
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.1k
25.4k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 582
39.1k
| num_tokens
int64 271
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_4028
|
rasdani/github-patches
|
git_diff
|
diofant__diofant-852
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Project logo
There are few places to put images:
- [x] Top left corner of https://diofant.readthedocs.io/ (see e.g. https://sphinx-rtd-theme.readthedocs.io/)
- [x] favicon.ico.
- [x] logo for pdf logs
- [x] Organization profile on the Github (at least 200x200px)
- [x] ~~repository’s social media preview (640×320px - 1280×640px for best display)~~
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/conf.py`
Content:
```
1 #
2 # Diofant documentation build configuration file.
3 #
4 # This file is execfile()d with the current directory set to its
5 # containing dir.
6 #
7 # The contents of this file are pickled, so don't put values in the
8 # namespace that aren't pickleable (module imports are okay, they're
9 # removed automatically).
10 #
11
12 import warnings
13
14 import diofant
15
16
17 # Turns numpydoc's section warnings to exceptions, see numpy/numpydoc#58.
18 warnings.simplefilter('error', UserWarning)
19
20 # Add any Sphinx extension module names here, as strings.
21 extensions = ['sphinx.ext.autodoc', 'sphinx.ext.viewcode', 'sphinx.ext.mathjax',
22 'sphinx.ext.graphviz', 'sphinx.ext.intersphinx',
23 'sphinx.ext.extlinks', 'sphinx.ext.napoleon',
24 'sphinxcontrib.bibtex']
25
26 napoleon_google_docstring = False
27 napoleon_use_param = False
28 napoleon_use_rtype = False
29
30 # Sphinx will warn about all references where the target cannot be found.
31 nitpicky = True
32
33 # Glob-style patterns that should be excluded when looking for sources.
34 exclude_patterns = ['README.rst']
35
36 # The document name of the "master" document, that is, the document
37 # that contains the root toctree directive.
38 master_doc = 'index'
39
40 # Project information.
41 project = 'Diofant'
42 copyright = '2006-2018 SymPy Development Team, 2013-2019 Sergey B Kirpichev'
43 version = diofant.__version__
44 release = version
45
46 # The name of default reST role, that is, for text marked up `like this`.
47 default_role = 'math'
48
49 # The theme to use for HTML and HTML Help pages.
50 html_theme = 'sphinx_rtd_theme'
51
52 # The LaTeX engine to build the docs.
53 latex_engine = 'xelatex'
54
55 # If True, the PDF build from the LaTeX files created by Sphinx will use xindy
56 # rather than makeindex.
57 latex_use_xindy = False
58
59 # This value determines how to group the document tree into LaTeX source
60 # files. It must be a list of tuples (startdocname, targetname, title,
61 # author, documentclass, toctree_only),
62 latex_documents = [('index', 'diofant.tex', 'Diofant Documentation',
63 'Diofant Development Team', 'manual', True)]
64
65 # A dictionary that contains LaTeX snippets that override predefined.
66 latex_elements = {
67 'preamble': r'''
68 \setmainfont{DejaVu Serif}
69 \setsansfont{DejaVu Sans}
70 \setmonofont{DejaVu Sans Mono}
71 % redefine \LaTeX to be usable in math mode
72 \expandafter\def\expandafter\LaTeX\expandafter{\expandafter\text\expandafter{\LaTeX}}
73 '''
74 }
75
76 # Add page references after internal references.
77 latex_show_pagerefs = True
78
79 # The output format for Graphviz when building HTML files.
80 graphviz_output_format = 'svg'
81
82 # Contains mapping the locations and names of other projects that
83 # should be linked to in this documentation.
84 intersphinx_mapping = {
85 'python3': ('https://docs.python.org/3/', None),
86 'numpy': ('https://docs.scipy.org/doc/numpy', None),
87 'scipy': ('https://docs.scipy.org/doc/scipy/reference', None),
88 }
89
90 # Dictionary of external sites, mapping unique short alias names to a
91 # base URL and a prefix.
92 extlinks = {
93 'issue': ('https://github.com/diofant/diofant/issues/%s', '#'),
94 'pull': ('https://github.com/diofant/diofant/pull/%s', '#'),
95 'commit': ('https://github.com/diofant/diofant/commit/%s', ''),
96 'sympyissue': ('https://github.com/sympy/sympy/issues/%s', 'sympy/sympy#'),
97 'sympypull': ('https://github.com/sympy/sympy/pull/%s', 'sympy/sympy#'),
98 }
99
100 # The number of times the linkcheck builder will attempt to check a URL
101 # before declaring it broken.
102 linkcheck_retries = 3
103
104 # A list of regular expressions that match URIs that should not be checked.
105 linkcheck_ignore = [r'https://primes.utm.edu/notes/gaps.html',
106 r'https://primes.utm.edu/glossary/xpage/BertrandsPostulate.html',
107 r'https://primes.utm.edu/prove/prove2_3.html',
108 r'https://primes.utm.edu/glossary/xpage/Pseudoprime.html']
109
110 # This value controls if docstring for classes or methods, if not explicitly
111 # set, is inherited form parents.
112 autodoc_inherit_docstrings = False
113
114 # A list of paths that contain custom static files. Relative paths are taken as
115 # relative to the configuration directory. They are copied to the output’s
116 # _static directory.
117 html_static_path = ['_static']
118
119 # Should we show "Created using Sphinx" in the HTML footer?
120 html_show_sphinx = False
121
122 # Theme-specific options.
123 html_theme_options = {
124 'logo_only': True,
125 'display_version': False,
126 }
127
128 mathjax_config = {
129 'CommonHTML': {'linebreaks': {'automatic': True}},
130 'HTML-CSS': {'linebreaks': {'automatic': True}},
131 'SVG': {'linebreaks': {'automatic': True}},
132 }
133
134
135 # https://docs.readthedocs.io/en/latest/guides/adding-custom-css.html
136 def setup(app):
137 app.add_stylesheet('custom.css')
138
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -119,6 +119,11 @@
# Should we show "Created using Sphinx" in the HTML footer?
html_show_sphinx = False
+# Paths to the logo and favicon.ico, relative to the conf.py's directory.
+html_logo = '_static/logo.svg'
+html_favicon = '_static/favicon.ico'
+latex_logo = '_static/logo.png'
+
# Theme-specific options.
html_theme_options = {
'logo_only': True,
|
{"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -119,6 +119,11 @@\n # Should we show \"Created using Sphinx\" in the HTML footer?\n html_show_sphinx = False\n \n+# Paths to the logo and favicon.ico, relative to the conf.py's directory.\n+html_logo = '_static/logo.svg'\n+html_favicon = '_static/favicon.ico'\n+latex_logo = '_static/logo.png'\n+\n # Theme-specific options.\n html_theme_options = {\n 'logo_only': True,\n", "issue": "Project logo\nThere are few places to put images:\r\n- [x] Top left corner of https://diofant.readthedocs.io/ (see e.g. https://sphinx-rtd-theme.readthedocs.io/)\r\n- [x] favicon.ico.\r\n- [x] logo for pdf logs\r\n- [x] Organization profile on the Github (at least 200x200px)\r\n- [x] ~~repository\u2019s social media preview (640\u00d7320px - 1280\u00d7640px for best display)~~\r\n\n", "before_files": [{"content": "#\n# Diofant documentation build configuration file.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# The contents of this file are pickled, so don't put values in the\n# namespace that aren't pickleable (module imports are okay, they're\n# removed automatically).\n#\n\nimport warnings\n\nimport diofant\n\n\n# Turns numpydoc's section warnings to exceptions, see numpy/numpydoc#58.\nwarnings.simplefilter('error', UserWarning)\n\n# Add any Sphinx extension module names here, as strings.\nextensions = ['sphinx.ext.autodoc', 'sphinx.ext.viewcode', 'sphinx.ext.mathjax',\n 'sphinx.ext.graphviz', 'sphinx.ext.intersphinx',\n 'sphinx.ext.extlinks', 'sphinx.ext.napoleon',\n 'sphinxcontrib.bibtex']\n\nnapoleon_google_docstring = False\nnapoleon_use_param = False\nnapoleon_use_rtype = False\n\n# Sphinx will warn about all references where the target cannot be found.\nnitpicky = True\n\n# Glob-style patterns that should be excluded when looking for sources.\nexclude_patterns = ['README.rst']\n\n# The document name of the \"master\" document, that is, the document\n# that contains the root toctree directive.\nmaster_doc = 'index'\n\n# Project information.\nproject = 'Diofant'\ncopyright = '2006-2018 SymPy Development Team, 2013-2019 Sergey B Kirpichev'\nversion = diofant.__version__\nrelease = version\n\n# The name of default reST role, that is, for text marked up `like this`.\ndefault_role = 'math'\n\n# The theme to use for HTML and HTML Help pages.\nhtml_theme = 'sphinx_rtd_theme'\n\n# The LaTeX engine to build the docs.\nlatex_engine = 'xelatex'\n\n# If True, the PDF build from the LaTeX files created by Sphinx will use xindy\n# rather than makeindex.\nlatex_use_xindy = False\n\n# This value determines how to group the document tree into LaTeX source\n# files. It must be a list of tuples (startdocname, targetname, title,\n# author, documentclass, toctree_only),\nlatex_documents = [('index', 'diofant.tex', 'Diofant Documentation',\n 'Diofant Development Team', 'manual', True)]\n\n# A dictionary that contains LaTeX snippets that override predefined.\nlatex_elements = {\n 'preamble': r'''\n\\setmainfont{DejaVu Serif}\n\\setsansfont{DejaVu Sans}\n\\setmonofont{DejaVu Sans Mono}\n% redefine \\LaTeX to be usable in math mode\n\\expandafter\\def\\expandafter\\LaTeX\\expandafter{\\expandafter\\text\\expandafter{\\LaTeX}}\n'''\n}\n\n# Add page references after internal references.\nlatex_show_pagerefs = True\n\n# The output format for Graphviz when building HTML files.\ngraphviz_output_format = 'svg'\n\n# Contains mapping the locations and names of other projects that\n# should be linked to in this documentation.\nintersphinx_mapping = {\n 'python3': ('https://docs.python.org/3/', None),\n 'numpy': ('https://docs.scipy.org/doc/numpy', None),\n 'scipy': ('https://docs.scipy.org/doc/scipy/reference', None),\n}\n\n# Dictionary of external sites, mapping unique short alias names to a\n# base URL and a prefix.\nextlinks = {\n 'issue': ('https://github.com/diofant/diofant/issues/%s', '#'),\n 'pull': ('https://github.com/diofant/diofant/pull/%s', '#'),\n 'commit': ('https://github.com/diofant/diofant/commit/%s', ''),\n 'sympyissue': ('https://github.com/sympy/sympy/issues/%s', 'sympy/sympy#'),\n 'sympypull': ('https://github.com/sympy/sympy/pull/%s', 'sympy/sympy#'),\n}\n\n# The number of times the linkcheck builder will attempt to check a URL\n# before declaring it broken.\nlinkcheck_retries = 3\n\n# A list of regular expressions that match URIs that should not be checked.\nlinkcheck_ignore = [r'https://primes.utm.edu/notes/gaps.html',\n r'https://primes.utm.edu/glossary/xpage/BertrandsPostulate.html',\n r'https://primes.utm.edu/prove/prove2_3.html',\n r'https://primes.utm.edu/glossary/xpage/Pseudoprime.html']\n\n# This value controls if docstring for classes or methods, if not explicitly\n# set, is inherited form parents.\nautodoc_inherit_docstrings = False\n\n# A list of paths that contain custom static files. Relative paths are taken as\n# relative to the configuration directory. They are copied to the output\u2019s\n# _static directory.\nhtml_static_path = ['_static']\n\n# Should we show \"Created using Sphinx\" in the HTML footer?\nhtml_show_sphinx = False\n\n# Theme-specific options.\nhtml_theme_options = {\n 'logo_only': True,\n 'display_version': False,\n}\n\nmathjax_config = {\n 'CommonHTML': {'linebreaks': {'automatic': True}},\n 'HTML-CSS': {'linebreaks': {'automatic': True}},\n 'SVG': {'linebreaks': {'automatic': True}},\n}\n\n\n# https://docs.readthedocs.io/en/latest/guides/adding-custom-css.html\ndef setup(app):\n app.add_stylesheet('custom.css')\n", "path": "docs/conf.py"}], "after_files": [{"content": "#\n# Diofant documentation build configuration file.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# The contents of this file are pickled, so don't put values in the\n# namespace that aren't pickleable (module imports are okay, they're\n# removed automatically).\n#\n\nimport warnings\n\nimport diofant\n\n\n# Turns numpydoc's section warnings to exceptions, see numpy/numpydoc#58.\nwarnings.simplefilter('error', UserWarning)\n\n# Add any Sphinx extension module names here, as strings.\nextensions = ['sphinx.ext.autodoc', 'sphinx.ext.viewcode', 'sphinx.ext.mathjax',\n 'sphinx.ext.graphviz', 'sphinx.ext.intersphinx',\n 'sphinx.ext.extlinks', 'sphinx.ext.napoleon',\n 'sphinxcontrib.bibtex']\n\nnapoleon_google_docstring = False\nnapoleon_use_param = False\nnapoleon_use_rtype = False\n\n# Sphinx will warn about all references where the target cannot be found.\nnitpicky = True\n\n# Glob-style patterns that should be excluded when looking for sources.\nexclude_patterns = ['README.rst']\n\n# The document name of the \"master\" document, that is, the document\n# that contains the root toctree directive.\nmaster_doc = 'index'\n\n# Project information.\nproject = 'Diofant'\ncopyright = '2006-2018 SymPy Development Team, 2013-2019 Sergey B Kirpichev'\nversion = diofant.__version__\nrelease = version\n\n# The name of default reST role, that is, for text marked up `like this`.\ndefault_role = 'math'\n\n# The theme to use for HTML and HTML Help pages.\nhtml_theme = 'sphinx_rtd_theme'\n\n# The LaTeX engine to build the docs.\nlatex_engine = 'xelatex'\n\n# If True, the PDF build from the LaTeX files created by Sphinx will use xindy\n# rather than makeindex.\nlatex_use_xindy = False\n\n# This value determines how to group the document tree into LaTeX source\n# files. It must be a list of tuples (startdocname, targetname, title,\n# author, documentclass, toctree_only),\nlatex_documents = [('index', 'diofant.tex', 'Diofant Documentation',\n 'Diofant Development Team', 'manual', True)]\n\n# A dictionary that contains LaTeX snippets that override predefined.\nlatex_elements = {\n 'preamble': r'''\n\\setmainfont{DejaVu Serif}\n\\setsansfont{DejaVu Sans}\n\\setmonofont{DejaVu Sans Mono}\n% redefine \\LaTeX to be usable in math mode\n\\expandafter\\def\\expandafter\\LaTeX\\expandafter{\\expandafter\\text\\expandafter{\\LaTeX}}\n'''\n}\n\n# Add page references after internal references.\nlatex_show_pagerefs = True\n\n# The output format for Graphviz when building HTML files.\ngraphviz_output_format = 'svg'\n\n# Contains mapping the locations and names of other projects that\n# should be linked to in this documentation.\nintersphinx_mapping = {\n 'python3': ('https://docs.python.org/3/', None),\n 'numpy': ('https://docs.scipy.org/doc/numpy', None),\n 'scipy': ('https://docs.scipy.org/doc/scipy/reference', None),\n}\n\n# Dictionary of external sites, mapping unique short alias names to a\n# base URL and a prefix.\nextlinks = {\n 'issue': ('https://github.com/diofant/diofant/issues/%s', '#'),\n 'pull': ('https://github.com/diofant/diofant/pull/%s', '#'),\n 'commit': ('https://github.com/diofant/diofant/commit/%s', ''),\n 'sympyissue': ('https://github.com/sympy/sympy/issues/%s', 'sympy/sympy#'),\n 'sympypull': ('https://github.com/sympy/sympy/pull/%s', 'sympy/sympy#'),\n}\n\n# The number of times the linkcheck builder will attempt to check a URL\n# before declaring it broken.\nlinkcheck_retries = 3\n\n# A list of regular expressions that match URIs that should not be checked.\nlinkcheck_ignore = [r'https://primes.utm.edu/notes/gaps.html',\n r'https://primes.utm.edu/glossary/xpage/BertrandsPostulate.html',\n r'https://primes.utm.edu/prove/prove2_3.html',\n r'https://primes.utm.edu/glossary/xpage/Pseudoprime.html']\n\n# This value controls if docstring for classes or methods, if not explicitly\n# set, is inherited form parents.\nautodoc_inherit_docstrings = False\n\n# A list of paths that contain custom static files. Relative paths are taken as\n# relative to the configuration directory. They are copied to the output\u2019s\n# _static directory.\nhtml_static_path = ['_static']\n\n# Should we show \"Created using Sphinx\" in the HTML footer?\nhtml_show_sphinx = False\n\n# Paths to the logo and favicon.ico, relative to the conf.py's directory.\nhtml_logo = '_static/logo.svg'\nhtml_favicon = '_static/favicon.ico'\nlatex_logo = '_static/logo.png'\n\n# Theme-specific options.\nhtml_theme_options = {\n 'logo_only': True,\n 'display_version': False,\n}\n\nmathjax_config = {\n 'CommonHTML': {'linebreaks': {'automatic': True}},\n 'HTML-CSS': {'linebreaks': {'automatic': True}},\n 'SVG': {'linebreaks': {'automatic': True}},\n}\n\n\n# https://docs.readthedocs.io/en/latest/guides/adding-custom-css.html\ndef setup(app):\n app.add_stylesheet('custom.css')\n", "path": "docs/conf.py"}]}
| 1,927 | 123 |
gh_patches_debug_16223
|
rasdani/github-patches
|
git_diff
|
microsoft__botbuilder-python-1930
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bump msrest to the 0.6.19 or higher
Is your feature request related to a problem? Please describe.
Old version of msrest is used in botframework components -> https://github.com/microsoft/botbuilder-python/search?q=msrest%3D%3D0.6.10 . This blocks us to use latest versions of the service bus client or event using the new language studio python libraries.
With msrest=0.6.10, we're blocked to using 0.50 service bus package and other packages like event grid.
Describe the solution you'd like
EDITED: Upgrade msrest to the at least 0.6.19 or higher.
Describe alternatives you've considered
No alternatives.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `libraries/botframework-connector/setup.py`
Content:
```
1 # Copyright (c) Microsoft Corporation. All rights reserved.
2 # Licensed under the MIT License.
3
4 import os
5 from setuptools import setup
6
7 NAME = "botframework-connector"
8 VERSION = os.environ["packageVersion"] if "packageVersion" in os.environ else "4.15.0"
9 REQUIRES = [
10 "msrest==0.6.10",
11 "requests>=2.23.0,<2.26",
12 "PyJWT>=1.5.3,<2.0.0",
13 "botbuilder-schema==4.15.0",
14 "msal==1.6.0",
15 ]
16
17 root = os.path.abspath(os.path.dirname(__file__))
18
19 with open(os.path.join(root, "README.rst"), encoding="utf-8") as f:
20 long_description = f.read()
21
22 setup(
23 name=NAME,
24 version=VERSION,
25 description="Microsoft Bot Framework Bot Builder SDK for Python.",
26 author="Microsoft",
27 url="https://www.github.com/Microsoft/botbuilder-python",
28 keywords=["BotFrameworkConnector", "bots", "ai", "botframework", "botbuilder"],
29 install_requires=REQUIRES,
30 packages=[
31 "botframework.connector",
32 "botframework.connector.auth",
33 "botframework.connector.async_mixin",
34 "botframework.connector.operations",
35 "botframework.connector.models",
36 "botframework.connector.aio",
37 "botframework.connector.aio.operations_async",
38 "botframework.connector.skills",
39 "botframework.connector.teams",
40 "botframework.connector.teams.operations",
41 "botframework.connector.token_api",
42 "botframework.connector.token_api.aio",
43 "botframework.connector.token_api.aio.operations_async",
44 "botframework.connector.token_api.models",
45 "botframework.connector.token_api.operations",
46 ],
47 include_package_data=True,
48 long_description=long_description,
49 long_description_content_type="text/x-rst",
50 license="MIT",
51 classifiers=[
52 "Programming Language :: Python :: 3.7",
53 "Intended Audience :: Developers",
54 "License :: OSI Approved :: MIT License",
55 "Operating System :: OS Independent",
56 "Development Status :: 5 - Production/Stable",
57 "Topic :: Scientific/Engineering :: Artificial Intelligence",
58 ],
59 )
60
```
Path: `libraries/botbuilder-schema/setup.py`
Content:
```
1 # Copyright (c) Microsoft Corporation. All rights reserved.
2 # Licensed under the MIT License.
3
4 import os
5 from setuptools import setup
6
7 NAME = "botbuilder-schema"
8 VERSION = os.environ["packageVersion"] if "packageVersion" in os.environ else "4.15.0"
9 REQUIRES = ["msrest==0.6.10"]
10
11 root = os.path.abspath(os.path.dirname(__file__))
12
13 with open(os.path.join(root, "README.rst"), encoding="utf-8") as f:
14 long_description = f.read()
15
16 setup(
17 name=NAME,
18 version=VERSION,
19 description="BotBuilder Schema",
20 author="Microsoft",
21 url="https://github.com/Microsoft/botbuilder-python",
22 keywords=["BotBuilderSchema", "bots", "ai", "botframework", "botbuilder"],
23 long_description=long_description,
24 long_description_content_type="text/x-rst",
25 license="MIT",
26 install_requires=REQUIRES,
27 packages=["botbuilder.schema", "botbuilder.schema.teams",],
28 include_package_data=True,
29 classifiers=[
30 "Programming Language :: Python :: 3.7",
31 "Intended Audience :: Developers",
32 "License :: OSI Approved :: MIT License",
33 "Operating System :: OS Independent",
34 "Development Status :: 5 - Production/Stable",
35 "Topic :: Scientific/Engineering :: Artificial Intelligence",
36 ],
37 )
38
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/libraries/botbuilder-schema/setup.py b/libraries/botbuilder-schema/setup.py
--- a/libraries/botbuilder-schema/setup.py
+++ b/libraries/botbuilder-schema/setup.py
@@ -6,7 +6,7 @@
NAME = "botbuilder-schema"
VERSION = os.environ["packageVersion"] if "packageVersion" in os.environ else "4.15.0"
-REQUIRES = ["msrest==0.6.10"]
+REQUIRES = ["msrest==0.6.19"]
root = os.path.abspath(os.path.dirname(__file__))
diff --git a/libraries/botframework-connector/setup.py b/libraries/botframework-connector/setup.py
--- a/libraries/botframework-connector/setup.py
+++ b/libraries/botframework-connector/setup.py
@@ -7,7 +7,7 @@
NAME = "botframework-connector"
VERSION = os.environ["packageVersion"] if "packageVersion" in os.environ else "4.15.0"
REQUIRES = [
- "msrest==0.6.10",
+ "msrest==0.6.19",
"requests>=2.23.0,<2.26",
"PyJWT>=1.5.3,<2.0.0",
"botbuilder-schema==4.15.0",
|
{"golden_diff": "diff --git a/libraries/botbuilder-schema/setup.py b/libraries/botbuilder-schema/setup.py\n--- a/libraries/botbuilder-schema/setup.py\n+++ b/libraries/botbuilder-schema/setup.py\n@@ -6,7 +6,7 @@\n \r\n NAME = \"botbuilder-schema\"\r\n VERSION = os.environ[\"packageVersion\"] if \"packageVersion\" in os.environ else \"4.15.0\"\r\n-REQUIRES = [\"msrest==0.6.10\"]\r\n+REQUIRES = [\"msrest==0.6.19\"]\r\n \r\n root = os.path.abspath(os.path.dirname(__file__))\r\n \r\ndiff --git a/libraries/botframework-connector/setup.py b/libraries/botframework-connector/setup.py\n--- a/libraries/botframework-connector/setup.py\n+++ b/libraries/botframework-connector/setup.py\n@@ -7,7 +7,7 @@\n NAME = \"botframework-connector\"\n VERSION = os.environ[\"packageVersion\"] if \"packageVersion\" in os.environ else \"4.15.0\"\n REQUIRES = [\n- \"msrest==0.6.10\",\n+ \"msrest==0.6.19\",\n \"requests>=2.23.0,<2.26\",\n \"PyJWT>=1.5.3,<2.0.0\",\n \"botbuilder-schema==4.15.0\",\n", "issue": "Bump msrest to the 0.6.19 or higher\nIs your feature request related to a problem? Please describe.\r\nOld version of msrest is used in botframework components -> https://github.com/microsoft/botbuilder-python/search?q=msrest%3D%3D0.6.10 . This blocks us to use latest versions of the service bus client or event using the new language studio python libraries.\r\n\r\nWith msrest=0.6.10, we're blocked to using 0.50 service bus package and other packages like event grid.\r\n\r\nDescribe the solution you'd like\r\nEDITED: Upgrade msrest to the at least 0.6.19 or higher.\r\n\r\nDescribe alternatives you've considered\r\nNo alternatives.\r\n\n", "before_files": [{"content": "# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License.\n\nimport os\nfrom setuptools import setup\n\nNAME = \"botframework-connector\"\nVERSION = os.environ[\"packageVersion\"] if \"packageVersion\" in os.environ else \"4.15.0\"\nREQUIRES = [\n \"msrest==0.6.10\",\n \"requests>=2.23.0,<2.26\",\n \"PyJWT>=1.5.3,<2.0.0\",\n \"botbuilder-schema==4.15.0\",\n \"msal==1.6.0\",\n]\n\nroot = os.path.abspath(os.path.dirname(__file__))\n\nwith open(os.path.join(root, \"README.rst\"), encoding=\"utf-8\") as f:\n long_description = f.read()\n\nsetup(\n name=NAME,\n version=VERSION,\n description=\"Microsoft Bot Framework Bot Builder SDK for Python.\",\n author=\"Microsoft\",\n url=\"https://www.github.com/Microsoft/botbuilder-python\",\n keywords=[\"BotFrameworkConnector\", \"bots\", \"ai\", \"botframework\", \"botbuilder\"],\n install_requires=REQUIRES,\n packages=[\n \"botframework.connector\",\n \"botframework.connector.auth\",\n \"botframework.connector.async_mixin\",\n \"botframework.connector.operations\",\n \"botframework.connector.models\",\n \"botframework.connector.aio\",\n \"botframework.connector.aio.operations_async\",\n \"botframework.connector.skills\",\n \"botframework.connector.teams\",\n \"botframework.connector.teams.operations\",\n \"botframework.connector.token_api\",\n \"botframework.connector.token_api.aio\",\n \"botframework.connector.token_api.aio.operations_async\",\n \"botframework.connector.token_api.models\",\n \"botframework.connector.token_api.operations\",\n ],\n include_package_data=True,\n long_description=long_description,\n long_description_content_type=\"text/x-rst\",\n license=\"MIT\",\n classifiers=[\n \"Programming Language :: Python :: 3.7\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: MIT License\",\n \"Operating System :: OS Independent\",\n \"Development Status :: 5 - Production/Stable\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n)\n", "path": "libraries/botframework-connector/setup.py"}, {"content": "# Copyright (c) Microsoft Corporation. All rights reserved.\r\n# Licensed under the MIT License.\r\n\r\nimport os\r\nfrom setuptools import setup\r\n\r\nNAME = \"botbuilder-schema\"\r\nVERSION = os.environ[\"packageVersion\"] if \"packageVersion\" in os.environ else \"4.15.0\"\r\nREQUIRES = [\"msrest==0.6.10\"]\r\n\r\nroot = os.path.abspath(os.path.dirname(__file__))\r\n\r\nwith open(os.path.join(root, \"README.rst\"), encoding=\"utf-8\") as f:\r\n long_description = f.read()\r\n\r\nsetup(\r\n name=NAME,\r\n version=VERSION,\r\n description=\"BotBuilder Schema\",\r\n author=\"Microsoft\",\r\n url=\"https://github.com/Microsoft/botbuilder-python\",\r\n keywords=[\"BotBuilderSchema\", \"bots\", \"ai\", \"botframework\", \"botbuilder\"],\r\n long_description=long_description,\r\n long_description_content_type=\"text/x-rst\",\r\n license=\"MIT\",\r\n install_requires=REQUIRES,\r\n packages=[\"botbuilder.schema\", \"botbuilder.schema.teams\",],\r\n include_package_data=True,\r\n classifiers=[\r\n \"Programming Language :: Python :: 3.7\",\r\n \"Intended Audience :: Developers\",\r\n \"License :: OSI Approved :: MIT License\",\r\n \"Operating System :: OS Independent\",\r\n \"Development Status :: 5 - Production/Stable\",\r\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\r\n ],\r\n)\r\n", "path": "libraries/botbuilder-schema/setup.py"}], "after_files": [{"content": "# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License.\n\nimport os\nfrom setuptools import setup\n\nNAME = \"botframework-connector\"\nVERSION = os.environ[\"packageVersion\"] if \"packageVersion\" in os.environ else \"4.15.0\"\nREQUIRES = [\n \"msrest==0.6.19\",\n \"requests>=2.23.0,<2.26\",\n \"PyJWT>=1.5.3,<2.0.0\",\n \"botbuilder-schema==4.15.0\",\n \"msal==1.6.0\",\n]\n\nroot = os.path.abspath(os.path.dirname(__file__))\n\nwith open(os.path.join(root, \"README.rst\"), encoding=\"utf-8\") as f:\n long_description = f.read()\n\nsetup(\n name=NAME,\n version=VERSION,\n description=\"Microsoft Bot Framework Bot Builder SDK for Python.\",\n author=\"Microsoft\",\n url=\"https://www.github.com/Microsoft/botbuilder-python\",\n keywords=[\"BotFrameworkConnector\", \"bots\", \"ai\", \"botframework\", \"botbuilder\"],\n install_requires=REQUIRES,\n packages=[\n \"botframework.connector\",\n \"botframework.connector.auth\",\n \"botframework.connector.async_mixin\",\n \"botframework.connector.operations\",\n \"botframework.connector.models\",\n \"botframework.connector.aio\",\n \"botframework.connector.aio.operations_async\",\n \"botframework.connector.skills\",\n \"botframework.connector.teams\",\n \"botframework.connector.teams.operations\",\n \"botframework.connector.token_api\",\n \"botframework.connector.token_api.aio\",\n \"botframework.connector.token_api.aio.operations_async\",\n \"botframework.connector.token_api.models\",\n \"botframework.connector.token_api.operations\",\n ],\n include_package_data=True,\n long_description=long_description,\n long_description_content_type=\"text/x-rst\",\n license=\"MIT\",\n classifiers=[\n \"Programming Language :: Python :: 3.7\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: MIT License\",\n \"Operating System :: OS Independent\",\n \"Development Status :: 5 - Production/Stable\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n)\n", "path": "libraries/botframework-connector/setup.py"}, {"content": "# Copyright (c) Microsoft Corporation. All rights reserved.\r\n# Licensed under the MIT License.\r\n\r\nimport os\r\nfrom setuptools import setup\r\n\r\nNAME = \"botbuilder-schema\"\r\nVERSION = os.environ[\"packageVersion\"] if \"packageVersion\" in os.environ else \"4.15.0\"\r\nREQUIRES = [\"msrest==0.6.19\"]\r\n\r\nroot = os.path.abspath(os.path.dirname(__file__))\r\n\r\nwith open(os.path.join(root, \"README.rst\"), encoding=\"utf-8\") as f:\r\n long_description = f.read()\r\n\r\nsetup(\r\n name=NAME,\r\n version=VERSION,\r\n description=\"BotBuilder Schema\",\r\n author=\"Microsoft\",\r\n url=\"https://github.com/Microsoft/botbuilder-python\",\r\n keywords=[\"BotBuilderSchema\", \"bots\", \"ai\", \"botframework\", \"botbuilder\"],\r\n long_description=long_description,\r\n long_description_content_type=\"text/x-rst\",\r\n license=\"MIT\",\r\n install_requires=REQUIRES,\r\n packages=[\"botbuilder.schema\", \"botbuilder.schema.teams\",],\r\n include_package_data=True,\r\n classifiers=[\r\n \"Programming Language :: Python :: 3.7\",\r\n \"Intended Audience :: Developers\",\r\n \"License :: OSI Approved :: MIT License\",\r\n \"Operating System :: OS Independent\",\r\n \"Development Status :: 5 - Production/Stable\",\r\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\r\n ],\r\n)\r\n", "path": "libraries/botbuilder-schema/setup.py"}]}
| 1,390 | 298 |
gh_patches_debug_11520
|
rasdani/github-patches
|
git_diff
|
gratipay__gratipay.com-2999
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Font problem in production
> Font from origin 'https://assets.gratipay.com' has been blocked from loading by Cross-Origin Resource Sharing policy: No 'Access-Control-Allow-Origin' header is present on the requested resource. Origin 'https://gratipay.com' is therefore not allowed access.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `gratipay/utils/cache_static.py`
Content:
```
1 """
2 Handles caching of static resources.
3 """
4 from base64 import b64encode
5 from hashlib import md5
6
7 from aspen import Response
8
9
10 ETAGS = {}
11
12
13 def asset_etag(path):
14 if path.endswith('.spt'):
15 return ''
16 if path in ETAGS:
17 h = ETAGS[path]
18 else:
19 with open(path) as f:
20 h = ETAGS[path] = b64encode(md5(f.read()).digest(), '-_').replace('=', '~')
21 return h
22
23
24 # algorithm functions
25
26 def get_etag_for_file(dispatch_result):
27 return {'etag': asset_etag(dispatch_result.match)}
28
29
30 def try_to_serve_304(website, dispatch_result, request, etag):
31 """Try to serve a 304 for static resources.
32 """
33 if not etag:
34 # This is a request for a dynamic resource.
35 return
36
37 qs_etag = request.line.uri.querystring.get('etag')
38 if qs_etag and qs_etag != etag:
39 # Don't serve one version of a file as if it were another.
40 raise Response(410)
41
42 headers_etag = request.headers.get('If-None-Match')
43 if not headers_etag:
44 # This client doesn't want a 304.
45 return
46
47 if headers_etag != etag:
48 # Cache miss, the client sent an old or invalid etag.
49 return
50
51 # Huzzah!
52 # =======
53 # We can serve a 304! :D
54
55 raise Response(304)
56
57
58 def add_caching_to_response(website, response, request=None, etag=None):
59 """Set caching headers for static resources.
60 """
61 if etag is None:
62 return
63 assert request is not None # sanity check
64
65 if response.code not in (200, 304):
66 return
67
68 # https://developers.google.com/speed/docs/best-practices/caching
69 response.headers['Vary'] = 'accept-encoding'
70 response.headers['Etag'] = etag
71
72 if request.line.uri.querystring.get('etag'):
73 # We can cache "indefinitely" when the querystring contains the etag.
74 response.headers['Cache-Control'] = 'public, max-age=31536000'
75 else:
76 # Otherwise we cache for 5 seconds
77 response.headers['Cache-Control'] = 'public, max-age=5'
78
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/gratipay/utils/cache_static.py b/gratipay/utils/cache_static.py
--- a/gratipay/utils/cache_static.py
+++ b/gratipay/utils/cache_static.py
@@ -68,6 +68,9 @@
# https://developers.google.com/speed/docs/best-practices/caching
response.headers['Vary'] = 'accept-encoding'
response.headers['Etag'] = etag
+ # Set CORS header for https://assets.gratipay.com (see issue #2970)
+ if 'Access-Control-Allow-Origin' not in response.headers:
+ response.headers['Access-Control-Allow-Origin'] = 'https://gratipay.com'
if request.line.uri.querystring.get('etag'):
# We can cache "indefinitely" when the querystring contains the etag.
|
{"golden_diff": "diff --git a/gratipay/utils/cache_static.py b/gratipay/utils/cache_static.py\n--- a/gratipay/utils/cache_static.py\n+++ b/gratipay/utils/cache_static.py\n@@ -68,6 +68,9 @@\n # https://developers.google.com/speed/docs/best-practices/caching\n response.headers['Vary'] = 'accept-encoding'\n response.headers['Etag'] = etag\n+ # Set CORS header for https://assets.gratipay.com (see issue #2970)\n+ if 'Access-Control-Allow-Origin' not in response.headers:\n+ response.headers['Access-Control-Allow-Origin'] = 'https://gratipay.com'\n \n if request.line.uri.querystring.get('etag'):\n # We can cache \"indefinitely\" when the querystring contains the etag.\n", "issue": "Font problem in production\n> Font from origin 'https://assets.gratipay.com' has been blocked from loading by Cross-Origin Resource Sharing policy: No 'Access-Control-Allow-Origin' header is present on the requested resource. Origin 'https://gratipay.com' is therefore not allowed access. \n\n", "before_files": [{"content": "\"\"\"\nHandles caching of static resources.\n\"\"\"\nfrom base64 import b64encode\nfrom hashlib import md5\n\nfrom aspen import Response\n\n\nETAGS = {}\n\n\ndef asset_etag(path):\n if path.endswith('.spt'):\n return ''\n if path in ETAGS:\n h = ETAGS[path]\n else:\n with open(path) as f:\n h = ETAGS[path] = b64encode(md5(f.read()).digest(), '-_').replace('=', '~')\n return h\n\n\n# algorithm functions\n\ndef get_etag_for_file(dispatch_result):\n return {'etag': asset_etag(dispatch_result.match)}\n\n\ndef try_to_serve_304(website, dispatch_result, request, etag):\n \"\"\"Try to serve a 304 for static resources.\n \"\"\"\n if not etag:\n # This is a request for a dynamic resource.\n return\n\n qs_etag = request.line.uri.querystring.get('etag')\n if qs_etag and qs_etag != etag:\n # Don't serve one version of a file as if it were another.\n raise Response(410)\n\n headers_etag = request.headers.get('If-None-Match')\n if not headers_etag:\n # This client doesn't want a 304.\n return\n\n if headers_etag != etag:\n # Cache miss, the client sent an old or invalid etag.\n return\n\n # Huzzah!\n # =======\n # We can serve a 304! :D\n\n raise Response(304)\n\n\ndef add_caching_to_response(website, response, request=None, etag=None):\n \"\"\"Set caching headers for static resources.\n \"\"\"\n if etag is None:\n return\n assert request is not None # sanity check\n\n if response.code not in (200, 304):\n return\n\n # https://developers.google.com/speed/docs/best-practices/caching\n response.headers['Vary'] = 'accept-encoding'\n response.headers['Etag'] = etag\n\n if request.line.uri.querystring.get('etag'):\n # We can cache \"indefinitely\" when the querystring contains the etag.\n response.headers['Cache-Control'] = 'public, max-age=31536000'\n else:\n # Otherwise we cache for 5 seconds\n response.headers['Cache-Control'] = 'public, max-age=5'\n", "path": "gratipay/utils/cache_static.py"}], "after_files": [{"content": "\"\"\"\nHandles caching of static resources.\n\"\"\"\nfrom base64 import b64encode\nfrom hashlib import md5\n\nfrom aspen import Response\n\n\nETAGS = {}\n\n\ndef asset_etag(path):\n if path.endswith('.spt'):\n return ''\n if path in ETAGS:\n h = ETAGS[path]\n else:\n with open(path) as f:\n h = ETAGS[path] = b64encode(md5(f.read()).digest(), '-_').replace('=', '~')\n return h\n\n\n# algorithm functions\n\ndef get_etag_for_file(dispatch_result):\n return {'etag': asset_etag(dispatch_result.match)}\n\n\ndef try_to_serve_304(website, dispatch_result, request, etag):\n \"\"\"Try to serve a 304 for static resources.\n \"\"\"\n if not etag:\n # This is a request for a dynamic resource.\n return\n\n qs_etag = request.line.uri.querystring.get('etag')\n if qs_etag and qs_etag != etag:\n # Don't serve one version of a file as if it were another.\n raise Response(410)\n\n headers_etag = request.headers.get('If-None-Match')\n if not headers_etag:\n # This client doesn't want a 304.\n return\n\n if headers_etag != etag:\n # Cache miss, the client sent an old or invalid etag.\n return\n\n # Huzzah!\n # =======\n # We can serve a 304! :D\n\n raise Response(304)\n\n\ndef add_caching_to_response(website, response, request=None, etag=None):\n \"\"\"Set caching headers for static resources.\n \"\"\"\n if etag is None:\n return\n assert request is not None # sanity check\n\n if response.code not in (200, 304):\n return\n\n # https://developers.google.com/speed/docs/best-practices/caching\n response.headers['Vary'] = 'accept-encoding'\n response.headers['Etag'] = etag\n # Set CORS header for https://assets.gratipay.com (see issue #2970)\n if 'Access-Control-Allow-Origin' not in response.headers:\n response.headers['Access-Control-Allow-Origin'] = 'https://gratipay.com'\n\n if request.line.uri.querystring.get('etag'):\n # We can cache \"indefinitely\" when the querystring contains the etag.\n response.headers['Cache-Control'] = 'public, max-age=31536000'\n else:\n # Otherwise we cache for 5 seconds\n response.headers['Cache-Control'] = 'public, max-age=5'\n", "path": "gratipay/utils/cache_static.py"}]}
| 1,021 | 180 |
gh_patches_debug_2632
|
rasdani/github-patches
|
git_diff
|
hpcaitech__ColossalAI-5433
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[tensor] fix some unittests
[tensor] fix some unittests
[tensor] fix some unittests
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `extensions/inference/inference_ops_cuda.py`
Content:
```
1 from ..cuda_extension import _CudaExtension
2 from ..utils import get_cuda_cc_flag
3
4
5 class InferenceOpsCudaExtension(_CudaExtension):
6 def __init__(self):
7 super().__init__(name="inference_ops_cuda")
8
9 def sources_files(self):
10 ret = [
11 self.csrc_abs_path(fname)
12 for fname in [
13 "cuda/colossal_inference_C_frontend.cpp",
14 "cuda/decode_kv_cache_memcpy_kernel.cu",
15 ]
16 ]
17 return ret
18
19 def include_dirs(self):
20 ret = [self.get_cuda_home_include()]
21 return ret
22
23 def cxx_flags(self):
24 version_dependent_macros = ["-DVERSION_GE_1_1", "-DVERSION_GE_1_3", "-DVERSION_GE_1_5"]
25 return ["-O3"] + version_dependent_macros
26
27 def nvcc_flags(self):
28 extra_cuda_flags = ["-lineinfo"]
29 extra_cuda_flags.extend(get_cuda_cc_flag())
30 return ["-O3", "--use_fast_math"] + extra_cuda_flags
31
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/extensions/inference/inference_ops_cuda.py b/extensions/inference/inference_ops_cuda.py
--- a/extensions/inference/inference_ops_cuda.py
+++ b/extensions/inference/inference_ops_cuda.py
@@ -12,6 +12,7 @@
for fname in [
"cuda/colossal_inference_C_frontend.cpp",
"cuda/decode_kv_cache_memcpy_kernel.cu",
+ "cuda/activation_kernel.cu",
]
]
return ret
|
{"golden_diff": "diff --git a/extensions/inference/inference_ops_cuda.py b/extensions/inference/inference_ops_cuda.py\n--- a/extensions/inference/inference_ops_cuda.py\n+++ b/extensions/inference/inference_ops_cuda.py\n@@ -12,6 +12,7 @@\n for fname in [\n \"cuda/colossal_inference_C_frontend.cpp\",\n \"cuda/decode_kv_cache_memcpy_kernel.cu\",\n+ \"cuda/activation_kernel.cu\",\n ]\n ]\n return ret\n", "issue": "[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n", "before_files": [{"content": "from ..cuda_extension import _CudaExtension\nfrom ..utils import get_cuda_cc_flag\n\n\nclass InferenceOpsCudaExtension(_CudaExtension):\n def __init__(self):\n super().__init__(name=\"inference_ops_cuda\")\n\n def sources_files(self):\n ret = [\n self.csrc_abs_path(fname)\n for fname in [\n \"cuda/colossal_inference_C_frontend.cpp\",\n \"cuda/decode_kv_cache_memcpy_kernel.cu\",\n ]\n ]\n return ret\n\n def include_dirs(self):\n ret = [self.get_cuda_home_include()]\n return ret\n\n def cxx_flags(self):\n version_dependent_macros = [\"-DVERSION_GE_1_1\", \"-DVERSION_GE_1_3\", \"-DVERSION_GE_1_5\"]\n return [\"-O3\"] + version_dependent_macros\n\n def nvcc_flags(self):\n extra_cuda_flags = [\"-lineinfo\"]\n extra_cuda_flags.extend(get_cuda_cc_flag())\n return [\"-O3\", \"--use_fast_math\"] + extra_cuda_flags\n", "path": "extensions/inference/inference_ops_cuda.py"}], "after_files": [{"content": "from ..cuda_extension import _CudaExtension\nfrom ..utils import get_cuda_cc_flag\n\n\nclass InferenceOpsCudaExtension(_CudaExtension):\n def __init__(self):\n super().__init__(name=\"inference_ops_cuda\")\n\n def sources_files(self):\n ret = [\n self.csrc_abs_path(fname)\n for fname in [\n \"cuda/colossal_inference_C_frontend.cpp\",\n \"cuda/decode_kv_cache_memcpy_kernel.cu\",\n \"cuda/activation_kernel.cu\",\n ]\n ]\n return ret\n\n def include_dirs(self):\n ret = [self.get_cuda_home_include()]\n return ret\n\n def cxx_flags(self):\n version_dependent_macros = [\"-DVERSION_GE_1_1\", \"-DVERSION_GE_1_3\", \"-DVERSION_GE_1_5\"]\n return [\"-O3\"] + version_dependent_macros\n\n def nvcc_flags(self):\n extra_cuda_flags = [\"-lineinfo\"]\n extra_cuda_flags.extend(get_cuda_cc_flag())\n return [\"-O3\", \"--use_fast_math\"] + extra_cuda_flags\n", "path": "extensions/inference/inference_ops_cuda.py"}]}
| 568 | 103 |
gh_patches_debug_153
|
rasdani/github-patches
|
git_diff
|
bookwyrm-social__bookwyrm-1018
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Ratings don't federate
**Describe the bug**
I do follow someone on bookwyrm.social from bookwyrm.social and wyrms.de. I have seen on b.s that they rated some books without reviewing them, but those ratings do not appear on w.d. All other posts federate properly (I think).
**Expeceted behaviour**
The rating should show up on connected instances and ideally also be used on those to calculate the average rating of the book.
Here is one example that's not visible from w.d: https://bookwyrm.social/user/tastytea/reviewrating/21469
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bookwyrm/activitypub/note.py`
Content:
```
1 """ note serializer and children thereof """
2 from dataclasses import dataclass, field
3 from typing import Dict, List
4 from django.apps import apps
5
6 from .base_activity import ActivityObject, Link
7 from .image import Document
8
9
10 @dataclass(init=False)
11 class Tombstone(ActivityObject):
12 """the placeholder for a deleted status"""
13
14 type: str = "Tombstone"
15
16 def to_model(self, *args, **kwargs): # pylint: disable=unused-argument
17 """this should never really get serialized, just searched for"""
18 model = apps.get_model("bookwyrm.Status")
19 return model.find_existing_by_remote_id(self.id)
20
21
22 @dataclass(init=False)
23 class Note(ActivityObject):
24 """Note activity"""
25
26 published: str
27 attributedTo: str
28 content: str = ""
29 to: List[str] = field(default_factory=lambda: [])
30 cc: List[str] = field(default_factory=lambda: [])
31 replies: Dict = field(default_factory=lambda: {})
32 inReplyTo: str = ""
33 summary: str = ""
34 tag: List[Link] = field(default_factory=lambda: [])
35 attachment: List[Document] = field(default_factory=lambda: [])
36 sensitive: bool = False
37 type: str = "Note"
38
39
40 @dataclass(init=False)
41 class Article(Note):
42 """what's an article except a note with more fields"""
43
44 name: str
45 type: str = "Article"
46
47
48 @dataclass(init=False)
49 class GeneratedNote(Note):
50 """just a re-typed note"""
51
52 type: str = "GeneratedNote"
53
54
55 @dataclass(init=False)
56 class Comment(Note):
57 """like a note but with a book"""
58
59 inReplyToBook: str
60 type: str = "Comment"
61
62
63 @dataclass(init=False)
64 class Quotation(Comment):
65 """a quote and commentary on a book"""
66
67 quote: str
68 type: str = "Quotation"
69
70
71 @dataclass(init=False)
72 class Review(Comment):
73 """a full book review"""
74
75 name: str = None
76 rating: int = None
77 type: str = "Review"
78
79
80 @dataclass(init=False)
81 class Rating(Comment):
82 """just a star rating"""
83
84 rating: int
85 content: str = None
86 type: str = "Rating"
87
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/bookwyrm/activitypub/note.py b/bookwyrm/activitypub/note.py
--- a/bookwyrm/activitypub/note.py
+++ b/bookwyrm/activitypub/note.py
@@ -83,4 +83,5 @@
rating: int
content: str = None
+ name: str = None # not used, but the model inherits from Review
type: str = "Rating"
|
{"golden_diff": "diff --git a/bookwyrm/activitypub/note.py b/bookwyrm/activitypub/note.py\n--- a/bookwyrm/activitypub/note.py\n+++ b/bookwyrm/activitypub/note.py\n@@ -83,4 +83,5 @@\n \n rating: int\n content: str = None\n+ name: str = None # not used, but the model inherits from Review\n type: str = \"Rating\"\n", "issue": "Ratings don't federate\n**Describe the bug**\r\nI do follow someone on bookwyrm.social from bookwyrm.social and wyrms.de. I have seen on b.s that they rated some books without reviewing them, but those ratings do not appear on w.d. All other posts federate properly (I think).\r\n\r\n**Expeceted behaviour**\r\nThe rating should show up on connected instances and ideally also be used on those to calculate the average rating of the book.\r\n\r\nHere is one example that's not visible from w.d: https://bookwyrm.social/user/tastytea/reviewrating/21469\n", "before_files": [{"content": "\"\"\" note serializer and children thereof \"\"\"\nfrom dataclasses import dataclass, field\nfrom typing import Dict, List\nfrom django.apps import apps\n\nfrom .base_activity import ActivityObject, Link\nfrom .image import Document\n\n\n@dataclass(init=False)\nclass Tombstone(ActivityObject):\n \"\"\"the placeholder for a deleted status\"\"\"\n\n type: str = \"Tombstone\"\n\n def to_model(self, *args, **kwargs): # pylint: disable=unused-argument\n \"\"\"this should never really get serialized, just searched for\"\"\"\n model = apps.get_model(\"bookwyrm.Status\")\n return model.find_existing_by_remote_id(self.id)\n\n\n@dataclass(init=False)\nclass Note(ActivityObject):\n \"\"\"Note activity\"\"\"\n\n published: str\n attributedTo: str\n content: str = \"\"\n to: List[str] = field(default_factory=lambda: [])\n cc: List[str] = field(default_factory=lambda: [])\n replies: Dict = field(default_factory=lambda: {})\n inReplyTo: str = \"\"\n summary: str = \"\"\n tag: List[Link] = field(default_factory=lambda: [])\n attachment: List[Document] = field(default_factory=lambda: [])\n sensitive: bool = False\n type: str = \"Note\"\n\n\n@dataclass(init=False)\nclass Article(Note):\n \"\"\"what's an article except a note with more fields\"\"\"\n\n name: str\n type: str = \"Article\"\n\n\n@dataclass(init=False)\nclass GeneratedNote(Note):\n \"\"\"just a re-typed note\"\"\"\n\n type: str = \"GeneratedNote\"\n\n\n@dataclass(init=False)\nclass Comment(Note):\n \"\"\"like a note but with a book\"\"\"\n\n inReplyToBook: str\n type: str = \"Comment\"\n\n\n@dataclass(init=False)\nclass Quotation(Comment):\n \"\"\"a quote and commentary on a book\"\"\"\n\n quote: str\n type: str = \"Quotation\"\n\n\n@dataclass(init=False)\nclass Review(Comment):\n \"\"\"a full book review\"\"\"\n\n name: str = None\n rating: int = None\n type: str = \"Review\"\n\n\n@dataclass(init=False)\nclass Rating(Comment):\n \"\"\"just a star rating\"\"\"\n\n rating: int\n content: str = None\n type: str = \"Rating\"\n", "path": "bookwyrm/activitypub/note.py"}], "after_files": [{"content": "\"\"\" note serializer and children thereof \"\"\"\nfrom dataclasses import dataclass, field\nfrom typing import Dict, List\nfrom django.apps import apps\n\nfrom .base_activity import ActivityObject, Link\nfrom .image import Document\n\n\n@dataclass(init=False)\nclass Tombstone(ActivityObject):\n \"\"\"the placeholder for a deleted status\"\"\"\n\n type: str = \"Tombstone\"\n\n def to_model(self, *args, **kwargs): # pylint: disable=unused-argument\n \"\"\"this should never really get serialized, just searched for\"\"\"\n model = apps.get_model(\"bookwyrm.Status\")\n return model.find_existing_by_remote_id(self.id)\n\n\n@dataclass(init=False)\nclass Note(ActivityObject):\n \"\"\"Note activity\"\"\"\n\n published: str\n attributedTo: str\n content: str = \"\"\n to: List[str] = field(default_factory=lambda: [])\n cc: List[str] = field(default_factory=lambda: [])\n replies: Dict = field(default_factory=lambda: {})\n inReplyTo: str = \"\"\n summary: str = \"\"\n tag: List[Link] = field(default_factory=lambda: [])\n attachment: List[Document] = field(default_factory=lambda: [])\n sensitive: bool = False\n type: str = \"Note\"\n\n\n@dataclass(init=False)\nclass Article(Note):\n \"\"\"what's an article except a note with more fields\"\"\"\n\n name: str\n type: str = \"Article\"\n\n\n@dataclass(init=False)\nclass GeneratedNote(Note):\n \"\"\"just a re-typed note\"\"\"\n\n type: str = \"GeneratedNote\"\n\n\n@dataclass(init=False)\nclass Comment(Note):\n \"\"\"like a note but with a book\"\"\"\n\n inReplyToBook: str\n type: str = \"Comment\"\n\n\n@dataclass(init=False)\nclass Quotation(Comment):\n \"\"\"a quote and commentary on a book\"\"\"\n\n quote: str\n type: str = \"Quotation\"\n\n\n@dataclass(init=False)\nclass Review(Comment):\n \"\"\"a full book review\"\"\"\n\n name: str = None\n rating: int = None\n type: str = \"Review\"\n\n\n@dataclass(init=False)\nclass Rating(Comment):\n \"\"\"just a star rating\"\"\"\n\n rating: int\n content: str = None\n name: str = None # not used, but the model inherits from Review\n type: str = \"Rating\"\n", "path": "bookwyrm/activitypub/note.py"}]}
| 1,059 | 96 |
gh_patches_debug_591
|
rasdani/github-patches
|
git_diff
|
pex-tool__pex-1140
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Release 2.1.23
On the docket:
+ [x] Upgrade Pex to Pip 20.3.1. #1133
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pex/version.py`
Content:
```
1 # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 __version__ = "2.1.22"
5
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pex/version.py b/pex/version.py
--- a/pex/version.py
+++ b/pex/version.py
@@ -1,4 +1,4 @@
# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
# Licensed under the Apache License, Version 2.0 (see LICENSE).
-__version__ = "2.1.22"
+__version__ = "2.1.23"
|
{"golden_diff": "diff --git a/pex/version.py b/pex/version.py\n--- a/pex/version.py\n+++ b/pex/version.py\n@@ -1,4 +1,4 @@\n # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n # Licensed under the Apache License, Version 2.0 (see LICENSE).\n \n-__version__ = \"2.1.22\"\n+__version__ = \"2.1.23\"\n", "issue": "Release 2.1.23\nOn the docket:\r\n+ [x] Upgrade Pex to Pip 20.3.1. #1133\r\n\n", "before_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = \"2.1.22\"\n", "path": "pex/version.py"}], "after_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = \"2.1.23\"\n", "path": "pex/version.py"}]}
| 345 | 96 |
gh_patches_debug_13712
|
rasdani/github-patches
|
git_diff
|
chainer__chainer-1312
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`split_axis` doesn't support empty sections
This code causes a TypeError.
`functions.split_axis(x, [], 0)`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `chainer/functions/array/split_axis.py`
Content:
```
1 import collections
2
3 import six
4
5 import chainer
6 from chainer import cuda
7 from chainer import function
8 from chainer.utils import type_check
9
10
11 class SplitAxis(function.Function):
12
13 """Function that splits multiple arrays along the specified axis."""
14
15 def __init__(self, indices_or_sections, axis):
16 if not isinstance(indices_or_sections, (int, collections.Iterable)):
17 raise TypeError('indices_or_sections must be integer or 1-D array')
18 self.indices_or_sections = indices_or_sections
19 self.axis = axis
20
21 def check_type_forward(self, in_types):
22 type_check.expect(in_types.size() == 1)
23 type_check.expect(in_types[0].ndim > self.axis)
24
25 if isinstance(self.indices_or_sections, collections.Iterable):
26 max_index = type_check.Variable(
27 self.indices_or_sections[-1], 'max_index')
28 type_check.expect(in_types[0].shape[self.axis] > max_index)
29 else:
30 sections = type_check.Variable(
31 self.indices_or_sections, 'sections')
32 type_check.expect(in_types[0].shape[self.axis] % sections == 0)
33
34 def forward(self, x):
35 if isinstance(self.indices_or_sections, collections.Iterable):
36 cdimx = x[0].shape[self.axis]
37 ind = list(self.indices_or_sections)
38 ind.append(cdimx)
39 prev_i = 0
40 for i in ind:
41 cdimy = max(0, min(i, cdimx) - prev_i)
42 if cdimy == 0:
43 raise ValueError('Not support if shape contains 0')
44 prev_i = i
45 xp = cuda.get_array_module(*x)
46 return tuple(xp.split(x[0], self.indices_or_sections, self.axis))
47
48 def backward(self, x, gys):
49 xp = cuda.get_array_module(*x)
50 if any(gy is None for gy in gys):
51 gx = xp.zeros_like(x[0])
52 gxs = xp.split(gx, self.indices_or_sections, self.axis)
53 for gxi, gy in six.moves.zip(gxs, gys):
54 if gy is None:
55 continue
56 gxi[:] = gy
57 return gx,
58 else:
59 return xp.concatenate(gys, axis=self.axis),
60
61
62 def split_axis(x, indices_or_sections, axis, force_tuple=False):
63 """Splits given variables along an axis.
64
65 Args:
66 x (tuple of Variables): Variables to be split.
67 indices_or_sections (int or 1-D array): If this argument is an integer,
68 N, the array will be divided into N equal arrays along axis.
69 If it is a 1-D array of sorted integers, it
70 indicates the positions where the array is split.
71 axis (int): Axis that the input array is split along.
72 force_tuple (bool): If ``True``, this method returns a tuple even when
73 the number of outputs is one.
74
75 Returns:
76 tuple or Variable: Tuple of :class:`~chainer.Variable` objects
77 if the number of outputs is more than 1 or
78 :class:`~chainer.Variable` otherwise.
79 When ``force_tuple`` is ``True``, returned value is always a tuple
80 regardless of the number of outputs.
81
82 .. note::
83 This function raises :class:`ValueError` if at least
84 one of the outputs is split to zero-size
85 (i.e. ``axis``-th value of its shape is zero).
86
87 """
88 res = SplitAxis(indices_or_sections, axis)(x)
89 if force_tuple and isinstance(res, chainer.Variable):
90 res = (res,)
91 return res
92
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/chainer/functions/array/split_axis.py b/chainer/functions/array/split_axis.py
--- a/chainer/functions/array/split_axis.py
+++ b/chainer/functions/array/split_axis.py
@@ -23,9 +23,10 @@
type_check.expect(in_types[0].ndim > self.axis)
if isinstance(self.indices_or_sections, collections.Iterable):
- max_index = type_check.Variable(
- self.indices_or_sections[-1], 'max_index')
- type_check.expect(in_types[0].shape[self.axis] > max_index)
+ if len(self.indices_or_sections) > 0:
+ max_index = type_check.Variable(
+ self.indices_or_sections[-1], 'max_index')
+ type_check.expect(in_types[0].shape[self.axis] > max_index)
else:
sections = type_check.Variable(
self.indices_or_sections, 'sections')
|
{"golden_diff": "diff --git a/chainer/functions/array/split_axis.py b/chainer/functions/array/split_axis.py\n--- a/chainer/functions/array/split_axis.py\n+++ b/chainer/functions/array/split_axis.py\n@@ -23,9 +23,10 @@\n type_check.expect(in_types[0].ndim > self.axis)\n \n if isinstance(self.indices_or_sections, collections.Iterable):\n- max_index = type_check.Variable(\n- self.indices_or_sections[-1], 'max_index')\n- type_check.expect(in_types[0].shape[self.axis] > max_index)\n+ if len(self.indices_or_sections) > 0:\n+ max_index = type_check.Variable(\n+ self.indices_or_sections[-1], 'max_index')\n+ type_check.expect(in_types[0].shape[self.axis] > max_index)\n else:\n sections = type_check.Variable(\n self.indices_or_sections, 'sections')\n", "issue": "`split_axis` doesn't support empty sections\nThis code causes a TypeError.\n`functions.split_axis(x, [], 0)`\n\n", "before_files": [{"content": "import collections\n\nimport six\n\nimport chainer\nfrom chainer import cuda\nfrom chainer import function\nfrom chainer.utils import type_check\n\n\nclass SplitAxis(function.Function):\n\n \"\"\"Function that splits multiple arrays along the specified axis.\"\"\"\n\n def __init__(self, indices_or_sections, axis):\n if not isinstance(indices_or_sections, (int, collections.Iterable)):\n raise TypeError('indices_or_sections must be integer or 1-D array')\n self.indices_or_sections = indices_or_sections\n self.axis = axis\n\n def check_type_forward(self, in_types):\n type_check.expect(in_types.size() == 1)\n type_check.expect(in_types[0].ndim > self.axis)\n\n if isinstance(self.indices_or_sections, collections.Iterable):\n max_index = type_check.Variable(\n self.indices_or_sections[-1], 'max_index')\n type_check.expect(in_types[0].shape[self.axis] > max_index)\n else:\n sections = type_check.Variable(\n self.indices_or_sections, 'sections')\n type_check.expect(in_types[0].shape[self.axis] % sections == 0)\n\n def forward(self, x):\n if isinstance(self.indices_or_sections, collections.Iterable):\n cdimx = x[0].shape[self.axis]\n ind = list(self.indices_or_sections)\n ind.append(cdimx)\n prev_i = 0\n for i in ind:\n cdimy = max(0, min(i, cdimx) - prev_i)\n if cdimy == 0:\n raise ValueError('Not support if shape contains 0')\n prev_i = i\n xp = cuda.get_array_module(*x)\n return tuple(xp.split(x[0], self.indices_or_sections, self.axis))\n\n def backward(self, x, gys):\n xp = cuda.get_array_module(*x)\n if any(gy is None for gy in gys):\n gx = xp.zeros_like(x[0])\n gxs = xp.split(gx, self.indices_or_sections, self.axis)\n for gxi, gy in six.moves.zip(gxs, gys):\n if gy is None:\n continue\n gxi[:] = gy\n return gx,\n else:\n return xp.concatenate(gys, axis=self.axis),\n\n\ndef split_axis(x, indices_or_sections, axis, force_tuple=False):\n \"\"\"Splits given variables along an axis.\n\n Args:\n x (tuple of Variables): Variables to be split.\n indices_or_sections (int or 1-D array): If this argument is an integer,\n N, the array will be divided into N equal arrays along axis.\n If it is a 1-D array of sorted integers, it\n indicates the positions where the array is split.\n axis (int): Axis that the input array is split along.\n force_tuple (bool): If ``True``, this method returns a tuple even when\n the number of outputs is one.\n\n Returns:\n tuple or Variable: Tuple of :class:`~chainer.Variable` objects\n if the number of outputs is more than 1 or\n :class:`~chainer.Variable` otherwise.\n When ``force_tuple`` is ``True``, returned value is always a tuple\n regardless of the number of outputs.\n\n .. note::\n This function raises :class:`ValueError` if at least\n one of the outputs is split to zero-size\n (i.e. ``axis``-th value of its shape is zero).\n\n \"\"\"\n res = SplitAxis(indices_or_sections, axis)(x)\n if force_tuple and isinstance(res, chainer.Variable):\n res = (res,)\n return res\n", "path": "chainer/functions/array/split_axis.py"}], "after_files": [{"content": "import collections\n\nimport six\n\nimport chainer\nfrom chainer import cuda\nfrom chainer import function\nfrom chainer.utils import type_check\n\n\nclass SplitAxis(function.Function):\n\n \"\"\"Function that splits multiple arrays along the specified axis.\"\"\"\n\n def __init__(self, indices_or_sections, axis):\n if not isinstance(indices_or_sections, (int, collections.Iterable)):\n raise TypeError('indices_or_sections must be integer or 1-D array')\n self.indices_or_sections = indices_or_sections\n self.axis = axis\n\n def check_type_forward(self, in_types):\n type_check.expect(in_types.size() == 1)\n type_check.expect(in_types[0].ndim > self.axis)\n\n if isinstance(self.indices_or_sections, collections.Iterable):\n if len(self.indices_or_sections) > 0:\n max_index = type_check.Variable(\n self.indices_or_sections[-1], 'max_index')\n type_check.expect(in_types[0].shape[self.axis] > max_index)\n else:\n sections = type_check.Variable(\n self.indices_or_sections, 'sections')\n type_check.expect(in_types[0].shape[self.axis] % sections == 0)\n\n def forward(self, x):\n if isinstance(self.indices_or_sections, collections.Iterable):\n cdimx = x[0].shape[self.axis]\n ind = list(self.indices_or_sections)\n ind.append(cdimx)\n prev_i = 0\n for i in ind:\n cdimy = max(0, min(i, cdimx) - prev_i)\n if cdimy == 0:\n raise ValueError('Not support if shape contains 0')\n prev_i = i\n xp = cuda.get_array_module(*x)\n return tuple(xp.split(x[0], self.indices_or_sections, self.axis))\n\n def backward(self, x, gys):\n xp = cuda.get_array_module(*x)\n if any(gy is None for gy in gys):\n gx = xp.zeros_like(x[0])\n gxs = xp.split(gx, self.indices_or_sections, self.axis)\n for gxi, gy in six.moves.zip(gxs, gys):\n if gy is None:\n continue\n gxi[:] = gy\n return gx,\n else:\n return xp.concatenate(gys, axis=self.axis),\n\n\ndef split_axis(x, indices_or_sections, axis, force_tuple=False):\n \"\"\"Splits given variables along an axis.\n\n Args:\n x (tuple of Variables): Variables to be split.\n indices_or_sections (int or 1-D array): If this argument is an integer,\n N, the array will be divided into N equal arrays along axis.\n If it is a 1-D array of sorted integers, it\n indicates the positions where the array is split.\n axis (int): Axis that the input array is split along.\n force_tuple (bool): If ``True``, this method returns a tuple even when\n the number of outputs is one.\n\n Returns:\n tuple or Variable: Tuple of :class:`~chainer.Variable` objects\n if the number of outputs is more than 1 or\n :class:`~chainer.Variable` otherwise.\n When ``force_tuple`` is ``True``, returned value is always a tuple\n regardless of the number of outputs.\n\n .. note::\n This function raises :class:`ValueError` if at least\n one of the outputs is split to zero-size\n (i.e. ``axis``-th value of its shape is zero).\n\n \"\"\"\n res = SplitAxis(indices_or_sections, axis)(x)\n if force_tuple and isinstance(res, chainer.Variable):\n res = (res,)\n return res\n", "path": "chainer/functions/array/split_axis.py"}]}
| 1,247 | 197 |
gh_patches_debug_26510
|
rasdani/github-patches
|
git_diff
|
mitmproxy__mitmproxy-2325
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
HEAD method not allowed to access mitm.it
##### Steps to reproduce the problem:
1. Using mitmdump in transparent mode, with on-boarding port on 6969 (did not test on 80)
/mitmdump -T --host --insecure --onboarding-port 6969
2. On iPad + Chrome + Transparent mode, access to http://mitm.it:6969
3. An HEAD /cert/pem is sent, receive an "405 Method Not Allowed"
Any idea of any workaround?
##### Any other comments? What have you tried so far?
Exact packet:
Hypertext Transfer Protocol
HEAD /cert/pem HTTP/1.1\r\n
Host: mitm.it:6969\r\n
Connection: keep-alive\r\n
User-Agent: Mozilla/5.0 (iPad; CPU OS 9_2 like Mac OS X) AppleWebKit/601.1 (KHTML, like Gecko) CriOS/55.0.2883.79 Mobile/13C75 Safari/601.1.46\r\n
Accept-Encoding: gzip, deflate, sdch\r\n
Accept-Language: fr-FR,fr;q=0.8,en-US;q=0.6,en;q=0.4\r\n
\r\n
Answer:
Hypertext Transfer Protocol
HTTP/1.1 405 Method Not Allowed\r\n
Server: TornadoServer/4.4.2\r\n
Content-Length: 87\r\n
Date: Tue, 09 May 2017 13:35:38 GMT\r\n
Content-Type: text/html; charset=UTF-8\r\n
\r\n
##### System information
mitmdump --version
Mitmproxy version: 2.0.1 (release version) Precompiled Binary
Python version: 3.5.2
Platform: Darwin-16.5.0-x86_64-i386-64bit
SSL version: OpenSSL 1.0.2j 26 Sep 2016
Mac version: 10.12.4 ('', '', '') x86_64
HEAD method not allowed to access mitm.it
##### Steps to reproduce the problem:
1. Using mitmdump in transparent mode, with on-boarding port on 6969 (did not test on 80)
/mitmdump -T --host --insecure --onboarding-port 6969
2. On iPad + Chrome + Transparent mode, access to http://mitm.it:6969
3. An HEAD /cert/pem is sent, receive an "405 Method Not Allowed"
Any idea of any workaround?
##### Any other comments? What have you tried so far?
Exact packet:
Hypertext Transfer Protocol
HEAD /cert/pem HTTP/1.1\r\n
Host: mitm.it:6969\r\n
Connection: keep-alive\r\n
User-Agent: Mozilla/5.0 (iPad; CPU OS 9_2 like Mac OS X) AppleWebKit/601.1 (KHTML, like Gecko) CriOS/55.0.2883.79 Mobile/13C75 Safari/601.1.46\r\n
Accept-Encoding: gzip, deflate, sdch\r\n
Accept-Language: fr-FR,fr;q=0.8,en-US;q=0.6,en;q=0.4\r\n
\r\n
Answer:
Hypertext Transfer Protocol
HTTP/1.1 405 Method Not Allowed\r\n
Server: TornadoServer/4.4.2\r\n
Content-Length: 87\r\n
Date: Tue, 09 May 2017 13:35:38 GMT\r\n
Content-Type: text/html; charset=UTF-8\r\n
\r\n
##### System information
mitmdump --version
Mitmproxy version: 2.0.1 (release version) Precompiled Binary
Python version: 3.5.2
Platform: Darwin-16.5.0-x86_64-i386-64bit
SSL version: OpenSSL 1.0.2j 26 Sep 2016
Mac version: 10.12.4 ('', '', '') x86_64
HEAD method not allowed to access mitm.it
##### Steps to reproduce the problem:
1. Using mitmdump in transparent mode, with on-boarding port on 6969 (did not test on 80)
/mitmdump -T --host --insecure --onboarding-port 6969
2. On iPad + Chrome + Transparent mode, access to http://mitm.it:6969
3. An HEAD /cert/pem is sent, receive an "405 Method Not Allowed"
Any idea of any workaround?
##### Any other comments? What have you tried so far?
Exact packet:
Hypertext Transfer Protocol
HEAD /cert/pem HTTP/1.1\r\n
Host: mitm.it:6969\r\n
Connection: keep-alive\r\n
User-Agent: Mozilla/5.0 (iPad; CPU OS 9_2 like Mac OS X) AppleWebKit/601.1 (KHTML, like Gecko) CriOS/55.0.2883.79 Mobile/13C75 Safari/601.1.46\r\n
Accept-Encoding: gzip, deflate, sdch\r\n
Accept-Language: fr-FR,fr;q=0.8,en-US;q=0.6,en;q=0.4\r\n
\r\n
Answer:
Hypertext Transfer Protocol
HTTP/1.1 405 Method Not Allowed\r\n
Server: TornadoServer/4.4.2\r\n
Content-Length: 87\r\n
Date: Tue, 09 May 2017 13:35:38 GMT\r\n
Content-Type: text/html; charset=UTF-8\r\n
\r\n
##### System information
mitmdump --version
Mitmproxy version: 2.0.1 (release version) Precompiled Binary
Python version: 3.5.2
Platform: Darwin-16.5.0-x86_64-i386-64bit
SSL version: OpenSSL 1.0.2j 26 Sep 2016
Mac version: 10.12.4 ('', '', '') x86_64
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mitmproxy/addons/onboardingapp/app.py`
Content:
```
1 import os
2
3 import tornado.template
4 import tornado.web
5 import tornado.wsgi
6
7 from mitmproxy.utils import data
8 from mitmproxy.proxy import config
9
10 loader = tornado.template.Loader(data.pkg_data.path("addons/onboardingapp/templates"))
11
12
13 class Adapter(tornado.wsgi.WSGIAdapter):
14 # Tornado doesn't make the WSGI environment available to pages, so this
15 # hideous monkey patch is the easiest way to get to the mitmproxy.master
16 # variable.
17
18 def __init__(self, application):
19 self._application = application
20
21 def application(self, request):
22 request.master = self.environ["mitmproxy.master"]
23 return self._application(request)
24
25 def __call__(self, environ, start_response):
26 self.environ = environ
27 return tornado.wsgi.WSGIAdapter.__call__(
28 self,
29 environ,
30 start_response
31 )
32
33
34 class Index(tornado.web.RequestHandler):
35
36 def get(self):
37 t = loader.load("index.html")
38 self.write(t.generate())
39
40
41 class PEM(tornado.web.RequestHandler):
42
43 @property
44 def filename(self):
45 return config.CONF_BASENAME + "-ca-cert.pem"
46
47 def get(self):
48 p = os.path.join(self.request.master.options.cadir, self.filename)
49 p = os.path.expanduser(p)
50 self.set_header("Content-Type", "application/x-x509-ca-cert")
51 self.set_header(
52 "Content-Disposition",
53 "inline; filename={}".format(
54 self.filename))
55
56 with open(p, "rb") as f:
57 self.write(f.read())
58
59
60 class P12(tornado.web.RequestHandler):
61
62 @property
63 def filename(self):
64 return config.CONF_BASENAME + "-ca-cert.p12"
65
66 def get(self):
67 p = os.path.join(self.request.master.options.cadir, self.filename)
68 p = os.path.expanduser(p)
69 self.set_header("Content-Type", "application/x-pkcs12")
70 self.set_header(
71 "Content-Disposition",
72 "inline; filename={}".format(
73 self.filename))
74
75 with open(p, "rb") as f:
76 self.write(f.read())
77
78
79 application = tornado.web.Application(
80 [
81 (r"/", Index),
82 (r"/cert/pem", PEM),
83 (r"/cert/p12", P12),
84 (
85 r"/static/(.*)",
86 tornado.web.StaticFileHandler,
87 {
88 "path": data.pkg_data.path("addons/onboardingapp/static")
89 }
90 ),
91 ],
92 # debug=True
93 )
94
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mitmproxy/addons/onboardingapp/app.py b/mitmproxy/addons/onboardingapp/app.py
--- a/mitmproxy/addons/onboardingapp/app.py
+++ b/mitmproxy/addons/onboardingapp/app.py
@@ -44,6 +44,18 @@
def filename(self):
return config.CONF_BASENAME + "-ca-cert.pem"
+ def head(self):
+ p = os.path.join(self.request.master.options.cadir, self.filename)
+ p = os.path.expanduser(p)
+ content_length = os.path.getsize(p)
+
+ self.set_header("Content-Type", "application/x-x509-ca-cert")
+ self.set_header(
+ "Content-Disposition",
+ "inline; filename={}".format(
+ self.filename))
+ self.set_header("Content-Length", content_length)
+
def get(self):
p = os.path.join(self.request.master.options.cadir, self.filename)
p = os.path.expanduser(p)
@@ -63,6 +75,19 @@
def filename(self):
return config.CONF_BASENAME + "-ca-cert.p12"
+ def head(self):
+ p = os.path.join(self.request.master.options.cadir, self.filename)
+ p = os.path.expanduser(p)
+ content_length = os.path.getsize(p)
+
+ self.set_header("Content-Type", "application/x-pkcs12")
+ self.set_header(
+ "Content-Disposition",
+ "inline; filename={}".format(
+ self.filename))
+
+ self.set_header("Content-Length", content_length)
+
def get(self):
p = os.path.join(self.request.master.options.cadir, self.filename)
p = os.path.expanduser(p)
|
{"golden_diff": "diff --git a/mitmproxy/addons/onboardingapp/app.py b/mitmproxy/addons/onboardingapp/app.py\n--- a/mitmproxy/addons/onboardingapp/app.py\n+++ b/mitmproxy/addons/onboardingapp/app.py\n@@ -44,6 +44,18 @@\n def filename(self):\n return config.CONF_BASENAME + \"-ca-cert.pem\"\n \n+ def head(self):\n+ p = os.path.join(self.request.master.options.cadir, self.filename)\n+ p = os.path.expanduser(p)\n+ content_length = os.path.getsize(p)\n+\n+ self.set_header(\"Content-Type\", \"application/x-x509-ca-cert\")\n+ self.set_header(\n+ \"Content-Disposition\",\n+ \"inline; filename={}\".format(\n+ self.filename))\n+ self.set_header(\"Content-Length\", content_length)\n+\n def get(self):\n p = os.path.join(self.request.master.options.cadir, self.filename)\n p = os.path.expanduser(p)\n@@ -63,6 +75,19 @@\n def filename(self):\n return config.CONF_BASENAME + \"-ca-cert.p12\"\n \n+ def head(self):\n+ p = os.path.join(self.request.master.options.cadir, self.filename)\n+ p = os.path.expanduser(p)\n+ content_length = os.path.getsize(p)\n+\n+ self.set_header(\"Content-Type\", \"application/x-pkcs12\")\n+ self.set_header(\n+ \"Content-Disposition\",\n+ \"inline; filename={}\".format(\n+ self.filename))\n+\n+ self.set_header(\"Content-Length\", content_length)\n+\n def get(self):\n p = os.path.join(self.request.master.options.cadir, self.filename)\n p = os.path.expanduser(p)\n", "issue": "HEAD method not allowed to access mitm.it\n##### Steps to reproduce the problem:\r\n\r\n1. Using mitmdump in transparent mode, with on-boarding port on 6969 (did not test on 80)\r\n/mitmdump -T --host --insecure --onboarding-port 6969\r\n\r\n2. On iPad + Chrome + Transparent mode, access to http://mitm.it:6969\r\n\r\n3. An HEAD /cert/pem is sent, receive an \"405 Method Not Allowed\"\r\n\r\nAny idea of any workaround?\r\n\r\n\r\n##### Any other comments? What have you tried so far?\r\n\r\nExact packet:\r\nHypertext Transfer Protocol\r\n HEAD /cert/pem HTTP/1.1\\r\\n\r\n Host: mitm.it:6969\\r\\n\r\n Connection: keep-alive\\r\\n\r\n User-Agent: Mozilla/5.0 (iPad; CPU OS 9_2 like Mac OS X) AppleWebKit/601.1 (KHTML, like Gecko) CriOS/55.0.2883.79 Mobile/13C75 Safari/601.1.46\\r\\n\r\n Accept-Encoding: gzip, deflate, sdch\\r\\n\r\n Accept-Language: fr-FR,fr;q=0.8,en-US;q=0.6,en;q=0.4\\r\\n\r\n \\r\\n\r\n\r\n\r\n\r\nAnswer:\r\nHypertext Transfer Protocol\r\n HTTP/1.1 405 Method Not Allowed\\r\\n\r\n Server: TornadoServer/4.4.2\\r\\n\r\n Content-Length: 87\\r\\n\r\n Date: Tue, 09 May 2017 13:35:38 GMT\\r\\n\r\n Content-Type: text/html; charset=UTF-8\\r\\n\r\n \\r\\n\r\n\r\n\r\n\r\n##### System information\r\n\r\nmitmdump --version\r\nMitmproxy version: 2.0.1 (release version) Precompiled Binary\r\nPython version: 3.5.2\r\nPlatform: Darwin-16.5.0-x86_64-i386-64bit\r\nSSL version: OpenSSL 1.0.2j 26 Sep 2016\r\nMac version: 10.12.4 ('', '', '') x86_64\r\n\nHEAD method not allowed to access mitm.it\n##### Steps to reproduce the problem:\r\n\r\n1. Using mitmdump in transparent mode, with on-boarding port on 6969 (did not test on 80)\r\n/mitmdump -T --host --insecure --onboarding-port 6969\r\n\r\n2. On iPad + Chrome + Transparent mode, access to http://mitm.it:6969\r\n\r\n3. An HEAD /cert/pem is sent, receive an \"405 Method Not Allowed\"\r\n\r\nAny idea of any workaround?\r\n\r\n\r\n##### Any other comments? What have you tried so far?\r\n\r\nExact packet:\r\nHypertext Transfer Protocol\r\n HEAD /cert/pem HTTP/1.1\\r\\n\r\n Host: mitm.it:6969\\r\\n\r\n Connection: keep-alive\\r\\n\r\n User-Agent: Mozilla/5.0 (iPad; CPU OS 9_2 like Mac OS X) AppleWebKit/601.1 (KHTML, like Gecko) CriOS/55.0.2883.79 Mobile/13C75 Safari/601.1.46\\r\\n\r\n Accept-Encoding: gzip, deflate, sdch\\r\\n\r\n Accept-Language: fr-FR,fr;q=0.8,en-US;q=0.6,en;q=0.4\\r\\n\r\n \\r\\n\r\n\r\n\r\n\r\nAnswer:\r\nHypertext Transfer Protocol\r\n HTTP/1.1 405 Method Not Allowed\\r\\n\r\n Server: TornadoServer/4.4.2\\r\\n\r\n Content-Length: 87\\r\\n\r\n Date: Tue, 09 May 2017 13:35:38 GMT\\r\\n\r\n Content-Type: text/html; charset=UTF-8\\r\\n\r\n \\r\\n\r\n\r\n\r\n\r\n##### System information\r\n\r\nmitmdump --version\r\nMitmproxy version: 2.0.1 (release version) Precompiled Binary\r\nPython version: 3.5.2\r\nPlatform: Darwin-16.5.0-x86_64-i386-64bit\r\nSSL version: OpenSSL 1.0.2j 26 Sep 2016\r\nMac version: 10.12.4 ('', '', '') x86_64\r\n\nHEAD method not allowed to access mitm.it\n##### Steps to reproduce the problem:\r\n\r\n1. Using mitmdump in transparent mode, with on-boarding port on 6969 (did not test on 80)\r\n/mitmdump -T --host --insecure --onboarding-port 6969\r\n\r\n2. On iPad + Chrome + Transparent mode, access to http://mitm.it:6969\r\n\r\n3. An HEAD /cert/pem is sent, receive an \"405 Method Not Allowed\"\r\n\r\nAny idea of any workaround?\r\n\r\n\r\n##### Any other comments? What have you tried so far?\r\n\r\nExact packet:\r\nHypertext Transfer Protocol\r\n HEAD /cert/pem HTTP/1.1\\r\\n\r\n Host: mitm.it:6969\\r\\n\r\n Connection: keep-alive\\r\\n\r\n User-Agent: Mozilla/5.0 (iPad; CPU OS 9_2 like Mac OS X) AppleWebKit/601.1 (KHTML, like Gecko) CriOS/55.0.2883.79 Mobile/13C75 Safari/601.1.46\\r\\n\r\n Accept-Encoding: gzip, deflate, sdch\\r\\n\r\n Accept-Language: fr-FR,fr;q=0.8,en-US;q=0.6,en;q=0.4\\r\\n\r\n \\r\\n\r\n\r\n\r\n\r\nAnswer:\r\nHypertext Transfer Protocol\r\n HTTP/1.1 405 Method Not Allowed\\r\\n\r\n Server: TornadoServer/4.4.2\\r\\n\r\n Content-Length: 87\\r\\n\r\n Date: Tue, 09 May 2017 13:35:38 GMT\\r\\n\r\n Content-Type: text/html; charset=UTF-8\\r\\n\r\n \\r\\n\r\n\r\n\r\n\r\n##### System information\r\n\r\nmitmdump --version\r\nMitmproxy version: 2.0.1 (release version) Precompiled Binary\r\nPython version: 3.5.2\r\nPlatform: Darwin-16.5.0-x86_64-i386-64bit\r\nSSL version: OpenSSL 1.0.2j 26 Sep 2016\r\nMac version: 10.12.4 ('', '', '') x86_64\r\n\n", "before_files": [{"content": "import os\n\nimport tornado.template\nimport tornado.web\nimport tornado.wsgi\n\nfrom mitmproxy.utils import data\nfrom mitmproxy.proxy import config\n\nloader = tornado.template.Loader(data.pkg_data.path(\"addons/onboardingapp/templates\"))\n\n\nclass Adapter(tornado.wsgi.WSGIAdapter):\n # Tornado doesn't make the WSGI environment available to pages, so this\n # hideous monkey patch is the easiest way to get to the mitmproxy.master\n # variable.\n\n def __init__(self, application):\n self._application = application\n\n def application(self, request):\n request.master = self.environ[\"mitmproxy.master\"]\n return self._application(request)\n\n def __call__(self, environ, start_response):\n self.environ = environ\n return tornado.wsgi.WSGIAdapter.__call__(\n self,\n environ,\n start_response\n )\n\n\nclass Index(tornado.web.RequestHandler):\n\n def get(self):\n t = loader.load(\"index.html\")\n self.write(t.generate())\n\n\nclass PEM(tornado.web.RequestHandler):\n\n @property\n def filename(self):\n return config.CONF_BASENAME + \"-ca-cert.pem\"\n\n def get(self):\n p = os.path.join(self.request.master.options.cadir, self.filename)\n p = os.path.expanduser(p)\n self.set_header(\"Content-Type\", \"application/x-x509-ca-cert\")\n self.set_header(\n \"Content-Disposition\",\n \"inline; filename={}\".format(\n self.filename))\n\n with open(p, \"rb\") as f:\n self.write(f.read())\n\n\nclass P12(tornado.web.RequestHandler):\n\n @property\n def filename(self):\n return config.CONF_BASENAME + \"-ca-cert.p12\"\n\n def get(self):\n p = os.path.join(self.request.master.options.cadir, self.filename)\n p = os.path.expanduser(p)\n self.set_header(\"Content-Type\", \"application/x-pkcs12\")\n self.set_header(\n \"Content-Disposition\",\n \"inline; filename={}\".format(\n self.filename))\n\n with open(p, \"rb\") as f:\n self.write(f.read())\n\n\napplication = tornado.web.Application(\n [\n (r\"/\", Index),\n (r\"/cert/pem\", PEM),\n (r\"/cert/p12\", P12),\n (\n r\"/static/(.*)\",\n tornado.web.StaticFileHandler,\n {\n \"path\": data.pkg_data.path(\"addons/onboardingapp/static\")\n }\n ),\n ],\n # debug=True\n)\n", "path": "mitmproxy/addons/onboardingapp/app.py"}], "after_files": [{"content": "import os\n\nimport tornado.template\nimport tornado.web\nimport tornado.wsgi\n\nfrom mitmproxy.utils import data\nfrom mitmproxy.proxy import config\n\nloader = tornado.template.Loader(data.pkg_data.path(\"addons/onboardingapp/templates\"))\n\n\nclass Adapter(tornado.wsgi.WSGIAdapter):\n # Tornado doesn't make the WSGI environment available to pages, so this\n # hideous monkey patch is the easiest way to get to the mitmproxy.master\n # variable.\n\n def __init__(self, application):\n self._application = application\n\n def application(self, request):\n request.master = self.environ[\"mitmproxy.master\"]\n return self._application(request)\n\n def __call__(self, environ, start_response):\n self.environ = environ\n return tornado.wsgi.WSGIAdapter.__call__(\n self,\n environ,\n start_response\n )\n\n\nclass Index(tornado.web.RequestHandler):\n\n def get(self):\n t = loader.load(\"index.html\")\n self.write(t.generate())\n\n\nclass PEM(tornado.web.RequestHandler):\n\n @property\n def filename(self):\n return config.CONF_BASENAME + \"-ca-cert.pem\"\n\n def head(self):\n p = os.path.join(self.request.master.options.cadir, self.filename)\n p = os.path.expanduser(p)\n content_length = os.path.getsize(p)\n\n self.set_header(\"Content-Type\", \"application/x-x509-ca-cert\")\n self.set_header(\n \"Content-Disposition\",\n \"inline; filename={}\".format(\n self.filename))\n self.set_header(\"Content-Length\", content_length)\n\n def get(self):\n p = os.path.join(self.request.master.options.cadir, self.filename)\n p = os.path.expanduser(p)\n self.set_header(\"Content-Type\", \"application/x-x509-ca-cert\")\n self.set_header(\n \"Content-Disposition\",\n \"inline; filename={}\".format(\n self.filename))\n\n with open(p, \"rb\") as f:\n self.write(f.read())\n\n\nclass P12(tornado.web.RequestHandler):\n\n @property\n def filename(self):\n return config.CONF_BASENAME + \"-ca-cert.p12\"\n\n def head(self):\n p = os.path.join(self.request.master.options.cadir, self.filename)\n p = os.path.expanduser(p)\n content_length = os.path.getsize(p)\n\n self.set_header(\"Content-Type\", \"application/x-pkcs12\")\n self.set_header(\n \"Content-Disposition\",\n \"inline; filename={}\".format(\n self.filename))\n\n self.set_header(\"Content-Length\", content_length)\n\n def get(self):\n p = os.path.join(self.request.master.options.cadir, self.filename)\n p = os.path.expanduser(p)\n self.set_header(\"Content-Type\", \"application/x-pkcs12\")\n self.set_header(\n \"Content-Disposition\",\n \"inline; filename={}\".format(\n self.filename))\n\n with open(p, \"rb\") as f:\n self.write(f.read())\n\n\napplication = tornado.web.Application(\n [\n (r\"/\", Index),\n (r\"/cert/pem\", PEM),\n (r\"/cert/p12\", P12),\n (\n r\"/static/(.*)\",\n tornado.web.StaticFileHandler,\n {\n \"path\": data.pkg_data.path(\"addons/onboardingapp/static\")\n }\n ),\n ],\n # debug=True\n)\n", "path": "mitmproxy/addons/onboardingapp/app.py"}]}
| 2,499 | 386 |
gh_patches_debug_35028
|
rasdani/github-patches
|
git_diff
|
strawberry-graphql__strawberry-1071
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Compatibility with pydantic 1.4
I'm trying to use strawberry in a project that has pydantic pinned at 1.4. I chatted with @patrick91 on discord about this, and he thought it would be reasonable to achieve compatibility with this version.
Pydantic appears to only be used in the [strawberry.experimental](https://github.com/strawberry-graphql/strawberry/blob/main/strawberry/experimental/__init__.py) module, which only gets loaded if pydantic is present. One way to solve this for me in particular would be to lazily load strawberry.experimental/pydantic, such that when an older version of pydantic is present, one can still import other packages in strawberry.
Thank you!
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `strawberry/experimental/pydantic/fields.py`
Content:
```
1 from decimal import Decimal
2 from typing import Optional
3 from uuid import UUID
4
5 import pydantic
6
7 from .exceptions import UnsupportedTypeError
8
9
10 FIELDS_MAP = {
11 pydantic.NoneStr: Optional[str],
12 pydantic.NoneBytes: Optional[bytes],
13 pydantic.StrBytes: None,
14 pydantic.NoneStrBytes: None,
15 pydantic.StrictStr: str,
16 pydantic.ConstrainedBytes: bytes,
17 pydantic.conbytes: bytes,
18 pydantic.ConstrainedList: None,
19 pydantic.conlist: None,
20 pydantic.ConstrainedSet: None,
21 pydantic.conset: None,
22 pydantic.ConstrainedStr: str,
23 pydantic.constr: str,
24 pydantic.EmailStr: str,
25 pydantic.PyObject: None,
26 pydantic.ConstrainedInt: int,
27 pydantic.conint: int,
28 pydantic.PositiveInt: int,
29 pydantic.NegativeInt: int,
30 pydantic.ConstrainedFloat: float,
31 pydantic.confloat: float,
32 pydantic.PositiveFloat: float,
33 pydantic.NegativeFloat: float,
34 pydantic.ConstrainedDecimal: Decimal,
35 pydantic.condecimal: Decimal,
36 pydantic.UUID1: UUID,
37 pydantic.UUID3: UUID,
38 pydantic.UUID4: UUID,
39 pydantic.UUID5: UUID,
40 pydantic.FilePath: None,
41 pydantic.DirectoryPath: None,
42 pydantic.Json: None,
43 pydantic.JsonWrapper: None,
44 pydantic.SecretStr: str,
45 pydantic.SecretBytes: bytes,
46 pydantic.StrictBool: bool,
47 pydantic.StrictInt: int,
48 pydantic.StrictFloat: float,
49 pydantic.PaymentCardNumber: None,
50 pydantic.ByteSize: None,
51 pydantic.AnyUrl: str,
52 pydantic.AnyHttpUrl: str,
53 pydantic.HttpUrl: str,
54 pydantic.PostgresDsn: str,
55 pydantic.RedisDsn: str,
56 }
57
58
59 def get_basic_type(type_):
60 if isinstance(type_, type):
61 if issubclass(type_, pydantic.ConstrainedInt):
62 return int
63 if issubclass(type_, pydantic.ConstrainedStr):
64 return str
65
66 if type_ in FIELDS_MAP:
67 type_ = FIELDS_MAP.get(type_)
68
69 if type_ is None:
70 raise UnsupportedTypeError()
71
72 return type_
73
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/strawberry/experimental/pydantic/fields.py b/strawberry/experimental/pydantic/fields.py
--- a/strawberry/experimental/pydantic/fields.py
+++ b/strawberry/experimental/pydantic/fields.py
@@ -7,52 +7,59 @@
from .exceptions import UnsupportedTypeError
+ATTR_TO_TYPE_MAP = {
+ "NoneStr": Optional[str],
+ "NoneBytes": Optional[bytes],
+ "StrBytes": None,
+ "NoneStrBytes": None,
+ "StrictStr": str,
+ "ConstrainedBytes": bytes,
+ "conbytes": bytes,
+ "ConstrainedList": None,
+ "conlist": None,
+ "ConstrainedSet": None,
+ "conset": None,
+ "ConstrainedStr": str,
+ "constr": str,
+ "EmailStr": str,
+ "PyObject": None,
+ "ConstrainedInt": int,
+ "conint": int,
+ "PositiveInt": int,
+ "NegativeInt": int,
+ "ConstrainedFloat": float,
+ "confloat": float,
+ "PositiveFloat": float,
+ "NegativeFloat": float,
+ "ConstrainedDecimal": Decimal,
+ "condecimal": Decimal,
+ "UUID1": UUID,
+ "UUID3": UUID,
+ "UUID4": UUID,
+ "UUID5": UUID,
+ "FilePath": None,
+ "DirectoryPath": None,
+ "Json": None,
+ "JsonWrapper": None,
+ "SecretStr": str,
+ "SecretBytes": bytes,
+ "StrictBool": bool,
+ "StrictInt": int,
+ "StrictFloat": float,
+ "PaymentCardNumber": None,
+ "ByteSize": None,
+ "AnyUrl": str,
+ "AnyHttpUrl": str,
+ "HttpUrl": str,
+ "PostgresDsn": str,
+ "RedisDsn": str,
+}
+
+
FIELDS_MAP = {
- pydantic.NoneStr: Optional[str],
- pydantic.NoneBytes: Optional[bytes],
- pydantic.StrBytes: None,
- pydantic.NoneStrBytes: None,
- pydantic.StrictStr: str,
- pydantic.ConstrainedBytes: bytes,
- pydantic.conbytes: bytes,
- pydantic.ConstrainedList: None,
- pydantic.conlist: None,
- pydantic.ConstrainedSet: None,
- pydantic.conset: None,
- pydantic.ConstrainedStr: str,
- pydantic.constr: str,
- pydantic.EmailStr: str,
- pydantic.PyObject: None,
- pydantic.ConstrainedInt: int,
- pydantic.conint: int,
- pydantic.PositiveInt: int,
- pydantic.NegativeInt: int,
- pydantic.ConstrainedFloat: float,
- pydantic.confloat: float,
- pydantic.PositiveFloat: float,
- pydantic.NegativeFloat: float,
- pydantic.ConstrainedDecimal: Decimal,
- pydantic.condecimal: Decimal,
- pydantic.UUID1: UUID,
- pydantic.UUID3: UUID,
- pydantic.UUID4: UUID,
- pydantic.UUID5: UUID,
- pydantic.FilePath: None,
- pydantic.DirectoryPath: None,
- pydantic.Json: None,
- pydantic.JsonWrapper: None,
- pydantic.SecretStr: str,
- pydantic.SecretBytes: bytes,
- pydantic.StrictBool: bool,
- pydantic.StrictInt: int,
- pydantic.StrictFloat: float,
- pydantic.PaymentCardNumber: None,
- pydantic.ByteSize: None,
- pydantic.AnyUrl: str,
- pydantic.AnyHttpUrl: str,
- pydantic.HttpUrl: str,
- pydantic.PostgresDsn: str,
- pydantic.RedisDsn: str,
+ getattr(pydantic, field_name): type
+ for field_name, type in ATTR_TO_TYPE_MAP.items()
+ if hasattr(pydantic, field_name)
}
|
{"golden_diff": "diff --git a/strawberry/experimental/pydantic/fields.py b/strawberry/experimental/pydantic/fields.py\n--- a/strawberry/experimental/pydantic/fields.py\n+++ b/strawberry/experimental/pydantic/fields.py\n@@ -7,52 +7,59 @@\n from .exceptions import UnsupportedTypeError\n \n \n+ATTR_TO_TYPE_MAP = {\n+ \"NoneStr\": Optional[str],\n+ \"NoneBytes\": Optional[bytes],\n+ \"StrBytes\": None,\n+ \"NoneStrBytes\": None,\n+ \"StrictStr\": str,\n+ \"ConstrainedBytes\": bytes,\n+ \"conbytes\": bytes,\n+ \"ConstrainedList\": None,\n+ \"conlist\": None,\n+ \"ConstrainedSet\": None,\n+ \"conset\": None,\n+ \"ConstrainedStr\": str,\n+ \"constr\": str,\n+ \"EmailStr\": str,\n+ \"PyObject\": None,\n+ \"ConstrainedInt\": int,\n+ \"conint\": int,\n+ \"PositiveInt\": int,\n+ \"NegativeInt\": int,\n+ \"ConstrainedFloat\": float,\n+ \"confloat\": float,\n+ \"PositiveFloat\": float,\n+ \"NegativeFloat\": float,\n+ \"ConstrainedDecimal\": Decimal,\n+ \"condecimal\": Decimal,\n+ \"UUID1\": UUID,\n+ \"UUID3\": UUID,\n+ \"UUID4\": UUID,\n+ \"UUID5\": UUID,\n+ \"FilePath\": None,\n+ \"DirectoryPath\": None,\n+ \"Json\": None,\n+ \"JsonWrapper\": None,\n+ \"SecretStr\": str,\n+ \"SecretBytes\": bytes,\n+ \"StrictBool\": bool,\n+ \"StrictInt\": int,\n+ \"StrictFloat\": float,\n+ \"PaymentCardNumber\": None,\n+ \"ByteSize\": None,\n+ \"AnyUrl\": str,\n+ \"AnyHttpUrl\": str,\n+ \"HttpUrl\": str,\n+ \"PostgresDsn\": str,\n+ \"RedisDsn\": str,\n+}\n+\n+\n FIELDS_MAP = {\n- pydantic.NoneStr: Optional[str],\n- pydantic.NoneBytes: Optional[bytes],\n- pydantic.StrBytes: None,\n- pydantic.NoneStrBytes: None,\n- pydantic.StrictStr: str,\n- pydantic.ConstrainedBytes: bytes,\n- pydantic.conbytes: bytes,\n- pydantic.ConstrainedList: None,\n- pydantic.conlist: None,\n- pydantic.ConstrainedSet: None,\n- pydantic.conset: None,\n- pydantic.ConstrainedStr: str,\n- pydantic.constr: str,\n- pydantic.EmailStr: str,\n- pydantic.PyObject: None,\n- pydantic.ConstrainedInt: int,\n- pydantic.conint: int,\n- pydantic.PositiveInt: int,\n- pydantic.NegativeInt: int,\n- pydantic.ConstrainedFloat: float,\n- pydantic.confloat: float,\n- pydantic.PositiveFloat: float,\n- pydantic.NegativeFloat: float,\n- pydantic.ConstrainedDecimal: Decimal,\n- pydantic.condecimal: Decimal,\n- pydantic.UUID1: UUID,\n- pydantic.UUID3: UUID,\n- pydantic.UUID4: UUID,\n- pydantic.UUID5: UUID,\n- pydantic.FilePath: None,\n- pydantic.DirectoryPath: None,\n- pydantic.Json: None,\n- pydantic.JsonWrapper: None,\n- pydantic.SecretStr: str,\n- pydantic.SecretBytes: bytes,\n- pydantic.StrictBool: bool,\n- pydantic.StrictInt: int,\n- pydantic.StrictFloat: float,\n- pydantic.PaymentCardNumber: None,\n- pydantic.ByteSize: None,\n- pydantic.AnyUrl: str,\n- pydantic.AnyHttpUrl: str,\n- pydantic.HttpUrl: str,\n- pydantic.PostgresDsn: str,\n- pydantic.RedisDsn: str,\n+ getattr(pydantic, field_name): type\n+ for field_name, type in ATTR_TO_TYPE_MAP.items()\n+ if hasattr(pydantic, field_name)\n }\n", "issue": "Compatibility with pydantic 1.4\nI'm trying to use strawberry in a project that has pydantic pinned at 1.4. I chatted with @patrick91 on discord about this, and he thought it would be reasonable to achieve compatibility with this version.\r\n\r\nPydantic appears to only be used in the [strawberry.experimental](https://github.com/strawberry-graphql/strawberry/blob/main/strawberry/experimental/__init__.py) module, which only gets loaded if pydantic is present. One way to solve this for me in particular would be to lazily load strawberry.experimental/pydantic, such that when an older version of pydantic is present, one can still import other packages in strawberry.\r\n\r\nThank you!\n", "before_files": [{"content": "from decimal import Decimal\nfrom typing import Optional\nfrom uuid import UUID\n\nimport pydantic\n\nfrom .exceptions import UnsupportedTypeError\n\n\nFIELDS_MAP = {\n pydantic.NoneStr: Optional[str],\n pydantic.NoneBytes: Optional[bytes],\n pydantic.StrBytes: None,\n pydantic.NoneStrBytes: None,\n pydantic.StrictStr: str,\n pydantic.ConstrainedBytes: bytes,\n pydantic.conbytes: bytes,\n pydantic.ConstrainedList: None,\n pydantic.conlist: None,\n pydantic.ConstrainedSet: None,\n pydantic.conset: None,\n pydantic.ConstrainedStr: str,\n pydantic.constr: str,\n pydantic.EmailStr: str,\n pydantic.PyObject: None,\n pydantic.ConstrainedInt: int,\n pydantic.conint: int,\n pydantic.PositiveInt: int,\n pydantic.NegativeInt: int,\n pydantic.ConstrainedFloat: float,\n pydantic.confloat: float,\n pydantic.PositiveFloat: float,\n pydantic.NegativeFloat: float,\n pydantic.ConstrainedDecimal: Decimal,\n pydantic.condecimal: Decimal,\n pydantic.UUID1: UUID,\n pydantic.UUID3: UUID,\n pydantic.UUID4: UUID,\n pydantic.UUID5: UUID,\n pydantic.FilePath: None,\n pydantic.DirectoryPath: None,\n pydantic.Json: None,\n pydantic.JsonWrapper: None,\n pydantic.SecretStr: str,\n pydantic.SecretBytes: bytes,\n pydantic.StrictBool: bool,\n pydantic.StrictInt: int,\n pydantic.StrictFloat: float,\n pydantic.PaymentCardNumber: None,\n pydantic.ByteSize: None,\n pydantic.AnyUrl: str,\n pydantic.AnyHttpUrl: str,\n pydantic.HttpUrl: str,\n pydantic.PostgresDsn: str,\n pydantic.RedisDsn: str,\n}\n\n\ndef get_basic_type(type_):\n if isinstance(type_, type):\n if issubclass(type_, pydantic.ConstrainedInt):\n return int\n if issubclass(type_, pydantic.ConstrainedStr):\n return str\n\n if type_ in FIELDS_MAP:\n type_ = FIELDS_MAP.get(type_)\n\n if type_ is None:\n raise UnsupportedTypeError()\n\n return type_\n", "path": "strawberry/experimental/pydantic/fields.py"}], "after_files": [{"content": "from decimal import Decimal\nfrom typing import Optional\nfrom uuid import UUID\n\nimport pydantic\n\nfrom .exceptions import UnsupportedTypeError\n\n\nATTR_TO_TYPE_MAP = {\n \"NoneStr\": Optional[str],\n \"NoneBytes\": Optional[bytes],\n \"StrBytes\": None,\n \"NoneStrBytes\": None,\n \"StrictStr\": str,\n \"ConstrainedBytes\": bytes,\n \"conbytes\": bytes,\n \"ConstrainedList\": None,\n \"conlist\": None,\n \"ConstrainedSet\": None,\n \"conset\": None,\n \"ConstrainedStr\": str,\n \"constr\": str,\n \"EmailStr\": str,\n \"PyObject\": None,\n \"ConstrainedInt\": int,\n \"conint\": int,\n \"PositiveInt\": int,\n \"NegativeInt\": int,\n \"ConstrainedFloat\": float,\n \"confloat\": float,\n \"PositiveFloat\": float,\n \"NegativeFloat\": float,\n \"ConstrainedDecimal\": Decimal,\n \"condecimal\": Decimal,\n \"UUID1\": UUID,\n \"UUID3\": UUID,\n \"UUID4\": UUID,\n \"UUID5\": UUID,\n \"FilePath\": None,\n \"DirectoryPath\": None,\n \"Json\": None,\n \"JsonWrapper\": None,\n \"SecretStr\": str,\n \"SecretBytes\": bytes,\n \"StrictBool\": bool,\n \"StrictInt\": int,\n \"StrictFloat\": float,\n \"PaymentCardNumber\": None,\n \"ByteSize\": None,\n \"AnyUrl\": str,\n \"AnyHttpUrl\": str,\n \"HttpUrl\": str,\n \"PostgresDsn\": str,\n \"RedisDsn\": str,\n}\n\n\nFIELDS_MAP = {\n getattr(pydantic, field_name): type\n for field_name, type in ATTR_TO_TYPE_MAP.items()\n if hasattr(pydantic, field_name)\n}\n\n\ndef get_basic_type(type_):\n if isinstance(type_, type):\n if issubclass(type_, pydantic.ConstrainedInt):\n return int\n if issubclass(type_, pydantic.ConstrainedStr):\n return str\n\n if type_ in FIELDS_MAP:\n type_ = FIELDS_MAP.get(type_)\n\n if type_ is None:\n raise UnsupportedTypeError()\n\n return type_\n", "path": "strawberry/experimental/pydantic/fields.py"}]}
| 1,110 | 975 |
gh_patches_debug_26101
|
rasdani/github-patches
|
git_diff
|
meltano__meltano-6433
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Disallow calling a `mapper` by name in `meltano run` and alert to use a `mapping` name
The document misses a step for mapper configuration. Property `mapping_name` has to be added to the mappers extras, and its value need to match with the name under mappings. It doesn't seem been documented anywhere.
```yaml
plugins:
mappers:
- name: transform-field
variant: transferwise
pip_url: pipelinewise-transform-field
executable: transform-field
mapping_name: transform-field-hash
mappings:
- name: transform-field-hash
config:
transformations:
- field_id: Name
tap_stream_name: dbo-Test
type: MASK-HIDDEN
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/meltano/core/block/parser.py`
Content:
```
1 """Utilities for turning a string list of plugins into a usable list of BlockSet and PluginCommand objects."""
2 from typing import Dict, Generator, List, Optional, Tuple, Union
3
4 import click
5 import structlog
6
7 from meltano.core.plugin import PluginType
8 from meltano.core.plugin.error import PluginNotFoundError
9 from meltano.core.plugin.project_plugin import ProjectPlugin
10 from meltano.core.project_plugins_service import ProjectPluginsService
11 from meltano.core.task_sets_service import TaskSetsService
12
13 from .blockset import BlockSet, BlockSetValidationError
14 from .extract_load import ELBContextBuilder, ExtractLoadBlocks
15 from .plugin_command import PluginCommandBlock, plugin_command_invoker
16 from .singer import CONSUMERS, SingerBlock
17
18
19 def is_command_block(plugin: ProjectPlugin) -> bool:
20 """Check if a plugin is a command block.
21
22 Args:
23 plugin: Plugin to check.
24
25 Returns:
26 True if plugin is a command block.
27 """
28 return plugin.type not in {
29 PluginType.EXTRACTORS,
30 PluginType.LOADERS,
31 PluginType.MAPPERS,
32 }
33
34
35 def validate_block_sets(
36 log: structlog.BoundLogger, blocks: List[Union[BlockSet, PluginCommandBlock]]
37 ) -> bool:
38 """Perform validation of all blocks in a list that implement the BlockSet interface.
39
40 Args:
41 log: Logger to use in the event of a validation error.
42 blocks: A list of blocks.
43
44 Returns:
45 True if all blocks are valid, False otherwise.
46 """
47 for idx, blk in enumerate(blocks):
48 if blk == BlockSet:
49 log.debug("validating ExtractLoadBlock.", set_number=idx)
50 try:
51 blk.validate_set()
52 except Exception as err:
53 log.error("Validation failed.", err=err)
54 return False
55 return True
56
57
58 class BlockParser: # noqa: D101
59 def __init__(
60 self,
61 log: structlog.BoundLogger,
62 project,
63 blocks: List[str],
64 full_refresh: Optional[bool] = False,
65 no_state_update: Optional[bool] = False,
66 force: Optional[bool] = False,
67 ):
68 """
69 Parse a meltano run command invocation into a list of blocks.
70
71 Args:
72 log: Logger to use.
73 project: Project to use.
74 blocks: List of block names to parse.
75 full_refresh: Whether to perform a full refresh (applies to all found sets).
76 no_state_update: Whether to run with or without state updates.
77 force: Whether to force a run if a job is already running (applies to all found sets).
78
79 Raises:
80 ClickException: If a block name is not found.
81 """
82 self.log = log
83 self.project = project
84
85 self._full_refresh = full_refresh
86 self._no_state_update = no_state_update
87 self._force = force
88
89 self._plugins_service = ProjectPluginsService(project)
90 self._plugins: List[ProjectPlugin] = []
91
92 self._commands: Dict[int, str] = {}
93 self._mappings_ref: Dict[int, str] = {}
94
95 task_sets_service: TaskSetsService = TaskSetsService(project)
96
97 blocks = self._expand_jobs(blocks, task_sets_service)
98
99 for idx, name in enumerate(blocks):
100
101 try:
102 parsed_name, command_name = name.split(":")
103 except ValueError:
104 parsed_name = name
105 command_name = None
106
107 plugin = self._find_plugin_or_mapping(parsed_name)
108 if plugin is None:
109 raise click.ClickException(f"Block {name} not found")
110
111 if plugin and task_sets_service.exists(name):
112 raise click.ClickException(
113 f"Ambiguous reference to '{name}' which matches a job name AND a plugin name."
114 )
115
116 if plugin.type == PluginType.MAPPERS:
117 self._mappings_ref[idx] = parsed_name
118
119 self._plugins.append(plugin)
120 if command_name:
121 self._commands[idx] = command_name
122 self.log.debug(
123 "plugin command added for execution",
124 commands=self._commands,
125 command_name=command_name,
126 plugin_name=parsed_name,
127 )
128
129 self.log.debug("found plugin in cli invocation", plugin_name=plugin.name)
130
131 def _expand_jobs(self, blocks: List[str], task_sets: TaskSetsService) -> List[str]:
132 """Expand any jobs present in a list of blocks into their raw block names.
133
134 Example:
135 Given a job named "somejob" which consists of a single task of "tap target":
136 ["somejob", "dbt:run"] -> ["tap", "target", "dbt:run"]
137
138 Args:
139 blocks: List of block names to parse.
140 task_sets: TaskSetsService to use.
141
142 Returns:
143 List of block names with jobs expanded.
144 """
145 expanded_blocks: List[str] = []
146 for name in blocks:
147 if task_sets.exists(name):
148 self.log.debug(
149 "expanding job to tasks",
150 job_name=name,
151 tasks=task_sets.get(name).flat_args,
152 )
153 expanded_blocks.extend(task_sets.get(name).flat_args)
154 else:
155 expanded_blocks.append(name)
156 return expanded_blocks
157
158 def find_blocks(
159 self, offset: int = 0
160 ) -> Generator[Union[BlockSet, PluginCommandBlock], None, None]:
161 """
162 Find all blocks in the invocation.
163
164 Args:
165 offset: Offset to start from.
166
167 Yields:
168 Generator of blocks (either BlockSet or PluginCommandBlock).
169
170 Raises:
171 BlockSetValidationError: If unknown command is found or if a unexpected block sequence is found.
172 """
173 cur = offset
174 while cur < len(self._plugins):
175 plugin = self._plugins[cur]
176 elb, idx = self._find_next_elb_set(cur)
177 if elb:
178 self.log.debug("found ExtractLoadBlocks set", offset=cur)
179 yield elb
180 cur += idx
181 elif is_command_block(plugin):
182 self.log.debug(
183 "found PluginCommand",
184 offset=cur,
185 plugin_type=plugin.type,
186 )
187 yield plugin_command_invoker(
188 self._plugins[cur],
189 self.project,
190 command=self._commands.get(cur),
191 )
192 cur += 1
193 else:
194 raise BlockSetValidationError(
195 f"Unknown command type or bad block sequence at index {cur + 1}, starting block '{plugin.name}'" # noqa: WPS237
196 )
197
198 def _find_plugin_or_mapping(self, name: str) -> Optional[ProjectPlugin]:
199 """Find a plugin by name OR by mapping name.
200
201 Args:
202 name: Name of the plugin or mapping.
203
204 Returns:
205 The actual plugin.
206
207 Raises:
208 ClickException: If mapping name returns multiple matches.
209 """
210 try:
211 return self._plugins_service.find_plugin(name)
212 except PluginNotFoundError:
213 pass
214
215 mapper = None
216 try:
217 mapper = self._plugins_service.find_plugins_by_mapping_name(name)
218 except PluginNotFoundError:
219 pass
220
221 if mapper is None:
222 return None
223
224 if len(mapper) > 1:
225 raise click.ClickException(
226 f"Ambiguous mapping name {name}, found multiple matches."
227 )
228 return mapper[0] if mapper else None
229
230 def _find_next_elb_set( # noqa: WPS231, WPS213
231 self,
232 offset: int = 0,
233 ) -> Tuple[Optional[ExtractLoadBlocks], int]: # noqa: WPS231, WPS213
234 """
235 Search a list of project plugins trying to find an extract ExtractLoad block set.
236
237 Args:
238 offset: Optional starting offset for search.
239
240 Returns:
241 The ExtractLoad object.
242 Offset for remaining plugins.
243
244 Raises:
245 BlockSetValidationError: If the block set is not valid.
246 """
247 blocks: List[SingerBlock] = []
248
249 base_builder = ELBContextBuilder(
250 self.project, self._plugins_service
251 ) # lint work around
252 builder = (
253 base_builder.with_force(self._force)
254 .with_full_refresh(self._full_refresh)
255 .with_no_state_update(self._no_state_update)
256 )
257
258 if self._plugins[offset].type != PluginType.EXTRACTORS:
259 self.log.debug(
260 "next block not extractor",
261 offset=offset,
262 plugin_type=self._plugins[offset].type,
263 )
264 return None, offset
265
266 self.log.debug(
267 "head of set is extractor as expected", block=self._plugins[offset]
268 )
269
270 blocks.append(builder.make_block(self._plugins[offset]))
271
272 for idx, plugin in enumerate(self._plugins[offset + 1 :]): # noqa: E203
273 next_block = idx + 1
274
275 if plugin.type not in CONSUMERS:
276 self.log.debug(
277 "next block not a consumer of output",
278 offset=offset,
279 plugin_type=plugin.type,
280 )
281 return None, offset + next_block
282
283 self.log.debug("found block", block_type=plugin.type, index=next_block)
284
285 if plugin.type == PluginType.MAPPERS:
286 self.log.debug(
287 "found mapper",
288 plugin_type=plugin.type,
289 plugin_name=plugin.name,
290 mapping=self._mappings_ref.get(next_block),
291 idx=next_block,
292 )
293 blocks.append(
294 builder.make_block(
295 plugin,
296 )
297 )
298 elif plugin.type == PluginType.LOADERS:
299 self.log.debug("blocks", offset=offset, idx=next_block)
300 blocks.append(builder.make_block(plugin))
301 elb = ExtractLoadBlocks(builder.context(), blocks)
302 return elb, idx + 2
303 else:
304 self.log.warning(
305 "Found unexpected plugin type for block in middle of block set.",
306 plugin_type=plugin.type,
307 plugin_name=plugin.name,
308 )
309 raise BlockSetValidationError(
310 f"Expected {PluginType.MAPPERS} or {PluginType.LOADERS}."
311 )
312 raise BlockSetValidationError("Found no end in block set!")
313
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/meltano/core/block/parser.py b/src/meltano/core/block/parser.py
--- a/src/meltano/core/block/parser.py
+++ b/src/meltano/core/block/parser.py
@@ -290,11 +290,25 @@
mapping=self._mappings_ref.get(next_block),
idx=next_block,
)
- blocks.append(
- builder.make_block(
- plugin,
+ # Checks to see if the mapper plugin name is the same as the mappings name
+ # If they both match then a validation error is raised because the
+ # meltano run command needs the mappings name to obtain the settings to
+ # pass to the parent mapper plugin. We also want to fail if the user names them
+ # the same to stop errors due to ambiguous commands.
+ if plugin.name == self._mappings_ref.get(next_block):
+ self.log.warning(
+ "Found unexpected mapper plugin name. ",
+ plugin_name=plugin.name,
+ )
+ raise BlockSetValidationError(
+ f"Expected unique mappings name not the mapper plugin name: {plugin.name}."
+ )
+ else:
+ blocks.append(
+ builder.make_block(
+ plugin,
+ )
)
- )
elif plugin.type == PluginType.LOADERS:
self.log.debug("blocks", offset=offset, idx=next_block)
blocks.append(builder.make_block(plugin))
|
{"golden_diff": "diff --git a/src/meltano/core/block/parser.py b/src/meltano/core/block/parser.py\n--- a/src/meltano/core/block/parser.py\n+++ b/src/meltano/core/block/parser.py\n@@ -290,11 +290,25 @@\n mapping=self._mappings_ref.get(next_block),\n idx=next_block,\n )\n- blocks.append(\n- builder.make_block(\n- plugin,\n+ # Checks to see if the mapper plugin name is the same as the mappings name\n+ # If they both match then a validation error is raised because the\n+ # meltano run command needs the mappings name to obtain the settings to\n+ # pass to the parent mapper plugin. We also want to fail if the user names them\n+ # the same to stop errors due to ambiguous commands.\n+ if plugin.name == self._mappings_ref.get(next_block):\n+ self.log.warning(\n+ \"Found unexpected mapper plugin name. \",\n+ plugin_name=plugin.name,\n+ )\n+ raise BlockSetValidationError(\n+ f\"Expected unique mappings name not the mapper plugin name: {plugin.name}.\"\n+ )\n+ else:\n+ blocks.append(\n+ builder.make_block(\n+ plugin,\n+ )\n )\n- )\n elif plugin.type == PluginType.LOADERS:\n self.log.debug(\"blocks\", offset=offset, idx=next_block)\n blocks.append(builder.make_block(plugin))\n", "issue": "Disallow calling a `mapper` by name in `meltano run` and alert to use a `mapping` name\nThe document misses a step for mapper configuration. Property `mapping_name` has to be added to the mappers extras, and its value need to match with the name under mappings. It doesn't seem been documented anywhere.\r\n\r\n```yaml\r\nplugins:\r\n mappers:\r\n - name: transform-field\r\n variant: transferwise\r\n pip_url: pipelinewise-transform-field\r\n executable: transform-field\r\n mapping_name: transform-field-hash\r\n mappings:\r\n - name: transform-field-hash\r\n config:\r\n transformations:\r\n - field_id: Name\r\n tap_stream_name: dbo-Test\r\n type: MASK-HIDDEN\r\n```\n", "before_files": [{"content": "\"\"\"Utilities for turning a string list of plugins into a usable list of BlockSet and PluginCommand objects.\"\"\"\nfrom typing import Dict, Generator, List, Optional, Tuple, Union\n\nimport click\nimport structlog\n\nfrom meltano.core.plugin import PluginType\nfrom meltano.core.plugin.error import PluginNotFoundError\nfrom meltano.core.plugin.project_plugin import ProjectPlugin\nfrom meltano.core.project_plugins_service import ProjectPluginsService\nfrom meltano.core.task_sets_service import TaskSetsService\n\nfrom .blockset import BlockSet, BlockSetValidationError\nfrom .extract_load import ELBContextBuilder, ExtractLoadBlocks\nfrom .plugin_command import PluginCommandBlock, plugin_command_invoker\nfrom .singer import CONSUMERS, SingerBlock\n\n\ndef is_command_block(plugin: ProjectPlugin) -> bool:\n \"\"\"Check if a plugin is a command block.\n\n Args:\n plugin: Plugin to check.\n\n Returns:\n True if plugin is a command block.\n \"\"\"\n return plugin.type not in {\n PluginType.EXTRACTORS,\n PluginType.LOADERS,\n PluginType.MAPPERS,\n }\n\n\ndef validate_block_sets(\n log: structlog.BoundLogger, blocks: List[Union[BlockSet, PluginCommandBlock]]\n) -> bool:\n \"\"\"Perform validation of all blocks in a list that implement the BlockSet interface.\n\n Args:\n log: Logger to use in the event of a validation error.\n blocks: A list of blocks.\n\n Returns:\n True if all blocks are valid, False otherwise.\n \"\"\"\n for idx, blk in enumerate(blocks):\n if blk == BlockSet:\n log.debug(\"validating ExtractLoadBlock.\", set_number=idx)\n try:\n blk.validate_set()\n except Exception as err:\n log.error(\"Validation failed.\", err=err)\n return False\n return True\n\n\nclass BlockParser: # noqa: D101\n def __init__(\n self,\n log: structlog.BoundLogger,\n project,\n blocks: List[str],\n full_refresh: Optional[bool] = False,\n no_state_update: Optional[bool] = False,\n force: Optional[bool] = False,\n ):\n \"\"\"\n Parse a meltano run command invocation into a list of blocks.\n\n Args:\n log: Logger to use.\n project: Project to use.\n blocks: List of block names to parse.\n full_refresh: Whether to perform a full refresh (applies to all found sets).\n no_state_update: Whether to run with or without state updates.\n force: Whether to force a run if a job is already running (applies to all found sets).\n\n Raises:\n ClickException: If a block name is not found.\n \"\"\"\n self.log = log\n self.project = project\n\n self._full_refresh = full_refresh\n self._no_state_update = no_state_update\n self._force = force\n\n self._plugins_service = ProjectPluginsService(project)\n self._plugins: List[ProjectPlugin] = []\n\n self._commands: Dict[int, str] = {}\n self._mappings_ref: Dict[int, str] = {}\n\n task_sets_service: TaskSetsService = TaskSetsService(project)\n\n blocks = self._expand_jobs(blocks, task_sets_service)\n\n for idx, name in enumerate(blocks):\n\n try:\n parsed_name, command_name = name.split(\":\")\n except ValueError:\n parsed_name = name\n command_name = None\n\n plugin = self._find_plugin_or_mapping(parsed_name)\n if plugin is None:\n raise click.ClickException(f\"Block {name} not found\")\n\n if plugin and task_sets_service.exists(name):\n raise click.ClickException(\n f\"Ambiguous reference to '{name}' which matches a job name AND a plugin name.\"\n )\n\n if plugin.type == PluginType.MAPPERS:\n self._mappings_ref[idx] = parsed_name\n\n self._plugins.append(plugin)\n if command_name:\n self._commands[idx] = command_name\n self.log.debug(\n \"plugin command added for execution\",\n commands=self._commands,\n command_name=command_name,\n plugin_name=parsed_name,\n )\n\n self.log.debug(\"found plugin in cli invocation\", plugin_name=plugin.name)\n\n def _expand_jobs(self, blocks: List[str], task_sets: TaskSetsService) -> List[str]:\n \"\"\"Expand any jobs present in a list of blocks into their raw block names.\n\n Example:\n Given a job named \"somejob\" which consists of a single task of \"tap target\":\n [\"somejob\", \"dbt:run\"] -> [\"tap\", \"target\", \"dbt:run\"]\n\n Args:\n blocks: List of block names to parse.\n task_sets: TaskSetsService to use.\n\n Returns:\n List of block names with jobs expanded.\n \"\"\"\n expanded_blocks: List[str] = []\n for name in blocks:\n if task_sets.exists(name):\n self.log.debug(\n \"expanding job to tasks\",\n job_name=name,\n tasks=task_sets.get(name).flat_args,\n )\n expanded_blocks.extend(task_sets.get(name).flat_args)\n else:\n expanded_blocks.append(name)\n return expanded_blocks\n\n def find_blocks(\n self, offset: int = 0\n ) -> Generator[Union[BlockSet, PluginCommandBlock], None, None]:\n \"\"\"\n Find all blocks in the invocation.\n\n Args:\n offset: Offset to start from.\n\n Yields:\n Generator of blocks (either BlockSet or PluginCommandBlock).\n\n Raises:\n BlockSetValidationError: If unknown command is found or if a unexpected block sequence is found.\n \"\"\"\n cur = offset\n while cur < len(self._plugins):\n plugin = self._plugins[cur]\n elb, idx = self._find_next_elb_set(cur)\n if elb:\n self.log.debug(\"found ExtractLoadBlocks set\", offset=cur)\n yield elb\n cur += idx\n elif is_command_block(plugin):\n self.log.debug(\n \"found PluginCommand\",\n offset=cur,\n plugin_type=plugin.type,\n )\n yield plugin_command_invoker(\n self._plugins[cur],\n self.project,\n command=self._commands.get(cur),\n )\n cur += 1\n else:\n raise BlockSetValidationError(\n f\"Unknown command type or bad block sequence at index {cur + 1}, starting block '{plugin.name}'\" # noqa: WPS237\n )\n\n def _find_plugin_or_mapping(self, name: str) -> Optional[ProjectPlugin]:\n \"\"\"Find a plugin by name OR by mapping name.\n\n Args:\n name: Name of the plugin or mapping.\n\n Returns:\n The actual plugin.\n\n Raises:\n ClickException: If mapping name returns multiple matches.\n \"\"\"\n try:\n return self._plugins_service.find_plugin(name)\n except PluginNotFoundError:\n pass\n\n mapper = None\n try:\n mapper = self._plugins_service.find_plugins_by_mapping_name(name)\n except PluginNotFoundError:\n pass\n\n if mapper is None:\n return None\n\n if len(mapper) > 1:\n raise click.ClickException(\n f\"Ambiguous mapping name {name}, found multiple matches.\"\n )\n return mapper[0] if mapper else None\n\n def _find_next_elb_set( # noqa: WPS231, WPS213\n self,\n offset: int = 0,\n ) -> Tuple[Optional[ExtractLoadBlocks], int]: # noqa: WPS231, WPS213\n \"\"\"\n Search a list of project plugins trying to find an extract ExtractLoad block set.\n\n Args:\n offset: Optional starting offset for search.\n\n Returns:\n The ExtractLoad object.\n Offset for remaining plugins.\n\n Raises:\n BlockSetValidationError: If the block set is not valid.\n \"\"\"\n blocks: List[SingerBlock] = []\n\n base_builder = ELBContextBuilder(\n self.project, self._plugins_service\n ) # lint work around\n builder = (\n base_builder.with_force(self._force)\n .with_full_refresh(self._full_refresh)\n .with_no_state_update(self._no_state_update)\n )\n\n if self._plugins[offset].type != PluginType.EXTRACTORS:\n self.log.debug(\n \"next block not extractor\",\n offset=offset,\n plugin_type=self._plugins[offset].type,\n )\n return None, offset\n\n self.log.debug(\n \"head of set is extractor as expected\", block=self._plugins[offset]\n )\n\n blocks.append(builder.make_block(self._plugins[offset]))\n\n for idx, plugin in enumerate(self._plugins[offset + 1 :]): # noqa: E203\n next_block = idx + 1\n\n if plugin.type not in CONSUMERS:\n self.log.debug(\n \"next block not a consumer of output\",\n offset=offset,\n plugin_type=plugin.type,\n )\n return None, offset + next_block\n\n self.log.debug(\"found block\", block_type=plugin.type, index=next_block)\n\n if plugin.type == PluginType.MAPPERS:\n self.log.debug(\n \"found mapper\",\n plugin_type=plugin.type,\n plugin_name=plugin.name,\n mapping=self._mappings_ref.get(next_block),\n idx=next_block,\n )\n blocks.append(\n builder.make_block(\n plugin,\n )\n )\n elif plugin.type == PluginType.LOADERS:\n self.log.debug(\"blocks\", offset=offset, idx=next_block)\n blocks.append(builder.make_block(plugin))\n elb = ExtractLoadBlocks(builder.context(), blocks)\n return elb, idx + 2\n else:\n self.log.warning(\n \"Found unexpected plugin type for block in middle of block set.\",\n plugin_type=plugin.type,\n plugin_name=plugin.name,\n )\n raise BlockSetValidationError(\n f\"Expected {PluginType.MAPPERS} or {PluginType.LOADERS}.\"\n )\n raise BlockSetValidationError(\"Found no end in block set!\")\n", "path": "src/meltano/core/block/parser.py"}], "after_files": [{"content": "\"\"\"Utilities for turning a string list of plugins into a usable list of BlockSet and PluginCommand objects.\"\"\"\nfrom typing import Dict, Generator, List, Optional, Tuple, Union\n\nimport click\nimport structlog\n\nfrom meltano.core.plugin import PluginType\nfrom meltano.core.plugin.error import PluginNotFoundError\nfrom meltano.core.plugin.project_plugin import ProjectPlugin\nfrom meltano.core.project_plugins_service import ProjectPluginsService\nfrom meltano.core.task_sets_service import TaskSetsService\n\nfrom .blockset import BlockSet, BlockSetValidationError\nfrom .extract_load import ELBContextBuilder, ExtractLoadBlocks\nfrom .plugin_command import PluginCommandBlock, plugin_command_invoker\nfrom .singer import CONSUMERS, SingerBlock\n\n\ndef is_command_block(plugin: ProjectPlugin) -> bool:\n \"\"\"Check if a plugin is a command block.\n\n Args:\n plugin: Plugin to check.\n\n Returns:\n True if plugin is a command block.\n \"\"\"\n return plugin.type not in {\n PluginType.EXTRACTORS,\n PluginType.LOADERS,\n PluginType.MAPPERS,\n }\n\n\ndef validate_block_sets(\n log: structlog.BoundLogger, blocks: List[Union[BlockSet, PluginCommandBlock]]\n) -> bool:\n \"\"\"Perform validation of all blocks in a list that implement the BlockSet interface.\n\n Args:\n log: Logger to use in the event of a validation error.\n blocks: A list of blocks.\n\n Returns:\n True if all blocks are valid, False otherwise.\n \"\"\"\n for idx, blk in enumerate(blocks):\n if blk == BlockSet:\n log.debug(\"validating ExtractLoadBlock.\", set_number=idx)\n try:\n blk.validate_set()\n except Exception as err:\n log.error(\"Validation failed.\", err=err)\n return False\n return True\n\n\nclass BlockParser: # noqa: D101\n def __init__(\n self,\n log: structlog.BoundLogger,\n project,\n blocks: List[str],\n full_refresh: Optional[bool] = False,\n no_state_update: Optional[bool] = False,\n force: Optional[bool] = False,\n ):\n \"\"\"\n Parse a meltano run command invocation into a list of blocks.\n\n Args:\n log: Logger to use.\n project: Project to use.\n blocks: List of block names to parse.\n full_refresh: Whether to perform a full refresh (applies to all found sets).\n no_state_update: Whether to run with or without state updates.\n force: Whether to force a run if a job is already running (applies to all found sets).\n\n Raises:\n ClickException: If a block name is not found.\n \"\"\"\n self.log = log\n self.project = project\n\n self._full_refresh = full_refresh\n self._no_state_update = no_state_update\n self._force = force\n\n self._plugins_service = ProjectPluginsService(project)\n self._plugins: List[ProjectPlugin] = []\n\n self._commands: Dict[int, str] = {}\n self._mappings_ref: Dict[int, str] = {}\n\n task_sets_service: TaskSetsService = TaskSetsService(project)\n\n blocks = self._expand_jobs(blocks, task_sets_service)\n\n for idx, name in enumerate(blocks):\n\n try:\n parsed_name, command_name = name.split(\":\")\n except ValueError:\n parsed_name = name\n command_name = None\n\n plugin = self._find_plugin_or_mapping(parsed_name)\n if plugin is None:\n raise click.ClickException(f\"Block {name} not found\")\n\n if plugin and task_sets_service.exists(name):\n raise click.ClickException(\n f\"Ambiguous reference to '{name}' which matches a job name AND a plugin name.\"\n )\n\n if plugin.type == PluginType.MAPPERS:\n self._mappings_ref[idx] = parsed_name\n\n self._plugins.append(plugin)\n if command_name:\n self._commands[idx] = command_name\n self.log.debug(\n \"plugin command added for execution\",\n commands=self._commands,\n command_name=command_name,\n plugin_name=parsed_name,\n )\n\n self.log.debug(\"found plugin in cli invocation\", plugin_name=plugin.name)\n\n def _expand_jobs(self, blocks: List[str], task_sets: TaskSetsService) -> List[str]:\n \"\"\"Expand any jobs present in a list of blocks into their raw block names.\n\n Example:\n Given a job named \"somejob\" which consists of a single task of \"tap target\":\n [\"somejob\", \"dbt:run\"] -> [\"tap\", \"target\", \"dbt:run\"]\n\n Args:\n blocks: List of block names to parse.\n task_sets: TaskSetsService to use.\n\n Returns:\n List of block names with jobs expanded.\n \"\"\"\n expanded_blocks: List[str] = []\n for name in blocks:\n if task_sets.exists(name):\n self.log.debug(\n \"expanding job to tasks\",\n job_name=name,\n tasks=task_sets.get(name).flat_args,\n )\n expanded_blocks.extend(task_sets.get(name).flat_args)\n else:\n expanded_blocks.append(name)\n return expanded_blocks\n\n def find_blocks(\n self, offset: int = 0\n ) -> Generator[Union[BlockSet, PluginCommandBlock], None, None]:\n \"\"\"\n Find all blocks in the invocation.\n\n Args:\n offset: Offset to start from.\n\n Yields:\n Generator of blocks (either BlockSet or PluginCommandBlock).\n\n Raises:\n BlockSetValidationError: If unknown command is found or if a unexpected block sequence is found.\n \"\"\"\n cur = offset\n while cur < len(self._plugins):\n plugin = self._plugins[cur]\n elb, idx = self._find_next_elb_set(cur)\n if elb:\n self.log.debug(\"found ExtractLoadBlocks set\", offset=cur)\n yield elb\n cur += idx\n elif is_command_block(plugin):\n self.log.debug(\n \"found PluginCommand\",\n offset=cur,\n plugin_type=plugin.type,\n )\n yield plugin_command_invoker(\n self._plugins[cur],\n self.project,\n command=self._commands.get(cur),\n )\n cur += 1\n else:\n raise BlockSetValidationError(\n f\"Unknown command type or bad block sequence at index {cur + 1}, starting block '{plugin.name}'\" # noqa: WPS237\n )\n\n def _find_plugin_or_mapping(self, name: str) -> Optional[ProjectPlugin]:\n \"\"\"Find a plugin by name OR by mapping name.\n\n Args:\n name: Name of the plugin or mapping.\n\n Returns:\n The actual plugin.\n\n Raises:\n ClickException: If mapping name returns multiple matches.\n \"\"\"\n try:\n return self._plugins_service.find_plugin(name)\n except PluginNotFoundError:\n pass\n\n mapper = None\n try:\n mapper = self._plugins_service.find_plugins_by_mapping_name(name)\n except PluginNotFoundError:\n pass\n\n if mapper is None:\n return None\n\n if len(mapper) > 1:\n raise click.ClickException(\n f\"Ambiguous mapping name {name}, found multiple matches.\"\n )\n return mapper[0] if mapper else None\n\n def _find_next_elb_set( # noqa: WPS231, WPS213\n self,\n offset: int = 0,\n ) -> Tuple[Optional[ExtractLoadBlocks], int]: # noqa: WPS231, WPS213\n \"\"\"\n Search a list of project plugins trying to find an extract ExtractLoad block set.\n\n Args:\n offset: Optional starting offset for search.\n\n Returns:\n The ExtractLoad object.\n Offset for remaining plugins.\n\n Raises:\n BlockSetValidationError: If the block set is not valid.\n \"\"\"\n blocks: List[SingerBlock] = []\n\n base_builder = ELBContextBuilder(\n self.project, self._plugins_service\n ) # lint work around\n builder = (\n base_builder.with_force(self._force)\n .with_full_refresh(self._full_refresh)\n .with_no_state_update(self._no_state_update)\n )\n\n if self._plugins[offset].type != PluginType.EXTRACTORS:\n self.log.debug(\n \"next block not extractor\",\n offset=offset,\n plugin_type=self._plugins[offset].type,\n )\n return None, offset\n\n self.log.debug(\n \"head of set is extractor as expected\", block=self._plugins[offset]\n )\n\n blocks.append(builder.make_block(self._plugins[offset]))\n\n for idx, plugin in enumerate(self._plugins[offset + 1 :]): # noqa: E203\n next_block = idx + 1\n\n if plugin.type not in CONSUMERS:\n self.log.debug(\n \"next block not a consumer of output\",\n offset=offset,\n plugin_type=plugin.type,\n )\n return None, offset + next_block\n\n self.log.debug(\"found block\", block_type=plugin.type, index=next_block)\n\n if plugin.type == PluginType.MAPPERS:\n self.log.debug(\n \"found mapper\",\n plugin_type=plugin.type,\n plugin_name=plugin.name,\n mapping=self._mappings_ref.get(next_block),\n idx=next_block,\n )\n # Checks to see if the mapper plugin name is the same as the mappings name\n # If they both match then a validation error is raised because the\n # meltano run command needs the mappings name to obtain the settings to\n # pass to the parent mapper plugin. We also want to fail if the user names them\n # the same to stop errors due to ambiguous commands.\n if plugin.name == self._mappings_ref.get(next_block):\n self.log.warning(\n \"Found unexpected mapper plugin name. \",\n plugin_name=plugin.name,\n )\n raise BlockSetValidationError(\n f\"Expected unique mappings name not the mapper plugin name: {plugin.name}.\"\n )\n else:\n blocks.append(\n builder.make_block(\n plugin,\n )\n )\n elif plugin.type == PluginType.LOADERS:\n self.log.debug(\"blocks\", offset=offset, idx=next_block)\n blocks.append(builder.make_block(plugin))\n elb = ExtractLoadBlocks(builder.context(), blocks)\n return elb, idx + 2\n else:\n self.log.warning(\n \"Found unexpected plugin type for block in middle of block set.\",\n plugin_type=plugin.type,\n plugin_name=plugin.name,\n )\n raise BlockSetValidationError(\n f\"Expected {PluginType.MAPPERS} or {PluginType.LOADERS}.\"\n )\n raise BlockSetValidationError(\"Found no end in block set!\")\n", "path": "src/meltano/core/block/parser.py"}]}
| 3,433 | 314 |
gh_patches_debug_18236
|
rasdani/github-patches
|
git_diff
|
spectrochempy__spectrochempy-742
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Bug]: Install dependencies for testing: Could not build wheels for ruamel.yaml
### What happened?
The install dependencies for testing fails due to ruamel.yaml package, see:
https://github.com/spectrochempy/spectrochempy/actions/runs/7918492722/job/21660419471?pr=734
https://github.com/spectrochempy/spectrochempy/actions/runs/7918492722/job/21660419097?pr=734
### What did you expect to happen?
the install should go smoothly
### Minimal Complete Verifiable Example
_No response_
### Relevant log output
_No response_
### Anything else we need to know?
_No response_
### Environment
N/A
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `spectrochempy/analysis/decomposition/fast_ica.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 # ======================================================================================
3 # Copyright (©) 2015-2023 LCS - Laboratoire Catalyse et Spectrochimie, Caen, France.
4 # CeCILL-B FREE SOFTWARE LICENSE AGREEMENT
5 # See full LICENSE agreement in the root directory.
6 # ======================================================================================
7 """
8 Implementation of FastICA model (using scikit-learn library)
9 """
10
11 import traitlets as tr
12 from numpy.random import RandomState
13 from sklearn import decomposition
14
15 from spectrochempy.analysis._base._analysisbase import (
16 DecompositionAnalysis,
17 _wrap_ndarray_output_to_nddataset,
18 )
19 from spectrochempy.utils.decorators import signature_has_configurable_traits
20 from spectrochempy.utils.docstrings import _docstring
21 from spectrochempy.utils.traits import NDDatasetType
22
23 __all__ = ["FastICA"]
24 __configurables__ = ["FastICA"]
25
26
27 # ======================================================================================
28 # class FastICA
29 # ======================================================================================
30 @signature_has_configurable_traits
31 class FastICA(DecompositionAnalysis):
32 _docstring.delete_params("DecompositionAnalysis.see_also", "FastICA")
33
34 __doc__ = _docstring.dedent(
35 r"""
36 Fast algorithm for Independent Component Analysis (FastICA).
37
38 A wrapper of `sklearn.decomposition.FastICA`\ .
39
40 :term:`ICA` (Independent Component Analysis) extracts the underlying sources of
41 the variability of a set of spectra :math:`X` into the spectral profiles :math:`S^t`
42 of the underelying sources and a mixing matrix :math:`A`\ .
43
44 In terms of matrix equation:
45
46 .. math:: X = \bar{X} + A \cdot S^t + E
47
48 where :math:`\bar{X}` is the mean of the dataset and :math:`E` is the matrix of
49 residuals.
50
51 Parameters
52 ----------
53 %(AnalysisConfigurable.parameters)s
54
55 See Also
56 --------
57 %(DecompositionAnalysis.see_also.no_FastICA)s
58 """
59 )
60
61 # ----------------------------------------------------------------------------------
62 # Runtime Parameters,
63 # only those specific to FastICA, the other being defined in AnalysisConfigurable.
64 # ----------------------------------------------------------------------------------
65 # define here only the variable that you use in fit or transform functions
66 _fastica = tr.Instance(
67 decomposition.FastICA,
68 help="The instance of sklearn.decomposition.FastICA used in this model",
69 )
70
71 # ----------------------------------------------------------------------------------
72 # Configuration parameters
73 # ----------------------------------------------------------------------------------
74
75 n_components = tr.Integer(
76 default_value=None,
77 allow_none=True,
78 help="Number of components (sources) to use.",
79 ).tag(config=True)
80
81 algorithm = tr.Enum(
82 ["parallel", "deflation"],
83 default_value="parallel",
84 help=("""Specify which algorithm to use for FastICA."""),
85 ).tag(config=True)
86
87 whiten = tr.Union(
88 (tr.Enum(["arbitrary-variance", "unit-variance"]), tr.Bool(False)),
89 default_value="arbitrary-variance",
90 allow_none=True,
91 help=(
92 """Specify the whitening strategy to use.
93
94 - ``"arbitrary-variance"``\ : a whitening with variance arbitrary is used.
95 - "unit-variance" : the whitening matrix is rescaled to ensure that each recovered
96 source has unit variance.
97 - False : the data is already considered to be whitened, and no whitening is performed.
98 """
99 ),
100 ).tag(config=True)
101
102 fun = tr.Union(
103 (tr.Enum(["logcosh", "exp", "cube"]), tr.Callable(), tr.Unicode()),
104 default_value="logcosh",
105 allow_none=True,
106 help=(
107 r"""The functional form of the function used in the approximation to neg-entropy.
108
109 - ``string``\ : could be either ``"logcosh"``\ , ``"exp"``\ , or ``"cube"``\ .
110 - ``callable``\ : You can provide your own function. It should return a tuple containing
111 the value of the function, and of its derivative, in the point. The derivative should
112 be averaged along its last dimension.
113
114 .. code-block::
115
116 def my_g(x):
117 return x ** 3, (3 * x ** 2).mean(axis=-1)
118
119 .. note::
120 ``fun`` can be also a serialized function created using dill and base64
121 python libraries. Normally not used directly, it is here for internal
122 process. """
123 ),
124 ).tag(config=True)
125
126 fun_args = tr.Dict(
127 default_value=None,
128 allow_none=True,
129 help=(
130 """Arguments to send to the functional form.
131
132 If empty or None and if ``fun=="logcosh"`` , `fun_args` will take value
133 ``{alpha : 1.0}``."""
134 ),
135 ).tag(config=True)
136
137 tol = tr.Float(
138 default_value=1e-4,
139 help="Tolerance at which the un-mixing matrix is considered to have converged.",
140 ).tag(config=True)
141
142 max_iter = tr.Integer(
143 default_value=200, help="Maximum number of iterations before timing out."
144 ).tag(config=True)
145
146 w_init = tr.Union(
147 (NDDatasetType(),),
148 default_value=None,
149 allow_none=True,
150 help=(
151 r"""Initial un-mixing array.
152
153 NDDataset or array-like of shape (n_components, n_components). If w_init=None, then an
154 array of values drawn from a normal distribution is used."""
155 ),
156 ).tag(config=True)
157
158 whiten_solver = tr.Enum(
159 ["svd", "eigh"],
160 default_value="svd",
161 help=(
162 """The solver to use for whitening.
163
164 - ``"svd"``\ : is more stable numerically if the problem is degenerate, and often faster
165 when :term:`n_observations` <= :term:`n_features`\ .
166 - ``"eigh"``\ : is generally more memory efficient when
167 :term:`n_observations` >= :term:`n_features`\ , and can be faster when
168 :term:`n_observations` >= 50 * :term:`n_features`\ . """
169 ),
170 ).tag(config=True)
171
172 random_state = tr.Union(
173 (tr.Integer(), tr.Instance(RandomState)),
174 allow_none=True,
175 default_value=None,
176 help=(
177 "Used to initialize ``w_init`` when not specified, with a normal"
178 "distribution. Pass an ``int``, for reproducible results across "
179 "multiple function calls."
180 ),
181 ).tag(config=True)
182
183 # ----------------------------------------------------------------------------------
184 # Initialization
185 # ----------------------------------------------------------------------------------
186 def __init__(
187 self,
188 *,
189 log_level="WARNING",
190 warm_start=False,
191 **kwargs,
192 ):
193 # call the super class for initialisation of the configuration parameters
194 # to do before anything else!
195 super().__init__(
196 log_level=log_level,
197 warm_start=warm_start,
198 **kwargs,
199 )
200
201 # initialize sklearn Fast!ICA
202 self._fast_ica = decomposition.FastICA(
203 n_components=self.n_components,
204 algorithm=self.algorithm,
205 whiten=self.whiten,
206 fun=self.fun,
207 fun_args=self.fun_args,
208 tol=self.tol,
209 max_iter=self.max_iter,
210 w_init=self.w_init,
211 whiten_solver=self.whiten_solver,
212 random_state=self.random_state,
213 )
214
215 # ----------------------------------------------------------------------------------
216 # Private methods (overloading abstract classes)
217 # ----------------------------------------------------------------------------------
218 def _fit(self, X, Y=None):
219 # this method is called by the abstract class fit.
220 # Input X is a np.ndarray
221 # Y is ignored in this model
222
223 # call the sklearn _fit function on data
224 # _outfit is a tuple handle the eventual output of _fit for further processing.
225
226 # The _outfit members are np.ndarrays
227 _outfit = self._fast_ica.fit(X)
228 self._n_components = int(
229 self._fast_ica.n_components
230 ) # cast the returned int64 to int
231 return _outfit
232
233 def _transform(self, X):
234 return self._fast_ica.transform(X)
235
236 def _inverse_transform(self, X_transform):
237 # we need to set self._fast_ica.components_ to a compatible size but without
238 # destroying the full matrix:
239 store_components_ = self._fast_ica.components_
240 self._fast_ica.components_ = self._fast_ica.components_[: X_transform.shape[1]]
241 X = self._fast_ica.inverse_transform(X_transform)
242 # restore
243 self._fast_ica.components_ = store_components_
244 return X
245
246 def _get_components(self):
247 self._components = self._fast_ica.components_
248 return self._components
249
250 _docstring.keep_params("analysis_fit.parameters", "X")
251
252 @_docstring.dedent
253 def fit(self, X):
254 """
255 Fit the FastICA model on X.
256
257 Parameters
258 ----------
259 %(analysis_fit.parameters.X)s
260
261 Returns
262 -------
263 %(analysis_fit.returns)s
264
265 See Also
266 --------
267 %(analysis_fit.see_also)s
268 """
269 return super().fit(X, Y=None)
270
271 @property
272 @_wrap_ndarray_output_to_nddataset(
273 units=None, title=None, typey="features", typex="components"
274 )
275 def mixing(self):
276 """
277 The pseudo inverse of components.
278
279 NDDataset of size (`n_features`\ , `n_components`\ ). It is the linear operator
280 that maps independent sources to the data, and the transpose of `St`\ .
281 """
282 return self._fast_ica.mixing_
283
284 @property
285 @_wrap_ndarray_output_to_nddataset(
286 units=None,
287 title=None,
288 typey="components",
289 )
290 def St(self):
291 """
292 The spectral profiles of the independant sources.
293
294 NDDataset of size (`n_components`\ , `n_features`\ ). It is the transpose of the
295 ``mixing_`` matrix returned by Scikit-Learn.
296 """
297 return self._fast_ica.mixing_.T
298
299 @property
300 @_wrap_ndarray_output_to_nddataset(
301 units=None,
302 title=None,
303 typex="components",
304 )
305 def A(self):
306 """
307 The mixing system A.
308
309 NDDataset of size (`n_observations`\ , `n_components`\ ). It is the matrix
310 returned by the `transform()` method.
311 """
312 return self._fast_ica.transform(self.X.data)
313
314 @property
315 @_wrap_ndarray_output_to_nddataset()
316 def mean(self):
317 """
318 The mean of X over features.
319
320 Only set if `whiten` is True, it is needed (and used) to reconstruct a dataset
321 by ``inverse_transform(A)``\ .
322 """
323 return self._fast_ica.mean_
324
325 @property
326 def n_iter(self):
327 """
328 Number of iterations.
329
330 If the algorithm is “deflation”, n_iter is the maximum number of iterations run
331 across all components. Else they are just the number of iterations taken to
332 converge.
333 """
334 return self._fast_ica.n_iter_
335
336 @property
337 @_wrap_ndarray_output_to_nddataset(
338 units=None,
339 title=None,
340 typey="components",
341 )
342 def whitening(self):
343 """
344 NDDataset of shape (n_components, n_features).
345
346 Only set if whiten is not None. This is the pre-whitening matrix that projects
347 data onto the first n_components principal components.
348 """
349 if self.whiten:
350 return self._fast_ica.whitening_
351
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/spectrochempy/analysis/decomposition/fast_ica.py b/spectrochempy/analysis/decomposition/fast_ica.py
--- a/spectrochempy/analysis/decomposition/fast_ica.py
+++ b/spectrochempy/analysis/decomposition/fast_ica.py
@@ -39,7 +39,7 @@
:term:`ICA` (Independent Component Analysis) extracts the underlying sources of
the variability of a set of spectra :math:`X` into the spectral profiles :math:`S^t`
- of the underelying sources and a mixing matrix :math:`A`\ .
+ of the underlying sources and a mixing matrix :math:`A`\ .
In terms of matrix equation:
@@ -86,7 +86,7 @@
whiten = tr.Union(
(tr.Enum(["arbitrary-variance", "unit-variance"]), tr.Bool(False)),
- default_value="arbitrary-variance",
+ default_value="unit-variance",
allow_none=True,
help=(
"""Specify the whitening strategy to use.
|
{"golden_diff": "diff --git a/spectrochempy/analysis/decomposition/fast_ica.py b/spectrochempy/analysis/decomposition/fast_ica.py\n--- a/spectrochempy/analysis/decomposition/fast_ica.py\n+++ b/spectrochempy/analysis/decomposition/fast_ica.py\n@@ -39,7 +39,7 @@\n \n :term:`ICA` (Independent Component Analysis) extracts the underlying sources of\n the variability of a set of spectra :math:`X` into the spectral profiles :math:`S^t`\n- of the underelying sources and a mixing matrix :math:`A`\\ .\n+ of the underlying sources and a mixing matrix :math:`A`\\ .\n \n In terms of matrix equation:\n \n@@ -86,7 +86,7 @@\n \n whiten = tr.Union(\n (tr.Enum([\"arbitrary-variance\", \"unit-variance\"]), tr.Bool(False)),\n- default_value=\"arbitrary-variance\",\n+ default_value=\"unit-variance\",\n allow_none=True,\n help=(\n \"\"\"Specify the whitening strategy to use.\n", "issue": "[Bug]: Install dependencies for testing: Could not build wheels for ruamel.yaml\n### What happened?\n\nThe install dependencies for testing fails due to ruamel.yaml package, see: \r\n\r\nhttps://github.com/spectrochempy/spectrochempy/actions/runs/7918492722/job/21660419471?pr=734\r\nhttps://github.com/spectrochempy/spectrochempy/actions/runs/7918492722/job/21660419097?pr=734\n\n### What did you expect to happen?\n\nthe install should go smoothly\n\n### Minimal Complete Verifiable Example\n\n_No response_\n\n### Relevant log output\n\n_No response_\n\n### Anything else we need to know?\n\n_No response_\n\n### Environment\n\nN/A\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# ======================================================================================\n# Copyright (\u00a9) 2015-2023 LCS - Laboratoire Catalyse et Spectrochimie, Caen, France.\n# CeCILL-B FREE SOFTWARE LICENSE AGREEMENT\n# See full LICENSE agreement in the root directory.\n# ======================================================================================\n\"\"\"\nImplementation of FastICA model (using scikit-learn library)\n\"\"\"\n\nimport traitlets as tr\nfrom numpy.random import RandomState\nfrom sklearn import decomposition\n\nfrom spectrochempy.analysis._base._analysisbase import (\n DecompositionAnalysis,\n _wrap_ndarray_output_to_nddataset,\n)\nfrom spectrochempy.utils.decorators import signature_has_configurable_traits\nfrom spectrochempy.utils.docstrings import _docstring\nfrom spectrochempy.utils.traits import NDDatasetType\n\n__all__ = [\"FastICA\"]\n__configurables__ = [\"FastICA\"]\n\n\n# ======================================================================================\n# class FastICA\n# ======================================================================================\n@signature_has_configurable_traits\nclass FastICA(DecompositionAnalysis):\n _docstring.delete_params(\"DecompositionAnalysis.see_also\", \"FastICA\")\n\n __doc__ = _docstring.dedent(\n r\"\"\"\n Fast algorithm for Independent Component Analysis (FastICA).\n\n A wrapper of `sklearn.decomposition.FastICA`\\ .\n\n :term:`ICA` (Independent Component Analysis) extracts the underlying sources of\n the variability of a set of spectra :math:`X` into the spectral profiles :math:`S^t`\n of the underelying sources and a mixing matrix :math:`A`\\ .\n\n In terms of matrix equation:\n\n .. math:: X = \\bar{X} + A \\cdot S^t + E\n\n where :math:`\\bar{X}` is the mean of the dataset and :math:`E` is the matrix of\n residuals.\n\n Parameters\n ----------\n %(AnalysisConfigurable.parameters)s\n\n See Also\n --------\n %(DecompositionAnalysis.see_also.no_FastICA)s\n \"\"\"\n )\n\n # ----------------------------------------------------------------------------------\n # Runtime Parameters,\n # only those specific to FastICA, the other being defined in AnalysisConfigurable.\n # ----------------------------------------------------------------------------------\n # define here only the variable that you use in fit or transform functions\n _fastica = tr.Instance(\n decomposition.FastICA,\n help=\"The instance of sklearn.decomposition.FastICA used in this model\",\n )\n\n # ----------------------------------------------------------------------------------\n # Configuration parameters\n # ----------------------------------------------------------------------------------\n\n n_components = tr.Integer(\n default_value=None,\n allow_none=True,\n help=\"Number of components (sources) to use.\",\n ).tag(config=True)\n\n algorithm = tr.Enum(\n [\"parallel\", \"deflation\"],\n default_value=\"parallel\",\n help=(\"\"\"Specify which algorithm to use for FastICA.\"\"\"),\n ).tag(config=True)\n\n whiten = tr.Union(\n (tr.Enum([\"arbitrary-variance\", \"unit-variance\"]), tr.Bool(False)),\n default_value=\"arbitrary-variance\",\n allow_none=True,\n help=(\n \"\"\"Specify the whitening strategy to use.\n\n- ``\"arbitrary-variance\"``\\ : a whitening with variance arbitrary is used.\n- \"unit-variance\" : the whitening matrix is rescaled to ensure that each recovered\n source has unit variance.\n- False : the data is already considered to be whitened, and no whitening is performed.\n\"\"\"\n ),\n ).tag(config=True)\n\n fun = tr.Union(\n (tr.Enum([\"logcosh\", \"exp\", \"cube\"]), tr.Callable(), tr.Unicode()),\n default_value=\"logcosh\",\n allow_none=True,\n help=(\n r\"\"\"The functional form of the function used in the approximation to neg-entropy.\n\n- ``string``\\ : could be either ``\"logcosh\"``\\ , ``\"exp\"``\\ , or ``\"cube\"``\\ .\n- ``callable``\\ : You can provide your own function. It should return a tuple containing\n the value of the function, and of its derivative, in the point. The derivative should\n be averaged along its last dimension.\n\n.. code-block::\n\n def my_g(x):\n return x ** 3, (3 * x ** 2).mean(axis=-1)\n\n.. note::\n ``fun`` can be also a serialized function created using dill and base64\n python libraries. Normally not used directly, it is here for internal\n process. \"\"\"\n ),\n ).tag(config=True)\n\n fun_args = tr.Dict(\n default_value=None,\n allow_none=True,\n help=(\n \"\"\"Arguments to send to the functional form.\n\nIf empty or None and if ``fun==\"logcosh\"`` , `fun_args` will take value\n``{alpha : 1.0}``.\"\"\"\n ),\n ).tag(config=True)\n\n tol = tr.Float(\n default_value=1e-4,\n help=\"Tolerance at which the un-mixing matrix is considered to have converged.\",\n ).tag(config=True)\n\n max_iter = tr.Integer(\n default_value=200, help=\"Maximum number of iterations before timing out.\"\n ).tag(config=True)\n\n w_init = tr.Union(\n (NDDatasetType(),),\n default_value=None,\n allow_none=True,\n help=(\n r\"\"\"Initial un-mixing array.\n\nNDDataset or array-like of shape (n_components, n_components). If w_init=None, then an\narray of values drawn from a normal distribution is used.\"\"\"\n ),\n ).tag(config=True)\n\n whiten_solver = tr.Enum(\n [\"svd\", \"eigh\"],\n default_value=\"svd\",\n help=(\n \"\"\"The solver to use for whitening.\n\n- ``\"svd\"``\\ : is more stable numerically if the problem is degenerate, and often faster\n when :term:`n_observations` <= :term:`n_features`\\ .\n- ``\"eigh\"``\\ : is generally more memory efficient when\n :term:`n_observations` >= :term:`n_features`\\ , and can be faster when\n :term:`n_observations` >= 50 * :term:`n_features`\\ . \"\"\"\n ),\n ).tag(config=True)\n\n random_state = tr.Union(\n (tr.Integer(), tr.Instance(RandomState)),\n allow_none=True,\n default_value=None,\n help=(\n \"Used to initialize ``w_init`` when not specified, with a normal\"\n \"distribution. Pass an ``int``, for reproducible results across \"\n \"multiple function calls.\"\n ),\n ).tag(config=True)\n\n # ----------------------------------------------------------------------------------\n # Initialization\n # ----------------------------------------------------------------------------------\n def __init__(\n self,\n *,\n log_level=\"WARNING\",\n warm_start=False,\n **kwargs,\n ):\n # call the super class for initialisation of the configuration parameters\n # to do before anything else!\n super().__init__(\n log_level=log_level,\n warm_start=warm_start,\n **kwargs,\n )\n\n # initialize sklearn Fast!ICA\n self._fast_ica = decomposition.FastICA(\n n_components=self.n_components,\n algorithm=self.algorithm,\n whiten=self.whiten,\n fun=self.fun,\n fun_args=self.fun_args,\n tol=self.tol,\n max_iter=self.max_iter,\n w_init=self.w_init,\n whiten_solver=self.whiten_solver,\n random_state=self.random_state,\n )\n\n # ----------------------------------------------------------------------------------\n # Private methods (overloading abstract classes)\n # ----------------------------------------------------------------------------------\n def _fit(self, X, Y=None):\n # this method is called by the abstract class fit.\n # Input X is a np.ndarray\n # Y is ignored in this model\n\n # call the sklearn _fit function on data\n # _outfit is a tuple handle the eventual output of _fit for further processing.\n\n # The _outfit members are np.ndarrays\n _outfit = self._fast_ica.fit(X)\n self._n_components = int(\n self._fast_ica.n_components\n ) # cast the returned int64 to int\n return _outfit\n\n def _transform(self, X):\n return self._fast_ica.transform(X)\n\n def _inverse_transform(self, X_transform):\n # we need to set self._fast_ica.components_ to a compatible size but without\n # destroying the full matrix:\n store_components_ = self._fast_ica.components_\n self._fast_ica.components_ = self._fast_ica.components_[: X_transform.shape[1]]\n X = self._fast_ica.inverse_transform(X_transform)\n # restore\n self._fast_ica.components_ = store_components_\n return X\n\n def _get_components(self):\n self._components = self._fast_ica.components_\n return self._components\n\n _docstring.keep_params(\"analysis_fit.parameters\", \"X\")\n\n @_docstring.dedent\n def fit(self, X):\n \"\"\"\n Fit the FastICA model on X.\n\n Parameters\n ----------\n %(analysis_fit.parameters.X)s\n\n Returns\n -------\n %(analysis_fit.returns)s\n\n See Also\n --------\n %(analysis_fit.see_also)s\n \"\"\"\n return super().fit(X, Y=None)\n\n @property\n @_wrap_ndarray_output_to_nddataset(\n units=None, title=None, typey=\"features\", typex=\"components\"\n )\n def mixing(self):\n \"\"\"\n The pseudo inverse of components.\n\n NDDataset of size (`n_features`\\ , `n_components`\\ ). It is the linear operator\n that maps independent sources to the data, and the transpose of `St`\\ .\n \"\"\"\n return self._fast_ica.mixing_\n\n @property\n @_wrap_ndarray_output_to_nddataset(\n units=None,\n title=None,\n typey=\"components\",\n )\n def St(self):\n \"\"\"\n The spectral profiles of the independant sources.\n\n NDDataset of size (`n_components`\\ , `n_features`\\ ). It is the transpose of the\n ``mixing_`` matrix returned by Scikit-Learn.\n \"\"\"\n return self._fast_ica.mixing_.T\n\n @property\n @_wrap_ndarray_output_to_nddataset(\n units=None,\n title=None,\n typex=\"components\",\n )\n def A(self):\n \"\"\"\n The mixing system A.\n\n NDDataset of size (`n_observations`\\ , `n_components`\\ ). It is the matrix\n returned by the `transform()` method.\n \"\"\"\n return self._fast_ica.transform(self.X.data)\n\n @property\n @_wrap_ndarray_output_to_nddataset()\n def mean(self):\n \"\"\"\n The mean of X over features.\n\n Only set if `whiten` is True, it is needed (and used) to reconstruct a dataset\n by ``inverse_transform(A)``\\ .\n \"\"\"\n return self._fast_ica.mean_\n\n @property\n def n_iter(self):\n \"\"\"\n Number of iterations.\n\n If the algorithm is \u201cdeflation\u201d, n_iter is the maximum number of iterations run\n across all components. Else they are just the number of iterations taken to\n converge.\n \"\"\"\n return self._fast_ica.n_iter_\n\n @property\n @_wrap_ndarray_output_to_nddataset(\n units=None,\n title=None,\n typey=\"components\",\n )\n def whitening(self):\n \"\"\"\n NDDataset of shape (n_components, n_features).\n\n Only set if whiten is not None. This is the pre-whitening matrix that projects\n data onto the first n_components principal components.\n \"\"\"\n if self.whiten:\n return self._fast_ica.whitening_\n", "path": "spectrochempy/analysis/decomposition/fast_ica.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n# ======================================================================================\n# Copyright (\u00a9) 2015-2023 LCS - Laboratoire Catalyse et Spectrochimie, Caen, France.\n# CeCILL-B FREE SOFTWARE LICENSE AGREEMENT\n# See full LICENSE agreement in the root directory.\n# ======================================================================================\n\"\"\"\nImplementation of FastICA model (using scikit-learn library)\n\"\"\"\n\nimport traitlets as tr\nfrom numpy.random import RandomState\nfrom sklearn import decomposition\n\nfrom spectrochempy.analysis._base._analysisbase import (\n DecompositionAnalysis,\n _wrap_ndarray_output_to_nddataset,\n)\nfrom spectrochempy.utils.decorators import signature_has_configurable_traits\nfrom spectrochempy.utils.docstrings import _docstring\nfrom spectrochempy.utils.traits import NDDatasetType\n\n__all__ = [\"FastICA\"]\n__configurables__ = [\"FastICA\"]\n\n\n# ======================================================================================\n# class FastICA\n# ======================================================================================\n@signature_has_configurable_traits\nclass FastICA(DecompositionAnalysis):\n _docstring.delete_params(\"DecompositionAnalysis.see_also\", \"FastICA\")\n\n __doc__ = _docstring.dedent(\n r\"\"\"\n Fast algorithm for Independent Component Analysis (FastICA).\n\n A wrapper of `sklearn.decomposition.FastICA`\\ .\n\n :term:`ICA` (Independent Component Analysis) extracts the underlying sources of\n the variability of a set of spectra :math:`X` into the spectral profiles :math:`S^t`\n of the underlying sources and a mixing matrix :math:`A`\\ .\n\n In terms of matrix equation:\n\n .. math:: X = \\bar{X} + A \\cdot S^t + E\n\n where :math:`\\bar{X}` is the mean of the dataset and :math:`E` is the matrix of\n residuals.\n\n Parameters\n ----------\n %(AnalysisConfigurable.parameters)s\n\n See Also\n --------\n %(DecompositionAnalysis.see_also.no_FastICA)s\n \"\"\"\n )\n\n # ----------------------------------------------------------------------------------\n # Runtime Parameters,\n # only those specific to FastICA, the other being defined in AnalysisConfigurable.\n # ----------------------------------------------------------------------------------\n # define here only the variable that you use in fit or transform functions\n _fastica = tr.Instance(\n decomposition.FastICA,\n help=\"The instance of sklearn.decomposition.FastICA used in this model\",\n )\n\n # ----------------------------------------------------------------------------------\n # Configuration parameters\n # ----------------------------------------------------------------------------------\n\n n_components = tr.Integer(\n default_value=None,\n allow_none=True,\n help=\"Number of components (sources) to use.\",\n ).tag(config=True)\n\n algorithm = tr.Enum(\n [\"parallel\", \"deflation\"],\n default_value=\"parallel\",\n help=(\"\"\"Specify which algorithm to use for FastICA.\"\"\"),\n ).tag(config=True)\n\n whiten = tr.Union(\n (tr.Enum([\"arbitrary-variance\", \"unit-variance\"]), tr.Bool(False)),\n default_value=\"unit-variance\",\n allow_none=True,\n help=(\n \"\"\"Specify the whitening strategy to use.\n\n- ``\"arbitrary-variance\"``\\ : a whitening with variance arbitrary is used.\n- \"unit-variance\" : the whitening matrix is rescaled to ensure that each recovered\n source has unit variance.\n- False : the data is already considered to be whitened, and no whitening is performed.\n\"\"\"\n ),\n ).tag(config=True)\n\n fun = tr.Union(\n (tr.Enum([\"logcosh\", \"exp\", \"cube\"]), tr.Callable(), tr.Unicode()),\n default_value=\"logcosh\",\n allow_none=True,\n help=(\n r\"\"\"The functional form of the function used in the approximation to neg-entropy.\n\n- ``string``\\ : could be either ``\"logcosh\"``\\ , ``\"exp\"``\\ , or ``\"cube\"``\\ .\n- ``callable``\\ : You can provide your own function. It should return a tuple containing\n the value of the function, and of its derivative, in the point. The derivative should\n be averaged along its last dimension.\n\n.. code-block::\n\n def my_g(x):\n return x ** 3, (3 * x ** 2).mean(axis=-1)\n\n.. note::\n ``fun`` can be also a serialized function created using dill and base64\n python libraries. Normally not used directly, it is here for internal\n process. \"\"\"\n ),\n ).tag(config=True)\n\n fun_args = tr.Dict(\n default_value=None,\n allow_none=True,\n help=(\n \"\"\"Arguments to send to the functional form.\n\nIf empty or None and if ``fun==\"logcosh\"`` , `fun_args` will take value\n``{alpha : 1.0}``.\"\"\"\n ),\n ).tag(config=True)\n\n tol = tr.Float(\n default_value=1e-4,\n help=\"Tolerance at which the un-mixing matrix is considered to have converged.\",\n ).tag(config=True)\n\n max_iter = tr.Integer(\n default_value=200, help=\"Maximum number of iterations before timing out.\"\n ).tag(config=True)\n\n w_init = tr.Union(\n (NDDatasetType(),),\n default_value=None,\n allow_none=True,\n help=(\n r\"\"\"Initial un-mixing array.\n\nNDDataset or array-like of shape (n_components, n_components). If w_init=None, then an\narray of values drawn from a normal distribution is used.\"\"\"\n ),\n ).tag(config=True)\n\n whiten_solver = tr.Enum(\n [\"svd\", \"eigh\"],\n default_value=\"svd\",\n help=(\n \"\"\"The solver to use for whitening.\n\n- ``\"svd\"``\\ : is more stable numerically if the problem is degenerate, and often faster\n when :term:`n_observations` <= :term:`n_features`\\ .\n- ``\"eigh\"``\\ : is generally more memory efficient when\n :term:`n_observations` >= :term:`n_features`\\ , and can be faster when\n :term:`n_observations` >= 50 * :term:`n_features`\\ . \"\"\"\n ),\n ).tag(config=True)\n\n random_state = tr.Union(\n (tr.Integer(), tr.Instance(RandomState)),\n allow_none=True,\n default_value=None,\n help=(\n \"Used to initialize ``w_init`` when not specified, with a normal\"\n \"distribution. Pass an ``int``, for reproducible results across \"\n \"multiple function calls.\"\n ),\n ).tag(config=True)\n\n # ----------------------------------------------------------------------------------\n # Initialization\n # ----------------------------------------------------------------------------------\n def __init__(\n self,\n *,\n log_level=\"WARNING\",\n warm_start=False,\n **kwargs,\n ):\n # call the super class for initialisation of the configuration parameters\n # to do before anything else!\n super().__init__(\n log_level=log_level,\n warm_start=warm_start,\n **kwargs,\n )\n\n # initialize sklearn Fast!ICA\n self._fast_ica = decomposition.FastICA(\n n_components=self.n_components,\n algorithm=self.algorithm,\n whiten=self.whiten,\n fun=self.fun,\n fun_args=self.fun_args,\n tol=self.tol,\n max_iter=self.max_iter,\n w_init=self.w_init,\n whiten_solver=self.whiten_solver,\n random_state=self.random_state,\n )\n\n # ----------------------------------------------------------------------------------\n # Private methods (overloading abstract classes)\n # ----------------------------------------------------------------------------------\n def _fit(self, X, Y=None):\n # this method is called by the abstract class fit.\n # Input X is a np.ndarray\n # Y is ignored in this model\n\n # call the sklearn _fit function on data\n # _outfit is a tuple handle the eventual output of _fit for further processing.\n\n # The _outfit members are np.ndarrays\n _outfit = self._fast_ica.fit(X)\n self._n_components = int(\n self._fast_ica.n_components\n ) # cast the returned int64 to int\n return _outfit\n\n def _transform(self, X):\n return self._fast_ica.transform(X)\n\n def _inverse_transform(self, X_transform):\n # we need to set self._fast_ica.components_ to a compatible size but without\n # destroying the full matrix:\n store_components_ = self._fast_ica.components_\n self._fast_ica.components_ = self._fast_ica.components_[: X_transform.shape[1]]\n X = self._fast_ica.inverse_transform(X_transform)\n # restore\n self._fast_ica.components_ = store_components_\n return X\n\n def _get_components(self):\n self._components = self._fast_ica.components_\n return self._components\n\n _docstring.keep_params(\"analysis_fit.parameters\", \"X\")\n\n @_docstring.dedent\n def fit(self, X):\n \"\"\"\n Fit the FastICA model on X.\n\n Parameters\n ----------\n %(analysis_fit.parameters.X)s\n\n Returns\n -------\n %(analysis_fit.returns)s\n\n See Also\n --------\n %(analysis_fit.see_also)s\n \"\"\"\n return super().fit(X, Y=None)\n\n @property\n @_wrap_ndarray_output_to_nddataset(\n units=None, title=None, typey=\"features\", typex=\"components\"\n )\n def mixing(self):\n \"\"\"\n The pseudo inverse of components.\n\n NDDataset of size (`n_features`\\ , `n_components`\\ ). It is the linear operator\n that maps independent sources to the data, and the transpose of `St`\\ .\n \"\"\"\n return self._fast_ica.mixing_\n\n @property\n @_wrap_ndarray_output_to_nddataset(\n units=None,\n title=None,\n typey=\"components\",\n )\n def St(self):\n \"\"\"\n The spectral profiles of the independant sources.\n\n NDDataset of size (`n_components`\\ , `n_features`\\ ). It is the transpose of the\n ``mixing_`` matrix returned by Scikit-Learn.\n \"\"\"\n return self._fast_ica.mixing_.T\n\n @property\n @_wrap_ndarray_output_to_nddataset(\n units=None,\n title=None,\n typex=\"components\",\n )\n def A(self):\n \"\"\"\n The mixing system A.\n\n NDDataset of size (`n_observations`\\ , `n_components`\\ ). It is the matrix\n returned by the `transform()` method.\n \"\"\"\n return self._fast_ica.transform(self.X.data)\n\n @property\n @_wrap_ndarray_output_to_nddataset()\n def mean(self):\n \"\"\"\n The mean of X over features.\n\n Only set if `whiten` is True, it is needed (and used) to reconstruct a dataset\n by ``inverse_transform(A)``\\ .\n \"\"\"\n return self._fast_ica.mean_\n\n @property\n def n_iter(self):\n \"\"\"\n Number of iterations.\n\n If the algorithm is \u201cdeflation\u201d, n_iter is the maximum number of iterations run\n across all components. Else they are just the number of iterations taken to\n converge.\n \"\"\"\n return self._fast_ica.n_iter_\n\n @property\n @_wrap_ndarray_output_to_nddataset(\n units=None,\n title=None,\n typey=\"components\",\n )\n def whitening(self):\n \"\"\"\n NDDataset of shape (n_components, n_features).\n\n Only set if whiten is not None. This is the pre-whitening matrix that projects\n data onto the first n_components principal components.\n \"\"\"\n if self.whiten:\n return self._fast_ica.whitening_\n", "path": "spectrochempy/analysis/decomposition/fast_ica.py"}]}
| 3,939 | 238 |
gh_patches_debug_9298
|
rasdani/github-patches
|
git_diff
|
joke2k__faker-1607
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
es_ES postalcode is not generating valid codes
* Faker version: 11.3
* OS: Any
When using postcode for es_ES and using it with a field that requires a valid Postal Code, it fails sometimes.
I will assume that there is no logic with postal code generation for Spain.
### Steps to reproduce
Generate postal codes
### Expected behavior
Get a valid Spain postal code
### Actual behavior
Unexpected. Many are wrong
----
I'll dig now into the code. Let's see if I can get some more information and fix it :thinking: Do not expect much from me
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `faker/providers/address/es_ES/__init__.py`
Content:
```
1 from ..es import Provider as AddressProvider
2
3
4 class Provider(AddressProvider):
5 building_number_formats = ("%", "%#", "%#", "%#", "%##")
6 street_prefixes = (
7 "Plaza",
8 "Calle",
9 "Avenida",
10 "Via",
11 "Vial",
12 "Rambla",
13 "Glorieta",
14 "Urbanización",
15 "Callejón",
16 "Cañada",
17 "Alameda",
18 "Acceso",
19 "C.",
20 "Ronda",
21 "Pasaje",
22 "Cuesta",
23 "Pasadizo",
24 "Paseo",
25 "Camino",
26 )
27 postcode_formats = ("#####",)
28 states = (
29 "Álava",
30 "Albacete",
31 "Alicante",
32 "Almería",
33 "Asturias",
34 "Ávila",
35 "Badajoz",
36 "Baleares",
37 "Barcelona",
38 "Burgos",
39 "Cáceres",
40 "Cádiz",
41 "Cantabria",
42 "Castellón",
43 "Ceuta",
44 "Ciudad",
45 "Córdoba",
46 "Cuenca",
47 "Girona",
48 "Granada",
49 "Guadalajara",
50 "Guipúzcoa",
51 "Huelva",
52 "Huesca",
53 "Jaén",
54 "La Coruña",
55 "La Rioja",
56 "Las Palmas",
57 "León",
58 "Lleida",
59 "Lugo",
60 "Madrid",
61 "Málaga",
62 "Melilla",
63 "Murcia",
64 "Navarra",
65 "Ourense",
66 "Palencia",
67 "Pontevedra",
68 "Salamanca",
69 "Santa Cruz de Tenerife",
70 "Segovia",
71 "Sevilla",
72 "Soria",
73 "Tarragona",
74 "Teruel",
75 "Toledo",
76 "Valencia",
77 "Valladolid",
78 "Vizcaya",
79 "Zamora",
80 "Zaragoza",
81 )
82
83 # Source:
84 # https://administracionelectronica.gob.es/ctt/resources/Soluciones
85 # /238/Descargas/Catalogo-de-Comunidades-Autonomas.xlsx
86 regions = (
87 "Andalucía",
88 "Aragón",
89 "Principado de Asturias",
90 "Illes Balears",
91 "Canarias",
92 "Cantabria",
93 "Castilla y León",
94 "Castilla-La Mancha",
95 "Cataluña",
96 "Comunitat Valenciana",
97 "Extremadura",
98 "Galicia",
99 "Comunidad de Madrid",
100 "Región de Murcia",
101 "Comunidad Foral de Navarra",
102 "País Vasco",
103 "La Rioja",
104 "Ciudad Autónoma de Ceuta",
105 "Ciudad Autónoma de Melilla",
106 )
107
108 city_formats = ("{{state_name}}",)
109
110 street_name_formats = (
111 "{{street_prefix}} {{first_name}} {{last_name}}",
112 "{{street_prefix}} de {{first_name}} {{last_name}}",
113 )
114 street_address_formats = (
115 "{{street_name}} {{building_number}}",
116 "{{street_name}} {{building_number}} {{secondary_address}} ",
117 )
118 address_formats = ("{{street_address}}\n{{city}}, {{postcode}}",)
119 secondary_address_formats = ("Apt. ##", "Piso #", "Puerta #")
120
121 def state_name(self) -> str:
122 return self.random_element(self.states)
123
124 def street_prefix(self) -> str:
125 return self.random_element(self.street_prefixes)
126
127 def secondary_address(self) -> str:
128 return self.numerify(self.random_element(self.secondary_address_formats))
129
130 def administrative_unit(self) -> str:
131 return self.random_element(self.states)
132
133 state = administrative_unit
134
135 def region(self) -> str:
136 return self.random_element(self.regions)
137
138 autonomous_community = region
139
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/faker/providers/address/es_ES/__init__.py b/faker/providers/address/es_ES/__init__.py
--- a/faker/providers/address/es_ES/__init__.py
+++ b/faker/providers/address/es_ES/__init__.py
@@ -24,7 +24,6 @@
"Paseo",
"Camino",
)
- postcode_formats = ("#####",)
states = (
"Álava",
"Albacete",
@@ -135,4 +134,7 @@
def region(self) -> str:
return self.random_element(self.regions)
+ def postcode(self) -> str:
+ return str(self.generator.random.randint(1000, 52100)).zfill(5)
+
autonomous_community = region
|
{"golden_diff": "diff --git a/faker/providers/address/es_ES/__init__.py b/faker/providers/address/es_ES/__init__.py\n--- a/faker/providers/address/es_ES/__init__.py\n+++ b/faker/providers/address/es_ES/__init__.py\n@@ -24,7 +24,6 @@\n \"Paseo\",\n \"Camino\",\n )\n- postcode_formats = (\"#####\",)\n states = (\n \"\u00c1lava\",\n \"Albacete\",\n@@ -135,4 +134,7 @@\n def region(self) -> str:\n return self.random_element(self.regions)\n \n+ def postcode(self) -> str:\n+ return str(self.generator.random.randint(1000, 52100)).zfill(5)\n+\n autonomous_community = region\n", "issue": "es_ES postalcode is not generating valid codes\n* Faker version: 11.3\r\n* OS: Any\r\n\r\nWhen using postcode for es_ES and using it with a field that requires a valid Postal Code, it fails sometimes.\r\nI will assume that there is no logic with postal code generation for Spain.\r\n\r\n### Steps to reproduce\r\n\r\nGenerate postal codes\r\n\r\n### Expected behavior\r\n\r\nGet a valid Spain postal code\r\n\r\n### Actual behavior\r\n\r\nUnexpected. Many are wrong\r\n\r\n----\r\n\r\nI'll dig now into the code. Let's see if I can get some more information and fix it :thinking: Do not expect much from me\n", "before_files": [{"content": "from ..es import Provider as AddressProvider\n\n\nclass Provider(AddressProvider):\n building_number_formats = (\"%\", \"%#\", \"%#\", \"%#\", \"%##\")\n street_prefixes = (\n \"Plaza\",\n \"Calle\",\n \"Avenida\",\n \"Via\",\n \"Vial\",\n \"Rambla\",\n \"Glorieta\",\n \"Urbanizaci\u00f3n\",\n \"Callej\u00f3n\",\n \"Ca\u00f1ada\",\n \"Alameda\",\n \"Acceso\",\n \"C.\",\n \"Ronda\",\n \"Pasaje\",\n \"Cuesta\",\n \"Pasadizo\",\n \"Paseo\",\n \"Camino\",\n )\n postcode_formats = (\"#####\",)\n states = (\n \"\u00c1lava\",\n \"Albacete\",\n \"Alicante\",\n \"Almer\u00eda\",\n \"Asturias\",\n \"\u00c1vila\",\n \"Badajoz\",\n \"Baleares\",\n \"Barcelona\",\n \"Burgos\",\n \"C\u00e1ceres\",\n \"C\u00e1diz\",\n \"Cantabria\",\n \"Castell\u00f3n\",\n \"Ceuta\",\n \"Ciudad\",\n \"C\u00f3rdoba\",\n \"Cuenca\",\n \"Girona\",\n \"Granada\",\n \"Guadalajara\",\n \"Guip\u00fazcoa\",\n \"Huelva\",\n \"Huesca\",\n \"Ja\u00e9n\",\n \"La Coru\u00f1a\",\n \"La Rioja\",\n \"Las Palmas\",\n \"Le\u00f3n\",\n \"Lleida\",\n \"Lugo\",\n \"Madrid\",\n \"M\u00e1laga\",\n \"Melilla\",\n \"Murcia\",\n \"Navarra\",\n \"Ourense\",\n \"Palencia\",\n \"Pontevedra\",\n \"Salamanca\",\n \"Santa Cruz de Tenerife\",\n \"Segovia\",\n \"Sevilla\",\n \"Soria\",\n \"Tarragona\",\n \"Teruel\",\n \"Toledo\",\n \"Valencia\",\n \"Valladolid\",\n \"Vizcaya\",\n \"Zamora\",\n \"Zaragoza\",\n )\n\n # Source:\n # https://administracionelectronica.gob.es/ctt/resources/Soluciones\n # /238/Descargas/Catalogo-de-Comunidades-Autonomas.xlsx\n regions = (\n \"Andaluc\u00eda\",\n \"Arag\u00f3n\",\n \"Principado de Asturias\",\n \"Illes Balears\",\n \"Canarias\",\n \"Cantabria\",\n \"Castilla y Le\u00f3n\",\n \"Castilla-La Mancha\",\n \"Catalu\u00f1a\",\n \"Comunitat Valenciana\",\n \"Extremadura\",\n \"Galicia\",\n \"Comunidad de Madrid\",\n \"Regi\u00f3n de Murcia\",\n \"Comunidad Foral de Navarra\",\n \"Pa\u00eds Vasco\",\n \"La Rioja\",\n \"Ciudad Aut\u00f3noma de Ceuta\",\n \"Ciudad Aut\u00f3noma de Melilla\",\n )\n\n city_formats = (\"{{state_name}}\",)\n\n street_name_formats = (\n \"{{street_prefix}} {{first_name}} {{last_name}}\",\n \"{{street_prefix}} de {{first_name}} {{last_name}}\",\n )\n street_address_formats = (\n \"{{street_name}} {{building_number}}\",\n \"{{street_name}} {{building_number}} {{secondary_address}} \",\n )\n address_formats = (\"{{street_address}}\\n{{city}}, {{postcode}}\",)\n secondary_address_formats = (\"Apt. ##\", \"Piso #\", \"Puerta #\")\n\n def state_name(self) -> str:\n return self.random_element(self.states)\n\n def street_prefix(self) -> str:\n return self.random_element(self.street_prefixes)\n\n def secondary_address(self) -> str:\n return self.numerify(self.random_element(self.secondary_address_formats))\n\n def administrative_unit(self) -> str:\n return self.random_element(self.states)\n\n state = administrative_unit\n\n def region(self) -> str:\n return self.random_element(self.regions)\n\n autonomous_community = region\n", "path": "faker/providers/address/es_ES/__init__.py"}], "after_files": [{"content": "from ..es import Provider as AddressProvider\n\n\nclass Provider(AddressProvider):\n building_number_formats = (\"%\", \"%#\", \"%#\", \"%#\", \"%##\")\n street_prefixes = (\n \"Plaza\",\n \"Calle\",\n \"Avenida\",\n \"Via\",\n \"Vial\",\n \"Rambla\",\n \"Glorieta\",\n \"Urbanizaci\u00f3n\",\n \"Callej\u00f3n\",\n \"Ca\u00f1ada\",\n \"Alameda\",\n \"Acceso\",\n \"C.\",\n \"Ronda\",\n \"Pasaje\",\n \"Cuesta\",\n \"Pasadizo\",\n \"Paseo\",\n \"Camino\",\n )\n states = (\n \"\u00c1lava\",\n \"Albacete\",\n \"Alicante\",\n \"Almer\u00eda\",\n \"Asturias\",\n \"\u00c1vila\",\n \"Badajoz\",\n \"Baleares\",\n \"Barcelona\",\n \"Burgos\",\n \"C\u00e1ceres\",\n \"C\u00e1diz\",\n \"Cantabria\",\n \"Castell\u00f3n\",\n \"Ceuta\",\n \"Ciudad\",\n \"C\u00f3rdoba\",\n \"Cuenca\",\n \"Girona\",\n \"Granada\",\n \"Guadalajara\",\n \"Guip\u00fazcoa\",\n \"Huelva\",\n \"Huesca\",\n \"Ja\u00e9n\",\n \"La Coru\u00f1a\",\n \"La Rioja\",\n \"Las Palmas\",\n \"Le\u00f3n\",\n \"Lleida\",\n \"Lugo\",\n \"Madrid\",\n \"M\u00e1laga\",\n \"Melilla\",\n \"Murcia\",\n \"Navarra\",\n \"Ourense\",\n \"Palencia\",\n \"Pontevedra\",\n \"Salamanca\",\n \"Santa Cruz de Tenerife\",\n \"Segovia\",\n \"Sevilla\",\n \"Soria\",\n \"Tarragona\",\n \"Teruel\",\n \"Toledo\",\n \"Valencia\",\n \"Valladolid\",\n \"Vizcaya\",\n \"Zamora\",\n \"Zaragoza\",\n )\n\n # Source:\n # https://administracionelectronica.gob.es/ctt/resources/Soluciones\n # /238/Descargas/Catalogo-de-Comunidades-Autonomas.xlsx\n regions = (\n \"Andaluc\u00eda\",\n \"Arag\u00f3n\",\n \"Principado de Asturias\",\n \"Illes Balears\",\n \"Canarias\",\n \"Cantabria\",\n \"Castilla y Le\u00f3n\",\n \"Castilla-La Mancha\",\n \"Catalu\u00f1a\",\n \"Comunitat Valenciana\",\n \"Extremadura\",\n \"Galicia\",\n \"Comunidad de Madrid\",\n \"Regi\u00f3n de Murcia\",\n \"Comunidad Foral de Navarra\",\n \"Pa\u00eds Vasco\",\n \"La Rioja\",\n \"Ciudad Aut\u00f3noma de Ceuta\",\n \"Ciudad Aut\u00f3noma de Melilla\",\n )\n\n city_formats = (\"{{state_name}}\",)\n\n street_name_formats = (\n \"{{street_prefix}} {{first_name}} {{last_name}}\",\n \"{{street_prefix}} de {{first_name}} {{last_name}}\",\n )\n street_address_formats = (\n \"{{street_name}} {{building_number}}\",\n \"{{street_name}} {{building_number}} {{secondary_address}} \",\n )\n address_formats = (\"{{street_address}}\\n{{city}}, {{postcode}}\",)\n secondary_address_formats = (\"Apt. ##\", \"Piso #\", \"Puerta #\")\n\n def state_name(self) -> str:\n return self.random_element(self.states)\n\n def street_prefix(self) -> str:\n return self.random_element(self.street_prefixes)\n\n def secondary_address(self) -> str:\n return self.numerify(self.random_element(self.secondary_address_formats))\n\n def administrative_unit(self) -> str:\n return self.random_element(self.states)\n\n state = administrative_unit\n\n def region(self) -> str:\n return self.random_element(self.regions)\n\n def postcode(self) -> str:\n return str(self.generator.random.randint(1000, 52100)).zfill(5)\n\n autonomous_community = region\n", "path": "faker/providers/address/es_ES/__init__.py"}]}
| 1,598 | 176 |
gh_patches_debug_3386
|
rasdani/github-patches
|
git_diff
|
svthalia__concrexit-1550
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Event registrations api returns 500
### Describe the bug
`/api/v1/events/{pk}/registrations/` returns a 500
### How to reproduce
1. Register for an event
2. Go to `/api/v1/events/{pk}/registrations/`
3. See a 500
### Expected behaviour
No 500
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `website/events/api/v1/serializers/event_registrations/list.py`
Content:
```
1 from django.conf import settings
2 from django.templatetags.static import static
3 from rest_framework import serializers
4 from rest_framework.fields import empty
5
6 from events import services
7 from events.exceptions import RegistrationError
8 from events.models import EventRegistration, RegistrationInformationField
9 from payments.api.v1.fields import PaymentTypeField
10 from payments.models import Payment
11 from thaliawebsite.api.services import create_image_thumbnail_dict
12
13
14 class EventRegistrationListSerializer(serializers.ModelSerializer):
15 """Custom registration list serializer."""
16
17 class Meta:
18 model = EventRegistration
19 fields = ("pk", "member", "name", "avatar")
20
21 name = serializers.SerializerMethodField("_name")
22 avatar = serializers.SerializerMethodField("_avatar")
23 member = serializers.SerializerMethodField("_member")
24
25 def _member(self, instance):
26 if instance.member:
27 return instance.member.pk
28 return None
29
30 def _name(self, instance):
31 if instance.member:
32 return instance.member.profile.display_name()
33 return instance.name
34
35 def _avatar(self, instance):
36 placeholder = self.context["request"].build_absolute_uri(
37 static("members/images/default-avatar.jpg")
38 )
39 file = None
40 if instance.member and instance.member.profile.photo:
41 file = instance.member.profile.photo
42 return create_image_thumbnail_dict(
43 self.context["request"], file, placeholder=placeholder, size_large="800x800"
44 )
45
46
47 class EventRegistrationAdminListSerializer(EventRegistrationListSerializer):
48 """Custom registration admin list serializer."""
49
50 class Meta:
51 model = EventRegistration
52 fields = (
53 "pk",
54 "member",
55 "name",
56 "registered_on",
57 "is_cancelled",
58 "is_late_cancellation",
59 "queue_position",
60 "payment",
61 "present",
62 "avatar",
63 )
64
65 registered_on = serializers.DateTimeField(source="date")
66 is_cancelled = serializers.SerializerMethodField("_is_cancelled")
67 is_late_cancellation = serializers.SerializerMethodField("_is_late_cancellation")
68 queue_position = serializers.SerializerMethodField("_queue_position")
69 payment = PaymentTypeField(source="payment.type", choices=Payment.PAYMENT_TYPE)
70
71 def _is_late_cancellation(self, instance):
72 return instance.is_late_cancellation()
73
74 def _queue_position(self, instance):
75 pos = instance.queue_position
76 return pos if pos > 0 else None
77
78 def _is_cancelled(self, instance):
79 return instance.date_cancelled is not None
80
81 def _name(self, instance):
82 if instance.member:
83 return instance.member.get_full_name()
84 return instance.name
85
86
87 class EventRegistrationSerializer(serializers.ModelSerializer):
88 """Registration serializer."""
89
90 information_fields = None
91
92 class Meta:
93 model = EventRegistration
94 fields = (
95 "pk",
96 "member",
97 "name",
98 "photo",
99 "avatar",
100 "registered_on",
101 "is_late_cancellation",
102 "is_cancelled",
103 "queue_position",
104 "fields",
105 "payment",
106 "present",
107 )
108
109 name = serializers.SerializerMethodField("_name")
110 photo = serializers.SerializerMethodField("_photo")
111 avatar = serializers.SerializerMethodField("_avatar")
112 member = serializers.SerializerMethodField("_member")
113 payment = PaymentTypeField(source="payment.type", choices=Payment.PAYMENT_TYPE)
114 registered_on = serializers.DateTimeField(source="date", read_only=True)
115 is_cancelled = serializers.SerializerMethodField("_is_cancelled")
116 is_late_cancellation = serializers.SerializerMethodField("_is_late_cancellation")
117 fields = serializers.HiddenField(default="")
118
119 def _is_late_cancellation(self, instance):
120 val = instance.is_late_cancellation()
121 return False if val is None else val
122
123 def _is_cancelled(self, instance):
124 return instance.date_cancelled is not None
125
126 def _member(self, instance):
127 if instance.member:
128 return instance.member.pk
129 return None
130
131 def _name(self, instance):
132 if instance.member:
133 return instance.member.profile.display_name()
134 return instance.name
135
136 def _photo(self, instance):
137 if instance.member and instance.member.profile.photo:
138 return self.context["request"].build_absolute_uri(
139 f"{settings.MEDIA_URL}{instance.member.profile.photo}"
140 )
141 return self.context["request"].build_absolute_uri(
142 static("members/images/default-avatar.jpg")
143 )
144
145 def _avatar(self, instance):
146 placeholder = self.context["request"].build_absolute_uri(
147 static("members/images/default-avatar.jpg")
148 )
149 file = None
150 if instance.member and instance.member.profile.photo:
151 file = instance.member.profile.photo
152 return create_image_thumbnail_dict(
153 self.context["request"], file, placeholder=placeholder, size_large="800x800"
154 )
155
156 def __init__(self, instance=None, data=empty, **kwargs):
157 super().__init__(instance, data, **kwargs)
158 try:
159 if instance:
160 self.information_fields = services.registration_fields(
161 kwargs["context"]["request"], registration=instance
162 )
163 except RegistrationError:
164 pass
165
166 def get_fields(self):
167 fields = super().get_fields()
168
169 if self.information_fields:
170 for key, field in self.information_fields.items():
171 key = "fields[{}]".format(key)
172 field_type = field["type"]
173
174 if field_type == RegistrationInformationField.BOOLEAN_FIELD:
175 fields[key] = serializers.BooleanField(
176 required=False, write_only=True
177 )
178 elif field_type == RegistrationInformationField.INTEGER_FIELD:
179 fields[key] = serializers.IntegerField(
180 required=field["required"],
181 write_only=True,
182 allow_null=not field["required"],
183 )
184 elif field_type == RegistrationInformationField.TEXT_FIELD:
185 fields[key] = serializers.CharField(
186 required=field["required"],
187 write_only=True,
188 allow_blank=not field["required"],
189 allow_null=not field["required"],
190 )
191
192 fields[key].label = field["label"]
193 fields[key].help_text = field["description"]
194 fields[key].initial = field["value"]
195 fields[key].default = field["value"]
196
197 try:
198 if key in self.information_fields:
199 fields[key].initial = self.validated_data[key]
200 except AssertionError:
201 pass
202
203 return fields
204
205 def to_representation(self, instance):
206 data = super().to_representation(instance)
207 data["fields"] = self.information_fields
208 return data
209
210 def field_values(self):
211 return (
212 (name[7 : len(name) - 1], value)
213 for name, value in self.validated_data.items()
214 if "info_field" in name
215 )
216
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/website/events/api/v1/serializers/event_registrations/list.py b/website/events/api/v1/serializers/event_registrations/list.py
--- a/website/events/api/v1/serializers/event_registrations/list.py
+++ b/website/events/api/v1/serializers/event_registrations/list.py
@@ -73,7 +73,7 @@
def _queue_position(self, instance):
pos = instance.queue_position
- return pos if pos > 0 else None
+ return pos if pos and pos > 0 else None
def _is_cancelled(self, instance):
return instance.date_cancelled is not None
|
{"golden_diff": "diff --git a/website/events/api/v1/serializers/event_registrations/list.py b/website/events/api/v1/serializers/event_registrations/list.py\n--- a/website/events/api/v1/serializers/event_registrations/list.py\n+++ b/website/events/api/v1/serializers/event_registrations/list.py\n@@ -73,7 +73,7 @@\n \n def _queue_position(self, instance):\n pos = instance.queue_position\n- return pos if pos > 0 else None\n+ return pos if pos and pos > 0 else None\n \n def _is_cancelled(self, instance):\n return instance.date_cancelled is not None\n", "issue": "Event registrations api returns 500\n### Describe the bug\r\n`/api/v1/events/{pk}/registrations/` returns a 500\r\n\r\n### How to reproduce\r\n1. Register for an event\r\n2. Go to `/api/v1/events/{pk}/registrations/`\r\n3. See a 500\r\n\r\n### Expected behaviour\r\nNo 500\r\n\n", "before_files": [{"content": "from django.conf import settings\nfrom django.templatetags.static import static\nfrom rest_framework import serializers\nfrom rest_framework.fields import empty\n\nfrom events import services\nfrom events.exceptions import RegistrationError\nfrom events.models import EventRegistration, RegistrationInformationField\nfrom payments.api.v1.fields import PaymentTypeField\nfrom payments.models import Payment\nfrom thaliawebsite.api.services import create_image_thumbnail_dict\n\n\nclass EventRegistrationListSerializer(serializers.ModelSerializer):\n \"\"\"Custom registration list serializer.\"\"\"\n\n class Meta:\n model = EventRegistration\n fields = (\"pk\", \"member\", \"name\", \"avatar\")\n\n name = serializers.SerializerMethodField(\"_name\")\n avatar = serializers.SerializerMethodField(\"_avatar\")\n member = serializers.SerializerMethodField(\"_member\")\n\n def _member(self, instance):\n if instance.member:\n return instance.member.pk\n return None\n\n def _name(self, instance):\n if instance.member:\n return instance.member.profile.display_name()\n return instance.name\n\n def _avatar(self, instance):\n placeholder = self.context[\"request\"].build_absolute_uri(\n static(\"members/images/default-avatar.jpg\")\n )\n file = None\n if instance.member and instance.member.profile.photo:\n file = instance.member.profile.photo\n return create_image_thumbnail_dict(\n self.context[\"request\"], file, placeholder=placeholder, size_large=\"800x800\"\n )\n\n\nclass EventRegistrationAdminListSerializer(EventRegistrationListSerializer):\n \"\"\"Custom registration admin list serializer.\"\"\"\n\n class Meta:\n model = EventRegistration\n fields = (\n \"pk\",\n \"member\",\n \"name\",\n \"registered_on\",\n \"is_cancelled\",\n \"is_late_cancellation\",\n \"queue_position\",\n \"payment\",\n \"present\",\n \"avatar\",\n )\n\n registered_on = serializers.DateTimeField(source=\"date\")\n is_cancelled = serializers.SerializerMethodField(\"_is_cancelled\")\n is_late_cancellation = serializers.SerializerMethodField(\"_is_late_cancellation\")\n queue_position = serializers.SerializerMethodField(\"_queue_position\")\n payment = PaymentTypeField(source=\"payment.type\", choices=Payment.PAYMENT_TYPE)\n\n def _is_late_cancellation(self, instance):\n return instance.is_late_cancellation()\n\n def _queue_position(self, instance):\n pos = instance.queue_position\n return pos if pos > 0 else None\n\n def _is_cancelled(self, instance):\n return instance.date_cancelled is not None\n\n def _name(self, instance):\n if instance.member:\n return instance.member.get_full_name()\n return instance.name\n\n\nclass EventRegistrationSerializer(serializers.ModelSerializer):\n \"\"\"Registration serializer.\"\"\"\n\n information_fields = None\n\n class Meta:\n model = EventRegistration\n fields = (\n \"pk\",\n \"member\",\n \"name\",\n \"photo\",\n \"avatar\",\n \"registered_on\",\n \"is_late_cancellation\",\n \"is_cancelled\",\n \"queue_position\",\n \"fields\",\n \"payment\",\n \"present\",\n )\n\n name = serializers.SerializerMethodField(\"_name\")\n photo = serializers.SerializerMethodField(\"_photo\")\n avatar = serializers.SerializerMethodField(\"_avatar\")\n member = serializers.SerializerMethodField(\"_member\")\n payment = PaymentTypeField(source=\"payment.type\", choices=Payment.PAYMENT_TYPE)\n registered_on = serializers.DateTimeField(source=\"date\", read_only=True)\n is_cancelled = serializers.SerializerMethodField(\"_is_cancelled\")\n is_late_cancellation = serializers.SerializerMethodField(\"_is_late_cancellation\")\n fields = serializers.HiddenField(default=\"\")\n\n def _is_late_cancellation(self, instance):\n val = instance.is_late_cancellation()\n return False if val is None else val\n\n def _is_cancelled(self, instance):\n return instance.date_cancelled is not None\n\n def _member(self, instance):\n if instance.member:\n return instance.member.pk\n return None\n\n def _name(self, instance):\n if instance.member:\n return instance.member.profile.display_name()\n return instance.name\n\n def _photo(self, instance):\n if instance.member and instance.member.profile.photo:\n return self.context[\"request\"].build_absolute_uri(\n f\"{settings.MEDIA_URL}{instance.member.profile.photo}\"\n )\n return self.context[\"request\"].build_absolute_uri(\n static(\"members/images/default-avatar.jpg\")\n )\n\n def _avatar(self, instance):\n placeholder = self.context[\"request\"].build_absolute_uri(\n static(\"members/images/default-avatar.jpg\")\n )\n file = None\n if instance.member and instance.member.profile.photo:\n file = instance.member.profile.photo\n return create_image_thumbnail_dict(\n self.context[\"request\"], file, placeholder=placeholder, size_large=\"800x800\"\n )\n\n def __init__(self, instance=None, data=empty, **kwargs):\n super().__init__(instance, data, **kwargs)\n try:\n if instance:\n self.information_fields = services.registration_fields(\n kwargs[\"context\"][\"request\"], registration=instance\n )\n except RegistrationError:\n pass\n\n def get_fields(self):\n fields = super().get_fields()\n\n if self.information_fields:\n for key, field in self.information_fields.items():\n key = \"fields[{}]\".format(key)\n field_type = field[\"type\"]\n\n if field_type == RegistrationInformationField.BOOLEAN_FIELD:\n fields[key] = serializers.BooleanField(\n required=False, write_only=True\n )\n elif field_type == RegistrationInformationField.INTEGER_FIELD:\n fields[key] = serializers.IntegerField(\n required=field[\"required\"],\n write_only=True,\n allow_null=not field[\"required\"],\n )\n elif field_type == RegistrationInformationField.TEXT_FIELD:\n fields[key] = serializers.CharField(\n required=field[\"required\"],\n write_only=True,\n allow_blank=not field[\"required\"],\n allow_null=not field[\"required\"],\n )\n\n fields[key].label = field[\"label\"]\n fields[key].help_text = field[\"description\"]\n fields[key].initial = field[\"value\"]\n fields[key].default = field[\"value\"]\n\n try:\n if key in self.information_fields:\n fields[key].initial = self.validated_data[key]\n except AssertionError:\n pass\n\n return fields\n\n def to_representation(self, instance):\n data = super().to_representation(instance)\n data[\"fields\"] = self.information_fields\n return data\n\n def field_values(self):\n return (\n (name[7 : len(name) - 1], value)\n for name, value in self.validated_data.items()\n if \"info_field\" in name\n )\n", "path": "website/events/api/v1/serializers/event_registrations/list.py"}], "after_files": [{"content": "from django.conf import settings\nfrom django.templatetags.static import static\nfrom rest_framework import serializers\nfrom rest_framework.fields import empty\n\nfrom events import services\nfrom events.exceptions import RegistrationError\nfrom events.models import EventRegistration, RegistrationInformationField\nfrom payments.api.v1.fields import PaymentTypeField\nfrom payments.models import Payment\nfrom thaliawebsite.api.services import create_image_thumbnail_dict\n\n\nclass EventRegistrationListSerializer(serializers.ModelSerializer):\n \"\"\"Custom registration list serializer.\"\"\"\n\n class Meta:\n model = EventRegistration\n fields = (\"pk\", \"member\", \"name\", \"avatar\")\n\n name = serializers.SerializerMethodField(\"_name\")\n avatar = serializers.SerializerMethodField(\"_avatar\")\n member = serializers.SerializerMethodField(\"_member\")\n\n def _member(self, instance):\n if instance.member:\n return instance.member.pk\n return None\n\n def _name(self, instance):\n if instance.member:\n return instance.member.profile.display_name()\n return instance.name\n\n def _avatar(self, instance):\n placeholder = self.context[\"request\"].build_absolute_uri(\n static(\"members/images/default-avatar.jpg\")\n )\n file = None\n if instance.member and instance.member.profile.photo:\n file = instance.member.profile.photo\n return create_image_thumbnail_dict(\n self.context[\"request\"], file, placeholder=placeholder, size_large=\"800x800\"\n )\n\n\nclass EventRegistrationAdminListSerializer(EventRegistrationListSerializer):\n \"\"\"Custom registration admin list serializer.\"\"\"\n\n class Meta:\n model = EventRegistration\n fields = (\n \"pk\",\n \"member\",\n \"name\",\n \"registered_on\",\n \"is_cancelled\",\n \"is_late_cancellation\",\n \"queue_position\",\n \"payment\",\n \"present\",\n \"avatar\",\n )\n\n registered_on = serializers.DateTimeField(source=\"date\")\n is_cancelled = serializers.SerializerMethodField(\"_is_cancelled\")\n is_late_cancellation = serializers.SerializerMethodField(\"_is_late_cancellation\")\n queue_position = serializers.SerializerMethodField(\"_queue_position\")\n payment = PaymentTypeField(source=\"payment.type\", choices=Payment.PAYMENT_TYPE)\n\n def _is_late_cancellation(self, instance):\n return instance.is_late_cancellation()\n\n def _queue_position(self, instance):\n pos = instance.queue_position\n return pos if pos and pos > 0 else None\n\n def _is_cancelled(self, instance):\n return instance.date_cancelled is not None\n\n def _name(self, instance):\n if instance.member:\n return instance.member.get_full_name()\n return instance.name\n\n\nclass EventRegistrationSerializer(serializers.ModelSerializer):\n \"\"\"Registration serializer.\"\"\"\n\n information_fields = None\n\n class Meta:\n model = EventRegistration\n fields = (\n \"pk\",\n \"member\",\n \"name\",\n \"photo\",\n \"avatar\",\n \"registered_on\",\n \"is_late_cancellation\",\n \"is_cancelled\",\n \"queue_position\",\n \"fields\",\n \"payment\",\n \"present\",\n )\n\n name = serializers.SerializerMethodField(\"_name\")\n photo = serializers.SerializerMethodField(\"_photo\")\n avatar = serializers.SerializerMethodField(\"_avatar\")\n member = serializers.SerializerMethodField(\"_member\")\n payment = PaymentTypeField(source=\"payment.type\", choices=Payment.PAYMENT_TYPE)\n registered_on = serializers.DateTimeField(source=\"date\", read_only=True)\n is_cancelled = serializers.SerializerMethodField(\"_is_cancelled\")\n is_late_cancellation = serializers.SerializerMethodField(\"_is_late_cancellation\")\n fields = serializers.HiddenField(default=\"\")\n\n def _is_late_cancellation(self, instance):\n val = instance.is_late_cancellation()\n return False if val is None else val\n\n def _is_cancelled(self, instance):\n return instance.date_cancelled is not None\n\n def _member(self, instance):\n if instance.member:\n return instance.member.pk\n return None\n\n def _name(self, instance):\n if instance.member:\n return instance.member.profile.display_name()\n return instance.name\n\n def _photo(self, instance):\n if instance.member and instance.member.profile.photo:\n return self.context[\"request\"].build_absolute_uri(\n f\"{settings.MEDIA_URL}{instance.member.profile.photo}\"\n )\n return self.context[\"request\"].build_absolute_uri(\n static(\"members/images/default-avatar.jpg\")\n )\n\n def _avatar(self, instance):\n placeholder = self.context[\"request\"].build_absolute_uri(\n static(\"members/images/default-avatar.jpg\")\n )\n file = None\n if instance.member and instance.member.profile.photo:\n file = instance.member.profile.photo\n return create_image_thumbnail_dict(\n self.context[\"request\"], file, placeholder=placeholder, size_large=\"800x800\"\n )\n\n def __init__(self, instance=None, data=empty, **kwargs):\n super().__init__(instance, data, **kwargs)\n try:\n if instance:\n self.information_fields = services.registration_fields(\n kwargs[\"context\"][\"request\"], registration=instance\n )\n except RegistrationError:\n pass\n\n def get_fields(self):\n fields = super().get_fields()\n\n if self.information_fields:\n for key, field in self.information_fields.items():\n key = \"fields[{}]\".format(key)\n field_type = field[\"type\"]\n\n if field_type == RegistrationInformationField.BOOLEAN_FIELD:\n fields[key] = serializers.BooleanField(\n required=False, write_only=True\n )\n elif field_type == RegistrationInformationField.INTEGER_FIELD:\n fields[key] = serializers.IntegerField(\n required=field[\"required\"],\n write_only=True,\n allow_null=not field[\"required\"],\n )\n elif field_type == RegistrationInformationField.TEXT_FIELD:\n fields[key] = serializers.CharField(\n required=field[\"required\"],\n write_only=True,\n allow_blank=not field[\"required\"],\n allow_null=not field[\"required\"],\n )\n\n fields[key].label = field[\"label\"]\n fields[key].help_text = field[\"description\"]\n fields[key].initial = field[\"value\"]\n fields[key].default = field[\"value\"]\n\n try:\n if key in self.information_fields:\n fields[key].initial = self.validated_data[key]\n except AssertionError:\n pass\n\n return fields\n\n def to_representation(self, instance):\n data = super().to_representation(instance)\n data[\"fields\"] = self.information_fields\n return data\n\n def field_values(self):\n return (\n (name[7 : len(name) - 1], value)\n for name, value in self.validated_data.items()\n if \"info_field\" in name\n )\n", "path": "website/events/api/v1/serializers/event_registrations/list.py"}]}
| 2,316 | 147 |
gh_patches_debug_23070
|
rasdani/github-patches
|
git_diff
|
pwndbg__pwndbg-1709
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
bugreport command: show more info
The bugreport command should display more information like:
* show osabi
* show architecture
* show endian
Depending on current arch -- note that those are only available if given arch is supported by current GDB, like `gdb-multiarch`:
* show arm
* show mips
Maybe also:
* show charset
* show width
* show height
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pwndbg/commands/version.py`
Content:
```
1 """
2 Displays gdb, python and pwndbg versions.
3 """
4
5
6 import argparse
7 import os
8 import platform
9 import re
10 import sys
11 from subprocess import check_call
12 from subprocess import check_output
13 from tempfile import NamedTemporaryFile
14 from urllib.parse import quote
15
16 import gdb
17
18 import pwndbg
19 import pwndbg.commands
20 import pwndbg.ida
21 from pwndbg.color import message
22 from pwndbg.commands import CommandCategory
23
24
25 def _gdb_version():
26 try:
27 return gdb.VERSION # GDB >= 8.1 (or earlier?)
28 except AttributeError:
29 return gdb.execute("show version", to_string=True).split("\n")[0]
30
31
32 def _py_version():
33 return sys.version.replace("\n", " ")
34
35
36 def capstone_version():
37 try:
38 import capstone
39
40 return ".".join(map(str, capstone.cs_version()))
41 except ImportError:
42 return "not found"
43
44
45 def unicorn_version():
46 try:
47 import unicorn
48
49 return unicorn.__version__
50 except ImportError:
51 return "not found"
52
53
54 def all_versions():
55 gdb_str = "Gdb: %s" % _gdb_version()
56 py_str = "Python: %s" % _py_version()
57 pwndbg_str = "Pwndbg: %s" % pwndbg.__version__
58
59 capstone_str = "Capstone: %s" % capstone_version()
60 unicorn_str = "Unicorn: %s" % unicorn_version()
61
62 all_versions = (gdb_str, py_str, pwndbg_str, capstone_str, unicorn_str)
63
64 ida_versions = pwndbg.ida.get_ida_versions()
65
66 if ida_versions is not None:
67 ida_version = "IDA PRO: %s" % ida_versions["ida"]
68 ida_py_ver = "IDA Py: %s" % ida_versions["python"]
69 ida_hr_ver = "Hexrays: %s" % ida_versions["hexrays"]
70 all_versions += (ida_version, ida_py_ver, ida_hr_ver)
71 return all_versions
72
73
74 @pwndbg.commands.ArgparsedCommand(
75 "Displays GDB, Python, and pwndbg versions.", category=CommandCategory.PWNDBG
76 )
77 def version() -> None:
78 """
79 Displays GDB, Python, and pwndbg versions.
80 """
81 print("\n".join(map(message.system, all_versions())))
82
83
84 bugreport_parser = argparse.ArgumentParser(description="Generate a bug report.")
85 bugreport_group = bugreport_parser.add_mutually_exclusive_group()
86 bugreport_group.add_argument(
87 "--run-browser", "-b", action="store_true", help="Open browser on github/issues/new"
88 )
89 bugreport_group.add_argument(
90 "--use-gh", "-g", action="store_true", help="Create issue using Github CLI"
91 )
92
93
94 @pwndbg.commands.ArgparsedCommand(bugreport_parser, category=CommandCategory.PWNDBG)
95 def bugreport(run_browser=False, use_gh=False):
96 ISSUE_TEMPLATE = """
97 <!--
98 Before reporting a new issue, make sure that we do not have any duplicates already open.
99 If there is one it might be good to take part in the discussion there.
100
101 Please make sure you have checked that the issue persists on LATEST pwndbg version.
102
103 Below is a template for BUG REPORTS.
104 Don't include it if this is a FEATURE REQUEST.
105 -->
106
107
108 ### Description
109
110 <!--
111 Briefly describe the problem you are having in a few paragraphs.
112 -->
113
114 ### Steps to reproduce
115
116 <!--
117 What do we have to do to reproduce the problem?
118 If this is connected to particular C/asm code or a binary,
119 please provide the binary or if possible, a smallest C code that reproduces the issue.
120 -->
121
122 Gdb session history:
123 ```
124 {gdb_history}
125 ```
126
127 ### My setup
128
129 <!--
130 Show us your gdb/python/pwndbg/OS/IDA Pro version (depending on your case).
131
132 NOTE: We are currently testing Pwndbg only on Ubuntu installations but it should work fine on other distros as well.
133
134 This can be displayed in pwndbg through `version` command.
135
136 If it is somehow unavailable, use:
137 * `show version` - for gdb
138 * `py import sys; print(sys.version)` - for python
139 * pwndbg version/git commit id
140 -->
141
142 ```
143 {setup}
144 ```"""
145
146 gdb_config = gdb.execute("show configuration", to_string=True).split("\n")
147 all_info = all_versions()
148 os_info = platform.system()
149
150 current_setup = "Platform: %s\n" % platform.platform()
151
152 if os_info.lower() == "linux" and os.path.isfile("/etc/os-release"):
153 with open("/etc/os-release", "r") as os_release:
154 contents = os_release.read()
155 match = re.search('PRETTY_NAME="?([^",\n]+)', contents)
156 if match:
157 os_info = match.group(1)
158
159 current_setup += "OS: %s\n" % os_info
160 current_setup += "\n".join(all_info)
161 current_setup += "\n" + "\n".join(gdb_config)
162
163 # get saved history size (not including current gdb session)
164 gdb_history_file = gdb.execute("show history filename", to_string=True)
165 gdb_history_file = gdb_history_file[
166 gdb_history_file.index('"') + 1 : gdb_history_file.rindex('"')
167 ]
168 gdb_history_len = 0
169 try:
170 with open(gdb_history_file, "r") as f:
171 gdb_history_len = len(f.readlines())
172 except FileNotFoundError:
173 pass
174
175 max_command_no = 0
176 history_commands = gdb.execute("show commands", to_string=True)
177 if history_commands:
178 history_commands = history_commands.split("\n")
179 if len(history_commands) > 1:
180 # The last element of the list is the `show commands` command we
181 # just ran, so we need to get the second to last one
182 last_command = history_commands[-2]
183 max_command_no = int(last_command.split()[0]) - 1
184
185 show_command_size = 10 # 'show command' returns 10 commands
186 gdb_current_session_history = {}
187 current_command_no = gdb_history_len + 1
188
189 while current_command_no <= max_command_no:
190 cmds = gdb.execute(
191 "show commands " + str(current_command_no + (show_command_size // 2) + 1),
192 to_string=True,
193 ).split("\n")[:-1]
194 for cmd in cmds:
195 cmd_no, cmd = cmd.split(maxsplit=1)
196 cmd_no = int(cmd_no)
197 if cmd_no <= gdb_history_len:
198 continue
199 if current_command_no > max_command_no:
200 break
201 gdb_current_session_history[cmd_no] = cmd
202 current_command_no += 1
203
204 gdb_current_session_history = (v for (k, v) in sorted(gdb_current_session_history.items()))
205 gdb_current_session_history = "\n".join(gdb_current_session_history)
206
207 issue_bugreport = ISSUE_TEMPLATE.format(
208 gdb_history=gdb_current_session_history, setup=current_setup
209 )
210 print(issue_bugreport)
211
212 please_please_submit = "Please submit the bugreport generated above at "
213 github_issue_url = "https://github.com/pwndbg/pwndbg/issues/new"
214 github_issue_body = "?body=" + quote(issue_bugreport)
215
216 if use_gh:
217 try:
218 with NamedTemporaryFile("w", delete=True) as f:
219 f.write(issue_bugreport)
220 f.flush()
221 check_call([os.environ.get("EDITOR", "vi"), f.name])
222 check_call(["gh", "issue", "create", "--body-file", f.name])
223 except Exception:
224 print(please_please_submit + github_issue_url)
225 raise
226 elif run_browser:
227 try:
228 check_output(["xdg-open", github_issue_url + github_issue_body])
229 except Exception:
230 print(please_please_submit + github_issue_url)
231 else:
232 print(please_please_submit + github_issue_url)
233
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pwndbg/commands/version.py b/pwndbg/commands/version.py
--- a/pwndbg/commands/version.py
+++ b/pwndbg/commands/version.py
@@ -157,6 +157,40 @@
os_info = match.group(1)
current_setup += "OS: %s\n" % os_info
+
+ # 1. showing osabi
+ osabi_info = platform.uname().version
+ current_setup += "OS ABI: %s\n" % osabi_info
+
+ # 2. showing architecture
+ arch_info = platform.machine()
+ current_setup += "Architecture: %s\n" % arch_info
+
+ # 3. showing endian
+ endian_info = sys.byteorder
+ current_setup += "Endian: %s\n" % endian_info
+
+ # 4. Depending on current arch -- note that those are only available if given arch is supported by current GDB, like gdb-multiarch
+ if arch_info in ["armv7l", "aarch64"]:
+ arm_info = gdb.execute("show arm", to_string=True)
+ current_setup += "ARM: %s\n" % arm_info
+
+ elif arch_info in ["mips", "mips64"]:
+ mips_info = gdb.execute("show mips", to_string=True)
+ current_setup += "MIPS: %s\n" % mips_info
+
+ # 7. showing charset
+ charset_info = sys.getdefaultencoding()
+ current_setup += "Charset: %s\n" % charset_info
+
+ # 8. showing width
+ width_info = os.get_terminal_size().columns
+ current_setup += "Width: %s\n" % width_info
+
+ # 9. showing height
+ height_info = os.get_terminal_size().lines
+ current_setup += "Height: %s\n" % height_info
+
current_setup += "\n".join(all_info)
current_setup += "\n" + "\n".join(gdb_config)
|
{"golden_diff": "diff --git a/pwndbg/commands/version.py b/pwndbg/commands/version.py\n--- a/pwndbg/commands/version.py\n+++ b/pwndbg/commands/version.py\n@@ -157,6 +157,40 @@\n os_info = match.group(1)\n \n current_setup += \"OS: %s\\n\" % os_info\n+\n+ # 1. showing osabi\n+ osabi_info = platform.uname().version\n+ current_setup += \"OS ABI: %s\\n\" % osabi_info\n+\n+ # 2. showing architecture\n+ arch_info = platform.machine()\n+ current_setup += \"Architecture: %s\\n\" % arch_info\n+\n+ # 3. showing endian\n+ endian_info = sys.byteorder\n+ current_setup += \"Endian: %s\\n\" % endian_info\n+\n+ # 4. Depending on current arch -- note that those are only available if given arch is supported by current GDB, like gdb-multiarch\n+ if arch_info in [\"armv7l\", \"aarch64\"]:\n+ arm_info = gdb.execute(\"show arm\", to_string=True)\n+ current_setup += \"ARM: %s\\n\" % arm_info\n+\n+ elif arch_info in [\"mips\", \"mips64\"]:\n+ mips_info = gdb.execute(\"show mips\", to_string=True)\n+ current_setup += \"MIPS: %s\\n\" % mips_info\n+\n+ # 7. showing charset\n+ charset_info = sys.getdefaultencoding()\n+ current_setup += \"Charset: %s\\n\" % charset_info\n+\n+ # 8. showing width\n+ width_info = os.get_terminal_size().columns\n+ current_setup += \"Width: %s\\n\" % width_info\n+\n+ # 9. showing height\n+ height_info = os.get_terminal_size().lines\n+ current_setup += \"Height: %s\\n\" % height_info\n+\n current_setup += \"\\n\".join(all_info)\n current_setup += \"\\n\" + \"\\n\".join(gdb_config)\n", "issue": "bugreport command: show more info\nThe bugreport command should display more information like:\r\n* show osabi\r\n* show architecture\r\n* show endian\r\n\r\nDepending on current arch -- note that those are only available if given arch is supported by current GDB, like `gdb-multiarch`:\r\n* show arm\r\n* show mips\r\n\r\nMaybe also:\r\n* show charset\r\n* show width\r\n* show height\r\n\r\n\n", "before_files": [{"content": "\"\"\"\nDisplays gdb, python and pwndbg versions.\n\"\"\"\n\n\nimport argparse\nimport os\nimport platform\nimport re\nimport sys\nfrom subprocess import check_call\nfrom subprocess import check_output\nfrom tempfile import NamedTemporaryFile\nfrom urllib.parse import quote\n\nimport gdb\n\nimport pwndbg\nimport pwndbg.commands\nimport pwndbg.ida\nfrom pwndbg.color import message\nfrom pwndbg.commands import CommandCategory\n\n\ndef _gdb_version():\n try:\n return gdb.VERSION # GDB >= 8.1 (or earlier?)\n except AttributeError:\n return gdb.execute(\"show version\", to_string=True).split(\"\\n\")[0]\n\n\ndef _py_version():\n return sys.version.replace(\"\\n\", \" \")\n\n\ndef capstone_version():\n try:\n import capstone\n\n return \".\".join(map(str, capstone.cs_version()))\n except ImportError:\n return \"not found\"\n\n\ndef unicorn_version():\n try:\n import unicorn\n\n return unicorn.__version__\n except ImportError:\n return \"not found\"\n\n\ndef all_versions():\n gdb_str = \"Gdb: %s\" % _gdb_version()\n py_str = \"Python: %s\" % _py_version()\n pwndbg_str = \"Pwndbg: %s\" % pwndbg.__version__\n\n capstone_str = \"Capstone: %s\" % capstone_version()\n unicorn_str = \"Unicorn: %s\" % unicorn_version()\n\n all_versions = (gdb_str, py_str, pwndbg_str, capstone_str, unicorn_str)\n\n ida_versions = pwndbg.ida.get_ida_versions()\n\n if ida_versions is not None:\n ida_version = \"IDA PRO: %s\" % ida_versions[\"ida\"]\n ida_py_ver = \"IDA Py: %s\" % ida_versions[\"python\"]\n ida_hr_ver = \"Hexrays: %s\" % ida_versions[\"hexrays\"]\n all_versions += (ida_version, ida_py_ver, ida_hr_ver)\n return all_versions\n\n\[email protected](\n \"Displays GDB, Python, and pwndbg versions.\", category=CommandCategory.PWNDBG\n)\ndef version() -> None:\n \"\"\"\n Displays GDB, Python, and pwndbg versions.\n \"\"\"\n print(\"\\n\".join(map(message.system, all_versions())))\n\n\nbugreport_parser = argparse.ArgumentParser(description=\"Generate a bug report.\")\nbugreport_group = bugreport_parser.add_mutually_exclusive_group()\nbugreport_group.add_argument(\n \"--run-browser\", \"-b\", action=\"store_true\", help=\"Open browser on github/issues/new\"\n)\nbugreport_group.add_argument(\n \"--use-gh\", \"-g\", action=\"store_true\", help=\"Create issue using Github CLI\"\n)\n\n\[email protected](bugreport_parser, category=CommandCategory.PWNDBG)\ndef bugreport(run_browser=False, use_gh=False):\n ISSUE_TEMPLATE = \"\"\"\n<!--\nBefore reporting a new issue, make sure that we do not have any duplicates already open.\nIf there is one it might be good to take part in the discussion there.\n\nPlease make sure you have checked that the issue persists on LATEST pwndbg version.\n\nBelow is a template for BUG REPORTS.\nDon't include it if this is a FEATURE REQUEST.\n-->\n\n\n### Description\n\n<!--\nBriefly describe the problem you are having in a few paragraphs.\n-->\n\n### Steps to reproduce\n\n<!--\nWhat do we have to do to reproduce the problem?\nIf this is connected to particular C/asm code or a binary,\nplease provide the binary or if possible, a smallest C code that reproduces the issue.\n-->\n\nGdb session history:\n```\n{gdb_history}\n```\n\n### My setup\n\n<!--\nShow us your gdb/python/pwndbg/OS/IDA Pro version (depending on your case).\n\nNOTE: We are currently testing Pwndbg only on Ubuntu installations but it should work fine on other distros as well.\n\nThis can be displayed in pwndbg through `version` command.\n\nIf it is somehow unavailable, use:\n* `show version` - for gdb\n* `py import sys; print(sys.version)` - for python\n* pwndbg version/git commit id\n-->\n\n```\n{setup}\n```\"\"\"\n\n gdb_config = gdb.execute(\"show configuration\", to_string=True).split(\"\\n\")\n all_info = all_versions()\n os_info = platform.system()\n\n current_setup = \"Platform: %s\\n\" % platform.platform()\n\n if os_info.lower() == \"linux\" and os.path.isfile(\"/etc/os-release\"):\n with open(\"/etc/os-release\", \"r\") as os_release:\n contents = os_release.read()\n match = re.search('PRETTY_NAME=\"?([^\",\\n]+)', contents)\n if match:\n os_info = match.group(1)\n\n current_setup += \"OS: %s\\n\" % os_info\n current_setup += \"\\n\".join(all_info)\n current_setup += \"\\n\" + \"\\n\".join(gdb_config)\n\n # get saved history size (not including current gdb session)\n gdb_history_file = gdb.execute(\"show history filename\", to_string=True)\n gdb_history_file = gdb_history_file[\n gdb_history_file.index('\"') + 1 : gdb_history_file.rindex('\"')\n ]\n gdb_history_len = 0\n try:\n with open(gdb_history_file, \"r\") as f:\n gdb_history_len = len(f.readlines())\n except FileNotFoundError:\n pass\n\n max_command_no = 0\n history_commands = gdb.execute(\"show commands\", to_string=True)\n if history_commands:\n history_commands = history_commands.split(\"\\n\")\n if len(history_commands) > 1:\n # The last element of the list is the `show commands` command we\n # just ran, so we need to get the second to last one\n last_command = history_commands[-2]\n max_command_no = int(last_command.split()[0]) - 1\n\n show_command_size = 10 # 'show command' returns 10 commands\n gdb_current_session_history = {}\n current_command_no = gdb_history_len + 1\n\n while current_command_no <= max_command_no:\n cmds = gdb.execute(\n \"show commands \" + str(current_command_no + (show_command_size // 2) + 1),\n to_string=True,\n ).split(\"\\n\")[:-1]\n for cmd in cmds:\n cmd_no, cmd = cmd.split(maxsplit=1)\n cmd_no = int(cmd_no)\n if cmd_no <= gdb_history_len:\n continue\n if current_command_no > max_command_no:\n break\n gdb_current_session_history[cmd_no] = cmd\n current_command_no += 1\n\n gdb_current_session_history = (v for (k, v) in sorted(gdb_current_session_history.items()))\n gdb_current_session_history = \"\\n\".join(gdb_current_session_history)\n\n issue_bugreport = ISSUE_TEMPLATE.format(\n gdb_history=gdb_current_session_history, setup=current_setup\n )\n print(issue_bugreport)\n\n please_please_submit = \"Please submit the bugreport generated above at \"\n github_issue_url = \"https://github.com/pwndbg/pwndbg/issues/new\"\n github_issue_body = \"?body=\" + quote(issue_bugreport)\n\n if use_gh:\n try:\n with NamedTemporaryFile(\"w\", delete=True) as f:\n f.write(issue_bugreport)\n f.flush()\n check_call([os.environ.get(\"EDITOR\", \"vi\"), f.name])\n check_call([\"gh\", \"issue\", \"create\", \"--body-file\", f.name])\n except Exception:\n print(please_please_submit + github_issue_url)\n raise\n elif run_browser:\n try:\n check_output([\"xdg-open\", github_issue_url + github_issue_body])\n except Exception:\n print(please_please_submit + github_issue_url)\n else:\n print(please_please_submit + github_issue_url)\n", "path": "pwndbg/commands/version.py"}], "after_files": [{"content": "\"\"\"\nDisplays gdb, python and pwndbg versions.\n\"\"\"\n\n\nimport argparse\nimport os\nimport platform\nimport re\nimport sys\nfrom subprocess import check_call\nfrom subprocess import check_output\nfrom tempfile import NamedTemporaryFile\nfrom urllib.parse import quote\n\nimport gdb\n\nimport pwndbg\nimport pwndbg.commands\nimport pwndbg.ida\nfrom pwndbg.color import message\nfrom pwndbg.commands import CommandCategory\n\n\ndef _gdb_version():\n try:\n return gdb.VERSION # GDB >= 8.1 (or earlier?)\n except AttributeError:\n return gdb.execute(\"show version\", to_string=True).split(\"\\n\")[0]\n\n\ndef _py_version():\n return sys.version.replace(\"\\n\", \" \")\n\n\ndef capstone_version():\n try:\n import capstone\n\n return \".\".join(map(str, capstone.cs_version()))\n except ImportError:\n return \"not found\"\n\n\ndef unicorn_version():\n try:\n import unicorn\n\n return unicorn.__version__\n except ImportError:\n return \"not found\"\n\n\ndef all_versions():\n gdb_str = \"Gdb: %s\" % _gdb_version()\n py_str = \"Python: %s\" % _py_version()\n pwndbg_str = \"Pwndbg: %s\" % pwndbg.__version__\n\n capstone_str = \"Capstone: %s\" % capstone_version()\n unicorn_str = \"Unicorn: %s\" % unicorn_version()\n\n all_versions = (gdb_str, py_str, pwndbg_str, capstone_str, unicorn_str)\n\n ida_versions = pwndbg.ida.get_ida_versions()\n\n if ida_versions is not None:\n ida_version = \"IDA PRO: %s\" % ida_versions[\"ida\"]\n ida_py_ver = \"IDA Py: %s\" % ida_versions[\"python\"]\n ida_hr_ver = \"Hexrays: %s\" % ida_versions[\"hexrays\"]\n all_versions += (ida_version, ida_py_ver, ida_hr_ver)\n return all_versions\n\n\[email protected](\n \"Displays GDB, Python, and pwndbg versions.\", category=CommandCategory.PWNDBG\n)\ndef version() -> None:\n \"\"\"\n Displays GDB, Python, and pwndbg versions.\n \"\"\"\n print(\"\\n\".join(map(message.system, all_versions())))\n\n\nbugreport_parser = argparse.ArgumentParser(description=\"Generate a bug report.\")\nbugreport_group = bugreport_parser.add_mutually_exclusive_group()\nbugreport_group.add_argument(\n \"--run-browser\", \"-b\", action=\"store_true\", help=\"Open browser on github/issues/new\"\n)\nbugreport_group.add_argument(\n \"--use-gh\", \"-g\", action=\"store_true\", help=\"Create issue using Github CLI\"\n)\n\n\[email protected](bugreport_parser, category=CommandCategory.PWNDBG)\ndef bugreport(run_browser=False, use_gh=False):\n ISSUE_TEMPLATE = \"\"\"\n<!--\nBefore reporting a new issue, make sure that we do not have any duplicates already open.\nIf there is one it might be good to take part in the discussion there.\n\nPlease make sure you have checked that the issue persists on LATEST pwndbg version.\n\nBelow is a template for BUG REPORTS.\nDon't include it if this is a FEATURE REQUEST.\n-->\n\n\n### Description\n\n<!--\nBriefly describe the problem you are having in a few paragraphs.\n-->\n\n### Steps to reproduce\n\n<!--\nWhat do we have to do to reproduce the problem?\nIf this is connected to particular C/asm code or a binary,\nplease provide the binary or if possible, a smallest C code that reproduces the issue.\n-->\n\nGdb session history:\n```\n{gdb_history}\n```\n\n### My setup\n\n<!--\nShow us your gdb/python/pwndbg/OS/IDA Pro version (depending on your case).\n\nNOTE: We are currently testing Pwndbg only on Ubuntu installations but it should work fine on other distros as well.\n\nThis can be displayed in pwndbg through `version` command.\n\nIf it is somehow unavailable, use:\n* `show version` - for gdb\n* `py import sys; print(sys.version)` - for python\n* pwndbg version/git commit id\n-->\n\n```\n{setup}\n```\"\"\"\n\n gdb_config = gdb.execute(\"show configuration\", to_string=True).split(\"\\n\")\n all_info = all_versions()\n os_info = platform.system()\n\n current_setup = \"Platform: %s\\n\" % platform.platform()\n\n if os_info.lower() == \"linux\" and os.path.isfile(\"/etc/os-release\"):\n with open(\"/etc/os-release\", \"r\") as os_release:\n contents = os_release.read()\n match = re.search('PRETTY_NAME=\"?([^\",\\n]+)', contents)\n if match:\n os_info = match.group(1)\n\n current_setup += \"OS: %s\\n\" % os_info\n\n # 1. showing osabi\n osabi_info = platform.uname().version\n current_setup += \"OS ABI: %s\\n\" % osabi_info\n\n # 2. showing architecture\n arch_info = platform.machine()\n current_setup += \"Architecture: %s\\n\" % arch_info\n\n # 3. showing endian\n endian_info = sys.byteorder\n current_setup += \"Endian: %s\\n\" % endian_info\n\n # 4. Depending on current arch -- note that those are only available if given arch is supported by current GDB, like gdb-multiarch\n if arch_info in [\"armv7l\", \"aarch64\"]:\n arm_info = gdb.execute(\"show arm\", to_string=True)\n current_setup += \"ARM: %s\\n\" % arm_info\n\n elif arch_info in [\"mips\", \"mips64\"]:\n mips_info = gdb.execute(\"show mips\", to_string=True)\n current_setup += \"MIPS: %s\\n\" % mips_info\n\n # 7. showing charset\n charset_info = sys.getdefaultencoding()\n current_setup += \"Charset: %s\\n\" % charset_info\n\n # 8. showing width\n width_info = os.get_terminal_size().columns\n current_setup += \"Width: %s\\n\" % width_info\n\n # 9. showing height\n height_info = os.get_terminal_size().lines\n current_setup += \"Height: %s\\n\" % height_info\n\n current_setup += \"\\n\".join(all_info)\n current_setup += \"\\n\" + \"\\n\".join(gdb_config)\n\n # get saved history size (not including current gdb session)\n gdb_history_file = gdb.execute(\"show history filename\", to_string=True)\n gdb_history_file = gdb_history_file[\n gdb_history_file.index('\"') + 1 : gdb_history_file.rindex('\"')\n ]\n gdb_history_len = 0\n try:\n with open(gdb_history_file, \"r\") as f:\n gdb_history_len = len(f.readlines())\n except FileNotFoundError:\n pass\n\n max_command_no = 0\n history_commands = gdb.execute(\"show commands\", to_string=True)\n if history_commands:\n history_commands = history_commands.split(\"\\n\")\n if len(history_commands) > 1:\n # The last element of the list is the `show commands` command we\n # just ran, so we need to get the second to last one\n last_command = history_commands[-2]\n max_command_no = int(last_command.split()[0]) - 1\n\n show_command_size = 10 # 'show command' returns 10 commands\n gdb_current_session_history = {}\n current_command_no = gdb_history_len + 1\n\n while current_command_no <= max_command_no:\n cmds = gdb.execute(\n \"show commands \" + str(current_command_no + (show_command_size // 2) + 1),\n to_string=True,\n ).split(\"\\n\")[:-1]\n for cmd in cmds:\n cmd_no, cmd = cmd.split(maxsplit=1)\n cmd_no = int(cmd_no)\n if cmd_no <= gdb_history_len:\n continue\n if current_command_no > max_command_no:\n break\n gdb_current_session_history[cmd_no] = cmd\n current_command_no += 1\n\n gdb_current_session_history = (v for (k, v) in sorted(gdb_current_session_history.items()))\n gdb_current_session_history = \"\\n\".join(gdb_current_session_history)\n\n issue_bugreport = ISSUE_TEMPLATE.format(\n gdb_history=gdb_current_session_history, setup=current_setup\n )\n print(issue_bugreport)\n\n please_please_submit = \"Please submit the bugreport generated above at \"\n github_issue_url = \"https://github.com/pwndbg/pwndbg/issues/new\"\n github_issue_body = \"?body=\" + quote(issue_bugreport)\n\n if use_gh:\n try:\n with NamedTemporaryFile(\"w\", delete=True) as f:\n f.write(issue_bugreport)\n f.flush()\n check_call([os.environ.get(\"EDITOR\", \"vi\"), f.name])\n check_call([\"gh\", \"issue\", \"create\", \"--body-file\", f.name])\n except Exception:\n print(please_please_submit + github_issue_url)\n raise\n elif run_browser:\n try:\n check_output([\"xdg-open\", github_issue_url + github_issue_body])\n except Exception:\n print(please_please_submit + github_issue_url)\n else:\n print(please_please_submit + github_issue_url)\n", "path": "pwndbg/commands/version.py"}]}
| 2,682 | 464 |
gh_patches_debug_28461
|
rasdani/github-patches
|
git_diff
|
elastic__apm-agent-python-708
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
database trace show twice
maybe this is not a bug
kibana show every database trace will show twice

but in 4.2.2 version, it show this

i think its related to span? in 4.2.2 agent won't upload span log, please tell me how to resovle it 😢
(forgive my poor English)
**Environment (please complete the following information)**
- OS: [e.g. Linux] linux
- Python version: 3.7.
- Framework and version [e.g. Django 2.1]: Django 3.0
- APM Server version: 7.4.2
- Agent version: 5.3.3
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `elasticapm/instrumentation/packages/base.py`
Content:
```
1 # BSD 3-Clause License
2 #
3 # Copyright (c) 2019, Elasticsearch BV
4 # All rights reserved.
5 #
6 # Redistribution and use in source and binary forms, with or without
7 # modification, are permitted provided that the following conditions are met:
8 #
9 # * Redistributions of source code must retain the above copyright notice, this
10 # list of conditions and the following disclaimer.
11 #
12 # * Redistributions in binary form must reproduce the above copyright notice,
13 # this list of conditions and the following disclaimer in the documentation
14 # and/or other materials provided with the distribution.
15 #
16 # * Neither the name of the copyright holder nor the names of its
17 # contributors may be used to endorse or promote products derived from
18 # this software without specific prior written permission.
19 #
20 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
21 # AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
22 # IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
23 # DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
24 # FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
25 # DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
26 # SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
27 # CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
28 # OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
29 # OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
30
31 import functools
32 import os
33
34 from elasticapm.traces import execution_context
35 from elasticapm.utils import wrapt
36 from elasticapm.utils.logging import get_logger
37
38 logger = get_logger("elasticapm.instrument")
39
40
41 class AbstractInstrumentedModule(object):
42 """
43 This class is designed to reduce the amount of code required to
44 instrument library functions using wrapt.
45
46 Instrumentation modules inherit from this class and override pieces as
47 needed. Only `name`, `instrumented_list`, and `call` are required in
48 the inheriting class.
49
50 The `instrument_list` is a list of (module, method) pairs that will be
51 instrumented. The module/method need not be imported -- in fact, because
52 instrumentation modules are all processed during the instrumentation
53 process, lazy imports should be used in order to avoid ImportError
54 exceptions.
55
56 The `instrument()` method will be called for each InstrumentedModule
57 listed in the instrument register (elasticapm.instrumentation.register),
58 and each method in the `instrument_list` will be wrapped (using wrapt)
59 with the `call_if_sampling()` function, which (by default) will either
60 call the wrapped function by itself, or pass it into `call()` to be
61 called if there is a transaction active.
62
63 For simple span-wrapping of instrumented libraries, a very simple
64 InstrumentedModule might look like this::
65
66 from elasticapm.instrumentation.packages.base import AbstractInstrumentedModule
67 from elasticapm.traces import capture_span
68
69 class Jinja2Instrumentation(AbstractInstrumentedModule):
70 name = "jinja2"
71 instrument_list = [("jinja2", "Template.render")]
72 def call(self, module, method, wrapped, instance, args, kwargs):
73 signature = instance.name or instance.filename
74 with capture_span(signature, span_type="template", span_subtype="jinja2", span_action="render"):
75 return wrapped(*args, **kwargs)
76
77 This class can also be used to instrument callables which are expected to
78 create their own transactions (rather than spans within a transaction).
79 In this case, set `creates_transaction = True` next to your `name` and
80 `instrument_list`. This tells the instrumenting code to always wrap the
81 method with `call()`, even if there is no transaction active. It is
82 expected in this case that a new transaction will be created as part of
83 your `call()` method.
84 """
85
86 name = None
87 mutates_unsampled_arguments = False
88 creates_transactions = False
89
90 instrument_list = [
91 # List of (module, method) pairs to instrument. E.g.:
92 # ("requests.sessions", "Session.send"),
93 ]
94
95 def __init__(self):
96 self.originals = {}
97 self.instrumented = False
98
99 assert self.name is not None
100
101 def get_wrapped_name(self, wrapped, instance, fallback_method=None):
102 wrapped_name = []
103 if hasattr(instance, "__class__") and hasattr(instance.__class__, "__name__"):
104 wrapped_name.append(instance.__class__.__name__)
105
106 if hasattr(wrapped, "__name__"):
107 wrapped_name.append(wrapped.__name__)
108 elif fallback_method:
109 attribute = fallback_method.split(".")
110 if len(attribute) == 2:
111 wrapped_name.append(attribute[1])
112
113 return ".".join(wrapped_name)
114
115 def get_instrument_list(self):
116 return self.instrument_list
117
118 def instrument(self):
119 if self.instrumented:
120 return
121
122 skip_env_var = "SKIP_INSTRUMENT_" + str(self.name.upper())
123 if skip_env_var in os.environ:
124 logger.debug("Skipping instrumentation of %s. %s is set.", self.name, skip_env_var)
125 return
126 try:
127 instrument_list = self.get_instrument_list()
128 skipped_modules = set()
129 instrumented_methods = []
130
131 for module, method in instrument_list:
132 try:
133 # Skip modules we already failed to load
134 if module in skipped_modules:
135 continue
136 # We jump through hoop here to get the original
137 # `module`/`method` in the call to `call_if_sampling`
138 parent, attribute, original = wrapt.resolve_path(module, method)
139 self.originals[(module, method)] = original
140 wrapper = wrapt.FunctionWrapper(original, functools.partial(self.call_if_sampling, module, method))
141 wrapt.apply_patch(parent, attribute, wrapper)
142 instrumented_methods.append((module, method))
143 except ImportError:
144 # Could not import module
145 logger.debug("Skipping instrumentation of %s. Module %s not found", self.name, module)
146
147 # Keep track of modules we couldn't load so we don't
148 # try to instrument anything in that module again
149 skipped_modules.add(module)
150 except AttributeError as ex:
151 # Could not find thing in module
152 logger.debug("Skipping instrumentation of %s.%s: %s", module, method, ex)
153 if instrumented_methods:
154 logger.debug("Instrumented %s, %s", self.name, ", ".join(".".join(m) for m in instrumented_methods))
155
156 except ImportError as ex:
157 logger.debug("Skipping instrumentation of %s. %s", self.name, ex)
158 self.instrumented = True
159
160 def uninstrument(self):
161 if not self.instrumented or not self.originals:
162 return
163 uninstrumented_methods = []
164 for module, method in self.get_instrument_list():
165 if (module, method) in self.originals:
166 parent, attribute, wrapper = wrapt.resolve_path(module, method)
167 wrapt.apply_patch(parent, attribute, self.originals[(module, method)])
168 uninstrumented_methods.append((module, method))
169 if uninstrumented_methods:
170 logger.debug("Uninstrumented %s, %s", self.name, ", ".join(".".join(m) for m in uninstrumented_methods))
171 self.instrumented = False
172 self.originals = {}
173
174 def call_if_sampling(self, module, method, wrapped, instance, args, kwargs):
175 """
176 This is the function which will wrap the instrumented method/function.
177
178 By default, will call the instrumented method/function, via `call()`,
179 only if a transaction is active and sampled. This behavior can be
180 overridden by setting `creates_transactions = True` at the class
181 level.
182
183 If `creates_transactions == False` and there's an active transaction
184 with `transaction.is_sampled == False`, then the
185 `mutate_unsampled_call_args()` method is called, and the resulting
186 args and kwargs are passed into the wrapped function directly, not
187 via `call()`. This can e.g. be used to add traceparent headers to the
188 underlying http call for HTTP instrumentations, even if we're not
189 sampling the transaction.
190 """
191 if self.creates_transactions:
192 return self.call(module, method, wrapped, instance, args, kwargs)
193 transaction = execution_context.get_transaction()
194 if not transaction:
195 return wrapped(*args, **kwargs)
196 elif not transaction.is_sampled:
197 args, kwargs = self.mutate_unsampled_call_args(module, method, wrapped, instance, args, kwargs, transaction)
198 return wrapped(*args, **kwargs)
199 else:
200 return self.call(module, method, wrapped, instance, args, kwargs)
201
202 def mutate_unsampled_call_args(self, module, method, wrapped, instance, args, kwargs, transaction):
203 """
204 Method called for unsampled wrapped calls. This can e.g. be used to
205 add traceparent headers to the underlying http call for HTTP
206 instrumentations.
207
208 :param module:
209 :param method:
210 :param wrapped:
211 :param instance:
212 :param args:
213 :param kwargs:
214 :param transaction:
215 :return:
216 """
217 return args, kwargs
218
219 def call(self, module, method, wrapped, instance, args, kwargs):
220 """
221 Wrapped call. This method should gather all necessary data, then call
222 `wrapped` in a `capture_span` context manager.
223
224 Note that by default this wrapper will only be used if a transaction is
225 currently active. If you want the ability to create a transaction in
226 your `call()` method, set `create_transactions = True` at the class
227 level.
