, call_credentials, compression, wait_for_ready, timeout, metadata)
125
126 @staticmethod
127 def QueryAffectedBatch(request,
128 target,
129 options=(),
130 channel_credentials=None,
131 call_credentials=None,
132 insecure=False,
133 compression=None,
134 wait_for_ready=None,
135 timeout=None,
136 metadata=None):
137 return grpc.experimental.unary_unary(request, target, '/osv.v1.OSV/QueryAffectedBatch',
138 osv__service__v1__pb2.QueryAffectedBatchParameters.SerializeToString,
139 osv__service__v1__pb2.BatchVulnerabilityList.FromString,
140 options, channel_credentials,
141 insecure, call_credentials, compression, wait_for_ready, timeout, metadata)
142
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docs/build.py b/docs/build.py
--- a/docs/build.py
+++ b/docs/build.py
@@ -76,7 +76,7 @@
spec['tags'] = [{
'name': 'api',
'x-displayName': 'API',
- 'description': 'The API has 2 methods:'
+ 'description': 'The API has 3 methods:'
}, {
'name': 'vulnerability_schema',
'x-displayName': 'Vulnerability schema',
@@ -93,6 +93,7 @@
}]
spec['paths']['/v1/query']['post']['tags'] = ['api']
+ spec['paths']['/v1/querybatch']['post']['tags'] = ['api']
spec['paths']['/v1/vulns/{id}']['get']['tags'] = ['api']
spec['paths']['/v1/query']['post']['x-code-samples'] = [{
@@ -107,6 +108,33 @@
' "https://api.osv.dev/v1/query"')
}]
+ spec['paths']['/v1/querybatch']['post']['x-code-samples'] = [{
+ 'lang':
+ 'Curl example',
+ 'source':
+ ("""cat <<EOF | curl -X POST -d @- "https://api.osv.dev/v1/querybatch"
+{
+ "queries": [
+ {
+ "package": {
+ "purl": "pkg:pypi/[email protected]"
+ }
+ },
+ {
+ "commit": "6879efc2c1596d11a6a6ad296f80063b558d5e0f"
+ },
+ {
+ "package": {
+ "ecosystem": "PyPI",
+ "name": "jinja2"
+ },
+ "version": "2.4.1"
+ }
+ ]
+}
+EOF""")
+ }]
+
spec['paths']['/v1/vulns/{id}']['get']['x-code-samples'] = [{
'lang': 'Curl example',
'source': 'curl "https://api.osv.dev/v1/vulns/OSV-2020-111"'
diff --git a/gcp/api/osv_service_v1_pb2_grpc.py b/gcp/api/osv_service_v1_pb2_grpc.py
--- a/gcp/api/osv_service_v1_pb2_grpc.py
+++ b/gcp/api/osv_service_v1_pb2_grpc.py
@@ -53,8 +53,7 @@
raise NotImplementedError('Method not implemented!')
def QueryAffectedBatch(self, request, context):
- """Query vulnerabilities for a particular project at given commits and
- versions.
+ """Query vulnerabilities (batched) for given package versions and commits.
"""
context.set_code(grpc.StatusCode.UNIMPLEMENTED)
context.set_details('Method not implemented!')
|
{"golden_diff": "diff --git a/docs/build.py b/docs/build.py\n--- a/docs/build.py\n+++ b/docs/build.py\n@@ -76,7 +76,7 @@\n spec['tags'] = [{\n 'name': 'api',\n 'x-displayName': 'API',\n- 'description': 'The API has 2 methods:'\n+ 'description': 'The API has 3 methods:'\n }, {\n 'name': 'vulnerability_schema',\n 'x-displayName': 'Vulnerability schema',\n@@ -93,6 +93,7 @@\n }]\n \n spec['paths']['/v1/query']['post']['tags'] = ['api']\n+ spec['paths']['/v1/querybatch']['post']['tags'] = ['api']\n spec['paths']['/v1/vulns/{id}']['get']['tags'] = ['api']\n \n spec['paths']['/v1/query']['post']['x-code-samples'] = [{\n@@ -107,6 +108,33 @@\n ' \"https://api.osv.dev/v1/query\"')\n }]\n \n+ spec['paths']['/v1/querybatch']['post']['x-code-samples'] = [{\n+ 'lang':\n+ 'Curl example',\n+ 'source':\n+ (\"\"\"cat <<EOF | curl -X POST -d @- \"https://api.osv.dev/v1/querybatch\"\n+{\n+ \"queries\": [\n+ {\n+ \"package\": {\n+ \"purl\": \"pkg:pypi/[email protected]\"\n+ }\n+ },\n+ {\n+ \"commit\": \"6879efc2c1596d11a6a6ad296f80063b558d5e0f\"\n+ },\n+ {\n+ \"package\": {\n+ \"ecosystem\": \"PyPI\",\n+ \"name\": \"jinja2\"\n+ },\n+ \"version\": \"2.4.1\"\n+ }\n+ ]\n+}\n+EOF\"\"\")\n+ }]\n+\n spec['paths']['/v1/vulns/{id}']['get']['x-code-samples'] = [{\n 'lang': 'Curl example',\n 'source': 'curl \"https://api.osv.dev/v1/vulns/OSV-2020-111\"'\ndiff --git a/gcp/api/osv_service_v1_pb2_grpc.py b/gcp/api/osv_service_v1_pb2_grpc.py\n--- a/gcp/api/osv_service_v1_pb2_grpc.py\n+++ b/gcp/api/osv_service_v1_pb2_grpc.py\n@@ -53,8 +53,7 @@\n raise NotImplementedError('Method not implemented!')\n \n def QueryAffectedBatch(self, request, context):\n- \"\"\"Query vulnerabilities for a particular project at given commits and\n- versions.\n+ \"\"\"Query vulnerabilities (batched) for given package versions and commits.\n \"\"\"\n context.set_code(grpc.StatusCode.UNIMPLEMENTED)\n context.set_details('Method not implemented!')\n", "issue": "Bulk query API\nA bulk query API would allow developers to more easily query the API without hitting rate limits. It would also help with scenarios like #257, where an SBOM will contain many dependencies.\n", "before_files": [{"content": "# Copyright 2021 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Documentation builder.\"\"\"\n\nimport json\nimport os\nimport shutil\nimport subprocess\n\n_ROOT_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\n_GENERATED_FILENAME = 'v1/osv_service_v1.swagger.json'\n\n\ndef property_description_workaround(definition):\n \"\"\"Work around an OpenAPI limitation with a field descriptions getting\n replaced by the object descriptions.\"\"\"\n # Workaround described in https://github.com/Redocly/redoc/issues/835.\n for value in definition['properties'].values():\n if '$ref' in value:\n value['allOf'] = [{'$ref': value['$ref']}]\n del value['$ref']\n\n\ndef replace_property_name(definition, key, replacement):\n \"\"\"Replace property name.\"\"\"\n definition['properties'][replacement] = definition['properties'][key]\n del definition['properties'][key]\n\n\ndef main():\n api_dir = os.path.join(_ROOT_DIR, 'gcp', 'api')\n v1_api_dir = os.path.join(api_dir, 'v1')\n googleapis_dir = os.path.join(api_dir, 'googleapis')\n service_proto_path = os.path.join(v1_api_dir, 'osv_service_v1.proto')\n\n # Add OSV dependencies.\n osv_path = os.path.join(api_dir, 'osv')\n if os.path.exists(osv_path):\n shutil.rmtree(osv_path)\n\n shutil.copytree(os.path.join(_ROOT_DIR, 'lib', 'osv'), osv_path)\n\n subprocess.run([\n 'protoc',\n '-I',\n api_dir,\n '-I',\n v1_api_dir,\n '-I',\n googleapis_dir,\n '--openapiv2_out',\n '.',\n '--openapiv2_opt',\n 'logtostderr=true',\n service_proto_path,\n ],\n check=True)\n\n with open(_GENERATED_FILENAME) as f:\n spec = json.load(f)\n\n spec['host'] = 'api.osv.dev'\n spec['info']['title'] = 'OSV'\n spec['info']['version'] = '1.0'\n spec['tags'] = [{\n 'name': 'api',\n 'x-displayName': 'API',\n 'description': 'The API has 2 methods:'\n }, {\n 'name': 'vulnerability_schema',\n 'x-displayName': 'Vulnerability schema',\n 'description': 'Please see the [OpenSSF Open Source Vulnerability spec]'\n '(https://ossf.github.io/osv-schema/).',\n }]\n\n spec['x-tagGroups'] = [{\n 'name': 'API',\n 'tags': ['api']\n }, {\n 'name': 'Schema',\n 'tags': ['vulnerability_schema']\n }]\n\n spec['paths']['/v1/query']['post']['tags'] = ['api']\n spec['paths']['/v1/vulns/{id}']['get']['tags'] = ['api']\n\n spec['paths']['/v1/query']['post']['x-code-samples'] = [{\n 'lang':\n 'Curl example',\n 'source':\n ('curl -X POST -d \\\\\\n'\n ' \\'{\"commit\": \"6879efc2c1596d11a6a6ad296f80063b558d5e0f\"}\\' \\\\\\n'\n ' \"https://api.osv.dev/v1/query\"\\n\\n'\n 'curl -X POST -d \\\\\\n'\n ' \\'{\"package\": {\"name\": \"mruby\"}, \"version\": \"2.1.2rc\"}\\' \\\\\\n'\n ' \"https://api.osv.dev/v1/query\"')\n }]\n\n spec['paths']['/v1/vulns/{id}']['get']['x-code-samples'] = [{\n 'lang': 'Curl example',\n 'source': 'curl \"https://api.osv.dev/v1/vulns/OSV-2020-111\"'\n }]\n\n property_description_workaround(spec['definitions']['v1Query'])\n property_description_workaround(spec['definitions']['osvVulnerability'])\n\n replace_property_name(spec['definitions']['osvVulnerability'],\n 'databaseSpecific', 'database_specific')\n\n with open('sections.md') as f:\n spec['info']['description'] = f.read()\n\n with open(_GENERATED_FILENAME, 'w') as f:\n f.write(json.dumps(spec, indent=2))\n\n shutil.move(_GENERATED_FILENAME, os.path.basename(_GENERATED_FILENAME))\n\n\nif __name__ == '__main__':\n main()\n", "path": "docs/build.py"}, {"content": "# Generated by the gRPC Python protocol compiler plugin. DO NOT EDIT!