228
229 :param module: Name of the wrapped module
230 :param method: Name of the wrapped method/function
231 :param wrapped: the wrapped method/function object
232 :param instance: the wrapped instance
233 :param args: arguments to the wrapped method/function
234 :param kwargs: keyword arguments to the wrapped method/function
235 :return: the result of calling the wrapped method/function
236 """
237 raise NotImplementedError
238
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/elasticapm/instrumentation/packages/base.py b/elasticapm/instrumentation/packages/base.py
--- a/elasticapm/instrumentation/packages/base.py
+++ b/elasticapm/instrumentation/packages/base.py
@@ -38,6 +38,11 @@
logger = get_logger("elasticapm.instrument")
+class ElasticAPMFunctionWrapper(wrapt.FunctionWrapper):
+ # used to differentiate between our own function wrappers and 1st/3rd party wrappers
+ pass
+
+
class AbstractInstrumentedModule(object):
"""
This class is designed to reduce the amount of code required to
@@ -136,8 +141,13 @@
# We jump through hoop here to get the original
# `module`/`method` in the call to `call_if_sampling`
parent, attribute, original = wrapt.resolve_path(module, method)
+ if isinstance(original, ElasticAPMFunctionWrapper):
+ logger.debug("%s.%s already instrumented, skipping", module, method)
+ continue
self.originals[(module, method)] = original
- wrapper = wrapt.FunctionWrapper(original, functools.partial(self.call_if_sampling, module, method))
+ wrapper = ElasticAPMFunctionWrapper(
+ original, functools.partial(self.call_if_sampling, module, method)
+ )
wrapt.apply_patch(parent, attribute, wrapper)
instrumented_methods.append((module, method))
except ImportError:
|
{"golden_diff": "diff --git a/elasticapm/instrumentation/packages/base.py b/elasticapm/instrumentation/packages/base.py\n--- a/elasticapm/instrumentation/packages/base.py\n+++ b/elasticapm/instrumentation/packages/base.py\n@@ -38,6 +38,11 @@\n logger = get_logger(\"elasticapm.instrument\")\n \n \n+class ElasticAPMFunctionWrapper(wrapt.FunctionWrapper):\n+ # used to differentiate between our own function wrappers and 1st/3rd party wrappers\n+ pass\n+\n+\n class AbstractInstrumentedModule(object):\n \"\"\"\n This class is designed to reduce the amount of code required to\n@@ -136,8 +141,13 @@\n # We jump through hoop here to get the original\n # `module`/`method` in the call to `call_if_sampling`\n parent, attribute, original = wrapt.resolve_path(module, method)\n+ if isinstance(original, ElasticAPMFunctionWrapper):\n+ logger.debug(\"%s.%s already instrumented, skipping\", module, method)\n+ continue\n self.originals[(module, method)] = original\n- wrapper = wrapt.FunctionWrapper(original, functools.partial(self.call_if_sampling, module, method))\n+ wrapper = ElasticAPMFunctionWrapper(\n+ original, functools.partial(self.call_if_sampling, module, method)\n+ )\n wrapt.apply_patch(parent, attribute, wrapper)\n instrumented_methods.append((module, method))\n except ImportError:\n", "issue": "database trace show twice\nmaybe this is not a bug\r\nkibana show every database trace will show twice\r\n\r\n\r\nbut in 4.2.2 version, it show this \r\n\r\n\r\ni think its related to span? in 4.2.2 agent won't upload span log, please tell me how to resovle it \ud83d\ude22\r\n(forgive my poor English)\r\n\r\n**Environment (please complete the following information)**\r\n- OS: [e.g. Linux] linux\r\n- Python version: 3.7.\r\n- Framework and version [e.g. Django 2.1]: Django 3.0\r\n- APM Server version: 7.4.2\r\n- Agent version: 5.3.3\r\n\n", "before_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2019, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n\nimport functools\nimport os\n\nfrom elasticapm.traces import execution_context\nfrom elasticapm.utils import wrapt\nfrom elasticapm.utils.logging import get_logger\n\nlogger = get_logger(\"elasticapm.instrument\")\n\n\nclass AbstractInstrumentedModule(object):\n \"\"\"\n This class is designed to reduce the amount of code required to\n instrument library functions using wrapt.\n\n Instrumentation modules inherit from this class and override pieces as\n needed. Only `name`, `instrumented_list`, and `call` are required in\n the inheriting class.\n\n The `instrument_list` is a list of (module, method) pairs that will be\n instrumented. The module/method need not be imported -- in fact, because\n instrumentation modules are all processed during the instrumentation\n process, lazy imports should be used in order to avoid ImportError\n exceptions.\n\n The `instrument()` method will be called for each InstrumentedModule\n listed in the instrument register (elasticapm.instrumentation.register),\n and each method in the `instrument_list` will be wrapped (using wrapt)\n with the `call_if_sampling()` function, which (by default) will either\n call the wrapped function by itself, or pass it into `call()` to be\n called if there is a transaction active.\n\n For simple span-wrapping of instrumented libraries, a very simple\n InstrumentedModule might look like this::\n\n from elasticapm.instrumentation.packages.base import AbstractInstrumentedModule\n from elasticapm.traces import capture_span\n\n class Jinja2Instrumentation(AbstractInstrumentedModule):\n name = \"jinja2\"\n instrument_list = [(\"jinja2\", \"Template.render\")]\n def call(self, module, method, wrapped, instance, args, kwargs):\n signature = instance.name or instance.filename\n with capture_span(signature, span_type=\"template\", span_subtype=\"jinja2\", span_action=\"render\"):\n return wrapped(*args, **kwargs)\n\n This class can also be used to instrument callables which are expected to\n create their own transactions (rather than spans within a transaction).\n In this case, set `creates_transaction = True` next to your `name` and\n `instrument_list`. This tells the instrumenting code to always wrap the\n method with `call()`, even if there is no transaction active. It is\n expected in this case that a new transaction will be created as part of\n your `call()` method.\n \"\"\"\n\n name = None\n mutates_unsampled_arguments = False\n creates_transactions = False\n\n instrument_list = [\n # List of (module, method) pairs to instrument. E.g.:\n # (\"requests.sessions\", \"Session.send\"),\n ]\n\n def __init__(self):\n self.originals = {}\n self.instrumented = False\n\n assert self.name is not None\n\n def get_wrapped_name(self, wrapped, instance, fallback_method=None):\n wrapped_name = []\n if hasattr(instance, \"__class__\") and hasattr(instance.__class__, \"__name__\"):\n wrapped_name.append(instance.__class__.__name__)\n\n if hasattr(wrapped, \"__name__\"):\n wrapped_name.append(wrapped.__name__)\n elif fallback_method:\n attribute = fallback_method.split(\".\")\n if len(attribute) == 2:\n wrapped_name.append(attribute[1])\n\n return \".\".join(wrapped_name)\n\n def get_instrument_list(self):\n return self.instrument_list\n\n def instrument(self):\n if self.instrumented:\n return\n\n skip_env_var = \"SKIP_INSTRUMENT_\" + str(self.name.upper())\n if skip_env_var in os.environ:\n logger.debug(\"Skipping instrumentation of %s. %s is set.\", self.name, skip_env_var)\n return\n try:\n instrument_list = self.get_instrument_list()\n skipped_modules = set()\n instrumented_methods = []\n\n for module, method in instrument_list:\n try:\n # Skip modules we already failed to load\n if module in skipped_modules:\n continue\n # We jump through hoop here to get the original\n # `module`/`method` in the call to `call_if_sampling`\n parent, attribute, original = wrapt.resolve_path(module, method)\n self.originals[(module, method)] = original\n wrapper = wrapt.FunctionWrapper(original, functools.partial(self.call_if_sampling, module, method))\n wrapt.apply_patch(parent, attribute, wrapper)\n instrumented_methods.append((module, method))\n except ImportError:\n # Could not import module\n logger.debug(\"Skipping instrumentation of %s. Module %s not found\", self.name, module)\n\n # Keep track of modules we couldn't load so we don't\n # try to instrument anything in that module again\n skipped_modules.add(module)\n except AttributeError as ex:\n # Could not find thing in module\n logger.debug(\"Skipping instrumentation of %s.%s: %s\", module, method, ex)\n if instrumented_methods:\n logger.debug(\"Instrumented %s, %s\", self.name, \", \".join(\".\".join(m) for m in instrumented_methods))\n\n except ImportError as ex:\n logger.debug(\"Skipping instrumentation of %s. %s\", self.name, ex)\n self.instrumented = True\n\n def uninstrument(self):\n if not self.instrumented or not self.originals:\n return\n uninstrumented_methods = []\n for module, method in self.get_instrument_list():\n if (module, method) in self.originals:\n parent, attribute, wrapper = wrapt.resolve_path(module, method)\n wrapt.apply_patch(parent, attribute, self.originals[(module, method)])\n uninstrumented_methods.append((module, method))\n if uninstrumented_methods:\n logger.debug(\"Uninstrumented %s, %s\", self.name, \", \".join(\".\".join(m) for m in uninstrumented_methods))\n self.instrumented = False\n self.originals = {}\n\n def call_if_sampling(self, module, method, wrapped, instance, args, kwargs):\n \"\"\"\n This is the function which will wrap the instrumented method/function.\n\n By default, will call the instrumented method/function, via `call()`,\n only if a transaction is active and sampled. This behavior can be\n overridden by setting `creates_transactions = True` at the class\n level.\n\n If `creates_transactions == False` and there's an active transaction\n with `transaction.is_sampled == False`, then the\n `mutate_unsampled_call_args()` method is called, and the resulting\n args and kwargs are passed into the wrapped function directly, not\n via `call()`. This can e.g. be used to add traceparent headers to the\n underlying http call for HTTP instrumentations, even if we're not\n sampling the transaction.\n \"\"\"\n if self.creates_transactions:\n return self.call(module, method, wrapped, instance, args, kwargs)\n transaction = execution_context.get_transaction()\n if not transaction:\n return wrapped(*args, **kwargs)\n elif not transaction.is_sampled:\n args, kwargs = self.mutate_unsampled_call_args(module, method, wrapped, instance, args, kwargs, transaction)\n return wrapped(*args, **kwargs)\n else:\n return self.call(module, method, wrapped, instance, args, kwargs)\n\n def mutate_unsampled_call_args(self, module, method, wrapped, instance, args, kwargs, transaction):\n \"\"\"\n Method called for unsampled wrapped calls. This can e.g. be used to\n add traceparent headers to the underlying http call for HTTP\n instrumentations.\n\n :param module:\n :param method:\n :param wrapped:\n :param instance:\n :param args:\n :param kwargs:\n :param transaction:\n :return:\n \"\"\"\n return args, kwargs\n\n def call(self, module, method, wrapped, instance, args, kwargs):\n \"\"\"\n Wrapped call. This method should gather all necessary data, then call\n `wrapped` in a `capture_span` context manager.\n\n Note that by default this wrapper will only be used if a transaction is\n currently active. If you want the ability to create a transaction in\n your `call()` method, set `create_transactions = True` at the class\n level.\n\n :param module: Name of the wrapped module\n :param method: Name of the wrapped method/function\n :param wrapped: the wrapped method/function object\n :param instance: the wrapped instance\n :param args: arguments to the wrapped method/function\n :param kwargs: keyword arguments to the wrapped method/function\n :return: the result of calling the wrapped method/function\n \"\"\"\n raise NotImplementedError\n", "path": "elasticapm/instrumentation/packages/base.py"}], "after_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2019, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n\nimport functools\nimport os\n\nfrom elasticapm.traces import execution_context\nfrom elasticapm.utils import wrapt\nfrom elasticapm.utils.logging import get_logger\n\nlogger = get_logger(\"elasticapm.instrument\")\n\n\nclass ElasticAPMFunctionWrapper(wrapt.FunctionWrapper):\n # used to differentiate between our own function wrappers and 1st/3rd party wrappers\n pass\n\n\nclass AbstractInstrumentedModule(object):\n \"\"\"\n This class is designed to reduce the amount of code required to\n instrument library functions using wrapt.\n\n Instrumentation modules inherit from this class and override pieces as\n needed. Only `name`, `instrumented_list`, and `call` are required in\n the inheriting class.\n\n The `instrument_list` is a list of (module, method) pairs that will be\n instrumented. The module/method need not be imported -- in fact, because\n instrumentation modules are all processed during the instrumentation\n process, lazy imports should be used in order to avoid ImportError\n exceptions.\n\n The `instrument()` method will be called for each InstrumentedModule\n listed in the instrument register (elasticapm.instrumentation.register),\n and each method in the `instrument_list` will be wrapped (using wrapt)\n with the `call_if_sampling()` function, which (by default) will either\n call the wrapped function by itself, or pass it into `call()` to be\n called if there is a transaction active.\n\n For simple span-wrapping of instrumented libraries, a very simple\n InstrumentedModule might look like this::\n\n from elasticapm.instrumentation.packages.base import AbstractInstrumentedModule\n from elasticapm.traces import capture_span\n\n class Jinja2Instrumentation(AbstractInstrumentedModule):\n name = \"jinja2\"\n instrument_list = [(\"jinja2\", \"Template.render\")]\n def call(self, module, method, wrapped, instance, args, kwargs):\n signature = instance.name or instance.filename\n with capture_span(signature, span_type=\"template\", span_subtype=\"jinja2\", span_action=\"render\"):\n return wrapped(*args, **kwargs)\n\n This class can also be used to instrument callables which are expected to\n create their own transactions (rather than spans within a transaction).\n In this case, set `creates_transaction = True` next to your `name` and\n `instrument_list`. This tells the instrumenting code to always wrap the\n method with `call()`, even if there is no transaction active. It is\n expected in this case that a new transaction will be created as part of\n your `call()` method.\n \"\"\"\n\n name = None\n mutates_unsampled_arguments = False\n creates_transactions = False\n\n instrument_list = [\n # List of (module, method) pairs to instrument. E.g.:\n # (\"requests.sessions\", \"Session.send\"),\n ]\n\n def __init__(self):\n self.originals = {}\n self.instrumented = False\n\n assert self.name is not None\n\n def get_wrapped_name(self, wrapped, instance, fallback_method=None):\n wrapped_name = []\n if hasattr(instance, \"__class__\") and hasattr(instance.__class__, \"__name__\"):\n wrapped_name.append(instance.__class__.__name__)\n\n if hasattr(wrapped, \"__name__\"):\n wrapped_name.append(wrapped.__name__)\n elif fallback_method:\n attribute = fallback_method.split(\".\")\n if len(attribute) == 2:\n wrapped_name.append(attribute[1])\n\n return \".\".join(wrapped_name)\n\n def get_instrument_list(self):\n return self.instrument_list\n\n def instrument(self):\n if self.instrumented:\n return\n\n skip_env_var = \"SKIP_INSTRUMENT_\" + str(self.name.upper())\n if skip_env_var in os.environ:\n logger.debug(\"Skipping instrumentation of %s. %s is set.\", self.name, skip_env_var)\n return\n try:\n instrument_list = self.get_instrument_list()\n skipped_modules = set()\n instrumented_methods = []\n\n for module, method in instrument_list:\n try:\n # Skip modules we already failed to load\n if module in skipped_modules:\n continue\n # We jump through hoop here to get the original\n # `module`/`method` in the call to `call_if_sampling`\n parent, attribute, original = wrapt.resolve_path(module, method)\n if isinstance(original, ElasticAPMFunctionWrapper):\n logger.debug(\"%s.%s already instrumented, skipping\", module, method)\n continue\n self.originals[(module, method)] = original\n wrapper = ElasticAPMFunctionWrapper(\n original, functools.partial(self.call_if_sampling, module, method)\n )\n wrapt.apply_patch(parent, attribute, wrapper)\n instrumented_methods.append((module, method))\n except ImportError:\n # Could not import module\n logger.debug(\"Skipping instrumentation of %s. Module %s not found\", self.name, module)\n\n # Keep track of modules we couldn't load so we don't\n # try to instrument anything in that module again\n skipped_modules.add(module)\n except AttributeError as ex:\n # Could not find thing in module\n logger.debug(\"Skipping instrumentation of %s.%s: %s\", module, method, ex)\n if instrumented_methods:\n logger.debug(\"Instrumented %s, %s\", self.name, \", \".join(\".\".join(m) for m in instrumented_methods))\n\n except ImportError as ex:\n logger.debug(\"Skipping instrumentation of %s. %s\", self.name, ex)\n self.instrumented = True\n\n def uninstrument(self):\n if not self.instrumented or not self.originals:\n return\n uninstrumented_methods = []\n for module, method in self.get_instrument_list():\n if (module, method) in self.originals:\n parent, attribute, wrapper = wrapt.resolve_path(module, method)\n wrapt.apply_patch(parent, attribute, self.originals[(module, method)])\n uninstrumented_methods.append((module, method))\n if uninstrumented_methods:\n logger.debug(\"Uninstrumented %s, %s\", self.name, \", \".join(\".\".join(m) for m in uninstrumented_methods))\n self.instrumented = False\n self.originals = {}\n\n def call_if_sampling(self, module, method, wrapped, instance, args, kwargs):\n \"\"\"\n This is the function which will wrap the instrumented method/function.\n\n By default, will call the instrumented method/function, via `call()`,\n only if a transaction is active and sampled. This behavior can be\n overridden by setting `creates_transactions = True` at the class\n level.\n\n If `creates_transactions == False` and there's an active transaction\n with `transaction.is_sampled == False`, then the\n `mutate_unsampled_call_args()` method is called, and the resulting\n args and kwargs are passed into the wrapped function directly, not\n via `call()`. This can e.g. be used to add traceparent headers to the\n underlying http call for HTTP instrumentations, even if we're not\n sampling the transaction.\n \"\"\"\n if self.creates_transactions:\n return self.call(module, method, wrapped, instance, args, kwargs)\n transaction = execution_context.get_transaction()\n if not transaction:\n return wrapped(*args, **kwargs)\n elif not transaction.is_sampled:\n args, kwargs = self.mutate_unsampled_call_args(module, method, wrapped, instance, args, kwargs, transaction)\n return wrapped(*args, **kwargs)\n else:\n return self.call(module, method, wrapped, instance, args, kwargs)\n\n def mutate_unsampled_call_args(self, module, method, wrapped, instance, args, kwargs, transaction):\n \"\"\"\n Method called for unsampled wrapped calls. This can e.g. be used to\n add traceparent headers to the underlying http call for HTTP\n instrumentations.\n\n :param module:\n :param method:\n :param wrapped:\n :param instance:\n :param args:\n :param kwargs:\n :param transaction:\n :return:\n \"\"\"\n return args, kwargs\n\n def call(self, module, method, wrapped, instance, args, kwargs):\n \"\"\"\n Wrapped call. This method should gather all necessary data, then call\n `wrapped` in a `capture_span` context manager.\n\n Note that by default this wrapper will only be used if a transaction is\n currently active. If you want the ability to create a transaction in\n your `call()` method, set `create_transactions = True` at the class\n level.\n\n :param module: Name of the wrapped module\n :param method: Name of the wrapped method/function\n :param wrapped: the wrapped method/function object\n :param instance: the wrapped instance\n :param args: arguments to the wrapped method/function\n :param kwargs: keyword arguments to the wrapped method/function\n :return: the result of calling the wrapped method/function\n \"\"\"\n raise NotImplementedError\n", "path": "elasticapm/instrumentation/packages/base.py"}]}
| 3,377 | 319 |
gh_patches_debug_14157
|
rasdani/github-patches
|
git_diff
|
jazzband__pip-tools-1159
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
5.1.2 regression: lost dependencies using same zip file with different subdirectories
In `pip-tools` 5.1.2 and later, when I provide two copies of the same zip file URL with different subdirectories, the dependencies of the first are lost:
```
https://github.com/zulip/python-zulip-api/archive/0.7.0.zip#egg=zulip==0.7.0&subdirectory=zulip
https://github.com/zulip/python-zulip-api/archive/0.7.0.zip#egg=zulip-bots==0.7.0&subdirectory=zulip_bots
```
`git bisect` shows that this regression was introduced in commit c0b33e7f2224758524001e755cc338965ca0b2c0 (#1132).
Cc @richafrank
#### Environment Versions
1. OS Type: Ubuntu 18.04
1. Python version: 3.6.9
1. pip version: 20.1.1
1. pip-tools version: 5.2.0
#### Steps to replicate
```sh
cat > z.in <<EOF
https://github.com/zulip/python-zulip-api/archive/0.7.0.zip#egg=zulip==0.7.0&subdirectory=zulip
https://github.com/zulip/python-zulip-api/archive/0.7.0.zip#egg=zulip-bots==0.7.0&subdirectory=zulip_bots
EOF
pip-compile z.in
```
#### Expected result
```
#
# This file is autogenerated by pip-compile
# To update, run:
#
# pip-compile z.in
#
beautifulsoup4==4.9.1 # via zulip-bots
certifi==2020.4.5.1 # via requests
cffi==1.14.0 # via cryptography
chardet==3.0.4 # via requests
cryptography==2.9.2 # via pyopenssl, requests
distro==1.5.0 # via zulip
html2text==2020.1.16 # via zulip-bots
idna==2.9 # via requests
lxml==4.5.1 # via zulip-bots
matrix-client==0.3.2 # via zulip
pycparser==2.20 # via cffi
pyopenssl==19.1.0 # via requests
requests[security]==2.23.0 # via matrix-client, zulip
six==1.15.0 # via cryptography, pyopenssl, zulip
soupsieve==2.0.1 # via beautifulsoup4
urllib3==1.25.9 # via requests
https://github.com/zulip/python-zulip-api/archive/0.7.0.zip#egg=zulip-bots==0.7.0&subdirectory=zulip_bots # via -r z.in
https://github.com/zulip/python-zulip-api/archive/0.7.0.zip#egg=zulip==0.7.0&subdirectory=zulip # via -r z.in, zulip-bots
# The following packages are considered to be unsafe in a requirements file:
# pip
```
#### Actual result
```
#
# This file is autogenerated by pip-compile
# To update, run:
#
# pip-compile z.in
#
beautifulsoup4==4.9.1 # via zulip-bots
html2text==2020.1.16 # via zulip-bots
lxml==4.5.1 # via zulip-bots
soupsieve==2.0.1 # via beautifulsoup4
https://github.com/zulip/python-zulip-api/archive/0.7.0.zip#egg=zulip-bots==0.7.0&subdirectory=zulip_bots # via -r z.in
https://github.com/zulip/python-zulip-api/archive/0.7.0.zip#egg=zulip==0.7.0&subdirectory=zulip # via -r z.in, zulip-bots
# The following packages are considered to be unsafe in a requirements file:
# pip
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `piptools/repositories/base.py`
Content:
```
1 # coding: utf-8
2 from __future__ import absolute_import, division, print_function, unicode_literals
3
4 from abc import ABCMeta, abstractmethod
5 from contextlib import contextmanager
6
7 from six import add_metaclass
8
9
10 @add_metaclass(ABCMeta)
11 class BaseRepository(object):
12 def clear_caches(self):
13 """Should clear any caches used by the implementation."""
14
15 def freshen_build_caches(self):
16 """Should start with fresh build/source caches."""
17
18 @abstractmethod
19 def find_best_match(self, ireq):
20 """
21 Return a Version object that indicates the best match for the given
22 InstallRequirement according to the repository.
23 """
24
25 @abstractmethod
26 def get_dependencies(self, ireq):
27 """
28 Given a pinned, URL, or editable InstallRequirement, returns a set of
29 dependencies (also InstallRequirements, but not necessarily pinned).
30 They indicate the secondary dependencies for the given requirement.
31 """
32
33 @abstractmethod
34 def get_hashes(self, ireq):
35 """
36 Given a pinned InstallRequire, returns a set of hashes that represent
37 all of the files for a given requirement. It is not acceptable for an
38 editable or unpinned requirement to be passed to this function.
39 """
40
41 @abstractmethod
42 @contextmanager
43 def allow_all_wheels(self):
44 """
45 Monkey patches pip.Wheel to allow wheels from all platforms and Python versions.
46 """
47
48 def copy_ireq_dependencies(self, source, dest):
49 """
50 Notifies the repository that `dest` is a copy of `source`, and so it
51 has the same dependencies. Otherwise, once we prepare an ireq to assign
52 it its name, we would lose track of those dependencies on combining
53 that ireq with others.
54 """
55
```
Path: `piptools/repositories/local.py`
Content:
```
1 # coding: utf-8
2 from __future__ import absolute_import, division, print_function, unicode_literals
3
4 from contextlib import contextmanager
5
6 from pip._internal.utils.hashes import FAVORITE_HASH
7
8 from .._compat import PIP_VERSION
9 from .base import BaseRepository
10
11 from piptools.utils import as_tuple, key_from_ireq, make_install_requirement
12
13
14 def ireq_satisfied_by_existing_pin(ireq, existing_pin):
15 """
16 Return True if the given InstallationRequirement is satisfied by the
17 previously encountered version pin.
18 """
19 version = next(iter(existing_pin.req.specifier)).version
20 return ireq.req.specifier.contains(
21 version, prereleases=existing_pin.req.specifier.prereleases
22 )
23
24
25 class LocalRequirementsRepository(BaseRepository):
26 """
27 The LocalRequirementsRepository proxied the _real_ repository by first
28 checking if a requirement can be satisfied by existing pins (i.e. the
29 result of a previous compile step).
30
31 In effect, if a requirement can be satisfied with a version pinned in the
32 requirements file, we prefer that version over the best match found in
33 PyPI. This keeps updates to the requirements.txt down to a minimum.
34 """
35
36 def __init__(self, existing_pins, proxied_repository):
37 self.repository = proxied_repository
38 self.existing_pins = existing_pins
39
40 @property
41 def options(self):
42 return self.repository.options
43
44 @property
45 def finder(self):
46 return self.repository.finder
47
48 @property
49 def session(self):
50 return self.repository.session
51
52 @property
53 def DEFAULT_INDEX_URL(self):
54 return self.repository.DEFAULT_INDEX_URL
55
56 def clear_caches(self):
57 self.repository.clear_caches()
58
59 def freshen_build_caches(self):
60 self.repository.freshen_build_caches()
61
62 def find_best_match(self, ireq, prereleases=None):
63 key = key_from_ireq(ireq)
64 existing_pin = self.existing_pins.get(key)
65 if existing_pin and ireq_satisfied_by_existing_pin(ireq, existing_pin):
66 project, version, _ = as_tuple(existing_pin)
67 return make_install_requirement(
68 project, version, ireq.extras, constraint=ireq.constraint
69 )
70 else:
71 return self.repository.find_best_match(ireq, prereleases)
72
73 def get_dependencies(self, ireq):
74 return self.repository.get_dependencies(ireq)
75
76 def get_hashes(self, ireq):
77 key = key_from_ireq(ireq)
78 existing_pin = self.existing_pins.get(key)
79 if existing_pin and ireq_satisfied_by_existing_pin(ireq, existing_pin):
80 if PIP_VERSION[:2] <= (20, 0):
81 hashes = existing_pin.options.get("hashes", {})
82 else:
83 hashes = existing_pin.hash_options
84 hexdigests = hashes.get(FAVORITE_HASH)
85 if hexdigests:
86 return {
87 ":".join([FAVORITE_HASH, hexdigest]) for hexdigest in hexdigests
88 }
89 return self.repository.get_hashes(ireq)
90
91 @contextmanager
92 def allow_all_wheels(self):
93 with self.repository.allow_all_wheels():
94 yield
95
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/piptools/repositories/base.py b/piptools/repositories/base.py
--- a/piptools/repositories/base.py
+++ b/piptools/repositories/base.py
@@ -45,6 +45,7 @@
Monkey patches pip.Wheel to allow wheels from all platforms and Python versions.
"""
+ @abstractmethod
def copy_ireq_dependencies(self, source, dest):
"""
Notifies the repository that `dest` is a copy of `source`, and so it
diff --git a/piptools/repositories/local.py b/piptools/repositories/local.py
--- a/piptools/repositories/local.py
+++ b/piptools/repositories/local.py
@@ -92,3 +92,6 @@
def allow_all_wheels(self):
with self.repository.allow_all_wheels():
yield
+
+ def copy_ireq_dependencies(self, source, dest):
+ self.repository.copy_ireq_dependencies(source, dest)
|
{"golden_diff": "diff --git a/piptools/repositories/base.py b/piptools/repositories/base.py\n--- a/piptools/repositories/base.py\n+++ b/piptools/repositories/base.py\n@@ -45,6 +45,7 @@\n Monkey patches pip.Wheel to allow wheels from all platforms and Python versions.\n \"\"\"\n \n+ @abstractmethod\n def copy_ireq_dependencies(self, source, dest):\n \"\"\"\n Notifies the repository that `dest` is a copy of `source`, and so it\ndiff --git a/piptools/repositories/local.py b/piptools/repositories/local.py\n--- a/piptools/repositories/local.py\n+++ b/piptools/repositories/local.py\n@@ -92,3 +92,6 @@\n def allow_all_wheels(self):\n with self.repository.allow_all_wheels():\n yield\n+\n+ def copy_ireq_dependencies(self, source, dest):\n+ self.repository.copy_ireq_dependencies(source, dest)\n", "issue": "5.1.2 regression: lost dependencies using same zip file with different subdirectories\nIn `pip-tools` 5.1.2 and later, when I provide two copies of the same zip file URL with different subdirectories, the dependencies of the first are lost:\r\n\r\n```\r\nhttps://github.com/zulip/python-zulip-api/archive/0.7.0.zip#egg=zulip==0.7.0&subdirectory=zulip\r\nhttps://github.com/zulip/python-zulip-api/archive/0.7.0.zip#egg=zulip-bots==0.7.0&subdirectory=zulip_bots\r\n```\r\n\r\n`git bisect` shows that this regression was introduced in commit c0b33e7f2224758524001e755cc338965ca0b2c0 (#1132).\r\n\r\nCc @richafrank\r\n\r\n#### Environment Versions\r\n\r\n1. OS Type: Ubuntu 18.04\r\n1. Python version: 3.6.9\r\n1. pip version: 20.1.1\r\n1. pip-tools version: 5.2.0\r\n\r\n#### Steps to replicate\r\n\r\n```sh\r\ncat > z.in <<EOF\r\nhttps://github.com/zulip/python-zulip-api/archive/0.7.0.zip#egg=zulip==0.7.0&subdirectory=zulip\r\nhttps://github.com/zulip/python-zulip-api/archive/0.7.0.zip#egg=zulip-bots==0.7.0&subdirectory=zulip_bots\r\nEOF\r\npip-compile z.in\r\n```\r\n\r\n#### Expected result\r\n\r\n```\r\n#\r\n# This file is autogenerated by pip-compile\r\n# To update, run:\r\n#\r\n# pip-compile z.in\r\n#\r\nbeautifulsoup4==4.9.1 # via zulip-bots\r\ncertifi==2020.4.5.1 # via requests\r\ncffi==1.14.0 # via cryptography\r\nchardet==3.0.4 # via requests\r\ncryptography==2.9.2 # via pyopenssl, requests\r\ndistro==1.5.0 # via zulip\r\nhtml2text==2020.1.16 # via zulip-bots\r\nidna==2.9 # via requests\r\nlxml==4.5.1 # via zulip-bots\r\nmatrix-client==0.3.2 # via zulip\r\npycparser==2.20 # via cffi\r\npyopenssl==19.1.0 # via requests\r\nrequests[security]==2.23.0 # via matrix-client, zulip\r\nsix==1.15.0 # via cryptography, pyopenssl, zulip\r\nsoupsieve==2.0.1 # via beautifulsoup4\r\nurllib3==1.25.9 # via requests\r\nhttps://github.com/zulip/python-zulip-api/archive/0.7.0.zip#egg=zulip-bots==0.7.0&subdirectory=zulip_bots # via -r z.in\r\nhttps://github.com/zulip/python-zulip-api/archive/0.7.0.zip#egg=zulip==0.7.0&subdirectory=zulip # via -r z.in, zulip-bots\r\n\r\n# The following packages are considered to be unsafe in a requirements file:\r\n# pip\r\n```\r\n\r\n#### Actual result\r\n\r\n```\r\n#\r\n# This file is autogenerated by pip-compile\r\n# To update, run:\r\n#\r\n# pip-compile z.in\r\n#\r\nbeautifulsoup4==4.9.1 # via zulip-bots\r\nhtml2text==2020.1.16 # via zulip-bots\r\nlxml==4.5.1 # via zulip-bots\r\nsoupsieve==2.0.1 # via beautifulsoup4\r\nhttps://github.com/zulip/python-zulip-api/archive/0.7.0.zip#egg=zulip-bots==0.7.0&subdirectory=zulip_bots # via -r z.in\r\nhttps://github.com/zulip/python-zulip-api/archive/0.7.0.zip#egg=zulip==0.7.0&subdirectory=zulip # via -r z.in, zulip-bots\r\n\r\n# The following packages are considered to be unsafe in a requirements file:\r\n# pip\r\n```\r\n\n", "before_files": [{"content": "# coding: utf-8\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nfrom abc import ABCMeta, abstractmethod\nfrom contextlib import contextmanager\n\nfrom six import add_metaclass\n\n\n@add_metaclass(ABCMeta)\nclass BaseRepository(object):\n def clear_caches(self):\n \"\"\"Should clear any caches used by the implementation.\"\"\"\n\n def freshen_build_caches(self):\n \"\"\"Should start with fresh build/source caches.\"\"\"\n\n @abstractmethod\n def find_best_match(self, ireq):\n \"\"\"\n Return a Version object that indicates the best match for the given\n InstallRequirement according to the repository.\n \"\"\"\n\n @abstractmethod\n def get_dependencies(self, ireq):\n \"\"\"\n Given a pinned, URL, or editable InstallRequirement, returns a set of\n dependencies (also InstallRequirements, but not necessarily pinned).\n They indicate the secondary dependencies for the given requirement.\n \"\"\"\n\n @abstractmethod\n def get_hashes(self, ireq):\n \"\"\"\n Given a pinned InstallRequire, returns a set of hashes that represent\n all of the files for a given requirement. It is not acceptable for an\n editable or unpinned requirement to be passed to this function.\n \"\"\"\n\n @abstractmethod\n @contextmanager\n def allow_all_wheels(self):\n \"\"\"\n Monkey patches pip.Wheel to allow wheels from all platforms and Python versions.\n \"\"\"\n\n def copy_ireq_dependencies(self, source, dest):\n \"\"\"\n Notifies the repository that `dest` is a copy of `source`, and so it\n has the same dependencies. Otherwise, once we prepare an ireq to assign\n it its name, we would lose track of those dependencies on combining\n that ireq with others.\n \"\"\"\n", "path": "piptools/repositories/base.py"}, {"content": "# coding: utf-8\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nfrom contextlib import contextmanager\n\nfrom pip._internal.utils.hashes import FAVORITE_HASH\n\nfrom .._compat import PIP_VERSION\nfrom .base import BaseRepository\n\nfrom piptools.utils import as_tuple, key_from_ireq, make_install_requirement\n\n\ndef ireq_satisfied_by_existing_pin(ireq, existing_pin):\n \"\"\"\n Return True if the given InstallationRequirement is satisfied by the\n previously encountered version pin.\n \"\"\"\n version = next(iter(existing_pin.req.specifier)).version\n return ireq.req.specifier.contains(\n version, prereleases=existing_pin.req.specifier.prereleases\n )\n\n\nclass LocalRequirementsRepository(BaseRepository):\n \"\"\"\n The LocalRequirementsRepository proxied the _real_ repository by first\n checking if a requirement can be satisfied by existing pins (i.e. the\n result of a previous compile step).\n\n In effect, if a requirement can be satisfied with a version pinned in the\n requirements file, we prefer that version over the best match found in\n PyPI. This keeps updates to the requirements.txt down to a minimum.\n \"\"\"\n\n def __init__(self, existing_pins, proxied_repository):\n self.repository = proxied_repository\n self.existing_pins = existing_pins\n\n @property\n def options(self):\n return self.repository.options\n\n @property\n def finder(self):\n return self.repository.finder\n\n @property\n def session(self):\n return self.repository.session\n\n @property\n def DEFAULT_INDEX_URL(self):\n return self.repository.DEFAULT_INDEX_URL\n\n def clear_caches(self):\n self.repository.clear_caches()\n\n def freshen_build_caches(self):\n self.repository.freshen_build_caches()\n\n def find_best_match(self, ireq, prereleases=None):\n key = key_from_ireq(ireq)\n existing_pin = self.existing_pins.get(key)\n if existing_pin and ireq_satisfied_by_existing_pin(ireq, existing_pin):\n project, version, _ = as_tuple(existing_pin)\n return make_install_requirement(\n project, version, ireq.extras, constraint=ireq.constraint\n )\n else:\n return self.repository.find_best_match(ireq, prereleases)\n\n def get_dependencies(self, ireq):\n return self.repository.get_dependencies(ireq)\n\n def get_hashes(self, ireq):\n key = key_from_ireq(ireq)\n existing_pin = self.existing_pins.get(key)\n if existing_pin and ireq_satisfied_by_existing_pin(ireq, existing_pin):\n if PIP_VERSION[:2] <= (20, 0):\n hashes = existing_pin.options.get(\"hashes\", {})\n else:\n hashes = existing_pin.hash_options\n hexdigests = hashes.get(FAVORITE_HASH)\n if hexdigests:\n return {\n \":\".join([FAVORITE_HASH, hexdigest]) for hexdigest in hexdigests\n }\n return self.repository.get_hashes(ireq)\n\n @contextmanager\n def allow_all_wheels(self):\n with self.repository.allow_all_wheels():\n yield\n", "path": "piptools/repositories/local.py"}], "after_files": [{"content": "# coding: utf-8\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nfrom abc import ABCMeta, abstractmethod\nfrom contextlib import contextmanager\n\nfrom six import add_metaclass\n\n\n@add_metaclass(ABCMeta)\nclass BaseRepository(object):\n def clear_caches(self):\n \"\"\"Should clear any caches used by the implementation.\"\"\"\n\n def freshen_build_caches(self):\n \"\"\"Should start with fresh build/source caches.\"\"\"\n\n @abstractmethod\n def find_best_match(self, ireq):\n \"\"\"\n Return a Version object that indicates the best match for the given\n InstallRequirement according to the repository.\n \"\"\"\n\n @abstractmethod\n def get_dependencies(self, ireq):\n \"\"\"\n Given a pinned, URL, or editable InstallRequirement, returns a set of\n dependencies (also InstallRequirements, but not necessarily pinned).\n They indicate the secondary dependencies for the given requirement.\n \"\"\"\n\n @abstractmethod\n def get_hashes(self, ireq):\n \"\"\"\n Given a pinned InstallRequire, returns a set of hashes that represent\n all of the files for a given requirement. It is not acceptable for an\n editable or unpinned requirement to be passed to this function.\n \"\"\"\n\n @abstractmethod\n @contextmanager\n def allow_all_wheels(self):\n \"\"\"\n Monkey patches pip.Wheel to allow wheels from all platforms and Python versions.\n \"\"\"\n\n @abstractmethod\n def copy_ireq_dependencies(self, source, dest):\n \"\"\"\n Notifies the repository that `dest` is a copy of `source`, and so it\n has the same dependencies. Otherwise, once we prepare an ireq to assign\n it its name, we would lose track of those dependencies on combining\n that ireq with others.\n \"\"\"\n", "path": "piptools/repositories/base.py"}, {"content": "# coding: utf-8\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nfrom contextlib import contextmanager\n\nfrom pip._internal.utils.hashes import FAVORITE_HASH\n\nfrom .._compat import PIP_VERSION\nfrom .base import BaseRepository\n\nfrom piptools.utils import as_tuple, key_from_ireq, make_install_requirement\n\n\ndef ireq_satisfied_by_existing_pin(ireq, existing_pin):\n \"\"\"\n Return True if the given InstallationRequirement is satisfied by the\n previously encountered version pin.\n \"\"\"\n version = next(iter(existing_pin.req.specifier)).version\n return ireq.req.specifier.contains(\n version, prereleases=existing_pin.req.specifier.prereleases\n )\n\n\nclass LocalRequirementsRepository(BaseRepository):\n \"\"\"\n The LocalRequirementsRepository proxied the _real_ repository by first\n checking if a requirement can be satisfied by existing pins (i.e. the\n result of a previous compile step).\n\n In effect, if a requirement can be satisfied with a version pinned in the\n requirements file, we prefer that version over the best match found in\n PyPI. This keeps updates to the requirements.txt down to a minimum.\n \"\"\"\n\n def __init__(self, existing_pins, proxied_repository):\n self.repository = proxied_repository\n self.existing_pins = existing_pins\n\n @property\n def options(self):\n return self.repository.options\n\n @property\n def finder(self):\n return self.repository.finder\n\n @property\n def session(self):\n return self.repository.session\n\n @property\n def DEFAULT_INDEX_URL(self):\n return self.repository.DEFAULT_INDEX_URL\n\n def clear_caches(self):\n self.repository.clear_caches()\n\n def freshen_build_caches(self):\n self.repository.freshen_build_caches()\n\n def find_best_match(self, ireq, prereleases=None):\n key = key_from_ireq(ireq)\n existing_pin = self.existing_pins.get(key)\n if existing_pin and ireq_satisfied_by_existing_pin(ireq, existing_pin):\n project, version, _ = as_tuple(existing_pin)\n return make_install_requirement(\n project, version, ireq.extras, constraint=ireq.constraint\n )\n else:\n return self.repository.find_best_match(ireq, prereleases)\n\n def get_dependencies(self, ireq):\n return self.repository.get_dependencies(ireq)\n\n def get_hashes(self, ireq):\n key = key_from_ireq(ireq)\n existing_pin = self.existing_pins.get(key)\n if existing_pin and ireq_satisfied_by_existing_pin(ireq, existing_pin):\n if PIP_VERSION[:2] <= (20, 0):\n hashes = existing_pin.options.get(\"hashes\", {})\n else:\n hashes = existing_pin.hash_options\n hexdigests = hashes.get(FAVORITE_HASH)\n if hexdigests:\n return {\n \":\".join([FAVORITE_HASH, hexdigest]) for hexdigest in hexdigests\n }\n return self.repository.get_hashes(ireq)\n\n @contextmanager\n def allow_all_wheels(self):\n with self.repository.allow_all_wheels():\n yield\n\n def copy_ireq_dependencies(self, source, dest):\n self.repository.copy_ireq_dependencies(source, dest)\n", "path": "piptools/repositories/local.py"}]}
| 2,650 | 211 |
gh_patches_debug_40411
|
rasdani/github-patches
|
git_diff
|
pytorch__audio-1826
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
doc for bg_iterator et al
The [documentation](https://pytorch.org/audio/datasets.html) for torchaudio does not include `bg_iterator` and `disk_cache_iterator` from [code](https://github.com/pytorch/audio/blob/master/torchaudio/datasets/utils.py). Thanks to [comment](https://discuss.pytorch.org/t/audio-dataset-load-large-file-into-memory-in-background/85943) to point this out :)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `torchaudio/datasets/__init__.py`
Content:
```
1 from .commonvoice import COMMONVOICE
2 from .librispeech import LIBRISPEECH
3 from .speechcommands import SPEECHCOMMANDS
4 from .utils import bg_iterator, diskcache_iterator
5 from .vctk import VCTK_092
6 from .gtzan import GTZAN
7 from .yesno import YESNO
8 from .ljspeech import LJSPEECH
9 from .cmuarctic import CMUARCTIC
10 from .cmudict import CMUDict
11 from .libritts import LIBRITTS
12 from .tedlium import TEDLIUM
13
14
15 __all__ = [
16 "COMMONVOICE",
17 "LIBRISPEECH",
18 "SPEECHCOMMANDS",
19 "VCTK_092",
20 "YESNO",
21 "LJSPEECH",
22 "GTZAN",
23 "CMUARCTIC",
24 "CMUDict",
25 "LIBRITTS",
26 "diskcache_iterator",
27 "bg_iterator",
28 "TEDLIUM",
29 ]
30
```
Path: `torchaudio/datasets/utils.py`
Content:
```
1 import hashlib
2 import logging
3 import os
4 import tarfile
5 import threading
6 import urllib
7 import urllib.request
8 import zipfile
9 from queue import Queue
10 from typing import Any, Iterable, List, Optional
11
12 import torch
13 from torch.utils.data import Dataset
14 from torch.utils.model_zoo import tqdm
15
16 from torchaudio._internal.module_utils import deprecated
17
18
19 def stream_url(url: str,
20 start_byte: Optional[int] = None,
21 block_size: int = 32 * 1024,
22 progress_bar: bool = True) -> Iterable:
23 """Stream url by chunk
24
25 Args:
26 url (str): Url.
27 start_byte (int or None, optional): Start streaming at that point (Default: ``None``).
28 block_size (int, optional): Size of chunks to stream (Default: ``32 * 1024``).
29 progress_bar (bool, optional): Display a progress bar (Default: ``True``).
30 """
31
32 # If we already have the whole file, there is no need to download it again
33 req = urllib.request.Request(url, method="HEAD")
34 with urllib.request.urlopen(req) as response:
35 url_size = int(response.info().get("Content-Length", -1))
36 if url_size == start_byte:
37 return
38
39 req = urllib.request.Request(url)
40 if start_byte:
41 req.headers["Range"] = "bytes={}-".format(start_byte)
42
43 with urllib.request.urlopen(req) as upointer, tqdm(
44 unit="B",
45 unit_scale=True,
46 unit_divisor=1024,
47 total=url_size,
48 disable=not progress_bar,
49 ) as pbar:
50
51 num_bytes = 0
52 while True:
53 chunk = upointer.read(block_size)
54 if not chunk:
55 break
56 yield chunk
57 num_bytes += len(chunk)
58 pbar.update(len(chunk))
59
60
61 def download_url(url: str,
62 download_folder: str,
63 filename: Optional[str] = None,
64 hash_value: Optional[str] = None,
65 hash_type: str = "sha256",
66 progress_bar: bool = True,
67 resume: bool = False) -> None:
68 """Download file to disk.
69
70 Args:
71 url (str): Url.
72 download_folder (str): Folder to download file.
73 filename (str or None, optional): Name of downloaded file. If None, it is inferred from the url
74 (Default: ``None``).
75 hash_value (str or None, optional): Hash for url (Default: ``None``).
76 hash_type (str, optional): Hash type, among "sha256" and "md5" (Default: ``"sha256"``).
77 progress_bar (bool, optional): Display a progress bar (Default: ``True``).
78 resume (bool, optional): Enable resuming download (Default: ``False``).
79 """
80
81 req = urllib.request.Request(url, method="HEAD")
82 req_info = urllib.request.urlopen(req).info()
83
84 # Detect filename
85 filename = filename or req_info.get_filename() or os.path.basename(url)
86 filepath = os.path.join(download_folder, filename)
87 if resume and os.path.exists(filepath):
88 mode = "ab"
89 local_size: Optional[int] = os.path.getsize(filepath)
90
91 elif not resume and os.path.exists(filepath):
92 raise RuntimeError(
93 "{} already exists. Delete the file manually and retry.".format(filepath)
94 )
95 else:
96 mode = "wb"
97 local_size = None
98
99 if hash_value and local_size == int(req_info.get("Content-Length", -1)):
100 with open(filepath, "rb") as file_obj:
101 if validate_file(file_obj, hash_value, hash_type):
102 return
103 raise RuntimeError(
104 "The hash of {} does not match. Delete the file manually and retry.".format(
105 filepath
106 )
107 )
108
109 with open(filepath, mode) as fpointer:
110 for chunk in stream_url(url, start_byte=local_size, progress_bar=progress_bar):
111 fpointer.write(chunk)
112
113 with open(filepath, "rb") as file_obj:
114 if hash_value and not validate_file(file_obj, hash_value, hash_type):
115 raise RuntimeError(
116 "The hash of {} does not match. Delete the file manually and retry.".format(
117 filepath
118 )
119 )
120
121
122 def validate_file(file_obj: Any, hash_value: str, hash_type: str = "sha256") -> bool:
123 """Validate a given file object with its hash.
124
125 Args:
126 file_obj: File object to read from.
127 hash_value (str): Hash for url.
128 hash_type (str, optional): Hash type, among "sha256" and "md5" (Default: ``"sha256"``).
129
130 Returns:
131 bool: return True if its a valid file, else False.
132 """
133
134 if hash_type == "sha256":
135 hash_func = hashlib.sha256()
136 elif hash_type == "md5":
137 hash_func = hashlib.md5()
138 else:
139 raise ValueError
140
141 while True:
142 # Read by chunk to avoid filling memory
143 chunk = file_obj.read(1024 ** 2)
144 if not chunk:
145 break
146 hash_func.update(chunk)
147
148 return hash_func.hexdigest() == hash_value
149
150
151 def extract_archive(from_path: str, to_path: Optional[str] = None, overwrite: bool = False) -> List[str]:
152 """Extract archive.
153 Args:
154 from_path (str): the path of the archive.
155 to_path (str or None, optional): the root path of the extraced files (directory of from_path)
156 (Default: ``None``)
157 overwrite (bool, optional): overwrite existing files (Default: ``False``)
158
159 Returns:
160 list: List of paths to extracted files even if not overwritten.
161
162 Examples:
163 >>> url = 'http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/validation.tar.gz'
164 >>> from_path = './validation.tar.gz'
165 >>> to_path = './'
166 >>> torchaudio.datasets.utils.download_from_url(url, from_path)
167 >>> torchaudio.datasets.utils.extract_archive(from_path, to_path)
168 """
169
170 if to_path is None:
171 to_path = os.path.dirname(from_path)
172
173 try:
174 with tarfile.open(from_path, "r") as tar:
175 logging.info("Opened tar file {}.".format(from_path))
176 files = []
177 for file_ in tar: # type: Any
178 file_path = os.path.join(to_path, file_.name)
179 if file_.isfile():
180 files.append(file_path)
181 if os.path.exists(file_path):
182 logging.info("{} already extracted.".format(file_path))
183 if not overwrite:
184 continue
185 tar.extract(file_, to_path)
186 return files
187 except tarfile.ReadError:
188 pass
189
190 try:
191 with zipfile.ZipFile(from_path, "r") as zfile:
192 logging.info("Opened zip file {}.".format(from_path))
193 files = zfile.namelist()
194 for file_ in files:
195 file_path = os.path.join(to_path, file_)
196 if os.path.exists(file_path):
197 logging.info("{} already extracted.".format(file_path))
198 if not overwrite:
199 continue
200 zfile.extract(file_, to_path)
201 return files
202 except zipfile.BadZipFile:
203 pass
204
205 raise NotImplementedError("We currently only support tar.gz, tgz, and zip achives.")
206
207
208 class _DiskCache(Dataset):
209 """
210 Wrap a dataset so that, whenever a new item is returned, it is saved to disk.
211 """
212
213 def __init__(self, dataset: Dataset, location: str = ".cached") -> None:
214 self.dataset = dataset
215 self.location = location
216
217 self._id = id(self)
218 self._cache: List = [None] * len(dataset)
219
220 def __getitem__(self, n: int) -> Any:
221 if self._cache[n]:
222 f = self._cache[n]
223 return torch.load(f)
224
225 f = str(self._id) + "-" + str(n)
226 f = os.path.join(self.location, f)
227 item = self.dataset[n]
228
229 self._cache[n] = f
230 os.makedirs(self.location, exist_ok=True)
231 torch.save(item, f)
232
233 return item
234
235 def __len__(self) -> int:
236 return len(self.dataset)
237
238
239 @deprecated('', version='0.11')
240 def diskcache_iterator(dataset: Dataset, location: str = ".cached") -> Dataset:
241 return _DiskCache(dataset, location)
242
243
244 class _ThreadedIterator(threading.Thread):
245 """
246 Prefetch the next queue_length items from iterator in a background thread.
247
248 Example:
249 >> for i in bg_iterator(range(10)):
250 >> print(i)
251 """
252
253 class _End:
254 pass
255
256 def __init__(self, generator: Iterable, maxsize: int) -> None:
257 threading.Thread.__init__(self)
258 self.queue: Queue = Queue(maxsize)
259 self.generator = generator
260 self.daemon = True
261 self.start()
262
263 def run(self) -> None:
264 for item in self.generator:
265 self.queue.put(item)
266 self.queue.put(self._End)
267
268 def __iter__(self) -> Any:
269 return self
270
271 def __next__(self) -> Any:
272 next_item = self.queue.get()
273 if next_item == self._End:
274 raise StopIteration
275 return next_item
276
277 # Required for Python 2.7 compatibility
278 def next(self) -> Any:
279 return self.__next__()
280
281
282 @deprecated('', version='0.11')
283 def bg_iterator(iterable: Iterable, maxsize: int) -> Any:
284 return _ThreadedIterator(iterable, maxsize=maxsize)
285
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/torchaudio/datasets/__init__.py b/torchaudio/datasets/__init__.py
--- a/torchaudio/datasets/__init__.py
+++ b/torchaudio/datasets/__init__.py
@@ -1,7 +1,6 @@
from .commonvoice import COMMONVOICE
from .librispeech import LIBRISPEECH
from .speechcommands import SPEECHCOMMANDS
-from .utils import bg_iterator, diskcache_iterator
from .vctk import VCTK_092
from .gtzan import GTZAN
from .yesno import YESNO
@@ -23,7 +22,5 @@
"CMUARCTIC",
"CMUDict",
"LIBRITTS",
- "diskcache_iterator",
- "bg_iterator",
"TEDLIUM",
]
diff --git a/torchaudio/datasets/utils.py b/torchaudio/datasets/utils.py
--- a/torchaudio/datasets/utils.py
+++ b/torchaudio/datasets/utils.py
@@ -2,19 +2,13 @@
import logging
import os
import tarfile
-import threading
import urllib
import urllib.request
import zipfile
-from queue import Queue
from typing import Any, Iterable, List, Optional
-import torch
-from torch.utils.data import Dataset
from torch.utils.model_zoo import tqdm
-from torchaudio._internal.module_utils import deprecated
-
def stream_url(url: str,
start_byte: Optional[int] = None,
@@ -203,82 +197,3 @@
pass
raise NotImplementedError("We currently only support tar.gz, tgz, and zip achives.")
-
-
-class _DiskCache(Dataset):
- """
- Wrap a dataset so that, whenever a new item is returned, it is saved to disk.
- """
-
- def __init__(self, dataset: Dataset, location: str = ".cached") -> None:
- self.dataset = dataset
- self.location = location
-
- self._id = id(self)
- self._cache: List = [None] * len(dataset)
-
- def __getitem__(self, n: int) -> Any:
- if self._cache[n]:
- f = self._cache[n]
- return torch.load(f)
-
- f = str(self._id) + "-" + str(n)
- f = os.path.join(self.location, f)
- item = self.dataset[n]
-
- self._cache[n] = f
- os.makedirs(self.location, exist_ok=True)
- torch.save(item, f)
-
- return item
-
- def __len__(self) -> int:
- return len(self.dataset)
-
-
-@deprecated('', version='0.11')
-def diskcache_iterator(dataset: Dataset, location: str = ".cached") -> Dataset:
- return _DiskCache(dataset, location)
-
-
-class _ThreadedIterator(threading.Thread):
- """
- Prefetch the next queue_length items from iterator in a background thread.
-
- Example:
- >> for i in bg_iterator(range(10)):
- >> print(i)
- """
-
- class _End:
- pass
-
- def __init__(self, generator: Iterable, maxsize: int) -> None:
- threading.Thread.__init__(self)
- self.queue: Queue = Queue(maxsize)
- self.generator = generator
- self.daemon = True
- self.start()
-
- def run(self) -> None:
- for item in self.generator:
- self.queue.put(item)
- self.queue.put(self._End)
-
- def __iter__(self) -> Any:
- return self
-
- def __next__(self) -> Any:
- next_item = self.queue.get()
- if next_item == self._End:
- raise StopIteration
- return next_item
-
- # Required for Python 2.7 compatibility
- def next(self) -> Any:
- return self.__next__()
-
-
-@deprecated('', version='0.11')
-def bg_iterator(iterable: Iterable, maxsize: int) -> Any:
- return _ThreadedIterator(iterable, maxsize=maxsize)
|
{"golden_diff": "diff --git a/torchaudio/datasets/__init__.py b/torchaudio/datasets/__init__.py\n--- a/torchaudio/datasets/__init__.py\n+++ b/torchaudio/datasets/__init__.py\n@@ -1,7 +1,6 @@\n from .commonvoice import COMMONVOICE\n from .librispeech import LIBRISPEECH\n from .speechcommands import SPEECHCOMMANDS\n-from .utils import bg_iterator, diskcache_iterator\n from .vctk import VCTK_092\n from .gtzan import GTZAN\n from .yesno import YESNO\n@@ -23,7 +22,5 @@\n \"CMUARCTIC\",\n \"CMUDict\",\n \"LIBRITTS\",\n- \"diskcache_iterator\",\n- \"bg_iterator\",\n \"TEDLIUM\",\n ]\ndiff --git a/torchaudio/datasets/utils.py b/torchaudio/datasets/utils.py\n--- a/torchaudio/datasets/utils.py\n+++ b/torchaudio/datasets/utils.py\n@@ -2,19 +2,13 @@\n import logging\n import os\n import tarfile\n-import threading\n import urllib\n import urllib.request\n import zipfile\n-from queue import Queue\n from typing import Any, Iterable, List, Optional\n \n-import torch\n-from torch.utils.data import Dataset\n from torch.utils.model_zoo import tqdm\n \n-from torchaudio._internal.module_utils import deprecated\n-\n \n def stream_url(url: str,\n start_byte: Optional[int] = None,\n@@ -203,82 +197,3 @@\n pass\n \n raise NotImplementedError(\"We currently only support tar.gz, tgz, and zip achives.\")\n-\n-\n-class _DiskCache(Dataset):\n- \"\"\"\n- Wrap a dataset so that, whenever a new item is returned, it is saved to disk.\n- \"\"\"\n-\n- def __init__(self, dataset: Dataset, location: str = \".cached\") -> None:\n- self.dataset = dataset\n- self.location = location\n-\n- self._id = id(self)\n- self._cache: List = [None] * len(dataset)\n-\n- def __getitem__(self, n: int) -> Any:\n- if self._cache[n]:\n- f = self._cache[n]\n- return torch.load(f)\n-\n- f = str(self._id) + \"-\" + str(n)\n- f = os.path.join(self.location, f)\n- item = self.dataset[n]\n-\n- self._cache[n] = f\n- os.makedirs(self.location, exist_ok=True)\n- torch.save(item, f)\n-\n- return item\n-\n- def __len__(self) -> int:\n- return len(self.dataset)\n-\n-\n-@deprecated('', version='0.11')\n-def diskcache_iterator(dataset: Dataset, location: str = \".cached\") -> Dataset:\n- return _DiskCache(dataset, location)\n-\n-\n-class _ThreadedIterator(threading.Thread):\n- \"\"\"\n- Prefetch the next queue_length items from iterator in a background thread.\n-\n- Example:\n- >> for i in bg_iterator(range(10)):\n- >> print(i)\n- \"\"\"\n-\n- class _End:\n- pass\n-\n- def __init__(self, generator: Iterable, maxsize: int) -> None:\n- threading.Thread.__init__(self)\n- self.queue: Queue = Queue(maxsize)\n- self.generator = generator\n- self.daemon = True\n- self.start()\n-\n- def run(self) -> None:\n- for item in self.generator:\n- self.queue.put(item)\n- self.queue.put(self._End)\n-\n- def __iter__(self) -> Any:\n- return self\n-\n- def __next__(self) -> Any:\n- next_item = self.queue.get()\n- if next_item == self._End:\n- raise StopIteration\n- return next_item\n-\n- # Required for Python 2.7 compatibility\n- def next(self) -> Any:\n- return self.__next__()\n-\n-\n-@deprecated('', version='0.11')\n-def bg_iterator(iterable: Iterable, maxsize: int) -> Any:\n- return _ThreadedIterator(iterable, maxsize=maxsize)\n", "issue": "doc for bg_iterator et al\nThe [documentation](https://pytorch.org/audio/datasets.html) for torchaudio does not include `bg_iterator` and `disk_cache_iterator` from [code](https://github.com/pytorch/audio/blob/master/torchaudio/datasets/utils.py). Thanks to [comment](https://discuss.pytorch.org/t/audio-dataset-load-large-file-into-memory-in-background/85943) to point this out :)\n", "before_files": [{"content": "from .commonvoice import COMMONVOICE\nfrom .librispeech import LIBRISPEECH\nfrom .speechcommands import SPEECHCOMMANDS\nfrom .utils import bg_iterator, diskcache_iterator\nfrom .vctk import VCTK_092\nfrom .gtzan import GTZAN\nfrom .yesno import YESNO\nfrom .ljspeech import LJSPEECH\nfrom .cmuarctic import CMUARCTIC\nfrom .cmudict import CMUDict\nfrom .libritts import LIBRITTS\nfrom .tedlium import TEDLIUM\n\n\n__all__ = [\n \"COMMONVOICE\",\n \"LIBRISPEECH\",\n \"SPEECHCOMMANDS\",\n \"VCTK_092\",\n \"YESNO\",\n \"LJSPEECH\",\n \"GTZAN\",\n \"CMUARCTIC\",\n \"CMUDict\",\n \"LIBRITTS\",\n \"diskcache_iterator\",\n \"bg_iterator\",\n \"TEDLIUM\",\n]\n", "path": "torchaudio/datasets/__init__.py"}, {"content": "import hashlib\nimport logging\nimport os\nimport tarfile\nimport threading\nimport urllib\nimport urllib.request\nimport zipfile\nfrom queue import Queue\nfrom typing import Any, Iterable, List, Optional\n\nimport torch\nfrom torch.utils.data import Dataset\nfrom torch.utils.model_zoo import tqdm\n\nfrom torchaudio._internal.module_utils import deprecated\n\n\ndef stream_url(url: str,\n start_byte: Optional[int] = None,\n block_size: int = 32 * 1024,\n progress_bar: bool = True) -> Iterable:\n \"\"\"Stream url by chunk\n\n Args:\n url (str): Url.\n start_byte (int or None, optional): Start streaming at that point (Default: ``None``).\n block_size (int, optional): Size of chunks to stream (Default: ``32 * 1024``).\n progress_bar (bool, optional): Display a progress bar (Default: ``True``).\n \"\"\"\n\n # If we already have the whole file, there is no need to download it again\n req = urllib.request.Request(url, method=\"HEAD\")\n with urllib.request.urlopen(req) as response:\n url_size = int(response.info().get(\"Content-Length\", -1))\n if url_size == start_byte:\n return\n\n req = urllib.request.Request(url)\n if start_byte:\n req.headers[\"Range\"] = \"bytes={}-\".format(start_byte)\n\n with urllib.request.urlopen(req) as upointer, tqdm(\n unit=\"B\",\n unit_scale=True,\n unit_divisor=1024,\n total=url_size,\n disable=not progress_bar,\n ) as pbar:\n\n num_bytes = 0\n while True:\n chunk = upointer.read(block_size)\n if not chunk:\n break\n yield chunk\n num_bytes += len(chunk)\n pbar.update(len(chunk))\n\n\ndef download_url(url: str,\n download_folder: str,\n filename: Optional[str] = None,\n hash_value: Optional[str] = None,\n hash_type: str = \"sha256\",\n progress_bar: bool = True,\n resume: bool = False) -> None:\n \"\"\"Download file to disk.\n\n Args:\n url (str): Url.\n download_folder (str): Folder to download file.\n filename (str or None, optional): Name of downloaded file. If None, it is inferred from the url\n (Default: ``None``).\n hash_value (str or None, optional): Hash for url (Default: ``None``).\n hash_type (str, optional): Hash type, among \"sha256\" and \"md5\" (Default: ``\"sha256\"``).\n progress_bar (bool, optional): Display a progress bar (Default: ``True``).\n resume (bool, optional): Enable resuming download (Default: ``False``).\n \"\"\"\n\n req = urllib.request.Request(url, method=\"HEAD\")\n req_info = urllib.request.urlopen(req).info()\n\n # Detect filename\n filename = filename or req_info.get_filename() or os.path.basename(url)\n filepath = os.path.join(download_folder, filename)\n if resume and os.path.exists(filepath):\n mode = \"ab\"\n local_size: Optional[int] = os.path.getsize(filepath)\n\n elif not resume and os.path.exists(filepath):\n raise RuntimeError(\n \"{} already exists. Delete the file manually and retry.\".format(filepath)\n )\n else:\n mode = \"wb\"\n local_size = None\n\n if hash_value and local_size == int(req_info.get(\"Content-Length\", -1)):\n with open(filepath, \"rb\") as file_obj:\n if validate_file(file_obj, hash_value, hash_type):\n return\n raise RuntimeError(\n \"The hash of {} does not match. Delete the file manually and retry.\".format(\n filepath\n )\n )\n\n with open(filepath, mode) as fpointer:\n for chunk in stream_url(url, start_byte=local_size, progress_bar=progress_bar):\n fpointer.write(chunk)\n\n with open(filepath, \"rb\") as file_obj:\n if hash_value and not validate_file(file_obj, hash_value, hash_type):\n raise RuntimeError(\n \"The hash of {} does not match. Delete the file manually and retry.\".format(\n filepath\n )\n )\n\n\ndef validate_file(file_obj: Any, hash_value: str, hash_type: str = \"sha256\") -> bool:\n \"\"\"Validate a given file object with its hash.\n\n Args:\n file_obj: File object to read from.\n hash_value (str): Hash for url.\n hash_type (str, optional): Hash type, among \"sha256\" and \"md5\" (Default: ``\"sha256\"``).\n\n Returns:\n bool: return True if its a valid file, else False.\n \"\"\"\n\n if hash_type == \"sha256\":\n hash_func = hashlib.sha256()\n elif hash_type == \"md5\":\n hash_func = hashlib.md5()\n else:\n raise ValueError\n\n while True:\n # Read by chunk to avoid filling memory\n chunk = file_obj.read(1024 ** 2)\n if not chunk:\n break\n hash_func.update(chunk)\n\n return hash_func.hexdigest() == hash_value\n\n\ndef extract_archive(from_path: str, to_path: Optional[str] = None, overwrite: bool = False) -> List[str]:\n \"\"\"Extract archive.\n Args:\n from_path (str): the path of the archive.\n to_path (str or None, optional): the root path of the extraced files (directory of from_path)\n (Default: ``None``)\n overwrite (bool, optional): overwrite existing files (Default: ``False``)\n\n Returns:\n list: List of paths to extracted files even if not overwritten.\n\n Examples:\n >>> url = 'http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/validation.tar.gz'\n >>> from_path = './validation.tar.gz'\n >>> to_path = './'\n >>> torchaudio.datasets.utils.download_from_url(url, from_path)\n >>> torchaudio.datasets.utils.extract_archive(from_path, to_path)\n \"\"\"\n\n if to_path is None:\n to_path = os.path.dirname(from_path)\n\n try:\n with tarfile.open(from_path, \"r\") as tar:\n logging.info(\"Opened tar file {}.\".format(from_path))\n files = []\n for file_ in tar: # type: Any\n file_path = os.path.join(to_path, file_.name)\n if file_.isfile():\n files.append(file_path)\n if os.path.exists(file_path):\n logging.info(\"{} already extracted.\".format(file_path))\n if not overwrite:\n continue\n tar.extract(file_, to_path)\n return files\n except tarfile.ReadError:\n pass\n\n try:\n with zipfile.ZipFile(from_path, \"r\") as zfile:\n logging.info(\"Opened zip file {}.\".format(from_path))\n files = zfile.namelist()\n for file_ in files:\n file_path = os.path.join(to_path, file_)\n if os.path.exists(file_path):\n logging.info(\"{} already extracted.\".format(file_path))\n if not overwrite:\n continue\n zfile.extract(file_, to_path)\n return files\n except zipfile.BadZipFile:\n pass\n\n raise NotImplementedError(\"We currently only support tar.gz, tgz, and zip achives.\")\n\n\nclass _DiskCache(Dataset):\n \"\"\"\n Wrap a dataset so that, whenever a new item is returned, it is saved to disk.\n \"\"\"\n\n def __init__(self, dataset: Dataset, location: str = \".cached\") -> None:\n self.dataset = dataset\n self.location = location\n\n self._id = id(self)\n self._cache: List = [None] * len(dataset)\n\n def __getitem__(self, n: int) -> Any:\n if self._cache[n]:\n f = self._cache[n]\n return torch.load(f)\n\n f = str(self._id) + \"-\" + str(n)\n f = os.path.join(self.location, f)\n item = self.dataset[n]\n\n self._cache[n] = f\n os.makedirs(self.location, exist_ok=True)\n torch.save(item, f)\n\n return item\n\n def __len__(self) -> int:\n return len(self.dataset)\n\n\n@deprecated('', version='0.11')\ndef diskcache_iterator(dataset: Dataset, location: str = \".cached\") -> Dataset:\n return _DiskCache(dataset, location)\n\n\nclass _ThreadedIterator(threading.Thread):\n \"\"\"\n Prefetch the next queue_length items from iterator in a background thread.\n\n Example:\n >> for i in bg_iterator(range(10)):\n >> print(i)\n \"\"\"\n\n class _End:\n pass\n\n def __init__(self, generator: Iterable, maxsize: int) -> None:\n threading.Thread.__init__(self)\n self.queue: Queue = Queue(maxsize)\n self.generator = generator\n self.daemon = True\n self.start()\n\n def run(self) -> None:\n for item in self.generator:\n self.queue.put(item)\n self.queue.put(self._End)\n\n def __iter__(self) -> Any:\n return self\n\n def __next__(self) -> Any:\n next_item = self.queue.get()\n if next_item == self._End:\n raise StopIteration\n return next_item\n\n # Required for Python 2.7 compatibility\n def next(self) -> Any:\n return self.__next__()\n\n\n@deprecated('', version='0.11')\ndef bg_iterator(iterable: Iterable, maxsize: int) -> Any:\n return _ThreadedIterator(iterable, maxsize=maxsize)\n", "path": "torchaudio/datasets/utils.py"}], "after_files": [{"content": "from .commonvoice import COMMONVOICE\nfrom .librispeech import LIBRISPEECH\nfrom .speechcommands import SPEECHCOMMANDS\nfrom .vctk import VCTK_092\nfrom .gtzan import GTZAN\nfrom .yesno import YESNO\nfrom .ljspeech import LJSPEECH\nfrom .cmuarctic import CMUARCTIC\nfrom .cmudict import CMUDict\nfrom .libritts import LIBRITTS\nfrom .tedlium import TEDLIUM\n\n\n__all__ = [\n \"COMMONVOICE\",\n \"LIBRISPEECH\",\n \"SPEECHCOMMANDS\",\n \"VCTK_092\",\n \"YESNO\",\n \"LJSPEECH\",\n \"GTZAN\",\n \"CMUARCTIC\",\n \"CMUDict\",\n \"LIBRITTS\",\n \"TEDLIUM\",\n]\n", "path": "torchaudio/datasets/__init__.py"}, {"content": "import hashlib\nimport logging\nimport os\nimport tarfile\nimport urllib\nimport urllib.request\nimport zipfile\nfrom typing import Any, Iterable, List, Optional\n\nfrom torch.utils.model_zoo import tqdm\n\n\ndef stream_url(url: str,\n start_byte: Optional[int] = None,\n block_size: int = 32 * 1024,\n progress_bar: bool = True) -> Iterable:\n \"\"\"Stream url by chunk\n\n Args:\n url (str): Url.\n start_byte (int or None, optional): Start streaming at that point (Default: ``None``).\n block_size (int, optional): Size of chunks to stream (Default: ``32 * 1024``).\n progress_bar (bool, optional): Display a progress bar (Default: ``True``).\n \"\"\"\n\n # If we already have the whole file, there is no need to download it again\n req = urllib.request.Request(url, method=\"HEAD\")\n with urllib.request.urlopen(req) as response:\n url_size = int(response.info().get(\"Content-Length\", -1))\n if url_size == start_byte:\n return\n\n req = urllib.request.Request(url)\n if start_byte:\n req.headers[\"Range\"] = \"bytes={}-\".format(start_byte)\n\n with urllib.request.urlopen(req) as upointer, tqdm(\n unit=\"B\",\n unit_scale=True,\n unit_divisor=1024,\n total=url_size,\n disable=not progress_bar,\n ) as pbar:\n\n num_bytes = 0\n while True:\n chunk = upointer.read(block_size)\n if not chunk:\n break\n yield chunk\n num_bytes += len(chunk)\n pbar.update(len(chunk))\n\n\ndef download_url(url: str,\n download_folder: str,\n filename: Optional[str] = None,\n hash_value: Optional[str] = None,\n hash_type: str = \"sha256\",\n progress_bar: bool = True,\n resume: bool = False) -> None:\n \"\"\"Download file to disk.\n\n Args:\n url (str): Url.\n download_folder (str): Folder to download file.\n filename (str or None, optional): Name of downloaded file. If None, it is inferred from the url\n (Default: ``None``).\n hash_value (str or None, optional): Hash for url (Default: ``None``).\n hash_type (str, optional): Hash type, among \"sha256\" and \"md5\" (Default: ``\"sha256\"``).\n progress_bar (bool, optional): Display a progress bar (Default: ``True``).\n resume (bool, optional): Enable resuming download (Default: ``False``).\n \"\"\"\n\n req = urllib.request.Request(url, method=\"HEAD\")\n req_info = urllib.request.urlopen(req).info()\n\n # Detect filename\n filename = filename or req_info.get_filename() or os.path.basename(url)\n filepath = os.path.join(download_folder, filename)\n if resume and os.path.exists(filepath):\n mode = \"ab\"\n local_size: Optional[int] = os.path.getsize(filepath)\n\n elif not resume and os.path.exists(filepath):\n raise RuntimeError(\n \"{} already exists. Delete the file manually and retry.\".format(filepath)\n )\n else:\n mode = \"wb\"\n local_size = None\n\n if hash_value and local_size == int(req_info.get(\"Content-Length\", -1)):\n with open(filepath, \"rb\") as file_obj:\n if validate_file(file_obj, hash_value, hash_type):\n return\n raise RuntimeError(\n \"The hash of {} does not match. Delete the file manually and retry.\".format(\n filepath\n )\n )\n\n with open(filepath, mode) as fpointer:\n for chunk in stream_url(url, start_byte=local_size, progress_bar=progress_bar):\n fpointer.write(chunk)\n\n with open(filepath, \"rb\") as file_obj:\n if hash_value and not validate_file(file_obj, hash_value, hash_type):\n raise RuntimeError(\n \"The hash of {} does not match. Delete the file manually and retry.\".format(\n filepath\n )\n )\n\n\ndef validate_file(file_obj: Any, hash_value: str, hash_type: str = \"sha256\") -> bool:\n \"\"\"Validate a given file object with its hash.\n\n Args:\n file_obj: File object to read from.\n hash_value (str): Hash for url.\n hash_type (str, optional): Hash type, among \"sha256\" and \"md5\" (Default: ``\"sha256\"``).\n\n Returns:\n bool: return True if its a valid file, else False.\n \"\"\"\n\n if hash_type == \"sha256\":\n hash_func = hashlib.sha256()\n elif hash_type == \"md5\":\n hash_func = hashlib.md5()\n else:\n raise ValueError\n\n while True:\n # Read by chunk to avoid filling memory\n chunk = file_obj.read(1024 ** 2)\n if not chunk:\n break\n hash_func.update(chunk)\n\n return hash_func.hexdigest() == hash_value\n\n\ndef extract_archive(from_path: str, to_path: Optional[str] = None, overwrite: bool = False) -> List[str]:\n \"\"\"Extract archive.\n Args:\n from_path (str): the path of the archive.\n to_path (str or None, optional): the root path of the extraced files (directory of from_path)\n (Default: ``None``)\n overwrite (bool, optional): overwrite existing files (Default: ``False``)\n\n Returns:\n list: List of paths to extracted files even if not overwritten.\n\n Examples:\n >>> url = 'http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/validation.tar.gz'\n >>> from_path = './validation.tar.gz'\n >>> to_path = './'\n >>> torchaudio.datasets.utils.download_from_url(url, from_path)\n >>> torchaudio.datasets.utils.extract_archive(from_path, to_path)\n \"\"\"\n\n if to_path is None:\n to_path = os.path.dirname(from_path)\n\n try:\n with tarfile.open(from_path, \"r\") as tar:\n logging.info(\"Opened tar file {}.\".format(from_path))\n files = []\n for file_ in tar: # type: Any\n file_path = os.path.join(to_path, file_.name)\n if file_.isfile():\n files.append(file_path)\n if os.path.exists(file_path):\n logging.info(\"{} already extracted.\".format(file_path))\n if not overwrite:\n continue\n tar.extract(file_, to_path)\n return files\n except tarfile.ReadError:\n pass\n\n try:\n with zipfile.ZipFile(from_path, \"r\") as zfile:\n logging.info(\"Opened zip file {}.\".format(from_path))\n files = zfile.namelist()\n for file_ in files:\n file_path = os.path.join(to_path, file_)\n if os.path.exists(file_path):\n logging.info(\"{} already extracted.\".format(file_path))\n if not overwrite:\n continue\n zfile.extract(file_, to_path)\n return files\n except zipfile.BadZipFile:\n pass\n\n raise NotImplementedError(\"We currently only support tar.gz, tgz, and zip achives.\")\n", "path": "torchaudio/datasets/utils.py"}]}
| 3,535 | 935 |
gh_patches_debug_11009
|
rasdani/github-patches
|
git_diff
|
pyca__cryptography-7895
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bump BoringSSL and/or OpenSSL in CI
## BoringSSL
[Commit: e2e613c269a6bb3d7c0271150fff48d11fdbbace](https://boringssl.googlesource.com/boringssl/+/e2e613c269a6bb3d7c0271150fff48d11fdbbace)
[Diff](https://boringssl.googlesource.com/boringssl/+/d77fdbff010ee70776036c41155d1b3711ede548..e2e613c269a6bb3d7c0271150fff48d11fdbbace) between the last commit hash merged to this repository and the new commit.
## OpenSSL
[Commit: dc45d4c6faeb53bb68401141d899b9f857bbc51d](https://github.com/openssl/openssl/commit/dc45d4c6faeb53bb68401141d899b9f857bbc51d)
[Diff](https://github.com/openssl/openssl/compare/efec0f4611ee854f2b0b3da0c135e839bf8e7d04...dc45d4c6faeb53bb68401141d899b9f857bbc51d) between the last commit hash merged to this repository and the new commit.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/_cffi_src/openssl/rsa.py`
Content:
```
1 # This file is dual licensed under the terms of the Apache License, Version
2 # 2.0, and the BSD License. See the LICENSE file in the root of this repository
3 # for complete details.
4
5
6 INCLUDES = """
7 #include <openssl/rsa.h>
8 """
9
10 TYPES = """
11 typedef ... RSA;
12 typedef ... BN_GENCB;
13 static const int RSA_PKCS1_PADDING;
14 static const int RSA_NO_PADDING;
15 static const int RSA_PKCS1_OAEP_PADDING;
16 static const int RSA_PKCS1_PSS_PADDING;
17 static const int RSA_F4;
18 static const int RSA_PSS_SALTLEN_AUTO;
19 """
20
21 FUNCTIONS = """
22 RSA *RSA_new(void);
23 void RSA_free(RSA *);
24 int RSA_generate_key_ex(RSA *, int, BIGNUM *, BN_GENCB *);
25 int RSA_check_key(const RSA *);
26 RSA *RSAPublicKey_dup(RSA *);
27 int RSA_blinding_on(RSA *, BN_CTX *);
28 int RSA_print(BIO *, const RSA *, int);
29
30 int RSA_set0_key(RSA *, BIGNUM *, BIGNUM *, BIGNUM *);
31 int RSA_set0_factors(RSA *, BIGNUM *, BIGNUM *);
32 int RSA_set0_crt_params(RSA *, BIGNUM *, BIGNUM *, BIGNUM *);
33 void RSA_get0_key(const RSA *, const BIGNUM **, const BIGNUM **,
34 const BIGNUM **);
35 void RSA_get0_factors(const RSA *, const BIGNUM **, const BIGNUM **);
36 void RSA_get0_crt_params(const RSA *, const BIGNUM **, const BIGNUM **,
37 const BIGNUM **);
38 int EVP_PKEY_CTX_set_rsa_padding(EVP_PKEY_CTX *, int);
39 int EVP_PKEY_CTX_set_rsa_pss_saltlen(EVP_PKEY_CTX *, int);
40 int EVP_PKEY_CTX_set_rsa_mgf1_md(EVP_PKEY_CTX *, EVP_MD *);
41 int EVP_PKEY_CTX_set0_rsa_oaep_label(EVP_PKEY_CTX *, unsigned char *, int);
42
43 int EVP_PKEY_CTX_set_rsa_oaep_md(EVP_PKEY_CTX *, EVP_MD *);
44 """
45
46 CUSTOMIZATIONS = """
47 // BoringSSL doesn't define this constant, but the value is used for
48 // automatic salt length computation as in OpenSSL and LibreSSL
49 #if !defined(RSA_PSS_SALTLEN_AUTO)
50 #define RSA_PSS_SALTLEN_AUTO -2
51 #endif
52 """
53
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/_cffi_src/openssl/rsa.py b/src/_cffi_src/openssl/rsa.py
--- a/src/_cffi_src/openssl/rsa.py
+++ b/src/_cffi_src/openssl/rsa.py
@@ -16,6 +16,8 @@
static const int RSA_PKCS1_PSS_PADDING;
static const int RSA_F4;
static const int RSA_PSS_SALTLEN_AUTO;
+
+static const int Cryptography_HAS_IMPLICIT_RSA_REJECTION;
"""
FUNCTIONS = """
@@ -49,4 +51,10 @@
#if !defined(RSA_PSS_SALTLEN_AUTO)
#define RSA_PSS_SALTLEN_AUTO -2
#endif
+
+#if defined(EVP_PKEY_CTRL_RSA_IMPLICIT_REJECTION)
+static const int Cryptography_HAS_IMPLICIT_RSA_REJECTION = 1;
+#else
+static const int Cryptography_HAS_IMPLICIT_RSA_REJECTION = 0;
+#endif
"""
|
{"golden_diff": "diff --git a/src/_cffi_src/openssl/rsa.py b/src/_cffi_src/openssl/rsa.py\n--- a/src/_cffi_src/openssl/rsa.py\n+++ b/src/_cffi_src/openssl/rsa.py\n@@ -16,6 +16,8 @@\n static const int RSA_PKCS1_PSS_PADDING;\n static const int RSA_F4;\n static const int RSA_PSS_SALTLEN_AUTO;\n+\n+static const int Cryptography_HAS_IMPLICIT_RSA_REJECTION;\n \"\"\"\n \n FUNCTIONS = \"\"\"\n@@ -49,4 +51,10 @@\n #if !defined(RSA_PSS_SALTLEN_AUTO)\n #define RSA_PSS_SALTLEN_AUTO -2\n #endif\n+\n+#if defined(EVP_PKEY_CTRL_RSA_IMPLICIT_REJECTION)\n+static const int Cryptography_HAS_IMPLICIT_RSA_REJECTION = 1;\n+#else\n+static const int Cryptography_HAS_IMPLICIT_RSA_REJECTION = 0;\n+#endif\n \"\"\"\n", "issue": "Bump BoringSSL and/or OpenSSL in CI\n## BoringSSL\n[Commit: e2e613c269a6bb3d7c0271150fff48d11fdbbace](https://boringssl.googlesource.com/boringssl/+/e2e613c269a6bb3d7c0271150fff48d11fdbbace)\n\n[Diff](https://boringssl.googlesource.com/boringssl/+/d77fdbff010ee70776036c41155d1b3711ede548..e2e613c269a6bb3d7c0271150fff48d11fdbbace) between the last commit hash merged to this repository and the new commit.\n## OpenSSL\n[Commit: dc45d4c6faeb53bb68401141d899b9f857bbc51d](https://github.com/openssl/openssl/commit/dc45d4c6faeb53bb68401141d899b9f857bbc51d)\n\n[Diff](https://github.com/openssl/openssl/compare/efec0f4611ee854f2b0b3da0c135e839bf8e7d04...dc45d4c6faeb53bb68401141d899b9f857bbc51d) between the last commit hash merged to this repository and the new commit.\n", "before_files": [{"content": "# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\n\nINCLUDES = \"\"\"\n#include <openssl/rsa.h>\n\"\"\"\n\nTYPES = \"\"\"\ntypedef ... RSA;\ntypedef ... BN_GENCB;\nstatic const int RSA_PKCS1_PADDING;\nstatic const int RSA_NO_PADDING;\nstatic const int RSA_PKCS1_OAEP_PADDING;\nstatic const int RSA_PKCS1_PSS_PADDING;\nstatic const int RSA_F4;\nstatic const int RSA_PSS_SALTLEN_AUTO;\n\"\"\"\n\nFUNCTIONS = \"\"\"\nRSA *RSA_new(void);\nvoid RSA_free(RSA *);\nint RSA_generate_key_ex(RSA *, int, BIGNUM *, BN_GENCB *);\nint RSA_check_key(const RSA *);\nRSA *RSAPublicKey_dup(RSA *);\nint RSA_blinding_on(RSA *, BN_CTX *);\nint RSA_print(BIO *, const RSA *, int);\n\nint RSA_set0_key(RSA *, BIGNUM *, BIGNUM *, BIGNUM *);\nint RSA_set0_factors(RSA *, BIGNUM *, BIGNUM *);\nint RSA_set0_crt_params(RSA *, BIGNUM *, BIGNUM *, BIGNUM *);\nvoid RSA_get0_key(const RSA *, const BIGNUM **, const BIGNUM **,\n const BIGNUM **);\nvoid RSA_get0_factors(const RSA *, const BIGNUM **, const BIGNUM **);\nvoid RSA_get0_crt_params(const RSA *, const BIGNUM **, const BIGNUM **,\n const BIGNUM **);\nint EVP_PKEY_CTX_set_rsa_padding(EVP_PKEY_CTX *, int);\nint EVP_PKEY_CTX_set_rsa_pss_saltlen(EVP_PKEY_CTX *, int);\nint EVP_PKEY_CTX_set_rsa_mgf1_md(EVP_PKEY_CTX *, EVP_MD *);\nint EVP_PKEY_CTX_set0_rsa_oaep_label(EVP_PKEY_CTX *, unsigned char *, int);\n\nint EVP_PKEY_CTX_set_rsa_oaep_md(EVP_PKEY_CTX *, EVP_MD *);\n\"\"\"\n\nCUSTOMIZATIONS = \"\"\"\n// BoringSSL doesn't define this constant, but the value is used for\n// automatic salt length computation as in OpenSSL and LibreSSL\n#if !defined(RSA_PSS_SALTLEN_AUTO)\n#define RSA_PSS_SALTLEN_AUTO -2\n#endif\n\"\"\"\n", "path": "src/_cffi_src/openssl/rsa.py"}], "after_files": [{"content": "# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\n\nINCLUDES = \"\"\"\n#include <openssl/rsa.h>\n\"\"\"\n\nTYPES = \"\"\"\ntypedef ... RSA;\ntypedef ... BN_GENCB;\nstatic const int RSA_PKCS1_PADDING;\nstatic const int RSA_NO_PADDING;\nstatic const int RSA_PKCS1_OAEP_PADDING;\nstatic const int RSA_PKCS1_PSS_PADDING;\nstatic const int RSA_F4;\nstatic const int RSA_PSS_SALTLEN_AUTO;\n\nstatic const int Cryptography_HAS_IMPLICIT_RSA_REJECTION;\n\"\"\"\n\nFUNCTIONS = \"\"\"\nRSA *RSA_new(void);\nvoid RSA_free(RSA *);\nint RSA_generate_key_ex(RSA *, int, BIGNUM *, BN_GENCB *);\nint RSA_check_key(const RSA *);\nRSA *RSAPublicKey_dup(RSA *);\nint RSA_blinding_on(RSA *, BN_CTX *);\nint RSA_print(BIO *, const RSA *, int);\n\nint RSA_set0_key(RSA *, BIGNUM *, BIGNUM *, BIGNUM *);\nint RSA_set0_factors(RSA *, BIGNUM *, BIGNUM *);\nint RSA_set0_crt_params(RSA *, BIGNUM *, BIGNUM *, BIGNUM *);\nvoid RSA_get0_key(const RSA *, const BIGNUM **, const BIGNUM **,\n const BIGNUM **);\nvoid RSA_get0_factors(const RSA *, const BIGNUM **, const BIGNUM **);\nvoid RSA_get0_crt_params(const RSA *, const BIGNUM **, const BIGNUM **,\n const BIGNUM **);\nint EVP_PKEY_CTX_set_rsa_padding(EVP_PKEY_CTX *, int);\nint EVP_PKEY_CTX_set_rsa_pss_saltlen(EVP_PKEY_CTX *, int);\nint EVP_PKEY_CTX_set_rsa_mgf1_md(EVP_PKEY_CTX *, EVP_MD *);\nint EVP_PKEY_CTX_set0_rsa_oaep_label(EVP_PKEY_CTX *, unsigned char *, int);\n\nint EVP_PKEY_CTX_set_rsa_oaep_md(EVP_PKEY_CTX *, EVP_MD *);\n\"\"\"\n\nCUSTOMIZATIONS = \"\"\"\n// BoringSSL doesn't define this constant, but the value is used for\n// automatic salt length computation as in OpenSSL and LibreSSL\n#if !defined(RSA_PSS_SALTLEN_AUTO)\n#define RSA_PSS_SALTLEN_AUTO -2\n#endif\n\n#if defined(EVP_PKEY_CTRL_RSA_IMPLICIT_REJECTION)\nstatic const int Cryptography_HAS_IMPLICIT_RSA_REJECTION = 1;\n#else\nstatic const int Cryptography_HAS_IMPLICIT_RSA_REJECTION = 0;\n#endif\n\"\"\"\n", "path": "src/_cffi_src/openssl/rsa.py"}]}
| 1,251 | 207 |
gh_patches_debug_9169
|
rasdani/github-patches
|
git_diff
|
qutebrowser__qutebrowser-2400
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Disable the automatic "Run :adblock-update" info message on startup
Every time I start qutebrowser I got a message:
> Run :adblock-update to get adblock lists
I've set `host-blocking-enabled = false` in the config, because I have my own hosts file in /etc + I have privoxy.
I couldn't find a way to disable this message. I searched in the config, in the man page, in the help, here through the issues... Am I missing something? :confused:
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `qutebrowser/browser/adblock.py`
Content:
```
1 # vim: ft=python fileencoding=utf-8 sts=4 sw=4 et:
2
3 # Copyright 2014-2016 Florian Bruhin (The Compiler) <[email protected]>
4 #
5 # This file is part of qutebrowser.
6 #
7 # qutebrowser is free software: you can redistribute it and/or modify
8 # it under the terms of the GNU General Public License as published by
9 # the Free Software Foundation, either version 3 of the License, or
10 # (at your option) any later version.
11 #
12 # qutebrowser is distributed in the hope that it will be useful,
13 # but WITHOUT ANY WARRANTY; without even the implied warranty of
14 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
15 # GNU General Public License for more details.
16 #
17 # You should have received a copy of the GNU General Public License
18 # along with qutebrowser. If not, see <http://www.gnu.org/licenses/>.
19
20 """Functions related to ad blocking."""
21
22 import io
23 import os.path
24 import functools
25 import posixpath
26 import zipfile
27 import fnmatch
28
29 from qutebrowser.browser import downloads
30 from qutebrowser.config import config
31 from qutebrowser.utils import objreg, standarddir, log, message
32 from qutebrowser.commands import cmdutils
33
34
35 def guess_zip_filename(zf):
36 """Guess which file to use inside a zip file.
37
38 Args:
39 zf: A ZipFile instance.
40 """
41 files = zf.namelist()
42 if len(files) == 1:
43 return files[0]
44 else:
45 for e in files:
46 if posixpath.splitext(e)[0].lower() == 'hosts':
47 return e
48 raise FileNotFoundError("No hosts file found in zip")
49
50
51 def get_fileobj(byte_io):
52 """Get a usable file object to read the hosts file from."""
53 byte_io.seek(0) # rewind downloaded file
54 if zipfile.is_zipfile(byte_io):
55 byte_io.seek(0) # rewind what zipfile.is_zipfile did
56 zf = zipfile.ZipFile(byte_io)
57 filename = guess_zip_filename(zf)
58 byte_io = zf.open(filename, mode='r')
59 else:
60 byte_io.seek(0) # rewind what zipfile.is_zipfile did
61 return io.TextIOWrapper(byte_io, encoding='utf-8')
62
63
64 def is_whitelisted_host(host):
65 """Check if the given host is on the adblock whitelist.
66
67 Args:
68 host: The host of the request as string.
69 """
70 whitelist = config.get('content', 'host-blocking-whitelist')
71 if whitelist is None:
72 return False
73
74 for pattern in whitelist:
75 if fnmatch.fnmatch(host, pattern.lower()):
76 return True
77 return False
78
79
80 class FakeDownload:
81
82 """A download stub to use on_download_finished with local files."""
83
84 def __init__(self, fileobj):
85 self.basename = os.path.basename(fileobj.name)
86 self.fileobj = fileobj
87 self.successful = True
88
89
90 class HostBlocker:
91
92 """Manage blocked hosts based from /etc/hosts-like files.
93
94 Attributes:
95 _blocked_hosts: A set of blocked hosts.
96 _config_blocked_hosts: A set of blocked hosts from ~/.config.
97 _in_progress: The DownloadItems which are currently downloading.
98 _done_count: How many files have been read successfully.
99 _local_hosts_file: The path to the blocked-hosts file.
100 _config_hosts_file: The path to a blocked-hosts in ~/.config
101
102 Class attributes:
103 WHITELISTED: Hosts which never should be blocked.
104 """
105
106 WHITELISTED = ('localhost', 'localhost.localdomain', 'broadcasthost',
107 'local')
108
109 def __init__(self):
110 self._blocked_hosts = set()
111 self._config_blocked_hosts = set()
112 self._in_progress = []
113 self._done_count = 0
114
115 data_dir = standarddir.data()
116 self._local_hosts_file = os.path.join(data_dir, 'blocked-hosts')
117 self.on_config_changed()
118
119 config_dir = standarddir.config()
120 self._config_hosts_file = os.path.join(config_dir, 'blocked-hosts')
121
122 objreg.get('config').changed.connect(self.on_config_changed)
123
124 def is_blocked(self, url):
125 """Check if the given URL (as QUrl) is blocked."""
126 if not config.get('content', 'host-blocking-enabled'):
127 return False
128 host = url.host()
129 return ((host in self._blocked_hosts or
130 host in self._config_blocked_hosts) and
131 not is_whitelisted_host(host))
132
133 def _read_hosts_file(self, filename, target):
134 """Read hosts from the given filename.
135
136 Args:
137 filename: The file to read.
138 target: The set to store the hosts in.
139
140 Return:
141 True if a read was attempted, False otherwise
142 """
143 if not os.path.exists(filename):
144 return False
145
146 try:
147 with open(filename, 'r', encoding='utf-8') as f:
148 for line in f:
149 target.add(line.strip())
150 except OSError:
151 log.misc.exception("Failed to read host blocklist!")
152
153 return True
154
155 def read_hosts(self):
156 """Read hosts from the existing blocked-hosts file."""
157 self._blocked_hosts = set()
158
159 self._read_hosts_file(self._config_hosts_file,
160 self._config_blocked_hosts)
161
162 found = self._read_hosts_file(self._local_hosts_file,
163 self._blocked_hosts)
164
165 if not found:
166 args = objreg.get('args')
167 if (config.get('content', 'host-block-lists') is not None and
168 args.basedir is None):
169 message.info("Run :adblock-update to get adblock lists.")
170
171 @cmdutils.register(instance='host-blocker')
172 def adblock_update(self):
173 """Update the adblock block lists.
174
175 This updates `~/.local/share/qutebrowser/blocked-hosts` with downloaded
176 host lists and re-reads `~/.config/qutebrowser/blocked-hosts`.
177 """
178 self._read_hosts_file(self._config_hosts_file,
179 self._config_blocked_hosts)
180 self._blocked_hosts = set()
181 self._done_count = 0
182 urls = config.get('content', 'host-block-lists')
183 download_manager = objreg.get('qtnetwork-download-manager',
184 scope='window', window='last-focused')
185 if urls is None:
186 return
187 for url in urls:
188 if url.scheme() == 'file':
189 try:
190 fileobj = open(url.path(), 'rb')
191 except OSError as e:
192 message.error("adblock: Error while reading {}: {}".format(
193 url.path(), e.strerror))
194 continue
195 download = FakeDownload(fileobj)
196 self._in_progress.append(download)
197 self.on_download_finished(download)
198 else:
199 fobj = io.BytesIO()
200 fobj.name = 'adblock: ' + url.host()
201 target = downloads.FileObjDownloadTarget(fobj)
202 download = download_manager.get(url, target=target,
203 auto_remove=True)
204 self._in_progress.append(download)
205 download.finished.connect(
206 functools.partial(self.on_download_finished, download))
207
208 def _merge_file(self, byte_io):
209 """Read and merge host files.
210
211 Args:
212 byte_io: The BytesIO object of the completed download.
213
214 Return:
215 A set of the merged hosts.
216 """
217 error_count = 0
218 line_count = 0
219 try:
220 f = get_fileobj(byte_io)
221 except (OSError, UnicodeDecodeError, zipfile.BadZipFile,
222 zipfile.LargeZipFile, LookupError) as e:
223 message.error("adblock: Error while reading {}: {} - {}".format(
224 byte_io.name, e.__class__.__name__, e))
225 return
226 for line in f:
227 line_count += 1
228 # Remove comments
229 try:
230 hash_idx = line.index('#')
231 line = line[:hash_idx]
232 except ValueError:
233 pass
234 line = line.strip()
235 # Skip empty lines
236 if not line:
237 continue
238 parts = line.split()
239 if len(parts) == 1:
240 # "one host per line" format
241 host = parts[0]
242 elif len(parts) == 2:
243 # /etc/hosts format
244 host = parts[1]
245 else:
246 error_count += 1
247 continue
248 if host not in self.WHITELISTED:
249 self._blocked_hosts.add(host)
250 log.misc.debug("{}: read {} lines".format(byte_io.name, line_count))
251 if error_count > 0:
252 message.error("adblock: {} read errors for {}".format(
253 error_count, byte_io.name))
254
255 def on_lists_downloaded(self):
256 """Install block lists after files have been downloaded."""
257 with open(self._local_hosts_file, 'w', encoding='utf-8') as f:
258 for host in sorted(self._blocked_hosts):
259 f.write(host + '\n')
260 message.info("adblock: Read {} hosts from {} sources.".format(
261 len(self._blocked_hosts), self._done_count))
262
263 @config.change_filter('content', 'host-block-lists')
264 def on_config_changed(self):
265 """Update files when the config changed."""
266 urls = config.get('content', 'host-block-lists')
267 if urls is None:
268 try:
269 os.remove(self._local_hosts_file)
270 except FileNotFoundError:
271 pass
272 except OSError as e:
273 log.misc.exception("Failed to delete hosts file: {}".format(e))
274
275 def on_download_finished(self, download):
276 """Check if all downloads are finished and if so, trigger reading.
277
278 Arguments:
279 download: The finished DownloadItem.
280 """
281 self._in_progress.remove(download)
282 if download.successful:
283 self._done_count += 1
284 try:
285 self._merge_file(download.fileobj)
286 finally:
287 download.fileobj.close()
288 if not self._in_progress:
289 try:
290 self.on_lists_downloaded()
291 except OSError:
292 log.misc.exception("Failed to write host block list!")
293
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/qutebrowser/browser/adblock.py b/qutebrowser/browser/adblock.py
--- a/qutebrowser/browser/adblock.py
+++ b/qutebrowser/browser/adblock.py
@@ -165,7 +165,8 @@
if not found:
args = objreg.get('args')
if (config.get('content', 'host-block-lists') is not None and
- args.basedir is None):
+ args.basedir is None and
+ config.get('content', 'host-blocking-enabled')):
message.info("Run :adblock-update to get adblock lists.")
@cmdutils.register(instance='host-blocker')
|
{"golden_diff": "diff --git a/qutebrowser/browser/adblock.py b/qutebrowser/browser/adblock.py\n--- a/qutebrowser/browser/adblock.py\n+++ b/qutebrowser/browser/adblock.py\n@@ -165,7 +165,8 @@\n if not found:\n args = objreg.get('args')\n if (config.get('content', 'host-block-lists') is not None and\n- args.basedir is None):\n+ args.basedir is None and\n+ config.get('content', 'host-blocking-enabled')):\n message.info(\"Run :adblock-update to get adblock lists.\")\n \n @cmdutils.register(instance='host-blocker')\n", "issue": "Disable the automatic \"Run :adblock-update\" info message on startup\nEvery time I start qutebrowser I got a message:\r\n\r\n> Run :adblock-update to get adblock lists\r\n\r\nI've set `host-blocking-enabled = false` in the config, because I have my own hosts file in /etc + I have privoxy.\r\n\r\nI couldn't find a way to disable this message. I searched in the config, in the man page, in the help, here through the issues... Am I missing something? :confused: \n", "before_files": [{"content": "# vim: ft=python fileencoding=utf-8 sts=4 sw=4 et:\n\n# Copyright 2014-2016 Florian Bruhin (The Compiler) <[email protected]>\n#\n# This file is part of qutebrowser.\n#\n# qutebrowser is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# qutebrowser is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with qutebrowser. If not, see <http://www.gnu.org/licenses/>.\n\n\"\"\"Functions related to ad blocking.\"\"\"\n\nimport io\nimport os.path\nimport functools\nimport posixpath\nimport zipfile\nimport fnmatch\n\nfrom qutebrowser.browser import downloads\nfrom qutebrowser.config import config\nfrom qutebrowser.utils import objreg, standarddir, log, message\nfrom qutebrowser.commands import cmdutils\n\n\ndef guess_zip_filename(zf):\n \"\"\"Guess which file to use inside a zip file.\n\n Args:\n zf: A ZipFile instance.\n \"\"\"\n files = zf.namelist()\n if len(files) == 1:\n return files[0]\n else:\n for e in files:\n if posixpath.splitext(e)[0].lower() == 'hosts':\n return e\n raise FileNotFoundError(\"No hosts file found in zip\")\n\n\ndef get_fileobj(byte_io):\n \"\"\"Get a usable file object to read the hosts file from.\"\"\"\n byte_io.seek(0) # rewind downloaded file\n if zipfile.is_zipfile(byte_io):\n byte_io.seek(0) # rewind what zipfile.is_zipfile did\n zf = zipfile.ZipFile(byte_io)\n filename = guess_zip_filename(zf)\n byte_io = zf.open(filename, mode='r')\n else:\n byte_io.seek(0) # rewind what zipfile.is_zipfile did\n return io.TextIOWrapper(byte_io, encoding='utf-8')\n\n\ndef is_whitelisted_host(host):\n \"\"\"Check if the given host is on the adblock whitelist.\n\n Args:\n host: The host of the request as string.\n \"\"\"\n whitelist = config.get('content', 'host-blocking-whitelist')\n if whitelist is None:\n return False\n\n for pattern in whitelist:\n if fnmatch.fnmatch(host, pattern.lower()):\n return True\n return False\n\n\nclass FakeDownload:\n\n \"\"\"A download stub to use on_download_finished with local files.\"\"\"\n\n def __init__(self, fileobj):\n self.basename = os.path.basename(fileobj.name)\n self.fileobj = fileobj\n self.successful = True\n\n\nclass HostBlocker:\n\n \"\"\"Manage blocked hosts based from /etc/hosts-like files.\n\n Attributes:\n _blocked_hosts: A set of blocked hosts.\n _config_blocked_hosts: A set of blocked hosts from ~/.config.\n _in_progress: The DownloadItems which are currently downloading.\n _done_count: How many files have been read successfully.\n _local_hosts_file: The path to the blocked-hosts file.\n _config_hosts_file: The path to a blocked-hosts in ~/.config\n\n Class attributes:\n WHITELISTED: Hosts which never should be blocked.\n \"\"\"\n\n WHITELISTED = ('localhost', 'localhost.localdomain', 'broadcasthost',\n 'local')\n\n def __init__(self):\n self._blocked_hosts = set()\n self._config_blocked_hosts = set()\n self._in_progress = []\n self._done_count = 0\n\n data_dir = standarddir.data()\n self._local_hosts_file = os.path.join(data_dir, 'blocked-hosts')\n self.on_config_changed()\n\n config_dir = standarddir.config()\n self._config_hosts_file = os.path.join(config_dir, 'blocked-hosts')\n\n objreg.get('config').changed.connect(self.on_config_changed)\n\n def is_blocked(self, url):\n \"\"\"Check if the given URL (as QUrl) is blocked.\"\"\"\n if not config.get('content', 'host-blocking-enabled'):\n return False\n host = url.host()\n return ((host in self._blocked_hosts or\n host in self._config_blocked_hosts) and\n not is_whitelisted_host(host))\n\n def _read_hosts_file(self, filename, target):\n \"\"\"Read hosts from the given filename.\n\n Args:\n filename: The file to read.\n target: The set to store the hosts in.\n\n Return:\n True if a read was attempted, False otherwise\n \"\"\"\n if not os.path.exists(filename):\n return False\n\n try:\n with open(filename, 'r', encoding='utf-8') as f:\n for line in f:\n target.add(line.strip())\n except OSError:\n log.misc.exception(\"Failed to read host blocklist!\")\n\n return True\n\n def read_hosts(self):\n \"\"\"Read hosts from the existing blocked-hosts file.\"\"\"\n self._blocked_hosts = set()\n\n self._read_hosts_file(self._config_hosts_file,\n self._config_blocked_hosts)\n\n found = self._read_hosts_file(self._local_hosts_file,\n self._blocked_hosts)\n\n if not found:\n args = objreg.get('args')\n if (config.get('content', 'host-block-lists') is not None and\n args.basedir is None):\n message.info(\"Run :adblock-update to get adblock lists.\")\n\n @cmdutils.register(instance='host-blocker')\n def adblock_update(self):\n \"\"\"Update the adblock block lists.\n\n This updates `~/.local/share/qutebrowser/blocked-hosts` with downloaded\n host lists and re-reads `~/.config/qutebrowser/blocked-hosts`.\n \"\"\"\n self._read_hosts_file(self._config_hosts_file,\n self._config_blocked_hosts)\n self._blocked_hosts = set()\n self._done_count = 0\n urls = config.get('content', 'host-block-lists')\n download_manager = objreg.get('qtnetwork-download-manager',\n scope='window', window='last-focused')\n if urls is None:\n return\n for url in urls:\n if url.scheme() == 'file':\n try:\n fileobj = open(url.path(), 'rb')\n except OSError as e:\n message.error(\"adblock: Error while reading {}: {}\".format(\n url.path(), e.strerror))\n continue\n download = FakeDownload(fileobj)\n self._in_progress.append(download)\n self.on_download_finished(download)\n else:\n fobj = io.BytesIO()\n fobj.name = 'adblock: ' + url.host()\n target = downloads.FileObjDownloadTarget(fobj)\n download = download_manager.get(url, target=target,\n auto_remove=True)\n self._in_progress.append(download)\n download.finished.connect(\n functools.partial(self.on_download_finished, download))\n\n def _merge_file(self, byte_io):\n \"\"\"Read and merge host files.\n\n Args:\n byte_io: The BytesIO object of the completed download.\n\n Return:\n A set of the merged hosts.\n \"\"\"\n error_count = 0\n line_count = 0\n try:\n f = get_fileobj(byte_io)\n except (OSError, UnicodeDecodeError, zipfile.BadZipFile,\n zipfile.LargeZipFile, LookupError) as e:\n message.error(\"adblock: Error while reading {}: {} - {}\".format(\n byte_io.name, e.__class__.__name__, e))\n return\n for line in f:\n line_count += 1\n # Remove comments\n try:\n hash_idx = line.index('#')\n line = line[:hash_idx]\n except ValueError:\n pass\n line = line.strip()\n # Skip empty lines\n if not line:\n continue\n parts = line.split()\n if len(parts) == 1:\n # \"one host per line\" format\n host = parts[0]\n elif len(parts) == 2:\n # /etc/hosts format\n host = parts[1]\n else:\n error_count += 1\n continue\n if host not in self.WHITELISTED:\n self._blocked_hosts.add(host)\n log.misc.debug(\"{}: read {} lines\".format(byte_io.name, line_count))\n if error_count > 0:\n message.error(\"adblock: {} read errors for {}\".format(\n error_count, byte_io.name))\n\n def on_lists_downloaded(self):\n \"\"\"Install block lists after files have been downloaded.\"\"\"\n with open(self._local_hosts_file, 'w', encoding='utf-8') as f:\n for host in sorted(self._blocked_hosts):\n f.write(host + '\\n')\n message.info(\"adblock: Read {} hosts from {} sources.\".format(\n len(self._blocked_hosts), self._done_count))\n\n @config.change_filter('content', 'host-block-lists')\n def on_config_changed(self):\n \"\"\"Update files when the config changed.\"\"\"\n urls = config.get('content', 'host-block-lists')\n if urls is None:\n try:\n os.remove(self._local_hosts_file)\n except FileNotFoundError:\n pass\n except OSError as e:\n log.misc.exception(\"Failed to delete hosts file: {}\".format(e))\n\n def on_download_finished(self, download):\n \"\"\"Check if all downloads are finished and if so, trigger reading.\n\n Arguments:\n download: The finished DownloadItem.\n \"\"\"\n self._in_progress.remove(download)\n if download.successful:\n self._done_count += 1\n try:\n self._merge_file(download.fileobj)\n finally:\n download.fileobj.close()\n if not self._in_progress:\n try:\n self.on_lists_downloaded()\n except OSError:\n log.misc.exception(\"Failed to write host block list!\")\n", "path": "qutebrowser/browser/adblock.py"}], "after_files": [{"content": "# vim: ft=python fileencoding=utf-8 sts=4 sw=4 et:\n\n# Copyright 2014-2016 Florian Bruhin (The Compiler) <[email protected]>\n#\n# This file is part of qutebrowser.\n#\n# qutebrowser is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# qutebrowser is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with qutebrowser. If not, see <http://www.gnu.org/licenses/>.\n\n\"\"\"Functions related to ad blocking.\"\"\"\n\nimport io\nimport os.path\nimport functools\nimport posixpath\nimport zipfile\nimport fnmatch\n\nfrom qutebrowser.browser import downloads\nfrom qutebrowser.config import config\nfrom qutebrowser.utils import objreg, standarddir, log, message\nfrom qutebrowser.commands import cmdutils\n\n\ndef guess_zip_filename(zf):\n \"\"\"Guess which file to use inside a zip file.\n\n Args:\n zf: A ZipFile instance.\n \"\"\"\n files = zf.namelist()\n if len(files) == 1:\n return files[0]\n else:\n for e in files:\n if posixpath.splitext(e)[0].lower() == 'hosts':\n return e\n raise FileNotFoundError(\"No hosts file found in zip\")\n\n\ndef get_fileobj(byte_io):\n \"\"\"Get a usable file object to read the hosts file from.\"\"\"\n byte_io.seek(0) # rewind downloaded file\n if zipfile.is_zipfile(byte_io):\n byte_io.seek(0) # rewind what zipfile.is_zipfile did\n zf = zipfile.ZipFile(byte_io)\n filename = guess_zip_filename(zf)\n byte_io = zf.open(filename, mode='r')\n else:\n byte_io.seek(0) # rewind what zipfile.is_zipfile did\n return io.TextIOWrapper(byte_io, encoding='utf-8')\n\n\ndef is_whitelisted_host(host):\n \"\"\"Check if the given host is on the adblock whitelist.\n\n Args:\n host: The host of the request as string.\n \"\"\"\n whitelist = config.get('content', 'host-blocking-whitelist')\n if whitelist is None:\n return False\n\n for pattern in whitelist:\n if fnmatch.fnmatch(host, pattern.lower()):\n return True\n return False\n\n\nclass FakeDownload:\n\n \"\"\"A download stub to use on_download_finished with local files.\"\"\"\n\n def __init__(self, fileobj):\n self.basename = os.path.basename(fileobj.name)\n self.fileobj = fileobj\n self.successful = True\n\n\nclass HostBlocker:\n\n \"\"\"Manage blocked hosts based from /etc/hosts-like files.\n\n Attributes:\n _blocked_hosts: A set of blocked hosts.\n _config_blocked_hosts: A set of blocked hosts from ~/.config.\n _in_progress: The DownloadItems which are currently downloading.\n _done_count: How many files have been read successfully.\n _local_hosts_file: The path to the blocked-hosts file.\n _config_hosts_file: The path to a blocked-hosts in ~/.config\n\n Class attributes:\n WHITELISTED: Hosts which never should be blocked.\n \"\"\"\n\n WHITELISTED = ('localhost', 'localhost.localdomain', 'broadcasthost',\n 'local')\n\n def __init__(self):\n self._blocked_hosts = set()\n self._config_blocked_hosts = set()\n self._in_progress = []\n self._done_count = 0\n\n data_dir = standarddir.data()\n self._local_hosts_file = os.path.join(data_dir, 'blocked-hosts')\n self.on_config_changed()\n\n config_dir = standarddir.config()\n self._config_hosts_file = os.path.join(config_dir, 'blocked-hosts')\n\n objreg.get('config').changed.connect(self.on_config_changed)\n\n def is_blocked(self, url):\n \"\"\"Check if the given URL (as QUrl) is blocked.\"\"\"\n if not config.get('content', 'host-blocking-enabled'):\n return False\n host = url.host()\n return ((host in self._blocked_hosts or\n host in self._config_blocked_hosts) and\n not is_whitelisted_host(host))\n\n def _read_hosts_file(self, filename, target):\n \"\"\"Read hosts from the given filename.\n\n Args:\n filename: The file to read.\n target: The set to store the hosts in.\n\n Return:\n True if a read was attempted, False otherwise\n \"\"\"\n if not os.path.exists(filename):\n return False\n\n try:\n with open(filename, 'r', encoding='utf-8') as f:\n for line in f:\n target.add(line.strip())\n except OSError:\n log.misc.exception(\"Failed to read host blocklist!\")\n\n return True\n\n def read_hosts(self):\n \"\"\"Read hosts from the existing blocked-hosts file.\"\"\"\n self._blocked_hosts = set()\n\n self._read_hosts_file(self._config_hosts_file,\n self._config_blocked_hosts)\n\n found = self._read_hosts_file(self._local_hosts_file,\n self._blocked_hosts)\n\n if not found:\n args = objreg.get('args')\n if (config.get('content', 'host-block-lists') is not None and\n args.basedir is None and\n config.get('content', 'host-blocking-enabled')):\n message.info(\"Run :adblock-update to get adblock lists.\")\n\n @cmdutils.register(instance='host-blocker')\n def adblock_update(self):\n \"\"\"Update the adblock block lists.\n\n This updates `~/.local/share/qutebrowser/blocked-hosts` with downloaded\n host lists and re-reads `~/.config/qutebrowser/blocked-hosts`.\n \"\"\"\n self._read_hosts_file(self._config_hosts_file,\n self._config_blocked_hosts)\n self._blocked_hosts = set()\n self._done_count = 0\n urls = config.get('content', 'host-block-lists')\n download_manager = objreg.get('qtnetwork-download-manager',\n scope='window', window='last-focused')\n if urls is None:\n return\n for url in urls:\n if url.scheme() == 'file':\n try:\n fileobj = open(url.path(), 'rb')\n except OSError as e:\n message.error(\"adblock: Error while reading {}: {}\".format(\n url.path(), e.strerror))\n continue\n download = FakeDownload(fileobj)\n self._in_progress.append(download)\n self.on_download_finished(download)\n else:\n fobj = io.BytesIO()\n fobj.name = 'adblock: ' + url.host()\n target = downloads.FileObjDownloadTarget(fobj)\n download = download_manager.get(url, target=target,\n auto_remove=True)\n self._in_progress.append(download)\n download.finished.connect(\n functools.partial(self.on_download_finished, download))\n\n def _merge_file(self, byte_io):\n \"\"\"Read and merge host files.\n\n Args:\n byte_io: The BytesIO object of the completed download.\n\n Return:\n A set of the merged hosts.\n \"\"\"\n error_count = 0\n line_count = 0\n try:\n f = get_fileobj(byte_io)\n except (OSError, UnicodeDecodeError, zipfile.BadZipFile,\n zipfile.LargeZipFile, LookupError) as e:\n message.error(\"adblock: Error while reading {}: {} - {}\".format(\n byte_io.name, e.__class__.__name__, e))\n return\n for line in f:\n line_count += 1\n # Remove comments\n try:\n hash_idx = line.index('#')\n line = line[:hash_idx]\n except ValueError:\n pass\n line = line.strip()\n # Skip empty lines\n if not line:\n continue\n parts = line.split()\n if len(parts) == 1:\n # \"one host per line\" format\n host = parts[0]\n elif len(parts) == 2:\n # /etc/hosts format\n host = parts[1]\n else:\n error_count += 1\n continue\n if host not in self.WHITELISTED:\n self._blocked_hosts.add(host)\n log.misc.debug(\"{}: read {} lines\".format(byte_io.name, line_count))\n if error_count > 0:\n message.error(\"adblock: {} read errors for {}\".format(\n error_count, byte_io.name))\n\n def on_lists_downloaded(self):\n \"\"\"Install block lists after files have been downloaded.\"\"\"\n with open(self._local_hosts_file, 'w', encoding='utf-8') as f:\n for host in sorted(self._blocked_hosts):\n f.write(host + '\\n')\n message.info(\"adblock: Read {} hosts from {} sources.\".format(\n len(self._blocked_hosts), self._done_count))\n\n @config.change_filter('content', 'host-block-lists')\n def on_config_changed(self):\n \"\"\"Update files when the config changed.\"\"\"\n urls = config.get('content', 'host-block-lists')\n if urls is None:\n try:\n os.remove(self._local_hosts_file)\n except FileNotFoundError:\n pass\n except OSError as e:\n log.misc.exception(\"Failed to delete hosts file: {}\".format(e))\n\n def on_download_finished(self, download):\n \"\"\"Check if all downloads are finished and if so, trigger reading.\n\n Arguments:\n download: The finished DownloadItem.\n \"\"\"\n self._in_progress.remove(download)\n if download.successful:\n self._done_count += 1\n try:\n self._merge_file(download.fileobj)\n finally:\n download.fileobj.close()\n if not self._in_progress:\n try:\n self.on_lists_downloaded()\n except OSError:\n log.misc.exception(\"Failed to write host block list!\")\n", "path": "qutebrowser/browser/adblock.py"}]}
| 3,335 | 145 |
gh_patches_debug_23346
|
rasdani/github-patches
|
git_diff
|
aws-cloudformation__cfn-lint-440
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Invalid PrimaryKey attribute crashes cfn-lint instead of raising lint error.
Hi AWS,
I found a minor bug on cfn-lint version: cfn-lint 0.8.3
An attribute in Resource -> Properties-> PrimaryKey leads to crash instead of a raised lint error
Here is a sample template. If MyInvalidAttr is replaced with a correct attribute eg Name then the template works.
```AWSTemplateFormatVersion: "2010-09-09"
Transform: AWS::Serverless-2016-10-31
Description: >
sam-app
Sample SAM Template for sam-app
Globals:
Function:
Timeout: 3
Resources:
MyTable:
Type: AWS::Serverless::SimpleTable
Properties:
TableName: MyTable
PrimaryKey:
MyInvalidAttr: id
Type: String
```
Below is the error:
```
$ cfn-lint -t template.yaml
Traceback (most recent call last):
File "/Users/emilbryggare/Library/Python/2.7/bin/cfn-lint", line 11, in <module>
sys.exit(main())
File "/Users/emilbryggare/Library/Python/2.7/lib/python/site-packages/cfnlint/__main__.py", line 36, in main
args.regions, args.override_spec))
File "/Users/emilbryggare/Library/Python/2.7/lib/python/site-packages/cfnlint/core.py", line 46, in run_cli
return run_checks(filename, template, rules, regions)
File "/Users/emilbryggare/Library/Python/2.7/lib/python/site-packages/cfnlint/core.py", line 316, in run_checks
matches.extend(runner.transform())
File "/Users/emilbryggare/Library/Python/2.7/lib/python/site-packages/cfnlint/__init__.py", line 894, in transform
matches = transform.transform_template()
File "/Users/emilbryggare/Library/Python/2.7/lib/python/site-packages/cfnlint/transform.py", line 115, in transform_template
sam_translator.translate(sam_template=self._template, parameter_values={}))
File "/Users/emilbryggare/Library/Python/2.7/lib/python/site-packages/samtranslator/translator/translator.py", line 72, in translate
translated = macro.to_cloudformation(**kwargs)
File "/Users/emilbryggare/Library/Python/2.7/lib/python/site-packages/samtranslator/model/sam_resources.py", line 537, in to_cloudformation
dynamodb_resources = self._construct_dynamodb_table()
File "/Users/emilbryggare/Library/Python/2.7/lib/python/site-packages/samtranslator/model/sam_resources.py", line 546, in _construct_dynamodb_table
'AttributeName': self.PrimaryKey['Name'],
KeyError: 'Name'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/cfnlint/transform.py`
Content:
```
1 """
2 Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.
3
4 Permission is hereby granted, free of charge, to any person obtaining a copy of this
5 software and associated documentation files (the "Software"), to deal in the Software
6 without restriction, including without limitation the rights to use, copy, modify,
7 merge, publish, distribute, sublicense, and/or sell copies of the Software, and to
8 permit persons to whom the Software is furnished to do so.
9
10 THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,
11 INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A
12 PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT
13 HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
14 OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
15 SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
16 """
17 import os
18 import six
19
20 from samtranslator.parser import parser
21 from samtranslator.translator.translator import Translator
22 from samtranslator.public.exceptions import InvalidDocumentException
23
24 import cfnlint.helpers
25
26
27 class Transform(object):
28 """
29 Application Serverless Module tranform Wrappor. Based on code from AWS SAM CLI:
30 https://github.com/awslabs/aws-sam-cli/blob/develop/samcli/commands/validate/lib/sam_template_validator.py
31 """
32
33 def __init__(self, filename, template, region):
34 """
35 Initialize Transform class
36 """
37 self._filename = filename
38 self._template = template
39 self._region = region
40
41 self._managed_policy_map = self.load_managed_policies()
42 self._sam_parser = parser.Parser()
43
44 def template(self):
45 """Get the template"""
46 return self._template
47
48 def load_managed_policies(self):
49 """
50 Load the ManagedPolicies locally, based on the AWS-CLI:
51 https://github.com/awslabs/aws-sam-cli/blob/develop/samcli/lib/samlib/default_managed_policies.json
52 """
53 return cfnlint.helpers.load_resources('data/Serverless/ManagedPolicies.json')
54
55 def _replace_local_codeuri(self):
56 """
57 Replaces the CodeUri in AWS::Serverless::Function and DefinitionUri in AWS::Serverless::Api to a fake
58 S3 Uri. This is to support running the SAM Translator with valid values for these fields. If this in not done,
59 the template is invalid in the eyes of SAM Translator (the translator does not support local paths)
60 """
61
62 all_resources = self._template.get('Resources', {})
63
64 for _, resource in all_resources.items():
65
66 resource_type = resource.get('Type')
67 resource_dict = resource.get('Properties')
68
69 if resource_type == 'AWS::Serverless::Function':
70
71 Transform._update_to_s3_uri('CodeUri', resource_dict)
72
73 if resource_type == 'AWS::Serverless::Api':
74 if 'DefinitionBody' not in resource_dict:
75 Transform._update_to_s3_uri('DefinitionUri', resource_dict)
76
77 def transform_template(self):
78 """
79 Transform the Template using the Serverless Application Model.
80 """
81 matches = []
82
83 try:
84 sam_translator = Translator(managed_policy_map=self._managed_policy_map,
85 sam_parser=self._sam_parser)
86
87 self._replace_local_codeuri()
88
89 # Tell SAM to use the region we're linting in, this has to be controlled using the default AWS mechanisms, see also:
90 # https://github.com/awslabs/serverless-application-model/blob/master/samtranslator/translator/arn_generator.py
91 os.environ['AWS_DEFAULT_REGION'] = self._region
92
93 # In the Paser class, within the SAM Translator, they log a warning for when the template
94 # does not match the schema. The logger they use is the root logger instead of one scoped to
95 # their module. Currently this does not cause templates to fail, so we will suppress this
96 # by patching the logging.warning method that is used in that class.
97 class WarningSuppressLogger(object):
98 """ Patch the Logger in SAM """
99
100 def __init__(self, obj_to_patch):
101 self.obj_to_patch = obj_to_patch
102
103 def __enter__(self):
104 self.obj_to_patch.warning = self.warning
105
106 def __exit__(self, exc_type, exc_val, exc_tb):
107 self.obj_to_patch.warning = self.obj_to_patch.warning
108
109 def warning(self, message):
110 """ Ignore warnings from SAM """
111 pass
112
113 with WarningSuppressLogger(parser.logging):
114 self._template = cfnlint.helpers.convert_dict(
115 sam_translator.translate(sam_template=self._template, parameter_values={}))
116 except InvalidDocumentException as e:
117 for cause in e.causes:
118 matches.append(cfnlint.Match(
119 1, 1,
120 1, 1,
121 self._filename, cfnlint.TransformError(), cause.message))
122
123 return matches
124
125 @staticmethod
126 def is_s3_uri(uri):
127 """
128 Checks the uri and determines if it is a valid S3 Uri
129 Parameters
130 ----------
131 uri str, required
132 Uri to check
133 Returns
134 -------
135 bool
136 Returns True if the uri given is an S3 uri, otherwise False
137 """
138 return isinstance(uri, six.string_types) and uri.startswith('s3://')
139
140 @staticmethod
141 def _update_to_s3_uri(property_key, resource_property_dict, s3_uri_value='s3://bucket/value'):
142 """
143 Updates the 'property_key' in the 'resource_property_dict' to the value of 's3_uri_value'
144 Note: The function will mutate the resource_property_dict that is pass in
145 Parameters
146 ----------
147 property_key str, required
148 Key in the resource_property_dict
149 resource_property_dict dict, required
150 Property dictionary of a Resource in the template to replace
151 s3_uri_value str, optional
152 Value to update the value of the property_key to
153 """
154 uri_property = resource_property_dict.get(property_key, '.')
155
156 # ignore if dict or already an S3 Uri
157 if isinstance(uri_property, dict) or Transform.is_s3_uri(uri_property):
158 return
159
160 resource_property_dict[property_key] = s3_uri_value
161
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/cfnlint/transform.py b/src/cfnlint/transform.py
--- a/src/cfnlint/transform.py
+++ b/src/cfnlint/transform.py
@@ -15,14 +15,14 @@
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
"""
import os
+import logging
import six
-
from samtranslator.parser import parser
from samtranslator.translator.translator import Translator
from samtranslator.public.exceptions import InvalidDocumentException
import cfnlint.helpers
-
+LOGGER = logging.getLogger('cfnlint')
class Transform(object):
"""
@@ -119,6 +119,14 @@
1, 1,
1, 1,
self._filename, cfnlint.TransformError(), cause.message))
+ except Exception as e: # pylint: disable=W0703
+ LOGGER.debug('Error transforming template: %s', str(e))
+ LOGGER.debug('Stack trace: %s', e, exc_info=True)
+ message = 'Error transforming template: {0}'
+ matches.append(cfnlint.Match(
+ 1, 1,
+ 1, 1,
+ self._filename, cfnlint.TransformError(), message.format(str(e))))
return matches
|
{"golden_diff": "diff --git a/src/cfnlint/transform.py b/src/cfnlint/transform.py\n--- a/src/cfnlint/transform.py\n+++ b/src/cfnlint/transform.py\n@@ -15,14 +15,14 @@\n SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n \"\"\"\n import os\n+import logging\n import six\n-\n from samtranslator.parser import parser\n from samtranslator.translator.translator import Translator\n from samtranslator.public.exceptions import InvalidDocumentException\n \n import cfnlint.helpers\n-\n+LOGGER = logging.getLogger('cfnlint')\n \n class Transform(object):\n \"\"\"\n@@ -119,6 +119,14 @@\n 1, 1,\n 1, 1,\n self._filename, cfnlint.TransformError(), cause.message))\n+ except Exception as e: # pylint: disable=W0703\n+ LOGGER.debug('Error transforming template: %s', str(e))\n+ LOGGER.debug('Stack trace: %s', e, exc_info=True)\n+ message = 'Error transforming template: {0}'\n+ matches.append(cfnlint.Match(\n+ 1, 1,\n+ 1, 1,\n+ self._filename, cfnlint.TransformError(), message.format(str(e))))\n \n return matches\n", "issue": "Invalid PrimaryKey attribute crashes cfn-lint instead of raising lint error.\nHi AWS,\r\n\r\nI found a minor bug on cfn-lint version: cfn-lint 0.8.3\r\n\r\nAn attribute in Resource -> Properties-> PrimaryKey leads to crash instead of a raised lint error\r\n\r\nHere is a sample template. If MyInvalidAttr is replaced with a correct attribute eg Name then the template works.\r\n```AWSTemplateFormatVersion: \"2010-09-09\"\r\nTransform: AWS::Serverless-2016-10-31\r\nDescription: >\r\n sam-app\r\n\r\n Sample SAM Template for sam-app\r\n\r\nGlobals:\r\n Function:\r\n Timeout: 3\r\n\r\nResources:\r\n MyTable:\r\n Type: AWS::Serverless::SimpleTable\r\n Properties:\r\n TableName: MyTable\r\n PrimaryKey:\r\n MyInvalidAttr: id\r\n Type: String\r\n```\r\nBelow is the error:\r\n```\r\n$ cfn-lint -t template.yaml\r\nTraceback (most recent call last):\r\n File \"/Users/emilbryggare/Library/Python/2.7/bin/cfn-lint\", line 11, in <module>\r\n sys.exit(main())\r\n File \"/Users/emilbryggare/Library/Python/2.7/lib/python/site-packages/cfnlint/__main__.py\", line 36, in main\r\n args.regions, args.override_spec))\r\n File \"/Users/emilbryggare/Library/Python/2.7/lib/python/site-packages/cfnlint/core.py\", line 46, in run_cli\r\n return run_checks(filename, template, rules, regions)\r\n File \"/Users/emilbryggare/Library/Python/2.7/lib/python/site-packages/cfnlint/core.py\", line 316, in run_checks\r\n matches.extend(runner.transform())\r\n File \"/Users/emilbryggare/Library/Python/2.7/lib/python/site-packages/cfnlint/__init__.py\", line 894, in transform\r\n matches = transform.transform_template()\r\n File \"/Users/emilbryggare/Library/Python/2.7/lib/python/site-packages/cfnlint/transform.py\", line 115, in transform_template\r\n sam_translator.translate(sam_template=self._template, parameter_values={}))\r\n File \"/Users/emilbryggare/Library/Python/2.7/lib/python/site-packages/samtranslator/translator/translator.py\", line 72, in translate\r\n translated = macro.to_cloudformation(**kwargs)\r\n File \"/Users/emilbryggare/Library/Python/2.7/lib/python/site-packages/samtranslator/model/sam_resources.py\", line 537, in to_cloudformation\r\n dynamodb_resources = self._construct_dynamodb_table()\r\n File \"/Users/emilbryggare/Library/Python/2.7/lib/python/site-packages/samtranslator/model/sam_resources.py\", line 546, in _construct_dynamodb_table\r\n 'AttributeName': self.PrimaryKey['Name'],\r\nKeyError: 'Name'\r\n```\r\n\n", "before_files": [{"content": "\"\"\"\n Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n\n Permission is hereby granted, free of charge, to any person obtaining a copy of this\n software and associated documentation files (the \"Software\"), to deal in the Software\n without restriction, including without limitation the rights to use, copy, modify,\n merge, publish, distribute, sublicense, and/or sell copies of the Software, and to\n permit persons to whom the Software is furnished to do so.\n\n THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,\n INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A\n PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT\n HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION\n OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\"\"\"\nimport os\nimport six\n\nfrom samtranslator.parser import parser\nfrom samtranslator.translator.translator import Translator\nfrom samtranslator.public.exceptions import InvalidDocumentException\n\nimport cfnlint.helpers\n\n\nclass Transform(object):\n \"\"\"\n Application Serverless Module tranform Wrappor. Based on code from AWS SAM CLI:\n https://github.com/awslabs/aws-sam-cli/blob/develop/samcli/commands/validate/lib/sam_template_validator.py\n \"\"\"\n\n def __init__(self, filename, template, region):\n \"\"\"\n Initialize Transform class\n \"\"\"\n self._filename = filename\n self._template = template\n self._region = region\n\n self._managed_policy_map = self.load_managed_policies()\n self._sam_parser = parser.Parser()\n\n def template(self):\n \"\"\"Get the template\"\"\"\n return self._template\n\n def load_managed_policies(self):\n \"\"\"\n Load the ManagedPolicies locally, based on the AWS-CLI:\n https://github.com/awslabs/aws-sam-cli/blob/develop/samcli/lib/samlib/default_managed_policies.json\n \"\"\"\n return cfnlint.helpers.load_resources('data/Serverless/ManagedPolicies.json')\n\n def _replace_local_codeuri(self):\n \"\"\"\n Replaces the CodeUri in AWS::Serverless::Function and DefinitionUri in AWS::Serverless::Api to a fake\n S3 Uri. This is to support running the SAM Translator with valid values for these fields. If this in not done,\n the template is invalid in the eyes of SAM Translator (the translator does not support local paths)\n \"\"\"\n\n all_resources = self._template.get('Resources', {})\n\n for _, resource in all_resources.items():\n\n resource_type = resource.get('Type')\n resource_dict = resource.get('Properties')\n\n if resource_type == 'AWS::Serverless::Function':\n\n Transform._update_to_s3_uri('CodeUri', resource_dict)\n\n if resource_type == 'AWS::Serverless::Api':\n if 'DefinitionBody' not in resource_dict:\n Transform._update_to_s3_uri('DefinitionUri', resource_dict)\n\n def transform_template(self):\n \"\"\"\n Transform the Template using the Serverless Application Model.\n \"\"\"\n matches = []\n\n try:\n sam_translator = Translator(managed_policy_map=self._managed_policy_map,\n sam_parser=self._sam_parser)\n\n self._replace_local_codeuri()\n\n # Tell SAM to use the region we're linting in, this has to be controlled using the default AWS mechanisms, see also:\n # https://github.com/awslabs/serverless-application-model/blob/master/samtranslator/translator/arn_generator.py\n os.environ['AWS_DEFAULT_REGION'] = self._region\n\n # In the Paser class, within the SAM Translator, they log a warning for when the template\n # does not match the schema. The logger they use is the root logger instead of one scoped to\n # their module. Currently this does not cause templates to fail, so we will suppress this\n # by patching the logging.warning method that is used in that class.\n class WarningSuppressLogger(object):\n \"\"\" Patch the Logger in SAM \"\"\"\n\n def __init__(self, obj_to_patch):\n self.obj_to_patch = obj_to_patch\n\n def __enter__(self):\n self.obj_to_patch.warning = self.warning\n\n def __exit__(self, exc_type, exc_val, exc_tb):\n self.obj_to_patch.warning = self.obj_to_patch.warning\n\n def warning(self, message):\n \"\"\" Ignore warnings from SAM \"\"\"\n pass\n\n with WarningSuppressLogger(parser.logging):\n self._template = cfnlint.helpers.convert_dict(\n sam_translator.translate(sam_template=self._template, parameter_values={}))\n except InvalidDocumentException as e:\n for cause in e.causes:\n matches.append(cfnlint.Match(\n 1, 1,\n 1, 1,\n self._filename, cfnlint.TransformError(), cause.message))\n\n return matches\n\n @staticmethod\n def is_s3_uri(uri):\n \"\"\"\n Checks the uri and determines if it is a valid S3 Uri\n Parameters\n ----------\n uri str, required\n Uri to check\n Returns\n -------\n bool\n Returns True if the uri given is an S3 uri, otherwise False\n \"\"\"\n return isinstance(uri, six.string_types) and uri.startswith('s3://')\n\n @staticmethod\n def _update_to_s3_uri(property_key, resource_property_dict, s3_uri_value='s3://bucket/value'):\n \"\"\"\n Updates the 'property_key' in the 'resource_property_dict' to the value of 's3_uri_value'\n Note: The function will mutate the resource_property_dict that is pass in\n Parameters\n ----------\n property_key str, required\n Key in the resource_property_dict\n resource_property_dict dict, required\n Property dictionary of a Resource in the template to replace\n s3_uri_value str, optional\n Value to update the value of the property_key to\n \"\"\"\n uri_property = resource_property_dict.get(property_key, '.')\n\n # ignore if dict or already an S3 Uri\n if isinstance(uri_property, dict) or Transform.is_s3_uri(uri_property):\n return\n\n resource_property_dict[property_key] = s3_uri_value\n", "path": "src/cfnlint/transform.py"}], "after_files": [{"content": "\"\"\"\n Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n\n Permission is hereby granted, free of charge, to any person obtaining a copy of this\n software and associated documentation files (the \"Software\"), to deal in the Software\n without restriction, including without limitation the rights to use, copy, modify,\n merge, publish, distribute, sublicense, and/or sell copies of the Software, and to\n permit persons to whom the Software is furnished to do so.\n\n THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,\n INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A\n PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT\n HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION\n OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\"\"\"\nimport os\nimport logging\nimport six\nfrom samtranslator.parser import parser\nfrom samtranslator.translator.translator import Translator\nfrom samtranslator.public.exceptions import InvalidDocumentException\n\nimport cfnlint.helpers\nLOGGER = logging.getLogger('cfnlint')\n\nclass Transform(object):\n \"\"\"\n Application Serverless Module tranform Wrappor. Based on code from AWS SAM CLI:\n https://github.com/awslabs/aws-sam-cli/blob/develop/samcli/commands/validate/lib/sam_template_validator.py\n \"\"\"\n\n def __init__(self, filename, template, region):\n \"\"\"\n Initialize Transform class\n \"\"\"\n self._filename = filename\n self._template = template\n self._region = region\n\n self._managed_policy_map = self.load_managed_policies()\n self._sam_parser = parser.Parser()\n\n def template(self):\n \"\"\"Get the template\"\"\"\n return self._template\n\n def load_managed_policies(self):\n \"\"\"\n Load the ManagedPolicies locally, based on the AWS-CLI:\n https://github.com/awslabs/aws-sam-cli/blob/develop/samcli/lib/samlib/default_managed_policies.json\n \"\"\"\n return cfnlint.helpers.load_resources('data/Serverless/ManagedPolicies.json')\n\n def _replace_local_codeuri(self):\n \"\"\"\n Replaces the CodeUri in AWS::Serverless::Function and DefinitionUri in AWS::Serverless::Api to a fake\n S3 Uri. This is to support running the SAM Translator with valid values for these fields. If this in not done,\n the template is invalid in the eyes of SAM Translator (the translator does not support local paths)\n \"\"\"\n\n all_resources = self._template.get('Resources', {})\n\n for _, resource in all_resources.items():\n\n resource_type = resource.get('Type')\n resource_dict = resource.get('Properties')\n\n if resource_type == 'AWS::Serverless::Function':\n\n Transform._update_to_s3_uri('CodeUri', resource_dict)\n\n if resource_type == 'AWS::Serverless::Api':\n if 'DefinitionBody' not in resource_dict:\n Transform._update_to_s3_uri('DefinitionUri', resource_dict)\n\n def transform_template(self):\n \"\"\"\n Transform the Template using the Serverless Application Model.\n \"\"\"\n matches = []\n\n try:\n sam_translator = Translator(managed_policy_map=self._managed_policy_map,\n sam_parser=self._sam_parser)\n\n self._replace_local_codeuri()\n\n # Tell SAM to use the region we're linting in, this has to be controlled using the default AWS mechanisms, see also:\n # https://github.com/awslabs/serverless-application-model/blob/master/samtranslator/translator/arn_generator.py\n os.environ['AWS_DEFAULT_REGION'] = self._region\n\n # In the Paser class, within the SAM Translator, they log a warning for when the template\n # does not match the schema. The logger they use is the root logger instead of one scoped to\n # their module. Currently this does not cause templates to fail, so we will suppress this\n # by patching the logging.warning method that is used in that class.\n class WarningSuppressLogger(object):\n \"\"\" Patch the Logger in SAM \"\"\"\n\n def __init__(self, obj_to_patch):\n self.obj_to_patch = obj_to_patch\n\n def __enter__(self):\n self.obj_to_patch.warning = self.warning\n\n def __exit__(self, exc_type, exc_val, exc_tb):\n self.obj_to_patch.warning = self.obj_to_patch.warning\n\n def warning(self, message):\n \"\"\" Ignore warnings from SAM \"\"\"\n pass\n\n with WarningSuppressLogger(parser.logging):\n self._template = cfnlint.helpers.convert_dict(\n sam_translator.translate(sam_template=self._template, parameter_values={}))\n except InvalidDocumentException as e:\n for cause in e.causes:\n matches.append(cfnlint.Match(\n 1, 1,\n 1, 1,\n self._filename, cfnlint.TransformError(), cause.message))\n except Exception as e: # pylint: disable=W0703\n LOGGER.debug('Error transforming template: %s', str(e))\n LOGGER.debug('Stack trace: %s', e, exc_info=True)\n message = 'Error transforming template: {0}'\n matches.append(cfnlint.Match(\n 1, 1,\n 1, 1,\n self._filename, cfnlint.TransformError(), message.format(str(e))))\n\n return matches\n\n @staticmethod\n def is_s3_uri(uri):\n \"\"\"\n Checks the uri and determines if it is a valid S3 Uri\n Parameters\n ----------\n uri str, required\n Uri to check\n Returns\n -------\n bool\n Returns True if the uri given is an S3 uri, otherwise False\n \"\"\"\n return isinstance(uri, six.string_types) and uri.startswith('s3://')\n\n @staticmethod\n def _update_to_s3_uri(property_key, resource_property_dict, s3_uri_value='s3://bucket/value'):\n \"\"\"\n Updates the 'property_key' in the 'resource_property_dict' to the value of 's3_uri_value'\n Note: The function will mutate the resource_property_dict that is pass in\n Parameters\n ----------\n property_key str, required\n Key in the resource_property_dict\n resource_property_dict dict, required\n Property dictionary of a Resource in the template to replace\n s3_uri_value str, optional\n Value to update the value of the property_key to\n \"\"\"\n uri_property = resource_property_dict.get(property_key, '.')\n\n # ignore if dict or already an S3 Uri\n if isinstance(uri_property, dict) or Transform.is_s3_uri(uri_property):\n return\n\n resource_property_dict[property_key] = s3_uri_value\n", "path": "src/cfnlint/transform.py"}]}
| 2,650 | 281 |
gh_patches_debug_37855
|
rasdani/github-patches
|
git_diff
|
tensorflow__addons-2368
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Lookahead might divide weights with mixed_float16
**System information**
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 18.04
- TensorFlow version and how it was installed (source or binary): 2.3.0-rc2 (source)
- TensorFlow-Addons version and how it was installed (source or binary): Just lookahead extracted from the source (master)
- Python version: 3.6.9
- Is GPU used? (yes/no): yes
When tf.keras.mixed_precision.experimental.set_policy('mixed_float16') is set, using LookAhead divides the layers weights after a few gradient updates (for example 7 in my case).
After investigating, I think the reason is that when mixed_float16 is used with automatic loss scaling, the loss scale is initialized very high. Thus the first few gradient updates do nothing (see https://github.com/tensorflow/tensorflow/blob/582c8d236cb079023657287c318ff26adb239002/tensorflow/python/keras/mixed_precision/loss_scale_optimizer.py#L714 for how updates are skipped).
As a result, LookAhead ends up with its 'slow vars' initialized to 0 instead of the original layer weight. Indeed the vars are initialized to the correct value only on the first iteration during the gradient update (https://github.com/tensorflow/addons/blob/master/tensorflow_addons/optimizers/lookahead.py#L106).
Thus when the gradient update finally does something, the first variable update does average them with the slow variables (initialized to zero). Which would explain the weight division I'm seeing.
I don't have a short code to replicate the bug, but I think the above explanation and links should highlight well enough the issue with the current way LookAhead's slow variables are initialized.
Lookahead might divide weights with mixed_float16
**System information**
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 18.04
- TensorFlow version and how it was installed (source or binary): 2.3.0-rc2 (source)
- TensorFlow-Addons version and how it was installed (source or binary): Just lookahead extracted from the source (master)
- Python version: 3.6.9
- Is GPU used? (yes/no): yes
When tf.keras.mixed_precision.experimental.set_policy('mixed_float16') is set, using LookAhead divides the layers weights after a few gradient updates (for example 7 in my case).
After investigating, I think the reason is that when mixed_float16 is used with automatic loss scaling, the loss scale is initialized very high. Thus the first few gradient updates do nothing (see https://github.com/tensorflow/tensorflow/blob/582c8d236cb079023657287c318ff26adb239002/tensorflow/python/keras/mixed_precision/loss_scale_optimizer.py#L714 for how updates are skipped).
As a result, LookAhead ends up with its 'slow vars' initialized to 0 instead of the original layer weight. Indeed the vars are initialized to the correct value only on the first iteration during the gradient update (https://github.com/tensorflow/addons/blob/master/tensorflow_addons/optimizers/lookahead.py#L106).
Thus when the gradient update finally does something, the first variable update does average them with the slow variables (initialized to zero). Which would explain the weight division I'm seeing.
I don't have a short code to replicate the bug, but I think the above explanation and links should highlight well enough the issue with the current way LookAhead's slow variables are initialized.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `tensorflow_addons/optimizers/lookahead.py`
Content:
```
1 # Copyright 2019 The TensorFlow Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 # ==============================================================================
15
16 import tensorflow as tf
17 from tensorflow_addons.utils import types
18
19 from typeguard import typechecked
20
21
22 @tf.keras.utils.register_keras_serializable(package="Addons")
23 class Lookahead(tf.keras.optimizers.Optimizer):
24 """This class allows to extend optimizers with the lookahead mechanism.
25
26 The mechanism is proposed by Michael R. Zhang et.al in the paper
27 [Lookahead Optimizer: k steps forward, 1 step back]
28 (https://arxiv.org/abs/1907.08610v1). The optimizer iteratively updates two
29 sets of weights: the search directions for weights are chosen by the inner
30 optimizer, while the "slow weights" are updated each `k` steps based on the
31 directions of the "fast weights" and the two sets of weights are
32 synchronized. This method improves the learning stability and lowers the
33 variance of its inner optimizer.
34
35 Example of usage:
36
37 ```python
38 opt = tf.keras.optimizers.SGD(learning_rate)
39 opt = tfa.optimizers.Lookahead(opt)
40 ```
41 """
42
43 @typechecked
44 def __init__(
45 self,
46 optimizer: types.Optimizer,
47 sync_period: int = 6,
48 slow_step_size: types.FloatTensorLike = 0.5,
49 name: str = "Lookahead",
50 **kwargs,
51 ):
52 r"""Wrap optimizer with the lookahead mechanism.
53
54 Args:
55 optimizer: The original optimizer that will be used to compute
56 and apply the gradients.
57 sync_period: An integer. The synchronization period of lookahead.
58 Enable lookahead mechanism by setting it with a positive value.
59 slow_step_size: A floating point value.
60 The ratio for updating the slow weights.
61 name: Optional name for the operations created when applying
62 gradients. Defaults to "Lookahead".
63 **kwargs: keyword arguments. Allowed to be {`clipnorm`,
64 `clipvalue`, `lr`, `decay`}. `clipnorm` is clip gradients
65 by norm; `clipvalue` is clip gradients by value, `decay` is
66 included for backward compatibility to allow time inverse
67 decay of learning rate. `lr` is included for backward
68 compatibility, recommended to use `learning_rate` instead.
69 """
70 super().__init__(name, **kwargs)
71
72 if isinstance(optimizer, str):
73 optimizer = tf.keras.optimizers.get(optimizer)
74 if not isinstance(optimizer, tf.keras.optimizers.Optimizer):
75 raise TypeError(
76 "optimizer is not an object of tf.keras.optimizers.Optimizer"
77 )
78
79 self._optimizer = optimizer
80 self._set_hyper("sync_period", sync_period)
81 self._set_hyper("slow_step_size", slow_step_size)
82 self._initialized = False
83 self._track_trackable(self._optimizer, "lh_base_optimizer")
84
85 def _create_slots(self, var_list):
86 self._optimizer._create_slots(
87 var_list=var_list
88 ) # pylint: disable=protected-access
89 for var in var_list:
90 self.add_slot(var, "slow")
91
92 def _create_hypers(self):
93 self._optimizer._create_hypers() # pylint: disable=protected-access
94
95 def _prepare(self, var_list):
96 return self._optimizer._prepare(
97 var_list=var_list
98 ) # pylint: disable=protected-access
99
100 def apply_gradients(self, grads_and_vars, name=None, **kwargs):
101 self._optimizer._iterations = (
102 self.iterations
103 ) # pylint: disable=protected-access
104 return super().apply_gradients(grads_and_vars, name, **kwargs)
105
106 def _init_op(self, var):
107 slow_var = self.get_slot(var, "slow")
108 return slow_var.assign(
109 tf.where(
110 tf.equal(self.iterations, tf.constant(0, dtype=self.iterations.dtype)),
111 var,
112 slow_var,
113 ),
114 use_locking=self._use_locking,
115 )
116
117 def _look_ahead_op(self, var):
118 var_dtype = var.dtype.base_dtype
119 slow_var = self.get_slot(var, "slow")
120 local_step = tf.cast(self.iterations + 1, tf.dtypes.int64)
121 sync_period = self._get_hyper("sync_period", tf.dtypes.int64)
122 slow_step_size = self._get_hyper("slow_step_size", var_dtype)
123 step_back = slow_var + slow_step_size * (var - slow_var)
124 sync_cond = tf.equal(
125 tf.math.floordiv(local_step, sync_period) * sync_period, local_step
126 )
127 with tf.control_dependencies([step_back]):
128 slow_update = slow_var.assign(
129 tf.where(sync_cond, step_back, slow_var), use_locking=self._use_locking
130 )
131 var_update = var.assign(
132 tf.where(sync_cond, step_back, var), use_locking=self._use_locking
133 )
134 return tf.group(slow_update, var_update)
135
136 @property
137 def weights(self):
138 return self._weights + self._optimizer.weights
139
140 def _resource_apply_dense(self, grad, var):
141 init_op = self._init_op(var)
142 with tf.control_dependencies([init_op]):
143 train_op = self._optimizer._resource_apply_dense(
144 grad, var
145 ) # pylint: disable=protected-access
146 with tf.control_dependencies([train_op]):
147 look_ahead_op = self._look_ahead_op(var)
148 return tf.group(init_op, train_op, look_ahead_op)
149
150 def _resource_apply_sparse(self, grad, var, indices):
151 init_op = self._init_op(var)
152 with tf.control_dependencies([init_op]):
153 train_op = self._optimizer._resource_apply_sparse( # pylint: disable=protected-access
154 grad, var, indices
155 )
156 with tf.control_dependencies([train_op]):
157 look_ahead_op = self._look_ahead_op(var)
158 return tf.group(init_op, train_op, look_ahead_op)
159
160 def get_config(self):
161 config = {
162 "optimizer": tf.keras.optimizers.serialize(self._optimizer),
163 "sync_period": self._serialize_hyperparameter("sync_period"),
164 "slow_step_size": self._serialize_hyperparameter("slow_step_size"),
165 }
166 base_config = super().get_config()
167 return {**base_config, **config}
168
169 @property
170 def learning_rate(self):
171 return self._optimizer._get_hyper("learning_rate")
172
173 @learning_rate.setter
174 def learning_rate(self, learning_rate):
175 self._optimizer._set_hyper("learning_rate", learning_rate)
176
177 @property
178 def lr(self):
179 return self.learning_rate
180
181 @lr.setter
182 def lr(self, lr):
183 self.learning_rate = lr
184
185 @classmethod
186 def from_config(cls, config, custom_objects=None):
187 optimizer = tf.keras.optimizers.deserialize(
188 config.pop("optimizer"), custom_objects=custom_objects
189 )
190 return cls(optimizer, **config)
191
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/tensorflow_addons/optimizers/lookahead.py b/tensorflow_addons/optimizers/lookahead.py
--- a/tensorflow_addons/optimizers/lookahead.py
+++ b/tensorflow_addons/optimizers/lookahead.py
@@ -87,7 +87,7 @@
var_list=var_list
) # pylint: disable=protected-access
for var in var_list:
- self.add_slot(var, "slow")
+ self.add_slot(var, "slow", initializer=var)
def _create_hypers(self):
self._optimizer._create_hypers() # pylint: disable=protected-access
@@ -103,17 +103,6 @@
) # pylint: disable=protected-access
return super().apply_gradients(grads_and_vars, name, **kwargs)
- def _init_op(self, var):
- slow_var = self.get_slot(var, "slow")
- return slow_var.assign(
- tf.where(
- tf.equal(self.iterations, tf.constant(0, dtype=self.iterations.dtype)),
- var,
- slow_var,
- ),
- use_locking=self._use_locking,
- )
-
def _look_ahead_op(self, var):
var_dtype = var.dtype.base_dtype
slow_var = self.get_slot(var, "slow")
@@ -138,24 +127,22 @@
return self._weights + self._optimizer.weights
def _resource_apply_dense(self, grad, var):
- init_op = self._init_op(var)
- with tf.control_dependencies([init_op]):
- train_op = self._optimizer._resource_apply_dense(
- grad, var
- ) # pylint: disable=protected-access
- with tf.control_dependencies([train_op]):
- look_ahead_op = self._look_ahead_op(var)
- return tf.group(init_op, train_op, look_ahead_op)
+ train_op = self._optimizer._resource_apply_dense(
+ grad, var
+ ) # pylint: disable=protected-access
+ with tf.control_dependencies([train_op]):
+ look_ahead_op = self._look_ahead_op(var)
+ return tf.group(train_op, look_ahead_op)
def _resource_apply_sparse(self, grad, var, indices):
- init_op = self._init_op(var)
- with tf.control_dependencies([init_op]):
- train_op = self._optimizer._resource_apply_sparse( # pylint: disable=protected-access
+ train_op = (
+ self._optimizer._resource_apply_sparse( # pylint: disable=protected-access
grad, var, indices
)
- with tf.control_dependencies([train_op]):
- look_ahead_op = self._look_ahead_op(var)
- return tf.group(init_op, train_op, look_ahead_op)
+ )
+ with tf.control_dependencies([train_op]):
+ look_ahead_op = self._look_ahead_op(var)
+ return tf.group(train_op, look_ahead_op)
def get_config(self):
config = {
|
{"golden_diff": "diff --git a/tensorflow_addons/optimizers/lookahead.py b/tensorflow_addons/optimizers/lookahead.py\n--- a/tensorflow_addons/optimizers/lookahead.py\n+++ b/tensorflow_addons/optimizers/lookahead.py\n@@ -87,7 +87,7 @@\n var_list=var_list\n ) # pylint: disable=protected-access\n for var in var_list:\n- self.add_slot(var, \"slow\")\n+ self.add_slot(var, \"slow\", initializer=var)\n \n def _create_hypers(self):\n self._optimizer._create_hypers() # pylint: disable=protected-access\n@@ -103,17 +103,6 @@\n ) # pylint: disable=protected-access\n return super().apply_gradients(grads_and_vars, name, **kwargs)\n \n- def _init_op(self, var):\n- slow_var = self.get_slot(var, \"slow\")\n- return slow_var.assign(\n- tf.where(\n- tf.equal(self.iterations, tf.constant(0, dtype=self.iterations.dtype)),\n- var,\n- slow_var,\n- ),\n- use_locking=self._use_locking,\n- )\n-\n def _look_ahead_op(self, var):\n var_dtype = var.dtype.base_dtype\n slow_var = self.get_slot(var, \"slow\")\n@@ -138,24 +127,22 @@\n return self._weights + self._optimizer.weights\n \n def _resource_apply_dense(self, grad, var):\n- init_op = self._init_op(var)\n- with tf.control_dependencies([init_op]):\n- train_op = self._optimizer._resource_apply_dense(\n- grad, var\n- ) # pylint: disable=protected-access\n- with tf.control_dependencies([train_op]):\n- look_ahead_op = self._look_ahead_op(var)\n- return tf.group(init_op, train_op, look_ahead_op)\n+ train_op = self._optimizer._resource_apply_dense(\n+ grad, var\n+ ) # pylint: disable=protected-access\n+ with tf.control_dependencies([train_op]):\n+ look_ahead_op = self._look_ahead_op(var)\n+ return tf.group(train_op, look_ahead_op)\n \n def _resource_apply_sparse(self, grad, var, indices):\n- init_op = self._init_op(var)\n- with tf.control_dependencies([init_op]):\n- train_op = self._optimizer._resource_apply_sparse( # pylint: disable=protected-access\n+ train_op = (\n+ self._optimizer._resource_apply_sparse( # pylint: disable=protected-access\n grad, var, indices\n )\n- with tf.control_dependencies([train_op]):\n- look_ahead_op = self._look_ahead_op(var)\n- return tf.group(init_op, train_op, look_ahead_op)\n+ )\n+ with tf.control_dependencies([train_op]):\n+ look_ahead_op = self._look_ahead_op(var)\n+ return tf.group(train_op, look_ahead_op)\n \n def get_config(self):\n config = {\n", "issue": "Lookahead might divide weights with mixed_float16\n**System information**\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 18.04\r\n- TensorFlow version and how it was installed (source or binary): 2.3.0-rc2 (source)\r\n- TensorFlow-Addons version and how it was installed (source or binary): Just lookahead extracted from the source (master)\r\n- Python version: 3.6.9\r\n- Is GPU used? (yes/no): yes\r\n\r\nWhen tf.keras.mixed_precision.experimental.set_policy('mixed_float16') is set, using LookAhead divides the layers weights after a few gradient updates (for example 7 in my case).\r\n\r\nAfter investigating, I think the reason is that when mixed_float16 is used with automatic loss scaling, the loss scale is initialized very high. Thus the first few gradient updates do nothing (see https://github.com/tensorflow/tensorflow/blob/582c8d236cb079023657287c318ff26adb239002/tensorflow/python/keras/mixed_precision/loss_scale_optimizer.py#L714 for how updates are skipped).\r\n\r\nAs a result, LookAhead ends up with its 'slow vars' initialized to 0 instead of the original layer weight. Indeed the vars are initialized to the correct value only on the first iteration during the gradient update (https://github.com/tensorflow/addons/blob/master/tensorflow_addons/optimizers/lookahead.py#L106).\r\n\r\nThus when the gradient update finally does something, the first variable update does average them with the slow variables (initialized to zero). Which would explain the weight division I'm seeing.\r\n\r\nI don't have a short code to replicate the bug, but I think the above explanation and links should highlight well enough the issue with the current way LookAhead's slow variables are initialized.\r\n\nLookahead might divide weights with mixed_float16\n**System information**\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 18.04\r\n- TensorFlow version and how it was installed (source or binary): 2.3.0-rc2 (source)\r\n- TensorFlow-Addons version and how it was installed (source or binary): Just lookahead extracted from the source (master)\r\n- Python version: 3.6.9\r\n- Is GPU used? (yes/no): yes\r\n\r\nWhen tf.keras.mixed_precision.experimental.set_policy('mixed_float16') is set, using LookAhead divides the layers weights after a few gradient updates (for example 7 in my case).\r\n\r\nAfter investigating, I think the reason is that when mixed_float16 is used with automatic loss scaling, the loss scale is initialized very high. Thus the first few gradient updates do nothing (see https://github.com/tensorflow/tensorflow/blob/582c8d236cb079023657287c318ff26adb239002/tensorflow/python/keras/mixed_precision/loss_scale_optimizer.py#L714 for how updates are skipped).\r\n\r\nAs a result, LookAhead ends up with its 'slow vars' initialized to 0 instead of the original layer weight. Indeed the vars are initialized to the correct value only on the first iteration during the gradient update (https://github.com/tensorflow/addons/blob/master/tensorflow_addons/optimizers/lookahead.py#L106).\r\n\r\nThus when the gradient update finally does something, the first variable update does average them with the slow variables (initialized to zero). Which would explain the weight division I'm seeing.\r\n\r\nI don't have a short code to replicate the bug, but I think the above explanation and links should highlight well enough the issue with the current way LookAhead's slow variables are initialized.\r\n\n", "before_files": [{"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\nimport tensorflow as tf\nfrom tensorflow_addons.utils import types\n\nfrom typeguard import typechecked\n\n\[email protected]_keras_serializable(package=\"Addons\")\nclass Lookahead(tf.keras.optimizers.Optimizer):\n \"\"\"This class allows to extend optimizers with the lookahead mechanism.\n\n The mechanism is proposed by Michael R. Zhang et.al in the paper\n [Lookahead Optimizer: k steps forward, 1 step back]\n (https://arxiv.org/abs/1907.08610v1). The optimizer iteratively updates two\n sets of weights: the search directions for weights are chosen by the inner\n optimizer, while the \"slow weights\" are updated each `k` steps based on the\n directions of the \"fast weights\" and the two sets of weights are\n synchronized. This method improves the learning stability and lowers the\n variance of its inner optimizer.\n\n Example of usage:\n\n ```python\n opt = tf.keras.optimizers.SGD(learning_rate)\n opt = tfa.optimizers.Lookahead(opt)\n ```\n \"\"\"\n\n @typechecked\n def __init__(\n self,\n optimizer: types.Optimizer,\n sync_period: int = 6,\n slow_step_size: types.FloatTensorLike = 0.5,\n name: str = \"Lookahead\",\n **kwargs,\n ):\n r\"\"\"Wrap optimizer with the lookahead mechanism.\n\n Args:\n optimizer: The original optimizer that will be used to compute\n and apply the gradients.\n sync_period: An integer. The synchronization period of lookahead.\n Enable lookahead mechanism by setting it with a positive value.\n slow_step_size: A floating point value.\n The ratio for updating the slow weights.\n name: Optional name for the operations created when applying\n gradients. Defaults to \"Lookahead\".\n **kwargs: keyword arguments. Allowed to be {`clipnorm`,\n `clipvalue`, `lr`, `decay`}. `clipnorm` is clip gradients\n by norm; `clipvalue` is clip gradients by value, `decay` is\n included for backward compatibility to allow time inverse\n decay of learning rate. `lr` is included for backward\n compatibility, recommended to use `learning_rate` instead.\n \"\"\"\n super().__init__(name, **kwargs)\n\n if isinstance(optimizer, str):\n optimizer = tf.keras.optimizers.get(optimizer)\n if not isinstance(optimizer, tf.keras.optimizers.Optimizer):\n raise TypeError(\n \"optimizer is not an object of tf.keras.optimizers.Optimizer\"\n )\n\n self._optimizer = optimizer\n self._set_hyper(\"sync_period\", sync_period)\n self._set_hyper(\"slow_step_size\", slow_step_size)\n self._initialized = False\n self._track_trackable(self._optimizer, \"lh_base_optimizer\")\n\n def _create_slots(self, var_list):\n self._optimizer._create_slots(\n var_list=var_list\n ) # pylint: disable=protected-access\n for var in var_list:\n self.add_slot(var, \"slow\")\n\n def _create_hypers(self):\n self._optimizer._create_hypers() # pylint: disable=protected-access\n\n def _prepare(self, var_list):\n return self._optimizer._prepare(\n var_list=var_list\n ) # pylint: disable=protected-access\n\n def apply_gradients(self, grads_and_vars, name=None, **kwargs):\n self._optimizer._iterations = (\n self.iterations\n ) # pylint: disable=protected-access\n return super().apply_gradients(grads_and_vars, name, **kwargs)\n\n def _init_op(self, var):\n slow_var = self.get_slot(var, \"slow\")\n return slow_var.assign(\n tf.where(\n tf.equal(self.iterations, tf.constant(0, dtype=self.iterations.dtype)),\n var,\n slow_var,\n ),\n use_locking=self._use_locking,\n )\n\n def _look_ahead_op(self, var):\n var_dtype = var.dtype.base_dtype\n slow_var = self.get_slot(var, \"slow\")\n local_step = tf.cast(self.iterations + 1, tf.dtypes.int64)\n sync_period = self._get_hyper(\"sync_period\", tf.dtypes.int64)\n slow_step_size = self._get_hyper(\"slow_step_size\", var_dtype)\n step_back = slow_var + slow_step_size * (var - slow_var)\n sync_cond = tf.equal(\n tf.math.floordiv(local_step, sync_period) * sync_period, local_step\n )\n with tf.control_dependencies([step_back]):\n slow_update = slow_var.assign(\n tf.where(sync_cond, step_back, slow_var), use_locking=self._use_locking\n )\n var_update = var.assign(\n tf.where(sync_cond, step_back, var), use_locking=self._use_locking\n )\n return tf.group(slow_update, var_update)\n\n @property\n def weights(self):\n return self._weights + self._optimizer.weights\n\n def _resource_apply_dense(self, grad, var):\n init_op = self._init_op(var)\n with tf.control_dependencies([init_op]):\n train_op = self._optimizer._resource_apply_dense(\n grad, var\n ) # pylint: disable=protected-access\n with tf.control_dependencies([train_op]):\n look_ahead_op = self._look_ahead_op(var)\n return tf.group(init_op, train_op, look_ahead_op)\n\n def _resource_apply_sparse(self, grad, var, indices):\n init_op = self._init_op(var)\n with tf.control_dependencies([init_op]):\n train_op = self._optimizer._resource_apply_sparse( # pylint: disable=protected-access\n grad, var, indices\n )\n with tf.control_dependencies([train_op]):\n look_ahead_op = self._look_ahead_op(var)\n return tf.group(init_op, train_op, look_ahead_op)\n\n def get_config(self):\n config = {\n \"optimizer\": tf.keras.optimizers.serialize(self._optimizer),\n \"sync_period\": self._serialize_hyperparameter(\"sync_period\"),\n \"slow_step_size\": self._serialize_hyperparameter(\"slow_step_size\"),\n }\n base_config = super().get_config()\n return {**base_config, **config}\n\n @property\n def learning_rate(self):\n return self._optimizer._get_hyper(\"learning_rate\")\n\n @learning_rate.setter\n def learning_rate(self, learning_rate):\n self._optimizer._set_hyper(\"learning_rate\", learning_rate)\n\n @property\n def lr(self):\n return self.learning_rate\n\n @lr.setter\n def lr(self, lr):\n self.learning_rate = lr\n\n @classmethod\n def from_config(cls, config, custom_objects=None):\n optimizer = tf.keras.optimizers.deserialize(\n config.pop(\"optimizer\"), custom_objects=custom_objects\n )\n return cls(optimizer, **config)\n", "path": "tensorflow_addons/optimizers/lookahead.py"}], "after_files": [{"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\nimport tensorflow as tf\nfrom tensorflow_addons.utils import types\n\nfrom typeguard import typechecked\n\n\[email protected]_keras_serializable(package=\"Addons\")\nclass Lookahead(tf.keras.optimizers.Optimizer):\n \"\"\"This class allows to extend optimizers with the lookahead mechanism.\n\n The mechanism is proposed by Michael R. Zhang et.al in the paper\n [Lookahead Optimizer: k steps forward, 1 step back]\n (https://arxiv.org/abs/1907.08610v1). The optimizer iteratively updates two\n sets of weights: the search directions for weights are chosen by the inner\n optimizer, while the \"slow weights\" are updated each `k` steps based on the\n directions of the \"fast weights\" and the two sets of weights are\n synchronized. This method improves the learning stability and lowers the\n variance of its inner optimizer.\n\n Example of usage:\n\n ```python\n opt = tf.keras.optimizers.SGD(learning_rate)\n opt = tfa.optimizers.Lookahead(opt)\n ```\n \"\"\"\n\n @typechecked\n def __init__(\n self,\n optimizer: types.Optimizer,\n sync_period: int = 6,\n slow_step_size: types.FloatTensorLike = 0.5,\n name: str = \"Lookahead\",\n **kwargs,\n ):\n r\"\"\"Wrap optimizer with the lookahead mechanism.\n\n Args:\n optimizer: The original optimizer that will be used to compute\n and apply the gradients.\n sync_period: An integer. The synchronization period of lookahead.\n Enable lookahead mechanism by setting it with a positive value.\n slow_step_size: A floating point value.\n The ratio for updating the slow weights.\n name: Optional name for the operations created when applying\n gradients. Defaults to \"Lookahead\".\n **kwargs: keyword arguments. Allowed to be {`clipnorm`,\n `clipvalue`, `lr`, `decay`}. `clipnorm` is clip gradients\n by norm; `clipvalue` is clip gradients by value, `decay` is\n included for backward compatibility to allow time inverse\n decay of learning rate. `lr` is included for backward\n compatibility, recommended to use `learning_rate` instead.\n \"\"\"\n super().__init__(name, **kwargs)\n\n if isinstance(optimizer, str):\n optimizer = tf.keras.optimizers.get(optimizer)\n if not isinstance(optimizer, tf.keras.optimizers.Optimizer):\n raise TypeError(\n \"optimizer is not an object of tf.keras.optimizers.Optimizer\"\n )\n\n self._optimizer = optimizer\n self._set_hyper(\"sync_period\", sync_period)\n self._set_hyper(\"slow_step_size\", slow_step_size)\n self._initialized = False\n self._track_trackable(self._optimizer, \"lh_base_optimizer\")\n\n def _create_slots(self, var_list):\n self._optimizer._create_slots(\n var_list=var_list\n ) # pylint: disable=protected-access\n for var in var_list:\n self.add_slot(var, \"slow\", initializer=var)\n\n def _create_hypers(self):\n self._optimizer._create_hypers() # pylint: disable=protected-access\n\n def _prepare(self, var_list):\n return self._optimizer._prepare(\n var_list=var_list\n ) # pylint: disable=protected-access\n\n def apply_gradients(self, grads_and_vars, name=None, **kwargs):\n self._optimizer._iterations = (\n self.iterations\n ) # pylint: disable=protected-access\n return super().apply_gradients(grads_and_vars, name, **kwargs)\n\n def _look_ahead_op(self, var):\n var_dtype = var.dtype.base_dtype\n slow_var = self.get_slot(var, \"slow\")\n local_step = tf.cast(self.iterations + 1, tf.dtypes.int64)\n sync_period = self._get_hyper(\"sync_period\", tf.dtypes.int64)\n slow_step_size = self._get_hyper(\"slow_step_size\", var_dtype)\n step_back = slow_var + slow_step_size * (var - slow_var)\n sync_cond = tf.equal(\n tf.math.floordiv(local_step, sync_period) * sync_period, local_step\n )\n with tf.control_dependencies([step_back]):\n slow_update = slow_var.assign(\n tf.where(sync_cond, step_back, slow_var), use_locking=self._use_locking\n )\n var_update = var.assign(\n tf.where(sync_cond, step_back, var), use_locking=self._use_locking\n )\n return tf.group(slow_update, var_update)\n\n @property\n def weights(self):\n return self._weights + self._optimizer.weights\n\n def _resource_apply_dense(self, grad, var):\n train_op = self._optimizer._resource_apply_dense(\n grad, var\n ) # pylint: disable=protected-access\n with tf.control_dependencies([train_op]):\n look_ahead_op = self._look_ahead_op(var)\n return tf.group(train_op, look_ahead_op)\n\n def _resource_apply_sparse(self, grad, var, indices):\n train_op = (\n self._optimizer._resource_apply_sparse( # pylint: disable=protected-access\n grad, var, indices\n )\n )\n with tf.control_dependencies([train_op]):\n look_ahead_op = self._look_ahead_op(var)\n return tf.group(train_op, look_ahead_op)\n\n def get_config(self):\n config = {\n \"optimizer\": tf.keras.optimizers.serialize(self._optimizer),\n \"sync_period\": self._serialize_hyperparameter(\"sync_period\"),\n \"slow_step_size\": self._serialize_hyperparameter(\"slow_step_size\"),\n }\n base_config = super().get_config()\n return {**base_config, **config}\n\n @property\n def learning_rate(self):\n return self._optimizer._get_hyper(\"learning_rate\")\n\n @learning_rate.setter\n def learning_rate(self, learning_rate):\n self._optimizer._set_hyper(\"learning_rate\", learning_rate)\n\n @property\n def lr(self):\n return self.learning_rate\n\n @lr.setter\n def lr(self, lr):\n self.learning_rate = lr\n\n @classmethod\n def from_config(cls, config, custom_objects=None):\n optimizer = tf.keras.optimizers.deserialize(\n config.pop(\"optimizer\"), custom_objects=custom_objects\n )\n return cls(optimizer, **config)\n", "path": "tensorflow_addons/optimizers/lookahead.py"}]}
| 3,199 | 692 |
gh_patches_debug_13019
|
rasdani/github-patches
|
git_diff
|
getsentry__sentry-52100
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
SDK Crash Detection: Store Project ID and Event ID
Store project ID and event ID in the SDK crash detection context to find the original SDK crash event, which is only possible with admin Sentry rights.
https://github.com/getsentry/sentry/blob/2c31ee009b44964f78b9e7e8282e602b7ef849b0/src/sentry/utils/sdk_crashes/sdk_crash_detection.py#L40C2-L42
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/sentry/utils/sdk_crashes/sdk_crash_detection.py`
Content:
```
1 from __future__ import annotations
2
3 from typing import Any, Mapping, Optional
4
5 from sentry.eventstore.models import Event
6 from sentry.issues.grouptype import GroupCategory
7 from sentry.utils.safe import get_path, set_path
8 from sentry.utils.sdk_crashes.cocoa_sdk_crash_detector import CocoaSDKCrashDetector
9 from sentry.utils.sdk_crashes.event_stripper import strip_event_data
10 from sentry.utils.sdk_crashes.sdk_crash_detector import SDKCrashDetector
11
12
13 class SDKCrashReporter:
14 def report(self, event_data: Mapping[str, Any], event_project_id: int) -> Event:
15 from sentry.event_manager import EventManager
16
17 manager = EventManager(dict(event_data))
18 manager.normalize()
19 return manager.save(project_id=event_project_id)
20
21
22 class SDKCrashDetection:
23 def __init__(
24 self,
25 sdk_crash_reporter: SDKCrashReporter,
26 sdk_crash_detector: SDKCrashDetector,
27 ):
28 self.sdk_crash_reporter = sdk_crash_reporter
29 self.cocoa_sdk_crash_detector = sdk_crash_detector
30
31 def detect_sdk_crash(self, event: Event, event_project_id: int) -> Optional[Event]:
32 should_detect_sdk_crash = (
33 event.group
34 and event.group.issue_category == GroupCategory.ERROR
35 and event.group.platform == "cocoa"
36 )
37 if not should_detect_sdk_crash:
38 return None
39
40 context = get_path(event.data, "contexts", "sdk_crash_detection")
41 if context is not None and context.get("detected", False):
42 return None
43
44 # Getting the frames and checking if the event is unhandled might different per platform.
45 # We will change this once we implement this for more platforms.
46 is_unhandled = (
47 get_path(event.data, "exception", "values", -1, "mechanism", "handled") is False
48 )
49 if is_unhandled is False:
50 return None
51
52 frames = get_path(event.data, "exception", "values", -1, "stacktrace", "frames")
53 if not frames:
54 return None
55
56 if self.cocoa_sdk_crash_detector.is_sdk_crash(frames):
57 sdk_crash_event_data = strip_event_data(event.data, self.cocoa_sdk_crash_detector)
58
59 set_path(
60 sdk_crash_event_data, "contexts", "sdk_crash_detection", value={"detected": True}
61 )
62
63 return self.sdk_crash_reporter.report(sdk_crash_event_data, event_project_id)
64
65 return None
66
67
68 _crash_reporter = SDKCrashReporter()
69 _cocoa_sdk_crash_detector = CocoaSDKCrashDetector()
70
71 sdk_crash_detection = SDKCrashDetection(_crash_reporter, _cocoa_sdk_crash_detector)
72
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/sentry/utils/sdk_crashes/sdk_crash_detection.py b/src/sentry/utils/sdk_crashes/sdk_crash_detection.py
--- a/src/sentry/utils/sdk_crashes/sdk_crash_detection.py
+++ b/src/sentry/utils/sdk_crashes/sdk_crash_detection.py
@@ -57,7 +57,14 @@
sdk_crash_event_data = strip_event_data(event.data, self.cocoa_sdk_crash_detector)
set_path(
- sdk_crash_event_data, "contexts", "sdk_crash_detection", value={"detected": True}
+ sdk_crash_event_data,
+ "contexts",
+ "sdk_crash_detection",
+ value={
+ "detected": True,
+ "original_project_id": event.project.id,
+ "original_event_id": event.event_id,
+ },
)
return self.sdk_crash_reporter.report(sdk_crash_event_data, event_project_id)
|
{"golden_diff": "diff --git a/src/sentry/utils/sdk_crashes/sdk_crash_detection.py b/src/sentry/utils/sdk_crashes/sdk_crash_detection.py\n--- a/src/sentry/utils/sdk_crashes/sdk_crash_detection.py\n+++ b/src/sentry/utils/sdk_crashes/sdk_crash_detection.py\n@@ -57,7 +57,14 @@\n sdk_crash_event_data = strip_event_data(event.data, self.cocoa_sdk_crash_detector)\n \n set_path(\n- sdk_crash_event_data, \"contexts\", \"sdk_crash_detection\", value={\"detected\": True}\n+ sdk_crash_event_data,\n+ \"contexts\",\n+ \"sdk_crash_detection\",\n+ value={\n+ \"detected\": True,\n+ \"original_project_id\": event.project.id,\n+ \"original_event_id\": event.event_id,\n+ },\n )\n \n return self.sdk_crash_reporter.report(sdk_crash_event_data, event_project_id)\n", "issue": "SDK Crash Detection: Store Project ID and Event ID\nStore project ID and event ID in the SDK crash detection context to find the original SDK crash event, which is only possible with admin Sentry rights.\r\n\r\nhttps://github.com/getsentry/sentry/blob/2c31ee009b44964f78b9e7e8282e602b7ef849b0/src/sentry/utils/sdk_crashes/sdk_crash_detection.py#L40C2-L42\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom typing import Any, Mapping, Optional\n\nfrom sentry.eventstore.models import Event\nfrom sentry.issues.grouptype import GroupCategory\nfrom sentry.utils.safe import get_path, set_path\nfrom sentry.utils.sdk_crashes.cocoa_sdk_crash_detector import CocoaSDKCrashDetector\nfrom sentry.utils.sdk_crashes.event_stripper import strip_event_data\nfrom sentry.utils.sdk_crashes.sdk_crash_detector import SDKCrashDetector\n\n\nclass SDKCrashReporter:\n def report(self, event_data: Mapping[str, Any], event_project_id: int) -> Event:\n from sentry.event_manager import EventManager\n\n manager = EventManager(dict(event_data))\n manager.normalize()\n return manager.save(project_id=event_project_id)\n\n\nclass SDKCrashDetection:\n def __init__(\n self,\n sdk_crash_reporter: SDKCrashReporter,\n sdk_crash_detector: SDKCrashDetector,\n ):\n self.sdk_crash_reporter = sdk_crash_reporter\n self.cocoa_sdk_crash_detector = sdk_crash_detector\n\n def detect_sdk_crash(self, event: Event, event_project_id: int) -> Optional[Event]:\n should_detect_sdk_crash = (\n event.group\n and event.group.issue_category == GroupCategory.ERROR\n and event.group.platform == \"cocoa\"\n )\n if not should_detect_sdk_crash:\n return None\n\n context = get_path(event.data, \"contexts\", \"sdk_crash_detection\")\n if context is not None and context.get(\"detected\", False):\n return None\n\n # Getting the frames and checking if the event is unhandled might different per platform.\n # We will change this once we implement this for more platforms.\n is_unhandled = (\n get_path(event.data, \"exception\", \"values\", -1, \"mechanism\", \"handled\") is False\n )\n if is_unhandled is False:\n return None\n\n frames = get_path(event.data, \"exception\", \"values\", -1, \"stacktrace\", \"frames\")\n if not frames:\n return None\n\n if self.cocoa_sdk_crash_detector.is_sdk_crash(frames):\n sdk_crash_event_data = strip_event_data(event.data, self.cocoa_sdk_crash_detector)\n\n set_path(\n sdk_crash_event_data, \"contexts\", \"sdk_crash_detection\", value={\"detected\": True}\n )\n\n return self.sdk_crash_reporter.report(sdk_crash_event_data, event_project_id)\n\n return None\n\n\n_crash_reporter = SDKCrashReporter()\n_cocoa_sdk_crash_detector = CocoaSDKCrashDetector()\n\nsdk_crash_detection = SDKCrashDetection(_crash_reporter, _cocoa_sdk_crash_detector)\n", "path": "src/sentry/utils/sdk_crashes/sdk_crash_detection.py"}], "after_files": [{"content": "from __future__ import annotations\n\nfrom typing import Any, Mapping, Optional\n\nfrom sentry.eventstore.models import Event\nfrom sentry.issues.grouptype import GroupCategory\nfrom sentry.utils.safe import get_path, set_path\nfrom sentry.utils.sdk_crashes.cocoa_sdk_crash_detector import CocoaSDKCrashDetector\nfrom sentry.utils.sdk_crashes.event_stripper import strip_event_data\nfrom sentry.utils.sdk_crashes.sdk_crash_detector import SDKCrashDetector\n\n\nclass SDKCrashReporter:\n def report(self, event_data: Mapping[str, Any], event_project_id: int) -> Event:\n from sentry.event_manager import EventManager\n\n manager = EventManager(dict(event_data))\n manager.normalize()\n return manager.save(project_id=event_project_id)\n\n\nclass SDKCrashDetection:\n def __init__(\n self,\n sdk_crash_reporter: SDKCrashReporter,\n sdk_crash_detector: SDKCrashDetector,\n ):\n self.sdk_crash_reporter = sdk_crash_reporter\n self.cocoa_sdk_crash_detector = sdk_crash_detector\n\n def detect_sdk_crash(self, event: Event, event_project_id: int) -> Optional[Event]:\n should_detect_sdk_crash = (\n event.group\n and event.group.issue_category == GroupCategory.ERROR\n and event.group.platform == \"cocoa\"\n )\n if not should_detect_sdk_crash:\n return None\n\n context = get_path(event.data, \"contexts\", \"sdk_crash_detection\")\n if context is not None and context.get(\"detected\", False):\n return None\n\n # Getting the frames and checking if the event is unhandled might different per platform.\n # We will change this once we implement this for more platforms.\n is_unhandled = (\n get_path(event.data, \"exception\", \"values\", -1, \"mechanism\", \"handled\") is False\n )\n if is_unhandled is False:\n return None\n\n frames = get_path(event.data, \"exception\", \"values\", -1, \"stacktrace\", \"frames\")\n if not frames:\n return None\n\n if self.cocoa_sdk_crash_detector.is_sdk_crash(frames):\n sdk_crash_event_data = strip_event_data(event.data, self.cocoa_sdk_crash_detector)\n\n set_path(\n sdk_crash_event_data,\n \"contexts\",\n \"sdk_crash_detection\",\n value={\n \"detected\": True,\n \"original_project_id\": event.project.id,\n \"original_event_id\": event.event_id,\n },\n )\n\n return self.sdk_crash_reporter.report(sdk_crash_event_data, event_project_id)\n\n return None\n\n\n_crash_reporter = SDKCrashReporter()\n_cocoa_sdk_crash_detector = CocoaSDKCrashDetector()\n\nsdk_crash_detection = SDKCrashDetection(_crash_reporter, _cocoa_sdk_crash_detector)\n", "path": "src/sentry/utils/sdk_crashes/sdk_crash_detection.py"}]}
| 1,114 | 204 |
gh_patches_debug_12199
|
rasdani/github-patches
|
git_diff
|
Cloud-CV__EvalAI-475
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Participant teams not showing up
The participant teams to which the user has been invited does not show up if that user logs in.
For instance: User A creates a team ABC and invites User B
User B logs in, and goes to the participant teams page.
User B does not see team ABC.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `apps/participants/views.py`
Content:
```
1 from rest_framework import permissions, status
2 from rest_framework.decorators import (api_view,
3 authentication_classes,
4 permission_classes,
5 throttle_classes,)
6 from rest_framework.response import Response
7 from rest_framework_expiring_authtoken.authentication import (
8 ExpiringTokenAuthentication,)
9 from rest_framework.throttling import UserRateThrottle
10
11 from accounts.permissions import HasVerifiedEmail
12 from base.utils import paginated_queryset
13 from challenges.models import Challenge
14
15 from .models import (Participant, ParticipantTeam)
16 from .serializers import (InviteParticipantToTeamSerializer,
17 ParticipantTeamSerializer,
18 ChallengeParticipantTeam,
19 ChallengeParticipantTeamList,
20 ChallengeParticipantTeamListSerializer,)
21
22
23 @throttle_classes([UserRateThrottle])
24 @api_view(['GET', 'POST'])
25 @permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))
26 @authentication_classes((ExpiringTokenAuthentication,))
27 def participant_team_list(request):
28
29 if request.method == 'GET':
30 participant_teams = ParticipantTeam.objects.filter(
31 created_by=request.user)
32 paginator, result_page = paginated_queryset(participant_teams, request)
33 serializer = ParticipantTeamSerializer(result_page, many=True)
34 response_data = serializer.data
35 return paginator.get_paginated_response(response_data)
36
37 elif request.method == 'POST':
38 serializer = ParticipantTeamSerializer(data=request.data,
39 context={'request': request})
40 if serializer.is_valid():
41 serializer.save()
42 response_data = serializer.data
43 participant_team = serializer.instance
44 participant = Participant(user=request.user,
45 status=Participant.SELF,
46 team=participant_team)
47 participant.save()
48 return Response(response_data, status=status.HTTP_201_CREATED)
49 return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
50
51
52 @throttle_classes([UserRateThrottle])
53 @api_view(['GET', 'PUT', 'PATCH', 'DELETE'])
54 @permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))
55 @authentication_classes((ExpiringTokenAuthentication,))
56 def participant_team_detail(request, pk):
57
58 try:
59 participant_team = ParticipantTeam.objects.get(pk=pk)
60 except ParticipantTeam.DoesNotExist:
61 response_data = {'error': 'ParticipantTeam does not exist'}
62 return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)
63
64 if request.method == 'GET':
65 serializer = ParticipantTeamSerializer(participant_team)
66 response_data = serializer.data
67 return Response(response_data, status=status.HTTP_200_OK)
68
69 elif request.method in ['PUT', 'PATCH']:
70
71 if request.method == 'PATCH':
72 serializer = ParticipantTeamSerializer(participant_team, data=request.data,
73 context={
74 'request': request},
75 partial=True)
76 else:
77 serializer = ParticipantTeamSerializer(participant_team, data=request.data,
78 context={'request': request})
79 if serializer.is_valid():
80 serializer.save()
81 response_data = serializer.data
82 return Response(response_data, status=status.HTTP_200_OK)
83 else:
84 return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
85
86 elif request.method == 'DELETE':
87 participant_team.delete()
88 return Response(status=status.HTTP_204_NO_CONTENT)
89
90
91 @throttle_classes([UserRateThrottle])
92 @api_view(['POST'])
93 @permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))
94 @authentication_classes((ExpiringTokenAuthentication,))
95 def invite_participant_to_team(request, pk):
96
97 try:
98 participant_team = ParticipantTeam.objects.get(pk=pk)
99 except ParticipantTeam.DoesNotExist:
100 response_data = {'error': 'ParticipantTeam does not exist'}
101 return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)
102
103 serializer = InviteParticipantToTeamSerializer(data=request.data,
104 context={'participant_team': participant_team,
105 'request': request})
106 if serializer.is_valid():
107 serializer.save()
108 response_data = {
109 'message': 'User has been added successfully to the team'}
110 return Response(response_data, status=status.HTTP_202_ACCEPTED)
111 return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
112
113
114 @throttle_classes([UserRateThrottle])
115 @api_view(['DELETE'])
116 @permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))
117 @authentication_classes((ExpiringTokenAuthentication,))
118 def delete_participant_from_team(request, participant_team_pk, participant_pk):
119 """
120 Deletes a participant from a Participant Team
121 """
122 try:
123 participant_team = ParticipantTeam.objects.get(pk=participant_team_pk)
124 except ParticipantTeam.DoesNotExist:
125 response_data = {'error': 'ParticipantTeam does not exist'}
126 return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)
127
128 try:
129 participant = Participant.objects.get(pk=participant_pk)
130 except Participant.DoesNotExist:
131 response_data = {'error': 'Participant does not exist'}
132 return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)
133
134 if participant_team.created_by == request.user:
135
136 if participant.user == request.user: # when the user tries to remove himself
137 response_data = {
138 'error': 'You are not allowed to remove yourself since you are admin. Please delete the team if you want to do so!'} # noqa: ignore=E501
139 return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)
140 else:
141 participant.delete()
142 return Response(status=status.HTTP_204_NO_CONTENT)
143 else:
144 response_data = {
145 'error': 'Sorry, you do not have permissions to remove this participant'}
146 return Response(response_data, status=status.HTTP_401_UNAUTHORIZED)
147
148
149 @throttle_classes([UserRateThrottle])
150 @api_view(['GET', ])
151 @permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))
152 @authentication_classes((ExpiringTokenAuthentication,))
153 def get_teams_and_corresponding_challenges_for_a_participant(request):
154 """
155 Returns list of teams and corresponding challenges for a participant
156 """
157 # first get list of all the participants and teams related to the user
158 participant_objs = Participant.objects.filter(user=request.user).prefetch_related('team')
159
160 challenge_participated_teams = []
161 for participant_obj in participant_objs:
162 participant_team = participant_obj.team
163 try:
164 challenge = Challenge.objects.get(
165 participant_teams=participant_team)
166 except Challenge.DoesNotExist:
167 challenge = None
168
169 challenge_participated_teams.append(ChallengeParticipantTeam(
170 challenge, participant_team))
171
172 serializer = ChallengeParticipantTeamListSerializer(ChallengeParticipantTeamList(challenge_participated_teams))
173 return Response(serializer.data, status=status.HTTP_200_OK)
174
175
176 @throttle_classes([UserRateThrottle])
177 @api_view(['DELETE', ])
178 @permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))
179 @authentication_classes((ExpiringTokenAuthentication,))
180 def remove_self_from_participant_team(request, participant_team_pk):
181 """
182 A user can remove himself from the participant team.
183 """
184 try:
185 ParticipantTeam.objects.get(pk=participant_team_pk)
186 except ParticipantTeam.DoesNotExist:
187 response_data = {'error': 'ParticipantTeam does not exist'}
188 return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)
189
190 try:
191 participant = Participant.objects.get(user=request.user.id, team__pk=participant_team_pk)
192 participant.delete()
193 return Response(status=status.HTTP_204_NO_CONTENT)
194 except:
195 response_data = {'error': 'Sorry, you do not belong to this team.'}
196 return Response(response_data, status=status.HTTP_401_UNAUTHORIZED)
197
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/apps/participants/views.py b/apps/participants/views.py
--- a/apps/participants/views.py
+++ b/apps/participants/views.py
@@ -27,8 +27,9 @@
def participant_team_list(request):
if request.method == 'GET':
+ participant_teams_id = Participant.objects.filter(user_id=request.user).values_list('team_id', flat=True)
participant_teams = ParticipantTeam.objects.filter(
- created_by=request.user)
+ id__in=participant_teams_id)
paginator, result_page = paginated_queryset(participant_teams, request)
serializer = ParticipantTeamSerializer(result_page, many=True)
response_data = serializer.data
|
{"golden_diff": "diff --git a/apps/participants/views.py b/apps/participants/views.py\n--- a/apps/participants/views.py\n+++ b/apps/participants/views.py\n@@ -27,8 +27,9 @@\n def participant_team_list(request):\n \n if request.method == 'GET':\n+ participant_teams_id = Participant.objects.filter(user_id=request.user).values_list('team_id', flat=True)\n participant_teams = ParticipantTeam.objects.filter(\n- created_by=request.user)\n+ id__in=participant_teams_id)\n paginator, result_page = paginated_queryset(participant_teams, request)\n serializer = ParticipantTeamSerializer(result_page, many=True)\n response_data = serializer.data\n", "issue": "Participant teams not showing up\nThe participant teams to which the user has been invited does not show up if that user logs in.\r\n\r\nFor instance: User A creates a team ABC and invites User B\r\nUser B logs in, and goes to the participant teams page. \r\nUser B does not see team ABC. \n", "before_files": [{"content": "from rest_framework import permissions, status\nfrom rest_framework.decorators import (api_view,\n authentication_classes,\n permission_classes,\n throttle_classes,)\nfrom rest_framework.response import Response\nfrom rest_framework_expiring_authtoken.authentication import (\n ExpiringTokenAuthentication,)\nfrom rest_framework.throttling import UserRateThrottle\n\nfrom accounts.permissions import HasVerifiedEmail\nfrom base.utils import paginated_queryset\nfrom challenges.models import Challenge\n\nfrom .models import (Participant, ParticipantTeam)\nfrom .serializers import (InviteParticipantToTeamSerializer,\n ParticipantTeamSerializer,\n ChallengeParticipantTeam,\n ChallengeParticipantTeamList,\n ChallengeParticipantTeamListSerializer,)\n\n\n@throttle_classes([UserRateThrottle])\n@api_view(['GET', 'POST'])\n@permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))\n@authentication_classes((ExpiringTokenAuthentication,))\ndef participant_team_list(request):\n\n if request.method == 'GET':\n participant_teams = ParticipantTeam.objects.filter(\n created_by=request.user)\n paginator, result_page = paginated_queryset(participant_teams, request)\n serializer = ParticipantTeamSerializer(result_page, many=True)\n response_data = serializer.data\n return paginator.get_paginated_response(response_data)\n\n elif request.method == 'POST':\n serializer = ParticipantTeamSerializer(data=request.data,\n context={'request': request})\n if serializer.is_valid():\n serializer.save()\n response_data = serializer.data\n participant_team = serializer.instance\n participant = Participant(user=request.user,\n status=Participant.SELF,\n team=participant_team)\n participant.save()\n return Response(response_data, status=status.HTTP_201_CREATED)\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n\n@throttle_classes([UserRateThrottle])\n@api_view(['GET', 'PUT', 'PATCH', 'DELETE'])\n@permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))\n@authentication_classes((ExpiringTokenAuthentication,))\ndef participant_team_detail(request, pk):\n\n try:\n participant_team = ParticipantTeam.objects.get(pk=pk)\n except ParticipantTeam.DoesNotExist:\n response_data = {'error': 'ParticipantTeam does not exist'}\n return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)\n\n if request.method == 'GET':\n serializer = ParticipantTeamSerializer(participant_team)\n response_data = serializer.data\n return Response(response_data, status=status.HTTP_200_OK)\n\n elif request.method in ['PUT', 'PATCH']:\n\n if request.method == 'PATCH':\n serializer = ParticipantTeamSerializer(participant_team, data=request.data,\n context={\n 'request': request},\n partial=True)\n else:\n serializer = ParticipantTeamSerializer(participant_team, data=request.data,\n context={'request': request})\n if serializer.is_valid():\n serializer.save()\n response_data = serializer.data\n return Response(response_data, status=status.HTTP_200_OK)\n else:\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n elif request.method == 'DELETE':\n participant_team.delete()\n return Response(status=status.HTTP_204_NO_CONTENT)\n\n\n@throttle_classes([UserRateThrottle])\n@api_view(['POST'])\n@permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))\n@authentication_classes((ExpiringTokenAuthentication,))\ndef invite_participant_to_team(request, pk):\n\n try:\n participant_team = ParticipantTeam.objects.get(pk=pk)\n except ParticipantTeam.DoesNotExist:\n response_data = {'error': 'ParticipantTeam does not exist'}\n return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)\n\n serializer = InviteParticipantToTeamSerializer(data=request.data,\n context={'participant_team': participant_team,\n 'request': request})\n if serializer.is_valid():\n serializer.save()\n response_data = {\n 'message': 'User has been added successfully to the team'}\n return Response(response_data, status=status.HTTP_202_ACCEPTED)\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n\n@throttle_classes([UserRateThrottle])\n@api_view(['DELETE'])\n@permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))\n@authentication_classes((ExpiringTokenAuthentication,))\ndef delete_participant_from_team(request, participant_team_pk, participant_pk):\n \"\"\"\n Deletes a participant from a Participant Team\n \"\"\"\n try:\n participant_team = ParticipantTeam.objects.get(pk=participant_team_pk)\n except ParticipantTeam.DoesNotExist:\n response_data = {'error': 'ParticipantTeam does not exist'}\n return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)\n\n try:\n participant = Participant.objects.get(pk=participant_pk)\n except Participant.DoesNotExist:\n response_data = {'error': 'Participant does not exist'}\n return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)\n\n if participant_team.created_by == request.user:\n\n if participant.user == request.user: # when the user tries to remove himself\n response_data = {\n 'error': 'You are not allowed to remove yourself since you are admin. Please delete the team if you want to do so!'} # noqa: ignore=E501\n return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)\n else:\n participant.delete()\n return Response(status=status.HTTP_204_NO_CONTENT)\n else:\n response_data = {\n 'error': 'Sorry, you do not have permissions to remove this participant'}\n return Response(response_data, status=status.HTTP_401_UNAUTHORIZED)\n\n\n@throttle_classes([UserRateThrottle])\n@api_view(['GET', ])\n@permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))\n@authentication_classes((ExpiringTokenAuthentication,))\ndef get_teams_and_corresponding_challenges_for_a_participant(request):\n \"\"\"\n Returns list of teams and corresponding challenges for a participant\n \"\"\"\n # first get list of all the participants and teams related to the user\n participant_objs = Participant.objects.filter(user=request.user).prefetch_related('team')\n\n challenge_participated_teams = []\n for participant_obj in participant_objs:\n participant_team = participant_obj.team\n try:\n challenge = Challenge.objects.get(\n participant_teams=participant_team)\n except Challenge.DoesNotExist:\n challenge = None\n\n challenge_participated_teams.append(ChallengeParticipantTeam(\n challenge, participant_team))\n\n serializer = ChallengeParticipantTeamListSerializer(ChallengeParticipantTeamList(challenge_participated_teams))\n return Response(serializer.data, status=status.HTTP_200_OK)\n\n\n@throttle_classes([UserRateThrottle])\n@api_view(['DELETE', ])\n@permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))\n@authentication_classes((ExpiringTokenAuthentication,))\ndef remove_self_from_participant_team(request, participant_team_pk):\n \"\"\"\n A user can remove himself from the participant team.\n \"\"\"\n try:\n ParticipantTeam.objects.get(pk=participant_team_pk)\n except ParticipantTeam.DoesNotExist:\n response_data = {'error': 'ParticipantTeam does not exist'}\n return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)\n\n try:\n participant = Participant.objects.get(user=request.user.id, team__pk=participant_team_pk)\n participant.delete()\n return Response(status=status.HTTP_204_NO_CONTENT)\n except:\n response_data = {'error': 'Sorry, you do not belong to this team.'}\n return Response(response_data, status=status.HTTP_401_UNAUTHORIZED)\n", "path": "apps/participants/views.py"}], "after_files": [{"content": "from rest_framework import permissions, status\nfrom rest_framework.decorators import (api_view,\n authentication_classes,\n permission_classes,\n throttle_classes,)\nfrom rest_framework.response import Response\nfrom rest_framework_expiring_authtoken.authentication import (\n ExpiringTokenAuthentication,)\nfrom rest_framework.throttling import UserRateThrottle\n\nfrom accounts.permissions import HasVerifiedEmail\nfrom base.utils import paginated_queryset\nfrom challenges.models import Challenge\n\nfrom .models import (Participant, ParticipantTeam)\nfrom .serializers import (InviteParticipantToTeamSerializer,\n ParticipantTeamSerializer,\n ChallengeParticipantTeam,\n ChallengeParticipantTeamList,\n ChallengeParticipantTeamListSerializer,)\n\n\n@throttle_classes([UserRateThrottle])\n@api_view(['GET', 'POST'])\n@permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))\n@authentication_classes((ExpiringTokenAuthentication,))\ndef participant_team_list(request):\n\n if request.method == 'GET':\n participant_teams_id = Participant.objects.filter(user_id=request.user).values_list('team_id', flat=True)\n participant_teams = ParticipantTeam.objects.filter(\n id__in=participant_teams_id)\n paginator, result_page = paginated_queryset(participant_teams, request)\n serializer = ParticipantTeamSerializer(result_page, many=True)\n response_data = serializer.data\n return paginator.get_paginated_response(response_data)\n\n elif request.method == 'POST':\n serializer = ParticipantTeamSerializer(data=request.data,\n context={'request': request})\n if serializer.is_valid():\n serializer.save()\n response_data = serializer.data\n participant_team = serializer.instance\n participant = Participant(user=request.user,\n status=Participant.SELF,\n team=participant_team)\n participant.save()\n return Response(response_data, status=status.HTTP_201_CREATED)\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n\n@throttle_classes([UserRateThrottle])\n@api_view(['GET', 'PUT', 'PATCH', 'DELETE'])\n@permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))\n@authentication_classes((ExpiringTokenAuthentication,))\ndef participant_team_detail(request, pk):\n\n try:\n participant_team = ParticipantTeam.objects.get(pk=pk)\n except ParticipantTeam.DoesNotExist:\n response_data = {'error': 'ParticipantTeam does not exist'}\n return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)\n\n if request.method == 'GET':\n serializer = ParticipantTeamSerializer(participant_team)\n response_data = serializer.data\n return Response(response_data, status=status.HTTP_200_OK)\n\n elif request.method in ['PUT', 'PATCH']:\n\n if request.method == 'PATCH':\n serializer = ParticipantTeamSerializer(participant_team, data=request.data,\n context={\n 'request': request},\n partial=True)\n else:\n serializer = ParticipantTeamSerializer(participant_team, data=request.data,\n context={'request': request})\n if serializer.is_valid():\n serializer.save()\n response_data = serializer.data\n return Response(response_data, status=status.HTTP_200_OK)\n else:\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n elif request.method == 'DELETE':\n participant_team.delete()\n return Response(status=status.HTTP_204_NO_CONTENT)\n\n\n@throttle_classes([UserRateThrottle])\n@api_view(['POST'])\n@permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))\n@authentication_classes((ExpiringTokenAuthentication,))\ndef invite_participant_to_team(request, pk):\n\n try:\n participant_team = ParticipantTeam.objects.get(pk=pk)\n except ParticipantTeam.DoesNotExist:\n response_data = {'error': 'ParticipantTeam does not exist'}\n return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)\n\n serializer = InviteParticipantToTeamSerializer(data=request.data,\n context={'participant_team': participant_team,\n 'request': request})\n if serializer.is_valid():\n serializer.save()\n response_data = {\n 'message': 'User has been added successfully to the team'}\n return Response(response_data, status=status.HTTP_202_ACCEPTED)\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n\n@throttle_classes([UserRateThrottle])\n@api_view(['DELETE'])\n@permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))\n@authentication_classes((ExpiringTokenAuthentication,))\ndef delete_participant_from_team(request, participant_team_pk, participant_pk):\n \"\"\"\n Deletes a participant from a Participant Team\n \"\"\"\n try:\n participant_team = ParticipantTeam.objects.get(pk=participant_team_pk)\n except ParticipantTeam.DoesNotExist:\n response_data = {'error': 'ParticipantTeam does not exist'}\n return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)\n\n try:\n participant = Participant.objects.get(pk=participant_pk)\n except Participant.DoesNotExist:\n response_data = {'error': 'Participant does not exist'}\n return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)\n\n if participant_team.created_by == request.user:\n\n if participant.user == request.user: # when the user tries to remove himself\n response_data = {\n 'error': 'You are not allowed to remove yourself since you are admin. Please delete the team if you want to do so!'} # noqa: ignore=E501\n return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)\n else:\n participant.delete()\n return Response(status=status.HTTP_204_NO_CONTENT)\n else:\n response_data = {\n 'error': 'Sorry, you do not have permissions to remove this participant'}\n return Response(response_data, status=status.HTTP_401_UNAUTHORIZED)\n\n\n@throttle_classes([UserRateThrottle])\n@api_view(['GET', ])\n@permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))\n@authentication_classes((ExpiringTokenAuthentication,))\ndef get_teams_and_corresponding_challenges_for_a_participant(request):\n \"\"\"\n Returns list of teams and corresponding challenges for a participant\n \"\"\"\n # first get list of all the participants and teams related to the user\n participant_objs = Participant.objects.filter(user=request.user).prefetch_related('team')\n\n challenge_participated_teams = []\n for participant_obj in participant_objs:\n participant_team = participant_obj.team\n try:\n challenge = Challenge.objects.get(\n participant_teams=participant_team)\n except Challenge.DoesNotExist:\n challenge = None\n\n challenge_participated_teams.append(ChallengeParticipantTeam(\n challenge, participant_team))\n\n serializer = ChallengeParticipantTeamListSerializer(ChallengeParticipantTeamList(challenge_participated_teams))\n return Response(serializer.data, status=status.HTTP_200_OK)\n\n\n@throttle_classes([UserRateThrottle])\n@api_view(['DELETE', ])\n@permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))\n@authentication_classes((ExpiringTokenAuthentication,))\ndef remove_self_from_participant_team(request, participant_team_pk):\n \"\"\"\n A user can remove himself from the participant team.\n \"\"\"\n try:\n ParticipantTeam.objects.get(pk=participant_team_pk)\n except ParticipantTeam.DoesNotExist:\n response_data = {'error': 'ParticipantTeam does not exist'}\n return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)\n\n try:\n participant = Participant.objects.get(user=request.user.id, team__pk=participant_team_pk)\n participant.delete()\n return Response(status=status.HTTP_204_NO_CONTENT)\n except:\n response_data = {'error': 'Sorry, you do not belong to this team.'}\n return Response(response_data, status=status.HTTP_401_UNAUTHORIZED)\n", "path": "apps/participants/views.py"}]}
| 2,383 | 142 |
gh_patches_debug_35563
|
rasdani/github-patches
|
git_diff
|
litestar-org__litestar-784
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bug: StaticFiles sends files as `content-disposition: 'attachment'` in html-mode
**Describe the bug**
When using `StaticFiles` in html-mode, files are being sent with `content-disposition: 'attachment'`
**To Reproduce**
Create an `html/index.html` file. Run:
```python
from starlite import Starlite, StaticFilesConfig, TestClient
app = Starlite(
static_files_config=[StaticFilesConfig(path="/", directories=["html"], html_mode=True)], route_handlers=[]
)
with TestClient(app=app) as client:
res = client.get("/index.html")
assert not res.headers["content-disposition"].startswith("attachment")
```
Bug: StaticFiles sends files as `content-disposition: 'attachment'` in html-mode
**Describe the bug**
When using `StaticFiles` in html-mode, files are being sent with `content-disposition: 'attachment'`
**To Reproduce**
Create an `html/index.html` file. Run:
```python
from starlite import Starlite, StaticFilesConfig, TestClient
app = Starlite(
static_files_config=[StaticFilesConfig(path="/", directories=["html"], html_mode=True)], route_handlers=[]
)
with TestClient(app=app) as client:
res = client.get("/index.html")
assert not res.headers["content-disposition"].startswith("attachment")
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `starlite/static_files/base.py`
Content:
```
1 from os.path import commonpath, join
2 from typing import TYPE_CHECKING, List, Tuple, Union
3
4 from starlite.enums import ScopeType
5 from starlite.exceptions import MethodNotAllowedException, NotFoundException
6 from starlite.response import FileResponse
7 from starlite.status_codes import HTTP_404_NOT_FOUND
8 from starlite.utils.file import FileSystemAdapter
9
10 if TYPE_CHECKING:
11
12 from starlite.types import Receive, Scope, Send
13 from starlite.types.composite_types import PathType
14 from starlite.types.file_types import FileInfo, FileSystemProtocol
15
16
17 class StaticFiles:
18 __slots__ = ("is_html_mode", "directories", "adapter")
19
20 def __init__(self, is_html_mode: bool, directories: List["PathType"], file_system: "FileSystemProtocol") -> None:
21 """This class is an ASGI App that handles file sending.
22
23 Args:
24 is_html_mode: Flag dictating whether serving html. If true, the default file will be 'index.html'.
25 directories: A list of directories to serve files from.
26 file_system: The file_system spec to use for serving files.
27 """
28 self.adapter = FileSystemAdapter(file_system)
29 self.directories = directories
30 self.is_html_mode = is_html_mode
31
32 async def get_fs_info(
33 self, directories: List["PathType"], file_path: str
34 ) -> Union[Tuple[str, "FileInfo"], Tuple[None, None]]:
35 """Resolves the file path and returns the resolved path and a.
36
37 [stat_result][os.stat_result].
38
39 Args:
40 directories: A list of directory paths.
41 file_path: A file path to resolve
42
43 Returns:
44 A tuple with an optional resolved [Path][anyio.Path] instance and an optional [stat_result][os.stat_result].
45 """
46 for directory in directories:
47 try:
48 joined_path = join(directory, file_path) # noqa: PL118
49 file_info = await self.adapter.info(joined_path)
50 if file_info and commonpath([str(directory), file_info["name"], joined_path]) == str(directory):
51 return joined_path, file_info
52 except FileNotFoundError:
53 continue
54 return None, None
55
56 async def __call__(self, scope: "Scope", receive: "Receive", send: "Send") -> None:
57 if scope["type"] != ScopeType.HTTP or scope["method"] not in {"GET", "HEAD"}:
58 raise MethodNotAllowedException()
59
60 split_path = scope["path"].split("/")
61 filename = split_path[-1]
62 joined_path = join(*split_path) # noqa: PL118
63 resolved_path, fs_info = await self.get_fs_info(directories=self.directories, file_path=joined_path)
64
65 if fs_info and fs_info["type"] == "directory" and self.is_html_mode:
66 filename = "index.html"
67 resolved_path, fs_info = await self.get_fs_info(
68 directories=self.directories, file_path=join(resolved_path or joined_path, filename)
69 )
70
71 if fs_info and fs_info["type"] == "file":
72 await FileResponse(
73 path=resolved_path or joined_path,
74 file_info=fs_info,
75 file_system=self.adapter.file_system,
76 filename=filename,
77 is_head_response=scope["method"] == "HEAD",
78 )(scope, receive, send)
79 return
80
81 if self.is_html_mode:
82 filename = "404.html"
83 resolved_path, fs_info = await self.get_fs_info(directories=self.directories, file_path=filename)
84 if fs_info and fs_info["type"] == "file":
85 await FileResponse(
86 path=resolved_path or joined_path,
87 file_info=fs_info,
88 file_system=self.adapter.file_system,
89 filename=filename,
90 is_head_response=scope["method"] == "HEAD",
91 status_code=HTTP_404_NOT_FOUND,
92 )(scope, receive, send)
93 return
94
95 raise NotFoundException(f"no file or directory match the path {resolved_path or joined_path} was found")
96
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/starlite/static_files/base.py b/starlite/static_files/base.py
--- a/starlite/static_files/base.py
+++ b/starlite/static_files/base.py
@@ -8,6 +8,7 @@
from starlite.utils.file import FileSystemAdapter
if TYPE_CHECKING:
+ from typing_extensions import Literal
from starlite.types import Receive, Scope, Send
from starlite.types.composite_types import PathType
@@ -61,12 +62,15 @@
filename = split_path[-1]
joined_path = join(*split_path) # noqa: PL118
resolved_path, fs_info = await self.get_fs_info(directories=self.directories, file_path=joined_path)
+ content_disposition_type: "Literal['inline', 'attachment']" = "attachment"
- if fs_info and fs_info["type"] == "directory" and self.is_html_mode:
- filename = "index.html"
- resolved_path, fs_info = await self.get_fs_info(
- directories=self.directories, file_path=join(resolved_path or joined_path, filename)
- )
+ if self.is_html_mode:
+ content_disposition_type = "inline"
+ if fs_info and fs_info["type"] == "directory":
+ filename = "index.html"
+ resolved_path, fs_info = await self.get_fs_info(
+ directories=self.directories, file_path=join(resolved_path or joined_path, filename)
+ )
if fs_info and fs_info["type"] == "file":
await FileResponse(
@@ -75,6 +79,7 @@
file_system=self.adapter.file_system,
filename=filename,
is_head_response=scope["method"] == "HEAD",
+ content_disposition_type=content_disposition_type,
)(scope, receive, send)
return
@@ -89,6 +94,7 @@
filename=filename,
is_head_response=scope["method"] == "HEAD",
status_code=HTTP_404_NOT_FOUND,
+ content_disposition_type=content_disposition_type,
)(scope, receive, send)
return
|
{"golden_diff": "diff --git a/starlite/static_files/base.py b/starlite/static_files/base.py\n--- a/starlite/static_files/base.py\n+++ b/starlite/static_files/base.py\n@@ -8,6 +8,7 @@\n from starlite.utils.file import FileSystemAdapter\n \n if TYPE_CHECKING:\n+ from typing_extensions import Literal\n \n from starlite.types import Receive, Scope, Send\n from starlite.types.composite_types import PathType\n@@ -61,12 +62,15 @@\n filename = split_path[-1]\n joined_path = join(*split_path) # noqa: PL118\n resolved_path, fs_info = await self.get_fs_info(directories=self.directories, file_path=joined_path)\n+ content_disposition_type: \"Literal['inline', 'attachment']\" = \"attachment\"\n \n- if fs_info and fs_info[\"type\"] == \"directory\" and self.is_html_mode:\n- filename = \"index.html\"\n- resolved_path, fs_info = await self.get_fs_info(\n- directories=self.directories, file_path=join(resolved_path or joined_path, filename)\n- )\n+ if self.is_html_mode:\n+ content_disposition_type = \"inline\"\n+ if fs_info and fs_info[\"type\"] == \"directory\":\n+ filename = \"index.html\"\n+ resolved_path, fs_info = await self.get_fs_info(\n+ directories=self.directories, file_path=join(resolved_path or joined_path, filename)\n+ )\n \n if fs_info and fs_info[\"type\"] == \"file\":\n await FileResponse(\n@@ -75,6 +79,7 @@\n file_system=self.adapter.file_system,\n filename=filename,\n is_head_response=scope[\"method\"] == \"HEAD\",\n+ content_disposition_type=content_disposition_type,\n )(scope, receive, send)\n return\n \n@@ -89,6 +94,7 @@\n filename=filename,\n is_head_response=scope[\"method\"] == \"HEAD\",\n status_code=HTTP_404_NOT_FOUND,\n+ content_disposition_type=content_disposition_type,\n )(scope, receive, send)\n return\n", "issue": "Bug: StaticFiles sends files as `content-disposition: 'attachment'` in html-mode\n**Describe the bug**\r\nWhen using `StaticFiles` in html-mode, files are being sent with `content-disposition: 'attachment'`\r\n\r\n**To Reproduce**\r\nCreate an `html/index.html` file. Run:\r\n\r\n```python\r\nfrom starlite import Starlite, StaticFilesConfig, TestClient\r\n\r\napp = Starlite(\r\n static_files_config=[StaticFilesConfig(path=\"/\", directories=[\"html\"], html_mode=True)], route_handlers=[]\r\n)\r\n\r\nwith TestClient(app=app) as client:\r\n res = client.get(\"/index.html\")\r\n assert not res.headers[\"content-disposition\"].startswith(\"attachment\")\r\n```\r\n\nBug: StaticFiles sends files as `content-disposition: 'attachment'` in html-mode\n**Describe the bug**\r\nWhen using `StaticFiles` in html-mode, files are being sent with `content-disposition: 'attachment'`\r\n\r\n**To Reproduce**\r\nCreate an `html/index.html` file. Run:\r\n\r\n```python\r\nfrom starlite import Starlite, StaticFilesConfig, TestClient\r\n\r\napp = Starlite(\r\n static_files_config=[StaticFilesConfig(path=\"/\", directories=[\"html\"], html_mode=True)], route_handlers=[]\r\n)\r\n\r\nwith TestClient(app=app) as client:\r\n res = client.get(\"/index.html\")\r\n assert not res.headers[\"content-disposition\"].startswith(\"attachment\")\r\n```\r\n\n", "before_files": [{"content": "from os.path import commonpath, join\nfrom typing import TYPE_CHECKING, List, Tuple, Union\n\nfrom starlite.enums import ScopeType\nfrom starlite.exceptions import MethodNotAllowedException, NotFoundException\nfrom starlite.response import FileResponse\nfrom starlite.status_codes import HTTP_404_NOT_FOUND\nfrom starlite.utils.file import FileSystemAdapter\n\nif TYPE_CHECKING:\n\n from starlite.types import Receive, Scope, Send\n from starlite.types.composite_types import PathType\n from starlite.types.file_types import FileInfo, FileSystemProtocol\n\n\nclass StaticFiles:\n __slots__ = (\"is_html_mode\", \"directories\", \"adapter\")\n\n def __init__(self, is_html_mode: bool, directories: List[\"PathType\"], file_system: \"FileSystemProtocol\") -> None:\n \"\"\"This class is an ASGI App that handles file sending.\n\n Args:\n is_html_mode: Flag dictating whether serving html. If true, the default file will be 'index.html'.\n directories: A list of directories to serve files from.\n file_system: The file_system spec to use for serving files.\n \"\"\"\n self.adapter = FileSystemAdapter(file_system)\n self.directories = directories\n self.is_html_mode = is_html_mode\n\n async def get_fs_info(\n self, directories: List[\"PathType\"], file_path: str\n ) -> Union[Tuple[str, \"FileInfo\"], Tuple[None, None]]:\n \"\"\"Resolves the file path and returns the resolved path and a.\n\n [stat_result][os.stat_result].\n\n Args:\n directories: A list of directory paths.\n file_path: A file path to resolve\n\n Returns:\n A tuple with an optional resolved [Path][anyio.Path] instance and an optional [stat_result][os.stat_result].\n \"\"\"\n for directory in directories:\n try:\n joined_path = join(directory, file_path) # noqa: PL118\n file_info = await self.adapter.info(joined_path)\n if file_info and commonpath([str(directory), file_info[\"name\"], joined_path]) == str(directory):\n return joined_path, file_info\n except FileNotFoundError:\n continue\n return None, None\n\n async def __call__(self, scope: \"Scope\", receive: \"Receive\", send: \"Send\") -> None:\n if scope[\"type\"] != ScopeType.HTTP or scope[\"method\"] not in {\"GET\", \"HEAD\"}:\n raise MethodNotAllowedException()\n\n split_path = scope[\"path\"].split(\"/\")\n filename = split_path[-1]\n joined_path = join(*split_path) # noqa: PL118\n resolved_path, fs_info = await self.get_fs_info(directories=self.directories, file_path=joined_path)\n\n if fs_info and fs_info[\"type\"] == \"directory\" and self.is_html_mode:\n filename = \"index.html\"\n resolved_path, fs_info = await self.get_fs_info(\n directories=self.directories, file_path=join(resolved_path or joined_path, filename)\n )\n\n if fs_info and fs_info[\"type\"] == \"file\":\n await FileResponse(\n path=resolved_path or joined_path,\n file_info=fs_info,\n file_system=self.adapter.file_system,\n filename=filename,\n is_head_response=scope[\"method\"] == \"HEAD\",\n )(scope, receive, send)\n return\n\n if self.is_html_mode:\n filename = \"404.html\"\n resolved_path, fs_info = await self.get_fs_info(directories=self.directories, file_path=filename)\n if fs_info and fs_info[\"type\"] == \"file\":\n await FileResponse(\n path=resolved_path or joined_path,\n file_info=fs_info,\n file_system=self.adapter.file_system,\n filename=filename,\n is_head_response=scope[\"method\"] == \"HEAD\",\n status_code=HTTP_404_NOT_FOUND,\n )(scope, receive, send)\n return\n\n raise NotFoundException(f\"no file or directory match the path {resolved_path or joined_path} was found\")\n", "path": "starlite/static_files/base.py"}], "after_files": [{"content": "from os.path import commonpath, join\nfrom typing import TYPE_CHECKING, List, Tuple, Union\n\nfrom starlite.enums import ScopeType\nfrom starlite.exceptions import MethodNotAllowedException, NotFoundException\nfrom starlite.response import FileResponse\nfrom starlite.status_codes import HTTP_404_NOT_FOUND\nfrom starlite.utils.file import FileSystemAdapter\n\nif TYPE_CHECKING:\n from typing_extensions import Literal\n\n from starlite.types import Receive, Scope, Send\n from starlite.types.composite_types import PathType\n from starlite.types.file_types import FileInfo, FileSystemProtocol\n\n\nclass StaticFiles:\n __slots__ = (\"is_html_mode\", \"directories\", \"adapter\")\n\n def __init__(self, is_html_mode: bool, directories: List[\"PathType\"], file_system: \"FileSystemProtocol\") -> None:\n \"\"\"This class is an ASGI App that handles file sending.\n\n Args:\n is_html_mode: Flag dictating whether serving html. If true, the default file will be 'index.html'.\n directories: A list of directories to serve files from.\n file_system: The file_system spec to use for serving files.\n \"\"\"\n self.adapter = FileSystemAdapter(file_system)\n self.directories = directories\n self.is_html_mode = is_html_mode\n\n async def get_fs_info(\n self, directories: List[\"PathType\"], file_path: str\n ) -> Union[Tuple[str, \"FileInfo\"], Tuple[None, None]]:\n \"\"\"Resolves the file path and returns the resolved path and a.\n\n [stat_result][os.stat_result].\n\n Args:\n directories: A list of directory paths.\n file_path: A file path to resolve\n\n Returns:\n A tuple with an optional resolved [Path][anyio.Path] instance and an optional [stat_result][os.stat_result].\n \"\"\"\n for directory in directories:\n try:\n joined_path = join(directory, file_path) # noqa: PL118\n file_info = await self.adapter.info(joined_path)\n if file_info and commonpath([str(directory), file_info[\"name\"], joined_path]) == str(directory):\n return joined_path, file_info\n except FileNotFoundError:\n continue\n return None, None\n\n async def __call__(self, scope: \"Scope\", receive: \"Receive\", send: \"Send\") -> None:\n if scope[\"type\"] != ScopeType.HTTP or scope[\"method\"] not in {\"GET\", \"HEAD\"}:\n raise MethodNotAllowedException()\n\n split_path = scope[\"path\"].split(\"/\")\n filename = split_path[-1]\n joined_path = join(*split_path) # noqa: PL118\n resolved_path, fs_info = await self.get_fs_info(directories=self.directories, file_path=joined_path)\n content_disposition_type: \"Literal['inline', 'attachment']\" = \"attachment\"\n\n if self.is_html_mode:\n content_disposition_type = \"inline\"\n if fs_info and fs_info[\"type\"] == \"directory\":\n filename = \"index.html\"\n resolved_path, fs_info = await self.get_fs_info(\n directories=self.directories, file_path=join(resolved_path or joined_path, filename)\n )\n\n if fs_info and fs_info[\"type\"] == \"file\":\n await FileResponse(\n path=resolved_path or joined_path,\n file_info=fs_info,\n file_system=self.adapter.file_system,\n filename=filename,\n is_head_response=scope[\"method\"] == \"HEAD\",\n content_disposition_type=content_disposition_type,\n )(scope, receive, send)\n return\n\n if self.is_html_mode:\n filename = \"404.html\"\n resolved_path, fs_info = await self.get_fs_info(directories=self.directories, file_path=filename)\n if fs_info and fs_info[\"type\"] == \"file\":\n await FileResponse(\n path=resolved_path or joined_path,\n file_info=fs_info,\n file_system=self.adapter.file_system,\n filename=filename,\n is_head_response=scope[\"method\"] == \"HEAD\",\n status_code=HTTP_404_NOT_FOUND,\n content_disposition_type=content_disposition_type,\n )(scope, receive, send)\n return\n\n raise NotFoundException(f\"no file or directory match the path {resolved_path or joined_path} was found\")\n", "path": "starlite/static_files/base.py"}]}
| 1,608 | 468 |
gh_patches_debug_24510
|
rasdani/github-patches
|
git_diff
|
pytorch__vision-3628
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Select subset of classes to sample from
## 🚀 Feature
When loading a dataset with `ImageFolder` provide an optional argument to select a subset of classes.
## Motivation
I deal with large (1000+) multi-class datasets upon which I train image classifiers. However, I usually don't want to train for all the classes at the same time.
## Pitch
I'd like to change `find_classes` function
https://github.com/pytorch/vision/blob/20a771e5143c6867eee63868c38a5bcc272a35e7/torchvision/datasets/folder.py#L61
to
```python
classes = sorted(entry.name for entry in os.scandir(directory)
if entry.is_dir() and (entry.name in allowed_classes or not allowed_classes))
```
where `allowed_classes: Optional[str] = []` is an empty list by default but it can given to `ImageFolder` at initialisation time (it has to be propagated back to `DatasetFolder` where `find_classes` is used).
## Alternatives
I tried to
1) manually create a new folder structure with only the relevant classes. This gets messy quite fast as I have now multiple versions of the same folders
2) resort to a custom dataloader filtering loaded samples after initialisation (obviously this is very slow as soon as the number of images increases)
## Additional context
Here I found a discussion on the same topic.
https://discuss.pytorch.org/t/how-to-sample-images-belonging-to-particular-classes/43776/8
cc @pmeier
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `torchvision/datasets/folder.py`
Content:
```
1 from .vision import VisionDataset
2
3 from PIL import Image
4
5 import os
6 import os.path
7 from typing import Any, Callable, cast, Dict, List, Optional, Tuple
8
9
10 def has_file_allowed_extension(filename: str, extensions: Tuple[str, ...]) -> bool:
11 """Checks if a file is an allowed extension.
12
13 Args:
14 filename (string): path to a file
15 extensions (tuple of strings): extensions to consider (lowercase)
16
17 Returns:
18 bool: True if the filename ends with one of given extensions
19 """
20 return filename.lower().endswith(extensions)
21
22
23 def is_image_file(filename: str) -> bool:
24 """Checks if a file is an allowed image extension.
25
26 Args:
27 filename (string): path to a file
28
29 Returns:
30 bool: True if the filename ends with a known image extension
31 """
32 return has_file_allowed_extension(filename, IMG_EXTENSIONS)
33
34
35 def find_classes(directory: str) -> Tuple[List[str], Dict[str, int]]:
36 """Finds the class folders in a dataset structured as follows:
37
38 .. code::
39
40 directory/
41 ├── class_x
42 │ ├── xxx.ext
43 │ ├── xxy.ext
44 │ └── ...
45 │ └── xxz.ext
46 └── class_y
47 ├── 123.ext
48 ├── nsdf3.ext
49 └── ...
50 └── asd932_.ext
51
52 Args:
53 directory (str): Root directory path.
54
55 Raises:
56 FileNotFoundError: If ``directory`` has no class folders.
57
58 Returns:
59 (Tuple[List[str], Dict[str, int]]): List of all classes and dictionary mapping each class to an index.
60 """
61 classes = sorted(entry.name for entry in os.scandir(directory) if entry.is_dir())
62 if not classes:
63 raise FileNotFoundError(f"Couldn't find any class folder in {directory}.")
64
65 class_to_idx = {cls_name: i for i, cls_name in enumerate(classes)}
66 return classes, class_to_idx
67
68
69 def make_dataset(
70 directory: str,
71 class_to_idx: Optional[Dict[str, int]] = None,
72 extensions: Optional[Tuple[str, ...]] = None,
73 is_valid_file: Optional[Callable[[str], bool]] = None,
74 ) -> List[Tuple[str, int]]:
75 """Generates a list of samples of a form (path_to_sample, class).
76
77 Args:
78 directory (str): root dataset directory
79 class_to_idx (Optional[Dict[str, int]]): Dictionary mapping class name to class index. If omitted, is generated
80 by :func:`find_classes`.
81 extensions (optional): A list of allowed extensions.
82 Either extensions or is_valid_file should be passed. Defaults to None.
83 is_valid_file (optional): A function that takes path of a file
84 and checks if the file is a valid file
85 (used to check of corrupt files) both extensions and
86 is_valid_file should not be passed. Defaults to None.
87
88 Raises:
89 ValueError: In case ``class_to_idx`` is empty.
90 ValueError: In case ``extensions`` and ``is_valid_file`` are None or both are not None.
91 FileNotFoundError: In case no valid file was found for any class.
92
93 Returns:
94 List[Tuple[str, int]]: samples of a form (path_to_sample, class)
95 """
96 directory = os.path.expanduser(directory)
97
98 if class_to_idx is None:
99 _, class_to_idx = find_classes(directory)
100 elif not class_to_idx:
101 raise ValueError("'class_to_index' must have at least one entry to collect any samples.")
102
103 both_none = extensions is None and is_valid_file is None
104 both_something = extensions is not None and is_valid_file is not None
105 if both_none or both_something:
106 raise ValueError("Both extensions and is_valid_file cannot be None or not None at the same time")
107
108 if extensions is not None:
109
110 def is_valid_file(x: str) -> bool:
111 return has_file_allowed_extension(x, cast(Tuple[str, ...], extensions))
112
113 is_valid_file = cast(Callable[[str], bool], is_valid_file)
114
115 instances = []
116 available_classes = set()
117 for target_class in sorted(class_to_idx.keys()):
118 class_index = class_to_idx[target_class]
119 target_dir = os.path.join(directory, target_class)
120 if not os.path.isdir(target_dir):
121 continue
122 for root, _, fnames in sorted(os.walk(target_dir, followlinks=True)):
123 for fname in sorted(fnames):
124 path = os.path.join(root, fname)
125 if is_valid_file(path):
126 item = path, class_index
127 instances.append(item)
128
129 if target_class not in available_classes:
130 available_classes.add(target_class)
131
132 empty_classes = set(class_to_idx.keys()) - available_classes
133 if empty_classes:
134 msg = f"Found no valid file for the classes {', '.join(sorted(empty_classes))}. "
135 if extensions is not None:
136 msg += f"Supported extensions are: {', '.join(extensions)}"
137 raise FileNotFoundError(msg)
138
139 return instances
140
141
142 class DatasetFolder(VisionDataset):
143 """A generic data loader where the samples are arranged in this way: ::
144
145 root/class_x/xxx.ext
146 root/class_x/xxy.ext
147 root/class_x/[...]/xxz.ext
148
149 root/class_y/123.ext
150 root/class_y/nsdf3.ext
151 root/class_y/[...]/asd932_.ext
152
153 Args:
154 root (string): Root directory path.
155 loader (callable): A function to load a sample given its path.
156 extensions (tuple[string]): A list of allowed extensions.
157 both extensions and is_valid_file should not be passed.
158 transform (callable, optional): A function/transform that takes in
159 a sample and returns a transformed version.
160 E.g, ``transforms.RandomCrop`` for images.
161 target_transform (callable, optional): A function/transform that takes
162 in the target and transforms it.
163 is_valid_file (callable, optional): A function that takes path of a file
164 and check if the file is a valid file (used to check of corrupt files)
165 both extensions and is_valid_file should not be passed.
166
167 Attributes:
168 classes (list): List of the class names sorted alphabetically.
169 class_to_idx (dict): Dict with items (class_name, class_index).
170 samples (list): List of (sample path, class_index) tuples
171 targets (list): The class_index value for each image in the dataset
172 """
173
174 def __init__(
175 self,
176 root: str,
177 loader: Callable[[str], Any],
178 extensions: Optional[Tuple[str, ...]] = None,
179 transform: Optional[Callable] = None,
180 target_transform: Optional[Callable] = None,
181 is_valid_file: Optional[Callable[[str], bool]] = None,
182 ) -> None:
183 super(DatasetFolder, self).__init__(root, transform=transform,
184 target_transform=target_transform)
185 classes, class_to_idx = self._find_classes(self.root)
186 samples = self.make_dataset(self.root, class_to_idx, extensions, is_valid_file)
187
188 self.loader = loader
189 self.extensions = extensions
190
191 self.classes = classes
192 self.class_to_idx = class_to_idx
193 self.samples = samples
194 self.targets = [s[1] for s in samples]
195
196 @staticmethod
197 def make_dataset(
198 directory: str,
199 class_to_idx: Dict[str, int],
200 extensions: Optional[Tuple[str, ...]] = None,
201 is_valid_file: Optional[Callable[[str], bool]] = None,
202 ) -> List[Tuple[str, int]]:
203 return make_dataset(directory, class_to_idx, extensions=extensions, is_valid_file=is_valid_file)
204
205 @staticmethod
206 def _find_classes(dir: str) -> Tuple[List[str], Dict[str, int]]:
207 return find_classes(dir)
208
209 def __getitem__(self, index: int) -> Tuple[Any, Any]:
210 """
211 Args:
212 index (int): Index
213
214 Returns:
215 tuple: (sample, target) where target is class_index of the target class.
216 """
217 path, target = self.samples[index]
218 sample = self.loader(path)
219 if self.transform is not None:
220 sample = self.transform(sample)
221 if self.target_transform is not None:
222 target = self.target_transform(target)
223
224 return sample, target
225
226 def __len__(self) -> int:
227 return len(self.samples)
228
229
230 IMG_EXTENSIONS = ('.jpg', '.jpeg', '.png', '.ppm', '.bmp', '.pgm', '.tif', '.tiff', '.webp')
231
232
233 def pil_loader(path: str) -> Image.Image:
234 # open path as file to avoid ResourceWarning (https://github.com/python-pillow/Pillow/issues/835)
235 with open(path, 'rb') as f:
236 img = Image.open(f)
237 return img.convert('RGB')
238
239
240 # TODO: specify the return type
241 def accimage_loader(path: str) -> Any:
242 import accimage
243 try:
244 return accimage.Image(path)
245 except IOError:
246 # Potentially a decoding problem, fall back to PIL.Image
247 return pil_loader(path)
248
249
250 def default_loader(path: str) -> Any:
251 from torchvision import get_image_backend
252 if get_image_backend() == 'accimage':
253 return accimage_loader(path)
254 else:
255 return pil_loader(path)
256
257
258 class ImageFolder(DatasetFolder):
259 """A generic data loader where the images are arranged in this way: ::
260
261 root/dog/xxx.png
262 root/dog/xxy.png
263 root/dog/[...]/xxz.png
264
265 root/cat/123.png
266 root/cat/nsdf3.png
267 root/cat/[...]/asd932_.png
268
269 Args:
270 root (string): Root directory path.
271 transform (callable, optional): A function/transform that takes in an PIL image
272 and returns a transformed version. E.g, ``transforms.RandomCrop``
273 target_transform (callable, optional): A function/transform that takes in the
274 target and transforms it.
275 loader (callable, optional): A function to load an image given its path.
276 is_valid_file (callable, optional): A function that takes path of an Image file
277 and check if the file is a valid file (used to check of corrupt files)
278
279 Attributes:
280 classes (list): List of the class names sorted alphabetically.
281 class_to_idx (dict): Dict with items (class_name, class_index).
282 imgs (list): List of (image path, class_index) tuples
283 """
284
285 def __init__(
286 self,
287 root: str,
288 transform: Optional[Callable] = None,
289 target_transform: Optional[Callable] = None,
290 loader: Callable[[str], Any] = default_loader,
291 is_valid_file: Optional[Callable[[str], bool]] = None,
292 ):
293 super(ImageFolder, self).__init__(root, loader, IMG_EXTENSIONS if is_valid_file is None else None,
294 transform=transform,
295 target_transform=target_transform,
296 is_valid_file=is_valid_file)
297 self.imgs = self.samples
298
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/torchvision/datasets/folder.py b/torchvision/datasets/folder.py
--- a/torchvision/datasets/folder.py
+++ b/torchvision/datasets/folder.py
@@ -182,7 +182,7 @@
) -> None:
super(DatasetFolder, self).__init__(root, transform=transform,
target_transform=target_transform)
- classes, class_to_idx = self._find_classes(self.root)
+ classes, class_to_idx = self.find_classes(self.root)
samples = self.make_dataset(self.root, class_to_idx, extensions, is_valid_file)
self.loader = loader
@@ -202,8 +202,12 @@
) -> List[Tuple[str, int]]:
return make_dataset(directory, class_to_idx, extensions=extensions, is_valid_file=is_valid_file)
- @staticmethod
- def _find_classes(dir: str) -> Tuple[List[str], Dict[str, int]]:
+ def find_classes(self, dir: str) -> Tuple[List[str], Dict[str, int]]:
+ """Same as :func:`find_classes`.
+
+ This method can be overridden to only consider
+ a subset of classes, or to adapt to a different dataset directory structure.
+ """
return find_classes(dir)
def __getitem__(self, index: int) -> Tuple[Any, Any]:
|
{"golden_diff": "diff --git a/torchvision/datasets/folder.py b/torchvision/datasets/folder.py\n--- a/torchvision/datasets/folder.py\n+++ b/torchvision/datasets/folder.py\n@@ -182,7 +182,7 @@\n ) -> None:\n super(DatasetFolder, self).__init__(root, transform=transform,\n target_transform=target_transform)\n- classes, class_to_idx = self._find_classes(self.root)\n+ classes, class_to_idx = self.find_classes(self.root)\n samples = self.make_dataset(self.root, class_to_idx, extensions, is_valid_file)\n \n self.loader = loader\n@@ -202,8 +202,12 @@\n ) -> List[Tuple[str, int]]:\n return make_dataset(directory, class_to_idx, extensions=extensions, is_valid_file=is_valid_file)\n \n- @staticmethod\n- def _find_classes(dir: str) -> Tuple[List[str], Dict[str, int]]:\n+ def find_classes(self, dir: str) -> Tuple[List[str], Dict[str, int]]:\n+ \"\"\"Same as :func:`find_classes`.\n+\n+ This method can be overridden to only consider\n+ a subset of classes, or to adapt to a different dataset directory structure.\n+ \"\"\"\n return find_classes(dir)\n \n def __getitem__(self, index: int) -> Tuple[Any, Any]:\n", "issue": "Select subset of classes to sample from\n## \ud83d\ude80 Feature\r\n\r\nWhen loading a dataset with `ImageFolder` provide an optional argument to select a subset of classes.\r\n\r\n## Motivation\r\n\r\nI deal with large (1000+) multi-class datasets upon which I train image classifiers. However, I usually don't want to train for all the classes at the same time.\r\n## Pitch\r\n\r\nI'd like to change `find_classes` function\r\nhttps://github.com/pytorch/vision/blob/20a771e5143c6867eee63868c38a5bcc272a35e7/torchvision/datasets/folder.py#L61\r\n\r\nto \r\n\r\n```python\r\nclasses = sorted(entry.name for entry in os.scandir(directory) \r\n if entry.is_dir() and (entry.name in allowed_classes or not allowed_classes))\r\n```\r\n\r\nwhere `allowed_classes: Optional[str] = []` is an empty list by default but it can given to `ImageFolder` at initialisation time (it has to be propagated back to `DatasetFolder` where `find_classes` is used).\r\n\r\n## Alternatives\r\n\r\nI tried to\r\n\r\n1) manually create a new folder structure with only the relevant classes. This gets messy quite fast as I have now multiple versions of the same folders\r\n2) resort to a custom dataloader filtering loaded samples after initialisation (obviously this is very slow as soon as the number of images increases)\r\n\r\n## Additional context\r\n\r\nHere I found a discussion on the same topic.\r\n\r\nhttps://discuss.pytorch.org/t/how-to-sample-images-belonging-to-particular-classes/43776/8\r\n\n\ncc @pmeier\n", "before_files": [{"content": "from .vision import VisionDataset\n\nfrom PIL import Image\n\nimport os\nimport os.path\nfrom typing import Any, Callable, cast, Dict, List, Optional, Tuple\n\n\ndef has_file_allowed_extension(filename: str, extensions: Tuple[str, ...]) -> bool:\n \"\"\"Checks if a file is an allowed extension.\n\n Args:\n filename (string): path to a file\n extensions (tuple of strings): extensions to consider (lowercase)\n\n Returns:\n bool: True if the filename ends with one of given extensions\n \"\"\"\n return filename.lower().endswith(extensions)\n\n\ndef is_image_file(filename: str) -> bool:\n \"\"\"Checks if a file is an allowed image extension.\n\n Args:\n filename (string): path to a file\n\n Returns:\n bool: True if the filename ends with a known image extension\n \"\"\"\n return has_file_allowed_extension(filename, IMG_EXTENSIONS)\n\n\ndef find_classes(directory: str) -> Tuple[List[str], Dict[str, int]]:\n \"\"\"Finds the class folders in a dataset structured as follows:\n\n .. code::\n\n directory/\n \u251c\u2500\u2500 class_x\n \u2502 \u251c\u2500\u2500 xxx.ext\n \u2502 \u251c\u2500\u2500 xxy.ext\n \u2502 \u2514\u2500\u2500 ...\n \u2502 \u2514\u2500\u2500 xxz.ext\n \u2514\u2500\u2500 class_y\n \u251c\u2500\u2500 123.ext\n \u251c\u2500\u2500 nsdf3.ext\n \u2514\u2500\u2500 ...\n \u2514\u2500\u2500 asd932_.ext\n\n Args:\n directory (str): Root directory path.\n\n Raises:\n FileNotFoundError: If ``directory`` has no class folders.\n\n Returns:\n (Tuple[List[str], Dict[str, int]]): List of all classes and dictionary mapping each class to an index.\n \"\"\"\n classes = sorted(entry.name for entry in os.scandir(directory) if entry.is_dir())\n if not classes:\n raise FileNotFoundError(f\"Couldn't find any class folder in {directory}.\")\n\n class_to_idx = {cls_name: i for i, cls_name in enumerate(classes)}\n return classes, class_to_idx\n\n\ndef make_dataset(\n directory: str,\n class_to_idx: Optional[Dict[str, int]] = None,\n extensions: Optional[Tuple[str, ...]] = None,\n is_valid_file: Optional[Callable[[str], bool]] = None,\n) -> List[Tuple[str, int]]:\n \"\"\"Generates a list of samples of a form (path_to_sample, class).\n\n Args:\n directory (str): root dataset directory\n class_to_idx (Optional[Dict[str, int]]): Dictionary mapping class name to class index. If omitted, is generated\n by :func:`find_classes`.\n extensions (optional): A list of allowed extensions.\n Either extensions or is_valid_file should be passed. Defaults to None.\n is_valid_file (optional): A function that takes path of a file\n and checks if the file is a valid file\n (used to check of corrupt files) both extensions and\n is_valid_file should not be passed. Defaults to None.\n\n Raises:\n ValueError: In case ``class_to_idx`` is empty.\n ValueError: In case ``extensions`` and ``is_valid_file`` are None or both are not None.\n FileNotFoundError: In case no valid file was found for any class.\n\n Returns:\n List[Tuple[str, int]]: samples of a form (path_to_sample, class)\n \"\"\"\n directory = os.path.expanduser(directory)\n\n if class_to_idx is None:\n _, class_to_idx = find_classes(directory)\n elif not class_to_idx:\n raise ValueError(\"'class_to_index' must have at least one entry to collect any samples.\")\n\n both_none = extensions is None and is_valid_file is None\n both_something = extensions is not None and is_valid_file is not None\n if both_none or both_something:\n raise ValueError(\"Both extensions and is_valid_file cannot be None or not None at the same time\")\n\n if extensions is not None:\n\n def is_valid_file(x: str) -> bool:\n return has_file_allowed_extension(x, cast(Tuple[str, ...], extensions))\n\n is_valid_file = cast(Callable[[str], bool], is_valid_file)\n\n instances = []\n available_classes = set()\n for target_class in sorted(class_to_idx.keys()):\n class_index = class_to_idx[target_class]\n target_dir = os.path.join(directory, target_class)\n if not os.path.isdir(target_dir):\n continue\n for root, _, fnames in sorted(os.walk(target_dir, followlinks=True)):\n for fname in sorted(fnames):\n path = os.path.join(root, fname)\n if is_valid_file(path):\n item = path, class_index\n instances.append(item)\n\n if target_class not in available_classes:\n available_classes.add(target_class)\n\n empty_classes = set(class_to_idx.keys()) - available_classes\n if empty_classes:\n msg = f\"Found no valid file for the classes {', '.join(sorted(empty_classes))}. \"\n if extensions is not None:\n msg += f\"Supported extensions are: {', '.join(extensions)}\"\n raise FileNotFoundError(msg)\n\n return instances\n\n\nclass DatasetFolder(VisionDataset):\n \"\"\"A generic data loader where the samples are arranged in this way: ::\n\n root/class_x/xxx.ext\n root/class_x/xxy.ext\n root/class_x/[...]/xxz.ext\n\n root/class_y/123.ext\n root/class_y/nsdf3.ext\n root/class_y/[...]/asd932_.ext\n\n Args:\n root (string): Root directory path.\n loader (callable): A function to load a sample given its path.\n extensions (tuple[string]): A list of allowed extensions.\n both extensions and is_valid_file should not be passed.\n transform (callable, optional): A function/transform that takes in\n a sample and returns a transformed version.\n E.g, ``transforms.RandomCrop`` for images.\n target_transform (callable, optional): A function/transform that takes\n in the target and transforms it.\n is_valid_file (callable, optional): A function that takes path of a file\n and check if the file is a valid file (used to check of corrupt files)\n both extensions and is_valid_file should not be passed.\n\n Attributes:\n classes (list): List of the class names sorted alphabetically.\n class_to_idx (dict): Dict with items (class_name, class_index).\n samples (list): List of (sample path, class_index) tuples\n targets (list): The class_index value for each image in the dataset\n \"\"\"\n\n def __init__(\n self,\n root: str,\n loader: Callable[[str], Any],\n extensions: Optional[Tuple[str, ...]] = None,\n transform: Optional[Callable] = None,\n target_transform: Optional[Callable] = None,\n is_valid_file: Optional[Callable[[str], bool]] = None,\n ) -> None:\n super(DatasetFolder, self).__init__(root, transform=transform,\n target_transform=target_transform)\n classes, class_to_idx = self._find_classes(self.root)\n samples = self.make_dataset(self.root, class_to_idx, extensions, is_valid_file)\n\n self.loader = loader\n self.extensions = extensions\n\n self.classes = classes\n self.class_to_idx = class_to_idx\n self.samples = samples\n self.targets = [s[1] for s in samples]\n\n @staticmethod\n def make_dataset(\n directory: str,\n class_to_idx: Dict[str, int],\n extensions: Optional[Tuple[str, ...]] = None,\n is_valid_file: Optional[Callable[[str], bool]] = None,\n ) -> List[Tuple[str, int]]:\n return make_dataset(directory, class_to_idx, extensions=extensions, is_valid_file=is_valid_file)\n\n @staticmethod\n def _find_classes(dir: str) -> Tuple[List[str], Dict[str, int]]:\n return find_classes(dir)\n\n def __getitem__(self, index: int) -> Tuple[Any, Any]:\n \"\"\"\n Args:\n index (int): Index\n\n Returns:\n tuple: (sample, target) where target is class_index of the target class.\n \"\"\"\n path, target = self.samples[index]\n sample = self.loader(path)\n if self.transform is not None:\n sample = self.transform(sample)\n if self.target_transform is not None:\n target = self.target_transform(target)\n\n return sample, target\n\n def __len__(self) -> int:\n return len(self.samples)\n\n\nIMG_EXTENSIONS = ('.jpg', '.jpeg', '.png', '.ppm', '.bmp', '.pgm', '.tif', '.tiff', '.webp')\n\n\ndef pil_loader(path: str) -> Image.Image:\n # open path as file to avoid ResourceWarning (https://github.com/python-pillow/Pillow/issues/835)\n with open(path, 'rb') as f:\n img = Image.open(f)\n return img.convert('RGB')\n\n\n# TODO: specify the return type\ndef accimage_loader(path: str) -> Any:\n import accimage\n try:\n return accimage.Image(path)\n except IOError:\n # Potentially a decoding problem, fall back to PIL.Image\n return pil_loader(path)\n\n\ndef default_loader(path: str) -> Any:\n from torchvision import get_image_backend\n if get_image_backend() == 'accimage':\n return accimage_loader(path)\n else:\n return pil_loader(path)\n\n\nclass ImageFolder(DatasetFolder):\n \"\"\"A generic data loader where the images are arranged in this way: ::\n\n root/dog/xxx.png\n root/dog/xxy.png\n root/dog/[...]/xxz.png\n\n root/cat/123.png\n root/cat/nsdf3.png\n root/cat/[...]/asd932_.png\n\n Args:\n root (string): Root directory path.\n transform (callable, optional): A function/transform that takes in an PIL image\n and returns a transformed version. E.g, ``transforms.RandomCrop``\n target_transform (callable, optional): A function/transform that takes in the\n target and transforms it.\n loader (callable, optional): A function to load an image given its path.\n is_valid_file (callable, optional): A function that takes path of an Image file\n and check if the file is a valid file (used to check of corrupt files)\n\n Attributes:\n classes (list): List of the class names sorted alphabetically.\n class_to_idx (dict): Dict with items (class_name, class_index).\n imgs (list): List of (image path, class_index) tuples\n \"\"\"\n\n def __init__(\n self,\n root: str,\n transform: Optional[Callable] = None,\n target_transform: Optional[Callable] = None,\n loader: Callable[[str], Any] = default_loader,\n is_valid_file: Optional[Callable[[str], bool]] = None,\n ):\n super(ImageFolder, self).__init__(root, loader, IMG_EXTENSIONS if is_valid_file is None else None,\n transform=transform,\n target_transform=target_transform,\n is_valid_file=is_valid_file)\n self.imgs = self.samples\n", "path": "torchvision/datasets/folder.py"}], "after_files": [{"content": "from .vision import VisionDataset\n\nfrom PIL import Image\n\nimport os\nimport os.path\nfrom typing import Any, Callable, cast, Dict, List, Optional, Tuple\n\n\ndef has_file_allowed_extension(filename: str, extensions: Tuple[str, ...]) -> bool:\n \"\"\"Checks if a file is an allowed extension.\n\n Args:\n filename (string): path to a file\n extensions (tuple of strings): extensions to consider (lowercase)\n\n Returns:\n bool: True if the filename ends with one of given extensions\n \"\"\"\n return filename.lower().endswith(extensions)\n\n\ndef is_image_file(filename: str) -> bool:\n \"\"\"Checks if a file is an allowed image extension.\n\n Args:\n filename (string): path to a file\n\n Returns:\n bool: True if the filename ends with a known image extension\n \"\"\"\n return has_file_allowed_extension(filename, IMG_EXTENSIONS)\n\n\ndef find_classes(directory: str) -> Tuple[List[str], Dict[str, int]]:\n \"\"\"Finds the class folders in a dataset structured as follows:\n\n .. code::\n\n directory/\n \u251c\u2500\u2500 class_x\n \u2502 \u251c\u2500\u2500 xxx.ext\n \u2502 \u251c\u2500\u2500 xxy.ext\n \u2502 \u2514\u2500\u2500 ...\n \u2502 \u2514\u2500\u2500 xxz.ext\n \u2514\u2500\u2500 class_y\n \u251c\u2500\u2500 123.ext\n \u251c\u2500\u2500 nsdf3.ext\n \u2514\u2500\u2500 ...\n \u2514\u2500\u2500 asd932_.ext\n\n Args:\n directory (str): Root directory path.\n\n Raises:\n FileNotFoundError: If ``directory`` has no class folders.\n\n Returns:\n (Tuple[List[str], Dict[str, int]]): List of all classes and dictionary mapping each class to an index.\n \"\"\"\n classes = sorted(entry.name for entry in os.scandir(directory) if entry.is_dir())\n if not classes:\n raise FileNotFoundError(f\"Couldn't find any class folder in {directory}.\")\n\n class_to_idx = {cls_name: i for i, cls_name in enumerate(classes)}\n return classes, class_to_idx\n\n\ndef make_dataset(\n directory: str,\n class_to_idx: Optional[Dict[str, int]] = None,\n extensions: Optional[Tuple[str, ...]] = None,\n is_valid_file: Optional[Callable[[str], bool]] = None,\n) -> List[Tuple[str, int]]:\n \"\"\"Generates a list of samples of a form (path_to_sample, class).\n\n Args:\n directory (str): root dataset directory\n class_to_idx (Optional[Dict[str, int]]): Dictionary mapping class name to class index. If omitted, is generated\n by :func:`find_classes`.\n extensions (optional): A list of allowed extensions.\n Either extensions or is_valid_file should be passed. Defaults to None.\n is_valid_file (optional): A function that takes path of a file\n and checks if the file is a valid file\n (used to check of corrupt files) both extensions and\n is_valid_file should not be passed. Defaults to None.\n\n Raises:\n ValueError: In case ``class_to_idx`` is empty.\n ValueError: In case ``extensions`` and ``is_valid_file`` are None or both are not None.\n FileNotFoundError: In case no valid file was found for any class.\n\n Returns:\n List[Tuple[str, int]]: samples of a form (path_to_sample, class)\n \"\"\"\n directory = os.path.expanduser(directory)\n\n if class_to_idx is None:\n _, class_to_idx = find_classes(directory)\n elif not class_to_idx:\n raise ValueError(\"'class_to_index' must have at least one entry to collect any samples.\")\n\n both_none = extensions is None and is_valid_file is None\n both_something = extensions is not None and is_valid_file is not None\n if both_none or both_something:\n raise ValueError(\"Both extensions and is_valid_file cannot be None or not None at the same time\")\n\n if extensions is not None:\n\n def is_valid_file(x: str) -> bool:\n return has_file_allowed_extension(x, cast(Tuple[str, ...], extensions))\n\n is_valid_file = cast(Callable[[str], bool], is_valid_file)\n\n instances = []\n available_classes = set()\n for target_class in sorted(class_to_idx.keys()):\n class_index = class_to_idx[target_class]\n target_dir = os.path.join(directory, target_class)\n if not os.path.isdir(target_dir):\n continue\n for root, _, fnames in sorted(os.walk(target_dir, followlinks=True)):\n for fname in sorted(fnames):\n path = os.path.join(root, fname)\n if is_valid_file(path):\n item = path, class_index\n instances.append(item)\n\n if target_class not in available_classes:\n available_classes.add(target_class)\n\n empty_classes = set(class_to_idx.keys()) - available_classes\n if empty_classes:\n msg = f\"Found no valid file for the classes {', '.join(sorted(empty_classes))}. \"\n if extensions is not None:\n msg += f\"Supported extensions are: {', '.join(extensions)}\"\n raise FileNotFoundError(msg)\n\n return instances\n\n\nclass DatasetFolder(VisionDataset):\n \"\"\"A generic data loader where the samples are arranged in this way: ::\n\n root/class_x/xxx.ext\n root/class_x/xxy.ext\n root/class_x/[...]/xxz.ext\n\n root/class_y/123.ext\n root/class_y/nsdf3.ext\n root/class_y/[...]/asd932_.ext\n\n Args:\n root (string): Root directory path.\n loader (callable): A function to load a sample given its path.\n extensions (tuple[string]): A list of allowed extensions.\n both extensions and is_valid_file should not be passed.\n transform (callable, optional): A function/transform that takes in\n a sample and returns a transformed version.\n E.g, ``transforms.RandomCrop`` for images.\n target_transform (callable, optional): A function/transform that takes\n in the target and transforms it.\n is_valid_file (callable, optional): A function that takes path of a file\n and check if the file is a valid file (used to check of corrupt files)\n both extensions and is_valid_file should not be passed.\n\n Attributes:\n classes (list): List of the class names sorted alphabetically.\n class_to_idx (dict): Dict with items (class_name, class_index).\n samples (list): List of (sample path, class_index) tuples\n targets (list): The class_index value for each image in the dataset\n \"\"\"\n\n def __init__(\n self,\n root: str,\n loader: Callable[[str], Any],\n extensions: Optional[Tuple[str, ...]] = None,\n transform: Optional[Callable] = None,\n target_transform: Optional[Callable] = None,\n is_valid_file: Optional[Callable[[str], bool]] = None,\n ) -> None:\n super(DatasetFolder, self).__init__(root, transform=transform,\n target_transform=target_transform)\n classes, class_to_idx = self.find_classes(self.root)\n samples = self.make_dataset(self.root, class_to_idx, extensions, is_valid_file)\n\n self.loader = loader\n self.extensions = extensions\n\n self.classes = classes\n self.class_to_idx = class_to_idx\n self.samples = samples\n self.targets = [s[1] for s in samples]\n\n @staticmethod\n def make_dataset(\n directory: str,\n class_to_idx: Dict[str, int],\n extensions: Optional[Tuple[str, ...]] = None,\n is_valid_file: Optional[Callable[[str], bool]] = None,\n ) -> List[Tuple[str, int]]:\n return make_dataset(directory, class_to_idx, extensions=extensions, is_valid_file=is_valid_file)\n\n def find_classes(self, dir: str) -> Tuple[List[str], Dict[str, int]]:\n \"\"\"Same as :func:`find_classes`.\n\n This method can be overridden to only consider\n a subset of classes, or to adapt to a different dataset directory structure.\n \"\"\"\n return find_classes(dir)\n\n def __getitem__(self, index: int) -> Tuple[Any, Any]:\n \"\"\"\n Args:\n index (int): Index\n\n Returns:\n tuple: (sample, target) where target is class_index of the target class.\n \"\"\"\n path, target = self.samples[index]\n sample = self.loader(path)\n if self.transform is not None:\n sample = self.transform(sample)\n if self.target_transform is not None:\n target = self.target_transform(target)\n\n return sample, target\n\n def __len__(self) -> int:\n return len(self.samples)\n\n\nIMG_EXTENSIONS = ('.jpg', '.jpeg', '.png', '.ppm', '.bmp', '.pgm', '.tif', '.tiff', '.webp')\n\n\ndef pil_loader(path: str) -> Image.Image:\n # open path as file to avoid ResourceWarning (https://github.com/python-pillow/Pillow/issues/835)\n with open(path, 'rb') as f:\n img = Image.open(f)\n return img.convert('RGB')\n\n\n# TODO: specify the return type\ndef accimage_loader(path: str) -> Any:\n import accimage\n try:\n return accimage.Image(path)\n except IOError:\n # Potentially a decoding problem, fall back to PIL.Image\n return pil_loader(path)\n\n\ndef default_loader(path: str) -> Any:\n from torchvision import get_image_backend\n if get_image_backend() == 'accimage':\n return accimage_loader(path)\n else:\n return pil_loader(path)\n\n\nclass ImageFolder(DatasetFolder):\n \"\"\"A generic data loader where the images are arranged in this way: ::\n\n root/dog/xxx.png\n root/dog/xxy.png\n root/dog/[...]/xxz.png\n\n root/cat/123.png\n root/cat/nsdf3.png\n root/cat/[...]/asd932_.png\n\n Args:\n root (string): Root directory path.\n transform (callable, optional): A function/transform that takes in an PIL image\n and returns a transformed version. E.g, ``transforms.RandomCrop``\n target_transform (callable, optional): A function/transform that takes in the\n target and transforms it.\n loader (callable, optional): A function to load an image given its path.\n is_valid_file (callable, optional): A function that takes path of an Image file\n and check if the file is a valid file (used to check of corrupt files)\n\n Attributes:\n classes (list): List of the class names sorted alphabetically.\n class_to_idx (dict): Dict with items (class_name, class_index).\n imgs (list): List of (image path, class_index) tuples\n \"\"\"\n\n def __init__(\n self,\n root: str,\n transform: Optional[Callable] = None,\n target_transform: Optional[Callable] = None,\n loader: Callable[[str], Any] = default_loader,\n is_valid_file: Optional[Callable[[str], bool]] = None,\n ):\n super(ImageFolder, self).__init__(root, loader, IMG_EXTENSIONS if is_valid_file is None else None,\n transform=transform,\n target_transform=target_transform,\n is_valid_file=is_valid_file)\n self.imgs = self.samples\n", "path": "torchvision/datasets/folder.py"}]}
| 3,840 | 300 |
gh_patches_debug_42468
|
rasdani/github-patches
|
git_diff
|
pex-tool__pex-701
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
If sys.executable is not on PATH a pex will re-exec itself forever.