\n\"\"\"Client and server classes corresponding to protobuf-defined services.\"\"\"\nimport grpc\n\nfrom osv import vulnerability_pb2 as osv_dot_vulnerability__pb2\nimport osv_service_v1_pb2 as osv__service__v1__pb2\n\n\nclass OSVStub(object):\n \"\"\"Open source vulnerability database.\n \"\"\"\n\n def __init__(self, channel):\n \"\"\"Constructor.\n\n Args:\n channel: A grpc.Channel.\n \"\"\"\n self.GetVulnById = channel.unary_unary(\n '/osv.v1.OSV/GetVulnById',\n request_serializer=osv__service__v1__pb2.GetVulnByIdParameters.SerializeToString,\n response_deserializer=osv_dot_vulnerability__pb2.Vulnerability.FromString,\n )\n self.QueryAffected = channel.unary_unary(\n '/osv.v1.OSV/QueryAffected',\n request_serializer=osv__service__v1__pb2.QueryAffectedParameters.SerializeToString,\n response_deserializer=osv__service__v1__pb2.VulnerabilityList.FromString,\n )\n self.QueryAffectedBatch = channel.unary_unary(\n '/osv.v1.OSV/QueryAffectedBatch',\n request_serializer=osv__service__v1__pb2.QueryAffectedBatchParameters.SerializeToString,\n response_deserializer=osv__service__v1__pb2.BatchVulnerabilityList.FromString,\n )\n\n\nclass OSVServicer(object):\n \"\"\"Open source vulnerability database.\n \"\"\"\n\n def GetVulnById(self, request, context):\n \"\"\"Return a `Vulnerability` object for a given OSV ID.\n \"\"\"\n context.set_code(grpc.StatusCode.UNIMPLEMENTED)\n context.set_details('Method not implemented!')\n raise NotImplementedError('Method not implemented!')\n\n def QueryAffected(self, request, context):\n \"\"\"Query vulnerabilities for a particular project at a given commit or\n version.\n \"\"\"\n context.set_code(grpc.StatusCode.UNIMPLEMENTED)\n context.set_details('Method not implemented!')\n raise NotImplementedError('Method not implemented!')\n\n def QueryAffectedBatch(self, request, context):\n \"\"\"Query vulnerabilities for a particular project at given commits and\n versions.\n \"\"\"\n context.set_code(grpc.StatusCode.UNIMPLEMENTED)\n context.set_details('Method not implemented!')\n raise NotImplementedError('Method not implemented!')\n\n\ndef add_OSVServicer_to_server(servicer, server):\n rpc_method_handlers = {\n 'GetVulnById': grpc.unary_unary_rpc_method_handler(\n servicer.GetVulnById,\n request_deserializer=osv__service__v1__pb2.GetVulnByIdParameters.FromString,\n response_serializer=osv_dot_vulnerability__pb2.Vulnerability.SerializeToString,\n ),\n 'QueryAffected': grpc.unary_unary_rpc_method_handler(\n servicer.QueryAffected,\n request_deserializer=osv__service__v1__pb2.QueryAffectedParameters.FromString,\n response_serializer=osv__service__v1__pb2.VulnerabilityList.SerializeToString,\n ),\n 'QueryAffectedBatch': grpc.unary_unary_rpc_method_handler(\n servicer.QueryAffectedBatch,\n request_deserializer=osv__service__v1__pb2.QueryAffectedBatchParameters.FromString,\n response_serializer=osv__service__v1__pb2.BatchVulnerabilityList.SerializeToString,\n ),\n }\n generic_handler = grpc.method_handlers_generic_handler(\n 'osv.v1.OSV', rpc_method_handlers)\n server.add_generic_rpc_handlers((generic_handler,))\n\n\n # This class is part of an EXPERIMENTAL API.\nclass OSV(object):\n \"\"\"Open source vulnerability database.\n \"\"\"\n\n @staticmethod\n def GetVulnById(request,\n target,\n options=(),\n channel_credentials=None,\n call_credentials=None,\n insecure=False,\n compression=None,\n wait_for_ready=None,\n timeout=None,\n metadata=None):\n return grpc.experimental.unary_unary(request, target, '/osv.v1.OSV/GetVulnById',\n osv__service__v1__pb2.GetVulnByIdParameters.SerializeToString,\n osv_dot_vulnerability__pb2.Vulnerability.FromString,\n options, channel_credentials,\n insecure, call_credentials, compression, wait_for_ready, timeout, metadata)\n\n @staticmethod\n def QueryAffected(request,\n target,\n options=(),\n channel_credentials=None,\n call_credentials=None,\n insecure=False,\n compression=None,\n wait_for_ready=None,\n timeout=None,\n metadata=None):\n return grpc.experimental.unary_unary(request, target, '/osv.v1.OSV/QueryAffected',\n osv__service__v1__pb2.QueryAffectedParameters.SerializeToString,\n osv__service__v1__pb2.VulnerabilityList.FromString,\n options, channel_credentials,\n insecure, call_credentials, compression, wait_for_ready, timeout, metadata)\n\n @staticmethod\n def QueryAffectedBatch(request,\n target,\n options=(),\n channel_credentials=None,\n call_credentials=None,\n insecure=False,\n compression=None,\n wait_for_ready=None,\n timeout=None,\n metadata=None):\n return grpc.experimental.unary_unary(request, target, '/osv.v1.OSV/QueryAffectedBatch',\n osv__service__v1__pb2.QueryAffectedBatchParameters.SerializeToString,\n osv__service__v1__pb2.BatchVulnerabilityList.FromString,\n options, channel_credentials,\n insecure, call_credentials, compression, wait_for_ready, timeout, metadata)\n", "path": "gcp/api/osv_service_v1_pb2_grpc.py"}], "after_files": [{"content": "# Copyright 2021 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Documentation builder.\"\"\"\n\nimport json\nimport os\nimport shutil\nimport subprocess\n\n_ROOT_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\n_GENERATED_FILENAME = 'v1/osv_service_v1.swagger.json'\n\n\ndef property_description_workaround(definition):\n \"\"\"Work around an OpenAPI limitation with a field descriptions getting\n replaced by the object descriptions.\"\"\"\n # Workaround described in https://github.com/Redocly/redoc/issues/835.\n for value in definition['properties'].values():\n if '$ref' in value:\n value['allOf'] = [{'$ref': value['$ref']}]\n del value['$ref']\n\n\ndef replace_property_name(definition, key, replacement):\n \"\"\"Replace property name.\"\"\"\n definition['properties'][replacement] = definition['properties'][key]\n del definition['properties'][key]\n\n\ndef main():\n api_dir = os.path.join(_ROOT_DIR, 'gcp', 'api')\n v1_api_dir = os.path.join(api_dir, 'v1')\n googleapis_dir = os.path.join(api_dir, 'googleapis')\n service_proto_path = os.path.join(v1_api_dir, 'osv_service_v1.proto')\n\n # Add OSV dependencies.