This can happen via:
```
/not/on/PATH/python a.pex
```
If `a.pex` in this example has compatibility constraints that rule out all other interpreters on `PATH` (or there are no intepreters on `PATH`!, c.f.: #53), then, even if sys.executable would be compatible to execute `a.pex` with, it is not considered useable:
https://github.com/pantsbuild/pex/blob/442ce7952674cb8a367ecded7d138661194d4f12/pex/pex_bootstrapper.py#L45-L50
https://github.com/pantsbuild/pex/blob/442ce7952674cb8a367ecded7d138661194d4f12/pex/interpreter.py#L283-L287
And so the pex_bootstrapper re-execs the pex ad infinitum:
https://github.com/pantsbuild/pex/blob/442ce7952674cb8a367ecded7d138661194d4f12/pex/pex_bootstrapper.py#L122-L137
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pex/pex_bootstrapper.py`
Content:
```
1 # Copyright 2014 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 from __future__ import absolute_import, print_function
5
6 import os
7 import sys
8
9 from pex import pex_warnings
10 from pex.common import die
11 from pex.executor import Executor
12 from pex.interpreter import PythonInterpreter
13 from pex.interpreter_constraints import matched_interpreters
14 from pex.tracer import TRACER
15 from pex.variables import ENV
16
17 __all__ = ('bootstrap_pex',)
18
19
20 def find_in_path(target_interpreter):
21 if os.path.exists(target_interpreter):
22 return target_interpreter
23
24 for directory in os.getenv('PATH', '').split(os.pathsep):
25 try_path = os.path.join(directory, target_interpreter)
26 if os.path.exists(try_path):
27 return try_path
28
29
30 def find_compatible_interpreters(pex_python_path, compatibility_constraints):
31 """Find all compatible interpreters on the system within the supplied constraints and use
32 PEX_PYTHON_PATH if it is set. If not, fall back to interpreters on $PATH.
33 """
34 if pex_python_path:
35 interpreters = []
36 for binary in pex_python_path.split(os.pathsep):
37 try:
38 interpreters.append(PythonInterpreter.from_binary(binary))
39 except Executor.ExecutionError:
40 print("Python interpreter %s in PEX_PYTHON_PATH failed to load properly." % binary,
41 file=sys.stderr)
42 if not interpreters:
43 die('PEX_PYTHON_PATH was defined, but no valid interpreters could be identified. Exiting.')
44 else:
45 if not os.getenv('PATH', ''):
46 # no $PATH, use sys.executable
47 interpreters = [PythonInterpreter.get()]
48 else:
49 # get all qualifying interpreters found in $PATH
50 interpreters = PythonInterpreter.all()
51
52 return list(
53 matched_interpreters(interpreters, compatibility_constraints)
54 if compatibility_constraints
55 else interpreters
56 )
57
58
59 def _select_pex_python_interpreter(target_python, compatibility_constraints):
60 target = find_in_path(target_python)
61
62 if not target:
63 die('Failed to find interpreter specified by PEX_PYTHON: %s' % target)
64 if compatibility_constraints:
65 pi = PythonInterpreter.from_binary(target)
66 if not list(matched_interpreters([pi], compatibility_constraints)):
67 die('Interpreter specified by PEX_PYTHON (%s) is not compatible with specified '
68 'interpreter constraints: %s' % (target, str(compatibility_constraints)))
69 if not os.path.exists(target):
70 die('Target interpreter specified by PEX_PYTHON %s does not exist. Exiting.' % target)
71 return target
72
73
74 def _select_interpreter(pex_python_path, compatibility_constraints):
75 compatible_interpreters = find_compatible_interpreters(
76 pex_python_path, compatibility_constraints)
77
78 if not compatible_interpreters:
79 die('Failed to find compatible interpreter for constraints: %s'
80 % str(compatibility_constraints))
81 # TODO: https://github.com/pantsbuild/pex/issues/430
82 target = min(compatible_interpreters).binary
83
84 if os.path.exists(target):
85 return target
86
87
88 def maybe_reexec_pex(compatibility_constraints):
89 """
90 Handle environment overrides for the Python interpreter to use when executing this pex.
91
92 This function supports interpreter filtering based on interpreter constraints stored in PEX-INFO
93 metadata. If PEX_PYTHON is set in a pexrc, it attempts to obtain the binary location of the
94 interpreter specified by PEX_PYTHON. If PEX_PYTHON_PATH is set, it attempts to search the path for
95 a matching interpreter in accordance with the interpreter constraints. If both variables are
96 present in a pexrc, this function gives precedence to PEX_PYTHON_PATH and errors out if no
97 compatible interpreters can be found on said path.
98
99 If neither variable is set, we fall back to plain PEX execution using PATH searching or the
100 currently executing interpreter. If compatibility constraints are used, we match those constraints
101 against these interpreters.
102
103 :param compatibility_constraints: list of requirements-style strings that constrain the
104 Python interpreter to re-exec this pex with.
105 """
106 if os.environ.pop('SHOULD_EXIT_BOOTSTRAP_REEXEC', None):
107 # We've already been here and selected an interpreter. Continue to execution.
108 return
109
110 target = None
111 with TRACER.timed('Selecting runtime interpreter based on pexrc', V=3):
112 if ENV.PEX_PYTHON and not ENV.PEX_PYTHON_PATH:
113 # preserve PEX_PYTHON re-exec for backwards compatibility
114 # TODO: Kill this off completely in favor of PEX_PYTHON_PATH
115 # https://github.com/pantsbuild/pex/issues/431
116 target = _select_pex_python_interpreter(ENV.PEX_PYTHON,
117 compatibility_constraints)
118 elif ENV.PEX_PYTHON_PATH:
119 target = _select_interpreter(ENV.PEX_PYTHON_PATH, compatibility_constraints)
120
121 elif compatibility_constraints:
122 # Apply constraints to target using regular PATH
123 target = _select_interpreter(
124 pex_python_path=None,
125 compatibility_constraints=compatibility_constraints
126 )
127
128 if target and os.path.realpath(target) != os.path.realpath(sys.executable):
129 cmdline = [target] + sys.argv
130 TRACER.log('Re-executing: cmdline="%s", sys.executable="%s", PEX_PYTHON="%s", '
131 'PEX_PYTHON_PATH="%s", COMPATIBILITY_CONSTRAINTS="%s"'
132 % (cmdline, sys.executable, ENV.PEX_PYTHON, ENV.PEX_PYTHON_PATH,
133 compatibility_constraints))
134 ENV.delete('PEX_PYTHON')
135 ENV.delete('PEX_PYTHON_PATH')
136 os.environ['SHOULD_EXIT_BOOTSTRAP_REEXEC'] = '1'
137 os.execve(target, cmdline, ENV.copy())
138
139
140 def _bootstrap(entry_point):
141 from .pex_info import PexInfo
142 pex_info = PexInfo.from_pex(entry_point)
143 pex_warnings.configure_warnings(pex_info)
144
145 from .finders import register_finders
146 register_finders()
147
148 return pex_info
149
150
151 def bootstrap_pex(entry_point):
152 pex_info = _bootstrap(entry_point)
153 maybe_reexec_pex(pex_info.interpreter_constraints)
154
155 from . import pex
156 pex.PEX(entry_point).execute()
157
158
159 # NB: This helper is used by third party libs - namely https://github.com/wickman/lambdex.
160 # TODO(John Sirois): Kill once https://github.com/wickman/lambdex/issues/5 is resolved.
161 def is_compressed(entry_point):
162 from .pex_info import PexInfo
163 return os.path.exists(entry_point) and not os.path.exists(os.path.join(entry_point, PexInfo.PATH))
164
165
166 def bootstrap_pex_env(entry_point):
167 """Bootstrap the current runtime environment using a given pex."""
168 pex_info = _bootstrap(entry_point)
169
170 from .environment import PEXEnvironment
171 PEXEnvironment(entry_point, pex_info).activate()
172
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pex/pex_bootstrapper.py b/pex/pex_bootstrapper.py
--- a/pex/pex_bootstrapper.py
+++ b/pex/pex_bootstrapper.py
@@ -11,6 +11,7 @@
from pex.executor import Executor
from pex.interpreter import PythonInterpreter
from pex.interpreter_constraints import matched_interpreters
+from pex.orderedset import OrderedSet
from pex.tracer import TRACER
from pex.variables import ENV
@@ -27,7 +28,7 @@
return try_path
-def find_compatible_interpreters(pex_python_path, compatibility_constraints):
+def find_compatible_interpreters(pex_python_path=None, compatibility_constraints=None):
"""Find all compatible interpreters on the system within the supplied constraints and use
PEX_PYTHON_PATH if it is set. If not, fall back to interpreters on $PATH.
"""
@@ -42,12 +43,12 @@
if not interpreters:
die('PEX_PYTHON_PATH was defined, but no valid interpreters could be identified. Exiting.')
else:
- if not os.getenv('PATH', ''):
- # no $PATH, use sys.executable
- interpreters = [PythonInterpreter.get()]
- else:
- # get all qualifying interpreters found in $PATH
- interpreters = PythonInterpreter.all()
+ # We may have been invoked with a specific interpreter not on the $PATH, make sure our
+ # sys.executable is included as a candidate in this case.
+ interpreters = OrderedSet([PythonInterpreter.get()])
+
+ # Add all qualifying interpreters found in $PATH.
+ interpreters.update(PythonInterpreter.all())
return list(
matched_interpreters(interpreters, compatibility_constraints)
@@ -56,7 +57,7 @@
)
-def _select_pex_python_interpreter(target_python, compatibility_constraints):
+def _select_pex_python_interpreter(target_python, compatibility_constraints=None):
target = find_in_path(target_python)
if not target:
@@ -71,9 +72,9 @@
return target
-def _select_interpreter(pex_python_path, compatibility_constraints):
+def _select_interpreter(pex_python_path=None, compatibility_constraints=None):
compatible_interpreters = find_compatible_interpreters(
- pex_python_path, compatibility_constraints)
+ pex_python_path=pex_python_path, compatibility_constraints=compatibility_constraints)
if not compatible_interpreters:
die('Failed to find compatible interpreter for constraints: %s'
@@ -114,16 +115,14 @@
# TODO: Kill this off completely in favor of PEX_PYTHON_PATH
# https://github.com/pantsbuild/pex/issues/431
target = _select_pex_python_interpreter(ENV.PEX_PYTHON,
- compatibility_constraints)
+ compatibility_constraints=compatibility_constraints)
elif ENV.PEX_PYTHON_PATH:
- target = _select_interpreter(ENV.PEX_PYTHON_PATH, compatibility_constraints)
+ target = _select_interpreter(pex_python_path=ENV.PEX_PYTHON_PATH,
+ compatibility_constraints=compatibility_constraints)
elif compatibility_constraints:
# Apply constraints to target using regular PATH
- target = _select_interpreter(
- pex_python_path=None,
- compatibility_constraints=compatibility_constraints
- )
+ target = _select_interpreter(compatibility_constraints=compatibility_constraints)
if target and os.path.realpath(target) != os.path.realpath(sys.executable):
cmdline = [target] + sys.argv
|
{"golden_diff": "diff --git a/pex/pex_bootstrapper.py b/pex/pex_bootstrapper.py\n--- a/pex/pex_bootstrapper.py\n+++ b/pex/pex_bootstrapper.py\n@@ -11,6 +11,7 @@\n from pex.executor import Executor\n from pex.interpreter import PythonInterpreter\n from pex.interpreter_constraints import matched_interpreters\n+from pex.orderedset import OrderedSet\n from pex.tracer import TRACER\n from pex.variables import ENV\n \n@@ -27,7 +28,7 @@\n return try_path\n \n \n-def find_compatible_interpreters(pex_python_path, compatibility_constraints):\n+def find_compatible_interpreters(pex_python_path=None, compatibility_constraints=None):\n \"\"\"Find all compatible interpreters on the system within the supplied constraints and use\n PEX_PYTHON_PATH if it is set. If not, fall back to interpreters on $PATH.\n \"\"\"\n@@ -42,12 +43,12 @@\n if not interpreters:\n die('PEX_PYTHON_PATH was defined, but no valid interpreters could be identified. Exiting.')\n else:\n- if not os.getenv('PATH', ''):\n- # no $PATH, use sys.executable\n- interpreters = [PythonInterpreter.get()]\n- else:\n- # get all qualifying interpreters found in $PATH\n- interpreters = PythonInterpreter.all()\n+ # We may have been invoked with a specific interpreter not on the $PATH, make sure our\n+ # sys.executable is included as a candidate in this case.\n+ interpreters = OrderedSet([PythonInterpreter.get()])\n+\n+ # Add all qualifying interpreters found in $PATH.\n+ interpreters.update(PythonInterpreter.all())\n \n return list(\n matched_interpreters(interpreters, compatibility_constraints)\n@@ -56,7 +57,7 @@\n )\n \n \n-def _select_pex_python_interpreter(target_python, compatibility_constraints):\n+def _select_pex_python_interpreter(target_python, compatibility_constraints=None):\n target = find_in_path(target_python)\n \n if not target:\n@@ -71,9 +72,9 @@\n return target\n \n \n-def _select_interpreter(pex_python_path, compatibility_constraints):\n+def _select_interpreter(pex_python_path=None, compatibility_constraints=None):\n compatible_interpreters = find_compatible_interpreters(\n- pex_python_path, compatibility_constraints)\n+ pex_python_path=pex_python_path, compatibility_constraints=compatibility_constraints)\n \n if not compatible_interpreters:\n die('Failed to find compatible interpreter for constraints: %s'\n@@ -114,16 +115,14 @@\n # TODO: Kill this off completely in favor of PEX_PYTHON_PATH\n # https://github.com/pantsbuild/pex/issues/431\n target = _select_pex_python_interpreter(ENV.PEX_PYTHON,\n- compatibility_constraints)\n+ compatibility_constraints=compatibility_constraints)\n elif ENV.PEX_PYTHON_PATH:\n- target = _select_interpreter(ENV.PEX_PYTHON_PATH, compatibility_constraints)\n+ target = _select_interpreter(pex_python_path=ENV.PEX_PYTHON_PATH,\n+ compatibility_constraints=compatibility_constraints)\n \n elif compatibility_constraints:\n # Apply constraints to target using regular PATH\n- target = _select_interpreter(\n- pex_python_path=None,\n- compatibility_constraints=compatibility_constraints\n- )\n+ target = _select_interpreter(compatibility_constraints=compatibility_constraints)\n \n if target and os.path.realpath(target) != os.path.realpath(sys.executable):\n cmdline = [target] + sys.argv\n", "issue": "If sys.executable is not on PATH a pex will re-exec itself forever.\nThis can happen via:\r\n```\r\n/not/on/PATH/python a.pex\r\n```\r\n\r\nIf `a.pex` in this example has compatibility constraints that rule out all other interpreters on `PATH` (or there are no intepreters on `PATH`!, c.f.: #53), then, even if sys.executable would be compatible to execute `a.pex` with, it is not considered useable:\r\nhttps://github.com/pantsbuild/pex/blob/442ce7952674cb8a367ecded7d138661194d4f12/pex/pex_bootstrapper.py#L45-L50\r\nhttps://github.com/pantsbuild/pex/blob/442ce7952674cb8a367ecded7d138661194d4f12/pex/interpreter.py#L283-L287\r\n\r\nAnd so the pex_bootstrapper re-execs the pex ad infinitum:\r\nhttps://github.com/pantsbuild/pex/blob/442ce7952674cb8a367ecded7d138661194d4f12/pex/pex_bootstrapper.py#L122-L137\n", "before_files": [{"content": "# Copyright 2014 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\nfrom __future__ import absolute_import, print_function\n\nimport os\nimport sys\n\nfrom pex import pex_warnings\nfrom pex.common import die\nfrom pex.executor import Executor\nfrom pex.interpreter import PythonInterpreter\nfrom pex.interpreter_constraints import matched_interpreters\nfrom pex.tracer import TRACER\nfrom pex.variables import ENV\n\n__all__ = ('bootstrap_pex',)\n\n\ndef find_in_path(target_interpreter):\n if os.path.exists(target_interpreter):\n return target_interpreter\n\n for directory in os.getenv('PATH', '').split(os.pathsep):\n try_path = os.path.join(directory, target_interpreter)\n if os.path.exists(try_path):\n return try_path\n\n\ndef find_compatible_interpreters(pex_python_path, compatibility_constraints):\n \"\"\"Find all compatible interpreters on the system within the supplied constraints and use\n PEX_PYTHON_PATH if it is set. If not, fall back to interpreters on $PATH.\n \"\"\"\n if pex_python_path:\n interpreters = []\n for binary in pex_python_path.split(os.pathsep):\n try:\n interpreters.append(PythonInterpreter.from_binary(binary))\n except Executor.ExecutionError:\n print(\"Python interpreter %s in PEX_PYTHON_PATH failed to load properly.\" % binary,\n file=sys.stderr)\n if not interpreters:\n die('PEX_PYTHON_PATH was defined, but no valid interpreters could be identified. Exiting.')\n else:\n if not os.getenv('PATH', ''):\n # no $PATH, use sys.executable\n interpreters = [PythonInterpreter.get()]\n else:\n # get all qualifying interpreters found in $PATH\n interpreters = PythonInterpreter.all()\n\n return list(\n matched_interpreters(interpreters, compatibility_constraints)\n if compatibility_constraints\n else interpreters\n )\n\n\ndef _select_pex_python_interpreter(target_python, compatibility_constraints):\n target = find_in_path(target_python)\n\n if not target:\n die('Failed to find interpreter specified by PEX_PYTHON: %s' % target)\n if compatibility_constraints:\n pi = PythonInterpreter.from_binary(target)\n if not list(matched_interpreters([pi], compatibility_constraints)):\n die('Interpreter specified by PEX_PYTHON (%s) is not compatible with specified '\n 'interpreter constraints: %s' % (target, str(compatibility_constraints)))\n if not os.path.exists(target):\n die('Target interpreter specified by PEX_PYTHON %s does not exist. Exiting.' % target)\n return target\n\n\ndef _select_interpreter(pex_python_path, compatibility_constraints):\n compatible_interpreters = find_compatible_interpreters(\n pex_python_path, compatibility_constraints)\n\n if not compatible_interpreters:\n die('Failed to find compatible interpreter for constraints: %s'\n % str(compatibility_constraints))\n # TODO: https://github.com/pantsbuild/pex/issues/430\n target = min(compatible_interpreters).binary\n\n if os.path.exists(target):\n return target\n\n\ndef maybe_reexec_pex(compatibility_constraints):\n \"\"\"\n Handle environment overrides for the Python interpreter to use when executing this pex.\n\n This function supports interpreter filtering based on interpreter constraints stored in PEX-INFO\n metadata. If PEX_PYTHON is set in a pexrc, it attempts to obtain the binary location of the\n interpreter specified by PEX_PYTHON. If PEX_PYTHON_PATH is set, it attempts to search the path for\n a matching interpreter in accordance with the interpreter constraints. If both variables are\n present in a pexrc, this function gives precedence to PEX_PYTHON_PATH and errors out if no\n compatible interpreters can be found on said path.\n\n If neither variable is set, we fall back to plain PEX execution using PATH searching or the\n currently executing interpreter. If compatibility constraints are used, we match those constraints\n against these interpreters.\n\n :param compatibility_constraints: list of requirements-style strings that constrain the\n Python interpreter to re-exec this pex with.\n \"\"\"\n if os.environ.pop('SHOULD_EXIT_BOOTSTRAP_REEXEC', None):\n # We've already been here and selected an interpreter. Continue to execution.\n return\n\n target = None\n with TRACER.timed('Selecting runtime interpreter based on pexrc', V=3):\n if ENV.PEX_PYTHON and not ENV.PEX_PYTHON_PATH:\n # preserve PEX_PYTHON re-exec for backwards compatibility\n # TODO: Kill this off completely in favor of PEX_PYTHON_PATH\n # https://github.com/pantsbuild/pex/issues/431\n target = _select_pex_python_interpreter(ENV.PEX_PYTHON,\n compatibility_constraints)\n elif ENV.PEX_PYTHON_PATH:\n target = _select_interpreter(ENV.PEX_PYTHON_PATH, compatibility_constraints)\n\n elif compatibility_constraints:\n # Apply constraints to target using regular PATH\n target = _select_interpreter(\n pex_python_path=None,\n compatibility_constraints=compatibility_constraints\n )\n\n if target and os.path.realpath(target) != os.path.realpath(sys.executable):\n cmdline = [target] + sys.argv\n TRACER.log('Re-executing: cmdline=\"%s\", sys.executable=\"%s\", PEX_PYTHON=\"%s\", '\n 'PEX_PYTHON_PATH=\"%s\", COMPATIBILITY_CONSTRAINTS=\"%s\"'\n % (cmdline, sys.executable, ENV.PEX_PYTHON, ENV.PEX_PYTHON_PATH,\n compatibility_constraints))\n ENV.delete('PEX_PYTHON')\n ENV.delete('PEX_PYTHON_PATH')\n os.environ['SHOULD_EXIT_BOOTSTRAP_REEXEC'] = '1'\n os.execve(target, cmdline, ENV.copy())\n\n\ndef _bootstrap(entry_point):\n from .pex_info import PexInfo\n pex_info = PexInfo.from_pex(entry_point)\n pex_warnings.configure_warnings(pex_info)\n\n from .finders import register_finders\n register_finders()\n\n return pex_info\n\n\ndef bootstrap_pex(entry_point):\n pex_info = _bootstrap(entry_point)\n maybe_reexec_pex(pex_info.interpreter_constraints)\n\n from . import pex\n pex.PEX(entry_point).execute()\n\n\n# NB: This helper is used by third party libs - namely https://github.com/wickman/lambdex.\n# TODO(John Sirois): Kill once https://github.com/wickman/lambdex/issues/5 is resolved.\ndef is_compressed(entry_point):\n from .pex_info import PexInfo\n return os.path.exists(entry_point) and not os.path.exists(os.path.join(entry_point, PexInfo.PATH))\n\n\ndef bootstrap_pex_env(entry_point):\n \"\"\"Bootstrap the current runtime environment using a given pex.\"\"\"\n pex_info = _bootstrap(entry_point)\n\n from .environment import PEXEnvironment\n PEXEnvironment(entry_point, pex_info).activate()\n", "path": "pex/pex_bootstrapper.py"}], "after_files": [{"content": "# Copyright 2014 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\nfrom __future__ import absolute_import, print_function\n\nimport os\nimport sys\n\nfrom pex import pex_warnings\nfrom pex.common import die\nfrom pex.executor import Executor\nfrom pex.interpreter import PythonInterpreter\nfrom pex.interpreter_constraints import matched_interpreters\nfrom pex.orderedset import OrderedSet\nfrom pex.tracer import TRACER\nfrom pex.variables import ENV\n\n__all__ = ('bootstrap_pex',)\n\n\ndef find_in_path(target_interpreter):\n if os.path.exists(target_interpreter):\n return target_interpreter\n\n for directory in os.getenv('PATH', '').split(os.pathsep):\n try_path = os.path.join(directory, target_interpreter)\n if os.path.exists(try_path):\n return try_path\n\n\ndef find_compatible_interpreters(pex_python_path=None, compatibility_constraints=None):\n \"\"\"Find all compatible interpreters on the system within the supplied constraints and use\n PEX_PYTHON_PATH if it is set. If not, fall back to interpreters on $PATH.\n \"\"\"\n if pex_python_path:\n interpreters = []\n for binary in pex_python_path.split(os.pathsep):\n try:\n interpreters.append(PythonInterpreter.from_binary(binary))\n except Executor.ExecutionError:\n print(\"Python interpreter %s in PEX_PYTHON_PATH failed to load properly.\" % binary,\n file=sys.stderr)\n if not interpreters:\n die('PEX_PYTHON_PATH was defined, but no valid interpreters could be identified. Exiting.')\n else:\n # We may have been invoked with a specific interpreter not on the $PATH, make sure our\n # sys.executable is included as a candidate in this case.\n interpreters = OrderedSet([PythonInterpreter.get()])\n\n # Add all qualifying interpreters found in $PATH.\n interpreters.update(PythonInterpreter.all())\n\n return list(\n matched_interpreters(interpreters, compatibility_constraints)\n if compatibility_constraints\n else interpreters\n )\n\n\ndef _select_pex_python_interpreter(target_python, compatibility_constraints=None):\n target = find_in_path(target_python)\n\n if not target:\n die('Failed to find interpreter specified by PEX_PYTHON: %s' % target)\n if compatibility_constraints:\n pi = PythonInterpreter.from_binary(target)\n if not list(matched_interpreters([pi], compatibility_constraints)):\n die('Interpreter specified by PEX_PYTHON (%s) is not compatible with specified '\n 'interpreter constraints: %s' % (target, str(compatibility_constraints)))\n if not os.path.exists(target):\n die('Target interpreter specified by PEX_PYTHON %s does not exist. Exiting.' % target)\n return target\n\n\ndef _select_interpreter(pex_python_path=None, compatibility_constraints=None):\n compatible_interpreters = find_compatible_interpreters(\n pex_python_path=pex_python_path, compatibility_constraints=compatibility_constraints)\n\n if not compatible_interpreters:\n die('Failed to find compatible interpreter for constraints: %s'\n % str(compatibility_constraints))\n # TODO: https://github.com/pantsbuild/pex/issues/430\n target = min(compatible_interpreters).binary\n\n if os.path.exists(target):\n return target\n\n\ndef maybe_reexec_pex(compatibility_constraints):\n \"\"\"\n Handle environment overrides for the Python interpreter to use when executing this pex.\n\n This function supports interpreter filtering based on interpreter constraints stored in PEX-INFO\n metadata. If PEX_PYTHON is set in a pexrc, it attempts to obtain the binary location of the\n interpreter specified by PEX_PYTHON. If PEX_PYTHON_PATH is set, it attempts to search the path for\n a matching interpreter in accordance with the interpreter constraints. If both variables are\n present in a pexrc, this function gives precedence to PEX_PYTHON_PATH and errors out if no\n compatible interpreters can be found on said path.\n\n If neither variable is set, we fall back to plain PEX execution using PATH searching or the\n currently executing interpreter. If compatibility constraints are used, we match those constraints\n against these interpreters.\n\n :param compatibility_constraints: list of requirements-style strings that constrain the\n Python interpreter to re-exec this pex with.\n \"\"\"\n if os.environ.pop('SHOULD_EXIT_BOOTSTRAP_REEXEC', None):\n # We've already been here and selected an interpreter. Continue to execution.\n return\n\n target = None\n with TRACER.timed('Selecting runtime interpreter based on pexrc', V=3):\n if ENV.PEX_PYTHON and not ENV.PEX_PYTHON_PATH:\n # preserve PEX_PYTHON re-exec for backwards compatibility\n # TODO: Kill this off completely in favor of PEX_PYTHON_PATH\n # https://github.com/pantsbuild/pex/issues/431\n target = _select_pex_python_interpreter(ENV.PEX_PYTHON,\n compatibility_constraints=compatibility_constraints)\n elif ENV.PEX_PYTHON_PATH:\n target = _select_interpreter(pex_python_path=ENV.PEX_PYTHON_PATH,\n compatibility_constraints=compatibility_constraints)\n\n elif compatibility_constraints:\n # Apply constraints to target using regular PATH\n target = _select_interpreter(compatibility_constraints=compatibility_constraints)\n\n if target and os.path.realpath(target) != os.path.realpath(sys.executable):\n cmdline = [target] + sys.argv\n TRACER.log('Re-executing: cmdline=\"%s\", sys.executable=\"%s\", PEX_PYTHON=\"%s\", '\n 'PEX_PYTHON_PATH=\"%s\", COMPATIBILITY_CONSTRAINTS=\"%s\"'\n % (cmdline, sys.executable, ENV.PEX_PYTHON, ENV.PEX_PYTHON_PATH,\n compatibility_constraints))\n ENV.delete('PEX_PYTHON')\n ENV.delete('PEX_PYTHON_PATH')\n os.environ['SHOULD_EXIT_BOOTSTRAP_REEXEC'] = '1'\n os.execve(target, cmdline, ENV.copy())\n\n\ndef _bootstrap(entry_point):\n from .pex_info import PexInfo\n pex_info = PexInfo.from_pex(entry_point)\n pex_warnings.configure_warnings(pex_info)\n\n from .finders import register_finders\n register_finders()\n\n return pex_info\n\n\ndef bootstrap_pex(entry_point):\n pex_info = _bootstrap(entry_point)\n maybe_reexec_pex(pex_info.interpreter_constraints)\n\n from . import pex\n pex.PEX(entry_point).execute()\n\n\n# NB: This helper is used by third party libs - namely https://github.com/wickman/lambdex.\n# TODO(John Sirois): Kill once https://github.com/wickman/lambdex/issues/5 is resolved.\ndef is_compressed(entry_point):\n from .pex_info import PexInfo\n return os.path.exists(entry_point) and not os.path.exists(os.path.join(entry_point, PexInfo.PATH))\n\n\ndef bootstrap_pex_env(entry_point):\n \"\"\"Bootstrap the current runtime environment using a given pex.\"\"\"\n pex_info = _bootstrap(entry_point)\n\n from .environment import PEXEnvironment\n PEXEnvironment(entry_point, pex_info).activate()\n", "path": "pex/pex_bootstrapper.py"}]}
| 2,528 | 796 |
gh_patches_debug_27756
|
rasdani/github-patches
|
git_diff
|
scrapy__scrapy-5002
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
refactoring curl_to_request_kwargs to reduce cyclomatic complexity
<!--
Thanks for taking an interest in Scrapy!
If you have a question that starts with "How to...", please see the Scrapy Community page: https://scrapy.org/community/.
The GitHub issue tracker's purpose is to deal with bug reports and feature requests for the project itself.
Keep in mind that by filing an issue, you are expected to comply with Scrapy's Code of Conduct, including treating everyone with respect: https://github.com/scrapy/scrapy/blob/master/CODE_OF_CONDUCT.md
The following is a suggested template to structure your pull request, you can find more guidelines at https://doc.scrapy.org/en/latest/contributing.html#writing-patches and https://doc.scrapy.org/en/latest/contributing.html#submitting-patches
-->
## Summary
After some exploring with cyclomatic complexity tools (lizard), the function was found to have the second highest complexity.
## Motivation
Low complexity allows for higher readability, testability and maintainability.
## Solution
Refactor
## Additional context
N/A
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `scrapy/utils/curl.py`
Content:
```
1 import argparse
2 import warnings
3 from shlex import split
4 from http.cookies import SimpleCookie
5 from urllib.parse import urlparse
6
7 from w3lib.http import basic_auth_header
8
9
10 class CurlParser(argparse.ArgumentParser):
11 def error(self, message):
12 error_msg = f'There was an error parsing the curl command: {message}'
13 raise ValueError(error_msg)
14
15
16 curl_parser = CurlParser()
17 curl_parser.add_argument('url')
18 curl_parser.add_argument('-H', '--header', dest='headers', action='append')
19 curl_parser.add_argument('-X', '--request', dest='method')
20 curl_parser.add_argument('-d', '--data', '--data-raw', dest='data')
21 curl_parser.add_argument('-u', '--user', dest='auth')
22
23
24 safe_to_ignore_arguments = [
25 ['--compressed'],
26 # `--compressed` argument is not safe to ignore, but it's included here
27 # because the `HttpCompressionMiddleware` is enabled by default
28 ['-s', '--silent'],
29 ['-v', '--verbose'],
30 ['-#', '--progress-bar']
31 ]
32
33 for argument in safe_to_ignore_arguments:
34 curl_parser.add_argument(*argument, action='store_true')
35
36
37 def curl_to_request_kwargs(curl_command, ignore_unknown_options=True):
38 """Convert a cURL command syntax to Request kwargs.
39
40 :param str curl_command: string containing the curl command
41 :param bool ignore_unknown_options: If true, only a warning is emitted when
42 cURL options are unknown. Otherwise
43 raises an error. (default: True)
44 :return: dictionary of Request kwargs
45 """
46
47 curl_args = split(curl_command)
48
49 if curl_args[0] != 'curl':
50 raise ValueError('A curl command must start with "curl"')
51
52 parsed_args, argv = curl_parser.parse_known_args(curl_args[1:])
53
54 if argv:
55 msg = f'Unrecognized options: {", ".join(argv)}'
56 if ignore_unknown_options:
57 warnings.warn(msg)
58 else:
59 raise ValueError(msg)
60
61 url = parsed_args.url
62
63 # curl automatically prepends 'http' if the scheme is missing, but Request
64 # needs the scheme to work
65 parsed_url = urlparse(url)
66 if not parsed_url.scheme:
67 url = 'http://' + url
68
69 method = parsed_args.method or 'GET'
70
71 result = {'method': method.upper(), 'url': url}
72
73 headers = []
74 cookies = {}
75 for header in parsed_args.headers or ():
76 name, val = header.split(':', 1)
77 name = name.strip()
78 val = val.strip()
79 if name.title() == 'Cookie':
80 for name, morsel in SimpleCookie(val).items():
81 cookies[name] = morsel.value
82 else:
83 headers.append((name, val))
84
85 if parsed_args.auth:
86 user, password = parsed_args.auth.split(':', 1)
87 headers.append(('Authorization', basic_auth_header(user, password)))
88
89 if headers:
90 result['headers'] = headers
91 if cookies:
92 result['cookies'] = cookies
93 if parsed_args.data:
94 result['body'] = parsed_args.data
95 if not parsed_args.method:
96 # if the "data" is specified but the "method" is not specified,
97 # the default method is 'POST'
98 result['method'] = 'POST'
99
100 return result
101
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/scrapy/utils/curl.py b/scrapy/utils/curl.py
--- a/scrapy/utils/curl.py
+++ b/scrapy/utils/curl.py
@@ -34,6 +34,26 @@
curl_parser.add_argument(*argument, action='store_true')
+def _parse_headers_and_cookies(parsed_args):
+ headers = []
+ cookies = {}
+ for header in parsed_args.headers or ():
+ name, val = header.split(':', 1)
+ name = name.strip()
+ val = val.strip()
+ if name.title() == 'Cookie':
+ for name, morsel in SimpleCookie(val).items():
+ cookies[name] = morsel.value
+ else:
+ headers.append((name, val))
+
+ if parsed_args.auth:
+ user, password = parsed_args.auth.split(':', 1)
+ headers.append(('Authorization', basic_auth_header(user, password)))
+
+ return headers, cookies
+
+
def curl_to_request_kwargs(curl_command, ignore_unknown_options=True):
"""Convert a cURL command syntax to Request kwargs.
@@ -70,21 +90,7 @@
result = {'method': method.upper(), 'url': url}
- headers = []
- cookies = {}
- for header in parsed_args.headers or ():
- name, val = header.split(':', 1)
- name = name.strip()
- val = val.strip()
- if name.title() == 'Cookie':
- for name, morsel in SimpleCookie(val).items():
- cookies[name] = morsel.value
- else:
- headers.append((name, val))
-
- if parsed_args.auth:
- user, password = parsed_args.auth.split(':', 1)
- headers.append(('Authorization', basic_auth_header(user, password)))
+ headers, cookies = _parse_headers_and_cookies(parsed_args)
if headers:
result['headers'] = headers
|
{"golden_diff": "diff --git a/scrapy/utils/curl.py b/scrapy/utils/curl.py\n--- a/scrapy/utils/curl.py\n+++ b/scrapy/utils/curl.py\n@@ -34,6 +34,26 @@\n curl_parser.add_argument(*argument, action='store_true')\n \n \n+def _parse_headers_and_cookies(parsed_args):\n+ headers = []\n+ cookies = {}\n+ for header in parsed_args.headers or ():\n+ name, val = header.split(':', 1)\n+ name = name.strip()\n+ val = val.strip()\n+ if name.title() == 'Cookie':\n+ for name, morsel in SimpleCookie(val).items():\n+ cookies[name] = morsel.value\n+ else:\n+ headers.append((name, val))\n+\n+ if parsed_args.auth:\n+ user, password = parsed_args.auth.split(':', 1)\n+ headers.append(('Authorization', basic_auth_header(user, password)))\n+\n+ return headers, cookies\n+\n+\n def curl_to_request_kwargs(curl_command, ignore_unknown_options=True):\n \"\"\"Convert a cURL command syntax to Request kwargs.\n \n@@ -70,21 +90,7 @@\n \n result = {'method': method.upper(), 'url': url}\n \n- headers = []\n- cookies = {}\n- for header in parsed_args.headers or ():\n- name, val = header.split(':', 1)\n- name = name.strip()\n- val = val.strip()\n- if name.title() == 'Cookie':\n- for name, morsel in SimpleCookie(val).items():\n- cookies[name] = morsel.value\n- else:\n- headers.append((name, val))\n-\n- if parsed_args.auth:\n- user, password = parsed_args.auth.split(':', 1)\n- headers.append(('Authorization', basic_auth_header(user, password)))\n+ headers, cookies = _parse_headers_and_cookies(parsed_args)\n \n if headers:\n result['headers'] = headers\n", "issue": "refactoring curl_to_request_kwargs to reduce cyclomatic complexity\n<!--\r\n\r\nThanks for taking an interest in Scrapy!\r\n\r\nIf you have a question that starts with \"How to...\", please see the Scrapy Community page: https://scrapy.org/community/.\r\nThe GitHub issue tracker's purpose is to deal with bug reports and feature requests for the project itself.\r\n\r\nKeep in mind that by filing an issue, you are expected to comply with Scrapy's Code of Conduct, including treating everyone with respect: https://github.com/scrapy/scrapy/blob/master/CODE_OF_CONDUCT.md\r\n\r\nThe following is a suggested template to structure your pull request, you can find more guidelines at https://doc.scrapy.org/en/latest/contributing.html#writing-patches and https://doc.scrapy.org/en/latest/contributing.html#submitting-patches\r\n\r\n-->\r\n\r\n## Summary\r\n\r\nAfter some exploring with cyclomatic complexity tools (lizard), the function was found to have the second highest complexity. \r\n\r\n## Motivation\r\n\r\nLow complexity allows for higher readability, testability and maintainability. \r\n\r\n## Solution\r\n\r\nRefactor\r\n\r\n## Additional context\r\n\r\nN/A\r\n\n", "before_files": [{"content": "import argparse\nimport warnings\nfrom shlex import split\nfrom http.cookies import SimpleCookie\nfrom urllib.parse import urlparse\n\nfrom w3lib.http import basic_auth_header\n\n\nclass CurlParser(argparse.ArgumentParser):\n def error(self, message):\n error_msg = f'There was an error parsing the curl command: {message}'\n raise ValueError(error_msg)\n\n\ncurl_parser = CurlParser()\ncurl_parser.add_argument('url')\ncurl_parser.add_argument('-H', '--header', dest='headers', action='append')\ncurl_parser.add_argument('-X', '--request', dest='method')\ncurl_parser.add_argument('-d', '--data', '--data-raw', dest='data')\ncurl_parser.add_argument('-u', '--user', dest='auth')\n\n\nsafe_to_ignore_arguments = [\n ['--compressed'],\n # `--compressed` argument is not safe to ignore, but it's included here\n # because the `HttpCompressionMiddleware` is enabled by default\n ['-s', '--silent'],\n ['-v', '--verbose'],\n ['-#', '--progress-bar']\n]\n\nfor argument in safe_to_ignore_arguments:\n curl_parser.add_argument(*argument, action='store_true')\n\n\ndef curl_to_request_kwargs(curl_command, ignore_unknown_options=True):\n \"\"\"Convert a cURL command syntax to Request kwargs.\n\n :param str curl_command: string containing the curl command\n :param bool ignore_unknown_options: If true, only a warning is emitted when\n cURL options are unknown. Otherwise\n raises an error. (default: True)\n :return: dictionary of Request kwargs\n \"\"\"\n\n curl_args = split(curl_command)\n\n if curl_args[0] != 'curl':\n raise ValueError('A curl command must start with \"curl\"')\n\n parsed_args, argv = curl_parser.parse_known_args(curl_args[1:])\n\n if argv:\n msg = f'Unrecognized options: {\", \".join(argv)}'\n if ignore_unknown_options:\n warnings.warn(msg)\n else:\n raise ValueError(msg)\n\n url = parsed_args.url\n\n # curl automatically prepends 'http' if the scheme is missing, but Request\n # needs the scheme to work\n parsed_url = urlparse(url)\n if not parsed_url.scheme:\n url = 'http://' + url\n\n method = parsed_args.method or 'GET'\n\n result = {'method': method.upper(), 'url': url}\n\n headers = []\n cookies = {}\n for header in parsed_args.headers or ():\n name, val = header.split(':', 1)\n name = name.strip()\n val = val.strip()\n if name.title() == 'Cookie':\n for name, morsel in SimpleCookie(val).items():\n cookies[name] = morsel.value\n else:\n headers.append((name, val))\n\n if parsed_args.auth:\n user, password = parsed_args.auth.split(':', 1)\n headers.append(('Authorization', basic_auth_header(user, password)))\n\n if headers:\n result['headers'] = headers\n if cookies:\n result['cookies'] = cookies\n if parsed_args.data:\n result['body'] = parsed_args.data\n if not parsed_args.method:\n # if the \"data\" is specified but the \"method\" is not specified,\n # the default method is 'POST'\n result['method'] = 'POST'\n\n return result\n", "path": "scrapy/utils/curl.py"}], "after_files": [{"content": "import argparse\nimport warnings\nfrom shlex import split\nfrom http.cookies import SimpleCookie\nfrom urllib.parse import urlparse\n\nfrom w3lib.http import basic_auth_header\n\n\nclass CurlParser(argparse.ArgumentParser):\n def error(self, message):\n error_msg = f'There was an error parsing the curl command: {message}'\n raise ValueError(error_msg)\n\n\ncurl_parser = CurlParser()\ncurl_parser.add_argument('url')\ncurl_parser.add_argument('-H', '--header', dest='headers', action='append')\ncurl_parser.add_argument('-X', '--request', dest='method')\ncurl_parser.add_argument('-d', '--data', '--data-raw', dest='data')\ncurl_parser.add_argument('-u', '--user', dest='auth')\n\n\nsafe_to_ignore_arguments = [\n ['--compressed'],\n # `--compressed` argument is not safe to ignore, but it's included here\n # because the `HttpCompressionMiddleware` is enabled by default\n ['-s', '--silent'],\n ['-v', '--verbose'],\n ['-#', '--progress-bar']\n]\n\nfor argument in safe_to_ignore_arguments:\n curl_parser.add_argument(*argument, action='store_true')\n\n\ndef _parse_headers_and_cookies(parsed_args):\n headers = []\n cookies = {}\n for header in parsed_args.headers or ():\n name, val = header.split(':', 1)\n name = name.strip()\n val = val.strip()\n if name.title() == 'Cookie':\n for name, morsel in SimpleCookie(val).items():\n cookies[name] = morsel.value\n else:\n headers.append((name, val))\n\n if parsed_args.auth:\n user, password = parsed_args.auth.split(':', 1)\n headers.append(('Authorization', basic_auth_header(user, password)))\n\n return headers, cookies\n\n\ndef curl_to_request_kwargs(curl_command, ignore_unknown_options=True):\n \"\"\"Convert a cURL command syntax to Request kwargs.\n\n :param str curl_command: string containing the curl command\n :param bool ignore_unknown_options: If true, only a warning is emitted when\n cURL options are unknown. Otherwise\n raises an error. (default: True)\n :return: dictionary of Request kwargs\n \"\"\"\n\n curl_args = split(curl_command)\n\n if curl_args[0] != 'curl':\n raise ValueError('A curl command must start with \"curl\"')\n\n parsed_args, argv = curl_parser.parse_known_args(curl_args[1:])\n\n if argv:\n msg = f'Unrecognized options: {\", \".join(argv)}'\n if ignore_unknown_options:\n warnings.warn(msg)\n else:\n raise ValueError(msg)\n\n url = parsed_args.url\n\n # curl automatically prepends 'http' if the scheme is missing, but Request\n # needs the scheme to work\n parsed_url = urlparse(url)\n if not parsed_url.scheme:\n url = 'http://' + url\n\n method = parsed_args.method or 'GET'\n\n result = {'method': method.upper(), 'url': url}\n\n headers, cookies = _parse_headers_and_cookies(parsed_args)\n\n if headers:\n result['headers'] = headers\n if cookies:\n result['cookies'] = cookies\n if parsed_args.data:\n result['body'] = parsed_args.data\n if not parsed_args.method:\n # if the \"data\" is specified but the \"method\" is not specified,\n # the default method is 'POST'\n result['method'] = 'POST'\n\n return result\n", "path": "scrapy/utils/curl.py"}]}
| 1,406 | 429 |
gh_patches_debug_802
|
rasdani/github-patches
|
git_diff
|
pyca__cryptography-1599
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Update year in copyright notice for vectors
Refs #1597
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `vectors/cryptography_vectors/__about__.py`
Content:
```
1 # This file is dual licensed under the terms of the Apache License, Version
2 # 2.0, and the BSD License. See the LICENSE file in the root of this repository
3 # for complete details.
4
5 from __future__ import absolute_import, division, print_function
6
7 __all__ = [
8 "__title__", "__summary__", "__uri__", "__version__", "__author__",
9 "__email__", "__license__", "__copyright__",
10 ]
11
12 __title__ = "cryptography_vectors"
13 __summary__ = "Test vectors for the cryptography package."
14
15 __uri__ = "https://github.com/pyca/cryptography"
16
17 __version__ = "0.8.dev1"
18
19 __author__ = "The cryptography developers"
20 __email__ = "[email protected]"
21
22 __license__ = "BSD or Apache License, Version 2.0"
23 __copyright__ = "Copyright 2013-2014 %s" % __author__
24
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/vectors/cryptography_vectors/__about__.py b/vectors/cryptography_vectors/__about__.py
--- a/vectors/cryptography_vectors/__about__.py
+++ b/vectors/cryptography_vectors/__about__.py
@@ -20,4 +20,4 @@
__email__ = "[email protected]"
__license__ = "BSD or Apache License, Version 2.0"
-__copyright__ = "Copyright 2013-2014 %s" % __author__
+__copyright__ = "Copyright 2013-2015 %s" % __author__
|
{"golden_diff": "diff --git a/vectors/cryptography_vectors/__about__.py b/vectors/cryptography_vectors/__about__.py\n--- a/vectors/cryptography_vectors/__about__.py\n+++ b/vectors/cryptography_vectors/__about__.py\n@@ -20,4 +20,4 @@\n __email__ = \"[email protected]\"\n \n __license__ = \"BSD or Apache License, Version 2.0\"\n-__copyright__ = \"Copyright 2013-2014 %s\" % __author__\n+__copyright__ = \"Copyright 2013-2015 %s\" % __author__\n", "issue": "Update year in copyright notice for vectors\nRefs #1597 \n\n", "before_files": [{"content": "# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\nfrom __future__ import absolute_import, division, print_function\n\n__all__ = [\n \"__title__\", \"__summary__\", \"__uri__\", \"__version__\", \"__author__\",\n \"__email__\", \"__license__\", \"__copyright__\",\n]\n\n__title__ = \"cryptography_vectors\"\n__summary__ = \"Test vectors for the cryptography package.\"\n\n__uri__ = \"https://github.com/pyca/cryptography\"\n\n__version__ = \"0.8.dev1\"\n\n__author__ = \"The cryptography developers\"\n__email__ = \"[email protected]\"\n\n__license__ = \"BSD or Apache License, Version 2.0\"\n__copyright__ = \"Copyright 2013-2014 %s\" % __author__\n", "path": "vectors/cryptography_vectors/__about__.py"}], "after_files": [{"content": "# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\nfrom __future__ import absolute_import, division, print_function\n\n__all__ = [\n \"__title__\", \"__summary__\", \"__uri__\", \"__version__\", \"__author__\",\n \"__email__\", \"__license__\", \"__copyright__\",\n]\n\n__title__ = \"cryptography_vectors\"\n__summary__ = \"Test vectors for the cryptography package.\"\n\n__uri__ = \"https://github.com/pyca/cryptography\"\n\n__version__ = \"0.8.dev1\"\n\n__author__ = \"The cryptography developers\"\n__email__ = \"[email protected]\"\n\n__license__ = \"BSD or Apache License, Version 2.0\"\n__copyright__ = \"Copyright 2013-2015 %s\" % __author__\n", "path": "vectors/cryptography_vectors/__about__.py"}]}
| 526 | 137 |
gh_patches_debug_1453
|
rasdani/github-patches
|
git_diff
|
rlworkgroup__garage-971
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
pytest flag --strict-markers requires version 4.5.0
pytest flag `--strict-markers` in https://github.com/rlworkgroup/garage/blob/master/setup.cfg#L79 requires version >= 4.5.0.
See https://docs.pytest.org/en/latest/changelog.html#pytest-4-5-0-2019-05-11
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 """setuptools based setup module."""
2 from setuptools import find_packages
3 from setuptools import setup
4
5 TF_VERSION = '<1.16,>=1.15.0'
6 GYM_VERSION = '==0.12.4'
7
8 # Required dependencies
9 REQUIRED = [
10 # Please keep alphabetized
11 'akro==0.0.6',
12 'cached_property',
13 'click',
14 'cloudpickle',
15 'cma==2.7.0',
16 'dowel==0.0.2',
17 'gym[atari,box2d,classic_control]' + GYM_VERSION,
18 'joblib<0.13,>=0.12',
19 'matplotlib',
20 'numpy>=1.14.5',
21 'psutil',
22 # Pyglet 1.4.0 introduces some api change which breaks some
23 # gym environments
24 # See: https://github.com/openai/gym/issues/1588
25 'pyglet<1.4.0,>=1.3.0',
26 'pyprind',
27 'python-dateutil',
28 'torch==1.3.0',
29 'ray',
30 'scikit-image',
31 'scipy',
32 'tensorflow' + TF_VERSION,
33 'tensorflow-probability',
34 'torchvision==0.4.1'
35 ]
36
37 # Dependencies for optional features
38 EXTRAS = {}
39
40 EXTRAS['mujoco'] = [
41 'mujoco-py<2.1,>=2.0',
42 'gym[all]' + GYM_VERSION,
43 ]
44
45 EXTRAS['dm_control'] = [
46 # dm_control throws an error during install about not being able to
47 # find a build dependency (absl-py). Later pip executes the `install`
48 # command again and the install succeeds because absl-py has been
49 # installed. This is stupid, but harmless.
50 'dm_control @ https://api.github.com/repos/deepmind/dm_control/tarball/7a36377879c57777e5d5b4da5aae2cd2a29b607a', # pylint: disable=line-too-long; # noqa: E501
51 ]
52
53 EXTRAS['all'] = list(set(sum(EXTRAS.values(), [])))
54
55 # dependencies for using gpu, not included in 'all'
56 EXTRAS['gpu'] = ['tensorflow-gpu' + TF_VERSION]
57
58 # Development dependencies (*not* included in 'all')
59 EXTRAS['dev'] = [
60 # Please keep alphabetized
61 'baselines @ https://api.github.com/repos/openai/baselines/tarball/f2729693253c0ef4d4086231d36e0a4307ec1cb3', # pylint: disable=line-too-long; # noqa: E501
62 'flake8',
63 'flake8-docstrings>=1.5.0',
64 'flake8-import-order',
65 'gtimer',
66 'pandas',
67 'pep8-naming==0.7.0',
68 'pre-commit',
69 'pycodestyle>=2.5.0',
70 'pydocstyle>=4.0.0',
71 'pylint>=2.4.3',
72 'pytest>=3.6', # Required for pytest-cov on Python 3.6
73 'pytest-cov',
74 'pytest-xdist',
75 'recommonmark',
76 'rlkit @ git+https://github.com/vitchyr/rlkit/@1d469a509b797ca04a39b8734c1816ca7d108fc8', # pylint: disable=line-too-long; # noqa: E501
77 'seaborn',
78 'sphinx',
79 'sphinx_rtd_theme',
80 'yapf==0.28.0',
81 ]
82
83 with open('README.md') as f:
84 README = f.read()
85
86 # Get the package version dynamically
87 with open('VERSION') as v:
88 VERSION = v.read().strip()
89
90 setup(
91 name='garage',
92 version=VERSION,
93 author='Reinforcement Learning Working Group',
94 description='A toolkit for reproducible reinforcement learning research',
95 url='https://github.com/rlworkgroup/garage',
96 packages=find_packages(where='src'),
97 package_dir={'': 'src'},
98 scripts=['scripts/garage'],
99 python_requires='>=3.5',
100 install_requires=REQUIRED,
101 extras_require=EXTRAS,
102 license='MIT',
103 long_description=README,
104 long_description_content_type='text/markdown',
105 classifiers=[
106 'Development Status :: 4 - Beta',
107 'Intended Audience :: Developers',
108 'Intended Audience :: Education',
109 'Intended Audience :: Science/Research',
110 'License :: OSI Approved :: MIT License',
111 'Programming Language :: Python :: 3.5',
112 'Programming Language :: Python :: 3.6',
113 'Programming Language :: Python :: 3.7',
114 'Programming Language :: Python :: 3 :: Only',
115 'Topic :: Scientific/Engineering :: Artificial Intelligence',
116 'Topic :: Scientific/Engineering :: Mathematics',
117 'Topic :: Software Development :: Libraries',
118 ],
119 )
120
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -69,7 +69,7 @@
'pycodestyle>=2.5.0',
'pydocstyle>=4.0.0',
'pylint>=2.4.3',
- 'pytest>=3.6', # Required for pytest-cov on Python 3.6
+ 'pytest>=4.5.0', # Required for strict-markers
'pytest-cov',
'pytest-xdist',
'recommonmark',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -69,7 +69,7 @@\n 'pycodestyle>=2.5.0',\n 'pydocstyle>=4.0.0',\n 'pylint>=2.4.3',\n- 'pytest>=3.6', # Required for pytest-cov on Python 3.6\n+ 'pytest>=4.5.0', # Required for strict-markers\n 'pytest-cov',\n 'pytest-xdist',\n 'recommonmark',\n", "issue": "pytest flag --strict-markers requires version 4.5.0\npytest flag `--strict-markers` in https://github.com/rlworkgroup/garage/blob/master/setup.cfg#L79 requires version >= 4.5.0. \r\n\r\nSee https://docs.pytest.org/en/latest/changelog.html#pytest-4-5-0-2019-05-11\n", "before_files": [{"content": "\"\"\"setuptools based setup module.\"\"\"\nfrom setuptools import find_packages\nfrom setuptools import setup\n\nTF_VERSION = '<1.16,>=1.15.0'\nGYM_VERSION = '==0.12.4'\n\n# Required dependencies\nREQUIRED = [\n # Please keep alphabetized\n 'akro==0.0.6',\n 'cached_property',\n 'click',\n 'cloudpickle',\n 'cma==2.7.0',\n 'dowel==0.0.2',\n 'gym[atari,box2d,classic_control]' + GYM_VERSION,\n 'joblib<0.13,>=0.12',\n 'matplotlib',\n 'numpy>=1.14.5',\n 'psutil',\n # Pyglet 1.4.0 introduces some api change which breaks some\n # gym environments\n # See: https://github.com/openai/gym/issues/1588\n 'pyglet<1.4.0,>=1.3.0',\n 'pyprind',\n 'python-dateutil',\n 'torch==1.3.0',\n 'ray',\n 'scikit-image',\n 'scipy',\n 'tensorflow' + TF_VERSION,\n 'tensorflow-probability',\n 'torchvision==0.4.1'\n]\n\n# Dependencies for optional features\nEXTRAS = {}\n\nEXTRAS['mujoco'] = [\n 'mujoco-py<2.1,>=2.0',\n 'gym[all]' + GYM_VERSION,\n]\n\nEXTRAS['dm_control'] = [\n # dm_control throws an error during install about not being able to\n # find a build dependency (absl-py). Later pip executes the `install`\n # command again and the install succeeds because absl-py has been\n # installed. This is stupid, but harmless.\n 'dm_control @ https://api.github.com/repos/deepmind/dm_control/tarball/7a36377879c57777e5d5b4da5aae2cd2a29b607a', # pylint: disable=line-too-long; # noqa: E501\n]\n\nEXTRAS['all'] = list(set(sum(EXTRAS.values(), [])))\n\n# dependencies for using gpu, not included in 'all'\nEXTRAS['gpu'] = ['tensorflow-gpu' + TF_VERSION]\n\n# Development dependencies (*not* included in 'all')\nEXTRAS['dev'] = [\n # Please keep alphabetized\n 'baselines @ https://api.github.com/repos/openai/baselines/tarball/f2729693253c0ef4d4086231d36e0a4307ec1cb3', # pylint: disable=line-too-long; # noqa: E501\n 'flake8',\n 'flake8-docstrings>=1.5.0',\n 'flake8-import-order',\n 'gtimer',\n 'pandas',\n 'pep8-naming==0.7.0',\n 'pre-commit',\n 'pycodestyle>=2.5.0',\n 'pydocstyle>=4.0.0',\n 'pylint>=2.4.3',\n 'pytest>=3.6', # Required for pytest-cov on Python 3.6\n 'pytest-cov',\n 'pytest-xdist',\n 'recommonmark',\n 'rlkit @ git+https://github.com/vitchyr/rlkit/@1d469a509b797ca04a39b8734c1816ca7d108fc8', # pylint: disable=line-too-long; # noqa: E501\n 'seaborn',\n 'sphinx',\n 'sphinx_rtd_theme',\n 'yapf==0.28.0',\n]\n\nwith open('README.md') as f:\n README = f.read()\n\n# Get the package version dynamically\nwith open('VERSION') as v:\n VERSION = v.read().strip()\n\nsetup(\n name='garage',\n version=VERSION,\n author='Reinforcement Learning Working Group',\n description='A toolkit for reproducible reinforcement learning research',\n url='https://github.com/rlworkgroup/garage',\n packages=find_packages(where='src'),\n package_dir={'': 'src'},\n scripts=['scripts/garage'],\n python_requires='>=3.5',\n install_requires=REQUIRED,\n extras_require=EXTRAS,\n license='MIT',\n long_description=README,\n long_description_content_type='text/markdown',\n classifiers=[\n 'Development Status :: 4 - Beta',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Education',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: MIT License',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3 :: Only',\n 'Topic :: Scientific/Engineering :: Artificial Intelligence',\n 'Topic :: Scientific/Engineering :: Mathematics',\n 'Topic :: Software Development :: Libraries',\n ],\n)\n", "path": "setup.py"}], "after_files": [{"content": "\"\"\"setuptools based setup module.\"\"\"\nfrom setuptools import find_packages\nfrom setuptools import setup\n\nTF_VERSION = '<1.16,>=1.15.0'\nGYM_VERSION = '==0.12.4'\n\n# Required dependencies\nREQUIRED = [\n # Please keep alphabetized\n 'akro==0.0.6',\n 'cached_property',\n 'click',\n 'cloudpickle',\n 'cma==2.7.0',\n 'dowel==0.0.2',\n 'gym[atari,box2d,classic_control]' + GYM_VERSION,\n 'joblib<0.13,>=0.12',\n 'matplotlib',\n 'numpy>=1.14.5',\n 'psutil',\n # Pyglet 1.4.0 introduces some api change which breaks some\n # gym environments\n # See: https://github.com/openai/gym/issues/1588\n 'pyglet<1.4.0,>=1.3.0',\n 'pyprind',\n 'python-dateutil',\n 'torch==1.3.0',\n 'ray',\n 'scikit-image',\n 'scipy',\n 'tensorflow' + TF_VERSION,\n 'tensorflow-probability',\n 'torchvision==0.4.1'\n]\n\n# Dependencies for optional features\nEXTRAS = {}\n\nEXTRAS['mujoco'] = [\n 'mujoco-py<2.1,>=2.0',\n 'gym[all]' + GYM_VERSION,\n]\n\nEXTRAS['dm_control'] = [\n # dm_control throws an error during install about not being able to\n # find a build dependency (absl-py). Later pip executes the `install`\n # command again and the install succeeds because absl-py has been\n # installed. This is stupid, but harmless.\n 'dm_control @ https://api.github.com/repos/deepmind/dm_control/tarball/7a36377879c57777e5d5b4da5aae2cd2a29b607a', # pylint: disable=line-too-long; # noqa: E501\n]\n\nEXTRAS['all'] = list(set(sum(EXTRAS.values(), [])))\n\n# dependencies for using gpu, not included in 'all'\nEXTRAS['gpu'] = ['tensorflow-gpu' + TF_VERSION]\n\n# Development dependencies (*not* included in 'all')\nEXTRAS['dev'] = [\n # Please keep alphabetized\n 'baselines @ https://api.github.com/repos/openai/baselines/tarball/f2729693253c0ef4d4086231d36e0a4307ec1cb3', # pylint: disable=line-too-long; # noqa: E501\n 'flake8',\n 'flake8-docstrings>=1.5.0',\n 'flake8-import-order',\n 'gtimer',\n 'pandas',\n 'pep8-naming==0.7.0',\n 'pre-commit',\n 'pycodestyle>=2.5.0',\n 'pydocstyle>=4.0.0',\n 'pylint>=2.4.3',\n 'pytest>=4.5.0', # Required for strict-markers\n 'pytest-cov',\n 'pytest-xdist',\n 'recommonmark',\n 'rlkit @ git+https://github.com/vitchyr/rlkit/@1d469a509b797ca04a39b8734c1816ca7d108fc8', # pylint: disable=line-too-long; # noqa: E501\n 'seaborn',\n 'sphinx',\n 'sphinx_rtd_theme',\n 'yapf==0.28.0',\n]\n\nwith open('README.md') as f:\n README = f.read()\n\n# Get the package version dynamically\nwith open('VERSION') as v:\n VERSION = v.read().strip()\n\nsetup(\n name='garage',\n version=VERSION,\n author='Reinforcement Learning Working Group',\n description='A toolkit for reproducible reinforcement learning research',\n url='https://github.com/rlworkgroup/garage',\n packages=find_packages(where='src'),\n package_dir={'': 'src'},\n scripts=['scripts/garage'],\n python_requires='>=3.5',\n install_requires=REQUIRED,\n extras_require=EXTRAS,\n license='MIT',\n long_description=README,\n long_description_content_type='text/markdown',\n classifiers=[\n 'Development Status :: 4 - Beta',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Education',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: MIT License',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3 :: Only',\n 'Topic :: Scientific/Engineering :: Artificial Intelligence',\n 'Topic :: Scientific/Engineering :: Mathematics',\n 'Topic :: Software Development :: Libraries',\n ],\n)\n", "path": "setup.py"}]}
| 1,758 | 127 |
gh_patches_debug_20214
|
rasdani/github-patches
|
git_diff
|
getsentry__sentry-python-921
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Not working with older boto version
Hello, we use it in Django==2.1.7 app and this row breaks the app.
https://github.com/getsentry/sentry-python/blob/cc08a6bed116e09db41c712c20ab63eb0a839e41/sentry_sdk/integrations/boto3.py#L36
For versions
boto3==1.7.45
botocore==1.10.84
this throws
`
AttributeError: 'str' object has no attribute 'hyphenize'`
I'm not sure the base of the integrations but I thought they must be enabled in settings, but this part of Boto3Integration is triggered even if we have not enabled it in django settings.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sentry_sdk/integrations/boto3.py`
Content:
```
1 from __future__ import absolute_import
2
3 from sentry_sdk import Hub
4 from sentry_sdk.integrations import Integration, DidNotEnable
5 from sentry_sdk.tracing import Span
6
7 from sentry_sdk._functools import partial
8 from sentry_sdk._types import MYPY
9
10 if MYPY:
11 from typing import Any
12 from typing import Dict
13 from typing import Optional
14 from typing import Type
15
16 try:
17 from botocore.client import BaseClient # type: ignore
18 from botocore.response import StreamingBody # type: ignore
19 from botocore.awsrequest import AWSRequest # type: ignore
20 except ImportError:
21 raise DidNotEnable("botocore is not installed")
22
23
24 class Boto3Integration(Integration):
25 identifier = "boto3"
26
27 @staticmethod
28 def setup_once():
29 # type: () -> None
30 orig_init = BaseClient.__init__
31
32 def sentry_patched_init(self, *args, **kwargs):
33 # type: (Type[BaseClient], *Any, **Any) -> None
34 orig_init(self, *args, **kwargs)
35 meta = self.meta
36 service_id = meta.service_model.service_id.hyphenize()
37 meta.events.register(
38 "request-created",
39 partial(_sentry_request_created, service_id=service_id),
40 )
41 meta.events.register("after-call", _sentry_after_call)
42 meta.events.register("after-call-error", _sentry_after_call_error)
43
44 BaseClient.__init__ = sentry_patched_init
45
46
47 def _sentry_request_created(service_id, request, operation_name, **kwargs):
48 # type: (str, AWSRequest, str, **Any) -> None
49 hub = Hub.current
50 if hub.get_integration(Boto3Integration) is None:
51 return
52
53 description = "aws.%s.%s" % (service_id, operation_name)
54 span = hub.start_span(
55 hub=hub,
56 op="aws.request",
57 description=description,
58 )
59 span.set_tag("aws.service_id", service_id)
60 span.set_tag("aws.operation_name", operation_name)
61 span.set_data("aws.request.url", request.url)
62
63 # We do it in order for subsequent http calls/retries be
64 # attached to this span.
65 span.__enter__()
66
67 # request.context is an open-ended data-structure
68 # where we can add anything useful in request life cycle.
69 request.context["_sentrysdk_span"] = span
70
71
72 def _sentry_after_call(context, parsed, **kwargs):
73 # type: (Dict[str, Any], Dict[str, Any], **Any) -> None
74 span = context.pop("_sentrysdk_span", None) # type: Optional[Span]
75
76 # Span could be absent if the integration is disabled.
77 if span is None:
78 return
79 span.__exit__(None, None, None)
80
81 body = parsed.get("Body")
82 if not isinstance(body, StreamingBody):
83 return
84
85 streaming_span = span.start_child(
86 op="aws.request.stream",
87 description=span.description,
88 )
89
90 orig_read = body.read
91 orig_close = body.close
92
93 def sentry_streaming_body_read(*args, **kwargs):
94 # type: (*Any, **Any) -> bytes
95 try:
96 ret = orig_read(*args, **kwargs)
97 if not ret:
98 streaming_span.finish()
99 return ret
100 except Exception:
101 streaming_span.finish()
102 raise
103
104 body.read = sentry_streaming_body_read
105
106 def sentry_streaming_body_close(*args, **kwargs):
107 # type: (*Any, **Any) -> None
108 streaming_span.finish()
109 orig_close(*args, **kwargs)
110
111 body.close = sentry_streaming_body_close
112
113
114 def _sentry_after_call_error(context, exception, **kwargs):
115 # type: (Dict[str, Any], Type[BaseException], **Any) -> None
116 span = context.pop("_sentrysdk_span", None) # type: Optional[Span]
117
118 # Span could be absent if the integration is disabled.
119 if span is None:
120 return
121 span.__exit__(type(exception), exception, None)
122
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sentry_sdk/integrations/boto3.py b/sentry_sdk/integrations/boto3.py
--- a/sentry_sdk/integrations/boto3.py
+++ b/sentry_sdk/integrations/boto3.py
@@ -14,6 +14,7 @@
from typing import Type
try:
+ from botocore import __version__ as BOTOCORE_VERSION # type: ignore
from botocore.client import BaseClient # type: ignore
from botocore.response import StreamingBody # type: ignore
from botocore.awsrequest import AWSRequest # type: ignore
@@ -27,6 +28,14 @@
@staticmethod
def setup_once():
# type: () -> None
+ try:
+ version = tuple(map(int, BOTOCORE_VERSION.split(".")[:3]))
+ except (ValueError, TypeError):
+ raise DidNotEnable(
+ "Unparsable botocore version: {}".format(BOTOCORE_VERSION)
+ )
+ if version < (1, 12):
+ raise DidNotEnable("Botocore 1.12 or newer is required.")
orig_init = BaseClient.__init__
def sentry_patched_init(self, *args, **kwargs):
|
{"golden_diff": "diff --git a/sentry_sdk/integrations/boto3.py b/sentry_sdk/integrations/boto3.py\n--- a/sentry_sdk/integrations/boto3.py\n+++ b/sentry_sdk/integrations/boto3.py\n@@ -14,6 +14,7 @@\n from typing import Type\n \n try:\n+ from botocore import __version__ as BOTOCORE_VERSION # type: ignore\n from botocore.client import BaseClient # type: ignore\n from botocore.response import StreamingBody # type: ignore\n from botocore.awsrequest import AWSRequest # type: ignore\n@@ -27,6 +28,14 @@\n @staticmethod\n def setup_once():\n # type: () -> None\n+ try:\n+ version = tuple(map(int, BOTOCORE_VERSION.split(\".\")[:3]))\n+ except (ValueError, TypeError):\n+ raise DidNotEnable(\n+ \"Unparsable botocore version: {}\".format(BOTOCORE_VERSION)\n+ )\n+ if version < (1, 12):\n+ raise DidNotEnable(\"Botocore 1.12 or newer is required.\")\n orig_init = BaseClient.__init__\n \n def sentry_patched_init(self, *args, **kwargs):\n", "issue": "Not working with older boto version\nHello, we use it in Django==2.1.7 app and this row breaks the app.\r\n\r\nhttps://github.com/getsentry/sentry-python/blob/cc08a6bed116e09db41c712c20ab63eb0a839e41/sentry_sdk/integrations/boto3.py#L36\r\n\r\nFor versions\r\nboto3==1.7.45\r\nbotocore==1.10.84\r\n\r\nthis throws\r\n`\r\nAttributeError: 'str' object has no attribute 'hyphenize'`\r\n\r\nI'm not sure the base of the integrations but I thought they must be enabled in settings, but this part of Boto3Integration is triggered even if we have not enabled it in django settings.\r\n\n", "before_files": [{"content": "from __future__ import absolute_import\n\nfrom sentry_sdk import Hub\nfrom sentry_sdk.integrations import Integration, DidNotEnable\nfrom sentry_sdk.tracing import Span\n\nfrom sentry_sdk._functools import partial\nfrom sentry_sdk._types import MYPY\n\nif MYPY:\n from typing import Any\n from typing import Dict\n from typing import Optional\n from typing import Type\n\ntry:\n from botocore.client import BaseClient # type: ignore\n from botocore.response import StreamingBody # type: ignore\n from botocore.awsrequest import AWSRequest # type: ignore\nexcept ImportError:\n raise DidNotEnable(\"botocore is not installed\")\n\n\nclass Boto3Integration(Integration):\n identifier = \"boto3\"\n\n @staticmethod\n def setup_once():\n # type: () -> None\n orig_init = BaseClient.__init__\n\n def sentry_patched_init(self, *args, **kwargs):\n # type: (Type[BaseClient], *Any, **Any) -> None\n orig_init(self, *args, **kwargs)\n meta = self.meta\n service_id = meta.service_model.service_id.hyphenize()\n meta.events.register(\n \"request-created\",\n partial(_sentry_request_created, service_id=service_id),\n )\n meta.events.register(\"after-call\", _sentry_after_call)\n meta.events.register(\"after-call-error\", _sentry_after_call_error)\n\n BaseClient.__init__ = sentry_patched_init\n\n\ndef _sentry_request_created(service_id, request, operation_name, **kwargs):\n # type: (str, AWSRequest, str, **Any) -> None\n hub = Hub.current\n if hub.get_integration(Boto3Integration) is None:\n return\n\n description = \"aws.%s.%s\" % (service_id, operation_name)\n span = hub.start_span(\n hub=hub,\n op=\"aws.request\",\n description=description,\n )\n span.set_tag(\"aws.service_id\", service_id)\n span.set_tag(\"aws.operation_name\", operation_name)\n span.set_data(\"aws.request.url\", request.url)\n\n # We do it in order for subsequent http calls/retries be\n # attached to this span.\n span.__enter__()\n\n # request.context is an open-ended data-structure\n # where we can add anything useful in request life cycle.\n request.context[\"_sentrysdk_span\"] = span\n\n\ndef _sentry_after_call(context, parsed, **kwargs):\n # type: (Dict[str, Any], Dict[str, Any], **Any) -> None\n span = context.pop(\"_sentrysdk_span\", None) # type: Optional[Span]\n\n # Span could be absent if the integration is disabled.\n if span is None:\n return\n span.__exit__(None, None, None)\n\n body = parsed.get(\"Body\")\n if not isinstance(body, StreamingBody):\n return\n\n streaming_span = span.start_child(\n op=\"aws.request.stream\",\n description=span.description,\n )\n\n orig_read = body.read\n orig_close = body.close\n\n def sentry_streaming_body_read(*args, **kwargs):\n # type: (*Any, **Any) -> bytes\n try:\n ret = orig_read(*args, **kwargs)\n if not ret:\n streaming_span.finish()\n return ret\n except Exception:\n streaming_span.finish()\n raise\n\n body.read = sentry_streaming_body_read\n\n def sentry_streaming_body_close(*args, **kwargs):\n # type: (*Any, **Any) -> None\n streaming_span.finish()\n orig_close(*args, **kwargs)\n\n body.close = sentry_streaming_body_close\n\n\ndef _sentry_after_call_error(context, exception, **kwargs):\n # type: (Dict[str, Any], Type[BaseException], **Any) -> None\n span = context.pop(\"_sentrysdk_span\", None) # type: Optional[Span]\n\n # Span could be absent if the integration is disabled.\n if span is None:\n return\n span.__exit__(type(exception), exception, None)\n", "path": "sentry_sdk/integrations/boto3.py"}], "after_files": [{"content": "from __future__ import absolute_import\n\nfrom sentry_sdk import Hub\nfrom sentry_sdk.integrations import Integration, DidNotEnable\nfrom sentry_sdk.tracing import Span\n\nfrom sentry_sdk._functools import partial\nfrom sentry_sdk._types import MYPY\n\nif MYPY:\n from typing import Any\n from typing import Dict\n from typing import Optional\n from typing import Type\n\ntry:\n from botocore import __version__ as BOTOCORE_VERSION # type: ignore\n from botocore.client import BaseClient # type: ignore\n from botocore.response import StreamingBody # type: ignore\n from botocore.awsrequest import AWSRequest # type: ignore\nexcept ImportError:\n raise DidNotEnable(\"botocore is not installed\")\n\n\nclass Boto3Integration(Integration):\n identifier = \"boto3\"\n\n @staticmethod\n def setup_once():\n # type: () -> None\n try:\n version = tuple(map(int, BOTOCORE_VERSION.split(\".\")[:3]))\n except (ValueError, TypeError):\n raise DidNotEnable(\n \"Unparsable botocore version: {}\".format(BOTOCORE_VERSION)\n )\n if version < (1, 12):\n raise DidNotEnable(\"Botocore 1.12 or newer is required.\")\n orig_init = BaseClient.__init__\n\n def sentry_patched_init(self, *args, **kwargs):\n # type: (Type[BaseClient], *Any, **Any) -> None\n orig_init(self, *args, **kwargs)\n meta = self.meta\n service_id = meta.service_model.service_id.hyphenize()\n meta.events.register(\n \"request-created\",\n partial(_sentry_request_created, service_id=service_id),\n )\n meta.events.register(\"after-call\", _sentry_after_call)\n meta.events.register(\"after-call-error\", _sentry_after_call_error)\n\n BaseClient.__init__ = sentry_patched_init\n\n\ndef _sentry_request_created(service_id, request, operation_name, **kwargs):\n # type: (str, AWSRequest, str, **Any) -> None\n hub = Hub.current\n if hub.get_integration(Boto3Integration) is None:\n return\n\n description = \"aws.%s.%s\" % (service_id, operation_name)\n span = hub.start_span(\n hub=hub,\n op=\"aws.request\",\n description=description,\n )\n span.set_tag(\"aws.service_id\", service_id)\n span.set_tag(\"aws.operation_name\", operation_name)\n span.set_data(\"aws.request.url\", request.url)\n\n # We do it in order for subsequent http calls/retries be\n # attached to this span.\n span.__enter__()\n\n # request.context is an open-ended data-structure\n # where we can add anything useful in request life cycle.\n request.context[\"_sentrysdk_span\"] = span\n\n\ndef _sentry_after_call(context, parsed, **kwargs):\n # type: (Dict[str, Any], Dict[str, Any], **Any) -> None\n span = context.pop(\"_sentrysdk_span\", None) # type: Optional[Span]\n\n # Span could be absent if the integration is disabled.\n if span is None:\n return\n span.__exit__(None, None, None)\n\n body = parsed.get(\"Body\")\n if not isinstance(body, StreamingBody):\n return\n\n streaming_span = span.start_child(\n op=\"aws.request.stream\",\n description=span.description,\n )\n\n orig_read = body.read\n orig_close = body.close\n\n def sentry_streaming_body_read(*args, **kwargs):\n # type: (*Any, **Any) -> bytes\n try:\n ret = orig_read(*args, **kwargs)\n if not ret:\n streaming_span.finish()\n return ret\n except Exception:\n streaming_span.finish()\n raise\n\n body.read = sentry_streaming_body_read\n\n def sentry_streaming_body_close(*args, **kwargs):\n # type: (*Any, **Any) -> None\n streaming_span.finish()\n orig_close(*args, **kwargs)\n\n body.close = sentry_streaming_body_close\n\n\ndef _sentry_after_call_error(context, exception, **kwargs):\n # type: (Dict[str, Any], Type[BaseException], **Any) -> None\n span = context.pop(\"_sentrysdk_span\", None) # type: Optional[Span]\n\n # Span could be absent if the integration is disabled.\n if span is None:\n return\n span.__exit__(type(exception), exception, None)\n", "path": "sentry_sdk/integrations/boto3.py"}]}
| 1,618 | 285 |
gh_patches_debug_12093
|
rasdani/github-patches
|
git_diff
|
AnalogJ__lexicon-374
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
DNSimple crash with team member that does not have a plan
Here's the error I get (I have redacted my account number, domain and auth token)
```sh
$ lexicon dnsimple --auth-token REDACTED list REDACTED A
Traceback (most recent call last):
File "/usr/local/bin/lexicon", line 11, in <module>
sys.exit(main())
File "/usr/local/lib/python2.7/dist-packages/lexicon/cli.py", line 117, in main
results = client.execute()
File "/usr/local/lib/python2.7/dist-packages/lexicon/client.py", line 64, in execute
self.provider.authenticate()
File "/usr/local/lib/python2.7/dist-packages/lexicon/providers/dnsimple.py", line 43, in authenticate
'/{0}/domains'.format(account['id']), query_params={'name_like': self.domain})
File "/usr/local/lib/python2.7/dist-packages/lexicon/providers/base.py", line 87, in _get
return self._request('GET', url, query_params=query_params)
File "/usr/local/lib/python2.7/dist-packages/lexicon/providers/dnsimple.py", line 189, in _request
r.raise_for_status()
File "/usr/lib/python2.7/dist-packages/requests/models.py", line 935, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 402 Client Error: Payment Required for url: https://api.dnsimple.com/v2/REDACTED/domains?name_like=REDACTED
```
I believe that this happens because of the way the domain I have is configured. We have a domain configured with a team. There is one account that has a professional plan (with our domain) and we have other users as team members of that account. The only account that has a plan is the one mentioned. Other users have personal accounts by default but they don't have a plan configured at all.
I believe that the code responsible is this: https://github.com/AnalogJ/lexicon/blob/master/lexicon/providers/dnsimple.py#L37-L52
The dnsimple provider iterates through all accounts that the token has access to and tried to see if they have a domain similar to the one specified. When it tries to do this on an account that is not configured it will crash with the http error `402 Client Error: Payment Required for url: ...`.
This is consistent with the documentation from dnsimple: https://developer.dnsimple.com/v2/#response-codes
> `402 Payment Required` - Your account is not subscribed or not in good standing.
I think that it's possible to figure out if an account is not configured by using the `GET /accounts` endpoint. Accounts that are not configured have their `plan_identifier` set to `null`. This does not seem to be documented in the API references tho.
When I do this request I get the following json as output
```json
{
"data": [
{
"created_at": "2018-06-05T19:23:59Z",
"email": "REDACTED",
"id": "REDACTED",
"plan_identifier": "dnsimple-professional",
"updated_at": "2019-01-06T21:16:40Z"
},
{
"created_at": "2018-06-08T19:48:59Z",
"email": "REDACTED",
"id": "REDACTED",
"plan_identifier": null,
"updated_at": "2018-06-08T19:48:59Z"
}
]
}
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lexicon/providers/dnsimple.py`
Content:
```
1 """Module provider for DNS Simple"""
2 from __future__ import absolute_import
3 import json
4 import logging
5
6 import requests
7 from lexicon.providers.base import Provider as BaseProvider
8
9
10 LOGGER = logging.getLogger(__name__)
11
12 NAMESERVER_DOMAINS = ['dnsimple.com']
13
14
15 def provider_parser(subparser):
16 """Configure provider parser for DNS Simple"""
17 subparser.add_argument(
18 "--auth-token", help="specify api token for authentication")
19 subparser.add_argument(
20 "--auth-username", help="specify email address for authentication")
21 subparser.add_argument(
22 "--auth-password", help="specify password for authentication")
23 subparser.add_argument(
24 "--auth-2fa",
25 help="specify two-factor auth token (OTP) to use with email/password authentication")
26
27
28 class Provider(BaseProvider):
29 """Provider class for DNS Simple"""
30 def __init__(self, config):
31 super(Provider, self).__init__(config)
32 self.domain_id = None
33 self.account_id = None
34 self.api_endpoint = self._get_provider_option(
35 'api_endpoint') or 'https://api.dnsimple.com/v2'
36
37 def _authenticate(self):
38
39 payload = self._get('/accounts')
40
41 if not payload[0]['id']:
42 raise Exception('No account id found')
43
44 for account in payload:
45 dompayload = self._get(
46 '/{0}/domains'.format(account['id']), query_params={'name_like': self.domain})
47 if dompayload and dompayload[0]['id']:
48 self.account_id = account['id']
49 self.domain_id = dompayload[0]['id']
50
51 if not self.account_id:
52 raise Exception('No domain found like {}'.format(self.domain))
53
54 # Create record. If record already exists with the same content, do nothing
55
56 def _create_record(self, rtype, name, content):
57 # check if record already exists
58 existing_records = self._list_records(rtype, name, content)
59 if len(existing_records) == 1:
60 return True
61
62 record = {
63 'type': rtype,
64 'name': self._relative_name(name),
65 'content': content
66 }
67 if self._get_lexicon_option('ttl'):
68 record['ttl'] = self._get_lexicon_option('ttl')
69 if self._get_lexicon_option('priority'):
70 record['priority'] = self._get_lexicon_option('priority')
71 if self._get_provider_option('regions'):
72 record['regions'] = self._get_provider_option('regions')
73
74 payload = self._post(
75 '/{0}/zones/{1}/records'.format(self.account_id, self.domain), record)
76
77 LOGGER.debug('create_record: %s', 'id' in payload)
78 return 'id' in payload
79
80 # List all records. Return an empty list if no records found
81 # type, name and content are used to filter records.
82 # If possible filter during the query, otherwise filter after response is received.
83 def _list_records(self, rtype=None, name=None, content=None):
84 filter_query = {}
85 if rtype:
86 filter_query['type'] = rtype
87 if name:
88 filter_query['name'] = self._relative_name(name)
89 payload = self._get(
90 '/{0}/zones/{1}/records'.format(self.account_id, self.domain),
91 query_params=filter_query)
92
93 records = []
94 for record in payload:
95 processed_record = {
96 'type': record['type'],
97 'name': '{}'.format(
98 self.domain) if record['name'] == "" else '{0}.{1}'.format(
99 record['name'],
100 self.domain),
101 'ttl': record['ttl'],
102 'content': record['content'],
103 'id': record['id']}
104 if record['priority']:
105 processed_record['priority'] = record['priority']
106 records.append(processed_record)
107
108 if content:
109 records = [
110 record for record in records if record['content'] == content]
111
112 LOGGER.debug('list_records: %s', records)
113 return records
114
115 # Create or update a record.
116 def _update_record(self, identifier, rtype=None, name=None, content=None):
117
118 data = {}
119
120 if identifier is None:
121 records = self._list_records(rtype, name, content)
122 identifiers = [record["id"] for record in records]
123 else:
124 identifiers = [identifier]
125
126 if name:
127 data['name'] = self._relative_name(name)
128 if content:
129 data['content'] = content
130 if self._get_lexicon_option('ttl'):
131 data['ttl'] = self._get_lexicon_option('ttl')
132 if self._get_lexicon_option('priority'):
133 data['priority'] = self._get_lexicon_option('priority')
134 if self._get_provider_option('regions'):
135 data['regions'] = self._get_provider_option('regions')
136
137 for one_identifier in identifiers:
138 self._patch('/{0}/zones/{1}/records/{2}'
139 .format(self.account_id, self.domain, one_identifier), data)
140 LOGGER.debug('update_record: %s', one_identifier)
141
142 LOGGER.debug('update_record: %s', True)
143 return True
144
145 # Delete an existing record.
146 # If record does not exist, do nothing.
147 def _delete_record(self, identifier=None, rtype=None, name=None, content=None):
148 delete_record_id = []
149 if not identifier:
150 records = self._list_records(rtype, name, content)
151 delete_record_id = [record['id'] for record in records]
152 else:
153 delete_record_id.append(identifier)
154
155 LOGGER.debug('delete_records: %s', delete_record_id)
156
157 for record_id in delete_record_id:
158 self._delete(
159 '/{0}/zones/{1}/records/{2}'.format(self.account_id, self.domain, record_id))
160
161 # is always True at this point; if a non 2xx response is returned, an error is raised.
162 LOGGER.debug('delete_record: True')
163 return True
164
165 # Helpers
166
167 def _request(self, action='GET', url='/', data=None, query_params=None):
168 if data is None:
169 data = {}
170 if query_params is None:
171 query_params = {}
172 default_headers = {
173 'Accept': 'application/json',
174 'Content-Type': 'application/json'
175 }
176 default_auth = None
177
178 if self._get_provider_option('auth_token'):
179 default_headers['Authorization'] = "Bearer {0}".format(
180 self._get_provider_option('auth_token'))
181 elif (self._get_provider_option('auth_username')
182 and self._get_provider_option('auth_password')):
183 default_auth = (self._get_provider_option(
184 'auth_username'), self._get_provider_option('auth_password'))
185 if self._get_provider_option('auth_2fa'):
186 default_headers['X-Dnsimple-OTP'] = self._get_provider_option(
187 'auth_2fa')
188 else:
189 raise Exception('No valid authentication mechanism found')
190
191 response = requests.request(action, self.api_endpoint + url, params=query_params,
192 data=json.dumps(data),
193 headers=default_headers,
194 auth=default_auth)
195 # if the request fails for any reason, throw an error.
196 response.raise_for_status()
197 if response.text and response.json()['data'] is None:
198 raise Exception('No data returned')
199
200 return response.json()['data'] if response.text else None
201
202 def _patch(self, url='/', data=None, query_params=None):
203 return self._request('PATCH', url, data=data, query_params=query_params)
204
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lexicon/providers/dnsimple.py b/lexicon/providers/dnsimple.py
--- a/lexicon/providers/dnsimple.py
+++ b/lexicon/providers/dnsimple.py
@@ -42,6 +42,13 @@
raise Exception('No account id found')
for account in payload:
+ if account['plan_identifier'] is None:
+ logging.warning(
+ 'Skipping unconfigured account %s (%d). ' \
+ 'To use this account, you must select a plan.',
+ account['email'], account['id'])
+ continue
+
dompayload = self._get(
'/{0}/domains'.format(account['id']), query_params={'name_like': self.domain})
if dompayload and dompayload[0]['id']:
|
{"golden_diff": "diff --git a/lexicon/providers/dnsimple.py b/lexicon/providers/dnsimple.py\n--- a/lexicon/providers/dnsimple.py\n+++ b/lexicon/providers/dnsimple.py\n@@ -42,6 +42,13 @@\n raise Exception('No account id found')\n \n for account in payload:\n+ if account['plan_identifier'] is None:\n+ logging.warning(\n+ 'Skipping unconfigured account %s (%d). ' \\\n+ 'To use this account, you must select a plan.',\n+ account['email'], account['id'])\n+ continue\n+\n dompayload = self._get(\n '/{0}/domains'.format(account['id']), query_params={'name_like': self.domain})\n if dompayload and dompayload[0]['id']:\n", "issue": "DNSimple crash with team member that does not have a plan\nHere's the error I get (I have redacted my account number, domain and auth token)\r\n\r\n```sh\r\n$ lexicon dnsimple --auth-token REDACTED list REDACTED A\r\nTraceback (most recent call last):\r\n File \"/usr/local/bin/lexicon\", line 11, in <module>\r\n sys.exit(main())\r\n File \"/usr/local/lib/python2.7/dist-packages/lexicon/cli.py\", line 117, in main\r\n results = client.execute()\r\n File \"/usr/local/lib/python2.7/dist-packages/lexicon/client.py\", line 64, in execute\r\n self.provider.authenticate()\r\n File \"/usr/local/lib/python2.7/dist-packages/lexicon/providers/dnsimple.py\", line 43, in authenticate\r\n '/{0}/domains'.format(account['id']), query_params={'name_like': self.domain})\r\n File \"/usr/local/lib/python2.7/dist-packages/lexicon/providers/base.py\", line 87, in _get\r\n return self._request('GET', url, query_params=query_params)\r\n File \"/usr/local/lib/python2.7/dist-packages/lexicon/providers/dnsimple.py\", line 189, in _request\r\n r.raise_for_status()\r\n File \"/usr/lib/python2.7/dist-packages/requests/models.py\", line 935, in raise_for_status\r\n raise HTTPError(http_error_msg, response=self)\r\nrequests.exceptions.HTTPError: 402 Client Error: Payment Required for url: https://api.dnsimple.com/v2/REDACTED/domains?name_like=REDACTED\r\n```\r\n\r\nI believe that this happens because of the way the domain I have is configured. We have a domain configured with a team. There is one account that has a professional plan (with our domain) and we have other users as team members of that account. The only account that has a plan is the one mentioned. Other users have personal accounts by default but they don't have a plan configured at all.\r\n\r\nI believe that the code responsible is this: https://github.com/AnalogJ/lexicon/blob/master/lexicon/providers/dnsimple.py#L37-L52\r\n\r\nThe dnsimple provider iterates through all accounts that the token has access to and tried to see if they have a domain similar to the one specified. When it tries to do this on an account that is not configured it will crash with the http error `402 Client Error: Payment Required for url: ...`.\r\n\r\nThis is consistent with the documentation from dnsimple: https://developer.dnsimple.com/v2/#response-codes\r\n\r\n> `402 Payment Required` - Your account is not subscribed or not in good standing.\r\n\r\nI think that it's possible to figure out if an account is not configured by using the `GET /accounts` endpoint. Accounts that are not configured have their `plan_identifier` set to `null`. This does not seem to be documented in the API references tho.\r\n\r\nWhen I do this request I get the following json as output\r\n\r\n```json\r\n{\r\n \"data\": [\r\n {\r\n \"created_at\": \"2018-06-05T19:23:59Z\",\r\n \"email\": \"REDACTED\",\r\n \"id\": \"REDACTED\",\r\n \"plan_identifier\": \"dnsimple-professional\",\r\n \"updated_at\": \"2019-01-06T21:16:40Z\"\r\n },\r\n {\r\n \"created_at\": \"2018-06-08T19:48:59Z\",\r\n \"email\": \"REDACTED\",\r\n \"id\": \"REDACTED\",\r\n \"plan_identifier\": null,\r\n \"updated_at\": \"2018-06-08T19:48:59Z\"\r\n }\r\n ]\r\n}\r\n```\n", "before_files": [{"content": "\"\"\"Module provider for DNS Simple\"\"\"\nfrom __future__ import absolute_import\nimport json\nimport logging\n\nimport requests\nfrom lexicon.providers.base import Provider as BaseProvider\n\n\nLOGGER = logging.getLogger(__name__)\n\nNAMESERVER_DOMAINS = ['dnsimple.com']\n\n\ndef provider_parser(subparser):\n \"\"\"Configure provider parser for DNS Simple\"\"\"\n subparser.add_argument(\n \"--auth-token\", help=\"specify api token for authentication\")\n subparser.add_argument(\n \"--auth-username\", help=\"specify email address for authentication\")\n subparser.add_argument(\n \"--auth-password\", help=\"specify password for authentication\")\n subparser.add_argument(\n \"--auth-2fa\",\n help=\"specify two-factor auth token (OTP) to use with email/password authentication\")\n\n\nclass Provider(BaseProvider):\n \"\"\"Provider class for DNS Simple\"\"\"\n def __init__(self, config):\n super(Provider, self).__init__(config)\n self.domain_id = None\n self.account_id = None\n self.api_endpoint = self._get_provider_option(\n 'api_endpoint') or 'https://api.dnsimple.com/v2'\n\n def _authenticate(self):\n\n payload = self._get('/accounts')\n\n if not payload[0]['id']:\n raise Exception('No account id found')\n\n for account in payload:\n dompayload = self._get(\n '/{0}/domains'.format(account['id']), query_params={'name_like': self.domain})\n if dompayload and dompayload[0]['id']:\n self.account_id = account['id']\n self.domain_id = dompayload[0]['id']\n\n if not self.account_id:\n raise Exception('No domain found like {}'.format(self.domain))\n\n # Create record. If record already exists with the same content, do nothing\n\n def _create_record(self, rtype, name, content):\n # check if record already exists\n existing_records = self._list_records(rtype, name, content)\n if len(existing_records) == 1:\n return True\n\n record = {\n 'type': rtype,\n 'name': self._relative_name(name),\n 'content': content\n }\n if self._get_lexicon_option('ttl'):\n record['ttl'] = self._get_lexicon_option('ttl')\n if self._get_lexicon_option('priority'):\n record['priority'] = self._get_lexicon_option('priority')\n if self._get_provider_option('regions'):\n record['regions'] = self._get_provider_option('regions')\n\n payload = self._post(\n '/{0}/zones/{1}/records'.format(self.account_id, self.domain), record)\n\n LOGGER.debug('create_record: %s', 'id' in payload)\n return 'id' in payload\n\n # List all records. Return an empty list if no records found\n # type, name and content are used to filter records.\n # If possible filter during the query, otherwise filter after response is received.\n def _list_records(self, rtype=None, name=None, content=None):\n filter_query = {}\n if rtype:\n filter_query['type'] = rtype\n if name:\n filter_query['name'] = self._relative_name(name)\n payload = self._get(\n '/{0}/zones/{1}/records'.format(self.account_id, self.domain),\n query_params=filter_query)\n\n records = []\n for record in payload:\n processed_record = {\n 'type': record['type'],\n 'name': '{}'.format(\n self.domain) if record['name'] == \"\" else '{0}.{1}'.format(\n record['name'],\n self.domain),\n 'ttl': record['ttl'],\n 'content': record['content'],\n 'id': record['id']}\n if record['priority']:\n processed_record['priority'] = record['priority']\n records.append(processed_record)\n\n if content:\n records = [\n record for record in records if record['content'] == content]\n\n LOGGER.debug('list_records: %s', records)\n return records\n\n # Create or update a record.\n def _update_record(self, identifier, rtype=None, name=None, content=None):\n\n data = {}\n\n if identifier is None:\n records = self._list_records(rtype, name, content)\n identifiers = [record[\"id\"] for record in records]\n else:\n identifiers = [identifier]\n\n if name:\n data['name'] = self._relative_name(name)\n if content:\n data['content'] = content\n if self._get_lexicon_option('ttl'):\n data['ttl'] = self._get_lexicon_option('ttl')\n if self._get_lexicon_option('priority'):\n data['priority'] = self._get_lexicon_option('priority')\n if self._get_provider_option('regions'):\n data['regions'] = self._get_provider_option('regions')\n\n for one_identifier in identifiers:\n self._patch('/{0}/zones/{1}/records/{2}'\n .format(self.account_id, self.domain, one_identifier), data)\n LOGGER.debug('update_record: %s', one_identifier)\n\n LOGGER.debug('update_record: %s', True)\n return True\n\n # Delete an existing record.\n # If record does not exist, do nothing.\n def _delete_record(self, identifier=None, rtype=None, name=None, content=None):\n delete_record_id = []\n if not identifier:\n records = self._list_records(rtype, name, content)\n delete_record_id = [record['id'] for record in records]\n else:\n delete_record_id.append(identifier)\n\n LOGGER.debug('delete_records: %s', delete_record_id)\n\n for record_id in delete_record_id:\n self._delete(\n '/{0}/zones/{1}/records/{2}'.format(self.account_id, self.domain, record_id))\n\n # is always True at this point; if a non 2xx response is returned, an error is raised.\n LOGGER.debug('delete_record: True')\n return True\n\n # Helpers\n\n def _request(self, action='GET', url='/', data=None, query_params=None):\n if data is None:\n data = {}\n if query_params is None:\n query_params = {}\n default_headers = {\n 'Accept': 'application/json',\n 'Content-Type': 'application/json'\n }\n default_auth = None\n\n if self._get_provider_option('auth_token'):\n default_headers['Authorization'] = \"Bearer {0}\".format(\n self._get_provider_option('auth_token'))\n elif (self._get_provider_option('auth_username')\n and self._get_provider_option('auth_password')):\n default_auth = (self._get_provider_option(\n 'auth_username'), self._get_provider_option('auth_password'))\n if self._get_provider_option('auth_2fa'):\n default_headers['X-Dnsimple-OTP'] = self._get_provider_option(\n 'auth_2fa')\n else:\n raise Exception('No valid authentication mechanism found')\n\n response = requests.request(action, self.api_endpoint + url, params=query_params,\n data=json.dumps(data),\n headers=default_headers,\n auth=default_auth)\n # if the request fails for any reason, throw an error.\n response.raise_for_status()\n if response.text and response.json()['data'] is None:\n raise Exception('No data returned')\n\n return response.json()['data'] if response.text else None\n\n def _patch(self, url='/', data=None, query_params=None):\n return self._request('PATCH', url, data=data, query_params=query_params)\n", "path": "lexicon/providers/dnsimple.py"}], "after_files": [{"content": "\"\"\"Module provider for DNS Simple\"\"\"\nfrom __future__ import absolute_import\nimport json\nimport logging\n\nimport requests\nfrom lexicon.providers.base import Provider as BaseProvider\n\n\nLOGGER = logging.getLogger(__name__)\n\nNAMESERVER_DOMAINS = ['dnsimple.com']\n\n\ndef provider_parser(subparser):\n \"\"\"Configure provider parser for DNS Simple\"\"\"\n subparser.add_argument(\n \"--auth-token\", help=\"specify api token for authentication\")\n subparser.add_argument(\n \"--auth-username\", help=\"specify email address for authentication\")\n subparser.add_argument(\n \"--auth-password\", help=\"specify password for authentication\")\n subparser.add_argument(\n \"--auth-2fa\",\n help=\"specify two-factor auth token (OTP) to use with email/password authentication\")\n\n\nclass Provider(BaseProvider):\n \"\"\"Provider class for DNS Simple\"\"\"\n def __init__(self, config):\n super(Provider, self).__init__(config)\n self.domain_id = None\n self.account_id = None\n self.api_endpoint = self._get_provider_option(\n 'api_endpoint') or 'https://api.dnsimple.com/v2'\n\n def _authenticate(self):\n\n payload = self._get('/accounts')\n\n if not payload[0]['id']:\n raise Exception('No account id found')\n\n for account in payload:\n if account['plan_identifier'] is None:\n logging.warning(\n 'Skipping unconfigured account %s (%d). ' \\\n 'To use this account, you must select a plan.',\n account['email'], account['id'])\n continue\n\n dompayload = self._get(\n '/{0}/domains'.format(account['id']), query_params={'name_like': self.domain})\n if dompayload and dompayload[0]['id']:\n self.account_id = account['id']\n self.domain_id = dompayload[0]['id']\n\n if not self.account_id:\n raise Exception('No domain found like {}'.format(self.domain))\n\n # Create record. If record already exists with the same content, do nothing\n\n def _create_record(self, rtype, name, content):\n # check if record already exists\n existing_records = self._list_records(rtype, name, content)\n if len(existing_records) == 1:\n return True\n\n record = {\n 'type': rtype,\n 'name': self._relative_name(name),\n 'content': content\n }\n if self._get_lexicon_option('ttl'):\n record['ttl'] = self._get_lexicon_option('ttl')\n if self._get_lexicon_option('priority'):\n record['priority'] = self._get_lexicon_option('priority')\n if self._get_provider_option('regions'):\n record['regions'] = self._get_provider_option('regions')\n\n payload = self._post(\n '/{0}/zones/{1}/records'.format(self.account_id, self.domain), record)\n\n LOGGER.debug('create_record: %s', 'id' in payload)\n return 'id' in payload\n\n # List all records. Return an empty list if no records found\n # type, name and content are used to filter records.\n # If possible filter during the query, otherwise filter after response is received.\n def _list_records(self, rtype=None, name=None, content=None):\n filter_query = {}\n if rtype:\n filter_query['type'] = rtype\n if name:\n filter_query['name'] = self._relative_name(name)\n payload = self._get(\n '/{0}/zones/{1}/records'.format(self.account_id, self.domain),\n query_params=filter_query)\n\n records = []\n for record in payload:\n processed_record = {\n 'type': record['type'],\n 'name': '{}'.format(\n self.domain) if record['name'] == \"\" else '{0}.{1}'.format(\n record['name'],\n self.domain),\n 'ttl': record['ttl'],\n 'content': record['content'],\n 'id': record['id']}\n if record['priority']:\n processed_record['priority'] = record['priority']\n records.append(processed_record)\n\n if content:\n records = [\n record for record in records if record['content'] == content]\n\n LOGGER.debug('list_records: %s', records)\n return records\n\n # Create or update a record.\n def _update_record(self, identifier, rtype=None, name=None, content=None):\n\n data = {}\n\n if identifier is None:\n records = self._list_records(rtype, name, content)\n identifiers = [record[\"id\"] for record in records]\n else:\n identifiers = [identifier]\n\n if name:\n data['name'] = self._relative_name(name)\n if content:\n data['content'] = content\n if self._get_lexicon_option('ttl'):\n data['ttl'] = self._get_lexicon_option('ttl')\n if self._get_lexicon_option('priority'):\n data['priority'] = self._get_lexicon_option('priority')\n if self._get_provider_option('regions'):\n data['regions'] = self._get_provider_option('regions')\n\n for one_identifier in identifiers:\n self._patch('/{0}/zones/{1}/records/{2}'\n .format(self.account_id, self.domain, one_identifier), data)\n LOGGER.debug('update_record: %s', one_identifier)\n\n LOGGER.debug('update_record: %s', True)\n return True\n\n # Delete an existing record.\n # If record does not exist, do nothing.\n def _delete_record(self, identifier=None, rtype=None, name=None, content=None):\n delete_record_id = []\n if not identifier:\n records = self._list_records(rtype, name, content)\n delete_record_id = [record['id'] for record in records]\n else:\n delete_record_id.append(identifier)\n\n LOGGER.debug('delete_records: %s', delete_record_id)\n\n for record_id in delete_record_id:\n self._delete(\n '/{0}/zones/{1}/records/{2}'.format(self.account_id, self.domain, record_id))\n\n # is always True at this point; if a non 2xx response is returned, an error is raised.\n LOGGER.debug('delete_record: True')\n return True\n\n # Helpers\n\n def _request(self, action='GET', url='/', data=None, query_params=None):\n if data is None:\n data = {}\n if query_params is None:\n query_params = {}\n default_headers = {\n 'Accept': 'application/json',\n 'Content-Type': 'application/json'\n }\n default_auth = None\n\n if self._get_provider_option('auth_token'):\n default_headers['Authorization'] = \"Bearer {0}\".format(\n self._get_provider_option('auth_token'))\n elif (self._get_provider_option('auth_username')\n and self._get_provider_option('auth_password')):\n default_auth = (self._get_provider_option(\n 'auth_username'), self._get_provider_option('auth_password'))\n if self._get_provider_option('auth_2fa'):\n default_headers['X-Dnsimple-OTP'] = self._get_provider_option(\n 'auth_2fa')\n else:\n raise Exception('No valid authentication mechanism found')\n\n response = requests.request(action, self.api_endpoint + url, params=query_params,\n data=json.dumps(data),\n headers=default_headers,\n auth=default_auth)\n # if the request fails for any reason, throw an error.\n response.raise_for_status()\n if response.text and response.json()['data'] is None:\n raise Exception('No data returned')\n\n return response.json()['data'] if response.text else None\n\n def _patch(self, url='/', data=None, query_params=None):\n return self._request('PATCH', url, data=data, query_params=query_params)\n", "path": "lexicon/providers/dnsimple.py"}]}
| 3,255 | 173 |
gh_patches_debug_9048
|
rasdani/github-patches
|
git_diff
|
frappe__frappe-20401
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
SQL SyntaxError in queries in DocTypes with Table Multiselect fields
### App Versions
```json
{
"frappe": "15.0.0-dev"
}
```
### Route
`List/User Group/List` and `Form/User Group/new-user-group-1`
### Traceback
```python
Syntax error in query:
select distinct
from `tabUser Group`
Traceback (most recent call last):
File "apps/frappe/frappe/app.py", line 53, in application
response = frappe.api.handle()
File "apps/frappe/frappe/api.py", line 53, in handle
return _RESTAPIHandler(call, doctype, name).get_response()
File "apps/frappe/frappe/api.py", line 69, in get_response
return self.handle_method()
File "apps/frappe/frappe/api.py", line 79, in handle_method
return frappe.handler.handle()
File "apps/frappe/frappe/handler.py", line 48, in handle
data = execute_cmd(cmd)
File "apps/frappe/frappe/handler.py", line 86, in execute_cmd
return frappe.call(method, **frappe.form_dict)
File "apps/frappe/frappe/__init__.py", line 1591, in call
return fn(*args, **newargs)
File "apps/frappe/frappe/utils/typing_validations.py", line 33, in wrapper
return func(*args, **kwargs)
File "apps/frappe/frappe/__init__.py", line 796, in wrapper_fn
retval = fn(*args, **get_newargs(fn, kwargs))
File "apps/frappe/frappe/desk/reportview.py", line 58, in get_count
data = execute(**args)[0].get("total_count")
File "apps/frappe/frappe/desk/reportview.py", line 64, in execute
return DatabaseQuery(doctype).execute(*args, **kwargs)
File "apps/frappe/frappe/model/db_query.py", line 202, in execute
result = self.build_and_run()
File "apps/frappe/frappe/model/db_query.py", line 242, in build_and_run
return frappe.db.sql(
File "apps/frappe/frappe/database/database.py", line 222, in sql
self._cursor.execute(query, values)
File "env/lib/python3.10/site-packages/pymysql/cursors.py", line 148, in execute
result = self._query(query)
File "env/lib/python3.10/site-packages/pymysql/cursors.py", line 310, in _query
conn.query(q)
File "env/lib/python3.10/site-packages/pymysql/connections.py", line 548, in query
self._affected_rows = self._read_query_result(unbuffered=unbuffered)
File "env/lib/python3.10/site-packages/pymysql/connections.py", line 775, in _read_query_result
result.read()
File "env/lib/python3.10/site-packages/pymysql/connections.py", line 1156, in read
first_packet = self.connection._read_packet()
File "env/lib/python3.10/site-packages/pymysql/connections.py", line 725, in _read_packet
packet.raise_for_error()
File "env/lib/python3.10/site-packages/pymysql/protocol.py", line 221, in raise_for_error
err.raise_mysql_exception(self._data)
File "env/lib/python3.10/site-packages/pymysql/err.py", line 143, in raise_mysql_exception
raise errorclass(errno, errval)
pymysql.err.ProgrammingError: (1064, "You have an error in your SQL syntax; check the manual that corresponds to your MariaDB server version for the right syntax to use near 'from `tabUser Group`' at line 2")
```
### Request Data
```json
{
"type": "POST",
"args": {
"doctype": "User Group",
"filters": "[]",
"fields": "[]",
"distinct": false
},
"headers": {},
"error_handlers": {},
"url": "/api/method/frappe.desk.reportview.get_count"
}
```
### Response Data
```json
{
"exception": "pymysql.err.ProgrammingError: (1064, \"You have an error in your SQL syntax; check the manual that corresponds to your MariaDB server version for the right syntax to use near 'from `tabUser Group`' at line 2\")",
"_debug_messages": "[\"method:frappe.desk.reportview.get_count\", \"<<<< query\\nSELECT `is_virtual` FROM `tabDocType` WHERE `name`='User Group' ORDER BY `modified` DESC LIMIT 1\\n>>>>\", \"<<<< query\\nselect `share_name`\\n\\t\\t\\tfrom `tabDocShare`\\n\\t\\t\\twhere `tabDocShare`.`read` = 1.0 and `tabDocShare`.`share_doctype` = 'User Group' and (`tabDocShare`.`user` = 'Administrator' or `tabDocShare`.`everyone` = 1.0)\\n\\t\\t\\t\\n\\t\\t\\t order by `tabDocShare`.`modified` DESC\\n>>>>\"]"
}
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `frappe/model/__init__.py`
Content:
```
1 # Copyright (c) 2015, Frappe Technologies Pvt. Ltd. and Contributors
2 # License: MIT. See LICENSE
3
4 # model __init__.py
5 import frappe
6
7 data_fieldtypes = (
8 "Currency",
9 "Int",
10 "Long Int",
11 "Float",
12 "Percent",
13 "Check",
14 "Small Text",
15 "Long Text",
16 "Code",
17 "Text Editor",
18 "Markdown Editor",
19 "HTML Editor",
20 "Date",
21 "Datetime",
22 "Time",
23 "Text",
24 "Data",
25 "Link",
26 "Dynamic Link",
27 "Password",
28 "Select",
29 "Rating",
30 "Read Only",
31 "Attach",
32 "Attach Image",
33 "Signature",
34 "Color",
35 "Barcode",
36 "Geolocation",
37 "Duration",
38 "Icon",
39 "Phone",
40 "Autocomplete",
41 "JSON",
42 )
43
44 float_like_fields = {"Float", "Currency", "Percent"}
45 datetime_fields = {"Datetime", "Date", "Time"}
46
47 attachment_fieldtypes = (
48 "Attach",
49 "Attach Image",
50 )
51
52 no_value_fields = (
53 "Section Break",
54 "Column Break",
55 "Tab Break",
56 "HTML",
57 "Table",
58 "Table MultiSelect",
59 "Button",
60 "Image",
61 "Fold",
62 "Heading",
63 )
64
65 display_fieldtypes = (
66 "Section Break",
67 "Column Break",
68 "Tab Break",
69 "HTML",
70 "Button",
71 "Image",
72 "Fold",
73 "Heading",
74 )
75
76 numeric_fieldtypes = ("Currency", "Int", "Long Int", "Float", "Percent", "Check")
77
78 data_field_options = ("Email", "Name", "Phone", "URL", "Barcode")
79
80 default_fields = (
81 "doctype",
82 "name",
83 "owner",
84 "creation",
85 "modified",
86 "modified_by",
87 "docstatus",
88 "idx",
89 )
90
91 child_table_fields = ("parent", "parentfield", "parenttype")
92
93 optional_fields = ("_user_tags", "_comments", "_assign", "_liked_by", "_seen")
94
95 table_fields = ("Table", "Table MultiSelect")
96
97 core_doctypes_list = (
98 "DefaultValue",
99 "DocType",
100 "DocField",
101 "DocPerm",
102 "DocType Action",
103 "DocType Link",
104 "User",
105 "Role",
106 "Has Role",
107 "Page",
108 "Module Def",
109 "Print Format",
110 "Report",
111 "Customize Form",
112 "Customize Form Field",
113 "Property Setter",
114 "Custom Field",
115 "Client Script",
116 )
117
118 # NOTE: this is being used for dynamic autoincrement in new sites,
119 # removing any of these will require patches.
120 log_types = (
121 "Version",
122 "Error Log",
123 "Scheduled Job Log",
124 "Event Sync Log",
125 "Event Update Log",
126 "Access Log",
127 "View Log",
128 "Activity Log",
129 "Energy Point Log",
130 "Notification Log",
131 "Email Queue",
132 "DocShare",
133 "Document Follow",
134 "Console Log",
135 )
136
137
138 def delete_fields(args_dict, delete=0):
139 """
140 Delete a field.
141 * Deletes record from `tabDocField`
142 * If not single doctype: Drops column from table
143 * If single, deletes record from `tabSingles`
144 args_dict = { dt: [field names] }
145 """
146 import frappe.utils
147
148 for dt in args_dict:
149 fields = args_dict[dt]
150 if not fields:
151 continue
152
153 frappe.db.delete(
154 "DocField",
155 {
156 "parent": dt,
157 "fieldname": ("in", fields),
158 },
159 )
160
161 # Delete the data/column only if delete is specified
162 if not delete:
163 continue
164
165 if frappe.db.get_value("DocType", dt, "issingle"):
166 frappe.db.delete(
167 "Singles",
168 {
169 "doctype": dt,
170 "field": ("in", fields),
171 },
172 )
173 else:
174 existing_fields = frappe.db.describe(dt)
175 existing_fields = existing_fields and [e[0] for e in existing_fields] or []
176 fields_need_to_delete = set(fields) & set(existing_fields)
177 if not fields_need_to_delete:
178 continue
179
180 if frappe.db.db_type == "mariadb":
181 # mariadb implicitly commits before DDL, make it explicit
182 frappe.db.commit()
183
184 query = "ALTER TABLE `tab%s` " % dt + ", ".join(
185 "DROP COLUMN `%s`" % f for f in fields_need_to_delete
186 )
187 frappe.db.sql(query)
188
189 if frappe.db.db_type == "postgres":
190 # commit the results to db
191 frappe.db.commit()
192
193
194 def get_permitted_fields(
195 doctype: str, parenttype: str | None = None, user: str | None = None
196 ) -> list[str]:
197 meta = frappe.get_meta(doctype)
198 valid_columns = meta.get_valid_columns()
199
200 if doctype in core_doctypes_list:
201 return valid_columns
202
203 if permitted_fields := meta.get_permitted_fieldnames(parenttype=parenttype, user=user):
204 meta_fields = meta.default_fields.copy()
205 optional_meta_fields = [x for x in optional_fields if x in valid_columns]
206
207 if meta.istable:
208 meta_fields.extend(child_table_fields)
209
210 return meta_fields + permitted_fields + optional_meta_fields
211
212 return []
213
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/frappe/model/__init__.py b/frappe/model/__init__.py
--- a/frappe/model/__init__.py
+++ b/frappe/model/__init__.py
@@ -200,6 +200,10 @@
if doctype in core_doctypes_list:
return valid_columns
+ # DocType has only fields of type Table (Table, Table MultiSelect)
+ if set(valid_columns).issubset(default_fields):
+ return valid_columns
+
if permitted_fields := meta.get_permitted_fieldnames(parenttype=parenttype, user=user):
meta_fields = meta.default_fields.copy()
optional_meta_fields = [x for x in optional_fields if x in valid_columns]
|
{"golden_diff": "diff --git a/frappe/model/__init__.py b/frappe/model/__init__.py\n--- a/frappe/model/__init__.py\n+++ b/frappe/model/__init__.py\n@@ -200,6 +200,10 @@\n \tif doctype in core_doctypes_list:\n \t\treturn valid_columns\n \n+\t# DocType has only fields of type Table (Table, Table MultiSelect)\n+\tif set(valid_columns).issubset(default_fields):\n+\t\treturn valid_columns\n+\n \tif permitted_fields := meta.get_permitted_fieldnames(parenttype=parenttype, user=user):\n \t\tmeta_fields = meta.default_fields.copy()\n \t\toptional_meta_fields = [x for x in optional_fields if x in valid_columns]\n", "issue": "SQL SyntaxError in queries in DocTypes with Table Multiselect fields\n### App Versions\r\n```json\r\n{\r\n\t\"frappe\": \"15.0.0-dev\"\r\n}\r\n```\r\n### Route\r\n\r\n`List/User Group/List` and `Form/User Group/new-user-group-1`\r\n\r\n### Traceback\r\n\r\n```python\r\nSyntax error in query:\r\nselect distinct \r\n\t\t\tfrom `tabUser Group` \r\nTraceback (most recent call last):\r\n File \"apps/frappe/frappe/app.py\", line 53, in application\r\n response = frappe.api.handle()\r\n File \"apps/frappe/frappe/api.py\", line 53, in handle\r\n return _RESTAPIHandler(call, doctype, name).get_response()\r\n File \"apps/frappe/frappe/api.py\", line 69, in get_response\r\n return self.handle_method()\r\n File \"apps/frappe/frappe/api.py\", line 79, in handle_method\r\n return frappe.handler.handle()\r\n File \"apps/frappe/frappe/handler.py\", line 48, in handle\r\n data = execute_cmd(cmd)\r\n File \"apps/frappe/frappe/handler.py\", line 86, in execute_cmd\r\n return frappe.call(method, **frappe.form_dict)\r\n File \"apps/frappe/frappe/__init__.py\", line 1591, in call\r\n return fn(*args, **newargs)\r\n File \"apps/frappe/frappe/utils/typing_validations.py\", line 33, in wrapper\r\n return func(*args, **kwargs)\r\n File \"apps/frappe/frappe/__init__.py\", line 796, in wrapper_fn\r\n retval = fn(*args, **get_newargs(fn, kwargs))\r\n File \"apps/frappe/frappe/desk/reportview.py\", line 58, in get_count\r\n data = execute(**args)[0].get(\"total_count\")\r\n File \"apps/frappe/frappe/desk/reportview.py\", line 64, in execute\r\n return DatabaseQuery(doctype).execute(*args, **kwargs)\r\n File \"apps/frappe/frappe/model/db_query.py\", line 202, in execute\r\n result = self.build_and_run()\r\n File \"apps/frappe/frappe/model/db_query.py\", line 242, in build_and_run\r\n return frappe.db.sql(\r\n File \"apps/frappe/frappe/database/database.py\", line 222, in sql\r\n self._cursor.execute(query, values)\r\n File \"env/lib/python3.10/site-packages/pymysql/cursors.py\", line 148, in execute\r\n result = self._query(query)\r\n File \"env/lib/python3.10/site-packages/pymysql/cursors.py\", line 310, in _query\r\n conn.query(q)\r\n File \"env/lib/python3.10/site-packages/pymysql/connections.py\", line 548, in query\r\n self._affected_rows = self._read_query_result(unbuffered=unbuffered)\r\n File \"env/lib/python3.10/site-packages/pymysql/connections.py\", line 775, in _read_query_result\r\n result.read()\r\n File \"env/lib/python3.10/site-packages/pymysql/connections.py\", line 1156, in read\r\n first_packet = self.connection._read_packet()\r\n File \"env/lib/python3.10/site-packages/pymysql/connections.py\", line 725, in _read_packet\r\n packet.raise_for_error()\r\n File \"env/lib/python3.10/site-packages/pymysql/protocol.py\", line 221, in raise_for_error\r\n err.raise_mysql_exception(self._data)\r\n File \"env/lib/python3.10/site-packages/pymysql/err.py\", line 143, in raise_mysql_exception\r\n raise errorclass(errno, errval)\r\npymysql.err.ProgrammingError: (1064, \"You have an error in your SQL syntax; check the manual that corresponds to your MariaDB server version for the right syntax to use near 'from `tabUser Group`' at line 2\")\r\n\r\n```\r\n### Request Data\r\n\r\n```json\r\n{\r\n\t\"type\": \"POST\",\r\n\t\"args\": {\r\n\t\t\"doctype\": \"User Group\",\r\n\t\t\"filters\": \"[]\",\r\n\t\t\"fields\": \"[]\",\r\n\t\t\"distinct\": false\r\n\t},\r\n\t\"headers\": {},\r\n\t\"error_handlers\": {},\r\n\t\"url\": \"/api/method/frappe.desk.reportview.get_count\"\r\n}\r\n```\r\n### Response Data\r\n\r\n```json\r\n{\r\n\t\"exception\": \"pymysql.err.ProgrammingError: (1064, \\\"You have an error in your SQL syntax; check the manual that corresponds to your MariaDB server version for the right syntax to use near 'from `tabUser Group`' at line 2\\\")\",\r\n\t\"_debug_messages\": \"[\\\"method:frappe.desk.reportview.get_count\\\", \\\"<<<< query\\\\nSELECT `is_virtual` FROM `tabDocType` WHERE `name`='User Group' ORDER BY `modified` DESC LIMIT 1\\\\n>>>>\\\", \\\"<<<< query\\\\nselect `share_name`\\\\n\\\\t\\\\t\\\\tfrom `tabDocShare`\\\\n\\\\t\\\\t\\\\twhere `tabDocShare`.`read` = 1.0 and `tabDocShare`.`share_doctype` = 'User Group' and (`tabDocShare`.`user` = 'Administrator' or `tabDocShare`.`everyone` = 1.0)\\\\n\\\\t\\\\t\\\\t\\\\n\\\\t\\\\t\\\\t order by `tabDocShare`.`modified` DESC\\\\n>>>>\\\"]\"\r\n}\r\n```\n", "before_files": [{"content": "# Copyright (c) 2015, Frappe Technologies Pvt. Ltd. and Contributors\n# License: MIT. See LICENSE\n\n# model __init__.py\nimport frappe\n\ndata_fieldtypes = (\n\t\"Currency\",\n\t\"Int\",\n\t\"Long Int\",\n\t\"Float\",\n\t\"Percent\",\n\t\"Check\",\n\t\"Small Text\",\n\t\"Long Text\",\n\t\"Code\",\n\t\"Text Editor\",\n\t\"Markdown Editor\",\n\t\"HTML Editor\",\n\t\"Date\",\n\t\"Datetime\",\n\t\"Time\",\n\t\"Text\",\n\t\"Data\",\n\t\"Link\",\n\t\"Dynamic Link\",\n\t\"Password\",\n\t\"Select\",\n\t\"Rating\",\n\t\"Read Only\",\n\t\"Attach\",\n\t\"Attach Image\",\n\t\"Signature\",\n\t\"Color\",\n\t\"Barcode\",\n\t\"Geolocation\",\n\t\"Duration\",\n\t\"Icon\",\n\t\"Phone\",\n\t\"Autocomplete\",\n\t\"JSON\",\n)\n\nfloat_like_fields = {\"Float\", \"Currency\", \"Percent\"}\ndatetime_fields = {\"Datetime\", \"Date\", \"Time\"}\n\nattachment_fieldtypes = (\n\t\"Attach\",\n\t\"Attach Image\",\n)\n\nno_value_fields = (\n\t\"Section Break\",\n\t\"Column Break\",\n\t\"Tab Break\",\n\t\"HTML\",\n\t\"Table\",\n\t\"Table MultiSelect\",\n\t\"Button\",\n\t\"Image\",\n\t\"Fold\",\n\t\"Heading\",\n)\n\ndisplay_fieldtypes = (\n\t\"Section Break\",\n\t\"Column Break\",\n\t\"Tab Break\",\n\t\"HTML\",\n\t\"Button\",\n\t\"Image\",\n\t\"Fold\",\n\t\"Heading\",\n)\n\nnumeric_fieldtypes = (\"Currency\", \"Int\", \"Long Int\", \"Float\", \"Percent\", \"Check\")\n\ndata_field_options = (\"Email\", \"Name\", \"Phone\", \"URL\", \"Barcode\")\n\ndefault_fields = (\n\t\"doctype\",\n\t\"name\",\n\t\"owner\",\n\t\"creation\",\n\t\"modified\",\n\t\"modified_by\",\n\t\"docstatus\",\n\t\"idx\",\n)\n\nchild_table_fields = (\"parent\", \"parentfield\", \"parenttype\")\n\noptional_fields = (\"_user_tags\", \"_comments\", \"_assign\", \"_liked_by\", \"_seen\")\n\ntable_fields = (\"Table\", \"Table MultiSelect\")\n\ncore_doctypes_list = (\n\t\"DefaultValue\",\n\t\"DocType\",\n\t\"DocField\",\n\t\"DocPerm\",\n\t\"DocType Action\",\n\t\"DocType Link\",\n\t\"User\",\n\t\"Role\",\n\t\"Has Role\",\n\t\"Page\",\n\t\"Module Def\",\n\t\"Print Format\",\n\t\"Report\",\n\t\"Customize Form\",\n\t\"Customize Form Field\",\n\t\"Property Setter\",\n\t\"Custom Field\",\n\t\"Client Script\",\n)\n\n# NOTE: this is being used for dynamic autoincrement in new sites,\n# removing any of these will require patches.\nlog_types = (\n\t\"Version\",\n\t\"Error Log\",\n\t\"Scheduled Job Log\",\n\t\"Event Sync Log\",\n\t\"Event Update Log\",\n\t\"Access Log\",\n\t\"View Log\",\n\t\"Activity Log\",\n\t\"Energy Point Log\",\n\t\"Notification Log\",\n\t\"Email Queue\",\n\t\"DocShare\",\n\t\"Document Follow\",\n\t\"Console Log\",\n)\n\n\ndef delete_fields(args_dict, delete=0):\n\t\"\"\"\n\tDelete a field.\n\t* Deletes record from `tabDocField`\n\t* If not single doctype: Drops column from table\n\t* If single, deletes record from `tabSingles`\n\targs_dict = { dt: [field names] }\n\t\"\"\"\n\timport frappe.utils\n\n\tfor dt in args_dict:\n\t\tfields = args_dict[dt]\n\t\tif not fields:\n\t\t\tcontinue\n\n\t\tfrappe.db.delete(\n\t\t\t\"DocField\",\n\t\t\t{\n\t\t\t\t\"parent\": dt,\n\t\t\t\t\"fieldname\": (\"in\", fields),\n\t\t\t},\n\t\t)\n\n\t\t# Delete the data/column only if delete is specified\n\t\tif not delete:\n\t\t\tcontinue\n\n\t\tif frappe.db.get_value(\"DocType\", dt, \"issingle\"):\n\t\t\tfrappe.db.delete(\n\t\t\t\t\"Singles\",\n\t\t\t\t{\n\t\t\t\t\t\"doctype\": dt,\n\t\t\t\t\t\"field\": (\"in\", fields),\n\t\t\t\t},\n\t\t\t)\n\t\telse:\n\t\t\texisting_fields = frappe.db.describe(dt)\n\t\t\texisting_fields = existing_fields and [e[0] for e in existing_fields] or []\n\t\t\tfields_need_to_delete = set(fields) & set(existing_fields)\n\t\t\tif not fields_need_to_delete:\n\t\t\t\tcontinue\n\n\t\t\tif frappe.db.db_type == \"mariadb\":\n\t\t\t\t# mariadb implicitly commits before DDL, make it explicit\n\t\t\t\tfrappe.db.commit()\n\n\t\t\tquery = \"ALTER TABLE `tab%s` \" % dt + \", \".join(\n\t\t\t\t\"DROP COLUMN `%s`\" % f for f in fields_need_to_delete\n\t\t\t)\n\t\t\tfrappe.db.sql(query)\n\n\t\tif frappe.db.db_type == \"postgres\":\n\t\t\t# commit the results to db\n\t\t\tfrappe.db.commit()\n\n\ndef get_permitted_fields(\n\tdoctype: str, parenttype: str | None = None, user: str | None = None\n) -> list[str]:\n\tmeta = frappe.get_meta(doctype)\n\tvalid_columns = meta.get_valid_columns()\n\n\tif doctype in core_doctypes_list:\n\t\treturn valid_columns\n\n\tif permitted_fields := meta.get_permitted_fieldnames(parenttype=parenttype, user=user):\n\t\tmeta_fields = meta.default_fields.copy()\n\t\toptional_meta_fields = [x for x in optional_fields if x in valid_columns]\n\n\t\tif meta.istable:\n\t\t\tmeta_fields.extend(child_table_fields)\n\n\t\treturn meta_fields + permitted_fields + optional_meta_fields\n\n\treturn []\n", "path": "frappe/model/__init__.py"}], "after_files": [{"content": "# Copyright (c) 2015, Frappe Technologies Pvt. Ltd. and Contributors\n# License: MIT. See LICENSE\n\n# model __init__.py\nimport frappe\n\ndata_fieldtypes = (\n\t\"Currency\",\n\t\"Int\",\n\t\"Long Int\",\n\t\"Float\",\n\t\"Percent\",\n\t\"Check\",\n\t\"Small Text\",\n\t\"Long Text\",\n\t\"Code\",\n\t\"Text Editor\",\n\t\"Markdown Editor\",\n\t\"HTML Editor\",\n\t\"Date\",\n\t\"Datetime\",\n\t\"Time\",\n\t\"Text\",\n\t\"Data\",\n\t\"Link\",\n\t\"Dynamic Link\",\n\t\"Password\",\n\t\"Select\",\n\t\"Rating\",\n\t\"Read Only\",\n\t\"Attach\",\n\t\"Attach Image\",\n\t\"Signature\",\n\t\"Color\",\n\t\"Barcode\",\n\t\"Geolocation\",\n\t\"Duration\",\n\t\"Icon\",\n\t\"Phone\",\n\t\"Autocomplete\",\n\t\"JSON\",\n)\n\nfloat_like_fields = {\"Float\", \"Currency\", \"Percent\"}\ndatetime_fields = {\"Datetime\", \"Date\", \"Time\"}\n\nattachment_fieldtypes = (\n\t\"Attach\",\n\t\"Attach Image\",\n)\n\nno_value_fields = (\n\t\"Section Break\",\n\t\"Column Break\",\n\t\"Tab Break\",\n\t\"HTML\",\n\t\"Table\",\n\t\"Table MultiSelect\",\n\t\"Button\",\n\t\"Image\",\n\t\"Fold\",\n\t\"Heading\",\n)\n\ndisplay_fieldtypes = (\n\t\"Section Break\",\n\t\"Column Break\",\n\t\"Tab Break\",\n\t\"HTML\",\n\t\"Button\",\n\t\"Image\",\n\t\"Fold\",\n\t\"Heading\",\n)\n\nnumeric_fieldtypes = (\"Currency\", \"Int\", \"Long Int\", \"Float\", \"Percent\", \"Check\")\n\ndata_field_options = (\"Email\", \"Name\", \"Phone\", \"URL\", \"Barcode\")\n\ndefault_fields = (\n\t\"doctype\",\n\t\"name\",\n\t\"owner\",\n\t\"creation\",\n\t\"modified\",\n\t\"modified_by\",\n\t\"docstatus\",\n\t\"idx\",\n)\n\nchild_table_fields = (\"parent\", \"parentfield\", \"parenttype\")\n\noptional_fields = (\"_user_tags\", \"_comments\", \"_assign\", \"_liked_by\", \"_seen\")\n\ntable_fields = (\"Table\", \"Table MultiSelect\")\n\ncore_doctypes_list = (\n\t\"DefaultValue\",\n\t\"DocType\",\n\t\"DocField\",\n\t\"DocPerm\",\n\t\"DocType Action\",\n\t\"DocType Link\",\n\t\"User\",\n\t\"Role\",\n\t\"Has Role\",\n\t\"Page\",\n\t\"Module Def\",\n\t\"Print Format\",\n\t\"Report\",\n\t\"Customize Form\",\n\t\"Customize Form Field\",\n\t\"Property Setter\",\n\t\"Custom Field\",\n\t\"Client Script\",\n)\n\n# NOTE: this is being used for dynamic autoincrement in new sites,\n# removing any of these will require patches.\nlog_types = (\n\t\"Version\",\n\t\"Error Log\",\n\t\"Scheduled Job Log\",\n\t\"Event Sync Log\",\n\t\"Event Update Log\",\n\t\"Access Log\",\n\t\"View Log\",\n\t\"Activity Log\",\n\t\"Energy Point Log\",\n\t\"Notification Log\",\n\t\"Email Queue\",\n\t\"DocShare\",\n\t\"Document Follow\",\n\t\"Console Log\",\n)\n\n\ndef delete_fields(args_dict, delete=0):\n\t\"\"\"\n\tDelete a field.\n\t* Deletes record from `tabDocField`\n\t* If not single doctype: Drops column from table\n\t* If single, deletes record from `tabSingles`\n\targs_dict = { dt: [field names] }\n\t\"\"\"\n\timport frappe.utils\n\n\tfor dt in args_dict:\n\t\tfields = args_dict[dt]\n\t\tif not fields:\n\t\t\tcontinue\n\n\t\tfrappe.db.delete(\n\t\t\t\"DocField\",\n\t\t\t{\n\t\t\t\t\"parent\": dt,\n\t\t\t\t\"fieldname\": (\"in\", fields),\n\t\t\t},\n\t\t)\n\n\t\t# Delete the data/column only if delete is specified\n\t\tif not delete:\n\t\t\tcontinue\n\n\t\tif frappe.db.get_value(\"DocType\", dt, \"issingle\"):\n\t\t\tfrappe.db.delete(\n\t\t\t\t\"Singles\",\n\t\t\t\t{\n\t\t\t\t\t\"doctype\": dt,\n\t\t\t\t\t\"field\": (\"in\", fields),\n\t\t\t\t},\n\t\t\t)\n\t\telse:\n\t\t\texisting_fields = frappe.db.describe(dt)\n\t\t\texisting_fields = existing_fields and [e[0] for e in existing_fields] or []\n\t\t\tfields_need_to_delete = set(fields) & set(existing_fields)\n\t\t\tif not fields_need_to_delete:\n\t\t\t\tcontinue\n\n\t\t\tif frappe.db.db_type == \"mariadb\":\n\t\t\t\t# mariadb implicitly commits before DDL, make it explicit\n\t\t\t\tfrappe.db.commit()\n\n\t\t\tquery = \"ALTER TABLE `tab%s` \" % dt + \", \".join(\n\t\t\t\t\"DROP COLUMN `%s`\" % f for f in fields_need_to_delete\n\t\t\t)\n\t\t\tfrappe.db.sql(query)\n\n\t\tif frappe.db.db_type == \"postgres\":\n\t\t\t# commit the results to db\n\t\t\tfrappe.db.commit()\n\n\ndef get_permitted_fields(\n\tdoctype: str, parenttype: str | None = None, user: str | None = None\n) -> list[str]:\n\tmeta = frappe.get_meta(doctype)\n\tvalid_columns = meta.get_valid_columns()\n\n\tif doctype in core_doctypes_list:\n\t\treturn valid_columns\n\n\t# DocType has only fields of type Table (Table, Table MultiSelect)\n\tif set(valid_columns).issubset(default_fields):\n\t\treturn valid_columns\n\n\tif permitted_fields := meta.get_permitted_fieldnames(parenttype=parenttype, user=user):\n\t\tmeta_fields = meta.default_fields.copy()\n\t\toptional_meta_fields = [x for x in optional_fields if x in valid_columns]\n\n\t\tif meta.istable:\n\t\t\tmeta_fields.extend(child_table_fields)\n\n\t\treturn meta_fields + permitted_fields + optional_meta_fields\n\n\treturn []\n", "path": "frappe/model/__init__.py"}]}
| 3,325 | 156 |
gh_patches_debug_30061
|
rasdani/github-patches
|
git_diff
|
Miserlou__Zappa-1993
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Set_Cookie option sets duplicate cookies on AWS Lambda
## Context
I have an API running Python3.7 and Zappa (in a virtualenv).
I am setting 6 cookies by using the option "set_cookie" in flask. It looks something like this:
```
resp = make_response(jsonify({'success':'true', 'message': 'Successfully authenticated!'}), 200)
resp.set_cookie("1", value="1", secure=True, samesite='Lax', domain=".example.com",max_age=3600)
resp.set_cookie("2", value="2", secure=True, samesite='Lax', domain=".example.com",max_age=3600)
resp.set_cookie("3", value="3", secure=True, samesite='Lax', domain=".example.com",max_age=3600)
resp.set_cookie("4", value="4", secure=True, samesite='Lax', domain=".example.com",max_age=3600)
resp.set_cookie("5", value="5", secure=True, samesite='Lax', domain=".example.com",max_age=3600)
resp.set_cookie("6", value="6", secure=True, samesite='Lax', domain=".example.com",max_age=3600)
return resp
```
On localhost testing Flask, this works as expected.
If I deploy the same code to AWS using Zappa, the response header will show 36 "set-cookie" headers. So the formula here is n^2. So if I add 4 cookies using the above method, it will show 16 in the request header.
The browser takes care of duplicate cookies, but the response from the API is still huge because of this issue.
Same thing happens if I use:
`resp.headers.add("set-cookie""1"="1; Domain=.example.com; Max-Age=3600; Secure; Path=/; SameSite=Lax")`
## Expected Behavior
I believe Zappa or something at AWS is at fault here. Expected behaviour is to send 6 "set-cookie" headers and not 36.
## Actual Behavior
Sets n^2 cookies as response.
## Steps to Reproduce
Deploy a Flask route using Zappa which sets the cookies. Use the code above.
## Your Environment
* Zappa version used: 0.48.2
* Operating System and Python version: Ubuntu 18.04, Python3.7
* The output of `pip freeze`: https://pastebin.com/d4QTaTuG
* Your `zappa_settings.py`: https://pastebin.com/d1GK8sbe
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `zappa/middleware.py`
Content:
```
1 from werkzeug.wsgi import ClosingIterator
2
3
4 def all_casings(input_string):
5 """
6 Permute all casings of a given string.
7
8 A pretty algorithm, via @Amber
9 http://stackoverflow.com/questions/6792803/finding-all-possible-case-permutations-in-python
10 """
11 if not input_string:
12 yield ""
13 else:
14 first = input_string[:1]
15 if first.lower() == first.upper():
16 for sub_casing in all_casings(input_string[1:]):
17 yield first + sub_casing
18 else:
19 for sub_casing in all_casings(input_string[1:]):
20 yield first.lower() + sub_casing
21 yield first.upper() + sub_casing
22
23
24 class ZappaWSGIMiddleware(object):
25 """
26 Middleware functions necessary for a Zappa deployment.
27
28 Most hacks have now been remove except for Set-Cookie permutation.
29 """
30 def __init__(self, application):
31 self.application = application
32
33 def __call__(self, environ, start_response):
34 """
35 We must case-mangle the Set-Cookie header name or AWS will use only a
36 single one of these headers.
37 """
38
39 def encode_response(status, headers, exc_info=None):
40 """
41 Create an APIGW-acceptable version of our cookies.
42
43 We have to use a bizarre hack that turns multiple Set-Cookie headers into
44 their case-permutated format, ex:
45
46 Set-cookie:
47 sEt-cookie:
48 seT-cookie:
49
50 To get around an API Gateway limitation.
51
52 This is weird, but better than our previous hack of creating a Base58-encoded
53 supercookie.
54 """
55
56 # All the non-cookie headers should be sent unharmed.
57
58 # The main app can send 'set-cookie' headers in any casing
59 # Related: https://github.com/Miserlou/Zappa/issues/990
60 new_headers = [header for header in headers
61 if ((type(header[0]) != str) or (header[0].lower() != 'set-cookie'))]
62 cookie_headers = [header for header in headers
63 if ((type(header[0]) == str) and (header[0].lower() == "set-cookie"))]
64 for header, new_name in zip(cookie_headers,
65 all_casings("Set-Cookie")):
66 new_headers.append((new_name, header[1]))
67 return start_response(status, new_headers, exc_info)
68
69 # Call the application with our modifier
70 response = self.application(environ, encode_response)
71
72 # Return the response as a WSGI-safe iterator
73 return ClosingIterator(response)
74
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/zappa/middleware.py b/zappa/middleware.py
--- a/zappa/middleware.py
+++ b/zappa/middleware.py
@@ -38,32 +38,17 @@
def encode_response(status, headers, exc_info=None):
"""
- Create an APIGW-acceptable version of our cookies.
-
- We have to use a bizarre hack that turns multiple Set-Cookie headers into
- their case-permutated format, ex:
-
- Set-cookie:
- sEt-cookie:
- seT-cookie:
-
- To get around an API Gateway limitation.
-
- This is weird, but better than our previous hack of creating a Base58-encoded
- supercookie.
+ This makes the 'set-cookie' headers name lowercase,
+ all the non-cookie headers should be sent unharmed.
+ Related: https://github.com/Miserlou/Zappa/issues/1965
"""
- # All the non-cookie headers should be sent unharmed.
-
- # The main app can send 'set-cookie' headers in any casing
- # Related: https://github.com/Miserlou/Zappa/issues/990
new_headers = [header for header in headers
if ((type(header[0]) != str) or (header[0].lower() != 'set-cookie'))]
- cookie_headers = [header for header in headers
+ cookie_headers = [(header[0].lower(), header[1]) for header in headers
if ((type(header[0]) == str) and (header[0].lower() == "set-cookie"))]
- for header, new_name in zip(cookie_headers,
- all_casings("Set-Cookie")):
- new_headers.append((new_name, header[1]))
+ new_headers = new_headers + cookie_headers
+
return start_response(status, new_headers, exc_info)
# Call the application with our modifier
|
{"golden_diff": "diff --git a/zappa/middleware.py b/zappa/middleware.py\n--- a/zappa/middleware.py\n+++ b/zappa/middleware.py\n@@ -38,32 +38,17 @@\n \n def encode_response(status, headers, exc_info=None):\n \"\"\"\n- Create an APIGW-acceptable version of our cookies.\n-\n- We have to use a bizarre hack that turns multiple Set-Cookie headers into\n- their case-permutated format, ex:\n-\n- Set-cookie:\n- sEt-cookie:\n- seT-cookie:\n-\n- To get around an API Gateway limitation.\n-\n- This is weird, but better than our previous hack of creating a Base58-encoded\n- supercookie.\n+ This makes the 'set-cookie' headers name lowercase,\n+ all the non-cookie headers should be sent unharmed.\n+ Related: https://github.com/Miserlou/Zappa/issues/1965\n \"\"\"\n \n- # All the non-cookie headers should be sent unharmed.\n- \n- # The main app can send 'set-cookie' headers in any casing\n- # Related: https://github.com/Miserlou/Zappa/issues/990\n new_headers = [header for header in headers\n if ((type(header[0]) != str) or (header[0].lower() != 'set-cookie'))]\n- cookie_headers = [header for header in headers \n+ cookie_headers = [(header[0].lower(), header[1]) for header in headers\n if ((type(header[0]) == str) and (header[0].lower() == \"set-cookie\"))]\n- for header, new_name in zip(cookie_headers,\n- all_casings(\"Set-Cookie\")):\n- new_headers.append((new_name, header[1]))\n+ new_headers = new_headers + cookie_headers\n+\n return start_response(status, new_headers, exc_info)\n \n # Call the application with our modifier\n", "issue": "Set_Cookie option sets duplicate cookies on AWS Lambda\n## Context\r\nI have an API running Python3.7 and Zappa (in a virtualenv).\r\nI am setting 6 cookies by using the option \"set_cookie\" in flask. It looks something like this:\r\n```\r\nresp = make_response(jsonify({'success':'true', 'message': 'Successfully authenticated!'}), 200)\r\nresp.set_cookie(\"1\", value=\"1\", secure=True, samesite='Lax', domain=\".example.com\",max_age=3600)\r\nresp.set_cookie(\"2\", value=\"2\", secure=True, samesite='Lax', domain=\".example.com\",max_age=3600)\r\nresp.set_cookie(\"3\", value=\"3\", secure=True, samesite='Lax', domain=\".example.com\",max_age=3600)\r\nresp.set_cookie(\"4\", value=\"4\", secure=True, samesite='Lax', domain=\".example.com\",max_age=3600)\r\nresp.set_cookie(\"5\", value=\"5\", secure=True, samesite='Lax', domain=\".example.com\",max_age=3600)\r\nresp.set_cookie(\"6\", value=\"6\", secure=True, samesite='Lax', domain=\".example.com\",max_age=3600)\r\nreturn resp\r\n```\r\n\r\nOn localhost testing Flask, this works as expected.\r\n\r\nIf I deploy the same code to AWS using Zappa, the response header will show 36 \"set-cookie\" headers. So the formula here is n^2. So if I add 4 cookies using the above method, it will show 16 in the request header.\r\n\r\nThe browser takes care of duplicate cookies, but the response from the API is still huge because of this issue.\r\n\r\nSame thing happens if I use: \r\n`resp.headers.add(\"set-cookie\"\"1\"=\"1; Domain=.example.com; Max-Age=3600; Secure; Path=/; SameSite=Lax\")`\r\n\r\n## Expected Behavior\r\nI believe Zappa or something at AWS is at fault here. Expected behaviour is to send 6 \"set-cookie\" headers and not 36.\r\n\r\n## Actual Behavior\r\nSets n^2 cookies as response.\r\n\r\n## Steps to Reproduce\r\nDeploy a Flask route using Zappa which sets the cookies. Use the code above.\r\n\r\n## Your Environment\r\n* Zappa version used: 0.48.2\r\n* Operating System and Python version: Ubuntu 18.04, Python3.7\r\n* The output of `pip freeze`: https://pastebin.com/d4QTaTuG\r\n* Your `zappa_settings.py`: https://pastebin.com/d1GK8sbe\n", "before_files": [{"content": "from werkzeug.wsgi import ClosingIterator\n\n\ndef all_casings(input_string):\n \"\"\"\n Permute all casings of a given string.\n\n A pretty algorithm, via @Amber\n http://stackoverflow.com/questions/6792803/finding-all-possible-case-permutations-in-python\n \"\"\"\n if not input_string:\n yield \"\"\n else:\n first = input_string[:1]\n if first.lower() == first.upper():\n for sub_casing in all_casings(input_string[1:]):\n yield first + sub_casing\n else:\n for sub_casing in all_casings(input_string[1:]):\n yield first.lower() + sub_casing\n yield first.upper() + sub_casing\n\n\nclass ZappaWSGIMiddleware(object):\n \"\"\"\n Middleware functions necessary for a Zappa deployment.\n\n Most hacks have now been remove except for Set-Cookie permutation.\n \"\"\"\n def __init__(self, application):\n self.application = application\n\n def __call__(self, environ, start_response):\n \"\"\"\n We must case-mangle the Set-Cookie header name or AWS will use only a\n single one of these headers.\n \"\"\"\n\n def encode_response(status, headers, exc_info=None):\n \"\"\"\n Create an APIGW-acceptable version of our cookies.\n\n We have to use a bizarre hack that turns multiple Set-Cookie headers into\n their case-permutated format, ex:\n\n Set-cookie:\n sEt-cookie:\n seT-cookie:\n\n To get around an API Gateway limitation.\n\n This is weird, but better than our previous hack of creating a Base58-encoded\n supercookie.\n \"\"\"\n\n # All the non-cookie headers should be sent unharmed.\n \n # The main app can send 'set-cookie' headers in any casing\n # Related: https://github.com/Miserlou/Zappa/issues/990\n new_headers = [header for header in headers\n if ((type(header[0]) != str) or (header[0].lower() != 'set-cookie'))]\n cookie_headers = [header for header in headers \n if ((type(header[0]) == str) and (header[0].lower() == \"set-cookie\"))]\n for header, new_name in zip(cookie_headers,\n all_casings(\"Set-Cookie\")):\n new_headers.append((new_name, header[1]))\n return start_response(status, new_headers, exc_info)\n\n # Call the application with our modifier\n response = self.application(environ, encode_response)\n\n # Return the response as a WSGI-safe iterator\n return ClosingIterator(response)\n", "path": "zappa/middleware.py"}], "after_files": [{"content": "from werkzeug.wsgi import ClosingIterator\n\n\ndef all_casings(input_string):\n \"\"\"\n Permute all casings of a given string.\n\n A pretty algorithm, via @Amber\n http://stackoverflow.com/questions/6792803/finding-all-possible-case-permutations-in-python\n \"\"\"\n if not input_string:\n yield \"\"\n else:\n first = input_string[:1]\n if first.lower() == first.upper():\n for sub_casing in all_casings(input_string[1:]):\n yield first + sub_casing\n else:\n for sub_casing in all_casings(input_string[1:]):\n yield first.lower() + sub_casing\n yield first.upper() + sub_casing\n\n\nclass ZappaWSGIMiddleware(object):\n \"\"\"\n Middleware functions necessary for a Zappa deployment.\n\n Most hacks have now been remove except for Set-Cookie permutation.\n \"\"\"\n def __init__(self, application):\n self.application = application\n\n def __call__(self, environ, start_response):\n \"\"\"\n We must case-mangle the Set-Cookie header name or AWS will use only a\n single one of these headers.\n \"\"\"\n\n def encode_response(status, headers, exc_info=None):\n \"\"\"\n This makes the 'set-cookie' headers name lowercase,\n all the non-cookie headers should be sent unharmed.\n Related: https://github.com/Miserlou/Zappa/issues/1965\n \"\"\"\n\n new_headers = [header for header in headers\n if ((type(header[0]) != str) or (header[0].lower() != 'set-cookie'))]\n cookie_headers = [(header[0].lower(), header[1]) for header in headers\n if ((type(header[0]) == str) and (header[0].lower() == \"set-cookie\"))]\n new_headers = new_headers + cookie_headers\n\n return start_response(status, new_headers, exc_info)\n\n # Call the application with our modifier\n response = self.application(environ, encode_response)\n\n # Return the response as a WSGI-safe iterator\n return ClosingIterator(response)\n", "path": "zappa/middleware.py"}]}
| 1,546 | 430 |
gh_patches_debug_32826
|
rasdani/github-patches
|
git_diff
|
dotkom__onlineweb4-1498
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Don't send additional 500 email if no useful information in it.
After the implementation if #1485 we get an additional email for _all_ 500 errors, even if there is no supplied information. Let's not send an email if there's no useful information in it.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `onlineweb4/views.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 import logging
3 from smtplib import SMTPException
4
5 from django.conf import settings
6 from django.contrib import messages
7 from django.core.mail import send_mail
8 from django.shortcuts import redirect, render
9 from onlineweb4.forms import ErrorForm
10
11
12 def server_error(request):
13 log = logging.getLogger(__name__)
14
15 if request.method == 'POST':
16 form = ErrorForm(request.POST)
17 message = request.POST.get('reason', 'Ingen forklaring oppgitt.')
18 try:
19 log.error('%s triggered a 500 server error and provided the following description: %s' % (
20 request.user,
21 message
22 ))
23 send_mail('500error user-report', message,
24 settings.DEFAULT_FROM_EMAIL, [settings.EMAIL_DOTKOM])
25 log.debug('Finished sending error email to %s' % settings.EMAIL_DOTKOM)
26
27 messages.success(request, 'Feilmeldingen din ble sendt til %s' % settings.EMAIL_DOTKOM)
28
29 return redirect('home')
30 except SMTPException:
31 messages.error(request, 'Det oppstod en uventet feil under sending av feilmeldingen')
32 return redirect('home')
33
34 return render(request, '500.html', {'error_form': ErrorForm})
35
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/onlineweb4/views.py b/onlineweb4/views.py
--- a/onlineweb4/views.py
+++ b/onlineweb4/views.py
@@ -1,21 +1,22 @@
# -*- coding: utf-8 -*-
import logging
-from smtplib import SMTPException
from django.conf import settings
from django.contrib import messages
from django.core.mail import send_mail
from django.shortcuts import redirect, render
from onlineweb4.forms import ErrorForm
+from smtplib import SMTPException
def server_error(request):
log = logging.getLogger(__name__)
if request.method == 'POST':
- form = ErrorForm(request.POST)
- message = request.POST.get('reason', 'Ingen forklaring oppgitt.')
- try:
+ message = request.POST.get('reason')
+ if not message:
+ return redirect('home')
+ try:
log.error('%s triggered a 500 server error and provided the following description: %s' % (
request.user,
message
@@ -23,12 +24,9 @@
send_mail('500error user-report', message,
settings.DEFAULT_FROM_EMAIL, [settings.EMAIL_DOTKOM])
log.debug('Finished sending error email to %s' % settings.EMAIL_DOTKOM)
-
messages.success(request, 'Feilmeldingen din ble sendt til %s' % settings.EMAIL_DOTKOM)
-
return redirect('home')
except SMTPException:
messages.error(request, 'Det oppstod en uventet feil under sending av feilmeldingen')
return redirect('home')
-
return render(request, '500.html', {'error_form': ErrorForm})
|
{"golden_diff": "diff --git a/onlineweb4/views.py b/onlineweb4/views.py\n--- a/onlineweb4/views.py\n+++ b/onlineweb4/views.py\n@@ -1,21 +1,22 @@\n # -*- coding: utf-8 -*-\n import logging\n-from smtplib import SMTPException\n \n from django.conf import settings\n from django.contrib import messages\n from django.core.mail import send_mail\n from django.shortcuts import redirect, render\n from onlineweb4.forms import ErrorForm\n+from smtplib import SMTPException\n \n \n def server_error(request):\n log = logging.getLogger(__name__)\n \n if request.method == 'POST':\n- form = ErrorForm(request.POST)\n- message = request.POST.get('reason', 'Ingen forklaring oppgitt.')\n- try: \n+ message = request.POST.get('reason')\n+ if not message:\n+ return redirect('home')\n+ try:\n log.error('%s triggered a 500 server error and provided the following description: %s' % (\n request.user,\n message\n@@ -23,12 +24,9 @@\n send_mail('500error user-report', message,\n settings.DEFAULT_FROM_EMAIL, [settings.EMAIL_DOTKOM])\n log.debug('Finished sending error email to %s' % settings.EMAIL_DOTKOM)\n-\n messages.success(request, 'Feilmeldingen din ble sendt til %s' % settings.EMAIL_DOTKOM)\n-\n return redirect('home')\n except SMTPException:\n messages.error(request, 'Det oppstod en uventet feil under sending av feilmeldingen')\n return redirect('home')\n-\n return render(request, '500.html', {'error_form': ErrorForm})\n", "issue": "Don't send additional 500 email if no useful information in it.\nAfter the implementation if #1485 we get an additional email for _all_ 500 errors, even if there is no supplied information. Let's not send an email if there's no useful information in it.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nimport logging\nfrom smtplib import SMTPException\n\nfrom django.conf import settings\nfrom django.contrib import messages\nfrom django.core.mail import send_mail\nfrom django.shortcuts import redirect, render\nfrom onlineweb4.forms import ErrorForm\n\n\ndef server_error(request):\n log = logging.getLogger(__name__)\n\n if request.method == 'POST':\n form = ErrorForm(request.POST)\n message = request.POST.get('reason', 'Ingen forklaring oppgitt.')\n try: \n log.error('%s triggered a 500 server error and provided the following description: %s' % (\n request.user,\n message\n ))\n send_mail('500error user-report', message,\n settings.DEFAULT_FROM_EMAIL, [settings.EMAIL_DOTKOM])\n log.debug('Finished sending error email to %s' % settings.EMAIL_DOTKOM)\n\n messages.success(request, 'Feilmeldingen din ble sendt til %s' % settings.EMAIL_DOTKOM)\n\n return redirect('home')\n except SMTPException:\n messages.error(request, 'Det oppstod en uventet feil under sending av feilmeldingen')\n return redirect('home')\n\n return render(request, '500.html', {'error_form': ErrorForm})\n", "path": "onlineweb4/views.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\nimport logging\n\nfrom django.conf import settings\nfrom django.contrib import messages\nfrom django.core.mail import send_mail\nfrom django.shortcuts import redirect, render\nfrom onlineweb4.forms import ErrorForm\nfrom smtplib import SMTPException\n\n\ndef server_error(request):\n log = logging.getLogger(__name__)\n\n if request.method == 'POST':\n message = request.POST.get('reason')\n if not message:\n return redirect('home')\n try:\n log.error('%s triggered a 500 server error and provided the following description: %s' % (\n request.user,\n message\n ))\n send_mail('500error user-report', message,\n settings.DEFAULT_FROM_EMAIL, [settings.EMAIL_DOTKOM])\n log.debug('Finished sending error email to %s' % settings.EMAIL_DOTKOM)\n messages.success(request, 'Feilmeldingen din ble sendt til %s' % settings.EMAIL_DOTKOM)\n return redirect('home')\n except SMTPException:\n messages.error(request, 'Det oppstod en uventet feil under sending av feilmeldingen')\n return redirect('home')\n return render(request, '500.html', {'error_form': ErrorForm})\n", "path": "onlineweb4/views.py"}]}
| 663 | 377 |
gh_patches_debug_8684
|
rasdani/github-patches
|
git_diff
|
rpm-software-management__dnf-1907
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bug on almalinux 9
Hi,
I have these messages on almalinux 9/ Rocky Linux 9
[mickael@srvalmalinux ~]$ sudo /usr/bin/dnf-automatic /etc/dnf/automatic.conf --timer
Last metadata expiration check: 2:45:52 ago on Fri Mar 10 14:38:38 2023.
Running transaction check
Transaction check succeeded.
Running transaction test
Transaction test succeeded.
Running transaction
Traceback (most recent call last):
File "/usr/bin/dnf-automatic", line 36, in <module>
sys.exit(dnf.automatic.main.main(sys.argv[1:]))
File "/usr/lib/python3.9/site-packages/dnf/automatic/main.py", line 342, in main
emitters.commit()
File "/usr/lib/python3.9/site-packages/dnf/util.py", line 526, in fn
return list(map(call_what, self))
File "/usr/lib/python3.9/site-packages/dnf/util.py", line 525, in call_what
return method(*args, **kwargs)
File "/usr/lib/python3.9/site-packages/dnf/automatic/emitter.py", line 106, in commit
smtp = smtplib.SMTP(self._conf.email_host, timeout=300)
File "/usr/lib64/python3.9/smtplib.py", line 255, in __init__
(code, msg) = self.connect(host, port)
File "/usr/lib64/python3.9/smtplib.py", line 341, in connect
self.sock = self._get_socket(host, port, self.timeout)
File "/usr/lib64/python3.9/smtplib.py", line 312, in _get_socket
return socket.create_connection((host, port), timeout,
File "/usr/lib64/python3.9/socket.py", line 844, in create_connection
raise err
File "/usr/lib64/python3.9/socket.py", line 832, in create_connection
sock.connect(sa)
ConnectionRefusedError: [Errno 111] Connection refused
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `dnf/automatic/emitter.py`
Content:
```
1 # emitter.py
2 # Emitters for dnf-automatic.
3 #
4 # Copyright (C) 2014-2016 Red Hat, Inc.
5 #
6 # This copyrighted material is made available to anyone wishing to use,
7 # modify, copy, or redistribute it subject to the terms and conditions of
8 # the GNU General Public License v.2, or (at your option) any later version.
9 # This program is distributed in the hope that it will be useful, but WITHOUT
10 # ANY WARRANTY expressed or implied, including the implied warranties of
11 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General
12 # Public License for more details. You should have received a copy of the
13 # GNU General Public License along with this program; if not, write to the
14 # Free Software Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA
15 # 02110-1301, USA. Any Red Hat trademarks that are incorporated in the
16 # source code or documentation are not subject to the GNU General Public
17 # License and may only be used or replicated with the express permission of
18 # Red Hat, Inc.
19 #
20
21 from __future__ import absolute_import
22 from __future__ import print_function
23 from __future__ import unicode_literals
24 from dnf.i18n import _
25 import logging
26 import dnf.pycomp
27 import smtplib
28 import email.utils
29 import subprocess
30 import time
31
32 APPLIED = _("The following updates have been applied on '%s':")
33 APPLIED_TIMESTAMP = _("Updates completed at %s")
34 AVAILABLE = _("The following updates are available on '%s':")
35 DOWNLOADED = _("The following updates were downloaded on '%s':")
36
37 logger = logging.getLogger('dnf')
38
39
40 class Emitter(object):
41 def __init__(self, system_name):
42 self._applied = False
43 self._available_msg = None
44 self._downloaded = False
45 self._system_name = system_name
46 self._trans_msg = None
47
48 def _prepare_msg(self):
49 msg = []
50 if self._applied:
51 msg.append(APPLIED % self._system_name)
52 msg.append(self._available_msg)
53 msg.append(APPLIED_TIMESTAMP % time.strftime("%c"))
54 elif self._downloaded:
55 msg.append(DOWNLOADED % self._system_name)
56 msg.append(self._available_msg)
57 elif self._available_msg:
58 msg.append(AVAILABLE % self._system_name)
59 msg.append(self._available_msg)
60 else:
61 return None
62 return '\n'.join(msg)
63
64 def notify_applied(self):
65 assert self._available_msg
66 self._applied = True
67
68 def notify_available(self, msg):
69 self._available_msg = msg
70
71 def notify_downloaded(self):
72 assert self._available_msg
73 self._downloaded = True
74
75
76 class EmailEmitter(Emitter):
77 def __init__(self, system_name, conf):
78 super(EmailEmitter, self).__init__(system_name)
79 self._conf = conf
80
81 def _prepare_msg(self):
82 if self._applied:
83 subj = _("Updates applied on '%s'.") % self._system_name
84 elif self._downloaded:
85 subj = _("Updates downloaded on '%s'.") % self._system_name
86 elif self._available_msg:
87 subj = _("Updates available on '%s'.") % self._system_name
88 else:
89 return None, None
90 return subj, super(EmailEmitter, self)._prepare_msg()
91
92 def commit(self):
93 subj, body = self._prepare_msg()
94 message = dnf.pycomp.email_mime(body)
95 message.set_charset('utf-8')
96 email_from = self._conf.email_from
97 email_to = self._conf.email_to
98 message['Date'] = email.utils.formatdate()
99 message['From'] = email_from
100 message['Subject'] = subj
101 message['To'] = ','.join(email_to)
102 message['Message-ID'] = email.utils.make_msgid()
103
104 # Send the email
105 try:
106 smtp = smtplib.SMTP(self._conf.email_host, timeout=300)
107 smtp.sendmail(email_from, email_to, message.as_string())
108 smtp.close()
109 except smtplib.SMTPException as exc:
110 msg = _("Failed to send an email via '%s': %s") % (
111 self._conf.email_host, exc)
112 logger.error(msg)
113
114
115 class CommandEmitterMixIn(object):
116 """
117 Executes a desired command, and pushes data into its stdin.
118 Both data and command can be formatted according to user preference.
119 For this reason, this class expects a {str:str} dictionary as _prepare_msg
120 return value.
121 Meant for mixing with Emitter classes, as it does not define any names used
122 for formatting on its own.
123 """
124 def commit(self):
125 command_fmt = self._conf.command_format
126 stdin_fmt = self._conf.stdin_format
127 msg = self._prepare_msg()
128 # all strings passed to shell should be quoted to avoid accidental code
129 # execution
130 quoted_msg = dict((key, dnf.pycomp.shlex_quote(val))
131 for key, val in msg.items())
132 command = command_fmt.format(**quoted_msg)
133 stdin_feed = stdin_fmt.format(**msg).encode('utf-8')
134
135 # Execute the command
136 subp = subprocess.Popen(command, shell=True, stdin=subprocess.PIPE)
137 subp.communicate(stdin_feed)
138 subp.stdin.close()
139 if subp.wait() != 0:
140 msg = _("Failed to execute command '%s': returned %d") \
141 % (command, subp.returncode)
142 logger.error(msg)
143
144
145 class CommandEmitter(CommandEmitterMixIn, Emitter):
146 def __init__(self, system_name, conf):
147 super(CommandEmitter, self).__init__(system_name)
148 self._conf = conf
149
150 def _prepare_msg(self):
151 return {'body': super(CommandEmitter, self)._prepare_msg()}
152
153
154 class CommandEmailEmitter(CommandEmitterMixIn, EmailEmitter):
155 def _prepare_msg(self):
156 subject, body = super(CommandEmailEmitter, self)._prepare_msg()
157 return {'subject': subject,
158 'body': body,
159 'email_from': self._conf.email_from,
160 'email_to': ' '.join(self._conf.email_to)}
161
162
163 class StdIoEmitter(Emitter):
164 def commit(self):
165 msg = self._prepare_msg()
166 print(msg)
167
168
169 class MotdEmitter(Emitter):
170 def commit(self):
171 msg = self._prepare_msg()
172 with open('/etc/motd', 'w') as fobj:
173 fobj.write(msg)
174
175
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/dnf/automatic/emitter.py b/dnf/automatic/emitter.py
--- a/dnf/automatic/emitter.py
+++ b/dnf/automatic/emitter.py
@@ -106,7 +106,7 @@
smtp = smtplib.SMTP(self._conf.email_host, timeout=300)
smtp.sendmail(email_from, email_to, message.as_string())
smtp.close()
- except smtplib.SMTPException as exc:
+ except OSError as exc:
msg = _("Failed to send an email via '%s': %s") % (
self._conf.email_host, exc)
logger.error(msg)
|
{"golden_diff": "diff --git a/dnf/automatic/emitter.py b/dnf/automatic/emitter.py\n--- a/dnf/automatic/emitter.py\n+++ b/dnf/automatic/emitter.py\n@@ -106,7 +106,7 @@\n smtp = smtplib.SMTP(self._conf.email_host, timeout=300)\n smtp.sendmail(email_from, email_to, message.as_string())\n smtp.close()\n- except smtplib.SMTPException as exc:\n+ except OSError as exc:\n msg = _(\"Failed to send an email via '%s': %s\") % (\n self._conf.email_host, exc)\n logger.error(msg)\n", "issue": "Bug on almalinux 9\nHi,\r\n\r\nI have these messages on almalinux 9/ Rocky Linux 9\r\n\r\n\r\n[mickael@srvalmalinux ~]$ sudo /usr/bin/dnf-automatic /etc/dnf/automatic.conf --timer\r\nLast metadata expiration check: 2:45:52 ago on Fri Mar 10 14:38:38 2023.\r\nRunning transaction check\r\nTransaction check succeeded.\r\nRunning transaction test\r\nTransaction test succeeded.\r\nRunning transaction\r\nTraceback (most recent call last):\r\n File \"/usr/bin/dnf-automatic\", line 36, in <module>\r\n sys.exit(dnf.automatic.main.main(sys.argv[1:]))\r\n File \"/usr/lib/python3.9/site-packages/dnf/automatic/main.py\", line 342, in main\r\n emitters.commit()\r\n File \"/usr/lib/python3.9/site-packages/dnf/util.py\", line 526, in fn\r\n return list(map(call_what, self))\r\n File \"/usr/lib/python3.9/site-packages/dnf/util.py\", line 525, in call_what\r\n return method(*args, **kwargs)\r\n File \"/usr/lib/python3.9/site-packages/dnf/automatic/emitter.py\", line 106, in commit\r\n smtp = smtplib.SMTP(self._conf.email_host, timeout=300)\r\n File \"/usr/lib64/python3.9/smtplib.py\", line 255, in __init__\r\n (code, msg) = self.connect(host, port)\r\n File \"/usr/lib64/python3.9/smtplib.py\", line 341, in connect\r\n self.sock = self._get_socket(host, port, self.timeout)\r\n File \"/usr/lib64/python3.9/smtplib.py\", line 312, in _get_socket\r\n return socket.create_connection((host, port), timeout,\r\n File \"/usr/lib64/python3.9/socket.py\", line 844, in create_connection\r\n raise err\r\n File \"/usr/lib64/python3.9/socket.py\", line 832, in create_connection\r\n sock.connect(sa)\r\nConnectionRefusedError: [Errno 111] Connection refused\r\n\n", "before_files": [{"content": "# emitter.py\n# Emitters for dnf-automatic.\n#\n# Copyright (C) 2014-2016 Red Hat, Inc.\n#\n# This copyrighted material is made available to anyone wishing to use,\n# modify, copy, or redistribute it subject to the terms and conditions of\n# the GNU General Public License v.2, or (at your option) any later version.\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY expressed or implied, including the implied warranties of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General\n# Public License for more details. You should have received a copy of the\n# GNU General Public License along with this program; if not, write to the\n# Free Software Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA\n# 02110-1301, USA. Any Red Hat trademarks that are incorporated in the\n# source code or documentation are not subject to the GNU General Public\n# License and may only be used or replicated with the express permission of\n# Red Hat, Inc.\n#\n\nfrom __future__ import absolute_import\nfrom __future__ import print_function\nfrom __future__ import unicode_literals\nfrom dnf.i18n import _\nimport logging\nimport dnf.pycomp\nimport smtplib\nimport email.utils\nimport subprocess\nimport time\n\nAPPLIED = _(\"The following updates have been applied on '%s':\")\nAPPLIED_TIMESTAMP = _(\"Updates completed at %s\")\nAVAILABLE = _(\"The following updates are available on '%s':\")\nDOWNLOADED = _(\"The following updates were downloaded on '%s':\")\n\nlogger = logging.getLogger('dnf')\n\n\nclass Emitter(object):\n def __init__(self, system_name):\n self._applied = False\n self._available_msg = None\n self._downloaded = False\n self._system_name = system_name\n self._trans_msg = None\n\n def _prepare_msg(self):\n msg = []\n if self._applied:\n msg.append(APPLIED % self._system_name)\n msg.append(self._available_msg)\n msg.append(APPLIED_TIMESTAMP % time.strftime(\"%c\"))\n elif self._downloaded:\n msg.append(DOWNLOADED % self._system_name)\n msg.append(self._available_msg)\n elif self._available_msg:\n msg.append(AVAILABLE % self._system_name)\n msg.append(self._available_msg)\n else:\n return None\n return '\\n'.join(msg)\n\n def notify_applied(self):\n assert self._available_msg\n self._applied = True\n\n def notify_available(self, msg):\n self._available_msg = msg\n\n def notify_downloaded(self):\n assert self._available_msg\n self._downloaded = True\n\n\nclass EmailEmitter(Emitter):\n def __init__(self, system_name, conf):\n super(EmailEmitter, self).__init__(system_name)\n self._conf = conf\n\n def _prepare_msg(self):\n if self._applied:\n subj = _(\"Updates applied on '%s'.\") % self._system_name\n elif self._downloaded:\n subj = _(\"Updates downloaded on '%s'.\") % self._system_name\n elif self._available_msg:\n subj = _(\"Updates available on '%s'.\") % self._system_name\n else:\n return None, None\n return subj, super(EmailEmitter, self)._prepare_msg()\n\n def commit(self):\n subj, body = self._prepare_msg()\n message = dnf.pycomp.email_mime(body)\n message.set_charset('utf-8')\n email_from = self._conf.email_from\n email_to = self._conf.email_to\n message['Date'] = email.utils.formatdate()\n message['From'] = email_from\n message['Subject'] = subj\n message['To'] = ','.join(email_to)\n message['Message-ID'] = email.utils.make_msgid()\n\n # Send the email\n try:\n smtp = smtplib.SMTP(self._conf.email_host, timeout=300)\n smtp.sendmail(email_from, email_to, message.as_string())\n smtp.close()\n except smtplib.SMTPException as exc:\n msg = _(\"Failed to send an email via '%s': %s\") % (\n self._conf.email_host, exc)\n logger.error(msg)\n\n\nclass CommandEmitterMixIn(object):\n \"\"\"\n Executes a desired command, and pushes data into its stdin.\n Both data and command can be formatted according to user preference.\n For this reason, this class expects a {str:str} dictionary as _prepare_msg\n return value.\n Meant for mixing with Emitter classes, as it does not define any names used\n for formatting on its own.\n \"\"\"\n def commit(self):\n command_fmt = self._conf.command_format\n stdin_fmt = self._conf.stdin_format\n msg = self._prepare_msg()\n # all strings passed to shell should be quoted to avoid accidental code\n # execution\n quoted_msg = dict((key, dnf.pycomp.shlex_quote(val))\n for key, val in msg.items())\n command = command_fmt.format(**quoted_msg)\n stdin_feed = stdin_fmt.format(**msg).encode('utf-8')\n\n # Execute the command\n subp = subprocess.Popen(command, shell=True, stdin=subprocess.PIPE)\n subp.communicate(stdin_feed)\n subp.stdin.close()\n if subp.wait() != 0:\n msg = _(\"Failed to execute command '%s': returned %d\") \\\n % (command, subp.returncode)\n logger.error(msg)\n\n\nclass CommandEmitter(CommandEmitterMixIn, Emitter):\n def __init__(self, system_name, conf):\n super(CommandEmitter, self).__init__(system_name)\n self._conf = conf\n\n def _prepare_msg(self):\n return {'body': super(CommandEmitter, self)._prepare_msg()}\n\n\nclass CommandEmailEmitter(CommandEmitterMixIn, EmailEmitter):\n def _prepare_msg(self):\n subject, body = super(CommandEmailEmitter, self)._prepare_msg()\n return {'subject': subject,\n 'body': body,\n 'email_from': self._conf.email_from,\n 'email_to': ' '.join(self._conf.email_to)}\n\n\nclass StdIoEmitter(Emitter):\n def commit(self):\n msg = self._prepare_msg()\n print(msg)\n\n\nclass MotdEmitter(Emitter):\n def commit(self):\n msg = self._prepare_msg()\n with open('/etc/motd', 'w') as fobj:\n fobj.write(msg)\n\n", "path": "dnf/automatic/emitter.py"}], "after_files": [{"content": "# emitter.py\n# Emitters for dnf-automatic.\n#\n# Copyright (C) 2014-2016 Red Hat, Inc.\n#\n# This copyrighted material is made available to anyone wishing to use,\n# modify, copy, or redistribute it subject to the terms and conditions of\n# the GNU General Public License v.2, or (at your option) any later version.\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY expressed or implied, including the implied warranties of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General\n# Public License for more details. You should have received a copy of the\n# GNU General Public License along with this program; if not, write to the\n# Free Software Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA\n# 02110-1301, USA. Any Red Hat trademarks that are incorporated in the\n# source code or documentation are not subject to the GNU General Public\n# License and may only be used or replicated with the express permission of\n# Red Hat, Inc.\n#\n\nfrom __future__ import absolute_import\nfrom __future__ import print_function\nfrom __future__ import unicode_literals\nfrom dnf.i18n import _\nimport logging\nimport dnf.pycomp\nimport smtplib\nimport email.utils\nimport subprocess\nimport time\n\nAPPLIED = _(\"The following updates have been applied on '%s':\")\nAPPLIED_TIMESTAMP = _(\"Updates completed at %s\")\nAVAILABLE = _(\"The following updates are available on '%s':\")\nDOWNLOADED = _(\"The following updates were downloaded on '%s':\")\n\nlogger = logging.getLogger('dnf')\n\n\nclass Emitter(object):\n def __init__(self, system_name):\n self._applied = False\n self._available_msg = None\n self._downloaded = False\n self._system_name = system_name\n self._trans_msg = None\n\n def _prepare_msg(self):\n msg = []\n if self._applied:\n msg.append(APPLIED % self._system_name)\n msg.append(self._available_msg)\n msg.append(APPLIED_TIMESTAMP % time.strftime(\"%c\"))\n elif self._downloaded:\n msg.append(DOWNLOADED % self._system_name)\n msg.append(self._available_msg)\n elif self._available_msg:\n msg.append(AVAILABLE % self._system_name)\n msg.append(self._available_msg)\n else:\n return None\n return '\\n'.join(msg)\n\n def notify_applied(self):\n assert self._available_msg\n self._applied = True\n\n def notify_available(self, msg):\n self._available_msg = msg\n\n def notify_downloaded(self):\n assert self._available_msg\n self._downloaded = True\n\n\nclass EmailEmitter(Emitter):\n def __init__(self, system_name, conf):\n super(EmailEmitter, self).__init__(system_name)\n self._conf = conf\n\n def _prepare_msg(self):\n if self._applied:\n subj = _(\"Updates applied on '%s'.\") % self._system_name\n elif self._downloaded:\n subj = _(\"Updates downloaded on '%s'.\") % self._system_name\n elif self._available_msg:\n subj = _(\"Updates available on '%s'.\") % self._system_name\n else:\n return None, None\n return subj, super(EmailEmitter, self)._prepare_msg()\n\n def commit(self):\n subj, body = self._prepare_msg()\n message = dnf.pycomp.email_mime(body)\n message.set_charset('utf-8')\n email_from = self._conf.email_from\n email_to = self._conf.email_to\n message['Date'] = email.utils.formatdate()\n message['From'] = email_from\n message['Subject'] = subj\n message['To'] = ','.join(email_to)\n message['Message-ID'] = email.utils.make_msgid()\n\n # Send the email\n try:\n smtp = smtplib.SMTP(self._conf.email_host, timeout=300)\n smtp.sendmail(email_from, email_to, message.as_string())\n smtp.close()\n except OSError as exc:\n msg = _(\"Failed to send an email via '%s': %s\") % (\n self._conf.email_host, exc)\n logger.error(msg)\n\n\nclass CommandEmitterMixIn(object):\n \"\"\"\n Executes a desired command, and pushes data into its stdin.\n Both data and command can be formatted according to user preference.\n For this reason, this class expects a {str:str} dictionary as _prepare_msg\n return value.\n Meant for mixing with Emitter classes, as it does not define any names used\n for formatting on its own.\n \"\"\"\n def commit(self):\n command_fmt = self._conf.command_format\n stdin_fmt = self._conf.stdin_format\n msg = self._prepare_msg()\n # all strings passed to shell should be quoted to avoid accidental code\n # execution\n quoted_msg = dict((key, dnf.pycomp.shlex_quote(val))\n for key, val in msg.items())\n command = command_fmt.format(**quoted_msg)\n stdin_feed = stdin_fmt.format(**msg).encode('utf-8')\n\n # Execute the command\n subp = subprocess.Popen(command, shell=True, stdin=subprocess.PIPE)\n subp.communicate(stdin_feed)\n subp.stdin.close()\n if subp.wait() != 0:\n msg = _(\"Failed to execute command '%s': returned %d\") \\\n % (command, subp.returncode)\n logger.error(msg)\n\n\nclass CommandEmitter(CommandEmitterMixIn, Emitter):\n def __init__(self, system_name, conf):\n super(CommandEmitter, self).__init__(system_name)\n self._conf = conf\n\n def _prepare_msg(self):\n return {'body': super(CommandEmitter, self)._prepare_msg()}\n\n\nclass CommandEmailEmitter(CommandEmitterMixIn, EmailEmitter):\n def _prepare_msg(self):\n subject, body = super(CommandEmailEmitter, self)._prepare_msg()\n return {'subject': subject,\n 'body': body,\n 'email_from': self._conf.email_from,\n 'email_to': ' '.join(self._conf.email_to)}\n\n\nclass StdIoEmitter(Emitter):\n def commit(self):\n msg = self._prepare_msg()\n print(msg)\n\n\nclass MotdEmitter(Emitter):\n def commit(self):\n msg = self._prepare_msg()\n with open('/etc/motd', 'w') as fobj:\n fobj.write(msg)\n\n", "path": "dnf/automatic/emitter.py"}]}
| 2,595 | 141 |
gh_patches_debug_4302
|
rasdani/github-patches
|
git_diff
|
ydataai__ydata-profiling-588
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Nullable types not fully supported
Using pandas >= 1, columns of nullable integer type with low numbers of distinct values appear as "UNSUPPORTED".
This comes down to the check in `is_numeric` on whether there are infinite values in the series.
https://github.com/pandas-profiling/pandas-profiling/blob/216704bc6643ac691f3d1c513c0328c8cb29d088/src/pandas_profiling/model/base.py#L126
The following code gives a TypeError, which triggers the "except" branch in `get_var_type`
```
import pandas as pd
import numpy as np
series = pd.Series([1, None], dtype="Int64")
has_inf = any(np.inf == s or -np.inf == s for s in series)
```
I think that the following would be better:
```
has_inf = series.isin({np.inf, -np.inf}).any()
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/pandas_profiling/model/base.py`
Content:
```
1 """Common parts to all other modules, mainly utility functions."""
2 import imghdr
3 import os
4 from enum import Enum, unique
5 from urllib.parse import ParseResult, urlparse
6
7 import numpy as np
8 import pandas as pd
9 from pandas.api.types import is_categorical_dtype
10
11 from pandas_profiling.config import config
12
13
14 @unique
15 class Variable(Enum):
16 """The possible types of variables in the Profiling Report."""
17
18 TYPE_CAT = "CAT"
19 """A categorical variable"""
20
21 TYPE_BOOL = "BOOL"
22 """A boolean variable"""
23
24 TYPE_NUM = "NUM"
25 """A numeric variable"""
26
27 TYPE_DATE = "DATE"
28 """A date variable"""
29
30 TYPE_URL = "URL"
31 """A URL variable"""
32
33 TYPE_COMPLEX = "COMPLEX"
34
35 TYPE_PATH = "PATH"
36 """Absolute path"""
37
38 TYPE_FILE = "FILE"
39 """File (i.e. existing path)"""
40
41 TYPE_IMAGE = "IMAGE"
42 """Images"""
43
44 S_TYPE_UNSUPPORTED = "UNSUPPORTED"
45 """An unsupported variable"""
46
47
48 # Temporary mapping
49 Boolean = Variable.TYPE_BOOL
50 Real = Variable.TYPE_NUM
51 Count = Variable.TYPE_NUM
52 Complex = Variable.TYPE_COMPLEX
53 Date = Variable.TYPE_DATE
54 Categorical = Variable.TYPE_CAT
55 Url = Variable.TYPE_URL
56 AbsolutePath = Variable.TYPE_PATH
57 FilePath = Variable.TYPE_FILE
58 ImagePath = Variable.TYPE_IMAGE
59 Generic = Variable.S_TYPE_UNSUPPORTED
60
61
62 def get_counts(series: pd.Series) -> dict:
63 """Counts the values in a series (with and without NaN, distinct).
64
65 Args:
66 series: Series for which we want to calculate the values.
67
68 Returns:
69 A dictionary with the count values (with and without NaN, distinct).
70 """
71 if is_categorical_dtype(series):
72 series = series.cat.remove_unused_categories()
73
74 value_counts_with_nan = series.value_counts(dropna=False)
75 value_counts_without_nan = (
76 value_counts_with_nan.reset_index().dropna().set_index("index").iloc[:, 0]
77 )
78 distinct_count_with_nan = value_counts_with_nan.count()
79 distinct_count_without_nan = value_counts_without_nan.count()
80
81 return {
82 "value_counts": value_counts_without_nan, # Alias
83 "value_counts_with_nan": value_counts_with_nan,
84 "value_counts_without_nan": value_counts_without_nan,
85 "distinct_count_with_nan": distinct_count_with_nan,
86 "distinct_count_without_nan": distinct_count_without_nan,
87 }
88
89
90 def is_boolean(series: pd.Series, series_description: dict) -> bool:
91 """Is the series boolean type?
92
93 Args:
94 series: Series
95 series_description: Series description
96
97 Returns:
98 True is the series is boolean type in the broad sense (e.g. including yes/no, NaNs allowed).
99 """
100 keys = series_description["value_counts_without_nan"].keys()
101 if pd.api.types.is_bool_dtype(keys):
102 return True
103 elif (
104 1 <= series_description["distinct_count_without_nan"] <= 2
105 and pd.api.types.is_numeric_dtype(series)
106 and series[~series.isnull()].between(0, 1).all()
107 ):
108 return True
109 elif 1 <= series_description["distinct_count_without_nan"] <= 4:
110 unique_values = set([str(value).lower() for value in keys.values])
111 accepted_combinations = [
112 ["y", "n"],
113 ["yes", "no"],
114 ["true", "false"],
115 ["t", "f"],
116 ]
117
118 if len(unique_values) == 2 and any(
119 [unique_values == set(bools) for bools in accepted_combinations]
120 ):
121 return True
122
123 return False
124
125
126 def is_numeric(series: pd.Series, series_description: dict) -> bool:
127 """Is the series numeric type?
128
129 Args:
130 series: Series
131 series_description: Series description
132
133 Returns:
134 True is the series is numeric type (NaNs allowed).
135 """
136 return pd.api.types.is_numeric_dtype(series) and (
137 series_description["distinct_count_without_nan"]
138 >= config["vars"]["num"]["low_categorical_threshold"].get(int)
139 or any(np.inf == s or -np.inf == s for s in series)
140 )
141
142
143 def is_url(series: pd.Series, series_description: dict) -> bool:
144 """Is the series url type?
145
146 Args:
147 series: Series
148 series_description: Series description
149
150 Returns:
151 True is the series is url type (NaNs allowed).
152 """
153
154 def is_url_item(x):
155 return isinstance(x, ParseResult) and all((x.netloc, x.scheme, x.path))
156
157 if series_description["distinct_count_without_nan"] > 0:
158 try:
159 result = series[~series.isnull()].astype(str)
160 return all(is_url_item(urlparse(x)) for x in result)
161 except ValueError:
162 return False
163 else:
164 return False
165
166
167 def is_path(series, series_description) -> bool:
168 """Is the series of the path type (i.e. absolute path)?
169
170 Args:
171 series: Series
172 series_description: Series description
173
174 Returns:
175 True is the series is path type (NaNs allowed).
176 """
177 if series_description["distinct_count_without_nan"] == 0:
178 return False
179
180 try:
181 result = series[~series.isnull()].astype(str)
182 return all(os.path.isabs(p) for p in result)
183 except (ValueError, TypeError):
184 return False
185
186
187 def is_file(series, series_description) -> bool:
188 """Is the series of the type "file" (i.e. existing paths)?
189
190 Args:
191 series: Series
192 series_description: Series description
193
194 Returns:
195 True is the series is of the file type (NaNs allowed).
196 """
197 if series_description["distinct_count_without_nan"] == 0:
198 return False
199
200 try:
201 result = series[~series.isnull()].astype(str)
202 return all(os.path.exists(p) for p in result)
203 except (ValueError, TypeError):
204 return False
205
206
207 def is_image(series, series_description) -> bool:
208 """Is the series of the image type (i.e. "file" with image extensions)?
209
210 Args:
211 series: Series
212 series_description: Series description
213
214 Returns:
215 True is the series is of the image type (NaNs allowed).
216 """
217 if series_description["distinct_count_without_nan"] > 0:
218 try:
219 result = series[~series.isnull()].astype(str)
220 return all(imghdr.what(p) for p in result)
221 except (TypeError, ValueError):
222 return False
223 else:
224 return False
225
226
227 def is_date(series) -> bool:
228 """Is the variable of type datetime? Throws a warning if the series looks like a datetime, but is not typed as
229 datetime64.
230
231 Args:
232 series: Series
233
234 Returns:
235 True if the variable is of type datetime.
236 """
237 is_date_value = pd.api.types.is_datetime64_dtype(series)
238
239 return is_date_value
240
241
242 def get_var_type(series: pd.Series) -> dict:
243 """Get the variable type of a series.
244
245 Args:
246 series: Series for which we want to infer the variable type.
247
248 Returns:
249 The series updated with the variable type included.
250 """
251
252 series_description = {}
253
254 try:
255 series_description = get_counts(series)
256
257 # When the inferred type of the index is just "mixed" probably the types within the series are tuple, dict,
258 # list and so on...
259 if series_description[
260 "value_counts_without_nan"
261 ].index.inferred_type.startswith("mixed"):
262 raise TypeError("Not supported mixed type")
263
264 if series_description["distinct_count_without_nan"] == 0:
265 # Empty
266 var_type = Variable.S_TYPE_UNSUPPORTED
267 elif is_boolean(series, series_description):
268 var_type = Variable.TYPE_BOOL
269 elif is_numeric(series, series_description):
270 var_type = Variable.TYPE_NUM
271 elif is_date(series):
272 var_type = Variable.TYPE_DATE
273 elif is_url(series, series_description):
274 var_type = Variable.TYPE_URL
275 elif is_path(series, series_description):
276 if config["vars"]["file"]["active"].get(bool) and is_file(
277 series, series_description
278 ):
279 if config["vars"]["image"]["active"].get(bool) and is_image(
280 series, series_description
281 ):
282 var_type = Variable.TYPE_IMAGE
283 else:
284 var_type = Variable.TYPE_FILE
285 else:
286 var_type = Variable.TYPE_PATH
287 else:
288 var_type = Variable.TYPE_CAT
289 except TypeError:
290 var_type = Variable.S_TYPE_UNSUPPORTED
291
292 series_description.update({"type": var_type})
293
294 return series_description
295
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/pandas_profiling/model/base.py b/src/pandas_profiling/model/base.py
--- a/src/pandas_profiling/model/base.py
+++ b/src/pandas_profiling/model/base.py
@@ -136,7 +136,7 @@
return pd.api.types.is_numeric_dtype(series) and (
series_description["distinct_count_without_nan"]
>= config["vars"]["num"]["low_categorical_threshold"].get(int)
- or any(np.inf == s or -np.inf == s for s in series)
+ or series.isin({np.inf, -np.inf}).any()
)
|
{"golden_diff": "diff --git a/src/pandas_profiling/model/base.py b/src/pandas_profiling/model/base.py\n--- a/src/pandas_profiling/model/base.py\n+++ b/src/pandas_profiling/model/base.py\n@@ -136,7 +136,7 @@\n return pd.api.types.is_numeric_dtype(series) and (\n series_description[\"distinct_count_without_nan\"]\n >= config[\"vars\"][\"num\"][\"low_categorical_threshold\"].get(int)\n- or any(np.inf == s or -np.inf == s for s in series)\n+ or series.isin({np.inf, -np.inf}).any()\n )\n", "issue": "Nullable types not fully supported\nUsing pandas >= 1, columns of nullable integer type with low numbers of distinct values appear as \"UNSUPPORTED\".\r\n\r\nThis comes down to the check in `is_numeric` on whether there are infinite values in the series.\r\n\r\nhttps://github.com/pandas-profiling/pandas-profiling/blob/216704bc6643ac691f3d1c513c0328c8cb29d088/src/pandas_profiling/model/base.py#L126\r\n\r\nThe following code gives a TypeError, which triggers the \"except\" branch in `get_var_type`\r\n\r\n```\r\nimport pandas as pd\r\nimport numpy as np\r\n\r\nseries = pd.Series([1, None], dtype=\"Int64\")\r\nhas_inf = any(np.inf == s or -np.inf == s for s in series)\r\n```\r\n\r\nI think that the following would be better:\r\n\r\n```\r\nhas_inf = series.isin({np.inf, -np.inf}).any()\r\n```\r\n\n", "before_files": [{"content": "\"\"\"Common parts to all other modules, mainly utility functions.\"\"\"\nimport imghdr\nimport os\nfrom enum import Enum, unique\nfrom urllib.parse import ParseResult, urlparse\n\nimport numpy as np\nimport pandas as pd\nfrom pandas.api.types import is_categorical_dtype\n\nfrom pandas_profiling.config import config\n\n\n@unique\nclass Variable(Enum):\n \"\"\"The possible types of variables in the Profiling Report.\"\"\"\n\n TYPE_CAT = \"CAT\"\n \"\"\"A categorical variable\"\"\"\n\n TYPE_BOOL = \"BOOL\"\n \"\"\"A boolean variable\"\"\"\n\n TYPE_NUM = \"NUM\"\n \"\"\"A numeric variable\"\"\"\n\n TYPE_DATE = \"DATE\"\n \"\"\"A date variable\"\"\"\n\n TYPE_URL = \"URL\"\n \"\"\"A URL variable\"\"\"\n\n TYPE_COMPLEX = \"COMPLEX\"\n\n TYPE_PATH = \"PATH\"\n \"\"\"Absolute path\"\"\"\n\n TYPE_FILE = \"FILE\"\n \"\"\"File (i.e. existing path)\"\"\"\n\n TYPE_IMAGE = \"IMAGE\"\n \"\"\"Images\"\"\"\n\n S_TYPE_UNSUPPORTED = \"UNSUPPORTED\"\n \"\"\"An unsupported variable\"\"\"\n\n\n# Temporary mapping\nBoolean = Variable.TYPE_BOOL\nReal = Variable.TYPE_NUM\nCount = Variable.TYPE_NUM\nComplex = Variable.TYPE_COMPLEX\nDate = Variable.TYPE_DATE\nCategorical = Variable.TYPE_CAT\nUrl = Variable.TYPE_URL\nAbsolutePath = Variable.TYPE_PATH\nFilePath = Variable.TYPE_FILE\nImagePath = Variable.TYPE_IMAGE\nGeneric = Variable.S_TYPE_UNSUPPORTED\n\n\ndef get_counts(series: pd.Series) -> dict:\n \"\"\"Counts the values in a series (with and without NaN, distinct).\n\n Args:\n series: Series for which we want to calculate the values.\n\n Returns:\n A dictionary with the count values (with and without NaN, distinct).\n \"\"\"\n if is_categorical_dtype(series):\n series = series.cat.remove_unused_categories()\n\n value_counts_with_nan = series.value_counts(dropna=False)\n value_counts_without_nan = (\n value_counts_with_nan.reset_index().dropna().set_index(\"index\").iloc[:, 0]\n )\n distinct_count_with_nan = value_counts_with_nan.count()\n distinct_count_without_nan = value_counts_without_nan.count()\n\n return {\n \"value_counts\": value_counts_without_nan, # Alias\n \"value_counts_with_nan\": value_counts_with_nan,\n \"value_counts_without_nan\": value_counts_without_nan,\n \"distinct_count_with_nan\": distinct_count_with_nan,\n \"distinct_count_without_nan\": distinct_count_without_nan,\n }\n\n\ndef is_boolean(series: pd.Series, series_description: dict) -> bool:\n \"\"\"Is the series boolean type?\n\n Args:\n series: Series\n series_description: Series description\n\n Returns:\n True is the series is boolean type in the broad sense (e.g. including yes/no, NaNs allowed).\n \"\"\"\n keys = series_description[\"value_counts_without_nan\"].keys()\n if pd.api.types.is_bool_dtype(keys):\n return True\n elif (\n 1 <= series_description[\"distinct_count_without_nan\"] <= 2\n and pd.api.types.is_numeric_dtype(series)\n and series[~series.isnull()].between(0, 1).all()\n ):\n return True\n elif 1 <= series_description[\"distinct_count_without_nan\"] <= 4:\n unique_values = set([str(value).lower() for value in keys.values])\n accepted_combinations = [\n [\"y\", \"n\"],\n [\"yes\", \"no\"],\n [\"true\", \"false\"],\n [\"t\", \"f\"],\n ]\n\n if len(unique_values) == 2 and any(\n [unique_values == set(bools) for bools in accepted_combinations]\n ):\n return True\n\n return False\n\n\ndef is_numeric(series: pd.Series, series_description: dict) -> bool:\n \"\"\"Is the series numeric type?\n\n Args:\n series: Series\n series_description: Series description\n\n Returns:\n True is the series is numeric type (NaNs allowed).\n \"\"\"\n return pd.api.types.is_numeric_dtype(series) and (\n series_description[\"distinct_count_without_nan\"]\n >= config[\"vars\"][\"num\"][\"low_categorical_threshold\"].get(int)\n or any(np.inf == s or -np.inf == s for s in series)\n )\n\n\ndef is_url(series: pd.Series, series_description: dict) -> bool:\n \"\"\"Is the series url type?\n\n Args:\n series: Series\n series_description: Series description\n\n Returns:\n True is the series is url type (NaNs allowed).\n \"\"\"\n\n def is_url_item(x):\n return isinstance(x, ParseResult) and all((x.netloc, x.scheme, x.path))\n\n if series_description[\"distinct_count_without_nan\"] > 0:\n try:\n result = series[~series.isnull()].astype(str)\n return all(is_url_item(urlparse(x)) for x in result)\n except ValueError:\n return False\n else:\n return False\n\n\ndef is_path(series, series_description) -> bool:\n \"\"\"Is the series of the path type (i.e. absolute path)?\n\n Args:\n series: Series\n series_description: Series description\n\n Returns:\n True is the series is path type (NaNs allowed).\n \"\"\"\n if series_description[\"distinct_count_without_nan\"] == 0:\n return False\n\n try:\n result = series[~series.isnull()].astype(str)\n return all(os.path.isabs(p) for p in result)\n except (ValueError, TypeError):\n return False\n\n\ndef is_file(series, series_description) -> bool:\n \"\"\"Is the series of the type \"file\" (i.e. existing paths)?\n\n Args:\n series: Series\n series_description: Series description\n\n Returns:\n True is the series is of the file type (NaNs allowed).\n \"\"\"\n if series_description[\"distinct_count_without_nan\"] == 0:\n return False\n\n try:\n result = series[~series.isnull()].astype(str)\n return all(os.path.exists(p) for p in result)\n except (ValueError, TypeError):\n return False\n\n\ndef is_image(series, series_description) -> bool:\n \"\"\"Is the series of the image type (i.e. \"file\" with image extensions)?\n\n Args:\n series: Series\n series_description: Series description\n\n Returns:\n True is the series is of the image type (NaNs allowed).\n \"\"\"\n if series_description[\"distinct_count_without_nan\"] > 0:\n try:\n result = series[~series.isnull()].astype(str)\n return all(imghdr.what(p) for p in result)\n except (TypeError, ValueError):\n return False\n else:\n return False\n\n\ndef is_date(series) -> bool:\n \"\"\"Is the variable of type datetime? Throws a warning if the series looks like a datetime, but is not typed as\n datetime64.\n\n Args:\n series: Series\n\n Returns:\n True if the variable is of type datetime.\n \"\"\"\n is_date_value = pd.api.types.is_datetime64_dtype(series)\n\n return is_date_value\n\n\ndef get_var_type(series: pd.Series) -> dict:\n \"\"\"Get the variable type of a series.\n\n Args:\n series: Series for which we want to infer the variable type.\n\n Returns:\n The series updated with the variable type included.\n \"\"\"\n\n series_description = {}\n\n try:\n series_description = get_counts(series)\n\n # When the inferred type of the index is just \"mixed\" probably the types within the series are tuple, dict,\n # list and so on...\n if series_description[\n \"value_counts_without_nan\"\n ].index.inferred_type.startswith(\"mixed\"):\n raise TypeError(\"Not supported mixed type\")\n\n if series_description[\"distinct_count_without_nan\"] == 0:\n # Empty\n var_type = Variable.S_TYPE_UNSUPPORTED\n elif is_boolean(series, series_description):\n var_type = Variable.TYPE_BOOL\n elif is_numeric(series, series_description):\n var_type = Variable.TYPE_NUM\n elif is_date(series):\n var_type = Variable.TYPE_DATE\n elif is_url(series, series_description):\n var_type = Variable.TYPE_URL\n elif is_path(series, series_description):\n if config[\"vars\"][\"file\"][\"active\"].get(bool) and is_file(\n series, series_description\n ):\n if config[\"vars\"][\"image\"][\"active\"].get(bool) and is_image(\n series, series_description\n ):\n var_type = Variable.TYPE_IMAGE\n else:\n var_type = Variable.TYPE_FILE\n else:\n var_type = Variable.TYPE_PATH\n else:\n var_type = Variable.TYPE_CAT\n except TypeError:\n var_type = Variable.S_TYPE_UNSUPPORTED\n\n series_description.update({\"type\": var_type})\n\n return series_description\n", "path": "src/pandas_profiling/model/base.py"}], "after_files": [{"content": "\"\"\"Common parts to all other modules, mainly utility functions.\"\"\"\nimport imghdr\nimport os\nfrom enum import Enum, unique\nfrom urllib.parse import ParseResult, urlparse\n\nimport numpy as np\nimport pandas as pd\nfrom pandas.api.types import is_categorical_dtype\n\nfrom pandas_profiling.config import config\n\n\n@unique\nclass Variable(Enum):\n \"\"\"The possible types of variables in the Profiling Report.\"\"\"\n\n TYPE_CAT = \"CAT\"\n \"\"\"A categorical variable\"\"\"\n\n TYPE_BOOL = \"BOOL\"\n \"\"\"A boolean variable\"\"\"\n\n TYPE_NUM = \"NUM\"\n \"\"\"A numeric variable\"\"\"\n\n TYPE_DATE = \"DATE\"\n \"\"\"A date variable\"\"\"\n\n TYPE_URL = \"URL\"\n \"\"\"A URL variable\"\"\"\n\n TYPE_COMPLEX = \"COMPLEX\"\n\n TYPE_PATH = \"PATH\"\n \"\"\"Absolute path\"\"\"\n\n TYPE_FILE = \"FILE\"\n \"\"\"File (i.e. existing path)\"\"\"\n\n TYPE_IMAGE = \"IMAGE\"\n \"\"\"Images\"\"\"\n\n S_TYPE_UNSUPPORTED = \"UNSUPPORTED\"\n \"\"\"An unsupported variable\"\"\"\n\n\n# Temporary mapping\nBoolean = Variable.TYPE_BOOL\nReal = Variable.TYPE_NUM\nCount = Variable.TYPE_NUM\nComplex = Variable.TYPE_COMPLEX\nDate = Variable.TYPE_DATE\nCategorical = Variable.TYPE_CAT\nUrl = Variable.TYPE_URL\nAbsolutePath = Variable.TYPE_PATH\nFilePath = Variable.TYPE_FILE\nImagePath = Variable.TYPE_IMAGE\nGeneric = Variable.S_TYPE_UNSUPPORTED\n\n\ndef get_counts(series: pd.Series) -> dict:\n \"\"\"Counts the values in a series (with and without NaN, distinct).\n\n Args:\n series: Series for which we want to calculate the values.\n\n Returns:\n A dictionary with the count values (with and without NaN, distinct).\n \"\"\"\n if is_categorical_dtype(series):\n series = series.cat.remove_unused_categories()\n\n value_counts_with_nan = series.value_counts(dropna=False)\n value_counts_without_nan = (\n value_counts_with_nan.reset_index().dropna().set_index(\"index\").iloc[:, 0]\n )\n distinct_count_with_nan = value_counts_with_nan.count()\n distinct_count_without_nan = value_counts_without_nan.count()\n\n return {\n \"value_counts\": value_counts_without_nan, # Alias\n \"value_counts_with_nan\": value_counts_with_nan,\n \"value_counts_without_nan\": value_counts_without_nan,\n \"distinct_count_with_nan\": distinct_count_with_nan,\n \"distinct_count_without_nan\": distinct_count_without_nan,\n }\n\n\ndef is_boolean(series: pd.Series, series_description: dict) -> bool:\n \"\"\"Is the series boolean type?\n\n Args:\n series: Series\n series_description: Series description\n\n Returns:\n True is the series is boolean type in the broad sense (e.g. including yes/no, NaNs allowed).\n \"\"\"\n keys = series_description[\"value_counts_without_nan\"].keys()\n if pd.api.types.is_bool_dtype(keys):\n return True\n elif (\n 1 <= series_description[\"distinct_count_without_nan\"] <= 2\n and pd.api.types.is_numeric_dtype(series)\n and series[~series.isnull()].between(0, 1).all()\n ):\n return True\n elif 1 <= series_description[\"distinct_count_without_nan\"] <= 4:\n unique_values = set([str(value).lower() for value in keys.values])\n accepted_combinations = [\n [\"y\", \"n\"],\n [\"yes\", \"no\"],\n [\"true\", \"false\"],\n [\"t\", \"f\"],\n ]\n\n if len(unique_values) == 2 and any(\n [unique_values == set(bools) for bools in accepted_combinations]\n ):\n return True\n\n return False\n\n\ndef is_numeric(series: pd.Series, series_description: dict) -> bool:\n \"\"\"Is the series numeric type?\n\n Args:\n series: Series\n series_description: Series description\n\n Returns:\n True is the series is numeric type (NaNs allowed).\n \"\"\"\n return pd.api.types.is_numeric_dtype(series) and (\n series_description[\"distinct_count_without_nan\"]\n >= config[\"vars\"][\"num\"][\"low_categorical_threshold\"].get(int)\n or series.isin({np.inf, -np.inf}).any()\n )\n\n\ndef is_url(series: pd.Series, series_description: dict) -> bool:\n \"\"\"Is the series url type?\n\n Args:\n series: Series\n series_description: Series description\n\n Returns:\n True is the series is url type (NaNs allowed).\n \"\"\"\n\n def is_url_item(x):\n return isinstance(x, ParseResult) and all((x.netloc, x.scheme, x.path))\n\n if series_description[\"distinct_count_without_nan\"] > 0:\n try:\n result = series[~series.isnull()].astype(str)\n return all(is_url_item(urlparse(x)) for x in result)\n except ValueError:\n return False\n else:\n return False\n\n\ndef is_path(series, series_description) -> bool:\n \"\"\"Is the series of the path type (i.e. absolute path)?\n\n Args:\n series: Series\n series_description: Series description\n\n Returns:\n True is the series is path type (NaNs allowed).\n \"\"\"\n if series_description[\"distinct_count_without_nan\"] == 0:\n return False\n\n try:\n result = series[~series.isnull()].astype(str)\n return all(os.path.isabs(p) for p in result)\n except (ValueError, TypeError):\n return False\n\n\ndef is_file(series, series_description) -> bool:\n \"\"\"Is the series of the type \"file\" (i.e. existing paths)?\n\n Args:\n series: Series\n series_description: Series description\n\n Returns:\n True is the series is of the file type (NaNs allowed).\n \"\"\"\n if series_description[\"distinct_count_without_nan\"] == 0:\n return False\n\n try:\n result = series[~series.isnull()].astype(str)\n return all(os.path.exists(p) for p in result)\n except (ValueError, TypeError):\n return False\n\n\ndef is_image(series, series_description) -> bool:\n \"\"\"Is the series of the image type (i.e. \"file\" with image extensions)?\n\n Args:\n series: Series\n series_description: Series description\n\n Returns:\n True is the series is of the image type (NaNs allowed).\n \"\"\"\n if series_description[\"distinct_count_without_nan\"] > 0:\n try:\n result = series[~series.isnull()].astype(str)\n return all(imghdr.what(p) for p in result)\n except (TypeError, ValueError):\n return False\n else:\n return False\n\n\ndef is_date(series) -> bool:\n \"\"\"Is the variable of type datetime? Throws a warning if the series looks like a datetime, but is not typed as\n datetime64.\n\n Args:\n series: Series\n\n Returns:\n True if the variable is of type datetime.\n \"\"\"\n is_date_value = pd.api.types.is_datetime64_dtype(series)\n\n return is_date_value\n\n\ndef get_var_type(series: pd.Series) -> dict:\n \"\"\"Get the variable type of a series.\n\n Args:\n series: Series for which we want to infer the variable type.\n\n Returns:\n The series updated with the variable type included.\n \"\"\"\n\n series_description = {}\n\n try:\n series_description = get_counts(series)\n\n # When the inferred type of the index is just \"mixed\" probably the types within the series are tuple, dict,\n # list and so on...\n if series_description[\n \"value_counts_without_nan\"\n ].index.inferred_type.startswith(\"mixed\"):\n raise TypeError(\"Not supported mixed type\")\n\n if series_description[\"distinct_count_without_nan\"] == 0:\n # Empty\n var_type = Variable.S_TYPE_UNSUPPORTED\n elif is_boolean(series, series_description):\n var_type = Variable.TYPE_BOOL\n elif is_numeric(series, series_description):\n var_type = Variable.TYPE_NUM\n elif is_date(series):\n var_type = Variable.TYPE_DATE\n elif is_url(series, series_description):\n var_type = Variable.TYPE_URL\n elif is_path(series, series_description):\n if config[\"vars\"][\"file\"][\"active\"].get(bool) and is_file(\n series, series_description\n ):\n if config[\"vars\"][\"image\"][\"active\"].get(bool) and is_image(\n series, series_description\n ):\n var_type = Variable.TYPE_IMAGE\n else:\n var_type = Variable.TYPE_FILE\n else:\n var_type = Variable.TYPE_PATH\n else:\n var_type = Variable.TYPE_CAT\n except TypeError:\n var_type = Variable.S_TYPE_UNSUPPORTED\n\n series_description.update({\"type\": var_type})\n\n return series_description\n", "path": "src/pandas_profiling/model/base.py"}]}
| 3,142 | 131 |
gh_patches_debug_1048
|
rasdani/github-patches
|
git_diff
|
mindee__doctr-243
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Pb: unitest text_export_size not passing on tf 2.3.1
Unitest text_export_size not OK locally on tf 2.3.1 :
```
def test_export_sizes(test_convert_to_tflite, test_convert_to_fp16, test_quantize_model):
assert sys.getsizeof(test_convert_to_tflite) > sys.getsizeof(test_convert_to_fp16)
> assert sys.getsizeof(test_convert_to_fp16) > sys.getsizeof(test_quantize_model)
E AssertionError: assert 3041 > 3041
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 # Copyright (C) 2021, Mindee.
2
3 # This program is licensed under the Apache License version 2.
4 # See LICENSE or go to <https://www.apache.org/licenses/LICENSE-2.0.txt> for full license details.
5
6 """
7 Package installation setup
8 """
9
10 import os
11 from pathlib import Path
12 import subprocess
13
14 from setuptools import find_packages, setup
15
16
17 version = "0.1.2a0"
18 sha = 'Unknown'
19 package_name = 'doctr'
20
21 cwd = Path(__file__).parent.absolute()
22
23 if os.getenv('BUILD_VERSION'):
24 version = os.getenv('BUILD_VERSION')
25 elif sha != 'Unknown':
26 try:
27 sha = subprocess.check_output(['git', 'rev-parse', 'HEAD'], cwd=cwd).decode('ascii').strip()
28 except Exception:
29 pass
30 version += '+' + sha[:7]
31 print(f"Building wheel {package_name}-{version}")
32
33 with open(cwd.joinpath(package_name, 'version.py'), 'w') as f:
34 f.write(f"__version__ = '{version}'\n")
35
36 with open('README.md', 'r') as f:
37 readme = f.read()
38
39 requirements = [
40 "numpy>=1.16.0",
41 "scipy>=1.4.0",
42 "opencv-python>=4.2",
43 "tensorflow>=2.3.0",
44 "PyMuPDF>=1.16.0,<1.18.11",
45 "pyclipper>=1.2.0",
46 "shapely>=1.6.0",
47 "matplotlib>=3.1.0",
48 "mplcursors>=0.3",
49 "rapidfuzz>=1.0.0",
50 "weasyprint>=52.2",
51 ]
52
53 setup(
54 # Metadata
55 name=os.getenv('PKG_INDEX') if os.getenv('PKG_INDEX') else package_name,
56 version=version,
57 author='François-Guillaume Fernandez, Charles Gaillard',
58 author_email='[email protected]',
59 description='Extract valuable text information from your documents',
60 long_description=readme,
61 long_description_content_type="text/markdown",
62 url='https://github.com/mindee/doctr',
63 download_url='https://github.com/mindee/doctr/tags',
64 license='Apache',
65 classifiers=[
66 'Development Status :: 3 - Alpha',
67 'Intended Audience :: Developers',
68 'Intended Audience :: Science/Research',
69 'License :: OSI Approved :: Apache Software License',
70 'Natural Language :: English',
71 'Operating System :: OS Independent',
72 'Programming Language :: Python :: 3',
73 'Programming Language :: Python :: 3.6',
74 'Programming Language :: Python :: 3.7',
75 'Topic :: Scientific/Engineering',
76 'Topic :: Scientific/Engineering :: Artificial Intelligence',
77 'Topic :: Software Development',
78 'Topic :: Software Development :: Libraries',
79 'Topic :: Software Development :: Libraries :: Python Modules',
80 ],
81 keywords=['ocr', 'deep learning', 'tensorflow', 'text detection', 'text recognition'],
82
83 # Package info
84 packages=find_packages(exclude=('test',)),
85 zip_safe=True,
86 python_requires='>=3.6.0',
87 include_package_data=True,
88 install_requires=requirements,
89 package_data={'': ['LICENSE']}
90 )
91
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -40,7 +40,7 @@
"numpy>=1.16.0",
"scipy>=1.4.0",
"opencv-python>=4.2",
- "tensorflow>=2.3.0",
+ "tensorflow>=2.4.0",
"PyMuPDF>=1.16.0,<1.18.11",
"pyclipper>=1.2.0",
"shapely>=1.6.0",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -40,7 +40,7 @@\n \"numpy>=1.16.0\",\n \"scipy>=1.4.0\",\n \"opencv-python>=4.2\",\n- \"tensorflow>=2.3.0\",\n+ \"tensorflow>=2.4.0\",\n \"PyMuPDF>=1.16.0,<1.18.11\",\n \"pyclipper>=1.2.0\",\n \"shapely>=1.6.0\",\n", "issue": "Pb: unitest text_export_size not passing on tf 2.3.1\nUnitest text_export_size not OK locally on tf 2.3.1 : \r\n\r\n```\r\ndef test_export_sizes(test_convert_to_tflite, test_convert_to_fp16, test_quantize_model):\r\n assert sys.getsizeof(test_convert_to_tflite) > sys.getsizeof(test_convert_to_fp16)\r\n> assert sys.getsizeof(test_convert_to_fp16) > sys.getsizeof(test_quantize_model)\r\nE AssertionError: assert 3041 > 3041\r\n\r\n```\n", "before_files": [{"content": "# Copyright (C) 2021, Mindee.\n\n# This program is licensed under the Apache License version 2.\n# See LICENSE or go to <https://www.apache.org/licenses/LICENSE-2.0.txt> for full license details.\n\n\"\"\"\nPackage installation setup\n\"\"\"\n\nimport os\nfrom pathlib import Path\nimport subprocess\n\nfrom setuptools import find_packages, setup\n\n\nversion = \"0.1.2a0\"\nsha = 'Unknown'\npackage_name = 'doctr'\n\ncwd = Path(__file__).parent.absolute()\n\nif os.getenv('BUILD_VERSION'):\n version = os.getenv('BUILD_VERSION')\nelif sha != 'Unknown':\n try:\n sha = subprocess.check_output(['git', 'rev-parse', 'HEAD'], cwd=cwd).decode('ascii').strip()\n except Exception:\n pass\n version += '+' + sha[:7]\nprint(f\"Building wheel {package_name}-{version}\")\n\nwith open(cwd.joinpath(package_name, 'version.py'), 'w') as f:\n f.write(f\"__version__ = '{version}'\\n\")\n\nwith open('README.md', 'r') as f:\n readme = f.read()\n\nrequirements = [\n \"numpy>=1.16.0\",\n \"scipy>=1.4.0\",\n \"opencv-python>=4.2\",\n \"tensorflow>=2.3.0\",\n \"PyMuPDF>=1.16.0,<1.18.11\",\n \"pyclipper>=1.2.0\",\n \"shapely>=1.6.0\",\n \"matplotlib>=3.1.0\",\n \"mplcursors>=0.3\",\n \"rapidfuzz>=1.0.0\",\n \"weasyprint>=52.2\",\n]\n\nsetup(\n # Metadata\n name=os.getenv('PKG_INDEX') if os.getenv('PKG_INDEX') else package_name,\n version=version,\n author='Fran\u00e7ois-Guillaume Fernandez, Charles Gaillard',\n author_email='[email protected]',\n description='Extract valuable text information from your documents',\n long_description=readme,\n long_description_content_type=\"text/markdown\",\n url='https://github.com/mindee/doctr',\n download_url='https://github.com/mindee/doctr/tags',\n license='Apache',\n classifiers=[\n 'Development Status :: 3 - Alpha',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: Apache Software License',\n 'Natural Language :: English',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Topic :: Scientific/Engineering',\n 'Topic :: Scientific/Engineering :: Artificial Intelligence',\n 'Topic :: Software Development',\n 'Topic :: Software Development :: Libraries',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n ],\n keywords=['ocr', 'deep learning', 'tensorflow', 'text detection', 'text recognition'],\n\n # Package info\n packages=find_packages(exclude=('test',)),\n zip_safe=True,\n python_requires='>=3.6.0',\n include_package_data=True,\n install_requires=requirements,\n package_data={'': ['LICENSE']}\n)\n", "path": "setup.py"}], "after_files": [{"content": "# Copyright (C) 2021, Mindee.\n\n# This program is licensed under the Apache License version 2.\n# See LICENSE or go to <https://www.apache.org/licenses/LICENSE-2.0.txt> for full license details.\n\n\"\"\"\nPackage installation setup\n\"\"\"\n\nimport os\nfrom pathlib import Path\nimport subprocess\n\nfrom setuptools import find_packages, setup\n\n\nversion = \"0.1.2a0\"\nsha = 'Unknown'\npackage_name = 'doctr'\n\ncwd = Path(__file__).parent.absolute()\n\nif os.getenv('BUILD_VERSION'):\n version = os.getenv('BUILD_VERSION')\nelif sha != 'Unknown':\n try:\n sha = subprocess.check_output(['git', 'rev-parse', 'HEAD'], cwd=cwd).decode('ascii').strip()\n except Exception:\n pass\n version += '+' + sha[:7]\nprint(f\"Building wheel {package_name}-{version}\")\n\nwith open(cwd.joinpath(package_name, 'version.py'), 'w') as f:\n f.write(f\"__version__ = '{version}'\\n\")\n\nwith open('README.md', 'r') as f:\n readme = f.read()\n\nrequirements = [\n \"numpy>=1.16.0\",\n \"scipy>=1.4.0\",\n \"opencv-python>=4.2\",\n \"tensorflow>=2.4.0\",\n \"PyMuPDF>=1.16.0,<1.18.11\",\n \"pyclipper>=1.2.0\",\n \"shapely>=1.6.0\",\n \"matplotlib>=3.1.0\",\n \"mplcursors>=0.3\",\n \"rapidfuzz>=1.0.0\",\n \"weasyprint>=52.2\",\n]\n\nsetup(\n # Metadata\n name=os.getenv('PKG_INDEX') if os.getenv('PKG_INDEX') else package_name,\n version=version,\n author='Fran\u00e7ois-Guillaume Fernandez, Charles Gaillard',\n author_email='[email protected]',\n description='Extract valuable text information from your documents',\n long_description=readme,\n long_description_content_type=\"text/markdown\",\n url='https://github.com/mindee/doctr',\n download_url='https://github.com/mindee/doctr/tags',\n license='Apache',\n classifiers=[\n 'Development Status :: 3 - Alpha',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: Apache Software License',\n 'Natural Language :: English',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Topic :: Scientific/Engineering',\n 'Topic :: Scientific/Engineering :: Artificial Intelligence',\n 'Topic :: Software Development',\n 'Topic :: Software Development :: Libraries',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n ],\n keywords=['ocr', 'deep learning', 'tensorflow', 'text detection', 'text recognition'],\n\n # Package info\n packages=find_packages(exclude=('test',)),\n zip_safe=True,\n python_requires='>=3.6.0',\n include_package_data=True,\n install_requires=requirements,\n package_data={'': ['LICENSE']}\n)\n", "path": "setup.py"}]}
| 1,263 | 130 |
gh_patches_debug_1303
|
rasdani/github-patches
|
git_diff
|
fossasia__open-event-server-9132
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add the unique ticket code into the downlad CSV file
The CSV download file of the attendee list does not include the numbers on the QR Code. Please add this field "Ticket-ID".
The ticket ID has the following format: 135ccbd7-9b23-4a52-a7fd-326fec1b2c1c
Whereas the order has a format like this: #O1691408152-34896

Expected: The exported CSV should have a table column "Ticket ID" with the ticket ID number that is encoded in the QR code as well.

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `app/models/ticket_holder.py`
Content:
```
1 import base64
2 from dataclasses import dataclass
3 from datetime import datetime
4 from io import BytesIO
5
6 import qrcode
7 from citext import CIText
8
9 from app.api.helpers.storage import UPLOAD_PATHS, generate_hash
10 from app.models import db
11 from app.models.base import SoftDeletionModel
12
13
14 @dataclass(init=False, unsafe_hash=True)
15 class TicketHolder(SoftDeletionModel):
16 __tablename__ = "ticket_holders"
17
18 id: int = db.Column(db.Integer, primary_key=True)
19 firstname: str = db.Column(db.String)
20 lastname: str = db.Column(db.String)
21 email: str = db.Column(CIText)
22 address: str = db.Column(db.String)
23 city: str = db.Column(db.String)
24 state: str = db.Column(db.String)
25 country: str = db.Column(db.String)
26 job_title: str = db.Column(db.String)
27 phone: str = db.Column(db.String)
28 tax_business_info: str = db.Column(db.String)
29 billing_address: str = db.Column(db.String)
30 home_address: str = db.Column(db.String)
31 shipping_address: str = db.Column(db.String)
32 company: str = db.Column(db.String)
33 work_address: str = db.Column(db.String)
34 work_phone: str = db.Column(db.String)
35 website: str = db.Column(db.String)
36 blog: str = db.Column(db.String)
37 twitter: str = db.Column(db.String)
38 facebook: str = db.Column(db.String)
39 instagram: str = db.Column(db.String)
40 linkedin: str = db.Column(db.String)
41 github: str = db.Column(db.String)
42 gender: str = db.Column(db.String)
43 accept_video_recording: bool = db.Column(db.Boolean)
44 accept_share_details: bool = db.Column(db.Boolean)
45 accept_receive_emails: bool = db.Column(db.Boolean)
46 age_group: str = db.Column(db.String)
47 home_wiki: str = db.Column(db.String)
48 wiki_scholarship: str = db.Column(db.String)
49 birth_date: datetime = db.Column(db.DateTime(timezone=True))
50 pdf_url: str = db.Column(db.String)
51 ticket_id: int = db.Column(
52 db.Integer, db.ForeignKey('tickets.id', ondelete='CASCADE'), nullable=False
53 )
54 order_id: int = db.Column(db.Integer, db.ForeignKey('orders.id', ondelete='CASCADE'))
55 is_checked_in: bool = db.Column(db.Boolean, default=False)
56 is_checked_out: bool = db.Column(db.Boolean, default=False)
57 is_registered: bool = db.Column(db.Boolean, default=False)
58 device_name_checkin: str = db.Column(db.String)
59 checkin_times: str = db.Column(db.String)
60 checkout_times: str = db.Column(db.String)
61 register_times: str = db.Column(db.String)
62 attendee_notes: str = db.Column(db.String)
63 event_id: int = db.Column(
64 db.Integer, db.ForeignKey('events.id', ondelete='CASCADE'), nullable=False
65 )
66 created_at: datetime = db.Column(db.DateTime(timezone=True), default=datetime.utcnow)
67 modified_at: datetime = db.Column(
68 db.DateTime(timezone=True), default=datetime.utcnow, onupdate=datetime.utcnow
69 )
70 complex_field_values: str = db.Column(db.JSON)
71 is_consent_of_refund_policy: bool = db.Column(db.Boolean, default=False)
72 native_language: str = db.Column(db.JSON)
73 fluent_language: str = db.Column(db.JSON)
74 user = db.relationship(
75 'User',
76 foreign_keys=[email],
77 primaryjoin='User.email == TicketHolder.email',
78 viewonly=True,
79 backref='attendees',
80 sync_backref=False,
81 )
82 order = db.relationship('Order', backref='ticket_holders')
83 ticket = db.relationship('Ticket', backref='ticket_holders')
84 is_consent_form_field: bool = db.Column(db.Boolean, default=False)
85 is_consent_form_field_photo: bool = db.Column(db.Boolean, default=False)
86 is_consent_form_field_email: bool = db.Column(db.Boolean, default=False)
87 is_badge_printed: bool = db.Column(db.Boolean, default=False)
88 badge_printed_at: datetime = db.Column(db.DateTime(timezone=True))
89 is_discount_applied: bool = db.Column(db.Boolean, default=False)
90 is_access_code_applied: bool = db.Column(db.Boolean, default=False)
91 tag_id: int = db.Column(db.Integer, db.ForeignKey('tags.id', ondelete='CASCADE'))
92 tag = db.relationship('Tag', backref='ticket_holders')
93
94 @property
95 def name(self):
96 firstname = self.firstname if self.firstname else ''
97 lastname = self.lastname if self.lastname else ''
98 if firstname and lastname:
99 return f'{firstname} {lastname}'
100 else:
101 return ''
102
103 @property
104 def qr_code(self):
105 qr = qrcode.QRCode(
106 version=1,
107 error_correction=qrcode.constants.ERROR_CORRECT_L,
108 box_size=10,
109 border=0,
110 )
111 qr.add_data(self.order.identifier + "-" + str(self.id))
112 qr.make(fit=True)
113 img = qr.make_image()
114
115 buffer = BytesIO()
116 img.save(buffer, format="JPEG")
117 img_str = str(base64.b64encode(buffer.getvalue()), 'utf-8')
118 return img_str
119
120 @property
121 def serialize(self):
122 """Return object data in easily serializable format"""
123 return {
124 'id': self.id,
125 'firstname': self.firstname,
126 'lastname': self.lastname,
127 'email': self.email,
128 'city': self.city,
129 'address': self.address,
130 'state': self.state,
131 'country': self.country,
132 'company': self.company,
133 'taxBusinessInfo': self.tax_business_info,
134 }
135
136 @property
137 def pdf_url_path(self) -> str:
138 key = UPLOAD_PATHS['pdf']['tickets_all'].format(
139 identifier=self.order.identifier, extra_identifier=self.id
140 )
141 return (
142 f'generated/tickets/{key}/{generate_hash(key)}/'
143 + self.order.identifier
144 + '.pdf'
145 )
146
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/app/models/ticket_holder.py b/app/models/ticket_holder.py
--- a/app/models/ticket_holder.py
+++ b/app/models/ticket_holder.py
@@ -108,7 +108,7 @@
box_size=10,
border=0,
)
- qr.add_data(self.order.identifier + "-" + str(self.id))
+ qr.add_data(self.order.identifier)
qr.make(fit=True)
img = qr.make_image()
|
{"golden_diff": "diff --git a/app/models/ticket_holder.py b/app/models/ticket_holder.py\n--- a/app/models/ticket_holder.py\n+++ b/app/models/ticket_holder.py\n@@ -108,7 +108,7 @@\n box_size=10,\n border=0,\n )\n- qr.add_data(self.order.identifier + \"-\" + str(self.id))\n+ qr.add_data(self.order.identifier)\n qr.make(fit=True)\n img = qr.make_image()\n", "issue": "Add the unique ticket code into the downlad CSV file\nThe CSV download file of the attendee list does not include the numbers on the QR Code. Please add this field \"Ticket-ID\".\r\n\r\nThe ticket ID has the following format: 135ccbd7-9b23-4a52-a7fd-326fec1b2c1c\r\nWhereas the order has a format like this: #O1691408152-34896\r\n\r\n\r\n\r\nExpected: The exported CSV should have a table column \"Ticket ID\" with the ticket ID number that is encoded in the QR code as well.\r\n\r\n\r\n\n", "before_files": [{"content": "import base64\nfrom dataclasses import dataclass\nfrom datetime import datetime\nfrom io import BytesIO\n\nimport qrcode\nfrom citext import CIText\n\nfrom app.api.helpers.storage import UPLOAD_PATHS, generate_hash\nfrom app.models import db\nfrom app.models.base import SoftDeletionModel\n\n\n@dataclass(init=False, unsafe_hash=True)\nclass TicketHolder(SoftDeletionModel):\n __tablename__ = \"ticket_holders\"\n\n id: int = db.Column(db.Integer, primary_key=True)\n firstname: str = db.Column(db.String)\n lastname: str = db.Column(db.String)\n email: str = db.Column(CIText)\n address: str = db.Column(db.String)\n city: str = db.Column(db.String)\n state: str = db.Column(db.String)\n country: str = db.Column(db.String)\n job_title: str = db.Column(db.String)\n phone: str = db.Column(db.String)\n tax_business_info: str = db.Column(db.String)\n billing_address: str = db.Column(db.String)\n home_address: str = db.Column(db.String)\n shipping_address: str = db.Column(db.String)\n company: str = db.Column(db.String)\n work_address: str = db.Column(db.String)\n work_phone: str = db.Column(db.String)\n website: str = db.Column(db.String)\n blog: str = db.Column(db.String)\n twitter: str = db.Column(db.String)\n facebook: str = db.Column(db.String)\n instagram: str = db.Column(db.String)\n linkedin: str = db.Column(db.String)\n github: str = db.Column(db.String)\n gender: str = db.Column(db.String)\n accept_video_recording: bool = db.Column(db.Boolean)\n accept_share_details: bool = db.Column(db.Boolean)\n accept_receive_emails: bool = db.Column(db.Boolean)\n age_group: str = db.Column(db.String)\n home_wiki: str = db.Column(db.String)\n wiki_scholarship: str = db.Column(db.String)\n birth_date: datetime = db.Column(db.DateTime(timezone=True))\n pdf_url: str = db.Column(db.String)\n ticket_id: int = db.Column(\n db.Integer, db.ForeignKey('tickets.id', ondelete='CASCADE'), nullable=False\n )\n order_id: int = db.Column(db.Integer, db.ForeignKey('orders.id', ondelete='CASCADE'))\n is_checked_in: bool = db.Column(db.Boolean, default=False)\n is_checked_out: bool = db.Column(db.Boolean, default=False)\n is_registered: bool = db.Column(db.Boolean, default=False)\n device_name_checkin: str = db.Column(db.String)\n checkin_times: str = db.Column(db.String)\n checkout_times: str = db.Column(db.String)\n register_times: str = db.Column(db.String)\n attendee_notes: str = db.Column(db.String)\n event_id: int = db.Column(\n db.Integer, db.ForeignKey('events.id', ondelete='CASCADE'), nullable=False\n )\n created_at: datetime = db.Column(db.DateTime(timezone=True), default=datetime.utcnow)\n modified_at: datetime = db.Column(\n db.DateTime(timezone=True), default=datetime.utcnow, onupdate=datetime.utcnow\n )\n complex_field_values: str = db.Column(db.JSON)\n is_consent_of_refund_policy: bool = db.Column(db.Boolean, default=False)\n native_language: str = db.Column(db.JSON)\n fluent_language: str = db.Column(db.JSON)\n user = db.relationship(\n 'User',\n foreign_keys=[email],\n primaryjoin='User.email == TicketHolder.email',\n viewonly=True,\n backref='attendees',\n sync_backref=False,\n )\n order = db.relationship('Order', backref='ticket_holders')\n ticket = db.relationship('Ticket', backref='ticket_holders')\n is_consent_form_field: bool = db.Column(db.Boolean, default=False)\n is_consent_form_field_photo: bool = db.Column(db.Boolean, default=False)\n is_consent_form_field_email: bool = db.Column(db.Boolean, default=False)\n is_badge_printed: bool = db.Column(db.Boolean, default=False)\n badge_printed_at: datetime = db.Column(db.DateTime(timezone=True))\n is_discount_applied: bool = db.Column(db.Boolean, default=False)\n is_access_code_applied: bool = db.Column(db.Boolean, default=False)\n tag_id: int = db.Column(db.Integer, db.ForeignKey('tags.id', ondelete='CASCADE'))\n tag = db.relationship('Tag', backref='ticket_holders')\n\n @property\n def name(self):\n firstname = self.firstname if self.firstname else ''\n lastname = self.lastname if self.lastname else ''\n if firstname and lastname:\n return f'{firstname} {lastname}'\n else:\n return ''\n\n @property\n def qr_code(self):\n qr = qrcode.QRCode(\n version=1,\n error_correction=qrcode.constants.ERROR_CORRECT_L,\n box_size=10,\n border=0,\n )\n qr.add_data(self.order.identifier + \"-\" + str(self.id))\n qr.make(fit=True)\n img = qr.make_image()\n\n buffer = BytesIO()\n img.save(buffer, format=\"JPEG\")\n img_str = str(base64.b64encode(buffer.getvalue()), 'utf-8')\n return img_str\n\n @property\n def serialize(self):\n \"\"\"Return object data in easily serializable format\"\"\"\n return {\n 'id': self.id,\n 'firstname': self.firstname,\n 'lastname': self.lastname,\n 'email': self.email,\n 'city': self.city,\n 'address': self.address,\n 'state': self.state,\n 'country': self.country,\n 'company': self.company,\n 'taxBusinessInfo': self.tax_business_info,\n }\n\n @property\n def pdf_url_path(self) -> str:\n key = UPLOAD_PATHS['pdf']['tickets_all'].format(\n identifier=self.order.identifier, extra_identifier=self.id\n )\n return (\n f'generated/tickets/{key}/{generate_hash(key)}/'\n + self.order.identifier\n + '.pdf'\n )\n", "path": "app/models/ticket_holder.py"}], "after_files": [{"content": "import base64\nfrom dataclasses import dataclass\nfrom datetime import datetime\nfrom io import BytesIO\n\nimport qrcode\nfrom citext import CIText\n\nfrom app.api.helpers.storage import UPLOAD_PATHS, generate_hash\nfrom app.models import db\nfrom app.models.base import SoftDeletionModel\n\n\n@dataclass(init=False, unsafe_hash=True)\nclass TicketHolder(SoftDeletionModel):\n __tablename__ = \"ticket_holders\"\n\n id: int = db.Column(db.Integer, primary_key=True)\n firstname: str = db.Column(db.String)\n lastname: str = db.Column(db.String)\n email: str = db.Column(CIText)\n address: str = db.Column(db.String)\n city: str = db.Column(db.String)\n state: str = db.Column(db.String)\n country: str = db.Column(db.String)\n job_title: str = db.Column(db.String)\n phone: str = db.Column(db.String)\n tax_business_info: str = db.Column(db.String)\n billing_address: str = db.Column(db.String)\n home_address: str = db.Column(db.String)\n shipping_address: str = db.Column(db.String)\n company: str = db.Column(db.String)\n work_address: str = db.Column(db.String)\n work_phone: str = db.Column(db.String)\n website: str = db.Column(db.String)\n blog: str = db.Column(db.String)\n twitter: str = db.Column(db.String)\n facebook: str = db.Column(db.String)\n instagram: str = db.Column(db.String)\n linkedin: str = db.Column(db.String)\n github: str = db.Column(db.String)\n gender: str = db.Column(db.String)\n accept_video_recording: bool = db.Column(db.Boolean)\n accept_share_details: bool = db.Column(db.Boolean)\n accept_receive_emails: bool = db.Column(db.Boolean)\n age_group: str = db.Column(db.String)\n home_wiki: str = db.Column(db.String)\n wiki_scholarship: str = db.Column(db.String)\n birth_date: datetime = db.Column(db.DateTime(timezone=True))\n pdf_url: str = db.Column(db.String)\n ticket_id: int = db.Column(\n db.Integer, db.ForeignKey('tickets.id', ondelete='CASCADE'), nullable=False\n )\n order_id: int = db.Column(db.Integer, db.ForeignKey('orders.id', ondelete='CASCADE'))\n is_checked_in: bool = db.Column(db.Boolean, default=False)\n is_checked_out: bool = db.Column(db.Boolean, default=False)\n is_registered: bool = db.Column(db.Boolean, default=False)\n device_name_checkin: str = db.Column(db.String)\n checkin_times: str = db.Column(db.String)\n checkout_times: str = db.Column(db.String)\n register_times: str = db.Column(db.String)\n attendee_notes: str = db.Column(db.String)\n event_id: int = db.Column(\n db.Integer, db.ForeignKey('events.id', ondelete='CASCADE'), nullable=False\n )\n created_at: datetime = db.Column(db.DateTime(timezone=True), default=datetime.utcnow)\n modified_at: datetime = db.Column(\n db.DateTime(timezone=True), default=datetime.utcnow, onupdate=datetime.utcnow\n )\n complex_field_values: str = db.Column(db.JSON)\n is_consent_of_refund_policy: bool = db.Column(db.Boolean, default=False)\n native_language: str = db.Column(db.JSON)\n fluent_language: str = db.Column(db.JSON)\n user = db.relationship(\n 'User',\n foreign_keys=[email],\n primaryjoin='User.email == TicketHolder.email',\n viewonly=True,\n backref='attendees',\n sync_backref=False,\n )\n order = db.relationship('Order', backref='ticket_holders')\n ticket = db.relationship('Ticket', backref='ticket_holders')\n is_consent_form_field: bool = db.Column(db.Boolean, default=False)\n is_consent_form_field_photo: bool = db.Column(db.Boolean, default=False)\n is_consent_form_field_email: bool = db.Column(db.Boolean, default=False)\n is_badge_printed: bool = db.Column(db.Boolean, default=False)\n badge_printed_at: datetime = db.Column(db.DateTime(timezone=True))\n is_discount_applied: bool = db.Column(db.Boolean, default=False)\n is_access_code_applied: bool = db.Column(db.Boolean, default=False)\n tag_id: int = db.Column(db.Integer, db.ForeignKey('tags.id', ondelete='CASCADE'))\n tag = db.relationship('Tag', backref='ticket_holders')\n\n @property\n def name(self):\n firstname = self.firstname if self.firstname else ''\n lastname = self.lastname if self.lastname else ''\n if firstname and lastname:\n return f'{firstname} {lastname}'\n else:\n return ''\n\n @property\n def qr_code(self):\n qr = qrcode.QRCode(\n version=1,\n error_correction=qrcode.constants.ERROR_CORRECT_L,\n box_size=10,\n border=0,\n )\n qr.add_data(self.order.identifier)\n qr.make(fit=True)\n img = qr.make_image()\n\n buffer = BytesIO()\n img.save(buffer, format=\"JPEG\")\n img_str = str(base64.b64encode(buffer.getvalue()), 'utf-8')\n return img_str\n\n @property\n def serialize(self):\n \"\"\"Return object data in easily serializable format\"\"\"\n return {\n 'id': self.id,\n 'firstname': self.firstname,\n 'lastname': self.lastname,\n 'email': self.email,\n 'city': self.city,\n 'address': self.address,\n 'state': self.state,\n 'country': self.country,\n 'company': self.company,\n 'taxBusinessInfo': self.tax_business_info,\n }\n\n @property\n def pdf_url_path(self) -> str:\n key = UPLOAD_PATHS['pdf']['tickets_all'].format(\n identifier=self.order.identifier, extra_identifier=self.id\n )\n return (\n f'generated/tickets/{key}/{generate_hash(key)}/'\n + self.order.identifier\n + '.pdf'\n )\n", "path": "app/models/ticket_holder.py"}]}
| 2,201 | 102 |
gh_patches_debug_30338
|
rasdani/github-patches
|
git_diff
|
ansible__molecule-3105
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add support for checking exit codes on shell dependencies
# Issue Type
- Feature request
# Molecule and Ansible details
```
ansible 2.10.5
config file = /Users/jhg03a/<redacted>/ansible.cfg
configured module search path = ['/Users/jhg03a/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']
ansible python module location = /usr/local/lib/python3.9/site-packages/ansible
executable location = /usr/local/bin/ansible
python version = 3.9.2 (default, Feb 24 2021, 13:26:09) [Clang 12.0.0 (clang-1200.0.32.29)]
molecule 3.2.3 using python 3.9
ansible:2.10.5
delegated:3.2.3 from molecule
docker:0.2.4 from molecule_docker
```
Molecule installation method (one of):
- pip
Ansible installation method (one of):
- pip
# Desired Behavior
Currently it appears that the dependency shell module doesn't take into account the exit code from the command. If something goes wrong in the dependency phase, it's highly likely the rest of the run is going to fail or have inconsistent results.
### Example:
```yaml
dependency:
name: shell
command: 'false'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/molecule/dependency/base.py`
Content:
```
1 # Copyright (c) 2015-2018 Cisco Systems, Inc.
2 #
3 # Permission is hereby granted, free of charge, to any person obtaining a copy
4 # of this software and associated documentation files (the "Software"), to
5 # deal in the Software without restriction, including without limitation the
6 # rights to use, copy, modify, merge, publish, distribute, sublicense, and/or
7 # sell copies of the Software, and to permit persons to whom the Software is
8 # furnished to do so, subject to the following conditions:
9 #
10 # The above copyright notice and this permission notice shall be included in
11 # all copies or substantial portions of the Software.
12 #
13 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
14 # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
15 # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
16 # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
17 # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
18 # FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
19 # DEALINGS IN THE SOFTWARE.
20 """Base Dependency Module."""
21
22 import abc
23 import logging
24 import os
25 import time
26
27 from molecule import constants, util
28
29 LOG = logging.getLogger(__name__)
30
31
32 class Base(object):
33 """Dependency Base Class."""
34
35 __metaclass__ = abc.ABCMeta
36
37 RETRY = 3
38 SLEEP = 3
39 BACKOFF = 3
40
41 def __init__(self, config):
42 """
43 Initialize code for all :ref:`Dependency` classes.
44
45 :param config: An instance of a Molecule config.
46 :returns: None
47 """
48 self._config = config
49
50 def execute_with_retries(self):
51 """Run dependency downloads with retry and timed back-off."""
52 exception = None
53
54 try:
55 # print(555, self._sh_command)
56 util.run_command(self._sh_command, debug=self._config.debug)
57 msg = "Dependency completed successfully."
58 LOG.info(msg)
59 return
60 except Exception:
61 pass
62
63 for counter in range(1, (self.RETRY + 1)):
64 msg = "Retrying dependency ... {}/{} time(s)".format(counter, self.RETRY)
65 LOG.warning(msg)
66
67 msg = "Sleeping {} seconds before retrying ...".format(self.SLEEP)
68 LOG.warning(msg)
69 time.sleep(self.SLEEP)
70 self.SLEEP += self.BACKOFF
71
72 try:
73 util.run_command(self._sh_command, debug=self._config.debug)
74 msg = "Dependency completed successfully."
75 LOG.info(msg)
76 return
77 except Exception as _exception:
78 exception = _exception
79
80 LOG.error(str(exception), self._sh_command)
81 util.sysexit(getattr(exception, "exit_code", constants.RC_UNKNOWN_ERROR))
82
83 @abc.abstractmethod
84 def execute(self): # pragma: no cover
85 """
86 Execute ``cmd`` and returns None.
87
88 :return: None
89 """
90
91 @abc.abstractproperty
92 def default_options(self): # pragma: no cover
93 """
94 Get default CLI arguments provided to ``cmd`` as a dict.
95
96 :return: dict
97 """
98
99 @property
100 def default_env(self): # pragma: no cover
101 """
102 Get default env variables provided to ``cmd`` as a dict.
103
104 :return: dict
105 """
106 env = util.merge_dicts(os.environ, self._config.env)
107 # inject ephemeral_directory on top of path
108 env[self._config.ansible_collections_path] = os.path.join(
109 self._config.scenario.ephemeral_directory, "collections"
110 )
111 return env
112
113 @property
114 def name(self):
115 """
116 Name of the dependency and returns a string.
117
118 :returns: str
119 """
120 return self._config.config["dependency"]["name"]
121
122 @property
123 def enabled(self):
124 return self._config.config["dependency"]["enabled"]
125
126 @property
127 def options(self):
128 return util.merge_dicts(
129 self.default_options, self._config.config["dependency"]["options"]
130 )
131
132 @property
133 def env(self):
134 return util.merge_dicts(
135 self.default_env, self._config.config["dependency"]["env"]
136 )
137
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/molecule/dependency/base.py b/src/molecule/dependency/base.py
--- a/src/molecule/dependency/base.py
+++ b/src/molecule/dependency/base.py
@@ -23,8 +23,9 @@
import logging
import os
import time
+from subprocess import CalledProcessError
-from molecule import constants, util
+from molecule import util
LOG = logging.getLogger(__name__)
@@ -53,11 +54,11 @@
try:
# print(555, self._sh_command)
- util.run_command(self._sh_command, debug=self._config.debug)
+ util.run_command(self._sh_command, debug=self._config.debug, check=True)
msg = "Dependency completed successfully."
LOG.info(msg)
return
- except Exception:
+ except CalledProcessError:
pass
for counter in range(1, (self.RETRY + 1)):
@@ -70,15 +71,15 @@
self.SLEEP += self.BACKOFF
try:
- util.run_command(self._sh_command, debug=self._config.debug)
+ util.run_command(self._sh_command, debug=self._config.debug, check=True)
msg = "Dependency completed successfully."
LOG.info(msg)
return
- except Exception as _exception:
+ except CalledProcessError as _exception:
exception = _exception
- LOG.error(str(exception), self._sh_command)
- util.sysexit(getattr(exception, "exit_code", constants.RC_UNKNOWN_ERROR))
+ LOG.error(str(exception))
+ util.sysexit(exception.returncode)
@abc.abstractmethod
def execute(self): # pragma: no cover
|
{"golden_diff": "diff --git a/src/molecule/dependency/base.py b/src/molecule/dependency/base.py\n--- a/src/molecule/dependency/base.py\n+++ b/src/molecule/dependency/base.py\n@@ -23,8 +23,9 @@\n import logging\n import os\n import time\n+from subprocess import CalledProcessError\n \n-from molecule import constants, util\n+from molecule import util\n \n LOG = logging.getLogger(__name__)\n \n@@ -53,11 +54,11 @@\n \n try:\n # print(555, self._sh_command)\n- util.run_command(self._sh_command, debug=self._config.debug)\n+ util.run_command(self._sh_command, debug=self._config.debug, check=True)\n msg = \"Dependency completed successfully.\"\n LOG.info(msg)\n return\n- except Exception:\n+ except CalledProcessError:\n pass\n \n for counter in range(1, (self.RETRY + 1)):\n@@ -70,15 +71,15 @@\n self.SLEEP += self.BACKOFF\n \n try:\n- util.run_command(self._sh_command, debug=self._config.debug)\n+ util.run_command(self._sh_command, debug=self._config.debug, check=True)\n msg = \"Dependency completed successfully.\"\n LOG.info(msg)\n return\n- except Exception as _exception:\n+ except CalledProcessError as _exception:\n exception = _exception\n \n- LOG.error(str(exception), self._sh_command)\n- util.sysexit(getattr(exception, \"exit_code\", constants.RC_UNKNOWN_ERROR))\n+ LOG.error(str(exception))\n+ util.sysexit(exception.returncode)\n \n @abc.abstractmethod\n def execute(self): # pragma: no cover\n", "issue": "Add support for checking exit codes on shell dependencies\n# Issue Type\r\n\r\n- Feature request\r\n\r\n# Molecule and Ansible details\r\n\r\n```\r\nansible 2.10.5\r\n config file = /Users/jhg03a/<redacted>/ansible.cfg\r\n configured module search path = ['/Users/jhg03a/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']\r\n ansible python module location = /usr/local/lib/python3.9/site-packages/ansible\r\n executable location = /usr/local/bin/ansible\r\n python version = 3.9.2 (default, Feb 24 2021, 13:26:09) [Clang 12.0.0 (clang-1200.0.32.29)]\r\nmolecule 3.2.3 using python 3.9\r\n ansible:2.10.5\r\n delegated:3.2.3 from molecule\r\n docker:0.2.4 from molecule_docker\r\n```\r\n\r\nMolecule installation method (one of):\r\n\r\n- pip\r\n\r\nAnsible installation method (one of):\r\n\r\n- pip\r\n\r\n# Desired Behavior\r\n\r\nCurrently it appears that the dependency shell module doesn't take into account the exit code from the command. If something goes wrong in the dependency phase, it's highly likely the rest of the run is going to fail or have inconsistent results.\r\n\r\n### Example:\r\n```yaml\r\ndependency:\r\n name: shell\r\n command: 'false'\r\n```\r\n\n", "before_files": [{"content": "# Copyright (c) 2015-2018 Cisco Systems, Inc.\n#\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to\n# deal in the Software without restriction, including without limitation the\n# rights to use, copy, modify, merge, publish, distribute, sublicense, and/or\n# sell copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING\n# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER\n# DEALINGS IN THE SOFTWARE.\n\"\"\"Base Dependency Module.\"\"\"\n\nimport abc\nimport logging\nimport os\nimport time\n\nfrom molecule import constants, util\n\nLOG = logging.getLogger(__name__)\n\n\nclass Base(object):\n \"\"\"Dependency Base Class.\"\"\"\n\n __metaclass__ = abc.ABCMeta\n\n RETRY = 3\n SLEEP = 3\n BACKOFF = 3\n\n def __init__(self, config):\n \"\"\"\n Initialize code for all :ref:`Dependency` classes.\n\n :param config: An instance of a Molecule config.\n :returns: None\n \"\"\"\n self._config = config\n\n def execute_with_retries(self):\n \"\"\"Run dependency downloads with retry and timed back-off.\"\"\"\n exception = None\n\n try:\n # print(555, self._sh_command)\n util.run_command(self._sh_command, debug=self._config.debug)\n msg = \"Dependency completed successfully.\"\n LOG.info(msg)\n return\n except Exception:\n pass\n\n for counter in range(1, (self.RETRY + 1)):\n msg = \"Retrying dependency ... {}/{} time(s)\".format(counter, self.RETRY)\n LOG.warning(msg)\n\n msg = \"Sleeping {} seconds before retrying ...\".format(self.SLEEP)\n LOG.warning(msg)\n time.sleep(self.SLEEP)\n self.SLEEP += self.BACKOFF\n\n try:\n util.run_command(self._sh_command, debug=self._config.debug)\n msg = \"Dependency completed successfully.\"\n LOG.info(msg)\n return\n except Exception as _exception:\n exception = _exception\n\n LOG.error(str(exception), self._sh_command)\n util.sysexit(getattr(exception, \"exit_code\", constants.RC_UNKNOWN_ERROR))\n\n @abc.abstractmethod\n def execute(self): # pragma: no cover\n \"\"\"\n Execute ``cmd`` and returns None.\n\n :return: None\n \"\"\"\n\n @abc.abstractproperty\n def default_options(self): # pragma: no cover\n \"\"\"\n Get default CLI arguments provided to ``cmd`` as a dict.\n\n :return: dict\n \"\"\"\n\n @property\n def default_env(self): # pragma: no cover\n \"\"\"\n Get default env variables provided to ``cmd`` as a dict.\n\n :return: dict\n \"\"\"\n env = util.merge_dicts(os.environ, self._config.env)\n # inject ephemeral_directory on top of path\n env[self._config.ansible_collections_path] = os.path.join(\n self._config.scenario.ephemeral_directory, \"collections\"\n )\n return env\n\n @property\n def name(self):\n \"\"\"\n Name of the dependency and returns a string.\n\n :returns: str\n \"\"\"\n return self._config.config[\"dependency\"][\"name\"]\n\n @property\n def enabled(self):\n return self._config.config[\"dependency\"][\"enabled\"]\n\n @property\n def options(self):\n return util.merge_dicts(\n self.default_options, self._config.config[\"dependency\"][\"options\"]\n )\n\n @property\n def env(self):\n return util.merge_dicts(\n self.default_env, self._config.config[\"dependency\"][\"env\"]\n )\n", "path": "src/molecule/dependency/base.py"}], "after_files": [{"content": "# Copyright (c) 2015-2018 Cisco Systems, Inc.\n#\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to\n# deal in the Software without restriction, including without limitation the\n# rights to use, copy, modify, merge, publish, distribute, sublicense, and/or\n# sell copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING\n# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER\n# DEALINGS IN THE SOFTWARE.\n\"\"\"Base Dependency Module.\"\"\"\n\nimport abc\nimport logging\nimport os\nimport time\nfrom subprocess import CalledProcessError\n\nfrom molecule import util\n\nLOG = logging.getLogger(__name__)\n\n\nclass Base(object):\n \"\"\"Dependency Base Class.\"\"\"\n\n __metaclass__ = abc.ABCMeta\n\n RETRY = 3\n SLEEP = 3\n BACKOFF = 3\n\n def __init__(self, config):\n \"\"\"\n Initialize code for all :ref:`Dependency` classes.\n\n :param config: An instance of a Molecule config.\n :returns: None\n \"\"\"\n self._config = config\n\n def execute_with_retries(self):\n \"\"\"Run dependency downloads with retry and timed back-off.\"\"\"\n exception = None\n\n try:\n # print(555, self._sh_command)\n util.run_command(self._sh_command, debug=self._config.debug, check=True)\n msg = \"Dependency completed successfully.\"\n LOG.info(msg)\n return\n except CalledProcessError:\n pass\n\n for counter in range(1, (self.RETRY + 1)):\n msg = \"Retrying dependency ... {}/{} time(s)\".format(counter, self.RETRY)\n LOG.warning(msg)\n\n msg = \"Sleeping {} seconds before retrying ...\".format(self.SLEEP)\n LOG.warning(msg)\n time.sleep(self.SLEEP)\n self.SLEEP += self.BACKOFF\n\n try:\n util.run_command(self._sh_command, debug=self._config.debug, check=True)\n msg = \"Dependency completed successfully.\"\n LOG.info(msg)\n return\n except CalledProcessError as _exception:\n exception = _exception\n\n LOG.error(str(exception))\n util.sysexit(exception.returncode)\n\n @abc.abstractmethod\n def execute(self): # pragma: no cover\n \"\"\"\n Execute ``cmd`` and returns None.\n\n :return: None\n \"\"\"\n\n @abc.abstractproperty\n def default_options(self): # pragma: no cover\n \"\"\"\n Get default CLI arguments provided to ``cmd`` as a dict.\n\n :return: dict\n \"\"\"\n\n @property\n def default_env(self): # pragma: no cover\n \"\"\"\n Get default env variables provided to ``cmd`` as a dict.\n\n :return: dict\n \"\"\"\n env = util.merge_dicts(os.environ, self._config.env)\n # inject ephemeral_directory on top of path\n env[self._config.ansible_collections_path] = os.path.join(\n self._config.scenario.ephemeral_directory, \"collections\"\n )\n return env\n\n @property\n def name(self):\n \"\"\"\n Name of the dependency and returns a string.\n\n :returns: str\n \"\"\"\n return self._config.config[\"dependency\"][\"name\"]\n\n @property\n def enabled(self):\n return self._config.config[\"dependency\"][\"enabled\"]\n\n @property\n def options(self):\n return util.merge_dicts(\n self.default_options, self._config.config[\"dependency\"][\"options\"]\n )\n\n @property\n def env(self):\n return util.merge_dicts(\n self.default_env, self._config.config[\"dependency\"][\"env\"]\n )\n", "path": "src/molecule/dependency/base.py"}]}
| 1,829 | 372 |
gh_patches_debug_4099
|
rasdani/github-patches
|
git_diff
|
interlegis__sapl-1234
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Aumenta o tamanho máximo de arquivos de upload para 10MB
Atualmente o tamanho máximo de arquivos de upload é de 5MB. Ao menos uma casa reclamou que este tamanho é insuficiente então vamos dobrar e ver se mais alguém ainda reclama do tamanho de 10MB.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sapl/settings.py`
Content:
```
1 """
2 Django settings for sapl project.
3
4 Generated by 'django-admin startproject' using Django 1.8.2.
5
6 For more information on this file, see
7 https://docs.djangoproject.com/en/1.8/topics/settings/
8
9 For the full list of settings and their values, see
10 https://docs.djangoproject.com/en/1.8/ref/settings/
11
12 Quick-start development settings - unsuitable for production
13 See https://docs.djangoproject.com/en/1.8/howto/deployment/checklist/
14
15 """
16 import logging
17
18 from decouple import config
19 from dj_database_url import parse as db_url
20 from unipath import Path
21
22 from .temp_suppress_crispy_form_warnings import \
23 SUPRESS_CRISPY_FORM_WARNINGS_LOGGING
24
25 BASE_DIR = Path(__file__).ancestor(1)
26 PROJECT_DIR = Path(__file__).ancestor(2)
27
28
29 # SECURITY WARNING: keep the secret key used in production secret!
30 SECRET_KEY = config('SECRET_KEY', default='')
31 # SECURITY WARNING: don't run with debug turned on in production!
32 DEBUG = config('DEBUG', default=False, cast=bool)
33
34 MESSAGE_STORAGE = 'django.contrib.messages.storage.session.SessionStorage'
35
36 ALLOWED_HOSTS = ['*']
37
38 LOGIN_REDIRECT_URL = '/'
39 LOGIN_URL = '/login/?next='
40
41 EMAIL_BACKEND = 'django.core.mail.backends.smtp.EmailBackend'
42
43
44 # SAPL business apps in dependency order
45 SAPL_APPS = (
46 'sapl.base',
47 'sapl.crud',
48 'sapl.parlamentares',
49 'sapl.comissoes',
50 'sapl.materia',
51 'sapl.norma',
52 'sapl.sessao',
53 'sapl.lexml',
54 'sapl.painel',
55 'sapl.protocoloadm',
56 'sapl.redireciona_urls',
57 'sapl.compilacao',
58 'sapl.api',
59
60 'sapl.rules'
61
62 )
63
64 INSTALLED_APPS = (
65 'django_admin_bootstrapped', # must come before django.contrib.admin
66 'django.contrib.admin',
67 'django.contrib.auth',
68 'django.contrib.contenttypes',
69 'django.contrib.sessions',
70 'django.contrib.messages',
71 'django.contrib.staticfiles',
72
73 # more
74 'django_extensions',
75 'djangobower',
76 'bootstrap3', # basically for django_admin_bootstrapped
77 'crispy_forms',
78 'easy_thumbnails',
79 'floppyforms',
80 'haystack',
81 'sass_processor',
82 'rest_framework',
83 'reversion',
84 'whoosh',
85
86 ) + SAPL_APPS
87
88 # FTS = Full Text Search
89 SEARCH_BACKEND = 'haystack.backends.whoosh_backend.WhooshEngine'
90 SEARCH_URL = ('PATH', PROJECT_DIR.child('whoosh'))
91
92 SOLR_URL = config('SOLR_URL', cast=str, default='')
93 if SOLR_URL:
94 SEARCH_BACKEND = 'haystack.backends.solr_backend.SolrEngine'
95 SEARCH_URL = ('URL', config('SOLR_URL', cast=str))
96 # ...or for multicore...
97 # 'URL': 'http://127.0.0.1:8983/solr/mysite',
98
99
100 HAYSTACK_CONNECTIONS = {
101 'default': {
102 'ENGINE': SEARCH_BACKEND,
103 SEARCH_URL[0] : SEARCH_URL[1]
104 },
105 }
106
107
108 if DEBUG:
109 INSTALLED_APPS += ('debug_toolbar', 'rest_framework_docs',)
110
111 MIDDLEWARE_CLASSES = (
112 'reversion.middleware.RevisionMiddleware',
113 'django.contrib.sessions.middleware.SessionMiddleware',
114 'django.middleware.locale.LocaleMiddleware',
115 'django.middleware.common.CommonMiddleware',
116 'django.middleware.csrf.CsrfViewMiddleware',
117 'django.contrib.auth.middleware.AuthenticationMiddleware',
118 'django.contrib.auth.middleware.SessionAuthenticationMiddleware',
119 'django.contrib.messages.middleware.MessageMiddleware',
120 'django.middleware.clickjacking.XFrameOptionsMiddleware',
121 'django.middleware.security.SecurityMiddleware',
122 )
123
124
125 REST_FRAMEWORK = {
126 "UNICODE_JSON": False,
127 "DEFAULT_PARSER_CLASSES": (
128 "rest_framework.parsers.JSONParser",
129 ),
130 "DEFAULT_PERMISSION_CLASSES": (
131 "rest_framework.permissions.IsAuthenticated",
132 "sapl.api.permissions.DjangoModelPermissions",
133 ),
134 "DEFAULT_AUTHENTICATION_CLASSES": (
135 "rest_framework.authentication.SessionAuthentication",
136 ),
137 "DEFAULT_PAGINATION_CLASS": "sapl.api.pagination.StandardPagination",
138 "DEFAULT_FILTER_BACKENDS": (
139 "rest_framework.filters.SearchFilter",
140 "rest_framework.filters.DjangoFilterBackend",
141 ),
142 }
143
144
145 ROOT_URLCONF = 'sapl.urls'
146
147 TEMPLATES = [
148 {
149 'BACKEND': 'django.template.backends.django.DjangoTemplates',
150 'DIRS': ['sapl/templates'],
151 'APP_DIRS': True,
152 'OPTIONS': {
153 'context_processors': [
154 'django.template.context_processors.debug',
155 'django.template.context_processors.request',
156 'django.contrib.auth.context_processors.auth',
157 "django.template.context_processors.media",
158 "django.template.context_processors.static",
159 'django.contrib.messages.context_processors.messages',
160 'sapl.context_processors.parliament_info',
161 ],
162 'debug': DEBUG
163 },
164 },
165 ]
166
167
168 WSGI_APPLICATION = 'sapl.wsgi.application'
169
170 # Database
171 # https://docs.djangoproject.com/en/1.8/ref/settings/#databases
172
173 DATABASES = {
174 'default': config(
175 'DATABASE_URL', default='sqlite://:memory:',
176 cast=db_url,
177 )
178 }
179
180 # troque no caso de reimplementação da classe User conforme
181 # https://docs.djangoproject.com/en/1.9/topics/auth/customizing/#substituting-a-custom-user-model
182 AUTH_USER_MODEL = 'auth.User'
183
184 X_FRAME_OPTIONS = 'ALLOWALL'
185
186 EMAIL_HOST = config('EMAIL_HOST', default='localhost')
187 EMAIL_PORT = config('EMAIL_PORT', cast=int, default=587)
188 EMAIL_HOST_USER = config('EMAIL_HOST_USER', default='')
189 EMAIL_HOST_PASSWORD = config('EMAIL_HOST_PASSWORD', default='')
190 EMAIL_USE_TLS = config('EMAIL_USE_TLS', cast=bool, default=True)
191 EMAIL_SEND_USER = config('EMAIL_SEND_USER', cast=str, default='')
192 DEFAULT_FROM_EMAIL = config('DEFAULT_FROM_EMAIL', cast=str, default='')
193 SERVER_EMAIL = config('SERVER_EMAIL', cast=str, default='')
194
195 MAX_DOC_UPLOAD_SIZE = 5 * 1024 * 1024 # 5MB
196 MAX_IMAGE_UPLOAD_SIZE = 2 * 1024 * 1024 # 2MB
197
198 # Internationalization
199 # https://docs.djangoproject.com/en/1.8/topics/i18n/
200 LANGUAGE_CODE = 'pt-br'
201 LANGUAGES = (
202 ('pt-br', u'Português'),
203 )
204
205 TIME_ZONE = 'America/Sao_Paulo'
206 USE_I18N = True
207 USE_L10N = False
208 USE_TZ = False
209 # DATE_FORMAT = 'N j, Y'
210 DATE_FORMAT = 'd/m/Y'
211 SHORT_DATE_FORMAT = 'd/m/Y'
212 DATETIME_FORMAT = 'd/m/Y H:i:s'
213 SHORT_DATETIME_FORMAT = 'd/m/Y H:i'
214 DATE_INPUT_FORMATS = ('%d/%m/%Y', '%m-%d-%Y', '%Y-%m-%d')
215
216 LOCALE_PATHS = (
217 'locale',
218 )
219
220 # Static files (CSS, JavaScript, Images)
221 # https://docs.djangoproject.com/en/1.8/howto/static-files/
222
223 STATIC_URL = '/static/'
224 STATIC_ROOT = PROJECT_DIR.child("collected_static")
225 STATICFILES_DIRS = (BASE_DIR.child("static"),)
226 STATICFILES_FINDERS = (
227 'django.contrib.staticfiles.finders.FileSystemFinder',
228 'django.contrib.staticfiles.finders.AppDirectoriesFinder',
229 'djangobower.finders.BowerFinder',
230 'sass_processor.finders.CssFinder',
231 )
232
233 MEDIA_ROOT = PROJECT_DIR.child("media")
234 MEDIA_URL = '/media/'
235
236 DAB_FIELD_RENDERER = \
237 'django_admin_bootstrapped.renderers.BootstrapFieldRenderer'
238 CRISPY_TEMPLATE_PACK = 'bootstrap3'
239 CRISPY_ALLOWED_TEMPLATE_PACKS = 'bootstrap3'
240 CRISPY_FAIL_SILENTLY = not DEBUG
241
242 BOWER_COMPONENTS_ROOT = PROJECT_DIR.child("bower")
243 BOWER_INSTALLED_APPS = (
244 'jquery#3.1.1',
245 'bootstrap-sass#3.3.7',
246 'components-font-awesome#4.5.0',
247 'tinymce#4.3.8',
248 'jquery-ui#1.12.1',
249 'jQuery-Mask-Plugin#1.14.0',
250 'jsdiff#2.2.2',
251 'https://github.com/interlegis/drunken-parrot-flat-ui.git',
252 'jquery-query-object#2.2.3',
253 )
254
255 # Additional search paths for SASS files when using the @import statement
256 SASS_PROCESSOR_INCLUDE_DIRS = (BOWER_COMPONENTS_ROOT.child(
257 'bower_components', 'bootstrap-sass', 'assets', 'stylesheets'),
258 )
259
260 # suprime texto de ajuda default do django-filter
261 FILTERS_HELP_TEXT_FILTER = False
262
263
264 # FIXME update cripy-forms and remove this
265 # hack to suppress many annoying warnings from crispy_forms
266 # see sapl.temp_suppress_crispy_form_warnings
267 LOGGING = SUPRESS_CRISPY_FORM_WARNINGS_LOGGING
268
269
270 LOGGING_CONSOLE = config('LOGGING_CONSOLE', default=False, cast=bool)
271 if DEBUG and LOGGING_CONSOLE:
272 # Descomentar linha abaixo fará com que logs aparecam, inclusive SQL
273 # LOGGING['handlers']['console']['level'] = 'DEBUG'
274 LOGGING['loggers']['django']['level'] = 'DEBUG'
275 LOGGING.update({
276 'formatters': {
277 'verbose': {
278 'format': '%(levelname)s %(asctime)s %(pathname)s '
279 '%(funcName)s %(message)s'
280 },
281 'simple': {
282 'format': '%(levelname)s %(message)s'
283 },
284 },
285 })
286 LOGGING['handlers']['console']['formatter'] = 'verbose'
287 LOGGING['loggers'][BASE_DIR.name] = {
288 'handlers': ['console'],
289 'level': 'DEBUG',
290 }
291
292
293 def excepthook(*args):
294 logging.getLogger(BASE_DIR.name).error(
295 'Uncaught exception:', exc_info=args)
296
297 # sys.excepthook = excepthook
298
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sapl/settings.py b/sapl/settings.py
--- a/sapl/settings.py
+++ b/sapl/settings.py
@@ -192,7 +192,7 @@
DEFAULT_FROM_EMAIL = config('DEFAULT_FROM_EMAIL', cast=str, default='')
SERVER_EMAIL = config('SERVER_EMAIL', cast=str, default='')
-MAX_DOC_UPLOAD_SIZE = 5 * 1024 * 1024 # 5MB
+MAX_DOC_UPLOAD_SIZE = 10 * 1024 * 1024 # 10MB
MAX_IMAGE_UPLOAD_SIZE = 2 * 1024 * 1024 # 2MB
# Internationalization
|
{"golden_diff": "diff --git a/sapl/settings.py b/sapl/settings.py\n--- a/sapl/settings.py\n+++ b/sapl/settings.py\n@@ -192,7 +192,7 @@\n DEFAULT_FROM_EMAIL = config('DEFAULT_FROM_EMAIL', cast=str, default='')\n SERVER_EMAIL = config('SERVER_EMAIL', cast=str, default='')\n \n-MAX_DOC_UPLOAD_SIZE = 5 * 1024 * 1024 # 5MB\n+MAX_DOC_UPLOAD_SIZE = 10 * 1024 * 1024 # 10MB\n MAX_IMAGE_UPLOAD_SIZE = 2 * 1024 * 1024 # 2MB\n \n # Internationalization\n", "issue": "Aumenta o tamanho m\u00e1ximo de arquivos de upload para 10MB\nAtualmente o tamanho m\u00e1ximo de arquivos de upload \u00e9 de 5MB. Ao menos uma casa reclamou que este tamanho \u00e9 insuficiente ent\u00e3o vamos dobrar e ver se mais algu\u00e9m ainda reclama do tamanho de 10MB.\n", "before_files": [{"content": "\"\"\"\nDjango settings for sapl project.\n\nGenerated by 'django-admin startproject' using Django 1.8.2.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/1.8/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/1.8/ref/settings/\n\nQuick-start development settings - unsuitable for production\nSee https://docs.djangoproject.com/en/1.8/howto/deployment/checklist/\n\n\"\"\"\nimport logging\n\nfrom decouple import config\nfrom dj_database_url import parse as db_url\nfrom unipath import Path\n\nfrom .temp_suppress_crispy_form_warnings import \\\n SUPRESS_CRISPY_FORM_WARNINGS_LOGGING\n\nBASE_DIR = Path(__file__).ancestor(1)\nPROJECT_DIR = Path(__file__).ancestor(2)\n\n\n# SECURITY WARNING: keep the secret key used in production secret!\nSECRET_KEY = config('SECRET_KEY', default='')\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = config('DEBUG', default=False, cast=bool)\n\nMESSAGE_STORAGE = 'django.contrib.messages.storage.session.SessionStorage'\n\nALLOWED_HOSTS = ['*']\n\nLOGIN_REDIRECT_URL = '/'\nLOGIN_URL = '/login/?next='\n\nEMAIL_BACKEND = 'django.core.mail.backends.smtp.EmailBackend'\n\n\n# SAPL business apps in dependency order\nSAPL_APPS = (\n 'sapl.base',\n 'sapl.crud',\n 'sapl.parlamentares',\n 'sapl.comissoes',\n 'sapl.materia',\n 'sapl.norma',\n 'sapl.sessao',\n 'sapl.lexml',\n 'sapl.painel',\n 'sapl.protocoloadm',\n 'sapl.redireciona_urls',\n 'sapl.compilacao',\n 'sapl.api',\n\n 'sapl.rules'\n\n)\n\nINSTALLED_APPS = (\n 'django_admin_bootstrapped', # must come before django.contrib.admin\n 'django.contrib.admin',\n 'django.contrib.auth',\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.messages',\n 'django.contrib.staticfiles',\n\n # more\n 'django_extensions',\n 'djangobower',\n 'bootstrap3', # basically for django_admin_bootstrapped\n 'crispy_forms',\n 'easy_thumbnails',\n 'floppyforms',\n 'haystack',\n 'sass_processor',\n 'rest_framework',\n 'reversion',\n 'whoosh',\n\n) + SAPL_APPS\n\n# FTS = Full Text Search\nSEARCH_BACKEND = 'haystack.backends.whoosh_backend.WhooshEngine'\nSEARCH_URL = ('PATH', PROJECT_DIR.child('whoosh'))\n\nSOLR_URL = config('SOLR_URL', cast=str, default='')\nif SOLR_URL:\n SEARCH_BACKEND = 'haystack.backends.solr_backend.SolrEngine'\n SEARCH_URL = ('URL', config('SOLR_URL', cast=str))\n # ...or for multicore...\n # 'URL': 'http://127.0.0.1:8983/solr/mysite',\n\n\nHAYSTACK_CONNECTIONS = {\n 'default': {\n 'ENGINE': SEARCH_BACKEND,\n SEARCH_URL[0] : SEARCH_URL[1]\n },\n}\n\n\nif DEBUG:\n INSTALLED_APPS += ('debug_toolbar', 'rest_framework_docs',)\n\nMIDDLEWARE_CLASSES = (\n 'reversion.middleware.RevisionMiddleware',\n 'django.contrib.sessions.middleware.SessionMiddleware',\n 'django.middleware.locale.LocaleMiddleware',\n 'django.middleware.common.CommonMiddleware',\n 'django.middleware.csrf.CsrfViewMiddleware',\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n 'django.contrib.auth.middleware.SessionAuthenticationMiddleware',\n 'django.contrib.messages.middleware.MessageMiddleware',\n 'django.middleware.clickjacking.XFrameOptionsMiddleware',\n 'django.middleware.security.SecurityMiddleware',\n)\n\n\nREST_FRAMEWORK = {\n \"UNICODE_JSON\": False,\n \"DEFAULT_PARSER_CLASSES\": (\n \"rest_framework.parsers.JSONParser\",\n ),\n \"DEFAULT_PERMISSION_CLASSES\": (\n \"rest_framework.permissions.IsAuthenticated\",\n \"sapl.api.permissions.DjangoModelPermissions\",\n ),\n \"DEFAULT_AUTHENTICATION_CLASSES\": (\n \"rest_framework.authentication.SessionAuthentication\",\n ),\n \"DEFAULT_PAGINATION_CLASS\": \"sapl.api.pagination.StandardPagination\",\n \"DEFAULT_FILTER_BACKENDS\": (\n \"rest_framework.filters.SearchFilter\",\n \"rest_framework.filters.DjangoFilterBackend\",\n ),\n}\n\n\nROOT_URLCONF = 'sapl.urls'\n\nTEMPLATES = [\n {\n 'BACKEND': 'django.template.backends.django.DjangoTemplates',\n 'DIRS': ['sapl/templates'],\n 'APP_DIRS': True,\n 'OPTIONS': {\n 'context_processors': [\n 'django.template.context_processors.debug',\n 'django.template.context_processors.request',\n 'django.contrib.auth.context_processors.auth',\n \"django.template.context_processors.media\",\n \"django.template.context_processors.static\",\n 'django.contrib.messages.context_processors.messages',\n 'sapl.context_processors.parliament_info',\n ],\n 'debug': DEBUG\n },\n },\n]\n\n\nWSGI_APPLICATION = 'sapl.wsgi.application'\n\n# Database\n# https://docs.djangoproject.com/en/1.8/ref/settings/#databases\n\nDATABASES = {\n 'default': config(\n 'DATABASE_URL', default='sqlite://:memory:',\n cast=db_url,\n )\n}\n\n# troque no caso de reimplementa\u00e7\u00e3o da classe User conforme\n# https://docs.djangoproject.com/en/1.9/topics/auth/customizing/#substituting-a-custom-user-model\nAUTH_USER_MODEL = 'auth.User'\n\nX_FRAME_OPTIONS = 'ALLOWALL'\n\nEMAIL_HOST = config('EMAIL_HOST', default='localhost')\nEMAIL_PORT = config('EMAIL_PORT', cast=int, default=587)\nEMAIL_HOST_USER = config('EMAIL_HOST_USER', default='')\nEMAIL_HOST_PASSWORD = config('EMAIL_HOST_PASSWORD', default='')\nEMAIL_USE_TLS = config('EMAIL_USE_TLS', cast=bool, default=True)\nEMAIL_SEND_USER = config('EMAIL_SEND_USER', cast=str, default='')\nDEFAULT_FROM_EMAIL = config('DEFAULT_FROM_EMAIL', cast=str, default='')\nSERVER_EMAIL = config('SERVER_EMAIL', cast=str, default='')\n\nMAX_DOC_UPLOAD_SIZE = 5 * 1024 * 1024 # 5MB\nMAX_IMAGE_UPLOAD_SIZE = 2 * 1024 * 1024 # 2MB\n\n# Internationalization\n# https://docs.djangoproject.com/en/1.8/topics/i18n/\nLANGUAGE_CODE = 'pt-br'\nLANGUAGES = (\n ('pt-br', u'Portugu\u00eas'),\n)\n\nTIME_ZONE = 'America/Sao_Paulo'\nUSE_I18N = True\nUSE_L10N = False\nUSE_TZ = False\n# DATE_FORMAT = 'N j, Y'\nDATE_FORMAT = 'd/m/Y'\nSHORT_DATE_FORMAT = 'd/m/Y'\nDATETIME_FORMAT = 'd/m/Y H:i:s'\nSHORT_DATETIME_FORMAT = 'd/m/Y H:i'\nDATE_INPUT_FORMATS = ('%d/%m/%Y', '%m-%d-%Y', '%Y-%m-%d')\n\nLOCALE_PATHS = (\n 'locale',\n)\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/1.8/howto/static-files/\n\nSTATIC_URL = '/static/'\nSTATIC_ROOT = PROJECT_DIR.child(\"collected_static\")\nSTATICFILES_DIRS = (BASE_DIR.child(\"static\"),)\nSTATICFILES_FINDERS = (\n 'django.contrib.staticfiles.finders.FileSystemFinder',\n 'django.contrib.staticfiles.finders.AppDirectoriesFinder',\n 'djangobower.finders.BowerFinder',\n 'sass_processor.finders.CssFinder',\n)\n\nMEDIA_ROOT = PROJECT_DIR.child(\"media\")\nMEDIA_URL = '/media/'\n\nDAB_FIELD_RENDERER = \\\n 'django_admin_bootstrapped.renderers.BootstrapFieldRenderer'\nCRISPY_TEMPLATE_PACK = 'bootstrap3'\nCRISPY_ALLOWED_TEMPLATE_PACKS = 'bootstrap3'\nCRISPY_FAIL_SILENTLY = not DEBUG\n\nBOWER_COMPONENTS_ROOT = PROJECT_DIR.child(\"bower\")\nBOWER_INSTALLED_APPS = (\n 'jquery#3.1.1',\n 'bootstrap-sass#3.3.7',\n 'components-font-awesome#4.5.0',\n 'tinymce#4.3.8',\n 'jquery-ui#1.12.1',\n 'jQuery-Mask-Plugin#1.14.0',\n 'jsdiff#2.2.2',\n 'https://github.com/interlegis/drunken-parrot-flat-ui.git',\n 'jquery-query-object#2.2.3',\n)\n\n# Additional search paths for SASS files when using the @import statement\nSASS_PROCESSOR_INCLUDE_DIRS = (BOWER_COMPONENTS_ROOT.child(\n 'bower_components', 'bootstrap-sass', 'assets', 'stylesheets'),\n)\n\n# suprime texto de ajuda default do django-filter\nFILTERS_HELP_TEXT_FILTER = False\n\n\n# FIXME update cripy-forms and remove this\n# hack to suppress many annoying warnings from crispy_forms\n# see sapl.temp_suppress_crispy_form_warnings\nLOGGING = SUPRESS_CRISPY_FORM_WARNINGS_LOGGING\n\n\nLOGGING_CONSOLE = config('LOGGING_CONSOLE', default=False, cast=bool)\nif DEBUG and LOGGING_CONSOLE:\n # Descomentar linha abaixo far\u00e1 com que logs aparecam, inclusive SQL\n # LOGGING['handlers']['console']['level'] = 'DEBUG'\n LOGGING['loggers']['django']['level'] = 'DEBUG'\n LOGGING.update({\n 'formatters': {\n 'verbose': {\n 'format': '%(levelname)s %(asctime)s %(pathname)s '\n '%(funcName)s %(message)s'\n },\n 'simple': {\n 'format': '%(levelname)s %(message)s'\n },\n },\n })\n LOGGING['handlers']['console']['formatter'] = 'verbose'\n LOGGING['loggers'][BASE_DIR.name] = {\n 'handlers': ['console'],\n 'level': 'DEBUG',\n }\n\n\ndef excepthook(*args):\n logging.getLogger(BASE_DIR.name).error(\n 'Uncaught exception:', exc_info=args)\n\n# sys.excepthook = excepthook\n", "path": "sapl/settings.py"}], "after_files": [{"content": "\"\"\"\nDjango settings for sapl project.\n\nGenerated by 'django-admin startproject' using Django 1.8.2.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/1.8/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/1.8/ref/settings/\n\nQuick-start development settings - unsuitable for production\nSee https://docs.djangoproject.com/en/1.8/howto/deployment/checklist/\n\n\"\"\"\nimport logging\n\nfrom decouple import config\nfrom dj_database_url import parse as db_url\nfrom unipath import Path\n\nfrom .temp_suppress_crispy_form_warnings import \\\n SUPRESS_CRISPY_FORM_WARNINGS_LOGGING\n\nBASE_DIR = Path(__file__).ancestor(1)\nPROJECT_DIR = Path(__file__).ancestor(2)\n\n\n# SECURITY WARNING: keep the secret key used in production secret!\nSECRET_KEY = config('SECRET_KEY', default='')\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = config('DEBUG', default=False, cast=bool)\n\nMESSAGE_STORAGE = 'django.contrib.messages.storage.session.SessionStorage'\n\nALLOWED_HOSTS = ['*']\n\nLOGIN_REDIRECT_URL = '/'\nLOGIN_URL = '/login/?next='\n\nEMAIL_BACKEND = 'django.core.mail.backends.smtp.EmailBackend'\n\n\n# SAPL business apps in dependency order\nSAPL_APPS = (\n 'sapl.base',\n 'sapl.crud',\n 'sapl.parlamentares',\n 'sapl.comissoes',\n 'sapl.materia',\n 'sapl.norma',\n 'sapl.sessao',\n 'sapl.lexml',\n 'sapl.painel',\n 'sapl.protocoloadm',\n 'sapl.redireciona_urls',\n 'sapl.compilacao',\n 'sapl.api',\n\n 'sapl.rules'\n\n)\n\nINSTALLED_APPS = (\n 'django_admin_bootstrapped', # must come before django.contrib.admin\n 'django.contrib.admin',\n 'django.contrib.auth',\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.messages',\n 'django.contrib.staticfiles',\n\n # more\n 'django_extensions',\n 'djangobower',\n 'bootstrap3', # basically for django_admin_bootstrapped\n 'crispy_forms',\n 'easy_thumbnails',\n 'floppyforms',\n 'haystack',\n 'sass_processor',\n 'rest_framework',\n 'reversion',\n 'whoosh',\n\n) + SAPL_APPS\n\n# FTS = Full Text Search\nSEARCH_BACKEND = 'haystack.backends.whoosh_backend.WhooshEngine'\nSEARCH_URL = ('PATH', PROJECT_DIR.child('whoosh'))\n\nSOLR_URL = config('SOLR_URL', cast=str, default='')\nif SOLR_URL:\n SEARCH_BACKEND = 'haystack.backends.solr_backend.SolrEngine'\n SEARCH_URL = ('URL', config('SOLR_URL', cast=str))\n # ...or for multicore...\n # 'URL': 'http://127.0.0.1:8983/solr/mysite',\n\n\nHAYSTACK_CONNECTIONS = {\n 'default': {\n 'ENGINE': SEARCH_BACKEND,\n SEARCH_URL[0] : SEARCH_URL[1]\n },\n}\n\n\nif DEBUG:\n INSTALLED_APPS += ('debug_toolbar', 'rest_framework_docs',)\n\nMIDDLEWARE_CLASSES = (\n 'reversion.middleware.RevisionMiddleware',\n 'django.contrib.sessions.middleware.SessionMiddleware',\n 'django.middleware.locale.LocaleMiddleware',\n 'django.middleware.common.CommonMiddleware',\n 'django.middleware.csrf.CsrfViewMiddleware',\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n 'django.contrib.auth.middleware.SessionAuthenticationMiddleware',\n 'django.contrib.messages.middleware.MessageMiddleware',\n 'django.middleware.clickjacking.XFrameOptionsMiddleware',\n 'django.middleware.security.SecurityMiddleware',\n)\n\n\nREST_FRAMEWORK = {\n \"UNICODE_JSON\": False,\n \"DEFAULT_PARSER_CLASSES\": (\n \"rest_framework.parsers.JSONParser\",\n ),\n \"DEFAULT_PERMISSION_CLASSES\": (\n \"rest_framework.permissions.IsAuthenticated\",\n \"sapl.api.permissions.DjangoModelPermissions\",\n ),\n \"DEFAULT_AUTHENTICATION_CLASSES\": (\n \"rest_framework.authentication.SessionAuthentication\",\n ),\n \"DEFAULT_PAGINATION_CLASS\": \"sapl.api.pagination.StandardPagination\",\n \"DEFAULT_FILTER_BACKENDS\": (\n \"rest_framework.filters.SearchFilter\",\n \"rest_framework.filters.DjangoFilterBackend\",\n ),\n}\n\n\nROOT_URLCONF = 'sapl.urls'\n\nTEMPLATES = [\n {\n 'BACKEND': 'django.template.backends.django.DjangoTemplates',\n 'DIRS': ['sapl/templates'],\n 'APP_DIRS': True,\n 'OPTIONS': {\n 'context_processors': [\n 'django.template.context_processors.debug',\n 'django.template.context_processors.request',\n 'django.contrib.auth.context_processors.auth',\n \"django.template.context_processors.media\",\n \"django.template.context_processors.static\",\n 'django.contrib.messages.context_processors.messages',\n 'sapl.context_processors.parliament_info',\n ],\n 'debug': DEBUG\n },\n },\n]\n\n\nWSGI_APPLICATION = 'sapl.wsgi.application'\n\n# Database\n# https://docs.djangoproject.com/en/1.8/ref/settings/#databases\n\nDATABASES = {\n 'default': config(\n 'DATABASE_URL', default='sqlite://:memory:',\n cast=db_url,\n )\n}\n\n# troque no caso de reimplementa\u00e7\u00e3o da classe User conforme\n# https://docs.djangoproject.com/en/1.9/topics/auth/customizing/#substituting-a-custom-user-model\nAUTH_USER_MODEL = 'auth.User'\n\nX_FRAME_OPTIONS = 'ALLOWALL'\n\nEMAIL_HOST = config('EMAIL_HOST', default='localhost')\nEMAIL_PORT = config('EMAIL_PORT', cast=int, default=587)\nEMAIL_HOST_USER = config('EMAIL_HOST_USER', default='')\nEMAIL_HOST_PASSWORD = config('EMAIL_HOST_PASSWORD', default='')\nEMAIL_USE_TLS = config('EMAIL_USE_TLS', cast=bool, default=True)\nEMAIL_SEND_USER = config('EMAIL_SEND_USER', cast=str, default='')\nDEFAULT_FROM_EMAIL = config('DEFAULT_FROM_EMAIL', cast=str, default='')\nSERVER_EMAIL = config('SERVER_EMAIL', cast=str, default='')\n\nMAX_DOC_UPLOAD_SIZE = 10 * 1024 * 1024 # 10MB\nMAX_IMAGE_UPLOAD_SIZE = 2 * 1024 * 1024 # 2MB\n\n# Internationalization\n# https://docs.djangoproject.com/en/1.8/topics/i18n/\nLANGUAGE_CODE = 'pt-br'\nLANGUAGES = (\n ('pt-br', u'Portugu\u00eas'),\n)\n\nTIME_ZONE = 'America/Sao_Paulo'\nUSE_I18N = True\nUSE_L10N = False\nUSE_TZ = False\n# DATE_FORMAT = 'N j, Y'\nDATE_FORMAT = 'd/m/Y'\nSHORT_DATE_FORMAT = 'd/m/Y'\nDATETIME_FORMAT = 'd/m/Y H:i:s'\nSHORT_DATETIME_FORMAT = 'd/m/Y H:i'\nDATE_INPUT_FORMATS = ('%d/%m/%Y', '%m-%d-%Y', '%Y-%m-%d')\n\nLOCALE_PATHS = (\n 'locale',\n)\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/1.8/howto/static-files/\n\nSTATIC_URL = '/static/'\nSTATIC_ROOT = PROJECT_DIR.child(\"collected_static\")\nSTATICFILES_DIRS = (BASE_DIR.child(\"static\"),)\nSTATICFILES_FINDERS = (\n 'django.contrib.staticfiles.finders.FileSystemFinder',\n 'django.contrib.staticfiles.finders.AppDirectoriesFinder',\n 'djangobower.finders.BowerFinder',\n 'sass_processor.finders.CssFinder',\n)\n\nMEDIA_ROOT = PROJECT_DIR.child(\"media\")\nMEDIA_URL = '/media/'\n\nDAB_FIELD_RENDERER = \\\n 'django_admin_bootstrapped.renderers.BootstrapFieldRenderer'\nCRISPY_TEMPLATE_PACK = 'bootstrap3'\nCRISPY_ALLOWED_TEMPLATE_PACKS = 'bootstrap3'\nCRISPY_FAIL_SILENTLY = not DEBUG\n\nBOWER_COMPONENTS_ROOT = PROJECT_DIR.child(\"bower\")\nBOWER_INSTALLED_APPS = (\n 'jquery#3.1.1',\n 'bootstrap-sass#3.3.7',\n 'components-font-awesome#4.5.0',\n 'tinymce#4.3.8',\n 'jquery-ui#1.12.1',\n 'jQuery-Mask-Plugin#1.14.0',\n 'jsdiff#2.2.2',\n 'https://github.com/interlegis/drunken-parrot-flat-ui.git',\n 'jquery-query-object#2.2.3',\n)\n\n# Additional search paths for SASS files when using the @import statement\nSASS_PROCESSOR_INCLUDE_DIRS = (BOWER_COMPONENTS_ROOT.child(\n 'bower_components', 'bootstrap-sass', 'assets', 'stylesheets'),\n)\n\n# suprime texto de ajuda default do django-filter\nFILTERS_HELP_TEXT_FILTER = False\n\n\n# FIXME update cripy-forms and remove this\n# hack to suppress many annoying warnings from crispy_forms\n# see sapl.temp_suppress_crispy_form_warnings\nLOGGING = SUPRESS_CRISPY_FORM_WARNINGS_LOGGING\n\n\nLOGGING_CONSOLE = config('LOGGING_CONSOLE', default=False, cast=bool)\nif DEBUG and LOGGING_CONSOLE:\n # Descomentar linha abaixo far\u00e1 com que logs aparecam, inclusive SQL\n # LOGGING['handlers']['console']['level'] = 'DEBUG'\n LOGGING['loggers']['django']['level'] = 'DEBUG'\n LOGGING.update({\n 'formatters': {\n 'verbose': {\n 'format': '%(levelname)s %(asctime)s %(pathname)s '\n '%(funcName)s %(message)s'\n },\n 'simple': {\n 'format': '%(levelname)s %(message)s'\n },\n },\n })\n LOGGING['handlers']['console']['formatter'] = 'verbose'\n LOGGING['loggers'][BASE_DIR.name] = {\n 'handlers': ['console'],\n 'level': 'DEBUG',\n }\n\n\ndef excepthook(*args):\n logging.getLogger(BASE_DIR.name).error(\n 'Uncaught exception:', exc_info=args)\n\n# sys.excepthook = excepthook\n", "path": "sapl/settings.py"}]}
| 3,317 | 154 |
gh_patches_debug_15732
|
rasdani/github-patches
|
git_diff
|
praw-dev__praw-711
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
LiveContributorRelationship.__call__() returns a list of RedditorList if caller have 'manage' permission
## Issue Description
As the title said. To reproduce:
```
>>> import praw
>>> reddit = praw.Reddit(...)
>>> thread = reddit.live(...) # thread I created
>>> thread.contributor()
[<praw.models.list.redditor.RedditorList object at 0x101865d50>, <praw.models.list.redditor.RedditorList object at 0x100be6f90>]
```
JSON (copied from browser):
```
[
{
"kind": "UserList",
"data": {
"children": [
{
"permissions": [
"all"
],
"id": "t2_ll32z",
"name": "nmtake"
}
]
}
},
{
"kind": "UserList",
"data": {
"children": [ ]
}
}
]
```
It seems that latter UserList reprsents invited users who didn't accept invitation yet: ([source](https://github.com/reddit/reddit-plugin-liveupdate/blob/a7cde1cf917c4118c4cb114c73a92f272e439816/reddit_liveupdate/controllers.py#L515-L540))
## System Information
PRAW Version: 50516a
Python Version: 2.7.13
Operating System: OS X 10.11.6
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `praw/models/reddit/live.py`
Content:
```
1 """Provide the LiveThread class."""
2 from ...const import API_PATH
3 from ..listing.generator import ListingGenerator
4 from .base import RedditBase
5 from .redditor import Redditor
6
7
8 class LiveThread(RedditBase):
9 """An individual LiveThread object."""
10
11 STR_FIELD = 'id'
12
13 @property
14 def contributor(self):
15 """An instance of :class:`.LiveContributorRelationship`.
16
17 Usage:
18
19 .. code-block:: python
20
21 thread = reddit.live('ukaeu1ik4sw5')
22 for contributor in thread.contributor():
23 print(contributor)
24
25 """
26 if self._contributor is None:
27 self._contributor = LiveContributorRelationship(self)
28 return self._contributor
29
30 def __eq__(self, other):
31 """Return whether the other instance equals the current.
32
33 .. note:: This comparison is case sensitive.
34 """
35 if isinstance(other, str):
36 return other == str(self)
37 return (isinstance(other, self.__class__) and
38 str(self) == str(other))
39
40 def __getitem__(self, update_id):
41 """Return a lazy :class:`.LiveUpdate` instance.
42
43 .. warning:: At this time, accesing lazy attributes, whose value
44 have not loaded, raises ``AttributeError``.
45
46 :param update_id: A live update ID, e.g.,
47 ``'7827987a-c998-11e4-a0b9-22000b6a88d2'``.
48
49 Usage:
50
51 .. code-block:: python
52
53 thread = reddit.live('ukaeu1ik4sw5')
54 update = thread['7827987a-c998-11e4-a0b9-22000b6a88d2']
55 update.thread # LiveThread(id='ukaeu1ik4sw5')
56 update.id # '7827987a-c998-11e4-a0b9-22000b6a88d2'
57 update.author # raise ``AttributeError``
58 """
59 return LiveUpdate(self._reddit, self.id, update_id)
60
61 def __hash__(self):
62 """Return the hash of the current instance."""
63 return hash(self.__class__.__name__) ^ hash(str(self))
64
65 def __init__(self, reddit, id=None, # pylint: disable=redefined-builtin
66 _data=None):
67 """Initialize a lazy :class:`.LiveThread` instance.
68
69 :param reddit: An instance of :class:`.Reddit`.
70 :param id: A live thread ID, e.g., ``'ukaeu1ik4sw5'``
71 """
72 if bool(id) == bool(_data):
73 raise TypeError('Either `id` or `_data` must be provided.')
74 super(LiveThread, self).__init__(reddit, _data)
75 if id:
76 self.id = id # pylint: disable=invalid-name
77 self._contributor = None
78
79 def _info_path(self):
80 return API_PATH['liveabout'].format(id=self.id)
81
82 def updates(self, **generator_kwargs):
83 """Return a :class:`.ListingGenerator` yields :class:`.LiveUpdate` s.
84
85 :param generator_kwargs: keyword arguments passed to
86 :class:`.ListingGenerator` constructor.
87 :returns: A :class:`.ListingGenerator` object which yields
88 :class:`.LiveUpdate` object.
89 """
90 url = API_PATH['live_updates'].format(id=self.id)
91 for update in ListingGenerator(self._reddit, url,
92 **generator_kwargs):
93 update._thread = self
94 yield update
95
96
97 class LiveContributorRelationship(object):
98 """Provide methods to interact with live threads' contributors."""
99
100 def __call__(self):
101 """Return a :class:`.RedditorList` for live threads' contributors.
102
103 Usage:
104
105 .. code-block:: python
106
107 thread = reddit.live('ukaeu1ik4sw5')
108 for contributor in thread.contributor():
109 print(contributor)
110
111 """
112 url = API_PATH['live_contributors'].format(id=self.thread.id)
113 return self.thread._reddit.get(url)
114
115 def __init__(self, thread):
116 """Create a LiveContributorRelationship instance.
117
118 :param thread: An instance of :class:`.LiveThread`.
119
120 """
121 self.thread = thread
122
123
124 class LiveUpdate(RedditBase):
125 """An individual :class:`.LiveUpdate` object."""
126
127 STR_FIELD = 'id'
128
129 @property
130 def thread(self):
131 """Return :class:`.LiveThread` object the update object belongs to."""
132 return self._thread
133
134 def __init__(self, reddit, thread_id=None, update_id=None, _data=None):
135 """Initialize a lazy :class:`.LiveUpdate` instance.
136
137 Either ``thread_id`` and ``update_id``, or ``_data`` must be
138 provided.
139
140 .. warning:: At this time, accesing lazy attributes, whose value
141 have not loaded, raises ``AttributeError``.
142
143 :param reddit: An instance of :class:`.Reddit`.
144 :param thread_id: A live thread ID, e.g., ``'ukaeu1ik4sw5'``.
145 :param update_id: A live update ID, e.g.,
146 ``'7827987a-c998-11e4-a0b9-22000b6a88d2'``.
147
148 Usage:
149
150 .. code-block:: python
151
152 update = LiveUpdate(reddit, 'ukaeu1ik4sw5',
153 '7827987a-c998-11e4-a0b9-22000b6a88d2')
154 update.thread # LiveThread(id='ukaeu1ik4sw5')
155 update.id # '7827987a-c998-11e4-a0b9-22000b6a88d2'
156 update.author # raise ``AttributeError``
157 """
158 if _data is not None:
159 super(LiveUpdate, self).__init__(reddit, _data)
160 self._fetched = True
161 elif thread_id and update_id:
162 super(LiveUpdate, self).__init__(reddit, None)
163 self._thread = LiveThread(self._reddit, thread_id)
164 self.id = update_id # pylint: disable=invalid-name
165 self._fetched = True
166 else:
167 raise TypeError('Either `thread_id` and `update_id`, or '
168 '`_data` must be provided.')
169
170 def __setattr__(self, attribute, value):
171 """Objectify author."""
172 if attribute == 'author':
173 value = Redditor(self._reddit, name=value)
174 super(LiveUpdate, self).__setattr__(attribute, value)
175
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/praw/models/reddit/live.py b/praw/models/reddit/live.py
--- a/praw/models/reddit/live.py
+++ b/praw/models/reddit/live.py
@@ -1,6 +1,7 @@
"""Provide the LiveThread class."""
from ...const import API_PATH
from ..listing.generator import ListingGenerator
+from ..list.redditor import RedditorList
from .base import RedditBase
from .redditor import Redditor
@@ -110,7 +111,8 @@
"""
url = API_PATH['live_contributors'].format(id=self.thread.id)
- return self.thread._reddit.get(url)
+ temp = self.thread._reddit.get(url)
+ return temp if isinstance(temp, RedditorList) else temp[0]
def __init__(self, thread):
"""Create a LiveContributorRelationship instance.
|
{"golden_diff": "diff --git a/praw/models/reddit/live.py b/praw/models/reddit/live.py\n--- a/praw/models/reddit/live.py\n+++ b/praw/models/reddit/live.py\n@@ -1,6 +1,7 @@\n \"\"\"Provide the LiveThread class.\"\"\"\n from ...const import API_PATH\n from ..listing.generator import ListingGenerator\n+from ..list.redditor import RedditorList\n from .base import RedditBase\n from .redditor import Redditor\n \n@@ -110,7 +111,8 @@\n \n \"\"\"\n url = API_PATH['live_contributors'].format(id=self.thread.id)\n- return self.thread._reddit.get(url)\n+ temp = self.thread._reddit.get(url)\n+ return temp if isinstance(temp, RedditorList) else temp[0]\n \n def __init__(self, thread):\n \"\"\"Create a LiveContributorRelationship instance.\n", "issue": "LiveContributorRelationship.__call__() returns a list of RedditorList if caller have 'manage' permission\n## Issue Description\r\n\r\nAs the title said. To reproduce:\r\n\r\n```\r\n>>> import praw\r\n>>> reddit = praw.Reddit(...)\r\n>>> thread = reddit.live(...) # thread I created \r\n>>> thread.contributor()\r\n[<praw.models.list.redditor.RedditorList object at 0x101865d50>, <praw.models.list.redditor.RedditorList object at 0x100be6f90>]\r\n```\r\n\r\nJSON (copied from browser):\r\n\r\n```\r\n[\r\n {\r\n \"kind\": \"UserList\",\r\n \"data\": {\r\n \"children\": [\r\n {\r\n \"permissions\": [\r\n \"all\"\r\n ],\r\n \"id\": \"t2_ll32z\",\r\n \"name\": \"nmtake\"\r\n }\r\n ]\r\n }\r\n },\r\n {\r\n \"kind\": \"UserList\",\r\n \"data\": {\r\n \"children\": [ ]\r\n }\r\n }\r\n]\r\n```\r\n\r\nIt seems that latter UserList reprsents invited users who didn't accept invitation yet: ([source](https://github.com/reddit/reddit-plugin-liveupdate/blob/a7cde1cf917c4118c4cb114c73a92f272e439816/reddit_liveupdate/controllers.py#L515-L540))\r\n\r\n## System Information\r\n\r\n PRAW Version: 50516a\r\n Python Version: 2.7.13\r\n Operating System: OS X 10.11.6\n", "before_files": [{"content": "\"\"\"Provide the LiveThread class.\"\"\"\nfrom ...const import API_PATH\nfrom ..listing.generator import ListingGenerator\nfrom .base import RedditBase\nfrom .redditor import Redditor\n\n\nclass LiveThread(RedditBase):\n \"\"\"An individual LiveThread object.\"\"\"\n\n STR_FIELD = 'id'\n\n @property\n def contributor(self):\n \"\"\"An instance of :class:`.LiveContributorRelationship`.\n\n Usage:\n\n .. code-block:: python\n\n thread = reddit.live('ukaeu1ik4sw5')\n for contributor in thread.contributor():\n print(contributor)\n\n \"\"\"\n if self._contributor is None:\n self._contributor = LiveContributorRelationship(self)\n return self._contributor\n\n def __eq__(self, other):\n \"\"\"Return whether the other instance equals the current.\n\n .. note:: This comparison is case sensitive.\n \"\"\"\n if isinstance(other, str):\n return other == str(self)\n return (isinstance(other, self.__class__) and\n str(self) == str(other))\n\n def __getitem__(self, update_id):\n \"\"\"Return a lazy :class:`.LiveUpdate` instance.\n\n .. warning:: At this time, accesing lazy attributes, whose value\n have not loaded, raises ``AttributeError``.\n\n :param update_id: A live update ID, e.g.,\n ``'7827987a-c998-11e4-a0b9-22000b6a88d2'``.\n\n Usage:\n\n .. code-block:: python\n\n thread = reddit.live('ukaeu1ik4sw5')\n update = thread['7827987a-c998-11e4-a0b9-22000b6a88d2']\n update.thread # LiveThread(id='ukaeu1ik4sw5')\n update.id # '7827987a-c998-11e4-a0b9-22000b6a88d2'\n update.author # raise ``AttributeError``\n \"\"\"\n return LiveUpdate(self._reddit, self.id, update_id)\n\n def __hash__(self):\n \"\"\"Return the hash of the current instance.\"\"\"\n return hash(self.__class__.__name__) ^ hash(str(self))\n\n def __init__(self, reddit, id=None, # pylint: disable=redefined-builtin\n _data=None):\n \"\"\"Initialize a lazy :class:`.LiveThread` instance.\n\n :param reddit: An instance of :class:`.Reddit`.\n :param id: A live thread ID, e.g., ``'ukaeu1ik4sw5'``\n \"\"\"\n if bool(id) == bool(_data):\n raise TypeError('Either `id` or `_data` must be provided.')\n super(LiveThread, self).__init__(reddit, _data)\n if id:\n self.id = id # pylint: disable=invalid-name\n self._contributor = None\n\n def _info_path(self):\n return API_PATH['liveabout'].format(id=self.id)\n\n def updates(self, **generator_kwargs):\n \"\"\"Return a :class:`.ListingGenerator` yields :class:`.LiveUpdate` s.\n\n :param generator_kwargs: keyword arguments passed to\n :class:`.ListingGenerator` constructor.\n :returns: A :class:`.ListingGenerator` object which yields\n :class:`.LiveUpdate` object.\n \"\"\"\n url = API_PATH['live_updates'].format(id=self.id)\n for update in ListingGenerator(self._reddit, url,\n **generator_kwargs):\n update._thread = self\n yield update\n\n\nclass LiveContributorRelationship(object):\n \"\"\"Provide methods to interact with live threads' contributors.\"\"\"\n\n def __call__(self):\n \"\"\"Return a :class:`.RedditorList` for live threads' contributors.\n\n Usage:\n\n .. code-block:: python\n\n thread = reddit.live('ukaeu1ik4sw5')\n for contributor in thread.contributor():\n print(contributor)\n\n \"\"\"\n url = API_PATH['live_contributors'].format(id=self.thread.id)\n return self.thread._reddit.get(url)\n\n def __init__(self, thread):\n \"\"\"Create a LiveContributorRelationship instance.\n\n :param thread: An instance of :class:`.LiveThread`.\n\n \"\"\"\n self.thread = thread\n\n\nclass LiveUpdate(RedditBase):\n \"\"\"An individual :class:`.LiveUpdate` object.\"\"\"\n\n STR_FIELD = 'id'\n\n @property\n def thread(self):\n \"\"\"Return :class:`.LiveThread` object the update object belongs to.\"\"\"\n return self._thread\n\n def __init__(self, reddit, thread_id=None, update_id=None, _data=None):\n \"\"\"Initialize a lazy :class:`.LiveUpdate` instance.\n\n Either ``thread_id`` and ``update_id``, or ``_data`` must be\n provided.\n\n .. warning:: At this time, accesing lazy attributes, whose value\n have not loaded, raises ``AttributeError``.\n\n :param reddit: An instance of :class:`.Reddit`.\n :param thread_id: A live thread ID, e.g., ``'ukaeu1ik4sw5'``.\n :param update_id: A live update ID, e.g.,\n ``'7827987a-c998-11e4-a0b9-22000b6a88d2'``.\n\n Usage:\n\n .. code-block:: python\n\n update = LiveUpdate(reddit, 'ukaeu1ik4sw5',\n '7827987a-c998-11e4-a0b9-22000b6a88d2')\n update.thread # LiveThread(id='ukaeu1ik4sw5')\n update.id # '7827987a-c998-11e4-a0b9-22000b6a88d2'\n update.author # raise ``AttributeError``\n \"\"\"\n if _data is not None:\n super(LiveUpdate, self).__init__(reddit, _data)\n self._fetched = True\n elif thread_id and update_id:\n super(LiveUpdate, self).__init__(reddit, None)\n self._thread = LiveThread(self._reddit, thread_id)\n self.id = update_id # pylint: disable=invalid-name\n self._fetched = True\n else:\n raise TypeError('Either `thread_id` and `update_id`, or '\n '`_data` must be provided.')\n\n def __setattr__(self, attribute, value):\n \"\"\"Objectify author.\"\"\"\n if attribute == 'author':\n value = Redditor(self._reddit, name=value)\n super(LiveUpdate, self).__setattr__(attribute, value)\n", "path": "praw/models/reddit/live.py"}], "after_files": [{"content": "\"\"\"Provide the LiveThread class.\"\"\"\nfrom ...const import API_PATH\nfrom ..listing.generator import ListingGenerator\nfrom ..list.redditor import RedditorList\nfrom .base import RedditBase\nfrom .redditor import Redditor\n\n\nclass LiveThread(RedditBase):\n \"\"\"An individual LiveThread object.\"\"\"\n\n STR_FIELD = 'id'\n\n @property\n def contributor(self):\n \"\"\"An instance of :class:`.LiveContributorRelationship`.\n\n Usage:\n\n .. code-block:: python\n\n thread = reddit.live('ukaeu1ik4sw5')\n for contributor in thread.contributor():\n print(contributor)\n\n \"\"\"\n if self._contributor is None:\n self._contributor = LiveContributorRelationship(self)\n return self._contributor\n\n def __eq__(self, other):\n \"\"\"Return whether the other instance equals the current.\n\n .. note:: This comparison is case sensitive.\n \"\"\"\n if isinstance(other, str):\n return other == str(self)\n return (isinstance(other, self.__class__) and\n str(self) == str(other))\n\n def __getitem__(self, update_id):\n \"\"\"Return a lazy :class:`.LiveUpdate` instance.\n\n .. warning:: At this time, accesing lazy attributes, whose value\n have not loaded, raises ``AttributeError``.\n\n :param update_id: A live update ID, e.g.,\n ``'7827987a-c998-11e4-a0b9-22000b6a88d2'``.\n\n Usage:\n\n .. code-block:: python\n\n thread = reddit.live('ukaeu1ik4sw5')\n update = thread['7827987a-c998-11e4-a0b9-22000b6a88d2']\n update.thread # LiveThread(id='ukaeu1ik4sw5')\n update.id # '7827987a-c998-11e4-a0b9-22000b6a88d2'\n update.author # raise ``AttributeError``\n \"\"\"\n return LiveUpdate(self._reddit, self.id, update_id)\n\n def __hash__(self):\n \"\"\"Return the hash of the current instance.\"\"\"\n return hash(self.__class__.__name__) ^ hash(str(self))\n\n def __init__(self, reddit, id=None, # pylint: disable=redefined-builtin\n _data=None):\n \"\"\"Initialize a lazy :class:`.LiveThread` instance.\n\n :param reddit: An instance of :class:`.Reddit`.\n :param id: A live thread ID, e.g., ``'ukaeu1ik4sw5'``\n \"\"\"\n if bool(id) == bool(_data):\n raise TypeError('Either `id` or `_data` must be provided.')\n super(LiveThread, self).__init__(reddit, _data)\n if id:\n self.id = id # pylint: disable=invalid-name\n self._contributor = None\n\n def _info_path(self):\n return API_PATH['liveabout'].format(id=self.id)\n\n def updates(self, **generator_kwargs):\n \"\"\"Return a :class:`.ListingGenerator` yields :class:`.LiveUpdate` s.\n\n :param generator_kwargs: keyword arguments passed to\n :class:`.ListingGenerator` constructor.\n :returns: A :class:`.ListingGenerator` object which yields\n :class:`.LiveUpdate` object.\n \"\"\"\n url = API_PATH['live_updates'].format(id=self.id)\n for update in ListingGenerator(self._reddit, url,\n **generator_kwargs):\n update._thread = self\n yield update\n\n\nclass LiveContributorRelationship(object):\n \"\"\"Provide methods to interact with live threads' contributors.\"\"\"\n\n def __call__(self):\n \"\"\"Return a :class:`.RedditorList` for live threads' contributors.\n\n Usage:\n\n .. code-block:: python\n\n thread = reddit.live('ukaeu1ik4sw5')\n for contributor in thread.contributor():\n print(contributor)\n\n \"\"\"\n url = API_PATH['live_contributors'].format(id=self.thread.id)\n temp = self.thread._reddit.get(url)\n return temp if isinstance(temp, RedditorList) else temp[0]\n\n def __init__(self, thread):\n \"\"\"Create a LiveContributorRelationship instance.\n\n :param thread: An instance of :class:`.LiveThread`.\n\n \"\"\"\n self.thread = thread\n\n\nclass LiveUpdate(RedditBase):\n \"\"\"An individual :class:`.LiveUpdate` object.\"\"\"\n\n STR_FIELD = 'id'\n\n @property\n def thread(self):\n \"\"\"Return :class:`.LiveThread` object the update object belongs to.\"\"\"\n return self._thread\n\n def __init__(self, reddit, thread_id=None, update_id=None, _data=None):\n \"\"\"Initialize a lazy :class:`.LiveUpdate` instance.\n\n Either ``thread_id`` and ``update_id``, or ``_data`` must be\n provided.\n\n .. warning:: At this time, accesing lazy attributes, whose value\n have not loaded, raises ``AttributeError``.\n\n :param reddit: An instance of :class:`.Reddit`.\n :param thread_id: A live thread ID, e.g., ``'ukaeu1ik4sw5'``.\n :param update_id: A live update ID, e.g.,\n ``'7827987a-c998-11e4-a0b9-22000b6a88d2'``.\n\n Usage:\n\n .. code-block:: python\n\n update = LiveUpdate(reddit, 'ukaeu1ik4sw5',\n '7827987a-c998-11e4-a0b9-22000b6a88d2')\n update.thread # LiveThread(id='ukaeu1ik4sw5')\n update.id # '7827987a-c998-11e4-a0b9-22000b6a88d2'\n update.author # raise ``AttributeError``\n \"\"\"\n if _data is not None:\n super(LiveUpdate, self).__init__(reddit, _data)\n self._fetched = True\n elif thread_id and update_id:\n super(LiveUpdate, self).__init__(reddit, None)\n self._thread = LiveThread(self._reddit, thread_id)\n self.id = update_id # pylint: disable=invalid-name\n self._fetched = True\n else:\n raise TypeError('Either `thread_id` and `update_id`, or '\n '`_data` must be provided.')\n\n def __setattr__(self, attribute, value):\n \"\"\"Objectify author.\"\"\"\n if attribute == 'author':\n value = Redditor(self._reddit, name=value)\n super(LiveUpdate, self).__setattr__(attribute, value)\n", "path": "praw/models/reddit/live.py"}]}
| 2,564 | 190 |
gh_patches_debug_32742
|
rasdani/github-patches
|
git_diff
|
freedomofpress__securedrop-3379
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Debian package securedrop-app-code is not getting upgraded
# Bug
## Description
In my prod vm `securedrop-app-code` package is not getting upgraded.
## Steps to Reproduce
Follow the QA steps to fetch the latest packages from apt-test repo.
## Expected Behavior
We should get the 0.7~RC1 packages.
## Actual Behavior
```
$ dpkg -al | grep secure
ii openssh-client 1:6.6p1-2ubuntu2.10 amd64 secure shell (SSH) client, for secure access to remote machines
ii openssh-server 1:6.6p1-2ubuntu2.10 amd64 secure shell (SSH) server, for secure access from remote machines
ii openssh-sftp-server 1:6.6p1-2ubuntu2.10 amd64 secure shell (SSH) sftp server module, for SFTP access from remote machines
ii secure-delete 3.1-6 amd64 tools to wipe files, free disk space, swap and memory
ii securedrop-app-code 0.6 amd64 Packages the SecureDrop application code pip dependencies and apparmor profiles. This package will put the apparmor profiles in enforce mode. This package does use pip to install the pip wheelhouse
ii securedrop-config 0.1.1+0.7.0~rc1 all Establishes baseline system state for running SecureDrop.
ii securedrop-grsec 4.4.115+r1 amd64 Metapackage providing a grsecurity-patched Linux kernel for use
ii securedrop-keyring 0.1.1+0.7.0~rc1 amd64 Provides an apt keyring for SecureDrop-related packages, so the master signing key used for SecureDrop packages can be updated via apt.
ii securedrop-ossec-agent 2.8.2+0.7.0~rc1 amd64 Installs the securedrop pre-configured OSSEC agent
ii ssh-import-id 3.21-0ubuntu1 all securely retrieve an SSH public key and install it locally
```
```
$ sudo apt-get upgrade
Reading package lists... Done
Building dependency tree
Reading state information... Done
Calculating upgrade... Done
The following packages have been kept back:
securedrop-app-code
0 upgraded, 0 newly installed, 0 to remove and 1 not upgraded.
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `securedrop/journalist_app/forms.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 from flask_babel import lazy_gettext as gettext
4 from flask_wtf import FlaskForm
5 from flask_wtf.file import FileField, FileAllowed, FileRequired
6 from wtforms import (TextAreaField, TextField, BooleanField, HiddenField,
7 ValidationError)
8 from wtforms.validators import InputRequired, Optional
9
10 from models import Journalist
11
12
13 def otp_secret_validation(form, field):
14 strip_whitespace = field.data.replace(' ', '')
15 if len(strip_whitespace) != 40:
16 raise ValidationError(gettext(
17 'HOTP secrets are 40 characters long - '
18 'you have entered {num_chars}.'.format(
19 num_chars=len(strip_whitespace)
20 )))
21
22
23 def minimum_length_validation(form, field):
24 if len(field.data) < Journalist.MIN_USERNAME_LEN:
25 raise ValidationError(
26 gettext('Field must be at least {min_chars} '
27 'characters long but only got '
28 '{num_chars}.'.format(
29 min_chars=Journalist.MIN_USERNAME_LEN,
30 num_chars=len(field.data))))
31
32
33 class NewUserForm(FlaskForm):
34 username = TextField('username', validators=[
35 InputRequired(message=gettext('This field is required.')),
36 minimum_length_validation
37 ])
38 password = HiddenField('password')
39 is_admin = BooleanField('is_admin')
40 is_hotp = BooleanField('is_hotp')
41 otp_secret = TextField('otp_secret', validators=[
42 otp_secret_validation,
43 Optional()
44 ])
45
46
47 class ReplyForm(FlaskForm):
48 message = TextAreaField(
49 u'Message',
50 id="content-area",
51 validators=[
52 InputRequired(message=gettext(
53 'You cannot send an empty reply.')),
54 ],
55 )
56
57
58 class LogoForm(FlaskForm):
59 logo = FileField(validators=[
60 FileRequired(message=gettext('File required.')),
61 FileAllowed(['jpg', 'png', 'jpeg'],
62 message=gettext("You can only upload JPG/JPEG"
63 " or PNG image files."))
64 ])
65
```
Path: `securedrop/journalist_app/admin.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 from PIL import Image
4
5 import os
6
7 from flask import (Blueprint, render_template, request, url_for, redirect, g,
8 current_app, flash, abort)
9 from flask_babel import gettext
10 from sqlalchemy.exc import IntegrityError
11 from sqlalchemy.orm.exc import NoResultFound
12
13 from db import db
14 from models import Journalist, InvalidUsernameException, PasswordError
15 from journalist_app.decorators import admin_required
16 from journalist_app.utils import (make_password, commit_account_changes,
17 set_diceware_password, validate_hotp_secret)
18 from journalist_app.forms import LogoForm, NewUserForm
19
20
21 def make_blueprint(config):
22 view = Blueprint('admin', __name__)
23
24 @view.route('/', methods=('GET', 'POST'))
25 @admin_required
26 def index():
27 users = Journalist.query.all()
28 return render_template("admin.html", users=users)
29
30 @view.route('/config', methods=('GET', 'POST'))
31 @admin_required
32 def manage_config():
33 form = LogoForm()
34 if form.validate_on_submit():
35 f = form.logo.data
36 custom_logo_filepath = os.path.join(config.SECUREDROP_ROOT,
37 "static/i/custom_logo.png")
38 try:
39 with Image.open(f) as im:
40 im.thumbnail((500, 450), resample=3)
41 im.save(custom_logo_filepath, "PNG")
42 flash(gettext("Image updated."), "logo-success")
43 except Exception:
44 flash("Unable to process the image file."
45 " Try another one.", "logo-error")
46 finally:
47 return redirect(url_for("admin.manage_config"))
48
49 else:
50 for field, errors in form.errors.items():
51 for error in errors:
52 flash(error, "logo-error")
53 return render_template("config.html", form=form)
54
55 @view.route('/add', methods=('GET', 'POST'))
56 @admin_required
57 def add_user():
58 form = NewUserForm()
59 if form.validate_on_submit():
60 form_valid = True
61 username = request.form['username']
62 password = request.form['password']
63 is_admin = bool(request.form.get('is_admin'))
64
65 try:
66 otp_secret = None
67 if request.form.get('is_hotp', False):
68 otp_secret = request.form.get('otp_secret', '')
69 new_user = Journalist(username=username,
70 password=password,
71 is_admin=is_admin,
72 otp_secret=otp_secret)
73 db.session.add(new_user)
74 db.session.commit()
75 except PasswordError:
76 flash(gettext(
77 'There was an error with the autogenerated password. '
78 'User not created. Please try again.'), 'error')
79 form_valid = False
80 except InvalidUsernameException as e:
81 form_valid = False
82 flash('Invalid username: ' + str(e), "error")
83 except IntegrityError as e:
84 db.session.rollback()
85 form_valid = False
86 if "UNIQUE constraint failed: journalists.username" in str(e):
87 flash(gettext('Username "{user}" already taken.'.format(
88 user=username)), "error")
89 else:
90 flash(gettext("An error occurred saving this user"
91 " to the database."
92 " Please inform your administrator."),
93 "error")
94 current_app.logger.error("Adding user "
95 "'{}' failed: {}".format(
96 username, e))
97
98 if form_valid:
99 return redirect(url_for('admin.new_user_two_factor',
100 uid=new_user.id))
101
102 return render_template("admin_add_user.html",
103 password=make_password(config),
104 form=form)
105
106 @view.route('/2fa', methods=('GET', 'POST'))
107 @admin_required
108 def new_user_two_factor():
109 user = Journalist.query.get(request.args['uid'])
110
111 if request.method == 'POST':
112 token = request.form['token']
113 if user.verify_token(token):
114 flash(gettext(
115 "Token in two-factor authentication "
116 "accepted for user {user}.").format(
117 user=user.username),
118 "notification")
119 return redirect(url_for("admin.index"))
120 else:
121 flash(gettext(
122 "Could not verify token in two-factor authentication."),
123 "error")
124
125 return render_template("admin_new_user_two_factor.html", user=user)
126
127 @view.route('/reset-2fa-totp', methods=['POST'])
128 @admin_required
129 def reset_two_factor_totp():
130 uid = request.form['uid']
131 user = Journalist.query.get(uid)
132 user.is_totp = True
133 user.regenerate_totp_shared_secret()
134 db.session.commit()
135 return redirect(url_for('admin.new_user_two_factor', uid=uid))
136
137 @view.route('/reset-2fa-hotp', methods=['POST'])
138 @admin_required
139 def reset_two_factor_hotp():
140 uid = request.form['uid']
141 otp_secret = request.form.get('otp_secret', None)
142 if otp_secret:
143 user = Journalist.query.get(uid)
144 if not validate_hotp_secret(user, otp_secret):
145 return render_template('admin_edit_hotp_secret.html', uid=uid)
146 db.session.commit()
147 return redirect(url_for('admin.new_user_two_factor', uid=uid))
148 else:
149 return render_template('admin_edit_hotp_secret.html', uid=uid)
150
151 @view.route('/edit/<int:user_id>', methods=('GET', 'POST'))
152 @admin_required
153 def edit_user(user_id):
154 user = Journalist.query.get(user_id)
155
156 if request.method == 'POST':
157 if request.form.get('username', None):
158 new_username = request.form['username']
159
160 try:
161 Journalist.check_username_acceptable(new_username)
162 except InvalidUsernameException as e:
163 flash('Invalid username: ' + str(e), 'error')
164 return redirect(url_for("admin.edit_user",
165 user_id=user_id))
166
167 if new_username == user.username:
168 pass
169 elif Journalist.query.filter_by(
170 username=new_username).one_or_none():
171 flash(gettext(
172 'Username "{user}" already taken.').format(
173 user=new_username),
174 "error")
175 return redirect(url_for("admin.edit_user",
176 user_id=user_id))
177 else:
178 user.username = new_username
179
180 user.is_admin = bool(request.form.get('is_admin'))
181
182 commit_account_changes(user)
183
184 password = make_password(config)
185 return render_template("edit_account.html", user=user,
186 password=password)
187
188 @view.route('/edit/<int:user_id>/new-password', methods=('POST',))
189 @admin_required
190 def set_password(user_id):
191 try:
192 user = Journalist.query.get(user_id)
193 except NoResultFound:
194 abort(404)
195
196 password = request.form.get('password')
197 set_diceware_password(user, password)
198 return redirect(url_for('admin.edit_user', user_id=user_id))
199
200 @view.route('/delete/<int:user_id>', methods=('POST',))
201 @admin_required
202 def delete_user(user_id):
203 user = Journalist.query.get(user_id)
204 if user_id == g.user.id:
205 # Do not flash because the interface already has safe guards.
206 # It can only happen by manually crafting a POST request
207 current_app.logger.error(
208 "Admin {} tried to delete itself".format(g.user.username))
209 abort(403)
210 elif user:
211 db.session.delete(user)
212 db.session.commit()
213 flash(gettext("Deleted user '{user}'").format(
214 user=user.username), "notification")
215 else:
216 current_app.logger.error(
217 "Admin {} tried to delete nonexistent user with pk={}".format(
218 g.user.username, user_id))
219 abort(404)
220
221 return redirect(url_for('admin.index'))
222
223 @view.route('/edit/<int:user_id>/new-password', methods=('POST',))
224 @admin_required
225 def new_password(user_id):
226 try:
227 user = Journalist.query.get(user_id)
228 except NoResultFound:
229 abort(404)
230
231 password = request.form.get('password')
232 set_diceware_password(user, password)
233 return redirect(url_for('admin.edit_user', user_id=user_id))
234
235 @view.route('/ossec-test')
236 @admin_required
237 def ossec_test():
238 current_app.logger.error('This is a test OSSEC alert')
239 flash(gettext('Test alert sent. Please check your email.'),
240 'notification')
241 return redirect(url_for('admin.manage_config'))
242
243 return view
244
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/securedrop/journalist_app/admin.py b/securedrop/journalist_app/admin.py
--- a/securedrop/journalist_app/admin.py
+++ b/securedrop/journalist_app/admin.py
@@ -1,7 +1,5 @@
# -*- coding: utf-8 -*-
-from PIL import Image
-
import os
from flask import (Blueprint, render_template, request, url_for, redirect, g,
@@ -33,19 +31,16 @@
form = LogoForm()
if form.validate_on_submit():
f = form.logo.data
- custom_logo_filepath = os.path.join(config.SECUREDROP_ROOT,
- "static/i/custom_logo.png")
+ custom_logo_filepath = os.path.join(current_app.static_folder, 'i',
+ 'custom_logo.png')
try:
- with Image.open(f) as im:
- im.thumbnail((500, 450), resample=3)
- im.save(custom_logo_filepath, "PNG")
+ f.save(custom_logo_filepath)
flash(gettext("Image updated."), "logo-success")
except Exception:
flash("Unable to process the image file."
" Try another one.", "logo-error")
finally:
return redirect(url_for("admin.manage_config"))
-
else:
for field, errors in form.errors.items():
for error in errors:
diff --git a/securedrop/journalist_app/forms.py b/securedrop/journalist_app/forms.py
--- a/securedrop/journalist_app/forms.py
+++ b/securedrop/journalist_app/forms.py
@@ -58,7 +58,6 @@
class LogoForm(FlaskForm):
logo = FileField(validators=[
FileRequired(message=gettext('File required.')),
- FileAllowed(['jpg', 'png', 'jpeg'],
- message=gettext("You can only upload JPG/JPEG"
- " or PNG image files."))
+ FileAllowed(['png'],
+ message=gettext("Upload images only."))
])
|
{"golden_diff": "diff --git a/securedrop/journalist_app/admin.py b/securedrop/journalist_app/admin.py\n--- a/securedrop/journalist_app/admin.py\n+++ b/securedrop/journalist_app/admin.py\n@@ -1,7 +1,5 @@\n # -*- coding: utf-8 -*-\n \n-from PIL import Image\n-\n import os\n \n from flask import (Blueprint, render_template, request, url_for, redirect, g,\n@@ -33,19 +31,16 @@\n form = LogoForm()\n if form.validate_on_submit():\n f = form.logo.data\n- custom_logo_filepath = os.path.join(config.SECUREDROP_ROOT,\n- \"static/i/custom_logo.png\")\n+ custom_logo_filepath = os.path.join(current_app.static_folder, 'i',\n+ 'custom_logo.png')\n try:\n- with Image.open(f) as im:\n- im.thumbnail((500, 450), resample=3)\n- im.save(custom_logo_filepath, \"PNG\")\n+ f.save(custom_logo_filepath)\n flash(gettext(\"Image updated.\"), \"logo-success\")\n except Exception:\n flash(\"Unable to process the image file.\"\n \" Try another one.\", \"logo-error\")\n finally:\n return redirect(url_for(\"admin.manage_config\"))\n-\n else:\n for field, errors in form.errors.items():\n for error in errors:\ndiff --git a/securedrop/journalist_app/forms.py b/securedrop/journalist_app/forms.py\n--- a/securedrop/journalist_app/forms.py\n+++ b/securedrop/journalist_app/forms.py\n@@ -58,7 +58,6 @@\n class LogoForm(FlaskForm):\n logo = FileField(validators=[\n FileRequired(message=gettext('File required.')),\n- FileAllowed(['jpg', 'png', 'jpeg'],\n- message=gettext(\"You can only upload JPG/JPEG\"\n- \" or PNG image files.\"))\n+ FileAllowed(['png'],\n+ message=gettext(\"Upload images only.\"))\n ])\n", "issue": "Debian package securedrop-app-code is not getting upgraded\n# Bug\r\n\r\n## Description\r\n\r\nIn my prod vm `securedrop-app-code` package is not getting upgraded.\r\n\r\n## Steps to Reproduce\r\n\r\nFollow the QA steps to fetch the latest packages from apt-test repo.\r\n\r\n## Expected Behavior\r\n\r\nWe should get the 0.7~RC1 packages.\r\n\r\n## Actual Behavior\r\n\r\n```\r\n$ dpkg -al | grep secure\r\nii openssh-client 1:6.6p1-2ubuntu2.10 amd64 secure shell (SSH) client, for secure access to remote machines\r\nii openssh-server 1:6.6p1-2ubuntu2.10 amd64 secure shell (SSH) server, for secure access from remote machines\r\nii openssh-sftp-server 1:6.6p1-2ubuntu2.10 amd64 secure shell (SSH) sftp server module, for SFTP access from remote machines\r\nii secure-delete 3.1-6 amd64 tools to wipe files, free disk space, swap and memory\r\nii securedrop-app-code 0.6 amd64 Packages the SecureDrop application code pip dependencies and apparmor profiles. This package will put the apparmor profiles in enforce mode. This package does use pip to install the pip wheelhouse\r\nii securedrop-config 0.1.1+0.7.0~rc1 all Establishes baseline system state for running SecureDrop.\r\nii securedrop-grsec 4.4.115+r1 amd64 Metapackage providing a grsecurity-patched Linux kernel for use\r\nii securedrop-keyring 0.1.1+0.7.0~rc1 amd64 Provides an apt keyring for SecureDrop-related packages, so the master signing key used for SecureDrop packages can be updated via apt.\r\nii securedrop-ossec-agent 2.8.2+0.7.0~rc1 amd64 Installs the securedrop pre-configured OSSEC agent\r\nii ssh-import-id 3.21-0ubuntu1 all securely retrieve an SSH public key and install it locally\r\n```\r\n\r\n```\r\n$ sudo apt-get upgrade\r\nReading package lists... Done\r\nBuilding dependency tree \r\nReading state information... Done\r\nCalculating upgrade... Done\r\nThe following packages have been kept back:\r\n securedrop-app-code\r\n0 upgraded, 0 newly installed, 0 to remove and 1 not upgraded.\r\n\r\n```\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\nfrom flask_babel import lazy_gettext as gettext\nfrom flask_wtf import FlaskForm\nfrom flask_wtf.file import FileField, FileAllowed, FileRequired\nfrom wtforms import (TextAreaField, TextField, BooleanField, HiddenField,\n ValidationError)\nfrom wtforms.validators import InputRequired, Optional\n\nfrom models import Journalist\n\n\ndef otp_secret_validation(form, field):\n strip_whitespace = field.data.replace(' ', '')\n if len(strip_whitespace) != 40:\n raise ValidationError(gettext(\n 'HOTP secrets are 40 characters long - '\n 'you have entered {num_chars}.'.format(\n num_chars=len(strip_whitespace)\n )))\n\n\ndef minimum_length_validation(form, field):\n if len(field.data) < Journalist.MIN_USERNAME_LEN:\n raise ValidationError(\n gettext('Field must be at least {min_chars} '\n 'characters long but only got '\n '{num_chars}.'.format(\n min_chars=Journalist.MIN_USERNAME_LEN,\n num_chars=len(field.data))))\n\n\nclass NewUserForm(FlaskForm):\n username = TextField('username', validators=[\n InputRequired(message=gettext('This field is required.')),\n minimum_length_validation\n ])\n password = HiddenField('password')\n is_admin = BooleanField('is_admin')\n is_hotp = BooleanField('is_hotp')\n otp_secret = TextField('otp_secret', validators=[\n otp_secret_validation,\n Optional()\n ])\n\n\nclass ReplyForm(FlaskForm):\n message = TextAreaField(\n u'Message',\n id=\"content-area\",\n validators=[\n InputRequired(message=gettext(\n 'You cannot send an empty reply.')),\n ],\n )\n\n\nclass LogoForm(FlaskForm):\n logo = FileField(validators=[\n FileRequired(message=gettext('File required.')),\n FileAllowed(['jpg', 'png', 'jpeg'],\n message=gettext(\"You can only upload JPG/JPEG\"\n \" or PNG image files.\"))\n ])\n", "path": "securedrop/journalist_app/forms.py"}, {"content": "# -*- coding: utf-8 -*-\n\nfrom PIL import Image\n\nimport os\n\nfrom flask import (Blueprint, render_template, request, url_for, redirect, g,\n current_app, flash, abort)\nfrom flask_babel import gettext\nfrom sqlalchemy.exc import IntegrityError\nfrom sqlalchemy.orm.exc import NoResultFound\n\nfrom db import db\nfrom models import Journalist, InvalidUsernameException, PasswordError\nfrom journalist_app.decorators import admin_required\nfrom journalist_app.utils import (make_password, commit_account_changes,\n set_diceware_password, validate_hotp_secret)\nfrom journalist_app.forms import LogoForm, NewUserForm\n\n\ndef make_blueprint(config):\n view = Blueprint('admin', __name__)\n\n @view.route('/', methods=('GET', 'POST'))\n @admin_required\n def index():\n users = Journalist.query.all()\n return render_template(\"admin.html\", users=users)\n\n @view.route('/config', methods=('GET', 'POST'))\n @admin_required\n def manage_config():\n form = LogoForm()\n if form.validate_on_submit():\n f = form.logo.data\n custom_logo_filepath = os.path.join(config.SECUREDROP_ROOT,\n \"static/i/custom_logo.png\")\n try:\n with Image.open(f) as im:\n im.thumbnail((500, 450), resample=3)\n im.save(custom_logo_filepath, \"PNG\")\n flash(gettext(\"Image updated.\"), \"logo-success\")\n except Exception:\n flash(\"Unable to process the image file.\"\n \" Try another one.\", \"logo-error\")\n finally:\n return redirect(url_for(\"admin.manage_config\"))\n\n else:\n for field, errors in form.errors.items():\n for error in errors:\n flash(error, \"logo-error\")\n return render_template(\"config.html\", form=form)\n\n @view.route('/add', methods=('GET', 'POST'))\n @admin_required\n def add_user():\n form = NewUserForm()\n if form.validate_on_submit():\n form_valid = True\n username = request.form['username']\n password = request.form['password']\n is_admin = bool(request.form.get('is_admin'))\n\n try:\n otp_secret = None\n if request.form.get('is_hotp', False):\n otp_secret = request.form.get('otp_secret', '')\n new_user = Journalist(username=username,\n password=password,\n is_admin=is_admin,\n otp_secret=otp_secret)\n db.session.add(new_user)\n db.session.commit()\n except PasswordError:\n flash(gettext(\n 'There was an error with the autogenerated password. '\n 'User not created. Please try again.'), 'error')\n form_valid = False\n except InvalidUsernameException as e:\n form_valid = False\n flash('Invalid username: ' + str(e), \"error\")\n except IntegrityError as e:\n db.session.rollback()\n form_valid = False\n if \"UNIQUE constraint failed: journalists.username\" in str(e):\n flash(gettext('Username \"{user}\" already taken.'.format(\n user=username)), \"error\")\n else:\n flash(gettext(\"An error occurred saving this user\"\n \" to the database.\"\n \" Please inform your administrator.\"),\n \"error\")\n current_app.logger.error(\"Adding user \"\n \"'{}' failed: {}\".format(\n username, e))\n\n if form_valid:\n return redirect(url_for('admin.new_user_two_factor',\n uid=new_user.id))\n\n return render_template(\"admin_add_user.html\",\n password=make_password(config),\n form=form)\n\n @view.route('/2fa', methods=('GET', 'POST'))\n @admin_required\n def new_user_two_factor():\n user = Journalist.query.get(request.args['uid'])\n\n if request.method == 'POST':\n token = request.form['token']\n if user.verify_token(token):\n flash(gettext(\n \"Token in two-factor authentication \"\n \"accepted for user {user}.\").format(\n user=user.username),\n \"notification\")\n return redirect(url_for(\"admin.index\"))\n else:\n flash(gettext(\n \"Could not verify token in two-factor authentication.\"),\n \"error\")\n\n return render_template(\"admin_new_user_two_factor.html\", user=user)\n\n @view.route('/reset-2fa-totp', methods=['POST'])\n @admin_required\n def reset_two_factor_totp():\n uid = request.form['uid']\n user = Journalist.query.get(uid)\n user.is_totp = True\n user.regenerate_totp_shared_secret()\n db.session.commit()\n return redirect(url_for('admin.new_user_two_factor', uid=uid))\n\n @view.route('/reset-2fa-hotp', methods=['POST'])\n @admin_required\n def reset_two_factor_hotp():\n uid = request.form['uid']\n otp_secret = request.form.get('otp_secret', None)\n if otp_secret:\n user = Journalist.query.get(uid)\n if not validate_hotp_secret(user, otp_secret):\n return render_template('admin_edit_hotp_secret.html', uid=uid)\n db.session.commit()\n return redirect(url_for('admin.new_user_two_factor', uid=uid))\n else:\n return render_template('admin_edit_hotp_secret.html', uid=uid)\n\n @view.route('/edit/<int:user_id>', methods=('GET', 'POST'))\n @admin_required\n def edit_user(user_id):\n user = Journalist.query.get(user_id)\n\n if request.method == 'POST':\n if request.form.get('username', None):\n new_username = request.form['username']\n\n try:\n Journalist.check_username_acceptable(new_username)\n except InvalidUsernameException as e:\n flash('Invalid username: ' + str(e), 'error')\n return redirect(url_for(\"admin.edit_user\",\n user_id=user_id))\n\n if new_username == user.username:\n pass\n elif Journalist.query.filter_by(\n username=new_username).one_or_none():\n flash(gettext(\n 'Username \"{user}\" already taken.').format(\n user=new_username),\n \"error\")\n return redirect(url_for(\"admin.edit_user\",\n user_id=user_id))\n else:\n user.username = new_username\n\n user.is_admin = bool(request.form.get('is_admin'))\n\n commit_account_changes(user)\n\n password = make_password(config)\n return render_template(\"edit_account.html\", user=user,\n password=password)\n\n @view.route('/edit/<int:user_id>/new-password', methods=('POST',))\n @admin_required\n def set_password(user_id):\n try:\n user = Journalist.query.get(user_id)\n except NoResultFound:\n abort(404)\n\n password = request.form.get('password')\n set_diceware_password(user, password)\n return redirect(url_for('admin.edit_user', user_id=user_id))\n\n @view.route('/delete/<int:user_id>', methods=('POST',))\n @admin_required\n def delete_user(user_id):\n user = Journalist.query.get(user_id)\n if user_id == g.user.id:\n # Do not flash because the interface already has safe guards.\n # It can only happen by manually crafting a POST request\n current_app.logger.error(\n \"Admin {} tried to delete itself\".format(g.user.username))\n abort(403)\n elif user:\n db.session.delete(user)\n db.session.commit()\n flash(gettext(\"Deleted user '{user}'\").format(\n user=user.username), \"notification\")\n else:\n current_app.logger.error(\n \"Admin {} tried to delete nonexistent user with pk={}\".format(\n g.user.username, user_id))\n abort(404)\n\n return redirect(url_for('admin.index'))\n\n @view.route('/edit/<int:user_id>/new-password', methods=('POST',))\n @admin_required\n def new_password(user_id):\n try:\n user = Journalist.query.get(user_id)\n except NoResultFound:\n abort(404)\n\n password = request.form.get('password')\n set_diceware_password(user, password)\n return redirect(url_for('admin.edit_user', user_id=user_id))\n\n @view.route('/ossec-test')\n @admin_required\n def ossec_test():\n current_app.logger.error('This is a test OSSEC alert')\n flash(gettext('Test alert sent. Please check your email.'),\n 'notification')\n return redirect(url_for('admin.manage_config'))\n\n return view\n", "path": "securedrop/journalist_app/admin.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\nfrom flask_babel import lazy_gettext as gettext\nfrom flask_wtf import FlaskForm\nfrom flask_wtf.file import FileField, FileAllowed, FileRequired\nfrom wtforms import (TextAreaField, TextField, BooleanField, HiddenField,\n ValidationError)\nfrom wtforms.validators import InputRequired, Optional\n\nfrom models import Journalist\n\n\ndef otp_secret_validation(form, field):\n strip_whitespace = field.data.replace(' ', '')\n if len(strip_whitespace) != 40:\n raise ValidationError(gettext(\n 'HOTP secrets are 40 characters long - '\n 'you have entered {num_chars}.'.format(\n num_chars=len(strip_whitespace)\n )))\n\n\ndef minimum_length_validation(form, field):\n if len(field.data) < Journalist.MIN_USERNAME_LEN:\n raise ValidationError(\n gettext('Field must be at least {min_chars} '\n 'characters long but only got '\n '{num_chars}.'.format(\n min_chars=Journalist.MIN_USERNAME_LEN,\n num_chars=len(field.data))))\n\n\nclass NewUserForm(FlaskForm):\n username = TextField('username', validators=[\n InputRequired(message=gettext('This field is required.')),\n minimum_length_validation\n ])\n password = HiddenField('password')\n is_admin = BooleanField('is_admin')\n is_hotp = BooleanField('is_hotp')\n otp_secret = TextField('otp_secret', validators=[\n otp_secret_validation,\n Optional()\n ])\n\n\nclass ReplyForm(FlaskForm):\n message = TextAreaField(\n u'Message',\n id=\"content-area\",\n validators=[\n InputRequired(message=gettext(\n 'You cannot send an empty reply.')),\n ],\n )\n\n\nclass LogoForm(FlaskForm):\n logo = FileField(validators=[\n FileRequired(message=gettext('File required.')),\n FileAllowed(['png'],\n message=gettext(\"Upload images only.\"))\n ])\n", "path": "securedrop/journalist_app/forms.py"}, {"content": "# -*- coding: utf-8 -*-\n\nimport os\n\nfrom flask import (Blueprint, render_template, request, url_for, redirect, g,\n current_app, flash, abort)\nfrom flask_babel import gettext\nfrom sqlalchemy.exc import IntegrityError\nfrom sqlalchemy.orm.exc import NoResultFound\n\nfrom db import db\nfrom models import Journalist, InvalidUsernameException, PasswordError\nfrom journalist_app.decorators import admin_required\nfrom journalist_app.utils import (make_password, commit_account_changes,\n set_diceware_password, validate_hotp_secret)\nfrom journalist_app.forms import LogoForm, NewUserForm\n\n\ndef make_blueprint(config):\n view = Blueprint('admin', __name__)\n\n @view.route('/', methods=('GET', 'POST'))\n @admin_required\n def index():\n users = Journalist.query.all()\n return render_template(\"admin.html\", users=users)\n\n @view.route('/config', methods=('GET', 'POST'))\n @admin_required\n def manage_config():\n form = LogoForm()\n if form.validate_on_submit():\n f = form.logo.data\n custom_logo_filepath = os.path.join(current_app.static_folder, 'i',\n 'custom_logo.png')\n try:\n f.save(custom_logo_filepath)\n flash(gettext(\"Image updated.\"), \"logo-success\")\n except Exception:\n flash(\"Unable to process the image file.\"\n \" Try another one.\", \"logo-error\")\n finally:\n return redirect(url_for(\"admin.manage_config\"))\n else:\n for field, errors in form.errors.items():\n for error in errors:\n flash(error, \"logo-error\")\n return render_template(\"config.html\", form=form)\n\n @view.route('/add', methods=('GET', 'POST'))\n @admin_required\n def add_user():\n form = NewUserForm()\n if form.validate_on_submit():\n form_valid = True\n username = request.form['username']\n password = request.form['password']\n is_admin = bool(request.form.get('is_admin'))\n\n try:\n otp_secret = None\n if request.form.get('is_hotp', False):\n otp_secret = request.form.get('otp_secret', '')\n new_user = Journalist(username=username,\n password=password,\n is_admin=is_admin,\n otp_secret=otp_secret)\n db.session.add(new_user)\n db.session.commit()\n except PasswordError:\n flash(gettext(\n 'There was an error with the autogenerated password. '\n 'User not created. Please try again.'), 'error')\n form_valid = False\n except InvalidUsernameException as e:\n form_valid = False\n flash('Invalid username: ' + str(e), \"error\")\n except IntegrityError as e:\n db.session.rollback()\n form_valid = False\n if \"UNIQUE constraint failed: journalists.username\" in str(e):\n flash(gettext('Username \"{user}\" already taken.'.format(\n user=username)), \"error\")\n else:\n flash(gettext(\"An error occurred saving this user\"\n \" to the database.\"\n \" Please inform your administrator.\"),\n \"error\")\n current_app.logger.error(\"Adding user \"\n \"'{}' failed: {}\".format(\n username, e))\n\n if form_valid:\n return redirect(url_for('admin.new_user_two_factor',\n uid=new_user.id))\n\n return render_template(\"admin_add_user.html\",\n password=make_password(config),\n form=form)\n\n @view.route('/2fa', methods=('GET', 'POST'))\n @admin_required\n def new_user_two_factor():\n user = Journalist.query.get(request.args['uid'])\n\n if request.method == 'POST':\n token = request.form['token']\n if user.verify_token(token):\n flash(gettext(\n \"Token in two-factor authentication \"\n \"accepted for user {user}.\").format(\n user=user.username),\n \"notification\")\n return redirect(url_for(\"admin.index\"))\n else:\n flash(gettext(\n \"Could not verify token in two-factor authentication.\"),\n \"error\")\n\n return render_template(\"admin_new_user_two_factor.html\", user=user)\n\n @view.route('/reset-2fa-totp', methods=['POST'])\n @admin_required\n def reset_two_factor_totp():\n uid = request.form['uid']\n user = Journalist.query.get(uid)\n user.is_totp = True\n user.regenerate_totp_shared_secret()\n db.session.commit()\n return redirect(url_for('admin.new_user_two_factor', uid=uid))\n\n @view.route('/reset-2fa-hotp', methods=['POST'])\n @admin_required\n def reset_two_factor_hotp():\n uid = request.form['uid']\n otp_secret = request.form.get('otp_secret', None)\n if otp_secret:\n user = Journalist.query.get(uid)\n if not validate_hotp_secret(user, otp_secret):\n return render_template('admin_edit_hotp_secret.html', uid=uid)\n db.session.commit()\n return redirect(url_for('admin.new_user_two_factor', uid=uid))\n else:\n return render_template('admin_edit_hotp_secret.html', uid=uid)\n\n @view.route('/edit/<int:user_id>', methods=('GET', 'POST'))\n @admin_required\n def edit_user(user_id):\n user = Journalist.query.get(user_id)\n\n if request.method == 'POST':\n if request.form.get('username', None):\n new_username = request.form['username']\n\n try:\n Journalist.check_username_acceptable(new_username)\n except InvalidUsernameException as e:\n flash('Invalid username: ' + str(e), 'error')\n return redirect(url_for(\"admin.edit_user\",\n user_id=user_id))\n\n if new_username == user.username:\n pass\n elif Journalist.query.filter_by(\n username=new_username).one_or_none():\n flash(gettext(\n 'Username \"{user}\" already taken.').format(\n user=new_username),\n \"error\")\n return redirect(url_for(\"admin.edit_user\",\n user_id=user_id))\n else:\n user.username = new_username\n\n user.is_admin = bool(request.form.get('is_admin'))\n\n commit_account_changes(user)\n\n password = make_password(config)\n return render_template(\"edit_account.html\", user=user,\n password=password)\n\n @view.route('/edit/<int:user_id>/new-password', methods=('POST',))\n @admin_required\n def set_password(user_id):\n try:\n user = Journalist.query.get(user_id)\n except NoResultFound:\n abort(404)\n\n password = request.form.get('password')\n set_diceware_password(user, password)\n return redirect(url_for('admin.edit_user', user_id=user_id))\n\n @view.route('/delete/<int:user_id>', methods=('POST',))\n @admin_required\n def delete_user(user_id):\n user = Journalist.query.get(user_id)\n if user_id == g.user.id:\n # Do not flash because the interface already has safe guards.\n # It can only happen by manually crafting a POST request\n current_app.logger.error(\n \"Admin {} tried to delete itself\".format(g.user.username))\n abort(403)\n elif user:\n db.session.delete(user)\n db.session.commit()\n flash(gettext(\"Deleted user '{user}'\").format(\n user=user.username), \"notification\")\n else:\n current_app.logger.error(\n \"Admin {} tried to delete nonexistent user with pk={}\".format(\n g.user.username, user_id))\n abort(404)\n\n return redirect(url_for('admin.index'))\n\n @view.route('/edit/<int:user_id>/new-password', methods=('POST',))\n @admin_required\n def new_password(user_id):\n try:\n user = Journalist.query.get(user_id)\n except NoResultFound:\n abort(404)\n\n password = request.form.get('password')\n set_diceware_password(user, password)\n return redirect(url_for('admin.edit_user', user_id=user_id))\n\n @view.route('/ossec-test')\n @admin_required\n def ossec_test():\n current_app.logger.error('This is a test OSSEC alert')\n flash(gettext('Test alert sent. Please check your email.'),\n 'notification')\n return redirect(url_for('admin.manage_config'))\n\n return view\n", "path": "securedrop/journalist_app/admin.py"}]}
| 3,811 | 439 |
gh_patches_debug_16475
|
rasdani/github-patches
|
git_diff
|
pyinstaller__pyinstaller-8544
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Could not import `pywintypes` or `win32api` from `win32ctypes.pywin32`
## Description of the issue
Error when running the executable.
Issue is present in 6.6.0 and "latest development version". Issue is not present in 6.5.0.
Output differs between versions at this point:
6.6.0:
```
import 'win32ctypes.core' # <_frozen_importlib_external.SourcelessFileLoader object at 0x000001C6D9E41BB0>
# win32ctypes.core._common not found in PYZ
# win32ctypes.core.ctypes not found in PYZ
# destroy win32ctypes.pywin32.win32api
# destroy win32ctypes.pywin32
# destroy PyInstaller
Could not import `pywintypes` or `win32api` from `win32ctypes.pywin32`.
Please make sure that `pywin32-ctypes` is installed and importable, for example:
pip install pywin32-ctypes
```
6.5.0:
```
# cffi not found in PYZ
# code object from '[...]\\cffi\\__init__.pyc'
# cffi.api not found in PYZ
# code object from '[...]\\cffi\\api.pyc'
# cffi.lock not found in PYZ
# code object from '[...]\\cffi\\lock.pyc'
import 'cffi.lock' # <_frozen_importlib_external.SourcelessFileLoader object at 0x000001F4AEB845C0>
# cffi.error not found in PYZ
# code object from '[...]\\cffi\\error.pyc'
import 'cffi.error' # <_frozen_importlib_external.SourcelessFileLoader object at 0x000001F4AEB846B0>
# cffi.model not found in PYZ
# code object from '[...]\\cffi\\model.pyc'
import 'cffi.model' # <_frozen_importlib_external.SourcelessFileLoader object at 0x000001F4AEB848F0>
import 'cffi.api' # <_frozen_importlib_external.SourcelessFileLoader object at 0x000001F4AEB52330>
import 'cffi' # <_frozen_importlib_external.SourcelessFileLoader object at 0x000001F4AEB51EB0>
import 'win32ctypes.core' # <_frozen_importlib_external.SourcelessFileLoader object at 0x000001F4AEB51B80>
# win32ctypes.core._common not found in PYZ
# win32ctypes.core.cffi not found in PYZ
# code object from '[...]\\win32ctypes\\core\\cffi\\__init__.pyc'
import 'win32ctypes.core.cffi' # <_frozen_importlib_external.SourcelessFileLoader object at 0x000001F4AEB86BA0>
# win32ctypes.core.cffi._common not found in PYZ
# code object from '[...]\\win32ctypes\\core\\cffi\\_common.pyc'
# win32ctypes.core.cffi._util not found in PYZ
# code object from '[...]\\win32ctypes\\core\\cffi\\_util.pyc'
# win32ctypes.core.compat not found in PYZ
# code object from '[...]\\win32ctypes\\core\\compat.pyc'
import 'win32ctypes.core.compat' # <_frozen_importlib_external.SourcelessFileLoader object at 0x000001F4AEB87440>
# _cffi_backend not found in PYZ
# extension module '_cffi_backend' loaded from '[...]\\_cffi_backend.cp312-win_amd64.pyd'
# extension module '_cffi_backend' executed from '[...]\\_cffi_backend.cp312-win_amd64.pyd'
import '_cffi_backend' # <_frozen_importlib_external.ExtensionFileLoader object at 0x000001F4AEB876B0>
# cffi.cparser not found in PYZ
# code object from '[...]\\cffi\\cparser.pyc'
# cffi.commontypes not found in PYZ
# code object from '[...]\\cffi\\commontypes.pyc'
import 'cffi.commontypes' # <_frozen_importlib_external.SourcelessFileLoader object at 0x000001F4AEBA91F0>
```
### Context information (for bug reports)
* 502 INFO: PyInstaller: 6.6.0, contrib hooks: 2024.6
* 503 INFO: Python: 3.12.0
* 541 INFO: Platform: Windows-10-10.0.19045-SP0
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `PyInstaller/hooks/hook-win32ctypes.core.py`
Content:
```
1 #-----------------------------------------------------------------------------
2 # Copyright (c) 2020-2023, PyInstaller Development Team.
3 #
4 # Distributed under the terms of the GNU General Public License (version 2
5 # or later) with exception for distributing the bootloader.
6 #
7 # The full license is in the file COPYING.txt, distributed with this software.
8 #
9 # SPDX-License-Identifier: (GPL-2.0-or-later WITH Bootloader-exception)
10 #-----------------------------------------------------------------------------
11
12 # TODO: remove this hook during PyInstaller 4.5 release cycle!
13
14 from PyInstaller.utils.hooks import can_import_module, collect_submodules
15
16 # We need to collect submodules from win32ctypes.core.cffi or win32ctypes.core.ctypes for win32ctypes.core to work. The
17 # use of the backend is determined by availability of cffi.
18 if can_import_module('cffi'):
19 hiddenimports = collect_submodules('win32ctypes.core.cffi')
20 else:
21 hiddenimports = collect_submodules('win32ctypes.core.ctypes')
22
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/PyInstaller/hooks/hook-win32ctypes.core.py b/PyInstaller/hooks/hook-win32ctypes.core.py
--- a/PyInstaller/hooks/hook-win32ctypes.core.py
+++ b/PyInstaller/hooks/hook-win32ctypes.core.py
@@ -13,9 +13,10 @@
from PyInstaller.utils.hooks import can_import_module, collect_submodules
-# We need to collect submodules from win32ctypes.core.cffi or win32ctypes.core.ctypes for win32ctypes.core to work. The
-# use of the backend is determined by availability of cffi.
+# We need to collect submodules from win32ctypes.core.cffi or win32ctypes.core.ctypes for win32ctypes.core to work.
+# Always collect the `ctypes` backend, and add the `cffi` one if `cffi` is available. Having the `ctypes` backend always
+# available helps in situations when `cffi` is available in the build environment, but is disabled at run-time or not
+# collected (e.g., due to `--exclude cffi`).
+hiddenimports = collect_submodules('win32ctypes.core.ctypes')
if can_import_module('cffi'):
- hiddenimports = collect_submodules('win32ctypes.core.cffi')
-else:
- hiddenimports = collect_submodules('win32ctypes.core.ctypes')
+ hiddenimports += collect_submodules('win32ctypes.core.cffi')
|
{"golden_diff": "diff --git a/PyInstaller/hooks/hook-win32ctypes.core.py b/PyInstaller/hooks/hook-win32ctypes.core.py\n--- a/PyInstaller/hooks/hook-win32ctypes.core.py\n+++ b/PyInstaller/hooks/hook-win32ctypes.core.py\n@@ -13,9 +13,10 @@\n \n from PyInstaller.utils.hooks import can_import_module, collect_submodules\n \n-# We need to collect submodules from win32ctypes.core.cffi or win32ctypes.core.ctypes for win32ctypes.core to work. The\n-# use of the backend is determined by availability of cffi.\n+# We need to collect submodules from win32ctypes.core.cffi or win32ctypes.core.ctypes for win32ctypes.core to work.\n+# Always collect the `ctypes` backend, and add the `cffi` one if `cffi` is available. Having the `ctypes` backend always\n+# available helps in situations when `cffi` is available in the build environment, but is disabled at run-time or not\n+# collected (e.g., due to `--exclude cffi`).\n+hiddenimports = collect_submodules('win32ctypes.core.ctypes')\n if can_import_module('cffi'):\n- hiddenimports = collect_submodules('win32ctypes.core.cffi')\n-else:\n- hiddenimports = collect_submodules('win32ctypes.core.ctypes')\n+ hiddenimports += collect_submodules('win32ctypes.core.cffi')\n", "issue": "Could not import `pywintypes` or `win32api` from `win32ctypes.pywin32`\n## Description of the issue\r\n\r\nError when running the executable.\r\n\r\nIssue is present in 6.6.0 and \"latest development version\". Issue is not present in 6.5.0.\r\n\r\nOutput differs between versions at this point:\r\n\r\n6.6.0:\r\n```\r\nimport 'win32ctypes.core' # <_frozen_importlib_external.SourcelessFileLoader object at 0x000001C6D9E41BB0>\r\n# win32ctypes.core._common not found in PYZ\r\n# win32ctypes.core.ctypes not found in PYZ\r\n# destroy win32ctypes.pywin32.win32api\r\n# destroy win32ctypes.pywin32\r\n# destroy PyInstaller\r\nCould not import `pywintypes` or `win32api` from `win32ctypes.pywin32`.\r\nPlease make sure that `pywin32-ctypes` is installed and importable, for example:\r\n\r\npip install pywin32-ctypes\r\n\r\n```\r\n\r\n6.5.0:\r\n```\r\n# cffi not found in PYZ\r\n# code object from '[...]\\\\cffi\\\\__init__.pyc'\r\n# cffi.api not found in PYZ\r\n# code object from '[...]\\\\cffi\\\\api.pyc'\r\n# cffi.lock not found in PYZ\r\n# code object from '[...]\\\\cffi\\\\lock.pyc'\r\nimport 'cffi.lock' # <_frozen_importlib_external.SourcelessFileLoader object at 0x000001F4AEB845C0>\r\n# cffi.error not found in PYZ\r\n# code object from '[...]\\\\cffi\\\\error.pyc'\r\nimport 'cffi.error' # <_frozen_importlib_external.SourcelessFileLoader object at 0x000001F4AEB846B0>\r\n# cffi.model not found in PYZ\r\n# code object from '[...]\\\\cffi\\\\model.pyc'\r\nimport 'cffi.model' # <_frozen_importlib_external.SourcelessFileLoader object at 0x000001F4AEB848F0>\r\nimport 'cffi.api' # <_frozen_importlib_external.SourcelessFileLoader object at 0x000001F4AEB52330>\r\nimport 'cffi' # <_frozen_importlib_external.SourcelessFileLoader object at 0x000001F4AEB51EB0>\r\nimport 'win32ctypes.core' # <_frozen_importlib_external.SourcelessFileLoader object at 0x000001F4AEB51B80>\r\n# win32ctypes.core._common not found in PYZ\r\n# win32ctypes.core.cffi not found in PYZ\r\n# code object from '[...]\\\\win32ctypes\\\\core\\\\cffi\\\\__init__.pyc'\r\nimport 'win32ctypes.core.cffi' # <_frozen_importlib_external.SourcelessFileLoader object at 0x000001F4AEB86BA0>\r\n# win32ctypes.core.cffi._common not found in PYZ\r\n# code object from '[...]\\\\win32ctypes\\\\core\\\\cffi\\\\_common.pyc'\r\n# win32ctypes.core.cffi._util not found in PYZ\r\n# code object from '[...]\\\\win32ctypes\\\\core\\\\cffi\\\\_util.pyc'\r\n# win32ctypes.core.compat not found in PYZ\r\n# code object from '[...]\\\\win32ctypes\\\\core\\\\compat.pyc'\r\nimport 'win32ctypes.core.compat' # <_frozen_importlib_external.SourcelessFileLoader object at 0x000001F4AEB87440>\r\n# _cffi_backend not found in PYZ\r\n# extension module '_cffi_backend' loaded from '[...]\\\\_cffi_backend.cp312-win_amd64.pyd'\r\n# extension module '_cffi_backend' executed from '[...]\\\\_cffi_backend.cp312-win_amd64.pyd'\r\nimport '_cffi_backend' # <_frozen_importlib_external.ExtensionFileLoader object at 0x000001F4AEB876B0>\r\n# cffi.cparser not found in PYZ\r\n# code object from '[...]\\\\cffi\\\\cparser.pyc'\r\n# cffi.commontypes not found in PYZ\r\n# code object from '[...]\\\\cffi\\\\commontypes.pyc'\r\nimport 'cffi.commontypes' # <_frozen_importlib_external.SourcelessFileLoader object at 0x000001F4AEBA91F0>\r\n```\r\n\r\n\r\n### Context information (for bug reports)\r\n\r\n* 502 INFO: PyInstaller: 6.6.0, contrib hooks: 2024.6\r\n* 503 INFO: Python: 3.12.0\r\n* 541 INFO: Platform: Windows-10-10.0.19045-SP0\r\n\r\n\r\n\n", "before_files": [{"content": "#-----------------------------------------------------------------------------\n# Copyright (c) 2020-2023, PyInstaller Development Team.\n#\n# Distributed under the terms of the GNU General Public License (version 2\n# or later) with exception for distributing the bootloader.\n#\n# The full license is in the file COPYING.txt, distributed with this software.\n#\n# SPDX-License-Identifier: (GPL-2.0-or-later WITH Bootloader-exception)\n#-----------------------------------------------------------------------------\n\n# TODO: remove this hook during PyInstaller 4.5 release cycle!\n\nfrom PyInstaller.utils.hooks import can_import_module, collect_submodules\n\n# We need to collect submodules from win32ctypes.core.cffi or win32ctypes.core.ctypes for win32ctypes.core to work. The\n# use of the backend is determined by availability of cffi.\nif can_import_module('cffi'):\n hiddenimports = collect_submodules('win32ctypes.core.cffi')\nelse:\n hiddenimports = collect_submodules('win32ctypes.core.ctypes')\n", "path": "PyInstaller/hooks/hook-win32ctypes.core.py"}], "after_files": [{"content": "#-----------------------------------------------------------------------------\n# Copyright (c) 2020-2023, PyInstaller Development Team.\n#\n# Distributed under the terms of the GNU General Public License (version 2\n# or later) with exception for distributing the bootloader.\n#\n# The full license is in the file COPYING.txt, distributed with this software.\n#\n# SPDX-License-Identifier: (GPL-2.0-or-later WITH Bootloader-exception)\n#-----------------------------------------------------------------------------\n\n# TODO: remove this hook during PyInstaller 4.5 release cycle!\n\nfrom PyInstaller.utils.hooks import can_import_module, collect_submodules\n\n# We need to collect submodules from win32ctypes.core.cffi or win32ctypes.core.ctypes for win32ctypes.core to work.\n# Always collect the `ctypes` backend, and add the `cffi` one if `cffi` is available. Having the `ctypes` backend always\n# available helps in situations when `cffi` is available in the build environment, but is disabled at run-time or not\n# collected (e.g., due to `--exclude cffi`).\nhiddenimports = collect_submodules('win32ctypes.core.ctypes')\nif can_import_module('cffi'):\n hiddenimports += collect_submodules('win32ctypes.core.cffi')\n", "path": "PyInstaller/hooks/hook-win32ctypes.core.py"}]}
| 1,677 | 338 |
gh_patches_debug_20424
|
rasdani/github-patches
|
git_diff
|
AnalogJ__lexicon-1568
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Misleading error message: ProviderNotAvailableError - This provider (plesk) has required dependencies that are missing. Please install lexicon[plesk] first.
```
(venv) mypc:~/myprojects/dns-lexicon$ pip freeze
certifi==2019.9.11
cffi==1.13.2
chardet==3.0.4
cryptography==2.8
dns-lexicon==3.3.10
future==0.18.2
idna==2.8
pycparser==2.19
pyOpenSSL==19.0.0
PyYAML==5.1.2
requests==2.22.0
requests-file==1.4.3
six==1.13.0
tldextract==2.2.2
urllib3==1.25.7
(venv) mypc:~/myprojects/dns-lexicon$ python main.py
Traceback (most recent call last):
File "main.py", line 111, in <module>
update_server_record(data[0], data[1])
File "main.py", line 62, in update_server_record
plesk_record = list_action(filter_name=server_name, filter_type='A')
File "main.py", line 58, in list_action
return lexicon.client.Client(config).execute()
File "/home/joe/myprojects/dns-lexicon/venv/lib/python3.6/site-packages/lexicon/client.py", line 36, in __init__
self._validate_config()
File "/home/joe/myprojects/dns-lexicon/venv/lib/python3.6/site-packages/lexicon/client.py", line 105, in _validate_config
'Please install lexicon[{0}] first.'.format(provider_name))
lexicon.client.ProviderNotAvailableError: This provider (plesk) has required dependencies that are missing. Please install lexicon[plesk] first.
```
Error is misleading because of this part:
> Please install **lexicon[plesk]** first.
it should be
> Please install **dns-lexicon[plesk]** first.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lexicon/client.py`
Content:
```
1 """Main module of Lexicon. Defines the Client class, that holds all Lexicon logic."""
2 import importlib
3 import logging
4 import os
5 from typing import Dict, List, Optional, Type, Union, cast
6
7 import tldextract # type: ignore
8
9 from lexicon import config as helper_config
10 from lexicon import discovery
11 from lexicon.exceptions import ProviderNotAvailableError
12 from lexicon.providers.base import Provider
13
14
15 class Client(object):
16 """This is the Lexicon client, that will execute all the logic."""
17
18 def __init__(
19 self, config: Optional[Union[helper_config.ConfigResolver, Dict]] = None
20 ):
21 if not config:
22 # If there is not config specified, we load a non-interactive configuration.
23 self.config = helper_config.non_interactive_config_resolver()
24 elif not isinstance(config, helper_config.ConfigResolver):
25 # If config is not a ConfigResolver, we are in a legacy situation.
26 # We protect this part of the Client API.
27 self.config = helper_config.legacy_config_resolver(config)
28 else:
29 self.config = config
30
31 # Validate configuration
32 self._validate_config()
33
34 runtime_config = {}
35
36 # Process domain, strip subdomain
37 try:
38 domain_extractor = tldextract.TLDExtract(
39 cache_dir=_get_tldextract_cache_path(), include_psl_private_domains=True
40 )
41 except TypeError:
42 domain_extractor = tldextract.TLDExtract(
43 cache_file=_get_tldextract_cache_path(), include_psl_private_domains=True # type: ignore
44 )
45 domain_parts = domain_extractor(
46 cast(str, self.config.resolve("lexicon:domain"))
47 )
48 runtime_config["domain"] = f"{domain_parts.domain}.{domain_parts.suffix}"
49
50 delegated = self.config.resolve("lexicon:delegated")
51 if delegated:
52 # handle delegated domain
53 delegated = str(delegated).rstrip(".")
54 initial_domain = str(runtime_config.get("domain"))
55 if delegated != initial_domain:
56 # convert to relative name
57 if delegated.endswith(initial_domain):
58 delegated = delegated[: -len(initial_domain)]
59 delegated = delegated.rstrip(".")
60 # update domain
61 runtime_config["domain"] = f"{delegated}.{initial_domain}"
62
63 self.action = self.config.resolve("lexicon:action")
64 self.provider_name = self.config.resolve(
65 "lexicon:provider_name"
66 ) or self.config.resolve("lexicon:provider")
67
68 if not self.provider_name:
69 raise ValueError("Could not resolve provider name.")
70
71 self.config.add_config_source(helper_config.DictConfigSource(runtime_config), 0)
72
73 provider_module = importlib.import_module(
74 "lexicon.providers." + self.provider_name
75 )
76 provider_class: Type[Provider] = getattr(provider_module, "Provider")
77 self.provider = provider_class(self.config)
78
79 def execute(self) -> Union[bool, List[Dict]]:
80 """Execute provided configuration in class constructor to the DNS records"""
81 self.provider.authenticate()
82 identifier = self.config.resolve("lexicon:identifier")
83 record_type = self.config.resolve("lexicon:type")
84 name = self.config.resolve("lexicon:name")
85 content = self.config.resolve("lexicon:content")
86
87 if self.action == "create":
88 if not record_type or not name or not content:
89 raise ValueError("Missing record_type, name or content parameters.")
90 return self.provider.create_record(record_type, name, content)
91
92 if self.action == "list":
93 return self.provider.list_records(record_type, name, content)
94
95 if self.action == "update":
96 return self.provider.update_record(identifier, record_type, name, content)
97
98 if self.action == "delete":
99 return self.provider.delete_record(identifier, record_type, name, content)
100
101 raise ValueError(f"Invalid action statement: {self.action}")
102
103 def _validate_config(self) -> None:
104 provider_name = self.config.resolve("lexicon:provider_name")
105 if not provider_name:
106 raise AttributeError("provider_name")
107
108 try:
109 available = discovery.find_providers()[provider_name]
110 except KeyError:
111 raise ProviderNotAvailableError(
112 f"This provider ({provider_name}) is not supported by Lexicon."
113 )
114 else:
115 if not available:
116 raise ProviderNotAvailableError(
117 f"This provider ({provider_name}) has required extra dependencies that are missing. "
118 f"Please run `pip install lexicon[{provider_name}]` first before using it."
119 )
120
121 if not self.config.resolve("lexicon:action"):
122 raise AttributeError("action")
123 if not self.config.resolve("lexicon:domain"):
124 raise AttributeError("domain")
125 if not self.config.resolve("lexicon:type"):
126 raise AttributeError("type")
127
128
129 def _get_tldextract_cache_path() -> str:
130 if os.environ.get("TLDEXTRACT_CACHE_FILE"):
131 logging.warning(
132 "TLD_EXTRACT_CACHE_FILE environment variable is deprecated, please use TLDEXTRACT_CACHE_PATH instead."
133 )
134 os.environ["TLDEXTRACT_CACHE_PATH"] = os.environ["TLDEXTRACT_CACHE_FILE"]
135
136 return os.path.expanduser(
137 os.environ.get("TLDEXTRACT_CACHE_PATH", os.path.join("~", ".lexicon_tld_set"))
138 )
139
```
Path: `lexicon/discovery.py`
Content:
```
1 """
2 This module takes care of finding information about the runtime of Lexicon:
3 * what are the providers installed, and available
4 * what is the version of Lexicon
5 """
6 import pkgutil
7 import re
8 from typing import Dict
9
10 try:
11 from importlib.metadata import Distribution, PackageNotFoundError
12 except ModuleNotFoundError:
13 from importlib_metadata import Distribution, PackageNotFoundError # type: ignore[assignment]
14
15 from lexicon import providers
16
17
18 def find_providers() -> Dict[str, bool]:
19 """Find all providers registered in Lexicon, and their availability"""
20 providers_list = sorted(
21 {
22 modname
23 for (_, modname, _) in pkgutil.iter_modules(providers.__path__) # type: ignore
24 if modname != "base"
25 }
26 )
27
28 try:
29 distribution = Distribution.from_name("dns-lexicon")
30 except PackageNotFoundError:
31 return {provider: True for provider in providers_list}
32 else:
33 return {
34 provider: _resolve_requirements(provider, distribution)
35 for provider in providers_list
36 }
37
38
39 def lexicon_version() -> str:
40 """Retrieve current Lexicon version"""
41 try:
42 return Distribution.from_name("dns-lexicon").version
43 except PackageNotFoundError:
44 return "unknown"
45
46
47 def _resolve_requirements(provider: str, distribution: Distribution) -> bool:
48 requires = distribution.requires
49 if requires is None:
50 raise ValueError("Error while trying finding requirements.")
51
52 requirements = [
53 re.sub(r"^(.*)\s\(.*\)(?:;.*|)$", r"\1", requirement)
54 for requirement in requires
55 if f'extra == "{provider}"' in requirement
56 ]
57
58 if not requirements:
59 # No extra for this provider
60 return True
61
62 for requirement in requirements:
63 try:
64 Distribution.from_name(requirement)
65 except PackageNotFoundError:
66 # At least one extra requirement is not fulfilled
67 return False
68
69 # All extra requirements are fulfilled
70 return True
71
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lexicon/client.py b/lexicon/client.py
--- a/lexicon/client.py
+++ b/lexicon/client.py
@@ -115,7 +115,7 @@
if not available:
raise ProviderNotAvailableError(
f"This provider ({provider_name}) has required extra dependencies that are missing. "
- f"Please run `pip install lexicon[{provider_name}]` first before using it."
+ f"Please run `pip install dns-lexicon[{provider_name}]` first before using it."
)
if not self.config.resolve("lexicon:action"):
diff --git a/lexicon/discovery.py b/lexicon/discovery.py
--- a/lexicon/discovery.py
+++ b/lexicon/discovery.py
@@ -50,7 +50,7 @@
raise ValueError("Error while trying finding requirements.")
requirements = [
- re.sub(r"^(.*)\s\(.*\)(?:;.*|)$", r"\1", requirement)
+ re.sub(r"^(.*)\s\(.*\)(?:\s*;.*|)$", r"\1", requirement)
for requirement in requires
if f'extra == "{provider}"' in requirement
]
|
{"golden_diff": "diff --git a/lexicon/client.py b/lexicon/client.py\n--- a/lexicon/client.py\n+++ b/lexicon/client.py\n@@ -115,7 +115,7 @@\n if not available:\n raise ProviderNotAvailableError(\n f\"This provider ({provider_name}) has required extra dependencies that are missing. \"\n- f\"Please run `pip install lexicon[{provider_name}]` first before using it.\"\n+ f\"Please run `pip install dns-lexicon[{provider_name}]` first before using it.\"\n )\n \n if not self.config.resolve(\"lexicon:action\"):\ndiff --git a/lexicon/discovery.py b/lexicon/discovery.py\n--- a/lexicon/discovery.py\n+++ b/lexicon/discovery.py\n@@ -50,7 +50,7 @@\n raise ValueError(\"Error while trying finding requirements.\")\n \n requirements = [\n- re.sub(r\"^(.*)\\s\\(.*\\)(?:;.*|)$\", r\"\\1\", requirement)\n+ re.sub(r\"^(.*)\\s\\(.*\\)(?:\\s*;.*|)$\", r\"\\1\", requirement)\n for requirement in requires\n if f'extra == \"{provider}\"' in requirement\n ]\n", "issue": "Misleading error message: ProviderNotAvailableError - This provider (plesk) has required dependencies that are missing. Please install lexicon[plesk] first.\n```\r\n(venv) mypc:~/myprojects/dns-lexicon$ pip freeze\r\ncertifi==2019.9.11\r\ncffi==1.13.2\r\nchardet==3.0.4\r\ncryptography==2.8\r\ndns-lexicon==3.3.10\r\nfuture==0.18.2\r\nidna==2.8\r\npycparser==2.19\r\npyOpenSSL==19.0.0\r\nPyYAML==5.1.2\r\nrequests==2.22.0\r\nrequests-file==1.4.3\r\nsix==1.13.0\r\ntldextract==2.2.2\r\nurllib3==1.25.7\r\n(venv) mypc:~/myprojects/dns-lexicon$ python main.py \r\nTraceback (most recent call last):\r\n File \"main.py\", line 111, in <module>\r\n update_server_record(data[0], data[1])\r\n File \"main.py\", line 62, in update_server_record\r\n plesk_record = list_action(filter_name=server_name, filter_type='A')\r\n File \"main.py\", line 58, in list_action\r\n return lexicon.client.Client(config).execute()\r\n File \"/home/joe/myprojects/dns-lexicon/venv/lib/python3.6/site-packages/lexicon/client.py\", line 36, in __init__\r\n self._validate_config()\r\n File \"/home/joe/myprojects/dns-lexicon/venv/lib/python3.6/site-packages/lexicon/client.py\", line 105, in _validate_config\r\n 'Please install lexicon[{0}] first.'.format(provider_name))\r\nlexicon.client.ProviderNotAvailableError: This provider (plesk) has required dependencies that are missing. Please install lexicon[plesk] first.\r\n\r\n```\r\nError is misleading because of this part: \r\n> Please install **lexicon[plesk]** first.\r\n\r\nit should be \r\n> Please install **dns-lexicon[plesk]** first.\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "\"\"\"Main module of Lexicon. Defines the Client class, that holds all Lexicon logic.\"\"\"\nimport importlib\nimport logging\nimport os\nfrom typing import Dict, List, Optional, Type, Union, cast\n\nimport tldextract # type: ignore\n\nfrom lexicon import config as helper_config\nfrom lexicon import discovery\nfrom lexicon.exceptions import ProviderNotAvailableError\nfrom lexicon.providers.base import Provider\n\n\nclass Client(object):\n \"\"\"This is the Lexicon client, that will execute all the logic.\"\"\"\n\n def __init__(\n self, config: Optional[Union[helper_config.ConfigResolver, Dict]] = None\n ):\n if not config:\n # If there is not config specified, we load a non-interactive configuration.\n self.config = helper_config.non_interactive_config_resolver()\n elif not isinstance(config, helper_config.ConfigResolver):\n # If config is not a ConfigResolver, we are in a legacy situation.\n # We protect this part of the Client API.\n self.config = helper_config.legacy_config_resolver(config)\n else:\n self.config = config\n\n # Validate configuration\n self._validate_config()\n\n runtime_config = {}\n\n # Process domain, strip subdomain\n try:\n domain_extractor = tldextract.TLDExtract(\n cache_dir=_get_tldextract_cache_path(), include_psl_private_domains=True\n )\n except TypeError:\n domain_extractor = tldextract.TLDExtract(\n cache_file=_get_tldextract_cache_path(), include_psl_private_domains=True # type: ignore\n )\n domain_parts = domain_extractor(\n cast(str, self.config.resolve(\"lexicon:domain\"))\n )\n runtime_config[\"domain\"] = f\"{domain_parts.domain}.{domain_parts.suffix}\"\n\n delegated = self.config.resolve(\"lexicon:delegated\")\n if delegated:\n # handle delegated domain\n delegated = str(delegated).rstrip(\".\")\n initial_domain = str(runtime_config.get(\"domain\"))\n if delegated != initial_domain:\n # convert to relative name\n if delegated.endswith(initial_domain):\n delegated = delegated[: -len(initial_domain)]\n delegated = delegated.rstrip(\".\")\n # update domain\n runtime_config[\"domain\"] = f\"{delegated}.{initial_domain}\"\n\n self.action = self.config.resolve(\"lexicon:action\")\n self.provider_name = self.config.resolve(\n \"lexicon:provider_name\"\n ) or self.config.resolve(\"lexicon:provider\")\n\n if not self.provider_name:\n raise ValueError(\"Could not resolve provider name.\")\n\n self.config.add_config_source(helper_config.DictConfigSource(runtime_config), 0)\n\n provider_module = importlib.import_module(\n \"lexicon.providers.\" + self.provider_name\n )\n provider_class: Type[Provider] = getattr(provider_module, \"Provider\")\n self.provider = provider_class(self.config)\n\n def execute(self) -> Union[bool, List[Dict]]:\n \"\"\"Execute provided configuration in class constructor to the DNS records\"\"\"\n self.provider.authenticate()\n identifier = self.config.resolve(\"lexicon:identifier\")\n record_type = self.config.resolve(\"lexicon:type\")\n name = self.config.resolve(\"lexicon:name\")\n content = self.config.resolve(\"lexicon:content\")\n\n if self.action == \"create\":\n if not record_type or not name or not content:\n raise ValueError(\"Missing record_type, name or content parameters.\")\n return self.provider.create_record(record_type, name, content)\n\n if self.action == \"list\":\n return self.provider.list_records(record_type, name, content)\n\n if self.action == \"update\":\n return self.provider.update_record(identifier, record_type, name, content)\n\n if self.action == \"delete\":\n return self.provider.delete_record(identifier, record_type, name, content)\n\n raise ValueError(f\"Invalid action statement: {self.action}\")\n\n def _validate_config(self) -> None:\n provider_name = self.config.resolve(\"lexicon:provider_name\")\n if not provider_name:\n raise AttributeError(\"provider_name\")\n\n try:\n available = discovery.find_providers()[provider_name]\n except KeyError:\n raise ProviderNotAvailableError(\n f\"This provider ({provider_name}) is not supported by Lexicon.\"\n )\n else:\n if not available:\n raise ProviderNotAvailableError(\n f\"This provider ({provider_name}) has required extra dependencies that are missing. \"\n f\"Please run `pip install lexicon[{provider_name}]` first before using it.\"\n )\n\n if not self.config.resolve(\"lexicon:action\"):\n raise AttributeError(\"action\")\n if not self.config.resolve(\"lexicon:domain\"):\n raise AttributeError(\"domain\")\n if not self.config.resolve(\"lexicon:type\"):\n raise AttributeError(\"type\")\n\n\ndef _get_tldextract_cache_path() -> str:\n if os.environ.get(\"TLDEXTRACT_CACHE_FILE\"):\n logging.warning(\n \"TLD_EXTRACT_CACHE_FILE environment variable is deprecated, please use TLDEXTRACT_CACHE_PATH instead.\"\n )\n os.environ[\"TLDEXTRACT_CACHE_PATH\"] = os.environ[\"TLDEXTRACT_CACHE_FILE\"]\n\n return os.path.expanduser(\n os.environ.get(\"TLDEXTRACT_CACHE_PATH\", os.path.join(\"~\", \".lexicon_tld_set\"))\n )\n", "path": "lexicon/client.py"}, {"content": "\"\"\"\nThis module takes care of finding information about the runtime of Lexicon:\n* what are the providers installed, and available\n* what is the version of Lexicon\n\"\"\"\nimport pkgutil\nimport re\nfrom typing import Dict\n\ntry:\n from importlib.metadata import Distribution, PackageNotFoundError\nexcept ModuleNotFoundError:\n from importlib_metadata import Distribution, PackageNotFoundError # type: ignore[assignment]\n\nfrom lexicon import providers\n\n\ndef find_providers() -> Dict[str, bool]:\n \"\"\"Find all providers registered in Lexicon, and their availability\"\"\"\n providers_list = sorted(\n {\n modname\n for (_, modname, _) in pkgutil.iter_modules(providers.__path__) # type: ignore\n if modname != \"base\"\n }\n )\n\n try:\n distribution = Distribution.from_name(\"dns-lexicon\")\n except PackageNotFoundError:\n return {provider: True for provider in providers_list}\n else:\n return {\n provider: _resolve_requirements(provider, distribution)\n for provider in providers_list\n }\n\n\ndef lexicon_version() -> str:\n \"\"\"Retrieve current Lexicon version\"\"\"\n try:\n return Distribution.from_name(\"dns-lexicon\").version\n except PackageNotFoundError:\n return \"unknown\"\n\n\ndef _resolve_requirements(provider: str, distribution: Distribution) -> bool:\n requires = distribution.requires\n if requires is None:\n raise ValueError(\"Error while trying finding requirements.\")\n\n requirements = [\n re.sub(r\"^(.*)\\s\\(.*\\)(?:;.*|)$\", r\"\\1\", requirement)\n for requirement in requires\n if f'extra == \"{provider}\"' in requirement\n ]\n\n if not requirements:\n # No extra for this provider\n return True\n\n for requirement in requirements:\n try:\n Distribution.from_name(requirement)\n except PackageNotFoundError:\n # At least one extra requirement is not fulfilled\n return False\n\n # All extra requirements are fulfilled\n return True\n", "path": "lexicon/discovery.py"}], "after_files": [{"content": "\"\"\"Main module of Lexicon. Defines the Client class, that holds all Lexicon logic.\"\"\"\nimport importlib\nimport logging\nimport os\nfrom typing import Dict, List, Optional, Type, Union, cast\n\nimport tldextract # type: ignore\n\nfrom lexicon import config as helper_config\nfrom lexicon import discovery\nfrom lexicon.exceptions import ProviderNotAvailableError\nfrom lexicon.providers.base import Provider\n\n\nclass Client(object):\n \"\"\"This is the Lexicon client, that will execute all the logic.\"\"\"\n\n def __init__(\n self, config: Optional[Union[helper_config.ConfigResolver, Dict]] = None\n ):\n if not config:\n # If there is not config specified, we load a non-interactive configuration.\n self.config = helper_config.non_interactive_config_resolver()\n elif not isinstance(config, helper_config.ConfigResolver):\n # If config is not a ConfigResolver, we are in a legacy situation.\n # We protect this part of the Client API.\n self.config = helper_config.legacy_config_resolver(config)\n else:\n self.config = config\n\n # Validate configuration\n self._validate_config()\n\n runtime_config = {}\n\n # Process domain, strip subdomain\n try:\n domain_extractor = tldextract.TLDExtract(\n cache_dir=_get_tldextract_cache_path(), include_psl_private_domains=True\n )\n except TypeError:\n domain_extractor = tldextract.TLDExtract(\n cache_file=_get_tldextract_cache_path(), include_psl_private_domains=True # type: ignore\n )\n domain_parts = domain_extractor(\n cast(str, self.config.resolve(\"lexicon:domain\"))\n )\n runtime_config[\"domain\"] = f\"{domain_parts.domain}.{domain_parts.suffix}\"\n\n delegated = self.config.resolve(\"lexicon:delegated\")\n if delegated:\n # handle delegated domain\n delegated = str(delegated).rstrip(\".\")\n initial_domain = str(runtime_config.get(\"domain\"))\n if delegated != initial_domain:\n # convert to relative name\n if delegated.endswith(initial_domain):\n delegated = delegated[: -len(initial_domain)]\n delegated = delegated.rstrip(\".\")\n # update domain\n runtime_config[\"domain\"] = f\"{delegated}.{initial_domain}\"\n\n self.action = self.config.resolve(\"lexicon:action\")\n self.provider_name = self.config.resolve(\n \"lexicon:provider_name\"\n ) or self.config.resolve(\"lexicon:provider\")\n\n if not self.provider_name:\n raise ValueError(\"Could not resolve provider name.\")\n\n self.config.add_config_source(helper_config.DictConfigSource(runtime_config), 0)\n\n provider_module = importlib.import_module(\n \"lexicon.providers.\" + self.provider_name\n )\n provider_class: Type[Provider] = getattr(provider_module, \"Provider\")\n self.provider = provider_class(self.config)\n\n def execute(self) -> Union[bool, List[Dict]]:\n \"\"\"Execute provided configuration in class constructor to the DNS records\"\"\"\n self.provider.authenticate()\n identifier = self.config.resolve(\"lexicon:identifier\")\n record_type = self.config.resolve(\"lexicon:type\")\n name = self.config.resolve(\"lexicon:name\")\n content = self.config.resolve(\"lexicon:content\")\n\n if self.action == \"create\":\n if not record_type or not name or not content:\n raise ValueError(\"Missing record_type, name or content parameters.\")\n return self.provider.create_record(record_type, name, content)\n\n if self.action == \"list\":\n return self.provider.list_records(record_type, name, content)\n\n if self.action == \"update\":\n return self.provider.update_record(identifier, record_type, name, content)\n\n if self.action == \"delete\":\n return self.provider.delete_record(identifier, record_type, name, content)\n\n raise ValueError(f\"Invalid action statement: {self.action}\")\n\n def _validate_config(self) -> None:\n provider_name = self.config.resolve(\"lexicon:provider_name\")\n if not provider_name:\n raise AttributeError(\"provider_name\")\n\n try:\n available = discovery.find_providers()[provider_name]\n except KeyError:\n raise ProviderNotAvailableError(\n f\"This provider ({provider_name}) is not supported by Lexicon.\"\n )\n else:\n if not available:\n raise ProviderNotAvailableError(\n f\"This provider ({provider_name}) has required extra dependencies that are missing. \"\n f\"Please run `pip install dns-lexicon[{provider_name}]` first before using it.\"\n )\n\n if not self.config.resolve(\"lexicon:action\"):\n raise AttributeError(\"action\")\n if not self.config.resolve(\"lexicon:domain\"):\n raise AttributeError(\"domain\")\n if not self.config.resolve(\"lexicon:type\"):\n raise AttributeError(\"type\")\n\n\ndef _get_tldextract_cache_path() -> str:\n if os.environ.get(\"TLDEXTRACT_CACHE_FILE\"):\n logging.warning(\n \"TLD_EXTRACT_CACHE_FILE environment variable is deprecated, please use TLDEXTRACT_CACHE_PATH instead.\"\n )\n os.environ[\"TLDEXTRACT_CACHE_PATH\"] = os.environ[\"TLDEXTRACT_CACHE_FILE\"]\n\n return os.path.expanduser(\n os.environ.get(\"TLDEXTRACT_CACHE_PATH\", os.path.join(\"~\", \".lexicon_tld_set\"))\n )\n", "path": "lexicon/client.py"}, {"content": "\"\"\"\nThis module takes care of finding information about the runtime of Lexicon:\n* what are the providers installed, and available\n* what is the version of Lexicon\n\"\"\"\nimport pkgutil\nimport re\nfrom typing import Dict\n\ntry:\n from importlib.metadata import Distribution, PackageNotFoundError\nexcept ModuleNotFoundError:\n from importlib_metadata import Distribution, PackageNotFoundError # type: ignore[assignment]\n\nfrom lexicon import providers\n\n\ndef find_providers() -> Dict[str, bool]:\n \"\"\"Find all providers registered in Lexicon, and their availability\"\"\"\n providers_list = sorted(\n {\n modname\n for (_, modname, _) in pkgutil.iter_modules(providers.__path__) # type: ignore\n if modname != \"base\"\n }\n )\n\n try:\n distribution = Distribution.from_name(\"dns-lexicon\")\n except PackageNotFoundError:\n return {provider: True for provider in providers_list}\n else:\n return {\n provider: _resolve_requirements(provider, distribution)\n for provider in providers_list\n }\n\n\ndef lexicon_version() -> str:\n \"\"\"Retrieve current Lexicon version\"\"\"\n try:\n return Distribution.from_name(\"dns-lexicon\").version\n except PackageNotFoundError:\n return \"unknown\"\n\n\ndef _resolve_requirements(provider: str, distribution: Distribution) -> bool:\n requires = distribution.requires\n if requires is None:\n raise ValueError(\"Error while trying finding requirements.\")\n\n requirements = [\n re.sub(r\"^(.*)\\s\\(.*\\)(?:\\s*;.*|)$\", r\"\\1\", requirement)\n for requirement in requires\n if f'extra == \"{provider}\"' in requirement\n ]\n\n if not requirements:\n # No extra for this provider\n return True\n\n for requirement in requirements:\n try:\n Distribution.from_name(requirement)\n except PackageNotFoundError:\n # At least one extra requirement is not fulfilled\n return False\n\n # All extra requirements are fulfilled\n return True\n", "path": "lexicon/discovery.py"}]}
| 2,747 | 273 |
gh_patches_debug_35519
|
rasdani/github-patches
|
git_diff
|
certbot__certbot-1842
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Domain with german umlauts ('ascii' codec can't encode character)
CentOS 7.1.1503
I tried to create an certificat with domain contains german umlauts. Domain is: entä.de
I getting in the console this error:
```
An unexpected error occurred:
UnicodeEncodeError: 'ascii' codec can't encode character u'\xe4' in position 3: ordinal not in range(128)
Please see the logfiles in /var/log/letsencrypt for more details.
```
Logfile:
``` python
2015-12-08 17:58:44,353:DEBUG:letsencrypt.cli:Exiting abnormally:
Traceback (most recent call last):
File "/root/.local/share/letsencrypt/bin/letsencrypt", line 11, in <module>
sys.exit(main())
File "/root/.local/share/letsencrypt/lib/python2.7/site-packages/letsencrypt/cli.py", line 1283, in main
return args.func(args, config, plugins)
File "/root/.local/share/letsencrypt/lib/python2.7/site-packages/letsencrypt/cli.py", line 511, in obtain_cert
domains = _find_domains(args, installer)
File "/root/.local/share/letsencrypt/lib/python2.7/site-packages/letsencrypt/cli.py", line 106, in _find_domains
domains = display_ops.choose_names(installer)
File "/root/.local/share/letsencrypt/lib/python2.7/site-packages/letsencrypt/display/ops.py", line 187, in choose_names
return _choose_names_manually()
File "/root/.local/share/letsencrypt/lib/python2.7/site-packages/letsencrypt/display/ops.py", line 235, in _choose_names_manually
return display_util.separate_list_input(input_)
File "/root/.local/share/letsencrypt/lib/python2.7/site-packages/letsencrypt/display/util.py", line 419, in separate_list_input
return [str(string) for string in no_commas.split()]
UnicodeEncodeError: 'ascii' codec can't encode character u'\xe4' in position 3: ordinal not in range(128)
```
Is there a way to fix this?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `letsencrypt/display/ops.py`
Content:
```
1 """Contains UI methods for LE user operations."""
2 import logging
3 import os
4
5 import zope.component
6
7 from letsencrypt import errors
8 from letsencrypt import interfaces
9 from letsencrypt import le_util
10 from letsencrypt.display import util as display_util
11
12
13 logger = logging.getLogger(__name__)
14
15 # Define a helper function to avoid verbose code
16 util = zope.component.getUtility
17
18
19 def choose_plugin(prepared, question):
20 """Allow the user to choose their plugin.
21
22 :param list prepared: List of `~.PluginEntryPoint`.
23 :param str question: Question to be presented to the user.
24
25 :returns: Plugin entry point chosen by the user.
26 :rtype: `~.PluginEntryPoint`
27
28 """
29 opts = [plugin_ep.description_with_name +
30 (" [Misconfigured]" if plugin_ep.misconfigured else "")
31 for plugin_ep in prepared]
32
33 while True:
34 code, index = util(interfaces.IDisplay).menu(
35 question, opts, help_label="More Info")
36
37 if code == display_util.OK:
38 plugin_ep = prepared[index]
39 if plugin_ep.misconfigured:
40 util(interfaces.IDisplay).notification(
41 "The selected plugin encountered an error while parsing "
42 "your server configuration and cannot be used. The error "
43 "was:\n\n{0}".format(plugin_ep.prepare()),
44 height=display_util.HEIGHT, pause=False)
45 else:
46 return plugin_ep
47 elif code == display_util.HELP:
48 if prepared[index].misconfigured:
49 msg = "Reported Error: %s" % prepared[index].prepare()
50 else:
51 msg = prepared[index].init().more_info()
52 util(interfaces.IDisplay).notification(
53 msg, height=display_util.HEIGHT)
54 else:
55 return None
56
57
58 def pick_plugin(config, default, plugins, question, ifaces):
59 """Pick plugin.
60
61 :param letsencrypt.interfaces.IConfig: Configuration
62 :param str default: Plugin name supplied by user or ``None``.
63 :param letsencrypt.plugins.disco.PluginsRegistry plugins:
64 All plugins registered as entry points.
65 :param str question: Question to be presented to the user in case
66 multiple candidates are found.
67 :param list ifaces: Interfaces that plugins must provide.
68
69 :returns: Initialized plugin.
70 :rtype: IPlugin
71
72 """
73 if default is not None:
74 # throw more UX-friendly error if default not in plugins
75 filtered = plugins.filter(lambda p_ep: p_ep.name == default)
76 else:
77 filtered = plugins.visible().ifaces(ifaces)
78
79 filtered.init(config)
80 verified = filtered.verify(ifaces)
81 verified.prepare()
82 prepared = verified.available()
83
84 if len(prepared) > 1:
85 logger.debug("Multiple candidate plugins: %s", prepared)
86 plugin_ep = choose_plugin(prepared.values(), question)
87 if plugin_ep is None:
88 return None
89 else:
90 return plugin_ep.init()
91 elif len(prepared) == 1:
92 plugin_ep = prepared.values()[0]
93 logger.debug("Single candidate plugin: %s", plugin_ep)
94 if plugin_ep.misconfigured:
95 return None
96 return plugin_ep.init()
97 else:
98 logger.debug("No candidate plugin")
99 return None
100
101
102 def pick_authenticator(
103 config, default, plugins, question="How would you "
104 "like to authenticate with the Let's Encrypt CA?"):
105 """Pick authentication plugin."""
106 return pick_plugin(
107 config, default, plugins, question, (interfaces.IAuthenticator,))
108
109
110 def pick_installer(config, default, plugins,
111 question="How would you like to install certificates?"):
112 """Pick installer plugin."""
113 return pick_plugin(
114 config, default, plugins, question, (interfaces.IInstaller,))
115
116
117 def pick_configurator(
118 config, default, plugins,
119 question="How would you like to authenticate and install "
120 "certificates?"):
121 """Pick configurator plugin."""
122 return pick_plugin(
123 config, default, plugins, question,
124 (interfaces.IAuthenticator, interfaces.IInstaller))
125
126 def get_email(more=False, invalid=False):
127 """Prompt for valid email address.
128
129 :param bool more: explain why the email is strongly advisable, but how to
130 skip it
131 :param bool invalid: true if the user just typed something, but it wasn't
132 a valid-looking email
133
134 :returns: Email or ``None`` if cancelled by user.
135 :rtype: str
136
137 """
138 msg = "Enter email address (used for urgent notices and lost key recovery)"
139 if invalid:
140 msg = "There seem to be problems with that address. " + msg
141 if more:
142 msg += ('\n\nIf you really want to skip this, you can run the client with '
143 '--register-unsafely-without-email but make sure you backup your '
144 'account key from /etc/letsencrypt/accounts\n\n')
145 code, email = zope.component.getUtility(interfaces.IDisplay).input(msg)
146
147 if code == display_util.OK:
148 if le_util.safe_email(email):
149 return email
150 else:
151 # TODO catch the server's ACME invalid email address error, and
152 # make a similar call when that happens
153 return get_email(more=True, invalid=(email != ""))
154 else:
155 return None
156
157
158 def choose_account(accounts):
159 """Choose an account.
160
161 :param list accounts: Containing at least one
162 :class:`~letsencrypt.account.Account`
163
164 """
165 # Note this will get more complicated once we start recording authorizations
166 labels = [acc.slug for acc in accounts]
167
168 code, index = util(interfaces.IDisplay).menu(
169 "Please choose an account", labels)
170 if code == display_util.OK:
171 return accounts[index]
172 else:
173 return None
174
175
176 def choose_names(installer):
177 """Display screen to select domains to validate.
178
179 :param installer: An installer object
180 :type installer: :class:`letsencrypt.interfaces.IInstaller`
181
182 :returns: List of selected names
183 :rtype: `list` of `str`
184
185 """
186 if installer is None:
187 logger.debug("No installer, picking names manually")
188 return _choose_names_manually()
189
190 domains = list(installer.get_all_names())
191 names = get_valid_domains(domains)
192
193 if not names:
194 manual = util(interfaces.IDisplay).yesno(
195 "No names were found in your configuration files.{0}You should "
196 "specify ServerNames in your config files in order to allow for "
197 "accurate installation of your certificate.{0}"
198 "If you do use the default vhost, you may specify the name "
199 "manually. Would you like to continue?{0}".format(os.linesep))
200
201 if manual:
202 return _choose_names_manually()
203 else:
204 return []
205
206 code, names = _filter_names(names)
207 if code == display_util.OK and names:
208 return names
209 else:
210 return []
211
212 def get_valid_domains(domains):
213 """Helper method for choose_names that implements basic checks
214 on domain names
215
216 :param list domains: Domain names to validate
217 :return: List of valid domains
218 :rtype: list
219 """
220 valid_domains = []
221 for domain in domains:
222 try:
223 le_util.check_domain_sanity(domain)
224 valid_domains.append(domain)
225 except errors.ConfigurationError:
226 continue
227 return valid_domains
228
229 def _filter_names(names):
230 """Determine which names the user would like to select from a list.
231
232 :param list names: domain names
233
234 :returns: tuple of the form (`code`, `names`) where
235 `code` - str display exit code
236 `names` - list of names selected
237 :rtype: tuple
238
239 """
240 code, names = util(interfaces.IDisplay).checklist(
241 "Which names would you like to activate HTTPS for?",
242 tags=names)
243 return code, [str(s) for s in names]
244
245
246 def _choose_names_manually():
247 """Manually input names for those without an installer."""
248
249 code, input_ = util(interfaces.IDisplay).input(
250 "Please enter in your domain name(s) (comma and/or space separated) ")
251
252 if code == display_util.OK:
253 return display_util.separate_list_input(input_)
254 return []
255
256
257 def success_installation(domains):
258 """Display a box confirming the installation of HTTPS.
259
260 .. todo:: This should be centered on the screen
261
262 :param list domains: domain names which were enabled
263
264 """
265 util(interfaces.IDisplay).notification(
266 "Congratulations! You have successfully enabled {0}{1}{1}"
267 "You should test your configuration at:{1}{2}".format(
268 _gen_https_names(domains),
269 os.linesep,
270 os.linesep.join(_gen_ssl_lab_urls(domains))),
271 height=(10 + len(domains)),
272 pause=False)
273
274
275 def success_renewal(domains):
276 """Display a box confirming the renewal of an existing certificate.
277
278 .. todo:: This should be centered on the screen
279
280 :param list domains: domain names which were renewed
281
282 """
283 util(interfaces.IDisplay).notification(
284 "Your existing certificate has been successfully renewed, and the "
285 "new certificate has been installed.{1}{1}"
286 "The new certificate covers the following domains: {0}{1}{1}"
287 "You should test your configuration at:{1}{2}".format(
288 _gen_https_names(domains),
289 os.linesep,
290 os.linesep.join(_gen_ssl_lab_urls(domains))),
291 height=(14 + len(domains)),
292 pause=False)
293
294
295 def _gen_ssl_lab_urls(domains):
296 """Returns a list of urls.
297
298 :param list domains: Each domain is a 'str'
299
300 """
301 return ["https://www.ssllabs.com/ssltest/analyze.html?d=%s" % dom for dom in domains]
302
303
304 def _gen_https_names(domains):
305 """Returns a string of the https domains.
306
307 Domains are formatted nicely with https:// prepended to each.
308
309 :param list domains: Each domain is a 'str'
310
311 """
312 if len(domains) == 1:
313 return "https://{0}".format(domains[0])
314 elif len(domains) == 2:
315 return "https://{dom[0]} and https://{dom[1]}".format(dom=domains)
316 elif len(domains) > 2:
317 return "{0}{1}{2}".format(
318 ", ".join("https://%s" % dom for dom in domains[:-1]),
319 ", and https://",
320 domains[-1])
321
322 return ""
323
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/letsencrypt/display/ops.py b/letsencrypt/display/ops.py
--- a/letsencrypt/display/ops.py
+++ b/letsencrypt/display/ops.py
@@ -123,6 +123,7 @@
config, default, plugins, question,
(interfaces.IAuthenticator, interfaces.IInstaller))
+
def get_email(more=False, invalid=False):
"""Prompt for valid email address.
@@ -209,6 +210,7 @@
else:
return []
+
def get_valid_domains(domains):
"""Helper method for choose_names that implements basic checks
on domain names
@@ -226,6 +228,7 @@
continue
return valid_domains
+
def _filter_names(names):
"""Determine which names the user would like to select from a list.
@@ -250,7 +253,41 @@
"Please enter in your domain name(s) (comma and/or space separated) ")
if code == display_util.OK:
- return display_util.separate_list_input(input_)
+ invalid_domains = dict()
+ retry_message = ""
+ try:
+ domain_list = display_util.separate_list_input(input_)
+ except UnicodeEncodeError:
+ domain_list = []
+ retry_message = (
+ "Internationalized domain names are not presently "
+ "supported.{0}{0}Would you like to re-enter the "
+ "names?{0}").format(os.linesep)
+
+ for domain in domain_list:
+ try:
+ le_util.check_domain_sanity(domain)
+ except errors.ConfigurationError as e:
+ invalid_domains[domain] = e.message
+
+ if len(invalid_domains):
+ retry_message = (
+ "One or more of the entered domain names was not valid:"
+ "{0}{0}").format(os.linesep)
+ for domain in invalid_domains:
+ retry_message = retry_message + "{1}: {2}{0}".format(
+ os.linesep, domain, invalid_domains[domain])
+ retry_message = retry_message + (
+ "{0}Would you like to re-enter the names?{0}").format(
+ os.linesep)
+
+ if retry_message:
+ # We had error in input
+ retry = util(interfaces.IDisplay).yesno(retry_message)
+ if retry:
+ return _choose_names_manually()
+ else:
+ return domain_list
return []
|
{"golden_diff": "diff --git a/letsencrypt/display/ops.py b/letsencrypt/display/ops.py\n--- a/letsencrypt/display/ops.py\n+++ b/letsencrypt/display/ops.py\n@@ -123,6 +123,7 @@\n config, default, plugins, question,\n (interfaces.IAuthenticator, interfaces.IInstaller))\n \n+\n def get_email(more=False, invalid=False):\n \"\"\"Prompt for valid email address.\n \n@@ -209,6 +210,7 @@\n else:\n return []\n \n+\n def get_valid_domains(domains):\n \"\"\"Helper method for choose_names that implements basic checks\n on domain names\n@@ -226,6 +228,7 @@\n continue\n return valid_domains\n \n+\n def _filter_names(names):\n \"\"\"Determine which names the user would like to select from a list.\n \n@@ -250,7 +253,41 @@\n \"Please enter in your domain name(s) (comma and/or space separated) \")\n \n if code == display_util.OK:\n- return display_util.separate_list_input(input_)\n+ invalid_domains = dict()\n+ retry_message = \"\"\n+ try:\n+ domain_list = display_util.separate_list_input(input_)\n+ except UnicodeEncodeError:\n+ domain_list = []\n+ retry_message = (\n+ \"Internationalized domain names are not presently \"\n+ \"supported.{0}{0}Would you like to re-enter the \"\n+ \"names?{0}\").format(os.linesep)\n+\n+ for domain in domain_list:\n+ try:\n+ le_util.check_domain_sanity(domain)\n+ except errors.ConfigurationError as e:\n+ invalid_domains[domain] = e.message\n+\n+ if len(invalid_domains):\n+ retry_message = (\n+ \"One or more of the entered domain names was not valid:\"\n+ \"{0}{0}\").format(os.linesep)\n+ for domain in invalid_domains:\n+ retry_message = retry_message + \"{1}: {2}{0}\".format(\n+ os.linesep, domain, invalid_domains[domain])\n+ retry_message = retry_message + (\n+ \"{0}Would you like to re-enter the names?{0}\").format(\n+ os.linesep)\n+\n+ if retry_message:\n+ # We had error in input\n+ retry = util(interfaces.IDisplay).yesno(retry_message)\n+ if retry:\n+ return _choose_names_manually()\n+ else:\n+ return domain_list\n return []\n", "issue": "Domain with german umlauts ('ascii' codec can't encode character)\nCentOS 7.1.1503\n\nI tried to create an certificat with domain contains german umlauts. Domain is: ent\u00e4.de\nI getting in the console this error:\n\n```\nAn unexpected error occurred:\nUnicodeEncodeError: 'ascii' codec can't encode character u'\\xe4' in position 3: ordinal not in range(128)\nPlease see the logfiles in /var/log/letsencrypt for more details.\n```\n\nLogfile:\n\n``` python\n2015-12-08 17:58:44,353:DEBUG:letsencrypt.cli:Exiting abnormally:\nTraceback (most recent call last):\n File \"/root/.local/share/letsencrypt/bin/letsencrypt\", line 11, in <module>\n sys.exit(main())\n File \"/root/.local/share/letsencrypt/lib/python2.7/site-packages/letsencrypt/cli.py\", line 1283, in main\n return args.func(args, config, plugins)\n File \"/root/.local/share/letsencrypt/lib/python2.7/site-packages/letsencrypt/cli.py\", line 511, in obtain_cert\n domains = _find_domains(args, installer)\n File \"/root/.local/share/letsencrypt/lib/python2.7/site-packages/letsencrypt/cli.py\", line 106, in _find_domains\n domains = display_ops.choose_names(installer)\n File \"/root/.local/share/letsencrypt/lib/python2.7/site-packages/letsencrypt/display/ops.py\", line 187, in choose_names\n return _choose_names_manually()\n File \"/root/.local/share/letsencrypt/lib/python2.7/site-packages/letsencrypt/display/ops.py\", line 235, in _choose_names_manually\n return display_util.separate_list_input(input_)\n File \"/root/.local/share/letsencrypt/lib/python2.7/site-packages/letsencrypt/display/util.py\", line 419, in separate_list_input\n return [str(string) for string in no_commas.split()]\nUnicodeEncodeError: 'ascii' codec can't encode character u'\\xe4' in position 3: ordinal not in range(128)\n```\n\nIs there a way to fix this?\n\n", "before_files": [{"content": "\"\"\"Contains UI methods for LE user operations.\"\"\"\nimport logging\nimport os\n\nimport zope.component\n\nfrom letsencrypt import errors\nfrom letsencrypt import interfaces\nfrom letsencrypt import le_util\nfrom letsencrypt.display import util as display_util\n\n\nlogger = logging.getLogger(__name__)\n\n# Define a helper function to avoid verbose code\nutil = zope.component.getUtility\n\n\ndef choose_plugin(prepared, question):\n \"\"\"Allow the user to choose their plugin.\n\n :param list prepared: List of `~.PluginEntryPoint`.\n :param str question: Question to be presented to the user.\n\n :returns: Plugin entry point chosen by the user.\n :rtype: `~.PluginEntryPoint`\n\n \"\"\"\n opts = [plugin_ep.description_with_name +\n (\" [Misconfigured]\" if plugin_ep.misconfigured else \"\")\n for plugin_ep in prepared]\n\n while True:\n code, index = util(interfaces.IDisplay).menu(\n question, opts, help_label=\"More Info\")\n\n if code == display_util.OK:\n plugin_ep = prepared[index]\n if plugin_ep.misconfigured:\n util(interfaces.IDisplay).notification(\n \"The selected plugin encountered an error while parsing \"\n \"your server configuration and cannot be used. The error \"\n \"was:\\n\\n{0}\".format(plugin_ep.prepare()),\n height=display_util.HEIGHT, pause=False)\n else:\n return plugin_ep\n elif code == display_util.HELP:\n if prepared[index].misconfigured:\n msg = \"Reported Error: %s\" % prepared[index].prepare()\n else:\n msg = prepared[index].init().more_info()\n util(interfaces.IDisplay).notification(\n msg, height=display_util.HEIGHT)\n else:\n return None\n\n\ndef pick_plugin(config, default, plugins, question, ifaces):\n \"\"\"Pick plugin.\n\n :param letsencrypt.interfaces.IConfig: Configuration\n :param str default: Plugin name supplied by user or ``None``.\n :param letsencrypt.plugins.disco.PluginsRegistry plugins:\n All plugins registered as entry points.\n :param str question: Question to be presented to the user in case\n multiple candidates are found.\n :param list ifaces: Interfaces that plugins must provide.\n\n :returns: Initialized plugin.\n :rtype: IPlugin\n\n \"\"\"\n if default is not None:\n # throw more UX-friendly error if default not in plugins\n filtered = plugins.filter(lambda p_ep: p_ep.name == default)\n else:\n filtered = plugins.visible().ifaces(ifaces)\n\n filtered.init(config)\n verified = filtered.verify(ifaces)\n verified.prepare()\n prepared = verified.available()\n\n if len(prepared) > 1:\n logger.debug(\"Multiple candidate plugins: %s\", prepared)\n plugin_ep = choose_plugin(prepared.values(), question)\n if plugin_ep is None:\n return None\n else:\n return plugin_ep.init()\n elif len(prepared) == 1:\n plugin_ep = prepared.values()[0]\n logger.debug(\"Single candidate plugin: %s\", plugin_ep)\n if plugin_ep.misconfigured:\n return None\n return plugin_ep.init()\n else:\n logger.debug(\"No candidate plugin\")\n return None\n\n\ndef pick_authenticator(\n config, default, plugins, question=\"How would you \"\n \"like to authenticate with the Let's Encrypt CA?\"):\n \"\"\"Pick authentication plugin.\"\"\"\n return pick_plugin(\n config, default, plugins, question, (interfaces.IAuthenticator,))\n\n\ndef pick_installer(config, default, plugins,\n question=\"How would you like to install certificates?\"):\n \"\"\"Pick installer plugin.\"\"\"\n return pick_plugin(\n config, default, plugins, question, (interfaces.IInstaller,))\n\n\ndef pick_configurator(\n config, default, plugins,\n question=\"How would you like to authenticate and install \"\n \"certificates?\"):\n \"\"\"Pick configurator plugin.\"\"\"\n return pick_plugin(\n config, default, plugins, question,\n (interfaces.IAuthenticator, interfaces.IInstaller))\n\ndef get_email(more=False, invalid=False):\n \"\"\"Prompt for valid email address.\n\n :param bool more: explain why the email is strongly advisable, but how to\n skip it\n :param bool invalid: true if the user just typed something, but it wasn't\n a valid-looking email\n\n :returns: Email or ``None`` if cancelled by user.\n :rtype: str\n\n \"\"\"\n msg = \"Enter email address (used for urgent notices and lost key recovery)\"\n if invalid:\n msg = \"There seem to be problems with that address. \" + msg\n if more:\n msg += ('\\n\\nIf you really want to skip this, you can run the client with '\n '--register-unsafely-without-email but make sure you backup your '\n 'account key from /etc/letsencrypt/accounts\\n\\n')\n code, email = zope.component.getUtility(interfaces.IDisplay).input(msg)\n\n if code == display_util.OK:\n if le_util.safe_email(email):\n return email\n else:\n # TODO catch the server's ACME invalid email address error, and\n # make a similar call when that happens\n return get_email(more=True, invalid=(email != \"\"))\n else:\n return None\n\n\ndef choose_account(accounts):\n \"\"\"Choose an account.\n\n :param list accounts: Containing at least one\n :class:`~letsencrypt.account.Account`\n\n \"\"\"\n # Note this will get more complicated once we start recording authorizations\n labels = [acc.slug for acc in accounts]\n\n code, index = util(interfaces.IDisplay).menu(\n \"Please choose an account\", labels)\n if code == display_util.OK:\n return accounts[index]\n else:\n return None\n\n\ndef choose_names(installer):\n \"\"\"Display screen to select domains to validate.\n\n :param installer: An installer object\n :type installer: :class:`letsencrypt.interfaces.IInstaller`\n\n :returns: List of selected names\n :rtype: `list` of `str`\n\n \"\"\"\n if installer is None:\n logger.debug(\"No installer, picking names manually\")\n return _choose_names_manually()\n\n domains = list(installer.get_all_names())\n names = get_valid_domains(domains)\n\n if not names:\n manual = util(interfaces.IDisplay).yesno(\n \"No names were found in your configuration files.{0}You should \"\n \"specify ServerNames in your config files in order to allow for \"\n \"accurate installation of your certificate.{0}\"\n \"If you do use the default vhost, you may specify the name \"\n \"manually. Would you like to continue?{0}\".format(os.linesep))\n\n if manual:\n return _choose_names_manually()\n else:\n return []\n\n code, names = _filter_names(names)\n if code == display_util.OK and names:\n return names\n else:\n return []\n\ndef get_valid_domains(domains):\n \"\"\"Helper method for choose_names that implements basic checks\n on domain names\n\n :param list domains: Domain names to validate\n :return: List of valid domains\n :rtype: list\n \"\"\"\n valid_domains = []\n for domain in domains:\n try:\n le_util.check_domain_sanity(domain)\n valid_domains.append(domain)\n except errors.ConfigurationError:\n continue\n return valid_domains\n\ndef _filter_names(names):\n \"\"\"Determine which names the user would like to select from a list.\n\n :param list names: domain names\n\n :returns: tuple of the form (`code`, `names`) where\n `code` - str display exit code\n `names` - list of names selected\n :rtype: tuple\n\n \"\"\"\n code, names = util(interfaces.IDisplay).checklist(\n \"Which names would you like to activate HTTPS for?\",\n tags=names)\n return code, [str(s) for s in names]\n\n\ndef _choose_names_manually():\n \"\"\"Manually input names for those without an installer.\"\"\"\n\n code, input_ = util(interfaces.IDisplay).input(\n \"Please enter in your domain name(s) (comma and/or space separated) \")\n\n if code == display_util.OK:\n return display_util.separate_list_input(input_)\n return []\n\n\ndef success_installation(domains):\n \"\"\"Display a box confirming the installation of HTTPS.\n\n .. todo:: This should be centered on the screen\n\n :param list domains: domain names which were enabled\n\n \"\"\"\n util(interfaces.IDisplay).notification(\n \"Congratulations! You have successfully enabled {0}{1}{1}\"\n \"You should test your configuration at:{1}{2}\".format(\n _gen_https_names(domains),\n os.linesep,\n os.linesep.join(_gen_ssl_lab_urls(domains))),\n height=(10 + len(domains)),\n pause=False)\n\n\ndef success_renewal(domains):\n \"\"\"Display a box confirming the renewal of an existing certificate.\n\n .. todo:: This should be centered on the screen\n\n :param list domains: domain names which were renewed\n\n \"\"\"\n util(interfaces.IDisplay).notification(\n \"Your existing certificate has been successfully renewed, and the \"\n \"new certificate has been installed.{1}{1}\"\n \"The new certificate covers the following domains: {0}{1}{1}\"\n \"You should test your configuration at:{1}{2}\".format(\n _gen_https_names(domains),\n os.linesep,\n os.linesep.join(_gen_ssl_lab_urls(domains))),\n height=(14 + len(domains)),\n pause=False)\n\n\ndef _gen_ssl_lab_urls(domains):\n \"\"\"Returns a list of urls.\n\n :param list domains: Each domain is a 'str'\n\n \"\"\"\n return [\"https://www.ssllabs.com/ssltest/analyze.html?d=%s\" % dom for dom in domains]\n\n\ndef _gen_https_names(domains):\n \"\"\"Returns a string of the https domains.\n\n Domains are formatted nicely with https:// prepended to each.\n\n :param list domains: Each domain is a 'str'\n\n \"\"\"\n if len(domains) == 1:\n return \"https://{0}\".format(domains[0])\n elif len(domains) == 2:\n return \"https://{dom[0]} and https://{dom[1]}\".format(dom=domains)\n elif len(domains) > 2:\n return \"{0}{1}{2}\".format(\n \", \".join(\"https://%s\" % dom for dom in domains[:-1]),\n \", and https://\",\n domains[-1])\n\n return \"\"\n", "path": "letsencrypt/display/ops.py"}], "after_files": [{"content": "\"\"\"Contains UI methods for LE user operations.\"\"\"\nimport logging\nimport os\n\nimport zope.component\n\nfrom letsencrypt import errors\nfrom letsencrypt import interfaces\nfrom letsencrypt import le_util\nfrom letsencrypt.display import util as display_util\n\n\nlogger = logging.getLogger(__name__)\n\n# Define a helper function to avoid verbose code\nutil = zope.component.getUtility\n\n\ndef choose_plugin(prepared, question):\n \"\"\"Allow the user to choose their plugin.\n\n :param list prepared: List of `~.PluginEntryPoint`.\n :param str question: Question to be presented to the user.\n\n :returns: Plugin entry point chosen by the user.\n :rtype: `~.PluginEntryPoint`\n\n \"\"\"\n opts = [plugin_ep.description_with_name +\n (\" [Misconfigured]\" if plugin_ep.misconfigured else \"\")\n for plugin_ep in prepared]\n\n while True:\n code, index = util(interfaces.IDisplay).menu(\n question, opts, help_label=\"More Info\")\n\n if code == display_util.OK:\n plugin_ep = prepared[index]\n if plugin_ep.misconfigured:\n util(interfaces.IDisplay).notification(\n \"The selected plugin encountered an error while parsing \"\n \"your server configuration and cannot be used. The error \"\n \"was:\\n\\n{0}\".format(plugin_ep.prepare()),\n height=display_util.HEIGHT, pause=False)\n else:\n return plugin_ep\n elif code == display_util.HELP:\n if prepared[index].misconfigured:\n msg = \"Reported Error: %s\" % prepared[index].prepare()\n else:\n msg = prepared[index].init().more_info()\n util(interfaces.IDisplay).notification(\n msg, height=display_util.HEIGHT)\n else:\n return None\n\n\ndef pick_plugin(config, default, plugins, question, ifaces):\n \"\"\"Pick plugin.\n\n :param letsencrypt.interfaces.IConfig: Configuration\n :param str default: Plugin name supplied by user or ``None``.\n :param letsencrypt.plugins.disco.PluginsRegistry plugins:\n All plugins registered as entry points.\n :param str question: Question to be presented to the user in case\n multiple candidates are found.\n :param list ifaces: Interfaces that plugins must provide.\n\n :returns: Initialized plugin.\n :rtype: IPlugin\n\n \"\"\"\n if default is not None:\n # throw more UX-friendly error if default not in plugins\n filtered = plugins.filter(lambda p_ep: p_ep.name == default)\n else:\n filtered = plugins.visible().ifaces(ifaces)\n\n filtered.init(config)\n verified = filtered.verify(ifaces)\n verified.prepare()\n prepared = verified.available()\n\n if len(prepared) > 1:\n logger.debug(\"Multiple candidate plugins: %s\", prepared)\n plugin_ep = choose_plugin(prepared.values(), question)\n if plugin_ep is None:\n return None\n else:\n return plugin_ep.init()\n elif len(prepared) == 1:\n plugin_ep = prepared.values()[0]\n logger.debug(\"Single candidate plugin: %s\", plugin_ep)\n if plugin_ep.misconfigured:\n return None\n return plugin_ep.init()\n else:\n logger.debug(\"No candidate plugin\")\n return None\n\n\ndef pick_authenticator(\n config, default, plugins, question=\"How would you \"\n \"like to authenticate with the Let's Encrypt CA?\"):\n \"\"\"Pick authentication plugin.\"\"\"\n return pick_plugin(\n config, default, plugins, question, (interfaces.IAuthenticator,))\n\n\ndef pick_installer(config, default, plugins,\n question=\"How would you like to install certificates?\"):\n \"\"\"Pick installer plugin.\"\"\"\n return pick_plugin(\n config, default, plugins, question, (interfaces.IInstaller,))\n\n\ndef pick_configurator(\n config, default, plugins,\n question=\"How would you like to authenticate and install \"\n \"certificates?\"):\n \"\"\"Pick configurator plugin.\"\"\"\n return pick_plugin(\n config, default, plugins, question,\n (interfaces.IAuthenticator, interfaces.IInstaller))\n\n\ndef get_email(more=False, invalid=False):\n \"\"\"Prompt for valid email address.\n\n :param bool more: explain why the email is strongly advisable, but how to\n skip it\n :param bool invalid: true if the user just typed something, but it wasn't\n a valid-looking email\n\n :returns: Email or ``None`` if cancelled by user.\n :rtype: str\n\n \"\"\"\n msg = \"Enter email address (used for urgent notices and lost key recovery)\"\n if invalid:\n msg = \"There seem to be problems with that address. \" + msg\n if more:\n msg += ('\\n\\nIf you really want to skip this, you can run the client with '\n '--register-unsafely-without-email but make sure you backup your '\n 'account key from /etc/letsencrypt/accounts\\n\\n')\n code, email = zope.component.getUtility(interfaces.IDisplay).input(msg)\n\n if code == display_util.OK:\n if le_util.safe_email(email):\n return email\n else:\n # TODO catch the server's ACME invalid email address error, and\n # make a similar call when that happens\n return get_email(more=True, invalid=(email != \"\"))\n else:\n return None\n\n\ndef choose_account(accounts):\n \"\"\"Choose an account.\n\n :param list accounts: Containing at least one\n :class:`~letsencrypt.account.Account`\n\n \"\"\"\n # Note this will get more complicated once we start recording authorizations\n labels = [acc.slug for acc in accounts]\n\n code, index = util(interfaces.IDisplay).menu(\n \"Please choose an account\", labels)\n if code == display_util.OK:\n return accounts[index]\n else:\n return None\n\n\ndef choose_names(installer):\n \"\"\"Display screen to select domains to validate.\n\n :param installer: An installer object\n :type installer: :class:`letsencrypt.interfaces.IInstaller`\n\n :returns: List of selected names\n :rtype: `list` of `str`\n\n \"\"\"\n if installer is None:\n logger.debug(\"No installer, picking names manually\")\n return _choose_names_manually()\n\n domains = list(installer.get_all_names())\n names = get_valid_domains(domains)\n\n if not names:\n manual = util(interfaces.IDisplay).yesno(\n \"No names were found in your configuration files.{0}You should \"\n \"specify ServerNames in your config files in order to allow for \"\n \"accurate installation of your certificate.{0}\"\n \"If you do use the default vhost, you may specify the name \"\n \"manually. Would you like to continue?{0}\".format(os.linesep))\n\n if manual:\n return _choose_names_manually()\n else:\n return []\n\n code, names = _filter_names(names)\n if code == display_util.OK and names:\n return names\n else:\n return []\n\n\ndef get_valid_domains(domains):\n \"\"\"Helper method for choose_names that implements basic checks\n on domain names\n\n :param list domains: Domain names to validate\n :return: List of valid domains\n :rtype: list\n \"\"\"\n valid_domains = []\n for domain in domains:\n try:\n le_util.check_domain_sanity(domain)\n valid_domains.append(domain)\n except errors.ConfigurationError:\n continue\n return valid_domains\n\n\ndef _filter_names(names):\n \"\"\"Determine which names the user would like to select from a list.\n\n :param list names: domain names\n\n :returns: tuple of the form (`code`, `names`) where\n `code` - str display exit code\n `names` - list of names selected\n :rtype: tuple\n\n \"\"\"\n code, names = util(interfaces.IDisplay).checklist(\n \"Which names would you like to activate HTTPS for?\",\n tags=names)\n return code, [str(s) for s in names]\n\n\ndef _choose_names_manually():\n \"\"\"Manually input names for those without an installer.\"\"\"\n\n code, input_ = util(interfaces.IDisplay).input(\n \"Please enter in your domain name(s) (comma and/or space separated) \")\n\n if code == display_util.OK:\n invalid_domains = dict()\n retry_message = \"\"\n try:\n domain_list = display_util.separate_list_input(input_)\n except UnicodeEncodeError:\n domain_list = []\n retry_message = (\n \"Internationalized domain names are not presently \"\n \"supported.{0}{0}Would you like to re-enter the \"\n \"names?{0}\").format(os.linesep)\n\n for domain in domain_list:\n try:\n le_util.check_domain_sanity(domain)\n except errors.ConfigurationError as e:\n invalid_domains[domain] = e.message\n\n if len(invalid_domains):\n retry_message = (\n \"One or more of the entered domain names was not valid:\"\n \"{0}{0}\").format(os.linesep)\n for domain in invalid_domains:\n retry_message = retry_message + \"{1}: {2}{0}\".format(\n os.linesep, domain, invalid_domains[domain])\n retry_message = retry_message + (\n \"{0}Would you like to re-enter the names?{0}\").format(\n os.linesep)\n\n if retry_message:\n # We had error in input\n retry = util(interfaces.IDisplay).yesno(retry_message)\n if retry:\n return _choose_names_manually()\n else:\n return domain_list\n return []\n\n\ndef success_installation(domains):\n \"\"\"Display a box confirming the installation of HTTPS.\n\n .. todo:: This should be centered on the screen\n\n :param list domains: domain names which were enabled\n\n \"\"\"\n util(interfaces.IDisplay).notification(\n \"Congratulations! You have successfully enabled {0}{1}{1}\"\n \"You should test your configuration at:{1}{2}\".format(\n _gen_https_names(domains),\n os.linesep,\n os.linesep.join(_gen_ssl_lab_urls(domains))),\n height=(10 + len(domains)),\n pause=False)\n\n\ndef success_renewal(domains):\n \"\"\"Display a box confirming the renewal of an existing certificate.\n\n .. todo:: This should be centered on the screen\n\n :param list domains: domain names which were renewed\n\n \"\"\"\n util(interfaces.IDisplay).notification(\n \"Your existing certificate has been successfully renewed, and the \"\n \"new certificate has been installed.{1}{1}\"\n \"The new certificate covers the following domains: {0}{1}{1}\"\n \"You should test your configuration at:{1}{2}\".format(\n _gen_https_names(domains),\n os.linesep,\n os.linesep.join(_gen_ssl_lab_urls(domains))),\n height=(14 + len(domains)),\n pause=False)\n\n\ndef _gen_ssl_lab_urls(domains):\n \"\"\"Returns a list of urls.\n\n :param list domains: Each domain is a 'str'\n\n \"\"\"\n return [\"https://www.ssllabs.com/ssltest/analyze.html?d=%s\" % dom for dom in domains]\n\n\ndef _gen_https_names(domains):\n \"\"\"Returns a string of the https domains.\n\n Domains are formatted nicely with https:// prepended to each.\n\n :param list domains: Each domain is a 'str'\n\n \"\"\"\n if len(domains) == 1:\n return \"https://{0}\".format(domains[0])\n elif len(domains) == 2:\n return \"https://{dom[0]} and https://{dom[1]}\".format(dom=domains)\n elif len(domains) > 2:\n return \"{0}{1}{2}\".format(\n \", \".join(\"https://%s\" % dom for dom in domains[:-1]),\n \", and https://\",\n domains[-1])\n\n return \"\"\n", "path": "letsencrypt/display/ops.py"}]}
| 3,938 | 550 |
gh_patches_debug_16407
|
rasdani/github-patches
|
git_diff
|
buildbot__buildbot-5729
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
change_hook/poller not working for ReconfigurablePollingChangeSource
In [poller.py](https://github.com/buildbot/buildbot/blob/a0e1d8840e8856ead136a1ad6e2021931355af15/master/buildbot/www/hooks/poller.py#L40), the change sources are filtered like this:
```python
for source in change_svc:
if not isinstance(source, PollingChangeSource):
continue
```
This means that any pollers derived from the super-class `ReconfigurablePollingChangeSource` will not be found. Since [new code is supposed to use `ReconfigurablePollingChangeSource`](https://docs.buildbot.net/current/developer/cls-changesources.html?highlight=reconfigurablepollingchangesource#pollingchangesource), the code should probably read:
```python
for source in change_svc:
if not isinstance(source, ReconfigurablePollingChangeSource):
continue
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `master/buildbot/www/hooks/poller.py`
Content:
```
1 # This file is part of Buildbot. Buildbot is free software: you can
2 # redistribute it and/or modify it under the terms of the GNU General Public
3 # License as published by the Free Software Foundation, version 2.
4 #
5 # This program is distributed in the hope that it will be useful, but WITHOUT
6 # ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
7 # FOR A PARTICULAR PURPOSE. See the GNU General Public License for more
8 # details.
9 #
10 # You should have received a copy of the GNU General Public License along with
11 # this program; if not, write to the Free Software Foundation, Inc., 51
12 # Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
13 #
14 # Copyright Buildbot Team Members
15
16 # This change hook allows GitHub or a hand crafted curl invocation to "knock on
17 # the door" and trigger a change source to poll.
18
19
20 from buildbot.changes.base import PollingChangeSource
21 from buildbot.util import bytes2unicode
22 from buildbot.util import unicode2bytes
23 from buildbot.www.hooks.base import BaseHookHandler
24
25
26 class PollingHandler(BaseHookHandler):
27
28 def getChanges(self, req):
29 change_svc = req.site.master.change_svc
30 poll_all = b"poller" not in req.args
31
32 allow_all = True
33 allowed = []
34 if isinstance(self.options, dict) and b"allowed" in self.options:
35 allow_all = False
36 allowed = self.options[b"allowed"]
37
38 pollers = []
39
40 for source in change_svc:
41 if not isinstance(source, PollingChangeSource):
42 continue
43 if not hasattr(source, "name"):
44 continue
45 if (not poll_all and
46 unicode2bytes(source.name) not in req.args[b'poller']):
47 continue
48 if not allow_all and unicode2bytes(source.name) not in allowed:
49 continue
50 pollers.append(source)
51
52 if not poll_all:
53 missing = (set(req.args[b'poller']) -
54 set(unicode2bytes(s.name) for s in pollers))
55 if missing:
56 raise ValueError("Could not find pollers: {}".format(
57 bytes2unicode(b",".join(missing))))
58
59 for p in pollers:
60 p.force()
61
62 return [], None
63
64
65 poller = PollingHandler
66
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/master/buildbot/www/hooks/poller.py b/master/buildbot/www/hooks/poller.py
--- a/master/buildbot/www/hooks/poller.py
+++ b/master/buildbot/www/hooks/poller.py
@@ -17,7 +17,7 @@
# the door" and trigger a change source to poll.
-from buildbot.changes.base import PollingChangeSource
+from buildbot.changes.base import ReconfigurablePollingChangeSource
from buildbot.util import bytes2unicode
from buildbot.util import unicode2bytes
from buildbot.www.hooks.base import BaseHookHandler
@@ -38,7 +38,7 @@
pollers = []
for source in change_svc:
- if not isinstance(source, PollingChangeSource):
+ if not isinstance(source, ReconfigurablePollingChangeSource):
continue
if not hasattr(source, "name"):
continue
|
{"golden_diff": "diff --git a/master/buildbot/www/hooks/poller.py b/master/buildbot/www/hooks/poller.py\n--- a/master/buildbot/www/hooks/poller.py\n+++ b/master/buildbot/www/hooks/poller.py\n@@ -17,7 +17,7 @@\n # the door\" and trigger a change source to poll.\n \n \n-from buildbot.changes.base import PollingChangeSource\n+from buildbot.changes.base import ReconfigurablePollingChangeSource\n from buildbot.util import bytes2unicode\n from buildbot.util import unicode2bytes\n from buildbot.www.hooks.base import BaseHookHandler\n@@ -38,7 +38,7 @@\n pollers = []\n \n for source in change_svc:\n- if not isinstance(source, PollingChangeSource):\n+ if not isinstance(source, ReconfigurablePollingChangeSource):\n continue\n if not hasattr(source, \"name\"):\n continue\n", "issue": "change_hook/poller not working for ReconfigurablePollingChangeSource\nIn [poller.py](https://github.com/buildbot/buildbot/blob/a0e1d8840e8856ead136a1ad6e2021931355af15/master/buildbot/www/hooks/poller.py#L40), the change sources are filtered like this:\r\n\r\n```python\r\n for source in change_svc:\r\n if not isinstance(source, PollingChangeSource):\r\n continue\r\n```\r\n\r\nThis means that any pollers derived from the super-class `ReconfigurablePollingChangeSource` will not be found. Since [new code is supposed to use `ReconfigurablePollingChangeSource`](https://docs.buildbot.net/current/developer/cls-changesources.html?highlight=reconfigurablepollingchangesource#pollingchangesource), the code should probably read:\r\n\r\n```python\r\n for source in change_svc:\r\n if not isinstance(source, ReconfigurablePollingChangeSource):\r\n continue\r\n```\r\n\n", "before_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\n# This change hook allows GitHub or a hand crafted curl invocation to \"knock on\n# the door\" and trigger a change source to poll.\n\n\nfrom buildbot.changes.base import PollingChangeSource\nfrom buildbot.util import bytes2unicode\nfrom buildbot.util import unicode2bytes\nfrom buildbot.www.hooks.base import BaseHookHandler\n\n\nclass PollingHandler(BaseHookHandler):\n\n def getChanges(self, req):\n change_svc = req.site.master.change_svc\n poll_all = b\"poller\" not in req.args\n\n allow_all = True\n allowed = []\n if isinstance(self.options, dict) and b\"allowed\" in self.options:\n allow_all = False\n allowed = self.options[b\"allowed\"]\n\n pollers = []\n\n for source in change_svc:\n if not isinstance(source, PollingChangeSource):\n continue\n if not hasattr(source, \"name\"):\n continue\n if (not poll_all and\n unicode2bytes(source.name) not in req.args[b'poller']):\n continue\n if not allow_all and unicode2bytes(source.name) not in allowed:\n continue\n pollers.append(source)\n\n if not poll_all:\n missing = (set(req.args[b'poller']) -\n set(unicode2bytes(s.name) for s in pollers))\n if missing:\n raise ValueError(\"Could not find pollers: {}\".format(\n bytes2unicode(b\",\".join(missing))))\n\n for p in pollers:\n p.force()\n\n return [], None\n\n\npoller = PollingHandler\n", "path": "master/buildbot/www/hooks/poller.py"}], "after_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\n# This change hook allows GitHub or a hand crafted curl invocation to \"knock on\n# the door\" and trigger a change source to poll.\n\n\nfrom buildbot.changes.base import ReconfigurablePollingChangeSource\nfrom buildbot.util import bytes2unicode\nfrom buildbot.util import unicode2bytes\nfrom buildbot.www.hooks.base import BaseHookHandler\n\n\nclass PollingHandler(BaseHookHandler):\n\n def getChanges(self, req):\n change_svc = req.site.master.change_svc\n poll_all = b\"poller\" not in req.args\n\n allow_all = True\n allowed = []\n if isinstance(self.options, dict) and b\"allowed\" in self.options:\n allow_all = False\n allowed = self.options[b\"allowed\"]\n\n pollers = []\n\n for source in change_svc:\n if not isinstance(source, ReconfigurablePollingChangeSource):\n continue\n if not hasattr(source, \"name\"):\n continue\n if (not poll_all and\n unicode2bytes(source.name) not in req.args[b'poller']):\n continue\n if not allow_all and unicode2bytes(source.name) not in allowed:\n continue\n pollers.append(source)\n\n if not poll_all:\n missing = (set(req.args[b'poller']) -\n set(unicode2bytes(s.name) for s in pollers))\n if missing:\n raise ValueError(\"Could not find pollers: {}\".format(\n bytes2unicode(b\",\".join(missing))))\n\n for p in pollers:\n p.force()\n\n return [], None\n\n\npoller = PollingHandler\n", "path": "master/buildbot/www/hooks/poller.py"}]}
| 1,117 | 194 |
gh_patches_debug_19683
|
rasdani/github-patches
|
git_diff
|
pallets__werkzeug-2413
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`any` converter should validate value to `url_for`
Expectation:
When using `url_for` for an endpoint with an `<any(foo, bar):arg>` argument in its route, it will raise an error for arguments that are not part of the any statement.
Actual result:
It returns an invalid URL
Example:
```
from flask import Flask, url_for, redirect
app = Flask(__name__)
@app.route("/any/<any(foo, bar):part>")
def url_with_any(part):
return part
@app.route("/")
def index():
return redirect(url_for("url_with_any", part="doesnotexist")) # this will 404
```
Environment:
- Python version: Python 3.10.4
- Flask version: Flask 2.1.1
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/werkzeug/routing/converters.py`
Content:
```
1 import re
2 import typing as t
3 import uuid
4
5 from ..urls import _fast_url_quote
6
7 if t.TYPE_CHECKING:
8 from .map import Map
9
10
11 class ValidationError(ValueError):
12 """Validation error. If a rule converter raises this exception the rule
13 does not match the current URL and the next URL is tried.
14 """
15
16
17 class BaseConverter:
18 """Base class for all converters."""
19
20 regex = "[^/]+"
21 weight = 100
22 part_isolating = True
23
24 def __init__(self, map: "Map", *args: t.Any, **kwargs: t.Any) -> None:
25 self.map = map
26
27 def to_python(self, value: str) -> t.Any:
28 return value
29
30 def to_url(self, value: t.Any) -> str:
31 if isinstance(value, (bytes, bytearray)):
32 return _fast_url_quote(value)
33 return _fast_url_quote(str(value).encode(self.map.charset))
34
35
36 class UnicodeConverter(BaseConverter):
37 """This converter is the default converter and accepts any string but
38 only one path segment. Thus the string can not include a slash.
39
40 This is the default validator.
41
42 Example::
43
44 Rule('/pages/<page>'),
45 Rule('/<string(length=2):lang_code>')
46
47 :param map: the :class:`Map`.
48 :param minlength: the minimum length of the string. Must be greater
49 or equal 1.
50 :param maxlength: the maximum length of the string.
51 :param length: the exact length of the string.
52 """
53
54 part_isolating = True
55
56 def __init__(
57 self,
58 map: "Map",
59 minlength: int = 1,
60 maxlength: t.Optional[int] = None,
61 length: t.Optional[int] = None,
62 ) -> None:
63 super().__init__(map)
64 if length is not None:
65 length_regex = f"{{{int(length)}}}"
66 else:
67 if maxlength is None:
68 maxlength_value = ""
69 else:
70 maxlength_value = str(int(maxlength))
71 length_regex = f"{{{int(minlength)},{maxlength_value}}}"
72 self.regex = f"[^/]{length_regex}"
73
74
75 class AnyConverter(BaseConverter):
76 """Matches one of the items provided. Items can either be Python
77 identifiers or strings::
78
79 Rule('/<any(about, help, imprint, class, "foo,bar"):page_name>')
80
81 :param map: the :class:`Map`.
82 :param items: this function accepts the possible items as positional
83 arguments.
84 """
85
86 part_isolating = True
87
88 def __init__(self, map: "Map", *items: str) -> None:
89 super().__init__(map)
90 self.regex = f"(?:{'|'.join([re.escape(x) for x in items])})"
91
92
93 class PathConverter(BaseConverter):
94 """Like the default :class:`UnicodeConverter`, but it also matches
95 slashes. This is useful for wikis and similar applications::
96
97 Rule('/<path:wikipage>')
98 Rule('/<path:wikipage>/edit')
99
100 :param map: the :class:`Map`.
101 """
102
103 regex = "[^/].*?"
104 weight = 200
105 part_isolating = False
106
107
108 class NumberConverter(BaseConverter):
109 """Baseclass for `IntegerConverter` and `FloatConverter`.
110
111 :internal:
112 """
113
114 weight = 50
115 num_convert: t.Callable = int
116 part_isolating = True
117
118 def __init__(
119 self,
120 map: "Map",
121 fixed_digits: int = 0,
122 min: t.Optional[int] = None,
123 max: t.Optional[int] = None,
124 signed: bool = False,
125 ) -> None:
126 if signed:
127 self.regex = self.signed_regex
128 super().__init__(map)
129 self.fixed_digits = fixed_digits
130 self.min = min
131 self.max = max
132 self.signed = signed
133
134 def to_python(self, value: str) -> t.Any:
135 if self.fixed_digits and len(value) != self.fixed_digits:
136 raise ValidationError()
137 value = self.num_convert(value)
138 if (self.min is not None and value < self.min) or (
139 self.max is not None and value > self.max
140 ):
141 raise ValidationError()
142 return value
143
144 def to_url(self, value: t.Any) -> str:
145 value = str(self.num_convert(value))
146 if self.fixed_digits:
147 value = value.zfill(self.fixed_digits)
148 return value
149
150 @property
151 def signed_regex(self) -> str:
152 return f"-?{self.regex}"
153
154
155 class IntegerConverter(NumberConverter):
156 """This converter only accepts integer values::
157
158 Rule("/page/<int:page>")
159
160 By default it only accepts unsigned, positive values. The ``signed``
161 parameter will enable signed, negative values. ::
162
163 Rule("/page/<int(signed=True):page>")
164
165 :param map: The :class:`Map`.
166 :param fixed_digits: The number of fixed digits in the URL. If you
167 set this to ``4`` for example, the rule will only match if the
168 URL looks like ``/0001/``. The default is variable length.
169 :param min: The minimal value.
170 :param max: The maximal value.
171 :param signed: Allow signed (negative) values.
172
173 .. versionadded:: 0.15
174 The ``signed`` parameter.
175 """
176
177 regex = r"\d+"
178 part_isolating = True
179
180
181 class FloatConverter(NumberConverter):
182 """This converter only accepts floating point values::
183
184 Rule("/probability/<float:probability>")
185
186 By default it only accepts unsigned, positive values. The ``signed``
187 parameter will enable signed, negative values. ::
188
189 Rule("/offset/<float(signed=True):offset>")
190
191 :param map: The :class:`Map`.
192 :param min: The minimal value.
193 :param max: The maximal value.
194 :param signed: Allow signed (negative) values.
195
196 .. versionadded:: 0.15
197 The ``signed`` parameter.
198 """
199
200 regex = r"\d+\.\d+"
201 num_convert = float
202 part_isolating = True
203
204 def __init__(
205 self,
206 map: "Map",
207 min: t.Optional[float] = None,
208 max: t.Optional[float] = None,
209 signed: bool = False,
210 ) -> None:
211 super().__init__(map, min=min, max=max, signed=signed) # type: ignore
212
213
214 class UUIDConverter(BaseConverter):
215 """This converter only accepts UUID strings::
216
217 Rule('/object/<uuid:identifier>')
218
219 .. versionadded:: 0.10
220
221 :param map: the :class:`Map`.
222 """
223
224 regex = (
225 r"[A-Fa-f0-9]{8}-[A-Fa-f0-9]{4}-"
226 r"[A-Fa-f0-9]{4}-[A-Fa-f0-9]{4}-[A-Fa-f0-9]{12}"
227 )
228 part_isolating = True
229
230 def to_python(self, value: str) -> uuid.UUID:
231 return uuid.UUID(value)
232
233 def to_url(self, value: uuid.UUID) -> str:
234 return str(value)
235
236
237 #: the default converter mapping for the map.
238 DEFAULT_CONVERTERS: t.Mapping[str, t.Type[BaseConverter]] = {
239 "default": UnicodeConverter,
240 "string": UnicodeConverter,
241 "any": AnyConverter,
242 "path": PathConverter,
243 "int": IntegerConverter,
244 "float": FloatConverter,
245 "uuid": UUIDConverter,
246 }
247
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/werkzeug/routing/converters.py b/src/werkzeug/routing/converters.py
--- a/src/werkzeug/routing/converters.py
+++ b/src/werkzeug/routing/converters.py
@@ -81,14 +81,25 @@
:param map: the :class:`Map`.
:param items: this function accepts the possible items as positional
arguments.
+
+ .. versionchanged:: 2.2
+ Value is validated when building a URL.
"""
part_isolating = True
def __init__(self, map: "Map", *items: str) -> None:
super().__init__(map)
+ self.items = set(items)
self.regex = f"(?:{'|'.join([re.escape(x) for x in items])})"
+ def to_url(self, value: t.Any) -> str:
+ if value in self.items:
+ return str(value)
+
+ valid_values = ", ".join(f"'{item}'" for item in sorted(self.items))
+ raise ValueError(f"'{value}' is not one of {valid_values}")
+
class PathConverter(BaseConverter):
"""Like the default :class:`UnicodeConverter`, but it also matches
|
{"golden_diff": "diff --git a/src/werkzeug/routing/converters.py b/src/werkzeug/routing/converters.py\n--- a/src/werkzeug/routing/converters.py\n+++ b/src/werkzeug/routing/converters.py\n@@ -81,14 +81,25 @@\n :param map: the :class:`Map`.\n :param items: this function accepts the possible items as positional\n arguments.\n+\n+ .. versionchanged:: 2.2\n+ Value is validated when building a URL.\n \"\"\"\n \n part_isolating = True\n \n def __init__(self, map: \"Map\", *items: str) -> None:\n super().__init__(map)\n+ self.items = set(items)\n self.regex = f\"(?:{'|'.join([re.escape(x) for x in items])})\"\n \n+ def to_url(self, value: t.Any) -> str:\n+ if value in self.items:\n+ return str(value)\n+\n+ valid_values = \", \".join(f\"'{item}'\" for item in sorted(self.items))\n+ raise ValueError(f\"'{value}' is not one of {valid_values}\")\n+\n \n class PathConverter(BaseConverter):\n \"\"\"Like the default :class:`UnicodeConverter`, but it also matches\n", "issue": "`any` converter should validate value to `url_for`\nExpectation:\r\nWhen using `url_for` for an endpoint with an `<any(foo, bar):arg>` argument in its route, it will raise an error for arguments that are not part of the any statement.\r\n\r\nActual result:\r\nIt returns an invalid URL\r\n\r\n\r\nExample:\r\n```\r\nfrom flask import Flask, url_for, redirect\r\n\r\napp = Flask(__name__)\r\n\r\[email protected](\"/any/<any(foo, bar):part>\")\r\ndef url_with_any(part):\r\n return part\r\n\r\[email protected](\"/\")\r\ndef index():\r\n return redirect(url_for(\"url_with_any\", part=\"doesnotexist\")) # this will 404\r\n\r\n```\r\n\r\nEnvironment:\r\n\r\n- Python version: Python 3.10.4\r\n- Flask version: Flask 2.1.1\r\n\n", "before_files": [{"content": "import re\nimport typing as t\nimport uuid\n\nfrom ..urls import _fast_url_quote\n\nif t.TYPE_CHECKING:\n from .map import Map\n\n\nclass ValidationError(ValueError):\n \"\"\"Validation error. If a rule converter raises this exception the rule\n does not match the current URL and the next URL is tried.\n \"\"\"\n\n\nclass BaseConverter:\n \"\"\"Base class for all converters.\"\"\"\n\n regex = \"[^/]+\"\n weight = 100\n part_isolating = True\n\n def __init__(self, map: \"Map\", *args: t.Any, **kwargs: t.Any) -> None:\n self.map = map\n\n def to_python(self, value: str) -> t.Any:\n return value\n\n def to_url(self, value: t.Any) -> str:\n if isinstance(value, (bytes, bytearray)):\n return _fast_url_quote(value)\n return _fast_url_quote(str(value).encode(self.map.charset))\n\n\nclass UnicodeConverter(BaseConverter):\n \"\"\"This converter is the default converter and accepts any string but\n only one path segment. Thus the string can not include a slash.\n\n This is the default validator.\n\n Example::\n\n Rule('/pages/<page>'),\n Rule('/<string(length=2):lang_code>')\n\n :param map: the :class:`Map`.\n :param minlength: the minimum length of the string. Must be greater\n or equal 1.\n :param maxlength: the maximum length of the string.\n :param length: the exact length of the string.\n \"\"\"\n\n part_isolating = True\n\n def __init__(\n self,\n map: \"Map\",\n minlength: int = 1,\n maxlength: t.Optional[int] = None,\n length: t.Optional[int] = None,\n ) -> None:\n super().__init__(map)\n if length is not None:\n length_regex = f\"{{{int(length)}}}\"\n else:\n if maxlength is None:\n maxlength_value = \"\"\n else:\n maxlength_value = str(int(maxlength))\n length_regex = f\"{{{int(minlength)},{maxlength_value}}}\"\n self.regex = f\"[^/]{length_regex}\"\n\n\nclass AnyConverter(BaseConverter):\n \"\"\"Matches one of the items provided. Items can either be Python\n identifiers or strings::\n\n Rule('/<any(about, help, imprint, class, \"foo,bar\"):page_name>')\n\n :param map: the :class:`Map`.\n :param items: this function accepts the possible items as positional\n arguments.\n \"\"\"\n\n part_isolating = True\n\n def __init__(self, map: \"Map\", *items: str) -> None:\n super().__init__(map)\n self.regex = f\"(?:{'|'.join([re.escape(x) for x in items])})\"\n\n\nclass PathConverter(BaseConverter):\n \"\"\"Like the default :class:`UnicodeConverter`, but it also matches\n slashes. This is useful for wikis and similar applications::\n\n Rule('/<path:wikipage>')\n Rule('/<path:wikipage>/edit')\n\n :param map: the :class:`Map`.\n \"\"\"\n\n regex = \"[^/].*?\"\n weight = 200\n part_isolating = False\n\n\nclass NumberConverter(BaseConverter):\n \"\"\"Baseclass for `IntegerConverter` and `FloatConverter`.\n\n :internal:\n \"\"\"\n\n weight = 50\n num_convert: t.Callable = int\n part_isolating = True\n\n def __init__(\n self,\n map: \"Map\",\n fixed_digits: int = 0,\n min: t.Optional[int] = None,\n max: t.Optional[int] = None,\n signed: bool = False,\n ) -> None:\n if signed:\n self.regex = self.signed_regex\n super().__init__(map)\n self.fixed_digits = fixed_digits\n self.min = min\n self.max = max\n self.signed = signed\n\n def to_python(self, value: str) -> t.Any:\n if self.fixed_digits and len(value) != self.fixed_digits:\n raise ValidationError()\n value = self.num_convert(value)\n if (self.min is not None and value < self.min) or (\n self.max is not None and value > self.max\n ):\n raise ValidationError()\n return value\n\n def to_url(self, value: t.Any) -> str:\n value = str(self.num_convert(value))\n if self.fixed_digits:\n value = value.zfill(self.fixed_digits)\n return value\n\n @property\n def signed_regex(self) -> str:\n return f\"-?{self.regex}\"\n\n\nclass IntegerConverter(NumberConverter):\n \"\"\"This converter only accepts integer values::\n\n Rule(\"/page/<int:page>\")\n\n By default it only accepts unsigned, positive values. The ``signed``\n parameter will enable signed, negative values. ::\n\n Rule(\"/page/<int(signed=True):page>\")\n\n :param map: The :class:`Map`.\n :param fixed_digits: The number of fixed digits in the URL. If you\n set this to ``4`` for example, the rule will only match if the\n URL looks like ``/0001/``. The default is variable length.\n :param min: The minimal value.\n :param max: The maximal value.\n :param signed: Allow signed (negative) values.\n\n .. versionadded:: 0.15\n The ``signed`` parameter.\n \"\"\"\n\n regex = r\"\\d+\"\n part_isolating = True\n\n\nclass FloatConverter(NumberConverter):\n \"\"\"This converter only accepts floating point values::\n\n Rule(\"/probability/<float:probability>\")\n\n By default it only accepts unsigned, positive values. The ``signed``\n parameter will enable signed, negative values. ::\n\n Rule(\"/offset/<float(signed=True):offset>\")\n\n :param map: The :class:`Map`.\n :param min: The minimal value.\n :param max: The maximal value.\n :param signed: Allow signed (negative) values.\n\n .. versionadded:: 0.15\n The ``signed`` parameter.\n \"\"\"\n\n regex = r\"\\d+\\.\\d+\"\n num_convert = float\n part_isolating = True\n\n def __init__(\n self,\n map: \"Map\",\n min: t.Optional[float] = None,\n max: t.Optional[float] = None,\n signed: bool = False,\n ) -> None:\n super().__init__(map, min=min, max=max, signed=signed) # type: ignore\n\n\nclass UUIDConverter(BaseConverter):\n \"\"\"This converter only accepts UUID strings::\n\n Rule('/object/<uuid:identifier>')\n\n .. versionadded:: 0.10\n\n :param map: the :class:`Map`.\n \"\"\"\n\n regex = (\n r\"[A-Fa-f0-9]{8}-[A-Fa-f0-9]{4}-\"\n r\"[A-Fa-f0-9]{4}-[A-Fa-f0-9]{4}-[A-Fa-f0-9]{12}\"\n )\n part_isolating = True\n\n def to_python(self, value: str) -> uuid.UUID:\n return uuid.UUID(value)\n\n def to_url(self, value: uuid.UUID) -> str:\n return str(value)\n\n\n#: the default converter mapping for the map.\nDEFAULT_CONVERTERS: t.Mapping[str, t.Type[BaseConverter]] = {\n \"default\": UnicodeConverter,\n \"string\": UnicodeConverter,\n \"any\": AnyConverter,\n \"path\": PathConverter,\n \"int\": IntegerConverter,\n \"float\": FloatConverter,\n \"uuid\": UUIDConverter,\n}\n", "path": "src/werkzeug/routing/converters.py"}], "after_files": [{"content": "import re\nimport typing as t\nimport uuid\n\nfrom ..urls import _fast_url_quote\n\nif t.TYPE_CHECKING:\n from .map import Map\n\n\nclass ValidationError(ValueError):\n \"\"\"Validation error. If a rule converter raises this exception the rule\n does not match the current URL and the next URL is tried.\n \"\"\"\n\n\nclass BaseConverter:\n \"\"\"Base class for all converters.\"\"\"\n\n regex = \"[^/]+\"\n weight = 100\n part_isolating = True\n\n def __init__(self, map: \"Map\", *args: t.Any, **kwargs: t.Any) -> None:\n self.map = map\n\n def to_python(self, value: str) -> t.Any:\n return value\n\n def to_url(self, value: t.Any) -> str:\n if isinstance(value, (bytes, bytearray)):\n return _fast_url_quote(value)\n return _fast_url_quote(str(value).encode(self.map.charset))\n\n\nclass UnicodeConverter(BaseConverter):\n \"\"\"This converter is the default converter and accepts any string but\n only one path segment. Thus the string can not include a slash.\n\n This is the default validator.\n\n Example::\n\n Rule('/pages/<page>'),\n Rule('/<string(length=2):lang_code>')\n\n :param map: the :class:`Map`.\n :param minlength: the minimum length of the string. Must be greater\n or equal 1.\n :param maxlength: the maximum length of the string.\n :param length: the exact length of the string.\n \"\"\"\n\n part_isolating = True\n\n def __init__(\n self,\n map: \"Map\",\n minlength: int = 1,\n maxlength: t.Optional[int] = None,\n length: t.Optional[int] = None,\n ) -> None:\n super().__init__(map)\n if length is not None:\n length_regex = f\"{{{int(length)}}}\"\n else:\n if maxlength is None:\n maxlength_value = \"\"\n else:\n maxlength_value = str(int(maxlength))\n length_regex = f\"{{{int(minlength)},{maxlength_value}}}\"\n self.regex = f\"[^/]{length_regex}\"\n\n\nclass AnyConverter(BaseConverter):\n \"\"\"Matches one of the items provided. Items can either be Python\n identifiers or strings::\n\n Rule('/<any(about, help, imprint, class, \"foo,bar\"):page_name>')\n\n :param map: the :class:`Map`.\n :param items: this function accepts the possible items as positional\n arguments.\n\n .. versionchanged:: 2.2\n Value is validated when building a URL.\n \"\"\"\n\n part_isolating = True\n\n def __init__(self, map: \"Map\", *items: str) -> None:\n super().__init__(map)\n self.items = set(items)\n self.regex = f\"(?:{'|'.join([re.escape(x) for x in items])})\"\n\n def to_url(self, value: t.Any) -> str:\n if value in self.items:\n return str(value)\n\n valid_values = \", \".join(f\"'{item}'\" for item in sorted(self.items))\n raise ValueError(f\"'{value}' is not one of {valid_values}\")\n\n\nclass PathConverter(BaseConverter):\n \"\"\"Like the default :class:`UnicodeConverter`, but it also matches\n slashes. This is useful for wikis and similar applications::\n\n Rule('/<path:wikipage>')\n Rule('/<path:wikipage>/edit')\n\n :param map: the :class:`Map`.\n \"\"\"\n\n regex = \"[^/].*?\"\n weight = 200\n part_isolating = False\n\n\nclass NumberConverter(BaseConverter):\n \"\"\"Baseclass for `IntegerConverter` and `FloatConverter`.\n\n :internal:\n \"\"\"\n\n weight = 50\n num_convert: t.Callable = int\n part_isolating = True\n\n def __init__(\n self,\n map: \"Map\",\n fixed_digits: int = 0,\n min: t.Optional[int] = None,\n max: t.Optional[int] = None,\n signed: bool = False,\n ) -> None:\n if signed:\n self.regex = self.signed_regex\n super().__init__(map)\n self.fixed_digits = fixed_digits\n self.min = min\n self.max = max\n self.signed = signed\n\n def to_python(self, value: str) -> t.Any:\n if self.fixed_digits and len(value) != self.fixed_digits:\n raise ValidationError()\n value = self.num_convert(value)\n if (self.min is not None and value < self.min) or (\n self.max is not None and value > self.max\n ):\n raise ValidationError()\n return value\n\n def to_url(self, value: t.Any) -> str:\n value = str(self.num_convert(value))\n if self.fixed_digits:\n value = value.zfill(self.fixed_digits)\n return value\n\n @property\n def signed_regex(self) -> str:\n return f\"-?{self.regex}\"\n\n\nclass IntegerConverter(NumberConverter):\n \"\"\"This converter only accepts integer values::\n\n Rule(\"/page/<int:page>\")\n\n By default it only accepts unsigned, positive values. The ``signed``\n parameter will enable signed, negative values. ::\n\n Rule(\"/page/<int(signed=True):page>\")\n\n :param map: The :class:`Map`.\n :param fixed_digits: The number of fixed digits in the URL. If you\n set this to ``4`` for example, the rule will only match if the\n URL looks like ``/0001/``. The default is variable length.\n :param min: The minimal value.\n :param max: The maximal value.\n :param signed: Allow signed (negative) values.\n\n .. versionadded:: 0.15\n The ``signed`` parameter.\n \"\"\"\n\n regex = r\"\\d+\"\n part_isolating = True\n\n\nclass FloatConverter(NumberConverter):\n \"\"\"This converter only accepts floating point values::\n\n Rule(\"/probability/<float:probability>\")\n\n By default it only accepts unsigned, positive values. The ``signed``\n parameter will enable signed, negative values. ::\n\n Rule(\"/offset/<float(signed=True):offset>\")\n\n :param map: The :class:`Map`.\n :param min: The minimal value.\n :param max: The maximal value.\n :param signed: Allow signed (negative) values.\n\n .. versionadded:: 0.15\n The ``signed`` parameter.\n \"\"\"\n\n regex = r\"\\d+\\.\\d+\"\n num_convert = float\n part_isolating = True\n\n def __init__(\n self,\n map: \"Map\",\n min: t.Optional[float] = None,\n max: t.Optional[float] = None,\n signed: bool = False,\n ) -> None:\n super().__init__(map, min=min, max=max, signed=signed) # type: ignore\n\n\nclass UUIDConverter(BaseConverter):\n \"\"\"This converter only accepts UUID strings::\n\n Rule('/object/<uuid:identifier>')\n\n .. versionadded:: 0.10\n\n :param map: the :class:`Map`.\n \"\"\"\n\n regex = (\n r\"[A-Fa-f0-9]{8}-[A-Fa-f0-9]{4}-\"\n r\"[A-Fa-f0-9]{4}-[A-Fa-f0-9]{4}-[A-Fa-f0-9]{12}\"\n )\n part_isolating = True\n\n def to_python(self, value: str) -> uuid.UUID:\n return uuid.UUID(value)\n\n def to_url(self, value: uuid.UUID) -> str:\n return str(value)\n\n\n#: the default converter mapping for the map.\nDEFAULT_CONVERTERS: t.Mapping[str, t.Type[BaseConverter]] = {\n \"default\": UnicodeConverter,\n \"string\": UnicodeConverter,\n \"any\": AnyConverter,\n \"path\": PathConverter,\n \"int\": IntegerConverter,\n \"float\": FloatConverter,\n \"uuid\": UUIDConverter,\n}\n", "path": "src/werkzeug/routing/converters.py"}]}
| 2,765 | 277 |
gh_patches_debug_12830
|
rasdani/github-patches
|
git_diff
|
mars-project__mars-82
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
By default use core number as n_parallel for threaded scheduling
Use core number as `n_parallel` for threaded scheduling, currently 1 thread by default.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mars/session.py`
Content:
```
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 # Copyright 1999-2018 Alibaba Group Holding Ltd.
4 #
5 # Licensed under the Apache License, Version 2.0 (the "License");
6 # you may not use this file except in compliance with the License.
7 # You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing, software
12 # distributed under the License is distributed on an "AS IS" BASIS,
13 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 # See the License for the specific language governing permissions and
15 # limitations under the License.
16
17 import numpy as np
18
19
20 class LocalSession(object):
21 def __init__(self):
22 from .tensor.execution.core import Executor
23
24 self._executor = Executor()
25 self._endpoint = None
26
27 @property
28 def endpoint(self):
29 return self._endpoint
30
31 @endpoint.setter
32 def endpoint(self, endpoint):
33 if endpoint is not None:
34 raise ValueError('Local session cannot set endpoint')
35 self._endpoint = endpoint
36
37 def run(self, *tensors, **kw):
38 if self._executor is None:
39 raise RuntimeError('Session has closed')
40 return self._executor.execute_tensors(tensors, **kw)
41
42 def decref(self, *keys):
43 self._executor.decref(*keys)
44
45 def __enter__(self):
46 return self
47
48 def __exit__(self, *_):
49 self._executor = None
50
51
52 class Session(object):
53 _default_session = None
54
55 def __init__(self, endpoint=None):
56 if endpoint is not None:
57 if 'http' in endpoint:
58 # connect to web
59 from .web.session import Session as WebSession
60
61 self._sess = WebSession(endpoint)
62 else:
63 # connect to local cluster
64 from .deploy.local.session import LocalClusterSession
65
66 self._sess = LocalClusterSession(endpoint)
67 else:
68 self._sess = LocalSession()
69
70 self._executed_keys = set()
71
72 def run(self, *tensors, **kw):
73 from . import tensor as mt
74
75 ret_list = False
76 if len(tensors) == 1 and isinstance(tensors[0], (tuple, list)):
77 ret_list = True
78 tensors = tensors[0]
79 elif len(tensors) > 1:
80 ret_list = True
81
82 tensors = tuple(mt.tensor(t) for t in tensors)
83 result = self._sess.run(*tensors, **kw)
84 self._executed_keys.update(t.key for t in tensors)
85 for t in tensors:
86 t._execute_session = self
87
88 ret = []
89 for r, t in zip(result, tensors):
90 if r is None:
91 ret.append(r)
92 continue
93 if t.isscalar() and hasattr(r, 'item'):
94 ret.append(np.asscalar(r))
95 else:
96 ret.append(r)
97 if ret_list:
98 return ret
99 return ret[0]
100
101 @property
102 def endpoint(self):
103 return self._sess.endpoint
104
105 @endpoint.setter
106 def endpoint(self, endpoint):
107 self._sess.endpoint = endpoint
108
109 def decref(self, *keys):
110 if hasattr(self._sess, 'decref'):
111 self._sess.decref(*keys)
112
113 def __getattr__(self, attr):
114 try:
115 obj = self._sess.__getattribute__(attr)
116 return obj
117 except AttributeError:
118 raise
119
120 def __enter__(self):
121 self._sess.__enter__()
122 return self
123
124 def __exit__(self, exc_type, exc_val, exc_tb):
125 self._sess.__exit__(exc_type, exc_val, exc_tb)
126
127 close = __exit__
128
129 def as_default(self):
130 Session._default_session = self
131 return self
132
133 @classmethod
134 def default_or_local(cls):
135 if cls._default_session is not None:
136 return cls._default_session
137
138 cls._default_session = Session()
139 return cls._default_session
140
141
142 def new_session(scheduler=None):
143 return Session(scheduler)
144
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mars/session.py b/mars/session.py
--- a/mars/session.py
+++ b/mars/session.py
@@ -16,6 +16,11 @@
import numpy as np
+try:
+ from .resource import cpu_count
+except ImportError:
+ from multiprocessing import cpu_count
+
class LocalSession(object):
def __init__(self):
@@ -37,6 +42,8 @@
def run(self, *tensors, **kw):
if self._executor is None:
raise RuntimeError('Session has closed')
+ if 'n_parallel' not in kw:
+ kw['n_parallel'] = cpu_count()
return self._executor.execute_tensors(tensors, **kw)
def decref(self, *keys):
|
{"golden_diff": "diff --git a/mars/session.py b/mars/session.py\n--- a/mars/session.py\n+++ b/mars/session.py\n@@ -16,6 +16,11 @@\n \n import numpy as np\n \n+try:\n+ from .resource import cpu_count\n+except ImportError:\n+ from multiprocessing import cpu_count\n+\n \n class LocalSession(object):\n def __init__(self):\n@@ -37,6 +42,8 @@\n def run(self, *tensors, **kw):\n if self._executor is None:\n raise RuntimeError('Session has closed')\n+ if 'n_parallel' not in kw:\n+ kw['n_parallel'] = cpu_count()\n return self._executor.execute_tensors(tensors, **kw)\n \n def decref(self, *keys):\n", "issue": "By default use core number as n_parallel for threaded scheduling\nUse core number as `n_parallel` for threaded scheduling, currently 1 thread by default.\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n# Copyright 1999-2018 Alibaba Group Holding Ltd.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport numpy as np\n\n\nclass LocalSession(object):\n def __init__(self):\n from .tensor.execution.core import Executor\n\n self._executor = Executor()\n self._endpoint = None\n\n @property\n def endpoint(self):\n return self._endpoint\n\n @endpoint.setter\n def endpoint(self, endpoint):\n if endpoint is not None:\n raise ValueError('Local session cannot set endpoint')\n self._endpoint = endpoint\n\n def run(self, *tensors, **kw):\n if self._executor is None:\n raise RuntimeError('Session has closed')\n return self._executor.execute_tensors(tensors, **kw)\n\n def decref(self, *keys):\n self._executor.decref(*keys)\n\n def __enter__(self):\n return self\n\n def __exit__(self, *_):\n self._executor = None\n\n\nclass Session(object):\n _default_session = None\n\n def __init__(self, endpoint=None):\n if endpoint is not None:\n if 'http' in endpoint:\n # connect to web\n from .web.session import Session as WebSession\n\n self._sess = WebSession(endpoint)\n else:\n # connect to local cluster\n from .deploy.local.session import LocalClusterSession\n\n self._sess = LocalClusterSession(endpoint)\n else:\n self._sess = LocalSession()\n\n self._executed_keys = set()\n\n def run(self, *tensors, **kw):\n from . import tensor as mt\n\n ret_list = False\n if len(tensors) == 1 and isinstance(tensors[0], (tuple, list)):\n ret_list = True\n tensors = tensors[0]\n elif len(tensors) > 1:\n ret_list = True\n\n tensors = tuple(mt.tensor(t) for t in tensors)\n result = self._sess.run(*tensors, **kw)\n self._executed_keys.update(t.key for t in tensors)\n for t in tensors:\n t._execute_session = self\n\n ret = []\n for r, t in zip(result, tensors):\n if r is None:\n ret.append(r)\n continue\n if t.isscalar() and hasattr(r, 'item'):\n ret.append(np.asscalar(r))\n else:\n ret.append(r)\n if ret_list:\n return ret\n return ret[0]\n\n @property\n def endpoint(self):\n return self._sess.endpoint\n\n @endpoint.setter\n def endpoint(self, endpoint):\n self._sess.endpoint = endpoint\n\n def decref(self, *keys):\n if hasattr(self._sess, 'decref'):\n self._sess.decref(*keys)\n\n def __getattr__(self, attr):\n try:\n obj = self._sess.__getattribute__(attr)\n return obj\n except AttributeError:\n raise\n\n def __enter__(self):\n self._sess.__enter__()\n return self\n\n def __exit__(self, exc_type, exc_val, exc_tb):\n self._sess.__exit__(exc_type, exc_val, exc_tb)\n\n close = __exit__\n\n def as_default(self):\n Session._default_session = self\n return self\n\n @classmethod\n def default_or_local(cls):\n if cls._default_session is not None:\n return cls._default_session\n\n cls._default_session = Session()\n return cls._default_session\n\n\ndef new_session(scheduler=None):\n return Session(scheduler)\n", "path": "mars/session.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n# Copyright 1999-2018 Alibaba Group Holding Ltd.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport numpy as np\n\ntry:\n from .resource import cpu_count\nexcept ImportError:\n from multiprocessing import cpu_count\n\n\nclass LocalSession(object):\n def __init__(self):\n from .tensor.execution.core import Executor\n\n self._executor = Executor()\n self._endpoint = None\n\n @property\n def endpoint(self):\n return self._endpoint\n\n @endpoint.setter\n def endpoint(self, endpoint):\n if endpoint is not None:\n raise ValueError('Local session cannot set endpoint')\n self._endpoint = endpoint\n\n def run(self, *tensors, **kw):\n if self._executor is None:\n raise RuntimeError('Session has closed')\n if 'n_parallel' not in kw:\n kw['n_parallel'] = cpu_count()\n return self._executor.execute_tensors(tensors, **kw)\n\n def decref(self, *keys):\n self._executor.decref(*keys)\n\n def __enter__(self):\n return self\n\n def __exit__(self, *_):\n self._executor = None\n\n\nclass Session(object):\n _default_session = None\n\n def __init__(self, endpoint=None):\n if endpoint is not None:\n if 'http' in endpoint:\n # connect to web\n from .web.session import Session as WebSession\n\n self._sess = WebSession(endpoint)\n else:\n # connect to local cluster\n from .deploy.local.session import LocalClusterSession\n\n self._sess = LocalClusterSession(endpoint)\n else:\n self._sess = LocalSession()\n\n self._executed_keys = set()\n\n def run(self, *tensors, **kw):\n from . import tensor as mt\n\n ret_list = False\n if len(tensors) == 1 and isinstance(tensors[0], (tuple, list)):\n ret_list = True\n tensors = tensors[0]\n elif len(tensors) > 1:\n ret_list = True\n\n tensors = tuple(mt.tensor(t) for t in tensors)\n result = self._sess.run(*tensors, **kw)\n self._executed_keys.update(t.key for t in tensors)\n for t in tensors:\n t._execute_session = self\n\n ret = []\n for r, t in zip(result, tensors):\n if r is None:\n ret.append(r)\n continue\n if t.isscalar() and hasattr(r, 'item'):\n ret.append(np.asscalar(r))\n else:\n ret.append(r)\n if ret_list:\n return ret\n return ret[0]\n\n @property\n def endpoint(self):\n return self._sess.endpoint\n\n @endpoint.setter\n def endpoint(self, endpoint):\n self._sess.endpoint = endpoint\n\n def decref(self, *keys):\n if hasattr(self._sess, 'decref'):\n self._sess.decref(*keys)\n\n def __getattr__(self, attr):\n try:\n obj = self._sess.__getattribute__(attr)\n return obj\n except AttributeError:\n raise\n\n def __enter__(self):\n self._sess.__enter__()\n return self\n\n def __exit__(self, exc_type, exc_val, exc_tb):\n self._sess.__exit__(exc_type, exc_val, exc_tb)\n\n close = __exit__\n\n def as_default(self):\n Session._default_session = self\n return self\n\n @classmethod\n def default_or_local(cls):\n if cls._default_session is not None:\n return cls._default_session\n\n cls._default_session = Session()\n return cls._default_session\n\n\ndef new_session(scheduler=None):\n return Session(scheduler)\n", "path": "mars/session.py"}]}
| 1,525 | 170 |
gh_patches_debug_15984
|
rasdani/github-patches
|
git_diff
|
OpenMined__PySyft-5397
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Adding loguru compatiblity with pytest caplog
## Description
`caplog` fixture in pytest captures the logging output for testing if appropriate warnings have been raised.
By default pytest uses the standard `logging` module, but since we are using `loguru` appropriate patching needs to be added.
## Additional Context
https://loguru.readthedocs.io/en/stable/resources/migration.html#making-things-work-with-pytest-and-caplog
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/syft/logger.py`
Content:
```
1 # stdlib
2 import os
3 from typing import Any
4 from typing import Callable
5 from typing import NoReturn
6 from typing import TextIO
7 from typing import Union
8
9 # third party
10 from loguru import logger
11
12 LOG_FORMAT = "[{time}][{level}][{module}]][{process.id}] {message}"
13
14 logger.remove()
15 DEFAULT_SINK = "syft_{time}.log"
16
17
18 def remove() -> None:
19 logger.remove()
20
21
22 def add(
23 sink: Union[None, str, os.PathLike, TextIO] = None,
24 level: str = "ERROR",
25 ) -> None:
26 sink = DEFAULT_SINK if sink is None else sink
27 try:
28 logger.add(
29 sink=sink,
30 format=LOG_FORMAT,
31 enqueue=True,
32 colorize=False,
33 diagnose=True,
34 backtrace=True,
35 rotation="10 MB",
36 retention="1 day",
37 level=level,
38 )
39 except BaseException:
40 logger.add(
41 sink=sink,
42 format=LOG_FORMAT,
43 enqueue=True,
44 colorize=False,
45 diagnose=True,
46 backtrace=True,
47 level=level,
48 )
49
50
51 def traceback_and_raise(e: Any, verbose: bool = False) -> NoReturn:
52 try:
53 if verbose:
54 logger.opt(lazy=True).exception(e)
55 else:
56 logger.opt(lazy=True).critical(e)
57 except BaseException as ex:
58 logger.debug("failed to print exception", ex)
59 if not issubclass(type(e), Exception):
60 e = Exception(e)
61 raise e
62
63
64 def create_log_and_print_function(level: str) -> Callable:
65 def log_and_print(*args: Any, **kwargs: Any) -> None:
66 try:
67 method = getattr(logger.opt(lazy=True), level, None)
68 if "print" in kwargs and kwargs["print"] is True:
69 del kwargs["print"]
70 print(*args, **kwargs)
71 if "end" in kwargs:
72 # clean up extra end for printing
73 del kwargs["end"]
74
75 if method is not None:
76 method(*args, **kwargs)
77 else:
78 raise Exception(f"no method {level} on logger")
79 except BaseException as e:
80 msg = f"failed to log exception. {e}"
81 try:
82 logger.debug(msg)
83 except Exception as e:
84 print(f"{msg}. {e}")
85
86 return log_and_print
87
88
89 def traceback(*args: Any, **kwargs: Any) -> None:
90 return create_log_and_print_function(level="exception")(*args, **kwargs)
91
92
93 def critical(*args: Any, **kwargs: Any) -> None:
94 return create_log_and_print_function(level="critical")(*args, **kwargs)
95
96
97 def error(*args: Any, **kwargs: Any) -> None:
98 return create_log_and_print_function(level="error")(*args, **kwargs)
99
100
101 def warning(*args: Any, **kwargs: Any) -> None:
102 return create_log_and_print_function(level="warning")(*args, **kwargs)
103
104
105 def info(*args: Any, **kwargs: Any) -> None:
106 return create_log_and_print_function(level="info")(*args, **kwargs)
107
108
109 def debug(*args: Any, **kwargs: Any) -> None:
110 return create_log_and_print_function(level="debug")(*args, **kwargs)
111
112
113 def trace(*args: Any, **kwargs: Any) -> None:
114 return create_log_and_print_function(level="trace")(*args, **kwargs)
115
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/syft/logger.py b/src/syft/logger.py
--- a/src/syft/logger.py
+++ b/src/syft/logger.py
@@ -1,4 +1,5 @@
# stdlib
+import logging
import os
from typing import Any
from typing import Callable
@@ -20,7 +21,7 @@
def add(
- sink: Union[None, str, os.PathLike, TextIO] = None,
+ sink: Union[None, str, os.PathLike, TextIO, logging.Handler] = None,
level: str = "ERROR",
) -> None:
sink = DEFAULT_SINK if sink is None else sink
@@ -40,7 +41,6 @@
logger.add(
sink=sink,
format=LOG_FORMAT,
- enqueue=True,
colorize=False,
diagnose=True,
backtrace=True,
|
{"golden_diff": "diff --git a/src/syft/logger.py b/src/syft/logger.py\n--- a/src/syft/logger.py\n+++ b/src/syft/logger.py\n@@ -1,4 +1,5 @@\n # stdlib\n+import logging\n import os\n from typing import Any\n from typing import Callable\n@@ -20,7 +21,7 @@\n \n \n def add(\n- sink: Union[None, str, os.PathLike, TextIO] = None,\n+ sink: Union[None, str, os.PathLike, TextIO, logging.Handler] = None,\n level: str = \"ERROR\",\n ) -> None:\n sink = DEFAULT_SINK if sink is None else sink\n@@ -40,7 +41,6 @@\n logger.add(\n sink=sink,\n format=LOG_FORMAT,\n- enqueue=True,\n colorize=False,\n diagnose=True,\n backtrace=True,\n", "issue": "Adding loguru compatiblity with pytest caplog\n## Description\r\n`caplog` fixture in pytest captures the logging output for testing if appropriate warnings have been raised.\r\n\r\nBy default pytest uses the standard `logging` module, but since we are using `loguru` appropriate patching needs to be added.\r\n\r\n## Additional Context\r\nhttps://loguru.readthedocs.io/en/stable/resources/migration.html#making-things-work-with-pytest-and-caplog\r\n\n", "before_files": [{"content": "# stdlib\nimport os\nfrom typing import Any\nfrom typing import Callable\nfrom typing import NoReturn\nfrom typing import TextIO\nfrom typing import Union\n\n# third party\nfrom loguru import logger\n\nLOG_FORMAT = \"[{time}][{level}][{module}]][{process.id}] {message}\"\n\nlogger.remove()\nDEFAULT_SINK = \"syft_{time}.log\"\n\n\ndef remove() -> None:\n logger.remove()\n\n\ndef add(\n sink: Union[None, str, os.PathLike, TextIO] = None,\n level: str = \"ERROR\",\n) -> None:\n sink = DEFAULT_SINK if sink is None else sink\n try:\n logger.add(\n sink=sink,\n format=LOG_FORMAT,\n enqueue=True,\n colorize=False,\n diagnose=True,\n backtrace=True,\n rotation=\"10 MB\",\n retention=\"1 day\",\n level=level,\n )\n except BaseException:\n logger.add(\n sink=sink,\n format=LOG_FORMAT,\n enqueue=True,\n colorize=False,\n diagnose=True,\n backtrace=True,\n level=level,\n )\n\n\ndef traceback_and_raise(e: Any, verbose: bool = False) -> NoReturn:\n try:\n if verbose:\n logger.opt(lazy=True).exception(e)\n else:\n logger.opt(lazy=True).critical(e)\n except BaseException as ex:\n logger.debug(\"failed to print exception\", ex)\n if not issubclass(type(e), Exception):\n e = Exception(e)\n raise e\n\n\ndef create_log_and_print_function(level: str) -> Callable:\n def log_and_print(*args: Any, **kwargs: Any) -> None:\n try:\n method = getattr(logger.opt(lazy=True), level, None)\n if \"print\" in kwargs and kwargs[\"print\"] is True:\n del kwargs[\"print\"]\n print(*args, **kwargs)\n if \"end\" in kwargs:\n # clean up extra end for printing\n del kwargs[\"end\"]\n\n if method is not None:\n method(*args, **kwargs)\n else:\n raise Exception(f\"no method {level} on logger\")\n except BaseException as e:\n msg = f\"failed to log exception. {e}\"\n try:\n logger.debug(msg)\n except Exception as e:\n print(f\"{msg}. {e}\")\n\n return log_and_print\n\n\ndef traceback(*args: Any, **kwargs: Any) -> None:\n return create_log_and_print_function(level=\"exception\")(*args, **kwargs)\n\n\ndef critical(*args: Any, **kwargs: Any) -> None:\n return create_log_and_print_function(level=\"critical\")(*args, **kwargs)\n\n\ndef error(*args: Any, **kwargs: Any) -> None:\n return create_log_and_print_function(level=\"error\")(*args, **kwargs)\n\n\ndef warning(*args: Any, **kwargs: Any) -> None:\n return create_log_and_print_function(level=\"warning\")(*args, **kwargs)\n\n\ndef info(*args: Any, **kwargs: Any) -> None:\n return create_log_and_print_function(level=\"info\")(*args, **kwargs)\n\n\ndef debug(*args: Any, **kwargs: Any) -> None:\n return create_log_and_print_function(level=\"debug\")(*args, **kwargs)\n\n\ndef trace(*args: Any, **kwargs: Any) -> None:\n return create_log_and_print_function(level=\"trace\")(*args, **kwargs)\n", "path": "src/syft/logger.py"}], "after_files": [{"content": "# stdlib\nimport logging\nimport os\nfrom typing import Any\nfrom typing import Callable\nfrom typing import NoReturn\nfrom typing import TextIO\nfrom typing import Union\n\n# third party\nfrom loguru import logger\n\nLOG_FORMAT = \"[{time}][{level}][{module}]][{process.id}] {message}\"\n\nlogger.remove()\nDEFAULT_SINK = \"syft_{time}.log\"\n\n\ndef remove() -> None:\n logger.remove()\n\n\ndef add(\n sink: Union[None, str, os.PathLike, TextIO, logging.Handler] = None,\n level: str = \"ERROR\",\n) -> None:\n sink = DEFAULT_SINK if sink is None else sink\n try:\n logger.add(\n sink=sink,\n format=LOG_FORMAT,\n enqueue=True,\n colorize=False,\n diagnose=True,\n backtrace=True,\n rotation=\"10 MB\",\n retention=\"1 day\",\n level=level,\n )\n except BaseException:\n logger.add(\n sink=sink,\n format=LOG_FORMAT,\n colorize=False,\n diagnose=True,\n backtrace=True,\n level=level,\n )\n\n\ndef traceback_and_raise(e: Any, verbose: bool = False) -> NoReturn:\n try:\n if verbose:\n logger.opt(lazy=True).exception(e)\n else:\n logger.opt(lazy=True).critical(e)\n except BaseException as ex:\n logger.debug(\"failed to print exception\", ex)\n if not issubclass(type(e), Exception):\n e = Exception(e)\n raise e\n\n\ndef create_log_and_print_function(level: str) -> Callable:\n def log_and_print(*args: Any, **kwargs: Any) -> None:\n try:\n method = getattr(logger.opt(lazy=True), level, None)\n if \"print\" in kwargs and kwargs[\"print\"] is True:\n del kwargs[\"print\"]\n print(*args, **kwargs)\n if \"end\" in kwargs:\n # clean up extra end for printing\n del kwargs[\"end\"]\n\n if method is not None:\n method(*args, **kwargs)\n else:\n raise Exception(f\"no method {level} on logger\")\n except BaseException as e:\n msg = f\"failed to log exception. {e}\"\n try:\n logger.debug(msg)\n except Exception as e:\n print(f\"{msg}. {e}\")\n\n return log_and_print\n\n\ndef traceback(*args: Any, **kwargs: Any) -> None:\n return create_log_and_print_function(level=\"exception\")(*args, **kwargs)\n\n\ndef critical(*args: Any, **kwargs: Any) -> None:\n return create_log_and_print_function(level=\"critical\")(*args, **kwargs)\n\n\ndef error(*args: Any, **kwargs: Any) -> None:\n return create_log_and_print_function(level=\"error\")(*args, **kwargs)\n\n\ndef warning(*args: Any, **kwargs: Any) -> None:\n return create_log_and_print_function(level=\"warning\")(*args, **kwargs)\n\n\ndef info(*args: Any, **kwargs: Any) -> None:\n return create_log_and_print_function(level=\"info\")(*args, **kwargs)\n\n\ndef debug(*args: Any, **kwargs: Any) -> None:\n return create_log_and_print_function(level=\"debug\")(*args, **kwargs)\n\n\ndef trace(*args: Any, **kwargs: Any) -> None:\n return create_log_and_print_function(level=\"trace\")(*args, **kwargs)\n", "path": "src/syft/logger.py"}]}
| 1,350 | 197 |
gh_patches_debug_36091
|
rasdani/github-patches
|
git_diff
|
freedomofpress__securedrop-5894
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
v2 removal on restore does not cover HTTPS services
The logic added in https://github.com/freedomofpress/securedrop/pull/5677 to disable v2 onion services when a backup is restored to a Focal server does not remove config lines for HTTPS services (port 443), potentially resulting in a broken configuration.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `install_files/ansible-base/roles/restore/files/disable_v2.py`
Content:
```
1 #!/usr/bin/env python3
2 # To execute on prod:
3 # python3 disable_v2.py /etc/tor/torrc /etc/tor/torrc
4 # To execute for testing locally:
5 # python3 disable_v2.py /etc/tor/torrc /tmp/dumytorrc
6 import sys
7
8
9 def filter_v2(filename):
10 # Read the file
11 with open(filename) as f:
12 data = f.readlines()
13 # We will store the filtered lines to result
14 result = []
15
16 i = 0
17 while i < len(data):
18 line = data[i]
19 if line == "HiddenServiceDir /var/lib/tor/services/source\n":
20 i += 1
21 while data[i].strip() == "":
22 i += 1
23 line = data[i]
24 if line == "HiddenServiceVersion 2\n":
25 i += 1
26 line = data[i]
27 while data[i].strip() == "":
28 i += 1
29 line = data[i]
30 if line == "HiddenServicePort 80 127.0.0.1:80\n":
31 i += 1
32 continue
33 # Now check for journalist
34 if line == "HiddenServiceDir /var/lib/tor/services/journalist\n":
35 i += 1
36 while data[i].strip() == "":
37 i += 1
38 line = data[i]
39 if line == "HiddenServiceVersion 2\n":
40 i += 1
41 line = data[i]
42 while data[i].strip() == "":
43 i += 1
44 line = data[i]
45 if line == "HiddenServicePort 80 127.0.0.1:8080\n":
46 i += 1
47 line = data[i]
48 while data[i].strip() == "":
49 i += 1
50 line = data[i]
51 if line == "HiddenServiceAuthorizeClient stealth journalist\n":
52 i += 1
53 continue
54 # Now the v2 ssh access
55 if line == "HiddenServiceDir /var/lib/tor/services/ssh\n":
56 i += 1
57 while data[i].strip() == "":
58 i += 1
59 line = data[i]
60 if line == "HiddenServiceVersion 2\n":
61 i += 1
62 line = data[i]
63 while data[i].strip() == "":
64 i += 1
65 line = data[i]
66 if line == "HiddenServicePort 22 127.0.0.1:22\n":
67 i += 1
68 line = data[i]
69 while data[i].strip() == "":
70 i += 1
71 line = data[i]
72 if line == "HiddenServiceAuthorizeClient stealth admin\n":
73 i += 1
74 continue
75
76 result.append(line)
77 i += 1
78
79 # Now return the result
80 return result
81
82
83 if __name__ == "__main__":
84 filename = sys.argv[1]
85 outputfilename = sys.argv[2]
86 result = filter_v2(filename)
87 with open(outputfilename, "w") as fobj:
88 for line in result:
89 fobj.write(line)
90
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/install_files/ansible-base/roles/restore/files/disable_v2.py b/install_files/ansible-base/roles/restore/files/disable_v2.py
deleted file mode 100644
--- a/install_files/ansible-base/roles/restore/files/disable_v2.py
+++ /dev/null
@@ -1,89 +0,0 @@
-#!/usr/bin/env python3
-# To execute on prod:
-# python3 disable_v2.py /etc/tor/torrc /etc/tor/torrc
-# To execute for testing locally:
-# python3 disable_v2.py /etc/tor/torrc /tmp/dumytorrc
-import sys
-
-
-def filter_v2(filename):
- # Read the file
- with open(filename) as f:
- data = f.readlines()
- # We will store the filtered lines to result
- result = []
-
- i = 0
- while i < len(data):
- line = data[i]
- if line == "HiddenServiceDir /var/lib/tor/services/source\n":
- i += 1
- while data[i].strip() == "":
- i += 1
- line = data[i]
- if line == "HiddenServiceVersion 2\n":
- i += 1
- line = data[i]
- while data[i].strip() == "":
- i += 1
- line = data[i]
- if line == "HiddenServicePort 80 127.0.0.1:80\n":
- i += 1
- continue
- # Now check for journalist
- if line == "HiddenServiceDir /var/lib/tor/services/journalist\n":
- i += 1
- while data[i].strip() == "":
- i += 1
- line = data[i]
- if line == "HiddenServiceVersion 2\n":
- i += 1
- line = data[i]
- while data[i].strip() == "":
- i += 1
- line = data[i]
- if line == "HiddenServicePort 80 127.0.0.1:8080\n":
- i += 1
- line = data[i]
- while data[i].strip() == "":
- i += 1
- line = data[i]
- if line == "HiddenServiceAuthorizeClient stealth journalist\n":
- i += 1
- continue
- # Now the v2 ssh access
- if line == "HiddenServiceDir /var/lib/tor/services/ssh\n":
- i += 1
- while data[i].strip() == "":
- i += 1
- line = data[i]
- if line == "HiddenServiceVersion 2\n":
- i += 1
- line = data[i]
- while data[i].strip() == "":
- i += 1
- line = data[i]
- if line == "HiddenServicePort 22 127.0.0.1:22\n":
- i += 1
- line = data[i]
- while data[i].strip() == "":
- i += 1
- line = data[i]
- if line == "HiddenServiceAuthorizeClient stealth admin\n":
- i += 1
- continue
-
- result.append(line)
- i += 1
-
- # Now return the result
- return result
-
-
-if __name__ == "__main__":
- filename = sys.argv[1]
- outputfilename = sys.argv[2]
- result = filter_v2(filename)
- with open(outputfilename, "w") as fobj:
- for line in result:
- fobj.write(line)
|
{"golden_diff": "diff --git a/install_files/ansible-base/roles/restore/files/disable_v2.py b/install_files/ansible-base/roles/restore/files/disable_v2.py\ndeleted file mode 100644\n--- a/install_files/ansible-base/roles/restore/files/disable_v2.py\n+++ /dev/null\n@@ -1,89 +0,0 @@\n-#!/usr/bin/env python3\n-# To execute on prod:\n-# python3 disable_v2.py /etc/tor/torrc /etc/tor/torrc\n-# To execute for testing locally:\n-# python3 disable_v2.py /etc/tor/torrc /tmp/dumytorrc\n-import sys\n-\n-\n-def filter_v2(filename):\n- # Read the file\n- with open(filename) as f:\n- data = f.readlines()\n- # We will store the filtered lines to result\n- result = []\n-\n- i = 0\n- while i < len(data):\n- line = data[i]\n- if line == \"HiddenServiceDir /var/lib/tor/services/source\\n\":\n- i += 1\n- while data[i].strip() == \"\":\n- i += 1\n- line = data[i]\n- if line == \"HiddenServiceVersion 2\\n\":\n- i += 1\n- line = data[i]\n- while data[i].strip() == \"\":\n- i += 1\n- line = data[i]\n- if line == \"HiddenServicePort 80 127.0.0.1:80\\n\":\n- i += 1\n- continue\n- # Now check for journalist\n- if line == \"HiddenServiceDir /var/lib/tor/services/journalist\\n\":\n- i += 1\n- while data[i].strip() == \"\":\n- i += 1\n- line = data[i]\n- if line == \"HiddenServiceVersion 2\\n\":\n- i += 1\n- line = data[i]\n- while data[i].strip() == \"\":\n- i += 1\n- line = data[i]\n- if line == \"HiddenServicePort 80 127.0.0.1:8080\\n\":\n- i += 1\n- line = data[i]\n- while data[i].strip() == \"\":\n- i += 1\n- line = data[i]\n- if line == \"HiddenServiceAuthorizeClient stealth journalist\\n\":\n- i += 1\n- continue\n- # Now the v2 ssh access\n- if line == \"HiddenServiceDir /var/lib/tor/services/ssh\\n\":\n- i += 1\n- while data[i].strip() == \"\":\n- i += 1\n- line = data[i]\n- if line == \"HiddenServiceVersion 2\\n\":\n- i += 1\n- line = data[i]\n- while data[i].strip() == \"\":\n- i += 1\n- line = data[i]\n- if line == \"HiddenServicePort 22 127.0.0.1:22\\n\":\n- i += 1\n- line = data[i]\n- while data[i].strip() == \"\":\n- i += 1\n- line = data[i]\n- if line == \"HiddenServiceAuthorizeClient stealth admin\\n\":\n- i += 1\n- continue\n-\n- result.append(line)\n- i += 1\n-\n- # Now return the result\n- return result\n-\n-\n-if __name__ == \"__main__\":\n- filename = sys.argv[1]\n- outputfilename = sys.argv[2]\n- result = filter_v2(filename)\n- with open(outputfilename, \"w\") as fobj:\n- for line in result:\n- fobj.write(line)\n", "issue": "v2 removal on restore does not cover HTTPS services\nThe logic added in https://github.com/freedomofpress/securedrop/pull/5677 to disable v2 onion services when a backup is restored to a Focal server does not remove config lines for HTTPS services (port 443), potentially resulting in a broken configuration.\n", "before_files": [{"content": "#!/usr/bin/env python3\n# To execute on prod:\n# python3 disable_v2.py /etc/tor/torrc /etc/tor/torrc\n# To execute for testing locally:\n# python3 disable_v2.py /etc/tor/torrc /tmp/dumytorrc\nimport sys\n\n\ndef filter_v2(filename):\n # Read the file\n with open(filename) as f:\n data = f.readlines()\n # We will store the filtered lines to result\n result = []\n\n i = 0\n while i < len(data):\n line = data[i]\n if line == \"HiddenServiceDir /var/lib/tor/services/source\\n\":\n i += 1\n while data[i].strip() == \"\":\n i += 1\n line = data[i]\n if line == \"HiddenServiceVersion 2\\n\":\n i += 1\n line = data[i]\n while data[i].strip() == \"\":\n i += 1\n line = data[i]\n if line == \"HiddenServicePort 80 127.0.0.1:80\\n\":\n i += 1\n continue\n # Now check for journalist\n if line == \"HiddenServiceDir /var/lib/tor/services/journalist\\n\":\n i += 1\n while data[i].strip() == \"\":\n i += 1\n line = data[i]\n if line == \"HiddenServiceVersion 2\\n\":\n i += 1\n line = data[i]\n while data[i].strip() == \"\":\n i += 1\n line = data[i]\n if line == \"HiddenServicePort 80 127.0.0.1:8080\\n\":\n i += 1\n line = data[i]\n while data[i].strip() == \"\":\n i += 1\n line = data[i]\n if line == \"HiddenServiceAuthorizeClient stealth journalist\\n\":\n i += 1\n continue\n # Now the v2 ssh access\n if line == \"HiddenServiceDir /var/lib/tor/services/ssh\\n\":\n i += 1\n while data[i].strip() == \"\":\n i += 1\n line = data[i]\n if line == \"HiddenServiceVersion 2\\n\":\n i += 1\n line = data[i]\n while data[i].strip() == \"\":\n i += 1\n line = data[i]\n if line == \"HiddenServicePort 22 127.0.0.1:22\\n\":\n i += 1\n line = data[i]\n while data[i].strip() == \"\":\n i += 1\n line = data[i]\n if line == \"HiddenServiceAuthorizeClient stealth admin\\n\":\n i += 1\n continue\n\n result.append(line)\n i += 1\n\n # Now return the result\n return result\n\n\nif __name__ == \"__main__\":\n filename = sys.argv[1]\n outputfilename = sys.argv[2]\n result = filter_v2(filename)\n with open(outputfilename, \"w\") as fobj:\n for line in result:\n fobj.write(line)\n", "path": "install_files/ansible-base/roles/restore/files/disable_v2.py"}], "after_files": [{"content": null, "path": "install_files/ansible-base/roles/restore/files/disable_v2.py"}]}
| 1,211 | 856 |
gh_patches_debug_41198
|
rasdani/github-patches
|
git_diff
|
cupy__cupy-6872
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
array_api sort() does not work
### Description
The array_api sort() is copied from the NumPy implementation, but passes through a `kind` keyword which doesn't exist in `cupy.sort`.
### To Reproduce
```py
>>> a = xp.asarray([1, 0, 2])
>>> xp.sort(a)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/aaronmeurer/anaconda3/envs/array-api/lib/python3.10/site-packages/cupy/array_api/_sorting_functions.py", line 45, in sort
res = np.sort(x._array, axis=axis, kind=kind)
TypeError: sort() got an unexpected keyword argument 'kind'
```
### Installation
Conda-Forge (`conda install ...`)
### Environment
```
# Paste the output here
```
### Additional Information
The array API does require support for a `stable` keyword. If `cupy.sort` is always stable, it can just ignore this flag, as `stable=False` is allowed to be stable (see https://data-apis.org/array-api/latest/API_specification/generated/signatures.sorting_functions.sort.html). Otherwise, I would suggest raising NotImplementedError for `stable=True` (which is unfortunately the default).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cupy/array_api/_sorting_functions.py`
Content:
```
1 # mypy: ignore-errors
2
3 from __future__ import annotations
4
5 from ._array_object import Array
6
7 import cupy as np
8
9
10 def argsort(
11 x: Array, /, *, axis: int = -1, descending: bool = False, stable: bool = True
12 ) -> Array:
13 """
14 Array API compatible wrapper for :py:func:`np.argsort <numpy.argsort>`.
15
16 See its docstring for more information.
17 """
18 # Note: this keyword argument is different, and the default is different.
19 kind = "stable" if stable else "quicksort"
20 if not descending:
21 res = np.argsort(x._array, axis=axis, kind=kind)
22 else:
23 # As NumPy has no native descending sort, we imitate it here. Note that
24 # simply flipping the results of np.argsort(x._array, ...) would not
25 # respect the relative order like it would in native descending sorts.
26 res = np.flip(
27 np.argsort(np.flip(x._array, axis=axis), axis=axis, kind=kind),
28 axis=axis,
29 )
30 # Rely on flip()/argsort() to validate axis
31 normalised_axis = axis if axis >= 0 else x.ndim + axis
32 max_i = x.shape[normalised_axis] - 1
33 res = max_i - res
34 return Array._new(res)
35
36
37 def sort(
38 x: Array, /, *, axis: int = -1, descending: bool = False, stable: bool = True
39 ) -> Array:
40 """
41 Array API compatible wrapper for :py:func:`np.sort <numpy.sort>`.
42
43 See its docstring for more information.
44 """
45 # Note: this keyword argument is different, and the default is different.
46 kind = "stable" if stable else "quicksort"
47 res = np.sort(x._array, axis=axis, kind=kind)
48 if descending:
49 res = np.flip(res, axis=axis)
50 return Array._new(res)
51
```
Path: `cupy/_sorting/sort.py`
Content:
```
1 import cupy
2 import numpy
3
4 from cupy.cuda import thrust
5
6
7 def sort(a, axis=-1):
8 """Returns a sorted copy of an array with a stable sorting algorithm.
9
10 Args:
11 a (cupy.ndarray): Array to be sorted.
12 axis (int or None): Axis along which to sort. Default is -1, which
13 means sort along the last axis. If None is supplied, the array is
14 flattened before sorting.
15
16 Returns:
17 cupy.ndarray: Array of the same type and shape as ``a``.
18
19 .. note::
20 For its implementation reason, ``cupy.sort`` currently does not support
21 ``kind`` and ``order`` parameters that ``numpy.sort`` does
22 support.
23
24 .. seealso:: :func:`numpy.sort`
25
26 """
27 if axis is None:
28 ret = a.flatten()
29 axis = -1
30 else:
31 ret = a.copy()
32 ret.sort(axis=axis)
33 return ret
34
35
36 def lexsort(keys):
37 """Perform an indirect sort using an array of keys.
38
39 Args:
40 keys (cupy.ndarray): ``(k, N)`` array containing ``k`` ``(N,)``-shaped
41 arrays. The ``k`` different "rows" to be sorted. The last row is
42 the primary sort key.
43
44 Returns:
45 cupy.ndarray: Array of indices that sort the keys.
46
47 .. note::
48 For its implementation reason, ``cupy.lexsort`` currently supports only
49 keys with their rank of one or two and does not support ``axis``
50 parameter that ``numpy.lexsort`` supports.
51
52 .. seealso:: :func:`numpy.lexsort`
53
54 """
55
56 # TODO(takagi): Support axis argument.
57
58 if not cupy.cuda.thrust.available:
59 raise RuntimeError('Thrust is needed to use cupy.lexsort. Please '
60 'install CUDA Toolkit with Thrust then reinstall '
61 'CuPy after uninstalling it.')
62
63 if keys.ndim == ():
64 # as numpy.lexsort() raises
65 raise TypeError('need sequence of keys with len > 0 in lexsort')
66
67 if keys.ndim == 1:
68 return 0
69
70 # TODO(takagi): Support ranks of three or more.
71 if keys.ndim > 2:
72 raise NotImplementedError('Keys with the rank of three or more is not '
73 'supported in lexsort')
74
75 # thrust.lexsort() assumes a C-contiguous array
76 if not keys.flags.c_contiguous:
77 keys = keys.copy('C')
78
79 idx_array = cupy.ndarray(keys._shape[1:], dtype=numpy.intp)
80 k = keys._shape[0]
81 n = keys._shape[1]
82 thrust.lexsort(keys.dtype, idx_array.data.ptr, keys.data.ptr, k, n)
83
84 return idx_array
85
86
87 def argsort(a, axis=-1):
88 """Returns the indices that would sort an array with a stable sorting.
89
90 Args:
91 a (cupy.ndarray): Array to sort.
92 axis (int or None): Axis along which to sort. Default is -1, which
93 means sort along the last axis. If None is supplied, the array is
94 flattened before sorting.
95
96 Returns:
97 cupy.ndarray: Array of indices that sort ``a``.
98
99 .. note::
100 For its implementation reason, ``cupy.argsort`` does not support
101 ``kind`` and ``order`` parameters.
102
103 .. seealso:: :func:`numpy.argsort`
104
105 """
106 return a.argsort(axis=axis)
107
108
109 def msort(a):
110 """Returns a copy of an array sorted along the first axis.
111
112 Args:
113 a (cupy.ndarray): Array to be sorted.
114
115 Returns:
116 cupy.ndarray: Array of the same type and shape as ``a``.
117
118 .. note:
119 ``cupy.msort(a)``, the CuPy counterpart of ``numpy.msort(a)``, is
120 equivalent to ``cupy.sort(a, axis=0)``.
121
122 .. seealso:: :func:`numpy.msort`
123
124 """
125
126 return sort(a, axis=0)
127
128
129 def sort_complex(a):
130 """Sort a complex array using the real part first,
131 then the imaginary part.
132
133 Args:
134 a (cupy.ndarray): Array to be sorted.
135
136 Returns:
137 cupy.ndarray: sorted complex array.
138
139 .. seealso:: :func:`numpy.sort_complex`
140
141 """
142 if a.dtype.char in 'bhBHF':
143 a = a.astype('F')
144 else:
145 a = a.astype('D')
146 a.sort()
147 return a
148
149
150 def partition(a, kth, axis=-1):
151 """Returns a partitioned copy of an array.
152
153 Creates a copy of the array whose elements are rearranged such that the
154 value of the element in k-th position would occur in that position in a
155 sorted array. All of the elements before the new k-th element are less
156 than or equal to the elements after the new k-th element.
157
158 Args:
159 a (cupy.ndarray): Array to be sorted.
160 kth (int or sequence of ints): Element index to partition by. If
161 supplied with a sequence of k-th it will partition all elements
162 indexed by k-th of them into their sorted position at once.
163 axis (int or None): Axis along which to sort. Default is -1, which
164 means sort along the last axis. If None is supplied, the array is
165 flattened before sorting.
166
167 Returns:
168 cupy.ndarray: Array of the same type and shape as ``a``.
169
170 .. seealso:: :func:`numpy.partition`
171
172 """
173 if axis is None:
174 ret = a.flatten()
175 axis = -1
176 else:
177 ret = a.copy()
178 ret.partition(kth, axis=axis)
179 return ret
180
181
182 def argpartition(a, kth, axis=-1):
183 """Returns the indices that would partially sort an array.
184
185 Args:
186 a (cupy.ndarray): Array to be sorted.
187 kth (int or sequence of ints): Element index to partition by. If
188 supplied with a sequence of k-th it will partition all elements
189 indexed by k-th of them into their sorted position at once.
190 axis (int or None): Axis along which to sort. Default is -1, which
191 means sort along the last axis. If None is supplied, the array is
192 flattened before sorting.
193
194 Returns:
195 cupy.ndarray: Array of the same type and shape as ``a``.
196
197 .. note::
198 For its implementation reason, `cupy.argpartition` fully sorts the
199 given array as `cupy.argsort` does. It also does not support ``kind``
200 and ``order`` parameters that ``numpy.argpartition`` supports.
201
202 .. seealso:: :func:`numpy.argpartition`
203
204 """
205 return a.argpartition(kth, axis=axis)
206
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/cupy/_sorting/sort.py b/cupy/_sorting/sort.py
--- a/cupy/_sorting/sort.py
+++ b/cupy/_sorting/sort.py
@@ -4,7 +4,7 @@
from cupy.cuda import thrust
-def sort(a, axis=-1):
+def sort(a, axis=-1, kind=None):
"""Returns a sorted copy of an array with a stable sorting algorithm.
Args:
@@ -12,6 +12,8 @@
axis (int or None): Axis along which to sort. Default is -1, which
means sort along the last axis. If None is supplied, the array is
flattened before sorting.
+ kind: Default is `None`, which is equivalent to 'stable'. Unlike in
+ NumPy any other options are not accepted here.
Returns:
cupy.ndarray: Array of the same type and shape as ``a``.
@@ -24,6 +26,8 @@
.. seealso:: :func:`numpy.sort`
"""
+ if kind is not None and kind != 'stable':
+ raise ValueError("kind can only be None or 'stable'")
if axis is None:
ret = a.flatten()
axis = -1
@@ -84,7 +88,7 @@
return idx_array
-def argsort(a, axis=-1):
+def argsort(a, axis=-1, kind=None):
"""Returns the indices that would sort an array with a stable sorting.
Args:
@@ -92,6 +96,8 @@
axis (int or None): Axis along which to sort. Default is -1, which
means sort along the last axis. If None is supplied, the array is
flattened before sorting.
+ kind: Default is `None`, which is equivalent to 'stable'. Unlike in
+ NumPy any other options are not accepted here.
Returns:
cupy.ndarray: Array of indices that sort ``a``.
@@ -103,6 +109,8 @@
.. seealso:: :func:`numpy.argsort`
"""
+ if kind is not None and kind != 'stable':
+ raise ValueError("kind can only be None or 'stable'")
return a.argsort(axis=axis)
diff --git a/cupy/array_api/_sorting_functions.py b/cupy/array_api/_sorting_functions.py
--- a/cupy/array_api/_sorting_functions.py
+++ b/cupy/array_api/_sorting_functions.py
@@ -15,8 +15,9 @@
See its docstring for more information.
"""
- # Note: this keyword argument is different, and the default is different.
- kind = "stable" if stable else "quicksort"
+ # Note: Unlike in NumPy we only support kind={None, 'stable'}, but the standard
+ # does *not* require we need to support unstable sort.
+ kind = None
if not descending:
res = np.argsort(x._array, axis=axis, kind=kind)
else:
@@ -42,8 +43,9 @@
See its docstring for more information.
"""
- # Note: this keyword argument is different, and the default is different.
- kind = "stable" if stable else "quicksort"
+ # Note: Unlike in NumPy we only support kind={None, 'stable'}, but the standard
+ # does *not* require we need to support unstable sort.