\n osv_path = os.path.join(api_dir, 'osv')\n if os.path.exists(osv_path):\n shutil.rmtree(osv_path)\n\n shutil.copytree(os.path.join(_ROOT_DIR, 'lib', 'osv'), osv_path)\n\n subprocess.run([\n 'protoc',\n '-I',\n api_dir,\n '-I',\n v1_api_dir,\n '-I',\n googleapis_dir,\n '--openapiv2_out',\n '.',\n '--openapiv2_opt',\n 'logtostderr=true',\n service_proto_path,\n ],\n check=True)\n\n with open(_GENERATED_FILENAME) as f:\n spec = json.load(f)\n\n spec['host'] = 'api.osv.dev'\n spec['info']['title'] = 'OSV'\n spec['info']['version'] = '1.0'\n spec['tags'] = [{\n 'name': 'api',\n 'x-displayName': 'API',\n 'description': 'The API has 3 methods:'\n }, {\n 'name': 'vulnerability_schema',\n 'x-displayName': 'Vulnerability schema',\n 'description': 'Please see the [OpenSSF Open Source Vulnerability spec]'\n '(https://ossf.github.io/osv-schema/).',\n }]\n\n spec['x-tagGroups'] = [{\n 'name': 'API',\n 'tags': ['api']\n }, {\n 'name': 'Schema',\n 'tags': ['vulnerability_schema']\n }]\n\n spec['paths']['/v1/query']['post']['tags'] = ['api']\n spec['paths']['/v1/querybatch']['post']['tags'] = ['api']\n spec['paths']['/v1/vulns/{id}']['get']['tags'] = ['api']\n\n spec['paths']['/v1/query']['post']['x-code-samples'] = [{\n 'lang':\n 'Curl example',\n 'source':\n ('curl -X POST -d \\\\\\n'\n ' \\'{\"commit\": \"6879efc2c1596d11a6a6ad296f80063b558d5e0f\"}\\' \\\\\\n'\n ' \"https://api.osv.dev/v1/query\"\\n\\n'\n 'curl -X POST -d \\\\\\n'\n ' \\'{\"package\": {\"name\": \"mruby\"}, \"version\": \"2.1.2rc\"}\\' \\\\\\n'\n ' \"https://api.osv.dev/v1/query\"')\n }]\n\n spec['paths']['/v1/querybatch']['post']['x-code-samples'] = [{\n 'lang':\n 'Curl example',\n 'source':\n (\"\"\"cat <<EOF | curl -X POST -d @- \"https://api.osv.dev/v1/querybatch\"\n{\n \"queries\": [\n {\n \"package\": {\n \"purl\": \"pkg:pypi/[email protected]\"\n }\n },\n {\n \"commit\": \"6879efc2c1596d11a6a6ad296f80063b558d5e0f\"\n },\n {\n \"package\": {\n \"ecosystem\": \"PyPI\",\n \"name\": \"jinja2\"\n },\n \"version\": \"2.4.1\"\n }\n ]\n}\nEOF\"\"\")\n }]\n\n spec['paths']['/v1/vulns/{id}']['get']['x-code-samples'] = [{\n 'lang': 'Curl example',\n 'source': 'curl \"https://api.osv.dev/v1/vulns/OSV-2020-111\"'\n }]\n\n property_description_workaround(spec['definitions']['v1Query'])\n property_description_workaround(spec['definitions']['osvVulnerability'])\n\n replace_property_name(spec['definitions']['osvVulnerability'],\n 'databaseSpecific', 'database_specific')\n\n with open('sections.md') as f:\n spec['info']['description'] = f.read()\n\n with open(_GENERATED_FILENAME, 'w') as f:\n f.write(json.dumps(spec, indent=2))\n\n shutil.move(_GENERATED_FILENAME, os.path.basename(_GENERATED_FILENAME))\n\n\nif __name__ == '__main__':\n main()\n", "path": "docs/build.py"}, {"content": "# Generated by the gRPC Python protocol compiler plugin. DO NOT EDIT!\n\"\"\"Client and server classes corresponding to protobuf-defined services.\"\"\"\nimport grpc\n\nfrom osv import vulnerability_pb2 as osv_dot_vulnerability__pb2\nimport osv_service_v1_pb2 as osv__service__v1__pb2\n\n\nclass OSVStub(object):\n \"\"\"Open source vulnerability database.\n \"\"\"\n\n def __init__(self, channel):\n \"\"\"Constructor.\n\n Args:\n channel: A grpc.Channel.\n \"\"\"\n self.GetVulnById = channel.unary_unary(\n '/osv.v1.OSV/GetVulnById',\n request_serializer=osv__service__v1__pb2.GetVulnByIdParameters.SerializeToString,\n response_deserializer=osv_dot_vulnerability__pb2.Vulnerability.FromString,\n )\n self.QueryAffected = channel.unary_unary(\n '/osv.v1.OSV/QueryAffected',\n request_serializer=osv__service__v1__pb2.QueryAffectedParameters.SerializeToString,\n response_deserializer=osv__service__v1__pb2.VulnerabilityList.FromString,\n )\n self.QueryAffectedBatch = channel.unary_unary(\n '/osv.v1.OSV/QueryAffectedBatch',\n request_serializer=osv__service__v1__pb2.QueryAffectedBatchParameters.SerializeToString,\n response_deserializer=osv__service__v1__pb2.BatchVulnerabilityList.FromString,\n )\n\n\nclass OSVServicer(object):\n \"\"\"Open source vulnerability database.\n \"\"\"\n\n def GetVulnById(self, request, context):\n \"\"\"Return a `Vulnerability` object for a given OSV ID.\n \"\"\"\n context.set_code(grpc.StatusCode.UNIMPLEMENTED)\n context.set_details('Method not implemented!')\n raise NotImplementedError('Method not implemented!')\n\n def QueryAffected(self, request, context):\n \"\"\"Query vulnerabilities for a particular project at a given commit or\n version.\n \"\"\"\n context.set_code(grpc.StatusCode.UNIMPLEMENTED)\n context.set_details('Method not implemented!')\n raise NotImplementedError('Method not implemented!')\n\n def QueryAffectedBatch(self, request, context):\n \"\"\"Query vulnerabilities (batched) for given package versions and commits.\n \"\"\"\n context.set_code(grpc.StatusCode.UNIMPLEMENTED)\n context.set_details('Method not implemented!')\n raise NotImplementedError('Method not implemented!')\n\n\ndef add_OSVServicer_to_server(servicer, server):\n rpc_method_handlers = {\n 'GetVulnById': grpc.unary_unary_rpc_method_handler(\n servicer.GetVulnById,\n request_deserializer=osv__service__v1__pb2.GetVulnByIdParameters.FromString,\n response_serializer=osv_dot_vulnerability__pb2.Vulnerability.SerializeToString,\n ),\n 'QueryAffected': grpc.unary_unary_rpc_method_handler(\n servicer.QueryAffected,\n request_deserializer=osv__service__v1__pb2.QueryAffectedParameters.FromString,\n response_serializer=osv__service__v1__pb2.VulnerabilityList.SerializeToString,\n ),\n 'QueryAffectedBatch': grpc.unary_unary_rpc_method_handler(\n servicer.QueryAffectedBatch,\n request_deserializer=osv__service__v1__pb2.QueryAffectedBatchParameters.FromString,\n response_serializer=osv__service__v1__pb2.BatchVulnerabilityList.SerializeToString,\n ),\n }\n generic_handler = grpc.method_handlers_generic_handler(\n 'osv.v1.OSV', rpc_method_handlers)\n server.add_generic_rpc_handlers((generic_handler,))\n\n\n # This class is part of an EXPERIMENTAL API.\nclass OSV(object):\n \"\"\"Open source vulnerability database.\n \"\"\"\n\n @staticmethod\n def GetVulnById(request,\n target,\n options=(),\n channel_credentials=None,\n call_credentials=None,\n insecure=False,\n compression=None,\n wait_for_ready=None,\n timeout=None,\n metadata=None):\n return grpc.experimental.unary_unary(request, target, '/osv.v1.OSV/GetVulnById',\n osv__service__v1__pb2.GetVulnByIdParameters.SerializeToString,\n osv_dot_vulnerability__pb2.Vulnerability.FromString,\n options, channel_credentials,\n insecure, call_credentials, compression, wait_for_ready, timeout, metadata)\n\n @staticmethod\n def QueryAffected(request,\n target,\n options=(),\n channel_credentials=None,\n call_credentials=None,\n insecure=False,\n compression=None,\n wait_for_ready=None,\n timeout=None,\n metadata=None):\n return grpc.experimental.unary_unary(request, target, '/osv.v1.OSV/QueryAffected',\n osv__service__v1__pb2.QueryAffectedParameters.SerializeToString,\n osv__service__v1__pb2.VulnerabilityList.FromString,\n options, channel_credentials,\n insecure, call_credentials, compression, wait_for_ready, timeout, metadata)\n\n @staticmethod\n def QueryAffectedBatch(request,\n target,\n options=(),\n channel_credentials=None,\n call_credentials=None,\n insecure=False,\n compression=None,\n wait_for_ready=None,\n timeout=None,\n metadata=None):\n return grpc.experimental.unary_unary(request, target, '/osv.v1.OSV/QueryAffectedBatch',\n osv__service__v1__pb2.QueryAffectedBatchParameters.SerializeToString,\n osv__service__v1__pb2.BatchVulnerabilityList.FromString,\n options, channel_credentials,\n insecure, call_credentials, compression, wait_for_ready, timeout, metadata)\n", "path": "gcp/api/osv_service_v1_pb2_grpc.py"}]}
| 3,266 | 677 |
gh_patches_debug_10980
|
rasdani/github-patches
|
git_diff
|
rucio__rucio-1478
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
readthedocs build fails due to pycurl
Motivation
----------
Currently the build process on readthedocs fails.
```
Collecting pycurl>=7.19 (from fts3-rest-API==3.7.1->-r requirements.readthedocs.txt (line 44))
Using cached https://files.pythonhosted.org/packages/e8/e4/0dbb8735407189f00b33d84122b9be52c790c7c3b25286826f4e1bdb7bde/pycurl-7.43.0.2.tar.gz
Complete output from command python setup.py egg_info:
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/tmp/pip-build-jSh8ZH/pycurl/setup.py", line 913, in <module>
ext = get_extension(sys.argv, split_extension_source=split_extension_source)
File "/tmp/pip-build-jSh8ZH/pycurl/setup.py", line 582, in get_extension
ext_config = ExtensionConfiguration(argv)
File "/tmp/pip-build-jSh8ZH/pycurl/setup.py", line 99, in __init__
self.configure()
File "/tmp/pip-build-jSh8ZH/pycurl/setup.py", line 227, in configure_unix
raise ConfigurationError(msg)
__main__.ConfigurationError: Could not run curl-config: [Errno 2] No such file or directory
----------------------------------------
Command "python setup.py egg_info" failed with error code 1 in /tmp/pip-build-jSh8ZH/pycurl/
You are using pip version 9.0.1, however version 18.0 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `doc/source/conf.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 #
3 # Rucio documentation build configuration file, created by
4 # sphinx-quickstart on Fri Oct 27 14:25:40 2017.
5 #
6 # This file is execfile()d with the current directory set to its
7 # containing dir.
8 #
9 # Note that not all possible configuration values are present in this
10 # autogenerated file.
11 #
12 # All configuration values have a default; values that are commented out
13 # serve to show the default.
14
15 # If extensions (or modules to document with autodoc) are in another directory,
16 # add these directories to sys.path here. If the directory is relative to the
17 # documentation root, use os.path.abspath to make it absolute, like shown here.
18 #
19 import os
20 import sys
21 # sys.path.insert(0, os.path.abspath('.'))
22
23 from mock import Mock as MagicMock
24
25
26 class Mock(MagicMock):
27 @classmethod
28 def __getattr__(cls, name):
29 return Mock()
30
31 @classmethod
32 def __getitem__(cls, name):
33 return Mock()
34
35
36 MOCK_MODULES = ['pycurl']
37 sys.modules.update((mod_name, Mock()) for mod_name in MOCK_MODULES)
38
39 # -- General configuration ------------------------------------------------
40
41 # If your documentation needs a minimal Sphinx version, state it here.
42 #
43 # needs_sphinx = '1.0'
44
45 # Add any Sphinx extension module names here, as strings. They can be
46 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
47 # ones.
48 extensions = ['sphinx.ext.autodoc',
49 'sphinx.ext.doctest',
50 'sphinx.ext.todo',
51 'rucio.common.doc.argparse.ext',
52 'sphinxcontrib.httpdomain',
53 'sphinxcontrib.autohttp.flask',
54 'sphinxcontrib.autohttp.flaskqref']
55
56
57 on_rtd = os.environ.get('READTHEDOCS', None) == 'True'
58
59 if not on_rtd: # only import and set the theme if we're building docs locally
60 import sphinx_rtd_theme
61 html_theme = 'sphinx_rtd_theme'
62 html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]
63
64
65 # Add any paths that contain templates here, relative to this directory.
66 templates_path = ['_templates']
67
68 # The suffix(es) of source filenames.
69 # You can specify multiple suffix as a list of string:
70 #
71 # source_suffix = ['.rst', '.md']
72 source_suffix = '.rst'
73
74 # The master toctree document.
75 master_doc = 'index'
76
77 # General information about the project.
78 project = u'Rucio'
79 copyright = u'2012-2018 CERN for the benefit of the ATLAS collaboration'
80 author = u'[email protected]'
81
82 # The version info for the project you're documenting, acts as replacement for
83 # |version| and |release|, also used in various other places throughout the
84 # built documents.
85 #
86 # The short X.Y version.
87 version = u''
88 # The full version, including alpha/beta/rc tags.
89 release = u'1.2'
90
91 # The language for content autogenerated by Sphinx. Refer to documentation
92 # for a list of supported languages.
93 #
94 # This is also used if you do content translation via gettext catalogs.
95 # Usually you set "language" from the command line for these cases.
96 language = None
97
98 # List of patterns, relative to source directory, that match files and
99 # directories to ignore when looking for source files.
100 # This patterns also effect to html_static_path and html_extra_path
101 exclude_patterns = []
102
103 # The name of the Pygments (syntax highlighting) style to use.
104 pygments_style = 'sphinx'
105
106 # If true, `todo` and `todoList` produce output, else they produce nothing.
107 todo_include_todos = True
108
109
110 # -- Options for HTML output ----------------------------------------------
111
112 # The theme to use for HTML and HTML Help pages. See the documentation for
113 # a list of builtin themes.
114 #
115 # html_theme = 'alabaster'
116
117 # Theme options are theme-specific and customize the look and feel of a theme
118 # further. For a list of options available for each theme, see the
119 # documentation.
120 #
121 # html_theme_options = {}
122
123 # Add any paths that contain custom static files (such as style sheets) here,
124 # relative to this directory. They are copied after the builtin static files,
125 # so a file named "default.css" will overwrite the builtin "default.css".
126 # html_static_path = ['_static']
127
128 # Custom sidebar templates, must be a dictionary that maps document names
129 # to template names.
130 #
131 # This is required for the alabaster theme
132 # refs: http://alabaster.readthedocs.io/en/latest/installation.html#sidebars
133 # html_sidebars = {
134 # '**': [
135 # 'about.html',
136 # 'navigation.html',
137 # 'relations.html', # needs 'show_related': True theme option to display
138 # 'searchbox.html',
139 # 'donate.html',
140 # ]
141 # }
142
143
144 # -- Options for HTMLHelp output ------------------------------------------
145
146 # Output file base name for HTML help builder.
147 htmlhelp_basename = 'Ruciodoc'
148
149
150 # -- Options for LaTeX output ---------------------------------------------
151
152 latex_elements = {
153 # The paper size ('letterpaper' or 'a4paper').
154 #
155 # 'papersize': 'letterpaper',
156
157 # The font size ('10pt', '11pt' or '12pt').
158 #
159 # 'pointsize': '10pt',
160
161 # Additional stuff for the LaTeX preamble.
162 #
163 # 'preamble': '',
164
165 # Latex figure (float) alignment
166 #
167 # 'figure_align': 'htbp',
168 }
169
170 # Grouping the document tree into LaTeX files. List of tuples
171 # (source start file, target name, title,
172 # author, documentclass [howto, manual, or own class]).
173 latex_documents = [
174 (master_doc, 'Rucio.tex', u'Rucio Documentation',
175 u'[email protected]', 'manual'),
176 ]
177
178
179 # -- Options for manual page output ---------------------------------------
180
181 # One entry per manual page. List of tuples
182 # (source start file, name, description, authors, manual section).