+ kind = None
res = np.sort(x._array, axis=axis, kind=kind)
if descending:
res = np.flip(res, axis=axis)
|
{"golden_diff": "diff --git a/cupy/_sorting/sort.py b/cupy/_sorting/sort.py\n--- a/cupy/_sorting/sort.py\n+++ b/cupy/_sorting/sort.py\n@@ -4,7 +4,7 @@\n from cupy.cuda import thrust\n \n \n-def sort(a, axis=-1):\n+def sort(a, axis=-1, kind=None):\n \"\"\"Returns a sorted copy of an array with a stable sorting algorithm.\n \n Args:\n@@ -12,6 +12,8 @@\n axis (int or None): Axis along which to sort. Default is -1, which\n means sort along the last axis. If None is supplied, the array is\n flattened before sorting.\n+ kind: Default is `None`, which is equivalent to 'stable'. Unlike in\n+ NumPy any other options are not accepted here.\n \n Returns:\n cupy.ndarray: Array of the same type and shape as ``a``.\n@@ -24,6 +26,8 @@\n .. seealso:: :func:`numpy.sort`\n \n \"\"\"\n+ if kind is not None and kind != 'stable':\n+ raise ValueError(\"kind can only be None or 'stable'\")\n if axis is None:\n ret = a.flatten()\n axis = -1\n@@ -84,7 +88,7 @@\n return idx_array\n \n \n-def argsort(a, axis=-1):\n+def argsort(a, axis=-1, kind=None):\n \"\"\"Returns the indices that would sort an array with a stable sorting.\n \n Args:\n@@ -92,6 +96,8 @@\n axis (int or None): Axis along which to sort. Default is -1, which\n means sort along the last axis. If None is supplied, the array is\n flattened before sorting.\n+ kind: Default is `None`, which is equivalent to 'stable'. Unlike in\n+ NumPy any other options are not accepted here.\n \n Returns:\n cupy.ndarray: Array of indices that sort ``a``.\n@@ -103,6 +109,8 @@\n .. seealso:: :func:`numpy.argsort`\n \n \"\"\"\n+ if kind is not None and kind != 'stable':\n+ raise ValueError(\"kind can only be None or 'stable'\")\n return a.argsort(axis=axis)\n \n \ndiff --git a/cupy/array_api/_sorting_functions.py b/cupy/array_api/_sorting_functions.py\n--- a/cupy/array_api/_sorting_functions.py\n+++ b/cupy/array_api/_sorting_functions.py\n@@ -15,8 +15,9 @@\n \n See its docstring for more information.\n \"\"\"\n- # Note: this keyword argument is different, and the default is different.\n- kind = \"stable\" if stable else \"quicksort\"\n+ # Note: Unlike in NumPy we only support kind={None, 'stable'}, but the standard\n+ # does *not* require we need to support unstable sort.\n+ kind = None\n if not descending:\n res = np.argsort(x._array, axis=axis, kind=kind)\n else:\n@@ -42,8 +43,9 @@\n \n See its docstring for more information.\n \"\"\"\n- # Note: this keyword argument is different, and the default is different.\n- kind = \"stable\" if stable else \"quicksort\"\n+ # Note: Unlike in NumPy we only support kind={None, 'stable'}, but the standard\n+ # does *not* require we need to support unstable sort.\n+ kind = None\n res = np.sort(x._array, axis=axis, kind=kind)\n if descending:\n res = np.flip(res, axis=axis)\n", "issue": "array_api sort() does not work\n### Description\n\nThe array_api sort() is copied from the NumPy implementation, but passes through a `kind` keyword which doesn't exist in `cupy.sort`.\n\n### To Reproduce\n\n```py\r\n>>> a = xp.asarray([1, 0, 2])\r\n>>> xp.sort(a)\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/aaronmeurer/anaconda3/envs/array-api/lib/python3.10/site-packages/cupy/array_api/_sorting_functions.py\", line 45, in sort\r\n res = np.sort(x._array, axis=axis, kind=kind)\r\nTypeError: sort() got an unexpected keyword argument 'kind'\r\n```\r\n\n\n### Installation\n\nConda-Forge (`conda install ...`)\n\n### Environment\n\n```\r\n# Paste the output here\r\n```\r\n\n\n### Additional Information\n\nThe array API does require support for a `stable` keyword. If `cupy.sort` is always stable, it can just ignore this flag, as `stable=False` is allowed to be stable (see https://data-apis.org/array-api/latest/API_specification/generated/signatures.sorting_functions.sort.html). Otherwise, I would suggest raising NotImplementedError for `stable=True` (which is unfortunately the default). \n", "before_files": [{"content": "# mypy: ignore-errors\n\nfrom __future__ import annotations\n\nfrom ._array_object import Array\n\nimport cupy as np\n\n\ndef argsort(\n x: Array, /, *, axis: int = -1, descending: bool = False, stable: bool = True\n) -> Array:\n \"\"\"\n Array API compatible wrapper for :py:func:`np.argsort <numpy.argsort>`.\n\n See its docstring for more information.\n \"\"\"\n # Note: this keyword argument is different, and the default is different.\n kind = \"stable\" if stable else \"quicksort\"\n if not descending:\n res = np.argsort(x._array, axis=axis, kind=kind)\n else:\n # As NumPy has no native descending sort, we imitate it here. Note that\n # simply flipping the results of np.argsort(x._array, ...) would not\n # respect the relative order like it would in native descending sorts.\n res = np.flip(\n np.argsort(np.flip(x._array, axis=axis), axis=axis, kind=kind),\n axis=axis,\n )\n # Rely on flip()/argsort() to validate axis\n normalised_axis = axis if axis >= 0 else x.ndim + axis\n max_i = x.shape[normalised_axis] - 1\n res = max_i - res\n return Array._new(res)\n\n\ndef sort(\n x: Array, /, *, axis: int = -1, descending: bool = False, stable: bool = True\n) -> Array:\n \"\"\"\n Array API compatible wrapper for :py:func:`np.sort <numpy.sort>`.\n\n See its docstring for more information.\n \"\"\"\n # Note: this keyword argument is different, and the default is different.\n kind = \"stable\" if stable else \"quicksort\"\n res = np.sort(x._array, axis=axis, kind=kind)\n if descending:\n res = np.flip(res, axis=axis)\n return Array._new(res)\n", "path": "cupy/array_api/_sorting_functions.py"}, {"content": "import cupy\nimport numpy\n\nfrom cupy.cuda import thrust\n\n\ndef sort(a, axis=-1):\n \"\"\"Returns a sorted copy of an array with a stable sorting algorithm.\n\n Args:\n a (cupy.ndarray): Array to be sorted.\n axis (int or None): Axis along which to sort. Default is -1, which\n means sort along the last axis. If None is supplied, the array is\n flattened before sorting.\n\n Returns:\n cupy.ndarray: Array of the same type and shape as ``a``.\n\n .. note::\n For its implementation reason, ``cupy.sort`` currently does not support\n ``kind`` and ``order`` parameters that ``numpy.sort`` does\n support.\n\n .. seealso:: :func:`numpy.sort`\n\n \"\"\"\n if axis is None:\n ret = a.flatten()\n axis = -1\n else:\n ret = a.copy()\n ret.sort(axis=axis)\n return ret\n\n\ndef lexsort(keys):\n \"\"\"Perform an indirect sort using an array of keys.\n\n Args:\n keys (cupy.ndarray): ``(k, N)`` array containing ``k`` ``(N,)``-shaped\n arrays. The ``k`` different \"rows\" to be sorted. The last row is\n the primary sort key.\n\n Returns:\n cupy.ndarray: Array of indices that sort the keys.\n\n .. note::\n For its implementation reason, ``cupy.lexsort`` currently supports only\n keys with their rank of one or two and does not support ``axis``\n parameter that ``numpy.lexsort`` supports.\n\n .. seealso:: :func:`numpy.lexsort`\n\n \"\"\"\n\n # TODO(takagi): Support axis argument.\n\n if not cupy.cuda.thrust.available:\n raise RuntimeError('Thrust is needed to use cupy.lexsort. Please '\n 'install CUDA Toolkit with Thrust then reinstall '\n 'CuPy after uninstalling it.')\n\n if keys.ndim == ():\n # as numpy.lexsort() raises\n raise TypeError('need sequence of keys with len > 0 in lexsort')\n\n if keys.ndim == 1:\n return 0\n\n # TODO(takagi): Support ranks of three or more.\n if keys.ndim > 2:\n raise NotImplementedError('Keys with the rank of three or more is not '\n 'supported in lexsort')\n\n # thrust.lexsort() assumes a C-contiguous array\n if not keys.flags.c_contiguous:\n keys = keys.copy('C')\n\n idx_array = cupy.ndarray(keys._shape[1:], dtype=numpy.intp)\n k = keys._shape[0]\n n = keys._shape[1]\n thrust.lexsort(keys.dtype, idx_array.data.ptr, keys.data.ptr, k, n)\n\n return idx_array\n\n\ndef argsort(a, axis=-1):\n \"\"\"Returns the indices that would sort an array with a stable sorting.\n\n Args:\n a (cupy.ndarray): Array to sort.\n axis (int or None): Axis along which to sort. Default is -1, which\n means sort along the last axis. If None is supplied, the array is\n flattened before sorting.\n\n Returns:\n cupy.ndarray: Array of indices that sort ``a``.\n\n .. note::\n For its implementation reason, ``cupy.argsort`` does not support\n ``kind`` and ``order`` parameters.\n\n .. seealso:: :func:`numpy.argsort`\n\n \"\"\"\n return a.argsort(axis=axis)\n\n\ndef msort(a):\n \"\"\"Returns a copy of an array sorted along the first axis.\n\n Args:\n a (cupy.ndarray): Array to be sorted.\n\n Returns:\n cupy.ndarray: Array of the same type and shape as ``a``.\n\n .. note:\n ``cupy.msort(a)``, the CuPy counterpart of ``numpy.msort(a)``, is\n equivalent to ``cupy.sort(a, axis=0)``.\n\n .. seealso:: :func:`numpy.msort`\n\n \"\"\"\n\n return sort(a, axis=0)\n\n\ndef sort_complex(a):\n \"\"\"Sort a complex array using the real part first,\n then the imaginary part.\n\n Args:\n a (cupy.ndarray): Array to be sorted.\n\n Returns:\n cupy.ndarray: sorted complex array.\n\n .. seealso:: :func:`numpy.sort_complex`\n\n \"\"\"\n if a.dtype.char in 'bhBHF':\n a = a.astype('F')\n else:\n a = a.astype('D')\n a.sort()\n return a\n\n\ndef partition(a, kth, axis=-1):\n \"\"\"Returns a partitioned copy of an array.\n\n Creates a copy of the array whose elements are rearranged such that the\n value of the element in k-th position would occur in that position in a\n sorted array. All of the elements before the new k-th element are less\n than or equal to the elements after the new k-th element.\n\n Args:\n a (cupy.ndarray): Array to be sorted.\n kth (int or sequence of ints): Element index to partition by. If\n supplied with a sequence of k-th it will partition all elements\n indexed by k-th of them into their sorted position at once.\n axis (int or None): Axis along which to sort. Default is -1, which\n means sort along the last axis. If None is supplied, the array is\n flattened before sorting.\n\n Returns:\n cupy.ndarray: Array of the same type and shape as ``a``.\n\n .. seealso:: :func:`numpy.partition`\n\n \"\"\"\n if axis is None:\n ret = a.flatten()\n axis = -1\n else:\n ret = a.copy()\n ret.partition(kth, axis=axis)\n return ret\n\n\ndef argpartition(a, kth, axis=-1):\n \"\"\"Returns the indices that would partially sort an array.\n\n Args:\n a (cupy.ndarray): Array to be sorted.\n kth (int or sequence of ints): Element index to partition by. If\n supplied with a sequence of k-th it will partition all elements\n indexed by k-th of them into their sorted position at once.\n axis (int or None): Axis along which to sort. Default is -1, which\n means sort along the last axis. If None is supplied, the array is\n flattened before sorting.\n\n Returns:\n cupy.ndarray: Array of the same type and shape as ``a``.\n\n .. note::\n For its implementation reason, `cupy.argpartition` fully sorts the\n given array as `cupy.argsort` does. It also does not support ``kind``\n and ``order`` parameters that ``numpy.argpartition`` supports.\n\n .. seealso:: :func:`numpy.argpartition`\n\n \"\"\"\n return a.argpartition(kth, axis=axis)\n", "path": "cupy/_sorting/sort.py"}], "after_files": [{"content": "# mypy: ignore-errors\n\nfrom __future__ import annotations\n\nfrom ._array_object import Array\n\nimport cupy as np\n\n\ndef argsort(\n x: Array, /, *, axis: int = -1, descending: bool = False, stable: bool = True\n) -> Array:\n \"\"\"\n Array API compatible wrapper for :py:func:`np.argsort <numpy.argsort>`.\n\n See its docstring for more information.\n \"\"\"\n # Note: Unlike in NumPy we only support kind={None, 'stable'}, but the standard\n # does *not* require we need to support unstable sort.\n kind = None\n if not descending:\n res = np.argsort(x._array, axis=axis, kind=kind)\n else:\n # As NumPy has no native descending sort, we imitate it here. Note that\n # simply flipping the results of np.argsort(x._array, ...) would not\n # respect the relative order like it would in native descending sorts.\n res = np.flip(\n np.argsort(np.flip(x._array, axis=axis), axis=axis, kind=kind),\n axis=axis,\n )\n # Rely on flip()/argsort() to validate axis\n normalised_axis = axis if axis >= 0 else x.ndim + axis\n max_i = x.shape[normalised_axis] - 1\n res = max_i - res\n return Array._new(res)\n\n\ndef sort(\n x: Array, /, *, axis: int = -1, descending: bool = False, stable: bool = True\n) -> Array:\n \"\"\"\n Array API compatible wrapper for :py:func:`np.sort <numpy.sort>`.\n\n See its docstring for more information.\n \"\"\"\n # Note: Unlike in NumPy we only support kind={None, 'stable'}, but the standard\n # does *not* require we need to support unstable sort.\n kind = None\n res = np.sort(x._array, axis=axis, kind=kind)\n if descending:\n res = np.flip(res, axis=axis)\n return Array._new(res)\n", "path": "cupy/array_api/_sorting_functions.py"}, {"content": "import cupy\nimport numpy\n\nfrom cupy.cuda import thrust\n\n\ndef sort(a, axis=-1, kind=None):\n \"\"\"Returns a sorted copy of an array with a stable sorting algorithm.\n\n Args:\n a (cupy.ndarray): Array to be sorted.\n axis (int or None): Axis along which to sort. Default is -1, which\n means sort along the last axis. If None is supplied, the array is\n flattened before sorting.\n kind: Default is `None`, which is equivalent to 'stable'. Unlike in\n NumPy any other options are not accepted here.\n\n Returns:\n cupy.ndarray: Array of the same type and shape as ``a``.\n\n .. note::\n For its implementation reason, ``cupy.sort`` currently does not support\n ``kind`` and ``order`` parameters that ``numpy.sort`` does\n support.\n\n .. seealso:: :func:`numpy.sort`\n\n \"\"\"\n if kind is not None and kind != 'stable':\n raise ValueError(\"kind can only be None or 'stable'\")\n if axis is None:\n ret = a.flatten()\n axis = -1\n else:\n ret = a.copy()\n ret.sort(axis=axis)\n return ret\n\n\ndef lexsort(keys):\n \"\"\"Perform an indirect sort using an array of keys.\n\n Args:\n keys (cupy.ndarray): ``(k, N)`` array containing ``k`` ``(N,)``-shaped\n arrays. The ``k`` different \"rows\" to be sorted. The last row is\n the primary sort key.\n\n Returns:\n cupy.ndarray: Array of indices that sort the keys.\n\n .. note::\n For its implementation reason, ``cupy.lexsort`` currently supports only\n keys with their rank of one or two and does not support ``axis``\n parameter that ``numpy.lexsort`` supports.\n\n .. seealso:: :func:`numpy.lexsort`\n\n \"\"\"\n\n # TODO(takagi): Support axis argument.\n\n if not cupy.cuda.thrust.available:\n raise RuntimeError('Thrust is needed to use cupy.lexsort. Please '\n 'install CUDA Toolkit with Thrust then reinstall '\n 'CuPy after uninstalling it.')\n\n if keys.ndim == ():\n # as numpy.lexsort() raises\n raise TypeError('need sequence of keys with len > 0 in lexsort')\n\n if keys.ndim == 1:\n return 0\n\n # TODO(takagi): Support ranks of three or more.\n if keys.ndim > 2:\n raise NotImplementedError('Keys with the rank of three or more is not '\n 'supported in lexsort')\n\n # thrust.lexsort() assumes a C-contiguous array\n if not keys.flags.c_contiguous:\n keys = keys.copy('C')\n\n idx_array = cupy.ndarray(keys._shape[1:], dtype=numpy.intp)\n k = keys._shape[0]\n n = keys._shape[1]\n thrust.lexsort(keys.dtype, idx_array.data.ptr, keys.data.ptr, k, n)\n\n return idx_array\n\n\ndef argsort(a, axis=-1, kind=None):\n \"\"\"Returns the indices that would sort an array with a stable sorting.\n\n Args:\n a (cupy.ndarray): Array to sort.\n axis (int or None): Axis along which to sort. Default is -1, which\n means sort along the last axis. If None is supplied, the array is\n flattened before sorting.\n kind: Default is `None`, which is equivalent to 'stable'. Unlike in\n NumPy any other options are not accepted here.\n\n Returns:\n cupy.ndarray: Array of indices that sort ``a``.\n\n .. note::\n For its implementation reason, ``cupy.argsort`` does not support\n ``kind`` and ``order`` parameters.\n\n .. seealso:: :func:`numpy.argsort`\n\n \"\"\"\n if kind is not None and kind != 'stable':\n raise ValueError(\"kind can only be None or 'stable'\")\n return a.argsort(axis=axis)\n\n\ndef msort(a):\n \"\"\"Returns a copy of an array sorted along the first axis.\n\n Args:\n a (cupy.ndarray): Array to be sorted.\n\n Returns:\n cupy.ndarray: Array of the same type and shape as ``a``.\n\n .. note:\n ``cupy.msort(a)``, the CuPy counterpart of ``numpy.msort(a)``, is\n equivalent to ``cupy.sort(a, axis=0)``.\n\n .. seealso:: :func:`numpy.msort`\n\n \"\"\"\n\n return sort(a, axis=0)\n\n\ndef sort_complex(a):\n \"\"\"Sort a complex array using the real part first,\n then the imaginary part.\n\n Args:\n a (cupy.ndarray): Array to be sorted.\n\n Returns:\n cupy.ndarray: sorted complex array.\n\n .. seealso:: :func:`numpy.sort_complex`\n\n \"\"\"\n if a.dtype.char in 'bhBHF':\n a = a.astype('F')\n else:\n a = a.astype('D')\n a.sort()\n return a\n\n\ndef partition(a, kth, axis=-1):\n \"\"\"Returns a partitioned copy of an array.\n\n Creates a copy of the array whose elements are rearranged such that the\n value of the element in k-th position would occur in that position in a\n sorted array. All of the elements before the new k-th element are less\n than or equal to the elements after the new k-th element.\n\n Args:\n a (cupy.ndarray): Array to be sorted.\n kth (int or sequence of ints): Element index to partition by. If\n supplied with a sequence of k-th it will partition all elements\n indexed by k-th of them into their sorted position at once.\n axis (int or None): Axis along which to sort. Default is -1, which\n means sort along the last axis. If None is supplied, the array is\n flattened before sorting.\n\n Returns:\n cupy.ndarray: Array of the same type and shape as ``a``.\n\n .. seealso:: :func:`numpy.partition`\n\n \"\"\"\n if axis is None:\n ret = a.flatten()\n axis = -1\n else:\n ret = a.copy()\n ret.partition(kth, axis=axis)\n return ret\n\n\ndef argpartition(a, kth, axis=-1):\n \"\"\"Returns the indices that would partially sort an array.\n\n Args:\n a (cupy.ndarray): Array to be sorted.\n kth (int or sequence of ints): Element index to partition by. If\n supplied with a sequence of k-th it will partition all elements\n indexed by k-th of them into their sorted position at once.\n axis (int or None): Axis along which to sort. Default is -1, which\n means sort along the last axis. If None is supplied, the array is\n flattened before sorting.\n\n Returns:\n cupy.ndarray: Array of the same type and shape as ``a``.\n\n .. note::\n For its implementation reason, `cupy.argpartition` fully sorts the\n given array as `cupy.argsort` does. It also does not support ``kind``\n and ``order`` parameters that ``numpy.argpartition`` supports.\n\n .. seealso:: :func:`numpy.argpartition`\n\n \"\"\"\n return a.argpartition(kth, axis=axis)\n", "path": "cupy/_sorting/sort.py"}]}
| 3,104 | 801 |
gh_patches_debug_2992
|
rasdani/github-patches
|
git_diff
|
freedomofpress__securedrop-6408
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Test securedrop-admin with Tails 5.0
## Description
https://tails.boum.org/news/test_5.0-beta1/
Tails 5.0 is based on Debian Bullseye, which means it's using a newer Python version (3.9) among plenty of other things.
It's probably worth walking through a full SD install + backup/restore to make sure it works as expected.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `admin/bootstrap.py`
Content:
```
1 # -*- mode: python; coding: utf-8 -*-
2 #
3 # Copyright (C) 2013-2018 Freedom of the Press Foundation & al
4 # Copyright (C) 2018 Loic Dachary <[email protected]>
5 #
6 # This program is free software: you can redistribute it and/or modify
7 # it under the terms of the GNU General Public License as published by
8 # the Free Software Foundation, either version 3 of the License, or
9 # (at your option) any later version.
10 #
11 # This program is distributed in the hope that it will be useful,
12 # but WITHOUT ANY WARRANTY; without even the implied warranty of
13 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
14 # GNU General Public License for more details.
15 #
16 # You should have received a copy of the GNU General Public License
17 # along with this program. If not, see <http://www.gnu.org/licenses/>.
18 #
19
20 import argparse
21 import logging
22 import os
23 import shutil
24 import subprocess
25 import sys
26 from typing import Iterator
27
28 from typing import List
29
30 sdlog = logging.getLogger(__name__)
31
32 DIR = os.path.dirname(os.path.realpath(__file__))
33 VENV_DIR = os.path.join(DIR, ".venv3")
34
35
36 def setup_logger(verbose: bool = False) -> None:
37 """ Configure logging handler """
38 # Set default level on parent
39 sdlog.setLevel(logging.DEBUG)
40 level = logging.DEBUG if verbose else logging.INFO
41
42 stdout = logging.StreamHandler(sys.stdout)
43 stdout.setFormatter(logging.Formatter('%(levelname)s: %(message)s'))
44 stdout.setLevel(level)
45 sdlog.addHandler(stdout)
46
47
48 def run_command(command: List[str]) -> Iterator[bytes]:
49 """
50 Wrapper function to display stdout for running command,
51 similar to how shelling out in a Bash script displays rolling output.
52
53 Yields a list of the stdout from the `command`, and raises a
54 CalledProcessError if `command` returns non-zero.
55 """
56 popen = subprocess.Popen(command,
57 stdout=subprocess.PIPE,
58 stderr=subprocess.STDOUT)
59 if popen.stdout is None:
60 raise EnvironmentError("Could not run command: None stdout")
61 for stdout_line in iter(popen.stdout.readline, b""):
62 yield stdout_line
63 popen.stdout.close()
64 return_code = popen.wait()
65 if return_code:
66 raise subprocess.CalledProcessError(return_code, command)
67
68
69 def is_tails() -> bool:
70 try:
71 id = subprocess.check_output('lsb_release --id --short',
72 shell=True).decode('utf-8').strip()
73 except subprocess.CalledProcessError:
74 return False
75
76 # dirty hack to unreliably detect Tails 4.0~beta2
77 if id == 'Debian':
78 if os.uname()[1] == 'amnesia':
79 id = 'Tails'
80
81 return id == 'Tails'
82
83
84 def clean_up_tails3_venv(virtualenv_dir: str = VENV_DIR) -> None:
85 """
86 Tails 3.x, based on debian stretch uses libpython3.5, whereas Tails 4.x is
87 based on Debian Buster and uses libpython3.7. This means that the Tails 3.x
88 virtualenv will not work under Tails 4.x, and will need to be destroyed and
89 rebuilt. We can detect if the version of libpython is 3.5 in the
90 admin/.venv3/ folder, and delete it if that's the case. This will ensure a
91 smooth upgrade from Tails 3.x to Tails 4.x.
92 """
93 if is_tails():
94 try:
95 dist = subprocess.check_output('lsb_release --codename --short',
96 shell=True).strip()
97 except subprocess.CalledProcessError:
98 return None
99
100 # tails4 is based on buster
101 if dist == b'buster':
102 python_lib_path = os.path.join(virtualenv_dir, "lib/python3.5")
103 if os.path.exists(os.path.join(python_lib_path)):
104 sdlog.info(
105 "Tails 3 Python 3 virtualenv detected. "
106 "Removing it."
107 )
108 shutil.rmtree(virtualenv_dir)
109 sdlog.info("Tails 3 Python 3 virtualenv deleted.")
110
111
112 def checkenv(args: argparse.Namespace) -> None:
113 clean_up_tails3_venv(VENV_DIR)
114 if not os.path.exists(os.path.join(VENV_DIR, "bin/activate")):
115 sdlog.error('Please run "securedrop-admin setup".')
116 sys.exit(1)
117
118
119 def maybe_torify() -> List[str]:
120 if is_tails():
121 return ['torify']
122 else:
123 return []
124
125
126 def install_apt_dependencies(args: argparse.Namespace) -> None:
127 """
128 Install apt dependencies in Tails. In order to install Ansible in
129 a virtualenv, first there are a number of Python prerequisites.
130 """
131 sdlog.info("Installing SecureDrop Admin dependencies")
132 sdlog.info(("You'll be prompted for the temporary Tails admin password,"
133 " which was set on Tails login screen"))
134
135 apt_command = ['sudo', 'su', '-c',
136 "apt-get update && \
137 apt-get -q -o=Dpkg::Use-Pty=0 install -y \
138 python3-virtualenv \
139 python3-yaml \
140 python3-pip \
141 ccontrol \
142 virtualenv \
143 libffi-dev \
144 libssl-dev \
145 libpython3-dev",
146 ]
147
148 try:
149 # Print command results in real-time, to keep Admin apprised
150 # of progress during long-running command.
151 for output_line in run_command(apt_command):
152 print(output_line.decode('utf-8').rstrip())
153 except subprocess.CalledProcessError:
154 # Tails supports apt persistence, which was used by SecureDrop
155 # under Tails 2.x. If updates are being applied, don't try to pile
156 # on with more apt requests.
157 sdlog.error(("Failed to install apt dependencies. Check network"
158 " connection and try again."))
159 raise
160
161
162 def envsetup(args: argparse.Namespace, virtualenv_dir: str = VENV_DIR) -> None:
163 """Installs Admin tooling required for managing SecureDrop. Specifically:
164
165 * updates apt-cache
166 * installs apt packages for Python virtualenv
167 * creates virtualenv
168 * installs pip packages inside virtualenv
169
170 The virtualenv is created within the Persistence volume in Tails, so that
171 Ansible is available to the Admin on subsequent boots without requiring
172 installation of packages again.
173 """
174 # clean up Tails 3.x venv when migrating to Tails 4.x
175 clean_up_tails3_venv(virtualenv_dir)
176
177 # virtualenv doesnt exist? Install dependencies and create
178 if not os.path.exists(virtualenv_dir):
179
180 install_apt_dependencies(args)
181
182 # Technically you can create a virtualenv from within python
183 # but pip can only be run over Tor on Tails, and debugging that
184 # along with instaling a third-party dependency is not worth
185 # the effort here.
186 sdlog.info("Setting up virtualenv")
187 try:
188 sdlog.debug(subprocess.check_output(
189 maybe_torify() + ['virtualenv',
190 '--python=python3',
191 virtualenv_dir
192 ],
193 stderr=subprocess.STDOUT))
194 except subprocess.CalledProcessError as e:
195 sdlog.debug(e.output)
196 sdlog.error(("Unable to create virtualenv. Check network settings"
197 " and try again."))
198 sdlog.debug("Cleaning up virtualenv")
199 if os.path.exists(virtualenv_dir):
200 shutil.rmtree(virtualenv_dir)
201 raise
202 else:
203 sdlog.info("Virtualenv already exists, not creating")
204
205 if args.t:
206 install_pip_dependencies(
207 args,
208 requirements_file='requirements-testinfra.txt',
209 desc="dependencies with verification support"
210 )
211 else:
212 install_pip_dependencies(args)
213
214 if os.path.exists(os.path.join(DIR, 'setup.py')):
215 install_pip_self(args)
216
217 sdlog.info("Finished installing SecureDrop dependencies")
218
219
220 def install_pip_self(args: argparse.Namespace) -> None:
221 pip_install_cmd = [
222 os.path.join(VENV_DIR, 'bin', 'pip3'),
223 'install', '-e', DIR
224 ]
225 try:
226 subprocess.check_output(maybe_torify() + pip_install_cmd,
227 stderr=subprocess.STDOUT)
228 except subprocess.CalledProcessError as e:
229 sdlog.debug(e.output)
230 sdlog.error("Unable to install self, run with -v for more information")
231 raise
232
233
234 def install_pip_dependencies(
235 args: argparse.Namespace,
236 requirements_file: str = "requirements.txt",
237 desc: str = "Python dependencies",
238 ) -> None:
239 """
240 Install Python dependencies via pip into virtualenv.
241 """
242 pip_install_cmd = [
243 os.path.join(VENV_DIR, 'bin', 'pip3'),
244 'install',
245 '--no-deps',
246 '-r', os.path.join(DIR, requirements_file),
247 '--require-hashes',
248 '-U', '--upgrade-strategy', 'only-if-needed',
249 ]
250
251 sdlog.info("Checking {} for securedrop-admin".format(desc))
252 try:
253 pip_output = subprocess.check_output(maybe_torify() + pip_install_cmd,
254 stderr=subprocess.STDOUT)
255 except subprocess.CalledProcessError as e:
256 sdlog.debug(e.output)
257 sdlog.error(("Failed to install {}. Check network"
258 " connection and try again.".format(desc)))
259 raise
260
261 sdlog.debug(pip_output)
262 if "Successfully installed" in str(pip_output):
263 sdlog.info("{} for securedrop-admin upgraded".format(desc))
264 else:
265 sdlog.info("{} for securedrop-admin are up-to-date".format(desc))
266
267
268 def parse_argv(argv: List[str]) -> argparse.Namespace:
269 parser = argparse.ArgumentParser()
270 parser.add_argument('-v', action='store_true', default=False,
271 help="Increase verbosity on output")
272 parser.add_argument('-t', action='store_true', default=False,
273 help="Install additional test dependencies")
274 parser.set_defaults(func=envsetup)
275
276 subparsers = parser.add_subparsers()
277
278 envsetup_parser = subparsers.add_parser(
279 'envsetup',
280 help='Set up the admin virtualenv.'
281 )
282 envsetup_parser.set_defaults(func=envsetup)
283
284 checkenv_parser = subparsers.add_parser(
285 'checkenv',
286 help='Check that the admin virtualenv is properly set up.'
287 )
288 checkenv_parser.set_defaults(func=checkenv)
289
290 return parser.parse_args(argv)
291
292
293 if __name__ == "__main__":
294 args = parse_argv(sys.argv[1:])
295 setup_logger(args.v)
296
297 try:
298 args.func(args)
299 except Exception:
300 sys.exit(1)
301 else:
302 sys.exit(0)
303
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/admin/bootstrap.py b/admin/bootstrap.py
--- a/admin/bootstrap.py
+++ b/admin/bootstrap.py
@@ -138,7 +138,6 @@
python3-virtualenv \
python3-yaml \
python3-pip \
- ccontrol \
virtualenv \
libffi-dev \
libssl-dev \
|
{"golden_diff": "diff --git a/admin/bootstrap.py b/admin/bootstrap.py\n--- a/admin/bootstrap.py\n+++ b/admin/bootstrap.py\n@@ -138,7 +138,6 @@\n python3-virtualenv \\\n python3-yaml \\\n python3-pip \\\n- ccontrol \\\n virtualenv \\\n libffi-dev \\\n libssl-dev \\\n", "issue": "Test securedrop-admin with Tails 5.0\n## Description\r\n\r\nhttps://tails.boum.org/news/test_5.0-beta1/\r\n\r\nTails 5.0 is based on Debian Bullseye, which means it's using a newer Python version (3.9) among plenty of other things.\r\n\r\nIt's probably worth walking through a full SD install + backup/restore to make sure it works as expected.\n", "before_files": [{"content": "# -*- mode: python; coding: utf-8 -*-\n#\n# Copyright (C) 2013-2018 Freedom of the Press Foundation & al\n# Copyright (C) 2018 Loic Dachary <[email protected]>\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this program. If not, see <http://www.gnu.org/licenses/>.\n#\n\nimport argparse\nimport logging\nimport os\nimport shutil\nimport subprocess\nimport sys\nfrom typing import Iterator\n\nfrom typing import List\n\nsdlog = logging.getLogger(__name__)\n\nDIR = os.path.dirname(os.path.realpath(__file__))\nVENV_DIR = os.path.join(DIR, \".venv3\")\n\n\ndef setup_logger(verbose: bool = False) -> None:\n \"\"\" Configure logging handler \"\"\"\n # Set default level on parent\n sdlog.setLevel(logging.DEBUG)\n level = logging.DEBUG if verbose else logging.INFO\n\n stdout = logging.StreamHandler(sys.stdout)\n stdout.setFormatter(logging.Formatter('%(levelname)s: %(message)s'))\n stdout.setLevel(level)\n sdlog.addHandler(stdout)\n\n\ndef run_command(command: List[str]) -> Iterator[bytes]:\n \"\"\"\n Wrapper function to display stdout for running command,\n similar to how shelling out in a Bash script displays rolling output.\n\n Yields a list of the stdout from the `command`, and raises a\n CalledProcessError if `command` returns non-zero.\n \"\"\"\n popen = subprocess.Popen(command,\n stdout=subprocess.PIPE,\n stderr=subprocess.STDOUT)\n if popen.stdout is None:\n raise EnvironmentError(\"Could not run command: None stdout\")\n for stdout_line in iter(popen.stdout.readline, b\"\"):\n yield stdout_line\n popen.stdout.close()\n return_code = popen.wait()\n if return_code:\n raise subprocess.CalledProcessError(return_code, command)\n\n\ndef is_tails() -> bool:\n try:\n id = subprocess.check_output('lsb_release --id --short',\n shell=True).decode('utf-8').strip()\n except subprocess.CalledProcessError:\n return False\n\n # dirty hack to unreliably detect Tails 4.0~beta2\n if id == 'Debian':\n if os.uname()[1] == 'amnesia':\n id = 'Tails'\n\n return id == 'Tails'\n\n\ndef clean_up_tails3_venv(virtualenv_dir: str = VENV_DIR) -> None:\n \"\"\"\n Tails 3.x, based on debian stretch uses libpython3.5, whereas Tails 4.x is\n based on Debian Buster and uses libpython3.7. This means that the Tails 3.x\n virtualenv will not work under Tails 4.x, and will need to be destroyed and\n rebuilt. We can detect if the version of libpython is 3.5 in the\n admin/.venv3/ folder, and delete it if that's the case. This will ensure a\n smooth upgrade from Tails 3.x to Tails 4.x.\n \"\"\"\n if is_tails():\n try:\n dist = subprocess.check_output('lsb_release --codename --short',\n shell=True).strip()\n except subprocess.CalledProcessError:\n return None\n\n # tails4 is based on buster\n if dist == b'buster':\n python_lib_path = os.path.join(virtualenv_dir, \"lib/python3.5\")\n if os.path.exists(os.path.join(python_lib_path)):\n sdlog.info(\n \"Tails 3 Python 3 virtualenv detected. \"\n \"Removing it.\"\n )\n shutil.rmtree(virtualenv_dir)\n sdlog.info(\"Tails 3 Python 3 virtualenv deleted.\")\n\n\ndef checkenv(args: argparse.Namespace) -> None:\n clean_up_tails3_venv(VENV_DIR)\n if not os.path.exists(os.path.join(VENV_DIR, \"bin/activate\")):\n sdlog.error('Please run \"securedrop-admin setup\".')\n sys.exit(1)\n\n\ndef maybe_torify() -> List[str]:\n if is_tails():\n return ['torify']\n else:\n return []\n\n\ndef install_apt_dependencies(args: argparse.Namespace) -> None:\n \"\"\"\n Install apt dependencies in Tails. In order to install Ansible in\n a virtualenv, first there are a number of Python prerequisites.\n \"\"\"\n sdlog.info(\"Installing SecureDrop Admin dependencies\")\n sdlog.info((\"You'll be prompted for the temporary Tails admin password,\"\n \" which was set on Tails login screen\"))\n\n apt_command = ['sudo', 'su', '-c',\n \"apt-get update && \\\n apt-get -q -o=Dpkg::Use-Pty=0 install -y \\\n python3-virtualenv \\\n python3-yaml \\\n python3-pip \\\n ccontrol \\\n virtualenv \\\n libffi-dev \\\n libssl-dev \\\n libpython3-dev\",\n ]\n\n try:\n # Print command results in real-time, to keep Admin apprised\n # of progress during long-running command.\n for output_line in run_command(apt_command):\n print(output_line.decode('utf-8').rstrip())\n except subprocess.CalledProcessError:\n # Tails supports apt persistence, which was used by SecureDrop\n # under Tails 2.x. If updates are being applied, don't try to pile\n # on with more apt requests.\n sdlog.error((\"Failed to install apt dependencies. Check network\"\n \" connection and try again.\"))\n raise\n\n\ndef envsetup(args: argparse.Namespace, virtualenv_dir: str = VENV_DIR) -> None:\n \"\"\"Installs Admin tooling required for managing SecureDrop. Specifically:\n\n * updates apt-cache\n * installs apt packages for Python virtualenv\n * creates virtualenv\n * installs pip packages inside virtualenv\n\n The virtualenv is created within the Persistence volume in Tails, so that\n Ansible is available to the Admin on subsequent boots without requiring\n installation of packages again.\n \"\"\"\n # clean up Tails 3.x venv when migrating to Tails 4.x\n clean_up_tails3_venv(virtualenv_dir)\n\n # virtualenv doesnt exist? Install dependencies and create\n if not os.path.exists(virtualenv_dir):\n\n install_apt_dependencies(args)\n\n # Technically you can create a virtualenv from within python\n # but pip can only be run over Tor on Tails, and debugging that\n # along with instaling a third-party dependency is not worth\n # the effort here.\n sdlog.info(\"Setting up virtualenv\")\n try:\n sdlog.debug(subprocess.check_output(\n maybe_torify() + ['virtualenv',\n '--python=python3',\n virtualenv_dir\n ],\n stderr=subprocess.STDOUT))\n except subprocess.CalledProcessError as e:\n sdlog.debug(e.output)\n sdlog.error((\"Unable to create virtualenv. Check network settings\"\n \" and try again.\"))\n sdlog.debug(\"Cleaning up virtualenv\")\n if os.path.exists(virtualenv_dir):\n shutil.rmtree(virtualenv_dir)\n raise\n else:\n sdlog.info(\"Virtualenv already exists, not creating\")\n\n if args.t:\n install_pip_dependencies(\n args,\n requirements_file='requirements-testinfra.txt',\n desc=\"dependencies with verification support\"\n )\n else:\n install_pip_dependencies(args)\n\n if os.path.exists(os.path.join(DIR, 'setup.py')):\n install_pip_self(args)\n\n sdlog.info(\"Finished installing SecureDrop dependencies\")\n\n\ndef install_pip_self(args: argparse.Namespace) -> None:\n pip_install_cmd = [\n os.path.join(VENV_DIR, 'bin', 'pip3'),\n 'install', '-e', DIR\n ]\n try:\n subprocess.check_output(maybe_torify() + pip_install_cmd,\n stderr=subprocess.STDOUT)\n except subprocess.CalledProcessError as e:\n sdlog.debug(e.output)\n sdlog.error(\"Unable to install self, run with -v for more information\")\n raise\n\n\ndef install_pip_dependencies(\n args: argparse.Namespace,\n requirements_file: str = \"requirements.txt\",\n desc: str = \"Python dependencies\",\n) -> None:\n \"\"\"\n Install Python dependencies via pip into virtualenv.\n \"\"\"\n pip_install_cmd = [\n os.path.join(VENV_DIR, 'bin', 'pip3'),\n 'install',\n '--no-deps',\n '-r', os.path.join(DIR, requirements_file),\n '--require-hashes',\n '-U', '--upgrade-strategy', 'only-if-needed',\n ]\n\n sdlog.info(\"Checking {} for securedrop-admin\".format(desc))\n try:\n pip_output = subprocess.check_output(maybe_torify() + pip_install_cmd,\n stderr=subprocess.STDOUT)\n except subprocess.CalledProcessError as e:\n sdlog.debug(e.output)\n sdlog.error((\"Failed to install {}. Check network\"\n \" connection and try again.\".format(desc)))\n raise\n\n sdlog.debug(pip_output)\n if \"Successfully installed\" in str(pip_output):\n sdlog.info(\"{} for securedrop-admin upgraded\".format(desc))\n else:\n sdlog.info(\"{} for securedrop-admin are up-to-date\".format(desc))\n\n\ndef parse_argv(argv: List[str]) -> argparse.Namespace:\n parser = argparse.ArgumentParser()\n parser.add_argument('-v', action='store_true', default=False,\n help=\"Increase verbosity on output\")\n parser.add_argument('-t', action='store_true', default=False,\n help=\"Install additional test dependencies\")\n parser.set_defaults(func=envsetup)\n\n subparsers = parser.add_subparsers()\n\n envsetup_parser = subparsers.add_parser(\n 'envsetup',\n help='Set up the admin virtualenv.'\n )\n envsetup_parser.set_defaults(func=envsetup)\n\n checkenv_parser = subparsers.add_parser(\n 'checkenv',\n help='Check that the admin virtualenv is properly set up.'\n )\n checkenv_parser.set_defaults(func=checkenv)\n\n return parser.parse_args(argv)\n\n\nif __name__ == \"__main__\":\n args = parse_argv(sys.argv[1:])\n setup_logger(args.v)\n\n try:\n args.func(args)\n except Exception:\n sys.exit(1)\n else:\n sys.exit(0)\n", "path": "admin/bootstrap.py"}], "after_files": [{"content": "# -*- mode: python; coding: utf-8 -*-\n#\n# Copyright (C) 2013-2018 Freedom of the Press Foundation & al\n# Copyright (C) 2018 Loic Dachary <[email protected]>\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this program. If not, see <http://www.gnu.org/licenses/>.\n#\n\nimport argparse\nimport logging\nimport os\nimport shutil\nimport subprocess\nimport sys\nfrom typing import Iterator\n\nfrom typing import List\n\nsdlog = logging.getLogger(__name__)\n\nDIR = os.path.dirname(os.path.realpath(__file__))\nVENV_DIR = os.path.join(DIR, \".venv3\")\n\n\ndef setup_logger(verbose: bool = False) -> None:\n \"\"\" Configure logging handler \"\"\"\n # Set default level on parent\n sdlog.setLevel(logging.DEBUG)\n level = logging.DEBUG if verbose else logging.INFO\n\n stdout = logging.StreamHandler(sys.stdout)\n stdout.setFormatter(logging.Formatter('%(levelname)s: %(message)s'))\n stdout.setLevel(level)\n sdlog.addHandler(stdout)\n\n\ndef run_command(command: List[str]) -> Iterator[bytes]:\n \"\"\"\n Wrapper function to display stdout for running command,\n similar to how shelling out in a Bash script displays rolling output.\n\n Yields a list of the stdout from the `command`, and raises a\n CalledProcessError if `command` returns non-zero.\n \"\"\"\n popen = subprocess.Popen(command,\n stdout=subprocess.PIPE,\n stderr=subprocess.STDOUT)\n if popen.stdout is None:\n raise EnvironmentError(\"Could not run command: None stdout\")\n for stdout_line in iter(popen.stdout.readline, b\"\"):\n yield stdout_line\n popen.stdout.close()\n return_code = popen.wait()\n if return_code:\n raise subprocess.CalledProcessError(return_code, command)\n\n\ndef is_tails() -> bool:\n try:\n id = subprocess.check_output('lsb_release --id --short',\n shell=True).decode('utf-8').strip()\n except subprocess.CalledProcessError:\n return False\n\n # dirty hack to unreliably detect Tails 4.0~beta2\n if id == 'Debian':\n if os.uname()[1] == 'amnesia':\n id = 'Tails'\n\n return id == 'Tails'\n\n\ndef clean_up_tails3_venv(virtualenv_dir: str = VENV_DIR) -> None:\n \"\"\"\n Tails 3.x, based on debian stretch uses libpython3.5, whereas Tails 4.x is\n based on Debian Buster and uses libpython3.7. This means that the Tails 3.x\n virtualenv will not work under Tails 4.x, and will need to be destroyed and\n rebuilt. We can detect if the version of libpython is 3.5 in the\n admin/.venv3/ folder, and delete it if that's the case. This will ensure a\n smooth upgrade from Tails 3.x to Tails 4.x.\n \"\"\"\n if is_tails():\n try:\n dist = subprocess.check_output('lsb_release --codename --short',\n shell=True).strip()\n except subprocess.CalledProcessError:\n return None\n\n # tails4 is based on buster\n if dist == b'buster':\n python_lib_path = os.path.join(virtualenv_dir, \"lib/python3.5\")\n if os.path.exists(os.path.join(python_lib_path)):\n sdlog.info(\n \"Tails 3 Python 3 virtualenv detected. \"\n \"Removing it.\"\n )\n shutil.rmtree(virtualenv_dir)\n sdlog.info(\"Tails 3 Python 3 virtualenv deleted.\")\n\n\ndef checkenv(args: argparse.Namespace) -> None:\n clean_up_tails3_venv(VENV_DIR)\n if not os.path.exists(os.path.join(VENV_DIR, \"bin/activate\")):\n sdlog.error('Please run \"securedrop-admin setup\".')\n sys.exit(1)\n\n\ndef maybe_torify() -> List[str]:\n if is_tails():\n return ['torify']\n else:\n return []\n\n\ndef install_apt_dependencies(args: argparse.Namespace) -> None:\n \"\"\"\n Install apt dependencies in Tails. In order to install Ansible in\n a virtualenv, first there are a number of Python prerequisites.\n \"\"\"\n sdlog.info(\"Installing SecureDrop Admin dependencies\")\n sdlog.info((\"You'll be prompted for the temporary Tails admin password,\"\n \" which was set on Tails login screen\"))\n\n apt_command = ['sudo', 'su', '-c',\n \"apt-get update && \\\n apt-get -q -o=Dpkg::Use-Pty=0 install -y \\\n python3-virtualenv \\\n python3-yaml \\\n python3-pip \\\n virtualenv \\\n libffi-dev \\\n libssl-dev \\\n libpython3-dev\",\n ]\n\n try:\n # Print command results in real-time, to keep Admin apprised\n # of progress during long-running command.\n for output_line in run_command(apt_command):\n print(output_line.decode('utf-8').rstrip())\n except subprocess.CalledProcessError:\n # Tails supports apt persistence, which was used by SecureDrop\n # under Tails 2.x. If updates are being applied, don't try to pile\n # on with more apt requests.\n sdlog.error((\"Failed to install apt dependencies. Check network\"\n \" connection and try again.\"))\n raise\n\n\ndef envsetup(args: argparse.Namespace, virtualenv_dir: str = VENV_DIR) -> None:\n \"\"\"Installs Admin tooling required for managing SecureDrop. Specifically:\n\n * updates apt-cache\n * installs apt packages for Python virtualenv\n * creates virtualenv\n * installs pip packages inside virtualenv\n\n The virtualenv is created within the Persistence volume in Tails, so that\n Ansible is available to the Admin on subsequent boots without requiring\n installation of packages again.\n \"\"\"\n # clean up Tails 3.x venv when migrating to Tails 4.x\n clean_up_tails3_venv(virtualenv_dir)\n\n # virtualenv doesnt exist? Install dependencies and create\n if not os.path.exists(virtualenv_dir):\n\n install_apt_dependencies(args)\n\n # Technically you can create a virtualenv from within python\n # but pip can only be run over Tor on Tails, and debugging that\n # along with instaling a third-party dependency is not worth\n # the effort here.\n sdlog.info(\"Setting up virtualenv\")\n try:\n sdlog.debug(subprocess.check_output(\n maybe_torify() + ['virtualenv',\n '--python=python3',\n virtualenv_dir\n ],\n stderr=subprocess.STDOUT))\n except subprocess.CalledProcessError as e:\n sdlog.debug(e.output)\n sdlog.error((\"Unable to create virtualenv. Check network settings\"\n \" and try again.\"))\n sdlog.debug(\"Cleaning up virtualenv\")\n if os.path.exists(virtualenv_dir):\n shutil.rmtree(virtualenv_dir)\n raise\n else:\n sdlog.info(\"Virtualenv already exists, not creating\")\n\n if args.t:\n install_pip_dependencies(\n args,\n requirements_file='requirements-testinfra.txt',\n desc=\"dependencies with verification support\"\n )\n else:\n install_pip_dependencies(args)\n\n if os.path.exists(os.path.join(DIR, 'setup.py')):\n install_pip_self(args)\n\n sdlog.info(\"Finished installing SecureDrop dependencies\")\n\n\ndef install_pip_self(args: argparse.Namespace) -> None:\n pip_install_cmd = [\n os.path.join(VENV_DIR, 'bin', 'pip3'),\n 'install', '-e', DIR\n ]\n try:\n subprocess.check_output(maybe_torify() + pip_install_cmd,\n stderr=subprocess.STDOUT)\n except subprocess.CalledProcessError as e:\n sdlog.debug(e.output)\n sdlog.error(\"Unable to install self, run with -v for more information\")\n raise\n\n\ndef install_pip_dependencies(\n args: argparse.Namespace,\n requirements_file: str = \"requirements.txt\",\n desc: str = \"Python dependencies\",\n) -> None:\n \"\"\"\n Install Python dependencies via pip into virtualenv.\n \"\"\"\n pip_install_cmd = [\n os.path.join(VENV_DIR, 'bin', 'pip3'),\n 'install',\n '--no-deps',\n '-r', os.path.join(DIR, requirements_file),\n '--require-hashes',\n '-U', '--upgrade-strategy', 'only-if-needed',\n ]\n\n sdlog.info(\"Checking {} for securedrop-admin\".format(desc))\n try:\n pip_output = subprocess.check_output(maybe_torify() + pip_install_cmd,\n stderr=subprocess.STDOUT)\n except subprocess.CalledProcessError as e:\n sdlog.debug(e.output)\n sdlog.error((\"Failed to install {}. Check network\"\n \" connection and try again.\".format(desc)))\n raise\n\n sdlog.debug(pip_output)\n if \"Successfully installed\" in str(pip_output):\n sdlog.info(\"{} for securedrop-admin upgraded\".format(desc))\n else:\n sdlog.info(\"{} for securedrop-admin are up-to-date\".format(desc))\n\n\ndef parse_argv(argv: List[str]) -> argparse.Namespace:\n parser = argparse.ArgumentParser()\n parser.add_argument('-v', action='store_true', default=False,\n help=\"Increase verbosity on output\")\n parser.add_argument('-t', action='store_true', default=False,\n help=\"Install additional test dependencies\")\n parser.set_defaults(func=envsetup)\n\n subparsers = parser.add_subparsers()\n\n envsetup_parser = subparsers.add_parser(\n 'envsetup',\n help='Set up the admin virtualenv.'\n )\n envsetup_parser.set_defaults(func=envsetup)\n\n checkenv_parser = subparsers.add_parser(\n 'checkenv',\n help='Check that the admin virtualenv is properly set up.'\n )\n checkenv_parser.set_defaults(func=checkenv)\n\n return parser.parse_args(argv)\n\n\nif __name__ == \"__main__\":\n args = parse_argv(sys.argv[1:])\n setup_logger(args.v)\n\n try:\n args.func(args)\n except Exception:\n sys.exit(1)\n else:\n sys.exit(0)\n", "path": "admin/bootstrap.py"}]}
| 3,520 | 76 |
gh_patches_debug_11992
|
rasdani/github-patches
|
git_diff
|
Cloud-CV__EvalAI-674
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Hosts: User cannot see all of his Host Teams
## CURRENT STATE -
`challenge-host-teams` page only shows teams `created_by` the user.
## ISSUE -
On `challenge-host-teams` page, user should be able to see all host teams he is a part of.
## RELATED ISSUE -
#607 Refer to this issue also.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `apps/hosts/views.py`
Content:
```
1 from rest_framework import permissions, status
2 from rest_framework.decorators import (api_view,
3 authentication_classes,
4 permission_classes,
5 throttle_classes,)
6 from rest_framework.response import Response
7 from rest_framework_expiring_authtoken.authentication import (ExpiringTokenAuthentication,)
8 from rest_framework.throttling import UserRateThrottle
9
10 from accounts.permissions import HasVerifiedEmail
11 from base.utils import paginated_queryset
12 from .models import (ChallengeHost,
13 ChallengeHostTeam,)
14 from .serializers import (ChallengeHostSerializer,
15 ChallengeHostTeamSerializer,
16 InviteHostToTeamSerializer,
17 HostTeamDetailSerializer,)
18
19
20 @throttle_classes([UserRateThrottle])
21 @api_view(['GET', 'POST'])
22 @permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))
23 @authentication_classes((ExpiringTokenAuthentication,))
24 def challenge_host_team_list(request):
25
26 if request.method == 'GET':
27 challenge_host_teams = ChallengeHostTeam.objects.filter(created_by=request.user)
28 paginator, result_page = paginated_queryset(challenge_host_teams, request)
29 serializer = HostTeamDetailSerializer(result_page, many=True)
30 response_data = serializer.data
31 return paginator.get_paginated_response(response_data)
32
33 elif request.method == 'POST':
34 serializer = ChallengeHostTeamSerializer(data=request.data,
35 context={'request': request})
36 if serializer.is_valid():
37 serializer.save()
38 response_data = serializer.data
39 return Response(response_data, status=status.HTTP_201_CREATED)
40 return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
41
42
43 @throttle_classes([UserRateThrottle])
44 @api_view(['GET', 'PUT', 'PATCH', 'DELETE'])
45 @permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))
46 @authentication_classes((ExpiringTokenAuthentication,))
47 def challenge_host_team_detail(request, pk):
48 try:
49 challenge_host_team = ChallengeHostTeam.objects.get(pk=pk)
50 except ChallengeHostTeam.DoesNotExist:
51 response_data = {'error': 'ChallengeHostTeam does not exist'}
52 return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)
53
54 if request.method == 'GET':
55 serializer = HostTeamDetailSerializer(challenge_host_team)
56 response_data = serializer.data
57 return Response(response_data, status=status.HTTP_200_OK)
58
59 elif request.method in ['PUT', 'PATCH']:
60
61 if request.method == 'PATCH':
62 serializer = ChallengeHostTeamSerializer(challenge_host_team,
63 data=request.data,
64 context={'request': request},
65 partial=True)
66 else:
67 serializer = ChallengeHostTeamSerializer(challenge_host_team,
68 data=request.data,
69 context={'request': request})
70 if serializer.is_valid():
71 serializer.save()
72 response_data = serializer.data
73 return Response(response_data, status=status.HTTP_200_OK)
74 else:
75 return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
76
77 elif request.method == 'DELETE':
78 challenge_host_team.delete()
79 return Response(status=status.HTTP_204_NO_CONTENT)
80
81
82 @throttle_classes([UserRateThrottle])
83 @api_view(['GET', 'POST'])
84 @permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))
85 @authentication_classes((ExpiringTokenAuthentication,))
86 def challenge_host_list(request, challenge_host_team_pk):
87
88 try:
89 challenge_host_team = ChallengeHostTeam.objects.get(pk=challenge_host_team_pk)
90 except ChallengeHostTeam.DoesNotExist:
91 response_data = {'error': 'ChallengeHostTeam does not exist'}
92 return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)
93
94 if request.method == 'GET':
95 challenge_host_status = request.query_params.get('status', None)
96 filter_condition = {
97 'team_name': challenge_host_team,
98 'user': request.user
99 }
100 if challenge_host_status:
101 challenge_host_status = challenge_host_status.split(',')
102 filter_condition.update({'status__in': challenge_host_status})
103
104 challenge_host = ChallengeHost.objects.filter(**filter_condition)
105 paginator, result_page = paginated_queryset(challenge_host, request)
106 serializer = ChallengeHostSerializer(result_page, many=True)
107 response_data = serializer.data
108 return paginator.get_paginated_response(response_data)
109
110 elif request.method == 'POST':
111 serializer = ChallengeHostSerializer(data=request.data,
112 context={'challenge_host_team': challenge_host_team,
113 'request': request})
114 if serializer.is_valid():
115 serializer.save()
116 response_data = serializer.data
117 return Response(response_data, status=status.HTTP_201_CREATED)
118 return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
119
120
121 @throttle_classes([UserRateThrottle])
122 @api_view(['GET', 'PUT', 'PATCH', 'DELETE'])
123 @permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))
124 @authentication_classes((ExpiringTokenAuthentication,))
125 def challenge_host_detail(request, challenge_host_team_pk, pk):
126 try:
127 challenge_host_team = ChallengeHostTeam.objects.get(pk=challenge_host_team_pk)
128 except ChallengeHostTeam.DoesNotExist:
129 response_data = {'error': 'ChallengeHostTeam does not exist'}
130 return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)
131
132 try:
133 challenge_host = ChallengeHost.objects.get(pk=pk)
134 except ChallengeHost.DoesNotExist:
135 response_data = {'error': 'ChallengeHost does not exist'}
136 return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)
137
138 if request.method == 'GET':
139 serializer = ChallengeHostSerializer(challenge_host)
140 response_data = serializer.data
141 return Response(response_data, status=status.HTTP_200_OK)
142
143 elif request.method in ['PUT', 'PATCH']:
144 if request.method == 'PATCH':
145 serializer = ChallengeHostSerializer(challenge_host,
146 data=request.data,
147 context={'challenge_host_team': challenge_host_team,
148 'request': request},
149 partial=True)
150 else:
151 serializer = ChallengeHostSerializer(challenge_host,
152 data=request.data,
153 context={'challenge_host_team': challenge_host_team,
154 'request': request})
155 if serializer.is_valid():
156 serializer.save()
157 response_data = serializer.data
158 return Response(response_data, status=status.HTTP_200_OK)
159 else:
160 return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
161
162 elif request.method == 'DELETE':
163 challenge_host.delete()
164 return Response(status=status.HTTP_204_NO_CONTENT)
165
166
167 @throttle_classes([UserRateThrottle])
168 @api_view(['POST'])
169 @permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))
170 @authentication_classes((ExpiringTokenAuthentication,))
171 def create_challenge_host_team(request):
172
173 serializer = ChallengeHostTeamSerializer(data=request.data,
174 context={'request': request})
175 if serializer.is_valid():
176 serializer.save()
177 response_data = serializer.data
178 challenge_host_team = serializer.instance
179 challenge_host = ChallengeHost(user=request.user,
180 status=ChallengeHost.SELF,
181 permissions=ChallengeHost.ADMIN,
182 team_name=challenge_host_team)
183 challenge_host.save()
184 return Response(response_data, status=status.HTTP_201_CREATED)
185 return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
186
187
188 @throttle_classes([UserRateThrottle, ])
189 @api_view(['DELETE', ])
190 @permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))
191 @authentication_classes((ExpiringTokenAuthentication, ))
192 def remove_self_from_challenge_host_team(request, challenge_host_team_pk):
193 """
194 A user can remove himself from the challenge host team.
195 """
196 try:
197 ChallengeHostTeam.objects.get(pk=challenge_host_team_pk)
198 except ChallengeHostTeam.DoesNotExist:
199 response_data = {'error': 'ChallengeHostTeam does not exist'}
200 return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)
201 try:
202 challenge_host = ChallengeHost.objects.filter(user=request.user.id, team_name__pk=challenge_host_team_pk)
203 challenge_host.delete()
204 return Response(status=status.HTTP_204_NO_CONTENT)
205 except:
206 response_data = {'error': 'Sorry, you do not belong to this team.'}
207 return Response(response_data, status=status.HTTP_401_UNAUTHORIZED)
208
209
210 @throttle_classes([UserRateThrottle])
211 @api_view(['POST'])
212 @permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))
213 @authentication_classes((ExpiringTokenAuthentication,))
214 def invite_host_to_team(request, pk):
215
216 try:
217 challenge_host_team = ChallengeHostTeam.objects.get(pk=pk)
218 except ChallengeHostTeam.DoesNotExist:
219 response_data = {'error': 'ChallengeHostTeam does not exist'}
220 return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)
221
222 serializer = InviteHostToTeamSerializer(data=request.data,
223 context={'challenge_host_team': challenge_host_team,
224 'request': request})
225 if serializer.is_valid():
226 serializer.save()
227 response_data = {
228 'message': 'User has been added successfully to the host team'}
229 return Response(response_data, status=status.HTTP_202_ACCEPTED)
230 return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
231
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/apps/hosts/views.py b/apps/hosts/views.py
--- a/apps/hosts/views.py
+++ b/apps/hosts/views.py
@@ -24,7 +24,8 @@
def challenge_host_team_list(request):
if request.method == 'GET':
- challenge_host_teams = ChallengeHostTeam.objects.filter(created_by=request.user)
+ challenge_host_team_ids = ChallengeHost.objects.filter(user=request.user).values_list('team_name', flat=True)
+ challenge_host_teams = ChallengeHostTeam.objects.filter(id__in=challenge_host_team_ids)
paginator, result_page = paginated_queryset(challenge_host_teams, request)
serializer = HostTeamDetailSerializer(result_page, many=True)
response_data = serializer.data
|
{"golden_diff": "diff --git a/apps/hosts/views.py b/apps/hosts/views.py\n--- a/apps/hosts/views.py\n+++ b/apps/hosts/views.py\n@@ -24,7 +24,8 @@\n def challenge_host_team_list(request):\n \n if request.method == 'GET':\n- challenge_host_teams = ChallengeHostTeam.objects.filter(created_by=request.user)\n+ challenge_host_team_ids = ChallengeHost.objects.filter(user=request.user).values_list('team_name', flat=True)\n+ challenge_host_teams = ChallengeHostTeam.objects.filter(id__in=challenge_host_team_ids)\n paginator, result_page = paginated_queryset(challenge_host_teams, request)\n serializer = HostTeamDetailSerializer(result_page, many=True)\n response_data = serializer.data\n", "issue": "Hosts: User cannot see all of his Host Teams\n## CURRENT STATE - \r\n`challenge-host-teams` page only shows teams `created_by` the user.\r\n\r\n## ISSUE - \r\nOn `challenge-host-teams` page, user should be able to see all host teams he is a part of.\r\n\r\n## RELATED ISSUE -\r\n#607 Refer to this issue also. \r\n\n", "before_files": [{"content": "from rest_framework import permissions, status\nfrom rest_framework.decorators import (api_view,\n authentication_classes,\n permission_classes,\n throttle_classes,)\nfrom rest_framework.response import Response\nfrom rest_framework_expiring_authtoken.authentication import (ExpiringTokenAuthentication,)\nfrom rest_framework.throttling import UserRateThrottle\n\nfrom accounts.permissions import HasVerifiedEmail\nfrom base.utils import paginated_queryset\nfrom .models import (ChallengeHost,\n ChallengeHostTeam,)\nfrom .serializers import (ChallengeHostSerializer,\n ChallengeHostTeamSerializer,\n InviteHostToTeamSerializer,\n HostTeamDetailSerializer,)\n\n\n@throttle_classes([UserRateThrottle])\n@api_view(['GET', 'POST'])\n@permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))\n@authentication_classes((ExpiringTokenAuthentication,))\ndef challenge_host_team_list(request):\n\n if request.method == 'GET':\n challenge_host_teams = ChallengeHostTeam.objects.filter(created_by=request.user)\n paginator, result_page = paginated_queryset(challenge_host_teams, request)\n serializer = HostTeamDetailSerializer(result_page, many=True)\n response_data = serializer.data\n return paginator.get_paginated_response(response_data)\n\n elif request.method == 'POST':\n serializer = ChallengeHostTeamSerializer(data=request.data,\n context={'request': request})\n if serializer.is_valid():\n serializer.save()\n response_data = serializer.data\n return Response(response_data, status=status.HTTP_201_CREATED)\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n\n@throttle_classes([UserRateThrottle])\n@api_view(['GET', 'PUT', 'PATCH', 'DELETE'])\n@permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))\n@authentication_classes((ExpiringTokenAuthentication,))\ndef challenge_host_team_detail(request, pk):\n try:\n challenge_host_team = ChallengeHostTeam.objects.get(pk=pk)\n except ChallengeHostTeam.DoesNotExist:\n response_data = {'error': 'ChallengeHostTeam does not exist'}\n return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)\n\n if request.method == 'GET':\n serializer = HostTeamDetailSerializer(challenge_host_team)\n response_data = serializer.data\n return Response(response_data, status=status.HTTP_200_OK)\n\n elif request.method in ['PUT', 'PATCH']:\n\n if request.method == 'PATCH':\n serializer = ChallengeHostTeamSerializer(challenge_host_team,\n data=request.data,\n context={'request': request},\n partial=True)\n else:\n serializer = ChallengeHostTeamSerializer(challenge_host_team,\n data=request.data,\n context={'request': request})\n if serializer.is_valid():\n serializer.save()\n response_data = serializer.data\n return Response(response_data, status=status.HTTP_200_OK)\n else:\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n elif request.method == 'DELETE':\n challenge_host_team.delete()\n return Response(status=status.HTTP_204_NO_CONTENT)\n\n\n@throttle_classes([UserRateThrottle])\n@api_view(['GET', 'POST'])\n@permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))\n@authentication_classes((ExpiringTokenAuthentication,))\ndef challenge_host_list(request, challenge_host_team_pk):\n\n try:\n challenge_host_team = ChallengeHostTeam.objects.get(pk=challenge_host_team_pk)\n except ChallengeHostTeam.DoesNotExist:\n response_data = {'error': 'ChallengeHostTeam does not exist'}\n return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)\n\n if request.method == 'GET':\n challenge_host_status = request.query_params.get('status', None)\n filter_condition = {\n 'team_name': challenge_host_team,\n 'user': request.user\n }\n if challenge_host_status:\n challenge_host_status = challenge_host_status.split(',')\n filter_condition.update({'status__in': challenge_host_status})\n\n challenge_host = ChallengeHost.objects.filter(**filter_condition)\n paginator, result_page = paginated_queryset(challenge_host, request)\n serializer = ChallengeHostSerializer(result_page, many=True)\n response_data = serializer.data\n return paginator.get_paginated_response(response_data)\n\n elif request.method == 'POST':\n serializer = ChallengeHostSerializer(data=request.data,\n context={'challenge_host_team': challenge_host_team,\n 'request': request})\n if serializer.is_valid():\n serializer.save()\n response_data = serializer.data\n return Response(response_data, status=status.HTTP_201_CREATED)\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n\n@throttle_classes([UserRateThrottle])\n@api_view(['GET', 'PUT', 'PATCH', 'DELETE'])\n@permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))\n@authentication_classes((ExpiringTokenAuthentication,))\ndef challenge_host_detail(request, challenge_host_team_pk, pk):\n try:\n challenge_host_team = ChallengeHostTeam.objects.get(pk=challenge_host_team_pk)\n except ChallengeHostTeam.DoesNotExist:\n response_data = {'error': 'ChallengeHostTeam does not exist'}\n return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)\n\n try:\n challenge_host = ChallengeHost.objects.get(pk=pk)\n except ChallengeHost.DoesNotExist:\n response_data = {'error': 'ChallengeHost does not exist'}\n return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)\n\n if request.method == 'GET':\n serializer = ChallengeHostSerializer(challenge_host)\n response_data = serializer.data\n return Response(response_data, status=status.HTTP_200_OK)\n\n elif request.method in ['PUT', 'PATCH']:\n if request.method == 'PATCH':\n serializer = ChallengeHostSerializer(challenge_host,\n data=request.data,\n context={'challenge_host_team': challenge_host_team,\n 'request': request},\n partial=True)\n else:\n serializer = ChallengeHostSerializer(challenge_host,\n data=request.data,\n context={'challenge_host_team': challenge_host_team,\n 'request': request})\n if serializer.is_valid():\n serializer.save()\n response_data = serializer.data\n return Response(response_data, status=status.HTTP_200_OK)\n else:\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n elif request.method == 'DELETE':\n challenge_host.delete()\n return Response(status=status.HTTP_204_NO_CONTENT)\n\n\n@throttle_classes([UserRateThrottle])\n@api_view(['POST'])\n@permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))\n@authentication_classes((ExpiringTokenAuthentication,))\ndef create_challenge_host_team(request):\n\n serializer = ChallengeHostTeamSerializer(data=request.data,\n context={'request': request})\n if serializer.is_valid():\n serializer.save()\n response_data = serializer.data\n challenge_host_team = serializer.instance\n challenge_host = ChallengeHost(user=request.user,\n status=ChallengeHost.SELF,\n permissions=ChallengeHost.ADMIN,\n team_name=challenge_host_team)\n challenge_host.save()\n return Response(response_data, status=status.HTTP_201_CREATED)\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n\n@throttle_classes([UserRateThrottle, ])\n@api_view(['DELETE', ])\n@permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))\n@authentication_classes((ExpiringTokenAuthentication, ))\ndef remove_self_from_challenge_host_team(request, challenge_host_team_pk):\n \"\"\"\n A user can remove himself from the challenge host team.\n \"\"\"\n try:\n ChallengeHostTeam.objects.get(pk=challenge_host_team_pk)\n except ChallengeHostTeam.DoesNotExist:\n response_data = {'error': 'ChallengeHostTeam does not exist'}\n return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)\n try:\n challenge_host = ChallengeHost.objects.filter(user=request.user.id, team_name__pk=challenge_host_team_pk)\n challenge_host.delete()\n return Response(status=status.HTTP_204_NO_CONTENT)\n except:\n response_data = {'error': 'Sorry, you do not belong to this team.'}\n return Response(response_data, status=status.HTTP_401_UNAUTHORIZED)\n\n\n@throttle_classes([UserRateThrottle])\n@api_view(['POST'])\n@permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))\n@authentication_classes((ExpiringTokenAuthentication,))\ndef invite_host_to_team(request, pk):\n\n try:\n challenge_host_team = ChallengeHostTeam.objects.get(pk=pk)\n except ChallengeHostTeam.DoesNotExist:\n response_data = {'error': 'ChallengeHostTeam does not exist'}\n return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)\n\n serializer = InviteHostToTeamSerializer(data=request.data,\n context={'challenge_host_team': challenge_host_team,\n 'request': request})\n if serializer.is_valid():\n serializer.save()\n response_data = {\n 'message': 'User has been added successfully to the host team'}\n return Response(response_data, status=status.HTTP_202_ACCEPTED)\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n", "path": "apps/hosts/views.py"}], "after_files": [{"content": "from rest_framework import permissions, status\nfrom rest_framework.decorators import (api_view,\n authentication_classes,\n permission_classes,\n throttle_classes,)\nfrom rest_framework.response import Response\nfrom rest_framework_expiring_authtoken.authentication import (ExpiringTokenAuthentication,)\nfrom rest_framework.throttling import UserRateThrottle\n\nfrom accounts.permissions import HasVerifiedEmail\nfrom base.utils import paginated_queryset\nfrom .models import (ChallengeHost,\n ChallengeHostTeam,)\nfrom .serializers import (ChallengeHostSerializer,\n ChallengeHostTeamSerializer,\n InviteHostToTeamSerializer,\n HostTeamDetailSerializer,)\n\n\n@throttle_classes([UserRateThrottle])\n@api_view(['GET', 'POST'])\n@permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))\n@authentication_classes((ExpiringTokenAuthentication,))\ndef challenge_host_team_list(request):\n\n if request.method == 'GET':\n challenge_host_team_ids = ChallengeHost.objects.filter(user=request.user).values_list('team_name', flat=True)\n challenge_host_teams = ChallengeHostTeam.objects.filter(id__in=challenge_host_team_ids)\n paginator, result_page = paginated_queryset(challenge_host_teams, request)\n serializer = HostTeamDetailSerializer(result_page, many=True)\n response_data = serializer.data\n return paginator.get_paginated_response(response_data)\n\n elif request.method == 'POST':\n serializer = ChallengeHostTeamSerializer(data=request.data,\n context={'request': request})\n if serializer.is_valid():\n serializer.save()\n response_data = serializer.data\n return Response(response_data, status=status.HTTP_201_CREATED)\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n\n@throttle_classes([UserRateThrottle])\n@api_view(['GET', 'PUT', 'PATCH', 'DELETE'])\n@permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))\n@authentication_classes((ExpiringTokenAuthentication,))\ndef challenge_host_team_detail(request, pk):\n try:\n challenge_host_team = ChallengeHostTeam.objects.get(pk=pk)\n except ChallengeHostTeam.DoesNotExist:\n response_data = {'error': 'ChallengeHostTeam does not exist'}\n return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)\n\n if request.method == 'GET':\n serializer = HostTeamDetailSerializer(challenge_host_team)\n response_data = serializer.data\n return Response(response_data, status=status.HTTP_200_OK)\n\n elif request.method in ['PUT', 'PATCH']:\n\n if request.method == 'PATCH':\n serializer = ChallengeHostTeamSerializer(challenge_host_team,\n data=request.data,\n context={'request': request},\n partial=True)\n else:\n serializer = ChallengeHostTeamSerializer(challenge_host_team,\n data=request.data,\n context={'request': request})\n if serializer.is_valid():\n serializer.save()\n response_data = serializer.data\n return Response(response_data, status=status.HTTP_200_OK)\n else:\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n elif request.method == 'DELETE':\n challenge_host_team.delete()\n return Response(status=status.HTTP_204_NO_CONTENT)\n\n\n@throttle_classes([UserRateThrottle])\n@api_view(['GET', 'POST'])\n@permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))\n@authentication_classes((ExpiringTokenAuthentication,))\ndef challenge_host_list(request, challenge_host_team_pk):\n\n try:\n challenge_host_team = ChallengeHostTeam.objects.get(pk=challenge_host_team_pk)\n except ChallengeHostTeam.DoesNotExist:\n response_data = {'error': 'ChallengeHostTeam does not exist'}\n return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)\n\n if request.method == 'GET':\n challenge_host_status = request.query_params.get('status', None)\n filter_condition = {\n 'team_name': challenge_host_team,\n 'user': request.user\n }\n if challenge_host_status:\n challenge_host_status = challenge_host_status.split(',')\n filter_condition.update({'status__in': challenge_host_status})\n\n challenge_host = ChallengeHost.objects.filter(**filter_condition)\n paginator, result_page = paginated_queryset(challenge_host, request)\n serializer = ChallengeHostSerializer(result_page, many=True)\n response_data = serializer.data\n return paginator.get_paginated_response(response_data)\n\n elif request.method == 'POST':\n serializer = ChallengeHostSerializer(data=request.data,\n context={'challenge_host_team': challenge_host_team,\n 'request': request})\n if serializer.is_valid():\n serializer.save()\n response_data = serializer.data\n return Response(response_data, status=status.HTTP_201_CREATED)\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n\n@throttle_classes([UserRateThrottle])\n@api_view(['GET', 'PUT', 'PATCH', 'DELETE'])\n@permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))\n@authentication_classes((ExpiringTokenAuthentication,))\ndef challenge_host_detail(request, challenge_host_team_pk, pk):\n try:\n challenge_host_team = ChallengeHostTeam.objects.get(pk=challenge_host_team_pk)\n except ChallengeHostTeam.DoesNotExist:\n response_data = {'error': 'ChallengeHostTeam does not exist'}\n return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)\n\n try:\n challenge_host = ChallengeHost.objects.get(pk=pk)\n except ChallengeHost.DoesNotExist:\n response_data = {'error': 'ChallengeHost does not exist'}\n return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)\n\n if request.method == 'GET':\n serializer = ChallengeHostSerializer(challenge_host)\n response_data = serializer.data\n return Response(response_data, status=status.HTTP_200_OK)\n\n elif request.method in ['PUT', 'PATCH']:\n if request.method == 'PATCH':\n serializer = ChallengeHostSerializer(challenge_host,\n data=request.data,\n context={'challenge_host_team': challenge_host_team,\n 'request': request},\n partial=True)\n else:\n serializer = ChallengeHostSerializer(challenge_host,\n data=request.data,\n context={'challenge_host_team': challenge_host_team,\n 'request': request})\n if serializer.is_valid():\n serializer.save()\n response_data = serializer.data\n return Response(response_data, status=status.HTTP_200_OK)\n else:\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n elif request.method == 'DELETE':\n challenge_host.delete()\n return Response(status=status.HTTP_204_NO_CONTENT)\n\n\n@throttle_classes([UserRateThrottle])\n@api_view(['POST'])\n@permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))\n@authentication_classes((ExpiringTokenAuthentication,))\ndef create_challenge_host_team(request):\n\n serializer = ChallengeHostTeamSerializer(data=request.data,\n context={'request': request})\n if serializer.is_valid():\n serializer.save()\n response_data = serializer.data\n challenge_host_team = serializer.instance\n challenge_host = ChallengeHost(user=request.user,\n status=ChallengeHost.SELF,\n permissions=ChallengeHost.ADMIN,\n team_name=challenge_host_team)\n challenge_host.save()\n return Response(response_data, status=status.HTTP_201_CREATED)\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n\n@throttle_classes([UserRateThrottle, ])\n@api_view(['DELETE', ])\n@permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))\n@authentication_classes((ExpiringTokenAuthentication, ))\ndef remove_self_from_challenge_host_team(request, challenge_host_team_pk):\n \"\"\"\n A user can remove himself from the challenge host team.\n \"\"\"\n try:\n ChallengeHostTeam.objects.get(pk=challenge_host_team_pk)\n except ChallengeHostTeam.DoesNotExist:\n response_data = {'error': 'ChallengeHostTeam does not exist'}\n return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)\n try:\n challenge_host = ChallengeHost.objects.filter(user=request.user.id, team_name__pk=challenge_host_team_pk)\n challenge_host.delete()\n return Response(status=status.HTTP_204_NO_CONTENT)\n except:\n response_data = {'error': 'Sorry, you do not belong to this team.'}\n return Response(response_data, status=status.HTTP_401_UNAUTHORIZED)\n\n\n@throttle_classes([UserRateThrottle])\n@api_view(['POST'])\n@permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))\n@authentication_classes((ExpiringTokenAuthentication,))\ndef invite_host_to_team(request, pk):\n\n try:\n challenge_host_team = ChallengeHostTeam.objects.get(pk=pk)\n except ChallengeHostTeam.DoesNotExist:\n response_data = {'error': 'ChallengeHostTeam does not exist'}\n return Response(response_data, status=status.HTTP_406_NOT_ACCEPTABLE)\n\n serializer = InviteHostToTeamSerializer(data=request.data,\n context={'challenge_host_team': challenge_host_team,\n 'request': request})\n if serializer.is_valid():\n serializer.save()\n response_data = {\n 'message': 'User has been added successfully to the host team'}\n return Response(response_data, status=status.HTTP_202_ACCEPTED)\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n", "path": "apps/hosts/views.py"}]}
| 2,827 | 156 |
gh_patches_debug_10651
|
rasdani/github-patches
|
git_diff
|
hpcaitech__ColossalAI-5440
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[tensor] fix some unittests
[tensor] fix some unittests
[tensor] fix some unittests
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `colossalai/legacy/tensor/tensor_spec.py`
Content:
```
1 from dataclasses import dataclass
2 from typing import Optional
3
4 from colossalai.legacy.tensor.distspec import DistPlacementPattern, _DistSpec
5 from colossalai.legacy.tensor.process_group import ProcessGroup
6
7 from .compute_spec import ComputeSpec
8
9
10 @dataclass
11 class ColoTensorSpec:
12 """ColoTensorSpec
13
14 A data class for specifications of the `ColoTensor`.
15 It contains attributes of `ProcessGroup`, `_DistSpec`, `ComputeSpec`.
16 The latter two attributes are optional. If not set, they are default value is `Replicate()` and `None`.
17 """
18
19 pg: ProcessGroup
20 dist_attr: Optional[_DistSpec] = _DistSpec(DistPlacementPattern.REPLICATE)
21 compute_attr: Optional[ComputeSpec] = None
22
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/colossalai/legacy/tensor/tensor_spec.py b/colossalai/legacy/tensor/tensor_spec.py
--- a/colossalai/legacy/tensor/tensor_spec.py
+++ b/colossalai/legacy/tensor/tensor_spec.py
@@ -1,4 +1,4 @@
-from dataclasses import dataclass
+from dataclasses import dataclass, field
from typing import Optional
from colossalai.legacy.tensor.distspec import DistPlacementPattern, _DistSpec
@@ -17,5 +17,5 @@
"""
pg: ProcessGroup
- dist_attr: Optional[_DistSpec] = _DistSpec(DistPlacementPattern.REPLICATE)
+ dist_attr: Optional[_DistSpec] = field(default_factory=lambda: _DistSpec(DistPlacementPattern.REPLICATE))
compute_attr: Optional[ComputeSpec] = None
|
{"golden_diff": "diff --git a/colossalai/legacy/tensor/tensor_spec.py b/colossalai/legacy/tensor/tensor_spec.py\n--- a/colossalai/legacy/tensor/tensor_spec.py\n+++ b/colossalai/legacy/tensor/tensor_spec.py\n@@ -1,4 +1,4 @@\n-from dataclasses import dataclass\n+from dataclasses import dataclass, field\n from typing import Optional\n \n from colossalai.legacy.tensor.distspec import DistPlacementPattern, _DistSpec\n@@ -17,5 +17,5 @@\n \"\"\"\n \n pg: ProcessGroup\n- dist_attr: Optional[_DistSpec] = _DistSpec(DistPlacementPattern.REPLICATE)\n+ dist_attr: Optional[_DistSpec] = field(default_factory=lambda: _DistSpec(DistPlacementPattern.REPLICATE))\n compute_attr: Optional[ComputeSpec] = None\n", "issue": "[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n", "before_files": [{"content": "from dataclasses import dataclass\nfrom typing import Optional\n\nfrom colossalai.legacy.tensor.distspec import DistPlacementPattern, _DistSpec\nfrom colossalai.legacy.tensor.process_group import ProcessGroup\n\nfrom .compute_spec import ComputeSpec\n\n\n@dataclass\nclass ColoTensorSpec:\n \"\"\"ColoTensorSpec\n\n A data class for specifications of the `ColoTensor`.\n It contains attributes of `ProcessGroup`, `_DistSpec`, `ComputeSpec`.\n The latter two attributes are optional. If not set, they are default value is `Replicate()` and `None`.\n \"\"\"\n\n pg: ProcessGroup\n dist_attr: Optional[_DistSpec] = _DistSpec(DistPlacementPattern.REPLICATE)\n compute_attr: Optional[ComputeSpec] = None\n", "path": "colossalai/legacy/tensor/tensor_spec.py"}], "after_files": [{"content": "from dataclasses import dataclass, field\nfrom typing import Optional\n\nfrom colossalai.legacy.tensor.distspec import DistPlacementPattern, _DistSpec\nfrom colossalai.legacy.tensor.process_group import ProcessGroup\n\nfrom .compute_spec import ComputeSpec\n\n\n@dataclass\nclass ColoTensorSpec:\n \"\"\"ColoTensorSpec\n\n A data class for specifications of the `ColoTensor`.\n It contains attributes of `ProcessGroup`, `_DistSpec`, `ComputeSpec`.\n The latter two attributes are optional. If not set, they are default value is `Replicate()` and `None`.\n \"\"\"\n\n pg: ProcessGroup\n dist_attr: Optional[_DistSpec] = field(default_factory=lambda: _DistSpec(DistPlacementPattern.REPLICATE))\n compute_attr: Optional[ComputeSpec] = None\n", "path": "colossalai/legacy/tensor/tensor_spec.py"}]}
| 491 | 190 |
gh_patches_debug_29270
|
rasdani/github-patches
|
git_diff
|
mlflow__mlflow-1504
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Unable to specify destination path when download_artifacts with MlflowClient
### The problem
When downloading artifacts with download_artifacts on MlflowClient there is no argument that can specify what is the destination path where the artifacts should be downloaded to.
I will open a PR that fixes it.
### Source code
**mlflow/tracking/client.py**
def download_artifacts(self, run_id, path):
"""
Download an artifact file or directory from a run to a local directory if applicable,
and return a local path for it.
:param run_id: The run to download artifacts from.
:param path: Relative source path to the desired artifact.
:return: Local path of desired artifact.
"""
run = self.get_run(run_id)
artifact_root = run.info.artifact_uri
artifact_repo = get_artifact_repository(artifact_root, self.store)
return artifact_repo.download_artifacts(path)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mlflow/tracking/client.py`
Content:
```
1 """
2 Internal package providing a Python CRUD interface to MLflow experiments and runs.
3 This is a lower level API than the :py:mod:`mlflow.tracking.fluent` module, and is
4 exposed in the :py:mod:`mlflow.tracking` module.
5 """
6
7 import time
8 from six import iteritems
9
10 from mlflow.store import SEARCH_MAX_RESULTS_DEFAULT
11 from mlflow.tracking import utils
12 from mlflow.utils.validation import _validate_param_name, _validate_tag_name, _validate_run_id, \
13 _validate_experiment_artifact_location, _validate_experiment_name, _validate_metric
14 from mlflow.entities import Param, Metric, RunStatus, RunTag, ViewType
15 from mlflow.store.artifact_repository_registry import get_artifact_repository
16 from mlflow.utils.mlflow_tags import MLFLOW_USER
17
18
19 class MlflowClient(object):
20 """
21 Client of an MLflow Tracking Server that creates and manages experiments and runs.
22 """
23
24 def __init__(self, tracking_uri=None):
25 """
26 :param tracking_uri: Address of local or remote tracking server. If not provided, defaults
27 to the service set by ``mlflow.tracking.set_tracking_uri``. See
28 `Where Runs Get Recorded <../tracking.html#where-runs-get-recorded>`_
29 for more info.
30 """
31 self.tracking_uri = tracking_uri or utils.get_tracking_uri()
32 self.store = utils._get_store(self.tracking_uri)
33
34 def get_run(self, run_id):
35 """
36 Fetch the run from backend store. The resulting :py:class:`Run <mlflow.entities.Run>`
37 contains a collection of run metadata -- :py:class:`RunInfo <mlflow.entities.RunInfo>`,
38 as well as a collection of run parameters, tags, and metrics --
39 :py:class:`RunData <mlflow.entities.RunData>`. In the case where multiple metrics with the
40 same key are logged for the run, the :py:class:`RunData <mlflow.entities.RunData>` contains
41 the most recently logged value at the largest step for each metric.
42
43 :param run_id: Unique identifier for the run.
44
45 :return: A single :py:class:`mlflow.entities.Run` object, if the run exists. Otherwise,
46 raises an exception.
47 """
48 _validate_run_id(run_id)
49 return self.store.get_run(run_id)
50
51 def get_metric_history(self, run_id, key):
52 """
53 Return a list of metric objects corresponding to all values logged for a given metric.
54
55 :param run_id: Unique identifier for run
56 :param key: Metric name within the run
57
58 :return: A list of :py:class:`mlflow.entities.Metric` entities if logged, else empty list
59 """
60 return self.store.get_metric_history(run_id=run_id, metric_key=key)
61
62 def create_run(self, experiment_id, start_time=None, tags=None):
63 """
64 Create a :py:class:`mlflow.entities.Run` object that can be associated with
65 metrics, parameters, artifacts, etc.
66 Unlike :py:func:`mlflow.projects.run`, creates objects but does not run code.
67 Unlike :py:func:`mlflow.start_run`, does not change the "active run" used by
68 :py:func:`mlflow.log_param`.
69
70 :param experiment_id: The ID of then experiment to create a run in.
71 :param start_time: If not provided, use the current timestamp.
72 :param tags: A dictionary of key-value pairs that are converted into
73 :py:class:`mlflow.entities.RunTag` objects.
74 :return: :py:class:`mlflow.entities.Run` that was created.
75 """
76
77 tags = tags if tags else {}
78
79 # Extract user from tags
80 # This logic is temporary; the user_id attribute of runs is deprecated and will be removed
81 # in a later release.
82 user_id = tags.get(MLFLOW_USER, "unknown")
83
84 return self.store.create_run(
85 experiment_id=experiment_id,
86 user_id=user_id,
87 start_time=start_time or int(time.time() * 1000),
88 tags=[RunTag(key, value) for (key, value) in iteritems(tags)]
89 )
90
91 def list_run_infos(self, experiment_id, run_view_type=ViewType.ACTIVE_ONLY):
92 """:return: List of :py:class:`mlflow.entities.RunInfo`"""
93 return self.store.list_run_infos(experiment_id, run_view_type)
94
95 def list_experiments(self, view_type=None):
96 """
97 :return: List of :py:class:`mlflow.entities.Experiment`
98 """
99 final_view_type = ViewType.ACTIVE_ONLY if view_type is None else view_type
100 return self.store.list_experiments(view_type=final_view_type)
101
102 def get_experiment(self, experiment_id):
103 """
104 :param experiment_id: The experiment ID returned from ``create_experiment``.
105 :return: :py:class:`mlflow.entities.Experiment`
106 """
107 return self.store.get_experiment(experiment_id)
108
109 def get_experiment_by_name(self, name):
110 """
111 :param name: The experiment name.
112 :return: :py:class:`mlflow.entities.Experiment`
113 """
114 return self.store.get_experiment_by_name(name)
115
116 def create_experiment(self, name, artifact_location=None):
117 """Create an experiment.
118
119 :param name: The experiment name. Must be unique.
120 :param artifact_location: The location to store run artifacts.
121 If not provided, the server picks an appropriate default.
122 :return: Integer ID of the created experiment.
123 """
124 _validate_experiment_name(name)
125 _validate_experiment_artifact_location(artifact_location)
126 return self.store.create_experiment(
127 name=name,
128 artifact_location=artifact_location,
129 )
130
131 def delete_experiment(self, experiment_id):
132 """
133 Delete an experiment from the backend store.
134
135 :param experiment_id: The experiment ID returned from ``create_experiment``.
136 """
137 self.store.delete_experiment(experiment_id)
138
139 def restore_experiment(self, experiment_id):
140 """
141 Restore a deleted experiment unless permanently deleted.
142
143 :param experiment_id: The experiment ID returned from ``create_experiment``.
144 """
145 self.store.restore_experiment(experiment_id)
146
147 def rename_experiment(self, experiment_id, new_name):
148 """
149 Update an experiment's name. The new name must be unique.
150
151 :param experiment_id: The experiment ID returned from ``create_experiment``.
152 """
153 self.store.rename_experiment(experiment_id, new_name)
154
155 def log_metric(self, run_id, key, value, timestamp=None, step=None):
156 """
157 Log a metric against the run ID. The timestamp defaults to the current timestamp.
158 The step defaults to 0.
159 """
160 timestamp = timestamp if timestamp is not None else int(time.time())
161 step = step if step is not None else 0
162 _validate_metric(key, value, timestamp, step)
163 metric = Metric(key, value, timestamp, step)
164 self.store.log_metric(run_id, metric)
165
166 def log_param(self, run_id, key, value):
167 """
168 Log a parameter against the run ID. Value is converted to a string.
169 """
170 _validate_param_name(key)
171 param = Param(key, str(value))
172 self.store.log_param(run_id, param)
173
174 def set_tag(self, run_id, key, value):
175 """
176 Set a tag on the run ID. Value is converted to a string.
177 """
178 _validate_tag_name(key)
179 tag = RunTag(key, str(value))
180 self.store.set_tag(run_id, tag)
181
182 def log_batch(self, run_id, metrics, params, tags):
183 """
184 Log multiple metrics, params, and/or tags.
185
186 :param metrics: List of Metric(key, value, timestamp) instances.
187 :param params: List of Param(key, value) instances.
188 :param tags: List of RunTag(key, value) instances.
189
190 Raises an MlflowException if any errors occur.
191 :returns: None
192 """
193 for metric in metrics:
194 _validate_metric(metric.key, metric.value, metric.timestamp, metric.step)
195 for param in params:
196 _validate_param_name(param.key)
197 for tag in tags:
198 _validate_tag_name(tag.key)
199 self.store.log_batch(run_id=run_id, metrics=metrics, params=params, tags=tags)
200
201 def log_artifact(self, run_id, local_path, artifact_path=None):
202 """
203 Write a local file to the remote ``artifact_uri``.
204
205 :param local_path: Path to the file to write.
206 :param artifact_path: If provided, the directory in ``artifact_uri`` to write to.
207 """
208 run = self.get_run(run_id)
209 artifact_repo = get_artifact_repository(run.info.artifact_uri)
210 artifact_repo.log_artifact(local_path, artifact_path)
211
212 def log_artifacts(self, run_id, local_dir, artifact_path=None):
213 """
214 Write a directory of files to the remote ``artifact_uri``.
215
216 :param local_dir: Path to the directory of files to write.
217 :param artifact_path: If provided, the directory in ``artifact_uri`` to write to.
218 """
219 run = self.get_run(run_id)
220 artifact_repo = get_artifact_repository(run.info.artifact_uri)
221 artifact_repo.log_artifacts(local_dir, artifact_path)
222
223 def list_artifacts(self, run_id, path=None):
224 """
225 List the artifacts for a run.
226
227 :param run_id: The run to list artifacts from.
228 :param path: The run's relative artifact path to list from. By default it is set to None
229 or the root artifact path.
230 :return: List of :py:class:`mlflow.entities.FileInfo`
231 """
232 run = self.get_run(run_id)
233 artifact_root = run.info.artifact_uri
234 artifact_repo = get_artifact_repository(artifact_root)
235 return artifact_repo.list_artifacts(path)
236
237 def download_artifacts(self, run_id, path):
238 """
239 Download an artifact file or directory from a run to a local directory if applicable,
240 and return a local path for it.
241
242 :param run_id: The run to download artifacts from.
243 :param path: Relative source path to the desired artifact.
244 :return: Local path of desired artifact.
245 """
246 run = self.get_run(run_id)
247 artifact_root = run.info.artifact_uri
248 artifact_repo = get_artifact_repository(artifact_root)
249 return artifact_repo.download_artifacts(path)
250
251 def set_terminated(self, run_id, status=None, end_time=None):
252 """Set a run's status to terminated.
253
254 :param status: A string value of :py:class:`mlflow.entities.RunStatus`.
255 Defaults to "FINISHED".
256 :param end_time: If not provided, defaults to the current time."""
257 end_time = end_time if end_time else int(time.time() * 1000)
258 status = status if status else RunStatus.to_string(RunStatus.FINISHED)
259 self.store.update_run_info(run_id, run_status=RunStatus.from_string(status),
260 end_time=end_time)
261
262 def delete_run(self, run_id):
263 """
264 Deletes a run with the given ID.
265 """
266 self.store.delete_run(run_id)
267
268 def restore_run(self, run_id):
269 """
270 Restores a deleted run with the given ID.
271 """
272 self.store.restore_run(run_id)
273
274 def search_runs(self, experiment_ids, filter_string="", run_view_type=ViewType.ACTIVE_ONLY,
275 max_results=SEARCH_MAX_RESULTS_DEFAULT, order_by=None, page_token=None):
276 """
277 Search experiments that fit the search criteria.
278
279 :param experiment_ids: List of experiment IDs, or a single int or string id.
280 :param filter_string: Filter query string, defaults to searching all runs.
281 :param run_view_type: one of enum values ACTIVE_ONLY, DELETED_ONLY, or ALL runs
282 defined in :py:class:`mlflow.entities.ViewType`.
283 :param max_results: Maximum number of runs desired.
284 :param order_by: List of columns to order by (e.g., "metrics.rmse"). The default
285 ordering is to sort by start_time DESC, then run_id.
286 :param page_token: Token specifying the next page of results. It should be obtained from
287 a ``search_runs`` call.
288
289 :return: A list of :py:class:`mlflow.entities.Run` objects that satisfy the search
290 expressions. If the underlying tracking store supports pagination, the token for
291 the next page may be obtained via the ``token`` attribute of the returned object.
292 """
293 if isinstance(experiment_ids, int) or isinstance(experiment_ids, str):
294 experiment_ids = [experiment_ids]
295 return self.store.search_runs(experiment_ids=experiment_ids, filter_string=filter_string,
296 run_view_type=run_view_type, max_results=max_results,
297 order_by=order_by, page_token=page_token)
298
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mlflow/tracking/client.py b/mlflow/tracking/client.py
--- a/mlflow/tracking/client.py
+++ b/mlflow/tracking/client.py
@@ -234,19 +234,24 @@
artifact_repo = get_artifact_repository(artifact_root)
return artifact_repo.list_artifacts(path)
- def download_artifacts(self, run_id, path):
+ def download_artifacts(self, run_id, path, dst_path=None):
"""
Download an artifact file or directory from a run to a local directory if applicable,
and return a local path for it.
:param run_id: The run to download artifacts from.
:param path: Relative source path to the desired artifact.
+ :param dst_path: Absolute path of the local filesystem destination directory to which to
+ download the specified artifacts. This directory must already exist.
+ If unspecified, the artifacts will either be downloaded to a new
+ uniquely-named directory on the local filesystem or will be returned
+ directly in the case of the LocalArtifactRepository.
:return: Local path of desired artifact.
"""
run = self.get_run(run_id)
artifact_root = run.info.artifact_uri
artifact_repo = get_artifact_repository(artifact_root)
- return artifact_repo.download_artifacts(path)
+ return artifact_repo.download_artifacts(path, dst_path)
def set_terminated(self, run_id, status=None, end_time=None):
"""Set a run's status to terminated.
|
{"golden_diff": "diff --git a/mlflow/tracking/client.py b/mlflow/tracking/client.py\n--- a/mlflow/tracking/client.py\n+++ b/mlflow/tracking/client.py\n@@ -234,19 +234,24 @@\n artifact_repo = get_artifact_repository(artifact_root)\n return artifact_repo.list_artifacts(path)\n \n- def download_artifacts(self, run_id, path):\n+ def download_artifacts(self, run_id, path, dst_path=None):\n \"\"\"\n Download an artifact file or directory from a run to a local directory if applicable,\n and return a local path for it.\n \n :param run_id: The run to download artifacts from.\n :param path: Relative source path to the desired artifact.\n+ :param dst_path: Absolute path of the local filesystem destination directory to which to\n+ download the specified artifacts. This directory must already exist.\n+ If unspecified, the artifacts will either be downloaded to a new\n+ uniquely-named directory on the local filesystem or will be returned\n+ directly in the case of the LocalArtifactRepository.\n :return: Local path of desired artifact.\n \"\"\"\n run = self.get_run(run_id)\n artifact_root = run.info.artifact_uri\n artifact_repo = get_artifact_repository(artifact_root)\n- return artifact_repo.download_artifacts(path)\n+ return artifact_repo.download_artifacts(path, dst_path)\n \n def set_terminated(self, run_id, status=None, end_time=None):\n \"\"\"Set a run's status to terminated.\n", "issue": "Unable to specify destination path when download_artifacts with MlflowClient\n### The problem\r\nWhen downloading artifacts with download_artifacts on MlflowClient there is no argument that can specify what is the destination path where the artifacts should be downloaded to. \r\n\r\nI will open a PR that fixes it.\r\n\r\n### Source code\r\n**mlflow/tracking/client.py**\r\n\r\n def download_artifacts(self, run_id, path):\r\n \"\"\"\r\n Download an artifact file or directory from a run to a local directory if applicable,\r\n and return a local path for it.\r\n\r\n :param run_id: The run to download artifacts from.\r\n :param path: Relative source path to the desired artifact.\r\n :return: Local path of desired artifact.\r\n \"\"\"\r\n run = self.get_run(run_id)\r\n artifact_root = run.info.artifact_uri\r\n artifact_repo = get_artifact_repository(artifact_root, self.store)\r\n return artifact_repo.download_artifacts(path)\r\n\n", "before_files": [{"content": "\"\"\"\nInternal package providing a Python CRUD interface to MLflow experiments and runs.\nThis is a lower level API than the :py:mod:`mlflow.tracking.fluent` module, and is\nexposed in the :py:mod:`mlflow.tracking` module.\n\"\"\"\n\nimport time\nfrom six import iteritems\n\nfrom mlflow.store import SEARCH_MAX_RESULTS_DEFAULT\nfrom mlflow.tracking import utils\nfrom mlflow.utils.validation import _validate_param_name, _validate_tag_name, _validate_run_id, \\\n _validate_experiment_artifact_location, _validate_experiment_name, _validate_metric\nfrom mlflow.entities import Param, Metric, RunStatus, RunTag, ViewType\nfrom mlflow.store.artifact_repository_registry import get_artifact_repository\nfrom mlflow.utils.mlflow_tags import MLFLOW_USER\n\n\nclass MlflowClient(object):\n \"\"\"\n Client of an MLflow Tracking Server that creates and manages experiments and runs.\n \"\"\"\n\n def __init__(self, tracking_uri=None):\n \"\"\"\n :param tracking_uri: Address of local or remote tracking server. If not provided, defaults\n to the service set by ``mlflow.tracking.set_tracking_uri``. See\n `Where Runs Get Recorded <../tracking.html#where-runs-get-recorded>`_\n for more info.\n \"\"\"\n self.tracking_uri = tracking_uri or utils.get_tracking_uri()\n self.store = utils._get_store(self.tracking_uri)\n\n def get_run(self, run_id):\n \"\"\"\n Fetch the run from backend store. The resulting :py:class:`Run <mlflow.entities.Run>`\n contains a collection of run metadata -- :py:class:`RunInfo <mlflow.entities.RunInfo>`,\n as well as a collection of run parameters, tags, and metrics --\n :py:class:`RunData <mlflow.entities.RunData>`. In the case where multiple metrics with the\n same key are logged for the run, the :py:class:`RunData <mlflow.entities.RunData>` contains\n the most recently logged value at the largest step for each metric.\n\n :param run_id: Unique identifier for the run.\n\n :return: A single :py:class:`mlflow.entities.Run` object, if the run exists. Otherwise,\n raises an exception.\n \"\"\"\n _validate_run_id(run_id)\n return self.store.get_run(run_id)\n\n def get_metric_history(self, run_id, key):\n \"\"\"\n Return a list of metric objects corresponding to all values logged for a given metric.\n\n :param run_id: Unique identifier for run\n :param key: Metric name within the run\n\n :return: A list of :py:class:`mlflow.entities.Metric` entities if logged, else empty list\n \"\"\"\n return self.store.get_metric_history(run_id=run_id, metric_key=key)\n\n def create_run(self, experiment_id, start_time=None, tags=None):\n \"\"\"\n Create a :py:class:`mlflow.entities.Run` object that can be associated with\n metrics, parameters, artifacts, etc.\n Unlike :py:func:`mlflow.projects.run`, creates objects but does not run code.\n Unlike :py:func:`mlflow.start_run`, does not change the \"active run\" used by\n :py:func:`mlflow.log_param`.\n\n :param experiment_id: The ID of then experiment to create a run in.\n :param start_time: If not provided, use the current timestamp.\n :param tags: A dictionary of key-value pairs that are converted into\n :py:class:`mlflow.entities.RunTag` objects.\n :return: :py:class:`mlflow.entities.Run` that was created.\n \"\"\"\n\n tags = tags if tags else {}\n\n # Extract user from tags\n # This logic is temporary; the user_id attribute of runs is deprecated and will be removed\n # in a later release.\n user_id = tags.get(MLFLOW_USER, \"unknown\")\n\n return self.store.create_run(\n experiment_id=experiment_id,\n user_id=user_id,\n start_time=start_time or int(time.time() * 1000),\n tags=[RunTag(key, value) for (key, value) in iteritems(tags)]\n )\n\n def list_run_infos(self, experiment_id, run_view_type=ViewType.ACTIVE_ONLY):\n \"\"\":return: List of :py:class:`mlflow.entities.RunInfo`\"\"\"\n return self.store.list_run_infos(experiment_id, run_view_type)\n\n def list_experiments(self, view_type=None):\n \"\"\"\n :return: List of :py:class:`mlflow.entities.Experiment`\n \"\"\"\n final_view_type = ViewType.ACTIVE_ONLY if view_type is None else view_type\n return self.store.list_experiments(view_type=final_view_type)\n\n def get_experiment(self, experiment_id):\n \"\"\"\n :param experiment_id: The experiment ID returned from ``create_experiment``.\n :return: :py:class:`mlflow.entities.Experiment`\n \"\"\"\n return self.store.get_experiment(experiment_id)\n\n def get_experiment_by_name(self, name):\n \"\"\"\n :param name: The experiment name.\n :return: :py:class:`mlflow.entities.Experiment`\n \"\"\"\n return self.store.get_experiment_by_name(name)\n\n def create_experiment(self, name, artifact_location=None):\n \"\"\"Create an experiment.\n\n :param name: The experiment name. Must be unique.\n :param artifact_location: The location to store run artifacts.\n If not provided, the server picks an appropriate default.\n :return: Integer ID of the created experiment.\n \"\"\"\n _validate_experiment_name(name)\n _validate_experiment_artifact_location(artifact_location)\n return self.store.create_experiment(\n name=name,\n artifact_location=artifact_location,\n )\n\n def delete_experiment(self, experiment_id):\n \"\"\"\n Delete an experiment from the backend store.\n\n :param experiment_id: The experiment ID returned from ``create_experiment``.\n \"\"\"\n self.store.delete_experiment(experiment_id)\n\n def restore_experiment(self, experiment_id):\n \"\"\"\n Restore a deleted experiment unless permanently deleted.\n\n :param experiment_id: The experiment ID returned from ``create_experiment``.\n \"\"\"\n self.store.restore_experiment(experiment_id)\n\n def rename_experiment(self, experiment_id, new_name):\n \"\"\"\n Update an experiment's name. The new name must be unique.\n\n :param experiment_id: The experiment ID returned from ``create_experiment``.\n \"\"\"\n self.store.rename_experiment(experiment_id, new_name)\n\n def log_metric(self, run_id, key, value, timestamp=None, step=None):\n \"\"\"\n Log a metric against the run ID. The timestamp defaults to the current timestamp.\n The step defaults to 0.\n \"\"\"\n timestamp = timestamp if timestamp is not None else int(time.time())\n step = step if step is not None else 0\n _validate_metric(key, value, timestamp, step)\n metric = Metric(key, value, timestamp, step)\n self.store.log_metric(run_id, metric)\n\n def log_param(self, run_id, key, value):\n \"\"\"\n Log a parameter against the run ID. Value is converted to a string.\n \"\"\"\n _validate_param_name(key)\n param = Param(key, str(value))\n self.store.log_param(run_id, param)\n\n def set_tag(self, run_id, key, value):\n \"\"\"\n Set a tag on the run ID. Value is converted to a string.\n \"\"\"\n _validate_tag_name(key)\n tag = RunTag(key, str(value))\n self.store.set_tag(run_id, tag)\n\n def log_batch(self, run_id, metrics, params, tags):\n \"\"\"\n Log multiple metrics, params, and/or tags.\n\n :param metrics: List of Metric(key, value, timestamp) instances.\n :param params: List of Param(key, value) instances.\n :param tags: List of RunTag(key, value) instances.\n\n Raises an MlflowException if any errors occur.\n :returns: None\n \"\"\"\n for metric in metrics:\n _validate_metric(metric.key, metric.value, metric.timestamp, metric.step)\n for param in params:\n _validate_param_name(param.key)\n for tag in tags:\n _validate_tag_name(tag.key)\n self.store.log_batch(run_id=run_id, metrics=metrics, params=params, tags=tags)\n\n def log_artifact(self, run_id, local_path, artifact_path=None):\n \"\"\"\n Write a local file to the remote ``artifact_uri``.\n\n :param local_path: Path to the file to write.\n :param artifact_path: If provided, the directory in ``artifact_uri`` to write to.\n \"\"\"\n run = self.get_run(run_id)\n artifact_repo = get_artifact_repository(run.info.artifact_uri)\n artifact_repo.log_artifact(local_path, artifact_path)\n\n def log_artifacts(self, run_id, local_dir, artifact_path=None):\n \"\"\"\n Write a directory of files to the remote ``artifact_uri``.\n\n :param local_dir: Path to the directory of files to write.\n :param artifact_path: If provided, the directory in ``artifact_uri`` to write to.\n \"\"\"\n run = self.get_run(run_id)\n artifact_repo = get_artifact_repository(run.info.artifact_uri)\n artifact_repo.log_artifacts(local_dir, artifact_path)\n\n def list_artifacts(self, run_id, path=None):\n \"\"\"\n List the artifacts for a run.\n\n :param run_id: The run to list artifacts from.\n :param path: The run's relative artifact path to list from. By default it is set to None\n or the root artifact path.\n :return: List of :py:class:`mlflow.entities.FileInfo`\n \"\"\"\n run = self.get_run(run_id)\n artifact_root = run.info.artifact_uri\n artifact_repo = get_artifact_repository(artifact_root)\n return artifact_repo.list_artifacts(path)\n\n def download_artifacts(self, run_id, path):\n \"\"\"\n Download an artifact file or directory from a run to a local directory if applicable,\n and return a local path for it.\n\n :param run_id: The run to download artifacts from.\n :param path: Relative source path to the desired artifact.\n :return: Local path of desired artifact.\n \"\"\"\n run = self.get_run(run_id)\n artifact_root = run.info.artifact_uri\n artifact_repo = get_artifact_repository(artifact_root)\n return artifact_repo.download_artifacts(path)\n\n def set_terminated(self, run_id, status=None, end_time=None):\n \"\"\"Set a run's status to terminated.\n\n :param status: A string value of :py:class:`mlflow.entities.RunStatus`.\n Defaults to \"FINISHED\".\n :param end_time: If not provided, defaults to the current time.\"\"\"\n end_time = end_time if end_time else int(time.time() * 1000)\n status = status if status else RunStatus.to_string(RunStatus.FINISHED)\n self.store.update_run_info(run_id, run_status=RunStatus.from_string(status),\n end_time=end_time)\n\n def delete_run(self, run_id):\n \"\"\"\n Deletes a run with the given ID.\n \"\"\"\n self.store.delete_run(run_id)\n\n def restore_run(self, run_id):\n \"\"\"\n Restores a deleted run with the given ID.\n \"\"\"\n self.store.restore_run(run_id)\n\n def search_runs(self, experiment_ids, filter_string=\"\", run_view_type=ViewType.ACTIVE_ONLY,\n max_results=SEARCH_MAX_RESULTS_DEFAULT, order_by=None, page_token=None):\n \"\"\"\n Search experiments that fit the search criteria.\n\n :param experiment_ids: List of experiment IDs, or a single int or string id.\n :param filter_string: Filter query string, defaults to searching all runs.\n :param run_view_type: one of enum values ACTIVE_ONLY, DELETED_ONLY, or ALL runs\n defined in :py:class:`mlflow.entities.ViewType`.\n :param max_results: Maximum number of runs desired.\n :param order_by: List of columns to order by (e.g., \"metrics.rmse\"). The default\n ordering is to sort by start_time DESC, then run_id.\n :param page_token: Token specifying the next page of results. It should be obtained from\n a ``search_runs`` call.\n\n :return: A list of :py:class:`mlflow.entities.Run` objects that satisfy the search\n expressions. If the underlying tracking store supports pagination, the token for\n the next page may be obtained via the ``token`` attribute of the returned object.\n \"\"\"\n if isinstance(experiment_ids, int) or isinstance(experiment_ids, str):\n experiment_ids = [experiment_ids]\n return self.store.search_runs(experiment_ids=experiment_ids, filter_string=filter_string,\n run_view_type=run_view_type, max_results=max_results,\n order_by=order_by, page_token=page_token)\n", "path": "mlflow/tracking/client.py"}], "after_files": [{"content": "\"\"\"\nInternal package providing a Python CRUD interface to MLflow experiments and runs.\nThis is a lower level API than the :py:mod:`mlflow.tracking.fluent` module, and is\nexposed in the :py:mod:`mlflow.tracking` module.\n\"\"\"\n\nimport time\nfrom six import iteritems\n\nfrom mlflow.store import SEARCH_MAX_RESULTS_DEFAULT\nfrom mlflow.tracking import utils\nfrom mlflow.utils.validation import _validate_param_name, _validate_tag_name, _validate_run_id, \\\n _validate_experiment_artifact_location, _validate_experiment_name, _validate_metric\nfrom mlflow.entities import Param, Metric, RunStatus, RunTag, ViewType\nfrom mlflow.store.artifact_repository_registry import get_artifact_repository\nfrom mlflow.utils.mlflow_tags import MLFLOW_USER\n\n\nclass MlflowClient(object):\n \"\"\"\n Client of an MLflow Tracking Server that creates and manages experiments and runs.\n \"\"\"\n\n def __init__(self, tracking_uri=None):\n \"\"\"\n :param tracking_uri: Address of local or remote tracking server. If not provided, defaults\n to the service set by ``mlflow.tracking.set_tracking_uri``. See\n `Where Runs Get Recorded <../tracking.html#where-runs-get-recorded>`_\n for more info.\n \"\"\"\n self.tracking_uri = tracking_uri or utils.get_tracking_uri()\n self.store = utils._get_store(self.tracking_uri)\n\n def get_run(self, run_id):\n \"\"\"\n Fetch the run from backend store. The resulting :py:class:`Run <mlflow.entities.Run>`\n contains a collection of run metadata -- :py:class:`RunInfo <mlflow.entities.RunInfo>`,\n as well as a collection of run parameters, tags, and metrics --\n :py:class:`RunData <mlflow.entities.RunData>`. In the case where multiple metrics with the\n same key are logged for the run, the :py:class:`RunData <mlflow.entities.RunData>` contains\n the most recently logged value at the largest step for each metric.\n\n :param run_id: Unique identifier for the run.\n\n :return: A single :py:class:`mlflow.entities.Run` object, if the run exists. Otherwise,\n raises an exception.\n \"\"\"\n _validate_run_id(run_id)\n return self.store.get_run(run_id)\n\n def get_metric_history(self, run_id, key):\n \"\"\"\n Return a list of metric objects corresponding to all values logged for a given metric.\n\n :param run_id: Unique identifier for run\n :param key: Metric name within the run\n\n :return: A list of :py:class:`mlflow.entities.Metric` entities if logged, else empty list\n \"\"\"\n return self.store.get_metric_history(run_id=run_id, metric_key=key)\n\n def create_run(self, experiment_id, start_time=None, tags=None):\n \"\"\"\n Create a :py:class:`mlflow.entities.Run` object that can be associated with\n metrics, parameters, artifacts, etc.\n Unlike :py:func:`mlflow.projects.run`, creates objects but does not run code.\n Unlike :py:func:`mlflow.start_run`, does not change the \"active run\" used by\n :py:func:`mlflow.log_param`.\n\n :param experiment_id: The ID of then experiment to create a run in.\n :param start_time: If not provided, use the current timestamp.\n :param tags: A dictionary of key-value pairs that are converted into\n :py:class:`mlflow.entities.RunTag` objects.\n :return: :py:class:`mlflow.entities.Run` that was created.\n \"\"\"\n\n tags = tags if tags else {}\n\n # Extract user from tags\n # This logic is temporary; the user_id attribute of runs is deprecated and will be removed\n # in a later release.\n user_id = tags.get(MLFLOW_USER, \"unknown\")\n\n return self.store.create_run(\n experiment_id=experiment_id,\n user_id=user_id,\n start_time=start_time or int(time.time() * 1000),\n tags=[RunTag(key, value) for (key, value) in iteritems(tags)]\n )\n\n def list_run_infos(self, experiment_id, run_view_type=ViewType.ACTIVE_ONLY):\n \"\"\":return: List of :py:class:`mlflow.entities.RunInfo`\"\"\"\n return self.store.list_run_infos(experiment_id, run_view_type)\n\n def list_experiments(self, view_type=None):\n \"\"\"\n :return: List of :py:class:`mlflow.entities.Experiment`\n \"\"\"\n final_view_type = ViewType.ACTIVE_ONLY if view_type is None else view_type\n return self.store.list_experiments(view_type=final_view_type)\n\n def get_experiment(self, experiment_id):\n \"\"\"\n :param experiment_id: The experiment ID returned from ``create_experiment``.\n :return: :py:class:`mlflow.entities.Experiment`\n \"\"\"\n return self.store.get_experiment(experiment_id)\n\n def get_experiment_by_name(self, name):\n \"\"\"\n :param name: The experiment name.\n :return: :py:class:`mlflow.entities.Experiment`\n \"\"\"\n return self.store.get_experiment_by_name(name)\n\n def create_experiment(self, name, artifact_location=None):\n \"\"\"Create an experiment.\n\n :param name: The experiment name. Must be unique.\n :param artifact_location: The location to store run artifacts.\n If not provided, the server picks an appropriate default.\n :return: Integer ID of the created experiment.\n \"\"\"\n _validate_experiment_name(name)\n _validate_experiment_artifact_location(artifact_location)\n return self.store.create_experiment(\n name=name,\n artifact_location=artifact_location,\n )\n\n def delete_experiment(self, experiment_id):\n \"\"\"\n Delete an experiment from the backend store.\n\n :param experiment_id: The experiment ID returned from ``create_experiment``.\n \"\"\"\n self.store.delete_experiment(experiment_id)\n\n def restore_experiment(self, experiment_id):\n \"\"\"\n Restore a deleted experiment unless permanently deleted.\n\n :param experiment_id: The experiment ID returned from ``create_experiment``.\n \"\"\"\n self.store.restore_experiment(experiment_id)\n\n def rename_experiment(self, experiment_id, new_name):\n \"\"\"\n Update an experiment's name. The new name must be unique.\n\n :param experiment_id: The experiment ID returned from ``create_experiment``.\n \"\"\"\n self.store.rename_experiment(experiment_id, new_name)\n\n def log_metric(self, run_id, key, value, timestamp=None, step=None):\n \"\"\"\n Log a metric against the run ID. The timestamp defaults to the current timestamp.\n The step defaults to 0.\n \"\"\"\n timestamp = timestamp if timestamp is not None else int(time.time())\n step = step if step is not None else 0\n _validate_metric(key, value, timestamp, step)\n metric = Metric(key, value, timestamp, step)\n self.store.log_metric(run_id, metric)\n\n def log_param(self, run_id, key, value):\n \"\"\"\n Log a parameter against the run ID. Value is converted to a string.\n \"\"\"\n _validate_param_name(key)\n param = Param(key, str(value))\n self.store.log_param(run_id, param)\n\n def set_tag(self, run_id, key, value):\n \"\"\"\n Set a tag on the run ID. Value is converted to a string.\n \"\"\"\n _validate_tag_name(key)\n tag = RunTag(key, str(value))\n self.store.set_tag(run_id, tag)\n\n def log_batch(self, run_id, metrics, params, tags):\n \"\"\"\n Log multiple metrics, params, and/or tags.\n\n :param metrics: List of Metric(key, value, timestamp) instances.\n :param params: List of Param(key, value) instances.\n :param tags: List of RunTag(key, value) instances.\n\n Raises an MlflowException if any errors occur.\n :returns: None\n \"\"\"\n for metric in metrics:\n _validate_metric(metric.key, metric.value, metric.timestamp, metric.step)\n for param in params:\n _validate_param_name(param.key)\n for tag in tags:\n _validate_tag_name(tag.key)\n self.store.log_batch(run_id=run_id, metrics=metrics, params=params, tags=tags)\n\n def log_artifact(self, run_id, local_path, artifact_path=None):\n \"\"\"\n Write a local file to the remote ``artifact_uri``.\n\n :param local_path: Path to the file to write.\n :param artifact_path: If provided, the directory in ``artifact_uri`` to write to.\n \"\"\"\n run = self.get_run(run_id)\n artifact_repo = get_artifact_repository(run.info.artifact_uri)\n artifact_repo.log_artifact(local_path, artifact_path)\n\n def log_artifacts(self, run_id, local_dir, artifact_path=None):\n \"\"\"\n Write a directory of files to the remote ``artifact_uri``.\n\n :param local_dir: Path to the directory of files to write.\n :param artifact_path: If provided, the directory in ``artifact_uri`` to write to.\n \"\"\"\n run = self.get_run(run_id)\n artifact_repo = get_artifact_repository(run.info.artifact_uri)\n artifact_repo.log_artifacts(local_dir, artifact_path)\n\n def list_artifacts(self, run_id, path=None):\n \"\"\"\n List the artifacts for a run.\n\n :param run_id: The run to list artifacts from.\n :param path: The run's relative artifact path to list from. By default it is set to None\n or the root artifact path.\n :return: List of :py:class:`mlflow.entities.FileInfo`\n \"\"\"\n run = self.get_run(run_id)\n artifact_root = run.info.artifact_uri\n artifact_repo = get_artifact_repository(artifact_root)\n return artifact_repo.list_artifacts(path)\n\n def download_artifacts(self, run_id, path, dst_path=None):\n \"\"\"\n Download an artifact file or directory from a run to a local directory if applicable,\n and return a local path for it.\n\n :param run_id: The run to download artifacts from.\n :param path: Relative source path to the desired artifact.\n :param dst_path: Absolute path of the local filesystem destination directory to which to\n download the specified artifacts. This directory must already exist.\n If unspecified, the artifacts will either be downloaded to a new\n uniquely-named directory on the local filesystem or will be returned\n directly in the case of the LocalArtifactRepository.\n :return: Local path of desired artifact.\n \"\"\"\n run = self.get_run(run_id)\n artifact_root = run.info.artifact_uri\n artifact_repo = get_artifact_repository(artifact_root)\n return artifact_repo.download_artifacts(path, dst_path)\n\n def set_terminated(self, run_id, status=None, end_time=None):\n \"\"\"Set a run's status to terminated.\n\n :param status: A string value of :py:class:`mlflow.entities.RunStatus`.\n Defaults to \"FINISHED\".\n :param end_time: If not provided, defaults to the current time.\"\"\"\n end_time = end_time if end_time else int(time.time() * 1000)\n status = status if status else RunStatus.to_string(RunStatus.FINISHED)\n self.store.update_run_info(run_id, run_status=RunStatus.from_string(status),\n end_time=end_time)\n\n def delete_run(self, run_id):\n \"\"\"\n Deletes a run with the given ID.\n \"\"\"\n self.store.delete_run(run_id)\n\n def restore_run(self, run_id):\n \"\"\"\n Restores a deleted run with the given ID.\n \"\"\"\n self.store.restore_run(run_id)\n\n def search_runs(self, experiment_ids, filter_string=\"\", run_view_type=ViewType.ACTIVE_ONLY,\n max_results=SEARCH_MAX_RESULTS_DEFAULT, order_by=None, page_token=None):\n \"\"\"\n Search experiments that fit the search criteria.\n\n :param experiment_ids: List of experiment IDs, or a single int or string id.\n :param filter_string: Filter query string, defaults to searching all runs.\n :param run_view_type: one of enum values ACTIVE_ONLY, DELETED_ONLY, or ALL runs\n defined in :py:class:`mlflow.entities.ViewType`.\n :param max_results: Maximum number of runs desired.\n :param order_by: List of columns to order by (e.g., \"metrics.rmse\"). The default\n ordering is to sort by start_time DESC, then run_id.\n :param page_token: Token specifying the next page of results. It should be obtained from\n a ``search_runs`` call.\n\n :return: A list of :py:class:`mlflow.entities.Run` objects that satisfy the search\n expressions. If the underlying tracking store supports pagination, the token for\n the next page may be obtained via the ``token`` attribute of the returned object.\n \"\"\"\n if isinstance(experiment_ids, int) or isinstance(experiment_ids, str):\n experiment_ids = [experiment_ids]\n return self.store.search_runs(experiment_ids=experiment_ids, filter_string=filter_string,\n run_view_type=run_view_type, max_results=max_results,\n order_by=order_by, page_token=page_token)\n", "path": "mlflow/tracking/client.py"}]}
| 4,011 | 327 |
gh_patches_debug_12715
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-3240
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Export ExponentialBucketHistogramAggregation in opentelemetry.sdk.metrics.view
**Is your feature request related to a problem?**
We want to use the Exponential Histograms features publicly released in version [1.17.0](https://github.com/open-telemetry/opentelemetry-python/blob/main/CHANGELOG.md#version-1170038b0-2023-03-22).
**Describe the solution you'd like**
I'd like to use the public API.
**Describe alternatives you've considered**
One can import it from `opentelemetry.sdk.metrics._internal.aggregation`
**Additional context**
Currently the code in https://github.com/open-telemetry/opentelemetry-python/blob/b6a1b22fa65f41bdefb01d64b76e5e793d039f6d/opentelemetry-sdk/src/opentelemetry/sdk/metrics/view/__init__.py#L25-L33 is not exporting the newly added `ExponentialBucketHistogramAggregation`
Export ExponentialBucketHistogramAggregation in opentelemetry.sdk.metrics.view
**Is your feature request related to a problem?**
We want to use the Exponential Histograms features publicly released in version [1.17.0](https://github.com/open-telemetry/opentelemetry-python/blob/main/CHANGELOG.md#version-1170038b0-2023-03-22).
**Describe the solution you'd like**
I'd like to use the public API.
**Describe alternatives you've considered**
One can import it from `opentelemetry.sdk.metrics._internal.aggregation`
**Additional context**
Currently the code in https://github.com/open-telemetry/opentelemetry-python/blob/b6a1b22fa65f41bdefb01d64b76e5e793d039f6d/opentelemetry-sdk/src/opentelemetry/sdk/metrics/view/__init__.py#L25-L33 is not exporting the newly added `ExponentialBucketHistogramAggregation`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `opentelemetry-sdk/src/opentelemetry/sdk/metrics/view/__init__.py`
Content:
```
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from opentelemetry.sdk.metrics._internal.aggregation import (
16 Aggregation,
17 DefaultAggregation,
18 DropAggregation,
19 ExplicitBucketHistogramAggregation,
20 LastValueAggregation,
21 SumAggregation,
22 )
23 from opentelemetry.sdk.metrics._internal.view import View
24
25 __all__ = [
26 "Aggregation",
27 "DefaultAggregation",
28 "DropAggregation",
29 "ExplicitBucketHistogramAggregation",
30 "LastValueAggregation",
31 "SumAggregation",
32 "View",
33 ]
34
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/opentelemetry-sdk/src/opentelemetry/sdk/metrics/view/__init__.py b/opentelemetry-sdk/src/opentelemetry/sdk/metrics/view/__init__.py
--- a/opentelemetry-sdk/src/opentelemetry/sdk/metrics/view/__init__.py
+++ b/opentelemetry-sdk/src/opentelemetry/sdk/metrics/view/__init__.py
@@ -17,6 +17,7 @@
DefaultAggregation,
DropAggregation,
ExplicitBucketHistogramAggregation,
+ ExponentialBucketHistogramAggregation,
LastValueAggregation,
SumAggregation,
)
@@ -27,6 +28,7 @@
"DefaultAggregation",
"DropAggregation",
"ExplicitBucketHistogramAggregation",
+ "ExponentialBucketHistogramAggregation",
"LastValueAggregation",
"SumAggregation",
"View",
|
{"golden_diff": "diff --git a/opentelemetry-sdk/src/opentelemetry/sdk/metrics/view/__init__.py b/opentelemetry-sdk/src/opentelemetry/sdk/metrics/view/__init__.py\n--- a/opentelemetry-sdk/src/opentelemetry/sdk/metrics/view/__init__.py\n+++ b/opentelemetry-sdk/src/opentelemetry/sdk/metrics/view/__init__.py\n@@ -17,6 +17,7 @@\n DefaultAggregation,\n DropAggregation,\n ExplicitBucketHistogramAggregation,\n+ ExponentialBucketHistogramAggregation,\n LastValueAggregation,\n SumAggregation,\n )\n@@ -27,6 +28,7 @@\n \"DefaultAggregation\",\n \"DropAggregation\",\n \"ExplicitBucketHistogramAggregation\",\n+ \"ExponentialBucketHistogramAggregation\",\n \"LastValueAggregation\",\n \"SumAggregation\",\n \"View\",\n", "issue": "Export ExponentialBucketHistogramAggregation in opentelemetry.sdk.metrics.view\n**Is your feature request related to a problem?**\r\nWe want to use the Exponential Histograms features publicly released in version [1.17.0](https://github.com/open-telemetry/opentelemetry-python/blob/main/CHANGELOG.md#version-1170038b0-2023-03-22).\r\n\r\n**Describe the solution you'd like**\r\nI'd like to use the public API.\r\n\r\n**Describe alternatives you've considered**\r\nOne can import it from `opentelemetry.sdk.metrics._internal.aggregation`\r\n\r\n**Additional context**\r\nCurrently the code in https://github.com/open-telemetry/opentelemetry-python/blob/b6a1b22fa65f41bdefb01d64b76e5e793d039f6d/opentelemetry-sdk/src/opentelemetry/sdk/metrics/view/__init__.py#L25-L33 is not exporting the newly added `ExponentialBucketHistogramAggregation`\r\n\nExport ExponentialBucketHistogramAggregation in opentelemetry.sdk.metrics.view\n**Is your feature request related to a problem?**\r\nWe want to use the Exponential Histograms features publicly released in version [1.17.0](https://github.com/open-telemetry/opentelemetry-python/blob/main/CHANGELOG.md#version-1170038b0-2023-03-22).\r\n\r\n**Describe the solution you'd like**\r\nI'd like to use the public API.\r\n\r\n**Describe alternatives you've considered**\r\nOne can import it from `opentelemetry.sdk.metrics._internal.aggregation`\r\n\r\n**Additional context**\r\nCurrently the code in https://github.com/open-telemetry/opentelemetry-python/blob/b6a1b22fa65f41bdefb01d64b76e5e793d039f6d/opentelemetry-sdk/src/opentelemetry/sdk/metrics/view/__init__.py#L25-L33 is not exporting the newly added `ExponentialBucketHistogramAggregation`\r\n\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom opentelemetry.sdk.metrics._internal.aggregation import (\n Aggregation,\n DefaultAggregation,\n DropAggregation,\n ExplicitBucketHistogramAggregation,\n LastValueAggregation,\n SumAggregation,\n)\nfrom opentelemetry.sdk.metrics._internal.view import View\n\n__all__ = [\n \"Aggregation\",\n \"DefaultAggregation\",\n \"DropAggregation\",\n \"ExplicitBucketHistogramAggregation\",\n \"LastValueAggregation\",\n \"SumAggregation\",\n \"View\",\n]\n", "path": "opentelemetry-sdk/src/opentelemetry/sdk/metrics/view/__init__.py"}], "after_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom opentelemetry.sdk.metrics._internal.aggregation import (\n Aggregation,\n DefaultAggregation,\n DropAggregation,\n ExplicitBucketHistogramAggregation,\n ExponentialBucketHistogramAggregation,\n LastValueAggregation,\n SumAggregation,\n)\nfrom opentelemetry.sdk.metrics._internal.view import View\n\n__all__ = [\n \"Aggregation\",\n \"DefaultAggregation\",\n \"DropAggregation\",\n \"ExplicitBucketHistogramAggregation\",\n \"ExponentialBucketHistogramAggregation\",\n \"LastValueAggregation\",\n \"SumAggregation\",\n \"View\",\n]\n", "path": "opentelemetry-sdk/src/opentelemetry/sdk/metrics/view/__init__.py"}]}
| 1,017 | 185 |
gh_patches_debug_9367
|
rasdani/github-patches
|
git_diff
|
ytdl-org__youtube-dl-14997
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[https://www.franceinter.fr] WARNING: unable to extract upload date
---
### Make sure you are using the *latest* version: run `youtube-dl --version` and ensure your version is *2017.12.14*. If it's not, read [this FAQ entry](https://github.com/rg3/youtube-dl/blob/master/README.md#how-do-i-update-youtube-dl) and update. Issues with outdated version will be rejected.
- [x] I've **verified** and **I assure** that I'm running youtube-dl **2017.12.14**
### Before submitting an *issue* make sure you have:
- [x] At least skimmed through the [README](https://github.com/rg3/youtube-dl/blob/master/README.md), **most notably** the [FAQ](https://github.com/rg3/youtube-dl#faq) and [BUGS](https://github.com/rg3/youtube-dl#bugs) sections
- [x] [Searched](https://github.com/rg3/youtube-dl/search?type=Issues) the bugtracker for similar issues including closed ones
### What is the purpose of your *issue*?
- [ ] Bug report (encountered problems with youtube-dl)
- [x] Site support request (request for adding support for a new site)
- [ ] Feature request (request for a new functionality)
- [ ] Question
- [ ] Other
---
```
youtube-dl-mp3 "https://www.franceinter.fr/emissions/les-concerts-d-inter/les-concerts-d-inter-14-decembre-2017"
[FranceInter] les-concerts-d-inter/les-concerts-d-inter-14-decembre-2017: Downloading webpage
WARNING: unable to extract upload date; please report this issue on https://yt-dl.org/bug . Make sure you are using the latest version; see https://yt-dl.org/update on how to update. Be sure to call youtube-dl with the --verbose flag and include its complete output.
```
```
[debug] System config: []
[debug] User config: []
[debug] Custom config: []
[debug] Command-line args: [u'-v']
[debug] Encodings: locale UTF-8, fs UTF-8, out UTF-8, pref UTF-8
[debug] youtube-dl version 2017.12.14
[debug] Python version 2.7.12 - Linux-4.4.0-103-generic-x86_64-with-Ubuntu-16.04-xenial
[debug] exe versions: avconv 2.8.11-0ubuntu0.16.04.1, avprobe 2.8.11-0ubuntu0.16.04.1, ffmpeg 2.8.11-0ubuntu0.16.04.1, ffprobe 2.8.11-0ubuntu0.16.04.1
[debug] Proxy map: {}
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `youtube_dl/extractor/franceinter.py`
Content:
```
1 # coding: utf-8
2 from __future__ import unicode_literals
3
4 from .common import InfoExtractor
5 from ..utils import month_by_name
6
7
8 class FranceInterIE(InfoExtractor):
9 _VALID_URL = r'https?://(?:www\.)?franceinter\.fr/emissions/(?P<id>[^?#]+)'
10
11 _TEST = {
12 'url': 'https://www.franceinter.fr/emissions/affaires-sensibles/affaires-sensibles-07-septembre-2016',
13 'md5': '9e54d7bdb6fdc02a841007f8a975c094',
14 'info_dict': {
15 'id': 'affaires-sensibles/affaires-sensibles-07-septembre-2016',
16 'ext': 'mp3',
17 'title': 'Affaire Cahuzac : le contentieux du compte en Suisse',
18 'description': 'md5:401969c5d318c061f86bda1fa359292b',
19 'upload_date': '20160907',
20 },
21 }
22
23 def _real_extract(self, url):
24 video_id = self._match_id(url)
25
26 webpage = self._download_webpage(url, video_id)
27
28 video_url = self._search_regex(
29 r'(?s)<div[^>]+class=["\']page-diffusion["\'][^>]*>.*?<button[^>]+data-url=(["\'])(?P<url>(?:(?!\1).)+)\1',
30 webpage, 'video url', group='url')
31
32 title = self._og_search_title(webpage)
33 description = self._og_search_description(webpage)
34
35 upload_date_str = self._search_regex(
36 r'class=["\']cover-emission-period["\'][^>]*>[^<]+\s+(\d{1,2}\s+[^\s]+\s+\d{4})<',
37 webpage, 'upload date', fatal=False)
38 if upload_date_str:
39 upload_date_list = upload_date_str.split()
40 upload_date_list.reverse()
41 upload_date_list[1] = '%02d' % (month_by_name(upload_date_list[1], lang='fr') or 0)
42 upload_date_list[2] = '%02d' % int(upload_date_list[2])
43 upload_date = ''.join(upload_date_list)
44 else:
45 upload_date = None
46
47 return {
48 'id': video_id,
49 'title': title,
50 'description': description,
51 'upload_date': upload_date,
52 'formats': [{
53 'url': video_url,
54 'vcodec': 'none',
55 }],
56 }
57
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/youtube_dl/extractor/franceinter.py b/youtube_dl/extractor/franceinter.py
--- a/youtube_dl/extractor/franceinter.py
+++ b/youtube_dl/extractor/franceinter.py
@@ -33,7 +33,7 @@
description = self._og_search_description(webpage)
upload_date_str = self._search_regex(
- r'class=["\']cover-emission-period["\'][^>]*>[^<]+\s+(\d{1,2}\s+[^\s]+\s+\d{4})<',
+ r'class=["\']\s*cover-emission-period\s*["\'][^>]*>[^<]+\s+(\d{1,2}\s+[^\s]+\s+\d{4})<',
webpage, 'upload date', fatal=False)
if upload_date_str:
upload_date_list = upload_date_str.split()
|
{"golden_diff": "diff --git a/youtube_dl/extractor/franceinter.py b/youtube_dl/extractor/franceinter.py\n--- a/youtube_dl/extractor/franceinter.py\n+++ b/youtube_dl/extractor/franceinter.py\n@@ -33,7 +33,7 @@\n description = self._og_search_description(webpage)\n \n upload_date_str = self._search_regex(\n- r'class=[\"\\']cover-emission-period[\"\\'][^>]*>[^<]+\\s+(\\d{1,2}\\s+[^\\s]+\\s+\\d{4})<',\n+ r'class=[\"\\']\\s*cover-emission-period\\s*[\"\\'][^>]*>[^<]+\\s+(\\d{1,2}\\s+[^\\s]+\\s+\\d{4})<',\n webpage, 'upload date', fatal=False)\n if upload_date_str:\n upload_date_list = upload_date_str.split()\n", "issue": "[https://www.franceinter.fr] WARNING: unable to extract upload date\n---\r\n\r\n### Make sure you are using the *latest* version: run `youtube-dl --version` and ensure your version is *2017.12.14*. If it's not, read [this FAQ entry](https://github.com/rg3/youtube-dl/blob/master/README.md#how-do-i-update-youtube-dl) and update. Issues with outdated version will be rejected.\r\n- [x] I've **verified** and **I assure** that I'm running youtube-dl **2017.12.14**\r\n\r\n### Before submitting an *issue* make sure you have:\r\n- [x] At least skimmed through the [README](https://github.com/rg3/youtube-dl/blob/master/README.md), **most notably** the [FAQ](https://github.com/rg3/youtube-dl#faq) and [BUGS](https://github.com/rg3/youtube-dl#bugs) sections\r\n- [x] [Searched](https://github.com/rg3/youtube-dl/search?type=Issues) the bugtracker for similar issues including closed ones\r\n\r\n### What is the purpose of your *issue*?\r\n- [ ] Bug report (encountered problems with youtube-dl)\r\n- [x] Site support request (request for adding support for a new site)\r\n- [ ] Feature request (request for a new functionality)\r\n- [ ] Question\r\n- [ ] Other\r\n\r\n---\r\n\r\n``` \r\nyoutube-dl-mp3 \"https://www.franceinter.fr/emissions/les-concerts-d-inter/les-concerts-d-inter-14-decembre-2017\"\r\n[FranceInter] les-concerts-d-inter/les-concerts-d-inter-14-decembre-2017: Downloading webpage\r\nWARNING: unable to extract upload date; please report this issue on https://yt-dl.org/bug . Make sure you are using the latest version; see https://yt-dl.org/update on how to update. Be sure to call youtube-dl with the --verbose flag and include its complete output.\r\n```\r\n\r\n```\r\n[debug] System config: []\r\n[debug] User config: []\r\n[debug] Custom config: []\r\n[debug] Command-line args: [u'-v']\r\n[debug] Encodings: locale UTF-8, fs UTF-8, out UTF-8, pref UTF-8\r\n[debug] youtube-dl version 2017.12.14\r\n[debug] Python version 2.7.12 - Linux-4.4.0-103-generic-x86_64-with-Ubuntu-16.04-xenial\r\n[debug] exe versions: avconv 2.8.11-0ubuntu0.16.04.1, avprobe 2.8.11-0ubuntu0.16.04.1, ffmpeg 2.8.11-0ubuntu0.16.04.1, ffprobe 2.8.11-0ubuntu0.16.04.1\r\n[debug] Proxy map: {}\r\n```\n", "before_files": [{"content": "# coding: utf-8\nfrom __future__ import unicode_literals\n\nfrom .common import InfoExtractor\nfrom ..utils import month_by_name\n\n\nclass FranceInterIE(InfoExtractor):\n _VALID_URL = r'https?://(?:www\\.)?franceinter\\.fr/emissions/(?P<id>[^?#]+)'\n\n _TEST = {\n 'url': 'https://www.franceinter.fr/emissions/affaires-sensibles/affaires-sensibles-07-septembre-2016',\n 'md5': '9e54d7bdb6fdc02a841007f8a975c094',\n 'info_dict': {\n 'id': 'affaires-sensibles/affaires-sensibles-07-septembre-2016',\n 'ext': 'mp3',\n 'title': 'Affaire Cahuzac : le contentieux du compte en Suisse',\n 'description': 'md5:401969c5d318c061f86bda1fa359292b',\n 'upload_date': '20160907',\n },\n }\n\n def _real_extract(self, url):\n video_id = self._match_id(url)\n\n webpage = self._download_webpage(url, video_id)\n\n video_url = self._search_regex(\n r'(?s)<div[^>]+class=[\"\\']page-diffusion[\"\\'][^>]*>.*?<button[^>]+data-url=([\"\\'])(?P<url>(?:(?!\\1).)+)\\1',\n webpage, 'video url', group='url')\n\n title = self._og_search_title(webpage)\n description = self._og_search_description(webpage)\n\n upload_date_str = self._search_regex(\n r'class=[\"\\']cover-emission-period[\"\\'][^>]*>[^<]+\\s+(\\d{1,2}\\s+[^\\s]+\\s+\\d{4})<',\n webpage, 'upload date', fatal=False)\n if upload_date_str:\n upload_date_list = upload_date_str.split()\n upload_date_list.reverse()\n upload_date_list[1] = '%02d' % (month_by_name(upload_date_list[1], lang='fr') or 0)\n upload_date_list[2] = '%02d' % int(upload_date_list[2])\n upload_date = ''.join(upload_date_list)\n else:\n upload_date = None\n\n return {\n 'id': video_id,\n 'title': title,\n 'description': description,\n 'upload_date': upload_date,\n 'formats': [{\n 'url': video_url,\n 'vcodec': 'none',\n }],\n }\n", "path": "youtube_dl/extractor/franceinter.py"}], "after_files": [{"content": "# coding: utf-8\nfrom __future__ import unicode_literals\n\nfrom .common import InfoExtractor\nfrom ..utils import month_by_name\n\n\nclass FranceInterIE(InfoExtractor):\n _VALID_URL = r'https?://(?:www\\.)?franceinter\\.fr/emissions/(?P<id>[^?#]+)'\n\n _TEST = {\n 'url': 'https://www.franceinter.fr/emissions/affaires-sensibles/affaires-sensibles-07-septembre-2016',\n 'md5': '9e54d7bdb6fdc02a841007f8a975c094',\n 'info_dict': {\n 'id': 'affaires-sensibles/affaires-sensibles-07-septembre-2016',\n 'ext': 'mp3',\n 'title': 'Affaire Cahuzac : le contentieux du compte en Suisse',\n 'description': 'md5:401969c5d318c061f86bda1fa359292b',\n 'upload_date': '20160907',\n },\n }\n\n def _real_extract(self, url):\n video_id = self._match_id(url)\n\n webpage = self._download_webpage(url, video_id)\n\n video_url = self._search_regex(\n r'(?s)<div[^>]+class=[\"\\']page-diffusion[\"\\'][^>]*>.*?<button[^>]+data-url=([\"\\'])(?P<url>(?:(?!\\1).)+)\\1',\n webpage, 'video url', group='url')\n\n title = self._og_search_title(webpage)\n description = self._og_search_description(webpage)\n\n upload_date_str = self._search_regex(\n r'class=[\"\\']\\s*cover-emission-period\\s*[\"\\'][^>]*>[^<]+\\s+(\\d{1,2}\\s+[^\\s]+\\s+\\d{4})<',\n webpage, 'upload date', fatal=False)\n if upload_date_str:\n upload_date_list = upload_date_str.split()\n upload_date_list.reverse()\n upload_date_list[1] = '%02d' % (month_by_name(upload_date_list[1], lang='fr') or 0)\n upload_date_list[2] = '%02d' % int(upload_date_list[2])\n upload_date = ''.join(upload_date_list)\n else:\n upload_date = None\n\n return {\n 'id': video_id,\n 'title': title,\n 'description': description,\n 'upload_date': upload_date,\n 'formats': [{\n 'url': video_url,\n 'vcodec': 'none',\n }],\n }\n", "path": "youtube_dl/extractor/franceinter.py"}]}
| 1,676 | 201 |
gh_patches_debug_7992
|
rasdani/github-patches
|
git_diff
|
lightly-ai__lightly-305
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Fix import of ApiWorkflowClient
# Fix import of ApiWorkflowClient
Currently, the following import statement (from the docs) does not work:
```python
from lightly.api import ApiWorkflowClient
```
TODO:
- [x] We need to fix this by exposing the client in the `__init__.py` file.
- [x] Make sure the other imports in the docs work as well
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lightly/active_learning/utils/__init__.py`
Content:
```
```
Path: `lightly/api/__init__.py`
Content:
```
1 """ The lightly.api module provides access to the Lightly web-app. """
2
3 # Copyright (c) 2020. Lightly AG and its affiliates.
4 # All Rights Reserved
5
6 from lightly.api import routes
7
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lightly/active_learning/utils/__init__.py b/lightly/active_learning/utils/__init__.py
--- a/lightly/active_learning/utils/__init__.py
+++ b/lightly/active_learning/utils/__init__.py
@@ -0,0 +1,7 @@
+""" Collection of Utils for Active Learning """
+
+# Copyright (c) 2020. Lightly AG and its affiliates.
+# All Rights Reserved
+
+from lightly.active_learning.utils.bounding_box import BoundingBox
+from lightly.active_learning.utils.object_detection_output import ObjectDetectionOutput
\ No newline at end of file
diff --git a/lightly/api/__init__.py b/lightly/api/__init__.py
--- a/lightly/api/__init__.py
+++ b/lightly/api/__init__.py
@@ -3,4 +3,5 @@
# Copyright (c) 2020. Lightly AG and its affiliates.
# All Rights Reserved
+from lightly.api.api_workflow_client import ApiWorkflowClient
from lightly.api import routes
|
{"golden_diff": "diff --git a/lightly/active_learning/utils/__init__.py b/lightly/active_learning/utils/__init__.py\n--- a/lightly/active_learning/utils/__init__.py\n+++ b/lightly/active_learning/utils/__init__.py\n@@ -0,0 +1,7 @@\n+\"\"\" Collection of Utils for Active Learning \"\"\"\n+\n+# Copyright (c) 2020. Lightly AG and its affiliates.\n+# All Rights Reserved\n+\n+from lightly.active_learning.utils.bounding_box import BoundingBox\n+from lightly.active_learning.utils.object_detection_output import ObjectDetectionOutput\n\\ No newline at end of file\ndiff --git a/lightly/api/__init__.py b/lightly/api/__init__.py\n--- a/lightly/api/__init__.py\n+++ b/lightly/api/__init__.py\n@@ -3,4 +3,5 @@\n # Copyright (c) 2020. Lightly AG and its affiliates.\n # All Rights Reserved\n \n+from lightly.api.api_workflow_client import ApiWorkflowClient\n from lightly.api import routes\n", "issue": "Fix import of ApiWorkflowClient\n# Fix import of ApiWorkflowClient\r\n\r\nCurrently, the following import statement (from the docs) does not work:\r\n```python\r\nfrom lightly.api import ApiWorkflowClient\r\n```\r\n\r\nTODO:\r\n- [x] We need to fix this by exposing the client in the `__init__.py` file. \r\n- [x] Make sure the other imports in the docs work as well\n", "before_files": [{"content": "", "path": "lightly/active_learning/utils/__init__.py"}, {"content": "\"\"\" The lightly.api module provides access to the Lightly web-app. \"\"\"\n\n# Copyright (c) 2020. Lightly AG and its affiliates.\n# All Rights Reserved\n\nfrom lightly.api import routes\n", "path": "lightly/api/__init__.py"}], "after_files": [{"content": "\"\"\" Collection of Utils for Active Learning \"\"\"\n\n# Copyright (c) 2020. Lightly AG and its affiliates.\n# All Rights Reserved\n\nfrom lightly.active_learning.utils.bounding_box import BoundingBox\nfrom lightly.active_learning.utils.object_detection_output import ObjectDetectionOutput", "path": "lightly/active_learning/utils/__init__.py"}, {"content": "\"\"\" The lightly.api module provides access to the Lightly web-app. \"\"\"\n\n# Copyright (c) 2020. Lightly AG and its affiliates.\n# All Rights Reserved\n\nfrom lightly.api.api_workflow_client import ApiWorkflowClient\nfrom lightly.api import routes\n", "path": "lightly/api/__init__.py"}]}
| 418 | 222 |
gh_patches_debug_5392
|
rasdani/github-patches
|
git_diff
|
streamlink__streamlink-1351
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Kanal7 Defective again
Only 2 months later they have changed the design.
Not opening with latest 0.9.0 Release:
[cli][info] Found matching plugin kanal7 for URL http://www.kanal7.com/canli-izle
error: No playable streams found on this URL: http://www.kanal7.com/canli-izle
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/streamlink/plugins/kanal7.py`
Content:
```
1 from __future__ import print_function
2 import re
3
4 from streamlink.plugin import Plugin
5 from streamlink.plugin.api import http
6 from streamlink.plugin.api import useragents
7 from streamlink.plugin.api import validate
8 from streamlink.stream import HLSStream
9
10
11 class Kanal7(Plugin):
12 url_re = re.compile(r"https?://(?:www.)?kanal7.com/canli-izle")
13 iframe_re = re.compile(r'iframe .*?src="(http://[^"]*?)"')
14 stream_re = re.compile(r'src="(http[^"]*?)"')
15
16 @classmethod
17 def can_handle_url(cls, url):
18 return cls.url_re.match(url) is not None
19
20 def find_iframe(self, url):
21 res = http.get(url)
22 # find iframe url
23 iframe = self.iframe_re.search(res.text)
24 iframe_url = iframe and iframe.group(1)
25 if iframe_url:
26 self.logger.debug("Found iframe: {}", iframe_url)
27 return iframe_url
28
29 def _get_streams(self):
30 iframe1 = self.find_iframe(self.url)
31 if iframe1:
32 iframe2 = self.find_iframe(iframe1)
33 if iframe2:
34 ires = http.get(iframe2)
35 stream_m = self.stream_re.search(ires.text)
36 stream_url = stream_m and stream_m.group(1)
37 if stream_url:
38 yield "live", HLSStream(self.session, stream_url, headers={"Referer": iframe2})
39 else:
40 self.logger.error("Could not find second iframe, has the page layout changed?")
41 else:
42 self.logger.error("Could not find iframe, has the page layout changed?")
43
44
45 __plugin__ = Kanal7
46
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/streamlink/plugins/kanal7.py b/src/streamlink/plugins/kanal7.py
--- a/src/streamlink/plugins/kanal7.py
+++ b/src/streamlink/plugins/kanal7.py
@@ -11,7 +11,7 @@
class Kanal7(Plugin):
url_re = re.compile(r"https?://(?:www.)?kanal7.com/canli-izle")
iframe_re = re.compile(r'iframe .*?src="(http://[^"]*?)"')
- stream_re = re.compile(r'src="(http[^"]*?)"')
+ stream_re = re.compile(r'''tp_file\s+=\s+['"](http[^"]*?)['"]''')
@classmethod
def can_handle_url(cls, url):
|
{"golden_diff": "diff --git a/src/streamlink/plugins/kanal7.py b/src/streamlink/plugins/kanal7.py\n--- a/src/streamlink/plugins/kanal7.py\n+++ b/src/streamlink/plugins/kanal7.py\n@@ -11,7 +11,7 @@\n class Kanal7(Plugin):\n url_re = re.compile(r\"https?://(?:www.)?kanal7.com/canli-izle\")\n iframe_re = re.compile(r'iframe .*?src=\"(http://[^\"]*?)\"')\n- stream_re = re.compile(r'src=\"(http[^\"]*?)\"')\n+ stream_re = re.compile(r'''tp_file\\s+=\\s+['\"](http[^\"]*?)['\"]''')\n \n @classmethod\n def can_handle_url(cls, url):\n", "issue": "Kanal7 Defective again\nOnly 2 months later they have changed the design.\r\n\r\nNot opening with latest 0.9.0 Release:\r\n\r\n[cli][info] Found matching plugin kanal7 for URL http://www.kanal7.com/canli-izle\r\nerror: No playable streams found on this URL: http://www.kanal7.com/canli-izle\n", "before_files": [{"content": "from __future__ import print_function\nimport re\n\nfrom streamlink.plugin import Plugin\nfrom streamlink.plugin.api import http\nfrom streamlink.plugin.api import useragents\nfrom streamlink.plugin.api import validate\nfrom streamlink.stream import HLSStream\n\n\nclass Kanal7(Plugin):\n url_re = re.compile(r\"https?://(?:www.)?kanal7.com/canli-izle\")\n iframe_re = re.compile(r'iframe .*?src=\"(http://[^\"]*?)\"')\n stream_re = re.compile(r'src=\"(http[^\"]*?)\"')\n\n @classmethod\n def can_handle_url(cls, url):\n return cls.url_re.match(url) is not None\n\n def find_iframe(self, url):\n res = http.get(url)\n # find iframe url\n iframe = self.iframe_re.search(res.text)\n iframe_url = iframe and iframe.group(1)\n if iframe_url:\n self.logger.debug(\"Found iframe: {}\", iframe_url)\n return iframe_url\n\n def _get_streams(self):\n iframe1 = self.find_iframe(self.url)\n if iframe1:\n iframe2 = self.find_iframe(iframe1)\n if iframe2:\n ires = http.get(iframe2)\n stream_m = self.stream_re.search(ires.text)\n stream_url = stream_m and stream_m.group(1)\n if stream_url:\n yield \"live\", HLSStream(self.session, stream_url, headers={\"Referer\": iframe2})\n else:\n self.logger.error(\"Could not find second iframe, has the page layout changed?\")\n else:\n self.logger.error(\"Could not find iframe, has the page layout changed?\")\n\n\n__plugin__ = Kanal7\n", "path": "src/streamlink/plugins/kanal7.py"}], "after_files": [{"content": "from __future__ import print_function\nimport re\n\nfrom streamlink.plugin import Plugin\nfrom streamlink.plugin.api import http\nfrom streamlink.plugin.api import useragents\nfrom streamlink.plugin.api import validate\nfrom streamlink.stream import HLSStream\n\n\nclass Kanal7(Plugin):\n url_re = re.compile(r\"https?://(?:www.)?kanal7.com/canli-izle\")\n iframe_re = re.compile(r'iframe .*?src=\"(http://[^\"]*?)\"')\n stream_re = re.compile(r'''tp_file\\s+=\\s+['\"](http[^\"]*?)['\"]''')\n\n @classmethod\n def can_handle_url(cls, url):\n return cls.url_re.match(url) is not None\n\n def find_iframe(self, url):\n res = http.get(url)\n # find iframe url\n iframe = self.iframe_re.search(res.text)\n iframe_url = iframe and iframe.group(1)\n if iframe_url:\n self.logger.debug(\"Found iframe: {}\", iframe_url)\n return iframe_url\n\n def _get_streams(self):\n iframe1 = self.find_iframe(self.url)\n if iframe1:\n iframe2 = self.find_iframe(iframe1)\n if iframe2:\n ires = http.get(iframe2)\n stream_m = self.stream_re.search(ires.text)\n stream_url = stream_m and stream_m.group(1)\n if stream_url:\n yield \"live\", HLSStream(self.session, stream_url, headers={\"Referer\": iframe2})\n else:\n self.logger.error(\"Could not find second iframe, has the page layout changed?\")\n else:\n self.logger.error(\"Could not find iframe, has the page layout changed?\")\n\n\n__plugin__ = Kanal7\n", "path": "src/streamlink/plugins/kanal7.py"}]}
| 795 | 172 |
gh_patches_debug_41012
|
rasdani/github-patches
|
git_diff
|
cornellius-gp__gpytorch-1468
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Docs] Missing Grid.py documentation
# 📚 Documentation/Examples
** Is there documentation missing? **
The utils section of [GPyTorch documentation](https://gpytorch.readthedocs.io) does not include any information on grid.py, which is referenced [elsewhere in the docs](https://docs.gpytorch.ai/en/stable/kernels.html?highlight=choose_grid_size#gpytorch.kernels.GridKernel.update_grid).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `gpytorch/utils/grid.py`
Content:
```
1 #!/usr/bin/env python3
2
3 import math
4 from typing import List, Tuple
5
6 import torch
7
8
9 def scale_to_bounds(x, lower_bound, upper_bound):
10 """
11 Scale the input data so that it lies in between the lower and upper bounds.
12
13 Args:
14 :attr:`x` (Tensor `n` or `b x n`):
15 the input
16 :attr:`lower_bound` (float)
17 :attr:`upper_bound` (float)
18
19 Returns:
20 :obj:`torch.Tensor`
21 """
22 # Scale features so they fit inside grid bounds
23 min_val = x.min()
24 max_val = x.max()
25 diff = max_val - min_val
26 x = (x - min_val) * (0.95 * (upper_bound - lower_bound) / diff) + 0.95 * lower_bound
27 return x
28
29
30 def choose_grid_size(train_inputs, ratio=1.0, kronecker_structure=True):
31 """
32 Given some training inputs, determine a good grid size for KISS-GP.
33
34 Args:
35 :attr:`train_inputs` (Tensor `n` or `n x d` or `b x n x d`):
36 training data
37 :attr:`ratio` (float, optional):
38 Ratio - number of grid points to the amount of data (default: 1.)
39 :attr:`kronecker_structure` (bool, default=True):
40 Whether or not the model will use Kronecker structure in the grid
41 (set to True unless there is an additive or product decomposition in the prior)
42
43 Returns:
44 :obj:`int`
45 """
46 # Scale features so they fit inside grid bounds
47 num_data = train_inputs.numel() if train_inputs.dim() == 1 else train_inputs.size(-2)
48 num_dim = 1 if train_inputs.dim() == 1 else train_inputs.size(-1)
49 if kronecker_structure:
50 return int(ratio * math.pow(num_data, 1.0 / num_dim))
51 else:
52 return ratio * num_data
53
54
55 def convert_legacy_grid(grid: torch.Tensor) -> List[torch.Tensor]:
56 return [grid[:, i] for i in range(grid.size(-1))]
57
58
59 def create_data_from_grid(grid: List[torch.Tensor]) -> torch.Tensor:
60 """
61 Args:
62 :attr:`grid` (List[Tensor])
63 Each Tensor is a 1D set of increments for the grid in that dimension
64 Returns:
65 `grid_data` (Tensor)
66 Returns the set of points on the grid going by column-major order
67 (due to legacy reasons).
68 """
69 if torch.is_tensor(grid):
70 grid = convert_legacy_grid(grid)
71 ndims = len(grid)
72 assert all(axis.dim() == 1 for axis in grid)
73 projections = torch.meshgrid(*grid)
74 grid_tensor = torch.stack(projections, axis=-1)
75 # Note that if we did
76 # grid_data = grid_tensor.reshape(-1, ndims)
77 # instead, we would be iterating through the points of our grid from the
78 # last data dimension to the first data dimension. However, due to legacy
79 # reasons, we need to iterate from the first data dimension to the last data
80 # dimension when creating grid_data
81 grid_data = grid_tensor.permute(*(reversed(range(ndims + 1)))).reshape(ndims, -1).transpose(0, 1)
82 return grid_data
83
84
85 def create_grid(
86 grid_sizes: List[int], grid_bounds: List[Tuple[float, float]], extend: bool = True, device="cpu", dtype=torch.float,
87 ) -> List[torch.Tensor]:
88 """
89 Creates a grid represented by a list of 1D Tensors representing the
90 projections of the grid into each dimension
91
92 If `extend`, we extend the grid by two points past the specified boundary
93 which can be important for getting good grid interpolations
94 """
95 grid = []
96 for i in range(len(grid_bounds)):
97 grid_diff = float(grid_bounds[i][1] - grid_bounds[i][0]) / (grid_sizes[i] - 2)
98 if extend:
99 proj = torch.linspace(
100 grid_bounds[i][0] - grid_diff, grid_bounds[i][1] + grid_diff, grid_sizes[i], device=device, dtype=dtype,
101 )
102 else:
103 proj = torch.linspace(grid_bounds[i][0], grid_bounds[i][1], grid_sizes[i], device=device, dtype=dtype,)
104 grid.append(proj)
105 return grid
106
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/gpytorch/utils/grid.py b/gpytorch/utils/grid.py
--- a/gpytorch/utils/grid.py
+++ b/gpytorch/utils/grid.py
@@ -10,14 +10,12 @@
"""
Scale the input data so that it lies in between the lower and upper bounds.
- Args:
- :attr:`x` (Tensor `n` or `b x n`):
- the input
- :attr:`lower_bound` (float)
- :attr:`upper_bound` (float)
-
- Returns:
- :obj:`torch.Tensor`
+ :param x: the input data
+ :type x: torch.Tensor (... x n x d)
+ :param float lower_bound: lower bound of scaled data
+ :param float upper_bound: upper bound of scaled data
+ :return: scaled data
+ :rtype: torch.Tensor (... x n x d)
"""
# Scale features so they fit inside grid bounds
min_val = x.min()
@@ -31,17 +29,15 @@
"""
Given some training inputs, determine a good grid size for KISS-GP.
- Args:
- :attr:`train_inputs` (Tensor `n` or `n x d` or `b x n x d`):
- training data
- :attr:`ratio` (float, optional):
- Ratio - number of grid points to the amount of data (default: 1.)
- :attr:`kronecker_structure` (bool, default=True):
- Whether or not the model will use Kronecker structure in the grid
- (set to True unless there is an additive or product decomposition in the prior)
-
- Returns:
- :obj:`int`
+ :param x: the input data
+ :type x: torch.Tensor (... x n x d)
+ :param ratio: Amount of grid points per data point (default: 1.)
+ :type ratio: float, optional
+ :param kronecker_structure: Whether or not the model will use Kronecker structure in the grid
+ (set to True unless there is an additive or product decomposition in the prior)
+ :type kronecker_structure: bool, optional
+ :return: Grid size
+ :rtype: int
"""
# Scale features so they fit inside grid bounds
num_data = train_inputs.numel() if train_inputs.dim() == 1 else train_inputs.size(-2)
@@ -58,13 +54,10 @@
def create_data_from_grid(grid: List[torch.Tensor]) -> torch.Tensor:
"""
- Args:
- :attr:`grid` (List[Tensor])
- Each Tensor is a 1D set of increments for the grid in that dimension
- Returns:
- `grid_data` (Tensor)
- Returns the set of points on the grid going by column-major order
- (due to legacy reasons).
+ :param grid: Each Tensor is a 1D set of increments for the grid in that dimension
+ :type grid: List[torch.Tensor]
+ :return: The set of points on the grid going by column-major order
+ :rtype: torch.Tensor
"""
if torch.is_tensor(grid):
grid = convert_legacy_grid(grid)
@@ -90,7 +83,18 @@
projections of the grid into each dimension
If `extend`, we extend the grid by two points past the specified boundary
- which can be important for getting good grid interpolations
+ which can be important for getting good grid interpolations.
+
+ :param grid_sizes: Sizes of each grid dimension
+ :type grid_sizes: List[int]
+ :param grid_bounds: Lower and upper bounds of each grid dimension
+ :type grid_sizes: List[Tuple[float, float]]
+ :param device: target device for output (default: cpu)
+ :type device: torch.device, optional
+ :param dtype: target dtype for output (default: torch.float)
+ :type dtype: torch.dtype, optional
+ :return: Grid points for each dimension. Grid points are stored in a :obj:`torch.Tensor` with shape `grid_sizes[i]`.
+ :rtype: List[torch.Tensor]
"""
grid = []
for i in range(len(grid_bounds)):
|
{"golden_diff": "diff --git a/gpytorch/utils/grid.py b/gpytorch/utils/grid.py\n--- a/gpytorch/utils/grid.py\n+++ b/gpytorch/utils/grid.py\n@@ -10,14 +10,12 @@\n \"\"\"\n Scale the input data so that it lies in between the lower and upper bounds.\n \n- Args:\n- :attr:`x` (Tensor `n` or `b x n`):\n- the input\n- :attr:`lower_bound` (float)\n- :attr:`upper_bound` (float)\n-\n- Returns:\n- :obj:`torch.Tensor`\n+ :param x: the input data\n+ :type x: torch.Tensor (... x n x d)\n+ :param float lower_bound: lower bound of scaled data\n+ :param float upper_bound: upper bound of scaled data\n+ :return: scaled data\n+ :rtype: torch.Tensor (... x n x d)\n \"\"\"\n # Scale features so they fit inside grid bounds\n min_val = x.min()\n@@ -31,17 +29,15 @@\n \"\"\"\n Given some training inputs, determine a good grid size for KISS-GP.\n \n- Args:\n- :attr:`train_inputs` (Tensor `n` or `n x d` or `b x n x d`):\n- training data\n- :attr:`ratio` (float, optional):\n- Ratio - number of grid points to the amount of data (default: 1.)\n- :attr:`kronecker_structure` (bool, default=True):\n- Whether or not the model will use Kronecker structure in the grid\n- (set to True unless there is an additive or product decomposition in the prior)\n-\n- Returns:\n- :obj:`int`\n+ :param x: the input data\n+ :type x: torch.Tensor (... x n x d)\n+ :param ratio: Amount of grid points per data point (default: 1.)\n+ :type ratio: float, optional\n+ :param kronecker_structure: Whether or not the model will use Kronecker structure in the grid\n+ (set to True unless there is an additive or product decomposition in the prior)\n+ :type kronecker_structure: bool, optional\n+ :return: Grid size\n+ :rtype: int\n \"\"\"\n # Scale features so they fit inside grid bounds\n num_data = train_inputs.numel() if train_inputs.dim() == 1 else train_inputs.size(-2)\n@@ -58,13 +54,10 @@\n \n def create_data_from_grid(grid: List[torch.Tensor]) -> torch.Tensor:\n \"\"\"\n- Args:\n- :attr:`grid` (List[Tensor])\n- Each Tensor is a 1D set of increments for the grid in that dimension\n- Returns:\n- `grid_data` (Tensor)\n- Returns the set of points on the grid going by column-major order\n- (due to legacy reasons).\n+ :param grid: Each Tensor is a 1D set of increments for the grid in that dimension\n+ :type grid: List[torch.Tensor]\n+ :return: The set of points on the grid going by column-major order\n+ :rtype: torch.Tensor\n \"\"\"\n if torch.is_tensor(grid):\n grid = convert_legacy_grid(grid)\n@@ -90,7 +83,18 @@\n projections of the grid into each dimension\n \n If `extend`, we extend the grid by two points past the specified boundary\n- which can be important for getting good grid interpolations\n+ which can be important for getting good grid interpolations.\n+\n+ :param grid_sizes: Sizes of each grid dimension\n+ :type grid_sizes: List[int]\n+ :param grid_bounds: Lower and upper bounds of each grid dimension\n+ :type grid_sizes: List[Tuple[float, float]]\n+ :param device: target device for output (default: cpu)\n+ :type device: torch.device, optional\n+ :param dtype: target dtype for output (default: torch.float)\n+ :type dtype: torch.dtype, optional\n+ :return: Grid points for each dimension. Grid points are stored in a :obj:`torch.Tensor` with shape `grid_sizes[i]`.\n+ :rtype: List[torch.Tensor]\n \"\"\"\n grid = []\n for i in range(len(grid_bounds)):\n", "issue": "[Docs] Missing Grid.py documentation\n# \ud83d\udcda Documentation/Examples\r\n\r\n** Is there documentation missing? **\r\nThe utils section of [GPyTorch documentation](https://gpytorch.readthedocs.io) does not include any information on grid.py, which is referenced [elsewhere in the docs](https://docs.gpytorch.ai/en/stable/kernels.html?highlight=choose_grid_size#gpytorch.kernels.GridKernel.update_grid).\r\n\n", "before_files": [{"content": "#!/usr/bin/env python3\n\nimport math\nfrom typing import List, Tuple\n\nimport torch\n\n\ndef scale_to_bounds(x, lower_bound, upper_bound):\n \"\"\"\n Scale the input data so that it lies in between the lower and upper bounds.\n\n Args:\n :attr:`x` (Tensor `n` or `b x n`):\n the input\n :attr:`lower_bound` (float)\n :attr:`upper_bound` (float)\n\n Returns:\n :obj:`torch.Tensor`\n \"\"\"\n # Scale features so they fit inside grid bounds\n min_val = x.min()\n max_val = x.max()\n diff = max_val - min_val\n x = (x - min_val) * (0.95 * (upper_bound - lower_bound) / diff) + 0.95 * lower_bound\n return x\n\n\ndef choose_grid_size(train_inputs, ratio=1.0, kronecker_structure=True):\n \"\"\"\n Given some training inputs, determine a good grid size for KISS-GP.\n\n Args:\n :attr:`train_inputs` (Tensor `n` or `n x d` or `b x n x d`):\n training data\n :attr:`ratio` (float, optional):\n Ratio - number of grid points to the amount of data (default: 1.)\n :attr:`kronecker_structure` (bool, default=True):\n Whether or not the model will use Kronecker structure in the grid\n (set to True unless there is an additive or product decomposition in the prior)\n\n Returns:\n :obj:`int`\n \"\"\"\n # Scale features so they fit inside grid bounds\n num_data = train_inputs.numel() if train_inputs.dim() == 1 else train_inputs.size(-2)\n num_dim = 1 if train_inputs.dim() == 1 else train_inputs.size(-1)\n if kronecker_structure:\n return int(ratio * math.pow(num_data, 1.0 / num_dim))\n else:\n return ratio * num_data\n\n\ndef convert_legacy_grid(grid: torch.Tensor) -> List[torch.Tensor]:\n return [grid[:, i] for i in range(grid.size(-1))]\n\n\ndef create_data_from_grid(grid: List[torch.Tensor]) -> torch.Tensor:\n \"\"\"\n Args:\n :attr:`grid` (List[Tensor])\n Each Tensor is a 1D set of increments for the grid in that dimension\n Returns:\n `grid_data` (Tensor)\n Returns the set of points on the grid going by column-major order\n (due to legacy reasons).\n \"\"\"\n if torch.is_tensor(grid):\n grid = convert_legacy_grid(grid)\n ndims = len(grid)\n assert all(axis.dim() == 1 for axis in grid)\n projections = torch.meshgrid(*grid)\n grid_tensor = torch.stack(projections, axis=-1)\n # Note that if we did\n # grid_data = grid_tensor.reshape(-1, ndims)\n # instead, we would be iterating through the points of our grid from the\n # last data dimension to the first data dimension. However, due to legacy\n # reasons, we need to iterate from the first data dimension to the last data\n # dimension when creating grid_data\n grid_data = grid_tensor.permute(*(reversed(range(ndims + 1)))).reshape(ndims, -1).transpose(0, 1)\n return grid_data\n\n\ndef create_grid(\n grid_sizes: List[int], grid_bounds: List[Tuple[float, float]], extend: bool = True, device=\"cpu\", dtype=torch.float,\n) -> List[torch.Tensor]:\n \"\"\"\n Creates a grid represented by a list of 1D Tensors representing the\n projections of the grid into each dimension\n\n If `extend`, we extend the grid by two points past the specified boundary\n which can be important for getting good grid interpolations\n \"\"\"\n grid = []\n for i in range(len(grid_bounds)):\n grid_diff = float(grid_bounds[i][1] - grid_bounds[i][0]) / (grid_sizes[i] - 2)\n if extend:\n proj = torch.linspace(\n grid_bounds[i][0] - grid_diff, grid_bounds[i][1] + grid_diff, grid_sizes[i], device=device, dtype=dtype,\n )\n else:\n proj = torch.linspace(grid_bounds[i][0], grid_bounds[i][1], grid_sizes[i], device=device, dtype=dtype,)\n grid.append(proj)\n return grid\n", "path": "gpytorch/utils/grid.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n\nimport math\nfrom typing import List, Tuple\n\nimport torch\n\n\ndef scale_to_bounds(x, lower_bound, upper_bound):\n \"\"\"\n Scale the input data so that it lies in between the lower and upper bounds.\n\n :param x: the input data\n :type x: torch.Tensor (... x n x d)\n :param float lower_bound: lower bound of scaled data\n :param float upper_bound: upper bound of scaled data\n :return: scaled data\n :rtype: torch.Tensor (... x n x d)\n \"\"\"\n # Scale features so they fit inside grid bounds\n min_val = x.min()\n max_val = x.max()\n diff = max_val - min_val\n x = (x - min_val) * (0.95 * (upper_bound - lower_bound) / diff) + 0.95 * lower_bound\n return x\n\n\ndef choose_grid_size(train_inputs, ratio=1.0, kronecker_structure=True):\n \"\"\"\n Given some training inputs, determine a good grid size for KISS-GP.\n\n :param x: the input data\n :type x: torch.Tensor (... x n x d)\n :param ratio: Amount of grid points per data point (default: 1.)\n :type ratio: float, optional\n :param kronecker_structure: Whether or not the model will use Kronecker structure in the grid\n (set to True unless there is an additive or product decomposition in the prior)\n :type kronecker_structure: bool, optional\n :return: Grid size\n :rtype: int\n \"\"\"\n # Scale features so they fit inside grid bounds\n num_data = train_inputs.numel() if train_inputs.dim() == 1 else train_inputs.size(-2)\n num_dim = 1 if train_inputs.dim() == 1 else train_inputs.size(-1)\n if kronecker_structure:\n return int(ratio * math.pow(num_data, 1.0 / num_dim))\n else:\n return ratio * num_data\n\n\ndef convert_legacy_grid(grid: torch.Tensor) -> List[torch.Tensor]:\n return [grid[:, i] for i in range(grid.size(-1))]\n\n\ndef create_data_from_grid(grid: List[torch.Tensor]) -> torch.Tensor:\n \"\"\"\n :param grid: Each Tensor is a 1D set of increments for the grid in that dimension\n :type grid: List[torch.Tensor]\n :return: The set of points on the grid going by column-major order\n :rtype: torch.Tensor\n \"\"\"\n if torch.is_tensor(grid):\n grid = convert_legacy_grid(grid)\n ndims = len(grid)\n assert all(axis.dim() == 1 for axis in grid)\n projections = torch.meshgrid(*grid)\n grid_tensor = torch.stack(projections, axis=-1)\n # Note that if we did\n # grid_data = grid_tensor.reshape(-1, ndims)\n # instead, we would be iterating through the points of our grid from the\n # last data dimension to the first data dimension. However, due to legacy\n # reasons, we need to iterate from the first data dimension to the last data\n # dimension when creating grid_data\n grid_data = grid_tensor.permute(*(reversed(range(ndims + 1)))).reshape(ndims, -1).transpose(0, 1)\n return grid_data\n\n\ndef create_grid(\n grid_sizes: List[int], grid_bounds: List[Tuple[float, float]], extend: bool = True, device=\"cpu\", dtype=torch.float,\n) -> List[torch.Tensor]:\n \"\"\"\n Creates a grid represented by a list of 1D Tensors representing the\n projections of the grid into each dimension\n\n If `extend`, we extend the grid by two points past the specified boundary\n which can be important for getting good grid interpolations.\n\n :param grid_sizes: Sizes of each grid dimension\n :type grid_sizes: List[int]\n :param grid_bounds: Lower and upper bounds of each grid dimension\n :type grid_sizes: List[Tuple[float, float]]\n :param device: target device for output (default: cpu)\n :type device: torch.device, optional\n :param dtype: target dtype for output (default: torch.float)\n :type dtype: torch.dtype, optional\n :return: Grid points for each dimension. Grid points are stored in a :obj:`torch.Tensor` with shape `grid_sizes[i]`.\n :rtype: List[torch.Tensor]\n \"\"\"\n grid = []\n for i in range(len(grid_bounds)):\n grid_diff = float(grid_bounds[i][1] - grid_bounds[i][0]) / (grid_sizes[i] - 2)\n if extend:\n proj = torch.linspace(\n grid_bounds[i][0] - grid_diff, grid_bounds[i][1] + grid_diff, grid_sizes[i], device=device, dtype=dtype,\n )\n else:\n proj = torch.linspace(grid_bounds[i][0], grid_bounds[i][1], grid_sizes[i], device=device, dtype=dtype,)\n grid.append(proj)\n return grid\n", "path": "gpytorch/utils/grid.py"}]}
| 1,538 | 961 |
gh_patches_debug_18841
|
rasdani/github-patches
|
git_diff
|
unionai-oss__pandera-681
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Nullable pandas BooleanDtype should be exposed as `pandera.typing.BOOL`
**Is your feature request related to a problem? Please describe.**
A clear and concise description of what the problem is.
Other nullable types are exposed, eg as `P.INT64`, or `P.STRING`.
`P.BOOL` is missing, even though it is defined.
**Describe the solution you'd like**
A clear and concise description of what you want to happen.
`BOOL` is already defined, so it should be aliased in typing/common.py as
```py
BOOL = pandas_engine.BOOL
```
and added to `GenericDtype` in the same file, then imported again in `typing/__init__.py` to expose it like other generic types.
**Describe alternatives you've considered**
A clear and concise description of any alternative solutions or features you've considered.
We had been using `P.Series[pd.BooleanDtype]`, but this appears not to be prefered in v0.8.0
**Additional context**
Add any other context or screenshots about the feature request here.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pandera/typing/common.py`
Content:
```
1 """Common typing functionality."""
2 # pylint:disable=abstract-method,disable=too-many-ancestors
3
4 import inspect
5 from typing import TYPE_CHECKING, Any, Generic, Type, TypeVar
6
7 import pandas as pd
8 import typing_inspect
9
10 from .. import dtypes
11 from ..engines import numpy_engine, pandas_engine
12
13 Bool = dtypes.Bool #: ``"bool"`` numpy dtype
14 DateTime = dtypes.DateTime #: ``"datetime64[ns]"`` numpy dtype
15 Timedelta = dtypes.Timedelta #: ``"timedelta64[ns]"`` numpy dtype
16 Category = dtypes.Category #: pandas ``"categorical"`` datatype
17 Float = dtypes.Float #: ``"float"`` numpy dtype
18 Float16 = dtypes.Float16 #: ``"float16"`` numpy dtype
19 Float32 = dtypes.Float32 #: ``"float32"`` numpy dtype
20 Float64 = dtypes.Float64 #: ``"float64"`` numpy dtype
21 Int = dtypes.Int #: ``"int"`` numpy dtype
22 Int8 = dtypes.Int8 #: ``"int8"`` numpy dtype
23 Int16 = dtypes.Int16 #: ``"int16"`` numpy dtype
24 Int32 = dtypes.Int32 #: ``"int32"`` numpy dtype
25 Int64 = dtypes.Int64 #: ``"int64"`` numpy dtype
26 UInt8 = dtypes.UInt8 #: ``"uint8"`` numpy dtype
27 UInt16 = dtypes.UInt16 #: ``"uint16"`` numpy dtype
28 UInt32 = dtypes.UInt32 #: ``"uint32"`` numpy dtype
29 UInt64 = dtypes.UInt64 #: ``"uint64"`` numpy dtype
30 INT8 = pandas_engine.INT8 #: ``"Int8"`` pandas dtype:: pandas 0.24.0+
31 INT16 = pandas_engine.INT16 #: ``"Int16"`` pandas dtype: pandas 0.24.0+
32 INT32 = pandas_engine.INT32 #: ``"Int32"`` pandas dtype: pandas 0.24.0+
33 INT64 = pandas_engine.INT64 #: ``"Int64"`` pandas dtype: pandas 0.24.0+
34 UINT8 = pandas_engine.UINT8 #: ``"UInt8"`` pandas dtype:: pandas 0.24.0+
35 UINT16 = pandas_engine.UINT16 #: ``"UInt16"`` pandas dtype: pandas 0.24.0+
36 UINT32 = pandas_engine.UINT32 #: ``"UInt32"`` pandas dtype: pandas 0.24.0+
37 UINT64 = pandas_engine.UINT64 #: ``"UInt64"`` pandas dtype: pandas 0.24.0+
38 Object = numpy_engine.Object #: ``"object"`` numpy dtype
39 String = dtypes.String #: ``"str"`` numpy dtype
40 #: ``"string"`` pandas dtypes: pandas 1.0.0+. For <1.0.0, this enum will
41 #: fall back on the str-as-object-array representation.
42 STRING = pandas_engine.STRING #: ``"str"`` numpy dtype
43
44 GenericDtype = TypeVar( # type: ignore
45 "GenericDtype",
46 bool,
47 int,
48 str,
49 float,
50 pd.core.dtypes.base.ExtensionDtype,
51 Bool,
52 DateTime,
53 Timedelta,
54 Category,
55 Float,
56 Float16,
57 Float32,
58 Float64,
59 Int,
60 Int8,
61 Int16,
62 Int32,
63 Int64,
64 UInt8,
65 UInt16,
66 UInt32,
67 UInt64,
68 INT8,
69 INT16,
70 INT32,
71 INT64,
72 UINT8,
73 UINT16,
74 UINT32,
75 UINT64,
76 Object,
77 String,
78 STRING,
79 covariant=True,
80 )
81 Schema = TypeVar("Schema", bound="SchemaModel") # type: ignore
82
83
84 # pylint:disable=invalid-name
85 if TYPE_CHECKING:
86 T = TypeVar("T") # pragma: no cover
87 else:
88 T = Schema
89
90
91 class DataFrameBase(Generic[T]):
92 # pylint: disable=too-few-public-methods
93 """
94 Pandera Dataframe base class for validating dataframes on
95 initialization.
96 """
97
98 def __setattr__(self, name: str, value: Any) -> None:
99 # pylint: disable=no-member
100 object.__setattr__(self, name, value)
101 if name == "__orig_class__":
102 orig_class = getattr(self, "__orig_class__")
103 class_args = getattr(orig_class, "__args__", None)
104 if any(
105 x.__name__ == "SchemaModel"
106 for x in inspect.getmro(class_args[0])
107 ):
108 schema_model = value.__args__[0]
109
110 # prevent the double validation problem by preventing checks for
111 # dataframes with a defined pandera.schema
112 pandera = getattr(self, "pandera")
113 if (
114 pandera.schema is None
115 or pandera.schema != schema_model.to_schema()
116 ):
117 # pylint: disable=self-cls-assignment
118 self = schema_model.validate(self)
119 pandera.add_schema(schema_model.to_schema())
120
121
122 # pylint:disable=too-few-public-methods
123 class SeriesBase(Generic[GenericDtype]):
124 """Pandera Series base class to use for all pandas-like APIs."""
125
126 def __get__(
127 self, instance: object, owner: Type
128 ) -> str: # pragma: no cover
129 raise AttributeError("Series should resolve to Field-s")
130
131
132 # pylint:disable=too-few-public-methods
133 class IndexBase(Generic[GenericDtype]):
134 """Representation of pandas.Index, only used for type annotation.
135
136 *new in 0.5.0*
137 """
138
139
140 class AnnotationInfo: # pylint:disable=too-few-public-methods
141 """Captures extra information about an annotation.
142
143 Attributes:
144 origin: The non-parameterized generic class.
145 arg: The first generic type (SchemaModel does not support more than
146 1 argument).
147 literal: Whether the annotation is a literal.
148 optional: Whether the annotation is optional.
149 raw_annotation: The raw annotation.
150 metadata: Extra arguments passed to :data:`typing.Annotated`.
151 """
152
153 def __init__(self, raw_annotation: Type) -> None:
154 self._parse_annotation(raw_annotation)
155
156 @property
157 def is_generic_df(self) -> bool:
158 """True if the annotation is a DataFrameBase subclass."""
159 try:
160 if self.origin is None:
161 return False
162 return issubclass(self.origin, DataFrameBase)
163 except TypeError:
164 return False
165
166 def _parse_annotation(self, raw_annotation: Type) -> None:
167 """Parse key information from annotation.
168
169 :param annotation: A subscripted type.
170 :returns: Annotation
171 """
172 self.raw_annotation = raw_annotation
173 self.origin = self.arg = None
174
175 self.optional = typing_inspect.is_optional_type(raw_annotation)
176 if self.optional and typing_inspect.is_union_type(raw_annotation):
177 # Annotated with Optional or Union[..., NoneType]
178 # get_args -> (pandera.typing.Index[str], <class 'NoneType'>)
179 raw_annotation = typing_inspect.get_args(raw_annotation)[0]
180
181 self.origin = typing_inspect.get_origin(raw_annotation)
182 # Replace empty tuple returned from get_args by None
183 args = typing_inspect.get_args(raw_annotation) or None
184 self.arg = args[0] if args else args
185
186 self.metadata = getattr(self.arg, "__metadata__", None)
187 if self.metadata:
188 self.arg = typing_inspect.get_args(self.arg)[0]
189
190 self.literal = typing_inspect.is_literal_type(self.arg)
191 if self.literal:
192 self.arg = typing_inspect.get_args(self.arg)[0]
193
```
Path: `pandera/typing/__init__.py`
Content:
```
1 """Typing module.
2
3 For backwards compatibility, pandas types are exposed to the top-level scope of
4 the typing module.
5 """
6
7 from . import dask, koalas, modin
8 from .common import (
9 INT8,
10 INT16,
11 INT32,
12 INT64,
13 STRING,
14 UINT8,
15 UINT16,
16 UINT32,
17 UINT64,
18 AnnotationInfo,
19 Bool,
20 Category,
21 DateTime,
22 Float,
23 Float16,
24 Float32,
25 Float64,
26 Int,
27 Int8,
28 Int16,
29 Int32,
30 Int64,
31 Object,
32 String,
33 Timedelta,
34 UInt8,
35 UInt16,
36 UInt32,
37 UInt64,
38 )
39 from .pandas import DataFrame, Index, Series
40
41 DATAFRAME_TYPES = {DataFrame}
42 SERIES_TYPES = {Series}
43 INDEX_TYPES = {Index}
44
45 if dask.DASK_INSTALLED:
46 DATAFRAME_TYPES.update({dask.DataFrame})
47 SERIES_TYPES.update({dask.Series})
48 INDEX_TYPES.update({dask.Index})
49
50 if modin.MODIN_INSTALLED:
51 DATAFRAME_TYPES.update({modin.DataFrame})
52 SERIES_TYPES.update({modin.Series})
53 INDEX_TYPES.update({modin.Index})
54
55 if koalas.KOALAS_INSTALLED:
56 DATAFRAME_TYPES.update({koalas.DataFrame})
57 SERIES_TYPES.update({koalas.Series})
58 INDEX_TYPES.update({koalas.Index})
59
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pandera/typing/__init__.py b/pandera/typing/__init__.py
--- a/pandera/typing/__init__.py
+++ b/pandera/typing/__init__.py
@@ -6,6 +6,7 @@
from . import dask, koalas, modin
from .common import (
+ BOOL,
INT8,
INT16,
INT32,
diff --git a/pandera/typing/common.py b/pandera/typing/common.py
--- a/pandera/typing/common.py
+++ b/pandera/typing/common.py
@@ -40,6 +40,7 @@
#: ``"string"`` pandas dtypes: pandas 1.0.0+. For <1.0.0, this enum will
#: fall back on the str-as-object-array representation.
STRING = pandas_engine.STRING #: ``"str"`` numpy dtype
+BOOL = pandas_engine.BOOL #: ``"str"`` numpy dtype
GenericDtype = TypeVar( # type: ignore
"GenericDtype",
@@ -76,6 +77,7 @@
Object,
String,
STRING,
+ BOOL,
covariant=True,
)
Schema = TypeVar("Schema", bound="SchemaModel") # type: ignore
|
{"golden_diff": "diff --git a/pandera/typing/__init__.py b/pandera/typing/__init__.py\n--- a/pandera/typing/__init__.py\n+++ b/pandera/typing/__init__.py\n@@ -6,6 +6,7 @@\n \n from . import dask, koalas, modin\n from .common import (\n+ BOOL,\n INT8,\n INT16,\n INT32,\ndiff --git a/pandera/typing/common.py b/pandera/typing/common.py\n--- a/pandera/typing/common.py\n+++ b/pandera/typing/common.py\n@@ -40,6 +40,7 @@\n #: ``\"string\"`` pandas dtypes: pandas 1.0.0+. For <1.0.0, this enum will\n #: fall back on the str-as-object-array representation.\n STRING = pandas_engine.STRING #: ``\"str\"`` numpy dtype\n+BOOL = pandas_engine.BOOL #: ``\"str\"`` numpy dtype\n \n GenericDtype = TypeVar( # type: ignore\n \"GenericDtype\",\n@@ -76,6 +77,7 @@\n Object,\n String,\n STRING,\n+ BOOL,\n covariant=True,\n )\n Schema = TypeVar(\"Schema\", bound=\"SchemaModel\") # type: ignore\n", "issue": "Nullable pandas BooleanDtype should be exposed as `pandera.typing.BOOL`\n**Is your feature request related to a problem? Please describe.**\r\nA clear and concise description of what the problem is.\r\n\r\nOther nullable types are exposed, eg as `P.INT64`, or `P.STRING`. \r\n\r\n`P.BOOL` is missing, even though it is defined.\r\n\r\n**Describe the solution you'd like**\r\nA clear and concise description of what you want to happen.\r\n\r\n`BOOL` is already defined, so it should be aliased in typing/common.py as \r\n\r\n```py \r\nBOOL = pandas_engine.BOOL\r\n```\r\nand added to `GenericDtype` in the same file, then imported again in `typing/__init__.py` to expose it like other generic types.\r\n\r\n**Describe alternatives you've considered**\r\nA clear and concise description of any alternative solutions or features you've considered.\r\n\r\nWe had been using `P.Series[pd.BooleanDtype]`, but this appears not to be prefered in v0.8.0\r\n\r\n**Additional context**\r\nAdd any other context or screenshots about the feature request here.\r\n\n", "before_files": [{"content": "\"\"\"Common typing functionality.\"\"\"\n# pylint:disable=abstract-method,disable=too-many-ancestors\n\nimport inspect\nfrom typing import TYPE_CHECKING, Any, Generic, Type, TypeVar\n\nimport pandas as pd\nimport typing_inspect\n\nfrom .. import dtypes\nfrom ..engines import numpy_engine, pandas_engine\n\nBool = dtypes.Bool #: ``\"bool\"`` numpy dtype\nDateTime = dtypes.DateTime #: ``\"datetime64[ns]\"`` numpy dtype\nTimedelta = dtypes.Timedelta #: ``\"timedelta64[ns]\"`` numpy dtype\nCategory = dtypes.Category #: pandas ``\"categorical\"`` datatype\nFloat = dtypes.Float #: ``\"float\"`` numpy dtype\nFloat16 = dtypes.Float16 #: ``\"float16\"`` numpy dtype\nFloat32 = dtypes.Float32 #: ``\"float32\"`` numpy dtype\nFloat64 = dtypes.Float64 #: ``\"float64\"`` numpy dtype\nInt = dtypes.Int #: ``\"int\"`` numpy dtype\nInt8 = dtypes.Int8 #: ``\"int8\"`` numpy dtype\nInt16 = dtypes.Int16 #: ``\"int16\"`` numpy dtype\nInt32 = dtypes.Int32 #: ``\"int32\"`` numpy dtype\nInt64 = dtypes.Int64 #: ``\"int64\"`` numpy dtype\nUInt8 = dtypes.UInt8 #: ``\"uint8\"`` numpy dtype\nUInt16 = dtypes.UInt16 #: ``\"uint16\"`` numpy dtype\nUInt32 = dtypes.UInt32 #: ``\"uint32\"`` numpy dtype\nUInt64 = dtypes.UInt64 #: ``\"uint64\"`` numpy dtype\nINT8 = pandas_engine.INT8 #: ``\"Int8\"`` pandas dtype:: pandas 0.24.0+\nINT16 = pandas_engine.INT16 #: ``\"Int16\"`` pandas dtype: pandas 0.24.0+\nINT32 = pandas_engine.INT32 #: ``\"Int32\"`` pandas dtype: pandas 0.24.0+\nINT64 = pandas_engine.INT64 #: ``\"Int64\"`` pandas dtype: pandas 0.24.0+\nUINT8 = pandas_engine.UINT8 #: ``\"UInt8\"`` pandas dtype:: pandas 0.24.0+\nUINT16 = pandas_engine.UINT16 #: ``\"UInt16\"`` pandas dtype: pandas 0.24.0+\nUINT32 = pandas_engine.UINT32 #: ``\"UInt32\"`` pandas dtype: pandas 0.24.0+\nUINT64 = pandas_engine.UINT64 #: ``\"UInt64\"`` pandas dtype: pandas 0.24.0+\nObject = numpy_engine.Object #: ``\"object\"`` numpy dtype\nString = dtypes.String #: ``\"str\"`` numpy dtype\n#: ``\"string\"`` pandas dtypes: pandas 1.0.0+. For <1.0.0, this enum will\n#: fall back on the str-as-object-array representation.\nSTRING = pandas_engine.STRING #: ``\"str\"`` numpy dtype\n\nGenericDtype = TypeVar( # type: ignore\n \"GenericDtype\",\n bool,\n int,\n str,\n float,\n pd.core.dtypes.base.ExtensionDtype,\n Bool,\n DateTime,\n Timedelta,\n Category,\n Float,\n Float16,\n Float32,\n Float64,\n Int,\n Int8,\n Int16,\n Int32,\n Int64,\n UInt8,\n UInt16,\n UInt32,\n UInt64,\n INT8,\n INT16,\n INT32,\n INT64,\n UINT8,\n UINT16,\n UINT32,\n UINT64,\n Object,\n String,\n STRING,\n covariant=True,\n)\nSchema = TypeVar(\"Schema\", bound=\"SchemaModel\") # type: ignore\n\n\n# pylint:disable=invalid-name\nif TYPE_CHECKING:\n T = TypeVar(\"T\") # pragma: no cover\nelse:\n T = Schema\n\n\nclass DataFrameBase(Generic[T]):\n # pylint: disable=too-few-public-methods\n \"\"\"\n Pandera Dataframe base class for validating dataframes on\n initialization.\n \"\"\"\n\n def __setattr__(self, name: str, value: Any) -> None:\n # pylint: disable=no-member\n object.__setattr__(self, name, value)\n if name == \"__orig_class__\":\n orig_class = getattr(self, \"__orig_class__\")\n class_args = getattr(orig_class, \"__args__\", None)\n if any(\n x.__name__ == \"SchemaModel\"\n for x in inspect.getmro(class_args[0])\n ):\n schema_model = value.__args__[0]\n\n # prevent the double validation problem by preventing checks for\n # dataframes with a defined pandera.schema\n pandera = getattr(self, \"pandera\")\n if (\n pandera.schema is None\n or pandera.schema != schema_model.to_schema()\n ):\n # pylint: disable=self-cls-assignment\n self = schema_model.validate(self)\n pandera.add_schema(schema_model.to_schema())\n\n\n# pylint:disable=too-few-public-methods\nclass SeriesBase(Generic[GenericDtype]):\n \"\"\"Pandera Series base class to use for all pandas-like APIs.\"\"\"\n\n def __get__(\n self, instance: object, owner: Type\n ) -> str: # pragma: no cover\n raise AttributeError(\"Series should resolve to Field-s\")\n\n\n# pylint:disable=too-few-public-methods\nclass IndexBase(Generic[GenericDtype]):\n \"\"\"Representation of pandas.Index, only used for type annotation.\n\n *new in 0.5.0*\n \"\"\"\n\n\nclass AnnotationInfo: # pylint:disable=too-few-public-methods\n \"\"\"Captures extra information about an annotation.\n\n Attributes:\n origin: The non-parameterized generic class.\n arg: The first generic type (SchemaModel does not support more than\n 1 argument).\n literal: Whether the annotation is a literal.\n optional: Whether the annotation is optional.\n raw_annotation: The raw annotation.\n metadata: Extra arguments passed to :data:`typing.Annotated`.\n \"\"\"\n\n def __init__(self, raw_annotation: Type) -> None:\n self._parse_annotation(raw_annotation)\n\n @property\n def is_generic_df(self) -> bool:\n \"\"\"True if the annotation is a DataFrameBase subclass.\"\"\"\n try:\n if self.origin is None:\n return False\n return issubclass(self.origin, DataFrameBase)\n except TypeError:\n return False\n\n def _parse_annotation(self, raw_annotation: Type) -> None:\n \"\"\"Parse key information from annotation.\n\n :param annotation: A subscripted type.\n :returns: Annotation\n \"\"\"\n self.raw_annotation = raw_annotation\n self.origin = self.arg = None\n\n self.optional = typing_inspect.is_optional_type(raw_annotation)\n if self.optional and typing_inspect.is_union_type(raw_annotation):\n # Annotated with Optional or Union[..., NoneType]\n # get_args -> (pandera.typing.Index[str], <class 'NoneType'>)\n raw_annotation = typing_inspect.get_args(raw_annotation)[0]\n\n self.origin = typing_inspect.get_origin(raw_annotation)\n # Replace empty tuple returned from get_args by None\n args = typing_inspect.get_args(raw_annotation) or None\n self.arg = args[0] if args else args\n\n self.metadata = getattr(self.arg, \"__metadata__\", None)\n if self.metadata:\n self.arg = typing_inspect.get_args(self.arg)[0]\n\n self.literal = typing_inspect.is_literal_type(self.arg)\n if self.literal:\n self.arg = typing_inspect.get_args(self.arg)[0]\n", "path": "pandera/typing/common.py"}, {"content": "\"\"\"Typing module.\n\nFor backwards compatibility, pandas types are exposed to the top-level scope of\nthe typing module.\n\"\"\"\n\nfrom . import dask, koalas, modin\nfrom .common import (\n INT8,\n INT16,\n INT32,\n INT64,\n STRING,\n UINT8,\n UINT16,\n UINT32,\n UINT64,\n AnnotationInfo,\n Bool,\n Category,\n DateTime,\n Float,\n Float16,\n Float32,\n Float64,\n Int,\n Int8,\n Int16,\n Int32,\n Int64,\n Object,\n String,\n Timedelta,\n UInt8,\n UInt16,\n UInt32,\n UInt64,\n)\nfrom .pandas import DataFrame, Index, Series\n\nDATAFRAME_TYPES = {DataFrame}\nSERIES_TYPES = {Series}\nINDEX_TYPES = {Index}\n\nif dask.DASK_INSTALLED:\n DATAFRAME_TYPES.update({dask.DataFrame})\n SERIES_TYPES.update({dask.Series})\n INDEX_TYPES.update({dask.Index})\n\nif modin.MODIN_INSTALLED:\n DATAFRAME_TYPES.update({modin.DataFrame})\n SERIES_TYPES.update({modin.Series})\n INDEX_TYPES.update({modin.Index})\n\nif koalas.KOALAS_INSTALLED:\n DATAFRAME_TYPES.update({koalas.DataFrame})\n SERIES_TYPES.update({koalas.Series})\n INDEX_TYPES.update({koalas.Index})\n", "path": "pandera/typing/__init__.py"}], "after_files": [{"content": "\"\"\"Common typing functionality.\"\"\"\n# pylint:disable=abstract-method,disable=too-many-ancestors\n\nimport inspect\nfrom typing import TYPE_CHECKING, Any, Generic, Type, TypeVar\n\nimport pandas as pd\nimport typing_inspect\n\nfrom .. import dtypes\nfrom ..engines import numpy_engine, pandas_engine\n\nBool = dtypes.Bool #: ``\"bool\"`` numpy dtype\nDateTime = dtypes.DateTime #: ``\"datetime64[ns]\"`` numpy dtype\nTimedelta = dtypes.Timedelta #: ``\"timedelta64[ns]\"`` numpy dtype\nCategory = dtypes.Category #: pandas ``\"categorical\"`` datatype\nFloat = dtypes.Float #: ``\"float\"`` numpy dtype\nFloat16 = dtypes.Float16 #: ``\"float16\"`` numpy dtype\nFloat32 = dtypes.Float32 #: ``\"float32\"`` numpy dtype\nFloat64 = dtypes.Float64 #: ``\"float64\"`` numpy dtype\nInt = dtypes.Int #: ``\"int\"`` numpy dtype\nInt8 = dtypes.Int8 #: ``\"int8\"`` numpy dtype\nInt16 = dtypes.Int16 #: ``\"int16\"`` numpy dtype\nInt32 = dtypes.Int32 #: ``\"int32\"`` numpy dtype\nInt64 = dtypes.Int64 #: ``\"int64\"`` numpy dtype\nUInt8 = dtypes.UInt8 #: ``\"uint8\"`` numpy dtype\nUInt16 = dtypes.UInt16 #: ``\"uint16\"`` numpy dtype\nUInt32 = dtypes.UInt32 #: ``\"uint32\"`` numpy dtype\nUInt64 = dtypes.UInt64 #: ``\"uint64\"`` numpy dtype\nINT8 = pandas_engine.INT8 #: ``\"Int8\"`` pandas dtype:: pandas 0.24.0+\nINT16 = pandas_engine.INT16 #: ``\"Int16\"`` pandas dtype: pandas 0.24.0+\nINT32 = pandas_engine.INT32 #: ``\"Int32\"`` pandas dtype: pandas 0.24.0+\nINT64 = pandas_engine.INT64 #: ``\"Int64\"`` pandas dtype: pandas 0.24.0+\nUINT8 = pandas_engine.UINT8 #: ``\"UInt8\"`` pandas dtype:: pandas 0.24.0+\nUINT16 = pandas_engine.UINT16 #: ``\"UInt16\"`` pandas dtype: pandas 0.24.0+\nUINT32 = pandas_engine.UINT32 #: ``\"UInt32\"`` pandas dtype: pandas 0.24.0+\nUINT64 = pandas_engine.UINT64 #: ``\"UInt64\"`` pandas dtype: pandas 0.24.0+\nObject = numpy_engine.Object #: ``\"object\"`` numpy dtype\nString = dtypes.String #: ``\"str\"`` numpy dtype\n#: ``\"string\"`` pandas dtypes: pandas 1.0.0+. For <1.0.0, this enum will\n#: fall back on the str-as-object-array representation.\nSTRING = pandas_engine.STRING #: ``\"str\"`` numpy dtype\nBOOL = pandas_engine.BOOL #: ``\"str\"`` numpy dtype\n\nGenericDtype = TypeVar( # type: ignore\n \"GenericDtype\",\n bool,\n int,\n str,\n float,\n pd.core.dtypes.base.ExtensionDtype,\n Bool,\n DateTime,\n Timedelta,\n Category,\n Float,\n Float16,\n Float32,\n Float64,\n Int,\n Int8,\n Int16,\n Int32,\n Int64,\n UInt8,\n UInt16,\n UInt32,\n UInt64,\n INT8,\n INT16,\n INT32,\n INT64,\n UINT8,\n UINT16,\n UINT32,\n UINT64,\n Object,\n String,\n STRING,\n BOOL,\n covariant=True,\n)\nSchema = TypeVar(\"Schema\", bound=\"SchemaModel\") # type: ignore\n\n\n# pylint:disable=invalid-name\nif TYPE_CHECKING:\n T = TypeVar(\"T\") # pragma: no cover\nelse:\n T = Schema\n\n\nclass DataFrameBase(Generic[T]):\n # pylint: disable=too-few-public-methods\n \"\"\"\n Pandera Dataframe base class for validating dataframes on\n initialization.\n \"\"\"\n\n def __setattr__(self, name: str, value: Any) -> None:\n # pylint: disable=no-member\n object.__setattr__(self, name, value)\n if name == \"__orig_class__\":\n orig_class = getattr(self, \"__orig_class__\")\n class_args = getattr(orig_class, \"__args__\", None)\n if any(\n x.__name__ == \"SchemaModel\"\n for x in inspect.getmro(class_args[0])\n ):\n schema_model = value.__args__[0]\n\n # prevent the double validation problem by preventing checks for\n # dataframes with a defined pandera.schema\n pandera = getattr(self, \"pandera\")\n if (\n pandera.schema is None\n or pandera.schema != schema_model.to_schema()\n ):\n # pylint: disable=self-cls-assignment\n self = schema_model.validate(self)\n pandera.add_schema(schema_model.to_schema())\n\n\n# pylint:disable=too-few-public-methods\nclass SeriesBase(Generic[GenericDtype]):\n \"\"\"Pandera Series base class to use for all pandas-like APIs.\"\"\"\n\n def __get__(\n self, instance: object, owner: Type\n ) -> str: # pragma: no cover\n raise AttributeError(\"Series should resolve to Field-s\")\n\n\n# pylint:disable=too-few-public-methods\nclass IndexBase(Generic[GenericDtype]):\n \"\"\"Representation of pandas.Index, only used for type annotation.\n\n *new in 0.5.0*\n \"\"\"\n\n\nclass AnnotationInfo: # pylint:disable=too-few-public-methods\n \"\"\"Captures extra information about an annotation.\n\n Attributes:\n origin: The non-parameterized generic class.\n arg: The first generic type (SchemaModel does not support more than\n 1 argument).\n literal: Whether the annotation is a literal.\n optional: Whether the annotation is optional.\n raw_annotation: The raw annotation.\n metadata: Extra arguments passed to :data:`typing.Annotated`.\n \"\"\"\n\n def __init__(self, raw_annotation: Type) -> None:\n self._parse_annotation(raw_annotation)\n\n @property\n def is_generic_df(self) -> bool:\n \"\"\"True if the annotation is a DataFrameBase subclass.\"\"\"\n try:\n if self.origin is None:\n return False\n return issubclass(self.origin, DataFrameBase)\n except TypeError:\n return False\n\n def _parse_annotation(self, raw_annotation: Type) -> None:\n \"\"\"Parse key information from annotation.\n\n :param annotation: A subscripted type.\n :returns: Annotation\n \"\"\"\n self.raw_annotation = raw_annotation\n self.origin = self.arg = None\n\n self.optional = typing_inspect.is_optional_type(raw_annotation)\n if self.optional and typing_inspect.is_union_type(raw_annotation):\n # Annotated with Optional or Union[..., NoneType]\n # get_args -> (pandera.typing.Index[str], <class 'NoneType'>)\n raw_annotation = typing_inspect.get_args(raw_annotation)[0]\n\n self.origin = typing_inspect.get_origin(raw_annotation)\n # Replace empty tuple returned from get_args by None\n args = typing_inspect.get_args(raw_annotation) or None\n self.arg = args[0] if args else args\n\n self.metadata = getattr(self.arg, \"__metadata__\", None)\n if self.metadata:\n self.arg = typing_inspect.get_args(self.arg)[0]\n\n self.literal = typing_inspect.is_literal_type(self.arg)\n if self.literal:\n self.arg = typing_inspect.get_args(self.arg)[0]\n", "path": "pandera/typing/common.py"}, {"content": "\"\"\"Typing module.\n\nFor backwards compatibility, pandas types are exposed to the top-level scope of\nthe typing module.\n\"\"\"\n\nfrom . import dask, koalas, modin\nfrom .common import (\n BOOL,\n INT8,\n INT16,\n INT32,\n INT64,\n STRING,\n UINT8,\n UINT16,\n UINT32,\n UINT64,\n AnnotationInfo,\n Bool,\n Category,\n DateTime,\n Float,\n Float16,\n Float32,\n Float64,\n Int,\n Int8,\n Int16,\n Int32,\n Int64,\n Object,\n String,\n Timedelta,\n UInt8,\n UInt16,\n UInt32,\n UInt64,\n)\nfrom .pandas import DataFrame, Index, Series\n\nDATAFRAME_TYPES = {DataFrame}\nSERIES_TYPES = {Series}\nINDEX_TYPES = {Index}\n\nif dask.DASK_INSTALLED:\n DATAFRAME_TYPES.update({dask.DataFrame})\n SERIES_TYPES.update({dask.Series})\n INDEX_TYPES.update({dask.Index})\n\nif modin.MODIN_INSTALLED:\n DATAFRAME_TYPES.update({modin.DataFrame})\n SERIES_TYPES.update({modin.Series})\n INDEX_TYPES.update({modin.Index})\n\nif koalas.KOALAS_INSTALLED:\n DATAFRAME_TYPES.update({koalas.DataFrame})\n SERIES_TYPES.update({koalas.Series})\n INDEX_TYPES.update({koalas.Index})\n", "path": "pandera/typing/__init__.py"}]}
| 3,165 | 288 |
gh_patches_debug_11978
|
rasdani/github-patches
|
git_diff
|
sublimelsp__LSP-242
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
space wrongly triggers autocompletion
following https://github.com/tomv564/LSP/pull/197#discussion_r151605795
<img width="418" alt="screen shot 2017-11-17 at 12 23 30 am" src="https://user-images.githubusercontent.com/1690993/32930648-f23bb3be-cb2d-11e7-96bf-437671397099.png">
It could be reproduced by typing `y` and `<space>` very quickly or when the language server responds slowly.
We might need to check if the context which triggered the completion is still a prefix of the current cursor.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `plugin/completion.py`
Content:
```
1 import sublime
2 import sublime_plugin
3
4 try:
5 from typing import Any, List, Dict, Tuple, Callable, Optional
6 assert Any and List and Dict and Tuple and Callable and Optional
7 except ImportError:
8 pass
9
10 from .core.protocol import Request
11 from .core.settings import settings
12 from .core.logging import debug, exception_log
13 from .core.protocol import CompletionItemKind
14 from .core.clients import client_for_view
15 from .core.configurations import is_supported_syntax
16 from .core.documents import get_document_position, purge_did_change
17
18
19 NO_COMPLETION_SCOPES = 'comment, string'
20 completion_item_kind_names = {v: k for k, v in CompletionItemKind.__dict__.items()}
21
22
23 class CompletionState(object):
24 IDLE = 0
25 REQUESTING = 1
26 APPLYING = 2
27 CANCELLING = 3
28
29
30 resolvable_completion_items = [] # type: List[Any]
31
32
33 def find_completion_item(label: str) -> 'Optional[Any]':
34 matches = list(filter(lambda i: i.get("label") == label, resolvable_completion_items))
35 return matches[0] if matches else None
36
37
38 class CompletionContext(object):
39
40 def __init__(self, begin):
41 self.begin = begin # type: Optional[int]
42 self.end = None # type: Optional[int]
43 self.region = None # type: Optional[sublime.Region]
44 self.committing = False
45
46 def committed_at(self, end):
47 self.end = end
48 self.region = sublime.Region(self.begin, self.end)
49 self.committing = False
50
51
52 current_completion = None # type: Optional[CompletionContext]
53
54
55 def has_resolvable_completions(view):
56 client = client_for_view(view)
57 if client:
58 completionProvider = client.get_capability(
59 'completionProvider')
60 if completionProvider:
61 if completionProvider.get('resolveProvider', False):
62 return True
63 return False
64
65
66 class CompletionSnippetHandler(sublime_plugin.EventListener):
67
68 def on_query_completions(self, view, prefix, locations):
69 global current_completion
70 if settings.resolve_completion_for_snippets and has_resolvable_completions(view):
71 current_completion = CompletionContext(view.sel()[0].begin())
72
73 def on_text_command(self, view, command_name, args):
74 if settings.resolve_completion_for_snippets and current_completion:
75 current_completion.committing = command_name in ('commit_completion', 'insert_best_completion')
76
77 def on_modified(self, view):
78 global current_completion
79
80 if settings.resolve_completion_for_snippets and view.file_name():
81 if current_completion and current_completion.committing:
82 current_completion.committed_at(view.sel()[0].end())
83 inserted = view.substr(current_completion.region)
84 item = find_completion_item(inserted)
85 if item:
86 self.resolve_completion(item, view)
87 else:
88 current_completion = None
89
90 def resolve_completion(self, item, view):
91 client = client_for_view(view)
92 if not client:
93 return
94
95 client.send_request(
96 Request.resolveCompletionItem(item),
97 lambda response: self.handle_resolve_response(response, view))
98
99 def handle_resolve_response(self, response, view):
100 # replace inserted text if a snippet was returned.
101 if current_completion and response.get('insertTextFormat') == 2: # snippet
102 insertText = response.get('insertText')
103 try:
104 sel = view.sel()
105 sel.clear()
106 sel.add(current_completion.region)
107 view.run_command("insert_snippet", {"contents": insertText})
108 except Exception as err:
109 exception_log("Error inserting snippet: " + insertText, err)
110
111
112 last_text_command = None
113
114
115 class CompletionHelper(sublime_plugin.EventListener):
116 def on_text_command(self, view, command_name, args):
117 global last_text_command
118 last_text_command = command_name
119
120
121 class CompletionHandler(sublime_plugin.ViewEventListener):
122 def __init__(self, view):
123 self.view = view
124 self.initialized = False
125 self.enabled = False
126 self.trigger_chars = [] # type: List[str]
127 self.resolve = False
128 self.resolve_details = [] # type: List[Tuple[str, str]]
129 self.state = CompletionState.IDLE
130 self.completions = [] # type: List[Any]
131 self.next_request = None # type: Optional[Tuple[str, List[int]]]
132 self.last_prefix = ""
133 self.last_location = 0
134
135 @classmethod
136 def is_applicable(cls, settings):
137 syntax = settings.get('syntax')
138 if syntax is not None:
139 return is_supported_syntax(syntax)
140 else:
141 return False
142
143 def initialize(self):
144 self.initialized = True
145 client = client_for_view(self.view)
146 if client:
147 completionProvider = client.get_capability(
148 'completionProvider')
149 if completionProvider:
150 self.enabled = True
151 self.trigger_chars = completionProvider.get(
152 'triggerCharacters') or []
153 self.has_resolve_provider = completionProvider.get('resolveProvider', False)
154
155 def is_after_trigger_character(self, location):
156 if location > 0:
157 prev_char = self.view.substr(location - 1)
158 return prev_char in self.trigger_chars
159
160 def is_same_completion(self, prefix, locations):
161 # completion requests from the same location with the same prefix are cached.
162 current_start = locations[0] - len(prefix)
163 last_start = self.last_location - len(self.last_prefix)
164 return prefix.startswith(self.last_prefix) and current_start == last_start
165
166 def on_modified(self):
167 # hide completion when backspacing past last completion.
168 if self.view.sel()[0].begin() < self.last_location:
169 self.last_location = 0
170 self.view.run_command("hide_auto_complete")
171
172 def on_query_completions(self, prefix, locations):
173 if self.view.match_selector(locations[0], NO_COMPLETION_SCOPES):
174 return (
175 [],
176 sublime.INHIBIT_WORD_COMPLETIONS | sublime.INHIBIT_EXPLICIT_COMPLETIONS
177 )
178
179 if not self.initialized:
180 self.initialize()
181
182 if self.enabled:
183 reuse_completion = self.is_same_completion(prefix, locations)
184 if self.state == CompletionState.IDLE:
185 if not reuse_completion:
186 self.last_prefix = prefix
187 self.last_location = locations[0]
188 self.do_request(prefix, locations)
189 self.completions = []
190
191 elif self.state in (CompletionState.REQUESTING, CompletionState.CANCELLING):
192 self.next_request = (prefix, locations)
193 self.state = CompletionState.CANCELLING
194
195 elif self.state == CompletionState.APPLYING:
196 self.state = CompletionState.IDLE
197
198 return (
199 self.completions,
200 0 if not settings.only_show_lsp_completions
201 else sublime.INHIBIT_WORD_COMPLETIONS | sublime.INHIBIT_EXPLICIT_COMPLETIONS
202 )
203
204 def do_request(self, prefix: str, locations: 'List[int]'):
205 self.next_request = None
206 view = self.view
207
208 # don't store client so we can handle restarts
209 client = client_for_view(view)
210 if not client:
211 return
212
213 if settings.complete_all_chars or self.is_after_trigger_character(locations[0]):
214 purge_did_change(view.buffer_id())
215 document_position = get_document_position(view, locations[0])
216 if document_position:
217 client.send_request(
218 Request.complete(document_position),
219 self.handle_response,
220 self.handle_error)
221 self.state = CompletionState.REQUESTING
222
223 def format_completion(self, item: dict) -> 'Tuple[str, str]':
224 # Sublime handles snippets automatically, so we don't have to care about insertTextFormat.
225 label = item["label"]
226 # choose hint based on availability and user preference
227 hint = None
228 if settings.completion_hint_type == "auto":
229 hint = item.get("detail")
230 if not hint:
231 kind = item.get("kind")
232 if kind:
233 hint = completion_item_kind_names[kind]
234 elif settings.completion_hint_type == "detail":
235 hint = item.get("detail")
236 elif settings.completion_hint_type == "kind":
237 kind = item.get("kind")
238 if kind:
239 hint = completion_item_kind_names[kind]
240 # label is an alternative for insertText if insertText not provided
241 insert_text = item.get("insertText") or label
242 if len(insert_text) > 0 and insert_text[0] == '$': # sublime needs leading '$' escaped.
243 insert_text = '\$' + insert_text[1:]
244 # only return label with a hint if available
245 return "\t ".join((label, hint)) if hint else label, insert_text
246
247 def handle_response(self, response: dict):
248 global resolvable_completion_items
249
250 if self.state == CompletionState.REQUESTING:
251 items = response["items"] if isinstance(response,
252 dict) else response
253 if len(items) > 1 and items[0].get("sortText") is not None:
254 # If the first item has a sortText value, assume all of them have a sortText value.
255 items = sorted(items, key=lambda item: item["sortText"])
256 self.completions = list(self.format_completion(item) for item in items)
257
258 if self.has_resolve_provider:
259 resolvable_completion_items = items
260
261 # if insert_best_completion was just ran, undo it before presenting new completions.
262 prev_char = self.view.substr(self.view.sel()[0].begin() - 1)
263 if prev_char.isspace():
264 if last_text_command == "insert_best_completion":
265 self.view.run_command("undo")
266
267 self.state = CompletionState.APPLYING
268 self.view.run_command("hide_auto_complete")
269 self.run_auto_complete()
270 elif self.state == CompletionState.CANCELLING:
271 if self.next_request:
272 prefix, locations = self.next_request
273 self.do_request(prefix, locations)
274 else:
275 debug('Got unexpected response while in state {}'.format(self.state))
276
277 def handle_error(self, error: dict):
278 sublime.status_message('Completion error: ' + str(error.get('message')))
279 self.state = CompletionState.IDLE
280
281 def run_auto_complete(self):
282 self.view.run_command(
283 "auto_complete", {
284 'disable_auto_insert': True,
285 'api_completions_only': settings.only_show_lsp_completions,
286 'next_completion_if_showing': False
287 })
288
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/plugin/completion.py b/plugin/completion.py
--- a/plugin/completion.py
+++ b/plugin/completion.py
@@ -168,6 +168,10 @@
if self.view.sel()[0].begin() < self.last_location:
self.last_location = 0
self.view.run_command("hide_auto_complete")
+ # cancel current completion if the previous input is an space
+ prev_char = self.view.substr(self.view.sel()[0].begin() - 1)
+ if self.state == CompletionState.REQUESTING and prev_char.isspace():
+ self.state = CompletionState.CANCELLING
def on_query_completions(self, prefix, locations):
if self.view.match_selector(locations[0], NO_COMPLETION_SCOPES):
|
{"golden_diff": "diff --git a/plugin/completion.py b/plugin/completion.py\n--- a/plugin/completion.py\n+++ b/plugin/completion.py\n@@ -168,6 +168,10 @@\n if self.view.sel()[0].begin() < self.last_location:\n self.last_location = 0\n self.view.run_command(\"hide_auto_complete\")\n+ # cancel current completion if the previous input is an space\n+ prev_char = self.view.substr(self.view.sel()[0].begin() - 1)\n+ if self.state == CompletionState.REQUESTING and prev_char.isspace():\n+ self.state = CompletionState.CANCELLING\n \n def on_query_completions(self, prefix, locations):\n if self.view.match_selector(locations[0], NO_COMPLETION_SCOPES):\n", "issue": "space wrongly triggers autocompletion\nfollowing https://github.com/tomv564/LSP/pull/197#discussion_r151605795\r\n\r\n<img width=\"418\" alt=\"screen shot 2017-11-17 at 12 23 30 am\" src=\"https://user-images.githubusercontent.com/1690993/32930648-f23bb3be-cb2d-11e7-96bf-437671397099.png\">\r\n\r\nIt could be reproduced by typing `y` and `<space>` very quickly or when the language server responds slowly.\r\n\r\nWe might need to check if the context which triggered the completion is still a prefix of the current cursor.\n", "before_files": [{"content": "import sublime\nimport sublime_plugin\n\ntry:\n from typing import Any, List, Dict, Tuple, Callable, Optional\n assert Any and List and Dict and Tuple and Callable and Optional\nexcept ImportError:\n pass\n\nfrom .core.protocol import Request\nfrom .core.settings import settings\nfrom .core.logging import debug, exception_log\nfrom .core.protocol import CompletionItemKind\nfrom .core.clients import client_for_view\nfrom .core.configurations import is_supported_syntax\nfrom .core.documents import get_document_position, purge_did_change\n\n\nNO_COMPLETION_SCOPES = 'comment, string'\ncompletion_item_kind_names = {v: k for k, v in CompletionItemKind.__dict__.items()}\n\n\nclass CompletionState(object):\n IDLE = 0\n REQUESTING = 1\n APPLYING = 2\n CANCELLING = 3\n\n\nresolvable_completion_items = [] # type: List[Any]\n\n\ndef find_completion_item(label: str) -> 'Optional[Any]':\n matches = list(filter(lambda i: i.get(\"label\") == label, resolvable_completion_items))\n return matches[0] if matches else None\n\n\nclass CompletionContext(object):\n\n def __init__(self, begin):\n self.begin = begin # type: Optional[int]\n self.end = None # type: Optional[int]\n self.region = None # type: Optional[sublime.Region]\n self.committing = False\n\n def committed_at(self, end):\n self.end = end\n self.region = sublime.Region(self.begin, self.end)\n self.committing = False\n\n\ncurrent_completion = None # type: Optional[CompletionContext]\n\n\ndef has_resolvable_completions(view):\n client = client_for_view(view)\n if client:\n completionProvider = client.get_capability(\n 'completionProvider')\n if completionProvider:\n if completionProvider.get('resolveProvider', False):\n return True\n return False\n\n\nclass CompletionSnippetHandler(sublime_plugin.EventListener):\n\n def on_query_completions(self, view, prefix, locations):\n global current_completion\n if settings.resolve_completion_for_snippets and has_resolvable_completions(view):\n current_completion = CompletionContext(view.sel()[0].begin())\n\n def on_text_command(self, view, command_name, args):\n if settings.resolve_completion_for_snippets and current_completion:\n current_completion.committing = command_name in ('commit_completion', 'insert_best_completion')\n\n def on_modified(self, view):\n global current_completion\n\n if settings.resolve_completion_for_snippets and view.file_name():\n if current_completion and current_completion.committing:\n current_completion.committed_at(view.sel()[0].end())\n inserted = view.substr(current_completion.region)\n item = find_completion_item(inserted)\n if item:\n self.resolve_completion(item, view)\n else:\n current_completion = None\n\n def resolve_completion(self, item, view):\n client = client_for_view(view)\n if not client:\n return\n\n client.send_request(\n Request.resolveCompletionItem(item),\n lambda response: self.handle_resolve_response(response, view))\n\n def handle_resolve_response(self, response, view):\n # replace inserted text if a snippet was returned.\n if current_completion and response.get('insertTextFormat') == 2: # snippet\n insertText = response.get('insertText')\n try:\n sel = view.sel()\n sel.clear()\n sel.add(current_completion.region)\n view.run_command(\"insert_snippet\", {\"contents\": insertText})\n except Exception as err:\n exception_log(\"Error inserting snippet: \" + insertText, err)\n\n\nlast_text_command = None\n\n\nclass CompletionHelper(sublime_plugin.EventListener):\n def on_text_command(self, view, command_name, args):\n global last_text_command\n last_text_command = command_name\n\n\nclass CompletionHandler(sublime_plugin.ViewEventListener):\n def __init__(self, view):\n self.view = view\n self.initialized = False\n self.enabled = False\n self.trigger_chars = [] # type: List[str]\n self.resolve = False\n self.resolve_details = [] # type: List[Tuple[str, str]]\n self.state = CompletionState.IDLE\n self.completions = [] # type: List[Any]\n self.next_request = None # type: Optional[Tuple[str, List[int]]]\n self.last_prefix = \"\"\n self.last_location = 0\n\n @classmethod\n def is_applicable(cls, settings):\n syntax = settings.get('syntax')\n if syntax is not None:\n return is_supported_syntax(syntax)\n else:\n return False\n\n def initialize(self):\n self.initialized = True\n client = client_for_view(self.view)\n if client:\n completionProvider = client.get_capability(\n 'completionProvider')\n if completionProvider:\n self.enabled = True\n self.trigger_chars = completionProvider.get(\n 'triggerCharacters') or []\n self.has_resolve_provider = completionProvider.get('resolveProvider', False)\n\n def is_after_trigger_character(self, location):\n if location > 0:\n prev_char = self.view.substr(location - 1)\n return prev_char in self.trigger_chars\n\n def is_same_completion(self, prefix, locations):\n # completion requests from the same location with the same prefix are cached.\n current_start = locations[0] - len(prefix)\n last_start = self.last_location - len(self.last_prefix)\n return prefix.startswith(self.last_prefix) and current_start == last_start\n\n def on_modified(self):\n # hide completion when backspacing past last completion.\n if self.view.sel()[0].begin() < self.last_location:\n self.last_location = 0\n self.view.run_command(\"hide_auto_complete\")\n\n def on_query_completions(self, prefix, locations):\n if self.view.match_selector(locations[0], NO_COMPLETION_SCOPES):\n return (\n [],\n sublime.INHIBIT_WORD_COMPLETIONS | sublime.INHIBIT_EXPLICIT_COMPLETIONS\n )\n\n if not self.initialized:\n self.initialize()\n\n if self.enabled:\n reuse_completion = self.is_same_completion(prefix, locations)\n if self.state == CompletionState.IDLE:\n if not reuse_completion:\n self.last_prefix = prefix\n self.last_location = locations[0]\n self.do_request(prefix, locations)\n self.completions = []\n\n elif self.state in (CompletionState.REQUESTING, CompletionState.CANCELLING):\n self.next_request = (prefix, locations)\n self.state = CompletionState.CANCELLING\n\n elif self.state == CompletionState.APPLYING:\n self.state = CompletionState.IDLE\n\n return (\n self.completions,\n 0 if not settings.only_show_lsp_completions\n else sublime.INHIBIT_WORD_COMPLETIONS | sublime.INHIBIT_EXPLICIT_COMPLETIONS\n )\n\n def do_request(self, prefix: str, locations: 'List[int]'):\n self.next_request = None\n view = self.view\n\n # don't store client so we can handle restarts\n client = client_for_view(view)\n if not client:\n return\n\n if settings.complete_all_chars or self.is_after_trigger_character(locations[0]):\n purge_did_change(view.buffer_id())\n document_position = get_document_position(view, locations[0])\n if document_position:\n client.send_request(\n Request.complete(document_position),\n self.handle_response,\n self.handle_error)\n self.state = CompletionState.REQUESTING\n\n def format_completion(self, item: dict) -> 'Tuple[str, str]':\n # Sublime handles snippets automatically, so we don't have to care about insertTextFormat.\n label = item[\"label\"]\n # choose hint based on availability and user preference\n hint = None\n if settings.completion_hint_type == \"auto\":\n hint = item.get(\"detail\")\n if not hint:\n kind = item.get(\"kind\")\n if kind:\n hint = completion_item_kind_names[kind]\n elif settings.completion_hint_type == \"detail\":\n hint = item.get(\"detail\")\n elif settings.completion_hint_type == \"kind\":\n kind = item.get(\"kind\")\n if kind:\n hint = completion_item_kind_names[kind]\n # label is an alternative for insertText if insertText not provided\n insert_text = item.get(\"insertText\") or label\n if len(insert_text) > 0 and insert_text[0] == '$': # sublime needs leading '$' escaped.\n insert_text = '\\$' + insert_text[1:]\n # only return label with a hint if available\n return \"\\t \".join((label, hint)) if hint else label, insert_text\n\n def handle_response(self, response: dict):\n global resolvable_completion_items\n\n if self.state == CompletionState.REQUESTING:\n items = response[\"items\"] if isinstance(response,\n dict) else response\n if len(items) > 1 and items[0].get(\"sortText\") is not None:\n # If the first item has a sortText value, assume all of them have a sortText value.\n items = sorted(items, key=lambda item: item[\"sortText\"])\n self.completions = list(self.format_completion(item) for item in items)\n\n if self.has_resolve_provider:\n resolvable_completion_items = items\n\n # if insert_best_completion was just ran, undo it before presenting new completions.\n prev_char = self.view.substr(self.view.sel()[0].begin() - 1)\n if prev_char.isspace():\n if last_text_command == \"insert_best_completion\":\n self.view.run_command(\"undo\")\n\n self.state = CompletionState.APPLYING\n self.view.run_command(\"hide_auto_complete\")\n self.run_auto_complete()\n elif self.state == CompletionState.CANCELLING:\n if self.next_request:\n prefix, locations = self.next_request\n self.do_request(prefix, locations)\n else:\n debug('Got unexpected response while in state {}'.format(self.state))\n\n def handle_error(self, error: dict):\n sublime.status_message('Completion error: ' + str(error.get('message')))\n self.state = CompletionState.IDLE\n\n def run_auto_complete(self):\n self.view.run_command(\n \"auto_complete\", {\n 'disable_auto_insert': True,\n 'api_completions_only': settings.only_show_lsp_completions,\n 'next_completion_if_showing': False\n })\n", "path": "plugin/completion.py"}], "after_files": [{"content": "import sublime\nimport sublime_plugin\n\ntry:\n from typing import Any, List, Dict, Tuple, Callable, Optional\n assert Any and List and Dict and Tuple and Callable and Optional\nexcept ImportError:\n pass\n\nfrom .core.protocol import Request\nfrom .core.settings import settings\nfrom .core.logging import debug, exception_log\nfrom .core.protocol import CompletionItemKind\nfrom .core.clients import client_for_view\nfrom .core.configurations import is_supported_syntax\nfrom .core.documents import get_document_position, purge_did_change\n\n\nNO_COMPLETION_SCOPES = 'comment, string'\ncompletion_item_kind_names = {v: k for k, v in CompletionItemKind.__dict__.items()}\n\n\nclass CompletionState(object):\n IDLE = 0\n REQUESTING = 1\n APPLYING = 2\n CANCELLING = 3\n\n\nresolvable_completion_items = [] # type: List[Any]\n\n\ndef find_completion_item(label: str) -> 'Optional[Any]':\n matches = list(filter(lambda i: i.get(\"label\") == label, resolvable_completion_items))\n return matches[0] if matches else None\n\n\nclass CompletionContext(object):\n\n def __init__(self, begin):\n self.begin = begin # type: Optional[int]\n self.end = None # type: Optional[int]\n self.region = None # type: Optional[sublime.Region]\n self.committing = False\n\n def committed_at(self, end):\n self.end = end\n self.region = sublime.Region(self.begin, self.end)\n self.committing = False\n\n\ncurrent_completion = None # type: Optional[CompletionContext]\n\n\ndef has_resolvable_completions(view):\n client = client_for_view(view)\n if client:\n completionProvider = client.get_capability(\n 'completionProvider')\n if completionProvider:\n if completionProvider.get('resolveProvider', False):\n return True\n return False\n\n\nclass CompletionSnippetHandler(sublime_plugin.EventListener):\n\n def on_query_completions(self, view, prefix, locations):\n global current_completion\n if settings.resolve_completion_for_snippets and has_resolvable_completions(view):\n current_completion = CompletionContext(view.sel()[0].begin())\n\n def on_text_command(self, view, command_name, args):\n if settings.resolve_completion_for_snippets and current_completion:\n current_completion.committing = command_name in ('commit_completion', 'insert_best_completion')\n\n def on_modified(self, view):\n global current_completion\n\n if settings.resolve_completion_for_snippets and view.file_name():\n if current_completion and current_completion.committing:\n current_completion.committed_at(view.sel()[0].end())\n inserted = view.substr(current_completion.region)\n item = find_completion_item(inserted)\n if item:\n self.resolve_completion(item, view)\n else:\n current_completion = None\n\n def resolve_completion(self, item, view):\n client = client_for_view(view)\n if not client:\n return\n\n client.send_request(\n Request.resolveCompletionItem(item),\n lambda response: self.handle_resolve_response(response, view))\n\n def handle_resolve_response(self, response, view):\n # replace inserted text if a snippet was returned.\n if current_completion and response.get('insertTextFormat') == 2: # snippet\n insertText = response.get('insertText')\n try:\n sel = view.sel()\n sel.clear()\n sel.add(current_completion.region)\n view.run_command(\"insert_snippet\", {\"contents\": insertText})\n except Exception as err:\n exception_log(\"Error inserting snippet: \" + insertText, err)\n\n\nlast_text_command = None\n\n\nclass CompletionHelper(sublime_plugin.EventListener):\n def on_text_command(self, view, command_name, args):\n global last_text_command\n last_text_command = command_name\n\n\nclass CompletionHandler(sublime_plugin.ViewEventListener):\n def __init__(self, view):\n self.view = view\n self.initialized = False\n self.enabled = False\n self.trigger_chars = [] # type: List[str]\n self.resolve = False\n self.resolve_details = [] # type: List[Tuple[str, str]]\n self.state = CompletionState.IDLE\n self.completions = [] # type: List[Any]\n self.next_request = None # type: Optional[Tuple[str, List[int]]]\n self.last_prefix = \"\"\n self.last_location = 0\n\n @classmethod\n def is_applicable(cls, settings):\n syntax = settings.get('syntax')\n if syntax is not None:\n return is_supported_syntax(syntax)\n else:\n return False\n\n def initialize(self):\n self.initialized = True\n client = client_for_view(self.view)\n if client:\n completionProvider = client.get_capability(\n 'completionProvider')\n if completionProvider:\n self.enabled = True\n self.trigger_chars = completionProvider.get(\n 'triggerCharacters') or []\n self.has_resolve_provider = completionProvider.get('resolveProvider', False)\n\n def is_after_trigger_character(self, location):\n if location > 0:\n prev_char = self.view.substr(location - 1)\n return prev_char in self.trigger_chars\n\n def is_same_completion(self, prefix, locations):\n # completion requests from the same location with the same prefix are cached.\n current_start = locations[0] - len(prefix)\n last_start = self.last_location - len(self.last_prefix)\n return prefix.startswith(self.last_prefix) and current_start == last_start\n\n def on_modified(self):\n # hide completion when backspacing past last completion.\n if self.view.sel()[0].begin() < self.last_location:\n self.last_location = 0\n self.view.run_command(\"hide_auto_complete\")\n # cancel current completion if the previous input is an space\n prev_char = self.view.substr(self.view.sel()[0].begin() - 1)\n if self.state == CompletionState.REQUESTING and prev_char.isspace():\n self.state = CompletionState.CANCELLING\n\n def on_query_completions(self, prefix, locations):\n if self.view.match_selector(locations[0], NO_COMPLETION_SCOPES):\n return (\n [],\n sublime.INHIBIT_WORD_COMPLETIONS | sublime.INHIBIT_EXPLICIT_COMPLETIONS\n )\n\n if not self.initialized:\n self.initialize()\n\n if self.enabled:\n reuse_completion = self.is_same_completion(prefix, locations)\n if self.state == CompletionState.IDLE:\n if not reuse_completion:\n self.last_prefix = prefix\n self.last_location = locations[0]\n self.do_request(prefix, locations)\n self.completions = []\n\n elif self.state in (CompletionState.REQUESTING, CompletionState.CANCELLING):\n self.next_request = (prefix, locations)\n self.state = CompletionState.CANCELLING\n\n elif self.state == CompletionState.APPLYING:\n self.state = CompletionState.IDLE\n\n return (\n self.completions,\n 0 if not settings.only_show_lsp_completions\n else sublime.INHIBIT_WORD_COMPLETIONS | sublime.INHIBIT_EXPLICIT_COMPLETIONS\n )\n\n def do_request(self, prefix: str, locations: 'List[int]'):\n self.next_request = None\n view = self.view\n\n # don't store client so we can handle restarts\n client = client_for_view(view)\n if not client:\n return\n\n if settings.complete_all_chars or self.is_after_trigger_character(locations[0]):\n purge_did_change(view.buffer_id())\n document_position = get_document_position(view, locations[0])\n if document_position:\n client.send_request(\n Request.complete(document_position),\n self.handle_response,\n self.handle_error)\n self.state = CompletionState.REQUESTING\n\n def format_completion(self, item: dict) -> 'Tuple[str, str]':\n # Sublime handles snippets automatically, so we don't have to care about insertTextFormat.\n label = item[\"label\"]\n # choose hint based on availability and user preference\n hint = None\n if settings.completion_hint_type == \"auto\":\n hint = item.get(\"detail\")\n if not hint:\n kind = item.get(\"kind\")\n if kind:\n hint = completion_item_kind_names[kind]\n elif settings.completion_hint_type == \"detail\":\n hint = item.get(\"detail\")\n elif settings.completion_hint_type == \"kind\":\n kind = item.get(\"kind\")\n if kind:\n hint = completion_item_kind_names[kind]\n # label is an alternative for insertText if insertText not provided\n insert_text = item.get(\"insertText\") or label\n if len(insert_text) > 0 and insert_text[0] == '$': # sublime needs leading '$' escaped.\n insert_text = '\\$' + insert_text[1:]\n # only return label with a hint if available\n return \"\\t \".join((label, hint)) if hint else label, insert_text\n\n def handle_response(self, response: dict):\n global resolvable_completion_items\n\n if self.state == CompletionState.REQUESTING:\n items = response[\"items\"] if isinstance(response,\n dict) else response\n if len(items) > 1 and items[0].get(\"sortText\") is not None:\n # If the first item has a sortText value, assume all of them have a sortText value.\n items = sorted(items, key=lambda item: item[\"sortText\"])\n self.completions = list(self.format_completion(item) for item in items)\n\n if self.has_resolve_provider:\n resolvable_completion_items = items\n\n # if insert_best_completion was just ran, undo it before presenting new completions.\n prev_char = self.view.substr(self.view.sel()[0].begin() - 1)\n if prev_char.isspace():\n if last_text_command == \"insert_best_completion\":\n self.view.run_command(\"undo\")\n\n self.state = CompletionState.APPLYING\n self.view.run_command(\"hide_auto_complete\")\n self.run_auto_complete()\n elif self.state == CompletionState.CANCELLING:\n if self.next_request:\n prefix, locations = self.next_request\n self.do_request(prefix, locations)\n else:\n debug('Got unexpected response while in state {}'.format(self.state))\n\n def handle_error(self, error: dict):\n sublime.status_message('Completion error: ' + str(error.get('message')))\n self.state = CompletionState.IDLE\n\n def run_auto_complete(self):\n self.view.run_command(\n \"auto_complete\", {\n 'disable_auto_insert': True,\n 'api_completions_only': settings.only_show_lsp_completions,\n 'next_completion_if_showing': False\n })\n", "path": "plugin/completion.py"}]}
| 3,450 | 169 |
gh_patches_debug_24180
|
rasdani/github-patches
|
git_diff
|
pypi__warehouse-960
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Default search message
We need to add a message for when a search doesn't match any packages.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `warehouse/utils/paginate.py`
Content:
```
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12
13 from paginate import Page
14
15
16 class _ElasticsearchWrapper:
17
18 def __init__(self, query):
19 self.query = query
20 self.results = None
21
22 def __getitem__(self, range):
23 if self.results is not None:
24 raise RuntimeError("Cannot reslice after having already sliced.")
25 self.results = self.query[range].execute()
26
27 return list(self.results)
28
29 def __len__(self):
30 if self.results is None:
31 raise RuntimeError("Cannot get length until a slice.")
32 return self.results.hits.total
33
34
35 def ElasticsearchPage(*args, **kwargs): # noqa
36 kwargs.setdefault("wrapper_class", _ElasticsearchWrapper)
37 return Page(*args, **kwargs)
38
39
40 def paginate_url_factory(request, query_arg="page"):
41 def make_url(page):
42 query_seq = [
43 (k, v)
44 for k, vs in request.GET.dict_of_lists().items()
45 for v in vs
46 if k != query_arg
47 ]
48 query_seq += [(query_arg, page)]
49 return request.current_route_path(_query=query_seq)
50 return make_url
51
```
Path: `warehouse/views.py`
Content:
```
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12
13 from pyramid.httpexceptions import (
14 HTTPException, HTTPSeeOther, HTTPMovedPermanently,
15 )
16 from pyramid.view import (
17 notfound_view_config, forbidden_view_config, view_config,
18 )
19 from sqlalchemy import func
20 from sqlalchemy.orm import aliased, joinedload
21
22 from warehouse.accounts import REDIRECT_FIELD_NAME
23 from warehouse.accounts.models import User
24 from warehouse.cache.origin import origin_cache
25 from warehouse.cache.http import cache_control
26 from warehouse.csrf import csrf_exempt
27 from warehouse.packaging.models import Project, Release, File
28 from warehouse.sessions import uses_session
29 from warehouse.utils.row_counter import RowCount
30 from warehouse.utils.paginate import ElasticsearchPage, paginate_url_factory
31
32
33 @view_config(context=HTTPException, decorator=[csrf_exempt])
34 @notfound_view_config(
35 append_slash=HTTPMovedPermanently,
36 decorator=[csrf_exempt],
37 )
38 def httpexception_view(exc, request):
39 return exc
40
41
42 @forbidden_view_config()
43 def forbidden(exc, request):
44 # If the forbidden error is because the user isn't logged in, then we'll
45 # redirect them to the log in page.
46 if request.authenticated_userid is None:
47 url = request.route_url(
48 "accounts.login",
49 _query={REDIRECT_FIELD_NAME: request.path_qs},
50 )
51 return HTTPSeeOther(url)
52
53 # If we've reached here, then the user is logged in and they are genuinely
54 # not allowed to access this page.
55 # TODO: Style the forbidden page.
56 return exc
57
58
59 @view_config(
60 route_name="robots.txt",
61 renderer="robots.txt",
62 decorator=[
63 cache_control(1 * 24 * 60 * 60), # 1 day
64 origin_cache(
65 1 * 24 * 60 * 60, # 1 day
66 stale_while_revalidate=6 * 60 * 60, # 6 hours
67 stale_if_error=1 * 24 * 60 * 60, # 1 day
68 ),
69 ],
70 )
71 def robotstxt(request):
72 request.response.content_type = "text/plain"
73 return {}
74
75
76 @view_config(
77 route_name="index",
78 renderer="index.html",
79 decorator=[
80 origin_cache(
81 1 * 60 * 60, # 1 hour
82 stale_while_revalidate=10 * 60, # 10 minutes
83 stale_if_error=1 * 24 * 60 * 60, # 1 day
84 keys=["all-projects"],
85 ),
86 ]
87 )
88 def index(request):
89 project_names = [
90 r[0] for r in (
91 request.db.query(File.name)
92 .group_by(File.name)
93 .order_by(func.sum(File.downloads).desc())
94 .limit(5)
95 .all())
96 ]
97 release_a = aliased(
98 Release,
99 request.db.query(Release)
100 .distinct(Release.name)
101 .filter(Release.name.in_(project_names))
102 .order_by(Release.name, Release._pypi_ordering.desc())
103 .subquery(),
104 )
105 top_projects = (
106 request.db.query(release_a)
107 .options(joinedload(release_a.project),
108 joinedload(release_a.uploader))
109 .order_by(func.array_idx(project_names, release_a.name))
110 .all()
111 )
112
113 latest_releases = (
114 request.db.query(Release)
115 .options(joinedload(Release.project),
116 joinedload(Release.uploader))
117 .order_by(Release.created.desc())
118 .limit(5)
119 .all()
120 )
121
122 counts = dict(
123 request.db.query(RowCount.table_name, RowCount.count)
124 .filter(
125 RowCount.table_name.in_([
126 Project.__tablename__,
127 Release.__tablename__,
128 File.__tablename__,
129 User.__tablename__,
130 ]))
131 .all()
132 )
133
134 return {
135 "latest_releases": latest_releases,
136 "top_projects": top_projects,
137 "num_projects": counts.get(Project.__tablename__, 0),
138 "num_releases": counts.get(Release.__tablename__, 0),
139 "num_files": counts.get(File.__tablename__, 0),
140 "num_users": counts.get(User.__tablename__, 0),
141 }
142
143
144 @view_config(
145 route_name="search",
146 renderer="search/results.html",
147 decorator=[
148 origin_cache(
149 1 * 60 * 60, # 1 hour
150 stale_while_revalidate=10 * 60, # 10 minutes
151 stale_if_error=1 * 24 * 60 * 60, # 1 day
152 keys=["all-projects"],
153 )
154 ],
155 )
156 def search(request):
157 if request.params.get("q"):
158 query = request.es.query(
159 "multi_match",
160 query=request.params["q"],
161 fields=[
162 "name", "version", "author", "author_email", "maintainer",
163 "maintainer_email", "home_page", "license", "summary",
164 "description", "keywords", "platform", "download_url",
165 ],
166 )
167 else:
168 query = request.es.query()
169
170 page = ElasticsearchPage(
171 query,
172 page=int(request.params.get("page", 1)),
173 url_maker=paginate_url_factory(request),
174 )
175
176 return {"page": page, "term": request.params.get("q")}
177
178
179 @view_config(
180 route_name="includes.current-user-indicator",
181 renderer="includes/current-user-indicator.html",
182 decorator=[uses_session],
183 )
184 def current_user_indicator(request):
185 return {}
186
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/warehouse/utils/paginate.py b/warehouse/utils/paginate.py
--- a/warehouse/utils/paginate.py
+++ b/warehouse/utils/paginate.py
@@ -18,12 +18,18 @@
def __init__(self, query):
self.query = query
self.results = None
+ self.best_guess = None
def __getitem__(self, range):
if self.results is not None:
raise RuntimeError("Cannot reslice after having already sliced.")
self.results = self.query[range].execute()
+ if hasattr(self.results, "suggest"):
+ suggestion = self.results.suggest.name_suggestion[0]
+ if suggestion.options:
+ self.best_guess = suggestion.options[0]
+
return list(self.results)
def __len__(self):
diff --git a/warehouse/views.py b/warehouse/views.py
--- a/warehouse/views.py
+++ b/warehouse/views.py
@@ -163,6 +163,10 @@
"maintainer_email", "home_page", "license", "summary",
"description", "keywords", "platform", "download_url",
],
+ ).suggest(
+ name="name_suggestion",
+ text=request.params["q"],
+ term={"field": "name"}
)
else:
query = request.es.query()
|
{"golden_diff": "diff --git a/warehouse/utils/paginate.py b/warehouse/utils/paginate.py\n--- a/warehouse/utils/paginate.py\n+++ b/warehouse/utils/paginate.py\n@@ -18,12 +18,18 @@\n def __init__(self, query):\n self.query = query\n self.results = None\n+ self.best_guess = None\n \n def __getitem__(self, range):\n if self.results is not None:\n raise RuntimeError(\"Cannot reslice after having already sliced.\")\n self.results = self.query[range].execute()\n \n+ if hasattr(self.results, \"suggest\"):\n+ suggestion = self.results.suggest.name_suggestion[0]\n+ if suggestion.options:\n+ self.best_guess = suggestion.options[0]\n+\n return list(self.results)\n \n def __len__(self):\ndiff --git a/warehouse/views.py b/warehouse/views.py\n--- a/warehouse/views.py\n+++ b/warehouse/views.py\n@@ -163,6 +163,10 @@\n \"maintainer_email\", \"home_page\", \"license\", \"summary\",\n \"description\", \"keywords\", \"platform\", \"download_url\",\n ],\n+ ).suggest(\n+ name=\"name_suggestion\",\n+ text=request.params[\"q\"],\n+ term={\"field\": \"name\"}\n )\n else:\n query = request.es.query()\n", "issue": "Default search message\nWe need to add a message for when a search doesn't match any packages.\n\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom paginate import Page\n\n\nclass _ElasticsearchWrapper:\n\n def __init__(self, query):\n self.query = query\n self.results = None\n\n def __getitem__(self, range):\n if self.results is not None:\n raise RuntimeError(\"Cannot reslice after having already sliced.\")\n self.results = self.query[range].execute()\n\n return list(self.results)\n\n def __len__(self):\n if self.results is None:\n raise RuntimeError(\"Cannot get length until a slice.\")\n return self.results.hits.total\n\n\ndef ElasticsearchPage(*args, **kwargs): # noqa\n kwargs.setdefault(\"wrapper_class\", _ElasticsearchWrapper)\n return Page(*args, **kwargs)\n\n\ndef paginate_url_factory(request, query_arg=\"page\"):\n def make_url(page):\n query_seq = [\n (k, v)\n for k, vs in request.GET.dict_of_lists().items()\n for v in vs\n if k != query_arg\n ]\n query_seq += [(query_arg, page)]\n return request.current_route_path(_query=query_seq)\n return make_url\n", "path": "warehouse/utils/paginate.py"}, {"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom pyramid.httpexceptions import (\n HTTPException, HTTPSeeOther, HTTPMovedPermanently,\n)\nfrom pyramid.view import (\n notfound_view_config, forbidden_view_config, view_config,\n)\nfrom sqlalchemy import func\nfrom sqlalchemy.orm import aliased, joinedload\n\nfrom warehouse.accounts import REDIRECT_FIELD_NAME\nfrom warehouse.accounts.models import User\nfrom warehouse.cache.origin import origin_cache\nfrom warehouse.cache.http import cache_control\nfrom warehouse.csrf import csrf_exempt\nfrom warehouse.packaging.models import Project, Release, File\nfrom warehouse.sessions import uses_session\nfrom warehouse.utils.row_counter import RowCount\nfrom warehouse.utils.paginate import ElasticsearchPage, paginate_url_factory\n\n\n@view_config(context=HTTPException, decorator=[csrf_exempt])\n@notfound_view_config(\n append_slash=HTTPMovedPermanently,\n decorator=[csrf_exempt],\n)\ndef httpexception_view(exc, request):\n return exc\n\n\n@forbidden_view_config()\ndef forbidden(exc, request):\n # If the forbidden error is because the user isn't logged in, then we'll\n # redirect them to the log in page.\n if request.authenticated_userid is None:\n url = request.route_url(\n \"accounts.login\",\n _query={REDIRECT_FIELD_NAME: request.path_qs},\n )\n return HTTPSeeOther(url)\n\n # If we've reached here, then the user is logged in and they are genuinely\n # not allowed to access this page.\n # TODO: Style the forbidden page.\n return exc\n\n\n@view_config(\n route_name=\"robots.txt\",\n renderer=\"robots.txt\",\n decorator=[\n cache_control(1 * 24 * 60 * 60), # 1 day\n origin_cache(\n 1 * 24 * 60 * 60, # 1 day\n stale_while_revalidate=6 * 60 * 60, # 6 hours\n stale_if_error=1 * 24 * 60 * 60, # 1 day\n ),\n ],\n)\ndef robotstxt(request):\n request.response.content_type = \"text/plain\"\n return {}\n\n\n@view_config(\n route_name=\"index\",\n renderer=\"index.html\",\n decorator=[\n origin_cache(\n 1 * 60 * 60, # 1 hour\n stale_while_revalidate=10 * 60, # 10 minutes\n stale_if_error=1 * 24 * 60 * 60, # 1 day\n keys=[\"all-projects\"],\n ),\n ]\n)\ndef index(request):\n project_names = [\n r[0] for r in (\n request.db.query(File.name)\n .group_by(File.name)\n .order_by(func.sum(File.downloads).desc())\n .limit(5)\n .all())\n ]\n release_a = aliased(\n Release,\n request.db.query(Release)\n .distinct(Release.name)\n .filter(Release.name.in_(project_names))\n .order_by(Release.name, Release._pypi_ordering.desc())\n .subquery(),\n )\n top_projects = (\n request.db.query(release_a)\n .options(joinedload(release_a.project),\n joinedload(release_a.uploader))\n .order_by(func.array_idx(project_names, release_a.name))\n .all()\n )\n\n latest_releases = (\n request.db.query(Release)\n .options(joinedload(Release.project),\n joinedload(Release.uploader))\n .order_by(Release.created.desc())\n .limit(5)\n .all()\n )\n\n counts = dict(\n request.db.query(RowCount.table_name, RowCount.count)\n .filter(\n RowCount.table_name.in_([\n Project.__tablename__,\n Release.__tablename__,\n File.__tablename__,\n User.__tablename__,\n ]))\n .all()\n )\n\n return {\n \"latest_releases\": latest_releases,\n \"top_projects\": top_projects,\n \"num_projects\": counts.get(Project.__tablename__, 0),\n \"num_releases\": counts.get(Release.__tablename__, 0),\n \"num_files\": counts.get(File.__tablename__, 0),\n \"num_users\": counts.get(User.__tablename__, 0),\n }\n\n\n@view_config(\n route_name=\"search\",\n renderer=\"search/results.html\",\n decorator=[\n origin_cache(\n 1 * 60 * 60, # 1 hour\n stale_while_revalidate=10 * 60, # 10 minutes\n stale_if_error=1 * 24 * 60 * 60, # 1 day\n keys=[\"all-projects\"],\n )\n ],\n)\ndef search(request):\n if request.params.get(\"q\"):\n query = request.es.query(\n \"multi_match\",\n query=request.params[\"q\"],\n fields=[\n \"name\", \"version\", \"author\", \"author_email\", \"maintainer\",\n \"maintainer_email\", \"home_page\", \"license\", \"summary\",\n \"description\", \"keywords\", \"platform\", \"download_url\",\n ],\n )\n else:\n query = request.es.query()\n\n page = ElasticsearchPage(\n query,\n page=int(request.params.get(\"page\", 1)),\n url_maker=paginate_url_factory(request),\n )\n\n return {\"page\": page, \"term\": request.params.get(\"q\")}\n\n\n@view_config(\n route_name=\"includes.current-user-indicator\",\n renderer=\"includes/current-user-indicator.html\",\n decorator=[uses_session],\n)\ndef current_user_indicator(request):\n return {}\n", "path": "warehouse/views.py"}], "after_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom paginate import Page\n\n\nclass _ElasticsearchWrapper:\n\n def __init__(self, query):\n self.query = query\n self.results = None\n self.best_guess = None\n\n def __getitem__(self, range):\n if self.results is not None:\n raise RuntimeError(\"Cannot reslice after having already sliced.\")\n self.results = self.query[range].execute()\n\n if hasattr(self.results, \"suggest\"):\n suggestion = self.results.suggest.name_suggestion[0]\n if suggestion.options:\n self.best_guess = suggestion.options[0]\n\n return list(self.results)\n\n def __len__(self):\n if self.results is None:\n raise RuntimeError(\"Cannot get length until a slice.\")\n return self.results.hits.total\n\n\ndef ElasticsearchPage(*args, **kwargs): # noqa\n kwargs.setdefault(\"wrapper_class\", _ElasticsearchWrapper)\n return Page(*args, **kwargs)\n\n\ndef paginate_url_factory(request, query_arg=\"page\"):\n def make_url(page):\n query_seq = [\n (k, v)\n for k, vs in request.GET.dict_of_lists().items()\n for v in vs\n if k != query_arg\n ]\n query_seq += [(query_arg, page)]\n return request.current_route_path(_query=query_seq)\n return make_url\n", "path": "warehouse/utils/paginate.py"}, {"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom pyramid.httpexceptions import (\n HTTPException, HTTPSeeOther, HTTPMovedPermanently,\n)\nfrom pyramid.view import (\n notfound_view_config, forbidden_view_config, view_config,\n)\nfrom sqlalchemy import func\nfrom sqlalchemy.orm import aliased, joinedload\n\nfrom warehouse.accounts import REDIRECT_FIELD_NAME\nfrom warehouse.accounts.models import User\nfrom warehouse.cache.origin import origin_cache\nfrom warehouse.cache.http import cache_control\nfrom warehouse.csrf import csrf_exempt\nfrom warehouse.packaging.models import Project, Release, File\nfrom warehouse.sessions import uses_session\nfrom warehouse.utils.row_counter import RowCount\nfrom warehouse.utils.paginate import ElasticsearchPage, paginate_url_factory\n\n\n@view_config(context=HTTPException, decorator=[csrf_exempt])\n@notfound_view_config(\n append_slash=HTTPMovedPermanently,\n decorator=[csrf_exempt],\n)\ndef httpexception_view(exc, request):\n return exc\n\n\n@forbidden_view_config()\ndef forbidden(exc, request):\n # If the forbidden error is because the user isn't logged in, then we'll\n # redirect them to the log in page.\n if request.authenticated_userid is None:\n url = request.route_url(\n \"accounts.login\",\n _query={REDIRECT_FIELD_NAME: request.path_qs},\n )\n return HTTPSeeOther(url)\n\n # If we've reached here, then the user is logged in and they are genuinely\n # not allowed to access this page.\n # TODO: Style the forbidden page.\n return exc\n\n\n@view_config(\n route_name=\"robots.txt\",\n renderer=\"robots.txt\",\n decorator=[\n cache_control(1 * 24 * 60 * 60), # 1 day\n origin_cache(\n 1 * 24 * 60 * 60, # 1 day\n stale_while_revalidate=6 * 60 * 60, # 6 hours\n stale_if_error=1 * 24 * 60 * 60, # 1 day\n ),\n ],\n)\ndef robotstxt(request):\n request.response.content_type = \"text/plain\"\n return {}\n\n\n@view_config(\n route_name=\"index\",\n renderer=\"index.html\",\n decorator=[\n origin_cache(\n 1 * 60 * 60, # 1 hour\n stale_while_revalidate=10 * 60, # 10 minutes\n stale_if_error=1 * 24 * 60 * 60, # 1 day\n keys=[\"all-projects\"],\n ),\n ]\n)\ndef index(request):\n project_names = [\n r[0] for r in (\n request.db.query(File.name)\n .group_by(File.name)\n .order_by(func.sum(File.downloads).desc())\n .limit(5)\n .all())\n ]\n release_a = aliased(\n Release,\n request.db.query(Release)\n .distinct(Release.name)\n .filter(Release.name.in_(project_names))\n .order_by(Release.name, Release._pypi_ordering.desc())\n .subquery(),\n )\n top_projects = (\n request.db.query(release_a)\n .options(joinedload(release_a.project),\n joinedload(release_a.uploader))\n .order_by(func.array_idx(project_names, release_a.name))\n .all()\n )\n\n latest_releases = (\n request.db.query(Release)\n .options(joinedload(Release.project),\n joinedload(Release.uploader))\n .order_by(Release.created.desc())\n .limit(5)\n .all()\n )\n\n counts = dict(\n request.db.query(RowCount.table_name, RowCount.count)\n .filter(\n RowCount.table_name.in_([\n Project.__tablename__,\n Release.__tablename__,\n File.__tablename__,\n User.__tablename__,\n ]))\n .all()\n )\n\n return {\n \"latest_releases\": latest_releases,\n \"top_projects\": top_projects,\n \"num_projects\": counts.get(Project.__tablename__, 0),\n \"num_releases\": counts.get(Release.__tablename__, 0),\n \"num_files\": counts.get(File.__tablename__, 0),\n \"num_users\": counts.get(User.__tablename__, 0),\n }\n\n\n@view_config(\n route_name=\"search\",\n renderer=\"search/results.html\",\n decorator=[\n origin_cache(\n 1 * 60 * 60, # 1 hour\n stale_while_revalidate=10 * 60, # 10 minutes\n stale_if_error=1 * 24 * 60 * 60, # 1 day\n keys=[\"all-projects\"],\n )\n ],\n)\ndef search(request):\n if request.params.get(\"q\"):\n query = request.es.query(\n \"multi_match\",\n query=request.params[\"q\"],\n fields=[\n \"name\", \"version\", \"author\", \"author_email\", \"maintainer\",\n \"maintainer_email\", \"home_page\", \"license\", \"summary\",\n \"description\", \"keywords\", \"platform\", \"download_url\",\n ],\n ).suggest(\n name=\"name_suggestion\",\n text=request.params[\"q\"],\n term={\"field\": \"name\"}\n )\n else:\n query = request.es.query()\n\n page = ElasticsearchPage(\n query,\n page=int(request.params.get(\"page\", 1)),\n url_maker=paginate_url_factory(request),\n )\n\n return {\"page\": page, \"term\": request.params.get(\"q\")}\n\n\n@view_config(\n route_name=\"includes.current-user-indicator\",\n renderer=\"includes/current-user-indicator.html\",\n decorator=[uses_session],\n)\ndef current_user_indicator(request):\n return {}\n", "path": "warehouse/views.py"}]}
| 2,525 | 297 |
gh_patches_debug_63588
|
rasdani/github-patches
|
git_diff
|
docker__docker-py-2687
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Plugin model upgrade: object has no attribute '_reload'
I've already got a fix for this that I'm about to submit. For reference, here are the steps to reproduce in ipython:
```
~$ ipython [venv]
Python 3.7.6 (default, Dec 22 2019, 01:09:06)
Type 'copyright', 'credits' or 'license' for more information
IPython 7.18.1 -- An enhanced Interactive Python. Type '?' for help.