183 man_pages = [
184 (master_doc, 'rucio', u'Rucio Documentation',
185 [author], 1)
186 ]
187
188
189 # -- Options for Texinfo output -------------------------------------------
190
191 # Grouping the document tree into Texinfo files. List of tuples
192 # (source start file, target name, title, author,
193 # dir menu entry, description, category)
194 texinfo_documents = [
195 (master_doc, 'Rucio', u'Rucio Documentation',
196 author, 'Rucio', 'One line description of project.',
197 'Miscellaneous'),
198 ]
199
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/doc/source/conf.py b/doc/source/conf.py
--- a/doc/source/conf.py
+++ b/doc/source/conf.py
@@ -17,9 +17,24 @@
# documentation root, use os.path.abspath to make it absolute, like shown here.
#
import os
-# import sys
+import sys
# sys.path.insert(0, os.path.abspath('.'))
+from mock import Mock as MagicMock
+
+
+class Mock(MagicMock):
+ @classmethod
+ def __getattr__(cls, name):
+ return Mock()
+
+ @classmethod
+ def __getitem__(cls, name):
+ return Mock()
+
+
+MOCK_MODULES = ['pycurl', 'M2Crypto']
+sys.modules.update((mod_name, Mock()) for mod_name in MOCK_MODULES)
# -- General configuration ------------------------------------------------
|
{"golden_diff": "diff --git a/doc/source/conf.py b/doc/source/conf.py\n--- a/doc/source/conf.py\n+++ b/doc/source/conf.py\n@@ -17,9 +17,24 @@\n # documentation root, use os.path.abspath to make it absolute, like shown here.\n #\n import os\n-# import sys\n+import sys\n # sys.path.insert(0, os.path.abspath('.'))\n \n+from mock import Mock as MagicMock\n+\n+\n+class Mock(MagicMock):\n+ @classmethod\n+ def __getattr__(cls, name):\n+ return Mock()\n+\n+ @classmethod\n+ def __getitem__(cls, name):\n+ return Mock()\n+\n+\n+MOCK_MODULES = ['pycurl', 'M2Crypto']\n+sys.modules.update((mod_name, Mock()) for mod_name in MOCK_MODULES)\n \n # -- General configuration ------------------------------------------------\n", "issue": "readthedocs build fails due to pycurl\nMotivation\r\n----------\r\nCurrently the build process on readthedocs fails.\r\n\r\n```\r\nCollecting pycurl>=7.19 (from fts3-rest-API==3.7.1->-r requirements.readthedocs.txt (line 44))\r\n Using cached https://files.pythonhosted.org/packages/e8/e4/0dbb8735407189f00b33d84122b9be52c790c7c3b25286826f4e1bdb7bde/pycurl-7.43.0.2.tar.gz\r\n Complete output from command python setup.py egg_info:\r\n Traceback (most recent call last):\r\n File \"<string>\", line 1, in <module>\r\n File \"/tmp/pip-build-jSh8ZH/pycurl/setup.py\", line 913, in <module>\r\n ext = get_extension(sys.argv, split_extension_source=split_extension_source)\r\n File \"/tmp/pip-build-jSh8ZH/pycurl/setup.py\", line 582, in get_extension\r\n ext_config = ExtensionConfiguration(argv)\r\n File \"/tmp/pip-build-jSh8ZH/pycurl/setup.py\", line 99, in __init__\r\n self.configure()\r\n File \"/tmp/pip-build-jSh8ZH/pycurl/setup.py\", line 227, in configure_unix\r\n raise ConfigurationError(msg)\r\n __main__.ConfigurationError: Could not run curl-config: [Errno 2] No such file or directory\r\n \r\n ----------------------------------------\r\nCommand \"python setup.py egg_info\" failed with error code 1 in /tmp/pip-build-jSh8ZH/pycurl/\r\nYou are using pip version 9.0.1, however version 18.0 is available.\r\nYou should consider upgrading via the 'pip install --upgrade pip' command.\r\n```\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Rucio documentation build configuration file, created by\n# sphinx-quickstart on Fri Oct 27 14:25:40 2017.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\nimport os\nimport sys\n# sys.path.insert(0, os.path.abspath('.'))\n\nfrom mock import Mock as MagicMock\n\n\nclass Mock(MagicMock):\n @classmethod\n def __getattr__(cls, name):\n return Mock()\n\n @classmethod\n def __getitem__(cls, name):\n return Mock()\n\n\nMOCK_MODULES = ['pycurl']\nsys.modules.update((mod_name, Mock()) for mod_name in MOCK_MODULES)\n\n# -- General configuration ------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\n# needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = ['sphinx.ext.autodoc',\n 'sphinx.ext.doctest',\n 'sphinx.ext.todo',\n 'rucio.common.doc.argparse.ext',\n 'sphinxcontrib.httpdomain',\n 'sphinxcontrib.autohttp.flask',\n 'sphinxcontrib.autohttp.flaskqref']\n\n\non_rtd = os.environ.get('READTHEDOCS', None) == 'True'\n\nif not on_rtd: # only import and set the theme if we're building docs locally\n import sphinx_rtd_theme\n html_theme = 'sphinx_rtd_theme'\n html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]\n\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\n# source_suffix = ['.rst', '.md']\nsource_suffix = '.rst'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = u'Rucio'\ncopyright = u'2012-2018 CERN for the benefit of the ATLAS collaboration'\nauthor = u'[email protected]'\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = u''\n# The full version, including alpha/beta/rc tags.\nrelease = u'1.2'\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = None\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This patterns also effect to html_static_path and html_extra_path\nexclude_patterns = []\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = True\n\n\n# -- Options for HTML output ----------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\n# html_theme = 'alabaster'\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#\n# html_theme_options = {}\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\n# html_static_path = ['_static']\n\n# Custom sidebar templates, must be a dictionary that maps document names\n# to template names.\n#\n# This is required for the alabaster theme\n# refs: http://alabaster.readthedocs.io/en/latest/installation.html#sidebars\n# html_sidebars = {\n# '**': [\n# 'about.html',\n# 'navigation.html',\n# 'relations.html', # needs 'show_related': True theme option to display\n# 'searchbox.html',\n# 'donate.html',\n# ]\n# }\n\n\n# -- Options for HTMLHelp output ------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'Ruciodoc'\n\n\n# -- Options for LaTeX output ---------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n #\n # 'papersize': 'letterpaper',\n\n # The font size ('10pt', '11pt' or '12pt').\n #\n # 'pointsize': '10pt',\n\n # Additional stuff for the LaTeX preamble.\n #\n # 'preamble': '',\n\n # Latex figure (float) alignment\n #\n # 'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (master_doc, 'Rucio.tex', u'Rucio Documentation',\n u'[email protected]', 'manual'),\n]\n\n\n# -- Options for manual page output ---------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n (master_doc, 'rucio', u'Rucio Documentation',\n [author], 1)\n]\n\n\n# -- Options for Texinfo output -------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (master_doc, 'Rucio', u'Rucio Documentation',\n author, 'Rucio', 'One line description of project.',\n 'Miscellaneous'),\n]\n", "path": "doc/source/conf.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Rucio documentation build configuration file, created by\n# sphinx-quickstart on Fri Oct 27 14:25:40 2017.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\nimport os\nimport sys\n# sys.path.insert(0, os.path.abspath('.'))\n\nfrom mock import Mock as MagicMock\n\n\nclass Mock(MagicMock):\n @classmethod\n def __getattr__(cls, name):\n return Mock()\n\n @classmethod\n def __getitem__(cls, name):\n return Mock()\n\n\nMOCK_MODULES = ['pycurl', 'M2Crypto']\nsys.modules.update((mod_name, Mock()) for mod_name in MOCK_MODULES)\n\n# -- General configuration ------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\n# needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = ['sphinx.ext.autodoc',\n 'sphinx.ext.doctest',\n 'sphinx.ext.todo',\n 'rucio.common.doc.argparse.ext',\n 'sphinxcontrib.httpdomain',\n 'sphinxcontrib.autohttp.flask',\n 'sphinxcontrib.autohttp.flaskqref']\n\n\non_rtd = os.environ.get('READTHEDOCS', None) == 'True'\n\nif not on_rtd: # only import and set the theme if we're building docs locally\n import sphinx_rtd_theme\n html_theme = 'sphinx_rtd_theme'\n html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]\n\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\n# source_suffix = ['.rst', '.md']\nsource_suffix = '.rst'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = u'Rucio'\ncopyright = u'2012-2018 CERN for the benefit of the ATLAS collaboration'\nauthor = u'[email protected]'\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = u''\n# The full version, including alpha/beta/rc tags.