In [1]: import docker
In [2]: c = docker.DockerClient(base_url='unix://var/run/docker.sock')
In [3]: p = c.plugins.get('loki')
In [4]: list(p.upgrade("grafana/loki-docker-driver:latest"))
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-4-e5fc26fa0514> in <module>
----> 1 list(p.upgrade("grafana/loki-docker-driver:latest"))
~/venv/lib/python3.7/site-packages/docker/models/plugins.py in upgrade(self, remote)
120 for d in self.client.api.upgrade_plugin(self.name, remote, privileges):
121 yield d
--> 122 self._reload()
123
124
AttributeError: 'Plugin' object has no attribute '_reload'
```
```
docker==4.3.1
Python 3.7.6
Client: Docker Engine - Community
Cloud integration 0.1.18
Version: 19.03.13
API version: 1.40
Go version: go1.13.15
Git commit: 4484c46d9d
Built: Wed Sep 16 16:58:31 2020
OS/Arch: darwin/amd64
Experimental: true
Server: Docker Engine - Community
Engine:
Version: 19.03.13
API version: 1.40 (minimum version 1.12)
Go version: go1.13.15
Git commit: 4484c46d9d
Built: Wed Sep 16 17:07:04 2020
OS/Arch: linux/amd64
Experimental: true
containerd:
Version: v1.3.7
GitCommit: 8fba4e9a7d01810a393d5d25a3621dc101981175
runc:
Version: 1.0.0-rc10
GitCommit: dc9208a3303feef5b3839f4323d9beb36df0a9dd
docker-init:
Version: 0.18.0
GitCommit: fec3683
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docker/models/plugins.py`
Content:
```
1 from .. import errors
2 from .resource import Collection, Model
3
4
5 class Plugin(Model):
6 """
7 A plugin on the server.
8 """
9 def __repr__(self):
10 return "<%s: '%s'>" % (self.__class__.__name__, self.name)
11
12 @property
13 def name(self):
14 """
15 The plugin's name.
16 """
17 return self.attrs.get('Name')
18
19 @property
20 def enabled(self):
21 """
22 Whether the plugin is enabled.
23 """
24 return self.attrs.get('Enabled')
25
26 @property
27 def settings(self):
28 """
29 A dictionary representing the plugin's configuration.
30 """
31 return self.attrs.get('Settings')
32
33 def configure(self, options):
34 """
35 Update the plugin's settings.
36
37 Args:
38 options (dict): A key-value mapping of options.
39
40 Raises:
41 :py:class:`docker.errors.APIError`
42 If the server returns an error.
43 """
44 self.client.api.configure_plugin(self.name, options)
45 self.reload()
46
47 def disable(self):
48 """
49 Disable the plugin.
50
51 Raises:
52 :py:class:`docker.errors.APIError`
53 If the server returns an error.
54 """
55
56 self.client.api.disable_plugin(self.name)
57 self.reload()
58
59 def enable(self, timeout=0):
60 """
61 Enable the plugin.
62
63 Args:
64 timeout (int): Timeout in seconds. Default: 0
65
66 Raises:
67 :py:class:`docker.errors.APIError`
68 If the server returns an error.
69 """
70 self.client.api.enable_plugin(self.name, timeout)
71 self.reload()
72
73 def push(self):
74 """
75 Push the plugin to a remote registry.
76
77 Returns:
78 A dict iterator streaming the status of the upload.
79
80 Raises:
81 :py:class:`docker.errors.APIError`
82 If the server returns an error.
83 """
84 return self.client.api.push_plugin(self.name)
85
86 def remove(self, force=False):
87 """
88 Remove the plugin from the server.
89
90 Args:
91 force (bool): Remove even if the plugin is enabled.
92 Default: False
93
94 Raises:
95 :py:class:`docker.errors.APIError`
96 If the server returns an error.
97 """
98 return self.client.api.remove_plugin(self.name, force=force)
99
100 def upgrade(self, remote=None):
101 """
102 Upgrade the plugin.
103
104 Args:
105 remote (string): Remote reference to upgrade to. The
106 ``:latest`` tag is optional and is the default if omitted.
107 Default: this plugin's name.
108
109 Returns:
110 A generator streaming the decoded API logs
111 """
112 if self.enabled:
113 raise errors.DockerError(
114 'Plugin must be disabled before upgrading.'
115 )
116
117 if remote is None:
118 remote = self.name
119 privileges = self.client.api.plugin_privileges(remote)
120 for d in self.client.api.upgrade_plugin(self.name, remote, privileges):
121 yield d
122 self._reload()
123
124
125 class PluginCollection(Collection):
126 model = Plugin
127
128 def create(self, name, plugin_data_dir, gzip=False):
129 """
130 Create a new plugin.
131
132 Args:
133 name (string): The name of the plugin. The ``:latest`` tag is
134 optional, and is the default if omitted.
135 plugin_data_dir (string): Path to the plugin data directory.
136 Plugin data directory must contain the ``config.json``
137 manifest file and the ``rootfs`` directory.
138 gzip (bool): Compress the context using gzip. Default: False
139
140 Returns:
141 (:py:class:`Plugin`): The newly created plugin.
142 """
143 self.client.api.create_plugin(name, plugin_data_dir, gzip)
144 return self.get(name)
145
146 def get(self, name):
147 """
148 Gets a plugin.
149
150 Args:
151 name (str): The name of the plugin.
152
153 Returns:
154 (:py:class:`Plugin`): The plugin.
155
156 Raises:
157 :py:class:`docker.errors.NotFound` If the plugin does not
158 exist.
159 :py:class:`docker.errors.APIError`
160 If the server returns an error.
161 """
162 return self.prepare_model(self.client.api.inspect_plugin(name))
163
164 def install(self, remote_name, local_name=None):
165 """
166 Pull and install a plugin.
167
168 Args:
169 remote_name (string): Remote reference for the plugin to
170 install. The ``:latest`` tag is optional, and is the
171 default if omitted.
172 local_name (string): Local name for the pulled plugin.
173 The ``:latest`` tag is optional, and is the default if
174 omitted. Optional.
175
176 Returns:
177 (:py:class:`Plugin`): The installed plugin
178 Raises:
179 :py:class:`docker.errors.APIError`
180 If the server returns an error.
181 """
182 privileges = self.client.api.plugin_privileges(remote_name)
183 it = self.client.api.pull_plugin(remote_name, privileges, local_name)
184 for data in it:
185 pass
186 return self.get(local_name or remote_name)
187
188 def list(self):
189 """
190 List plugins installed on the server.
191
192 Returns:
193 (list of :py:class:`Plugin`): The plugins.
194
195 Raises:
196 :py:class:`docker.errors.APIError`
197 If the server returns an error.
198 """
199 resp = self.client.api.plugins()
200 return [self.prepare_model(r) for r in resp]
201
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docker/models/plugins.py b/docker/models/plugins.py
--- a/docker/models/plugins.py
+++ b/docker/models/plugins.py
@@ -119,7 +119,7 @@
privileges = self.client.api.plugin_privileges(remote)
for d in self.client.api.upgrade_plugin(self.name, remote, privileges):
yield d
- self._reload()
+ self.reload()
class PluginCollection(Collection):
|
{"golden_diff": "diff --git a/docker/models/plugins.py b/docker/models/plugins.py\n--- a/docker/models/plugins.py\n+++ b/docker/models/plugins.py\n@@ -119,7 +119,7 @@\n privileges = self.client.api.plugin_privileges(remote)\n for d in self.client.api.upgrade_plugin(self.name, remote, privileges):\n yield d\n- self._reload()\n+ self.reload()\n \n \n class PluginCollection(Collection):\n", "issue": "Plugin model upgrade: object has no attribute '_reload'\nI've already got a fix for this that I'm about to submit. For reference, here are the steps to reproduce in ipython:\r\n```\r\n~$ ipython [venv]\r\nPython 3.7.6 (default, Dec 22 2019, 01:09:06)\r\nType 'copyright', 'credits' or 'license' for more information\r\nIPython 7.18.1 -- An enhanced Interactive Python. Type '?' for help.\r\n\r\nIn [1]: import docker\r\n\r\nIn [2]: c = docker.DockerClient(base_url='unix://var/run/docker.sock')\r\n\r\nIn [3]: p = c.plugins.get('loki')\r\n\r\nIn [4]: list(p.upgrade(\"grafana/loki-docker-driver:latest\"))\r\n---------------------------------------------------------------------------\r\nAttributeError Traceback (most recent call last)\r\n<ipython-input-4-e5fc26fa0514> in <module>\r\n----> 1 list(p.upgrade(\"grafana/loki-docker-driver:latest\"))\r\n\r\n~/venv/lib/python3.7/site-packages/docker/models/plugins.py in upgrade(self, remote)\r\n 120 for d in self.client.api.upgrade_plugin(self.name, remote, privileges):\r\n 121 yield d\r\n--> 122 self._reload()\r\n 123\r\n 124\r\n\r\nAttributeError: 'Plugin' object has no attribute '_reload'\r\n```\r\n\r\n```\r\ndocker==4.3.1\r\nPython 3.7.6\r\nClient: Docker Engine - Community\r\n Cloud integration 0.1.18\r\n Version: 19.03.13\r\n API version: 1.40\r\n Go version: go1.13.15\r\n Git commit: 4484c46d9d\r\n Built: Wed Sep 16 16:58:31 2020\r\n OS/Arch: darwin/amd64\r\n Experimental: true\r\n\r\nServer: Docker Engine - Community\r\n Engine:\r\n Version: 19.03.13\r\n API version: 1.40 (minimum version 1.12)\r\n Go version: go1.13.15\r\n Git commit: 4484c46d9d\r\n Built: Wed Sep 16 17:07:04 2020\r\n OS/Arch: linux/amd64\r\n Experimental: true\r\n containerd:\r\n Version: v1.3.7\r\n GitCommit: 8fba4e9a7d01810a393d5d25a3621dc101981175\r\n runc:\r\n Version: 1.0.0-rc10\r\n GitCommit: dc9208a3303feef5b3839f4323d9beb36df0a9dd\r\n docker-init:\r\n Version: 0.18.0\r\n GitCommit: fec3683\r\n```\n", "before_files": [{"content": "from .. import errors\nfrom .resource import Collection, Model\n\n\nclass Plugin(Model):\n \"\"\"\n A plugin on the server.\n \"\"\"\n def __repr__(self):\n return \"<%s: '%s'>\" % (self.__class__.__name__, self.name)\n\n @property\n def name(self):\n \"\"\"\n The plugin's name.\n \"\"\"\n return self.attrs.get('Name')\n\n @property\n def enabled(self):\n \"\"\"\n Whether the plugin is enabled.\n \"\"\"\n return self.attrs.get('Enabled')\n\n @property\n def settings(self):\n \"\"\"\n A dictionary representing the plugin's configuration.\n \"\"\"\n return self.attrs.get('Settings')\n\n def configure(self, options):\n \"\"\"\n Update the plugin's settings.\n\n Args:\n options (dict): A key-value mapping of options.\n\n Raises:\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n \"\"\"\n self.client.api.configure_plugin(self.name, options)\n self.reload()\n\n def disable(self):\n \"\"\"\n Disable the plugin.\n\n Raises:\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n \"\"\"\n\n self.client.api.disable_plugin(self.name)\n self.reload()\n\n def enable(self, timeout=0):\n \"\"\"\n Enable the plugin.\n\n Args:\n timeout (int): Timeout in seconds. Default: 0\n\n Raises:\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n \"\"\"\n self.client.api.enable_plugin(self.name, timeout)\n self.reload()\n\n def push(self):\n \"\"\"\n Push the plugin to a remote registry.\n\n Returns:\n A dict iterator streaming the status of the upload.\n\n Raises:\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n \"\"\"\n return self.client.api.push_plugin(self.name)\n\n def remove(self, force=False):\n \"\"\"\n Remove the plugin from the server.\n\n Args:\n force (bool): Remove even if the plugin is enabled.\n Default: False\n\n Raises:\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n \"\"\"\n return self.client.api.remove_plugin(self.name, force=force)\n\n def upgrade(self, remote=None):\n \"\"\"\n Upgrade the plugin.\n\n Args:\n remote (string): Remote reference to upgrade to. The\n ``:latest`` tag is optional and is the default if omitted.\n Default: this plugin's name.\n\n Returns:\n A generator streaming the decoded API logs\n \"\"\"\n if self.enabled:\n raise errors.DockerError(\n 'Plugin must be disabled before upgrading.'\n )\n\n if remote is None:\n remote = self.name\n privileges = self.client.api.plugin_privileges(remote)\n for d in self.client.api.upgrade_plugin(self.name, remote, privileges):\n yield d\n self._reload()\n\n\nclass PluginCollection(Collection):\n model = Plugin\n\n def create(self, name, plugin_data_dir, gzip=False):\n \"\"\"\n Create a new plugin.\n\n Args:\n name (string): The name of the plugin. The ``:latest`` tag is\n optional, and is the default if omitted.\n plugin_data_dir (string): Path to the plugin data directory.\n Plugin data directory must contain the ``config.json``\n manifest file and the ``rootfs`` directory.\n gzip (bool): Compress the context using gzip. Default: False\n\n Returns:\n (:py:class:`Plugin`): The newly created plugin.\n \"\"\"\n self.client.api.create_plugin(name, plugin_data_dir, gzip)\n return self.get(name)\n\n def get(self, name):\n \"\"\"\n Gets a plugin.\n\n Args:\n name (str): The name of the plugin.\n\n Returns:\n (:py:class:`Plugin`): The plugin.\n\n Raises:\n :py:class:`docker.errors.NotFound` If the plugin does not\n exist.\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n \"\"\"\n return self.prepare_model(self.client.api.inspect_plugin(name))\n\n def install(self, remote_name, local_name=None):\n \"\"\"\n Pull and install a plugin.\n\n Args:\n remote_name (string): Remote reference for the plugin to\n install. The ``:latest`` tag is optional, and is the\n default if omitted.\n local_name (string): Local name for the pulled plugin.\n The ``:latest`` tag is optional, and is the default if\n omitted. Optional.\n\n Returns:\n (:py:class:`Plugin`): The installed plugin\n Raises:\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n \"\"\"\n privileges = self.client.api.plugin_privileges(remote_name)\n it = self.client.api.pull_plugin(remote_name, privileges, local_name)\n for data in it:\n pass\n return self.get(local_name or remote_name)\n\n def list(self):\n \"\"\"\n List plugins installed on the server.\n\n Returns:\n (list of :py:class:`Plugin`): The plugins.\n\n Raises:\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n \"\"\"\n resp = self.client.api.plugins()\n return [self.prepare_model(r) for r in resp]\n", "path": "docker/models/plugins.py"}], "after_files": [{"content": "from .. import errors\nfrom .resource import Collection, Model\n\n\nclass Plugin(Model):\n \"\"\"\n A plugin on the server.\n \"\"\"\n def __repr__(self):\n return \"<%s: '%s'>\" % (self.__class__.__name__, self.name)\n\n @property\n def name(self):\n \"\"\"\n The plugin's name.\n \"\"\"\n return self.attrs.get('Name')\n\n @property\n def enabled(self):\n \"\"\"\n Whether the plugin is enabled.\n \"\"\"\n return self.attrs.get('Enabled')\n\n @property\n def settings(self):\n \"\"\"\n A dictionary representing the plugin's configuration.\n \"\"\"\n return self.attrs.get('Settings')\n\n def configure(self, options):\n \"\"\"\n Update the plugin's settings.\n\n Args:\n options (dict): A key-value mapping of options.\n\n Raises:\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n \"\"\"\n self.client.api.configure_plugin(self.name, options)\n self.reload()\n\n def disable(self):\n \"\"\"\n Disable the plugin.\n\n Raises:\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n \"\"\"\n\n self.client.api.disable_plugin(self.name)\n self.reload()\n\n def enable(self, timeout=0):\n \"\"\"\n Enable the plugin.\n\n Args:\n timeout (int): Timeout in seconds. Default: 0\n\n Raises:\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n \"\"\"\n self.client.api.enable_plugin(self.name, timeout)\n self.reload()\n\n def push(self):\n \"\"\"\n Push the plugin to a remote registry.\n\n Returns:\n A dict iterator streaming the status of the upload.\n\n Raises:\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n \"\"\"\n return self.client.api.push_plugin(self.name)\n\n def remove(self, force=False):\n \"\"\"\n Remove the plugin from the server.\n\n Args:\n force (bool): Remove even if the plugin is enabled.\n Default: False\n\n Raises:\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n \"\"\"\n return self.client.api.remove_plugin(self.name, force=force)\n\n def upgrade(self, remote=None):\n \"\"\"\n Upgrade the plugin.\n\n Args:\n remote (string): Remote reference to upgrade to. The\n ``:latest`` tag is optional and is the default if omitted.\n Default: this plugin's name.\n\n Returns:\n A generator streaming the decoded API logs\n \"\"\"\n if self.enabled:\n raise errors.DockerError(\n 'Plugin must be disabled before upgrading.'\n )\n\n if remote is None:\n remote = self.name\n privileges = self.client.api.plugin_privileges(remote)\n for d in self.client.api.upgrade_plugin(self.name, remote, privileges):\n yield d\n self.reload()\n\n\nclass PluginCollection(Collection):\n model = Plugin\n\n def create(self, name, plugin_data_dir, gzip=False):\n \"\"\"\n Create a new plugin.\n\n Args:\n name (string): The name of the plugin. The ``:latest`` tag is\n optional, and is the default if omitted.\n plugin_data_dir (string): Path to the plugin data directory.\n Plugin data directory must contain the ``config.json``\n manifest file and the ``rootfs`` directory.\n gzip (bool): Compress the context using gzip. Default: False\n\n Returns:\n (:py:class:`Plugin`): The newly created plugin.\n \"\"\"\n self.client.api.create_plugin(name, plugin_data_dir, gzip)\n return self.get(name)\n\n def get(self, name):\n \"\"\"\n Gets a plugin.\n\n Args:\n name (str): The name of the plugin.\n\n Returns:\n (:py:class:`Plugin`): The plugin.\n\n Raises:\n :py:class:`docker.errors.NotFound` If the plugin does not\n exist.\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n \"\"\"\n return self.prepare_model(self.client.api.inspect_plugin(name))\n\n def install(self, remote_name, local_name=None):\n \"\"\"\n Pull and install a plugin.\n\n Args:\n remote_name (string): Remote reference for the plugin to\n install. The ``:latest`` tag is optional, and is the\n default if omitted.\n local_name (string): Local name for the pulled plugin.\n The ``:latest`` tag is optional, and is the default if\n omitted. Optional.\n\n Returns:\n (:py:class:`Plugin`): The installed plugin\n Raises:\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n \"\"\"\n privileges = self.client.api.plugin_privileges(remote_name)\n it = self.client.api.pull_plugin(remote_name, privileges, local_name)\n for data in it:\n pass\n return self.get(local_name or remote_name)\n\n def list(self):\n \"\"\"\n List plugins installed on the server.\n\n Returns:\n (list of :py:class:`Plugin`): The plugins.\n\n Raises:\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n \"\"\"\n resp = self.client.api.plugins()\n return [self.prepare_model(r) for r in resp]\n", "path": "docker/models/plugins.py"}]}
| 2,606 | 91 |
gh_patches_debug_49586
|
rasdani/github-patches
|
git_diff
|
quantumlib__Cirq-3358
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
upgrade to numpy 1.19
Discover all the issues / test failures related to numpy 0.19 and upgrade our requirements.txt.
More context: https://github.com/quantumlib/Cirq/pull/3106
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cirq/optimizers/decompositions.py`
Content:
```
1 # Copyright 2018 The Cirq Developers
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Utility methods related to optimizing quantum circuits."""
16
17 import math
18 from typing import List, Optional, Tuple, cast
19
20 import numpy as np
21 import sympy
22
23 from cirq import ops, linalg, protocols
24 from cirq.linalg.tolerance import near_zero_mod
25
26
27 def is_negligible_turn(turns: float, tolerance: float) -> bool:
28 if isinstance(turns, sympy.Basic):
29 if not turns.is_constant():
30 return False
31 turns = float(turns)
32 return abs(_signed_mod_1(turns)) <= tolerance
33
34
35 def _signed_mod_1(x: float) -> float:
36 return (x + 0.5) % 1 - 0.5
37
38
39 def single_qubit_matrix_to_pauli_rotations(
40 mat: np.ndarray, atol: float = 0
41 ) -> List[Tuple[ops.Pauli, float]]:
42 """Implements a single-qubit operation with few rotations.
43
44 Args:
45 mat: The 2x2 unitary matrix of the operation to implement.
46 atol: A limit on the amount of absolute error introduced by the
47 construction.
48
49 Returns:
50 A list of (Pauli, half_turns) tuples that, when applied in order,
51 perform the desired operation.
52 """
53
54 def is_clifford_rotation(half_turns):
55 return near_zero_mod(half_turns, 0.5, atol=atol)
56
57 def to_quarter_turns(half_turns):
58 return round(2 * half_turns) % 4
59
60 def is_quarter_turn(half_turns):
61 return (is_clifford_rotation(half_turns) and
62 to_quarter_turns(half_turns) % 2 == 1)
63
64 def is_half_turn(half_turns):
65 return (is_clifford_rotation(half_turns) and
66 to_quarter_turns(half_turns) == 2)
67
68 def is_no_turn(half_turns):
69 return (is_clifford_rotation(half_turns) and
70 to_quarter_turns(half_turns) == 0)
71
72 # Decompose matrix
73 z_rad_before, y_rad, z_rad_after = (
74 linalg.deconstruct_single_qubit_matrix_into_angles(mat))
75 z_ht_before = z_rad_before / np.pi - 0.5
76 m_ht = y_rad / np.pi
77 m_pauli = ops.X # type: ops.Pauli
78 z_ht_after = z_rad_after / np.pi + 0.5
79
80 # Clean up angles
81 if is_clifford_rotation(z_ht_before):
82 if ((is_quarter_turn(z_ht_before) or is_quarter_turn(z_ht_after)) ^
83 (is_half_turn(m_ht) and is_no_turn(z_ht_before-z_ht_after))):
84 z_ht_before += 0.5
85 z_ht_after -= 0.5
86 m_pauli = ops.Y
87 if is_half_turn(z_ht_before) or is_half_turn(z_ht_after):
88 z_ht_before -= 1
89 z_ht_after += 1
90 m_ht = -m_ht
91 if is_no_turn(m_ht):
92 z_ht_before += z_ht_after
93 z_ht_after = 0
94 elif is_half_turn(m_ht):
95 z_ht_after -= z_ht_before
96 z_ht_before = 0
97
98 # Generate operations
99 rotation_list = [(ops.Z, z_ht_before), (m_pauli, m_ht), (ops.Z, z_ht_after)]
100 return [(pauli, ht) for pauli, ht in rotation_list if not is_no_turn(ht)]
101
102
103 def single_qubit_matrix_to_gates(
104 mat: np.ndarray, tolerance: float = 0
105 ) -> List[ops.SingleQubitGate]:
106 """Implements a single-qubit operation with few gates.
107
108 Args:
109 mat: The 2x2 unitary matrix of the operation to implement.
110 tolerance: A limit on the amount of error introduced by the
111 construction.
112
113 Returns:
114 A list of gates that, when applied in order, perform the desired
115 operation.
116 """
117 rotations = single_qubit_matrix_to_pauli_rotations(mat, tolerance)
118 return [cast(ops.SingleQubitGate, pauli)**ht for pauli, ht in rotations]
119
120
121 def single_qubit_op_to_framed_phase_form(
122 mat: np.ndarray) -> Tuple[np.ndarray, complex, complex]:
123 """Decomposes a 2x2 unitary M into U^-1 * diag(1, r) * U * diag(g, g).
124
125 U translates the rotation axis of M to the Z axis.
126 g fixes a global phase factor difference caused by the translation.
127 r's phase is the amount of rotation around M's rotation axis.
128
129 This decomposition can be used to decompose controlled single-qubit
130 rotations into controlled-Z operations bordered by single-qubit operations.
131
132 Args:
133 mat: The qubit operation as a 2x2 unitary matrix.
134
135 Returns:
136 A 2x2 unitary U, the complex relative phase factor r, and the complex
137 global phase factor g. Applying M is equivalent (up to global phase) to
138 applying U, rotating around the Z axis to apply r, then un-applying U.
139 When M is controlled, the control must be rotated around the Z axis to
140 apply g.
141 """
142 vals, vecs = np.linalg.eig(mat)
143 u = np.conj(vecs).T
144 r = vals[1] / vals[0]
145 g = vals[0]
146 return u, r, g
147
148
149 def _deconstruct_single_qubit_matrix_into_gate_turns(
150 mat: np.ndarray) -> Tuple[float, float, float]:
151 """Breaks down a 2x2 unitary into gate parameters.
152
153 Args:
154 mat: The 2x2 unitary matrix to break down.
155
156 Returns:
157 A tuple containing the amount to rotate around an XY axis, the phase of
158 that axis, and the amount to phase around Z. All results will be in
159 fractions of a whole turn, with values canonicalized into the range
160 [-0.5, 0.5).
161 """
162 pre_phase, rotation, post_phase = (
163 linalg.deconstruct_single_qubit_matrix_into_angles(mat))
164
165 # Figure out parameters of the actual gates we will do.
166 tau = 2 * np.pi
167 xy_turn = rotation / tau
168 xy_phase_turn = 0.25 - pre_phase / tau
169 total_z_turn = (post_phase + pre_phase) / tau
170
171 # Normalize turns into the range [-0.5, 0.5).
172 return (_signed_mod_1(xy_turn), _signed_mod_1(xy_phase_turn),
173 _signed_mod_1(total_z_turn))
174
175
176 def single_qubit_matrix_to_phased_x_z(
177 mat: np.ndarray,
178 atol: float = 0
179 ) -> List[ops.SingleQubitGate]:
180 """Implements a single-qubit operation with a PhasedX and Z gate.
181
182 If one of the gates isn't needed, it will be omitted.
183
184 Args:
185 mat: The 2x2 unitary matrix of the operation to implement.
186 atol: A limit on the amount of error introduced by the
187 construction.
188
189 Returns:
190 A list of gates that, when applied in order, perform the desired
191 operation.
192 """
193
194 xy_turn, xy_phase_turn, total_z_turn = (
195 _deconstruct_single_qubit_matrix_into_gate_turns(mat))
196
197 # Build the intended operation out of non-negligible XY and Z rotations.
198 result = [
199 ops.PhasedXPowGate(exponent=2 * xy_turn,
200 phase_exponent=2 * xy_phase_turn),
201 ops.Z**(2 * total_z_turn)
202 ]
203 result = [
204 g for g in result
205 if protocols.trace_distance_bound(g) > atol
206 ]
207
208 # Special case: XY half-turns can absorb Z rotations.
209 if len(result) == 2 and math.isclose(abs(xy_turn), 0.5, abs_tol=atol):
210 return [
211 ops.PhasedXPowGate(phase_exponent=2 * xy_phase_turn + total_z_turn)
212 ]
213
214 return result
215
216
217 def single_qubit_matrix_to_phxz(
218 mat: np.ndarray,
219 atol: float = 0,
220 ) -> Optional[ops.PhasedXZGate]:
221 """Implements a single-qubit operation with a PhasedXZ gate.
222
223 Under the hood, this uses deconstruct_single_qubit_matrix_into_angles which
224 converts the given matrix to a series of three rotations around the Z, Y, Z
225 axes. This is then converted to a phased X rotation followed by a Z, in the
226 form of a single PhasedXZ gate.
227
228 Args:
229 mat: The 2x2 unitary matrix of the operation to implement.
230 atol: A limit on the amount of error introduced by the
231 construction.
232
233 Returns:
234 A PhasedXZ gate that implements the given matrix, or None if it is
235 close to identity (trace distance <= atol).
236 """
237
238 xy_turn, xy_phase_turn, total_z_turn = (
239 _deconstruct_single_qubit_matrix_into_gate_turns(mat))
240
241 # Build the intended operation out of non-negligible XY and Z rotations.
242 g = ops.PhasedXZGate(
243 axis_phase_exponent=2 * xy_phase_turn,
244 x_exponent=2 * xy_turn,
245 z_exponent=2 * total_z_turn,
246 )
247
248 if protocols.trace_distance_bound(g) <= atol:
249 return None
250
251 # Special case: XY half-turns can absorb Z rotations.
252 if math.isclose(abs(xy_turn), 0.5, abs_tol=atol):
253 g = ops.PhasedXZGate(
254 axis_phase_exponent=2 * xy_phase_turn + total_z_turn,
255 x_exponent=1,
256 z_exponent=0,
257 )
258
259 return g
260
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/cirq/optimizers/decompositions.py b/cirq/optimizers/decompositions.py
--- a/cirq/optimizers/decompositions.py
+++ b/cirq/optimizers/decompositions.py
@@ -139,7 +139,7 @@
When M is controlled, the control must be rotated around the Z axis to
apply g.
"""
- vals, vecs = np.linalg.eig(mat)
+ vals, vecs = linalg.unitary_eig(mat)
u = np.conj(vecs).T
r = vals[1] / vals[0]
g = vals[0]
|
{"golden_diff": "diff --git a/cirq/optimizers/decompositions.py b/cirq/optimizers/decompositions.py\n--- a/cirq/optimizers/decompositions.py\n+++ b/cirq/optimizers/decompositions.py\n@@ -139,7 +139,7 @@\n When M is controlled, the control must be rotated around the Z axis to\n apply g.\n \"\"\"\n- vals, vecs = np.linalg.eig(mat)\n+ vals, vecs = linalg.unitary_eig(mat)\n u = np.conj(vecs).T\n r = vals[1] / vals[0]\n g = vals[0]\n", "issue": "upgrade to numpy 1.19\nDiscover all the issues / test failures related to numpy 0.19 and upgrade our requirements.txt.\r\nMore context: https://github.com/quantumlib/Cirq/pull/3106\n", "before_files": [{"content": "# Copyright 2018 The Cirq Developers\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Utility methods related to optimizing quantum circuits.\"\"\"\n\nimport math\nfrom typing import List, Optional, Tuple, cast\n\nimport numpy as np\nimport sympy\n\nfrom cirq import ops, linalg, protocols\nfrom cirq.linalg.tolerance import near_zero_mod\n\n\ndef is_negligible_turn(turns: float, tolerance: float) -> bool:\n if isinstance(turns, sympy.Basic):\n if not turns.is_constant():\n return False\n turns = float(turns)\n return abs(_signed_mod_1(turns)) <= tolerance\n\n\ndef _signed_mod_1(x: float) -> float:\n return (x + 0.5) % 1 - 0.5\n\n\ndef single_qubit_matrix_to_pauli_rotations(\n mat: np.ndarray, atol: float = 0\n) -> List[Tuple[ops.Pauli, float]]:\n \"\"\"Implements a single-qubit operation with few rotations.\n\n Args:\n mat: The 2x2 unitary matrix of the operation to implement.\n atol: A limit on the amount of absolute error introduced by the\n construction.\n\n Returns:\n A list of (Pauli, half_turns) tuples that, when applied in order,\n perform the desired operation.\n \"\"\"\n\n def is_clifford_rotation(half_turns):\n return near_zero_mod(half_turns, 0.5, atol=atol)\n\n def to_quarter_turns(half_turns):\n return round(2 * half_turns) % 4\n\n def is_quarter_turn(half_turns):\n return (is_clifford_rotation(half_turns) and\n to_quarter_turns(half_turns) % 2 == 1)\n\n def is_half_turn(half_turns):\n return (is_clifford_rotation(half_turns) and\n to_quarter_turns(half_turns) == 2)\n\n def is_no_turn(half_turns):\n return (is_clifford_rotation(half_turns) and\n to_quarter_turns(half_turns) == 0)\n\n # Decompose matrix\n z_rad_before, y_rad, z_rad_after = (\n linalg.deconstruct_single_qubit_matrix_into_angles(mat))\n z_ht_before = z_rad_before / np.pi - 0.5\n m_ht = y_rad / np.pi\n m_pauli = ops.X # type: ops.Pauli\n z_ht_after = z_rad_after / np.pi + 0.5\n\n # Clean up angles\n if is_clifford_rotation(z_ht_before):\n if ((is_quarter_turn(z_ht_before) or is_quarter_turn(z_ht_after)) ^\n (is_half_turn(m_ht) and is_no_turn(z_ht_before-z_ht_after))):\n z_ht_before += 0.5\n z_ht_after -= 0.5\n m_pauli = ops.Y\n if is_half_turn(z_ht_before) or is_half_turn(z_ht_after):\n z_ht_before -= 1\n z_ht_after += 1\n m_ht = -m_ht\n if is_no_turn(m_ht):\n z_ht_before += z_ht_after\n z_ht_after = 0\n elif is_half_turn(m_ht):\n z_ht_after -= z_ht_before\n z_ht_before = 0\n\n # Generate operations\n rotation_list = [(ops.Z, z_ht_before), (m_pauli, m_ht), (ops.Z, z_ht_after)]\n return [(pauli, ht) for pauli, ht in rotation_list if not is_no_turn(ht)]\n\n\ndef single_qubit_matrix_to_gates(\n mat: np.ndarray, tolerance: float = 0\n) -> List[ops.SingleQubitGate]:\n \"\"\"Implements a single-qubit operation with few gates.\n\n Args:\n mat: The 2x2 unitary matrix of the operation to implement.\n tolerance: A limit on the amount of error introduced by the\n construction.\n\n Returns:\n A list of gates that, when applied in order, perform the desired\n operation.\n \"\"\"\n rotations = single_qubit_matrix_to_pauli_rotations(mat, tolerance)\n return [cast(ops.SingleQubitGate, pauli)**ht for pauli, ht in rotations]\n\n\ndef single_qubit_op_to_framed_phase_form(\n mat: np.ndarray) -> Tuple[np.ndarray, complex, complex]:\n \"\"\"Decomposes a 2x2 unitary M into U^-1 * diag(1, r) * U * diag(g, g).\n\n U translates the rotation axis of M to the Z axis.\n g fixes a global phase factor difference caused by the translation.\n r's phase is the amount of rotation around M's rotation axis.\n\n This decomposition can be used to decompose controlled single-qubit\n rotations into controlled-Z operations bordered by single-qubit operations.\n\n Args:\n mat: The qubit operation as a 2x2 unitary matrix.\n\n Returns:\n A 2x2 unitary U, the complex relative phase factor r, and the complex\n global phase factor g. Applying M is equivalent (up to global phase) to\n applying U, rotating around the Z axis to apply r, then un-applying U.\n When M is controlled, the control must be rotated around the Z axis to\n apply g.\n \"\"\"\n vals, vecs = np.linalg.eig(mat)\n u = np.conj(vecs).T\n r = vals[1] / vals[0]\n g = vals[0]\n return u, r, g\n\n\ndef _deconstruct_single_qubit_matrix_into_gate_turns(\n mat: np.ndarray) -> Tuple[float, float, float]:\n \"\"\"Breaks down a 2x2 unitary into gate parameters.\n\n Args:\n mat: The 2x2 unitary matrix to break down.\n\n Returns:\n A tuple containing the amount to rotate around an XY axis, the phase of\n that axis, and the amount to phase around Z. All results will be in\n fractions of a whole turn, with values canonicalized into the range\n [-0.5, 0.5).\n \"\"\"\n pre_phase, rotation, post_phase = (\n linalg.deconstruct_single_qubit_matrix_into_angles(mat))\n\n # Figure out parameters of the actual gates we will do.\n tau = 2 * np.pi\n xy_turn = rotation / tau\n xy_phase_turn = 0.25 - pre_phase / tau\n total_z_turn = (post_phase + pre_phase) / tau\n\n # Normalize turns into the range [-0.5, 0.5).\n return (_signed_mod_1(xy_turn), _signed_mod_1(xy_phase_turn),\n _signed_mod_1(total_z_turn))\n\n\ndef single_qubit_matrix_to_phased_x_z(\n mat: np.ndarray,\n atol: float = 0\n) -> List[ops.SingleQubitGate]:\n \"\"\"Implements a single-qubit operation with a PhasedX and Z gate.\n\n If one of the gates isn't needed, it will be omitted.\n\n Args:\n mat: The 2x2 unitary matrix of the operation to implement.\n atol: A limit on the amount of error introduced by the\n construction.\n\n Returns:\n A list of gates that, when applied in order, perform the desired\n operation.\n \"\"\"\n\n xy_turn, xy_phase_turn, total_z_turn = (\n _deconstruct_single_qubit_matrix_into_gate_turns(mat))\n\n # Build the intended operation out of non-negligible XY and Z rotations.\n result = [\n ops.PhasedXPowGate(exponent=2 * xy_turn,\n phase_exponent=2 * xy_phase_turn),\n ops.Z**(2 * total_z_turn)\n ]\n result = [\n g for g in result\n if protocols.trace_distance_bound(g) > atol\n ]\n\n # Special case: XY half-turns can absorb Z rotations.\n if len(result) == 2 and math.isclose(abs(xy_turn), 0.5, abs_tol=atol):\n return [\n ops.PhasedXPowGate(phase_exponent=2 * xy_phase_turn + total_z_turn)\n ]\n\n return result\n\n\ndef single_qubit_matrix_to_phxz(\n mat: np.ndarray,\n atol: float = 0,\n) -> Optional[ops.PhasedXZGate]:\n \"\"\"Implements a single-qubit operation with a PhasedXZ gate.\n\n Under the hood, this uses deconstruct_single_qubit_matrix_into_angles which\n converts the given matrix to a series of three rotations around the Z, Y, Z\n axes. This is then converted to a phased X rotation followed by a Z, in the\n form of a single PhasedXZ gate.\n\n Args:\n mat: The 2x2 unitary matrix of the operation to implement.\n atol: A limit on the amount of error introduced by the\n construction.\n\n Returns:\n A PhasedXZ gate that implements the given matrix, or None if it is\n close to identity (trace distance <= atol).\n \"\"\"\n\n xy_turn, xy_phase_turn, total_z_turn = (\n _deconstruct_single_qubit_matrix_into_gate_turns(mat))\n\n # Build the intended operation out of non-negligible XY and Z rotations.\n g = ops.PhasedXZGate(\n axis_phase_exponent=2 * xy_phase_turn,\n x_exponent=2 * xy_turn,\n z_exponent=2 * total_z_turn,\n )\n\n if protocols.trace_distance_bound(g) <= atol:\n return None\n\n # Special case: XY half-turns can absorb Z rotations.\n if math.isclose(abs(xy_turn), 0.5, abs_tol=atol):\n g = ops.PhasedXZGate(\n axis_phase_exponent=2 * xy_phase_turn + total_z_turn,\n x_exponent=1,\n z_exponent=0,\n )\n\n return g\n", "path": "cirq/optimizers/decompositions.py"}], "after_files": [{"content": "# Copyright 2018 The Cirq Developers\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Utility methods related to optimizing quantum circuits.\"\"\"\n\nimport math\nfrom typing import List, Optional, Tuple, cast\n\nimport numpy as np\nimport sympy\n\nfrom cirq import ops, linalg, protocols\nfrom cirq.linalg.tolerance import near_zero_mod\n\n\ndef is_negligible_turn(turns: float, tolerance: float) -> bool:\n if isinstance(turns, sympy.Basic):\n if not turns.is_constant():\n return False\n turns = float(turns)\n return abs(_signed_mod_1(turns)) <= tolerance\n\n\ndef _signed_mod_1(x: float) -> float:\n return (x + 0.5) % 1 - 0.5\n\n\ndef single_qubit_matrix_to_pauli_rotations(\n mat: np.ndarray, atol: float = 0\n) -> List[Tuple[ops.Pauli, float]]:\n \"\"\"Implements a single-qubit operation with few rotations.\n\n Args:\n mat: The 2x2 unitary matrix of the operation to implement.\n atol: A limit on the amount of absolute error introduced by the\n construction.\n\n Returns:\n A list of (Pauli, half_turns) tuples that, when applied in order,\n perform the desired operation.\n \"\"\"\n\n def is_clifford_rotation(half_turns):\n return near_zero_mod(half_turns, 0.5, atol=atol)\n\n def to_quarter_turns(half_turns):\n return round(2 * half_turns) % 4\n\n def is_quarter_turn(half_turns):\n return (is_clifford_rotation(half_turns) and\n to_quarter_turns(half_turns) % 2 == 1)\n\n def is_half_turn(half_turns):\n return (is_clifford_rotation(half_turns) and\n to_quarter_turns(half_turns) == 2)\n\n def is_no_turn(half_turns):\n return (is_clifford_rotation(half_turns) and\n to_quarter_turns(half_turns) == 0)\n\n # Decompose matrix\n z_rad_before, y_rad, z_rad_after = (\n linalg.deconstruct_single_qubit_matrix_into_angles(mat))\n z_ht_before = z_rad_before / np.pi - 0.5\n m_ht = y_rad / np.pi\n m_pauli = ops.X # type: ops.Pauli\n z_ht_after = z_rad_after / np.pi + 0.5\n\n # Clean up angles\n if is_clifford_rotation(z_ht_before):\n if ((is_quarter_turn(z_ht_before) or is_quarter_turn(z_ht_after)) ^\n (is_half_turn(m_ht) and is_no_turn(z_ht_before-z_ht_after))):\n z_ht_before += 0.5\n z_ht_after -= 0.5\n m_pauli = ops.Y\n if is_half_turn(z_ht_before) or is_half_turn(z_ht_after):\n z_ht_before -= 1\n z_ht_after += 1\n m_ht = -m_ht\n if is_no_turn(m_ht):\n z_ht_before += z_ht_after\n z_ht_after = 0\n elif is_half_turn(m_ht):\n z_ht_after -= z_ht_before\n z_ht_before = 0\n\n # Generate operations\n rotation_list = [(ops.Z, z_ht_before), (m_pauli, m_ht), (ops.Z, z_ht_after)]\n return [(pauli, ht) for pauli, ht in rotation_list if not is_no_turn(ht)]\n\n\ndef single_qubit_matrix_to_gates(\n mat: np.ndarray, tolerance: float = 0\n) -> List[ops.SingleQubitGate]:\n \"\"\"Implements a single-qubit operation with few gates.\n\n Args:\n mat: The 2x2 unitary matrix of the operation to implement.\n tolerance: A limit on the amount of error introduced by the\n construction.\n\n Returns:\n A list of gates that, when applied in order, perform the desired\n operation.\n \"\"\"\n rotations = single_qubit_matrix_to_pauli_rotations(mat, tolerance)\n return [cast(ops.SingleQubitGate, pauli)**ht for pauli, ht in rotations]\n\n\ndef single_qubit_op_to_framed_phase_form(\n mat: np.ndarray) -> Tuple[np.ndarray, complex, complex]:\n \"\"\"Decomposes a 2x2 unitary M into U^-1 * diag(1, r) * U * diag(g, g).\n\n U translates the rotation axis of M to the Z axis.\n g fixes a global phase factor difference caused by the translation.\n r's phase is the amount of rotation around M's rotation axis.\n\n This decomposition can be used to decompose controlled single-qubit\n rotations into controlled-Z operations bordered by single-qubit operations.\n\n Args:\n mat: The qubit operation as a 2x2 unitary matrix.\n\n Returns:\n A 2x2 unitary U, the complex relative phase factor r, and the complex\n global phase factor g. Applying M is equivalent (up to global phase) to\n applying U, rotating around the Z axis to apply r, then un-applying U.\n When M is controlled, the control must be rotated around the Z axis to\n apply g.\n \"\"\"\n vals, vecs = linalg.unitary_eig(mat)\n u = np.conj(vecs).T\n r = vals[1] / vals[0]\n g = vals[0]\n return u, r, g\n\n\ndef _deconstruct_single_qubit_matrix_into_gate_turns(\n mat: np.ndarray) -> Tuple[float, float, float]:\n \"\"\"Breaks down a 2x2 unitary into gate parameters.\n\n Args:\n mat: The 2x2 unitary matrix to break down.\n\n Returns:\n A tuple containing the amount to rotate around an XY axis, the phase of\n that axis, and the amount to phase around Z. All results will be in\n fractions of a whole turn, with values canonicalized into the range\n [-0.5, 0.5).\n \"\"\"\n pre_phase, rotation, post_phase = (\n linalg.deconstruct_single_qubit_matrix_into_angles(mat))\n\n # Figure out parameters of the actual gates we will do.\n tau = 2 * np.pi\n xy_turn = rotation / tau\n xy_phase_turn = 0.25 - pre_phase / tau\n total_z_turn = (post_phase + pre_phase) / tau\n\n # Normalize turns into the range [-0.5, 0.5).\n return (_signed_mod_1(xy_turn), _signed_mod_1(xy_phase_turn),\n _signed_mod_1(total_z_turn))\n\n\ndef single_qubit_matrix_to_phased_x_z(\n mat: np.ndarray,\n atol: float = 0\n) -> List[ops.SingleQubitGate]:\n \"\"\"Implements a single-qubit operation with a PhasedX and Z gate.\n\n If one of the gates isn't needed, it will be omitted.\n\n Args:\n mat: The 2x2 unitary matrix of the operation to implement.\n atol: A limit on the amount of error introduced by the\n construction.\n\n Returns:\n A list of gates that, when applied in order, perform the desired\n operation.\n \"\"\"\n\n xy_turn, xy_phase_turn, total_z_turn = (\n _deconstruct_single_qubit_matrix_into_gate_turns(mat))\n\n # Build the intended operation out of non-negligible XY and Z rotations.\n result = [\n ops.PhasedXPowGate(exponent=2 * xy_turn,\n phase_exponent=2 * xy_phase_turn),\n ops.Z**(2 * total_z_turn)\n ]\n result = [\n g for g in result\n if protocols.trace_distance_bound(g) > atol\n ]\n\n # Special case: XY half-turns can absorb Z rotations.\n if len(result) == 2 and math.isclose(abs(xy_turn), 0.5, abs_tol=atol):\n return [\n ops.PhasedXPowGate(phase_exponent=2 * xy_phase_turn + total_z_turn)\n ]\n\n return result\n\n\ndef single_qubit_matrix_to_phxz(\n mat: np.ndarray,\n atol: float = 0,\n) -> Optional[ops.PhasedXZGate]:\n \"\"\"Implements a single-qubit operation with a PhasedXZ gate.\n\n Under the hood, this uses deconstruct_single_qubit_matrix_into_angles which\n converts the given matrix to a series of three rotations around the Z, Y, Z\n axes. This is then converted to a phased X rotation followed by a Z, in the\n form of a single PhasedXZ gate.\n\n Args:\n mat: The 2x2 unitary matrix of the operation to implement.\n atol: A limit on the amount of error introduced by the\n construction.\n\n Returns:\n A PhasedXZ gate that implements the given matrix, or None if it is\n close to identity (trace distance <= atol).\n \"\"\"\n\n xy_turn, xy_phase_turn, total_z_turn = (\n _deconstruct_single_qubit_matrix_into_gate_turns(mat))\n\n # Build the intended operation out of non-negligible XY and Z rotations.\n g = ops.PhasedXZGate(\n axis_phase_exponent=2 * xy_phase_turn,\n x_exponent=2 * xy_turn,\n z_exponent=2 * total_z_turn,\n )\n\n if protocols.trace_distance_bound(g) <= atol:\n return None\n\n # Special case: XY half-turns can absorb Z rotations.\n if math.isclose(abs(xy_turn), 0.5, abs_tol=atol):\n g = ops.PhasedXZGate(\n axis_phase_exponent=2 * xy_phase_turn + total_z_turn,\n x_exponent=1,\n z_exponent=0,\n )\n\n return g\n", "path": "cirq/optimizers/decompositions.py"}]}
| 3,319 | 143 |
gh_patches_debug_22333
|
rasdani/github-patches
|
git_diff
|
iterative__dvc-3284
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add a way to suppress dvc changes to .gitignore
At the moment, DVC make changes to the .gitignore after commands like `dvc add`. There are cases, like mine, where it's not needed as .gitignore already exclude whole directory where data is kept.
Add a configuration that allow to suppress dvc changes to .gitignore.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `dvc/scm/git/__init__.py`
Content:
```
1 """Manages Git."""
2
3 import logging
4 import os
5
6 from funcy import cached_property
7 from pathspec.patterns import GitWildMatchPattern
8
9 from dvc.exceptions import GitHookAlreadyExistsError
10 from dvc.scm.base import Base
11 from dvc.scm.base import CloneError
12 from dvc.scm.base import FileNotInRepoError
13 from dvc.scm.base import RevError
14 from dvc.scm.base import SCMError
15 from dvc.scm.git.tree import GitTree
16 from dvc.utils import fix_env
17 from dvc.utils import is_binary
18 from dvc.utils import relpath
19 from dvc.utils.fs import path_isin
20
21
22 logger = logging.getLogger(__name__)
23
24
25 class Git(Base):
26 """Class for managing Git."""
27
28 GITIGNORE = ".gitignore"
29 GIT_DIR = ".git"
30
31 def __init__(self, root_dir=os.curdir):
32 """Git class constructor.
33 Requires `Repo` class from `git` module (from gitpython package).
34 """
35 super().__init__(root_dir)
36
37 import git
38 from git.exc import InvalidGitRepositoryError
39
40 try:
41 self.repo = git.Repo(self.root_dir)
42 except InvalidGitRepositoryError:
43 msg = "{} is not a git repository"
44 raise SCMError(msg.format(self.root_dir))
45
46 # NOTE: fixing LD_LIBRARY_PATH for binary built by PyInstaller.
47 # http://pyinstaller.readthedocs.io/en/stable/runtime-information.html
48 env = fix_env(None)
49 libpath = env.get("LD_LIBRARY_PATH", None)
50 self.repo.git.update_environment(LD_LIBRARY_PATH=libpath)
51
52 self.ignored_paths = []
53 self.files_to_track = set()
54
55 @staticmethod
56 def clone(url, to_path, rev=None):
57 import git
58
59 ld_key = "LD_LIBRARY_PATH"
60
61 env = fix_env(None)
62 if is_binary() and ld_key not in env.keys():
63 # In fix_env, we delete LD_LIBRARY_PATH key if it was empty before
64 # PyInstaller modified it. GitPython, in git.Repo.clone_from, uses
65 # env to update its own internal state. When there is no key in
66 # env, this value is not updated and GitPython re-uses
67 # LD_LIBRARY_PATH that has been set by PyInstaller.
68 # See [1] for more info.
69 # [1] https://github.com/gitpython-developers/GitPython/issues/924
70 env[ld_key] = ""
71
72 try:
73 tmp_repo = git.Repo.clone_from(
74 url,
75 to_path,
76 env=env, # needed before we can fix it in __init__
77 no_single_branch=True,
78 )
79 tmp_repo.close()
80 except git.exc.GitCommandError as exc:
81 raise CloneError(url, to_path) from exc
82
83 # NOTE: using our wrapper to make sure that env is fixed in __init__
84 repo = Git(to_path)
85
86 if rev:
87 try:
88 repo.checkout(rev)
89 except git.exc.GitCommandError as exc:
90 raise RevError(
91 "failed to access revision '{}' for repo '{}'".format(
92 rev, url
93 )
94 ) from exc
95
96 return repo
97
98 @staticmethod
99 def is_repo(root_dir):
100 return os.path.isdir(Git._get_git_dir(root_dir))
101
102 @staticmethod
103 def is_submodule(root_dir):
104 return os.path.isfile(Git._get_git_dir(root_dir))
105
106 @staticmethod
107 def _get_git_dir(root_dir):
108 return os.path.join(root_dir, Git.GIT_DIR)
109
110 @property
111 def dir(self):
112 return self.repo.git_dir
113
114 @property
115 def ignore_file(self):
116 return self.GITIGNORE
117
118 def _get_gitignore(self, path):
119 ignore_file_dir = os.path.dirname(path)
120
121 assert os.path.isabs(path)
122 assert os.path.isabs(ignore_file_dir)
123
124 entry = relpath(path, ignore_file_dir).replace(os.sep, "/")
125 # NOTE: using '/' prefix to make path unambiguous
126 if len(entry) > 0 and entry[0] != "/":
127 entry = "/" + entry
128
129 gitignore = os.path.join(ignore_file_dir, self.GITIGNORE)
130
131 if not path_isin(gitignore, os.path.realpath(self.root_dir)):
132 raise FileNotInRepoError(path)
133
134 return entry, gitignore
135
136 @staticmethod
137 def _ignored(entry, gitignore_path):
138 if os.path.exists(gitignore_path):
139 with open(gitignore_path, "r") as fobj:
140 ignore_list = fobj.readlines()
141 return any(
142 filter(lambda x: x.strip() == entry.strip(), ignore_list)
143 )
144 return False
145
146 def ignore(self, path):
147 entry, gitignore = self._get_gitignore(path)
148
149 if self._ignored(entry, gitignore):
150 return
151
152 msg = "Adding '{}' to '{}'.".format(relpath(path), relpath(gitignore))
153 logger.debug(msg)
154
155 self._add_entry_to_gitignore(entry, gitignore)
156
157 self.track_file(relpath(gitignore))
158
159 self.ignored_paths.append(path)
160
161 def _add_entry_to_gitignore(self, entry, gitignore):
162 entry = GitWildMatchPattern.escape(entry)
163
164 with open(gitignore, "a+", encoding="utf-8") as fobj:
165 fobj.seek(0, os.SEEK_END)
166 if fobj.tell() == 0:
167 # Empty file
168 prefix = ""
169 else:
170 fobj.seek(fobj.tell() - 1, os.SEEK_SET)
171 last = fobj.read(1)
172 prefix = "" if last == "\n" else "\n"
173 fobj.write("{}{}\n".format(prefix, entry))
174
175 def ignore_remove(self, path):
176 entry, gitignore = self._get_gitignore(path)
177
178 if not os.path.exists(gitignore):
179 return
180
181 with open(gitignore, "r") as fobj:
182 lines = fobj.readlines()
183
184 filtered = list(filter(lambda x: x.strip() != entry.strip(), lines))
185
186 with open(gitignore, "w") as fobj:
187 fobj.writelines(filtered)
188
189 self.track_file(relpath(gitignore))
190
191 def add(self, paths):
192 # NOTE: GitPython is not currently able to handle index version >= 3.
193 # See https://github.com/iterative/dvc/issues/610 for more details.
194 try:
195 self.repo.index.add(paths)
196 except AssertionError:
197 msg = (
198 "failed to add '{}' to git. You can add those files "
199 "manually using `git add`. See "
200 "https://github.com/iterative/dvc/issues/610 for more "
201 "details.".format(str(paths))
202 )
203
204 logger.exception(msg)
205
206 def commit(self, msg):
207 self.repo.index.commit(msg)
208
209 def checkout(self, branch, create_new=False):
210 if create_new:
211 self.repo.git.checkout("HEAD", b=branch)
212 else:
213 self.repo.git.checkout(branch)
214
215 def pull(self):
216 info, = self.repo.remote().pull()
217 if info.flags & info.ERROR:
218 raise SCMError("pull failed: {}".format(info.note))
219
220 def push(self):
221 info, = self.repo.remote().push()
222 if info.flags & info.ERROR:
223 raise SCMError("push failed: {}".format(info.summary))
224
225 def branch(self, branch):
226 self.repo.git.branch(branch)
227
228 def tag(self, tag):
229 self.repo.git.tag(tag)
230
231 def untracked_files(self):
232 files = self.repo.untracked_files
233 return [os.path.join(self.repo.working_dir, fname) for fname in files]
234
235 def is_tracked(self, path):
236 # it is equivalent to `bool(self.repo.git.ls_files(path))` by
237 # functionality, but ls_files fails on unicode filenames
238 path = relpath(path, self.root_dir)
239 # There are 4 stages, see BaseIndexEntry.stage
240 return any((path, i) in self.repo.index.entries for i in (0, 1, 2, 3))
241
242 def is_dirty(self):
243 return self.repo.is_dirty()
244
245 def active_branch(self):
246 return self.repo.active_branch.name
247
248 def list_branches(self):
249 return [h.name for h in self.repo.heads]
250
251 def list_tags(self):
252 return [t.name for t in self.repo.tags]
253
254 def list_all_commits(self):
255 return [c.hexsha for c in self.repo.iter_commits("--all")]
256
257 def _install_hook(self, name, preconditions, cmd):
258 # only run in dvc repo
259 in_dvc_repo = '[ -n "$(git ls-files --full-name .dvc)" ]'
260
261 command = "if {}; then exec dvc {}; fi".format(
262 " && ".join([in_dvc_repo] + preconditions), cmd
263 )
264
265 hook = self._hook_path(name)
266
267 if os.path.isfile(hook):
268 with open(hook, "r+") as fobj:
269 if command not in fobj.read():
270 fobj.write("{command}\n".format(command=command))
271 else:
272 with open(hook, "w+") as fobj:
273 fobj.write("#!/bin/sh\n" "{command}\n".format(command=command))
274
275 os.chmod(hook, 0o777)
276
277 def install(self):
278 self._verify_dvc_hooks()
279
280 self._install_hook(
281 "post-checkout",
282 [
283 # checking out some reference and not specific file.
284 '[ "$3" = "1" ]',
285 # make sure we are not in the middle of a rebase/merge, so we
286 # don't accidentally break it with an unsuccessful checkout.
287 # Note that git hooks are always running in repo root.
288 "[ ! -d .git/rebase-merge ]",
289 ],
290 "checkout",
291 )
292 self._install_hook("pre-commit", [], "status")
293 self._install_hook("pre-push", [], "push")
294
295 def cleanup_ignores(self):
296 for path in self.ignored_paths:
297 self.ignore_remove(path)
298 self.reset_ignores()
299
300 def reset_ignores(self):
301 self.ignored_paths = []
302
303 def reset_tracked_files(self):
304 self.files_to_track = set()
305
306 def remind_to_track(self):
307 if not self.files_to_track:
308 return
309
310 logger.info(
311 "\n"
312 "To track the changes with git, run:\n"
313 "\n"
314 "\tgit add {files}".format(files=" ".join(self.files_to_track))
315 )
316
317 def track_file(self, path):
318 self.files_to_track.add(path)
319
320 def belongs_to_scm(self, path):
321 basename = os.path.basename(path)
322 path_parts = os.path.normpath(path).split(os.path.sep)
323 return basename == self.ignore_file or Git.GIT_DIR in path_parts
324
325 def get_tree(self, rev):
326 return GitTree(self.repo, self.resolve_rev(rev))
327
328 def get_rev(self):
329 return self.repo.git.rev_parse("HEAD")
330
331 def resolve_rev(self, rev):
332 from git.exc import GitCommandError
333
334 try:
335 return self.repo.git.rev_parse(rev)
336 except GitCommandError:
337 raise RevError("unknown Git revision '{}'".format(rev))
338
339 def close(self):
340 self.repo.close()
341
342 @cached_property
343 def _hooks_home(self):
344 return os.path.join(self.root_dir, self.GIT_DIR, "hooks")
345
346 def _hook_path(self, name):
347 return os.path.join(self._hooks_home, name)
348
349 def _verify_hook(self, name):
350 if os.path.exists(self._hook_path(name)):
351 raise GitHookAlreadyExistsError(name)
352
353 def _verify_dvc_hooks(self):
354 self._verify_hook("post-checkout")
355 self._verify_hook("pre-commit")
356 self._verify_hook("pre-push")
357
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/dvc/scm/git/__init__.py b/dvc/scm/git/__init__.py
--- a/dvc/scm/git/__init__.py
+++ b/dvc/scm/git/__init__.py
@@ -18,7 +18,6 @@
from dvc.utils import relpath
from dvc.utils.fs import path_isin
-
logger = logging.getLogger(__name__)
@@ -133,20 +132,19 @@
return entry, gitignore
- @staticmethod
- def _ignored(entry, gitignore_path):
- if os.path.exists(gitignore_path):
- with open(gitignore_path, "r") as fobj:
- ignore_list = fobj.readlines()
- return any(
- filter(lambda x: x.strip() == entry.strip(), ignore_list)
- )
- return False
+ def _ignored(self, path):
+ from git.exc import GitCommandError
+
+ try:
+ self.repo.git.check_ignore(path)
+ return True
+ except GitCommandError:
+ return False
def ignore(self, path):
entry, gitignore = self._get_gitignore(path)
- if self._ignored(entry, gitignore):
+ if self._ignored(path):
return
msg = "Adding '{}' to '{}'.".format(relpath(path), relpath(gitignore))
|
{"golden_diff": "diff --git a/dvc/scm/git/__init__.py b/dvc/scm/git/__init__.py\n--- a/dvc/scm/git/__init__.py\n+++ b/dvc/scm/git/__init__.py\n@@ -18,7 +18,6 @@\n from dvc.utils import relpath\n from dvc.utils.fs import path_isin\n \n-\n logger = logging.getLogger(__name__)\n \n \n@@ -133,20 +132,19 @@\n \n return entry, gitignore\n \n- @staticmethod\n- def _ignored(entry, gitignore_path):\n- if os.path.exists(gitignore_path):\n- with open(gitignore_path, \"r\") as fobj:\n- ignore_list = fobj.readlines()\n- return any(\n- filter(lambda x: x.strip() == entry.strip(), ignore_list)\n- )\n- return False\n+ def _ignored(self, path):\n+ from git.exc import GitCommandError\n+\n+ try:\n+ self.repo.git.check_ignore(path)\n+ return True\n+ except GitCommandError:\n+ return False\n \n def ignore(self, path):\n entry, gitignore = self._get_gitignore(path)\n \n- if self._ignored(entry, gitignore):\n+ if self._ignored(path):\n return\n \n msg = \"Adding '{}' to '{}'.\".format(relpath(path), relpath(gitignore))\n", "issue": "Add a way to suppress dvc changes to .gitignore\nAt the moment, DVC make changes to the .gitignore after commands like `dvc add`. There are cases, like mine, where it's not needed as .gitignore already exclude whole directory where data is kept.\r\nAdd a configuration that allow to suppress dvc changes to .gitignore.\n", "before_files": [{"content": "\"\"\"Manages Git.\"\"\"\n\nimport logging\nimport os\n\nfrom funcy import cached_property\nfrom pathspec.patterns import GitWildMatchPattern\n\nfrom dvc.exceptions import GitHookAlreadyExistsError\nfrom dvc.scm.base import Base\nfrom dvc.scm.base import CloneError\nfrom dvc.scm.base import FileNotInRepoError\nfrom dvc.scm.base import RevError\nfrom dvc.scm.base import SCMError\nfrom dvc.scm.git.tree import GitTree\nfrom dvc.utils import fix_env\nfrom dvc.utils import is_binary\nfrom dvc.utils import relpath\nfrom dvc.utils.fs import path_isin\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass Git(Base):\n \"\"\"Class for managing Git.\"\"\"\n\n GITIGNORE = \".gitignore\"\n GIT_DIR = \".git\"\n\n def __init__(self, root_dir=os.curdir):\n \"\"\"Git class constructor.\n Requires `Repo` class from `git` module (from gitpython package).\n \"\"\"\n super().__init__(root_dir)\n\n import git\n from git.exc import InvalidGitRepositoryError\n\n try:\n self.repo = git.Repo(self.root_dir)\n except InvalidGitRepositoryError:\n msg = \"{} is not a git repository\"\n raise SCMError(msg.format(self.root_dir))\n\n # NOTE: fixing LD_LIBRARY_PATH for binary built by PyInstaller.\n # http://pyinstaller.readthedocs.io/en/stable/runtime-information.html\n env = fix_env(None)\n libpath = env.get(\"LD_LIBRARY_PATH\", None)\n self.repo.git.update_environment(LD_LIBRARY_PATH=libpath)\n\n self.ignored_paths = []\n self.files_to_track = set()\n\n @staticmethod\n def clone(url, to_path, rev=None):\n import git\n\n ld_key = \"LD_LIBRARY_PATH\"\n\n env = fix_env(None)\n if is_binary() and ld_key not in env.keys():\n # In fix_env, we delete LD_LIBRARY_PATH key if it was empty before\n # PyInstaller modified it. GitPython, in git.Repo.clone_from, uses\n # env to update its own internal state. When there is no key in\n # env, this value is not updated and GitPython re-uses\n # LD_LIBRARY_PATH that has been set by PyInstaller.\n # See [1] for more info.\n # [1] https://github.com/gitpython-developers/GitPython/issues/924\n env[ld_key] = \"\"\n\n try:\n tmp_repo = git.Repo.clone_from(\n url,\n to_path,\n env=env, # needed before we can fix it in __init__\n no_single_branch=True,\n )\n tmp_repo.close()\n except git.exc.GitCommandError as exc:\n raise CloneError(url, to_path) from exc\n\n # NOTE: using our wrapper to make sure that env is fixed in __init__\n repo = Git(to_path)\n\n if rev:\n try:\n repo.checkout(rev)\n except git.exc.GitCommandError as exc:\n raise RevError(\n \"failed to access revision '{}' for repo '{}'\".format(\n rev, url\n )\n ) from exc\n\n return repo\n\n @staticmethod\n def is_repo(root_dir):\n return os.path.isdir(Git._get_git_dir(root_dir))\n\n @staticmethod\n def is_submodule(root_dir):\n return os.path.isfile(Git._get_git_dir(root_dir))\n\n @staticmethod\n def _get_git_dir(root_dir):\n return os.path.join(root_dir, Git.GIT_DIR)\n\n @property\n def dir(self):\n return self.repo.git_dir\n\n @property\n def ignore_file(self):\n return self.GITIGNORE\n\n def _get_gitignore(self, path):\n ignore_file_dir = os.path.dirname(path)\n\n assert os.path.isabs(path)\n assert os.path.isabs(ignore_file_dir)\n\n entry = relpath(path, ignore_file_dir).replace(os.sep, \"/\")\n # NOTE: using '/' prefix to make path unambiguous\n if len(entry) > 0 and entry[0] != \"/\":\n entry = \"/\" + entry\n\n gitignore = os.path.join(ignore_file_dir, self.GITIGNORE)\n\n if not path_isin(gitignore, os.path.realpath(self.root_dir)):\n raise FileNotInRepoError(path)\n\n return entry, gitignore\n\n @staticmethod\n def _ignored(entry, gitignore_path):\n if os.path.exists(gitignore_path):\n with open(gitignore_path, \"r\") as fobj:\n ignore_list = fobj.readlines()\n return any(\n filter(lambda x: x.strip() == entry.strip(), ignore_list)\n )\n return False\n\n def ignore(self, path):\n entry, gitignore = self._get_gitignore(path)\n\n if self._ignored(entry, gitignore):\n return\n\n msg = \"Adding '{}' to '{}'.\".format(relpath(path), relpath(gitignore))\n logger.debug(msg)\n\n self._add_entry_to_gitignore(entry, gitignore)\n\n self.track_file(relpath(gitignore))\n\n self.ignored_paths.append(path)\n\n def _add_entry_to_gitignore(self, entry, gitignore):\n entry = GitWildMatchPattern.escape(entry)\n\n with open(gitignore, \"a+\", encoding=\"utf-8\") as fobj:\n fobj.seek(0, os.SEEK_END)\n if fobj.tell() == 0:\n # Empty file\n prefix = \"\"\n else:\n fobj.seek(fobj.tell() - 1, os.SEEK_SET)\n last = fobj.read(1)\n prefix = \"\" if last == \"\\n\" else \"\\n\"\n fobj.write(\"{}{}\\n\".format(prefix, entry))\n\n def ignore_remove(self, path):\n entry, gitignore = self._get_gitignore(path)\n\n if not os.path.exists(gitignore):\n return\n\n with open(gitignore, \"r\") as fobj:\n lines = fobj.readlines()\n\n filtered = list(filter(lambda x: x.strip() != entry.strip(), lines))\n\n with open(gitignore, \"w\") as fobj:\n fobj.writelines(filtered)\n\n self.track_file(relpath(gitignore))\n\n def add(self, paths):\n # NOTE: GitPython is not currently able to handle index version >= 3.\n # See https://github.com/iterative/dvc/issues/610 for more details.\n try:\n self.repo.index.add(paths)\n except AssertionError:\n msg = (\n \"failed to add '{}' to git. You can add those files \"\n \"manually using `git add`. See \"\n \"https://github.com/iterative/dvc/issues/610 for more \"\n \"details.\".format(str(paths))\n )\n\n logger.exception(msg)\n\n def commit(self, msg):\n self.repo.index.commit(msg)\n\n def checkout(self, branch, create_new=False):\n if create_new:\n self.repo.git.checkout(\"HEAD\", b=branch)\n else:\n self.repo.git.checkout(branch)\n\n def pull(self):\n info, = self.repo.remote().pull()\n if info.flags & info.ERROR:\n raise SCMError(\"pull failed: {}\".format(info.note))\n\n def push(self):\n info, = self.repo.remote().push()\n if info.flags & info.ERROR:\n raise SCMError(\"push failed: {}\".format(info.summary))\n\n def branch(self, branch):\n self.repo.git.branch(branch)\n\n def tag(self, tag):\n self.repo.git.tag(tag)\n\n def untracked_files(self):\n files = self.repo.untracked_files\n return [os.path.join(self.repo.working_dir, fname) for fname in files]\n\n def is_tracked(self, path):\n # it is equivalent to `bool(self.repo.git.ls_files(path))` by\n # functionality, but ls_files fails on unicode filenames\n path = relpath(path, self.root_dir)\n # There are 4 stages, see BaseIndexEntry.stage\n return any((path, i) in self.repo.index.entries for i in (0, 1, 2, 3))\n\n def is_dirty(self):\n return self.repo.is_dirty()\n\n def active_branch(self):\n return self.repo.active_branch.name\n\n def list_branches(self):\n return [h.name for h in self.repo.heads]\n\n def list_tags(self):\n return [t.name for t in self.repo.tags]\n\n def list_all_commits(self):\n return [c.hexsha for c in self.repo.iter_commits(\"--all\")]\n\n def _install_hook(self, name, preconditions, cmd):\n # only run in dvc repo\n in_dvc_repo = '[ -n \"$(git ls-files --full-name .dvc)\" ]'\n\n command = \"if {}; then exec dvc {}; fi\".format(\n \" && \".join([in_dvc_repo] + preconditions), cmd\n )\n\n hook = self._hook_path(name)\n\n if os.path.isfile(hook):\n with open(hook, \"r+\") as fobj:\n if command not in fobj.read():\n fobj.write(\"{command}\\n\".format(command=command))\n else:\n with open(hook, \"w+\") as fobj:\n fobj.write(\"#!/bin/sh\\n\" \"{command}\\n\".format(command=command))\n\n os.chmod(hook, 0o777)\n\n def install(self):\n self._verify_dvc_hooks()\n\n self._install_hook(\n \"post-checkout\",\n [\n # checking out some reference and not specific file.\n '[ \"$3\" = \"1\" ]',\n # make sure we are not in the middle of a rebase/merge, so we\n # don't accidentally break it with an unsuccessful checkout.\n # Note that git hooks are always running in repo root.\n \"[ ! -d .git/rebase-merge ]\",\n ],\n \"checkout\",\n )\n self._install_hook(\"pre-commit\", [], \"status\")\n self._install_hook(\"pre-push\", [], \"push\")\n\n def cleanup_ignores(self):\n for path in self.ignored_paths:\n self.ignore_remove(path)\n self.reset_ignores()\n\n def reset_ignores(self):\n self.ignored_paths = []\n\n def reset_tracked_files(self):\n self.files_to_track = set()\n\n def remind_to_track(self):\n if not self.files_to_track:\n return\n\n logger.info(\n \"\\n\"\n \"To track the changes with git, run:\\n\"\n \"\\n\"\n \"\\tgit add {files}\".format(files=\" \".join(self.files_to_track))\n )\n\n def track_file(self, path):\n self.files_to_track.add(path)\n\n def belongs_to_scm(self, path):\n basename = os.path.basename(path)\n path_parts = os.path.normpath(path).split(os.path.sep)\n return basename == self.ignore_file or Git.GIT_DIR in path_parts\n\n def get_tree(self, rev):\n return GitTree(self.repo, self.resolve_rev(rev))\n\n def get_rev(self):\n return self.repo.git.rev_parse(\"HEAD\")\n\n def resolve_rev(self, rev):\n from git.exc import GitCommandError\n\n try:\n return self.repo.git.rev_parse(rev)\n except GitCommandError:\n raise RevError(\"unknown Git revision '{}'\".format(rev))\n\n def close(self):\n self.repo.close()\n\n @cached_property\n def _hooks_home(self):\n return os.path.join(self.root_dir, self.GIT_DIR, \"hooks\")\n\n def _hook_path(self, name):\n return os.path.join(self._hooks_home, name)\n\n def _verify_hook(self, name):\n if os.path.exists(self._hook_path(name)):\n raise GitHookAlreadyExistsError(name)\n\n def _verify_dvc_hooks(self):\n self._verify_hook(\"post-checkout\")\n self._verify_hook(\"pre-commit\")\n self._verify_hook(\"pre-push\")\n", "path": "dvc/scm/git/__init__.py"}], "after_files": [{"content": "\"\"\"Manages Git.\"\"\"\n\nimport logging\nimport os\n\nfrom funcy import cached_property\nfrom pathspec.patterns import GitWildMatchPattern\n\nfrom dvc.exceptions import GitHookAlreadyExistsError\nfrom dvc.scm.base import Base\nfrom dvc.scm.base import CloneError\nfrom dvc.scm.base import FileNotInRepoError\nfrom dvc.scm.base import RevError\nfrom dvc.scm.base import SCMError\nfrom dvc.scm.git.tree import GitTree\nfrom dvc.utils import fix_env\nfrom dvc.utils import is_binary\nfrom dvc.utils import relpath\nfrom dvc.utils.fs import path_isin\n\nlogger = logging.getLogger(__name__)\n\n\nclass Git(Base):\n \"\"\"Class for managing Git.\"\"\"\n\n GITIGNORE = \".gitignore\"\n GIT_DIR = \".git\"\n\n def __init__(self, root_dir=os.curdir):\n \"\"\"Git class constructor.\n Requires `Repo` class from `git` module (from gitpython package).\n \"\"\"\n super().__init__(root_dir)\n\n import git\n from git.exc import InvalidGitRepositoryError\n\n try:\n self.repo = git.Repo(self.root_dir)\n except InvalidGitRepositoryError:\n msg = \"{} is not a git repository\"\n raise SCMError(msg.format(self.root_dir))\n\n # NOTE: fixing LD_LIBRARY_PATH for binary built by PyInstaller.\n # http://pyinstaller.readthedocs.io/en/stable/runtime-information.html\n env = fix_env(None)\n libpath = env.get(\"LD_LIBRARY_PATH\", None)\n self.repo.git.update_environment(LD_LIBRARY_PATH=libpath)\n\n self.ignored_paths = []\n self.files_to_track = set()\n\n @staticmethod\n def clone(url, to_path, rev=None):\n import git\n\n ld_key = \"LD_LIBRARY_PATH\"\n\n env = fix_env(None)\n if is_binary() and ld_key not in env.keys():\n # In fix_env, we delete LD_LIBRARY_PATH key if it was empty before\n # PyInstaller modified it. GitPython, in git.Repo.clone_from, uses\n # env to update its own internal state. When there is no key in\n # env, this value is not updated and GitPython re-uses\n # LD_LIBRARY_PATH that has been set by PyInstaller.\n # See [1] for more info.\n # [1] https://github.com/gitpython-developers/GitPython/issues/924\n env[ld_key] = \"\"\n\n try:\n tmp_repo = git.Repo.clone_from(\n url,\n to_path,\n env=env, # needed before we can fix it in __init__\n no_single_branch=True,\n )\n tmp_repo.close()\n except git.exc.GitCommandError as exc:\n raise CloneError(url, to_path) from exc\n\n # NOTE: using our wrapper to make sure that env is fixed in __init__\n repo = Git(to_path)\n\n if rev:\n try:\n repo.checkout(rev)\n except git.exc.GitCommandError as exc:\n raise RevError(\n \"failed to access revision '{}' for repo '{}'\".format(\n rev, url\n )\n ) from exc\n\n return repo\n\n @staticmethod\n def is_repo(root_dir):\n return os.path.isdir(Git._get_git_dir(root_dir))\n\n @staticmethod\n def is_submodule(root_dir):\n return os.path.isfile(Git._get_git_dir(root_dir))\n\n @staticmethod\n def _get_git_dir(root_dir):\n return os.path.join(root_dir, Git.GIT_DIR)\n\n @property\n def dir(self):\n return self.repo.git_dir\n\n @property\n def ignore_file(self):\n return self.GITIGNORE\n\n def _get_gitignore(self, path):\n ignore_file_dir = os.path.dirname(path)\n\n assert os.path.isabs(path)\n assert os.path.isabs(ignore_file_dir)\n\n entry = relpath(path, ignore_file_dir).replace(os.sep, \"/\")\n # NOTE: using '/' prefix to make path unambiguous\n if len(entry) > 0 and entry[0] != \"/\":\n entry = \"/\" + entry\n\n gitignore = os.path.join(ignore_file_dir, self.GITIGNORE)\n\n if not path_isin(gitignore, os.path.realpath(self.root_dir)):\n raise FileNotInRepoError(path)\n\n return entry, gitignore\n\n def _ignored(self, path):\n from git.exc import GitCommandError\n\n try:\n self.repo.git.check_ignore(path)\n return True\n except GitCommandError:\n return False\n\n def ignore(self, path):\n entry, gitignore = self._get_gitignore(path)\n\n if self._ignored(path):\n return\n\n msg = \"Adding '{}' to '{}'.\".format(relpath(path), relpath(gitignore))\n logger.debug(msg)\n\n self._add_entry_to_gitignore(entry, gitignore)\n\n self.track_file(relpath(gitignore))\n\n self.ignored_paths.append(path)\n\n def _add_entry_to_gitignore(self, entry, gitignore):\n entry = GitWildMatchPattern.escape(entry)\n\n with open(gitignore, \"a+\", encoding=\"utf-8\") as fobj:\n fobj.seek(0, os.SEEK_END)\n if fobj.tell() == 0:\n # Empty file\n prefix = \"\"\n else:\n fobj.seek(fobj.tell() - 1, os.SEEK_SET)\n last = fobj.read(1)\n prefix = \"\" if last == \"\\n\" else \"\\n\"\n fobj.write(\"{}{}\\n\".format(prefix, entry))\n\n def ignore_remove(self, path):\n entry, gitignore = self._get_gitignore(path)\n\n if not os.path.exists(gitignore):\n return\n\n with open(gitignore, \"r\") as fobj:\n lines = fobj.readlines()\n\n filtered = list(filter(lambda x: x.strip() != entry.strip(), lines))\n\n with open(gitignore, \"w\") as fobj:\n fobj.writelines(filtered)\n\n self.track_file(relpath(gitignore))\n\n def add(self, paths):\n # NOTE: GitPython is not currently able to handle index version >= 3.\n # See https://github.com/iterative/dvc/issues/610 for more details.\n try:\n self.repo.index.add(paths)\n except AssertionError:\n msg = (\n \"failed to add '{}' to git. You can add those files \"\n \"manually using `git add`. See \"\n \"https://github.com/iterative/dvc/issues/610 for more \"\n \"details.\".format(str(paths))\n )\n\n logger.exception(msg)\n\n def commit(self, msg):\n self.repo.index.commit(msg)\n\n def checkout(self, branch, create_new=False):\n if create_new:\n self.repo.git.checkout(\"HEAD\", b=branch)\n else:\n self.repo.git.checkout(branch)\n\n def pull(self):\n info, = self.repo.remote().pull()\n if info.flags & info.ERROR:\n raise SCMError(\"pull failed: {}\".format(info.note))\n\n def push(self):\n info, = self.repo.remote().push()\n if info.flags & info.ERROR:\n raise SCMError(\"push failed: {}\".format(info.summary))\n\n def branch(self, branch):\n self.repo.git.branch(branch)\n\n def tag(self, tag):\n self.repo.git.tag(tag)\n\n def untracked_files(self):\n files = self.repo.untracked_files\n return [os.path.join(self.repo.working_dir, fname) for fname in files]\n\n def is_tracked(self, path):\n # it is equivalent to `bool(self.repo.git.ls_files(path))` by\n # functionality, but ls_files fails on unicode filenames\n path = relpath(path, self.root_dir)\n # There are 4 stages, see BaseIndexEntry.stage\n return any((path, i) in self.repo.index.entries for i in (0, 1, 2, 3))\n\n def is_dirty(self):\n return self.repo.is_dirty()\n\n def active_branch(self):\n return self.repo.active_branch.name\n\n def list_branches(self):\n return [h.name for h in self.repo.heads]\n\n def list_tags(self):\n return [t.name for t in self.repo.tags]\n\n def list_all_commits(self):\n return [c.hexsha for c in self.repo.iter_commits(\"--all\")]\n\n def _install_hook(self, name, preconditions, cmd):\n # only run in dvc repo\n in_dvc_repo = '[ -n \"$(git ls-files --full-name .dvc)\" ]'\n\n command = \"if {}; then exec dvc {}; fi\".format(\n \" && \".join([in_dvc_repo] + preconditions), cmd\n )\n\n hook = self._hook_path(name)\n\n if os.path.isfile(hook):\n with open(hook, \"r+\") as fobj:\n if command not in fobj.read():\n fobj.write(\"{command}\\n\".format(command=command))\n else:\n with open(hook, \"w+\") as fobj:\n fobj.write(\"#!/bin/sh\\n\" \"{command}\\n\".format(command=command))\n\n os.chmod(hook, 0o777)\n\n def install(self):\n self._verify_dvc_hooks()\n\n self._install_hook(\n \"post-checkout\",\n [\n # checking out some reference and not specific file.\n '[ \"$3\" = \"1\" ]',\n # make sure we are not in the middle of a rebase/merge, so we\n # don't accidentally break it with an unsuccessful checkout.\n # Note that git hooks are always running in repo root.\n \"[ ! -d .git/rebase-merge ]\",\n ],\n \"checkout\",\n )\n self._install_hook(\"pre-commit\", [], \"status\")\n self._install_hook(\"pre-push\", [], \"push\")\n\n def cleanup_ignores(self):\n for path in self.ignored_paths:\n self.ignore_remove(path)\n self.reset_ignores()\n\n def reset_ignores(self):\n self.ignored_paths = []\n\n def reset_tracked_files(self):\n self.files_to_track = set()\n\n def remind_to_track(self):\n if not self.files_to_track:\n return\n\n logger.info(\n \"\\n\"\n \"To track the changes with git, run:\\n\"\n \"\\n\"\n \"\\tgit add {files}\".format(files=\" \".join(self.files_to_track))\n )\n\n def track_file(self, path):\n self.files_to_track.add(path)\n\n def belongs_to_scm(self, path):\n basename = os.path.basename(path)\n path_parts = os.path.normpath(path).split(os.path.sep)\n return basename == self.ignore_file or Git.GIT_DIR in path_parts\n\n def get_tree(self, rev):\n return GitTree(self.repo, self.resolve_rev(rev))\n\n def get_rev(self):\n return self.repo.git.rev_parse(\"HEAD\")\n\n def resolve_rev(self, rev):\n from git.exc import GitCommandError\n\n try:\n return self.repo.git.rev_parse(rev)\n except GitCommandError:\n raise RevError(\"unknown Git revision '{}'\".format(rev))\n\n def close(self):\n self.repo.close()\n\n @cached_property\n def _hooks_home(self):\n return os.path.join(self.root_dir, self.GIT_DIR, \"hooks\")\n\n def _hook_path(self, name):\n return os.path.join(self._hooks_home, name)\n\n def _verify_hook(self, name):\n if os.path.exists(self._hook_path(name)):\n raise GitHookAlreadyExistsError(name)\n\n def _verify_dvc_hooks(self):\n self._verify_hook(\"post-checkout\")\n self._verify_hook(\"pre-commit\")\n self._verify_hook(\"pre-push\")\n", "path": "dvc/scm/git/__init__.py"}]}
| 3,929 | 305 |
gh_patches_debug_27885
|
rasdani/github-patches
|
git_diff
|
pwr-Solaar__Solaar-743
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
authorship of Solaar in setup.py
Daniel Pavel is listed as the sole author of Solaar in setup.py
As far as I can tell, this puts him and his email in several repositories, such as PyPI https://pypi.org/project/solaar/
Who should be put there?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python3
2
3 from glob import glob as _glob
4 try:
5 from setuptools import setup
6 except ImportError:
7 from distutils.core import setup
8
9 autostart_path = '/etc/xdg/autostart'
10
11 import sys
12 backup_path_0 = sys.path[0]
13 sys.path[0] = backup_path_0 + '/lib'
14 #from solaar import NAME, __version__
15 __version__ = '1.0.2-rc1'
16 NAME = 'Solaar'
17
18 sys.path[0] = backup_path_0
19
20 if 'install' in sys.argv:
21 # naively guess where the autostart .desktop file should be installed
22 if '--prefix' in sys.argv or any(x.startswith('--prefix=') for x in sys.argv) or '--home' in sys.argv:
23 autostart_path = 'etc/xdg/autostart'
24 elif '--user' in sys.argv:
25 from os import environ
26 from os import path
27 xdg_config_home = environ.get('XDG_CONFIG_HOME', path.expanduser(path.join('~', '.config')))
28 autostart_path = path.join(xdg_config_home, 'autostart')
29 del environ, path, xdg_config_home
30
31 del sys, backup_path_0
32
33
34 def _data_files():
35 from os.path import dirname as _dirname
36
37 yield 'share/solaar/icons', _glob('share/solaar/icons/solaar*.svg')
38 yield 'share/solaar/icons', _glob('share/solaar/icons/light_*.png')
39 yield 'share/icons/hicolor/scalable/apps', ['share/solaar/icons/solaar.svg']
40
41 for mo in _glob('share/locale/*/LC_MESSAGES/solaar.mo'):
42 yield _dirname(mo), [mo]
43
44 yield 'share/applications', ['share/applications/solaar.desktop']
45 yield autostart_path, ['share/autostart/solaar.desktop']
46
47 del _dirname
48
49
50 setup(name=NAME.lower(),
51 version=__version__,
52 description='Linux devices manager for the Logitech Unifying Receiver.',
53 long_description='''
54 Solaar is a Linux device manager for Logitech's Unifying Receiver peripherals.
55 It is able to pair/unpair devices to the receiver, and for some devices read
56 battery status.
57 '''.strip(),
58 author='Daniel Pavel',
59 author_email='[email protected]',
60 license='GPLv2',
61 url='http://pwr-solaar.github.io/Solaar/',
62 classifiers=[
63 'Development Status :: 4 - Beta',
64 'Environment :: X11 Applications :: GTK',
65 'Environment :: Console',
66 'Intended Audience :: End Users/Desktop',
67 'License :: DFSG approved',
68 'License :: OSI Approved :: GNU General Public License v2 (GPLv2)',
69 'Natural Language :: English',
70 'Programming Language :: Python :: 3 :: Only',
71 'Operating System :: POSIX :: Linux',
72 'Topic :: Utilities',
73 ],
74
75 platforms=['linux'],
76
77 # sudo apt install python-gi python3-gi \
78 # gir1.2-gtk-3.0 gir1.2-notify-0.7 gir1.2-ayatanaappindicator3-0.1
79 # os_requires=['gi.repository.GObject (>= 2.0)', 'gi.repository.Gtk (>= 3.0)'],
80
81 python_requires='>=3.2',
82 install_requires=['pyudev (>= 0.13)', ],
83 package_dir={'': 'lib'},
84 packages=['hidapi', 'logitech_receiver', 'solaar', 'solaar.ui', 'solaar.cli'],
85 data_files=list(_data_files()),
86 scripts=_glob('bin/*'),
87 )
88
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -8,28 +8,10 @@
autostart_path = '/etc/xdg/autostart'
-import sys
-backup_path_0 = sys.path[0]
-sys.path[0] = backup_path_0 + '/lib'
#from solaar import NAME, __version__
__version__ = '1.0.2-rc1'
NAME = 'Solaar'
-sys.path[0] = backup_path_0
-
-if 'install' in sys.argv:
- # naively guess where the autostart .desktop file should be installed
- if '--prefix' in sys.argv or any(x.startswith('--prefix=') for x in sys.argv) or '--home' in sys.argv:
- autostart_path = 'etc/xdg/autostart'
- elif '--user' in sys.argv:
- from os import environ
- from os import path
- xdg_config_home = environ.get('XDG_CONFIG_HOME', path.expanduser(path.join('~', '.config')))
- autostart_path = path.join(xdg_config_home, 'autostart')
- del environ, path, xdg_config_home
-
-del sys, backup_path_0
-
def _data_files():
from os.path import dirname as _dirname
@@ -43,6 +25,7 @@
yield 'share/applications', ['share/applications/solaar.desktop']
yield autostart_path, ['share/autostart/solaar.desktop']
+ yield '/etc/udev/rules.d', ['rules.d/42-logitech-unify-permissions.rules']
del _dirname
@@ -56,7 +39,6 @@
battery status.
'''.strip(),
author='Daniel Pavel',
- author_email='[email protected]',
license='GPLv2',
url='http://pwr-solaar.github.io/Solaar/',
classifiers=[
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -8,28 +8,10 @@\n \n autostart_path = '/etc/xdg/autostart'\n \n-import sys\n-backup_path_0 = sys.path[0]\n-sys.path[0] = backup_path_0 + '/lib'\n #from solaar import NAME, __version__\n __version__ = '1.0.2-rc1'\n NAME = 'Solaar'\n \n-sys.path[0] = backup_path_0\n-\n-if 'install' in sys.argv:\n-\t# naively guess where the autostart .desktop file should be installed\n-\tif '--prefix' in sys.argv or any(x.startswith('--prefix=') for x in sys.argv) or '--home' in sys.argv:\n-\t\tautostart_path = 'etc/xdg/autostart'\n-\telif '--user' in sys.argv:\n-\t\tfrom os import environ\n-\t\tfrom os import path\n-\t\txdg_config_home = environ.get('XDG_CONFIG_HOME', path.expanduser(path.join('~', '.config')))\n-\t\tautostart_path = path.join(xdg_config_home, 'autostart')\n-\t\tdel environ, path, xdg_config_home\n-\n-del sys, backup_path_0\n-\n \n def _data_files():\n \tfrom os.path import dirname as _dirname\n@@ -43,6 +25,7 @@\n \n \tyield 'share/applications', ['share/applications/solaar.desktop']\n \tyield autostart_path, ['share/autostart/solaar.desktop']\n+\tyield '/etc/udev/rules.d', ['rules.d/42-logitech-unify-permissions.rules']\n \n \tdel _dirname\n \n@@ -56,7 +39,6 @@\n battery status.\n '''.strip(),\n \t\tauthor='Daniel Pavel',\n-\t\tauthor_email='[email protected]',\n \t\tlicense='GPLv2',\n \t\turl='http://pwr-solaar.github.io/Solaar/',\n \t\tclassifiers=[\n", "issue": "authorship of Solaar in setup.py\nDaniel Pavel is listed as the sole author of Solaar in setup.py \r\n\r\nAs far as I can tell, this puts him and his email in several repositories, such as PyPI https://pypi.org/project/solaar/\r\n\r\nWho should be put there?\n", "before_files": [{"content": "#!/usr/bin/env python3\n\nfrom glob import glob as _glob\ntry:\n from setuptools import setup\nexcept ImportError:\n from distutils.core import setup\n\nautostart_path = '/etc/xdg/autostart'\n\nimport sys\nbackup_path_0 = sys.path[0]\nsys.path[0] = backup_path_0 + '/lib'\n#from solaar import NAME, __version__\n__version__ = '1.0.2-rc1'\nNAME = 'Solaar'\n\nsys.path[0] = backup_path_0\n\nif 'install' in sys.argv:\n\t# naively guess where the autostart .desktop file should be installed\n\tif '--prefix' in sys.argv or any(x.startswith('--prefix=') for x in sys.argv) or '--home' in sys.argv:\n\t\tautostart_path = 'etc/xdg/autostart'\n\telif '--user' in sys.argv:\n\t\tfrom os import environ\n\t\tfrom os import path\n\t\txdg_config_home = environ.get('XDG_CONFIG_HOME', path.expanduser(path.join('~', '.config')))\n\t\tautostart_path = path.join(xdg_config_home, 'autostart')\n\t\tdel environ, path, xdg_config_home\n\ndel sys, backup_path_0\n\n\ndef _data_files():\n\tfrom os.path import dirname as _dirname\n\n\tyield 'share/solaar/icons', _glob('share/solaar/icons/solaar*.svg')\n\tyield 'share/solaar/icons', _glob('share/solaar/icons/light_*.png')\n\tyield 'share/icons/hicolor/scalable/apps', ['share/solaar/icons/solaar.svg']\n\n\tfor mo in _glob('share/locale/*/LC_MESSAGES/solaar.mo'):\n\t\tyield _dirname(mo), [mo]\n\n\tyield 'share/applications', ['share/applications/solaar.desktop']\n\tyield autostart_path, ['share/autostart/solaar.desktop']\n\n\tdel _dirname\n\n\nsetup(name=NAME.lower(),\n\t\tversion=__version__,\n\t\tdescription='Linux devices manager for the Logitech Unifying Receiver.',\n\t\tlong_description='''\nSolaar is a Linux device manager for Logitech's Unifying Receiver peripherals.\nIt is able to pair/unpair devices to the receiver, and for some devices read\nbattery status.\n'''.strip(),\n\t\tauthor='Daniel Pavel',\n\t\tauthor_email='[email protected]',\n\t\tlicense='GPLv2',\n\t\turl='http://pwr-solaar.github.io/Solaar/',\n\t\tclassifiers=[\n\t\t\t'Development Status :: 4 - Beta',\n\t\t\t'Environment :: X11 Applications :: GTK',\n\t\t\t'Environment :: Console',\n\t\t\t'Intended Audience :: End Users/Desktop',\n\t\t\t'License :: DFSG approved',\n\t\t\t'License :: OSI Approved :: GNU General Public License v2 (GPLv2)',\n\t\t\t'Natural Language :: English',\n\t\t\t'Programming Language :: Python :: 3 :: Only',\n\t\t\t'Operating System :: POSIX :: Linux',\n\t\t\t'Topic :: Utilities',\n\t\t\t],\n\n\t\tplatforms=['linux'],\n\n\t\t# sudo apt install python-gi python3-gi \\\n\t\t# gir1.2-gtk-3.0 gir1.2-notify-0.7 gir1.2-ayatanaappindicator3-0.1\n\t\t# os_requires=['gi.repository.GObject (>= 2.0)', 'gi.repository.Gtk (>= 3.0)'],\n\n\t\tpython_requires='>=3.2',\n\t\tinstall_requires=['pyudev (>= 0.13)', ],\n\t\tpackage_dir={'': 'lib'},\n\t\tpackages=['hidapi', 'logitech_receiver', 'solaar', 'solaar.ui', 'solaar.cli'],\n\t\tdata_files=list(_data_files()),\n\t\tscripts=_glob('bin/*'),\n\t)\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n\nfrom glob import glob as _glob\ntry:\n from setuptools import setup\nexcept ImportError:\n from distutils.core import setup\n\nautostart_path = '/etc/xdg/autostart'\n\n#from solaar import NAME, __version__\n__version__ = '1.0.2-rc1'\nNAME = 'Solaar'\n\n\ndef _data_files():\n\tfrom os.path import dirname as _dirname\n\n\tyield 'share/solaar/icons', _glob('share/solaar/icons/solaar*.svg')\n\tyield 'share/solaar/icons', _glob('share/solaar/icons/light_*.png')\n\tyield 'share/icons/hicolor/scalable/apps', ['share/solaar/icons/solaar.svg']\n\n\tfor mo in _glob('share/locale/*/LC_MESSAGES/solaar.mo'):\n\t\tyield _dirname(mo), [mo]\n\n\tyield 'share/applications', ['share/applications/solaar.desktop']\n\tyield autostart_path, ['share/autostart/solaar.desktop']\n\tyield '/etc/udev/rules.d', ['rules.d/42-logitech-unify-permissions.rules']\n\n\tdel _dirname\n\n\nsetup(name=NAME.lower(),\n\t\tversion=__version__,\n\t\tdescription='Linux devices manager for the Logitech Unifying Receiver.',\n\t\tlong_description='''\nSolaar is a Linux device manager for Logitech's Unifying Receiver peripherals.\nIt is able to pair/unpair devices to the receiver, and for some devices read\nbattery status.\n'''.strip(),\n\t\tauthor='Daniel Pavel',\n\t\tlicense='GPLv2',\n\t\turl='http://pwr-solaar.github.io/Solaar/',\n\t\tclassifiers=[\n\t\t\t'Development Status :: 4 - Beta',\n\t\t\t'Environment :: X11 Applications :: GTK',\n\t\t\t'Environment :: Console',\n\t\t\t'Intended Audience :: End Users/Desktop',\n\t\t\t'License :: DFSG approved',\n\t\t\t'License :: OSI Approved :: GNU General Public License v2 (GPLv2)',\n\t\t\t'Natural Language :: English',\n\t\t\t'Programming Language :: Python :: 3 :: Only',\n\t\t\t'Operating System :: POSIX :: Linux',\n\t\t\t'Topic :: Utilities',\n\t\t\t],\n\n\t\tplatforms=['linux'],\n\n\t\t# sudo apt install python-gi python3-gi \\\n\t\t# gir1.2-gtk-3.0 gir1.2-notify-0.7 gir1.2-ayatanaappindicator3-0.1\n\t\t# os_requires=['gi.repository.GObject (>= 2.0)', 'gi.repository.Gtk (>= 3.0)'],\n\n\t\tpython_requires='>=3.2',\n\t\tinstall_requires=['pyudev (>= 0.13)', ],\n\t\tpackage_dir={'': 'lib'},\n\t\tpackages=['hidapi', 'logitech_receiver', 'solaar', 'solaar.ui', 'solaar.cli'],\n\t\tdata_files=list(_data_files()),\n\t\tscripts=_glob('bin/*'),\n\t)\n", "path": "setup.py"}]}
| 1,332 | 447 |
gh_patches_debug_30750
|
rasdani/github-patches
|
git_diff
|
pyg-team__pytorch_geometric-8164
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
math term missed in dimenet_utils.associated_legendre_polynomials
### 🛠 Proposed Refactor
In order to get the function of 'spherical harmonics' basis used in DimeNet, we need to calc 'Associated Legendre Polynomial' in math. But I just found a term missed in torch_geometric.nn.models.dimenet_utils.associated_legendre_polynomials().
The author of DimeNet use `zero_m_only=True` by default, so there will be no error when running the code by default.
But just a warning for those who also read or use this code, the author of the code (version of pyg: 2.3.1) missed a term when calculating $P_l^l$ which make all results except $P_l^0$ wrong. [original code here](https://github.com/pyg-team/pytorch_geometric/blob/f71ead8ade8a67be23982114cfff649b7d074cfb/torch_geometric/nn/models/dimenet_utils.py#L86)
Take the result of $P_1^1$ as an example:
original code will output -1, but according to eq.14 at https://mathworld.wolfram.com/AssociatedLegendrePolynomial.html, the ground truth result is $-(1-x^2)^{0.5}$.
### Suggest a potential alternative/fix
Beyond adding the missed term, I also add some comment to help understanding.
```python
def associated_legendre_polynomials(k, zero_m_only=True):
'''
helper function to calc Y_l^m
'''
z = sym.symbols('z')
P_l_m = [[0] * (j + 1) for j in range(k)]
P_l_m[0][0] = 1
if k > 0:
P_l_m[1][0] = z
for j in range(2, k):
P_l_m[j][0] = sym.simplify(((2 * j - 1) * z * P_l_m[j - 1][0] -
(j - 1) * P_l_m[j - 2][0]) / j) # use the property of eq.7: https://mathworld.wolfram.com/AssociatedLegendrePolynomial.html
if not zero_m_only:
for i in range(1, k):
P_l_m[i][i] = sym.simplify((1 - 2 * i) * P_l_m[i - 1][i - 1]*(1-z**2)**0.5) # add missed term (*(1-z**2)**0.5) here
if i + 1 < k:
P_l_m[i + 1][i] = sym.simplify(
(2 * i + 1) * z * P_l_m[i][i]) # use the property of eq.11: https://mathworld.wolfram.com/AssociatedLegendrePolynomial.html
for j in range(i + 2, k):
P_l_m[j][i] = sym.simplify(
((2 * j - 1) * z * P_l_m[j - 1][i] -
(i + j - 1) * P_l_m[j - 2][i]) / (j - i)) # use the property of eq.7: https://mathworld.wolfram.com/AssociatedLegendrePolynomial.html
return P_l_m
```
After fixing this tiny bug, all the results are the right
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `torch_geometric/nn/models/dimenet_utils.py`
Content:
```
1 # Shameless steal from: https://github.com/klicperajo/dimenet
2
3 import numpy as np
4 from scipy import special as sp
5 from scipy.optimize import brentq
6
7 try:
8 import sympy as sym
9 except ImportError:
10 sym = None
11
12
13 def Jn(r, n):
14 return np.sqrt(np.pi / (2 * r)) * sp.jv(n + 0.5, r)
15
16
17 def Jn_zeros(n, k):
18 zerosj = np.zeros((n, k), dtype='float32')
19 zerosj[0] = np.arange(1, k + 1) * np.pi
20 points = np.arange(1, k + n) * np.pi
21 racines = np.zeros(k + n - 1, dtype='float32')
22 for i in range(1, n):
23 for j in range(k + n - 1 - i):
24 foo = brentq(Jn, points[j], points[j + 1], (i, ))
25 racines[j] = foo
26 points = racines
27 zerosj[i][:k] = racines[:k]
28
29 return zerosj
30
31
32 def spherical_bessel_formulas(n):
33 x = sym.symbols('x')
34
35 f = [sym.sin(x) / x]
36 a = sym.sin(x) / x
37 for i in range(1, n):
38 b = sym.diff(a, x) / x
39 f += [sym.simplify(b * (-x)**i)]
40 a = sym.simplify(b)
41 return f
42
43
44 def bessel_basis(n, k):
45 zeros = Jn_zeros(n, k)
46 normalizer = []
47 for order in range(n):
48 normalizer_tmp = []
49 for i in range(k):
50 normalizer_tmp += [0.5 * Jn(zeros[order, i], order + 1)**2]
51 normalizer_tmp = 1 / np.array(normalizer_tmp)**0.5
52 normalizer += [normalizer_tmp]
53
54 f = spherical_bessel_formulas(n)
55 x = sym.symbols('x')
56 bess_basis = []
57 for order in range(n):
58 bess_basis_tmp = []
59 for i in range(k):
60 bess_basis_tmp += [
61 sym.simplify(normalizer[order][i] *
62 f[order].subs(x, zeros[order, i] * x))
63 ]
64 bess_basis += [bess_basis_tmp]
65 return bess_basis
66
67
68 def sph_harm_prefactor(k, m):
69 return ((2 * k + 1) * np.math.factorial(k - abs(m)) /
70 (4 * np.pi * np.math.factorial(k + abs(m))))**0.5
71
72
73 def associated_legendre_polynomials(k, zero_m_only=True):
74 z = sym.symbols('z')
75 P_l_m = [[0] * (j + 1) for j in range(k)]
76
77 P_l_m[0][0] = 1
78 if k > 0:
79 P_l_m[1][0] = z
80
81 for j in range(2, k):
82 P_l_m[j][0] = sym.simplify(((2 * j - 1) * z * P_l_m[j - 1][0] -
83 (j - 1) * P_l_m[j - 2][0]) / j)
84 if not zero_m_only:
85 for i in range(1, k):
86 P_l_m[i][i] = sym.simplify((1 - 2 * i) * P_l_m[i - 1][i - 1])
87 if i + 1 < k:
88 P_l_m[i + 1][i] = sym.simplify(
89 (2 * i + 1) * z * P_l_m[i][i])
90 for j in range(i + 2, k):
91 P_l_m[j][i] = sym.simplify(
92 ((2 * j - 1) * z * P_l_m[j - 1][i] -
93 (i + j - 1) * P_l_m[j - 2][i]) / (j - i))
94
95 return P_l_m
96
97
98 def real_sph_harm(k, zero_m_only=True, spherical_coordinates=True):
99 if not zero_m_only:
100 S_m = [0]
101 C_m = [1]
102 for i in range(1, k):
103 x = sym.symbols('x')
104 y = sym.symbols('y')
105 S_m += [x * S_m[i - 1] + y * C_m[i - 1]]
106 C_m += [x * C_m[i - 1] - y * S_m[i - 1]]
107
108 P_l_m = associated_legendre_polynomials(k, zero_m_only)
109 if spherical_coordinates:
110 theta = sym.symbols('theta')
111 z = sym.symbols('z')
112 for i in range(len(P_l_m)):
113 for j in range(len(P_l_m[i])):
114 if not isinstance(P_l_m[i][j], int):
115 P_l_m[i][j] = P_l_m[i][j].subs(z, sym.cos(theta))
116 if not zero_m_only:
117 phi = sym.symbols('phi')
118 for i in range(len(S_m)):
119 S_m[i] = S_m[i].subs(x,
120 sym.sin(theta) * sym.cos(phi)).subs(
121 y,
122 sym.sin(theta) * sym.sin(phi))
123 for i in range(len(C_m)):
124 C_m[i] = C_m[i].subs(x,
125 sym.sin(theta) * sym.cos(phi)).subs(
126 y,
127 sym.sin(theta) * sym.sin(phi))
128
129 Y_func_l_m = [['0'] * (2 * j + 1) for j in range(k)]
130 for i in range(k):
131 Y_func_l_m[i][0] = sym.simplify(sph_harm_prefactor(i, 0) * P_l_m[i][0])
132
133 if not zero_m_only:
134 for i in range(1, k):
135 for j in range(1, i + 1):
136 Y_func_l_m[i][j] = sym.simplify(
137 2**0.5 * sph_harm_prefactor(i, j) * C_m[j] * P_l_m[i][j])
138 for i in range(1, k):
139 for j in range(1, i + 1):
140 Y_func_l_m[i][-j] = sym.simplify(
141 2**0.5 * sph_harm_prefactor(i, -j) * S_m[j] * P_l_m[i][j])
142
143 return Y_func_l_m
144
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/torch_geometric/nn/models/dimenet_utils.py b/torch_geometric/nn/models/dimenet_utils.py
--- a/torch_geometric/nn/models/dimenet_utils.py
+++ b/torch_geometric/nn/models/dimenet_utils.py
@@ -71,6 +71,7 @@
def associated_legendre_polynomials(k, zero_m_only=True):
+ r"""Helper function to calculate Y_l^m."""
z = sym.symbols('z')
P_l_m = [[0] * (j + 1) for j in range(k)]
@@ -79,15 +80,22 @@
P_l_m[1][0] = z
for j in range(2, k):
+ # Use the property of Eq (7) in
+ # https://mathworld.wolfram.com/AssociatedLegendrePolynomial.html:
P_l_m[j][0] = sym.simplify(((2 * j - 1) * z * P_l_m[j - 1][0] -
(j - 1) * P_l_m[j - 2][0]) / j)
if not zero_m_only:
for i in range(1, k):
- P_l_m[i][i] = sym.simplify((1 - 2 * i) * P_l_m[i - 1][i - 1])
+ P_l_m[i][i] = sym.simplify(
+ (1 - 2 * i) * P_l_m[i - 1][i - 1] * (1 - z**2)**0.5)
if i + 1 < k:
+ # Use the property of Eq (11) in
+ # https://mathworld.wolfram.com/AssociatedLegendrePolynomial.html:
P_l_m[i + 1][i] = sym.simplify(
(2 * i + 1) * z * P_l_m[i][i])
for j in range(i + 2, k):
+ # Use the property of Eq (7) in
+ # https://mathworld.wolfram.com/AssociatedLegendrePolynomial.html:
P_l_m[j][i] = sym.simplify(
((2 * j - 1) * z * P_l_m[j - 1][i] -
(i + j - 1) * P_l_m[j - 2][i]) / (j - i))
|
{"golden_diff": "diff --git a/torch_geometric/nn/models/dimenet_utils.py b/torch_geometric/nn/models/dimenet_utils.py\n--- a/torch_geometric/nn/models/dimenet_utils.py\n+++ b/torch_geometric/nn/models/dimenet_utils.py\n@@ -71,6 +71,7 @@\n \n \n def associated_legendre_polynomials(k, zero_m_only=True):\n+ r\"\"\"Helper function to calculate Y_l^m.\"\"\"\n z = sym.symbols('z')\n P_l_m = [[0] * (j + 1) for j in range(k)]\n \n@@ -79,15 +80,22 @@\n P_l_m[1][0] = z\n \n for j in range(2, k):\n+ # Use the property of Eq (7) in\n+ # https://mathworld.wolfram.com/AssociatedLegendrePolynomial.html:\n P_l_m[j][0] = sym.simplify(((2 * j - 1) * z * P_l_m[j - 1][0] -\n (j - 1) * P_l_m[j - 2][0]) / j)\n if not zero_m_only:\n for i in range(1, k):\n- P_l_m[i][i] = sym.simplify((1 - 2 * i) * P_l_m[i - 1][i - 1])\n+ P_l_m[i][i] = sym.simplify(\n+ (1 - 2 * i) * P_l_m[i - 1][i - 1] * (1 - z**2)**0.5)\n if i + 1 < k:\n+ # Use the property of Eq (11) in\n+ # https://mathworld.wolfram.com/AssociatedLegendrePolynomial.html:\n P_l_m[i + 1][i] = sym.simplify(\n (2 * i + 1) * z * P_l_m[i][i])\n for j in range(i + 2, k):\n+ # Use the property of Eq (7) in\n+ # https://mathworld.wolfram.com/AssociatedLegendrePolynomial.html:\n P_l_m[j][i] = sym.simplify(\n ((2 * j - 1) * z * P_l_m[j - 1][i] -\n (i + j - 1) * P_l_m[j - 2][i]) / (j - i))\n", "issue": "math term missed in dimenet_utils.associated_legendre_polynomials\n### \ud83d\udee0 Proposed Refactor\n\nIn order to get the function of 'spherical harmonics' basis used in DimeNet, we need to calc 'Associated Legendre Polynomial' in math. But I just found a term missed in torch_geometric.nn.models.dimenet_utils.associated_legendre_polynomials(). \r\n\r\nThe author of DimeNet use `zero_m_only=True` by default, so there will be no error when running the code by default. \r\n\r\nBut just a warning for those who also read or use this code, the author of the code (version of pyg: 2.3.1) missed a term when calculating $P_l^l$ which make all results except $P_l^0$ wrong. [original code here](https://github.com/pyg-team/pytorch_geometric/blob/f71ead8ade8a67be23982114cfff649b7d074cfb/torch_geometric/nn/models/dimenet_utils.py#L86)\r\n\r\nTake the result of $P_1^1$ as an example:\r\n\r\noriginal code will output -1, but according to eq.14 at https://mathworld.wolfram.com/AssociatedLegendrePolynomial.html, the ground truth result is $-(1-x^2)^{0.5}$. \n\n### Suggest a potential alternative/fix\n\nBeyond adding the missed term, I also add some comment to help understanding.\r\n```python\r\ndef associated_legendre_polynomials(k, zero_m_only=True):\r\n '''\r\n helper function to calc Y_l^m\r\n '''\r\n z = sym.symbols('z')\r\n P_l_m = [[0] * (j + 1) for j in range(k)]\r\n\r\n P_l_m[0][0] = 1\r\n if k > 0:\r\n P_l_m[1][0] = z\r\n\r\n for j in range(2, k):\r\n P_l_m[j][0] = sym.simplify(((2 * j - 1) * z * P_l_m[j - 1][0] -\r\n (j - 1) * P_l_m[j - 2][0]) / j) # use the property of eq.7: https://mathworld.wolfram.com/AssociatedLegendrePolynomial.html\r\n if not zero_m_only:\r\n for i in range(1, k):\r\n P_l_m[i][i] = sym.simplify((1 - 2 * i) * P_l_m[i - 1][i - 1]*(1-z**2)**0.5) # add missed term (*(1-z**2)**0.5) here\r\n if i + 1 < k:\r\n P_l_m[i + 1][i] = sym.simplify(\r\n (2 * i + 1) * z * P_l_m[i][i]) # use the property of eq.11: https://mathworld.wolfram.com/AssociatedLegendrePolynomial.html\r\n for j in range(i + 2, k):\r\n P_l_m[j][i] = sym.simplify(\r\n ((2 * j - 1) * z * P_l_m[j - 1][i] -\r\n (i + j - 1) * P_l_m[j - 2][i]) / (j - i)) # use the property of eq.7: https://mathworld.wolfram.com/AssociatedLegendrePolynomial.html\r\n\r\n return P_l_m\r\n```\r\nAfter fixing this tiny bug, all the results are the right\n", "before_files": [{"content": "# Shameless steal from: https://github.com/klicperajo/dimenet\n\nimport numpy as np\nfrom scipy import special as sp\nfrom scipy.optimize import brentq\n\ntry:\n import sympy as sym\nexcept ImportError:\n sym = None\n\n\ndef Jn(r, n):\n return np.sqrt(np.pi / (2 * r)) * sp.jv(n + 0.5, r)\n\n\ndef Jn_zeros(n, k):\n zerosj = np.zeros((n, k), dtype='float32')\n zerosj[0] = np.arange(1, k + 1) * np.pi\n points = np.arange(1, k + n) * np.pi\n racines = np.zeros(k + n - 1, dtype='float32')\n for i in range(1, n):\n for j in range(k + n - 1 - i):\n foo = brentq(Jn, points[j], points[j + 1], (i, ))\n racines[j] = foo\n points = racines\n zerosj[i][:k] = racines[:k]\n\n return zerosj\n\n\ndef spherical_bessel_formulas(n):\n x = sym.symbols('x')\n\n f = [sym.sin(x) / x]\n a = sym.sin(x) / x\n for i in range(1, n):\n b = sym.diff(a, x) / x\n f += [sym.simplify(b * (-x)**i)]\n a = sym.simplify(b)\n return f\n\n\ndef bessel_basis(n, k):\n zeros = Jn_zeros(n, k)\n normalizer = []\n for order in range(n):\n normalizer_tmp = []\n for i in range(k):\n normalizer_tmp += [0.5 * Jn(zeros[order, i], order + 1)**2]\n normalizer_tmp = 1 / np.array(normalizer_tmp)**0.5\n normalizer += [normalizer_tmp]\n\n f = spherical_bessel_formulas(n)\n x = sym.symbols('x')\n bess_basis = []\n for order in range(n):\n bess_basis_tmp = []\n for i in range(k):\n bess_basis_tmp += [\n sym.simplify(normalizer[order][i] *\n f[order].subs(x, zeros[order, i] * x))\n ]\n bess_basis += [bess_basis_tmp]\n return bess_basis\n\n\ndef sph_harm_prefactor(k, m):\n return ((2 * k + 1) * np.math.factorial(k - abs(m)) /\n (4 * np.pi * np.math.factorial(k + abs(m))))**0.5\n\n\ndef associated_legendre_polynomials(k, zero_m_only=True):\n z = sym.symbols('z')\n P_l_m = [[0] * (j + 1) for j in range(k)]\n\n P_l_m[0][0] = 1\n if k > 0:\n P_l_m[1][0] = z\n\n for j in range(2, k):\n P_l_m[j][0] = sym.simplify(((2 * j - 1) * z * P_l_m[j - 1][0] -\n (j - 1) * P_l_m[j - 2][0]) / j)\n if not zero_m_only:\n for i in range(1, k):\n P_l_m[i][i] = sym.simplify((1 - 2 * i) * P_l_m[i - 1][i - 1])\n if i + 1 < k:\n P_l_m[i + 1][i] = sym.simplify(\n (2 * i + 1) * z * P_l_m[i][i])\n for j in range(i + 2, k):\n P_l_m[j][i] = sym.simplify(\n ((2 * j - 1) * z * P_l_m[j - 1][i] -\n (i + j - 1) * P_l_m[j - 2][i]) / (j - i))\n\n return P_l_m\n\n\ndef real_sph_harm(k, zero_m_only=True, spherical_coordinates=True):\n if not zero_m_only:\n S_m = [0]\n C_m = [1]\n for i in range(1, k):\n x = sym.symbols('x')\n y = sym.symbols('y')\n S_m += [x * S_m[i - 1] + y * C_m[i - 1]]\n C_m += [x * C_m[i - 1] - y * S_m[i - 1]]\n\n P_l_m = associated_legendre_polynomials(k, zero_m_only)\n if spherical_coordinates:\n theta = sym.symbols('theta')\n z = sym.symbols('z')\n for i in range(len(P_l_m)):\n for j in range(len(P_l_m[i])):\n if not isinstance(P_l_m[i][j], int):\n P_l_m[i][j] = P_l_m[i][j].subs(z, sym.cos(theta))\n if not zero_m_only:\n phi = sym.symbols('phi')\n for i in range(len(S_m)):\n S_m[i] = S_m[i].subs(x,\n sym.sin(theta) * sym.cos(phi)).subs(\n y,\n sym.sin(theta) * sym.sin(phi))\n for i in range(len(C_m)):\n C_m[i] = C_m[i].subs(x,\n sym.sin(theta) * sym.cos(phi)).subs(\n y,\n sym.sin(theta) * sym.sin(phi))\n\n Y_func_l_m = [['0'] * (2 * j + 1) for j in range(k)]\n for i in range(k):\n Y_func_l_m[i][0] = sym.simplify(sph_harm_prefactor(i, 0) * P_l_m[i][0])\n\n if not zero_m_only:\n for i in range(1, k):\n for j in range(1, i + 1):\n Y_func_l_m[i][j] = sym.simplify(\n 2**0.5 * sph_harm_prefactor(i, j) * C_m[j] * P_l_m[i][j])\n for i in range(1, k):\n for j in range(1, i + 1):\n Y_func_l_m[i][-j] = sym.simplify(\n 2**0.5 * sph_harm_prefactor(i, -j) * S_m[j] * P_l_m[i][j])\n\n return Y_func_l_m\n", "path": "torch_geometric/nn/models/dimenet_utils.py"}], "after_files": [{"content": "# Shameless steal from: https://github.com/klicperajo/dimenet\n\nimport numpy as np\nfrom scipy import special as sp\nfrom scipy.optimize import brentq\n\ntry:\n import sympy as sym\nexcept ImportError:\n sym = None\n\n\ndef Jn(r, n):\n return np.sqrt(np.pi / (2 * r)) * sp.jv(n + 0.5, r)\n\n\ndef Jn_zeros(n, k):\n zerosj = np.zeros((n, k), dtype='float32')\n zerosj[0] = np.arange(1, k + 1) * np.pi\n points = np.arange(1, k + n) * np.pi\n racines = np.zeros(k + n - 1, dtype='float32')\n for i in range(1, n):\n for j in range(k + n - 1 - i):\n foo = brentq(Jn, points[j], points[j + 1], (i, ))\n racines[j] = foo\n points = racines\n zerosj[i][:k] = racines[:k]\n\n return zerosj\n\n\ndef spherical_bessel_formulas(n):\n x = sym.symbols('x')\n\n f = [sym.sin(x) / x]\n a = sym.sin(x) / x\n for i in range(1, n):\n b = sym.diff(a, x) / x\n f += [sym.simplify(b * (-x)**i)]\n a = sym.simplify(b)\n return f\n\n\ndef bessel_basis(n, k):\n zeros = Jn_zeros(n, k)\n normalizer = []\n for order in range(n):\n normalizer_tmp = []\n for i in range(k):\n normalizer_tmp += [0.5 * Jn(zeros[order, i], order + 1)**2]\n normalizer_tmp = 1 / np.array(normalizer_tmp)**0.5\n normalizer += [normalizer_tmp]\n\n f = spherical_bessel_formulas(n)\n x = sym.symbols('x')\n bess_basis = []\n for order in range(n):\n bess_basis_tmp = []\n for i in range(k):\n bess_basis_tmp += [\n sym.simplify(normalizer[order][i] *\n f[order].subs(x, zeros[order, i] * x))\n ]\n bess_basis += [bess_basis_tmp]\n return bess_basis\n\n\ndef sph_harm_prefactor(k, m):\n return ((2 * k + 1) * np.math.factorial(k - abs(m)) /\n (4 * np.pi * np.math.factorial(k + abs(m))))**0.5\n\n\ndef associated_legendre_polynomials(k, zero_m_only=True):\n r\"\"\"Helper function to calculate Y_l^m.\"\"\"\n z = sym.symbols('z')\n P_l_m = [[0] * (j + 1) for j in range(k)]\n\n P_l_m[0][0] = 1\n if k > 0:\n P_l_m[1][0] = z\n\n for j in range(2, k):\n # Use the property of Eq (7) in\n # https://mathworld.wolfram.com/AssociatedLegendrePolynomial.html:\n P_l_m[j][0] = sym.simplify(((2 * j - 1) * z * P_l_m[j - 1][0] -\n (j - 1) * P_l_m[j - 2][0]) / j)\n if not zero_m_only:\n for i in range(1, k):\n P_l_m[i][i] = sym.simplify(\n (1 - 2 * i) * P_l_m[i - 1][i - 1] * (1 - z**2)**0.5)\n if i + 1 < k:\n # Use the property of Eq (11) in\n # https://mathworld.wolfram.com/AssociatedLegendrePolynomial.html:\n P_l_m[i + 1][i] = sym.simplify(\n (2 * i + 1) * z * P_l_m[i][i])\n for j in range(i + 2, k):\n # Use the property of Eq (7) in\n # https://mathworld.wolfram.com/AssociatedLegendrePolynomial.html:\n P_l_m[j][i] = sym.simplify(\n ((2 * j - 1) * z * P_l_m[j - 1][i] -\n (i + j - 1) * P_l_m[j - 2][i]) / (j - i))\n\n return P_l_m\n\n\ndef real_sph_harm(k, zero_m_only=True, spherical_coordinates=True):\n if not zero_m_only:\n S_m = [0]\n C_m = [1]\n for i in range(1, k):\n x = sym.symbols('x')\n y = sym.symbols('y')\n S_m += [x * S_m[i - 1] + y * C_m[i - 1]]\n C_m += [x * C_m[i - 1] - y * S_m[i - 1]]\n\n P_l_m = associated_legendre_polynomials(k, zero_m_only)\n if spherical_coordinates:\n theta = sym.symbols('theta')\n z = sym.symbols('z')\n for i in range(len(P_l_m)):\n for j in range(len(P_l_m[i])):\n if not isinstance(P_l_m[i][j], int):\n P_l_m[i][j] = P_l_m[i][j].subs(z, sym.cos(theta))\n if not zero_m_only:\n phi = sym.symbols('phi')\n for i in range(len(S_m)):\n S_m[i] = S_m[i].subs(x,\n sym.sin(theta) * sym.cos(phi)).subs(\n y,\n sym.sin(theta) * sym.sin(phi))\n for i in range(len(C_m)):\n C_m[i] = C_m[i].subs(x,\n sym.sin(theta) * sym.cos(phi)).subs(\n y,\n sym.sin(theta) * sym.sin(phi))\n\n Y_func_l_m = [['0'] * (2 * j + 1) for j in range(k)]\n for i in range(k):\n Y_func_l_m[i][0] = sym.simplify(sph_harm_prefactor(i, 0) * P_l_m[i][0])\n\n if not zero_m_only:\n for i in range(1, k):\n for j in range(1, i + 1):\n Y_func_l_m[i][j] = sym.simplify(\n 2**0.5 * sph_harm_prefactor(i, j) * C_m[j] * P_l_m[i][j])\n for i in range(1, k):\n for j in range(1, i + 1):\n Y_func_l_m[i][-j] = sym.simplify(\n 2**0.5 * sph_harm_prefactor(i, -j) * S_m[j] * P_l_m[i][j])\n\n return Y_func_l_m\n", "path": "torch_geometric/nn/models/dimenet_utils.py"}]}
| 2,816 | 538 |
gh_patches_debug_60773
|
rasdani/github-patches
|
git_diff
|
data-for-change__anyway-1848
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Fix walla scraping - see test_scrape_sanity_online_walla
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `anyway/parsers/rss_sites.py`
Content:
```
1 import requests
2 from bs4 import BeautifulSoup
3 import feedparser
4 from anyway.parsers import timezones
5
6
7 def parse_html_walla(item_rss, html_soup):
8 # For some reason there's html here
9 description = BeautifulSoup(item_rss["summary"], features="lxml").text
10
11 author = html_soup.find("div", class_="author").find("a").get_text()
12 return author, description
13
14
15 def parse_html_ynet(item_rss, html_soup):
16 # This is rather fragile
17 # description_text: "[description] ([author]) [unrelated stuff]"
18 description_text = html_soup.find(id="ArticleBodyComponent").get_text()
19 author = description_text.split("(")[-1].split(")")[0].strip()
20 description = description_text.rsplit("(")[0].strip()
21 return author, description
22
23
24 sites_config = {
25 "ynet": {
26 "rss": "https://www.ynet.co.il:443/Integration/StoryRss1854.xml",
27 "parser": parse_html_ynet,
28 },
29 "walla": {"rss": "https://rss.walla.co.il:443/feed/22", "parser": parse_html_walla},
30 }
31
32
33 def _fetch(url: str) -> str:
34 return requests.get(url).text
35
36
37 def scrape_raw(site_name: str, *, rss_source=None, fetch_html=_fetch):
38 config = sites_config[site_name]
39 if rss_source is None:
40 rss_source = config["rss"]
41 rss_dict = feedparser.parse(rss_source)
42 if rss_dict.get("bozo_exception"):
43 raise rss_dict["bozo_exception"]
44
45 for item_rss in rss_dict["items"]:
46 html_text = fetch_html(item_rss["link"])
47 author, description = config["parser"](item_rss, BeautifulSoup(html_text, "lxml"))
48 yield {
49 "link": item_rss["link"],
50 "date": timezones.from_rss(item_rss["published_parsed"]),
51 "source": site_name,
52 "author": author,
53 "title": item_rss["title"],
54 "description": description,
55 "accident": False,
56 }
57
58
59 def scrape(*args, **kwargs):
60 # lazily load dependencies, so this module will behave like an independent library
61 from anyway.models import NewsFlash
62
63 for dict_item in scrape_raw(*args, **kwargs):
64 yield NewsFlash(**dict_item)
65
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/anyway/parsers/rss_sites.py b/anyway/parsers/rss_sites.py
--- a/anyway/parsers/rss_sites.py
+++ b/anyway/parsers/rss_sites.py
@@ -8,7 +8,7 @@
# For some reason there's html here
description = BeautifulSoup(item_rss["summary"], features="lxml").text
- author = html_soup.find("div", class_="author").find("a").get_text()
+ author = html_soup.find("div", class_="author").get_text().strip()
return author, description
|
{"golden_diff": "diff --git a/anyway/parsers/rss_sites.py b/anyway/parsers/rss_sites.py\n--- a/anyway/parsers/rss_sites.py\n+++ b/anyway/parsers/rss_sites.py\n@@ -8,7 +8,7 @@\n # For some reason there's html here\n description = BeautifulSoup(item_rss[\"summary\"], features=\"lxml\").text\n \n- author = html_soup.find(\"div\", class_=\"author\").find(\"a\").get_text()\n+ author = html_soup.find(\"div\", class_=\"author\").get_text().strip()\n return author, description\n", "issue": "Fix walla scraping - see test_scrape_sanity_online_walla\n\n", "before_files": [{"content": "import requests\nfrom bs4 import BeautifulSoup\nimport feedparser\nfrom anyway.parsers import timezones\n\n\ndef parse_html_walla(item_rss, html_soup):\n # For some reason there's html here\n description = BeautifulSoup(item_rss[\"summary\"], features=\"lxml\").text\n\n author = html_soup.find(\"div\", class_=\"author\").find(\"a\").get_text()\n return author, description\n\n\ndef parse_html_ynet(item_rss, html_soup):\n # This is rather fragile\n # description_text: \"[description] ([author]) [unrelated stuff]\"\n description_text = html_soup.find(id=\"ArticleBodyComponent\").get_text()\n author = description_text.split(\"(\")[-1].split(\")\")[0].strip()\n description = description_text.rsplit(\"(\")[0].strip()\n return author, description\n\n\nsites_config = {\n \"ynet\": {\n \"rss\": \"https://www.ynet.co.il:443/Integration/StoryRss1854.xml\",\n \"parser\": parse_html_ynet,\n },\n \"walla\": {\"rss\": \"https://rss.walla.co.il:443/feed/22\", \"parser\": parse_html_walla},\n}\n\n\ndef _fetch(url: str) -> str:\n return requests.get(url).text\n\n\ndef scrape_raw(site_name: str, *, rss_source=None, fetch_html=_fetch):\n config = sites_config[site_name]\n if rss_source is None:\n rss_source = config[\"rss\"]\n rss_dict = feedparser.parse(rss_source)\n if rss_dict.get(\"bozo_exception\"):\n raise rss_dict[\"bozo_exception\"]\n\n for item_rss in rss_dict[\"items\"]:\n html_text = fetch_html(item_rss[\"link\"])\n author, description = config[\"parser\"](item_rss, BeautifulSoup(html_text, \"lxml\"))\n yield {\n \"link\": item_rss[\"link\"],\n \"date\": timezones.from_rss(item_rss[\"published_parsed\"]),\n \"source\": site_name,\n \"author\": author,\n \"title\": item_rss[\"title\"],\n \"description\": description,\n \"accident\": False,\n }\n\n\ndef scrape(*args, **kwargs):\n # lazily load dependencies, so this module will behave like an independent library\n from anyway.models import NewsFlash\n\n for dict_item in scrape_raw(*args, **kwargs):\n yield NewsFlash(**dict_item)\n", "path": "anyway/parsers/rss_sites.py"}], "after_files": [{"content": "import requests\nfrom bs4 import BeautifulSoup\nimport feedparser\nfrom anyway.parsers import timezones\n\n\ndef parse_html_walla(item_rss, html_soup):\n # For some reason there's html here\n description = BeautifulSoup(item_rss[\"summary\"], features=\"lxml\").text\n\n author = html_soup.find(\"div\", class_=\"author\").get_text().strip()\n return author, description\n\n\ndef parse_html_ynet(item_rss, html_soup):\n # This is rather fragile\n # description_text: \"[description] ([author]) [unrelated stuff]\"\n description_text = html_soup.find(id=\"ArticleBodyComponent\").get_text()\n author = description_text.split(\"(\")[-1].split(\")\")[0].strip()\n description = description_text.rsplit(\"(\")[0].strip()\n return author, description\n\n\nsites_config = {\n \"ynet\": {\n \"rss\": \"https://www.ynet.co.il:443/Integration/StoryRss1854.xml\",\n \"parser\": parse_html_ynet,\n },\n \"walla\": {\"rss\": \"https://rss.walla.co.il:443/feed/22\", \"parser\": parse_html_walla},\n}\n\n\ndef _fetch(url: str) -> str:\n return requests.get(url).text\n\n\ndef scrape_raw(site_name: str, *, rss_source=None, fetch_html=_fetch):\n config = sites_config[site_name]\n if rss_source is None:\n rss_source = config[\"rss\"]\n rss_dict = feedparser.parse(rss_source)\n if rss_dict.get(\"bozo_exception\"):\n raise rss_dict[\"bozo_exception\"]\n\n for item_rss in rss_dict[\"items\"]:\n html_text = fetch_html(item_rss[\"link\"])\n author, description = config[\"parser\"](item_rss, BeautifulSoup(html_text, \"lxml\"))\n yield {\n \"link\": item_rss[\"link\"],\n \"date\": timezones.from_rss(item_rss[\"published_parsed\"]),\n \"source\": site_name,\n \"author\": author,\n \"title\": item_rss[\"title\"],\n \"description\": description,\n \"accident\": False,\n }\n\n\ndef scrape(*args, **kwargs):\n # lazily load dependencies, so this module will behave like an independent library\n from anyway.models import NewsFlash\n\n for dict_item in scrape_raw(*args, **kwargs):\n yield NewsFlash(**dict_item)\n", "path": "anyway/parsers/rss_sites.py"}]}
| 923 | 129 |
gh_patches_debug_25200
|
rasdani/github-patches
|
git_diff
|
internetarchive__openlibrary-6853
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
DeprecationWarning: `urllib.parse.splitquery()` is deprecated as of 3.8
<!-- What problem are we solving? What does the experience look like today? What are the symptoms? -->
### Evidence / Screenshot (if possible)
When we run pytest in our GitHub Actions, we get the following warning
```
=============================== warnings summary ===============================
openlibrary/coverstore/tests/test_doctests.py::test_doctest[openlibrary.coverstore.utils]
openlibrary/coverstore/tests/test_doctests.py::test_doctest[openlibrary.coverstore.utils]
openlibrary/coverstore/tests/test_doctests.py::test_doctest[openlibrary.coverstore.utils]
/home/runner/work/openlibrary/openlibrary/openlibrary/coverstore/utils.py:88:
DeprecationWarning: urllib.parse.splitquery() is deprecated as of 3.8, use urllib.parse.urlparse() instead
base, query = splitquery(URL)
```
https://github.com/internetarchive/openlibrary/blob/master/openlibrary/coverstore/utils.py#L88
### Relevant url?
<!-- `https://openlibrary.org/...` -->
### Steps to Reproduce
<!-- What steps caused you to find the bug? -->
1. Go to ...
2. Do ...
<!-- What actually happened after these steps? What did you expect to happen? -->
* Actual: pytest warning
* Expected: No pytest warning
### Details
- **Logged in (Y/N)?**
- **Browser type/version?**
- **Operating system?**
- **Environment (prod/dev/local)?** prod
<!-- If not sure, put prod -->
### Proposal & Constraints
<!-- What is the proposed solution / implementation? Is there a precedent of this approach succeeding elsewhere? -->
### Related files
<!-- Files related to this issue; this is super useful for new contributors who might want to help! If you're not sure, leave this blank; a maintainer will add them. -->
### Stakeholders
<!-- @ tag stakeholders of this bug -->
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `openlibrary/coverstore/utils.py`
Content:
```
1 """Utilities for coverstore"""
2
3 import json
4 import mimetypes
5 import os
6 import random
7 import socket
8 import string
9
10 import requests
11 import web
12 from urllib.parse import splitquery, unquote, unquote_plus # type: ignore[attr-defined]
13 from urllib.parse import urlencode as real_urlencode
14
15 from openlibrary.coverstore import config, oldb
16
17 from io import IOBase as file
18
19 socket.setdefaulttimeout(10.0)
20
21
22 def safeint(value, default=None):
23 """
24 >>> safeint('1')
25 1
26 >>> safeint('x')
27 >>> safeint('x', 0)
28 0
29 """
30 try:
31 return int(value)
32 except (TypeError, ValueError):
33 return default
34
35
36 def get_ol_url():
37 return web.rstrips(config.ol_url, "/")
38
39
40 def ol_things(key, value):
41 if oldb.is_supported():
42 return oldb.query(key, value)
43 else:
44 query = {
45 'type': '/type/edition',
46 key: value,
47 'sort': 'last_modified',
48 'limit': 10,
49 }
50 try:
51 d = dict(query=json.dumps(query))
52 result = download(get_ol_url() + '/api/things?' + real_urlencode(d))
53 result = json.loads(result)
54 return result['result']
55 except OSError:
56 import traceback
57
58 traceback.print_exc()
59 return []
60
61
62 def ol_get(olkey):
63 if oldb.is_supported():
64 return oldb.get(olkey)
65 else:
66 try:
67 return json.loads(download(get_ol_url() + olkey + ".json"))
68 except OSError:
69 return None
70
71
72 USER_AGENT = (
73 "Mozilla/5.0 (Compatible; coverstore downloader http://covers.openlibrary.org)"
74 )
75
76
77 def download(url):
78 return requests.get(url, headers={'User-Agent': USER_AGENT}).content
79
80
81 def urldecode(url):
82 """
83 >>> urldecode('http://google.com/search?q=bar&x=y')
84 ('http://google.com/search', {'q': 'bar', 'x': 'y'})
85 >>> urldecode('http://google.com/')
86 ('http://google.com/', {})
87 """
88 base, query = splitquery(url)
89 query = query or ""
90 items = [item.split('=', 1) for item in query.split('&') if '=' in item]
91 d = {unquote(k): unquote_plus(v) for (k, v) in items}
92 return base, d
93
94
95 def changequery(url, **kw):
96 """
97 >>> changequery('http://google.com/search?q=foo', q='bar', x='y')
98 'http://google.com/search?q=bar&x=y'
99 """
100 base, params = urldecode(url)
101 params.update(kw)
102 return base + '?' + real_urlencode(params)
103
104
105 def read_file(path, offset, size, chunk=50 * 1024):
106 """Returns an iterator over file data at specified offset and size.
107
108 >>> len(b"".join(read_file('/dev/urandom', 100, 10000)))
109 10000
110 """
111 with open(path, "rb") as f:
112 f.seek(offset)
113 while size:
114 data = f.read(min(chunk, size))
115 size -= len(data)
116 if data:
117 yield data
118 else:
119 raise OSError("file truncated")
120
121
122 def rm_f(filename):
123 try:
124 os.remove(filename)
125 except OSError:
126 pass
127
128
129 chars = string.ascii_letters + string.digits
130
131
132 def random_string(n):
133 return "".join([random.choice(chars) for i in range(n)])
134
135
136 def urlencode(data):
137 """
138 urlencodes the given data dictionary. If any of the value is a file object, data is multipart encoded.
139
140 @@@ should go into web.browser
141 """
142 multipart = False
143 for v in data.values():
144 if isinstance(v, file):
145 multipart = True
146 break
147
148 if not multipart:
149 return 'application/x-www-form-urlencoded', real_urlencode(data)
150 else:
151 # adopted from http://code.activestate.com/recipes/146306/
152 def get_content_type(filename):
153 return mimetypes.guess_type(filename)[0] or 'application/octet-stream'
154
155 def encode(key, value, out):
156 if isinstance(value, file):
157 out.append('--' + BOUNDARY)
158 out.append(
159 f'Content-Disposition: form-data; name="{key}"; filename="{value.name}"'
160 )
161 out.append('Content-Type: %s' % get_content_type(value.name))
162 out.append('')
163 out.append(value.read())
164 elif isinstance(value, list):
165 for v in value:
166 encode(key, v)
167 else:
168 out.append('--' + BOUNDARY)
169 out.append('Content-Disposition: form-data; name="%s"' % key)
170 out.append('')
171 out.append(value)
172
173 BOUNDARY = "----------ThIs_Is_tHe_bouNdaRY_$"
174 CRLF = '\r\n'
175 out = []
176 for k, v in data.items():
177 encode(k, v, out)
178 body = CRLF.join(out)
179 content_type = 'multipart/form-data; boundary=%s' % BOUNDARY
180 return content_type, body
181
182
183 if __name__ == "__main__":
184 import doctest
185
186 doctest.testmod()
187
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/openlibrary/coverstore/utils.py b/openlibrary/coverstore/utils.py
--- a/openlibrary/coverstore/utils.py
+++ b/openlibrary/coverstore/utils.py
@@ -9,7 +9,7 @@
import requests
import web
-from urllib.parse import splitquery, unquote, unquote_plus # type: ignore[attr-defined]
+from urllib.parse import urlsplit, urlunsplit, parse_qsl, unquote, unquote_plus # type: ignore[attr-defined]
from urllib.parse import urlencode as real_urlencode
from openlibrary.coverstore import config, oldb
@@ -78,17 +78,17 @@
return requests.get(url, headers={'User-Agent': USER_AGENT}).content
-def urldecode(url):
+def urldecode(url: str) -> tuple[str, dict[str, str]]:
"""
>>> urldecode('http://google.com/search?q=bar&x=y')
('http://google.com/search', {'q': 'bar', 'x': 'y'})
>>> urldecode('http://google.com/')
('http://google.com/', {})
"""
- base, query = splitquery(url)
- query = query or ""
- items = [item.split('=', 1) for item in query.split('&') if '=' in item]
+ split_url = urlsplit(url)
+ items = parse_qsl(split_url.query)
d = {unquote(k): unquote_plus(v) for (k, v) in items}
+ base = urlunsplit(split_url._replace(query=''))
return base, d
|
{"golden_diff": "diff --git a/openlibrary/coverstore/utils.py b/openlibrary/coverstore/utils.py\n--- a/openlibrary/coverstore/utils.py\n+++ b/openlibrary/coverstore/utils.py\n@@ -9,7 +9,7 @@\n \n import requests\n import web\n-from urllib.parse import splitquery, unquote, unquote_plus # type: ignore[attr-defined]\n+from urllib.parse import urlsplit, urlunsplit, parse_qsl, unquote, unquote_plus # type: ignore[attr-defined]\n from urllib.parse import urlencode as real_urlencode\n \n from openlibrary.coverstore import config, oldb\n@@ -78,17 +78,17 @@\n return requests.get(url, headers={'User-Agent': USER_AGENT}).content\n \n \n-def urldecode(url):\n+def urldecode(url: str) -> tuple[str, dict[str, str]]:\n \"\"\"\n >>> urldecode('http://google.com/search?q=bar&x=y')\n ('http://google.com/search', {'q': 'bar', 'x': 'y'})\n >>> urldecode('http://google.com/')\n ('http://google.com/', {})\n \"\"\"\n- base, query = splitquery(url)\n- query = query or \"\"\n- items = [item.split('=', 1) for item in query.split('&') if '=' in item]\n+ split_url = urlsplit(url)\n+ items = parse_qsl(split_url.query)\n d = {unquote(k): unquote_plus(v) for (k, v) in items}\n+ base = urlunsplit(split_url._replace(query=''))\n return base, d\n", "issue": "DeprecationWarning: `urllib.parse.splitquery()` is deprecated as of 3.8\n<!-- What problem are we solving? What does the experience look like today? What are the symptoms? -->\r\n\r\n\r\n### Evidence / Screenshot (if possible)\r\nWhen we run pytest in our GitHub Actions, we get the following warning\r\n```\r\n=============================== warnings summary ===============================\r\nopenlibrary/coverstore/tests/test_doctests.py::test_doctest[openlibrary.coverstore.utils]\r\nopenlibrary/coverstore/tests/test_doctests.py::test_doctest[openlibrary.coverstore.utils]\r\nopenlibrary/coverstore/tests/test_doctests.py::test_doctest[openlibrary.coverstore.utils]\r\n /home/runner/work/openlibrary/openlibrary/openlibrary/coverstore/utils.py:88:\r\n DeprecationWarning: urllib.parse.splitquery() is deprecated as of 3.8, use urllib.parse.urlparse() instead\r\n base, query = splitquery(URL)\r\n```\r\nhttps://github.com/internetarchive/openlibrary/blob/master/openlibrary/coverstore/utils.py#L88\r\n\r\n### Relevant url?\r\n<!-- `https://openlibrary.org/...` -->\r\n\r\n### Steps to Reproduce\r\n<!-- What steps caused you to find the bug? -->\r\n1. Go to ...\r\n2. Do ...\r\n\r\n<!-- What actually happened after these steps? What did you expect to happen? -->\r\n* Actual: pytest warning\r\n* Expected: No pytest warning\r\n\r\n### Details\r\n\r\n- **Logged in (Y/N)?**\r\n- **Browser type/version?**\r\n- **Operating system?**\r\n- **Environment (prod/dev/local)?** prod\r\n<!-- If not sure, put prod -->\r\n\r\n### Proposal & Constraints\r\n<!-- What is the proposed solution / implementation? Is there a precedent of this approach succeeding elsewhere? -->\r\n\r\n### Related files\r\n<!-- Files related to this issue; this is super useful for new contributors who might want to help! If you're not sure, leave this blank; a maintainer will add them. -->\r\n\r\n### Stakeholders\r\n<!-- @ tag stakeholders of this bug -->\r\n\n", "before_files": [{"content": "\"\"\"Utilities for coverstore\"\"\"\n\nimport json\nimport mimetypes\nimport os\nimport random\nimport socket\nimport string\n\nimport requests\nimport web\nfrom urllib.parse import splitquery, unquote, unquote_plus # type: ignore[attr-defined]\nfrom urllib.parse import urlencode as real_urlencode\n\nfrom openlibrary.coverstore import config, oldb\n\nfrom io import IOBase as file\n\nsocket.setdefaulttimeout(10.0)\n\n\ndef safeint(value, default=None):\n \"\"\"\n >>> safeint('1')\n 1\n >>> safeint('x')\n >>> safeint('x', 0)\n 0\n \"\"\"\n try:\n return int(value)\n except (TypeError, ValueError):\n return default\n\n\ndef get_ol_url():\n return web.rstrips(config.ol_url, \"/\")\n\n\ndef ol_things(key, value):\n if oldb.is_supported():\n return oldb.query(key, value)\n else:\n query = {\n 'type': '/type/edition',\n key: value,\n 'sort': 'last_modified',\n 'limit': 10,\n }\n try:\n d = dict(query=json.dumps(query))\n result = download(get_ol_url() + '/api/things?' + real_urlencode(d))\n result = json.loads(result)\n return result['result']\n except OSError:\n import traceback\n\n traceback.print_exc()\n return []\n\n\ndef ol_get(olkey):\n if oldb.is_supported():\n return oldb.get(olkey)\n else:\n try:\n return json.loads(download(get_ol_url() + olkey + \".json\"))\n except OSError:\n return None\n\n\nUSER_AGENT = (\n \"Mozilla/5.0 (Compatible; coverstore downloader http://covers.openlibrary.org)\"\n)\n\n\ndef download(url):\n return requests.get(url, headers={'User-Agent': USER_AGENT}).content\n\n\ndef urldecode(url):\n \"\"\"\n >>> urldecode('http://google.com/search?q=bar&x=y')\n ('http://google.com/search', {'q': 'bar', 'x': 'y'})\n >>> urldecode('http://google.com/')\n ('http://google.com/', {})\n \"\"\"\n base, query = splitquery(url)\n query = query or \"\"\n items = [item.split('=', 1) for item in query.split('&') if '=' in item]\n d = {unquote(k): unquote_plus(v) for (k, v) in items}\n return base, d\n\n\ndef changequery(url, **kw):\n \"\"\"\n >>> changequery('http://google.com/search?q=foo', q='bar', x='y')\n 'http://google.com/search?q=bar&x=y'\n \"\"\"\n base, params = urldecode(url)\n params.update(kw)\n return base + '?' + real_urlencode(params)\n\n\ndef read_file(path, offset, size, chunk=50 * 1024):\n \"\"\"Returns an iterator over file data at specified offset and size.\n\n >>> len(b\"\".join(read_file('/dev/urandom', 100, 10000)))\n 10000\n \"\"\"\n with open(path, \"rb\") as f:\n f.seek(offset)\n while size:\n data = f.read(min(chunk, size))\n size -= len(data)\n if data:\n yield data\n else:\n raise OSError(\"file truncated\")\n\n\ndef rm_f(filename):\n try:\n os.remove(filename)\n except OSError:\n pass\n\n\nchars = string.ascii_letters + string.digits\n\n\ndef random_string(n):\n return \"\".join([random.choice(chars) for i in range(n)])\n\n\ndef urlencode(data):\n \"\"\"\n urlencodes the given data dictionary. If any of the value is a file object, data is multipart encoded.\n\n @@@ should go into web.browser\n \"\"\"\n multipart = False\n for v in data.values():\n if isinstance(v, file):\n multipart = True\n break\n\n if not multipart:\n return 'application/x-www-form-urlencoded', real_urlencode(data)\n else:\n # adopted from http://code.activestate.com/recipes/146306/\n def get_content_type(filename):\n return mimetypes.guess_type(filename)[0] or 'application/octet-stream'\n\n def encode(key, value, out):\n if isinstance(value, file):\n out.append('--' + BOUNDARY)\n out.append(\n f'Content-Disposition: form-data; name=\"{key}\"; filename=\"{value.name}\"'\n )\n out.append('Content-Type: %s' % get_content_type(value.name))\n out.append('')\n out.append(value.read())\n elif isinstance(value, list):\n for v in value:\n encode(key, v)\n else:\n out.append('--' + BOUNDARY)\n out.append('Content-Disposition: form-data; name=\"%s\"' % key)\n out.append('')\n out.append(value)\n\n BOUNDARY = \"----------ThIs_Is_tHe_bouNdaRY_$\"\n CRLF = '\\r\\n'\n out = []\n for k, v in data.items():\n encode(k, v, out)\n body = CRLF.join(out)\n content_type = 'multipart/form-data; boundary=%s' % BOUNDARY\n return content_type, body\n\n\nif __name__ == \"__main__\":\n import doctest\n\n doctest.testmod()\n", "path": "openlibrary/coverstore/utils.py"}], "after_files": [{"content": "\"\"\"Utilities for coverstore\"\"\"\n\nimport json\nimport mimetypes\nimport os\nimport random\nimport socket\nimport string\n\nimport requests\nimport web\nfrom urllib.parse import urlsplit, urlunsplit, parse_qsl, unquote, unquote_plus # type: ignore[attr-defined]\nfrom urllib.parse import urlencode as real_urlencode\n\nfrom openlibrary.coverstore import config, oldb\n\nfrom io import IOBase as file\n\nsocket.setdefaulttimeout(10.0)\n\n\ndef safeint(value, default=None):\n \"\"\"\n >>> safeint('1')\n 1\n >>> safeint('x')\n >>> safeint('x', 0)\n 0\n \"\"\"\n try:\n return int(value)\n except (TypeError, ValueError):\n return default\n\n\ndef get_ol_url():\n return web.rstrips(config.ol_url, \"/\")\n\n\ndef ol_things(key, value):\n if oldb.is_supported():\n return oldb.query(key, value)\n else:\n query = {\n 'type': '/type/edition',\n key: value,\n 'sort': 'last_modified',\n 'limit': 10,\n }\n try:\n d = dict(query=json.dumps(query))\n result = download(get_ol_url() + '/api/things?' + real_urlencode(d))\n result = json.loads(result)\n return result['result']\n except OSError:\n import traceback\n\n traceback.print_exc()\n return []\n\n\ndef ol_get(olkey):\n if oldb.is_supported():\n return oldb.get(olkey)\n else:\n try:\n return json.loads(download(get_ol_url() + olkey + \".json\"))\n except OSError:\n return None\n\n\nUSER_AGENT = (\n \"Mozilla/5.0 (Compatible; coverstore downloader http://covers.openlibrary.org)\"\n)\n\n\ndef download(url):\n return requests.get(url, headers={'User-Agent': USER_AGENT}).content\n\n\ndef urldecode(url: str) -> tuple[str, dict[str, str]]:\n \"\"\"\n >>> urldecode('http://google.com/search?q=bar&x=y')\n ('http://google.com/search', {'q': 'bar', 'x': 'y'})\n >>> urldecode('http://google.com/')\n ('http://google.com/', {})\n \"\"\"\n split_url = urlsplit(url)\n items = parse_qsl(split_url.query)\n d = {unquote(k): unquote_plus(v) for (k, v) in items}\n base = urlunsplit(split_url._replace(query=''))\n return base, d\n\n\ndef changequery(url, **kw):\n \"\"\"\n >>> changequery('http://google.com/search?q=foo', q='bar', x='y')\n 'http://google.com/search?q=bar&x=y'\n \"\"\"\n base, params = urldecode(url)\n params.update(kw)\n return base + '?' + real_urlencode(params)\n\n\ndef read_file(path, offset, size, chunk=50 * 1024):\n \"\"\"Returns an iterator over file data at specified offset and size.\n\n >>> len(b\"\".join(read_file('/dev/urandom', 100, 10000)))\n 10000\n \"\"\"\n with open(path, \"rb\") as f:\n f.seek(offset)\n while size:\n data = f.read(min(chunk, size))\n size -= len(data)\n if data:\n yield data\n else:\n raise OSError(\"file truncated\")\n\n\ndef rm_f(filename):\n try:\n os.remove(filename)\n except OSError:\n pass\n\n\nchars = string.ascii_letters + string.digits\n\n\ndef random_string(n):\n return \"\".join([random.choice(chars) for i in range(n)])\n\n\ndef urlencode(data):\n \"\"\"\n urlencodes the given data dictionary. If any of the value is a file object, data is multipart encoded.\n\n @@@ should go into web.browser\n \"\"\"\n multipart = False\n for v in data.values():\n if isinstance(v, file):\n multipart = True\n break\n\n if not multipart:\n return 'application/x-www-form-urlencoded', real_urlencode(data)\n else:\n # adopted from http://code.activestate.com/recipes/146306/\n def get_content_type(filename):\n return mimetypes.guess_type(filename)[0] or 'application/octet-stream'\n\n def encode(key, value, out):\n if isinstance(value, file):\n out.append('--' + BOUNDARY)\n out.append(\n f'Content-Disposition: form-data; name=\"{key}\"; filename=\"{value.name}\"'\n )\n out.append('Content-Type: %s' % get_content_type(value.name))\n out.append('')\n out.append(value.read())\n elif isinstance(value, list):\n for v in value:\n encode(key, v)\n else:\n out.append('--' + BOUNDARY)\n out.append('Content-Disposition: form-data; name=\"%s\"' % key)\n out.append('')\n out.append(value)\n\n BOUNDARY = \"----------ThIs_Is_tHe_bouNdaRY_$\"\n CRLF = '\\r\\n'\n out = []\n for k, v in data.items():\n encode(k, v, out)\n body = CRLF.join(out)\n content_type = 'multipart/form-data; boundary=%s' % BOUNDARY\n return content_type, body\n\n\nif __name__ == \"__main__\":\n import doctest\n\n doctest.testmod()\n", "path": "openlibrary/coverstore/utils.py"}]}
| 2,319 | 344 |
gh_patches_debug_17789
|
rasdani/github-patches
|
git_diff
|
encode__starlette-1018
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Memory usage streaming large responses
We've been running into memory issues when providing very large async generators to a streaming response. We have these generators producing large (larger than memory set) responses in a way that allows us to only keep small chunks in memory at a time. However, it looks like the BaseHTTPMiddleware implementation uses an asyncio queue to store the individual chunks:
https://github.com/encode/starlette/blob/master/starlette/middleware/base.py#L30
This prevents any network backpressure handling -- if the client that is receiving the streaming response is on a slow connection, the queue will happily grow without bound and consume all memory, triggering kernel out-of-memory, when the ideal handling here would be for send to block (yield) when this happens. I believe this would naturally happen if there were no queue here at all, so I am wondering why it needs to be here?
Would a PR to remove the queueing be accepted?
If not, what is the appropriate way to override this to not use a queue? We can write our own, but the use of BaseHTTPMiddleware is hardcoded: https://github.com/encode/starlette/blob/519f5750b5e797bb3d4805fd29657674304ce397/starlette/applications.py#L197, leaving only some fairly hacky approaches to preventing this queueing.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `starlette/middleware/base.py`
Content:
```
1 import asyncio
2 import typing
3
4 from starlette.requests import Request
5 from starlette.responses import Response, StreamingResponse
6 from starlette.types import ASGIApp, Receive, Scope, Send
7
8 RequestResponseEndpoint = typing.Callable[[Request], typing.Awaitable[Response]]
9 DispatchFunction = typing.Callable[
10 [Request, RequestResponseEndpoint], typing.Awaitable[Response]
11 ]
12
13
14 class BaseHTTPMiddleware:
15 def __init__(self, app: ASGIApp, dispatch: DispatchFunction = None) -> None:
16 self.app = app
17 self.dispatch_func = self.dispatch if dispatch is None else dispatch
18
19 async def __call__(self, scope: Scope, receive: Receive, send: Send) -> None:
20 if scope["type"] != "http":
21 await self.app(scope, receive, send)
22 return
23
24 request = Request(scope, receive=receive)
25 response = await self.dispatch_func(request, self.call_next)
26 await response(scope, receive, send)
27
28 async def call_next(self, request: Request) -> Response:
29 loop = asyncio.get_event_loop()
30 queue = asyncio.Queue() # type: asyncio.Queue
31
32 scope = request.scope
33 receive = request.receive
34 send = queue.put
35
36 async def coro() -> None:
37 try:
38 await self.app(scope, receive, send)
39 finally:
40 await queue.put(None)
41
42 task = loop.create_task(coro())
43 message = await queue.get()
44 if message is None:
45 task.result()
46 raise RuntimeError("No response returned.")
47 assert message["type"] == "http.response.start"
48
49 async def body_stream() -> typing.AsyncGenerator[bytes, None]:
50 while True:
51 message = await queue.get()
52 if message is None:
53 break
54 assert message["type"] == "http.response.body"
55 yield message.get("body", b"")
56 task.result()
57
58 response = StreamingResponse(
59 status_code=message["status"], content=body_stream()
60 )
61 response.raw_headers = message["headers"]
62 return response
63
64 async def dispatch(
65 self, request: Request, call_next: RequestResponseEndpoint
66 ) -> Response:
67 raise NotImplementedError() # pragma: no cover
68
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/starlette/middleware/base.py b/starlette/middleware/base.py
--- a/starlette/middleware/base.py
+++ b/starlette/middleware/base.py
@@ -3,7 +3,7 @@
from starlette.requests import Request
from starlette.responses import Response, StreamingResponse
-from starlette.types import ASGIApp, Receive, Scope, Send
+from starlette.types import ASGIApp, Message, Receive, Scope, Send
RequestResponseEndpoint = typing.Callable[[Request], typing.Awaitable[Response]]
DispatchFunction = typing.Callable[
@@ -27,7 +27,7 @@
async def call_next(self, request: Request) -> Response:
loop = asyncio.get_event_loop()
- queue = asyncio.Queue() # type: asyncio.Queue
+ queue: "asyncio.Queue[typing.Optional[Message]]" = asyncio.Queue(maxsize=1)
scope = request.scope
receive = request.receive
|
{"golden_diff": "diff --git a/starlette/middleware/base.py b/starlette/middleware/base.py\n--- a/starlette/middleware/base.py\n+++ b/starlette/middleware/base.py\n@@ -3,7 +3,7 @@\n \n from starlette.requests import Request\n from starlette.responses import Response, StreamingResponse\n-from starlette.types import ASGIApp, Receive, Scope, Send\n+from starlette.types import ASGIApp, Message, Receive, Scope, Send\n \n RequestResponseEndpoint = typing.Callable[[Request], typing.Awaitable[Response]]\n DispatchFunction = typing.Callable[\n@@ -27,7 +27,7 @@\n \n async def call_next(self, request: Request) -> Response:\n loop = asyncio.get_event_loop()\n- queue = asyncio.Queue() # type: asyncio.Queue\n+ queue: \"asyncio.Queue[typing.Optional[Message]]\" = asyncio.Queue(maxsize=1)\n \n scope = request.scope\n receive = request.receive\n", "issue": "Memory usage streaming large responses\nWe've been running into memory issues when providing very large async generators to a streaming response. We have these generators producing large (larger than memory set) responses in a way that allows us to only keep small chunks in memory at a time. However, it looks like the BaseHTTPMiddleware implementation uses an asyncio queue to store the individual chunks:\r\n\r\nhttps://github.com/encode/starlette/blob/master/starlette/middleware/base.py#L30\r\n\r\nThis prevents any network backpressure handling -- if the client that is receiving the streaming response is on a slow connection, the queue will happily grow without bound and consume all memory, triggering kernel out-of-memory, when the ideal handling here would be for send to block (yield) when this happens. I believe this would naturally happen if there were no queue here at all, so I am wondering why it needs to be here?\r\n\r\nWould a PR to remove the queueing be accepted?\r\n\r\nIf not, what is the appropriate way to override this to not use a queue? We can write our own, but the use of BaseHTTPMiddleware is hardcoded: https://github.com/encode/starlette/blob/519f5750b5e797bb3d4805fd29657674304ce397/starlette/applications.py#L197, leaving only some fairly hacky approaches to preventing this queueing.\n", "before_files": [{"content": "import asyncio\nimport typing\n\nfrom starlette.requests import Request\nfrom starlette.responses import Response, StreamingResponse\nfrom starlette.types import ASGIApp, Receive, Scope, Send\n\nRequestResponseEndpoint = typing.Callable[[Request], typing.Awaitable[Response]]\nDispatchFunction = typing.Callable[\n [Request, RequestResponseEndpoint], typing.Awaitable[Response]\n]\n\n\nclass BaseHTTPMiddleware:\n def __init__(self, app: ASGIApp, dispatch: DispatchFunction = None) -> None:\n self.app = app\n self.dispatch_func = self.dispatch if dispatch is None else dispatch\n\n async def __call__(self, scope: Scope, receive: Receive, send: Send) -> None:\n if scope[\"type\"] != \"http\":\n await self.app(scope, receive, send)\n return\n\n request = Request(scope, receive=receive)\n response = await self.dispatch_func(request, self.call_next)\n await response(scope, receive, send)\n\n async def call_next(self, request: Request) -> Response:\n loop = asyncio.get_event_loop()\n queue = asyncio.Queue() # type: asyncio.Queue\n\n scope = request.scope\n receive = request.receive\n send = queue.put\n\n async def coro() -> None:\n try:\n await self.app(scope, receive, send)\n finally:\n await queue.put(None)\n\n task = loop.create_task(coro())\n message = await queue.get()\n if message is None:\n task.result()\n raise RuntimeError(\"No response returned.\")\n assert message[\"type\"] == \"http.response.start\"\n\n async def body_stream() -> typing.AsyncGenerator[bytes, None]:\n while True:\n message = await queue.get()\n if message is None:\n break\n assert message[\"type\"] == \"http.response.body\"\n yield message.get(\"body\", b\"\")\n task.result()\n\n response = StreamingResponse(\n status_code=message[\"status\"], content=body_stream()\n )\n response.raw_headers = message[\"headers\"]\n return response\n\n async def dispatch(\n self, request: Request, call_next: RequestResponseEndpoint\n ) -> Response:\n raise NotImplementedError() # pragma: no cover\n", "path": "starlette/middleware/base.py"}], "after_files": [{"content": "import asyncio\nimport typing\n\nfrom starlette.requests import Request\nfrom starlette.responses import Response, StreamingResponse\nfrom starlette.types import ASGIApp, Message, Receive, Scope, Send\n\nRequestResponseEndpoint = typing.Callable[[Request], typing.Awaitable[Response]]\nDispatchFunction = typing.Callable[\n [Request, RequestResponseEndpoint], typing.Awaitable[Response]\n]\n\n\nclass BaseHTTPMiddleware:\n def __init__(self, app: ASGIApp, dispatch: DispatchFunction = None) -> None:\n self.app = app\n self.dispatch_func = self.dispatch if dispatch is None else dispatch\n\n async def __call__(self, scope: Scope, receive: Receive, send: Send) -> None:\n if scope[\"type\"] != \"http\":\n await self.app(scope, receive, send)\n return\n\n request = Request(scope, receive=receive)\n response = await self.dispatch_func(request, self.call_next)\n await response(scope, receive, send)\n\n async def call_next(self, request: Request) -> Response:\n loop = asyncio.get_event_loop()\n queue: \"asyncio.Queue[typing.Optional[Message]]\" = asyncio.Queue(maxsize=1)\n\n scope = request.scope\n receive = request.receive\n send = queue.put\n\n async def coro() -> None:\n try:\n await self.app(scope, receive, send)\n finally:\n await queue.put(None)\n\n task = loop.create_task(coro())\n message = await queue.get()\n if message is None:\n task.result()\n raise RuntimeError(\"No response returned.\")\n assert message[\"type\"] == \"http.response.start\"\n\n async def body_stream() -> typing.AsyncGenerator[bytes, None]:\n while True:\n message = await queue.get()\n if message is None:\n break\n assert message[\"type\"] == \"http.response.body\"\n yield message.get(\"body\", b\"\")\n task.result()\n\n response = StreamingResponse(\n status_code=message[\"status\"], content=body_stream()\n )\n response.raw_headers = message[\"headers\"]\n return response\n\n async def dispatch(\n self, request: Request, call_next: RequestResponseEndpoint\n ) -> Response:\n raise NotImplementedError() # pragma: no cover\n", "path": "starlette/middleware/base.py"}]}
| 1,165 | 206 |
gh_patches_debug_26952
|
rasdani/github-patches
|
git_diff
|
certbot__certbot-2852
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Ensure rename doesn't break third party plugins
There are a lot of third party plugins for Let's Encrypt (listed here: https://letsencrypt.readthedocs.org/en/latest/using.html#plugins)
It's possible that they reference things in such a way that changing the name or package of LE will break their compatibility with the client - we should ensure that they are unbroken
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `certbot/constants.py`
Content:
```
1 """Certbot constants."""
2 import os
3 import logging
4
5 from acme import challenges
6
7
8 SETUPTOOLS_PLUGINS_ENTRY_POINT = "certbot.plugins"
9 """Setuptools entry point group name for plugins."""
10
11 CLI_DEFAULTS = dict(
12 config_files=[
13 "/etc/letsencrypt/cli.ini",
14 # http://freedesktop.org/wiki/Software/xdg-user-dirs/
15 os.path.join(os.environ.get("XDG_CONFIG_HOME", "~/.config"),
16 "letsencrypt", "cli.ini"),
17 ],
18 verbose_count=-(logging.WARNING / 10),
19 server="https://acme-v01.api.letsencrypt.org/directory",
20 rsa_key_size=2048,
21 rollback_checkpoints=1,
22 config_dir="/etc/letsencrypt",
23 work_dir="/var/lib/letsencrypt",
24 logs_dir="/var/log/letsencrypt",
25 no_verify_ssl=False,
26 http01_port=challenges.HTTP01Response.PORT,
27 tls_sni_01_port=challenges.TLSSNI01Response.PORT,
28
29 auth_cert_path="./cert.pem",
30 auth_chain_path="./chain.pem",
31 strict_permissions=False,
32 )
33 STAGING_URI = "https://acme-staging.api.letsencrypt.org/directory"
34
35 """Defaults for CLI flags and `.IConfig` attributes."""
36
37 RENEWER_DEFAULTS = dict(
38 renewer_enabled="yes",
39 renew_before_expiry="30 days",
40 # This value should ensure that there is never a deployment delay by
41 # default.
42 deploy_before_expiry="99 years",
43 )
44 """Defaults for renewer script."""
45
46
47 ENHANCEMENTS = ["redirect", "http-header", "ocsp-stapling", "spdy"]
48 """List of possible :class:`certbot.interfaces.IInstaller`
49 enhancements.
50
51 List of expected options parameters:
52 - redirect: None
53 - http-header: TODO
54 - ocsp-stapling: TODO
55 - spdy: TODO
56
57 """
58
59 ARCHIVE_DIR = "archive"
60 """Archive directory, relative to `IConfig.config_dir`."""
61
62 CONFIG_DIRS_MODE = 0o755
63 """Directory mode for ``.IConfig.config_dir`` et al."""
64
65 ACCOUNTS_DIR = "accounts"
66 """Directory where all accounts are saved."""
67
68 BACKUP_DIR = "backups"
69 """Directory (relative to `IConfig.work_dir`) where backups are kept."""
70
71 CSR_DIR = "csr"
72 """See `.IConfig.csr_dir`."""
73
74 IN_PROGRESS_DIR = "IN_PROGRESS"
75 """Directory used before a permanent checkpoint is finalized (relative to
76 `IConfig.work_dir`)."""
77
78 KEY_DIR = "keys"
79 """Directory (relative to `IConfig.config_dir`) where keys are saved."""
80
81 LIVE_DIR = "live"
82 """Live directory, relative to `IConfig.config_dir`."""
83
84 TEMP_CHECKPOINT_DIR = "temp_checkpoint"
85 """Temporary checkpoint directory (relative to `IConfig.work_dir`)."""
86
87 RENEWAL_CONFIGS_DIR = "renewal"
88 """Renewal configs directory, relative to `IConfig.config_dir`."""
89
90 RENEWER_CONFIG_FILENAME = "renewer.conf"
91 """Renewer config file name (relative to `IConfig.config_dir`)."""
92
```
Path: `certbot/plugins/disco.py`
Content:
```
1 """Utilities for plugins discovery and selection."""
2 import collections
3 import logging
4 import pkg_resources
5
6 import zope.interface
7 import zope.interface.verify
8
9 from certbot import constants
10 from certbot import errors
11 from certbot import interfaces
12
13
14 logger = logging.getLogger(__name__)
15
16
17 class PluginEntryPoint(object):
18 """Plugin entry point."""
19
20 PREFIX_FREE_DISTRIBUTIONS = [
21 "certbot",
22 "certbot-apache",
23 "certbot-nginx",
24 ]
25 """Distributions for which prefix will be omitted."""
26
27 # this object is mutable, don't allow it to be hashed!
28 __hash__ = None
29
30 def __init__(self, entry_point):
31 self.name = self.entry_point_to_plugin_name(entry_point)
32 self.plugin_cls = entry_point.load()
33 self.entry_point = entry_point
34 self._initialized = None
35 self._prepared = None
36
37 @classmethod
38 def entry_point_to_plugin_name(cls, entry_point):
39 """Unique plugin name for an ``entry_point``"""
40 if entry_point.dist.key in cls.PREFIX_FREE_DISTRIBUTIONS:
41 return entry_point.name
42 return entry_point.dist.key + ":" + entry_point.name
43
44 @property
45 def description(self):
46 """Description of the plugin."""
47 return self.plugin_cls.description
48
49 @property
50 def description_with_name(self):
51 """Description with name. Handy for UI."""
52 return "{0} ({1})".format(self.description, self.name)
53
54 @property
55 def hidden(self):
56 """Should this plugin be hidden from UI?"""
57 return getattr(self.plugin_cls, "hidden", False)
58
59 def ifaces(self, *ifaces_groups):
60 """Does plugin implements specified interface groups?"""
61 return not ifaces_groups or any(
62 all(iface.implementedBy(self.plugin_cls)
63 for iface in ifaces)
64 for ifaces in ifaces_groups)
65
66 @property
67 def initialized(self):
68 """Has the plugin been initialized already?"""
69 return self._initialized is not None
70
71 def init(self, config=None):
72 """Memoized plugin inititialization."""
73 if not self.initialized:
74 self.entry_point.require() # fetch extras!
75 self._initialized = self.plugin_cls(config, self.name)
76 return self._initialized
77
78 def verify(self, ifaces):
79 """Verify that the plugin conforms to the specified interfaces."""
80 assert self.initialized
81 for iface in ifaces: # zope.interface.providedBy(plugin)
82 try:
83 zope.interface.verify.verifyObject(iface, self.init())
84 except zope.interface.exceptions.BrokenImplementation as error:
85 if iface.implementedBy(self.plugin_cls):
86 logger.debug(
87 "%s implements %s but object does not verify: %s",
88 self.plugin_cls, iface.__name__, error, exc_info=True)
89 return False
90 return True
91
92 @property
93 def prepared(self):
94 """Has the plugin been prepared already?"""
95 if not self.initialized:
96 logger.debug(".prepared called on uninitialized %r", self)
97 return self._prepared is not None
98
99 def prepare(self):
100 """Memoized plugin preparation."""
101 assert self.initialized
102 if self._prepared is None:
103 try:
104 self._initialized.prepare()
105 except errors.MisconfigurationError as error:
106 logger.debug("Misconfigured %r: %s", self, error, exc_info=True)
107 self._prepared = error
108 except errors.NoInstallationError as error:
109 logger.debug(
110 "No installation (%r): %s", self, error, exc_info=True)
111 self._prepared = error
112 except errors.PluginError as error:
113 logger.debug("Other error:(%r): %s", self, error, exc_info=True)
114 self._prepared = error
115 else:
116 self._prepared = True
117 return self._prepared
118
119 @property
120 def misconfigured(self):
121 """Is plugin misconfigured?"""
122 return isinstance(self._prepared, errors.MisconfigurationError)
123
124 @property
125 def problem(self):
126 """Return the Exception raised during plugin setup, or None if all is well"""
127 if isinstance(self._prepared, Exception):
128 return self._prepared
129 return None
130
131 @property
132 def available(self):
133 """Is plugin available, i.e. prepared or misconfigured?"""
134 return self._prepared is True or self.misconfigured
135
136 def __repr__(self):
137 return "PluginEntryPoint#{0}".format(self.name)
138
139 def __str__(self):
140 lines = [
141 "* {0}".format(self.name),
142 "Description: {0}".format(self.plugin_cls.description),
143 "Interfaces: {0}".format(", ".join(
144 iface.__name__ for iface in zope.interface.implementedBy(
145 self.plugin_cls))),
146 "Entry point: {0}".format(self.entry_point),
147 ]
148
149 if self.initialized:
150 lines.append("Initialized: {0}".format(self.init()))
151 if self.prepared:
152 lines.append("Prep: {0}".format(self.prepare()))
153
154 return "\n".join(lines)
155
156
157 class PluginsRegistry(collections.Mapping):
158 """Plugins registry."""
159
160 def __init__(self, plugins):
161 self._plugins = plugins
162
163 @classmethod
164 def find_all(cls):
165 """Find plugins using setuptools entry points."""
166 plugins = {}
167 for entry_point in pkg_resources.iter_entry_points(
168 constants.SETUPTOOLS_PLUGINS_ENTRY_POINT):
169 plugin_ep = PluginEntryPoint(entry_point)
170 assert plugin_ep.name not in plugins, (
171 "PREFIX_FREE_DISTRIBUTIONS messed up")
172 # providedBy | pylint: disable=no-member
173 if interfaces.IPluginFactory.providedBy(plugin_ep.plugin_cls):
174 plugins[plugin_ep.name] = plugin_ep
175 else: # pragma: no cover
176 logger.warning(
177 "%r does not provide IPluginFactory, skipping", plugin_ep)
178 return cls(plugins)
179
180 def __getitem__(self, name):
181 return self._plugins[name]
182
183 def __iter__(self):
184 return iter(self._plugins)
185
186 def __len__(self):
187 return len(self._plugins)
188
189 def init(self, config):
190 """Initialize all plugins in the registry."""
191 return [plugin_ep.init(config) for plugin_ep
192 in self._plugins.itervalues()]
193
194 def filter(self, pred):
195 """Filter plugins based on predicate."""
196 return type(self)(dict((name, plugin_ep) for name, plugin_ep
197 in self._plugins.iteritems() if pred(plugin_ep)))
198
199 def visible(self):
200 """Filter plugins based on visibility."""
201 return self.filter(lambda plugin_ep: not plugin_ep.hidden)
202
203 def ifaces(self, *ifaces_groups):
204 """Filter plugins based on interfaces."""
205 # pylint: disable=star-args
206 return self.filter(lambda p_ep: p_ep.ifaces(*ifaces_groups))
207
208 def verify(self, ifaces):
209 """Filter plugins based on verification."""
210 return self.filter(lambda p_ep: p_ep.verify(ifaces))
211
212 def prepare(self):
213 """Prepare all plugins in the registry."""
214 return [plugin_ep.prepare() for plugin_ep in self._plugins.itervalues()]
215
216 def available(self):
217 """Filter plugins based on availability."""
218 return self.filter(lambda p_ep: p_ep.available)
219 # succefully prepared + misconfigured
220
221 def find_init(self, plugin):
222 """Find an initialized plugin.
223
224 This is particularly useful for finding a name for the plugin
225 (although `.IPluginFactory.__call__` takes ``name`` as one of
226 the arguments, ``IPlugin.name`` is not part of the interface)::
227
228 # plugin is an instance providing IPlugin, initialized
229 # somewhere else in the code
230 plugin_registry.find_init(plugin).name
231
232 Returns ``None`` if ``plugin`` is not found in the registry.
233
234 """
235 # use list instead of set because PluginEntryPoint is not hashable
236 candidates = [plugin_ep for plugin_ep in self._plugins.itervalues()
237 if plugin_ep.initialized and plugin_ep.init() is plugin]
238 assert len(candidates) <= 1
239 if candidates:
240 return candidates[0]
241 else:
242 return None
243
244 def __repr__(self):
245 return "{0}({1})".format(
246 self.__class__.__name__, ','.join(
247 repr(p_ep) for p_ep in self._plugins.itervalues()))
248
249 def __str__(self):
250 if not self._plugins:
251 return "No plugins"
252 return "\n\n".join(str(p_ep) for p_ep in self._plugins.itervalues())
253
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/certbot/constants.py b/certbot/constants.py
--- a/certbot/constants.py
+++ b/certbot/constants.py
@@ -8,6 +8,9 @@
SETUPTOOLS_PLUGINS_ENTRY_POINT = "certbot.plugins"
"""Setuptools entry point group name for plugins."""
+OLD_SETUPTOOLS_PLUGINS_ENTRY_POINT = "letsencrypt.plugins"
+"""Plugins Setuptools entry point before rename."""
+
CLI_DEFAULTS = dict(
config_files=[
"/etc/letsencrypt/cli.ini",
diff --git a/certbot/plugins/disco.py b/certbot/plugins/disco.py
--- a/certbot/plugins/disco.py
+++ b/certbot/plugins/disco.py
@@ -1,5 +1,6 @@
"""Utilities for plugins discovery and selection."""
import collections
+import itertools
import logging
import pkg_resources
@@ -164,8 +165,12 @@
def find_all(cls):
"""Find plugins using setuptools entry points."""
plugins = {}
- for entry_point in pkg_resources.iter_entry_points(
- constants.SETUPTOOLS_PLUGINS_ENTRY_POINT):
+ entry_points = itertools.chain(
+ pkg_resources.iter_entry_points(
+ constants.SETUPTOOLS_PLUGINS_ENTRY_POINT),
+ pkg_resources.iter_entry_points(
+ constants.OLD_SETUPTOOLS_PLUGINS_ENTRY_POINT),)
+ for entry_point in entry_points:
plugin_ep = PluginEntryPoint(entry_point)
assert plugin_ep.name not in plugins, (
"PREFIX_FREE_DISTRIBUTIONS messed up")
|
{"golden_diff": "diff --git a/certbot/constants.py b/certbot/constants.py\n--- a/certbot/constants.py\n+++ b/certbot/constants.py\n@@ -8,6 +8,9 @@\n SETUPTOOLS_PLUGINS_ENTRY_POINT = \"certbot.plugins\"\n \"\"\"Setuptools entry point group name for plugins.\"\"\"\n \n+OLD_SETUPTOOLS_PLUGINS_ENTRY_POINT = \"letsencrypt.plugins\"\n+\"\"\"Plugins Setuptools entry point before rename.\"\"\"\n+\n CLI_DEFAULTS = dict(\n config_files=[\n \"/etc/letsencrypt/cli.ini\",\ndiff --git a/certbot/plugins/disco.py b/certbot/plugins/disco.py\n--- a/certbot/plugins/disco.py\n+++ b/certbot/plugins/disco.py\n@@ -1,5 +1,6 @@\n \"\"\"Utilities for plugins discovery and selection.\"\"\"\n import collections\n+import itertools\n import logging\n import pkg_resources\n \n@@ -164,8 +165,12 @@\n def find_all(cls):\n \"\"\"Find plugins using setuptools entry points.\"\"\"\n plugins = {}\n- for entry_point in pkg_resources.iter_entry_points(\n- constants.SETUPTOOLS_PLUGINS_ENTRY_POINT):\n+ entry_points = itertools.chain(\n+ pkg_resources.iter_entry_points(\n+ constants.SETUPTOOLS_PLUGINS_ENTRY_POINT),\n+ pkg_resources.iter_entry_points(\n+ constants.OLD_SETUPTOOLS_PLUGINS_ENTRY_POINT),)\n+ for entry_point in entry_points:\n plugin_ep = PluginEntryPoint(entry_point)\n assert plugin_ep.name not in plugins, (\n \"PREFIX_FREE_DISTRIBUTIONS messed up\")\n", "issue": "Ensure rename doesn't break third party plugins\nThere are a lot of third party plugins for Let's Encrypt (listed here: https://letsencrypt.readthedocs.org/en/latest/using.html#plugins)\nIt's possible that they reference things in such a way that changing the name or package of LE will break their compatibility with the client - we should ensure that they are unbroken\n\n", "before_files": [{"content": "\"\"\"Certbot constants.\"\"\"\nimport os\nimport logging\n\nfrom acme import challenges\n\n\nSETUPTOOLS_PLUGINS_ENTRY_POINT = \"certbot.plugins\"\n\"\"\"Setuptools entry point group name for plugins.\"\"\"\n\nCLI_DEFAULTS = dict(\n config_files=[\n \"/etc/letsencrypt/cli.ini\",\n # http://freedesktop.org/wiki/Software/xdg-user-dirs/\n os.path.join(os.environ.get(\"XDG_CONFIG_HOME\", \"~/.config\"),\n \"letsencrypt\", \"cli.ini\"),\n ],\n verbose_count=-(logging.WARNING / 10),\n server=\"https://acme-v01.api.letsencrypt.org/directory\",\n rsa_key_size=2048,\n rollback_checkpoints=1,\n config_dir=\"/etc/letsencrypt\",\n work_dir=\"/var/lib/letsencrypt\",\n logs_dir=\"/var/log/letsencrypt\",\n no_verify_ssl=False,\n http01_port=challenges.HTTP01Response.PORT,\n tls_sni_01_port=challenges.TLSSNI01Response.PORT,\n\n auth_cert_path=\"./cert.pem\",\n auth_chain_path=\"./chain.pem\",\n strict_permissions=False,\n)\nSTAGING_URI = \"https://acme-staging.api.letsencrypt.org/directory\"\n\n\"\"\"Defaults for CLI flags and `.IConfig` attributes.\"\"\"\n\nRENEWER_DEFAULTS = dict(\n renewer_enabled=\"yes\",\n renew_before_expiry=\"30 days\",\n # This value should ensure that there is never a deployment delay by\n # default.\n deploy_before_expiry=\"99 years\",\n)\n\"\"\"Defaults for renewer script.\"\"\"\n\n\nENHANCEMENTS = [\"redirect\", \"http-header\", \"ocsp-stapling\", \"spdy\"]\n\"\"\"List of possible :class:`certbot.interfaces.IInstaller`\nenhancements.\n\nList of expected options parameters:\n- redirect: None\n- http-header: TODO\n- ocsp-stapling: TODO\n- spdy: TODO\n\n\"\"\"\n\nARCHIVE_DIR = \"archive\"\n\"\"\"Archive directory, relative to `IConfig.config_dir`.\"\"\"\n\nCONFIG_DIRS_MODE = 0o755\n\"\"\"Directory mode for ``.IConfig.config_dir`` et al.\"\"\"\n\nACCOUNTS_DIR = \"accounts\"\n\"\"\"Directory where all accounts are saved.\"\"\"\n\nBACKUP_DIR = \"backups\"\n\"\"\"Directory (relative to `IConfig.work_dir`) where backups are kept.\"\"\"\n\nCSR_DIR = \"csr\"\n\"\"\"See `.IConfig.csr_dir`.\"\"\"\n\nIN_PROGRESS_DIR = \"IN_PROGRESS\"\n\"\"\"Directory used before a permanent checkpoint is finalized (relative to\n`IConfig.work_dir`).\"\"\"\n\nKEY_DIR = \"keys\"\n\"\"\"Directory (relative to `IConfig.config_dir`) where keys are saved.\"\"\"\n\nLIVE_DIR = \"live\"\n\"\"\"Live directory, relative to `IConfig.config_dir`.\"\"\"\n\nTEMP_CHECKPOINT_DIR = \"temp_checkpoint\"\n\"\"\"Temporary checkpoint directory (relative to `IConfig.work_dir`).\"\"\"\n\nRENEWAL_CONFIGS_DIR = \"renewal\"\n\"\"\"Renewal configs directory, relative to `IConfig.config_dir`.\"\"\"\n\nRENEWER_CONFIG_FILENAME = \"renewer.conf\"\n\"\"\"Renewer config file name (relative to `IConfig.config_dir`).\"\"\"\n", "path": "certbot/constants.py"}, {"content": "\"\"\"Utilities for plugins discovery and selection.\"\"\"\nimport collections\nimport logging\nimport pkg_resources\n\nimport zope.interface\nimport zope.interface.verify\n\nfrom certbot import constants\nfrom certbot import errors\nfrom certbot import interfaces\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass PluginEntryPoint(object):\n \"\"\"Plugin entry point.\"\"\"\n\n PREFIX_FREE_DISTRIBUTIONS = [\n \"certbot\",\n \"certbot-apache\",\n \"certbot-nginx\",\n ]\n \"\"\"Distributions for which prefix will be omitted.\"\"\"\n\n # this object is mutable, don't allow it to be hashed!\n __hash__ = None\n\n def __init__(self, entry_point):\n self.name = self.entry_point_to_plugin_name(entry_point)\n self.plugin_cls = entry_point.load()\n self.entry_point = entry_point\n self._initialized = None\n self._prepared = None\n\n @classmethod\n def entry_point_to_plugin_name(cls, entry_point):\n \"\"\"Unique plugin name for an ``entry_point``\"\"\"\n if entry_point.dist.key in cls.PREFIX_FREE_DISTRIBUTIONS:\n return entry_point.name\n return entry_point.dist.key + \":\" + entry_point.name\n\n @property\n def description(self):\n \"\"\"Description of the plugin.\"\"\"\n return self.plugin_cls.description\n\n @property\n def description_with_name(self):\n \"\"\"Description with name. Handy for UI.\"\"\"\n return \"{0} ({1})\".format(self.description, self.name)\n\n @property\n def hidden(self):\n \"\"\"Should this plugin be hidden from UI?\"\"\"\n return getattr(self.plugin_cls, \"hidden\", False)\n\n def ifaces(self, *ifaces_groups):\n \"\"\"Does plugin implements specified interface groups?\"\"\"\n return not ifaces_groups or any(\n all(iface.implementedBy(self.plugin_cls)\n for iface in ifaces)\n for ifaces in ifaces_groups)\n\n @property\n def initialized(self):\n \"\"\"Has the plugin been initialized already?\"\"\"\n return self._initialized is not None\n\n def init(self, config=None):\n \"\"\"Memoized plugin inititialization.\"\"\"\n if not self.initialized:\n self.entry_point.require() # fetch extras!\n self._initialized = self.plugin_cls(config, self.name)\n return self._initialized\n\n def verify(self, ifaces):\n \"\"\"Verify that the plugin conforms to the specified interfaces.\"\"\"\n assert self.initialized\n for iface in ifaces: # zope.interface.providedBy(plugin)\n try:\n zope.interface.verify.verifyObject(iface, self.init())\n except zope.interface.exceptions.BrokenImplementation as error:\n if iface.implementedBy(self.plugin_cls):\n logger.debug(\n \"%s implements %s but object does not verify: %s\",\n self.plugin_cls, iface.__name__, error, exc_info=True)\n return False\n return True\n\n @property\n def prepared(self):\n \"\"\"Has the plugin been prepared already?\"\"\"\n if not self.initialized:\n logger.debug(\".prepared called on uninitialized %r\", self)\n return self._prepared is not None\n\n def prepare(self):\n \"\"\"Memoized plugin preparation.\"\"\"\n assert self.initialized\n if self._prepared is None:\n try:\n self._initialized.prepare()\n except errors.MisconfigurationError as error:\n logger.debug(\"Misconfigured %r: %s\", self, error, exc_info=True)\n self._prepared = error\n except errors.NoInstallationError as error:\n logger.debug(\n \"No installation (%r): %s\", self, error, exc_info=True)\n self._prepared = error\n except errors.PluginError as error:\n logger.debug(\"Other error:(%r): %s\", self, error, exc_info=True)\n self._prepared = error\n else:\n self._prepared = True\n return self._prepared\n\n @property\n def misconfigured(self):\n \"\"\"Is plugin misconfigured?\"\"\"\n return isinstance(self._prepared, errors.MisconfigurationError)\n\n @property\n def problem(self):\n \"\"\"Return the Exception raised during plugin setup, or None if all is well\"\"\"\n if isinstance(self._prepared, Exception):\n return self._prepared\n return None\n\n @property\n def available(self):\n \"\"\"Is plugin available, i.e. prepared or misconfigured?\"\"\"\n return self._prepared is True or self.misconfigured\n\n def __repr__(self):\n return \"PluginEntryPoint#{0}\".format(self.name)\n\n def __str__(self):\n lines = [\n \"* {0}\".format(self.name),\n \"Description: {0}\".format(self.plugin_cls.description),\n \"Interfaces: {0}\".format(\", \".join(\n iface.__name__ for iface in zope.interface.implementedBy(\n self.plugin_cls))),\n \"Entry point: {0}\".format(self.entry_point),\n ]\n\n if self.initialized:\n lines.append(\"Initialized: {0}\".format(self.init()))\n if self.prepared:\n lines.append(\"Prep: {0}\".format(self.prepare()))\n\n return \"\\n\".join(lines)\n\n\nclass PluginsRegistry(collections.Mapping):\n \"\"\"Plugins registry.\"\"\"\n\n def __init__(self, plugins):\n self._plugins = plugins\n\n @classmethod\n def find_all(cls):\n \"\"\"Find plugins using setuptools entry points.\"\"\"\n plugins = {}\n for entry_point in pkg_resources.iter_entry_points(\n constants.SETUPTOOLS_PLUGINS_ENTRY_POINT):\n plugin_ep = PluginEntryPoint(entry_point)\n assert plugin_ep.name not in plugins, (\n \"PREFIX_FREE_DISTRIBUTIONS messed up\")\n # providedBy | pylint: disable=no-member\n if interfaces.IPluginFactory.providedBy(plugin_ep.plugin_cls):\n plugins[plugin_ep.name] = plugin_ep\n else: # pragma: no cover\n logger.warning(\n \"%r does not provide IPluginFactory, skipping\", plugin_ep)\n return cls(plugins)\n\n def __getitem__(self, name):\n return self._plugins[name]\n\n def __iter__(self):\n return iter(self._plugins)\n\n def __len__(self):\n return len(self._plugins)\n\n def init(self, config):\n \"\"\"Initialize all plugins in the registry.\"\"\"\n return [plugin_ep.init(config) for plugin_ep\n in self._plugins.itervalues()]\n\n def filter(self, pred):\n \"\"\"Filter plugins based on predicate.\"\"\"\n return type(self)(dict((name, plugin_ep) for name, plugin_ep\n in self._plugins.iteritems() if pred(plugin_ep)))\n\n def visible(self):\n \"\"\"Filter plugins based on visibility.\"\"\"\n return self.filter(lambda plugin_ep: not plugin_ep.hidden)\n\n def ifaces(self, *ifaces_groups):\n \"\"\"Filter plugins based on interfaces.\"\"\"\n # pylint: disable=star-args\n return self.filter(lambda p_ep: p_ep.ifaces(*ifaces_groups))\n\n def verify(self, ifaces):\n \"\"\"Filter plugins based on verification.\"\"\"\n return self.filter(lambda p_ep: p_ep.verify(ifaces))\n\n def prepare(self):\n \"\"\"Prepare all plugins in the registry.\"\"\"\n return [plugin_ep.prepare() for plugin_ep in self._plugins.itervalues()]\n\n def available(self):\n \"\"\"Filter plugins based on availability.\"\"\"\n return self.filter(lambda p_ep: p_ep.available)\n # succefully prepared + misconfigured\n\n def find_init(self, plugin):\n \"\"\"Find an initialized plugin.\n\n This is particularly useful for finding a name for the plugin\n (although `.IPluginFactory.__call__` takes ``name`` as one of\n the arguments, ``IPlugin.name`` is not part of the interface)::\n\n # plugin is an instance providing IPlugin, initialized\n # somewhere else in the code\n plugin_registry.find_init(plugin).name\n\n Returns ``None`` if ``plugin`` is not found in the registry.\n\n \"\"\"\n # use list instead of set because PluginEntryPoint is not hashable\n candidates = [plugin_ep for plugin_ep in self._plugins.itervalues()\n if plugin_ep.initialized and plugin_ep.init() is plugin]\n assert len(candidates) <= 1\n if candidates:\n return candidates[0]\n else:\n return None\n\n def __repr__(self):\n return \"{0}({1})\".format(\n self.__class__.__name__, ','.join(\n repr(p_ep) for p_ep in self._plugins.itervalues()))\n\n def __str__(self):\n if not self._plugins:\n return \"No plugins\"\n return \"\\n\\n\".join(str(p_ep) for p_ep in self._plugins.itervalues())\n", "path": "certbot/plugins/disco.py"}], "after_files": [{"content": "\"\"\"Certbot constants.\"\"\"\nimport os\nimport logging\n\nfrom acme import challenges\n\n\nSETUPTOOLS_PLUGINS_ENTRY_POINT = \"certbot.plugins\"\n\"\"\"Setuptools entry point group name for plugins.\"\"\"\n\nOLD_SETUPTOOLS_PLUGINS_ENTRY_POINT = \"letsencrypt.plugins\"\n\"\"\"Plugins Setuptools entry point before rename.\"\"\"\n\nCLI_DEFAULTS = dict(\n config_files=[\n \"/etc/letsencrypt/cli.ini\",\n # http://freedesktop.org/wiki/Software/xdg-user-dirs/\n os.path.join(os.environ.get(\"XDG_CONFIG_HOME\", \"~/.config\"),\n \"letsencrypt\", \"cli.ini\"),\n ],\n verbose_count=-(logging.WARNING / 10),\n server=\"https://acme-v01.api.letsencrypt.org/directory\",\n rsa_key_size=2048,\n rollback_checkpoints=1,\n config_dir=\"/etc/letsencrypt\",\n work_dir=\"/var/lib/letsencrypt\",\n logs_dir=\"/var/log/letsencrypt\",\n no_verify_ssl=False,\n http01_port=challenges.HTTP01Response.PORT,\n tls_sni_01_port=challenges.TLSSNI01Response.PORT,\n\n auth_cert_path=\"./cert.pem\",\n auth_chain_path=\"./chain.pem\",\n strict_permissions=False,\n)\nSTAGING_URI = \"https://acme-staging.api.letsencrypt.org/directory\"\n\n\"\"\"Defaults for CLI flags and `.IConfig` attributes.\"\"\"\n\nRENEWER_DEFAULTS = dict(\n renewer_enabled=\"yes\",\n renew_before_expiry=\"30 days\",\n # This value should ensure that there is never a deployment delay by\n # default.\n deploy_before_expiry=\"99 years\",\n)\n\"\"\"Defaults for renewer script.\"\"\"\n\n\nENHANCEMENTS = [\"redirect\", \"http-header\", \"ocsp-stapling\", \"spdy\"]\n\"\"\"List of possible :class:`certbot.interfaces.IInstaller`\nenhancements.\n\nList of expected options parameters:\n- redirect: None\n- http-header: TODO\n- ocsp-stapling: TODO\n- spdy: TODO\n\n\"\"\"\n\nARCHIVE_DIR = \"archive\"\n\"\"\"Archive directory, relative to `IConfig.config_dir`.\"\"\"\n\nCONFIG_DIRS_MODE = 0o755\n\"\"\"Directory mode for ``.IConfig.config_dir`` et al.\"\"\"\n\nACCOUNTS_DIR = \"accounts\"\n\"\"\"Directory where all accounts are saved.\"\"\"\n\nBACKUP_DIR = \"backups\"\n\"\"\"Directory (relative to `IConfig.work_dir`) where backups are kept.\"\"\"\n\nCSR_DIR = \"csr\"\n\"\"\"See `.IConfig.csr_dir`.\"\"\"\n\nIN_PROGRESS_DIR = \"IN_PROGRESS\"\n\"\"\"Directory used before a permanent checkpoint is finalized (relative to\n`IConfig.work_dir`).\"\"\"\n\nKEY_DIR = \"keys\"\n\"\"\"Directory (relative to `IConfig.config_dir`) where keys are saved.\"\"\"\n\nLIVE_DIR = \"live\"\n\"\"\"Live directory, relative to `IConfig.config_dir`.\"\"\"\n\nTEMP_CHECKPOINT_DIR = \"temp_checkpoint\"\n\"\"\"Temporary checkpoint directory (relative to `IConfig.work_dir`).\"\"\"\n\nRENEWAL_CONFIGS_DIR = \"renewal\"\n\"\"\"Renewal configs directory, relative to `IConfig.config_dir`.\"\"\"\n\nRENEWER_CONFIG_FILENAME = \"renewer.conf\"\n\"\"\"Renewer config file name (relative to `IConfig.config_dir`).\"\"\"\n", "path": "certbot/constants.py"}, {"content": "\"\"\"Utilities for plugins discovery and selection.\"\"\"\nimport collections\nimport itertools\nimport logging\nimport pkg_resources\n\nimport zope.interface\nimport zope.interface.verify\n\nfrom certbot import constants\nfrom certbot import errors\nfrom certbot import interfaces\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass PluginEntryPoint(object):\n \"\"\"Plugin entry point.\"\"\"\n\n PREFIX_FREE_DISTRIBUTIONS = [\n \"certbot\",\n \"certbot-apache\",\n \"certbot-nginx\",\n ]\n \"\"\"Distributions for which prefix will be omitted.\"\"\"\n\n # this object is mutable, don't allow it to be hashed!\n __hash__ = None\n\n def __init__(self, entry_point):\n self.name = self.entry_point_to_plugin_name(entry_point)\n self.plugin_cls = entry_point.load()\n self.entry_point = entry_point\n self._initialized = None\n self._prepared = None\n\n @classmethod\n def entry_point_to_plugin_name(cls, entry_point):\n \"\"\"Unique plugin name for an ``entry_point``\"\"\"\n if entry_point.dist.key in cls.PREFIX_FREE_DISTRIBUTIONS:\n return entry_point.name\n return entry_point.dist.key + \":\" + entry_point.name\n\n @property\n def description(self):\n \"\"\"Description of the plugin.\"\"\"\n return self.plugin_cls.description\n\n @property\n def description_with_name(self):\n \"\"\"Description with name. Handy for UI.\"\"\"\n return \"{0} ({1})\".format(self.description, self.name)\n\n @property\n def hidden(self):\n \"\"\"Should this plugin be hidden from UI?\"\"\"\n return getattr(self.plugin_cls, \"hidden\", False)\n\n def ifaces(self, *ifaces_groups):\n \"\"\"Does plugin implements specified interface groups?\"\"\"\n return not ifaces_groups or any(\n all(iface.implementedBy(self.plugin_cls)\n for iface in ifaces)\n for ifaces in ifaces_groups)\n\n @property\n def initialized(self):\n \"\"\"Has the plugin been initialized already?\"\"\"\n return self._initialized is not None\n\n def init(self, config=None):\n \"\"\"Memoized plugin inititialization.\"\"\"\n if not self.initialized:\n self.entry_point.require() # fetch extras!\n self._initialized = self.plugin_cls(config, self.name)\n return self._initialized\n\n def verify(self, ifaces):\n \"\"\"Verify that the plugin conforms to the specified interfaces.\"\"\"\n assert self.initialized\n for iface in ifaces: # zope.interface.providedBy(plugin)\n try:\n zope.interface.verify.verifyObject(iface, self.init())\n except zope.interface.exceptions.BrokenImplementation as error:\n if iface.implementedBy(self.plugin_cls):\n logger.debug(\n \"%s implements %s but object does not verify: %s\",\n self.plugin_cls, iface.__name__, error, exc_info=True)\n return False\n return True\n\n @property\n def prepared(self):\n \"\"\"Has the plugin been prepared already?\"\"\"\n if not self.initialized:\n logger.debug(\".prepared called on uninitialized %r\", self)\n return self._prepared is not None\n\n def prepare(self):\n \"\"\"Memoized plugin preparation.\"\"\"\n assert self.initialized\n if self._prepared is None:\n try:\n self._initialized.prepare()\n except errors.MisconfigurationError as error:\n logger.debug(\"Misconfigured %r: %s\", self, error, exc_info=True)\n self._prepared = error\n except errors.NoInstallationError as error:\n logger.debug(\n \"No installation (%r): %s\", self, error, exc_info=True)\n self._prepared = error\n except errors.PluginError as error:\n logger.debug(\"Other error:(%r): %s\", self, error, exc_info=True)\n self._prepared = error\n else:\n self._prepared = True\n return self._prepared\n\n @property\n def misconfigured(self):\n \"\"\"Is plugin misconfigured?\"\"\"\n return isinstance(self._prepared, errors.MisconfigurationError)\n\n @property\n def problem(self):\n \"\"\"Return the Exception raised during plugin setup, or None if all is well\"\"\"\n if isinstance(self._prepared, Exception):\n return self._prepared\n return None\n\n @property\n def available(self):\n \"\"\"Is plugin available, i.e. prepared or misconfigured?\"\"\"\n return self._prepared is True or self.misconfigured\n\n def __repr__(self):\n return \"PluginEntryPoint#{0}\".format(self.name)\n\n def __str__(self):\n lines = [\n \"* {0}\".format(self.name),\n \"Description: {0}\".format(self.plugin_cls.description),\n \"Interfaces: {0}\".format(\", \".join(\n iface.__name__ for iface in zope.interface.implementedBy(\n self.plugin_cls))),\n \"Entry point: {0}\".format(self.entry_point),\n ]\n\n if self.initialized:\n lines.append(\"Initialized: {0}\".format(self.init()))\n if self.prepared:\n lines.append(\"Prep: {0}\".format(self.prepare()))\n\n return \"\\n\".join(lines)\n\n\nclass PluginsRegistry(collections.Mapping):\n \"\"\"Plugins registry.\"\"\"\n\n def __init__(self, plugins):\n self._plugins = plugins\n\n @classmethod\n def find_all(cls):\n \"\"\"Find plugins using setuptools entry points.\"\"\"\n plugins = {}\n entry_points = itertools.chain(\n pkg_resources.iter_entry_points(\n constants.SETUPTOOLS_PLUGINS_ENTRY_POINT),\n pkg_resources.iter_entry_points(\n constants.OLD_SETUPTOOLS_PLUGINS_ENTRY_POINT),)\n for entry_point in entry_points:\n plugin_ep = PluginEntryPoint(entry_point)\n assert plugin_ep.name not in plugins, (\n \"PREFIX_FREE_DISTRIBUTIONS messed up\")\n # providedBy | pylint: disable=no-member\n if interfaces.IPluginFactory.providedBy(plugin_ep.plugin_cls):\n plugins[plugin_ep.name] = plugin_ep\n else: # pragma: no cover\n logger.warning(\n \"%r does not provide IPluginFactory, skipping\", plugin_ep)\n return cls(plugins)\n\n def __getitem__(self, name):\n return self._plugins[name]\n\n def __iter__(self):\n return iter(self._plugins)\n\n def __len__(self):\n return len(self._plugins)\n\n def init(self, config):\n \"\"\"Initialize all plugins in the registry.\"\"\"\n return [plugin_ep.init(config) for plugin_ep\n in self._plugins.itervalues()]\n\n def filter(self, pred):\n \"\"\"Filter plugins based on predicate.\"\"\"\n return type(self)(dict((name, plugin_ep) for name, plugin_ep\n in self._plugins.iteritems() if pred(plugin_ep)))\n\n def visible(self):\n \"\"\"Filter plugins based on visibility.\"\"\"\n return self.filter(lambda plugin_ep: not plugin_ep.hidden)\n\n def ifaces(self, *ifaces_groups):\n \"\"\"Filter plugins based on interfaces.\"\"\"\n # pylint: disable=star-args\n return self.filter(lambda p_ep: p_ep.ifaces(*ifaces_groups))\n\n def verify(self, ifaces):\n \"\"\"Filter plugins based on verification.\"\"\"\n return self.filter(lambda p_ep: p_ep.verify(ifaces))\n\n def prepare(self):\n \"\"\"Prepare all plugins in the registry.\"\"\"\n return [plugin_ep.prepare() for plugin_ep in self._plugins.itervalues()]\n\n def available(self):\n \"\"\"Filter plugins based on availability.\"\"\"\n return self.filter(lambda p_ep: p_ep.available)\n # succefully prepared + misconfigured\n\n def find_init(self, plugin):\n \"\"\"Find an initialized plugin.\n\n This is particularly useful for finding a name for the plugin\n (although `.IPluginFactory.__call__` takes ``name`` as one of\n the arguments, ``IPlugin.name`` is not part of the interface)::\n\n # plugin is an instance providing IPlugin, initialized\n # somewhere else in the code\n plugin_registry.find_init(plugin).name\n\n Returns ``None`` if ``plugin`` is not found in the registry.\n\n \"\"\"\n # use list instead of set because PluginEntryPoint is not hashable\n candidates = [plugin_ep for plugin_ep in self._plugins.itervalues()\n if plugin_ep.initialized and plugin_ep.init() is plugin]\n assert len(candidates) <= 1\n if candidates:\n return candidates[0]\n else:\n return None\n\n def __repr__(self):\n return \"{0}({1})\".format(\n self.__class__.__name__, ','.join(\n repr(p_ep) for p_ep in self._plugins.itervalues()))\n\n def __str__(self):\n if not self._plugins:\n return \"No plugins\"\n return \"\\n\\n\".join(str(p_ep) for p_ep in self._plugins.itervalues())\n", "path": "certbot/plugins/disco.py"}]}
| 3,709 | 337 |
gh_patches_debug_15866
|
rasdani/github-patches
|
git_diff
|
tornadoweb__tornado-2653
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
tornado.platform.twisted disappeared but did not explain its replacement
Many years' worth of documentation explains that folks can do
```
from tornado.platform.twisted import install
reactor = install()
```
I can see that in https://github.com/tornadoweb/tornado/commit/004de9c301cc4c2dae4d8f2507af1851d0c9763a#diff-77b5a8a33248ef0bcafbc1bb71e9f013 Twisted integration was removed, since we can all depend on the stdlib loop APIs. This is great, but it also breaks a bunch of Jupyter notebooks, tutorials, etc.
Could you be convinced to replace all those sprawling APIs with something like this:
```python3
def install():
from twisted.internet.asyncioreactor import install
install()
from twisted.internet import reactor
reactor.startRunning()
return reactor
```
possibly with a `warnings.warn` explaining that users could just call these APIs directly, if that's the desired end-state?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `tornado/platform/twisted.py`
Content:
```
1 # Licensed under the Apache License, Version 2.0 (the "License"); you may
2 # not use this file except in compliance with the License. You may obtain
3 # a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS, WITHOUT
9 # WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the
10 # License for the specific language governing permissions and limitations
11 # under the License.
12 """Bridges between the Twisted package and Tornado.
13 """
14
15 import socket
16 import sys
17
18 import twisted.internet.abstract # type: ignore
19 import twisted.internet.asyncioreactor # type: ignore
20 from twisted.internet.defer import Deferred # type: ignore
21 from twisted.python import failure # type: ignore
22 import twisted.names.cache # type: ignore
23 import twisted.names.client # type: ignore
24 import twisted.names.hosts # type: ignore
25 import twisted.names.resolve # type: ignore
26
27
28 from tornado.concurrent import Future, future_set_exc_info
29 from tornado.escape import utf8
30 from tornado import gen
31 from tornado.netutil import Resolver
32
33 import typing
34
35 if typing.TYPE_CHECKING:
36 from typing import Generator, Any, List, Tuple # noqa: F401
37
38
39 class TwistedResolver(Resolver):
40 """Twisted-based asynchronous resolver.
41
42 This is a non-blocking and non-threaded resolver. It is
43 recommended only when threads cannot be used, since it has
44 limitations compared to the standard ``getaddrinfo``-based
45 `~tornado.netutil.Resolver` and
46 `~tornado.netutil.DefaultExecutorResolver`. Specifically, it returns at
47 most one result, and arguments other than ``host`` and ``family``
48 are ignored. It may fail to resolve when ``family`` is not
49 ``socket.AF_UNSPEC``.
50
51 Requires Twisted 12.1 or newer.
52
53 .. versionchanged:: 5.0
54 The ``io_loop`` argument (deprecated since version 4.1) has been removed.
55 """
56
57 def initialize(self) -> None:
58 # partial copy of twisted.names.client.createResolver, which doesn't
59 # allow for a reactor to be passed in.
60 self.reactor = twisted.internet.asyncioreactor.AsyncioSelectorReactor()
61
62 host_resolver = twisted.names.hosts.Resolver("/etc/hosts")
63 cache_resolver = twisted.names.cache.CacheResolver(reactor=self.reactor)
64 real_resolver = twisted.names.client.Resolver(
65 "/etc/resolv.conf", reactor=self.reactor
66 )
67 self.resolver = twisted.names.resolve.ResolverChain(
68 [host_resolver, cache_resolver, real_resolver]
69 )
70
71 @gen.coroutine
72 def resolve(
73 self, host: str, port: int, family: int = 0
74 ) -> "Generator[Any, Any, List[Tuple[int, Any]]]":
75 # getHostByName doesn't accept IP addresses, so if the input
76 # looks like an IP address just return it immediately.
77 if twisted.internet.abstract.isIPAddress(host):
78 resolved = host
79 resolved_family = socket.AF_INET
80 elif twisted.internet.abstract.isIPv6Address(host):
81 resolved = host
82 resolved_family = socket.AF_INET6
83 else:
84 deferred = self.resolver.getHostByName(utf8(host))
85 fut = Future() # type: Future[Any]
86 deferred.addBoth(fut.set_result)
87 resolved = yield fut
88 if isinstance(resolved, failure.Failure):
89 try:
90 resolved.raiseException()
91 except twisted.names.error.DomainError as e:
92 raise IOError(e)
93 elif twisted.internet.abstract.isIPAddress(resolved):
94 resolved_family = socket.AF_INET
95 elif twisted.internet.abstract.isIPv6Address(resolved):
96 resolved_family = socket.AF_INET6
97 else:
98 resolved_family = socket.AF_UNSPEC
99 if family != socket.AF_UNSPEC and family != resolved_family:
100 raise Exception(
101 "Requested socket family %d but got %d" % (family, resolved_family)
102 )
103 result = [(typing.cast(int, resolved_family), (resolved, port))]
104 return result
105
106
107 if hasattr(gen.convert_yielded, "register"):
108
109 @gen.convert_yielded.register(Deferred) # type: ignore
110 def _(d: Deferred) -> Future:
111 f = Future() # type: Future[Any]
112
113 def errback(failure: failure.Failure) -> None:
114 try:
115 failure.raiseException()
116 # Should never happen, but just in case
117 raise Exception("errback called without error")
118 except:
119 future_set_exc_info(f, sys.exc_info())
120
121 d.addCallbacks(f.set_result, errback)
122 return f
123
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/tornado/platform/twisted.py b/tornado/platform/twisted.py
--- a/tornado/platform/twisted.py
+++ b/tornado/platform/twisted.py
@@ -104,6 +104,30 @@
return result
+def install() -> None:
+ """Install ``AsyncioSelectorReactor`` as the default Twisted reactor.
+
+ .. deprecated:: 5.1
+
+ This function is provided for backwards compatibility; code
+ that does not require compatibility with older versions of
+ Tornado should use
+ ``twisted.internet.asyncioreactor.install()`` directly.
+
+ .. versionchanged:: 6.0.3
+
+ In Tornado 5.x and before, this function installed a reactor
+ based on the Tornado ``IOLoop``. When that reactor
+ implementation was removed in Tornado 6.0.0, this function was
+ removed as well. It was restored in Tornado 6.0.3 using the
+ ``asyncio`` reactor instead.
+
+ """
+ from twisted.internet.asyncioreactor import install
+
+ install()
+
+
if hasattr(gen.convert_yielded, "register"):
@gen.convert_yielded.register(Deferred) # type: ignore
|
{"golden_diff": "diff --git a/tornado/platform/twisted.py b/tornado/platform/twisted.py\n--- a/tornado/platform/twisted.py\n+++ b/tornado/platform/twisted.py\n@@ -104,6 +104,30 @@\n return result\n \n \n+def install() -> None:\n+ \"\"\"Install ``AsyncioSelectorReactor`` as the default Twisted reactor.\n+\n+ .. deprecated:: 5.1\n+\n+ This function is provided for backwards compatibility; code\n+ that does not require compatibility with older versions of\n+ Tornado should use\n+ ``twisted.internet.asyncioreactor.install()`` directly.\n+\n+ .. versionchanged:: 6.0.3\n+\n+ In Tornado 5.x and before, this function installed a reactor\n+ based on the Tornado ``IOLoop``. When that reactor\n+ implementation was removed in Tornado 6.0.0, this function was\n+ removed as well. It was restored in Tornado 6.0.3 using the\n+ ``asyncio`` reactor instead.\n+\n+ \"\"\"\n+ from twisted.internet.asyncioreactor import install\n+\n+ install()\n+\n+\n if hasattr(gen.convert_yielded, \"register\"):\n \n @gen.convert_yielded.register(Deferred) # type: ignore\n", "issue": "tornado.platform.twisted disappeared but did not explain its replacement\nMany years' worth of documentation explains that folks can do\r\n\r\n```\r\nfrom tornado.platform.twisted import install\r\nreactor = install()\r\n```\r\n\r\nI can see that in https://github.com/tornadoweb/tornado/commit/004de9c301cc4c2dae4d8f2507af1851d0c9763a#diff-77b5a8a33248ef0bcafbc1bb71e9f013 Twisted integration was removed, since we can all depend on the stdlib loop APIs. This is great, but it also breaks a bunch of Jupyter notebooks, tutorials, etc.\r\n\r\nCould you be convinced to replace all those sprawling APIs with something like this:\r\n\r\n```python3\r\ndef install():\r\n from twisted.internet.asyncioreactor import install\r\n install()\r\n from twisted.internet import reactor\r\n reactor.startRunning()\r\n return reactor\r\n```\r\n\r\npossibly with a `warnings.warn` explaining that users could just call these APIs directly, if that's the desired end-state?\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\"); you may\n# not use this file except in compliance with the License. You may obtain\n# a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS, WITHOUT\n# WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the\n# License for the specific language governing permissions and limitations\n# under the License.\n\"\"\"Bridges between the Twisted package and Tornado.\n\"\"\"\n\nimport socket\nimport sys\n\nimport twisted.internet.abstract # type: ignore\nimport twisted.internet.asyncioreactor # type: ignore\nfrom twisted.internet.defer import Deferred # type: ignore\nfrom twisted.python import failure # type: ignore\nimport twisted.names.cache # type: ignore\nimport twisted.names.client # type: ignore\nimport twisted.names.hosts # type: ignore\nimport twisted.names.resolve # type: ignore\n\n\nfrom tornado.concurrent import Future, future_set_exc_info\nfrom tornado.escape import utf8\nfrom tornado import gen\nfrom tornado.netutil import Resolver\n\nimport typing\n\nif typing.TYPE_CHECKING:\n from typing import Generator, Any, List, Tuple # noqa: F401\n\n\nclass TwistedResolver(Resolver):\n \"\"\"Twisted-based asynchronous resolver.\n\n This is a non-blocking and non-threaded resolver. It is\n recommended only when threads cannot be used, since it has\n limitations compared to the standard ``getaddrinfo``-based\n `~tornado.netutil.Resolver` and\n `~tornado.netutil.DefaultExecutorResolver`. Specifically, it returns at\n most one result, and arguments other than ``host`` and ``family``\n are ignored. It may fail to resolve when ``family`` is not\n ``socket.AF_UNSPEC``.\n\n Requires Twisted 12.1 or newer.\n\n .. versionchanged:: 5.0\n The ``io_loop`` argument (deprecated since version 4.1) has been removed.\n \"\"\"\n\n def initialize(self) -> None:\n # partial copy of twisted.names.client.createResolver, which doesn't\n # allow for a reactor to be passed in.\n self.reactor = twisted.internet.asyncioreactor.AsyncioSelectorReactor()\n\n host_resolver = twisted.names.hosts.Resolver(\"/etc/hosts\")\n cache_resolver = twisted.names.cache.CacheResolver(reactor=self.reactor)\n real_resolver = twisted.names.client.Resolver(\n \"/etc/resolv.conf\", reactor=self.reactor\n )\n self.resolver = twisted.names.resolve.ResolverChain(\n [host_resolver, cache_resolver, real_resolver]\n )\n\n @gen.coroutine\n def resolve(\n self, host: str, port: int, family: int = 0\n ) -> \"Generator[Any, Any, List[Tuple[int, Any]]]\":\n # getHostByName doesn't accept IP addresses, so if the input\n # looks like an IP address just return it immediately.\n if twisted.internet.abstract.isIPAddress(host):\n resolved = host\n resolved_family = socket.AF_INET\n elif twisted.internet.abstract.isIPv6Address(host):\n resolved = host\n resolved_family = socket.AF_INET6\n else:\n deferred = self.resolver.getHostByName(utf8(host))\n fut = Future() # type: Future[Any]\n deferred.addBoth(fut.set_result)\n resolved = yield fut\n if isinstance(resolved, failure.Failure):\n try:\n resolved.raiseException()\n except twisted.names.error.DomainError as e:\n raise IOError(e)\n elif twisted.internet.abstract.isIPAddress(resolved):\n resolved_family = socket.AF_INET\n elif twisted.internet.abstract.isIPv6Address(resolved):\n resolved_family = socket.AF_INET6\n else:\n resolved_family = socket.AF_UNSPEC\n if family != socket.AF_UNSPEC and family != resolved_family:\n raise Exception(\n \"Requested socket family %d but got %d\" % (family, resolved_family)\n )\n result = [(typing.cast(int, resolved_family), (resolved, port))]\n return result\n\n\nif hasattr(gen.convert_yielded, \"register\"):\n\n @gen.convert_yielded.register(Deferred) # type: ignore\n def _(d: Deferred) -> Future:\n f = Future() # type: Future[Any]\n\n def errback(failure: failure.Failure) -> None:\n try:\n failure.raiseException()\n # Should never happen, but just in case\n raise Exception(\"errback called without error\")\n except:\n future_set_exc_info(f, sys.exc_info())\n\n d.addCallbacks(f.set_result, errback)\n return f\n", "path": "tornado/platform/twisted.py"}], "after_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\"); you may\n# not use this file except in compliance with the License. You may obtain\n# a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS, WITHOUT\n# WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the\n# License for the specific language governing permissions and limitations\n# under the License.\n\"\"\"Bridges between the Twisted package and Tornado.\n\"\"\"\n\nimport socket\nimport sys\n\nimport twisted.internet.abstract # type: ignore\nimport twisted.internet.asyncioreactor # type: ignore\nfrom twisted.internet.defer import Deferred # type: ignore\nfrom twisted.python import failure # type: ignore\nimport twisted.names.cache # type: ignore\nimport twisted.names.client # type: ignore\nimport twisted.names.hosts # type: ignore\nimport twisted.names.resolve # type: ignore\n\n\nfrom tornado.concurrent import Future, future_set_exc_info\nfrom tornado.escape import utf8\nfrom tornado import gen\nfrom tornado.netutil import Resolver\n\nimport typing\n\nif typing.TYPE_CHECKING:\n from typing import Generator, Any, List, Tuple # noqa: F401\n\n\nclass TwistedResolver(Resolver):\n \"\"\"Twisted-based asynchronous resolver.\n\n This is a non-blocking and non-threaded resolver. It is\n recommended only when threads cannot be used, since it has\n limitations compared to the standard ``getaddrinfo``-based\n `~tornado.netutil.Resolver` and\n `~tornado.netutil.DefaultExecutorResolver`. Specifically, it returns at\n most one result, and arguments other than ``host`` and ``family``\n are ignored. It may fail to resolve when ``family`` is not\n ``socket.AF_UNSPEC``.\n\n Requires Twisted 12.1 or newer.\n\n .. versionchanged:: 5.0\n The ``io_loop`` argument (deprecated since version 4.1) has been removed.\n \"\"\"\n\n def initialize(self) -> None:\n # partial copy of twisted.names.client.createResolver, which doesn't\n # allow for a reactor to be passed in.\n self.reactor = twisted.internet.asyncioreactor.AsyncioSelectorReactor()\n\n host_resolver = twisted.names.hosts.Resolver(\"/etc/hosts\")\n cache_resolver = twisted.names.cache.CacheResolver(reactor=self.reactor)\n real_resolver = twisted.names.client.Resolver(\n \"/etc/resolv.conf\", reactor=self.reactor\n )\n self.resolver = twisted.names.resolve.ResolverChain(\n [host_resolver, cache_resolver, real_resolver]\n )\n\n @gen.coroutine\n def resolve(\n self, host: str, port: int, family: int = 0\n ) -> \"Generator[Any, Any, List[Tuple[int, Any]]]\":\n # getHostByName doesn't accept IP addresses, so if the input\n # looks like an IP address just return it immediately.\n if twisted.internet.abstract.isIPAddress(host):\n resolved = host\n resolved_family = socket.AF_INET\n elif twisted.internet.abstract.isIPv6Address(host):\n resolved = host\n resolved_family = socket.AF_INET6\n else:\n deferred = self.resolver.getHostByName(utf8(host))\n fut = Future() # type: Future[Any]\n deferred.addBoth(fut.set_result)\n resolved = yield fut\n if isinstance(resolved, failure.Failure):\n try:\n resolved.raiseException()\n except twisted.names.error.DomainError as e:\n raise IOError(e)\n elif twisted.internet.abstract.isIPAddress(resolved):\n resolved_family = socket.AF_INET\n elif twisted.internet.abstract.isIPv6Address(resolved):\n resolved_family = socket.AF_INET6\n else:\n resolved_family = socket.AF_UNSPEC\n if family != socket.AF_UNSPEC and family != resolved_family:\n raise Exception(\n \"Requested socket family %d but got %d\" % (family, resolved_family)\n )\n result = [(typing.cast(int, resolved_family), (resolved, port))]\n return result\n\n\ndef install() -> None:\n \"\"\"Install ``AsyncioSelectorReactor`` as the default Twisted reactor.\n\n .. deprecated:: 5.1\n\n This function is provided for backwards compatibility; code\n that does not require compatibility with older versions of\n Tornado should use\n ``twisted.internet.asyncioreactor.install()`` directly.\n\n .. versionchanged:: 6.0.3\n\n In Tornado 5.x and before, this function installed a reactor\n based on the Tornado ``IOLoop``. When that reactor\n implementation was removed in Tornado 6.0.0, this function was\n removed as well. It was restored in Tornado 6.0.3 using the\n ``asyncio`` reactor instead.\n\n \"\"\"\n from twisted.internet.asyncioreactor import install\n\n install()\n\n\nif hasattr(gen.convert_yielded, \"register\"):\n\n @gen.convert_yielded.register(Deferred) # type: ignore\n def _(d: Deferred) -> Future:\n f = Future() # type: Future[Any]\n\n def errback(failure: failure.Failure) -> None:\n try:\n failure.raiseException()\n # Should never happen, but just in case\n raise Exception(\"errback called without error\")\n except:\n future_set_exc_info(f, sys.exc_info())\n\n d.addCallbacks(f.set_result, errback)\n return f\n", "path": "tornado/platform/twisted.py"}]}
| 1,797 | 289 |
gh_patches_debug_6078
|
rasdani/github-patches
|
git_diff
|
nerfstudio-project__nerfstudio-1094
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Training crashes if all cameras are deleted while in "Render View"
Steps to replicate:
1. Start train and open viewer
2. Add camera to scene
3. Switch to "RENDER VIEW"
4. Delete camera
Resulting error:
```
File "/projects/pyrad/scripts/train.py", line 234, in main
launch(
File "/projects/pyrad/scripts/train.py", line 173, in launch
main_func(local_rank=0, world_size=world_size, config=config)
File "/projects/pyrad/scripts/train.py", line 88, in train_loop
trainer.train()
File "/projects/pyrad/nerfstudio/engine/trainer.py", line 166, in train
self._update_viewer_state(step)
File "/projects/pyrad/nerfstudio/utils/decorators.py", line 58, in wrapper
ret = func(self, *args, **kwargs)
File "/projects/pyrad/nerfstudio/engine/trainer.py", line 229, in _update_viewer_state
self.viewer_state.update_scene(self, step, self.pipeline.model, num_rays_per_batch)
File "/projects/pyrad/nerfstudio/utils/decorators.py", line 82, in wrapper
ret = func(*args, **kwargs)
File "/projects/pyrad/nerfstudio/viewer/server/viewer_utils.py", line 398, in update_scene
self._render_image_in_viewer(camera_object, graph, is_training)
File "/projects/pyrad/nerfstudio/utils/decorators.py", line 82, in wrapper
ret = func(*args, **kwargs)
File "/projects/pyrad/nerfstudio/utils/profiler.py", line 43, in wrapper
ret = func(*args, **kwargs)
File "/projects/pyrad/nerfstudio/viewer/server/viewer_utils.py", line 745, in _render_image_in_viewer
intrinsics_matrix, camera_to_world_h = get_intrinsics_matrix_and_camera_to_world_h(
File "/projects/pyrad/nerfstudio/viewer/server/utils.py", line 77, in get_intrinsics_matrix_and_camera_to_world_h
focal_length = three_js_perspective_camera_focal_length(fov, image_height)
File "/projects/pyrad/nerfstudio/viewer/server/utils.py", line 58, in three_js_perspective_camera_focal_length
focal_length = pp_h / np.tan(fov * (np.pi / 180.0) / 2.0)
TypeError: unsupported operand type(s) for *: 'NoneType' and 'float'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nerfstudio/viewer/server/utils.py`
Content:
```
1 # Copyright 2022 The Nerfstudio Team. All rights reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Generic utility functions
16 """
17
18 import sys
19 from typing import Any, Callable, Dict, List, Optional, Tuple
20
21 import numpy as np
22 import torch
23 import zmq
24 from aiortc import RTCPeerConnection
25 from aiortc.rtcrtpsender import RTCRtpSender
26
27
28 def get_chunks(
29 lst: List[float], num_chunks: Optional[int] = None, size_of_chunk: Optional[int] = None
30 ) -> List[List[float]]:
31 """Returns list of n elements, constaining a sublist.
32
33 Args:
34 lst: List to be chunked up
35 num_chunks: number of chunks to split list into
36 size_of_chunk: size of each chunk
37 """
38 if num_chunks:
39 assert not size_of_chunk
40 size = len(lst) // num_chunks
41 if size_of_chunk:
42 assert not num_chunks
43 size = size_of_chunk
44 chunks = []
45 for i in range(0, len(lst), size):
46 chunks.append(lst[i : i + size])
47 return chunks
48
49
50 def three_js_perspective_camera_focal_length(fov: float, image_height: int):
51 """Returns the focal length of a three.js perspective camera.
52
53 Args:
54 fov: the field of view of the camera in degrees.
55 image_height: the height of the image in pixels.
56 """
57 pp_h = image_height / 2.0
58 focal_length = pp_h / np.tan(fov * (np.pi / 180.0) / 2.0)
59 return focal_length
60
61
62 def get_intrinsics_matrix_and_camera_to_world_h(
63 camera_object: Dict[str, Any], image_height: int
64 ) -> Tuple[torch.Tensor, torch.Tensor]:
65 """Returns the camera intrinsics matrix and the camera to world homogeneous matrix.
66
67 Args:
68 camera_object: a Camera object.
69 image_size: the size of the image (height, width)
70 """
71 # intrinsics
72 fov = camera_object["fov"]
73 aspect = camera_object["aspect"]
74 image_width = aspect * image_height
75 pp_w = image_width / 2.0
76 pp_h = image_height / 2.0
77 focal_length = three_js_perspective_camera_focal_length(fov, image_height)
78 intrinsics_matrix = torch.tensor([[focal_length, 0, pp_w], [0, focal_length, pp_h], [0, 0, 1]]).float()
79
80 # extrinsics
81 camera_to_world_h = torch.tensor(get_chunks(camera_object["matrix"], size_of_chunk=4)).T.float()
82 camera_to_world_h = torch.stack(
83 [
84 camera_to_world_h[0, :],
85 camera_to_world_h[2, :],
86 camera_to_world_h[1, :],
87 camera_to_world_h[3, :],
88 ],
89 dim=0,
90 )
91
92 return intrinsics_matrix, camera_to_world_h
93
94
95 def find_available_port(func: Callable, default_port: int, max_attempts: int = 1000, **kwargs) -> None:
96 """Finds and attempts to connect to a port
97
98 Args:
99 func: function used on connecting to port
100 default_port: the default port
101 max_attempts: max number of attempts to try connection. Defaults to MAX_ATTEMPTS.
102 """
103 for i in range(max_attempts):
104 port = default_port + i
105 try:
106 return func(port, **kwargs), port
107 except (OSError, zmq.error.ZMQError):
108 print(f"Port: {port:d} in use, trying another...", file=sys.stderr)
109 except Exception as e:
110 print(type(e))
111 raise
112 raise (
113 Exception(f"Could not find an available port in the range: [{default_port:d}, {max_attempts + default_port:d})")
114 )
115
116
117 def force_codec(pc: RTCPeerConnection, sender: RTCRtpSender, forced_codec: str) -> None:
118 """Sets the codec preferences on a connection between sender and reciever
119
120 Args:
121 pc: peer connection point
122 sender: sender that will send to connection point
123 forced_codec: codec to set
124 """
125 kind = forced_codec.split("/")[0]
126 codecs = RTCRtpSender.getCapabilities(kind).codecs
127 transceiver = next(t for t in pc.getTransceivers() if t.sender == sender)
128 transceiver.setCodecPreferences([codec for codec in codecs if codec.mimeType == forced_codec])
129
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nerfstudio/viewer/server/utils.py b/nerfstudio/viewer/server/utils.py
--- a/nerfstudio/viewer/server/utils.py
+++ b/nerfstudio/viewer/server/utils.py
@@ -54,6 +54,9 @@
fov: the field of view of the camera in degrees.
image_height: the height of the image in pixels.
"""
+ if fov is None:
+ print("Warning: fov is None, using default value")
+ return 50
pp_h = image_height / 2.0
focal_length = pp_h / np.tan(fov * (np.pi / 180.0) / 2.0)
return focal_length
|
{"golden_diff": "diff --git a/nerfstudio/viewer/server/utils.py b/nerfstudio/viewer/server/utils.py\n--- a/nerfstudio/viewer/server/utils.py\n+++ b/nerfstudio/viewer/server/utils.py\n@@ -54,6 +54,9 @@\n fov: the field of view of the camera in degrees.\n image_height: the height of the image in pixels.\n \"\"\"\n+ if fov is None:\n+ print(\"Warning: fov is None, using default value\")\n+ return 50\n pp_h = image_height / 2.0\n focal_length = pp_h / np.tan(fov * (np.pi / 180.0) / 2.0)\n return focal_length\n", "issue": "Training crashes if all cameras are deleted while in \"Render View\"\nSteps to replicate:\r\n1. Start train and open viewer\r\n2. Add camera to scene\r\n3. Switch to \"RENDER VIEW\"\r\n4. Delete camera\r\n\r\nResulting error:\r\n```\r\n File \"/projects/pyrad/scripts/train.py\", line 234, in main\r\n launch(\r\n File \"/projects/pyrad/scripts/train.py\", line 173, in launch\r\n main_func(local_rank=0, world_size=world_size, config=config)\r\n File \"/projects/pyrad/scripts/train.py\", line 88, in train_loop\r\n trainer.train()\r\n File \"/projects/pyrad/nerfstudio/engine/trainer.py\", line 166, in train\r\n self._update_viewer_state(step)\r\n File \"/projects/pyrad/nerfstudio/utils/decorators.py\", line 58, in wrapper\r\n ret = func(self, *args, **kwargs)\r\n File \"/projects/pyrad/nerfstudio/engine/trainer.py\", line 229, in _update_viewer_state\r\n self.viewer_state.update_scene(self, step, self.pipeline.model, num_rays_per_batch)\r\n File \"/projects/pyrad/nerfstudio/utils/decorators.py\", line 82, in wrapper\r\n ret = func(*args, **kwargs)\r\n File \"/projects/pyrad/nerfstudio/viewer/server/viewer_utils.py\", line 398, in update_scene\r\n self._render_image_in_viewer(camera_object, graph, is_training)\r\n File \"/projects/pyrad/nerfstudio/utils/decorators.py\", line 82, in wrapper\r\n ret = func(*args, **kwargs)\r\n File \"/projects/pyrad/nerfstudio/utils/profiler.py\", line 43, in wrapper\r\n ret = func(*args, **kwargs)\r\n File \"/projects/pyrad/nerfstudio/viewer/server/viewer_utils.py\", line 745, in _render_image_in_viewer\r\n intrinsics_matrix, camera_to_world_h = get_intrinsics_matrix_and_camera_to_world_h(\r\n File \"/projects/pyrad/nerfstudio/viewer/server/utils.py\", line 77, in get_intrinsics_matrix_and_camera_to_world_h\r\n focal_length = three_js_perspective_camera_focal_length(fov, image_height)\r\n File \"/projects/pyrad/nerfstudio/viewer/server/utils.py\", line 58, in three_js_perspective_camera_focal_length\r\n focal_length = pp_h / np.tan(fov * (np.pi / 180.0) / 2.0)\r\nTypeError: unsupported operand type(s) for *: 'NoneType' and 'float'\r\n```\n", "before_files": [{"content": "# Copyright 2022 The Nerfstudio Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Generic utility functions\n\"\"\"\n\nimport sys\nfrom typing import Any, Callable, Dict, List, Optional, Tuple\n\nimport numpy as np\nimport torch\nimport zmq\nfrom aiortc import RTCPeerConnection\nfrom aiortc.rtcrtpsender import RTCRtpSender\n\n\ndef get_chunks(\n lst: List[float], num_chunks: Optional[int] = None, size_of_chunk: Optional[int] = None\n) -> List[List[float]]:\n \"\"\"Returns list of n elements, constaining a sublist.\n\n Args:\n lst: List to be chunked up\n num_chunks: number of chunks to split list into\n size_of_chunk: size of each chunk\n \"\"\"\n if num_chunks:\n assert not size_of_chunk\n size = len(lst) // num_chunks\n if size_of_chunk:\n assert not num_chunks\n size = size_of_chunk\n chunks = []\n for i in range(0, len(lst), size):\n chunks.append(lst[i : i + size])\n return chunks\n\n\ndef three_js_perspective_camera_focal_length(fov: float, image_height: int):\n \"\"\"Returns the focal length of a three.js perspective camera.\n\n Args:\n fov: the field of view of the camera in degrees.\n image_height: the height of the image in pixels.\n \"\"\"\n pp_h = image_height / 2.0\n focal_length = pp_h / np.tan(fov * (np.pi / 180.0) / 2.0)\n return focal_length\n\n\ndef get_intrinsics_matrix_and_camera_to_world_h(\n camera_object: Dict[str, Any], image_height: int\n) -> Tuple[torch.Tensor, torch.Tensor]:\n \"\"\"Returns the camera intrinsics matrix and the camera to world homogeneous matrix.\n\n Args:\n camera_object: a Camera object.\n image_size: the size of the image (height, width)\n \"\"\"\n # intrinsics\n fov = camera_object[\"fov\"]\n aspect = camera_object[\"aspect\"]\n image_width = aspect * image_height\n pp_w = image_width / 2.0\n pp_h = image_height / 2.0\n focal_length = three_js_perspective_camera_focal_length(fov, image_height)\n intrinsics_matrix = torch.tensor([[focal_length, 0, pp_w], [0, focal_length, pp_h], [0, 0, 1]]).float()\n\n # extrinsics\n camera_to_world_h = torch.tensor(get_chunks(camera_object[\"matrix\"], size_of_chunk=4)).T.float()\n camera_to_world_h = torch.stack(\n [\n camera_to_world_h[0, :],\n camera_to_world_h[2, :],\n camera_to_world_h[1, :],\n camera_to_world_h[3, :],\n ],\n dim=0,\n )\n\n return intrinsics_matrix, camera_to_world_h\n\n\ndef find_available_port(func: Callable, default_port: int, max_attempts: int = 1000, **kwargs) -> None:\n \"\"\"Finds and attempts to connect to a port\n\n Args:\n func: function used on connecting to port\n default_port: the default port\n max_attempts: max number of attempts to try connection. Defaults to MAX_ATTEMPTS.\n \"\"\"\n for i in range(max_attempts):\n port = default_port + i\n try:\n return func(port, **kwargs), port\n except (OSError, zmq.error.ZMQError):\n print(f\"Port: {port:d} in use, trying another...\", file=sys.stderr)\n except Exception as e:\n print(type(e))\n raise\n raise (\n Exception(f\"Could not find an available port in the range: [{default_port:d}, {max_attempts + default_port:d})\")\n )\n\n\ndef force_codec(pc: RTCPeerConnection, sender: RTCRtpSender, forced_codec: str) -> None:\n \"\"\"Sets the codec preferences on a connection between sender and reciever\n\n Args:\n pc: peer connection point\n sender: sender that will send to connection point\n forced_codec: codec to set\n \"\"\"\n kind = forced_codec.split(\"/\")[0]\n codecs = RTCRtpSender.getCapabilities(kind).codecs\n transceiver = next(t for t in pc.getTransceivers() if t.sender == sender)\n transceiver.setCodecPreferences([codec for codec in codecs if codec.mimeType == forced_codec])\n", "path": "nerfstudio/viewer/server/utils.py"}], "after_files": [{"content": "# Copyright 2022 The Nerfstudio Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Generic utility functions\n\"\"\"\n\nimport sys\nfrom typing import Any, Callable, Dict, List, Optional, Tuple\n\nimport numpy as np\nimport torch\nimport zmq\nfrom aiortc import RTCPeerConnection\nfrom aiortc.rtcrtpsender import RTCRtpSender\n\n\ndef get_chunks(\n lst: List[float], num_chunks: Optional[int] = None, size_of_chunk: Optional[int] = None\n) -> List[List[float]]:\n \"\"\"Returns list of n elements, constaining a sublist.\n\n Args:\n lst: List to be chunked up\n num_chunks: number of chunks to split list into\n size_of_chunk: size of each chunk\n \"\"\"\n if num_chunks:\n assert not size_of_chunk\n size = len(lst) // num_chunks\n if size_of_chunk:\n assert not num_chunks\n size = size_of_chunk\n chunks = []\n for i in range(0, len(lst), size):\n chunks.append(lst[i : i + size])\n return chunks\n\n\ndef three_js_perspective_camera_focal_length(fov: float, image_height: int):\n \"\"\"Returns the focal length of a three.js perspective camera.\n\n Args:\n fov: the field of view of the camera in degrees.\n image_height: the height of the image in pixels.\n \"\"\"\n if fov is None:\n print(\"Warning: fov is None, using default value\")\n return 50\n pp_h = image_height / 2.0\n focal_length = pp_h / np.tan(fov * (np.pi / 180.0) / 2.0)\n return focal_length\n\n\ndef get_intrinsics_matrix_and_camera_to_world_h(\n camera_object: Dict[str, Any], image_height: int\n) -> Tuple[torch.Tensor, torch.Tensor]:\n \"\"\"Returns the camera intrinsics matrix and the camera to world homogeneous matrix.\n\n Args:\n camera_object: a Camera object.\n image_size: the size of the image (height, width)\n \"\"\"\n # intrinsics\n fov = camera_object[\"fov\"]\n aspect = camera_object[\"aspect\"]\n image_width = aspect * image_height\n pp_w = image_width / 2.0\n pp_h = image_height / 2.0\n focal_length = three_js_perspective_camera_focal_length(fov, image_height)\n intrinsics_matrix = torch.tensor([[focal_length, 0, pp_w], [0, focal_length, pp_h], [0, 0, 1]]).float()\n\n # extrinsics\n camera_to_world_h = torch.tensor(get_chunks(camera_object[\"matrix\"], size_of_chunk=4)).T.float()\n camera_to_world_h = torch.stack(\n [\n camera_to_world_h[0, :],\n camera_to_world_h[2, :],\n camera_to_world_h[1, :],\n camera_to_world_h[3, :],\n ],\n dim=0,\n )\n\n return intrinsics_matrix, camera_to_world_h\n\n\ndef find_available_port(func: Callable, default_port: int, max_attempts: int = 1000, **kwargs) -> None:\n \"\"\"Finds and attempts to connect to a port\n\n Args:\n func: function used on connecting to port\n default_port: the default port\n max_attempts: max number of attempts to try connection. Defaults to MAX_ATTEMPTS.\n \"\"\"\n for i in range(max_attempts):\n port = default_port + i\n try:\n return func(port, **kwargs), port\n except (OSError, zmq.error.ZMQError):\n print(f\"Port: {port:d} in use, trying another...\", file=sys.stderr)\n except Exception as e:\n print(type(e))\n raise\n raise (\n Exception(f\"Could not find an available port in the range: [{default_port:d}, {max_attempts + default_port:d})\")\n )\n\n\ndef force_codec(pc: RTCPeerConnection, sender: RTCRtpSender, forced_codec: str) -> None:\n \"\"\"Sets the codec preferences on a connection between sender and reciever\n\n Args:\n pc: peer connection point\n sender: sender that will send to connection point\n forced_codec: codec to set\n \"\"\"\n kind = forced_codec.split(\"/\")[0]\n codecs = RTCRtpSender.getCapabilities(kind).codecs\n transceiver = next(t for t in pc.getTransceivers() if t.sender == sender)\n transceiver.setCodecPreferences([codec for codec in codecs if codec.mimeType == forced_codec])\n", "path": "nerfstudio/viewer/server/utils.py"}]}
| 2,214 | 162 |
gh_patches_debug_28489
|
rasdani/github-patches
|
git_diff
|
sql-machine-learning__elasticdl-1214
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Remove manually create arguments in master/worker
In ElasticDL's master and worker. We manually create the arguments collection for them. It is a little hacky as we are adding more and more arguments.
After #1210 is merged, we can also update these two places where we manually add arguments.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `elasticdl/python/master/main.py`
Content:
```
1 import os
2 import time
3 from concurrent import futures
4
5 import grpc
6 from kubernetes.client import V1EnvVar
7
8 from elasticdl.proto import elasticdl_pb2_grpc
9 from elasticdl.python.common.args import parse_envs, parse_master_args
10 from elasticdl.python.common.constants import (
11 GRPC,
12 JobType,
13 WorkerManagerStatus,
14 )
15 from elasticdl.python.common.data_reader import RecordIODataReader
16 from elasticdl.python.common.k8s_tensorboard_client import TensorBoardClient
17 from elasticdl.python.common.log_util import get_logger
18 from elasticdl.python.common.model_helper import (
19 find_layer,
20 get_module_file_path,
21 load_model_from_module,
22 load_module,
23 )
24 from elasticdl.python.elasticdl.layers.embedding import Embedding
25 from elasticdl.python.master.checkpoint_service import CheckpointService
26 from elasticdl.python.master.embedding_service import EmbeddingService
27 from elasticdl.python.master.evaluation_service import EvaluationService
28 from elasticdl.python.master.k8s_worker_manager import WorkerManager
29 from elasticdl.python.master.servicer import MasterServicer
30 from elasticdl.python.master.task_dispatcher import _TaskDispatcher
31 from elasticdl.python.master.tensorboard_service import TensorboardService
32
33
34 def _make_task_dispatcher(
35 training_data_dir,
36 evaluation_data_dir,
37 prediction_data_dir,
38 records_per_task,
39 num_epochs,
40 ):
41 # TODO: Support any subclasses of `AbstractDataReader`
42 # and support passing specified parameters to the constructor
43 prediction_f_records = RecordIODataReader(
44 data_dir=prediction_data_dir
45 ).create_shards()
46
47 return _TaskDispatcher(
48 RecordIODataReader(data_dir=training_data_dir).create_shards(),
49 RecordIODataReader(data_dir=evaluation_data_dir).create_shards(),
50 prediction_f_records,
51 records_per_task,
52 # Only generate prediction tasks for 1 epoch
53 1 if prediction_f_records else num_epochs,
54 )
55
56
57 def main():
58 args = parse_master_args()
59 logger = get_logger("master", level=args.log_level.upper())
60
61 # Master addr
62 master_ip = os.getenv("MY_POD_IP", "localhost")
63 master_addr = "%s:%d" % (master_ip, args.port)
64
65 # Start TensorBoard service if requested
66 if args.tensorboard_log_dir:
67 logger.info(
68 "Starting TensorBoard service with log directory %s",
69 args.tensorboard_log_dir,
70 )
71 # Start TensorBoard CLI
72 tb_service = TensorboardService(args.tensorboard_log_dir, master_ip)
73 tb_service.start()
74 else:
75 tb_service = None
76
77 # Start task queue
78 logger.debug(
79 "Starting task queue with training data directory %s, "
80 "evaluation data directory %s, "
81 "and prediction data directory %s",
82 args.training_data_dir,
83 args.evaluation_data_dir,
84 args.prediction_data_dir,
85 )
86 task_d = _make_task_dispatcher(
87 args.training_data_dir,
88 args.evaluation_data_dir,
89 args.prediction_data_dir,
90 args.records_per_task,
91 args.num_epochs,
92 )
93 model_module = load_module(
94 get_module_file_path(args.model_zoo, args.model_def)
95 ).__dict__
96 model_inst = load_model_from_module(
97 args.model_def, model_module, args.model_params
98 )
99 optimizer = model_module[args.optimizer]()
100
101 if all(
102 (
103 args.training_data_dir,
104 args.evaluation_data_dir,
105 args.evaluation_throttle_secs or args.evaluation_steps,
106 )
107 ):
108 job_type = JobType.TRAINING_WITH_EVALUATION
109 elif all(
110 (
111 args.evaluation_data_dir,
112 not args.training_data_dir,
113 not args.prediction_data_dir,
114 )
115 ):
116 job_type = JobType.EVALUATION_ONLY
117 elif all(
118 (
119 args.prediction_data_dir,
120 not args.evaluation_data_dir,
121 not args.training_data_dir,
122 )
123 ):
124 job_type = JobType.PREDICTION_ONLY
125 else:
126 job_type = JobType.TRAINING_ONLY
127
128 # Initialize checkpoint service
129 if args.checkpoint_steps or job_type == JobType.TRAINING_WITH_EVALUATION:
130 logger.info("Starting checkpoint service")
131 checkpoint_service = CheckpointService(
132 args.checkpoint_dir,
133 args.checkpoint_steps,
134 args.keep_checkpoint_max,
135 job_type == JobType.TRAINING_WITH_EVALUATION,
136 )
137 else:
138 checkpoint_service = None
139
140 # Initialize evaluation service
141 evaluation_service = None
142 if (
143 job_type == JobType.TRAINING_WITH_EVALUATION
144 or job_type == JobType.EVALUATION_ONLY
145 ):
146 logger.info(
147 "Starting evaluation service with throttle seconds %d "
148 " and evaluation steps %d",
149 args.evaluation_throttle_secs,
150 args.evaluation_steps,
151 )
152 evaluation_service = EvaluationService(
153 checkpoint_service,
154 tb_service,
155 task_d,
156 args.evaluation_start_delay_secs,
157 args.evaluation_throttle_secs,
158 args.evaluation_steps,
159 job_type == JobType.EVALUATION_ONLY,
160 )
161 evaluation_service.start()
162 task_d.set_evaluation_service(evaluation_service)
163
164 embedding_service_endpoint = None
165 embedding_dims = {}
166 # Search for embedding layers in the model,
167 # if found, initialize embedding service
168 layers = find_layer(model_inst, Embedding)
169 if layers:
170 embedding_service = EmbeddingService()
171 embedding_service_endpoint = embedding_service.start_embedding_service(
172 job_name=args.job_name,
173 image_name=args.worker_image,
174 namespace=args.namespace,
175 resource_request=args.master_resource_request,
176 resource_limit=args.master_resource_limit,
177 pod_priority=args.worker_pod_priority,
178 volume=args.volume,
179 image_pull_policy=args.image_pull_policy,
180 restart_policy=args.restart_policy,
181 cluster_spec=args.cluster_spec,
182 )
183 logger.info(
184 "Embedding service start succeeded. The endpoint is %s."
185 % str(embedding_service_endpoint)
186 )
187 embedding_dims = dict(
188 [(layer.name, layer.output_dim) for layer in layers]
189 )
190
191 # The master service
192 logger.info("Starting master service")
193 server = grpc.server(
194 futures.ThreadPoolExecutor(max_workers=64),
195 options=[
196 ("grpc.max_send_message_length", GRPC.MAX_SEND_MESSAGE_LENGTH),
197 (
198 "grpc.max_receive_message_length",
199 GRPC.MAX_RECEIVE_MESSAGE_LENGTH,
200 ),
201 ],
202 )
203 master_servicer = MasterServicer(
204 args.grads_to_wait,
205 args.minibatch_size,
206 optimizer,
207 task_d,
208 init_var=model_inst.trainable_variables if model_inst.built else [],
209 embedding_dims=embedding_dims,
210 checkpoint_filename_for_init=args.checkpoint_filename_for_init,
211 checkpoint_service=checkpoint_service,
212 evaluation_service=evaluation_service,
213 embedding_service_endpoint=embedding_service_endpoint,
214 lr_staleness_modulation=args.lr_staleness_modulation,
215 use_async=args.use_async,
216 )
217 elasticdl_pb2_grpc.add_MasterServicer_to_server(master_servicer, server)
218 server.add_insecure_port("[::]:{}".format(args.port))
219 server.start()
220 logger.info("Server started at port: %d", args.port)
221
222 worker_manager = None
223 if args.num_workers:
224 assert args.worker_image, "Worker image cannot be empty"
225
226 worker_command = ["python"]
227 worker_args = [
228 "-m",
229 "elasticdl.python.worker.main",
230 "--model_zoo",
231 args.model_zoo,
232 "--master_addr",
233 master_addr,
234 "--log_level",
235 args.log_level,
236 "--dataset_fn",
237 args.dataset_fn,
238 "--loss",
239 args.loss,
240 "--optimizer",
241 args.optimizer,
242 "--eval_metrics_fn",
243 args.eval_metrics_fn,
244 "--model_def",
245 args.model_def,
246 "--job_type",
247 job_type,
248 "--minibatch_size",
249 str(args.minibatch_size),
250 "--embedding_service_endpoint",
251 str(embedding_service_endpoint),
252 "--get_model_steps",
253 str(args.get_model_steps),
254 ]
255
256 env_dict = parse_envs(args.envs)
257 env = []
258 for key in env_dict:
259 env.append(V1EnvVar(name=key, value=env_dict[key]))
260
261 worker_manager = WorkerManager(
262 task_d,
263 job_name=args.job_name,
264 image_name=args.worker_image,
265 command=worker_command,
266 args=worker_args,
267 namespace=args.namespace,
268 num_workers=args.num_workers,
269 worker_resource_request=args.worker_resource_request,
270 worker_resource_limit=args.worker_resource_limit,
271 pod_priority=args.worker_pod_priority,
272 volume=args.volume,
273 image_pull_policy=args.image_pull_policy,
274 restart_policy=args.restart_policy,
275 cluster_spec=args.cluster_spec,
276 envs=env,
277 )
278 worker_manager.update_status(WorkerManagerStatus.PENDING)
279 logger.info("Launching %d workers", args.num_workers)
280 worker_manager.start_workers()
281 worker_manager.update_status(WorkerManagerStatus.RUNNING)
282
283 # Start TensorBoard k8s Service if requested
284 if tb_service:
285 TensorBoardClient(
286 job_name=args.job_name,
287 image_name=args.worker_image,
288 namespace=args.namespace,
289 ).start_tensorboard_service()
290
291 try:
292 while True:
293 if task_d.finished():
294 if worker_manager:
295 worker_manager.update_status(WorkerManagerStatus.FINISHED)
296 if args.output:
297 master_servicer.save_latest_checkpoint(args.output)
298 break
299 time.sleep(30)
300 except KeyboardInterrupt:
301 logger.warning("Server stopping")
302
303 if evaluation_service:
304 logger.info("Stopping evaluation service")
305 evaluation_service.stop()
306
307 logger.info("Stopping RPC server")
308 server.stop(0)
309
310 # Keep TensorBoard running when all the tasks are finished
311 if tb_service:
312 logger.info(
313 "All tasks finished. Keeping TensorBoard service running..."
314 )
315 while True:
316 if tb_service.is_active():
317 time.sleep(10)
318 else:
319 logger.warning(
320 "Unable to keep TensorBoard running. "
321 "It has already terminated"
322 )
323 break
324 logger.info("Master stopped")
325
326
327 if __name__ == "__main__":
328 main()
329
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/elasticdl/python/master/main.py b/elasticdl/python/master/main.py
--- a/elasticdl/python/master/main.py
+++ b/elasticdl/python/master/main.py
@@ -6,7 +6,11 @@
from kubernetes.client import V1EnvVar
from elasticdl.proto import elasticdl_pb2_grpc
-from elasticdl.python.common.args import parse_envs, parse_master_args
+from elasticdl.python.common.args import (
+ build_arguments_from_parsed_result,
+ parse_envs,
+ parse_master_args,
+)
from elasticdl.python.common.constants import (
GRPC,
JobType,
@@ -227,31 +231,14 @@
worker_args = [
"-m",
"elasticdl.python.worker.main",
- "--model_zoo",
- args.model_zoo,
"--master_addr",
master_addr,
- "--log_level",
- args.log_level,
- "--dataset_fn",
- args.dataset_fn,
- "--loss",
- args.loss,
- "--optimizer",
- args.optimizer,
- "--eval_metrics_fn",
- args.eval_metrics_fn,
- "--model_def",
- args.model_def,
"--job_type",
job_type,
- "--minibatch_size",
- str(args.minibatch_size),
"--embedding_service_endpoint",
str(embedding_service_endpoint),
- "--get_model_steps",
- str(args.get_model_steps),
]
+ worker_args.extend(build_arguments_from_parsed_result(args))
env_dict = parse_envs(args.envs)
env = []
|
{"golden_diff": "diff --git a/elasticdl/python/master/main.py b/elasticdl/python/master/main.py\n--- a/elasticdl/python/master/main.py\n+++ b/elasticdl/python/master/main.py\n@@ -6,7 +6,11 @@\n from kubernetes.client import V1EnvVar\n \n from elasticdl.proto import elasticdl_pb2_grpc\n-from elasticdl.python.common.args import parse_envs, parse_master_args\n+from elasticdl.python.common.args import (\n+ build_arguments_from_parsed_result,\n+ parse_envs,\n+ parse_master_args,\n+)\n from elasticdl.python.common.constants import (\n GRPC,\n JobType,\n@@ -227,31 +231,14 @@\n worker_args = [\n \"-m\",\n \"elasticdl.python.worker.main\",\n- \"--model_zoo\",\n- args.model_zoo,\n \"--master_addr\",\n master_addr,\n- \"--log_level\",\n- args.log_level,\n- \"--dataset_fn\",\n- args.dataset_fn,\n- \"--loss\",\n- args.loss,\n- \"--optimizer\",\n- args.optimizer,\n- \"--eval_metrics_fn\",\n- args.eval_metrics_fn,\n- \"--model_def\",\n- args.model_def,\n \"--job_type\",\n job_type,\n- \"--minibatch_size\",\n- str(args.minibatch_size),\n \"--embedding_service_endpoint\",\n str(embedding_service_endpoint),\n- \"--get_model_steps\",\n- str(args.get_model_steps),\n ]\n+ worker_args.extend(build_arguments_from_parsed_result(args))\n \n env_dict = parse_envs(args.envs)\n env = []\n", "issue": "Remove manually create arguments in master/worker\nIn ElasticDL's master and worker. We manually create the arguments collection for them. It is a little hacky as we are adding more and more arguments.\r\nAfter #1210 is merged, we can also update these two places where we manually add arguments.\n", "before_files": [{"content": "import os\nimport time\nfrom concurrent import futures\n\nimport grpc\nfrom kubernetes.client import V1EnvVar\n\nfrom elasticdl.proto import elasticdl_pb2_grpc\nfrom elasticdl.python.common.args import parse_envs, parse_master_args\nfrom elasticdl.python.common.constants import (\n GRPC,\n JobType,\n WorkerManagerStatus,\n)\nfrom elasticdl.python.common.data_reader import RecordIODataReader\nfrom elasticdl.python.common.k8s_tensorboard_client import TensorBoardClient\nfrom elasticdl.python.common.log_util import get_logger\nfrom elasticdl.python.common.model_helper import (\n find_layer,\n get_module_file_path,\n load_model_from_module,\n load_module,\n)\nfrom elasticdl.python.elasticdl.layers.embedding import Embedding\nfrom elasticdl.python.master.checkpoint_service import CheckpointService\nfrom elasticdl.python.master.embedding_service import EmbeddingService\nfrom elasticdl.python.master.evaluation_service import EvaluationService\nfrom elasticdl.python.master.k8s_worker_manager import WorkerManager\nfrom elasticdl.python.master.servicer import MasterServicer\nfrom elasticdl.python.master.task_dispatcher import _TaskDispatcher\nfrom elasticdl.python.master.tensorboard_service import TensorboardService\n\n\ndef _make_task_dispatcher(\n training_data_dir,\n evaluation_data_dir,\n prediction_data_dir,\n records_per_task,\n num_epochs,\n):\n # TODO: Support any subclasses of `AbstractDataReader`\n # and support passing specified parameters to the constructor\n prediction_f_records = RecordIODataReader(\n data_dir=prediction_data_dir\n ).create_shards()\n\n return _TaskDispatcher(\n RecordIODataReader(data_dir=training_data_dir).create_shards(),\n RecordIODataReader(data_dir=evaluation_data_dir).create_shards(),\n prediction_f_records,\n records_per_task,\n # Only generate prediction tasks for 1 epoch\n 1 if prediction_f_records else num_epochs,\n )\n\n\ndef main():\n args = parse_master_args()\n logger = get_logger(\"master\", level=args.log_level.upper())\n\n # Master addr\n master_ip = os.getenv(\"MY_POD_IP\", \"localhost\")\n master_addr = \"%s:%d\" % (master_ip, args.port)\n\n # Start TensorBoard service if requested\n if args.tensorboard_log_dir:\n logger.info(\n \"Starting TensorBoard service with log directory %s\",\n args.tensorboard_log_dir,\n )\n # Start TensorBoard CLI\n tb_service = TensorboardService(args.tensorboard_log_dir, master_ip)\n tb_service.start()\n else:\n tb_service = None\n\n # Start task queue\n logger.debug(\n \"Starting task queue with training data directory %s, \"\n \"evaluation data directory %s, \"\n \"and prediction data directory %s\",\n args.training_data_dir,\n args.evaluation_data_dir,\n args.prediction_data_dir,\n )\n task_d = _make_task_dispatcher(\n args.training_data_dir,\n args.evaluation_data_dir,\n args.prediction_data_dir,\n args.records_per_task,\n args.num_epochs,\n )\n model_module = load_module(\n get_module_file_path(args.model_zoo, args.model_def)\n ).__dict__\n model_inst = load_model_from_module(\n args.model_def, model_module, args.model_params\n )\n optimizer = model_module[args.optimizer]()\n\n if all(\n (\n args.training_data_dir,\n args.evaluation_data_dir,\n args.evaluation_throttle_secs or args.evaluation_steps,\n )\n ):\n job_type = JobType.TRAINING_WITH_EVALUATION\n elif all(\n (\n args.evaluation_data_dir,\n not args.training_data_dir,\n not args.prediction_data_dir,\n )\n ):\n job_type = JobType.EVALUATION_ONLY\n elif all(\n (\n args.prediction_data_dir,\n not args.evaluation_data_dir,\n not args.training_data_dir,\n )\n ):\n job_type = JobType.PREDICTION_ONLY\n else:\n job_type = JobType.TRAINING_ONLY\n\n # Initialize checkpoint service\n if args.checkpoint_steps or job_type == JobType.TRAINING_WITH_EVALUATION:\n logger.info(\"Starting checkpoint service\")\n checkpoint_service = CheckpointService(\n args.checkpoint_dir,\n args.checkpoint_steps,\n args.keep_checkpoint_max,\n job_type == JobType.TRAINING_WITH_EVALUATION,\n )\n else:\n checkpoint_service = None\n\n # Initialize evaluation service\n evaluation_service = None\n if (\n job_type == JobType.TRAINING_WITH_EVALUATION\n or job_type == JobType.EVALUATION_ONLY\n ):\n logger.info(\n \"Starting evaluation service with throttle seconds %d \"\n \" and evaluation steps %d\",\n args.evaluation_throttle_secs,\n args.evaluation_steps,\n )\n evaluation_service = EvaluationService(\n checkpoint_service,\n tb_service,\n task_d,\n args.evaluation_start_delay_secs,\n args.evaluation_throttle_secs,\n args.evaluation_steps,\n job_type == JobType.EVALUATION_ONLY,\n )\n evaluation_service.start()\n task_d.set_evaluation_service(evaluation_service)\n\n embedding_service_endpoint = None\n embedding_dims = {}\n # Search for embedding layers in the model,\n # if found, initialize embedding service\n layers = find_layer(model_inst, Embedding)\n if layers:\n embedding_service = EmbeddingService()\n embedding_service_endpoint = embedding_service.start_embedding_service(\n job_name=args.job_name,\n image_name=args.worker_image,\n namespace=args.namespace,\n resource_request=args.master_resource_request,\n resource_limit=args.master_resource_limit,\n pod_priority=args.worker_pod_priority,\n volume=args.volume,\n image_pull_policy=args.image_pull_policy,\n restart_policy=args.restart_policy,\n cluster_spec=args.cluster_spec,\n )\n logger.info(\n \"Embedding service start succeeded. The endpoint is %s.\"\n % str(embedding_service_endpoint)\n )\n embedding_dims = dict(\n [(layer.name, layer.output_dim) for layer in layers]\n )\n\n # The master service\n logger.info(\"Starting master service\")\n server = grpc.server(\n futures.ThreadPoolExecutor(max_workers=64),\n options=[\n (\"grpc.max_send_message_length\", GRPC.MAX_SEND_MESSAGE_LENGTH),\n (\n \"grpc.max_receive_message_length\",\n GRPC.MAX_RECEIVE_MESSAGE_LENGTH,\n ),\n ],\n )\n master_servicer = MasterServicer(\n args.grads_to_wait,\n args.minibatch_size,\n optimizer,\n task_d,\n init_var=model_inst.trainable_variables if model_inst.built else [],\n embedding_dims=embedding_dims,\n checkpoint_filename_for_init=args.checkpoint_filename_for_init,\n checkpoint_service=checkpoint_service,\n evaluation_service=evaluation_service,\n embedding_service_endpoint=embedding_service_endpoint,\n lr_staleness_modulation=args.lr_staleness_modulation,\n use_async=args.use_async,\n )\n elasticdl_pb2_grpc.add_MasterServicer_to_server(master_servicer, server)\n server.add_insecure_port(\"[::]:{}\".format(args.port))\n server.start()\n logger.info(\"Server started at port: %d\", args.port)\n\n worker_manager = None\n if args.num_workers:\n assert args.worker_image, \"Worker image cannot be empty\"\n\n worker_command = [\"python\"]\n worker_args = [\n \"-m\",\n \"elasticdl.python.worker.main\",\n \"--model_zoo\",\n args.model_zoo,\n \"--master_addr\",\n master_addr,\n \"--log_level\",\n args.log_level,\n \"--dataset_fn\",\n args.dataset_fn,\n \"--loss\",\n args.loss,\n \"--optimizer\",\n args.optimizer,\n \"--eval_metrics_fn\",\n args.eval_metrics_fn,\n \"--model_def\",\n args.model_def,\n \"--job_type\",\n job_type,\n \"--minibatch_size\",\n str(args.minibatch_size),\n \"--embedding_service_endpoint\",\n str(embedding_service_endpoint),\n \"--get_model_steps\",\n str(args.get_model_steps),\n ]\n\n env_dict = parse_envs(args.envs)\n env = []\n for key in env_dict:\n env.append(V1EnvVar(name=key, value=env_dict[key]))\n\n worker_manager = WorkerManager(\n task_d,\n job_name=args.job_name,\n image_name=args.worker_image,\n command=worker_command,\n args=worker_args,\n namespace=args.namespace,\n num_workers=args.num_workers,\n worker_resource_request=args.worker_resource_request,\n worker_resource_limit=args.worker_resource_limit,\n pod_priority=args.worker_pod_priority,\n volume=args.volume,\n image_pull_policy=args.image_pull_policy,\n restart_policy=args.restart_policy,\n cluster_spec=args.cluster_spec,\n envs=env,\n )\n worker_manager.update_status(WorkerManagerStatus.PENDING)\n logger.info(\"Launching %d workers\", args.num_workers)\n worker_manager.start_workers()\n worker_manager.update_status(WorkerManagerStatus.RUNNING)\n\n # Start TensorBoard k8s Service if requested\n if tb_service:\n TensorBoardClient(\n job_name=args.job_name,\n image_name=args.worker_image,\n namespace=args.namespace,\n ).start_tensorboard_service()\n\n try:\n while True:\n if task_d.finished():\n if worker_manager:\n worker_manager.update_status(WorkerManagerStatus.FINISHED)\n if args.output:\n master_servicer.save_latest_checkpoint(args.output)\n break\n time.sleep(30)\n except KeyboardInterrupt:\n logger.warning(\"Server stopping\")\n\n if evaluation_service:\n logger.info(\"Stopping evaluation service\")\n evaluation_service.stop()\n\n logger.info(\"Stopping RPC server\")\n server.stop(0)\n\n # Keep TensorBoard running when all the tasks are finished\n if tb_service:\n logger.info(\n \"All tasks finished. Keeping TensorBoard service running...\"\n )\n while True:\n if tb_service.is_active():\n time.sleep(10)\n else:\n logger.warning(\n \"Unable to keep TensorBoard running. \"\n \"It has already terminated\"\n )\n break\n logger.info(\"Master stopped\")\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "elasticdl/python/master/main.py"}], "after_files": [{"content": "import os\nimport time\nfrom concurrent import futures\n\nimport grpc\nfrom kubernetes.client import V1EnvVar\n\nfrom elasticdl.proto import elasticdl_pb2_grpc\nfrom elasticdl.python.common.args import (\n build_arguments_from_parsed_result,\n parse_envs,\n parse_master_args,\n)\nfrom elasticdl.python.common.constants import (\n GRPC,\n JobType,\n WorkerManagerStatus,\n)\nfrom elasticdl.python.common.data_reader import RecordIODataReader\nfrom elasticdl.python.common.k8s_tensorboard_client import TensorBoardClient\nfrom elasticdl.python.common.log_util import get_logger\nfrom elasticdl.python.common.model_helper import (\n find_layer,\n get_module_file_path,\n load_model_from_module,\n load_module,\n)\nfrom elasticdl.python.elasticdl.layers.embedding import Embedding\nfrom elasticdl.python.master.checkpoint_service import CheckpointService\nfrom elasticdl.python.master.embedding_service import EmbeddingService\nfrom elasticdl.python.master.evaluation_service import EvaluationService\nfrom elasticdl.python.master.k8s_worker_manager import WorkerManager\nfrom elasticdl.python.master.servicer import MasterServicer\nfrom elasticdl.python.master.task_dispatcher import _TaskDispatcher\nfrom elasticdl.python.master.tensorboard_service import TensorboardService\n\n\ndef _make_task_dispatcher(\n training_data_dir,\n evaluation_data_dir,\n prediction_data_dir,\n records_per_task,\n num_epochs,\n):\n # TODO: Support any subclasses of `AbstractDataReader`\n # and support passing specified parameters to the constructor\n prediction_f_records = RecordIODataReader(\n data_dir=prediction_data_dir\n ).create_shards()\n\n return _TaskDispatcher(\n RecordIODataReader(data_dir=training_data_dir).create_shards(),\n RecordIODataReader(data_dir=evaluation_data_dir).create_shards(),\n prediction_f_records,\n records_per_task,\n # Only generate prediction tasks for 1 epoch\n 1 if prediction_f_records else num_epochs,\n )\n\n\ndef main():\n args = parse_master_args()\n logger = get_logger(\"master\", level=args.log_level.upper())\n\n # Master addr\n master_ip = os.getenv(\"MY_POD_IP\", \"localhost\")\n master_addr = \"%s:%d\" % (master_ip, args.port)\n\n # Start TensorBoard service if requested\n if args.tensorboard_log_dir:\n logger.info(\n \"Starting TensorBoard service with log directory %s\",\n args.tensorboard_log_dir,\n )\n # Start TensorBoard CLI\n tb_service = TensorboardService(args.tensorboard_log_dir, master_ip)\n tb_service.start()\n else:\n tb_service = None\n\n # Start task queue\n logger.debug(\n \"Starting task queue with training data directory %s, \"\n \"evaluation data directory %s, \"\n \"and prediction data directory %s\",\n args.training_data_dir,\n args.evaluation_data_dir,\n args.prediction_data_dir,\n )\n task_d = _make_task_dispatcher(\n args.training_data_dir,\n args.evaluation_data_dir,\n args.prediction_data_dir,\n args.records_per_task,\n args.num_epochs,\n )\n model_module = load_module(\n get_module_file_path(args.model_zoo, args.model_def)\n ).__dict__\n model_inst = load_model_from_module(\n args.model_def, model_module, args.model_params\n )\n optimizer = model_module[args.optimizer]()\n\n if all(\n (\n args.training_data_dir,\n args.evaluation_data_dir,\n args.evaluation_throttle_secs or args.evaluation_steps,\n )\n ):\n job_type = JobType.TRAINING_WITH_EVALUATION\n elif all(\n (\n args.evaluation_data_dir,\n not args.training_data_dir,\n not args.prediction_data_dir,\n )\n ):\n job_type = JobType.EVALUATION_ONLY\n elif all(\n (\n args.prediction_data_dir,\n not args.evaluation_data_dir,\n not args.training_data_dir,\n )\n ):\n job_type = JobType.PREDICTION_ONLY\n else:\n job_type = JobType.TRAINING_ONLY\n\n # Initialize checkpoint service\n if args.checkpoint_steps or job_type == JobType.TRAINING_WITH_EVALUATION:\n logger.info(\"Starting checkpoint service\")\n checkpoint_service = CheckpointService(\n args.checkpoint_dir,\n args.checkpoint_steps,\n args.keep_checkpoint_max,\n job_type == JobType.TRAINING_WITH_EVALUATION,\n )\n else:\n checkpoint_service = None\n\n # Initialize evaluation service\n evaluation_service = None\n if (\n job_type == JobType.TRAINING_WITH_EVALUATION\n or job_type == JobType.EVALUATION_ONLY\n ):\n logger.info(\n \"Starting evaluation service with throttle seconds %d \"\n \" and evaluation steps %d\",\n args.evaluation_throttle_secs,\n args.evaluation_steps,\n )\n evaluation_service = EvaluationService(\n checkpoint_service,\n tb_service,\n task_d,\n args.evaluation_start_delay_secs,\n args.evaluation_throttle_secs,\n args.evaluation_steps,\n job_type == JobType.EVALUATION_ONLY,\n )\n evaluation_service.start()\n task_d.set_evaluation_service(evaluation_service)\n\n embedding_service_endpoint = None\n embedding_dims = {}\n # Search for embedding layers in the model,\n # if found, initialize embedding service\n layers = find_layer(model_inst, Embedding)\n if layers:\n embedding_service = EmbeddingService()\n embedding_service_endpoint = embedding_service.start_embedding_service(\n job_name=args.job_name,\n image_name=args.worker_image,\n namespace=args.namespace,\n resource_request=args.master_resource_request,\n resource_limit=args.master_resource_limit,\n pod_priority=args.worker_pod_priority,\n volume=args.volume,\n image_pull_policy=args.image_pull_policy,\n restart_policy=args.restart_policy,\n cluster_spec=args.cluster_spec,\n )\n logger.info(\n \"Embedding service start succeeded. The endpoint is %s.\"\n % str(embedding_service_endpoint)\n )\n embedding_dims = dict(\n [(layer.name, layer.output_dim) for layer in layers]\n )\n\n # The master service\n logger.info(\"Starting master service\")\n server = grpc.server(\n futures.ThreadPoolExecutor(max_workers=64),\n options=[\n (\"grpc.max_send_message_length\", GRPC.MAX_SEND_MESSAGE_LENGTH),\n (\n \"grpc.max_receive_message_length\",\n GRPC.MAX_RECEIVE_MESSAGE_LENGTH,\n ),\n ],\n )\n master_servicer = MasterServicer(\n args.grads_to_wait,\n args.minibatch_size,\n optimizer,\n task_d,\n init_var=model_inst.trainable_variables if model_inst.built else [],\n embedding_dims=embedding_dims,\n checkpoint_filename_for_init=args.checkpoint_filename_for_init,\n checkpoint_service=checkpoint_service,\n evaluation_service=evaluation_service,\n embedding_service_endpoint=embedding_service_endpoint,\n lr_staleness_modulation=args.lr_staleness_modulation,\n use_async=args.use_async,\n )\n elasticdl_pb2_grpc.add_MasterServicer_to_server(master_servicer, server)\n server.add_insecure_port(\"[::]:{}\".format(args.port))\n server.start()\n logger.info(\"Server started at port: %d\", args.port)\n\n worker_manager = None\n if args.num_workers:\n assert args.worker_image, \"Worker image cannot be empty\"\n\n worker_command = [\"python\"]\n worker_args = [\n \"-m\",\n \"elasticdl.python.worker.main\",\n \"--master_addr\",\n master_addr,\n \"--job_type\",\n job_type,\n \"--embedding_service_endpoint\",\n str(embedding_service_endpoint),\n ]\n worker_args.extend(build_arguments_from_parsed_result(args))\n\n env_dict = parse_envs(args.envs)\n env = []\n for key in env_dict:\n env.append(V1EnvVar(name=key, value=env_dict[key]))\n\n worker_manager = WorkerManager(\n task_d,\n job_name=args.job_name,\n image_name=args.worker_image,\n command=worker_command,\n args=worker_args,\n namespace=args.namespace,\n num_workers=args.num_workers,\n worker_resource_request=args.worker_resource_request,\n worker_resource_limit=args.worker_resource_limit,\n pod_priority=args.worker_pod_priority,\n volume=args.volume,\n image_pull_policy=args.image_pull_policy,\n restart_policy=args.restart_policy,\n cluster_spec=args.cluster_spec,\n envs=env,\n )\n worker_manager.update_status(WorkerManagerStatus.PENDING)\n logger.info(\"Launching %d workers\", args.num_workers)\n worker_manager.start_workers()\n worker_manager.update_status(WorkerManagerStatus.RUNNING)\n\n # Start TensorBoard k8s Service if requested\n if tb_service:\n TensorBoardClient(\n job_name=args.job_name,\n image_name=args.worker_image,\n namespace=args.namespace,\n ).start_tensorboard_service()\n\n try:\n while True:\n if task_d.finished():\n if worker_manager:\n worker_manager.update_status(WorkerManagerStatus.FINISHED)\n if args.output:\n master_servicer.save_latest_checkpoint(args.output)\n break\n time.sleep(30)\n except KeyboardInterrupt:\n logger.warning(\"Server stopping\")\n\n if evaluation_service:\n logger.info(\"Stopping evaluation service\")\n evaluation_service.stop()\n\n logger.info(\"Stopping RPC server\")\n server.stop(0)\n\n # Keep TensorBoard running when all the tasks are finished\n if tb_service:\n logger.info(\n \"All tasks finished. Keeping TensorBoard service running...\"\n )\n while True:\n if tb_service.is_active():\n time.sleep(10)\n else:\n logger.warning(\n \"Unable to keep TensorBoard running. \"\n \"It has already terminated\"\n )\n break\n logger.info(\"Master stopped\")\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "elasticdl/python/master/main.py"}]}
| 3,356 | 345 |
gh_patches_debug_335
|
rasdani/github-patches
|
git_diff
|
pymodbus-dev__pymodbus-1395
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
pip show pymodbus, misses information.
```
pymodbus) pymodbus % pip show pymodbus
Name: pymodbus
Version: 3.1.x
Summary: A fully featured modbus protocol stack in python
Home-page: https://github.com/pymodbus-dev/pymodbus/
Author: attr: pymodbus.__author__
Author-email:
License: BSD-3-Clause
Location: /Users/jan/repos/pymodbus
Editable project location: /Users/jan/repos/pymodbus
Requires: setuptools
Required-by:
```
Normally it gets the information from setup.cfg, but for some reason it does not work with "pip show".
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pymodbus/__init__.py`
Content:
```
1 """Pymodbus: Modbus Protocol Implementation.
2
3 Released under the the BSD license
4 """
5
6 from logging import WARNING
7
8 import pymodbus.version as __version
9 from pymodbus.logging import Log
10
11
12 __version__ = __version.version.short()
13 __author__ = "Galen Collins"
14 __maintainer__ = "dhoomakethu, janiversen"
15
16
17 def pymodbus_apply_logging_config(level=WARNING):
18 """Apply basic logging configuration used by default by Pymodbus maintainers.
19
20 Please call this function to format logging appropriately when opening issues.
21 """
22 Log.apply_logging_config(level)
23
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pymodbus/__init__.py b/pymodbus/__init__.py
--- a/pymodbus/__init__.py
+++ b/pymodbus/__init__.py
@@ -10,7 +10,7 @@
__version__ = __version.version.short()
-__author__ = "Galen Collins"
+__author__ = "Galen Collins, Jan Iversen"
__maintainer__ = "dhoomakethu, janiversen"
|
{"golden_diff": "diff --git a/pymodbus/__init__.py b/pymodbus/__init__.py\n--- a/pymodbus/__init__.py\n+++ b/pymodbus/__init__.py\n@@ -10,7 +10,7 @@\n \n \n __version__ = __version.version.short()\n-__author__ = \"Galen Collins\"\n+__author__ = \"Galen Collins, Jan Iversen\"\n __maintainer__ = \"dhoomakethu, janiversen\"\n", "issue": "pip show pymodbus, misses information.\n```\r\npymodbus) pymodbus % pip show pymodbus\r\n\r\nName: pymodbus\r\nVersion: 3.1.x\r\nSummary: A fully featured modbus protocol stack in python\r\nHome-page: https://github.com/pymodbus-dev/pymodbus/\r\nAuthor: attr: pymodbus.__author__\r\nAuthor-email: \r\nLicense: BSD-3-Clause\r\nLocation: /Users/jan/repos/pymodbus\r\nEditable project location: /Users/jan/repos/pymodbus\r\nRequires: setuptools\r\nRequired-by: \r\n```\r\nNormally it gets the information from setup.cfg, but for some reason it does not work with \"pip show\".\n", "before_files": [{"content": "\"\"\"Pymodbus: Modbus Protocol Implementation.\n\nReleased under the the BSD license\n\"\"\"\n\nfrom logging import WARNING\n\nimport pymodbus.version as __version\nfrom pymodbus.logging import Log\n\n\n__version__ = __version.version.short()\n__author__ = \"Galen Collins\"\n__maintainer__ = \"dhoomakethu, janiversen\"\n\n\ndef pymodbus_apply_logging_config(level=WARNING):\n \"\"\"Apply basic logging configuration used by default by Pymodbus maintainers.\n\n Please call this function to format logging appropriately when opening issues.\n \"\"\"\n Log.apply_logging_config(level)\n", "path": "pymodbus/__init__.py"}], "after_files": [{"content": "\"\"\"Pymodbus: Modbus Protocol Implementation.\n\nReleased under the the BSD license\n\"\"\"\n\nfrom logging import WARNING\n\nimport pymodbus.version as __version\nfrom pymodbus.logging import Log\n\n\n__version__ = __version.version.short()\n__author__ = \"Galen Collins, Jan Iversen\"\n__maintainer__ = \"dhoomakethu, janiversen\"\n\n\ndef pymodbus_apply_logging_config(level=WARNING):\n \"\"\"Apply basic logging configuration used by default by Pymodbus maintainers.\n\n Please call this function to format logging appropriately when opening issues.\n \"\"\"\n Log.apply_logging_config(level)\n", "path": "pymodbus/__init__.py"}]}
| 581 | 107 |
gh_patches_debug_17036
|
rasdani/github-patches
|
git_diff
|
HybirdCorp__creme_crm-234
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
management command 'geolocation --stat' failed
really not a blocking bug, but seems very easy to fix:
```
self.sysout(f'{Town.objects.count()} town(s) in database.')
TypeError: sysout() missing 1 required positional argument: 'visible'
```
there is just a missing argument in self.sysout()
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `creme/geolocation/management/commands/geolocation.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 ################################################################################
4 # Creme is a free/open-source Customer Relationship Management software
5 # Copyright (C) 2015-2021 Hybird
6 #
7 # This program is free software: you can redistribute it and/or modify
8 # it under the terms of the GNU Affero General Public License as published by
9 # the Free Software Foundation, either version 3 of the License, or
10 # (at your option) any later version.
11 #
12 # This program is distributed in the hope that it will be useful,
13 # but WITHOUT ANY WARRANTY; without even the implied warranty of
14 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
15 # GNU Affero General Public License for more details.
16 #
17 # You should have received a copy of the GNU Affero General Public License
18 # along with this program. If not, see <http://www.gnu.org/licenses/>.
19 ################################################################################
20
21 import csv
22 import io
23 import logging
24 from functools import partial
25 from urllib.request import urlopen
26 from zipfile import ZipFile
27
28 from django.conf import settings
29 from django.core.management.base import BaseCommand
30 from django.db import transaction
31 from django.template.defaultfilters import slugify
32
33 from creme.creme_core.utils.chunktools import iter_as_chunk
34 from creme.creme_core.utils.collections import OrderedSet
35 from creme.creme_core.utils.url import parse_path
36 from creme.persons import get_address_model
37
38 from ...models import GeoAddress, Town
39
40 logger = logging.getLogger(__name__)
41
42
43 class CSVPopulatorError(Exception):
44 pass
45
46
47 class CSVPopulator:
48 class ProtocolError(CSVPopulatorError):
49 pass
50
51 class ReadError(CSVPopulatorError):
52 pass
53
54 class ParseError(CSVPopulatorError):
55 pass
56
57 class Context:
58 def __init__(self, defaults):
59 self.line = 1
60 self.defaults = defaults
61
62 def __init__(self, columns, defaults=None, chunksize=50):
63 """Constructor.
64 @param columns: Names of columns to extract from CSV file.
65 Raises an error if a column is neither in file nor in defaults.
66 @param defaults: dict of default values.
67 @param chunksize: Number of lines in same transaction.
68 By default sqlite supports 999 entries for each transaction,
69 so use 999/fields as max chunksize value.
70 """
71 self.columns = columns
72 self.defaults = defaults or {}
73 self.chunksize = chunksize
74
75 def _get_source_file(self, url_info):
76 if url_info.scheme in {'file', ''}:
77 self.info(f'Reading database from {url_info.geturl()}...')
78 return open(url_info.path, 'rb')
79 elif url_info.scheme in {'http', 'https'}:
80 self.info(f'Downloading database from {url_info.geturl()}...')
81 return urlopen(url_info.geturl())
82 else:
83 raise self.ProtocolError(
84 f'Unable to open CSV data from {url_info.geturl()} : '
85 f'unsupported protocol.'
86 )
87
88 def _mapper(self, header):
89 columns = self.columns
90 defaults = self.defaults
91
92 column_keys = OrderedSet(h.lower() for h in columns) # TODO: OrderedFrozenSet
93 row_keys = frozenset(k.lower() for k in header)
94
95 missings = []
96 constants = {}
97 indices = [(key, index) for index, key in enumerate(header) if key in column_keys]
98
99 for key in column_keys:
100 if key not in row_keys:
101 try:
102 constants[key] = defaults[key]
103 except KeyError:
104 missings.append(key)
105
106 if missings:
107 raise self.ParseError(
108 f"Following columns are missing and haven't got any default value : {missings}"
109 )
110
111 def _aux(row):
112 data = {key: row[index] or defaults.get(key) for key, index in indices}
113 data.update(constants)
114 return data
115
116 return _aux
117
118 def create(self, row, context):
119 raise NotImplementedError
120
121 def save(self, entries, context):
122 raise NotImplementedError
123
124 def pre(self, rows, context):
125 pass
126
127 def post(self, entries, context):
128 pass
129
130 def line_error(self, e, row, context):
131 pass
132
133 def chunk_error(self, e, rows, context):
134 pass
135
136 def info(self, message):
137 logger.info(message)
138
139 def populate(self, source):
140 if isinstance(source, str):
141 try:
142 url_info = parse_path(source)
143
144 with self._get_source_file(url_info) as bytes_input:
145 if url_info.path.endswith('.zip'):
146 archive = ZipFile(
147 bytes_input
148 if bytes_input.seekable() else
149 io.BytesIO(bytes_input.read())
150 )
151
152 with archive.open(archive.namelist()[0]) as zipped_bytes_input:
153 self._populate_from_bytes(zipped_bytes_input)
154 else:
155 self._populate_from_bytes(bytes_input)
156 except CSVPopulatorError:
157 raise
158 except Exception as e:
159 raise self.ReadError(f'Unable to open CSV data from {source} : {e}') from e
160 elif hasattr(source, '__iter__'):
161 self._populate_from_lines(iter(source))
162 else:
163 raise ValueError('The source must be a path or an iterable.')
164
165 def _populate_from_bytes(self, bytes_input):
166 with io.TextIOWrapper(bytes_input) as wrapped_bytes_input:
167 self._populate_from_lines(csv.reader(wrapped_bytes_input))
168
169 def _populate_from_lines(self, lines):
170 mapper = self._mapper(next(lines))
171 context = self.Context(self.defaults)
172
173 for rows in iter_as_chunk(lines, self.chunksize):
174 entries = []
175
176 if mapper:
177 rows = [mapper(row) for row in rows]
178
179 try:
180 self.pre(rows, context)
181
182 for row in rows:
183 try:
184 entries.extend(self.create(row, context))
185 except Exception as e:
186 self.line_error(e, row, context)
187
188 context.line += 1
189
190 self.save(entries, context)
191 self.post(entries, context)
192 except Exception as e:
193 self.chunk_error(e, rows, context)
194
195 def sync(self, model, entries, build_pk):
196 created = []
197 updated = []
198
199 for t in entries:
200 pk = build_pk(t)
201
202 if not pk:
203 created.append(t)
204 else:
205 t.pk = pk
206 updated.append(t)
207
208 with transaction.atomic():
209 model.objects.bulk_create(created)
210
211 # TODO: bulk_update() ?
212 for entry in updated:
213 entry.save(force_update=True)
214
215
216 class CSVTownPopulator(CSVPopulator):
217 def __init__(self, defaults=None, chunksize=100):
218 super().__init__(['title', 'zipcode', 'latitude', 'longitude', 'country'],
219 defaults=defaults, chunksize=chunksize,
220 )
221
222 def line_error(self, e, row, context):
223 logger.error(' invalid data (line %d) : %s', context.line, e)
224
225 def chunk_error(self, e, rows, context):
226 logger.error(' invalid data chunk : %s', e)
227
228 def create(self, row, context):
229 zipcodes = row['zipcode'].split('-')
230
231 name = row['title']
232 latitude = row['latitude']
233 longitude = row['longitude']
234
235 slug = slugify(name)
236 country = row['country']
237
238 build_town = partial(Town, country=country)
239
240 return [build_town(name=name,
241 slug=slug,
242 zipcode=zipcode,
243 latitude=latitude,
244 longitude=longitude,
245 ) for zipcode in zipcodes
246 ]
247
248 def save(self, entries, context):
249 get_existing_pk_by_zipcode = dict(
250 Town.objects.filter(
251 zipcode__in=(t.zipcode for t in entries),
252 slug__in=(t.slug for t in entries),
253 ).values_list('zipcode', 'pk')
254 ).get
255
256 self.sync(
257 Town, entries,
258 lambda town: get_existing_pk_by_zipcode(town.zipcode),
259 )
260
261
262 class Command(BaseCommand):
263 def add_arguments(self, parser):
264 add_argument = parser.add_argument
265 add_argument(
266 '-p', '--populate', action='store_true', dest='populate',
267 help='Populate addresses', default=False,
268 )
269 add_argument(
270 '-s', '--stat', action='store_true', dest='stats',
271 help='Display geolocation database stats', default=False,
272 )
273 add_argument(
274 '-i', '--import', action='store_true', dest='import', default=False,
275 help='Import towns configured in GEOLOCATION_TOWNS setting',
276 )
277
278 def sysout(self, message, visible):
279 if visible:
280 self.stdout.write(message)
281
282 def syserr(self, message):
283 self.stderr.write(message)
284
285 def populate_addresses(self, verbosity=0):
286 self.sysout('Populate geolocation information of addresses...', verbosity > 0)
287 GeoAddress.populate_geoaddresses(get_address_model().objects.exclude(zipcode='', city=''))
288
289 def import_town_database(self, url, defaults):
290 try:
291 CSVTownPopulator(defaults=defaults).populate(url)
292 except Exception as e:
293 self.syserr(str(e))
294
295 def import_town_all(self, verbosity=0):
296 self.sysout('Importing Towns database...', verbosity > 0)
297
298 for url, defaults in settings.GEOLOCATION_TOWNS:
299 self.sysout(url, verbosity > 1)
300 self.import_town_database(url, defaults)
301
302 def print_stats(self):
303 self.sysout(f'{Town.objects.count()} town(s) in database.')
304
305 def handle(self, *args, **options):
306 populate = options.get('populate')
307 stats = options.get('stats')
308 imports = options.get('import')
309 verbosity = options.get('verbosity')
310
311 if stats:
312 self.print_stats()
313
314 if imports:
315 self.import_town_all(verbosity)
316
317 if populate:
318 self.populate_addresses(verbosity)
319
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/creme/geolocation/management/commands/geolocation.py b/creme/geolocation/management/commands/geolocation.py
--- a/creme/geolocation/management/commands/geolocation.py
+++ b/creme/geolocation/management/commands/geolocation.py
@@ -299,8 +299,8 @@
self.sysout(url, verbosity > 1)
self.import_town_database(url, defaults)
- def print_stats(self):
- self.sysout(f'{Town.objects.count()} town(s) in database.')
+ def print_stats(self, verbosity=0):
+ self.sysout(f'{Town.objects.count()} town(s) in database.', verbosity > 0)
def handle(self, *args, **options):
populate = options.get('populate')
@@ -309,7 +309,7 @@
verbosity = options.get('verbosity')
if stats:
- self.print_stats()
+ self.print_stats(verbosity)
if imports:
self.import_town_all(verbosity)
|
{"golden_diff": "diff --git a/creme/geolocation/management/commands/geolocation.py b/creme/geolocation/management/commands/geolocation.py\n--- a/creme/geolocation/management/commands/geolocation.py\n+++ b/creme/geolocation/management/commands/geolocation.py\n@@ -299,8 +299,8 @@\n self.sysout(url, verbosity > 1)\n self.import_town_database(url, defaults)\n \n- def print_stats(self):\n- self.sysout(f'{Town.objects.count()} town(s) in database.')\n+ def print_stats(self, verbosity=0):\n+ self.sysout(f'{Town.objects.count()} town(s) in database.', verbosity > 0)\n \n def handle(self, *args, **options):\n populate = options.get('populate')\n@@ -309,7 +309,7 @@\n verbosity = options.get('verbosity')\n \n if stats:\n- self.print_stats()\n+ self.print_stats(verbosity)\n \n if imports:\n self.import_town_all(verbosity)\n", "issue": "management command 'geolocation --stat' failed\nreally not a blocking bug, but seems very easy to fix:\r\n```\r\n self.sysout(f'{Town.objects.count()} town(s) in database.')\r\nTypeError: sysout() missing 1 required positional argument: 'visible'\r\n```\r\n\r\nthere is just a missing argument in self.sysout()\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n################################################################################\n# Creme is a free/open-source Customer Relationship Management software\n# Copyright (C) 2015-2021 Hybird\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU Affero General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU Affero General Public License for more details.\n#\n# You should have received a copy of the GNU Affero General Public License\n# along with this program. If not, see <http://www.gnu.org/licenses/>.\n################################################################################\n\nimport csv\nimport io\nimport logging\nfrom functools import partial\nfrom urllib.request import urlopen\nfrom zipfile import ZipFile\n\nfrom django.conf import settings\nfrom django.core.management.base import BaseCommand\nfrom django.db import transaction\nfrom django.template.defaultfilters import slugify\n\nfrom creme.creme_core.utils.chunktools import iter_as_chunk\nfrom creme.creme_core.utils.collections import OrderedSet\nfrom creme.creme_core.utils.url import parse_path\nfrom creme.persons import get_address_model\n\nfrom ...models import GeoAddress, Town\n\nlogger = logging.getLogger(__name__)\n\n\nclass CSVPopulatorError(Exception):\n pass\n\n\nclass CSVPopulator:\n class ProtocolError(CSVPopulatorError):\n pass\n\n class ReadError(CSVPopulatorError):\n pass\n\n class ParseError(CSVPopulatorError):\n pass\n\n class Context:\n def __init__(self, defaults):\n self.line = 1\n self.defaults = defaults\n\n def __init__(self, columns, defaults=None, chunksize=50):\n \"\"\"Constructor.\n @param columns: Names of columns to extract from CSV file.\n Raises an error if a column is neither in file nor in defaults.\n @param defaults: dict of default values.\n @param chunksize: Number of lines in same transaction.\n By default sqlite supports 999 entries for each transaction,\n so use 999/fields as max chunksize value.\n \"\"\"\n self.columns = columns\n self.defaults = defaults or {}\n self.chunksize = chunksize\n\n def _get_source_file(self, url_info):\n if url_info.scheme in {'file', ''}:\n self.info(f'Reading database from {url_info.geturl()}...')\n return open(url_info.path, 'rb')\n elif url_info.scheme in {'http', 'https'}:\n self.info(f'Downloading database from {url_info.geturl()}...')\n return urlopen(url_info.geturl())\n else:\n raise self.ProtocolError(\n f'Unable to open CSV data from {url_info.geturl()} : '\n f'unsupported protocol.'\n )\n\n def _mapper(self, header):\n columns = self.columns\n defaults = self.defaults\n\n column_keys = OrderedSet(h.lower() for h in columns) # TODO: OrderedFrozenSet\n row_keys = frozenset(k.lower() for k in header)\n\n missings = []\n constants = {}\n indices = [(key, index) for index, key in enumerate(header) if key in column_keys]\n\n for key in column_keys:\n if key not in row_keys:\n try:\n constants[key] = defaults[key]\n except KeyError:\n missings.append(key)\n\n if missings:\n raise self.ParseError(\n f\"Following columns are missing and haven't got any default value : {missings}\"\n )\n\n def _aux(row):\n data = {key: row[index] or defaults.get(key) for key, index in indices}\n data.update(constants)\n return data\n\n return _aux\n\n def create(self, row, context):\n raise NotImplementedError\n\n def save(self, entries, context):\n raise NotImplementedError\n\n def pre(self, rows, context):\n pass\n\n def post(self, entries, context):\n pass\n\n def line_error(self, e, row, context):\n pass\n\n def chunk_error(self, e, rows, context):\n pass\n\n def info(self, message):\n logger.info(message)\n\n def populate(self, source):\n if isinstance(source, str):\n try:\n url_info = parse_path(source)\n\n with self._get_source_file(url_info) as bytes_input:\n if url_info.path.endswith('.zip'):\n archive = ZipFile(\n bytes_input\n if bytes_input.seekable() else\n io.BytesIO(bytes_input.read())\n )\n\n with archive.open(archive.namelist()[0]) as zipped_bytes_input:\n self._populate_from_bytes(zipped_bytes_input)\n else:\n self._populate_from_bytes(bytes_input)\n except CSVPopulatorError:\n raise\n except Exception as e:\n raise self.ReadError(f'Unable to open CSV data from {source} : {e}') from e\n elif hasattr(source, '__iter__'):\n self._populate_from_lines(iter(source))\n else:\n raise ValueError('The source must be a path or an iterable.')\n\n def _populate_from_bytes(self, bytes_input):\n with io.TextIOWrapper(bytes_input) as wrapped_bytes_input:\n self._populate_from_lines(csv.reader(wrapped_bytes_input))\n\n def _populate_from_lines(self, lines):\n mapper = self._mapper(next(lines))\n context = self.Context(self.defaults)\n\n for rows in iter_as_chunk(lines, self.chunksize):\n entries = []\n\n if mapper:\n rows = [mapper(row) for row in rows]\n\n try:\n self.pre(rows, context)\n\n for row in rows:\n try:\n entries.extend(self.create(row, context))\n except Exception as e:\n self.line_error(e, row, context)\n\n context.line += 1\n\n self.save(entries, context)\n self.post(entries, context)\n except Exception as e:\n self.chunk_error(e, rows, context)\n\n def sync(self, model, entries, build_pk):\n created = []\n updated = []\n\n for t in entries:\n pk = build_pk(t)\n\n if not pk:\n created.append(t)\n else:\n t.pk = pk\n updated.append(t)\n\n with transaction.atomic():\n model.objects.bulk_create(created)\n\n # TODO: bulk_update() ?\n for entry in updated:\n entry.save(force_update=True)\n\n\nclass CSVTownPopulator(CSVPopulator):\n def __init__(self, defaults=None, chunksize=100):\n super().__init__(['title', 'zipcode', 'latitude', 'longitude', 'country'],\n defaults=defaults, chunksize=chunksize,\n )\n\n def line_error(self, e, row, context):\n logger.error(' invalid data (line %d) : %s', context.line, e)\n\n def chunk_error(self, e, rows, context):\n logger.error(' invalid data chunk : %s', e)\n\n def create(self, row, context):\n zipcodes = row['zipcode'].split('-')\n\n name = row['title']\n latitude = row['latitude']\n longitude = row['longitude']\n\n slug = slugify(name)\n country = row['country']\n\n build_town = partial(Town, country=country)\n\n return [build_town(name=name,\n slug=slug,\n zipcode=zipcode,\n latitude=latitude,\n longitude=longitude,\n ) for zipcode in zipcodes\n ]\n\n def save(self, entries, context):\n get_existing_pk_by_zipcode = dict(\n Town.objects.filter(\n zipcode__in=(t.zipcode for t in entries),\n slug__in=(t.slug for t in entries),\n ).values_list('zipcode', 'pk')\n ).get\n\n self.sync(\n Town, entries,\n lambda town: get_existing_pk_by_zipcode(town.zipcode),\n )\n\n\nclass Command(BaseCommand):\n def add_arguments(self, parser):\n add_argument = parser.add_argument\n add_argument(\n '-p', '--populate', action='store_true', dest='populate',\n help='Populate addresses', default=False,\n )\n add_argument(\n '-s', '--stat', action='store_true', dest='stats',\n help='Display geolocation database stats', default=False,\n )\n add_argument(\n '-i', '--import', action='store_true', dest='import', default=False,\n help='Import towns configured in GEOLOCATION_TOWNS setting',\n )\n\n def sysout(self, message, visible):\n if visible:\n self.stdout.write(message)\n\n def syserr(self, message):\n self.stderr.write(message)\n\n def populate_addresses(self, verbosity=0):\n self.sysout('Populate geolocation information of addresses...', verbosity > 0)\n GeoAddress.populate_geoaddresses(get_address_model().objects.exclude(zipcode='', city=''))\n\n def import_town_database(self, url, defaults):\n try:\n CSVTownPopulator(defaults=defaults).populate(url)\n except Exception as e:\n self.syserr(str(e))\n\n def import_town_all(self, verbosity=0):\n self.sysout('Importing Towns database...', verbosity > 0)\n\n for url, defaults in settings.GEOLOCATION_TOWNS:\n self.sysout(url, verbosity > 1)\n self.import_town_database(url, defaults)\n\n def print_stats(self):\n self.sysout(f'{Town.objects.count()} town(s) in database.')\n\n def handle(self, *args, **options):\n populate = options.get('populate')\n stats = options.get('stats')\n imports = options.get('import')\n verbosity = options.get('verbosity')\n\n if stats:\n self.print_stats()\n\n if imports:\n self.import_town_all(verbosity)\n\n if populate:\n self.populate_addresses(verbosity)\n", "path": "creme/geolocation/management/commands/geolocation.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n################################################################################\n# Creme is a free/open-source Customer Relationship Management software\n# Copyright (C) 2015-2021 Hybird\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU Affero General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU Affero General Public License for more details.\n#\n# You should have received a copy of the GNU Affero General Public License\n# along with this program. If not, see <http://www.gnu.org/licenses/>.\n################################################################################\n\nimport csv\nimport io\nimport logging\nfrom functools import partial\nfrom urllib.request import urlopen\nfrom zipfile import ZipFile\n\nfrom django.conf import settings\nfrom django.core.management.base import BaseCommand\nfrom django.db import transaction\nfrom django.template.defaultfilters import slugify\n\nfrom creme.creme_core.utils.chunktools import iter_as_chunk\nfrom creme.creme_core.utils.collections import OrderedSet\nfrom creme.creme_core.utils.url import parse_path\nfrom creme.persons import get_address_model\n\nfrom ...models import GeoAddress, Town\n\nlogger = logging.getLogger(__name__)\n\n\nclass CSVPopulatorError(Exception):\n pass\n\n\nclass CSVPopulator:\n class ProtocolError(CSVPopulatorError):\n pass\n\n class ReadError(CSVPopulatorError):\n pass\n\n class ParseError(CSVPopulatorError):\n pass\n\n class Context:\n def __init__(self, defaults):\n self.line = 1\n self.defaults = defaults\n\n def __init__(self, columns, defaults=None, chunksize=50):\n \"\"\"Constructor.\n @param columns: Names of columns to extract from CSV file.\n Raises an error if a column is neither in file nor in defaults.\n @param defaults: dict of default values.\n @param chunksize: Number of lines in same transaction.\n By default sqlite supports 999 entries for each transaction,\n so use 999/fields as max chunksize value.\n \"\"\"\n self.columns = columns\n self.defaults = defaults or {}\n self.chunksize = chunksize\n\n def _get_source_file(self, url_info):\n if url_info.scheme in {'file', ''}:\n self.info(f'Reading database from {url_info.geturl()}...')\n return open(url_info.path, 'rb')\n elif url_info.scheme in {'http', 'https'}:\n self.info(f'Downloading database from {url_info.geturl()}...')\n return urlopen(url_info.geturl())\n else:\n raise self.ProtocolError(\n f'Unable to open CSV data from {url_info.geturl()} : '\n f'unsupported protocol.'\n )\n\n def _mapper(self, header):\n columns = self.columns\n defaults = self.defaults\n\n column_keys = OrderedSet(h.lower() for h in columns) # TODO: OrderedFrozenSet\n row_keys = frozenset(k.lower() for k in header)\n\n missings = []\n constants = {}\n indices = [(key, index) for index, key in enumerate(header) if key in column_keys]\n\n for key in column_keys:\n if key not in row_keys:\n try:\n constants[key] = defaults[key]\n except KeyError:\n missings.append(key)\n\n if missings:\n raise self.ParseError(\n f\"Following columns are missing and haven't got any default value : {missings}\"\n )\n\n def _aux(row):\n data = {key: row[index] or defaults.get(key) for key, index in indices}\n data.update(constants)\n return data\n\n return _aux\n\n def create(self, row, context):\n raise NotImplementedError\n\n def save(self, entries, context):\n raise NotImplementedError\n\n def pre(self, rows, context):\n pass\n\n def post(self, entries, context):\n pass\n\n def line_error(self, e, row, context):\n pass\n\n def chunk_error(self, e, rows, context):\n pass\n\n def info(self, message):\n logger.info(message)\n\n def populate(self, source):\n if isinstance(source, str):\n try:\n url_info = parse_path(source)\n\n with self._get_source_file(url_info) as bytes_input:\n if url_info.path.endswith('.zip'):\n archive = ZipFile(\n bytes_input\n if bytes_input.seekable() else\n io.BytesIO(bytes_input.read())\n )\n\n with archive.open(archive.namelist()[0]) as zipped_bytes_input:\n self._populate_from_bytes(zipped_bytes_input)\n else:\n self._populate_from_bytes(bytes_input)\n except CSVPopulatorError:\n raise\n except Exception as e:\n raise self.ReadError(f'Unable to open CSV data from {source} : {e}') from e\n elif hasattr(source, '__iter__'):\n self._populate_from_lines(iter(source))\n else:\n raise ValueError('The source must be a path or an iterable.')\n\n def _populate_from_bytes(self, bytes_input):\n with io.TextIOWrapper(bytes_input) as wrapped_bytes_input:\n self._populate_from_lines(csv.reader(wrapped_bytes_input))\n\n def _populate_from_lines(self, lines):\n mapper = self._mapper(next(lines))\n context = self.Context(self.defaults)\n\n for rows in iter_as_chunk(lines, self.chunksize):\n entries = []\n\n if mapper:\n rows = [mapper(row) for row in rows]\n\n try:\n self.pre(rows, context)\n\n for row in rows:\n try:\n entries.extend(self.create(row, context))\n except Exception as e:\n self.line_error(e, row, context)\n\n context.line += 1\n\n self.save(entries, context)\n self.post(entries, context)\n except Exception as e:\n self.chunk_error(e, rows, context)\n\n def sync(self, model, entries, build_pk):\n created = []\n updated = []\n\n for t in entries:\n pk = build_pk(t)\n\n if not pk:\n created.append(t)\n else:\n t.pk = pk\n updated.append(t)\n\n with transaction.atomic():\n model.objects.bulk_create(created)\n\n # TODO: bulk_update() ?\n for entry in updated:\n entry.save(force_update=True)\n\n\nclass CSVTownPopulator(CSVPopulator):\n def __init__(self, defaults=None, chunksize=100):\n super().__init__(['title', 'zipcode', 'latitude', 'longitude', 'country'],\n defaults=defaults, chunksize=chunksize,\n )\n\n def line_error(self, e, row, context):\n logger.error(' invalid data (line %d) : %s', context.line, e)\n\n def chunk_error(self, e, rows, context):\n logger.error(' invalid data chunk : %s', e)\n\n def create(self, row, context):\n zipcodes = row['zipcode'].split('-')\n\n name = row['title']\n latitude = row['latitude']\n longitude = row['longitude']\n\n slug = slugify(name)\n country = row['country']\n\n build_town = partial(Town, country=country)\n\n return [build_town(name=name,\n slug=slug,\n zipcode=zipcode,\n latitude=latitude,\n longitude=longitude,\n ) for zipcode in zipcodes\n ]\n\n def save(self, entries, context):\n get_existing_pk_by_zipcode = dict(\n Town.objects.filter(\n zipcode__in=(t.zipcode for t in entries),\n slug__in=(t.slug for t in entries),\n ).values_list('zipcode', 'pk')\n ).get\n\n self.sync(\n Town, entries,\n lambda town: get_existing_pk_by_zipcode(town.zipcode),\n )\n\n\nclass Command(BaseCommand):\n def add_arguments(self, parser):\n add_argument = parser.add_argument\n add_argument(\n '-p', '--populate', action='store_true', dest='populate',\n help='Populate addresses', default=False,\n )\n add_argument(\n '-s', '--stat', action='store_true', dest='stats',\n help='Display geolocation database stats', default=False,\n )\n add_argument(\n '-i', '--import', action='store_true', dest='import', default=False,\n help='Import towns configured in GEOLOCATION_TOWNS setting',\n )\n\n def sysout(self, message, visible):\n if visible:\n self.stdout.write(message)\n\n def syserr(self, message):\n self.stderr.write(message)\n\n def populate_addresses(self, verbosity=0):\n self.sysout('Populate geolocation information of addresses...', verbosity > 0)\n GeoAddress.populate_geoaddresses(get_address_model().objects.exclude(zipcode='', city=''))\n\n def import_town_database(self, url, defaults):\n try:\n CSVTownPopulator(defaults=defaults).populate(url)\n except Exception as e:\n self.syserr(str(e))\n\n def import_town_all(self, verbosity=0):\n self.sysout('Importing Towns database...', verbosity > 0)\n\n for url, defaults in settings.GEOLOCATION_TOWNS:\n self.sysout(url, verbosity > 1)\n self.import_town_database(url, defaults)\n\n def print_stats(self, verbosity=0):\n self.sysout(f'{Town.objects.count()} town(s) in database.', verbosity > 0)\n\n def handle(self, *args, **options):\n populate = options.get('populate')\n stats = options.get('stats')\n imports = options.get('import')\n verbosity = options.get('verbosity')\n\n if stats:\n self.print_stats(verbosity)\n\n if imports:\n self.import_town_all(verbosity)\n\n if populate:\n self.populate_addresses(verbosity)\n", "path": "creme/geolocation/management/commands/geolocation.py"}]}
| 3,378 | 228 |
gh_patches_debug_1055
|
rasdani/github-patches
|
git_diff
|
huggingface__transformers-4448
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
LayerNorm not excluded from weight decay in TF
# 🐛 Bug
## Information
Model I am using (Bert, XLNet ...):
bert-base-cased
Language I am using the model on (English, Chinese ...):
English
The problem arises when using:
* [X] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [X] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. Add a print statement to `_do_use_weight_decay` in [AdamWeightDecay](https://github.com/huggingface/transformers/blob/master/src/transformers/optimization_tf.py) to see which parameters are actually excluded:
```python
def _do_use_weight_decay(self, param_name):
"""Whether to use L2 weight decay for `param_name`."""
if self.weight_decay_rate == 0:
return False
if self._include_in_weight_decay:
for r in self._include_in_weight_decay:
if re.search(r, param_name) is not None:
return True
if self._exclude_from_weight_decay:
for r in self._exclude_from_weight_decay:
if re.search(r, param_name) is not None:
print(f"Found: {param_name}")
return False
return True
```
2. run `python examples/text-classification/run_tf_glue.py --model_name_or_path bert-base-cased --task_name mrpc --output_dir temp --logging_dir temp --do_train --overwrite_output_dir --optimizer_name adamw`.
3. Observe that no weights related to layer norms are printed.
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
The weights of the layer norms (and the biases) should be printed.
See for example: https://github.com/google-research/bert/blob/f39e881b169b9d53bea03d2d341b31707a6c052b/optimization.py.
Based on the fact that no layer norm weights are printed with "layer_norm" simply switching "layer_norm" to "LayerNorm" seems like the easiest change.
## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 2.9.0
- Platform: Darwin-19.4.0-x86_64-i386-64bit
- Python version: 3.7.7
- PyTorch version (GPU?): 1.5.0 (False)
- Tensorflow version (GPU?): 2.2.0 (False)
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/transformers/optimization_tf.py`
Content:
```
1 # Copyright 2019 The TensorFlow Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 # ==============================================================================
15 """Functions and classes related to optimization (weight updates)."""
16
17
18 import re
19
20 import tensorflow as tf
21
22
23 class WarmUp(tf.keras.optimizers.schedules.LearningRateSchedule):
24 """Applies a warmup schedule on a given learning rate decay schedule."""
25
26 def __init__(
27 self, initial_learning_rate, decay_schedule_fn, warmup_steps, power=1.0, name=None,
28 ):
29 super().__init__()
30 self.initial_learning_rate = initial_learning_rate
31 self.warmup_steps = warmup_steps
32 self.power = power
33 self.decay_schedule_fn = decay_schedule_fn
34 self.name = name
35
36 def __call__(self, step):
37 with tf.name_scope(self.name or "WarmUp") as name:
38 # Implements polynomial warmup. i.e., if global_step < warmup_steps, the
39 # learning rate will be `global_step/num_warmup_steps * init_lr`.
40 global_step_float = tf.cast(step, tf.float32)
41 warmup_steps_float = tf.cast(self.warmup_steps, tf.float32)
42 warmup_percent_done = global_step_float / warmup_steps_float
43 warmup_learning_rate = self.initial_learning_rate * tf.math.pow(warmup_percent_done, self.power)
44 return tf.cond(
45 global_step_float < warmup_steps_float,
46 lambda: warmup_learning_rate,
47 lambda: self.decay_schedule_fn(step),
48 name=name,
49 )
50
51 def get_config(self):
52 return {
53 "initial_learning_rate": self.initial_learning_rate,
54 "decay_schedule_fn": self.decay_schedule_fn,
55 "warmup_steps": self.warmup_steps,
56 "power": self.power,
57 "name": self.name,
58 }
59
60
61 def create_optimizer(init_lr, num_train_steps, num_warmup_steps, end_lr=0.0, optimizer_type="adamw"):
62 """Creates an optimizer with learning rate schedule."""
63 # Implements linear decay of the learning rate.
64 lr_schedule = tf.keras.optimizers.schedules.PolynomialDecay(
65 initial_learning_rate=init_lr, decay_steps=num_train_steps, end_learning_rate=end_lr,
66 )
67 if num_warmup_steps:
68 lr_schedule = WarmUp(
69 initial_learning_rate=init_lr, decay_schedule_fn=lr_schedule, warmup_steps=num_warmup_steps,
70 )
71
72 optimizer = AdamWeightDecay(
73 learning_rate=lr_schedule,
74 weight_decay_rate=0.01,
75 beta_1=0.9,
76 beta_2=0.999,
77 epsilon=1e-6,
78 exclude_from_weight_decay=["layer_norm", "bias"],
79 )
80
81 return optimizer
82
83
84 class AdamWeightDecay(tf.keras.optimizers.Adam):
85 """Adam enables L2 weight decay and clip_by_global_norm on gradients.
86 Just adding the square of the weights to the loss function is *not* the
87 correct way of using L2 regularization/weight decay with Adam, since that will
88 interact with the m and v parameters in strange ways.
89 Instead we want ot decay the weights in a manner that doesn't interact with
90 the m/v parameters. This is equivalent to adding the square of the weights to
91 the loss with plain (non-momentum) SGD.
92 """
93
94 def __init__(
95 self,
96 learning_rate=0.001,
97 beta_1=0.9,
98 beta_2=0.999,
99 epsilon=1e-7,
100 amsgrad=False,
101 weight_decay_rate=0.0,
102 include_in_weight_decay=None,
103 exclude_from_weight_decay=None,
104 name="AdamWeightDecay",
105 **kwargs
106 ):
107 super().__init__(learning_rate, beta_1, beta_2, epsilon, amsgrad, name, **kwargs)
108 self.weight_decay_rate = weight_decay_rate
109 self._include_in_weight_decay = include_in_weight_decay
110 self._exclude_from_weight_decay = exclude_from_weight_decay
111
112 @classmethod
113 def from_config(cls, config):
114 """Creates an optimizer from its config with WarmUp custom object."""
115 custom_objects = {"WarmUp": WarmUp}
116 return super(AdamWeightDecay, cls).from_config(config, custom_objects=custom_objects)
117
118 def _prepare_local(self, var_device, var_dtype, apply_state):
119 super(AdamWeightDecay, self)._prepare_local(var_device, var_dtype, apply_state)
120 apply_state[(var_device, var_dtype)]["weight_decay_rate"] = tf.constant(
121 self.weight_decay_rate, name="adam_weight_decay_rate"
122 )
123
124 def _decay_weights_op(self, var, learning_rate, apply_state):
125 do_decay = self._do_use_weight_decay(var.name)
126 if do_decay:
127 return var.assign_sub(
128 learning_rate * var * apply_state[(var.device, var.dtype.base_dtype)]["weight_decay_rate"],
129 use_locking=self._use_locking,
130 )
131 return tf.no_op()
132
133 def apply_gradients(self, grads_and_vars, name=None):
134 grads, tvars = list(zip(*grads_and_vars))
135 return super(AdamWeightDecay, self).apply_gradients(zip(grads, tvars), name=name,)
136
137 def _get_lr(self, var_device, var_dtype, apply_state):
138 """Retrieves the learning rate with the given state."""
139 if apply_state is None:
140 return self._decayed_lr_t[var_dtype], {}
141
142 apply_state = apply_state or {}
143 coefficients = apply_state.get((var_device, var_dtype))
144 if coefficients is None:
145 coefficients = self._fallback_apply_state(var_device, var_dtype)
146 apply_state[(var_device, var_dtype)] = coefficients
147
148 return coefficients["lr_t"], dict(apply_state=apply_state)
149
150 def _resource_apply_dense(self, grad, var, apply_state=None):
151 lr_t, kwargs = self._get_lr(var.device, var.dtype.base_dtype, apply_state)
152 decay = self._decay_weights_op(var, lr_t, apply_state)
153 with tf.control_dependencies([decay]):
154 return super(AdamWeightDecay, self)._resource_apply_dense(grad, var, **kwargs)
155
156 def _resource_apply_sparse(self, grad, var, indices, apply_state=None):
157 lr_t, kwargs = self._get_lr(var.device, var.dtype.base_dtype, apply_state)
158 decay = self._decay_weights_op(var, lr_t, apply_state)
159 with tf.control_dependencies([decay]):
160 return super(AdamWeightDecay, self)._resource_apply_sparse(grad, var, indices, **kwargs)
161
162 def get_config(self):
163 config = super().get_config()
164 config.update({"weight_decay_rate": self.weight_decay_rate})
165 return config
166
167 def _do_use_weight_decay(self, param_name):
168 """Whether to use L2 weight decay for `param_name`."""
169 if self.weight_decay_rate == 0:
170 return False
171
172 if self._include_in_weight_decay:
173 for r in self._include_in_weight_decay:
174 if re.search(r, param_name) is not None:
175 return True
176
177 if self._exclude_from_weight_decay:
178 for r in self._exclude_from_weight_decay:
179 if re.search(r, param_name) is not None:
180 return False
181 return True
182
183
184 # Extracted from https://github.com/OpenNMT/OpenNMT-tf/blob/master/opennmt/optimizers/utils.py
185 class GradientAccumulator(object):
186 """Gradient accumulation utility.
187 When used with a distribution strategy, the accumulator should be called in a
188 replica context. Gradients will be accumulated locally on each replica and
189 without synchronization. Users should then call ``.gradients``, scale the
190 gradients if required, and pass the result to ``apply_gradients``.
191 """
192
193 # We use the ON_READ synchronization policy so that no synchronization is
194 # performed on assignment. To get the value, we call .value() which returns the
195 # value on the current replica without synchronization.
196
197 def __init__(self):
198 """Initializes the accumulator."""
199 self._gradients = []
200 self._accum_steps = None
201
202 @property
203 def step(self):
204 """Number of accumulated steps."""
205 if self._accum_steps is None:
206 self._accum_steps = tf.Variable(
207 tf.constant(0, dtype=tf.int64),
208 trainable=False,
209 synchronization=tf.VariableSynchronization.ON_READ,
210 aggregation=tf.VariableAggregation.ONLY_FIRST_REPLICA,
211 )
212
213 return self._accum_steps.value()
214
215 @property
216 def gradients(self):
217 """The accumulated gradients on the current replica."""
218 if not self._gradients:
219 raise ValueError("The accumulator should be called first to initialize the gradients")
220 return list(gradient.value() if gradient is not None else gradient for gradient in self._gradients)
221
222 def __call__(self, gradients):
223 """Accumulates :obj:`gradients` on the current replica."""
224 if not self._gradients:
225 _ = self.step # Create the step variable.
226 self._gradients.extend(
227 [
228 tf.Variable(
229 tf.zeros_like(gradient),
230 trainable=False,
231 synchronization=tf.VariableSynchronization.ON_READ,
232 aggregation=tf.VariableAggregation.ONLY_FIRST_REPLICA,
233 )
234 if gradient is not None
235 else gradient
236 for gradient in gradients
237 ]
238 )
239 if len(gradients) != len(self._gradients):
240 raise ValueError("Expected %s gradients, but got %d" % (len(self._gradients), len(gradients)))
241
242 for accum_gradient, gradient in zip(self._gradients, gradients):
243 if accum_gradient is not None and gradient is not None:
244 accum_gradient.assign_add(gradient)
245
246 self._accum_steps.assign_add(1)
247
248 def reset(self):
249 """Resets the accumulated gradients on the current replica."""
250 if not self._gradients:
251 return
252 self._accum_steps.assign(0)
253 for gradient in self._gradients:
254 if gradient is not None:
255 gradient.assign(tf.zeros_like(gradient))
256
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/transformers/optimization_tf.py b/src/transformers/optimization_tf.py
--- a/src/transformers/optimization_tf.py
+++ b/src/transformers/optimization_tf.py
@@ -75,7 +75,7 @@
beta_1=0.9,
beta_2=0.999,
epsilon=1e-6,
- exclude_from_weight_decay=["layer_norm", "bias"],
+ exclude_from_weight_decay=["LayerNorm", "layer_norm", "bias"],
)
return optimizer
|
{"golden_diff": "diff --git a/src/transformers/optimization_tf.py b/src/transformers/optimization_tf.py\n--- a/src/transformers/optimization_tf.py\n+++ b/src/transformers/optimization_tf.py\n@@ -75,7 +75,7 @@\n beta_1=0.9,\n beta_2=0.999,\n epsilon=1e-6,\n- exclude_from_weight_decay=[\"layer_norm\", \"bias\"],\n+ exclude_from_weight_decay=[\"LayerNorm\", \"layer_norm\", \"bias\"],\n )\n \n return optimizer\n", "issue": "LayerNorm not excluded from weight decay in TF\n# \ud83d\udc1b Bug\r\n\r\n## Information\r\n\r\nModel I am using (Bert, XLNet ...):\r\nbert-base-cased\r\n\r\nLanguage I am using the model on (English, Chinese ...):\r\nEnglish\r\n\r\nThe problem arises when using:\r\n* [X] the official example scripts: (give details below)\r\n* [ ] my own modified scripts: (give details below)\r\n\r\nThe tasks I am working on is:\r\n* [X] an official GLUE/SQUaD task: (give the name)\r\n* [ ] my own task or dataset: (give details below)\r\n\r\n## To reproduce\r\n\r\nSteps to reproduce the behavior:\r\n\r\n1. Add a print statement to `_do_use_weight_decay` in [AdamWeightDecay](https://github.com/huggingface/transformers/blob/master/src/transformers/optimization_tf.py) to see which parameters are actually excluded:\r\n```python\r\n def _do_use_weight_decay(self, param_name):\r\n \"\"\"Whether to use L2 weight decay for `param_name`.\"\"\"\r\n if self.weight_decay_rate == 0:\r\n return False\r\n\r\n if self._include_in_weight_decay:\r\n for r in self._include_in_weight_decay:\r\n if re.search(r, param_name) is not None:\r\n return True\r\n\r\n if self._exclude_from_weight_decay:\r\n for r in self._exclude_from_weight_decay:\r\n if re.search(r, param_name) is not None:\r\n print(f\"Found: {param_name}\")\r\n return False\r\n return True\r\n```\r\n2. run `python examples/text-classification/run_tf_glue.py --model_name_or_path bert-base-cased --task_name mrpc --output_dir temp --logging_dir temp --do_train --overwrite_output_dir --optimizer_name adamw`. \r\n3. Observe that no weights related to layer norms are printed. \r\n\r\n<!-- If you have code snippets, error messages, stack traces please provide them here as well.\r\n Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting\r\n Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->\r\n\r\n## Expected behavior\r\n\r\n<!-- A clear and concise description of what you would expect to happen. -->\r\nThe weights of the layer norms (and the biases) should be printed. \r\n\r\nSee for example: https://github.com/google-research/bert/blob/f39e881b169b9d53bea03d2d341b31707a6c052b/optimization.py. \r\n\r\nBased on the fact that no layer norm weights are printed with \"layer_norm\" simply switching \"layer_norm\" to \"LayerNorm\" seems like the easiest change. \r\n\r\n## Environment info\r\n<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.\r\n Don't forget to fill out the missing fields in that output! -->\r\n \r\n- `transformers` version: 2.9.0\r\n- Platform: Darwin-19.4.0-x86_64-i386-64bit\r\n- Python version: 3.7.7\r\n- PyTorch version (GPU?): 1.5.0 (False)\r\n- Tensorflow version (GPU?): 2.2.0 (False)\r\n- Using GPU in script?: No\r\n- Using distributed or parallel set-up in script?: No\r\n\n", "before_files": [{"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"Functions and classes related to optimization (weight updates).\"\"\"\n\n\nimport re\n\nimport tensorflow as tf\n\n\nclass WarmUp(tf.keras.optimizers.schedules.LearningRateSchedule):\n \"\"\"Applies a warmup schedule on a given learning rate decay schedule.\"\"\"\n\n def __init__(\n self, initial_learning_rate, decay_schedule_fn, warmup_steps, power=1.0, name=None,\n ):\n super().__init__()\n self.initial_learning_rate = initial_learning_rate\n self.warmup_steps = warmup_steps\n self.power = power\n self.decay_schedule_fn = decay_schedule_fn\n self.name = name\n\n def __call__(self, step):\n with tf.name_scope(self.name or \"WarmUp\") as name:\n # Implements polynomial warmup. i.e., if global_step < warmup_steps, the\n # learning rate will be `global_step/num_warmup_steps * init_lr`.\n global_step_float = tf.cast(step, tf.float32)\n warmup_steps_float = tf.cast(self.warmup_steps, tf.float32)\n warmup_percent_done = global_step_float / warmup_steps_float\n warmup_learning_rate = self.initial_learning_rate * tf.math.pow(warmup_percent_done, self.power)\n return tf.cond(\n global_step_float < warmup_steps_float,\n lambda: warmup_learning_rate,\n lambda: self.decay_schedule_fn(step),\n name=name,\n )\n\n def get_config(self):\n return {\n \"initial_learning_rate\": self.initial_learning_rate,\n \"decay_schedule_fn\": self.decay_schedule_fn,\n \"warmup_steps\": self.warmup_steps,\n \"power\": self.power,\n \"name\": self.name,\n }\n\n\ndef create_optimizer(init_lr, num_train_steps, num_warmup_steps, end_lr=0.0, optimizer_type=\"adamw\"):\n \"\"\"Creates an optimizer with learning rate schedule.\"\"\"\n # Implements linear decay of the learning rate.\n lr_schedule = tf.keras.optimizers.schedules.PolynomialDecay(\n initial_learning_rate=init_lr, decay_steps=num_train_steps, end_learning_rate=end_lr,\n )\n if num_warmup_steps:\n lr_schedule = WarmUp(\n initial_learning_rate=init_lr, decay_schedule_fn=lr_schedule, warmup_steps=num_warmup_steps,\n )\n\n optimizer = AdamWeightDecay(\n learning_rate=lr_schedule,\n weight_decay_rate=0.01,\n beta_1=0.9,\n beta_2=0.999,\n epsilon=1e-6,\n exclude_from_weight_decay=[\"layer_norm\", \"bias\"],\n )\n\n return optimizer\n\n\nclass AdamWeightDecay(tf.keras.optimizers.Adam):\n \"\"\"Adam enables L2 weight decay and clip_by_global_norm on gradients.\n Just adding the square of the weights to the loss function is *not* the\n correct way of using L2 regularization/weight decay with Adam, since that will\n interact with the m and v parameters in strange ways.\n Instead we want ot decay the weights in a manner that doesn't interact with\n the m/v parameters. This is equivalent to adding the square of the weights to\n the loss with plain (non-momentum) SGD.\n \"\"\"\n\n def __init__(\n self,\n learning_rate=0.001,\n beta_1=0.9,\n beta_2=0.999,\n epsilon=1e-7,\n amsgrad=False,\n weight_decay_rate=0.0,\n include_in_weight_decay=None,\n exclude_from_weight_decay=None,\n name=\"AdamWeightDecay\",\n **kwargs\n ):\n super().__init__(learning_rate, beta_1, beta_2, epsilon, amsgrad, name, **kwargs)\n self.weight_decay_rate = weight_decay_rate\n self._include_in_weight_decay = include_in_weight_decay\n self._exclude_from_weight_decay = exclude_from_weight_decay\n\n @classmethod\n def from_config(cls, config):\n \"\"\"Creates an optimizer from its config with WarmUp custom object.\"\"\"\n custom_objects = {\"WarmUp\": WarmUp}\n return super(AdamWeightDecay, cls).from_config(config, custom_objects=custom_objects)\n\n def _prepare_local(self, var_device, var_dtype, apply_state):\n super(AdamWeightDecay, self)._prepare_local(var_device, var_dtype, apply_state)\n apply_state[(var_device, var_dtype)][\"weight_decay_rate\"] = tf.constant(\n self.weight_decay_rate, name=\"adam_weight_decay_rate\"\n )\n\n def _decay_weights_op(self, var, learning_rate, apply_state):\n do_decay = self._do_use_weight_decay(var.name)\n if do_decay:\n return var.assign_sub(\n learning_rate * var * apply_state[(var.device, var.dtype.base_dtype)][\"weight_decay_rate\"],\n use_locking=self._use_locking,\n )\n return tf.no_op()\n\n def apply_gradients(self, grads_and_vars, name=None):\n grads, tvars = list(zip(*grads_and_vars))\n return super(AdamWeightDecay, self).apply_gradients(zip(grads, tvars), name=name,)\n\n def _get_lr(self, var_device, var_dtype, apply_state):\n \"\"\"Retrieves the learning rate with the given state.\"\"\"\n if apply_state is None:\n return self._decayed_lr_t[var_dtype], {}\n\n apply_state = apply_state or {}\n coefficients = apply_state.get((var_device, var_dtype))\n if coefficients is None:\n coefficients = self._fallback_apply_state(var_device, var_dtype)\n apply_state[(var_device, var_dtype)] = coefficients\n\n return coefficients[\"lr_t\"], dict(apply_state=apply_state)\n\n def _resource_apply_dense(self, grad, var, apply_state=None):\n lr_t, kwargs = self._get_lr(var.device, var.dtype.base_dtype, apply_state)\n decay = self._decay_weights_op(var, lr_t, apply_state)\n with tf.control_dependencies([decay]):\n return super(AdamWeightDecay, self)._resource_apply_dense(grad, var, **kwargs)\n\n def _resource_apply_sparse(self, grad, var, indices, apply_state=None):\n lr_t, kwargs = self._get_lr(var.device, var.dtype.base_dtype, apply_state)\n decay = self._decay_weights_op(var, lr_t, apply_state)\n with tf.control_dependencies([decay]):\n return super(AdamWeightDecay, self)._resource_apply_sparse(grad, var, indices, **kwargs)\n\n def get_config(self):\n config = super().get_config()\n config.update({\"weight_decay_rate\": self.weight_decay_rate})\n return config\n\n def _do_use_weight_decay(self, param_name):\n \"\"\"Whether to use L2 weight decay for `param_name`.\"\"\"\n if self.weight_decay_rate == 0:\n return False\n\n if self._include_in_weight_decay:\n for r in self._include_in_weight_decay:\n if re.search(r, param_name) is not None:\n return True\n\n if self._exclude_from_weight_decay:\n for r in self._exclude_from_weight_decay:\n if re.search(r, param_name) is not None:\n return False\n return True\n\n\n# Extracted from https://github.com/OpenNMT/OpenNMT-tf/blob/master/opennmt/optimizers/utils.py\nclass GradientAccumulator(object):\n \"\"\"Gradient accumulation utility.\n When used with a distribution strategy, the accumulator should be called in a\n replica context. Gradients will be accumulated locally on each replica and\n without synchronization. Users should then call ``.gradients``, scale the\n gradients if required, and pass the result to ``apply_gradients``.\n \"\"\"\n\n # We use the ON_READ synchronization policy so that no synchronization is\n # performed on assignment. To get the value, we call .value() which returns the\n # value on the current replica without synchronization.\n\n def __init__(self):\n \"\"\"Initializes the accumulator.\"\"\"\n self._gradients = []\n self._accum_steps = None\n\n @property\n def step(self):\n \"\"\"Number of accumulated steps.\"\"\"\n if self._accum_steps is None:\n self._accum_steps = tf.Variable(\n tf.constant(0, dtype=tf.int64),\n trainable=False,\n synchronization=tf.VariableSynchronization.ON_READ,\n aggregation=tf.VariableAggregation.ONLY_FIRST_REPLICA,\n )\n\n return self._accum_steps.value()\n\n @property\n def gradients(self):\n \"\"\"The accumulated gradients on the current replica.\"\"\"\n if not self._gradients:\n raise ValueError(\"The accumulator should be called first to initialize the gradients\")\n return list(gradient.value() if gradient is not None else gradient for gradient in self._gradients)\n\n def __call__(self, gradients):\n \"\"\"Accumulates :obj:`gradients` on the current replica.\"\"\"\n if not self._gradients:\n _ = self.step # Create the step variable.\n self._gradients.extend(\n [\n tf.Variable(\n tf.zeros_like(gradient),\n trainable=False,\n synchronization=tf.VariableSynchronization.ON_READ,\n aggregation=tf.VariableAggregation.ONLY_FIRST_REPLICA,\n )\n if gradient is not None\n else gradient\n for gradient in gradients\n ]\n )\n if len(gradients) != len(self._gradients):\n raise ValueError(\"Expected %s gradients, but got %d\" % (len(self._gradients), len(gradients)))\n\n for accum_gradient, gradient in zip(self._gradients, gradients):\n if accum_gradient is not None and gradient is not None:\n accum_gradient.assign_add(gradient)\n\n self._accum_steps.assign_add(1)\n\n def reset(self):\n \"\"\"Resets the accumulated gradients on the current replica.\"\"\"\n if not self._gradients:\n return\n self._accum_steps.assign(0)\n for gradient in self._gradients:\n if gradient is not None:\n gradient.assign(tf.zeros_like(gradient))\n", "path": "src/transformers/optimization_tf.py"}], "after_files": [{"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"Functions and classes related to optimization (weight updates).\"\"\"\n\n\nimport re\n\nimport tensorflow as tf\n\n\nclass WarmUp(tf.keras.optimizers.schedules.LearningRateSchedule):\n \"\"\"Applies a warmup schedule on a given learning rate decay schedule.\"\"\"\n\n def __init__(\n self, initial_learning_rate, decay_schedule_fn, warmup_steps, power=1.0, name=None,\n ):\n super().__init__()\n self.initial_learning_rate = initial_learning_rate\n self.warmup_steps = warmup_steps\n self.power = power\n self.decay_schedule_fn = decay_schedule_fn\n self.name = name\n\n def __call__(self, step):\n with tf.name_scope(self.name or \"WarmUp\") as name:\n # Implements polynomial warmup. i.e., if global_step < warmup_steps, the\n # learning rate will be `global_step/num_warmup_steps * init_lr`.\n global_step_float = tf.cast(step, tf.float32)\n warmup_steps_float = tf.cast(self.warmup_steps, tf.float32)\n warmup_percent_done = global_step_float / warmup_steps_float\n warmup_learning_rate = self.initial_learning_rate * tf.math.pow(warmup_percent_done, self.power)\n return tf.cond(\n global_step_float < warmup_steps_float,\n lambda: warmup_learning_rate,\n lambda: self.decay_schedule_fn(step),\n name=name,\n )\n\n def get_config(self):\n return {\n \"initial_learning_rate\": self.initial_learning_rate,\n \"decay_schedule_fn\": self.decay_schedule_fn,\n \"warmup_steps\": self.warmup_steps,\n \"power\": self.power,\n \"name\": self.name,\n }\n\n\ndef create_optimizer(init_lr, num_train_steps, num_warmup_steps, end_lr=0.0, optimizer_type=\"adamw\"):\n \"\"\"Creates an optimizer with learning rate schedule.\"\"\"\n # Implements linear decay of the learning rate.\n lr_schedule = tf.keras.optimizers.schedules.PolynomialDecay(\n initial_learning_rate=init_lr, decay_steps=num_train_steps, end_learning_rate=end_lr,\n )\n if num_warmup_steps:\n lr_schedule = WarmUp(\n initial_learning_rate=init_lr, decay_schedule_fn=lr_schedule, warmup_steps=num_warmup_steps,\n )\n\n optimizer = AdamWeightDecay(\n learning_rate=lr_schedule,\n weight_decay_rate=0.01,\n beta_1=0.9,\n beta_2=0.999,\n epsilon=1e-6,\n exclude_from_weight_decay=[\"LayerNorm\", \"layer_norm\", \"bias\"],\n )\n\n return optimizer\n\n\nclass AdamWeightDecay(tf.keras.optimizers.Adam):\n \"\"\"Adam enables L2 weight decay and clip_by_global_norm on gradients.\n Just adding the square of the weights to the loss function is *not* the\n correct way of using L2 regularization/weight decay with Adam, since that will\n interact with the m and v parameters in strange ways.\n Instead we want ot decay the weights in a manner that doesn't interact with\n the m/v parameters. This is equivalent to adding the square of the weights to\n the loss with plain (non-momentum) SGD.\n \"\"\"\n\n def __init__(\n self,\n learning_rate=0.001,\n beta_1=0.9,\n beta_2=0.999,\n epsilon=1e-7,\n amsgrad=False,\n weight_decay_rate=0.0,\n include_in_weight_decay=None,\n exclude_from_weight_decay=None,\n name=\"AdamWeightDecay\",\n **kwargs\n ):\n super().__init__(learning_rate, beta_1, beta_2, epsilon, amsgrad, name, **kwargs)\n self.weight_decay_rate = weight_decay_rate\n self._include_in_weight_decay = include_in_weight_decay\n self._exclude_from_weight_decay = exclude_from_weight_decay\n\n @classmethod\n def from_config(cls, config):\n \"\"\"Creates an optimizer from its config with WarmUp custom object.\"\"\"\n custom_objects = {\"WarmUp\": WarmUp}\n return super(AdamWeightDecay, cls).from_config(config, custom_objects=custom_objects)\n\n def _prepare_local(self, var_device, var_dtype, apply_state):\n super(AdamWeightDecay, self)._prepare_local(var_device, var_dtype, apply_state)\n apply_state[(var_device, var_dtype)][\"weight_decay_rate\"] = tf.constant(\n self.weight_decay_rate, name=\"adam_weight_decay_rate\"\n )\n\n def _decay_weights_op(self, var, learning_rate, apply_state):\n do_decay = self._do_use_weight_decay(var.name)\n if do_decay:\n return var.assign_sub(\n learning_rate * var * apply_state[(var.device, var.dtype.base_dtype)][\"weight_decay_rate\"],\n use_locking=self._use_locking,\n )\n return tf.no_op()\n\n def apply_gradients(self, grads_and_vars, name=None):\n grads, tvars = list(zip(*grads_and_vars))\n return super(AdamWeightDecay, self).apply_gradients(zip(grads, tvars), name=name,)\n\n def _get_lr(self, var_device, var_dtype, apply_state):\n \"\"\"Retrieves the learning rate with the given state.\"\"\"\n if apply_state is None:\n return self._decayed_lr_t[var_dtype], {}\n\n apply_state = apply_state or {}\n coefficients = apply_state.get((var_device, var_dtype))\n if coefficients is None:\n coefficients = self._fallback_apply_state(var_device, var_dtype)\n apply_state[(var_device, var_dtype)] = coefficients\n\n return coefficients[\"lr_t\"], dict(apply_state=apply_state)\n\n def _resource_apply_dense(self, grad, var, apply_state=None):\n lr_t, kwargs = self._get_lr(var.device, var.dtype.base_dtype, apply_state)\n decay = self._decay_weights_op(var, lr_t, apply_state)\n with tf.control_dependencies([decay]):\n return super(AdamWeightDecay, self)._resource_apply_dense(grad, var, **kwargs)\n\n def _resource_apply_sparse(self, grad, var, indices, apply_state=None):\n lr_t, kwargs = self._get_lr(var.device, var.dtype.base_dtype, apply_state)\n decay = self._decay_weights_op(var, lr_t, apply_state)\n with tf.control_dependencies([decay]):\n return super(AdamWeightDecay, self)._resource_apply_sparse(grad, var, indices, **kwargs)\n\n def get_config(self):\n config = super().get_config()\n config.update({\"weight_decay_rate\": self.weight_decay_rate})\n return config\n\n def _do_use_weight_decay(self, param_name):\n \"\"\"Whether to use L2 weight decay for `param_name`.\"\"\"\n if self.weight_decay_rate == 0:\n return False\n\n if self._include_in_weight_decay:\n for r in self._include_in_weight_decay:\n if re.search(r, param_name) is not None:\n return True\n\n if self._exclude_from_weight_decay:\n for r in self._exclude_from_weight_decay:\n if re.search(r, param_name) is not None:\n return False\n return True\n\n\n# Extracted from https://github.com/OpenNMT/OpenNMT-tf/blob/master/opennmt/optimizers/utils.py\nclass GradientAccumulator(object):\n \"\"\"Gradient accumulation utility.\n When used with a distribution strategy, the accumulator should be called in a\n replica context. Gradients will be accumulated locally on each replica and\n without synchronization. Users should then call ``.gradients``, scale the\n gradients if required, and pass the result to ``apply_gradients``.\n \"\"\"\n\n # We use the ON_READ synchronization policy so that no synchronization is\n # performed on assignment. To get the value, we call .value() which returns the\n # value on the current replica without synchronization.\n\n def __init__(self):\n \"\"\"Initializes the accumulator.\"\"\"\n self._gradients = []\n self._accum_steps = None\n\n @property\n def step(self):\n \"\"\"Number of accumulated steps.\"\"\"\n if self._accum_steps is None:\n self._accum_steps = tf.Variable(\n tf.constant(0, dtype=tf.int64),\n trainable=False,\n synchronization=tf.VariableSynchronization.ON_READ,\n aggregation=tf.VariableAggregation.ONLY_FIRST_REPLICA,\n )\n\n return self._accum_steps.value()\n\n @property\n def gradients(self):\n \"\"\"The accumulated gradients on the current replica.\"\"\"\n if not self._gradients:\n raise ValueError(\"The accumulator should be called first to initialize the gradients\")\n return list(gradient.value() for gradient in self._gradients)\n\n def __call__(self, gradients):\n \"\"\"Accumulates :obj:`gradients` on the current replica.\"\"\"\n if not self._gradients:\n _ = self.step # Create the step variable.\n self._gradients.extend(\n [\n tf.Variable(\n tf.zeros_like(gradient),\n trainable=False,\n synchronization=tf.VariableSynchronization.ON_READ,\n aggregation=tf.VariableAggregation.ONLY_FIRST_REPLICA,\n )\n for gradient in gradients\n ]\n )\n if len(gradients) != len(self._gradients):\n raise ValueError(\"Expected %s gradients, but got %d\" % (len(self._gradients), len(gradients)))\n\n for accum_gradient, gradient in zip(self._gradients, gradients):\n accum_gradient.assign_add(gradient)\n\n self._accum_steps.assign_add(1)\n\n def reset(self):\n \"\"\"Resets the accumulated gradients on the current replica.\"\"\"\n if not self._gradients:\n return\n self._accum_steps.assign(0)\n for gradient in self._gradients:\n gradient.assign(tf.zeros_like(gradient))\n", "path": "src/transformers/optimization_tf.py"}]}
| 3,962 | 125 |
gh_patches_debug_26733
|
rasdani/github-patches
|
git_diff
|
pytorch__vision-2696
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Reading PNG/JPG images into a torch::tensor and saving a torch::tensor to PNG/JPG in C++ without OpenCV
## 🚀 Feature
After integrating Siv3D with Libtorch (https://github.com/QuantScientist/Siv3DTorch) I am now trying to read and write images from and to Siv3D **in C++, not Python**. The way it works is:
## Motivation
In C++ I need to do the following:
1. An image is read from disk (usually using OpenCV which is easy but I am trying to avoid)
2. The image is converted to torch::tensor
3. A DL model is applied on the tensor
4. A tensor is returned from the model
5. The tensor is converted to an image for display/saving purposes.
This is one example where they used stb_image to this, avoiding the use of OpenCV.
https://github.com/prabhuomkar/pytorch-cpp/blob/master/utils/image_io/src/image_io.cpp
## Pitch
## Alternatives
For reference this is the OpenCV to Libtorch conversion utils which I use, I would like something very similiar:
```
at::Tensor matToTensor(cv::Mat frame, int h, int w, int c) {
cv::cvtColor(frame, frame, CV_BGR2RGB);
frame.convertTo(frame, CV_32FC3, 1.0f / 255.0f);
auto input_tensor = torch::from_blob(frame.data, {1, h, w, c});
input_tensor = input_tensor.permute({0, 3, 1, 2});
torch::DeviceType device_type = torch::kCPU;
// if (torch::cuda::is_available()) {
device_type = torch::kCUDA;
// }
input_tensor = input_tensor.to(device_type);
return input_tensor;
}
cv::Mat tensorToOpenCv(at::Tensor out_tensor, int h, int w, int c) {
out_tensor = out_tensor.squeeze().detach().permute({1, 2, 0});
out_tensor = out_tensor.mul(255).clamp(0, 255).to(torch::kU8);
out_tensor = out_tensor.to(torch::kCPU);
cv::Mat resultImg(h, w, CV_8UC3);
// cv::Mat resultImg(h, w, CV_8UC1);
std::memcpy((void *) resultImg.data, out_tensor.data_ptr(), sizeof(torch::kU8) * out_tensor.numel());
return resultImg;
}
```
## Additional context
I found this:"https://github.com/pytorch/vision/blob/5e4a9f6d1a2bf85137f4826dbf76e4f25986f878/torchvision/csrc/cpu/image/readpng_cpu.cpp
however, could not get any useful method out of it.
Thanks,
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `torchvision/io/image.py`
Content:
```
1 import torch
2
3 import os
4 import os.path as osp
5 import importlib.machinery
6
7 _HAS_IMAGE_OPT = False
8
9 try:
10 lib_dir = osp.join(osp.dirname(__file__), "..")
11
12 loader_details = (
13 importlib.machinery.ExtensionFileLoader,
14 importlib.machinery.EXTENSION_SUFFIXES
15 )
16
17 extfinder = importlib.machinery.FileFinder(lib_dir, loader_details) # type: ignore[arg-type]
18 ext_specs = extfinder.find_spec("image")
19 if ext_specs is not None:
20 torch.ops.load_library(ext_specs.origin)
21 _HAS_IMAGE_OPT = True
22 except (ImportError, OSError):
23 pass
24
25
26 def decode_png(input: torch.Tensor) -> torch.Tensor:
27 """
28 Decodes a PNG image into a 3 dimensional RGB Tensor.
29 The values of the output tensor are uint8 between 0 and 255.
30
31 Arguments:
32 input (Tensor[1]): a one dimensional int8 tensor containing
33 the raw bytes of the PNG image.
34
35 Returns:
36 output (Tensor[3, image_height, image_width])
37 """
38 if not isinstance(input, torch.Tensor) or input.numel() == 0 or input.ndim != 1: # type: ignore[attr-defined]
39 raise ValueError("Expected a non empty 1-dimensional tensor.")
40
41 if not input.dtype == torch.uint8:
42 raise ValueError("Expected a torch.uint8 tensor.")
43 output = torch.ops.image.decode_png(input)
44 return output
45
46
47 def read_png(path: str) -> torch.Tensor:
48 """
49 Reads a PNG image into a 3 dimensional RGB Tensor.
50 The values of the output tensor are uint8 between 0 and 255.
51
52 Arguments:
53 path (str): path of the PNG image.
54
55 Returns:
56 output (Tensor[3, image_height, image_width])
57 """
58 if not os.path.isfile(path):
59 raise ValueError("Expected a valid file path.")
60
61 size = os.path.getsize(path)
62 if size == 0:
63 raise ValueError("Expected a non empty file.")
64 data = torch.from_file(path, dtype=torch.uint8, size=size)
65 return decode_png(data)
66
67
68 def decode_jpeg(input: torch.Tensor) -> torch.Tensor:
69 """
70 Decodes a JPEG image into a 3 dimensional RGB Tensor.
71 The values of the output tensor are uint8 between 0 and 255.
72 Arguments:
73 input (Tensor[1]): a one dimensional int8 tensor containing
74 the raw bytes of the JPEG image.
75 Returns:
76 output (Tensor[3, image_height, image_width])
77 """
78 if not isinstance(input, torch.Tensor) or len(input) == 0 or input.ndim != 1: # type: ignore[attr-defined]
79 raise ValueError("Expected a non empty 1-dimensional tensor.")
80
81 if not input.dtype == torch.uint8:
82 raise ValueError("Expected a torch.uint8 tensor.")
83
84 output = torch.ops.image.decode_jpeg(input)
85 return output
86
87
88 def read_jpeg(path: str) -> torch.Tensor:
89 """
90 Reads a JPEG image into a 3 dimensional RGB Tensor.
91 The values of the output tensor are uint8 between 0 and 255.
92 Arguments:
93 path (str): path of the JPEG image.
94 Returns:
95 output (Tensor[3, image_height, image_width])
96 """
97 if not os.path.isfile(path):
98 raise ValueError("Expected a valid file path.")
99
100 size = os.path.getsize(path)
101 if size == 0:
102 raise ValueError("Expected a non empty file.")
103 data = torch.from_file(path, dtype=torch.uint8, size=size)
104 return decode_jpeg(data)
105
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/torchvision/io/image.py b/torchvision/io/image.py
--- a/torchvision/io/image.py
+++ b/torchvision/io/image.py
@@ -102,3 +102,42 @@
raise ValueError("Expected a non empty file.")
data = torch.from_file(path, dtype=torch.uint8, size=size)
return decode_jpeg(data)
+
+
+def encode_jpeg(input: torch.Tensor, quality: int = 75) -> torch.Tensor:
+ """
+ Takes an input tensor in CHW layout (or HW in the case of grayscale images)
+ and returns a buffer with the contents of its corresponding JPEG file.
+ Arguments:
+ input (Tensor[channels, image_height, image_width]): int8 image tensor
+ of `c` channels, where `c` must be 1 or 3.
+ quality (int): Quality of the resulting JPEG file, it must be a number
+ between 1 and 100. Default: 75
+ Returns
+ output (Tensor[1]): A one dimensional int8 tensor that contains the raw
+ bytes of the JPEG file.
+ """
+ if quality < 1 or quality > 100:
+ raise ValueError('Image quality should be a positive number '
+ 'between 1 and 100')
+
+ output = torch.ops.image.encode_jpeg(input, quality)
+ return output
+
+
+def write_jpeg(input: torch.Tensor, filename: str, quality: int = 75):
+ """
+ Takes an input tensor in CHW layout (or HW in the case of grayscale images)
+ and saves it in a JPEG file.
+ Arguments:
+ input (Tensor[channels, image_height, image_width]): int8 image tensor
+ of `c` channels, where `c` must be 1 or 3.
+ filename (str): Path to save the image.
+ quality (int): Quality of the resulting JPEG file, it must be a number
+ between 1 and 100. Default: 75
+ """
+ if quality < 1 or quality > 100:
+ raise ValueError('Image quality should be a positive number '
+ 'between 1 and 100')
+
+ torch.ops.image.write_jpeg(input, filename, quality)
|
{"golden_diff": "diff --git a/torchvision/io/image.py b/torchvision/io/image.py\n--- a/torchvision/io/image.py\n+++ b/torchvision/io/image.py\n@@ -102,3 +102,42 @@\n raise ValueError(\"Expected a non empty file.\")\n data = torch.from_file(path, dtype=torch.uint8, size=size)\n return decode_jpeg(data)\n+\n+\n+def encode_jpeg(input: torch.Tensor, quality: int = 75) -> torch.Tensor:\n+ \"\"\"\n+ Takes an input tensor in CHW layout (or HW in the case of grayscale images)\n+ and returns a buffer with the contents of its corresponding JPEG file.\n+ Arguments:\n+ input (Tensor[channels, image_height, image_width]): int8 image tensor\n+ of `c` channels, where `c` must be 1 or 3.\n+ quality (int): Quality of the resulting JPEG file, it must be a number\n+ between 1 and 100. Default: 75\n+ Returns\n+ output (Tensor[1]): A one dimensional int8 tensor that contains the raw\n+ bytes of the JPEG file.\n+ \"\"\"\n+ if quality < 1 or quality > 100:\n+ raise ValueError('Image quality should be a positive number '\n+ 'between 1 and 100')\n+\n+ output = torch.ops.image.encode_jpeg(input, quality)\n+ return output\n+\n+\n+def write_jpeg(input: torch.Tensor, filename: str, quality: int = 75):\n+ \"\"\"\n+ Takes an input tensor in CHW layout (or HW in the case of grayscale images)\n+ and saves it in a JPEG file.\n+ Arguments:\n+ input (Tensor[channels, image_height, image_width]): int8 image tensor\n+ of `c` channels, where `c` must be 1 or 3.\n+ filename (str): Path to save the image.\n+ quality (int): Quality of the resulting JPEG file, it must be a number\n+ between 1 and 100. Default: 75\n+ \"\"\"\n+ if quality < 1 or quality > 100:\n+ raise ValueError('Image quality should be a positive number '\n+ 'between 1 and 100')\n+\n+ torch.ops.image.write_jpeg(input, filename, quality)\n", "issue": "Reading PNG/JPG images into a torch::tensor and saving a torch::tensor to PNG/JPG in C++ without OpenCV \n## \ud83d\ude80 Feature\r\n\r\nAfter integrating Siv3D with Libtorch (https://github.com/QuantScientist/Siv3DTorch) I am now trying to read and write images from and to Siv3D **in C++, not Python**. The way it works is:\r\n\r\n## Motivation\r\nIn C++ I need to do the following:\r\n1. An image is read from disk (usually using OpenCV which is easy but I am trying to avoid)\r\n2. The image is converted to torch::tensor\r\n3. A DL model is applied on the tensor\r\n4. A tensor is returned from the model\r\n5. The tensor is converted to an image for display/saving purposes.\r\n\r\nThis is one example where they used stb_image to this, avoiding the use of OpenCV.\r\nhttps://github.com/prabhuomkar/pytorch-cpp/blob/master/utils/image_io/src/image_io.cpp\r\n\r\n## Pitch\r\n\r\n## Alternatives\r\n\r\nFor reference this is the OpenCV to Libtorch conversion utils which I use, I would like something very similiar:\r\n```\r\nat::Tensor matToTensor(cv::Mat frame, int h, int w, int c) {\r\n cv::cvtColor(frame, frame, CV_BGR2RGB);\r\n frame.convertTo(frame, CV_32FC3, 1.0f / 255.0f);\r\n auto input_tensor = torch::from_blob(frame.data, {1, h, w, c});\r\n input_tensor = input_tensor.permute({0, 3, 1, 2});\r\n\r\n torch::DeviceType device_type = torch::kCPU;\r\n// if (torch::cuda::is_available()) {\r\n device_type = torch::kCUDA;\r\n// }\r\n input_tensor = input_tensor.to(device_type);\r\n return input_tensor;\r\n}\r\n\r\ncv::Mat tensorToOpenCv(at::Tensor out_tensor, int h, int w, int c) {\r\n out_tensor = out_tensor.squeeze().detach().permute({1, 2, 0});\r\n out_tensor = out_tensor.mul(255).clamp(0, 255).to(torch::kU8);\r\n out_tensor = out_tensor.to(torch::kCPU);\r\n cv::Mat resultImg(h, w, CV_8UC3);\r\n // cv::Mat resultImg(h, w, CV_8UC1);\r\n std::memcpy((void *) resultImg.data, out_tensor.data_ptr(), sizeof(torch::kU8) * out_tensor.numel());\r\n return resultImg;\r\n}\r\n\r\n```\r\n## Additional context\r\n\r\nI found this:\"https://github.com/pytorch/vision/blob/5e4a9f6d1a2bf85137f4826dbf76e4f25986f878/torchvision/csrc/cpu/image/readpng_cpu.cpp\r\nhowever, could not get any useful method out of it. \r\n\r\nThanks, \r\n\r\n\r\n\r\n\n", "before_files": [{"content": "import torch\n\nimport os\nimport os.path as osp\nimport importlib.machinery\n\n_HAS_IMAGE_OPT = False\n\ntry:\n lib_dir = osp.join(osp.dirname(__file__), \"..\")\n\n loader_details = (\n importlib.machinery.ExtensionFileLoader,\n importlib.machinery.EXTENSION_SUFFIXES\n )\n\n extfinder = importlib.machinery.FileFinder(lib_dir, loader_details) # type: ignore[arg-type]\n ext_specs = extfinder.find_spec(\"image\")\n if ext_specs is not None:\n torch.ops.load_library(ext_specs.origin)\n _HAS_IMAGE_OPT = True\nexcept (ImportError, OSError):\n pass\n\n\ndef decode_png(input: torch.Tensor) -> torch.Tensor:\n \"\"\"\n Decodes a PNG image into a 3 dimensional RGB Tensor.\n The values of the output tensor are uint8 between 0 and 255.\n\n Arguments:\n input (Tensor[1]): a one dimensional int8 tensor containing\n the raw bytes of the PNG image.\n\n Returns:\n output (Tensor[3, image_height, image_width])\n \"\"\"\n if not isinstance(input, torch.Tensor) or input.numel() == 0 or input.ndim != 1: # type: ignore[attr-defined]\n raise ValueError(\"Expected a non empty 1-dimensional tensor.\")\n\n if not input.dtype == torch.uint8:\n raise ValueError(\"Expected a torch.uint8 tensor.\")\n output = torch.ops.image.decode_png(input)\n return output\n\n\ndef read_png(path: str) -> torch.Tensor:\n \"\"\"\n Reads a PNG image into a 3 dimensional RGB Tensor.\n The values of the output tensor are uint8 between 0 and 255.\n\n Arguments:\n path (str): path of the PNG image.\n\n Returns:\n output (Tensor[3, image_height, image_width])\n \"\"\"\n if not os.path.isfile(path):\n raise ValueError(\"Expected a valid file path.\")\n\n size = os.path.getsize(path)\n if size == 0:\n raise ValueError(\"Expected a non empty file.\")\n data = torch.from_file(path, dtype=torch.uint8, size=size)\n return decode_png(data)\n\n\ndef decode_jpeg(input: torch.Tensor) -> torch.Tensor:\n \"\"\"\n Decodes a JPEG image into a 3 dimensional RGB Tensor.\n The values of the output tensor are uint8 between 0 and 255.\n Arguments:\n input (Tensor[1]): a one dimensional int8 tensor containing\n the raw bytes of the JPEG image.\n Returns:\n output (Tensor[3, image_height, image_width])\n \"\"\"\n if not isinstance(input, torch.Tensor) or len(input) == 0 or input.ndim != 1: # type: ignore[attr-defined]\n raise ValueError(\"Expected a non empty 1-dimensional tensor.\")\n\n if not input.dtype == torch.uint8:\n raise ValueError(\"Expected a torch.uint8 tensor.\")\n\n output = torch.ops.image.decode_jpeg(input)\n return output\n\n\ndef read_jpeg(path: str) -> torch.Tensor:\n \"\"\"\n Reads a JPEG image into a 3 dimensional RGB Tensor.\n The values of the output tensor are uint8 between 0 and 255.\n Arguments:\n path (str): path of the JPEG image.\n Returns:\n output (Tensor[3, image_height, image_width])\n \"\"\"\n if not os.path.isfile(path):\n raise ValueError(\"Expected a valid file path.\")\n\n size = os.path.getsize(path)\n if size == 0:\n raise ValueError(\"Expected a non empty file.\")\n data = torch.from_file(path, dtype=torch.uint8, size=size)\n return decode_jpeg(data)\n", "path": "torchvision/io/image.py"}], "after_files": [{"content": "import torch\n\nimport os\nimport os.path as osp\nimport importlib.machinery\n\n_HAS_IMAGE_OPT = False\n\ntry:\n lib_dir = osp.join(osp.dirname(__file__), \"..\")\n\n loader_details = (\n importlib.machinery.ExtensionFileLoader,\n importlib.machinery.EXTENSION_SUFFIXES\n )\n\n extfinder = importlib.machinery.FileFinder(lib_dir, loader_details) # type: ignore[arg-type]\n ext_specs = extfinder.find_spec(\"image\")\n if ext_specs is not None:\n torch.ops.load_library(ext_specs.origin)\n _HAS_IMAGE_OPT = True\nexcept (ImportError, OSError):\n pass\n\n\ndef decode_png(input: torch.Tensor) -> torch.Tensor:\n \"\"\"\n Decodes a PNG image into a 3 dimensional RGB Tensor.\n The values of the output tensor are uint8 between 0 and 255.\n\n Arguments:\n input (Tensor[1]): a one dimensional int8 tensor containing\n the raw bytes of the PNG image.\n\n Returns:\n output (Tensor[3, image_height, image_width])\n \"\"\"\n if not isinstance(input, torch.Tensor) or input.numel() == 0 or input.ndim != 1: # type: ignore[attr-defined]\n raise ValueError(\"Expected a non empty 1-dimensional tensor.\")\n\n if not input.dtype == torch.uint8:\n raise ValueError(\"Expected a torch.uint8 tensor.\")\n output = torch.ops.image.decode_png(input)\n return output\n\n\ndef read_png(path: str) -> torch.Tensor:\n \"\"\"\n Reads a PNG image into a 3 dimensional RGB Tensor.\n The values of the output tensor are uint8 between 0 and 255.\n\n Arguments:\n path (str): path of the PNG image.\n\n Returns:\n output (Tensor[3, image_height, image_width])\n \"\"\"\n if not os.path.isfile(path):\n raise ValueError(\"Expected a valid file path.\")\n\n size = os.path.getsize(path)\n if size == 0:\n raise ValueError(\"Expected a non empty file.\")\n data = torch.from_file(path, dtype=torch.uint8, size=size)\n return decode_png(data)\n\n\ndef decode_jpeg(input: torch.Tensor) -> torch.Tensor:\n \"\"\"\n Decodes a JPEG image into a 3 dimensional RGB Tensor.\n The values of the output tensor are uint8 between 0 and 255.\n Arguments:\n input (Tensor[1]): a one dimensional int8 tensor containing\n the raw bytes of the JPEG image.\n Returns:\n output (Tensor[3, image_height, image_width])\n \"\"\"\n if not isinstance(input, torch.Tensor) or len(input) == 0 or input.ndim != 1: # type: ignore[attr-defined]\n raise ValueError(\"Expected a non empty 1-dimensional tensor.\")\n\n if not input.dtype == torch.uint8:\n raise ValueError(\"Expected a torch.uint8 tensor.\")\n\n output = torch.ops.image.decode_jpeg(input)\n return output\n\n\ndef read_jpeg(path: str) -> torch.Tensor:\n \"\"\"\n Reads a JPEG image into a 3 dimensional RGB Tensor.\n The values of the output tensor are uint8 between 0 and 255.\n Arguments:\n path (str): path of the JPEG image.\n Returns:\n output (Tensor[3, image_height, image_width])\n \"\"\"\n if not os.path.isfile(path):\n raise ValueError(\"Expected a valid file path.\")\n\n size = os.path.getsize(path)\n if size == 0:\n raise ValueError(\"Expected a non empty file.\")\n data = torch.from_file(path, dtype=torch.uint8, size=size)\n return decode_jpeg(data)\n\n\ndef encode_jpeg(input: torch.Tensor, quality: int = 75) -> torch.Tensor:\n \"\"\"\n Takes an input tensor in CHW layout (or HW in the case of grayscale images)\n and returns a buffer with the contents of its corresponding JPEG file.\n Arguments:\n input (Tensor[channels, image_height, image_width]): int8 image tensor\n of `c` channels, where `c` must be 1 or 3.\n quality (int): Quality of the resulting JPEG file, it must be a number\n between 1 and 100. Default: 75\n Returns\n output (Tensor[1]): A one dimensional int8 tensor that contains the raw\n bytes of the JPEG file.\n \"\"\"\n if quality < 1 or quality > 100:\n raise ValueError('Image quality should be a positive number '\n 'between 1 and 100')\n\n output = torch.ops.image.encode_jpeg(input, quality)\n return output\n\n\ndef write_jpeg(input: torch.Tensor, filename: str, quality: int = 75):\n \"\"\"\n Takes an input tensor in CHW layout (or HW in the case of grayscale images)\n and saves it in a JPEG file.\n Arguments:\n input (Tensor[channels, image_height, image_width]): int8 image tensor\n of `c` channels, where `c` must be 1 or 3.\n filename (str): Path to save the image.\n quality (int): Quality of the resulting JPEG file, it must be a number\n between 1 and 100. Default: 75\n \"\"\"\n if quality < 1 or quality > 100:\n raise ValueError('Image quality should be a positive number '\n 'between 1 and 100')\n\n torch.ops.image.write_jpeg(input, filename, quality)\n", "path": "torchvision/io/image.py"}]}
| 1,904 | 525 |
gh_patches_debug_33263
|
rasdani/github-patches
|
git_diff
|
kserve__kserve-2684
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
GPL License Violation in the kserve python package
The version of the `kserve` package that is currently on PyPI (version `0.10`) violates the GPL license because it depends on [`table-logger`](https://github.com/AleksTk/table-logger), distributed under GPLv2 (you'll see that the library is now MIT, the author updated the license just a few days ago, but hasn't released a new version with the new license yet). No GPLv2 packages should be imported given that `kserve` has an Apache 2 license.
This was recently fixed by this PR https://github.com/kserve/kserve/pull/2673, which accidentally resolved the issue by replacing `table-logger` with `tabulate` (MIT License)
cc @yuzisun @cliveseldon @jinchihe @ellistarn
Is it possible to quickly release a patch release `0.10.1` to include the above patch and make sure `kserve` is compliant with the Apache license? As it stands, any distribution and vendor using `kserve` is liable for a license violation.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `python/kserve/kserve/api/watch.py`
Content:
```
1 # Copyright 2021 The KServe Authors.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import time
16 from kubernetes import client
17 from kubernetes import watch as k8s_watch
18 from table_logger import TableLogger
19
20 from ..constants import constants
21 from ..utils import utils
22
23
24 def isvc_watch(name=None, namespace=None, timeout_seconds=600, generation=0):
25 """Watch the created or patched InferenceService in the specified namespace"""
26
27 if namespace is None:
28 namespace = utils.get_default_target_namespace()
29
30 tbl = TableLogger(
31 columns='NAME,READY,PREV,LATEST,URL',
32 colwidth={'NAME': 20, 'READY': 10, 'PREV': 25, 'LATEST': 25, 'URL': 65},
33 border=False)
34
35 stream = k8s_watch.Watch().stream(
36 client.CustomObjectsApi().list_namespaced_custom_object,
37 constants.KSERVE_GROUP,
38 constants.KSERVE_V1BETA1_VERSION,
39 namespace,
40 constants.KSERVE_PLURAL,
41 timeout_seconds=timeout_seconds)
42
43 for event in stream:
44 isvc = event['object']
45 isvc_name = isvc['metadata']['name']
46 if name and name != isvc_name:
47 continue
48 else:
49 status = 'Unknown'
50 if isvc.get('status', ''):
51 url = isvc['status'].get('url', '')
52 traffic = isvc['status'].get('components', {}).get(
53 'predictor', {}).get('traffic', [])
54 traffic_percent = 100
55 if constants.OBSERVED_GENERATION in isvc['status']:
56 observed_generation = isvc['status'][constants.OBSERVED_GENERATION]
57 for t in traffic:
58 if t["latestRevision"]:
59 traffic_percent = t["percent"]
60
61 if generation != 0 and observed_generation != generation:
62 continue
63 for condition in isvc['status'].get('conditions', {}):
64 if condition.get('type', '') == 'Ready':
65 status = condition.get('status', 'Unknown')
66 tbl(isvc_name, status, 100-traffic_percent, traffic_percent, url)
67 if status == 'True':
68 break
69
70 else:
71 tbl(isvc_name, status, '', '', '')
72 # Sleep 2 to avoid status section is not generated within a very short time.
73 time.sleep(2)
74 continue
75
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/python/kserve/kserve/api/watch.py b/python/kserve/kserve/api/watch.py
--- a/python/kserve/kserve/api/watch.py
+++ b/python/kserve/kserve/api/watch.py
@@ -13,9 +13,10 @@
# limitations under the License.
import time
+
from kubernetes import client
from kubernetes import watch as k8s_watch
-from table_logger import TableLogger
+from tabulate import tabulate
from ..constants import constants
from ..utils import utils
@@ -27,10 +28,8 @@
if namespace is None:
namespace = utils.get_default_target_namespace()
- tbl = TableLogger(
- columns='NAME,READY,PREV,LATEST,URL',
- colwidth={'NAME': 20, 'READY': 10, 'PREV': 25, 'LATEST': 25, 'URL': 65},
- border=False)
+ headers = ['NAME', 'READY', 'PREV', 'LATEST', 'URL']
+ table_fmt = 'plain'
stream = k8s_watch.Watch().stream(
client.CustomObjectsApi().list_namespaced_custom_object,
@@ -63,12 +62,13 @@
for condition in isvc['status'].get('conditions', {}):
if condition.get('type', '') == 'Ready':
status = condition.get('status', 'Unknown')
- tbl(isvc_name, status, 100-traffic_percent, traffic_percent, url)
+ print(tabulate([[isvc_name, status, 100 - traffic_percent, traffic_percent, url]],
+ headers=headers, tablefmt=table_fmt))
if status == 'True':
break
else:
- tbl(isvc_name, status, '', '', '')
+ print(tabulate([[isvc_name, status, '', '', '']], headers=headers, tablefmt=table_fmt))
# Sleep 2 to avoid status section is not generated within a very short time.
time.sleep(2)
continue
|
{"golden_diff": "diff --git a/python/kserve/kserve/api/watch.py b/python/kserve/kserve/api/watch.py\n--- a/python/kserve/kserve/api/watch.py\n+++ b/python/kserve/kserve/api/watch.py\n@@ -13,9 +13,10 @@\n # limitations under the License.\n \n import time\n+\n from kubernetes import client\n from kubernetes import watch as k8s_watch\n-from table_logger import TableLogger\n+from tabulate import tabulate\n \n from ..constants import constants\n from ..utils import utils\n@@ -27,10 +28,8 @@\n if namespace is None:\n namespace = utils.get_default_target_namespace()\n \n- tbl = TableLogger(\n- columns='NAME,READY,PREV,LATEST,URL',\n- colwidth={'NAME': 20, 'READY': 10, 'PREV': 25, 'LATEST': 25, 'URL': 65},\n- border=False)\n+ headers = ['NAME', 'READY', 'PREV', 'LATEST', 'URL']\n+ table_fmt = 'plain'\n \n stream = k8s_watch.Watch().stream(\n client.CustomObjectsApi().list_namespaced_custom_object,\n@@ -63,12 +62,13 @@\n for condition in isvc['status'].get('conditions', {}):\n if condition.get('type', '') == 'Ready':\n status = condition.get('status', 'Unknown')\n- tbl(isvc_name, status, 100-traffic_percent, traffic_percent, url)\n+ print(tabulate([[isvc_name, status, 100 - traffic_percent, traffic_percent, url]],\n+ headers=headers, tablefmt=table_fmt))\n if status == 'True':\n break\n \n else:\n- tbl(isvc_name, status, '', '', '')\n+ print(tabulate([[isvc_name, status, '', '', '']], headers=headers, tablefmt=table_fmt))\n # Sleep 2 to avoid status section is not generated within a very short time.\n time.sleep(2)\n continue\n", "issue": "GPL License Violation in the kserve python package\nThe version of the `kserve` package that is currently on PyPI (version `0.10`) violates the GPL license because it depends on [`table-logger`](https://github.com/AleksTk/table-logger), distributed under GPLv2 (you'll see that the library is now MIT, the author updated the license just a few days ago, but hasn't released a new version with the new license yet). No GPLv2 packages should be imported given that `kserve` has an Apache 2 license.\r\n\r\n\r\nThis was recently fixed by this PR https://github.com/kserve/kserve/pull/2673, which accidentally resolved the issue by replacing `table-logger` with `tabulate` (MIT License)\r\n\r\ncc @yuzisun @cliveseldon @jinchihe @ellistarn \r\n\r\nIs it possible to quickly release a patch release `0.10.1` to include the above patch and make sure `kserve` is compliant with the Apache license? As it stands, any distribution and vendor using `kserve` is liable for a license violation.\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "# Copyright 2021 The KServe Authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport time\nfrom kubernetes import client\nfrom kubernetes import watch as k8s_watch\nfrom table_logger import TableLogger\n\nfrom ..constants import constants\nfrom ..utils import utils\n\n\ndef isvc_watch(name=None, namespace=None, timeout_seconds=600, generation=0):\n \"\"\"Watch the created or patched InferenceService in the specified namespace\"\"\"\n\n if namespace is None:\n namespace = utils.get_default_target_namespace()\n\n tbl = TableLogger(\n columns='NAME,READY,PREV,LATEST,URL',\n colwidth={'NAME': 20, 'READY': 10, 'PREV': 25, 'LATEST': 25, 'URL': 65},\n border=False)\n\n stream = k8s_watch.Watch().stream(\n client.CustomObjectsApi().list_namespaced_custom_object,\n constants.KSERVE_GROUP,\n constants.KSERVE_V1BETA1_VERSION,\n namespace,\n constants.KSERVE_PLURAL,\n timeout_seconds=timeout_seconds)\n\n for event in stream:\n isvc = event['object']\n isvc_name = isvc['metadata']['name']\n if name and name != isvc_name:\n continue\n else:\n status = 'Unknown'\n if isvc.get('status', ''):\n url = isvc['status'].get('url', '')\n traffic = isvc['status'].get('components', {}).get(\n 'predictor', {}).get('traffic', [])\n traffic_percent = 100\n if constants.OBSERVED_GENERATION in isvc['status']:\n observed_generation = isvc['status'][constants.OBSERVED_GENERATION]\n for t in traffic:\n if t[\"latestRevision\"]:\n traffic_percent = t[\"percent\"]\n\n if generation != 0 and observed_generation != generation:\n continue\n for condition in isvc['status'].get('conditions', {}):\n if condition.get('type', '') == 'Ready':\n status = condition.get('status', 'Unknown')\n tbl(isvc_name, status, 100-traffic_percent, traffic_percent, url)\n if status == 'True':\n break\n\n else:\n tbl(isvc_name, status, '', '', '')\n # Sleep 2 to avoid status section is not generated within a very short time.\n time.sleep(2)\n continue\n", "path": "python/kserve/kserve/api/watch.py"}], "after_files": [{"content": "# Copyright 2021 The KServe Authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport time\n\nfrom kubernetes import client\nfrom kubernetes import watch as k8s_watch\nfrom tabulate import tabulate\n\nfrom ..constants import constants\nfrom ..utils import utils\n\n\ndef isvc_watch(name=None, namespace=None, timeout_seconds=600, generation=0):\n \"\"\"Watch the created or patched InferenceService in the specified namespace\"\"\"\n\n if namespace is None:\n namespace = utils.get_default_target_namespace()\n\n headers = ['NAME', 'READY', 'PREV', 'LATEST', 'URL']\n table_fmt = 'plain'\n\n stream = k8s_watch.Watch().stream(\n client.CustomObjectsApi().list_namespaced_custom_object,\n constants.KSERVE_GROUP,\n constants.KSERVE_V1BETA1_VERSION,\n namespace,\n constants.KSERVE_PLURAL,\n timeout_seconds=timeout_seconds)\n\n for event in stream:\n isvc = event['object']\n isvc_name = isvc['metadata']['name']\n if name and name != isvc_name:\n continue\n else:\n status = 'Unknown'\n if isvc.get('status', ''):\n url = isvc['status'].get('url', '')\n traffic = isvc['status'].get('components', {}).get(\n 'predictor', {}).get('traffic', [])\n traffic_percent = 100\n if constants.OBSERVED_GENERATION in isvc['status']:\n observed_generation = isvc['status'][constants.OBSERVED_GENERATION]\n for t in traffic:\n if t[\"latestRevision\"]:\n traffic_percent = t[\"percent\"]\n\n if generation != 0 and observed_generation != generation:\n continue\n for condition in isvc['status'].get('conditions', {}):\n if condition.get('type', '') == 'Ready':\n status = condition.get('status', 'Unknown')\n print(tabulate([[isvc_name, status, 100 - traffic_percent, traffic_percent, url]],\n headers=headers, tablefmt=table_fmt))\n if status == 'True':\n break\n\n else:\n print(tabulate([[isvc_name, status, '', '', '']], headers=headers, tablefmt=table_fmt))\n # Sleep 2 to avoid status section is not generated within a very short time.\n time.sleep(2)\n continue\n", "path": "python/kserve/kserve/api/watch.py"}]}
| 1,283 | 450 |
gh_patches_debug_13710
|
rasdani/github-patches
|
git_diff
|
openfun__marsha-2238
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Properly clause websocket connection on video/webinar deletion
## Bug Report
**Problematic Behavior**
When a video/webinar is deleted, a websocket connection is still open. The dashboard is unmounted by react so it tries to close it but an error is thrown because on closing the connection, the weboscket tries to fetch the attached live session in database but this one does not exists anymore.
**Expected behavior/code**
When a video/webinar is deleted, the websocket should be properly closed.
**Steps to Reproduce**
1. Create a webinar
2. Delete it
**Additional context/Screenshots**
https://gip-fun-mooc.sentry.io/share/issue/668071c3736a446a890af2b99df1c6c6/
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/backend/marsha/websocket/consumers/video.py`
Content:
```
1 """Video consumer module"""
2 from urllib.parse import parse_qs
3
4 from django.db.models import Q
5
6 from channels.db import database_sync_to_async
7 from channels.generic.websocket import AsyncJsonWebsocketConsumer
8
9 from marsha.core.models import (
10 ADMINISTRATOR,
11 INSTRUCTOR,
12 SharedLiveMedia,
13 Thumbnail,
14 TimedTextTrack,
15 Video,
16 )
17 from marsha.core.permissions import IsTokenAdmin, IsTokenInstructor
18 from marsha.core.services import live_session as LiveSessionServices
19 from marsha.core.simple_jwt.tokens import ResourceAccessToken, UserAccessToken
20 from marsha.websocket import defaults
21
22
23 class VideoConsumer(AsyncJsonWebsocketConsumer):
24 """Video consumer."""
25
26 room_group_name = None
27 is_connected = False
28
29 def __get_video_id(self):
30 return self.scope["url_route"]["kwargs"]["video_id"]
31
32 async def _check_permissions(self):
33 """
34 Check if the user has the required permissions.
35
36 Raises:
37 ConnectionRefusedError: if the user does not have the required permissions.
38 """
39 token = self.scope["token"]
40 if token is None:
41 raise ConnectionRefusedError()
42
43 # Check permissions, MUST be the same as in the `retrieve` method
44 # of the Video API view set.
45
46 if isinstance(token, ResourceAccessToken):
47 # With LTI: anyone with a valid token for the video can access
48 if token.payload.get("resource_id") != self.__get_video_id():
49 raise ConnectionRefusedError()
50
51 elif isinstance(token, UserAccessToken):
52 # With standalone site, only playlist admin or organization admin can access
53 if not await self._user_has_playlist_or_organization_admin_role(
54 token.payload.get("user_id")
55 ):
56 raise ConnectionRefusedError()
57
58 else:
59 raise RuntimeError("This should not happen")
60
61 async def connect(self):
62 """
63 Manage connection to this consumer.
64 During handshake it is not possible to close the websocket with a specific
65 code. To do that we must accept first the connection and then close it with the code we
66 want
67 """
68 try:
69 await self._check_permissions()
70 await self._check_video_exists()
71 if not await self._is_admin():
72 live_session = await self.retrieve_live_session()
73 await self.update_live_session_with_channel_name(
74 live_session=live_session
75 )
76 except ConnectionRefusedError:
77 await self.accept()
78 return await self.close(code=4003)
79
80 self.room_group_name = await self._get_room_name()
81 # Join room group
82 await self.channel_layer.group_add(self.room_group_name, self.channel_name)
83
84 await self.accept()
85 self.is_connected = True
86
87 async def _check_video_exists(self):
88 """Close the room if the video does not exists."""
89 if not await self._video_exists():
90 raise ConnectionRefusedError()
91
92 @database_sync_to_async
93 def _video_exists(self):
94 """Return if a video exists in database or not."""
95 return Video.objects.filter(pk=self.__get_video_id()).exists()
96
97 @database_sync_to_async
98 def _user_has_playlist_or_organization_admin_role(self, user_id):
99 """Return if the user belongs to the video playlist admin or organization admin."""
100 return Video.objects.filter(
101 Q(pk=self.__get_video_id())
102 & (
103 Q(
104 playlist__user_accesses__user_id=user_id,
105 playlist__user_accesses__role__in=[ADMINISTRATOR, INSTRUCTOR],
106 )
107 | Q(
108 playlist__organization__user_accesses__user_id=user_id,
109 playlist__organization__user_accesses__role=ADMINISTRATOR,
110 )
111 )
112 ).exists()
113
114 @database_sync_to_async
115 def retrieve_live_session(self):
116 """Guess a live_session from the token and create it id not present."""
117 token = self.scope["token"]
118 if LiveSessionServices.is_lti_token(token):
119 live_session, _ = LiveSessionServices.get_livesession_from_lti(token)
120 else:
121 query_string = parse_qs(self.scope["query_string"])
122 if b"anonymous_id" not in query_string:
123 raise ConnectionRefusedError()
124 live_session, _ = LiveSessionServices.get_livesession_from_anonymous_id(
125 anonymous_id=query_string[b"anonymous_id"][0].decode("utf-8"),
126 video_id=token.payload["resource_id"],
127 )
128
129 return live_session
130
131 @database_sync_to_async
132 def update_live_session_with_channel_name(self, live_session):
133 """Update the live_session with the current channel_name."""
134 live_session.channel_name = self.channel_name
135 live_session.save()
136
137 @database_sync_to_async
138 def reset_live_session(self, live_session):
139 """Reset to None the live_session channel_name."""
140 live_session.channel_name = None
141 live_session.save()
142
143 async def _is_admin(self):
144 """Check if the connected user has admin permissions."""
145 token = self.scope["token"]
146 if not token:
147 return False
148
149 if isinstance(token, ResourceAccessToken):
150 return IsTokenInstructor().check_role(token) or IsTokenAdmin().check_role(
151 token
152 )
153
154 if isinstance(token, UserAccessToken):
155 return await self._user_has_playlist_or_organization_admin_role(
156 token.payload.get("user_id"),
157 )
158
159 raise RuntimeError("Should not be called please check the code.", type(token))
160
161 async def _get_room_name(self):
162 """Generate the room name the user is connected on depending its permissions."""
163 if await self._is_admin():
164 return defaults.VIDEO_ADMIN_ROOM_NAME.format(video_id=self.__get_video_id())
165
166 return defaults.VIDEO_ROOM_NAME.format(video_id=self.__get_video_id())
167
168 # pylint: disable=unused-argument
169 async def disconnect(self, code):
170 """Manage disconnection to this consumer."""
171 # If connection was previously aborted nothing to do
172 if not self.is_connected:
173 return
174
175 # Leave room group
176 await self.channel_layer.group_discard(self.room_group_name, self.channel_name)
177 if not await self._is_admin():
178 live_session = await self.retrieve_live_session()
179 await self.reset_live_session(live_session)
180
181 async def video_updated(self, event):
182 """Listener for the video_updated event."""
183 message = {"type": Video.RESOURCE_NAME, "resource": event["video"]}
184 await self.send_json(message)
185
186 async def thumbnail_updated(self, event):
187 """Listener for the thumbnail updated event."""
188 message = {"type": Thumbnail.RESOURCE_NAME, "resource": event["thumbnail"]}
189 await self.send_json(message)
190
191 async def timed_text_track_updated(self, event):
192 """Listener for the timed text track updated event."""
193 message = {
194 "type": TimedTextTrack.RESOURCE_NAME,
195 "resource": event["timed_text_track"],
196 }
197 await self.send_json(message)
198
199 async def shared_live_media_updated(self, event):
200 """Listener for the shared_live_media updated event."""
201 message = {
202 "type": SharedLiveMedia.RESOURCE_NAME,
203 "resource": event["shared_live_media"],
204 }
205 await self.send_json(message)
206
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/backend/marsha/websocket/consumers/video.py b/src/backend/marsha/websocket/consumers/video.py
--- a/src/backend/marsha/websocket/consumers/video.py
+++ b/src/backend/marsha/websocket/consumers/video.py
@@ -175,8 +175,12 @@
# Leave room group
await self.channel_layer.group_discard(self.room_group_name, self.channel_name)
if not await self._is_admin():
- live_session = await self.retrieve_live_session()
- await self.reset_live_session(live_session)
+ try:
+ live_session = await self.retrieve_live_session()
+ await self.reset_live_session(live_session)
+ except ConnectionRefusedError:
+ # No live session found, nothing to do
+ pass
async def video_updated(self, event):
"""Listener for the video_updated event."""
|
{"golden_diff": "diff --git a/src/backend/marsha/websocket/consumers/video.py b/src/backend/marsha/websocket/consumers/video.py\n--- a/src/backend/marsha/websocket/consumers/video.py\n+++ b/src/backend/marsha/websocket/consumers/video.py\n@@ -175,8 +175,12 @@\n # Leave room group\n await self.channel_layer.group_discard(self.room_group_name, self.channel_name)\n if not await self._is_admin():\n- live_session = await self.retrieve_live_session()\n- await self.reset_live_session(live_session)\n+ try:\n+ live_session = await self.retrieve_live_session()\n+ await self.reset_live_session(live_session)\n+ except ConnectionRefusedError:\n+ # No live session found, nothing to do\n+ pass\n \n async def video_updated(self, event):\n \"\"\"Listener for the video_updated event.\"\"\"\n", "issue": "Properly clause websocket connection on video/webinar deletion\n## Bug Report\r\n\r\n**Problematic Behavior**\r\n\r\nWhen a video/webinar is deleted, a websocket connection is still open. The dashboard is unmounted by react so it tries to close it but an error is thrown because on closing the connection, the weboscket tries to fetch the attached live session in database but this one does not exists anymore.\r\n\r\n**Expected behavior/code**\r\n\r\nWhen a video/webinar is deleted, the websocket should be properly closed.\r\n\r\n**Steps to Reproduce**\r\n1. Create a webinar\r\n2. Delete it\r\n\r\n\r\n**Additional context/Screenshots**\r\n\r\nhttps://gip-fun-mooc.sentry.io/share/issue/668071c3736a446a890af2b99df1c6c6/\r\n\n", "before_files": [{"content": "\"\"\"Video consumer module\"\"\"\nfrom urllib.parse import parse_qs\n\nfrom django.db.models import Q\n\nfrom channels.db import database_sync_to_async\nfrom channels.generic.websocket import AsyncJsonWebsocketConsumer\n\nfrom marsha.core.models import (\n ADMINISTRATOR,\n INSTRUCTOR,\n SharedLiveMedia,\n Thumbnail,\n TimedTextTrack,\n Video,\n)\nfrom marsha.core.permissions import IsTokenAdmin, IsTokenInstructor\nfrom marsha.core.services import live_session as LiveSessionServices\nfrom marsha.core.simple_jwt.tokens import ResourceAccessToken, UserAccessToken\nfrom marsha.websocket import defaults\n\n\nclass VideoConsumer(AsyncJsonWebsocketConsumer):\n \"\"\"Video consumer.\"\"\"\n\n room_group_name = None\n is_connected = False\n\n def __get_video_id(self):\n return self.scope[\"url_route\"][\"kwargs\"][\"video_id\"]\n\n async def _check_permissions(self):\n \"\"\"\n Check if the user has the required permissions.\n\n Raises:\n ConnectionRefusedError: if the user does not have the required permissions.\n \"\"\"\n token = self.scope[\"token\"]\n if token is None:\n raise ConnectionRefusedError()\n\n # Check permissions, MUST be the same as in the `retrieve` method\n # of the Video API view set.\n\n if isinstance(token, ResourceAccessToken):\n # With LTI: anyone with a valid token for the video can access\n if token.payload.get(\"resource_id\") != self.__get_video_id():\n raise ConnectionRefusedError()\n\n elif isinstance(token, UserAccessToken):\n # With standalone site, only playlist admin or organization admin can access\n if not await self._user_has_playlist_or_organization_admin_role(\n token.payload.get(\"user_id\")\n ):\n raise ConnectionRefusedError()\n\n else:\n raise RuntimeError(\"This should not happen\")\n\n async def connect(self):\n \"\"\"\n Manage connection to this consumer.\n During handshake it is not possible to close the websocket with a specific\n code. To do that we must accept first the connection and then close it with the code we\n want\n \"\"\"\n try:\n await self._check_permissions()\n await self._check_video_exists()\n if not await self._is_admin():\n live_session = await self.retrieve_live_session()\n await self.update_live_session_with_channel_name(\n live_session=live_session\n )\n except ConnectionRefusedError:\n await self.accept()\n return await self.close(code=4003)\n\n self.room_group_name = await self._get_room_name()\n # Join room group\n await self.channel_layer.group_add(self.room_group_name, self.channel_name)\n\n await self.accept()\n self.is_connected = True\n\n async def _check_video_exists(self):\n \"\"\"Close the room if the video does not exists.\"\"\"\n if not await self._video_exists():\n raise ConnectionRefusedError()\n\n @database_sync_to_async\n def _video_exists(self):\n \"\"\"Return if a video exists in database or not.\"\"\"\n return Video.objects.filter(pk=self.__get_video_id()).exists()\n\n @database_sync_to_async\n def _user_has_playlist_or_organization_admin_role(self, user_id):\n \"\"\"Return if the user belongs to the video playlist admin or organization admin.\"\"\"\n return Video.objects.filter(\n Q(pk=self.__get_video_id())\n & (\n Q(\n playlist__user_accesses__user_id=user_id,\n playlist__user_accesses__role__in=[ADMINISTRATOR, INSTRUCTOR],\n )\n | Q(\n playlist__organization__user_accesses__user_id=user_id,\n playlist__organization__user_accesses__role=ADMINISTRATOR,\n )\n )\n ).exists()\n\n @database_sync_to_async\n def retrieve_live_session(self):\n \"\"\"Guess a live_session from the token and create it id not present.\"\"\"\n token = self.scope[\"token\"]\n if LiveSessionServices.is_lti_token(token):\n live_session, _ = LiveSessionServices.get_livesession_from_lti(token)\n else:\n query_string = parse_qs(self.scope[\"query_string\"])\n if b\"anonymous_id\" not in query_string:\n raise ConnectionRefusedError()\n live_session, _ = LiveSessionServices.get_livesession_from_anonymous_id(\n anonymous_id=query_string[b\"anonymous_id\"][0].decode(\"utf-8\"),\n video_id=token.payload[\"resource_id\"],\n )\n\n return live_session\n\n @database_sync_to_async\n def update_live_session_with_channel_name(self, live_session):\n \"\"\"Update the live_session with the current channel_name.\"\"\"\n live_session.channel_name = self.channel_name\n live_session.save()\n\n @database_sync_to_async\n def reset_live_session(self, live_session):\n \"\"\"Reset to None the live_session channel_name.\"\"\"\n live_session.channel_name = None\n live_session.save()\n\n async def _is_admin(self):\n \"\"\"Check if the connected user has admin permissions.\"\"\"\n token = self.scope[\"token\"]\n if not token:\n return False\n\n if isinstance(token, ResourceAccessToken):\n return IsTokenInstructor().check_role(token) or IsTokenAdmin().check_role(\n token\n )\n\n if isinstance(token, UserAccessToken):\n return await self._user_has_playlist_or_organization_admin_role(\n token.payload.get(\"user_id\"),\n )\n\n raise RuntimeError(\"Should not be called please check the code.\", type(token))\n\n async def _get_room_name(self):\n \"\"\"Generate the room name the user is connected on depending its permissions.\"\"\"\n if await self._is_admin():\n return defaults.VIDEO_ADMIN_ROOM_NAME.format(video_id=self.__get_video_id())\n\n return defaults.VIDEO_ROOM_NAME.format(video_id=self.__get_video_id())\n\n # pylint: disable=unused-argument\n async def disconnect(self, code):\n \"\"\"Manage disconnection to this consumer.\"\"\"\n # If connection was previously aborted nothing to do\n if not self.is_connected:\n return\n\n # Leave room group\n await self.channel_layer.group_discard(self.room_group_name, self.channel_name)\n if not await self._is_admin():\n live_session = await self.retrieve_live_session()\n await self.reset_live_session(live_session)\n\n async def video_updated(self, event):\n \"\"\"Listener for the video_updated event.\"\"\"\n message = {\"type\": Video.RESOURCE_NAME, \"resource\": event[\"video\"]}\n await self.send_json(message)\n\n async def thumbnail_updated(self, event):\n \"\"\"Listener for the thumbnail updated event.\"\"\"\n message = {\"type\": Thumbnail.RESOURCE_NAME, \"resource\": event[\"thumbnail\"]}\n await self.send_json(message)\n\n async def timed_text_track_updated(self, event):\n \"\"\"Listener for the timed text track updated event.\"\"\"\n message = {\n \"type\": TimedTextTrack.RESOURCE_NAME,\n \"resource\": event[\"timed_text_track\"],\n }\n await self.send_json(message)\n\n async def shared_live_media_updated(self, event):\n \"\"\"Listener for the shared_live_media updated event.\"\"\"\n message = {\n \"type\": SharedLiveMedia.RESOURCE_NAME,\n \"resource\": event[\"shared_live_media\"],\n }\n await self.send_json(message)\n", "path": "src/backend/marsha/websocket/consumers/video.py"}], "after_files": [{"content": "\"\"\"Video consumer module\"\"\"\nfrom urllib.parse import parse_qs\n\nfrom django.db.models import Q\n\nfrom channels.db import database_sync_to_async\nfrom channels.generic.websocket import AsyncJsonWebsocketConsumer\n\nfrom marsha.core.models import (\n ADMINISTRATOR,\n INSTRUCTOR,\n SharedLiveMedia,\n Thumbnail,\n TimedTextTrack,\n Video,\n)\nfrom marsha.core.permissions import IsTokenAdmin, IsTokenInstructor\nfrom marsha.core.services import live_session as LiveSessionServices\nfrom marsha.core.simple_jwt.tokens import ResourceAccessToken, UserAccessToken\nfrom marsha.websocket import defaults\n\n\nclass VideoConsumer(AsyncJsonWebsocketConsumer):\n \"\"\"Video consumer.\"\"\"\n\n room_group_name = None\n is_connected = False\n\n def __get_video_id(self):\n return self.scope[\"url_route\"][\"kwargs\"][\"video_id\"]\n\n async def _check_permissions(self):\n \"\"\"\n Check if the user has the required permissions.\n\n Raises:\n ConnectionRefusedError: if the user does not have the required permissions.\n \"\"\"\n token = self.scope[\"token\"]\n if token is None:\n raise ConnectionRefusedError()\n\n # Check permissions, MUST be the same as in the `retrieve` method\n # of the Video API view set.\n\n if isinstance(token, ResourceAccessToken):\n # With LTI: anyone with a valid token for the video can access\n if token.payload.get(\"resource_id\") != self.__get_video_id():\n raise ConnectionRefusedError()\n\n elif isinstance(token, UserAccessToken):\n # With standalone site, only playlist admin or organization admin can access\n if not await self._user_has_playlist_or_organization_admin_role(\n token.payload.get(\"user_id\")\n ):\n raise ConnectionRefusedError()\n\n else:\n raise RuntimeError(\"This should not happen\")\n\n async def connect(self):\n \"\"\"\n Manage connection to this consumer.\n During handshake it is not possible to close the websocket with a specific\n code. To do that we must accept first the connection and then close it with the code we\n want\n \"\"\"\n try:\n await self._check_permissions()\n await self._check_video_exists()\n if not await self._is_admin():\n live_session = await self.retrieve_live_session()\n await self.update_live_session_with_channel_name(\n live_session=live_session\n )\n except ConnectionRefusedError:\n await self.accept()\n return await self.close(code=4003)\n\n self.room_group_name = await self._get_room_name()\n # Join room group\n await self.channel_layer.group_add(self.room_group_name, self.channel_name)\n\n await self.accept()\n self.is_connected = True\n\n async def _check_video_exists(self):\n \"\"\"Close the room if the video does not exists.\"\"\"\n if not await self._video_exists():\n raise ConnectionRefusedError()\n\n @database_sync_to_async\n def _video_exists(self):\n \"\"\"Return if a video exists in database or not.\"\"\"\n return Video.objects.filter(pk=self.__get_video_id()).exists()\n\n @database_sync_to_async\n def _user_has_playlist_or_organization_admin_role(self, user_id):\n \"\"\"Return if the user belongs to the video playlist admin or organization admin.\"\"\"\n return Video.objects.filter(\n Q(pk=self.__get_video_id())\n & (\n Q(\n playlist__user_accesses__user_id=user_id,\n playlist__user_accesses__role__in=[ADMINISTRATOR, INSTRUCTOR],\n )\n | Q(\n playlist__organization__user_accesses__user_id=user_id,\n playlist__organization__user_accesses__role=ADMINISTRATOR,\n )\n )\n ).exists()\n\n @database_sync_to_async\n def retrieve_live_session(self):\n \"\"\"Guess a live_session from the token and create it id not present.\"\"\"\n token = self.scope[\"token\"]\n if LiveSessionServices.is_lti_token(token):\n live_session, _ = LiveSessionServices.get_livesession_from_lti(token)\n else:\n query_string = parse_qs(self.scope[\"query_string\"])\n if b\"anonymous_id\" not in query_string:\n raise ConnectionRefusedError()\n live_session, _ = LiveSessionServices.get_livesession_from_anonymous_id(\n anonymous_id=query_string[b\"anonymous_id\"][0].decode(\"utf-8\"),\n video_id=token.payload[\"resource_id\"],\n )\n\n return live_session\n\n @database_sync_to_async\n def update_live_session_with_channel_name(self, live_session):\n \"\"\"Update the live_session with the current channel_name.\"\"\"\n live_session.channel_name = self.channel_name\n live_session.save()\n\n @database_sync_to_async\n def reset_live_session(self, live_session):\n \"\"\"Reset to None the live_session channel_name.\"\"\"\n live_session.channel_name = None\n live_session.save()\n\n async def _is_admin(self):\n \"\"\"Check if the connected user has admin permissions.\"\"\"\n token = self.scope[\"token\"]\n if not token:\n return False\n\n if isinstance(token, ResourceAccessToken):\n return IsTokenInstructor().check_role(token) or IsTokenAdmin().check_role(\n token\n )\n\n if isinstance(token, UserAccessToken):\n return await self._user_has_playlist_or_organization_admin_role(\n token.payload.get(\"user_id\"),\n )\n\n raise RuntimeError(\"Should not be called please check the code.\", type(token))\n\n async def _get_room_name(self):\n \"\"\"Generate the room name the user is connected on depending its permissions.\"\"\"\n if await self._is_admin():\n return defaults.VIDEO_ADMIN_ROOM_NAME.format(video_id=self.__get_video_id())\n\n return defaults.VIDEO_ROOM_NAME.format(video_id=self.__get_video_id())\n\n # pylint: disable=unused-argument\n async def disconnect(self, code):\n \"\"\"Manage disconnection to this consumer.\"\"\"\n # If connection was previously aborted nothing to do\n if not self.is_connected:\n return\n\n # Leave room group\n await self.channel_layer.group_discard(self.room_group_name, self.channel_name)\n if not await self._is_admin():\n try:\n live_session = await self.retrieve_live_session()\n await self.reset_live_session(live_session)\n except ConnectionRefusedError:\n # No live session found, nothing to do\n pass\n\n async def video_updated(self, event):\n \"\"\"Listener for the video_updated event.\"\"\"\n message = {\"type\": Video.RESOURCE_NAME, \"resource\": event[\"video\"]}\n await self.send_json(message)\n\n async def thumbnail_updated(self, event):\n \"\"\"Listener for the thumbnail updated event.\"\"\"\n message = {\"type\": Thumbnail.RESOURCE_NAME, \"resource\": event[\"thumbnail\"]}\n await self.send_json(message)\n\n async def timed_text_track_updated(self, event):\n \"\"\"Listener for the timed text track updated event.\"\"\"\n message = {\n \"type\": TimedTextTrack.RESOURCE_NAME,\n \"resource\": event[\"timed_text_track\"],\n }\n await self.send_json(message)\n\n async def shared_live_media_updated(self, event):\n \"\"\"Listener for the shared_live_media updated event.\"\"\"\n message = {\n \"type\": SharedLiveMedia.RESOURCE_NAME,\n \"resource\": event[\"shared_live_media\"],\n }\n await self.send_json(message)\n", "path": "src/backend/marsha/websocket/consumers/video.py"}]}
| 2,475 | 197 |
gh_patches_debug_43411
|
rasdani/github-patches
|
git_diff
|
ansible__ansible-modules-extras-3032
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Slack does not escape/encode ampersand (&) correctly
<!--- Verify first that your issue/request is not already reported in GitHub -->
##### ISSUE TYPE
<!--- Pick one below and delete the rest: -->
- Bug Report
##### COMPONENT NAME
Slack module
##### ANSIBLE VERSION
<!--- Paste verbatim output from “ansible --version” between quotes below -->
```
ansible 2.1.1.0
config file = /etc/ansible/ansible.cfg
configured module search path = Default w/o overrides
```
##### CONFIGURATION
<!---
Mention any settings you have changed/added/removed in ansible.cfg
(or using the ANSIBLE_* environment variables).
-->
N/A
##### OS / ENVIRONMENT
<!---
Mention the OS you are running Ansible from, and the OS you are
managing, or say “N/A” for anything that is not platform-specific.
-->
Mac OS X 10.11.4 (but probably N/A)
##### SUMMARY
<!--- Explain the problem briefly -->
Whenever the `msg` or a `text` inside `attachments` contains an ampersand (`&`), the Slack module fails with `HTTP Error 400: Bad Request`.
##### STEPS TO REPRODUCE
<!---
For bugs, show exactly how to reproduce the problem.
For new features, show how the feature would be used.
-->
Simply try to send a slack notification and make sure there is a `"&"` somewhere in the `msg` parameter (or inside a `attachments[].text`).
<!--- Paste example playbooks or commands between quotes below -->
```
- name: Send slack test message
hosts: MyHost
tasks:
- slack:
token: "xxx/yyy/zzz"
channel: "#my-channel"
username: "Ansible"
msg: "one & two"
```
<!--- You can also paste gist.github.com links for larger files -->
##### EXPECTED RESULTS
<!--- What did you expect to happen when running the steps above? -->
You'd expect to correctly receive the slack notification containing `"one & two"` as the message.
##### ACTUAL RESULTS
<!--- What actually happened? If possible run with high verbosity (-vvvv) -->
The module fails.
<!--- Paste verbatim command output between quotes below -->
```
fatal: [MyHost]: FAILED! => {"changed": false, "failed": true, "invocation": {"module_args": {"attachments": null, "channel": "#my-channel", "color": "normal", "domain": null, "icon_emoji": null, "icon_url": "http://www.ansible.com/favicon.ico", "link_names": 1, "msg": "one & two", "parse": null, "token": "VALUE_SPECIFIED_IN_NO_LOG_PARAMETER", "username": "Ansible", "validate_certs": true}, "module_name": "slack"}, "msg": " failed to send payload={\"username\": \"Ansible\", \"text\": \"one & two\", \"link_names\": 1, \"channel\": \"#my-channel\", \"icon_url\": \"http://www.ansible.com/favicon.ico\"} to https://hooks.slack.com/services/[obscured]: HTTP Error 400: Bad Request"}
```
##### Temporary workaround
I found that when I manually replace all `&` with `%26` (URL escaped ampersand), I receive the correct notification. For people wanting a temporary fix: `- text: "{{ originalText | replace('&', '%26') }}"`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `notification/slack.py`
Content:
```
1 #!/usr/bin/python
2 # -*- coding: utf-8 -*-
3
4 # (c) 2015, Stefan Berggren <[email protected]>
5 # (c) 2014, Ramon de la Fuente <[email protected]>
6 #
7 # This file is part of Ansible
8 #
9 # Ansible is free software: you can redistribute it and/or modify
10 # it under the terms of the GNU General Public License as published by
11 # the Free Software Foundation, either version 3 of the License, or
12 # (at your option) any later version.
13 #
14 # Ansible is distributed in the hope that it will be useful,
15 # but WITHOUT ANY WARRANTY; without even the implied warranty of
16 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
17 # GNU General Public License for more details.
18 #
19 # You should have received a copy of the GNU General Public License
20 # along with Ansible. If not, see <http://www.gnu.org/licenses/>.
21
22 DOCUMENTATION = """
23 module: slack
24 short_description: Send Slack notifications
25 description:
26 - The M(slack) module sends notifications to U(http://slack.com) via the Incoming WebHook integration
27 version_added: "1.6"
28 author: "Ramon de la Fuente (@ramondelafuente)"
29 options:
30 domain:
31 description:
32 - Slack (sub)domain for your environment without protocol. (i.e.
33 C(future500.slack.com)) In 1.8 and beyond, this is deprecated and may
34 be ignored. See token documentation for information.
35 required: false
36 default: None
37 token:
38 description:
39 - Slack integration token. This authenticates you to the slack service.
40 Prior to 1.8, a token looked like C(3Ffe373sfhRE6y42Fg3rvf4GlK). In
41 1.8 and above, ansible adapts to the new slack API where tokens look
42 like C(G922VJP24/D921DW937/3Ffe373sfhRE6y42Fg3rvf4GlK). If tokens
43 are in the new format then slack will ignore any value of domain. If
44 the token is in the old format the domain is required. Ansible has no
45 control of when slack will get rid of the old API. When slack does
46 that the old format will stop working.
47 required: true
48 msg:
49 description:
50 - Message to send.
51 required: false
52 default: None
53 channel:
54 description:
55 - Channel to send the message to. If absent, the message goes to the channel selected for the I(token).
56 required: false
57 default: None
58 username:
59 description:
60 - This is the sender of the message.
61 required: false
62 default: "Ansible"
63 icon_url:
64 description:
65 - Url for the message sender's icon (default C(https://www.ansible.com/favicon.ico))
66 required: false
67 icon_emoji:
68 description:
69 - Emoji for the message sender. See Slack documentation for options.
70 (if I(icon_emoji) is set, I(icon_url) will not be used)
71 required: false
72 default: None
73 link_names:
74 description:
75 - Automatically create links for channels and usernames in I(msg).
76 required: false
77 default: 1
78 choices:
79 - 1
80 - 0
81 parse:
82 description:
83 - Setting for the message parser at Slack
84 required: false
85 default: None
86 choices:
87 - 'full'
88 - 'none'
89 validate_certs:
90 description:
91 - If C(no), SSL certificates will not be validated. This should only be used
92 on personally controlled sites using self-signed certificates.
93 required: false
94 default: 'yes'
95 choices:
96 - 'yes'
97 - 'no'
98 color:
99 version_added: "2.0"
100 description:
101 - Allow text to use default colors - use the default of 'normal' to not send a custom color bar at the start of the message
102 required: false
103 default: 'normal'
104 choices:
105 - 'normal'
106 - 'good'
107 - 'warning'
108 - 'danger'
109 attachments:
110 description:
111 - Define a list of attachments. This list mirrors the Slack JSON API. For more information, see https://api.slack.com/docs/attachments
112 required: false
113 default: None
114 """
115
116 EXAMPLES = """
117 - name: Send notification message via Slack
118 local_action:
119 module: slack
120 token: thetoken/generatedby/slack
121 msg: "{{ inventory_hostname }} completed"
122
123 - name: Send notification message via Slack all options
124 local_action:
125 module: slack
126 token: thetoken/generatedby/slack
127 msg: "{{ inventory_hostname }} completed"
128 channel: "#ansible"
129 username: "Ansible on {{ inventory_hostname }}"
130 icon_url: "http://www.example.com/some-image-file.png"
131 link_names: 0
132 parse: 'none'
133
134 - name: insert a color bar in front of the message for visibility purposes and use the default webhook icon and name configured in Slack
135 slack:
136 token: thetoken/generatedby/slack
137 msg: "{{ inventory_hostname }} is alive!"
138 color: good
139 username: ""
140 icon_url: ""
141
142 - name: Use the attachments API
143 slack:
144 token: thetoken/generatedby/slack
145 attachments:
146 - text: "Display my system load on host A and B"
147 color: "#ff00dd"
148 title: "System load"
149 fields:
150 - title: "System A"
151 value: "load average: 0,74, 0,66, 0,63"
152 short: "true"
153 - title: "System B"
154 value: "load average: 5,16, 4,64, 2,43"
155 short: "true"
156
157 - name: Send notification message via Slack (deprecated API using domian)
158 local_action:
159 module: slack
160 domain: future500.slack.com
161 token: thetokengeneratedbyslack
162 msg: "{{ inventory_hostname }} completed"
163
164 """
165
166 OLD_SLACK_INCOMING_WEBHOOK = 'https://%s/services/hooks/incoming-webhook?token=%s'
167 SLACK_INCOMING_WEBHOOK = 'https://hooks.slack.com/services/%s'
168
169 def build_payload_for_slack(module, text, channel, username, icon_url, icon_emoji, link_names, parse, color, attachments):
170 payload = {}
171 if color == "normal" and text is not None:
172 payload = dict(text=text)
173 elif text is not None:
174 # With a custom color we have to set the message as attachment, and explicitely turn markdown parsing on for it.
175 payload = dict(attachments=[dict(text=text, color=color, mrkdwn_in=["text"])])
176 if channel is not None:
177 if (channel[0] == '#') or (channel[0] == '@'):
178 payload['channel'] = channel
179 else:
180 payload['channel'] = '#'+channel
181 if username is not None:
182 payload['username'] = username
183 if icon_emoji is not None:
184 payload['icon_emoji'] = icon_emoji
185 else:
186 payload['icon_url'] = icon_url
187 if link_names is not None:
188 payload['link_names'] = link_names
189 if parse is not None:
190 payload['parse'] = parse
191
192 if attachments is not None:
193 if 'attachments' not in payload:
194 payload['attachments'] = []
195
196 if attachments is not None:
197 for attachment in attachments:
198 if 'fallback' not in attachment:
199 attachment['fallback'] = attachment['text']
200 payload['attachments'].append(attachment)
201
202 payload="payload=" + module.jsonify(payload)
203 return payload
204
205 def do_notify_slack(module, domain, token, payload):
206 if token.count('/') >= 2:
207 # New style token
208 slack_incoming_webhook = SLACK_INCOMING_WEBHOOK % (token)
209 else:
210 if not domain:
211 module.fail_json(msg="Slack has updated its webhook API. You need to specify a token of the form XXXX/YYYY/ZZZZ in your playbook")
212 slack_incoming_webhook = OLD_SLACK_INCOMING_WEBHOOK % (domain, token)
213
214 response, info = fetch_url(module, slack_incoming_webhook, data=payload)
215 if info['status'] != 200:
216 obscured_incoming_webhook = SLACK_INCOMING_WEBHOOK % ('[obscured]')
217 module.fail_json(msg=" failed to send %s to %s: %s" % (payload, obscured_incoming_webhook, info['msg']))
218
219 def main():
220 module = AnsibleModule(
221 argument_spec = dict(
222 domain = dict(type='str', required=False, default=None),
223 token = dict(type='str', required=True, no_log=True),
224 msg = dict(type='str', required=False, default=None),
225 channel = dict(type='str', default=None),
226 username = dict(type='str', default='Ansible'),
227 icon_url = dict(type='str', default='https://www.ansible.com/favicon.ico'),
228 icon_emoji = dict(type='str', default=None),
229 link_names = dict(type='int', default=1, choices=[0,1]),
230 parse = dict(type='str', default=None, choices=['none', 'full']),
231 validate_certs = dict(default='yes', type='bool'),
232 color = dict(type='str', default='normal', choices=['normal', 'good', 'warning', 'danger']),
233 attachments = dict(type='list', required=False, default=None)
234 )
235 )
236
237 domain = module.params['domain']
238 token = module.params['token']
239 text = module.params['msg']
240 channel = module.params['channel']
241 username = module.params['username']
242 icon_url = module.params['icon_url']
243 icon_emoji = module.params['icon_emoji']
244 link_names = module.params['link_names']
245 parse = module.params['parse']
246 color = module.params['color']
247 attachments = module.params['attachments']
248
249 payload = build_payload_for_slack(module, text, channel, username, icon_url, icon_emoji, link_names, parse, color, attachments)
250 do_notify_slack(module, domain, token, payload)
251
252 module.exit_json(msg="OK")
253
254 # import module snippets
255 from ansible.module_utils.basic import *
256 from ansible.module_utils.urls import *
257
258 if __name__ == '__main__':
259 main()
260
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/notification/slack.py b/notification/slack.py
--- a/notification/slack.py
+++ b/notification/slack.py
@@ -1,6 +1,7 @@
#!/usr/bin/python
# -*- coding: utf-8 -*-
+# (c) 2016, René Moser <[email protected]>
# (c) 2015, Stefan Berggren <[email protected]>
# (c) 2014, Ramon de la Fuente <[email protected]>
#
@@ -154,7 +155,7 @@
value: "load average: 5,16, 4,64, 2,43"
short: "true"
-- name: Send notification message via Slack (deprecated API using domian)
+- name: Send notification message via Slack (deprecated API using domain)
local_action:
module: slack
domain: future500.slack.com
@@ -166,13 +167,27 @@
OLD_SLACK_INCOMING_WEBHOOK = 'https://%s/services/hooks/incoming-webhook?token=%s'
SLACK_INCOMING_WEBHOOK = 'https://hooks.slack.com/services/%s'
+# See https://api.slack.com/docs/message-formatting#how_to_escape_characters
+# Escaping quotes and apostrophe however is related to how Ansible handles them.
+html_escape_table = {
+ '&': "&",
+ '>': ">",
+ '<': "<",
+ '"': "\"",
+ "'": "\'",
+}
+
+def html_escape(text):
+ '''Produce entities within text.'''
+ return "".join(html_escape_table.get(c,c) for c in text)
+
def build_payload_for_slack(module, text, channel, username, icon_url, icon_emoji, link_names, parse, color, attachments):
payload = {}
if color == "normal" and text is not None:
- payload = dict(text=text)
+ payload = dict(text=html_escape(text))
elif text is not None:
# With a custom color we have to set the message as attachment, and explicitely turn markdown parsing on for it.
- payload = dict(attachments=[dict(text=text, color=color, mrkdwn_in=["text"])])
+ payload = dict(attachments=[dict(text=html_escape(text), color=color, mrkdwn_in=["text"])])
if channel is not None:
if (channel[0] == '#') or (channel[0] == '@'):
payload['channel'] = channel
@@ -194,12 +209,24 @@
payload['attachments'] = []
if attachments is not None:
+ keys_to_escape = [
+ 'title',
+ 'text',
+ 'author_name',
+ 'pretext',
+ 'fallback',
+ ]
for attachment in attachments:
+ for key in keys_to_escape:
+ if key in attachment:
+ attachment[key] = html_escape(attachment[key])
+
if 'fallback' not in attachment:
attachment['fallback'] = attachment['text']
+
payload['attachments'].append(attachment)
- payload="payload=" + module.jsonify(payload)
+ payload=module.jsonify(payload)
return payload
def do_notify_slack(module, domain, token, payload):
@@ -211,7 +238,12 @@
module.fail_json(msg="Slack has updated its webhook API. You need to specify a token of the form XXXX/YYYY/ZZZZ in your playbook")
slack_incoming_webhook = OLD_SLACK_INCOMING_WEBHOOK % (domain, token)
- response, info = fetch_url(module, slack_incoming_webhook, data=payload)
+ headers = {
+ 'Content-Type': 'application/json',
+ 'Accept': 'application/json',
+ }
+ response, info = fetch_url(module=module, url=slack_incoming_webhook, headers=headers, method='POST', data=payload)
+
if info['status'] != 200:
obscured_incoming_webhook = SLACK_INCOMING_WEBHOOK % ('[obscured]')
module.fail_json(msg=" failed to send %s to %s: %s" % (payload, obscured_incoming_webhook, info['msg']))
|
{"golden_diff": "diff --git a/notification/slack.py b/notification/slack.py\n--- a/notification/slack.py\n+++ b/notification/slack.py\n@@ -1,6 +1,7 @@\n #!/usr/bin/python\n # -*- coding: utf-8 -*-\n \n+# (c) 2016, Ren\u00e9 Moser <[email protected]>\n # (c) 2015, Stefan Berggren <[email protected]>\n # (c) 2014, Ramon de la Fuente <[email protected]>\n #\n@@ -154,7 +155,7 @@\n value: \"load average: 5,16, 4,64, 2,43\"\n short: \"true\"\n \n-- name: Send notification message via Slack (deprecated API using domian)\n+- name: Send notification message via Slack (deprecated API using domain)\n local_action:\n module: slack\n domain: future500.slack.com\n@@ -166,13 +167,27 @@\n OLD_SLACK_INCOMING_WEBHOOK = 'https://%s/services/hooks/incoming-webhook?token=%s'\n SLACK_INCOMING_WEBHOOK = 'https://hooks.slack.com/services/%s'\n \n+# See https://api.slack.com/docs/message-formatting#how_to_escape_characters\n+# Escaping quotes and apostrophe however is related to how Ansible handles them.\n+html_escape_table = {\n+ '&': \"&\",\n+ '>': \">\",\n+ '<': \"<\",\n+ '\"': \"\\\"\",\n+ \"'\": \"\\'\",\n+}\n+\n+def html_escape(text):\n+ '''Produce entities within text.'''\n+ return \"\".join(html_escape_table.get(c,c) for c in text)\n+\n def build_payload_for_slack(module, text, channel, username, icon_url, icon_emoji, link_names, parse, color, attachments):\n payload = {}\n if color == \"normal\" and text is not None:\n- payload = dict(text=text)\n+ payload = dict(text=html_escape(text))\n elif text is not None:\n # With a custom color we have to set the message as attachment, and explicitely turn markdown parsing on for it.\n- payload = dict(attachments=[dict(text=text, color=color, mrkdwn_in=[\"text\"])])\n+ payload = dict(attachments=[dict(text=html_escape(text), color=color, mrkdwn_in=[\"text\"])])\n if channel is not None:\n if (channel[0] == '#') or (channel[0] == '@'):\n payload['channel'] = channel\n@@ -194,12 +209,24 @@\n payload['attachments'] = []\n \n if attachments is not None:\n+ keys_to_escape = [\n+ 'title',\n+ 'text',\n+ 'author_name',\n+ 'pretext',\n+ 'fallback',\n+ ]\n for attachment in attachments:\n+ for key in keys_to_escape:\n+ if key in attachment:\n+ attachment[key] = html_escape(attachment[key])\n+\n if 'fallback' not in attachment:\n attachment['fallback'] = attachment['text']\n+\n payload['attachments'].append(attachment)\n \n- payload=\"payload=\" + module.jsonify(payload)\n+ payload=module.jsonify(payload)\n return payload\n \n def do_notify_slack(module, domain, token, payload):\n@@ -211,7 +238,12 @@\n module.fail_json(msg=\"Slack has updated its webhook API. You need to specify a token of the form XXXX/YYYY/ZZZZ in your playbook\")\n slack_incoming_webhook = OLD_SLACK_INCOMING_WEBHOOK % (domain, token)\n \n- response, info = fetch_url(module, slack_incoming_webhook, data=payload)\n+ headers = {\n+ 'Content-Type': 'application/json',\n+ 'Accept': 'application/json',\n+ }\n+ response, info = fetch_url(module=module, url=slack_incoming_webhook, headers=headers, method='POST', data=payload)\n+\n if info['status'] != 200:\n obscured_incoming_webhook = SLACK_INCOMING_WEBHOOK % ('[obscured]')\n module.fail_json(msg=\" failed to send %s to %s: %s\" % (payload, obscured_incoming_webhook, info['msg']))\n", "issue": "Slack does not escape/encode ampersand (&) correctly\n<!--- Verify first that your issue/request is not already reported in GitHub -->\n##### ISSUE TYPE\n\n<!--- Pick one below and delete the rest: -->\n- Bug Report\n##### COMPONENT NAME\n\nSlack module\n##### ANSIBLE VERSION\n\n<!--- Paste verbatim output from \u201cansible --version\u201d between quotes below -->\n\n```\nansible 2.1.1.0\n config file = /etc/ansible/ansible.cfg\n configured module search path = Default w/o overrides\n```\n##### CONFIGURATION\n\n<!---\nMention any settings you have changed/added/removed in ansible.cfg\n(or using the ANSIBLE_* environment variables).\n-->\n\nN/A\n##### OS / ENVIRONMENT\n\n<!---\nMention the OS you are running Ansible from, and the OS you are\nmanaging, or say \u201cN/A\u201d for anything that is not platform-specific.\n-->\n\nMac OS X 10.11.4 (but probably N/A)\n##### SUMMARY\n\n<!--- Explain the problem briefly -->\n\nWhenever the `msg` or a `text` inside `attachments` contains an ampersand (`&`), the Slack module fails with `HTTP Error 400: Bad Request`.\n##### STEPS TO REPRODUCE\n\n<!---\nFor bugs, show exactly how to reproduce the problem.\nFor new features, show how the feature would be used.\n-->\n\nSimply try to send a slack notification and make sure there is a `\"&\"` somewhere in the `msg` parameter (or inside a `attachments[].text`).\n\n<!--- Paste example playbooks or commands between quotes below -->\n\n```\n- name: Send slack test message\n hosts: MyHost\n tasks:\n - slack:\n token: \"xxx/yyy/zzz\"\n channel: \"#my-channel\"\n username: \"Ansible\"\n msg: \"one & two\"\n```\n\n<!--- You can also paste gist.github.com links for larger files -->\n##### EXPECTED RESULTS\n\n<!--- What did you expect to happen when running the steps above? -->\n\nYou'd expect to correctly receive the slack notification containing `\"one & two\"` as the message.\n##### ACTUAL RESULTS\n\n<!--- What actually happened? If possible run with high verbosity (-vvvv) -->\n\nThe module fails.\n\n<!--- Paste verbatim command output between quotes below -->\n\n```\nfatal: [MyHost]: FAILED! => {\"changed\": false, \"failed\": true, \"invocation\": {\"module_args\": {\"attachments\": null, \"channel\": \"#my-channel\", \"color\": \"normal\", \"domain\": null, \"icon_emoji\": null, \"icon_url\": \"http://www.ansible.com/favicon.ico\", \"link_names\": 1, \"msg\": \"one & two\", \"parse\": null, \"token\": \"VALUE_SPECIFIED_IN_NO_LOG_PARAMETER\", \"username\": \"Ansible\", \"validate_certs\": true}, \"module_name\": \"slack\"}, \"msg\": \" failed to send payload={\\\"username\\\": \\\"Ansible\\\", \\\"text\\\": \\\"one & two\\\", \\\"link_names\\\": 1, \\\"channel\\\": \\\"#my-channel\\\", \\\"icon_url\\\": \\\"http://www.ansible.com/favicon.ico\\\"} to https://hooks.slack.com/services/[obscured]: HTTP Error 400: Bad Request\"}\n```\n##### Temporary workaround\n\nI found that when I manually replace all `&` with `%26` (URL escaped ampersand), I receive the correct notification. For people wanting a temporary fix: `- text: \"{{ originalText | replace('&', '%26') }}\"`\n\n", "before_files": [{"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n# (c) 2015, Stefan Berggren <[email protected]>\n# (c) 2014, Ramon de la Fuente <[email protected]>\n#\n# This file is part of Ansible\n#\n# Ansible is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Ansible is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Ansible. If not, see <http://www.gnu.org/licenses/>.\n\nDOCUMENTATION = \"\"\"\nmodule: slack\nshort_description: Send Slack notifications\ndescription:\n - The M(slack) module sends notifications to U(http://slack.com) via the Incoming WebHook integration\nversion_added: \"1.6\"\nauthor: \"Ramon de la Fuente (@ramondelafuente)\"\noptions:\n domain:\n description:\n - Slack (sub)domain for your environment without protocol. (i.e.\n C(future500.slack.com)) In 1.8 and beyond, this is deprecated and may\n be ignored. See token documentation for information.\n required: false\n default: None\n token:\n description:\n - Slack integration token. This authenticates you to the slack service.\n Prior to 1.8, a token looked like C(3Ffe373sfhRE6y42Fg3rvf4GlK). In\n 1.8 and above, ansible adapts to the new slack API where tokens look\n like C(G922VJP24/D921DW937/3Ffe373sfhRE6y42Fg3rvf4GlK). If tokens\n are in the new format then slack will ignore any value of domain. If\n the token is in the old format the domain is required. Ansible has no\n control of when slack will get rid of the old API. When slack does\n that the old format will stop working.\n required: true\n msg:\n description:\n - Message to send.\n required: false\n default: None\n channel:\n description:\n - Channel to send the message to. If absent, the message goes to the channel selected for the I(token).\n required: false\n default: None\n username:\n description:\n - This is the sender of the message.\n required: false\n default: \"Ansible\"\n icon_url:\n description:\n - Url for the message sender's icon (default C(https://www.ansible.com/favicon.ico))\n required: false\n icon_emoji:\n description:\n - Emoji for the message sender. See Slack documentation for options.\n (if I(icon_emoji) is set, I(icon_url) will not be used)\n required: false\n default: None\n link_names:\n description:\n - Automatically create links for channels and usernames in I(msg).\n required: false\n default: 1\n choices:\n - 1\n - 0\n parse:\n description:\n - Setting for the message parser at Slack\n required: false\n default: None\n choices:\n - 'full'\n - 'none'\n validate_certs:\n description:\n - If C(no), SSL certificates will not be validated. This should only be used\n on personally controlled sites using self-signed certificates.\n required: false\n default: 'yes'\n choices:\n - 'yes'\n - 'no'\n color:\n version_added: \"2.0\"\n description:\n - Allow text to use default colors - use the default of 'normal' to not send a custom color bar at the start of the message\n required: false\n default: 'normal'\n choices:\n - 'normal'\n - 'good'\n - 'warning'\n - 'danger'\n attachments:\n description:\n - Define a list of attachments. This list mirrors the Slack JSON API. For more information, see https://api.slack.com/docs/attachments\n required: false\n default: None\n\"\"\"\n\nEXAMPLES = \"\"\"\n- name: Send notification message via Slack\n local_action:\n module: slack\n token: thetoken/generatedby/slack\n msg: \"{{ inventory_hostname }} completed\"\n\n- name: Send notification message via Slack all options\n local_action:\n module: slack\n token: thetoken/generatedby/slack\n msg: \"{{ inventory_hostname }} completed\"\n channel: \"#ansible\"\n username: \"Ansible on {{ inventory_hostname }}\"\n icon_url: \"http://www.example.com/some-image-file.png\"\n link_names: 0\n parse: 'none'\n\n- name: insert a color bar in front of the message for visibility purposes and use the default webhook icon and name configured in Slack\n slack:\n token: thetoken/generatedby/slack\n msg: \"{{ inventory_hostname }} is alive!\"\n color: good\n username: \"\"\n icon_url: \"\"\n\n- name: Use the attachments API\n slack:\n token: thetoken/generatedby/slack\n attachments:\n - text: \"Display my system load on host A and B\"\n color: \"#ff00dd\"\n title: \"System load\"\n fields:\n - title: \"System A\"\n value: \"load average: 0,74, 0,66, 0,63\"\n short: \"true\"\n - title: \"System B\"\n value: \"load average: 5,16, 4,64, 2,43\"\n short: \"true\"\n\n- name: Send notification message via Slack (deprecated API using domian)\n local_action:\n module: slack\n domain: future500.slack.com\n token: thetokengeneratedbyslack\n msg: \"{{ inventory_hostname }} completed\"\n\n\"\"\"\n\nOLD_SLACK_INCOMING_WEBHOOK = 'https://%s/services/hooks/incoming-webhook?token=%s'\nSLACK_INCOMING_WEBHOOK = 'https://hooks.slack.com/services/%s'\n\ndef build_payload_for_slack(module, text, channel, username, icon_url, icon_emoji, link_names, parse, color, attachments):\n payload = {}\n if color == \"normal\" and text is not None:\n payload = dict(text=text)\n elif text is not None:\n # With a custom color we have to set the message as attachment, and explicitely turn markdown parsing on for it.\n payload = dict(attachments=[dict(text=text, color=color, mrkdwn_in=[\"text\"])])\n if channel is not None:\n if (channel[0] == '#') or (channel[0] == '@'):\n payload['channel'] = channel\n else:\n payload['channel'] = '#'+channel\n if username is not None:\n payload['username'] = username\n if icon_emoji is not None:\n payload['icon_emoji'] = icon_emoji\n else:\n payload['icon_url'] = icon_url\n if link_names is not None:\n payload['link_names'] = link_names\n if parse is not None:\n payload['parse'] = parse\n\n if attachments is not None:\n if 'attachments' not in payload:\n payload['attachments'] = []\n\n if attachments is not None:\n for attachment in attachments:\n if 'fallback' not in attachment:\n attachment['fallback'] = attachment['text']\n payload['attachments'].append(attachment)\n\n payload=\"payload=\" + module.jsonify(payload)\n return payload\n\ndef do_notify_slack(module, domain, token, payload):\n if token.count('/') >= 2:\n # New style token\n slack_incoming_webhook = SLACK_INCOMING_WEBHOOK % (token)\n else:\n if not domain:\n module.fail_json(msg=\"Slack has updated its webhook API. You need to specify a token of the form XXXX/YYYY/ZZZZ in your playbook\")\n slack_incoming_webhook = OLD_SLACK_INCOMING_WEBHOOK % (domain, token)\n\n response, info = fetch_url(module, slack_incoming_webhook, data=payload)\n if info['status'] != 200:\n obscured_incoming_webhook = SLACK_INCOMING_WEBHOOK % ('[obscured]')\n module.fail_json(msg=\" failed to send %s to %s: %s\" % (payload, obscured_incoming_webhook, info['msg']))\n\ndef main():\n module = AnsibleModule(\n argument_spec = dict(\n domain = dict(type='str', required=False, default=None),\n token = dict(type='str', required=True, no_log=True),\n msg = dict(type='str', required=False, default=None),\n channel = dict(type='str', default=None),\n username = dict(type='str', default='Ansible'),\n icon_url = dict(type='str', default='https://www.ansible.com/favicon.ico'),\n icon_emoji = dict(type='str', default=None),\n link_names = dict(type='int', default=1, choices=[0,1]),\n parse = dict(type='str', default=None, choices=['none', 'full']),\n validate_certs = dict(default='yes', type='bool'),\n color = dict(type='str', default='normal', choices=['normal', 'good', 'warning', 'danger']),\n attachments = dict(type='list', required=False, default=None)\n )\n )\n\n domain = module.params['domain']\n token = module.params['token']\n text = module.params['msg']\n channel = module.params['channel']\n username = module.params['username']\n icon_url = module.params['icon_url']\n icon_emoji = module.params['icon_emoji']\n link_names = module.params['link_names']\n parse = module.params['parse']\n color = module.params['color']\n attachments = module.params['attachments']\n\n payload = build_payload_for_slack(module, text, channel, username, icon_url, icon_emoji, link_names, parse, color, attachments)\n do_notify_slack(module, domain, token, payload)\n\n module.exit_json(msg=\"OK\")\n\n# import module snippets\nfrom ansible.module_utils.basic import *\nfrom ansible.module_utils.urls import *\n\nif __name__ == '__main__':\n main()\n", "path": "notification/slack.py"}], "after_files": [{"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n# (c) 2016, Ren\u00e9 Moser <[email protected]>\n# (c) 2015, Stefan Berggren <[email protected]>\n# (c) 2014, Ramon de la Fuente <[email protected]>\n#\n# This file is part of Ansible\n#\n# Ansible is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Ansible is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Ansible. If not, see <http://www.gnu.org/licenses/>.\n\nDOCUMENTATION = \"\"\"\nmodule: slack\nshort_description: Send Slack notifications\ndescription:\n - The M(slack) module sends notifications to U(http://slack.com) via the Incoming WebHook integration\nversion_added: \"1.6\"\nauthor: \"Ramon de la Fuente (@ramondelafuente)\"\noptions:\n domain:\n description:\n - Slack (sub)domain for your environment without protocol. (i.e.\n C(future500.slack.com)) In 1.8 and beyond, this is deprecated and may\n be ignored. See token documentation for information.\n required: false\n default: None\n token:\n description:\n - Slack integration token. This authenticates you to the slack service.\n Prior to 1.8, a token looked like C(3Ffe373sfhRE6y42Fg3rvf4GlK). In\n 1.8 and above, ansible adapts to the new slack API where tokens look\n like C(G922VJP24/D921DW937/3Ffe373sfhRE6y42Fg3rvf4GlK). If tokens\n are in the new format then slack will ignore any value of domain. If\n the token is in the old format the domain is required. Ansible has no\n control of when slack will get rid of the old API. When slack does\n that the old format will stop working.\n required: true\n msg:\n description:\n - Message to send.\n required: false\n default: None\n channel:\n description:\n - Channel to send the message to. If absent, the message goes to the channel selected for the I(token).\n required: false\n default: None\n username:\n description:\n - This is the sender of the message.\n required: false\n default: \"Ansible\"\n icon_url:\n description:\n - Url for the message sender's icon (default C(https://www.ansible.com/favicon.ico))\n required: false\n icon_emoji:\n description:\n - Emoji for the message sender. See Slack documentation for options.\n (if I(icon_emoji) is set, I(icon_url) will not be used)\n required: false\n default: None\n link_names:\n description:\n - Automatically create links for channels and usernames in I(msg).\n required: false\n default: 1\n choices:\n - 1\n - 0\n parse:\n description:\n - Setting for the message parser at Slack\n required: false\n default: None\n choices:\n - 'full'\n - 'none'\n validate_certs:\n description:\n - If C(no), SSL certificates will not be validated. This should only be used\n on personally controlled sites using self-signed certificates.\n required: false\n default: 'yes'\n choices:\n - 'yes'\n - 'no'\n color:\n version_added: \"2.0\"\n description:\n - Allow text to use default colors - use the default of 'normal' to not send a custom color bar at the start of the message\n required: false\n default: 'normal'\n choices:\n - 'normal'\n - 'good'\n - 'warning'\n - 'danger'\n attachments:\n description:\n - Define a list of attachments. This list mirrors the Slack JSON API. For more information, see https://api.slack.com/docs/attachments\n required: false\n default: None\n\"\"\"\n\nEXAMPLES = \"\"\"\n- name: Send notification message via Slack\n local_action:\n module: slack\n token: thetoken/generatedby/slack\n msg: \"{{ inventory_hostname }} completed\"\n\n- name: Send notification message via Slack all options\n local_action:\n module: slack\n token: thetoken/generatedby/slack\n msg: \"{{ inventory_hostname }} completed\"\n channel: \"#ansible\"\n username: \"Ansible on {{ inventory_hostname }}\"\n icon_url: \"http://www.example.com/some-image-file.png\"\n link_names: 0\n parse: 'none'\n\n- name: insert a color bar in front of the message for visibility purposes and use the default webhook icon and name configured in Slack\n slack:\n token: thetoken/generatedby/slack\n msg: \"{{ inventory_hostname }} is alive!\"\n color: good\n username: \"\"\n icon_url: \"\"\n\n- name: Use the attachments API\n slack:\n token: thetoken/generatedby/slack\n attachments:\n - text: \"Display my system load on host A and B\"\n color: \"#ff00dd\"\n title: \"System load\"\n fields:\n - title: \"System A\"\n value: \"load average: 0,74, 0,66, 0,63\"\n short: \"true\"\n - title: \"System B\"\n value: \"load average: 5,16, 4,64, 2,43\"\n short: \"true\"\n\n- name: Send notification message via Slack (deprecated API using domain)\n local_action:\n module: slack\n domain: future500.slack.com\n token: thetokengeneratedbyslack\n msg: \"{{ inventory_hostname }} completed\"\n\n\"\"\"\n\nOLD_SLACK_INCOMING_WEBHOOK = 'https://%s/services/hooks/incoming-webhook?token=%s'\nSLACK_INCOMING_WEBHOOK = 'https://hooks.slack.com/services/%s'\n\n# See https://api.slack.com/docs/message-formatting#how_to_escape_characters\n# Escaping quotes and apostrophe however is related to how Ansible handles them.\nhtml_escape_table = {\n '&': \"&\",\n '>': \">\",\n '<': \"<\",\n '\"': \"\\\"\",\n \"'\": \"\\'\",\n}\n\ndef html_escape(text):\n '''Produce entities within text.'''\n return \"\".join(html_escape_table.get(c,c) for c in text)\n\ndef build_payload_for_slack(module, text, channel, username, icon_url, icon_emoji, link_names, parse, color, attachments):\n payload = {}\n if color == \"normal\" and text is not None:\n payload = dict(text=html_escape(text))\n elif text is not None:\n # With a custom color we have to set the message as attachment, and explicitely turn markdown parsing on for it.\n payload = dict(attachments=[dict(text=html_escape(text), color=color, mrkdwn_in=[\"text\"])])\n if channel is not None:\n if (channel[0] == '#') or (channel[0] == '@'):\n payload['channel'] = channel\n else:\n payload['channel'] = '#'+channel\n if username is not None:\n payload['username'] = username\n if icon_emoji is not None:\n payload['icon_emoji'] = icon_emoji\n else:\n payload['icon_url'] = icon_url\n if link_names is not None:\n payload['link_names'] = link_names\n if parse is not None:\n payload['parse'] = parse\n\n if attachments is not None:\n if 'attachments' not in payload:\n payload['attachments'] = []\n\n if attachments is not None:\n keys_to_escape = [\n 'title',\n 'text',\n 'author_name',\n 'pretext',\n 'fallback',\n ]\n for attachment in attachments:\n for key in keys_to_escape:\n if key in attachment:\n attachment[key] = html_escape(attachment[key])\n\n if 'fallback' not in attachment:\n attachment['fallback'] = attachment['text']\n\n payload['attachments'].append(attachment)\n\n payload=module.jsonify(payload)\n return payload\n\ndef do_notify_slack(module, domain, token, payload):\n if token.count('/') >= 2:\n # New style token\n slack_incoming_webhook = SLACK_INCOMING_WEBHOOK % (token)\n else:\n if not domain:\n module.fail_json(msg=\"Slack has updated its webhook API. You need to specify a token of the form XXXX/YYYY/ZZZZ in your playbook\")\n slack_incoming_webhook = OLD_SLACK_INCOMING_WEBHOOK % (domain, token)\n\n headers = {\n 'Content-Type': 'application/json',\n 'Accept': 'application/json',\n }\n response, info = fetch_url(module=module, url=slack_incoming_webhook, headers=headers, method='POST', data=payload)\n\n if info['status'] != 200:\n obscured_incoming_webhook = SLACK_INCOMING_WEBHOOK % ('[obscured]')\n module.fail_json(msg=\" failed to send %s to %s: %s\" % (payload, obscured_incoming_webhook, info['msg']))\n\ndef main():\n module = AnsibleModule(\n argument_spec = dict(\n domain = dict(type='str', required=False, default=None),\n token = dict(type='str', required=True, no_log=True),\n msg = dict(type='str', required=False, default=None),\n channel = dict(type='str', default=None),\n username = dict(type='str', default='Ansible'),\n icon_url = dict(type='str', default='https://www.ansible.com/favicon.ico'),\n icon_emoji = dict(type='str', default=None),\n link_names = dict(type='int', default=1, choices=[0,1]),\n parse = dict(type='str', default=None, choices=['none', 'full']),\n validate_certs = dict(default='yes', type='bool'),\n color = dict(type='str', default='normal', choices=['normal', 'good', 'warning', 'danger']),\n attachments = dict(type='list', required=False, default=None)\n )\n )\n\n domain = module.params['domain']\n token = module.params['token']\n text = module.params['msg']\n channel = module.params['channel']\n username = module.params['username']\n icon_url = module.params['icon_url']\n icon_emoji = module.params['icon_emoji']\n link_names = module.params['link_names']\n parse = module.params['parse']\n color = module.params['color']\n attachments = module.params['attachments']\n\n payload = build_payload_for_slack(module, text, channel, username, icon_url, icon_emoji, link_names, parse, color, attachments)\n do_notify_slack(module, domain, token, payload)\n\n module.exit_json(msg=\"OK\")\n\n# import module snippets\nfrom ansible.module_utils.basic import *\nfrom ansible.module_utils.urls import *\n\nif __name__ == '__main__':\n main()\n", "path": "notification/slack.py"}]}
| 4,026 | 955 |
gh_patches_debug_27026
|
rasdani/github-patches
|
git_diff
|
DataDog__integrations-core-619
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
postfix integration should not require sudo to root
Reading the source code to integrations-core/postfix/check.py I note that it does a sudo to root to run the find command.
This is noted in the docs / comments :
> WARNING: the user that dd-agent runs as must have sudo access for the 'find' command
> --
> | sudo access is not required when running dd-agent as root (not recommended)
> |
> | example /etc/sudoers entry:
> | dd-agent ALL=(ALL) NOPASSWD:/usr/bin/find /var/spool/postfix* -type f
root should not be required here - postfix user should be sufficient. That would be combined with a '-u postfix' on line 64's sudo command to allow this to work.
This is a concern because find has a -exec parameter and your command list has a wildcard in it - this could be used to run arbitrary commands as root if the dd-agent user is compromised.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `postfix/check.py`
Content:
```
1 # (C) Datadog, Inc. 2013-2016
2 # (C) Josiah C Webb <[email protected]> 2013
3 # All rights reserved
4 # Licensed under Simplified BSD License (see LICENSE)
5
6 # stdlib
7 import os
8
9 # project
10 from checks import AgentCheck
11 from utils.subprocess_output import get_subprocess_output
12
13 class PostfixCheck(AgentCheck):
14 """This check provides metrics on the number of messages in a given postfix queue
15
16 WARNING: the user that dd-agent runs as must have sudo access for the 'find' command
17 sudo access is not required when running dd-agent as root (not recommended)
18
19 example /etc/sudoers entry:
20 dd-agent ALL=(ALL) NOPASSWD:/usr/bin/find /var/spool/postfix* -type f
21
22 YAML config options:
23 "directory" - the value of 'postconf -h queue_directory'
24 "queues" - the postfix mail queues you would like to get message count totals for
25 """
26 def check(self, instance):
27 config = self._get_config(instance)
28
29 directory = config['directory']
30 queues = config['queues']
31 tags = config['tags']
32
33 self._get_queue_count(directory, queues, tags)
34
35 def _get_config(self, instance):
36 directory = instance.get('directory', None)
37 queues = instance.get('queues', None)
38 tags = instance.get('tags', [])
39 if not queues or not directory:
40 raise Exception('missing required yaml config entry')
41
42 instance_config = {
43 'directory': directory,
44 'queues': queues,
45 'tags': tags,
46 }
47
48 return instance_config
49
50 def _get_queue_count(self, directory, queues, tags):
51 for queue in queues:
52 queue_path = os.path.join(directory, queue)
53 if not os.path.exists(queue_path):
54 raise Exception('%s does not exist' % queue_path)
55
56 count = 0
57 if os.geteuid() == 0:
58 # dd-agent is running as root (not recommended)
59 count = sum(len(files) for root, dirs, files in os.walk(queue_path))
60 else:
61 # can dd-agent user run sudo?
62 test_sudo = os.system('setsid sudo -l < /dev/null')
63 if test_sudo == 0:
64 output, _, _ = get_subprocess_output(['sudo', 'find', queue_path, '-type', 'f'], self.log, False)
65 count = len(output.splitlines())
66 else:
67 raise Exception('The dd-agent user does not have sudo access')
68
69 # emit an individually tagged metric
70 self.gauge('postfix.queue.size', count, tags=tags + ['queue:%s' % queue, 'instance:%s' % os.path.basename(directory)])
71
72 # these can be retrieved in a single graph statement
73 # for example:
74 # sum:postfix.queue.size{instance:postfix-2,queue:incoming,host:hostname.domain.tld}
75
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/postfix/check.py b/postfix/check.py
--- a/postfix/check.py
+++ b/postfix/check.py
@@ -17,7 +17,9 @@
sudo access is not required when running dd-agent as root (not recommended)
example /etc/sudoers entry:
- dd-agent ALL=(ALL) NOPASSWD:/usr/bin/find /var/spool/postfix* -type f
+ dd-agent ALL=(postfix) NOPASSWD:/usr/bin/find /var/spool/postfix/incoming -type f
+ dd-agent ALL=(postfix) NOPASSWD:/usr/bin/find /var/spool/postfix/active -type f
+ dd-agent ALL=(postfix) NOPASSWD:/usr/bin/find /var/spool/postfix/deferred -type f
YAML config options:
"directory" - the value of 'postconf -h queue_directory'
@@ -61,7 +63,9 @@
# can dd-agent user run sudo?
test_sudo = os.system('setsid sudo -l < /dev/null')
if test_sudo == 0:
- output, _, _ = get_subprocess_output(['sudo', 'find', queue_path, '-type', 'f'], self.log, False)
+ # default to `root` for backward compatibility
+ postfix_user = self.init_config.get('postfix_user', 'root')
+ output, _, _ = get_subprocess_output(['sudo', '-u', postfix_user, 'find', queue_path, '-type', 'f'], self.log, False)
count = len(output.splitlines())
else:
raise Exception('The dd-agent user does not have sudo access')
|
{"golden_diff": "diff --git a/postfix/check.py b/postfix/check.py\n--- a/postfix/check.py\n+++ b/postfix/check.py\n@@ -17,7 +17,9 @@\n sudo access is not required when running dd-agent as root (not recommended)\n \n example /etc/sudoers entry:\n- dd-agent ALL=(ALL) NOPASSWD:/usr/bin/find /var/spool/postfix* -type f\n+ dd-agent ALL=(postfix) NOPASSWD:/usr/bin/find /var/spool/postfix/incoming -type f\n+ dd-agent ALL=(postfix) NOPASSWD:/usr/bin/find /var/spool/postfix/active -type f\n+ dd-agent ALL=(postfix) NOPASSWD:/usr/bin/find /var/spool/postfix/deferred -type f\n \n YAML config options:\n \"directory\" - the value of 'postconf -h queue_directory'\n@@ -61,7 +63,9 @@\n # can dd-agent user run sudo?\n test_sudo = os.system('setsid sudo -l < /dev/null')\n if test_sudo == 0:\n- output, _, _ = get_subprocess_output(['sudo', 'find', queue_path, '-type', 'f'], self.log, False)\n+ # default to `root` for backward compatibility\n+ postfix_user = self.init_config.get('postfix_user', 'root')\n+ output, _, _ = get_subprocess_output(['sudo', '-u', postfix_user, 'find', queue_path, '-type', 'f'], self.log, False)\n count = len(output.splitlines())\n else:\n raise Exception('The dd-agent user does not have sudo access')\n", "issue": "postfix integration should not require sudo to root\nReading the source code to integrations-core/postfix/check.py I note that it does a sudo to root to run the find command.\r\n\r\nThis is noted in the docs / comments :\r\n\r\n> WARNING: the user that dd-agent runs as must have sudo access for the 'find' command\r\n> --\r\n> \u00a0 | sudo access is not required when running dd-agent as root (not recommended)\r\n> \u00a0 | \u00a0\r\n> \u00a0 | example /etc/sudoers entry:\r\n> \u00a0 | dd-agent ALL=(ALL) NOPASSWD:/usr/bin/find /var/spool/postfix* -type f\r\n\r\nroot should not be required here - postfix user should be sufficient. That would be combined with a '-u postfix' on line 64's sudo command to allow this to work.\r\n\r\nThis is a concern because find has a -exec parameter and your command list has a wildcard in it - this could be used to run arbitrary commands as root if the dd-agent user is compromised.\r\n\n", "before_files": [{"content": "# (C) Datadog, Inc. 2013-2016\n# (C) Josiah C Webb <[email protected]> 2013\n# All rights reserved\n# Licensed under Simplified BSD License (see LICENSE)\n\n# stdlib\nimport os\n\n# project\nfrom checks import AgentCheck\nfrom utils.subprocess_output import get_subprocess_output\n\nclass PostfixCheck(AgentCheck):\n \"\"\"This check provides metrics on the number of messages in a given postfix queue\n\n WARNING: the user that dd-agent runs as must have sudo access for the 'find' command\n sudo access is not required when running dd-agent as root (not recommended)\n\n example /etc/sudoers entry:\n dd-agent ALL=(ALL) NOPASSWD:/usr/bin/find /var/spool/postfix* -type f\n\n YAML config options:\n \"directory\" - the value of 'postconf -h queue_directory'\n \"queues\" - the postfix mail queues you would like to get message count totals for\n \"\"\"\n def check(self, instance):\n config = self._get_config(instance)\n\n directory = config['directory']\n queues = config['queues']\n tags = config['tags']\n\n self._get_queue_count(directory, queues, tags)\n\n def _get_config(self, instance):\n directory = instance.get('directory', None)\n queues = instance.get('queues', None)\n tags = instance.get('tags', [])\n if not queues or not directory:\n raise Exception('missing required yaml config entry')\n\n instance_config = {\n 'directory': directory,\n 'queues': queues,\n 'tags': tags,\n }\n\n return instance_config\n\n def _get_queue_count(self, directory, queues, tags):\n for queue in queues:\n queue_path = os.path.join(directory, queue)\n if not os.path.exists(queue_path):\n raise Exception('%s does not exist' % queue_path)\n\n count = 0\n if os.geteuid() == 0:\n # dd-agent is running as root (not recommended)\n count = sum(len(files) for root, dirs, files in os.walk(queue_path))\n else:\n # can dd-agent user run sudo?\n test_sudo = os.system('setsid sudo -l < /dev/null')\n if test_sudo == 0:\n output, _, _ = get_subprocess_output(['sudo', 'find', queue_path, '-type', 'f'], self.log, False)\n count = len(output.splitlines())\n else:\n raise Exception('The dd-agent user does not have sudo access')\n\n # emit an individually tagged metric\n self.gauge('postfix.queue.size', count, tags=tags + ['queue:%s' % queue, 'instance:%s' % os.path.basename(directory)])\n\n # these can be retrieved in a single graph statement\n # for example:\n # sum:postfix.queue.size{instance:postfix-2,queue:incoming,host:hostname.domain.tld}\n", "path": "postfix/check.py"}], "after_files": [{"content": "# (C) Datadog, Inc. 2013-2016\n# (C) Josiah C Webb <[email protected]> 2013\n# All rights reserved\n# Licensed under Simplified BSD License (see LICENSE)\n\n# stdlib\nimport os\n\n# project\nfrom checks import AgentCheck\nfrom utils.subprocess_output import get_subprocess_output\n\nclass PostfixCheck(AgentCheck):\n \"\"\"This check provides metrics on the number of messages in a given postfix queue\n\n WARNING: the user that dd-agent runs as must have sudo access for the 'find' command\n sudo access is not required when running dd-agent as root (not recommended)\n\n example /etc/sudoers entry:\n dd-agent ALL=(postfix) NOPASSWD:/usr/bin/find /var/spool/postfix/incoming -type f\n dd-agent ALL=(postfix) NOPASSWD:/usr/bin/find /var/spool/postfix/active -type f\n dd-agent ALL=(postfix) NOPASSWD:/usr/bin/find /var/spool/postfix/deferred -type f\n\n YAML config options:\n \"directory\" - the value of 'postconf -h queue_directory'\n \"queues\" - the postfix mail queues you would like to get message count totals for\n \"\"\"\n def check(self, instance):\n config = self._get_config(instance)\n\n directory = config['directory']\n queues = config['queues']\n tags = config['tags']\n\n self._get_queue_count(directory, queues, tags)\n\n def _get_config(self, instance):\n directory = instance.get('directory', None)\n queues = instance.get('queues', None)\n tags = instance.get('tags', [])\n if not queues or not directory:\n raise Exception('missing required yaml config entry')\n\n instance_config = {\n 'directory': directory,\n 'queues': queues,\n 'tags': tags,\n }\n\n return instance_config\n\n def _get_queue_count(self, directory, queues, tags):\n for queue in queues:\n queue_path = os.path.join(directory, queue)\n if not os.path.exists(queue_path):\n raise Exception('%s does not exist' % queue_path)\n\n count = 0\n if os.geteuid() == 0:\n # dd-agent is running as root (not recommended)\n count = sum(len(files) for root, dirs, files in os.walk(queue_path))\n else:\n # can dd-agent user run sudo?\n test_sudo = os.system('setsid sudo -l < /dev/null')\n if test_sudo == 0:\n # default to `root` for backward compatibility\n postfix_user = self.init_config.get('postfix_user', 'root')\n output, _, _ = get_subprocess_output(['sudo', '-u', postfix_user, 'find', queue_path, '-type', 'f'], self.log, False)\n count = len(output.splitlines())\n else:\n raise Exception('The dd-agent user does not have sudo access')\n\n # emit an individually tagged metric\n self.gauge('postfix.queue.size', count, tags=tags + ['queue:%s' % queue, 'instance:%s' % os.path.basename(directory)])\n\n # these can be retrieved in a single graph statement\n # for example:\n # sum:postfix.queue.size{instance:postfix-2,queue:incoming,host:hostname.domain.tld}\n", "path": "postfix/check.py"}]}
| 1,265 | 368 |
gh_patches_debug_21267
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-8625
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Remove removal of "sh" from path for MinGW in CMake
New conan.tools.cmake CMake helper contains:
```python
if is_windows_mingw:
with tools.remove_from_path("sh"):
self._conanfile.run(command)
```
This is no longer necessary, can be replaced by ``set(DCMAKE_SH="CMAKE_SH-NOTFOUND")``. Please remove it and add a red/green test for it.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conan/tools/cmake/cmake.py`
Content:
```
1 import os
2 import platform
3
4 from conan.tools.cmake.base import CMakeToolchainBase
5 from conan.tools.cmake.utils import get_generator, is_multi_configuration
6 from conan.tools.microsoft.msbuild import msbuild_verbosity_cmd_line_arg
7 from conans.client import tools
8 from conans.client.build import join_arguments
9 from conans.client.tools.files import chdir
10 from conans.client.tools.oss import cpu_count, args_to_string
11 from conans.errors import ConanException
12 from conans.model.version import Version
13 from conans.util.conan_v2_mode import conan_v2_error
14 from conans.util.files import mkdir
15
16
17 def _validate_recipe(conanfile):
18 forbidden_generators = ["cmake", "cmake_multi"]
19 if any(it in conanfile.generators for it in forbidden_generators):
20 raise ConanException("Usage of toolchain is only supported with 'cmake_find_package'"
21 " or 'cmake_find_package_multi' generators")
22
23
24 def _cmake_cmd_line_args(conanfile, generator, parallel):
25 args = []
26 compiler_version = conanfile.settings.get_safe("compiler.version")
27 if generator and parallel:
28 if ("Makefiles" in generator or "Ninja" in generator) and "NMake" not in generator:
29 args.append("-j%i" % cpu_count(conanfile.output))
30 elif "Visual Studio" in generator and compiler_version and Version(compiler_version) >= "10":
31 # Parallel for building projects in the solution
32 args.append("/m:%i" % cpu_count(output=conanfile.output))
33
34 if generator and "Visual Studio" in generator:
35 verbosity = msbuild_verbosity_cmd_line_arg(conanfile)
36 if verbosity:
37 args.append(verbosity)
38
39 return args
40
41
42 class CMake(object):
43 """ CMake helper to use together with the toolchain feature. It implements a very simple
44 wrapper to call the cmake executable, but without passing compile flags, preprocessor
45 definitions... all that is set by the toolchain. Only the generator and the CMAKE_TOOLCHAIN_FILE
46 are passed to the command line, plus the ``--config Release`` for builds in multi-config
47 """
48
49 def __init__(self, conanfile, generator=None, build_folder=None, parallel=True):
50 _validate_recipe(conanfile)
51
52 # assert generator is None, "'generator' is handled by the toolchain"
53 self._generator = generator or get_generator(conanfile)
54 self._is_multiconfiguration = is_multi_configuration(self._generator)
55
56 # Store a reference to useful data
57 self._conanfile = conanfile
58 self._parallel = parallel
59
60 self._build_folder = build_folder
61 self._cmake_program = "cmake" # Path to CMake should be handled by environment
62
63 def configure(self, source_folder=None):
64 # TODO: environment?
65 if not self._conanfile.should_configure:
66 return
67
68 source = self._conanfile.source_folder
69 if source_folder:
70 source = os.path.join(self._conanfile.source_folder, source_folder)
71
72 build_folder = self._conanfile.build_folder
73 if self._build_folder:
74 build_folder = os.path.join(self._conanfile.build_folder, self._build_folder)
75
76 mkdir(build_folder)
77 arg_list = '-DCMAKE_TOOLCHAIN_FILE="{}" -DCMAKE_INSTALL_PREFIX="{}" "{}"'.format(
78 CMakeToolchainBase.filename,
79 self._conanfile.package_folder.replace("\\", "/"),
80 source)
81
82 generator = '-G "{}" '.format(self._generator) if self._generator else ""
83 command = "%s %s%s" % (self._cmake_program, generator, arg_list)
84
85 is_windows_mingw = platform.system() == "Windows" and self._generator == "MinGW Makefiles"
86 self._conanfile.output.info("CMake command: %s" % command)
87 with chdir(build_folder):
88 if is_windows_mingw:
89 with tools.remove_from_path("sh"):
90 self._conanfile.run(command)
91 else:
92 self._conanfile.run(command)
93
94 def _build(self, build_type=None, target=None):
95 bf = self._conanfile.build_folder
96 if self._build_folder:
97 bf = os.path.join(self._conanfile.build_folder, self._build_folder)
98
99 if build_type and not self._is_multiconfiguration:
100 self._conanfile.output.error("Don't specify 'build_type' at build time for "
101 "single-config build systems")
102
103 bt = build_type or self._conanfile.settings.get_safe("build_type")
104 conan_v2_error("build_type setting should be defined.", not bt)
105
106 if bt and self._is_multiconfiguration:
107 build_config = "--config %s" % bt
108 else:
109 build_config = ""
110
111 args = []
112 if target is not None:
113 args = ["--target", target]
114
115 cmd_line_args = _cmake_cmd_line_args(self._conanfile, self._generator, self._parallel)
116 if cmd_line_args:
117 args += ['--'] + cmd_line_args
118
119 arg_list = [args_to_string([bf]), build_config, args_to_string(args)]
120 command = "%s --build %s" % (self._cmake_program, join_arguments(arg_list))
121 self._conanfile.output.info("CMake command: %s" % command)
122 self._conanfile.run(command)
123
124 def build(self, build_type=None, target=None):
125 if not self._conanfile.should_build:
126 return
127 self._build(build_type, target)
128
129 def install(self, build_type=None):
130 if not self._conanfile.should_install:
131 return
132 mkdir(self._conanfile.package_folder)
133 self._build(build_type=build_type, target="install")
134
135 def test(self, build_type=None, target=None, output_on_failure=False):
136 if not self._conanfile.should_test:
137 return
138 if not target:
139 target = "RUN_TESTS" if self._is_multiconfiguration else "test"
140
141 env = {'CTEST_OUTPUT_ON_FAILURE': '1' if output_on_failure else '0'}
142 if self._parallel:
143 env['CTEST_PARALLEL_LEVEL'] = str(cpu_count(self._conanfile.output))
144 with tools.environment_append(env):
145 self._build(build_type=build_type, target=target)
146
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/conan/tools/cmake/cmake.py b/conan/tools/cmake/cmake.py
--- a/conan/tools/cmake/cmake.py
+++ b/conan/tools/cmake/cmake.py
@@ -79,17 +79,15 @@
self._conanfile.package_folder.replace("\\", "/"),
source)
+ if platform.system() == "Windows" and self._generator == "MinGW Makefiles":
+ arg_list += ' -DCMAKE_SH="CMAKE_SH-NOTFOUND"'
+
generator = '-G "{}" '.format(self._generator) if self._generator else ""
command = "%s %s%s" % (self._cmake_program, generator, arg_list)
- is_windows_mingw = platform.system() == "Windows" and self._generator == "MinGW Makefiles"
self._conanfile.output.info("CMake command: %s" % command)
with chdir(build_folder):
- if is_windows_mingw:
- with tools.remove_from_path("sh"):
- self._conanfile.run(command)
- else:
- self._conanfile.run(command)
+ self._conanfile.run(command)
def _build(self, build_type=None, target=None):
bf = self._conanfile.build_folder
|
{"golden_diff": "diff --git a/conan/tools/cmake/cmake.py b/conan/tools/cmake/cmake.py\n--- a/conan/tools/cmake/cmake.py\n+++ b/conan/tools/cmake/cmake.py\n@@ -79,17 +79,15 @@\n self._conanfile.package_folder.replace(\"\\\\\", \"/\"),\n source)\n \n+ if platform.system() == \"Windows\" and self._generator == \"MinGW Makefiles\":\n+ arg_list += ' -DCMAKE_SH=\"CMAKE_SH-NOTFOUND\"'\n+\n generator = '-G \"{}\" '.format(self._generator) if self._generator else \"\"\n command = \"%s %s%s\" % (self._cmake_program, generator, arg_list)\n \n- is_windows_mingw = platform.system() == \"Windows\" and self._generator == \"MinGW Makefiles\"\n self._conanfile.output.info(\"CMake command: %s\" % command)\n with chdir(build_folder):\n- if is_windows_mingw:\n- with tools.remove_from_path(\"sh\"):\n- self._conanfile.run(command)\n- else:\n- self._conanfile.run(command)\n+ self._conanfile.run(command)\n \n def _build(self, build_type=None, target=None):\n bf = self._conanfile.build_folder\n", "issue": "Remove removal of \"sh\" from path for MinGW in CMake\nNew conan.tools.cmake CMake helper contains:\r\n\r\n```python\r\n if is_windows_mingw:\r\n with tools.remove_from_path(\"sh\"):\r\n self._conanfile.run(command)\r\n```\r\n\r\nThis is no longer necessary, can be replaced by ``set(DCMAKE_SH=\"CMAKE_SH-NOTFOUND\")``. Please remove it and add a red/green test for it.\n", "before_files": [{"content": "import os\nimport platform\n\nfrom conan.tools.cmake.base import CMakeToolchainBase\nfrom conan.tools.cmake.utils import get_generator, is_multi_configuration\nfrom conan.tools.microsoft.msbuild import msbuild_verbosity_cmd_line_arg\nfrom conans.client import tools\nfrom conans.client.build import join_arguments\nfrom conans.client.tools.files import chdir\nfrom conans.client.tools.oss import cpu_count, args_to_string\nfrom conans.errors import ConanException\nfrom conans.model.version import Version\nfrom conans.util.conan_v2_mode import conan_v2_error\nfrom conans.util.files import mkdir\n\n\ndef _validate_recipe(conanfile):\n forbidden_generators = [\"cmake\", \"cmake_multi\"]\n if any(it in conanfile.generators for it in forbidden_generators):\n raise ConanException(\"Usage of toolchain is only supported with 'cmake_find_package'\"\n \" or 'cmake_find_package_multi' generators\")\n\n\ndef _cmake_cmd_line_args(conanfile, generator, parallel):\n args = []\n compiler_version = conanfile.settings.get_safe(\"compiler.version\")\n if generator and parallel:\n if (\"Makefiles\" in generator or \"Ninja\" in generator) and \"NMake\" not in generator:\n args.append(\"-j%i\" % cpu_count(conanfile.output))\n elif \"Visual Studio\" in generator and compiler_version and Version(compiler_version) >= \"10\":\n # Parallel for building projects in the solution\n args.append(\"/m:%i\" % cpu_count(output=conanfile.output))\n\n if generator and \"Visual Studio\" in generator:\n verbosity = msbuild_verbosity_cmd_line_arg(conanfile)\n if verbosity:\n args.append(verbosity)\n\n return args\n\n\nclass CMake(object):\n \"\"\" CMake helper to use together with the toolchain feature. It implements a very simple\n wrapper to call the cmake executable, but without passing compile flags, preprocessor\n definitions... all that is set by the toolchain. Only the generator and the CMAKE_TOOLCHAIN_FILE\n are passed to the command line, plus the ``--config Release`` for builds in multi-config\n \"\"\"\n\n def __init__(self, conanfile, generator=None, build_folder=None, parallel=True):\n _validate_recipe(conanfile)\n\n # assert generator is None, \"'generator' is handled by the toolchain\"\n self._generator = generator or get_generator(conanfile)\n self._is_multiconfiguration = is_multi_configuration(self._generator)\n\n # Store a reference to useful data\n self._conanfile = conanfile\n self._parallel = parallel\n\n self._build_folder = build_folder\n self._cmake_program = \"cmake\" # Path to CMake should be handled by environment\n\n def configure(self, source_folder=None):\n # TODO: environment?\n if not self._conanfile.should_configure:\n return\n\n source = self._conanfile.source_folder\n if source_folder:\n source = os.path.join(self._conanfile.source_folder, source_folder)\n\n build_folder = self._conanfile.build_folder\n if self._build_folder:\n build_folder = os.path.join(self._conanfile.build_folder, self._build_folder)\n\n mkdir(build_folder)\n arg_list = '-DCMAKE_TOOLCHAIN_FILE=\"{}\" -DCMAKE_INSTALL_PREFIX=\"{}\" \"{}\"'.format(\n CMakeToolchainBase.filename,\n self._conanfile.package_folder.replace(\"\\\\\", \"/\"),\n source)\n\n generator = '-G \"{}\" '.format(self._generator) if self._generator else \"\"\n command = \"%s %s%s\" % (self._cmake_program, generator, arg_list)\n\n is_windows_mingw = platform.system() == \"Windows\" and self._generator == \"MinGW Makefiles\"\n self._conanfile.output.info(\"CMake command: %s\" % command)\n with chdir(build_folder):\n if is_windows_mingw:\n with tools.remove_from_path(\"sh\"):\n self._conanfile.run(command)\n else:\n self._conanfile.run(command)\n\n def _build(self, build_type=None, target=None):\n bf = self._conanfile.build_folder\n if self._build_folder:\n bf = os.path.join(self._conanfile.build_folder, self._build_folder)\n\n if build_type and not self._is_multiconfiguration:\n self._conanfile.output.error(\"Don't specify 'build_type' at build time for \"\n \"single-config build systems\")\n\n bt = build_type or self._conanfile.settings.get_safe(\"build_type\")\n conan_v2_error(\"build_type setting should be defined.\", not bt)\n\n if bt and self._is_multiconfiguration:\n build_config = \"--config %s\" % bt\n else:\n build_config = \"\"\n\n args = []\n if target is not None:\n args = [\"--target\", target]\n\n cmd_line_args = _cmake_cmd_line_args(self._conanfile, self._generator, self._parallel)\n if cmd_line_args:\n args += ['--'] + cmd_line_args\n\n arg_list = [args_to_string([bf]), build_config, args_to_string(args)]\n command = \"%s --build %s\" % (self._cmake_program, join_arguments(arg_list))\n self._conanfile.output.info(\"CMake command: %s\" % command)\n self._conanfile.run(command)\n\n def build(self, build_type=None, target=None):\n if not self._conanfile.should_build:\n return\n self._build(build_type, target)\n\n def install(self, build_type=None):\n if not self._conanfile.should_install:\n return\n mkdir(self._conanfile.package_folder)\n self._build(build_type=build_type, target=\"install\")\n\n def test(self, build_type=None, target=None, output_on_failure=False):\n if not self._conanfile.should_test:\n return\n if not target:\n target = \"RUN_TESTS\" if self._is_multiconfiguration else \"test\"\n\n env = {'CTEST_OUTPUT_ON_FAILURE': '1' if output_on_failure else '0'}\n if self._parallel:\n env['CTEST_PARALLEL_LEVEL'] = str(cpu_count(self._conanfile.output))\n with tools.environment_append(env):\n self._build(build_type=build_type, target=target)\n", "path": "conan/tools/cmake/cmake.py"}], "after_files": [{"content": "import os\nimport platform\n\nfrom conan.tools.cmake.base import CMakeToolchainBase\nfrom conan.tools.cmake.utils import get_generator, is_multi_configuration\nfrom conan.tools.microsoft.msbuild import msbuild_verbosity_cmd_line_arg\nfrom conans.client import tools\nfrom conans.client.build import join_arguments\nfrom conans.client.tools.files import chdir\nfrom conans.client.tools.oss import cpu_count, args_to_string\nfrom conans.errors import ConanException\nfrom conans.model.version import Version\nfrom conans.util.conan_v2_mode import conan_v2_error\nfrom conans.util.files import mkdir\n\n\ndef _validate_recipe(conanfile):\n forbidden_generators = [\"cmake\", \"cmake_multi\"]\n if any(it in conanfile.generators for it in forbidden_generators):\n raise ConanException(\"Usage of toolchain is only supported with 'cmake_find_package'\"\n \" or 'cmake_find_package_multi' generators\")\n\n\ndef _cmake_cmd_line_args(conanfile, generator, parallel):\n args = []\n compiler_version = conanfile.settings.get_safe(\"compiler.version\")\n if generator and parallel:\n if (\"Makefiles\" in generator or \"Ninja\" in generator) and \"NMake\" not in generator:\n args.append(\"-j%i\" % cpu_count(conanfile.output))\n elif \"Visual Studio\" in generator and compiler_version and Version(compiler_version) >= \"10\":\n # Parallel for building projects in the solution\n args.append(\"/m:%i\" % cpu_count(output=conanfile.output))\n\n if generator and \"Visual Studio\" in generator:\n verbosity = msbuild_verbosity_cmd_line_arg(conanfile)\n if verbosity:\n args.append(verbosity)\n\n return args\n\n\nclass CMake(object):\n \"\"\" CMake helper to use together with the toolchain feature. It implements a very simple\n wrapper to call the cmake executable, but without passing compile flags, preprocessor\n definitions... all that is set by the toolchain. Only the generator and the CMAKE_TOOLCHAIN_FILE\n are passed to the command line, plus the ``--config Release`` for builds in multi-config\n \"\"\"\n\n def __init__(self, conanfile, generator=None, build_folder=None, parallel=True):\n _validate_recipe(conanfile)\n\n # assert generator is None, \"'generator' is handled by the toolchain\"\n self._generator = generator or get_generator(conanfile)\n self._is_multiconfiguration = is_multi_configuration(self._generator)\n\n # Store a reference to useful data\n self._conanfile = conanfile\n self._parallel = parallel\n\n self._build_folder = build_folder\n self._cmake_program = \"cmake\" # Path to CMake should be handled by environment\n\n def configure(self, source_folder=None):\n # TODO: environment?\n if not self._conanfile.should_configure:\n return\n\n source = self._conanfile.source_folder\n if source_folder:\n source = os.path.join(self._conanfile.source_folder, source_folder)\n\n build_folder = self._conanfile.build_folder\n if self._build_folder:\n build_folder = os.path.join(self._conanfile.build_folder, self._build_folder)\n\n mkdir(build_folder)\n arg_list = '-DCMAKE_TOOLCHAIN_FILE=\"{}\" -DCMAKE_INSTALL_PREFIX=\"{}\" \"{}\"'.format(\n CMakeToolchainBase.filename,\n self._conanfile.package_folder.replace(\"\\\\\", \"/\"),\n source)\n\n if platform.system() == \"Windows\" and self._generator == \"MinGW Makefiles\":\n arg_list += ' -DCMAKE_SH=\"CMAKE_SH-NOTFOUND\"'\n\n generator = '-G \"{}\" '.format(self._generator) if self._generator else \"\"\n command = \"%s %s%s\" % (self._cmake_program, generator, arg_list)\n\n self._conanfile.output.info(\"CMake command: %s\" % command)\n with chdir(build_folder):\n self._conanfile.run(command)\n\n def _build(self, build_type=None, target=None):\n bf = self._conanfile.build_folder\n if self._build_folder:\n bf = os.path.join(self._conanfile.build_folder, self._build_folder)\n\n if build_type and not self._is_multiconfiguration:\n self._conanfile.output.error(\"Don't specify 'build_type' at build time for \"\n \"single-config build systems\")\n\n bt = build_type or self._conanfile.settings.get_safe(\"build_type\")\n conan_v2_error(\"build_type setting should be defined.\", not bt)\n\n if bt and self._is_multiconfiguration:\n build_config = \"--config %s\" % bt\n else:\n build_config = \"\"\n\n args = []\n if target is not None:\n args = [\"--target\", target]\n\n cmd_line_args = _cmake_cmd_line_args(self._conanfile, self._generator, self._parallel)\n if cmd_line_args:\n args += ['--'] + cmd_line_args\n\n arg_list = [args_to_string([bf]), build_config, args_to_string(args)]\n command = \"%s --build %s\" % (self._cmake_program, join_arguments(arg_list))\n self._conanfile.output.info(\"CMake command: %s\" % command)\n self._conanfile.run(command)\n\n def build(self, build_type=None, target=None):\n if not self._conanfile.should_build:\n return\n self._build(build_type, target)\n\n def install(self, build_type=None):\n if not self._conanfile.should_install:\n return\n mkdir(self._conanfile.package_folder)\n self._build(build_type=build_type, target=\"install\")\n\n def test(self, build_type=None, target=None, output_on_failure=False):\n if not self._conanfile.should_test:\n return\n if not target:\n target = \"RUN_TESTS\" if self._is_multiconfiguration else \"test\"\n\n env = {'CTEST_OUTPUT_ON_FAILURE': '1' if output_on_failure else '0'}\n if self._parallel:\n env['CTEST_PARALLEL_LEVEL'] = str(cpu_count(self._conanfile.output))\n with tools.environment_append(env):\n self._build(build_type=build_type, target=target)\n", "path": "conan/tools/cmake/cmake.py"}]}
| 2,090 | 287 |
gh_patches_debug_15930
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-4591
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[question][suggestion] Listing profile should be recursive
Hello,
I use multiple profiles, and those are organized in subdirectories:
+ `~/.conan/profiles/application/x64_gcc6_app1`
+ `~/.conan/profiles/application/x64_msvc_app1`
+ `~/.conan/profiles/compilers/x64_gcc6`
+ `~/.conan/profiles/compilers/x64_msvc`
The "applications" profile include other profiles etc. This works pretty well, so I assume
using subdirectory in profiles is supported and is not a problem.
However, the `conan profile list` command does not list profiles contained in subdirectories.
I believe it should recursively search for profile files rather than only list the files available directly in the `~/.conan/profiles` directory.
I'm wondering if there is a particular reason why the search is limited to the `~/.conan/profiles` directory and if you'd be open to changing this behavior.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conans/client/cmd/profile.py`
Content:
```
1 import os
2
3 from conans.client.conf.detect import detect_defaults_settings
4 from conans.client.profile_loader import get_profile_path, read_profile
5 from conans.errors import ConanException
6 from conans.model.options import OptionsValues
7 from conans.model.profile import Profile
8 from conans.unicode import get_cwd
9 from conans.util.files import save
10
11
12 def _get_profile_keys(key):
13 # settings.compiler.version => settings, compiler.version
14 tmp = key.split(".")
15 first_key = tmp[0]
16 rest_key = ".".join(tmp[1:]) if len(tmp) > 1 else None
17 if first_key not in ("build_requires", "settings", "options", "env"):
18 raise ConanException("Invalid specified key: %s" % key)
19
20 return first_key, rest_key
21
22
23 def cmd_profile_list(cache_profiles_path, output):
24 folder = cache_profiles_path
25 if os.path.exists(folder):
26 return [name for name in os.listdir(folder)
27 if not os.path.isdir(os.path.join(folder, name))]
28 else:
29 output.info("No profiles defined")
30 return []
31
32
33 def cmd_profile_create(profile_name, cache_profiles_path, output, detect=False):
34 profile_path = get_profile_path(profile_name, cache_profiles_path, get_cwd(),
35 exists=False)
36 if os.path.exists(profile_path):
37 raise ConanException("Profile already exists")
38
39 profile = Profile()
40 if detect:
41 settings = detect_defaults_settings(output)
42 for name, value in settings:
43 profile.settings[name] = value
44
45 contents = profile.dumps()
46 save(profile_path, contents)
47
48 if detect:
49 output.info("Profile created with detected settings: %s" % profile_path)
50 else:
51 output.info("Empty profile created: %s" % profile_path)
52 return profile_path
53
54
55 def cmd_profile_update(profile_name, key, value, cache_profiles_path):
56 first_key, rest_key = _get_profile_keys(key)
57
58 profile, _ = read_profile(profile_name, get_cwd(), cache_profiles_path)
59 if first_key == "settings":
60 profile.settings[rest_key] = value
61 elif first_key == "options":
62 tmp = OptionsValues([(rest_key, value)])
63 profile.options.update(tmp)
64 elif first_key == "env":
65 profile.env_values.update_replace(rest_key, value)
66 elif first_key == "build_requires":
67 raise ConanException("Edit the profile manually to change the build_requires")
68
69 contents = profile.dumps()
70 profile_path = get_profile_path(profile_name, cache_profiles_path, get_cwd())
71 save(profile_path, contents)
72
73
74 def cmd_profile_get(profile_name, key, cache_profiles_path):
75 first_key, rest_key = _get_profile_keys(key)
76 profile, _ = read_profile(profile_name, get_cwd(), cache_profiles_path)
77 try:
78 if first_key == "settings":
79 return profile.settings[rest_key]
80 elif first_key == "options":
81 return dict(profile.options.as_list())[rest_key]
82 elif first_key == "env":
83 package = None
84 var = rest_key
85 if ":" in rest_key:
86 package, var = rest_key.split(":")
87 return profile.env_values.data[package][var]
88 elif first_key == "build_requires":
89 raise ConanException("List the profile manually to see the build_requires")
90 except KeyError:
91 raise ConanException("Key not found: '%s'" % key)
92
93
94 def cmd_profile_delete_key(profile_name, key, cache_profiles_path):
95 first_key, rest_key = _get_profile_keys(key)
96 profile, _ = read_profile(profile_name, get_cwd(), cache_profiles_path)
97
98 try:
99 package, name = rest_key.split(":")
100 except ValueError:
101 package = None
102 name = rest_key
103
104 try:
105 if first_key == "settings":
106 del profile.settings[rest_key]
107 elif first_key == "options":
108 profile.options.remove(name, package)
109 elif first_key == "env":
110 profile.env_values.remove(name, package)
111 elif first_key == "build_requires":
112 raise ConanException("Edit the profile manually to delete a build_require")
113 except KeyError:
114 raise ConanException("Profile key '%s' doesn't exist" % key)
115
116 contents = profile.dumps()
117 profile_path = get_profile_path(profile_name, cache_profiles_path, get_cwd())
118 save(profile_path, contents)
119
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/conans/client/cmd/profile.py b/conans/client/cmd/profile.py
--- a/conans/client/cmd/profile.py
+++ b/conans/client/cmd/profile.py
@@ -21,13 +21,18 @@
def cmd_profile_list(cache_profiles_path, output):
- folder = cache_profiles_path
- if os.path.exists(folder):
- return [name for name in os.listdir(folder)
- if not os.path.isdir(os.path.join(folder, name))]
- else:
+ profiles = []
+ if os.path.exists(cache_profiles_path):
+ for current_directory, _, files in os.walk(cache_profiles_path, followlinks=True):
+ for filename in files:
+ rel_path = os.path.relpath(os.path.join(current_directory, filename),
+ cache_profiles_path)
+ profiles.append(rel_path)
+
+ if not profiles:
output.info("No profiles defined")
- return []
+ profiles.sort()
+ return profiles
def cmd_profile_create(profile_name, cache_profiles_path, output, detect=False):
|
{"golden_diff": "diff --git a/conans/client/cmd/profile.py b/conans/client/cmd/profile.py\n--- a/conans/client/cmd/profile.py\n+++ b/conans/client/cmd/profile.py\n@@ -21,13 +21,18 @@\n \n \n def cmd_profile_list(cache_profiles_path, output):\n- folder = cache_profiles_path\n- if os.path.exists(folder):\n- return [name for name in os.listdir(folder)\n- if not os.path.isdir(os.path.join(folder, name))]\n- else:\n+ profiles = []\n+ if os.path.exists(cache_profiles_path):\n+ for current_directory, _, files in os.walk(cache_profiles_path, followlinks=True):\n+ for filename in files:\n+ rel_path = os.path.relpath(os.path.join(current_directory, filename),\n+ cache_profiles_path)\n+ profiles.append(rel_path)\n+\n+ if not profiles:\n output.info(\"No profiles defined\")\n- return []\n+ profiles.sort()\n+ return profiles\n \n \n def cmd_profile_create(profile_name, cache_profiles_path, output, detect=False):\n", "issue": "[question][suggestion] Listing profile should be recursive\nHello,\r\n\r\nI use multiple profiles, and those are organized in subdirectories:\r\n + `~/.conan/profiles/application/x64_gcc6_app1`\r\n + `~/.conan/profiles/application/x64_msvc_app1`\r\n + `~/.conan/profiles/compilers/x64_gcc6`\r\n + `~/.conan/profiles/compilers/x64_msvc`\r\n\r\nThe \"applications\" profile include other profiles etc. This works pretty well, so I assume \r\nusing subdirectory in profiles is supported and is not a problem.\r\n\r\nHowever, the `conan profile list` command does not list profiles contained in subdirectories.\r\nI believe it should recursively search for profile files rather than only list the files available directly in the `~/.conan/profiles` directory.\r\n\r\nI'm wondering if there is a particular reason why the search is limited to the `~/.conan/profiles` directory and if you'd be open to changing this behavior.\r\n\n", "before_files": [{"content": "import os\n\nfrom conans.client.conf.detect import detect_defaults_settings\nfrom conans.client.profile_loader import get_profile_path, read_profile\nfrom conans.errors import ConanException\nfrom conans.model.options import OptionsValues\nfrom conans.model.profile import Profile\nfrom conans.unicode import get_cwd\nfrom conans.util.files import save\n\n\ndef _get_profile_keys(key):\n # settings.compiler.version => settings, compiler.version\n tmp = key.split(\".\")\n first_key = tmp[0]\n rest_key = \".\".join(tmp[1:]) if len(tmp) > 1 else None\n if first_key not in (\"build_requires\", \"settings\", \"options\", \"env\"):\n raise ConanException(\"Invalid specified key: %s\" % key)\n\n return first_key, rest_key\n\n\ndef cmd_profile_list(cache_profiles_path, output):\n folder = cache_profiles_path\n if os.path.exists(folder):\n return [name for name in os.listdir(folder)\n if not os.path.isdir(os.path.join(folder, name))]\n else:\n output.info(\"No profiles defined\")\n return []\n\n\ndef cmd_profile_create(profile_name, cache_profiles_path, output, detect=False):\n profile_path = get_profile_path(profile_name, cache_profiles_path, get_cwd(),\n exists=False)\n if os.path.exists(profile_path):\n raise ConanException(\"Profile already exists\")\n\n profile = Profile()\n if detect:\n settings = detect_defaults_settings(output)\n for name, value in settings:\n profile.settings[name] = value\n\n contents = profile.dumps()\n save(profile_path, contents)\n\n if detect:\n output.info(\"Profile created with detected settings: %s\" % profile_path)\n else:\n output.info(\"Empty profile created: %s\" % profile_path)\n return profile_path\n\n\ndef cmd_profile_update(profile_name, key, value, cache_profiles_path):\n first_key, rest_key = _get_profile_keys(key)\n\n profile, _ = read_profile(profile_name, get_cwd(), cache_profiles_path)\n if first_key == \"settings\":\n profile.settings[rest_key] = value\n elif first_key == \"options\":\n tmp = OptionsValues([(rest_key, value)])\n profile.options.update(tmp)\n elif first_key == \"env\":\n profile.env_values.update_replace(rest_key, value)\n elif first_key == \"build_requires\":\n raise ConanException(\"Edit the profile manually to change the build_requires\")\n\n contents = profile.dumps()\n profile_path = get_profile_path(profile_name, cache_profiles_path, get_cwd())\n save(profile_path, contents)\n\n\ndef cmd_profile_get(profile_name, key, cache_profiles_path):\n first_key, rest_key = _get_profile_keys(key)\n profile, _ = read_profile(profile_name, get_cwd(), cache_profiles_path)\n try:\n if first_key == \"settings\":\n return profile.settings[rest_key]\n elif first_key == \"options\":\n return dict(profile.options.as_list())[rest_key]\n elif first_key == \"env\":\n package = None\n var = rest_key\n if \":\" in rest_key:\n package, var = rest_key.split(\":\")\n return profile.env_values.data[package][var]\n elif first_key == \"build_requires\":\n raise ConanException(\"List the profile manually to see the build_requires\")\n except KeyError:\n raise ConanException(\"Key not found: '%s'\" % key)\n\n\ndef cmd_profile_delete_key(profile_name, key, cache_profiles_path):\n first_key, rest_key = _get_profile_keys(key)\n profile, _ = read_profile(profile_name, get_cwd(), cache_profiles_path)\n\n try:\n package, name = rest_key.split(\":\")\n except ValueError:\n package = None\n name = rest_key\n\n try:\n if first_key == \"settings\":\n del profile.settings[rest_key]\n elif first_key == \"options\":\n profile.options.remove(name, package)\n elif first_key == \"env\":\n profile.env_values.remove(name, package)\n elif first_key == \"build_requires\":\n raise ConanException(\"Edit the profile manually to delete a build_require\")\n except KeyError:\n raise ConanException(\"Profile key '%s' doesn't exist\" % key)\n\n contents = profile.dumps()\n profile_path = get_profile_path(profile_name, cache_profiles_path, get_cwd())\n save(profile_path, contents)\n", "path": "conans/client/cmd/profile.py"}], "after_files": [{"content": "import os\n\nfrom conans.client.conf.detect import detect_defaults_settings\nfrom conans.client.profile_loader import get_profile_path, read_profile\nfrom conans.errors import ConanException\nfrom conans.model.options import OptionsValues\nfrom conans.model.profile import Profile\nfrom conans.unicode import get_cwd\nfrom conans.util.files import save\n\n\ndef _get_profile_keys(key):\n # settings.compiler.version => settings, compiler.version\n tmp = key.split(\".\")\n first_key = tmp[0]\n rest_key = \".\".join(tmp[1:]) if len(tmp) > 1 else None\n if first_key not in (\"build_requires\", \"settings\", \"options\", \"env\"):\n raise ConanException(\"Invalid specified key: %s\" % key)\n\n return first_key, rest_key\n\n\ndef cmd_profile_list(cache_profiles_path, output):\n profiles = []\n if os.path.exists(cache_profiles_path):\n for current_directory, _, files in os.walk(cache_profiles_path, followlinks=True):\n for filename in files:\n rel_path = os.path.relpath(os.path.join(current_directory, filename),\n cache_profiles_path)\n profiles.append(rel_path)\n\n if not profiles:\n output.info(\"No profiles defined\")\n profiles.sort()\n return profiles\n\n\ndef cmd_profile_create(profile_name, cache_profiles_path, output, detect=False):\n profile_path = get_profile_path(profile_name, cache_profiles_path, get_cwd(),\n exists=False)\n if os.path.exists(profile_path):\n raise ConanException(\"Profile already exists\")\n\n profile = Profile()\n if detect:\n settings = detect_defaults_settings(output)\n for name, value in settings:\n profile.settings[name] = value\n\n contents = profile.dumps()\n save(profile_path, contents)\n\n if detect:\n output.info(\"Profile created with detected settings: %s\" % profile_path)\n else:\n output.info(\"Empty profile created: %s\" % profile_path)\n return profile_path\n\n\ndef cmd_profile_update(profile_name, key, value, cache_profiles_path):\n first_key, rest_key = _get_profile_keys(key)\n\n profile, _ = read_profile(profile_name, get_cwd(), cache_profiles_path)\n if first_key == \"settings\":\n profile.settings[rest_key] = value\n elif first_key == \"options\":\n tmp = OptionsValues([(rest_key, value)])\n profile.options.update(tmp)\n elif first_key == \"env\":\n profile.env_values.update_replace(rest_key, value)\n elif first_key == \"build_requires\":\n raise ConanException(\"Edit the profile manually to change the build_requires\")\n\n contents = profile.dumps()\n profile_path = get_profile_path(profile_name, cache_profiles_path, get_cwd())\n save(profile_path, contents)\n\n\ndef cmd_profile_get(profile_name, key, cache_profiles_path):\n first_key, rest_key = _get_profile_keys(key)\n profile, _ = read_profile(profile_name, get_cwd(), cache_profiles_path)\n try:\n if first_key == \"settings\":\n return profile.settings[rest_key]\n elif first_key == \"options\":\n return dict(profile.options.as_list())[rest_key]\n elif first_key == \"env\":\n package = None\n var = rest_key\n if \":\" in rest_key:\n package, var = rest_key.split(\":\")\n return profile.env_values.data[package][var]\n elif first_key == \"build_requires\":\n raise ConanException(\"List the profile manually to see the build_requires\")\n except KeyError:\n raise ConanException(\"Key not found: '%s'\" % key)\n\n\ndef cmd_profile_delete_key(profile_name, key, cache_profiles_path):\n first_key, rest_key = _get_profile_keys(key)\n profile, _ = read_profile(profile_name, get_cwd(), cache_profiles_path)\n\n try:\n package, name = rest_key.split(\":\")\n except ValueError:\n package = None\n name = rest_key\n\n try:\n if first_key == \"settings\":\n del profile.settings[rest_key]\n elif first_key == \"options\":\n profile.options.remove(name, package)\n elif first_key == \"env\":\n profile.env_values.remove(name, package)\n elif first_key == \"build_requires\":\n raise ConanException(\"Edit the profile manually to delete a build_require\")\n except KeyError:\n raise ConanException(\"Profile key '%s' doesn't exist\" % key)\n\n contents = profile.dumps()\n profile_path = get_profile_path(profile_name, cache_profiles_path, get_cwd())\n save(profile_path, contents)\n", "path": "conans/client/cmd/profile.py"}]}
| 1,661 | 224 |
gh_patches_debug_24330
|
rasdani/github-patches
|
git_diff
|
cookiecutter__cookiecutter-1626
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Boolean parameters parsed as String
* Cookiecutter version: 2.0
* Template project url: https://github.com/cookiecutter/cookiecutter-django
* Python version: 3.8
* Operating System: Linux
### Description:
We want to be able to ask the user for true/false questions.
The example template shows the current usage of boolean parameters, in {{cookiecutter.project_slug}}/.github/dependabot.yml:
`{%- if cookiecutter.use_docker == 'y' %}`
This usage is rather problematic, as it is requires the user to enter exactly 'y'. If the user enters "yes" or "true" it won't be valid.
We want to add the ability to specify boolean parameters as "true" JSON booleans and naturally prompt for them.
Thus the usage of booleans in the template's cookiecutter.json would look like:
`"use_docker": false`
Instead of the current usage, which is:
`"use_docker": "n"`
Currently this example boolean which is specified in the cookiecutter.json file is parsed as a string and thus checking for it would require a string comparison, which raises and exact same problem as the user would have to explicitly enter "true" or "false" instead of a boolean.
This would also simplify the usage of the boolean parameters in files, so the above shown dependabot.yml would change to:
`{%- if cookiecutter.use_docker %}`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cookiecutter/prompt.py`
Content:
```
1 """Functions for prompting the user for project info."""
2 import functools
3 import json
4 from collections import OrderedDict
5
6 import click
7 from jinja2.exceptions import UndefinedError
8
9 from cookiecutter.environment import StrictEnvironment
10 from cookiecutter.exceptions import UndefinedVariableInTemplate
11
12
13 def read_user_variable(var_name, default_value):
14 """Prompt user for variable and return the entered value or given default.
15
16 :param str var_name: Variable of the context to query the user
17 :param default_value: Value that will be returned if no input happens
18 """
19 # Please see https://click.palletsprojects.com/en/7.x/api/#click.prompt
20 return click.prompt(var_name, default=default_value)
21
22
23 def read_user_yes_no(question, default_value):
24 """Prompt the user to reply with 'yes' or 'no' (or equivalent values).
25
26 Note:
27 Possible choices are 'true', '1', 'yes', 'y' or 'false', '0', 'no', 'n'
28
29 :param str question: Question to the user
30 :param default_value: Value that will be returned if no input happens
31 """
32 # Please see https://click.palletsprojects.com/en/7.x/api/#click.prompt
33 return click.prompt(question, default=default_value, type=click.BOOL)
34
35
36 def read_repo_password(question):
37 """Prompt the user to enter a password.
38
39 :param str question: Question to the user
40 """
41 # Please see https://click.palletsprojects.com/en/7.x/api/#click.prompt
42 return click.prompt(question, hide_input=True)
43
44
45 def read_user_choice(var_name, options):
46 """Prompt the user to choose from several options for the given variable.
47
48 The first item will be returned if no input happens.
49
50 :param str var_name: Variable as specified in the context
51 :param list options: Sequence of options that are available to select from
52 :return: Exactly one item of ``options`` that has been chosen by the user
53 """
54 # Please see https://click.palletsprojects.com/en/7.x/api/#click.prompt
55 if not isinstance(options, list):
56 raise TypeError
57
58 if not options:
59 raise ValueError
60
61 choice_map = OrderedDict((f'{i}', value) for i, value in enumerate(options, 1))
62 choices = choice_map.keys()
63 default = '1'
64
65 choice_lines = ['{} - {}'.format(*c) for c in choice_map.items()]
66 prompt = '\n'.join(
67 (
68 f'Select {var_name}:',
69 '\n'.join(choice_lines),
70 'Choose from {}'.format(', '.join(choices)),
71 )
72 )
73
74 user_choice = click.prompt(
75 prompt, type=click.Choice(choices), default=default, show_choices=False
76 )
77 return choice_map[user_choice]
78
79
80 DEFAULT_DISPLAY = 'default'
81
82
83 def process_json(user_value, default_value=None):
84 """Load user-supplied value as a JSON dict.
85
86 :param str user_value: User-supplied value to load as a JSON dict
87 """
88 if user_value == DEFAULT_DISPLAY:
89 # Return the given default w/o any processing
90 return default_value
91
92 try:
93 user_dict = json.loads(user_value, object_pairs_hook=OrderedDict)
94 except Exception:
95 # Leave it up to click to ask the user again
96 raise click.UsageError('Unable to decode to JSON.')
97
98 if not isinstance(user_dict, dict):
99 # Leave it up to click to ask the user again
100 raise click.UsageError('Requires JSON dict.')
101
102 return user_dict
103
104
105 def read_user_dict(var_name, default_value):
106 """Prompt the user to provide a dictionary of data.
107
108 :param str var_name: Variable as specified in the context
109 :param default_value: Value that will be returned if no input is provided
110 :return: A Python dictionary to use in the context.
111 """
112 # Please see https://click.palletsprojects.com/en/7.x/api/#click.prompt
113 if not isinstance(default_value, dict):
114 raise TypeError
115
116 user_value = click.prompt(
117 var_name,
118 default=DEFAULT_DISPLAY,
119 type=click.STRING,
120 value_proc=functools.partial(process_json, default_value=default_value),
121 )
122
123 if click.__version__.startswith("7.") and user_value == DEFAULT_DISPLAY:
124 # click 7.x does not invoke value_proc on the default value.
125 return default_value # pragma: no cover
126 return user_value
127
128
129 def render_variable(env, raw, cookiecutter_dict):
130 """Render the next variable to be displayed in the user prompt.
131
132 Inside the prompting taken from the cookiecutter.json file, this renders
133 the next variable. For example, if a project_name is "Peanut Butter
134 Cookie", the repo_name could be be rendered with:
135
136 `{{ cookiecutter.project_name.replace(" ", "_") }}`.
137
138 This is then presented to the user as the default.
139
140 :param Environment env: A Jinja2 Environment object.
141 :param raw: The next value to be prompted for by the user.
142 :param dict cookiecutter_dict: The current context as it's gradually
143 being populated with variables.
144 :return: The rendered value for the default variable.
145 """
146 if raw is None:
147 return None
148 elif isinstance(raw, dict):
149 return {
150 render_variable(env, k, cookiecutter_dict): render_variable(
151 env, v, cookiecutter_dict
152 )
153 for k, v in raw.items()
154 }
155 elif isinstance(raw, list):
156 return [render_variable(env, v, cookiecutter_dict) for v in raw]
157 elif not isinstance(raw, str):
158 raw = str(raw)
159
160 template = env.from_string(raw)
161
162 rendered_template = template.render(cookiecutter=cookiecutter_dict)
163 return rendered_template
164
165
166 def prompt_choice_for_config(cookiecutter_dict, env, key, options, no_input):
167 """Prompt user with a set of options to choose from.
168
169 :param no_input: Do not prompt for user input and return the first available option.
170 """
171 rendered_options = [render_variable(env, raw, cookiecutter_dict) for raw in options]
172 if no_input:
173 return rendered_options[0]
174 return read_user_choice(key, rendered_options)
175
176
177 def prompt_for_config(context, no_input=False):
178 """Prompt user to enter a new config.
179
180 :param dict context: Source for field names and sample values.
181 :param no_input: Do not prompt for user input and use only values from context.
182 """
183 cookiecutter_dict = OrderedDict([])
184 env = StrictEnvironment(context=context)
185
186 # First pass: Handle simple and raw variables, plus choices.
187 # These must be done first because the dictionaries keys and
188 # values might refer to them.
189 for key, raw in context['cookiecutter'].items():
190 if key.startswith('_') and not key.startswith('__'):
191 cookiecutter_dict[key] = raw
192 continue
193 elif key.startswith('__'):
194 cookiecutter_dict[key] = render_variable(env, raw, cookiecutter_dict)
195 continue
196
197 try:
198 if isinstance(raw, list):
199 # We are dealing with a choice variable
200 val = prompt_choice_for_config(
201 cookiecutter_dict, env, key, raw, no_input
202 )
203 cookiecutter_dict[key] = val
204 elif not isinstance(raw, dict):
205 # We are dealing with a regular variable
206 val = render_variable(env, raw, cookiecutter_dict)
207
208 if not no_input:
209 val = read_user_variable(key, val)
210
211 cookiecutter_dict[key] = val
212 except UndefinedError as err:
213 msg = f"Unable to render variable '{key}'"
214 raise UndefinedVariableInTemplate(msg, err, context)
215
216 # Second pass; handle the dictionaries.
217 for key, raw in context['cookiecutter'].items():
218 # Skip private type dicts not ot be rendered.
219 if key.startswith('_') and not key.startswith('__'):
220 continue
221
222 try:
223 if isinstance(raw, dict):
224 # We are dealing with a dict variable
225 val = render_variable(env, raw, cookiecutter_dict)
226
227 if not no_input and not key.startswith('__'):
228 val = read_user_dict(key, val)
229
230 cookiecutter_dict[key] = val
231 except UndefinedError as err:
232 msg = f"Unable to render variable '{key}'"
233 raise UndefinedVariableInTemplate(msg, err, context)
234
235 return cookiecutter_dict
236
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/cookiecutter/prompt.py b/cookiecutter/prompt.py
--- a/cookiecutter/prompt.py
+++ b/cookiecutter/prompt.py
@@ -143,8 +143,8 @@
being populated with variables.
:return: The rendered value for the default variable.