\nrelease = u'1.2'\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = None\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This patterns also effect to html_static_path and html_extra_path\nexclude_patterns = []\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = True\n\n\n# -- Options for HTML output ----------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\n# html_theme = 'alabaster'\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#\n# html_theme_options = {}\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\n# html_static_path = ['_static']\n\n# Custom sidebar templates, must be a dictionary that maps document names\n# to template names.\n#\n# This is required for the alabaster theme\n# refs: http://alabaster.readthedocs.io/en/latest/installation.html#sidebars\n# html_sidebars = {\n# '**': [\n# 'about.html',\n# 'navigation.html',\n# 'relations.html', # needs 'show_related': True theme option to display\n# 'searchbox.html',\n# 'donate.html',\n# ]\n# }\n\n\n# -- Options for HTMLHelp output ------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'Ruciodoc'\n\n\n# -- Options for LaTeX output ---------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n #\n # 'papersize': 'letterpaper',\n\n # The font size ('10pt', '11pt' or '12pt').\n #\n # 'pointsize': '10pt',\n\n # Additional stuff for the LaTeX preamble.\n #\n # 'preamble': '',\n\n # Latex figure (float) alignment\n #\n # 'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (master_doc, 'Rucio.tex', u'Rucio Documentation',\n u'[email protected]', 'manual'),\n]\n\n\n# -- Options for manual page output ---------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n (master_doc, 'rucio', u'Rucio Documentation',\n [author], 1)\n]\n\n\n# -- Options for Texinfo output -------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (master_doc, 'Rucio', u'Rucio Documentation',\n author, 'Rucio', 'One line description of project.',\n 'Miscellaneous'),\n]\n", "path": "doc/source/conf.py"}]}
| 2,632 | 182 |
gh_patches_debug_39416
|
rasdani/github-patches
|
git_diff
|
buildbot__buildbot-244
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Don't subclass ThreadPool.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `master/contrib/googlecode_atom.py`
Content:
```
1 # GoogleCode Atom Feed Poller
2 # Author: Srivats P. <pstavirs>
3 # Based on Mozilla's HgPoller
4 # http://bonsai.mozilla.org/cvsblame.cgi?file=/mozilla/tools/buildbot/buildbot/changes/Attic/hgpoller.py&revision=1.1.4.2
5 #
6 # Description:
7 # Use this ChangeSource for projects hosted on http://code.google.com/
8 #
9 # This ChangeSource uses the project's commit Atom feed. Depending upon the
10 # frequency of commits, you can tune the polling interval for the feed
11 # (default is 1 hour)
12 #
13 # Parameters:
14 # feedurl (MANDATORY): The Atom feed URL of the GoogleCode repo
15 # pollinterval (OPTIONAL): Polling frequency for the feed (in seconds)
16 #
17 # Example:
18 # To poll the Ostinato project's commit feed every 3 hours, use -
19 # from googlecode_atom import GoogleCodeAtomPoller
20 # poller = GoogleCodeAtomPoller(
21 # feedurl="http://code.google.com/feeds/p/ostinato/hgchanges/basic",
22 # pollinterval=10800)
23 # c['change_source'] = [ poller ]
24 #
25
26 from time import strptime
27 from calendar import timegm
28 from xml.dom import minidom, Node
29
30 from twisted.python import log, failure
31 from twisted.internet import defer, reactor
32 from twisted.internet.task import LoopingCall
33 from twisted.web.client import getPage
34
35 from buildbot.changes import base, changes
36
37 def googleCodePollerForProject(project, vcs, pollinterval=3600):
38 return GoogleCodeAtomPoller(
39 'http://code.google.com/feeds/p/%s/%schanges/basic' % (project, vcs),
40 pollinterval=pollinterval)
41
42
43 class GoogleCodeAtomPoller(base.ChangeSource):
44 """This source will poll a GoogleCode Atom feed for changes and
45 submit them to the change master. Works for both Svn, Git, and Hg
46 repos.
47 TODO: branch processing
48 """
49
50 compare_attrs = ['feedurl', 'pollinterval']
51 parent = None
52 loop = None
53 volatile = ['loop']
54 working = False
55
56 def __init__(self, feedurl, pollinterval=3600):
57 """
58 @type feedurl: string
59 @param feedurl: The Atom feed URL of the GoogleCode repo
60 (e.g. http://code.google.com/feeds/p/ostinato/hgchanges/basic)
61
62 @type pollinterval: int
63 @param pollinterval: The time (in seconds) between queries for
64 changes (default is 1 hour)
65 """
66
67 self.feedurl = feedurl
68 self.branch = None
69 self.pollinterval = pollinterval
70 self.lastChange = None
71 self.loop = LoopingCall(self.poll)
72 self.src = None
73 for word in self.feedurl.split('/'):
74 if word == 'svnchanges':
75 self.src = 'svn'
76 break
77 elif word == 'hgchanges':
78 self.src = 'hg'
79 break
80 elif word == 'gitchanges':
81 self.src = 'git'
82 break
83
84 def startService(self):
85 log.msg("GoogleCodeAtomPoller starting")
86 base.ChangeSource.startService(self)
87 reactor.callLater(0, self.loop.start, self.pollinterval)
88
89 def stopService(self):
90 log.msg("GoogleCodeAtomPoller stoppping")
91 self.loop.stop()
92 return base.ChangeSource.stopService(self)
93
94 def describe(self):
95 return ("Getting changes from the GoogleCode repo changes feed %s" %
96 self._make_url())
97
98 def poll(self):
99 if self.working:
100 log.msg("Not polling because last poll is still working")
101 else:
102 self.working = True
103 d = self._get_changes()
104 d.addCallback(self._process_changes)
105 d.addCallbacks(self._finished_ok, self._finished_failure)
106
107 def _finished_ok(self, res):
108 assert self.working
109 self.working = False
110 log.msg("GoogleCodeAtomPoller poll success")
111
112 return res
113
114 def _finished_failure(self, res):
115 log.msg("GoogleCodeAtomPoller poll failed: %s" % res)
116 assert self.working
117 self.working = False
118 return None
119
120 def _make_url(self):
121 return "%s" % (self.feedurl)
122
123 def _get_changes(self):
124 url = self._make_url()
125 log.msg("GoogleCodeAtomPoller polling %s" % url)
126
127 return getPage(url, timeout=self.pollinterval)
128
129 def _parse_changes(self, query):
130 dom = minidom.parseString(query)
131 entries = dom.getElementsByTagName("entry")
132 changes = []
133 # Entries come in reverse chronological order
134 for i in entries:
135 d = {}
136
137 # revision is the last part of the 'id' url
138 d["revision"] = i.getElementsByTagName(
139 "id")[0].firstChild.data.split('/')[-1]
140 if d["revision"] == self.lastChange:
141 break # no more new changes
142
143 d["when"] = timegm(strptime(
144 i.getElementsByTagName("updated")[0].firstChild.data,
145 "%Y-%m-%dT%H:%M:%SZ"))
146 d["author"] = i.getElementsByTagName(
147 "author")[0].getElementsByTagName("name")[0].firstChild.data
148 # files and commit msg are separated by 2 consecutive <br/>
149 content = i.getElementsByTagName(
150 "content")[0].firstChild.data.split("<br/>\n <br/>")
151 # Remove the action keywords from the file list
152 fl = content[0].replace(
153 u' \xa0\xa0\xa0\xa0Add\xa0\xa0\xa0\xa0', '').replace(
154 u' \xa0\xa0\xa0\xa0Delete\xa0\xa0\xa0\xa0', '').replace(
155 u' \xa0\xa0\xa0\xa0Modify\xa0\xa0\xa0\xa0', '')
156 # Get individual files and remove the 'header'
157 d["files"] = fl.encode("ascii", "replace").split("<br/>")[1:]
158 d["files"] = [f.strip() for f in d["files"]]
159 try:
160 d["comments"] = content[1].encode("ascii", "replace")
161 except:
162 d["comments"] = "No commit message provided"
163
164 changes.append(d)
165
166 changes.reverse() # want them in chronological order
167 return changes
168
169 def _process_changes(self, query):
170 change_list = self._parse_changes(query)
171
172 # Skip calling addChange() if this is the first successful poll.