"""
- if raw is None:
- return None
+ if raw is None or isinstance(raw, bool):
+ return raw
elif isinstance(raw, dict):
return {
render_variable(env, k, cookiecutter_dict): render_variable(
@@ -201,6 +201,14 @@
cookiecutter_dict, env, key, raw, no_input
)
cookiecutter_dict[key] = val
+ elif isinstance(raw, bool):
+ # We are dealing with a boolean variable
+ if no_input:
+ cookiecutter_dict[key] = render_variable(
+ env, raw, cookiecutter_dict
+ )
+ else:
+ cookiecutter_dict[key] = read_user_yes_no(key, raw)
elif not isinstance(raw, dict):
# We are dealing with a regular variable
val = render_variable(env, raw, cookiecutter_dict)
|
{"golden_diff": "diff --git a/cookiecutter/prompt.py b/cookiecutter/prompt.py\n--- a/cookiecutter/prompt.py\n+++ b/cookiecutter/prompt.py\n@@ -143,8 +143,8 @@\n being populated with variables.\n :return: The rendered value for the default variable.\n \"\"\"\n- if raw is None:\n- return None\n+ if raw is None or isinstance(raw, bool):\n+ return raw\n elif isinstance(raw, dict):\n return {\n render_variable(env, k, cookiecutter_dict): render_variable(\n@@ -201,6 +201,14 @@\n cookiecutter_dict, env, key, raw, no_input\n )\n cookiecutter_dict[key] = val\n+ elif isinstance(raw, bool):\n+ # We are dealing with a boolean variable\n+ if no_input:\n+ cookiecutter_dict[key] = render_variable(\n+ env, raw, cookiecutter_dict\n+ )\n+ else:\n+ cookiecutter_dict[key] = read_user_yes_no(key, raw)\n elif not isinstance(raw, dict):\n # We are dealing with a regular variable\n val = render_variable(env, raw, cookiecutter_dict)\n", "issue": "Boolean parameters parsed as String\n* Cookiecutter version: 2.0\r\n* Template project url: https://github.com/cookiecutter/cookiecutter-django\r\n* Python version: 3.8\r\n* Operating System: Linux\r\n\r\n### Description:\r\n\r\nWe want to be able to ask the user for true/false questions.\r\nThe example template shows the current usage of boolean parameters, in {{cookiecutter.project_slug}}/.github/dependabot.yml:\r\n`{%- if cookiecutter.use_docker == 'y' %}` \r\nThis usage is rather problematic, as it is requires the user to enter exactly 'y'. If the user enters \"yes\" or \"true\" it won't be valid.\r\n\r\nWe want to add the ability to specify boolean parameters as \"true\" JSON booleans and naturally prompt for them.\r\nThus the usage of booleans in the template's cookiecutter.json would look like:\r\n`\"use_docker\": false`\r\nInstead of the current usage, which is:\r\n `\"use_docker\": \"n\"`\r\n\r\nCurrently this example boolean which is specified in the cookiecutter.json file is parsed as a string and thus checking for it would require a string comparison, which raises and exact same problem as the user would have to explicitly enter \"true\" or \"false\" instead of a boolean.\r\n\r\nThis would also simplify the usage of the boolean parameters in files, so the above shown dependabot.yml would change to:\r\n`{%- if cookiecutter.use_docker %}` \n", "before_files": [{"content": "\"\"\"Functions for prompting the user for project info.\"\"\"\nimport functools\nimport json\nfrom collections import OrderedDict\n\nimport click\nfrom jinja2.exceptions import UndefinedError\n\nfrom cookiecutter.environment import StrictEnvironment\nfrom cookiecutter.exceptions import UndefinedVariableInTemplate\n\n\ndef read_user_variable(var_name, default_value):\n \"\"\"Prompt user for variable and return the entered value or given default.\n\n :param str var_name: Variable of the context to query the user\n :param default_value: Value that will be returned if no input happens\n \"\"\"\n # Please see https://click.palletsprojects.com/en/7.x/api/#click.prompt\n return click.prompt(var_name, default=default_value)\n\n\ndef read_user_yes_no(question, default_value):\n \"\"\"Prompt the user to reply with 'yes' or 'no' (or equivalent values).\n\n Note:\n Possible choices are 'true', '1', 'yes', 'y' or 'false', '0', 'no', 'n'\n\n :param str question: Question to the user\n :param default_value: Value that will be returned if no input happens\n \"\"\"\n # Please see https://click.palletsprojects.com/en/7.x/api/#click.prompt\n return click.prompt(question, default=default_value, type=click.BOOL)\n\n\ndef read_repo_password(question):\n \"\"\"Prompt the user to enter a password.\n\n :param str question: Question to the user\n \"\"\"\n # Please see https://click.palletsprojects.com/en/7.x/api/#click.prompt\n return click.prompt(question, hide_input=True)\n\n\ndef read_user_choice(var_name, options):\n \"\"\"Prompt the user to choose from several options for the given variable.\n\n The first item will be returned if no input happens.\n\n :param str var_name: Variable as specified in the context\n :param list options: Sequence of options that are available to select from\n :return: Exactly one item of ``options`` that has been chosen by the user\n \"\"\"\n # Please see https://click.palletsprojects.com/en/7.x/api/#click.prompt\n if not isinstance(options, list):\n raise TypeError\n\n if not options:\n raise ValueError\n\n choice_map = OrderedDict((f'{i}', value) for i, value in enumerate(options, 1))\n choices = choice_map.keys()\n default = '1'\n\n choice_lines = ['{} - {}'.format(*c) for c in choice_map.items()]\n prompt = '\\n'.join(\n (\n f'Select {var_name}:',\n '\\n'.join(choice_lines),\n 'Choose from {}'.format(', '.join(choices)),\n )\n )\n\n user_choice = click.prompt(\n prompt, type=click.Choice(choices), default=default, show_choices=False\n )\n return choice_map[user_choice]\n\n\nDEFAULT_DISPLAY = 'default'\n\n\ndef process_json(user_value, default_value=None):\n \"\"\"Load user-supplied value as a JSON dict.\n\n :param str user_value: User-supplied value to load as a JSON dict\n \"\"\"\n if user_value == DEFAULT_DISPLAY:\n # Return the given default w/o any processing\n return default_value\n\n try:\n user_dict = json.loads(user_value, object_pairs_hook=OrderedDict)\n except Exception:\n # Leave it up to click to ask the user again\n raise click.UsageError('Unable to decode to JSON.')\n\n if not isinstance(user_dict, dict):\n # Leave it up to click to ask the user again\n raise click.UsageError('Requires JSON dict.')\n\n return user_dict\n\n\ndef read_user_dict(var_name, default_value):\n \"\"\"Prompt the user to provide a dictionary of data.\n\n :param str var_name: Variable as specified in the context\n :param default_value: Value that will be returned if no input is provided\n :return: A Python dictionary to use in the context.\n \"\"\"\n # Please see https://click.palletsprojects.com/en/7.x/api/#click.prompt\n if not isinstance(default_value, dict):\n raise TypeError\n\n user_value = click.prompt(\n var_name,\n default=DEFAULT_DISPLAY,\n type=click.STRING,\n value_proc=functools.partial(process_json, default_value=default_value),\n )\n\n if click.__version__.startswith(\"7.\") and user_value == DEFAULT_DISPLAY:\n # click 7.x does not invoke value_proc on the default value.\n return default_value # pragma: no cover\n return user_value\n\n\ndef render_variable(env, raw, cookiecutter_dict):\n \"\"\"Render the next variable to be displayed in the user prompt.\n\n Inside the prompting taken from the cookiecutter.json file, this renders\n the next variable. For example, if a project_name is \"Peanut Butter\n Cookie\", the repo_name could be be rendered with:\n\n `{{ cookiecutter.project_name.replace(\" \", \"_\") }}`.\n\n This is then presented to the user as the default.\n\n :param Environment env: A Jinja2 Environment object.\n :param raw: The next value to be prompted for by the user.\n :param dict cookiecutter_dict: The current context as it's gradually\n being populated with variables.\n :return: The rendered value for the default variable.\n \"\"\"\n if raw is None:\n return None\n elif isinstance(raw, dict):\n return {\n render_variable(env, k, cookiecutter_dict): render_variable(\n env, v, cookiecutter_dict\n )\n for k, v in raw.items()\n }\n elif isinstance(raw, list):\n return [render_variable(env, v, cookiecutter_dict) for v in raw]\n elif not isinstance(raw, str):\n raw = str(raw)\n\n template = env.from_string(raw)\n\n rendered_template = template.render(cookiecutter=cookiecutter_dict)\n return rendered_template\n\n\ndef prompt_choice_for_config(cookiecutter_dict, env, key, options, no_input):\n \"\"\"Prompt user with a set of options to choose from.\n\n :param no_input: Do not prompt for user input and return the first available option.\n \"\"\"\n rendered_options = [render_variable(env, raw, cookiecutter_dict) for raw in options]\n if no_input:\n return rendered_options[0]\n return read_user_choice(key, rendered_options)\n\n\ndef prompt_for_config(context, no_input=False):\n \"\"\"Prompt user to enter a new config.\n\n :param dict context: Source for field names and sample values.\n :param no_input: Do not prompt for user input and use only values from context.\n \"\"\"\n cookiecutter_dict = OrderedDict([])\n env = StrictEnvironment(context=context)\n\n # First pass: Handle simple and raw variables, plus choices.\n # These must be done first because the dictionaries keys and\n # values might refer to them.\n for key, raw in context['cookiecutter'].items():\n if key.startswith('_') and not key.startswith('__'):\n cookiecutter_dict[key] = raw\n continue\n elif key.startswith('__'):\n cookiecutter_dict[key] = render_variable(env, raw, cookiecutter_dict)\n continue\n\n try:\n if isinstance(raw, list):\n # We are dealing with a choice variable\n val = prompt_choice_for_config(\n cookiecutter_dict, env, key, raw, no_input\n )\n cookiecutter_dict[key] = val\n elif not isinstance(raw, dict):\n # We are dealing with a regular variable\n val = render_variable(env, raw, cookiecutter_dict)\n\n if not no_input:\n val = read_user_variable(key, val)\n\n cookiecutter_dict[key] = val\n except UndefinedError as err:\n msg = f\"Unable to render variable '{key}'\"\n raise UndefinedVariableInTemplate(msg, err, context)\n\n # Second pass; handle the dictionaries.\n for key, raw in context['cookiecutter'].items():\n # Skip private type dicts not ot be rendered.\n if key.startswith('_') and not key.startswith('__'):\n continue\n\n try:\n if isinstance(raw, dict):\n # We are dealing with a dict variable\n val = render_variable(env, raw, cookiecutter_dict)\n\n if not no_input and not key.startswith('__'):\n val = read_user_dict(key, val)\n\n cookiecutter_dict[key] = val\n except UndefinedError as err:\n msg = f\"Unable to render variable '{key}'\"\n raise UndefinedVariableInTemplate(msg, err, context)\n\n return cookiecutter_dict\n", "path": "cookiecutter/prompt.py"}], "after_files": [{"content": "\"\"\"Functions for prompting the user for project info.\"\"\"\nimport functools\nimport json\nfrom collections import OrderedDict\n\nimport click\nfrom jinja2.exceptions import UndefinedError\n\nfrom cookiecutter.environment import StrictEnvironment\nfrom cookiecutter.exceptions import UndefinedVariableInTemplate\n\n\ndef read_user_variable(var_name, default_value):\n \"\"\"Prompt user for variable and return the entered value or given default.\n\n :param str var_name: Variable of the context to query the user\n :param default_value: Value that will be returned if no input happens\n \"\"\"\n # Please see https://click.palletsprojects.com/en/7.x/api/#click.prompt\n return click.prompt(var_name, default=default_value)\n\n\ndef read_user_yes_no(question, default_value):\n \"\"\"Prompt the user to reply with 'yes' or 'no' (or equivalent values).\n\n Note:\n Possible choices are 'true', '1', 'yes', 'y' or 'false', '0', 'no', 'n'\n\n :param str question: Question to the user\n :param default_value: Value that will be returned if no input happens\n \"\"\"\n # Please see https://click.palletsprojects.com/en/7.x/api/#click.prompt\n return click.prompt(question, default=default_value, type=click.BOOL)\n\n\ndef read_repo_password(question):\n \"\"\"Prompt the user to enter a password.\n\n :param str question: Question to the user\n \"\"\"\n # Please see https://click.palletsprojects.com/en/7.x/api/#click.prompt\n return click.prompt(question, hide_input=True)\n\n\ndef read_user_choice(var_name, options):\n \"\"\"Prompt the user to choose from several options for the given variable.\n\n The first item will be returned if no input happens.\n\n :param str var_name: Variable as specified in the context\n :param list options: Sequence of options that are available to select from\n :return: Exactly one item of ``options`` that has been chosen by the user\n \"\"\"\n # Please see https://click.palletsprojects.com/en/7.x/api/#click.prompt\n if not isinstance(options, list):\n raise TypeError\n\n if not options:\n raise ValueError\n\n choice_map = OrderedDict((f'{i}', value) for i, value in enumerate(options, 1))\n choices = choice_map.keys()\n default = '1'\n\n choice_lines = ['{} - {}'.format(*c) for c in choice_map.items()]\n prompt = '\\n'.join(\n (\n f'Select {var_name}:',\n '\\n'.join(choice_lines),\n 'Choose from {}'.format(', '.join(choices)),\n )\n )\n\n user_choice = click.prompt(\n prompt, type=click.Choice(choices), default=default, show_choices=False\n )\n return choice_map[user_choice]\n\n\nDEFAULT_DISPLAY = 'default'\n\n\ndef process_json(user_value, default_value=None):\n \"\"\"Load user-supplied value as a JSON dict.\n\n :param str user_value: User-supplied value to load as a JSON dict\n \"\"\"\n if user_value == DEFAULT_DISPLAY:\n # Return the given default w/o any processing\n return default_value\n\n try:\n user_dict = json.loads(user_value, object_pairs_hook=OrderedDict)\n except Exception:\n # Leave it up to click to ask the user again\n raise click.UsageError('Unable to decode to JSON.')\n\n if not isinstance(user_dict, dict):\n # Leave it up to click to ask the user again\n raise click.UsageError('Requires JSON dict.')\n\n return user_dict\n\n\ndef read_user_dict(var_name, default_value):\n \"\"\"Prompt the user to provide a dictionary of data.\n\n :param str var_name: Variable as specified in the context\n :param default_value: Value that will be returned if no input is provided\n :return: A Python dictionary to use in the context.\n \"\"\"\n # Please see https://click.palletsprojects.com/en/7.x/api/#click.prompt\n if not isinstance(default_value, dict):\n raise TypeError\n\n user_value = click.prompt(\n var_name,\n default=DEFAULT_DISPLAY,\n type=click.STRING,\n value_proc=functools.partial(process_json, default_value=default_value),\n )\n\n if click.__version__.startswith(\"7.\") and user_value == DEFAULT_DISPLAY:\n # click 7.x does not invoke value_proc on the default value.\n return default_value # pragma: no cover\n return user_value\n\n\ndef render_variable(env, raw, cookiecutter_dict):\n \"\"\"Render the next variable to be displayed in the user prompt.\n\n Inside the prompting taken from the cookiecutter.json file, this renders\n the next variable. For example, if a project_name is \"Peanut Butter\n Cookie\", the repo_name could be be rendered with:\n\n `{{ cookiecutter.project_name.replace(\" \", \"_\") }}`.\n\n This is then presented to the user as the default.\n\n :param Environment env: A Jinja2 Environment object.\n :param raw: The next value to be prompted for by the user.\n :param dict cookiecutter_dict: The current context as it's gradually\n being populated with variables.\n :return: The rendered value for the default variable.\n \"\"\"\n if raw is None or isinstance(raw, bool):\n return raw\n elif isinstance(raw, dict):\n return {\n render_variable(env, k, cookiecutter_dict): render_variable(\n env, v, cookiecutter_dict\n )\n for k, v in raw.items()\n }\n elif isinstance(raw, list):\n return [render_variable(env, v, cookiecutter_dict) for v in raw]\n elif not isinstance(raw, str):\n raw = str(raw)\n\n template = env.from_string(raw)\n\n rendered_template = template.render(cookiecutter=cookiecutter_dict)\n return rendered_template\n\n\ndef prompt_choice_for_config(cookiecutter_dict, env, key, options, no_input):\n \"\"\"Prompt user with a set of options to choose from.\n\n :param no_input: Do not prompt for user input and return the first available option.\n \"\"\"\n rendered_options = [render_variable(env, raw, cookiecutter_dict) for raw in options]\n if no_input:\n return rendered_options[0]\n return read_user_choice(key, rendered_options)\n\n\ndef prompt_for_config(context, no_input=False):\n \"\"\"Prompt user to enter a new config.\n\n :param dict context: Source for field names and sample values.\n :param no_input: Do not prompt for user input and use only values from context.\n \"\"\"\n cookiecutter_dict = OrderedDict([])\n env = StrictEnvironment(context=context)\n\n # First pass: Handle simple and raw variables, plus choices.\n # These must be done first because the dictionaries keys and\n # values might refer to them.\n for key, raw in context['cookiecutter'].items():\n if key.startswith('_') and not key.startswith('__'):\n cookiecutter_dict[key] = raw\n continue\n elif key.startswith('__'):\n cookiecutter_dict[key] = render_variable(env, raw, cookiecutter_dict)\n continue\n\n try:\n if isinstance(raw, list):\n # We are dealing with a choice variable\n val = prompt_choice_for_config(\n cookiecutter_dict, env, key, raw, no_input\n )\n cookiecutter_dict[key] = val\n elif isinstance(raw, bool):\n # We are dealing with a boolean variable\n if no_input:\n cookiecutter_dict[key] = render_variable(\n env, raw, cookiecutter_dict\n )\n else:\n cookiecutter_dict[key] = read_user_yes_no(key, raw)\n elif not isinstance(raw, dict):\n # We are dealing with a regular variable\n val = render_variable(env, raw, cookiecutter_dict)\n\n if not no_input:\n val = read_user_variable(key, val)\n\n cookiecutter_dict[key] = val\n except UndefinedError as err:\n msg = f\"Unable to render variable '{key}'\"\n raise UndefinedVariableInTemplate(msg, err, context)\n\n # Second pass; handle the dictionaries.\n for key, raw in context['cookiecutter'].items():\n # Skip private type dicts not ot be rendered.\n if key.startswith('_') and not key.startswith('__'):\n continue\n\n try:\n if isinstance(raw, dict):\n # We are dealing with a dict variable\n val = render_variable(env, raw, cookiecutter_dict)\n\n if not no_input and not key.startswith('__'):\n val = read_user_dict(key, val)\n\n cookiecutter_dict[key] = val\n except UndefinedError as err:\n msg = f\"Unable to render variable '{key}'\"\n raise UndefinedVariableInTemplate(msg, err, context)\n\n return cookiecutter_dict\n", "path": "cookiecutter/prompt.py"}]}
| 3,024 | 274 |
gh_patches_debug_60854
|
rasdani/github-patches
|
git_diff
|
airctic__icevision-441
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add icedata to icevision.all
## 🚀 Feature
Currently to train a dataset available with icedata the following two lines are necessary:
```python
import icedata
from icevision.all import *
```
Because icedata already depends on icevision, icevision cannot depend on icedata. **But** I guess we can add icedata as a soft dependency to `.all`, we just have to be sure not to use `icedata` internally in icevision.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `icevision/all.py`
Content:
```
1 from icevision.imports import *
2 from icevision import *
3
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/icevision/all.py b/icevision/all.py
--- a/icevision/all.py
+++ b/icevision/all.py
@@ -1,2 +1,9 @@
from icevision.imports import *
from icevision import *
+
+# soft import icedata
+try:
+ import icedata
+except ModuleNotFoundError as e:
+ if str(e) != f"No module named 'icedata'":
+ raise e
|
{"golden_diff": "diff --git a/icevision/all.py b/icevision/all.py\n--- a/icevision/all.py\n+++ b/icevision/all.py\n@@ -1,2 +1,9 @@\n from icevision.imports import *\n from icevision import *\n+\n+# soft import icedata\n+try:\n+ import icedata\n+except ModuleNotFoundError as e:\n+ if str(e) != f\"No module named 'icedata'\":\n+ raise e\n", "issue": "Add icedata to icevision.all\n## \ud83d\ude80 Feature\r\nCurrently to train a dataset available with icedata the following two lines are necessary:\r\n```python\r\nimport icedata\r\nfrom icevision.all import *\r\n```\r\n\r\nBecause icedata already depends on icevision, icevision cannot depend on icedata. **But** I guess we can add icedata as a soft dependency to `.all`, we just have to be sure not to use `icedata` internally in icevision.\n", "before_files": [{"content": "from icevision.imports import *\nfrom icevision import *\n", "path": "icevision/all.py"}], "after_files": [{"content": "from icevision.imports import *\nfrom icevision import *\n\n# soft import icedata\ntry:\n import icedata\nexcept ModuleNotFoundError as e:\n if str(e) != f\"No module named 'icedata'\":\n raise e\n", "path": "icevision/all.py"}]}
| 377 | 100 |
gh_patches_debug_5156
|
rasdani/github-patches
|
git_diff
|
DataBiosphere__toil-2834
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Example script duplicated
`examples/hello.py` and `src/toil/test/docs/scripts/tutorial_arguments.py` are duplicate scripts with the same contents.
┆Issue is synchronized with this [Jira Task](https://ucsc-cgl.atlassian.net/browse/TOIL-443)
┆Issue Number: TOIL-443
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/hello.py`
Content:
```
1 from toil.common import Toil
2 from toil.job import Job
3
4 class HelloWorld(Job):
5 def __init__(self, message):
6 Job.__init__(self, memory="1G", cores=2, disk="2G")
7 self.message = message
8
9 def run(self, fileStore):
10 return "Hello, world!, here's a message: %s" % self.message
11
12 if __name__=="__main__":
13 parser = Job.Runner.getDefaultArgumentParser()
14 options = parser.parse_args()
15
16 hello_job = HelloWorld("Woot")
17
18 with Toil(options) as toil:
19 print(toil.start(hello_job))
20
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/hello.py b/examples/hello.py
deleted file mode 100644
--- a/examples/hello.py
+++ /dev/null
@@ -1,19 +0,0 @@
-from toil.common import Toil
-from toil.job import Job
-
-class HelloWorld(Job):
- def __init__(self, message):
- Job.__init__(self, memory="1G", cores=2, disk="2G")
- self.message = message
-
- def run(self, fileStore):
- return "Hello, world!, here's a message: %s" % self.message
-
-if __name__=="__main__":
- parser = Job.Runner.getDefaultArgumentParser()
- options = parser.parse_args()
-
- hello_job = HelloWorld("Woot")
-
- with Toil(options) as toil:
- print(toil.start(hello_job))
|
{"golden_diff": "diff --git a/examples/hello.py b/examples/hello.py\ndeleted file mode 100644\n--- a/examples/hello.py\n+++ /dev/null\n@@ -1,19 +0,0 @@\n-from toil.common import Toil\n-from toil.job import Job\n-\n-class HelloWorld(Job):\n- def __init__(self, message):\n- Job.__init__(self, memory=\"1G\", cores=2, disk=\"2G\")\n- self.message = message\n-\n- def run(self, fileStore):\n- return \"Hello, world!, here's a message: %s\" % self.message\n-\n-if __name__==\"__main__\":\n- parser = Job.Runner.getDefaultArgumentParser()\n- options = parser.parse_args()\n-\n- hello_job = HelloWorld(\"Woot\")\n-\n- with Toil(options) as toil:\n- print(toil.start(hello_job))\n", "issue": "Example script duplicated\n`examples/hello.py` and `src/toil/test/docs/scripts/tutorial_arguments.py` are duplicate scripts with the same contents.\n\n\u2506Issue is synchronized with this [Jira Task](https://ucsc-cgl.atlassian.net/browse/TOIL-443)\n\u2506Issue Number: TOIL-443\n\n", "before_files": [{"content": "from toil.common import Toil\nfrom toil.job import Job\n\nclass HelloWorld(Job):\n def __init__(self, message):\n Job.__init__(self, memory=\"1G\", cores=2, disk=\"2G\")\n self.message = message\n\n def run(self, fileStore):\n return \"Hello, world!, here's a message: %s\" % self.message\n\nif __name__==\"__main__\":\n parser = Job.Runner.getDefaultArgumentParser()\n options = parser.parse_args()\n\n hello_job = HelloWorld(\"Woot\")\n\n with Toil(options) as toil:\n print(toil.start(hello_job))\n", "path": "examples/hello.py"}], "after_files": [{"content": null, "path": "examples/hello.py"}]}
| 502 | 199 |
gh_patches_debug_18244
|
rasdani/github-patches
|
git_diff
|
interlegis__sapl-1606
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Exclusão Tramitação - status de tramitação
Ao incluir uma tramitação à matéria, em que esta tramitação tenha seu indicador de tramitação definido nas tabelas auxiliares como fim, a matéria em questão passa de "em tramitação - sim para não" corretamente. Se essa tramitação por ventura for excluída, não seria o caso de alterar novamente a matéria de "em tramitação - não para sim" ?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sapl/materia/receivers.py`
Content:
```
1 from django.dispatch import receiver
2
3 from sapl.materia.signals import tramitacao_signal
4 from sapl.utils import get_base_url
5
6 from .email_utils import do_envia_email_tramitacao
7
8
9 @receiver(tramitacao_signal)
10 def handle_tramitacao_signal(sender, **kwargs):
11 tramitacao = kwargs.get("post")
12 request = kwargs.get("request")
13 materia = tramitacao.materia
14
15 do_envia_email_tramitacao(
16 get_base_url(request),
17 materia,
18 tramitacao.status,
19 tramitacao.unidade_tramitacao_destino)
20
```
Path: `sapl/materia/apps.py`
Content:
```
1 from django import apps
2 from django.utils.translation import ugettext_lazy as _
3
4
5 class AppConfig(apps.AppConfig):
6 name = 'sapl.materia'
7 label = 'materia'
8 verbose_name = _('Matéria')
9
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sapl/materia/apps.py b/sapl/materia/apps.py
--- a/sapl/materia/apps.py
+++ b/sapl/materia/apps.py
@@ -6,3 +6,6 @@
name = 'sapl.materia'
label = 'materia'
verbose_name = _('Matéria')
+
+ def ready(self):
+ from . import receivers
\ No newline at end of file
diff --git a/sapl/materia/receivers.py b/sapl/materia/receivers.py
--- a/sapl/materia/receivers.py
+++ b/sapl/materia/receivers.py
@@ -1,5 +1,7 @@
+from django.db.models.signals import post_delete, post_save
from django.dispatch import receiver
+from sapl.materia.models import Tramitacao
from sapl.materia.signals import tramitacao_signal
from sapl.utils import get_base_url
@@ -17,3 +19,11 @@
materia,
tramitacao.status,
tramitacao.unidade_tramitacao_destino)
+
+
+@receiver(post_delete, sender=Tramitacao)
+def status_tramitacao_materia(sender, instance, **kwargs):
+ if instance.turno == 'F':
+ materia = instance.materia
+ materia.em_tramitacao = True
+ materia.save()
|
{"golden_diff": "diff --git a/sapl/materia/apps.py b/sapl/materia/apps.py\n--- a/sapl/materia/apps.py\n+++ b/sapl/materia/apps.py\n@@ -6,3 +6,6 @@\n name = 'sapl.materia'\n label = 'materia'\n verbose_name = _('Mat\u00e9ria')\n+\n+ def ready(self):\n+ from . import receivers\n\\ No newline at end of file\ndiff --git a/sapl/materia/receivers.py b/sapl/materia/receivers.py\n--- a/sapl/materia/receivers.py\n+++ b/sapl/materia/receivers.py\n@@ -1,5 +1,7 @@\n+from django.db.models.signals import post_delete, post_save\n from django.dispatch import receiver\n \n+from sapl.materia.models import Tramitacao\n from sapl.materia.signals import tramitacao_signal\n from sapl.utils import get_base_url\n \n@@ -17,3 +19,11 @@\n materia,\n tramitacao.status,\n tramitacao.unidade_tramitacao_destino)\n+\n+\n+@receiver(post_delete, sender=Tramitacao)\n+def status_tramitacao_materia(sender, instance, **kwargs):\n+ if instance.turno == 'F':\n+ materia = instance.materia\n+ materia.em_tramitacao = True\n+ materia.save()\n", "issue": "Exclus\u00e3o Tramita\u00e7\u00e3o - status de tramita\u00e7\u00e3o\nAo incluir uma tramita\u00e7\u00e3o \u00e0 mat\u00e9ria, em que esta tramita\u00e7\u00e3o tenha seu indicador de tramita\u00e7\u00e3o definido nas tabelas auxiliares como fim, a mat\u00e9ria em quest\u00e3o passa de \"em tramita\u00e7\u00e3o - sim para n\u00e3o\" corretamente. Se essa tramita\u00e7\u00e3o por ventura for exclu\u00edda, n\u00e3o seria o caso de alterar novamente a mat\u00e9ria de \"em tramita\u00e7\u00e3o - n\u00e3o para sim\" ?\n", "before_files": [{"content": "from django.dispatch import receiver\n\nfrom sapl.materia.signals import tramitacao_signal\nfrom sapl.utils import get_base_url\n\nfrom .email_utils import do_envia_email_tramitacao\n\n\n@receiver(tramitacao_signal)\ndef handle_tramitacao_signal(sender, **kwargs):\n tramitacao = kwargs.get(\"post\")\n request = kwargs.get(\"request\")\n materia = tramitacao.materia\n\n do_envia_email_tramitacao(\n get_base_url(request),\n materia,\n tramitacao.status,\n tramitacao.unidade_tramitacao_destino)\n", "path": "sapl/materia/receivers.py"}, {"content": "from django import apps\nfrom django.utils.translation import ugettext_lazy as _\n\n\nclass AppConfig(apps.AppConfig):\n name = 'sapl.materia'\n label = 'materia'\n verbose_name = _('Mat\u00e9ria')\n", "path": "sapl/materia/apps.py"}], "after_files": [{"content": "from django.db.models.signals import post_delete, post_save\nfrom django.dispatch import receiver\n\nfrom sapl.materia.models import Tramitacao\nfrom sapl.materia.signals import tramitacao_signal\nfrom sapl.utils import get_base_url\n\nfrom .email_utils import do_envia_email_tramitacao\n\n\n@receiver(tramitacao_signal)\ndef handle_tramitacao_signal(sender, **kwargs):\n tramitacao = kwargs.get(\"post\")\n request = kwargs.get(\"request\")\n materia = tramitacao.materia\n\n do_envia_email_tramitacao(\n get_base_url(request),\n materia,\n tramitacao.status,\n tramitacao.unidade_tramitacao_destino)\n\n\n@receiver(post_delete, sender=Tramitacao)\ndef status_tramitacao_materia(sender, instance, **kwargs):\n if instance.turno == 'F':\n materia = instance.materia\n materia.em_tramitacao = True\n materia.save()\n", "path": "sapl/materia/receivers.py"}, {"content": "from django import apps\nfrom django.utils.translation import ugettext_lazy as _\n\n\nclass AppConfig(apps.AppConfig):\n name = 'sapl.materia'\n label = 'materia'\n verbose_name = _('Mat\u00e9ria')\n\n def ready(self):\n from . import receivers", "path": "sapl/materia/apps.py"}]}
| 604 | 300 |
gh_patches_debug_34214
|
rasdani/github-patches
|
git_diff
|
deepchecks__deepchecks-740
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[FEAT] Add force permutation option in UnusedFeatures check
`UnusedFeatures` looks for the feature importance attr if possible, which is bias in some [sklearn models](https://explained.ai/rf-importance/).
I suggest adding an option to override this behaviour. This is already an option in `.utils.features.calculate_feature_importance`.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `deepchecks/checks/methodology/unused_features.py`
Content:
```
1 # ----------------------------------------------------------------------------
2 # Copyright (C) 2021 Deepchecks (https://www.deepchecks.com)
3 #
4 # This file is part of Deepchecks.
5 # Deepchecks is distributed under the terms of the GNU Affero General
6 # Public License (version 3 or later).
7 # You should have received a copy of the GNU Affero General Public License
8 # along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.
9 # ----------------------------------------------------------------------------
10 #
11 """The UnusedFeatures check module."""
12 from typing import Tuple
13
14 import plotly.graph_objects as go
15 import numpy as np
16 import pandas as pd
17 from sklearn.base import TransformerMixin
18 from sklearn.compose import ColumnTransformer
19 from sklearn.decomposition import PCA
20 from sklearn.impute import SimpleImputer
21 from sklearn.pipeline import Pipeline
22 from sklearn.preprocessing import RobustScaler, OrdinalEncoder
23
24 from deepchecks.base.check_context import CheckRunContext
25 from deepchecks import Dataset, CheckResult, TrainTestBaseCheck, ConditionResult, ConditionCategory
26
27
28 __all__ = ['UnusedFeatures']
29
30
31 class UnusedFeatures(TrainTestBaseCheck):
32 """Detect features that are nearly unused by the model.
33
34 The check uses feature importance (either internally computed in appropriate models or calculated by permutation
35 feature importance) to detect features that are not used by the model. From this list, the check sorts the features
36 by their variance (as calculated by a PCA transformation). High variance unused features may be containing
37 information that is ignored by the model.
38
39 Parameters
40 ----------
41 feature_importance_threshold : float , default: 0.2
42 A cutoff value for the feature importance, measured by the ratio of
43 each features' feature importance to the mean feature importance. Features with lower importance
44 are not shown in the check display.
45 feature_variance_threshold : float , default: 0.4
46 A cutoff value for the feature variance, measured by the ratio of
47 each features' feature variance to the mean feature variance. Unused features with lower variance
48 are not shown in the check display.
49 n_top_fi_to_show : int , default: 5
50 The max number of important features to show in the check display.
51 n_top_unused_to_show : int , default: 15
52 The max number of unused features to show in the check display, from among
53 unused features that have higher variance then is defined by feature_variance_threshold.
54 random_state : int , default: 42
55 The random state to use for permutation feature importance and PCA.
56 """
57
58 def __init__(self, feature_importance_threshold: float = 0.2, feature_variance_threshold: float = 0.4,
59 n_top_fi_to_show: int = 5, n_top_unused_to_show: int = 15, random_state: int = 42):
60 super().__init__()
61 self.feature_importance_threshold = feature_importance_threshold
62 self.feature_variance_threshold = feature_variance_threshold
63 self.n_top_fi_to_show = n_top_fi_to_show
64 self.n_top_unused_to_show = n_top_unused_to_show
65 self.random_state = random_state
66
67 def run_logic(self, context: CheckRunContext) -> CheckResult:
68 """Run check.
69
70 Returns
71 -------
72 CheckResult
73 value is a dataframe with metrics as indexes, and scores per training and test in the columns.
74 display data is a bar graph of the metrics for training and test data.
75
76 Raises
77 ------
78 DeepchecksValueError
79 If neither train dataset nor test dataset exist, or either of the dataset objects are
80 not a Dataset instance with a label.
81 """
82 if context.have_test():
83 dataset = context.test
84 else:
85 dataset = context.train
86
87 feature_importance = context.features_importance
88 features = context.features
89
90 # Calculate normalized variance per feature based on PCA decomposition
91 pre_pca_transformer, var_col_order = naive_encoder(dataset)
92 pca_trans = PCA(n_components=len(dataset.features) // 2, random_state=self.random_state)
93 n_samples = min(10000, dataset.n_samples)
94 pca_trans.fit(pre_pca_transformer.fit_transform(
95 dataset.data[features].sample(n_samples, random_state=self.random_state)
96 ))
97
98 feature_normed_variance = pd.Series(np.abs(pca_trans.components_).sum(axis=0), index=var_col_order)
99 feature_normed_variance = feature_normed_variance / feature_normed_variance.sum()
100
101 feature_df = pd.concat([feature_importance, feature_normed_variance], axis=1)
102 feature_df.columns = ['Feature Importance', 'Feature Variance']
103 feature_df.sort_values(by='Feature Importance', ascending=False, inplace=True)
104
105 # For feature importance and variance, calculate their "ratio to average" per feature. The ratio to average
106 # is, for example, the amount of feature importance a feature has, divided by the the amount he would have
107 # if all features where equally important (which is basically 1 / n_of_features).
108 feature_ratio_to_avg_df = feature_df / (1 / len(feature_importance))
109
110 # Find last viable feature (not unused). All features from there on are sorted by variance
111 last_important_feature_index = sum(
112 feature_ratio_to_avg_df['Feature Importance'] > self.feature_importance_threshold
113 ) - 1
114
115 unviable_feature_df = feature_df.iloc[(last_important_feature_index + 1):]
116 # Only display if there are features considered unimportant
117 if not unviable_feature_df.empty:
118 unviable_feature_df.sort_values(by='Feature Variance', ascending=False, inplace=True)
119 unviable_feature_ratio_to_avg_df = unviable_feature_df / (1 / len(feature_df))
120 last_variable_feature_index = sum(
121 unviable_feature_ratio_to_avg_df['Feature Variance'] > self.feature_variance_threshold
122 )
123
124 # limit display to n_top_to_show params
125 display_feature_df = pd.concat(
126 [feature_df.iloc[:(last_important_feature_index + 1)].head(self.n_top_fi_to_show),
127 unviable_feature_df.iloc[:last_variable_feature_index].head(self.n_top_unused_to_show)],
128 axis=0)
129
130 fig = go.Figure()
131 fig.add_trace(go.Bar(
132 y=display_feature_df.index,
133 x=display_feature_df['Feature Importance'].multiply(100).values.flatten(),
134 name='Feature Importance %',
135 marker_color='indianred',
136 orientation='h'
137 ))
138 fig.add_trace(go.Bar(
139 y=display_feature_df.index,
140 x=display_feature_df['Feature Variance'].multiply(100).values.flatten(),
141 name='Feature Variance %',
142 marker_color='lightsalmon',
143 orientation='h'
144 ))
145
146 fig.update_yaxes(autorange='reversed')
147 fig.update_layout(title_text='Unused features compared to top important features',
148 width=800, height=500)
149
150 last_important_feature_index_to_plot = min(last_important_feature_index, self.n_top_fi_to_show - 1)
151
152 if last_important_feature_index_to_plot < len(display_feature_df) - 1:
153 last_important_feature_line_loc = last_important_feature_index_to_plot + 0.5
154 fig.add_hline(y=last_important_feature_line_loc, line_width=2, line_dash='dash', line_color='green',
155 annotation_text='Last shown significant feature')
156
157 # display only if high variance features exist (as set by self.feature_variance_threshold)
158 if not last_variable_feature_index:
159 display_list = []
160 else:
161 display_list = [
162 'Features above the line are a sample of the most important features, while the features '
163 'below the line are the unused features with highest variance, as defined by check'
164 ' parameters', fig]
165
166 else:
167 display_list = []
168
169 return_value = {
170 'used features': feature_df.index[:(last_important_feature_index + 1)].values.tolist(),
171 'unused features': {
172 'high variance': (
173 [] if unviable_feature_df.empty
174 else unviable_feature_df.index[:last_variable_feature_index].values.tolist()
175 ),
176 'low variance': (
177 [] if unviable_feature_df.empty
178 else unviable_feature_df.index[last_variable_feature_index:].values.tolist()
179 )
180 }}
181
182 return CheckResult(return_value, header='Unused Features', display=display_list)
183
184 def add_condition_number_of_high_variance_unused_features_not_greater_than(
185 self, max_high_variance_unused_features: int = 5):
186 """Add condition - require number of high variance unused features to be not greater than a given number.
187
188 Parameters
189 ----------
190 max_high_variance_unused_features : int , default: 5
191 Maximum allowed number of high variance unused features.
192 """
193 def max_high_variance_unused_features_condition(result: dict) -> ConditionResult:
194 high_var_features = result['unused features']['high variance']
195 if len(high_var_features) > max_high_variance_unused_features:
196 return ConditionResult(
197 False,
198 f'Found number of unused high variance features above threshold: {high_var_features}',
199 category=ConditionCategory.WARN)
200 else:
201 return ConditionResult(True)
202
203 return self.add_condition(f'Number of high variance unused features is not greater than'
204 f' {max_high_variance_unused_features}',
205 max_high_variance_unused_features_condition)
206
207
208 def naive_encoder(dataset: Dataset) -> Tuple[TransformerMixin, list]:
209 """Create a naive encoder for categorical and numerical features.
210
211 The encoder handles nans for all features and uses label encoder for categorical features. Then, all features are
212 scaled using RobustScaler.
213
214 Parameters
215 ----------
216 dataset : Dataset
217 The dataset to encode.
218
219 Returns
220 -------
221 Tuple[TransformerMixin, list]
222 A transformer object, a list of columns returned
223 """
224 numeric_features = [col for col in dataset.features if col not in dataset.cat_features]
225
226 return ColumnTransformer(
227 transformers=[
228 ('num', Pipeline([
229 ('nan_handling', SimpleImputer()),
230 ('norm', RobustScaler())
231 ]),
232 numeric_features),
233 ('cat',
234 Pipeline([
235 ('nan_handling', SimpleImputer(strategy='most_frequent')),
236 ('encode', OrdinalEncoder(handle_unknown='use_encoded_value', unknown_value=-1)),
237 ('norm', RobustScaler())
238 ]),
239 dataset.cat_features)
240 ]
241 ), numeric_features + dataset.cat_features
242
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/deepchecks/checks/methodology/unused_features.py b/deepchecks/checks/methodology/unused_features.py
--- a/deepchecks/checks/methodology/unused_features.py
+++ b/deepchecks/checks/methodology/unused_features.py
@@ -23,6 +23,7 @@
from deepchecks.base.check_context import CheckRunContext
from deepchecks import Dataset, CheckResult, TrainTestBaseCheck, ConditionResult, ConditionCategory
+from deepchecks.utils.typing import BasicModel
__all__ = ['UnusedFeatures']
@@ -64,8 +65,26 @@
self.n_top_unused_to_show = n_top_unused_to_show
self.random_state = random_state
- def run_logic(self, context: CheckRunContext) -> CheckResult:
- """Run check.
+ def run(self,
+ train_dataset: Dataset,
+ test_dataset: Dataset,
+ model: BasicModel = None,
+ feature_importance_force_permutation: bool = False,
+ feature_importance_timeout: int = None) -> CheckResult:
+ """Run the check.
+
+ Parameters
+ ----------
+ train_dataset : Dataset
+ dataset representing data an estimator was fitted on
+ test_dataset : Dataset
+ dataset representing data an estimator predicts on
+ model : BasicModel
+ A scikit-learn-compatible fitted estimator instance
+ feature_importance_force_permutation : bool , default: False
+ force calculation of permutation features importance
+ feature_importance_timeout : int , default: None
+ timeout in second for the permutation features importance calculation
Returns
-------
@@ -79,6 +98,13 @@
If neither train dataset nor test dataset exist, or either of the dataset objects are
not a Dataset instance with a label.
"""
+ c = CheckRunContext(train_dataset, test_dataset, model,
+ feature_importance_force_permutation=feature_importance_force_permutation,
+ feature_importance_timeout=feature_importance_timeout)
+ return self.run_logic(c)
+
+ def run_logic(self, context: CheckRunContext) -> CheckResult:
+ """Run check."""
if context.have_test():
dataset = context.test
else:
|
{"golden_diff": "diff --git a/deepchecks/checks/methodology/unused_features.py b/deepchecks/checks/methodology/unused_features.py\n--- a/deepchecks/checks/methodology/unused_features.py\n+++ b/deepchecks/checks/methodology/unused_features.py\n@@ -23,6 +23,7 @@\n \n from deepchecks.base.check_context import CheckRunContext\n from deepchecks import Dataset, CheckResult, TrainTestBaseCheck, ConditionResult, ConditionCategory\n+from deepchecks.utils.typing import BasicModel\n \n \n __all__ = ['UnusedFeatures']\n@@ -64,8 +65,26 @@\n self.n_top_unused_to_show = n_top_unused_to_show\n self.random_state = random_state\n \n- def run_logic(self, context: CheckRunContext) -> CheckResult:\n- \"\"\"Run check.\n+ def run(self,\n+ train_dataset: Dataset,\n+ test_dataset: Dataset,\n+ model: BasicModel = None,\n+ feature_importance_force_permutation: bool = False,\n+ feature_importance_timeout: int = None) -> CheckResult:\n+ \"\"\"Run the check.\n+\n+ Parameters\n+ ----------\n+ train_dataset : Dataset\n+ dataset representing data an estimator was fitted on\n+ test_dataset : Dataset\n+ dataset representing data an estimator predicts on\n+ model : BasicModel\n+ A scikit-learn-compatible fitted estimator instance\n+ feature_importance_force_permutation : bool , default: False\n+ force calculation of permutation features importance\n+ feature_importance_timeout : int , default: None\n+ timeout in second for the permutation features importance calculation\n \n Returns\n -------\n@@ -79,6 +98,13 @@\n If neither train dataset nor test dataset exist, or either of the dataset objects are\n not a Dataset instance with a label.\n \"\"\"\n+ c = CheckRunContext(train_dataset, test_dataset, model,\n+ feature_importance_force_permutation=feature_importance_force_permutation,\n+ feature_importance_timeout=feature_importance_timeout)\n+ return self.run_logic(c)\n+\n+ def run_logic(self, context: CheckRunContext) -> CheckResult:\n+ \"\"\"Run check.\"\"\"\n if context.have_test():\n dataset = context.test\n else:\n", "issue": "[FEAT] Add force permutation option in UnusedFeatures check\n`UnusedFeatures` looks for the feature importance attr if possible, which is bias in some [sklearn models](https://explained.ai/rf-importance/).\r\nI suggest adding an option to override this behaviour. This is already an option in `.utils.features.calculate_feature_importance`.\r\n\r\n\r\n\n", "before_files": [{"content": "# ----------------------------------------------------------------------------\n# Copyright (C) 2021 Deepchecks (https://www.deepchecks.com)\n#\n# This file is part of Deepchecks.\n# Deepchecks is distributed under the terms of the GNU Affero General\n# Public License (version 3 or later).\n# You should have received a copy of the GNU Affero General Public License\n# along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.\n# ----------------------------------------------------------------------------\n#\n\"\"\"The UnusedFeatures check module.\"\"\"\nfrom typing import Tuple\n\nimport plotly.graph_objects as go\nimport numpy as np\nimport pandas as pd\nfrom sklearn.base import TransformerMixin\nfrom sklearn.compose import ColumnTransformer\nfrom sklearn.decomposition import PCA\nfrom sklearn.impute import SimpleImputer\nfrom sklearn.pipeline import Pipeline\nfrom sklearn.preprocessing import RobustScaler, OrdinalEncoder\n\nfrom deepchecks.base.check_context import CheckRunContext\nfrom deepchecks import Dataset, CheckResult, TrainTestBaseCheck, ConditionResult, ConditionCategory\n\n\n__all__ = ['UnusedFeatures']\n\n\nclass UnusedFeatures(TrainTestBaseCheck):\n \"\"\"Detect features that are nearly unused by the model.\n\n The check uses feature importance (either internally computed in appropriate models or calculated by permutation\n feature importance) to detect features that are not used by the model. From this list, the check sorts the features\n by their variance (as calculated by a PCA transformation). High variance unused features may be containing\n information that is ignored by the model.\n\n Parameters\n ----------\n feature_importance_threshold : float , default: 0.2\n A cutoff value for the feature importance, measured by the ratio of\n each features' feature importance to the mean feature importance. Features with lower importance\n are not shown in the check display.\n feature_variance_threshold : float , default: 0.4\n A cutoff value for the feature variance, measured by the ratio of\n each features' feature variance to the mean feature variance. Unused features with lower variance\n are not shown in the check display.\n n_top_fi_to_show : int , default: 5\n The max number of important features to show in the check display.\n n_top_unused_to_show : int , default: 15\n The max number of unused features to show in the check display, from among\n unused features that have higher variance then is defined by feature_variance_threshold.\n random_state : int , default: 42\n The random state to use for permutation feature importance and PCA.\n \"\"\"\n\n def __init__(self, feature_importance_threshold: float = 0.2, feature_variance_threshold: float = 0.4,\n n_top_fi_to_show: int = 5, n_top_unused_to_show: int = 15, random_state: int = 42):\n super().__init__()\n self.feature_importance_threshold = feature_importance_threshold\n self.feature_variance_threshold = feature_variance_threshold\n self.n_top_fi_to_show = n_top_fi_to_show\n self.n_top_unused_to_show = n_top_unused_to_show\n self.random_state = random_state\n\n def run_logic(self, context: CheckRunContext) -> CheckResult:\n \"\"\"Run check.\n\n Returns\n -------\n CheckResult\n value is a dataframe with metrics as indexes, and scores per training and test in the columns.\n display data is a bar graph of the metrics for training and test data.\n\n Raises\n ------\n DeepchecksValueError\n If neither train dataset nor test dataset exist, or either of the dataset objects are\n not a Dataset instance with a label.\n \"\"\"\n if context.have_test():\n dataset = context.test\n else:\n dataset = context.train\n\n feature_importance = context.features_importance\n features = context.features\n\n # Calculate normalized variance per feature based on PCA decomposition\n pre_pca_transformer, var_col_order = naive_encoder(dataset)\n pca_trans = PCA(n_components=len(dataset.features) // 2, random_state=self.random_state)\n n_samples = min(10000, dataset.n_samples)\n pca_trans.fit(pre_pca_transformer.fit_transform(\n dataset.data[features].sample(n_samples, random_state=self.random_state)\n ))\n\n feature_normed_variance = pd.Series(np.abs(pca_trans.components_).sum(axis=0), index=var_col_order)\n feature_normed_variance = feature_normed_variance / feature_normed_variance.sum()\n\n feature_df = pd.concat([feature_importance, feature_normed_variance], axis=1)\n feature_df.columns = ['Feature Importance', 'Feature Variance']\n feature_df.sort_values(by='Feature Importance', ascending=False, inplace=True)\n\n # For feature importance and variance, calculate their \"ratio to average\" per feature. The ratio to average\n # is, for example, the amount of feature importance a feature has, divided by the the amount he would have\n # if all features where equally important (which is basically 1 / n_of_features).\n feature_ratio_to_avg_df = feature_df / (1 / len(feature_importance))\n\n # Find last viable feature (not unused). All features from there on are sorted by variance\n last_important_feature_index = sum(\n feature_ratio_to_avg_df['Feature Importance'] > self.feature_importance_threshold\n ) - 1\n\n unviable_feature_df = feature_df.iloc[(last_important_feature_index + 1):]\n # Only display if there are features considered unimportant\n if not unviable_feature_df.empty:\n unviable_feature_df.sort_values(by='Feature Variance', ascending=False, inplace=True)\n unviable_feature_ratio_to_avg_df = unviable_feature_df / (1 / len(feature_df))\n last_variable_feature_index = sum(\n unviable_feature_ratio_to_avg_df['Feature Variance'] > self.feature_variance_threshold\n )\n\n # limit display to n_top_to_show params\n display_feature_df = pd.concat(\n [feature_df.iloc[:(last_important_feature_index + 1)].head(self.n_top_fi_to_show),\n unviable_feature_df.iloc[:last_variable_feature_index].head(self.n_top_unused_to_show)],\n axis=0)\n\n fig = go.Figure()\n fig.add_trace(go.Bar(\n y=display_feature_df.index,\n x=display_feature_df['Feature Importance'].multiply(100).values.flatten(),\n name='Feature Importance %',\n marker_color='indianred',\n orientation='h'\n ))\n fig.add_trace(go.Bar(\n y=display_feature_df.index,\n x=display_feature_df['Feature Variance'].multiply(100).values.flatten(),\n name='Feature Variance %',\n marker_color='lightsalmon',\n orientation='h'\n ))\n\n fig.update_yaxes(autorange='reversed')\n fig.update_layout(title_text='Unused features compared to top important features',\n width=800, height=500)\n\n last_important_feature_index_to_plot = min(last_important_feature_index, self.n_top_fi_to_show - 1)\n\n if last_important_feature_index_to_plot < len(display_feature_df) - 1:\n last_important_feature_line_loc = last_important_feature_index_to_plot + 0.5\n fig.add_hline(y=last_important_feature_line_loc, line_width=2, line_dash='dash', line_color='green',\n annotation_text='Last shown significant feature')\n\n # display only if high variance features exist (as set by self.feature_variance_threshold)\n if not last_variable_feature_index:\n display_list = []\n else:\n display_list = [\n 'Features above the line are a sample of the most important features, while the features '\n 'below the line are the unused features with highest variance, as defined by check'\n ' parameters', fig]\n\n else:\n display_list = []\n\n return_value = {\n 'used features': feature_df.index[:(last_important_feature_index + 1)].values.tolist(),\n 'unused features': {\n 'high variance': (\n [] if unviable_feature_df.empty\n else unviable_feature_df.index[:last_variable_feature_index].values.tolist()\n ),\n 'low variance': (\n [] if unviable_feature_df.empty\n else unviable_feature_df.index[last_variable_feature_index:].values.tolist()\n )\n }}\n\n return CheckResult(return_value, header='Unused Features', display=display_list)\n\n def add_condition_number_of_high_variance_unused_features_not_greater_than(\n self, max_high_variance_unused_features: int = 5):\n \"\"\"Add condition - require number of high variance unused features to be not greater than a given number.\n\n Parameters\n ----------\n max_high_variance_unused_features : int , default: 5\n Maximum allowed number of high variance unused features.\n \"\"\"\n def max_high_variance_unused_features_condition(result: dict) -> ConditionResult:\n high_var_features = result['unused features']['high variance']\n if len(high_var_features) > max_high_variance_unused_features:\n return ConditionResult(\n False,\n f'Found number of unused high variance features above threshold: {high_var_features}',\n category=ConditionCategory.WARN)\n else:\n return ConditionResult(True)\n\n return self.add_condition(f'Number of high variance unused features is not greater than'\n f' {max_high_variance_unused_features}',\n max_high_variance_unused_features_condition)\n\n\ndef naive_encoder(dataset: Dataset) -> Tuple[TransformerMixin, list]:\n \"\"\"Create a naive encoder for categorical and numerical features.\n\n The encoder handles nans for all features and uses label encoder for categorical features. Then, all features are\n scaled using RobustScaler.\n\n Parameters\n ----------\n dataset : Dataset\n The dataset to encode.\n\n Returns\n -------\n Tuple[TransformerMixin, list]\n A transformer object, a list of columns returned\n \"\"\"\n numeric_features = [col for col in dataset.features if col not in dataset.cat_features]\n\n return ColumnTransformer(\n transformers=[\n ('num', Pipeline([\n ('nan_handling', SimpleImputer()),\n ('norm', RobustScaler())\n ]),\n numeric_features),\n ('cat',\n Pipeline([\n ('nan_handling', SimpleImputer(strategy='most_frequent')),\n ('encode', OrdinalEncoder(handle_unknown='use_encoded_value', unknown_value=-1)),\n ('norm', RobustScaler())\n ]),\n dataset.cat_features)\n ]\n ), numeric_features + dataset.cat_features\n", "path": "deepchecks/checks/methodology/unused_features.py"}], "after_files": [{"content": "# ----------------------------------------------------------------------------\n# Copyright (C) 2021 Deepchecks (https://www.deepchecks.com)\n#\n# This file is part of Deepchecks.\n# Deepchecks is distributed under the terms of the GNU Affero General\n# Public License (version 3 or later).\n# You should have received a copy of the GNU Affero General Public License\n# along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.\n# ----------------------------------------------------------------------------\n#\n\"\"\"The UnusedFeatures check module.\"\"\"\nfrom typing import Tuple\n\nimport plotly.graph_objects as go\nimport numpy as np\nimport pandas as pd\nfrom sklearn.base import TransformerMixin\nfrom sklearn.compose import ColumnTransformer\nfrom sklearn.decomposition import PCA\nfrom sklearn.impute import SimpleImputer\nfrom sklearn.pipeline import Pipeline\nfrom sklearn.preprocessing import RobustScaler, OrdinalEncoder\n\nfrom deepchecks.base.check_context import CheckRunContext\nfrom deepchecks import Dataset, CheckResult, TrainTestBaseCheck, ConditionResult, ConditionCategory\nfrom deepchecks.utils.typing import BasicModel\n\n\n__all__ = ['UnusedFeatures']\n\n\nclass UnusedFeatures(TrainTestBaseCheck):\n \"\"\"Detect features that are nearly unused by the model.\n\n The check uses feature importance (either internally computed in appropriate models or calculated by permutation\n feature importance) to detect features that are not used by the model. From this list, the check sorts the features\n by their variance (as calculated by a PCA transformation). High variance unused features may be containing\n information that is ignored by the model.\n\n Parameters\n ----------\n feature_importance_threshold : float , default: 0.2\n A cutoff value for the feature importance, measured by the ratio of\n each features' feature importance to the mean feature importance. Features with lower importance\n are not shown in the check display.\n feature_variance_threshold : float , default: 0.4\n A cutoff value for the feature variance, measured by the ratio of\n each features' feature variance to the mean feature variance. Unused features with lower variance\n are not shown in the check display.\n n_top_fi_to_show : int , default: 5\n The max number of important features to show in the check display.\n n_top_unused_to_show : int , default: 15\n The max number of unused features to show in the check display, from among\n unused features that have higher variance then is defined by feature_variance_threshold.\n random_state : int , default: 42\n The random state to use for permutation feature importance and PCA.\n \"\"\"\n\n def __init__(self, feature_importance_threshold: float = 0.2, feature_variance_threshold: float = 0.4,\n n_top_fi_to_show: int = 5, n_top_unused_to_show: int = 15, random_state: int = 42):\n super().__init__()\n self.feature_importance_threshold = feature_importance_threshold\n self.feature_variance_threshold = feature_variance_threshold\n self.n_top_fi_to_show = n_top_fi_to_show\n self.n_top_unused_to_show = n_top_unused_to_show\n self.random_state = random_state\n\n def run(self,\n train_dataset: Dataset,\n test_dataset: Dataset,\n model: BasicModel = None,\n feature_importance_force_permutation: bool = False,\n feature_importance_timeout: int = None) -> CheckResult:\n \"\"\"Run the check.\n\n Parameters\n ----------\n train_dataset : Dataset\n dataset representing data an estimator was fitted on\n test_dataset : Dataset\n dataset representing data an estimator predicts on\n model : BasicModel\n A scikit-learn-compatible fitted estimator instance\n feature_importance_force_permutation : bool , default: False\n force calculation of permutation features importance\n feature_importance_timeout : int , default: None\n timeout in second for the permutation features importance calculation\n\n Returns\n -------\n CheckResult\n value is a dataframe with metrics as indexes, and scores per training and test in the columns.\n display data is a bar graph of the metrics for training and test data.\n\n Raises\n ------\n DeepchecksValueError\n If neither train dataset nor test dataset exist, or either of the dataset objects are\n not a Dataset instance with a label.\n \"\"\"\n c = CheckRunContext(train_dataset, test_dataset, model,\n feature_importance_force_permutation=feature_importance_force_permutation,\n feature_importance_timeout=feature_importance_timeout)\n return self.run_logic(c)\n\n def run_logic(self, context: CheckRunContext) -> CheckResult:\n \"\"\"Run check.\"\"\"\n if context.have_test():\n dataset = context.test\n else:\n dataset = context.train\n\n feature_importance = context.features_importance\n features = context.features\n\n # Calculate normalized variance per feature based on PCA decomposition\n pre_pca_transformer, var_col_order = naive_encoder(dataset)\n pca_trans = PCA(n_components=len(dataset.features) // 2, random_state=self.random_state)\n n_samples = min(10000, dataset.n_samples)\n pca_trans.fit(pre_pca_transformer.fit_transform(\n dataset.data[features].sample(n_samples, random_state=self.random_state)\n ))\n\n feature_normed_variance = pd.Series(np.abs(pca_trans.components_).sum(axis=0), index=var_col_order)\n feature_normed_variance = feature_normed_variance / feature_normed_variance.sum()\n\n feature_df = pd.concat([feature_importance, feature_normed_variance], axis=1)\n feature_df.columns = ['Feature Importance', 'Feature Variance']\n feature_df.sort_values(by='Feature Importance', ascending=False, inplace=True)\n\n # For feature importance and variance, calculate their \"ratio to average\" per feature. The ratio to average\n # is, for example, the amount of feature importance a feature has, divided by the the amount he would have\n # if all features where equally important (which is basically 1 / n_of_features).\n feature_ratio_to_avg_df = feature_df / (1 / len(feature_importance))\n\n # Find last viable feature (not unused). All features from there on are sorted by variance\n last_important_feature_index = sum(\n feature_ratio_to_avg_df['Feature Importance'] > self.feature_importance_threshold\n ) - 1\n\n unviable_feature_df = feature_df.iloc[(last_important_feature_index + 1):]\n # Only display if there are features considered unimportant\n if not unviable_feature_df.empty:\n unviable_feature_df.sort_values(by='Feature Variance', ascending=False, inplace=True)\n unviable_feature_ratio_to_avg_df = unviable_feature_df / (1 / len(feature_df))\n last_variable_feature_index = sum(\n unviable_feature_ratio_to_avg_df['Feature Variance'] > self.feature_variance_threshold\n )\n\n # limit display to n_top_to_show params\n display_feature_df = pd.concat(\n [feature_df.iloc[:(last_important_feature_index + 1)].head(self.n_top_fi_to_show),\n unviable_feature_df.iloc[:last_variable_feature_index].head(self.n_top_unused_to_show)],\n axis=0)\n\n fig = go.Figure()\n fig.add_trace(go.Bar(\n y=display_feature_df.index,\n x=display_feature_df['Feature Importance'].multiply(100).values.flatten(),\n name='Feature Importance %',\n marker_color='indianred',\n orientation='h'\n ))\n fig.add_trace(go.Bar(\n y=display_feature_df.index,\n x=display_feature_df['Feature Variance'].multiply(100).values.flatten(),\n name='Feature Variance %',\n marker_color='lightsalmon',\n orientation='h'\n ))\n\n fig.update_yaxes(autorange='reversed')\n fig.update_layout(title_text='Unused features compared to top important features',\n width=800, height=500)\n\n last_important_feature_index_to_plot = min(last_important_feature_index, self.n_top_fi_to_show - 1)\n\n if last_important_feature_index_to_plot < len(display_feature_df) - 1:\n last_important_feature_line_loc = last_important_feature_index_to_plot + 0.5\n fig.add_hline(y=last_important_feature_line_loc, line_width=2, line_dash='dash', line_color='green',\n annotation_text='Last shown significant feature')\n\n # display only if high variance features exist (as set by self.feature_variance_threshold)\n if not last_variable_feature_index:\n display_list = []\n else:\n display_list = [\n 'Features above the line are a sample of the most important features, while the features '\n 'below the line are the unused features with highest variance, as defined by check'\n ' parameters', fig]\n\n else:\n display_list = []\n\n return_value = {\n 'used features': feature_df.index[:(last_important_feature_index + 1)].values.tolist(),\n 'unused features': {\n 'high variance': (\n [] if unviable_feature_df.empty\n else unviable_feature_df.index[:last_variable_feature_index].values.tolist()\n ),\n 'low variance': (\n [] if unviable_feature_df.empty\n else unviable_feature_df.index[last_variable_feature_index:].values.tolist()\n )\n }}\n\n return CheckResult(return_value, header='Unused Features', display=display_list)\n\n def add_condition_number_of_high_variance_unused_features_not_greater_than(\n self, max_high_variance_unused_features: int = 5):\n \"\"\"Add condition - require number of high variance unused features to be not greater than a given number.\n\n Parameters\n ----------\n max_high_variance_unused_features : int , default: 5\n Maximum allowed number of high variance unused features.\n \"\"\"\n def max_high_variance_unused_features_condition(result: dict) -> ConditionResult:\n high_var_features = result['unused features']['high variance']\n if len(high_var_features) > max_high_variance_unused_features:\n return ConditionResult(\n False,\n f'Found number of unused high variance features above threshold: {high_var_features}',\n category=ConditionCategory.WARN)\n else:\n return ConditionResult(True)\n\n return self.add_condition(f'Number of high variance unused features is not greater than'\n f' {max_high_variance_unused_features}',\n max_high_variance_unused_features_condition)\n\n\ndef naive_encoder(dataset: Dataset) -> Tuple[TransformerMixin, list]:\n \"\"\"Create a naive encoder for categorical and numerical features.\n\n The encoder handles nans for all features and uses label encoder for categorical features. Then, all features are\n scaled using RobustScaler.\n\n Parameters\n ----------\n dataset : Dataset\n The dataset to encode.\n\n Returns\n -------\n Tuple[TransformerMixin, list]\n A transformer object, a list of columns returned\n \"\"\"\n numeric_features = [col for col in dataset.features if col not in dataset.cat_features]\n\n return ColumnTransformer(\n transformers=[\n ('num', Pipeline([\n ('nan_handling', SimpleImputer()),\n ('norm', RobustScaler())\n ]),\n numeric_features),\n ('cat',\n Pipeline([\n ('nan_handling', SimpleImputer(strategy='most_frequent')),\n ('encode', OrdinalEncoder(handle_unknown='use_encoded_value', unknown_value=-1)),\n ('norm', RobustScaler())\n ]),\n dataset.cat_features)\n ]\n ), numeric_features + dataset.cat_features\n", "path": "deepchecks/checks/methodology/unused_features.py"}]}
| 3,199 | 490 |
gh_patches_debug_4716
|
rasdani/github-patches
|
git_diff
|
crytic__slither-2331
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Bug]: High level call does not always have function
### Describe the issue:
I have two somehow similar examples, in the first one I have the function on the high level call in function safeAdd. In the next example I edited the array size to be constant instead of a literal, and I got None instead of a function object
### Code example to reproduce the issue:
```solidity
library SafeMath {
uint256 private constant twelve = 12;
struct A {uint256 a;}
function add(A[twelve] storage z) internal { }
}
contract MathContract {
uint256 private constant twelve = 12;
using SafeMath for SafeMath.A[12];
SafeMath.A[12] public z;
function safeAdd() public {
z.add();
}
}
```
```solidity
library SafeMath {
uint256 private constant twelve = 12;
struct A {uint256 a;}
function add(A[twelve] storage z) internal { }
}
contract MathContract {
uint256 private constant twelve = 12;
using SafeMath for SafeMath.A[twelve];
SafeMath.A[twelve] public z;
function safeAdd() public {
z.add();
}
}
```
### Version:
0.10.0
### Relevant log output:
```shell
>>> from slither import Slither
>>> math = Slither('a.sol').contracts[1]
>>> math.name
'MathContract'
>>> f = math.functions[0]
>>> f.name
'safeAdd'
>>> f.nodes
[<slither.core.cfg.node.Node object at 0x7f5460aa1e50>, <slither.core.cfg.node.No
de object at 0x7f5460aa2090>]
>>> f.nodes[1]
<slither.core.cfg.node.Node object at 0x7f5460aa2090>
>>> f.nodes[1].irs
[<slither.slithir.operations.library_call.LibraryCall object at 0x7f5460a748d0>]
>>> f.nodes[1].irs[0].function
<slither.core.declarations.function_contract.FunctionContract object at 0x7f5460a
9e090>
>>> f.nodes[1].irs[0].function.name
'add'
----------------------------------------------------------------------------------
>>> from slither import Slither
>>> math = Slither('a.sol').contracts[1]
>>> math.name
'MathContract'
>>> f = math.functions[0]
>>> f.name
'safeAdd'
>>> f.nodes
[<slither.core.cfg.node.Node object at 0x7f9d6379db10>, <slither.core.cfg.node.No
de object at 0x7f9d63a47850>]
>>> f.nodes[1]
<slither.core.cfg.node.Node object at 0x7f9d63a47850>
>>> f.nodes[1].irs
[<slither.slithir.operations.high_level_call.HighLevelCall object at 0x7f9d63a376
90>]
>>> f.nodes[1].irs[0].function
>>> print(f.nodes[1].irs[0].function)
None
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `slither/core/solidity_types/array_type.py`
Content:
```
1 from typing import Union, Optional, Tuple, Any, TYPE_CHECKING
2
3 from slither.core.expressions.expression import Expression
4 from slither.core.expressions.literal import Literal
5 from slither.core.solidity_types.elementary_type import ElementaryType
6 from slither.core.solidity_types.type import Type
7 from slither.visitors.expression.constants_folding import ConstantFolding
8
9 if TYPE_CHECKING:
10 from slither.core.expressions.binary_operation import BinaryOperation
11 from slither.core.expressions.identifier import Identifier
12
13
14 class ArrayType(Type):
15 def __init__(
16 self,
17 t: Type,
18 length: Optional[Union["Identifier", Literal, "BinaryOperation", int]],
19 ) -> None:
20 assert isinstance(t, Type)
21 if length:
22 if isinstance(length, int):
23 length = Literal(length, ElementaryType("uint256"))
24
25 super().__init__()
26 self._type: Type = t
27 assert length is None or isinstance(length, Expression)
28 self._length: Optional[Expression] = length
29
30 if length:
31 if not isinstance(length, Literal):
32 cf = ConstantFolding(length, "uint256")
33 length = cf.result()
34 self._length_value: Optional[Literal] = length
35 else:
36 self._length_value = None
37
38 @property
39 def type(self) -> Type:
40 return self._type
41
42 @property
43 def is_dynamic(self) -> bool:
44 return self.length is None
45
46 @property
47 def length(self) -> Optional[Expression]:
48 return self._length
49
50 @property
51 def length_value(self) -> Optional[Literal]:
52 return self._length_value
53
54 @property
55 def is_fixed_array(self) -> bool:
56 return bool(self.length)
57
58 @property
59 def is_dynamic_array(self) -> bool:
60 return not self.is_fixed_array
61
62 @property
63 def storage_size(self) -> Tuple[int, bool]:
64 if self._length_value:
65 elem_size, _ = self._type.storage_size
66 return elem_size * int(str(self._length_value)), True
67 return 32, True
68
69 def __str__(self) -> str:
70 if self._length:
71 return str(self._type) + f"[{str(self._length_value)}]"
72 return str(self._type) + "[]"
73
74 def __eq__(self, other: Any) -> bool:
75 if not isinstance(other, ArrayType):
76 return False
77 return self._type == other.type and self.length == other.length
78
79 def __hash__(self) -> int:
80 return hash(str(self))
81
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/slither/core/solidity_types/array_type.py b/slither/core/solidity_types/array_type.py
--- a/slither/core/solidity_types/array_type.py
+++ b/slither/core/solidity_types/array_type.py
@@ -74,7 +74,7 @@
def __eq__(self, other: Any) -> bool:
if not isinstance(other, ArrayType):
return False
- return self._type == other.type and self.length == other.length
+ return self._type == other.type and self._length_value == other.length_value
def __hash__(self) -> int:
return hash(str(self))
|
{"golden_diff": "diff --git a/slither/core/solidity_types/array_type.py b/slither/core/solidity_types/array_type.py\n--- a/slither/core/solidity_types/array_type.py\n+++ b/slither/core/solidity_types/array_type.py\n@@ -74,7 +74,7 @@\n def __eq__(self, other: Any) -> bool:\n if not isinstance(other, ArrayType):\n return False\n- return self._type == other.type and self.length == other.length\n+ return self._type == other.type and self._length_value == other.length_value\n \n def __hash__(self) -> int:\n return hash(str(self))\n", "issue": "[Bug]: High level call does not always have function\n### Describe the issue:\r\n\r\nI have two somehow similar examples, in the first one I have the function on the high level call in function safeAdd. In the next example I edited the array size to be constant instead of a literal, and I got None instead of a function object\r\n\r\n### Code example to reproduce the issue:\r\n\r\n```solidity\r\nlibrary SafeMath {\r\n uint256 private constant twelve = 12; \r\n struct A {uint256 a;}\r\n function add(A[twelve] storage z) internal { }\r\n}\r\n\r\ncontract MathContract {\r\n uint256 private constant twelve = 12; \r\n using SafeMath for SafeMath.A[12];\r\n SafeMath.A[12] public z;\r\n function safeAdd() public {\r\n z.add();\r\n }\r\n}\r\n```\r\n```solidity\r\nlibrary SafeMath {\r\n uint256 private constant twelve = 12; \r\n struct A {uint256 a;}\r\n function add(A[twelve] storage z) internal { }\r\n}\r\n\r\ncontract MathContract {\r\n uint256 private constant twelve = 12; \r\n using SafeMath for SafeMath.A[twelve];\r\n SafeMath.A[twelve] public z;\r\n function safeAdd() public {\r\n z.add();\r\n }\r\n}\r\n```\r\n\r\n### Version:\r\n\r\n0.10.0\r\n\r\n### Relevant log output:\r\n\r\n```shell\r\n>>> from slither import Slither\r\n>>> math = Slither('a.sol').contracts[1]\r\n>>> math.name\r\n'MathContract'\r\n>>> f = math.functions[0]\r\n>>> f.name\r\n'safeAdd'\r\n>>> f.nodes\r\n[<slither.core.cfg.node.Node object at 0x7f5460aa1e50>, <slither.core.cfg.node.No\r\nde object at 0x7f5460aa2090>]\r\n>>> f.nodes[1]\r\n<slither.core.cfg.node.Node object at 0x7f5460aa2090>\r\n>>> f.nodes[1].irs\r\n[<slither.slithir.operations.library_call.LibraryCall object at 0x7f5460a748d0>]\r\n>>> f.nodes[1].irs[0].function\r\n<slither.core.declarations.function_contract.FunctionContract object at 0x7f5460a\r\n9e090>\r\n>>> f.nodes[1].irs[0].function.name\r\n'add'\r\n----------------------------------------------------------------------------------\r\n>>> from slither import Slither\r\n>>> math = Slither('a.sol').contracts[1]\r\n>>> math.name\r\n'MathContract'\r\n>>> f = math.functions[0]\r\n>>> f.name\r\n'safeAdd'\r\n>>> f.nodes\r\n[<slither.core.cfg.node.Node object at 0x7f9d6379db10>, <slither.core.cfg.node.No\r\nde object at 0x7f9d63a47850>]\r\n>>> f.nodes[1]\r\n<slither.core.cfg.node.Node object at 0x7f9d63a47850>\r\n>>> f.nodes[1].irs\r\n[<slither.slithir.operations.high_level_call.HighLevelCall object at 0x7f9d63a376\r\n90>]\r\n>>> f.nodes[1].irs[0].function\r\n>>> print(f.nodes[1].irs[0].function)\r\nNone\r\n```\r\n\n", "before_files": [{"content": "from typing import Union, Optional, Tuple, Any, TYPE_CHECKING\n\nfrom slither.core.expressions.expression import Expression\nfrom slither.core.expressions.literal import Literal\nfrom slither.core.solidity_types.elementary_type import ElementaryType\nfrom slither.core.solidity_types.type import Type\nfrom slither.visitors.expression.constants_folding import ConstantFolding\n\nif TYPE_CHECKING:\n from slither.core.expressions.binary_operation import BinaryOperation\n from slither.core.expressions.identifier import Identifier\n\n\nclass ArrayType(Type):\n def __init__(\n self,\n t: Type,\n length: Optional[Union[\"Identifier\", Literal, \"BinaryOperation\", int]],\n ) -> None:\n assert isinstance(t, Type)\n if length:\n if isinstance(length, int):\n length = Literal(length, ElementaryType(\"uint256\"))\n\n super().__init__()\n self._type: Type = t\n assert length is None or isinstance(length, Expression)\n self._length: Optional[Expression] = length\n\n if length:\n if not isinstance(length, Literal):\n cf = ConstantFolding(length, \"uint256\")\n length = cf.result()\n self._length_value: Optional[Literal] = length\n else:\n self._length_value = None\n\n @property\n def type(self) -> Type:\n return self._type\n\n @property\n def is_dynamic(self) -> bool:\n return self.length is None\n\n @property\n def length(self) -> Optional[Expression]:\n return self._length\n\n @property\n def length_value(self) -> Optional[Literal]:\n return self._length_value\n\n @property\n def is_fixed_array(self) -> bool:\n return bool(self.length)\n\n @property\n def is_dynamic_array(self) -> bool:\n return not self.is_fixed_array\n\n @property\n def storage_size(self) -> Tuple[int, bool]:\n if self._length_value:\n elem_size, _ = self._type.storage_size\n return elem_size * int(str(self._length_value)), True\n return 32, True\n\n def __str__(self) -> str:\n if self._length:\n return str(self._type) + f\"[{str(self._length_value)}]\"\n return str(self._type) + \"[]\"\n\n def __eq__(self, other: Any) -> bool:\n if not isinstance(other, ArrayType):\n return False\n return self._type == other.type and self.length == other.length\n\n def __hash__(self) -> int:\n return hash(str(self))\n", "path": "slither/core/solidity_types/array_type.py"}], "after_files": [{"content": "from typing import Union, Optional, Tuple, Any, TYPE_CHECKING\n\nfrom slither.core.expressions.expression import Expression\nfrom slither.core.expressions.literal import Literal\nfrom slither.core.solidity_types.elementary_type import ElementaryType\nfrom slither.core.solidity_types.type import Type\nfrom slither.visitors.expression.constants_folding import ConstantFolding\n\nif TYPE_CHECKING:\n from slither.core.expressions.binary_operation import BinaryOperation\n from slither.core.expressions.identifier import Identifier\n\n\nclass ArrayType(Type):\n def __init__(\n self,\n t: Type,\n length: Optional[Union[\"Identifier\", Literal, \"BinaryOperation\", int]],\n ) -> None:\n assert isinstance(t, Type)\n if length:\n if isinstance(length, int):\n length = Literal(length, ElementaryType(\"uint256\"))\n\n super().__init__()\n self._type: Type = t\n assert length is None or isinstance(length, Expression)\n self._length: Optional[Expression] = length\n\n if length:\n if not isinstance(length, Literal):\n cf = ConstantFolding(length, \"uint256\")\n length = cf.result()\n self._length_value: Optional[Literal] = length\n else:\n self._length_value = None\n\n @property\n def type(self) -> Type:\n return self._type\n\n @property\n def is_dynamic(self) -> bool:\n return self.length is None\n\n @property\n def length(self) -> Optional[Expression]:\n return self._length\n\n @property\n def length_value(self) -> Optional[Literal]:\n return self._length_value\n\n @property\n def is_fixed_array(self) -> bool:\n return bool(self.length)\n\n @property\n def is_dynamic_array(self) -> bool:\n return not self.is_fixed_array\n\n @property\n def storage_size(self) -> Tuple[int, bool]:\n if self._length_value:\n elem_size, _ = self._type.storage_size\n return elem_size * int(str(self._length_value)), True\n return 32, True\n\n def __str__(self) -> str:\n if self._length:\n return str(self._type) + f\"[{str(self._length_value)}]\"\n return str(self._type) + \"[]\"\n\n def __eq__(self, other: Any) -> bool:\n if not isinstance(other, ArrayType):\n return False\n return self._type == other.type and self._length_value == other.length_value\n\n def __hash__(self) -> int:\n return hash(str(self))\n", "path": "slither/core/solidity_types/array_type.py"}]}
| 1,722 | 142 |
gh_patches_debug_1930
|
rasdani/github-patches
|
git_diff
|
CTFd__CTFd-1800
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Invalid model identifier
https://github.com/CTFd/CTFd/blob/master/CTFd/themes/core/templates/scoreboard.html#L26
This should change depending on the mode of the CTF
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `CTFd/plugins/__init__.py`
Content:
```
1 import glob
2 import importlib
3 import os
4 from collections import namedtuple
5
6 from flask import current_app as app
7 from flask import send_file, send_from_directory, url_for
8
9 from CTFd.utils.config.pages import get_pages
10 from CTFd.utils.decorators import admins_only as admins_only_wrapper
11 from CTFd.utils.plugins import override_template as utils_override_template
12 from CTFd.utils.plugins import (
13 register_admin_script as utils_register_admin_plugin_script,
14 )
15 from CTFd.utils.plugins import (
16 register_admin_stylesheet as utils_register_admin_plugin_stylesheet,
17 )
18 from CTFd.utils.plugins import register_script as utils_register_plugin_script
19 from CTFd.utils.plugins import register_stylesheet as utils_register_plugin_stylesheet
20
21 Menu = namedtuple("Menu", ["title", "route"])
22
23
24 def register_plugin_assets_directory(app, base_path, admins_only=False, endpoint=None):
25 """
26 Registers a directory to serve assets
27
28 :param app: A CTFd application
29 :param string base_path: The path to the directory
30 :param boolean admins_only: Whether or not the assets served out of the directory should be accessible to the public
31 :return:
32 """
33 base_path = base_path.strip("/")
34 if endpoint is None:
35 endpoint = base_path.replace("/", ".")
36
37 def assets_handler(path):
38 return send_from_directory(base_path, path)
39
40 rule = "/" + base_path + "/<path:path>"
41 app.add_url_rule(rule=rule, endpoint=endpoint, view_func=assets_handler)
42
43
44 def register_plugin_asset(app, asset_path, admins_only=False, endpoint=None):
45 """
46 Registers an file path to be served by CTFd
47
48 :param app: A CTFd application
49 :param string asset_path: The path to the asset file
50 :param boolean admins_only: Whether or not this file should be accessible to the public
51 :return:
52 """
53 asset_path = asset_path.strip("/")
54 if endpoint is None:
55 endpoint = asset_path.replace("/", ".")
56
57 def asset_handler():
58 return send_file(asset_path)
59
60 if admins_only:
61 asset_handler = admins_only_wrapper(asset_handler)
62 rule = "/" + asset_path
63 app.add_url_rule(rule=rule, endpoint=endpoint, view_func=asset_handler)
64
65
66 def override_template(*args, **kwargs):
67 """
68 Overrides a template with the provided html content.
69
70 e.g. override_template('scoreboard.html', '<h1>scores</h1>')
71 """
72 utils_override_template(*args, **kwargs)
73
74
75 def register_plugin_script(*args, **kwargs):
76 """
77 Adds a given script to the base.html template which all pages inherit from
78 """
79 utils_register_plugin_script(*args, **kwargs)
80
81
82 def register_plugin_stylesheet(*args, **kwargs):
83 """
84 Adds a given stylesheet to the base.html template which all pages inherit from.
85 """
86 utils_register_plugin_stylesheet(*args, **kwargs)
87
88
89 def register_admin_plugin_script(*args, **kwargs):
90 """
91 Adds a given script to the base.html of the admin theme which all admin pages inherit from
92 :param args:
93 :param kwargs:
94 :return:
95 """
96 utils_register_admin_plugin_script(*args, **kwargs)
97
98
99 def register_admin_plugin_stylesheet(*args, **kwargs):
100 """
101 Adds a given stylesheet to the base.html of the admin theme which all admin pages inherit from
102 :param args:
103 :param kwargs:
104 :return:
105 """
106 utils_register_admin_plugin_stylesheet(*args, **kwargs)
107
108
109 def register_admin_plugin_menu_bar(title, route):
110 """
111 Registers links on the Admin Panel menubar/navbar
112
113 :param name: A string that is shown on the navbar HTML
114 :param route: A string that is the href used by the link
115 :return:
116 """
117 am = Menu(title=title, route=route)
118 app.admin_plugin_menu_bar.append(am)
119
120
121 def get_admin_plugin_menu_bar():
122 """
123 Access the list used to store the plugin menu bar
124
125 :return: Returns a list of Menu namedtuples. They have name, and route attributes.
126 """
127 return app.admin_plugin_menu_bar
128
129
130 def register_user_page_menu_bar(title, route):
131 """
132 Registers links on the User side menubar/navbar
133
134 :param name: A string that is shown on the navbar HTML
135 :param route: A string that is the href used by the link
136 :return:
137 """
138 p = Menu(title=title, route=route)
139 app.plugin_menu_bar.append(p)
140
141
142 def get_user_page_menu_bar():
143 """
144 Access the list used to store the user page menu bar
145
146 :return: Returns a list of Menu namedtuples. They have name, and route attributes.
147 """
148 pages = []
149 for p in get_pages() + app.plugin_menu_bar:
150 if p.route.startswith("http"):
151 route = p.route
152 else:
153 route = url_for("views.static_html", route=p.route)
154 print(route)
155 pages.append(Menu(title=p.title, route=route))
156 return pages
157
158
159 def bypass_csrf_protection(f):
160 """
161 Decorator that allows a route to bypass the need for a CSRF nonce on POST requests.
162
163 This should be considered beta and may change in future versions.
164
165 :param f: A function that needs to bypass CSRF protection
166 :return: Returns a function with the _bypass_csrf attribute set which tells CTFd to not require CSRF protection.
167 """
168 f._bypass_csrf = True
169 return f
170
171
172 def get_plugin_names():
173 modules = sorted(glob.glob(app.plugins_dir + "/*"))
174 blacklist = {"__pycache__"}
175 plugins = []
176 for module in modules:
177 module_name = os.path.basename(module)
178 if os.path.isdir(module) and module_name not in blacklist:
179 plugins.append(module_name)
180 return plugins
181
182
183 def init_plugins(app):
184 """
185 Searches for the load function in modules in the CTFd/plugins folder. This function is called with the current CTFd
186 app as a parameter. This allows CTFd plugins to modify CTFd's behavior.
187
188 :param app: A CTFd application
189 :return:
190 """
191 app.admin_plugin_scripts = []
192 app.admin_plugin_stylesheets = []
193 app.plugin_scripts = []
194 app.plugin_stylesheets = []
195
196 app.admin_plugin_menu_bar = []
197 app.plugin_menu_bar = []
198 app.plugins_dir = os.path.dirname(__file__)
199
200 if app.config.get("SAFE_MODE", False) is False:
201 for plugin in get_plugin_names():
202 module = "." + plugin
203 module = importlib.import_module(module, package="CTFd.plugins")
204 module.load(app)
205 print(" * Loaded module, %s" % module)
206
207 app.jinja_env.globals.update(get_admin_plugin_menu_bar=get_admin_plugin_menu_bar)
208 app.jinja_env.globals.update(get_user_page_menu_bar=get_user_page_menu_bar)
209
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/CTFd/plugins/__init__.py b/CTFd/plugins/__init__.py
--- a/CTFd/plugins/__init__.py
+++ b/CTFd/plugins/__init__.py
@@ -151,7 +151,6 @@
route = p.route
else:
route = url_for("views.static_html", route=p.route)
- print(route)
pages.append(Menu(title=p.title, route=route))
return pages
|
{"golden_diff": "diff --git a/CTFd/plugins/__init__.py b/CTFd/plugins/__init__.py\n--- a/CTFd/plugins/__init__.py\n+++ b/CTFd/plugins/__init__.py\n@@ -151,7 +151,6 @@\n route = p.route\n else:\n route = url_for(\"views.static_html\", route=p.route)\n- print(route)\n pages.append(Menu(title=p.title, route=route))\n return pages\n", "issue": "Invalid model identifier\nhttps://github.com/CTFd/CTFd/blob/master/CTFd/themes/core/templates/scoreboard.html#L26\r\n\r\nThis should change depending on the mode of the CTF\n", "before_files": [{"content": "import glob\nimport importlib\nimport os\nfrom collections import namedtuple\n\nfrom flask import current_app as app\nfrom flask import send_file, send_from_directory, url_for\n\nfrom CTFd.utils.config.pages import get_pages\nfrom CTFd.utils.decorators import admins_only as admins_only_wrapper\nfrom CTFd.utils.plugins import override_template as utils_override_template\nfrom CTFd.utils.plugins import (\n register_admin_script as utils_register_admin_plugin_script,\n)\nfrom CTFd.utils.plugins import (\n register_admin_stylesheet as utils_register_admin_plugin_stylesheet,\n)\nfrom CTFd.utils.plugins import register_script as utils_register_plugin_script\nfrom CTFd.utils.plugins import register_stylesheet as utils_register_plugin_stylesheet\n\nMenu = namedtuple(\"Menu\", [\"title\", \"route\"])\n\n\ndef register_plugin_assets_directory(app, base_path, admins_only=False, endpoint=None):\n \"\"\"\n Registers a directory to serve assets\n\n :param app: A CTFd application\n :param string base_path: The path to the directory\n :param boolean admins_only: Whether or not the assets served out of the directory should be accessible to the public\n :return:\n \"\"\"\n base_path = base_path.strip(\"/\")\n if endpoint is None:\n endpoint = base_path.replace(\"/\", \".\")\n\n def assets_handler(path):\n return send_from_directory(base_path, path)\n\n rule = \"/\" + base_path + \"/<path:path>\"\n app.add_url_rule(rule=rule, endpoint=endpoint, view_func=assets_handler)\n\n\ndef register_plugin_asset(app, asset_path, admins_only=False, endpoint=None):\n \"\"\"\n Registers an file path to be served by CTFd\n\n :param app: A CTFd application\n :param string asset_path: The path to the asset file\n :param boolean admins_only: Whether or not this file should be accessible to the public\n :return:\n \"\"\"\n asset_path = asset_path.strip(\"/\")\n if endpoint is None:\n endpoint = asset_path.replace(\"/\", \".\")\n\n def asset_handler():\n return send_file(asset_path)\n\n if admins_only:\n asset_handler = admins_only_wrapper(asset_handler)\n rule = \"/\" + asset_path\n app.add_url_rule(rule=rule, endpoint=endpoint, view_func=asset_handler)\n\n\ndef override_template(*args, **kwargs):\n \"\"\"\n Overrides a template with the provided html content.\n\n e.g. override_template('scoreboard.html', '<h1>scores</h1>')\n \"\"\"\n utils_override_template(*args, **kwargs)\n\n\ndef register_plugin_script(*args, **kwargs):\n \"\"\"\n Adds a given script to the base.html template which all pages inherit from\n \"\"\"\n utils_register_plugin_script(*args, **kwargs)\n\n\ndef register_plugin_stylesheet(*args, **kwargs):\n \"\"\"\n Adds a given stylesheet to the base.html template which all pages inherit from.\n \"\"\"\n utils_register_plugin_stylesheet(*args, **kwargs)\n\n\ndef register_admin_plugin_script(*args, **kwargs):\n \"\"\"\n Adds a given script to the base.html of the admin theme which all admin pages inherit from\n :param args:\n :param kwargs:\n :return:\n \"\"\"\n utils_register_admin_plugin_script(*args, **kwargs)\n\n\ndef register_admin_plugin_stylesheet(*args, **kwargs):\n \"\"\"\n Adds a given stylesheet to the base.html of the admin theme which all admin pages inherit from\n :param args:\n :param kwargs:\n :return:\n \"\"\"\n utils_register_admin_plugin_stylesheet(*args, **kwargs)\n\n\ndef register_admin_plugin_menu_bar(title, route):\n \"\"\"\n Registers links on the Admin Panel menubar/navbar\n\n :param name: A string that is shown on the navbar HTML\n :param route: A string that is the href used by the link\n :return:\n \"\"\"\n am = Menu(title=title, route=route)\n app.admin_plugin_menu_bar.append(am)\n\n\ndef get_admin_plugin_menu_bar():\n \"\"\"\n Access the list used to store the plugin menu bar\n\n :return: Returns a list of Menu namedtuples. They have name, and route attributes.\n \"\"\"\n return app.admin_plugin_menu_bar\n\n\ndef register_user_page_menu_bar(title, route):\n \"\"\"\n Registers links on the User side menubar/navbar\n\n :param name: A string that is shown on the navbar HTML\n :param route: A string that is the href used by the link\n :return:\n \"\"\"\n p = Menu(title=title, route=route)\n app.plugin_menu_bar.append(p)\n\n\ndef get_user_page_menu_bar():\n \"\"\"\n Access the list used to store the user page menu bar\n\n :return: Returns a list of Menu namedtuples. They have name, and route attributes.\n \"\"\"\n pages = []\n for p in get_pages() + app.plugin_menu_bar:\n if p.route.startswith(\"http\"):\n route = p.route\n else:\n route = url_for(\"views.static_html\", route=p.route)\n print(route)\n pages.append(Menu(title=p.title, route=route))\n return pages\n\n\ndef bypass_csrf_protection(f):\n \"\"\"\n Decorator that allows a route to bypass the need for a CSRF nonce on POST requests.\n\n This should be considered beta and may change in future versions.\n\n :param f: A function that needs to bypass CSRF protection\n :return: Returns a function with the _bypass_csrf attribute set which tells CTFd to not require CSRF protection.\n \"\"\"\n f._bypass_csrf = True\n return f\n\n\ndef get_plugin_names():\n modules = sorted(glob.glob(app.plugins_dir + \"/*\"))\n blacklist = {\"__pycache__\"}\n plugins = []\n for module in modules:\n module_name = os.path.basename(module)\n if os.path.isdir(module) and module_name not in blacklist:\n plugins.append(module_name)\n return plugins\n\n\ndef init_plugins(app):\n \"\"\"\n Searches for the load function in modules in the CTFd/plugins folder. This function is called with the current CTFd\n app as a parameter. This allows CTFd plugins to modify CTFd's behavior.\n\n :param app: A CTFd application\n :return:\n \"\"\"\n app.admin_plugin_scripts = []\n app.admin_plugin_stylesheets = []\n app.plugin_scripts = []\n app.plugin_stylesheets = []\n\n app.admin_plugin_menu_bar = []\n app.plugin_menu_bar = []\n app.plugins_dir = os.path.dirname(__file__)\n\n if app.config.get(\"SAFE_MODE\", False) is False:\n for plugin in get_plugin_names():\n module = \".\" + plugin\n module = importlib.import_module(module, package=\"CTFd.plugins\")\n module.load(app)\n print(\" * Loaded module, %s\" % module)\n\n app.jinja_env.globals.update(get_admin_plugin_menu_bar=get_admin_plugin_menu_bar)\n app.jinja_env.globals.update(get_user_page_menu_bar=get_user_page_menu_bar)\n", "path": "CTFd/plugins/__init__.py"}], "after_files": [{"content": "import glob\nimport importlib\nimport os\nfrom collections import namedtuple\n\nfrom flask import current_app as app\nfrom flask import send_file, send_from_directory, url_for\n\nfrom CTFd.utils.config.pages import get_pages\nfrom CTFd.utils.decorators import admins_only as admins_only_wrapper\nfrom CTFd.utils.plugins import override_template as utils_override_template\nfrom CTFd.utils.plugins import (\n register_admin_script as utils_register_admin_plugin_script,\n)\nfrom CTFd.utils.plugins import (\n register_admin_stylesheet as utils_register_admin_plugin_stylesheet,\n)\nfrom CTFd.utils.plugins import register_script as utils_register_plugin_script\nfrom CTFd.utils.plugins import register_stylesheet as utils_register_plugin_stylesheet\n\nMenu = namedtuple(\"Menu\", [\"title\", \"route\"])\n\n\ndef register_plugin_assets_directory(app, base_path, admins_only=False, endpoint=None):\n \"\"\"\n Registers a directory to serve assets\n\n :param app: A CTFd application\n :param string base_path: The path to the directory\n :param boolean admins_only: Whether or not the assets served out of the directory should be accessible to the public\n :return:\n \"\"\"\n base_path = base_path.strip(\"/\")\n if endpoint is None:\n endpoint = base_path.replace(\"/\", \".\")\n\n def assets_handler(path):\n return send_from_directory(base_path, path)\n\n rule = \"/\" + base_path + \"/<path:path>\"\n app.add_url_rule(rule=rule, endpoint=endpoint, view_func=assets_handler)\n\n\ndef register_plugin_asset(app, asset_path, admins_only=False, endpoint=None):\n \"\"\"\n Registers an file path to be served by CTFd\n\n :param app: A CTFd application\n :param string asset_path: The path to the asset file\n :param boolean admins_only: Whether or not this file should be accessible to the public\n :return:\n \"\"\"\n asset_path = asset_path.strip(\"/\")\n if endpoint is None:\n endpoint = asset_path.replace(\"/\", \".\")\n\n def asset_handler():\n return send_file(asset_path)\n\n if admins_only:\n asset_handler = admins_only_wrapper(asset_handler)\n rule = \"/\" + asset_path\n app.add_url_rule(rule=rule, endpoint=endpoint, view_func=asset_handler)\n\n\ndef override_template(*args, **kwargs):\n \"\"\"\n Overrides a template with the provided html content.\n\n e.g. override_template('scoreboard.html', '<h1>scores</h1>')\n \"\"\"\n utils_override_template(*args, **kwargs)\n\n\ndef register_plugin_script(*args, **kwargs):\n \"\"\"\n Adds a given script to the base.html template which all pages inherit from\n \"\"\"\n utils_register_plugin_script(*args, **kwargs)\n\n\ndef register_plugin_stylesheet(*args, **kwargs):\n \"\"\"\n Adds a given stylesheet to the base.html template which all pages inherit from.\n \"\"\"\n utils_register_plugin_stylesheet(*args, **kwargs)\n\n\ndef register_admin_plugin_script(*args, **kwargs):\n \"\"\"\n Adds a given script to the base.html of the admin theme which all admin pages inherit from\n :param args:\n :param kwargs:\n :return:\n \"\"\"\n utils_register_admin_plugin_script(*args, **kwargs)\n\n\ndef register_admin_plugin_stylesheet(*args, **kwargs):\n \"\"\"\n Adds a given stylesheet to the base.html of the admin theme which all admin pages inherit from\n :param args:\n :param kwargs:\n :return:\n \"\"\"\n utils_register_admin_plugin_stylesheet(*args, **kwargs)\n\n\ndef register_admin_plugin_menu_bar(title, route):\n \"\"\"\n Registers links on the Admin Panel menubar/navbar\n\n :param name: A string that is shown on the navbar HTML\n :param route: A string that is the href used by the link\n :return:\n \"\"\"\n am = Menu(title=title, route=route)\n app.admin_plugin_menu_bar.append(am)\n\n\ndef get_admin_plugin_menu_bar():\n \"\"\"\n Access the list used to store the plugin menu bar\n\n :return: Returns a list of Menu namedtuples. They have name, and route attributes.\n \"\"\"\n return app.admin_plugin_menu_bar\n\n\ndef register_user_page_menu_bar(title, route):\n \"\"\"\n Registers links on the User side menubar/navbar\n\n :param name: A string that is shown on the navbar HTML\n :param route: A string that is the href used by the link\n :return:\n \"\"\"\n p = Menu(title=title, route=route)\n app.plugin_menu_bar.append(p)\n\n\ndef get_user_page_menu_bar():\n \"\"\"\n Access the list used to store the user page menu bar\n\n :return: Returns a list of Menu namedtuples. They have name, and route attributes.\n \"\"\"\n pages = []\n for p in get_pages() + app.plugin_menu_bar:\n if p.route.startswith(\"http\"):\n route = p.route\n else:\n route = url_for(\"views.static_html\", route=p.route)\n pages.append(Menu(title=p.title, route=route))\n return pages\n\n\ndef bypass_csrf_protection(f):\n \"\"\"\n Decorator that allows a route to bypass the need for a CSRF nonce on POST requests.\n\n This should be considered beta and may change in future versions.\n\n :param f: A function that needs to bypass CSRF protection\n :return: Returns a function with the _bypass_csrf attribute set which tells CTFd to not require CSRF protection.\n \"\"\"\n f._bypass_csrf = True\n return f\n\n\ndef get_plugin_names():\n modules = sorted(glob.glob(app.plugins_dir + \"/*\"))\n blacklist = {\"__pycache__\"}\n plugins = []\n for module in modules:\n module_name = os.path.basename(module)\n if os.path.isdir(module) and module_name not in blacklist:\n plugins.append(module_name)\n return plugins\n\n\ndef init_plugins(app):\n \"\"\"\n Searches for the load function in modules in the CTFd/plugins folder. This function is called with the current CTFd\n app as a parameter. This allows CTFd plugins to modify CTFd's behavior.\n\n :param app: A CTFd application\n :return:\n \"\"\"\n app.admin_plugin_scripts = []\n app.admin_plugin_stylesheets = []\n app.plugin_scripts = []\n app.plugin_stylesheets = []\n\n app.admin_plugin_menu_bar = []\n app.plugin_menu_bar = []\n app.plugins_dir = os.path.dirname(__file__)\n\n if app.config.get(\"SAFE_MODE\", False) is False:\n for plugin in get_plugin_names():\n module = \".\" + plugin\n module = importlib.import_module(module, package=\"CTFd.plugins\")\n module.load(app)\n print(\" * Loaded module, %s\" % module)\n\n app.jinja_env.globals.update(get_admin_plugin_menu_bar=get_admin_plugin_menu_bar)\n app.jinja_env.globals.update(get_user_page_menu_bar=get_user_page_menu_bar)\n", "path": "CTFd/plugins/__init__.py"}]}
| 2,314 | 102 |
gh_patches_debug_20362
|
rasdani/github-patches
|
git_diff
|
elastic__apm-agent-python-1593
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Performance Bug in the varmap function
**Describe the bug**: ...
When python code throws an error, and one of the local variables contains a very large list of lists of lists, it takes the elastic python apm client a very long time to process through the list. In our case it was taking over 60 seconds for the code to complete.
**To Reproduce**
To simply replicate the issue, I: (see code snipit in the elastic forum, link below)
- created a simple script to create a list of list of lists of integers.
- in one method I had my "with elasticAPMTransaction:" statement.
- under this I created the list (200 integers) of list (300 integers) of list (40 integers) aka 24M items total.
- started to iterate through the outer list and picked an arbitrary spot to through an exception. This essentially mimicked the method where the real code threw an exception.
- wrapped this whole thing in a profiler and evaluated the output.
This would take 60 seconds +/- to complete.
Seems like the issue is in the varmap function in elasticapm\utils_init_.py but there maybe lots of ways to solve this issue.
**Environment (please complete the following information)**
- OS: [e.g. Linux]
- Python version: 3.x
- Framework and version [e.g. Django 2.1]:
- APM Server version: N/A
- Agent version: 6.7.2
**Additional context**
Created a case here https://discuss.elastic.co/t/python-client-apm-very-slow-when-local-list-variable-is-very-large/309935. See this for additional details.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `elasticapm/utils/__init__.py`
Content:
```
1 # BSD 3-Clause License
2 #
3 # Copyright (c) 2012, the Sentry Team, see AUTHORS for more details
4 # Copyright (c) 2019, Elasticsearch BV
5 # All rights reserved.
6 #
7 # Redistribution and use in source and binary forms, with or without
8 # modification, are permitted provided that the following conditions are met:
9 #
10 # * Redistributions of source code must retain the above copyright notice, this
11 # list of conditions and the following disclaimer.
12 #
13 # * Redistributions in binary form must reproduce the above copyright notice,
14 # this list of conditions and the following disclaimer in the documentation
15 # and/or other materials provided with the distribution.
16 #
17 # * Neither the name of the copyright holder nor the names of its
18 # contributors may be used to endorse or promote products derived from
19 # this software without specific prior written permission.
20 #
21 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
22 # AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
23 # IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
24 # DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
25 # FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
26 # DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
27 # SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
28 # CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
29 # OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
30
31 import base64
32 import os
33 import re
34 import urllib.parse
35 from functools import partial
36 from types import FunctionType
37 from typing import Pattern
38
39 from elasticapm.conf import constants
40 from elasticapm.utils import encoding
41
42 try:
43 from functools import partialmethod
44
45 partial_types = (partial, partialmethod)
46 except ImportError:
47 # Python 2
48 partial_types = (partial,)
49
50
51 default_ports = {"https": 443, "http": 80, "postgresql": 5432, "mysql": 3306, "mssql": 1433}
52
53
54 def varmap(func, var, context=None, name=None, **kwargs):
55 """
56 Executes ``func(key_name, value)`` on all values,
57 recursively discovering dict and list scoped
58 values.
59 """
60 if context is None:
61 context = set()
62 objid = id(var)
63 if objid in context:
64 return func(name, "<...>", **kwargs)
65 context.add(objid)
66 if isinstance(var, dict):
67 # iterate over a copy of the dictionary to avoid "dictionary changed size during iteration" issues
68 ret = func(name, dict((k, varmap(func, v, context, k, **kwargs)) for k, v in var.copy().items()), **kwargs)
69 elif isinstance(var, (list, tuple)):
70 ret = func(name, [varmap(func, f, context, name, **kwargs) for f in var], **kwargs)
71 else:
72 ret = func(name, var, **kwargs)
73 context.remove(objid)
74 return ret
75
76
77 def get_name_from_func(func: FunctionType) -> str:
78 # partials don't have `__module__` or `__name__`, so we use the values from the "inner" function
79 if isinstance(func, partial_types):
80 return "partial({})".format(get_name_from_func(func.func))
81 elif hasattr(func, "_partialmethod") and hasattr(func._partialmethod, "func"):
82 return "partial({})".format(get_name_from_func(func._partialmethod.func))
83
84 module = func.__module__
85
86 if hasattr(func, "view_class"):
87 view_name = func.view_class.__name__
88 elif hasattr(func, "__name__"):
89 view_name = func.__name__
90 else: # Fall back if there's no __name__
91 view_name = func.__class__.__name__
92
93 return "{0}.{1}".format(module, view_name)
94
95
96 def build_name_with_http_method_prefix(name, request):
97 return " ".join((request.method, name)) if name else name
98
99
100 def is_master_process() -> bool:
101 # currently only recognizes uwsgi master process
102 try:
103 import uwsgi
104
105 return os.getpid() == uwsgi.masterpid()
106 except ImportError:
107 return False
108
109
110 def get_url_dict(url: str) -> dict:
111 parse_result = urllib.parse.urlparse(url)
112
113 url_dict = {
114 "full": encoding.keyword_field(url),
115 "protocol": parse_result.scheme + ":",
116 "hostname": encoding.keyword_field(parse_result.hostname),
117 "pathname": encoding.keyword_field(parse_result.path),
118 }
119
120 port = None if parse_result.port is None else str(parse_result.port)
121
122 if port:
123 url_dict["port"] = port
124 if parse_result.query:
125 url_dict["search"] = encoding.keyword_field("?" + parse_result.query)
126 return url_dict
127
128
129 def sanitize_url(url: str) -> str:
130 if "@" not in url:
131 return url
132 parts = urllib.parse.urlparse(url)
133 return url.replace("%s:%s" % (parts.username, parts.password), "%s:%s" % (parts.username, constants.MASK))
134
135
136 def get_host_from_url(url: str) -> str:
137 parsed_url = urllib.parse.urlparse(url)
138 host = parsed_url.hostname or " "
139
140 if parsed_url.port and default_ports.get(parsed_url.scheme) != parsed_url.port:
141 host += ":" + str(parsed_url.port)
142
143 return host
144
145
146 def url_to_destination_resource(url: str) -> str:
147 parts = urllib.parse.urlsplit(url)
148 hostname = parts.hostname if parts.hostname else ""
149 # preserve brackets for IPv6 URLs
150 if "://[" in url:
151 hostname = "[%s]" % hostname
152 try:
153 port = parts.port
154 except ValueError:
155 # Malformed port, just use None rather than raising an exception
156 port = None
157 default_port = default_ports.get(parts.scheme, None)
158 name = "%s://%s" % (parts.scheme, hostname)
159 resource = hostname
160 if not port and parts.scheme in default_ports:
161 port = default_ports[parts.scheme]
162 if port:
163 if port != default_port:
164 name += ":%d" % port
165 resource += ":%d" % port
166 return resource
167
168
169 def read_pem_file(file_obj) -> bytes:
170 cert = b""
171 for line in file_obj:
172 if line.startswith(b"-----BEGIN CERTIFICATE-----"):
173 break
174 # scan until we find the first END CERTIFICATE marker
175 for line in file_obj:
176 if line.startswith(b"-----END CERTIFICATE-----"):
177 break
178 cert += line.strip()
179 return base64.b64decode(cert)
180
181
182 def starmatch_to_regex(pattern: str) -> Pattern:
183 options = re.DOTALL
184 # check if we are case sensitive
185 if pattern.startswith("(?-i)"):
186 pattern = pattern[5:]
187 else:
188 options |= re.IGNORECASE
189 i, n = 0, len(pattern)
190 res = []
191 while i < n:
192 c = pattern[i]
193 i = i + 1
194 if c == "*":
195 res.append(".*")
196 else:
197 res.append(re.escape(c))
198 return re.compile(r"(?:%s)\Z" % "".join(res), options)
199
200
201 def nested_key(d: dict, *args):
202 """
203 Traverses a dictionary for nested keys. Returns `None` if the at any point
204 in the traversal a key cannot be found.
205
206 Example:
207
208 >>> from elasticapm.utils import nested_key
209 >>> d = {"a": {"b": {"c": 0}}}
210 >>> nested_key(d, "a", "b", "c")
211 0
212 >>> nested_key(d, "a", "b", "d")
213 None
214 """
215 for arg in args:
216 try:
217 d = d[arg]
218 except (TypeError, KeyError):
219 d = None
220 break
221 return d
222
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/elasticapm/utils/__init__.py b/elasticapm/utils/__init__.py
--- a/elasticapm/utils/__init__.py
+++ b/elasticapm/utils/__init__.py
@@ -64,10 +64,14 @@
return func(name, "<...>", **kwargs)
context.add(objid)
if isinstance(var, dict):
+ # Apply func() before recursion, so that `shorten()` doesn't have to iterate over all the trimmed values
+ ret = func(name, var, **kwargs)
# iterate over a copy of the dictionary to avoid "dictionary changed size during iteration" issues
- ret = func(name, dict((k, varmap(func, v, context, k, **kwargs)) for k, v in var.copy().items()), **kwargs)
+ ret = dict((k, varmap(func, v, context, k, **kwargs)) for k, v in ret.copy().items())
elif isinstance(var, (list, tuple)):
- ret = func(name, [varmap(func, f, context, name, **kwargs) for f in var], **kwargs)
+ # Apply func() before recursion, so that `shorten()` doesn't have to iterate over all the trimmed values
+ ret = func(name, var, **kwargs)
+ ret = [varmap(func, f, context, name, **kwargs) for f in ret]
else:
ret = func(name, var, **kwargs)
context.remove(objid)
|
{"golden_diff": "diff --git a/elasticapm/utils/__init__.py b/elasticapm/utils/__init__.py\n--- a/elasticapm/utils/__init__.py\n+++ b/elasticapm/utils/__init__.py\n@@ -64,10 +64,14 @@\n return func(name, \"<...>\", **kwargs)\n context.add(objid)\n if isinstance(var, dict):\n+ # Apply func() before recursion, so that `shorten()` doesn't have to iterate over all the trimmed values\n+ ret = func(name, var, **kwargs)\n # iterate over a copy of the dictionary to avoid \"dictionary changed size during iteration\" issues\n- ret = func(name, dict((k, varmap(func, v, context, k, **kwargs)) for k, v in var.copy().items()), **kwargs)\n+ ret = dict((k, varmap(func, v, context, k, **kwargs)) for k, v in ret.copy().items())\n elif isinstance(var, (list, tuple)):\n- ret = func(name, [varmap(func, f, context, name, **kwargs) for f in var], **kwargs)\n+ # Apply func() before recursion, so that `shorten()` doesn't have to iterate over all the trimmed values\n+ ret = func(name, var, **kwargs)\n+ ret = [varmap(func, f, context, name, **kwargs) for f in ret]\n else:\n ret = func(name, var, **kwargs)\n context.remove(objid)\n", "issue": "Performance Bug in the varmap function\n**Describe the bug**: ...\r\nWhen python code throws an error, and one of the local variables contains a very large list of lists of lists, it takes the elastic python apm client a very long time to process through the list. In our case it was taking over 60 seconds for the code to complete.\r\n\r\n\r\n**To Reproduce**\r\nTo simply replicate the issue, I: (see code snipit in the elastic forum, link below)\r\n\r\n- created a simple script to create a list of list of lists of integers.\r\n- in one method I had my \"with elasticAPMTransaction:\" statement.\r\n- under this I created the list (200 integers) of list (300 integers) of list (40 integers) aka 24M items total.\r\n- started to iterate through the outer list and picked an arbitrary spot to through an exception. This essentially mimicked the method where the real code threw an exception.\r\n- wrapped this whole thing in a profiler and evaluated the output.\r\nThis would take 60 seconds +/- to complete.\r\n\r\nSeems like the issue is in the varmap function in elasticapm\\utils_init_.py but there maybe lots of ways to solve this issue.\r\n\r\n**Environment (please complete the following information)**\r\n- OS: [e.g. Linux]\r\n- Python version: 3.x\r\n- Framework and version [e.g. Django 2.1]:\r\n- APM Server version: N/A\r\n- Agent version: 6.7.2\r\n\r\n\r\n**Additional context**\r\nCreated a case here https://discuss.elastic.co/t/python-client-apm-very-slow-when-local-list-variable-is-very-large/309935. See this for additional details.\n", "before_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2012, the Sentry Team, see AUTHORS for more details\n# Copyright (c) 2019, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n\nimport base64\nimport os\nimport re\nimport urllib.parse\nfrom functools import partial\nfrom types import FunctionType\nfrom typing import Pattern\n\nfrom elasticapm.conf import constants\nfrom elasticapm.utils import encoding\n\ntry:\n from functools import partialmethod\n\n partial_types = (partial, partialmethod)\nexcept ImportError:\n # Python 2\n partial_types = (partial,)\n\n\ndefault_ports = {\"https\": 443, \"http\": 80, \"postgresql\": 5432, \"mysql\": 3306, \"mssql\": 1433}\n\n\ndef varmap(func, var, context=None, name=None, **kwargs):\n \"\"\"\n Executes ``func(key_name, value)`` on all values,\n recursively discovering dict and list scoped\n values.\n \"\"\"\n if context is None:\n context = set()\n objid = id(var)\n if objid in context:\n return func(name, \"<...>\", **kwargs)\n context.add(objid)\n if isinstance(var, dict):\n # iterate over a copy of the dictionary to avoid \"dictionary changed size during iteration\" issues\n ret = func(name, dict((k, varmap(func, v, context, k, **kwargs)) for k, v in var.copy().items()), **kwargs)\n elif isinstance(var, (list, tuple)):\n ret = func(name, [varmap(func, f, context, name, **kwargs) for f in var], **kwargs)\n else:\n ret = func(name, var, **kwargs)\n context.remove(objid)\n return ret\n\n\ndef get_name_from_func(func: FunctionType) -> str:\n # partials don't have `__module__` or `__name__`, so we use the values from the \"inner\" function\n if isinstance(func, partial_types):\n return \"partial({})\".format(get_name_from_func(func.func))\n elif hasattr(func, \"_partialmethod\") and hasattr(func._partialmethod, \"func\"):\n return \"partial({})\".format(get_name_from_func(func._partialmethod.func))\n\n module = func.__module__\n\n if hasattr(func, \"view_class\"):\n view_name = func.view_class.__name__\n elif hasattr(func, \"__name__\"):\n view_name = func.__name__\n else: # Fall back if there's no __name__\n view_name = func.__class__.__name__\n\n return \"{0}.{1}\".format(module, view_name)\n\n\ndef build_name_with_http_method_prefix(name, request):\n return \" \".join((request.method, name)) if name else name\n\n\ndef is_master_process() -> bool:\n # currently only recognizes uwsgi master process\n try:\n import uwsgi\n\n return os.getpid() == uwsgi.masterpid()\n except ImportError:\n return False\n\n\ndef get_url_dict(url: str) -> dict:\n parse_result = urllib.parse.urlparse(url)\n\n url_dict = {\n \"full\": encoding.keyword_field(url),\n \"protocol\": parse_result.scheme + \":\",\n \"hostname\": encoding.keyword_field(parse_result.hostname),\n \"pathname\": encoding.keyword_field(parse_result.path),\n }\n\n port = None if parse_result.port is None else str(parse_result.port)\n\n if port:\n url_dict[\"port\"] = port\n if parse_result.query:\n url_dict[\"search\"] = encoding.keyword_field(\"?\" + parse_result.query)\n return url_dict\n\n\ndef sanitize_url(url: str) -> str:\n if \"@\" not in url:\n return url\n parts = urllib.parse.urlparse(url)\n return url.replace(\"%s:%s\" % (parts.username, parts.password), \"%s:%s\" % (parts.username, constants.MASK))\n\n\ndef get_host_from_url(url: str) -> str:\n parsed_url = urllib.parse.urlparse(url)\n host = parsed_url.hostname or \" \"\n\n if parsed_url.port and default_ports.get(parsed_url.scheme) != parsed_url.port:\n host += \":\" + str(parsed_url.port)\n\n return host\n\n\ndef url_to_destination_resource(url: str) -> str:\n parts = urllib.parse.urlsplit(url)\n hostname = parts.hostname if parts.hostname else \"\"\n # preserve brackets for IPv6 URLs\n if \"://[\" in url:\n hostname = \"[%s]\" % hostname\n try:\n port = parts.port\n except ValueError:\n # Malformed port, just use None rather than raising an exception\n port = None\n default_port = default_ports.get(parts.scheme, None)\n name = \"%s://%s\" % (parts.scheme, hostname)\n resource = hostname\n if not port and parts.scheme in default_ports:\n port = default_ports[parts.scheme]\n if port:\n if port != default_port:\n name += \":%d\" % port\n resource += \":%d\" % port\n return resource\n\n\ndef read_pem_file(file_obj) -> bytes:\n cert = b\"\"\n for line in file_obj:\n if line.startswith(b\"-----BEGIN CERTIFICATE-----\"):\n break\n # scan until we find the first END CERTIFICATE marker\n for line in file_obj:\n if line.startswith(b\"-----END CERTIFICATE-----\"):\n break\n cert += line.strip()\n return base64.b64decode(cert)\n\n\ndef starmatch_to_regex(pattern: str) -> Pattern:\n options = re.DOTALL\n # check if we are case sensitive\n if pattern.startswith(\"(?-i)\"):\n pattern = pattern[5:]\n else:\n options |= re.IGNORECASE\n i, n = 0, len(pattern)\n res = []\n while i < n:\n c = pattern[i]\n i = i + 1\n if c == \"*\":\n res.append(\".*\")\n else:\n res.append(re.escape(c))\n return re.compile(r\"(?:%s)\\Z\" % \"\".join(res), options)\n\n\ndef nested_key(d: dict, *args):\n \"\"\"\n Traverses a dictionary for nested keys. Returns `None` if the at any point\n in the traversal a key cannot be found.\n\n Example:\n\n >>> from elasticapm.utils import nested_key\n >>> d = {\"a\": {\"b\": {\"c\": 0}}}\n >>> nested_key(d, \"a\", \"b\", \"c\")\n 0\n >>> nested_key(d, \"a\", \"b\", \"d\")\n None\n \"\"\"\n for arg in args:\n try:\n d = d[arg]\n except (TypeError, KeyError):\n d = None\n break\n return d\n", "path": "elasticapm/utils/__init__.py"}], "after_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2012, the Sentry Team, see AUTHORS for more details\n# Copyright (c) 2019, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n\nimport base64\nimport os\nimport re\nimport urllib.parse\nfrom functools import partial\nfrom types import FunctionType\nfrom typing import Pattern\n\nfrom elasticapm.conf import constants\nfrom elasticapm.utils import encoding\n\ntry:\n from functools import partialmethod\n\n partial_types = (partial, partialmethod)\nexcept ImportError:\n # Python 2\n partial_types = (partial,)\n\n\ndefault_ports = {\"https\": 443, \"http\": 80, \"postgresql\": 5432, \"mysql\": 3306, \"mssql\": 1433}\n\n\ndef varmap(func, var, context=None, name=None, **kwargs):\n \"\"\"\n Executes ``func(key_name, value)`` on all values,\n recursively discovering dict and list scoped\n values.\n \"\"\"\n if context is None:\n context = set()\n objid = id(var)\n if objid in context:\n return func(name, \"<...>\", **kwargs)\n context.add(objid)\n if isinstance(var, dict):\n # Apply func() before recursion, so that `shorten()` doesn't have to iterate over all the trimmed values\n ret = func(name, var, **kwargs)\n # iterate over a copy of the dictionary to avoid \"dictionary changed size during iteration\" issues\n ret = dict((k, varmap(func, v, context, k, **kwargs)) for k, v in ret.copy().items())\n elif isinstance(var, (list, tuple)):\n # Apply func() before recursion, so that `shorten()` doesn't have to iterate over all the trimmed values\n ret = func(name, var, **kwargs)\n ret = [varmap(func, f, context, name, **kwargs) for f in ret]\n else:\n ret = func(name, var, **kwargs)\n context.remove(objid)\n return ret\n\n\ndef get_name_from_func(func: FunctionType) -> str:\n # partials don't have `__module__` or `__name__`, so we use the values from the \"inner\" function\n if isinstance(func, partial_types):\n return \"partial({})\".format(get_name_from_func(func.func))\n elif hasattr(func, \"_partialmethod\") and hasattr(func._partialmethod, \"func\"):\n return \"partial({})\".format(get_name_from_func(func._partialmethod.func))\n\n module = func.__module__\n\n if hasattr(func, \"view_class\"):\n view_name = func.view_class.__name__\n elif hasattr(func, \"__name__\"):\n view_name = func.__name__\n else: # Fall back if there's no __name__\n view_name = func.__class__.__name__\n\n return \"{0}.{1}\".format(module, view_name)\n\n\ndef build_name_with_http_method_prefix(name, request):\n return \" \".join((request.method, name)) if name else name\n\n\ndef is_master_process() -> bool:\n # currently only recognizes uwsgi master process\n try:\n import uwsgi\n\n return os.getpid() == uwsgi.masterpid()\n except ImportError:\n return False\n\n\ndef get_url_dict(url: str) -> dict:\n parse_result = urllib.parse.urlparse(url)\n\n url_dict = {\n \"full\": encoding.keyword_field(url),\n \"protocol\": parse_result.scheme + \":\",\n \"hostname\": encoding.keyword_field(parse_result.hostname),\n \"pathname\": encoding.keyword_field(parse_result.path),\n }\n\n port = None if parse_result.port is None else str(parse_result.port)\n\n if port:\n url_dict[\"port\"] = port\n if parse_result.query:\n url_dict[\"search\"] = encoding.keyword_field(\"?\" + parse_result.query)\n return url_dict\n\n\ndef sanitize_url(url: str) -> str:\n if \"@\" not in url:\n return url\n parts = urllib.parse.urlparse(url)\n return url.replace(\"%s:%s\" % (parts.username, parts.password), \"%s:%s\" % (parts.username, constants.MASK))\n\n\ndef get_host_from_url(url: str) -> str:\n parsed_url = urllib.parse.urlparse(url)\n host = parsed_url.hostname or \" \"\n\n if parsed_url.port and default_ports.get(parsed_url.scheme) != parsed_url.port:\n host += \":\" + str(parsed_url.port)\n\n return host\n\n\ndef url_to_destination_resource(url: str) -> str:\n parts = urllib.parse.urlsplit(url)\n hostname = parts.hostname if parts.hostname else \"\"\n # preserve brackets for IPv6 URLs\n if \"://[\" in url:\n hostname = \"[%s]\" % hostname\n try:\n port = parts.port\n except ValueError:\n # Malformed port, just use None rather than raising an exception\n port = None\n default_port = default_ports.get(parts.scheme, None)\n name = \"%s://%s\" % (parts.scheme, hostname)\n resource = hostname\n if not port and parts.scheme in default_ports:\n port = default_ports[parts.scheme]\n if port:\n if port != default_port:\n name += \":%d\" % port\n resource += \":%d\" % port\n return resource\n\n\ndef read_pem_file(file_obj) -> bytes:\n cert = b\"\"\n for line in file_obj:\n if line.startswith(b\"-----BEGIN CERTIFICATE-----\"):\n break\n # scan until we find the first END CERTIFICATE marker\n for line in file_obj:\n if line.startswith(b\"-----END CERTIFICATE-----\"):\n break\n cert += line.strip()\n return base64.b64decode(cert)\n\n\ndef starmatch_to_regex(pattern: str) -> Pattern:\n options = re.DOTALL\n # check if we are case sensitive\n if pattern.startswith(\"(?-i)\"):\n pattern = pattern[5:]\n else:\n options |= re.IGNORECASE\n i, n = 0, len(pattern)\n res = []\n while i < n:\n c = pattern[i]\n i = i + 1\n if c == \"*\":\n res.append(\".*\")\n else:\n res.append(re.escape(c))\n return re.compile(r\"(?:%s)\\Z\" % \"\".join(res), options)\n\n\ndef nested_key(d: dict, *args):\n \"\"\"\n Traverses a dictionary for nested keys. Returns `None` if the at any point\n in the traversal a key cannot be found.\n\n Example:\n\n >>> from elasticapm.utils import nested_key\n >>> d = {\"a\": {\"b\": {\"c\": 0}}}\n >>> nested_key(d, \"a\", \"b\", \"c\")\n 0\n >>> nested_key(d, \"a\", \"b\", \"d\")\n None\n \"\"\"\n for arg in args:\n try:\n d = d[arg]\n except (TypeError, KeyError):\n d = None\n break\n return d\n", "path": "elasticapm/utils/__init__.py"}]}
| 2,958 | 332 |
gh_patches_debug_21235
|
rasdani/github-patches
|
git_diff
|
facebookresearch__hydra-1630
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Document hydra.callbacks api.
- [ ] Document API
- [ ] Add news fragment if missing
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `hydra/experimental/callback.py`
Content:
```
1 # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
2 import logging
3 from typing import Any
4
5 from omegaconf import DictConfig
6
7 from hydra.core.utils import JobReturn
8
9 logger = logging.getLogger(__name__)
10
11
12 class Callback:
13 def on_run_start(self, config: DictConfig, **kwargs: Any) -> None:
14 """
15 Called in RUN mode before job starts.
16 """
17 ...
18
19 def on_run_end(self, config: DictConfig, **kwargs: Any) -> None:
20 """
21 Called in RUN mode after job ends.
22 """
23 ...
24
25 def on_multirun_start(self, config: DictConfig, **kwargs: Any) -> None:
26 """
27 Called in MULTIRUN mode before any job starts.
28 """
29 ...
30
31 def on_multirun_end(self, config: DictConfig, **kwargs: Any) -> None:
32 """
33 Called in MULTIRUN mode after all job end.
34 """
35 ...
36
37 def on_job_start(self, config: DictConfig, **kwargs: Any) -> None:
38 """
39 Called in both RUN and MULTIRUN modes inside a Hydra job; before running
40 application code.
41 """
42 ...
43
44 def on_job_end(
45 self, config: DictConfig, job_return: JobReturn, **kwargs: Any
46 ) -> None:
47 """
48 Called in both RUN and MULTIRUN modes inside a Hydra job; after running
49 application code.
50 """
51 ...
52
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/hydra/experimental/callback.py b/hydra/experimental/callback.py
--- a/hydra/experimental/callback.py
+++ b/hydra/experimental/callback.py
@@ -30,14 +30,14 @@
def on_multirun_end(self, config: DictConfig, **kwargs: Any) -> None:
"""
- Called in MULTIRUN mode after all job end.
+ Called in MULTIRUN mode after all jobs end.
"""
...
def on_job_start(self, config: DictConfig, **kwargs: Any) -> None:
"""
- Called in both RUN and MULTIRUN modes inside a Hydra job; before running
- application code.
+ Called in both RUN and MULTIRUN modes, once for each Hydra job (before running
+ application code).
"""
...
@@ -45,7 +45,7 @@
self, config: DictConfig, job_return: JobReturn, **kwargs: Any
) -> None:
"""
- Called in both RUN and MULTIRUN modes inside a Hydra job; after running
- application code.
+ Called in both RUN and MULTIRUN modes, once for each Hydra job (after running
+ application code).
"""
...
|
{"golden_diff": "diff --git a/hydra/experimental/callback.py b/hydra/experimental/callback.py\n--- a/hydra/experimental/callback.py\n+++ b/hydra/experimental/callback.py\n@@ -30,14 +30,14 @@\n \n def on_multirun_end(self, config: DictConfig, **kwargs: Any) -> None:\n \"\"\"\n- Called in MULTIRUN mode after all job end.\n+ Called in MULTIRUN mode after all jobs end.\n \"\"\"\n ...\n \n def on_job_start(self, config: DictConfig, **kwargs: Any) -> None:\n \"\"\"\n- Called in both RUN and MULTIRUN modes inside a Hydra job; before running\n- application code.\n+ Called in both RUN and MULTIRUN modes, once for each Hydra job (before running\n+ application code).\n \"\"\"\n ...\n \n@@ -45,7 +45,7 @@\n self, config: DictConfig, job_return: JobReturn, **kwargs: Any\n ) -> None:\n \"\"\"\n- Called in both RUN and MULTIRUN modes inside a Hydra job; after running\n- application code.\n+ Called in both RUN and MULTIRUN modes, once for each Hydra job (after running\n+ application code).\n \"\"\"\n ...\n", "issue": "Document hydra.callbacks api.\n- [ ] Document API\r\n- [ ] Add news fragment if missing\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\nimport logging\nfrom typing import Any\n\nfrom omegaconf import DictConfig\n\nfrom hydra.core.utils import JobReturn\n\nlogger = logging.getLogger(__name__)\n\n\nclass Callback:\n def on_run_start(self, config: DictConfig, **kwargs: Any) -> None:\n \"\"\"\n Called in RUN mode before job starts.\n \"\"\"\n ...\n\n def on_run_end(self, config: DictConfig, **kwargs: Any) -> None:\n \"\"\"\n Called in RUN mode after job ends.\n \"\"\"\n ...\n\n def on_multirun_start(self, config: DictConfig, **kwargs: Any) -> None:\n \"\"\"\n Called in MULTIRUN mode before any job starts.\n \"\"\"\n ...\n\n def on_multirun_end(self, config: DictConfig, **kwargs: Any) -> None:\n \"\"\"\n Called in MULTIRUN mode after all job end.\n \"\"\"\n ...\n\n def on_job_start(self, config: DictConfig, **kwargs: Any) -> None:\n \"\"\"\n Called in both RUN and MULTIRUN modes inside a Hydra job; before running\n application code.\n \"\"\"\n ...\n\n def on_job_end(\n self, config: DictConfig, job_return: JobReturn, **kwargs: Any\n ) -> None:\n \"\"\"\n Called in both RUN and MULTIRUN modes inside a Hydra job; after running\n application code.\n \"\"\"\n ...\n", "path": "hydra/experimental/callback.py"}], "after_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\nimport logging\nfrom typing import Any\n\nfrom omegaconf import DictConfig\n\nfrom hydra.core.utils import JobReturn\n\nlogger = logging.getLogger(__name__)\n\n\nclass Callback:\n def on_run_start(self, config: DictConfig, **kwargs: Any) -> None:\n \"\"\"\n Called in RUN mode before job starts.\n \"\"\"\n ...\n\n def on_run_end(self, config: DictConfig, **kwargs: Any) -> None:\n \"\"\"\n Called in RUN mode after job ends.\n \"\"\"\n ...\n\n def on_multirun_start(self, config: DictConfig, **kwargs: Any) -> None:\n \"\"\"\n Called in MULTIRUN mode before any job starts.\n \"\"\"\n ...\n\n def on_multirun_end(self, config: DictConfig, **kwargs: Any) -> None:\n \"\"\"\n Called in MULTIRUN mode after all jobs end.\n \"\"\"\n ...\n\n def on_job_start(self, config: DictConfig, **kwargs: Any) -> None:\n \"\"\"\n Called in both RUN and MULTIRUN modes, once for each Hydra job (before running\n application code).\n \"\"\"\n ...\n\n def on_job_end(\n self, config: DictConfig, job_return: JobReturn, **kwargs: Any\n ) -> None:\n \"\"\"\n Called in both RUN and MULTIRUN modes, once for each Hydra job (after running\n application code).\n \"\"\"\n ...\n", "path": "hydra/experimental/callback.py"}]}
| 695 | 279 |
gh_patches_debug_37206
|
rasdani/github-patches
|
git_diff
|
PokemonGoF__PokemonGo-Bot-5067
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Assign to Team after reaching lvl 5
<!-- ===============FEATURE REQUEST SECTION===============
Before you create a Feature Request, please check the following:
1. Have you [searched our feature tracker](https://github.com/PokemonGoF/PokemonGo-Bot/labels/Feature%20Request) first to ensure someone else hasn't already come up with the same great idea. If so then be sure to +1 it
2. While you're there, be sure to vote on other feature requests to let the devs know what is important to you.
-->
<!-- Note: Delete this line and everything ABOVE if creating a Feature Request -->
### Short Description
<!-- Tell us a short description of your request -->
Add the ability to assign to a team (blue, red, yellow) after bot is reaching lvl5
<!-- ==========END OF FEATURE REQUEST SECTION========== -->
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pokemongo_bot/cell_workers/complete_tutorial.py`
Content:
```
1 import random
2
3 from pokemongo_bot import logger
4 from pokemongo_bot.base_task import BaseTask
5 from pokemongo_bot.worker_result import WorkerResult
6 from pokemongo_bot.human_behaviour import sleep
7
8
9
10 class CompleteTutorial(BaseTask):
11
12 SUPPORTED_TASK_API_VERSION = 1
13
14 def initialize(self):
15 self.api = self.bot.api
16 self.nickname = self.config.get('nickname','')
17 self.team = self.config.get('team',0)
18 self.may_run = True
19
20 def should_run(self):
21 return self.may_run
22
23 def work(self):
24
25 if not self.should_run():
26 return WorkerResult.SUCCESS
27
28 # Only execute the worker once to avoid error loop
29 self.may_run = False
30
31 if self._check_tutorial_state():
32 return WorkerResult.SUCCESS
33 else:
34 return WorkerResult.ERROR
35
36 def _check_tutorial_state(self):
37 self._player=self.bot.player_data
38
39 tutorial_state = self._player.get('tutorial_state', [])
40 # LEGAL_SCREEN = 0
41 if not 0 in tutorial_state:
42 sleep(2)
43 if self._set_tutorial_state(0):
44 self.logger.info('Completed legal screen')
45 tutorial_state = self._player.get('tutorial_state', [])
46 else:
47 return False
48
49 # AVATAR_SELECTION = 1
50 if not 1 in tutorial_state:
51 sleep(7)
52 if self._set_avatar():
53 if self._set_tutorial_state(1):
54 self.logger.info('Completed avatar selection')
55 tutorial_state = self._player.get('tutorial_state', [])
56 else:
57 return False
58 else:
59 self.logger.error('Error during avatar selection')
60 return False
61
62 # POKEMON_CAPTURE = 3
63 if not 3 in tutorial_state:
64 sleep(10)
65 if self._encounter_tutorial():
66 self.logger.info('Completed first capture')
67 else:
68 self.logger.error('Error during first capture')
69 return False
70
71 # NAME_SELECTION = 4
72 if not 4 in tutorial_state:
73 if not self.nickname:
74 self.logger.info("No nickname defined in config")
75 return False
76
77 self.logger.info(u'Trying to set {} as nickname'.format(self.nickname))
78 sleep(5)
79 if self._set_nickname(self.nickname):
80 self._set_tutorial_state(4)
81 tutorial_state = self._player.get('tutorial_state', [])
82 else:
83 self.logger.error('Error trying to set nickname')
84 return False
85
86 # FIRST_TIME_EXPERIENCE_COMPLETE = 7
87 if not 7 in tutorial_state:
88 if self._set_tutorial_state(7):
89 self.logger.info('Completed first time experience')
90 else:
91 return False
92
93 return True
94
95 def _encounter_tutorial(self):
96 # You just need to call the API with the pokemon you choose
97 # Probably can't get MewTwo as first pokemon though
98 first_pokemon_id = random.choice([1, 4, 7])
99 response_dict = self.api.encounter_tutorial_complete(
100 pokemon_id=first_pokemon_id)
101 try:
102 if response_dict['responses']['ENCOUNTER_TUTORIAL_COMPLETE']['result'] == 1:
103 return True
104 else:
105 self.logger.error("Error during encouter tutorial")
106 return False
107 except KeyError:
108 self.logger.error("KeyError during encouter tutorial")
109 return False
110
111 def _random_avatar(self):
112 avatar= {}
113 # 0 = Male, 1 = Female
114 avatar['gender']=random.randint(0,1)
115 # What is the max value of each parameter ?
116 # Default is 0, anyway human player will stop
117 # at the first choices in general, so fully
118 # random on the whole avatar space is not the way to go either
119 avatar['skin']=random.randint(0,3)
120 avatar['hair']=random.randint(0,3)
121 avatar['shirt']=random.randint(0,3)
122 avatar['pants']=random.randint(0,3)
123 avatar['hat']=random.randint(0,3)
124 avatar['shoes']=random.randint(0,3)
125 avatar['eyes']=random.randint(0,3)
126 avatar['backpack']=random.randint(0,3)
127 return avatar
128
129 def _set_avatar(self):
130 avatar = self._random_avatar()
131 response_dict = self.api.set_avatar(player_avatar=avatar)
132 status = response_dict['responses']['SET_AVATAR']['status']
133 try:
134 if status == 1:
135 return True
136 else:
137 error_codes = {
138 0: 'UNSET',
139 1: 'SUCCESS',
140 2: 'AVATAR_ALREADY_SET',
141 3: 'FAILURE',
142 }
143 self.logger.error("Error during avatar selection : {}".format(error_codes[status]))
144 return False
145 except KeyError:
146 self.logger.error("KeyError during avatar selection")
147 return False
148
149 def _set_nickname(self, nickname):
150 response_dict = self.api.claim_codename(codename=nickname)
151 try:
152 result = response_dict['responses']['CLAIM_CODENAME']['status']
153 if result == 1:
154 self.logger.info(u'Name changed to {}'.format(nickname))
155 return True
156 else:
157 # Would be nice to get the text directly from the proto Enum
158 error_codes = {
159 0: 'UNSET',
160 1: 'SUCCESS',
161 2: 'CODENAME_NOT_AVAILABLE',
162 3: 'CODENAME_NOT_VALID',
163 4: 'CURRENT_OWNER',
164 5: 'CODENAME_CHANGE_NOT_ALLOWED'
165 }
166 self.logger.error(
167 u'Error while changing nickname : {}'.format(error_codes[result]))
168 return False
169 except KeyError:
170 return False
171
172 def _set_tutorial_state(self, completed):
173 response_dict = self.api.mark_tutorial_complete(tutorials_completed=[
174 completed], send_marketing_emails=False, send_push_notifications=False)
175 try:
176 self._player = response_dict['responses'][
177 'MARK_TUTORIAL_COMPLETE']['player_data']
178 return response_dict['responses']['MARK_TUTORIAL_COMPLETE']['success']
179 except KeyError:
180 self.logger.error("KeyError while setting tutorial state")
181 return False
182
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pokemongo_bot/cell_workers/complete_tutorial.py b/pokemongo_bot/cell_workers/complete_tutorial.py
--- a/pokemongo_bot/cell_workers/complete_tutorial.py
+++ b/pokemongo_bot/cell_workers/complete_tutorial.py
@@ -1,6 +1,7 @@
import random
from pokemongo_bot import logger
+from pokemongo_bot.inventory import player
from pokemongo_bot.base_task import BaseTask
from pokemongo_bot.worker_result import WorkerResult
from pokemongo_bot.human_behaviour import sleep
@@ -15,23 +16,22 @@
self.api = self.bot.api
self.nickname = self.config.get('nickname','')
self.team = self.config.get('team',0)
- self.may_run = True
-
- def should_run(self):
- return self.may_run
+ self.tutorial_run = True
+ self.team_run = True
def work(self):
- if not self.should_run():
- return WorkerResult.SUCCESS
+ if self.tutorial_run:
+ self.tutorial_run = False
+ if not self._check_tutorial_state():
+ return WorkerResult.ERROR
- # Only execute the worker once to avoid error loop
- self.may_run = False
+ if self.team_run and player()._level >= 5:
+ self.team_run = False
+ if not self._set_team():
+ return WorkerResult.ERROR
- if self._check_tutorial_state():
- return WorkerResult.SUCCESS
- else:
- return WorkerResult.ERROR
+ return WorkerResult.SUCCESS
def _check_tutorial_state(self):
self._player=self.bot.player_data
@@ -179,3 +179,36 @@
except KeyError:
self.logger.error("KeyError while setting tutorial state")
return False
+
+ def _set_team(self):
+ if self.team == 0:
+ return True
+
+ if self.bot.player_data.get('team', 0) != 0:
+ self.logger.info(u'Team already picked')
+ return True
+
+ sleep(10)
+ response_dict = self.api.set_player_team(team=self.team)
+ try:
+ result = response_dict['responses']['SET_PLAYER_TEAM']['status']
+ if result == 1:
+ team_codes = {
+ 1: 'Mystic (BLUE)',
+ 2: 'Valor (RED)',
+ 3: 'Instinct (YELLOW)'
+ }
+ self.logger.info(u'Picked Team {}.'.format(team_codes[self.team]))
+ return True
+ else:
+ error_codes = {
+ 0: 'UNSET',
+ 1: 'SUCCESS',
+ 2: 'TEAM_ALREADY_SET',
+ 3: 'FAILURE'
+ }
+ self.logger.error(u'Error while picking team : {}'.format(error_codes[result]))
+ return False
+ except KeyError:
+ return False
+
|
{"golden_diff": "diff --git a/pokemongo_bot/cell_workers/complete_tutorial.py b/pokemongo_bot/cell_workers/complete_tutorial.py\n--- a/pokemongo_bot/cell_workers/complete_tutorial.py\n+++ b/pokemongo_bot/cell_workers/complete_tutorial.py\n@@ -1,6 +1,7 @@\n import random\n \n from pokemongo_bot import logger\n+from pokemongo_bot.inventory import player\n from pokemongo_bot.base_task import BaseTask\n from pokemongo_bot.worker_result import WorkerResult\n from pokemongo_bot.human_behaviour import sleep\n@@ -15,23 +16,22 @@\n self.api = self.bot.api\n self.nickname = self.config.get('nickname','')\n self.team = self.config.get('team',0)\n- self.may_run = True\n-\n- def should_run(self):\n- return self.may_run\n+ self.tutorial_run = True\n+ self.team_run = True\n \n def work(self):\n \n- if not self.should_run():\n- return WorkerResult.SUCCESS\n+ if self.tutorial_run:\n+ self.tutorial_run = False\n+ if not self._check_tutorial_state():\n+ return WorkerResult.ERROR\n \n- # Only execute the worker once to avoid error loop\n- self.may_run = False\n+ if self.team_run and player()._level >= 5:\n+ self.team_run = False\n+ if not self._set_team():\n+ return WorkerResult.ERROR\n \n- if self._check_tutorial_state():\n- return WorkerResult.SUCCESS\n- else:\n- return WorkerResult.ERROR\n+ return WorkerResult.SUCCESS\n \n def _check_tutorial_state(self):\n self._player=self.bot.player_data\n@@ -179,3 +179,36 @@\n except KeyError:\n self.logger.error(\"KeyError while setting tutorial state\")\n return False\n+\n+ def _set_team(self):\n+ if self.team == 0:\n+ return True\n+\n+ if self.bot.player_data.get('team', 0) != 0:\n+ self.logger.info(u'Team already picked')\n+ return True\n+\n+ sleep(10)\n+ response_dict = self.api.set_player_team(team=self.team)\n+ try:\n+ result = response_dict['responses']['SET_PLAYER_TEAM']['status']\n+ if result == 1:\n+ team_codes = {\n+ 1: 'Mystic (BLUE)',\n+ 2: 'Valor (RED)',\n+ 3: 'Instinct (YELLOW)'\n+ }\n+ self.logger.info(u'Picked Team {}.'.format(team_codes[self.team]))\n+ return True\n+ else:\n+ error_codes = {\n+ 0: 'UNSET',\n+ 1: 'SUCCESS',\n+ 2: 'TEAM_ALREADY_SET',\n+ 3: 'FAILURE'\n+ }\n+ self.logger.error(u'Error while picking team : {}'.format(error_codes[result]))\n+ return False\n+ except KeyError:\n+ return False\n+\n", "issue": "Assign to Team after reaching lvl 5\n<!-- ===============FEATURE REQUEST SECTION===============\n\nBefore you create a Feature Request, please check the following:\n\n1. Have you [searched our feature tracker](https://github.com/PokemonGoF/PokemonGo-Bot/labels/Feature%20Request) first to ensure someone else hasn't already come up with the same great idea. If so then be sure to +1 it \n2. While you're there, be sure to vote on other feature requests to let the devs know what is important to you.\n-->\n\n<!-- Note: Delete this line and everything ABOVE if creating a Feature Request -->\n### Short Description\n\n<!-- Tell us a short description of your request -->\n\nAdd the ability to assign to a team (blue, red, yellow) after bot is reaching lvl5\n\n<!-- ==========END OF FEATURE REQUEST SECTION========== -->\n\n", "before_files": [{"content": "import random\n\nfrom pokemongo_bot import logger\nfrom pokemongo_bot.base_task import BaseTask\nfrom pokemongo_bot.worker_result import WorkerResult\nfrom pokemongo_bot.human_behaviour import sleep\n\n\n\nclass CompleteTutorial(BaseTask):\n\n SUPPORTED_TASK_API_VERSION = 1\n\n def initialize(self):\n self.api = self.bot.api\n self.nickname = self.config.get('nickname','')\n self.team = self.config.get('team',0)\n self.may_run = True\n\n def should_run(self):\n return self.may_run\n\n def work(self):\n\n if not self.should_run():\n return WorkerResult.SUCCESS\n\n # Only execute the worker once to avoid error loop\n self.may_run = False\n\n if self._check_tutorial_state():\n return WorkerResult.SUCCESS\n else:\n return WorkerResult.ERROR\n\n def _check_tutorial_state(self):\n self._player=self.bot.player_data\n\n tutorial_state = self._player.get('tutorial_state', [])\n # LEGAL_SCREEN = 0\n if not 0 in tutorial_state:\n sleep(2)\n if self._set_tutorial_state(0):\n self.logger.info('Completed legal screen')\n tutorial_state = self._player.get('tutorial_state', [])\n else:\n return False\n\n # AVATAR_SELECTION = 1\n if not 1 in tutorial_state:\n sleep(7)\n if self._set_avatar():\n if self._set_tutorial_state(1):\n self.logger.info('Completed avatar selection')\n tutorial_state = self._player.get('tutorial_state', [])\n else:\n return False\n else:\n self.logger.error('Error during avatar selection')\n return False\n\n # POKEMON_CAPTURE = 3\n if not 3 in tutorial_state:\n sleep(10)\n if self._encounter_tutorial():\n self.logger.info('Completed first capture')\n else:\n self.logger.error('Error during first capture')\n return False\n\n # NAME_SELECTION = 4\n if not 4 in tutorial_state:\n if not self.nickname:\n self.logger.info(\"No nickname defined in config\")\n return False\n\n self.logger.info(u'Trying to set {} as nickname'.format(self.nickname))\n sleep(5)\n if self._set_nickname(self.nickname):\n self._set_tutorial_state(4)\n tutorial_state = self._player.get('tutorial_state', [])\n else:\n self.logger.error('Error trying to set nickname')\n return False\n\n # FIRST_TIME_EXPERIENCE_COMPLETE = 7\n if not 7 in tutorial_state:\n if self._set_tutorial_state(7):\n self.logger.info('Completed first time experience')\n else:\n return False\n\n return True\n\n def _encounter_tutorial(self):\n # You just need to call the API with the pokemon you choose\n # Probably can't get MewTwo as first pokemon though\n first_pokemon_id = random.choice([1, 4, 7])\n response_dict = self.api.encounter_tutorial_complete(\n pokemon_id=first_pokemon_id)\n try:\n if response_dict['responses']['ENCOUNTER_TUTORIAL_COMPLETE']['result'] == 1:\n return True\n else:\n self.logger.error(\"Error during encouter tutorial\")\n return False\n except KeyError:\n self.logger.error(\"KeyError during encouter tutorial\")\n return False\n\n def _random_avatar(self):\n avatar= {}\n # 0 = Male, 1 = Female\n avatar['gender']=random.randint(0,1)\n # What is the max value of each parameter ?\n # Default is 0, anyway human player will stop\n # at the first choices in general, so fully\n # random on the whole avatar space is not the way to go either\n avatar['skin']=random.randint(0,3)\n avatar['hair']=random.randint(0,3)\n avatar['shirt']=random.randint(0,3)\n avatar['pants']=random.randint(0,3)\n avatar['hat']=random.randint(0,3)\n avatar['shoes']=random.randint(0,3)\n avatar['eyes']=random.randint(0,3)\n avatar['backpack']=random.randint(0,3)\n return avatar\n\n def _set_avatar(self):\n avatar = self._random_avatar()\n response_dict = self.api.set_avatar(player_avatar=avatar)\n status = response_dict['responses']['SET_AVATAR']['status']\n try:\n if status == 1:\n return True\n else:\n error_codes = {\n 0: 'UNSET',\n 1: 'SUCCESS',\n 2: 'AVATAR_ALREADY_SET',\n 3: 'FAILURE',\n }\n self.logger.error(\"Error during avatar selection : {}\".format(error_codes[status]))\n return False\n except KeyError:\n self.logger.error(\"KeyError during avatar selection\")\n return False\n\n def _set_nickname(self, nickname):\n response_dict = self.api.claim_codename(codename=nickname)\n try:\n result = response_dict['responses']['CLAIM_CODENAME']['status']\n if result == 1:\n self.logger.info(u'Name changed to {}'.format(nickname))\n return True\n else:\n # Would be nice to get the text directly from the proto Enum\n error_codes = {\n 0: 'UNSET',\n 1: 'SUCCESS',\n 2: 'CODENAME_NOT_AVAILABLE',\n 3: 'CODENAME_NOT_VALID',\n 4: 'CURRENT_OWNER',\n 5: 'CODENAME_CHANGE_NOT_ALLOWED'\n }\n self.logger.error(\n u'Error while changing nickname : {}'.format(error_codes[result]))\n return False\n except KeyError:\n return False\n\n def _set_tutorial_state(self, completed):\n response_dict = self.api.mark_tutorial_complete(tutorials_completed=[\n completed], send_marketing_emails=False, send_push_notifications=False)\n try:\n self._player = response_dict['responses'][\n 'MARK_TUTORIAL_COMPLETE']['player_data']\n return response_dict['responses']['MARK_TUTORIAL_COMPLETE']['success']\n except KeyError:\n self.logger.error(\"KeyError while setting tutorial state\")\n return False\n", "path": "pokemongo_bot/cell_workers/complete_tutorial.py"}], "after_files": [{"content": "import random\n\nfrom pokemongo_bot import logger\nfrom pokemongo_bot.inventory import player\nfrom pokemongo_bot.base_task import BaseTask\nfrom pokemongo_bot.worker_result import WorkerResult\nfrom pokemongo_bot.human_behaviour import sleep\n\n\n\nclass CompleteTutorial(BaseTask):\n\n SUPPORTED_TASK_API_VERSION = 1\n\n def initialize(self):\n self.api = self.bot.api\n self.nickname = self.config.get('nickname','')\n self.team = self.config.get('team',0)\n self.tutorial_run = True\n self.team_run = True\n\n def work(self):\n\n if self.tutorial_run:\n self.tutorial_run = False\n if not self._check_tutorial_state():\n return WorkerResult.ERROR\n\n if self.team_run and player()._level >= 5:\n self.team_run = False\n if not self._set_team():\n return WorkerResult.ERROR\n\n return WorkerResult.SUCCESS\n\n def _check_tutorial_state(self):\n self._player=self.bot.player_data\n\n tutorial_state = self._player.get('tutorial_state', [])\n # LEGAL_SCREEN = 0\n if not 0 in tutorial_state:\n sleep(2)\n if self._set_tutorial_state(0):\n self.logger.info('Completed legal screen')\n tutorial_state = self._player.get('tutorial_state', [])\n else:\n return False\n\n # AVATAR_SELECTION = 1\n if not 1 in tutorial_state:\n sleep(7)\n if self._set_avatar():\n if self._set_tutorial_state(1):\n self.logger.info('Completed avatar selection')\n tutorial_state = self._player.get('tutorial_state', [])\n else:\n return False\n else:\n self.logger.error('Error during avatar selection')\n return False\n\n # POKEMON_CAPTURE = 3\n if not 3 in tutorial_state:\n sleep(10)\n if self._encounter_tutorial():\n self.logger.info('Completed first capture')\n else:\n self.logger.error('Error during first capture')\n return False\n\n # NAME_SELECTION = 4\n if not 4 in tutorial_state:\n if not self.nickname:\n self.logger.info(\"No nickname defined in config\")\n return False\n\n self.logger.info(u'Trying to set {} as nickname'.format(self.nickname))\n sleep(5)\n if self._set_nickname(self.nickname):\n self._set_tutorial_state(4)\n tutorial_state = self._player.get('tutorial_state', [])\n else:\n self.logger.error('Error trying to set nickname')\n return False\n\n # FIRST_TIME_EXPERIENCE_COMPLETE = 7\n if not 7 in tutorial_state:\n if self._set_tutorial_state(7):\n self.logger.info('Completed first time experience')\n else:\n return False\n\n return True\n\n def _encounter_tutorial(self):\n # You just need to call the API with the pokemon you choose\n # Probably can't get MewTwo as first pokemon though\n first_pokemon_id = random.choice([1, 4, 7])\n response_dict = self.api.encounter_tutorial_complete(\n pokemon_id=first_pokemon_id)\n try:\n if response_dict['responses']['ENCOUNTER_TUTORIAL_COMPLETE']['result'] == 1:\n return True\n else:\n self.logger.error(\"Error during encouter tutorial\")\n return False\n except KeyError:\n self.logger.error(\"KeyError during encouter tutorial\")\n return False\n\n def _random_avatar(self):\n avatar= {}\n # 0 = Male, 1 = Female\n avatar['gender']=random.randint(0,1)\n # What is the max value of each parameter ?\n # Default is 0, anyway human player will stop\n # at the first choices in general, so fully\n # random on the whole avatar space is not the way to go either\n avatar['skin']=random.randint(0,3)\n avatar['hair']=random.randint(0,3)\n avatar['shirt']=random.randint(0,3)\n avatar['pants']=random.randint(0,3)\n avatar['hat']=random.randint(0,3)\n avatar['shoes']=random.randint(0,3)\n avatar['eyes']=random.randint(0,3)\n avatar['backpack']=random.randint(0,3)\n return avatar\n\n def _set_avatar(self):\n avatar = self._random_avatar()\n response_dict = self.api.set_avatar(player_avatar=avatar)\n status = response_dict['responses']['SET_AVATAR']['status']\n try:\n if status == 1:\n return True\n else:\n error_codes = {\n 0: 'UNSET',\n 1: 'SUCCESS',\n 2: 'AVATAR_ALREADY_SET',\n 3: 'FAILURE',\n }\n self.logger.error(\"Error during avatar selection : {}\".format(error_codes[status]))\n return False\n except KeyError:\n self.logger.error(\"KeyError during avatar selection\")\n return False\n\n def _set_nickname(self, nickname):\n response_dict = self.api.claim_codename(codename=nickname)\n try:\n result = response_dict['responses']['CLAIM_CODENAME']['status']\n if result == 1:\n self.logger.info(u'Name changed to {}'.format(nickname))\n return True\n else:\n # Would be nice to get the text directly from the proto Enum\n error_codes = {\n 0: 'UNSET',\n 1: 'SUCCESS',\n 2: 'CODENAME_NOT_AVAILABLE',\n 3: 'CODENAME_NOT_VALID',\n 4: 'CURRENT_OWNER',\n 5: 'CODENAME_CHANGE_NOT_ALLOWED'\n }\n self.logger.error(\n u'Error while changing nickname : {}'.format(error_codes[result]))\n return False\n except KeyError:\n return False\n\n def _set_tutorial_state(self, completed):\n response_dict = self.api.mark_tutorial_complete(tutorials_completed=[\n completed], send_marketing_emails=False, send_push_notifications=False)\n try:\n self._player = response_dict['responses'][\n 'MARK_TUTORIAL_COMPLETE']['player_data']\n return response_dict['responses']['MARK_TUTORIAL_COMPLETE']['success']\n except KeyError:\n self.logger.error(\"KeyError while setting tutorial state\")\n return False\n\n def _set_team(self):\n if self.team == 0:\n return True\n\n if self.bot.player_data.get('team', 0) != 0:\n self.logger.info(u'Team already picked')\n return True\n\n sleep(10)\n response_dict = self.api.set_player_team(team=self.team)\n try:\n result = response_dict['responses']['SET_PLAYER_TEAM']['status']\n if result == 1:\n team_codes = {\n 1: 'Mystic (BLUE)',\n 2: 'Valor (RED)',\n 3: 'Instinct (YELLOW)'\n }\n self.logger.info(u'Picked Team {}.'.format(team_codes[self.team]))\n return True\n else:\n error_codes = {\n 0: 'UNSET',\n 1: 'SUCCESS',\n 2: 'TEAM_ALREADY_SET',\n 3: 'FAILURE'\n }\n self.logger.error(u'Error while picking team : {}'.format(error_codes[result]))\n return False\n except KeyError:\n return False\n\n", "path": "pokemongo_bot/cell_workers/complete_tutorial.py"}]}
| 2,235 | 674 |
gh_patches_debug_10147
|
rasdani/github-patches
|
git_diff
|
mesonbuild__meson-9561
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Require parallel tools when depending on HDF5
I have an application that specifically requires the availability of `h5pcc` instead of `h5cc`: https://github.com/mesonbuild/meson/blob/39ceb677744e1f959a0db6406d51a26d78f0ab68/mesonbuild/dependencies/hdf5.py#L97-L99
In my case HDF5 is only build with parallel compatibility and therefore `h5cc` is not available.
My current workaround is to simple edit this line and specify the other tool directly.
It there a more appropriate workaround for this issue?
Alternatively: Is it possible to add an optional parameter to `hdf5_dep = dependency('hdf5')` e.g. `dependency('hdf5', parallel: true)`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mesonbuild/dependencies/hdf5.py`
Content:
```
1 # Copyright 2013-2019 The Meson development team
2
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6
7 # http://www.apache.org/licenses/LICENSE-2.0
8
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 # This file contains the detection logic for miscellaneous external dependencies.
16
17 import functools
18 import os
19 import re
20 import shutil
21 import subprocess
22 from pathlib import Path
23
24 from ..mesonlib import OrderedSet, join_args
25 from .base import DependencyException, DependencyMethods
26 from .configtool import ConfigToolDependency
27 from .pkgconfig import PkgConfigDependency
28 from .factory import factory_methods
29 import typing as T
30
31 if T.TYPE_CHECKING:
32 from .factory import DependencyGenerator
33 from ..environment import Environment
34 from ..mesonlib import MachineChoice
35
36
37 class HDF5PkgConfigDependency(PkgConfigDependency):
38
39 """Handle brokenness in the HDF5 pkg-config files."""
40
41 def __init__(self, name: str, environment: 'Environment', kwargs: T.Dict[str, T.Any], language: T.Optional[str] = None) -> None:
42 language = language or 'c'
43 if language not in {'c', 'cpp', 'fortran'}:
44 raise DependencyException(f'Language {language} is not supported with HDF5.')
45
46 super().__init__(name, environment, kwargs, language)
47 if not self.is_found:
48 return
49
50 # some broken pkgconfig don't actually list the full path to the needed includes
51 newinc = [] # type: T.List[str]
52 for arg in self.compile_args:
53 if arg.startswith('-I'):
54 stem = 'static' if kwargs.get('static', False) else 'shared'
55 if (Path(arg[2:]) / stem).is_dir():
56 newinc.append('-I' + str(Path(arg[2:]) / stem))
57 self.compile_args += newinc
58
59 link_args = [] # type: T.List[str]
60 for larg in self.get_link_args():
61 lpath = Path(larg)
62 # some pkg-config hdf5.pc (e.g. Ubuntu) don't include the commonly-used HL HDF5 libraries,
63 # so let's add them if they exist
64 # additionally, some pkgconfig HDF5 HL files are malformed so let's be sure to find HL anyway
65 if lpath.is_file():
66 hl = []
67 if language == 'cpp':
68 hl += ['_hl_cpp', '_cpp']
69 elif language == 'fortran':
70 hl += ['_hl_fortran', 'hl_fortran', '_fortran']
71 hl += ['_hl'] # C HL library, always needed
72
73 suffix = '.' + lpath.name.split('.', 1)[1] # in case of .dll.a
74 for h in hl:
75 hlfn = lpath.parent / (lpath.name.split('.', 1)[0] + h + suffix)
76 if hlfn.is_file():
77 link_args.append(str(hlfn))
78 # HDF5 C libs are required by other HDF5 languages
79 link_args.append(larg)
80 else:
81 link_args.append(larg)
82
83 self.link_args = link_args
84
85
86 class HDF5ConfigToolDependency(ConfigToolDependency):
87
88 """Wrapper around hdf5 binary config tools."""
89
90 version_arg = '-showconfig'
91
92 def __init__(self, name: str, environment: 'Environment', kwargs: T.Dict[str, T.Any], language: T.Optional[str] = None) -> None:
93 language = language or 'c'
94 if language not in {'c', 'cpp', 'fortran'}:
95 raise DependencyException(f'Language {language} is not supported with HDF5.')
96
97 if language == 'c':
98 cenv = 'CC'
99 tools = ['h5cc']
100 elif language == 'cpp':
101 cenv = 'CXX'
102 tools = ['h5c++']
103 elif language == 'fortran':
104 cenv = 'FC'
105 tools = ['h5fc']
106 else:
107 raise DependencyException('How did you get here?')
108
109 # We need this before we call super()
110 for_machine = self.get_for_machine_from_kwargs(kwargs)
111
112 nkwargs = kwargs.copy()
113 nkwargs['tools'] = tools
114
115 # Override the compiler that the config tools are going to use by
116 # setting the environment variables that they use for the compiler and
117 # linkers.
118 compiler = environment.coredata.compilers[for_machine][language]
119 try:
120 os.environ[f'HDF5_{cenv}'] = join_args(compiler.get_exelist())
121 os.environ[f'HDF5_{cenv}LINKER'] = join_args(compiler.get_linker_exelist())
122 super().__init__(name, environment, nkwargs, language)
123 finally:
124 del os.environ[f'HDF5_{cenv}']
125 del os.environ[f'HDF5_{cenv}LINKER']
126 if not self.is_found:
127 return
128
129 # We first need to call the tool with -c to get the compile arguments
130 # and then without -c to get the link arguments.
131 args = self.get_config_value(['-show', '-c'], 'args')[1:]
132 args += self.get_config_value(['-show', '-noshlib' if kwargs.get('static', False) else '-shlib'], 'args')[1:]
133 for arg in args:
134 if arg.startswith(('-I', '-f', '-D')) or arg == '-pthread':
135 self.compile_args.append(arg)
136 elif arg.startswith(('-L', '-l', '-Wl')):
137 self.link_args.append(arg)
138 elif Path(arg).is_file():
139 self.link_args.append(arg)
140
141 # If the language is not C we need to add C as a subdependency
142 if language != 'c':
143 nkwargs = kwargs.copy()
144 nkwargs['language'] = 'c'
145 # I'm being too clever for mypy and pylint
146 self.is_found = self._add_sub_dependency(hdf5_factory(environment, for_machine, nkwargs)) # pylint: disable=no-value-for-parameter
147
148 def _sanitize_version(self, ver: str) -> str:
149 v = re.search(r'\s*HDF5 Version: (\d+\.\d+\.\d+)', ver)
150 return v.group(1)
151
152
153 @factory_methods({DependencyMethods.PKGCONFIG, DependencyMethods.CONFIG_TOOL})
154 def hdf5_factory(env: 'Environment', for_machine: 'MachineChoice',
155 kwargs: T.Dict[str, T.Any], methods: T.List[DependencyMethods]) -> T.List['DependencyGenerator']:
156 language = kwargs.get('language')
157 candidates: T.List['DependencyGenerator'] = []
158
159 if DependencyMethods.PKGCONFIG in methods:
160 # Use an ordered set so that these remain the first tried pkg-config files
161 pkgconfig_files = OrderedSet(['hdf5', 'hdf5-serial'])
162 # FIXME: This won't honor pkg-config paths, and cross-native files
163 PCEXE = shutil.which('pkg-config')
164 if PCEXE:
165 # some distros put hdf5-1.2.3.pc with version number in .pc filename.
166 ret = subprocess.run([PCEXE, '--list-all'], stdout=subprocess.PIPE, stderr=subprocess.DEVNULL,
167 universal_newlines=True)
168 if ret.returncode == 0:
169 for pkg in ret.stdout.split('\n'):
170 if pkg.startswith('hdf5'):
171 pkgconfig_files.add(pkg.split(' ', 1)[0])
172
173 for pkg in pkgconfig_files:
174 candidates.append(functools.partial(HDF5PkgConfigDependency, pkg, env, kwargs, language))
175
176 if DependencyMethods.CONFIG_TOOL in methods:
177 candidates.append(functools.partial(HDF5ConfigToolDependency, 'hdf5', env, kwargs, language))
178
179 return candidates
180
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mesonbuild/dependencies/hdf5.py b/mesonbuild/dependencies/hdf5.py
--- a/mesonbuild/dependencies/hdf5.py
+++ b/mesonbuild/dependencies/hdf5.py
@@ -96,13 +96,13 @@
if language == 'c':
cenv = 'CC'
- tools = ['h5cc']
+ tools = ['h5cc', 'h5pcc']
elif language == 'cpp':
cenv = 'CXX'
- tools = ['h5c++']
+ tools = ['h5c++', 'h5pc++']
elif language == 'fortran':
cenv = 'FC'
- tools = ['h5fc']
+ tools = ['h5fc', 'h5pfc']
else:
raise DependencyException('How did you get here?')
|
{"golden_diff": "diff --git a/mesonbuild/dependencies/hdf5.py b/mesonbuild/dependencies/hdf5.py\n--- a/mesonbuild/dependencies/hdf5.py\n+++ b/mesonbuild/dependencies/hdf5.py\n@@ -96,13 +96,13 @@\n \n if language == 'c':\n cenv = 'CC'\n- tools = ['h5cc']\n+ tools = ['h5cc', 'h5pcc']\n elif language == 'cpp':\n cenv = 'CXX'\n- tools = ['h5c++']\n+ tools = ['h5c++', 'h5pc++']\n elif language == 'fortran':\n cenv = 'FC'\n- tools = ['h5fc']\n+ tools = ['h5fc', 'h5pfc']\n else:\n raise DependencyException('How did you get here?')\n", "issue": "Require parallel tools when depending on HDF5\nI have an application that specifically requires the availability of `h5pcc` instead of `h5cc`: https://github.com/mesonbuild/meson/blob/39ceb677744e1f959a0db6406d51a26d78f0ab68/mesonbuild/dependencies/hdf5.py#L97-L99\r\n\r\nIn my case HDF5 is only build with parallel compatibility and therefore `h5cc` is not available. \r\nMy current workaround is to simple edit this line and specify the other tool directly. \r\n\r\nIt there a more appropriate workaround for this issue?\r\nAlternatively: Is it possible to add an optional parameter to `hdf5_dep = dependency('hdf5')` e.g. `dependency('hdf5', parallel: true)`\n", "before_files": [{"content": "# Copyright 2013-2019 The Meson development team\n\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n\n# http://www.apache.org/licenses/LICENSE-2.0\n\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n# This file contains the detection logic for miscellaneous external dependencies.\n\nimport functools\nimport os\nimport re\nimport shutil\nimport subprocess\nfrom pathlib import Path\n\nfrom ..mesonlib import OrderedSet, join_args\nfrom .base import DependencyException, DependencyMethods\nfrom .configtool import ConfigToolDependency\nfrom .pkgconfig import PkgConfigDependency\nfrom .factory import factory_methods\nimport typing as T\n\nif T.TYPE_CHECKING:\n from .factory import DependencyGenerator\n from ..environment import Environment\n from ..mesonlib import MachineChoice\n\n\nclass HDF5PkgConfigDependency(PkgConfigDependency):\n\n \"\"\"Handle brokenness in the HDF5 pkg-config files.\"\"\"\n\n def __init__(self, name: str, environment: 'Environment', kwargs: T.Dict[str, T.Any], language: T.Optional[str] = None) -> None:\n language = language or 'c'\n if language not in {'c', 'cpp', 'fortran'}:\n raise DependencyException(f'Language {language} is not supported with HDF5.')\n\n super().__init__(name, environment, kwargs, language)\n if not self.is_found:\n return\n\n # some broken pkgconfig don't actually list the full path to the needed includes\n newinc = [] # type: T.List[str]\n for arg in self.compile_args:\n if arg.startswith('-I'):\n stem = 'static' if kwargs.get('static', False) else 'shared'\n if (Path(arg[2:]) / stem).is_dir():\n newinc.append('-I' + str(Path(arg[2:]) / stem))\n self.compile_args += newinc\n\n link_args = [] # type: T.List[str]\n for larg in self.get_link_args():\n lpath = Path(larg)\n # some pkg-config hdf5.pc (e.g. Ubuntu) don't include the commonly-used HL HDF5 libraries,\n # so let's add them if they exist\n # additionally, some pkgconfig HDF5 HL files are malformed so let's be sure to find HL anyway\n if lpath.is_file():\n hl = []\n if language == 'cpp':\n hl += ['_hl_cpp', '_cpp']\n elif language == 'fortran':\n hl += ['_hl_fortran', 'hl_fortran', '_fortran']\n hl += ['_hl'] # C HL library, always needed\n\n suffix = '.' + lpath.name.split('.', 1)[1] # in case of .dll.a\n for h in hl:\n hlfn = lpath.parent / (lpath.name.split('.', 1)[0] + h + suffix)\n if hlfn.is_file():\n link_args.append(str(hlfn))\n # HDF5 C libs are required by other HDF5 languages\n link_args.append(larg)\n else:\n link_args.append(larg)\n\n self.link_args = link_args\n\n\nclass HDF5ConfigToolDependency(ConfigToolDependency):\n\n \"\"\"Wrapper around hdf5 binary config tools.\"\"\"\n\n version_arg = '-showconfig'\n\n def __init__(self, name: str, environment: 'Environment', kwargs: T.Dict[str, T.Any], language: T.Optional[str] = None) -> None:\n language = language or 'c'\n if language not in {'c', 'cpp', 'fortran'}:\n raise DependencyException(f'Language {language} is not supported with HDF5.')\n\n if language == 'c':\n cenv = 'CC'\n tools = ['h5cc']\n elif language == 'cpp':\n cenv = 'CXX'\n tools = ['h5c++']\n elif language == 'fortran':\n cenv = 'FC'\n tools = ['h5fc']\n else:\n raise DependencyException('How did you get here?')\n\n # We need this before we call super()\n for_machine = self.get_for_machine_from_kwargs(kwargs)\n\n nkwargs = kwargs.copy()\n nkwargs['tools'] = tools\n\n # Override the compiler that the config tools are going to use by\n # setting the environment variables that they use for the compiler and\n # linkers.\n compiler = environment.coredata.compilers[for_machine][language]\n try:\n os.environ[f'HDF5_{cenv}'] = join_args(compiler.get_exelist())\n os.environ[f'HDF5_{cenv}LINKER'] = join_args(compiler.get_linker_exelist())\n super().__init__(name, environment, nkwargs, language)\n finally:\n del os.environ[f'HDF5_{cenv}']\n del os.environ[f'HDF5_{cenv}LINKER']\n if not self.is_found:\n return\n\n # We first need to call the tool with -c to get the compile arguments\n # and then without -c to get the link arguments.\n args = self.get_config_value(['-show', '-c'], 'args')[1:]\n args += self.get_config_value(['-show', '-noshlib' if kwargs.get('static', False) else '-shlib'], 'args')[1:]\n for arg in args:\n if arg.startswith(('-I', '-f', '-D')) or arg == '-pthread':\n self.compile_args.append(arg)\n elif arg.startswith(('-L', '-l', '-Wl')):\n self.link_args.append(arg)\n elif Path(arg).is_file():\n self.link_args.append(arg)\n\n # If the language is not C we need to add C as a subdependency\n if language != 'c':\n nkwargs = kwargs.copy()\n nkwargs['language'] = 'c'\n # I'm being too clever for mypy and pylint\n self.is_found = self._add_sub_dependency(hdf5_factory(environment, for_machine, nkwargs)) # pylint: disable=no-value-for-parameter\n\n def _sanitize_version(self, ver: str) -> str:\n v = re.search(r'\\s*HDF5 Version: (\\d+\\.\\d+\\.\\d+)', ver)\n return v.group(1)\n\n\n@factory_methods({DependencyMethods.PKGCONFIG, DependencyMethods.CONFIG_TOOL})\ndef hdf5_factory(env: 'Environment', for_machine: 'MachineChoice',\n kwargs: T.Dict[str, T.Any], methods: T.List[DependencyMethods]) -> T.List['DependencyGenerator']:\n language = kwargs.get('language')\n candidates: T.List['DependencyGenerator'] = []\n\n if DependencyMethods.PKGCONFIG in methods:\n # Use an ordered set so that these remain the first tried pkg-config files\n pkgconfig_files = OrderedSet(['hdf5', 'hdf5-serial'])\n # FIXME: This won't honor pkg-config paths, and cross-native files\n PCEXE = shutil.which('pkg-config')\n if PCEXE:\n # some distros put hdf5-1.2.3.pc with version number in .pc filename.\n ret = subprocess.run([PCEXE, '--list-all'], stdout=subprocess.PIPE, stderr=subprocess.DEVNULL,\n universal_newlines=True)\n if ret.returncode == 0:\n for pkg in ret.stdout.split('\\n'):\n if pkg.startswith('hdf5'):\n pkgconfig_files.add(pkg.split(' ', 1)[0])\n\n for pkg in pkgconfig_files:\n candidates.append(functools.partial(HDF5PkgConfigDependency, pkg, env, kwargs, language))\n\n if DependencyMethods.CONFIG_TOOL in methods:\n candidates.append(functools.partial(HDF5ConfigToolDependency, 'hdf5', env, kwargs, language))\n\n return candidates\n", "path": "mesonbuild/dependencies/hdf5.py"}], "after_files": [{"content": "# Copyright 2013-2019 The Meson development team\n\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n\n# http://www.apache.org/licenses/LICENSE-2.0\n\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n# This file contains the detection logic for miscellaneous external dependencies.\n\nimport functools\nimport os\nimport re\nimport shutil\nimport subprocess\nfrom pathlib import Path\n\nfrom ..mesonlib import OrderedSet, join_args\nfrom .base import DependencyException, DependencyMethods\nfrom .configtool import ConfigToolDependency\nfrom .pkgconfig import PkgConfigDependency\nfrom .factory import factory_methods\nimport typing as T\n\nif T.TYPE_CHECKING:\n from .factory import DependencyGenerator\n from ..environment import Environment\n from ..mesonlib import MachineChoice\n\n\nclass HDF5PkgConfigDependency(PkgConfigDependency):\n\n \"\"\"Handle brokenness in the HDF5 pkg-config files.\"\"\"\n\n def __init__(self, name: str, environment: 'Environment', kwargs: T.Dict[str, T.Any], language: T.Optional[str] = None) -> None:\n language = language or 'c'\n if language not in {'c', 'cpp', 'fortran'}:\n raise DependencyException(f'Language {language} is not supported with HDF5.')\n\n super().__init__(name, environment, kwargs, language)\n if not self.is_found:\n return\n\n # some broken pkgconfig don't actually list the full path to the needed includes\n newinc = [] # type: T.List[str]\n for arg in self.compile_args:\n if arg.startswith('-I'):\n stem = 'static' if kwargs.get('static', False) else 'shared'\n if (Path(arg[2:]) / stem).is_dir():\n newinc.append('-I' + str(Path(arg[2:]) / stem))\n self.compile_args += newinc\n\n link_args = [] # type: T.List[str]\n for larg in self.get_link_args():\n lpath = Path(larg)\n # some pkg-config hdf5.pc (e.g. Ubuntu) don't include the commonly-used HL HDF5 libraries,\n # so let's add them if they exist\n # additionally, some pkgconfig HDF5 HL files are malformed so let's be sure to find HL anyway\n if lpath.is_file():\n hl = []\n if language == 'cpp':\n hl += ['_hl_cpp', '_cpp']\n elif language == 'fortran':\n hl += ['_hl_fortran', 'hl_fortran', '_fortran']\n hl += ['_hl'] # C HL library, always needed\n\n suffix = '.' + lpath.name.split('.', 1)[1] # in case of .dll.a\n for h in hl:\n hlfn = lpath.parent / (lpath.name.split('.', 1)[0] + h + suffix)\n if hlfn.is_file():\n link_args.append(str(hlfn))\n # HDF5 C libs are required by other HDF5 languages\n link_args.append(larg)\n else:\n link_args.append(larg)\n\n self.link_args = link_args\n\n\nclass HDF5ConfigToolDependency(ConfigToolDependency):\n\n \"\"\"Wrapper around hdf5 binary config tools.\"\"\"\n\n version_arg = '-showconfig'\n\n def __init__(self, name: str, environment: 'Environment', kwargs: T.Dict[str, T.Any], language: T.Optional[str] = None) -> None:\n language = language or 'c'\n if language not in {'c', 'cpp', 'fortran'}:\n raise DependencyException(f'Language {language} is not supported with HDF5.')\n\n if language == 'c':\n cenv = 'CC'\n tools = ['h5cc', 'h5pcc']\n elif language == 'cpp':\n cenv = 'CXX'\n tools = ['h5c++', 'h5pc++']\n elif language == 'fortran':\n cenv = 'FC'\n tools = ['h5fc', 'h5pfc']\n else:\n raise DependencyException('How did you get here?')\n\n # We need this before we call super()\n for_machine = self.get_for_machine_from_kwargs(kwargs)\n\n nkwargs = kwargs.copy()\n nkwargs['tools'] = tools\n\n # Override the compiler that the config tools are going to use by\n # setting the environment variables that they use for the compiler and\n # linkers.\n compiler = environment.coredata.compilers[for_machine][language]\n try:\n os.environ[f'HDF5_{cenv}'] = join_args(compiler.get_exelist())\n os.environ[f'HDF5_{cenv}LINKER'] = join_args(compiler.get_linker_exelist())\n super().__init__(name, environment, nkwargs, language)\n finally:\n del os.environ[f'HDF5_{cenv}']\n del os.environ[f'HDF5_{cenv}LINKER']\n if not self.is_found:\n return\n\n # We first need to call the tool with -c to get the compile arguments\n # and then without -c to get the link arguments.\n args = self.get_config_value(['-show', '-c'], 'args')[1:]\n args += self.get_config_value(['-show', '-noshlib' if kwargs.get('static', False) else '-shlib'], 'args')[1:]\n for arg in args:\n if arg.startswith(('-I', '-f', '-D')) or arg == '-pthread':\n self.compile_args.append(arg)\n elif arg.startswith(('-L', '-l', '-Wl')):\n self.link_args.append(arg)\n elif Path(arg).is_file():\n self.link_args.append(arg)\n\n # If the language is not C we need to add C as a subdependency\n if language != 'c':\n nkwargs = kwargs.copy()\n nkwargs['language'] = 'c'\n # I'm being too clever for mypy and pylint\n self.is_found = self._add_sub_dependency(hdf5_factory(environment, for_machine, nkwargs)) # pylint: disable=no-value-for-parameter\n\n def _sanitize_version(self, ver: str) -> str:\n v = re.search(r'\\s*HDF5 Version: (\\d+\\.\\d+\\.\\d+)', ver)\n return v.group(1)\n\n\n@factory_methods({DependencyMethods.PKGCONFIG, DependencyMethods.CONFIG_TOOL})\ndef hdf5_factory(env: 'Environment', for_machine: 'MachineChoice',\n kwargs: T.Dict[str, T.Any], methods: T.List[DependencyMethods]) -> T.List['DependencyGenerator']:\n language = kwargs.get('language')\n candidates: T.List['DependencyGenerator'] = []\n\n if DependencyMethods.PKGCONFIG in methods:\n # Use an ordered set so that these remain the first tried pkg-config files\n pkgconfig_files = OrderedSet(['hdf5', 'hdf5-serial'])\n # FIXME: This won't honor pkg-config paths, and cross-native files\n PCEXE = shutil.which('pkg-config')\n if PCEXE:\n # some distros put hdf5-1.2.3.pc with version number in .pc filename.\n ret = subprocess.run([PCEXE, '--list-all'], stdout=subprocess.PIPE, stderr=subprocess.DEVNULL,\n universal_newlines=True)\n if ret.returncode == 0:\n for pkg in ret.stdout.split('\\n'):\n if pkg.startswith('hdf5'):\n pkgconfig_files.add(pkg.split(' ', 1)[0])\n\n for pkg in pkgconfig_files:\n candidates.append(functools.partial(HDF5PkgConfigDependency, pkg, env, kwargs, language))\n\n if DependencyMethods.CONFIG_TOOL in methods:\n candidates.append(functools.partial(HDF5ConfigToolDependency, 'hdf5', env, kwargs, language))\n\n return candidates\n", "path": "mesonbuild/dependencies/hdf5.py"}]}
| 2,652 | 196 |
gh_patches_debug_17463
|
rasdani/github-patches
|
git_diff
|
chainer__chainer-7185
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Why `F.dropout` usually does not use CuDNN?
Currently, `F.dropout` uses cudnn only when `using_config('use_cudnn', 'always')`
https://github.com/chainer/chainer/blob/d7adbfb45d46fafa6bd0bbb9f0cebe5894489437/chainer/functions/noise/dropout.py#L46
But IMO, cudnn should be enabled when `>=auto`.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `chainer/functions/noise/dropout.py`
Content:
```
1 import numpy
2
3 import chainer
4 from chainer.backends import cuda
5 from chainer.backends import intel64
6 from chainer import configuration
7 from chainer import function_node
8 from chainer.utils import argument
9 from chainer.utils import type_check
10
11 if cuda.cudnn_enabled:
12 cudnn = cuda.cudnn
13
14
15 class Dropout(function_node.FunctionNode):
16
17 """Dropout regularization."""
18
19 def __init__(self, dropout_ratio, mask=None, return_mask=False):
20 if not 0.0 <= dropout_ratio < 1.0:
21 raise ValueError('dropout_ratio must be in the range [0, 1)')
22 self.dropout_ratio = dropout_ratio
23 self.mask = mask
24 self.return_mask = return_mask
25 self._use_cudnn = False
26
27 def check_type_forward(self, in_types):
28 type_check._argname(in_types, ('x',))
29 type_check.expect(in_types[0].dtype.kind == 'f')
30
31 def forward_cpu(self, x):
32 if (intel64.should_use_ideep('>=auto')
33 and intel64.inputs_all_ready(x)
34 and self.mask is None):
35 return self._forward_ideep(x)
36
37 if self.mask is not None:
38 y = x[0] * self.mask
39 else:
40 scale = x[0].dtype.type(1. / (1 - self.dropout_ratio))
41 flag = numpy.random.rand(*x[0].shape) >= self.dropout_ratio
42 self.mask = scale * flag
43 y = x[0] * self.mask
44 return y,
45
46 def forward_gpu(self, x):
47 if (chainer.should_use_cudnn('==always', 5000)
48 and x[0].flags.c_contiguous
49 and self.mask is None
50 and not self.return_mask):
51 self._use_cudnn = True
52
53 if hasattr(self, 'states'):
54 # if we already have a dropout mask,
55 # the forward operation is equal to backward.
56 return cuda.get_cudnn_dropout_states().backward(
57 None, x[0], self.dropout_ratio, self.states),
58
59 self.states, y = cuda.get_cudnn_dropout_states().forward(
60 None, x[0], self.dropout_ratio)
61 return y,
62 else:
63 if self.mask is not None:
64 y = x[0] * self.mask
65 else:
66 rand = cuda.cupy.random.rand(*x[0].shape, dtype=numpy.float32)
67 scale = x[0].dtype.type(1. / (1 - self.dropout_ratio))
68 self.mask, y = cuda.elementwise(
69 'T x, R r, T scale, T ratio', 'T mask, T y',
70 '''
71 mask = (r >= ratio) * scale;
72 y = x * mask;
73 ''',
74 'dropout_fwd',
75 )(x[0], rand, scale, self.dropout_ratio)
76 return y,
77
78 def _forward_ideep(self, x):
79 mask, y = intel64.ideep.dropout.Forward(
80 intel64.ideep.array(x[0]),
81 self.dropout_ratio)
82 self.mask = mask
83 return y,
84
85 def backward(self, x, gy):
86 if chainer.should_use_cudnn('==always', 5000) and self._use_cudnn:
87 return DropoutGradCuDNN(self.states, self.dropout_ratio).apply(gy)
88 else:
89 return DropoutGrad(self.mask).apply(gy)
90
91
92 class DropoutGrad(function_node.FunctionNode):
93 """Computes the gradient of the Dropout function."""
94
95 def __init__(self, mask):
96 self.mask = mask
97
98 def forward(self, inputs):
99 if (intel64.should_use_ideep('>=auto')
100 and intel64.inputs_all_ready(inputs)):
101 return self._forward_ideep(inputs)
102
103 y = inputs[0] * self.mask
104 return y,
105
106 def _forward_ideep(self, inputs):
107 return intel64.ideep.dropout.Backward(
108 intel64.ideep.array(self.mask),
109 intel64.ideep.array(inputs[0])),
110
111 def backward(self, indexes, gy):
112 return DropoutGrad(self.mask).apply(gy)
113
114
115 class DropoutGradCuDNN(function_node.FunctionNode):
116 """Computes the gradient of the Dropout function with cuDNN support."""
117
118 def __init__(self, states, dropout_ratio):
119 self.states = states
120 self.dropout_ratio = dropout_ratio
121
122 def forward(self, inputs):
123 return cuda.get_cudnn_dropout_states().backward(
124 None, inputs[0], self.dropout_ratio, self.states),
125
126 def backward(self, indexes, gy):
127 return DropoutGradCuDNN(self.states, self.dropout_ratio).apply(gy)
128
129
130 def dropout(x, ratio=.5, **kwargs):
131 """dropout(x, ratio=.5, *, mask=None, return_mask=False)
132
133 Drops elements of input variable randomly.
134
135 This function drops input elements randomly with probability ``ratio`` and
136 scales the remaining elements by factor ``1 / (1 - ratio)``. In testing
137 mode (i.e., ``chainer.config.train`` is set to ``False``), it does nothing
138 and just returns ``x``.
139
140 Args:
141 x (:class:`~chainer.Variable` or :ref:`ndarray`):
142 Input variable. A :math:`(s_1, s_2, ..., s_N)` -shaped float array.
143 ratio (float):
144 Dropout ratio. The ``ratio`` must be ``0.0 <= ratio < 1.0``.
145 mask (:ref:`ndarray` or None):
146 The mask to be used for dropout.
147 You do not have to specify this value, unless you need to make
148 results deterministic.
149 If ``mask`` is not specified or set to ``None``, a mask will be
150 generated randomly according to the given ``ratio``.
151 If ``mask`` is specified, ``ratio`` will be ignored.
152 The shape and dtype must be the same as ``x`` and should be on the
153 same device.
154 Note that iDeep and cuDNN will not be used for this function if
155 mask is specified, as iDeep and cuDNN do not support it.
156 return_mask (bool):
157 If ``True``, the mask used for dropout is returned together with
158 the output variable.
159 The returned mask can later be reused by passing it to ``mask``
160 argument.
161
162 Returns:
163 ~chainer.Variable or tuple:
164 When ``return_mask`` is ``False`` (default), returns the output
165 variable.
166 When ``True``, returns the tuple of the output variable and
167 mask (:ref:`ndarray`). The mask will be on the same device as the
168 input. The mask will become ``None`` when ``chainer.config.train``
169 is set to ``False``.
170
171 See the paper by G. Hinton: `Improving neural networks by preventing
172 co-adaptation of feature detectors <https://arxiv.org/abs/1207.0580>`_.
173
174 .. admonition:: Example
175
176 >>> x = np.array([[-1, 0], [2, -3], [-2, 1]], np.float32)
177 >>> with chainer.using_config('train', True):
178 ... y = F.dropout(x)
179 >>> y.array
180 array([[-2., 0.],
181 [ 4., -6.],
182 [-0., 2.]], dtype=float32)
183 >>> with chainer.using_config('train', True):
184 ... y = F.dropout(x, ratio=0.0) \
185 # dropout returns original input if ratio=0.0
186 >>> (x == y.array).all()
187 True
188 >>> with chainer.using_config('train', False):
189 ... y = F.dropout(x) \
190 # dropout in test mode returns original input
191 >>> (x == y.array).all()
192 True
193
194 """
195 mask = None
196 return_mask = False
197 if kwargs:
198 mask, return_mask = argument.parse_kwargs(
199 kwargs, ('mask', mask), ('return_mask', return_mask),
200 train='train argument is not supported anymore. '
201 'Use chainer.using_config')
202
203 if configuration.config.train:
204 func = Dropout(ratio, mask, return_mask)
205 out, = func.apply((x,))
206 mask = func.mask
207 else:
208 out = chainer.as_variable(x)
209 mask = None
210
211 if return_mask:
212 return out, mask
213 return out
214
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/chainer/functions/noise/dropout.py b/chainer/functions/noise/dropout.py
--- a/chainer/functions/noise/dropout.py
+++ b/chainer/functions/noise/dropout.py
@@ -44,7 +44,7 @@
return y,
def forward_gpu(self, x):
- if (chainer.should_use_cudnn('==always', 5000)
+ if (chainer.should_use_cudnn('>=auto', 5000)
and x[0].flags.c_contiguous
and self.mask is None
and not self.return_mask):
@@ -83,7 +83,7 @@
return y,
def backward(self, x, gy):
- if chainer.should_use_cudnn('==always', 5000) and self._use_cudnn:
+ if chainer.should_use_cudnn('>=auto', 5000) and self._use_cudnn:
return DropoutGradCuDNN(self.states, self.dropout_ratio).apply(gy)
else:
return DropoutGrad(self.mask).apply(gy)
|
{"golden_diff": "diff --git a/chainer/functions/noise/dropout.py b/chainer/functions/noise/dropout.py\n--- a/chainer/functions/noise/dropout.py\n+++ b/chainer/functions/noise/dropout.py\n@@ -44,7 +44,7 @@\n return y,\n \n def forward_gpu(self, x):\n- if (chainer.should_use_cudnn('==always', 5000)\n+ if (chainer.should_use_cudnn('>=auto', 5000)\n and x[0].flags.c_contiguous\n and self.mask is None\n and not self.return_mask):\n@@ -83,7 +83,7 @@\n return y,\n \n def backward(self, x, gy):\n- if chainer.should_use_cudnn('==always', 5000) and self._use_cudnn:\n+ if chainer.should_use_cudnn('>=auto', 5000) and self._use_cudnn:\n return DropoutGradCuDNN(self.states, self.dropout_ratio).apply(gy)\n else:\n return DropoutGrad(self.mask).apply(gy)\n", "issue": "Why `F.dropout` usually does not use CuDNN?\nCurrently, `F.dropout` uses cudnn only when `using_config('use_cudnn', 'always')`\r\nhttps://github.com/chainer/chainer/blob/d7adbfb45d46fafa6bd0bbb9f0cebe5894489437/chainer/functions/noise/dropout.py#L46\r\n\r\nBut IMO, cudnn should be enabled when `>=auto`.\n", "before_files": [{"content": "import numpy\n\nimport chainer\nfrom chainer.backends import cuda\nfrom chainer.backends import intel64\nfrom chainer import configuration\nfrom chainer import function_node\nfrom chainer.utils import argument\nfrom chainer.utils import type_check\n\nif cuda.cudnn_enabled:\n cudnn = cuda.cudnn\n\n\nclass Dropout(function_node.FunctionNode):\n\n \"\"\"Dropout regularization.\"\"\"\n\n def __init__(self, dropout_ratio, mask=None, return_mask=False):\n if not 0.0 <= dropout_ratio < 1.0:\n raise ValueError('dropout_ratio must be in the range [0, 1)')\n self.dropout_ratio = dropout_ratio\n self.mask = mask\n self.return_mask = return_mask\n self._use_cudnn = False\n\n def check_type_forward(self, in_types):\n type_check._argname(in_types, ('x',))\n type_check.expect(in_types[0].dtype.kind == 'f')\n\n def forward_cpu(self, x):\n if (intel64.should_use_ideep('>=auto')\n and intel64.inputs_all_ready(x)\n and self.mask is None):\n return self._forward_ideep(x)\n\n if self.mask is not None:\n y = x[0] * self.mask\n else:\n scale = x[0].dtype.type(1. / (1 - self.dropout_ratio))\n flag = numpy.random.rand(*x[0].shape) >= self.dropout_ratio\n self.mask = scale * flag\n y = x[0] * self.mask\n return y,\n\n def forward_gpu(self, x):\n if (chainer.should_use_cudnn('==always', 5000)\n and x[0].flags.c_contiguous\n and self.mask is None\n and not self.return_mask):\n self._use_cudnn = True\n\n if hasattr(self, 'states'):\n # if we already have a dropout mask,\n # the forward operation is equal to backward.\n return cuda.get_cudnn_dropout_states().backward(\n None, x[0], self.dropout_ratio, self.states),\n\n self.states, y = cuda.get_cudnn_dropout_states().forward(\n None, x[0], self.dropout_ratio)\n return y,\n else:\n if self.mask is not None:\n y = x[0] * self.mask\n else:\n rand = cuda.cupy.random.rand(*x[0].shape, dtype=numpy.float32)\n scale = x[0].dtype.type(1. / (1 - self.dropout_ratio))\n self.mask, y = cuda.elementwise(\n 'T x, R r, T scale, T ratio', 'T mask, T y',\n '''\n mask = (r >= ratio) * scale;\n y = x * mask;\n ''',\n 'dropout_fwd',\n )(x[0], rand, scale, self.dropout_ratio)\n return y,\n\n def _forward_ideep(self, x):\n mask, y = intel64.ideep.dropout.Forward(\n intel64.ideep.array(x[0]),\n self.dropout_ratio)\n self.mask = mask\n return y,\n\n def backward(self, x, gy):\n if chainer.should_use_cudnn('==always', 5000) and self._use_cudnn:\n return DropoutGradCuDNN(self.states, self.dropout_ratio).apply(gy)\n else:\n return DropoutGrad(self.mask).apply(gy)\n\n\nclass DropoutGrad(function_node.FunctionNode):\n \"\"\"Computes the gradient of the Dropout function.\"\"\"\n\n def __init__(self, mask):\n self.mask = mask\n\n def forward(self, inputs):\n if (intel64.should_use_ideep('>=auto')\n and intel64.inputs_all_ready(inputs)):\n return self._forward_ideep(inputs)\n\n y = inputs[0] * self.mask\n return y,\n\n def _forward_ideep(self, inputs):\n return intel64.ideep.dropout.Backward(\n intel64.ideep.array(self.mask),\n intel64.ideep.array(inputs[0])),\n\n def backward(self, indexes, gy):\n return DropoutGrad(self.mask).apply(gy)\n\n\nclass DropoutGradCuDNN(function_node.FunctionNode):\n \"\"\"Computes the gradient of the Dropout function with cuDNN support.\"\"\"\n\n def __init__(self, states, dropout_ratio):\n self.states = states\n self.dropout_ratio = dropout_ratio\n\n def forward(self, inputs):\n return cuda.get_cudnn_dropout_states().backward(\n None, inputs[0], self.dropout_ratio, self.states),\n\n def backward(self, indexes, gy):\n return DropoutGradCuDNN(self.states, self.dropout_ratio).apply(gy)\n\n\ndef dropout(x, ratio=.5, **kwargs):\n \"\"\"dropout(x, ratio=.5, *, mask=None, return_mask=False)\n\n Drops elements of input variable randomly.\n\n This function drops input elements randomly with probability ``ratio`` and\n scales the remaining elements by factor ``1 / (1 - ratio)``. In testing\n mode (i.e., ``chainer.config.train`` is set to ``False``), it does nothing\n and just returns ``x``.\n\n Args:\n x (:class:`~chainer.Variable` or :ref:`ndarray`):\n Input variable. A :math:`(s_1, s_2, ..., s_N)` -shaped float array.\n ratio (float):\n Dropout ratio. The ``ratio`` must be ``0.0 <= ratio < 1.0``.\n mask (:ref:`ndarray` or None):\n The mask to be used for dropout.\n You do not have to specify this value, unless you need to make\n results deterministic.\n If ``mask`` is not specified or set to ``None``, a mask will be\n generated randomly according to the given ``ratio``.\n If ``mask`` is specified, ``ratio`` will be ignored.\n The shape and dtype must be the same as ``x`` and should be on the\n same device.\n Note that iDeep and cuDNN will not be used for this function if\n mask is specified, as iDeep and cuDNN do not support it.\n return_mask (bool):\n If ``True``, the mask used for dropout is returned together with\n the output variable.\n The returned mask can later be reused by passing it to ``mask``\n argument.\n\n Returns:\n ~chainer.Variable or tuple:\n When ``return_mask`` is ``False`` (default), returns the output\n variable.\n When ``True``, returns the tuple of the output variable and\n mask (:ref:`ndarray`). The mask will be on the same device as the\n input. The mask will become ``None`` when ``chainer.config.train``\n is set to ``False``.\n\n See the paper by G. Hinton: `Improving neural networks by preventing\n co-adaptation of feature detectors <https://arxiv.org/abs/1207.0580>`_.\n\n .. admonition:: Example\n\n >>> x = np.array([[-1, 0], [2, -3], [-2, 1]], np.float32)\n >>> with chainer.using_config('train', True):\n ... y = F.dropout(x)\n >>> y.array\n array([[-2., 0.],\n [ 4., -6.],\n [-0., 2.]], dtype=float32)\n >>> with chainer.using_config('train', True):\n ... y = F.dropout(x, ratio=0.0) \\\n# dropout returns original input if ratio=0.0\n >>> (x == y.array).all()\n True\n >>> with chainer.using_config('train', False):\n ... y = F.dropout(x) \\\n# dropout in test mode returns original input\n >>> (x == y.array).all()\n True\n\n \"\"\"\n mask = None\n return_mask = False\n if kwargs:\n mask, return_mask = argument.parse_kwargs(\n kwargs, ('mask', mask), ('return_mask', return_mask),\n train='train argument is not supported anymore. '\n 'Use chainer.using_config')\n\n if configuration.config.train:\n func = Dropout(ratio, mask, return_mask)\n out, = func.apply((x,))\n mask = func.mask\n else:\n out = chainer.as_variable(x)\n mask = None\n\n if return_mask:\n return out, mask\n return out\n", "path": "chainer/functions/noise/dropout.py"}], "after_files": [{"content": "import numpy\n\nimport chainer\nfrom chainer.backends import cuda\nfrom chainer.backends import intel64\nfrom chainer import configuration\nfrom chainer import function_node\nfrom chainer.utils import argument\nfrom chainer.utils import type_check\n\nif cuda.cudnn_enabled:\n cudnn = cuda.cudnn\n\n\nclass Dropout(function_node.FunctionNode):\n\n \"\"\"Dropout regularization.\"\"\"\n\n def __init__(self, dropout_ratio, mask=None, return_mask=False):\n if not 0.0 <= dropout_ratio < 1.0:\n raise ValueError('dropout_ratio must be in the range [0, 1)')\n self.dropout_ratio = dropout_ratio\n self.mask = mask\n self.return_mask = return_mask\n self._use_cudnn = False\n\n def check_type_forward(self, in_types):\n type_check._argname(in_types, ('x',))\n type_check.expect(in_types[0].dtype.kind == 'f')\n\n def forward_cpu(self, x):\n if (intel64.should_use_ideep('>=auto')\n and intel64.inputs_all_ready(x)\n and self.mask is None):\n return self._forward_ideep(x)\n\n if self.mask is not None:\n y = x[0] * self.mask\n else:\n scale = x[0].dtype.type(1. / (1 - self.dropout_ratio))\n flag = numpy.random.rand(*x[0].shape) >= self.dropout_ratio\n self.mask = scale * flag\n y = x[0] * self.mask\n return y,\n\n def forward_gpu(self, x):\n if (chainer.should_use_cudnn('>=auto', 5000)\n and x[0].flags.c_contiguous\n and self.mask is None\n and not self.return_mask):\n self._use_cudnn = True\n\n if hasattr(self, 'states'):\n # if we already have a dropout mask,\n # the forward operation is equal to backward.\n return cuda.get_cudnn_dropout_states().backward(\n None, x[0], self.dropout_ratio, self.states),\n\n self.states, y = cuda.get_cudnn_dropout_states().forward(\n None, x[0], self.dropout_ratio)\n return y,\n else:\n if self.mask is not None:\n y = x[0] * self.mask\n else:\n rand = cuda.cupy.random.rand(*x[0].shape, dtype=numpy.float32)\n scale = x[0].dtype.type(1. / (1 - self.dropout_ratio))\n self.mask, y = cuda.elementwise(\n 'T x, R r, T scale, T ratio', 'T mask, T y',\n '''\n mask = (r >= ratio) * scale;\n y = x * mask;\n ''',\n 'dropout_fwd',\n )(x[0], rand, scale, self.dropout_ratio)\n return y,\n\n def _forward_ideep(self, x):\n mask, y = intel64.ideep.dropout.Forward(\n intel64.ideep.array(x[0]),\n self.dropout_ratio)\n self.mask = mask\n return y,\n\n def backward(self, x, gy):\n if chainer.should_use_cudnn('>=auto', 5000) and self._use_cudnn:\n return DropoutGradCuDNN(self.states, self.dropout_ratio).apply(gy)\n else:\n return DropoutGrad(self.mask).apply(gy)\n\n\nclass DropoutGrad(function_node.FunctionNode):\n \"\"\"Computes the gradient of the Dropout function.\"\"\"\n\n def __init__(self, mask):\n self.mask = mask\n\n def forward(self, inputs):\n if (intel64.should_use_ideep('>=auto')\n and intel64.inputs_all_ready(inputs)):\n return self._forward_ideep(inputs)\n\n y = inputs[0] * self.mask\n return y,\n\n def _forward_ideep(self, inputs):\n return intel64.ideep.dropout.Backward(\n intel64.ideep.array(self.mask),\n intel64.ideep.array(inputs[0])),\n\n def backward(self, indexes, gy):\n return DropoutGrad(self.mask).apply(gy)\n\n\nclass DropoutGradCuDNN(function_node.FunctionNode):\n \"\"\"Computes the gradient of the Dropout function with cuDNN support.\"\"\"\n\n def __init__(self, states, dropout_ratio):\n self.states = states\n self.dropout_ratio = dropout_ratio\n\n def forward(self, inputs):\n return cuda.get_cudnn_dropout_states().backward(\n None, inputs[0], self.dropout_ratio, self.states),\n\n def backward(self, indexes, gy):\n return DropoutGradCuDNN(self.states, self.dropout_ratio).apply(gy)\n\n\ndef dropout(x, ratio=.5, **kwargs):\n \"\"\"dropout(x, ratio=.5, *, mask=None, return_mask=False)\n\n Drops elements of input variable randomly.\n\n This function drops input elements randomly with probability ``ratio`` and\n scales the remaining elements by factor ``1 / (1 - ratio)``. In testing\n mode (i.e., ``chainer.config.train`` is set to ``False``), it does nothing\n and just returns ``x``.\n\n Args:\n x (:class:`~chainer.Variable` or :ref:`ndarray`):\n Input variable. A :math:`(s_1, s_2, ..., s_N)` -shaped float array.\n ratio (float):\n Dropout ratio. The ``ratio`` must be ``0.0 <= ratio < 1.0``.\n mask (:ref:`ndarray` or None):\n The mask to be used for dropout.\n You do not have to specify this value, unless you need to make\n results deterministic.\n If ``mask`` is not specified or set to ``None``, a mask will be\n generated randomly according to the given ``ratio``.\n If ``mask`` is specified, ``ratio`` will be ignored.\n The shape and dtype must be the same as ``x`` and should be on the\n same device.\n Note that iDeep and cuDNN will not be used for this function if\n mask is specified, as iDeep and cuDNN do not support it.\n return_mask (bool):\n If ``True``, the mask used for dropout is returned together with\n the output variable.\n The returned mask can later be reused by passing it to ``mask``\n argument.\n\n Returns:\n ~chainer.Variable or tuple:\n When ``return_mask`` is ``False`` (default), returns the output\n variable.\n When ``True``, returns the tuple of the output variable and\n mask (:ref:`ndarray`). The mask will be on the same device as the\n input. The mask will become ``None`` when ``chainer.config.train``\n is set to ``False``.\n\n See the paper by G. Hinton: `Improving neural networks by preventing\n co-adaptation of feature detectors <https://arxiv.org/abs/1207.0580>`_.\n\n .. admonition:: Example\n\n >>> x = np.array([[-1, 0], [2, -3], [-2, 1]], np.float32)\n >>> with chainer.using_config('train', True):\n ... y = F.dropout(x)\n >>> y.array\n array([[-2., 0.],\n [ 4., -6.],\n [-0., 2.]], dtype=float32)\n >>> with chainer.using_config('train', True):\n ... y = F.dropout(x, ratio=0.0) \\\n# dropout returns original input if ratio=0.0\n >>> (x == y.array).all()\n True\n >>> with chainer.using_config('train', False):\n ... y = F.dropout(x) \\\n# dropout in test mode returns original input\n >>> (x == y.array).all()\n True\n\n \"\"\"\n mask = None\n return_mask = False\n if kwargs:\n mask, return_mask = argument.parse_kwargs(\n kwargs, ('mask', mask), ('return_mask', return_mask),\n train='train argument is not supported anymore. '\n 'Use chainer.using_config')\n\n if configuration.config.train:\n func = Dropout(ratio, mask, return_mask)\n out, = func.apply((x,))\n mask = func.mask\n else:\n out = chainer.as_variable(x)\n mask = None\n\n if return_mask:\n return out, mask\n return out\n", "path": "chainer/functions/noise/dropout.py"}]}
| 2,772 | 254 |
gh_patches_debug_16806
|
rasdani/github-patches
|
git_diff
|
AUTOMATIC1111__stable-diffusion-webui-8931
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Bug]: loopback.py match-case traceback on Google Colab
### Is there an existing issue for this?
- [X] I have searched the existing issues and checked the recent builds/commits
### What happened?
what happened? I don't really know.
all of a sudden I'm getting tracebacks and the WebUI won't load properly, making it unuseable.
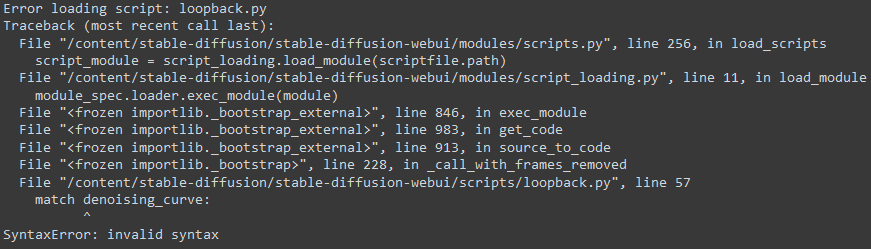
### Steps to reproduce the problem
1. open [this colab notebook](https://colab.research.google.com/github/shirooo39/MiXLab/blob/master/MiXLab.ipynb#scrollTo=6_Sxep-D4HEf)
2. change the runtime type to GPU
3. run the cell: Initialize
4. urn the cell: Download Diffusion Models
5. run the cell: Start WebUI
6. wait for error
### What should have happened?
it shouldn't've thrown those tracebacks and the WebUI loads properly.
### Commit where the problem happens
91ae48fd
### What platforms do you use to access the UI ?
Other/Cloud
### What browsers do you use to access the UI ?
Mozilla Firefox
### Command Line Arguments
```Shell
!COMMANDLINE_ARGS="--share --api --gradio-debug --gradio-queue --medvram --xformers --disable-safe-unpickle --enable-insecure-extension-access --no-half-vae --no-download-sd-model --disable-console-progressbars" REQS_FILE="requirements.txt" python launch.py
```
### List of extensions
No
### Console logs
```Shell
https://rentry.org/a1111webui91ae48fd
```
### Additional information
I'm the author of MiXLab notebook and I wrote my own simple Colab implementation of your WebUI.
it was working fine last night as of 2023-03-24, around 11 PM UTC+07:00, I was able to launch the WebUI without getting any tracebacks.
I was able to generate images at that time (the screenshot below is an image I generated on Colab and downloaded locally)
I'm constantly making changes to my notebook BUT I did not touch to the "Initialize" and "Start WebUI" cells.
I only touch to the model downloader cells.
so I don't think the issue is within my notebook, but I haven't tried TheLastBen's notebook either...
Colab still uses Python 3.7 and the match-case used in the loopback.py was only introduced in Python 3.10 and newer.
that could be the reason why Colab is throwing out tracebacks.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `scripts/loopback.py`
Content:
```
1 import math
2
3 import gradio as gr
4 import modules.scripts as scripts
5 from modules import deepbooru, images, processing, shared
6 from modules.processing import Processed
7 from modules.shared import opts, state
8
9
10 class Script(scripts.Script):
11 def title(self):
12 return "Loopback"
13
14 def show(self, is_img2img):
15 return is_img2img
16
17 def ui(self, is_img2img):
18 loops = gr.Slider(minimum=1, maximum=32, step=1, label='Loops', value=4, elem_id=self.elem_id("loops"))
19 final_denoising_strength = gr.Slider(minimum=0, maximum=1, step=0.01, label='Final denoising strength', value=0.5, elem_id=self.elem_id("final_denoising_strength"))
20 denoising_curve = gr.Dropdown(label="Denoising strength curve", choices=["Aggressive", "Linear", "Lazy"], value="Linear")
21 append_interrogation = gr.Dropdown(label="Append interrogated prompt at each iteration", choices=["None", "CLIP", "DeepBooru"], value="None")
22
23 return [loops, final_denoising_strength, denoising_curve, append_interrogation]
24
25 def run(self, p, loops, final_denoising_strength, denoising_curve, append_interrogation):
26 processing.fix_seed(p)
27 batch_count = p.n_iter
28 p.extra_generation_params = {
29 "Final denoising strength": final_denoising_strength,
30 "Denoising curve": denoising_curve
31 }
32
33 p.batch_size = 1
34 p.n_iter = 1
35
36 info = None
37 initial_seed = None
38 initial_info = None
39 initial_denoising_strength = p.denoising_strength
40
41 grids = []
42 all_images = []
43 original_init_image = p.init_images
44 original_prompt = p.prompt
45 original_inpainting_fill = p.inpainting_fill
46 state.job_count = loops * batch_count
47
48 initial_color_corrections = [processing.setup_color_correction(p.init_images[0])]
49
50 def calculate_denoising_strength(loop):
51 strength = initial_denoising_strength
52
53 if loops == 1:
54 return strength
55
56 progress = loop / (loops - 1)
57 match denoising_curve:
58 case "Aggressive":
59 strength = math.sin((progress) * math.pi * 0.5)
60
61 case "Lazy":
62 strength = 1 - math.cos((progress) * math.pi * 0.5)
63
64 case _:
65 strength = progress
66
67 change = (final_denoising_strength - initial_denoising_strength) * strength
68 return initial_denoising_strength + change
69
70 history = []
71
72 for n in range(batch_count):
73 # Reset to original init image at the start of each batch
74 p.init_images = original_init_image
75
76 # Reset to original denoising strength
77 p.denoising_strength = initial_denoising_strength
78
79 last_image = None
80
81 for i in range(loops):
82 p.n_iter = 1
83 p.batch_size = 1
84 p.do_not_save_grid = True
85
86 if opts.img2img_color_correction:
87 p.color_corrections = initial_color_corrections
88
89 if append_interrogation != "None":
90 p.prompt = original_prompt + ", " if original_prompt != "" else ""
91 if append_interrogation == "CLIP":
92 p.prompt += shared.interrogator.interrogate(p.init_images[0])
93 elif append_interrogation == "DeepBooru":
94 p.prompt += deepbooru.model.tag(p.init_images[0])
95
96 state.job = f"Iteration {i + 1}/{loops}, batch {n + 1}/{batch_count}"
97
98 processed = processing.process_images(p)
99
100 # Generation cancelled.
101 if state.interrupted:
102 break
103
104 if initial_seed is None:
105 initial_seed = processed.seed
106 initial_info = processed.info
107
108 p.seed = processed.seed + 1
109 p.denoising_strength = calculate_denoising_strength(i + 1)
110
111 if state.skipped:
112 break
113
114 last_image = processed.images[0]
115 p.init_images = [last_image]
116 p.inpainting_fill = 1 # Set "masked content" to "original" for next loop.
117
118 if batch_count == 1:
119 history.append(last_image)
120 all_images.append(last_image)
121
122 if batch_count > 1 and not state.skipped and not state.interrupted:
123 history.append(last_image)
124 all_images.append(last_image)
125
126 p.inpainting_fill = original_inpainting_fill
127
128 if state.interrupted:
129 break
130
131 if len(history) > 1:
132 grid = images.image_grid(history, rows=1)
133 if opts.grid_save:
134 images.save_image(grid, p.outpath_grids, "grid", initial_seed, p.prompt, opts.grid_format, info=info, short_filename=not opts.grid_extended_filename, grid=True, p=p)
135
136 if opts.return_grid:
137 grids.append(grid)
138
139 all_images = grids + all_images
140
141 processed = Processed(p, all_images, initial_seed, initial_info)
142
143 return processed
144
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/scripts/loopback.py b/scripts/loopback.py
--- a/scripts/loopback.py
+++ b/scripts/loopback.py
@@ -54,15 +54,12 @@
return strength
progress = loop / (loops - 1)
- match denoising_curve:
- case "Aggressive":
- strength = math.sin((progress) * math.pi * 0.5)
-
- case "Lazy":
- strength = 1 - math.cos((progress) * math.pi * 0.5)
-
- case _:
- strength = progress
+ if denoising_curve == "Aggressive":
+ strength = math.sin((progress) * math.pi * 0.5)
+ elif denoising_curve == "Lazy":
+ strength = 1 - math.cos((progress) * math.pi * 0.5)
+ else:
+ strength = progress
change = (final_denoising_strength - initial_denoising_strength) * strength
return initial_denoising_strength + change
|
{"golden_diff": "diff --git a/scripts/loopback.py b/scripts/loopback.py\n--- a/scripts/loopback.py\n+++ b/scripts/loopback.py\n@@ -54,15 +54,12 @@\n return strength\r\n \r\n progress = loop / (loops - 1)\r\n- match denoising_curve:\r\n- case \"Aggressive\":\r\n- strength = math.sin((progress) * math.pi * 0.5)\r\n-\r\n- case \"Lazy\":\r\n- strength = 1 - math.cos((progress) * math.pi * 0.5)\r\n-\r\n- case _:\r\n- strength = progress\r\n+ if denoising_curve == \"Aggressive\":\r\n+ strength = math.sin((progress) * math.pi * 0.5)\r\n+ elif denoising_curve == \"Lazy\":\r\n+ strength = 1 - math.cos((progress) * math.pi * 0.5)\r\n+ else:\r\n+ strength = progress\r\n \r\n change = (final_denoising_strength - initial_denoising_strength) * strength\r\n return initial_denoising_strength + change\n", "issue": "[Bug]: loopback.py match-case traceback on Google Colab\n### Is there an existing issue for this?\n\n- [X] I have searched the existing issues and checked the recent builds/commits\n\n### What happened?\n\nwhat happened? I don't really know.\r\nall of a sudden I'm getting tracebacks and the WebUI won't load properly, making it unuseable.\r\n\r\n\r\n\n\n### Steps to reproduce the problem\n\n1. open [this colab notebook](https://colab.research.google.com/github/shirooo39/MiXLab/blob/master/MiXLab.ipynb#scrollTo=6_Sxep-D4HEf)\r\n2. change the runtime type to GPU\r\n3. run the cell: Initialize\r\n4. urn the cell: Download Diffusion Models\r\n5. run the cell: Start WebUI\r\n6. wait for error\n\n### What should have happened?\n\nit shouldn't've thrown those tracebacks and the WebUI loads properly.\n\n### Commit where the problem happens\n\n91ae48fd\n\n### What platforms do you use to access the UI ?\n\nOther/Cloud\n\n### What browsers do you use to access the UI ?\n\nMozilla Firefox\n\n### Command Line Arguments\n\n```Shell\n!COMMANDLINE_ARGS=\"--share --api --gradio-debug --gradio-queue --medvram --xformers --disable-safe-unpickle --enable-insecure-extension-access --no-half-vae --no-download-sd-model --disable-console-progressbars\" REQS_FILE=\"requirements.txt\" python launch.py\n```\n\n\n### List of extensions\n\nNo\n\n### Console logs\n\n```Shell\nhttps://rentry.org/a1111webui91ae48fd\n```\n\n\n### Additional information\n\nI'm the author of MiXLab notebook and I wrote my own simple Colab implementation of your WebUI.\r\nit was working fine last night as of 2023-03-24, around 11 PM UTC+07:00, I was able to launch the WebUI without getting any tracebacks.\r\n\r\nI was able to generate images at that time (the screenshot below is an image I generated on Colab and downloaded locally)\r\n\r\n\r\nI'm constantly making changes to my notebook BUT I did not touch to the \"Initialize\" and \"Start WebUI\" cells. \r\nI only touch to the model downloader cells. \r\nso I don't think the issue is within my notebook, but I haven't tried TheLastBen's notebook either...\r\n\r\nColab still uses Python 3.7 and the match-case used in the loopback.py was only introduced in Python 3.10 and newer. \r\nthat could be the reason why Colab is throwing out tracebacks.\n", "before_files": [{"content": "import math\r\n\r\nimport gradio as gr\r\nimport modules.scripts as scripts\r\nfrom modules import deepbooru, images, processing, shared\r\nfrom modules.processing import Processed\r\nfrom modules.shared import opts, state\r\n\r\n\r\nclass Script(scripts.Script):\r\n def title(self):\r\n return \"Loopback\"\r\n\r\n def show(self, is_img2img):\r\n return is_img2img\r\n\r\n def ui(self, is_img2img): \r\n loops = gr.Slider(minimum=1, maximum=32, step=1, label='Loops', value=4, elem_id=self.elem_id(\"loops\"))\r\n final_denoising_strength = gr.Slider(minimum=0, maximum=1, step=0.01, label='Final denoising strength', value=0.5, elem_id=self.elem_id(\"final_denoising_strength\"))\r\n denoising_curve = gr.Dropdown(label=\"Denoising strength curve\", choices=[\"Aggressive\", \"Linear\", \"Lazy\"], value=\"Linear\")\r\n append_interrogation = gr.Dropdown(label=\"Append interrogated prompt at each iteration\", choices=[\"None\", \"CLIP\", \"DeepBooru\"], value=\"None\")\r\n\r\n return [loops, final_denoising_strength, denoising_curve, append_interrogation]\r\n\r\n def run(self, p, loops, final_denoising_strength, denoising_curve, append_interrogation):\r\n processing.fix_seed(p)\r\n batch_count = p.n_iter\r\n p.extra_generation_params = {\r\n \"Final denoising strength\": final_denoising_strength,\r\n \"Denoising curve\": denoising_curve\r\n }\r\n\r\n p.batch_size = 1\r\n p.n_iter = 1\r\n\r\n info = None\r\n initial_seed = None\r\n initial_info = None\r\n initial_denoising_strength = p.denoising_strength\r\n\r\n grids = []\r\n all_images = []\r\n original_init_image = p.init_images\r\n original_prompt = p.prompt\r\n original_inpainting_fill = p.inpainting_fill\r\n state.job_count = loops * batch_count\r\n\r\n initial_color_corrections = [processing.setup_color_correction(p.init_images[0])]\r\n\r\n def calculate_denoising_strength(loop):\r\n strength = initial_denoising_strength\r\n\r\n if loops == 1:\r\n return strength\r\n\r\n progress = loop / (loops - 1)\r\n match denoising_curve:\r\n case \"Aggressive\":\r\n strength = math.sin((progress) * math.pi * 0.5)\r\n\r\n case \"Lazy\":\r\n strength = 1 - math.cos((progress) * math.pi * 0.5)\r\n\r\n case _:\r\n strength = progress\r\n\r\n change = (final_denoising_strength - initial_denoising_strength) * strength\r\n return initial_denoising_strength + change\r\n\r\n history = []\r\n\r\n for n in range(batch_count):\r\n # Reset to original init image at the start of each batch\r\n p.init_images = original_init_image\r\n\r\n # Reset to original denoising strength\r\n p.denoising_strength = initial_denoising_strength\r\n\r\n last_image = None\r\n\r\n for i in range(loops):\r\n p.n_iter = 1\r\n p.batch_size = 1\r\n p.do_not_save_grid = True\r\n\r\n if opts.img2img_color_correction:\r\n p.color_corrections = initial_color_corrections\r\n\r\n if append_interrogation != \"None\":\r\n p.prompt = original_prompt + \", \" if original_prompt != \"\" else \"\"\r\n if append_interrogation == \"CLIP\":\r\n p.prompt += shared.interrogator.interrogate(p.init_images[0])\r\n elif append_interrogation == \"DeepBooru\":\r\n p.prompt += deepbooru.model.tag(p.init_images[0])\r\n\r\n state.job = f\"Iteration {i + 1}/{loops}, batch {n + 1}/{batch_count}\"\r\n\r\n processed = processing.process_images(p)\r\n\r\n # Generation cancelled.\r\n if state.interrupted:\r\n break\r\n\r\n if initial_seed is None:\r\n initial_seed = processed.seed\r\n initial_info = processed.info\r\n\r\n p.seed = processed.seed + 1\r\n p.denoising_strength = calculate_denoising_strength(i + 1)\r\n \r\n if state.skipped:\r\n break\r\n\r\n last_image = processed.images[0]\r\n p.init_images = [last_image]\r\n p.inpainting_fill = 1 # Set \"masked content\" to \"original\" for next loop.\r\n\r\n if batch_count == 1:\r\n history.append(last_image)\r\n all_images.append(last_image)\r\n\r\n if batch_count > 1 and not state.skipped and not state.interrupted:\r\n history.append(last_image)\r\n all_images.append(last_image)\r\n\r\n p.inpainting_fill = original_inpainting_fill\r\n \r\n if state.interrupted:\r\n break\r\n\r\n if len(history) > 1:\r\n grid = images.image_grid(history, rows=1)\r\n if opts.grid_save:\r\n images.save_image(grid, p.outpath_grids, \"grid\", initial_seed, p.prompt, opts.grid_format, info=info, short_filename=not opts.grid_extended_filename, grid=True, p=p)\r\n\r\n if opts.return_grid:\r\n grids.append(grid)\r\n \r\n all_images = grids + all_images\r\n\r\n processed = Processed(p, all_images, initial_seed, initial_info)\r\n\r\n return processed\r\n", "path": "scripts/loopback.py"}], "after_files": [{"content": "import math\r\n\r\nimport gradio as gr\r\nimport modules.scripts as scripts\r\nfrom modules import deepbooru, images, processing, shared\r\nfrom modules.processing import Processed\r\nfrom modules.shared import opts, state\r\n\r\n\r\nclass Script(scripts.Script):\r\n def title(self):\r\n return \"Loopback\"\r\n\r\n def show(self, is_img2img):\r\n return is_img2img\r\n\r\n def ui(self, is_img2img): \r\n loops = gr.Slider(minimum=1, maximum=32, step=1, label='Loops', value=4, elem_id=self.elem_id(\"loops\"))\r\n final_denoising_strength = gr.Slider(minimum=0, maximum=1, step=0.01, label='Final denoising strength', value=0.5, elem_id=self.elem_id(\"final_denoising_strength\"))\r\n denoising_curve = gr.Dropdown(label=\"Denoising strength curve\", choices=[\"Aggressive\", \"Linear\", \"Lazy\"], value=\"Linear\")\r\n append_interrogation = gr.Dropdown(label=\"Append interrogated prompt at each iteration\", choices=[\"None\", \"CLIP\", \"DeepBooru\"], value=\"None\")\r\n\r\n return [loops, final_denoising_strength, denoising_curve, append_interrogation]\r\n\r\n def run(self, p, loops, final_denoising_strength, denoising_curve, append_interrogation):\r\n processing.fix_seed(p)\r\n batch_count = p.n_iter\r\n p.extra_generation_params = {\r\n \"Final denoising strength\": final_denoising_strength,\r\n \"Denoising curve\": denoising_curve\r\n }\r\n\r\n p.batch_size = 1\r\n p.n_iter = 1\r\n\r\n info = None\r\n initial_seed = None\r\n initial_info = None\r\n initial_denoising_strength = p.denoising_strength\r\n\r\n grids = []\r\n all_images = []\r\n original_init_image = p.init_images\r\n original_prompt = p.prompt\r\n original_inpainting_fill = p.inpainting_fill\r\n state.job_count = loops * batch_count\r\n\r\n initial_color_corrections = [processing.setup_color_correction(p.init_images[0])]\r\n\r\n def calculate_denoising_strength(loop):\r\n strength = initial_denoising_strength\r\n\r\n if loops == 1:\r\n return strength\r\n\r\n progress = loop / (loops - 1)\r\n if denoising_curve == \"Aggressive\":\r\n strength = math.sin((progress) * math.pi * 0.5)\r\n elif denoising_curve == \"Lazy\":\r\n strength = 1 - math.cos((progress) * math.pi * 0.5)\r\n else:\r\n strength = progress\r\n\r\n change = (final_denoising_strength - initial_denoising_strength) * strength\r\n return initial_denoising_strength + change\r\n\r\n history = []\r\n\r\n for n in range(batch_count):\r\n # Reset to original init image at the start of each batch\r\n p.init_images = original_init_image\r\n\r\n # Reset to original denoising strength\r\n p.denoising_strength = initial_denoising_strength\r\n\r\n last_image = None\r\n\r\n for i in range(loops):\r\n p.n_iter = 1\r\n p.batch_size = 1\r\n p.do_not_save_grid = True\r\n\r\n if opts.img2img_color_correction:\r\n p.color_corrections = initial_color_corrections\r\n\r\n if append_interrogation != \"None\":\r\n p.prompt = original_prompt + \", \" if original_prompt != \"\" else \"\"\r\n if append_interrogation == \"CLIP\":\r\n p.prompt += shared.interrogator.interrogate(p.init_images[0])\r\n elif append_interrogation == \"DeepBooru\":\r\n p.prompt += deepbooru.model.tag(p.init_images[0])\r\n\r\n state.job = f\"Iteration {i + 1}/{loops}, batch {n + 1}/{batch_count}\"\r\n\r\n processed = processing.process_images(p)\r\n\r\n # Generation cancelled.\r\n if state.interrupted:\r\n break\r\n\r\n if initial_seed is None:\r\n initial_seed = processed.seed\r\n initial_info = processed.info\r\n\r\n p.seed = processed.seed + 1\r\n p.denoising_strength = calculate_denoising_strength(i + 1)\r\n \r\n if state.skipped:\r\n break\r\n\r\n last_image = processed.images[0]\r\n p.init_images = [last_image]\r\n p.inpainting_fill = 1 # Set \"masked content\" to \"original\" for next loop.\r\n\r\n if batch_count == 1:\r\n history.append(last_image)\r\n all_images.append(last_image)\r\n\r\n if batch_count > 1 and not state.skipped and not state.interrupted:\r\n history.append(last_image)\r\n all_images.append(last_image)\r\n\r\n p.inpainting_fill = original_inpainting_fill\r\n \r\n if state.interrupted:\r\n break\r\n\r\n if len(history) > 1:\r\n grid = images.image_grid(history, rows=1)\r\n if opts.grid_save:\r\n images.save_image(grid, p.outpath_grids, \"grid\", initial_seed, p.prompt, opts.grid_format, info=info, short_filename=not opts.grid_extended_filename, grid=True, p=p)\r\n\r\n if opts.return_grid:\r\n grids.append(grid)\r\n \r\n all_images = grids + all_images\r\n\r\n processed = Processed(p, all_images, initial_seed, initial_info)\r\n\r\n return processed\r\n", "path": "scripts/loopback.py"}]}
| 2,493 | 237 |
gh_patches_debug_21670
|
rasdani/github-patches
|
git_diff
|
open-mmlab__mmpretrain-474
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
RuntimeError: Pin memory thread exited unexpectedly
2021-10-04 15:14:24,792 - mmcls - INFO - workflow: [('train', 1)], max: 200 epochs
2021-10-04 15:14:33,806 - mmcls - INFO - Epoch [1][100/391] lr: 1.000e-01, eta: 1:57:16, time: 0.090, data_time: 0.022, memory: 76, loss: 2.0658
2021-10-04 15:14:39,876 - mmcls - INFO - Epoch [1][200/391] lr: 1.000e-01, eta: 1:38:01, time: 0.061, data_time: 0.000, memory: 76, loss: 1.8056
2021-10-04 15:14:45,923 - mmcls - INFO - Epoch [1][300/391] lr: 1.000e-01, eta: 1:31:25, time: 0.060, data_time: 0.000, memory: 76, loss: 1.6816
2021-10-04 15:14:51,428 - mmcls - INFO - Saving checkpoint at 1 epochs
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 10000/10000, 7696.3 task/s, elapsed: 1s, ETA: 0s2021-10-04 15:14:52,802 - mmcls - INFO - Epoch(val) [1][79] accuracy_top-1: 32.6600, accuracy_top-5: 84.0200
Exception in thread Thread-2:
Traceback (most recent call last):
File "/home/songyuan/anaconda3/envs/pytorch1.7.1/lib/python3.7/threading.py", line 926, in _bootstrap_inner
self.run()
File "/home/songyuan/anaconda3/envs/pytorch1.7.1/lib/python3.7/threading.py", line 870, in run
self._target(*self._args, **self._kwargs)
File "/home/songyuan/anaconda3/envs/pytorch1.7.1/lib/python3.7/site-packages/torch/utils/data/_utils/pin_memory.py", line 28, in _pin_memory_loop
idx, data = r
ValueError: not enough values to unpack (expected 2, got 0)
Traceback (most recent call last):
File "tools/train.py", line 157, in <module>
main()
File "tools/train.py", line 153, in main
meta=meta)
File "/home/songyuan/yty/mmclassification-0.15.0/mmcls/apis/train.py", line 160, in train_model
runner.run(data_loaders, cfg.workflow)
File "/home/songyuan/anaconda3/envs/pytorch1.7.1/lib/python3.7/site-packages/mmcv/runner/epoch_based_runner.py", line 127, in run
epoch_runner(data_loaders[i], **kwargs)
File "/home/songyuan/anaconda3/envs/pytorch1.7.1/lib/python3.7/site-packages/mmcv/runner/epoch_based_runner.py", line 47, in train
for i, data_batch in enumerate(self.data_loader):
File "/home/songyuan/anaconda3/envs/pytorch1.7.1/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 349, in __iter__
self._iterator._reset(self)
File "/home/songyuan/anaconda3/envs/pytorch1.7.1/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 852, in _reset
data = self._get_data()
File "/home/songyuan/anaconda3/envs/pytorch1.7.1/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 1029, in _get_data
raise RuntimeError('Pin memory thread exited unexpectedly')
RuntimeError: Pin memory thread exited unexpectedly
我用mmclassification-0.15.0在3090上跑的,pytorch版本为1.7,mmcv为1.3.14,然后训了一个epoch并完成验证后,就出现了这个问题。请问这是什么原因?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mmcls/datasets/builder.py`
Content:
```
1 # Copyright (c) OpenMMLab. All rights reserved.
2 import platform
3 import random
4 from distutils.version import LooseVersion
5 from functools import partial
6
7 import numpy as np
8 import torch
9 from mmcv.parallel import collate
10 from mmcv.runner import get_dist_info
11 from mmcv.utils import Registry, build_from_cfg
12 from torch.utils.data import DataLoader
13
14 from .samplers import DistributedSampler
15
16 if platform.system() != 'Windows':
17 # https://github.com/pytorch/pytorch/issues/973
18 import resource
19 rlimit = resource.getrlimit(resource.RLIMIT_NOFILE)
20 hard_limit = rlimit[1]
21 soft_limit = min(4096, hard_limit)
22 resource.setrlimit(resource.RLIMIT_NOFILE, (soft_limit, hard_limit))
23
24 DATASETS = Registry('dataset')
25 PIPELINES = Registry('pipeline')
26
27
28 def build_dataset(cfg, default_args=None):
29 from .dataset_wrappers import (ConcatDataset, RepeatDataset,
30 ClassBalancedDataset)
31 if isinstance(cfg, (list, tuple)):
32 dataset = ConcatDataset([build_dataset(c, default_args) for c in cfg])
33 elif cfg['type'] == 'RepeatDataset':
34 dataset = RepeatDataset(
35 build_dataset(cfg['dataset'], default_args), cfg['times'])
36 elif cfg['type'] == 'ClassBalancedDataset':
37 dataset = ClassBalancedDataset(
38 build_dataset(cfg['dataset'], default_args), cfg['oversample_thr'])
39 else:
40 dataset = build_from_cfg(cfg, DATASETS, default_args)
41
42 return dataset
43
44
45 def build_dataloader(dataset,
46 samples_per_gpu,
47 workers_per_gpu,
48 num_gpus=1,
49 dist=True,
50 shuffle=True,
51 round_up=True,
52 seed=None,
53 pin_memory=True,
54 persistent_workers=True,
55 **kwargs):
56 """Build PyTorch DataLoader.
57
58 In distributed training, each GPU/process has a dataloader.
59 In non-distributed training, there is only one dataloader for all GPUs.
60
61 Args:
62 dataset (Dataset): A PyTorch dataset.
63 samples_per_gpu (int): Number of training samples on each GPU, i.e.,
64 batch size of each GPU.
65 workers_per_gpu (int): How many subprocesses to use for data loading
66 for each GPU.
67 num_gpus (int): Number of GPUs. Only used in non-distributed training.
68 dist (bool): Distributed training/test or not. Default: True.
69 shuffle (bool): Whether to shuffle the data at every epoch.
70 Default: True.
71 round_up (bool): Whether to round up the length of dataset by adding
72 extra samples to make it evenly divisible. Default: True.
73 pin_memory (bool): Whether to use pin_memory in DataLoader.
74 Default: True
75 persistent_workers (bool): If True, the data loader will not shutdown
76 the worker processes after a dataset has been consumed once.
77 This allows to maintain the workers Dataset instances alive.
78 The argument also has effect in PyTorch>=1.7.0.
79 Default: True
80 kwargs: any keyword argument to be used to initialize DataLoader
81
82 Returns:
83 DataLoader: A PyTorch dataloader.
84 """
85 rank, world_size = get_dist_info()
86 if dist:
87 sampler = DistributedSampler(
88 dataset, world_size, rank, shuffle=shuffle, round_up=round_up)
89 shuffle = False
90 batch_size = samples_per_gpu
91 num_workers = workers_per_gpu
92 else:
93 sampler = None
94 batch_size = num_gpus * samples_per_gpu
95 num_workers = num_gpus * workers_per_gpu
96
97 init_fn = partial(
98 worker_init_fn, num_workers=num_workers, rank=rank,
99 seed=seed) if seed is not None else None
100
101 if LooseVersion(torch.__version__) >= LooseVersion('1.7.0'):
102 kwargs['persistent_workers'] = persistent_workers
103
104 data_loader = DataLoader(
105 dataset,
106 batch_size=batch_size,
107 sampler=sampler,
108 num_workers=num_workers,
109 collate_fn=partial(collate, samples_per_gpu=samples_per_gpu),
110 pin_memory=pin_memory,
111 shuffle=shuffle,
112 worker_init_fn=init_fn,
113 **kwargs)
114
115 return data_loader
116
117
118 def worker_init_fn(worker_id, num_workers, rank, seed):
119 # The seed of each worker equals to
120 # num_worker * rank + worker_id + user_seed
121 worker_seed = num_workers * rank + worker_id + seed
122 np.random.seed(worker_seed)
123 random.seed(worker_seed)
124
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mmcls/datasets/builder.py b/mmcls/datasets/builder.py
--- a/mmcls/datasets/builder.py
+++ b/mmcls/datasets/builder.py
@@ -1,14 +1,13 @@
# Copyright (c) OpenMMLab. All rights reserved.
import platform
import random
-from distutils.version import LooseVersion
from functools import partial
import numpy as np
import torch
from mmcv.parallel import collate
from mmcv.runner import get_dist_info
-from mmcv.utils import Registry, build_from_cfg
+from mmcv.utils import Registry, build_from_cfg, digit_version
from torch.utils.data import DataLoader
from .samplers import DistributedSampler
@@ -98,7 +97,7 @@
worker_init_fn, num_workers=num_workers, rank=rank,
seed=seed) if seed is not None else None
- if LooseVersion(torch.__version__) >= LooseVersion('1.7.0'):
+ if digit_version(torch.__version__) >= digit_version('1.8.0'):
kwargs['persistent_workers'] = persistent_workers
data_loader = DataLoader(
|
{"golden_diff": "diff --git a/mmcls/datasets/builder.py b/mmcls/datasets/builder.py\n--- a/mmcls/datasets/builder.py\n+++ b/mmcls/datasets/builder.py\n@@ -1,14 +1,13 @@\n # Copyright (c) OpenMMLab. All rights reserved.\n import platform\n import random\n-from distutils.version import LooseVersion\n from functools import partial\n \n import numpy as np\n import torch\n from mmcv.parallel import collate\n from mmcv.runner import get_dist_info\n-from mmcv.utils import Registry, build_from_cfg\n+from mmcv.utils import Registry, build_from_cfg, digit_version\n from torch.utils.data import DataLoader\n \n from .samplers import DistributedSampler\n@@ -98,7 +97,7 @@\n worker_init_fn, num_workers=num_workers, rank=rank,\n seed=seed) if seed is not None else None\n \n- if LooseVersion(torch.__version__) >= LooseVersion('1.7.0'):\n+ if digit_version(torch.__version__) >= digit_version('1.8.0'):\n kwargs['persistent_workers'] = persistent_workers\n \n data_loader = DataLoader(\n", "issue": "RuntimeError: Pin memory thread exited unexpectedly\n2021-10-04 15:14:24,792 - mmcls - INFO - workflow: [('train', 1)], max: 200 epochs\r\n2021-10-04 15:14:33,806 - mmcls - INFO - Epoch [1][100/391]\tlr: 1.000e-01, eta: 1:57:16, time: 0.090, data_time: 0.022, memory: 76, loss: 2.0658\r\n2021-10-04 15:14:39,876 - mmcls - INFO - Epoch [1][200/391]\tlr: 1.000e-01, eta: 1:38:01, time: 0.061, data_time: 0.000, memory: 76, loss: 1.8056\r\n2021-10-04 15:14:45,923 - mmcls - INFO - Epoch [1][300/391]\tlr: 1.000e-01, eta: 1:31:25, time: 0.060, data_time: 0.000, memory: 76, loss: 1.6816\r\n2021-10-04 15:14:51,428 - mmcls - INFO - Saving checkpoint at 1 epochs\r\n[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 10000/10000, 7696.3 task/s, elapsed: 1s, ETA: 0s2021-10-04 15:14:52,802 - mmcls - INFO - Epoch(val) [1][79]\taccuracy_top-1: 32.6600, accuracy_top-5: 84.0200\r\nException in thread Thread-2:\r\nTraceback (most recent call last):\r\n File \"/home/songyuan/anaconda3/envs/pytorch1.7.1/lib/python3.7/threading.py\", line 926, in _bootstrap_inner\r\n self.run()\r\n File \"/home/songyuan/anaconda3/envs/pytorch1.7.1/lib/python3.7/threading.py\", line 870, in run\r\n self._target(*self._args, **self._kwargs)\r\n File \"/home/songyuan/anaconda3/envs/pytorch1.7.1/lib/python3.7/site-packages/torch/utils/data/_utils/pin_memory.py\", line 28, in _pin_memory_loop\r\n idx, data = r\r\nValueError: not enough values to unpack (expected 2, got 0)\r\n\r\nTraceback (most recent call last):\r\n File \"tools/train.py\", line 157, in <module>\r\n main()\r\n File \"tools/train.py\", line 153, in main\r\n meta=meta)\r\n File \"/home/songyuan/yty/mmclassification-0.15.0/mmcls/apis/train.py\", line 160, in train_model\r\n runner.run(data_loaders, cfg.workflow)\r\n File \"/home/songyuan/anaconda3/envs/pytorch1.7.1/lib/python3.7/site-packages/mmcv/runner/epoch_based_runner.py\", line 127, in run\r\n epoch_runner(data_loaders[i], **kwargs)\r\n File \"/home/songyuan/anaconda3/envs/pytorch1.7.1/lib/python3.7/site-packages/mmcv/runner/epoch_based_runner.py\", line 47, in train\r\n for i, data_batch in enumerate(self.data_loader):\r\n File \"/home/songyuan/anaconda3/envs/pytorch1.7.1/lib/python3.7/site-packages/torch/utils/data/dataloader.py\", line 349, in __iter__\r\n self._iterator._reset(self)\r\n File \"/home/songyuan/anaconda3/envs/pytorch1.7.1/lib/python3.7/site-packages/torch/utils/data/dataloader.py\", line 852, in _reset\r\n data = self._get_data()\r\n File \"/home/songyuan/anaconda3/envs/pytorch1.7.1/lib/python3.7/site-packages/torch/utils/data/dataloader.py\", line 1029, in _get_data\r\n raise RuntimeError('Pin memory thread exited unexpectedly')\r\nRuntimeError: Pin memory thread exited unexpectedly\r\n\r\n\r\n\u6211\u7528mmclassification-0.15.0\u57283090\u4e0a\u8dd1\u7684\uff0cpytorch\u7248\u672c\u4e3a1.7\uff0cmmcv\u4e3a1.3.14\uff0c\u7136\u540e\u8bad\u4e86\u4e00\u4e2aepoch\u5e76\u5b8c\u6210\u9a8c\u8bc1\u540e\uff0c\u5c31\u51fa\u73b0\u4e86\u8fd9\u4e2a\u95ee\u9898\u3002\u8bf7\u95ee\u8fd9\u662f\u4ec0\u4e48\u539f\u56e0?\n", "before_files": [{"content": "# Copyright (c) OpenMMLab. All rights reserved.\nimport platform\nimport random\nfrom distutils.version import LooseVersion\nfrom functools import partial\n\nimport numpy as np\nimport torch\nfrom mmcv.parallel import collate\nfrom mmcv.runner import get_dist_info\nfrom mmcv.utils import Registry, build_from_cfg\nfrom torch.utils.data import DataLoader\n\nfrom .samplers import DistributedSampler\n\nif platform.system() != 'Windows':\n # https://github.com/pytorch/pytorch/issues/973\n import resource\n rlimit = resource.getrlimit(resource.RLIMIT_NOFILE)\n hard_limit = rlimit[1]\n soft_limit = min(4096, hard_limit)\n resource.setrlimit(resource.RLIMIT_NOFILE, (soft_limit, hard_limit))\n\nDATASETS = Registry('dataset')\nPIPELINES = Registry('pipeline')\n\n\ndef build_dataset(cfg, default_args=None):\n from .dataset_wrappers import (ConcatDataset, RepeatDataset,\n ClassBalancedDataset)\n if isinstance(cfg, (list, tuple)):\n dataset = ConcatDataset([build_dataset(c, default_args) for c in cfg])\n elif cfg['type'] == 'RepeatDataset':\n dataset = RepeatDataset(\n build_dataset(cfg['dataset'], default_args), cfg['times'])\n elif cfg['type'] == 'ClassBalancedDataset':\n dataset = ClassBalancedDataset(\n build_dataset(cfg['dataset'], default_args), cfg['oversample_thr'])\n else:\n dataset = build_from_cfg(cfg, DATASETS, default_args)\n\n return dataset\n\n\ndef build_dataloader(dataset,\n samples_per_gpu,\n workers_per_gpu,\n num_gpus=1,\n dist=True,\n shuffle=True,\n round_up=True,\n seed=None,\n pin_memory=True,\n persistent_workers=True,\n **kwargs):\n \"\"\"Build PyTorch DataLoader.\n\n In distributed training, each GPU/process has a dataloader.\n In non-distributed training, there is only one dataloader for all GPUs.\n\n Args:\n dataset (Dataset): A PyTorch dataset.\n samples_per_gpu (int): Number of training samples on each GPU, i.e.,\n batch size of each GPU.\n workers_per_gpu (int): How many subprocesses to use for data loading\n for each GPU.\n num_gpus (int): Number of GPUs. Only used in non-distributed training.\n dist (bool): Distributed training/test or not. Default: True.\n shuffle (bool): Whether to shuffle the data at every epoch.\n Default: True.\n round_up (bool): Whether to round up the length of dataset by adding\n extra samples to make it evenly divisible. Default: True.\n pin_memory (bool): Whether to use pin_memory in DataLoader.\n Default: True\n persistent_workers (bool): If True, the data loader will not shutdown\n the worker processes after a dataset has been consumed once.\n This allows to maintain the workers Dataset instances alive.\n The argument also has effect in PyTorch>=1.7.0.\n Default: True\n kwargs: any keyword argument to be used to initialize DataLoader\n\n Returns:\n DataLoader: A PyTorch dataloader.\n \"\"\"\n rank, world_size = get_dist_info()\n if dist:\n sampler = DistributedSampler(\n dataset, world_size, rank, shuffle=shuffle, round_up=round_up)\n shuffle = False\n batch_size = samples_per_gpu\n num_workers = workers_per_gpu\n else:\n sampler = None\n batch_size = num_gpus * samples_per_gpu\n num_workers = num_gpus * workers_per_gpu\n\n init_fn = partial(\n worker_init_fn, num_workers=num_workers, rank=rank,\n seed=seed) if seed is not None else None\n\n if LooseVersion(torch.__version__) >= LooseVersion('1.7.0'):\n kwargs['persistent_workers'] = persistent_workers\n\n data_loader = DataLoader(\n dataset,\n batch_size=batch_size,\n sampler=sampler,\n num_workers=num_workers,\n collate_fn=partial(collate, samples_per_gpu=samples_per_gpu),\n pin_memory=pin_memory,\n shuffle=shuffle,\n worker_init_fn=init_fn,\n **kwargs)\n\n return data_loader\n\n\ndef worker_init_fn(worker_id, num_workers, rank, seed):\n # The seed of each worker equals to\n # num_worker * rank + worker_id + user_seed\n worker_seed = num_workers * rank + worker_id + seed\n np.random.seed(worker_seed)\n random.seed(worker_seed)\n", "path": "mmcls/datasets/builder.py"}], "after_files": [{"content": "# Copyright (c) OpenMMLab. All rights reserved.\nimport platform\nimport random\nfrom functools import partial\n\nimport numpy as np\nimport torch\nfrom mmcv.parallel import collate\nfrom mmcv.runner import get_dist_info\nfrom mmcv.utils import Registry, build_from_cfg, digit_version\nfrom torch.utils.data import DataLoader\n\nfrom .samplers import DistributedSampler\n\nif platform.system() != 'Windows':\n # https://github.com/pytorch/pytorch/issues/973\n import resource\n rlimit = resource.getrlimit(resource.RLIMIT_NOFILE)\n hard_limit = rlimit[1]\n soft_limit = min(4096, hard_limit)\n resource.setrlimit(resource.RLIMIT_NOFILE, (soft_limit, hard_limit))\n\nDATASETS = Registry('dataset')\nPIPELINES = Registry('pipeline')\n\n\ndef build_dataset(cfg, default_args=None):\n from .dataset_wrappers import (ConcatDataset, RepeatDataset,\n ClassBalancedDataset)\n if isinstance(cfg, (list, tuple)):\n dataset = ConcatDataset([build_dataset(c, default_args) for c in cfg])\n elif cfg['type'] == 'RepeatDataset':\n dataset = RepeatDataset(\n build_dataset(cfg['dataset'], default_args), cfg['times'])\n elif cfg['type'] == 'ClassBalancedDataset':\n dataset = ClassBalancedDataset(\n build_dataset(cfg['dataset'], default_args), cfg['oversample_thr'])\n else:\n dataset = build_from_cfg(cfg, DATASETS, default_args)\n\n return dataset\n\n\ndef build_dataloader(dataset,\n samples_per_gpu,\n workers_per_gpu,\n num_gpus=1,\n dist=True,\n shuffle=True,\n round_up=True,\n seed=None,\n pin_memory=True,\n persistent_workers=True,\n **kwargs):\n \"\"\"Build PyTorch DataLoader.\n\n In distributed training, each GPU/process has a dataloader.\n In non-distributed training, there is only one dataloader for all GPUs.\n\n Args:\n dataset (Dataset): A PyTorch dataset.\n samples_per_gpu (int): Number of training samples on each GPU, i.e.,\n batch size of each GPU.\n workers_per_gpu (int): How many subprocesses to use for data loading\n for each GPU.\n num_gpus (int): Number of GPUs. Only used in non-distributed training.\n dist (bool): Distributed training/test or not. Default: True.\n shuffle (bool): Whether to shuffle the data at every epoch.\n Default: True.\n round_up (bool): Whether to round up the length of dataset by adding\n extra samples to make it evenly divisible. Default: True.\n pin_memory (bool): Whether to use pin_memory in DataLoader.\n Default: True\n persistent_workers (bool): If True, the data loader will not shutdown\n the worker processes after a dataset has been consumed once.\n This allows to maintain the workers Dataset instances alive.\n The argument also has effect in PyTorch>=1.7.0.\n Default: True\n kwargs: any keyword argument to be used to initialize DataLoader\n\n Returns:\n DataLoader: A PyTorch dataloader.\n \"\"\"\n rank, world_size = get_dist_info()\n if dist:\n sampler = DistributedSampler(\n dataset, world_size, rank, shuffle=shuffle, round_up=round_up)\n shuffle = False\n batch_size = samples_per_gpu\n num_workers = workers_per_gpu\n else:\n sampler = None\n batch_size = num_gpus * samples_per_gpu\n num_workers = num_gpus * workers_per_gpu\n\n init_fn = partial(\n worker_init_fn, num_workers=num_workers, rank=rank,\n seed=seed) if seed is not None else None\n\n if digit_version(torch.__version__) >= digit_version('1.8.0'):\n kwargs['persistent_workers'] = persistent_workers\n\n data_loader = DataLoader(\n dataset,\n batch_size=batch_size,\n sampler=sampler,\n num_workers=num_workers,\n collate_fn=partial(collate, samples_per_gpu=samples_per_gpu),\n pin_memory=pin_memory,\n shuffle=shuffle,\n worker_init_fn=init_fn,\n **kwargs)\n\n return data_loader\n\n\ndef worker_init_fn(worker_id, num_workers, rank, seed):\n # The seed of each worker equals to\n # num_worker * rank + worker_id + user_seed\n worker_seed = num_workers * rank + worker_id + seed\n np.random.seed(worker_seed)\n random.seed(worker_seed)\n", "path": "mmcls/datasets/builder.py"}]}
| 2,641 | 244 |
gh_patches_debug_8080
|
rasdani/github-patches
|
git_diff
|
keras-team__keras-nlp-195
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Why does the docstring say vocab size should be no larger than 999?
https://github.com/keras-team/keras-nlp/blob/e3adddaa98bbe1aee071117c01678fe3017dae80/keras_nlp/layers/token_and_position_embedding.py#L30
Seems like a very small vocab to me
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `keras_nlp/layers/token_and_position_embedding.py`
Content:
```
1 # Copyright 2022 The KerasNLP Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Creates an Embedding Layer and adds Positional Embeddings"""
16
17 from tensorflow import keras
18
19 import keras_nlp.layers
20
21
22 class TokenAndPositionEmbedding(keras.layers.Layer):
23 """A layer which sums a token and position embedding.
24
25 This layer assumes that the last dimension in the input corresponds
26 to the sequence dimension.
27
28 Args:
29 vocabulary_size: The size of the vocabulary (should be no larger
30 than 999)
31 sequence_length: The maximum length of input sequence
32 embedding_dim: The output dimension of the embedding layer
33 embeddings_initializer: The initializer to use for the Embedding
34 Layers
35 mask_zero: Boolean, whether or not the input value 0 is a special
36 "padding" value that should be masked out.
37 This is useful when using recurrent layers which may take variable
38 length input. If this is True, then all subsequent layers in the
39 model need to support masking or an exception will be raised.
40 If mask_zero` is set to True, as a consequence, index 0 cannot be
41 used in the vocabulary
42 (input_dim should equal size of vocabulary + 1).
43
44 Examples:
45 ```python
46 seq_length = 50
47 vocab_size = 5000
48 embed_dim = 128
49 inputs = keras.Input(shape=(seq_length,))
50 embedding_layer = keras_nlp.layers.TokenAndPositionEmbedding(
51 vocabulary_size=vocab_size,
52 sequence_length=seq_length,
53 embedding_dim=embed_dim,
54 )
55 outputs = embedding_layer(inputs)
56 ```
57 """
58
59 def __init__(
60 self,
61 vocabulary_size,
62 sequence_length,
63 embedding_dim,
64 embeddings_initializer="glorot_uniform",
65 mask_zero=False,
66 **kwargs
67 ):
68 super().__init__(**kwargs)
69 if vocabulary_size is None:
70 raise ValueError(
71 "`vocabulary_size` must be an Integer, received `None`."
72 )
73 if sequence_length is None:
74 raise ValueError(
75 "`sequence_length` must be an Integer, received `None`."
76 )
77 if embedding_dim is None:
78 raise ValueError(
79 "`embedding_dim` must be an Integer, received `None`."
80 )
81 self.vocabulary_size = int(vocabulary_size)
82 self.sequence_length = int(sequence_length)
83 self.embedding_dim = int(embedding_dim)
84 self.token_embedding = keras.layers.Embedding(
85 vocabulary_size,
86 embedding_dim,
87 embeddings_initializer=embeddings_initializer,
88 mask_zero=mask_zero,
89 )
90 self.position_embedding = keras_nlp.layers.PositionEmbedding(
91 sequence_length=sequence_length,
92 initializer=embeddings_initializer,
93 )
94 self.supports_masking = self.token_embedding.supports_masking
95
96 def get_config(self):
97 config = super().get_config()
98 config.update(
99 {
100 "vocabulary_size": self.vocabulary_size,
101 "sequence_length": self.sequence_length,
102 "embedding_dim": self.embedding_dim,
103 "embeddings_initializer": keras.initializers.serialize(
104 self.token_embedding.embeddings_initializer
105 ),
106 "mask_zero": self.token_embedding.mask_zero,
107 },
108 )
109 return config
110
111 def call(self, inputs):
112 embedded_tokens = self.token_embedding(inputs)
113 embedded_positions = self.position_embedding(embedded_tokens)
114 outputs = embedded_tokens + embedded_positions
115 return outputs
116
117 def compute_mask(self, inputs, mask=None):
118 return self.token_embedding.compute_mask(inputs, mask=mask)
119
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/keras_nlp/layers/token_and_position_embedding.py b/keras_nlp/layers/token_and_position_embedding.py
--- a/keras_nlp/layers/token_and_position_embedding.py
+++ b/keras_nlp/layers/token_and_position_embedding.py
@@ -26,8 +26,7 @@
to the sequence dimension.
Args:
- vocabulary_size: The size of the vocabulary (should be no larger
- than 999)
+ vocabulary_size: The size of the vocabulary.
sequence_length: The maximum length of input sequence
embedding_dim: The output dimension of the embedding layer
embeddings_initializer: The initializer to use for the Embedding
|
{"golden_diff": "diff --git a/keras_nlp/layers/token_and_position_embedding.py b/keras_nlp/layers/token_and_position_embedding.py\n--- a/keras_nlp/layers/token_and_position_embedding.py\n+++ b/keras_nlp/layers/token_and_position_embedding.py\n@@ -26,8 +26,7 @@\n to the sequence dimension.\n \n Args:\n- vocabulary_size: The size of the vocabulary (should be no larger\n- than 999)\n+ vocabulary_size: The size of the vocabulary.\n sequence_length: The maximum length of input sequence\n embedding_dim: The output dimension of the embedding layer\n embeddings_initializer: The initializer to use for the Embedding\n", "issue": "Why does the docstring say vocab size should be no larger than 999?\nhttps://github.com/keras-team/keras-nlp/blob/e3adddaa98bbe1aee071117c01678fe3017dae80/keras_nlp/layers/token_and_position_embedding.py#L30\r\n\r\nSeems like a very small vocab to me\n", "before_files": [{"content": "# Copyright 2022 The KerasNLP Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Creates an Embedding Layer and adds Positional Embeddings\"\"\"\n\nfrom tensorflow import keras\n\nimport keras_nlp.layers\n\n\nclass TokenAndPositionEmbedding(keras.layers.Layer):\n \"\"\"A layer which sums a token and position embedding.\n\n This layer assumes that the last dimension in the input corresponds\n to the sequence dimension.\n\n Args:\n vocabulary_size: The size of the vocabulary (should be no larger\n than 999)\n sequence_length: The maximum length of input sequence\n embedding_dim: The output dimension of the embedding layer\n embeddings_initializer: The initializer to use for the Embedding\n Layers\n mask_zero: Boolean, whether or not the input value 0 is a special\n \"padding\" value that should be masked out.\n This is useful when using recurrent layers which may take variable\n length input. If this is True, then all subsequent layers in the\n model need to support masking or an exception will be raised.\n If mask_zero` is set to True, as a consequence, index 0 cannot be\n used in the vocabulary\n (input_dim should equal size of vocabulary + 1).\n\n Examples:\n ```python\n seq_length = 50\n vocab_size = 5000\n embed_dim = 128\n inputs = keras.Input(shape=(seq_length,))\n embedding_layer = keras_nlp.layers.TokenAndPositionEmbedding(\n vocabulary_size=vocab_size,\n sequence_length=seq_length,\n embedding_dim=embed_dim,\n )\n outputs = embedding_layer(inputs)\n ```\n \"\"\"\n\n def __init__(\n self,\n vocabulary_size,\n sequence_length,\n embedding_dim,\n embeddings_initializer=\"glorot_uniform\",\n mask_zero=False,\n **kwargs\n ):\n super().__init__(**kwargs)\n if vocabulary_size is None:\n raise ValueError(\n \"`vocabulary_size` must be an Integer, received `None`.\"\n )\n if sequence_length is None:\n raise ValueError(\n \"`sequence_length` must be an Integer, received `None`.\"\n )\n if embedding_dim is None:\n raise ValueError(\n \"`embedding_dim` must be an Integer, received `None`.\"\n )\n self.vocabulary_size = int(vocabulary_size)\n self.sequence_length = int(sequence_length)\n self.embedding_dim = int(embedding_dim)\n self.token_embedding = keras.layers.Embedding(\n vocabulary_size,\n embedding_dim,\n embeddings_initializer=embeddings_initializer,\n mask_zero=mask_zero,\n )\n self.position_embedding = keras_nlp.layers.PositionEmbedding(\n sequence_length=sequence_length,\n initializer=embeddings_initializer,\n )\n self.supports_masking = self.token_embedding.supports_masking\n\n def get_config(self):\n config = super().get_config()\n config.update(\n {\n \"vocabulary_size\": self.vocabulary_size,\n \"sequence_length\": self.sequence_length,\n \"embedding_dim\": self.embedding_dim,\n \"embeddings_initializer\": keras.initializers.serialize(\n self.token_embedding.embeddings_initializer\n ),\n \"mask_zero\": self.token_embedding.mask_zero,\n },\n )\n return config\n\n def call(self, inputs):\n embedded_tokens = self.token_embedding(inputs)\n embedded_positions = self.position_embedding(embedded_tokens)\n outputs = embedded_tokens + embedded_positions\n return outputs\n\n def compute_mask(self, inputs, mask=None):\n return self.token_embedding.compute_mask(inputs, mask=mask)\n", "path": "keras_nlp/layers/token_and_position_embedding.py"}], "after_files": [{"content": "# Copyright 2022 The KerasNLP Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Creates an Embedding Layer and adds Positional Embeddings\"\"\"\n\nfrom tensorflow import keras\n\nimport keras_nlp.layers\n\n\nclass TokenAndPositionEmbedding(keras.layers.Layer):\n \"\"\"A layer which sums a token and position embedding.\n\n This layer assumes that the last dimension in the input corresponds\n to the sequence dimension.\n\n Args:\n vocabulary_size: The size of the vocabulary.\n sequence_length: The maximum length of input sequence\n embedding_dim: The output dimension of the embedding layer\n embeddings_initializer: The initializer to use for the Embedding\n Layers\n mask_zero: Boolean, whether or not the input value 0 is a special\n \"padding\" value that should be masked out.\n This is useful when using recurrent layers which may take variable\n length input. If this is True, then all subsequent layers in the\n model need to support masking or an exception will be raised.\n If mask_zero` is set to True, as a consequence, index 0 cannot be\n used in the vocabulary\n (input_dim should equal size of vocabulary + 1).\n\n Examples:\n ```python\n seq_length = 50\n vocab_size = 5000\n embed_dim = 128\n inputs = keras.Input(shape=(seq_length,))\n embedding_layer = keras_nlp.layers.TokenAndPositionEmbedding(\n vocabulary_size=vocab_size,\n sequence_length=seq_length,\n embedding_dim=embed_dim,\n )\n outputs = embedding_layer(inputs)\n ```\n \"\"\"\n\n def __init__(\n self,\n vocabulary_size,\n sequence_length,\n embedding_dim,\n embeddings_initializer=\"glorot_uniform\",\n mask_zero=False,\n **kwargs\n ):\n super().__init__(**kwargs)\n if vocabulary_size is None:\n raise ValueError(\n \"`vocabulary_size` must be an Integer, received `None`.\"\n )\n if sequence_length is None:\n raise ValueError(\n \"`sequence_length` must be an Integer, received `None`.\"\n )\n if embedding_dim is None:\n raise ValueError(\n \"`embedding_dim` must be an Integer, received `None`.\"\n )\n self.vocabulary_size = int(vocabulary_size)\n self.sequence_length = int(sequence_length)\n self.embedding_dim = int(embedding_dim)\n self.token_embedding = keras.layers.Embedding(\n vocabulary_size,\n embedding_dim,\n embeddings_initializer=embeddings_initializer,\n mask_zero=mask_zero,\n )\n self.position_embedding = keras_nlp.layers.PositionEmbedding(\n sequence_length=sequence_length,\n initializer=embeddings_initializer,\n )\n self.supports_masking = self.token_embedding.supports_masking\n\n def get_config(self):\n config = super().get_config()\n config.update(\n {\n \"vocabulary_size\": self.vocabulary_size,\n \"sequence_length\": self.sequence_length,\n \"embedding_dim\": self.embedding_dim,\n \"embeddings_initializer\": keras.initializers.serialize(\n self.token_embedding.embeddings_initializer\n ),\n \"mask_zero\": self.token_embedding.mask_zero,\n },\n )\n return config\n\n def call(self, inputs):\n embedded_tokens = self.token_embedding(inputs)\n embedded_positions = self.position_embedding(embedded_tokens)\n outputs = embedded_tokens + embedded_positions\n return outputs\n\n def compute_mask(self, inputs, mask=None):\n return self.token_embedding.compute_mask(inputs, mask=mask)\n", "path": "keras_nlp/layers/token_and_position_embedding.py"}]}
| 1,477 | 153 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.