173 if self.lastChange is not None:
174 for change in change_list:
175 c = changes.Change(revision = change["revision"],
176 who = change["author"],
177 files = change["files"],
178 comments = change["comments"],
179 when = change["when"],
180 branch = self.branch)
181 self.parent.addChange(c, src=self.src)
182 if change_list:
183 self.lastChange = change_list[-1]["revision"]
184
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/master/contrib/googlecode_atom.py b/master/contrib/googlecode_atom.py
--- a/master/contrib/googlecode_atom.py
+++ b/master/contrib/googlecode_atom.py
@@ -23,8 +23,7 @@
# c['change_source'] = [ poller ]
#
-from time import strptime
-from calendar import timegm
+import datetime
from xml.dom import minidom, Node
from twisted.python import log, failure
@@ -32,7 +31,8 @@
from twisted.internet.task import LoopingCall
from twisted.web.client import getPage
-from buildbot.changes import base, changes
+from buildbot.changes import base
+
def googleCodePollerForProject(project, vcs, pollinterval=3600):
return GoogleCodeAtomPoller(
@@ -140,9 +140,9 @@
if d["revision"] == self.lastChange:
break # no more new changes
- d["when"] = timegm(strptime(
+ d["when"] = datetime.datetime.strptime(
i.getElementsByTagName("updated")[0].firstChild.data,
- "%Y-%m-%dT%H:%M:%SZ"))
+ "%Y-%m-%dT%H:%M:%SZ")
d["author"] = i.getElementsByTagName(
"author")[0].getElementsByTagName("name")[0].firstChild.data
# files and commit msg are separated by 2 consecutive <br/>
@@ -166,18 +166,22 @@
changes.reverse() # want them in chronological order
return changes
+ @defer.deferredGenerator
def _process_changes(self, query):
change_list = self._parse_changes(query)
# Skip calling addChange() if this is the first successful poll.
if self.lastChange is not None:
for change in change_list:
- c = changes.Change(revision = change["revision"],
- who = change["author"],
- files = change["files"],
- comments = change["comments"],
- when = change["when"],
- branch = self.branch)
- self.parent.addChange(c, src=self.src)
+ d = self.master.addChange(author=change["author"],
+ revision=change["revision"],
+ files=change["files"],
+ comments=change["comments"],
+ when_timestamp=change["when"],
+ branch=self.branch,
+ src=self.src)
+ wfd = defer.waitForDeferred(d)
+ yield wfd
+ results = wfd.getResult()
if change_list:
self.lastChange = change_list[-1]["revision"]
|
{"golden_diff": "diff --git a/master/contrib/googlecode_atom.py b/master/contrib/googlecode_atom.py\n--- a/master/contrib/googlecode_atom.py\n+++ b/master/contrib/googlecode_atom.py\n@@ -23,8 +23,7 @@\n # c['change_source'] = [ poller ]\n #\n \n-from time import strptime\n-from calendar import timegm\n+import datetime\n from xml.dom import minidom, Node\n \n from twisted.python import log, failure\n@@ -32,7 +31,8 @@\n from twisted.internet.task import LoopingCall\n from twisted.web.client import getPage\n \n-from buildbot.changes import base, changes\n+from buildbot.changes import base\n+\n \n def googleCodePollerForProject(project, vcs, pollinterval=3600):\n return GoogleCodeAtomPoller(\n@@ -140,9 +140,9 @@\n if d[\"revision\"] == self.lastChange:\n break # no more new changes\n \n- d[\"when\"] = timegm(strptime(\n+ d[\"when\"] = datetime.datetime.strptime(\n i.getElementsByTagName(\"updated\")[0].firstChild.data,\n- \"%Y-%m-%dT%H:%M:%SZ\"))\n+ \"%Y-%m-%dT%H:%M:%SZ\")\n d[\"author\"] = i.getElementsByTagName(\n \"author\")[0].getElementsByTagName(\"name\")[0].firstChild.data\n # files and commit msg are separated by 2 consecutive <br/>\n@@ -166,18 +166,22 @@\n changes.reverse() # want them in chronological order\n return changes\n \n+ @defer.deferredGenerator\n def _process_changes(self, query):\n change_list = self._parse_changes(query)\n \n # Skip calling addChange() if this is the first successful poll.\n if self.lastChange is not None:\n for change in change_list:\n- c = changes.Change(revision = change[\"revision\"],\n- who = change[\"author\"],\n- files = change[\"files\"],\n- comments = change[\"comments\"],\n- when = change[\"when\"],\n- branch = self.branch)\n- self.parent.addChange(c, src=self.src)\n+ d = self.master.addChange(author=change[\"author\"],\n+ revision=change[\"revision\"],\n+ files=change[\"files\"],\n+ comments=change[\"comments\"],\n+ when_timestamp=change[\"when\"],\n+ branch=self.branch,\n+ src=self.src)\n+ wfd = defer.waitForDeferred(d)\n+ yield wfd\n+ results = wfd.getResult()\n if change_list:\n self.lastChange = change_list[-1][\"revision\"]\n", "issue": "Don't subclass ThreadPool.\n\n", "before_files": [{"content": "# GoogleCode Atom Feed Poller\n# Author: Srivats P. <pstavirs>\n# Based on Mozilla's HgPoller\n# http://bonsai.mozilla.org/cvsblame.cgi?file=/mozilla/tools/buildbot/buildbot/changes/Attic/hgpoller.py&revision=1.1.4.2\n#\n# Description:\n# Use this ChangeSource for projects hosted on http://code.google.com/\n#\n# This ChangeSource uses the project's commit Atom feed. Depending upon the\n# frequency of commits, you can tune the polling interval for the feed\n# (default is 1 hour)\n#\n# Parameters:\n# feedurl (MANDATORY): The Atom feed URL of the GoogleCode repo\n# pollinterval (OPTIONAL): Polling frequency for the feed (in seconds)\n#\n# Example:\n# To poll the Ostinato project's commit feed every 3 hours, use -\n# from googlecode_atom import GoogleCodeAtomPoller\n# poller = GoogleCodeAtomPoller(\n# feedurl=\"http://code.google.com/feeds/p/ostinato/hgchanges/basic\",\n# pollinterval=10800)\n# c['change_source'] = [ poller ]\n#\n\nfrom time import strptime\nfrom calendar import timegm\nfrom xml.dom import minidom, Node\n\nfrom twisted.python import log, failure\nfrom twisted.internet import defer, reactor\nfrom twisted.internet.task import LoopingCall\nfrom twisted.web.client import getPage\n\nfrom buildbot.changes import base, changes\n\ndef googleCodePollerForProject(project, vcs, pollinterval=3600):\n return GoogleCodeAtomPoller(\n 'http://code.google.com/feeds/p/%s/%schanges/basic' % (project, vcs),\n pollinterval=pollinterval)\n\n\nclass GoogleCodeAtomPoller(base.ChangeSource):\n \"\"\"This source will poll a GoogleCode Atom feed for changes and\n submit them to the change master. Works for both Svn, Git, and Hg\n repos.\n TODO: branch processing\n \"\"\"\n\n compare_attrs = ['feedurl', 'pollinterval']\n parent = None\n loop = None\n volatile = ['loop']\n working = False\n\n def __init__(self, feedurl, pollinterval=3600):\n \"\"\"\n @type feedurl: string\n @param feedurl: The Atom feed URL of the GoogleCode repo\n (e.g. http://code.google.com/feeds/p/ostinato/hgchanges/basic)\n\n @type pollinterval: int\n @param pollinterval: The time (in seconds) between queries for\n changes (default is 1 hour)\n \"\"\"\n\n self.feedurl = feedurl\n self.branch = None\n self.pollinterval = pollinterval\n self.lastChange = None\n self.loop = LoopingCall(self.poll)\n self.src = None\n for word in self.feedurl.split('/'):\n if word == 'svnchanges':\n self.src = 'svn'\n break\n elif word == 'hgchanges':\n self.src = 'hg'\n break\n elif word == 'gitchanges':\n self.src = 'git'\n break\n\n def startService(self):\n log.msg(\"GoogleCodeAtomPoller starting\")\n base.ChangeSource.startService(self)\n reactor.callLater(0, self.loop.start, self.pollinterval)\n\n def stopService(self):\n log.msg(\"GoogleCodeAtomPoller stoppping\")\n self.loop.stop()\n return base.ChangeSource.stopService(self)\n\n def describe(self):\n return (\"Getting changes from the GoogleCode repo changes feed %s\" %\n self._make_url())\n\n def poll(self):\n if self.working:\n log.msg(\"Not polling because last poll is still working\")\n else:\n self.working = True\n d = self._get_changes()\n d.addCallback(self._process_changes)\n d.addCallbacks(self._finished_ok, self._finished_failure)\n\n def _finished_ok(self, res):\n assert self.working\n self.working = False\n log.msg(\"GoogleCodeAtomPoller poll success\")\n\n return res\n\n def _finished_failure(self, res):\n log.msg(\"GoogleCodeAtomPoller poll failed: %s\" % res)\n assert self.working\n self.working = False\n return None\n\n def _make_url(self):\n return \"%s\" % (self.feedurl)\n\n def _get_changes(self):\n url = self._make_url()\n log.msg(\"GoogleCodeAtomPoller polling %s\" % url)\n\n return getPage(url, timeout=self.pollinterval)\n\n def _parse_changes(self, query):\n dom = minidom.parseString(query)\n entries = dom.getElementsByTagName(\"entry\")\n changes = []\n # Entries come in reverse chronological order\n for i in entries:\n d = {}\n\n # revision is the last part of the 'id' url\n d[\"revision\"] = i.getElementsByTagName(\n \"id\")[0].firstChild.data.split('/')[-1]\n if d[\"revision\"] == self.lastChange:\n break # no more new changes\n\n d[\"when\"] = timegm(strptime(\n i.getElementsByTagName(\"updated\")[0].firstChild.data,\n \"%Y-%m-%dT%H:%M:%SZ\"))\n d[\"author\"] = i.getElementsByTagName(\n \"author\")[0].getElementsByTagName(\"name\")[0].firstChild.data\n # files and commit msg are separated by 2 consecutive <br/>\n content = i.getElementsByTagName(\n \"content\")[0].firstChild.data.split(\"<br/>\\n <br/>\")\n # Remove the action keywords from the file list\n fl = content[0].replace(\n u' \\xa0\\xa0\\xa0\\xa0Add\\xa0\\xa0\\xa0\\xa0', '').replace(\n u' \\xa0\\xa0\\xa0\\xa0Delete\\xa0\\xa0\\xa0\\xa0', '').replace(\n u' \\xa0\\xa0\\xa0\\xa0Modify\\xa0\\xa0\\xa0\\xa0', '')\n # Get individual files and remove the 'header'\n d[\"files\"] = fl.encode(\"ascii\", \"replace\").split(\"<br/>\")[1:]\n d[\"files\"] = [f.strip() for f in d[\"files\"]]\n try:\n d[\"comments\"] = content[1].encode(\"ascii\", \"replace\")\n except:\n d[\"comments\"] = \"No commit message provided\"\n\n changes.append(d)\n\n changes.reverse() # want them in chronological order\n return changes\n\n def _process_changes(self, query):\n change_list = self._parse_changes(query)\n\n # Skip calling addChange() if this is the first successful poll.\n if self.lastChange is not None:\n for change in change_list:\n c = changes.Change(revision = change[\"revision\"],\n who = change[\"author\"],\n files = change[\"files\"],\n comments = change[\"comments\"],\n when = change[\"when\"],\n branch = self.branch)\n self.parent.addChange(c, src=self.src)\n if change_list:\n self.lastChange = change_list[-1][\"revision\"]\n", "path": "master/contrib/googlecode_atom.py"}], "after_files": [{"content": "# GoogleCode Atom Feed Poller\n# Author: Srivats P. <pstavirs>\n# Based on Mozilla's HgPoller\n# http://bonsai.mozilla.org/cvsblame.cgi?file=/mozilla/tools/buildbot/buildbot/changes/Attic/hgpoller.py&revision=1.1.4.2\n#\n# Description:\n# Use this ChangeSource for projects hosted on http://code.google.com/\n#\n# This ChangeSource uses the project's commit Atom feed. Depending upon the\n# frequency of commits, you can tune the polling interval for the feed\n# (default is 1 hour)\n#\n# Parameters:\n# feedurl (MANDATORY): The Atom feed URL of the GoogleCode repo\n# pollinterval (OPTIONAL): Polling frequency for the feed (in seconds)\n#\n# Example:\n# To poll the Ostinato project's commit feed every 3 hours, use -\n# from googlecode_atom import GoogleCodeAtomPoller\n# poller = GoogleCodeAtomPoller(\n# feedurl=\"http://code.google.com/feeds/p/ostinato/hgchanges/basic\",\n# pollinterval=10800)\n# c['change_source'] = [ poller ]\n#\n\nimport datetime\nfrom xml.dom import minidom, Node\n\nfrom twisted.python import log, failure\nfrom twisted.internet import defer, reactor\nfrom twisted.internet.task import LoopingCall\nfrom twisted.web.client import getPage\n\nfrom buildbot.changes import base\n\n\ndef googleCodePollerForProject(project, vcs, pollinterval=3600):\n return GoogleCodeAtomPoller(\n 'http://code.google.com/feeds/p/%s/%schanges/basic' % (project, vcs),\n pollinterval=pollinterval)\n\n\nclass GoogleCodeAtomPoller(base.ChangeSource):\n \"\"\"This source will poll a GoogleCode Atom feed for changes and\n submit them to the change master. Works for both Svn, Git, and Hg\n repos.\n TODO: branch processing\n \"\"\"\n\n compare_attrs = ['feedurl', 'pollinterval']\n parent = None\n loop = None\n volatile = ['loop']\n working = False\n\n def __init__(self, feedurl, pollinterval=3600):\n \"\"\"\n @type feedurl: string\n @param feedurl: The Atom feed URL of the GoogleCode repo\n (e.g. http://code.google.com/feeds/p/ostinato/hgchanges/basic)\n\n @type pollinterval: int\n @param pollinterval: The time (in seconds) between queries for\n changes (default is 1 hour)\n \"\"\"\n\n self.feedurl = feedurl\n self.branch = None\n self.pollinterval = pollinterval\n self.lastChange = None\n self.loop = LoopingCall(self.poll)\n self.src = None\n for word in self.feedurl.split('/'):\n if word == 'svnchanges':\n self.src = 'svn'\n break\n elif word == 'hgchanges':\n self.src = 'hg'\n break\n elif word == 'gitchanges':\n self.src = 'git'\n break\n\n def startService(self):\n log.msg(\"GoogleCodeAtomPoller starting\")\n base.ChangeSource.startService(self)\n reactor.callLater(0, self.loop.start, self.pollinterval)\n\n def stopService(self):\n log.msg(\"GoogleCodeAtomPoller stoppping\")\n self.loop.stop()\n return base.ChangeSource.stopService(self)\n\n def describe(self):\n return (\"Getting changes from the GoogleCode repo changes feed %s\" %\n self._make_url())\n\n def poll(self):\n if self.working:\n log.msg(\"Not polling because last poll is still working\")\n else:\n self.working = True\n d = self._get_changes()\n d.addCallback(self._process_changes)\n d.addCallbacks(self._finished_ok, self._finished_failure)\n\n def _finished_ok(self, res):\n assert self.working\n self.working = False\n log.msg(\"GoogleCodeAtomPoller poll success\")\n\n return res\n\n def _finished_failure(self, res):\n log.msg(\"GoogleCodeAtomPoller poll failed: %s\" % res)\n assert self.working\n self.working = False\n return None\n\n def _make_url(self):\n return \"%s\" % (self.feedurl)\n\n def _get_changes(self):\n url = self._make_url()\n log.msg(\"GoogleCodeAtomPoller polling %s\" % url)\n\n return getPage(url, timeout=self.pollinterval)\n\n def _parse_changes(self, query):\n dom = minidom.parseString(query)\n entries = dom.getElementsByTagName(\"entry\")\n changes = []\n # Entries come in reverse chronological order\n for i in entries:\n d = {}\n\n # revision is the last part of the 'id' url\n d[\"revision\"] = i.getElementsByTagName(\n \"id\")[0].firstChild.data.split('/')[-1]\n if d[\"revision\"] == self.lastChange:\n break # no more new changes\n\n d[\"when\"] = datetime.datetime.strptime(\n i.getElementsByTagName(\"updated\")[0].firstChild.data,\n \"%Y-%m-%dT%H:%M:%SZ\")\n d[\"author\"] = i.getElementsByTagName(\n \"author\")[0].getElementsByTagName(\"name\")[0].firstChild.data\n # files and commit msg are separated by 2 consecutive <br/>\n content = i.getElementsByTagName(\n \"content\")[0].firstChild.data.split(\"<br/>\\n <br/>\")\n # Remove the action keywords from the file list\n fl = content[0].replace(\n u' \\xa0\\xa0\\xa0\\xa0Add\\xa0\\xa0\\xa0\\xa0', '').replace(\n u' \\xa0\\xa0\\xa0\\xa0Delete\\xa0\\xa0\\xa0\\xa0', '').replace(\n u' \\xa0\\xa0\\xa0\\xa0Modify\\xa0\\xa0\\xa0\\xa0', '')\n # Get individual files and remove the 'header'\n d[\"files\"] = fl.encode(\"ascii\", \"replace\").split(\"<br/>\")[1:]\n d[\"files\"] = [f.strip() for f in d[\"files\"]]\n try:\n d[\"comments\"] = content[1].encode(\"ascii\", \"replace\")\n except:\n d[\"comments\"] = \"No commit message provided\"\n\n changes.append(d)\n\n changes.reverse() # want them in chronological order\n return changes\n\n @defer.deferredGenerator\n def _process_changes(self, query):\n change_list = self._parse_changes(query)\n\n # Skip calling addChange() if this is the first successful poll.\n if self.lastChange is not None:\n for change in change_list:\n d = self.master.addChange(author=change[\"author\"],\n revision=change[\"revision\"],\n files=change[\"files\"],\n comments=change[\"comments\"],\n when_timestamp=change[\"when\"],\n branch=self.branch,\n src=self.src)\n wfd = defer.waitForDeferred(d)\n yield wfd\n results = wfd.getResult()\n if change_list:\n self.lastChange = change_list[-1][\"revision\"]\n", "path": "master/contrib/googlecode_atom.py"}]}
| 2,268 | 568 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.